|
|
--- |
|
|
library_name: transformers |
|
|
license: apache-2.0 |
|
|
pipeline_tag: image-text-to-text |
|
|
language: |
|
|
- en |
|
|
base_model: |
|
|
- HuggingFaceTB/SmolVLM-256M-Instruct |
|
|
--- |
|
|
|
|
|
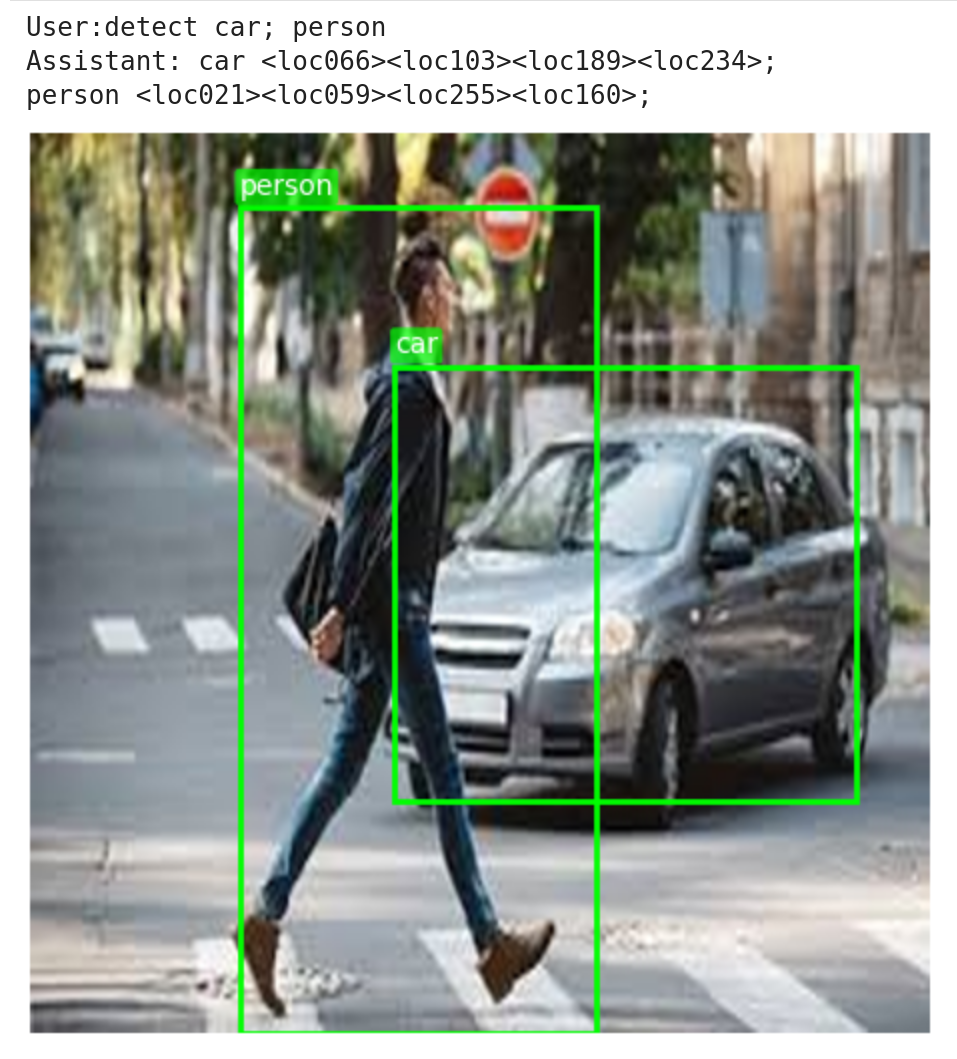
# SmolVLM-256M-Detection |
|
|
|
|
|
> experimental and for learning purposes; wouldn't recommend using unless |
|
|
|
|
|
check out [github/shreydan/VLM-OD](https://github.com/shreydan/VLM-OD/) for results and details. |
|
|
|
|
|
## Usage |
|
|
|
|
|
- load the model same as `HuggingFaceTB/SmolVLM-256M-Instruct` |
|
|
- inputs: `detect car` / `detect person;car` etc. Apply chat template with `add_generation_prompt=True` |
|
|
- parse the output tokens `<loc000>` to `<loc255>` (code in `eval.ipynb` of my github repo) |
|
|
- to reiterate I have not added any `<locXXX>` special tokens (that needs wayyy more training than this method), the model itself is generating them. |
|
|
|
|
|
 |
