
제공하신 코드에 대해, 오류가 발생하여 질문드립니다.

오류에 대한 원인을 찾을 수 있을까요?
video 파일이 없다고 해서 넣어주긴 했는데, 그것 때문일까요?
3초가량의 video 이고, 그 구문을 주석 처리 후에도 같은 에러가 발생합니다.
'''
That sounds like a fun challenge! Could you please provide me with a template or a specific scenario you'd like to use for this?<|im_end|><|endofturn|>
Both max_new_tokens (=8192) and max_length(=196) seem to have been set. max_new_tokens will take precedence. Please refer to the documentation for more information. (https://huggingface.co/docs/transformers/main/en/main_classes/text_generation)
RuntimeError Traceback (most recent call last)
Cell In[2], line 77
72 preprocessed = preprocessor(all_images, is_video_list=is_video_list)
73 input_ids = tokenizer.apply_chat_template(
74 new_vlm_chat, return_tensors="pt", tokenize=True, add_generation_prompt=True,
75 )
---> 77 output_ids = model.generate(
78 input_ids=input_ids.to(device="cuda"),
79 max_new_tokens=8192,
80 do_sample=True,
81 top_p=0.6,
82 temperature=0.5,
83 repetition_penalty=1.0,
84 **preprocessed,
85 )
86 print(tokenizer.batch_decode(output_ids)[0])
File /usr/local/lib/python3.9/dist-packages/torch/utils/_contextlib.py:116, in context_decorator..decorate_context(*args, **kwargs)
113 @functools.wraps(func)
114 def decorate_context(*args, **kwargs):
115 with ctx_factory():
--> 116 return func(*args, **kwargs)
File ~/.cache/huggingface/modules/transformers_modules/naver-hyperclovax/HyperCLOVAX-SEED-Vision-Instruct-3B/e9d93a47210f12fbee2b7b65f1561f37c872db2b/modeling_hyperclovax.py:1140, in HCXVisionForCausalLM.generate(self, input_ids, pixel_values, image_sizes, vision_query_lengths, non_vision_query_lengths, num_queries_vis_abstractors, num_queries_vis_abstractors_slow, first_last_frames_slows, is_videos, img_start_ids_list, pad_token_id, eos_token_id, bad_words_ids, max_length, min_length, do_sample, num_beams, top_p, top_k, temperature, repetition_penalty, length_penalty, use_cache, **kwargs)
1135 inputs_embeds = (
1136 inputs_embeds.to(self.base_model.device) if isinstance(inputs_embeds, torch.Tensor) else inputs_embeds
1137 )
1139 # pred : torch.int64 : [batchsize, generated token_length]
-> 1140 pred = self.language_model.generate(
1141 inputs_embeds=inputs_embeds,
1142 pad_token_id=pad_token_id,
1143 eos_token_id=eos_token_id,
1144 bad_words_ids=bad_words_ids,
1145 max_length=max_length,
1146 min_length=min_length,
1147 num_beams=num_beams,
1148 do_sample=(False if temperature == 0.0 else do_sample), # set do_sample=False if invalid temperature
1149 top_k=top_k,
1150 top_p=top_p,
1151 temperature=temperature,
1152 repetition_penalty=repetition_penalty,
1153 length_penalty=length_penalty,
1154 early_stopping=(False if num_beams <= 1 else True), # set early_stopping=False when not beam_search
1155 use_cache=use_cache,
1156 **kwargs,
1157 )
1159 return pred
File /usr/local/lib/python3.9/dist-packages/torch/utils/_contextlib.py:116, in context_decorator..decorate_context(*args, **kwargs)
113 @functools.wraps(func)
114 def decorate_context(*args, **kwargs):
115 with ctx_factory():
--> 116 return func(*args, **kwargs)
File /usr/local/lib/python3.9/dist-packages/transformers/generation/utils.py:2465, in GenerationMixin.generate(self, inputs, generation_config, logits_processor, stopping_criteria, prefix_allowed_tokens_fn, synced_gpus, assistant_model, streamer, negative_prompt_ids, negative_prompt_attention_mask, use_model_defaults, **kwargs)
2457 input_ids, model_kwargs = self._expand_inputs_for_generation(
2458 input_ids=input_ids,
2459 expand_size=generation_config.num_return_sequences,
2460 is_encoder_decoder=self.config.is_encoder_decoder,
2461 **model_kwargs,
2462 )
2464 # 12. run sample (it degenerates to greedy search when generation_config.do_sample=False)
-> 2465 result = self._sample(
2466 input_ids,
2467 logits_processor=prepared_logits_processor,
2468 stopping_criteria=prepared_stopping_criteria,
2469 generation_config=generation_config,
2470 synced_gpus=synced_gpus,
2471 streamer=streamer,
