
anchor
stringlengths 1
23.8k
| positive
stringlengths 1
23.8k
| negative
stringlengths 1
31k
| anchor_status
stringclasses 3
values |
|---|---|---|---|
## Inspiration
We built an AI-powered physical trainer/therapist that provides real-time feedback and companionship as you exercise.
With the rise of digitization, people are spending more time indoors, leading to increasing trends of obesity and inactivity. We wanted to make it easier for people to get into health and fitness, ultimately improving lives by combating these the downsides of these trends. Our team built an AI-powered personal trainer that provides real-time feedback on exercise form using computer vision to analyze body movements. By leveraging state-of-the-art technologies, we aim to bring accessible and personalized fitness coaching to those who might feel isolated or have busy schedules, encouraging a more active lifestyle where it can otherwise be intimidating.
## What it does
Our AI personal trainer is a web application compatible with laptops equipped with webcams, designed to lower the barriers to fitness. When a user performs an exercise, the AI analyzes their movements in real-time using a pre-trained deep learning model. It provides immediate feedback in both textual and visual formats, correcting form and offering tips for improvement. The system tracks progress over time, offering personalized workout recommendations and gradually increasing difficulty based on performance. With voice guidance included, users receive tailored fitness coaching from anywhere, empowering them to stay consistent in their journey and helping to combat inactivity and lower the barriers of entry to the great world of fitness.
## How we built it
To create a solution that makes fitness more approachable, we focused on three main components:
Computer Vision Model: We utilized MediaPipe and its Pose Landmarks to detect and analyze users' body movements during exercises. MediaPipe's lightweight framework allowed us to efficiently assess posture and angles in real-time, which is crucial for providing immediate form correction and ensuring effective workouts.
Audio Interface: We initially planned to integrate OpenAI’s real-time API for seamless text-to-speech and speech-to-text capabilities, enhancing user interaction. However, due to time constraints with the newly released documentation, we implemented a hybrid solution using the Vosk API for speech recognition. While this approach introduced slightly higher latency, it enabled us to provide real-time auditory feedback, making the experience more engaging and accessible.
User Interface: The front end was built using React with JavaScript for a responsive and intuitive design. The backend, developed in Flask with Python, manages communication between the AI model, audio interface, and user data. This setup allows the machine learning models to run efficiently, providing smooth real-time feedback without the need for powerful hardware.
On the user interface side, the front end was built using React with JavaScript for a responsive and intuitive design. The backend, developed in Flask with Python, handles the communication between the AI model, audio interface, and the user's data.
## Challenges we ran into
One of the major challenges was integrating the real-time audio interface. We initially planned to use OpenAI’s real-time API, but due to the recent release of the documentation, we didn’t have enough time to fully implement it. This led us to use the Vosk API in conjunction with our system, which introduced increased codebase complexity in handling real-time feedback.
## Accomplishments that we're proud of
We're proud to have developed a functional AI personal trainer that combines computer vision and audio feedback to lower the barriers to fitness. Despite technical hurdles, we created a platform that can help people improve their health by making professional fitness guidance more accessible. Our application runs smoothly on various devices, making it easier for people to incorporate exercise into their daily lives and address the challenges of obesity and inactivity.
## What we learned
Through this project, we learned that sometimes you need to take a "back door" approach when the original plan doesn’t go as expected. Our experience with OpenAI’s real-time API taught us that even with exciting new technologies, there can be limitations or time constraints that require alternative solutions. In this case, we had to pivot to using the Vosk API alongside our real-time system, which, while not ideal, allowed us to continue forward. This experience reinforced the importance of flexibility and problem-solving when working on complex, innovative projects.
## What's next for AI Personal Trainer
Looking ahead, we plan to push the limits of the OpenAI real-time API to enhance performance and reduce latency, further improving the user experience. We aim to expand our exercise library and refine our feedback mechanisms to cater to users of all fitness levels. Developing a mobile app is also on our roadmap, increasing accessibility and convenience. Ultimately, we hope to collaborate with fitness professionals to validate and enhance our AI personal trainer, making it a reliable tool that encourages more people to lead healthier, active lives. | ## Inspiration
With more people working at home due to the pandemic, we felt empowered to improve healthcare at an individual level. Existing solutions for posture detection are expensive, lack cross-platform support, and often require additional device purchases. We sought to remedy these issues by creating Upright.
## What it does
Upright uses your laptop's camera to analyze and help you improve your posture. Register and calibrate the system in less than two minutes, and simply keep Upright open in the background and continue working. Upright will notify you if you begin to slouch so you can correct it. Upright also has the Upright companion iOS app to view your daily metrics.
Some notable features include:
* Smart slouch detection with ML
* Little overhead - get started in < 2 min
* Native notifications on any platform
* Progress tracking with an iOS companion app
## How we built it
We created Upright’s desktop app using Electron.js, an npm package used to develop cross-platform apps. We created the individual pages for the app using HTML, CSS, and client-side JavaScript. For the onboarding screens, users fill out an HTML form which signs them in using Firebase Authentication and uploads information such as their name and preferences to Firestore. This data is also persisted locally using NeDB, a local JavaScript database. The menu bar addition incorporates a camera through a MediaDevices web API, which gives us frames of the user’s posture. Using Tensorflow’s PoseNet model, we analyzed these frames to determine if the user is slouching and if so, by how much. The app sends a desktop notification to alert the user about their posture and also uploads this data to Firestore. Lastly, our SwiftUI-based iOS app pulls this data to display metrics and graphs for the user about their posture over time.
## Challenges we ran into
We faced difficulties when managing data throughout the platform, from the desktop app backend to the frontend pages to the iOS app. As this was our first time using Electron, our team spent a lot of time discovering ways to pass data safely and efficiently, discussing the pros and cons of different solutions. Another significant challenge was performing the machine learning on the video frames. The task of taking in a stream of camera frames and outputting them into slouching percentage values was quite demanding, but we were able to overcome several bugs and obstacles along the way to create the final product.
## Accomplishments that we're proud of
We’re proud that we’ve come up with a seamless and beautiful design that takes less than a minute to setup. The slouch detection model is also pretty accurate, something that we’re pretty proud of. Overall, we’ve built a robust system that we believe outperforms other solutions using just the webcamera of your computer, while also integrating features to track slouching data on your mobile device.
## What we learned
This project taught us how to combine multiple complicated moving pieces into one application. Specifically, we learned how to make a native desktop application with features like notifications built-in using Electron. We also learned how to connect our backend posture data with Firestore to relay information from our Electron application to our OS app. Lastly, we learned how to integrate a machine learning model in Tensorflow within our Electron application.
## What's next for Upright
The next step is improving the posture detection model with more training data, tailored for each user. While the posture detection model we currently use is pretty accurate, by using more custom-tailored training data, it would take Upright to the next level. Another step for Upright would be adding Android integration for our mobile app, which currently only supports iOS as of now. | # Inspiration 🌟
**What is the problem?**
Physical activity early on can drastically increase longevity and productivity for later stages of life. Without finding a dependable routine during your younger years, you may experience physical impairment in the future. 50% of functional decline that occurs in those 30 to 70 years old is due to lack of exercise.
During the peak of the COVID-19 pandemic in Canada, nationwide isolation brought everyone indoors. There was still a vast number of people that managed to work out in their homes, which motivated us to create an application that further encouraged engaging in fitness, using their devices, from the convenience of their homes.
# Webapp Summary 📜
Inspired, our team decided to tackle this idea by creating a web app that helps its users maintain a consistent and disciplined routine.
# What does it do? 💻
*my trAIner* plans to aid you and your journey to healthy fitness by displaying the number of calories you have burned while also counting your reps. It additionally helps to motivate you through words of encouragement. For example, whenever nearing a rep goal, *my trAIner* will use phrases like, “almost there!” or “keep going!” to push you to the last rep. Once completing your set goal *my trAIner* will congratulate you.
We hope that people may utilize this to make the best of their workouts. Utilizing AI technology to help those reach their rep standard and track calories, we believe could help students and adults in the present and future.
# How we built it:🛠
To build this application, we used **JavaScript, CSS,** and **HTML.** To make the body mapping technology, we used a **TensorFlow** library. We mapped out different joints on the body and compared them as they moved, in order to determine when an exercise was completed. We also included features like parallax scrolling and sound effects from DeltaHacks staff.
# Challenges that we ran into 🚫
Learning how to use **TensorFlow**’s pose detection proved to be a challenge, as well as integrating our own artwork into the parallax scrolling. We also had to refine our backend as the library’s detection was shaky at times. Additional challenges included cleanly linking **HTML, JS, and CSS** as well as managing the short amount of time we were given.
# Accomplishments that we’re proud of 🎊
We are proud that we put out a product with great visual aesthetics as well as a refined detection method. We’re also proud that we were able to take a difficult idea and prove to ourselves that we were capable of creating this project in a short amount of time. More than that though, we are most proud that we could make a web app that could help out people trying to be more healthy.
# What we learned 🍎
Not only did we develop our technical skills like web development and AI, but we also learned crucial things about planning, dividing work, and time management. We learned the importance of keeping organized with things like to-do lists and constantly communicating to see what each other’s limitations and abilities were. When challenges arose, we weren't afraid to delve into unknown territories.
# Future plans 📅
Due to time constraints, we were not able to completely actualize our ideas, however, we will continue growing and raising efficiency by giving ourselves more time to work on *my trAIner*. Potential future ideas to incorporate may include constructive form correction, calorie intake calculator, meal preps, goal setting, recommended workouts based on BMI, and much more. We hope to keep on learning and applying newly obtained concepts to *my trAIner*. | winning |
## Inspiration
Minecraft has an interesting map mechanic where your character holds a map which "draws itself" while exploring the world. I am also very interested in building a plotter, which is a printer that uses a pen and (XY) gantry to produce images. These ideas seemed to fit together quite well.
## What it does
Press a button, copy GPS coordinates and run the custom "gcode" compiler to generate machine/motor driving code for the arduino. Wait around 15 minutes for a 48 x 48 output.
## How we built it
Mechanical assembly - Tore apart 3 dvd drives and extracted a multitude of components, including sled motors (linear rails). Unfortunately, they used limit switch + DC motor rather than stepper, so I had to saw apart the enclosure and **glue** in my own steppers with a gear which (you guessed it) was also glued to the motor shaft.
Electronics - I designed a simple algorithm to walk through an image matrix and translate it into motor code, that looks a lot like a video game control. Indeed, the stepperboi/autostepperboi main source code has utilities to manually control all three axes like a tiny claw machine :)
U - Pen Up
D - Pen Down
L - Pen Left
R - Pen Right
Y/T - Pen Forward (top)
B - Pen Backwards (bottom)
Z - zero the calibration
O - returned to previous zeroed position
## Challenges we ran into
* I have no idea about basic mechanics / manufacturing so it's pretty slipshod, the fractional resolution I managed to extract is impressive in its own right
* Designing my own 'gcode' simplification was a little complicated, and produces strange, pointillist results. I like it though.
## Accomplishments that we're proud of
* 24 hours and a pretty small cost in parts to make a functioning plotter!
* Connected to mapbox api and did image processing quite successfully, including machine code generation / interpretation
## What we learned
* You don't need to take MIE243 to do low precision work, all you need is superglue, a glue gun and a dream
* GPS modules are finnicky and need to be somewhat near to a window with built in antenna
* Vectorizing an image is quite a complex problem
* Mechanical engineering is difficult
* Steppers are *extremely* precise, and I am quite surprised at the output quality given that it's barely held together.
* Iteration for mechanical structure is possible, but difficult
* How to use rotary tool and not amputate fingers
* How to remove superglue from skin (lol)
## What's next for Cartoboy
* Compacting the design it so it can fit in a smaller profile, and work more like a polaroid camera as intended. (Maybe I will learn solidworks one of these days)
* Improving the gcode algorithm / tapping into existing gcode standard | ## Inspiration
Having previously volunteered and worked with children with cerebral palsy, we were struck with the monotony and inaccessibility of traditional physiotherapy. We came up with a cheaper, more portable, and more engaging way to deliver treatment by creating virtual reality games geared towards 12-15 year olds. We targeted this age group because puberty is a crucial period for retention of plasticity in a child's limbs. We implemented interactive games in VR using Oculus' Rift and Leap motion's controllers.
## What it does
We designed games that targeted specific hand/elbow/shoulder gestures and used a leap motion controller to track the gestures. Our system improves motor skill, cognitive abilities, emotional growth and social skills of children affected by cerebral palsy.
## How we built it
Our games use of leap-motion's hand-tracking technology and the Oculus' immersive system to deliver engaging, exciting, physiotherapy sessions that patients will look forward to playing. These games were created using Unity and C#, and could be played using an Oculus Rift with a Leap Motion controller mounted on top. We also used an Alienware computer with a dedicated graphics card to run the Oculus.
## Challenges we ran into
The biggest challenge we ran into was getting the Oculus running. None of our computers had the ports and the capabilities needed to run the Oculus because it needed so much power. Thankfully we were able to acquire an appropriate laptop through MLH, but the Alienware computer we got was locked out of windows. We then spent the first 6 hours re-installing windows and repairing the laptop, which was a challenge. We also faced difficulties programming the interactions between the hands and the objects in the games because it was our first time creating a VR game using Unity, leap motion controls, and Oculus Rift.
## Accomplishments that we're proud of
We were proud of our end result because it was our first time creating a VR game with an Oculus Rift and we were amazed by the user experience we were able to provide. Our games were really fun to play! It was intensely gratifying to see our games working, and to know that it would be able to help others!
## What we learned
This project gave us the opportunity to educate ourselves on the realities of not being able-bodied. We developed an appreciation for the struggles people living with cerebral palsy face, and also learned a lot of Unity.
## What's next for Alternative Physical Treatment
We will develop more advanced games involving a greater combination of hand and elbow gestures, and hopefully get testing in local rehabilitation hospitals. We also hope to integrate data recording and playback functions for treatment analysis.
## Business Model Canvas
<https://mcgill-my.sharepoint.com/:b:/g/personal/ion_banaru_mail_mcgill_ca/EYvNcH-mRI1Eo9bQFMoVu5sB7iIn1o7RXM_SoTUFdsPEdw?e=SWf6PO> | ## Inspiration
As a team, we were immediately intrigued by the creative freedom involved in building a ‘useless invention’ and inspiration was drawn from the ‘useless box’ that turns itself off. We thought ‘why not have it be a robot arm and give it an equally intriguing personality?’ and immediately got to work taking our own spin on the concept.
## What It Does
The robot has 3 servos that allow the robot to move with personality. Whenever the switch is pressed, the robot executes a sequence of actions in order to flick the switch and then shut down.
## How We Built It
We started by dividing tasks between members: the skeleton of the code, building the physical robot, and electronic components. A CAD model was drawn up to get a gauge for scale, and then it was right into cutting and glueing popsicle sticks. An Exacto blade was used to create holes in the base container for components to fit through to keep everything neat and compact. Simultaneously, as much of the code and electronic wiring was done to not waste time.
After the build was complete, a test code was run and highlighted areas that needed to be reinforced. While that was happening, calculations were being done to determine the locations the servo motors would need to reach in order to achieve our goal. Once a ‘default’ sequence was achieved, team members split to write 3 of our own sequences before converging to achieve the 5th and final sequence. After several tests were run and the code was tweaked, a demo video was filmed.
## Challenges We Ran Into
The design itself is rather rudimentary, being built out of a Tupperware container, popsicle sticks and various electronic components to create the features such as servo motors and a buzzer. Challenges consisted of working with materials as fickle as popsicle sticks – a decision driven mainly by the lack of realistic accessibility to 3D printers. The wood splintered and was weaker than expected, therefore creative design was necessary so that it held together.
Another challenge was the movement. Working with 3 servo motors proved difficult when assigning locations and movement sequences, but once we found a ‘default’ sequence that worked, the other following sequences slid into place. Unfortunately, our toils were not over as now the robot had to be able to push the switch, and initial force proved to be insufficient.
## Accomplishments That We’re Proud Of
About halfway through, while we were struggling with getting the movement to work, thoughts turned toward what we would do in different sequences. Out of inspiration from other activities occurring during the event, it was decided that we would add a musical element to our ‘useless machine’ in the form of a buzzer playing “Tequila” by The Champs. This was our easiest success despite involving transposing sheet music and changing rhythms until we found the desired effect.
We also got at least 3 sequences into the robot! That is more than we were expecting 12 hours into the build due to difficulties with programming the servos.
## What We Learned
When we assigned tasks, we all chose roles that we were not normally accustomed to. Our mechanical member worked heavily in software while another less familiar with design focused on the actual build. We all exchanged roles over the course of the project, but this rotation of focus allowed us to get the most out of the experience. You can do a lot with relatively few components; constraint leads to innovation.
## What’s Next for Little Dunce
So far, we have only built in the set of 5 sequences, but we want Little Dunce to have more of a personality and more varied and random reactions. As of now, it is a sequence of events, but we want Little Dunce to act randomly so that everyone can get a unique experience with the invention. We also want to add an RGB LED light for mood indication dependent on the sequence chosen. This would also serve as the “on/off” indicator since the initial proposal was to have a robot that goes to sleep. | winning |
## Inspiration
Sometimes, we all just have one of those days. Maybe you didn't make any plans and now you're sitting alone, eating lunch by yourself. Maybe it's a new semester of college in a new place, and you feel out of place and isolated. While the solution (make friends!) seems obvious enough, it's not always easy to approach people, and sometimes, we just don't have the energy to socialize on top of heavy course loads and extracurriculars.
## What it does
meet2eat is a website that makes it easy to spontaneously schedule a dinner with someone new. All you have to do is provide your name and when you're available, and meet2eat will randomly choose a dining hall setting and pair you with someone. Because meet2eat forgoes creating a profile, it's more convenient and places less social pressure on the user. Additionally, because meet2eat only lets users schedule a meal on the same day, meet2eat is very noncommittal. At its heart, meet2eat helps people across all years and backgrounds connect and hopefully, spark meaningful conversations and relationships.
meet2eat is not only for university students--it can also connect the elderly with university students for a meal, as loneliness is similarly a big issue for elderly people in nursing homes. University students can have a meal with the elderly and learn from them while earning service hours.
## How we built it
This web app was built using React as a front end and Flask as a back end.
## Challenges we ran into
We ran into some challenges with connecting front end with the back end, and using the REST API to transfer data between the two portions
## Accomplishments that we're proud of
Hashing out the structure, and learning new frameworks on the fly!
## What we learned
We learned how to leverage technology to help solve a growing problem on university campuses.
## What's next for meet2eat
Being able to provide seating options by including table reservations and live updates on seat availability. | ## Inspiration
We came up with the idea of Budget Bites when we faced the challenge of affording groceries and restaurants in the city, as well as the issue of food waste and environmental impact. We wanted to make a web app that would help people find the best deals on food and groceries that are close to expiry or on the date of expiry, and incentivize them to buy them before they go to waste by offering discounts on the items. With our app, you can easily find quick groceries for a fast meal, and see the cheapest and freshest options available in your area, along with the distance and directions to help you reduce your carbon footprint. Budget Bites is our pocket-friendly food guide that helps you save money, enjoy good food, and protect the planet every day of the week.
## What it does
Budget Bites is a website that gives you a list of the prices, freshness, and distance of food and groceries near you. You can also get discounts and coupons on items that are close to sale, and enjoy good food every day of the week without breaking the bank or harming the planet. Budget Bites is your pocket-friendly food guide that makes eating well easy and affordable.
## How we built it
We built the web app with React.js, Typescript, Vite, and React Router, as well as React Context Hooks. For styling and design, we utilized SASS and TailwindCSS. We used various React components/libraries such as Fuse.js and React-toast, as well as a payment system using Stripe.
## Challenges we ran into
One of our biggest challenges was trying to integrate the JavaScript SDK for Google Maps into our program. This was very new to us as none of us had any any experience with the Maps API. Getting the Google Maps API to function took hours of intense problems solving. It didn't stop there though as right after that we had to try adding landmarks which was another problem however we overcame it by looking through documentation and through the consultation of mentors
## Accomplishments that we're proud of
An accomplishment that we are proud of is that we figured out how to use google maps jdk and successfully implemented the google maps features to our web app. We also figured out how to calculate distances from where the user is to the store as well.
## What we learned
One of the key skills that we gained over the duration of this hackathon is that we learnt how to implement Google Maps to our system. This involved us learning how the Maps SDKs worked to integrate them into our application to provide proper location services. We also delved into the realm of distance and time calculations using two points. Using Google Maps, we learned how to determine the distance between where the user starts and where his end point is supposed to be as well as an estimate for the time it will take to reach the given point.
## What's next for Budget Bites
Our next steps for Budget Bites is to make it a more frequently used app as well as a global app that helps people around the world enjoy good food without wasting money or resources. To do this, we will make sure our app is tailored to the languages, cultures, preferences, and regulations of each market we enter. We will use Google Translate to make our app accessible and understandable in different languages. We will also work with local experts, partners, or customers to learn about their specific needs and expectations. We will also follow the local laws and standards that apply to our app and its features. We will design and execute a marketing strategy and a distribution plan for our app in each market we target. We will use Facebook Ads and Google Ads to create and run online campaigns that highlight the benefits and features of our app, such as saving money, reducing food waste, and enjoying good food. We will also use social media platforms such as Instagram and Twitter to share deals, testimonials, and reviews that showcase the experience that people have with budget bites to allow a greater influx of customers. | ## Inspiration
We set out to build a product that solves two core pain points in our daily lives: 1) figuring out what to do for every meal 😋 and 2) maintaining personal relationships 👥.
As college students, we find ourselves on a daily basis asking the question, “What should I do for lunch today?” 🍔 — many times with a little less than an hour left before it’s time to eat. The decision process usually involves determining if one has the willpower to cook at home, and if not, figuring out where to eat out and if there is anyone to eat out with. For us, this usually just ends up being our roommates, and we find ourselves quite challenged by maintaining depth of relationships with people we want to because the context windows are too large to juggle.
Enter, BiteBuddy.
## What it does
We divide the problem we’re solving into two main scenarios.
1. **Spontaneous (Eat Now!)**: It’s 12PM and Jason realizes that he doesn’t have lunch plans. BiteBuddy will help him make some! 🍱
2. **Futuristic (Schedule Ahead!)**: It’s Friday night and Parth decides that he wants to plan out his entire next week (Forkable, anyone?). 🕒
**Eat Now** allows you to find friends that are near you and automatically suggests nearby restaurants that would be amenable to both of you based on dietary and financial considerations. Read more below to learn some of the cool API interactions and ML behind this :’). 🗺️
**Schedule Ahead** allows you to plan your week ahead and actually think about personal relationships. It analyzes closeness between friends, how long it’s been since you last hung out, looks at calendars, and similar to above automatically suggests time and restaurants. Read more below for how! 🧠
We also offer a variety of other features to support the core experience:
1. **Feed**. View a streaming feed of the places your friends have been going. Enhance the social aspect of the network.
2. **Friends** (no, we don’t offer friends). Manage your relationships in a centralized way and view LLM-generated insights regarding relationships and when might be the right time/how to rekindle them.
## How we built it
The entire stack we used for this project was Python, with the full stack web development being enabled by the **Reflex** Python package, and database being Firebase.
**Eat Now** is a feature that bases itself around geolocation, dietary preferences, financial preferences, calendar availability, and LLM recommendation systems. We take your location, go through your friends list and find the friends who are near you and don’t have immediate conflicts on their calendar, compute an intersection of possible restaurants via the Yelp API that would be within a certain radius of both of you, filter this intersection with dietary + financial preferences (vegetarian? vegan? cheap?), then pass all our user context into a LLAMA-13B-Chat 💬 to generate a final recommendation. This recommendation surfaces itself as a potential invite (in figures above) that the user can choose whether or not to send to another person. If they accept, a calendar invite is automatically generated.
**Schedule Ahead** is a feature that bases itself around graph machine learning, calendar availability, personal relationship status (how close are y’all? When is the last time you saw each other?), dietary/financial preferences, and more. By looking ahead into the future, we take the time to look through our social network graph with associated metadata and infer relationships via Spectral Clustering 📊. Based on how long it’s been since you last hung out and the strength of your relationship, it will surface who to meet with as a priority queue and look at both calendars to determine mutually available times and locations with the same LLM.
We use retrieval augmented generation (RAG) 📝 throughout our app to power personalized friend insights (to learn more about which friends you should catch up with, learn that Jason is a foodie, and what cuisines you and Parth like). This method is also a part of our recommendation algorithm.
## Challenges we ran into
1. **Dealing with APIs.** We utilized a number of APIs to provide a level of granularity and practicality to this project, rather than something that’s solely a mockup. Dealing with APIs though comes with its own issues. The Yelp API, for example, continuously rate limited us even though we cycled through keys from all of our developer accounts :’). The Google Calendar API required a lot of exploration with refresh tokens, necessary scopes, managing state with google auth, etc.
2. **New Technologies.** We challenged ourselves by exploring some new technologies as a part of our stack to complete this project. Graph ML for example was a technology we hadn’t worked with much before, and we quickly ran into the cold start problem with meaningless graphs and unintuitive relationships. Reflex was another new technology that we used to complete our frontend and backend entirely in Python. None of us had ever even pip installed this package before, so learning how to work with it and then turn it into something complex and useful was a fun challenge. 💡
3. **Latency.** Because our app queries several APIs, we had to make our code as performant as possible, utilize concurrency where possible, and add caching for frequently-queried endpoints. 🖥️
## Accomplishments that we're proud of
The amount of complexity that we were able to introduce into this project made it mimic real-life as close as possible, which is something we’re very proud of. We’re also proud of all the new technologies and Machine Learning methods we were able to use to develop a product that would be most beneficial to end users.
## What we learned
This project was an incredible learning experience for our team as we took on multiple technically complex challenges to reach our ending solution -- something we all thought that we had a potential to use ourselves.
## What's next for BiteBuddy
The cool thing about this project was that there were a hundred more features we wanted to include but didn’t remotely have the time to implement. Here are some of our favorites 🙂:
1. **Groups.** Social circles often revolve around groups. Enabling the formation of groups on the app would give us more metadata information regarding the relationships between people, lending itself to improved GNN algorithms and recommendations, and improve the stickiness of the product by introducing network effects.
2. **New Intros: Extending to the Mutuals.** We’ve built a wonderful graph of relationships that includes metadata not super common to a social network. Why not leverage this to generate introductions and form new relationships between people?
3. **More Integrations.** Why use DonutBot when you can have BiteBuddy?
## Built with
Python, Reflex, Firebase, Together AI, ❤️, and boba 🧋 | losing |
## 💡 Inspiration
The objective of our application is to devise an effective and efficient written transmission optimization scheme, by converting esoteric text into an exoteric format.
If you read the above sentence more than once and the word ‘huh?’ came to mind, then you got my point. Jargon causes a problem when you are talking to someone who doesn't understand it. Yet, we face obscure, vague texts every day - from ['text speak'](https://www.goodnewsnetwork.org/dad-admits-hilarious-texting-blunder-on-the-moth/) to T&C agreements.
The most notoriously difficult to understand texts are legal documents, such as contracts or deeds. However, making legal language more straightforward would help people understand their rights better, be less susceptible to being punished or not being able to benefit from their entitled rights.
Introducing simpl.ai - A website application that uses NLP and Artificial Intelligence to recognize difficult to understand text and rephrase them with easy-to-understand language!
## 🔍 What it does
simpl.ai intelligently simplifies difficult text for faster comprehension. Users can send a PDF file of the document they are struggling to understand. They can select the exact sentences that are hard to read, and our NLP-model recognizes what elements make it tough. You'll love simpl.ai's clear, straightforward restatements - they change to match the original word or phrase's part of speech/verb tense/form, so they make sense!
## ⚙️ Our Tech Stack
[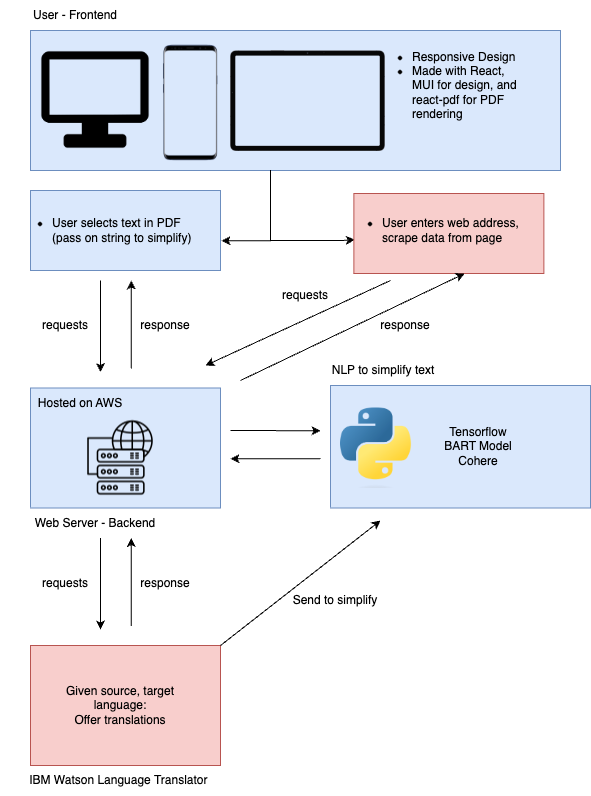](https://postimg.cc/gr2ZqkpW)
**Frontend:** We created the client side of our web app using React.js and JSX based on a high-fidelity prototype we created using Figma. Our components are styled using MaterialUI Library, and Intelllex's react-pdf package for rendering PDF documents within the app.
**Backend:** Python! The magic behind the scenes is powered by a combination of fastAPI, TensorFlow (TF), Torch and Cohere. Although we are newbies to the world of AI (NLP), we used a BART model and TF to create a working model that detects difficult-to-understand text! We used the following [dataset](https://www.inf.uni-hamburg.de/en/inst/ab/lt/resources/data/complex-word-identification-dataset/cwishareddataset.zip) from Stanford University to train our [model](http://nlp.stanford.edu/data/glove.6B.zip)- It's based on several interviews conducted with non-native English speakers, where they were tasked to identify difficult words and simpler synonyms for them. Finally, we used Cohere to rephrase the sentence and ensure it makes sense!
## 🚧 Challenges we ran into
This hackathon was filled with many challenges - but here are some of the most notable ones:
* We purposely choose an AI area where we didn't know too much in (NLP, TensorFlow, CohereAPI), which was a challenging and humbling experience. We faced several compatibility issues with TensorFlow when trying to deploy the server. We decided to go with AWS Platform after a couple of hours of trying to figure out Kubernetes 😅
* Finding a dataset that suited our needs! If there were no time constraints, we would have loved to develop a dataset that is more focused on addressing tacky legal and technical language. Since that was not the case, we made do with a database that enabled us to produce a proof-of-concept.
## ✔️ Accomplishments that we're proud of
* Creating a fully-functioning app with bi-directional communication between the AI server and the client.
* Working with NLP, despite having no prior experience or knowledge. The learning curve was immense!
* Able to come together as a team and move forward, despite all the challenges we faced together!
## 📚 What we learned
We learned so much in terms of the technical areas; using machine learning and having to pivot from one software to the other, state management and PDF rendering in React.
## 🔭 What's next for simpl.ai!
**1. Support Multilingual Documents.** The ability to translate documents and provide a simplified version in their desired language. We would use [IBM Watson's Language Translator API](https://cloud.ibm.com/apidocs/language-translator?code=node)
**2. URL Parameter** Currently, we are able to simplify text from a PDF, but we would like to be able to do the same for websites.
* Simplify legal jargon in T&C agreements to better understand what permissions and rights they are giving an application!
* We hope to extend this service as a Chrome Extension for easier access to the users.
**3. Relevant Datasets** We would like to expand our current model's capabilities to better understand legal jargon, technical documentation etc. by feeding it keywords in these areas. | ## Inspiration
Nowadays, we have been using **all** sorts of development tools for web development, from the simplest of HTML, to all sorts of high-level libraries, such as Bootstrap and React. However, what if we turned back time, and relived the *nostalgic*, good old times of programming in the 60s? A world where the programming language BASIC was prevalent. A world where coding on paper and on **office memo pads** were so popular. It is time, for you all to re-experience the programming of the **past**.
## What it does
It's a programming language compiler and runtime for the BASIC programming language. It allows users to write interactive programs for the web with the simple syntax and features of the BASIC language. Users can read our sample the BASIC code to understand what's happening, and write their own programs to deploy on the web. We're transforming code from paper to the internet.
## How we built it
The major part of the code is written in TypeScript, which includes the parser, compiler, and runtime, designed by us from scratch. After we parse and resolve the code, we generate an intermediate representation. This abstract syntax tree is parsed by the runtime library, which generates HTML code.
Using GitHub actions and GitHub Pages, we are able to implement a CI/CD pipeline to deploy the webpage, which is **entirely** written in BASIC! We also have GitHub Dependabot scanning for npm vulnerabilities.
We use Webpack to bundle code into one HTML file for easy deployment.
## Challenges we ran into
Creating a compiler from scratch within the 36-hour time frame was no easy feat, as most of us did not have prior experience in compiler concepts or building a compiler. Constructing and deciding on the syntactical features was quite confusing since BASIC was such a foreign language to all of us. Parsing the string took us the longest time due to the tedious procedure in processing strings and tokens, as well as understanding recursive descent parsing. Last but **definitely not least**, building the runtime library and constructing code samples caused us issues as minor errors can be difficult to detect.
## Accomplishments that we're proud of
We are very proud to have successfully "summoned" the **nostalgic** old times of programming and deployed all the syntactical features that we desired to create interactive features using just the BASIC language. We are delighted to come up with this innovative idea to fit with the theme **nostalgia**, and to retell the tales of programming.
## What we learned
We learned the basics of making a compiler and what is actually happening underneath the hood while compiling our code, through the *painstaking* process of writing compiler code and manually writing code samples as if we were the compiler.
## What's next for BASIC Web
This project can be integrated with a lot of modern features that is popular today. One of future directions can be to merge this project with generative AI, where we can feed the AI models with some of the syntactical features of the BASIC language and it will output code that is translated from the modern programming languages. Moreover, this can be a revamp of Bootstrap and React in creating interactive and eye-catching web pages. | ## Inspiration
I was compelled to undertake a project on my own for this first time in my hackathoning career. One that I covers my interests in web applications and image processing and would be something "do-able" within the competition.
## What it does
Umoji is a web-app that take's an image input and using facial recognition maps emoji symbols onto the faces in the image matching their emotion/facial expressions.
## How I built it
Using Google Cloud Vision API as the backbone for all the ML and visual recognition, flask to serve up the simple bootstrap based html front-end.
## Challenges I ran into
Creating an extensive list of Emoji to map to the different levels of emotion predicted by the ML Model. Web deployment / networking problems.
## Accomplishments that I'm proud of
That fact that I was able to hit all the check boxes for what I set out to do. Not overshooting with stretch features or getting to caught up with extending the main features beyond the original scope.
## What I learned
How to work with Google's cloud API / image processing and rapid live deployment.
## What's next for Umoji
More emojis, better UI/UX and social media integration for sharing. | winning |
## Inspiration
Over the Summer one of us was reading about climate change but then he realised that most of the news articles that he came across were very negative and affected his mental health to the point that it was hard to think about the world as a happy place. However one day he watched this one youtube video that was talking about the hope that exists in that sphere and realised the impact of this "goodNews" on his mental health. Our idea is fully inspired by the consumption of negative media and tries to combat it.
## What it does
We want to bring more positive news into people’s lives given that we’ve seen the tendency of people to only read negative news. Psychological studies have also shown that bringing positive news into our lives make us happier and significantly increases dopamine levels.
The idea is to maintain a score of how much negative content a user reads (detected using cohere) and once it reaches past a certain threshold (we store the scores using cockroach db) we show them a positive news related article in the same topic area that they were reading.
We do this by doing text analysis using a chrome extension front-end and flask, cockroach dp backend that uses cohere for natural language processing.
Since a lot of people also listen to news via video, we also created a part of our chrome extension to transcribe audio to text - so we included that into the start of our pipeline as well! At the end, if the “negativity threshold” is passed, the chrome extension tells the user that it’s time for some good news and suggests a relevant article.
## How we built it
**Frontend**
We used a chrome extension for the front end which included dealing with the user experience and making sure that our application actually gets the attention of the user while being useful. We used react js, HTML and CSS to handle this. There was also a lot of API calls because we needed to transcribe the audio from the chrome tabs and provide that information to the backend.
**Backend**
## Challenges we ran into
It was really hard to make the chrome extension work because of a lot of security constraints that websites have. We thought that making the basic chrome extension would be the easiest part but turned out to be the hardest. Also figuring out the overall structure and the flow of the program was a challenging task but we were able to achieve it.
## Accomplishments that we're proud of
1) (co:here) Finetuned a co:here model to semantically classify news articles based on emotional sentiment
2) (co:here) Developed a high-performing classification model to classify news articles by topic
3) Spun up a cockroach db node and client and used it to store all of our classification data
4) Added support for multiple users of the extension that can leverage the use of cockroach DB's relational schema.
5) Frontend: Implemented support for multimedia streaming and transcription from the browser, and used script injection into websites to scrape content.
6) Infrastructure: Deploying server code to the cloud and serving it using Nginx and port-forwarding.
## What we learned
1) We learned a lot about how to use cockroach DB in order to create a database of news articles and topics that also have multiple users
2) Script injection, cross-origin and cross-frame calls to handle multiple frontend elements. This was especially challenging for us as none of us had any frontend engineering experience.
3) Creating a data ingestion and machine learning inference pipeline that runs on the cloud, and finetuning the model using ensembles to get optimal results for our use case.
## What's next for goodNews
1) Currently, we push a notification to the user about negative pages viewed/a link to a positive article every time the user visits a negative page after the threshold has been crossed. The intended way to fix this would be to add a column to one of our existing cockroach db tables as a 'dirty bit' of sorts, which tracks whether a notification has been pushed to a user or not, since we don't want to notify them multiple times a day. After doing this, we can query the table to determine if we should push a notification to the user or not.
2) We also would like to finetune our machine learning more. For example, right now we classify articles by topic broadly (such as War, COVID, Sports etc) and show a related positive article in the same category. Given more time, we would want to provide more semantically similar positive article suggestions to those that the author is reading. We could use cohere or other large language models to potentially explore that. | ## Inspiration
When it comes to finding solutions to global issues, we often feel helpless: making us feel as if our small impact will not help the bigger picture. Climate change is a critical concern of our age; however, the extent of this matter often reaches beyond what one person can do....or so we think!
Inspired by the feeling of "not much we can do", we created *eatco*. *Eatco* allows the user to gain live updates and learn how their usage of the platform helps fight climate change. This allows us to not only present users with a medium to make an impact but also helps spread information about how mother nature can heal.
## What it does
While *eatco* is centered around providing an eco-friendly alternative lifestyle, we narrowed our approach to something everyone loves and can apt to; food! Other than the plenty of health benefits of adopting a vegetarian diet — such as lowering cholesterol intake and protecting against cardiovascular diseases — having a meatless diet also allows you to reduce greenhouse gas emissions which contribute to 60% of our climate crisis. Providing users with a vegetarian (or vegan!) alternative to their favourite foods, *eatco* aims to use small wins to create a big impact on the issue of global warming. Moreover, with an option to connect their *eatco* account with Spotify we engage our users and make them love the cooking process even more by using their personal song choices, mixed with the flavours of our recipe, to create a personalized playlist for every recipe.
## How we built it
For the front-end component of the website, we created our web-app pages in React and used HTML5 with CSS3 to style the site. There are three main pages the site routes to: the main app, and the login and register page. The login pages utilized a minimalist aesthetic with a CSS style sheet integrated into an HTML file while the recipe pages used React for the database. Because we wanted to keep the user experience cohesive and reduce the delay with rendering different pages through the backend, the main app — recipe searching and viewing — occurs on one page. We also wanted to reduce the wait time for fetching search results so rather than rendering a new page and searching again for the same query we use React to hide and render the appropriate components. We built the backend using the Flask framework. The required functionalities were implemented using specific libraries in python as well as certain APIs. For example, our web search API utilized the googlesearch and beautifulsoup4 libraries to access search results for vegetarian alternatives and return relevant data using web scraping. We also made use of Spotify Web API to access metadata about the user’s favourite artists and tracks to generate a personalized playlist based on the recipe being made. Lastly, we used a mongoDB database to store and access user-specific information such as their username, trees saved, recipes viewed, etc. We made multiple GET and POST requests to update the user’s info, i.e. saved recipes and recipes viewed, as well as making use of our web scraping API that retrieves recipe search results using the recipe query users submit.
## Challenges we ran into
In terms of the front-end, we should have considered implementing Routing earlier because when it came to doing so afterward, it would be too complicated to split up the main app page into different routes; this however ended up working out alright as we decided to keep the main page on one main component. Moreover, integrating animation transitions with React was something we hadn’t done and if we had more time we would’ve liked to add it in. Finally, only one of us working on the front-end was familiar with React so balancing what was familiar (HTML) and being able to integrate it into the React workflow took some time. Implementing the backend, particularly the spotify playlist feature, was quite tedious since some aspects of the spotify web API were not as well explained in online resources and hence, we had to rely solely on documentation. Furthermore, having web scraping and APIs in our project meant that we had to parse a lot of dictionaries and lists, making sure that all our keys were exactly correct. Additionally, since dictionaries in Python can have single quotes, when converting these to JSONs we had many issues with not having them be double quotes. The JSONs for the recipes also often had quotation marks in the title, so we had to carefully replace these before the recipes were themselves returned. Later, we also ran into issues with rate limiting which made it difficult to consistently test our application as it would send too many requests in a small period of time. As a result, we had to increase the pause interval between requests when testing which made it a slow and time consuming process. Integrating the Spotify API calls on the backend with the frontend proved quite difficult. This involved making sure that the authentication and redirects were done properly. We first planned to do this with a popup that called back to the original recipe page, but with the enormous amount of complexity of this task, we switched to have the playlist open in a separate page.
## Accomplishments that we're proud of
Besides our main idea of allowing users to create a better carbon footprint for themselves, we are proud of accomplishing our Spotify integration. Using the Spotify API and metadata was something none of the team had worked with before and we're glad we learned the new skill because it adds great character to the site. We all love music and being able to use metadata for personalized playlists satisfied our inner musical geek and the integration turned out great so we're really happy with the feature. Along with our vast recipe database this far, we are also proud of our integration! Creating a full-stack database application can be tough and putting together all of our different parts was quite hard, especially as it's something we have limited experience with; hence, we're really proud of our service layer for that. Finally, this was the first time our front-end developers used React for a hackathon; hence, using it in a time and resource constraint environment for the first time and managing to do it as well as we did is also one of our greatest accomplishments.
## What we learned
This hackathon was a great learning experience for all of us because everyone delved into a tool that they'd never used before! As a group, one of the main things we learned was the importance of a good git workflow because it allows all team members to have a medium to collaborate efficiently by combing individual parts. Moreover, we also learned about Spotify embedding which not only gave *eatco* a great feature but also provided us with exposure to metadata and API tools. Moreover, we also learned more about creating a component hierarchy and routing on the front end. Another new tool that we used in the back-end was learning how to perform database operations on a cloud-based MongoDB Atlas database from a python script using the pymongo API. This allowed us to complete our recipe database which was the biggest functionality in *eatco*.
## What's next for Eatco
Our team is proud of what *eatco* stands for and we want to continue this project beyond the scope of this hackathon and join the fight against climate change. We truly believe in this cause and feel eatco has the power to bring meaningful change; thus, we plan to improve the site further and release it as a web platform and a mobile application. Before making *eatco* available for users publically we want to add more functionality and further improve the database and present the user with a more accurate update of their carbon footprint. In addition to making our recipe database bigger, we also want to focus on enhancing the front-end for a better user experience. Furthermore, we also hope to include features such as connecting to maps (if the user doesn't have a certain ingredient, they will be directed to the nearest facility where that item can be found), and better use of the Spotify metadata to generate even better playlists. Lastly, we also want to add a saved water feature to also contribute into the global water crisis because eating green also helps cut back on wasteful water consumption! We firmly believe that *eatco* can go beyond the range of the last 36 hours and make impactful change on our planet; hence, we want to share with the world how global issues don't always need huge corporate or public support to be solved, but one person can also make a difference. | ## Inspiration
False news. False news. False news everywhere. Before reading your news article in depth, let us help you give you a brief overview of what you'll be ingesting.
## What it does
Our Google Chrome extension will analyze the news article you're about to read and give you a heads up on some on the article's sentiment (what emotion is the article trying to convey), top three keywords in the article, and the categories this article's topic belong to.
Our extension also allows you to fact check any statement by simply highlighting the statement, right-clicking, and selecting Fact check this with TruthBeTold.
## How we built it
Our Chrome extension pulls the url of the webpage you're browsing and sends that to our Google Cloud Platform hosted Google App Engine Python server. Our server is then able to parse the content of the page, determine the content of the news article through processing by Newspaper3k API. The scraped article is then sent to Google's Natural Language API Client which assess the article for sentiment, categories, and keywords. This data is then returned to your extension and displayed in a friendly manner.
Fact checking follows a similar path in that our extension sends the highlighted text to our server, which checks against Google's Fact Check Explorer API. The consensus is then returned and alerted.
## Challenges we ran into
* Understanding how to interact with Google's APIs.
* Working with Python flask and creating new endpoints in flask.
* Understanding how Google Chrome extensions are built.
## Accomplishments that I'm proud of
* It works! | winning |
## Inspiration
We were interested in machine learning and data analytics and decided to pursue a real-world application that could prove to have practical use for society. Many themes of this project were inspired by hip-hop artist Cardi B.
## What it does
Money Moves analyzes data about financial advisors and their attributes and uses machine's deep learning unsupervised algorithms to predict if certain financial advisors will most likely be beneficial or detrimental to an investor's financial standing.
## How we built it
We partially created a custom deep-learning library where we built a Self Organizing Map. The Self Organizing Map is a neural network that takes data and creates a layer of abstraction; essentially reducing the dimensionality of the data. To make this happened we had to parse several datasets. We used beautiful soup library, pandas and numpy to parse the data needed. Once it was parsed, we were able to pre-process the data, to feed it to our neural network (Self Organizing Map). After we were able to successfully analyze the data with the deep learning algorithm, we uploaded the neural network and dataset to our Google server where we are hosting a Django website. The website will show investors the best possible advisor within their region.
## Challenges we ran into
Due to the nature of this project, we struggled with moving large amounts of data through the internet, cloud computing, and designing a website to display analyzed data because of the difficult with WiFi connectivity that many hackers faced at this competition. We mostly overcame this through working late nights and lots of frustration.
We also struggled to find an optimal data structure for storing both raw and output data. We ended up using .csv files organized in a logical manner so that data is easier accessible through a simple parser.
## Accomplishments that we're proud of
Successfully parse the dataset needed to do preprocessing and analysis with deeplearing.
Being able to analyze our data with the Self Organizing Map neural network.
Side Note: Our team member Mikhail Sorokin placed 3rd in the Yhack Rap Battle
## What we learned
We learnt how to implement a Self Organizing Map, build a good file system and code base with Django. This led us to learn about Google's cloud service where we host our Django based website. In order to be able to analyze the data, we had to parse several files and format the data that we had to send through the network.
## What's next for Money Moves
We are looking to expand our Self Organizing Map to accept data from other financial dataset, other than stock advisors; this way we are able to have different models that will work together. One way we were thinking is to have unsupervised and supervised deep-learning systems where, we have the unsupervised find the patterns that would be challenging to find; and the supervised algorithm will direct the algorithm to a certain goal that could help investors choose the best decision possible for their financial options. | ## Inspiration
Members of our team know multiple people who suffer from permanent or partial paralysis. We wanted to build something that could be fun to develop and use, but at the same time make a real impact in people's everyday lives. We also wanted to make an affordable solution, as most solutions to paralysis cost thousands and are inaccessible. We wanted something that was modular, that we could 3rd print and also make open source for others to use.
## What it does and how we built it
The main component is a bionic hand assistant called The PulseGrip. We used an ECG sensor in order to detect electrical signals. When it detects your muscles are trying to close your hand it uses a servo motor in order to close your hand around an object (a foam baseball for example). If it stops detecting a signal (you're no longer trying to close) it will loosen your hand back to a natural resting position. Along with this at all times it sends a signal through websockets to our Amazon EC2 server and game. This is stored on a MongoDB database, using API requests we can communicate between our games, server and PostGrip. We can track live motor speed, angles, and if it's open or closed. Our website is a full-stack application (react styled with tailwind on the front end, node js on the backend). Our website also has games that communicate with the device to test the project and provide entertainment. We have one to test for continuous holding and another for rapid inputs, this could be used in recovery as well.
## Challenges we ran into
This project forced us to consider different avenues and work through difficulties. Our main problem was when we fried our EMG sensor, twice! This was a major setback since an EMG sensor was going to be the main detector for the project. We tried calling around the whole city but could not find a new one. We decided to switch paths and use an ECG sensor instead, this is designed for heartbeats but we managed to make it work. This involved wiring our project completely differently and using a very different algorithm. When we thought we were free, our websocket didn't work. We troubleshooted for an hour looking at the Wifi, the device itself and more. Without this, we couldn't send data from the PulseGrip to our server and games. We decided to ask for some mentor's help and reset the device completely, after using different libraries we managed to make it work. These experiences taught us to keep pushing even when we thought we were done, and taught us different ways to think about the same problem.
## Accomplishments that we're proud of
Firstly, just getting the device working was a huge achievement, as we had so many setbacks and times we thought the event was over for us. But we managed to keep going and got to the end, even if it wasn't exactly what we planned or expected. We are also proud of the breadth and depth of our project, we have a physical side with 3rd printed materials, sensors and complicated algorithms. But we also have a game side, with 2 (questionable original) games that can be used. But they are not just random games, but ones that test the user in 2 different ways that are critical to using the device. Short burst and hold term holding of objects. Lastly, we have a full-stack application that users can use to access the games and see live stats on the device.
## What's next for PulseGrip
* working to improve sensors, adding more games, seeing how we can help people
We think this project had a ton of potential and we can't wait to see what we can do with the ideas learned here.
## Check it out
<https://hacks.pulsegrip.design>
<https://github.com/PulseGrip> | ## Inspiration
Fraud is a crime that can impact any Canadian, regardless of their education, age or income.
From January 2014 to December 2017, Canadians lost more than $405 million to fraudsters. ~ [Statistic Info](https://www.competitionbureau.gc.ca/eic/site/cb-bc.nsf/eng/04334.html)
We wanted to develop technology that detects potentially fraudulent activity and give account owners the ability to cancel such transactions.
## How it works
Using scikit-learn, we were able to detect patterns in a user's previous banking data provided by TD's davinci API.
We examined categories such as the location of the purchase, the cost of the purchase, and the purchase category. Afterwards, we determined certain parameters for the cost of purchase based on the purchase category, and purchase locations to validate transactions that met the requirements. Transactions that were made outside of these parameters were deemed suspicious activity and an alert is sent to the account owner, providing them with the ability to validate/decline the purchase. If the transaction is approved, it is added to the MongoDB database with the rest of the user's previous transactions.
[TD's davinci API](https://td-davinci.com/)
[Presentation Slide Show](https://slides.com/malharshah/deck#/projectapati)
[Github Repository](https://github.com/mshah0722/FraudDetectionDeltaHacks2020)
## Challenges we ran into
Initially, we tried to use Tensorflow for our ML model to analyze the user's previous banking history to find patterns and make the parameters. However, we were having difficulty correctly implementing it and there were mistakes being made in the model. This is why we decided to switch to scikit-learn, which our team had success using and our ML model turned out as we had expected.
## Accomplishments that we are proud of
Learning to use and implement Machine Learning with such a large data set that we were provided with. Training the model to detect suspicious activity was finally achieved after several attempts.
## What we learned
Handling large data files.
Pattern detection/Data Analysis.
Data Interpretation and Model development.
## What's next for Project Apati
Improving the model by looking at other categories in the data to refine the model based on other transactions statistics. Providing more user's data to improve the training and testing data-set for the model. | winning |
## Inspiration
Our solution was named on remembrance of Mother Teresa
## What it does
Robotic technology to assist nurses and doctors in medicine delivery, patient handling across the hospital, including ICU’s. We are planning to build an app in Low code/No code that will help the covid patients to scan themselves as the mobile app is integrated with the CT Scanner for doctors to save their time and to prevent human error . Here we have trained with CT scans of Covid and developed a CNN model and integrated it into our application to help the covid patients. The data sets are been collected from the kaggle and tested with an efficient algorithm with the efficiency of around 80% and the doctors can maintain the patient’s record. The beneficiary of the app is PATIENTS.
## How we built it
Bots are potentially referred to as the most promising and advanced form of human-machine interactions. The designed bot can be handled with an app manually through go and cloud technology with e predefined databases of actions and further moves are manually controlled trough the mobile application. Simultaneously, to reduce he workload of doctor, a customized feature is included to process the x-ray image through the app based on Convolution neural networks part of image processing system. CNN are deep learning algorithms that are very powerful for the analysis of images which gives a quick and accurate classification of disease based on the information gained from the digital x-ray images .So to reduce the workload of doctors these features are included. To know get better efficiency on the detection I have used open source kaggle data set.
## Challenges we ran into
The data source for the initial stage can be collected from the kaggle and but during the real time implementation the working model and the mobile application using flutter need datasets that can be collected from the nearby hospitality which was the challenge.
## Accomplishments that we're proud of
* Counselling and Entertainment
* Diagnosing therapy using pose detection
* Regular checkup of vital parameters
* SOS to doctors with live telecast
-Supply off medicines and foods
## What we learned
* CNN
* Machine Learning
* Mobile Application
* Cloud Technology
* Computer Vision
* Pi Cam Interaction
* Flutter for Mobile application
## Implementation
* The bot is designed to have the supply carrier at the top and the motor driver connected with 4 wheels at the bottom.
* The battery will be placed in the middle and a display is placed in the front, which will be used for selecting the options and displaying the therapy exercise.
* The image aside is a miniature prototype with some features
* The bot will be integrated with path planning and this is done with the help mission planner, where we will be configuring the controller and selecting the location as a node
* If an obstacle is present in the path, it will be detected with lidar placed at the top.
* In some scenarios, if need to buy some medicines, the bot is attached with the audio receiver and speaker, so that once the bot reached a certain spot with the mission planning, it says the medicines and it can be placed at the carrier.
* The bot will have a carrier at the top, where the items will be placed.
* This carrier will also have a sub-section.
* So If the bot is carrying food for the patients in the ward, Once it reaches a certain patient, the LED in the section containing the food for particular will be blinked. | ## Inspiration
Donut was originally inspired by a viral story about dmdm hydantoin, a chemical preservative used in hair products rumoured to be toxic and lead to hair loss. This started a broader discussion about commercial products in general and the plethora of chemical substances and ingredients we blindly use and consume on a daily basis. We wanted to remove these veils that can impact the health of the community and encourage people to be more informed consumers.
## What it does
Donut uses computer vision to read the labels off packaging through a camera. After acquiring this data, it displays all the ingredients in a list and uses sentiment analysis to determine the general safety of each ingredient. Users can click into each ingredient to learn more and read related articles that we recommend in order to make more educated purchases.
## How we built it
## Challenges we ran into
Front end development was a challenge since it was something our team was inexperienced with, but there’s no better place to learn than at a hackathon! Fighting away the sleepiness was another hurdle too.
## Accomplishments that we're proud of
We got more done than we imagined with a 3 person team :)
Michael is proud that he was very productive with the backend code :D
Grace is proud that she wrote any code at all as a designer o\_o
Denny is proud to have learned more about HTTP requests and worked with both the front and backend :0
## What we learned
We could be benefitted from a more well-balanced team (befriend some front end devs!). Sleep is important. Have snacks at the ready.
## What's next for Donut Eat This
Features that we would love to implement next would be a way to upload photos from a user’s album and a way to view recent scans. | ## Inspiration
“**Social media sucks these days.**” — These were the first few words we heard from one of the speakers at the opening ceremony, and they struck a chord with us.
I’ve never genuinely felt good while being on my phone, and like many others I started viewing social media as nothing more than a source of distraction from my real life and the things I really cared about.
In December 2019, I deleted my accounts on Facebook, Instagram, Snapchat, and WhatsApp.
For the first few months — I honestly felt great. I got work done, focused on my small but valuable social circle, and didn’t spend hours on my phone.
But one year into my social media detox, I realized that **something substantial was still missing.** I had personal goals, routines, and daily checklists of what I did and what I needed to do — but I wasn’t talking about them. By not having social media I bypassed superficial and addictive content, but I was also entirely disconnected from my network of friends and acquaintances. Almost no one knew what I was up to, and I didn’t know what anyone was up to either. A part of me longed for a level of social interaction more sophisticated than Gmail, but I didn’t want to go back to the forms of social media I had escaped from.
One of the key aspects of being human is **personal growth and development** — having a set of values and living them out consistently. Especially in the age of excess content and the disorder of its partly-consumed debris, more people are craving a sense of **routine, orientation, and purpose** in their lives. But it’s undeniable that **humans are social animals** — we also crave **social interaction, entertainment, and being up-to-date with new trends.**
Our team’s problem with current social media is its attention-based reward system. Most platforms reward users based on numeric values of attention, through measures such as likes, comments and followers. Because of this reward system, people are inclined to create more appealing, artificial, and addictive content. This has led to some of the things we hate about social media today — **addictive and superficial content, and the scarcity of genuine interactions with people in the network.**
This leads to a **backward-looking user-experience** in social media. The person in the 1080x1080 square post is an ephemeral and limited representation of who the person really is. Once the ‘post’ button has been pressed, the post immediately becomes an invitation for users to trap themselves in the past — to feel dopamine boosts from likes and comments that have been designed to make them addicted to the platform and waste more time, ultimately **distorting users’ perception of themselves, and discouraging their personal growth outside of social media.**
In essence — We define the question of reinventing social media as the following:
*“How can social media align personal growth and development with meaningful content and genuine interaction among users?”*
**Our answer is High Resolution — a social media platform that orients people’s lives toward an overarching purpose and connects them with liked-minded, goal-oriented people.**
The platform seeks to do the following:
**1. Motivate users to visualize and consistently achieve healthy resolutions for personal growth**
**2. Promote genuine social interaction through the pursuit of shared interests and values**
**3. Allow users to see themselves and others for who they really are and want to be, through natural, progress-inspired content**
## What it does
The following are the functionalities of High Resolution (so far!):
After Log in or Sign Up:
**1. Create Resolution**
* Name your resolution, whether it be Learning Advanced Korean, or Spending More Time with Family.
* Set an end date to the resolution — i.e. December 31, 2022
* Set intervals that you want to commit to this goal for (Daily / Weekly / Monthly)
**2. Profile Page**
* Ongoing Resolutions
+ Ongoing resolutions and level of progress
+ Clicking on a resolution opens up the timeline of that resolution, containing all relevant posts and intervals
+ Option to create a new resolution, or ‘Discover’ resolutions
* ‘Discover’ Page
+ Explore other users’ resolutions, that you may be interested in
+ Clicking on a resolution opens up the timeline of that resolution, allowing you to view the user’s past posts and progress for that particular resolution and be inspired and motivated!
+ Clicking on a user takes you to that person’s profile
* Past Resolutions
+ Past resolutions and level of completion
+ Resolutions can either be fully completed or partly completed
+ Clicking on a past resolution opens up the timeline of that resolution, containing all relevant posts and intervals
**3. Search Bar**
* Search for and navigate to other users’ profiles!
**4. Sentiment Analysis based on IBM Watson to warn against highly negative or destructive content**
* Two functions for sentiment analysis textual data on platform:
* One function to analyze the overall positivity/negativity of the text
* Another function to analyze the user of the amount of joy, sadness, anger and disgust
* When the user tries to create a resolution that seems to be triggered by negativity, sadness, fear or anger, we show them a gentle alert that this may not be best for them, and ask if they would like to receive some support.
* In the future, we can further implement this feature to do the same for comments on posts.
* This particular functionality has been demo'ed in the video, during the new resolution creation.
* **There are two purposes for this functionality**:
* a) We want all our members to feel that they are in a safe space, and while they are free to express themselves freely, we also want to make sure that their verbal actions do not pose a threat to themselves or to others.
* b) Current social media has shown to be a propagator of hate speech leading to violent attacks in real life. One prime example are the Easter Attacks that took place in Sri Lanka exactly a year ago: <https://www.bbc.com/news/technology-48022530>
* If social media had a mechanism to prevent such speech from being rampant, the possibility of such incidents occurring could have been reduced.
* Our aim is not to police speech, but rather to make people more aware of the impact of their words, and in doing so also try to provide resources or guidance to help people with emotional stress that they might be feeling on a day-to-day basis.
* We believe that education at the grassroots level through social media will have an impact on elevating the overall wellbeing of society.
## How we built it
Our tech stack primarily consisted of React (with Material UI), Firebase and IBM Watson APIs. For the purpose of this project, we opted to use the full functionality of Firebase to handle the vast majority of functionality that would typically be done on a classic backend service built with NodeJS, etc. We also used Figma to prototype the platform, while IBM Watson was used for its Natural Language toolkits, in order to evaluate sentiment and emotion.
## Challenges we ran into
A bulk of the challenges we encountered had to do with React Hooks. A lot of us were only familiar with an older version of React that opted for class components instead of functional components, so getting used to Hooks took a bit of time.
Another issue that arose was pulling data from our Firebase datastore. Again, this was a result of lack of experience with serverless architecture, but we were able to pull through in the end.
## Accomplishments that we're proud of
We’re really happy that we were able to implement most of the functionality that we set out to when we first envisioned this idea. We admit that we might have bit a lot more than we could chew as we set out to recreate an entire social platform in a short amount of time, but we believe that the proof of concept is demonstrated through our demo
## What we learned
Through research and long contemplation on social media, we learned a lot about the shortcomings of modern social media platforms, for instance how they facilitate unhealthy addictive mechanisms that limit personal growth and genuine social connection, as well as how they have failed in various cases of social tragedies and hate speech. With that in mind, we set out to build a platform that could be on the forefront of a new form of social media.
From a technical standpoint, we learned a ton about how Firebase works, and we were quite amazed at how well we were able to work with it without a traditional backend.
## What's next for High Resolution
One of the first things that we’d like to implement next, is the ‘Group Resolution’ functionality. As of now, users browse through the platform, find and connect with liked-minded people pursuing similarly-themed interests. We think it would be interesting to allow users to create and pursue group resolutions with other users, to form more closely-knitted and supportive communities with people who are actively communicating and working towards achieving the same resolution.
We would also like to develop a sophisticated algorithm to tailor the users’ ‘Discover’ page, so that the shown content is relevant to their past resolutions. For instance, if the user has completed goals such as ‘Wake Up at 5:00AM’, and ‘Eat breakfast everyday’, we would recommend resolutions like ‘Morning jog’ on the discover page. By recommending content and resolutions based on past successful resolutions, we would motivate users to move onto the next step. In the case that a certain resolution was recommended because a user failed to complete a past resolution, we would be able to motivate them to pursue similar resolutions based on what we think is the direction the user wants to head towards.
We also think that High Resolution could be potentially become a platform for recruiters to spot dedicated and hardworking talent, through the visualization of users’ motivation, consistency, and progress. Recruiters may also be able to user the platform to communicate with users and host online workshops or events .
WIth more classes and educational content transitioning online, we think the platform could serve as a host for online lessons and bootcamps for users interested in various topics such as coding, music, gaming, art, and languages, as we envision our platform being highly compatible with existing online educational platforms such as Udemy, Leetcode, KhanAcademy, Duolingo, etc.
The overarching theme of High Resolution is **motivation, consistency, and growth.** We believe that having a user base that adheres passionately to these themes will open to new opportunities and both individual and collective growth. | winning |
## Inspiration
As a team, we wanted to help promote better workplace relationships and connections--especially since the workplace has been virtual for so long. To achieve this, we created a slack bot to increase the engagement between coworkers through various activities or experiences that can be shared among each other. This will allow team members to form more meaningful relationships which create a better work environment overall. Slack is a great tool for an online work platform and can be used better to increase social connections while also being effective for communicating goals for a team.
## What it does
When the Slackbot is added to a workplace on slack, the team is capable of accessing various commands. The commands are used with the / prefix. Some of the commands include:
* `help`: To get help
* `game-help` : To get game help
* `game-skribble` : Provides a link to a skribble.io game
* `game-chess` : Provides a link to a chess game
* `game-codenames` : Provides a link to a codenames game
* `game-uno` : Provides a link to a UNO game
* `game-monopoly` : Provides a link to a COVID-19 themed monopoly game
* `memes` :Generates randomized memes (for conversation starters with colleagues)
* `virtual-escape` : Allows users to see art, monuments, museums, etc (randomized QR codes) through augments reality for a short "virtual escape"
* `mystery`: Displays a mystery of the month for colleagues to enjoy and talk about amongst each other
We also have scheduled messages that we incorporated to help automate some processes in the workplace such as:
* `birthday reminders` : Used to send an automated message to the channel when it is someone's birthday
* `mystery` : Sends out the mystery of the month at beginning of each month
These features on our bot promote engagement between people with the various activities possible.
## How we built it
The Bot was designed using the SlackAPI and programmed using python. Using the SlackAPI commands the bot was programmed to increase social interaction and incite more conversations during the Covid-19 remote working regulation. The bot has a variety of commands to help workers engage in conversations with their fellow colleagues. With a wide selection of virtual games to be played during lunch breaks or perhaps take a short relaxing break using the EchoAR generated QR Codes to devel into the world of augmented reality and admire or play with what they are as shown. Workers are also able to request a singular meme from the bot and enjoy a short laugh or spark a funny conversation with others who also see the meme. Overall, the bot was built with the mindset of further enhancing social communication in a fun manner to help those working remotely feel more at ease.
## Challenges we ran into
This is the first time anyone from the team had worked with Slack and SlackAPI. There were alot of unfamiliar components and the project as a whole was a big learning experience for the team members. A few minor complications we had run into were mostly working out syntax and debugging code which no errors yet didn't display output properly. Overall, the team enjoyed working with Slack and creating our very first slack bot.
## Accomplishments that we're proud of
We are proud of all the work that was accomplished in one day! The bot was an interesting challenge for us that can be used throughout our daily lives as well (in our work or team clubs slack workplaces). Some commands we are especially proud of are:
* *virtual-escape* since it was able to incorporate echoAR technology. This was something new to us that we were able to successfully integrate into our bot and it has a huge impact on making our bot unique!
* *memes* as we were able to figure out a successful way to randomize the images
-*scheduled messages* since they allowed us to branch into making more dynamic bots
Overall, we are very proud of all the work that was accomplished and the bot that we created after the countless hours on Stack Overflow! :)
## What we learned
We became more familiar with using python in development projects and learned more about creating bots for different applications. We learned a lot of new things through trial and error as well as various youtube videos. As this was our first slack bot, the entire development process was new and challenging but we were able to create a working bot in the end. We want to continue developing bots in the future as there is so much that can be accomplished with them--we barely scratched the surface!
## What's next for Slackbot
The Future of slackbot looks bright. With new ideas emerging daily the team looks forward to building upon the social attraction of the bot and incorporating more work intensive themes with perhaps a file manager or an icebreakers for newer employees. Our SlackBot is no where near its end and with enough time it could become a truly wonderful AI for remote workers. | # Catch! (Around the World)
## Our Inspiration
Catch has to be one of our most favourite childhood games. Something about just throwing and receiving a ball does wonders for your serotonin. Since all of our team members have relatives throughout the entire world, we thought it'd be nice to play catch with those relatives that we haven't seen due to distance. Furthermore, we're all learning to social distance (physically!) during this pandemic that we're in, so who says we can't we play a little game while social distancing?
## What it does
Our application uses AR and Unity to allow you to play catch with another person from somewhere else in the globe! You can tap a button which allows you to throw a ball (or a random object) off into space, and then the person you send the ball/object to will be able to catch it and throw it back. We also allow users to chat with one another using our web-based chatting application so they can have some commentary going on while they are playing catch.
## How we built it
For the AR functionality of the application, we used **Unity** with **ARFoundations** and **ARKit/ARCore**. To record the user sending the ball/object to another user, we used a **Firebase Real-time Database** back-end that allowed users to create and join games/sessions and communicated when a ball was "thrown". We also utilized **EchoAR** to create/instantiate different 3D objects that users can choose to throw. Furthermore for the chat application, we developed it using **Python Flask**, **HTML** and **Socket.io** in order to create bi-directional communication between the web-user and server.
## Challenges we ran into
Initially we had a separate idea for what we wanted to do in this hackathon. After a couple of hours of planning and developing, we realized that our goal is far too complex and it was too difficult to complete in the given time-frame. As such, our biggest challenge had to do with figuring out a project that was doable within the time of this hackathon.
This also ties into another challenge we ran into was with initially creating the application and the learning portion of the hackathon. We did not have experience with some of the technologies we were using, so we had to overcome the inevitable learning curve.
There was also some difficulty learning how to use the EchoAR api with Unity since it had a specific method of generating the AR objects. However we were able to use the tool without investigating too far into the code.
## Accomplishments
* Working Unity application with AR
* Use of EchoAR and integrating with our application
* Learning how to use Firebase
* Creating a working chat application between multiple users | ## Inspiration
According to the World Health Organization, approximately 800,000 people die due to suicide every year, which is one person every 40 seconds. Suicide is a global phenomenon and some of our team members have also experienced people who decided to take their own lives. One of our teammates experienced a suicide where their parents did not know that their child was depressed even though it was evident on their child’s daily conversations with friends. To address this major issue, we decided to create a messaging chat extension that will prevent more suicides from happening by allowing people who are suffering from suicidal symptoms to be reached out by their family and friends.
## What it does
GIven their consent, the natural language processing algorithm will process the user’s daily conversations with other people and output a mental score from -1 to +1. This score will determine how likely/at risk they are to commiting suicide. For example, the user is more likely to commit suicide with a score of -1 compared to another user with a score of +1. The user can also decide to add their family members and friends to this infrastructure. When their score falls under a minimum score, their family and friends will be notified to reach out to them personally. Family and friends who are added by the user will also be able to see the user’s score to check on them daily.
## How I built it
We leveraged the google cloud suite to do sentiment analysis on conversation gathered from our slack channel. The conversations are recorded by the slack bot into our Firebase database and then analyzed periodically when the jobs scheduler triggers our ML cloud function. This cloud function saves the ML output in another subnode of our database. The Slackbot then reads from this database to calculate and output a metric.
Tools and Frameworks: Python, ngrok, Flask, Google Cloud Natural Language API, Cloud Functions, Cloud Job Scheduler, Slack API
## Challenges I ran into
Connecting the components together (Slackbot, databases, cloud functions) required making some tough design choices, and also gave rise to some weird bugs.
## Accomplishments that I'm proud of
Achieving our goal of building a service that can analyze text conversations based on sentiment and output an informed metric.
## What I learned
This was my first time using the Slack API and it was interesting to learn! Also, I learned how to use some new Google Cloud Suite tools like Cloud Function and Jobs Scheduler.
## What's next for Guardian
What we built at the hackathon was a proof of concept for a tool that can be integrated in traditional messaging applications (think: Facebook Messenger). Ultimately, we hope that this tool/idea can be adopted by messaging services to help reduce suicides around the world. We hope to continue to research the potential benefits and limitations of this technology and consult members of the psycho-therapist community in order to make sure we keep developing towards an ethical and socially useful tool. | partial |
## What it does
Guitar Typer takes in input entirely through a Guitar Hero Guitar controller and translates it into easy and usable text. This is naturally done through a rhythm-based interface in such a way that sacrifices little inconvenience for a large tradeoff in user enjoyment. Text is displayed to the user via falling letters in a highly optimized pattern that maximizes speed and efficiency while keeping true to the spirit of Guitar Hero gameplay.
## How I built it
Guitar Typer was built almost entirely in Java. We made use of various libraries and SDKs to generate the GUI interface and handle the logic involved with converting Notes-to-Text. We used XInput to take in the inputs from the user.
## Challenges I ran into
There was a large amount of planning needed before implementation. Deciding on the most capable frameworks and programming languages to use was one of the biggest challenges. We also dedicated a large amount of time on optimizing letter frequency with an ergonomic sense of playing Guitar Hero.
## What I learned
We learned a lot more about how the frameworks we used interact with the Windows operating system. We also spent a very large number of hours on polishing our guitar GUI as best as we could.
## What's next for Guitar Typer
We plan on implementing Guitar Typer for mobile computing devices and possibly other operating systems in the near future. Stay tuned to see more ! | ## Inspiration
I’m sure that many people will agree that in this new world where Covid exists, our main source of communication has been online, typing out messages through our keyboards. Whether it may be to plan a distanced hang out with friends, commenting on a funny TikTok, or even sending an email to your professors, we have gotten so used to the shape of our keyboard that some of us have developed the ability to type out messages without even looking at our keyboards! It has become second nature to us! This is the main idea that inspired us to make our program! TypingGame is a program where visually impaired users can practice and get feedback on their keyboard skills, until they are so comfortable with the keyboard layout that typing becomes second nature to them!
## What TypingGame does
TypingGame works exactly like a game. There are 10 words in the system that our program will shuffle and test the user on. Each time, the users will be given a word through an AI audio. Users will type in their answer and once they click enter they will be greeted with a sound that signals whether they have gotten the answer correct or not. Once the program is completed, the final score will be announced and users are free to repeat the program whenever they desire.
## How we built it
This program was built solely using Java. The IDE we all used was Visual Studio Code and we attached it to our remote repository on Github. We used a Java speech API to convert the text we wanted the program to say aloud to speech.
## Challenges we ran into
Our team had no prior experience with GitHub and for two of our team members it was our first hackathon. This made it an interesting challenge as we had to learn how to navigate softwares whilst developing and testing our product, putting our ability to execute our plan in an efficient manner. We also originally wanted to make a GUI for our game but we didn’t have enough time to implement the code.
## What's next for TypingGame
We have exciting things planned for TypingGame! We would first like to expand our program and create different levels of difficulty, ranging from simple words to challenging sentences! Our team believes that “leveling up” and having progress to look back on will be a huge motivation factor that will keep our users engaged and interested! Additionally, we would like to add a new feature on TypingGame that will analyze the pattern of users’ mistakes to provide detailed constructive feedback on how they can improve. We believe this will assist users’ in reaching their goals swiftly as well as increase their motivation to learn! | ## Inspiration
**Handwriting is such a beautiful form of art that is unique to every person, yet unfortunately, it is not accessible to everyone.**
[Parkinson’s](www.parkinson.org/Understanding-Parkinsons/Statistics) affects nearly 1 million people in the United States and more than 6 million people worldwide. For people who struggle with fine motor skills, picking up a pencil and writing is easier said than done. *We want to change that.*
We were inspired to help people who find difficulty in writing, whether it be those with Parkinson's or anyone else who has lost the ability to write with ease. We believe anyone, whether it be those suffering terminal illnesses, amputated limbs, or simply anyone who cannot write easily, should all be able to experience the joy of writing!
## What it does
Hand Spoken is an innovative solution that combines the ease of writing with the beauty of an individual's unique handwriting.
All you need to use our desktop application is an old handwritten letter saved by you! Simply pick up your paper of handwriting (or handwriting of choice) and take a picture. After submitting the picture into our website database, you are all set. Then, simply speak into the computer either using a microphone or a voice technology device. The user of the desktop application will automatically see their text appear on the screen in their own personal handwriting font! They can then save their message for later use.
## How we built it
We created a desktop application using C# with Visual Studio's WinForm framework. Handwriting images uploaded to the application is sent via HTTP request to the backend, where a python server identifies each letter using pytesseract. The recognized letters are used to generate a custom font, which is saved to the server. Future audio files recorded by the frontend are also sent into the backend, at which point AWS Transcribe services are contacted, giving us the transcribed text. This text is then processed using the custom handwriting font, being eventually returned to the frontend, ready to be downloaded by the user.
## Challenges we ran into
One main challenge our team ran into was working with pytesseract. To overcome this obstacle, we made sure we worked collaboratively as a team to divide roles and learn how to use these exciting softwares.
## Accomplishments that we're proud of
We are proud of creating a usable and functional database that incorporates UX/UI design!
## What we learned
Not only did we learn lots about OCR (Optical Character Recognition) and AWS Transcribe services, but we learned how to collaborate effectively as a team and maximize each other's strengths.
## What's next for Hand Spoken
Building upon on our idea and creating accessibility **for all** through the use of technology! | losing |
## Inspiration
We wanted to reduce global carbon footprint and pollution by optimizing waste management. 2019 was an incredible year for all environmental activities. We were inspired by the acts of 17-year old Greta Thunberg and how those acts created huge ripple effects across the world. With this passion for a greener world, synchronized with our technical knowledge, we created Recycle.space.
## What it does
Using modern tech, we provide users with an easy way to identify where to sort and dispose of their waste items simply by holding it up to a camera. This application will be especially useful when permanent fixtures are erect in malls, markets, and large public locations.
## How we built it
Using a flask-based backend to connect to Google Vision API, we captured images and categorized which waste categories the item belongs to. This was visualized using Reactstrap.
## Challenges I ran into
* Deployment
* Categorization of food items using Google API
* Setting up Dev. Environment for a brand new laptop
* Selecting appropriate backend framework
* Parsing image files using React
* UI designing using Reactstrap
## Accomplishments that I'm proud of
* WE MADE IT!
We are thrilled to create such an incredible app that would make people's lives easier while helping improve the global environment.
## What I learned
* UI is difficult
* Picking a good tech stack is important
* Good version control practices is crucial
## What's next for Recycle.space
Deploying a scalable and finalized version of the product to the cloud and working with local companies to deliver this product to public places such as malls. | # RecycPal

## Summary
RecycPal is your pal for creating a more sustainable world! RecycPal uses machine learning and artificial intelligence to help you identify what can be or cannot be recycled.
This project was developed during DeltaHacks 8. Please check out our DevPost here: <https://devpost.com/software/recycpal>
## Motivation
The effects of climate change are already being felt, especially in recent times with record breaking temperatures being recorded in alarming numbers each year [1]. According to the Environmental Protection Agency [2], Americans generated 292.4 million tons of material solid waste in 2018. Out of that amount, 69 million tons of waste were recycled and another 25 million tons were composted. This resulted in a 32.1 percent recycling and composting rate. These numbers must improve if we want a greener and sustainable future.
Our team believes that building software that will educate the public on the small things they can do to help will ultimately create a massive change. We developed RecycPal in pursuit of these greener goals and a desire to help other eco-friendly people make the world a better place.
## Meet the Team
* Denielle Abaquita (iOS Front-end)
* Jon Abrigo (iOS Front-end)
* Justin Esguerra (ML, Back-end)
* Ashley Hart (ML, Back-end)
## Tech Stack
RecycPal was designed and built with the following technolgies:
* Figma
* CoreML
* XCode
We also utilize some free art assets from Flaticon. [3]
## Frontend

### History Tab
| History Tab Main | Previous Picture |
| --- | --- |
| | |
The purpose of this tab is to let the user see the pictures they have taken in the past. At the top of this tab will be a cell that leads to finding the nearest recycling center for easy access to this important feature.
Each cell in this section will lead to a previously taken picture by the user and will be labeled with the date the user took the picture.
### Camera Tab
| Pointing the Camera | Picture Taken |
| --- | --- |
| | |
The purpose of this tab is to take a picture of the user's surroundings to identify any recyclable objects in the frame. Each picture will be automatically saved into the user's history. We utilized Apple's CoreML and Vision APIs to complete this section. [4, 5]
After the user takes a picture, the application will perform some machine learning algorithms in the backend to identify any objects in the picture. The user will then see the object highlighted and labeled within the picture.
Afterwards, the user has the option to take another picture.
### Information Tab
| Information Tab | More Info on Paper |
| --- | --- |
| | |
The purpose of this tab is to provide the user information on the nearest recycling centers and the best recycling practices based on the materials. We consulted resources provided by the Environmental Protection Agency to gather our information [6].
In this case, we have paper, plastic, and metal materials. We will also include glass and non-recyclables with information on how to deal with them.
## Backend
### Machine Learning
This was our team's first time tackling machine learning and we were able to learn about neural networks, dataseet preparation, the model training process and so much more. We took advantage of CoreML [7] to create a machine learning model that would receive a photo of an object taken by the user and attempt to classify it into one of the following categories:
1. Cardboard
2. Paper
3. Plastic
4. Metal
5. Glass
6. Trash
The training process introduced some new challenges that our team had to overcome. We used datasets from Kaggle [8, 9] and the TACO project [10] to train our model. In order to test our data, we utilized a portion of our data sets that we did not train with and took pictures of trash we had in our homes to give the model fresh input to predict on.
We worked to ensure that that our results would have a confidnece rating of at least 80% so the front-end of the application could take that result and display proper infromation to the user.
## What We Learned
### Denielle
RecycPal is the result of the cumulative effort of 3 friends wanting to build something useful and impactful. During this entire project, I was able to solidifiy my knowledge of iOS development after focusing on web development for the past few months. I was also able to learn AVFoundation and CoreML. AVFoundation is a framework in iOS that allows developers to incorporate the camera in their applications. CoreML, on the other hand, helps with training and developing models to be used in machine learning. Overall, I learned so much, and I am happy to have spent the time to work on this project with my friends.
### Justin
Starting on this project, I had a general idea of how machine learning models work, but nothing prepared for me the adventure that ensued these past 36 hours. I learned CoreML fundamentals, how to compile and annotate datasets, and expanded my knowledge in XCode. These are just the tip of the iceberg considering all of our prototypes we had to scrap, but it was a privelege to grind this out with my friends.
### Jon
I have learned A TON of things to put it simply. This was my first time developing on the frontend so most of the languages and process flow were new to me. I learned how to navigate and leverage the tools offered by Figma and helped create the proof of concept for RecycPal's application. Learned how to develop with Xcode and Swift and assist on creating the launch screen and home page of the application. Overall, I am thankful for the opportunity that I have been given throughout this Hackathon.
### Ashley
This project served as my first hands on experience with machine learning. I learned about machine learning tasks such as image classification, expermineted with the many utilities that Python offers for data science and I learned how to organize, label, create, and utilize data sets. I also lerned how libaries such as numpy and matplotlib could be combined with frameworks such as PyTorch to build neural networks. I was also able to experiment with Kaggle and Jyupter Notebooks.
## Challenges We Ran Into
### Denielle
The biggest challenges I have ran into are the latest updates to Xcode and iOS. Because it has been some time since I last developed for iOS, I have little familiarity with the updates to iOS 15.0 and above. In this case, I had to adjust to learn UIButton.Configuration and Appearance configurations for various components. As a result, that slowed down development a little bit, but I am happy to have learned about this updates! In the end, the updates are a welcome change, and I look forward to learning more and seeing what's in store in the future.
### Justin
I didn't run into challenges. The challenges ran over me. From failing to implent PyTorch into our application, struggling to create Numpy (Python) based datasets, and realizing that using Google Cloud Platform for remote access to the database was too tedious and too out of the scope for our project. Despite all these challenges we persevered until we found a solution, CoreML. Even then we still ran into Xcode and iOS updates and code depracations which made this inifinitely more frustrating but ten times more rewarding.
### Jon
This was my first time developing on the front end as I have mainly developed on the backend prior. Learning how to create prototypes like the color schema of the application, creating and resizing the application's logos and button icons, and developing on both the programmatic and Swift's storyboards methods were some of the challenges I faced throughout the event. Although this really slowed the development time, I am grateful for the experience and knowledge I have gained throughout this Hackathon.
### Ashley
I initially attempted to build a model for this application using PyTorch. I chose this framework because of its computing power, accessible documentation. Unfortunately, I ran into several errors when I had to convert my images into inputs for a neural network. On the bright side, we found Core ML and utilized it in our application with great success. My work with PyTorch is not over as I will continue to learn more about it for my personal studies and for future hackathons. I also conducted research for this project and learned more about how I can recycle waste.
## What's Next for RecycPal?
Future development goals include:
* Integrating computer vision, allowing the model to see and classify multiple objects in real time.
* Bolstering the accuracy of our model by providing it with more training data.
* Getting user feedback to improve user experience and accessibility.
* Conducting research to evaluate how effective the application is at helping people recycle their waste.
* Expanding the classifications of our model to include categories for electronics, compostables, and materials that need to be taken to a store/facility to be proccessed.
* Adding waste disposal location capabilites, so the user can be aware of nearby locarions where they can process their waste.
### Conclusion
Thank you for checking out our project! If you have suggestions, feel free to reach out to any of the RecycPal developers through the socials we have attached to our DevPost accounts.
## References
[1] Climate change evidence: How do we know? 2022. NASA. <https://climate.nasa.gov/evidence/>.
[2] EPA. 2018. National Overview: Facts and Figures on Materials, Wastes and Recycling. <https://www.epa.gov/facts-and-figures-about-materials-waste-and-recycling/national-overview-facts-and-figures-materials>.
[3] EPA. How Do I Recycle?: Common Recyclables. <https://www.epa.gov/recycle/how-do-i-recycle-common-recyclables>.
[4] Apple. Classifying Images with Vision and Core ML. Apple Developer Documentation. <https://developer.apple.com/documentation/vision/classifying_images_with_vision_and_core_ml>.
[5] Chang, C. 2018. Garbage Classification. Kaggle. <https://www.kaggle.com/asdasdasasdas/garbage-classification>.
