
Minerva LLMs
Collection
The first family of LLMs pretrained from scratch on Italian.
•
4 items
•
Updated
•
26

Minerva is the first family of LLMs pretrained from scratch on Italian developed by Sapienza NLP in collaboration with Future Artificial Intelligence Research (FAIR) and CINECA. Notably, the Minerva models are truly-open (data and model) Italian-English LLMs, with approximately half of the pretraining data including Italian text.
This is the model card for Minerva-3B-base-v1.0, a 3 billion parameter model trained on 660 billion tokens (330 billion in Italian, 330 billion in English).
This model is part of the Minerva LLM family:
This section identifies foreseeable harms and misunderstandings.
This is a foundation model, not subject to alignment. Model may:
We are aware of the biases and potential problematic/toxic content that current pretrained large language models exhibit: more specifically, as probabilistic models of (Italian and English) languages, they reflect and amplify the biases of their training data. For more information about this issue, please refer to our survey:
import transformers
import torch
model_id = "sapienzanlp/Minerva-3B-base-v1.0"
# Initialize the pipeline.
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto",
)
# Input text for the model.
input_text = "La capitale dell'Italia è"
# Compute the outputs.
output = pipeline(
input_text,
max_new_tokens=128,
)
# Output:
# [{'generated_text': "La capitale dell'Italia è la città di Roma, che si trova a [...]"}]
Minerva-3B-base-v1.0 is a Transformer model based on the Mistral architecture, where the number of layers, number of heads, and the hidden states dimension are modified to reach 3B parameters. Please, take a look at the configuration file for a detailed breakdown of the hyperparameters we chose for this model.
The Minerva LLM family is composed of:
| Model Name | Tokens | Layers | Hidden Size | Attention Heads | KV Heads | Sliding Window | Max Context Length |
|---|---|---|---|---|---|---|---|
| Minerva-350M-base-v1.0 | 70B (35B it + 35B en) | 16 | 1152 | 16 | 4 | 2048 | 16384 |
| Minerva-1B-base-v1.0 | 200B (100B it + 100B en) | 16 | 2048 | 16 | 4 | 2048 | 16384 |
| Minerva-3B-base-v1.0 | 660B (330B it + 330B en) | 32 | 2560 | 32 | 8 | 2048 | 16384 |
Minerva-3B-base-v1.0 was trained using llm-foundry 0.6.0 from MosaicML. The hyperparameters used are the following:
| Model Name | Optimizer | lr | betas | eps | weight decay | Scheduler | Warmup Steps | Batch Size (Tokens) | Total Steps |
|---|---|---|---|---|---|---|---|---|---|
| Minerva-350M-base-v1.0 | Decoupled AdamW | 2e-4 | (0.9, 0.95) | 1e-8 | 0.0 | Cosine | 2% | 4M | 16,690 |
| Minerva-1B-base-v1.0 | Decoupled AdamW | 2e-4 | (0.9, 0.95) | 1e-8 | 0.0 | Cosine | 2% | 4M | 47,684 |
| Minerva-3B-base-v1.0 | Decoupled AdamW | 2e-4 | (0.9, 0.95) | 1e-8 | 0.0 | Cosine | 2% | 4M | 157,357 |
We assessed our model using the LM-Evaluation-Harness library, which serves as a comprehensive framework for testing generative language models across a wide range of evaluation tasks.
All the reported benchmark data was already present in the LM-Evaluation-Harness suite.
Italian Data:
| Task | Accuracy |
|---|---|
| xcopa (0-shot) | 0.694 |
| Hellaswag (5-shot) | 0.5293 |
| Belebele (5-shot) | 0.2333 |
| TruthfulQA MC 1 (0-shot) | 0.2363 |
| TruthfulQA MC 2 (0-shot) | 0.3731 |
| M MMLU (5-shot) | 0.2612 |
| arc challenge (5-shot) | 0.3268 |
English Data:
| Task | Accuracy |
|---|---|
| Hellaswag (5-shot) | 0.6168 |
| piqa (5-shot) | 0.7535 |
| sciq (5-shot) | 0.925 |
| Belebele (5-shot) | 0.2278 |
| TruthfulQA MC 1 (0-shot) | 0.2142 |
| TruthfulQA MC 2 (0-shot) | 0.3643 |
| M MMLU (5-shot) | 0.263 |
| arc challenge (5-shot) | 0.3319 |
| arc easy (5-shot) | 0.6540 |
Minerva-3B-base-v1.0 was trained on 330B Italian tokens and 330B English tokens sampled from CulturaX.