2472 **model_kwargs,
2473 )
2475 elif generation_mode in (GenerationMode.BEAM_SAMPLE, GenerationMode.BEAM_SEARCH):
2476 # 11. interleave input_ids with num_beams additional sequences per batch
2477 input_ids, model_kwargs = self._expand_inputs_for_generation(
2478 input_ids=input_ids,
2479 expand_size=generation_config.num_beams,
2480 is_encoder_decoder=self.config.is_encoder_decoder,
2481 **model_kwargs,
2482 )
File /usr/local/lib/python3.9/dist-packages/transformers/generation/utils.py:3431, in GenerationMixin._sample(self, input_ids, logits_processor, stopping_criteria, generation_config, synced_gpus, streamer, **model_kwargs)
3428 model_inputs.update({"output_hidden_states": output_hidden_states} if output_hidden_states else {})
3430 if is_prefill:
-> 3431 outputs = self(**model_inputs, return_dict=True)
3432 is_prefill = False
3433 else:
File /usr/local/lib/python3.9/dist-packages/torch/nn/modules/module.py:1739, in Module._wrapped_call_impl(self, *args, **kwargs)
1737 return self._compiled_call_impl(*args, **kwargs) # type: ignore[misc]
1738 else:
-> 1739 return self._call_impl(*args, **kwargs)
File /usr/local/lib/python3.9/dist-packages/torch/nn/modules/module.py:1750, in Module._call_impl(self, *args, **kwargs)
1745 # If we don't have any hooks, we want to skip the rest of the logic in
1746 # this function, and just call forward.
1747 if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks or self._forward_pre_hooks
1748 or _global_backward_pre_hooks or _global_backward_hooks
1749 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1750 return forward_call(*args, **kwargs)
1752 result = None
1753 called_always_called_hooks = set()
File /usr/local/lib/python3.9/dist-packages/transformers/utils/generic.py:965, in can_return_tuple..wrapper(self, *args, **kwargs)
962 set_attribute_for_modules(self, "_is_top_level_module", False)
964 try:
--> 965 output = func(self, *args, **kwargs)
966 if is_requested_to_return_tuple or (is_configured_to_return_tuple and is_top_level_module):
967 output = output.to_tuple()
File /usr/local/lib/python3.9/dist-packages/transformers/utils/deprecation.py:172, in deprecate_kwarg..wrapper..wrapped_func(*args, **kwargs)
168 elif minimum_action in (Action.NOTIFY, Action.NOTIFY_ALWAYS) and not is_torchdynamo_compiling():
169 # DeprecationWarning is ignored by default, so we use FutureWarning instead
170 warnings.warn(message, FutureWarning, stacklevel=2)
--> 172 return func(*args, **kwargs)
File /usr/local/lib/python3.9/dist-packages/transformers/models/llama/modeling_llama.py:821, in LlamaForCausalLM.forward(self, input_ids, attention_mask, position_ids, past_key_values, inputs_embeds, labels, use_cache, output_attentions, output_hidden_states, cache_position, logits_to_keep, **kwargs)
816 output_hidden_states = (
817 output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
818 )
820 # decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
--> 821 outputs: BaseModelOutputWithPast = self.model(
822 input_ids=input_ids,
823 attention_mask=attention_mask,
824 position_ids=position_ids,
825 past_key_values=past_key_values,
826 inputs_embeds=inputs_embeds,
827 use_cache=use_cache,
828 output_attentions=output_attentions,
829 output_hidden_states=output_hidden_states,
830 cache_position=cache_position,
831 **kwargs,
832 )
834 hidden_states = outputs.last_hidden_state
835 # Only compute necessary logits, and do not upcast them to float if we are not computing the loss
File /usr/local/lib/python3.9/dist-packages/torch/nn/modules/module.py:1739, in Module._wrapped_call_impl(self, *args, **kwargs)
1737 return self._compiled_call_impl(*args, **kwargs) # type: ignore[misc]
1738 else:
-> 1739 return self._call_impl(*args, **kwargs)
File /usr/local/lib/python3.9/dist-packages/torch/nn/modules/module.py:1750, in Module._call_impl(self, *args, **kwargs)
1745 # If we don't have any hooks, we want to skip the rest of the logic in
1746 # this function, and just call forward.
