
anchor
stringlengths 1
23.8k
| positive
stringlengths 1
23.8k
| negative
stringlengths 1
31k
| anchor_status
stringclasses 3
values |
|---|---|---|---|
## Inspiration
The anonymity of cryptocurrencies is a blessing and a curse. One of Bitcoin's major shortcomings is its usefulness in criminal activity. Money laundering, drug sales, and other illegal activities use Bitcoin to evade law enforcement. This makes it hard for legitimate people and businesses to avoid dealing with criminals and their dirty (aka tainted) currency.
## What it does
BitTrace analyzes a Bitcoin address's involvement in potentially illegitimate transactions. The concept of marking an entity as 'tainted' has existed for a long time in many cryptocurrencies, but there is no easy way to track the flow of tainted money. When given a Bitcoin address, BitTrace painstakingly scans its transaction history, looking for dealings with tainted addresses. It then scores the target address based on its previous dealings. This allows the community to quickly build a crowdsourced map of bad actors.
## How I built it
We built our app in Expo and React Native. It connects to a backend written in NodeJS and Express, which calculates the taint level of a given address. It does this using BlockTrail and BlockCypher. We also maintain a separate MongoDB database of taint values in MLab (hosted in Google Cloud Platform), which allows us to record more detailed data on each address. Our server itself is run on Azure, which we chose for its speed, reliability, and ease of use.
## Challenges I ran into
We were very inexperienced with React Native and even more inexperienced with Expo. We had no idea how to accomplish simple effects like gradient buttons. Luckily, with the help of Expo's excellent documentation, we were able to overcome most issues.
## Accomplishments that I'm proud of
We have a very clean UI. We're proud of the cross-platform compatibility, speed, and reliability we were able to achieve with Expo/React Native. Our algorithm, which is highly optimized for a large network of transactions, is stable and fast.
## What I learned
We learned a huge amount about using React Native and Expo. We also learned much about analyzing transaction records on the blockchain.
## What's next for BitTrace
We want to add support for more currencies, like Ether and LiteCoin. We also want to show a more detailed analysis of an address's transactions (we already generate this data, but do not show it in the app).
|
## Inspiration
With the excitement of blockchain and the ever growing concerns regarding privacy, we wanted to disrupt one of the largest technology standards yet: Email. Email accounts are mostly centralized and contain highly valuable data, making one small breach, or corrupt act can serious jeopardize millions of people. The solution, lies with the blockchain. Providing encryption and anonymity, with no chance of anyone but you reading your email.
Our technology is named after Soteria, the goddess of safety and salvation, deliverance, and preservation from harm, which we believe perfectly represents our goals and aspirations with this project.
## What it does
First off, is the blockchain and message protocol. Similar to PGP protocol it offers \_ security \_, and \_ anonymity \_, while also **ensuring that messages can never be lost**. On top of that, we built a messenger application loaded with security features, such as our facial recognition access option. The only way to communicate with others is by sharing your 'address' with each other through a convenient QRCode system. This prevents anyone from obtaining a way to contact you without your **full discretion**, goodbye spam/scam email.
## How we built it
First, we built the block chain with a simple Python Flask API interface. The overall protocol is simple and can be built upon by many applications. Next, and all the remained was making an application to take advantage of the block chain. To do so, we built a React-Native mobile messenger app, with quick testing though Expo. The app features key and address generation, which then can be shared through QR codes so we implemented a scan and be scanned flow for engaging in communications, a fully consensual agreement, so that not anyone can message anyone. We then added an extra layer of security by harnessing Microsoft Azures Face API cognitive services with facial recognition. So every time the user opens the app they must scan their face for access, ensuring only the owner can view his messages, if they so desire.
## Challenges we ran into
Our biggest challenge came from the encryption/decryption process that we had to integrate into our mobile application. Since our platform was react native, running testing instances through Expo, we ran into many specific libraries which were not yet supported by the combination of Expo and React. Learning about cryptography and standard practices also played a major role and challenge as total security is hard to find.
## Accomplishments that we're proud of
We are really proud of our blockchain for its simplicity, while taking on a huge challenge. We also really like all the features we managed to pack into our app. None of us had too much React experience but we think we managed to accomplish a lot given the time. We also all came out as good friends still, which is a big plus when we all really like to be right :)
## What we learned
Some of us learned our appreciation for React Native, while some learned the opposite. On top of that we learned so much about security, and cryptography, and furthered our beliefs in the power of decentralization.
## What's next for The Soteria Network
Once we have our main application built we plan to start working on the tokens and distribution. With a bit more work and adoption we will find ourselves in a very possible position to pursue an ICO. This would then enable us to further develop and enhance our protocol and messaging app. We see lots of potential in our creation and believe privacy and consensual communication is an essential factor in our ever increasingly social networking world.
|
## Inspiration
It’s Friday afternoon, and as you return from your final class of the day cutting through the trailing winds of the Bay, you suddenly remember the Saturday trek you had planned with your friends. Equipment-less and desperate you race down to a nearby sports store and fish out $$$, not realising that the kid living two floors above you has the same equipment collecting dust. While this hypothetical may be based on real-life events, we see thousands of students and people alike impulsively spending money on goods that would eventually end up in their storage lockers. This cycle of buy-store-collect dust inspired us to develop Lendit this product aims to stagnate the growing waste economy and generate passive income for the users on the platform.
## What it does
A peer-to-peer lending and borrowing platform that allows users to generate passive income from the goods and garments collecting dust in the garage.
## How we built it
Our Smart Lockers are built with RaspberryPi3 (64bit, 1GB RAM, ARM-64) microcontrollers and are connected to our app through interfacing with Google's Firebase. The locker also uses Facial Recognition powered by OpenCV and object detection with Google's Cloud Vision API.
For our App, we've used Flutter/ Dart and interfaced with Firebase. To ensure *trust* - which is core to borrowing and lending, we've experimented with Ripple's API to create an Escrow system.
## Challenges we ran into
We learned that building a hardware hack can be quite challenging and can leave you with a few bald patches on your head. With no hardware equipment, half our team spent the first few hours running around the hotel and even the streets to arrange stepper motors and Micro-HDMI wires. In fact, we even borrowed another team's 3-D print to build the latch for our locker!
On the Flutter/ Dart side, we were sceptical about how the interfacing with Firebase and Raspberry Pi would work. Our App Developer previously worked with only Web Apps with SQL databases. However, NoSQL works a little differently and doesn't have a robust referential system. Therefore writing Queries for our Read Operations was tricky.
With the core tech of the project relying heavily on the Google Cloud Platform, we had to resolve to unconventional methods to utilize its capabilities with an internet that played Russian roulette.
## Accomplishments that we're proud of
The project has various hardware and software components like raspberry pi, Flutter, XRP Ledger Escrow, and Firebase, which all have their own independent frameworks. Integrating all of them together and making an end-to-end automated system for the users, is the biggest accomplishment we are proud of.
## What's next for LendIt
We believe that LendIt can be more than just a hackathon project. Over the course of the hackathon, we discussed the idea with friends and fellow participants and gained a pretty good Proof of Concept giving us the confidence that we can do a city-wide launch of the project in the near future. In order to see these ambitions come to life, we would have to improve our Object Detection and Facial Recognition models. From cardboard, we would like to see our lockers carved in metal at every corner of this city. As we continue to grow our skills as programmers we believe our product Lendit will grow with it. We would be honoured if we can contribute in any way to reduce the growing waste economy.
|
partial
|
## Inspiration
The first step of our development process was conducting user interviews with University students within our social circles. When asked of some recently developed pain points, 40% of respondents stated that grocery shopping has become increasingly stressful and difficult with the ongoing COVID-19 pandemic. The respondents also stated that some motivations included a loss of disposable time (due to an increase in workload from online learning), tight spending budgets, and fear of exposure to covid-19.
While developing our product strategy, we realized that a significant pain point in grocery shopping is the process of price-checking between different stores. This process would either require the user to visit each store (in-person and/or online) and check the inventory and manually price check. Consolidated platforms to help with grocery list generation and payment do not exist in the market today - as such, we decided to explore this idea.
**What does G.e.o.r.g.e stand for? : Grocery Examiner Organizer Registrator Generator (for) Everyone**
## What it does
The high-level workflow can be broken down into three major components:
1: Python (flask) and Firebase backend
2: React frontend
3: Stripe API integration
Our backend flask server is responsible for web scraping and generating semantic, usable JSON code for each product item, which is passed through to our React frontend.
Our React frontend acts as the hub for tangible user-product interactions. Users are given the option to search for grocery products, add them to a grocery list, generate the cheapest possible list, compare prices between stores, and make a direct payment for their groceries through the Stripe API.
## How we built it
We started our product development process with brainstorming various topics we would be interested in working on. Once we decided to proceed with our payment service application. We drew up designs as well as prototyped using Figma, then proceeded to implement the front end designs with React. Our backend uses Flask to handle Stripe API requests as well as web scraping. We also used Firebase to handle user authentication and storage of user data.
## Challenges we ran into
Once we had finished coming up with our problem scope, one of the first challenges we ran into was finding a reliable way to obtain grocery store information. There are no readily available APIs to access price data for grocery stores so we decided to do our own web scraping. This lead to complications with slower server response since some grocery stores have dynamically generated websites, causing some query results to be slower than desired. Due to the limited price availability of some grocery stores, we decided to pivot our focus towards e-commerce and online grocery vendors, which would allow us to flesh out our end-to-end workflow.
## Accomplishments that we're proud of
Some of the websites we had to scrape had lots of information to comb through and we are proud of how we could pick up new skills in Beautiful Soup and Selenium to automate that process! We are also proud of completing the ideation process with an application that included even more features than our original designs. Also, we were scrambling at the end to finish integrating the Stripe API, but it feels incredibly rewarding to be able to utilize real money with our app.
## What we learned
We picked up skills such as web scraping to automate the process of parsing through large data sets. Web scraping dynamically generated websites can also lead to slow server response times that are generally undesirable. It also became apparent to us that we should have set up virtual environments for flask applications so that team members do not have to reinstall every dependency. Last but not least, deciding to integrate a new API at 3am will make you want to pull out your hair, but at least we now know that it can be done :’)
## What's next for G.e.o.r.g.e.
Our next steps with G.e.o.r.g.e. would be to improve the overall user experience of the application by standardizing our UI components and UX workflows with Ecommerce industry standards. In the future, our goal is to work directly with more vendors to gain quicker access to price data, as well as creating more seamless payment solutions.
|
## Inspiration
We recognized how much time meal planning can cause, especially for busy young professionals and students who have little experience cooking. We wanted to provide an easy way to buy healthy, sustainable meals for the week, without compromising the budget or harming the environment.
## What it does
Similar to services like "Hello Fresh", this is a webapp for finding recipes and delivering the ingredients to your house. This is where the similarities end, however. Instead of shipping the ingredients to you directly, our app makes use of local grocery delivery services, such as the one provided by Loblaws. The advantages to this are two-fold: first, it helps keep the price down, as your main fee is for the groceries themselves, instead of paying large amounts in fees to a meal kit company. Second, this is more eco-friendly. Meal kit companies traditionally repackage the ingredients in house into single-use plastic packaging, before shipping it to the user, along with large coolers and ice packs which mostly are never re-used. Our app adds no additional packaging beyond that the groceries initially come in.
## How We built it
We made a web app, with the client side code written using React. The server was written in python using Flask, and was hosted on the cloud using Google App Engine. We used MongoDB Atlas, also hosted on Google Cloud.
On the server, we used the Spoonacular API to search for recipes, and Instacart for the grocery delivery.
## Challenges we ran into
The Instacart API is not publicly available, and there are no public API's for grocery delivery, so we had to reverse engineer this API to allow us to add things to the cart. The Spoonacular API was down for about 4 hours on Saturday evening, during which time we almost entirely switched over to a less functional API, before it came back online and we switched back.
## Accomplishments that we're proud of
Created a functional prototype capable of facilitating the order of recipes through Instacart. Learning new skills, like Flask, Google Cloud and for some of the team React.
## What we've learned
How to reverse engineer an API, using Python as a web server with Flask, Google Cloud, new API's, MongoDB
## What's next for Fiscal Fresh
Add additional functionality on the client side, such as browsing by popular recipes
|
## Purpose:
Food waste is an extensive issue touching all across the globe; in fact, according to the UN Environmente Programme, approximately ⅓ of food produced for human consumption globally is lost or wasted annually (Made in CA). After perceiving this information, we were inspired to create a website that provides you with numerous zero-waste recipes by just scanning your grocery receipt. Our innovative website not only addresses the pressing concern of food waste, but also empowers individuals to make a meaningful impact in their own kitchens!
## General Information:
Interactive website that offers clients vast and meaningful alternatives to unsustainable cooking.
Benefits range from the reduction of food waste to enhancing and simplifying meal planning.
Our model is unique because it incorporates fast and easy-to-use technology (i.e. receipt scanning) which will provide users recipes within seconds, in comparison to traditional, tedious websites on the market that require users to manually input each ingredient, unnecessarily prolonging their stay.
## How we built it:
The frontend of our project was created with HTML and CSS, whereas the backend was created with Flask. Image recognition services were implemented using Google Cloud API.
We chose HTML because it is light weighted and fast to load, ensuring a splendid user interface experience. We chose CSS in view of the fact that it is time-saving due to its simple-to-use nature, as well as its striking ability to offer flexible positioning of design elements. As first-time hackers without much experience, we chose Flask in view of its simplicity and features, such as a built-in development server and quick debugger. Google Cloud API was pivotal in extracting information provided by the user because of its text recognition feature in its OCR tool, allowing us to center our model around grocery receipts.
## Challenges we ran into:
Learning HTML and CSS - 2 of our group members were relatively new to coding and had no experience in frontend web dev whatsoever!
Delegating tasks effectively between team members spending the night vs. going home - Constant collaboration over Discord was crucial!
Learning Google Cloud API - All of our group members were new to Google Cloud API, so simultaneously learning + implementing it within 36 hours was definitely challenging.
## Accomplishments that we're proud of:
As a complete beginner team, we are extremely ecstatic about our large-scale efforts and progress at Hack the 6ix! From learning web dev from scratch to experimenting with completely new frameworks to creating our personal logo to making and editing a video in under an hour, our experience has been nothing short of a rollercoaster ride. Although new to the field, we made sure to bravely tackle each challenge presented to us and give our best efforts throughout the hacking period, which can be exemplified by our choices to work long hours past midnight, ask mentors for advice when needed, and constantly improvise our front and backend for a more complete user interface experience!
## What’s next for Eco Eats:
YES, we’re not done just yet! Here are a few things that we think we can consolidate with our current idea of Eco Eats to make it a cut above!
A feature to take a photo of your receipt on the website
A feature to let users see other recipes with similar ingredients that can be substituted with the ones they have
Expand our idea to PC parts, so that we can offer clients possible ideas for custom PCs to assemble with their old receipts
|
winning
|
## Inspiration
While there are several applications that use OCR to read receipts, few take the leap towards informing consumers on their purchase decisions. We decided to capitalize on this gap: we currently provide information to customers about the healthiness of the food they purchase at grocery stores by analyzing receipts. In order to encourage healthy eating, we are also donating a portion of the total value of healthy food to a food-related non-profit charity in the United States or abroad.
## What it does
Our application uses Optical Character Recognition (OCR) to capture items and their respective prices on scanned receipts. We then parse through these words and numbers using an advanced Natural Language Processing (NLP) algorithm to match grocery items with its nutritional values from a database. By analyzing the amount of calories, fats, saturates, sugars, and sodium in each of these grocery items, we determine if the food is relatively healthy or unhealthy. Then, we calculate the amount of money spent on healthy and unhealthy foods, and donate a portion of the total healthy values to a food-related charity. In the future, we plan to run analytics on receipts from other industries, including retail, clothing, wellness, and education to provide additional information on personal spending habits.
## How We Built It
We use AWS Textract and Instabase API for OCR to analyze the words and prices in receipts. After parsing out the purchases and prices in Python, we used Levenshtein distance optimization for text classification to associate grocery purchases with nutritional information from an online database. Our algorithm utilizes Pandas to sort nutritional facts of food and determine if grocery items are healthy or unhealthy by calculating a “healthiness” factor based on calories, fats, saturates, sugars, and sodium. Ultimately, we output the amount of money spent in a given month on healthy and unhealthy food.
## Challenges We Ran Into
Our product relies heavily on utilizing the capabilities of OCR APIs such as Instabase and AWS Textract to parse the receipts that we use as our dataset. While both of these APIs have been developed on finely-tuned algorithms, the accuracy of parsing from OCR was lower than desired due to abbreviations for items on receipts, brand names, and low resolution images. As a result, we were forced to dedicate a significant amount of time to augment abbreviations of words, and then match them to a large nutritional dataset.
## Accomplishments That We're Proud Of
Project Horus has the capability to utilize powerful APIs from both Instabase or AWS to solve the complex OCR problem of receipt parsing. By diversifying our software, we were able to glean useful information and higher accuracy from both services to further strengthen the project itself, which leaves us with a unique dual capability.
We are exceptionally satisfied with our solution’s food health classification. While our algorithm does not always identify the exact same food item on the receipt due to truncation and OCR inaccuracy, it still matches items to substitutes with similar nutritional information.
## What We Learned
Through this project, the team gained experience with developing on APIS from Amazon Web Services. We found Amazon Textract extremely powerful and integral to our work of reading receipts. We were also exposed to the power of natural language processing, and its applications in bringing ML solutions to everyday life. Finally, we learned about combining multiple algorithms in a sequential order to solve complex problems. This placed an emphasis on modularity, communication, and documentation.
## The Future Of Project Horus
We plan on using our application and algorithm to provide analytics on receipts from outside of the grocery industry, including the clothing, technology, wellness, education industries to improve spending decisions among the average consumers. Additionally, this technology can be applied to manage the finances of startups and analyze the spending of small businesses in their early stages. Finally, we can improve the individual components of our model to increase accuracy, particularly text classification.
|
# 🍅 NutriSnap
### NutriSnap is an intuitive nutrition tracker that seamlessly integrates into your daily life.
## Inspiration
Every time you go to a restaurant, its highly likely that you see someone taking a picture of their food before they eat it. We wanted to create a seamless way for people to keep track of their nutritional intake, minimizing the obstacles required to be aware of the food you consume. Building on the idea that people already often take pictures of the food they eat, we decided to utilize something as simple as one's camera app to keep track of their daily nutritional intake.
## What it does
NutriSnap analyzes pictures of food to detect its nutritional value. After simply scanning a picture of food, it summarizes all its nutritional information and displays it to the user, while also adding it to a log of all consumed food so people have more insight on all the food they consume. NutriSnap has two fundamental features:
* scan UPC codes on purchased items and fetch its nutritional information
* detect food from an image using a public ML food-classification API and estimate its nutritional information
This information is summarized and displayed to the user in a clean and concise manner, taking their recommended daily intake values into account. Furthermore, it is added to a log of all consumed food items so the user can always access a history of their nutritional intake.
## How we built it
The app uses React Native for its frontend and a Python Django API for its backend. If the app detects a UPC code in the photo, it retrieves nutritional information from a [UPC food nutrition API](https://world.openfoodfacts.org) and summarizes its data in a clean and concise manner. If the app fails to detect a UPC code in the photo, it forwards the photo to its Django backend, which proceeds to classify all the food in the image using another [open API](https://www.logmeal.es). All collected nutritional data is forwarded to the [OpenAI API](https://platform.openai.com/docs/guides/text-generation/json-mode) to summarize nutritional information of the food item, and to provide the item with a nutrition rating betwween 1 and 10. This data is displayed to the user, and also added to their log of consumed food.
## What's next for NutriSnap
As a standalone app, NutriSnap is still pretty inconvenient to integrate into your daily life. One amazing update would be to make the API more independent of the frontend, allowing people to sync their Google Photos library so NutriSnap automatically detects and summarizes all consumed food without the need for any manual user input.
|
## Inspiration
Almost 2.2 million tonnes of edible food is discarded each year in Canada alone, resulting in over 17 billion dollars in waste. A significant portion of this is due to the simple fact that keeping track of expiry dates for the wide range of groceries we buy is, put simply, a huge task. While brainstorming ideas to automate the management of these expiry dates, discussion came to the increasingly outdated usage of barcodes for Universal Product Codes (UPCs); when the largest QR codes can store [thousands of characters](https://stackoverflow.com/questions/12764334/qr-code-max-char-length), why use so much space for a 12 digit number?
By building upon existing standards and the everyday technology in our pockets, we're proud to present **poBop**: our answer to food waste in homes.
## What it does
Users are able to scan the barcodes on their products, and enter the expiration date written on the packaging. This information is securely stored under their account, which keeps track of what the user has in their pantry. When products have expired, the app triggers a notification. As a proof of concept, we have also made several QR codes which show how the same UPC codes can be encoded alongside expiration dates in a similar amount of space, simplifying this scanning process.
In addition to this expiration date tracking, the app is also able to recommend recipes based on what is currently in the user's pantry. In the event that no recipes are possible with the provided list, it will instead recommend recipes in which has the least number of missing ingredients.
## How we built it
The UI was made with native android, with the exception of the scanning view which made use of the [code scanner library](https://github.com/yuriy-budiyev/code-scanner).
Storage and hashing/authentication were taken care of by [MongoDB](https://www.mongodb.com/) and [Bcrypt](https://github.com/pyca/bcrypt/) respectively.
Finally in regards to food, we used [Buycott](https://www.buycott.com/)'s API for UPC lookup and [Spoonacular](https://spoonacular.com/) to look for valid recipes.
## Challenges we ran into
As there is no official API or publicly accessible database for UPCs, we had to test and compare multiple APIs before determining Buycott had the best support for Canadian markets. This caused some issues, as a lot of processing was needed to connect product information between the two food APIs.
Additionally, our decision to completely segregate the Flask server and apps occasionally resulted in delays when prioritizing which endpoints should be written first, how they should be structured etc.
## Accomplishments that we're proud of
We're very proud that we were able to use technology to do something about an issue that bothers not only everyone on our team on a frequent basis (something something cooking hard) but also something that has large scale impacts on the macro scale. Some of our members were also very new to working with REST APIs, but coded well nonetheless.
## What we learned
Flask is a very easy to use Python library for creating endpoints and working with REST APIs. We learned to work with endpoints and web requests using Java/Android. We also learned how to use local databases on Android applications.
## What's next for poBop
We thought of a number of features that unfortunately didn't make the final cut. Things like tracking nutrition of the items you have stored and consumed. By tracking nutrition information, it could also act as a nutrient planner for the day. The application may have also included a shopping list feature, where you can quickly add items you are missing from a recipe or use it to help track nutrition for your upcoming weeks.
We were also hoping to allow the user to add more details to the items they are storing, such as notes for what they plan on using it for or the quantity of items.
Some smaller features that didn't quite make it included getting a notification when the expiry date is getting close, and data sharing for people sharing a household. We were also thinking about creating a web application as well, so that it would be more widely available.
Finally, we strongly encourage you, if you are able and willing, to consider donating to food waste reduction initiatives and hunger elimination charities.
One of the many ways to get started can be found here:
<https://rescuefood.ca/>
<https://secondharvest.ca/>
<https://www.cityharvest.org/>
# Love,
# FSq x ANMOL
|
winning
|
# Trusty Paws
## Inspiration
We believe that every pet deserves to find a home. Animal shelters have often had to euthanize animals due to capacity issues and lack of adoptions. Our objective with Trusty Paws is to increase the rate of adoptions of these animals by increasing the exposure of shelters to potential pet owners as well as to provide an accessible platform for users to browse and adopt their next best friend.
Trusty Paws also aims to be an online hub for all things related to your pet, from offering an online marketplace for pet products to finding a vet near you.
## What it does
Our vision for Trusty Paws is to create a platform that brings together all the players that contribute to the health and happiness of our pawed friends, while allowing users to support local businesses. Each user, shelter, seller, and veterinarian contributes to a different aspect of Trusty Paws.
**Users**:
Users are your everyday users who own pets or are looking to adopt pets. They will be able to access the marketplace to buy items for their pets, browse through each shelter's pet profiles to fill out adoption requests, and find the nearest pet clinic.
**Shelters**:
Shelters accounts will be able to create pet profiles for each of their animals that are up for adoption! Each pet will have its own profile that can be customized with pictures and other fields providing further information on them. The shelter receives an adoption request form each time an user applies to adopt one of their pets.
**Sellers**:
Sellers will be able to set up stores showing all of their product listings, which include, but are not limited to, food, toys, accessories, and many other. Our marketplace will provide the opportunity for local businesses that have been affected by Covid-19 to reach their target audience while abiding by health and safety guidelines. For users, it will be a convenient way to satisfy all the needs of their pet in one place. Finally, our search bar will allow users to search for specific items for a quick and efficient shopping experience.
**Veterinarians**:
Veterinarians will be able to set up a profile for their clinic, with all the pertinent information such as their opening hours, services provided, and location.
## How we built it
For the front-end, React., Bootstrap and Materialized CSS were used to acquire the visual effects of the current website. In fact, the very first step we undertook was to draft an initial prototype of the product on Figma to ensure all the requirements and required features were met. After a few iterations of redesigning, we each dove into developing the necessary individual components, forms, and pages for the website. Once all components were completed, the next step was to route pages together in order to achieve a seamless navigation of the website.
We used Firebase within Node.Js to implement a framwork for the back-end. Using Firebase, we implemented a NoSQL database using Cloud Firestore. Data for users (all types), pets, products, and adoption forms along with their respective fields were stored as documents in their respective collections.
Finally, we used Google's Distance Matrix API to compute distances between two addresses and find the nearest services when necessary, such as the closest vet clinics or the closest shelters.
## Challenges we ran into
Although we were successful at accomplishing the major features of the website, we encountered many challenges throughout the weekend. As we started working on Trusty Paws, we realized that the initial implementation was not as user-friendly as we wanted it to be. We then decided to take a step back and to return to the initial design phase. Another challenge we ran into was that most of the team was unfamiliar with the development tools necessary for this project, such as Firebase, Node.Js, bootstrap, and redux.
## Accomplishments that we're proud of
We are proud that our team learned so much over the course of a few days.
## What's next for Trusty Paws
We want to keep improving our users' experience by optimizing the current features. We also want to improve the design and user friendliness of the interface.
|
## Inspiration 💡
**Due to rising real estate prices, many students are failing to find proper housing, and many landlords are failing to find good tenants**. Students looking for houses often have to hire some agent to get a nice place with a decent landlord. The same goes for house owners who need to hire agents to get good tenants. *The irony is that the agent is totally motivated by sheer commission and not by the wellbeing of any of the above two.*
Lack of communication is another issue as most of the things are conveyed by a middle person. It often leads to miscommunication between the house owner and the tenant, as they interpret the same rent agreement differently.
Expensive and time-consuming background checks of potential tenants are also prevalent, as landowners try to use every tool at their disposal to know if the person is really capable of paying rent on time, etc. Considering that current rent laws give tenants considerable power, it's very reasonable for landlords to perform background checks!
Existing online platforms can help us know which apartments are vacant in a locality, but they don't help either party know if the other person is really good! Their ranking algorithms aren't trustable with tenants. The landlords are also reluctant to use these services as they need to manually review applications from thousands of unverified individuals or even bots!
We observed that we are still using these old-age non-scalable methods to match the home seeker and homeowners willing to rent their place in this digital world! And we wish to change it with **RentEasy!**

## What it does 🤔
In this hackathon, we built a cross-platform mobile app that is trustable by both potential tenants and house owners.
The app implements a *rating system* where the students/tenants can give ratings for a house/landlord (ex: did not pay security deposit back for no reason), & the landlords can provide ratings for tenants (the house was not clean). In this way, clean tenants and honest landlords can meet each other.
This platform also helps the two stakeholders build an easily understandable contract that will establish better trust and mutual harmony. The contract is stored on an InterPlanetary File System (IPFS) and cannot be tampered by anyone.

Our application also has an end-to-end encrypted chatting module powered by @ Company. The landlords can filter through all the requests and send requests to tenants. This chatting module powers our contract generator module, where the two parties can discuss a particular agreement clause and decide whether to include it or not in the final contract.
## How we built it ️⚙️
Our beautiful and elegant mobile application was built using a cross-platform framework flutter.
We integrated the Google Maps SDK to build a map where the users can explore all the listings and used geocoding API to encode the addresses to geopoints.
We wanted our clients a sleek experience and have minimal overhead, so we exported all network heavy and resource-intensive tasks to firebase cloud functions. Our application also has a dedicated **end to end encrypted** chatting module powered by the **@-Company** SDK. The contract generator module is built with best practices and which the users can use to make a contract after having thorough private discussions. Once both parties are satisfied, we create the contract in PDF format and use Infura API to upload it to IPFS via the official [Filecoin gateway](https://www.ipfs.io/ipfs)

## Challenges we ran into 🧱
1. It was the first time we were trying to integrate the **@-company SDK** into our project. Although the SDK simplifies the end to end, we still had to explore a lot of resources and ask for assistance from representatives to get the final working build. It was very gruelling at first, but in the end, we all are really proud of having a dedicated end to end messaging module on our platform.
2. We used Firebase functions to build scalable serverless functions and used expressjs as a framework for convenience. Things were working fine locally, but our middleware functions like multer, urlencoder, and jsonencoder weren't working on the server. It took us more than 4 hours to know that "Firebase performs a lot of implicit parsing", and before these middleware functions get the data, Firebase already had removed them. As a result, we had to write the low-level encoding logic ourselves! After deploying these, the sense of satisfaction we got was immense, and now we appreciate millions of open source packages much more than ever.
## Accomplishments that we're proud of ✨
We are proud of finishing the project on time which seemed like a tough task as we started working on it quite late due to other commitments and were also able to add most of the features that we envisioned for the app during ideation. Moreover, we learned a lot about new web technologies and libraries that we could incorporate into our project to meet our unique needs. We also learned how to maintain great communication among all teammates. Each of us felt like a great addition to the team. From the backend, frontend, research, and design, we are proud of the great number of things we have built within 36 hours. And as always, working overnight was pretty fun! :)
---
## Design 🎨
We were heavily inspired by the revised version of **Iterative** design process, which not only includes visual design, but a full-fledged research cycle in which you must discover and define your problem before tackling your solution & then finally deploy it.

This time went for the minimalist **Material UI** design. We utilized design tools like Figma, Photoshop & Illustrator to prototype our designs before doing any coding. Through this, we are able to get iterative feedback so that we spend less time re-writing code.

