
GLiCLass-V3
Collection
Models for zero-shot text classification that are up to 50 times faster than Cross-Encoders and show the same or higher accuracy.
•
7 items
•
Updated
•
12

This is an efficient zero-shot classifier inspired by GLiNER work. It demonstrates the same performance as a cross-encoder while being more compute-efficient because classification is done at a single forward path.
It can be used for topic classification, sentiment analysis, and as a reranker in RAG pipelines.
The model was trained on logical tasks to induce reasoning. LoRa adapters were used to fine-tune the model without destroying the previous knowledge.
LoRA parameters:
| gliclass‑modern‑base‑v3.0 | gliclass‑modern‑large‑v3.0 | gliclass‑base‑v3.0 | gliclass‑large‑v3.0 | |
|---|---|---|---|---|
| LoRa r | 512 | 768 | 384 | 384 |
| LoRa α | 1024 | 1536 | 768 | 768 |
| focal loss α | 0.7 | 0.7 | 0.7 | 0.7 |
| Target modules | "Wqkv", "Wo", "Wi", "linear_1", "linear_2" | "Wqkv", "Wo", "Wi", "linear_1", "linear_2" | "query_proj", "key_proj", "value_proj", "dense", "linear_1", "linear_2", mlp.0", "mlp.2", "mlp.4" | "query_proj", "key_proj", "value_proj", "dense", "linear_1", "linear_2", mlp.0", "mlp.2", "mlp.4" |
GLiClass-V3 Models:
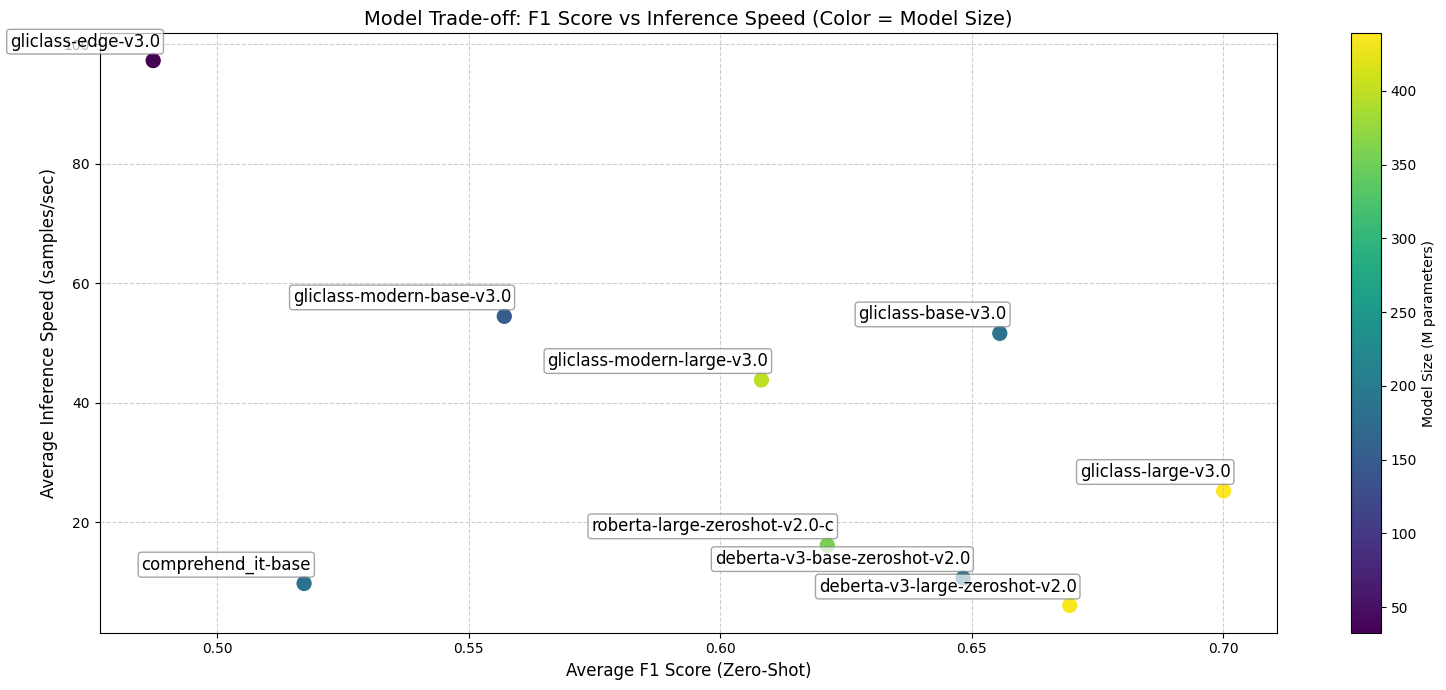
| Model name | Size | Params | Average Banchmark | Average Inference Speed (batch size = 1, a6000, examples/s) |
|---|---|---|---|---|
| gliclass‑edge‑v3.0 | 131 MB | 32.7M | 0.4873 | 97.29 |
| gliclass‑modern‑base‑v3.0 | 606 MB | 151M | 0.5571 | 54.46 |
| gliclass‑modern‑large‑v3.0 | 1.6 GB | 399M | 0.6082 | 43.80 |
| gliclass‑base‑v3.0 | 746 MB | 187M | 0.6556 | 51.61 |
| gliclass‑large‑v3.0 | 1.75 GB | 439M | 0.7001 | 25.22 |
First of all, you need to install GLiClass library:
pip install gliclass
pip install -U transformers>=4.48.0
Then you need to initialize a model and a pipeline:
from gliclass import GLiClassModel, ZeroShotClassificationPipeline
from transformers import AutoTokenizer
model = GLiClassModel.from_pretrained("knowledgator/gliclass-edge-v3.0")
