
SPIRAL
Collection
4 items
•
Updated
•
2
This model is trained with self-play on multi-games (TicTacToe, Kuhn Poker, Simple Negotiation) using the SPIRAL framework.
Recent advances in reinforcement learning have shown that language models can develop sophisticated reasoning through training on tasks with verifiable rewards, but these approaches depend on expert-curated problem-answer pairs and domain-specific reward engineering.
We introduce SPIRAL, a self-play framework where models learn by playing multi-turn, zero-sum games against continuously improving versions of themselves, eliminating the need for human supervision. Through zero-sum self-play, SPIRAL generates an infinite curriculum of progressively challenging problems as models must constantly adapt to stronger opponents.
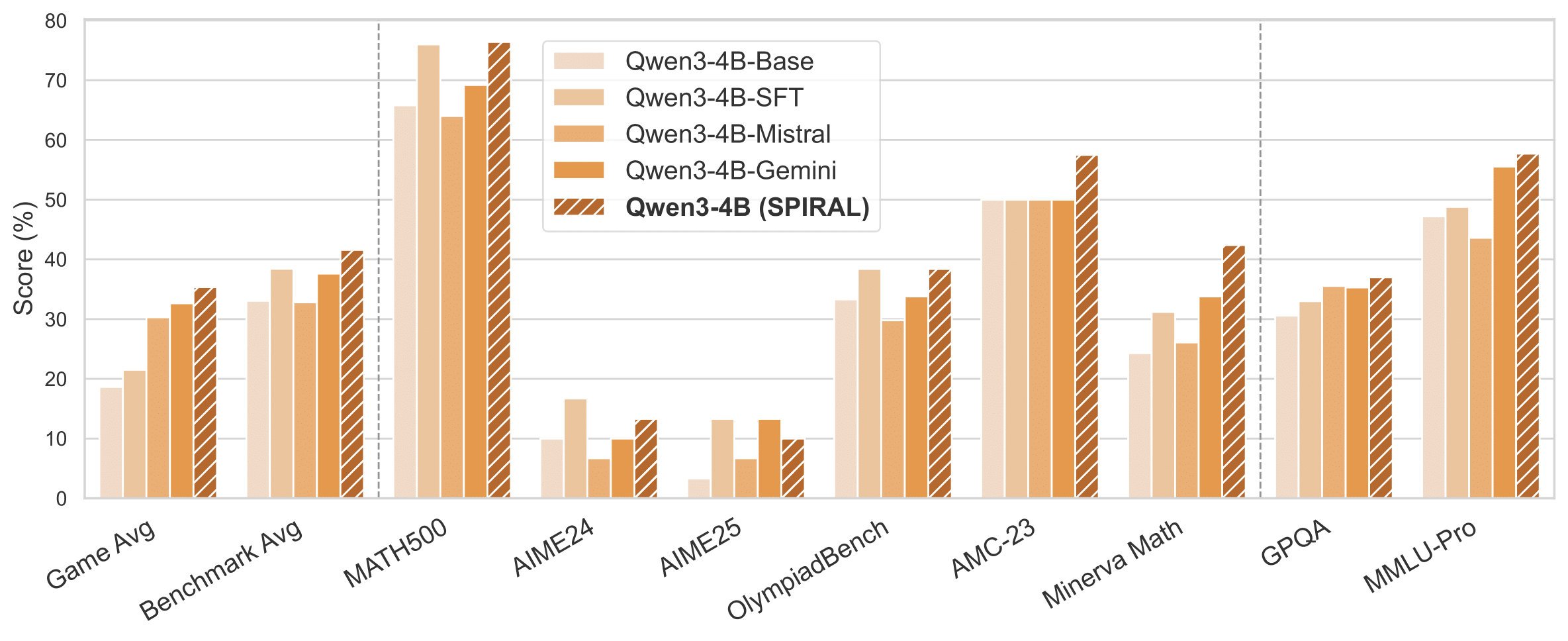
Applying SPIRAL to Qwen3 base models in two-player zero-sum text games, we observe the agents develop advanced reasoning strategies to win the competitive game. Furthermore, the trained models show substantial gains on a range of math and general reasoning benchmarks. These results suggest that self-play in zero-sum games can naturally induce transferable reasoning capabilities, highlighting a promising direction for autonomous reasoning development.

