
RecNeXt
Collection
37 items
•
Updated
•
2
Recent advances in vision transformers (ViTs) have demonstrated the advantage of global modeling capabilities, prompting widespread integration of large-kernel convolutions for enlarging the effective receptive field (ERF). However, the quadratic scaling of parameter count and computational complexity (FLOPs) with respect to kernel size poses significant efficiency and optimization challenges. This paper introduces RecConv, a recursive decomposition strategy that efficiently constructs multi-frequency representations using small-kernel convolutions. RecConv establishes a linear relationship between parameter growth and decomposing levels which determines the effective receptive field $k\times 2^\ell$ for a base kernel $k$ and $\ell$ levels of decomposition, while maintaining constant FLOPs regardless of the ERF expansion. Specifically, RecConv achieves a parameter expansion of only $\ell+2$ times and a maximum FLOPs increase of $5/3$ times, compared to the exponential growth ($4^\ell$) of standard and depthwise convolutions. RecNeXt-M3 outperforms RepViT-M1.1 by 1.9 $AP^{box}$ on COCO with similar FLOPs. This innovation provides a promising avenue towards designing efficient and compact networks across various modalities. Codes and models can be found at https://github.com/suous/RecNeXt.


Model Type: Image Classification / Feature Extraction
Model Series: M
Model Stats:
Architecture Configuration:
Paper: RecConv: Efficient Recursive Convolutions for Multi-Frequency Representations
Dataset: ImageNet-1K
UPDATES 🔥
from urllib.request import urlopen
from PIL import Image
import timm
import torch
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('recnext_m3', pretrained=True, distillation=False)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
import utils
# Convert training-time model to inference structure, fuse batchnorms
utils.replace_batchnorm(model)
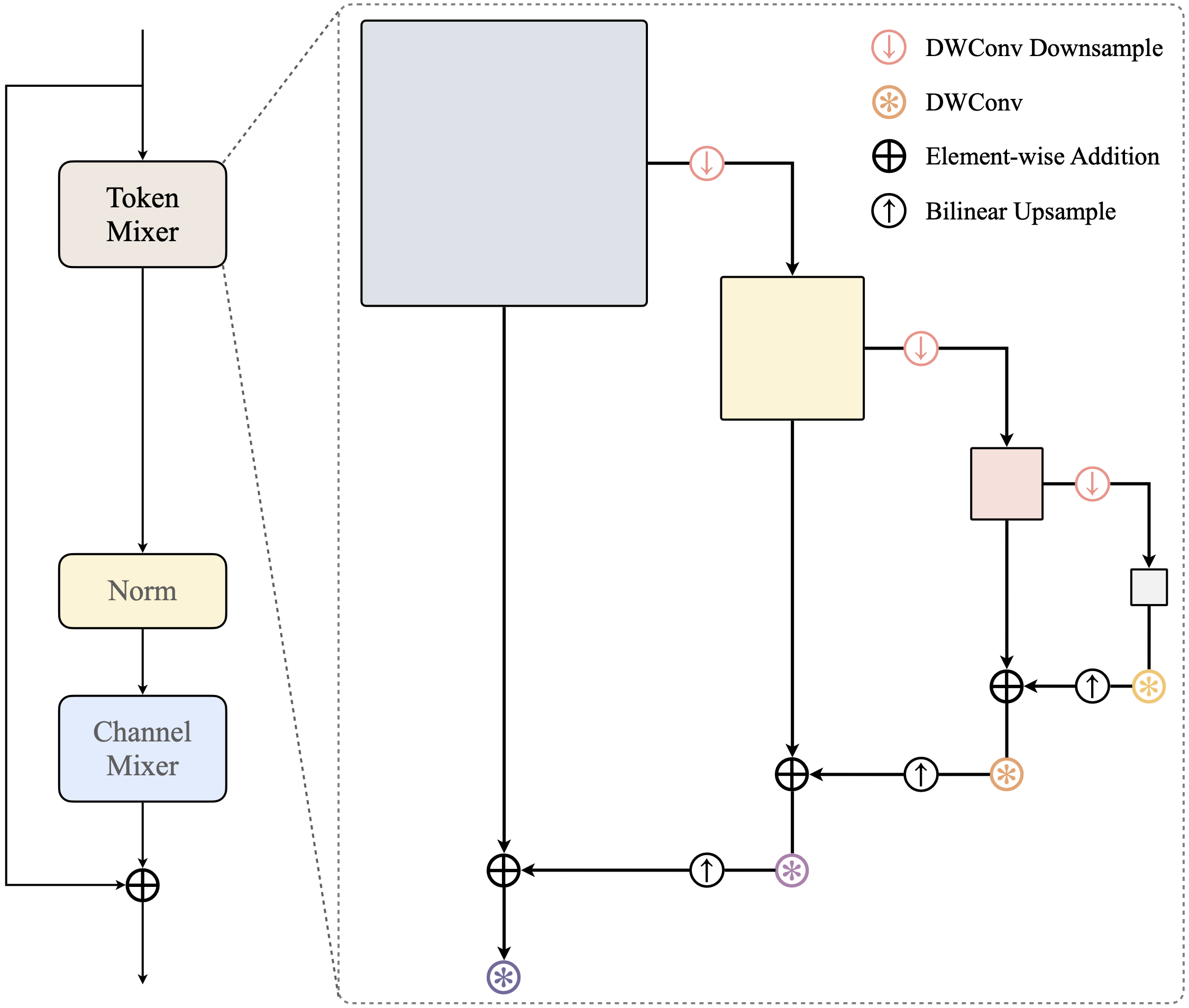
We introduce two series of models: the A series uses linear attention and nearest interpolation, while the M series employs convolution and bilinear interpolation for simplicity and broader hardware compatibility (e.g., to address suboptimal nearest interpolation support in some iOS versions).
dist: distillation; base: without distillation (all models are trained over 300 epochs).
