
UltraLong
Collection
3 items
•
Updated
•
6
We introduce UltraLong-8B, a series of ultra-long context language models designed to process extensive sequences of text (up to 1M, 2M, and 4M tokens) while maintaining competitive performance on standard benchmarks. Built on the Llama-3.1, UltraLong-8B leverages a systematic training recipe that combines efficient continued pretraining with instruction tuning to enhance long-context understanding and instruction-following capabilities. This approach enables our models to efficiently scale their context windows without sacrificing general performance.
Starting with transformers >= 4.43.0 onward, you can run conversational inference using the Transformers pipeline abstraction or by leveraging the Auto classes with the generate() function.
Make sure to update your transformers installation via pip install --upgrade transformers.
import transformers
import torch
model_id = "nvidia/Llama-3.1-8B-UltraLong-4M-Instruct"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto",
)
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
outputs = pipeline(
messages,
max_new_tokens=256,
)
print(outputs[0]["generated_text"][-1])
Base model: meta-llama/Llama-3.1-8B-Instruct
Continued Pretraining: The training data consists of 1B tokens sourced from a pretraining corpus using per-domain upsampling based on sample length. The model was trained for 150 iterations with a sequence length of 4M and a global batch size of 2.
Supervised fine-tuning (SFT): 1B tokens on open-source instruction datasets across general, mathematics, and code domains. We subsample the data from the ‘general_sft_stage2’ from AceMath-Instruct.
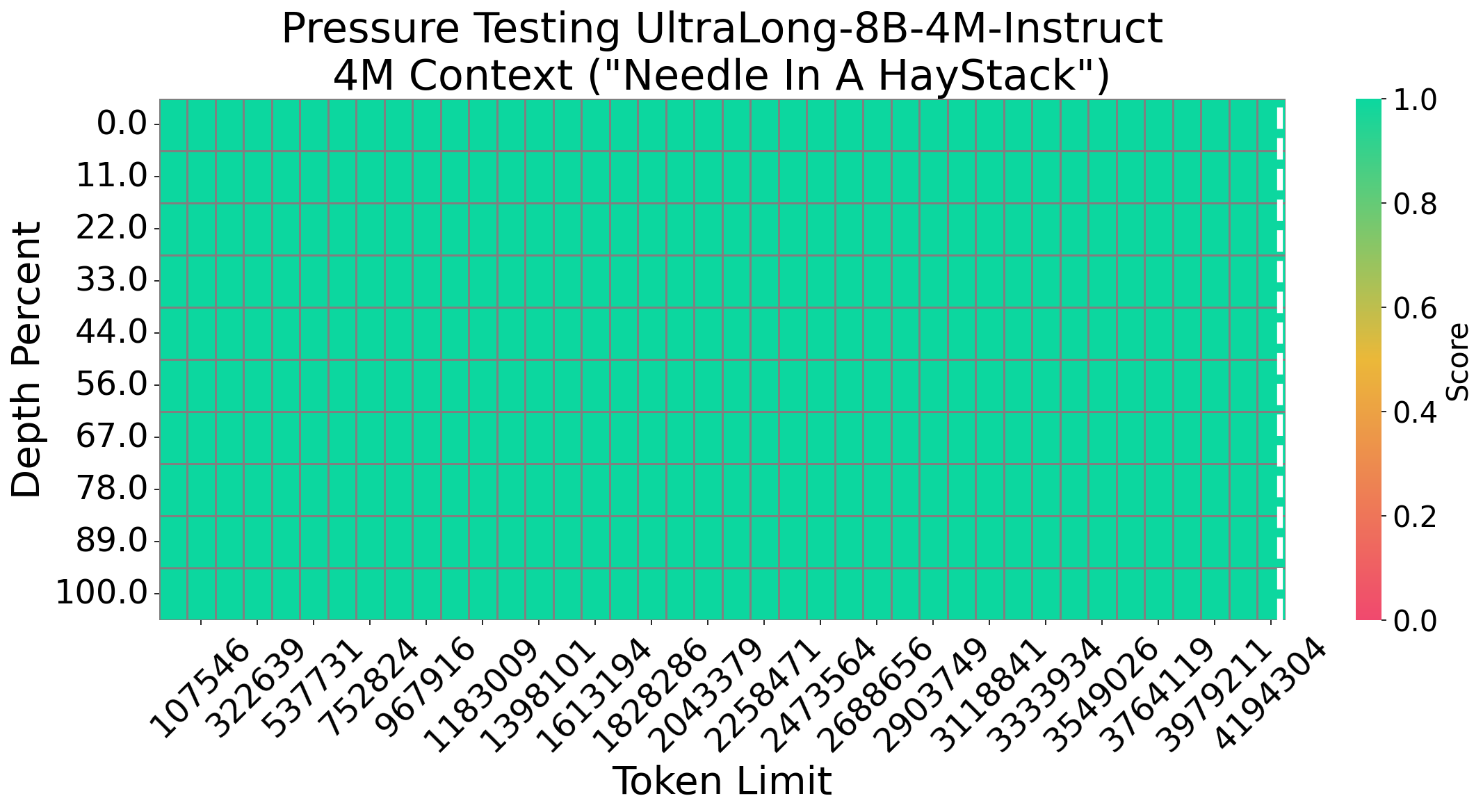
Maximum context window: 4M tokens
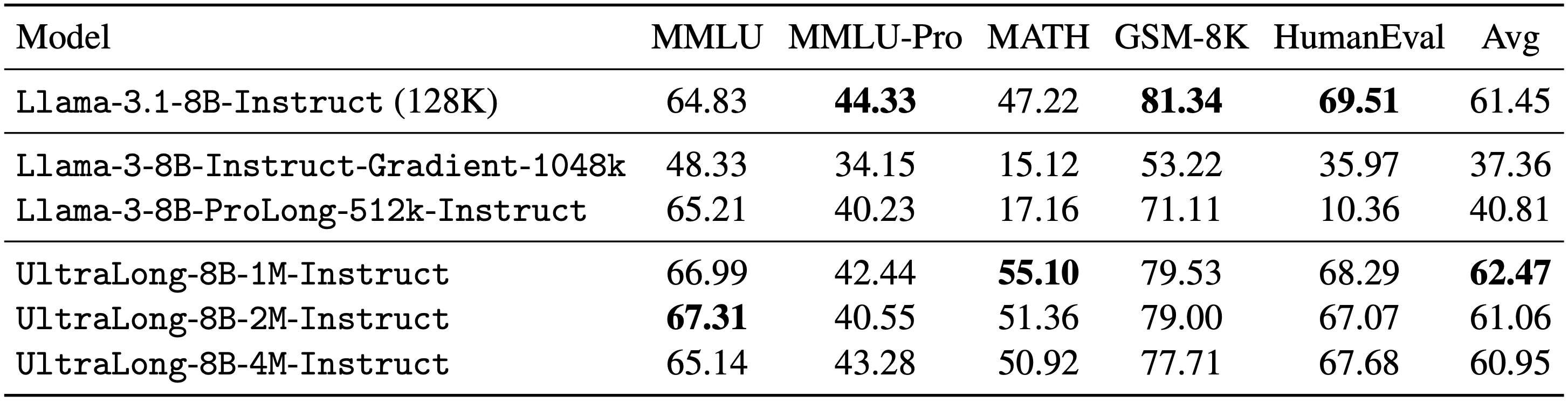
We evaluate UltraLong-8B on a diverse set of benchmarks, including long-context tasks (e.g., RULER, LV-Eval, and InfiniteBench) and standard tasks (e.g., MMLU, MATH, GSM-8K, and HumanEval). UltraLong-8B achieves superior performance on ultra-long context tasks while maintaining competitive results on standard benchmarks.

Chejian Xu ([email protected]), Wei Ping ([email protected])
@article{ulralong2025,
title={From 128K to 4M: Efficient Training of Ultra-Long Context Large Language Models},
author={Xu, Chejian and Ping, Wei and Xu, Peng and Liu, Zihan and Wang, Boxin and Shoeybi, Mohammad and Catanzaro, Bryan},
journal={arXiv preprint},
year={2025}
}