Spaces:
Running
on
Zero

transciption problem

file long 19:50 min
Transcription of part of the file went well, but then it glued the text into 1 whole and you can't see the correct time codes


Noted, thanks for feedback.
Temporarily you could segment audio in to 10 minutes each and transcribe, while we work on a fix for this.
This should be fixed now with space. Could you re-run and check. And also updated the space to support transcrption of audios upto 3hrs long
A little better but still problem:


It doesn’t seem to occur on all long-duration segments, and in our samples, the issue appears resolved. Unlikely but is it possible for you share a sample to test.
I gave you a link to the sample , with which there are problems (glued text), but further you have not corrected anything. We are waiting.
This issue occurs only with a very few files. While we understand the cause, I recommend using the chunking method for audios longer than 10 minutes with this script: speech_to_text_buffered_infer_rnnt.py. This should resolve the attention problem. Use large chunk_len and buffer_length to minimize overlap. We also identified a merging issue; the fix is here: PR #13500.
- I extracted the audio from the YouTube video. https://www.youtube.com/watch?v=_x07BqvRT74
8:12 minutes
And there is still a problem with the glued text.
So it's not a problem of length over 10 minutes.
And the problem occurs more often than you think.

- Please ADD SRT output.
I've been doing various tests and it's not the length that's the problem when pasting the resulting text.
This first file from Youtube with which there is a problem, even if I cut it into pieces of 2.5 minutes each, it still glues some piece of text together after processing.
I don't know why this is happening.
Thanks for adding SRT export.
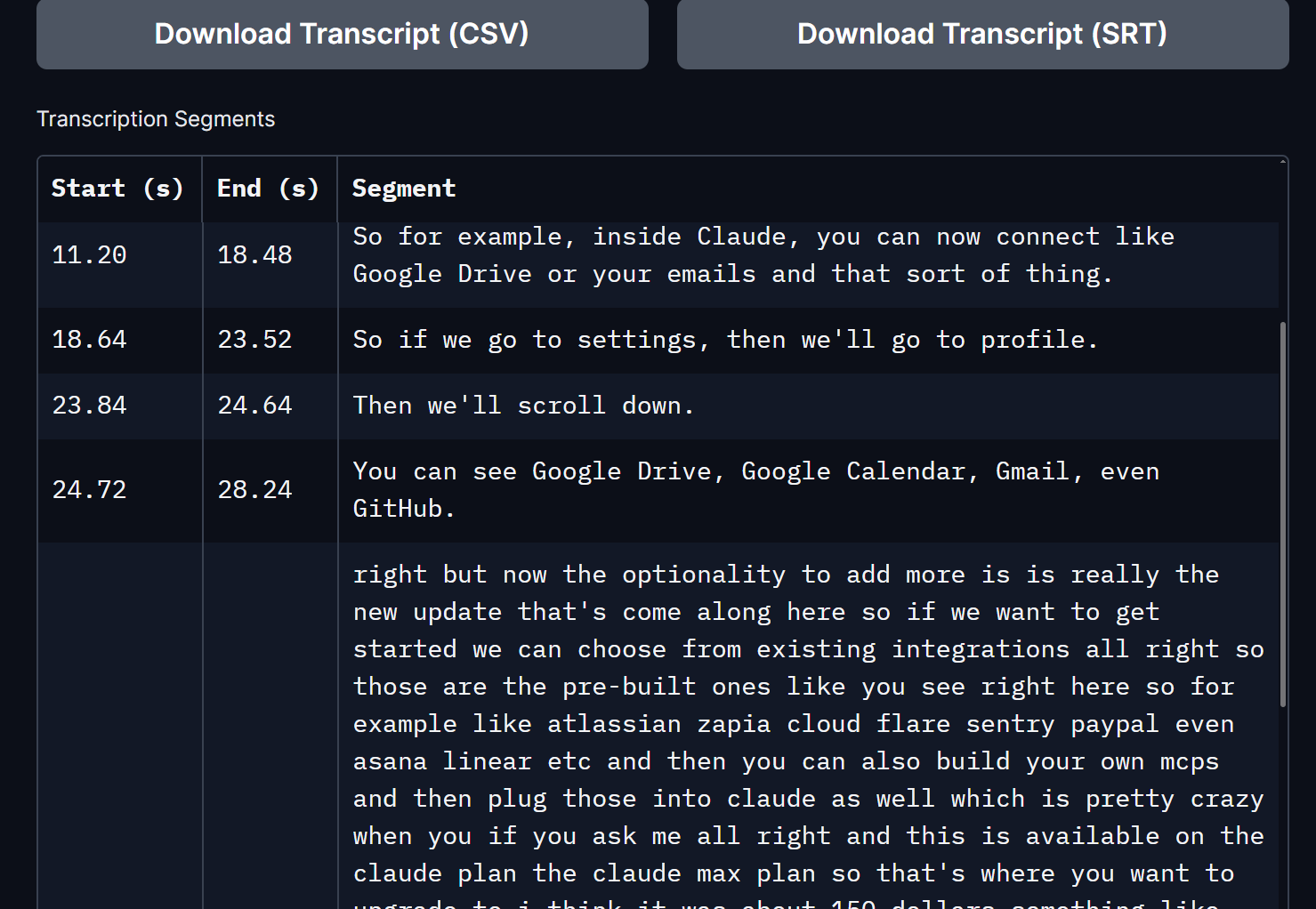

I do have the same issue, and it is not related to the length of the audio. It is very often. Does it also with my 9min segments (i cut into 9min segments because of sdram use that is very high (30GB for 9min segments). It tends to happens at the end i think. I cannot upload mp3 samples for privacy reasons.
Thanks for the feedback—appreciated! I’ll look into it and share an update here once I have a fix.

Some transcripts are wrong. How to edit it before download it?