| model | top_1_accuracy | params | gmacs | npu_latency | cpu_latency | throughput | fused_weights | training_logs |
|---|---|---|---|---|---|---|---|---|
| M0 | 74.7* | 73.2 | 2.5M | 0.4 | 1.0ms | 189ms | 750 | dist | base | dist | base |
| M1 | 79.2* | 78.0 | 5.2M | 0.9 | 1.4ms | 361ms | 384 | dist | base | dist | base |
| M2 | 80.3* | 79.2 | 6.8M | 1.2 | 1.5ms | 431ms | 325 | dist | base | dist | base |
| M3 | 80.9* | 79.6 | 8.2M | 1.4 | 1.6ms | 482ms | 314 | dist | base | dist | base |
| M4 | 82.5* | 81.4 | 14.1M | 2.4 | 2.4ms | 843ms | 169 | dist | base | dist | base |
| M5 | 83.3* | 82.9 | 22.9M | 4.7 | 3.4ms | 1487ms | 104 | dist | base | dist | base |
| A0 | 75.0* | 73.6 | 2.8M | 0.4 | 1.4ms | 177ms | 4891 | dist | base | dist | base |
| A1 | 79.6* | 78.3 | 5.9M | 0.9 | 1.9ms | 334ms | 2730 | dist | base | dist | base |
| A2 | 80.8* | 79.6 | 7.9M | 1.2 | 2.2ms | 413ms | 2331 | dist | base | dist | base |
| A3 | 81.1* | 80.1 | 9.0M | 1.4 | 2.4ms | 447ms | 2151 | dist | base | dist | base |
| A4 | 82.5* | 81.6 | 15.8M | 2.4 | 3.6ms | 764ms | 1265 | dist | base | dist | base |