We have extracted some statistics on Italian (115B tokens) and English (210B tokens) documents from CulturaX on the selected sources:
Proportion of number of tokens per domain (Italian)
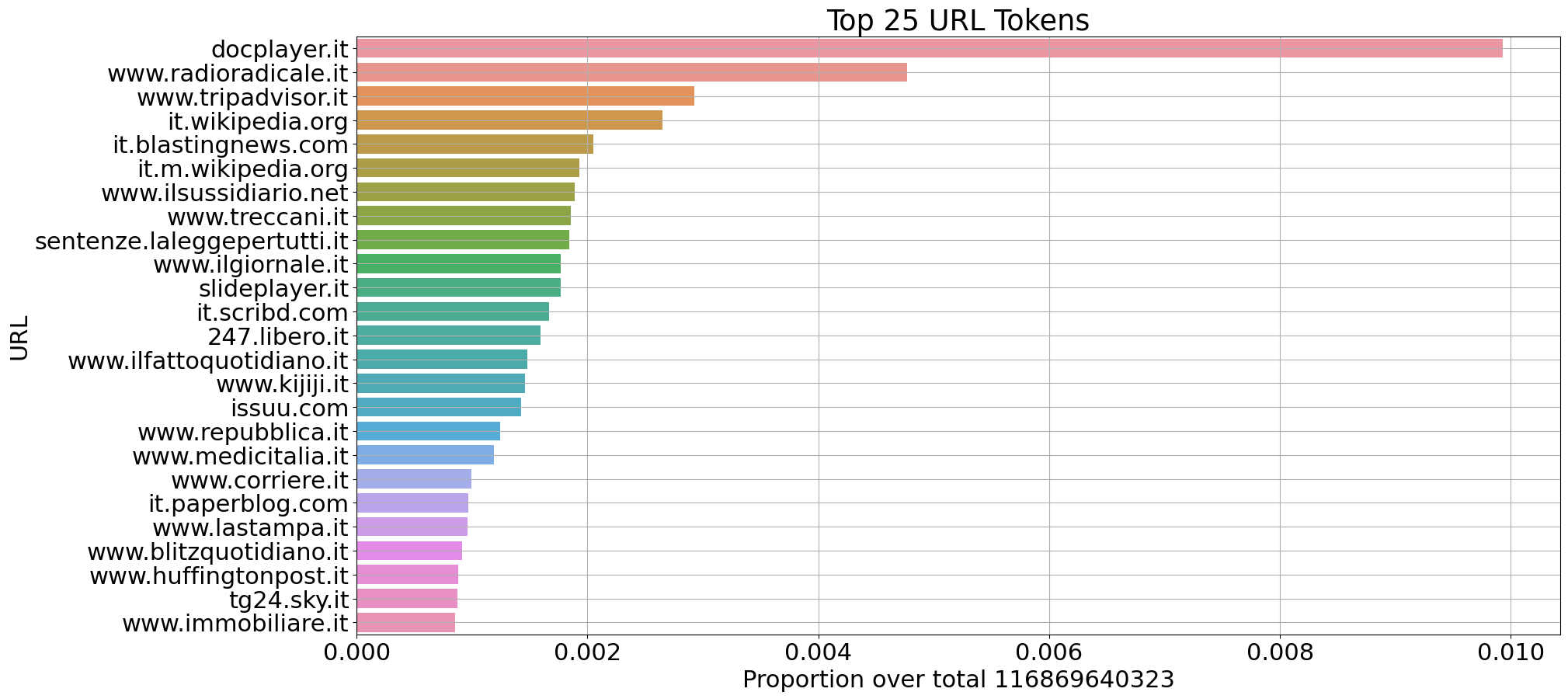
Proportion of number of tokens per domain (English)
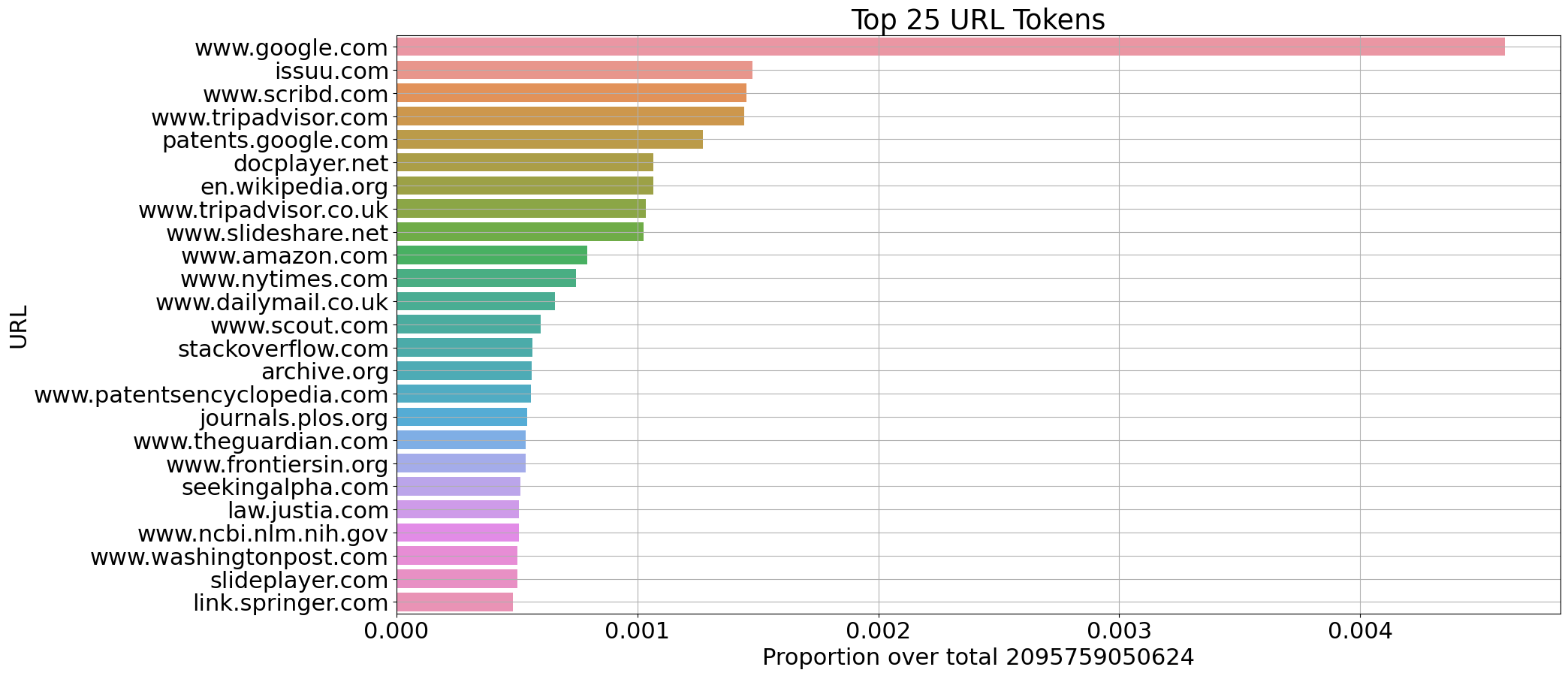
The tokenizer fertility measures the average amount of tokens produced per tokenized word. A tokenizer displaying high fertility values in a particular language typically indicates that it segments words in that language extensively. The tokenizer fertility is strictly correlated with the inference speed of the model with respect to a specific language, as higher values mean longer sequences of tokens to generate and thus lower inference speed.
Fertility computed over a sample of Cultura X (CX) data and Wikipedia (Wp):
| Model | Voc. Size | Fertility IT (CX) | Fertility EN (CX) | Fertility IT (Wp) | Fertility EN (Wp) |
|---|---|---|---|---|---|
| Mistral-7B-v0.1 | 32000 | 1.87 | 1.32 | 2.05 | 1.57 |
| gemma-7b | 256000 | 1.42 | 1.18 | 1.56 | 1.34 |
| Minerva-3B-base-v1.0 | 32768 | 1.39 | 1.32 | 1.66 | 1.59 |
Minerva-3B-base-v1.0 is a pretrained base model and, therefore, has no moderation mechanisms.
This work was funded by the PNRR MUR project PE0000013-FAIR. We acknowledge the CINECA award "IscB_medit" under the ISCRA initiative, for the availability of high performance computing resources and support.