
File size: 5,731 Bytes
ab2f482 36a6aad ab2f482 36a6aad ab2f482 36a6aad ab2f482 36a6aad ab2f482 36a6aad ab2f482 36a6aad ab2f482 91ff004 ab2f482 91ff004 ab2f482 36a6aad ab2f482 36a6aad ab2f482 36a6aad |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 |
---
license: mit
language:
- en
base_model:
- Qwen/Qwen2.5-1.5B-Instruct
library_name: transformers
---
# Aero-1-Audio
<!-- Provide a quick summary of what the model is/does. -->
`Aero-1-Audio` is a compact audio model adept at various audio tasks, including speech recognition, audio understanding, and following audio instructions.
1. Built upon the Qwen-2.5-1.5B language model, Aero delivers strong performance across multiple audio benchmarks while remaining parameter-efficient, even compared with larger advanced models like Whisper and Qwen-2-Audio and Phi-4-Multimodal, or commercial services like ElevenLabs/Scribe.
2. Aero is trained within one day on 16 H100 GPUs using just 50k hours of audio data. Our insight suggests that audio model training could be sample efficient with high quality and filtered data.
3. Aero can accurately perform ASR and audio understanding on continuous audio inputs up to 15 minutes in length, which we find the scenario is still a challenge for other models.
- **Developed by:** [LMMs-Lab]
- **Model type:** [LLM + Audio Encoder]
- **Language(s) (NLP):** [English]
- **License:** [MIT]
## How to Get Started with the Model
Use the code below to get started with the model.
You are encouraged to install transformers by using
```bash
python3 -m pip install transformers@git+https://github.com/huggingface/[email protected]
```
as this is the transformers version we are using when building this model.
### Simple Demo
```python
from transformers import AutoProcessor, AutoModelForCausalLM
import torch
import librosa
def load_audio():
return librosa.load(librosa.ex("libri1"), sr=16000)[0]
processor = AutoProcessor.from_pretrained("lmms-lab/Aero-1-Audio-1.5B", trust_remote_code=True)
# We encourage to use flash attention 2 for better performance
# Please install it with `pip install --no-build-isolation flash-attn`
# If you do not want flash attn, please use sdpa or eager`
model = AutoModelForCausalLM.from_pretrained("lmms-lab/Aero-1-Audio-1.5B", device_map="cuda", torch_dtype="auto", attn_implementation="flash_attention_2", trust_remote_code=True)
model.eval()
messages = [
{
"role": "user",
"content": [
{
"type": "audio_url",
"audio": "placeholder",
},
{
"type": "text",
"text": "Please transcribe the audio",
}
]
}
]
audios = [load_audio()]
prompt = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(text=prompt, audios=audios, sampling_rate=16000, return_tensors="pt")
inputs = {k: v.to("cuda") for k, v in inputs.items()}