tokenizer = AutoTokenizer.from_pretrained("knowledgator/gliclass-edge-v3.0", add_prefix_space=True)
pipeline = ZeroShotClassificationPipeline(model, tokenizer, classification_type='multi-label', device='cuda:0')
text = "One day I will see the world!"
labels = ["travel", "dreams", "sport", "science", "politics"]
results = pipeline(text, labels, threshold=0.5)[0] #because we have one text
for result in results:
print(result["label"], "=>", result["score"])
If you want to use it for NLI type of tasks, we recommend representing your premise as a text and hypothesis as a label, you can put several hypotheses, but the model works best with a single input hypothesis.
# Initialize model and multi-label pipeline
text = "The cat slept on the windowsill all afternoon"
labels = ["The cat was awake and playing outside."]
results = pipeline(text, labels, threshold=0.0)[0]
print(results)
Below, you can see the F1 score on several text classification datasets. All tested models were not fine-tuned on those datasets and were tested in a zero-shot setting.
GLiClass-V3:
| Dataset | gliclass‑large‑v3.0 | gliclass‑base‑v3.0 | gliclass‑modern‑large‑v3.0 | gliclass‑modern‑base‑v3.0 | gliclass‑edge‑v3.0 |
|---|---|---|---|---|---|
| CR | 0.9398 | 0.9127 | 0.8952 | 0.8902 | 0.8215 |
| sst2 | 0.9192 | 0.8959 | 0.9330 | 0.8959 | 0.8199 |
| sst5 | 0.4606 | 0.3376 | 0.4619 | 0.2756 | 0.2823 |
| 20_news_ groups |
0.5958 | 0.4759 | 0.3905 | 0.3433 | 0.2217 |
| spam | 0.7584 | 0.6760 | 0.5813 | 0.6398 | 0.5623 |
| financial_ phrasebank |
0.9000 | 0.8971 | 0.5929 | 0.4200 | 0.5004 |
| imdb | 0.9366 | 0.9251 | 0.9402 | 0.9158 | 0.8485 |
| ag_news | 0.7181 | 0.7279 | 0.7269 | 0.6663 | 0.6645 |
| emotion | 0.4506 | 0.4447 | 0.4517 | 0.4254 | 0.3851 |
| cap_sotu | 0.4589 | 0.4614 | 0.4072 | 0.3625 | 0.2583 |
| rotten_ tomatoes |
0.8411 | 0.7943 | 0.7664 | 0.7070 | 0.7024 |
| massive | 0.5649 | 0.5040 | 0.3905 | 0.3442 | 0.2414 |
| banking | 0.5574 | 0.4698 | 0.3683 | 0.3561 | 0.0272 |