[6] Sekar, S. 2019. Waste classification data. Kaggle. <https://www.kaggle.com/techsash/waste-classification-data>.
[7] Pedro F Proença and Pedro Simões. 2020. TACO: Trash Annotations in Context for Litter Detection. arXiv preprint arXiv:2003.06975 (2020). | ## Inspiration
While looking for genuine problems that we could solve, it came to our attention that recycling is actually much harder than it should be. For example, when you go to a place like Starbucks and are presented with the options of composting, recycling, or throwing away your empty coffee, it can be confusing and for many people, it can lead to selecting the wrong option.
## What it does
Ecolens uses a cloud-based machine learning webstream to scan for an item and tells the user the category of item it is that they scanned, providing them with a short description of the object and updating their overall count of consuming recyclable vs. unrecyclable items as well as updating the number of items that they consumed in that specific category (i.e. number of water bottle consumed)
## How we built it
This project consists of both a front end and a back end. The backend of this project was created using Java Spring and Javascript. Javascript was used in the backend in order to utilize Roboflow and Ultralytics which allowed us to display the visuals from Roboflow on the website for the user to see. Java Spring was used in the backend for creating a database that consisted of all of the scanned items and tracked them as they were altered (i.e. another item was scanned or the user decided to dump the data).
The front end of this project was built entirely through HTML, CSS, and Javascript. HTML and CSS were used in the front end to display text in a format specific to the User Interface, and Javascript was used in order to implement the functions (buttons) displayed in the User Interface.
## Challenges we ran into
This project was particularly difficult for all of us because of the fact that most of our team consists of beginners and there were multiple parts during the implementation of our application that no one was truly comfortable with. For example, integrating camera support into our website was particularly difficult as none of our members had experience with JavaScript, and none of us had fully fledged web development experience. Another notable challenge was presented with the backend of our project when attempting to delete the user history of items used while also simultaneously adding them to a larger “trash can” like a database.
From a non-technical perspective, our group also struggled to come to an agreeance on how to make our implementation truly useful and practical. Originally we thought to have hardware that would physically sort the items but we concluded that this was out of our skill range and also potentially less sustainable than simply telling the user what to do with their item digitally.
## Accomplishments that we're proud of
Although we can acknowledge that there are many improvements that could be made, such as having a cleaner UI, optimized (fast) usage of the camera scanner, or even better responses for when an item is accidentally scanned, we’re all collectively proud that we came together to find an idea that allowed each of us to not only have a positive impact on something we cared about but to also learn and practice things that we actually enjoy doing.
## What we learned
Although we can acknowledge that there are many improvements that could be made, such as having a cleaner UI, optimized (fast) usage of the camera scanner, or even better responses for when an item is accidentally scanned, we’re all collectively proud that we came together to find an idea that allowed each of us to not only have a positive impact on something we cared about but to also learn and practice things that we actually enjoy doing.
## What's next for Eco Lens
The most effective next course of action for EcoLens is to assess if there really is a demand for this product and what people think about it. Would most people genuinely use this if it was fully shipped? Answering these questions would provide us with grounds to move forward with our project. | winning |
### 🌟 Inspiration
We're inspired by the idea that emotions run deeper than a simple 'sad' or 'uplifting.' Our project was born from the realization that personalization is the key to managing emotional states effectively.
### 🤯🔍 What it does?
Our solution is an innovative platform that harnesses the power of AI and emotion recognition to create personalized Spotify playlists. It begins by analyzing a user's emotions, both from facial expressions and text input, to understand their current state of mind. We then use this emotional data, along with the user's music preferences, to curate a Spotify playlist that's tailored to their unique emotional needs.
What sets our solution apart is its ability to go beyond simplistic mood categorizations like 'happy' or 'sad.' We understand that emotions are nuanced, and our deep-thought algorithms ensure that the playlist doesn't worsen the user's emotional state but, rather, optimizes it. This means the music is not just a random collection; it's a therapeutic selection that can help users manage their emotions more effectively.
It's music therapy reimagined for the digital age, offering a new and more profound dimension in emotional support.
### 💡🛠💎 How we built it?
We crafted our project by combining advanced technologies and teamwork. We used Flask, Python, React, and TypeScript for the backend and frontend, alongside the Spotify and OpenAI APIs.
Our biggest challenge was integrating the Spotify API. When we faced issues with an existing wrapper, we created a custom solution to overcome the hurdle.
Throughout the process, our close collaboration allowed us to seamlessly blend emotion recognition, music curation, and user-friendly design, resulting in a platform that enhances emotional well-being through personalized music.
### 🧩🤔💡 Challenges we ran into
🔌 API Integration Complexities: We grappled with integrating and harmonizing multiple APIs.
🎭 Emotion Recognition Precision: Achieving high accuracy in emotion recognition was demanding.
📚 Algorithm Development: Crafting deep-thought algorithms required continuous refinement.
🌐 Cross-Platform Compatibility: Ensuring seamless functionality across devices was a technical challenge.
🔑 Custom Authorization Wrapper: Building a custom solution for Spotify API's authorization proved to be a major hurdle.
### 🏆🥇🎉 Accomplishments that we're proud of
#### Competition Win: 🥇
```
Our victory validates the effectiveness of our innovative project.
```
#### Functional Success: ✔️
```
The platform works seamlessly, delivering on its promise.
```
#### Overcoming Challenges: 🚀
```
Resilience in tackling API complexities and refining algorithms.
```
#### Cross-Platform Success: 🌐
```
Ensured a consistent experience across diverse devices.
```
#### Innovative Solutions: 🚧
```
Developed custom solutions, showcasing adaptability.
```
#### Positive User Impact: 🌟
```
Affirmed our platform's genuine enhancement of emotional well-being.
```
### 🧐📈🔎 What we learned
🛠 Tech Skills: We deepened our technical proficiency.
🤝 Teamwork: Collaboration and communication were key.
🚧 Problem Solving: Challenges pushed us to find innovative solutions.
🌟 User Focus: User feedback guided our development.
🚀 Innovation: We embraced creative thinking.
🌐 Global Impact: Technology can positively impact lives worldwide.
### 🌟👥🚀 What's next for Look 'n Listen
🚀 Scaling Up: Making our platform accessible to more users.
🔄 User Feedback: Continuous improvement based on user input.
🧠 Advanced AI: Integrating more advanced AI for better emotion understanding.
🎵 Enhanced Personalization: Tailoring the music therapy experience even more.
🤝 Partnerships: Collaborating with mental health professionals.
💻 Accessibility: Extending our platform to various devices and platforms. | ## Inspiration ✨
Seeing friends' lives being ruined through **unhealthy** attachment to video games. Struggling with regulating your emotions properly is one of the **biggest** negative effects of video games.
## What it does 🍎
YourHP is a webapp/discord bot designed to improve the mental health of gamers. By using ML and AI, when specific emotion spikes are detected, voice recordings are queued *accordingly*. When the sensor detects anger, calming reassurance is played. When happy, encouragement is given, to keep it up, etc.
The discord bot is an additional fun feature that sends messages with the same intention to improve mental health. It sends advice, motivation, and gifs when commands are sent by users.
## How we built it 🔧
Our entire web app is made using Javascript, CSS, and HTML. For our facial emotion detection, we used a javascript library built using TensorFlow API called FaceApi.js. Emotions are detected by what patterns can be found on the face such as eyebrow direction, mouth shape, and head tilt. We used their probability value to determine the emotional level and played voice lines accordingly.
The timer is a simple build that alerts users when they should take breaks from gaming and sends sound clips when the timer is up. It uses Javascript, CSS, and HTML.
## Challenges we ran into 🚧
Capturing images in JavaScript, making the discord bot, and hosting on GitHub pages, were all challenges we faced. We were constantly thinking of more ideas as we built our original project which led us to face time limitations and was not able to produce some of the more unique features to our webapp. This project was also difficult as we were fairly new to a lot of the tools we used. Before this Hackathon, we didn't know much about tensorflow, domain names, and discord bots.
## Accomplishments that we're proud of 🏆
We're proud to have finished this product to the best of our abilities. We were able to make the most out of our circumstances and adapt to our skills when obstacles were faced. Despite being sleep deprived, we still managed to persevere and almost kept up with our planned schedule.
## What we learned 🧠
We learned many priceless lessons, about new technology, teamwork, and dedication. Most importantly, we learned about failure, and redirection. Throughout the last few days, we were humbled and pushed to our limits. Many of our ideas were ambitious and unsuccessful, allowing us to be redirected into new doors and opening our minds to other possibilities that worked better.
## Future ⏭️
YourHP will continue to develop on our search for a new way to combat mental health caused by video games. Technological improvements to our systems such as speech to text can also greatly raise the efficiency of our product and towards reaching our goals! | ## Inspiration
We wanted to work with something that was impactful but fun to implement. We were able to incorporate interests within our team to work on a health-related project with interests to work with large amounts of data and interests to work with music.
There are currently very few metrics used as indicators of mental health issues outside of surveys and self-reports. We want to see if music preferences over time could help remedy this problem by providing another means of quantifying emotional and mental stability.
## What it does
Our project is able to collect a user’s history of music preferences on Spotify, and after comparing and normalizing to the Top 100 Billboard songs at that time, predict whether a user’s music listening patterns generally trend downwards, indicating that they have been listening to more negative songs recently. If the user seems to have this downward trend, we provide a survey to get a more holistic understanding of what emotional state they might be in. Combining all this data, we suggest whether the user might want to seek therapy or outside help. Regardless of what trends exist in a user’s data, we think everyone can benefit from happier music, which is why we create a custom playlist of generally happier music, tailored specifically to the user’s recent music preferences.
## How we built it
The first step was to access and process the music habit data that we needed. We used Spotify’s Web API to get user listening data by scraping their playlists and used Billboard Top 100 lists to get a baseline for a certain time period.
We then extracted three features: “danceability”, “valence”, and “energy” of all of this music data, calculating a score that took these three features into consideration. We then used the baseline data to normalize a user’s data (if popular music was mostly negative during a certain time period then a user’s score is naturally more likely to skew negative so we wanted to mitigate that effect).
Finally, to calculate whether we would assign a net “POSITIVE” or “NEGATIVE” classification to a user’s data, we took a weighted sum of slopes over various time spans, weighing more recent data more heavily.
## Challenges we ran into
Spotify’s API is intended for simple hobby use, not the levels of data collection and extraction that we required. The API often automatically rate-limited our application, preventing us from getting complete data. We were able to do some pre-calculation of data, specifically the Billboard data, but despite all the optimization we did, the web app is still susceptible to rate limiting by Spotify’s API. (At which point the user simply needs to wait 5 seconds and refresh to try again)
Another big challenge we ran into was in how we built our model and weighed our variables. Since we don’t have labeled data available to us and hand-labeling data would introduce our own bias into our model, we went with simple weights since we used various Spotify features that have been and keep being carefully calibrated to calculate sentiment.
## Accomplishments that we're proud of
Many of us lacked experience in web development/ React. To have built a complete, functional web app, in the end, was in itself highly satisfying, and in the process of doing so, we found a way to look at music from a new perspective as an analytical health tool.
## What we learned
Overall, we learned a lot about the process of taking multiple technical components and integrating them together into one cohesive product, from start to finish. Individually, we learned React, use of the Spotify API, data mining and analysis, and NLP.
## What's next for MusiCare
Implementing more sophisticated methods for extracting mood from music, such as lyric analysis with NLP. Finding/creating training data to train machine learning models to optimize weighting procedures for averages and comparing user data from our model and the survey to evaluate the model. Eventually, we hope to sync as part of Spotify’s background data analysis rather than a separate add-on web-app with extremely limited access to their API. Given the functionalities, we hope to provide subliminal messages with counseling ads and advertisements for other supportive services through Spotify as a means of raising awareness and having a larger impact. | winning |
## 💭 Inspiration
Throughout our Zoom university journey, our team noticed that we often forget to unmute our mics when we talk, or forget to mute it when we don't want others to listen in. To combat this problem, we created speakCV, a desktop client that automatically mutes and unmutes your mic for you using computer vision to understand when you are talking.
## 💻 What it does
speakCV automatically unmutes a user when they are about to speak and mutes them when they have not spoken for a while. The user does not have to interact with the mute/unmute button, creating a more natural and fluid experience.
## 🔧 How we built it
The application was written in Python: scipy and dlib for the machine learning, pyvirtualcam to access live Zoom video, and Tkinter for the GUI. OBS was used to provide the program access to a live Zoom call through virtual video, and the webpage for the application was built using Bootstrap.
## ⚙️ Challenges we ran into
A large challenge we ran into was fine tuning the mouth aspect ratio threshold for the model, which determined the model's sensitivity for mouth shape recognition. A low aspect ratio made the application unable to detect when a person started speaking, while a high aspect ratio caused the application to become too sensitive to small movements. We were able to find an acceptable value through trial and error.
Another problem we encountered was lag, as the application was unable to handle both the Tkinter event loop and the mouth shape analysis at the same time. We were able to remove the lag by isolating each process into separate threads.
## ⭐️ Accomplishments that we're proud of
We were proud to solve a problem involving a technology we use frequently in our daily lives. Coming up with a problem and finding a way to solve it was rewarding as well, especially integrating the different machine learning models, virtual video, and application together.
## 🧠 What we learned
* How to setup and use virtual environments in Anaconda to ensure the program can run locally without issues.
* Working with virtual video/audio to access the streams from our own program.
* GUI creation for Python applications with Tkinter.
## ❤️ What's next for speakCV.
* Improve the precision of the shape recognition model, by further adjusting the mouth aspect ratio or by tweaking the contour spots used in the algorithm for determining a user's mouth shape.
* Moving the application to the Zoom app marketplace by making the application with the Zoom SDK, which requires migrating the application to C++.
* Another option is to use the Zoom API and move the application onto the web. | ## Inspiration
Partially inspired by the Smart Cities track, we wanted our app to have the direct utility of ordering food, while still being fun to interact with. We aimed to combine convenience with entertainment, making the experience more enjoyable than your typical drive-through order.
## What it does
You interact using only your voice. The app automatically detects when you start and stop talking, uses AI to transcribe what you say, figures out the food items (with modifications) you want to order, and adds them to your current order. It even handles details like size and flavor preferences. The AI then generates text-to-speech audio, which is played back to confirm your order in a humorous, engaging way. There is absolutely zero set-up or management necessary, as the program will completely ignore all background noises and conversation. Even then, it will still take your order with staggering precision.
## How we built it
The frontend of the app is built with React and TypeScript, while the backend uses Flask and Python. We containerized the app using Docker and deployed it using Defang. The design of the menu is also done in Canva with a dash of Harvard colors.
## Challenges we ran into
One major challenge was getting the different parts of the app—frontend, backend, and AI—to communicate effectively. From media file conversions to AI prompt engineering, we worked through each of the problems together. We struggled particularly with maintaining smooth communication once the app was deployed. Additionally, fine-tuning the AI to accurately extract order information from voice inputs while keeping the interaction natural was a big hurdle.
## Accomplishments that we're proud of
We're proud of building a fully functioning product that successfully integrates all the features we envisioned. We also managed to deploy the app, which was a huge achievement given the complexity of the project. Completing our initial feature set within the hackathon timeframe was a key success for us. Trying to work with Python data type was difficult to manage, and we were proud to navigate around that. We are also extremely proud to meet a bunch of new people and tackle new challenges that we were not previously comfortable with.
## What we learned
We honed our skills in React, TypeScript, Flask, and Python, especially in how to make these technologies work together. We also learned how to containerize and deploy applications using Docker and Docker Compose, as well as how to use Defang for cloud deployment.
## What's next for Harvard Burger
Moving forward, we want to add a business-facing interface, where restaurant staff would be able to view and fulfill customer orders. There will also be individual kiosk devices to handle order inputs. These features would allow *Harvard Burger* to move from a demo to a fully functional app that restaurants could actually use. Lastly, we can sell the product by designing marketing strategies for fast food chains. | ## Inspiration
As first year university students, attending university lectures has been a frightening experience. Much different than how it is in high school, with a class of thousands of students, it’s much too easy to lose focus in lectures. One bad night of sleep can lead to valuable information lost and while one may think that only missing one lecture is alright, wait until they see the content they missed on the midterm. That is why we decided to build an application capable of speech to text recognition and a bunch of other useful features such as text summarization and text translation in order to help students with understanding lectures and avoid those days where one may zone out in class.
## What it does
Paying attention is hard. Only 6% of the world are native english speakers. heAR uses AR and NLP to help you take notes and understand other people
* To help the world understand each other better
* To improve the education of students
* To help connect the world
* So you can focus on the details that matter
* So people can talk about the details that matter
* To facilitate deeper human connections
* To facilitate understanding
* To facilitate communication
## How we built it
In order to build our project, we first came up with how we wanted our application to look like and what features we would like to implement. That discussion lead us on deciding that we wanted to add an Augmented Reality feature on our application because we felt like it would be more immersive and fun to see summarized notes that you take in AR. To build the UI/UX and augmented reality of the app, we used Unity and C#. In terms of text summarization and text translation, we used Co:here’s and Google Translate’s API in order to achieve this. Using python, we were able to build algorithms that would take in paragraphs and either translate them, summarize them or even both. We decided to add the translation feature because in University, and also in real life situations, not everyone speaks the same language and having that option to understand what people are saying in your own language is very beneficial.
## Challenges we ran into
A huge challenge we encountered was having Unity interact with our Python algorithms. The problem we faced was that our product is on a mobile phone and running Python on such device is not really feasible and so we had to come up with a creative way to fix our situation. After some thought, we landed on the idea of creating a backend python server using Flask where our C# code would be able to make request to it and vice versa to retrieve the data we wanted. While the idea seemed very farfetched at first, we slowly tackled the problem by dividing up the work and eventually we were able to get the server running
using Heruko.
## Accomplishments that we're proud of
A huge accomplishment that we are very proud of is our working demo. The reason why is because in our demo, we have essentially achieved every goal that we have set during the beginning of the hackathon. From registering speech to text in Unity to having text summarization, we have accomplished so much as a team and are very proud of our finished demo. As the project went on, we obviously wanted to add more and more, but just having the feeling of accomplishing our original goals is truly something we will cherish
as a team.
## What we learned
We have learnt so much from building this project; from improving our existing skills to learning more, we understood what it is like working in a team environment. Not only that, but for all of us, this is either our very first hackathon or first hackathon in person and so we have truly experienced what a hackathon really is and have learnt so much from industry professionals.
## What's next for heAR
To be honest, we are not really sure what is next for heAR. We did plan to add more UI/UX and Co:here features and possibly will continue or maybe venture into another topic. | winning |
## Inspiration
Homes are becoming more and more intelligent with Smart Home products such as the Amazon Echo or Google Home. However, users have limited information about the infrastructure's status.
## What it does
Our smart chat bot helps users to monitor their house's state from anywhere using low cost sensors. Our product is easy to install, user friendly and fully expandable.
**Easy to install**
By using compact sensors, HomeScan is able to monitor information from your house. Afraid of gas leaks or leaving the heating on? HomeScan has you covered. Our product requires minimum setup and is energy efficient. In addition, since we use a small cellular IoT board to gather the data, HomeScan sensors are wifi-independant. This way, HomeScan can be placed anywhere in the house.
**User Friendly**
HomeScan uses Cisco Spark bots to communicate data to the users. Run diagnostics, ask for specific sensor data, our bots can do it all. Best of all, there is no need to learn command lines as our smart bots use text analysis technologies to find the perfect answer to your question. Since we are using Cisco Spark, the bots can be accessed on the go on both the Spark mobile app or on our website.Therefore, you'll have no problem accessing your data while away from your home.
**Fully expandable**
HomeScan was built with the future in mind. Our product will fully benefit from future technological advancements. For instance, 5G will enable HomeScan to expand and reach places that currently have a poor cellular signal. In addition, the anticipated release of Cisco Spark's "guestID" will grant access to our smart bots to an even wider audience. Newer bot customization tools will also allow us to implement additional functionalities. Lastly, HomeScan can be expanded into an infrastructure ranking system. This could have a tremendous impact on the real-estate industry as houses could be rated based on their infrastructure performances. This way, data could be used for services such as AirBnB, insurance companies and even home-owners.
We are confident that HomeScan is the solution for monitoring a healthy house and improve your real-estate decisions.
future proof
## How I built it
The infrastructure's information are being gathered through a Particle Electron board running of cellular network. The data are then sent to an Amazon's Web Services server. Finally, a Cisco Spark chat bot retrieves the data and outputs relevant queries according to the user's inputs. The intelligent bot is also capable of warning the user in case of an emergency.
## Challenges I ran into
Early on, we ran into numerous hardware issues with the Particle Electron board. After consulting with industry professionals and hours of debugging, we managed to successfully get the board working the way we wanted. Additionally, with no experience with back-end programming, we struggled a lot understanding the tools and the interactions between platforms but ended with successful results.
## Accomplishments that we are proud of
We are proud to showcase a fully-stacked solution using various tools with very little to no experience with it.
## What we learned
With perservance and mutual moral support, anything is possible. And never be shy to ask for help. | ## Inspiration
A chatbot is often described as one of the most advanced and promising expressions of interaction between humans and machines. For this reason we wanted to create one in order to become affiliated with Natural Language Processing and Deep-Learning through neural networks.
Due to the current pandemic, we are truly living in an unprecedented time. As the virus' spread continues, it is important for all citizens to stay educated and informed on the pandemic. So, we decided to give back to communities by designing a chatbot named Rona who a user can talk to, and get latest information regarding COVID-19.
(This bot is designed to function similarly to ones used on websites for companies such as Amazon or Microsoft, in which users can interact with the bot to ask questions they would normally ask to a customer service member, although through the power of AI and deep learning, the bot can answer these questions for the customer on it's own)
## What it does
Rona answers questions the user has regarding COVID-19.
More specifically, the training data we fed into our feed-forward neural network to train Rona falls under 5 categories:
* Deaths from COVID-19
* Symptoms of COVID-19
* Current Cases of COVID-19
* Medicines/Vaccines
* New Technology/Start-up Companies working to fight coronavirus
We also added three more categories of data for Rona to learn, those being greetings, thanks and goodbyes, so the user can have a conversation with Rona which is more human-like.
## How we built it
First, we had to create my training data. Commonly referred to as 'intentions', the data we used to train Rona consisted of different phrases that a user could potentially ask. We split up all of my intentions into 7 categories, which we listed above, and these were called 'tags'. Under our sub-branch of tags, we would provide Rona several phrases the user could ask about that tag, and also gave it responses to choose from to answer questions related to that tag. Once the intentions were made, we put this data in a json file for easy access in the rest of the project.
Second, we had to use 3 artificial-intelligence, natural language processing, techniques to process the data, before it was fed into our training model. These were 'bag-of-words', 'tokenization' and 'stemming'. First, bag-of-words is a process which took a phrase, which were all listed under the tags, and created an array of all the words in that phrase, making sure there are no repeats of any words. This array was assigned to an x-variable. A second y-variable delineated which tag this bag-of-words belonged to. After these bags-of-words were created, tokenization was applied through each bag-of-words and split them up even further into individual words, special characters (like @,#,$,etc.) and punctuation. Finally, stemming created a crude heuristic, i.e. it chopped off the ending suffixes of the words (organize and organizes both becomes organ), and replaced the array again with these new elements. These three steps were necessary, because the training model is much more effective when the data is pre-processed in this way, it's most fundamental form.
Next, we made the actual training model. This model was a feed-forward neural network with 2 hidden layers. The first step was to create what are called hyper-parameters, which is a standard procedure for all neural networks. These are variables that can be adjusted by the user to change how accurate you want your data to be. Next, the network began with 3 layers which were linear, and these were the layers which inputted the data which was pre-processed earlier. After, these were passed on into what are called activation functions. Activation functions output a small value for small inputs, and a larger value if its inputs exceed a threshold. If the inputs are large enough, the activation function "fires", otherwise it does nothing. In other words, an activation function is like a gate that checks that an incoming value is greater than a critical number.
The training was completed, and the final saved model was saved into a 'data.pth' file using pytorch's save method.
## Challenges we ran into
The most obvious challenge was simply time constraints. We spent most of our time trying to make sure the training model was efficient, and had to search up several different articles and tutorials on the correct methodology and API's to use. Numpy and pytorch were the best ones.
## Accomplishments that we're proud of
This was our first deep-learning project so we are very proud of completing at least the basic prototype. Although we were aware of NLP techniques such as stemming and tokenization, this is our first time actually implementing them in action. We have created basic neural nets in the past, but also never a feed-forward one which provides an entire model as its output.
## What we learned
We learned a lot about deep learning, neural nets, and how AI is trained for communication in general. This was a big step up for us in Machine Learning.
## What's next for Rona: Deep Learning Chatbot for COVID-19
We will definitely improve on this in the future by updating the model, providing a lot more types of questions/data related to COVID-19 for Rona to be trained on, and potentially creating a complete service or platform for users to interact with Rona easily. | ## Inspiration
This project was inspired by a (not so friendly) house guest.
## What it does
We used a camera-motion sensor and Firebase's machine learning kit to implement object recognition so that users can be notified when motion is detected, as well as be notified if the motion is a human. Our end goal is to develop a cheap and practical house security system, that can make use of the billions of retired phones world wide. A personal side goal of ours is to catch a certain minuscule house guest is still alive and is scurrying around the house.
## How Our Team built it
We used the IntelliJ Idea IDE with the Android Studio plug-in to build this application and used Google's Firebase to not only keep track of users, but also incorporate the built-in machine learning kit.
## Challenges We ran into
Getting the camera to perform correctly was a larger than anticipated challenge. A security camera must take frequent photos on its own, so using the default camera app is not practical. We have to use lower level Android camera libraries, while dealing with various versions of APIs (for example, a well documented but deprecated version, vs. a new but poorly documented version). Once the camera was working, we had to learn how to use Firebase's machine learning libraries. None of us had experience with machine learning before, so this was a valuable experience for all of the team. | winning |
## Inspiration
At times, like any other city, Victoria is not always safe to travel by foot at night. With some portions of the population feeling concerned about safety in the area they live, the idea for creating an application to help users travel more safely would be a great way to give back. This would not only benefit our community, but can be easily applied to other cities as well.
## What it does
GetThereSafe maps the best route to your destination by determining where the most amount of light sources are.
## How we built it
Utilizing a Google Maps API, we built a PostgreSQL database that stores light source data from the Open Data Catalogue from the City of Victoria. When the Flask web app receives the start and destination locations, it calls upon our database to determine which route has the highest amount of light sources. It then returns the best routes for the user to use.
## Challenges we ran into
**Database Implementation**:
Our main challenge was creating a database (to store light source data) that could easily communicate with our app, which was being deployed via Heroku. The first attempt was to host our database with Orchestrate, but after determining that it would have taken far too much time to implement, it was decided that the team should change services.
On the advice of Artur from MLH, he suggested to spin up an Amazon Web Service that would host our database. Creating an EC2 instance running PostgreSQL inside, the database finally began to take form. However, we began to notice that there were going to be permission issues with our web app communicating with our EC2 instance.
An attempt to make a pg\_dump into an RDS instance was made, but after three different database implementation attempts and much research, it was decided that we would implement our database via Heroku's PostgreSQL add-on (which utilizes AWS in the background, but in a limited manner in comparison to our previous attempts).
We were hoping to utilize cloud services to make our data set easily scalable, with the goal of being able to add more information to make our user's route as safe as possible. Unfortunately, due to our utilization of Heroku to deploy our web app, this complicated our implementation attempts to allow our services to communicate with one another. In the end, this was a significant lesson in not just correct database implementation, but also how multiple services communicate with one another.
## Accomplishments that we're proud of
1. Implementing an EC2 server instance running a PostgreSQL DB instance
2. Managing to survive 15 hours of database brutality, and having created four different databases in that time.
3. Calculating the best amount of light source coordinates on each route
4. Site design!
5. Mobile responsiveness
6. Our logo is pretty cool - it's awesome!!!!
7. Utilizing our first Google API!
## What we learned
1. Heroku is not very good at communicating with multiple services - this was a hard earned lesson...
2. The scalability of AWS is GODLY - during the research phase, AWS proved to be a very viable option as we could add more data sets (e.g. crime) for our web app to work with.
3. Traversing routes from Google Maps and determining closest light source to each coordinate
## What's next for GetThereSafe
1. Getting our AWS EC2/RDS PostgreSQL instance communicating with our app instead of Heroku's add-on.
2. Add support for more cities! We will need to search for cities with this data openly available for them to be implemented within our application.
3. Able to toggle between each route that the user would want to take.
4. Start/Destination auto-completion fields.
5. Pull location search data from Google as replacement for addresses
6. Add more data sets to enhance route pathing (e.g. crime)
7. Add support for cycling (use topography map, cycling route maps, and lighting to determine route) | # Scenic
## 30 second pitch
A non-linear navigation model for exercise that maximizes air quality and reduces noise pollution. Sometimes it's not always about getting there fast. Want directions that take an extra 10 minutes, but cut your air and noise pollution intake in half? We've got your *Scenic* route.
## Story
Everyday, John and I ride our bikes to campus. We're both new to the city and finding a pleasant route is not always easy. Noise, air quality, and traffic all cause stress. Noticing a lack of solutions on the market, we came up with a better solution. From our conversations, Scenic is born.
## Technical approach
The following is our idealized algorithm. Given time constraints, our focus was on a thoughtful conversation around the story and what the Scenic app would look like.
Building a non-linear routing algorithm is a multi-step process. First, we need to learn about our user. Relying on a chatbot conversation based on-boarding process, we get to know our user's preferences. Are you okay with a **10%** longer route? How about a **30%** longer route? Do you usually **bike**, or are you a **runner**? This data is stored and then later used in our route ranking algorithm.
At the root of all navigation models is a graph of road vectors. For our application, we use OpenStreetMap (OSM) data loaded into a PostGIS enabled Postgresql database to satisfy this requirement. Next, our routing algorithm requires consuming a collection of historical sources for route segment classification and scoring. Relatively weighting these data sources allows us to compute a Scenic score and create a grid index in Postgresql. Then, at the time of navigation, we run a search that optimizes routes based on our historical grid Scenic scores and returns the top 20 route options. Before returning results to the user, we query live data sources (traffic, AirNow.gov, etc.) to create a secondary on-the-fly ranking of the top 20 routes. Once this ranking computation is complete, we send the top 3 route options to the user's client app.
Once the user selects a route, we navigate the user either directly in their app, or via their Apple watch, Garmin, or Android Wear device. At the end of the trip, we show a visualization comparing how much air and noise pollution they avoided.
This model works well for developed countries and for cities with a rich network of accessible sensors. For developing countries (often areas where we see some of the worst pollution) this default ranking algorithm falls short. Fortunately, we have a novel solution. As we develop road segment scores in data-rich locales, we feed common trait data into a neural net classifier, allowing us to create a classification model for cities with low-fidelity data. This approach allows us to create Scenic scores for cities around the world.
## Data sources
* Google traffic API
* Open Street Map (OSM)
+ road width
+ road type
+ road direction
* Darksky.net
+ Current temp
+ Current wind vector
* Expert users
+ uploaded known routes (segmented to help classify each road segment)
* IoT city sensors
+ Microphones
+ Air quality
* Machine learning
+ Classification trained on other cities with rich data sources
* AirQualityNow.com
+ PM2.5, PM5 levels
* Here.com
+ Fastest route
+ Map baselayers
* Open-elevation.com | ## Inspiration
Between 1994 and 2013 there were 6,873 natural disasters worldwide, which claimed 1.35 million lives or almost 68,000 lives on average each year. In many of these disasters, people don't know where to go, and where is safe. For example, during Hurricane Harvey, many people learned about dangers such as alligators or flooding through other other people, and through social media.
## What it does
* Post a natural disaster hazard in your area
* Crowd-sourced hazards
* Pulls government severe weather data
* IoT sensor system to take atmospheric measurements and display on map
* Twitter social media feed of trending natural disasters in the area
* Machine learning image processing to analyze posted images of natural disaster hazards
Our app **Eye in the Sky** allows users to post about various natural disaster hazards at their location, upload a photo, and share a description of the hazard. These points are crowd-sourced and displayed on a map, which also pulls live data from the web on natural disasters. It also allows these users to view a Twitter feed of current trending information on the natural disaster in their location. The last feature is the IoT sensor system, which take measurements about the environment in real time and displays them on the map.
## How I built it
We built this app using Android Studio. Our user-created posts are hosted on a Parse database (run with mongodb). We pull data from the National Oceanic and Atmospheric Administration severe weather data inventory. We used Particle Electron to collect atmospheric sensor data, and used AWS to store this data in a JSON.
## Challenges I ran into
We had some issues setting up an AWS instance to run our image processing on the backend, but other than that, decently smooth sailing.
## Accomplishments that I'm proud of
We were able to work really well together, using everyone's strengths as well as combining the pieces into a cohesive app that we're really proud of. Everyone's piece was integrated well into the app, and I think we demonstrated good software collaboration.
## What I learned
We learned how to effectively combine our code across various languages and databases, which is a big challenge in software as a whole. We learned Android Development, how to set up AWS, and how to create databases to store custom data. Most importantly, we learned to have fun!
## What's next for Eye in the Sky
In the future, we would like to add verification of people's self-reported hazards (through machine learning and through up-voting and down-voting)
We would also like to improve the efficiency of our app and reduce reliance on network because there might not be network, or very poor network, in a natural disaster
We would like to add more datasets from online, and to display storms with bigger bubbles, rather than just points
We would also like to attach our sensor to drones or automobiles to gather more weather data points to display on our map | partial |
. | ## Inspiration
Researching anything can be overwhelming - when you have so many tabs open you can barely click on them, and then when you do, you can’t seem to find what it is on that page you were looking at before. On top of that, it can be frustrating to have to read through an entire article just to realize that it isn’t relevant to what you’re looking for. That’s why we developed a chrome extension to help you stay focused and organized while researching or browsing the web.
## What it does
Team Breadstick’s Research Assistant chrome extension can be accessed directly from your browser while on another webpage, and includes multiple different features:
The highlighting tool allows you to highlight any selected text in bright yellow so you can easily find relevant information when you come back to it.
The summarizing tool makes use of Co:here’s NLP software that creates an AI-generated summary of all the text on that webpage. It publishes this summary to a separate document, including the URL for the webpage it was based off of so you can get a general idea of what an article is about, and come back to it later if you need to.
The Wiki search tool allows you to quickly search up a word or term and receive a summary without leaving the webpage you’re on.
The “Focus Mode” feature removes any distractions on the page you’re browsing, including ads, so you can focus on the important content of the webpage.
## How we built it
To create a chrome extension, we had to create a .JSON file called “manifest” to store the metadata of the extension, such as the name, icon and popup. We then decided to code each of the features separately, before combining them using one single HTML file creating the extension popup and shared .JS files to call the functions.
The highlight function was implemented using all JavaScript, and created a button that appears when text is highlighted. When clicked, a function is called that clones the text to a format with a bright yellow background, and then replaces the old text with the new text.
The summary function uses Django, and scrapes the text from the current website. It then feeds the text to Co:here’s NLP API, and returns the outputted summary on a new webpage.
The wiki search function calls upon the server created in Django and makes use of the Wikipedia package to search for the inputted term.
The focus function uses CSS to search for specific paragraph styles that we determined were ads or unnecessary spacing and remove them.
## Challenges we ran into
Co:here has a limit to how many tokens could be inputted, which we realized after waiting for what seemed like forever for it to process before getting multiple errors and summaries that didn’t make any sense. To solve this, we had to be more specific with the text we were scraping to ensure only essential, important information was being considered. We also implemented a multi-threaded system to improve user experience while waiting for summaries.
## Accomplishments that we're proud of
Despite reading that chrome extensions were made using JavaScript and none of us having ever used JavaScript before, we decided to challenge ourselves this weekend and give it a shot. We told ourselves we would be proud even if we were able to create just the most basic popup. We’re happy to say that we definitely exceeded our expectations and created a functional extension with a variety of useful, working features!
## What we learned
First and foremost, we learned how to make a Chrome extension, which was really cool. We learned what JavaScript is and how to use it. It was also cool to play around with Co:here’s API and see how it responded to given text. By observing it, we were able to somehow follow how it worked, so that we could troubleshoot our code for outputting a text summary.
## What's next for Research Assistant Chrome Extension
We believe that this project has a lot of potential, and there are so many other features we could implement given the time. For example, we wanted to be able to save all the highlighted text to a separate document, and to create a formatted citation for the url, but unfortunately ran out of time. In the future, we could see us polishing off the features we currently have and maybe adding a few new ones. Eventually, we could publish this to the chrome web store so that anyone could benefit from it! | ## What it does
"ImpromPPTX" uses your computer microphone to listen while you talk. Based on what you're speaking about, it generates content to appear on your screen in a presentation in real time. It can retrieve images and graphs, as well as making relevant titles, and summarizing your words into bullet points.
## How We built it
Our project is comprised of many interconnected components, which we detail below:
#### Formatting Engine
To know how to adjust the slide content when a new bullet point or image needs to be added, we had to build a formatting engine. This engine uses flex-boxes to distribute space between text and images, and has custom Javascript to resize images based on aspect ratio and fit, and to switch between the multiple slide types (Title slide, Image only, Text only, Image and Text, Big Number) when required.
#### Voice-to-speech
We use Google’s Text To Speech API to process audio on the microphone of the laptop. Mobile Phones currently do not support the continuous audio implementation of the spec, so we process audio on the presenter’s laptop instead. The Text To Speech is captured whenever a user holds down their clicker button, and when they let go the aggregated text is sent to the server over websockets to be processed.
#### Topic Analysis
Fundamentally we needed a way to determine whether a given sentence included a request to an image or not. So we gathered a repository of sample sentences from BBC news articles for “no” examples, and manually curated a list of “yes” examples. We then used Facebook’s Deep Learning text classificiation library, FastText, to train a custom NN that could perform text classification.
#### Image Scraping
Once we have a sentence that the NN classifies as a request for an image, such as “and here you can see a picture of a golden retriever”, we use part of speech tagging and some tree theory rules to extract the subject, “golden retriever”, and scrape Bing for pictures of the golden animal. These image urls are then sent over websockets to be rendered on screen.
#### Graph Generation
Once the backend detects that the user specifically wants a graph which demonstrates their point, we employ matplotlib code to programmatically generate graphs that align with the user’s expectations. These graphs are then added to the presentation in real-time.
#### Sentence Segmentation
When we receive text back from the google text to speech api, it doesn’t naturally add periods when we pause in our speech. This can give more conventional NLP analysis (like part-of-speech analysis), some trouble because the text is grammatically incorrect. We use a sequence to sequence transformer architecture, *seq2seq*, and transfer learned a new head that was capable of classifying the borders between sentences. This was then able to add punctuation back into the text before the rest of the processing pipeline.
#### Text Title-ification
Using Part-of-speech analysis, we determine which parts of a sentence (or sentences) would best serve as a title to a new slide. We do this by searching through sentence dependency trees to find short sub-phrases (1-5 words optimally) which contain important words and verbs. If the user is signalling the clicker that it needs a new slide, this function is run on their text until a suitable sub-phrase is found. When it is, a new slide is created using that sub-phrase as a title.
#### Text Summarization
When the user is talking “normally,” and not signalling for a new slide, image, or graph, we attempt to summarize their speech into bullet points which can be displayed on screen. This summarization is performed using custom Part-of-speech analysis, which starts at verbs with many dependencies and works its way outward in the dependency tree, pruning branches of the sentence that are superfluous.
#### Mobile Clicker
Since it is really convenient to have a clicker device that you can use while moving around during your presentation, we decided to integrate it into your mobile device. After logging into the website on your phone, we send you to a clicker page that communicates with the server when you click the “New Slide” or “New Element” buttons. Pressing and holding these buttons activates the microphone on your laptop and begins to analyze the text on the server and sends the information back in real-time. This real-time communication is accomplished using WebSockets.
#### Internal Socket Communication
In addition to the websockets portion of our project, we had to use internal socket communications to do the actual text analysis. Unfortunately, the machine learning prediction could not be run within the web app itself, so we had to put it into its own process and thread and send the information over regular sockets so that the website would work. When the server receives a relevant websockets message, it creates a connection to our socket server running the machine learning model and sends information about what the user has been saying to the model. Once it receives the details back from the model, it broadcasts the new elements that need to be added to the slides and the front-end JavaScript adds the content to the slides.
## Challenges We ran into
* Text summarization is extremely difficult -- while there are many powerful algorithms for turning articles into paragraph summaries, there is essentially nothing on shortening sentences into bullet points. We ended up having to develop a custom pipeline for bullet-point generation based on Part-of-speech and dependency analysis.
* The Web Speech API is not supported across all browsers, and even though it is "supported" on Android, Android devices are incapable of continuous streaming. Because of this, we had to move the recording segment of our code from the phone to the laptop.
## Accomplishments that we're proud of
* Making a multi-faceted application, with a variety of machine learning and non-machine learning techniques.
* Working on an unsolved machine learning problem (sentence simplification)
* Connecting a mobile device to the laptop browser’s mic using WebSockets
* Real-time text analysis to determine new elements
## What's next for ImpromPPTX
* Predict what the user intends to say next
* Scraping Primary sources to automatically add citations and definitions.
* Improving text summarization with word reordering and synonym analysis. | losing |
Prediction Market revolving around the following question: Which privacy oriented token will perform better, ZCash or Monero?
In the nascent crypto space without significant understanding or regulation, companies have been launching subpar ICOs to capitalize on hype, and currency trading is extremely volatile. Tokens often serve as a means for companies to raise money quickly with users either genuinely believing in the success of a venture, or looking to make a quick profit by playing off of volatility. There aren’t many valid written sources producing actionable information on the legitimacy of such companies. In order to obtain useful information, incentives must be aligned.
With prediction markets, users stand to profit off of outcomes if they occur, and as such are incentivized to “vote” in accordance with their views. Furthermore, these markets provide insight into public opinion and help hold companies accountable, when there aren’t any other entities that do so. By pitting two competitors against each other in a prediction market, they are each automatically incentivized to take action that would satisfy consumers, aligning with user behavior versus the alignment with investor needs brought about in ICOs with app tokens. Moreover, beyond just human users, bots with access to data streams on certain performance indicators can also contribute to the market. This whole process introduces oversight and accountability by a decentralized mass versus having any sort of centralized regulation. Users are able to hold corporations accountable through the simple economic principle of competition aligning incentives.
This specific use case focuses on the privacy token space in which accountability is especially necessary as consumers inherently expect privacy from each specific service, simply based on what each service promises to provide. Without a specific measure of accountability, these companies aren’t necessarily incentivized to uphold their promises.
Looking into Monero, up until September of 2017, RingCT was not mandatory in client software, meaning that 62% of transactions made before 2017 can be deanonymized, which presents a significant consumer vulnerability. This issue has been present since the inception of the currency, however, the company did nothing to resolve the issue until [MoneroLink](https://monerolink.com) published such results. With a prediction market, those aware of such issues can display their concerns allowing such vulnerabilities to be resolved sooner.
ZCash and Monero are the current leading tokens in this space - each one promising privacy, but tackling the issue from different perspectives. Monero takes the approach of distorting information utilizing RingCT, while ZCash makes use of zero-knowledge proofs. With ZCash working on protocol improvements to increase efficiency and reduce currently high costs, and Monero resolving some of its anonymity issues, these two cryptocurrencies are becoming more competitive in this space. Using a prediction market, we can determine which token is expected to perform better within the scope of the next year as both platforms plan to roll out significant improvements. In this manner, as they release updates and announcements, each company will be able to measure user satisfaction in relation to its competition and thus prioritize the needs of the user. This is basically a real-time indicator of feedback for each company.
The first iteration of this market is scheduled to run for one year, giving both companies time to build improvements, attend to user feedback, and respond accordingly. The market will decide on which token performed better. When we say “performed better,” we define this metric in relation to how widely used each token is. Since both ZCash and Monero are usage tokens, meaning that the token is needed to access the digital service each provides, actual usage of a token represents its value to consumers. In this case, that would be using ZCash or Monero to complete transactions which keep user data private. Thus, in measuring transaction volume of each token throughout the course of the year, we can measure token performance.
This same sort of ideology of pitting competitors against each other to benefit consumers can be applied to tokens in general beyond just the privacy space and multiple companies can be entered into such a marketplace.
This is implemented as a use case of [Gnosis'](https://gnosis.pm) prediction markets using gnosis.js and the gnosis market testing environment. | ## Inspiration
The cryptocurrency market is an industry which is expanding at an exponential rate. Everyday, thousands new investors of all kinds are getting into this volatile market. With more than 1,500 coins to choose from, it is extremely difficult to choose the wisest investment for those new investors. Our goal is to make it easier for those new investors to select the pearl amongst the sea of cryptocurrency.
## What it does
To directly tackle the challenge of selecting which cryptocurrency to choose, our website has a compare function which can add up to 4 different cryptos. All of the information from the chosen cryptocurrencies are pertinent and displayed in a organized way. We also have a news features for the investors to follow the trendiest news concerning their precious investments. Finally, we have an awesome bot which will answer any questions the user has about cryptocurrency. Our website is simple and elegant to provide a hassle-free user experience.
## How we built it
We started by building a design prototype of our website using Figma. As a result, we had a good idea of our design pattern and Figma provided us some CSS code from the prototype. Our front-end is built with React.js and our back-end with node.js. We used Firebase to host our website. We fetched datas of cryptocurrency from multiple APIs from: CoinMarketCap.com, CryptoCompare.com and NewsApi.org using Axios. Our website is composed of three components: the coin comparison tool, the news feed page, and the chatbot.
## Challenges we ran into
Throughout the hackathon, we ran into many challenges. First, since we had a huge amount of data at our disposal, we had to manipulate them very efficiently to keep a high performant and fast website. Then, there was many bugs we had to solve when integrating Cisco's widget to our code.
## Accomplishments that we're proud of
We are proud that we built a web app with three fully functional features. We worked well as a team and had fun while coding.
## What we learned
We learned to use many new api's including Cisco spark and Nuance nina. Furthermore, to always keep a backup plan when api's are not working in our favor. The distribution of the work was good, overall great team experience.
## What's next for AwsomeHack
* New stats for the crypto compare tools such as the number of twitter, reddit followers. Keeping track of the GitHub commits to provide a level of development activity.
* Sign in, register, portfolio and watchlist .
* Support for desktop applications (Mac/Windows) with electronjs | ## Inspiration
Independently finding optimal patterns within a dataset is extremely challenging in many cases. The amount of computing necessary to train machine learning models is immense, and in addition, others may be able to find trends that the host did not foresee. In the case of sensitive data, dataset owners may not want to expose their identity and competitors likewise. Moreover, sometimes difficult political circumstances may make it harder for aspiring researchers to be able to find mathematical patterns in their models. We decided to create a platform that allows dataset owners to offload the training process among others on the web.
## What it does
Our platform allows anonymous users to train models on a host-provided dataset and submit compressed model parameters to the blockchain to compete for the top test accuracy. The prize pool consists of an initial prize offered by the host in addition to buy-ins supplied by the individual competitors. The individual with the highest train accuracy wins 90% of the prize pool, with the remaining 10% of the prize pool being awarded to miners who work on validating the model accuracies.
We restrict the size of model parameters submitted to the blockchain to ensure that competitors cannot overfit their models to the dataset. As an individual can act as both a miner and a competitor, this prevents people from abusing access to both train and test datasets. Miners are responsible for retrieving submissions from the blockchain and ensuring that the test accuracies are indeed what was submitted to the network.
## How we built it
There are three main components to our project: the smart contract + blockchain, miner pipeline + model API retrieval, and the frontend dashboard.
The first component of our project deals with the compression and submission of a competitors model parameters. We allow for the submission of models made with either PyTorch or Tensorflow. With both types of models, we provide a library for users to convert models into json files (in the case of Tensorflow) and then to a sequence of bytes. The decompression function utilizes the zlib library and decoding the byte string to a base 64 binary object file. The smart contract was built with solidity. More information about this on the video, however, the contract contains functions and variables which allow us to store and distribute machine learning models across miners.
For miners we provide a Python API to interact with the smart contract. Miners are able to retrieve a set of compressed models which are ready for evaluation and the dataset to evaluate on. The miner can pick any one of these models to evaluate but must use our compression and decompression schemes to retrieve the model and send its accuracy to the smart contract via our API. The accuracy of a model is considered validated if 51% of the miners who evaluated that model agree upon its accuracy.
Our dashboard visualization was made with React.js. To access our platform, competitors must provide an address that corresponds to the specific dataset of the competition. Once authenticated, users are able to see a graph of their past submissions, a current leaderboard,
## Challenges we ran into
We ran into a large number of challenges during each step of our project.
For example, one of the largest ones was gas. Storing any kind of data will inevitably run into this problem, and its an especially annoying bug given that gas prices often fluctuate. However, we were able to deal with this in a few ways:
1. Storing an IPFS link for the dataset on the blockchain instead of trying to compress the dataset and store it all on the blockchain. This was an extremely large improvement in gas prices.
2. Limiting the byte size of models. In a straightforward way, this limited the total possible gas of the submitModel transaction.
Another major challenge we had was security. Specifically, how do we make sure no party to the contract can exploit any other. We initially thought about simply having one miner for each model, but we realized this was far too prone to manipulation; we needed to require multiple miners to balance it out. In order to further improve security for malicious miners, we also plan to add a system in which miners are only rewarded for their mining if they are within a certain threshold of the median submitted accuracy for a specific model over all miners. This goes some way towards averting Sybil attacks. We also envisioned adding some kind of proof of work algorithm for mining (such that running a model on a dataset could be turned into some easily verifiable proof that you did, indeed, run the model on the dataset), which would also combat Sybil attacks.
Finally, a big challenge we faced, especially near the end, was integration. We were integrating three different languages: Javascript (for the website), Solidity (for the contract), and Python (for miners). We had to deal with datatype and API differences between all 3, all while trying to work within the very strict confines of solidity (the lack of floating point numbers got us multiple times).
However, none of the challenges was ever overwhelming, and in the end, we were able to create a finished product.
## What's next for DeML: Decentralized Machine Learning
Our goal is to take this, and bring it to the next level. Decentralize training and make compute a lot cheaper, but we're still a far way away. | partial |
## Inspiration
Ever wish you didn’t need to purchase a stylus to handwrite your digital notes? Each person at some point hasn’t had the free hands to touch their keyboard. Whether you are a student learning to type or a parent juggling many tasks, sometimes a keyboard and stylus are not accessible. We believe the future of technology won’t even need to touch anything in order to take notes. HoverTouch utilizes touchless drawings and converts your (finger)written notes to typed text! We also have a text to speech function that is Google adjacent.
## What it does
Using your index finger as a touchless stylus, you can write new words and undo previous strokes, similar to features on popular note-taking apps like Goodnotes and OneNote. As a result, users can eat a slice of pizza or hold another device in hand while achieving their goal. HoverTouch tackles efficiency, convenience, and retention all in one.
## How we built it
Our pre-trained model from media pipe works in tandem with an Arduino nano, flex sensors, and resistors to track your index finger’s drawings. Once complete, you can tap your pinky to your thumb and HoverTouch captures a screenshot of your notes as a JPG. Afterward, the JPG undergoes a masking process where it is converted to a black and white picture. The blue ink (from the user’s pen strokes) becomes black and all other components of the screenshot such as the background become white. With our game-changing Google Cloud Vision API, custom ML model, and vertex AI vision, it reads the API and converts your text to be displayed on our web browser application.
## Challenges we ran into
Given that this was our first hackathon, we had to make many decisions regarding feasibility of our ideas and researching ways to implement them. In addition, this entire event has been an ongoing learning process where we have felt so many emotions — confusion, frustration, and excitement. This truly tested our grit but we persevered by uplifting one another’s spirits, recognizing our strengths, and helping each other out wherever we could.
One challenge we faced was importing the Google Cloud Vision API. For example, we learned that we were misusing the terminal and our disorganized downloads made it difficult to integrate the software with our backend components. Secondly, while developing the hand tracking system, we struggled with producing functional Python lists. We wanted to make line strokes when the index finger traced thin air, but we eventually transitioned to using dots instead to achieve the same outcome.
## Accomplishments that we're proud of
Ultimately, we are proud to have a working prototype that combines high-level knowledge and a solution with significance to the real world. Imagine how many students, parents, friends, in settings like your home, classroom, and workplace could benefit from HoverTouch's hands free writing technology.
This was the first hackathon for ¾ of our team, so we are thrilled to have undergone a time-bounded competition and all the stages of software development (ideation, designing, prototyping, etc.) toward a final product. We worked with many cutting-edge softwares and hardwares despite having zero experience before the hackathon.
In terms of technicals, we were able to develop varying thickness of the pen strokes based on the pressure of the index finger. This means you could write in a calligraphy style and it would be translated from image to text in the same manner.
## What we learned
This past weekend we learned that our **collaborative** efforts led to the best outcomes as our teamwork motivated us to preserve even in the face of adversity. Our continued **curiosity** led to novel ideas and encouraged new ways of thinking given our vastly different skill sets.
## What's next for HoverTouch
In the short term, we would like to develop shape recognition. This is similar to Goodnotes feature where a hand-drawn square or circle automatically corrects to perfection.
In the long term, we want to integrate our software into web-conferencing applications like Zoom. We initially tried to do this using WebRTC, something we were unfamiliar with, but the Zoom SDK had many complexities that were beyond our scope of knowledge and exceeded the amount of time we could spend on this stage.
### [HoverTouch Website](hoverpoggers.tech) | ## Inspiration
Minecraft has an interesting map mechanic where your character holds a map which "draws itself" while exploring the world. I am also very interested in building a plotter, which is a printer that uses a pen and (XY) gantry to produce images. These ideas seemed to fit together quite well.
## What it does
Press a button, copy GPS coordinates and run the custom "gcode" compiler to generate machine/motor driving code for the arduino. Wait around 15 minutes for a 48 x 48 output.
## How we built it
Mechanical assembly - Tore apart 3 dvd drives and extracted a multitude of components, including sled motors (linear rails). Unfortunately, they used limit switch + DC motor rather than stepper, so I had to saw apart the enclosure and **glue** in my own steppers with a gear which (you guessed it) was also glued to the motor shaft.
Electronics - I designed a simple algorithm to walk through an image matrix and translate it into motor code, that looks a lot like a video game control. Indeed, the stepperboi/autostepperboi main source code has utilities to manually control all three axes like a tiny claw machine :)
U - Pen Up
D - Pen Down
L - Pen Left
R - Pen Right
Y/T - Pen Forward (top)
B - Pen Backwards (bottom)
Z - zero the calibration
O - returned to previous zeroed position
## Challenges we ran into
* I have no idea about basic mechanics / manufacturing so it's pretty slipshod, the fractional resolution I managed to extract is impressive in its own right
* Designing my own 'gcode' simplification was a little complicated, and produces strange, pointillist results. I like it though.
## Accomplishments that we're proud of
* 24 hours and a pretty small cost in parts to make a functioning plotter!
* Connected to mapbox api and did image processing quite successfully, including machine code generation / interpretation
## What we learned
* You don't need to take MIE243 to do low precision work, all you need is superglue, a glue gun and a dream
* GPS modules are finnicky and need to be somewhat near to a window with built in antenna
* Vectorizing an image is quite a complex problem
* Mechanical engineering is difficult
* Steppers are *extremely* precise, and I am quite surprised at the output quality given that it's barely held together.
* Iteration for mechanical structure is possible, but difficult
* How to use rotary tool and not amputate fingers
* How to remove superglue from skin (lol)
## What's next for Cartoboy
* Compacting the design it so it can fit in a smaller profile, and work more like a polaroid camera as intended. (Maybe I will learn solidworks one of these days)
* Improving the gcode algorithm / tapping into existing gcode standard | ## Inspiration
With the coming of the IoT age, we wanted to explore the addition of new experiences in our interactions with physical objects and facilitate crossovers from the digital to the physical world. Since paper is a ubiquitous tool in our day to day life, we decided to try to push the boundaries of how we interact with paper.
## What it does
A user places any piece of paper with text/images on it on our clipboard and they can now work with the text on the paper as if it were hyperlinks. Our (augmented) paper allows users to physically touch keywords and instantly receive Google search results. The user first needs to take a picture of the paper being interacted with and place it on our enhanced clipboard and can then go about touching pieces of text to get more information.
## How I built it
We used ultrasonic sensors with an Arduino to determine the location of the user's finger. We used the Google Cloud API to preprocess the paper contents. In order to map the physical (ultrasonic data) with the digital (vision data), we use a standardized 1x1 inch token as a 'measure of scale' of the contents of the paper.
## Challenges I ran into
So many challenges! We initially tried to use a RFID tag but later figured that SONAR works better. We struggled with Mac-Windows compatibility issues and also struggled a fair bit with the 2D location and detection of the finger on the paper. Because of the time constraint of 24 hours, we could not develop more use cases and had to resort to just one.
## What I learned
We learned to work with the Google Cloud Vision API and interface with hardware in Python. We learned that there is a LOT of work that can be done to augment paper and similar physical objects that all of us interact with in the daily world.
## What's next for Augmented Paper
Add new applications to enhance the experience with paper further. Design more use cases for this kind of technology. | winning |
## Inspiration
This project was inspired by personal experience. As novice drivers, we are not comfortable with swerving the car just to avoid potholes, so the annoyance of hitting a pothole and the possibility of damaging the car suspension is a problem in our day-to-day lives. To solve this issue, we thought about a way to collect pothole data through cars, and then send this information to the related agencies so they know where to conduct repairs.
## What it does
This project uses an accelerometer to detect when a car experiences a rapid change in acceleration, indicating that it has hit a pothole. An Arduino with a GPS sensor sends the coordinates of the pothole to a MySQL database. The data can then be retrieved by the government so they can determine the location of the hole.
## How we built it
The project is based on an Arduino Uno, an accelerometer, and a GPS sensor. These sensors are connected to the Arduino through a breadboard. A Python program extracts data from the serial port and sends it to the database so the pothole coordinates can be recorded.
## Challenges we ran into
We ran into challenges with managing our time. Initially, we intended to use a Qualcomm Dragonboard rather than an Arduino. The Dragonboard took 6 hours to set up; however, due to wifi connectivity issues, we decided to change the hardware for our project. Because there was a limited amount of Wifi Shields available, we instead had to create a Python script that sends the data to the MySQL database manually.
## Accomplishments that we're proud of
We encountered many challenges with the hardware. As a result, we had to revise our plans and adapt to different hardware several times. In the end, we arrived at a solution that allows our prototype to sufficiently communicate our idea and showcase the functionalities we designed.
## What we learned
Matthew and Rebecca learned about MySQL database creation and queries. Esther learned how the accelerometer works, including calibrating the sensor and reducing noise using tolerance. Prerak learned about integrating the various sensors without a Grove-Base shield and extracting data from the GPS sensor.
## What's next for Pothole Finder
Our next step is to create a user interface to easily access the data stored in the database. In addition, we would create a map to show which areas of the city have a higher frequency of holes. | ## Inspiration
When looking at the themes from the Make-a-thon, one specifically stood out to us: accessibility. We thought about common disabilities, and one that we see on a regular basis is people who are visually impaired. We thought about how people who are visually impaired navigate around the world, and we realized there isn't a good solution besides holding your phone out that allows them to get around the world. We decided we would create a device that uses Google Maps API to read directions and sense the world around it to be able to help people who are blind navigate the world without running into things.
## What it does
Based on the user's desired destination, the program reads from Google API the checkpoints needed to cross in our path and audibly directs the user on how far they are from it. Their location is also repeatedly gathered through Google API to determine their longitude and latitude. Once the user reaches
the nearest checkpoint, they will be directed to the next checkpoint until they reach their destination.
## How we built it
Under a local hotspot host, we connected a phone and Google API to a Raspberry Pi 4. The phone would update the Raspberry Pi with our current location and Google API to determine the necessary checkpoints to get there. With all of the data being compiled on the microcontroller, it is then connected to a speaker through a Stereo Audio Amplifier Module (powered by an external power supply), which amplifies the audio sent out into the Raspberry Pi's audio jack. With all that, the directions conveyed to the user can be heard clearly.
## Challenges we ran into
Some of the challenges we faced were getting the stereo speaker to work and indicating to the user the distance from their next checkpoint, frequently within the range of the local network.
## Accomplishments that we're proud of
We were proud to have the user's current position updated according to the movement of the phone connected to the local network and be able to update the user's distance from a checkpoint in real time.
## What we learned
We learned to set up and work with a Raspberry Pi 4 through SSH.
We also learned how to use text-to-speech for the microcontroller using Python and how we can implement it in a practical application.
Finally, we were
## What's next for GPS Tracker for the Visually Impaired
During the hackathon, we were unable to implement the camera sensing the world around it to give the user live directions on what the world looks like in front of them and if they are going to run into anything or not. The next steps would include a depth camera implementation as well as an OpenCV object detection model to be able to sense the distance of things in front of you | ## Inspiration
People with hearing impairment are safe and capable drivers, although there remains some environmental cues which they cannot detect while on the road. We developed a tool that creates a safer driving experience by alerting hearing impaired drivers of other incoming vehicles.
## What it does
Three microphones are set up around a vehicle so that it samples sound from the environment in 360 degrees. If our machine-learning SVM algorithm detects an ambulance or honking car in the nearby area, it localizes the object based on the difference in amplitude of sound detected by each microphone and the time of delay between each microphone.
## How we built
We connected three microphones to an Arduino Uno for sound detection. The amplitude of sound and the time of
sound detection was read from the Arduino and channeled into a raspberry-pi for further processing. In Python, we used supervised learning with a support vector machine to detect whether a nearby sound was the siren of an ambulance or the persistent honk of a nearby car. Taking into account which microphone was persistently detecting the loudest sound, and the position of the microphone in relation to the driver, a dynamic GUI displays an arrow that tracks the position of the incoming vehicle to alert the driver.
## Difficulties encountered
Adjusting the sensitivity of the microphones so that they were providing rich enough data for training our machine learning algorithm. Interfacing the Arduino Uno with the Raspberry-Pi. Controlling our data flow so that our tool could support alerting from real-time data.
## What we're proud of
Setting up the hardware so that we could sensitively detect sounds in the environment, feeding that data into a raspberry-pi, and performing processing and supervised machine-learning in real-time.
## What we learned
We all started the project with zero experience in using Raspberry Pis or Arduinos so there was quite a learning curve for all of us. We also had never worked with triangulation, python GUIs or classifying sound data. We learned quite a bit about each topic through the course of the weekend.
## Next steps
Integrating more microphones for more sensitive and accurate 360 degree sound detection. Implementing microphones into vehicles in an effective but non-intrusive way. Training our algorithm on more environmental threats so that we may alert drivers. | losing |
## Inspiration
The Distillery District in Toronto with historical buildings.
## What it does
This is a game about how to make whiskey in the old distillery district. Following the process of whiskey-making with manual labor, you have to find out the perfect formula to make the best whiskey.
## How we built it
We built the game using pygame with user interaction, state machines, and GUIs. Furthermore, the scores were evaluated through different measures of success (ex. Gaussian Radial Basis)
## Challenges we ran into
Learning pygame and general problems of game development.
## Accomplishments that we're proud of
We each learned new tools and new concepts. We included collision detection, manual gradient formulas, and had members in the first hackathon. None of us were familiar with PyGame and so being able to create something with it was really cool!
## What we learned
We learned how to use pygame to make a python game
## What's next for Distillery Whiskey Maker
Using additional RBF to have a more robust scoring system. Including a story of progression to bring it from the past to the modern time | ## Inspiration
Osu! players often use drawing tablets instead of a normal mouse and keyboard setup because a tablet gives more precision than a mouse can provide. These tablets also provide a better way to input to devices. Overuse of conventional keyboards and mice can lead to carpal tunnel syndrome, and can be difficult to use for those that have specific disabilities. Tablet pens can provide an alternate form of HID, and have better ergonomics reducing the risk of carpal tunnel. Digital artists usually draw on these digital input tablets, as mice do not provide the control over the input as needed by artists. However, tablets can often come at a high cost of entry, and are not easy to bring around.
## What it does
Limestone is an alternate form of tablet input, allowing you to input using a normal pen and using computer vision for the rest. That way, you can use any flat surface as your tablet
## How we built it
Limestone is built on top of the neural network library mediapipe from google. mediapipe hands provide a pretrained network that returns the 3D position of 21 joints in any hands detected in a photo. This provides a lot of useful data, which we could probably use to find the direction each finger points in and derive the endpoint of the pen in the photo. To safe myself some work, I created a second neural network that takes in the joint data from mediapipe and derive the 2D endpoint of the pen. This second network is extremely simple, since all the complex image processing has already been done. I used 2 1D convolutional layers and 4 hidden dense layers for this second network. I was only able to create about 40 entries in a dataset after some experimentation with the formatting, but I found a way to generate fairly accurate datasets with some work.
## Dataset Creation
I created a small python script that marks small dots on your screen for accurate spacing. I could the place my pen on the dot, take a photo, and enter in the coordinate of the point as the label.
## Challenges we ran into
It took a while to tune the hyperparameters of the network. Fortunately, due to the small size it was not too hard to get it into a configuration that could train and improve. However, it doesn't perform as well as I would like it to but due to time constraints I couldn't experiment further. The mean average error loss of the final model trained for 1000 epochs was around 0.0015
Unfortunately, the model was very overtrained. The dataset was o where near large enough. Adding noise probably could have helped to reduce overtraining, but I doubt by much. There just wasn't anywhere enough data, but the framework is there.
## Whats Next
If this project is to be continued, the model architecture would have to be tuned much more, and the dataset expanded to at least a few hundred entries. Adding noise would also definitely help with the variance of the dataset. There is still a lot of work to be done on limestone, but the current code at least provides some structure and a proof of concept. | ## Inspiration
While looking for genuine problems that we could solve, it came to our attention that recycling is actually much harder than it should be. For example, when you go to a place like Starbucks and are presented with the options of composting, recycling, or throwing away your empty coffee, it can be confusing and for many people, it can lead to selecting the wrong option.
## What it does
Ecolens uses a cloud-based machine learning webstream to scan for an item and tells the user the category of item it is that they scanned, providing them with a short description of the object and updating their overall count of consuming recyclable vs. unrecyclable items as well as updating the number of items that they consumed in that specific category (i.e. number of water bottle consumed)
## How we built it
This project consists of both a front end and a back end. The backend of this project was created using Java Spring and Javascript. Javascript was used in the backend in order to utilize Roboflow and Ultralytics which allowed us to display the visuals from Roboflow on the website for the user to see. Java Spring was used in the backend for creating a database that consisted of all of the scanned items and tracked them as they were altered (i.e. another item was scanned or the user decided to dump the data).
The front end of this project was built entirely through HTML, CSS, and Javascript. HTML and CSS were used in the front end to display text in a format specific to the User Interface, and Javascript was used in order to implement the functions (buttons) displayed in the User Interface.
## Challenges we ran into
This project was particularly difficult for all of us because of the fact that most of our team consists of beginners and there were multiple parts during the implementation of our application that no one was truly comfortable with. For example, integrating camera support into our website was particularly difficult as none of our members had experience with JavaScript, and none of us had fully fledged web development experience. Another notable challenge was presented with the backend of our project when attempting to delete the user history of items used while also simultaneously adding them to a larger “trash can” like a database.
From a non-technical perspective, our group also struggled to come to an agreeance on how to make our implementation truly useful and practical. Originally we thought to have hardware that would physically sort the items but we concluded that this was out of our skill range and also potentially less sustainable than simply telling the user what to do with their item digitally.
## Accomplishments that we're proud of
Although we can acknowledge that there are many improvements that could be made, such as having a cleaner UI, optimized (fast) usage of the camera scanner, or even better responses for when an item is accidentally scanned, we’re all collectively proud that we came together to find an idea that allowed each of us to not only have a positive impact on something we cared about but to also learn and practice things that we actually enjoy doing.
## What we learned
Although we can acknowledge that there are many improvements that could be made, such as having a cleaner UI, optimized (fast) usage of the camera scanner, or even better responses for when an item is accidentally scanned, we’re all collectively proud that we came together to find an idea that allowed each of us to not only have a positive impact on something we cared about but to also learn and practice things that we actually enjoy doing.
## What's next for Eco Lens
The most effective next course of action for EcoLens is to assess if there really is a demand for this product and what people think about it. Would most people genuinely use this if it was fully shipped? Answering these questions would provide us with grounds to move forward with our project. | winning |
## Inspiration
Growing up in Palo Alto, California, a city where biking is a way of life, we experienced firsthand the frustrations and challenges of bike theft and accidents. These personal experiences became the catalyst for our innovation: the Smart Bike Lock. Our goal was to enhance the traditional bike lock, making it not only more safe and secure but also more convenient.
## What it does
The Smart Bike Lock is a leap forward from conventional locks. Its key feature is the ease of locking and unlocking via a smartphone, eliminating the hassle of remembering combinations or keys. This feature particularly addresses the common issue of being too lazy or forgetful to properly secure a bike.
To further increase security, we integrated a piezo vibration module capable of detecting a wide range of frequencies. This allows the lock to sense when it's being tampered with and trigger an alarm. This module also serves a dual purpose in enhancing rider safety through its crash detection capability.
## How we built it
Our electronic stack comprises:
* Arduino Uno
* NFC/RFID reader
* Solenoid
* Piezo vibration module
* 2 9V Batteries
We programmed the electronics using C and designed a custom CAD model for the bike lock. This model was then brought to life through 3D printing, creating a housing for the electronics and the solenoid locking mechanism.
## Challenges we ran into
The most daunting challenge was debugging the circuit. Due to the fragile nature of small electronic components, fixing one issue often led to another. This was compounded by the unreliability of some RFID/NFC readers and MCUs, which failed without clear reasons. Much of our time was spent meticulously verifying wiring to rule out connection issues.
## Accomplishments that we're proud of
We take immense pride in successfully developing a functional MVP with working electronics, achieved in a short period and with a team of just two. We are also proud of being able to hack together a product that took parts from lots of different places, from a random bike lock on the street to digging for parts deep in the hardware bins. This was also our first-ever hackathon for both of us and we were equally proud of our ability to just finish a design.
## What we learned
While obvious in hindsight, we learned that 36 hours is not a lot of time. We were too ambitious with how many features we wanted to incorporate and ended up having to cut out a lot of features. Simple is also better because it makes debugging much easier.
## What's next for Smart Lock
We hope to iron out some of the reliability and power issues we have as well as implement the full suite of sensors we initially planned such as a GPS for location tracking, laser for nighttime biker recognition, and sending this sensor data to the cloud so that it be can be used to learn your bike locking habits to automatically lock and unlock. | ## Inspiration
The inspiration behind Smart Passcode stemmed from the desire to enhance accessibility and security for visually impaired individuals, empowering them to independently access secure spaces with ease.
## What it does
In seek of devising a smart home and accessibility device that enhances access to a safe, our device "Smart Passcode" allows the visually impaired to use one hand to physically list the key digits. This convenient alternative omits having those are unsighted to be less
## How we built it
We built Smart Passcode using a combination of machine learning techniques, Python programming for algorithm development, and microcontroller technology for hardware integration. This program required pulling libraries from OpenCV and training the model to recognize hand patterns and shapes that correlate with a specified number.
## Challenges we ran into
One challenge we encountered was optimizing the machine learning algorithms to accurately interpret finger movements consistently and reliably. This was specifically because of the effect that differences in lighting, camera placement and time durations between finger movement placed on the learning model. Another challenge that we encountered was the implementation of a Rasberry Pi to make our device and system portable. We were unable to install large libraries such as TensorFlow onto the Rasberry Pi as it would take multiple hours. This limitation made us re-think our project idea and shifted towards using an arduino with a laptop for the image processing.
## Accomplishments that we're proud of
We're proud to have developed a solution that seamlessly integrates accessibility and security, providing visually impaired individuals with a reliable and efficient means of accessing secure spaces independently. Furthermore we are proud of developing a computer vision model and training the model with over 600 images.
## What we learned
Through the development of Smart Passcode, we gained valuable insights into the intersection of accessibility technology, machine learning, and hardware integration. We also deepened our understanding of the unique challenges faced by visually impaired individuals in everyday tasks. Prior to coming to MakeUofT no group members had any experience using a Rasberry Pi, we started from scratch learning how to boot strap it.
## What's next for Smart Passcode
In the future, we aim to further refine the device's functionality, explore additional security features, and expand its compatibility with various safe systems and environments. Additionally, we plan to seek feedback from users to continuously improve the device's usability and effectiveness. | # Cyclus
Cyclus is a project created to help provide cyclist and their bikes with safety and security for their daily commutes. Cyclus is
currently one small device created with an Arduno UNO, Raspberry Pi 4, and a TELUS Cat-M1 cellular shield. This bike has features to
keep cyclist safe on the roads, especially for cyclist who commute often on busy roads. It also comes with features to help fight against
theft and to track down bikes in case they get lost.
# Current Features
* Tracking Device with GPS (and to track down thieves in case your bike is ever stolen)
* Headlights on the front and back, including strobe lights for emergency situations
* An alarm that is toggled by a switch that will sound when someone tries to steal the bike
# To Be Created
* Web application to view all the data
* Dashcam to record footage and automatically upload to cloud
Here is the link to the intro video
<https://photos.app.goo.gl/YCwkEWhm7nuoHZbM6> | losing |
## Inspiration
*Do you have a habit that you want to fix?*
We sure do. As high school students studying for exams, we noticed we were often distracted by our phones, which greatly reduced our productivity. A study from Duke University found that up to 45% of all our daily actions are performed habitually, which is a huge problem especially during a time when many of us are confined to our homes, negatively impacting our productivity, as well as mental and physical health.
To fix this issue, we created HabiFix. We took the advice from a Harvard research paper to create a program that would not only help break unhealthy habits, but form healthy ones in place as well.
## What it does
Unlike many other products which have to be installed by professionals, highly specialized for one single habit, or just expensive, HabiFix only requires a computer with a webcam, and can help you fix a multitude of different habits. And the usage is very simple too, just launch HabiFix on your computer, and that’s it! HabiFix will run in the background, and as soon as you perform an undesirable habit, it will remind you. According to Harvard Health Publishing, the most important thing in habit fixing is a reminder, since people often perform habits without realizing it. So when you’re studying for tomorrow’s test and pick up your phone, your computer will gently remind you to get off your phone, so you can ace that test.
Every action you do is uploaded to our website, which users can see statistics of by logging in. Another important aspect of Habit Fixing that Harvard found is reward, which we believe we can provide users by showing them their growth over time. On the website, users are able to view how many times they had to be reminded, and by showing them how they have been requiring less reminders throughout the week, they’ll be able to know they have been fixing their habits.
## How we built it
The ML aspect of our project uses Tensorflow and openCV, more specifically an object detection library to capture the user’s actions. We wrote a program that would use OpenCV to provide webcam data to TensorFlow, which would output the user’s position relative to other objects, then analyzed by our Python code to determine if a user is performing a specific task. We then created a flask server which converts the analyzed data into JSON, stores it in our database, allowing our website to fetch the data. The HabiFix web app is built with React, and Chart.js was used to display data that was collected.
## Challenges we ran into
The biggest challenge we ran into was incorporating the machine learning aspect in it, as it was our first time using TensorFlow. While setting up the object detection algorithm using TensorFlow, we had difficulties installing all the dependencies and modules, and spent quite some time properly understanding the TensorFlow documentation which was needed to get outputs for analysis. However, after sleepless nights and a newfound love for coffee, we were able to finish setting up TensorFlow and write a program to extract the data and analyze it, which worked better than we thought it would, catching our developers on their phones even during development.
## Accomplishments that we're proud of
We’re quite proud of the accuracy that our program has in detecting habits and believe it is the key reason why this program will be so effective. So far, unless you make a conscious effort to hide from the camera, which wouldn’t be the case for those wanting to remove a habit, the program will detect the habit almost instantly. The fact that our program caught us off guard on our phones during development is a clear indicator that our program does what it’s supposed to, and we hope to use this tool ourselves to continue development and break our own bad habits.
## What we learned
Our team pretty much learnt everything we had to use for this project. The only tools that our team were familiar with were basic HTML/CSS and Python, which not all the members knew how to use. Throughout development, we learnt a lot about frontend, backend, and database development, and TensorFlow is definitely a tool we’re happy to have learnt.
## What's next for HabiFix
In the future, we hope to add to our list of habits that we can detect, and possibly create a mobile application to track habits even when users are away from their computer. We believe this idea has serious potential for preventing not only simple habits like biting nails, but also other habits such as drug and substance abuse and addiction. | ## Inspiration
While we were doing preliminary research, we had found overwhelming amounts of evidence of mental health deterioration as a consequence of life-altering lockdown restrictions. Academic research has shown that adolescents depend on friendship to maintain a sense of self-worth and to manage anxiety and depression. Intimate exchanges and self-esteem support significantly increased long-term self worth and decreased depression.
While people do have virtual classes and social media, some still had trouble feeling close with anyone. This is because conventional forums and social media did not provide a safe space for conversation beyond the superficial. User research also revealed that friendships formed by physical proximity don't necessarily make people feel understood and resulted in feelings of loneliness anyway. Proximity friendships formed in virtual classes also felt shallow in the sense that it only lasted for the duration of the online class.
With this in mind, we wanted to create a platform that encouraged users to talk about their true feelings, and maximize the chance that the user would get heartfelt and intimate replies.
## What it does
Reach is an anonymous forum that is focused on providing a safe space for people to talk about their personal struggles. The anonymity encourages people to speak from the heart. Users can talk about their struggles and categorize them, making it easy for others in similar positions to find these posts and build a sense of closeness with the poster. People with similar struggles have a higher chance of truly understanding each other. Since ill-mannered users can exploit anonymity, there is a tone analyzer that will block posts and replies that contain mean-spirited content from being published while still letting posts of a venting nature through. There is also ReCAPTCHA to block bot spamming.
## How we built it
* Wireframing and Prototyping: Figma
* Backend: Java 11 with Spring Boot
* Database: PostgresSQL
* Frontend: Bootstrap
* External Integration: Recaptcha v3 and IBM Watson - Tone Analyzer
* Cloud: Heroku
## Challenges we ran into
We initially found it a bit difficult to come up with ideas for a solution to the problem of helping people communicate. A plan for a VR space for 'physical' chatting was also scrapped due to time constraints, as we didn't have enough time left to do it by the time we came up with the idea. We knew that forums were already common enough on the internet, so it took time to come up with a product strategy that differentiated us. (Also, time zone issues. The UXer is Australian. They took caffeine pills and still fell asleep.)
## Accomplishments that we're proud of
Finishing it on time, for starters. It felt like we had a bit of a scope problem at the start when deciding to make a functional forum with all these extra features, but I think we pulled it off. The UXer also iterated about 30 screens in total. The Figma file is *messy.*
## What we learned
As our first virtual hackathon, this has been a learning experience for remote collaborative work.
UXer: I feel like i've gotten better at speedrunning the UX process even quicker than before. It usually takes a while for me to get started on things. I'm also not quite familiar with code (I only know python), so watching the dev work and finding out what kind of things people can code was exciting to see.
# What's next for Reach
If this was a real project, we'd work on implementing VR features for those who missed certain physical spaces. We'd also try to work out improvements to moderation, and perhaps a voice chat for users who want to call. | ## Story
Brown University has traditionally sent out emails every morning containing detailed information about campus events, but recently it completely overhauled its system and made it cumbersome and unintuitive to use. All of a sudden, Brown students weren't reading the daily mail about Brown's most important campus events anymore. And that is a tragedy!
We wanted to remedy that experience and bring a clean, compact, and fully informative organization of Brown's events, every day, to Brown students on a single lightweight web page.
## Priorities
Our biggest priority was designing a space in which the news delivered by Brown's Today@Brown system would be communicated in a clean, no-hassle interface. Our two greatest ideas were as follows:
1. Each student should be able to choose what types of events they want to appear on their feed. No more tech students having their dashboard flooded with architecture and literary arts events! Students would receive quick access to the events they'd be most likely to attend.
2. Students would be able to add any on-campus event to their Google Calendar in one or two clicks. *(We didn't end up finishing this feature.)*
Our project is full-stack and hosted in Node.js. Try it out! | winning |
## Inspiration
For the last 4 years of being a college student, I've often wandered across some leftover food from an event (or worse, empty boxes that used to have Panera in them!) and wanted an app to let me know when there was free food near me. As an event organizer, I've also desperately tried to get people to eat all the free food at my events when they are woefully under attended. We've been meaning to make this app for years, and have even said to each other "shoulda FoodReconned that!" to our friends when we get to the extra food before they did. It was James Whittaker who gave us the idea for the special sauce we could add to FoodRecon to make it an app for the future.
## What it does
FoodRecon not only shows you all the places around you with free food at the moment - it notifies you as soon as you walk in the vicinity of free food without you ever having to look at your phone.
## How We built it
FoodRecon is a Windows 10 Universal app. It will run on any phone, PC, tablet, or DeLorean running Windows 10. It also can pair with a Microsoft Band to send notifications directly to your wrist when you enter the geofence of a free food location. FoodRecon uses an Azure database on an Azure Mobile Service with push notifications on the back end. FoodRecon is even accessible to Master Chief via voice commands to Cortana.
## Challenges I ran into
Stitching Azure Mobile Services, push notifications, Windows 10 Universal apps (without full documentation yet), Microsoft Band SDK, geofences, and Cortana was mainly the difficult part. Eating cookies was the easy part.
## Accomplishments that I'm proud of
Finishing.
## What I learned
All hail Visual Studio 2015.
## What's next for FoodRecon
Making iOS and Android clients soon, all with the same back end. | ## Inspiration
Being frugal students, we all wanted to create an app that would tell us what kind of food we could find around us based on a budget that we set. And so that’s exactly what we made!
## What it does
You give us a price that you want to spend and the radius that you are willing to walk or drive to a restaurant; then voila! We give you suggestions based on what you can get in that price in different restaurants by providing all the menu items with price and calculated tax and tips! We keep the user history (the food items they chose) and by doing so we open the door to crowdsourcing massive amounts of user data and as well as the opportunity for machine learning so that we can give better suggestions for the foods that the user likes the most!
But we are not gonna stop here! Our goal is to implement the following in the future for this app:
* We can connect the app to delivery systems to get the food for you!
* Inform you about the food deals, coupons, and discounts near you
## How we built it
### Back-end
We have both an iOS and Android app that authenticates users via Facebook OAuth and stores user eating history in the Firebase database. We also made a REST server that conducts API calls (using Docker, Python and nginx) to amalgamate data from our targeted APIs and refine them for front-end use.
### iOS
Authentication using Facebook's OAuth with Firebase. Create UI using native iOS UI elements. Send API calls to Soheil’s backend server using json via HTTP. Using Google Map SDK to display geo location information. Using firebase to store user data on cloud and capability of updating to multiple devices in real time.
### Android
The android application is implemented with a great deal of material design while utilizing Firebase for OAuth and database purposes. The application utilizes HTTP POST/GET requests to retrieve data from our in-house backend server, uses the Google Maps API and SDK to display nearby restaurant information. The Android application also prompts the user for a rating of the visited stores based on how full they are; our goal was to compile a system that would incentive foodplaces to produce the highest “food per dollar” rating possible.
## Challenges we ran into
### Back-end
* Finding APIs to get menu items is really hard at least for Canada.
* An unknown API kept continuously pinging our server and used up a lot of our bandwith
### iOS
* First time using OAuth and Firebase
* Creating Tutorial page
### Android
* Implementing modern material design with deprecated/legacy Maps APIs and other various legacy code was a challenge
* Designing Firebase schema and generating structure for our API calls was very important
## Accomplishments that we're proud of
**A solid app for both Android and iOS that WORKS!**
### Back-end
* Dedicated server (VPS) on DigitalOcean!
### iOS
* Cool looking iOS animations and real time data update
* Nicely working location features
* Getting latest data from server
## What we learned
### Back-end
* How to use Docker
* How to setup VPS
* How to use nginx
### iOS
* How to use Firebase
* How to OAuth works
### Android
* How to utilize modern Android layouts such as the Coordinator, Appbar, and Collapsible Toolbar Layout
* Learned how to optimize applications when communicating with several different servers at once
## What's next for How Much
* If we get a chance we all wanted to work on it and hopefully publish the app.
* We were thinking to make it open source so everyone can contribute to the app. | ## Inspiration
Ordering delivery and eating out is a major aspect of our social lives. But when healthy eating and dieting comes into play it interferes with our ability to eat out and hangout with friends. With a wave of fitness hitting our generation as a storm we have to preserve our social relationships while allowing these health conscious people to feel at peace with their dieting plans. With NutroPNG, we enable these differences to be settled once in for all by allowing health freaks to keep up with their diet plans while still making restaurant eating possible.
## What it does
The user has the option to take a picture or upload their own picture using our the front end of our web application. With this input the backend detects the foods in the photo and labels them through AI image processing using Google Vision API. Finally with CalorieNinja API, these labels are sent to a remote database where we match up the labels to generate the nutritional contents of the food and we display these contents to our users in an interactive manner.
## How we built it
Frontend: Vue.js, tailwindCSS
Backend: Python Flask, Google Vision API, CalorieNinja API
## Challenges we ran into
As we are many first-year students, learning while developing a product within 24h is a big challenge.
## Accomplishments that we're proud of
We are proud to implement AI in a capacity to assist people in their daily lives. And to hopefully allow this idea to improve peoples relationships and social lives while still maintaining their goals.