| A5 | 83.5* | 83.1 | 25.7M | 4.7 | 5.6ms | 1376ms | 733 | dist | base | dist | base |
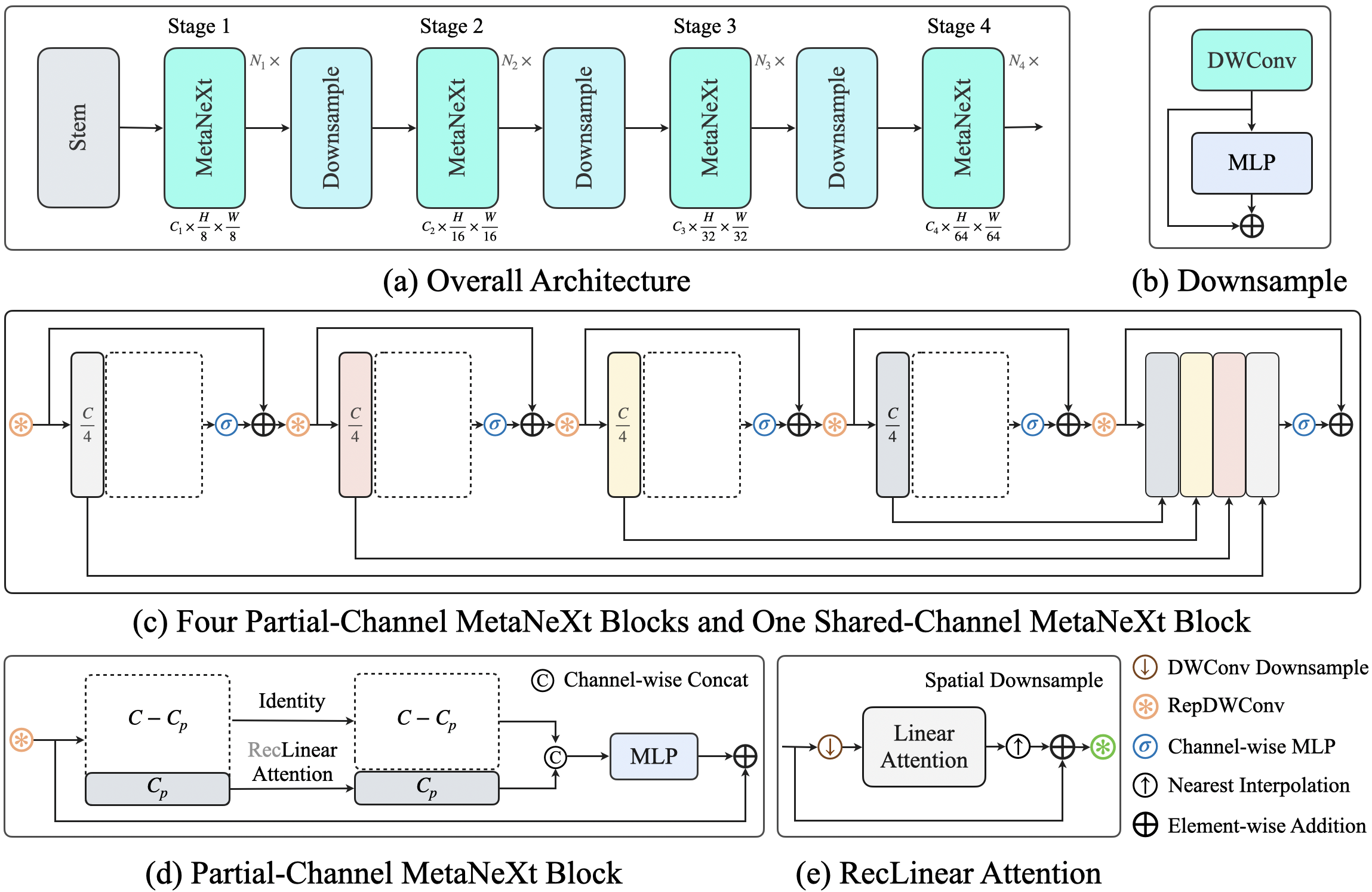
We present a simple architecture, the overall design follows LSNet. This framework centers around sharing channel features from the previous layers. Our motivation for doing so is to reduce the computational cost of token mixers and minimize feature redundancy in the final stage.
| model | top_1_accuracy | params | gmacs | npu_latency | cpu_latency | throughput | fused_weights | training_logs |
|---|---|---|---|---|---|---|---|---|
| T | 76.8 | 75.2 | 12.1M | 0.3 | 1.8ms | 105ms | 13957 | dist | norm | dist | norm |
| S | 79.5 | 78.3 | 15.8M | 0.7 | 2.0ms | 182ms | 8034 | dist | norm | dist | norm |
| B | 81.5 | 80.3 | 19.2M | 1.1 | 2.5ms | 296ms | 4472 | dist | norm | dist | norm |
| model | top_1_accuracy | params | gmacs | npu_latency | cpu_latency | throughput | fused_weights | training_logs |
|---|---|---|---|---|---|---|---|---|
| T | 76.6* | 75.1 | 12.1M | 0.3 | 1.8ms | 109ms | 13878 | dist | base | dist | base |
| S | 79.6* | 78.3 | 15.8M | 0.7 | 2.0ms | 188ms | 7989 | dist | base | dist | base |
