
A Closer Look at Spatiotemporal Convolutions for Action Recognition
Paper • 1711.11248 • Published • 1
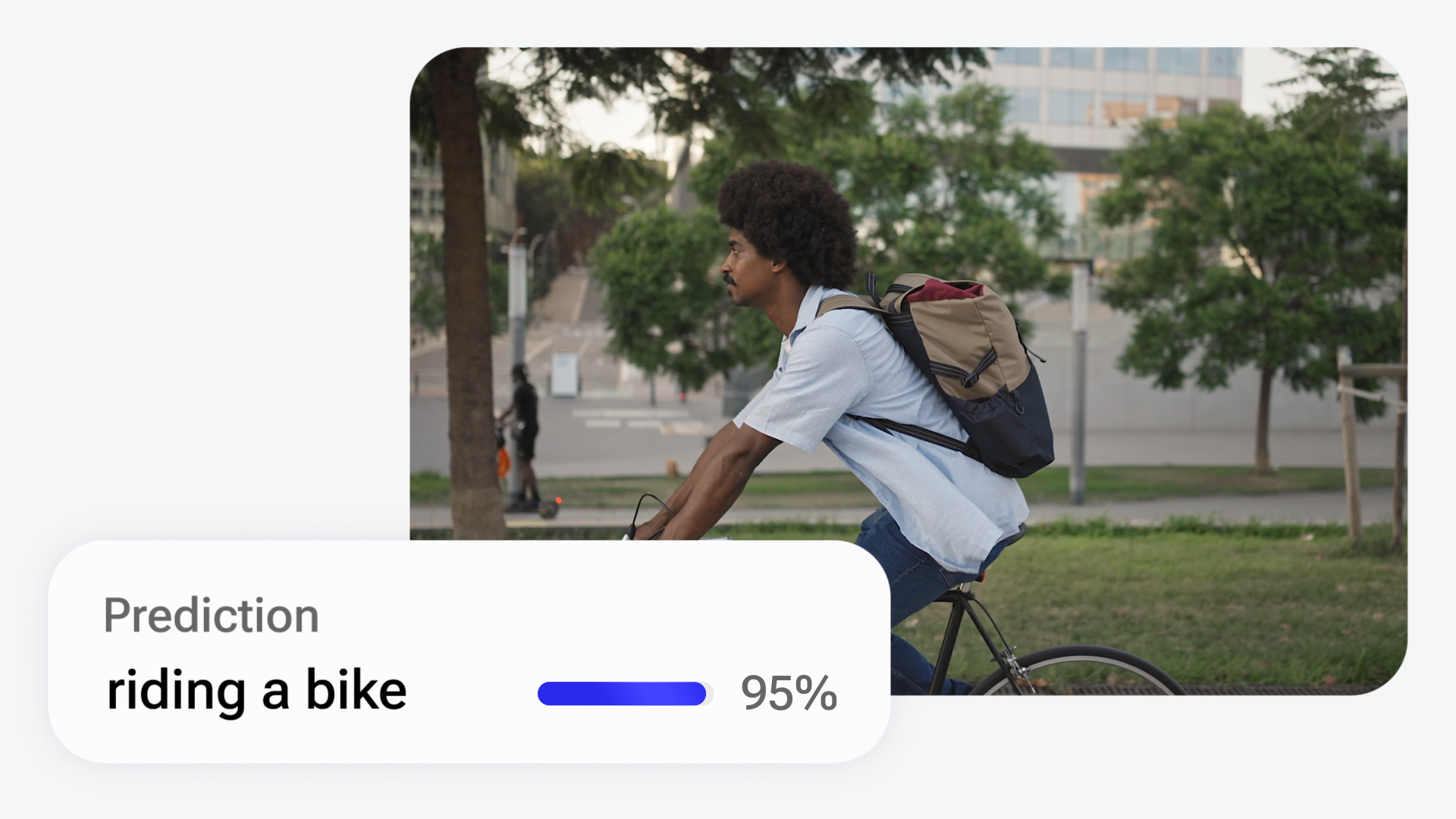
ResNet (2+1)D Convolutions is a network which explicitly factorizes 3D convolution into two separate and successive operations, a 2D spatial convolution and a 1D temporal convolution. It used for video understanding applications.