---
# Research 📚
Research is the key to empathizing with users: we found our specific user group early and that paves the way for our whole project. Here are few of the resources that were helpful to us —
* Legal Validity Of A Rent Agreement : <https://bit.ly/3vCcZfO>
* 2020-21 Top Ten Issues Affecting Real Estate : <https://bit.ly/2XF7YXc>
* Landlord and Tenant Causes of Action: "When Things go Wrong" : <https://bit.ly/3BemMtA>
* Landlord-Tenant Law : <https://bit.ly/3ptwmGR>
* Landlord-tenant disputes arbitrable when not covered by rent control : <https://bit.ly/2Zrpf7d>
* What Happens If One Party Fails To Honour Sale Agreement? : <https://bit.ly/3nr86ST>
* When Can a Buyer Terminate a Contract in Real Estate? : <https://bit.ly/3vDexWO>
**CREDITS**
* Design Resources : Freepik, Behance
* Icons : Icons8
* Font : Semibold / Montserrat / Roboto / Recoleta
---
# Takeways
## What we learned 🙌
**Sleep is very important!** 🤐 Well, jokes apart, this was an introduction to **Web3** & **Blockchain** technologies for some of us and introduction to mobile app developent to other. We managed to improve on our teamwork by actively discussing how we are planning to build it and how to make sure we make the best of our time. We learned a lot about atsign API and end-to-end encryption and how it works in the backend. We also practiced utilizing cloud functions to automate and ease the process of development.
## What's next for RentEasy 🚀
**We would like to make it a default standard of the housing market** and consider all the legal aspects too! It would be great to see rental application system more organized in the future. We are planning to implement more additional features such as landlord's view where he/she can go through the applicants and filter them through giving the landlord more options. Furthermore we are planning to launch it near university campuses since this is where people with least housing experience live. Since the framework we used can be used for any type of operating system, it gives us the flexibility to test and learn.
**Note** — **API credentials have been revoked. If you want to run the same on your local, use your own credentials.**
|
## Inspiration
A lot of great foundations help to rescue animals every day.
Nevertheless, every day a lot of animals die in shelters and even more suffer from their loss.
We prevent both: we want pets to stay in their personal environment and to be not given up.
## What it does
Our App builds up a social community with the goal to help struggling pet owners.
Caretakers in the local surrounding help to go out with the dog, spend time or even host it for most of the time.
No matter if the owner hasn't enough time, money or just no possibility in his new home - people in the neighborhood help and profit from caring. They are not only effectively helping the community and getting love in exchange, but also get the "Pet Experience".
Kids can grow up with animals, teenager can learn how take responsibility, families can test whether a pet would be a good fit for them and also seniors could enjoy an afternoon walk with a dog. We want people to test and get experience before a pet joins their family.
In the end the most profit gains the pet. It has not be taken out of its' environment, it gets more love, sympathy, can be more active and is not given up.
## Vision
We dream of a future without shelters. A future, in which people help each other even more than today!
We want to work closely together with shelters and foundations to prevent adoption before the problem occurs and motivate buyers to consider an adoption of animals from a shelter.
## Try it out
Link to Proto.io: <https://pr.to/42RX9M/>
HTML: <https://www.dropbox.com/sh/5rro9kjnptlun03/AAAM0HK_pq-1eURTYgOyKd_ka?dl=0>
|
winning
|
## Inspiration
It feels like elections are taking up an increasing portion of our mindshare, with every election cycle it only gets more insane. Constantly flooded by news, by opinions – it's like we never get a break. And yet, paradoxically, voters feel increasingly less connected to their politicians. They hear soliloquies about the terrible deeds of the politician's opponent, but rarely about how their policies will affect them personally. That changes today.
It's time we come back to a democracy which lives by the words *E pluribus unum* – from many, one. Citizens should understand exactly how politician's policies will affect them and their neighbours, and from that, a general consensus may form. And campaigners should be given the tools to allow them to do so.
Our team's been deeply involved in community and politics for years – which is why we care so much about a healthy democracy. Between the three of us over the years, we've spoken with campaign / PR managers at 70+ campaigns, PACs, and lobbies, and 40+ ad teams – all in a bid to understand how technology can help propel a democracy forward.
## What it does
Rally helps politicians meet voters where they are – in a figurative and digital sense. Politicians and campaign teams can use our platform to send geographically relevant campaign advertisements to voters – tailored towards issues they care deeply about. We thoroughly analyze the campaigner's policies to give a faithful representation of their ideas through AI-generated advertisements – using their likeness – and cross-correlate it with issues the voter is likely to care, and want to learn more, about. We avoid the uncanny valley with our content, we maintain compliance, and we produce content that drives voter engagement.
## How we built it
Rally is a web app powered by a complex multi-agent chain system, which uses natural language to understand both current local events and campaign policy in real-time, and advanced text-to-speech and video-to-video lip sync/facetune models to generate a faithful personalised campaign ad, with the politician speaking to voters about issues they truly care about.
* We use Firecrawl and the Perplexity API to scrape news and economic data about the town a voter is from, and to understand a politician's policies, and store GPT-curated insights on a Supabase database.
* Then, we use GPT4o-mini to parse through all that data and generate an ad speech, faithful to the politician's style, which'll cover issues relevant to the voter.
* This speech is sent to Cartesia.ai's excellent Sonic text-to-speech model which has already been trained on short clips of the politician's voice.
* Simultaneously, GPT4o-mini decides which parts of the ad should have B-roll/stock footage displayed, and about what.
* We use this to query Pexels for stock footage to be used during the ad.
* Once the voice narration has been generated, we send it to SyncLabs for lipsyncing over existing ad/interview footage of the politician.
* Finally, we overlay the the B-roll footage (at the previously decided time stamps) on the lip synced videos, to create a convincing campaign advertisement.
* All of this is packaged in a beautiful and modern UI built using NextJS and Tailwind.
And all of this is done in the space of just a few minutes! So whether the voter comes from New York City or Fairhope, Alabama, you can be sure that they'll receive a faithful campaign ad which puts the politician's best foot forward while helping the voter understand how their policies might affect them.
## Wait a minute, is this even legal?
***YES***. Currently, bills are being passed in states around the country limiting the use of deepfakes in political campaign – and for good reason. The potential damage is obvious. However, in every single proposed bill, a campaigner is absolutely allowed to create deepfakes of themselves for their own gains. Indeed, while we absolutely support all regulation on nefarious use of deepfakes, we also deeply believe in its immense potential for good. We've even built a database of all the bills that are in debate or have been enacted regarding AI political advertisement as part of this project, feel free to take a look!
Voter apathy is an epidemic, which slowly eats away at a democracy – Rally believes that personalised campaign messaging is one of the most promising avenues to battle against that.
## Challenges we ran into
The surface area for errors increase hugely with the amount of services we integrate with. Undocumented or badly documented APIs were huge time sinks – some of these services are so new that questions haven't been asked about them online. Another very large time sink was the video manipulation through FFMPEG. It's an extremely powerful tool, and doing simple things is very easy, but doing more complicated tasks ended up being very difficult to get right.
However, the biggest challenge by far was creating advertisements that maintained state-specific compliance, meaning they had different rules and regulations for each state and had to avoid negativity, misinformation, etc. This can be very hard as LLM outputs are often very subjective and hard to evaluate deterministically. We combatted this by building a chain of LLMs informed by data from the NCSL, OpenFEC, and other reliable sources to ensure all the information that we used in the process was thoroughly sourced, leading to better outcomes for content generation. We also used validator agents to verify results from particularly critical parts of the content generation flow before proceeding.
## Accomplishments that we're proud of
We're deeply satisfied with the fact that we were able to get the end-to-end voter-to-ad pipeline going while also creating a beautiful web app. It seemed daunting at first, with so many moving pieces, but through intelligent separation of tasks we were able to get through everything.
## What we learned
Premature optimization is the killer of speed – we initially tried to do some smart splicing of the base video data so that we wouldn't lip sync parts of the video that were going to be covered by the B-roll (and thus do the lip syncing generation in parallel) – but doing all the splicing and recombining ended up taking almost as long as simply passing the whole video to the lip syncing model, and with many engineer-hours lost. It's much better to do things that don't scale in these environments (and most, one could argue).
## What's next for Rally
Customized campaign material is a massive market – scraping data online has become almost trivial thanks to tools like Firecrawl – so a more holistic solution for helping campaigns/non-profits/etc. ideate, test, and craft campaign material (with AI solutions already part of it) is a huge opportunity.
|
## Inspiration
We like Pong. Pong is life. Pong is love.
We like Leap. Leap is cool. Leap is awesome.
## What it does
Classical game of Pong that can be controlled with the Leap Controller Motion sensor.
Supports different playing mode such as:
* Single player
+ Control with Mouse
+ Control with Keyboard
+ Control with Leap Controller
* Multi player
+ Control with Keyboard and Keyboard
+ Control with Keyboard and Mouse
+ Control with Leap Controller and Keyboard
+ Control with Leap Controller and Mouse
+ Control with 2 hands on one Leap Controller
## How we built it
* Unity
* Leap Controller Motion Sensor
* Tears, sweat, and Awake chocolate (#Awoke)
## Challenges we ran into
Too many. That's what happens when you work with things you've never touched before (and Git).
## Accomplishments that we're proud of
We created a functional game of Pong. And that beautiful opening screen.
## What we learned
Everything. We had to learn EVERYTHING.
## What's next for Pong2.0
Make it into a mobile app and/or turn your mobile phone into one of the controller! Not everyone has a Leap sensor but most people own a smartphone (monetize).
|
## Inspiration
Following the recent tragic attacks in Paris, Beirut, and other places, the world has seen the chaos that followed during and after the events. We saw how difficult it was for people to find everything they wanted to know as they searched through dozens of articles and sites to get a full perspective on these trending topics. We wanted to make learning everything there is to know about trending topics effortless.
## What it does
Our app provides varied information on trending topics aggregated from multiple news sources. Each article is automatically generated and is an aggregation of excerpts from many sources in such a way that there is as much unique information as possible. Each article also includes insights on the attitude of the writer and the political leaning of the excerpts and overall article.
**Procedure**
1. Trending topics are found on twitter (in accordance to pre-chosen location settings).
2. Find top 30 hits in each topic's Bing results.
3. Parse each article to find important name entities, keywords, etc. to be included in the article.
4. Use machine learning and our scripts to select unique excerpts and images from all articles to create a final briefing of each topic.
5. Use machine learning to collect data on political sentiment and positivity.
All of this is displayed in a user-friendly web app which features the articles on trending topics and associated data visualizations.
## How we built it
We began with the idea of aggregating news together in order to create nice-looking efficient briefings, but we quickly became aware of the additional benefits that could be included into our project.
Notably, data visualization became a core focus of ours when we realized that the Indico API was able to provide statistics on emotion and political stance. Using Charts.JS and EmojiOne, we created emoticons to indicate the general attitude towards a topic and displayed the political scattermap of each and every topic. These allow us to make very interesting finds, such as the observation that Sports articles tend to be more positive than breaking news. Indico was also able to provide us with mentioned locations, and these was subsequently plugged into the Google Places API to be verified and ultimately sent to the Wolfram API for additional insight.
A recurring object of difficulty within our project was ranking, where we had to figure out what was "better" and what was not. Ultimately, we came to the conclusion that keywords and points were scatted across all paragraphs within a news story. A challenge in itself, a solution came to our minds. If we matched each and every paragraph to each and every keyword, a graph was formed and all we needed was maximal matching! Google gods were consulted, programming rituals were done, and we finally implemented Kuhn's Max Matching algorithm to provide a concise and optimized matching of paragraphs to key points.
This recurring difficulty presented itself once again in terms of image matching, where we initially had large pools (up to 50%) of our images being logos, advertisements, and general unpleasantness. While a filtering of specific key words and image sizes eliminated the bulk of our issues, the final solution came from an important observation made by one of our team members: Unrelated images generally have either empty of poorly constructed alt tags. With this in mind, we simply sorted our images and the sky cleared up for another day.
### The list of technicalities:
* Implemented Kuhn's Max Matching
* Used Python Lambda expressions for quick and easy sorting
* Advanced angular techniques and security filters were used to provide optimal experiences
* Extensive use of CSS3 transforms allowed for faster and smoother animations (CSS Transforms and notably 3D transforms 1. utilize the GPU and 2. do not cause page content rerendering)
* Responsive design with Bootstrap made our lives easier
* Ionic Framework was used to quickly and easily build our mobile applications
* Our Python backend script had 17 imports. Seven-teen
* Used BeautifulSoup to parse images within articles, and [newspaper](http://newspaper.readthedocs.org/en/latest/) to scrape pages
## Challenges we ran into
* Not running out of API keys
* Getting our script to run at a speed faster than O(N!!) time
* Smoothly incorporating so many APIs
* Figuring out how to prioritize "better" content
## Accomplishments that we're proud of
* Finishing our project 50% ahead of schedule
* Using over 7 APIs with a script that would send 2K+ API requests per 5 minutes
* Having Mac and PC users work harmoniously in Github
* Successful implementation of Kuhn's Max Matching algorithm
## What's next for In The Loop
* Supporting all languages
|
winning
|
## Inspiration
As COVID-19 ravaged the world, people were told to isolate themselves, and stay inside. Many people started working from home. People started working in their beds, couches, and kitchen tables, often sitting for hours at a time without any breaks, causing many neck and back issues due to bad posture when sitting in those positions. We want to help correct that.
## What it does
Ensures that your posture is correct and encourages you to do some stretches given a timer,
## How we built it
Our application is really lightweight and built using electron.js, which means that our application can also run on your browser. We make use of ML5 on Tensorflow.js for our machine learning base, and we used Photon as a basis for our UI.
## Challenges we ran into
We initially had difficulty in connecting the two neural networks to our electron application. We handled it step by step and worked through each view. This way we were able to make it work eventually.
## Accomplishments that we are proud of
We are proud of building this application in 24 hours and making it fully functional within this timeframe. We are also proud of having a great developer coordination / collaboration.
## What we learned
This was the first time all of us worked on an electron project, but more importantly, with machine learning. We learned a lot about classification, which allows us to take inputs, specifically our body points, and use that to predict whether or not you have good posture.
We've learned a lot about Machine Learning, and how to set up Neural Networks and this hackathon was fun and a great learning experience.
## What's next for neckTech
This project is fully extensible and will include more exercises and help support seating ergonomics in different ways.
After this hackathon, we’d like to work on fine tuning our models and make it available for all students and employees around the world who are now working online.
|
## Inspiration
We've noticed that in our personal lives, posture in the office space and programming community is often neglected which results in long-term negative health effects. We set out to build a simple but powerful application that would empower individuals to build better posture habits.
## What it does
Align periodically analyzes your posture utilizing Google Cloud's Vision recognition AI and gently alerts you if your posture is poor.
## How we built it
ElectronJS was used to build a cross platform desktop application that uses your webcam and Google Cloud's Vision recognition AI to periodically analyze your posture. Coupled with our in-house developed algorith, Align is able to recognize when your posture is not ideal and notify you accordingly. The user interface built with HTML and CSS.
## Challenges we ran into
Initially, we hoped to develop a Chrome extension to increase the simplicity and ease of use for consumers. However, we ran into a roadblock as Chrome had removed camera access for extensions and had to find a different medium. We decided that Electron would provide the most utility even though we lacked experience with Electron which posed a significant learning curve.
## Accomplishments that we're proud of
We are proud to be able to tackle such a prominent issue that millions are facing everyday through an elegant and simple solution. We had achieved what we had set out to do, and it worked beyond our expectations. We are proud of creaitng something that can actually make a change in the workplace, school, and home. Furthermore, we are pleased that it is easily accessible and does not require additional hardware for deployment.
## What we learned
We learned a lot of Electron, JS, Google Cloud API integration, Git (many merge conflicts...), project delegation, and teamwork.
## What's next for Align
We want to make a downloadable executable that anyone will be able to use and help improve their posture. Through marketing we want to emphasize that we do not track nor store user data or images, and the only purpose is to improve posture.

|
## Inspiration
Feeling major self-doubt when you first start hitting the gym or injuring yourself accidentally while working out are not uncommon experiences for most people. This inspired us to create Core, a platform to empower our users to take control of their well-being by removing the financial barriers around fitness.
## What it does
Core analyses the movements performed by the user and provides live auditory feedback on their form, allowing them to stay fully present and engaged during their workout. Our users can also take advantage of the visual indications on the screen where they can view a graph of the keypoint which can be used to reduce the risk of potential injury.
## How we built it
Prior to development, a prototype was created on Figma which was used as a reference point when the app was developed in ReactJs. In order to recognize the joints of the user and perform analysis, Tensorflow's MoveNet model was integrated into Core.
## Challenges we ran into
Initially, it was planned that Core would serve as a mobile application built using React Native, but as we developed a better understanding of the structure, we saw more potential in a cross-platform website. Our team was relatively inexperienced with the technologies that were used, which meant learning had to be done in parallel with the development.
## Accomplishments that we're proud of
This hackathon allowed us to develop code in ReactJs, and we hope that our learnings can be applied to our future endeavours. Most of us were also new to hackathons, and it was really rewarding to see how much we accomplished throughout the weekend.
## What we learned
We gained a better understanding of the technologies used and learned how to develop for the fast-paced nature of hackathons.
## What's next for Core
Currently, Core uses TensorFlow to track several key points and analyzes the information with mathematical models to determine the statistical probability of the correctness of the user's form. However, there's scope for improvement by implementing a machine learning model that is trained on Big Data to yield higher performance and accuracy.
We'd also love to expand our collection of exercises to include a wider variety of possible workouts.
|
partial
|
## Inspiration
Learning a new instrument is hard. Inspired by games like Guitar Hero, we wanted to make a fun, interactive music experience but also have it translate to actually learning a new instrument. We chose the violin because most of our team members had never touched a violin prior to this hackathon. Learning the violin is also particularly difficult because there are no frets, such as those on a guitar, to help guide finger placement.
## What it does
Fretless is a modular attachment that can be placed onto any instrument. Users can upload any MIDI file through our GUI. The file is converted to music numbers and sent to the Arduino, which then lights up LEDs at locations corresponding to where the user needs to press down on the string.
## How we built it
Fretless is composed to software and hardware components.
We used a python MIDI library to convert MIDI files into music numbers readable by the Arduino. Then, we wrote an Arduino script to match the music numbers to the corresponding light. Because we were limited by the space on the violin board, we could not put four rows of LEDs (one for each string). Thus, we implemented logic to color code the lights to indicate which string to press.
## Challenges we ran into
One of the challenges we faced is that only one member on our team knew how to play the violin. Thus, the rest of the team was essentially learning how to play the violin and coding the functionalities and configuring the electronics of Fretless at the same time.
Another challenge we ran into was the lack of hardware available. In particular, we weren’t able to check out as many LEDs as we needed. We also needed some components, like a female DC power adapter, that were not present at the hardware booth. And so, we had limited resources and had to make do with what we had.
## Accomplishments that we're proud of
We’re really happy that we were able to create a working prototype together as a team. Some of the members on the team are also really proud of the fact that they are now able to play Ode to Joy on the violin!
## What we learned
Do not crimp lights too hard.
Things are always harder than they seem to be.
Ode to Joy on the violin :)
## What's next for Fretless
We can make the LEDs smaller and less intrusive on the violin, ideally a LED pad that covers the entire fingerboard. Also, we would like to expand the software to include more instruments, such as cello, bass, guitar, and pipa. Finally, we would like to corporate a PDF sheet music to MIDI file converter so that people can learn to play a wider range of songs.
|
## Inspiration
Our main inspiration for the idea of the Lead Zeppelin was a result of our wanting to help people with physical disorders still be able to appreciate and play music with restricted hand movements. There are countless--hundreds upon thousands of people who suffer from various physical disorders that prevent them from moving their arms much. When it comes to playing music, this proves a major issue as very few instruments can be played without open range of movement. Because every member of our team loves playing music, with the common instrument amongst all four of us being guitar, we decided to focus on trying to solve this issue for the acoustic guitar in particular.
## What it does
The Lead Zeppelin uses mechanical systems placed above the guitar frets and sound hole that allow the user to play the instrument using only two keypads. Through this system, the user is able to play the guitar without needing to move much more than his or her fingers, effectively helping those with restricted elbow or arm movement to play the guitar.
## How we built it
There were a lot of different components put into building the Lead Zeppelin. Starting with the frets, the main point was actually the inspiration for our project's name: the use of pencils--more specifically, their erasers. Each fret on each string has a pencil eraser hovering above it, which is used to press down the string at the user's intent. The pencils are able to be pushed down through the use of servos and a few mechanisms that were custom 3D printed. Above the sound hole, two servos are mounted to the guitar to allow for horizontal and vertical movement when plucking or strumming the strings. The last hardware parts were the circuit boards and the user's keypads, for which we utilized hot glue and sodder.
## Challenges we ran into
There were many obstacles as we approached this project from all different aspects of the design to the mechanics. On the other hand, however, we expected challenges since we delved into the idea knowing it was going to be ambitious for our time constraints. One of the first challenges we confronted was short-circuiting two Raspberry Pi's that we'd intended to use, forcing us to switch over to Arduino--which was entirely unplanned for. When it came time to build, one of the main challenges that we ran into was creating the mechanism for the pressing down of the strings on the frets of the guitar. This is because not only did we have to create multiple custom CAD parts, but the scale on the guitar is also one that works in millimeters--leaving little room for error when designing, and even less so when time is taken into consideration. In addition, there were many issues with the servos not functioning properly and the batteries' voltages being too low for the high-power servos, which ended up consuming more time than was allotted for solving them.
## Accomplishments that we're proud of
The biggest accomplishment for all of us is definitely pulling the whole project together to be able to create a guitar that can potentially be used for those with physical disabilities. When we were brainstorming ideas, there was a lot of doubt about every small detail that could potentially put everything we would work for to waste. Nonetheless, the idea and goal of our project was one that we really liked and so the fact that we were able to work together to make the project work was definitely impressive.
## What we learned
One of the biggest lessons we'll keep in mind for next time is time management. We spent relatively little time in the first day working on the project, and especially considering the scale of our idea, this resulted in our necessity to stay up later and sleep less the later it got in the hackathon as we realized the magnitude of work we had left.
## What's next for Lead Zeppelin
Currently, the model of Lead Zeppelin is only on a small scale meant to demonstrate proof of concept, considering the limited amount of time we had to work. In the future, this is an automated player that would be expanded to cover all of the frets and strings over the whole guitar. Furthermore, Lead Zeppelin is a step towards an entirely self-playing, automated guitar that could follow its complete development in the design helping those with physical disabilities.
|
## Inspiration
For this project, we wanted to work with hardware, and we wanted to experiment with processing sound or music on a microcontroller. From this came the idea of using a gyroscope and accelerometer as a means to control music.
## The project
The Music Glove has an accelerometer and gyroscope module combined with a buzzer. The user rotates their and to control the pitch of the music (cycle through a scale). We planned to combine this basic functionality with musical patterns (chords and rythms) generated from a large table of scales stored in flash memory, but we were unable to make the gyroscope work properly with this code.
## Challenges
We were initially very ambitious with the project. We wanted to have multiple speakers/buzzers to make chords or patterns that could be changed with one axis of hand rotation ("roll") as well as a speaker to establish a beat that could be changed with the other axis of hand rotation ("pitch"). We also wanted to have a third input (in the form of a keypad with multiple buttons or potentiometer) to change the key of the music.
Memory constraints on the Arduino made it initially more appealing to use an MP3 playing module to contain different background rythm patterns. However, this proved to be difficult to combine with the gyroscope functionality, especially considering the gyroscope module would sometimes crash inexplicably. It appears that the limited number of timers on an Arduino Uno/Nano (three in total) can make combining different functionalities into a single sketch difficult. For example, each tone being played at a set time requires its own timer, but serial communication often also requires a timer. We were also unable to add a third input (keypad) for changing the key separately.
## What we learned
We learned how to use a gyroscope and manipulate tones with an Arduino. We learned how to use various libraries to create sounds and patterns without a built-in digital to analog converter on the Arduino. We also learned how to use a keypad and an mp3 module, and working around combining different functionalities. Most of all, we had fun!
|
winning
|
## Inspiration
We are all a fan of Carrot, the app that rewards you for walking around. This gamification and point system of Carrot really contributed to its success. Carrot targeted the sedentary and unhealthy lives we were leading and tried to fix that. So why can't we fix our habit of polluting and creating greenhouse footprints using the same method? That's where Karbon comes in!
## What it does
Karbon gamifies how much you can reduce your CO₂ emissions by in a day. The more you reduce your carbon footprint, the more points you can earn. Users can then redeem these points at Eco-Friendly partners to either get discounts or buy items completely for free.
## How we built it
The app is created using Swift and Swift UI for the user interface. We also used HTML, CSS and Javascript to make a web app that shows the information as well.
## Challenges we ran into
Initially, when coming up with the idea and the economy of the app, we had difficulty modelling how points would be distributed by activity. Additionally, coming up with methods to track CO₂ emissions conveniently became an integral challenge to ensure a clean and effective user interface. As for technicalities, cleaning up the UI was a big issue as a lot of our time went into creating the app as we did not have much experience with the language.
## Accomplishments that we're proud of
Displaying the data using graphs
Implementing animated graphs
## What we learned
* Using animation in Swift
* Making Swift apps
* Making dynamic lists
* Debugging unexpected bugs
## What's next for Karbon
A fully functional Web app along with proper back and forth integration with the app.
|
## Inspiration 🌱
Climate change is affecting every region on earth. The changes are widespread, rapid, and intensifying. The UN states that we are at a pivotal moment and the urgency to protect our Earth is at an all-time high. We wanted to harness the power of social media for a greater purpose: promoting sustainability and environmental consciousness.
## What it does 🌎
Inspired by BeReal, the most popular app in 2022, BeGreen is your go-to platform for celebrating and sharing acts of sustainability. Everytime you make a sustainable choice, snap a photo, upload it, and you’ll be rewarded with Green points based on how impactful your act was! Compete with your friends to see who can rack up the most Green points by performing more acts of sustainability and even claim prizes once you have enough points 😍.
## How we built it 🧑💻
We used React with Javascript to create the app, coupled with firebase for the backend. We also used Microsoft Azure for computer vision and OpenAI for assessing the environmental impact of the sustainable act in a photo.
## Challenges we ran into 🥊
One of our biggest obstacles was settling on an idea as there were so many great challenges for us to be inspired from.
## Accomplishments that we're proud of 🏆
We are really happy to have worked so well as a team. Despite encountering various technological challenges, each team member embraced unfamiliar technologies with enthusiasm and determination. We were able to overcome obstacles by adapting and collaborating as a team and we’re all leaving uOttahack with new capabilities.
## What we learned 💚
Everyone was able to work with new technologies that they’ve never touched before while watching our idea come to life. For all of us, it was our first time developing a progressive web app. For some of us, it was our first time working with OpenAI, firebase, and working with routers in react.
## What's next for BeGreen ✨
It would be amazing to collaborate with brands to give more rewards as an incentive to make more sustainable choices. We’d also love to implement a streak feature, where you can get bonus points for posting multiple days in a row!
|
## Inspiration
Our team really wanted to create a new way to maximize productivity without the interference of modern technology. we often find ourselves reaching for our phones to scroll through social media for just a "5 minute break" which quickly turns into a 2 hours procrastination session. On top of that, we wanted the motivation to be delivered in a sarcastic/funny way. Thus, we developed a task manager app that bullies you into working.
## What it does
The app allows you to create a to-do list of tasks that you can complete at any time. Once you decide to start a task, distracting yourself with other applications is met with reinforcement to get you back to work. The reinforcement is done through text and sound based notifications. Not everyone is motivated in the same way, thus the intensity of the reinforcement can be calibrated to the user's personal needs. The levels include: Encouragement, Passive-Aggression and Bullying.
## How we built it
We built the our project as a mobile app using Swift and Apple's SwiftUI and UserNotification frameworks. Development was done via Xcode. The app is optimized for IOS 16.
## Challenges we ran into
Learning how to code in Swift. Our team did not have a lot of experience in mobile IOS development. Since we were only familiar with the basics, we wanted to include more advanced features that would force us to integrate new modules and frameworks.
## Accomplishments that we're proud of
Having a product we are proud enough to demo. This is the first time anyone in our team is demoing. We spent extra time polishing the design and including animations. We wanted to deliver an App that felt like a complete product, and not just a hack, even if the scope was not very large.
## What we learned
We learned front end in Swift (SwiftUI) including how to make animations. A lot about data transfer and persistence in IOS applications. And the entire development cycle of building a complete and kick-ass Application.
## What's next for TaskBully?
* Incorporate a scheduling/deadline feature to plan when to complete tasks.
* Include an achievement system based around successfully completing tasks.
* Implement even more custom sounds for different intensity levels.
* Add a social feature to share success with friends.
**A message from TaskBully:**
Here at TaskBully, our vast team of 2 employees is deeply committed to the goal of replacing bullying with motivation. We are actively looking for sponsorships, investments, and growth opportunities until we can eventually eradicate procrastination.
|
winning
|
## Inspiration
We noticed that we found it difficult to keep to our resolutions to exercise more, and also realized that we were worried if we were maintaining the correct form when exercising. While we wanted to take more ownership in our health, we found it difficult to do so on our own and at a low cost. That's why we built Health is Wealth!
## What it does
Health is wealth helps users take ownership of their health through helping users commit to their exercise goals through an in-built rewards system, and helps users correct their form when exercising on their own through computer vision.
## How we built it
React-native for the mobile application
face\_recognition to verify user faces
opencv, numpy, mediapipe to detect user form during exercises
flask for the backend server
## Challenges we ran into
We faced a poor WIFI connection throughout the hackathon, which made it hard to research and download packages
We ran into issues getting mediapipe to run, as it only worked with an older version of python.
## Accomplishments that we're proud of
We're proud of how we managed to solve 2 problems that we face in our daily lives when it comes to exercising
We're proud that we were able to integrate FHIR for healthcare apps.
## What we learned
We didn't know much about pose estimation and facial recognition, but managed to learn it through this Hackathon.
We also learned about FHIR through this hackathon, and its importance and usability when building healthcare apps.
## What's next for Health is Wealth
Future partnerships for different rewards schemes
|
## Inspiration
Instafit was developed in response to the high volume and low information approach of the current iterations of iOS Health and Google Fit. While they provide the user with a deluge of health information to consider, they leave it to the user to interpret this technical data and establish healthy habits without knowing which stats matter and which ones don't. Instafit fills the gaps by providing users with predictive modeling of potential health risks based on this wealth of data, and it also leverages cryptocurrency as an incentive for exercising.
## What it does
Instafit provides users with analytics that allow them to see their risk profiles without having to interpret the data themselves. It also provides suggestions to improve their health and cryptocurrency tokens that incentivize exercise and will allow for a gamified model of fitness.
## How we built it

We leveraged Supervised Machine Learning techniques to correlate LOINC values from the InterSystems FHIR server representing observational health data with conditions corresponding to heart health. Through the use of Python, Jupyter Notebooks, Dart, and Flutter, we created a dynamic multi-platform app through which the user can understand their health and interact with their network.
## Challenges we ran into
As the majority of us are beginners, we struggled on implementing an app for mobile devices using Flutter. Additionally, we struggled in getting risk assessment values based on individual health data. After many challenges, we learned about the FHIR API, which we utilized to predictively model risk assessment.