| snips | 0.9692 | 0.9474 | 0.7707 | 0.5663 | 0.5257 |
| AVERAGE | 0.7193 | 0.6764 | 0.6197 | 0.5577 | 0.4900 |
Previous GLiClass models:
| Dataset | gliclass‑large‑v1.0‑lw | gliclass‑base‑v1.0‑lw | gliclass‑modern‑large‑v2.0 | gliclass‑modern‑base‑v2.0 |
|---|---|---|---|---|
| CR | 0.9226 | 0.9097 | 0.9154 | 0.8977 |
| sst2 | 0.9247 | 0.8987 | 0.9308 | 0.8524 |
| sst5 | 0.2891 | 0.3779 | 0.2152 | 0.2346 |
| 20_news_ groups |
0.4083 | 0.3953 | 0.3813 | 0.3857 |
| spam | 0.3642 | 0.5126 | 0.6603 | 0.4608 |
| financial_ phrasebank |
0.9044 | 0.8880 | 0.3152 | 0.3465 |
| imdb | 0.9429 | 0.9351 | 0.9449 | 0.9188 |
| ag_news | 0.7559 | 0.6985 | 0.6999 | 0.6836 |
| emotion | 0.3951 | 0.3516 | 0.4341 | 0.3926 |
| cap_sotu | 0.4749 | 0.4643 | 0.4095 | 0.3588 |
| rotten_ tomatoes |
0.8807 | 0.8429 | 0.7386 | 0.6066 |
| massive | 0.5606 | 0.4635 | 0.2394 | 0.3458 |
| banking | 0.3317 | 0.4396 | 0.1355 | 0.2907 |
| snips | 0.9707 | 0.9572 | 0.8468 | 0.7378 |
| AVERAGE | 0.6518 | 0.6525 | 0.5619 | 0.5366 |
Cross-Encoders:
| Dataset | deberta‑v3‑large‑zeroshot‑v2.0 | deberta‑v3‑base‑zeroshot‑v2.0 | roberta‑large‑zeroshot‑v2.0‑c | comprehend_it‑base |
|---|---|---|---|---|
| CR | 0.9134 | 0.9051 | 0.9141 | 0.8936 |
| sst2 | 0.9272 | 0.9176 | 0.8573 | 0.9006 |
| sst5 | 0.3861 | 0.3848 | 0.4159 | 0.4140 |
| enron_ spam |
0.5970 | 0.4640 | 0.5040 | 0.3637 |
| financial_ phrasebank |
0.5820 | 0.6690 | 0.4550 | 0.4695 |
| imdb | 0.9180 | 0.8990 | 0.9040 | 0.4644 |
| ag_news | 0.7710 | 0.7420 | 0.7450 | 0.6016 |
| emotion | 0.4840 | 0.4950 | 0.4860 | 0.4165 |
| cap_sotu | 0.5020 | 0.4770 | 0.5230 | 0.3823 |
| rotten_ tomatoes |
0.8680 | 0.8600 | 0.8410 | 0.4728 |
| massive | 0.5180 | 0.5200 | 0.5200 | 0.3314 |
| banking77 | 0.5670 | 0.4460 | 0.2900 | 0.4972 |
| AVERAGE | 0.6695 | 0.6483 | 0.6213 | 0.5173 |
Inference Speed:
Each model was tested on examples with 64, 256, and 512 tokens in text and 1, 2, 4, 8, 16, 32, 64, and 128 labels on an a6000 GPU. Then, scores were averaged across text lengths.