This is based on the implementation of ResNet-2Plus1D found here. This repository contains pre-exported model files optimized for Qualcomm® devices. You can use the Qualcomm® AI Hub Models library to export with custom configurations. More details on model performance across various devices, can be found here.
Qualcomm AI Hub Models uses Qualcomm AI Hub Workbench to compile, profile, and evaluate this model. Sign up to run these models on a hosted Qualcomm® device.
There are two ways to deploy this model on your device:
Below are pre-exported model assets ready for deployment.
| Runtime | Precision | Chipset | SDK Versions | Download |
|---|---|---|---|---|
| ONNX | float | Universal | QAIRT 2.42, ONNX Runtime 1.25.0 | Download |
| ONNX | w8a8 | Universal | QAIRT 2.42, ONNX Runtime 1.25.0 | Download |
| QNN_DLC | float | Universal | QAIRT 2.45 | Download |
| QNN_DLC | w8a8 | Universal | QAIRT 2.45 | Download |
| TFLITE | float | Universal | QAIRT 2.45 | Download |
| TFLITE | w8a8 | Universal | QAIRT 2.45 | Download |
For more device-specific assets and performance metrics, visit ResNet-2Plus1D on Qualcomm® AI Hub.
Use the Qualcomm® AI Hub Models Python library to compile and export the model with your own:
This option is ideal if you need to customize the model beyond the default configuration provided here.
See our repository for ResNet-2Plus1D on GitHub for usage instructions.
Model Type: Model_use_case.video_classification
Model Stats:
| Model | Runtime | Precision | Chipset | Inference Time (ms) | Peak Memory Range (MB) | Primary Compute Unit |
|---|---|---|---|---|---|---|
| ResNet-2Plus1D | ONNX | float | Snapdragon® 8 Elite Gen 5 Mobile | 33.515 ms | 12 - 538 MB | NPU |
| ResNet-2Plus1D | ONNX | float | Snapdragon® X2 Elite | 34.135 ms | 169 - 169 MB | NPU |
| ResNet-2Plus1D | ONNX | float | Snapdragon® X Elite | 66.161 ms | 169 - 169 MB | NPU |
| ResNet-2Plus1D | ONNX | float | Snapdragon® 8 Gen 3 Mobile | 52.951 ms | 12 - 787 MB | NPU |
| ResNet-2Plus1D | ONNX | float | Qualcomm® QCS8550 (Proxy) | 68.26 ms | 12 - 131 MB | NPU |
| ResNet-2Plus1D | ONNX | float | Snapdragon® 8 Elite For Galaxy Mobile | 41.863 ms | 2 - 514 MB | NPU |
| ResNet-2Plus1D | ONNX | float | Qualcomm® QCS9075 | 110.494 ms | 11 - 68 MB | NPU |
| ResNet-2Plus1D | ONNX | float | Qualcomm® QCS8750 | 41.863 ms | 2 - 514 MB | NPU |