| B | 81.4* | 80.3 | 19.3M | 1.1 | 2.5ms | 290ms | 4450 | dist | base | dist | base |
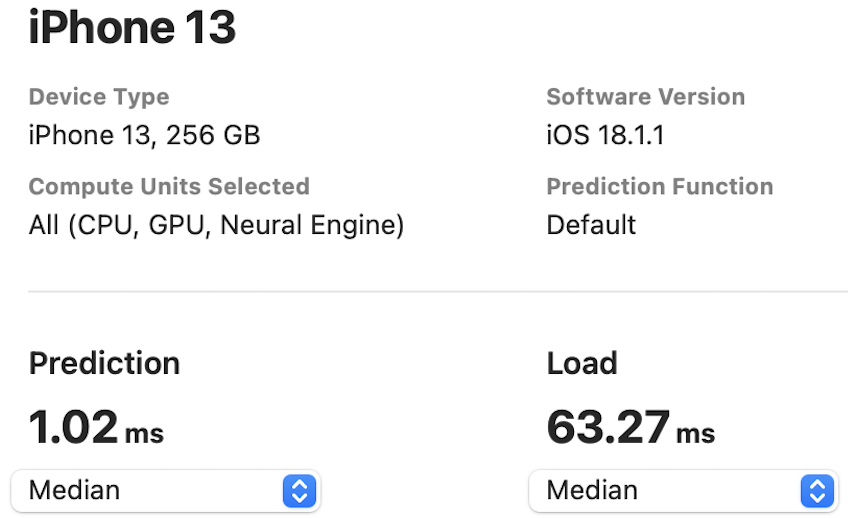
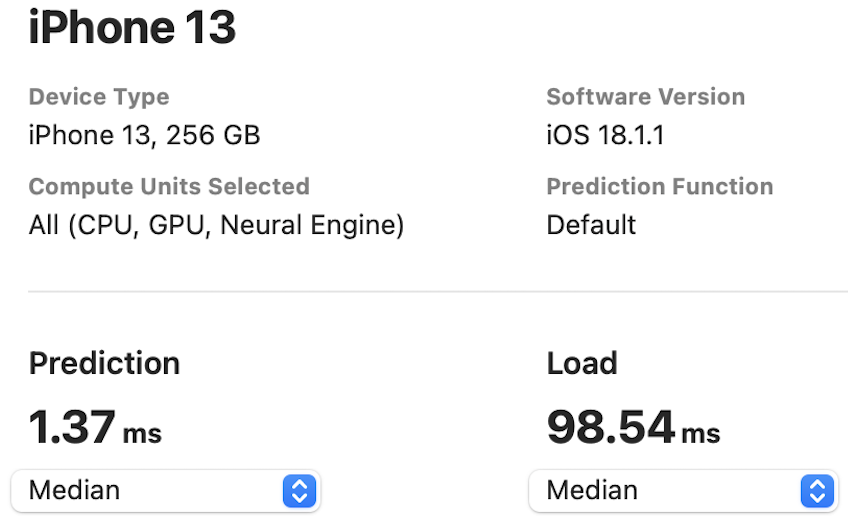
The NPU latency is measured on an iPhone 13 with models compiled by Core ML Tools. The CPU latency is accessed on a Quad-core ARM Cortex-A57 processor in ONNX format. And the throughput is tested on an Nvidia RTX3090 with maximum power-of-two batch size that fits in memory.
The latency reported in RecNeXt for iPhone 13 (iOS 18) uses the benchmark tool from XCode 14.
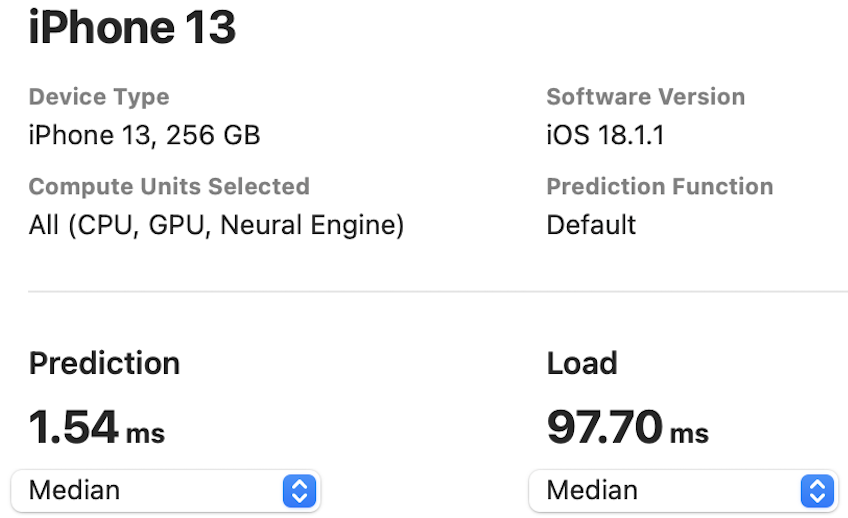
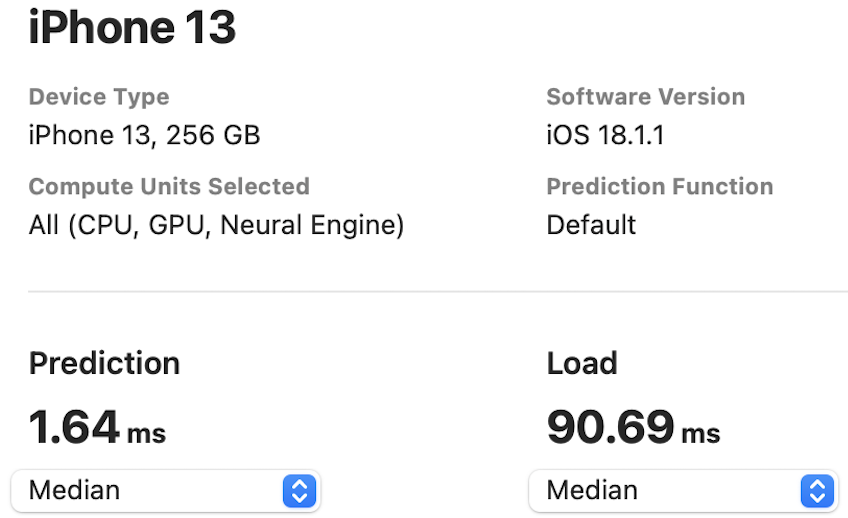
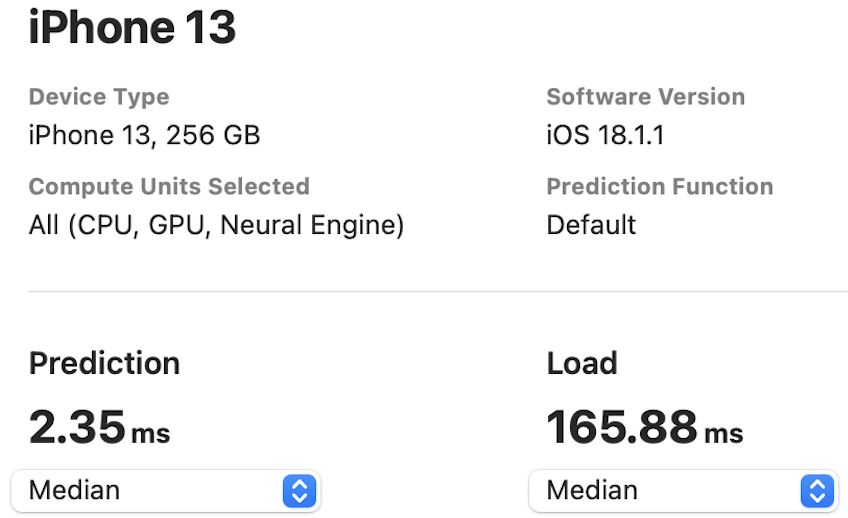
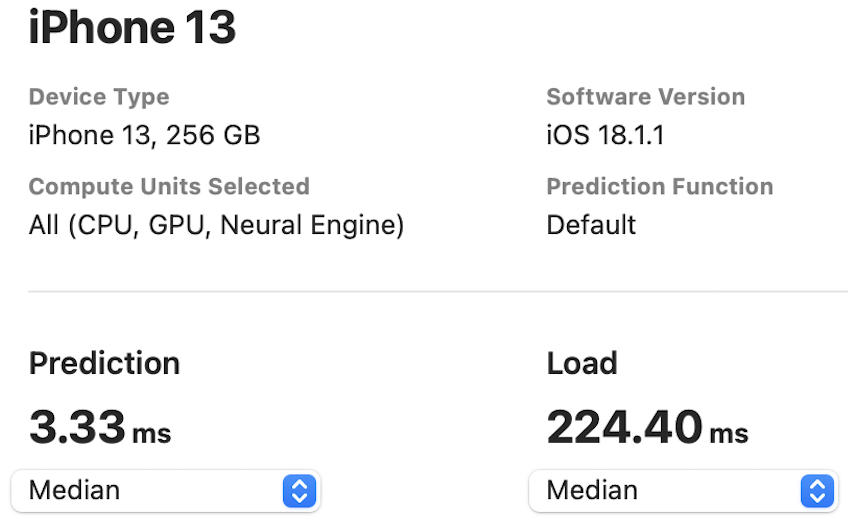
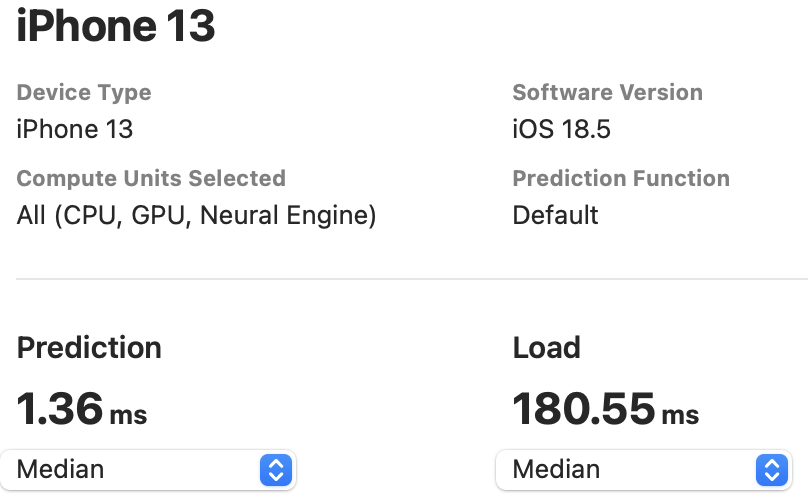
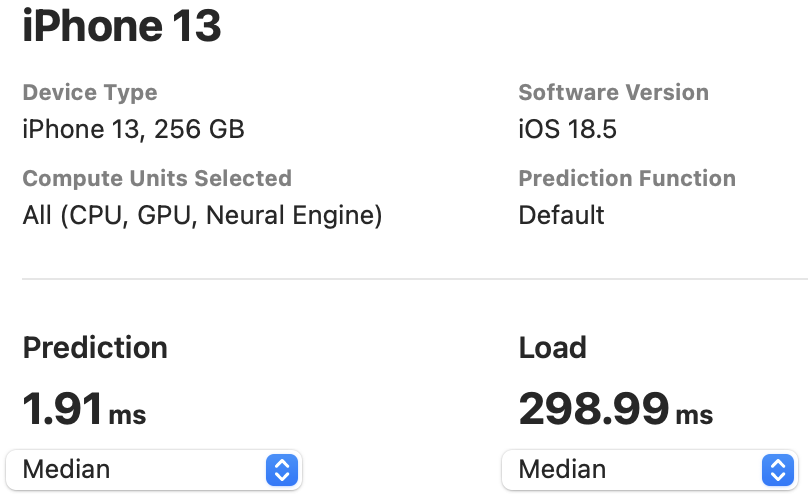
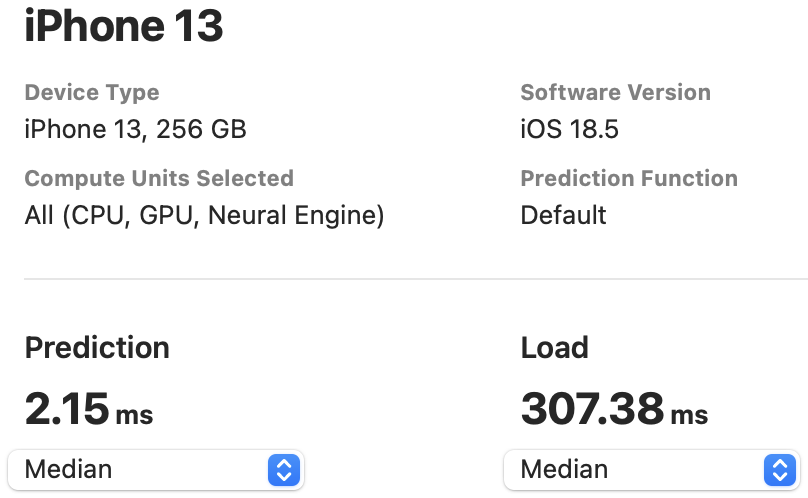
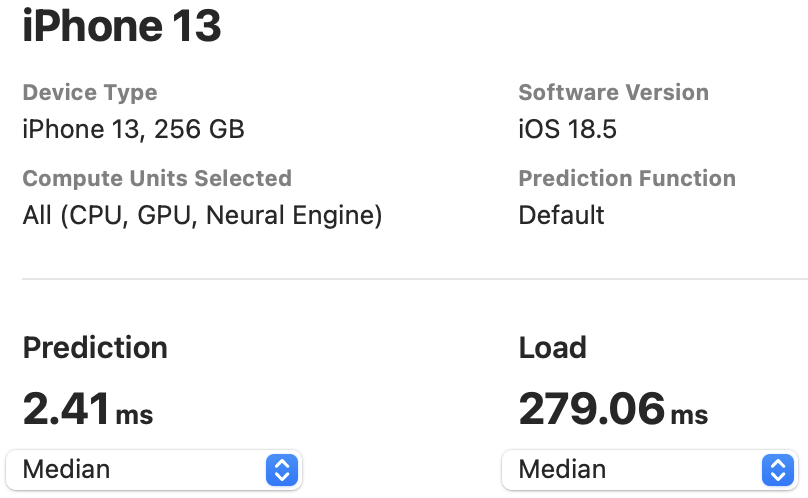
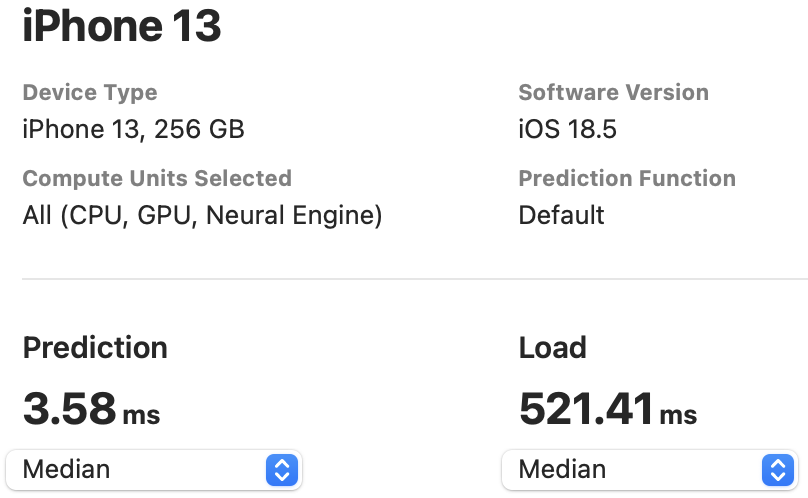
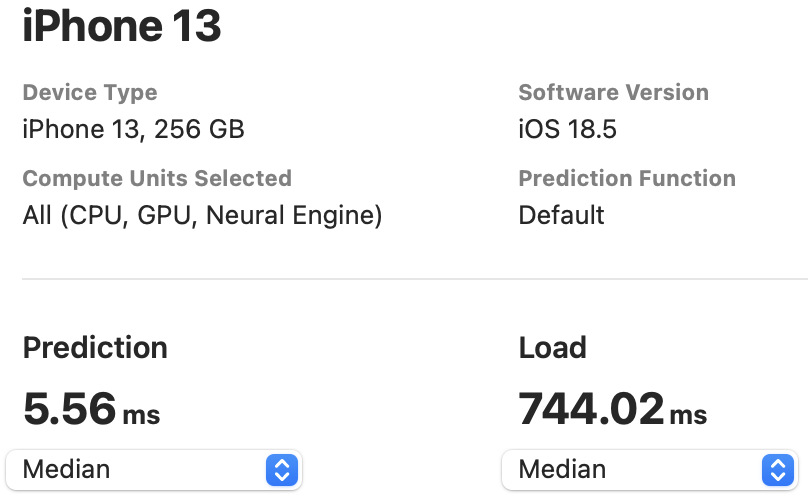
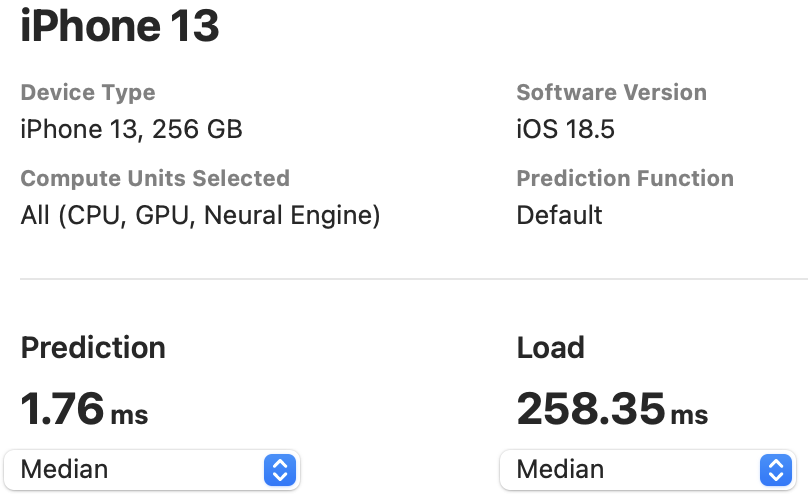
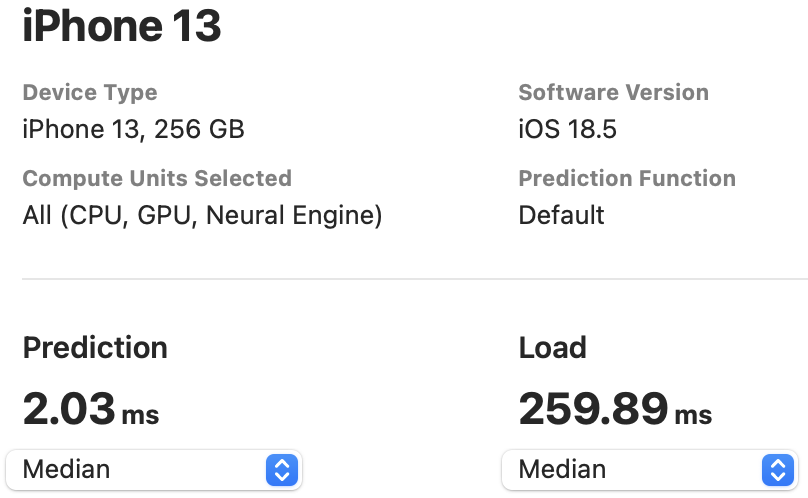
Tips: export the model to Core ML model
python export_coreml.py --model recnext_m1 --ckpt pretrain/recnext_m1_distill_300e.pth
Tips: measure the throughput on GPU
python speed_gpu.py --model recnext_m1
conda virtual environment is recommended.
conda create -n recnext python=3.8
pip install -r requirements.txt
Download and extract ImageNet train and val images from http://image-net.org/. The training and validation data are expected to be in the train folder and val folder respectively:
# script to extract ImageNet dataset: https://github.com/pytorch/examples/blob/main/imagenet/extract_ILSVRC.sh
# ILSVRC2012_img_train.tar (about 138 GB)
# ILSVRC2012_img_val.tar (about 6.3 GB)
# organize the ImageNet dataset as follows:
imagenet
├── train
│ ├── n01440764
│ │ ├── n01440764_10026.JPEG
│ │ ├── n01440764_10027.JPEG
│ │ ├── ......
│ ├── ......
├── val
│ ├── n01440764
│ │ ├── ILSVRC2012_val_00000293.JPEG
│ │ ├── ILSVRC2012_val_00002138.JPEG
│ │ ├── ......
│ ├── ......
To train RecNeXt-M1 on an 8-GPU machine:
python -m torch.distributed.launch --nproc_per_node=8 --master_port 12346 --use_env main.py --model recnext_m1 --data-path ~/imagenet --dist-eval
Tips: specify your data path and model name!