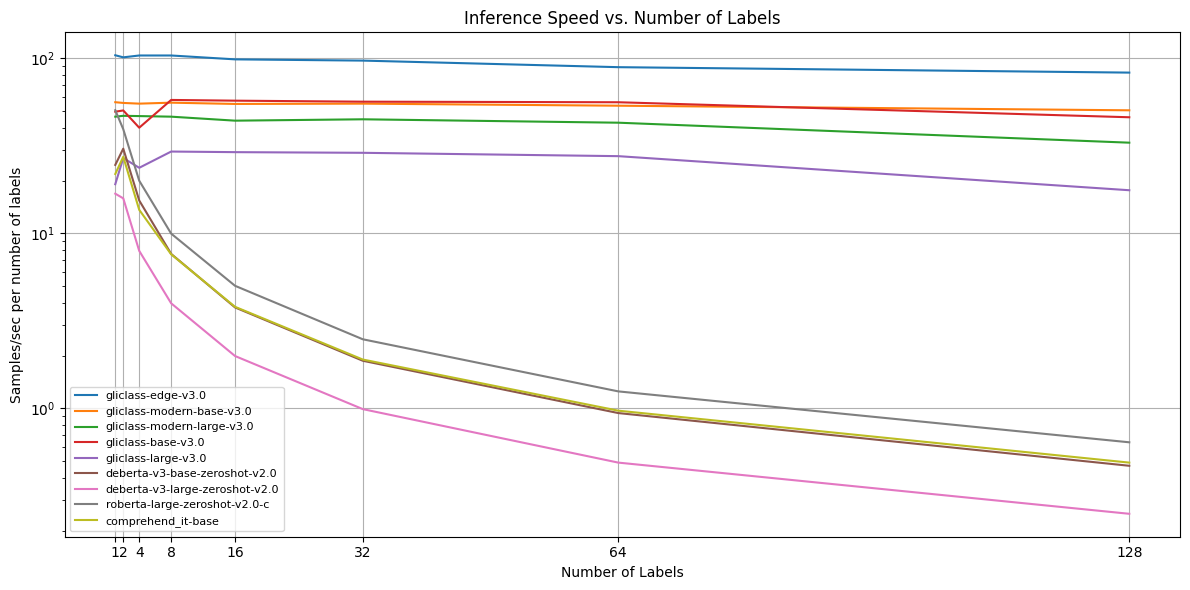
| Model Name / n samples per second per m labels | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | Average |
|---|---|---|---|---|---|---|---|---|---|
| gliclass‑edge‑v3.0 | 103.81 | 101.01 | 103.50 | 103.50 | 98.36 | 96.77 | 88.76 | 82.64 | 97.29 |
| gliclass‑modern‑base‑v3.0 | 56.00 | 55.46 | 54.95 | 55.66 | 54.73 | 54.95 | 53.48 | 50.34 | 54.46 |
| gliclass‑modern‑large‑v3.0 | 46.30 | 46.82 | 46.66 | 46.30 | 43.93 | 44.73 | 42.77 | 32.89 | 43.80 |
| gliclass‑base‑v3.0 | 49.42 | 50.25 | 40.05 | 57.69 | 57.14 | 56.39 | 55.97 | 45.94 | 51.61 |
| gliclass‑large‑v3.0 | 19.05 | 26.86 | 23.64 | 29.27 | 29.04 | 28.79 | 27.55 | 17.60 | 25.22 |
| deberta‑v3‑base‑zeroshot‑v2.0 | 24.55 | 30.40 | 15.38 | 7.62 | 3.77 | 1.87 | 0.94 | 0.47 | 10.63 |
| deberta‑v3‑large‑zeroshot‑v2.0 | 16.82 | 15.82 | 7.93 | 3.98 | 1.99 | 0.99 | 0.49 | 0.25 | 6.03 |
| roberta‑large‑zeroshot‑v2.0‑c | 50.42 | 39.27 | 19.95 | 9.95 | 5.01 | 2.48 | 1.25 | 0.64 | 16.12 |
| comprehend_it‑base | 21.79 | 27.32 | 13.60 | 7.58 | 3.80 | 1.90 | 0.97 | 0.49 | 9.72 |