
Churro
Collection
Dataset and model for handwritten and print text recognition in historical documents • 3 items • Updated • 3

CHURRO: Making History Readable with an Open-Weight Large Vision-Language Model for High-Accuracy, Low-Cost Historical Text Recognition

Handwritten and printed text recognition across 22 centuries and 46 language clusters, including historical and dead languages.
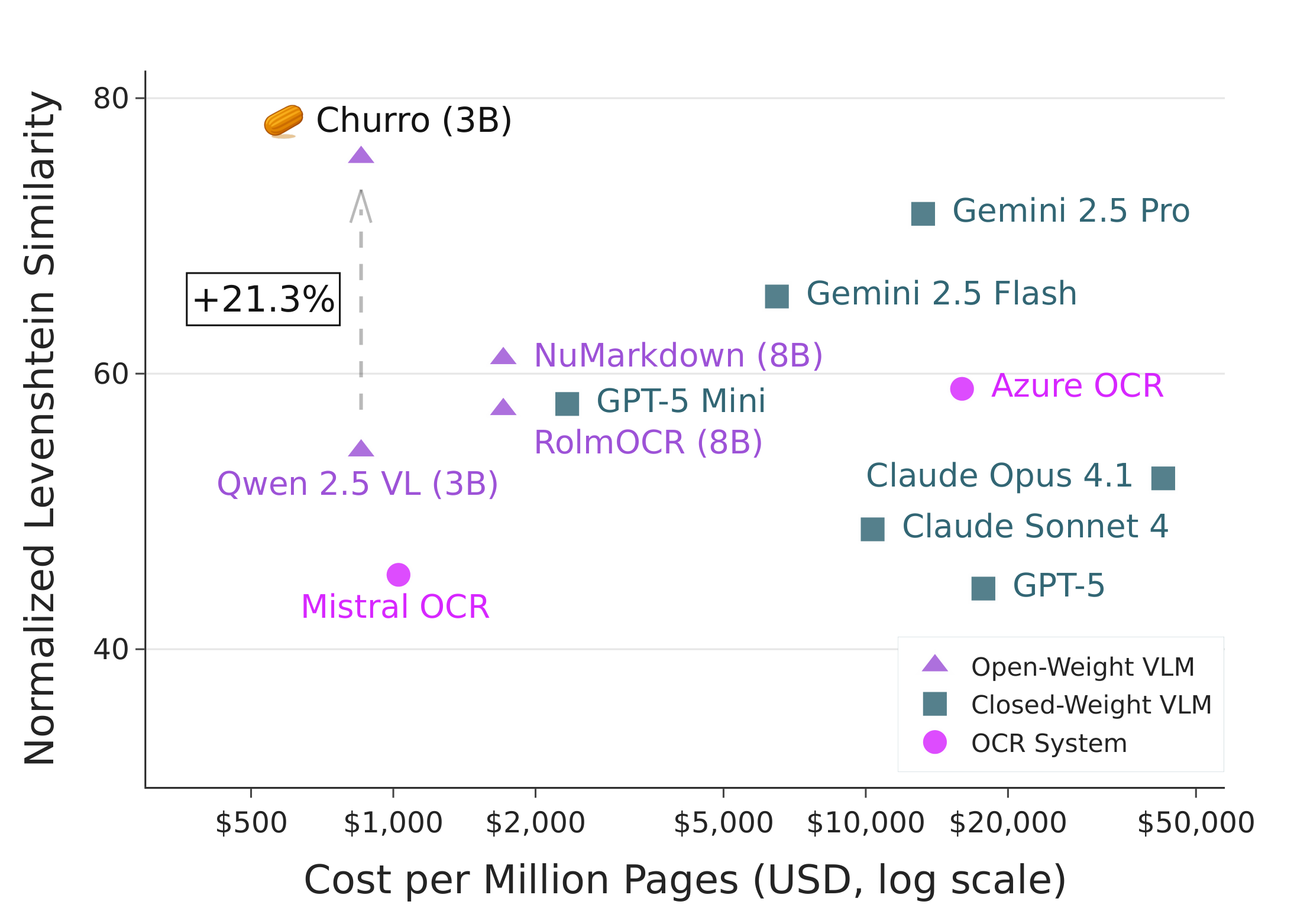
Cost vs. accuracy: CHURRO (3B) achieves higher accuracy than much larger commercial and open-weight VLMs while being substantially cheaper.
CHURRO is a 3B-parameter open-weight vision-language model (VLM) for historical document transcription. It is trained on CHURRO-DS, a curated dataset of ~100K pages from 155 historical collections spanning 22 centuries and 46 language clusters. On the CHURRO-DS test set, CHURRO delivers 15.5× lower cost than Gemini 2.5 Pro while exceeding its accuracy.
For more details and code see https://github.com/stanford-oval/Churro.
Base model
Qwen/Qwen2.5-VL-3B-Instruct