1747 if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks or self._forward_pre_hooks
1748 or _global_backward_pre_hooks or _global_backward_hooks
1749 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1750 return forward_call(*args, **kwargs)
1752 result = None
1753 called_always_called_hooks = set()
File /usr/local/lib/python3.9/dist-packages/transformers/utils/generic.py:965, in can_return_tuple..wrapper(self, *args, **kwargs)
962 set_attribute_for_modules(self, "_is_top_level_module", False)
964 try:
--> 965 output = func(self, *args, **kwargs)
966 if is_requested_to_return_tuple or (is_configured_to_return_tuple and is_top_level_module):
967 output = output.to_tuple()
File /usr/local/lib/python3.9/dist-packages/transformers/models/llama/modeling_llama.py:571, in LlamaModel.forward(self, input_ids, attention_mask, position_ids, past_key_values, inputs_embeds, use_cache, output_attentions, output_hidden_states, cache_position, **flash_attn_kwargs)
559 layer_outputs = self._gradient_checkpointing_func(
560 partial(decoder_layer.call, **flash_attn_kwargs),
561 hidden_states,
(...)
568 position_embeddings,
569 )
570 else:
--> 571 layer_outputs = decoder_layer(
572 hidden_states,
573 attention_mask=causal_mask,
574 position_ids=position_ids,
575 past_key_value=past_key_values,
576 output_attentions=output_attentions,
577 use_cache=use_cache,
578 cache_position=cache_position,
579 position_embeddings=position_embeddings,
580 **flash_attn_kwargs,
581 )
583 hidden_states = layer_outputs[0]
585 if output_attentions:
File /usr/local/lib/python3.9/dist-packages/torch/nn/modules/module.py:1739, in Module._wrapped_call_impl(self, *args, **kwargs)
1737 return self._compiled_call_impl(*args, **kwargs) # type: ignore[misc]
1738 else:
-> 1739 return self._call_impl(*args, **kwargs)
File /usr/local/lib/python3.9/dist-packages/torch/nn/modules/module.py:1750, in Module._call_impl(self, *args, **kwargs)
1745 # If we don't have any hooks, we want to skip the rest of the logic in
1746 # this function, and just call forward.
1747 if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks or self._forward_pre_hooks
1748 or _global_backward_pre_hooks or _global_backward_hooks
1749 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1750 return forward_call(*args, **kwargs)
1752 result = None
1753 called_always_called_hooks = set()
File /usr/local/lib/python3.9/dist-packages/transformers/models/llama/modeling_llama.py:318, in LlamaDecoderLayer.forward(self, hidden_states, attention_mask, position_ids, past_key_value, output_attentions, use_cache, cache_position, position_embeddings, **kwargs)
315 hidden_states = self.input_layernorm(hidden_states)
317 # Self Attention
--> 318 hidden_states, self_attn_weights = self.self_attn(
319 hidden_states=hidden_states,
320 attention_mask=attention_mask,
321 position_ids=position_ids,
322 past_key_value=past_key_value,
323 output_attentions=output_attentions,
324 use_cache=use_cache,
325 cache_position=cache_position,
326 position_embeddings=position_embeddings,
327 **kwargs,
328 )
329 hidden_states = residual + hidden_states
331 # Fully Connected
File /usr/local/lib/python3.9/dist-packages/torch/nn/modules/module.py:1739, in Module._wrapped_call_impl(self, *args, **kwargs)
1737 return self._compiled_call_impl(*args, **kwargs) # type: ignore[misc]
1738 else:
-> 1739 return self._call_impl(*args, **kwargs)
File /usr/local/lib/python3.9/dist-packages/torch/nn/modules/module.py:1750, in Module._call_impl(self, *args, **kwargs)
1745 # If we don't have any hooks, we want to skip the rest of the logic in
1746 # this function, and just call forward.