## What we learned
As most of our team are first-year students with minimal experience, we've leveraged our strengths to collaborate together. As well, we learned to use the Google Vision API with cameras, and we are now able to do even more.
## What's next for McHacks
* Calculate sum of calories, etc.
* Use image processing to estimate serving sizes
* Implement technology into prevalent nutrition trackers, i.e Lifesum, MyPlate, etc.
* Collaborate with local restaurant businesses | partial |
## Inspiration
Our inspiration for this project came from the issue we had in classrooms where many students would ask the same questions in slightly different ways, causing the teacher to use up valuable time addressing these questions instead of more pertinent and different ones.
Also, we felt that the bag of words embedding used to vectorize sentences does not make use of the sentence characteristics optimally, so we decided to create our structure in order to represent a sentence more efficiently.
## Overview
Our application allows students to submit questions onto a website which then determines whether this question is either:
1. The same as another question that was previously asked
2. The same topic as another question that was previously asked
3. A different topic entirely
The application does this by using the model proposed by the paper "Bilateral Multi-Perspective Matching for Natural Language Sentences" by Zhiguo et. al, with a new word structure input which we call "sentence tree" instead of a bag-of-words that outputs a prediction of whether the new question asked falls into one of the above 3 categories.
## Methodology
We built this project by splitting the task into multiple subtasks which could be done in parallel. Two team members worked on the web app while the other two worked on the machine learning model in order to our expertise efficiently and optimally. In terms of the model aspect, we split the task into getting the paper's code work and implementing our own word representation which we then combined into a single model.
## Challenges
Majorly, modifying the approach presented in the paper to suit our needs was challenging. On the web development side, we could not integrate the model in the web app easily as envisioned since we had customized our model.
## Accomplishments
We are proud that we were able to get accuracy close to the ones provided by the paper and for developing our own representation of a sentence apart from the classical bag of words approach.
Furthermore, we are excited to have created a novel system that eases the pain of classroom instructors a great deal.
## Takeaways
We learned how to implement research papers and improve on the results from these papers. Not only that, we learned more about how to use Tensorflow to create NLP applications and the differences between Tensorflow 1 and 2.
Going further, we also learned how to use the Stanford CoreNLP toolkit. We also learned more about web app design and how to connect a machine learning backend in order to run scripts from user input.
## What's next for AskMe.AI
We plan on finetuning the model to improve its accuracy and to also allow for questions that are multi sentence. Not only that, we plan to streamline our approach so that the tree sentence structure could be seamlessly integrated with other NLP models to replace bag of words and to also fully integrate the website with the backend. | ## Inspiration
We noticed a lot of stress among students around midterm season and wanted to utilize our programming skills to support them both mentally and academically. Our implementation was profoundly inspired by Jerry Xu's Simply Python Chatbot repository, which was built on a different framework called Keras. Through this project, we hoped to build a platform where students can freely reach out and find help whenever needed.
## What it does
Students can communicate their feelings, seek academic advice, or say anything else that is on their mind to the eTA. The eTA will respond with words of encouragement, point to helpful resources relevant to the student's coursework, or even make light conversation.
## How we built it
Our team used python as the main programming language including various frameworks, such as PyTorch for machine learning and Tkinter for the GUI. The machine learning model was trained by a manually produced dataset by considering possible user inputs and creating appropriate responses to given inputs.
## Challenges we ran into
It was difficult to fine tune the number of epochs of the machine learning algorithm in a way that it yielded the best final results. Using many of the necessary frameworks and packages generally posed a challenge as well.
## Accomplishments that we're proud of
We were impressed by the relative efficacy and stability of the final product, taking into account the fast-paced and time-sensitive nature of the event. We are also proud of the strong bonds that we have formed among team members through our collaborative efforts.
## What we learned
We discovered the versatility of machine learning algorithms but also their limitations in terms of accuracy and consistency under unexpected or ambiguous circumstances. We believe, however, that this drawback can be addressed with the usage of a more complex model, allotment of more resources, and a larger supply of training data.
## What's next for eTA
We would like to accommodate a wider variety of topics in the program by expanding the scope of the dataset--potentially through the collection of more diverse user inputs from a wider sample population at Berkeley. | ## Inspiration
Since the beginning of the hackathon, all of us were interested in building something related to helping the community. Initially we began with the idea of a trash bot, but quickly realized the scope of the project would make it unrealistic. We eventually decided to work on a project that would help ease the burden on both the teachers and students through technologies that not only make learning new things easier and more approachable, but also giving teachers more opportunities to interact and learn about their students.
## What it does
We built a Google Action that gives Google Assistant the ability to help the user learn a new language by quizzing the user on words of several languages, including Spanish and Mandarin. In addition to the Google Action, we also built a very PRETTY user interface that allows a user to add new words to the teacher's dictionary.
## How we built it
The Google Action was built using the Google DialogFlow Console. We designed a number of intents for the Action and implemented robust server code in Node.js and a Firebase database to control the behavior of Google Assistant. The PRETTY user interface to insert new words into the dictionary was built using React.js along with the same Firebase database.
## Challenges we ran into
We initially wanted to implement this project by using both Android Things and a Google Home. The Google Home would control verbal interaction and the Android Things screen would display visual information, helping with the user's experience. However, we had difficulty with both components, and we eventually decided to focus more on improving the user's experience through the Google Assistant itself rather than through external hardware. We also wanted to interface with Android things display to show words on screen, to strengthen the ability to read and write. An interface is easy to code, but a PRETTY interface is not.
## Accomplishments that we're proud of
None of the members of our group were at all familiar with any natural language parsing, interactive project. Yet, despite all the early and late bumps in the road, we were still able to create a robust, interactive, and useful piece of software. We all second guessed our ability to accomplish this project several times through this process, but we persevered and built something we're all proud of. And did we mention again that our interface is PRETTY and approachable?
Yes, we are THAT proud of our interface.
## What we learned
None of the members of our group were familiar with any aspects of this project. As a result, we all learned a substantial amount about natural language processing, serverless code, non-relational databases, JavaScript, Android Studio, and much more. This experience gave us exposure to a number of technologies we would've never seen otherwise, and we are all more capable because of it.
## What's next for Language Teacher
We have a number of ideas for improving and extending Language Teacher. We would like to make the conversational aspect of Language Teacher more natural. We would also like to have the capability to adjust the Action's behavior based on the student's level. Additionally, we would like to implement a visual interface that we were unable to implement with Android Things. Most importantly, an analyst of students performance and responses to better help teachers learn about the level of their students and how best to help them. | losing |
# Flash Computer Vision®
### Computer Vision for the World
Github: <https://github.com/AidanAbd/MA-3>
Try it Out: <http://flash-cv.com>
## Inspiration
Over the last century, computers have gained superhuman capabilities in computer vision. Unfortunately, these capabilities are not yet empowering everyday people because building an image classifier is still a fairly complicated task.
The easiest tools that currently exist still require a good amount of computing knowledge. A good example is [Google AutoML: Vision](https://cloud.google.com/vision/automl/docs/quickstart) which is regarded as the "simplest" solution and yet requires an extensive knowledge of web skills and some coding ability. We are determined to change that.
We were inspired by talking to farmers in Mexico who wanted to identify ready / diseased crops easily without having to train many workers. Despite the technology existing, their walk of life had not lent them the opportunity to do so. We were also inspired by people in developing countries who want access to the frontier of technology but lack the education to unlock it. While we explored an aspect of computer vision, we are interested in giving individuals the power to use all sorts of ML technologies and believe similar frameworks could be set up for natural language processing as well.
## The product: Flash Computer Vision
### Easy to use Image Classification Builder - The Front-end
Flash Magic is a website with an extremely simple interface. It has one functionality: it takes in a variable amount of image folders and gives back an image classification interface. Once the user uploads the image folders, he simply clicks the Magic Flash™ button. There is a short training process during which the website displays a progress bar. The website then returns an image classifier and a simplistic interface for using it. The user can use the interface (which is directly built on the website) to upload and classify new images. The user never has to worry about any of the “magic” that goes on in the backend.
### Magic Flash™ - The Backend
The front end’s connection to the backend sets up a Train image folder on the server. The name of each folder is the category that the pictures inside of it belong to. The backend will take the folder and transfer it into a CSV file. From this CSV file it creates a [Pytorch.utils.Dataset](https://pytorch.org/docs/stable/_modules/torch/utils/data/dataset.html) Class by inheriting Dataset and overriding three of its methods. When the dataset is ready, the data is augmented using a combination of 6 different augmentations: CenterCrop, ColorJitter, RandomAffine, RandomRotation, and Normalize. By doing those transformations, we ~10x the amount of data that we have for training. Once the data is in a CSV file and has been augmented, we are ready for training.
We import [SqueezeNet](https://pytorch.org/hub/pytorch_vision_squeezenet/) and use transfer learning to adjust it to our categories. What this means is that we erase the last layer of the original net, which was originally trained for ImageNet (1000 categories), and initialize a layer of size equal to the number of categories that the user defined, making sure to accurately match dimensions. We then run back-propagation on the network with all the weights “frozen” in place with exception to the ones in the last layer. As the model is training, it is informing the front-end that progress being made, allowing us to display a progress bar. Once the model converges, the final model is saved into a file that the API can easily call for inference (classification) when the user asks for prediction on new data.
## How we built it
The website was built using Node.js and javascript and it has three main functionalities: allowing the user to upload pictures into folders, sending the picture folders to the backend, making API calls to classify new images once the model is ready.
The backend is built in Python and PyTorch. On top of Python we used torch, torch.nn as nn, torch.optim as optim, torch.optim import lr\_scheduler, numpy as np, torchvision, from torchvision import datasets, models, and transforms, import matplotlib.pyplot as plt, import time, import os, import copy, import json, import sys.
## Accomplishments that we're proud of
Going into this, we were not sure if 36 hours were enough to build this product. The proudest moment of this project was the successful testing round at 1am on Sunday. While we had some machine learning experience on our team, none of us had experience with transfer learning or this sort of web application. At the beginning of our project, we sat down, learned about each task, and then drew a diagram of our project. We are especially proud of this step because coming into the coding portion with a clear API functionality understanding and delegated tasks saved us a lot of time and helped us integrate the final product.
## Obstacles we overcame and what we learned
Machine learning models are often finicky in their training patterns. Because our application allows users with little experience, we had to come up with a robust training pipeline. Designing this pipeline took a lot of thought and a few failures before we converged on a few data augmentation techniques that do the trick. After this hurdle, integrating a deep learning backend with the website interface was quite challenging, as the training pipeline requires very specific labels and file structure. Iterating the website to reflect the rigid protocol without over complicating the interface was thus a challenge. We learned a ton over this weekend. Firstly, getting the transfer learning to work was enlightening as freezing parts of the network and writing a functional training loop for specific layers required diving deep into the pytorch API. Secondly, the human-design aspect was a really interesting learning opportunity as we had to come up with the right line between abstraction and functionality. Finally, and perhaps most importantly, constantly meeting and syncing code taught us the importance of keeping a team on the same page at all times.
## What's next for Flash Computer Vision
### Application companion + Machine Learning on the Edge
We want to build a companion app with the same functionality as the website. The companion app would be even more powerful than the website because it would have the ability to quantize models (compression for ml) and to transfer them into TensorFlow Lite so that **models can be stored and used within the device.** This would especially benefit people in developing countries, where they sometimes cannot depend on having a cellular connection.
### Charge to use
We want to make a payment system within the website so that we can scale without worrying about computational cost. We do not want to make a business model out of charging per API call, as we do not believe this will pave a path forward for rapid adoption. **We want users to own their models, this will be our competitive differentiator.** We intentionally used a smaller neural network to reduce hosting and decrease inference time. Once we compress our already small models, this vision can be fully realized as we will not have to host anything, but rather return a mobile application. | ## Inspiration
The whiteboard or chalkboard is an essential tool in instructional settings - to learn better, students need a way to directly transport code from a non-text medium to a more workable environment.
## What it does
Enables someone to take a picture of handwritten or printed text converts it directly to code or text on your favorite text editor on your computer.
## How we built it
On the front end, we built an app using Ionic/Cordova so the user could take a picture of their code. Behind the scenes, using JavaScript, our software harnesses the power of the Google Cloud Vision API to perform intelligent character recognition (ICR) of handwritten words. Following that, we applied our own formatting algorithms to prettify the code. Finally, our server sends the formatted code to the desired computer, which opens it with the appropriate file extension in your favorite IDE. In addition, the client handles all scripting of minimization and fileOS.
## Challenges we ran into
The vision API is trained on text with correct grammar and punctuation. This makes recognition of code quite difficult, especially indentation and camel case. We were able to overcome this issue with some clever algorithms. Also, despite a general lack of JavaScript knowledge, we were able to make good use of documentation to solve our issues.
## Accomplishments that we're proud of
A beautiful spacing algorithm that recursively categorizes lines into indentation levels.
Getting the app to talk to the main server to talk to the target computer.
Scripting the client to display final result in a matter of seconds.
## What we learned
How to integrate and use the Google Cloud Vision API.
How to build and communicate across servers in JavaScript.
How to interact with native functions of a phone.
## What's next for Codify
It's feasibly to increase accuracy by using the Levenshtein distance between words. In addition, we can improve algorithms to work well with code. Finally, we can add image preprocessing (heighten image contrast, rotate accordingly) to make it more readable to the vision API. | ## Inspiration
Our team has always been concerned about the homogeneity of many computer vision training sets, given that they can introduce cultural and societal biases into the resulting machine learning algorithm.
CultureCV is designed to combat this highly relevant problem, with a user incentive for use: by taking pictures of objects that are culturally relevant to the user, then incorporating user-generated tagging into new data sets, our mobile app encourages both cultural exchange and a future with more diverse CV training sets.
By using our app, the user learns their target language from objects and situations they already see. The user is prompted to tag objects that are meaningful to them, which in turn strengthens the diversity of our custom training data set.
## What it does
CultureCV is a cross-platform real-time, real-world flashcard community. After starting the app, the phone's camera captures several images of an object the user is looking at, and sends them to the Microsoft Image Analysis API. As the API returns descriptions and tags for the object, our app displays and translates the best tags, using the Microsoft Translation API, as well as a brief description of the scene. The user can set the translation language (currently supported: French, Spanish, and German).
When our custom data set (using the Microsoft Custom Vision API) has a better match for the image than the tags returned by the Microsoft Image Analysis API, we instead display and translate our own tags.
Users can create their own language "flashcards" with any object they want, by tagging objects that they find meaningful. This is incredibly powerful both in its democratization of training data, and in its high level of personalized customization.
## How we built it
CultureCV was built entirely using Expo and React Native -- a huge advantage due to the fact that all of our team members had different mobile devices.
## Challenges we ran into
We spent a lot of time uncovering new features by poring through the new Microsoft documentation for the Custom Vision Service. Allowing the user to submit tags to the data set was particularly challenging.
Additionally, two out of three of our developers had never used Expo or React Native before. Thankfully, after the initial difficulties of getting up and running, we were all able to test using Expo.
## Accomplishments that we're proud of
We are especially proud of the instant training of our custom model -- users who use the "contribute" button to add tags for an object can see that object be correctly identified just a moment later.
## What we learned
The most exciting our team learned was that we could create a high-quality machine learning app without ever having to glance at a gradient!
Our team learned how to collaborate in a team using Expo (two of our members learned how to use Expo, full stop).
## What's next for CultureCV
The platform is scalable for any type of information -- we see future applications for museums, famous landmarks and historical sites, or even directly in the classroom. Ultimately, we see our platform becoming something like Wikipedia for the real world. | winning |
## Inspiration
No one likes waiting around too much, especially when we feel we need immediate attention. 95% of people in hospital waiting rooms tend to get frustrated over waiting times and uncertainty. And this problem affects around 60 million people every year, just in the US. We would like to alleviate this problem and offer alternative services to relieve the stress and frustration that people experience.
## What it does
We let people upload their medical history and list of symptoms before they reach the waiting rooms of hospitals. They can do this through the voice assistant feature, where in a conversation style they tell their symptoms, relating details and circumstances. They also have the option of just writing these in a standard form, if it's easier for them. Based on the symptoms and circumstances the patient receives a category label of 'mild', 'moderate' or 'critical' and is added to the virtual queue. This way the hospitals can take care of their patients more efficiently by having a fair ranking system (incl. time of arrival as well) that determines the queue and patients have a higher satisfaction level as well, because they see a transparent process without the usual uncertainty and they feel attended to. This way they can be told an estimate range of waiting time, which frees them from stress and they are also shown a progress bar to see if a doctor has reviewed his case already, insurance was contacted or any status changed. Patients are also provided with tips and educational content regarding their symptoms and pains, battling this way the abundant stream of misinformation and incorrectness that comes from the media and unreliable sources. Hospital experiences shouldn't be all negative, let's try try to change that!
## How we built it
We are running a Microsoft Azure server and developed the interface in React. We used the Houndify API for the voice assistance and the Azure Text Analytics API for processing. The designs were built in Figma.
## Challenges we ran into
Brainstorming took longer than we anticipated and had to keep our cool and not stress, but in the end we agreed on an idea that has enormous potential and it was worth it to chew on it longer. We have had a little experience with voice assistance in the past but have never user Houndify, so we spent a bit of time figuring out how to piece everything together. We were thinking of implementing multiple user input languages so that less fluent English speakers could use the app as well.
## Accomplishments that we're proud of
Treehacks had many interesting side events, so we're happy that we were able to piece everything together by the end. We believe that the project tackles a real and large-scale societal problem and we enjoyed creating something in the domain.
## What we learned
We learned a lot during the weekend about text and voice analytics and about the US healthcare system in general. Some of us flew in all the way from Sweden, for some of us this was the first hackathon attended so working together with new people with different experiences definitely proved to be exciting and valuable. | ## Inspiration
In a way, contracts form the backbone of modern society: every exchange of good or services rendered, every transaction where we seek the work and products of others is governed and regulated by these agreements. Without the ability to agree to contracts, we lose the ability to acquire services that may be vital for our well-being.
But we all know that contracts are often tedious and opaque, even for accustomed individuals. What about those groups which find this very hard?
The elderly are a large group affected by this. They have many transactions that require contracts: from medical care, to insurance policies, to financial management, and more. This is a group that tends to have trouble following long and complicated contracts. It is also a group that often has difficulty operating technology -- which can be perilous as contracts are increasingly paperless and online.
That's why we created *AgreeAble*, a contracts platform that is simple and universally welcoming to everyone. We wanted to make a platform that demystifies contracts for those who have trouble with them, making reading and signing as easy as possible.
## What it does
*AgreeAble* works as follows:
1) A family member or caretaker helps the user set up an account, storing a special "Visual Key" as their login instead of a password. This Visual Key makes it easy to verify the user's identity, without having to remember complicated logins.
2) The contract issuer enters a new contract for the individual to sign into the AgreeAble system.
3) The user gets a simple email notification that invites them to sign the contract on the AgreeAble website.
4) The user goes to the website where they can see the terms, validate using their Visual Key, and sign the contract.
The Visual Key is an important part of making the process easy. Current contract services like DocuSign require logins, which may be difficult for the elderly to remember. We wanted to make the login process as easy as "showing" the website something that proves your identity. So, that's what we made the Visual Key: to authenticate, the user just shows the website their favorite, physical object that only they have. (Facial recognition would work just as well, although that IBM service was under maintenance at the time of this hackathon.)
We wanted signing to be very easy too. That's why we chose DocuSign's Click API, which lets users sign an agreement in a single click. **We chose Click over the eSignature API because, by design, the Click API is optimized for as little interaction from the user as possible,** which is perfect for our audience. That being said, a future expansion could include integrating autofill into the form, which would be enabled by the eSignature API.
## How we built it
We built the website in python using the Django web framework. The server uses IBM Visual Recognition to process users' Visual Key, using the data return to generate a unique fingerprint for that key. We then use DocuSign's Clickwrap interface to display simple clickable contracts, retrieving the correct contract from the stored value in our Django database.
The Visual Key uses a fingerprint distance for validation; For an object to be considered a valid key, it must look sufficiently close to this fingerprint. Otherwise, it is rejected. This is an interesting use of data because we built this rather accurate fingerprint using standard vision models, without needing specific domain training.
## Challenges we ran into
Unfortunately, some services that we had wanted to use were not available at the time of this hackathon. We had wanted to use IBM Visual Recognition's Facial Recognition feature, but it was under maintenance at the time. So, we had to improvise, which is how we came up with our Visual Key technique...which arguably is even easier (and fun!) for an audience like the elderly.
## Accomplishments that we're proud of
We've successfully made a very simple and beautiful proof-of-concept for a platform that makes contracts easy for everyone! | ### 💡 Inspiration 💡
We call them heroes, **but the support we give them is equal to the one of a slave.**
Because of the COVID-19 pandemic, a lot of medics have to keep track of their patient's history, symptoms, and possible diseases. However, we've talked with a lot of medics, and almost all of them share the same problem when tracking the patients: **Their software is either clunky and bad for productivity, or too expensive to use on a bigger scale**. Most of the time, there is a lot of unnecessary management that needs to be done to get a patient on the record.
Moreover, the software can even get the clinician so tired they **have a risk of burnout, which makes their disease predictions even worse the more they work**, and with the average computer-assisted interview lasting more than 20 minutes and a medic having more than 30 patients on average a day, the risk is even worse. That's where we introduce **My MedicAid**. With our AI-assisted patient tracker, we reduce this time frame from 20 minutes to **only 5 minutes.** This platform is easy to use and focused on giving the medics the **ultimate productivity tool for patient tracking.**
### ❓ What it does ❓
My MedicAid gets rid of all of the unnecessary management that is unfortunately common in the medical software industry. With My MedicAid, medics can track their patients by different categories and even get help for their disease predictions **using an AI-assisted engine to guide them towards the urgency of the symptoms and the probable dangers that the patient is exposed to.** With all of the enhancements and our platform being easy to use, we give the user (medic) a 50-75% productivity enhancement compared to the older, expensive, and clunky patient tracking software.
### 🏗️ How we built it 🏗️
The patient's symptoms get tracked through an **AI-assisted symptom checker**, which uses [APIMedic](https://apimedic.com/i) to process all of the symptoms and quickly return the danger of them and any probable diseases to help the medic take a decision quickly without having to ask for the symptoms by themselves. This completely removes the process of having to ask the patient how they feel and speeds up the process for the medic to predict what disease their patient might have since they already have some possible diseases that were returned by the API. We used Tailwind CSS and Next JS for the Frontend, MongoDB for the patient tracking database, and Express JS for the Backend.
### 🚧 Challenges we ran into 🚧
We had never used APIMedic before, so going through their documentation and getting to implement it was one of the biggest challenges. However, we're happy that we now have experience with more 3rd party APIs, and this API is of great use, especially with this project. Integrating the backend and frontend was another one of the challenges.
### ✅ Accomplishments that we're proud of ✅
The accomplishment that we're the proudest of would probably be the fact that we got the management system and the 3rd party API working correctly. This opens the door to work further on this project in the future and get to fully deploy it to tackle its main objective, especially since this is of great importance in the pandemic, where a lot of patient management needs to be done.
### 🙋♂️ What we learned 🙋♂️
We learned a lot about CRUD APIs and the usage of 3rd party APIs in personal projects. We also learned a lot about the field of medical software by talking to medics in the field who have way more experience than us. However, we hope that this tool helps them in their productivity and to remove their burnout, which is something critical, especially in this pandemic.
### 💭 What's next for My MedicAid 💭
We plan on implementing an NLP-based service to make it easier for the medics to just type what the patient is feeling like a text prompt, and detect the possible diseases **just from that prompt.** We also plan on implementing a private 1-on-1 chat between the patient and the medic to resolve any complaints that the patient might have, and for the medic to use if they need more info from the patient. | partial |
## Inspiration
Given the current state of the COVID-19 pandemic, the recent approvals for numerous vaccines are a promising step towards returning to our normal lives. However, the fast tracked research and development processes for preparing this vaccine have caused many people to doubt its effectiveness and are concerned about potential side effects associated with it. Though this is a valid concern, there are many misconceptions about the vaccine’s side effects including rumours of microchips being implanted via the injection, or it potentially altering your DNA. For the average person, such rumours are enough to cause distrust in the available vaccines and many people make judgments without taking the time to fully understand the vaccine. This tool is meant for the average person to understand the covid situation and the importance of the vaccine in a concise manner.
## What it does
The web page displays covid-19 statistics in a user friendly interface. It also includes information regarding the covid-19 vaccine as an effort to reduce the stigma surrounding it. Additionally, there is a list of relevant news articles that are displayed based on the region the user is currently viewing.
## How we built it
From this past weekend, we are extremely proud of our efforts and the web-page our team came up with. More importantly, we achieved our goal of creating a page that de-stigmatizes the Covid-19 Vaccine.
## Challenges we ran into
We ran into challenges regarding connecting our various different data fields to the front end. We were pulling data from various sources such as covid-19 data and news from all provinces/territories as well as the country as a whole. Because of this, it was difficult to create a method to quickly update our current visualizations and access the new data fields without changing the visuals that we were using. Fixing this took a lot of trial and error and we attempted several solutions but learning how to create an adaptive visual and implementing a quick and flexible backend will definitely help with future projects.
We also wanted to build an algorithm that could predict future covid-19 hotspots using current data. Unfortunately, due to time constraints, we were not able to do so but it is something we would definitely like to work toward going forward.
## Accomplishments that we're proud of
This web-page was built using a react-template by MaterialUI for the frontend and express.js for the backend. Our backend is hosted on repl.it. For all the data displayed on the page, the Government of Canada Covid data API is used, and yahoo news is scaped to show relevant news articles based on the region selected by the user.
## What we learned
While integrating our application into a react theme template, we got to experience and play around with react structure and styling that none of us were familiar with from the template. As we started adding and modifying more code, we got to understand the design and the react component cycle of the theme, and got quite fluent at adding, modifying, restructuring components as we required by the time we completed our app. As this experience has definitely made us more comfortable with using themes and templates, this will become a useful skill for future projects since we will be able to do integration faster and more prepared.
## What's next for Still thinkin bout it
We hope to eventually develop a smart algorithm that can predict future covid 19 risk using existing data. We also hope to improve the UI and add more data fields such as daily changes fields visualized. The end goal of our web app is not only to eliminate misinformation surrounding the virus but also to act as an aggregator for all covid-19 related news and information for Canadian citizens so they can quickly learn everything they need to know about the virus without having to visit several sources. | ## Submission Links:
YouTube:
* <https://www.youtube.com/watch?v=9eHJ7draeAY&feature=youtu.be>
GitHub:
* Front-End: <https://github.com/manfredxu99/nwhacks-fe>
* Back-End: <https://github.com/manfredxu99/nwhacks-be>
## Inspiration
Imagine living in a world where you can feel safe when going to a specific restaurant or going to a public space. Covid map helps you see which areas and restaurants have the most people who have been in close contact with covid patients. Other apps only tell you after someone has been confirmed suspected with COVID. However, with covid map you can tell in advance whether or not you should go to a specific area.
## What it does
In COVIDMAP you can look up the location you are thinking of visiting and get an up to date report on how many confirmed cases have visited the location in the past 3 days. With the colour codes indicating the severity of the covid cases in the area, COVID map is an easy and intuitive way to find out whether or not a grocery store or public area is safe to visit.
## How I built it
We started by building the framework. I built it using React Native as front-end, ExpressJS backend server and Google Cloud SQL server.
## Challenges I ran into
Maintaining proper communication between front-end and back-end, and writing stored procedures in database for advanced database SQL queries
## Accomplishments that I'm proud of
We are honoured having the opportunity to contribute well to the one of the main health and safety concerns, by creating an app that provide our fellow citizens to reduce the worries and concerns towards being exposed to COVID patients.
Moreover, in technical aspects, we have successfully maintained the front-end to back-end communication, as our app successfully fetches and stores data properly in this short time span of 24 hours.
## What I learned
We have learnt that creating a complete app within 24-hours is fairly challenging. As we needed to distribute time well to brainstorm great app ideas, design and implement UI, manage data, etc. This hackathon also further enhanced my ability to practice teamwork.
## What's next for COVIDMAP
We hope to implement this app locally in Vancouver to test out the usability of this project. Eventually we wish to help hotspot cities reduce their cases. | ## Inspiration
On our way to PennApps, our team was hungrily waiting in line at Shake Shack while trying to think of the best hack idea to bring. Unfortunately, rather than being able to sit comfortably and pull out our laptops to research, we were forced to stand in a long line to reach the cashier, only to be handed a clunky buzzer that countless other greasy fingered customer had laid their hands on. We decided that there has to be a better way; a way to simply walk into a restaurant, be able to spend more time with friends, and to stand in line as little as possible. So we made it.
## What it does
Q'd (pronounced queued) digitizes the process of waiting in line by allowing restaurants and events to host a line through the mobile app and for users to line up digitally through their phones as well. Also, it functions to give users a sense of the different opportunities around them by searching for nearby queues. Once in a queue, the user "takes a ticket" which decrements until they are the first person in line. In the meantime, they are free to do whatever they want and not be limited to the 2-D pathway of a line for the next minutes (or even hours).
When the user is soon to be the first in line, they are sent a push notification and requested to appear at the entrance where the host of the queue can check them off, let them in, and remove them from the queue. In addition to removing the hassle of line waiting, hosts of queues can access their Q'd Analytics to learn how many people were in their queues at what times and learn key metrics about the visitors to their queues.
## How we built it
Q'd comes in three parts; the native mobile app, the web app client, and the Hasura server.
1. The mobile iOS application built with Apache Cordova in order to allow the native iOS app to be built in pure HTML and Javascript. This framework allows the application to work on both Android, iOS, and web applications as well as to be incredibly responsive.
2. The web application is built with good ol' HTML, CSS, and JavaScript. Using the Materialize CSS framework gives the application a professional feel as well as resources such as AmChart that provide the user a clear understanding of their queue metrics.
3. Our beast of a server was constructed with the Hasura application which allowed us to build our own data structure as well as to use the API calls for the data across all of our platforms. Therefore, every method dealing with queues or queue analytics deals with our Hasura server through API calls and database use.
## Challenges we ran into
A key challenge we discovered was the implementation of Cordova and its associated plugins. Having been primarily Android developers, the native environment of the iOS application challenged our skills and provided us a lot of learn before we were ready to properly implement it.
Next, although a less challenge, the Hasura application had a learning curve before we were able to really us it successfully. Particularly, we had issues with relationships between different objects within the database. Nevertheless, we persevered and were able to get it working really well which allowed for an easier time building the front end.
## Accomplishments that we're proud of
Overall, we're extremely proud of coming in with little knowledge about Cordova, iOS development, and only learning about Hasura at the hackathon, then being able to develop a fully responsive app using all of these technologies relatively well. While we considered making what we are comfortable with (particularly web apps), we wanted to push our limits to take the challenge to learn about mobile development and cloud databases.
Another accomplishment we're proud of is making it through our first hackathon longer than 24 hours :)
## What we learned
During our time developing Q'd, we were exposed to and became proficient in various technologies ranging from Cordova to Hasura. However, besides technology, we learned important lessons about taking the time to properly flesh out our ideas before jumping in headfirst. We devoted the first two hours of the hackathon to really understand what we wanted to accomplish with Q'd, so in the end, we can be truly satisfied with what we have been able to create.
## What's next for Q'd
In the future, we're looking towards enabling hosts of queues to include premium options for users to take advantage to skip lines of be part of more exclusive lines. Furthermore, we want to expand the data analytics that the hosts can take advantage of in order to improve their own revenue and to make a better experience for their visitors and customers. | losing |
## Inspiration
In a world where refrigerators are humble white boxes merely used to store food, average and ubiquitous are the most common adjectives when describing one of the most important appliances. Several upgrades are necessary for a technology that essentially hasn't changed much since its introduction a century ago. We wanted to tackle food waste and create a better experience with the Frigid
## What it does
Analyzes the image of the food placed in its basket using Microsoft's Computer Vision API, Raspberry Pi, and Arduino.
Places food in specific compartment for it using a laser-cut acrylic railing frame and basket, actuated by motors. The plan for a full product is to maintain a specific temperature for each compartment (our prototype uses LEDs as an example of different temperatures) that allows the food to last as long as possible, maintain flavor and nutrition, and either freeze or defrost foods such as meats from the tap of a finger. This also makes it much easier to arrange groceries after buying.
Using the identification from the vision system, Frigid can also warn you when you are running low on supplies or if the food has gone bad. Notifications over the internet allow you to easily order more food or freeze food that is getting close the expiration date.
## How we built it
Laser cut acrylic, stepper motors, Arduino, Raspberry Pi. As a hardware project, we spent most of our time trying to build our product from scratch and maintain structural rigidity. The laser cut acrylic is what we used to build the frame, basket holding the food, and compartments for food to be held in.
## Challenges we ran into
-limited laser cutting hours
-limited materials
-limited tools
-LED control
-power
-hot glue
-working with new technology
## Accomplishments that we're proud of
-Microsoft api
-first hardware hack
-first time using arduino and raspberry pi together
-first time working with Nelson
-lots of laser cutting
-learning about rigidity and structural design
-LED strips
-transistor logic
-power management
## What we learned
-soldering
-power management
-Controlling arduinos with raspberry pi
## What's next for Frigid
There is a huge potential for future development with Frigid, namely working in the temperature features and increasing the amount of food types the vision system can recognize. As more people use the product, we hope we can use the data to create better vision recognition and figure out ways to reduce food waste. | ## Inspiration
Whenever you get takeout or coffee, using a single use container is the only option. The single use, linear economy is not sustainable and I wanted to change that with a reusable item share system.
## What it does
ShareIT is a borrowing system that can be implemented securely anywhere, without fear of losing any items. To use the machine, you use the app to request a certain number of items. Then, it will allow you to take the items which are then stored under your username in order to prevent people from not returning the items. Removing items without using the app beforehand will cause the machine to make a sound until it is put back (It's a minor security system intended to prevent theft).
## How I built it
We used some old pipe shelving and cardboard to build the machine and we've set it up with a Raspberry Pi, and many ultrasonic sensors that are used to calculate the number of objects in a certain row. It is all handmade. I burnt myself a couple of times :)
## Challenges I ran into
The challenge that hindered our performance on the project the most was making a connection between Flutter and the Raspberry Pi. The soldering was also very difficult.
## Accomplishments that we're proud of
This is quite a large system and required a lot of hardware and software. We managed to make a reasonable amount of progress, and we're proud of that.
## What we learned
How to use a Raspberry Pi. How to make the Raspberry Pi communicate to the Arduino. How to connect the Ultrasonic sensors to every micro controller. A lot about the software and hardware connection interface.
## What's next for ShareIT
We plan to create a bigger shelf with more reusable times available. For instance, collapsible take-out boxes, metal straws, reusable utensils, and reusable bags. Also, instead of using regular plastic reusable items, we could even use bioplastic reusable items. Our current shelf prototype was created to be small for demonstration purposes. We plan to have a selection of self sizes which will be bigger and more robust. The current prototype design is customizable so each business owner can easily have a custom self for their location. This is key as each location will have different demands in terms of space and consumer base. With a PCB (or even with the Raspberry Pi we have with the current prototype) we can make the ShareIT’s hardware be the smart center of the location it is in. For example, at a cafe, ShareIT’s screen and onboard computer can function as a thermostat, music player, server and even a Google Assistant. With the PCB or Raspberry Pi, there are many features we can add with ease. These features along with the boast of being “green” will make it more intriguing for businesses to adopt ShareIT especially when it will be free of cost to them. On the software side, we plan on having a major update on the app where you can find out where the closest ShareIT is along with a better U.I. On the software side of the PCB/Raspberry Pi, we plan to further improve the U.I. and optimize the program so it can process transactions faster. All in all, we have a lot in mind for improvement. | ## Inspiration
As college students more accustomed to having meals prepared by someone else than doing so ourselves, we are not the best at keeping track of ingredients’ expiration dates. As a consequence, money is wasted and food waste is produced, thereby discounting the financially advantageous aspect of cooking and increasing the amount of food that is wasted. With this problem in mind, we built an iOS app that easily allows anyone to record and track expiration dates for groceries.
## What it does
The app, iPerish, allows users to either take a photo of a receipt or load a pre-saved picture of the receipt from their photo library. The app uses Tesseract OCR to identify and parse through the text scanned from the receipt, generating an estimated expiration date for each food item listed. It then sorts the items by their expiration dates and displays the items with their corresponding expiration dates in a tabular view, such that the user can easily keep track of food that needs to be consumed soon. Once the user has consumed or disposed of the food, they could then remove the corresponding item from the list. Furthermore, as the expiration date for an item approaches, the text is highlighted in red.
## How we built it
We used Swift, Xcode, and the Tesseract OCR API. To generate expiration dates for grocery items, we made a local database with standard expiration dates for common grocery goods.
## Challenges we ran into
We found out that one of our initial ideas had already been implemented by one of CalHacks' sponsors. After discovering this, we had to scrap the idea and restart our ideation stage.
Choosing the right API for OCR on an iOS app also required time. We tried many available APIs, including the Microsoft Cognitive Services and Google Computer Vision APIs, but they do not have iOS support (the former has a third-party SDK that unfortunately does not work, at least for OCR). We eventually decided to use Tesseract for our app.
Our team met at Cubstart; this hackathon *is* our first hackathon ever! So, while we had some challenges setting things up initially, this made the process all the more rewarding!
## Accomplishments that we're proud of
We successfully managed to learn the Tesseract OCR API and made a final, beautiful product - iPerish. Our app has a very intuitive, user-friendly UI and an elegant app icon and launch screen. We have a functional MVP, and we are proud that our idea has been successfully implemented. On top of that, we have a promising market in no small part due to the ubiquitous functionality of our app.
## What we learned
During the hackathon, we learned both hard and soft skills. We learned how to incorporate the Tesseract API and make an iOS mobile app. We also learned team building skills such as cooperating, communicating, and dividing labor to efficiently use each and every team member's assets and skill sets.
## What's next for iPerish
Machine learning can optimize iPerish greatly. For instance, it can be used to expand our current database of common expiration dates by extrapolating expiration dates for similar products (e.g. milk-based items). Machine learning can also serve to increase the accuracy of the estimates by learning the nuances in shelf life of similarly-worded products. Additionally, ML can help users identify their most frequently bought products using data from scanned receipts. The app could recommend future grocery items to users, streamlining their grocery list planning experience.
Aside from machine learning, another useful update would be a notification feature that alerts users about items that will expire soon, so that they can consume the items in question before the expiration date. | losing |
# Dataless: No Data? No Problem.
---
We started Cal Hacks tossing around ideas, came to the idea of providing smartphones with internet access through a solely SMS-based platform, and never turned back. To start, we quickly tested out some ideas (Android SMS send/receive, Twilio messaging, Amazon EC2) and found out they all individually worked. Initiate #DanceParty. It was time to get to work.
So here's the Android app: An internet portal using **no** cellular data, only SMS text messages. Access convenient services such as Wikipedia, Bing Search, USDA Nutritional Information, Weather, etc... using only SMS.
## Motivation
---
You own a smartphone with an SMS plan, but no data plan. How can you stay connected to the information of the modern world?
4.5 billion people lack internet access worldwide, yet smartphone ownership is growing faster than ever throughout even the most destitute of geographic locations. A vast number of these new smartphone users, however, lack access to data either because of financial constraints or a lack of geographically-available, data-enabling infrastructure. With an awareness of the power that connectivity and information has on empowering all realms of life, we wanted to create a platform that could provide data-less smartphone users with the power of information. Once we realized what that platform was, the inevitable dance party commenced before jumping into the world of hacking. | #### HackPrinceton - Clean Tech Category: **Tetra** ♻️
## Inspiration ✨♻️
We were inspired to create this project after reading ongoing [**news**](https://www.businessoffashion.com/articles/luxury/luxury-brands-burn-unsold-goods-what-should-they-do-instead) about famous luxury clothing brands yearly burning their unsold inventories. It was very surprising to learn about the number of high-quality goods these brands have burned when they could have recycled them or kept a better track of their supply chain in order to prevent the result. These brands also have more resources (which is why they are luxury brands) yet this problem keeps persisting which partly roots from a bigger issue of current supply chains not being sustainable enough to help brands improve their practices.
## What it does ⚡⚙️
**Tetra** is a sustainable supply chain management system that helps clothing brands have clear transparency into each stage of their supply chain while also helping them recycle more of their unsold inventory.
## How we built it 🖥️🌿
Tetra's technical backbone uses blockchain for business using Ethereum and Web3.js. This allows each product in the inventory to have a unique ID that can be traced and tracked to see which stages in the supply chain it has gone through (example: shipping stage, factory, supply). It will also show what types of materials this product is made out of. If this item is unsold, admins can send the item to a recycling facility. Once a product gets recycled, users of Tetra can also trace the history of the different parts that made up that product got recycled into.
### Some of the completed user stories are:
* As an admin, I am able to track which product to recycle
* As an admin, I am able to add a new product to the chain
* As an admin, I am able to add or ship new materials (that are parts of the product) to the chain
* As a customer, I am able to see a history/timeline of where the materials of a product have been recycled to
## Challenges we ran into 🤕
Since this was our first time working with Ethereum as a blockchain platform, and with writing Solidity smart contracts, we had to learn a lot of concepts as a team before we were able to fully grasp what the blockchain architecture would look like and how we were to structure the web app to get it talking the blockchain! 🔗
## Accomplishments that we're proud of 🦚
We are very proud of writing working smart contracts in solidity. We are happy with the progress we made and are stoked about the design and UI/UX of the web app. We are also proud to have tackled such a major issue - one that brings the earth closer to its destruction. 🌍
## What we learned 🏫
For this hackathon, we switched roles on the tech stack. So Ana and Tayeeb built out the backend while Krishna worked on the frontend. It was Anastasiya's first time working on the backend, and she is happy to have learned so much about Web Servers, and REST APIs. We all enjoyed diving into the world of blockchain and managing to create an MVP in one weekend. We also learned how to pitch and market our project.
## What's next for Tetra 🚀
We hope to make the MVP into an actual beta version that can be shipped out to various retail brands that can make use of a supply chain, and we hope that by using Tetra, we can help make a difference in the world!
## Contributors 👨🏻💻👩🏻💻
1. Tayeeb Hasan - [github](https://github.com/flozender)
2. Krishna - [github](https://github.com/JethroGibbsN)
3. Anastasiya Uraleva - [github](https://github.com/APiligrim) | ## Inspiration
Have you ever wanted to search something, but aren't connected to the internet? Data plans too expensive, but you really need to figure something out online quick? Us too, and that's why we created an application that allows you to search the internet without being connected.
## What it does
Text your search queries to (705) 710-3709, and the application will text back the results of your query.
Not happy with the first result? Specify a result using the `--result [number]` flag.
Want to save the URL to view your result when you are connected to the internet? Send your query with `--url` to get the url of your result.
Send `--help` to see a list of all the commands.
## How we built it
Built on a **Nodejs** backend, we leverage **Twilio** to send and receive text messages. When receiving a text message, we send this information using **RapidAPI**'s **Bing Search API**.
Our backend is **dockerized** and deployed continuously using **GitHub Actions** onto a **Google Cloud Run** server. Additionally, we make use of **Google Cloud's Secret Manager** to not expose our API Keys to the public.
Internally, we use a domain registered with **domain.com** to point our text messages to our server.
## Challenges we ran into
Our team is very inexperienced with Google Cloud, Docker and GitHub Actions so it was a challenge needing to deploy our app to the internet. We recognized that without deploying, we would could not allow anybody to demo our application.
* There was a lot of configuration with permissions, and service accounts that had a learning curve. Accessing our secrets from our backend, and ensuring that the backend is authenticated to access the secrets was a huge challenge.
We also have varying levels of skill with JavaScript. It was a challenge trying to understand each other's code and collaborating efficiently to get this done.
## Accomplishments that we're proud of
We honestly think that this is a really cool application. It's very practical, and we can't find any solutions like this that exist right now. There was not a moment where we dreaded working on this project.
This is the most well planned project that we've all made for a hackathon. We were always aware how our individual tasks contribute to the to project as a whole. When we felt that we were making an important part of the code, we would pair program together which accelerated our understanding.
Continuously deploying is awesome! Not having to click buttons to deploy our app was really cool, and it really made our testing in production a lot easier. It also reduced a lot of potential user errors when deploying.
## What we learned
Planning is very important in the early stages of a project. We could not have collaborated so well together, and separated the modules that we were coding the way we did without planning.
Hackathons are much more enjoyable when you get a full night sleep :D.
## What's next for NoData
In the future, we would love to use AI to better suit the search results of the client. Some search results have a very large scope right now.
We would also like to have more time to write some tests and have better error handling. | partial |
## Inspiration
How did you feel when you first sat behind the driving wheel? Scared? Excited? All of us on the team felt a similar way: nervous. Nervous that we'll drive too slow and have cars honk at us from behind. Or nervous that we'll crash into something or someone. We felt that this was something that most people encountered, and given the current technology and opportunity, this was the perfect chance to create a solution that can help inexperienced drivers.
## What it does
Drovo records average speed and composite jerk (the first derivative of acceleration with respect to time) over the course of a driver's trip. From this data, it determines a driving grade based on the results of a SVM machine learning model.
## How I built it
The technology making up Drovo can be summarized in three core components: the Android app, machine learning model, and Ford head unit. Interaction can start from either the Android app or Ford head unit. Once a trip is started, the Android app will compile data from its own accelerometer and multiple features from the Ford head unit which it will feed to a SVM machine learning model. The results of the analysis will be summarized with a single driving letter grade which will be read out to the user, surfaced to the head unit, and shown on the device.
## Challenges I ran into
Much of the hackathon was spent learning how to properly integrate our Android app and machine learning model with the Ford head unit via smart device link. This led to multiple challenges along the way such as figuring out how to properly communicate from the main Android activity to the smart device link service and from the service to the head unit via RPC.
## Accomplishments that I'm proud of
We are proud that we were able to make a fully connected user experience that enables interaction from multiple user interfaces such as the phone, Ford head unit, or voice.
## What I learned
We learned how to work with smart device link, various new Android techniques, and vehicle infotainment systems.
## What's next for Drovo
We think that Drovo should be more than just a one time measurement of driving skills. We are thinking of keeping track of your previous trips to see how your driving skills have changed over time. We would also like to return the vehicle data we analyzed to highlight specific periods of bad driving.
Beyond that, we think Drovo could be a great incentive for teenage drivers to be proud of good driving. By implementing a social leaderboard, users can see their friends' driving grades, which will in turn motivate them to increase their own driving skills. | ## Inspiration
In August, one of our team members was hit by a drunk driver. She survived with a few cuts and bruises, but unfortunately, there are many victims who are not as lucky. The emotional and physical trauma she and other drunk-driving victims experienced motivated us to try and create a solution in the problem space.
Our team initially started brainstorming ideas to help victims of car accidents contact first response teams faster, but then we thought, what if we could find an innovative way to reduce the amount of victims? How could we help victims by preventing them from being victims in the first place, and ensuring the safety of drivers themselves?
Despite current preventative methods, alcohol-related accidents still persist. According to the National Highway Traffic Safety Administration, in the United States, there is a death caused by motor vehicle crashes involving an alcohol-impaired driver every 50 minutes. The most common causes are rooted in failing to arrange for a designated driver, and drivers overestimating their sobriety. In order to combat these issues, we developed a hardware and software tool that can be integrated into motor vehicles.
We took inspiration from the theme “Hack for a Night out”. While we know this theme usually means making the night out a better time in terms of fun, we thought that another aspect of nights out that could be improved is getting everyone home safe. Its no fun at all if people end up getting tickets, injured, or worse after a fun night out, and we’re hoping that our app will make getting home a safer more secure journey.
## What it does
This tool saves lives.
It passively senses the alcohol levels in a vehicle using a gas sensor that can be embedded into a car’s wheel or seat. Using this data, it discerns whether or not the driver is fit to drive and notifies them. If they should not be driving, the app immediately connects the driver to alternative options of getting home such as Lyft, emergency contacts, and professional driving services, and sends out the driver’s location.
There are two thresholds from the sensor that are taken into account: no alcohol present and alcohol present. If there is no alcohol present, then the car functions normally. If there is alcohol present, the car immediately notifies the driver and provides the options listed above. Within the range between these two thresholds, our application uses car metrics and user data to determine whether the driver should pull over or not. In terms of user data, if the driver is under 21 based on configurations in the car such as teen mode, the app indicates that the driver should pull over. If the user is over 21, the app will notify if there is reckless driving detected, which is based on car speed, the presence of a seatbelt, and the brake pedal position.
## How we built it
Hardware Materials:
* Arduino uno
* Wires
* Grove alcohol sensor
* HC-05 bluetooth module
* USB 2.0 b-a
* Hand sanitizer (ethyl alcohol)
Software Materials:
* Android studio
* Arduino IDE
* General Motors Info3 API
* Lyft API
* FireBase
## Challenges we ran into
Some of the biggest challenges we ran into involved Android Studio. Fundamentally, testing the app on an emulator limited our ability to test things, with emulator incompatibilities causing a lot of issues. Fundamental problems such as lack of bluetooth also hindered our ability to work and prevented testing of some of the core functionality. In order to test erratic driving behavior on a road, we wanted to track a driver’s ‘Yaw Rate’ and ‘Wheel Angle’, however, these parameters were not available to emulate on the Mock Vehicle simulator app.
We also had issues picking up Android Studio for members of the team new to Android, as the software, while powerful, is not the easiest for beginners to learn. This led to a lot of time being used to spin up and just get familiar with the platform. Finally, we had several issues dealing with the hardware aspect of things, with the arduino platform being very finicky and often crashing due to various incompatible sensors, and sometimes just on its own regard.
## Accomplishments that we're proud of
We managed to get the core technical functionality of our project working, including a working alcohol air sensor, and the ability to pull low level information about the movement of the car to make an algorithmic decision as to how the driver was driving. We were also able to wirelessly link the data from the arduino platform onto the android application.
## What we learned
* Learn to adapt quickly and don’t get stuck for too long
* Always have a backup plan
## What's next for Drink+Dryve
* Minimize hardware to create a compact design for the alcohol sensor, built to be placed inconspicuously on the steering wheel
* Testing on actual car to simulate real driving circumstances (under controlled conditions), to get parameter data like ‘Yaw Rate’ and ‘Wheel Angle’, test screen prompts on car display (emulator did not have this feature so we mimicked it on our phones), and connecting directly to the Bluetooth feature of the car (a separate apk would need to be side-loaded onto the car or some wi-fi connection would need to be created because the car functionality does not allow non-phone Bluetooth devices to be detected)
* Other features: Add direct payment using service such as Plaid, facial authentication; use Docusign to share incidents with a driver’s insurance company to review any incidents of erratic/drunk-driving
* Our key priority is making sure the driver is no longer in a compromising position to hurt other drivers and is no longer a danger to themselves. We want to integrate more mixed mobility options, such as designated driver services such as Dryver that would allow users to have more options to get home outside of just ride share services, and we would want to include a service such as Plaid to allow for driver payment information to be transmitted securely.
We would also like to examine a driver’s behavior over a longer period of time, and collect relevant data to develop a machine learning model that would be able to indicate if the driver is drunk driving more accurately. Prior studies have shown that logistic regression, SVM, decision trees can be utilized to report drunk driving with 80% accuracy. | ## Inspiration
Did you know that traffic accidents are the leading cause of mortality in America? According to the US Department of Transportation, there are over 6 million automotive crashes each year. 60% of these 6 million could have been prevented had the driver been alerted a mere half second before the collision. Last summer, our teammate Colin drove 5 hours a day on what is known as "America's deadliest highway." He wished he was able to notify other cars when he wanted to pass them or merge into another lane.
## What it does
We created an app called "Aware" that allows vehicles to notify other vehicles if they wish to pass or merge. The app is purely voice command because driving should be hands-free with minimal distractions.
## How we built it
Hands-free interface using Android Text-to-Speech and Google Speech-to-Text, Android app using Android Studio, sending and receiving messages using Firebase. The reason we chose to do this as an app rather than integrated in a car is because not everyone's car has the technology to communicate with other cars (also because we're broke college students and don't have Teslas to test on). If many cars can't send/receive messages, then that defeats the purpose of our idea. However, almost everyone has a phone, meaning that the majority of drivers on the road will immediately be able to download our app and start using it to communicate with each other.
## Challenges we ran into
This is our first time using Google APIs, Android, and Firebase so there was a lot of time spent figuring out how these technologies worked.
## Accomplishments that we're proud of
Brainstorming an impactful idea! Learning new skills! Great teamwork!
## What we learned
Lots about Android development, Google APIs, Firebase, and voice integration!
## What's next for Aware
We plan to implement proactive warnings, for example if there is a pedestrian walking behind when a car is reversing. Additionally, Aware could interact with infrastructure, like detecting how much longer a light will be red or where the nearest empty parking lot is. | winning |
# ThreatTrace AI: Your Solution for Swift Violence Detection
## ThreatTrace AI eliminates the need for constant human monitoring of camera footage, facilitating faster threat identification and enhanced safety.
## Inspiration
In response to the rising weapon-related crimes in Toronto, we developed a weapon detection tool using artificial intelligence to reduce the potential for violence.
## What It Does
ThreatTrace AI is a peacekeeping platform aiming to utilize AI object detection to identify weapons and alert the authorities regarding potential threats and violence. Our ultimate vision was to monitor real-time security footage for violence detection, eliminating the need for human oversight across multiple screens. However, due to time constraints, we focused on training our machine learning model solely to detect weapons, namely pistols and guns from images.
## How We Built It
Our frontend utilizes Python's Flask library with HTML and CSS, while the backend is powered by TensorFlow and various other libraries and repositories. We trained our machine learning model with a specific dataset and organized selected images in a folder, which we iterate through to create a 'slideshow' on the frontend.
## Challenges We Ran Into
Throughout the event, we encountered numerous challenges that shaped the course of our inspiration development as a team. We started off as two separate groups of three people, but then one person from one team fell ill on the day of the event, and the other team was looking to form a team of four. However, since there were many teams of two or three looking for more members, one team had to disassemble into a group of two and join another group of two to finally form a group of four. During our setup phase, our computers ran into a lot of troubles while trying to install the necessary packages for the machine learning model to function. Our original goal was to have three to all four of us train the learning model with datasets, but unfortunately, we spent half of the time, and only two members managed to set up the machine learning model by the end of the event. In the end, only one member managed to train the model, making this the greatest technical challenge we've encountered in the event and slowing our progress by a margin.
## Accomplishments That We're Proud Of
We're proud of the progress made from utilizing machine learning APIs such as TensorFlow and object detection for the very first time. Additionally, two members had no experience with Flask, and yet we were still able to develop a functional frontend in conjunction with HTML and CSS.
## What We Learned
We have learned about numerous new technical knowledge regarding libraries, packages, and technologies such as TensorFlow, virtual environments, GitHub, CocoAPI, and ObjectDetectionAPI. Since three of our members use Windows as the main operating system, we had to utilize both the Windows and the bash terminals to set up our repository. Through our numerous trials, we have also learned about the vast amount of time it takes to train a machine learning model and dataset before being able to make use of it. Finally, the most important lesson we have learned was team collaboration, as each of us has made use of our strengths, and we utilized our abilities well to facilitate this project.
## What's Next for ThreatTrace AI
Our goal is to continue training our learning model to accept more weapons at different lighting levels and angles, so that our dataset can be more refined as time goes. Then we will transition into training video footages with the learning model. Ultimately, we will reach our original vision of a real-time video violence detection AI. | ## Inspiration
We were inspired by the recent interest of many companies in drone delivery and drone search. In particular, we wanted to bring drone abilities to the consumer – and we ended up doing even more.
There are many applications that can stem from our work, from search and rescue missions, drone delivery, or just finding your keys. In addition, we’ve brought the ability for a consumer to, with just their voice, train a classifier for object recognition.
[Voice Controlled Delivery Drone](https://youtu.be/8HKiQQVDcKQ)
[Real Time Search Drone](https://www.youtube.com/watch?v=CjqaV1Kw308)
## What it does
We build a pipeline that allows anyone to visually search for objects using a drone and simplified computer vision and machine learning.
It consists of mainly 3 parts:
1) A search drone (controlled normally with your phone) that performs image classification in real time for a given object
2) Being able to train an image classifier on any object by just using your voice.
3) A voice-controlled drone that can perform targeted delivery
## How we built it
We used an Amazon Echo to handle voice input, and the transcribed input was sent to a AWS Lambda server. Depending on the text, it was classified into one of several categories (such as commands). This server updated a Firebase database with the appropriate commands/information. Next, our local computers were notified whenever the database changed, and executed appropriate commands -- whether that be train an image classifier or fly a drone.
To get the non-programmable drone to become a search drone, we had it live stream its video feed to an Android phone, and we had a script that constantly took screenshots of the Android phone and stored them on our computer. Then we could use this images either for training data or to classify them in real time, using image segmentation and IBM Watson.
To train a classifier with only your voice, we would take the search term and use the Bing Search API to get images associated with that term. This served as the training data. We would then feed this training data into IBM Watson to build a classifier. This classifier could later be used for the search drone. All the consumer had to do was use their voice to do computer vision -- we took care of getting the data and applying the machine learning applications.
## Challenges we ran into
We are working with sandboxed technologies meant for the average consumer – but that are not developer friendly. It wasn't possible to take pictures or move the drone programmatically. We had to hack creative ways to enable this new capabilities for technologies, such as the screenshot pulling described above.
Additionally, the stack of coordinating communication with Alexa’s server, databases, and sending commands to the drone was quite a relay.
## Accomplishments that we're proud of
-Being able to create a super consumer-friendly way of training image classifiers.
-Taking a non-programmable drone and being able to hack with it still
-Being able to do voice control in general!
## What we learned
Hardware is finnicky.
## What's next for Recon
Even more precise control of the drone as well as potentially control over multiple drones. | ## Inspiration
How many clicks does it take to upload a file to Google Drive? TEN CLICKS. How many clicks does it take for PUT? **TWO** **(that's 1/5th the amount of clicks)**.
## What it does
Like the name, PUT is just as clean and concise. PUT is a storage universe designed for maximum upload efficiency, reliability, and security. Users can simply open our Chrome sidebar extension and drag files into it, or just click on any image and tap "upload". Our AI algorithm analyzes the file content and organizes files into appropriate folders. Users can easily access, share, and manage their files through our dashboard, chrome extension or CLI.
## How we built it
We the TUS protocol for secure and reliable file uploads, Cloudflare workers for AI content analysis and sorting, React and Next.js for the dashboard and Chrome extension, Python for the back-end, and Terraform allow anyone to deploy the workers and s3 bucket used by the app to their own account.
## Challenges we ran into
TUS. Let's prefix this by saying that one of us spent the first 18 hours of the hackathon on a golang backend then had to throw the code away due to a TUS protocol incompatibility. TUS, Cloudflare's AI suite and Chrome extension development were completely new to us and we've run into many difficulties relating to implementing and combining these technologies.
## Accomplishments that we're proud of
We managed to take 36 hours and craft them into a product that each and every one of us would genuinely use.
We actually received 30 downloads of the CLI from people interested in it.
## What's next for PUT
If given more time, we would make our platforms more interactive by utilizing AI and faster client-server communications. | partial |
## Coinbase Analytics
**Sign in with your Coinbase account, and get helpful analytics specific to your investment.**
See in depth returns, and a simple profit and cost analysis for Bitcoin, Ethereum, and Litecoin.
Hoping to help everyone that uses and will use Coinbase to purchase cryptocurrency. | .png)
## Inspiration
Over the last five years, we've seen the rise and the slow decline of the crypto market. It has made some people richer, and many have suffered because of it. We realized that this problem can be solved with data and machine learning - What if we can, accurately, predict forecast for crypto tokens so that the decisions are always calculated? What if we also include a chatbot to it - so that crypto is a lot less overwhelming for the users?
## What it does
*Blik* is an app and a machine learning model, made using MindsDB, that forecasts cryptocurrency data. Not only that, but it also comes with a chatbot that you can talk to, to make calculated decisions for your. Next trades.
The questions can be as simple as *"How's bitcoin been this year?"* to something as personal as *"I want to buy a tesla worth $50,000 by the end of next year. My salary is 4000$ per month. Which currency should I invest in?"*
We believe that this functionality can help the users make proper, calculated decisions into what they want to invest in. And in return, get high returns for their hard-earned money!
## How we built it
Our tech stack includes:
* **Flutter** for the mobile app
* **MindsDB** for the ML model + real time finetuning
* **Cohere** for AI model and NLP from user input
* **Python** backend to interact with MindsDB and CohereAI
* **FastAPI** to connect frontend and backend.
* **Kaggle** to source the datasets of historic crypto prices
## Challenges we ran into
We started off using the default model training using MindsDB, however, we realized that we would need many specific things like forecasting at specific dates, with a higher horizon etc. The mentors at the MindsDB counter helped us a real lot. With their help, we were able to set up a working prototype and were getting confident about our plan.
One more challenge we ran into was that the forecasts for a particular crypto would always end up spitting the same numbers, making it difficult for users to predict
Then, we ended up using the NeuralTS as our engine, which was perfect. Getting the forecasts to be as accurate as possible was definitely a challenge for us, while keeping it performant enough. Solving every small issue would give rise to another one; but thanks to the mentors and the amazing documentations, we were able to figure out the MindsDB part.
Then, we were trying to implement the AI chat feature, using CohereAI. We had a great experience with the API as it was easy to use, and the chat completions were also really good. We wanted the generated data from Cohere to generate an SQL query to use on MindsDB. Getting this right was challenging, as I'd always need the same datatype in a structured format in order to be able to stitch an SQL command. We figured this also out using advanced prompting techniques and changing the way we pass the data into the SQL. We also used some code to clean up the generated text and make sure that its always compatible.
## Accomplishments that we're proud of
Honestly, going from an early ideation phase to an entire product in just two days, for an indie team of two college freshmen is really a moment of pride. We created a fully working product with an AI chatbot, etc.
Even though we were both new to all of this - integrating crypto with AI techologies is a challenging problem, and thankfully MindsDB was very fun to work with. We are extremely happy about the mindsDB learnings as we can now implement it in our other projects to enhance them with machine learning.
## What we learned
We learnt AI and machine learning, using MindsDB, interacting with AI and advanced prompting, understanding user's needs, designing beautiful apps and presenting data in a useful yet beautiful way in the app.
## What's next for Blik.
At Blik, long term, we plan on expanding this to a full fledged crypto trading solution, where users can sign up and create automations that they can run, to "get rich quick". Short term, we plan to increase the model's accuracy by aggregating news into it, along with the cryptocurrency information like the founder information and the market ownership of the currency. All this data can help us further develop the model to be more accurate and helpful. | ## Inspiration
It’s Friday afternoon, and as you return from your final class of the day cutting through the trailing winds of the Bay, you suddenly remember the Saturday trek you had planned with your friends. Equipment-less and desperate you race down to a nearby sports store and fish out $$$, not realising that the kid living two floors above you has the same equipment collecting dust. While this hypothetical may be based on real-life events, we see thousands of students and people alike impulsively spending money on goods that would eventually end up in their storage lockers. This cycle of buy-store-collect dust inspired us to develop Lendit this product aims to stagnate the growing waste economy and generate passive income for the users on the platform.
## What it does
A peer-to-peer lending and borrowing platform that allows users to generate passive income from the goods and garments collecting dust in the garage.
## How we built it
Our Smart Lockers are built with RaspberryPi3 (64bit, 1GB RAM, ARM-64) microcontrollers and are connected to our app through interfacing with Google's Firebase. The locker also uses Facial Recognition powered by OpenCV and object detection with Google's Cloud Vision API.
For our App, we've used Flutter/ Dart and interfaced with Firebase. To ensure *trust* - which is core to borrowing and lending, we've experimented with Ripple's API to create an Escrow system.
## Challenges we ran into
We learned that building a hardware hack can be quite challenging and can leave you with a few bald patches on your head. With no hardware equipment, half our team spent the first few hours running around the hotel and even the streets to arrange stepper motors and Micro-HDMI wires. In fact, we even borrowed another team's 3-D print to build the latch for our locker!
On the Flutter/ Dart side, we were sceptical about how the interfacing with Firebase and Raspberry Pi would work. Our App Developer previously worked with only Web Apps with SQL databases. However, NoSQL works a little differently and doesn't have a robust referential system. Therefore writing Queries for our Read Operations was tricky.
With the core tech of the project relying heavily on the Google Cloud Platform, we had to resolve to unconventional methods to utilize its capabilities with an internet that played Russian roulette.
## Accomplishments that we're proud of
The project has various hardware and software components like raspberry pi, Flutter, XRP Ledger Escrow, and Firebase, which all have their own independent frameworks. Integrating all of them together and making an end-to-end automated system for the users, is the biggest accomplishment we are proud of.
## What's next for LendIt
We believe that LendIt can be more than just a hackathon project. Over the course of the hackathon, we discussed the idea with friends and fellow participants and gained a pretty good Proof of Concept giving us the confidence that we can do a city-wide launch of the project in the near future. In order to see these ambitions come to life, we would have to improve our Object Detection and Facial Recognition models. From cardboard, we would like to see our lockers carved in metal at every corner of this city. As we continue to grow our skills as programmers we believe our product Lendit will grow with it. We would be honoured if we can contribute in any way to reduce the growing waste economy. | partial |
## Inspiration
We recognized that packages left on porch are unsafe and can be easily stolen by passerby and mailmen. Delivery that requires signatures is safer, but since homeowners are not always home, deliveries often fail, causing inconvenience for both homeowners and mailmen.
The act of picking up packages and carrying packages into home can also be physically straining for some.
Package storage systems are available in condos and urban locations, such as concierge or Amazon lockers, but unavailable in the suburbs or rural region, such as many areas of Brampton.
Because of these pain points, we believe there is market potential for homeowners in rural areas for a personal delivery storage solution. With smart home hacking and AI innovation in mind, we improve the lives of all homeowners by ensuring their packages are efficiently delivered and securely stored.
## What it does
OWO is a novel package storage system designed to prevent theft in residential homes. It uses facial recognition, user ID, and passcode to verify the identity of mailman before unlocking the device and placing the package on the device. The automated device is connected to the interior of the house and contains a uniquely designed joint to securely bring packages into home. Named "One Way Only", it effectively prevents any possible theft by passerby or even another mailman who have access to the device.
## How I built it
We built a fully animated CAD design with Fusion 360. Then, we proceeded with an operating and automated prototype and user interface using Arduino, C++, light fabrication, 3D printing. Finally, we set up an environment to integrate facial recognition and other Smart Home monitoring measures using Huawei Atlas 310 AI processor.
## What's next for One Way Only (OWO)
Build a 1:1 scaled high fidelity prototype for real-world testing. Design for manufacturing and installation. Reach out to potential partners to implement the system, such as Amazon. | In the distant future, mysterious gatherings unfolded across the globe, where those with an affinity for technology convened. Oddly enough, participants carried only a singular item on their keychains: a small, unassuming stick. This cryptic phenomenon came to be known as "Drive Duels," born from a thirst to unite reality and the virtual realm. Its foundation rested upon its user’s thumb drives, serving as an interface to the strange world on the other side.
## Inspiration
We were inspired by the physicality of old video games by using physical hardware directly tied to the game. We wanted to use something that most people have: a thumb drive. The data stored on a small drive isn’t fit for something like an online game, so instead we used them to give each player a unique physical object that can be used to meet others physically and challenge them. Anyone can take their thumb drive and use it to play *Drive Duels*.
## What it does
*Drive Duels* is a gotta-catch-em-all-style turn-based combat game utilizing generative AI to create unique creatures and USB media to encourage physical interactions between players as they battle.
In *Drive Duels*, every creature (*Byteling*) is represented as a file that can be downloaded (“created”), transferred from disk to disk, or sent to a friend. Players carry USB drives to store their parties, which they may take into battle to fight on their behalf.
Players will primarily interact with two pieces of software:
The Byteling Manager app is accessible from your own computer at [driveduels.co](https://driveduels.co/), and allows you to both create new Bytelings and review your existing ones—heal them up after battles, track their stats, and more.
The Battle Station is accessible at select in-person locations and supports live, turn-based, two-player battles. Players choose to utilize their fielded Byteling’s moves or swap in other Bytelings to strategically outmaneuver opponents and seize victory.
## How we built it
Byteling Manager is built with React, TailwindCSS, and Chrome’s experimental filesystem API. A backend service utilizes the ChatGPT and DALL-E APIs to create new creatures with unique descriptions, art, and movesets when requests are sent from the front-end.
The Battle Station software is designed with Electron (for ease of direct filesystem access) and React. It utilizes a complex state machine to ensure that battles are always kept moving.
## Challenges we ran into
Recognizing the USB’s connection automatically was tough, and many of the methods we wanted to try with our Electron app were simply incompatible. ChatGPT had a tendency to generate overpowered, misleading, or flat-out useless attacks, so we designed a balancing system to reassign attack values based on internal scoring metrics, which helped counteract some of these broken character generations.
## Accomplishments that we're proud of
We’re especially proud of the creature creator, which takes inspiration from user-selected keywords to create monsters with their own unique lore, art assets, attacks, and more, using GPT-3 and DALL-E. We are also proud of the battle system, which allows Bytelings from different owners to engage in combat together on a shared system.
## What we learned
We learned how to design a website mockup in Figma, and how to use TailwindCSS to style the site to our liking. We also got a better understanding of integrating ChatGPT/DALL-E into our web apps and creating more complex data from it.
## What's next for Drive Duels
We’re hoping to flesh out a leveling system, with experience gained in battle and locked attacks. | ## Inspiration
A friend who is a veteran going through similar, but not as bad, situation.
## What it does
When called, drives to a location with your shoes and lifts them up so that they can be easily put on.
## How I built it
Built it with $160 hardware from micro-center and using Nuance API.
## Challenges I ran into
Not having hardware until fairly late (12 hours remaining) in the hackathon.
## Accomplishments that I'm proud of
Even though two parts are not yet connected, each part works perfectly on it's own.
## What I learned
Dealing with circuits, working with raspberry - Pi, working with natural language processing, and using Nuance speech to text API
## What's next for Kortana
Make it perfect. Add AI component to it so that it can do some things automatically (like height to lift shoes up to). Have multiple sources where shoes can be picked up from and make it so that it's ready with the shoes faster by having a passive listener on phone. | partial |
# Inspiration
Every year, 3,000 people pass away from distracted driving. And every year, it's the leading cause of car accidents. However, this is a problem that can be solved by a transition towards ambient and touchless computing.
From reducing distracted driving to having implications for in-home usage (for those unable to adjust lighting, for instance), having ambient and touchless computing entails major impacts on the future. Being able to simply raise fingers to adjust car hardware, such as the speed of the AC fan, the intensity of the lights in the car, or even in homes for those unable to reach or utilize household appliances such as light switches, has implications beyond driving. We hope ambi. will be applicable in increasing safety and effectiveness in the future.
# What it does
The ambi. app, downloadable on mobile, provides a guide corresponding to hardware settings with the number of fingers held in front of the camera—integrated into ambi. with computer vision to track hand movements. When the driver opens the app, they are presented with the option to raise one finger to adjust lighting, two fingers for the AC fan, three fingers for the radio volume, and 4 fingers for the radio station. From there, they can choose to adjust the specific hardware based on what they find (1 finger for on, 2 for off, 3 for increase, 4 for decrease). This helps to reduce distracted driving by keeping their hands on the wheel while driving.
# How we built it
We had four main components that were integrated into this project: hardware, firmware, backend, and frontend. The hardware represents the physical functionalities of the car (e.g. lights, fan, speaker). In our demonstration, we simulated the lights and the fan of a car.
We used hardware to control the peripherals of the car such as the fan and the LED strip lights (Neopixel). For the fan, we used a transistor-driver circuit and pulse width modulation from the Arduino UNO to vary the duty cycle of the input wave and hence change the speed of the fan. Two resistors were attached to the gate of the power transistor to ensure: one to drive the GPIO and the other to ensure that it was not floating when there was no voltage present at it. A diode was also attached between the drain and source in case the fan-generated back EMF. A regulator (78L05) was used to supply voltage and current to the LED since it needed a lower voltage supply but a higher current. This was easier to program as it didn’t require PWM. The Neopixel library was used to control the brightness of the LEDs, their color, etc. A radio module, nRF24L01+, was used to communicate between the first Arduino UNO connected to the peripherals and the second Arduino UNO connected to the laptop running the computer vision python script and the backend. The communication over the radio was done using a library and a single integer was sent that encoded both the device that was chosen as well as its control. More specifically, this was the encoding used - 1: light, 2: fan then 1: on, 2: off, 3: increase, 4: decrease.
We used firmware to change the physical state of the hardware by analyzing the motions of a hand using computer vision and then changing the physical features of the car to match the corresponding hand motions. The firmware was built in Python scripts, using the libraries of mediapipe, opencv, and numpy. A camera (from the user’s phone) that is mounted next to the steering wheel, tracks the motion of the user’s hand. If it detects some fingers that are being held up by the user (from 1 to 4 fingers) for over 2 seconds, it will record the number of fingers, that corresponds to a certain device (e.g. lights). Then, the camera will continue to record the user as they hold up different numbers of fingers. One finger corresponds to turning on the device, two fingers correspond to turning off the device, three fingers corresponds to increasing the device (e.g. increasing brightness), and four fingers corresponds to decreasing the device (e.g. decreasing brightness). Then, if the user holds up no fingers for an extended amount of time, the system will alert the user and revert back to waiting for the user to input another device.
Third, we used a backend Python script to integrate the data received and transmitted to the firmware and computer vision with the data received and transmitted to the frontend Frontend Swift App. The backend Python script would take in data from the Frontend Swift App that indicates what each number of fingers corresponds to which specific task. It will communicate that with the firmware, calling functions from the firmware library to start each of the different functions. For example, the backend Python script will call a function in the firmware library to wait until a device is selected, and then after this device is selected, to perform various functionalities. The speech is also configured in this script to indicate to the user what is currently being done.
Finally, the frontend of ambi. is built using SwiftUI and will be integrated on a user’s phone. The app will present the user with a guide corresponding to the number of fingers with hardware, as well as its specific adjustment, such as which fingers correspond to toggling on and off or increasing and decreasing a certain physical component of the car. This app will demonstrate what the users can control with the touchless computer, as well as generate discrete variables that can automatically toggle a specific state, such as a specific speed of the fan or turning a light completely off.
# Challenges we ran into
Throughout the process, we found it difficult to integrate the hardware with the software. Each member of the team worked on a specialized part of the project, from hardware to firmware to frontend UI/UX to backend. Bringing each piece together, and especially the computer vision with the camera set up on the ambi. app proved to be quite difficult. However, teamwork makes the dream work and we were able to get it done, especially since each of us focused on a specific part (i.e. one teammate worked on frontend, while another on firmware, and so on).
Here are some specific challenges we faced:
Downloading the libraries and configuring the paths - you may be surprised about how tricky this is
Ensuring that the computer vision algorithm had a high accuracy and wouldn't detect unwanted movements or gestures
Integrating the backend with the firmware Python script
Integrating the hardware (using Arduino IDE) with the firmware Python script
Learning Swift within a day and hence, building a functional frontend
Debugging hardware when PWM or on/off functionalities were going awry - this was resolved through a more careful understanding of the libraries that we were using
Adding the speech command as another feature of our Python script and backend
Accomplishments that we're proud of
We created a touchless computer that involved several integrations from hardware to front-end development. We demonstrated the capabilities of changing volume or fan speed in our hardware by using computer vision to track specific hand motions. This was integrated with a Python backend that was interfaced with a frontend app built in Swift.
# What we learned
During this process, we learned how to build a Restful API, mobile applications, techniques to interface between software and hardware, computer vision, and establish product-market fit. We also learned that hacking is not just about creating something new, but integrating several components together to create a product that creates a meaningful impact on society, while working together on a team.
We also learned what teamwork in a development project looks like. Often a task reaches a point where it cannot be split between developers, and given the limited time, this limited the scope of what we could code in such a short amount of time. However, we benefited from acknowledging this for the smooth development process. Moreover, since each member often had a completely different section that they worked in, we learned to integrate each vertical of the final project (such as firmware or frontend) with the other components using APIs.
# What's next for ambi.
Ambi.’s technology is hacked together currently. However, the first step would be more seamlessly integrating the frontend to the iPhone camera that acts as a sensor for movement. There is a lack of libraries to launch videos from a swift application, which means ambi. Will create another library for itself. We want to focus specifically on Site Reliability Engineering and creating a lighter tech stack to reduce latency as these drastically improve user adoption and retention.
Next, ambi. needs to connect to an actual car API and be able to manipulate some of its hardware devices. Teslas and other tech-forward cars are likely strong markets, as they have companion apps and digital ecosystems with native internet connections, increasing the seamless quality that we want ambi. to deliver.
Ambient computing has numerous applications with IoT and the digitization of non-digital interfaces (e.g. any embedded system operated by buttons instead of generalized input-output devices). We plan to consider applications for Google Nest, integrating geonets to sense when to begin touchless computing as well as kitchen appliance augmentations. | ## Inspiration
Car theft is a serious issue that has affected many people in the GTA. Car theft incidents have gone up 60% since 2021. That means thousands of cars are getting stolen PER WEEK, and right in front from their driveway. This problem is affecting middle class communities, most evidently at Markham, Ontario. This issue inspired us to create a tracking app and device that would prevent your car from being stolen, while keeping your friend’s car safe as well.
## What it does
We built two components in this project. A hardware security system and an app that connects to it.
In the app you can choose to turn on/off the hardware system by clicking lock/unlock inside the app. When on, the hardware component will use ultrasonic sensors to detect motion. If motion is detected, the hardware will start buzzing and will connect to Twilio to immediately send an SMS message to your phone. As while the app has many more user-friendly features including location tracking for the car and the option to add additional cars.
## How we built it
We built the front-end design with figma. This was our first time using it and it took some Youtube videos to get used to the software, but in the end we were happy with our builds. The hardware system incorporated an arduino yun that connected and made SMS text messages through twilio’s api system. As well, the arduino required C code for all the SMS calls, LED lights, and buzzer. The hardware also included some wiring and ultrasonic sensors for detection. We finally wanted to produce an even better product so we used CAD designs to expand upon our original hardware designs. Overall, we are extremely pleased with our final product.
## Business Aspect of SeCARity
As for the business side of things, we believe that this product can be easily marketable and attract many consumers. These types of products are in high demand currently as they solve an issue our society is currently facing. The market for this will be big and as this product holds hardware parts that can be bought for cheap, meaning that the product will be reasonably priced.
## Challenges we ran into
We had some trouble coming up with an idea, and specifically one that would allow our project to be different from other GPS tracker devices. We also ran into the issue of certain areas of our project not functioning the way we had ideally planned, so we had to use quick problem solving to think of an alternative solution. Our project went through many iterations to come up with a final product.
There were many challenges we ran into on Figma, especially regarding technical aspects. The most challenging aspect in this would’ve been the implementation of the design.
Finally, the virtual hacking part was difficult at times to communicate with each other, but we persisted and were able to work around this.
## Accomplishments that we're proud of
We are extremely proud of the polished CAD version of the more complex and specific and detailed car tracker. We are very proud of the app and all the designs. Furthermore, we were really happy with the hardware system and the 3-D printed model casing to cover it.
## What we learned
We learned how to use Figma and as well an Arduino Yun. We never used this model of an Arduino and it was definitely something really cool. As it had wifi capabilities, it was pretty fun to play around with and implement new creations to this type of model. As for Figma, we learned how to navigate around the application and create designs.
## What's next for SeCARity
-Using OpenCV to add camera detection
-Adding a laser detection hardware system
-Ability to connect with local authorities | ## Inspiration
Our inspiration for this idea came as we are becoming of age to drive and as we recognize the importance of safety on the road. We decided to address the topic of driver safety, specifically, distractions while driving, and crash detection. We are bombarded with countless distractions while driving, and as cars are at their fastest, the roads are significantly more dangerous than ever before. With these thoughts in mind, our project aims to make the roads safer for everyone, cars and pedestrians alike. We created a project that would notify and assist drivers to be focused on the road and send emergency messages when a crash is detected. Our goal is to make sure everyone on or near the road is safe and that no unnecessary accidents occur.
## What it does
The project is a live eye-tracking program that would increase overall driver safety on the road. Using the AdHawk MindLink, our program tracks the gaze of the driver and determines if the gaze has left the designated field of view, if so, causing auditory and visual notifications for the driver to re-focus on the road. The program also detects an open eye for 45 seconds or a closed eye for 45 seconds. If such conditions arise, the program recognizes it as a fatal crash by sending out a text message to emergency services. The eye tracking programming is made with python, an emergency text program with Twilio and the hardware is third-generation Arduino Uno integrated with a shield and equipped with a buzzer, LED, and programmed with C++.
## How we built it
The base of our project was inspired by AdHawk’s Mindlink glasses. Using Mindlink, we were able to extract the horizontal and vertical coordinates of the gaze. In combination with those position values, and predetermined zones (10 degrees on each side of origin), we programmed the Arduino to a buzzer and LED. For crash detection, we used an event, “Blink”, which will detect whether a blink has been made. However, if a blink is not preceded by a second one in 45 seconds, the program will recognize it as a fatal injury, triggering Twilio to send text messages to emergency services with accurate location data of the victim.
## Challenges we ran into
Throughout the hackathon, we had many minor speed bumps but our major issue was getting the accurate position values with AdHawk Mindlink. Mindlink returns vectors for indicating position which is really complicated to work with. We turned the vectors into angles (radians) and used those values to set the boundaries for what is considered distracting and considered focused.
## Accomplishments that we're proud of
An accomplishment that our team is most proud of is that our idea started as a small thought, but as we worked on the project, we were able to think about a variety of helpful features to add to our product. We went from using AdHawk's eye-tracking technology for just tracking the driver's gaze to actual safety features such as notifying drivers to be focused on the road and sending emergency messages when a crash is detected.
## What we learned
During Hack the North, we learned countless new things from how to use different programs and technologies to how to solve problems critically. We learned how to use AdHawk's eye-tracking technology by visiting their Hack the North help center website and asking questions at their venue. We learned how to use Twilio and program SMS text messages when the driver has closed/opened their eyes for more than 45 seconds. Throughout this progress, we went through a lot of trial and error, tackling one problem at a time and productively progressing through this project.
## What's next for iTrack
Several exciting ideas are planned for iTrack. Starting with Free Detection mode, currently, the driver needs to wear glasses for iTrack to work. With more time, we would be able to program and put cameras around the interior of the car and track the eye from that instead, making it less invasive. Next, we are planning to add additional sensors (accelerometer, gyroscope etc …) to the glasses to further enhance the crash detection system, which will act as additional sources of triggers for the Twilio emergency texting. Other improvements include auto-calibration, which will drastically reduce the amount of time needed to set up AdHawk Mindlink for the most accurate responses. | partial |
## Inspiration
Being a student of the University of Waterloo, every other semester I have to attend interviews for Co-op positions. Although it gets easier to talk to people, the more often you do it, I still feel slightly nervous during such face-to-face interactions. During this nervousness, the fluency of my conversion isn't always the best. I tend to use unnecessary filler words ("um, umm" etc.) and repeat the same adjectives over and over again. In order to improve my speech through practice against a program, I decided to create this application.
## What it does
InterPrep uses the IBM Watson "Speech-To-Text" API to convert spoken word into text. After doing this, it analyzes the words that are used by the user and highlights certain words that can be avoided, and maybe even improved to create a stronger presentation of ideas. By practicing speaking with InterPrep, one can keep track of their mistakes and improve themselves in time for "speaking events" such as interviews, speeches and/or presentations.
## How I built it
In order to build InterPrep, I used the Stdlib platform to host the site and create the backend service. The IBM Watson API was used to convert spoken word into text. The mediaRecorder API was used to receive and parse spoken text into an audio file which later gets transcribed by the Watson API.
The languages and tools used to build InterPrep are HTML5, CSS3, JavaScript and Node.JS.
## Challenges I ran into
"Speech-To-Text" API's, like the one offered by IBM tend to remove words of profanity, and words that don't exist in the English language. Therefore the word "um" wasn't sensed by the API at first. However, for my application, I needed to sense frequently used filler words such as "um", so that the user can be notified and can improve their overall speech delivery. Therefore, in order to implement this word, I had to create a custom language library within the Watson API platform and then connect it via Node.js on top of the Stdlib platform. This proved to be a very challenging task as I faced many errors and had to seek help from mentors before I could figure it out. However, once fixed, the project went by smoothly.
## Accomplishments that I'm proud of
I am very proud of the entire application itself. Before coming to Qhacks, I only knew how to do Front-End Web Development. I didn't have any knowledge of back-end development or with using API's. Therefore, by creating an application that contains all of the things stated above, I am really proud of the project as a whole. In terms of smaller individual accomplishments, I am very proud of creating my own custom language library and also for using multiple API's in one application successfully.
## What I learned
I learned a lot of things during this hackathon. I learned back-end programming, how to use API's and also how to develop a coherent web application from scratch.
## What's next for InterPrep
I would like to add more features for InterPrep as well as improve the UI/UX in the coming weeks after returning back home. There is a lot that can be done with additional technologies such as Machine Learning and Artificial Intelligence that I wish to further incorporate into my project! | ## Inspiration
While caught in the the excitement of coming up with project ideas, we found ourselves forgetting to follow up on action items brought up in the discussion. We felt that it would come in handy to have our own virtual meeting assistant to keep track of our ideas. We moved on to integrate features like automating the process of creating JIRA issues and providing a full transcript for participants to view in retrospect.