| ResNet-2Plus1D | ONNX | float | Qualcomm® QCS7181 | 66.161 ms | 169 - 169 MB | NPU |
| ResNet-2Plus1D | ONNX | w8a8 | Snapdragon® 8 Elite Gen 5 Mobile | 11.874 ms | 3 - 378 MB | NPU |
| ResNet-2Plus1D | ONNX | w8a8 | Snapdragon® X2 Elite | 12.181 ms | 209 - 209 MB | NPU |
| ResNet-2Plus1D | ONNX | w8a8 | Snapdragon® X Elite | 25.038 ms | 179 - 179 MB | NPU |
| ResNet-2Plus1D | ONNX | w8a8 | Snapdragon® 8 Gen 3 Mobile | 19.592 ms | 3 - 481 MB | NPU |
| ResNet-2Plus1D | ONNX | w8a8 | Qualcomm® QCS6490 | 1485.723 ms | 330 - 358 MB | CPU |
| ResNet-2Plus1D | ONNX | w8a8 | Qualcomm® QCS8550 (Proxy) | 25.113 ms | 0 - 53 MB | NPU |
| ResNet-2Plus1D | ONNX | w8a8 | Snapdragon® 7 Gen 4 Mobile | 1397.974 ms | 180 - 187 MB | CPU |
| ResNet-2Plus1D | ONNX | w8a8 | Qualcomm® QCM6690 | 1469.052 ms | 317 - 325 MB | CPU |
| ResNet-2Plus1D | ONNX | w8a8 | Snapdragon® 8 Elite For Galaxy Mobile | 15.91 ms | 0 - 368 MB | NPU |
| ResNet-2Plus1D | ONNX | w8a8 | Qualcomm® QCS9075 | 23.251 ms | 3 - 48 MB | NPU |
| ResNet-2Plus1D | ONNX | w8a8 | Qualcomm® QCS7790 | 1397.974 ms | 180 - 187 MB | CPU |
| ResNet-2Plus1D | ONNX | w8a8 | Qualcomm® QCS8750 | 15.91 ms | 0 - 368 MB | NPU |
| ResNet-2Plus1D | ONNX | w8a8 | Qualcomm® QCS7181 | 25.038 ms | 179 - 179 MB | NPU |
| ResNet-2Plus1D | QNN_DLC | float | Snapdragon® 8 Elite Gen 5 Mobile | 29.373 ms | 0 - 493 MB | NPU |
| ResNet-2Plus1D | QNN_DLC | float | Snapdragon® X2 Elite | 34.398 ms | 12 - 12 MB | NPU |
| ResNet-2Plus1D | QNN_DLC | float | Snapdragon® X Elite | 66.836 ms | 12 - 12 MB | NPU |
| ResNet-2Plus1D | QNN_DLC | float | Snapdragon® 8 Gen 3 Mobile | 51.98 ms | 8 - 715 MB | NPU |
| ResNet-2Plus1D | QNN_DLC | float | Qualcomm® QCS8275 | 424.819 ms | 1 - 493 MB | NPU |
| ResNet-2Plus1D | QNN_DLC | float | Qualcomm® QCS8550 (Proxy) | 69.925 ms | 12 - 817 MB | NPU |
| ResNet-2Plus1D | QNN_DLC | float | Qualcomm® SA8775P | 111.024 ms | 1 - 490 MB | NPU |
| ResNet-2Plus1D | QNN_DLC | float | Qualcomm® SA8650P | 111.024 ms | 1 - 490 MB | NPU |
| ResNet-2Plus1D | QNN_DLC | float | Qualcomm® SA8255P | 111.024 ms | 1 - 490 MB | NPU |
| ResNet-2Plus1D | QNN_DLC | float | Qualcomm® QCS8450 (Proxy) | 153.146 ms | 3 - 595 MB | NPU |
| ResNet-2Plus1D | QNN_DLC | float | Qualcomm® SA8295P | 118.455 ms | 0 - 398 MB | NPU |
| ResNet-2Plus1D | QNN_DLC | float | Snapdragon® 8 Elite For Galaxy Mobile | 41.774 ms | 12 - 499 MB | NPU |
