
Performance: Xeon W5-3425 + 72GB VRAM

System:
- Intel Xeon W5-3425 (12 cores)
- 512GB DDR5-4800. Getting ~160GB/s as measured my mlc
- Nvidia RTX4090D 48GB
- Nvidia RTX3090 24GB
Running 2025-July-04 build compiled with params:
cmake -B ./build \
-DGGML_CUDA=ON \
-DGGML_BLAS=0FF \
-DGGML_SCHED_MAX_COPIES=1 \
-DGGML_CUDA_IQK_FORCE_BF16=1
cmake --build ./build --config Release -j $(nproc)
running with params:
# CUDA0 - RTX 4090 48GB / 47GB used
# CUDA1 - RTX 3090 24GB / 23GB used
./build/bin/llama-server \
--model ./Qwen3-235B-A22B-mix-IQ3_K-00001-of-00003.gguf \
--alias qwen3-235b \
--temp 0.6 --min-p 0.0 --top-p 0.95 \
--ctx-size 32768 \
-ctk q8_0 -fa -fmoe \
-b 4096 -ub 4096 \
--n-gpu-layers 999 \
-ot "blk\.([0-9]|1[0-9]|2[0-9]|3[0-4])\.ffn=CUDA0" \
-ot "blk\.(5[0-9]|6[0-4])\.ffn=CUDA1" \
-ot exps=CPU \
--parallel 1 \
--threads 12 \
--host 0.0.0.0 --port 37000
Are all tensors equal? Or should I prefer to offload certain tensor vs others?
Getting speed:
prompt eval time = 6175.84 ms / 911 tokens ( 6.78 ms per token, 147.51 tokens per second)
generation eval time = 116075.92 ms / 1656 runs ( 70.09 ms per token, 14.27 tokens per second)
I found that -amb 512 doesn't affect inference speed.
I found that -rtr makes TG about 0.5t/s slower.
Are my settings optimal?
Few more lines from logs:
ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no
ggml_cuda_init: GGML_CUDA_FORCE_CUBLAS: no
ggml_cuda_init: found 2 CUDA devices:
Device 0: NVIDIA GeForce RTX 4090 D, compute capability 8.9, VMM: yes
Device 1: NVIDIA GeForce RTX 3090, compute capability 8.6, VMM: yes
INFO [ main] build info | tid="130735296229376" timestamp=1751925237 build=3787 commit="0678427f"
INFO [ main] system info | tid="130735296229376" timestamp=1751925237 n_threads=12 n_threads_batch=-1 total_threads=12 system_info="
AVX = 1 |
AVX_VNNI = 1 |
AVX2 = 1 |
AVX512 = 1 |
AVX512_VBMI = 1 |
AVX512_VNNI = 1 |
AVX512_BF16 = 1 |
FMA = 1 |
NEON = 0 |
SVE = 0 |
ARM_FMA = 0 |
F16C = 1 |
FP16_VA = 0 |
WASM_SIMD = 0 |
BLAS = 1 |
SSE3 = 1 |
SSSE3 = 1 |
VSX = 0 |
MATMUL_INT8 = 0 |
LLAMAFILE = 1 | "
llama_kv_cache_init: CUDA0 KV buffer size = 3136.03 MiB
llama_kv_cache_init: CUDA1 KV buffer size = 1470.01 MiB
I compared that to unsloth model:
https://huggingface.co/unsloth/Qwen3-235B-A22B-128K-GGUF
with UD-Q3_K_XL quants.
That quant is a bit smaller than mix-IQ3_K, so I can fit a bit more layers in VRAM:
in Docker, with params:
--model ./Qwen3-235B-A22B-128K-UD-Q3_K_XL-00001-of-00003.gguf
--ctx-size 32768
--flash-attn
--threads 12
--host 0.0.0.0 --port 37000
--temp 0.6
--min-p 0.0
--top-p 0.95
--top-k 20
--n-gpu-layers 999
-ot "blk\.([0-9]|1[0-9]|2[0-9]|3[0-9])\.ffn=CUDA0"
-ot "blk\.(5[0-9]|6[0-8])\.ffn=CUDA1"
-ot exps=CPU
In logs I see it uses more bits for KV cache:
llama_kv_cache_unified: CUDA0 KV buffer size = 4096.00 MiB
llama_kv_cache_unified: CUDA1 KV buffer size = 1920.00 MiB
Getting speed:
prompt eval time = 8747.69 ms / 911 tokens ( 9.60 ms per token, 104.14 tokens per second)
eval time = 129837.61 ms / 2077 tokens ( 62.51 ms per token, 16.00 tokens per second)
What would be comparison for perplexity for ubergarm/Qwen3-235B-A22B-GGUF/mix-IQ3_K vs unsloth/Qwen3-235B-A22B-128K-GGUF/UD-Q3_K_XL ?