## Accomplishments that we're proud of
We are proud of getting a mobile app implemented that represents the fusion of machine learning and cryptocurrency and helps users parse through health data without the noise. We are proud that our app is able to ease an individual’s stress by showing how their good habits are truly marks of health while also alerting users who may not understand the quantified impact of bad habits on their long-term prognosis. We were happy to find a useful tool in the InterSystems FHIR server for predictively modeling risk assessment with a robust electronic health data format, as we initially struggled to get risk assessment values based on an individual’s health data. The FHIR system provides many opportunities for scalability of our project, ranging from increasing our assessed parameters to personalizing health data for populations such as veterans.
## What we learned
As the majority of us are beginners, we were new to working with the Flutter SDK for app development. However, we were ultimately able to leverage the Flutter technology to create a clean, effective app. We were also very new to the idea of making an app that utilizes cryptocurrency. However, in the end, we made a successfully functional app that utilizes cryptocurrency as an incentive to exercise. Therefore, we learned how to leverage the benefits of cryptocurrency and combine them with building an app to create a better product.
## What's next for Instafit
In the future, we would like to scale with regards to incentives for health, such as by fostering healthy competition between users and their friends. Additionally, the Instafit platform could allow telehealth services to be recommended or even conducted through the app, and we could utilize the user's risk profile to provide personalized recommendations for nutrition and exercise. Most interestingly, the Instafit platform in conjunction with rapidly advancing wearable tech could provide relatively low-cost Early Warning Systems for assessing the stability of hospitalized patients and other individuals at immediate risk.
|
## Inspiration
Kevin, one of our team members, is an enthusiastic basketball player, and frequently went to physiotherapy for a knee injury. He realized that a large part of the physiotherapy was actually away from the doctors' office - he needed to complete certain exercises with perfect form at home, in order to consistently improve his strength and balance. Through his story, we realized that so many people across North America require physiotherapy for far more severe conditions, be it from sports injuries, spinal chord injuries, or recovery from surgeries. Likewise, they will need to do at-home exercises individually, without supervision. For the patients, any repeated error can actually cause a deterioration in health. Therefore, we decided to leverage computer vision technology, to provide real-time feedback to patients to help them improve their rehab exercise form. At the same time, reports will be generated to the doctors, so that they may monitor the progress of patients and prioritize their urgency accordingly. We hope that phys.io will strengthen the feedback loop between patient and doctor, and accelerate the physical rehabilitation process for many North Americans.
## What it does
Through a mobile app, the patients will be able to film and upload a video of themselves completing a certain rehab exercise. The video then gets analyzed using a machine vision neural network, such that the movements of each body segment is measured. This raw data is then further processed to yield measurements and benchmarks for the relative success of the movement. In the app, the patients will receive a general score for their physical health as measured against their individual milestones, tips to improve the form, and a timeline of progress over the past weeks. At the same time, the same video analysis will be sent to the corresponding doctor's dashboard, in which the doctor will receive a more thorough medical analysis in how the patient's body is working together and a timeline of progress. The algorithm will also provide suggestions for the doctors' treatment of the patient, such as prioritizing a next appointment or increasing the difficulty of the exercise.
## How we built it
At the heart of the application is a Google Cloud Compute instance running together with a blobstore instance. The cloud compute cluster will ingest raw video posted to blobstore, and performs the machine vision analysis to yield the timescale body data.
We used Google App Engine and Firebase to create the rest of the web application and API's for the 2 types of clients we support: an iOS app, and a doctor's dashboard site. This manages day to day operations such as data lookup, and account management, but also provides the interface for the mobile application to send video data to the compute cluster. Furthermore, the app engine sinks processed results and feedback from blobstore and populates it into Firebase, which is used as the database and data-sync.
Finally, In order to generate reports for the doctors on the platform, we used stdlib's tasks and scale-able one-off functions to process results from Firebase over time and aggregate the data into complete chunks, which are then posted back into Firebase.
## Challenges we ran into
One of the major challenges we ran into was interfacing each technology with each other. Overall, the data pipeline involves many steps that, while each in itself is critical, also involve too many diverse platforms and technologies for the time we had to build it.
## What's next for phys.io
<https://docs.google.com/presentation/d/1Aq5esOgTQTXBWUPiorwaZxqXRFCekPFsfWqFSQvO3_c/edit?fbclid=IwAR0vqVDMYcX-e0-2MhiFKF400YdL8yelyKrLznvsMJVq_8HoEgjc-ePy8Hs#slide=id.g4838b09a0c_0_0>
|
losing
|
## Inspiration
One of our group members wanted to create a chess game with 2 teams that vote on the next move.... we changed it to Tic Tac Toe :)
## What it does
A simple tic tac toe game where players connect to a server, are given a team and are prompted every 15 seconds to vote on the next move, the move with the most votes will be the location where the piece will be placed.
## How we built it
A simple socket server handles all the client data coming in and out. Voting system will choose randomly if no votes were submitted. A GUI was used to prompt the user for the next move and to display the board.
## Challenges we ran into
Unfortunately, we decided to switch our project half way through which really limited our time.
## What we learned
Threading & Socket Servers
|
## Inspiration
We thought it would be nice if, for example, while working in the Computer Science building, you could send out a little post asking for help from people around you.
Also, it would also enable greater interconnectivity between people at an event without needing to subscribe to anything.
## What it does
Users create posts that are then attached to their location, complete with a picture and a description. Other people can then view it two ways.
**1)** On a map, with markers indicating the location of the post that can be tapped on for more detail.
**2)** As a live feed, with the details of all the posts that are in your current location.
The posts don't last long, however, and only posts within a certain radius are visible to you.
## How we built it
Individual pages were built using HTML, CSS and JS, which would then interact with a server built using Node.js and Express.js. The database, which used cockroachDB, was hosted with Amazon Web Services. We used PHP to upload images onto a separate private server. Finally, the app was packaged using Apache Cordova to be runnable on the phone. Heroku allowed us to upload the Node.js portion on the cloud.
## Challenges we ran into
Setting up and using CockroachDB was difficult because we were unfamiliar with it. We were also not used to using so many technologies at once.
|
## Inspiration
The inspiration of our game came from the arcade game Cyclone, where the goal is to click the button when the LED lands on a signaled part of the circle.
## What it does
The goal of our game is to click the button when the LED reaches a designated part of the circle (the very last LED). Upon successfully doing this it will add 1 to your score, as well as increasing the speed of the LED, continually making it harder and harder to achieve this goal. The goal is for the player to get as high of a score as possible, as the higher your score is, the harder it will get. Upon clicking the wrong designated LED, the score will reset, as well as the speed value, effectively resetting the game.
## How we built it
The project was split into two parts; one was the physical building of the device and another was the making of the code.
In terms of building the physical device, at first we weren’t too sure what we wanted to do, so we ended up with a mix up of parts we could use. All of us were pretty new to using the Arduino, and its respective parts, so it was initially pretty complicated, before things started to fall into place. Through the use of many Youtube videos, and tinkering, we were able to get the physical device up and running. Much like our coding process, the building process was very dynamic. This is because at first, we weren’t completely sure which parts we wanted to use, so we had multiple components running at once, which allowed for more freedom and possibilities. When we figured out which components we would be using, everything sort of fell into place.
For the code process, it was quite messy at first. This was because none of us were completely familiar with the Arduino libraries, and so it was a challenge to write the proper code. However, with the help of online guides and open source material, we were eventually able to piece together what we needed. Furthermore, our coding process was very dynamic. We would switch out components constantly, and write many lines of code that was never going to be used. While this may have been inefficient, we learned much throughout the process, and it kept our options open and ideas flowing.
## Challenges we ran into
In terms of main challenges that we ran into along the way, the biggest challenge was getting our physical device to function the way we wanted it to. The initial challenge came from understanding our device, specifically the Arduino logic board, and all the connecting parts, which then moved to understanding the parts, as well as getting them to function properly.
## Accomplishments that we're proud of
In terms of main accomplishments, our biggest accomplishment is overall getting the device to work, and having a finished product. After running into many issues and challenges regarding the physical device and its functions, putting our project together was very satisfying, and a big accomplishment for us. In terms of specific accomplishments, the most important parts of our project was getting our physical device to function, as well as getting the initial codebase to function with our project. Getting the codebase to work in our favor was a big accomplishment, as we were mostly reliant on what we could find online, as we were essentially going in blind during the coding process (none of us knew too much about coding with Arduino).
## What we learned
During the process of building our device, we learned a lot about the Arduino ecosystem, as well as coding for it. When building the physical device, a lot of learning went into it, as we didn’t know that much about using it, as well as applying programs for it. We learned how important it is to have a strong connection for our components, as well as directly linking our parts with the Arduino board, and having it run proper code.
## What's next for Cyclone
In terms of what’s next for Cyclone, there are many possibilities for it. Some potential changes we could make would be making it more complex, and adding different modes to it. This would increase the challenge for the player, and give it more replay value as there is more to do with it. Another potential change we could make is to make it on a larger scale, with more LED lights and make attachments, such as the potential use of different types of sensors. In addition, we would like to add an LCD display or a 4 digit display to display the player’s current score and high score.
|
partial
|
## Inspiration
Imagine yourself in a calm, lush rainforest. You look up into the sky, through the tall green trees, and bask in the sights and sounds of the beautiful landscape. And then--a bird flies by...oh! It's a Spix's macaw!
We wanted to create a relaxing experience inspired by the flora and fauna of Amazon rainforests.
## What it does
Immerse yourself in a captivating environment, look around, listen to the sounds, and observe your surroundings and the beautiful voxel birds and trees.
## How we built it
We used MagicaVoxel to create the rainforest landscape and bird models in 3D. Then, we used Blender to rig and animate our bird models. Finally, we brought it all together in Godot.
## Challenges we ran into
* Creating 3D models was not easy, and often we had to spend lots of time going pixel-by-pixel to create our objects.
* Importing 3D models to Blender was simple, but rigging and animating them was not; after doing that dirty work, it was an even bigger problem trying to export the files to Godot.
* Once in Godot, navigating the coding language and intricacies of the platform proved difficult, especially in terms of importing an animated model into our 3D landscape and mapping a path of flight.
* Crafting beautiful lighting was hard to get right--it took a long time.
## Accomplishments that we're proud of
* We learned basic 3D modelling, rigging and animation
* We programmed the bird's flight using paths in Godot
* We composed a nice tune to go along with the ambient rainforest recordings.
## What we learned
* **Spix's macaws are likely extinct in the wild due to extreme deforestation!**
* How to make 3D models using voxels
* How to rig and animate 3D models
* How to import/export 3D models
* How to navigate Godot, Blender, and MagicaVoxel
* How to build an immersive experience from the ground-up
## What's next for Selva
* An in-game journal to record observations and learn more about the birds
* More birds
* More trees
* More sounds
* More flight paths
* A dynamic environment
|
## Inspiration
The invention of the internet brought a human catalog of memory that is freely accessible. Machine learning models that utilize stable diffusion manage to illustrate the internet's collective memory into images. We wanted to bring this novel tech to Virtual Reality, the most immersive interface between the senses and the digital.
## What it does
We insert a prompt to a "Text-to-3D" stable diffusion model (ex: prompt ["a green prickly cactus"](https://files.catbox.moe/y3czz2.mp4)) which automatically gets added to a Unity project which builds to a Quest 2 headset. We offer two modes: an art gallery that brings focus to the generated 3D model, and a planetary mode that allows the player to walk on the surface of these enlarged 3D models.
## How we built it
Using this implementation of [text-to-3D stable diffusion](https://github.com/ashawkey/stable-dreamfusion) with Google Colab as compute power, we send it to a Google Drive which is imported to our Unity project via the file system at runtime. The Unity project has complete VR functionality which we added using the XR Interaction Toolkit package. In the Unity environment, we place the generated 3D models into a virtualized space, creating an art gallery and a separate planetary mode, enlarge the generated model with a basic physics system to walk along a planetary surface.
## Challenges we ran into
Google Drive API work is very hard and we had to resort to downloading some things manually. The stable diffusion model we use is also very specific where it MUST be described as an object; for example, "a piano with legs". The inserted prompt cannot be an emotion such as "happiness" or a setting such as "forest". Additionally, we ran into several issues with our intended import flow into Unity, but we were able to get around this using an open-source async mesh loader for Unity called [AsImpL](https://github.com/gpvigano/AsImpL).
## Accomplishments that we're proud of
We're especially proud of managing to create an entire build flow, importing results from Google Colab into Unity at runtime, something not easily supported by Unity by default. We're also proud of our dedication, working through wi-fi issues and through the night to create something we're happy with as our first hackathon project.
## What we learned
This is our first foray into using ML-based art and Google Colab. We learned advanced git functionalities to support proactive and collaborative teamwork for a rapidly iterating project. We also learned how to properly navigate around the various Github repositories and APIs to properly choose what would be best for the purposes of our project.
## What's next for Dreamfusion VR
We would like to fully automate with Google Cloud APIs to allow for seamless importing through the cloud. We would also like to explore procedural generation using AI generated models, moving beyond viewing one model at a time to exploring an expansive dream-like world. A small thing we got really close to but didn't make the final cut was displaying the text prompt that formed the model in the art gallery; currently, we display the file name. Finally, we would like to find ways to increase compute power to achieve even more fully-formed models.
|
## Inspiration
Have you ever stared into your refrigerator or pantry and had no idea what to eat for dinner? Pantri provides a visually compelling picture of which foods you should eat based on your current nutritional needs and offers recipe suggestions through Amazon Alexa voice integration.
## What it does
Pantri uses FitBit data to determine which nutritional goals you have or haven't met for the day, then transforms your kitchen with Intel Edison-connected RGB LCD screens and LIFX lighting to lead you in the direction of healthy options as well as offer up recipe suggestions to balance out your diet and clean out your fridge.
## How we built it
The finished hack is a prototype food storage unit (pantry) made of cardboard, duct tape, and plexiglass. It is connected to the backend through button and touch sensors as well as LIFX lights and RGB LCD screens. Pressing the button allows you to view the nutritional distribution without opening the door, and opening the door activates the touch sensor. The lights and screens indicate which foods (sorted onto shelves based on nutritional groups) are the best choices. Users can also verbally request a dinner suggestion which will be offered based on which nutritional categories are most needed.
At the center of the project is a Ruby on Rails server hosted live on Heroku. It stores user nutrition data, provides a mobile web interface, processes input from the button and touch sensors, and controls the LIFX lights as well as the color and text of the RGB LCD screens.
Additionally, we set up three Intel Edison microprocessors running Cylon.js (built on top of Node.js) with API interfaces so information about their attached button, touch sensor, and RGB LCD screens can be connected to the Rails server.
Finally, an Amazon Alexa (connected through an Amazon Echo) connects users with the best recipes based on their nutritional needs through a voice interface.
|
losing
|
## Inspiration
While discussing potential ideas, Robin had to leave the call because of a fire alarm in his dorm — due to burning eggs in the dorm's kitchen. We saw potential for an easier and safer way to cook eggs.
## What it does
Eggsy makes cooking eggs easy. Simply place your egg in the machine, customize the settings on your phone, and get a fully-cooked egg in minutes. Eggsy is a great, healthy, quick food option that you can cook from anywhere!
## How we built it
The egg cracking and cooking are handled by a EZCracker egg cracker and hot plate, respectively. Servo motors control these devices and manage the movement of the egg within the machine. The servos are controlled by a Sparkfun Redboard, which is connected to a Raspberry Pi 3 running the back-end server. This server connects to the iOS app and web interface.
## Challenges we ran into
One of the most difficult challenges was managing all the resources that we needed in order to build the project. This included gaining access to a 3D printer, finding a reliable way to apply a force to crack an egg, and the tools to put it all together. Despite these issues, we are happy with what we were able to hack together in such a short period time with limited resources!
## Accomplishments that we're proud of
Creating a robust interface between hardware and software. We wanted the user to have multiple ways to interact with the device (the app, voice (Siri), quick actions, the web app) and the hardware to work reliably no matter how the user prefers to interact. We are proud of our ability to take a challenging project head-on, and get as much done as we possibly could.
## What we learned
Hardware is hard. Solid architecture is important, especially when connecting many pieces together in order to create a cohesive experience.
## What's next for Eggsy
We think Eggsy has a lot of potential, and many people we have demo'd to have really liked the idea. We would like to add additional egg-cooking options, including scrambled and hardboiled eggs. While Eggsy still a prototype, it's definitely possible to build a smaller, more reliable model in the future to market to consumers.
|
## Inspiration
The worst part about getting up in the morning is making coffee while you are half-asleep and wishing you were still in bed. This made me ask, why can't I have coffee already waiting for me right when I get out of bed? So i developed an idea, why don't I modify a coffee maker to have its own Twitter account. That way you can tweet the coffee maker from your bed. This way you will have hot coffee ready as soon you get up!
## What it does
The Electric Bean Coffee is a **IoT coffee maker** that connects to WiFi and has its own Twitter account. Whenever tweeted at to make coffee it begins brewing some coffee right away.
## How I built it
To build this project we used several hardware and software components.
To monitor the tweets we used a **Stdlib Twitter API** which is accessed using **Python**.
As for hardware we used a **Raspberry Pi** which runs our python code and controls an **Arduino**.
We used a **DigiKey** servo to control the modded coffee machine
## Challenges I ran into
We were all new to using **Arduino**. This proved challenging because we had to overcome many challenging getting software to play well with the hardware
## Accomplishments that I'm proud of
Being able to complete our first attempt at a hardware hack and venture into the expanding world of **IoT**
## What I learned
A lot about hardware and and extracting JSON objects in python using **Stdlib**
## What's next for Electric Beans -- IoT Twitter Coffee Machine
Creating a more visually appeal product
|
## Inspiration
COVID revolutionized the way we communicate and work by normalizing remoteness. **It also created a massive emotional drought -** we weren't made to empathize with each other through screens. As video conferencing turns into the new normal, marketers and managers continue to struggle with remote communication's lack of nuance and engagement, and those with sensory impairments likely have it even worse.
Given our team's experience with AI/ML, we wanted to leverage data to bridge this gap. Beginning with the idea to use computer vision to help sensory impaired users detect emotion, we generalized our use-case to emotional analytics and real-time emotion identification for video conferencing in general.
## What it does
In MVP form, empath.ly is a video conferencing web application with integrated emotional analytics and real-time emotion identification. During a video call, we analyze the emotions of each user sixty times a second through their camera feed.
After the call, a dashboard is available which displays emotional data and data-derived insights such as the most common emotions throughout the call, changes in emotions over time, and notable contrasts or sudden changes in emotion
**Update as of 7.15am: We've also implemented an accessibility feature which colors the screen based on the emotions detected, to aid people with learning disabilities/emotion recognition difficulties.**
**Update as of 7.36am: We've implemented another accessibility feature which uses text-to-speech to report emotions to users with visual impairments.**
## How we built it
Our backend is powered by Tensorflow, Keras and OpenCV. We use an ML model to detect the emotions of each user, sixty times a second. Each detection is stored in an array, and these are collectively stored in an array of arrays to be displayed later on the analytics dashboard. On the frontend, we built the video conferencing app using React and Agora SDK, and imported the ML model using Tensorflow.JS.
## Challenges we ran into
Initially, we attempted to train our own facial recognition model on 10-13k datapoints from Kaggle - the maximum load our laptops could handle. However, the results weren't too accurate, and we ran into issues integrating this with the frontend later on. The model's still available on our repository, and with access to a PC, we're confident we would have been able to use it.
## Accomplishments that we're proud of
We overcame our ML roadblock and managed to produce a fully-functioning, well-designed web app with a solid business case for B2B data analytics and B2C accessibility.
And our two last minute accessibility add-ons!
## What we learned
It's okay - and, in fact, in the spirit of hacking - to innovate and leverage on pre-existing builds. After our initial ML model failed, we found and utilized a pretrained model which proved to be more accurate and effective.
Inspiring users' trust and choosing a target market receptive to AI-based analytics is also important - that's why our go-to-market will focus on tech companies that rely on remote work and are staffed by younger employees.
## What's next for empath.ly
From short-term to long-term stretch goals:
* We want to add on AssemblyAI's NLP model to deliver better insights. For example, the dashboard could highlight times when a certain sentiment in speech triggered a visual emotional reaction from the audience.
* We want to port this to mobile and enable camera feed functionality, so those with visual impairments or other difficulties recognizing emotions can rely on our live detection for in-person interactions.
* We want to apply our project to the metaverse by allowing users' avatars to emote based on emotions detected from the user.
|
partial
|
## Inspiration
We were all very intrigued by machine learning and AI, so we decided to incorporate it into our project. We wanted to create something involving the webcam as well, so we tied it altogether with ScanAI.
## What it does
ScanAI aims to detect guns in schools and public areas to help alert authorities quickly in the event of a public shooting.
## How we built it
ScanAI is built entirely out of python. Computer vision python libraries were used including OpenCV, facial\_recognition, yolov5 and tkinter.
## Challenges we ran into
When training models, we ran into issues of a lack of ram and a lack of training data. We also were challenged by the problem of tackling multiple faces at once.
## Accomplishments that we're proud of
ScanAI is able to take imported files and detect multiple faces at once and apply facial recognition to all of them. ScanAI is highly accurate and has many features including Barack Obama facial recognition, object detection, live webcam viewing and scanning, and file uploading functionalities.
## What we learned
We all learned a lot about machine learning and its capabilities. Using these modules expanded our knowledge on AI and all its possible uses.
## What's next for ScanAI
Our next steps would be to improve our interface to improve user friendliness and platform compatibility. We would also want to incorporate our program with Raspberry Pi to increase its usage flexibility. Lastly, we would also want to work on improving the accuracy of the detection system by feeding it more images and feedback.
|
## Description
Using data coming from an Arduino equipped with a light, temperature, and noise sensor, we created a tool that allows participants at Hackathons to oversee all available hacking rooms and find one that would suit their personal hacking needs.
## How it's made
Using the Arduino, the base shield and multiple components, we're able to calculate the temperature of a room in Celsius and the noise level in decibels. The light level of a room was calculated within a range, and is scaled to a percentage. Each device connects to a Node backend which allows data to be displayed on a dashboard for a React frontend.
## Background
While brainstorming for an idea, our team was having great difficulty since the noise level in the hacking room was well over the decibels emitted by a commercial airliner and the overall room temperature was on par with the Sahara desert. To solve our predicament, we wandered through the halls of UWestern to find the perfect hacking room.
Once we found the perfect location, the idea came to us to make a hack that would display the current noise level, temperature and lighting of various locations in a building which would be essential for a team trying to find a good hacking spot.
|
## Inspiration 🍪
We’re fed up with our roommates stealing food from our designated kitchen cupboards. Few things are as soul-crushing as coming home after a long day and finding that someone has eaten the last Oreo cookie you had been saving. Suffice it to say, the university student population is in desperate need of an inexpensive, lightweight security solution to keep intruders out of our snacks...
Introducing **Craven**, an innovative end-to-end pipeline to put your roommates in check and keep your snacks in stock.
## What it does 📸
Craven is centered around a small Nest security camera placed at the back of your snack cupboard. Whenever the cupboard is opened by someone, the camera snaps a photo of them and sends it to our server, where a facial recognition algorithm determines if the cupboard has been opened by its rightful owner or by an intruder. In the latter case, the owner will instantly receive an SMS informing them of the situation, and then our 'security guard' LLM will decide on the appropriate punishment for the perpetrator, based on their snack-theft history. First-time burglars may receive a simple SMS warning, but repeat offenders will have a photo of their heist, embellished with an AI-generated caption, posted on [our X account](https://x.com/craven_htn) for all to see.
## How we built it 🛠️
* **Backend:** Node.js
* **Facial Recognition:** OpenCV, TensorFlow, DLib
* **Pipeline:** Twilio, X, Cohere
## Challenges we ran into 🚩
In order to have unfettered access to the Nest camera's feed, we had to find a way to bypass Google's security protocol. We achieved this by running an HTTP proxy to imitate the credentials of an iOS device, allowing us to fetch snapshots from the camera at any time.
Fine-tuning our facial recognition model also turned out to be a bit of a challenge. In order to ensure accuracy, it was important that we had a comprehensive set of training images for each roommate, and that the model was tested thoroughly. After many iterations, we settled on a K-nearest neighbours algorithm for classifying faces, which performed well both during the day and with night vision.
Additionally, integrating the X API to automate the public shaming process required specific prompt engineering to create captions that were both humorous and effective in discouraging repeat offenders.
## Accomplishments that we're proud of 💪
* Successfully bypassing Nest’s security measures to access the camera feed.
* Achieving high accuracy in facial recognition using a well-tuned K-nearest neighbours algorithm.
* Fine-tuning Cohere to generate funny and engaging social media captions.
* Creating a seamless, rapid security pipeline that requires no legwork from the cupboard owner.
## What we learned 🧠
Over the course of this hackathon, we gained valuable insights into how to circumvent API protocols to access hardware data streams (for a good cause, of course). We also deepened our understanding of facial recognition technology and learned how to tune computer vision models for improved accuracy. For our X integration, we learned how to engineer prompts for Cohere's API to ensure that the AI-generated captions were both humorous and contextual. Finally, we gained experience integrating multiple APIs (Nest, Twilio, X) into a cohesive, real-time application.
## What's next for Craven 🔮
* **Multi-owner support:** Extend Craven to work with multiple cupboards or fridges in shared spaces, creating a mutual accountability structure between roommates.
* **Machine learning improvement:** Experiment with more advanced facial recognition models like deep learning for even better accuracy.
* **Social features:** Create an online leaderboard for the most frequent offenders, and allow users to vote on the best captions generated for snack thieves.
* **Voice activation:** Add voice commands to interact with Craven, allowing roommates to issue verbal warnings when the cupboard is opened.
|
losing
|
# TranslateMe: Breaking Language Barriers, One Text at a Time
## Inspiration
Living in a diverse and interconnected world, our team of three has always been fascinated by the power of technology to bring people together, regardless of language barriers. As students who come from an immigrant background we understand the struggles of not being able to communicate with others who do not speak the same language. We noticed that language often stood in the way of these intercultural connections, hindering meaningful interactions to create a space where language isembraced. This inspired us to create TranslateMe, an app that makes it effortless for people to communicate across languages seamlessly.
## What We Learned
Building TranslateMe was a remarkable journey that taught us valuable lessons as a team. Here are some key takeaways:
**Effective Collaboration**: Working as a team, we learned the importance of effective collaboration. Each of us had unique skills and expertise, and we leveraged these strengths to build a well-rounded application.
**API Integration**: We gained a deep understanding of how to integrate third-party APIs into our project. In this case, we utilized Twilio's communications API for handling text messages and Google Translate API for language translation.
**Node.js Mastery**: We honed our Node.js skills throughout this project. Working with asynchronous operations and callbacks to handle communication between APIs and user interactions was challenging but rewarding.
**User-Centric Design**: We learned the importance of user-centric design. Making TranslateMe user-friendly and intuitive was crucial to ensure that anyone, regardless of their technical expertise, could benefit from it.
**Handling Errors and Edge Cases**: Dealing with potential errors and unexpected edge cases was a significant learning experience. We implemented error handling strategies to provide a smooth user experience even when things didn't go as planned.
## How We Built TranslateMe
# Technologies Used
**Twilio API**: We used Twilio's communication API to send and receive text messages. This allowed users to send messages in their preferred language.
**Google Translate API**: To perform the actual translation, we integrated the Google Translate API, which supports a wide range of languages.
**Node.js**: The backend of TranslateMe was built using Node.js, providing a robust and scalable foundation for the application.
## The Development Process
**Planning and Design**: We started by outlining the app's architecture, user flows, and wireframes. This helped us clarify the project's scope and user experience.
**Setting Up Twilio**: We set up a Twilio account and configured it to handle incoming and outgoing text messages. Twilio's documentation was incredibly helpful in this process.
**Implementing Translation Logic**: Using the Google Translate API, we developed the core functionality of translating incoming messages into the user's chosen language.
**Building the Frontend**: With the backend in place, we created a user-friendly frontend that allowed users to choose languages and see translated messages.
**Testing and Debugging**: Rigorous testing was essential to ensure that TranslateMe worked seamlessly. We focused on both functional and user experience testing.
**Deployment**: We deployed the application to a twilio server to make it as accessible as possible.
## Challenges Faced
While creating TranslateMe, we encountered several challenges:
**Limited by Trial Version**: The Twilio API didn't allow unauthorized phone-numbers to text back to a twilio in the trial version so we had to jump through a few hoops to get that working.
**Language Detection**: Some users might not specify their preferred language, so we needed to implement language detection to provide a seamless experience.
**NPM** version conflicts: When using the different APIs we ran into some npm versioning issues that took longer than we would have liked to complete.
## Conclusion
TranslateMe has been a fulfilling project that allowed our team to combine our passion for technology with a desire to break down language barriers. Two out of three of us are international students so we are painfully aware of the barriers presented by the lack of knowing a language. We're excited to see how TranslateMe helps people connect and communicate across languages, fostering greater understanding and unity in our diverse world.
|
## Inspiration
When Humam was in Syria, it was extremely hard for him to guide people to his house since there is no proper address, street number or postal code. It is like that in so many countries; over 70 countries share this problem and most of them are 3rd world countries, which are the countries that don't have it need it most. For that, there is an application that is called What3Words. They assign for each 3m square in the world a unique 3-word address that will never change. The problem that this application faces from most users (UPS drivers, people in need of AAA road assistance, and people with no data) is that this service is only accessible online and users are not allowed to download their database. That is where our SMS service comes in handy for users with no access to the internet when they are in need of it, especially since What3Words is used very often for emergencies.
## What it does
+Map is a messaging service that users are able to send their 3-word location and get the coordinates back or send their coordinates to the phone number and the user will get the 3-word address. Users can use the service in 35 different languages.
## How we built it
We used the Twilio api to create a phone number, which posts to an express.js server that uses the what3words API to translate 3-word addresses to precise coordinates, and vice-versa.
## Challenges we ran into
The Twilio API is very powerful, and it was our first time using it. This meant that there was a lot of documentation to read through, and we had to be smart about finding the right information to get done what we needed to get done.
## Accomplishments that we're proud of
We are most proud that our product can work in over 100 countries and in over 35 languages. We are also proud that we made our first ever SMS service and our first ever fully-featured Node.JS application, and that we made something that we all strongly feel we should continue working on in the future.
## What we learned
We learned to leverage the Twilio and what3words API. We also learned a lot about webhooks, node.JS, express, and Git. We also learned about the benefits and limitations of the SMS protocol.
## What's next for +Map
Twilio supports phone number availability in over 100 countries. This will make our service scalable to almost every country in the world. Twilio also has support for the popular messaging application WhatsApp (some providers support data only to WhatsApp)
|
**In times of disaster, there is an outpouring of desire to help from the public. We built a platform which connects people who want to help with people in need.**
## Inspiration
Natural disasters are an increasingly pertinent global issue which our team is quite concerned with. So when we encountered the IBM challenge relating to this topic, we took interest and further contemplated how we could create a phone application that would directly help with disaster relief.