| ResNet-2Plus1D | QNN_DLC | float | Qualcomm® SA7255P | 424.819 ms | 1 - 493 MB | NPU |
| ResNet-2Plus1D | QNN_DLC | float | Qualcomm® QCS9075 | 111.854 ms | 12 - 25 MB | NPU |
| ResNet-2Plus1D | QNN_DLC | float | Qualcomm® QCS8750 | 41.774 ms | 12 - 499 MB | NPU |
| ResNet-2Plus1D | QNN_DLC | float | Qualcomm® QCS7181 | 66.836 ms | 12 - 12 MB | NPU |
| ResNet-2Plus1D | QNN_DLC | w8a8 | Snapdragon® 8 Elite Gen 5 Mobile | 13.12 ms | 3 - 383 MB | NPU |
| ResNet-2Plus1D | QNN_DLC | w8a8 | Snapdragon® X2 Elite | 13.433 ms | 3 - 3 MB | NPU |
| ResNet-2Plus1D | QNN_DLC | w8a8 | Snapdragon® X Elite | 26.994 ms | 3 - 3 MB | NPU |
| ResNet-2Plus1D | QNN_DLC | w8a8 | Snapdragon® 8 Gen 3 Mobile | 21.099 ms | 3 - 466 MB | NPU |
| ResNet-2Plus1D | QNN_DLC | w8a8 | Qualcomm® QCS6490 | 87.688 ms | 3 - 7 MB | NPU |
| ResNet-2Plus1D | QNN_DLC | w8a8 | Qualcomm® QCS8275 | 75.301 ms | 2 - 372 MB | NPU |
| ResNet-2Plus1D | QNN_DLC | w8a8 | Qualcomm® QCS8550 (Proxy) | 27.766 ms | 3 - 6 MB | NPU |
| ResNet-2Plus1D | QNN_DLC | w8a8 | Qualcomm® SA8775P | 24.455 ms | 3 - 371 MB | NPU |
| ResNet-2Plus1D | QNN_DLC | w8a8 | Qualcomm® SA8650P | 24.455 ms | 3 - 371 MB | NPU |
| ResNet-2Plus1D | QNN_DLC | w8a8 | Qualcomm® SA8255P | 24.455 ms | 3 - 371 MB | NPU |
| ResNet-2Plus1D | QNN_DLC | w8a8 | Qualcomm® SA7255P | 75.301 ms | 2 - 372 MB | NPU |
| ResNet-2Plus1D | QNN_DLC | w8a8 | Snapdragon® 7 Gen 4 Mobile | 46.361 ms | 3 - 390 MB | NPU |
| ResNet-2Plus1D | QNN_DLC | w8a8 | Qualcomm® SA8295P | 41.941 ms | 1 - 368 MB | NPU |
| ResNet-2Plus1D | QNN_DLC | w8a8 | Qualcomm® QCM6690 | 423.138 ms | 3 - 426 MB | NPU |
| ResNet-2Plus1D | QNN_DLC | w8a8 | Snapdragon® 8 Elite For Galaxy Mobile | 16.908 ms | 3 - 373 MB | NPU |
| ResNet-2Plus1D | QNN_DLC | w8a8 | Qualcomm® QCS9075 | 24.213 ms | 0 - 5 MB | NPU |
| ResNet-2Plus1D | QNN_DLC | w8a8 | Qualcomm® QCS8450 (Proxy) | 47.71 ms | 3 - 459 MB | NPU |
| ResNet-2Plus1D | QNN_DLC | w8a8 | Qualcomm® QCS7790 | 46.361 ms | 3 - 390 MB | NPU |
| ResNet-2Plus1D | QNN_DLC | w8a8 | Qualcomm® QCS8750 | 16.908 ms | 3 - 373 MB | NPU |
| ResNet-2Plus1D | QNN_DLC | w8a8 | Qualcomm® QCS7181 | 26.994 ms | 3 - 3 MB | NPU |
| ResNet-2Plus1D | TFLITE | float | Snapdragon® 8 Elite Gen 5 Mobile | 1320.002 ms | 0 - 568 MB | NPU |
| ResNet-2Plus1D | TFLITE | float | Snapdragon® 8 Gen 3 Mobile | 1481.178 ms | 0 - 801 MB | NPU |