## What it does
*Minutes Made* acts as your own personal team assistant during meetings. It takes meeting minutes, creates transcripts, finds key tags and features and automates the process of creating Jira tickets for you.
It works in multiple spoken languages, and uses voice biometrics to identify key speakers.
For security, the data is encrypted locally - and since it is serverless, no sensitive data is exposed.
## How we built it
Minutes Made leverages Azure Cognitive Services for to translate between languages, identify speakers from voice patterns, and convert speech to text. It then uses custom natural language processing to parse out key issues. Interactions with slack and Jira are done through STDLIB.
## Challenges we ran into
We originally used Python libraries to manually perform the natural language processing, but found they didn't quite meet our demands with accuracy and latency. We found that Azure Cognitive services worked better. However, we did end up developing our own natural language processing algorithms to handle some of the functionality as well (e.g. creating Jira issues) since Azure didn't have everything we wanted.
As the speech conversion is done in real-time, it was necessary for our solution to be extremely performant. We needed an efficient way to store and fetch the chat transcripts. This was a difficult demand to meet, but we managed to rectify our issue with a Redis caching layer to fetch the chat transcripts quickly and persist to disk between sessions.
## Accomplishments that we're proud of
This was the first time that we all worked together, and we're glad that we were able to get a solution that actually worked and that we would actually use in real life. We became proficient with technology that we've never seen before and used it to build a nice product and an experience we're all grateful for.
## What we learned
This was a great learning experience for understanding cloud biometrics, and speech recognition technologies. We familiarised ourselves with STDLIB, and working with Jira and Slack APIs. Basically, we learned a lot about the technology we used and a lot about each other ❤️!
## What's next for Minutes Made
Next we plan to add more integrations to translate more languages and creating Github issues, Salesforce tickets, etc. We could also improve the natural language processing to handle more functions and edge cases. As we're using fairly new tech, there's a lot of room for improvement in the future. | ## Inspiration
Over [136,000](https://vancouversun.com/feature/how-international-students-are-filling-funding-shortfalls/chapter-4) international students choose to study in British Columbia each year, with learning English as their second language. With such a multi-cultural city, being able to communicate in English and different languages is crucial to connecting to others personally.
Despite the language learning apps out there, we realized that many of them do not give personalized feedback on the accuracy of their pronunciation and grammar - which is important to improvement in skills.
We wanted to make practicing languages easier, by creating an online coach (chat bot) that was accessible at anytime, as well as practice in a safe environment without judgment.
## What it does
Our website allows learners to choose from a selection of languages to practice on. The chat bot and the user begin a conversation, and the user speaks into their microphone to continue the conversation. The user can then stop the conversation and see an analysis of their speech - such as pronunciation, grammar, hesitation (pausing/filler words) and vocabulary.
## How we built it
We used speech-to-text package in npm to convert user dialogues into actual text for grammar analysis. We attempted speech analysis with Microsoft Azure as well.
The method we used to analyze grammar was keeping track of incorrect character counts and display the final grammatical correctness in percentage upon finishing conversation with the chat bot.
Website hosted with Azure
## Challenges we ran into
Speech to Text - attempted multiple methods of changing speech to text, experimenting with multiple APIs, such that we were able to convert speech accurately into text into readable files
Speech analysis - understanding the method of grammar analysis to use and comparing it to a baseline
Limitations of Azure API - troubles converting BLOB to Wav files in JavaScript - but found an alternative solution
## Accomplishments that we're proud of
Experimenting with new technologies
Well-flowing user interface
Integrating all our work together
Working on a project that could benefit many people
## What we learned
Without teamwork and supporting each other through the 24 hours, we wouldn't have been able to complete this project.
Some seemingly simple concepts can be much more complex than we thought.
## What's next for TicTalk
Chat bot speaks aloud
Additional metrics for speech analysis
Suggestions for conversations with the chat bot
Create a social component (and link to social media) to the app, where you can practice with a friend and use the platform as an analysis tool | winning |
## Inspiration
We were inspired by how there were many instances of fraud with regards to how donations were handled. It is heartbreaking to see how mismanagement can lead to victims of disasters not receiving the help that they desperately need.
## What it does
TrustTrace introduces unparalleled levels of transparency and accountability to charities and fundraisers. Donors will now feel more comfortable donating to causes such as helping earthquake victims since they will now know how their money will be spent, and where every dollar raised is going to.
## How we built it
We created a smart contract that allowed organisations to specify how much money they want to raise and how they want to segment their spending into specific categories. This is then enforced by the smart contract, which puts donors at ease as they know that their donations will not be misused, and will go to those who are truly in need.
## Challenges we ran into
The integration of smart contracts and the web development frameworks were more difficult than we expected, and we overcame them with lots of trial and error.
## Accomplishments that we're proud of
We are proud of being able to create this in under 36 hours for a noble cause. We hope that this creation can eventually evolve into a product that can raise interest, trust, and participation in donating to humanitarian causes across the world.
## What we learned
We learnt a lot about how smart contract works, how they are deployed, and how they can be used to enforce trust.
## What's next for TrustTrace
Expanding towards serving a wider range of fundraisers such as GoFundMes, Kickstarters, etc. | ## Inspiration
In a world where the voices of the minority are often not heard, technology must be adapted to fit the equitable needs of these groups. Picture the millions who live in a realm of silence, where for those who are deaf, you are constantly silenced and misinterpreted. Of the 50 million people in the United States with hearing loss, less than 500,000 — or about 1% — use sign language, according to Acessibility.com and a recent US Census. Over 466 million people across the globe struggle with deafness, a reality known to each in the deaf community. Imagine the pain where only 0.15% of people (in the United States) can understand you. As a mother, father, teacher, friend, or ally, there is a strong gap in communication that impacts deaf people every day. The need for a new technology is urgent from both an innovation perspective and a human rights perspective.
Amidst this urgent disaster of an industry, a revolutionary vision emerges – Caption Glasses, a beacon of hope for the American Sign Language (ASL) community. Caption Glasses bring the magic of real-time translation to life, using artificial neural networks (machine learning) to detect ASL "fingerspeaking" (their one-to-one version of the alphabet), and creating instant subtitles displayed on glasses. This revolutionary piece effortlessly bridges the divide between English and sign language. Instant captions allow for the deaf child to request food from their parents. Instant captions allow TAs to answer questions in sign language. Instant captions allow for the nurse to understand the deaf community seeking urgent care at hospitals. Amplifying communication for the deaf community to the unprecedented level that Caption Glasses does increases the diversity of humankind through equitable accessibility means!
With Caption Glasses, every sign becomes a verse, every gesture an eloquent expression. It's a revolution, a testament to humanity's potential to converse with one another. In a society where miscommunication causes wars, there is a huge profit associated with developing Caption Glasses. Join us in this journey as we redefine the meaning of connection, one word, one sign, and one profound moment at a time.
## What it does
The Caption Glasses provide captions displayed on glasses after detecting American Sign Language (ASL). The captions are instant and in real-time, allowing for effective translations into the English Language for the glasses wearer.
## How we built it
Recognizing the high learning curve of ASL, we began brainstorming for possible solutions to make sign language more approachable to everyone. We eventually settled on using AR-style glasses to display subtitles that can help an ASL learner quickly identify what sign they are looking at.
We started our build with hardware and design, starting off by programming a SSD1306 OLED 0.96'' display with an Arduino Nano. We also began designing our main apparatus around the key hardware components, and created a quick prototype using foam.
Next, we got to loading computer vision models onto a Raspberry Pi4. Although we were successful in loading a basic model that looks at generic object recognition, we were unable to find an ASL gesture recognition model that was compact enough to fit on the RPi.
To circumvent this problem, we made an approach change that involved more use of the MediaPipe Hand Recognition models. The particular model we chose marked out 21 landmarks of the human hand (including wrist, fingertips, knuckles, etc.). We then created and trained a custom Artificial Neural Network that takes the position of these landmarks, and determines what letter we are trying to sign.
At the same time, we 3D printed the main apparatus with a Prusa I3 3D printer, and put in all the key hardware components. This is when we became absolute best friends with hot glue!
## Challenges we ran into
The main challenges we ran into during this project mainly had to do with programming on an RPi and 3D printing.
Initially, we wanted to look for pre-trained models for recognizing ASL, but there were none that were compact enough to fit in the limited processing capability of the Raspberry Pi. We were able to circumvent the problem by creating a new model using MediaPipe and PyTorch, but we were unsuccessful in downloading the necessary libraries on the RPi to get the new model working. Thus, we were forced to use a laptop for the time being, but we will try to mitigate this problem by potentially looking into using ESP32i's in the future.
As a team, we were new to 3D printing, and we had a great experience learning about the importance of calibrating the 3D printer, and had the opportunity to deal with a severe printer jam. While this greatly slowed down the progression of our project, we were lucky enough to be able to fix our printer's jam!
## Accomplishments that we're proud of
Our biggest accomplishment is that we've brought our vision to life in the form of a physical working model. Employing the power of 3D printing through leveraging our expertise in SolidWorks design, we meticulously crafted the components, ensuring precision and functionality.
Our prototype seamlessly integrates into a pair of glasses, a sleek and practical design. At its heart lies an Arduino Nano, wired to synchronize with a 40mm lens and a precisely positioned mirror. This connection facilitates real-time translation and instant captioning. Though having extensive hardware is challenging and extremely time-consuming, we greatly take the attention of the deaf community seriously and believe having a practical model adds great value.
Another large accomplishment is creating our object detection model through a machine learning approach of detecting 21 points in a user's hand and creating the 'finger spelling' dataset. Training the machine learning model was fun but also an extensively difficult task. The process of developing the dataset through practicing ASL caused our team to pick up the useful language of ASL.
## What we learned
Our journey in developing Caption Glasses revealed the profound need within the deaf community for inclusive, diverse, and accessible communication solutions. As we delved deeper into understanding the daily lives of over 466 million deaf individuals worldwide, including more than 500,000 users of American Sign Language (ASL) in the United States alone, we became acutely aware of the barriers they face in a predominantly spoken word.
The hardware and machine learning development phases presented significant challenges. Integrating advanced technology into a compact, wearable form required a delicate balance of precision engineering and user-centric design. 3D printing, SolidWorks design, and intricate wiring demanded meticulous attention to detail. Overcoming these hurdles and achieving a seamless blend of hardware components within a pair of glasses was a monumental accomplishment.
The machine learning aspect, essential for real-time translation and captioning, was equally demanding. Developing a model capable of accurately interpreting finger spelling and converting it into meaningful captions involved extensive training and fine-tuning. Balancing accuracy, speed, and efficiency pushed the boundaries of our understanding and capabilities in this rapidly evolving field.
Through this journey, we've gained profound insights into the transformative potential of technology when harnessed for a noble cause. We've learned the true power of collaboration, dedication, and empathy. Our experiences have cemented our belief that innovation, coupled with a deep understanding of community needs, can drive positive change and improve the lives of many. With Caption Glasses, we're on a mission to redefine how the world communicates, striving for a future where every voice is heard, regardless of the language it speaks.
## What's next for Caption Glasses
The market for Caption Glasses is insanely large, with infinite potential for advancements and innovations. In terms of user design and wearability, we can improve user comfort and style. The prototype given can easily scale to be less bulky and lighter. We can allow for customization and design patterns (aesthetic choices to integrate into the fashion community).
In terms of our ML object detection model, we foresee its capability to decipher and translate various sign languages from across the globe pretty easily, not just ASL, promoting a universal mode of communication for the deaf community. Additionally, the potential to extend this technology to interpret and translate spoken languages, making Caption Glasses a tool for breaking down language barriers worldwide, is a vision that fuels our future endeavors. The possibilities are limitless, and we're dedicated to pushing boundaries, ensuring Caption Glasses evolve to embrace diverse forms of human expression, thus fostering an interconnected world. | ## We wanted to help the invisible people of Toronto, many homeless people do not have identification and often have a hard time keeping it due to their belongings being stolen. This prevents many homeless people to getting the care that they need and the access to resources that an ordinary person does not need to think about.
**How**
Our application would be set up as a booth or kiosks within pharmacies or clinics so homeless people can be verified easily.
We wanted to keep information of our patients to be secure and tamper-proof so we used the Ethereum blockchain and would compare our blockchain with the information of the patient within our database to ensure they are the same otherwise we know there was edits or a breach.
**Impact**
This would solve problems such as homeless people getting the prescriptions they need at local clinics and pharmacies. As well shelters would benefit from this as our application can track the persons: age, medical visits, allergies and past medical history experiences.
**Technologies**
For our facial recognition we used Facenet and tensor flow to train our models
For our back-end we used Python-Flask to communicate with Facenet and Node.JS to handle our routes on our site.
As well Ether.js handled most of our back-end code that had to deal with our smart contract for our blockchain.
We used Vue.JS for our front end to style our site. | winning |
## Inspiration
Our team members had grandparents who suffered from Type II diabetes. Because of the poor dietary choices they made in their daily lives, they had a difficult time controlling their glucose levels and suffered from severe health complications, which included kidney failure and heart attacks. After considering the problem, we realized that creating something that was easy to use.
## What it does
IntelliFridge recognizes food that is being taken out of the fridge and allows users to see the nutritional value before they decide to consume the item. This is especially helpful for Type II diabetics, who tend to be older people who are unlikely to make an effort to find out what is in their food before eating it. Intellifridge captures an image of the food and runs an ML algorithm to determine what the food is, after which we pull nutritional data from a 3rd party service. The information is displayed on the LCD screen and a recommendation is given to the user. Users can then consider what they have and decide whether or not to eat it.
## How we built it
We used the NXP development kit with Android Things. We used several APIs and machine learning models to create the core functionality.
## Challenges we ran into
We had an extremely hard time with getting Android Things onto our board. Initially we tried with the Raspberry Pi, but realized that we were unable to connect to the venue wifi due to some restrictions. With the NXP board, it took us several tries to setup the Wifi and then start working on the image capture and recognition system and the LCD display.
## Accomplishments that we're proud of
It was cool how we were able to figure out how to use the hardware even though we had no experience whatsoever. Getting over the initial barrier was the hardest but most rewarding part.
## What we learned
None of us had experience with hardware prior to the hackathon, and only one of our team members was experienced in Android development, so all of us ended up learning a good deal about flashing images and working in Android studio.
## What's next for IntelliFridge
We hope to implement a system that can recognize the faces of the users and give them recommendations accordingly. We also want to expand the functionality of our app to include predictive glucose monitoring.
## Domain submission
<http://youbreaderbelieveit.com> | ## Inspiration
We were inspired by the 63%, of edible food that Canadians throw away. The majority (45%) of this food (by weight) is fresh produce. We determined a large contributing factor to produce waste as the expiration dates— which can often be difficult to keep track of.
Food waste directly connects to global warming, as a large amount of resources are used to grow food. Thus, this excess waste translates directly into C02 emissions. We recognize that through simple actions we can all contribute to the preservation of our planet.
Our team found a very simple, viable solution to this problem as a convenient app that would allow users to keep track of all their fresh produce and expiration dates, simply by taking a photo.
## What it does
Our application, FOEX, provides an estimated time to expiry for produce items scanned in by the user. FOEX manages all expiry dates, allowing users to keep track of their food items. The app will automatically update the days left until an item expires. We hope to further develop this application by adding additional functionality that processes printed expiration dates on packaged items as well as enabling users to sort and arrange their inventory manually.
## How we built it
We first designed the application with a wireframe on Figma. Utilizing the pre-created format of Android Studio, we coded the back-end of our project in Java and the frontend in XML. Within the backend we used okHTTP to access the Microsoft Azure Computer Vision API. Throughout the whole process we utilized Git and Github to streamline the build process.
## Challenges we ran into
The largest challenge that we encountered was the implementation of the Computer Vision API into the application. Initially, we had utilized an external library that simplified calls to the API; however, after hours of debugging, we found it to be a source of many compilation and configuration errors. This required us to rethink our implementation and resort to OkHTTP to help us implement the API. In addition, the technical issues we experienced when configuring our API and APK resulted in smaller challenges such as Android Studio’s inability to handle lambda functions. Overall, we found it challenging to integrate all of the files together.
## Accomplishments that we're proud of
We are very proud of the dedication and hardwork put in by all of our members. With this being our second Hackathon, we found ourselves constantly learning new skills and experimenting with new tools throughout the entire process. We were able to successfully implement the Microsoft Azure API and strengthened our knowledge in Android Studio and Figma. Avoided mistakes from our first Hackathon, we applied knowledge to help organize ourselves effectively, ensuring that we considered all potential challenges while remaining grounded in our main idea without worrying about minor features. Despite facing some challenges, we persevered and had fun doing it!
## What we learned
Our team learned a lot about utilizing version control, we had some organization differences and difficulties. Throughout the process we became better at communicating which member was pushing specific changes, in order to avoid having the app crash upon compilation (of partially completed pieces of code).
In addition, our team became more fluid at debugging Android Studio, and coming up with unique, creative approaches to solving a problem. Often we would encounter a problem which there were multiple ways to fix, the first solution not always being the best.
## What's next for FOEX
We will further implement our algorithms to include a greater variety of produce and add support for scanning barcodes and expiry dates for packaged food items. We also plan to add notification alerts and potential recipes for items that will expire soon. FOEX will later be released on IOS in order to on expanding the app’s usage and impact on society. | ## \*\* Internet of Things 4 Diabetic Patient Care \*\*
## The Story Behind Our Device
One team member, from his foot doctor, heard of a story of a diabetic patient who almost lost his foot due to an untreated foot infection after stepping on a foreign object. Another team member came across a competitive shooter who had his lower leg amputated after an untreated foot ulcer resulted in gangrene.
A symptom in diabetic patients is diabetic nephropathy which results in loss of sensation in the extremities. This means a cut or a blister on a foot often goes unnoticed and untreated.
Occasionally, these small cuts or blisters don't heal properly due to poor blood circulation, which exacerbates the problem and leads to further complications. These further complications can result in serious infection and possibly amputation.
We decided to make a device that helped combat this problem. We invented IoT4DPC, a device that detects abnormal muscle activity caused by either stepping on potentially dangerous objects or caused by inflammation due to swelling.
## The technology behind it
A muscle sensor attaches to the Nucleo-L496ZG board that feeds data to a Azure IoT Hub. The IoT Hub, through Trillo, can notify the patient (or a physician, depending on the situation) via SMS that a problem has occurred, and the patient needs to get their feet checked or come in to see the doctor.
## Challenges
While the team was successful in prototyping data aquisition with an Arduino, we were unable to build a working prototype with the Nucleo board. We also came across serious hurdles with uploading any sensible data to the Azure IoTHub.
## What we did accomplish
We were able to set up an Azure IoT Hub and connect the Nucleo board to send JSON packages. We were also able to aquire test data in an excel file via the Arduino | partial |
## Inspiration
r.unear.me helps you get exactly where your friends are. In cases when you are supposed to meet them but can't exactly find them, unear.me helps you get to them.
r.unear.me is a webapp that that enables you and your friend to share each other's location on the same page, and the location updates continuously as the people in it move.
## How I built it
You go into the webapp and you get a custom code at the end of url with your location. You can then sent the url to your friends and their location markers will also be added to the page.
## Challenges I ran into
Updating the location coordinates, trying to get firebase, mapbox and azure working together | ## Inspiration
Many hackers cast their vision forward, looking for futuristic solutions for problems in the present. Instead, we cast our eyes backwards in time, looking to find our change in restoration and recreation. We were drawn to the ancient Athenian Agora -- a marketplace; not one where merchants sold goods, but one where thinkers and orators debated, discussed, and deliberated (with one another?) pressing social-political ideas and concerns. The foundation of community engagement in its era, the premise of the Agora survived in one form or another over the years in the various public spaces that have been focal points for communities to come together -- from churches to community centers.
In recent years, however, local community engagement has dwindled with the rise in power of modern technology and the Internet. When you're talking to a friend on the other side of the world, you're not talking a friend on the other side of the street. When you're organising with activists across countries, you're not organising with activists in your neighbourhood. The Internet has been a powerful force internationally, but Agora aims to restore some of the important ideas and institutions that it has left behind -- to make it just as powerful a force locally.
## What it does
Agora uses users' mobile phone's GPS location to determine the neighbourhood or city district they're currently in. With that information, they may enter a chat group specific to that small area. Having logged-on via Facebook, they're identified by their first name and thumbnail. Users can then chat and communicate with one another -- making it easy to plan neighbourhood events and stay involved in your local community.
## How we built it
Agora coordinates a variety of public tools and services (for something...). The application was developed using Android Studio (Java, XML). We began with the Facebook login API, which we used to distinguish and provide some basic information about our users. That led directly into the Google Maps Android API, which was a crucial component of our application. We drew polygons onto the map corresponding to various local neighbourhoods near the user. For the detailed and precise neighbourhood boundary data, we relied on StatsCan's census tracts, exporting the data as a .gml and then parsing it via python. With this completed, we had almost 200 polygons -- easily covering Hamilton and the surrounding areas - and a total of over 50,000 individual vertices. Upon pressing the map within the borders of any neighbourhood, the user will join that area's respective chat group.
## Challenges we ran into
The chat server was our greatest challenge; in particular, large amounts of structural work would need to be implemented on both the client and the server in order to set it up. Unfortunately, the other challenges we faced while developing the Android application diverted attention and delayed process on it. The design of the chat component of the application was also closely tied with our other components as well; such as receiving the channel ID from the map's polygons, and retrieving Facebook-login results to display user identification.
A further challenge, and one generally unexpected, came in synchronizing our work as we each tackled various aspects of a complex project. With little prior experience in Git or Android development, we found ourselves quickly in a sink-or-swim environment; learning about both best practices and dangerous pitfalls. It was demanding, and often-frustrating early on, but paid off immensely as the hack came together and the night went on.
## Accomplishments that we're proud of
1) Building a functioning Android app that incorporated a number of challenging elements.
2) Being able to make something that is really unique and really important. This is an issue that isn't going away and that is at the heart of a lot of social deterioration. Fixing it is key to effective positive social change -- and hopefully this is one step in that direction.
## What we learned
1) Get Git to Get Good. It's incredible how much of a weight of our shoulders it was to not have to worry about file versions or maintenance, given the sprawling size of an Android app. Git handled it all, and I don't think any of us will be working on a project without it again.
## What's next for Agora
First and foremost, the chat service will be fully expanded and polished. The next most obvious next step is towards expansion, which could be easily done via incorporating further census data. StatsCan has data for all of Canada that could be easily extracted, and we could rely on similar data sets from the U.S. Census Bureau to move international. Beyond simply expanding our scope, however, we would also like to add various other methods of engaging with the local community. One example would be temporary chat groups that form around given events -- from arts festivals to protests -- which would be similarly narrow in scope but not constrained to pre-existing neighbourhood definitions. | ## Inspiration
Arriving into new places always means starting all over again, including with friends and socializing. It was one lonely night when I had the idea to do something, but didn't ask anyone thinking they would be busy. Turns out they were thinking the same way too! We needed a way to communicate effectively and gather plans based on what we are up to doing, while reconnecting with some old friends in the process.
## What it does
You log in with Facebook and the app gets your friend connections who are also registered in the app. At any point you can set up a plan you want to do, maybe going for dinner at that new place, or hiking around the mountains near town. Maybe you will spend the night home and someone might want to hop in, or even you could schedule your gaming or streaming sessions for others to join you in your plan.
Maybe you don't know exactly what you want to do. Well, the inverse is also applied, you can hop in into the app and see the plans your friends have for a specific time. Just go into their post and tell them "I'm in"
## How we built it
In order to get the open access possible in a short ammount of time we implemented this as a Web Page using the MERN stack. Mongo, Express React and Node. This helps us build and deliver fast while also retaining most of the control over the control of our app. For this project in particular we tried an interesting approach in the file ordering system, emmulating the PODS system used in some frameworks or languages like Ember. This helps us group our code by entitied and also divide the workflow efficiently.
## Challenges we ran into
Because we are using the info from Facebook we frequently run into the problem and design decision of whether to cache the information or keep it flowing to maintain it updated. We want the user data to be always fresh, but this comes at a cost of multiple repeated fetches that we don't want to push into our clients. We ended up running with a mix of both, keeping the constant queries but optimizing our flow to do the least of them as possible.
## Accomplishments that we're proud of
The system in which the user friends are gathered for social communication depends heavily on the flow of the Facebook API, this was the most difficult thing to gather, especially ensuring a smooth onboarding experience in which the user would both login seamlessly with their social network, while at the same time we make all the preparations necessary for the user model to start using the app. It's kind of like a magic trick, and we learned how to juggle our cards on this one.
## What we learned
Returning to our fresh data problem, we realized the importance of determining earlier on when to normalize or not our data, seeing the tradeoffs this bring and when to use which one. Many times we rearranged code because we saw a more efficient way to build it. Knowing this from the beginning will save a lot of time in the next hackathons.
## What's next for Jalo
Make it big!! The basic functionality is already there but we can always improve upon it. By selecting which friends are going to be the ones invited to the events, setting filters and different functionalities like a specific date for responding, etc. Improving the chat is also necessary. But after all of that, make our friends use it and continue scaling it and see what more it needs to grow! | winning |
# Edu-Ai: Transforming Education with Innovation
## Inspiration
The inspiration for Edu-Ai stemmed from our collective vision to harness the power of artificial intelligence in education. We were motivated by the idea of creating a dynamic platform that goes beyond traditional boundaries, providing personalized and accessible learning experiences to students worldwide.
## What it does
Edu-Ai is a comprehensive education augmentation suite. It utilizes real-time facial tracking through machine learning libraries like dlib and OpenCV to analyze student attentiveness during lectures. The integration of OpenAI's Whisper model enables accurate transcription and summarization of recorded lectures. The forthcoming teacher-student interaction feature will further enhance the learning experience.
## How we built it
The project was crafted using Python as our primary language, leveraging essential libraries such as dlib and OpenCV for facial tracking. The integration of OpenAI's Whisper model for transcription added a sophisticated layer to our system. We embraced an iterative development process, continuously testing and refining our algorithms for optimal performance.
## Challenges we ran into
Our journey was not without challenges. Fine-tuning the machine learning algorithms for real-time facial tracking demanded meticulous attention to detail. Technical complexities arose during the integration of various components, requiring collaborative problem-solving. Overcoming these challenges became integral to the growth and success of Edu-Ai.
## Accomplishments that we're proud of
Our project's ability to seamlessly combine real-time facial tracking, transcription, and future teacher-student interaction showcases the depth of our innovation and technical expertise.
## What we learned
The development of Edu-Ai was a profound learning experience. We deepened our understanding of machine learning, honed our skills in Python, and gained insights into the complexities of integrating advanced models like OpenAI's Whisper. The collaborative nature of our team fostered continuous learning and growth.
## What's next for Edu-Ai
Looking ahead, Edu-Ai is poised for continuous improvement and expansion. We plan to refine the existing features, explore additional machine learning applications, and actively seek collaborations to further enhance the platform. Our goal is to make Edu-Ai a cornerstone in the transformative landscape of AI-driven education.
---
**Team Edu-Ai:**
* Ravikant Jain
* Rudra Joshi
* Lokesh Gupta | ## Inspiration
We were reading a lot of papers for classes and realized how difficult and uninterpretable some technical resources actually are. Additionally considering it from the perspective of people who are just learning English or young children, we wanted to build an easy-to-use application that will make understanding online resources easier.
## What it does
Simplext is a Chrome extension that parses a page and allows the user to query simplifications and summarizations of selected text as well as the entire page using the context menu. There is also an AI chatbot that takes questions about the page and tries to answer them. After these queries, we also highlight the parts of the page related to our AI's response, in order for the user to understand the context behind it.
## How we built it
We use the Chrome extension's API to extract the page's text and insertion location of each block of text, then we sent that to our backend which is built Flask and hosted on Google cloud. The backend then preprocess and extracts the key text. This is sent along with the user's query, either simplifying, summarizing or Q&A, and is sent to our model to generate a response. The model is built off of OpenAI's GPT-3 Davinci model with additional prompt engineering to allow for few shot learning, especially for the simplification queries. Once the model generates a response, we communicate it back to the Chrome extension which displays it in its appropriate format.
## Challenges we ran into
The main challenge we ran into was the limitation on the number of tokens we could pass into our model per prompt. This occurred mainly since we used few shot learning. In order to fix it, we had to find ways to compress the text into less tokens to prevent overflow while also preserving meaning.
## Accomplishments that we're proud of
We are most proud of getting the full pipeline from page opening to displaying results fully functional as well as integrating an attractive UI into our extension.
## What we learned
We learned how to create interactive chrome extensions and properly use these large language models, especially with the prompt engineering.
## What's next for Simplext
We think that Simplex could fine-tune the model with more data and better examples. Additionally, we could add more features to help understanding like direct word synonyms. | ## **Inspiration:**
Our inspiration stemmed from the realization that the pinnacle of innovation occurs at the intersection of deep curiosity and an expansive space to explore one's imagination. Recognizing the barriers faced by learners—particularly their inability to gain real-time, personalized, and contextualized support—we envisioned a solution that would empower anyone, anywhere to seamlessly pursue their inherent curiosity and desire to learn.
## **What it does:**
Our platform is a revolutionary step forward in the realm of AI-assisted learning. It integrates advanced AI technologies with intuitive human-computer interactions to enhance the context a generative AI model can work within. By analyzing screen content—be it text, graphics, or diagrams—and amalgamating it with the user's audio explanation, our platform grasps a nuanced understanding of the user's specific pain points. Imagine a learner pointing at a perplexing diagram while voicing out their doubts; our system swiftly responds by offering immediate clarifications, both verbally and with on-screen annotations.
## **How we built it**:
We architected a Flask-based backend, creating RESTful APIs to seamlessly interface with user input and machine learning models. Integration of Google's Speech-to-Text enabled the transcription of users' learning preferences, and the incorporation of the Mathpix API facilitated image content extraction. Harnessing the prowess of the GPT-4 model, we've been able to produce contextually rich textual and audio feedback based on captured screen content and stored user data. For frontend fluidity, audio responses were encoded into base64 format, ensuring efficient playback without unnecessary re-renders.
## **Challenges we ran into**:
Scaling the model to accommodate diverse learning scenarios, especially in the broad fields of maths and chemistry, was a notable challenge. Ensuring the accuracy of content extraction and effectively translating that into meaningful AI feedback required meticulous fine-tuning.
## **Accomplishments that we're proud of**:
Successfully building a digital platform that not only deciphers image and audio content but also produces high utility, real-time feedback stands out as a paramount achievement. This platform has the potential to revolutionize how learners interact with digital content, breaking down barriers of confusion in real-time. One of the aspects of our implementation that separates us from other approaches is that we allow the user to perform ICL (In Context Learning), a feature that not many large language models don't allow the user to do seamlessly.
## **What we learned**:
We learned the immense value of integrating multiple AI technologies for a holistic user experience. The project also reinforced the importance of continuous feedback loops in learning and the transformative potential of merging generative AI models with real-time user input. | losing |
## Inspiration
In this age of big tech companies and data privacy scares, it's more important than ever to make sure your data is safe. There have been many applications made to replicate existing products with the added benefit of data privacy, but one type of data that has yet to be decentralized is job application data. You could reveal a lot of private personal data while applying to jobs through job posting websites. We decided to make a site that guarantees this won't happen and also helps people automate the busy work involved with applying to jobs
## What it does
JOBd is a job postings website where users own all of their data and can automate a lot of the job search process. It uses Blockstack technology to ensure that all of your employment history, demographic info, and other personal details used during job applications are stored in a location you trust and that it can't be saved and used by the website. It also uses stdlib to automate email replies to job application updates and creates spreadsheets for user recordkeeping.
## How we built it
We used the Gaia storage system from Blockstack to store users' personal profile info and resumes. We used stdlib to easily create API workflows to integrate Gmail and Google sheets into our project. We built the website using React, Material UI, Mobx, and TypeScript.
## Challenges we ran into
Learning how to use Blockstack and stdlib during the hackathon, struggling to create a cohesive project with different skillsets, and maintaining sanity.
## Accomplishments that we're proud of
We got a functional website working and used the technologies and APIs we set out to use. We also came up with an idea we haven't found elsewhere and implemented the valuable features we came up with. | ## Inspiration
Data analytics can be **extremely** time-consuming. We strove to create a tool utilizing modern AI technology to generate analysis such as trend recognition on user-uploaded datasets.The inspiration behind our product stemmed from the growing complexity and volume of data in today's digital age. As businesses and organizations grapple with increasingly massive datasets, the need for efficient, accurate, and rapid data analysis became evident. We even saw this within one of our sponsor's work, CapitalOne, in which they have volumes of financial transaction data, which is very difficult to manually, or even programmatically parse.
We recognized the frustration many professionals faced when dealing with cumbersome manual data analysis processes. By combining **advanced machine learning algorithms** with **user-friendly design**, we aimed to empower users from various domains to effortlessly extract valuable insights from their data.
## What it does
On our website, a user can upload their data, generally in the form of a .csv file, which will then be sent to our backend processes. These backend processes utilize Docker and MLBot to train a LLM which performs the proper data analyses.
## How we built it
Front-end was very simple. We created the platform using Next.js and React.js and hosted on Vercel.
The back-end was created using Python, in which we employed use of technologies such as Docker and MLBot to perform data analyses as well as return charts, which were then processed on the front-end using ApexCharts.js.
## Challenges we ran into
* It was some of our first times working in live time with multiple people on the same project. This advanced our understand of how Git's features worked.
* There was difficulty getting the Docker server to be publicly available to our front-end, since we had our server locally hosted on the back-end.
* Even once it was publicly available, it was difficult to figure out how to actually connect it to the front-end.
## Accomplishments that we're proud of
* We were able to create a full-fledged, functional product within the allotted time we were given.
* We utilized our knowledge of how APIs worked to incorporate multiple of them into our project.
* We worked positively as a team even though we had not met each other before.
## What we learned
* Learning how to incorporate multiple APIs into one product with Next.
* Learned a new tech-stack
* Learned how to work simultaneously on the same product with multiple people.
## What's next for DataDaddy
### Short Term
* Add a more diverse applicability to different types of datasets and statistical analyses.
* Add more compatibility with SQL/NoSQL commands from Natural Language.
* Attend more hackathons :)
### Long Term
* Minimize the amount of work workers need to do for their data analyses, almost creating a pipeline from data to results.
* Have the product be able to interpret what type of data it has (e.g. financial, physical, etc.) to perform the most appropriate analyses. | ## Inspiration
The frustrations we’ve all faced while job hunting—spending hours sifting through job postings only to find few relevant roles and even fewer which match one's qualifications. And once found, applicants are forced to repeatedly answer the same questions—name, email, past experiences—on countless applications. We knew there had to be a better way. With Work'd, we sought to simplify and centralize the process, making job hunting quicker and more efficient. The app cuts through the clutter by providing tailored job recommendations, eliminating redundant steps, and creating a seamless, user-friendly experience for candidates and recruiters.
## What it does
Work'd creates an attractive and addictive way to job search and recruit right from your phone. Work'd provides an interactive and easy-to-use interface that allows future employees and recruiters to connect easily, eliminating the long recruiting and application process. By swiping left or right on jobs, you can instantly apply and indicate your interest in the position, and if you are matched with the recruiter, you can land your dream job!
## How we built it
This project was built with a Svelte-based frontend with TailwindCSS and a Python-based backend using Flask, Beautiful Soup web scraping, and the OpenAI API.
## Challenges we ran into
The major challenges that we ran into included on-time and relevant image generation and prompting for Dall-E and figuring out web scrapping and data retrieval.
## Accomplishments that we're proud of
Finishing a functioning project while studying for our midterm on Monday 😭
## What we learned
How to do web scraping and how to write a research paper.
## What's next for Work’d
Improving the job recommendation algorithm for users such that more relevant jobs will appear in the user's feed depending on the jobs they choose to apply for. | partial |
## Inspiration
Most of us have probably donated to a cause before — be it $1 or $1000. Resultantly, most of us here have probably also had the same doubts:
* who is my money really going to?
* what is my money providing for them...if it’s providing for them at all?
* how much of my money actually goes use by the individuals I’m trying to help?
* is my money really making a difference?
Carepak was founded to break down those barriers and connect more humans to other humans. We were motivated to create an application that could create a meaningful social impact. By creating a more transparent and personalized platform, we hope that more people can be inspired to donate in more meaningful ways.
As an avid donor, CarePak is a long-time dream of Aran’s to make.
## What it does
CarePak is a web application that seeks to simplify and personalize the charity donation process. In our original designs, CarePak was a mobile app. We decided to make it into a web app after a bit of deliberation, because we thought that we’d be able to get more coverage and serve more people.
Users are given options of packages made up of predetermined items created by charities for various causes, and they may pick and choose which of these items to donate towards at a variety of price levels. Instead of simply donating money to organizations,
CarePak's platform appeals to donators since they know exactly what their money is going towards. Once each item in a care package has been purchased, the charity now has a complete package to send to those in need. Through donating, the user will build up a history, which will be used by CarePak to recommend similar packages and charities based on the user's preferences. Users have the option to see popular donation packages in their area, as well as popular packages worldwide.
## How I built it
We used React with the Material UI framework, and NodeJS and Express on the backend. The database is SQLite.
## Challenges I ran into
We initially planned on using MongoDB but discovered that our database design did not seem to suit MongoDB too well and this led to some lengthy delays. On Saturday evening, we made the decision to switch to a SQLite database to simplify the development process and were able to entirely restructure the backend in a matter of hours. Thanks to carefully discussed designs and good teamwork, we were able to make the switch without any major issues.
## Accomplishments that I'm proud of
We made an elegant and simple application with ideas that could be applied in the real world. Both the front-end and back-end were designed to be modular and could easily support some of the enhancements that we had planned for CarePak but were unfortunately unable to implement within the deadline.
## What I learned
Have a more careful selection process of tools and languages at the beginning of the hackathon development process, reviewing their suitability in helping build an application that achieves our planned goals. Any extra time we could have spent on the planning process would definitely have been more than saved by not having to make major backend changes near the end of the Hackathon.
## What's next for CarePak
* We would love to integrate Machine Learning features from AWS in order to gather data and create improved suggestions and recommendations towards users.
* We would like to add a view for charities, as well, so that they may be able to sign up and create care packages for the individuals they serve. Hopefully, we would be able to create a more attractive option for them as well through a simple and streamlined process that brings them closer to donors. | **check out the project demo during the closing ceremony!**
<https://youtu.be/TnKxk-GelXg>
## Inspiration
On average, half of patients with chronic illnesses like heart disease or asthma don’t take their medication. Reports estimates that poor medication adherence could be costing the country $300 billion in increased medical costs.
So why is taking medication so tough? People get confused and people forget.
When the pharmacy hands over your medication, it usually comes with a stack of papers, stickers on the pill bottles, and then in addition the pharmacist tells you a bunch of mumble jumble that you won’t remember.
<http://www.nbcnews.com/id/20039597/ns/health-health_care/t/millions-skip-meds-dont-take-pills-correctly/#.XE3r2M9KjOQ>
## What it does
The solution:
How are we going to solve this? With a small scrap of paper.
NekoTap helps patients access important drug instructions quickly and when they need it.
On the pharmacist’s end, he only needs to go through 4 simple steps to relay the most important information to the patients.
1. Scan the product label to get the drug information.
2. Tap the cap to register the NFC tag. Now the product and pill bottle are connected.
3. Speak into the app to make an audio recording of the important dosage and usage instructions, as well as any other important notes.
4. Set a refill reminder for the patients. This will automatically alert the patient once they need refills, a service that most pharmacies don’t currently provide as it’s usually the patient’s responsibility.
On the patient’s end, after they open the app, they will come across 3 simple screens.
1. First, they can listen to the audio recording containing important information from the pharmacist.
2. If they swipe, they can see a copy of the text transcription. Notice how there are easy to access zoom buttons to enlarge the text size.
3. Next, there’s a youtube instructional video on how to use the drug in case the patient need visuals.
Lastly, the menu options here allow the patient to call the pharmacy if he has any questions, and also set a reminder for himself to take medication.
## How I built it
* Android
* Microsoft Azure mobile services
* Lottie
## Challenges I ran into
* Getting the backend to communicate with the clinician and the patient mobile apps.
## Accomplishments that I'm proud of
Translations to make it accessible for everyone! Developing a great UI/UX.
## What I learned
* UI/UX design
* android development | ## Inspiration
This project was inspired by one of the group member's grandmother and her friends. Each month, the grandmother and her friends each contribute $100 to a group donation, then discuss and decide where the money should be donated to. We found this to be a really interesting concept for those that aren't set on always donating to the same charity. As well, it is a unique way to spread awareness and promote charity in communities. We wanted to take this concept, and make it possible to join globally.
## What it does
Each user is prompted to sign up for a monthly Stripe donation. The user can then either create a new "Collective" with a specific purpose, or join an existing one. Once in a collective, the user is able to add new charities to the poll, vote for a charity, or post comments to convince others on why their chosen charity needs the money the most.
## How we built it
We used MongoDB as the database with Node.js + Express for the back-end, hosted on a Azure Linux Virtual Machine. We made the front-end a web app created with Vue. Finally, we used Pusher to implement real time updates to the poll as people vote.
## Challenges we ran into
Setting up real-time polling proved to be a challenge. We wanted to allow the user to see updates to the poll without having to refresh their page. We needed to subscribe to only certain channels of notifications, depending on which collective the user is a member of. This real-time aspect required a fair bit of thought on race conditions for when to subscribe, as well as how to display the data in real time. In the end, we implemented the real-time poll as a pie graph, which resizes as people vote for charities.
## Accomplishments that we're proud of
Our team has competed in several hackathons now. Since this isn't our first time putting a project together in 24 hours, we wanted to try to create a polished product that could be used in the real world. In the end, we think we met this goal.
## What we learned
Two of our team of three had never used Vue before, so it was an interesting framework to learn. As well, we learned how to manage our time and plan early, which saved us from having to scramble at the end.
## What's next for Collective
We plan to continue developing Collective to support multiple subscriptions from the same person, and a single person entering multiple collectives. | winning |
## Inspiration
We thought Adhawk's eye tracking technology was super cool, so we wanted to leverage it in a VR game. However, since Adhawk currently only has a Unity SDK, we thought we would demonstrate a way to build eye-tracking VR games for the web using WebVR.
## Our first game
You, a mad scientist, want to be able to be in two places at once. So, like any mad scientist, you develop cloning technology that allows you to inhabit your clone's body. But the authorities come in and arrest you and your clone for violating scientific ethics. Now, you and your clone are being held in two separate prison cells. Luckily, it seems like you should be able to escape by taking control of your clone. But, you can only take control of your clone by **blinking**. Seemed like a good idea at the time of developing the cloning technology, but it *might* prove to be a little annoying. Blink to change between you and your clone to solve puzzles in both prison cells and break out of prison together!
## How we built it
We extracted the blinking data from the Adhawk Quest 2 headset using the Adhawk Python SDK and routed it into a Three.js app that renders the rooms in VR.
## Challenges we ran into
Setting up the Quest 2 headset to even display WebVR data took a lot longer than expected.
## Accomplishments that we're proud of
Combining the Adhawk sensor data with the Quest 2 headset and WebVR to tell a story we could experience and explore!
## What we learned
Coming up with an idea is probably the hardest part of a hackathon. During the ideation process, we learned a lot about the applications of eye tracking in both VR and non-VR settings. Coming up with game mechanics specific to eye tracking input had our creative juices flowing; we really wanted to use eye tracking as its own special gameplay elements and not just as a substitute to other input methods (for example, keyboard or mouse).
And VR game development is a whole other beast.
## What's next for eye♥webvr
We want to continue developing our game to add more eye tracking functionality to make the world more realistic, such as being able to fixate on objects to be able to read them, receive hints, and "notice" things that you would normally miss if you didn't take a second glance. | ## Inspiration
In a world in which we all have the ability to put on a VR headset and see places we've never seen, search for questions in the back of our mind on Google and see knowledge we have never seen before, and send and receive photos we've never seen before, we wanted to provide a way for the visually impaired to also see as they have never seen before. We take for granted our ability to move around freely in the world. This inspired us to enable others more freedom to do the same. We called it "GuideCam" because like a guide dog, or application is meant to be a companion and a guide to the visually impaired.
## What it does
Guide cam provides an easy to use interface for the visually impaired to ask questions, either through a braille keyboard on their iPhone, or through speaking out loud into a microphone. They can ask questions like "Is there a bottle in front of me?", "How far away is it?", and "Notify me if there is a bottle in front of me" and our application will talk back to them and answer their questions, or notify them when certain objects appear in front of them.
## How we built it
We have python scripts running that continuously take webcam pictures from a laptop every 2 seconds and put this into a bucket. Upon user input like "Is there a bottle in front of me?" either from Braille keyboard input on the iPhone, or through speech (which is processed into text using Google's Speech API), we take the last picture uploaded to the bucket use Google's Vision API to determine if there is a bottle in the picture. Distance calculation is done using the following formula: distance = ( (known width of standard object) x (focal length of camera) ) / (width in pixels of object in picture).
## Challenges we ran into
Trying to find a way to get the iPhone and a separate laptop to communicate was difficult, as well as getting all the separate parts of this working together. We also had to change our ideas on what this app should do many times based on constraints.
## Accomplishments that we're proud of
We are proud that we were able to learn to use Google's ML APIs, and that we were able to get both keyboard Braille and voice input from the user working, as well as both providing image detection AND image distance (for our demo object). We are also proud that we were able to come up with an idea that can help people, and that we were able to work on a project that is important to us because we know that it will help people.
## What we learned
We learned to use Google's ML APIs, how to create iPhone applications, how to get an iPhone and laptop to communicate information, and how to collaborate on a big project and split up the work.
## What's next for GuideCam
We intend to improve the Braille keyboard to include a backspace, as well as making it so there is simultaneous pressing of keys to record 1 letter. | ## Inspiration
Video games evolved when the Xbox Kinect was released in 2010 but for some reason we reverted back to controller based games. We are here to bring back the amazingness of movement controlled games with a new twist- re innovating how mobile games are played!
## What it does
AR.cade uses a body part detection model to track movements that correspond to controls for classic games that are ran through an online browser. The user can choose from a variety of classic games such as temple run, super mario, and play them with their body movements.
## How we built it
* The first step was setting up opencv and importing the a body part tracking model from google mediapipe
* Next, based off the position and angles between the landmarks, we created classification functions that detected specific movements such as when an arm or leg was raised or the user jumped.
* Then we correlated these movement identifications to keybinds on the computer. For example when the user raises their right arm it corresponds to the right arrow key
* We then embedded some online games of our choice into our front and and when the user makes a certain movement which corresponds to a certain key, the respective action would happen
* Finally, we created a visually appealing and interactive frontend/loading page where the user can select which game they want to play
## Challenges we ran into
A large challenge we ran into was embedding the video output window into the front end. We tried passing it through an API and it worked with a basic plane video, however the difficulties arose when we tried to pass the video with the body tracking model overlay on it
## Accomplishments that we're proud of
We are proud of the fact that we are able to have a functioning product in the sense that multiple games can be controlled with body part commands of our specification. Thanks to threading optimization there is little latency between user input and video output which was a fear when starting the project.
## What we learned
We learned that it is possible to embed other websites (such as simple games) into our own local HTML sites.
We learned how to map landmark node positions into meaningful movement classifications considering positions, and angles.
We learned how to resize, move, and give priority to external windows such as the video output window
We learned how to run python files from JavaScript to make automated calls to further processes
## What's next for AR.cade
The next steps for AR.cade are to implement a more accurate body tracking model in order to track more precise parameters. This would allow us to scale our product to more modern games that require more user inputs such as Fortnite or Minecraft. | partial |
# BasicSloth
BasicSloth came with the recognition that there needs to be an effect ground communication method for people in unstable situations. BasicSloth attempts to tackle this issue in a few ways including:
* Using technology which allows for simple PGP encryption and decryption. This allows messages to only be unlocked by those intended.
* Using cheap radio systems that cost thousands of dollars less than "safe" military methods, which may have more vulnerabilities than our system.
* Using radios that can be used on a huge variety of frequencies, preventing blockers from hindering the transferring of information.
# Implementation
Basic Sloth consists of four main components, which are:
* Data entry and encryption - This was done using TK for the gui, and Keybase for data encryption.
* Speech to Text - This was accomplished using Nuance speech to text technology.
* Sending - This was accomplished using a simple file read of the information input, as well as frequency modulation.
* Receiving - This was accomplished using GnuRadio, as well as demodulation and 'segmentation'
# Thanks
We give a special thanks to the Nuance team for their assistance with speech to text. We also give a large thanks to the FSF and the GnuRadio team for continuing to support open source tools that allowed us to continue this project.
# Resources
[From Baseband to bitstream](https://cansecwest.com/slides/2015/From_Baseband_to_bitstream_Andy_Davis.pdf)
[US Frequency Allocations](http://www.ntia.doc.gov/files/ntia/publications/2003-allochrt.pdf)
 | ### Overview
Resililink is a node-based mesh network leveraging LoRa technology to facilitate communication in disaster-prone regions where traditional infrastructure, such as cell towers and internet services, is unavailable. The system is designed to operate in low-power environments and cover long distances, ensuring that essential communication can still occur when it is most needed. A key feature of this network is the integration of a "super" node equipped with satellite connectivity (via Skylo), which serves as the bridge between local nodes and a centralized server. The server processes the data and sends SMS notifications through Twilio to the intended recipients. Importantly, the system provides acknowledgment back to the originating node, confirming successful delivery of the message. This solution is aimed at enabling individuals to notify loved ones or emergency responders during critical times, such as natural disasters, when conventional communication channels are down.
### Project Inspiration
The inspiration for Resililink came from personal experiences of communication outages during hurricanes. In each instance, we found ourselves cut off from vital resources like the internet, making it impossible to check on family members, friends, or receive updates on the situation. These moments of helplessness highlighted the urgent need for a resilient communication network that could function even when the usual infrastructure fails.
### System Capabilities
Resililink is designed to be resilient, easy to deploy, and scalable, with several key features:
* **Ease of Deployment**: The network is fast to set up, making it particularly useful in emergency situations.
* **Dual Connectivity**: It allows communication both across the internet and in peer-to-peer fashion over long ranges, ensuring continuous data flow even in remote areas.
* **Cost-Efficiency**: The nodes are inexpensive to produce, as each consists of a single LoRa radio and an ESP32 microcontroller, keeping hardware costs to a minimum.
### Development Approach
The development of Resililink involved creating a custom communication protocol based on Protocol Buffers (protobufs) to efficiently manage data exchange. The core hardware components include LoRa radios, which provide long-range communication, and Skylo satellite connectivity, enabling nodes to transmit data to the internet using the MQTT protocol.
On the backend, a server hosted on Microsoft Azure handles the incoming MQTT messages, decrypts them, and forwards the relevant information to appropriate APIs, such as Twilio, for further processing and notification delivery. This seamless integration of satellite technology and cloud infrastructure ensures the reliability and scalability of the system.
### Key Challenges
Several challenges arose during the development process. One of the most significant issues was the lack of clear documentation for the AT commands on the Mutura evaluation board, which made it difficult to implement some of the core functionalities. Additionally, given the low-level nature of the project, debugging was particularly challenging, requiring in-depth tracing of system operations to identify and resolve issues. Another constraint was the limited packet size of 256 bytes, necessitating careful optimization to ensure efficient use of every byte of data transmitted.
### Achievements
Despite these challenges, we successfully developed a fully functional network, complete with a working demonstration. The system proved capable of delivering messages over long distances with low power consumption, validating the concept and laying the groundwork for future enhancements.
### Lessons Learned
Through this project, we gained a deeper understanding of computer networking, particularly in the context of low-power, long-range communication technologies like LoRa. The experience also provided valuable insights into the complexities of integrating satellite communication with terrestrial mesh networks.
### Future Plans for Resililink
Looking ahead, we plan to explore ways to scale the network, focusing on enhancing its reliability and expanding its reach to serve larger geographic areas. We are also interested in further refining the underlying protocol and exploring new applications for Resililink beyond disaster recovery scenarios, such as in rural connectivity or industrial IoT use cases. | ## Inspiration
When looking at the themes from the Make-a-thon, one specifically stood out to us: accessibility. We thought about common disabilities, and one that we see on a regular basis is people who are visually impaired. We thought about how people who are visually impaired navigate around the world, and we realized there isn't a good solution besides holding your phone out that allows them to get around the world. We decided we would create a device that uses Google Maps API to read directions and sense the world around it to be able to help people who are blind navigate the world without running into things.
## What it does
Based on the user's desired destination, the program reads from Google API the checkpoints needed to cross in our path and audibly directs the user on how far they are from it. Their location is also repeatedly gathered through Google API to determine their longitude and latitude. Once the user reaches
the nearest checkpoint, they will be directed to the next checkpoint until they reach their destination.
## How we built it
Under a local hotspot host, we connected a phone and Google API to a Raspberry Pi 4. The phone would update the Raspberry Pi with our current location and Google API to determine the necessary checkpoints to get there. With all of the data being compiled on the microcontroller, it is then connected to a speaker through a Stereo Audio Amplifier Module (powered by an external power supply), which amplifies the audio sent out into the Raspberry Pi's audio jack. With all that, the directions conveyed to the user can be heard clearly.
## Challenges we ran into
Some of the challenges we faced were getting the stereo speaker to work and indicating to the user the distance from their next checkpoint, frequently within the range of the local network.
## Accomplishments that we're proud of
We were proud to have the user's current position updated according to the movement of the phone connected to the local network and be able to update the user's distance from a checkpoint in real time.
## What we learned
We learned to set up and work with a Raspberry Pi 4 through SSH.
We also learned how to use text-to-speech for the microcontroller using Python and how we can implement it in a practical application.
Finally, we were
## What's next for GPS Tracker for the Visually Impaired
During the hackathon, we were unable to implement the camera sensing the world around it to give the user live directions on what the world looks like in front of them and if they are going to run into anything or not. The next steps would include a depth camera implementation as well as an OpenCV object detection model to be able to sense the distance of things in front of you | winning |
## Inspiration
WristPass was inspired by the fact that NFC is usually only authenticated using fingerprints. If your fingerprint is compromised, there is nothing you can do to change your fingerprint. We wanted to build a similarly intuitive technology that would allow users to change their unique ids at the push of a button. We envisioned it to be simple and not require many extra accessories which is exactly what we created.
## What it does
WristPass is a wearable Electro-Biometric transmission device and companion app for secure and reconfigurable personal identification with our universal receivers. Make purchases with a single touch. Check into events without worrying about forgetting tickets. Unlock doors by simply touching the handle.
## How we built it
WristPass was built using several different means of creation due to there being multiple parts to the projects. The WristPass itself was fabricated using various electronic components. The companion app uses Swift to transmit and display data to and from your device. The app also plugs into our back end to grab user data and information. Finally our receiving plates are able to handle the data in any way they want after the correct signal has been decoded. From here we demoed the unlocking of a door, a check in at a concert, and paying for a meal at your local subway shop.
## Challenges we ran into
By far the largest challenge we ran into was properly receiving and transcoding the user’s encoded information. We could reliably transmit data from our device using an alternating current, but it became a much larger ordeal when we had to reliably detect these incoming signals and process the information stored within. In the end we were able to both send and receive information.
## Accomplishments that we're proud of
1. Actually being able to transmit data using an alternating current
2. Building a successful coupling capacitor
3. The vast application of the product and how it can be expanded to so many different endpoints
## What we learned
1. We learned how to do capacitive coupling and decode signals transmitted from it.
2. We learned how to create a RESTful API using MongoDB, Spring and a Linode Instance.
3. We became more familiarized with new APIs including: Nexmo, Lyft, Capital One’s Nessie.
4. And a LOT of physics!
## What's next for WristPass
1. We plan on improving security of the device.
2. We plan to integrate Bluetooth in our serial communications to pair it with our companion iOS app.
3. Develop for android and create a web UI.
4. Partner with various companies to create an electro-biometric device ecosystem. | ## Inspiration
We saw problems with different kinds of payment systems. There are usually long wait times, which is further increased by people searching for their wallets (not to forget the added processing fees). We wanted to create something that was easy to use and that would remove the annoyances and obtrusiveness of payment, and to do this, we decided to approach the problem using bleeding-edge yet proven technology, such as blockchain (not part of demo, but lightly implemented) and proximity payment.
## What it does
Bloqpay will eventually run on blockchain (to secure payment and avert processing fees). It tracks a consumer's location to add and confirm payment. For our current use case, this will add and confirm movie theatre purchases. Very useful for events with different areas and many other similar scenarios - the potential for this technology is unbound!
## How we built it
We used Android Studio, Microsoft Azure, a Raspberry and Sketch, along with technologies like NodeJS, Socket.IO, and others listed above.
## Challenges we ran into
One of the Raspberry Pi's failed, and we lacked a keyboard and mouse to debug. Later, we lacked a sd-card adapter to reinstall the OS, so we travelled to the mall and lost a lot of time gathering equipment. However, we were still able to pull together a very strong prototype.
## Accomplishments that we're proud of
Getting the tech to work, and overcoming some very tough obstacles. We also overcame a major bug we were facing right on time.
## What we learned
We learned that this technology and payment system will eventually become part of our daily lives (decentralization is the future of payment and autonomous software). We learned how to use the raspberry pi and different low-level bluetooth software to gather proximity data.
## What's next for Bloqpay
We want to tackle other use cases and implement Blockchain. We are definitely going to pursue this idea further outside of the hackathon space. | ## Inspiration
Our inspiration for TapIt came from the potential of bus tickets, where a simple single-use ticket that would otherwise be thrown away (how wasteful!) can be configured to store information and interact with cell phones through Near Field Communication (NFC). We were intrigued by how this technology, often associated with expensive systems, could be repurposed and made accessible for everyday users. Additionally, while exploring networking features at Hack the North, we recognized the need for a more seamless and efficient way to exchange information. Traditional methods, like manually typing contact details or scanning QR codes, often feel cumbersome and time-consuming. We saw an opportunity to not only drastically simplify this process but also to reduce waste by giving disposable objects, like bus tickets, a new life as personalized digital cards. Our goal was to democratize this powerful technology, allowing anyone to easily share their information without the need for costly hardware or complex setups.
## What it does
TapIt turns any NFC-enabled object, such as bus tickets, NFC product tags, or even your student card, into a personalized digital card. Users can create profiles that include their contact details, social media links, and more, which can then be written onto NFC tags. When someone taps an NFC-enabled object on their phone, the profile information is instantly shared. This makes networking, sharing information, and staying connected easier and more intuitive than ever. Just tap it!
## How we built it
We used React Native and Expo to create a mobile app for Android and iOS. We used npm packages for NFC writing, and we used Flask to write a backend to create short profile URLs to write onto the NFC cards.
## Challenges we ran into
We had issues with device compatibility and NFC p2p software restrictions. We also had trouble setting up an auth0 authentication system. It was very difficult to compile applications at first with React Native.
## Accomplishments that we're proud of
We learned a lot about mobile application development and React Native in a very short period of time. Working with NFC technology was also really cool!
## What we learned
NFC/HCE technologies and mobile development were our main focuses - and we're proud to have created a product while learning about these things on the fly.
## What's next for TapIt
Features to support a wider range of NFC-enabled tags! We want to create an ecosystem that supports quick contact exchange with repurposed but readily accessible materials. | partial |
## Inspiration
During the past summer, we experienced the struggles of finding subletters for our apartment. Ads were posted in various locations, ranging from Facebook to WeChat. Our feeds were filled with other people looking for people to sublet as well. As a result, we decided to create Subletting Made Easy. We envision a platform where the process for students looking for a place to stay as well as students looking to rent their apartment out is as simple as possible.
## What it does
Our application provides an easy-to-use interface for both students looking for subletters, and studentsseeking sublets to find the right people/apartments.
## Challenges we ran into
Aside from building a clean UI and adding correct functionality, we wanted to create an extremely secure platform for each user on our app. Integrating multiple authentication tools from the Firebase and Docusign API caused various roadblocks in our application development. Additionally, despite working earlier in the morning, we ran into an Authentication Error when trying to access the HTTP Get REST API call within Click API, thus inhibiting our ability to verify the registration status of users.
## What we learned
We learned a lot about the process of building an application from scratch, from front-end/UI design to back-end/database integration.
## What's next
We built a functional MVP during this hackathon, but we want to expand our app to include more features such as adding secure payments and more methods to search and filter results. There's tons of possibilities for what we can add for the future to help students around the globe find sublets and subleters. | ## Inspiration
From our experience renting properties from private landlords, we think the rental experience is broken. Payments and communication are fragmented for both landlords and tenants. As tenants, we have to pay landlords through various payment channels, and that process is even more frustrating if you have roommates. On the other hand, landlords have trouble reconciling payments coming from these several sources.
We wanted to build a rental companion that initially tackles this problem of payments, but extends to saving time and headaches in other aspects of the rental experience. As we are improving convenience for landlords and tenants, we focused solely on a mobile application.
## What it does
* Allows tenants to make payments quickly in less than three clicks
* Chatbot interface that has information about the property's lease and state-specific rental regulation
* Landlords monitor the cash flow of their properties transparently and granularly
## How we built it
* Full stack React Native app
* Convex backend and storage
* Stripe credit card integration
* Python backend for Modal & GPT3 integration
## Challenges we ran into
* Choosing a payment method that is reliable and fast to implement
* Parsing lease agreements and training GPT3 models
* Deploying and running modal.com for the first time
* Ensuring transaction integrity and idempotency on Convex
## Accomplishments that we're proud of
* Shipped chat bot although we didn't plan to
* Pleased about the UI design
## What we learned
* Mobile apps are tough for hackathons
* Payment integrations have become very accessible
## What's next for Domi Rental Companion
* See if we provide value for target customers | ## Inspiration
We saw a short video on a Nepalese boy who had to walk 10 miles each way for school. From this video, we wanted to find a way to bring unique experiences to students in constrained locations. This could be for students in remote locations, or in cash strapped low income schools. We learned that we all share a passion for creating fair learning opportunities for everyone, which is why we created Magic School VR.
## What it does
Magic School VR is an immersive virtual reality educational platform where you can attend one-on-one lectures with historical figures, influential scientists, or the world's best teachers. You can have Albert Einstein teach you quantum theory, Bill Nye the Science Guy explain the importance of mitochondria, or Warren Buffet educate you on investing.
**Step 1:** Choose a subject *physics, biology, history, computer science, etc.*
**Step 2:** Choose your teacher *(Elon Musk, Albert Einstein, Neil Degrasse Tyson, etc.*
**Step 3:** Choose your specific topic *Quantum Theory, Data Structures, WWII, Nitrogen cycle, etc.*
**Step 4:** Get immersed in your virtual learning environment
**Step 5:** Examination *Small quizzes, short answers, etc.*
## How we built it
We used Unity, Oculus SDK, and Google VR to build the VR platform as well as a variety of tools and APIs such as:
* Lyrebird API to recreate Albert Einstein's voice. We trained the model by feeding it with audio data. Through machine learning, it generated audio clips for us.
* Cinema 4D to create and modify 3D models.
* Adobe Premiere to put together our 3D models and speech, as well to chroma key masking objects.
* Adobe After Effects to create UI animations.
* C# to code camera instructions, displays, and interactions in Unity.
* Hardware used: Samsung Gear VR headset, Oculus Rift VR Headset.
## Challenges we ran into
We ran into a lot of errors with deploying Magic School VR to the Samsung Gear Headset, so instead we used Oculus Rift. However, we had hardware limitations when it came to running Oculus Rift off our laptops as we did not have HDMI ports that connected to dedicated GPUs. This led to a lot of searching around trying to find a desktop PC that could run Oculus.
## Accomplishments that we're proud of
We are happy that we got the VR to work. Coming into QHacks we didn't have much experience in Unity so a lot of hacking was required :) Every little accomplishment motivated us to keep grinding. The moment we manged to display our program in the VR headset, we were mesmerized and in love with the technology. We experienced first hand how impactful VR can be in education.
## What we learned
* Developing with VR is very fun!!!
* How to build environments, camera movements, and interactions within Unity
* You don't need a technical background to make cool stuff.
## What's next for Magic School VR
Our next steps are to implement eye-tracking engagement metrics in order to see how engaged students are to the lessons. This will help give structure to create more engaging lesson plans. In terms of expanding it as a business, we plan on reaching out to VR partners such as Merge VR to distribute our lesson plans as well as to reach out to educational institutions to create lesson plans designed for the public school curriculum.
[via GIPHY](https://giphy.com/gifs/E0vLnuT7mmvc5L9cxp) | partial |
## Inspiration
When we travel to a new location, it's useful to figure out where to go, what to eat, and draw out a travel itinerary. Ideally, our day trips are organized so all the places we are visiting are easily and efficiently accessible away from each other.
## What is it
TravelPlanner is a web app that plans out your day trip itinerary for you. You start by answering a short survey about when you'd like to explore, what kind of activities/food you like, and whether you will be getting around by car, bike, public transportation, or on foot.
Then, it generates an efficient travel day plan of where to go and eat based on our preferences. For instance, if I write that I like outdoor activities, Japanese food, and museums, then TravelPlanner might create an itinerary of:
1. Lunch at a ramen shop
2. Snowboarding at Grouse Mountain
3. Dinner at a sushi restaurant
It would choose a highly-rated ramen shop and sushi restaurant nearby the mountain too, making it easy for me to get around.
## How we built it
We prototyped the UI in Figma, and translated it into HTML, CSS, and Javascript. The backend was built with Python, Flask, and the Yelp API.
## Challenges we ran into
We spent a lot of time trying to figure out how to generate the best itinerary for a traveller. It was also sort of a traveling salesman problem, since we wanted to have the shortest trip possible between all our places to visit. However, we had to face constraints such as spacing out meals evenly.
## Accomplishments that we're proud of
It's really pretty. The trip planning backend works well. We also had a chance to validate users, and get more insight into what our target audience would find valuable—these aspects were integrated into the project.
## What we learned
HTML, CSS, User journey, UI design, everything, Javascript
## What's next for Travel Planner
Support to find lodging. Planning multi-day trips. Group trips. A social feature where travellers can meet up if they happen to be planning similar itineraries | ## Inspiration
TripAdvisor and RoadTrippers
## What it does
Our project gives community-based and calculated plans to users based on points of attraction and personal preferences, like staying longer in nature spots or museums. The app blends information of popular spots and visualizations to provide easy interpretation of the plan, how long it would take, and how long each attraction usually takes. Users can upload their own plans and the most popular ones go up the list so that efficient but enjoyable trips are seen by the most people.
## How we built it
React Native, Figma, JSON schemas
## Challenges we ran into
Time :(. We weren't able to construct the backend or parts of the UI because we didn't enough time to implement the many good ideas that we threw around.
## Accomplishments that we're proud of
Building a semi-functional application that is styled well and has solid scalability if worked on for longer than a day. We tried to prioritize the planning instead of the development so that we could be able to truly build this out at a future time.
## What we learned
React Native app development, product development, forming ideas and refining them, researching existing services and identifying opportunities,
## What's next for Daytrips
Possible improvements in the UI and actual implementation of backend. Most likely, nothing will be done for the rest of this semester, but who knows | ## Inspiration
Travelling can be a pain. You have to look up attractions ahead of time and spend tons of time planning out what to do. Shouldn't travel be fun, seamless and stress-free?
## What it does
SightSee takes care of the annoying part of travel. You start by entering the city that you're visiting, your hotel, a few attractions that you'd like to see and we take care of the rest. We provide you with a curated list of recommendations based on TripAdvisor data depending on proximity to your attractions and rating. We help you discover new places to visit as well as convenient places for lunch and dinner. Once you've finalized your plans, out pops your itinerary for the day, complete with a walking route on Google Maps.
## How we built it
We used the TripAdvisor API and the Google Maps Embed API. It's built as a single-page Web application, powered by React and Redux. It's hosted on an Express.js-based web server on an Ubuntu 14.04 VM in Microsoft Azure.
## Challenges we ran into
We ran into challenges with the TripAdvisor API and its point of interest data, which can be inaccurate at times.
## Accomplishments that we're proud of
The most awesome user interface ever! | losing |
## FlyBabyFly
[link](https://i.imgur.com/9uIFF1K.png)
[link](https://i.imgur.com/O55PRJE.jpg)
## What it does
Its a mobile app that matches people with travel destinations while providing great deals.
Swipe right to like! Swipe left to see next deal.
After you like a city you can learn about the city's attractions, landmarks and history. It can help you book right from the app, just pick a date!
## How we built it
We used React Native and JetBlue's provided data.
## Accomplishments that we're proud of
We believe this is a refreshing approach to help people discover new cities and help them plan their next vacation
## What's next for FlyBabyFly
* Add vacation packages that include hotel bundles for better prices. | ## Inspiration
The mission of OpenDoAR is to empower universities and small businesses in a safe return to physical spaces for their people. We aim to improve outcomes for our users in affordable **health compliance** and **overall monitoring**.
In this year and the next, the return to physical spaces for organisations and educational institutions are in progress.
For big companies, advanced and expensive methods are employed to ensure healthy employees are entering the office. These methods are not always affordable or convenient for smaller organisations.
Looking at educational institutions, there is an ambiguity in compliance to the return-to-campus system.
Currently, UC Berkeley uses a badge system for COVID health monitoring and safety.
Everyday for a student on campus, a questionnaire is meant to be filled out via mobile which grants the student a badge status. E.g. Green badge granted (assuming student doesn’t have symptoms, are fully vaccinated, etc). There are yellow and red badges too from less ideal answers.
Before entering a lab or classroom, a Teaching Assistant (TA) is meant to check if the student has a green badge, and if not, entry is not granted. The effort from the student needing to pull out and display the green badge on their phone, and showing it to the TA at the door is higher than students are willing for. Hence, for over 90% of the time, this practice is ignored. This becomes more common as the reality and local-impact of COVID fades from people's minds (as infection rates drop).
We decided to use Face-Id now for our implementation since it is very commonplace with recent iPhones and simplifies ease of use. Within the last few years, it has become normal for people to look at their phone to unlock private information. Due it is simplicity of access, we hope to extend this to our AR application to allow for quick identification.
## Core Features
* AR based on text overlay and image query for mobile. Low effort scanning of students entering classroom.
* Mobile Dashboard to analyze core statistics about number of green/red badges
* User accounts and Authentication for multiple events and for authorized access
* Face detection of students ONLY in the TA's class
* Desktop Power BI Dashboard for higher management oversight on compliance and monitoring.
#### MobileApp Implementation
On the admin side, the camera aims towards the door of a classroom or space, and as students walk in, the app processes students’ faces against the pictures they provided to their organization (or uploaded via the app from their user side) and tags them as their respective colored badge (green for compliant, yellow for not having filled out a daily screening survey, and red for not compliant). The data is recorded for future reference on the compliance of the selected person. This data was kept in an anonymous fashion to prevent HIPAA issues.
#### WebApp Implementation
Primarily for use by admins, they can view data visualization of their attendees/students’ badge statuses and vaccination statuses and the proportion of badge statuses relative to the entire class/event to better plan future events with regards to health regulations and safety.
In order to support the backend, we created a flask server hosted on Azure. The face detection model uses dlib landmark dataset, which labels important features of the face and tries to detect similarity between faces with a 99% accuracy. The backend also supports users and groups and dynamically indexes sets of face databases into memory as needed. We also encrypt on transit and don’t store images that are processed to prevent issues with storage of possible personally identifiable information, breaking HIPPA policies.
For the website, we used React to build out the UI and NextJS for server-side rendering, and for the mobile app, we used Flutter and its ARKit framework to develop the frontend and the primary AR features of our solution.
Power BI was used to create a visualisation dashboard for higher management to understand their people's compliance and health in their return to physical spaces. An Azure Virtual machine with datascience configuration was used to build this.
## Challenges we ran into
* Initially implemented a trained keras model to predict face detection, but a raw dlib based face landmark detection worked better.
* Implementing AR functionality and sending Image had a different byte encoding, causing issues when sending it over to the flask server for processing.
* Struggled initially figuring out the scope, problem statement, and user cases for our idea that addressed a real problem and also targeted the primary categories of the hackathon.
* Used Azure VM for first time to build on Power BI.
* Publishing our Power BI dashboard to the the PBI service and then embedding it into our website was blocked as none of our members' school/work accounts permitted Power BI sign up. This is honestly a 5 min step if we gained permissions from our organisation accounts. File is attached in Github to allow running in PBI Desktop.
## What's next for OpenDoAR
For events, the world is returning to physical events. And during this transition period, the need for easy tools for health and safety is critical to keep re-emergence chances of the pandemic low. **We want to put an app into the hands of event organisers that easily allow them to check their attendees without making it take ages for people to get in.**
A side pivot, in the context of networking events, our infrastructure could allow for people at networking events to figure out who to talk to. At many networking events, people try to find others with similar interests, but might end up talking to the wrong people. In order to simplify this process, we can do a quick scan of the people’s face to see if the interests align (show AR overlay of profession, interest, company). This also reduces the social awkwardness/time spent in talking with someone you realise you're not interested in. The faces of the people at the event can be integrated into the database as attendees are there to be public and meet people. In terms of actual work, there isn’t too much involved in extending it to the networking space. Additionally, pronouns are something we can overlay (like LinkedIn) to clear any ambiguity in a socially conscious society.
For small and medium sized companies while people are re-integrating to the workplace, an automatic system to detect compliance people entering the property could be **difficult and expensive**. Even with security guards, which could be expensive, they are limited by very manual checking methods. With our system, we can help employees in their re-integrate into their work, by **simply downloading a new app to the phones security guards already have.**
Additionally, we are taking UC Berkeley as a proving ground in a simple effective tool. We want to roll this out to other universities in the US and beyond. Making it the solution that enables smoother exchanges and visits from people outside the university.
## Try it yourself at
<https://github.com/vikranth22446/greenhelth>
## See our prototype
<https://www.figma.com/proto/6k9jPCZPsMdHJeWmx7Jwlt/CalHacks-Wireframes?node-id=9%3A102&scaling=scale-down&page-id=0%3A1&starting-point-node-id=30%3A91>
# Website demo
<https://drive.google.com/file/d/1Fctu4RkF0ecVfJsftB7z6G8HFwNnv0DI/view?usp=sharing>
<http://opendoar.tech>
Username: [[email protected]](mailto:[email protected])
Password: test | # Get the Flight Out helps you GTFO ASAP
## Inspiration
Constantly stuck in meetings, classes, exams, work, with nowhere to go, we started to think. What if we could just press a button, and in a few hours, go somewhere awesome? It doesn't matter where, as long as its not here. We'd need a plane ticket, a ride to the airport, and someplace to stay. So can I book a ticket?
Every online booking site asks for where to go, but we just want to go. What if we could just set a modest budget, and take advantage of last minute flight and hotel discounts, and have all the details taken care of for us?
## What it does
With a push of a button or the flick of an Apple Watch, we'll find you a hotel at a great location, tickets out of your preferred airport, and an Uber to the airport, and email you the details for reference. | losing |
## 💡 Inspiration
Just DAO It! was heavily inspired by the Collective Intelligence Theory, which proposes that one person can easily make an unwise decision, but it is much more unlikely for a whole group of people to make that same unwise decision. We wanted to apply this theory to blockchain technology whilst avoiding the expensive managing fees of mutual funds. This is when we stumbled upon Axelar and the Decentralized Autonomous Organization (DAO) model which was perfect for applying the Collective Intelligence Theory across different chains. Using Axelar, our decentralized mutual fund can have token assets from varying chains, whether it’s MATIC on the Polygon network, or AVAX on Avalanche.
Hence… Enter a decentralized, democratic, mutual fund!
## 🔍 What it does
Just DAO It! Provides a framework for people to easily implement decentralized mutual funds. This allows for people to create their own mutual funds, without having to pay a management fee to the bank. We used smart contracts to act as mutual funds, with customers buying governance tokens with USDC. These governance tokens are both bought and sold, acting as shares to the mutual fund. This also dictates the amount of voting power they get. Every month, people can propose an investment in an asset via DAO proposals and the shareholders will decide as a group whether or not to approve or disapprove the request. The proposals are then sent via call contracts with tokens, which perform buy/sell operations on their chain. Proxy contracts swap USDC to native token to perform buy operation, or convert native token to USDC to transfer back to the DAO smart contract USDC from tokens sold is fed back into the DAO Fund Pool, to be exercised at a later point. To combat whales, we have implemented a quadratic voting system where the voting power corresponds to the transformed radical function of the governance tokens, meaning that it is near impossible to hold a share of over 50%. This allows the voting system to be truly democratic, and allows everyone to play their role in deciding how their money is invested. Finally, when a customer wishes to withdraw their money from the DAO, they do so by having their tokens burnt and the corresponding amount of USDC returned to them.
## ⚙️ Tech Stack
• The UI/UX was designed with Figma
• The front end was built on Next.js, the CSS was implemented with TailwindCSS, while the animations were done with framer-motion. We also used various dependencies such as TradingViewWidget to display the graphs
• The Web3 backend was coded in Solidity, Javascript, and Typescript
• The mutual funds were built with smart contracts, while proposals
are made via DAO proposals
• Blood, sweat, heart, and tears. Mostly tears tho.
## 🚧 Challenges we ran into
Throughout this hackathon, we ran into a plethora of challenges. For starters, none of us were familiar with Web3 technologies, meaning we had to learn everything from scratch. It was a huge struggle brainstorming an idea and architecturing a working structure that had no loopholes.This was an especially difficult challenge because Axelar was built for people who’ve had prior experience with Ethereum, which we did not. Hence, we had to read up on both Axelar and Ethereum! Finally, as these technologies are so new, there is still very limited documentation. In fact, most of the documentation we used was only 2-3 months old! This meant that we had very little to go off of, and required us to really rack our brains to figure out how to implement certain features. With guidance from Axelar mentors, we were able to surmount this gargantuan challenge. Overall, it was a huge challenge learning and implementing so many new concepts in such a short time frame!
## ✔️ Accomplishments that we're proud of
We are extremely proud of overcoming the seemingly endless stream of difficulties that come with using new, cutting edge technologies. We take pride in successfully navigating such a new technology, often having to come up with innovative ways to tackle certain problems because of the limited documentation. Additionally, this was all of our first times navigating such a foreign technology, and we take pride in the fact that we were able to understand, plan, and implement everything in such a short time frame. All in all, we are proud to be innovators, exploring the uncharted territories of Web3!
## 📚 What we learned
We can wholeheartedly say that we have come out with significantly more knowledge on Web3 compared to when we came in! For starters, before we even began architecting our project, we read multiple articles on DAO and Axelar. Whether it's engineering decentralized systems, architecting cross chain transaction systems, or working with smart contracts and solidity. Last but not least, we learned many core skills, imperative to a software developer. Whether it’s learning to navigate extremely new documentation, or implementing completely new algorithms within a short time span, or to invent innovative ways to bypass problems. We can confidently say that we have inarguably become a better developer throughout Hack the North!
## 🚀 What's next for Just DAO It!
We have a few things in mind to bring Just DAO It! to the next level:
* Allow for members to propose token-to-token trading (ex. direct MATIC -> AVAX)
* Deploy our DAO and Proxy contracts to the mainnet
* Support even more chains
* Use 0xsquid to convert tokens due to its direct compatibility with Axelar | # Inspiration
Traditional startup fundraising is often restricted by stringent regulations, which make it difficult for small investors and emerging founders to participate. These barriers favor established VC firms and high-networth individuals, limiting innovation and excluding a broad range of potential investors. Our goal is to break down these barriers by creating a decentralized, community-driven fundraising platform that democratizes startup investments through a Decentralized Autonomous Organization, also known as DAO.
# What It Does
To achieve this, our platform leverages blockchain technology and the DAO structure. Here’s how it works:
* **Tokenization**: We use blockchain technology to allow startups to issue digital tokens that represent company equity or utility, creating an investment proposal through the DAO.
* **Lender Participation**: Lenders join the DAO, where they use cryptocurrency, such as USDC, to review and invest in the startup proposals.
-**Startup Proposals**: Startup founders create proposals to request funding from the DAO. These proposals outline key details about the startup, its goals, and its token structure. Once submitted, DAO members review the proposal and decide whether to fund the startup based on its merits.
* **Governance-based Voting**: DAO members vote on which startups receive funding, ensuring that all investment decisions are made democratically and transparently. The voting is weighted based on the amount lent in a particular DAO.
# How We Built It
### Backend:
* **Solidity** for writing secure smart contracts to manage token issuance, investments, and voting in the DAO.
* **The Ethereum Blockchain** for decentralized investment and governance, where every transaction and vote is publicly recorded.
* **Hardhat** as our development environment for compiling, deploying, and testing the smart contracts efficiently.
* **Node.js** to handle API integrations and the interface between the blockchain and our frontend.
* **Sepolia** where the smart contracts have been deployed and connected to the web application.
### Frontend:
* **MetaMask** Integration to enable users to seamlessly connect their wallets and interact with the blockchain for transactions and voting.
* **React** and **Next.js** for building an intuitive, responsive user interface.
* **TypeScript** for type safety and better maintainability.
* **TailwindCSS** for rapid, visually appealing design.
* **Shadcn UI** for accessible and consistent component design.
# Challenges We Faced, Solutions, and Learning
### Challenge 1 - Creating a Unique Concept:
Our biggest challenge was coming up with an original, impactful idea. We explored various concepts, but many were already being implemented.
**Solution**:
After brainstorming, the idea of a DAO-driven decentralized fundraising platform emerged as the best way to democratize access to startup capital, offering a novel and innovative solution that stood out.
### Challenge 2 - DAO Governance:
Building a secure, fair, and transparent voting system within the DAO was complex, requiring deep integration with smart contracts, and we needed to ensure that all members, regardless of technical expertise, could participate easily.
**Solution**:
We developed a simple and intuitive voting interface, while implementing robust smart contracts to automate and secure the entire process. This ensured that users could engage in the decision-making process without needing to understand the underlying blockchain mechanics.
## Accomplishments that we're proud of
* **Developing a Fully Functional DAO-Driven Platform**: We successfully built a decentralized platform that allows startups to tokenize their assets and engage with a global community of investors.
* **Integration of Robust Smart Contracts for Secure Transactions**: We implemented robust smart contracts that govern token issuance, investments, and governance-based voting bhy writing extensice unit and e2e tests.
* **User-Friendly Interface**: Despite the complexities of blockchain and DAOs, we are proud of creating an intuitive and accessible user experience. This lowers the barrier for non-technical users to participate in the platform, making decentralized fundraising more inclusive.
## What we learned
* **The Importance of User Education**: As blockchain and DAOs can be intimidating for everyday users, we learned the value of simplifying the user experience and providing educational resources to help users understand the platform's functions and benefits.
* **Balancing Security with Usability**: Developing a secure voting and investment system with smart contracts was challenging, but we learned how to balance high-level security with a smooth user experience. Security doesn't have to come at the cost of usability, and this balance was key to making our platform accessible.
* **Iterative Problem Solving**: Throughout the project, we faced numerous technical challenges, particularly around integrating blockchain technology. We learned the importance of iterating on solutions and adapting quickly to overcome obstacles.
# What’s Next for DAFP
Looking ahead, we plan to:
* **Attract DAO Members**: Our immediate focus is to onboard more lenders to the DAO, building a large and diverse community that can fund a variety of startups.
* **Expand Stablecoin Options**: While USDC is our starting point, we plan to incorporate more blockchain networks to offer a wider range of stablecoin options for lenders (EURC, Tether, or Curve).
* **Compliance and Legal Framework**: Even though DAOs are decentralized, we recognize the importance of working within the law. We are actively exploring ways to ensure compliance with global regulations on securities, while maintaining the ethos of decentralized governance. | ## Inspiration
Want to experience culture through an authentic lens rather than through the eyes of a tourist
## What it does
Connects users with a local guide from a country that will take them to the hidden spots that are not filled with tourist traps.
## How we built it
We built it using ReactJS
## Challenges we ran into
We ran into many challenges especially concerning the technical aspect. We were not able to fully develop the website and only have a mockup.
## Accomplishments that we're proud of
Proud to come up with a startup level idea that we could continue after the hackathon.
## What we learned
Learned how to setup a business idea
## What's next for Tracks
Whats next for tracks is to first finish developing the website | winning |
## Meet Our Team :)
* Lucia Langaney, first-time React Native user, first in-person hackathon, messages magician, snack dealer
* Tracy Wei, first-time React Native user, first in-person hackathon, payments pro, puppy petter :)
* Jenny Duan, first in-person hackathon, sign-up specialist, honorary DJ
## Inspiration
First Plate was inspired by the idea that food can bring people together. Many people struggle with finding the perfect restaurant for a first date, which can cause stress and anxiety. By matching users with restaurants, First Plate eliminates the guesswork and allows users to focus on connecting with their potential partner over a shared culinary experience. In addition, food is a topic that many people are passionate about, so a food-based dating app can help users form deeper connections and potentially find a long-lasting relationship.
After all- the stomach is the way to the heart.
## What it does
Introducing First Plate, a new dating app that will change the way you connect with potential partners - by matching you with restaurants! Our app takes into account your preferences for cuisine location, along with your dating preferences such as age, interests, and more.
With our app, you'll be able to swipe through restaurant options that align with your preferences and match with potential partners who share your taste in food and atmosphere. Imagine being able to impress your date with a reservation at a restaurant that you both love, or discovering new culinary experiences together.