## What it does
**Stronger Together** connects people in need of disaster relief with local community members willing to volunteer their time and/or resources. Such resources include but are not limited to shelter, water, medicine, clothing, and hygiene products. People in need may input their information and what they need, and volunteers may then use the app to find people in need of what they can provide. For example, someone whose home is affected by flooding due to Hurricane Florence in North Carolina can input their name, email, and phone number in a request to find shelter so that this need is discoverable by any volunteers able to offer shelter. Such a volunteer may then contact the person in need through call, text, or email to work out the logistics of getting to the volunteer’s home to receive shelter.
## How we built it
We used Android Studio to build the Android app. We deployed an Azure server to handle our backend(Python). We used Google Maps API on our app. We are currently working on using Twilio for communication and IBM watson API to prioritize help requests in a community.
## Challenges we ran into
Integrating the Google Maps API into our app proved to be a great challenge for us. We also realized that our original idea of including a blood donation as one of the resources would require some correspondence with an organization such as the Red Cross in order to ensure the donation would be legal. Thus, we decided to add a blood donation to our future aspirations for this project due to the time constraint of the hackathon.
## Accomplishments that we're proud of
We are happy with our design and with the simplicity of our app. We learned a great deal about writing the server side of an app and designing an Android app using Java (and Google Map’s API” during the past 24 hours. We had huge aspirations and eventually we created an app that can potentially save people’s lives.
## What we learned
We learned how to integrate Google Maps API into our app. We learn how to deploy a server with Microsoft Azure. We also learned how to use Figma to prototype designs.
## What's next for Stronger Together
We have high hopes for the future of this app. The goal is to add an AI based notification system which alerts people who live in a predicted disaster area. We aim to decrease the impact of the disaster by alerting volunteers and locals in advance. We also may include some more resources such as blood donations.
|
losing
|
## Inspiration
Tinder but Volunteering
## What it does
Connects people to volunteering organizations. Makes volunteering fun, easy and social
## How we built it
react for web and react native
## Challenges we ran into
So MANY
## Accomplishments that we're proud of
Getting a really solid idea and a decent UI
## What we learned
SO MUCH
## What's next for hackMIT
|
## Inspiration
With the recent Corona Virus outbreak, we noticed a major issue in charitable donations of equipment/supplies ending up in the wrong hands or are lost in transit. How can donors know their support is really reaching those in need? At the same time, those in need would benefit from a way of customizing what they require, almost like a purchasing experience.
With these two needs in mind, we created Promise. A charity donation platform to ensure the right aid is provided to the right place.
## What it does
Promise has two components. First, a donation request view to submitting aid requests and confirm aids was received. Second, a donor world map view of where donation requests are coming from.
The request view allows aid workers, doctors, and responders to specificity the quantity/type of aid required (for our demo we've chosen quantity of syringes, medicine, and face masks as examples) after verifying their identity by taking a picture with their government IDs. We verify identities through Microsoft Azure's face verification service. Once a request is submitted, it and all previous requests will be visible in the donor world view.
The donor world view provides a Google Map overlay for potential donors to look at all current donation requests as pins. Donors can select these pins, see their details and make the choice to make a donation. Upon donating, donors are presented with a QR code that would be applied to the aid's packaging.
Once the aid has been received by the requesting individual(s), they would scan the QR code, confirm it has been received or notify the donor there's been an issue with the item/loss of items. The comments of the recipient are visible to the donor on the same pin.
## How we built it
Frontend: React
Backend: Flask, Node
DB: MySQL, Firebase Realtime DB
Hosting: Firebase, Oracle Cloud
Storage: Firebase
API: Google Maps, Azure Face Detection, Azure Face Verification
Design: Figma, Sketch
## Challenges we ran into
Some of the APIs we used had outdated documentation.
Finding a good of ensuring information flow (the correct request was referred to each time) for both the donor and recipient.
## Accomplishments that we're proud of
We utilized a good number of new technologies and created a solid project in the end which we believe has great potential for good.
We've built a platform that is design-led, and that we believe works well in practice, for both end-users and the overall experience.
## What we learned
Utilizing React states in a way that benefits a multi-page web app
Building facial recognition authentication with MS Azure
## What's next for Promise
Improve detail of information provided by a recipient on QR scan. Give donors a statistical view of how much aid is being received so both donors and recipients can better action going forward.
Add location-based package tracking similar to Amazon/Arrival by Shopify for transparency
|
## Inspiration
Examining our own internet-related tendencies revealed to us that although the internet presents itself as a connective hub, it can often be a very solitary place. As the internet continues to become a virtual extension of our physical world, we decided that working on an app that keeps people connected on the internet in a location-based way would be an interesting project. Building Surf led us to the realization that the most meaningful experiences are as unique as they are because of the people we experience them with. Social media, although built for connection, often serves only to widen gaps. In a nutshell, Surf serves to connect people across the internet in a more genuine way.
## What it does
Surf is a Chrome extension that allows you to converse with others on the same web page as you. For example, say you're chilling on Netflix, you could open up Surf and talk to anyone else watching the same episode of Breaking Bad as you. Surf also has a "Topics" feature which allows users to create their own personal discussion pages on sites. Similarly to how you may strike up a friendship discussing a painting with a stranger at the art museum, we designed Surf to encourage conversation between individuals from different backgrounds with similar interests.
## How we built it
We used Firebase Realtime Database for our chatrooms and Firebase Authentication for login. Paired with a Chrome extension leveraging some neat Bootstrap on the front end, we ended up with a pretty good looking build.
## Challenges we ran into
The hardest challenge for us was to come up with an idea that we were happy with. At first, all the ideas we came up with were either too complex or too basic. We longed for an idea that made us feel lucky to have thought of it. It wasn't until after many hours of brainstorming that we came up with Surf. Some earlier ideas included a CLI game in which you attempt to make guacamole and a timer that only starts from three minutes and thirty-four seconds.
## Accomplishments that we're proud of
We released a finished build on the Chrome Web Store in under twelve hours. Letting go of some perfectionism and going balls to the wall on our long-term goal really served us well in the end. However, despite having finished our hack early, we built in a huge V2 feature, which added up to twenty solid hours of hacking.
## What we learned
On top of figuring out how to authenticate users in a Chrome extension, we discovered the effects that five Red Bulls can have on the human bladder.
## What's next for Surf
Surf's site-specific chat data makes for a very nice business model – site owners crave user data, and the consensual, natural data generated by Surf is worth its weight in gold to web admins. On top of being economically capable, Surf has a means of providing users with analytics and recommendations, including letting them know how much time they spend on particular sites and which other pages they might enjoy based on their conversations and habits. We also envision a full-fledged browser for Surf, with a built in chat functionality.
|
winning
|
## Inspiration:
The single biggest problem and bottleneck in training large AI models today is compute. Just within the past week, Sam Altman tried raising an $8 trillion dollar fund to build a large network of computers for training larger multimodal models.
|
## Inspiration
In 2012 in the U.S infants and newborns made up 73% of hospitals stays and 57.9% of hospital costs. This adds up to $21,654.6 million dollars. As a group of students eager to make a change in the healthcare industry utilizing machine learning software, we thought this was the perfect project for us. Statistical data showed an increase in infant hospital visits in recent years which further solidified our mission to tackle this problem at its core.
## What it does
Our software uses a website with user authentication to collect data about an infant. This data considers factors such as temperature, time of last meal, fluid intake, etc. This data is then pushed onto a MySQL server and is fetched by a remote device using a python script. After loading the data onto a local machine, it is passed into a linear regression machine learning model which outputs the probability of the infant requiring medical attention. Analysis results from the ML model is passed back into the website where it is displayed through graphs and other means of data visualization. This created dashboard is visible to users through their accounts and to their family doctors. Family doctors can analyze the data for themselves and agree or disagree with the model result. This iterative process trains the model over time. This process looks to ease the stress on parents and insure those who seriously need medical attention are the ones receiving it. Alongside optimizing the procedure, the product also decreases hospital costs thereby lowering taxes. We also implemented a secure hash to uniquely and securely identify each user. Using a hyper-secure combination of the user's data, we gave each patient a way to receive the status of their infant's evaluation from our AI and doctor verification.
## Challenges we ran into
At first, we challenged ourselves to create an ethical hacking platform. After discussing and developing the idea, we realized it was already done. We were challenged to think of something new with the same amount of complexity. As first year students with little to no experience, we wanted to tinker with AI and push the bounds of healthcare efficiency. The algorithms didn't work, the server wouldn't connect, and the website wouldn't deploy. We persevered and through the help of mentors and peers we were able to make a fully functional product. As a team, we were able to pick up on ML concepts and data-basing at an accelerated pace. We were challenged as students, upcoming engineers, and as people. Our ability to push through and deliver results were shown over the course of this hackathon.
## Accomplishments that we're proud of
We're proud of our functional database that can be accessed from a remote device. The ML algorithm, python script, and website were all commendable achievements for us. These components on their own are fairly useless, our biggest accomplishment was interfacing all of these with one another and creating an overall user experience that delivers in performance and results. Using sha256 we securely passed each user a unique and near impossible to reverse hash to allow them to check the status of their evaluation.
## What we learned
We learnt about important concepts in neural networks using TensorFlow and the inner workings of the HTML code in a website. We also learnt how to set-up a server and configure it for remote access. We learned a lot about how cyber-security plays a crucial role in the information technology industry. This opportunity allowed us to connect on a more personal level with the users around us, being able to create a more reliable and user friendly interface.
## What's next for InfantXpert
We're looking to develop a mobile application in IOS and Android for this app. We'd like to provide this as a free service so everyone can access the application regardless of their financial status.
|
## Inspiration
We have a desire to spread awareness surrounding health issues in modern society. We also love data and the insights in can provide, so we wanted to build an application that made it easy and fun to explore the data that we all create and learn something about being active and healthy.
## What it does
Our web application processes data exported by Apple health and provides visualizations of the data as well as the ability to share data with others and be encouraged to remain healthy. Our educational component uses real world health data to educate users about the topics surrounding their health. Our application also provides insight into just how much data we all constantly are producing.
## How we built it
We build the application from the ground up, with a custom data processing pipeline from raw data upload to visualization and sharing. We designed the interface carefully to allow for the greatest impact of the data while still being enjoyable and easy to use.
## Challenges we ran into
We had a lot to learn, especially about moving and storing large amounts of data and especially doing it in a timely and user-friendly manner. Our biggest struggle was handling the daunting task of taking in raw data from Apple health and storing it in a format that was easy to access and analyze.
## Accomplishments that we're proud of
We're proud of the completed product that we came to despite early struggles to find the best approach to the challenge at hand. An architecture this complicated with so many moving components - large data, authentication, user experience design, and security - was above the scope of projects we worked on in the past, especially to complete in under 48 hours. We're proud to have come out with a complete and working product that has value to us and hopefully to others as well.
## What we learned
We learned a lot about building large scale applications and the challenges that come with rapid development. We had to move quickly, making many decisions while still focusing on producing a quality product that would stand the test of time.
## What's next for Open Health Board
We plan to expand the scope of our application to incorporate more data insights and educational components. While our platform is built entirely mobile friendly, a native iPhone application is hopefully in the near future to aid in keeping data up to sync with minimal work from the user. We plan to continue developing our data sharing and social aspects of the platform to encourage communication around the topic of health and wellness.
|
winning
|
## Inspiration
Currently, there are over **360 million people** across the globe who suffer from disabling hearing loss. When these individuals want to watch videos or movies online, they have no choice but to read the live captions.
Studies have shown that individuals who are hearing impaired generally **prefer having a sign-language interpreter** rather than reading closed captioning or reading subtitles. However, ASL interpreting technology available to the public is minimal.
**This is what inspired the creation of SignStream**. We identified a need for this technology and built what we believe is an **innovative technological solution.**
## What it does
**SignStream** creates a \**virtual ASL interpreter \** that translates speech from online videos in real-time. Users play videos or audio and an ASL translation is returned.
## How we built it
The initial design of the website layout was made on **Figma**. Unique graphics to SignStream were created on **Photoshop** and **Adobe-Illustrator**.
The frontend components including references to pages and interactive features were built through **React.js**.
To build the backend, **Python** and **Beautiful Soup** were first used to web scrape and store jpg/mp4 files of ASL vocabulary.
The **AssemblyAI API** was used to create the portion of the program that receives audio input and returns text.
Finally, the backend was written in **JavaScript** and interpreted by the website using **Node.js**.
## Challenges we ran into
The main challenge we faced was displaying the jpg/mp4 files onto our website in real time as audio was being input. This was primarily due to the fact that not all words can be displayed in ASL. This delay was created due to the run-time of sorting through the text output to identify words. However, by taking time to improve our code, we were able to reduce the delay.
## Accomplishments that we're proud of
As a team of first year students, we had very limited prior knowledge of web development. Elements such as coding the backend of our website and figuring out how to use the AssemblyAI API within 36 hours proved to be quite the challenge. However, after hard work and collaboration we were able to successfully implement the back end and feature a real-time streaming page.
## What we learned
During our QHacks weekend, every team member gained precious knowledge about web development and problem solving.
Our frontend developers increased their ability to build a website using React.js. For some of us, this was our first time working with the library. However, by the end of the weekend we created a fully-functioning, responsive website.
The backend developers learned a lot about working with APIs and Node.js. We learned the importance of persevering when faced with challenges and collaborating with fellow developers.
## What's next for SignStream
In the future we are looking to expand SignStream to provide an optimal all around user experience. There are a few steps we think could benefit the user experience of SignStream. First, we would like to expand our database of ASL vocabulary. There are over 10 000 signs in the ASL language and expanding our database would allow for clearer interpretation of audio for users.
We are also looking to implement SignStream as a Chrome/Web extension. This extension would have the virtual interpreter appear as a smaller window, and reduce the amount of the display required to use the program.
|
## Inspiration
With the interests and passions to learn sign language, we unfortunately found that resources for American Sign Language (ASL) were fairly limited and restricted. So, we made a "Google Translate" for ASL.
Of course, anyone can communicate without ASLTranslate by simply pulling out a phone or a piece of paper and writing down the words instead, but the aim of ASLTranslate is to foster the learning process of ASL to go beyond communication and generate deeper interpersonal connections. ASLTranslate's mission is to make learning ASL an enriching and accessible experience for everyone, because we are dedicated to providing a bridge between spoken language and sign language, fostering inclusivity, understanding, and connection.
## What it does
ASTranslation lets users type in words or sentences and to translate into ASL that is demonstrated by a video (gratefully from SigningSavvy). Additionally, there is a mini quiz page, where the user can test their vocabulary on commonly used signs. This provides the user with a tool to practice, familiarize, and increase exposure to sign language, important factors in learning any language.
## How we built it
We leveraged the fast development times of Flask and BeautifulSoup4 on the backend to retrieve the essential data required for crafting the output video. With the dynamic capabilities of React and JavaScript on the front end, we designed and developed an interactive and responsive user interface. Leveraging FFMpeg (available as a library in Python), we seamlessly stitched together the extracted videos, resulting in a cohesive and engaging final output to stream back to the user. We utilized MongoDB in order to perform file storing in order to cache words, trading network transfers in exchange for CPU cycles.
## Challenges we ran into
To ensure smooth teamwork, we needed consistent access to sample data for our individual project tasks. Connecting the frontend to the backend for testing had its challenges – data availability wasn't always the same on every machine. So, each developer had to set up both frontend and backend dependencies to access the required data for development and testing.Additionally, dealing with the backend's computational demands was tricky. We tried using a cloud server, but the resources we allocated were not enough. This led to different experiences in processing data on the backend for each team member.
## Accomplishments that we're proud of
For many of us, this project was the first time coding in a team environment. Furthermore, many of us were also working with full-stack development with React for the first time, and we are very content with our successfully completed the project. We overcame obstacles collaboratively despite being our first time working on a team project and we can’t be more proud of our team members who all worked very hard!
## What we learned
Throughout the building of the project, we learned a lot of meaningful lessons. Ranging from new tech-stacks, teamwork, the importance of sign language, and everything in between and combined. ASLTranslation has been a journey full of learning in hopes of learning journeys for others. All of our teammates had a wonderful time together and it has been an unforgettable experience that will become an important foundation for all of our future careers and life.
## What's next for ASLTranslate
We will add more user-interactive features such as sign language practice, where we build a program to detect the hand-motion to test the accuracy of the sign language.
To further expand, we will create an app-version of ASLTranslate and have it available to as many people as possible, through the website, mobile and more!
Additionally, as English and ASL does not always directly translate, ensuring grammatical accuracy would be highly beneficial. Currently, we prioritize generating user-friendly outputs over achieving perfect grammatical precision. We have considered the potential of employing artificial intelligence for this task, a avenue we are open to exploring further.
|
# Hide and Squeak
## Inspiration
The robotic mouse feeder is device is designed to help promote physical and mental health in indoor cats, by providing a way to hunt to kill - by pouncing or attacking the robotic mouse, the device will release some "random" amount of kibble (from a pre-determined set) for the cat to eat after successfully "catching" it's prey.
## What it does
Right now it it a proof of concept; the pounce sensor (a button) will trigger a stop in the motion and prints to the Serial monitor when the kibble would be released using a servo motor. The commands to a stepper motor (that acts as one of the two wheels on the mouse), will be printed to the Serial monitor. After a "random" time, the device chooses a new "random" speed and direction (CW or CCW) for the wheel. A "random" direction for the mouse itself would be achieved in that both wheels would be turning independently, each with a different speed. When the bumper button is hit (indicates running into an object in the environment) - the direction sent to the motors is reversed and runs at the same speed as before. This will need testing with an actual motor to see if it is sufficient to remove the robot from an obstacle.
## Challenges I ran into
The hardware lab had no wires that would connect to the stepper motor shield, so there was no way to debug or test the code with the motor itself. There is output to the Serial monitor in lieu of controlling the actual motor, which is mediocre at best for testing the parameters chosen to be the range for both speed and time.
## What's next
1. Attaching the stepper motor to see if the code functions properly with an actual motor; and testing the speed min and max (too slow? too fast?)
2. Programming with a second stepper motor to see how the code handles running two steppers at once;
3. Structural and mechanical design - designing the gears, wheels, casing, kibble pinwheel, etc., needed to bring the code to life.
## Future possibilities
1. Adding a remote feature so you can interact with your cat
2. Adding a camera and connecting to the home's WiFI so you can watch your cat play remotely
3. Adding an internal timer to turn on/off at specified times during the day
4. The ability to change the speeds, time until switching directions, or to pre-program a route
|
losing
|
## Inspiration 💥
Let's be honest... Presentations can be super boring to watch—*and* to present.
But, what if you could bring your biggest ideas to life in a VR world that literally puts you *in* the PowerPoint? Step beyond slides and into the future with SuperStage!
## What it does 🌟
SuperStage works in 3 simple steps:
1. Export any slideshow from PowerPoint, Google Slides, etc. as a series of images and import them into SuperStage.
2. Join your work/team/school meeting from your everyday video conferencing software (Zoom, Google Meet, etc.).
3. Instead of screen-sharing your PowerPoint window, screen-share your SuperStage window!
And just like that, your audience can watch your presentation as if you were Tim Cook in an Apple Keynote. You see a VR environment that feels exactly like standing up and presenting in real life, and the audience sees a 2-dimensional, front-row seat video of you on stage. It’s simple and only requires the presenter to own a VR headset.
Intuition was our goal when designing SuperStage: instead of using a physical laser pointer and remote, we used full-hand tracking to allow you to be the wizard that you are, pointing out content and flicking through your slides like magic. You can even use your hands to trigger special events to spice up your presentation! Make a fist with one hand to switch between 3D and 2D presenting modes, and make two thumbs-up to summon an epic fireworks display. Welcome to the next dimension of presentations!
## How we built it 🛠️
SuperStage was built using Unity 2022.3 and the C# programming language. A Meta Quest 2 headset was the hardware portion of the hack—we used the 4 external cameras on the front to capture hand movements and poses. We built our UI/UX using ray interactables in Unity to be able to flick through slides from a distance.
## Challenges we ran into 🌀
* 2-camera system. SuperStage is unique since we have to present 2 different views—one for the presenter and one for the audience. Some objects and UI in our scene must be occluded from view depending on the camera.
* Dynamic, automatic camera movement, which locked onto the player when not standing in front of a slide and balanced both slide + player when they were in front of a slide.
To build these features, we used multiple rendering layers in Unity where we could hide objects from one camera and make them visible to the other. We also wrote scripting to smoothly interpolate the camera between points and track the Quest position at all times.
## Accomplishments that we're proud of 🎊
* We’re super proud of our hand pose detection and gestures: it really feels so cool to “pull” the camera in with your hands to fullscreen your slides.
* We’re also proud of how SuperStage uses the extra dimension of VR to let you do things that aren’t possible on a laptop: showing and manipulating 3D models with your hands, and immersing the audience in a different 3D environment depending on the slide. These things add so much to the watching experience and we hope you find them cool!
## What we learned 🧠
Justin: I found learning about hand pose detection so interesting. Reading documentation and even anatomy diagrams about terms like finger abduction, opposition, etc. was like doing a science fair project.
Lily: The camera system! Learning how to run two non-conflicting cameras at the same time was super cool. The moment that we first made the switch from 3D -> 2D using a hand gesture was insane to see actually working.
Carolyn: I had a fun time learning to make cool 3D visuals!! I learned so much from building the background environment and figuring out how to create an awesome firework animation—especially because this was my first time working with Unity and C#! I also grew an even deeper appreciation for the power of caffeine… but let’s not talk about that part :)
## What's next for SuperStage ➡️
Dynamically generating presentation boards to spawn as the presenter paces the room
Providing customizable avatars to add a more personal touch to SuperStage
Adding a lip-sync feature that takes volume metrics from the Oculus headset to generate mouth animations
|
## Inspiration
We saw a short video on a Nepalese boy who had to walk 10 miles each way for school. From this video, we wanted to find a way to bring unique experiences to students in constrained locations. This could be for students in remote locations, or in cash strapped low income schools. We learned that we all share a passion for creating fair learning opportunities for everyone, which is why we created Magic School VR.
## What it does
Magic School VR is an immersive virtual reality educational platform where you can attend one-on-one lectures with historical figures, influential scientists, or the world's best teachers. You can have Albert Einstein teach you quantum theory, Bill Nye the Science Guy explain the importance of mitochondria, or Warren Buffet educate you on investing.
**Step 1:** Choose a subject *physics, biology, history, computer science, etc.*
**Step 2:** Choose your teacher *(Elon Musk, Albert Einstein, Neil Degrasse Tyson, etc.*
**Step 3:** Choose your specific topic *Quantum Theory, Data Structures, WWII, Nitrogen cycle, etc.*
**Step 4:** Get immersed in your virtual learning environment
**Step 5:** Examination *Small quizzes, short answers, etc.*
## How we built it
We used Unity, Oculus SDK, and Google VR to build the VR platform as well as a variety of tools and APIs such as:
* Lyrebird API to recreate Albert Einstein's voice. We trained the model by feeding it with audio data. Through machine learning, it generated audio clips for us.
* Cinema 4D to create and modify 3D models.
* Adobe Premiere to put together our 3D models and speech, as well to chroma key masking objects.
* Adobe After Effects to create UI animations.
* C# to code camera instructions, displays, and interactions in Unity.
* Hardware used: Samsung Gear VR headset, Oculus Rift VR Headset.
## Challenges we ran into
We ran into a lot of errors with deploying Magic School VR to the Samsung Gear Headset, so instead we used Oculus Rift. However, we had hardware limitations when it came to running Oculus Rift off our laptops as we did not have HDMI ports that connected to dedicated GPUs. This led to a lot of searching around trying to find a desktop PC that could run Oculus.
## Accomplishments that we're proud of
We are happy that we got the VR to work. Coming into QHacks we didn't have much experience in Unity so a lot of hacking was required :) Every little accomplishment motivated us to keep grinding. The moment we manged to display our program in the VR headset, we were mesmerized and in love with the technology. We experienced first hand how impactful VR can be in education.
## What we learned
* Developing with VR is very fun!!!
* How to build environments, camera movements, and interactions within Unity
* You don't need a technical background to make cool stuff.
## What's next for Magic School VR
Our next steps are to implement eye-tracking engagement metrics in order to see how engaged students are to the lessons. This will help give structure to create more engaging lesson plans. In terms of expanding it as a business, we plan on reaching out to VR partners such as Merge VR to distribute our lesson plans as well as to reach out to educational institutions to create lesson plans designed for the public school curriculum.
[via GIPHY](https://giphy.com/gifs/E0vLnuT7mmvc5L9cxp)
|
## Inspiration
Many people were left unprepared to effectively express their ideas over Zoom. As students we’ve noticed that with remote learning, instructors seem to feel very distant, teaching through either slides or drawing on a tablet, without us being able to see their face. We know body language is an important part of being a presenter, so why should Zoom limit us like this? Aside from instructional content, Zoom meetings are boring so we ought to spice it up. Introducing AirCanvas!
## What it does
AirCanvas allows you to have a virtual whiteboard powered by Deep Learning and Computer Vision! Simply stick out your index finger as the pen, and let your imagination unfold in the air that is your canvas. This adds an entirely new dimension of communication that is not possible in person. You can also erase the drawings, drag the canvas around and draw with both hands simultaneously!
## How we built it
We begin with OpenPose, a project by researchers at Carnegie Mellon which performs pose estimation on a video stream in real time. With it, we are able to extract information about one’s poses, including the locations of joints. With this information, we have developed our own algorithm to recognize gestures that indicate the user’s desired actions. We additionally employ motion smoothing, which we will discuss a bit later. Combining these, we can render the user’s drawings onto the webcam stream, as if the user is drawing in mid-air.
## Challenges we ran into
One of the major challenges was, due to the low framerates of OpenPose, the paths generated are choppy, where the lines go back and forth. To solve this issue, we employed motion smoothing, and we can do this rather efficiently in O(1) runtime with our own data structure. This way, we get smooth lines without much performance penalty. In addition, we spent many hours testing our model and refining hyperparameters to ensure it works intuitively.
## What's next for AirCanvas
We were inexperienced with this technology, and we wish we had more time to add the following features:
Support for multiple people drawing with one camera simultaneously
A friendlier interface for user to customize pen settings such as color, thickness etc.
Tools you’d see in note taking apps, such as ruler
|
winning
|
## Inspiration
## What it does
## It searches for a water Bottle!
## How we built it
## We built it using a roomba, raspberrypi with a picamera, python, and Microsoft's Custom Vision
## Challenges we ran into
## Attaining wireless communications between the pi and all of our PCs was tricky. Implementing Microsoft's API was troublesome as well. A few hours before judging we exceeded the call volume for the API and were forced to create a new account to use the service. This meant re-training the AI and altering code, and loosing access to our higher accuracy recognition iterations during final tests.
## Accomplishments that we're proud of
## Actually getting the wireless networking to consistently. Surpassing challenges like framework indecision between IBM and Microsoft. We are proud of making things that lacked proper documentation, like the pi camera, work.
## What we learned
## How to use Github, train AI object recognition system using Microsoft APIs, write clean drivers
## What's next for Cueball's New Pet
## Learn to recognize other objects.
|
## Inspiration
We wanted to solve a unique problem we felt was impacting many people but was not receiving enough attention. With emerging and developing technology, we implemented neural network models to recognize objects and images, and converting them to an auditory output.
## What it does
XTS takes an **X** and turns it **T**o **S**peech.
## How we built it
We used PyTorch, Torchvision, and OpenCV using Python. This allowed us to utilize pre-trained convolutional neural network models and region-based convolutional neural network models without investing too much time into training an accurate model, as we had limited time to build this program.
## Challenges we ran into
While attempting to run the Python code, the video rendering and text-to-speech were out of sync and the frame-by-frame object recognition was limited in speed by our system's graphics processing and machine-learning model implementing capabilities. We also faced an issue while trying to use our computer's GPU for faster video rendering, which led to long periods of frustration trying to solve this issue due to backwards incompatibilities between module versions.
## Accomplishments that we're proud of
We are so proud that we were able to implement neural networks as well as implement object detection using Python. We were also happy to be able to test our program with various images and video recordings, and get an accurate output. Lastly we were able to create a sleek user-interface that would be able to integrate our program.
## What we learned
We learned how neural networks function and how to augment the machine learning model including dataset creation. We also learned object detection using Python.
|
## Inspiration
There were two primary sources of inspiration. The first one was a paper published by University of Oxford researchers, who proposed a state of the art deep learning pipeline to extract spoken language from video. The paper can be found [here](http://www.robots.ox.ac.uk/%7Evgg/publications/2018/Afouras18b/afouras18b.pdf). The repo for the model used as a base template can be found [here](https://github.com/afourast/deep_lip_reading).
The second source of inspiration is an existing product on the market, [Focals by North](https://www.bynorth.com/). Focals are smart glasses that aim to put the important parts of your life right in front of you through a projected heads up display. We thought it would be a great idea to build onto a platform like this through adding a camera and using artificial intelligence to gain valuable insights about what you see, which in our case, is deciphering speech from visual input. This has applications in aiding individuals who are deaf or hard-of-hearing, noisy environments where automatic speech recognition is difficult, and in conjunction with speech recognition for ultra-accurate, real-time transcripts.
## What it does
The user presses a button on the side of the glasses, which begins recording, and upon pressing the button again, recording ends. The camera is connected to a raspberry pi, which is a web enabled device. The raspberry pi uploads the recording to google cloud, and submits a post to a web server along with the file name uploaded. The web server downloads the video from google cloud, runs facial detection through a haar cascade classifier, and feeds that into a transformer network which transcribes the video. Upon finished, a front-end web application is notified through socket communication, and this results in the front-end streaming the video from google cloud as well as displaying the transcription output from the back-end server.
## How we built it
The hardware platform is a raspberry pi zero interfaced with a pi camera. A python script is run on the raspberry pi to listen for GPIO, record video, upload to google cloud, and post to the back-end server. The back-end server is implemented using Flask, a web framework in Python. The back-end server runs the processing pipeline, which utilizes TensorFlow and OpenCV. The front-end is implemented using React in JavaScript.
## Challenges we ran into
* TensorFlow proved to be difficult to integrate with the back-end server due to dependency and driver compatibility issues, forcing us to run it on CPU only, which does not yield maximum performance
* It was difficult to establish a network connection on the Raspberry Pi, which we worked around through USB-tethering with a mobile device
## Accomplishments that we're proud of
* Establishing a multi-step pipeline that features hardware, cloud storage, a back-end server, and a front-end web application
* Design of the glasses prototype
## What we learned
* How to setup a back-end web server using Flask
* How to facilitate socket communication between Flask and React
* How to setup a web server through local host tunneling using ngrok
* How to convert a video into a text prediction through 3D spatio-temporal convolutions and transformer networks
* How to interface with Google Cloud for data storage between various components such as hardware, back-end, and front-end
## What's next for Synviz
* With stronger on-board battery, 5G network connection, and a computationally stronger compute server, we believe it will be possible to achieve near real-time transcription from a video feed that can be implemented on an existing platform like North's Focals to deliver a promising business appeal
|
partial
|
## Inspiration
The impact of COVID-19 has had lasting effects on the way we interact and socialize with each other. Even when engulfed by bustling crowds and crowded classrooms, it can be hard to find our friends and the comfort of not being alone. Too many times have we grabbed lunch, coffee, or boba alone only to find out later that there was someone who was right next to us!