For example, to test RecNeXt-M1:
python main.py --eval --model recnext_m1 --resume pretrain/recnext_m1_distill_300e.pth --data-path ~/imagenet
Use pretrained model without knowledge distillation from HuggingFace 🤗.
python main.py --eval --model recnext_m1 --data-path ~/imagenet --pretrained --distillation-type none
Use pretrained model with knowledge distillation from HuggingFace 🤗.
python main.py --eval --model recnext_m1 --data-path ~/imagenet --pretrained --distillation-type hard
For example, to evaluate RecNeXt-M1 with the fused model: ![]()
python fuse_eval.py --model recnext_m1 --resume pretrain/recnext_m1_distill_300e_fused.pt --data-path ~/imagenet
# without distillation
python publish.py --model_name recnext_m1 --checkpoint_path pretrain/checkpoint_best.pth --epochs 300
# with distillation
python publish.py --model_name recnext_m1 --checkpoint_path pretrain/checkpoint_best.pth --epochs 300 --distillation
# fused model
python publish.py --model_name recnext_m1 --checkpoint_path pretrain/checkpoint_best.pth --epochs 300 --fused
Object Detection and Instance Segmentation
| model | $AP^b$ | $AP_{50}^b$ | $AP_{75}^b$ | $AP^m$ | $AP_{50}^m$ | $AP_{75}^m$ | Latency | Ckpt | Log |
|---|---|---|---|---|---|---|---|---|---|
| M3 | 41.7 | 63.4 | 45.4 | 38.6 | 60.5 | 41.4 | 5.2ms | M3 | M3 |
| M4 | 43.5 | 64.9 | 47.7 | 39.7 | 62.1 | 42.4 | 7.6ms | M4 | M4 |
| M5 | 44.6 | 66.3 | 49.0 | 40.6 | 63.5 | 43.5 | 12.4ms | M5 | M5 |
| A3 | 42.1 | 64.1 | 46.2 | 38.8 | 61.1 | 41.6 | 8.3ms | A3 | A3 |
| A4 | 43.5 | 65.4 | 47.6 | 39.8 | 62.4 | 42.9 | 14.0ms | A4 | A4 |
| A5 | 44.4 | 66.3 | 48.9 | 40.3 | 63.3 | 43.4 | 25.3ms | A5 | A5 |
| Model | mIoU | Latency | Ckpt | Log |
|---|---|---|---|---|
| RecNeXt-M3 | 41.0 | 5.6ms | M3 | M3 |
| RecNeXt-M4 | 43.6 | 7.2ms | M4 | M4 |
| RecNeXt-M5 | 46.0 | 12.4ms | M5 | M5 |
| RecNeXt-A3 | 41.9 | 8.4ms | A3 | A3 |
| RecNeXt-A4 | 43.0 | 14.0ms | A4 | A4 |
| RecNeXt-A5 | 46.5 | 25.3ms | A5 | A5 |
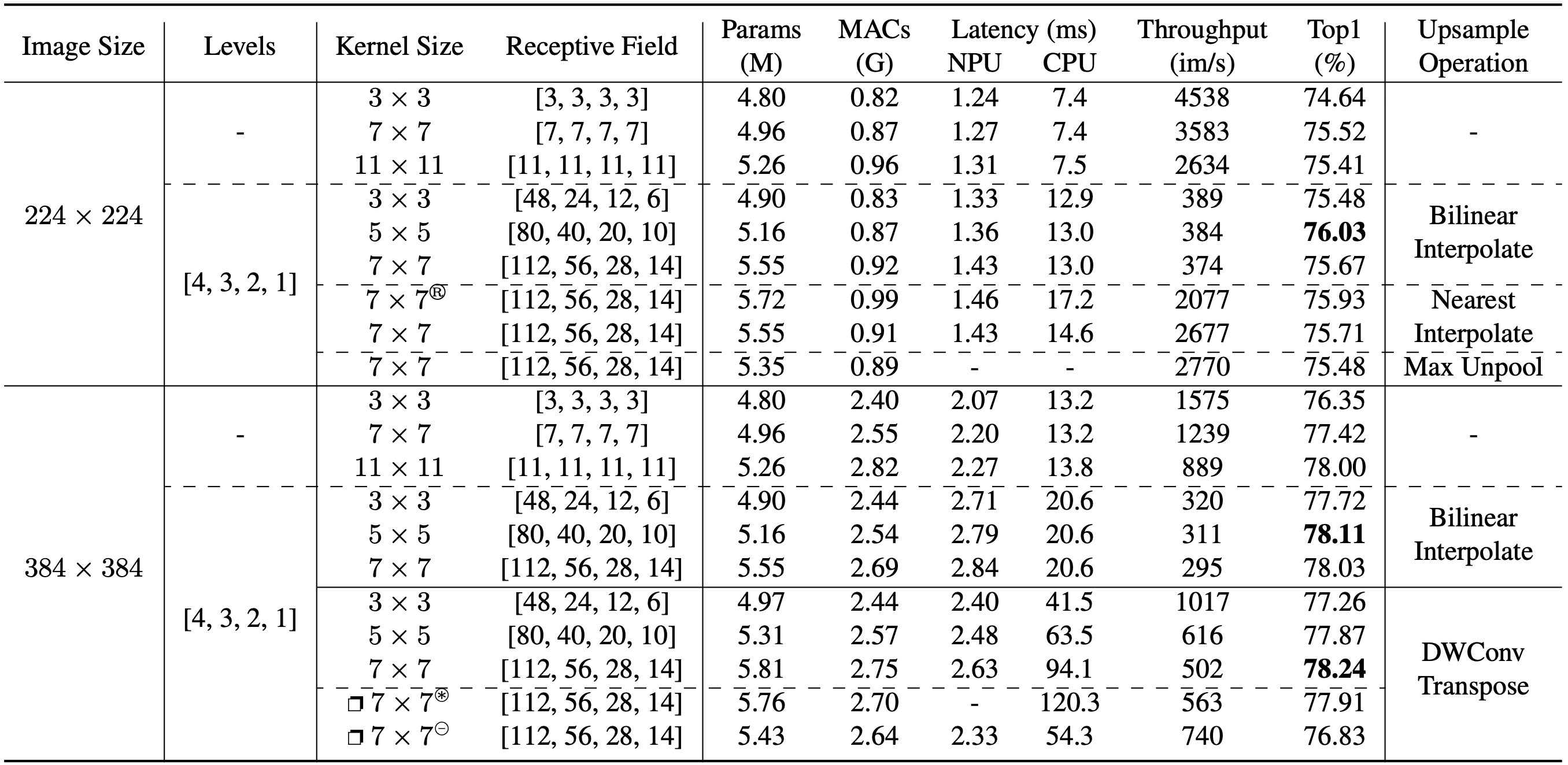
logs/ablation ├── 224 │ ├── recnext_m1_120e_224x224_3x3_7464.txt │ ├── recnext_m1_120e_224x224_7x7_7552.txt │ ├── recnext_m1_120e_224x224_bxb_7541.txt │ ├── recnext_m1_120e_224x224_rec_3x3_7548.txt │ ├── recnext_m1_120e_224x224_rec_5x5_7603.txt │ ├── recnext_m1_120e_224x224_rec_7x7_7567.txt │ ├── recnext_m1_120e_224x224_rec_7x7_nearest_7571.txt │ ├── recnext_m1_120e_224x224_rec_7x7_nearest_ssm_7593.txt │ └── recnext_m1_120e_224x224_rec_7x7_unpool_7548.txt └── 384 ├── recnext_m1_120e_384x384_3x3_7635.txt ├── recnext_m1_120e_384x384_7x7_7742.txt ├── recnext_m1_120e_384x384_bxb_7800.txt ├── recnext_m1_120e_384x384_rec_3x3_7772.txt ├── recnext_m1_120e_384x384_rec_5x5_7811.txt ├── recnext_m1_120e_384x384_rec_7x7_7803.txt ├── recnext_m1_120e_384x384_rec_convtrans_3x3_basic_7726.txt ├── recnext_m1_120e_384x384_rec_convtrans_5x5_basic_7787.txt ├── recnext_m1_120e_384x384_rec_convtrans_7x7_basic_7824.txt ├── recnext_m1_120e_384x384_rec_convtrans_7x7_group_7791.txt └── recnext_m1_120e_384x384_rec_convtrans_7x7_split_7683.txt
class RecConv2d(nn.Module):
def __init__(self, in_channels, kernel_size=5, bias=False, level=1, mode='nearest'):
super().__init__()
self.level = level
self.mode = mode
kwargs = {
'in_channels': in_channels,
'out_channels': in_channels,
'groups': in_channels,
'kernel_size': kernel_size,
'padding': kernel_size // 2,
'bias': bias
}
self.n = nn.Conv2d(stride=2, **kwargs)
self.a = nn.Conv2d(**kwargs) if level >1 else None
self.b = nn.Conv2d(**kwargs)
self.c = nn.Conv2d(**kwargs)
self.d = nn.Conv2d(**kwargs)
def forward(self, x):
