
SPARK models
Collection
Predictors of MIC of pathogenic bacteria, trained on the human-curated and standardized SPARK dataset after hyperparameter search.
•
12 items
•
Updated
Updated: Tue 1 Apr 08:03:01 BST 2025
Trained on the Yersinia pestis, WT accumulator phenotype subset of the human-curated SPARK dataset (10002 rows in total for Yersinia pestis).
This model was trained using our Duvida framework, as a result of hyperparameter searches and selecting the model that performs best on unseen test data (from a scaffold split).
Duvida also saves the training data in this checkpoint to allows the calculation of uncertainty metrics based on that training data.
This model is the best regression model from a hyperparameter search, determined by Pearson's $$r$$ on a held-out test set not used in training or early stopping.
{
"dropout": 0.0,
"ensemble_size": 3,
"extra_featurizers": null,
"learning_rate": 0.0001,
"model_class": "ChempropModelBox",
"n_hidden": 1,
"n_units": 256,
"use_2d": true,
"use_fp": true
}
You can use this model with:
from duvida.autoclasses import AutoModelBox
modelbox = AutoModelBox.from_pretrained("hf://scbirlab/spark-dv-2503-ypes")
modelbox.predict(filename=..., inputs=[...], columns=[...]) # make predictions on your own data
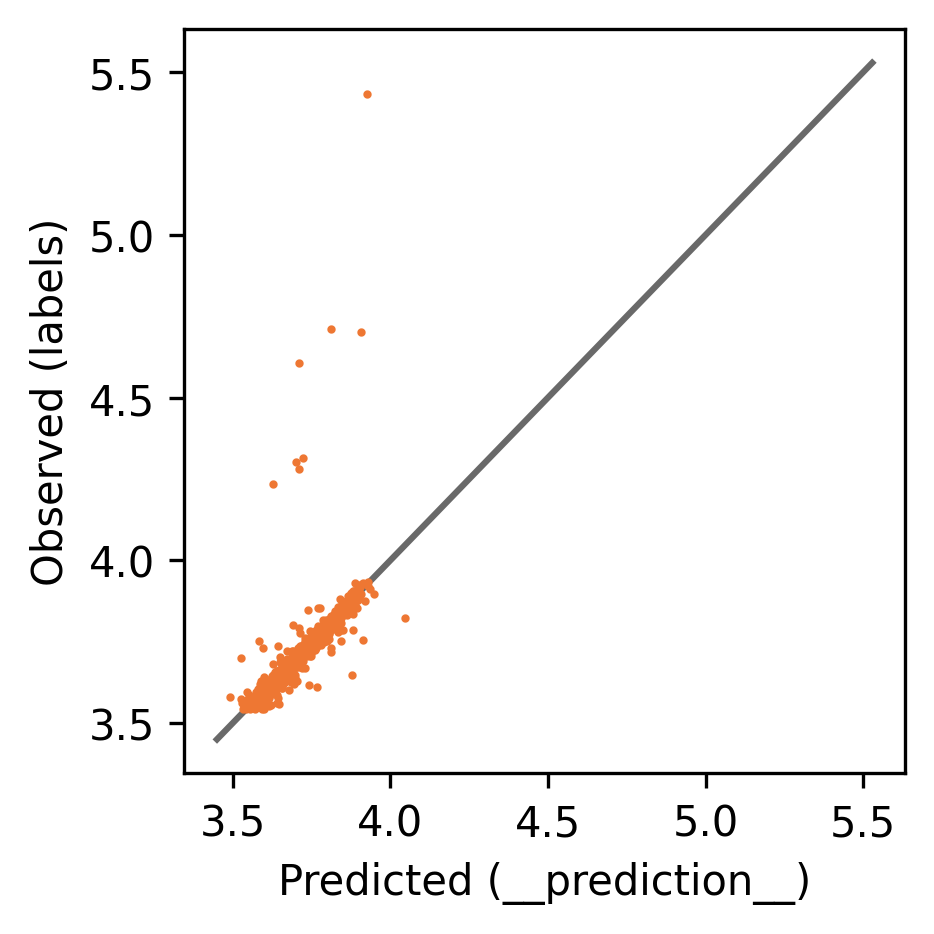
Here is the training log:

And these are the evaluation scores.
Train (7002 rows):
{
"Pearson r": 0.9997487398096949,
"RMSE": 0.001503719948232174,
"Spearman rho": 0.9995015503182805
}

Validation (1499 rows):
{
"Pearson r": 0.7851248408551393,
"RMSE": 0.019412975758314133,
"Spearman rho": 0.934205549109032
}

Test (1501 rows):
{
"Pearson r": 0.7895561902856947,
"RMSE": 0.016430044546723366,
"Spearman rho": 0.9670287095583492
}
The training data were collated by the authors of:
Joe Thomas, Marc Navre, Aileen Rubio, and Allan Coukell Shared Platform for Antibiotic Research and Knowledge: A Collaborative Tool to SPARK Antibiotic Discovery ACS Infectious Diseases 2018 4 (11), 1536-1539 DOI: 10.1021/acsinfecdis.8b00193
We cleaned the original SPARK dataset to subset the most relevant columns, remove empty values, give succint column titles, and split by species.
This particular dataset retains only measurements on bacteria with wild-type accumulation phenotypes.
Data were processed using schemist, a tool for processing chemical datasets.
The SMILES strings have been canonicalized, and split into training (70%), validation (15%), and test (15%) sets by Murcko scaffold for each species with more than 1000 entries. Additional features like molecular weight and topological polar surface area have also been calculated.
Joe Thomas, Marc Navre, Aileen Rubio, and Allan Coukell