1747 if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks or self._forward_pre_hooks
1748 or _global_backward_pre_hooks or _global_backward_hooks
1749 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1750 return forward_call(*args, **kwargs)
1752 result = None
1753 called_always_called_hooks = set()
File /usr/local/lib/python3.9/dist-packages/transformers/models/llama/modeling_llama.py:252, in LlamaAttention.forward(self, hidden_states, position_embeddings, attention_mask, past_key_value, cache_position, **kwargs)
249 input_shape = hidden_states.shape[:-1]
250 hidden_shape = (*input_shape, -1, self.head_dim)
--> 252 query_states = self.q_proj(hidden_states).view(hidden_shape).transpose(1, 2)
253 key_states = self.k_proj(hidden_states).view(hidden_shape).transpose(1, 2)
254 value_states = self.v_proj(hidden_states).view(hidden_shape).transpose(1, 2)
File /usr/local/lib/python3.9/dist-packages/torch/nn/modules/module.py:1739, in Module._wrapped_call_impl(self, *args, **kwargs)
1737 return self._compiled_call_impl(*args, **kwargs) # type: ignore[misc]
1738 else:
-> 1739 return self._call_impl(*args, **kwargs)
File /usr/local/lib/python3.9/dist-packages/torch/nn/modules/module.py:1750, in Module._call_impl(self, *args, **kwargs)
1745 # If we don't have any hooks, we want to skip the rest of the logic in
1746 # this function, and just call forward.
1747 if not (self._backward_hooks or self._backward_pre_hooks or self._forward_hooks or self._forward_pre_hooks
1748 or _global_backward_pre_hooks or _global_backward_hooks
1749 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1750 return forward_call(*args, **kwargs)
1752 result = None
1753 called_always_called_hooks = set()
File /usr/local/lib/python3.9/dist-packages/torch/nn/modules/linear.py:125, in Linear.forward(self, input)
124 def forward(self, input: Tensor) -> Tensor:
--> 125 return F.linear(input, self.weight, self.bias)
RuntimeError: expected mat1 and mat2 to have the same dtype, but got: float != c10::BFloat16
'''

image, video 형식의 데이터가 내부적으로 float 형식으로 처리되는 듯합니다.
이미지 입력 시 같은 에러를 겪었는데, 모델을 torch.float32 형식으로 로드하니 해결됐습니다.
model_name = "naver-hyperclovax/HyperCLOVAX-SEED-Vision-Instruct-3B"
model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True).to(device="cuda", dtype=torch.float32)
모델을 BFloat16 형식으로 사용하는 방법은 찾지 못했습니다.
감사합니다 long으로 바꿔도 안됬었는데 float32는 되는군요

model.generate() 함수를 with torch.amp.autocast(device_type="cuda"): 로 감싸주시면 bf16 으로 동작합니다.


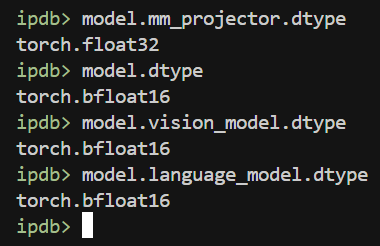
모델 릴리즈를 할 때, transformer 4.45.0 에서 모든 동작을 확인했습니다.
transformers 4.45.0 디펜던시를 맞추면 문제가 없지만, 최신 버전에서 동일한 이슈 발생함을 확인했습니다. (ver. 4.52.1)
성능재현까지 4.45.0 을 이용했기에 해당 버전 사용을 권장 드립니다.
하지만, 사용자 분들이 transformers 4.45.0 버전을 사용하지 못하는 경우도 있을 것으로 생각됩니다.
명시적으로 intermeidate tensor 를 language_model (llama3) 의 device, dtype 으로 이동시켰습니다.
inputs_embeds = inputs_embeds.to(device=self.language_model.device, dtype=self.language_model.dtype)
최신 버전 (4.52.1) 에서 정상 동작 확인했습니다.
@HERIUN 님께서 제안 주신 방법은 내부 인프라 코드 제거 중 수정이 덜 된 잔재로 보입니다. (torch.tensor 일 때만, .to 적용)
요 이슈와는 관련이 없는 점 확인했습니다.
PR 참고하여 따로 코드 업데이트 진행했습니다.
contribution 감사합니다.