CUDA_VISIBLE_DEVICES="0" LLAMA_ARG_NUMA="numactl" GGML_CUDA_ENABLE_UNIFIED_MEMORY=0 numactl --cpunodebind=0 --membind=0 ./bin/llama-server --model "/media/gopinath-s/C2A4E757A4E74D0B1/llama-cpp/models/Qwen3-235B-A22B-UD-Q6_K_XL-00001-of-00004.gguf" --ctx-size 22144 -mla 2 -fa -amb 512 -fmoe --n-gpu-layers 95 --override-tensor exps=CPU -b 2048 -ub 2048 --parallel 1 --threads 28 --threads-batch 28 --temp 0.7 --min-p 0.05 -ser 7,1 --run-time-repack --top-p 0.8 --host 127.0.0.1 --port 8080
@SlavikF can you try this ? i get arrount 4.5 t/sec on UD Q6
Are all tensors equal? Or should I prefer to offload certain tensor vs others?
For deepseek there are advantages to offloading all attn shexp and first three ffn dense layers along with MLA kv-cache. However qwen3moe does not have a shared expert nor extra three dense layers. So you're doing fine offloading all attn and as many additional layers as possible to GPU. For a dense LLM generally it doesn't matter much and plain old -ngl is sufficient in my experimenting.
Are my settings optimal?
You really have to test with llama-sweep-bench and compare all the options in a graph to visualize which is better for your needs. There is no "optimal" setting as some people might want more PP to process long text while others want to optimize something else etc. "It depends" haha...
If you want to make some graphs here is an example using your command plus some small changes I made:
./build/bin/llama-sweep-bench \
--model ./Qwen3-235B-A22B-mix-IQ3_K-00001-of-00003.gguf \
--ctx-size 32768 \
-ctk q8_0 -ctv q8_0 \
-fa -fmoe \
-b 4096 -ub 4096 \
--n-gpu-layers 999 \
-ot "blk\.([0-9]|1[0-9]|2[0-9]|3[0-4])\.ffn=CUDA0" \
-ot "blk\.(5[0-9]|6[0-4])\.ffn=CUDA1" \
-ot exps=CPU \
--threads 12 \
--warmup-batch
You were missing -ctv q8_0 as this is NOT an MLA model so you have to specify both -ctk and -ctv. With deepseek you only need -ctk because it is MLA.
Also keep in mind you only use -mla and -ambwith deepseek, it does nothing here on qwen3moe.
If you want more TG you might be able to reduce -ub to free up enough VRAM to offload another layer or two. Otherwise you are likely optimized for PP using large ubatch size. I'm assuming you have a single socket CPU configured in BIOS to asingle NUMA node.
What would be comparison for perplexity for ubergarm/Qwen3-235B-A22B-GGUF/mix-IQ3_K vs unsloth/Qwen3-235B-A22B-128K-GGUF/UD-Q3_K_XL ?
I have a full report on this here: https://www.reddit.com/r/LocalLLaMA/comments/1khwxal/the_great_quant_wars_of_2025/
tl;dr; my ubergarm/Qwen3-235B-A22B-mix-IQ3_K beats unsloth's especially since you chose the 128K version as that extends yarn out by default despite the official qwen model card warning that unless you really need 128k context don't do that as it hurts performance.