Inspired by our undevised use of Apple's FindMy feature, we wanted to create a cross-device platform that's actually designed for promoting interaction and social health!
## What it does
Bump! is a geolocation-based social networking platform that encourages and streamlines day-to-day interactions.
**The Map**
On the home map, you can see all your friends around you! By tapping on their icon, you can message them or even better, Bump! them.
If texting is like talking, you can think of a Bump! as a friendly wave. Just a friendly Bump! to let your friends know that you're there!
Your bestie cramming for a midterm at Mofitt? Bump! them for good luck!
Your roommate in the classroom above you? Bump! them to help them stay awake!
Your crush waiting in line for a boba? Make that two bobas! Bump! them.
**Built-in Chat**
Of course, Bump! comes with a built-in messaging chat feature!
**Add Your Friends**
Add your friends to allow them to see your location! Your unique settings and friends list are tied to the account that you register and log in with.
## How we built it
Using React Native and JavaScript, Bump! is built for both IOS and Android. For the Backend, we used MongoDB and Node.js. The project consisted of four major and distinct components.
**Geolocation Map**
For our geolocation map, we used the expo's geolocation library, which allowed us to cross-match the positional data of all the user's friends.
**User Authentication**
The user authentication proceeds was built using additional packages such as Passport.js, Jotai, and Bcrypt.js. Essentially, we wanted to store new users through registration and verify old users through login by searching them up in MongoDB, hashing and salting their password for registration using Bcrypt.js, and comparing their password hash to the existing hash in the database for login. We also used Passport.js to create Json Web Tokens, and Jotai to store user ID data globally in the front end.
**Routing and Web Sockets**
To keep track of user location data, friend lists, conversation logs, and notifications, we used MongoDB as our database and a node.js backend to save and access data from the database. While this worked for the majority of our use cases, using HTTP protocols for instant messaging proved to be too slow and clunky so we made the design choice to include WebSockets for client-client communication. Our architecture involved using the server as a WebSocket host that would receive all client communication but would filter messages so they would only be delivered to the intended recipient.
**Navigation and User Interface**:
For our UI, we wanted to focus on simplicity, cleanliness, and neutral aesthetics. After all, we felt that the Bump! the experience was really about the time spent with friends rather than on the app, so designed the UX such that Bump! is really easy to use.
## Challenges we ran into
To begin, package management and setup were fairly challenging. Since we've never done mobile development before, having to learn how to debug, structure, and develop our code was definitely tedious. In our project, we initially programmed our frontend and backend completely separately; integrating them both and working out the moving parts was really difficult and required everyone to teach each other how their part worked.
When building the instant messaging feature, we ran into several design hurdles; HTTP requests are only half-duplex, as they are designed with client initiation in mind. Thus, there is no elegant method for server-initiated client communication. Another challenge was that the server needed to act as the host for all WebSocket communication, resulting in the need to selectively filter and send received messages.
## Accomplishments that we're proud of
We're particularly proud of Bump! because we came in with limited or no mobile app development experience (in fact, this was the first hackathon for half the team). This project was definitely a huge learning experience for us; not only did we have to grind through tutorials, youtube videos, and a Stack Overflowing of tears, we also had to learn how to efficiently work together as a team. Moreover, we're also proud that we were not only able to build something that would make a positive impact in theory but a platform that we see ourselves actually using on a day-to-day basis. Lastly, despite setbacks and complications, we're super happy that we developed an end product that resembled our initial design.
## What we learned
In this project, we really had an opportunity to dive headfirst in mobile app development; specifically, learning all about React Native, JavaScript, and the unique challenges of implementing backend on mobile devices. We also learned how to delegate tasks more efficiently, and we also learned to give some big respect to front-end engineers!
## What's next for Bump!
**Deployment!**
We definitely plan on using the app with our extended friends, so the biggest next step for Bump! is polishing the rough edges and getting it on App Stores. To get Bump! production-ready, we're going to robustify the backend, as well as clean up the frontend for a smoother look.
**More Features!**
We also want to add some more functionality to Bump! Here are some of the ideas we had, let us know if there's any we missed!
* Adding friends with QR-code scanning
* Bump! leaderboards
* Status updates
* Siri! "Hey Siri, bump Emma!"
|
# Nexus, **Empowering Voices, Creating Connections**.
## Inspiration
The inspiration for our project, Nexus, comes from our experience as individuals with unique interests and challenges. Often, it isn't easy to meet others with these interests or who can relate to our challenges through traditional social media platforms.
With Nexus, people can effortlessly meet and converse with others who share these common interests and challenges, creating a vibrant community of like-minded individuals.
Our aim is to foster meaningful connections and empower our users to explore, engage, and grow together in a space that truly understands and values their uniqueness.
## What it Does
In Nexus, we empower our users to tailor their conversational experience. You have the flexibility to choose how you want to connect with others. Whether you prefer one-on-one interactions for more intimate conversations or want to participate in group discussions, our application Nexus has got you covered.
We allow users to either get matched with a single person, fostering deeper connections, or join one of the many voice chats to speak in a group setting, promoting diverse discussions and the opportunity to engage with a broader community. With Nexus, the power to connect is in your hands, and the choice is yours to make.
## How we built it
We built our application using a multitude of services/frameworks/tool:
* React.js for the core client frontend
* TypeScript for robust typing and abstraction support
* Tailwind for a utility-first CSS framework
* DaisyUI for animations and UI components
* 100ms live for real-time audio communication
* Clerk for a seamless and drop-in OAuth provider
* React-icons for drop-in pixel perfect icons
* Vite for simplified building and fast dev server
* Convex for vector search over our database
* React-router for client-side navigation
* Convex for real-time server and end-to-end type safety
* 100ms for real-time audio infrastructure and client SDK
* MLH for our free .tech domain
## Challenges We Ran Into
* Navigating new services and needing to read **a lot** of documentation -- since this was the first time any of us had used Convex and 100ms, it took a lot of research and heads-down coding to get Nexus working.
* Being **awake** to work as a team -- since this hackathon is both **in-person** and **through the weekend**, we had many sleepless nights to ensure we can successfully produce Nexus.
* Working with **very** poor internet throughout the duration of the hackathon, we estimate it cost us multiple hours of development time.
## Accomplishments that we're proud of
* Finishing our project and getting it working! We were honestly surprised at our progress this weekend and are super proud of our end product Nexus.
* Learning a ton of new technologies we would have never come across without Cal Hacks.
* Being able to code for at times 12-16 hours straight and still be having fun!
* Integrating 100ms well enough to experience bullet-proof audio communication.
## What we learned
* Tools are tools for a reason! Embrace them, learn from them, and utilize them to make your applications better.
* Sometimes, more sleep is better -- as humans, sleep can sometimes be the basis for our mental ability!
* How to work together on a team project with many commits and iterate fast on our moving parts.
## What's next for Nexus
* Make Nexus rooms only open at a cadence, ideally twice each day, formalizing the "meeting" aspect for users.
* Allow users to favorite or persist their favorite matches to possibly re-connect in the future.
* Create more options for users within rooms to interact with not just their own audio and voice but other users as well.
* Establishing a more sophisticated and bullet-proof matchmaking service and algorithm.
## 🚀 Contributors 🚀
| | | | |
| --- | --- | --- | --- |
| [Jeff Huang](https://github.com/solderq35) | [Derek Williams](https://github.com/derek-williams00) | [Tom Nyuma](https://github.com/Nyumat) | [Sankalp Patil](https://github.com/Sankalpsp21) |
|
# Lingle
##### Xinyi Ji, Allegra Chen, Jingfei Tan
---
### Website of Lingle
* COMING SOON
### Inspiration
* Language is the most powerful tool because it's what we use to communicate with each other. As specification and precision with language increases, people become close to understanding each other.
* We built Lingle because we were interested in machine learning APIs, and because all of the team members have had to learn English as a second language, so it was interesting to learn about English linguistics and linguistic computing, such as syntax, salience, etc.
* As students we have to read a lot of research papers. Being a citizen in the digital age means there is a plethora of online news. We hoped to make a web application that could identify focal entities in text (e.g. Person, Organization, etc.) and the negative, positive, mixed, and neutral connotations surrounding that entity in each sentence to isolate key sentences.
### Introduction to this project
* The purpose of Lingle is to try to read text, whether it be news or a research paper, and extract the significant sentences in the article based on the key entities (focal points) of the text, and analyze the sentiment around them (positive, negative, neutral, etc.)
#### Basic Functions
* After pasting the whole article on the dialog box and click on the "analyze" button, Lingle will show you the significant sentences placed in different categories ( positive attitude, negative attitude and neutral attitude). - Then you can now read the text much easier by just looking at the sentences extracted and knowing what kind of attitude these sentences represented.
### Great Features
* With the sentences being in different categories, users can get the general attitude of the whole article by just skim those sentences.
+ Provides a quick, visual sweep of long text inputs to identify key sentences concerning focal entities mentioned by the text.
### How we built it
* Built on the Django framework with Python and HTML/CSS, we utilized the Natural Language Machine Learning APIs from Google to analyze the context of the text entered in the form ( Thanks Google)
### Challenges we ran into
* We spent some time trying to show the context on the website with python connecting with html, css, Django framework which will show the sentences.
* This was our first time using Django and Machine Learning APIs. We were (pleasantly) surprised at how much data Google's Natural Language Processor, but it took a lot of effort to comb throw the seemingly endless dictionaries and lists.
### What we learned
* We learned how to utilize Machine Learning API, to access and analyze the data and perform operations on it to benefit a user
* We also learned about Python to HTML/CSS we development in Django, a completely new environment.
* We even learned a little Javascript on the go in while trying to implement a feature on our webpage.
### What's next
* We didn't have enough time, but we have a constant in our code called NUM\_ENTITIES, that sets the number of entities which the program looks for in the text with the highest salience (prevalence to text). We were hoping to let the user enter a number (e.g. 5) to denote the top n entities sentiment analysis would perform on.
* We would also like to provide some interactive ways to visualize the information by offering identification of key entities, so the user can select exactly which ones are used in the algorithm
### Notes
* To run, you need to install django and google-cloud
|
winning
|
## What it does
chat U is a slack bot that allows students at universities to learn where objects or specific places on campus are. We wanted to focus on some specific things that can be hard to find, like microwaves, study spaces, and power outlets.
## How we built it
We identified a problem. We talked about how finding objects on campus like microwaves, study spaces, and power outlets can be difficult. Some examples of this include students at Simon Fraser University (SFU) created a spreadsheet dedicated to where microwaves are on campus and it's a question asked often in their facebook student group. Karene talked about how frustrating it was to drive to campus to study and then finding that all of the study spaces were full of students. Finally, we all agreed that finding power outlets can be difficult, especially when your phone's dying and you have a limited amount of time.
We then brainstormed and finalized what capabilities we wanted our chatbot to have. Following this brainstorm we assigned tasks and got to work. Natalie worked on the logo and branding of the chatbot. Our team decided on the name chat U because it showcased the main functionality, chatting, and made references to the user and the university. Natalie also completed the conversation flow for the chatbot. Karene worked on compiling the microwave data and creating power outlet data. For the microwave data, she took the spreadsheet and translated that into a JSON file format. Hamza and Thai worked on researching how to code a facebook messenger bot and started working on coding the bot in C# and on Microsoft Azure.
Partway through the night, we realized that facebook messenger chatbots require approval via facebook which takes more than 24 hours. So we moved to coding a slack chat bot using StdLib and Python.
We also began coding a website, hosted on GitHub, to showcase our chatbot and provide a bit of background on the project. This pivot from facebook messenger to slack affected our ability to embed the bot into our website effectively. We attempted to use a third party service, Chatlio, but ran into issues of talking to the bot on the website using its @name. Additionally, we applied for a .tech domain name early on and never heard back, which was pretty disappointing.
## Challenges we ran into
We ran into a lot of technical problems throughout this project. C# and Microsoft Azure hit us with a learning curve. Learning that facebook messenger chatbots required approval, after we had worked on it for a couple hours and had thought that they didn't was frustrating and disheartening.
## Accomplishments that we're proud of
First, we're proud that this chatbot fulfills an actual need. During the hackathon, a student posted "is there a microwave in this building?" in the slack group. We all laughed at how applicable it was to our project, because our app would be able to give an answer.
We're proud that we were able to adapt quickly to a ton of technical problems! It was more difficult than we expected to code and implement a chatbot. Honestly, we're proud that we got it working!
## What we learned
We learned a lot about API implementation and also a lot about some languages we aren't used to using. We also learned about the conversational element of a chatbot and how that affects the user experience. Something that is important but not thought about is escape options!
## What's next for chat U
We would like to implement sensors in study area entrances to detect how many people are in study spaces. We would be interested in tracking movement in and out of the space. This anonymous data would allow us to calculate how many people are in a space while protecting these individuals privacy. This information can be useful for students to determine if they want to go to that space beforehand. Additionally, we would like the ability to expand to other universities and colleges by utilizing crowd sourced data.
## Work & Github Repositories
Initial chat bot (facebook messenger)
<https://github.com/thaingocnguyen/ChatU>
Website repository
<https://github.com/natc66/ChatU>
Website Link
<https://natc66.github.io/ChatU/>
Slack API
<https://stdlib.com/@karene/lib/chatu/>
Slack Bot Repository
<https://github.com/H-Kamal/slackMicrowaveBot.git>
|
## Being a university student during the pandemic is very difficult. Not being able to connect with peers, run study sessions with friends and experience university life can be challenging and demotivating. With no present implementation of a specific data base that allows students to meet people in their classes and be automatically put into group chats, we were inspired to create our own.
## Our app allows students to easily setup a personalized profile (school specific) to connect with fellow classmates, be automatically put into class group chats via schedule upload and be able to browse clubs and events specific to their school. This app is a great way for students to connect with others and stay on track of activities happening in their school community.
## We built this app using an open-source mobile application framework called React Native and a real-time, cloud hosted database called Firebase. We outlined the GUI with the app using flow diagrams and implemented an application design that could be used by students via mobile. To target a wide range of users, we made sure to implement an app that could be used on android and IOS.
## Being new to this form of mobile development, we faced many challenges creating this app. The first challenge we faced was using GitHub. Although being familiar to the platform, we were unsure how to use git commands to work on the project simultaneously. However, we were quick to learn the required commands to collaborate and deliver the app on GitHub. Another challenge we faced was nested navigation within the software. Since our project highly relied on a real-time database, we also encountered difficulties with implementing the data base framework into our implementation.
## An accomplishment we are proud of is learning a plethora of different frameworks and how to implement them. We are also proud of being able to learn, design and code a project that can potentially help current and future university students across Ontario enhance their university lifestyles.
## We learned many things implementing this project. Through this project we learned about version control and collaborative coding through Git Hub commands. Using Firebase, we learned how to handle changing data and multiple authentications. We were also able to learn how to use JavaScript fundamentals as a library to build GUI via React Native. Overall, we were able to learn how to create an android and IOS application from scratch.
## What's next for USL- University Student Life!
We hope to further our expertise with the various platforms used creating this project and be able to create a fully functioning version. We hope to be able to help students across the province through this application.
|
## Inspiration
While we were doing preliminary research, we had found overwhelming amounts of evidence of mental health deterioration as a consequence of life-altering lockdown restrictions. Academic research has shown that adolescents depend on friendship to maintain a sense of self-worth and to manage anxiety and depression. Intimate exchanges and self-esteem support significantly increased long-term self worth and decreased depression.
While people do have virtual classes and social media, some still had trouble feeling close with anyone. This is because conventional forums and social media did not provide a safe space for conversation beyond the superficial. User research also revealed that friendships formed by physical proximity don't necessarily make people feel understood and resulted in feelings of loneliness anyway. Proximity friendships formed in virtual classes also felt shallow in the sense that it only lasted for the duration of the online class.
With this in mind, we wanted to create a platform that encouraged users to talk about their true feelings, and maximize the chance that the user would get heartfelt and intimate replies.
## What it does
Reach is an anonymous forum that is focused on providing a safe space for people to talk about their personal struggles. The anonymity encourages people to speak from the heart. Users can talk about their struggles and categorize them, making it easy for others in similar positions to find these posts and build a sense of closeness with the poster. People with similar struggles have a higher chance of truly understanding each other. Since ill-mannered users can exploit anonymity, there is a tone analyzer that will block posts and replies that contain mean-spirited content from being published while still letting posts of a venting nature through. There is also ReCAPTCHA to block bot spamming.
## How we built it
* Wireframing and Prototyping: Figma
* Backend: Java 11 with Spring Boot
* Database: PostgresSQL
* Frontend: Bootstrap
* External Integration: Recaptcha v3 and IBM Watson - Tone Analyzer
* Cloud: Heroku
## Challenges we ran into
We initially found it a bit difficult to come up with ideas for a solution to the problem of helping people communicate. A plan for a VR space for 'physical' chatting was also scrapped due to time constraints, as we didn't have enough time left to do it by the time we came up with the idea. We knew that forums were already common enough on the internet, so it took time to come up with a product strategy that differentiated us. (Also, time zone issues. The UXer is Australian. They took caffeine pills and still fell asleep.)
## Accomplishments that we're proud of
Finishing it on time, for starters. It felt like we had a bit of a scope problem at the start when deciding to make a functional forum with all these extra features, but I think we pulled it off. The UXer also iterated about 30 screens in total. The Figma file is *messy.*
## What we learned
As our first virtual hackathon, this has been a learning experience for remote collaborative work.
UXer: I feel like i've gotten better at speedrunning the UX process even quicker than before. It usually takes a while for me to get started on things. I'm also not quite familiar with code (I only know python), so watching the dev work and finding out what kind of things people can code was exciting to see.
# What's next for Reach
If this was a real project, we'd work on implementing VR features for those who missed certain physical spaces. We'd also try to work out improvements to moderation, and perhaps a voice chat for users who want to call.
|
losing
|
## Inspiration
From a 7-minute presentation to a 3-minute time slot, the presentation was cut more than half from last year! This immediately threw out ideas and we had to start idea generation from scratch. This resulted in the AI-generated 2 in 1 slideshow and pitch deck creator! Easily fits your presentation within the 3-minute time slot.
In the modern world, this problem happens quite often. In fact, we, the students, have been struggling with tight deadlines, crazy ideas, and the will to pitch them out for a long time already. The truth is that many of us do not have the time, skills, or knowledge to make ideas happen and gain a following behind them. So, whether you are an aspiring entrepreneur, or perhaps a professional in the competitive business world, we know there is one thing you need the most: A quick and easy problem-solver.
We can look at a high school teacher, who may want to present something very quickly to a class of young pupils. Or, we can peek at a professional consultant, who has to meet with clients rapidly. Lastly, we can also check out a teenager looking at their first idea coming to life. The common denominator between all of these cases is reasonably straightforward: Pitches of all sorts are everywhere, used by all sorts of people with unique backgrounds. So, we picked up our notebooks and markers, then got to work.
## What it does
Pitch Perfect lets you enter a prompt, a logo idea, and the length of your pitch. The program then takes these inputs and generates slide decks using Artificial Intelligence. Every slide can be edited to fix mistakes or add information to help with context.
The program goes beyond just generating graphics and texts, as it also generates a script that fits perfectly into your presentation length. It completes your idea and flushes out as many details as possible without compromising your starting point.
Piqued your interest? Check out our code and instructions to run through our GitHub link below, or click on our fully-deployed link to a Heroku website that hosts our application. Our Figma file is also up for views if you would like to check it out!
## How we built it
We used OpenAI to generate outputs based on prompts given by user inputs. The data were then processed to be outputted to put on pitch deck templates. The code was made to be modular for future expansions, and UI/UX design was considered throughout the entire process.
Extensive economic research has been conducted to understand the target market and dive deeper into the product's purpose. The full details can be found below under Economic Report.
The front end involved HTML/CSS and JavaScript code in implementing the UI, as well as functions to support the core features of our completed MVP. The backend used Flask and Python to power advanced API calls from and to OpenAI, and was used to process data effectively for frontend deployment and rendering. Besides the slide deck templates and UI/UX design/implementation, nothing else was created using Artificial Intelligence.
## Challenges we ran into
There were many challenges in terms of frontend, backend, and design. The frontend integration with backend took a very long time, and there were many iterative design cycles to complete the frontend design. The backend involved many optimization and data processing issues, where we found it difficult to get the most ideal results for our test cases. For design, we expanded our scopes many times to include new ideas into our design files, so that they can be implemented in the future. However, this definitely drove up the creation time, and pushed our team to the limit to deliver a fully-completed initial product as our MVP.
In the end, we are proud to say that challenges were tackled and a functional product has been delivered. We hope you enjoy our work and have some fun with it! It never stops fascinating us to work with advanced technologies such as Machine Learning and Artificial Intelligence.
## Accomplishments that we're proud of
* For Michael, one of our members who is in first-year, this was his first ever Hackathon!
* We successfully implemented all features of our MVP, not a single loose end!
* We hosted it on Heroku. Although online hosting made it difficult to pass keys, we hope it can work for at least some of you so you can skip all the hassle to run our program
* We did a lot of research! A 6-page report has been done to analyze our product from the economics aspect. We came in wanting to solve a problem, and we definitely found ourselves a big one
* Our UI/UX took many hours and we are proud of it! The design itself satisfies many concerns that we hope to address, and experimenting with templates has allowed us to plan our the future steps for our application
* All of this was done over the last 36 hours! This was by far the most complete project that served a great purpose, and we hope to expand on it further in the future to cause a bigger impact
## What we learned
We learned to work in a very diverse team. None of our members did anything similar, and we learned many lessons from it. From UI/UX design to data processing, we rapidly grew to reach an ideal MVP. The challenges from integration made us comfortable with the Flask framework, and we cannot wait to apply it more in the future!
Designing the product was a big challenge. Our designer used Figma for the first time and made a name for himself! We also spent more than a quarter of the event brainstorming, so idea generation and product design have been firmly embedded into our heads.
For our programmers, it was challenging to integrate the backend modularly into a frontend environment, and we were glad to face many difficulties with almost all of our choices of programming languages. In the end, it was satisfying to see things come to fruition.
Our newest member, Michael, learned many product design, development, and management concepts. The discussions were very useful in understanding high-level and sometimes industry-standard problem-solving processes.
Heroku came as a bit of a surprise, and we hope to learn more about it to host our products online to reduce friction when accessing our app.
## What's next for Pitch Perfect
Our immediate next step involves creating more templates to satisfy more target audiences and designing a sound and fair monetization system. After that, we hope to optimize our design with a landing page and other support pages for our brand, and redesign some of the code to be more efficient.
We also hope to incorporate a database into our program, such as Firebase and MongoDB, to storage data for our users and allow membership on the website. Many features would be impossible without a data storage system, so we aim to get that done as soon as possible.
Lastly, we would love to sit down and do more research. This includes both user research and market research. To make a successful product, we are very interested to understand more of the industry and our target audiences, and hopefully discover new insights and rooms to improve.
This was a fantastic project, and we hope you like it as much as we do!
## Economic Report
QHacks 2023 Pitch Perfect Market Sizing (TAM, SAM, SOM) Analysis and Monetization
1. Monetization:
2. Paid content: Offering premium content or additional features to users who purchase a subscription can generate revenue, but it can also alienate casual users who are unwilling to pay.
3. Affiliate marketing: Partnering with other businesses and receiving a commission for sales generated from the website can be a great way to monetize the website without alienating users, but it requires a lot of effort to properly manage affiliates.
4. Licensing model: This strategy would involve selling licenses for the product to businesses or organizations that want to use it for their own presentations. The downside to this is that it may not generate as much revenue as other monetization strategies, and it may also limit the number of users that are willing to pay for the product.
5. Total Addressable Market (TAM):
2.1 Tourism Industry [1]:
6. User penetration is 24.3% in 2023 and is expected to hit 27.2% by 2027.
7. The average revenue per user (ARPU) is expected to amount to US$0.46k.
8. Revenue is expected to show an annual growth rate (CAGR 2023-2027) of 4.41%, resulting in a projected market volume of US$1,016.00bn by 2027.
9. In the Travel & Tourism market, 74% of total revenue will be generated through online sales by 2027.
10. Economical impacts to the tourism industry include another global pandemic, war, recession.
11. Since the tourism industry is a sales market, presentation is a key factor and there are many many middle men and smaller agents doing the selling. The trend is currently gearing towards online sales. US market is the largest.
2.2 Pharmaceutical Industry [2]:
1. Revenue is expected to show an annual growth rate (CAGR 2023-2027) of 5.39%, resulting in a market volume of US$1,435.00bn by 2027.
2. Impacts to this industry could be another global pandemic. Impacts are always happening as breakthrough medications and treatments are occurring. Disruptions in the market could include companies such as “Cost plus drugs” from Mark Cuban which aims to undercut the pharma industry. The pharma industry is and will continuously grow.
2.3 Medium to small companies:
1. The 27 million small businesses generate approximately 50% of the GDP in the United States [3].
2. The most common reasons small businesses fail include a lack of capital or funding, retaining an inadequate management team, a faulty infrastructure or business model, and unsuccessful marketing initiatives [4].
3. Marketing has a direct correlation with market demand in the sense that it targets a specific audience in which you as the marketer are looking for. The marketing creates demand and instigates interest in your product [5].
2.4 Education Industry:
1. In the United States, approximately 16.8 million students attend high school on average a year [6].
2. Approximately 19 million postsecondary students in the United States every year. 13.87 in public, 5.12 in private institutions [7].
3. Average global percent of GDP spent on education is 4.3%. Of this, 92.2% is spent in public institutions and the other 7.8 percent are divided between different forms of private education [8].
2.5 Media Industry:
1. In 2021, in the year of recovery from the effects of the global pandemic, the value of the media and entertainment market reached 2.34 trillion U.S. dollars, experiencing a growth of 10.4 percent compared to 2020. In the following years the growth is set to slow down, but dollar figures are expected to reach 2.93 trillion by the end of 2026 [9].
2. Media industry is threatened constantly with lawsuits with false information. The media is also in constant controversy which leads to ups and downs in attention. There are certain riskier outlets than others, and the mainstream media sources are sources that aren’t necessary trustworthy, but are here to stay for the long term.
2.6 Startups:
1. Data from the US Census Bureau shows that an average of 4.4 million businesses are started every year. That average is from the past five years of business formation data in the United States [10].
2. Startup owners can spend around 40% of their working hours on tasks that do not generate income such as hiring, HR tasks, and payroll [11].
3. The global startup economy remains large, creating nearly $3 trillion in value, a figure on par with the GDP of a G7 economy [12].
4. Artificial Intelligence (AI): industry is expected to grow at a compound annual growth rate (CAGR) of 42.2% from 2020 to 2027 [17].
5. Healthcare Tech: valued at $74.2 billion in 2020 and is expected to grow at a compound annual growth rate (CAGR) of 10.7% over the forecast period (2028) [17].
6. Educational Technology (Edtech): The edtech industry was valued at $89.49 billion in 2020, with an expected compound annual growth rate (CAGR) of 19.9% until 2028 [17]
7. Financial Technology (Fintech):To be exact, the fintech market was valued at $127.66 billion in 2018, and experts predict by 2022, the industry will be worth $309.98 billion. Fintech makes up 7.1% of the tech industry [17].
8. Serviceable Available Market (SAM):
9. 1 Education:
10. There are close to 85 million teachers worldwide: 9.4 million in pre-primary; 30.3 million in primary; 18.1 in lower secondary; 14.0 in upper secondary; and 12.5 in tertiary education. By 2030, an additional 68.8 million teachers will need to be recruited just for primary and secondary: 20 million are required to expand access to primary and secondary school and 49 million are needed to replace those who leave the workforce [13]. In fall 2020, of the 1.5 million faculty at degree-granting postsecondary institutions, 56 percent were full time and 44 percent were part time. Faculty include professors, associate professors, assistant professors, instructors, lecturers, assisting professors, adjunct professors, and interim professors [14]. As of 2019, there are 601 million secondary school students. This number continuously climbs every year up from 450 million in the year 2000 [15]. 235 million students are in post secondary institutions globally as of 2022. This number is up from 100 million in 2000 [16].
11. Geographic limitations occur when technology is not up to par. The reach of the internet and the electronics capable of taking full advantage of the slideshow need to be present or else the product cannot reach that audience.
12. Currently there is only 1 competitor associated with the product we are creating and to the scale being created. This product is pay to use only, and the product isn’t widespread and isn’t being pushed widespread.
13. Distribution can occur through presentations to districts and teacher conferences. Proof of scalability and alternative solutions must be provided to ensure success in the distribution phase. Distribution to students can be done organically through social media, this is a very similar way to how ChatGPT grew as the product has its own wow factor which is very promotable [18].
3.2 Startups:
14. The market's largest segment is Crowdlending (Business) with a projected total transaction value of C$40.70bn in 2023. Total transaction value in the Digital Capital Raising segment is projected to reach $84.13bn in 2023 [19]. The target audience are these startups that present and constantly pitch their ideas to investors for crowdfunding or venture capital.
15. There are no geographical limitations to our product as long as the startup has access to the internet and is able to present the created slideshow accordingly.
16. The distribution can be through ads or social media trends similar to ChatGPT.
17. Serviceable Obtainable Market (SOM)
4.1 University and Postsecondary Students
Targeting students and educators requires a well-planned strategy that centers on providing a valuable solution to their specific needs. Our AI-powered script and presentation creator addresses the common challenge of creating effective presentations and scripts, a problem that many students face. Additionally, it addresses the issue of educators spending a significant amount of time creating their own presentations, thereby allowing them to focus on research and other important areas. By providing a user-friendly interface and a free version of our product, we can effectively demonstrate its capabilities and value proposition to this demographic. While there is some competition in the market, our key differentiator is the ease of use, accessibility, and the ample features offered in the free version, which will drive adoption through user satisfaction. To increase brand awareness and drive initial adoption, targeted marketing efforts and paid usage may be necessary. However, the ultimate success of our product will be determined by its ability to effectively meet the needs of students and educators.
4.2 Startups
Startups often have limited budgets; therefore, our product will be offered at a free version but also an affordable price with premium features to cater to this market segment. Additionally, we will leverage online distribution channels such as social media and startup networks to reach our target market. Startups are often in need of efficient and cost-effective solutions for creating presentations and scripts. By focusing on this specific market segment, we have the potential to capture a significant share of the startup market. By targeting startups, we can tap into a niche market with a high potential for growth. We will leverage social media and startup networks to increase brand awareness and establish ourselves as a go-to solution for startups. There are a few AI script and presentation creator tools on the market, however, similar to our 1 competitor, they have not prioritized marketing and promoting themselves. By focusing on this niche market in startups that are constantly pitching themselves to venture capital and crowdfunding sources, we can differentiate ourselves from the competition.