outputs = model.generate(**inputs, eos_token_id=151645, max_new_tokens=4096)
cont = outputs[:, inputs["input_ids"].shape[-1] :]
print(processor.batch_decode(cont, skip_special_tokens=True)[0])
```
### Batch Inference
The model supports batch inference with transformers. An example demo is like this:
```python
from transformers import AutoProcessor, AutoModelForCausalLM
import torch
import librosa
def load_audio():
return librosa.load(librosa.ex("libri1"), sr=16000)[0]
def load_audio_2():
return librosa.load(librosa.ex("libri2"), sr=16000)[0]
processor = AutoProcessor.from_pretrained("lmms-lab/Aero-1-Audio-1.5B", trust_remote_code=True)
# We encourage to use flash attention 2 for better performance
# Please install it with `pip install --no-build-isolation flash-attn`
# If you do not want flash attn, please use sdpa or eager`
model = AutoModelForCausalLM.from_pretrained("lmms-lab/Aero-1-Audio-1.5B", device_map="cuda", torch_dtype="auto", attn_implementation="flash_attention_2", trust_remote_code=True)
model.eval()
messages = [
{
"role": "user",
"content": [
{
"type": "audio_url",
"audio": "placeholder",
},
{
"type": "text",
"text": "Please transcribe the audio",
}
]
}
]
messages = [messages, messages]
audios = [load_audio(), load_audio_2()]
processor.tokenizer.padding_side="left"
prompt = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(text=prompt, audios=audios, sampling_rate=16000, return_tensors="pt", padding=True)
inputs = {k: v.to("cuda") for k, v in inputs.items()}
outputs = model.generate(**inputs, eos_token_id=151645, pad_token_id=151643, max_new_tokens=4096)
cont = outputs[:, inputs["input_ids"].shape[-1] :]
print(processor.batch_decode(cont, skip_special_tokens=True))
```
## Training Details
### Training Data
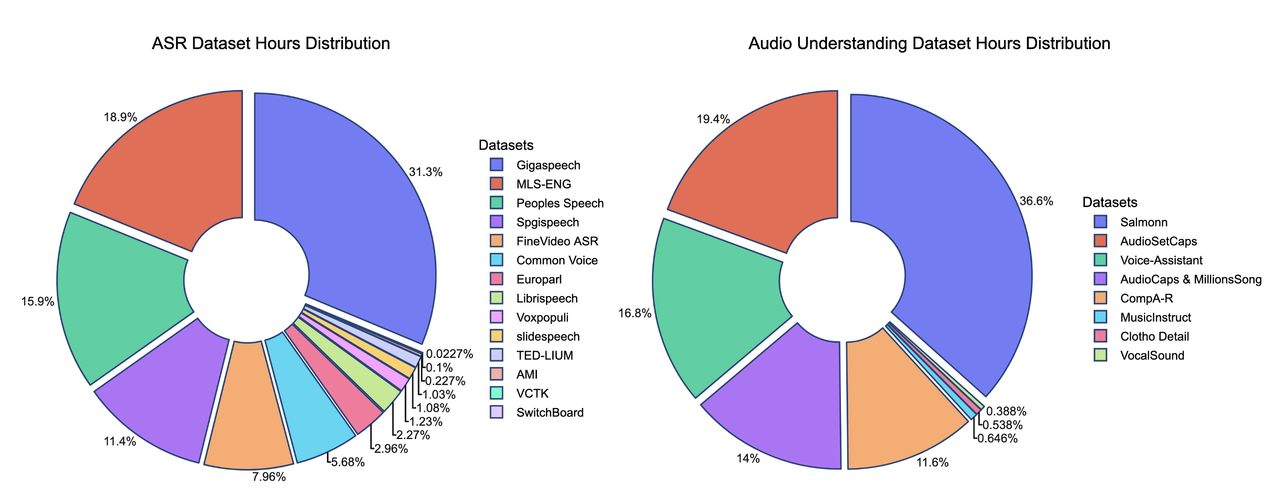
We present the contributions of our data mixture here. Our SFT data mixture includes over 20 publicly available datasets, and comparisons with other models highlight the data's lightweight nature.
[](https://postimg.cc/c6CB0HkF)
[](https://postimg.cc/XBrf8HBR)
*The hours of some training datasets are estimated and may not be fully accurate
<br>
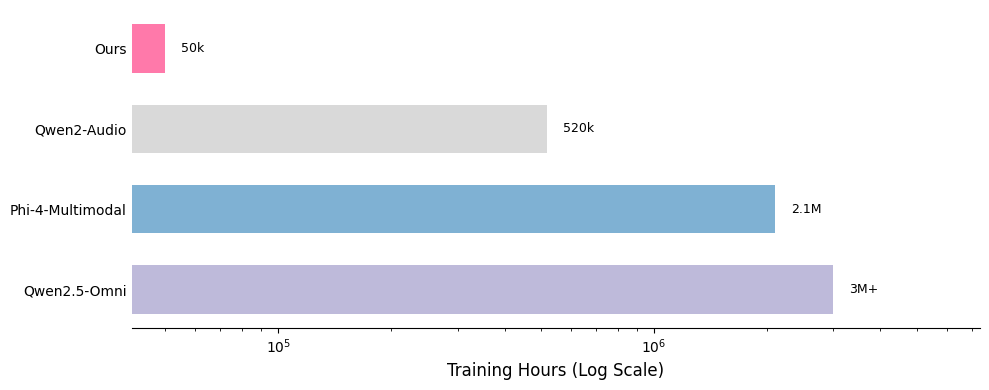
One of the key strengths of our training recipe lies in the quality and quantity of our data. Our training dataset consists of approximately 5 billion tokens, corresponding to around 50,000 hours of audio. Compared to models such as Qwen-Omni and Phi-4, our dataset is over 100 times smaller, yet our model achieves competitive performance. All data is sourced from publicly available open-source datasets, highlighting the sample efficiency of our training approach. A detailed breakdown of our data distribution is provided below, along with comparisons to other models.
|