# 1. Generate Multi-scale Features.
fs = [x]
for _ in range(self.level):
fs.append(self.n(fs[-1]))
# 2. Multi-scale Recurrent Aggregation.
h = None
for i, o in reversed(list(zip(fs[1:], fs[:-1]))):
h = self.a(h) + self.b(i) if h is not None else self.b(i)
h = nn.functional.interpolate(h, size=o.shape[2:], mode=self.mode)
return self.c(h) + self.d(x)
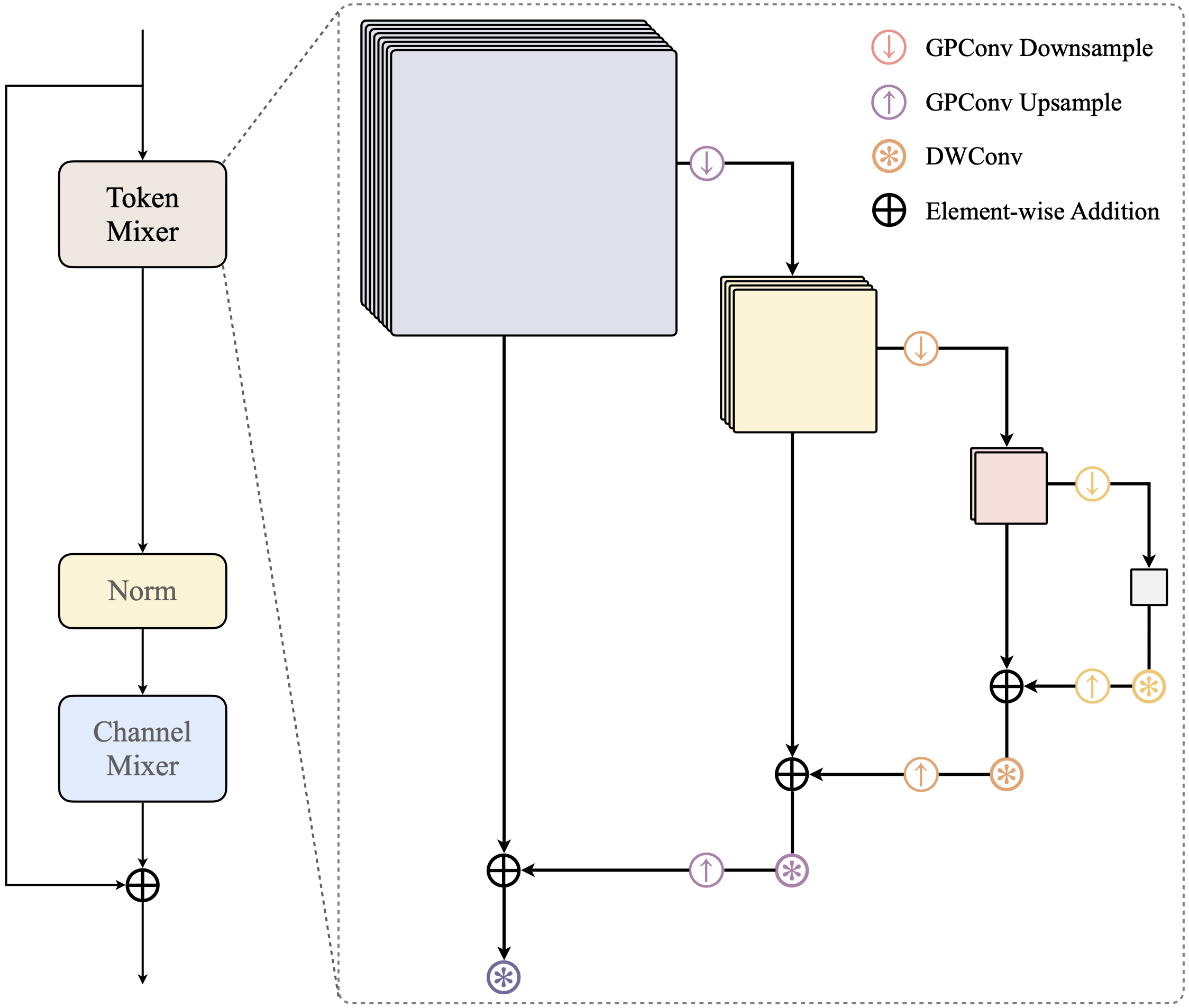
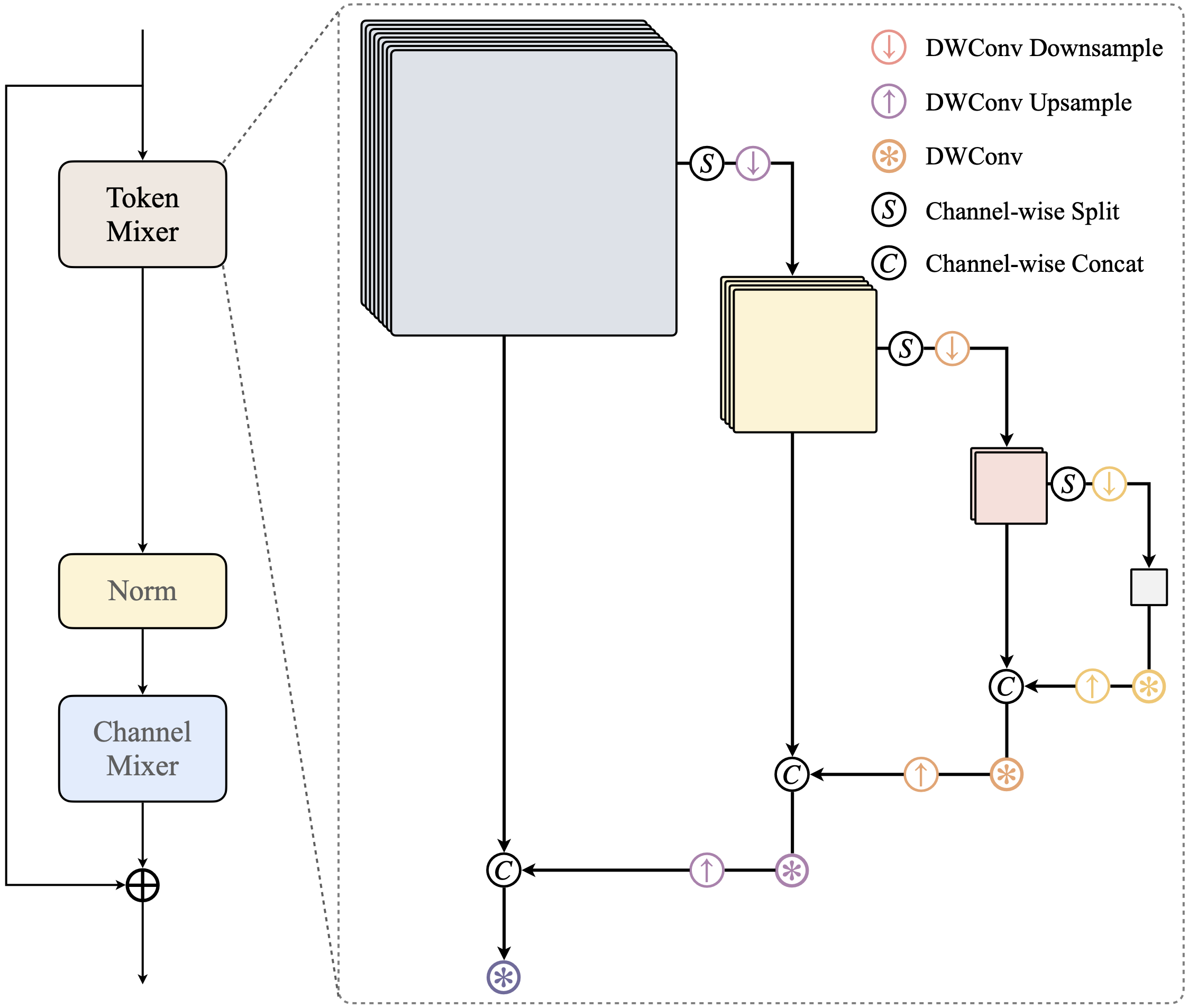
# RecConv Variant A
# recursive decomposition on both spatial and channel dimensions
# downsample and upsample through group convolutions
class RecConv2d(nn.Module):
def __init__(self, in_channels, kernel_size=5, bias=False, level=2):
super().__init__()
self.level = level
kwargs = {'kernel_size': kernel_size, 'padding': kernel_size // 2, 'bias': bias}
downs = []
for l in range(level):
i_channels = in_channels // (2 ** l)
o_channels = in_channels // (2 ** (l+1))
downs.append(nn.Conv2d(in_channels=i_channels, out_channels=o_channels, groups=o_channels, stride=2, **kwargs))
self.downs = nn.ModuleList(downs)
convs = []
for l in range(level+1):
channels = in_channels // (2 ** l)
convs.append(nn.Conv2d(in_channels=channels, out_channels=channels, groups=channels, **kwargs))
self.convs = nn.ModuleList(reversed(convs))
# this is the simplest modification, only support resoltions like 256, 384, etc
kwargs['kernel_size'] = kernel_size + 1
ups = []
for l in range(level):
i_channels = in_channels // (2 ** (l+1))
o_channels = in_channels // (2 ** l)
ups.append(nn.ConvTranspose2d(in_channels=i_channels, out_channels=o_channels, groups=i_channels, stride=2, **kwargs))
self.ups = nn.ModuleList(reversed(ups))
def forward(self, x):
i = x
features = []
for down in self.downs:
x, s = down(x), x.shape[2:]
features.append((x, s))
x = 0
for conv, up, (f, s) in zip(self.convs, self.ups, reversed(features)):
x = up(conv(f + x))
return self.convs[self.level](i + x)
# recursive decomposition on both spatial and channel dimensions
# downsample using channel-wise split, followed by depthwise convolution with a stride of 2
# upsample through channel-wise concatenation
class RecConv2d(nn.Module):
def __init__(self, in_channels, kernel_size=5, bias=False, level=2):