. If the average context length does not exceed 32,768 tokens, we do not recommend enabling YaRN in this scenario, as it may potentially degrade model performance.
https://huggingface.co/Qwen/Qwen3-235B-A22B#processing-long-texts
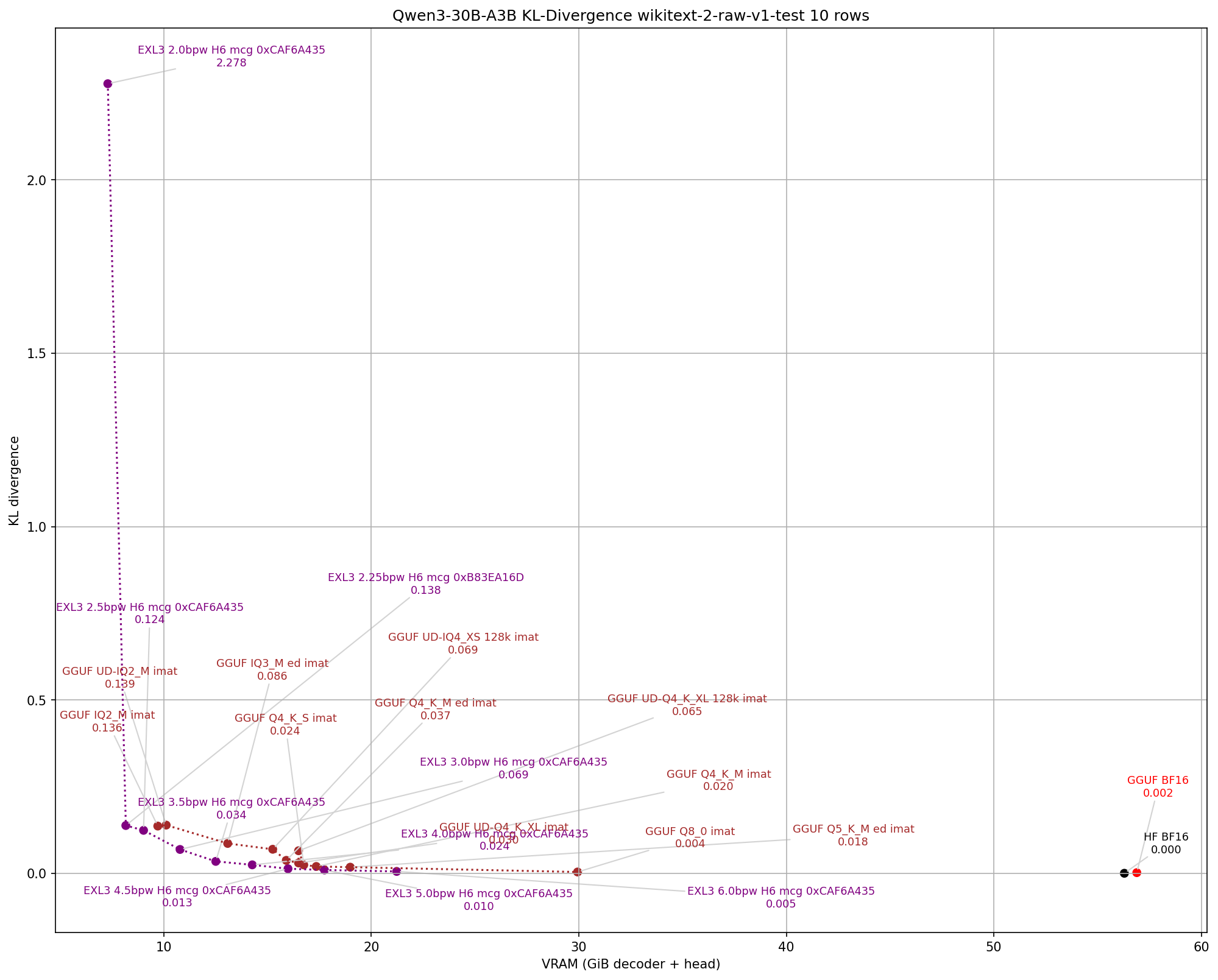
I've also shown this in graphs in the smaller Qwen3-30B-A3B where those "128k" versions have a noticeable increase in perplexity for the given size. Here is kld plotted with exllamav3 for some mainline GGUFs
I believe you were looking for a DeepSeek quant that fits into 256GB + 48GB VRAM or so? Currently uploading here: https://huggingface.co/ubergarm/DeepSeek-TNG-R1T2-Chimera-GGUF which might suit your needs.