| ResNet-2Plus1D | TFLITE | float | Qualcomm® QCS8275 | 3622.62 ms | 1 - 579 MB | NPU |
| ResNet-2Plus1D | TFLITE | float | Qualcomm® QCS8550 (Proxy) | 1935.795 ms | 1 - 4 MB | NPU |
| ResNet-2Plus1D | TFLITE | float | Qualcomm® SA8775P | 1954.941 ms | 1 - 580 MB | NPU |
| ResNet-2Plus1D | TFLITE | float | Qualcomm® SA8650P | 1954.941 ms | 1 - 580 MB | NPU |
| ResNet-2Plus1D | TFLITE | float | Qualcomm® SA8255P | 1954.941 ms | 1 - 580 MB | NPU |
| ResNet-2Plus1D | TFLITE | float | Qualcomm® QCS8450 (Proxy) | 2402.574 ms | 2 - 741 MB | NPU |
| ResNet-2Plus1D | TFLITE | float | Qualcomm® SA8295P | 2446.863 ms | 1 - 541 MB | NPU |
| ResNet-2Plus1D | TFLITE | float | Snapdragon® 8 Elite For Galaxy Mobile | 1400.198 ms | 0 - 572 MB | NPU |
| ResNet-2Plus1D | TFLITE | float | Qualcomm® SA7255P | 3622.62 ms | 1 - 579 MB | NPU |
| ResNet-2Plus1D | TFLITE | float | Qualcomm® QCS9075 | 2051.948 ms | 0 - 81 MB | NPU |
| ResNet-2Plus1D | TFLITE | float | Qualcomm® QCS8750 | 1400.198 ms | 0 - 572 MB | NPU |
| ResNet-2Plus1D | TFLITE | w8a8 | Snapdragon® 8 Elite Gen 5 Mobile | 3476.116 ms | 0 - 1435 MB | NPU |
| ResNet-2Plus1D | TFLITE | w8a8 | Snapdragon® 8 Gen 3 Mobile | 3092.161 ms | 1 - 1624 MB | NPU |
| ResNet-2Plus1D | TFLITE | w8a8 | Qualcomm® QCS6490 | 8769.594 ms | 1441 - 2233 MB | NPU |
| ResNet-2Plus1D | TFLITE | w8a8 | Qualcomm® QCS8275 | 8115.715 ms | 3 - 1383 MB | NPU |
| ResNet-2Plus1D | TFLITE | w8a8 | Qualcomm® QCS8550 (Proxy) | 4138.566 ms | 1 - 5 MB | NPU |
| ResNet-2Plus1D | TFLITE | w8a8 | Qualcomm® SA8775P | 4286.515 ms | 2 - 1381 MB | NPU |
| ResNet-2Plus1D | TFLITE | w8a8 | Qualcomm® SA8650P | 4286.515 ms | 2 - 1381 MB | NPU |
| ResNet-2Plus1D | TFLITE | w8a8 | Qualcomm® SA8255P | 4286.515 ms | 2 - 1381 MB | NPU |
| ResNet-2Plus1D | TFLITE | w8a8 | Qualcomm® SA7255P | 8115.715 ms | 3 - 1383 MB | NPU |
| ResNet-2Plus1D | TFLITE | w8a8 | Qualcomm® SA8295P | 4660.264 ms | 2 - 1091 MB | NPU |
| ResNet-2Plus1D | TFLITE | w8a8 | Qualcomm® QCM6690 | 8018.037 ms | 1299 - 1542 MB | NPU |
| ResNet-2Plus1D | TFLITE | w8a8 | Snapdragon® 8 Elite For Galaxy Mobile | 2824.929 ms | 1 - 1682 MB | NPU |
| ResNet-2Plus1D | TFLITE | w8a8 | Qualcomm® QCS9075 | 2951.371 ms | 0 - 74 MB | NPU |
| ResNet-2Plus1D | TFLITE | w8a8 | Qualcomm® QCS8450 (Proxy) | 4775.334 ms | 0 - 1338 MB | NPU |
| ResNet-2Plus1D | TFLITE | w8a8 | Qualcomm® QCS8750 | 2824.929 ms | 1 - 1682 MB | NPU |