super().__init__()
self.level = level
kwargs = {'kernel_size': kernel_size, 'padding': kernel_size // 2, 'bias': bias}
downs = []
for l in range(level):
channels = in_channels // (2 ** (l+1))
downs.append(nn.Conv2d(in_channels=channels, out_channels=channels, groups=channels, stride=2, **kwargs))
self.downs = nn.ModuleList(downs)
convs = []
for l in range(level+1):
channels = in_channels // (2 ** l)
convs.append(nn.Conv2d(in_channels=channels, out_channels=channels, groups=channels, **kwargs))
self.convs = nn.ModuleList(reversed(convs))
. # this is the simplest modification, only support resoltions like 256, 384, etc
kwargs['kernel_size'] = kernel_size + 1
ups = []
for l in range(level):
channels = in_channels // (2 ** (l+1))
ups.append(nn.ConvTranspose2d(in_channels=channels, out_channels=channels, groups=channels, stride=2, **kwargs))
self.ups = nn.ModuleList(reversed(ups))
def forward(self, x):
features = []
for down in self.downs:
r, x = torch.chunk(x, 2, dim=1)
x, s = down(x), x.shape[2:]
features.append((r, s))
for conv, up, (r, s) in zip(self.convs, self.ups, reversed(features)):
x = torch.cat([r, up(conv(x))], dim=1)
return self.convs[self.level](x)
We apply RecConv to MLLA small variants, replacing linear attention and downsampling layers. Result in higher throughput and less training memory usage.
mlla/logs ├── 1_mlla_nano │ ├── 01_baseline.txt │ ├── 02_recconv_5x5_conv_trans.txt │ ├── 03_recconv_5x5_nearest_interp.txt │ ├── 04_recattn_nearest_interp.txt │ └── 05_recattn_nearest_interp_simplify.txt └── 2_mlla_mini ├── 01_baseline.txt ├── 02_recconv_5x5_conv_trans.txt ├── 03_recconv_5x5_nearest_interp.txt ├── 04_recattn_nearest_interp.txt └── 05_recattn_nearest_interp_simplify.txt
Classification (ImageNet) code base is partly built with LeViT, PoolFormer, EfficientFormer, RepViT, LSNet, MLLA, and MogaNet.
The detection and segmentation pipeline is from MMCV (MMDetection and MMSegmentation).
Thanks for the great implementations!
@misc{zhao2024recnext,
title={RecConv: Efficient Recursive Convolutions for Multi-Frequency Representations},
author={Mingshu Zhao and Yi Luo and Yong Ouyang},
year={2024},
eprint={2412.19628},
archivePrefix={arXiv},
primaryClass={cs.CV}
}