18. References
[1] “Travel & tourism - worldwide: Statista market forecast,” Statista. [Online]. Available: <https://www.statista.com/outlook/mmo/travel-tourism/worldwide>. [Accessed: 28-Jan-2023].
[2] “Pharmaceuticals - worldwide: Statista market forecast,” Statista. [Online]. Available: <https://www.statista.com/outlook/hmo/pharmaceuticals/worldwide#revenue>. [Accessed: 28-Jan-2023].
[3] [Author removed at request of original publisher], “5.2 the importance of small business to the U.S. economy,” Exploring Business, 08-Apr-2016. [Online]. Available: [https://open.lib.umn.edu/exploringbusiness/chapter/5-2-the-importance-of-small-business-to-the-u-s-economy/#:~:text=The%20nearly%20twenty%2Dseven%20million,50%20percent%20of%20our%20GDP](https://open.lib.umn.edu/exploringbusiness/chapter/5-2-the-importance-of-small-business-to-the-u-s-economy/#:%7E:text=The%20nearly%20twenty%2Dseven%20million,50%20percent%20of%20our%20GDP). [Accessed: 28-Jan-2023].
[4] M. Horton, “The 4 most common reasons a small business fails,” Investopedia, 19-Jan-2023. [Online]. Available: [https://www.investopedia.com/articles/personal-finance/120815/4-most-common-reasons-small-business-fails.asp#:~:text=The%20most%20common%20reasons%20small,model%2C%20and%20unsuccessful%20marketing%20initiatives](https://www.investopedia.com/articles/personal-finance/120815/4-most-common-reasons-small-business-fails.asp#:%7E:text=The%20most%20common%20reasons%20small,model%2C%20and%20unsuccessful%20marketing%20initiatives). [Accessed: 28-Jan-2023].
[5] B. B. FZE, “Relationship between marketing and Consumer Demand,” UKEssays, 16-Jan-2023. [Online]. Available: [https://www.ukessays.com/essays/marketing/marketing-customer-value-and-their-relationships.php#:~:text=Marketing%20and%20customer%20value%20has,have%20to%20be%20customer%20orientated](https://www.ukessays.com/essays/marketing/marketing-customer-value-and-their-relationships.php#:%7E:text=Marketing%20and%20customer%20value%20has,have%20to%20be%20customer%20orientated). [Accessed: 28-Jan-2023].
[6] Published by Erin Duffin and D. 8, “High School enrollment in the U.S. 2030,” Statista, 08-Dec-2022. [Online]. Available: <https://www.statista.com/statistics/183996/us-high-school-enrollment-in-public-and-private-institutions/>. [Accessed: 28-Jan-2023].
[7] Published by Erin Duffin and J. 27, “U.S. college enrollment and forecast 1965-2030,” Statista, 27-Jul-2022. [Online]. Available: <https://www.statista.com/statistics/183995/us-college-enrollment-and-projections-in-public-and-private-institutions/>. [Accessed: 28-Jan-2023].
[8] “Government expenditure on education, total (% of GDP),” Data. [Online]. Available: <https://data.worldbank.org/indicator/SE.XPD.TOTL.GD.ZS>. [Accessed: 28-Jan-2023].
[9] A. Guttmann, “Global Entertainment and media market size 2026,” Statista, 27-Jul-2022. [Online]. Available: <https://www.statista.com/statistics/237749/value-of-the-global-entertainment-and-media-market/>. [Accessed: 28-Jan-2023].
[10] Commerce Institute, “How many new businesses are started each year? (2022 data),” Commerce Institute, 18-Jan-2023. [Online]. Available: <https://www.commerceinstitute.com/new-businesses-started-every-year/>. [Accessed: 28-Jan-2023].
[11] T. Gutner, “Is it time to outsource human resources?,” Entrepreneur, 14-Jan-2011. [Online]. Available: <https://www.entrepreneur.com/business-news/is-it-time-to-outsource-human-resources/217866>. [Accessed: 28-Jan-2023].
[12] Startup Genome, “State of the global startup economy,” Startup Genome. [Online]. Available: <https://startupgenome.com/article/state-of-the-global-startup-economy>. [Accessed: 28-Jan-2023].
[13] “Teachers,” World Bank. [Online]. Available: [https://www.worldbank.org/en/topic/teachers#:~:text=There%20are%20close%20to%2085,and%2012.5%20in%20tertiary%20education](https://www.worldbank.org/en/topic/teachers#:%7E:text=There%20are%20close%20to%2085,and%2012.5%20in%20tertiary%20education). [Accessed: 28-Jan-2023].
[14] “The NCES Fast Facts Tool provides quick answers to many education questions (National Center for Education Statistics),” National Center for Education Statistics (NCES) Home Page, a part of the U.S. Department of Education. [Online]. Available: <https://nces.ed.gov/fastfacts/display.asp?id=61>. [Accessed: 28-Jan-2023].
[15] Published by Statista Research Department and N. 23, “Global: Number of pupils in Secondary School,” Statista, 23-Nov-2022. [Online]. Available: <https://www.statista.com/statistics/1227098/number-of-pupils-in-secondary-education-worldwide/>. [Accessed: 28-Jan-2023].
[16] UNESCO Right to Education Initiative and Unesco, “Higher education,” UNESCO.org, 01-Jan-1970. [Online]. Available: [https://www.unesco.org/en/higher-education#:~:text=There%20are%20around%20235%20million,differences%20between%20countries%20and%20regions](https://www.unesco.org/en/higher-education#:%7E:text=There%20are%20around%20235%20million,differences%20between%20countries%20and%20regions). [Accessed: 28-Jan-2023].
[17] Truic, “Best Startup Industries,” Startupsavant.com, 09-Jan-2023. [Online]. Available: <https://startupsavant.com/best-industries-for-startups>. [Accessed: 28-Jan-2023].
[18] M. Lynch, “Tips for selling to districts, schools, and teachers,” The Tech Edvocate, 06-Aug-2019. [Online]. Available: <https://www.thetechedvocate.org/tips-for-selling-to-districts-schools-and-teachers/>. [Accessed: 28-Jan-2023].
[19] “Digital Capital Raising - Global: Statista market forecast,” Statista. [Online]. Available: <https://www.statista.com/outlook/dmo/fintech/digital-capital-raising/worldwide?currency=cad>. [Accessed: 28-Jan-2023].
|
## Inspiration
There's something about brief glints in the past that just stop you in your tracks: you dip down, pick up an old DVD of a movie while you're packing, and you're suddenly brought back to the innocent and carefree joy of when you were a kid. It's like comfort food.
So why not leverage this to make money? The ethos of nostalgic elements from everyone's favourite childhood relics turns heads. Nostalgic feelings have been repeatedly found in studies to increase consumer willingness to spend money, boosting brand exposure, conversion, and profit.
## What it does
Large Language Marketing (LLM) is a SaaS built for businesses looking to revamp their digital presence through "throwback"-themed product advertisements.
Tinder x Mean Girls? The Barbie Movie? Adobe x Bob Ross? Apple x Sesame Street? That could be your brand, too. Here's how:
1. You input a product description and target demographic to begin a profile
2. LLM uses the data with the Co:here API to generate a throwback theme and corresponding image descriptions of marketing posts
3. OpenAI prompt engineering generates a more detailed image generation prompt featuring motifs and composition elements
4. DALL-E 3 is fed the finalized image generation prompt and marketing campaign to generate a series of visual social media advertisements
5. The Co:here API generates captions for each advertisement
6. You're taken to a simplistic interface where you can directly view, edit, generate new components for, and publish each social media post, all in one!
7. You publish directly to your business's social media accounts to kick off a new campaign 🥳
## How we built it
* **Frontend**: React, TypeScript, Vite
* **Backend**: Python, Flask, PostgreSQL
* **APIs/services**: OpenAI, DALL-E 3, Co:here, Instagram Graph API
* **Design**: Figma
## Challenges we ran into
* **Prompt engineering**: tuning prompts to get our desired outputs was very, very difficult, where fixing one issue would open up another in a fine game of balance to maximize utility
* **CORS hell**: needing to serve externally-sourced images back and forth between frontend and backend meant fighting a battle with the browser -- we ended up writing a proxy
* **API integration**: with a lot of technologies being incorporated over our frontend, backend, database, data pipeline, and AI services, massive overhead was introduced into getting everything set up and running on everyone's devices -- npm versions, virtual environments, PostgreSQL, the Instagram Graph API (*especially*)...
* **Rate-limiting**: the number of calls we wanted to make versus the number of calls we were allowed was a small tragedy
## Accomplishments that we're proud of
We're really, really proud of integrating a lot of different technologies together in a fully functioning, cohesive manner! This project involved a genuinely technology-rich stack that allowed each one of us to pick up entirely new skills in web app development.
## What we learned
Our team was uniquely well-balanced in that every one of us ended up being able to partake in everything, especially things we hadn't done before, including:
1. DALL-E
2. OpenAI API
3. Co:here API
4. Integrating AI data pipelines into a web app
5. Using PostgreSQL with Flask
6. For our non-frontend-enthusiasts, atomic design and state-heavy UI creation :)
7. Auth0
## What's next for Large Language Marketing
* Optimizing the runtime of image/prompt generation
* Text-to-video output
* Abstraction allowing any user log in to make Instagram Posts
* More social media integration (YouTube, LinkedIn, Twitter, and WeChat support)
* AI-generated timelines for long-lasting campaigns
* AI-based partnership/collaboration suggestions and contact-finding
* UX revamp for collaboration
* Option to add original content alongside AI-generated content in our interface
|
## **Inspiration:**
Our inspiration stemmed from the realization that the pinnacle of innovation occurs at the intersection of deep curiosity and an expansive space to explore one's imagination. Recognizing the barriers faced by learners—particularly their inability to gain real-time, personalized, and contextualized support—we envisioned a solution that would empower anyone, anywhere to seamlessly pursue their inherent curiosity and desire to learn.
## **What it does:**
Our platform is a revolutionary step forward in the realm of AI-assisted learning. It integrates advanced AI technologies with intuitive human-computer interactions to enhance the context a generative AI model can work within. By analyzing screen content—be it text, graphics, or diagrams—and amalgamating it with the user's audio explanation, our platform grasps a nuanced understanding of the user's specific pain points. Imagine a learner pointing at a perplexing diagram while voicing out their doubts; our system swiftly responds by offering immediate clarifications, both verbally and with on-screen annotations.
## **How we built it**:
We architected a Flask-based backend, creating RESTful APIs to seamlessly interface with user input and machine learning models. Integration of Google's Speech-to-Text enabled the transcription of users' learning preferences, and the incorporation of the Mathpix API facilitated image content extraction. Harnessing the prowess of the GPT-4 model, we've been able to produce contextually rich textual and audio feedback based on captured screen content and stored user data. For frontend fluidity, audio responses were encoded into base64 format, ensuring efficient playback without unnecessary re-renders.
## **Challenges we ran into**:
Scaling the model to accommodate diverse learning scenarios, especially in the broad fields of maths and chemistry, was a notable challenge. Ensuring the accuracy of content extraction and effectively translating that into meaningful AI feedback required meticulous fine-tuning.
## **Accomplishments that we're proud of**:
Successfully building a digital platform that not only deciphers image and audio content but also produces high utility, real-time feedback stands out as a paramount achievement. This platform has the potential to revolutionize how learners interact with digital content, breaking down barriers of confusion in real-time. One of the aspects of our implementation that separates us from other approaches is that we allow the user to perform ICL (In Context Learning), a feature that not many large language models don't allow the user to do seamlessly.
## **What we learned**:
We learned the immense value of integrating multiple AI technologies for a holistic user experience. The project also reinforced the importance of continuous feedback loops in learning and the transformative potential of merging generative AI models with real-time user input.
|
winning
|
## Inspiration
Travelling can be expensive but data plans abroad can really push the expenses to a whole new level. With NavText, we were inspired to create an app fuelled by SMS messaging to do all the same services that might be useful while travellling. With this app, travelling can be made easy without the stress of finding Wifi or a data plan.
## What it does
NavText has multiple functionalities and is created as an all around app useful for travelling locally or abroad. NavText will guide you in navigating with multiple modes of transportation including requesting an uber driver nearby, taking the local transit, driving or walking. Information such as the estimated time of travel, step by step directions will be texted to your phone after making a request. You can also explore local attractions and food places which will text you the address, directions, opening hours, and price level.
## How we built it
Swift
Uber API
Google Maps API
Message Bird
## Challenges we ran into
Integrating Message Bird with the Google API. Working around iOS SMS limitations, such as reading and composing text messages.
## Accomplishments that we're proud of
Polished iOS app which allows easy use of the formatting of the text message.
## What we learned
## What's next for NavText
|
## Inspiration
Our team identified two intertwined health problems in developing countries:
1) Lack of easy-to-obtain medical advice due to economic, social and geographic problems, and
2) Difficulty of public health data collection in rural communities.
This weekend, we built SMS Doc, a single platform to help solve both of these problems at the same time. SMS Doc is an SMS-based healthcare information service for underserved populations around the globe.
Why text messages? Well, cell phones are extremely prevalent worldwide [1], but connection to the internet is not [2]. So, in many ways, SMS is the *perfect* platform for reaching our audience in the developing world: no data plan or smartphone necessary.
## What it does
Our product:
1) Democratizes healthcare information for people without Internet access by providing a guided diagnosis of symptoms the user is experiencing, and
2) Has a web application component for charitable NGOs and health orgs, populated with symptom data combined with time and location data.
That 2nd point in particular is what takes SMS Doc's impact from personal to global: by allowing people in developing countries access to medical diagnoses, we gain self-reported information on their condition. This information is then directly accessible by national health organizations and NGOs to help distribute aid appropriately, and importantly allows for epidemiological study.
**The big picture:** we'll have the data and the foresight to stop big epidemics much earlier on, so we'll be less likely to repeat crises like 2014's Ebola outbreak.
## Under the hood
* *Nexmo (Vonage) API* allowed us to keep our diagnosis platform exclusively on SMS, simplifying communication with the client on the frontend so we could worry more about data processing on the backend. **Sometimes the best UX comes with no UI**
* Some in-house natural language processing for making sense of user's replies
* *MongoDB* allowed us to easily store and access data about symptoms, conditions, and patient metadata
* *Infermedica API* for the symptoms and diagnosis pipeline: this API helps us figure out the right follow-up questions to ask the user, as well as the probability that the user has a certain condition.
* *Google Maps API* for locating nearby hospitals and clinics for the user to consider visiting.
All of this hosted on a Digital Ocean cloud droplet. The results are hooked-through to a node.js webapp which can be searched for relevant keywords, symptoms and conditions and then displays heatmaps over the relevant world locations.
## What's next for SMS Doc?
* Medical reports as output: we can tell the clinic that, for example, a 30-year old male exhibiting certain symptoms was recently diagnosed with a given illness and referred to them. This can allow them to prepare treatment, understand the local health needs, etc.
* Epidemiology data can be handed to national health boards as triggers for travel warnings.
* Allow medical professionals to communicate with patients through our SMS platform. The diagnosis system can be continually improved in sensitivity and breadth.
* More local language support
[1] <http://www.statista.com/statistics/274774/forecast-of-mobile-phone-users-worldwide/>
[2] <http://www.internetlivestats.com/internet-users/>
|
## Team
Hello and welcome to our project! We are Ben Wiebe, Erin Hacker, Iain Doran-Des Brisay, and Rachel Smith. We are all in our third year of computer engineering at Queen’s University.
## Inspiration
Something our team has in common is a love of road trips. However, road trips can be difficult to coordinate, and the fun of a road trip is lost when not everyone is travelling together. As such, we wanted to create an app that will help people stay in touch while travelling and feel connected even when apart.
## What it Does
The app gives users the ability to stay connected while travelling in separate cars. From the home screen, you are prompted to log in to Snapchat with your account. You then have the option to create a new trip or join an existing trip. If you create a trip, you are prompted to indicate the destination that your group will be travelling to, as well as a group name. You are then given a six-character code, randomly generated and consisting of numbers and letters, that you can copy and send to your friends so that they can join you.
Once in a trip, users are taken to a screen that displays a map as the main display on the screen. The map displays each member of the trip’s Bitmoji and will update with users’ locations. Based on location, an arrival time will be displayed, letting users give their friends updates on how far away they are from their destination.
As well, users can sign into Spotify, allowing all parties in the group to contribute to a shared playlist and listen to the same songs from this playlist at the same time, keeping the road trip fun despite the distance. So next time you want to take control of the aux, you’ll be taking control of all parties in your group!
The software currently maps a route as generated using a Google Maps API. However, the route is not yet drawn on to the map, a messaging feature would be implemented to allow users to communicate with one another. This feature would be limited to users of passenger status to discourage drivers from texting and driving. As well, weather and traffic updates would be implemented to further aid users on road trips.
## How We Built It
The team split into two sub-teams each to tackle independent tasks. Iain and Rachel took lead on the app interface. They worked in Android Studio, coding in Java, to get the activities, buttons, and screens in sync. They integrated Snapchat’s bitmoji kit, as well as the Google Maps APIs to streamline the process. Ben and Erin took lead on making the server and databases, using SQLite and Node.js. They also implemented security checks to ensure the app is not susceptible to SQL injections and to limit the accepted user inputs. The team came together as a whole to integrate all components smoothly, and efficiently as well as to test and fix errors.
## Challenges We Ran Into
Several technical challenges were encountered during the creation of Konvoi. One error was in the implementation of the map on the client side. Another main issue was finding the proper dependencies and matching their versions.
## Accomplishments That We’re Proud Of
First and for most, we are proud of each other’s hard work and dedication. We started this Hackathon with the mind set that we wanted to complete the app at all costs. Normally never running on less than six hours of sleep, the team struggled on only four hours per night. The best part? The team morale. Everyone had their ups and downs, and points when we did not think that we would finish and it seemed easiest to give up. We took turns being the support for each other and encouraging each other; from silly photos at 3am in matching onesies, to visiting the snack table…every…five…minutes… the team persevered and accomplished the project!
On the other hand, we are proud of the app and all the potential that it has. In only 36 hours, a fully functional app that we can share together on our next team road trip (Florida anyone??) has been built. From here, we believe that this app is marketable, especially to those 18 to 30.
## What We Learned
The team collectively agrees that we learned so much throughout this entire experience both technical and interpersonal. The team worked with mentors one on one multiple times throughout the hackathon, each of them bringing a new experience to our table. We spoke with Kevin from Scotiabank, who expanded our thought process with regards to how security plays a role in every project we work on.
We spoke with Mike from Ritual who taught us about the Android app integration and helped us with the app implementation. Some of us had no prior knowledge of APIs, so having a knowledgeable mentor teaching us was an invaluable experience.
## What’s the Next Step for Konvoi?
During the design phase, the team created a long list of features that we felt would be an asset to have. We then categorized them as mandatory (required in the Minimum Viable Product), desired (the goal of the project), nice to have (an extension of desired features), and stretch goals (interesting ideas that would be great in the future). From these lists, we were able to accomplish all mandatory and desired goals. We unfortunately did not hit an nice to have or stretch goals. They included:
• Planned stops
• Messaging between cars
• Cost tracking for the group (when someone rents the car, someone else the hotel, etc.)
• Roadside assistance (such as CAA connected into the app)
• Entertainment (extend it to passengers playing YouTube videos, etc.)
• Weather warnings and added predictions
• A feature for a packing list
|
winning
|
## Inspiration
As students and programmers we can spend countless iterations and follow ups prompting ChatGPT to give us the answer that we are looking for. Often before we reach a working solution we've already used up our tokens for ChatGPT 4.0. Not only is prompting time consuming, but also token-consuming. Thus, we decided to create something convenient and practical that we can use to help us engineer our prompts for large language models.
## What it does
Promptli is a prompt engineering chrome extension that provides personalized suggestions and improves your prompts as you type them live in the chatbot. By using frameworks from our research into prompt engineering, Promptli analyzes the prompt on the following dimensions:
1. Identify any ambiguities, vague terms, or areas that could benefit from more detail or context.
2. Assess the logical flow and organization of the prompt.
3. Evaluate the word choice, vocabulary precision, and overall readability.
4. Determine whether the prompt is appropriately focused and scoped for its intended purpose.
5. Making prompts more "AI-friendly"
Make the most out of AI with Promptli, your personal prompt engineer.
## How we built it
We built a chrome extension using:
* Javascript for the back-end server, scripting, and content rendering
* HTML & CSS for a user-friendly UI/UX that seamlessly integrates with the chat interface
* Gemini API for Promptli’s prompt engineering capabilities and JSON file rendering
* 100ms processing time for real time prompt improvement
* Effortless rendering of new prompts
* Interactive and easy-to-use UI/UX with single click per prompt
## Challenges we ran into
\We began this project without prior experience with creating web extensions. Our first step was looking at resources from the Chrome Developers site. Specifically focused on chrome extension sample code and familiarizing ourselves with their API.
Our second challenge was integrating our extension with AI platforms in a seamless fashion that was easy to use and wouldn’t block users’ workflow. This posed greater difficulties than we had initially anticipated as we needed to inject our JS into the website's dynamic layout. After several iterations of designs and troubleshooting our extensions compatibility with the AI site’s code, we were able to create something that works alongside the website’s ever changing layout and is intuitive to use.
Lastly, having to work in a time-crunch with little to no sleep was definitely challenging but at the same time thrilling to build something with our friends that we truly would use and love as a product.
## Accomplishments that we're proud of
We're proud of building an app that we could use ourselves and provides practical value to any daily user of a chat bot. A lot of the time, the world seems overcrowded with artificial intelligence and machines so we are also are proud of creating a more human friendly experience that allows better communication between machine learning models and the human being.
## What we learned
I think the best learning experience was about ourselves and our capabilities when working with friends for something we were passionate about. This was a really fun experience and we loved hacking our persimmon app: Promptli.
Other things we learned:
* how to code a chrome extension
* how to create a back end server
* how to utilize javascript to call API and parse it through
* how to prompt engineer
* how to prompt chatbots to output file structure
* how to sleep under a table
## What's next for Promptli
We're currently working on integration with a wider range of generative AI services and hope to make the product more accessible with future partnerships. We also hope for a custom prompting model for long term sustainability fine tuned for writing good prompts.
|
## Inspiration
>
> With 3/4 of our team comprised of students, we choose to develop a project inline with education. Due to the novel coronavirus, we have all been forced to learn virtually; however, this is approach does not always work for students. Our inspiration is to create a platform that allows students with different learning styles to easily be accommodated. Auditory learners will have the ability to listen to the live lessons as they currently do. Visual learners will have the ability to see both entire lecture notes and lecture summaries. Tactile learners will have the ability to complete 5-minute quizzes and interact with our chatbot.
>
>
>
## What it does
* Increase Engagement
* Pre-made Questions
* Study Guide Creation
* Feedback on Lectures
* Lesson and Lesson Summaries Transcript
* Archive of Information
## How we built it

## Tech Stacks & dependencies
| 🤖 Backend | 🪟 Frontend | 🖥 Machine Learning |
| --- | --- | --- |
| Django-rest-framework | Nextjs | Deep ai's summarizer |
| Python | Chrome extention | Matplotlib.pyplot |
| Azure | HTML/CSS | Pandas |
| Digital ocean | Javascript | Numpy |
| PostgreSQL | Tailwindcss | Textblob |
| | Vercel.app | Spacy en\_core\_web\_sm |
| | React-Toast-Notifications | Gensim |
| | React-Simple-Chatbot | Regular Expression |
| | React-Loader-Spinner | Textblob |
| | | Note-Worthy Chatbot |
## Challenges we ran into
* Handling background processes in Chrome Extension
* Generating real-time quizzes after some fixed intervals of time
* Generating summary of the transcript
* Integrating the chatbot
## Accomplishments that we're proud of
* Developing a Chrome extension dashboard to convert lectures to text
* Generating questions from summary using a Naive-Bayes Machine learning model
* Providing Graph analytics based on sentiment analysis for better understanding of lectures
## What we learned
* How the background processes work in a chrome extension
* Integrating chatbot into a website
## What's next for Note-Worthy
* Allowing teachers to prompt a quiz on demand
* Assist students by identifying weaknesses and providing resources
* Adding Lecture Insights for Webcam on sessions
* Connecting chat with Google Assistant & Amazon Alexa
|
## Inspiration
With a variety of language learning resources out there, we set out to create a tool that can help us practice a part of language that keeps things flowing -- conversation! LanguaLine aims to empower users to speak their foreign language by helping them develop their conversational skills.
## What it does
We wanted to create an interface that can help users practice speaking a foreign language. Through LanguaLine, users can:
* Select a language they wish to practice speaking in
* Select how "motivating" they want their Mentor to be (Basic is normal, Extra Motivation is a tough love approach).
* Enter their phone number and receive a **phone call** from our AI Mentor
* Answer questions posed by the Mentor
* Receive **real-time feedback** about their performance
* View a transcript and summary of the call after the conversation is completed
* View a **generalized report** on user's language strengths and weaknesses across all conversations
## How we built it
We used `React.js` for our frontend, and `Firebase` for our database. To style our components, we utilized `TailwindCSS` and `React MaterialUI`.
Our backend system is comprised of `Node.js` and `Express.js`, which we use to make calls to Google's **Gemini** model.
To create, tune, and prompt engineer our AI Mentor, we used the **VAPI.ai** API. Our **transcriber model** is Deepgram's **nova-2 multi** and our **model** is **gpt-4o-mini** provided by **Open.AI**.
We are also using **Gemini** to implement Retrieval-Augmented Generation (RAG). We use past call transcripts and summaries to train and optimize our model. This training data is maintained in our `Firebase` database. In addition, this feature analyzes users' call transcripts and generates a report identifying strengths and weaknesses in their speaking skills.
## Challenges we ran into
Our biggest challenge was understanding the VAPI documentation, as it was our first time working with a voice AI API. We had to make a few changes to our project stack to accommodate for VAPI, as we could only make client-side API calls.
Since the majority of our team has limited experience working with LLMs and voice AI Agents, we faced some difficulties prompt engineering our Mentor, requiring us to tweak various model parameters and experiment through VAPI's dashboard.
## Accomplishments that we're proud of
The turning point in our development process was when we were able to start conversing with our Mentor. After this was solidified, our project trajectory only went upwards. We're proud of the fact we were able to turn this idea into an operational and functional application.
## What we learned
The team behind LanguaLine had a variety of skill levels; for some, this was their first project using this tech stack, while for others, this was familiar. Some of us mastered the ability to send API calls and parse JSON data. Some of us also learned how to prompt engineer for a particular language choice. There were lessons being learned all throughout the 36 hours of development, which helped us feel connected to the project and motivated to keep creating.
## What's next for LanguaLine
Our biggest goal is to **deploy and market** this project. Being language learners ourselves, having a service like LanguaLine is invaluable to making progress toward achieving fluency. In addition, this increases **accessibility** for language learners by encompassing a wide range of supported languages and providing customizable support.
Our project aims to support all languages. Due to our lack of control regarding the accuracy across various languages within LLMs, this feature needs more testing and tuning to be perfected.
We plan to offer **more variation** in the Mentors we offer. Right now, we only offer Mentors based off of a language choice and motivation level. In the future, we plan to include language difficulties, personalities, a wider variety of supported languages, custom prompts, and scheduled calling.
We also plan to offer improvement plans for grammar, pronunciation, and vocabulary, as well as a scoring system for users' performances during Mentor sessions.
|
losing
|
## Inspiration
From experiencing moments of forgetfulness to facing the challenges of dementia, the loss of cherished memories can bring unimaginable pain. For individuals with Alzheimer's and other conditions that affect memory, losing recollections of loved ones can feel like losing a part of their identity. We want to provide support for those experiencing memory loss, no matter how severe it is. Our goal is to offer a tool that can assist in memory recall and enhance cognitive abilities. Remindful is designed to *complement* existing dementia treatments (not replace them!!), providing a non-invasive, accessible, and enjoyable supplemental aid.
What do you remember about your birthday last year? Chances are it's the people, location, cake, or decorations. Key visuals such as these often stick out in our memories more and can help jolt lost memories.
## What it does
Remindful makes use of active recall strategies and reminiscence therapy to help users recall their memories. It is both a health and educational tool that can help improve cognitive skills over time. It's a game that involves a picture depicting one of your memories. This could be a past event such as participating in UofTHacks!
Continuing with this example, imagine your hacking station right now. There are laptops sprawled across the table, sleeping bags on the floor, luggage set by your feet, and empty Red Bull cans waiting to be thrown out. But now, take away the laptops, the sleeping bags, the luggage, and the Red Bulls. This leaves you with an empty desk in the hacker room you chose on Friday.
Looking at this, try to remember what you were doing in here. Why were you in Myhal??
Users speak into the microphone, trying to recall this memory by making guesses and describing what they could have been doing.
"Hmmm I think I was working on a ***LAPTOP***!"
The keyword "laptop" then prompts Remindful to reveal the laptops we had originally hidden.
Now the user continues to try to piece together the memory, while the picture slowly comes returns to its original, complete state.
We then end the game with a total score on how the user did, based on how many mistakes they made, if they were able to complete the image by remembering all the key objects , how long it took them, and other related factors!
## How we built it
Our backend is built on Roboflow's YoloV8 object detection model which utilizies computer vision to detect the key objects (more on this in next steps) in the photo, python, and flask. Our frontend uses typescript and react to blur the images, build the user interface needed to make our web-app functioning. and handle the point system. We used the Web Speech API to transcribe your voice into text in real-time.
## Challenges we ran into
* Cors ....
* Controlling blur to make sure the base image is still visible enough to make inferences
* Slow response times
* Connecting backend to frontend
## Accomplishments that we're proud of
* We really tried to think outside the box for this year's theme and we think our project shows exactly that!
## What we learned
Team was new to most of the technologies since our project idea was pretty niche and specific, but here are all the new technologies we learned!
* Roboflow's Yolov8 object detection model
* Image manipulation and blurring
* Real-time transcriptions and needing to work with expecting instant results
## What's next for Remindful
* Build a model that determines the "importance" of an item such as frequency, identifiability, user feedback, etc...
* Optimize for faster response times
* More accurate object detection models
|
## Inspiration
One pressing issue amongst the elderly population that modern medicine has not been able to properly diagnose and solve is dementia and Alzheimer's disease. These two cripping diseases affect the mind, and their symptoms are similar: a loss of memory.
We took it upon ourselves to challenge the status quo and invent new ways to help elders who are struggling with these diseases. We recognized that memories are intangible, you cannot physically touch them in any way, shape, or for, but it is generally acknowlegded that everyone has them. Not only that, but these memories tend to evoke feelings of happiness, sadness, anger, and many more. Memories are crucial to one's identity and we wanted to preserve these memories in a way that could be possible: generative AI.