Not only does our app provide a fun and innovative way to connect with people, but it also takes the stress out of planning a first date by automatically placing reservations at a compatible restaurant. No more agonizing over where to go or what to eat - our app does the work for you.
So if you're tired of the same old dating apps and want to spice things up, try our new dating app that matches people with restaurants. Who knows, you might just find your perfect match over a plate of delicious food!
## How we built it
1. Figma mockup
2. Built React Native front-end
3. Added Supabase back-end
4. Implemented Checkbook API for pay-it-forward feature
5. Connecting navigation screens & debugging
6. Adding additional features
When developing a new app, it's important to have a clear plan and process in place to ensure its success. The first step we took was having a brainstorming session, where we defined the app's purpose, features, and goals. This helped everyone involved get on the same page and create a shared vision for the project. After that, we moved on to creating a Figma mockup, where we made visual prototypes of the app's user interface. This is a critical step in the development process as it allows the team to get a clear idea of how the app will look and feel. Once the mockup was completed, we commenced the React Native implementation. This step can be quite involved and requires careful planning and attention to detail. Finally, once we completed the app, we moved on to debugging and making final touches. This is a critical step in the process, as it ensures that the app is functioning as intended and any last-minute bugs or issues are resolved before submission. By following these steps, developers can create a successful app that meets the needs of its users and exceeds their expectations.
## Challenges we ran into
The app development using React Native was extremely difficult, as it was our first time coding in this language. The initial learning curve was steep, and the vast amount of information required to build the app, coupled with the time constraint, made the process even more challenging. Debugging the code also posed a significant obstacle, as we often struggled to identify and rectify errors in the codebase. Despite these difficulties, we persisted and learned a great deal about the React Native framework, as well as how to debug code more efficiently. The experience taught us valuable skills that will be useful for future projects.
## Accomplishments that we're proud of
We feel extremely proud of having coded First Plate as React Native beginners. Building this app meant learning a new programming language, developing a deep understanding of software development principles, and having a clear understanding of what the app is intended to do. We were able to translate an initial Figma design into a React Native app, creating a user-friendly, colorful, and bright interface. Beyond the frontend design, we learned how to create a login and sign-up page, securely connected to the Supabase backend, and integrated the Checkbook API for the "pay it forward" feature. Both of these features were also new to our team. Along the way, we encountered many React Native bugs, which were challenging and time-consuming to debug as a beginner team. We implemented front-end design features such as scroll view, flexbox, tab and stack navigation, a unique animation transition, and linking pages using a navigator, to create a seamless and intuitive user experience in our app. We are proud of our teamwork, determination, and hard work that culminated in a successful project.
## What we learned
In the course of developing First Plate, we learned many valuable lessons about app development. One of the most important things we learned was how to implement different views, and navigation bars, to create a seamless and intuitive user experience. These features are critical components of modern apps and can help to keep users engaged and increase their likelihood of returning to the app.
Another significant learning experience was our introduction to React Native, a powerful and versatile framework that allows developers to build high-quality cross-platform mobile apps. As previous Swift users, we had to learn the basics of this language, including how to use the terminal and Expo to write code efficiently and effectively.
In addition to learning how to code in React Native, we also gained valuable experience in backend development using Supabase, a platform that provides a range of powerful tools and features for building, scaling, and managing app infrastructure. We learned how to use Supabase to create a real-time database, manage authentication and authorization, and integrate with other popular services like Stripe, Slack, and GitHub.
Finally, we used the Checkbook API to allow the user to create digital payments and send digital checks within the app using only another user's name, email, and the amount the user wants to send. By leveraging these powerful tools and frameworks, we were able to build an app that was not only robust and scalable but also met the needs of our users. Overall, the experience of building First Plate taught us many valuable lessons about app development, and we look forward to applying these skills to future projects.
## What's next for First Plate
First Plate has exciting plans for the future, with the main focus being on fully implementing the front-end and back-end of the app. The aim is to create a seamless user experience that is efficient, secure, and easy to navigate. Along with this, our team is enthusiastic about implementing new features that will provide even more value to users. One such feature is expanding the "Pay It Forward" functionality to suggest who to send money to based on past matches, creating a streamlined and personalized experience for users. Another exciting feature is a feed where users can share their dining experiences and snaps of their dinner plates, or leave reviews on the restaurants they visited with their matches. These features will create a dynamic community where users can connect and share their love for food in new and exciting ways. In terms of security, our team is working on implementing end-to-end encryption on the app's chat feature to provide an extra layer of security for users' conversations. The app will also have a reporting feature that allows users to report any disrespectful or inappropriate behavior, ensuring that First Plate is a safe and respectful community for all. We believe that First Plate is a promising startup idea implementable on a larger scale. | ## Inspiration
We wanted to explore what GCP has to offer more in a practical sense, while trying to save money as poor students
## What it does
The app tracks you, and using Google Map's API, calculates a geofence that notifies the restaurants you are within vicinity to, and lets you load coupons that are valid.
## How we built it
React-native, Google Maps for pulling the location, python for the webscraper (*<https://www.retailmenot.ca/>*), Node.js for the backend, MongoDB to store authentication, location and coupons
## Challenges we ran into
React-Native was fairly new, linking a python script to a Node backend, connecting Node.js to react-native
## What we learned
New exposure APIs and gained experience on linking tools together
## What's next for Scrappy.io
Improvements to the web scraper, potentially expanding beyond restaurants. | ## Inspiration
For many college students, finding time to socialize and make new friends is hard. Everyone's schedule seems perpetually busy, and arranging a dinner chat with someone you know can be a hard and unrewarding task. At the same time, however, having dinner alone is definitely not a rare thing. We've probably all had the experience of having social energy on a particular day, but it's too late to put anything on the calendar. Our SMS dinner matching project exactly aims to **address the missed socializing opportunities in impromptu same-day dinner arrangements**. Starting from a basic dining-hall dinner matching tool for Penn students only, we **envision an event-centered, multi-channel social platform** that would make organizing events among friend groups, hobby groups, and nearby strangers effortless and sustainable in the long term for its users.
## What it does
Our current MVP, built entirely within the timeframe of this hackathon, allows users to interact with our web server via **SMS text messages** and get **matched to other users for dinner** on the same day based on dining preferences and time availabilities.
### The user journey:
1. User texts anything to our SMS number
2. Server responds with a welcome message and lists out Penn's 5 dining halls for the user to choose from
3. The user texts a list of numbers corresponding to the dining halls the user wants to have dinner at
4. The server sends the user input parsing result to the user and then asks the user to choose between 7 time slots (every 30 minutes between 5:00 pm and 8:00 pm) to meet with their dinner buddy
5. The user texts a list of numbers corresponding to the available time slots
6. The server attempts to match the user with another user. If no match is currently found, the server sends a text to the user confirming that matching is ongoing. If a match is found, the server sends the matched dinner time and location, as well as the phone number of the matched user, to each of the two users matched
7. The user can either choose to confirm or decline the match
8. If the user confirms the match, the server sends the user a confirmation message; and if the other user hasn't confirmed, notifies the other user that their buddy has already confirmed the match
9. If both users in the match confirm, the server sends a final dinner arrangement confirmed message to both users
10. If a user decides to decline, a message will be sent to the other user that the server is working on making a different match
11. 30 minutes before the arranged time, the server sends each user a reminder
###Other notable backend features
12. The server conducts user input validation for each user text to the server; if the user input is invalid, it sends an error message to the user asking the user to enter again
13. The database maintains all requests and dinner matches made on that day; at 12:00 am each day, the server moves all requests and matches to a separate archive database
## How we built it
We used the Node.js framework and built an Express.js web server connected to a hosted MongoDB instance via Mongoose.
We used Twilio Node.js SDK to send and receive SMS text messages.
We used Cron for time-based tasks.
Our notable abstracted functionality modules include routes and the main web app to handle SMS webhook, a session manager that contains our main business logic, a send module that constructs text messages to send to users, time-based task modules, and MongoDB schema modules.
## Challenges we ran into
Writing and debugging async functions poses an additional challenge. Keeping track of potentially concurrent interaction with multiple users also required additional design work.
## Accomplishments that we're proud of
Our main design principle for this project is to keep the application **simple and accessible**. Compared with other common approaches that require users to download an app and register before they can start using the service, using our tool requires **minimal effort**. The user can easily start using our tool even on a busy day.
In terms of architecture, we built a **well-abstracted modern web application** that can be easily modified for new features and can become **highly scalable** without significant additional effort (by converting the current web server into the AWS Lambda framework).
## What we learned
1. How to use asynchronous functions to build a server - multi-client web application
2. How to use posts and webhooks to send and receive information
3. How to build a MongoDB-backed web application via Mongoose
4. How to use Cron to automate time-sensitive workflows
## What's next for SMS dinner matching
### Short-term feature expansion plan
1. Expand location options to all UCity restaurants by enabling users to search locations by name
2. Build a light-weight mobile app that operates in parallel with the SMS service as the basis to expand with more features
3. Implement friend group features to allow making dinner arrangements with friends
###Architecture optimization
4. Convert to AWS Lamdba serverless framework to ensure application scalability and reduce hosting cost
5. Use MongoDB indexes and additional data structures to optimize Cron workflow and reduce the number of times we need to run time-based queries
### Long-term vision
6. Expand to general event-making beyond just making dinner arrangements
7. Create explore (even list) functionality and event feed based on user profile
8. Expand to the general population beyond Penn students; event matching will be based on the users' preferences, location, and friend groups | winning |
## Inspiration
In our daily lives we noticed that we were spending a lot of time shopping online and weighing many options. When I was looking to buy a mechanical keyboard last month, I spent over two days visiting countless sites to find a keyboard to buy. During this process, it was frustrating to keep track of everything I had looked at and compare them efficiently.
That’s why we built snip. It’s an ultra easy to use tool that extracts important features from your screenshots using AI, and automatically tabulates your data for easy visualization and comparison!
## What it does
Whenever you decide you’re about to take a series of related screenshots that you would like to have saved and organized automatically (in one centralized place), you can create a “snip” session. Then, whenever you take a screenshot of anything, it will automatically get added to the session, relevant features will be extracted of whatever item you took a screenshot of, and will be automatically added to a table (much easier to view for comparison).
## How we built it
We used Tauri to create a desktop app with a Rust backend (to interact natively with the device to monitor its clipboard) and a React frontend (to create the user interface). We also used the shadcn UI component library and Tailwind CSS to enhance our design.
## Challenges we ran into
Our team is comprised primarily of roboticists, infra, or backend people, and so trying to create a visually pleasing UI with React, shadcn, and Tailwind CSS (all technologies that we’re not used to using) was quite difficult - we often ran into CSS conflicts, UI library conflicts, and random things not working because of the smallest syntax errors.
## Accomplishments that we're proud of
We were able to finish creating our hack and make it look like an actual product.
## What we learned
We learned to prefer to use technologies that give us more speed, rather than perhaps better code quality - for example, we decided to use typescript on the frontend instead of javascript, but all the errors due to typing rules made it quite frustrating to go fast. Also, we learned that if you want to build something challenging and finish it, you should work with technologies that you are familiar with - for example, we were not as familiar with React, but still decided to use it for a core portion of our project and that cost us a lot of precious development time (due to the learning curve).
## What's next for snip.
Provide more powerful control over how you can manipulate data, better AI features, and enhanced ability to extract data from snapshots (and also extract the site they came from). | ## Inspiration
We've worked on e-commerce stores (Shopify/etc), and managing customer support calls was tedious and expensive (small businesses online typically have no number for contact), despite that ~60% of customers prefer calls for support questions and personalization. We wanted to automate the workflow to drive more sales and save working hours.
Existing solutions require custom setup in workflows for chatbots or asking; people still have to answer 20 percent of questions, and a lot are confirmation questions (IBM). People have question fatigue with bots to get to an actual human.
## What it does
It's an embeddable javascript widget/number for any e-commerce store or online product catalog that lets customers call, text, or message on site chat about products personalized to them, processing returns, and general support. We plan to expand out of e-commerce after signing on 100 true users who love us. Boost sales while you are asleep instead of directing customers to a support ticket line.
We plan to pursue routes of revenue with:
* % of revenue from boosted products
* Monthly subscription
* Costs savings from reduced call center capacity requirements
## How we built it
We used a HTML/CSS frontend connected to a backend of Twilio (phone call, transcription, and text-to-speech) and OpenAI APIs (LLMs, Vector DBQA customization).
## Challenges we ran into
* Deprecated Python functionality for Twilio that we did not initially realize, eventually discovered this while browsing documentation and switched to JS
* Accidentally dumped our TreeHacks shirt into a pot of curry
## Accomplishments that we're proud of
* Developed real-time transcription connected to a phone call, which we then streamed to a custom-trained model -- while maintaining conversational-level latency
* Somehow figured out a way to sleep
* Became addicted to Pocari Sweat
## What we learned
We realized the difficulty of navigating documentation while traversing several different APIs. For example, real-time transcription was a huge challenge.
Moreover, we learned about embedding functions that allowed us to customize the LLM for our use case. This enabled us to provide a performance improvement to the existing model while also not adding much compute cost. During our time at TreeHacks, we became close with the Modal team as they were incredibly supportive of our efforts. We also greatly enjoyed leveraging OpenAI to provide this critical website support.
## What's next for Ellum
We are releasing the service to close friends who have experienced these problems, particularly e-commerce distributors and beta-test the service with them. We know some Shopify owners who would be down to demo the service, and we hope to work closely with them to grow their businesses.
We would love to pursue our pain points even more for instantly providing support and setting it up. Valuable features, such as real-time chat, that can help connect us to more customers can be added in the future. We would also love to test out the service with brick-and-mortar stores, like Home Depot, Lowes, CVS, which also have a high need for customer support.
Slides: <https://drive.google.com/file/d/1fLFWAgsi1PXRVi5upMt-ZFivomOBo37k/view?usp=sharing>
Video Part 1: <https://youtu.be/QH33acDpBj8>
Video Part 2: <https://youtu.be/gOafS4ZoDRQ> | # So Many Languages
Web application to help convert one programming language's code to another within seconds while also enabling the user to generate code using just logic.
## Inspiration
Our team consists of 3 developers and all of us realised that we face the same problem- it's very hard to memorise all syntaxes since each language has its own different syntax. This not only causes confusion but also takes up a lot of our time.
## What it does
So Many Languages has various features to motivate students to learn competitive coding while also making the process easier.
SML helps:
1) Save time
2) Immediate language conversion
3) One of its kind language freedom
4) Voice to code templating
5) Code accurately
6) Code programs by just knowing the logic (no need to remember syntaxes)
7) Take tests and practice while also earning rewards for the same
## How to run
```
1) git clone https://github.com/akshatvg/So-Many-Languages
2) pip install -r requirements.txt
3) python3 run.py
```
## How to use
1) Run the software as mentioned above.
2) Use the default page to upload code of a programming language to be converted into any of the other listed languages in the dropdown menu.
3) Use the Voice to Code Templating page to give out intents to be converted into code. eg: "Open C++", "Show me how to print a statement", etc.
4) Use the Compete and Practice page to try out language specific programs to test out how much you learnt, compete against your peers and earn points.
5) Use the Rewards page to redeem the earnt Points.
## Its advantage
1) Run the code from the compiler to get desired result in the same place.
2) Easy to use and fast processing.
3) Save time from scrolling through Google searching for different answers and syntaxes by having everything come up on its own in one single page.
4) Learn and earn at the same time through the Compete and Rewards page.
## Target audience
Students- learning has no age & developers need to keep learning to stay updated with trends.
## Business model
We intend to provide free code templating and conversion for particular common languages like C++, Python, Java, etc and have paid packs for exclusive languages like Swift, PHP, JavaScript, etc.
## Marketing strategy
1) For every referral, points will be earned which help purchase premium and exclusive language packs once enough points are saved. These points can also be used to purchase schwags.
2) Schwags and discount benefits for Campus Ambassadors in different Universities and Colleges.
## How we built it
We built the assistive educative technology using:
1) HTML/ CSS/ JavaScript/ Bootstrap (Frontend Web Development),
2) Flask (Backend Web Development),
3) IBM Watson (To Gather User's Intent- NLU),
4) PHP, C++, Python (Test Programming Languages).
## Challenges we ran into
Other than the jet lag we still have from travelling all the way from India and hence lack of sleep, we came across a few technical challenges too. Creating algorithms to convert PHP code wasn't very easy at first, but we managed to pull it off in the end.
## Accomplishments that we're proud of
Creating a one of its kind product.
1) We are the first ever educative technological assistant to help learn and migrate to programming languages while also giving users a platform to practice and test how much they learnt using language specific problems.
2) We also help users completely convert one language's code to another language's code accurately within seconds.
## What we learned
This was our team's first international hackathon. We met hundreds of inspiring coders and developers who tried and tested our product and gave their views and suggestions which we then tried implementing. We saw how other teams functioned and what we may have been doing wrong before.
We also each learnt a technical skill for the project (Akshat learnt Animations and basics of Flask, Anand learnt using IBM Watson to its greatest extent and Sandeep learnt PHP just to implement it into this project).
## What's next for So Many Languages
We intend to add support for more programming languages as soon as possible while also making sure that any upcoming bugs are rectified. | losing |
## Inspiration
We want people to make right decision at right time so that they can get returns on their investments and trading in stock market.
## What it does
It will enable to invest and trade in the stock by using HFT and technical analysis techniques. The product will have large scale applications in situations where the investor or trader does not has much time for individual analysis and for professionals that would like to deploy their money on auto pilot.
## How we built it
We have only the idea :)
## Challenges we ran into
How to implement the web app and mobile app for auto trading.
## What's next for TradeGO
We want to implement the app so that it can be used for auto trading. | # 🪼 **SeaScript** 🪸
## Inspiration
Learning MATLAB can be as appealing as a jellyfish sting. Traditional resources often leave students lost at sea, making the process more exhausting than a shark's endless swim. SeaScript transforms this challenge into an underwater adventure, turning the tedious journey of mastering MATLAB into an exciting expedition.
## What it does
SeaScript plunges you into an oceanic MATLAB adventure with three distinct zones:
1. 🪼 Jellyfish Junction: Help bioluminescent jellies navigate nighttime waters.
2. 🦈 Shark Bay: Count endangered sharks to aid conservation efforts.
3. 🪸 Coral Code Reef: Assist Nemo in finding the tallest coral home.
Solve MATLAB challenges in each zone to collect puzzle pieces, unlocking a final mystery message. It's not just coding – it's saving the ocean, one function at a time!
## How we built it
* Python game engine for our underwater world
* MATLAB integration for real-time, LeetCode-style challenges
* MongoDB for data storage (player progress, challenges, marine trivia)
## Challenges we ran into
* Seamlessly integrating MATLAB with our Python game engine
* Crafting progressively difficult challenges without overwhelming players
* Balancing education and entertainment (fish puns have limits!)
## Accomplishments that we're proud of
* Created a unique three-part underwater journey for MATLAB learning
* Successfully merged MATLAB, Python, and MongoDB into a cohesive game
* Developed a rewarding puzzle system that tracks player progress
## What we learned
* MATLAB's capabilities are as vast as the ocean
* Gamification can transform challenging subjects into adventures
* The power of combining coding, marine biology, and puzzle-solving in education
## What's next for SeaScript
* Expand with more advanced MATLAB concepts
* Implement multiplayer modes for collaborative problem-solving
* Develop mobile and VR versions for on-the-go and immersive learning
Ready to dive in? Don't let MATLAB be the one that got away – catch the wave with SeaScript and code like a fish boss! 🐠👑 | ## Inspiration
Our biggest inspiration for this app was the Advice Company's category which was: *"Most Innovative Use of AI for Personal Finance."*
## What it does
The application tells you what stocks to invest in based on 3 parameters: risk profile(High risk, Medium Risk, and Low Risk), the desired return type(Low Return, Medium Return, High Return), and the industry the customer wants to invest in. Once the user has entered these 3 inputs the machine learning model is used to figure out which stocks are the best option for the user.
## How we built it
We used python Tkinter to create a GUI, excel to manage the dataset, jupyter notebook and TensorFlow to create the machine learning model
## Challenges we ran into
We ran into challenges quite often. One of our initial challenges was setting up the GUI to use the machine learning model. Making the machine learning model was also challenging as we have never used TensorFlow before. Also,
## Accomplishments that we're proud of
We created a machine learning model, We also created a gui so that anyone can use it.
## What we learned
We learned a lot in this project. None of us have ever used tensorflow before to create a machine learning model.
## What's next for PyTrade
Our next step for PyTrade is to make the machine learning model better by adding more criteria to our selection process | partial |
## Inspiration
After observing the news about the use of police force for so long, we considered to ourselves how to solve that. We realized that in some ways, the problem was made worse by a lack of trust in law enforcement. We then realized that we could use blockchain to create a better system for accountability in the use of force. We believe that it can help people trust law enforcement officers more and diminish the use of force when possible, saving lives.
## What it does
Chain Gun is a modification for a gun (a Nerf gun for the purposes of the hackathon) that sits behind the trigger mechanism. When the gun is fired, the GPS location and ID of the gun are put onto the Ethereum blockchain.
## Challenges we ran into
Some things did not work well with the new updates to Web3 causing a continuous stream of bugs. To add to this, the major updates broke most old code samples. Android lacks a good implementation of any Ethereum client making it a poor platform for connecting the gun to the blockchain. Sending raw transactions is not very well documented, especially when signing the transactions manually with a public/private keypair.
## Accomplishments that we're proud of
* Combining many parts to form a solution including an Android app, a smart contract, two different back ends, and a front end
* Working together to create something we believe has the ability to change the world for the better.
## What we learned
* Hardware prototyping
* Integrating a bunch of different platforms into one system (Arduino, Android, Ethereum Blockchain, Node.JS API, React.JS frontend)
* Web3 1.0.0
## What's next for Chain Gun
* Refine the prototype | ## Inspiration
It’s Friday afternoon, and as you return from your final class of the day cutting through the trailing winds of the Bay, you suddenly remember the Saturday trek you had planned with your friends. Equipment-less and desperate you race down to a nearby sports store and fish out $$$, not realising that the kid living two floors above you has the same equipment collecting dust. While this hypothetical may be based on real-life events, we see thousands of students and people alike impulsively spending money on goods that would eventually end up in their storage lockers. This cycle of buy-store-collect dust inspired us to develop Lendit this product aims to stagnate the growing waste economy and generate passive income for the users on the platform.
## What it does
A peer-to-peer lending and borrowing platform that allows users to generate passive income from the goods and garments collecting dust in the garage.
## How we built it
Our Smart Lockers are built with RaspberryPi3 (64bit, 1GB RAM, ARM-64) microcontrollers and are connected to our app through interfacing with Google's Firebase. The locker also uses Facial Recognition powered by OpenCV and object detection with Google's Cloud Vision API.
For our App, we've used Flutter/ Dart and interfaced with Firebase. To ensure *trust* - which is core to borrowing and lending, we've experimented with Ripple's API to create an Escrow system.
## Challenges we ran into
We learned that building a hardware hack can be quite challenging and can leave you with a few bald patches on your head. With no hardware equipment, half our team spent the first few hours running around the hotel and even the streets to arrange stepper motors and Micro-HDMI wires. In fact, we even borrowed another team's 3-D print to build the latch for our locker!
On the Flutter/ Dart side, we were sceptical about how the interfacing with Firebase and Raspberry Pi would work. Our App Developer previously worked with only Web Apps with SQL databases. However, NoSQL works a little differently and doesn't have a robust referential system. Therefore writing Queries for our Read Operations was tricky.
With the core tech of the project relying heavily on the Google Cloud Platform, we had to resolve to unconventional methods to utilize its capabilities with an internet that played Russian roulette.
## Accomplishments that we're proud of
The project has various hardware and software components like raspberry pi, Flutter, XRP Ledger Escrow, and Firebase, which all have their own independent frameworks. Integrating all of them together and making an end-to-end automated system for the users, is the biggest accomplishment we are proud of.
## What's next for LendIt
We believe that LendIt can be more than just a hackathon project. Over the course of the hackathon, we discussed the idea with friends and fellow participants and gained a pretty good Proof of Concept giving us the confidence that we can do a city-wide launch of the project in the near future. In order to see these ambitions come to life, we would have to improve our Object Detection and Facial Recognition models. From cardboard, we would like to see our lockers carved in metal at every corner of this city. As we continue to grow our skills as programmers we believe our product Lendit will grow with it. We would be honoured if we can contribute in any way to reduce the growing waste economy. | ## Inspiration
A twist on the classic game '**WikiRacer**', but better!
Players play Wikiracer by navigating from one Wikipedia page to another with the fewest clicks. WikiChess adds layers of turn-based strategy, a dual-win condition, and semantic similarity guesswork that introduces varying playstyles/adaptability in a way that is similar to chess.
It introduces **strategic** elements where players can choose to play **defensively or offensively**—misleading opponents or outsmarting them. **Victory can be achieved through both extensive general knowledge and understanding your opponent's tactics.**
## How to Play
**Setup**:
Click your chess piece to reveal your WikiWord—a secret word only you should know. Remember it well!
**Game Play**:
Each turn, you can choose to either **PLAY** or **GUESS**.
### **PLAY Mode**:
* You will start on a randomly selected Wikipedia page.
* Your goal is to navigate to your WikiWord's page by clicking hyperlinks.
+ For example, if your WikiWord is "BANANA," your goal is to reach the "Banana" Wikipedia article.
* You can click up to three hyperlinks per turn.
* After each click, you'll see a semantic similarity score indicating how close the current page's title is to your WikiWord.
* You can view the last ten articles you clicked, along with their semantic scores, by holding the **TAB** key.
* Be quick—if you run out of time, your turn is skipped!
### **GUESS Mode**:
* Attempt to guess your opponent’s WikiWord. You have three guesses per turn.
* Each guess provides a semantic similarity score to guide your future guesses.
* Use the article history and semantic scores shown when holding **TAB** to deduce your opponent's target word based on their navigation path.
**Example**:
If your opponent’s target is "BANANA," they might navigate through articles like "Central America" > "Plantains" > "Tropical Fruit." Pay attention to their clicks and semantic scores to infer their WikiWord.
## Let's talk strategy!
**Navigate Wisely in PLAY Mode!**
* Your navigation path's semantic similarity indicates how closely related each page's title is to your WikiWord. Use this to your advantage by advancing towards your target without being too predictable. Balance your moves between progress and deception to keep your opponent guessing.
**Leverage the Tug-of-War Dynamic**:
* Since both players share the same Wikipedia path, the article you end on affects your opponent's starting point in their next PLAY turn. Choose your final article wisely—landing on a less useful page can disrupt your opponent's strategy and force them to consider guessing instead.
+ However, if you choose a dead end, your opponent may choose to GUESS and skip their PLAY turn—you’ll be forced to keep playing the article you tried to give them!
**Semantic Similarity**: **May Not Be the Edge You Think It Is**
* Semantic similarity measures how closely related the page's title is to your target WikiWord, not how straightforward it is to navigate to; use this to make strategic moves that might seem less direct semantically, but can be advantageous to navigate through.
**To Advance or To Mislead?**
* It's tempting to sprint towards your WikiWord, but consider taking detours that maintain a high semantic score but obscure your ultimate destination. This can mislead your opponent and buy you time to plan your next moves.
**Adapt to Your Opponent**:
* Pay close attention to your opponent's navigation path and semantic scores. This information can offer valuable clues about their WikiWord and inform your GUESS strategy. Be ready to shift your tactics if their path becomes more apparent.
**Use GUESS Mode Strategically**:
* If you're stuck or suspect you know your opponent’s WikiWord, use GUESS mode to gain an advantage. Your guesses provide semantic feedback, helping refine your strategy and closing in on their target.
+ Choosing GUESS also automatically skips your PLAY turn and forces your opponent to click more links. You can get even more semantic feedback from this, however it may also be risky—the more PLAY moves you give them, the more likely they are to eventually navigate to their own WikiWord.
## How we built it
Several technologies and strategies were used to develop WikiChess. First, we used **web scraping** to fetch and clean Wikipedia content while bypassing iframes issues, allowing players to navigate and interact with real-time data from the site. To manage the game's state and progression, we updated game status based on each hyperlink click and used **Flask** for our framework. We incorporated **semantic analysis** using spaCy to calculate **NLP**similarity scores between articles to display to players. The game setup is coded with **Python**, featuring five categories—animals, sports, foods, professions, and sciences—generating two words from the same category to provide a cohesive and engaging experience. Players start from a page outside the common category to add an extra challenge. For the front end, we prioritized a user-friendly and interactive design, focusing on a minimalist aesthetic with **dynamic animations** and many smooth transitions. Front-end techstack was made up of **HTML/CSS, JS, image generation tools, Figma.**
## Challenges we ran into
One of our biggest challenges was dealing with **iframe access controls**. We faced persistent issues with blocked access, which prevented us from executing any logic beyond simply displaying the Wikipedia content. Despite trying various methods to bypass this limitation, including using proxy servers, the frequent need to check for user victories made it clear that iframes were not a viable solution. This challenge forced us to pivot from our initial plan of handling much of the game logic on the client side using JavaScript. Instead, we had to **rely heavily on backend solutions**, particularly web scraping, to manage and update game state.
## Accomplishments that we're proud of
Despite the unexpected shift in our solution approach, which significantly increased the complexity of our backend and required **major design adjustments**, we managed to overcome several challenges. Integrating web scraping with real-time game updates and **ensuring a smooth user experience** were particularly demanding. We tackled these issues by strengthening our backend logic and refining the frontend to enhance user engagement. Despite the text-heavy nature of the Wikipedia content, we aimed to make the interface visually appealing and fun, ensuring a seamless and enjoyable user experience.
## What we learned
As beginners in hacking, we are incredibly proud of our perseverance through these challenges. The experience was a great learning opportunity, and we successfully delivered a product that we find both enjoyable and educational. **Everyone was able to contribute in their own way!**
## What's next for WikiChess
Our first priority would be to implement an **online lobby feature** that would allow users to play virtually with their friends rather than only locally in person. We would also like to introduce more word categories, and to have a **more customized metric than semantics for the similarity score**. Ideally, the similarity score would account for the structure of Wikipedia and the strategies that WikiRacers use to reach their target article other than just by going with the closest in word meaning. We would also like to introduce a **timer-based gameplay** where players would be limited to time instead of turns to encourage a faster-paced game mode. | winning |
## Inspiration
These days, we’re all stuck at home, you know, cuz of COVID-19 and everything.
If you’re anything like me, the lockdown has changed my online shopping habits quite a bit, and I find myself shopping on websites like Amazon way more than I used to.
With this change to my lifestyle, I realized that e-commerce is weirdly inconvenient when you really want to get the best price. You have to go check each retailer’s website individually, and compare prices manually. I then thought to myself, “Hey, it would be really cool if I had a price comparison tool to search for the best price across a variety of online retailers”. Before I knew it, I came up with Buy It, an application that does just that.
## What it does
Given a product name to search, Buy It will return search results from different online retailers giving you all the information you need to save money, all in one place.
## How I built it
Buy It is a mobile app developed in Android Studio using Java and Kotlin. The pricing data presented in the app is actually collected via web scraping. To do that, I leveraged the ParseHub API after training their scraping bot to search e-commerce websites with whatever product the user is interested in. The main issue is, the API isn’t easily compatible with Java, so I thought to host an API endpoint with Flask in Python to then make data available for my Java app to request. But I had a better idea: using Solace’s PubSub+ Event Broker. This made a lot of sense, since Solace’s event driven programming solution allows for easy two-way communication between both the client and the publisher.
That means my app can send the user’s product search to the Python script, Python runs the API on that search to initiate a web scraping action, then Python also sends back whatever data it collects. Meanwhile, the Java app was simply waiting for messages on the topic of the search product. After receiving a response, it can then process the pricing information and display it to the user.
Another cool thing about using Solace is that it’s an extremely scalable solution. I could make this app track prices real time from a large number of retailers at once, in other words, I’d be generating constant heavy network traffic, and the event broker would have no issue. By leveraging PubSub+, I was able to make a quick, easy, and powerful communication pathway for all the components of my hack to talk through, while also future-proofing my app for further development and updates.
## Challenges we ran into
Unfortunately, I was not quite able to get the finishing touches in for this hack. The app was even able to receive the pricing information, it was just a matter of parsing it and displaying it in a user-friendly manner. With my only team member not being available to work with me last minute, this ended up being a solo hack programmed in Java and Python, languages I’ve never used before. That being said, the majority of it is done, and I put an immense amount of effort into learning all this.
## Accomplishments that we're proud of
I'm super excited about how much I've learned. I used Solace which was very useful and educational. I've also never built a mobile app, never done web scraping, never coded in Python or Java/Kotlin, so lots of new stuff. I was also impressed with my progress as a solo hack.
## What we learned
As previously mentioned, I learned how to build a mobile app in Android Studio with Java/Kotlin. I learned more about programming in Python (particularly API endpoints and such), as well as web scraping. Last but not least, I learned about Solace event brokers and how they can replace REST API endpoints.
## What's next for Buy It!
I was thinking of creating a watchlist, where the user can save items, which will subscribe the app to a topic that receives real-time price changes for said items. That way, the user is notified if the item is being sold below a certain price threshold. Because Buy It is built off of such a strong foundation with Solace, there’s lots of room for new features and enhancements, so I really look forward to getting creative with Buy It! | ## Inspiration
All of us have struggled with online shopping. There are so many similar products, which one should we buy? We often spend hours checking reviews and researching the best product and often still aren't sure if we made the right decision. ShopWise can easily solve this issue by analyzing customer reviews to identify trends and allow you to ask questions.
## What it does
Users can enter a product they want to buy, for example, 'frying pan'. Then we get the top 5 products on Amazon, analyze their respective reviews, and summarize the key info for each product. The user can also choose to engage in a conversation with these products. For example, 'Which pan is the most durable?'. If the user has narrowed down their own products and doesn't simply want the top 5, they can also enter the URLs for the chatbot and ask questions comparing them.
## How we built it
We used React for the front end to allow for dynamic and responsive rendering. We used Python-Flask for the backend. Once the user enters a product name, we scrape Amazon for the top 5 URLs. Then we scrape each URL using multithreading for all of the reviews and associated info. We then use gpt-4 to analyze the reviews and summarize the pros and cons. For the chatbot, we load the scraped reviews and reference them when answering the user questions, again using gpt-4. Then React calls the corresponding Flask APIs and renders the info.
## Challenges we ran into
Back-end wise, we struggled with making React work with Flask as there were many cross-platform (namely CORS) issues that made the API calls difficult. We also struggled with making so many requests for the URLs and accessing the reviews, as it took a long time. We learned how to use Multithreading to speed up requests.
Front-end wise, we struggled with rendering the 3D model since there were so many aspects to set up such as camera angle/rotation/lighting.
## Accomplishments that we're proud of
We are proud of being able to make multiple aesthetic web pages using React in such a short time frame. In addition, we were able to significantly speed up our requests and make the web app user-friendly.
## What we learned
We learned how to effectively make a cross-platform full-stack application and effectively use a wide variety of technologies.
## What's next for ShopWise
We plan on improving the technique used to select the top 5 products for a given item. Currently, we are just using Amazon's method of sorting, but we will implement optional filters to give more accurate results. | ## Inspiration 💡
The push behind EcoCart is the pressing call to weave sustainability into our everyday actions. I've envisioned a tool that makes it easy for people to opt for green choices when shopping.
## What it does 📑
EcoCart is your AI-guided Sustainable Shopping Assistant, designed to help shoppers minimize their carbon impact. It comes with a user-centric dashboard and a browser add-on for streamlined purchase monitoring.
By integrating EcoCart's browser add-on with favorite online shopping sites, users can easily oversee their carbon emissions. The AI functionality dives deep into the data, offering granular insights on the ecological implications of every transaction.
Our dashboard is crafted to help users see their sustainable journey and make educated choices. Engaging charts and a gamified approach nudge users towards greener options and aware buying behaviors.
EcoCart fosters an eco-friendly lifestyle, fusing AI, an accessible dashboard, and a purchase-monitoring add-on. Collectively, our choices can echo a positive note for the planet.
## How it's built 🏗️
EcoCart is carved out using avant-garde AI tools and a strong backend setup. While our AI digs into product specifics, the backend ensures smooth data workflow and user engagement. A pivotal feature is the inclusion of SGID to ward off bots and uphold genuine user interaction, delivering an uninterrupted user journey and trustworthy eco metrics.
## Challenges and hurdles along the way 🧱
* Regular hiccups with Chrome add-on's hot reloading during development
* Sparse online guides on meshing Supabase Google Auth with a Chrome add-on
* Encountered glitches when using Vite for bundling our Chrome extension
## Accomplishments that I'am proud of 🦚
* Striking user interface
* Working prototype
* Successful integration of Supabase in our Chrome add-on
* Advocacy for sustainability through #techforpublicgood
## What I've learned 🏫
* Integrating SGID into a NextJS CSR web platform
* Deploying Supabase in a Chrome add-on
* Crafting aesthetically appealing and practical charts via Chart.js
## What's next for EcoCart ⌛
* Expanding to more e-commerce giants like Carousell, Taobao, etc.
* Introducing a rewards mechanism linked with our gamified setup
* Launching a SaaS subscription model for our user base. | losing |
## Inspiration
Us college students all can relate to having a teacher that was not engaging enough during lectures or mumbling to the point where we cannot hear them at all. Instead of finding solutions to help the students outside of the classroom, we realized that the teachers need better feedback to see how they can improve themselves to create better lecture sessions and better ratemyprofessor ratings.
## What it does
Morpheus is a machine learning system that analyzes a professor’s lesson audio in order to differentiate between various emotions portrayed through his speech. We then use an original algorithm to grade the lecture. Similarly we record and score the professor’s body language throughout the lesson using motion detection/analyzing software. We then store everything on a database and show the data on a dashboard which the professor can access and utilize to improve their body and voice engagement with students. This is all in hopes of allowing the professor to be more engaging and effective during their lectures through their speech and body language.
## How we built it
### Visual Studio Code/Front End Development: Sovannratana Khek
Used a premade React foundation with Material UI to create a basic dashboard. I deleted and added certain pages which we needed for our specific purpose. Since the foundation came with components pre build, I looked into how they worked and edited them to work for our purpose instead of working from scratch to save time on styling to a theme. I needed to add a couple new original functionalities and connect to our database endpoints which required learning a fetching library in React. In the end we have a dashboard with a development history displayed through a line graph representing a score per lecture (refer to section 2) and a selection for a single lecture summary display. This is based on our backend database setup. There is also space available for scalability and added functionality.
### PHP-MySQL-Docker/Backend Development & DevOps: Giuseppe Steduto
I developed the backend for the application and connected the different pieces of the software together. I designed a relational database using MySQL and created API endpoints for the frontend using PHP. These endpoints filter and process the data generated by our machine learning algorithm before presenting it to the frontend side of the dashboard. I chose PHP because it gives the developer the option to quickly get an application running, avoiding the hassle of converters and compilers, and gives easy access to the SQL database. Since we’re dealing with personal data about the professor, every endpoint is only accessible prior authentication (handled with session tokens) and stored following security best-practices (e.g. salting and hashing passwords). I deployed a PhpMyAdmin instance to easily manage the database in a user-friendly way.
In order to make the software easily portable across different platforms, I containerized the whole tech stack using docker and docker-compose to handle the interaction among several containers at once.
### MATLAB/Machine Learning Model for Speech and Emotion Recognition: Braulio Aguilar Islas
I developed a machine learning model to recognize speech emotion patterns using MATLAB’s audio toolbox, simulink and deep learning toolbox. I used the Berlin Database of Emotional Speech To train my model. I augmented the dataset in order to increase accuracy of my results, normalized the data in order to seamlessly visualize it using a pie chart, providing an easy and seamless integration with our database that connects to our website.
### Solidworks/Product Design Engineering: Riki Osako
Utilizing Solidworks, I created the 3D model design of Morpheus including fixtures, sensors, and materials. Our team had to consider how this device would be tracking the teacher’s movements and hearing the volume while not disturbing the flow of class. Currently the main sensors being utilized in this product are a microphone (to detect volume for recording and data), nfc sensor (for card tapping), front camera, and tilt sensor (for vertical tilting and tracking professor). The device also has a magnetic connector on the bottom to allow itself to change from stationary position to mobility position. It’s able to modularly connect to a holonomic drivetrain to move freely around the classroom if the professor moves around a lot. Overall, this allowed us to create a visual model of how our product would look and how the professor could possibly interact with it. To keep the device and drivetrain up and running, it does require USB-C charging.
### Figma/UI Design of the Product: Riki Osako
Utilizing Figma, I created the UI design of Morpheus to show how the professor would interact with it. In the demo shown, we made it a simple interface for the professor so that all they would need to do is to scan in using their school ID, then either check his lecture data or start the lecture. Overall, the professor is able to see if the device is tracking his movements and volume throughout the lecture and see the results of their lecture at the end.
## Challenges we ran into
Riki Osako: Two issues I faced was learning how to model the product in a way that would feel simple for the user to understand through Solidworks and Figma (using it for the first time). I had to do a lot of research through Amazon videos and see how they created their amazon echo model and looking back in my UI/UX notes in the Google Coursera Certification course that I’m taking.
Sovannratana Khek: The main issues I ran into stemmed from my inexperience with the React framework. Oftentimes, I’m confused as to how to implement a certain feature I want to add. I overcame these by researching existing documentation on errors and utilizing existing libraries. There were some problems that couldn’t be solved with this method as it was logic specific to our software. Fortunately, these problems just needed time and a lot of debugging with some help from peers, existing resources, and since React is javascript based, I was able to use past experiences with JS and django to help despite using an unfamiliar framework.
Giuseppe Steduto: The main issue I faced was making everything run in a smooth way and interact in the correct manner. Often I ended up in a dependency hell, and had to rethink the architecture of the whole project to not over engineer it without losing speed or consistency.
Braulio Aguilar Islas: The main issue I faced was working with audio data in order to train my model and finding a way to quantify the fluctuations that resulted in different emotions when speaking. Also, the dataset was in german
## Accomplishments that we're proud of
Achieved about 60% accuracy in detecting speech emotion patterns, wrote data to our database, and created an attractive dashboard to present the results of the data analysis while learning new technologies (such as React and Docker), even though our time was short.
## What we learned
As a team coming from different backgrounds, we learned how we could utilize our strengths in different aspects of the project to smoothly operate. For example, Riki is a mechanical engineering major with little coding experience, but we were able to allow his strengths in that area to create us a visual model of our product and create a UI design interface using Figma. Sovannratana is a freshman that had his first hackathon experience and was able to utilize his experience to create a website for the first time. Braulio and Gisueppe were the most experienced in the team but we were all able to help each other not just in the coding aspect, with different ideas as well.
## What's next for Untitled
We have a couple of ideas on how we would like to proceed with this project after HackHarvard and after hibernating for a couple of days.
From a coding standpoint, we would like to improve the UI experience for the user on the website by adding more features and better style designs for the professor to interact with. In addition, add motion tracking data feedback to the professor to get a general idea of how they should be changing their gestures.
We would also like to integrate a student portal and gather data on their performance and help the teacher better understand where the students need most help with.
From a business standpoint, we would like to possibly see if we could team up with our university, Illinois Institute of Technology, and test the functionality of it in actual classrooms. | ## Inspiration
We got together a team passionate about social impact, and all the ideas we had kept going back to loneliness and isolation. We have all been in high pressure environments where mental health was not prioritized and we wanted to find a supportive and unobtrusive solution. After sharing some personal stories and observing our skillsets, the idea for Remy was born. **How can we create an AR buddy to be there for you?**
## What it does
**Remy** is an app that contains an AR buddy who serves as a mental health companion. Through information accessed from "Apple Health" and "Google Calendar," Remy is able to help you stay on top of your schedule. He gives you suggestions on when to eat, when to sleep, and personally recommends articles on mental health hygiene. All this data is aggregated into a report that can then be sent to medical professionals. Personally, our favorite feature is his suggestions on when to go on walks and your ability to meet other Remy owners.
## How we built it
We built an iOS application in Swift with ARKit and SceneKit with Apple Health data integration. Our 3D models were created from Mixima.
## Challenges we ran into
We did not want Remy to promote codependency in its users, so we specifically set time aside to think about how we could specifically create a feature that focused on socialization.
We've never worked with AR before, so this was an entirely new set of skills to learn. His biggest challenge was learning how to position AR models in a given scene.
## Accomplishments that we're proud of
We have a functioning app of an AR buddy that we have grown heavily attached to. We feel that we have created a virtual avatar that many people really can fall for.
## What we learned
Aside from this being many of the team's first times work on AR, the main learning point was about all the data that we gathered on the suicide epidemic for adolescents. Suicide rates have increased by 56% in the last 10 years, and this will only continue to get worse. We need change.
## What's next for Remy
While our team has set out for Remy to be used in a college setting, we envision many other relevant use cases where Remy will be able to better support one's mental health wellness.
Remy can be used as a tool by therapists to get better insights on sleep patterns and outdoor activity done by their clients, and this data can be used to further improve the client's recovery process. Clients who use Remy can send their activity logs to their therapists before sessions with a simple click of a button.
To top it off, we envisage the Remy application being a resource hub for users to improve their overall wellness. Through providing valuable sleep hygiene tips and even lifestyle advice, Remy will be the one-stop, holistic companion for users experiencing mental health difficulties to turn to as they take their steps towards recovery. | ## Inspiration
Our inspiration stems from a common everyday issue that has arisen amongst the younger generation in this quarantine season. Once Covid-19 started, many students started to suffer the issue of being incapable of getting out of bed. As first year post-secondary students, we have fallen victim to this trend and decided to do something about it.
## What it does
What WakeUP! essentially does is just act like an alarm clock, but with one crucial difference, there is no snooze button. Without a snooze button, someone could still turn off the alarm, however, even that is now not as easy. WakeUP! forces the user to get out of bed and go Barcode scanning in order to turn of the annoying alarm sound that would otherwise be rendered useless.
## How we built it
The development of the application was quite a story, but essentially there are 3 parts.
**Part 1 - Alarm Clock**
This part involves the creation of an alarm clock that does not rely on the stock android clock app. To build this the first step was to make an Android Studio TimeTicker that takes user input and registers it as a value. Through the usage of various intents, this information is then used in other parts of the application, including making the alarm part.
**Part 2 - Overlay**
In this part, there is a user interface that activates upon alarm ringing. On Overlay exists a weather API and a Barcode Scanner. Both were API and scanner were found on the internet and were implemented.
**Part 3 - Service**
This is the part that brought everything together. By using a service we were able to use elements from Alarm Clock to help run Overlay and vice versa. This will be used more for future development.
## Challenges we ran into
For starters, none of the team members have any experience with Android Studio, or any app creation for that matter. We had to learn how to code in Android Studio, during the 24h. Without the help of online resources and mentors, this would not have been possible.
## Accomplishments that we're proud of
Just to actually have a working app to begin with :).
## What we learned
We pretty much picked up a new language in 24h! From this experience we learned the fundamentals of making an Android App, from working with graphical elements in a xml file to implementing API's.
## What's next for Wakeup!
We have big plans for the application, as we want to eventually release it on the Google Play Store. As a sneak peak into the future, we have plans to implement a news api into the app! | winning |
## Inspiration
Although each of us came from different backgrounds, we each share similar experiences/challenges during our high school years: it was extremely hard to visualize difficult concepts, much less understand the the various complex interactions. This was most prominent in chemistry, where 3D molecular models were simply nonexistent, and 2D visualizations only served to increase confusion. Sometimes, teachers would use a combination of Styrofoam balls, toothpicks and pens to attempt to demonstrate, yet despite their efforts, there was very little effect. Thus, we decided to make an application which facilitates student comprehension by allowing them to take a picture of troubling text/images and get an interactive 3D augmented reality model.
## What it does
The app is split between two interfaces: one for text visualization, and another for diagram visualization. The app is currently functional solely with Chemistry, but can easily be expanded to other subjects as well.
If the text visualization is chosen, an in-built camera pops up and allows the user to take a picture of the body of text. We used Google's ML-Kit to parse the text on the image into a string, and ran a NLP algorithm (Rapid Automatic Keyword Extraction) to generate a comprehensive flashcard list. Users can click on each flashcard to see an interactive 3D model of the element, zooming and rotating it so it can be seen from every angle. If more information is desired, a Wikipedia tab can be pulled up by swiping upwards.
If diagram visualization is chosen, the camera remains perpetually on for the user to focus on a specific diagram. An augmented reality model will float above the corresponding diagrams, which can be clicked on for further enlargement and interaction.
## How we built it
Android Studio, Unity, Blender, Google ML-Kit
## Challenges we ran into
Developing and integrating 3D Models into the corresponding environments.
Merging the Unity and Android Studio mobile applications into a single cohesive interface.
## What's next for Stud\_Vision
The next step of our mobile application is increasing the database of 3D Models to include a wider variety of keywords. We also aim to be able to integrate with other core scholastic subjects, such as History and Math. | # Hack Western 2015 - BitFor.me
## Process
1. User loads Bitcoin into webapp
2. User creates simple task that others can easily do, such as purchasing coffee.
3. Another user finds the task based on location, and accepts it.
4. That user then completes the task by, for instance, purchasing coffee and delivering it to the first user.
5. After the task has been completed, the purchaser marks the transaction as complete and the Bitcoin is sent from the first user to the second.
6. ~~Both users can give either positive or negative feedback, based on how the transaction went~~. Coming soon. | ## Inspiration💡
As exam season concludes, we came up with the idea for our hackathon project after reflecting on our own experiences as students and discussing common challenges we face when studying. We found that searching through long textbooks and PDFs was a time-consuming and frustrating process, even with search tools such as CTRL + F. We wanted to create a solution that could simplify this process and help students save time. Additionally, we were inspired by the fact that our tool could be particularly useful for students with ADHD, dyslexia, or anyone who faces difficulty reading large pieces of text Ultimately, our goal was to create a tool that could help students focus on learning, efficiently at that, rather than spending unnecessary time on searching for information.
## What it does 🤨
[docuMind](https://github.com/cho4/PDFriend) is a web app that takes a PDF file as input and extracts text to train GPT-3.5. This allows for summaries and accurate answers according to textbook information.
## How we built it 👷♂️
To bring life to docuMind, we employed ReactJS as the frontend, while using Python with the Flask web framework and SQLite3 database. After extracting the text from the PDF file and doing some data cleaning, we used OpenAI to generate word embeddings that we used pickle to serialize and store in our database. Then we passed our prompts and data to langchain in order to provide a suitable answer to the user. In addition, we allow users to create accounts, login, and access chat history using querying and SQLite.
## Challenges we ran into 🏋️
One of the main challenges we faced during the hackathon was coming up with an idea for our project. We had a broad theme to work with, but it was difficult to brainstorm a solution that would be both feasible and useful. Another challenge we encountered was our lack of experience with Git, which at one point caused us to accidentally delete a source folder, spending a good chunk of time recovering it. This experience taught us the importance of backing up our work regularly and being more cautious when using Git. We also ran into some compatibility issues with the technologies we were using. Some of the tools and libraries we wanted to incorporate into our project were either not compatible with each other or presented problems, which required us to find workarounds or alternative solutions.
## Accomplishments that we're proud of 🙌
Each member on our team has different things we’re proud of, but generally we are all proud of the project we managed to put together despite our unfamiliarity with many technologies and concepts employed.
## What we learned 📚
We became much more familiar with the tools and techniques used in natural language processing, as well as frontend and backend development, connecting the two, and deploying an app. This experience has helped us to develop our technical skills and knowledge in this area and has inspired us to continue exploring this field further. Another important lesson we learned during the hackathon was the importance of time management. We spent a large portion of our time brainstorming and trying to come up with a project idea, which led to being slightly rushed when it came to the execution of our project. We also learned the importance of communication when working in a team setting. Since we were working on separate parts of the project at times, it was essential to keep each other updated on our progress and any changes we made. This helps prevent accidents like accidental code deletion or someone getting left behind so far they can’t push their code to our repository. Additionally, we learned the value of providing clear and concise documentation to help others understand our code and contributions to the project.
## What's next for docuMind 🔜
To enhance docuMind’s usability, we intend to implement features such as scanning handwritten PDFs, image and diagram recognition, multi-language support, audio input/output and cloud-based storage and collaboration tools. These additions could greatly expand the tool's utility and help users to easily organize and manage their documents. | winning |
## Inspiration
Since the breakout of the pandemic, we saw a surge in people’s need for an affordable, convenient, and environmentally friendly way of transportation. In particular, the main pain points in this area include taking public transportation is risky due to the pandemic, it’s strenuous to ride a bike for long-distance commuting, increasing traffic congestion, etc.
In the post-covid time, private and renewable energy transportation will be a huge market. Compared with the cutthroat competition in the EV industry, the eBike market has been ignored to some extent, so it is the competition is not as overwhelming and the market opportunity and potential are extremely promising.
At the moment, 95% of the bikes are exported from China, and they can not provide prompt aftersales service. The next step of our idea is to integrate resources to build an efficient service system for the current Chinese exporters.
We also see great progress and a promising future for carbon credit projects and decarbonization. This is what we are trying to integrate into our APP to track people’s carbon footprint and translate it into carbon credit to encourage people to make contributions to decarbonization.
## What it does
We are building an aftersales service system to integrate the existing resources such as manufacturers in China and more than 7000 brick and mortar shops in the US.
Unique value proposition: We have a strong supply chain management ability because most of the suppliers are from China and we have a close relationship with them, in the meantime, we are about to build an assembly line in the US to provide better service to the customers. Moreover, we are working on a system to integrate cyclists and carbon emissions, this unique model can make the rides more meaningful and intriguing.
## How we built it
The ecosystem will be built for various platforms and devices. The platform will include both Android and iOS apps because both operating systems have nearly equal percentages of users in the United States.
Google Cloud Maps API:
We'll be using Google Cloud Map API for receiving map location requests continuously and plot a path map accordingly. There will be metadata requests having direction, compass degrees, acceleration, speed, and height above sea level at every API request. These data features will be used to calculate reward points.
Detecting Mock Locations:
The above features can also be mapped for checking irregularities in the data received.
For instance, if a customer tries to trick the system to gain undue favors, these data features can be used to see if the location request data received is sent by a mock location app or a real one.
For example, a mock location app won't be able to give out varying directions. Moreover, the acceleration calculated by map request can be verified against the accelerometer sensor's values.
Fraud Prevention using Machine Learning:
Our app will be able to prevent various levels of fraud by cross-referencing different users and by using Machine Learning models of usage patterns. Such patterns which will be deviant from normal usage behavior will be evident and marked.
Trusted Platform Execution:
The app will be inherently secure as we will leverage the SDK APIs of phone platforms to check the integrity level of devices. It’ll be at the security level of banking apps using advanced program isolation techniques and cryptography to secure our app from other escalated processes. Our app won't work on rooted Android phones or jail-broken iPhones
## Challenges we ran into
How to precisely calculate the conversion from Mileage to Carbon Credits, currently we are using our own way to convert these numbers, but in the future when we have a huge enough customers base and want to work on the individual carbon credits trading, this conversion calculation would be meticulous.
During this week, a challenge we had was to time difference among the teammates. Our IT brain is in China so it was quite challenging for us to properly and fully communicate and make sure the information flow well within the team during such a short time.
## Accomplishments that we're proud of
We are the only company that combines micro mobility with climate change, as well as use this way to protect the forest.
## What we learned
We have talked to many existing and potential customers and learned a lot about their behavior patterns, preferences, social media exposure and comments on the eBike products.
We have learned a lot regarding APP design, product design, business development, and business model innovation through a lot of trial and error.
We have also learned how important partnership and relationships are and we have learned to invest a lot of time and resources into cultivating this.
Above up, we learned how fun hackathons can be!
## What's next for Meego Inc
Right now we have already built up the supply chain for eBikes and the next step of our idea is to integrate resources to build an efficient service system for the current Chinese exporters. | ## Inspiration
EV vehicles are environment friendly and yet it does not receive the recognition it deserves. Even today we do not find many users driving electric vehicles and we believe this must change. Our project aims to provide EV users with a travel route showcasing optimal (and functioning) charging stations to enhance the use of Electric Vehicles by resolving a major concern, range anxiety. We also believe that this will inherently promote the usage of electric vehicles amongst other technological advancements in the car industry.
## What it does
The primary aim of our project is to display the **ideal route** to the user for the electric vehicle to take along with the **optimal (and functional) charging stations** using markers based on the source and destination.
## How we built it
Primarily, in the backend, we integrated two APIs. The **first API** call is used to fetch the longitude as well as latitude coordinates of the start and destination addresses while the **second API** was used to locate stations within a **specific radius** along the journey route. This computation required the start and destination addresses leading to the display of the ideal route containing optimal (and functioning) charging points along the way. Along with CSS, the frontend utilizes **Leaflet (SDK/API)** to render the map which not only recommends the ideal route showing the source, destination, and optimal charging stations as markers but also provides a **side panel** displaying route details and turn-by-turn directions.
## Challenges we ran into
* Most of the APIs available to help develop our application were paid
* We found a **scarcity of reliable data sources** for EV charging stations
* It was difficult to understand the documentation for the Maps API
* Java Script
## Accomplishments that we're proud of
* We developed a **fully functioning app in < 24 hours**
* Understood as well as **integrated 3 APIs**
## What we learned
* Team work makes the dream work: we not only played off each others strengths but also individually tried things that are out of our comfort zone
* How Ford works (from the workshop) as well as more about EVs and charging stations
* We learnt about new APIs
* If we have a strong will to learn and develop something new, we can no matter how hard it is; We just have to keep at it
## What's next for ChargeRoute Navigator: Enhancing the EV Journey
* **Profile** | User Account: Display the user's profile picture or account details
* **Accessibility** features (e.g., alternative text)
* **Autocomplete** Suggestions: Provide autocomplete suggestions as users type, utilizing geolocation services for accuracy
* **Details on Clicking the Charging Station (on map)**: Provide additional information about each charging station, such as charging speed, availability, and user ratings
* **Save Routes**: Allow users to save frequently used routes for quick access.
* **Traffic Information (integration with GMaps API)**: Integrate real-time traffic data to optimize routes
* **User feedback** about (charging station recommendations and experience) to improve user experience | ## Inspiration
Inspired by carbon trading mechanism among nations proposed by Kyoto Protocol treaty in the response to the threat of climate change, and a bunch of cute gas sensors provided by MLH hardware lab, we want to build a similar mechanism among people to monetize our daily carbon emission rights, especially the vehicle carbon emission rights so as to raise people's awareness of green house gas(GHG) emission and climate change.
## What it does
We have designed a data platform for both regular users and the administrative party to manage carbon coins, a new financial concept we proposed, that refers to monetized personal carbon emission rights. To not exceed the annual limit of carbon emission, the administrative party will assign a certain amount of carbon coins to each user on a monthly/yearly basis, taking into consideration both the past carbon emission history and the future carbon emission amount predicted by machine learning algorithms. For regular users, they can monitor their real-time carbon coin consumption and trading carbon coins with each other once logging into our platform. Also, we designed a prototyped carbon emission measurement device for vehicles that includes a CO2 gas sensor, and an IoT system that can collect vehicle's carbon emission data and transmit these real-time data to our data cloud platform.
## How we built it
### Hardware
* Electronics
We built a real-time IoT system with Photon board that calculates the user carbon emission amount based on gas sensors’ input and update the right amount of account payable in their accounts. The Photon board processes the avarage concentration for the time of change from CO2 and CO sensors, and then use the Particle Cloud to publish the value to the web page.
* 3D Priniting
We designed the 3D structure for the eletronic parts. This strcture is meant to be attached to the end of the car gas pipe to measure the car carbon emission, whcih is one of the biggest emission for an average household. Similar structure design will be done for other carbon emission sources like heaters, air-conditioners as well in the future.
### Software
* Back end data analysis
We built a Long Short Term Memory(LSTM) model using Keras, a high-level neural networks API running on top of TensorFlow, to do time series prediction. Since we did not have enough carbon emission data in hand, we trained and evaluated our model on a energy consumption dataset, cause we found there is a strong correlation between the energy consumption data and the carbon emission data. Through this deep learning model, we can make a sound prediction of the carbon emission amount of the next month/year from the past emission history.
* Front end web interface
We built Web app where the user can access the real-time updates of their carbon consumption and balance, and the officials can suggest the currency value change based on the machine learning algorithm results shown in their own separate web interface.
## Challenges we ran into
* Machine learning algorithms
At first we have no clue about what kind of model should we use for time series prediction. After googling for a while, we found recurrent neural networks(RNN) that takes a history of past data points as input into the model is a common way for time series prediction, and its advanced variant, LSTM model has overcome some drawbacks of RNN. However, even for LSTM, we still have many ways to use this model: we have sequence-to-sequence prediction, sequence-to-one prediction and one-to-sequence prediction. After some failed experiments and carefully researching on the characteristics of our problem, finally we got a well-performed sequence-to-one LSTM model for energy consumption prediction.
* Hardware
We experience some technical difficulty when using the 3D printing with Ultimaker, but eventually use the more advanced FDM printer and get the part done. The gas sensor also takes us quite a while to calibrate and give out the right price based on consumption.
## Accomplishments that we're proud of
It feels so cool to propose this cool financial concept that can our planet a better place to live.
Though we only have 3 people, we finally turn tons of caffeine into what we want!
## What we learned
Sleep and Teamwork!!
## What's next for CarbonCoin
1) Expand sources of carbon emission measurements using our devices or convert other factors like electricity consumption into carbon emission as well. The module will be in the future incorprate into all the applicances.
2) Set up trading currency functionality to ensure the liquidity of CarbonCoin.
3) Explore the idea of blockchain usage on this idea | partial |
## Inspiration
A passion for crypto currencies and AI!
## What it does
Allows users to have a conversation with an AI chatbot that supports information for over 5000 cryptocurrencies. It gives users a conversational assistant that can get realtime market updates.
## How we built it
We used React to build out the frontend messaging UI. Then we built the backend with Node.js and used Microsoft Azure to produce accurate machine learning models.
## Challenges we ran into
We ran into a few challenges. The main one was creating a successful machine learning model and creating a template string that allowed us to input the current crypto.
## Accomplishments that we're proud of
We are proud to say that the bot works and has a user interface that one can use to converse with it. It allows for access to the many crypto currencies on the market.
## What we learned
We learnt to use Azure to create a bot with machine learning models. We also learned to build robust machine learning models.
## What's next for Crypto Assistant (Conversational AI Chatbot)
More conversation features, more chat options, better UI, and better training data. | ## Inspiration
For cryptocurrency investors and even people who are simply interested in cryptocurrencies, it is a pain to have to manually navigate to different places to check for all kinds of information about them every day. That is why we were prompted to create this intelligent virtual assistant for people to obtain all that they need with a single click.
## What it does and How we built it
Cryptant offers all-around daily feeds for subscribers on the currencies that they are interested in, and conducts checks on the prices hourly so that the users will be alerted via email and text message, should there be any significant fluctuation of the price of a cryptocurrency. The more interesting part is the text messaging system (powered by Twilio), which acts as a responsive chat-bot since the user can also query information (e.g. pricing, news, forum updates, or advice from AI) by sending keywords about a currency the other way around. Using Google's translation API and Google Cloud's Dialogflow, I enabled the system to recognize user "intents" represented in any natural language and provide feedback ("fulfillments") accordingly, and in the same language that the user uses. In addition, we applied Google Cloud's natural language API/library to analyze the sentiment of the content of all hot news articles and Reddit posts that we collect, so that if we detect some strong sentiment, we will mark the post as "Has a higher chance of containing important information".
Individuals interested in Cryptant can simply subscribe with first and last names, and phone numbers at the official site, which has been deployed to the internet using GCP's App Engine: <https://cryptant.uc.r.appspot.com>. The "daily feed" and "hourly check and alert" functionalities require that the Python scripts be executed on a regular basis, even when our own computers are shut down. In this case we set up a Linux virtual machine (a Compute Engine) in Google Cloud's console and used the [Crontab](https://opensource.com/article/17/11/how-use-cron-linux) utility in Linux operating system to schedule tasks.
Information collected and shared with users is powered by a cryptocurrency price and AI prediction API, a news API, and the "praw" (Reddit scraper) library in Python. We bought an idle mobile phone number configured Twilio so that we can let valuable messages be sent automatically from that number. We also used Ngrok to set up webhooks with Twilio SMS and Dialogflow, so that when the user sends a message for querying, the backend system will know that it receives a message, a callback function will be triggered, the query is parsed and pertinent answers be sent back. Twilio enables the entire system and process to be incredibly smooth and convenient. Twilio also allowed us to implement a subscriber verification system based on a randomly generated 5-digit code, so as to steer clear of malicious subscriptions. We used Google's Cloud Firestore to store miscellaneous information and their verification codes.
## Challenges we ran into & What we learned
We needed to learn how to set up a webhook with Twilio (to make the system responsive), and some other libraries very quickly and almost all from blank. We also needed to correctly parse the large payload sent from a bunch of endpoints. Finally, some companies such as Reddit have adjusted their sites in an advanced way so that scrapping via traditional means (using beautiful soup or selenium) turned out to be impossible, and so we were forced to opt for alternative approaches.
## Accomplishments that we were proud of
As a half-sized team, we were able to create, debug, and maintain hundreds of lines of code in around a day, and we made some sophisticated functionalities (especially the SMS messaging assistant and information collection from various sources) working as intended.
## What's next for Cryptant
I wish to turn Cryptant into Investment Assistant to provide virtual assistance on not only cryptocurrencies but also all kinds of other investments (e.g. stocks and normal currencies). I also envision developing an AI of our own with some advanced machine learning techniques such as neural networks to optimize predictive accuracy. | .png)
## Inspiration
Over the last five years, we've seen the rise and the slow decline of the crypto market. It has made some people richer, and many have suffered because of it. We realized that this problem can be solved with data and machine learning - What if we can, accurately, predict forecast for crypto tokens so that the decisions are always calculated? What if we also include a chatbot to it - so that crypto is a lot less overwhelming for the users?
## What it does
*Blik* is an app and a machine learning model, made using MindsDB, that forecasts cryptocurrency data. Not only that, but it also comes with a chatbot that you can talk to, to make calculated decisions for your. Next trades.
The questions can be as simple as *"How's bitcoin been this year?"* to something as personal as *"I want to buy a tesla worth $50,000 by the end of next year. My salary is 4000$ per month. Which currency should I invest in?"*
We believe that this functionality can help the users make proper, calculated decisions into what they want to invest in. And in return, get high returns for their hard-earned money!
## How we built it
Our tech stack includes:
* **Flutter** for the mobile app
* **MindsDB** for the ML model + real time finetuning
* **Cohere** for AI model and NLP from user input
* **Python** backend to interact with MindsDB and CohereAI
* **FastAPI** to connect frontend and backend.
* **Kaggle** to source the datasets of historic crypto prices
## Challenges we ran into
We started off using the default model training using MindsDB, however, we realized that we would need many specific things like forecasting at specific dates, with a higher horizon etc. The mentors at the MindsDB counter helped us a real lot. With their help, we were able to set up a working prototype and were getting confident about our plan.
One more challenge we ran into was that the forecasts for a particular crypto would always end up spitting the same numbers, making it difficult for users to predict
Then, we ended up using the NeuralTS as our engine, which was perfect. Getting the forecasts to be as accurate as possible was definitely a challenge for us, while keeping it performant enough. Solving every small issue would give rise to another one; but thanks to the mentors and the amazing documentations, we were able to figure out the MindsDB part.
Then, we were trying to implement the AI chat feature, using CohereAI. We had a great experience with the API as it was easy to use, and the chat completions were also really good. We wanted the generated data from Cohere to generate an SQL query to use on MindsDB. Getting this right was challenging, as I'd always need the same datatype in a structured format in order to be able to stitch an SQL command. We figured this also out using advanced prompting techniques and changing the way we pass the data into the SQL. We also used some code to clean up the generated text and make sure that its always compatible.
## Accomplishments that we're proud of
Honestly, going from an early ideation phase to an entire product in just two days, for an indie team of two college freshmen is really a moment of pride. We created a fully working product with an AI chatbot, etc.
Even though we were both new to all of this - integrating crypto with AI techologies is a challenging problem, and thankfully MindsDB was very fun to work with. We are extremely happy about the mindsDB learnings as we can now implement it in our other projects to enhance them with machine learning.
## What we learned
We learnt AI and machine learning, using MindsDB, interacting with AI and advanced prompting, understanding user's needs, designing beautiful apps and presenting data in a useful yet beautiful way in the app.
## What's next for Blik.
At Blik, long term, we plan on expanding this to a full fledged crypto trading solution, where users can sign up and create automations that they can run, to "get rich quick". Short term, we plan to increase the model's accuracy by aggregating news into it, along with the cryptocurrency information like the founder information and the market ownership of the currency. All this data can help us further develop the model to be more accurate and helpful. | losing |
## Inspiration
Inspired by the fintech challenge. We wanted to explore possible ways large-scale social trends could influence the market.
## What it does
Sentigrade is constantly listening to tweets and analyzing the sentiments of messages about different companies. Over time, it builds up an idea of which companies are viewed positively, and which negatively.
Sentigrade also shows historical stock data, allowing users to look for potential relations.
## How we built it
A service constantly updates the database with information from the real-time Twitter message stream. It performs sentiment analysis and aggregates the result over fixed intervals.
The web backend, written in Flask, pulls Twitter data from the database and stock data from Yahoo Finance. The frontend is a simple jQuery/Bootstrap page to display the results in an informative, nice-looking way.
## Challenges we ran into
We originally intended to use arbitrary lists of items, retrieving every message from Twitter. However, this functionality was not available. Also, the stock data retrieval proved messy, though it worked well in the end.
## Accomplishments that we're proud of
Finishing the project ahead of schedule and getting to really flesh out the details.
## What we learned
Web development is scary to start with since you don't know where to begin, but once you hash out all the details, everything comes through.
## What's next for Sentigrade
Sentiment history. Actionable insights, possibly. Per-user settings for filtering, etc. | ## What it does
Uses machine learning sentiment analysis algorithms to determine the positive or negative characteristics of a comment or tweet from social media. This was use in large numbers to generate a meaningful average score for the popularity of any arbitrary search query.
## How we built it
Python was a core part of our framework, as it was used to intelligently scrap multiple social media sites and was used to calculate the sentiment score of comments that had keywords in them. Flask was also used to serve the data to a easily accessible and usable web application.
## Challenges we ran into
The main challenge we faced was that many APIs were changed or had outdated documentation, requiring us to read through their source code and come up with more creative solutions. We also initially tried to learn react.js, even though none of us had ever done front-end web development before, which turned out to be a daunting task in such a short amount of time.
## Accomplishments that we're proud of
We're very proud of the connections we made and creating an application on time!
## What's next for GlobalPublicOpinion
We hope to integrate more social media platforms, and run a statistical analysis to prevent potential bias. | ## Inspiration
A [paper](https://arxiv.org/pdf/1610.09225.pdf) by Indian Institute of Technology researchers described that stock predictions using sentiment analysis had a higher accuracy rate than those analyzing previous trends. We decided to implement that idea and create a real-time, self-updating web-app that could visually show how the public felt towards the big stock name companies. What better way then, than to use the most popular and relatable images on the web, memes?
## What it does
The application retrieves text content from Twitter, performs sentiment analysis on tweets and generates meme images based on the sentiment.
## How we built it
The whole implementation process is divided into four parts: scraping data, processing data, analysing data, and visualizing data. For scraping data, we were planning to use python data scraping library and our target websites are the ones where users are active and able to speak out their own minds. We wanted unbiased and representative data to give us a more accurate result. For processing data, since we will get a lot of noise when we scrape data from websites and we try to make sure that our data is concise and less time-consuming to feed our algorithm, we planned to use regular expression to create a generic template where it ignores all the emoticons.
## Challenges we ran into
We encountered some technical, architectural, and timing issues. For example, in terms of technical problems, when we try to scrape data from twitter, we ran into noise issues. To clarify, a lot of users use emoticons and uncommon symbols when they post tweets, and those information is not helpful for us to find how users actually react to certain things. To solve this challenge, we came up with a idea where we use Regular Expression to form a template that only scrapes useful data for us. However, due to limited time during a hackathon, we increased efficiency by using Twitter’s Search API. Furthermore, we realized towards the end of our project that the MemeAPI had been discontinued and that it was not possible to generate memes with it.
## Accomplishments that we're proud of
* Designing the project based on the mechanism of multi servers
* Utilizing Google Cloud Platform, Twitter API, MemeAPI
## What we learned
* Google Could Platform, especially the Natural Language and Vision APIs
* AWS
* React
## What's next for $MMM
* Getting real time big data probably with Spark
* Including more data visualization method, possibly with D3.js
* Designing a better algorithm to find memes reflecting the sentiment of the public towards the company
* Creating more dank memes | partial |
## Inspiration
In response to the recent sexual assault cases on campus, we decided that there was a pressing need to create an app that would be a means for people to seek help from those around them, mitigating the bystander effect at the same time.
## What it does
Our cross-platform app allows users to send out a distress signal to others within close proximity (up to a five mile radius), and conversely, allows individuals to respond to such SOS calls. Users can include a brief description of their distress signal call, as well as an "Intensity Rating" to describe the enormity of their current situation.
## How we built it
We used Django as a server-side framework and hosted it using Heroku. React Native was chosen as the user interface platform due to its cross-platform abilities. We all shared the load of front end and back end development, along with feature spec writing and UX design.
## Challenges we ran into
Some of us had no experience working with React Native/Expo, so we ran into quite a few challenges with getting acclimated to the programming language. Additionally, deploying the server-side code onto an actual server, as well as deploying the application bundles as standalone apps on iOS and Android, caused us to spend significant amounts of time to figure out how to deploy everything properly.
## Accomplishments that we're proud of
This was the very first hackathon for the two of us (but surely, won’t be the last!). And, as a team, we built a full cross-platform MVP from the ground up in under 36 hours while learning the technologies used to create it.
## What we learned
We learned technical skills (React Native), as well as more soft skills (working as a team, coordinating tasks among members, incorporating all of our ideas/brainstorming, etc.).
## What's next for SOSed Up
Adding functionality to always send alerts to specific individuals (e.g. family, close friends) is high on the list of immediate things to add. | ## Inspiration
As students with family in West Africa, we’ve been close to personal situations in which the difference between life and death was quick access to medical aid. One call, quicker service or a nearby expert or volunteer could’ve made a big difference, preventing a life from being lost. We were inspired by this problem to pursue a community solution that would hopefully help to save lives.
Oftentimes, in developing countries, even big cities, speedy access to quick medical or a centralized emergency service is not possible, for many reasons. In the case of an emergency, time is often of the essence and a few minutes can be a vital difference. We wondered, what if you could crowdsource the power of the communities nearby and even faraway to aid in these situations? What if at the push of the button you could notify not only nearby health professionals, but also family members who may able to quickly come and help?
Having this in mind, we thought creating a platform to connect these professionals to those that need help would fill a significant gap, and use the power of communities to achieve that.
## What it does
Though we didn't get the chance to fully complete the app, the general idea was to build a phone app that acts as a LifeAlert for those who live in developing countries or rely on community-based healthcare. Specifically, we want to build a system that allows people to send alerts to a list of emergency contacts. The app would then search for others within a certain radius that have the app and are signed up as helpers and send a location to that person.
## How we built it
The app is build using React Native. We prototyped it using Figma and before that drew our prototypes.
## Challenges we ran into
As none of us have completed a hackathon prior to this one, we found that the scope of our project didn't quite match our teams skill level and time availability. Setup was a bit of a challenge, and we also ran into a couple issues integrating various APIs and building a backend. We spent hours figuring out how to use APIs, learning React-Native and all its packages, uploading to a fire-base. One big thing was figuring out how to collaborate with React-Native. We stayed up late trying Atom, GitHub, before finally resorting to a creative solution with expo snack, working on different components apart and bringing them together in one centralized screen.
## Accomplishments that we're proud of
We're proud of the fact that we were able to produce a semi-working app in the short span of time that we were given considering our experience at the time. From prototyping to an app in a day, we learned, used and synthesized skills in ways that we could have never imagined a week ago.
## What we learned
We learned a lot about React and about app development in general. Workshops and social learning allowed us to pick up skills that we wouldn’t have otherwise, and building an app front to back-end was relatively new to us. It’s awesome what the power of hackathons, with the time pressure and drive can accomplish! Thanks TreeHacks! | ## Inspiration
The idea for VenTalk originated from an everyday stressor that everyone on our team could relate to; commuting alone to and from class during the school year. After a stressful work or school day, we want to let out all our feelings and thoughts, but do not want to alarm or disturb our loved ones. Releasing built-up emotional tension is a highly effective form of self-care, but many people stay quiet as not to become a burden on those around them. Over time, this takes a toll on one’s well being, so we decided to tackle this issue in a creative yet simple way.
## What it does
VenTalk allows users to either chat with another user or request urgent mental health assistance. Based on their choice, they input how they are feeling on a mental health scale, or some topics they want to discuss with their paired user. The app searches for keywords and similarities to match 2 users who are looking to have a similar conversation. VenTalk is completely anonymous and thus guilt-free, and chats are permanently deleted once both users have left the conversation. This allows users to get any stressors from their day off their chest and rejuvenate their bodies and minds, while still connecting with others.
## How we built it
We began with building a framework in React Native and using Figma to design a clean, user-friendly app layout. After this, we wrote an algorithm that could detect common words from the user inputs, and finally pair up two users in the queue to start messaging. Then we integrated, tested, and refined how the app worked.
## Challenges we ran into
One of the biggest challenges we faced was learning how to interact with APIs and cloud programs. We had a lot of issues getting a reliable response from the web API we wanted to use, and a lot of requests just returned CORS errors. After some determination and a lot of hard work we finally got the API working with Axios.
## Accomplishments that we're proud of
In addition to the original plan for just messaging, we added a Helpful Hotline page with emergency mental health resources, in case a user is seeking professional help. We believe that since this app will be used when people are not in their best state of minds, it's a good idea to have some resources available to them.
## What we learned
Something we got to learn more about was the impact of user interface on the mood of the user, and how different shades and colours are connotated with emotions. We also discovered that having team members from different schools and programs creates a unique, dynamic atmosphere and a great final result!
## What's next for VenTalk
There are many potential next steps for VenTalk. We are going to continue developing the app, making it compatible with iOS, and maybe even a webapp version. We also want to add more personal features, such as a personal locker of stuff that makes you happy (such as a playlist, a subreddit or a netflix series). | losing |
## Inspiration
There are two types of pets wandering unsupervised in the streets - ones that are lost and ones that don't have a home to go to. Pet's Palace portable mini-shelters services these animals and connects them to necessary services while leveraging the power of IoT.
## What it does
The units are placed in streets and alleyways. As an animal approaches the unit, an ultrasonic sensor triggers the door to open and dispenses a pellet of food. Once inside, a live stream of the interior of the unit is sent to local animal shelters which they can then analyze and dispatch representatives accordingly. Backend analysis of the footage provides information on breed identification, custom trained data, and uploads an image to a lost and found database. A chatbot is implemented between the unit and a responder at the animal shelter.
## How we built it
Several Arduino microcontrollers distribute the hardware tasks within the unit with the aide of a wifi chip coded in Python. IBM Watson powers machine learning analysis of the video content generated in the interior of the unit. The adoption agency views the live stream and related data from a web interface coded with Javascript.
## Challenges we ran into
Integrating the various technologies/endpoints with one Firebase backend.
## Accomplishments that we're proud of
A fully functional prototype! | ## Inspiration
## What it does
PhyloForest helps researchers and educators by improving how we see phylogenetic trees. Strong, useful data visualization is key to new discoveries and patterns. Thanks to our product, users have a greater ability to perceive depth of trees by communicating widths rather than lengths. The length between proteins is based on actual lengths scaled to size.
## How we built it
We used EggNOG to get phylogenetic trees in Newick format, then parsed them using a recursive algorithm to get the differences between the protein group in question. We connected names to IDs using the EBI (European Bioinformatics Institute) database, then took the lengths between the proteins and scaled them to size for our Unity environment. After we put together all this information, we went through an extensive integration process with Unity. We used EBI APIs for Taxon information, EggNOG gave us NCBI (National Center for Biotechnology Information) identities and structure. We could not use local NCBI lookup (as eggNOG does) due to the limitations of Virtual Reality headsets, so we used the EBI taxon lookup API instead to make the tree interactive and accurately reflect the taxon information of each species in question. Lastly, we added UI components to make the app easy to use for both educators and researchers.
## Challenges we ran into
Parsing the EggNOG Newick tree was our first challenge because there was limited documentation and data sets were very large. Therefore, it was difficult to debug results, especially with the Unity interface. We also had difficulty finding a database that could connect NCBI IDs to taxon information with our VR headset. We also had to implement a binary tree structure from scratch in C#. Lastly, we had difficulty scaling the orthologs horizontally in VR, in a way that would preserve the true relationships between the species.
## Accomplishments that we're proud of
The user experience is very clean and immersive, allowing anyone to visualize these orthologous groups. Furthermore, we think this occupies a unique space that intersects the fields of VR and genetics. Our features, such as depth and linearized length, would not be as cleanly implemented in a 2-dimensional model.
## What we learned
We learned how to parse Newick trees, how to display a binary tree with branches dependent on certain lengths, and how to create a model that relates large amounts of data on base pair differences in DNA sequences to something that highlights these differences in an innovative way.
## What's next for PhyloForest
Making the UI more intuitive so that anyone would feel comfortable using it. We would also like to display more information when you click on each ortholog in a group. We want to expand the amount of proteins people can select, and we would like to manipulate proteins by dragging branches to better identify patterns between orthologs. | ## Inspiration
Climate change, deforestation. It is important to be able to track animals. This provides them with another layer of security and helps us see when there's something wrong. A change in migration patterns or sudden movements can indicate illegal activity.
## What it does
It is able to track movement and animals efficiently through a forest. These nodes can be placed at different points to track the movement of different species
## How we built it
works with 2 esp8266's. They are attached to a PIR motion sensor. When activated it sends location data to the database. It is then retrieved and plotted onto google maps.
## Challenges we ran into
Many issues were encountered during this project. Mainly firebase, and the esp32 cam. We were having extreme difficulties pulling the right data at the right time from the firebase database. The esp32 was also causing many issues. It was hard to set up and was hard to program. Due to this, we could no longer implement the object detection model and were forced to use only an esp8266 and no camera.
## Accomplishments that we're proud of
This was our first time using Firebase, and we figured it out
## What we learned
Firebase, IoT things gmaps api
## What's next for Animal Tracker
Integrate esp32cam and image classification model. Add more features to the site. | winning |
## Inspiration
* COVID-19 is impacting all musicians, from students to educators to professionals everywhere
* Performing physically together is not viable due to health risks
* School orchestras still need a way to perform to keep students interested and motivated
* A lot of effort is required to put together separate recordings virtually. Some ensembles don't have the time or resources to do it
## What it does
Ludwig is a direct response to the rise of remote learning. Our online platform optimizes virtual interaction between music educators and students by streamlining the process of creating music virtually. Educators can create new assignments and send them out with a description and sheet music to students. Students can then access the assignment, download the sheet music, and upload their recordings of the piece separately. Given the tempo and sampling specificity, Ludwig detects the musical start point of each recording, then syncs and merges them into one combined WAV file.
## Challenges we ran into
Our synchronization software is not perfect. On the software side, we have to balance the tradeoff between sampling specificity and delivery speed, so we sacrifice pinpoint synchronization to make sure our users don't get bored while using the platform. On the human side, without the presence of the rest of the ensemble, it is easy for students to play at an inconsistent tempo, play out of tune, or make other mistakes. These sorts of mistakes are hard for any software to adapt to.
## What's next for Ludwig
We aim to improve Ludwig's syncing algorithm by adjusting tuning and paying more attention to tempo. We will also refine and expand Ludwig's platform to allow teachers to have different classes with different sets of students. | ## Inspiration
Our project is inspired by the sister of one our creators, Joseph Ntaimo. Joseph often needs to help locate wheelchair accessible entrances to accommodate her, but they can be hard to find when buildings have multiple entrances. Therefore, we created our app as an innovative piece of assistive tech to improve accessibility across the campus.
## What it does
The user can find wheelchair accessible entrances with ease and get directions on where to find them.
## How we built it
We started off using MIT’s Accessible Routes interactive map to see where the wheelchair friendly entrances were located at MIT. We then inspected the JavaScript code running behind the map to find the latitude and longitude coordinates for each of the wheelchair locations.
We then created a Python script that filtered out the latitude and longitude values, ignoring the other syntax from the coordinate data, and stored the values in separate text files.
We tested whether our method would work in Python first, because it is the language we are most familiar with, by using string concatenation to add the proper Java syntax to the latitude and longitude points. Then we printed all of the points to the terminal and imported them into Android Studio.
After being certain that the method would work, we uploaded these files into the raw folder in Android Studio and wrote code in Java that would iterate through both of the latitude/longitude lists simultaneously and plot them onto the map.
The next step was learning how to change the color and image associated with each marker, which was very time intensive, but led us to having our custom logo for each of the markers.
Separately, we designed elements of the app in Adobe Illustrator and imported logos and button designs into Android Studio. Then, through trial and error (and YouTube videos), we figured out how to make buttons link to different pages, so we could have both a FAQ page and the map.
Then we combined both of the apps together atop of the original maps directory and ironed out the errors so that the pages would display properly.