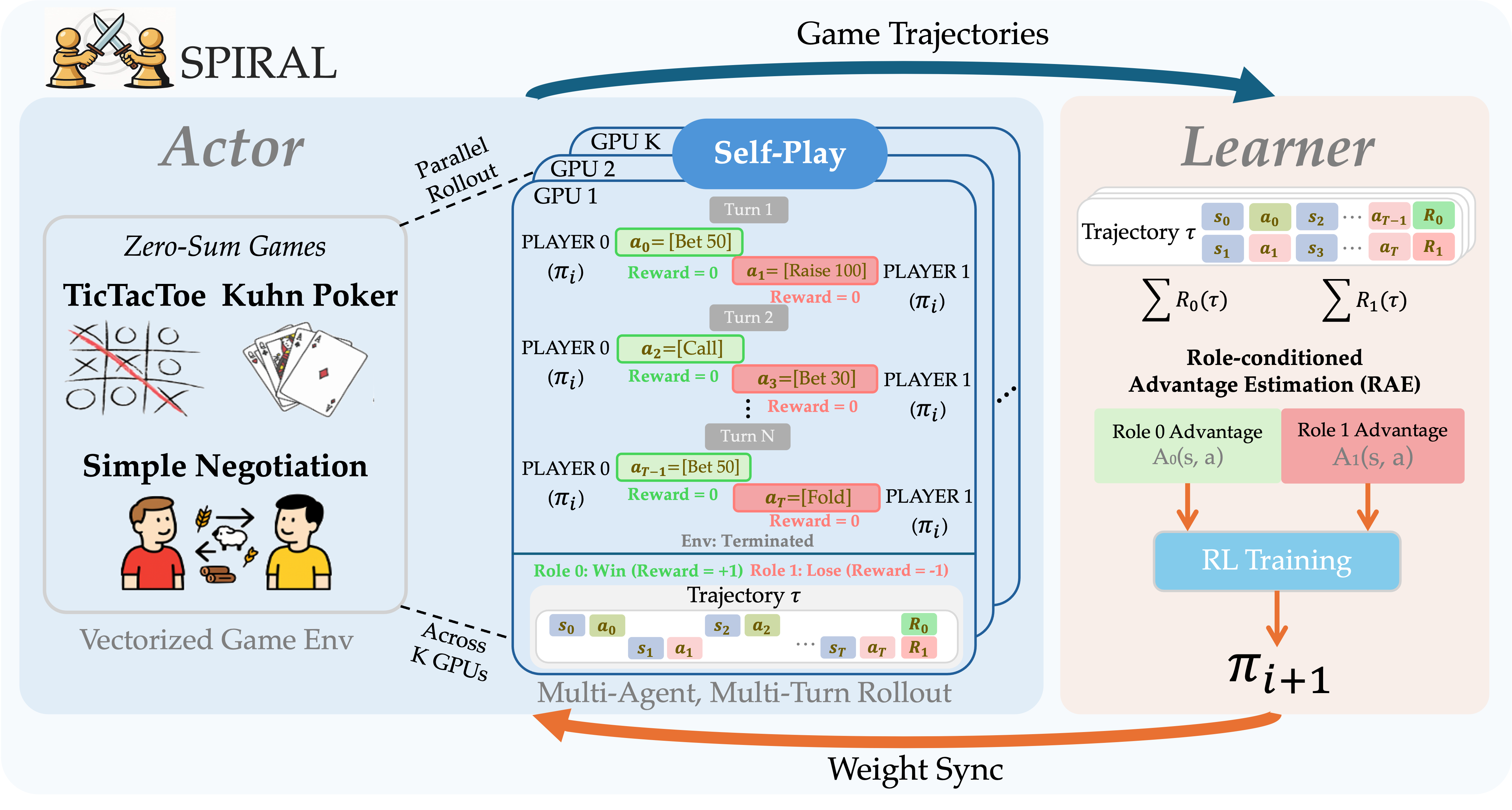
SPIRAL employs an actor-learner architecture for scalable self-play training. Parallel actors sample trajectories from a diverse set of games using vectorized environments. A single policy $\pi_t$ plays both roles, generating zero-sum, sparse reward game trajectories. The centralized learner processes these trajectories using Role-conditioned Advantage Estimation (RAE) to compute separate advantages, $A_0(s,a)$ and $A_1(s,a)$, for each role. These are then used for on-policy reinforcement learning updates.
You can easily load and use this model with the transformers library:
from transformers import AutoModelForCausalLM, AutoTokenizer, GenerationConfig
import torch
model_id = "spiral-rl/Spiral-Qwen3-4B"
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=torch.bfloat16, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_id)
# Example usage for text generation following Qwen chat template
prompt = "What is the capital of France?"
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
inputs = tokenizer(text, return_tensors="pt").to(model.device)
# Using a simple generation config (adjust as needed)
generation_config = GenerationConfig(
max_new_tokens=50,
temperature=0.7,
do_sample=True,
top_p=0.9
)
outputs = model.generate(**inputs, generation_config=generation_config)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(generated_text)
# Expected output: "What is the capital of France? Paris." (or similar)
For more advanced usage, including training and evaluation scripts, please refer to the GitHub repository.
If you find our work useful for your research, please consider citing:
@article{liu2025spiral,
title={SPIRAL: Self-Play on Zero-Sum Games Incentivizes Reasoning via Multi-Agent Multi-Turn Reinforcement Learning},
author={Liu, Bo and Guertler, Leon and Yu, Simon and Liu, Zichen and Qi, Penghui and Balcells, Daniel and Liu, Mickel and Tan, Cheston and Shi, Weiyan and Lin, Min and Lee, Wee Sun and Jaques, Natasha},
journal={arXiv preprint arXiv:2506.24119},
year={2025},
url={https://arxiv.org/abs/2506.24119}
}
This work is supported by PlasticLabs and Sea AI Lab for computing resources. The language games are sampled from TextArena, a collection of competitive text-based games for language model evaluation and reinforcement learning. The multi-agent, multi-turn RL training is implemented with 🌾 Oat, a modular and research-friendly LLM RL framework. We did exploration on PEFT experiments using UnstableBaselines, a lightweight, LoRA-first library for fast prototyping of self-play algorithms on TextArena. The base models are from Qwen3.