## What it does
In essence, we want *you* to tell us the type of memory you're trying to describe. Are you thinking of a loved one, a lover, or something else? Is it an object?
Then we ask: how does it make you feel? Sad? Happy? You don't know? Any of these options are valid - describing memories and how you felt about it is difficult.
After that, we prompt you to expand on this memory. What else do you have to say about it? Did this take place at the beach? Was it about food? The possibilities are endless.
Once you've finished trying to recollect your memory, we use generative AI to recreate a scene that is *similar* to what you've described. We hope that by generating scenes that are similar to what you've experienced, that, anytime you come back to revisit the website. You can see the image and the caption under it, and remember what lead you there in the first place.
## How we built it
The app was built using Next.js, a React framework. In terms of storing data, we used Supabase, a Postgres database. Much of the heavy lifting was from utilizing OpenAI API and Replicate API to conversate and generate image.
## Challenges we ran into
The main bulk of our issues were actually trying to use OpenAI API and Replicate API. For some unknown reason to us, these APIs were rather difficult to implement in conjuction to the scope of what we were tryinig to accomplish.
The second part of our issues was implenting Supabase into Next.js. This also took a long time because we weren't too familiar with setting up Supabase into a React framework like Next.js. This was a lot of learning and trial and error to get it up and running.
## Accomplishments that we're proud of
We're very proud of the fact that the three of us were able to create an app from scratch with the majority of us being unfamiliar with the tech stack involved.
In addition to that, we're very proud of the fact that we were successfully able to integrate some of the state-of-the-art technologies like ChatGPT and Stable Diffusion in our project.
Lastly, we're proud of ourselves because this was all of our first time doing something like this, and to be able to create something usable within this short amount of time is amazing; I am proud of our team.
## What we learned
Overall, as a team, we learned each other's strengths and incorporated it into our own skillsets.
For some of us, we learned how to use the Next.js framework and Supabase.
For others, it was learning how to leverage APIs like OpenAI and Replicate into Next.js.
## What's next for Rememory
What's next?
Well... I forgot...
Jokes aside, we see Rememory having massive potential to keep Alzheimers and dementia at bay. We're constantly reminding people of the memories and experiences that they have.
We see Rememory having many more features than what it already has. We had an idea of incorporated of a digital avator chatbot to make the experience more interactive and enjoyable for elders. As a standalone project, you can view this as a journal as well, documenting memories to access them later on.
We keep track of the prompts that are put in by the users to remind them of what led them to this memory. We can leverage these prompts in patients that are Alzheimers' and model a trend of where patients started to forget these memories, as sad as it does sound.
|
## Inspiration
The inspiration behind our innovative personal desk assistant was ignited by the fond memories of Furbys, those enchanting electronic companions that captivated children's hearts in the 2000s. These delightful toys, resembling a charming blend of an owl and a hamster, held an irresistible appeal, becoming the coveted must-haves for countless celebrations, such as Christmas or birthdays. The moment we learned that the theme centered around nostalgia, our minds instinctively gravitated toward the cherished toys of our youth, and Furbys became the perfect representation of that cherished era.
Why Furbys? Beyond their undeniable cuteness, these interactive marvels served as more than just toys; they were companions, each one embodying the essence of a cherished childhood friend. Thinking back to those special childhood moments, the idea for our personal desk assistant was sparked. Imagine it as a trip down memory lane to the days of playful joy and the magic of having an imaginary friend. It reflects the real bonds many of us formed during our younger years. Our goal is to bring the spirit of those adored Furbies into a modern, interactive personal assistant—a treasured piece from the past redesigned for today, capturing the memories that shaped our childhoods.
## What it does
Our project is more than just a nostalgic memory; it's a practical and interactive personal assistant designed to enhance daily life. Using facial recognition, the assistant detects the user's emotions and plays mood-appropriate songs, drawing from a range of childhood favorites, such as tunes from the renowned Kidz Bop musical group. With speech-to-text and text-to-speech capabilities, communication is seamless. The Furby-like body of the assistant dynamically moves to follow the user's face, creating an engaging and responsive interaction. Adding a touch of realism, the assistant engages in conversation and tells jokes to bring moments of joy. The integration of a dashboard website with the Furby enhances accessibility and control. Utilizing a chatbot that can efficiently handle tasks, ensuring a streamlined and personalized experience. Moreover, incorporating home security features adds an extra layer of practicality, making our personal desk assistant a comprehensive and essential addition to modern living.
## How we built it
Following extensive planning to outline the implementation of Furby's functions, our team seamlessly transitioned into the execution phase. The incorporation of Cohere's AI platform facilitated the development of a chatbot for our dashboard, enhancing user interaction. To infuse a playful element, ChatGBT was employed for animated jokes and interactive conversations, creating a lighthearted and toy-like atmosphere. Enabling the program to play music based on user emotions necessitated the integration of the Spotify API. Google's speech-to-text was chosen for its cost-effectiveness and exceptional accuracy, ensuring precise results when capturing user input. Given the project's hardware nature, various physical components such as microcontrollers, servos, cameras, speakers, and an Arduino were strategically employed. These elements served to make the Furby more lifelike and interactive, contributing to an enhanced and smoother user experience. The meticulous planning and thoughtful execution resulted in a program that seamlessly integrates diverse functionalities for an engaging and cohesive outcome.
## Challenges we ran into
During the development of our project, we encountered several challenges that required demanding problem-solving skills. A significant hurdle was establishing a seamless connection between the hardware and software components, ensuring the smooth integration of various functionalities for the intended outcome. This demanded a careful balance to guarantee that each feature worked harmoniously with others. Additionally, the creation of a website to display the Furby dashboard brought its own set of challenges, as we strived to ensure it not only functioned flawlessly but also adhered to the desired aesthetic. Overcoming these obstacles required a combination of technical expertise, attention to detail, and a commitment to delivering a cohesive and visually appealing user experience.
## Accomplishments that we're proud of
While embarking on numerous software projects, both in an academic setting and during our personal endeavors, we've consistently taken pride in various aspects of our work. However, the development of our personal assistant stands out as a transformative experience, pushing us to explore new techniques and skills. Venturing into unfamiliar territory, we successfully integrated Spotify to play songs based on facial expressions and working with various hardware components. The initial challenges posed by these tasks required substantial time for debugging and strategic thinking. Yet, after investing dedicated hours in problem-solving, we successfully incorporated these functionalities for Furby. The journey from initial unfamiliarity to practical application not only left us with a profound sense of accomplishment but also significantly elevated the quality of our final product.
## What we learned
Among the many lessons learned, machine learning stood out prominently as it was still a relatively new concept for us!
## What's next for FurMe
The future goals for FurMe include seamless integration with Google Calendar for efficient schedule management, a comprehensive daily overview feature, and productivity tools such as phone detection and a Pomodoro timer to assist users in maximizing their focus and workflow.
|
losing
|
## Inspiration
When reading news articles, we're aware that the writer has bias that affects the way they build their narrative. Throughout the article, we're constantly left wondering—"What did that article not tell me? What convenient facts were left out?"
## What it does
*News Report* collects news articles by topic from over 70 news sources and uses natural language processing (NLP) to determine the common truth among them. The user is first presented with an AI-generated summary of approximately 15 articles on the same event or subject. The references and original articles are at your fingertips as well!
## How we built it
First, we find the top 10 trending topics in the news. Then our spider crawls over 70 news sites to get their reporting on each topic specifically. Once we have our articles collected, our AI algorithms compare what is said in each article using a KL Sum, aggregating what is reported from all outlets to form a summary of these resources. The summary is about 5 sentences long—digested by the user with ease, with quick access to the resources that were used to create it!
## Challenges we ran into
We were really nervous about taking on a NLP problem and the complexity of creating an app that made complex articles simple to understand. We had to work with technologies that we haven't worked with before, and ran into some challenges with technologies we were already familiar with. Trying to define what makes a perspective "reasonable" versus "biased" versus "false/fake news" proved to be an extremely difficult task. We also had to learn to better adapt our mobile interface for an application that’s content varied so drastically in size and available content.
## Accomplishments that we're proud of
We’re so proud we were able to stretch ourselves by building a fully functional MVP with both a backend and iOS mobile client. On top of that we were able to submit our app to the App Store, get several well-deserved hours of sleep, and ultimately building a project with a large impact.
## What we learned
We learned a lot! On the backend, one of us got to look into NLP for the first time and learned about several summarization algorithms. While building the front end, we focused on iteration and got to learn more about how UIScrollView’s work and interact with other UI components. We also got to worked with several new libraries and APIs that we hadn't even heard of before. It was definitely an amazing learning experience!
## What's next for News Report
We’d love to start working on sentiment analysis on the headlines of articles to predict how distributed the perspectives are. After that we also want to be able to analyze and remove fake news sources from our spider's crawl.
|
# DashLab
DashLab is a way for individuals and businesses to share and collaborate within a data-driven environment through a real-time data visualization dashboard web application.
# The Overview
Within any corporate environment you'll find individuals working on some sort of analysis or analytics projects in general. Under one company, and sometimes even within teams, you'll find a loose approach to drilling down to the necessary insight that in the end drives both the low-level, daily decisions and the higher level, higher pressure ones. What often happens is at the same time these teams or employees will struggle to translate these findings to the necessary personnel.
There's so much going on when it comes to deriving necessary information that it often becomes less powerful as a business function. DashLab provides a simple, eloquent, and intuitive solution that brings together the need to save, share, and show this data. Whether it's a debriefing between internal teams across different departments, or be it a key process that involves internal and external influence, DashLab provides users with a collaborative and necessary environment for real-time drill-down data investigation.
# Other
To utilize full functionality of this website, test the real-time drill down events by viewing the site from two different clients. Open a web browser and visit the site from two different tabs, sort through the available fields within the line graph visualization, and click on cities and countries to see both tabs update to the current selection. **Total mobile compatibility not supported.**
|
## Inspiration
My father put me in charge of his finances and in contact with his advisor, a young, enterprising financial consultant eager to make large returns. That might sound pretty good, but to someone financially conservative like my father doesn't really want that kind of risk in this stage of his life. The opposite happened to my brother, who has time to spare and money to lose, but had a conservative advisor that didn't have the same fire. Both stopped their advisory services, but that came with its own problems. The issue is that most advisors have a preferred field but knowledge of everything, which makes the unknowing client susceptible to settling with someone who doesn't share their goals.
## What it does
Resonance analyses personal and investment traits to make the best matches between an individual and an advisor. We use basic information any financial institution has about their clients and financial assets as well as past interactions to create a deep and objective measure of interaction quality and maximize it through optimal matches.
## How we built it
The whole program is built in python using several libraries for gathering financial data, processing and building scalable models using aws. The main differential of our model is its full utilization of past data during training to make analyses more wholistic and accurate. Instead of going with a classification solution or neural network, we combine several models to analyze specific user features and classify broad features before the main model, where we build a regression model for each category.
## Challenges we ran into
Our group member crucial to building a front-end could not make it, so our designs are not fully interactive. We also had much to code but not enough time to debug, which makes the software unable to fully work. We spent a significant amount of time to figure out a logical way to measure the quality of interaction between clients and financial consultants. We came up with our own algorithm to quantify non-numerical data, as well as rating clients' investment habits on a numerical scale. We assigned a numerical bonus to clients who consistently invest at a certain rate. The Mathematics behind Resonance was one of the biggest challenges we encountered, but it ended up being the foundation of the whole idea.
## Accomplishments that we're proud of
Learning a whole new machine learning framework using SageMaker and crafting custom, objective algorithms for measuring interaction quality and fully utilizing past interaction data during training by using an innovative approach to categorical model building.
## What we learned
Coding might not take that long, but making it fully work takes just as much time.
## What's next for Resonance
Finish building the model and possibly trying to incubate it.
|
partial
|
## Inspiration
The phrase, "hey have you listened to this podcast", can be seen as the main source of inspiration for this project.
Andrew Huberman is a neuroscientist and tenured professor at Standford school of medicine. As a part of his desire to bring zero cost to consumer information about health and health-related subjects, he hosts the Huberman-lab podcast. The podcast is posted weekly, covering numerous topics all provided in an easy-to-understand format. With this, listeners are able to implement the systems he recommends with results that are backed by the academic literature.
## What it does
With over 90 episodes, wouldn't it be great to search through the episodes to have a deeper understanding of a topic? What if you are interested in what was said about a particular subject matter but don't have time to watch the whole episode? Better yet, what if you could ask the Dr. himself a question about something he has talked about (which people now can do, at a premium price of $100 a year).
With this in mind, I have created an immersive experience to allow individuals to ask him health-related questions through a model generated based on his podcasts.
## What problem does it solve
It is tough to find trustworthy advice on virtually any topic due to the rise of SEO and people fueled by greed. With this pseudo-chat bot, you can guarantee that the advice provided is peer reviewed or at the very least grounded in truth.
Many people append "Reddit" to their google searches to make sure the results they receive are trustworthy. With this model, the advice it provides is short, and to the point while removing the need to scour the internet for the right answer.
## How I built it
Frontend: NextJS (React) + ChakraUI + Three.js + ReadyPlayer (model and texture generation) + Adobe Mixamo (model animation)
Backend: Flask (Python)
Data sci: Pinecone (vector storage) + Cohere (word embedding, text generation, text summarization), nltk (English language tokenizer)
40 podcast episodes (almost ~35,000 sentences) were processed via the backend and stored on Pinecone to be called via Cohere. Once the backend receives a query request (question/prompt provided by the user):
1. A text prompt is generated based on Cohere's models (breaking down what the user meant)
2. The prompt is fed through their embedding, to embed the newly generated prompt (create something we can search the Pinecone db with)
3. Pinecone is queried, returning the top 10 blocks (sentences). Any block with an accuracy of over 0.45 is fed into the text summarization algorithm
4. Text is compiled, and summarized. The final summarized result is returned to the user.
## Challenges we ran into
tl;dr
* running the proper glb/gltf models while maintaining textures when porting over from fbx (three.js fun)
+ rendering, and animating models properly (more three.js fun)
+ creating a chat interface that I actually like lol
+ communicating with Cohere's API via the provided client and running large batch jobs with Pinecone (time out, performance issues on my laptop)
+ tweaking the parameters on the backend to receive a decent result
## Accomplishments that we're proud of
Firsts:
* creating a word-embedded model, or any AI model for that matter
* using Pinecone
* understanding how three.js works
* solo hack!
* making friends :.)
## What we learned
See above <3
## What's next for Ask Huberman
1. Allow users to generate text of X length or to click a button to learn more
2. Linking the text generated to the actual podcast episodes to watch the whole thing
3. Create a share feature to share useful/funny answers
4. Tweak the model output parameters
5. Embed amazon affiliate links based on what the answer is
## What would you do differently
* cut losses sooner with three.js
* go talk to the Cohere guys a little sooner (they are awesome)
* manage git better?
Huge thank you to the HW team - had a lot of fun.
|
## Inspiration
We built Crumbs off the idea that thoughts and memories are intimately linked to the physical places in which they occur. Crumbs will help facilitate the recollection and enjoyment of memories by creating a lasting link between thought and place.
## What it does
We created Crumbs to allow users to better tie their thoughts and feelings to specific places. Our app lets users anonymously drop “crumbs” -- messages, images, GIFs, or polls -- that are only visible to other users who enter within a 50 meter radius of where the crumb is dropped.
## How we built it
Crumbs is a Meteor.js hybrid mobile application. We built a significant portion of the UI/UX from bare bones components, including icons and transitions.
## Challenges we ran into
The many frustrations in porting a hybrid application to mobile, including rendering speeds, bulkiness, the need to recreate transitions and user experience.
## Accomplishments that we're proud of
We have a beautiful end product!
## What we learned
It's difficult to find balance between richness and variety of features, so it's important that you stay focused when moving forward in creating your product.
## What's next for Crumbs
Further building on the diversity of ways in which users can interact with crumbs, including exploring additional types of media and interactions. We also see Crumbs potentially being useful for a whole variety of locations-based communications and events, such as puzzle hunts, anonymous polling, and targeted advertising.
|
## Inspiration
In 2012 in the U.S infants and newborns made up 73% of hospitals stays and 57.9% of hospital costs. This adds up to $21,654.6 million dollars. As a group of students eager to make a change in the healthcare industry utilizing machine learning software, we thought this was the perfect project for us. Statistical data showed an increase in infant hospital visits in recent years which further solidified our mission to tackle this problem at its core.
## What it does
Our software uses a website with user authentication to collect data about an infant. This data considers factors such as temperature, time of last meal, fluid intake, etc. This data is then pushed onto a MySQL server and is fetched by a remote device using a python script. After loading the data onto a local machine, it is passed into a linear regression machine learning model which outputs the probability of the infant requiring medical attention. Analysis results from the ML model is passed back into the website where it is displayed through graphs and other means of data visualization. This created dashboard is visible to users through their accounts and to their family doctors. Family doctors can analyze the data for themselves and agree or disagree with the model result. This iterative process trains the model over time. This process looks to ease the stress on parents and insure those who seriously need medical attention are the ones receiving it. Alongside optimizing the procedure, the product also decreases hospital costs thereby lowering taxes. We also implemented a secure hash to uniquely and securely identify each user. Using a hyper-secure combination of the user's data, we gave each patient a way to receive the status of their infant's evaluation from our AI and doctor verification.
## Challenges we ran into
At first, we challenged ourselves to create an ethical hacking platform. After discussing and developing the idea, we realized it was already done. We were challenged to think of something new with the same amount of complexity. As first year students with little to no experience, we wanted to tinker with AI and push the bounds of healthcare efficiency. The algorithms didn't work, the server wouldn't connect, and the website wouldn't deploy. We persevered and through the help of mentors and peers we were able to make a fully functional product. As a team, we were able to pick up on ML concepts and data-basing at an accelerated pace. We were challenged as students, upcoming engineers, and as people. Our ability to push through and deliver results were shown over the course of this hackathon.
## Accomplishments that we're proud of
We're proud of our functional database that can be accessed from a remote device. The ML algorithm, python script, and website were all commendable achievements for us. These components on their own are fairly useless, our biggest accomplishment was interfacing all of these with one another and creating an overall user experience that delivers in performance and results. Using sha256 we securely passed each user a unique and near impossible to reverse hash to allow them to check the status of their evaluation.
## What we learned
We learnt about important concepts in neural networks using TensorFlow and the inner workings of the HTML code in a website. We also learnt how to set-up a server and configure it for remote access. We learned a lot about how cyber-security plays a crucial role in the information technology industry. This opportunity allowed us to connect on a more personal level with the users around us, being able to create a more reliable and user friendly interface.
## What's next for InfantXpert
We're looking to develop a mobile application in IOS and Android for this app. We'd like to provide this as a free service so everyone can access the application regardless of their financial status.
|
losing
|
## Inspiration
26% of UBC buildings are inaccessible. Students with disabilities face daily challenges to get to their classrooms, whether this be through a lack of wheelchair access or assistive listening-enabled spaces.
Additionally, 31.3% of UBC students find the current process of booking a study room terrible and inefficient. It is hard to navigate, confusing, and unclear. However, as students, we often find ourselves needing a study room to cram with a lack of means to do so. (Ex. see [Woodward](https://libcal.library.ubc.ca/reserve/woodward_group_study))
"Navigate" is an all-encompassing 3D interactive map with multiple features, such as viewing indoor accommodations, navigation to a room, and booking various services.
## What it does
An all-in-one interactive map of the UBC campus where one can view the indoor accommodations (such as wheelchair accessibility), book a study room, and book an appointment with community primary care. The maps offer navigation routes, as well as visual representations of available study rooms.
## How we built it
We build our project using the MERN stack. We implemented the MappedIn Maker SDK by creating a custom map of the ICICS building using floorplans. This allowed us to create custom functions to display room bookings and navigation paths. Our data is handled by MongoDB. Additionally, we re-engineered the 1Password Passage authentication to include JWT authentication using HTTPOnly cookies to prevent XSS attacks, thus making it fully protected from XSS, CSRF, SQL injection, and phishing attacks.
For Project management, we used Github Projects to create issues and tickets. Our PR required at least one peer review before squashing and merging into the main branch. UI/UX design was created using Figma.
## Challenges we ran into
We ran into technical challenges when attempting to implement the MappedIn Maker, as it was recently released and many features were unavailable.
## Accomplishments that we're proud of
Despite our challenges and delays, we completed an MVP version of our product with a functional back-end and custom UI.
## What's next for Navigate
The next step is to implement a quick-book feature that automatically books you a study room based on your current location. Furthermore, the health services feature requires implementation that can be built upon many existing functionalities.
|
## Inspiration
Our team was inspired to work on this project mainly due to two reasons:
1. As a Google Home owner, I regularly use voice-commands to control my smart home devices such as my Philips Hue lights and Wemo Smart Plugs. However, one Saturday morning, after a night of alcohol and karaoke, I opened my mouth in an attempt to turn on the lights, but the only sounds that came out of my mouth were “hey ggg...gg…, t…the...lights”. I’ve lost my voice, and along with it, my ability to turn on the lights! And then another thought hit me: how can the 18 million US adults (8% of the US population) who had suffered from voice problems in 2015, or the other billions of people who don't speak the language or have speech impairments, turn on and off their lights? Bam! An idea was born.
2. After experimenting with its capabilities and data output, our team immediately decided to create a hardware-integrated hack involving the Myo Armband. As a team of 4 mechanical engineers and 1 programmer, it was clear from the beginning that our best chances of success would be a hardware hack with either a web or mobile app GUI.
## What it does
Using the **Myo Armband**, users can control their smart home devices such as lights and fans at the flick of their wrist and arm. Based on how many devices there are, users can use the **MyoHome web app** to configure the gestures for each device, and save those customized gestures to a user profile. Although there are only 5 basic gestures built in to the **Myo Connect** app, there are essentially an infinite number of gestures that could be configured based on the raw data output from the **accelerometer**, **EMG sensors**, and **gyroscope**.
## How we built it
At first, we performed diagnostic tests to determine the accuracy, range, and capabilities of the Myo Armband through Myo Connect to get a feel of the range of motions and the capabilities of this armband. We then split into sub-teams to tackle the different challenges, including: **website and interface design, electronics control, mock house model design, and demo/presentation strategy**. Finally it all came back together with our completed prototype that shows how the Myo armband can truly be integrated into our lives and enable everyone - whether you’re mute or having speech difficulties - to fully enjoy smart home technologies.
## Challenges we ran into
* Designing a C++ application that could smoothly and efficiently bind to Myo’s C++ bindings
## Accomplishments that I'm proud of
* Prepared a powerful presentation of our proof-of-concept demonstration with our beautifully-built home
* Developed gesture combinations that are not native to the Myo SDK based on sensors data
## What we learned
* How to control hardware using a Myo Armband and Arduino
## What's next for MyoHome
Due to time constraint, the MyoHome app currently only works with hacked arduino-enabled LEDs and motors. The natural progression of this project would be towards enabling integration with smart home products and apps currently on the market from tech giants like Google and Samsung, as well as from other companies like Philips, TP-Link, and Wemo.
|
## Inspiration
Our project is inspired by the sister of one our creators, Joseph Ntaimo. Joseph often needs to help locate wheelchair accessible entrances to accommodate her, but they can be hard to find when buildings have multiple entrances. Therefore, we created our app as an innovative piece of assistive tech to improve accessibility across the campus.
## What it does
The user can find wheelchair accessible entrances with ease and get directions on where to find them.
## How we built it
We started off using MIT’s Accessible Routes interactive map to see where the wheelchair friendly entrances were located at MIT. We then inspected the JavaScript code running behind the map to find the latitude and longitude coordinates for each of the wheelchair locations.
We then created a Python script that filtered out the latitude and longitude values, ignoring the other syntax from the coordinate data, and stored the values in separate text files.
We tested whether our method would work in Python first, because it is the language we are most familiar with, by using string concatenation to add the proper Java syntax to the latitude and longitude points. Then we printed all of the points to the terminal and imported them into Android Studio.
After being certain that the method would work, we uploaded these files into the raw folder in Android Studio and wrote code in Java that would iterate through both of the latitude/longitude lists simultaneously and plot them onto the map.
The next step was learning how to change the color and image associated with each marker, which was very time intensive, but led us to having our custom logo for each of the markers.
Separately, we designed elements of the app in Adobe Illustrator and imported logos and button designs into Android Studio. Then, through trial and error (and YouTube videos), we figured out how to make buttons link to different pages, so we could have both a FAQ page and the map.
Then we combined both of the apps together atop of the original maps directory and ironed out the errors so that the pages would display properly.
## Challenges we ran into/Accomplishments
We had a lot more ideas than we were able to implement. Stripping our app to basic, reasonable features was something we had to tackle in the beginning, but it kept changing as we discovered the limitations of our project throughout the 24 hours. Therefore, we had to sacrifice features that we would otherwise have loved to add.
A big difficulty for our team was combining our different elements into a cohesive project. Since our team split up the usage of Android Studio, Adobe illustrator, and programming using the Google Maps API, it was most difficult to integrate all our work together.
We are proud of how effectively we were able to split up our team’s roles based on everyone’s unique skills. In this way, we were able to be maximally productive and play to our strengths.
We were also able to add Boston University accessible entrances in addition to MIT's, which proved that we could adopt this project for other schools and locations, not just MIT.
## What we learned
We used Android Studio for the first time to make apps. We discovered how much Google API had to offer, allowing us to make our map and include features such as instant directions to a location. This helped us realize that we should use our resources to their full capabilities.
## What's next for HandyMap
If given more time, we would have added many features such as accessibility for visually impaired students to help them find entrances, alerts for issues with accessing ramps and power doors, a community rating system of entrances, using machine learning and the community feature to auto-import maps that aren't interactive, and much, much more. Most important of all, we would apply it to all colleges and even anywhere in the world.
|
partial
|
## Inspiration
Essential workers are needed to fulfill tasks such as running restaurants, grocery shops, and travel services such as airports and train stations. Some of the tasks that these workers do include manual screening of customers entering trains and airports and checking if they are properly wearing masks. However, there have been frequent protest on the safety of these workers, with them being exposed to COVID-19 for prolonged periods and even potentially being harassed by those unsupportive of wearing masks. Hence, we wanted to find a solution that would prevent as many workers as possible from being exposed to danger. Additionally, we wanted to accomplish this goal while being environmentally-friendly in both our final design and process.
## What it does
This project is meant to provide an autonomous alternative to the manual inspection of masks by using computer technology to detect whether a user is wearing a mask properly, improperly, or not at all. To accomplish this, a camera records the user's face, and a trained machine learning algorithm determines whether the user is wearing a mask or not. To conserve energy and help the environment, an infrared sensor is used to detect nearby users, and shuts off the program and other hardware if no one is nearby. Depending on the result, a green LED light shines if the user is wearing a mask correctly while a red LED light shines and a buzzer sounds if it is not worn correctly. Additionally, if the user is not wearing a mask, the mask dispenser automatically activates to dispense a mask to the user's hands.
## How we built it
This project can de divided into two phases: the machine learning part and the physical hardware part. For the machine learning, we created a YOLOv5 algorithm with PyTorch to detect whether users are wearing a mask or not. To train the algorithm, a database of over 3000 pictures was used as the training data. Then, we used the computer camera to run the algorithm and categorize the resulting video feed into three categories with 0 to 100% confidence.
The physical hardware part consists of the infrared sensor prefacing the ML algorithm and the sensors and motors that act after obtaining the ML result. Both the sensors and motors were connected to a Raspberry Pi Pico microcontroller and controlled remotely through the computer. To control the sensors, MicroPython (RP2040) and Python were used to read the signal inputs, relay the signals between the Raspberry Pi and the computer, and finally perform sensor and motor outputs upon receiving results from the ML code. 3D modelled hardware was used alongside re-purposed recyclables to build the outer casings of our design.
## Challenges we ran into
The main challenge that the team ran into was to find a reliable method to relay signals between the Raspberry Pi Pico and the computer running the ML program. Originally, we thought that it would be possible to transfer information between the two systems through intermediary text files, but it turned out that the Pico was unable to manipulate files outside of its directory. Additionally, our subsequent idea of importing the Pico .py file into the computer failed as well. Thus, we had to implement USB serial connections to remotely modify the Pico script from within the computer.
Additionally, the wiring of the hardware components also proved to be a challenge, since caution must be exercised to prevent the project model from overheating. In many cases, this meant to use resistors when wiring the sensors and motor together with the breadboard. In essence, we had to be careful when testing our module and pay attention to any functional abnormalities and temperatures (which did happen once or twice!)
## Accomplishments that we're proud of
For many of us, we have only had experience in coding either hardware or software separately, either in classes or in other activities. Thus, the integration of the Pico Pi with the machine learning software proved to be a veritable challenge for us, since none of us were comfortable with it. With the help of mentors, we were proud of how we managed to combine our hardware and software skills together to form a coherent product with a tangible purpose. We were even more impressed of how this process was all learned and done in a short span of 24 hours.
## What we learned
From this project, we primarily learned how to integrate complex software such as machine learning and hardware together as a connected device. Since our team was new to these types of hackathons incorporating software and hardware together, building the project also proved to be a learning experience for us as a glimpse of how disciplines combining the two, such as robotics, function in real-life. Additionally, we also learned how to apply what we learned in class to real-life applications, since a good amount of information used in this project was from taught material, and it was satisfying to be able to visualize the importance of these concepts.
## What's next for AutoMask
Ideally, we would be able to introduce our physical prototype into the real world to realize our initial ambitions for this device. To successfully do so, we must first refine our algorithm bounds so that false positives and especially true negatives are minimized. Hence, a local application of our device would be our first move to obtain preliminary field results and to expand the training set as well for future calibrations. For this purpose, we could use our device for a small train station or a bus stop to test our device in a controlled manner.
Currently, AutoMask's low-fidelity prototype is only suited for a very specific type of mask dispenser. Our future goal is to make our model flexible to fit a variety of dispensers in a variety of situations. Thus, we must also refine our physical hardware to be industrially acceptable and mass producible to cover the large amount of applications this device potentially has. We want to accomplish this while maintaining our ecologically-friendly approach by continuing to use recycled and recyclable components.
|
## Inspiration
In the world where technology is intricately embedded into our lives, security is an exciting area where internet devices can unlock the efficiency and potential of the Internet of Things.
## What it does
Sesame is a smart lock that uses facial recognition in order to grant access. A picture is taken from the door and a call is made to a cloud service in order to authenticate the user. Once the user has been authenticated, the door lock opens and the user is free to enter the door.
## How we built it
We used a variety of technologies to build this project. First a Raspberry Pi is connected to the internet and has a servo motor, a button and a camera connected to it. The Pi is running a python client which makes call to a Node.js app running on IBM Bluemix. The app handles requests to train and test image classifiers using the Visual Recognition Watson. We trained a classifier with 20 pictures of each of us and we tested the classifier to unseen data by taking a new picture through our system. To control the lock we connected a servo to the Raspberry Pi and we wrote C with the wiringPi library and PWM to control it. The lock only opens if we reach an accuracy of 70% or above. We determined this number after several tests. The servo moves the lock by using a 3d-printed adapter that connects the servo to the lock.