## Challenges we ran into/Accomplishments
We had a lot more ideas than we were able to implement. Stripping our app to basic, reasonable features was something we had to tackle in the beginning, but it kept changing as we discovered the limitations of our project throughout the 24 hours. Therefore, we had to sacrifice features that we would otherwise have loved to add.
A big difficulty for our team was combining our different elements into a cohesive project. Since our team split up the usage of Android Studio, Adobe illustrator, and programming using the Google Maps API, it was most difficult to integrate all our work together.
We are proud of how effectively we were able to split up our team’s roles based on everyone’s unique skills. In this way, we were able to be maximally productive and play to our strengths.
We were also able to add Boston University accessible entrances in addition to MIT's, which proved that we could adopt this project for other schools and locations, not just MIT.
## What we learned
We used Android Studio for the first time to make apps. We discovered how much Google API had to offer, allowing us to make our map and include features such as instant directions to a location. This helped us realize that we should use our resources to their full capabilities.
## What's next for HandyMap
If given more time, we would have added many features such as accessibility for visually impaired students to help them find entrances, alerts for issues with accessing ramps and power doors, a community rating system of entrances, using machine learning and the community feature to auto-import maps that aren't interactive, and much, much more. Most important of all, we would apply it to all colleges and even anywhere in the world. | ## Inspiration
Our project was inspired by people who don't learn the "old school" way. Some people learn best by reciting things out loud, but the problem with that is sometimes it's too quiet to talk, and sometimes it's too loud to talk.
## What it does
Our project is a website that allows you to create a group with your classmates/coworkers, in which you can record video of yourself silently mouthing out whatever lecture or book you're reading, allowing you to pay full attention without worrying about writing notes, a loud environment, or an environment in which you're not allowed to talk. Our project reads your lips and puts it into text, creating notes for the video you take. Then, with your notes, we summarize your key points and build a quiz so you can focus on the important parts of your work.
## How we built it
For the front end of our website, we used React JS and Chakra. We used Auth0 to create an account system for our project. We used Symphonic Labs' API to read your lips and convert your silent words to text. We used MongoDB to save all your notes to a database in your group. We then used a Cohere API to summarize the key points of the text and make a quiz out of it. We also used an Open AI API to convert mp3 files to text, in case you wanted to record a lecturer or friend speaking, and then convert it to notes and quizzes.
## Challenges we ran into
We tried to get live video transcribing with Symphonic Lab's API using Open CV, but since Open CV was giving us frames of the video, Symphonic Lab's API wasn't able to transcribe it. Instead, we switched to allowing users to record their videos on the site, immediately download them and upload it for transcribing.
## Accomplishments that we're proud of
We are very proud of combining all the complicated API's to create a complete and flowing product, something that all of us will definitely be using for school.
## What we learned
This was our group's first time using more than one API for a project, but it ended up with a website that performs a useful and complicated function, and we will be using multiple APIs in the future!
## What's next for Studying with Hack the North | winning |
## Inspiration
The inspiration behind "Odin" stems from the growing need for efficient and creative content generation in various fields, from marketing to software development. Harnessing the power of artificial intelligence, we aimed to create a versatile SaaS platform that could streamline content creation across multiple media types.
## What it does
"Odin" is an AI-driven SaaS platform that redefines content generation. It utilizes cutting-edge machine learning models to generate a wide range of content, such as text, code, images, videos, music, and more. Whether you need compelling marketing copy, code snippets, stunning visuals, captivating videos, or original music compositions, Odin is here to empower your creativity.
## How we built it
The development of Odin involved a multi-faceted approach. We assembled a team of AI and software experts who combined their knowledge to create a robust and scalable system. We integrated state-of-the-art machine learning models, custom algorithms, and a user-friendly interface to make content generation accessible to everyone.
## Challenges we ran into
Building Odin presented various challenges, including optimizing the AI models for speed and efficiency, managing large datasets, and ensuring the generated content meets high-quality standards. We also had to address the unique technical requirements for each content type.
## Accomplishments that we're proud of
We're proud to have created a powerful AI SaaS platform that can transform the way content is generated across industries. Odin's ability to produce high-quality content at scale is a significant accomplishment, and we've received positive feedback from early adopters.
## What we learned
Throughout the development of Odin, we gained insights into the evolving field of AI and content generation. We learned about the capabilities and limitations of various AI models, as well as the importance of user customization and fine-tuning for specific applications.
## What's next for Odin
The future of Odin is exciting. We plan to continually improve the platform by expanding the range of content types it can generate and refining the user experience. We are also exploring opportunities to integrate Odin with other tools and platforms, making it even more accessible and versatile for content creators worldwide. | ## Inspiration
Viral content, particularly copyrighted material and deepfakes, has huge potential to be widely proliferated with Generative AI. This impacts artists, creators and businesses, as for example, copyright infringement causes $11.5 billion in lost profits within the film industry annually.
As students who regularly come across copyrighted material on social media, we know that manual reporting by users is clearly ineffective, and this problem lends itself well to the abilities of AI agents. A current solution by companies is to employ people to search for and remove content, which is time consuming and expensive. We are keen to leverage automatic detection through our software, and also serve individuals and businesses.
## What it does
PirateShield is a SaaS solution that automatically finds and detects videos that infringe a copyright owned by a user. We deploy AI agents to search online and flag content using semantic search. We also build agents to scrape this content and classify whether it is pirated, using comparisons to copyright licenses on Youtube. Our prototype focuses on the TikTok platform.
## How we built it:
Our platform includes AI agents built on Fetch.ai to perform automatic search and classification. This is split into a retrieval feature with semantic search, and a video classification feature. Our database is built with MongoDB to store videos and search queries.
Our frontend uses data visualisation to provide an analytics dashboard for the rate of True Positive classifications over time, as well as rates of video removal.
## Challenges we ran into
We initially considered many features for our platform, and had to distill this into a set of core prototype features. We were also initially unsure how we would implement the classification feature before deciding on using Youtube's database. Moreover, testing our agents end-to-end on queries involved much debugging!
## Accomplishments that we're proud of
As a team, we are proud of identifying this impactful problem to work on, and coordinating to implement a solution while meeting for the first time! In particular, we are proud of successfully building AI agents to search for and download videos, as well as classify them. We're excited to get our first users and deploy the remaining features of the platform.
## What we learned
Our tools used were Fetch.AI, Google APIs, fast RAG and MongoDB. We upskilled quickly in these frameworks, and also gained a lot from the advice of mentors and workshop speakers. | ## Inspiration 🌟
At the heart of Symphonic lies a vision – a world where non-profits can share their stories with powerful, emotion-evoking music, but without the high costs and legal hurdles. Our journey began with an insight into the challenges faced by non-profits in making their voices heard. The cost of quality music production often put it out of reach for many. Symphonic emerged from this need, driven by the belief that every story deserves to be told with the emotional depth it warrants. Leveraging AI/ML technology, Symphonic crafts custom music that not only complements but enhances the narrative of each video. It's our way of empowering these organizations to tell their stories, to reach hearts and minds in a way that truly resonates. 🎵❤️
## What it does 🚀
Symphonic is not just a tool; it's a revolution in video content creation. By harnessing advanced AI/ML algorithms, Symphonic can intuitively generate music that aligns perfectly with the emotional flow and pace of a video. Each frame is thoughtfully enhanced with a musical composition that echoes its sentiment, transforming the viewing experience into something deeply immersive. This technology is especially invaluable for non-profits, who can now create content with the emotional impact of high-budget productions, but within their means. Symphonic is here to ensure that impactful stories are not just told, but are felt. Here is a outline breakdown: 🎶
* **Custom AI-Generated Music**: Tailors unique musical compositions to each video, ensuring the score captures the emotional narrative perfectly.
* **Automatic Effects**: Seamlessly integrates transitions and fades that are in harmony with the music and video tempo, giving a polished, professional finish.
* **Intelligent Filtering**: Applies filters intelligently, considering the context and emotion of the video scene, to enhance visual appeal.
* **Auto Speed Adjustment**: Dynamically adjusts video playback speed to align with the music's tempo, adding a compelling rhythmic flow to the narrative.
* **Integrated Transcript**: Automatically generates a transcript of the video content, increasing accessibility and search engine discoverability.
* **Facial Landmark Detection**: Utilizes facial recognition to apply effects and transitions appropriately, ensuring seamless integration with the speaker's expressions.
* **Emotion Detection**: Analyzes users' emotions in the video to inform music generation, ensuring the soundtrack is in tune with the mood
* **Aesthetic Cohesion**: The intelligent application of filters and effects creates a visually coherent piece that speaks to the viewer's emotions.
* **Rhythmic Synchronization**: The dynamic adjustment of video elements to the music's rhythm brings a new level of sophistication to video production.
## How we built it 🔧
Creating Symphonic was a symphony of technology and creativity. Our team, a blend of AI experts, developers, and creatives, embarked on a mission to harness the nuanced capabilities of AI and machine learning for good. We focused on developing algorithms that don't just understand music but can interpret the emotional context and narrative flow of videos. The process involved selecting and integrating a range of tools and frameworks to create a seamless, intuitive music generation process. Our tech stack isn't just a collection of tools; it's the harmonious integration of various technologies, all working in concert to breathe musical life into stories. 🎹
## Challenges we ran into 🚧
Our journey with Symphonic was filled with learning curves and challenges. One of the most significant hurdles was ensuring that our AI could accurately interpret and reflect the emotional tone of diverse video content. Balancing the efficiency of music generation with the quality of output also presented a considerable challenge. Each obstacle we encountered was a chance to refine our approach, to learn, and to grow. These challenges were not roadblocks, but are stepping stones that helped us evolve Symphonic into the revolutionary tool. 🚀
## Accomplishments that we're proud of ✨
We take immense pride in having created a tool that does more than just generate music; it empowers and amplifies the voices of non-profits. Seeing Symphonic in action, enhancing video narratives and touching audiences, is a deeply gratifying experience. We've managed to break down a significant barrier in digital storytelling, providing high-quality, emotionally attuned music accessible to organizations with limited resources. Symphonic stands as a testament to how technology can be harnessed for social good, making a meaningful difference in the world of non-profits. 🌍🎉
## What we learned 📚
Our journey with Symphonic has been an incredible learning experience. We delved deep into the complexities of emotional storytelling and how music can amplify this narrative power. We've gained invaluable insights into the fields of AI/ML, particularly in audio synthesis and emotional analysis. But other than the technical knowledge, we learned about the resilience and determination of non-profits and the transformative power of technology in addressing their challenges. These lessons have been both humbling and inspiring. 📖💡
## What's next for Symphonic 🌈
Looking ahead, the potential for Symphonic is boundless. Our goal is to further refine our AI's emotional intelligence, ensuring an even deeper and more nuanced alignment between video content and music. We're also exploring partnerships with non-profits and social enterprises, aiming to bring the transformative power of Symphonic to a wider audience. Our vision extends beyond technology; it's about creating a global community where stories are shared and felt, one note at a time. The future is bright, and we're just getting started on this melodious journey of impact and innovation. 🚀 | losing |
## Inspiration
Our inspiration comes from people who require immediate medical assistance when they are located in remote areas. The project aims to reinvent the way people in rural or remote settings, especially seniors who are unable to travel frequently, obtain medical assistance by remotely connecting them to medical resources available in their nearby cities.
## What it does
Tango is a tool to help people in remote areas (e.g. villagers, people on camping/hiking trips, etc.) to have access to direct medical assistance in case of an emergency. The user would have the device on him while hiking along with a smart watch. If the device senses a sudden fall, the vital signs of the user provided by the watch would be sent to the nearest doctor/hospital in the area. The doctor could then assist the user in a most appropriate way now that the user's vital signs are directly relayed to the doctor. In a case of no response from the user, medical assistance can be sent using his location.
## How we built it
The sensor is made out of the Particle Electron Kit, which based on input from an accelerometer and a sound sensor, asseses whether the user has fallen down or not. Signals from this sensor are sent to the doctor if the user has fallen along with data from smart watch about patient health.
## Challenges we ran into
One of our biggest challenges we ran into was taking the data from the cloud and loading it on the web page to display it.
## Accomplishments that we are proud of
It is our first experience with the Particle Electron and for some of us their first experience in a hardware project.
## What we learned
We learned how to use the Particle Election.
## What's next for Tango
Integration of the Pebble watch to send the vital signs to the doctors. | ## Inspiration
In response to recent tragic events in Turkey, where the rescue efforts for the Earthquake have been very difficult. We decided to use Qualcomm’s hardware development kit to create an application for survivors of natural disasters like earthquakes to send out distress signals to local authorities.
## What it does
Our app aids disaster survivors by sending a distress signal with location & photo, chatbot updates on rescue efforts & triggering actuators on an Arduino, which helps rescuers find survivors.
## How we built it
We built it using Qualcomm’s hardware development kit and Arduino Due as well as many APIs to help assist our project goals.
## Challenges we ran into
We faced many challenges as we programmed the android application. Kotlin is a new language to us, so we had to spend a lot of time reading documentation and understanding the implementations. Debugging was also challenging as we faced errors that we were not familiar with. Ultimately, we used online forums like Stack Overflow to guide us through the project.
## Accomplishments that we're proud of
The ability to develop a Kotlin App without any previous experience in Kotlin. Using APIs such as OPENAI-GPT3 to provide a useful and working chatbox.
## What we learned
How to work as a team and work in separate subteams to integrate software and hardware together. Incorporating iterative workflow.
## What's next for ShakeSafe
Continuing to add more sensors, developing better search and rescue algorithms (i.e. travelling salesman problem, maybe using Dijkstra's Algorithm) | ## Inspiration
What is one of the biggest motivators at hackathons? The thrill of competition. What if you could bring that same excitement into your daily life, using your speech to challenge your friends? Our app gamifies everyday conversations and interactions, letting you and your friends compete to see who projects the most positive or negative aura.
## What it does
* Captures live audio input and converts it into text using React’s speech recognition library.
* Analyzes the transcribed text by running it through Cohere’s semantic similarity model by encoding both input data and our dataset into vector embeddings
* Uses cosine similarity to compare the input with synthetic data, generated using ChatGPT, in order to evaluate whether the speech conveys a positive or negative aura based.
## Challenges we ran into
* Integrating real-time speech recognition with accurate transcription, especially when dealing with diverse speech patterns and accents.
* Acquiring a continuous audio input which can then be passed along for efficient transcription.
* Configuring Cohere’s API to work seamlessly with a large dataset and ensure fast, accurate sentiment analysis.
* Getting accurate data on words/actions that constitute "positive aura" and "negative aura".
## Accomplishments that we're proud of
* Cohere Embeddings for Sentiment Analysis: Integrating Cohere’s powerful semantic embeddings was another significant milestone. We used their embeddings to analyze and determine the sentiment of transcribed text, mapping speech patterns to either positive or negative aura. We’re proud of this implementation because it brought depth to the app.
## What's next for Traura
* Turning this prototype into a full-fledged web app that users can access anywhere, including the full implementation of the leaderboard functionality to foster that friendly thrill of competition. | winning |
## Introduction
[Best Friends Animal Society](http://bestfriends.org)'s mission is to **bring about a time when there are No More Homeless Pets**
They have an ambitious goal of **reducing the death of homeless pets by 4 million/year**
(they are doing some amazing work in our local communities and definitely deserve more support from us)
## How this project fits in
Originally, I was only focusing on a very specific feature (adoption helper).
But after conversations with awesome folks at Best Friends came a realization that **bots can fit into a much bigger picture in how the organization is being run** to not only **save resources**, but also **increase engagement level** and **lower the barrier of entry points** for strangers to discover and become involved with the organization (volunteering, donating, etc.)
This "design hack" comprises of seven different features and use cases for integrating Facebook Messenger Bot to address Best Friends's organizational and operational needs with full mockups and animated demos:
1. Streamline volunteer sign-up process
2. Save human resource with FAQ bot
3. Lower the barrier for pet adoption
4. Easier donations
5. Increase visibility and drive engagement
6. Increase local event awareness
7. Realtime pet lost-and-found network
I also "designed" ~~(this is a design hack right)~~ the backend service architecture, which I'm happy to have discussions about too!
## How I built it
```
def design_hack():
s = get_sketch()
m = s.make_awesome_mockups()
k = get_apple_keynote()
return k.make_beautiful_presentation(m)
```
## Challenges I ran into
* Coming up with a meaningful set of features that can organically fit into the existing organization
* ~~Resisting the urge to write code~~
## What I learned
* Unique organizational and operational challenges that Best Friends is facing
* How to use Sketch
* How to create ~~quasi-~~prototypes with Keynote
## What's next for Messenger Bots' Best Friends
* Refine features and code :D | ## Inspiration
We got together a team passionate about social impact, and all the ideas we had kept going back to loneliness and isolation. We have all been in high pressure environments where mental health was not prioritized and we wanted to find a supportive and unobtrusive solution. After sharing some personal stories and observing our skillsets, the idea for Remy was born. **How can we create an AR buddy to be there for you?**
## What it does
**Remy** is an app that contains an AR buddy who serves as a mental health companion. Through information accessed from "Apple Health" and "Google Calendar," Remy is able to help you stay on top of your schedule. He gives you suggestions on when to eat, when to sleep, and personally recommends articles on mental health hygiene. All this data is aggregated into a report that can then be sent to medical professionals. Personally, our favorite feature is his suggestions on when to go on walks and your ability to meet other Remy owners.
## How we built it
We built an iOS application in Swift with ARKit and SceneKit with Apple Health data integration. Our 3D models were created from Mixima.
## Challenges we ran into
We did not want Remy to promote codependency in its users, so we specifically set time aside to think about how we could specifically create a feature that focused on socialization.
We've never worked with AR before, so this was an entirely new set of skills to learn. His biggest challenge was learning how to position AR models in a given scene.
## Accomplishments that we're proud of
We have a functioning app of an AR buddy that we have grown heavily attached to. We feel that we have created a virtual avatar that many people really can fall for.
## What we learned
Aside from this being many of the team's first times work on AR, the main learning point was about all the data that we gathered on the suicide epidemic for adolescents. Suicide rates have increased by 56% in the last 10 years, and this will only continue to get worse. We need change.
## What's next for Remy
While our team has set out for Remy to be used in a college setting, we envision many other relevant use cases where Remy will be able to better support one's mental health wellness.
Remy can be used as a tool by therapists to get better insights on sleep patterns and outdoor activity done by their clients, and this data can be used to further improve the client's recovery process. Clients who use Remy can send their activity logs to their therapists before sessions with a simple click of a button.
To top it off, we envisage the Remy application being a resource hub for users to improve their overall wellness. Through providing valuable sleep hygiene tips and even lifestyle advice, Remy will be the one-stop, holistic companion for users experiencing mental health difficulties to turn to as they take their steps towards recovery. | ## Inspiration
We hear all the time that people want a dog but they don't want the committment and yet there's still issues with finding a pet sitter! We flipped the 'tinder'-esque mobile app experience around to reflect just how many people are desparate and willing to spend time with a furry friend!
## What it does
Our web app allows users to create an account and see everyone who is currently looking to babysit a cute puppy or is trying to find a pet sitter so that they can go away for vacation! The app also allows users to engage in chat messages so they can find a perfect weekend getaway for their dogs.
## How we built it
Our web app is primariy a react app on the front end and we used a combination of individual programming and extreme programming when we hit walls.
Ruby on rails and SQLite run the back end and so with a team of four we had two people manning the keyboards for the front end and the other two working diligently on the backend.
## Challenges we ran into
GITHUB!!!! Merging, pushing, pulling, resolving, crying, fetching, syncing, sobbing, approving, etc etc. We put our repo through a stranglehold of indecipherable commits more than a few times and it was our greatest rival
## Accomplishments that we're proud of
IT WORKS! We're so proud to build an app that looks amazing and also communicates on a sophisticated level. The user experience is cute and delightful but the complexities are still baked in like session tokens and password hashing (plus salt!)
## What we learned
The only way to get fast is to go well. The collaboration phase with github ate up a large part of our time every couple of hours and there was nobody to blame but ourselves.
## What's next for Can I Borrow Your Dog
We think this a pretty cool little app that could do a LARGE refactoring. Whether we keep in touch as a gorup and maintain this project to spruce up our resumes is definitely being considered. We'd like to show our friends and family how much we accomplished in just 36 hours (straight lol)! | winning |
## Inspiration
Our app idea came from the experience of one of our team members when he was having lunch in one of the many food courts of Toronto's CBD. At the time, he was looking around and despite being surrounded by hundreds of people - he knew nothing about any of them. Of course, there were incredible people amongst the crowd, but there was no way to know who was who, who did what, and who was open to chatting with a stranger.
Everyday, we walk past hundreds of people from all walks of life, with thousands of different (or common!) experiences. Yet, perhaps because we've grown wary of being surrounded by so many people, we casually dismiss this opportunity to learn something new. Our app aims to unearth the incredible value of people and their stories, and make connecting with strangers, easier.
## What it does
In short, Peopledex allows you to find other users within a 1 minute walking distance to them and strike up a conversation about their favourite topics. Every user's profile consists of their name, a profile photo, occupation, and three topics that they'd like people to ask them about. Nearby users are viewable in a collection view, ordered by proximity.
After viewing a nearby user's profile, you can find them via GPS-based augmented reality, which places an arrow above their current location. Then, you make an introduction! No instant-messaging allowed - only real connections. When you don't want to be approached (e.g. you're busy meeting with friends), you can enable incognito mode so you won't be discoverable.
**Use cases:**
* Finding relevant connections at large conferences or expos
* Finding potential teammates at hackathons
* Finding someone to have lunch with in a food court
* Finding friendly strangers to talk to while travelling
## How we built it
Our team split off into two groups, one responsible for building the AR functionality and the other for UI/UX. The initial wireframe was built on Balsamiq Cloud's collaborative wireframing tool. The wireframe was then developed using Xcode Interface Builder & Swift. Login and signup functionality was achieved using Firebase authentication.
The AR functionality involved two components. The front end client, using ARKit API for iOS, consumed GPS coordinates in the form of longitude and latitude, and rendered it into 3D space in the augmented reality view. The GPS coordinates were supplied by another client, which sent a POST request to a Python based API that pushed updates to the AR client. These updates were pushed in realtime, using a web socket to lower latency.
## Challenges we ran into
None of our team members came into this hackathon with iOS experience, and only half of our group had developer experience. The AR component proved to be extremely challenging as well, as overcoming the inaccuracies of location finding made us use many engineering techniques. Specifically, rendering assets in real time based on a non-deterministically moving object caused us to take many hours of calibration in order to have a demoable product.
## Accomplishments that we're proud of
We had to apply a high pass filter on the noise from the GPS to smooth out the movement of both clients. This enabled us to have a relatively stable location for the AR client to track and render. We were also able to create a smoothly running and aesthetically-pleasing user interface. We're proud of the fact that all of us learned how to use new and challenging tools in an extremely short amount of time.
## What we learned
We learned:
* ARKit
* That real-time location tracking is hard
* Xcode & Swift
* Firebase
* Balsamiq
## What's next for Peopledex
Get users onboard! | ## FallCall
FallCall: Passive Reactive Safety Notifier
## Inspiration:
One of our teammate's grandfathers in Japan has an increased susceptibility of falling down as a result of getting older. Even though there are times when people are around to help, we cannot account for all the potential situations when he may fall down. While there are smartphone applications that can help many people, especially the elderly, many individuals simply do not have access to that technology. We want to make helping such people as accessible and predictive as possible. Meet FallCall.
## What It Does:
FallCall is an affordable wearable device that is able to detect if a person falls to the ground and contacts the appropriate person. When they fall, we will automatically send a call to the first emergency contact that they designate. If the first contact does not respond, then we will automatically trigger a call to the second emergency contact. If this person also doesn't respond, we will finally resort to calling emergency services (911) with the appropriate details to help the person who fell. This type of escalation procedure is something that sets us apart from other similar products that will automatically call 911, which would result in potentially unnecessary charges.
If the person who falls does not wish to reach out for help, that person will be able to prevent any calls/messages from being sent by simply pressing a button. This is a very intentional design choice, as there may be scenarios in which a person who falls is capable of getting up or the situation was somehow an accident. We will always resort to opting to help the faller, and simply allow that person to prevent notifications when necessary.
## How We Built It:
We connect an MPU6050, an accelerometer and gyroscope, to an Arduino, which processes the raw data. We implemented an algorithm (C++) to use that raw data to predict whether a person has fallen or not with high confidence. We made sure to calibrate the algorithm in order to reduce the likelihood of false positives and false negatives.
The Arduino is connected to a Particle Photon, which is responsible for taking the prediction value from the Arduino and making an HTTP POST request (C++) to a REST endpoint that is built by using the StdLib-Twilio Hub (NodeJS). The logic within the StdLib-Twilio Hub is essentially our intelligent escalation notification system.
Finally, we took our device and created an accessible, user friendly wearable for any consumer.
## Challenges We Ran Into:
None of our team have used the Photon Particle before, so we faced long challenges trying to understand problems with using the product and integrating it with our Arduino data. We also struggled with connecting our Arduino device to the Photon Particle, because there was not much documentation on the issues we faced.
## What’s Next for FallCall:
While we spent much time tweaking our fall-detection algorithm, we can take it a step further and be able to use machine learning to more accurately customize a fall-detection algorithm based on physical feature data of a user. We would also love to improve the actual physical wearable, and make it more user-friendly to accommodate all potential users. | ## Inspiration
One of our teammate’s grandfathers suffers from diabetic retinopathy, which causes severe vision loss.
Looking on a broader scale, over 2.2 billion people suffer from near or distant vision impairment worldwide. After examining the issue closer, it can be confirmed that the issue disproportionately affects people over the age of 50 years old. We wanted to create a solution that would help them navigate the complex world independently.
## What it does
### Object Identification:
Utilizes advanced computer vision to identify and describe objects in the user's surroundings, providing real-time audio feedback.
### Facial Recognition:
It employs machine learning for facial recognition, enabling users to recognize and remember familiar faces, and fostering a deeper connection with their environment.
### Interactive Question Answering:
Acts as an on-demand information resource, allowing users to ask questions and receive accurate answers, covering a wide range of topics.
### Voice Commands:
Features a user-friendly voice command system accessible to all, facilitating seamless interaction with the AI assistant: Sierra.
## How we built it
* Python
* OpenCV
* GCP & Firebase
* Google Maps API, Google Pyttsx3, Google’s VERTEX AI Toolkit (removed later due to inefficiency)
## Challenges we ran into
* Slow response times with Google Products, resulting in some replacements of services (e.g. Pyttsx3 was replaced by a faster, offline nlp model from Vosk)
* Due to the hardware capabilities of our low-end laptops, there is some amount of lag and slowness in the software with average response times of 7-8 seconds.
* Due to strict security measures and product design, we faced a lack of flexibility in working with the Maps API. After working together with each other and viewing some tutorials, we learned how to integrate Google Maps into the dashboard
## Accomplishments that we're proud of
We are proud that by the end of the hacking period, we had a working prototype and software. Both of these factors were able to integrate properly. The AI assistant, Sierra, can accurately recognize faces as well as detect settings in the real world. Although there were challenges along the way, the immense effort we put in paid off.
## What we learned
* How to work with a variety of Google Cloud-based tools and how to overcome potential challenges they pose to beginner users.
* How to connect a smartphone to a laptop with a remote connection to create more opportunities for practical designs and demonstrations.
How to connect a smartphone to a laptop with a remote connection to create more opportunities for practical designs and demonstrations.
How to create docker containers to deploy google cloud-based flask applications to host our dashboard.
How to develop Firebase Cloud Functions to implement cron jobs. We tried to developed a cron job that would send alerts to the user.
## What's next for Saight
### Optimizing the Response Time
Currently, the hardware limitations of our computers create a large delay in the assistant's response times. By improving the efficiency of the models used, we can improve the user experience in fast-paced environments.
### Testing Various Materials for the Mount
The physical prototype of the mount was mainly a proof-of-concept for the idea. In the future, we can conduct research and testing on various materials to find out which ones are most preferred by users. Factors such as density, cost and durability will all play a role in this decision. | partial |
## Inspiration
Moving away from home and being responsible for my spending was not easy, especially in a new country. After a while, it was evident that I was not alone in struggling to manage my money: fellow students, co-workers; the list can go on.
## What it does
The goal was to get the user's income information as well as their most common monthly spending, and that data would be used to help identify potential risks and offer advice. At the moment, the only thing that you can do is input your personal income and you can see where your income goes after tax
## How I built it
I decided to tackle this challenge with a website using HTML, CSS, and JavaScript.
## Challenges I ran into
I may have been too ambitious and overestimated what I could do alone in the timeframe that I had : ) I could not do everything I wanted, but I was happy to do enough for some sort of demo
## Accomplishments that I'm proud of
My knowledge of HTML, CSS, and JavaScript was relatively novice, so I'm happy with what I did in about 2 days (I have about a million tabs opened!). I'm especially proud of how I implemented JavaScript in the project to get the algorithms
## What I learned
HTML, CSS, and JavaScript aside, I learned a lot about my limits and how far I can go with limited time and limited knowledge
## What's next for Budget Ur Bred
I definitely want to continue working on this project as it does have some relevance in my life. I'm going to continue developing my skills, with an emphasis on CSS | ## Inspiration
Wanted to help people keep track of expenses
## What it does
Displays data based on inputs
## How we built it
We used Reflex
## Challenges we ran into
Unable to complete
## Accomplishments that we're proud of
We were able to get a basic understanding of Reflex
## What we learned
We need to get more familiar with Reflex
## What's next for Budget Web App
We can finish what we started | ## Inspiration
We wanted to build an app to help save people's money through smart budgeting. We want to integrate Alexa with personal finance skills which it is currently lacking.
## What it does
Budget It is a web app connected to the Amazon Alexa to inform users how much money they have spent or saved. Users can input how much they have spent on a certain category given their budget. The user interface is clean and easy to use and Alexa briefings make our application really easy to interact with.
## How I built it
We utilized a variety of tools to build the app such as HTML/CSS, Javascript, Java, and Python. As for platforms we used Google Cloud Platform's App Engine and Amazon Web Service.
## Challenges I ran into
We spent a long time brainstorming and learning about React but decided to switch to Web App in the end. With Google Cloud Platform, we struggled to authorize and debug with Firebase since it was our first time using the tool.
## Accomplishments that I'm proud of
Despite our difficulties, we are proud of what we were able to accomplish. We learned new frameworks, tools, and languages in a short amount of time. Our app is still a work in progress, but we are proud to have something to show our hard work.
## What I learned
We learned technical skills of using a large-scale platform and new programming languages. We also learned to persevere and never give up when faced with a barrier. With the new skills that we have acquired, we hope to create more.
## What's next for Budget It
We hope to allow users to connect with each other to compare each other's spending situations under their consent. We also hope to provide insights of national or state financial statistics and comparing individual data to it. | losing |
## Inspiration
Ever wish you didn’t need to purchase a stylus to handwrite your digital notes? Each person at some point hasn’t had the free hands to touch their keyboard. Whether you are a student learning to type or a parent juggling many tasks, sometimes a keyboard and stylus are not accessible. We believe the future of technology won’t even need to touch anything in order to take notes. HoverTouch utilizes touchless drawings and converts your (finger)written notes to typed text! We also have a text to speech function that is Google adjacent.
## What it does
Using your index finger as a touchless stylus, you can write new words and undo previous strokes, similar to features on popular note-taking apps like Goodnotes and OneNote. As a result, users can eat a slice of pizza or hold another device in hand while achieving their goal. HoverTouch tackles efficiency, convenience, and retention all in one.
## How we built it
Our pre-trained model from media pipe works in tandem with an Arduino nano, flex sensors, and resistors to track your index finger’s drawings. Once complete, you can tap your pinky to your thumb and HoverTouch captures a screenshot of your notes as a JPG. Afterward, the JPG undergoes a masking process where it is converted to a black and white picture. The blue ink (from the user’s pen strokes) becomes black and all other components of the screenshot such as the background become white. With our game-changing Google Cloud Vision API, custom ML model, and vertex AI vision, it reads the API and converts your text to be displayed on our web browser application.
## Challenges we ran into
Given that this was our first hackathon, we had to make many decisions regarding feasibility of our ideas and researching ways to implement them. In addition, this entire event has been an ongoing learning process where we have felt so many emotions — confusion, frustration, and excitement. This truly tested our grit but we persevered by uplifting one another’s spirits, recognizing our strengths, and helping each other out wherever we could.
One challenge we faced was importing the Google Cloud Vision API. For example, we learned that we were misusing the terminal and our disorganized downloads made it difficult to integrate the software with our backend components. Secondly, while developing the hand tracking system, we struggled with producing functional Python lists. We wanted to make line strokes when the index finger traced thin air, but we eventually transitioned to using dots instead to achieve the same outcome.
## Accomplishments that we're proud of
Ultimately, we are proud to have a working prototype that combines high-level knowledge and a solution with significance to the real world. Imagine how many students, parents, friends, in settings like your home, classroom, and workplace could benefit from HoverTouch's hands free writing technology.
This was the first hackathon for ¾ of our team, so we are thrilled to have undergone a time-bounded competition and all the stages of software development (ideation, designing, prototyping, etc.) toward a final product. We worked with many cutting-edge softwares and hardwares despite having zero experience before the hackathon.
In terms of technicals, we were able to develop varying thickness of the pen strokes based on the pressure of the index finger. This means you could write in a calligraphy style and it would be translated from image to text in the same manner.
## What we learned
This past weekend we learned that our **collaborative** efforts led to the best outcomes as our teamwork motivated us to preserve even in the face of adversity. Our continued **curiosity** led to novel ideas and encouraged new ways of thinking given our vastly different skill sets.
## What's next for HoverTouch
In the short term, we would like to develop shape recognition. This is similar to Goodnotes feature where a hand-drawn square or circle automatically corrects to perfection.
In the long term, we want to integrate our software into web-conferencing applications like Zoom. We initially tried to do this using WebRTC, something we were unfamiliar with, but the Zoom SDK had many complexities that were beyond our scope of knowledge and exceeded the amount of time we could spend on this stage.
### [HoverTouch Website](hoverpoggers.tech) | ## Inspiration
Living in the big city, we're often conflicted between the desire to get more involved in our communities, with the effort to minimize the bombardment of information we encounter on a daily basis. NoteThisBoard aims to bring the user closer to a happy medium by allowing them to maximize their insights in a glance. This application enables the user to take a photo of a noticeboard filled with posters, and, after specifying their preferences, select the events that are predicted to be of highest relevance to them.
## What it does
Our application uses computer vision and natural language processing to filter any notice board information in delivering pertinent and relevant information to our users based on selected preferences. This mobile application lets users to first choose different categories that they are interested in knowing about and can then either take or upload photos which are processed using Google Cloud APIs. The labels generated from the APIs are compared with chosen user preferences to display only applicable postings.
## How we built it
The the mobile application is made in a React Native environment with a Firebase backend. The first screen collects the categories specified by the user and are written to Firebase once the user advances. Then, they are prompted to either upload or capture a photo of a notice board. The photo is processed using the Google Cloud Vision Text Detection to obtain blocks of text to be further labelled appropriately with the Google Natural Language Processing API. The categories this returns are compared to user preferences, and matches are returned to the user.
## Challenges we ran into
One of the earlier challenges encountered was a proper parsing of the fullTextAnnotation retrieved from Google Vision. We found that two posters who's text were aligned, despite being contrasting colours, were mistaken as being part of the same paragraph. The json object had many subfields which from the terminal took a while to make sense of in order to parse it properly.
We further encountered troubles retrieving data back from Firebase as we switch from the first to second screens in React Native, finding the proper method of first making the comparison of categories to labels prior to the final component being rendered. Finally, some discrepancies in loading these Google APIs in a React Native environment, as opposed to Python, limited access to certain technologies, such as ImageAnnotation.
## Accomplishments that we're proud of
We feel accomplished in having been able to use RESTful APIs with React Native for the first time. We kept energy high and incorporated two levels of intelligent processing of data, in addition to smoothly integrating the various environments, yielding a smooth experience for the user.
## What we learned
We were at most familiar with ReactJS- all other technologies were new experiences for us. Most notably were the opportunities to learn about how to use Google Cloud APIs and what it entails to develop a RESTful API. Integrating Firebase with React Native exposed the nuances between them as we passed user data between them. Non-relational database design was also a shift in perspective, and finally, deploying the app with a custom domain name taught us more about DNS protocols.
## What's next for notethisboard
Included in the fullTextAnnotation object returned by the Google Vision API were bounding boxes at various levels of granularity. The natural next step for us would be to enhance the performance and user experience of our application by annotating the images for the user manually, utilizing other Google Cloud API services to obtain background colour, enabling us to further distinguish posters on the notice board to return more reliable results. The app can also be extended to identifying logos and timings within a poster, again catering to the filters selected by the user. On another front, this app could be extended to preference-based information detection from a broader source of visual input. | ## Inspiration
On social media, most of the things that come up are success stories. We've seen a lot of our friends complain that there are platforms where people keep bragging about what they've been achieving in life, but not a single one showing their failures.
We realized that there's a need for a platform where people can share their failure episodes for open and free discussion. So we have now decided to take matters in our own hands and are creating Failed-In to break the taboo around failures! On Failed-in, you realize - "You're NOT alone!"
## What it does
* It is a no-judgment platform to learn to celebrate failure tales.
* Enabled User to add failure episodes (anonymously/non-anonymously), allowing others to react and comment.
* Each episode on the platform has #tags associated with it, which helps filter out the episodes easily. A user's recommendation is based on the #tags with which they usually interact
* Implemented sentiment analysis to predict the sentiment score of a user from the episodes and comments posted.
* We have a motivational bot to lighten the user's mood.
* Allowed the users to report the episodes and comments for
+ NSFW images (integrated ML check to detect nudity)
+ Abusive language (integrated ML check to classify texts)
+ Spam (Checking the previous activity and finding similarities)
+ Flaunting success (Manual checks)
## How we built it
* We used Node for building REST API and MongoDb as database.
* For the client side we used flutter.
* Also we used tensorflowjs library and its built in models for NSFW, abusive text checks and sentiment analysis.
## Challenges we ran into
* While brainstorming on this particular idea, we weren't sure how to present it not to be misunderstood. Mental health issues from failure are serious, and using Failed-In, we wanted to break the taboo around discussing failures.
* It was the first time we tried using Flutter-beta instead of React with MongoDB and node. It took a little longer than usual to integrate the server-side with the client-side.
* Finding the versions of tensorflow and other libraries which could integrate with the remaining code.
## Accomplishments that we're proud of
* During the 36 hour time we were able to ideate and build a prototype for the same.
* From fixing bugs to resolving merge conflicts the whole experience is worth remembering.
## What we learned
* Team collaboration
* how to remain calm and patient during the 36 hours
* Remain up on caffeine.
## What's next for Failed-In
* Improve the model of sentiment analysis to get more accurate results so we can understand the users and recommend them famous failure to success stories using web scraping.
* Create separate discussion rooms for each #tag, facilitating users to communicate and discuss their failures.
* Also provide the option to follow/unfollow a user. | winning |
## Inspiration
If you were walking down Wyoming St in Detroit, Michigan, or 1st St in Jackson, Tennessee, you have reason to be terrified. You have a 10% chance of falling prey to violent crimes such as armed robbery and rape. In the “Land of the Free”, people ought to be free to tread quiet streets at night without fearing for their lives.
How can we improve the safety of people on America’s most dangerous streets? How can we shorten response times when a violent crime occurs? How can we make people feel safe and supported while walking alone at night?
At StreetSafe, we are seeking answers to these questions. Thus, we have created a virtual buddy that accompanies people on late-night walks and mobilizes for help when signs of violent crime are detected.
## What StreetSafe Does
StreetSafe is a virtual buddy app that accompanies you on late-night walks and alerts effective responders (i.e. police, people nearby) if any anomalies are detected. StreetSafe has the following unique features:
• Reliable Buddy: Powered by IBM Watson, StreetSafe tells stories, cracks jokes and sustains conversations for the entire duration of a walk. At the same time, it serves as a trusted guide—advising users on the safest path to take according to real-time crime information.
• Anomaly Detection: The app listens for sounds of distress (e.g. screams, danger words and long pauses in response). It also detects sudden acceleration and impact of a phone, which might indicate a snatch theft.
• Emergency Alerts: When something suspicious occurs, StreetSafe will ask a user thrice if everything is okay. If no response is given, the app will send out text alerts to effective responders. These include law enforcement agencies and anyone within a 1-mile radius of the incident site (who will receive an SMS). Information on the location and likely type of incident (e.g. snatch theft, kidnapping, etc) will be provided, thus facilitating quick mobilization of resources to help the victim.
## How We Built It
StreetSafe is conceptualized on Adobe XD Creative Cloud, and built on Android Studio with Java. We used sound level monitoring in Java to pick up any unusual voice modulations (e.g. loud screams).
To power our conversational feature, we personalised IBM Watson to respond to specific comments or requests (e.g. Tell me a short story). We used Twilio REST API to send SMS alerts to people within a 1-mile radius of a crime scene.
## Challenges We Ran Into
We tried to use Firebase to provide a Google login into the application, but we got stuck when the SSA1 key verification was failing continuously. It was also complex to figure out how to use sound libraries in Java.
## Accomplishments that We Are Proud Of
Our virtual buddy is able to hold **sustained and engaging conversations** with users. It goes beyond exchanging pleasantries to telling stories and cracking jokes.
Also, we are proud to have created the idea of **mobilizing potential good Samaritans** near a crime scene to assist a victim. Other apps on the market focus on alerting law enforcement, even though bystanders can be a great crime-fighting force.
## What We Learned
In the technical aspect, we improved our proficiencies in Java and IBM Watson, while learning how to solve problems when a particular tool did not work. In the team aspect, we learned how to combine our diverse skills in a complementary way, with the common goal of creating tech for good.
## What's next for StreetSafe
We plan to implement the following in the next six months:
• Build an ML model to classify different sound profiles better, in order to ascertain distress signs with greater accuracy.
• Use gyroscope to detect sudden acceleration the phone, such as when the phone is snatched or dropped on the ground.
• Create three different threat levels—high, medium and low—based on historical data on crime in an area and vary sensitivity to distress signs based on threat levels.
• Enable virtual buddy to process real-time crime data and advise users to change routes.
• Perform a trial of the SMS alert system on fifty participants in a controlled environment.
## Projected Use Case
Betty wants to go from her workplace to her friend’s house at a Tuesday night., but is concerned as the streets are dark and quiet. She pulls out her phone and opens StreetSafe. She types in her friend’s address and starts a conversation with her familiar virtual buddy, Lisa. Betty tells Lisa about her day at work, before asking Lisa to tell her a motivational story.
The walk is projected to last 20 minutes. All of a sudden, a man comes up to Betty and grabs her phone. Betty is too shocked, and stands transfixed and speechless as the man tearing down the street.
Detecting the sudden acceleration in Becky’s phone, Lisa asks Becky, “Becky, are you alright?”. After asking thrice with no response, StreetSafe sends a text alert to the Police, informing them of a suspected snatch theft. An SMS alert is also sent out to everyone in a 1-mile radius of the crime scene:
“
Dear Sir/Madam,
A suspected snatch theft has occurred at 2431 21st Street, which is in your vicinity. We urge you to exercise extreme caution in the area, while rendering assistance to the victim if you are able to do so. Thank you.”
George, who is walking along the street a block away, checks the SMS, looks up and sees a man sprinting towards him. “Stop! Stop!” he yells, but the man refuses to stop. George, a running enthusiast, gives chase to the thief and manages to pin him down with the help of other passers-by 5 minutes later. Soon enough, the police arrive at the scene to apprehend the thief, and Becky gets her stolen phone back.
A violent street crime is thwarted, thanks to Lisa’s alertness and ability to mobilize the community to come to Becky’s aid. | ## Inspiration
In response to recent tragic events in Turkey, where the rescue efforts for the Earthquake have been very difficult. We decided to use Qualcomm’s hardware development kit to create an application for survivors of natural disasters like earthquakes to send out distress signals to local authorities.
## What it does
Our app aids disaster survivors by sending a distress signal with location & photo, chatbot updates on rescue efforts & triggering actuators on an Arduino, which helps rescuers find survivors.
## How we built it
We built it using Qualcomm’s hardware development kit and Arduino Due as well as many APIs to help assist our project goals.
## Challenges we ran into
We faced many challenges as we programmed the android application. Kotlin is a new language to us, so we had to spend a lot of time reading documentation and understanding the implementations. Debugging was also challenging as we faced errors that we were not familiar with. Ultimately, we used online forums like Stack Overflow to guide us through the project.
## Accomplishments that we're proud of
The ability to develop a Kotlin App without any previous experience in Kotlin. Using APIs such as OPENAI-GPT3 to provide a useful and working chatbox.
## What we learned
How to work as a team and work in separate subteams to integrate software and hardware together. Incorporating iterative workflow.
## What's next for ShakeSafe
Continuing to add more sensors, developing better search and rescue algorithms (i.e. travelling salesman problem, maybe using Dijkstra's Algorithm) | ## Inspiration and What it does
We often go out with a lot of amazing friends for trips, restaurants, tourism, weekend expedition and what not. Every encounter has an associated messenger groupchat. We want a way to split money which is better than to discuss on the groupchat, ask people their public key/usernames and pay on a different platform. We've integrated them so that we can do transactions and chat at a single place.
We (our team) believe that **"The Future of money is Digital Currency "** (-Bill Gates), and so, we've integrated payment with Algorand's AlgoCoins with the chat. To make the process as simple as possible without being less robust, we extract payment information out of text as well as voice messages.
## How I built it
We used Google Cloud NLP and IBM Watson Natural Language Understanding apis to extract the relevant information. Voice messages are first converted to text using Rev.ai speech-to-text. We complete the payment using the blockchain set up with Algorand API. All scripts and database will be hosted on the AWS server
## Challenges I ran into
It turned out to be unexpectedly hard to accurately find out the payer and payee. Dealing with the blockchain part was a great learning experience.
## Accomplishments that I'm proud of
that we were able to make it work in less than 24 hours
## What I learned
A lot of different APIs
## What's next for Mess-Blockchain-enger
Different kinds of currencies, more messaging platforms | winning |
## Inspiration
Our team was determined to challenge a major problem in society, and create a practical solution. It occurred to us early on that **false facts** and **fake news** has become a growing problem, due to the availability of information over common forms of social media. Many initiatives and campaigns recently have used approaches, such as ML fact checkers, to identify and remove fake news across the Internet. Although we have seen this approach become evidently better over time, our group felt that there must be a way to innovate upon the foundations created from the ML.
In short, our aspirations to challenge an ever-growing issue within society, coupled with the thought of innovating upon current technological approaches to the solution, truly inspired what has become ETHentic.
## What it does
ETHentic is a **betting platform** with a twist. Rather than preying on luck, you play against the odds of truth and justice. Users are given random snippets of journalism and articles to review, and must determine whether the information presented within the article is false/fake news, or whether it is legitimate and truthful, **based on logical reasoning and honesty**.
Users must initially trade in Ether for a set number of tokens (0.30ETH = 100 tokens). One token can be used to review one article. Every article that is chosen from the Internet is first evaluated using an ML model, which determines whether the article is truthful or false. For a user to *win* the bet, they must evaluate the same choice as the ML model. By winning the bet, a user will receive a $0.40 gain on bet. This means a player is very capable of making a return on investment in the long run.
Any given article will only be reviewed 100 times by any unique user. Once the 100 cap has been met, the article will retire, and the results will be published to the Ethereum blockchain. The results will include anonymous statistics of ratio of truth:false evaluation, the article source, and the ML's original evaluation. This data is public, immutable, and has a number of advantages. All results going forward will be capable of improving the ML model's ability to recognize false information, by comparing the relationship of assessment to public review, and training the model in a cost-effective, open source method.
To summarize, ETHentic is an incentivized, fun way to educate the public about recognizing fake news across social media, while improving the ability of current ML technology to recognize such information. We are improving the two current best approaches to beating fake news manipulation, by educating the public, and improving technology capabilities.
## How we built it
ETHentic uses a multitude of tools and software to make the application possible. First, we drew out our task flow. After sketching wireframes, we designed a prototype in Framer X. We conducted informal user research to inform our UI decisions, and built the frontend with React.
We used **Blockstack** Gaia to store user metadata, such as user authentication, betting history, token balance, and Ethereum wallet ID in a decentralized manner. We then used MongoDB and Mongoose to create a DB of articles and a counter for the amount of people who have viewed any given article. Once an article is added, we currently outsourced to Google's fact checker ML API to generate a true/false value. This was added to the associated article in Mongo **temporarily**.
Users who wanted to purchase tokens would receive a Metamask request, which would process an Ether transfer to an admin wallet that handles all the money in/money out. Once the payment is received, our node server would update the Blockstack user file with the correct amount of tokens.
Users who perform betting receive instant results on whether they were correct or wrong, and are prompted to accept their winnings from Metamask.
Everytime the Mongo DB updates the counter, it checks if the count = 100. Upon an article reaching a count of 100, the article is removed from the DB and will no longer appear on the betting game. The ML's initial evaluation, the user results, and the source for the article are all published permanently onto an Ethereum blockchain. We used IPFS to create a hash that linked to this information, which meant that the cost for storing this data onto the blockchain was massively decreased. We used Infuria as a way to get access to IPFS without needing a more heavy package and library. Storing on the blockchain allows for easy access to useful data that can be used in the future to train ML models at a rate that matches the user base growth.
As for our brand concept, we used a green colour that reminded us of Ethereum Classic. Our logo is Lady Justice - she's blindfolded, holding a sword in one hand and a scale in the other. Her sword was created as a tribute to the Ethereum logo. We felt that Lady Justice was a good representation of what our project meant, because it gives users the power to be the judge of the content they view, equipping them with a sword and a scale. Our marketing website, ethergiveawayclaimnow.online, is a play on "false advertising" and not believing everything you see online, since we're not actually giving away Ether (sorry!). We thought this would be an interesting way to attract users.
## Challenges we ran into
Figuring out how to use and integrate new technologies such as Blockstack, Ethereum, etc., was the biggest challenge. Some of the documentation was also hard to follow, and because of the libraries being a little unstable/buggy, we were facing a lot of new errors and problems.
## Accomplishments that we're proud of
We are really proud of managing to create such an interesting, fun, yet practical potential solution to such a pressing issue. Overcoming the errors and bugs with little well documented resources, although frustrating at times, was another good experience.
## What we learned
We think this hack made us learn two main things:
1) Blockchain is more than just a cryptocurrency tool.
2) Sometimes even the most dubious subject areas can be made interesting.
The whole fake news problem is something that has traditionally been taken very seriously. We took the issue as an opportunity to create a solution through a different approach, which really stressed the lesson of thinking and viewing things in a multitude of perspectives.
## What's next for ETHentic
ETHentic is looking forward to the potential of continuing to develop the ML portion of the project, and making it available on test networks for others to use and play around with. | ## Inspiration
As more and more blockchains transition to using Proof of Stake as their primary consensus mechanism, the importance of validators becomes more apparent. The security of entire digital economies, people's assets, and global currencies rely on the security of the chain, which at its core is guaranteed by the number of tokens that are staked by validators. These staked tokens not only come from validators but also from everyday users of the network. In the current system there is very little distinguishing between validators other than the APY that each provides and their name (a.k.a. their brand). We aim to solve this issue with Ptolemy by creating a reputation score that is tied to a validator's DID using data found both on and off chain.
This pain point was discovered as our club, being validators on many chains such as Evmos, wanted a way to earn more delegations through putting in more effort into pushing the community forward. After talking with other university blockchain clubs, we discovered that the space was seriously lacking the UI and data aggregation processes to correlate delegations with engagement and involvement in a community.
We confirmed this issue by realizing our shared experiences as users of these protocols: when deciding which validators to delegate our tokens to on Osmosis we really had no way of choosing between validators other than judging based on APY looking them up on Twitter to see what they did for the community.
## What it does
Ptolemy calculates a reputation score based on a number of factors and ties this score to validators on chain using Sonr's DID module. These factors include both on-chain and off-chain metrics. We fetch on-chain validator data Cosmoscan and assign each validator a reputation score based on number of blocks proposed, governance votes, amount of delegators, and voting power, and create and evaluate a Validator based on a mathematical formula that normalized data gives them a score between 0-5. Our project includes not only the equation to arrive at this score but also a web app to showcase what a delegation UI would look like when including this reputation score. We also include mock data that ties data from social media platforms to highlight a validator's engagement with the community, such as Reddit, Twitter, and Discord, although this carries less weight than other factors.
## How we built it
First, we started with a design doc, laying out all the features. Next, we built out the design in Figma, looking at different Defi protocols for inspiration. Then we started coding.
We built it using Sonr as our management system for DIDs, React, and Chakra for the front end, and the backend in GoLang.
## Challenges we ran into
Integrating the Sonr API was quite difficult, we had to hop on call with an Engineer from the team to work through the bug. We ended up having to use the GoLang API instead of the Flutr SDK. During the ideating phase, we had to figure out what off-chain data was useful for choosing between validators.
## Accomplishments that we're proud of
We are proud of learning a new technology stack from the ground up in the form of the Sonr DID system and integrating it into a much-needed application in the blockchain space. We are also proud of the fact that we focused on deeply understanding the validator reputation issue so that our solution would be comprehensive in its coverage.
## What we learned
We learned how to bring together diverse areas of software to build a product that requires so many different moving components. We also learned how to look through many sets of documentation and learn what we minimally needed to hack out what we wanted to build within the time frame. Lastly, we also learned to efficiently bring together these different components in one final product that justice to each of their individual complexities.
## What's next for Ptolemy
Ptolemy is named in honor of the eponymous 2nd Century scientist who generated a system to chart the world in the form of longitude/latitude which illuminated the geography world. In a similar way, we hope to bring more light to the decision making process of directing delegations. Beyond this hackathon, we want to include more important metrics such as validator downtime, jail time, slashing history, and history of APY over a certain time period. Given more time, we could have fetched this data from an indexing service similar to The Graph. We also want to flesh out the onboarding process for validators to include signing into different social media platforms so we can fetch data to determine their engagement with communities, rather than using mock data. A huge feature for the app that we didn't have time to build out was staking directly on our platform, which would have involved an integration with Keplr wallet and the staking contracts on each of the appchains that we chose.
Besides these staking related features, we also had many ideas to make the reputation score a bigger component of everyone's on chain identity. The idea of a reputation score has huge network effects in the sense that as more users and protocols use it, the more significance it holds. Imagine a future where lending protocols, DEXes, liquidity mining programs, etc. all take into account your on-chain reputation score to further align incentives by rewarding good actors and slashing malicious ones. As more protocols integrate it, the more power it holds and the more seriously users will manage their reputation score. Beyond this, we want to build out an API that also allows developers to integrate our score into their own decentralized apps.
All this is to work towards a future where Ptolemy will fully encapsulate the power of DID’s in order to create a more transparent world for users that are delegating their tokens.
Before launch, we need to stream in data from Twitter, Reddit, and Discord, rather than using mock data. We will also allow users to directly stake our platform. Then we need to integrate with different lending platforms to generate the Validator's "reputation-score" on-chain. Then we will launch on test net. Right now, we have the top 20 validators, moving forwards we will add more validators. We want to query, jail time, and slashing of validators in order to create a more comprehensive reputation score for the validator., Off-chain, we want to aggregate Discord, Reddit, Twitter, and community forum posts to see their contributions to the chain they are validating on. We also want to create an API that allows developers to use this aggregated data on their platform. | ## Inspiration
Our main inspiration was Honey, the star of YouTube advertisements, as we recognized the convenience of seeing information about your shopping list right in the browser. More people would buy sustainable products if there was an indicator that they are, which is why ecolabels exist and are used widely. However, the rise of e-commerce has weakened the impact of printed symbols on packaging, and researching each product is a pain. Instead, we thought up a way to bring ecolabels to the attention of online shoppers right at checkout.
## What it does
EcoShop uses various web databases and APIs to read the product names on an online shopping cart (currently limited to Target). It then displays what sustainable certifications the products have earned through Type 1 programs, which are accredited through a third party. Upon clicking on the ecolabel, users are also provided with a detailed view of the certification, the qualifications necessary to earn it, and what that means about their product.
## How we built it
By using Target's Red Circle API, we were able to scrape data on products in a user’s shopping cart from the site. This data includes the UPC (Universal Product Code), which is compared to pre-acquired datasets from various certification organizations such as EPEAT (Electronic Product Environmental Assessment Tool), Energy Star, TCO, etc. The certification data, gathered through Javascript, was sent back to the extension which displayed the product list and corresponding certifications it has earned.
## Challenges we ran into
The majority of product certification datasets weren't available to the public since they either aren't digitized or needed a paid license to access. The data that was available for free use took hours to format, let alone process. Many also didn’t include a product's UPC, due to the lack of legal requirements for information on non-retail products. Target's Red Circle API was also not optimized enough for operating under a short time constraint, and we had to determine a way to efficiently and securely access the site data of the user.
## Accomplishments that we're proud of
We’re proud of the functionality that our product provides, even given the lack of time, experience, and resources our team struggled with. Our extension is only limited by the number of free, public datasets for sustainable product certifications, and can easily be expanded to other consumer categories and ecolabels if they become available to us. From our logic to our UI, our extension to our website, we’re psyched to be able to successfully inform online shoppers about whether they're shopping sustainably and influence them to get better at it.
## What we learned
Although some of us have had a surface-level experience with web development, this was the first time we took a deep dive into developing a web app. This was also the first time for all of us to learn how to make chrome extensions and use a REST API.
## What's next for EcoShop
We plan to extend EcoShop to all online shopping sites, certifications, and categories of consumer products. Given more data and time, we hope to provide a cumulative sustainability grade tailored for the user, as they can toggle through the sustainable development goals that they care about most. We also plan on implementing a recommendation system to ensure that shoppers are aware of more sustainable alternatives. And for further convenience for consumers, an iOS application could provide a simplified version of EcoShop to give more information about ecolabels directly in stores. | winning |
## Inspiration
eCommerce is a field that has seen astronomical growth in recent years, and shows no signs of slowing down. With a forecasted growth rate of 10.4% this year, up to $6.3 trillion in global revenues, we decided to tackle Noibu’s challenge to develop an extension to aide ecommerce developers with the impossible task of staying ahead amongst the fierce competitions in this space, all whilst providing a tremendous unique value to shoppers and eCommerce brands alike.
## What it does
Our extension. ShopSmart, aim to provide developers and brands with an accurate idea of how their website is being used, naturally. Unlike A/B testing, which forces a participant to use a given platform and provide feedback, ShopSmart analyzes user activity on any given website and produces a heatmap showing their exact usage patterns, all without collecting user identifying data. In tandem with the heatmap, ShopSmart provides insights as to the sequences of actions taken on their website, correlated with their heatmap usage, allowing an ever deeper understanding of what average usage truly looks like. To incentivize consumers, brands may elect to provide exclusive discount codes only available through ShopSmart, giving the shoppers a kickback for their invaluable input to the brand partners.
## How we built it
ShopSmart was built using the classic web languages HTML, CSS, and Javascript, keeping it simple, lightweight, and speedy.
## Challenges we ran into
We ran into several challenges throughout our development process, largely due to the complexity of the extension in theory being limited in execution to HTML, CSS, and Javascript (as those are the only allowed languages for use in developing extensions). One issue we had was finding a way to overlay the heatmap over the website so as to visually show the paths the user took. Whilst we were able to solve that challenge, we were sadly unable to finish fully integrating our database within the given timeframe into the extension due to the frequency of data collection/communication, and the complexity of the data itself.
## Accomplishments that we're proud of
Our team is very proud in being able to put out a working extension capable of tracking usage and overlaying the resulting heatmap data over the used website, especially as neither of us had any experience with developing extensions. Despite not being able to showcase our extensive database connections in the end as they are not finalized, we are proud of achieving reliable and consistent data flow to our cloud-based database within our testing environment. We are also proud of coming together and solving a problem none of us had considered before, and of course, of the sheer amount we learned over this short time span.
## What we learned
Our hackathon experience was truly transformative, as we not only gained invaluable technical knowledge in Javascript, but also cultivated essential soft skills that will serve us well in any future endeavors. By working together as a team, we were able to pool our unique strengths and collaborate effectively to solve complex problems and bring our ideas to life.
## What's next for ShopSmart
The next steps for ShopSmart are to focus on expanding its capabilities and increasing its reach. One area of focus could be on integrating the extension with more e-commerce platforms to make it more widely accessible to developers and brands. Another area for improvement could be on enhancing the heatmap visualization and adding more advanced analytics features to provide even deeper insights into user behavior. With the help of Machine Learning, developers and brands can utilize the data provided by ShopSmart to better recognize patterns within their customer's usage of their site to make better adjustments and improvements. Additionally, exploring partnerships with e-commerce brands to promote the extension and offer more exclusive discount codes to incentivize consumers could help increase its adoption. Overall, the goal is to continuously improve the extension and make it an indispensable tool for e-commerce businesses looking to stay ahead of the competition. | ## Inspiration 💡
The push behind EcoCart is the pressing call to weave sustainability into our everyday actions. I've envisioned a tool that makes it easy for people to opt for green choices when shopping.
## What it does 📑
EcoCart is your AI-guided Sustainable Shopping Assistant, designed to help shoppers minimize their carbon impact. It comes with a user-centric dashboard and a browser add-on for streamlined purchase monitoring.
By integrating EcoCart's browser add-on with favorite online shopping sites, users can easily oversee their carbon emissions. The AI functionality dives deep into the data, offering granular insights on the ecological implications of every transaction.
Our dashboard is crafted to help users see their sustainable journey and make educated choices. Engaging charts and a gamified approach nudge users towards greener options and aware buying behaviors.
EcoCart fosters an eco-friendly lifestyle, fusing AI, an accessible dashboard, and a purchase-monitoring add-on. Collectively, our choices can echo a positive note for the planet.
## How it's built 🏗️
EcoCart is carved out using avant-garde AI tools and a strong backend setup. While our AI digs into product specifics, the backend ensures smooth data workflow and user engagement. A pivotal feature is the inclusion of SGID to ward off bots and uphold genuine user interaction, delivering an uninterrupted user journey and trustworthy eco metrics.
## Challenges and hurdles along the way 🧱
* Regular hiccups with Chrome add-on's hot reloading during development
* Sparse online guides on meshing Supabase Google Auth with a Chrome add-on
* Encountered glitches when using Vite for bundling our Chrome extension
## Accomplishments that I'am proud of 🦚
* Striking user interface
* Working prototype
* Successful integration of Supabase in our Chrome add-on
* Advocacy for sustainability through #techforpublicgood
## What I've learned 🏫
* Integrating SGID into a NextJS CSR web platform
* Deploying Supabase in a Chrome add-on
* Crafting aesthetically appealing and practical charts via Chart.js
## What's next for EcoCart ⌛
* Expanding to more e-commerce giants like Carousell, Taobao, etc.
* Introducing a rewards mechanism linked with our gamified setup
* Launching a SaaS subscription model for our user base. | ## Inspiration
We wanted to explore what GCP has to offer more in a practical sense, while trying to save money as poor students
## What it does
The app tracks you, and using Google Map's API, calculates a geofence that notifies the restaurants you are within vicinity to, and lets you load coupons that are valid.
## How we built it
React-native, Google Maps for pulling the location, python for the webscraper (*<https://www.retailmenot.ca/>*), Node.js for the backend, MongoDB to store authentication, location and coupons
## Challenges we ran into
React-Native was fairly new, linking a python script to a Node backend, connecting Node.js to react-native
## What we learned
New exposure APIs and gained experience on linking tools together
## What's next for Scrappy.io
Improvements to the web scraper, potentially expanding beyond restaurants. | partial |
## GoogleSpy
### The guy in the van never really got much credit.
Take control of your fellow spy, sending him all the instructions he needs to complete the mission.
*Powered by Google Home & Unity.*
## Inspriation
Wanted to break the usual misrepresentation of sidekicks. They sometimes do more work than the big guys.
Shout-out to Wade from Kim Possible. Keep doing your thing.
## What it does
Uses Google Assistant to analyze user queries and transpose them into in-game actions in Unity.
## How we built it
Firebase database of most recent Google Assistant query results that we pull into Unity and parse.
## Challenges we ran into
Setting up and working with the Actions with Google console + database, and finding a way to connect to Unity (which is not supported out-the-box).
## Accomplishments that we're proud of
Character design, truly encapsulating the personality of the Google Assistant.
And I guess the third-party integration with Unity is pretty cool too. Yea that too.
## What we learned
Better teamwork and splitting tasks efficiently. How trust is crucial to the team dynamic.
## What's next for Google Spy
Expanding to concurrent users, more levels, more commands, and much more love for Wade in Kim Possible. | ## Inspiration
Current students struggle with gaining the most value in the shortest time, We learned about the best methods of consuming information - visual and summaries, but current teaching techniques lack these methods.
## What it does
Scan your writing using your phone which then converts it into a text file. Then extract the keywords from that file, look up most relevant google photos from that and brings it back to the phone to display the summary with the photo and the text below. Options of more specific summaries for the individual keywords will be provided as well. It can also read aloud the summary for the visually impaired in order to have better traction and user interaction.
## How I built it
We used unity to develop an augmented reality environment , we integrated machine learning model at the backend of that environment using rest API. We used the google cloud vision API to scan images for text and then using that text as our input to produce our text to speech , summarization and slideshow capabilities
## Challenges I ran into
1.)Difficulties in interaction/ creating communication channels between Unity applications and python machine learning models due to lack of existence of documentation and resources for the same
2.) integration of python models into REST APIs
3.) Difficulties in uploading our API into an online cloud based web hosting service ,due to its large size
## Accomplishments that I'm proud of
1.)Successfully integrating two different platforms together which end up linking two very powerful and vast fields(AR and machine learning)
2.)Creating a working app in 2 days which happens to be an unique product on the market
## What I learned
1.) we learnt how to form a data pipeline between Unity and python which supports AR and machine learning
2.) how to form realtime applications that run ML at thier backend
3.) how to effectively manage our time and make a product in 2 days as a team activity
4.) how to make our own APIs and how to work with them ,
## What's next for TextWiz
We currently only support english , we wish to support more languages in the future and we wish to be able to translate between those language to increase connectivity on a global level.
Our current machine learning model while being good still has room for improvement and we plan to increase the accuracy of our models in the future. | # DriveWise: Building a Safer Future in Route Planning
Motor vehicle crashes are the leading cause of death among teens, with over a third of teen fatalities resulting from traffic accidents. This represents one of the most pressing public safety issues today. While many route-planning algorithms exist, most prioritize speed over safety, often neglecting the inherent risks associated with certain routes. We set out to create a route-planning app that leverages past accident data to help users navigate safer routes.
## Inspiration
The inexperience of young drivers contributes to the sharp rise in accidents and deaths as can be seen in the figure below.
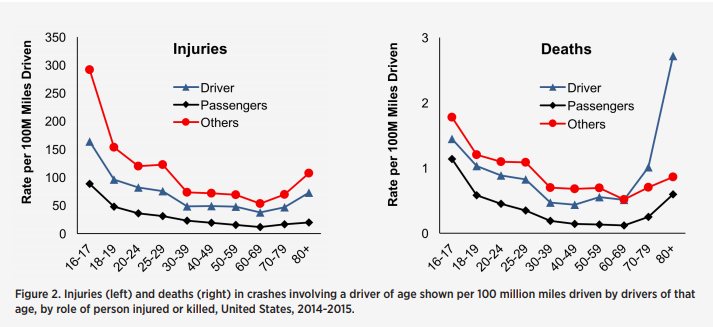
This issue is further intensified by challenging driving conditions, road hazards, and the lack of real-time risk assessment tools. With limited access to information about accident-prone areas and little experience on the road, new drivers often unknowingly enter high-risk zones—something traditional route planners like Waze or Google Maps fail to address. However, new drivers are often willing to sacrifice speed for safer, less-traveled routes. Addressing this gap requires providing insights that promote safer driving choices.
## What It Does
We developed **DriveWise**, a route-planning app that empowers users to make informed decisions about the safest routes. The app analyzes 22 years of historical accident data and utilizes a modified A\* heuristic for personalized planning. Based on this data, it suggests alternative routes that are statistically safer, tailoring recommendations to the driver’s skill level. By factoring in variables such as driver skill, accident density, and turn complexity, we aim to create a comprehensive tool that prioritizes road safety above all else.
### How It Works
Our route-planning algorithm is novel in its incorporation of historical accident data directly into the routing process. Traditional algorithms like those used by Google Maps or Waze prioritize the shortest or fastest routes, often overlooking safety considerations. **DriveWise** integrates safety metrics into the edge weights of the routing graph, allowing the A\* algorithm to favor routes with lower accident risk.
**Key components of our algorithm include:**
* **Accident Density Mapping**: We map over 3.1 million historical accident data points to the road network using spatial queries. Each road segment is assigned an accident count based on nearby accidents.
* **Turn Penalties**: Sharp turns are more challenging for new drivers and have been shown to contribute to unsafe routes. We calculate turn angles between road segments and apply penalties for turns exceeding a certain threshold.
* **Skillfulness Metric**: We introduce a driver skill level parameter that adjusts the influence of accident risk and turn penalties on route selection. New drivers are guided through safer, simpler routes, while experienced drivers receive more direct paths.
* **Risk-Aware Heuristic**: Unlike traditional A\* implementations that use distance-based heuristics, we modify the heuristic to account for accident density, further steering the route away from high-risk areas.
By integrating these elements, **DriveWise** offers personalized route recommendations that adapt as the driver's skill level increases, ultimately aiming to reduce the likelihood of accidents for new drivers.
## Accomplishments We're Proud Of
We are proud of developing an algorithm that not only works effectively but also has the potential to make a real difference in road safety. Creating a route-planning tool that factors in historical accident data is, to our knowledge, a novel approach in this domain. We successfully combined complex data analysis with an intuitive user interface, resulting in an app that is both powerful and user-friendly.
We are also kinda proud about our website. Learn more about us at [idontwannadie.lol](https://idontwannadie.lol/)
## Challenges We Faced
This was one of our first hackathons, and we faced several challenges. Having never deployed anything before, we spent a significant amount of time learning, debugging, and fixing deployment issues. Designing the algorithm to analyze accident patterns while keeping the route planning relatively simple added considerable complexity. We had to balance predictive analytics with real-world usability, ensuring that the app remained intuitive while delivering sophisticated results.
Another challenge was creating a user interface that encourages engagement without overwhelming the driver. We wanted users to trust the app’s recommendations without feeling burdened by excessive information. Striking the right balance between simplicity and effectiveness through gamified metrics proved to be an elegant solution.
## What We Learned
We learned a great deal about integrating large datasets into real-time applications, the complexities of route optimization algorithms, and the importance of user-centric design. Working with the OpenStreetMap and OSMnx libraries required a deep dive into geospatial analysis, which was both challenging and rewarding. We also discovered the joys and pains of deploying an application, from server configurations to domain name setups.
## Future Plans
In the future, we see the potential for **DriveWise** to go beyond individual drivers and benefit broader communities. Urban planners, law enforcement agencies, and policymakers could use aggregated data to identify high-risk areas and make informed decisions about where to invest in road safety improvements. By expanding our dataset and refining our algorithms, we aim to make **DriveWise** functional in more regions and for a wider audience.
## Links
* **Paper**: [Mathematical Background](https://drive.google.com/drive/folders/1Q9MRjBWQtXKwtlzObdAxtfBpXgLR7yfQ?usp=sharing)
* **GitHub**: [DriveWise Repository](https://github.com/pranavponnusamy/Drivewise)
* **Website**: [idontwannadie.lol](https://idontwannadie.lol/)
* **Video Demo**: [DriveWise Demo](https://www.veed.io/view/81d727bc-ed6b-4bba-95c1-97ed48b1738d?panel=share) | losing |
## Inspiration
More money, more problems.
Lacking an easy, accessible, and secure method of transferring money? Even more problems.
An interesting solution to this has been the rise of WeChat Pay, allowing for merchants to use QR codes and social media to make digital payments.
But where does this leave people without sufficient bandwidth? Without reliable, adequate Wi-Fi, technologies like WeChat Pay and Google Pay simply aren't options. People looking to make money transfers are forced to choose between bloated fees or dangerously long wait times.
As designers, programmers, and students, we tend to think about how we can design tech. But how do you design tech for that negative space? During our research, we found of the people that lack adequate bandwidth, 1.28 billion of them have access to mobile service. This ultimately led to our solution: **Money might not grow on trees, but Paypayas do.** 🍈
## What it does
Paypaya is an SMS chatbot application that allows users to perform simple and safe transfers using just text messages.
Users start by texting a toll free number. Doing so opens a digital wallet that is authenticated by their voice. From that point, users can easily transfer, deposit, withdraw, or view their balance.
Despite being built for low bandwidth regions, Paypaya also has huge market potential in high bandwidth areas as well. Whether you are a small business owner that can't afford a swipe machine or a charity trying to raise funds in a contactless way, the possibilities are endless.
Try it for yourself by texting +1-833-729-0967
## How we built it
We first set up our Flask application in a Docker container on Google Cloud Run to streamline cross OS development. We then set up our database using MongoDB Atlas. Within the app, we also integrated the Twilio and PayPal APIs to create a digital wallet and perform the application commands. After creating the primary functionality of the app, we implemented voice authentication by collecting voice clips from Twilio to be used in Microsoft Azure's Speaker Recognition API.
For our branding and slides, everything was made vector by vector on Figma.
## Challenges we ran into
Man. Where do we start. Although it was fun, working in a two person team meant that we were both wearing (too) many hats. In terms of technical problems, the PayPal API documentation was archaic, making it extremely difficult for us figure out how to call the necessary functions. It was also really difficult to convert the audio from Twilio to a byte-stream for the Azure API. Lastly, we had trouble keeping track of conversation state in the chatbot as we were limited by how the webhook was called by Twilio.
## Accomplishments that we're proud of
We're really proud of creating a fully functioning MVP! All of 6 of our moving parts came together to form a working proof of concept. All of our graphics (slides, logo, collages) are all made from scratch. :))
## What we learned
Anson - As a first time back end developer, I learned SO much about using APIs, webhooks, databases, and servers. I also learned that Jacky falls asleep super easily.
Jacky - I learned that Microsoft Azure and Twilio can be a pain to work with and that Google Cloud Run is a blessing and a half. I learned I don't have the energy to stay up 36 hours straight for a hackathon anymore 🙃
## What's next for Paypaya
More language options! English is far from the native tongue of the world. By expanding the languages available, Paypaya will be accessible to even more people. We would also love to do more with financial planning, providing a log of previous transactions for individuals to track their spending and income. There are also a lot of rough edges and edge cases in the program flow, so patching up those will be important in bringing this to market. | ## Inspiration
An article that was published last month by the CBC talked about CRA phone scams.
The article said that “Thousands of Canadians had been scammed over the past several years, at an estimated cost of more than $10 million dollars, falling prey to the dozens of call centers using the same scheme.”
We realized that we had to protect consumers and those not as informed.
## The app
We created a mobile app that warns users about incoming SMS or Phone fraud from scam numbers.
The mobile app as well offers a playback function so users can learn what scam calls sound like.
Alongside the mobile app we built a website that provides information on scamming and allows users to query to see if a number is a scam number.
## How it works
The PBX server gets an incoming phone call or SMS from a scamming bot and records/saves the information. Afterwards the data is fed into a trained classifier so that it can be determined as scam or not scam. If the sender was a scammer, they're entered into the Postgresql database to later be queried over HTTP. The extensions from here are endless. API's, User applications, Blacklisting etc . . .
## Challenges we ran into
At first, we were going to build a react native application. However, Apple does not support the retrieval of incoming call phone numbers so we defaulted to a android application instead. FreePBX runs PHP 5 which is either deprecated or near deprecation. We as well originally tried to use Postgresql for FreePBX but had to use MySQL instead. PBX call recording was not achieved unfortunately.
## Accomplishments that we're proud of
* Setting up FreePBX
* Finished Website
* Finished App
* Broadcast Receiver
## What we learned
* FreePBX
* NGINX
* Android Media Player
## What's next for Tenty
* Full SMS support
* Distributed PBX network to increase data input
* API for Financial Institutions, and or those affiliated with what is being scammed. Allowing them to protect their customers.
* Assisting Governments in catching scammers. | ## Inspiration
After the pandemic, we have been using online platforms very much. We have many platforms for all the major activities like online food ordering, online podcasts and etc. But we don't have any specific platform for the student to study with their friends, which indeed clears the doubts about the topic very easily and enhances the students to study efficiently.
We have zoom calls and other platforms but they have some barriers like not having a proper community, limited call duration and etc.
Here is the web app which solves the mentioned barriers <https://study-with-mee.herokuapp.com/>
## What it does
Using this web app we can easily connect with public ongoing study rooms and also we can have our own private rooms,
All you need is just a smartphone or laptop with a stable internet connection.
You need to go to the Join rooms in the web app and all done you are in a study room with your friends.
## How we built it
We have made this app with the mindset of making the process very simple and easy.
>
> * Frontend has been built using simple HTML, CSS, javascript.
> * Backend has been built using Node JS, Express JS, Peer JS, Socket IO and Paytm API.
> * The web app is deployed in heroku
>
>
>
## Challenges we ran into
>
> * I initially had an idea of building this app using react, but I had to learn react and need to implement it in this app. It was not feasible because of time constraints.
> * Initially my intention to use the Stripe Payment API, was giving many error, so I had to change it to Paytm API.
> * It was very difficult to understand Socket IO with video and audio streaming.
> * Integrating multiple video stream also one of the major hurdle.
>
>
>
## Accomplishments that we're proud of
The UI of the web app really looks very attractive and I have utilized major components of the UI very efficiently, integrating the payment gateway was one of the attractive components. I am very much proud that I have completed the project and it looks like what I imagined.
## What we learned
I have learned how to integrate video streaming with the Frontend and also how can we integrate payment API. Utilized the free deployment of Heroku and I have learned how to deploy the app to the cloud.
## What's next for Study with me
>
> * We can have a dedicated discord like community page.
> * A simple video-based beginners-friendly course page.
> * This app can also have a dedicated page for entertainment like online game streaming.
> * A comment box for all the video streams.
> * Converting it to a modern Frontend framework like react, Angular or Vue.
>
>
>
## Built With
>
> * Node JS
> * Express JS
> * Peer JS
> * Socket IO
> * HTML
> * CSS
> * JavaScript
> * Paytm Payment API
> * Heroku
>
>
> | winning |
## Inspiration
Our inspiration for GreenMaps stemmed from a vision for sustainability and helping the environment. We hoped to create a tool that empowers users to make eco-friendly transportation choices effortlessly.
## What it does
GreenMaps is a Chrome extension that calculates a Sustainability Score for different routes on Google Maps, helping users choose environmentally friendly routes. It takes into account distance, mode of transportation, time, and emissions data to provide users with a clear, low-impact navigation option. The "View Past Statistics" tab helps organize this data and more into readable visualizations. Our shop green function recommends sustainably practicing businesses in the area you are visiting, allowing you to travel green, spend green and live green.
## How we built it
* React.js front end to dynamically load API data into readable graphs and charts
* Chart.js to display graphs and charts
* AirVisual API to access pollution data, and atmospheric concentrations
* Metaphor API to scrape the web for nearby eco-friendly businesses
* Twilio API to send business recommendations to users
## Challenges we ran into
One of the challenges we faced was collecting accurate data to calculate the Sustainability Scores. Additionally, integrating our extension with Google Maps presented technical difficulties that required innovative brainstorming. Many of us were using technologies and frameworks for the first time so it required a lot of learning and thinking on our feet.
## Accomplishments that we're proud of
We are proud to develop an extension that aids users to make more sustainable transportation choices. Seeing our concept come to life and positively impact users' lives makes this project worthwhile to accomplish.
## What we learned
Through the development of GreenMaps, we gained a better understanding of JavaScript, web development, and creating an extension as well as the importance of data accuracy in sustainability applications. We also learned the value of teamwork and collaboration in turning an idea into a reality.
## What's next for GreenMaps
Our vision for GreenMaps includes expanding its reach to more platforms, including other map softwares and mobile devices. We also plan to upgrade the user experience with real-time data and personalized recommendations. Ultimately, we want to create a greener, more sustainable future by helping people make less carbon-costly decisions. | ## Inspiration
We wanted to promote environmental awareness through an app that people use everyday.
## What it does
Our web app is a chrome extension that converts the distance traveled and mode of transportation to carbon emissions.
## How we built it
We used JavaScript and multiple Google APIs to create an interactive sidebar to Google Maps that allows users to view the size of their carbon footprint.
## Challenges we ran into
One of our teammates left in the middle of the hackathon.
## Accomplishments that we're proud of
It was rewarding for us to create a chrome extension that looks very professional.
## What we learned
We learned a lot of web development programming, like writing HTML and CSS.
## What's next for EcoRoutes
We hope that other organizations can use our database of users' travel info in order to strategically target areas that aren't environmentally aware. | ## Inspiration
As a team, we had a collective interest in sustainability and knew that if we could focus on online consumerism, we would have much greater potential to influence sustainable purchases. We also were inspired by Honey -- we wanted to create something that is easily accessible across many websites, with readily available information for people to compare.
Lots of people we know don’t take the time to look for sustainable items. People typically say if they had a choice between sustainable and non-sustainable products around the same price point, they would choose the sustainable option. But, consumers often don't make the deliberate effort themselves. We’re making it easier for people to buy sustainably -- placing the products right in front of consumers.
## What it does
greenbeans is a Chrome extension that pops up when users are shopping for items online, offering similar alternative products that are more eco-friendly. The extension also displays a message if the product meets our sustainability criteria.
## How we built it
Designs in Figma, Bubble for backend, React for frontend.
## Challenges we ran into
Three beginner hackers! First time at a hackathon for three of us, for two of those three it was our first time formally coding in a product experience. Ideation was also challenging to decide which broad issue to focus on (nutrition, mental health, environment, education, etc.) and in determining specifics of project (how to implement, what audience/products we wanted to focus on, etc.)
## Accomplishments that we're proud of
Navigating Bubble for the first time, multiple members coding in a product setting for the first time... Pretty much creating a solid MVP with a team of beginners!
## What we learned
In order to ensure that a project is feasible, at times it’s necessary to scale back features and implementation to consider constraints. Especially when working on a team with 3 first time hackathon-goers, we had to ensure we were working in spaces where we could balance learning with making progress on the project.
## What's next for greenbeans
Lots to add on in the future:
Systems to reward sustainable product purchases. Storing data over time and tracking sustainable purchases. Incorporating a community aspect, where small businesses can link their products or websites to certain searches.
Including information on best prices for the various sustainable alternatives, or indicators that a product is being sold by a small business. More tailored or specific product recommendations that recognize style, scent, or other niche qualities. | losing |
Built what is to my knowledge the most complex brain-controlled video game to be created.
You can play a first-person shooter just using brain signals. You can move around, aim and shoot. | ## Inspiration
The original idea was to create an alarm clock that could aim at the ~~victim's~~ sleeping person's face and shoot water instead of playing a sound to wake-up.
Obviously, nobody carries around peristaltic pumps at hackathons so the water squirting part had to be removed, but the idea of getting a plateform that could aim at a person't face remained.
## What it does
It simply tries to always keep a webcam pointed directly at the largest face in it's field of view.
## How I built it
The brain is a Raspberry Pi model 3 with a webcam attachment that streams raw pictures to Microsoft Cognitive Services. The cloud API then identifies the faces (if any) in the picture and gives a coordinate in pixel of the position of the face.
These coordinates are then converted to an offset (in pixel) from the current position.
This offset (in X and Y but only X is used) is then transmitted to the Arduino that's in control of the stepper motor. This is done by encoding the data as a JSON string, sending it over the serial connection between the Pi and the Arduino and parsing the string on the Arduino. A translation is done to get an actual number of steps. The translation isn't necessarily precise, as the algorithm will naturally converge towards the center of the face.
## Challenges I ran into
Building the enclosure was a lot harder than what I believed initially. It was impossible to build it with two axis of freedom. A compromise was reached by having only the assembly rotate on the X axis (it can pan but not tilt.)
Acrylic panels were used. This was sub-optimal as we had no proper equipment to drill into acrylic to secure screws correctly. Furthermore, the shape of the stepper-motors made it very hard to secure anything to their rotating axis. This is the reason the tilt feature had to be abandoned.
Proper tooling *and expertise* could have fixed these issues.
## Accomplishments that I'm proud of
Stepping out of my confort zone by making a project that depends on areas of expertise I am not familiar with (physical fabrication).
## What I learned
It's easier to write software than to build *real* stuff. There is no "fast iterations" in hardware.
It was also my first time using epoxy resin as well as laser cuted acrylic. These two materials are interesting to work with and are a good alternative to using thin wood as I was used to before. It's incredibly faster to glue than wood and the laser cutting of the acrylic allows for a precision that's hard to match with wood.
It was a lot easier than what I imagined working with the electronics, as driver and library support was already existing and the pieces of equipment as well as the libraries where well documented.
## What's next for FaceTracker
Re-do the enclosure with appropriate materials and proper engineering.
Switch to OpenCV for image recognition as using a cloud service incurs too much latency.
Refine the algorithm to take advantage of the reduced latency.
