
Processing dataset?

Hi nemo team
Congrats on the work, I just want to try training model and I have a question.
with metadata for each data point (i've created by following tutorial):
Ex:
{"audio_filepath": "datasets/LibriLight/librispeech_finetuning/1h/2/clean/5778/12761/5778-12761-0005.flac", "duration": 10.945, "text": "but after our long wandering in rugged mountains where so frequently we had met with disappointments and where the crossing of every ridge displayed some unknown lake or river", "target_lang": "en", "source_lang": "en", "pnc": "False"}
How can I train the model to infer with timestamps?

Hi, @Nguyen667201 Thanks for your interest! You need to produce text with alignments as the new target for training. E.g. "text": "<|3|> it's <|7|> <|8|> almost <|9|> <|14|> beyond <|20|> <|20|> conjecture <|28|>", as described in "3. Training on a new task: A case of timestamp prediction". To do that, you can use any aligner (e.g. NeMo force aligner: https://docs.nvidia.com/nemo-framework/user-guide/latest/nemotoolkit/tools/nemo_forced_aligner.html) to align between speech and text.
Our code relevant to read text with timestamp is in this PR: https://github.com/NVIDIA/NeMo/pull/11591/files
We will publish a paper soon for more details about training process and data.
Hi
@huk-hf
,
I have tried training the model with both English and Vietnamese data. However, when I try to infer Vietnamese audio (assuming I set target_lang="fr" and source_lang="fr"), I still get a mix of Vietnamese and English transcription.
Does this mean that target_lang="fr" and source_lang="fr" are not actually being used during inference?
Could you please explain this to me?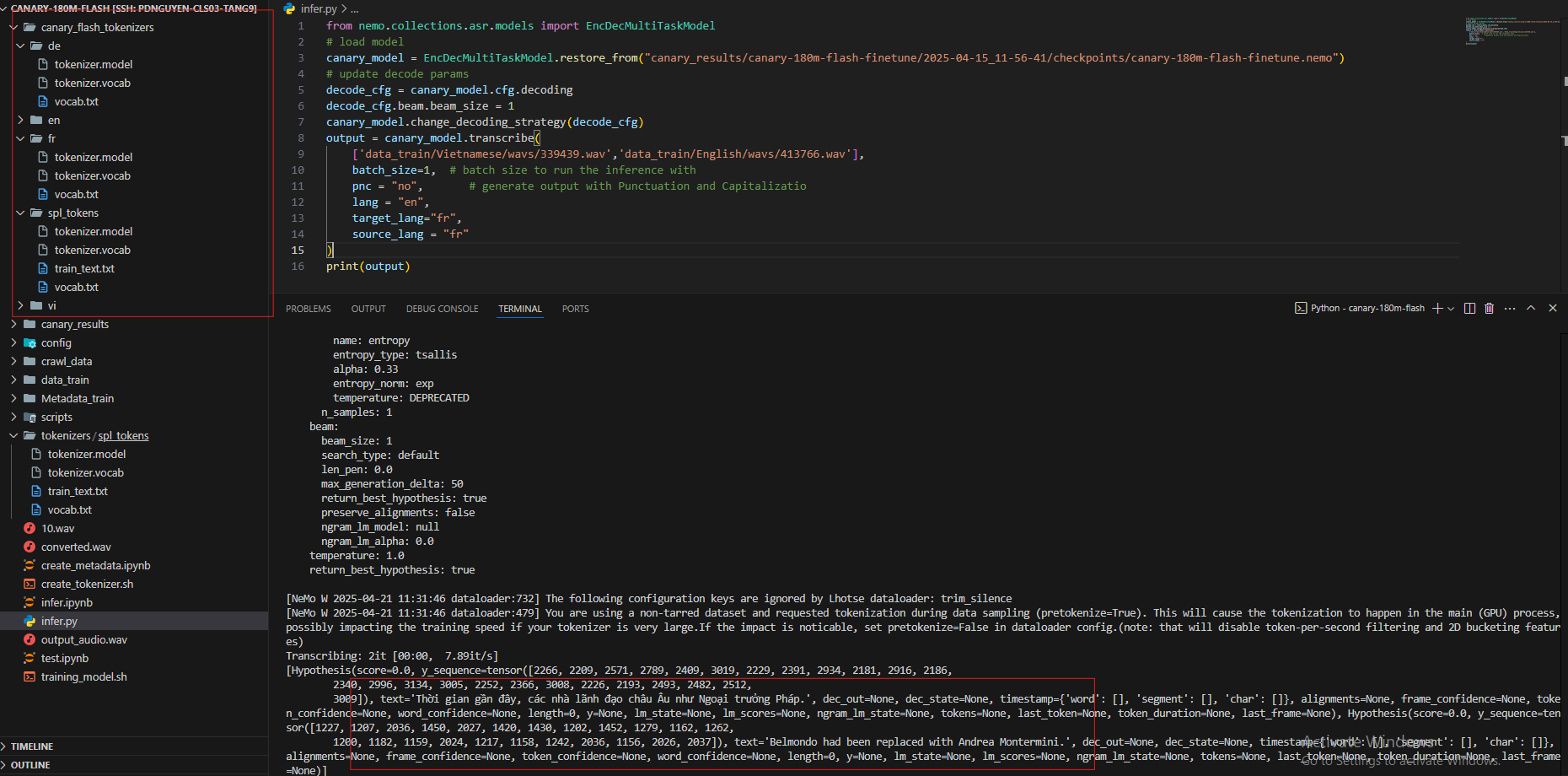

No, only those four mentioned languages. @Nguyen667201 maybe when you finetuned you probably have not used all combination of prompts and It could have affected the model performance.

Hi @Nguyen667201 , thank you for testing Canary models on a new language!
In the screenshot it looks like the Vietnamese audio has been transcribed in Vietnamese (correct me if I am wrong) and the English audio has English transcript. So, the model transcribes English utterance to English text even though both source_lang and target_lang are not English -- is that the unexpected part?
Since the model has not seen any English audio with source_lang=target_lang="fr" during training, it is hard to speculate what will it do on this unseen case during inference. It is possible that Canary model has learned some language ID inherently as a part of it's training and since the model has not been trained on English to Vietnamese translation, it defaults to transcribing in the original language being spoken.
Also a few pointers:
- The lang token "fr" is already used for French in Canary's training data. So, I'd recommend using a previously unused token for Vietnamese. You can see a list of available language tokens in the special tokenizer here.
- How much Vietnamese ASR data did you use for training? Maybe the amount of training data is not enough for the model to learn the function of
source_lang=target_lang="fr". - The way you are using
source_langandtarget_langkeys looks right to me, i.e. settingsource_lang='en'andtarget_lang='en'for English ASR, and accordingly for any other language. Make sure that you are usingsource_langandtarget_langin the same way during training and inference.