Add tilt capabilities to the project. | ## Inspiration
Some things can only be understood through experience, and Virtual Reality is the perfect medium for providing new experiences. VR allows for complete control over vision, hearing, and perception in a virtual world, allowing our team to effectively alter the senses of immersed users. We wanted to manipulate vision and hearing in order to allow players to view life from the perspective of those with various disorders such as colorblindness, prosopagnosia, deafness, and other conditions that are difficult to accurately simulate in the real world. Our goal is to educate and expose users to the various names, effects, and natures of conditions that are difficult to fully comprehend without first-hand experience. Doing so can allow individuals to empathize with and learn from various different disorders.
## What it does
Sensory is an HTC Vive Virtual Reality experience that allows users to experiment with different disorders from Visual, Cognitive, or Auditory disorder categories. Upon selecting a specific impairment, the user is subjected to what someone with that disorder may experience, and can view more information on the disorder. Some examples include achromatopsia, a rare form of complete colorblindness, and prosopagnosia, the inability to recognize faces. Users can combine these effects, view their surroundings from new perspectives, and educate themselves on how various disorders work.
## How we built it
We built Sensory using the Unity Game Engine, the C# Programming Language, and the HTC Vive. We imported a rare few models from the Unity Asset Store (All free!)
## Challenges we ran into
We chose this project because we hadn't experimented much with visual and audio effects in Unity and in VR before. Our team has done tons of VR, but never really dealt with any camera effects or postprocessing. As a result, there are many paths we attempted that ultimately led to failure (and lots of wasted time). For example, we wanted to make it so that users could only hear out of one ear - but after enough searching, we discovered it's very difficult to do this in Unity, and would've been much easier in a custom engine. As a result, we explored many aspects of Unity we'd never previously encountered in an attempt to change lots of effects.
## What's next for Sensory
There's still many more disorders we want to implement, and many categories we could potentially add. We envision this people a central hub for users, doctors, professionals, or patients to experience different disorders. Right now, it's primarily a tool for experimentation, but in the future it could be used for empathy, awareness, education and health. | losing |
## Inspiration
Many investors looking to invest in startup companies are often overwhelmed by the sheer number of investment opportunities, worried that they will miss promising ventures without doing adequate due diligence. Likewise, since startups all present their data in a unique way, it is challenging for investors to directly compare companies and effectively evaluate potential investments. On the other hand, thousands of startups with a lot of potential also lack visibility to the right investors. Thus, we came up with Disruptive as a way to bridge this gap and provide a database for investors to view important insights about startups tailored to specific criteria.
## What it does
Disruptive scrapes information from various sources: company websites, LinkedIn, news, and social media platforms to generate the newest possible market insights. After homepage authentication, investors are prompted to indicate their interest in either Pre/Post+ seed companies to invest in. When an option is selected, the investor is directed to a database of company data with search capabilities, scraped from Kaggle. From the results table, a company can be selected and the investor will be able to view company insights, business analyst data (graphs), fund companies, and a Streamlit Chatbot interface. You are able to add more data through a DAO platform, by getting funded by companies looking for data. The investor also has the option of adding a company to the database with information about it.
## How we built it
The frontend was built with Next.js, TypeScript, and Tailwind CSS. Firebase authentication was used to verify users from the home page. (Company scraping and proxies for company information) Selenium was used for web scraping for database information. Figma was used for design, authentication was done using Firebase.
The backend was built using Flask, StreamLit, and Taipy. We used the Circle API and Hedera to generate bounties using blockchain. SQL and graphQL were used to generate insights, OpenAI and QLoRa were used for semantic/similarity search, and GPT fine-tuning was used for few-shot prompting.
## Challenges we ran into
Having never worked with Selenium and web scraping, we found understanding the dynamic loading and retrieval of web content challenging. The measures some websites have against scraping were also interesting to learn and try to work around. We also worked with chat-GPT and did prompt engineering to generate business insights - a task that can sometimes yield unexpected responses from chat-GPT!
## Accomplishments that we're proud of + What we learned
We learned how to use a lot of new technology during this hackathon. As mentioned above, we learned how to use Selenium, as well as Firebase authentication and GPT fine-tuning.
## What's next for Disruptive
Disruptive can implement more scrapers for better data in terms of insight generation. This would involve scraping from other options than Golden once there is more funding. Furthermore, integration between frontend and blockchain can be improved further. Lastly, we could generate better insights into the format of proposals for clients. | ## Inspiration
We constantly have friends asking us for advice for investing, or ask for investing advice ourselves. We realized how easy a platform that allowed people to make collaboratively make investments would make sharing information between people. We formed this project out of inspiration to solve a problem in our own lives.
The word 'Omada' means group in Greek, and we thought it sounded official and got our message across.
## What it does
Our platform allows you to form groups with other people, put your money in a pool, and decide which stocks the group should buy. We use a unanimous voting system to make sure that everyone who has money involved agrees to the investments being made.
We also allow for searching up stocks and their graphs, as well as individual portfolio analysis.
The way that the buying and selling of stocks actually works is as follows: let's say a group has two members, A and B. If A has $75 on the app, and person B has $25 on the app, and they agree to buy a stock costing $100. When they sell the stock, person A gets 75% of the revenue from selling the stock and person B gets 25%.
Person A: $75
Person B: $25
Buy stock for $100
Stock increases to $200
Sell Stock
Person A: $150
Person B: $200
We use a proposal system in order to buy stocks. One person finds a stock that they want to buy with the group, and makes a proposal for the type of order, the amount, and the price they want to buy the stock at. The proposal then goes up for a vote. If everyone agrees to purchasing the stock, then the order is sent to the market. The same process occurs for selling a stock.
## How we built it
We built the webapp using Flask, specifically to handle routing and so that we could use python for the backend. We used BlackRock for the charts, and NASDAQ for live updates of charts. Additionally, we used mLab with MongoDB and Azure for our databases, and Azure for cloud hosting. Our frontend is JavaScript, HTML, and CSS.
## Challenges we ran into
We had a hard time initially with routing the app using Flask, as this was our first time using it. Additionally, Blackrock has an insane amount of data, so getting that organized and figuring out what we wanted to do with that and processing it was challenging, but also really fun.
## Accomplishments that we're proud of
I'm proud that we got the service working as much as we did! We decided to take on a huge project, which could realistically take months of time to make if this was a workplace, but we got a lot of features implemented and plan on continuing to work on the project as time moves forward. None of us had ever used Flask, MongoDB, Azure, BlackRock, or Nasdaq before this, so it was really cool getting everything together and working the way it does.
## What's next for Omada
We hope to polish everything off, add features we didn't have time to implement, and start using it for ourselves! If we are able to make it work, maybe even publishing it! | ## 💭 Inspiration
Throughout our Zoom university journey, our team noticed that we often forget to unmute our mics when we talk, or forget to mute it when we don't want others to listen in. To combat this problem, we created speakCV, a desktop client that automatically mutes and unmutes your mic for you using computer vision to understand when you are talking.
## 💻 What it does
speakCV automatically unmutes a user when they are about to speak and mutes them when they have not spoken for a while. The user does not have to interact with the mute/unmute button, creating a more natural and fluid experience.
## 🔧 How we built it
The application was written in Python: scipy and dlib for the machine learning, pyvirtualcam to access live Zoom video, and Tkinter for the GUI. OBS was used to provide the program access to a live Zoom call through virtual video, and the webpage for the application was built using Bootstrap.
## ⚙️ Challenges we ran into
A large challenge we ran into was fine tuning the mouth aspect ratio threshold for the model, which determined the model's sensitivity for mouth shape recognition. A low aspect ratio made the application unable to detect when a person started speaking, while a high aspect ratio caused the application to become too sensitive to small movements. We were able to find an acceptable value through trial and error.
Another problem we encountered was lag, as the application was unable to handle both the Tkinter event loop and the mouth shape analysis at the same time. We were able to remove the lag by isolating each process into separate threads.
## ⭐️ Accomplishments that we're proud of
We were proud to solve a problem involving a technology we use frequently in our daily lives. Coming up with a problem and finding a way to solve it was rewarding as well, especially integrating the different machine learning models, virtual video, and application together.
## 🧠 What we learned
* How to setup and use virtual environments in Anaconda to ensure the program can run locally without issues.
* Working with virtual video/audio to access the streams from our own program.
* GUI creation for Python applications with Tkinter.
## ❤️ What's next for speakCV.
* Improve the precision of the shape recognition model, by further adjusting the mouth aspect ratio or by tweaking the contour spots used in the algorithm for determining a user's mouth shape.
* Moving the application to the Zoom app marketplace by making the application with the Zoom SDK, which requires migrating the application to C++.
* Another option is to use the Zoom API and move the application onto the web. | partial |
## Inspiration
As citizens of the world, we all like to travel. However, the planning process can be a real pain, from coordinating with friends, to finding accommodations and flights, to splitting costs afterwards. Travel.io is an innovative web app that allows users to collaborate with their travel mates to make the planning process as smooth-sailing as possible.
## What it does
travel.io empowers users to focus on their travel ambitions and enjoying the company of their friends without having to worry about the monotonous aspects of trip planning. The web app aggregates flight and accommodation details for the user's destination of choice. The users are able to plan out events that fit every individual's schedule, and track their spending on the trip. Additionally, users are able to see a breakdown of who owes whom how much.
## How we built it
With great difficulty!
## Challenges we ran into
Real-time communications presented a challenge in their limited compatibility with their Google Cloud Platform.
## Accomplishments that we're proud of
We created a fully featured application in a limited amount of time. Although none of us are experienced at front-end, we still managed to create a web-app that is full of user interactivity.
## What we learned
We learnt about web sockets and the struggles that come with secured networking. We also learnt about sending HTTP requests, and became more familiar with source version control.
## What's next for travel.io
Creating a user authentication system that would allow for individuals to engage in multiple trip workspaces with different friend groups. | ## Inspiration
Inspired by a desire to be able to meet new people while travelling
## What it does
This web application takes users who are travelling aat similar times to similar places and allows them to connect to travel as a group
## How we built it
This web application is built using MEAN stack development (MongoDB, Express, AngularJS, NodeJS). | ## Inspiration
As college students who are on a budget when traveling from school to the airport, or from campus to a different city, we found it difficult to coordinate rides with other students. The facebook or groupme groupchats are always flooding with students scrambling to find people to carpool with at the last minute to save money.
## What it does
Ride Along finds and pre-schedules passengers who are headed between the same start and final location as each driver.
## How we built it
Built using Bubble.io framework. Utilized Google Maps API
## Challenges we ran into
Certain annoyances when using Bubble and figuring out how to use it. Had style issues with alignment, and certain functionalities were confusing at first and required debugging.
## Accomplishments that we're proud of
Using the Bubble framework properly and their built in backend data feature. Getting buttons and priority features implemented well, and having a decent MVP to present.
## What we learned
There are a lot of challenges when integrating multiple features together. Getting a proper workflow is tricky and takes lots of debugging and time.
## What's next for Ride Along
We want to get a Google Maps API key to properly be able to deploy the web app and be able to functionally use it. There are other features we wanted to implement, such as creating messages between users, etc. | losing |
## 💡 INSPIRATION 💡
Today, Ukraine is on the front lines of a renewed conflict with Russia. Russia's recent full-scale invasion of Ukraine has created more than 4.3 million refugees and displaced another 6.5 million citizens in the past 6 weeks according to the United Nations. Humanitarian aid organizations make trips into war-torn parts of Ukraine daily, but citizens are often unaware of their locations. Moreover, those fleeing the country into surrounding European countries don't know where they can stay. By connecting refugees with those willing to offer support and providing location data for humanitarian aid, YOUkraine hopes to support those unjustly suffering in Ukraine.
## ⚙️ WHAT IT DOES ⚙️
Connects refugees and support/humanitarian aid groups in Ukraine.
You can sign up on the app and declare yourself as either a refugee or supporter and connect with each other directly. Refugees will get tailored recommendations for places to stay, which are offered by supporters, based on family size and the desired country. Refugees will also be able to access a map to view the locations of humanitarian relief organizations such as UN Refugee Agency, Red Cross, Doctors Without Borders, Central Kitchen and many more.
## 🛠️ HOW WE BUILT IT🛠️
Tech Stack: MERN (Mongodb, Express.js, React.js, Node.js)
We used React (JS), Framer-motion, Axios, Bcrypt, uuid, and react-tinder to create a visually pleasing and accessible way for users to communicate.
For live chat and to store user data, we took advantage of MongoDB, express.js, and node.js because of its ease of access to set up and access data.
For the recommendation feature, we used Pandas, Numpy and Seaborn to preprocess our data. We trained our tf-idf model using Sklearn on 3000 different users.
## 😣 CHALLENGES WE RAN INTO 😣
* **3 person team** that started **late**, doesn't get the early worm :(
* It was the **first time** anyone on the team has worked with **MERN stack** (took a lil'figuring out, but it works!)
* Had to come up with our own dataset to train with and needed to remake the dataset and retrain the model multiple times
* **NO UI/UX DESIGNER** (don't take them for granted, they're GOD SENDS)
* We don't have much experience using cookies and we ran into a lot of challenges, but we stuck it out and made it work (WOOT WOOT!)
## 🎉 ACCOMPLISHMENTS WE ARE PROUD OF 🎉
* WE GOT IT DONE!! 30 hours of blood, sweat, and tears later, we have our functioning app :D
* We can now proudly say we're full stack developers because we made and implemented everything ourselves, top to bottom :)
* Designing the app from scratch (no figma/ uiux designer💀)
* USER AUTHENTICATION WORKS!! ( つ•̀ω•́)つ
* Using so many tools, languages and frameworks at once, and making them work together :D
* Submitting on time (I hope? 😬)
## ⏭️WHAT'S NEXT FOR YOUkraine⏭️
YOUkraine has a lot to do before it can be deployed as a genuine app.
* Add security features and encryption to ensure the app isn't misused
* Implement air raid warnings and 'danger sightings' so that users can stay informed and avoid conflict zones.
* Partner with NGO's/humanitarian relief organizations so we can update our map live and provide more insights concerning relief efforts.
* Enhance our recommendation feature (add more search terms)
* Possibly add a donation feature to support Ukraine
## 🎁 ABOUT THE TEAM🎁
Eric is a 3rd year computer science student. With experience in designing for social media apps and websites, he is interested in expanding his repertoire in designing for emerging technologies. You can connect with him at his [Portfolio](https://github.com/pidgeonforlife)
Alan is a 2nd year computer science student at the University of Calgary, currently interning at SimplySafe. He's has a wide variety of technical skills in frontend and backend development! Moreover, he has a strong passion for both data science and app development. You can reach out to him at his [LinkedIn](https://www.linkedin.com/in/alanayy/) or view his [Portfolio](https://github.com/AlanAyy)
Matthew is a 2nd year computer science student at Simon Fraser University, currently looking for a summer 2022 internship. He has formal training in data science. He's interested in learning new and honing his current frontend skills/technologies. Moreover, he has a deep understanding of machine learning, AI and neural networks. He's always willing to have a chat about games, school, data science and more! You can reach out to him at his [LinkedIn](https://www.linkedin.com/in/matthew-wong-240837124/) or view his [Portfolio](https://github.com/WongMatthew)
### 🥳🎉 THANK YOU YALE FOR HOSTING YHACKS🥳🎉 | ## Inspiration
We were interested in disaster relief for those impacted by Hurricances like Dorian and Maria for people that don't know what areas are affected and for first responders that don't know what infrastructure works are damaged and can't deliver appropriate resources in time.
## What it does
This website shows the location of the nearest natural disasters.
## How we built it
We used Amazon API and Google Cloud and Maps API and Python and Java Script.
## Challenges we ran into
We have not been to a hackathon before so we weren't sure about how in-depth or general our problem should be. We started with an app that first responders can use during a natural disasters to input vitals
## Accomplishments that we're proud of
A website that can map the GPS locations of flood data that we are confident in and a uniquely trained model for urban flooding.
## What we learned
We learned about Google Cloud APIs, AWS S3 Visual Recognition Software and about how to operate in a hackathon.
## What's next for Crisis Apps | ## Inspiration
The most important part in any quality conversation is knowledge. Knowledge is what ignites conversation and drive - knowledge is the spark that gets people on their feet to take the first step to change. While we live in a time where we are spoiled by the abundance of accessible information, trying to keep up and consume information from a multitude of sources can give you information indigestion: it can be confusing to extract the most relevant points of a new story.
## What it does
Macaron is a service that allows you to keep track of all the relevant events that happen in the world without combing through a long news feed. When a major event happens in the world, news outlets write articles. Articles are aggregated from multiple sources and uses NLP to condense the information, classify the summary into a topic, extracts some keywords, then presents it to the user in a digestible, bite-sized info page.
## How we built it
Macaron also goes through various social media platforms (twitter at the moment) to perform sentiment analysis to see what the public opinion is on the issue: displayed by the sentiment bar on every event card! We used a lot of Google Cloud Platform to help publish our app.
## What we learned
Macaron also finds the most relevant charities for an event (if applicable) and makes donating to it a super simple process. We think that by adding an easy call-to-action button on an article informing you about an event itself, we'll lower the barrier to everyday charity for the busy modern person.
Our front end was built on NextJS, with a neumorphism inspired design incorporating usable and contemporary UI/UX design.
We used the Tweepy library to scrape twitter for tweets relating to an event, then used NLTK's vader to perform sentiment analysis on each tweet to build a ratio of positive to negative tweets surrounding an event.
We also used MonkeyLearn's API to summarize text, extract keywords and classify the aggregated articles into a topic (Health, Society, Sports etc..) The scripts were all written in python.
The process was super challenging as the scope of our project was way bigger than we anticipated! Between getting rate limited by twitter and the script not running fast enough, we did hit a lot of roadbumps and had to make quick decisions to cut out the elements of the project we didn't or couldn't implement in time.
Overall, however, the experience was really rewarding and we had a lot of fun moving fast and breaking stuff in our 24 hours! | partial |
## Inspiration
Greenhouses require increased disease control and need to closely monitor their plants to ensure they're healthy. In particular, the project aims to capitalize on the recent cannabis interest.
## What it Does
It's a sensor system composed of cameras, temperature and humidity sensors layered with smart analytics that allows the user to tell when plants in his/her greenhouse are diseased.
## How We built it
We used the Telus IoT Dev Kit to build the sensor platform along with Twillio to send emergency texts (pending installation of the IoT edge runtime as of 8 am today).
Then we used azure to do transfer learning on vggnet to identify diseased plants and identify them to the user. The model is deployed to be used with IoT edge. Moreover, there is a web app that can be used to show that the
## Challenges We Ran Into
The data-sets for greenhouse plants are in fairly short supply so we had to use an existing network to help with saliency detection. Moreover, the low light conditions in the dataset were in direct contrast (pun intended) to the PlantVillage dataset used to train for diseased plants. As a result, we had to implement a few image preprocessing methods, including something that's been used for plant health detection in the past: eulerian magnification.
## Accomplishments that We're Proud of
Training a pytorch model at a hackathon and sending sensor data from the STM Nucleo board to Azure IoT Hub and Twilio SMS.
## What We Learned
When your model doesn't do what you want it to, hyperparameter tuning shouldn't always be the go to option. There might be (in this case, was) some intrinsic aspect of the model that needed to be looked over.
## What's next for Intelligent Agriculture Analytics with IoT Edge | ## Realm Inspiration
Our inspiration stemmed from our fascination in the growing fields of AR and virtual worlds, from full-body tracking to 3D-visualization. We were interested in realizing ideas in this space, specifically with sensor detecting movements and seamlessly integrating 3D gestures. We felt that the prime way we could display our interest in this technology and the potential was to communicate using it. This is what led us to create Realm, a technology that allows users to create dynamic, collaborative, presentations with voice commands, image searches and complete body-tracking for the most customizable and interactive presentations. We envision an increased ease in dynamic presentations and limitless collaborative work spaces with improvements to technology like Realm.
## Realm Tech Stack
Web View (AWS SageMaker, S3, Lex, DynamoDB and ReactJS): Realm's stack relies heavily on its reliance on AWS. We begin by receiving images from the frontend and passing it into SageMaker where the images are tagged corresponding to their content. These tags, and the images themselves, are put into an S3 bucket. Amazon Lex is used for dialog flow, where text is parsed and tools, animations or simple images are chosen. The Amazon Lex commands are completed by parsing through the S3 Bucket, selecting the desired image, and storing the image URL with all other on-screen images on to DynamoDB. The list of URLs are posted on an endpoint that Swift calls to render.
AR View ( AR-kit, Swift ): The Realm app renders text, images, slides and SCN animations in pixel perfect AR models that are interactive and are interactive with a physics engine. Some of the models we have included in our demo, are presentation functionality and rain interacting with an umbrella. Swift 3 allows full body tracking and we configure the tools to provide optimal tracking and placement gestures. Users can move objects in their hands, place objects and interact with 3D items to enhance the presentation.
## Applications of Realm:
In the future we hope to see our idea implemented in real workplaces in the future. We see classrooms using Realm to provide students interactive spaces to learn, professional employees a way to create interactive presentations, teams to come together and collaborate as easy as possible and so much more. Extensions include creating more animated/interactive AR features and real-time collaboration methods. We hope to further polish our features for usage in industries such as AR/VR gaming & marketing. | # Harvest Hero: Cultivating Innovation
## Inspiration
Our journey began with a shared passion for addressing pressing challenges in agriculture. Witnessing the struggles faced by farmers globally due to unpredictable weather, soil degradation, and crop diseases, we were inspired to create a solution that could empower farmers and revolutionize traditional farming practices.
## Staggering Statistics
In the initial research phase, we delved into staggering statistics. According to the Food and Agriculture Organization (FAO), around 20-40% of global crop yields are lost annually due to pests and diseases. Additionally, improper crop conditions contribute significantly to reduced agricultural productivity.
Learning about these challenges fueled our determination to develop a comprehensive solution that integrates soil analysis, environmental monitoring, and disease detection using cutting-edge technologies.
## Building HarvestHero
### 1. **Soil and Environmental Analysis**
We incorporated state-of-the-art sensors and IoT devices to measure soil moisture and environmental conditions such as light, temperature, and humidity accurately. Online agricultural databases provided insights into optimal conditions for various crops.
### 2. **Deep Learning for Disease Classification**
To tackle the complex issue of plant diseases, we leveraged deep learning algorithms. TensorFlow and PyTorch became our allies as we trained our model on extensive datasets of diseased and healthy crops, sourced from global agricultural research institutions.
### 3. **User-Friendly Interface**
Understanding that farmers may not be tech-savvy, we focused on creating an intuitive user interface. Feedback from potential users during the development phase was invaluable in refining the design for practicality and accessibility.
### Challenges Faced
1. **Data Quality and Diversity**: Acquiring diverse and high-quality datasets for training the deep learning model posed a significant challenge. Cleaning and preprocessing the data demanded meticulous attention.
2. **Real-Time Connectivity**: Ensuring real-time connectivity in remote agricultural areas was challenging. We had to optimize our system to function efficiently even in low-bandwidth environments.
3. **Algorithm Fine-Tuning**: Achieving a balance between sensitivity and specificity in disease detection was an ongoing process. Iterative testing and refining were essential to enhance the model's accuracy.
## Impact
HarvestHero aims to mitigate crop losses, boost yields, and contribute to sustainable agriculture. By addressing key pain points in farming, we aspire to make a meaningful impact on global food security. Our journey has not only been about developing a product but also about learning, adapting, and collaborating to create positive change in the agricultural landscape.
As we look to the future, we are excited about the potential of HarvestHero to empower farmers, enhance agricultural practices, and play a role in creating a more resilient and sustainable food system for generations to come. | winning |
## Inspiration
Our solution was named on remembrance of Mother Teresa
## What it does
Robotic technology to assist nurses and doctors in medicine delivery, patient handling across the hospital, including ICU’s. We are planning to build an app in Low code/No code that will help the covid patients to scan themselves as the mobile app is integrated with the CT Scanner for doctors to save their time and to prevent human error . Here we have trained with CT scans of Covid and developed a CNN model and integrated it into our application to help the covid patients. The data sets are been collected from the kaggle and tested with an efficient algorithm with the efficiency of around 80% and the doctors can maintain the patient’s record. The beneficiary of the app is PATIENTS.
## How we built it
Bots are potentially referred to as the most promising and advanced form of human-machine interactions. The designed bot can be handled with an app manually through go and cloud technology with e predefined databases of actions and further moves are manually controlled trough the mobile application. Simultaneously, to reduce he workload of doctor, a customized feature is included to process the x-ray image through the app based on Convolution neural networks part of image processing system. CNN are deep learning algorithms that are very powerful for the analysis of images which gives a quick and accurate classification of disease based on the information gained from the digital x-ray images .So to reduce the workload of doctors these features are included. To know get better efficiency on the detection I have used open source kaggle data set.
## Challenges we ran into
The data source for the initial stage can be collected from the kaggle and but during the real time implementation the working model and the mobile application using flutter need datasets that can be collected from the nearby hospitality which was the challenge.
## Accomplishments that we're proud of
* Counselling and Entertainment
* Diagnosing therapy using pose detection
* Regular checkup of vital parameters
* SOS to doctors with live telecast
-Supply off medicines and foods
## What we learned
* CNN
* Machine Learning
* Mobile Application
* Cloud Technology
* Computer Vision
* Pi Cam Interaction
* Flutter for Mobile application
## Implementation
* The bot is designed to have the supply carrier at the top and the motor driver connected with 4 wheels at the bottom.
* The battery will be placed in the middle and a display is placed in the front, which will be used for selecting the options and displaying the therapy exercise.
* The image aside is a miniature prototype with some features
* The bot will be integrated with path planning and this is done with the help mission planner, where we will be configuring the controller and selecting the location as a node
* If an obstacle is present in the path, it will be detected with lidar placed at the top.
* In some scenarios, if need to buy some medicines, the bot is attached with the audio receiver and speaker, so that once the bot reached a certain spot with the mission planning, it says the medicines and it can be placed at the carrier.
* The bot will have a carrier at the top, where the items will be placed.
* This carrier will also have a sub-section.
* So If the bot is carrying food for the patients in the ward, Once it reaches a certain patient, the LED in the section containing the food for particular will be blinked. | ## Inspiration
Rates of patient nonadherence to therapies average around 50%, particularly among those with chronic diseases. One of my closest friends has Crohn's disease, and I wanted to create something that would help with the challenges of managing a chronic illness. I built this app to provide an on-demand, supportive system for patients to manage their symptoms and find a sense of community.
## What it does
The app allows users to have on-demand check-ins with a chatbot. The chatbot provides fast inference, classifies actions and information related to the patient's condition, and flags when the patient’s health metrics fall below certain thresholds. The app also offers a community aspect, enabling users to connect with others who have chronic illnesses, helping to reduce the feelings of isolation.
## How we built it
We used Cerebras for the chatbot to ensure fast and efficient inference. The chatbot is integrated into the app for real-time check-ins. Roboflow was used for image processing and emotion detection, which aids in assessing patient well-being through facial recognition. We also used Next.js as the framework for building the app, with additional integrations for real-time community features.
## Challenges we ran into
One of the main challenges was ensuring the chatbot could provide real-time, accurate classifications and flagging low patient metrics in a timely manner. Managing the emotional detection accuracy using Roboflow's emotion model was also complex. Additionally, creating a supportive community environment without overwhelming the user with too much data posed a UX challenge.
## Accomplishments that we're proud of
✅deployed on defang
✅integrated roboflow
✅integrated cerebras
We’re proud of the fast inference times with the chatbot, ensuring that users get near-instant responses. We also managed to integrate an emotion detection feature that accurately tracks patient well-being. Finally, we’ve built a community aspect that feels genuine and supportive, which was crucial to the app's success.
## What we learned
We learned a lot about balancing fast inference with accuracy, especially when dealing with healthcare data and emotionally sensitive situations. The importance of providing users with a supportive, not overwhelming, environment was also a major takeaway.
## What's next for Muni
Next, we aim to improve the accuracy of the metrics classification, expand the community features to include more resources, and integrate personalized treatment plans with healthcare providers. We also want to enhance the emotion detection model for more nuanced assessments of patients' well-being. | ## Inspiration
We love the playing the game and were disappointed in the way that there wasnt a nice web implementation of the game that we could play with each other remotely. So we fixed that.
## What it does
Allows between 5 and 10 players to play Avalon over the web app.
## How we built it
We made extensive use of Meteor and forked a popular game called [Spyfall](https://github.com/evanbrumley/spyfall) to build it out. This game had a very basic subset of rules that were applicable to Avalon. Because of this we added a lot of the functionality we needed on top of Spyfall to make the Avalon game mechanics work.
## Challenges we ran into
Building realtime systems is hard. Moreover, using a framework like Meteor that makes a lot of things easy by black boxing them is also difficult by the same token. So a lot of the time we struggled with making things work that happened to not be able to work within the context of the framework we were using. We also ended up starting the project over again multiple times since we realized that we were going down a path in which it was impossible to build that application.
## Accomplishments that we're proud of
It works. Its crisp. Its clean. Its responsive. Its synchronized across clients.
## What we learned
Meteor is magic. We learned how to use a lot of the more magical client synchronization features to deal with race conditions and the difficulties of making a realtime application.
## What's next for Avalon
Fill out the different roles, add a chat client, integrate with a video chat feature. | winning |
## Inspiration
Due to a lot of work and family problems, People often forget to take care of their health and food. Common health problems people know a day's faces are BP, heart problems, and Diabetics. Most people face mental health problems, due to studies, jobs, or any other problems. This Project can help people find out their health problems.
It helps people in easy recycling of items, as they are divided into 12 different classes.
It will help people who do not have any knowledge of plants and predict if the plant is having any diseases or not.
## What it does
On the Garbage page, When we upload an image it classifies which kind of garbage it is. It helps people with easy recycling.
On the mental health page, When we answer some of the questions. It will predict If we are facing some kind of mental health issue.
The Health Page is divided into three parts. One page predicts if you are having heart disease or not. The second page predicts if you are having Diabetics or not. The third page predicts if you are having BP or not.
Covid 19 page classify if you are having covid or not
Plant\_Disease page predicts if a plant is having a disease or not.
## How we built it
I built it using streamlit and OpenCV.
## Challenges we ran into
Deploying the website to Heroku was very difficult because I generally deploy it. Most of this was new to us except for deep learning and ML so it was very difficult overall due to the time restraint. The overall logic and finding out how we should calculate everything was difficult to determine within the time limit. Overall, time was the biggest constraint.
## Accomplishments that we're proud of
## What we learned
Tensorflow, Streamlit, Python, HTML5, CSS3, Opencv, Machine learning, Deep learning, and using different python packages.
## What's next for Arogya | ## Inspiration
Unhealthy diet is the leading cause of death in the U.S., contributing to approximately 678,000 deaths each year, due to nutrition and obesity-related diseases, such as heart disease, cancer, and type 2 diabetes. Let that sink in; the leading cause of death in the U.S. could be completely nullified if only more people cared to monitor their daily nutrition and made better decisions as a result. But **who** has the time to meticulously track every thing they eat down to the individual almond, figure out how much sugar, dietary fiber, and cholesterol is really in their meals, and of course, keep track of their macros! In addition, how would somebody with accessibility problems, say blindness for example, even go about using an existing app to track their intake? Wouldn't it be amazing to be able to get the full nutritional breakdown of a meal consisting of a cup of grapes, 12 almonds, 5 peanuts, 46 grams of white rice, 250 mL of milk, a glass of red wine, and a big mac, all in a matter of **seconds**, and furthermore, if that really is your lunch for the day, be able to log it and view rich visualizations of what you're eating compared to your custom nutrition goals?? We set out to find the answer by developing macroS.
## What it does
macroS integrates seamlessly with the Google Assistant on your smartphone and let's you query for a full nutritional breakdown of any combination of foods that you can think of. Making a query is **so easy**, you can literally do it while *closing your eyes*. Users can also make a macroS account to log the meals they're eating everyday conveniently and without hassle with the powerful built-in natural language processing model. They can view their account on a browser to set nutrition goals and view rich visualizations of their nutrition habits to help them outline the steps they need to take to improve.
## How we built it
DialogFlow and the Google Action Console were used to build a realistic voice assistant that responds to user queries for nutritional data and food logging. We trained a natural language processing model to identify the difference between a call to log a food eaten entry and simply a request for a nutritional breakdown. We deployed our functions written in node.js to the Firebase Cloud, from where they process user input to the Google Assistant when the test app is started. When a request for nutritional information is made, the cloud function makes an external API call to nutrionix that provides nlp for querying from a database of over 900k grocery and restaurant foods. A mongo database is to be used to store user accounts and pass data from the cloud function API calls to the frontend of the web application, developed using HTML/CSS/Javascript.
## Challenges we ran into
Learning how to use the different APIs and the Google Action Console to create intents, contexts, and fulfillment was challenging on it's own, but the challenges amplified when we introduced the ambitious goal of training the voice agent to differentiate between a request to log a meal and a simple request for nutritional information. In addition, actually finding the data we needed to make the queries to nutrionix were often nested deep within various JSON objects that were being thrown all over the place between the voice assistant and cloud functions. The team was finally able to find what they were looking for after spending a lot of time in the firebase logs.In addition, the entire team lacked any experience using Natural Language Processing and voice enabled technologies, and 3 out of the 4 members had never even used an API before, so there was certainly a steep learning curve in getting comfortable with it all.
## Accomplishments that we're proud of
We are proud to tackle such a prominent issue with a very practical and convenient solution that really nobody would have any excuse not to use; by making something so important, self-monitoring of your health and nutrition, much more convenient and even more accessible, we're confident that we can help large amounts of people finally start making sense of what they're consuming on a daily basis. We're literally able to get full nutritional breakdowns of combinations of foods in a matter of **seconds**, that would otherwise take upwards of 30 minutes of tedious google searching and calculating. In addition, we're confident that this has never been done before to this extent with voice enabled technology. Finally, we're incredibly proud of ourselves for learning so much and for actually delivering on a product in the short amount of time that we had with the levels of experience we came into this hackathon with.
## What we learned
We made and deployed the cloud functions that integrated with our Google Action Console and trained the nlp model to differentiate between a food log and nutritional data request. In addition, we learned how to use DialogFlow to develop really nice conversations and gained a much greater appreciation to the power of voice enabled technologies. Team members who were interested in honing their front end skills also got the opportunity to do that by working on the actual web application. This was also most team members first hackathon ever, and nobody had ever used any of the APIs or tools that we used in this project but we were able to figure out how everything works by staying focused and dedicated to our work, which makes us really proud. We're all coming out of this hackathon with a lot more confidence in our own abilities.
## What's next for macroS
We want to finish building out the user database and integrating the voice application with the actual frontend. The technology is really scalable and once a database is complete, it can be made so valuable to really anybody who would like to monitor their health and nutrition more closely. Being able to, as a user, identify my own age, gender, weight, height, and possible dietary diseases could help us as macroS give users suggestions on what their goals should be, and in addition, we could build custom queries for certain profiles of individuals; for example, if a diabetic person asks macroS if they can eat a chocolate bar for lunch, macroS would tell them no because they should be monitoring their sugar levels more closely. There's really no end to where we can go with this! | ## Inspiration
Amidst the hectic lives and pandemic struck world, mental health has taken a back seat. This thought gave birth to our inspiration of this web based app that would provide activities customised to a person’s mood that will help relax and rejuvenate.
## What it does
We planned to create a platform that could detect a users mood through facial recognition, recommends yoga poses to enlighten the mood and evaluates their correctness, helps user jot their thoughts in self care journal.
## How we built it
Frontend: HTML5, CSS(frameworks used:Tailwind,CSS),Javascript
Backend: Python,Javascript
Server side> Nodejs, Passport js
Database> MongoDB( for user login), MySQL(for mood based music recommendations)
## Challenges we ran into
Incooperating the open CV in our project was a challenge, but it was very rewarding once it all worked .
But since all of us being first time hacker and due to time constraints we couldn't deploy our website externally.
## Accomplishments that we're proud of
Mental health issues are the least addressed diseases even though medically they rank in top 5 chronic health conditions.
We at umang are proud to have taken notice of such an issue and help people realise their moods and cope up with stresses encountered in their daily lives. Through are app we hope to give people are better perspective as well as push them towards a more sound mind and body
We are really proud that we could create a website that could help break the stigma associated with mental health. It was an achievement that in this website includes so many features to help improving the user's mental health like making the user vibe to music curated just for their mood, engaging the user into physical activity like yoga to relax their mind and soul and helping them evaluate their yoga posture just by sitting at home with an AI instructor.
Furthermore, completing this within 24 hours was an achievement in itself since it was our first hackathon which was very fun and challenging.
## What we learned
We have learnt on how to implement open CV in projects. Another skill set we gained was on how to use Css Tailwind. Besides, we learned a lot about backend and databases and how to create shareable links and how to create to do lists.
## What's next for Umang
While the core functionality of our app is complete, it can of course be further improved .
1)We would like to add a chatbot which can be the user's guide/best friend and give advice to the user when in condition of mental distress.
2)We would also like to add a mood log which can keep a track of the user's daily mood and if a serious degradation of mental health is seen it can directly connect the user to medical helpers, therapist for proper treatement.
This lays grounds for further expansion of our website. Our spirits are up and the sky is our limit | winning |
## Inspiration
Have you ever wondered what's actually in your shampoo or body wash? Have you ever been concerned about the toxicity of certain chemicals in them on your body and to the environment?
If you answered yes, you came to the right place. Welcome to the wonderful world of Goodgredients! 😀
Goodgredients provides a simple way to answer these questions. But how you may ask.
## What it does
Goodgredients provides a simple way to check the toxicity of certain chemicals in them on your body and to the environment. Simply take a picture of your Shampoo or body wash and check which ingredient might harmful to you.
## How I built it
The project built with React Native, Node JS, Express js, and Einstein API. The backend API has been deployed with Heroku.
The core of this application is Salesforce Einstein Vision. In particular, we are using Einstein OCR (Optical Character Recognition), which uses deep learning models to detect alphanumeric text in an image. You can find out more info about Einstein Vision here.
Essentially, we've created a backend api service that takes an image request from a client, uses the Einstein OCR model to extract text from the image, compares it to our dataset of chemical details (ex. toxicity, allergy, etc.), and sends a response containing the comparison results back to the client.
## Challenges I ran into
As first-time ReactNative developers, we have encountered a lot of environment set up issue, however, we could figure out within time!
## Accomplishments that I'm proud of
We had no experience with ReactNative but finished project with fully functional within 24hours.
## What I learned
## What's next for Goodgredients | ## Inspiration
It all started a couple days ago when my brother told me he'd need over an hour to pick up a few items from a grocery store because of the weekend checkout line. This led to us reaching out to other friends of ours and asking them about the biggest pitfalls of existing shopping systems. We got a whole variety of answers, but the overwhelming response was the time it takes to shop and more particularly checkout. This inspired us to ideate and come up with an innovative solution.
## What it does
Our app uses computer vision to add items to a customer's bill as they place items in the cart. Similarly, removing an item from the cart automatically subtracts them from the bill. After a customer has completed shopping, they can checkout on the app with the tap of a button, and walk out the store. It's that simple!
## How we built it
We used react with ionic for the frontend, and node.js for the backend. Our main priority was the completion of the computer vision model that detects items being added and removed from the cart. The model we used is a custom YOLO-v3Tiny model implemented in Tensorflow. We chose Tensorflow so that we could run the model using TensorflowJS on mobile.
## Challenges we ran into
The development phase had it's fair share of challenges. Some of these were:
* Deep learning models can never have too much data! Scraping enough images to get accurate predictions was a challenge.
* Adding our custom classes to the pre-trained YOLO-v3Tiny model.
* Coming up with solutions to security concerns.
* Last but not least, simulating shopping while quarantining at home.
## Accomplishments that we're proud of
We're extremely proud of completing a model that can detect objects in real time, as well as our rapid pace of frontend and backend development.
## What we learned
We learned and got hands on experience of Transfer Learning. This was always a concept that we knew in theory but had never implemented before. We also learned how to host tensorflow deep learning models on cloud, as well as make requests to them. Using google maps API with ionic react was a fun learning experience too!
## What's next for MoboShop
* Integrate with customer shopping lists.
* Display ingredients for recipes added by customer.
* Integration with existing security systems.
* Provide analytics and shopping trends to retailers, including insights based on previous orders, customer shopping trends among other statistics. | ## Inspiration
The idea for IngredientAI came from my personal frustration with navigating complex and often misleading ingredient labels on beauty and personal care products. I realized that many consumers struggle to understand what these ingredients actually do and whether they are safe. The lack of accessible information often leaves people in the dark about what they are using daily. I wanted to create a tool that brings transparency to this process, empowering users to make healthier and more informed choices about the products they use.
## What it does
The idea for IngredientAI was born out of the frustration of navigating complex and often misleading ingredient labels on beauty and personal care products. I realized that many consumers struggle to understand what these ingredients actually do and whether they are safe. The lack of accessible information often leaves people in the dark about what they are using daily. I wanted to create a tool that brings transparency to this process, empowering users to make healthier and more informed choices about the products they use.
## How I built It
The frontend is built using React Native and ran using Expo. Users interact with a FlatList component that accesses a backend database powered by Convex. Text extracted from images as well as generates ingredient descriptions is all done through OpenAI's gpt-4o-mini large-language model.
## Challenges I ran into
A big challenge that I come across was figuring out how to extract text from images. Originally, I planned on setting up a server-side script that makes use of Tesseract.js's OCR capabilities. However, after some testing, I realized that I did not have enough time to fine tune Tesseract so that it extracts text from images under a variety of different lighting. For IngredientAI to be used by consumers, it must be able to work under a wide variety of circumstances. To solve this issue, I decided it would be best for me to use OpenAI's new Vision capabilities. I did not go with this originally because I wanted to minimize the amount of OpenAI API calls I made. However, under time constraints, this was the best option.
## Accomplishments that I'm proud of
I am extremely proud of how far my App Development has come. At a previous hackathon in March, I had used React Native for the very first time. At that hackathon, I was completely clueless with the technology. A lot of my code was copy/pasted from ChatGPT and I did not have a proper understanding of how it worked. Now, this weekend, I was able to create a fully functional mobile application that has organized (enough) code that allows me to expand on this project in the future.
## What I learned
Every hackathon, my goal is to learn at least one new technology. This weekend, I decided to use Convex for the very first time. I really appreciated the amount of resources that Convex provides for learning their technology. It was especially convenient that they had a dedicated page for hackathon projects. It made setting up my database extremely fast and convenient, and as we know, speed is key in a hackathon.
## What's next for IngredientAI
My aim is to eventually bring IngredientAI to app stores. This is an app I would personally find use for, and I would like to share that with others. Future improvements and features include:
* Categorization and visualization of ingredient data
* Suggested products section
* One-button multi-store checkout
I hope you all get the chance to try out IngredientAI in the near future! | partial |
## Inspiration
Given the increase in mental health awareness, we wanted to focus on therapy treatment tools in order to enhance the effectiveness of therapy. Therapists rely on hand-written notes and personal memory to progress emotionally with their clients, and there is no assistive digital tool for therapists to keep track of clients’ sentiment throughout a session. Therefore, we want to equip therapists with the ability to better analyze raw data, and track patient progress over time.
## Our Team
* Vanessa Seto, Systems Design Engineering at the University of Waterloo
* Daniel Wang, CS at the University of Toronto
* Quinnan Gill, Computer Engineering at the University of Pittsburgh
* Sanchit Batra, CS at the University of Buffalo
## What it does
Inkblot is a digital tool to give therapists a second opinion, by performing sentimental analysis on a patient throughout a therapy session. It keeps track of client progress as they attend more therapy sessions, and gives therapists useful data points that aren't usually captured in typical hand-written notes.
Some key features include the ability to scrub across the entire therapy session, allowing the therapist to read the transcript, and look at specific key words associated with certain emotions. Another key feature is the progress tab, that displays past therapy sessions with easy to interpret sentiment data visualizations, to allow therapists to see the overall ups and downs in a patient's visits.
## How we built it
We built the front end using Angular and hosted the web page locally. Given a complex data set, we wanted to present our application in a simple and user-friendly manner. We created a styling and branding template for the application and designed the UI from scratch.
For the back-end we hosted a REST API built using Flask on GCP in order to easily access API's offered by GCP.
Most notably, we took advantage of Google Vision API to perform sentiment analysis and used their speech to text API to transcribe a patient's therapy session.
## Challenges we ran into
* Integrated a chart library in Angular that met our project’s complex data needs
* Working with raw data
* Audio processing and conversions for session video clips
## Accomplishments that we're proud of
* Using GCP in its full effectiveness for our use case, including technologies like Google Cloud Storage, Google Compute VM, Google Cloud Firewall / LoadBalancer, as well as both Vision API and Speech-To-Text
* Implementing the entire front-end from scratch in Angular, with the integration of real-time data
* Great UI Design :)
## What's next for Inkblot
* Database integration: Keeping user data, keeping historical data, user profiles (login)
* Twilio Integration
* HIPAA Compliancy
* Investigate blockchain technology with the help of BlockStack
* Testing the product with professional therapists | ## Inspiration
COVID revolutionized the way we communicate and work by normalizing remoteness. **It also created a massive emotional drought -** we weren't made to empathize with each other through screens. As video conferencing turns into the new normal, marketers and managers continue to struggle with remote communication's lack of nuance and engagement, and those with sensory impairments likely have it even worse.
Given our team's experience with AI/ML, we wanted to leverage data to bridge this gap. Beginning with the idea to use computer vision to help sensory impaired users detect emotion, we generalized our use-case to emotional analytics and real-time emotion identification for video conferencing in general.
## What it does
In MVP form, empath.ly is a video conferencing web application with integrated emotional analytics and real-time emotion identification. During a video call, we analyze the emotions of each user sixty times a second through their camera feed.
After the call, a dashboard is available which displays emotional data and data-derived insights such as the most common emotions throughout the call, changes in emotions over time, and notable contrasts or sudden changes in emotion
**Update as of 7.15am: We've also implemented an accessibility feature which colors the screen based on the emotions detected, to aid people with learning disabilities/emotion recognition difficulties.**
**Update as of 7.36am: We've implemented another accessibility feature which uses text-to-speech to report emotions to users with visual impairments.**
## How we built it
Our backend is powered by Tensorflow, Keras and OpenCV. We use an ML model to detect the emotions of each user, sixty times a second. Each detection is stored in an array, and these are collectively stored in an array of arrays to be displayed later on the analytics dashboard. On the frontend, we built the video conferencing app using React and Agora SDK, and imported the ML model using Tensorflow.JS.
## Challenges we ran into
Initially, we attempted to train our own facial recognition model on 10-13k datapoints from Kaggle - the maximum load our laptops could handle. However, the results weren't too accurate, and we ran into issues integrating this with the frontend later on. The model's still available on our repository, and with access to a PC, we're confident we would have been able to use it.
## Accomplishments that we're proud of
We overcame our ML roadblock and managed to produce a fully-functioning, well-designed web app with a solid business case for B2B data analytics and B2C accessibility.
And our two last minute accessibility add-ons!
## What we learned
It's okay - and, in fact, in the spirit of hacking - to innovate and leverage on pre-existing builds. After our initial ML model failed, we found and utilized a pretrained model which proved to be more accurate and effective.
Inspiring users' trust and choosing a target market receptive to AI-based analytics is also important - that's why our go-to-market will focus on tech companies that rely on remote work and are staffed by younger employees.
## What's next for empath.ly
From short-term to long-term stretch goals:
* We want to add on AssemblyAI's NLP model to deliver better insights. For example, the dashboard could highlight times when a certain sentiment in speech triggered a visual emotional reaction from the audience.
* We want to port this to mobile and enable camera feed functionality, so those with visual impairments or other difficulties recognizing emotions can rely on our live detection for in-person interactions.
* We want to apply our project to the metaverse by allowing users' avatars to emote based on emotions detected from the user. | ## Inspiration
In the past 2 years, the importance of mental health has never been so prominent on the global stage. With isolation leaving us with crippling effects, and social anxiety many have suffered in ways that could potentially be impacting them for the rest of their life. One of the difficulties that people with anxiety, depression, and some other mental health issues face, is imagination. Our main goal in this project was targeting this group (which includes our teammates) and helping them to take small steps towards bringing it back. clAIrity is a tool that offers users who are looking to express themselves with words and see a visual feedback representation of those exact words that they used to express themselves. clAIrity was inspired by the Health and Discovery portions of Hack the Valley, our team has all dealt with the effects of mental health, or lack thereof thought it would be a crazy, but awesome idea to build an app that would help promote the processing of our thoughts and emotions using words.
## What it does
The user inputs a journal entry into the app, and the app then uses co:here's NLP summarization tool to pass a JSON string of the user's journal entry into the Wombo API.
The dream API then returns an image generated by the user's journal entry prompt. Here the user can screenshot the generated image and keep a "visual diary".
The user can then save their journal entry in the app. This enables them to have a copy of the journal entries they submit
## Challenges
We ran into bundling an app that uses both java and Python was no short feat for us, using the Chaquopy plugin for Android Studio we integrated our python code to work in tandem with our java code.
## Accomplishment
We are proud of improving our development knowledge. As mentioned above this project is based on Java and Python and one of the big challenges was showcasing the received picture from API which was coded in python in the app. We overcame this challenge by lots of reading and trying different methods. The challenge was successfully solved by our group mates and we made a great group bond.
## What we learned
We learned a lot about Android Studio from a BOOK! We learned what different features do in the app and how we can modify them to achieve our goal. On the back end side, we worked with the dream API in python and used plug-ins for sending information from our python to java side of back end
##What's next
The next thing on the agenda for clAIrity is to add a voice to text feature so our users can talk and see the results | winning |
## Inspiration
We wanted to learn about using new technologies and were inspired by Buf's and Cohere's challenges. We brainstormed ideas and ended on a stock sentiment classifier.
## What it does
We pull tweets from the Twitter API and classify them using the Cohere NLP API. We then calculate an average sentiment based on the ratio of positive tweets (tweets are classified as positive or negative).
## How we built it
* Protobuf: we used protobufs (with help with the Buf CLI and Buf BSR) to communicate data between our Go & Python backend with our React frontend.
* Cohere NLP API: We trained a fine-tuned model to classify tweets to have either positive or negative sentiment.
* MYSQL: Database hosted on Google Cloud to cache sentiment data for a specific date and stock.
* Python - Flask backend to retrieve stock price data from Yahoo Finance API.
* Go - Backend service that queries tweets from Twitter API, filters the tweets and sends it to the Cohere NLP Classifier.
* React Frontend: UI to retrieve sentiment data for specified stock. Display graph with 7 days worth of stock prices and sentiment data along with examples of classified tweets.
## Challenges we ran into
We primarily ran into two challenges:
1. Creating a fine-tuned classifier model (required a large dataset of labeled data)
2. Querying Twitter to return high quality tweets (needed to continuously improve our queries and filters)
## Accomplishments that we're proud of
Learning new technologies like protobufs and using Cohere's NLP Classification API.
## What we learned
Everything!
## What's next for Happy Stocks
We want to make it possible to determine sentiment from various data sets (e.g. Reddit, Bloomberg News). We also would like to implement our own NLP model and improve it even more. We also would like to incorporate more data, by getting more tweets to increase the accuracy of the sentiment data. | ## Inspiration
We started off by thinking, "What is something someone needs today?". In light of the stock market not doing so well, and the amount of false information being spread over the Internet these days, we figured it was time to get things right by understanding the stock market. We know that no human could analyze a company without bias of the history of the company and its potential stereotypes, but nothing can beat using an NLP to understand the current situation of a company. Thinking about the capabilities of the Cohere NLP and what we know and want from the stock market led us to a solution: Stocker.
## What it does
The main application allows you to search up words that make up different stocks. Then, for each company which matches the inputted string, we run through the backend, which grabs the inputted company and searches through the recent news of the company via a web scrapper on Google News. Then, we collect all of the headings and evaluate the status of the company according to a rating system. Finally, we summarize all the data by using Generate on all of the text that was read through and outputs it.
## How we built it
The stocks corresponding to the search were grabbed via the NASDAQ API. Then, once the promise is fulfilled, the React page can update the list with ratings already prepended on there. The backend that is communicated runs through Google Cloud, and the backend was built in Python along with a Flask server. This backend communicates directly with the Cohere API, specifically on the Generate and Classify functionalities. Classify is used to evaluate company status from the headings, which is coupled with the Generate to get the text summary of all the headings. Then, the best ones are selected and then displayed with links to the specific articles for people to verify the truthfulness of the information. We trained the Classify with several tests in order to ensure the API understood what we were asking of it, rather than being too extreme or imprecise.
## Challenges we ran into
Coming up with a plan of how to bring everything together was difficult -- we knew that we wanted to get data to pass in to a Classify model, but how the scraping would work and being table to communicate that data took time to formulate a plan in order to execute. The entire backend was a little challenging for the team members, as it was the first time they worked with Flask on the backend. This resulted in some troubles with getting things set up, but more significantly, the process of deploying the backend involved lots of research and testing, as nobody on our team knew how our backend could specifically be deployed.
On the front-end side, there were some hiccups with getting the data to show for all objects being outputted (i.e., how mapping and conditional rendering would work in React was a learning curve). There were also some bugs with small technical details as well, but those were eventually figured out.
Finally, bringing together the back-end and front-end and troubleshooting all the small errors was a bit challenging, given the amount of time that was remaining. Overall though, most errors were solved in appropriate amounts of time.
## Accomplishments that we're proud of
Finally figuring out the deployment of the backend was one of the highlights for sure, as it took some time with researching and experimenting. Another big one was getting the front-end designed from the Figma prototype we made and combining it with the functional, but very barebones infrastructure of our app that we made as a POC. Being able to have the front-end design be very smooth and work with the object arrays as a whole rather than individual ones made the code a lot more standardized and consolidated in the end as well, which was nice to see.
## What we learned
We learned that it is important to do some more research on how standard templates on writing code in order to be deployed easily is very useful. Some of us also got experience in Flask while others fine-tuned their React skills, which was great to see as the proficiency became useful towards the point where the back-end, front-end, and REST API were coming together (sudden edits were very easy and smooth to make).
## What's next for Stocker
Stocker can have some more categories and get smarter for sure. For example, it can actually try to interpret the current trend of where the stock has been headed recently, and also maybe other sources of data other than the news. Stocker relies heavily on the training model and the severity of article names, but in the future it could get smarter with more sources such as these listed. | ## Inspiration
We were interested in machine learning and data analytics and decided to pursue a real-world application that could prove to have practical use for society. Many themes of this project were inspired by hip-hop artist Cardi B.
## What it does
Money Moves analyzes data about financial advisors and their attributes and uses machine's deep learning unsupervised algorithms to predict if certain financial advisors will most likely be beneficial or detrimental to an investor's financial standing.
## How we built it
We partially created a custom deep-learning library where we built a Self Organizing Map. The Self Organizing Map is a neural network that takes data and creates a layer of abstraction; essentially reducing the dimensionality of the data. To make this happened we had to parse several datasets. We used beautiful soup library, pandas and numpy to parse the data needed. Once it was parsed, we were able to pre-process the data, to feed it to our neural network (Self Organizing Map). After we were able to successfully analyze the data with the deep learning algorithm, we uploaded the neural network and dataset to our Google server where we are hosting a Django website. The website will show investors the best possible advisor within their region.
## Challenges we ran into
Due to the nature of this project, we struggled with moving large amounts of data through the internet, cloud computing, and designing a website to display analyzed data because of the difficult with WiFi connectivity that many hackers faced at this competition. We mostly overcame this through working late nights and lots of frustration.
We also struggled to find an optimal data structure for storing both raw and output data. We ended up using .csv files organized in a logical manner so that data is easier accessible through a simple parser.
## Accomplishments that we're proud of
Successfully parse the dataset needed to do preprocessing and analysis with deeplearing.
Being able to analyze our data with the Self Organizing Map neural network.
Side Note: Our team member Mikhail Sorokin placed 3rd in the Yhack Rap Battle
## What we learned
We learnt how to implement a Self Organizing Map, build a good file system and code base with Django. This led us to learn about Google's cloud service where we host our Django based website. In order to be able to analyze the data, we had to parse several files and format the data that we had to send through the network.
## What's next for Money Moves
We are looking to expand our Self Organizing Map to accept data from other financial dataset, other than stock advisors; this way we are able to have different models that will work together. One way we were thinking is to have unsupervised and supervised deep-learning systems where, we have the unsupervised find the patterns that would be challenging to find; and the supervised algorithm will direct the algorithm to a certain goal that could help investors choose the best decision possible for their financial options. | losing |
## Inspiration
Over this past semester, Alp and I were in the same data science class together, and we were really interested in how data can be applied through various statistical methods. Wanting to utilize this knowledge in a real-world application, we decided to create a prediction model using machine learning. This would allow us to apply the concepts that we learned in class, as well as to learn more about various algorithms and methods that are used to create better and more accurate predictions.
## What it does
This project consists of taking a dataset containing over 280,000 real-life credit card transactions made by European cardholders over a two-day period in September 2013, with a variable determining whether the transaction was fraudulent, also known as the ground truth. After conducting exploratory data analysis, we separated the dataset into training and testing data, before training the classification algorithms on the training data. After that, we observed how accurately each algorithm performed on the testing data to determine the best-performing algorithm.
## How we built it
We built it in Python using Jupyter notebooks, where we imported all our necessary libraries for plotting, visualizing and modeling the dataset. From there, we began to do some explanatory data analysis to figure out the imbalances of the data and the different variables. However, we discovered that there were several variables that were unknown to us due to customer confidentiality. From there, we first applied principal component analysis (PCA) to reduce the dimensionality of the dataset by removing the unknown variables and analyzing the data using the only two variables that were known to us, the amount and time of each transaction. Thereafter, we had to balance the dataset using the SMOTE technique in order to balance the dataset outcomes, as the majority of the data was determined to be not fraudulent. However, in order to detect fraud, we had to ensure that the training had an equal proportion of data values that were both fraudulent and not fraudulent in order to return accurate predictions. After that, we applied 6 different classification algorithms to the training data to train it to predict the respective outcomes, such as Naive Bayes, Decision Tree, Random Forest, K-Nearest Neighbor, Logistic Regression and XGBoost. After training the data, we then applied these algorithms to the testing data and observed how accurately does each algorithm predict fraudulent transactions. We then cross-validated each algorithm by applying it to every subset of the dataset in order to reduce overfitting. Finally, we used various evaluation metrics such as accuracy, precision, recall and F-1 scores to compare which algorithm performed the best in accurately predicting fraudulent transactions.
## Challenges we ran into
The biggest challenge was the sheer amount of research and trial and error required to build this model. As this was our first time building a prediction model, we had to do a lot of reading to understand the various steps and concepts needed to clean and explore the dataset, as well as the theory and mathematical concepts behind the classification algorithms in order to model the data and check for accuracy.
## Accomplishments that we're proud of
We are very proud that we are able to create a working model that is able to predict fraudulent transactions with very high accuracy, especially since this was our first major ML model that we have made.
## What we learned
We learned a lot about the processing of building a machine learning application, such as cleaning data, conducting explanatory data analysis, creating a balanced sample, and modeling the dataset using various classification strategies to find the model with the highest accuracy.
## What's next for Credit Card Fraud Detection
We want to do more research into the theory and concepts behind the modeling process, especially the classification strategies, as we work towards fine-tuning this model and building more machine learning projects in the future. | ## Inspiration
To any financial institution, the most valuable asset to increase revenue, remain competitive and drive innovation, is aggregated **market** and **client** **data**. However, a lot of data and information is left behind due to lack of *structure*.
So we asked ourselves, *what is a source of unstructured data in the financial industry that would provide novel client insight and color to market research*?. We chose to focus on phone call audio between a salesperson and client on an investment banking level. This source of unstructured data is more often then not, completely gone after a call is ended, leaving valuable information completely underutilized.
## What it does
**Structerall** is a web application that translates phone call recordings to structured data for client querying, portfolio switching/management and novel client insight. **Structerall** displays text dialogue transcription from a phone call and sentiment analysis specific to each trade idea proposed in the call.
Instead of loosing valuable client information, **Structerall** will aggregate this data, allowing the institution to leverage this underutilized data.
## How we built it
We worked with RevSpeech to transcribe call audio to text dialogue. From here, we connected to Microsoft Azure to conduct sentiment analysis on the trade ideas discussed, and displayed this analysis on our web app, deployed on Azure.
## Challenges we ran into
We had some trouble deploying our application on Azure. This was definitely a slow point for getting a minimum viable product on the table. Another challenge we faced was learning the domain to fit our product to, and what format/structure of data may be useful to our proposed end users.
## Accomplishments that we're proud of
We created a proof of concept solution to an issue that occurs across a multitude of domains; structuring call audio for data aggregation.
## What we learned
We learnt a lot about deploying web apps, server configurations, natural language processing and how to effectively delegate tasks among a team with diverse skill sets.
## What's next for Structurall
We also developed some machine learning algorithms/predictive analytics to model credit ratings of financial instruments. We built out a neural network to predict credit ratings of financial instruments and clustering techniques to map credit ratings independent of s\_and\_p and moodys. We unfortunately were not able to showcase this model but look forward to investigating this idea in the future. | ## Inspiration
We wanted to create something fun and social by bringing people together over music.
## How it Works
Juke Bot is a messenger chat bot that allows people to create collaborative playlists on the fly.
The Merchant: the DJ/owner of the establishment
The Customer: the people attending the establishment
The Establishment: A bar, coffee shop, restaurant, club
* A merchant is able to sign up for their own Juke Bot which is custom tailored to their establishment. Each establishment has a master playlist created by the merchant. The merchant is able to see all queued songs in real time, and can delete/add songs as they see fit directly from the Spotify app. The name of Juke Bot can be changed to match the brand of the establishment (ex: DJ Gert)..
* A customer walks into the establishment, and is able to message Juke Bot with song titles, artists, or albums, they would like to listen to. Juke Bot then adds the song to the playlist queue.
## Challenges we ran into
* Getting Spotify authentication
* Creating a clean code base to communicate with our APIs
## Accomplishments that we're proud of
* Smoothly integrating Spotify into the messenger bot
* Learning more about HTTP requests and NodeJS servers
* Learning 2 new APIs in a short time
* Learning how authentication and authentication tokens work
## What we learned
* How to use the Spotify API
* How to use the Facebook messenger bot API
* How authentication tokens work (and how fast they expire)
* Postman
* NodeJS
* HTTP requests
## What's next for Juke Bot
The Spotify API didn't let us retrieve the current playing song, so it limited us. If we had this feature, we would:
* Give the user a notification when their song is up
* See what's up next
* Show them what's playing right now
* Show them what songs they requested
* Allow them to remove their requested songs from the playlist
Giving the merchant analytics: who's requesting what, their ages/genders, popular request times, popular request songs
Allowing the merchant to send out push notifications via the bot about drink specials, last call, etc...
## Other use cases
* Instead of getting the song to queue on a playlist, send the info to a DJ who can see what songs are being requested, how often they are being requested, and if any songs are being requested a lot
* Hanging out with a group of friends | winning |
## Inspiration
The three of us believe that our worldview comes from what we read. Online news articles serve to be that engine, and for something so crucial as learning about current events, an all-encompassing worldview is not so accessible. Those new to politics and just entering the discourse may perceive an extreme partisan view on a breaking news to be the party's general take; On the flip side, those with entrenched radicalized views miss out on having productive conversations. Information is meant to be shared, perspectives from journals, big, and small, should be heard.
## What it does
WorldView is a Google Chrome extension that activates whenever someone is on a news article. The extension describes the overall sentiment of the article, describes "clusters" of other articles discussing the topic of interest, and provides a summary of each article. A similarity/dissimilarity score is displayed between pairs of articles so readers can read content with a different focus.
## How we built it
Development was broken into three components: scraping, NLP processing + API, and chrome extension development. Scraping involved using Selenium, BS4, DiffBot (API that scrapes text from websites and sanitizes), and Google Cloud Platform's Custom Search API to extract similar documents from the web. NLP processing involved using NLTK, KProtoype clustering algorithm. Chrome extension was built with React, which talked to a Flask API. Flask server is hosted on an AWS EC2 instance.
## Challenges we ran into
Scraping: Getting enough documents that match the original article was a challenge because of the rate limiting of the GCP API. NLP Processing: one challenge here was determining metrics for clustering a batch of documents. Sentiment scores + top keywords were used, but more robust metrics could have been developed for more accurate clusters. Chrome extension: Figuring out the layout of the graph representing clusters was difficult, as the library used required an unusual way of stating coordinates and edge links. Flask API: One challenge in the API construction was figuring out relative imports.
## Accomplishments that we're proud of
Scraping: Recursively discovering similar documents based on repeatedly searching up headline of an original article. NLP Processing: Able to quickly get a similarity matrix for a set of documents.
## What we learned
Learned a lot about data wrangling and shaping for front-end and backend scraping.
## What's next for WorldView
Explore possibility of letting those unable to bypass paywalls of various publishers to still get insights on perspectives. | ## Inspiration
As Chinese military general Sun Tzu's famously said: "Every battle is won before it is fought."
The phrase implies that planning and strategy - not the battles - win wars. Similarly, successful traders commonly quote the phrase: "Plan the trade and trade the plan."

Just like in war, planning ahead can often mean the difference between success and failure. After recent events of the election, there was a lot of panic and emotional trading in the financial markets but there were very few applications that help handle the emotional side of training, and being able to trade the plan not on your emotions.
Investing Hero was created to help investors be aware and learn more about the risks of emotional trading and trading in general.
## What it does
This application is a tool to help investors manage their risk and help them learn more about the stock-market.
This is accomplished through many ways, one of which is tracking each transaction in the market and ensuring that the investor trade's their plan.
This application does live analysis on trades, taking in real-time stock-market data, processing the data and delivering the proper guidance through at chat-style artificial intelligent user experience.
## How we built it
We started a NodeJS server to make a REST API, which our iOS application uses to get a lot of the data shown inside the app.
We also have a Web Front-End (angularJS) which we use to monitor the information on the server, and simulate the oscillation of the prices in the stock market.
Both the iOS app, and the web Front-End are in sync, and as soon as any information is edited/deleted on either one, the other one will also show the changes in real-time.
Nasdaq-On-Demand gets us the stock prices, and that's where we go from.
## Challenges we ran into
* Real-time database connection using Firebase
* Live stock market data not being available over the weekend, and us having to simulate it
## Accomplishments that we're proud of
We made a seamless platform that is in complete sync at all times.
## What we learned

Learned about Heroku, Firebase & Swift Animations.
We also learned about the different ways a User Experience built on research can help the user get much more out of an application.
## What's next for Investment Hero
Improved AI bot & more advanced ordering options (i.e. limit orders). | ## Inspiration
Over the Summer one of us was reading about climate change but then he realised that most of the news articles that he came across were very negative and affected his mental health to the point that it was hard to think about the world as a happy place. However one day he watched this one youtube video that was talking about the hope that exists in that sphere and realised the impact of this "goodNews" on his mental health. Our idea is fully inspired by the consumption of negative media and tries to combat it.
## What it does
We want to bring more positive news into people’s lives given that we’ve seen the tendency of people to only read negative news. Psychological studies have also shown that bringing positive news into our lives make us happier and significantly increases dopamine levels.
The idea is to maintain a score of how much negative content a user reads (detected using cohere) and once it reaches past a certain threshold (we store the scores using cockroach db) we show them a positive news related article in the same topic area that they were reading.
We do this by doing text analysis using a chrome extension front-end and flask, cockroach dp backend that uses cohere for natural language processing.
Since a lot of people also listen to news via video, we also created a part of our chrome extension to transcribe audio to text - so we included that into the start of our pipeline as well! At the end, if the “negativity threshold” is passed, the chrome extension tells the user that it’s time for some good news and suggests a relevant article.
## How we built it
**Frontend**
We used a chrome extension for the front end which included dealing with the user experience and making sure that our application actually gets the attention of the user while being useful. We used react js, HTML and CSS to handle this. There was also a lot of API calls because we needed to transcribe the audio from the chrome tabs and provide that information to the backend.
**Backend**
## Challenges we ran into
It was really hard to make the chrome extension work because of a lot of security constraints that websites have. We thought that making the basic chrome extension would be the easiest part but turned out to be the hardest. Also figuring out the overall structure and the flow of the program was a challenging task but we were able to achieve it.
## Accomplishments that we're proud of
1) (co:here) Finetuned a co:here model to semantically classify news articles based on emotional sentiment
2) (co:here) Developed a high-performing classification model to classify news articles by topic
3) Spun up a cockroach db node and client and used it to store all of our classification data
4) Added support for multiple users of the extension that can leverage the use of cockroach DB's relational schema.
5) Frontend: Implemented support for multimedia streaming and transcription from the browser, and used script injection into websites to scrape content.
6) Infrastructure: Deploying server code to the cloud and serving it using Nginx and port-forwarding.
## What we learned
1) We learned a lot about how to use cockroach DB in order to create a database of news articles and topics that also have multiple users
2) Script injection, cross-origin and cross-frame calls to handle multiple frontend elements. This was especially challenging for us as none of us had any frontend engineering experience.
3) Creating a data ingestion and machine learning inference pipeline that runs on the cloud, and finetuning the model using ensembles to get optimal results for our use case.
## What's next for goodNews
1) Currently, we push a notification to the user about negative pages viewed/a link to a positive article every time the user visits a negative page after the threshold has been crossed. The intended way to fix this would be to add a column to one of our existing cockroach db tables as a 'dirty bit' of sorts, which tracks whether a notification has been pushed to a user or not, since we don't want to notify them multiple times a day. After doing this, we can query the table to determine if we should push a notification to the user or not.
2) We also would like to finetune our machine learning more. For example, right now we classify articles by topic broadly (such as War, COVID, Sports etc) and show a related positive article in the same category. Given more time, we would want to provide more semantically similar positive article suggestions to those that the author is reading. We could use cohere or other large language models to potentially explore that. | partial |
## Inspiration
As someone who has always wanted to speak in ASL (American Sign Language), I have always struggled with practicing my gestures, as I, unfortunately, don't know any ASL speakers to try and have a conversation with. Learning ASL is an amazing way to foster an inclusive community, for those who are hearing impaired or deaf. DuoASL is the solution for practicing ASL for those who want to verify their correctness!
## What it does
DuoASL is a learning app, where users can sign in to their respective accounts, and learn/practice their ASL gestures through a series of levels.
Each level has a *"Learn"* section, with a short video on how to do the gesture (ie 'hello', 'goodbye'), and a *"Practice"* section, where the user can use their camera to record themselves performing the gesture. This recording is sent to the backend server, where it is validated with our Action Recognition neural network to determine if you did the gesture correctly!
## How we built it
DuoASL is built up of two separate components;
**Frontend** - The Frontend was built using Next.js (React framework), Tailwind and Typescript. It handles the entire UI, as well as video collection during the *"Learn"* Section, which it uploads to the backend
**Backend** - The Backend was built using Flask, Python, Jupyter Notebook and TensorFlow. It is run as a Flask server that communicates with the front end and stores the uploaded video. Once a video has been uploaded, the server runs the Jupyter Notebook containing the Action Recognition neural network, which uses OpenCV and Tensorflow to apply the model to the video and determine the most prevalent ASL gesture. It saves this output to an array, which the Flask server reads and responds to the front end.
## Challenges we ran into
As this was our first time using a neural network and computer vision, it took a lot of trial and error to determine which actions should be detected using OpenCV, and how the landmarks from the MediaPipe Holistic (which was used to track the hands and face) should be converted into formatted data for the TensorFlow model. We, unfortunately, ran into a very specific and undocumented bug with using Python to run Jupyter Notebooks that import Tensorflow, specifically on M1 Macs. I spent a short amount of time (6 hours :) ) trying to fix it before giving up and switching the system to a different computer.
## Accomplishments that we're proud of
We are proud of how quickly we were able to get most components of the project working, especially the frontend Next.js web app and the backend Flask server. The neural network and computer vision setup was pretty quickly finished too (excluding the bugs), especially considering how for many of us this was our first time even using machine learning on a project!
## What we learned
We learned how to integrate a Next.js web app with a backend Flask server to upload video files through HTTP requests. We also learned how to use OpenCV and MediaPipe Holistic to track a person's face, hands, and pose through a camera feed. Finally, we learned how to collect videos and convert them into data to train and apply an Action Detection network built using TensorFlow
## What's next for DuoASL
We would like to:
* Integrate video feedback, that provides detailed steps on how to improve (using an LLM?)
* Add more words to our model!
* Create a practice section that lets you form sentences!
* Integrate full mobile support with a PWA! | ## Overview
People today are as connected as they've ever been, but there are still obstacles in communication, particularly for people who are deaf/mute and can not communicate by speaking. Our app allows bi-directional communication between people who use sign language and those who speak.
You can use your device's camera to talk using ASL, and our app will convert it to text for the other person to view. Conversely, you can also use your microphone to record your audio which is converted into text for the other person to read.
## How we built it
We used **OpenCV** and **Tensorflow** to build the Sign to Text functionality, using over 2500 frames to train our model. For the Text to Sign functionality, we used **AssemblyAI** to convert audio files to transcripts. Both of these functions are written in **Python**, and our backend server uses **Flask** to make them accessible to the frontend.
For the frontend, we used **React** (JS) and MaterialUI to create a visual and accessible way for users to communicate.
## Challenges we ran into
* We had to re-train our models multiple times to get them to work well enough.
* We switched from running our applications entirely on Jupyter (using Anvil) to a React App last-minute
## Accomplishments that we're proud of
* Using so many tools, languages and frameworks at once, and making them work together :D
* submitting on time (I hope? 😬)
## What's next for SignTube
* Add more signs!
* Use AssemblyAI's real-time API for more streamlined communication
* Incorporate account functionality + storage of videos | ## Inspiration
We live in a digital world fueled and filled with more content than ever. After conducting extensive market research with numerous Twitch and YouTube creators, we stumbled upon a rather niche issue. Content creators face tremendous difficulty when having to edit lengthy videos; Their tools are often designed to be used by experts. To account for this, many have to waste a lot of time learning tools or resort to outsourcing their work. In addition to this, the user experience with certain editing software often feels archaic with a disproportionate amount of tools provided to the user.
## What it does
In comes Chopsticks, the premier AI-powered editing software that utilizes deep learning to improve efficiency, enhance user experience, and (amazingly) *increase* creator profits. Our platform consists of a dual-use system: one chat-powered end where we take user text queries and perform video manipulation, and another where we analyze the most entertaining and important parts of a video (based on developed metrics) and present the user with many different clips of short-form content.
With that being said, Chopsticks is a first-of-its-kind software coming to market, and here is how it works:
## How we built it
1. Retrieves voice transcription using Whisper, chat logs using OCR/Web Scraping, and creator expressions using OpenCV.
2. Uses Roberta's fine-tuned model to analyze the viewership engagement (chats) with the creator, and its sentiment.
3. Uses a fine-tuned T5 model to transcribe the stream and run a text-text analysis to gauge the streamer's key moments.
4. Uses a DeepFace model to read the streamer's reaction and weigh this metric with the models used above to produce valuable insights into key moments of a stream.
5 We normalize these metrics and generate "spikes" that occur at certain time intervals, representing high levels of engagement between the streamer and the viewer.
5. This data is fed into our LLM-based video clipping tool, to autogenerate or chop clips into short-form content.
6. Using Reflex, we created a simple user interface that allows users of any level to be able to edit their videos seamlessly.
## Challenges we ran into
1. One of our most complex challenges was regarding how to determine whether something was "entertaining" or not. When dealing with human emotions, classifying data in a meaningful way becomes less boolean and harder to quantify. To overcome some of this friction, we spent a lot of time identifying relevant factors that contribute to this metric. We decided to give custom weights to certain inputs (chats being the highest since we have more consistent data to rely on), leading to an overall better model.
2. Another big problem we faced technically was the memory and time needed to classify our inputs. For our first run with a 30-minute video, our combined time to gather transcription data, chat logs, and facial emotion recognition data took us well over an hour. Thinking about the consumer, we realized this wouldn't be sustainable in the long run so we cleaned up our algorithms, ignoring certain data to significantly reduce overhead. Recently, we were able to classify this large video in less than 20 minutes by running scripts at the same time and using better hardware.
3. Coming into TreeHacks we initially were on track to pursue a project that analyzes research papers for beginner researchers. When we talked to a mentor here (shoutout to Luke), he asked us the hard, but important questions. When we discussed who our consumers would be and the real use case of our product, we realized that maybe research was a track we didn't want to pursue. 4 hours into hacking we got back to the drawing board and went about choosing a project a different way.
## Accomplishments that we're proud of
1. Although coming up with an idea on the spot started very difficult, we approached the idea by first conducting heavy market research in many different fields which then led us down the content creation path. Coming across this hump in our journey was not only a breath of relief, but it also provided us with a newfound motivation to put all our effort into a singular goal that we all believed had potential.
2. On top of this, we all as a team have grown tremendously in the technical space. Being introduced to new sponsor technologies like Reflex, we were able to create a compelling web app using *only* python.
3. Lastly, our proudest moment was when our first output was generated. We had selected a random Pewdiepie Minecraft stream and when we saw the quality of the short format videos generated, we knew that all the work we had put in was not in vain and our project indeed had a future.
## What we learned
Coming in with a diverse range of skill sets, a quick thing we failed to grasp on our first night was splitting work efficiently. When we had our first team meeting the day after, we split up work better, allowing members who are proficient at doing something to create quality work in that area. This reduced our workload (still 2 all-nighters) and allowed us to get significantly more work done.
## What's next for Chopsticks?
As a potentially (very) successful startup, our goal for Chopsticks is to push directly into the market. One big constraint we had on us during TreeHacks was simply time. Our models were efficient but sometimes didn't classify our inputs perfectly. By having the time to fine-tune our custom models, generate better metrics for clips, and reduce overhead, we will be able to scale our company quickly and efficiently beat everyone to market. We hope to launch initially as open-source software to gain traction in the industry but then transition to a subscription-based model, which will allow us to pay for new hardware required to run our algorithm as fast as possible.
In terms of pure concept, our company has the potential to do good in our community. Not only is our product significantly cheaper than our direct customers, but our software has limitless applications to do social good, especially in the education space. By being able to quickly extract important bits of lectures into viewable content, students with short attention spans could easily learn content without being bored to death.
We hope to secure funding for this idea so we can keep spending time on a project we are all so passionate about. | winning |
## Inspiration
* None of my friends wanted to do an IOS application with me so I built an application to find friends to hack with
* I would like to reuse the swiping functionality in another personal project
## What it does
* Create an account
* Make a profile of skills, interests and languages
* Find matches to hack with based on profiles
* Check out my Video!
## How we built it
* Built using Swift in xCode
* Used Parse and Heroku for backend
## Challenges we ran into
* I got stuck on so many things, but luckily not for long because of..
* Stack overflow and youtube and all my hacking friends that lent me a hand!
## Accomplishments that we're proud of
* Able to finish a project in 36 hours
* Trying some of the
* No dying of caffeine overdose
## What we learned
* I had never made an IOS app before
* I had never used Heroku before
## What's next for HackMates
* Add chat capabilities
* Add UI
* Better matching algorithm | On late and caffeine-drive nights (aka almost every night), thousands of hackers are sitting at their desks coding. Thousands of lonely souls looking for the right debugging partner. Someone who will know that tabs should always be used instead of spaces. Someone that knows that Vim is clearly superior to Emacs (#flamewars). Someone that pushes all the right buttons. Tinder++, the next iteration of hookups but for hackers. Log in, say “hello world”, and find the 1.
## Inspiration
Valentine's Day. <3
## What it does
Based on your responses to a truly encompassing series of questions that polarize the hackathon community and a fast implementation of the GS Stable Matching algorithm, we try to find the ideal pairings, such that your debugging experience will be one you never forget. We make sure to match you with a partner such that you won’t waste anytime on the the small things like Mac vs. Windows and have time to truly focus on each other…...s code.
## How we built it
* Android
* Bluemix on the backend with NodeJS
## Challenges we ran into
We were android app dev virgins, and ran into challenges in determining which libraries to use and how to structure our app. As we delved deeper into development, we gradually found our footing.
## Accomplishments that we're proud of
Helping fellow developers get lucky
## What we learned
* The internet has a wide array of CS-specific pickup lines
*Is your name Google? Because you have everything I've been searching for*
* Structure of an android app
* Gender is a scale
## What's next for Tinder++
* Substantial UI overhaul
* Users | During the COVID-19 pandemic, time spent at home, time spent not exercising, and time spent alone has been at an all time high. This is why, we decided to introduce FITNER to the other fitness nerds like ourselves who struggle to find others to participate in exercise with. As we all know that it is easier to stay healthy, and happy with friends.
We created Fitner as a way to help you find friends to go hiking with, play tennis or even go bowling with! It can be difficult to practice the sport that you love when none of your existing friends are interested, and you do not have the time commitment to join a club. Fitner solves this issue by bridging the gap between fitness nerds who want to reach their potential but don't have the community to do so.
Fitner is a mobile application built with React Native for an iOS and Android front-end, and Google Cloud / Firebase as the backend. We were inspired by the opportunity to use Google Cloud platforms in our application, so we decided to do something we had never done before, which was real-time communication. Although it was our first time working with real-time communication, we found ourselves, in real-time, overtaking the challenges that came along with it. We are very proud of our work ethic, our resulting application and dedication to our first ever hackathon.
Future implementations of our application can include public chat rooms that users may join and plan public sporting events with, and a more sophisticated algorithm which would suggest members of the community that are at a similar skill and fitness goals as you. With FITNER, your fitness goals will be met easily and smoothly and you will meet lifelong friends on the way! | losing |
# Pythia Camera
Check out the [github](https://github.com/philipkiely/Pythia).
## Inspiration
#### Original Idea:
Deepfakes and more standard edits are a difficult threat to detect. Rather than reactively analyzing footage to attempt to find the marks of digital editing, we sign footage on the camera itself to allow the detection of edited footage.
#### Final Idea:
Using the same technology, but with a more limited threat model allowing for a narrower scope, we can create the world's most secure and intelligent home security camera.
## What it does
Pythia combines robust cryptography with AI video processing to bring you a unique home security camera. The system notifies you in near-real-time of potential incidents and lets you verify by viewing the video. Videos are signed by the camera and the server to prove their authenticity in courts and other legal matters. Improvements of the same technology have potential uses in social media, broadcasting, political advertising, and police body cameras.
## How we built it
* Records video and audio on a camera connected to a basic WIFI-enabled board, in our case a Raspberry Pi 4
At regular intervals:
* Combines video and audio into .mp4 file
* Signs combined file
* Sends file and metadata to AWS
On AWS:
* Verifies signature and adds server signature
* Uses Rekognition to detect violence or other suspicious behavior
* Uses Rekognition to detect the presence of people
* If there are people with detectable faces, uses Rekognition to
* Uses SMS to notify the property owner about the suspicious activity and links a video clip
## Challenges we ran into
None.
Just Kidding:
#### Hardware
Raspberry Pi
* All software runs on Raspberry Pi
* Wifi Issues
* Compatibility issues
* Finding a Screwdriver
Hardware lab didn't have the type of sensors we were hoping for so no heat map :(.
#### Software
* Continuous batched recording
* Creating complete .mp4 files
* Processing while recording
#### Web Services
* Asynchronous Architecture has lots of race conditions
## Accomplishments that we're proud of
* Complex AWS deployment
* Chained RSA Signature
* Proper video encoding and processing, combining separate frame and audio streams into a single .mp4
## What we learned
#### Bogdan
* Gained experience designing and implementing a complex, asynchronous AWS Architecture
* Practiced with several different Rekognition functions to generate useful results
#### Philip
* Video and audio encoding is complicated but fortunately we have great command-line tools like `ffmpeg`
* Watchdog is a Python library for watching folders for a variety fo events and changes. I'm excited to use it for future automation projects.
* Raspberry Pi never works right the first time
## What's next for Pythia Camera
A lot of work is required to fully realize our vision for Pythia Camera as a whole solution that resists a wide variety of much stronger threat models including state actors. Here are a few areas of interest:
#### Black-box resistance:
* A camera pointed at a screen will record and verify the video from the screen
* Solution: Capture IR footage to create a heat map of the video and compare the heat map against rekognition's object analysis (people should be hot, objects should be cold, etc.
* Solution: Use a laser dot projector like the iPhone's faceID sensor to measure distance and compare to machine learning models using Rekognition
#### Flexible Cryptography:
* Upgrade Chained RSA Signature to Chained RSA Additive Map Signature to allow for combining videos
* Allow for basic edits like cuts and filters while recording a signed record of changes
#### More Robust Server Architecture:
* Better RBAC for online assets
* Multi-region failover for constant operation | ## Inspiration
We are very interested in the idea of making computer understand human’s feeling from Mirum challenge. We apply this idea on calling center where customer support can’t see customers’ faces via phone calls or messages. Enabling the analysis of the emotional tone of consumers can help customer support understand their need and solve problems more efficient. Business can immediately see the detailed emotional state of the customers from voice or text messages.
## What it does
The text from customers are colored based on their tone. Red stands for anger, white stands for joy.
## How I built it
We utilize the iOS chat application from the Watson Developer Cloud Swift SDK to build this chat bot, and IBM Watson tone analyzer to examine the emotional tones, language tones, and social tones.
## Challenges I ran into
At the beginning, we had trouble running the app on iPhone. We spent a lot of time on debugging and testing. We also spent a lot of time on designing the graph of the analysis results.
## Accomplishments that I'm proud of
We are proud to show that our chat bot supports tone analysis and basic chatting.
## What I learned
We have learned and explored a few IBM Watson APIs. We also learned a lot while trouble shooting and fixing bugs.
## What's next for **Chattitude**
Our future plan for Chattitude is to color the text by sentence and make the interface more engaging. For the tone analysis result, we want to improve by presenting the real time animated analysis result as histogram. | ## Inspiration
In the world where technology is intricately embedded into our lives, security is an exciting area where internet devices can unlock the efficiency and potential of the Internet of Things.
## What it does
Sesame is a smart lock that uses facial recognition in order to grant access. A picture is taken from the door and a call is made to a cloud service in order to authenticate the user. Once the user has been authenticated, the door lock opens and the user is free to enter the door.
## How we built it
We used a variety of technologies to build this project. First a Raspberry Pi is connected to the internet and has a servo motor, a button and a camera connected to it. The Pi is running a python client which makes call to a Node.js app running on IBM Bluemix. The app handles requests to train and test image classifiers using the Visual Recognition Watson. We trained a classifier with 20 pictures of each of us and we tested the classifier to unseen data by taking a new picture through our system. To control the lock we connected a servo to the Raspberry Pi and we wrote C with the wiringPi library and PWM to control it. The lock only opens if we reach an accuracy of 70% or above. We determined this number after several tests. The servo moves the lock by using a 3d-printed adapter that connects the servo to the lock.
## Challenges we ran into
We wanted to make our whole project on python, by using a library for the GPIO interface of the Pi and OpenCV for the facial recognition. However, we missed some OpenCV packages and we did not have the time to rebuild the library. Also the GPIO library on python was not working properly to control the servo motor. After encountering these issues, we moved the direction of our project to focus on building a Node.js app to handle authentication and the Visual Recognition service to handle the classification of users.
## Accomplishments that we're proud of
What we are all proud of is that in just one weekend, we learned most of the skills required to finish our project. Ming learned 3D modeling and printing, and to program the GPIO interface on the Pi. Eddie learned the internet architecture and the process of creating a web app, from the client to the server. Atl learned how to use IBM technologies and to adapt to the unforeseen circumstances of the hackathon.
## What's next for Sesame
The prototype we built could be improved upon by adding additional features that would make it more convenient to use. Adding a mobile application that could directly send the images from an individual’s phone to Bluemix would make it so that the user could train the visual recognition application from anywhere and at anytime. Additionally, we have plans to discard the button and replace it with a proximity sensor so that the camera is efficient and only activates when an individual is present in front of the door. | winning |
## Inspiration
The growing technology
## What it does
making the time less to complete the task
## How we built it
using technologies
## Challenges we ran into
spending too much time in a single task
## Accomplishments that we're proud of
we can able to complete the task in minutes
## What we learned
we about the smartness of the human
## What's next for Artificial Intelligence
Narrow AI: Also known as weak AI, it is designed and trained for a specific task. Examples include voice assistants like Siri or Alexa, and recommendation systems on platforms like Netflix or Amazon. | ## Inspiration
Examining our difficulties in our daily workflow, we realized that we often could not find files that we knew we had written before. Lots of us had saved countless papers and books, only to be unsure of where we saved them. Not knowing where our old code was led us to rewrite old libraries and codebases. Thus, we all wished for a better file searcher. One which, instead of solely relying on filenames or exact string matching in the file content, also took into account how
## What it does
Chimera will first ask you to describe the file you are looking for. Then it will go through all the files in your directory and rank them according to which fit the prompt the best.
## How we built it
We used the Tauri framework to build the app and wrote it in Rust. The app first embedded the prompts and the files into a vector space (using OpenAI's embedding models), then compared the similarity between the prompts and each file, then outputted them in order of likelihood.
## Challenges we ran into
Building it in Rust was quite difficult, as some of us didn't know Rust and had to learn it on the fly, and there were a lot of issues working with some Rust libraries.
## Accomplishments that we're proud of
The end product, being built with Rust, is highly performant. Our embeddings framework is also easily parallelizable, so it can easily be extended to index every file in a user's computer relatively quickly.
## What we learned
We learned how to work with Rust (especially the Tauri framework and Apache Arrow's data format that LanceDB uses) and how to use a vector DB.
## What's next for Chimera
While this hackathon used OpenAI's embeddings API, the end goal would be to ship a local embeddings model to the user's computer so their files won't have to leave their personal laptop. In addition, we hope to fine-tune the embeddings model to perform better at the specific task of searching for files. | ## Away From Keyboard
## Inspiration
We wanted to create something that anyone can use AFK for chrome. Whether it be for accessibility reasons -- such as for those with disabilities that can't use the keyboard -- or for daily use when you're cooking, our aim was to make scrolling and Chrome browsing easier.
## What it does
Our app AFK (away from keyboard) helps users scroll and read, hands off. You can control the page by saying "go down/up", "open/close tab", "go back/forward", "reload/refresh", or reading the text on the page (it will autoscroll once you reach the bottom).
## How we built it
Stack overflow and lots of panicked googling -- we also used Mozilla's web speech API.
## Challenges we ran into
We had some difficulties scraping the text from sites for the reading function as well as some difficulty integrating the APIs into our extension. We started off with a completely different idea and had to pivot mid-hack. This cut down a lot of our time, and we had troubles re-organizing and gauging the situation.
However, as a team, we all worked on contributing parts to the project and, in the end we were able to create a working product despite the small road bumps we ran into.
## Accomplishments that we are proud of
As a team, we were able to learn how to make chrome extensions in 24 hours :D
## What we learned
We learned chrome extensions, using APIs in the extension and also had some side adventures with vue.js and vuetify for webapps.
## What's next for AFK
We wanted to include other functionalities like taking screen shots and taking notes with the voice. | losing |
## Inspiration
Software engineering interviews are really tough. How best to prepare? You can mock interview, but that requires two people. We wanted an easy way for speakers to gauge how well they're speaking and see how they improve over time.
## What it does
Provides a thoughtful interview prompt and analyzes speaking patterns according to four metrics - clarity, hesitations, words per minute, and word spacing. Users can access data from past sessions on their profile page.
## How we built it
An Express backend and MongoDB database that interfaces with the Nuance ASR API and IBM Watson Speech-to-Text.
## Challenges we ran into
* Determining a heuristic for judging speech
* Working with the speech services through web sockets
* Seeing what we could do with the supplied data
## Accomplishments that we're proud of
A clean, responsive UI!
## What we learned
Speech detection is really difficult and technologies that explore this area are still in their early stages. Knowing what content to expect can make things easier, and it's cool how Nuance is exploring the possibilities of machine learning through Bolt.
## What's next for rehearse
We want to take advantage of Nuance's contextual models by implementing rehearse modes for different use cases. For example, a technical interview module that identifies algorithm names and gives reactive hints/comments on a practice question. | ## Inspiration
As we are a group of students actively looking for summer internships, we felt that an application to assist in practicing for interviews would be highly impactful. In addition, we felt that there was an opportunity and gap regarding AI and interview prep.
## What it does
The app is comprised of two main parts: Interview question generation and video/audio sentiment analysis. The user first requests interview questions based on the job title they are applying for. Then, they film or record themselves answering the questions and submit their answers to be analyzed. The user is given back the 5 highest emotions sensed, which the user can take note of.
## How we built it
We built this in Python using Taipy, HumeAi, and OpenAI's ChatGPT API
## Challenges we ran into
As this is our first hackathon coordinating our group and utilizing the new software presented many challenges!
## Accomplishments that we're proud of
Utilizing Taipy and including HumeAI and OpenAI's APIS were great accomplishments for us.
## What's next for Proficient
We have plans to add many features including live video analysis and live question generation. | ## Inspiration
Public speaking is greatly feared by many, yet it is a part of life that most of us have to go through. Despite this, preparing for presentations effectively is *greatly limited*. Practicing with others is good, but that requires someone willing to listen to you for potentially hours. Talking in front of a mirror could work, but it does not live up to the real environment of a public speaker. As a result, public speaking is dreaded not only for the act itself, but also because it's *difficult to feel ready*. If there was an efficient way of ensuring you aced a presentation, the negative connotation associated with them would no longer exist . That is why we have created Speech Simulator, a VR web application used for practice public speaking. With it, we hope to alleviate the stress that comes with speaking in front of others.
## What it does
Speech Simulator is an easy to use VR web application. Simply login with discord, import your script into the site from any device, then put on your VR headset to enter a 3D classroom, a common location for public speaking. From there, you are able to practice speaking. Behind the user is a board containing your script, split into slides, emulating a real powerpoint styled presentation. Once you have run through your script, you may exit VR, where you will find results based on the application's recording of your presentation. From your talking speed to how many filler words said, Speech Simulator will provide you with stats based on your performance as well as a summary on what you did well and how you can improve. Presentations can be attempted again and are saved onto our database. Additionally, any adjustments to the presentation templates can be made using our editing feature.
## How we built it
Our project was created primarily using the T3 stack. The stack uses **Next.js** as our full-stack React framework. The frontend uses **React** and **Tailwind CSS** for component state and styling. The backend utilizes **NextAuth.js** for login and user authentication and **Prisma** as our ORM. The whole application was type safe ensured using **tRPC**, **Zod**, and **TypeScript**. For the VR aspect of our project, we used **React Three Fiber** for rendering **Three.js** objects in, **React XR**, and **React Speech Recognition** for transcribing speech to text. The server is hosted on Vercel and the database on **CockroachDB**.
## Challenges we ran into
Despite completing, there were numerous challenges that we ran into during the hackathon. The largest problem was the connection between the web app on computer and the VR headset. As both were two separate web clients, it was very challenging to communicate our sites' workflow between the two devices. For example, if a user finished their presentation in VR and wanted to view the results on their computer, how would this be accomplished without the user manually refreshing the page? After discussion between using web-sockets or polling, we went with polling + a queuing system, which allowed each respective client to know what to display. We decided to use polling because it enables a severless deploy and concluded that we did not have enough time to setup websockets. Another challenge we had run into was the 3D configuration on the application. As none of us have had real experience with 3D web applications, it was a very daunting task to try and work with meshes and various geometry. However, after a lot of trial and error, we were able to manage a VR solution for our application.
## What we learned
This hackathon provided us with a great amount of experience and lessons. Although each of us learned a lot on the technological aspect of this hackathon, there were many other takeaways during this weekend. As this was most of our group's first 24 hour hackathon, we were able to learn to manage our time effectively in a day's span. With a small time limit and semi large project, this hackathon also improved our communication skills and overall coherence of our team. However, we did not just learn from our own experiences, but also from others. Viewing everyone's creations gave us insight on what makes a project meaningful, and we gained a lot from looking at other hacker's projects and their presentations. Overall, this event provided us with an invaluable set of new skills and perspective.
## What's next for VR Speech Simulator
There are a ton of ways that we believe can improve Speech Simulator. The first and potentially most important change is the appearance of our VR setting. As this was our first project involving 3D rendering, we had difficulty adding colour to our classroom. This reduced the immersion that we originally hoped for, so improving our 3D environment would allow the user to more accurately practice. Furthermore, as public speaking infers speaking in front of others, large improvements can be made by adding human models into VR. On the other hand, we also believe that we can improve Speech Simulator by adding more functionality to the feedback it provides to the user. From hand gestures to tone of voice, there are so many ways of differentiating the quality of a presentation that could be added to our application. In the future, we hope to add these new features and further elevate Speech Simulator. | losing |
## Inspiration
<https://www.pewresearch.org/social-trends/?attachment_id=34762>
Pew Research Center lists barbers as among the groups of workers whose day-to-day job has the least exposure to AI.
To solve this problem, we propose an AI-powered mobile app which would allow users to preview potential haircuts together with a barber from the palm of their hands.
## Background
We searched *arxiv* for papers involving hair strand reconstruction, pose alignment, and haircut transfers.
We read and drew inspiration from the following papers:
[Neural Haircut: Prior-Guided Strand-Based Hair Reconstruction](https://arxiv.org/pdf/2306.05872.pdf)
[Style Your Hair: Latent Optimization for Pose-Invariant Hairstyle Transfer via Local-Style-Aware Hair Alignment](https://arxiv.org/pdf/2208.07765.pdf)
[Barbershop: GAN-based Image Compositing using Segmentation Masks](https://arxiv.org/pdf/2106.01505.pdf)
Ultimately, we decided to work with the code from the "Barbershop" and "Style Your Hair" paper to develop our backend.
## What is *kapper*?
**kapper** is a cutting-edge solution which utilizes generative artificial intelligence to create virtual haircuts for users. Users may simply upload a photo of themselves and upload another image of their desired haircut style. The models developed by the authors of "Barbershop" and "Style Your Hair" then process the images, identifying the hair, and user poses, and transplants the desired hairstyle onto the user's photo, creating a realistic and personalized virtual haircut.
## How we built it
*kapper* was developed using Python Flask as a backend, and React Native for frontend. *kapper*'s backend is hosted on Google Cloud Platform. *kapper*'s GAN models are written in Pytorch. We used React Native to create a user-friendly mobile app which allows users to easily upload their photos, select styles, and view their virtual haircuts.
## Challenges we ran into
One of the major challenges we encountered during the development of KapperAI was deploying the machine learning model on Google Cloud.
## Accomplishments that we're proud of
We are incredibly proud of several accomplishments in this project. Firstly, we successfully developed a full-stack application that empowers users, especially barbers, with the power of a GAN within the palms of their hands. We hope that in the future,
## What we learned
Throughout the development of KapperAI, our team gained valuable insights into various aspects of app development and machine learning integration. We deepened our understanding of React Native, which allowed us to create an intuitive user interface. Moreover, we learned how to utilize various components of a complex application, including backend machine learning algorithms and frontend user experiences.
## What's next for KapperAI
Our vision for *kapper* is to scale and expand its features. In the long future, we plan to incorporate more advanced machine learning techniques to offer even more realistic virtual haircuts. We also aim to collaborate with professional hairstylists to provide expert recommendations and styling tips to our users. Ultimately, our goal is for *kapper* to become a the goto tool for barber clients to find their next haircut, and to interact with their barbers. | ## Inspiration
It all started a couple days ago when my brother told me he'd need over an hour to pick up a few items from a grocery store because of the weekend checkout line. This led to us reaching out to other friends of ours and asking them about the biggest pitfalls of existing shopping systems. We got a whole variety of answers, but the overwhelming response was the time it takes to shop and more particularly checkout. This inspired us to ideate and come up with an innovative solution.
## What it does
Our app uses computer vision to add items to a customer's bill as they place items in the cart. Similarly, removing an item from the cart automatically subtracts them from the bill. After a customer has completed shopping, they can checkout on the app with the tap of a button, and walk out the store. It's that simple!
## How we built it
We used react with ionic for the frontend, and node.js for the backend. Our main priority was the completion of the computer vision model that detects items being added and removed from the cart. The model we used is a custom YOLO-v3Tiny model implemented in Tensorflow. We chose Tensorflow so that we could run the model using TensorflowJS on mobile.
## Challenges we ran into
The development phase had it's fair share of challenges. Some of these were:
* Deep learning models can never have too much data! Scraping enough images to get accurate predictions was a challenge.
* Adding our custom classes to the pre-trained YOLO-v3Tiny model.
* Coming up with solutions to security concerns.
* Last but not least, simulating shopping while quarantining at home.
## Accomplishments that we're proud of
We're extremely proud of completing a model that can detect objects in real time, as well as our rapid pace of frontend and backend development.
## What we learned
We learned and got hands on experience of Transfer Learning. This was always a concept that we knew in theory but had never implemented before. We also learned how to host tensorflow deep learning models on cloud, as well as make requests to them. Using google maps API with ionic react was a fun learning experience too!
## What's next for MoboShop
* Integrate with customer shopping lists.
* Display ingredients for recipes added by customer.
* Integration with existing security systems.
* Provide analytics and shopping trends to retailers, including insights based on previous orders, customer shopping trends among other statistics. | ## Inspiration
In recent years, especially post-COVID, online shopping has become extremely common. One big issue when shopping online is that users are unable to try on clothes before ordering them. This results in people getting clothes that end up not fitting or not looking great, which is something nobody wants. In addition, many people face constant difficulties in their life that limit their This gave us the inspiration to create Style AI as a way to let people try on clothes virtually before ordering them online.
## What it does
Style AI takes a photo of you and analyzes the clothes you are currently wearing and gives detailed clothing recommendations of specific brands, shirt types, and colors. Then, the user has the option to try on each of the recommendations virtually.
## How we built it
We used OpenCV to capture a photo of the user. Then the image is inputted to Gemini API to generate a list of clothing recommendations. These recommendations are then passed into google shopping API, which uses google search to find where the user can buy the recommended clothes. Then, we filter through the results to find clothes that have the correct image format.
The image of the shirt is superimposed onto a live OpenCV video stream of the user. To overlay the shirt on the user, we segmented the shirt image into 3 sections: left sleeve, center, and right sleeve. We also perform segmentation on the user using MediaPipe. Then, we warp each segment of the shirt onto the user's body in the video stream.
We made the website using Reflex.
## Challenges we ran into
The shirt overlay aspect was much more challenging than expected. At first, we planned to use a semantic segmentation model for the shirt of the user because then we could warp and transform the shape of the real shirt to the shirt mask on the user. The issue was that semantic segmentation was very slow so the shirt wasn't able to overlay on the user in real-time. We solved this by using a combination of various OpenCV functions so the shirt could be overlaid in real-time.
## Accomplishments that we're proud of
We are proud of every part of our project, since each required lots of research, and we are all proud of the individual contributions to the project. We are also proud that we were able to overcome many challenges and adapt to things that went wrong. Specifically, we were proud that we were able to use a completely new framework, reflex, which allowed us to work in python natively across both the frontend and the backend.
## What we learned
We learned how to use Reflex to create websites. We also learned how to use APIs. Also, we learned about more functionalities of MediaPipe and OpenCV when writing the shirt overlay code.
## What's next for Style AI
Expand Style AI for all types of clothing such as pants and shoes. Implementation of a "bulk order" functionality allowing users to order across online retailers. Add more personalized recommendations. Enable real-time voice assisted chat bot conversations to simulate talking to a fashion expert in-person. | partial |
## Inspiration
I was inspired to create ConnectOnCommute after experiencing my own new tribe moment moving out to Boston. I found it very challenging to break out and meet new people, make new friends, and really feel like I 'belonged' in my community here. After a few weeks of feeling increasingly disconnected from my environment, I decided to put on a namebadge that said "Ask me about tacos". Within the 4 hours I had been wearing the badge, 14 different people would jokingly walk up and.. well.. ask me about tacos. Before I knew it I was having a random conversation with almost each one of them.
After talking to some other people about my feelings at the beginning of my journey here, I found that I wasn't alone in feeling alone. It turns out 48% of Americans feel lonely most or all of the time, and 52% feel that no-one knows them well. Our brains have evolved to need social acceptance in much of the same way that we need food and oxygen- and it's because of this that many studies agree chronic loneliness can be more detrimental to our health than obesity and equivalent to smoking a pack of cigarettes a day.
When I got to #HackHarvard2019, I had spent a lot of time thinking about that experience and wanted to see how my team could use tech to help foster a world of more deep, meaningful connections. Social media does a great job maintaining friendships once they start, but there's somewhat of a gap in initializing that first conversation; ConnectOnCommute was designed specifically do promote serendipitous interactions with the people to the left and right of us, all across our community.
## What it does
ConnectOnCommute acts as an initiator for new, random conversations in real life with different people all around you in your community. Sometimes all we need is an invitation; users turn their 'social mode' on when they want to connect with others. As they're walking around, if another person in social mode is within range, both users receive a 'nudge' that includes the other person's name and a topic of interest to ask them about. Once both people click 'connect', a new connect-record is added to each users personal log.
## How we built it
The front-end was created with angular, typescript, and bootstrap; the back-end was developed using C#. ConnectOnCommute is hosted on an Azure server.
## Challenges we ran into
The initial idea for the app involved using nfc or bluetooth to gage the range for the popup. Without the experience that would typically allow us to develop this kind of feature, we had to get creative with how to track location in a way that was accurate enough and allowed us to set parameters- this involved math... a lot of math... by pulling the gps longitude and latitude coordinates provided by every google chrome browser, we had to use trigonometry, conversion formulas, and advanced algebra to calculate the distance of any two coordinate points, and make it so that only people within 100 meters of each other would appear on each user's screen. It was challenging finding a new and creative way to get beyond this issue, however making it work felt really good when it was done.
We also ran into some other minor technical issues, with things such as asynchronous functions/operations, typical bugs, and of course our favorite: syntax errors.
## Accomplishments that we're proud of
The biggest accomplishment was being able to roll out the completed, working, beta web-application within the 36 hour time period. At this moment, anyone can create an account, walk around, and find any other users that are also looking to converse. What would have normally taken us a few months to have professionally developed, we managed to accomplish in two nights.
## What's next for ConnectOnCommute
The initial beta for ConnectOnCommute was a major success, that's not to say that there aren't even more places to take this! First tweaks will need to be graphics, getting an experienced graphic designer to help improve the UX design and make the overall experience more aesthetic. Currently the team is working on making the web-app responsive for mobile displays, and in the next few months we're hoping to roll-out a complete IOS and Android app.
The IOS and Android app would integrate bluetooth or NFC to allow users to connect on trains and planes and many other places without wifi or LTE connectivity! | ## Inspiration
We love travelling. Two of us are actually travelling across the country to come to CalHacks. We were also inspired by reddit posts on /r/Berkeley describing some students feeling really lonely, despite being surrounded by people. In our generation it seems that a growing concern is the inability of people to meet new people. Despite that we see phenomena Ingress and PokemonGo that serendipitously bring people together. We wanted to capitalize on what problems we saw and what we enjoy doing by creating "Hello."
## What it does
We developed a travel app that brings you and other travellers to various local, when you arrive at an area the app asks you to find each other, then as a group you play a series of minigames to learn more about each other, level up, and ultimately capture the location. Our goal was not to necessarily force people to become friends, but give them the *opportunity* to meet new people.
## How we built it
We have a ReactNative client app for iOS and Android. We decided to use ReactNative for its ease of testing and cross platform availability. This connects to an expressJS backend that manages all the socket connections across the various client side applications, as well as generates the monster locations, and holds all user and game data.
## What's next for "Hello."?
Goodbye? | ## Inspiration
While we were doing preliminary research, we had found overwhelming amounts of evidence of mental health deterioration as a consequence of life-altering lockdown restrictions. Academic research has shown that adolescents depend on friendship to maintain a sense of self-worth and to manage anxiety and depression. Intimate exchanges and self-esteem support significantly increased long-term self worth and decreased depression.
While people do have virtual classes and social media, some still had trouble feeling close with anyone. This is because conventional forums and social media did not provide a safe space for conversation beyond the superficial. User research also revealed that friendships formed by physical proximity don't necessarily make people feel understood and resulted in feelings of loneliness anyway. Proximity friendships formed in virtual classes also felt shallow in the sense that it only lasted for the duration of the online class.
With this in mind, we wanted to create a platform that encouraged users to talk about their true feelings, and maximize the chance that the user would get heartfelt and intimate replies.
## What it does
Reach is an anonymous forum that is focused on providing a safe space for people to talk about their personal struggles. The anonymity encourages people to speak from the heart. Users can talk about their struggles and categorize them, making it easy for others in similar positions to find these posts and build a sense of closeness with the poster. People with similar struggles have a higher chance of truly understanding each other. Since ill-mannered users can exploit anonymity, there is a tone analyzer that will block posts and replies that contain mean-spirited content from being published while still letting posts of a venting nature through. There is also ReCAPTCHA to block bot spamming.
## How we built it
* Wireframing and Prototyping: Figma
* Backend: Java 11 with Spring Boot
* Database: PostgresSQL
* Frontend: Bootstrap
* External Integration: Recaptcha v3 and IBM Watson - Tone Analyzer
* Cloud: Heroku
## Challenges we ran into
We initially found it a bit difficult to come up with ideas for a solution to the problem of helping people communicate. A plan for a VR space for 'physical' chatting was also scrapped due to time constraints, as we didn't have enough time left to do it by the time we came up with the idea. We knew that forums were already common enough on the internet, so it took time to come up with a product strategy that differentiated us. (Also, time zone issues. The UXer is Australian. They took caffeine pills and still fell asleep.)
## Accomplishments that we're proud of
Finishing it on time, for starters. It felt like we had a bit of a scope problem at the start when deciding to make a functional forum with all these extra features, but I think we pulled it off. The UXer also iterated about 30 screens in total. The Figma file is *messy.*
## What we learned
As our first virtual hackathon, this has been a learning experience for remote collaborative work.
UXer: I feel like i've gotten better at speedrunning the UX process even quicker than before. It usually takes a while for me to get started on things. I'm also not quite familiar with code (I only know python), so watching the dev work and finding out what kind of things people can code was exciting to see.
# What's next for Reach
If this was a real project, we'd work on implementing VR features for those who missed certain physical spaces. We'd also try to work out improvements to moderation, and perhaps a voice chat for users who want to call. | losing |
## Inspiration
While using ridesharing apps such as Uber and Lyft, passengers, particularly those of marginalized identities, have reported feeling unsafe or uncomfortable being alone in a car. From user interviews, every woman has mentioned personal safety as one of their top concerns within a rideshare. About 23% of American women have reported a driver for inappropriate behavior. Many apps have attempted to mitigate this issue by creating rideshare services that may hire only female drivers. However, these apps have quickly gotten shut down due to discrimination laws. Additionally, around 40% of Uber and Lyft drivers are white males, possibly due to the fact that many minorities may feel uncomfortable in certain situations as a driver. We aimed to create a rideshare app which would provide the same sense of safeness and comfort that the aforementioned apps aimed to provide while making sure that all backgrounds are represented and accounted for.
## What it does
Our app, Driversity (stylized DRiveristy), works similarly to other ridesharing apps, with features put in place to assure that both riders and drivers feel safe. The most important feature we'd like to highlight is a feature that allows the user to be alerted if a driver goes off the correct path to the destination designated by the rider. The app will then ask the user if they would like to call 911 to notify them of the driver's actions. Additionally, many of the user interviews we conducted stated that many women prefer to walk around, especially at night, while waiting for a rideshare driver to pick them up for safety concerns. The app provides an option for users to select in order to allow them to walk around while waiting for their rideshare, also notifying the driver of their dynamic location. After selecting a destination, the user will be able to select a driver from a selection of three drivers on the app. On this selection screen, the app details both identity and personality traits of the drivers, so that riders can select drivers they feel comfortable riding with. Users also have the option to provide feedback on their trip afterward, as well as rating the driver on various aspects such as cleanliness, safe driving, and comfort level. The app will also use these ratings to suggest drivers to users that users similar to them rated highly.
## How we built it
We built it using Android Studio in Java for full-stack development. We used the Google JavaScript Map API to display the map for the user when selecting destinations and tracking their own location on the map. We used Firebase to store information and for authentication of the user. We used DocuSign in order for drivers to sign preliminary papers. We used OpenXC to calculate if a driver was traveling safely and at the speed limit. In order to give drivers benefits, we are giving them the choice to take 5% of their income and invest it, and it will grow naturally as the market rises.
## Challenges we ran into
We weren't very familiar with Android Studio, so we first attempted to use React Native for our application, but we struggled a lot implementing many of the APIs we were using with React Native, so we decided to use Android Studio as we originally intended.
## What's next for Driversity
We would like to develop more features on the driver's side that would help the drivers feel more comfortable as well. We also would like to include the usage of the Amadeus travel APIs. | ## Inspiration
Food is tastier when it's in season. It's also better for the environment, so we decided to promote seasonal foods to have a positive impact on both our taste buds and the planet!
## What it does
When you navigate to a recipe webpage, you can use our chrome extension to view which recipe ingredients are in season, and which ones are not, based on the current month. You also get an overall rating on the "in-season-ness" of the recipe, and you can hover over the produce to view the months when they will be the freshest.
## How we built it
The UI of the extension is built using vanilla JavaScript, HTML and CSS. The backend is written in python as a flask app, and is hosted on Heroku for it to be widely accessible.
## Challenges we ran into
We had trouble writing the logic to determine which produce appears in the ingredient list of the recipes.
We also had a really tough time uploading our backend server to Heroku. This was because we were running into CORS issues since we wanted our extension to be able to make a request from any domain. The fix was quite simple, but it still took a while for us to understand what was going on!
## Accomplishments that we're proud of
Pretty UI and nice animations.
Compatibility with most recipe sites.
We finished the project in time.
First hackathon for 3 out of 4 of our team members!
## What we learned
How to make a chrome extension.
How to build an API.
What CORS is.
Basic frontend development skills.
Onions have a season!
## What's next for Well Seasoned
Support locations outside of Canada.
Functionality to suggest recipes based on the season. | ## Inspiration
As college students learning to be socially responsible global citizens, we realized that it's important for all community members to feel a sense of ownership, responsibility, and equal access toward shared public spaces. Often, our interactions with public spaces inspire us to take action to help others in the community by initiating improvements and bringing up issues that need fixing. However, these issues don't always get addressed efficiently, in a way that empowers citizens to continue feeling that sense of ownership, or sometimes even at all! So, we devised a way to help FixIt for them!
## What it does
Our app provides a way for users to report Issues in their communities with the click of a button. They can also vote on existing Issues that they want Fixed! This crowdsourcing platform leverages the power of collective individuals to raise awareness and improve public spaces by demonstrating a collective effort for change to the individuals responsible for enacting it. For example, city officials who hear in passing that a broken faucet in a public park restroom needs fixing might not perceive a significant sense of urgency to initiate repairs, but they would get a different picture when 50+ individuals want them to FixIt now!
## How we built it
We started out by brainstorming use cases for our app and and discussing the populations we want to target with our app. Next, we discussed the main features of the app that we needed to ensure full functionality to serve these populations. We collectively decided to use Android Studio to build an Android app and use the Google Maps API to have an interactive map display.
## Challenges we ran into
Our team had little to no exposure to Android SDK before so we experienced a steep learning curve while developing a functional prototype in 36 hours. The Google Maps API took a lot of patience for us to get working and figuring out certain UI elements. We are very happy with our end result and all the skills we learned in 36 hours!
## Accomplishments that we're proud of
We are most proud of what we learned, how we grew as designers and programmers, and what we built with limited experience! As we were designing this app, we not only learned more about app design and technical expertise with the Google Maps API, but we also explored our roles as engineers that are also citizens. Empathizing with our user group showed us a clear way to lay out the key features of the app that we wanted to build and helped us create an efficient design and clear display.
## What we learned
As we mentioned above, this project helped us learn more about the design process, Android Studio, the Google Maps API, and also what it means to be a global citizen who wants to actively participate in the community! The technical skills we gained put us in an excellent position to continue growing!
## What's next for FixIt
An Issue’s Perspective
\* Progress bar, fancier rating system
\* Crowdfunding
A Finder’s Perspective
\* Filter Issues, badges/incentive system
A Fixer’s Perspective
\* Filter Issues off scores, Trending Issues | partial |
## Inspiration
Many students have learning disabilities that negatively impact their education. After doing some research, we learned that there were nearly 150,000 students in Ontario alone!
UofT offers note-taking services to students that are registered with accessibility services, but the service relies on the quality and availability of fellow student volunteers. After learning about Cohere, we realized that we could create a product that could more reliably provide this support to students.
## What it does
Scribes aims to address these issues by providing a service that simplifies and enhances accessibility in the note-taking process. The web app was built with accessibility as the main priority, delivered through high contrast, readable fonts and clear hierarchies.
To start saving lecture sessions, the user can simply sign up for free with their school email! Scribes allows students to record live lectures on either their phone or laptop, and then receive a live transcript that can be highlighted and commented on in real-time. Once class is done, the annotated transcript is summarized by Cohere's advanced NLP algorithms to provide an easily digestible overview of the session material.
The student is also presented with definitions and additional context to better understand key terms and difficult concepts. The recorded sessions and personalized notes are always accessible through the student's tailored dashboard, where they can organize their study material through the selection of tags and folders.
## How we built it
*Designers:*
* Conducted research to gain a better understanding of our target demographic, their pain points, and our general project scope.
* Produced wireframes to map out the user experience.
* Gathered visual inspiration and applied our own design system toward creating a final design for the web app.
*Devs:*
* Used Python and AssemblyAI API to convert audio files into text transcription
* Used Cohere to summarize text, and adjusted hyperparameters in order to generate accurate and succinct summarizations of the input text
* Used Flask to create a backend API to send data from the frontend to the backend and to retrieve data from the Cohere API
*Team:*
* Brainstormed potential project ideas and features specific to this flow.
* Shared ideas and portions of the project to combine into one overall project.
## Challenges we ran into
* Troubleshooting with code: some of our earlier approaches required components that were out of date/no longer hosted, and we had to adjust by shifting the input type
* The short timeframe was a barrier preventing us from implementing stylized front-end code. To make the most out of our time, we designed the interface on Figma, developed the back-end to transcribe the sessions, and created a simple front-end document to showcase the functionality and potential methods of integration.
* Figuring out which platform and which technologies to use such that our project would be reflective of our original idea, easy and fast to develop, and also extensible for future improvements
## Accomplishments that we're proud of
Over the course of 36 hours, we’ve managed to work together and create an effective business pitch, a Figma prototype for our web app, and a working website that transcribes and summarizes audio files.
## What we learned
Our team members learned a great deal this weekend, including: creating pitches, working in a tight timeframe, networking, learning about good accessibility practices in design when designing for those with learning needs, how to work with and train advanced machine learning models, python dependencies, working with APIs and Virtual Environments.
## What's next for Scribes
If provided with more time, we plan to implement other features — such as automatically generated cue cards, a bot to answer questions regarding session content, and collaborative notes. As we prioritize accessibility and ease-of-use, we would also conduct usability testing to continue ensuring that our users are at the forefront of our product.
To cover these additional goals, we may apply to receive funding dedicated to accessibility, such as the Government of Canada’s Enabling Education Fund. We could also partner with news platforms, wiki catalogs, and other informational websites to receive more funding and bridge the gap in accessing more knowledge online. We believe that everyone is equally deserving of receiving proper access to education and the necessary support it takes to help them make the most of it. | ## Inspiration
Professor Michelle McAllister, formerly at Northeastern University, provided notes styled in such a manner. These "incomplete" notes were filled out by students during her lectures. A team member was her student and, having done very well in her class, wanted to create similarly-styled notes for other classes. The team member envisioned other students being able to style their notes in such a way so they could practice for tests and ace their exams!
## What it does
By entering their notes to a textbox, students can use Text2Test to create fill-in-the-blank questions in order to practice for tests.
## How we built it
We used AWS APIs, specifically Lambda, Comprehend, Gateway. Additionally, we used HTML, JavaScript, Python and Ruby.
## Challenges we ran into
We had more ideas we wanted to implement, like running Optical Character Recognition (OCR) on an uploaded PDF scan of handwritten notes, but we would need more than 24 hours for such an ambitious idea. Having never used AWS prior, we had to learn how to upload code to the Lambda API and connect the Comprehend and Gateway APIs to it. We also had difficulty posting requests from the website to the Gateway API, but we eventually solved that problem. The Python code for Lambda code and the website code are saved to GitHub.
## Accomplishments that we're proud of
This website allows students to create a profile and login to a portal. Students can schedule exams, upload their notes via a submission portal, add notes to a particular subject, generate customized tests based on their notes, and test their knowledge by entering answers to fill-in-the-blank questions.
## What we learned
We learned how to utilize many AWS APIs like Comprehend, Lambda, and Gateway. In addition, we learned how to post requests in the right format from outside entities (like our Ruby on Rails website) to the AWS Gateway API.
## What's next for Text2Test
We want to give students the ability to upload handwritten notes. To increase the numbers of learning tools, we wish to include a multiple-choice section with "smart" answer choices. Finally, we want to allow images to be used as inputs and test students on content pertaining to the images. | ## Inspiration
As students who have lived through both the paper and digital forms of notes, there were many aspects of note-taking from our childhoods that we had missed out on with the newer applications for notes. To relive these nostalgic experiences, we created a note-taking application that reenacts the efficiency and simplicity of note-taking with sticky-notes. In addition, we added a modern twist of using AI through Cohere's AI API to help generate notes to help assist students with efficient note taking.
## What it does
Sticky acts similarly to other note-taking apps where users can upload pdf files of their textbook or lectures notes and make highlighted annotations along with sticky notes that can be AI generated to help assist with the student's note-taking skills.
## How we built it
The program is built with html, css, and javascript. The main pages were programmed using html and styled with css files. In addition, all interactive elements were programmed using common javascript. Initially, we were planning on using Taipy for our UI, but since we wanted more freedom in customization of interactive elements we decided to do our own UI through javascript.
## Challenges we ran into
Some of the challenges we went into were figuring out what framework we should use for this project. Different frameworks had their own benefits but ultimately due to time we decided to create an html web-app using javascript and css to add interactive elements. In addition, this was our first project where we implemented an API for our hackathon, so there were times where most time was spent on debugging. Finally, the biggest challenge was figuring out how we could annotate a PDF, or at least give users the experience of annotating a PDF with sticky notes. :)
## Accomplishments that we're proud of
We're most proud of how much new information we learned from this hackathon. Our idea had big potential to be expanded onto other programs and we continuously worked to solve any problems that occurred during the hackathon. (NEVER GIVE UP !!! )
## What we learned
We learned many new skills that are found in front-end programming, in addition to decision-making when it comes to design ideas. Initially, we had many ideas for our program and we wanted to explore as many libraries as possible. However, throughout the implementation, we recognized that throughout the design process of the app, not everything will always be compatible which caused us to use our decision-making skills to prioritize the use of some libraries over others.
## What's next for Sticky
In the future we hope to add export options for students to download use these annotated notes for other purposes. Additionally, we hope to also add an option for students to upload their own notes and compare it with lecture or textbook notes they made have to further improve their note-taking skills. :D | partial |
## Inspiration
Ever found yourself struggling to keep up during a lecture, caught between listening to the professor while scrambling to scribble down notes? It’s all too common to miss key points while juggling the demands of note-taking – that’s why we made a tool designed to do the hard work for you!
## What it does
With a simple click, you can start recording of your lecture, and NoteHacks will start generating clear, summarized notes in real time. The summary conciseness parameter can be fine tuned depending on how you want your notes written, and will take note of when it looks like you've been distracted so that you can have all those details you would have missed. These notes are stored for future review, where you can directly ask AI about the content without having to provide background details.
## How we built it
* Backend + database using Convex
* Frontend using Next.js
* Image, speech, and text models by Groq
## Challenges we ran into
* Chunking audio to stream and process it in real-time
* Summarizing a good portion of the text, without it being weirdly chopped off and losing context
* Merge conflicts T-T
* Windows can't open 2 cameras simultaneously
## Accomplishments that we're proud of
* Real-time speech processing that displays on the UI
* Gesture recognition
## What we learned
* Real-time streaming audio and video
* Convex & Groq APIs
* Image recognition
## What's next for NoteHacks
* Support capturing images and adding them to the notes
* Allow for text editing within the app (text formatting, adding/removing text, highlighting) | ## Inspiration
Many students have learning disabilities that negatively impact their education. After doing some research, we learned that there were nearly 150,000 students in Ontario alone!
UofT offers note-taking services to students that are registered with accessibility services, but the service relies on the quality and availability of fellow student volunteers. After learning about Cohere, we realized that we could create a product that could more reliably provide this support to students.
## What it does
Scribes aims to address these issues by providing a service that simplifies and enhances accessibility in the note-taking process. The web app was built with accessibility as the main priority, delivered through high contrast, readable fonts and clear hierarchies.
To start saving lecture sessions, the user can simply sign up for free with their school email! Scribes allows students to record live lectures on either their phone or laptop, and then receive a live transcript that can be highlighted and commented on in real-time. Once class is done, the annotated transcript is summarized by Cohere's advanced NLP algorithms to provide an easily digestible overview of the session material.
The student is also presented with definitions and additional context to better understand key terms and difficult concepts. The recorded sessions and personalized notes are always accessible through the student's tailored dashboard, where they can organize their study material through the selection of tags and folders.
## How we built it
*Designers:*
* Conducted research to gain a better understanding of our target demographic, their pain points, and our general project scope.
* Produced wireframes to map out the user experience.
* Gathered visual inspiration and applied our own design system toward creating a final design for the web app.
*Devs:*
* Used Python and AssemblyAI API to convert audio files into text transcription
* Used Cohere to summarize text, and adjusted hyperparameters in order to generate accurate and succinct summarizations of the input text
* Used Flask to create a backend API to send data from the frontend to the backend and to retrieve data from the Cohere API
*Team:*
* Brainstormed potential project ideas and features specific to this flow.
* Shared ideas and portions of the project to combine into one overall project.
## Challenges we ran into
* Troubleshooting with code: some of our earlier approaches required components that were out of date/no longer hosted, and we had to adjust by shifting the input type
* The short timeframe was a barrier preventing us from implementing stylized front-end code. To make the most out of our time, we designed the interface on Figma, developed the back-end to transcribe the sessions, and created a simple front-end document to showcase the functionality and potential methods of integration.
* Figuring out which platform and which technologies to use such that our project would be reflective of our original idea, easy and fast to develop, and also extensible for future improvements
## Accomplishments that we're proud of
Over the course of 36 hours, we’ve managed to work together and create an effective business pitch, a Figma prototype for our web app, and a working website that transcribes and summarizes audio files.
## What we learned
Our team members learned a great deal this weekend, including: creating pitches, working in a tight timeframe, networking, learning about good accessibility practices in design when designing for those with learning needs, how to work with and train advanced machine learning models, python dependencies, working with APIs and Virtual Environments.
## What's next for Scribes
If provided with more time, we plan to implement other features — such as automatically generated cue cards, a bot to answer questions regarding session content, and collaborative notes. As we prioritize accessibility and ease-of-use, we would also conduct usability testing to continue ensuring that our users are at the forefront of our product.
To cover these additional goals, we may apply to receive funding dedicated to accessibility, such as the Government of Canada’s Enabling Education Fund. We could also partner with news platforms, wiki catalogs, and other informational websites to receive more funding and bridge the gap in accessing more knowledge online. We believe that everyone is equally deserving of receiving proper access to education and the necessary support it takes to help them make the most of it. | ## Inspiration
**Introducing Ghostwriter: Your silent partner in progress.** Ever been in a class where resources are so hard to come by, you find yourself practically living at office hours? As teaching assistants on **increasingly short-handed course staffs**, it can be **difficult to keep up with student demands while making long-lasting improvements** to your favorite courses.
Imagine effortlessly improving your course materials as you interact with students during office hours. **Ghostwriter listens intelligently to these conversations**, capturing valuable insights and automatically updating your notes and class documentation. No more tedious post-session revisions or forgotten improvement ideas. Instead, you can really **focus on helping your students in the moment**.
Ghostwriter is your silent partner in educational excellence, turning every interaction into an opportunity for long-term improvement. It's the invisible presence that delivers visible results, making continuous refinement effortless and impactful. With Ghostwriter, you're not just tutoring or bug-bashing - **you're evolving your content with every conversation**.
## What it does
Ghostwriter hosts your class resources, and supports searching across them in many ways (by metadata, semantically by content). It allows adding, deleting, and rendering markdown notes. However, Ghostwriter's core feature is in its recording capabilities.
The record button starts a writing session. As you speak, Ghostwriter will transcribe and digest your speech, decide whether it's worth adding to your notes, and if so, navigate to the appropriate document and insert them at a line-by-line granularity in your notes, integrating seamlessly with your current formatting.
## How we built it
We used Reflex to build the app full-stack in Python, and support the various note-management features including addition, deleting, selecting, and rendering. As notes are added to the application database, they are also summarized and then embedded by Gemini 1.5 Flash-8B before being added to ChromaDB with a shared key. Our semantic search is also powered by Gemini-embedding and ChromaDB.
The recording feature is powered by Deepgram's threaded live-audio transcription API. The text is processed live by Gemini, and chunks are sent to ChromaDB for queries. Distance metrics are used as thresholds to not create notes, add to an existing note, or create a new note. In the latter two cases, llama3-70b-8192 is run through Groq to write on our (existing) documents. It does this through a RAG on our docs, as well as some prompt-engineering. To make insertion granular we add unique tokens to identify candidate insertion-points throughout our original text. We then structurally generate the desired markdown, as well as the desired point of insertion, and render the changes live to the user.
## Challenges we ran into
Using Deepgram and live-generation required a lot of tasks to run concurrently, without blocking UI interactivity. We had some trouble reconciling the requirements posed by Deepgram and Reflex on how these were handled, and required us redesign the backend a few times.
Generation was also rather difficult, as text would come out with irrelevant vestiges and explanations. It took a lot of trial and error through prompting and other tweaks to the generation calls and structure to get our required outputs.
## Accomplishments that we're proud of
* Our whole live note-generation pipeline!
* From audio transcription process to the granular retrieval-augmented structured generation process.
* Spinning up a full-stack application using Reflex (especially the frontend, as two backend engineers)
* We were also able to set up a few tools to push dummy data into various points of our process, which made debugging much, much easier.
## What's next for GhostWriter
Ghostwriter can work on the student-side as well, allowing a voice-interface to improving your own class notes, perhaps as a companion during lecture. We find Ghostwriter's note identification and improvement process very useful ourselves.
On the teaching end, we hope GhostWriter will continue to grow into a well-rounded platform for educators on all ends. We envision that office hour questions and engagement going through our platform can be aggregated to improve course planning to better fit students' needs.
Ghostwriter's potential doesn't stop at education. In the software world, where companies like AWS and Databricks struggle with complex documentation and enormous solutions teams, Ghostwriter shines. It transforms customer support calls into documentation gold, organizing and structuring information seamlessly. This means fewer repetitive calls and more self-sufficient users! | partial |
## Inspiration
We wanted to find a way to make transit data more accessible to the public as well as provide fun insights into their transit activity. As we've seen in Spotify Wrapped, people love seeing data about themselves. In addition, we wanted to develop a tool to help city organizers make data-driven decisions on how they operate their networks.
## What it does
Transit Tracker is simultaneously a tool for operators to analyze their network as well as an app for users to learn about their own activities and how it lessens their impact on the environment. For network operators, Transit Tracker allows them to manage data for a system of riders and individual trips. We developed a visual map that shows the activity of specific sections between train stations. For individuals, we created an app that shows data from their own transit activities. This includes gallons of gas saved, time spent riding, and their most visited stops.
## How we built it
We primarily used Palantir Foundry to provide a platform for our back-end data management. Used objects within Foundry to facilitate dataset transformation using SQL and python. Utilized Foundry Workshop to create user interface to display information.
## Challenges we ran into
Working with the geoJSON file format proved to be particularly challenging, because it is semi-structured data and not easily compatible with the datasets we were working with. Another large challenge we ran into was learning how to use Foundry. This was our first time using the software, we had to first learn the basics before we could even begin tackling our problem.
## Accomplishments that we're proud of
With Treehacks being all of our first hackathons, we're proud of making it to the finish line and building something that is both functional and practical. Additionally, we're proud of the skills we've gained from learning to deal with large data as well as our ability to learn and use foundry in the short time frame we had.
## What we learned
We learned just how much we take everyday data analysis for granted. The amount of information being processed everyday in regards to data is unreal. We only tackled a small level of data analysis and even we had a multitude of difficult issues that had to be dealt with. The understanding we’ve learned from dealing with data is so valuable and the skills we’ve gained in using a completely foreign application to build something in such a short amount of time has been truly insightful.
## What's next for Transit Tracker
The next step for Transit Tracker would be to be able to translate our data (that is being generated through objects) onto a visual map where the routes would constantly be changing in regards to the data being collected. Being able to visually represent the change onto a graph would be such a valuable step to achieve as it would mean we are working our way towards a functional application. | ## Inspiration
No one likes being stranded at late hours in an unknown place with unreliable transit as the only safe, affordable option to get home. Between paying for an expensive taxi ride yourself, or sharing a taxi with random street goers, the current options aren't looking great. WeGo aims to streamline taxi ride sharing, creating a safe, efficient and affordable option.
## What it does
WeGo connects you with people around with similar destinations who are also looking to share a taxi. The application aims to reduce taxi costs by splitting rides, improve taxi efficiency by intelligently routing taxi routes and improve sustainability by encouraging ride sharing.
### User Process
1. User logs in to the app/web
2. Nearby riders requesting rides are shown
3. The user then may choose to "request" a ride, by entering a destination.
4. Once the system finds a suitable group of people within close proximity, the user will be send the taxi pickup and rider information. (Taxi request is initiated)
5. User hops on the taxi, along with other members of the application!
## How we built it
The user begins by logging in through their web browser (ReactJS) or mobile device (Android). Through API calls to our NodeJS backend, our system analyzes outstanding requests and intelligently groups people together based on location, user ratings & similar destination - all in real time.
## Challenges we ran into
A big hurdle we faced was the complexity of our ride analysis algorithm. To create the most cost efficient solution for the user, we wanted to always try to fill up taxi cars completely. This, along with scaling up our system to support multiple locations with high taxi request traffic was definitely a challenge for our team.
## Accomplishments that we're proud of
Looking back on our work over the 24 hours, our team is really excited about a few things about WeGo. First, the fact that we're encouraging sustainability on a city-wide scale is something really important to us. With the future leaning towards autonomous vehicles & taxis, having a similar system like WeGo in place we see as something necessary for the future.
On the technical side, we're really excited to have a single, robust backend that can serve our multiple front end apps. We see this as something necessary for mass adoption of any product, especially for solving a problem like ours.
## What we learned
Our team members definitely learned quite a few things over the last 24 hours at nwHacks! (Both technical and non-technical!)
Working under a time crunch, we really had to rethink how we managed our time to ensure we were always working efficiently and working towards our goal. Coming from different backgrounds, team members learned new technical skills such as interfacing with the Google Maps API, using Node.JS on the backend or developing native mobile apps with Android Studio. Through all of this, we all learned the persistence is key when solving a new problem outside of your comfort zone. (Sometimes you need to throw everything and the kitchen sink at the problem at hand!)
## What's next for WeGo
The team wants to look at improving the overall user experience with better UI, figure out better tools for specificially what we're looking for, and add improved taxi & payment integration services. | ## Inspiration
The inspiration for this app was to create a system that is able to handle thousands of calculations per second, but still maintain a smooth, real-time updating UI for users. If designed well, our app could exhibit good scalability which could be useful, should the system ever require an expansion.
## What it does
Taxiify maps the position of taxis in real time on a clean map-based UI. Once some taxis are being mapped, 'Users' can be placed on our map. Once a user(s) is placed, our app would update, in real time, the ID and distance of the closest taxi available.
## How I built it
Since we did not have actual Taxis to map, we used a Python script to generate random paths for these taxis to follow. The script did everything from creating, deleting, and updating Taxi data. Our script was ran periodically from our Node.js backend using a cron job.
The taxi data is sent to our Firebase DB. A Node.js backend listens for changes in our firebase, and pulls any necessary data.
Once the data is pulled with Node.js, a React front-end is able to display the contents of our DB, in real time, while, continuously doing and updating calculations of distance for each user and each cab.
## Challenges I ran into
Much of the challenge with this project revolved around DevOps. We ran into tonnes of problems with setting up servers and connections, which drew us back many hours.
Also, none of us had ever used any of the tools that we ended up using for this project. So a lot of the time was spent learning how to use these tools, and then how to extend them to our project.
## Accomplishments that I'm proud of
I am happy that we were able to come up with a clean, understandable System Architecture. Once this was out of the way, we were able to focus all of our energy onto building the app. This went to show how important an understandable plan can be.
## What I learned
I learned that DevOps, while tremendously annoying, is of critical importance to any project. To avoid frustration in the future, it is important to do any DevOps work before hand as to not lose motivation during the building process.
Also, I learned that learning new tools from scratch may not be the best idea to do at a Hackathon, since time is of the essence. However, every groupmate did acquire at least one new skill and that is a victory in and of itself.
## What's next for Taxiify
Scalability, Scalability, Scalability... | partial |
## Introduction
[Best Friends Animal Society](http://bestfriends.org)'s mission is to **bring about a time when there are No More Homeless Pets**
They have an ambitious goal of **reducing the death of homeless pets by 4 million/year**
(they are doing some amazing work in our local communities and definitely deserve more support from us)
## How this project fits in
Originally, I was only focusing on a very specific feature (adoption helper).
But after conversations with awesome folks at Best Friends came a realization that **bots can fit into a much bigger picture in how the organization is being run** to not only **save resources**, but also **increase engagement level** and **lower the barrier of entry points** for strangers to discover and become involved with the organization (volunteering, donating, etc.)
This "design hack" comprises of seven different features and use cases for integrating Facebook Messenger Bot to address Best Friends's organizational and operational needs with full mockups and animated demos:
1. Streamline volunteer sign-up process
2. Save human resource with FAQ bot
3. Lower the barrier for pet adoption
4. Easier donations
5. Increase visibility and drive engagement
6. Increase local event awareness
7. Realtime pet lost-and-found network
I also "designed" ~~(this is a design hack right)~~ the backend service architecture, which I'm happy to have discussions about too!
## How I built it
```
def design_hack():
s = get_sketch()
m = s.make_awesome_mockups()
k = get_apple_keynote()
return k.make_beautiful_presentation(m)
```
## Challenges I ran into
* Coming up with a meaningful set of features that can organically fit into the existing organization
* ~~Resisting the urge to write code~~
## What I learned
* Unique organizational and operational challenges that Best Friends is facing
* How to use Sketch
* How to create ~~quasi-~~prototypes with Keynote
## What's next for Messenger Bots' Best Friends
* Refine features and code :D | ## Inspiration
There are two types of pets wandering unsupervised in the streets - ones that are lost and ones that don't have a home to go to. Pet's Palace portable mini-shelters services these animals and connects them to necessary services while leveraging the power of IoT.
## What it does
The units are placed in streets and alleyways. As an animal approaches the unit, an ultrasonic sensor triggers the door to open and dispenses a pellet of food. Once inside, a live stream of the interior of the unit is sent to local animal shelters which they can then analyze and dispatch representatives accordingly. Backend analysis of the footage provides information on breed identification, custom trained data, and uploads an image to a lost and found database. A chatbot is implemented between the unit and a responder at the animal shelter.
## How we built it
Several Arduino microcontrollers distribute the hardware tasks within the unit with the aide of a wifi chip coded in Python. IBM Watson powers machine learning analysis of the video content generated in the interior of the unit. The adoption agency views the live stream and related data from a web interface coded with Javascript.
## Challenges we ran into
Integrating the various technologies/endpoints with one Firebase backend.
## Accomplishments that we're proud of
A fully functional prototype! | ## Inspiration
We hear all the time that people want a dog but they don't want the committment and yet there's still issues with finding a pet sitter! We flipped the 'tinder'-esque mobile app experience around to reflect just how many people are desparate and willing to spend time with a furry friend!
## What it does
Our web app allows users to create an account and see everyone who is currently looking to babysit a cute puppy or is trying to find a pet sitter so that they can go away for vacation! The app also allows users to engage in chat messages so they can find a perfect weekend getaway for their dogs.
## How we built it
Our web app is primariy a react app on the front end and we used a combination of individual programming and extreme programming when we hit walls.
Ruby on rails and SQLite run the back end and so with a team of four we had two people manning the keyboards for the front end and the other two working diligently on the backend.
## Challenges we ran into
GITHUB!!!! Merging, pushing, pulling, resolving, crying, fetching, syncing, sobbing, approving, etc etc. We put our repo through a stranglehold of indecipherable commits more than a few times and it was our greatest rival
## Accomplishments that we're proud of
IT WORKS! We're so proud to build an app that looks amazing and also communicates on a sophisticated level. The user experience is cute and delightful but the complexities are still baked in like session tokens and password hashing (plus salt!)
## What we learned
The only way to get fast is to go well. The collaboration phase with github ate up a large part of our time every couple of hours and there was nobody to blame but ourselves.
## What's next for Can I Borrow Your Dog
We think this a pretty cool little app that could do a LARGE refactoring. Whether we keep in touch as a gorup and maintain this project to spruce up our resumes is definitely being considered. We'd like to show our friends and family how much we accomplished in just 36 hours (straight lol)! | winning |
***An interesting and easy-to-use mobile app that tells you more about the dog you love at the first sight.***
## Inspiration
Have you ever been attracted by a cuttie dog on the street but don't know what kinds of dog it is?
Don't Worry, PePuppy is right here for you! With a few simple operations, you will get all the information of the dog and the nearest location to adopt your own puppy.
## What it does
A simple click on the fuzzy icon to get start and you can choose either to take a photo of the dog or upload the photo from your album. Our app will identify the image and then show the information of the dog breed you are looking for!
## How we built it
We built our java-based android mobile app with Android Studio and registered the app on the Firebase platform to use its powerful toolkits. The app utilizes the Google Cloud APIs and ML Kit to label the photos and return the processed information about the identified dog breed.
## Challenges we faced
Since this is the first hackathon for most of us, we bumped into many issues while building our projects. We spent plenty of time studying the new development platforms and APIs and have hard time customizing our configuration settings.
## Our accomplishments
Although none of our team members has mobile development experience before, we made the idea of PePuppy come alive with a interesting Mobil App. From building framework to labeling images, we learned from scratch and failed so many times, but we finally did it! We also used Google Clouds to improve labeling accuracy, returning the specific breed of the dog instead of a general "dog" tag.
## What we learned
We learned to develop a fully-functioning android mobile app with Android Studio and used various APIs, such as ML kit, and Google Cloud Vision and Function APIs. It’s fun to work in team and eventually build up to something we are proud of!
## What's Next
We'll further optimize the accuracy of our app's labels by implementing our own classification models.
We would also like to perform the real-time query online to extract more exact and filtered information about the dog breeds, group, origin, habits and etc. We plan to use website crawler to get access to Wiki page and extract useful information for our users.
We would improves our UI to have more user-friendly features :)
There exists a privacy concern of the dogs that we may need to think more about in the future deployment of the app. | ## Inspiration
While brainstorming with our team, we discovered that all of us were extremely interested in learning and using Google Vision.
## What it does
Our web application allows users to upload a photo of an animal - this may be an animal they found on the street, faced while hiking, or discovered while exploring. Our web application then uses the Google Vision API to detect the name and species of the particular animal and return it to the user. Additionally, our app will provide the user with names, addresses, and numbers on nearby animal centers.
## How we built it
We built this by utilizing the Google Vision API, Google Maps API, and the Google Places API. With these tools, we were able to combine a few components to make a user-friendly web application. The backend is mostly designed in Python while the frontend design is built in HTML and CSS.
## Challenges we ran into
We ran into a few challenges. At first, we were trying to use react and javascript for the backend. However, we soon realized that this complicated things further when it came to connecting our elements of code together. We then had to adapt quickly and switch to a Python run program.
## Accomplishments that we're proud of
We are proud of the web application we have created. We're happy with the results of our backend and love the frontend design.
## What we learned
For most of us, this is our first hackathon or the first time creating a project with a team. We learned a ton of new things. We became familiar with the Google Cloud API and its documentation and implementation. For one of our teammates, this is the first time ever using or working with an API. Google's detailed documentation allowed easier learning. Not only that but, we learned how to work in a team, compromise with ideas, and help each other along the way when we didn't understand things.
## What's next for WhatIsThat?!
In the future, we would like to give information on what to do when you see an animal. For example, if the user snaps a shot of a poisonous snake, we want our app to give it what to do when they see this or how to respond in emergency situations. This web application has many paths and additions that can be made to make it even more useful. However, with the time constraint, we felt that we implemented everything we could. | ## Inspiration
Not all hackers wear capes - but not all capes get washed correctly. Dorming on a college campus the summer before our senior year of high school, we realized how difficult it was to decipher laundry tags and determine the correct settings to use while juggling a busy schedule and challenging classes. We decided to try Google's up and coming **AutoML Vision API Beta** to detect and classify laundry tags, to save headaches, washing cycles, and the world.
## What it does
L.O.A.D identifies the standardized care symbols on tags, considers the recommended washing settings for each item of clothing, clusters similar items into loads, and suggests care settings that optimize loading efficiency and prevent unnecessary wear and tear.
## How we built it
We took reference photos of hundreds of laundry tags (from our fellow hackers!) to train a Google AutoML Vision model. After trial and error and many camera modules, we built an Android app that allows the user to scan tags and fetch results from the model via a call to the Google Cloud API.
## Challenges we ran into
Acquiring a sufficiently sized training image dataset was especially challenging. While we had a sizable pool of laundry tags available here at PennApps, our reference images only represent a small portion of the vast variety of care symbols. As a proof of concept, we focused on identifying six of the most common care symbols we saw.
We originally planned to utilize the Android Things platform, but issues with image quality and processing power limited our scanning accuracy. Fortunately, the similarities between Android Things and Android allowed us to shift gears quickly and remain on track.
## Accomplishments that we're proud of
We knew that we would have to painstakingly acquire enough reference images to train a Google AutoML Vision model with crowd-sourced data, but we didn't anticipate just how awkward asking to take pictures of laundry tags could be. We can proudly say that this has been an uniquely interesting experience.
We managed to build our demo platform entirely out of salvaged sponsor swag.
## What we learned
As high school students with little experience in machine learning, Google AutoML Vision gave us a great first look into the world of AI. Working with Android and Google Cloud Platform gave us a lot of experience working in the Google ecosystem.
Ironically, working to translate the care-symbols has made us fluent in laundry. Feel free to ask us any questions,
## What's next for Load Optimization Assistance Device
We'd like to expand care symbol support and continue to train the machine-learned model with more data. We'd also like to move away from pure Android, and integrate the entire system into a streamlined hardware package. | losing |
## Problem
Going to Berkeley, it's a truism that dining hall food is, well, not great. As college students who don't necessarily have the monetary means to eat out, we are forced to eat whatever the dining hall throws us, whether that be uncooked pork, salads infested with E. coli, or salmonella-infested chicken. Often, we leave the dining hall with empty stomachs and demoralized state of mind. Furthermore, students currently have to message all social media in order to find a friend to eat, which creates significant friction in coordinating meals. Lastly, CalDining's improvements feel slow and inefficient with changes often feeling highly undemocratic.
## Target Market
Our primary target market is students at university. Students are the main users of our application because students eat at the dining hall on a large-scale basis daily. Our secondary target market is the university itself because universities will benefit greatly from the democratized access to information on our platform in order to improve their meal selection, waste management, and business model.
## Solution
DineRight has four key features to improve this experience for college students and university dining-hall management.
1. We enable **real-time reviews of dining hall food**. Each meal, students have multiple dining halls, and thus food options, to choose from. Currently, students will explore Cal Dining's online menu to help them decide which cafeteria to dine at. However, this method lacks democratization and information density than other applications like Yelp have. To solve this issue, DineRight imports the dining hall options and nutrition information for every meal each day and allows students to rate each of the items served at all dining halls in real-time. Other students can see these reviews live to advise their dining-hall decision. The fish tacos were a bit overcooked at Berkeley's Crossroads? We now know to avoid Crossroads (or at least avoid the tacos)!
2. Searching through dining hall reviews before every meal is tedious, especially on an empty stomach. We have a solution. After you review your first few meals, **we use machine learning (specifically clustering algorithms) in order to recommend the best dining hall for you at the current time, given the food being served and reviews**. More technically, if students who have similar tastes to you are enjoying a particular dining hall or food item, we infer that you have a higher probability of also enjoying the food and will recommend it. We will send you a notification along the lines of "We think you might like Cafe 3's Pesto Pasta with Sun-Dried Tomatoes." Your input on our recommendations will further improve the algorithm for everyone.
3. Finally, most students prefer to eat at the dining hall with a few friends. However, finding a group for three meals a day can be difficult given the student's busyness. We will thus notify you when your friends attend dining halls, so you can join them! **Get ready to receive notifications like "Hungry right now? Join Arjun, Tony, and Chris are at Clark Kerr dining hall!"** This information can also be viewed by opening the app.
4. This data is a treasure chest for dining halls, so we built a dining hall management portal, in addition. The portal allows dining halls to receive *actionable* feedback about their food. For example, Crossroads' reviews might indicate that Pork Lasanga was perfect, but a bit too salty; they can fix this for next time. ***Without DineRight, Crossroads' would just see the lasagna piling up in their compost bins, but not understand the cause.*** This will significantly reduce dining hall food waste and encourage dining halls to focus on quality.
## Competitive Growth Plan
1. Continuous R&D and Technical Strength: We plan to continue building our application with several key new features after the hackathon such as a DineRight Climate Score and DineRight Nutrition Score such that students are able to dine more consciously and holistically. Furthermore, some competitive elements we may add are Dining Hall wars or scavenger hunts in the dining halls in order to improve the social features in the dining hall.
2. Distribution and Marketing: We plan to distribute this application in both the App Store and the Google Play store for students to utilize. Furthermore, we plan to deploy our web app online for administrators to be able to take advantage of the system, similar to existing Berkeley applications like BerkeleyTime. In doing so, we plan to make a strategic partnership with CalDining as a starting point, which will provide us with the monetization necessary to scale. Afterward, we will apply our business model to other universities in hopes of viral growth and improvement in food quality.
3. First Mover Advantage: As first movers in the archaic domain of CalDining, we are able to capitalize on the existing market share and take advantage of the opportunities that currently exist. As we rapidly iterate and test our products at Berkeley and beyond, we hope to set the dominant design in the market.
## Technologies
Frontend:
Used the JavaScript framework Vue.js to streamline the development of our multi-page and multi-page component application. We also used Vuetify as a component library to incorporate material design into our user interface. Our application is a Progressive Web-App that is responsive based on the size of the screen, from phones to computer screens to suit the users' needs no matter what device they are using our web app on.
Natural Language Processing:
We are actively working on and improving a natural language processing algorithm that powers the dining hall and food recommendation system. It is an unsupervised machine learning algorithm that utilizes the TfIdfVectorizer with N-grams and K-means clustering in order to identify unique student subgroups in cuisine and restaurant preference. Digging deeper into the specifics, the TfIdfVectorizer converts the qualitative content from user comments and reviews and quantifies it in a manner such that we are able to identify words that probabilistically appear the most and least together. We believe that TfIdfVectorizer will be more effective in comparison to a more naive CountVectorizer approach because the TfIdfVectorizer accounts for the word distribution across documents.
Computer Vision:
We are also actively working on and improving a computer vision deep-learning algorithm. Because of the time constraints in this hackathon, we utilized an off-the-shelf pre-trained [VGG Neural Network Architecture](https://arxiv.org/pdf/1409.1556.pdf) in order to detect foods in images and label them. We chose the VGG Net because it has proven itself in object detection for large-scale images. To improve the transfer learning process to adapt more to CalDining specific foods, we are adding several layers beyond the current VGG Neural Network Architecture in order to better characterize these foods specifically. As we are able to build our own dataset of CalDining food, we will continuously train these algorithms. This computer vision algorithm will make the entire commenting and review process more seamless because it reduces the time spent tagging images.
CockroachDB:
Our Node.js backend connects to our CockroachDB which is running in CockroachDB Cloud on Google Cloud. We mainly rely on CockroachDB as our relational database of choice due to its focus on scalability and parallelism (thought of as a drop-in replacement for Google Spanner).
\*Due to time constraints, some of these features/concepts are not fully functioning/implemented in our current prototype. As we prepare for a wider release, these are the immediate items that will be fleshed out. | ## Inspiration
Everyone loves to eat. But whether you’re a college student, a fitness enthusiast trying to supplement your gains, or have dietary restrictions, it can be hard to come up with meal ideas. LetMeCook is an innovative computer vision-powered web application that combines a scan of a user’s fridge or cupboard with dietary needs to generate personalized recipes based on the ingredients they have.
## What it does
When opening LetMeCook, users are first prompted to take an image of their fridge or cupboard. After this, the taken image is sent to a backend server where it is entered into an object segmentation and image classification machine-learning algorithm to classify the food items being seen. Next, the app sends this data to the Edamam API, which then returns comprehensive nutritional facts for each ingredient. After this, users are presented with an option to add custom dietary needs or go directly to the recipe page. When adding dietary needs, users fill out a questionnaire regarding allergies, dietary preferences (such as vegetarian or vegan), or specific nutritional goals (like high-protein or low-carb). They are also prompted to select a meal type (like breakfast or dinner), time-to-prepare limit, and tools available for preparation (like microwave or stove). Next, the dietary criteria, classified ingredients, and corresponding nutritional facts are sent to the OpenAI API, and a personalized recipe is generated to match the user's needs. Finally, LetMeCook displays the recipe and step-by-step instructions for preparation onscreen. If users are unsatisfied with the recipe, they can add a comment and generate a new recipe.
## How we built it
The frontend was designed using React with Tailwind for styling. This was done to allow the UI to be dynamic and adjust seamlessly regardless of varying devices. A component library called Radix-UI was used for prefabricating components and Lucide was used for icon components. To use the device's local camera in the app, a library called react-dashcam was utilized. To edit the photos, a library called react-image-crop was used. After the initial image and dietary restrictions are entered, the image is encoded to base64 and entered as a parameter in an HTTP request to the backend server. The backend server is hosted using ngrok and passes the received image to the Google Cloud Vision API. A response containing the classified ingredients is then passed to the Edamam API where nutritional facts are stored about each respective ingredient. All of the information gathered until this point (ingredients, nutritional facts, dietary needs) is then passed to the OpenAI API where a custom recipe is generated and returned. Finally, a response containing the meal name, ingredients, step-by-step instructions for preparation, and nutritional information is returned to the interface and displayed onscreen.
## Challenges we ran into
One of the biggest challenges we ran into was creating the model to accurately and rapidly classify the objects in the taken picture. Because we were trying to classify multiple objects from the same image, we sought to create an object segmentation and classification model, but this required hardware capabilities incompatible with our laptops. As a result, we had to switch to using Google Cloud's Vision API, which would allow us to perform the same data extraction necessary. Additionally, we ran into many issues when working on the frontend and allowing it to be responsive regardless of device type, size, or orientation. Finally, we had to troubleshoot the sequence of HTTP communication between the interface and the backend server for specific data types and formatting.
## Accomplishments that we're proud of
We are proud to have recognized a very prevalent problem around us and engineered a seamless and powerful tool to solve it. We all enjoyed the bittersweet experience of discovering bugs, editing troublesome code, and staying up overnight working to overcome the various challenges we faced. Additionally, we are proud to have learned many new tools and technologies to create a successful mobile application. Ultimately, our efforts and determination culminated in an innovative, functional product we are all very proud of and excited to present. Lastly, we are proud to have created a product that could reduce food waste and revolutionize the home cooking space around the world.
## What we learned
First and foremost, we've learned the profound impact that technology can have on simplifying everyday challenges. In researching the problem, we learned how pervasive the problem of "What to make?" is in home cooking around the world. It can be painstakingly difficult to make home-cooked meals with limited ingredients and numerous dietary criteria. However, we also discovered how effective intelligent-recipe generation can be when paired with computer vision and user-entered dietary needs. Finally, the hackathon motivated us to learn a lot about the technologies we worked with - whether it be new errors or desired functions, new ideas and strategies had to be employed to make the solution work.
## What's next for LetMeCook
There is much potential for LetMeCook's functionality and interfacing. First, the ability to take photos of multiple food storages will be implemented. Additionally, we will add the ability to manually edit ingredients after scanning, such as removing detected ingredients or adding new ingredients. A feature allowing users to generate more detailed recipes with currently unavailable ingredients would also be useful for users willing to go to a grocery store. Overall, there are many improvements that could be made to elevate LetMeCook's overall functionality. | ## Inspiration
According to a study done by Forbes in 2022, nearly **40%** of US college students face food insecurity. It is a rather shocking number. Food insecurity on college campuses is now being called the *invisible epidemic*. As freshmen living on campus (who are required to be on university’s meal plans, which has a set number of meal swipes per week), we often see posts on platforms like Reddit and GroupMe by people who offer to share as well as request extra meal swipes without much follow up. We want to not only provide a better way for both parties to connect, but also to encourage students to participate in such activities.
## What it does
MealMate is an app -
1. Users (both sharers and requesters) sign up to the app to participate.
2. Users get reminded at the beginning of each week to toggle a status, indicating if they have extra meal swipes to share or not that week. This status can be toggled at any time.
3. The app’s home screen is a map of the dining halls and its number of sharers in real time, based on if the sharers have entered the dining hall locations (location data).
4. Requesters can then click on the dining hall and the app will randomly pick a sharer at that dining hall, notify them there’s a request. The selected sharer can then accept the request and meet the requester at the entrance of the dining hall.
5. The matching/connection process is automatic, and kept anonymous until the meeting (after the connection is made).
## How we built it
We brainstormed possible UX choices to ensure the easiest (most frictionless) way for both sharers’ and requesters' journey. We used figma to mock up the UX pretty quickly. We began to build the app using React and a backend database, but ended up running into a few challenges and weren’t able to get a full running demo.
## Challenges we ran into
1. React - we’ve heard alot about React and wanted to incorporate it into our project. Following the tutorials we ran into package installation issues on our machine, and spent most of the time searching for solutions. Unfortunately we weren’t able to find a solution in time for coding the web app.
2. Google API - We planned on hosting the webapp on google cloud and using google maps API and were able to setup services and an app project, but were not able to get the credentials working, partly due to our issues with installing React
## Accomplishments that we're proud of
We used design thinking methodology to brainstorm the UX design. Proud of the UX solution we came up with in order to make both the sharer and the requester experience frictionless. We are really looking forward to testing our prototype.
## What we learned
1. Don’t miss the workshops that can help with rapid prototyping. We could have tried out some of the new tools offered instead of learning React.
2. Get better at rapid prototyping by thinking through what’s required minimally and what can be “fake” to demonstrate the key idea. Worry about certain implementation details later.
## What's next for MealMate
1. Build the app prototype
2. Get the word out on campus and get adoption
3. Test, gather feedback, improve
4. We believe it can be expanded into a generalized match/connection app with more usage scenarios for finding people to do activities with - such as study groups, clubs, outings, rideshare, gym buddies… | partial |
## Inspiration
Having previously volunteered and worked with children with cerebral palsy, we were struck with the monotony and inaccessibility of traditional physiotherapy. We came up with a cheaper, more portable, and more engaging way to deliver treatment by creating virtual reality games geared towards 12-15 year olds. We targeted this age group because puberty is a crucial period for retention of plasticity in a child's limbs. We implemented interactive games in VR using Oculus' Rift and Leap motion's controllers.
## What it does
We designed games that targeted specific hand/elbow/shoulder gestures and used a leap motion controller to track the gestures. Our system improves motor skill, cognitive abilities, emotional growth and social skills of children affected by cerebral palsy.
## How we built it
Our games use of leap-motion's hand-tracking technology and the Oculus' immersive system to deliver engaging, exciting, physiotherapy sessions that patients will look forward to playing. These games were created using Unity and C#, and could be played using an Oculus Rift with a Leap Motion controller mounted on top. We also used an Alienware computer with a dedicated graphics card to run the Oculus.
## Challenges we ran into
The biggest challenge we ran into was getting the Oculus running. None of our computers had the ports and the capabilities needed to run the Oculus because it needed so much power. Thankfully we were able to acquire an appropriate laptop through MLH, but the Alienware computer we got was locked out of windows. We then spent the first 6 hours re-installing windows and repairing the laptop, which was a challenge. We also faced difficulties programming the interactions between the hands and the objects in the games because it was our first time creating a VR game using Unity, leap motion controls, and Oculus Rift.
## Accomplishments that we're proud of
We were proud of our end result because it was our first time creating a VR game with an Oculus Rift and we were amazed by the user experience we were able to provide. Our games were really fun to play! It was intensely gratifying to see our games working, and to know that it would be able to help others!
## What we learned
This project gave us the opportunity to educate ourselves on the realities of not being able-bodied. We developed an appreciation for the struggles people living with cerebral palsy face, and also learned a lot of Unity.
## What's next for Alternative Physical Treatment
We will develop more advanced games involving a greater combination of hand and elbow gestures, and hopefully get testing in local rehabilitation hospitals. We also hope to integrate data recording and playback functions for treatment analysis.
## Business Model Canvas
<https://mcgill-my.sharepoint.com/:b:/g/personal/ion_banaru_mail_mcgill_ca/EYvNcH-mRI1Eo9bQFMoVu5sB7iIn1o7RXM_SoTUFdsPEdw?e=SWf6PO> | ### 💡 Inspiration 💡
We call them heroes, **but the support we give them is equal to the one of a slave.**
Because of the COVID-19 pandemic, a lot of medics have to keep track of their patient's history, symptoms, and possible diseases. However, we've talked with a lot of medics, and almost all of them share the same problem when tracking the patients: **Their software is either clunky and bad for productivity, or too expensive to use on a bigger scale**. Most of the time, there is a lot of unnecessary management that needs to be done to get a patient on the record.
Moreover, the software can even get the clinician so tired they **have a risk of burnout, which makes their disease predictions even worse the more they work**, and with the average computer-assisted interview lasting more than 20 minutes and a medic having more than 30 patients on average a day, the risk is even worse. That's where we introduce **My MedicAid**. With our AI-assisted patient tracker, we reduce this time frame from 20 minutes to **only 5 minutes.** This platform is easy to use and focused on giving the medics the **ultimate productivity tool for patient tracking.**
### ❓ What it does ❓
My MedicAid gets rid of all of the unnecessary management that is unfortunately common in the medical software industry. With My MedicAid, medics can track their patients by different categories and even get help for their disease predictions **using an AI-assisted engine to guide them towards the urgency of the symptoms and the probable dangers that the patient is exposed to.** With all of the enhancements and our platform being easy to use, we give the user (medic) a 50-75% productivity enhancement compared to the older, expensive, and clunky patient tracking software.
### 🏗️ How we built it 🏗️
The patient's symptoms get tracked through an **AI-assisted symptom checker**, which uses [APIMedic](https://apimedic.com/i) to process all of the symptoms and quickly return the danger of them and any probable diseases to help the medic take a decision quickly without having to ask for the symptoms by themselves. This completely removes the process of having to ask the patient how they feel and speeds up the process for the medic to predict what disease their patient might have since they already have some possible diseases that were returned by the API. We used Tailwind CSS and Next JS for the Frontend, MongoDB for the patient tracking database, and Express JS for the Backend.
### 🚧 Challenges we ran into 🚧
We had never used APIMedic before, so going through their documentation and getting to implement it was one of the biggest challenges. However, we're happy that we now have experience with more 3rd party APIs, and this API is of great use, especially with this project. Integrating the backend and frontend was another one of the challenges.
### ✅ Accomplishments that we're proud of ✅
The accomplishment that we're the proudest of would probably be the fact that we got the management system and the 3rd party API working correctly. This opens the door to work further on this project in the future and get to fully deploy it to tackle its main objective, especially since this is of great importance in the pandemic, where a lot of patient management needs to be done.
### 🙋♂️ What we learned 🙋♂️
We learned a lot about CRUD APIs and the usage of 3rd party APIs in personal projects. We also learned a lot about the field of medical software by talking to medics in the field who have way more experience than us. However, we hope that this tool helps them in their productivity and to remove their burnout, which is something critical, especially in this pandemic.
### 💭 What's next for My MedicAid 💭
We plan on implementing an NLP-based service to make it easier for the medics to just type what the patient is feeling like a text prompt, and detect the possible diseases **just from that prompt.** We also plan on implementing a private 1-on-1 chat between the patient and the medic to resolve any complaints that the patient might have, and for the medic to use if they need more info from the patient. | ## Inspiration
Throughout the history of programming there has always been a barrier between humans and computers in terms of understanding on another. For example, there is no one simple way which we can both communicate but rather there are so called programming languages which we can understand and then the binary language which the computer understands. While it is close to impossible to eliminate that right now, we want to use the middle ground of the Assembly Language in order to educate prorgammers on how the computer attempts to understand us.
## What it does
When programmers develop code and press run, they just see an output dialog with their result. Through An Asm Reality, we allow users to develop code and understand how the computer converts that into Asm (assembly language) by allowing users to enter a virtual world using an Oculus Rift. In this world, they are able to see two different windows, one with the the code they have written and one with the assembly language the computer has generated. From there they are able to press on text in one area and see what it relates to in the other window. As well as that, a brief description of each area will pop up as the user views specific lines of code enlightening even the most advanced programmers on how assembly language decodes actual written code.
## How I built it
This was built using Unity which allowed for the creation of the virual world. Along with that languages such as Python and C# were used. Lastly we used the Oculus Rift and Leap Motion to bring this idea into our reality.
## Challenges I ran into
Our group was very unfamiliar with assembly language and therefore being able to understand how to convert programmed code into assembly language was a huge barrier as this type of reverse engineering has very limited resources and thus it came down to having to do tons of readings.
## Accomplishments that I'm proud of
We are proud of the fact that we were able to use Oculus Rift for the first time for all of the group members and sufficiently program the device using Unity.
## What I learned
Through this adventure we learned: how to interpret assembly language (or at least the basics of it), how to use linux (gcc and gdp), how to program scripts in C#, how to send information through a network in order to transfer files effortlessly, and lastly we learned how to work with the Unity environment along with Leap-Motion.
## What's next for An Asm Reality
We plan to make this application more complex where individuals are able to using multiple languages apart from C and visualize the assembly version of the code. Also we plan on making the UI more user friendly and more informative to allow others to educate themselves in a more interesting manner. | winning |
## Inspiration
We couldn't think of a project we both wanted to do — should we address a societal problem? Do something technically challenging hardware hack, in a field we were familiar with ? In the end, after about 20-30 hours of hemming and hawing, we decided we just wanted to have fun, and made the world's most useless and obnoxious Valentine's Day Chrome extension!
## What it does
Who needs constant reminders about love, go celebrate yourself! We replace any mention of Valentine and romance, and every link redirects to a single empowerment songs playlist. Queen Bey gifs make an appearance, and your cursor becomes a meme cat. It's a very chaotic chrome extension.
For text replacements, we created a dictionary of romance-related words and possible creative replacements to select from. We also drew custom graphics for this project (cursor, backgrounds, other icons).
## How we built it
We looked at tutorials online for making a Chrome extension and added our own flavor.
## Challenges we ran into
Neither of us know anything about front-end, so making a Chrome extension was a new learning process!
## Accomplishments that we're proud of
We made something that made us laugh!
## What we learned
How to badly front-end design.
## What's next for Happy Valentine's Day
Being single. | ## Inspiration
I was in incognito mode on google chrome and I thought to myself, what is the most useless thing I can make for people?
## What it does
It tracks your history and stores it in the console so you and everyone can see your secrets.
## How I built it
I used React.js to create the chrome extension.
## Challenges I ran into
I slowly realized how hard it was to listen and store to user's data on a browser mode that is made for it to NOT listen and store user's data.
## Accomplishments that I'm proud of
I am proud of learning a whole new framework (React.js) and making a semi-working product in such a short amount of time. I am also extremely proud of finding a loophole in an almost black box system (incognito).
## What I learned
I learned a new framework from scratch and learned how to create a google chrome extension for the first time.
## What's next for Uncognito
What's next? HTTP by default. No encryption over the air. Imagine doing important banking information in a nearby local Starbuck with ZERO protection! | ## Inspiration
Self-motivation is hard. It’s time for a social media platform that is meaningful and brings a sense of achievement instead of frustration.
While various pro-exercise campaigns and apps have tried inspire people, it is difficult to stay motivated with so many other more comfortable distractions around us. Surge is a social media platform that helps solve this problem by empowering people to exercise. Users compete against themselves or new friends to unlock content that is important to them through physical activity.
True friends and formed through adversity, and we believe that users will form more authentic, lasting relationships as they compete side-by-side in fitness challenges tailored to their ability levels.
## What it does
When you register for Surge, you take an initial survey about your overall fitness, preferred exercises, and the websites you are most addicted to. This survey will serve as the starting point from which Surge creates your own personalized challenges: Run 1 mile to watch Netflix for example. Surge links to your phone or IOT wrist device (Fitbit, Apple Watch, etc...) and, using its own Chrome browser extension, 'releases' content that is important to the user when they complete the challenges.
The platform is a 'mixed bag'. Sometimes users will unlock rewards such as vouchers or coupons, and sometimes they will need to complete the challenge to unlock their favorite streaming or gaming platforms.
## How we built it
Back-end:
We used Python Flask to run our webserver locally as we were familiar with it and it was easy to use it to communicate with our Chrome extension's Ajax. Our Chrome extension will check the URL of whatever webpage you are on against the URLs of sites for a given user. If the user has a URL locked, the Chrome extension will display their challenge instead of the original site at that URL. We used an ESP8266 (onboard Arduino) with an accelerometer in lieu of an IOT wrist device, as none of our team members own those devices. We don’t want an expensive wearable to be a barrier to our platform, so we might explore providing a low cost fitness tracker to our users as well.
We chose to use Google's Firebase as our database for this project as it supports calls from many different endpoints. We integrated it with our Python and Arduino code and intended to integrate it with our Chrome extension, however we ran into trouble doing that, so we used AJAX to send a request to our Flask server which then acts as a middleman between the Firebase database and our Chrome extension.
Front-end:
We used Figma to prototype our layout, and then converted to a mix of HTML/CSS and React.js.
## Challenges we ran into
Connecting all the moving parts: the IOT device to the database to the flask server to both the chrome extension and the app front end.
## Accomplishments that we're proud of
Please see above :)
## What we learned
Working with firebase and chrome extensions.
## What's next for SURGE
Continue to improve our front end. Incorporate analytics to accurately identify the type of physical activity the user is doing. We would also eventually like to include analytics that gauge how easily a person is completing a task, to ensure the fitness level that they have been assigned is accurate. | losing |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.