## Challenges we ran into
We wanted to make our whole project on python, by using a library for the GPIO interface of the Pi and OpenCV for the facial recognition. However, we missed some OpenCV packages and we did not have the time to rebuild the library. Also the GPIO library on python was not working properly to control the servo motor. After encountering these issues, we moved the direction of our project to focus on building a Node.js app to handle authentication and the Visual Recognition service to handle the classification of users.
## Accomplishments that we're proud of
What we are all proud of is that in just one weekend, we learned most of the skills required to finish our project. Ming learned 3D modeling and printing, and to program the GPIO interface on the Pi. Eddie learned the internet architecture and the process of creating a web app, from the client to the server. Atl learned how to use IBM technologies and to adapt to the unforeseen circumstances of the hackathon.
## What's next for Sesame
The prototype we built could be improved upon by adding additional features that would make it more convenient to use. Adding a mobile application that could directly send the images from an individual’s phone to Bluemix would make it so that the user could train the visual recognition application from anywhere and at anytime. Additionally, we have plans to discard the button and replace it with a proximity sensor so that the camera is efficient and only activates when an individual is present in front of the door.
|
## Inspiration
We came into the hackathon knowing we wanted to focus on a project concerning sustainability. While looking at problems, we found that lighting is a huge contributor to energy use, accounting for about 15% of global energy use (DOE, 2015). Our idea for this specific project came from the dark areas in the Pokémon video games, where the player only has limited visibility around them. While we didn't want to have as harsh of a limit on field of view, we wanted to be able to dim the lights in areas that weren't occupied, to save energy. We especially wanted to apply this to large buildings, such as Harvard's SEC, since oftentimes all of the lights are left on despite very few people being in the building. In the end, our solution is able to dynamically track humans, and adjust the lights to "spotlight" occupied areas, while also accounting for ambient light.
## Methodology
Our program takes video feed from an Intel RealSense D435 camera, which gives us both RGB and depth data. With OpenCV, we use Histogram of Oriented Gradients (HOG) feature extraction combined with a Support Vector Machine (SVM) classifier to detect the locations of people in a frame, which we then stitch with the camera's depth data to identify the locations of people relative to the camera’s location. Using user-provided knowledge of the room’s layout, we can then determine the position of the people relative to the room, and then use a custom algorithm to determine the power level for each light source in the room. We can visualize this in our custom simulator, developed to be able to see how multiple lights overlap.
## Ambient Light Sensing
We also implement a sensor system to sense ambient light, to ensure that when a room is brightly lit energy isn't wasted in lighting. Originally, we set up a photoresistor with a SparkFun RedBoard, but after having driver issues with Windows we decided to pivot and use camera feedback from a second camera to detect brightness. To accomplish this we use a 3-step process, within which we first convert the camera's input to grayscale, then apply a box filter to blur the image, and then finally sample random points within the image and average their intensity to get an estimate of brightness. The random sampling boosts our performance significantly, since we're able to run this algorithm far faster than if we sampled every single point's intensity.
## Highlights & Takeaways
One of our group members focused on using the video input to determine people’s location within the room, and the other worked on the algorithm for determining how the lights should be powered, as well as creating a simulator for the output. Given that neither of us had worked on a large-scale software project in a while, and one of us had practically never touched Python before the start of the hackathon, we had our work cut out for us.
Our proudest moment was by far when we finally got our video code working, and finally saw the bounding box appear around the person in front of the camera and the position data started streaming across our terminal. However between calibrating devices, debugging hardware issues, and a few dozen driver installations, we learned the hard way that working with external devices can be quite a challenge.
## Future steps
We've brainstormed a few ways to improve this project going forward: more optimized lighting algorithms could improve energy efficiency, and multiple cameras could be used to detect orientation and predict people's future states. A discrete ambient light sensor module could also be developed, for mounting anywhere the user desires. We also could develop a bulb socket adapter to retrofit existing lighting systems, instead of rebuilding from the ground up.
|
losing
|
## Inspiration
With the debates coming up, we wanted to come up with a way of involving everyone. We all have topics that we want to hear the candidates discuss most of all, and we realised that we could use markov chains to do it!
## What it does
Enter a topic, and watch as we generate a conversation between Hillary Clinton and Donald Trump on the subject.
## How we built it
We use a library of speeches from both candidates and markov chains to generate responses.
## Challenges we ran into
It was important to ensure coherency where possible - that was difficult since politicians are evasive at the best of times!
## Accomplishments that we're proud of
Our wonderful front end, and the unintentional hilarity of the candidates' responses.
|
# turnip - food was made for sharing.
## Inspiration
After reading about the possible projects, we decided to work with Velo by Wix on a food tech project. What are two things that we students never get tired of? Food and social media! We took some inspiration from Radish and GoodReads to throw together a platform for hungry students.
Have you ever wanted takeout but not been sure what you're in the mood for? turnip is here for you!
## What it does
turnip is a website that connects local friends with their favourite food takeout spots. You can leave reviews and share pictures, as well as post asking around for food recommendations. turnip also keeps track of your restaurant wishlist and past orders, so you never forget to check out that place your friend keeps telling you about. With integrated access to partnered restaurants, turnip would allow members to order right on the site seamlessly and get food delivered for cheap. Since the whole design is built around sharing (sharing thoughts, sharing secrets, sharing food), turnip would also allow users to place orders together, splitting the cost right at payment to avoid having to bring out the calculator and figure out who owes who what.
## How we built it
We used Velo by Wix for the entire project, with Carol leading the design of the website while Amir and Tudor worked on the functionality. We also used Wix's integrated "members" area and forum add-ons to implement the "feed".
## Challenges we ran into
One of the bigger challenges we had to face was that none of us had any experience developing full-stack, so we had to learn on the spot how to write a back-end and try to implement it into our website. It was honestly a lot of fun trying to "speedrun" learning the ins and outs of Javascript. Unfortunately, Wix made the project even more difficult to work on as it doesn't natively support multiple people working on it at the same time. As such, our plan to work concurrently fell through and we had to "pass the baton" when it came to working on the website and keep ourselves busy the rest of the time. Lastly, since we relied on Wix add-ons we were heavily limited in the functionality we could implement with Velo. We still created a few functions; however, much of it was already covered by the add-ons and what wasn't was made very difficult to access without rewriting the functionality of the modules from scratch. Given the time crunch, we made do with what we had and had to restrict the scope for McHacks.
## Accomplishments that we're proud of
We're super proud of how the design of the site came together, and all the art Carol drew really flowed great with the look we were aiming for. We're also very proud of what we managed to get together despite all the challenges we faced, and the back-end functionality we implemented.
## What we learned
Our team really learned about the importance of scope, as well as about the importance of really planning out the project before diving right in. Had we done some research to really familiarize ourselves with Wix and Velo we might have reconsidered the functionalities we would need to implement (and/or implemented them ourselves, which in hindsight would have been better), or chosen to tackle this project in a different way altogether!
## What's next for Turnip
We have a lot of features that we really wanted to implement but didn't quite have the time to.
A simple private messaging feature would have been great, as well as fully implementing the block feature (sometimes we don't get along with people, and that's okay!).
We love the idea that a food delivery service like Radish could implement some of our ideas, like the social media/recommendations/friends feature aspect of our project, and would love to help them do it.
Overall, we're extremely proud of the ideas we have come up with and what we have managed to implement, especially the fact that we kept in mind the environmental impact of meal deliveries with the order sharing.
|
## Inspiration
We wanted to do something fun this hackathon! First, we thought of making a bot that imitates Trump’s speech patterns, generating sentences that sound like things Trump would say. Then we thought, "Let’s expand on that! Make bots that imitate all major presidents’ speech patterns, plus a few surprises!"
## What it does
Two bots that are trained to imitate a famous person's speech patterns are randomly paired up and have a conversation about a random topic. Users then spectate for 60 seconds, and vote on who they think the bots are imitating.
## How we built it
1. Write web scraper to scrape online sources for corpuses of text (speeches, quotes)
2. Generate Markov Chains for each person/bot
3. Generate 100,000 sentences based on the Markov Chains
4. Reverse index sentences based on topic
5. Create web app
## Challenges we ran into
How to efficiently reverse index 100,000 generated sentences
## What we used
* Markov Chain
+ Web-scraped corpus
+ Speeches, quotes, scripts
+ IBM Bluemix instance
+ Flask, Django
## What's next for Robot Flame Wars
* Launch on a webserver to the general public to use
* Feed user response back into the model--e.g. if users consistently misidentify a certain bot's real life analog, automatically adjust sentence generation as appropriate.
|
partial
|
## Inspiration
Digitized conversations have given the hearing impaired and other persons with disabilities the ability to better communicate with others despite the barriers in place as a result of their disabilities. Through our app, we hope to build towards a solution where we can extend the effects of technological development to aid those with hearing disabilities to communicate with others in real life.
## What it does
Co:herent is (currently) a webapp which allows the hearing impaired to streamline their conversations with others by providing them sentence or phrase suggestions given the context of a conversation. We use Co:here's NLP text generation API in order to achieve this and in order to provide more accurate results we give the API context from the conversation as well as using prompt engineering in order to better tune the model. The other (non hearing impaired) person is able to communicate with the webapp naturally through speech-to-text inputs and text-to-speech functionalities are put in place in order to better facilitate the flow of the conversation.
## How we built it
We built the entire app using Next.js with the Co:here API, React Speech Recognition API, and React Speech Kit API.
## Challenges we ran into
* Coming up with an idea
* Learning Next.js as we go as this is all of our first time using it
* Calling APIs are difficult without a backend through a server side rendered framework such as Next.js
* Coordinating and designating tasks in order to be efficient and minimize code conflicts
* .env and SSR compatibility issues
## Accomplishments that we're proud of
Creating a fully functional app without cutting corners or deviating from the original plan despite various minor setbacks.
## What we learned
We were able to learn a lot about Next.js as well as the various APIs through our first time using them.
## What's next for Co:herent
* Better tuning the NLP model to generate better/more personal responses as well as storing and maintaining more information on the user through user profiles and database integrations
* Better tuning of the TTS, as well as giving users the choice to select from a menu of possible voices
* Possibility of alternative forms of input for those who may be physically impaired (such as in cases of cerebral palsy)
* Mobile support
* Better UI
|
## Inspiration
Our project, "**Jarvis**," was born out of a deep-seated desire to empower individuals with visual impairments by providing them with a groundbreaking tool for comprehending and navigating their surroundings. Our aspiration was to bridge the accessibility gap and ensure that blind individuals can fully grasp their environment. By providing the visually impaired community access to **auditory descriptions** of their surroundings, a **personal assistant**, and an understanding of **non-verbal cues**, we have built the world's most advanced tool for the visually impaired community.
## What it does
"**Jarvis**" is a revolutionary technology that boasts a multifaceted array of functionalities. It not only perceives and identifies elements in the blind person's surroundings but also offers **auditory descriptions**, effectively narrating the environmental aspects they encounter. We utilize a **speech-to-text** and **text-to-speech model** similar to **Siri** / **Alexa**, enabling ease of access. Moreover, our model possesses the remarkable capability to recognize and interpret the **facial expressions** of individuals who stand in close proximity to the blind person, providing them with invaluable social cues. Furthermore, users can ask questions that may require critical reasoning, such as what to order from a menu or navigating complex public-transport-maps. Our system is extended to the **Amazfit**, enabling users to get a description of their surroundings or identify the people around them with a single press.
## How we built it
The development of "**Jarvis**" was a meticulous and collaborative endeavor that involved a comprehensive array of cutting-edge technologies and methodologies. Our team harnessed state-of-the-art **machine learning frameworks** and sophisticated **computer vision techniques** to get analysis about the environment, like , **Hume**, **LlaVa**, **OpenCV**, a sophisticated computer vision techniques to get analysis about the environment, and used **next.js** to create our frontend which was established with the **ZeppOS** using **Amazfit smartwatch**.
## Challenges we ran into
Throughout the development process, we encountered a host of formidable challenges. These obstacles included the intricacies of training a model to recognize and interpret a diverse range of environmental elements and human expressions. We also had to grapple with the intricacies of optimizing the model for real-time usage on the **Zepp smartwatch** and get through the **vibrations** get enabled according to the **Hume** emotional analysis model, we faced issues while integrating **OCR (Optical Character Recognition)** capabilities with the **text-to speech** model. However, our team's relentless commitment and problem-solving skills enabled us to surmount these challenges.
## Accomplishments that we're proud of
Our proudest achievements in the course of this project encompass several remarkable milestones. These include the successful development of "**Jarvis**" a model that can audibly describe complex environments to blind individuals, thus enhancing their **situational awareness**. Furthermore, our model's ability to discern and interpret **human facial expressions** stands as a noteworthy accomplishment.
## What we learned
# Hume
**Hume** is instrumental for our project's **emotion-analysis**. This information is then translated into **audio descriptions** and the **vibrations** onto **Amazfit smartwatch**, providing users with valuable insights about their surroundings. By capturing facial expressions and analyzing them, our system can provide feedback on the **emotions** displayed by individuals in the user's vicinity. This feature is particularly beneficial in social interactions, as it aids users in understanding **non-verbal cues**.
# Zepp
Our project involved a deep dive into the capabilities of **ZeppOS**, and we successfully integrated the **Amazfit smartwatch** into our web application. This integration is not just a technical achievement; it has far-reaching implications for the visually impaired. With this technology, we've created a user-friendly application that provides an in-depth understanding of the user's surroundings, significantly enhancing their daily experiences. By using the **vibrations**, the visually impaired are notified of their actions. Furthermore, the intensity of the vibration is proportional to the intensity of the emotion measured through **Hume**.
# Ziiliz
We used **Zilliz** to host **Milvus** online, and stored a dataset of images and their vector embeddings. Each image was classified as a person; hence, we were able to build an **identity-classification** tool using **Zilliz's** reverse-image-search tool. We further set a minimum threshold below which people's identities were not recognized, i.e. their data was not in **Zilliz**. We estimate the accuracy of this model to be around **95%**.
# Github
We acquired a comprehensive understanding of the capabilities of version control using **Git** and established an organization. Within this organization, we allocated specific tasks labeled as "**TODO**" to each team member. **Git** was effectively employed to facilitate team discussions, workflows, and identify issues within each other's contributions.
The overall development of "**Jarvis**" has been a rich learning experience for our team. We have acquired a deep understanding of cutting-edge **machine learning**, **computer vision**, and **speech synthesis** techniques. Moreover, we have gained invaluable insights into the complexities of real-world application, particularly when adapting technology for wearable devices. This project has not only broadened our technical knowledge but has also instilled in us a profound sense of empathy and a commitment to enhancing the lives of visually impaired individuals.
## What's next for Jarvis
The future holds exciting prospects for "**Jarvis.**" We envision continuous development and refinement of our model, with a focus on expanding its capabilities to provide even more comprehensive **environmental descriptions**. In the pipeline are plans to extend its compatibility to a wider range of **wearable devices**, ensuring its accessibility to a broader audience. Additionally, we are exploring opportunities for collaboration with organizations dedicated to the betterment of **accessibility technology**. The journey ahead involves further advancements in **assistive technology** and greater empowerment for individuals with visual impairments.
|
## Inspiration
After witnessing the power of collectible games and card systems, our team was determined to prove that this enjoyable and unique game mechanism wasn't just some niche and could be applied to a social activity game that anyone could enjoy or use to better understand one another (taking a note from Cards Against Humanity's book).
## What it does
Words With Strangers pairs users up with a friend or stranger and gives each user a queue of words that they must make their opponent say without saying this word themselves. The first person to finish their queue wins the game. Players can then purchase collectible new words to build their deck and trade or give words to other friends or users they have given their code to.
## How we built it
Words With Strangers was built on Node.js with core HTML and CSS styling as well as usage of some bootstrap framework functionalities. It is deployed on Heroku and also makes use of TODAQ's TaaS service API to maintain the integrity of transactions as well as the unique rareness and collectibility of words and assets.
## Challenges we ran into
The main area of difficulty was incorporating TODAQ TaaS into our application since it was a new service that none of us had any experience with. In fact, it isn't blockchain, etc, but none of us had ever even touched application purchases before. Furthermore, creating a user-friendly UI that was fully functional with all our target functionalities was also a large issue and challenge that we tackled.
## Accomplishments that we're proud of
Our UI not only has all our desired features, but it also is user-friendly and stylish (comparable with Cards Against Humanity and other genre items), and we were able to add multiple word packages that users can buy and trade/transfer.
## What we learned
Through this project, we learned a great deal about the background of purchase transactions on applications. More importantly, though, we gained knowledge on the importance of what TODAQ does and were able to grasp knowledge on what it truly means to have an asset or application online that is utterly unique and one of a kind; passable without infinite duplicity.
## What's next for Words With Strangers
We would like to enhance the UI for WwS to look even more user friendly and be stylish enough for a successful deployment online and in app stores. We want to continue to program packages for it using TODAQ and use dynamic programming principles moving forward to simplify our process.
|
winning
|
## Inspiration
After seeing [Project Owl](http://www.project-owl.com/) in the initial HackMIT sponsored challenge email, we noted how their solution required "throwing out" all the old systems and replacing them with new ones. Despite the potential superiority of Project Owl's transceivers, it seemed unlikely that first responders would be eager to discard all their existing, expensive equipment. Following that, we decided to build a system that would allow interoperability without overhauling the preexisting communications infrastructure.
## What it does
It simulates several different first responders on different radio networks and it routes traffic between them as needed and streams data back to a central analytics server. Once the audio data reaches the analytics server, we use IBM Watson Natural Language Understanding features to semi-autonomously monitor the first responders and intelligently suggest dispatching other resources, for example sending a helicopter to a first responder who reports that they have a patient in need of a medivac.
## How we built it
We simulated the movement of the different first responders on the server and manually mocked up audio recordings to represent the radio traffic. We passed this data to our analytics server, queried several NLP and map APIs to collect information about the situation, and then streamed suggestions to a web app.
## Challenges we ran into
This was our first time working on a full stack web app, and it was one of our members' first hackathons. Because of this, we did not finish integrating all of our features, and the front-end is not yet complete.
## Accomplishments that we're proud of
We believe we had a very strong product idea and that we all learned a lot this weekend implementing the features that we could.
|
## Inspiration
After brainstorming for possible project ideas, we somehow discussed whether our toes be controlled at will. Unfortunately, none of us can. Therefore we decided to build a project that would help us to gain better control of our toes.
## What it does
It is a wearable electronic device that takes input from hand movement and translates it to toe movement.
## How we built it
The group started the project by building its physical frame where our devices are attached to. The Arduino Mega was selected due to its accommodation of many PWM ports and analog input ports. The grouped used stretch sensor in a voltage divider to generate output that can be mapped to determine the action of the servo motors. We then programmed the Arduino to provide an interface to the features above. Strings were attached to the foot to manage movement.
## Challenges we ran into
To connect the servo motors and the sensors for our design, we ran out of PWM and analog ports on our Arduino. We also didn't want to short our circuit with too many motors. Therefore, we unified the ground so the power is only provided by our external power supply. We also upgraded our Arduino Uno to Mega to fulfill our port demands.
## Accomplishments that we're proud of
* Perfect 90-degree angle of the frame
* The toes are controlled separately by different servo motors. Therefore depending on the stretch of the rubber cord, the toes may move separately or together in any order.
* We had fun while designing the project. :)
## What we learned
The group was able to learn carpentry skills during the process of fabricating wooden frames. We learned how to appropriately use the voltage divider to change the sensitivity of sensors. Each member gained hands-on experience on hardware debugging by utilizing multimeter and serial output.
## What's next for Puppet Master
The future for the puppet master project is boundless. The first step is to implement a more precise tracking and faster response time system. The next stage would be to open up more direction of movement such as spreading of the toes with different gap widths in between. The final stage would be allowing finger crossing on one's feet.
|
## Inspiration
Everybody carries a smartphone nowadays. Communication technologies contained within these devices could provide invaluable data for first responders, safety personnel, hosts of events, and even curious individuals. Furthermore, we combine quantitative data with context from social media to provide further insight to the activities of an area.
## What it does
reSCue is a web application that empowers first responders to view a live heatmap of a region as well as precise locations of individuals within a building if floor plan data exists. A live Twitter feed is viewable alongside the map to provide context for activity occurring within a given location.
## How we built it
We utilized **WRLD API** to create 3D heatmaps of regions as well as the interiors of buildings. **Cisco Meraki API** was used to gather the location data of individuals from installed routers. **Socket.io** was used to update the client with real-time data. **Twitter API** was used to power the activity feed.
The front-end was built with **Bootstrap** while the back-end ran on a **node.js** server. The project source is viewable at <https://github.com/DenimMazuki/reSCue>.
## Challenges we ran into and what we learned
Coding to properly overlay the heatmap in different contexts on the map forced us to account for different use cases.
Pipelining data between APIs required extensive reading of documentation.
## Accomplishments that we're proud of
This was the first hackathon for most of our team members. We learned much during this 36 hour journey about new and unfamiliar technologies and project management. We're proud of our product, which provides the users with a clean, beautiful experience where they can visualize and interact with the data they expect to see.
## What's next for reSCue
The technology behind reSCue may be ported to other applications, such as tracking events, office traffic, etc.
As more interior data becomes available, the application will only become more useful.
Features that may prove to be useful in the future include a **timeline to view historical location data**, **analysis** of social media feeds to highlight topics and events being discussed, notifications of spikes in traffic, and data from sources, such as USGS and NOAA.
|
losing
|
## Inspiration
Nowadays, AI and blockchain are emerging in the tech industry. But they are rarely put into use in our daily lives. ABFaucet wants to utilize these solutions to help people have better sentiments hence a happier life.
## What it does
It helps users to have a better dating experience using AI and Blockchain technologies.
## How we built it
We first use Twilio for KYC in order to have users have an account. In the meantime, we have users to have tokens registered in order for us to proceed with the blockchain DiD verification to achieve transparency and decentralization. In order to achieve the transparency part, we have come up with a matching algorithm using ML as our AI solution where it is statistical-based and distributive-based and zero-knowledge proof as our blockchain solution.
## Challenges we ran into
We ran into challenges like not being able to utilize some existing APIs for us to come up with results so we ended up building our own AI with unique features of being able to date with our chatbox if users do not feel prepared for the real-time dating.
## Accomplishments that we're proud of
We created our own matching algorithm.
Firstly, we will have users fill out the features they want in the ideal partners;
Secondly, we will based on the results recommend a list of profiles;
Then, we will based on the "like" and "dislike" results run a logistic regression model to learn users' behavior;
Then, we will have better classification which is personalized for the user and it is constantly changing and iterating just for the user;
In addition, we also offer an option for users to "date" with a robot if they are not ready for the real dating matching mechanism to happen.
## What we learned
Building this app out is so much fun and we enjoyed it!
## What's next for ABFaucet
We hope to build the actual application out on iOS and we wish to get funding to keep it going as we have support from PhD students who are researching blockchain topics and making sure the model is accurate.
|
You can check out our slideshow [here](https://docs.google.com/presentation/d/1tdBm_dqoSoXJAuXFBFdgPqQJ76uBXM1uGz6vjoJeMCc)!
## About
Many people turn to technology, especially dating apps, to find romantic interests in their lives.
One telling sign two people will get along is their interests. However, many people will lie about their hobbies in order to attract someone specific, leading to toxic relationships.
But, no one is lying about their search history!! Youtube is a great way to watch videos about things you love, and similar Youtube watch histories could be the start of a romantic love story 💗
So, we created MatchTube--the ultimate Tinder x Youtube crossover. Find matches based on your Youtube watch history and see your love life finally go somewhere!
## How it works
The frontend was built using React JS, Tailwind CSS, javascript, and some HTML. The backend (built with python, sentence transformers, Youtube API, PropelAuth, and MongoDB Atlas) takes in a Google takeout of a user's Youtube watch and search history. Then this data is parsed, and the sentence transformers transform the data into vectors. MongoDB Atlas stores these vectors and then finds vectors/data that is most is similar to that user -- this is there perfect match! The backend sends this up to the frontend. PropelAuth was also used for login
## Challenges + What We Learned
Throughout the two nights we stayed up battling errors we had, since we were learning a lot of new technologies, overall these challenges were worth it as they helped us learn new technologies.
* Learning how to use the platforms
* We had never used Flask, Hugging Face, PropelAuth, vector databases, or deployed the backend for a server before
Deployment
* CORS Errors
* Lag
* Large size of imports
## MatchTube in the future
* Offer instructions
* Deploy it to a server in a production environment (<https://matchtube.xyz/>)
* Hackathon group formation helper?
* Build out the user database
* Get everyone on Hack Club Slack to use it. (30K+ Teen Coders)
* Add more user profile customizations
* Bios, more contact options, ability to send messages on the website
* Expand to more platforms TikTok, Instagram, etc.
## Tracks + Prizes
This project is for the Entertainment Track. We believe our project represents entertainment because of its use of the Youtube API, a prominent social media platform.
* Best Use of AI: AI is used to transform the user's Youtube data to compare it that of others. AI is vital in our project and integrating it with data is a super cool way to use AI!
* Best Use of Statistics: We use user's Youtube statistical data, like their watch and search history to get the best full picture of their interests. We think this is a super unique way to use user stats!
* Most Creative Hack: Have you ever heard of a mix and mash of Youtube and Tinder? Most likely, you haven't! MatchTube combines two well known sites that you originally think wouldn't work-- leveraging creativity.
* Most Useless Hack: For most people, this wouldn't be a useless hack-- because it's your love life! But for a room full off coders, I don't think an extensive search history of 3 hour coding tutorials will find you your dream person....
* Best Design: Design is key in attracting users! MatchTube uses a familiar color palette to represent romance, while using simple UI to keep the site minimalistic. We also used tailwind CSS to keep the design and code clean.
* Best Use of MongoDB Atlas: MongoDB Atlas was used to store vectors and to compare user's Youtube data-- super important for our project.
* Best Use of PropelAuth: We used PropelAuth for user login, which was vital in making sure people have their own profiles.
|
## Inspiration
It’s Friday afternoon, and as you return from your final class of the day cutting through the trailing winds of the Bay, you suddenly remember the Saturday trek you had planned with your friends. Equipment-less and desperate you race down to a nearby sports store and fish out $$$, not realising that the kid living two floors above you has the same equipment collecting dust. While this hypothetical may be based on real-life events, we see thousands of students and people alike impulsively spending money on goods that would eventually end up in their storage lockers. This cycle of buy-store-collect dust inspired us to develop Lendit this product aims to stagnate the growing waste economy and generate passive income for the users on the platform.
## What it does
A peer-to-peer lending and borrowing platform that allows users to generate passive income from the goods and garments collecting dust in the garage.
## How we built it
Our Smart Lockers are built with RaspberryPi3 (64bit, 1GB RAM, ARM-64) microcontrollers and are connected to our app through interfacing with Google's Firebase. The locker also uses Facial Recognition powered by OpenCV and object detection with Google's Cloud Vision API.
For our App, we've used Flutter/ Dart and interfaced with Firebase. To ensure *trust* - which is core to borrowing and lending, we've experimented with Ripple's API to create an Escrow system.
## Challenges we ran into
We learned that building a hardware hack can be quite challenging and can leave you with a few bald patches on your head. With no hardware equipment, half our team spent the first few hours running around the hotel and even the streets to arrange stepper motors and Micro-HDMI wires. In fact, we even borrowed another team's 3-D print to build the latch for our locker!
On the Flutter/ Dart side, we were sceptical about how the interfacing with Firebase and Raspberry Pi would work. Our App Developer previously worked with only Web Apps with SQL databases. However, NoSQL works a little differently and doesn't have a robust referential system. Therefore writing Queries for our Read Operations was tricky.
With the core tech of the project relying heavily on the Google Cloud Platform, we had to resolve to unconventional methods to utilize its capabilities with an internet that played Russian roulette.
## Accomplishments that we're proud of
The project has various hardware and software components like raspberry pi, Flutter, XRP Ledger Escrow, and Firebase, which all have their own independent frameworks. Integrating all of them together and making an end-to-end automated system for the users, is the biggest accomplishment we are proud of.
## What's next for LendIt
We believe that LendIt can be more than just a hackathon project. Over the course of the hackathon, we discussed the idea with friends and fellow participants and gained a pretty good Proof of Concept giving us the confidence that we can do a city-wide launch of the project in the near future. In order to see these ambitions come to life, we would have to improve our Object Detection and Facial Recognition models. From cardboard, we would like to see our lockers carved in metal at every corner of this city. As we continue to grow our skills as programmers we believe our product Lendit will grow with it. We would be honoured if we can contribute in any way to reduce the growing waste economy.
|
partial
|
## Inspiration
We're all told that stocks are a good way to diversify our investments, but taking the leap into trading stocks is daunting. How do I open a brokerage account? What stocks should I invest in? How can one track their investments? We learned that we were not alone in our apprehensions, and that this problem is even worse in other countries. For example, in Indonesia (Scott's home country), only 0.3% of the population invests in the stock market.
A lack of active retail investor community in the domestic stock market is very problematic. Investment in the stock markets is one of the most important factors that contribute to the economic growth of a country. That is the problem we set out to address. In addition, the ability to invest one's savings can help people and families around the world grow their wealth -- we decided to create a product that makes it easy for those people to make informed, strategic investment decisions, wrapped up in a friendly, conversational interface.
## What It Does
PocketAnalyst is a Facebook messenger and Telegram chatbot that puts the brain of a financial analyst into your pockets, a buddy to help you navigate the investment world with the tap of your keyboard. Considering that two billion people around the world are unbanked, yet many of them have access to cell/smart phones, we see this as a big opportunity to push towards shaping the world into a more egalitarian future.
**Key features:**
* A bespoke investment strategy based on how much risk users opt to take on, based on a short onboarding questionnaire, powered by several AI models and data from Goldman Sachs and Blackrock.
* In-chat brokerage account registration process powered DocuSign's API.
* Stock purchase recommendations based on AI-powered technical analysis, sentiment analysis, and fundamental analysis based on data from Goldman Sachs' API, GIR data set, and IEXFinance.
* Pro-active warning against the purchase of a high-risk and high-beta assets for investors with low risk-tolerance powered by BlackRock's API.
* Beautiful, customized stock status updates, sent straight to users through your messaging platform of choice.
* Well-designed data visualizations for users' stock portfolios.
* In-message trade execution using your brokerage account (proof-of-concept for now, obviously)
## How We Built it
We used multiple LSTM neural networks to conduct both technical analysis on features of stocks and sentiment analysis on news related to particular companies
We used Goldman Sachs' GIR dataset and the Marquee API to conduct fundamental analysis. In addition, we used some of their data in verifying another one of our machine learning models. Goldman Sachs' data also proved invaluable for the creation of customized stock status "cards", sent through messenger.
We used Google Cloud Platform extensively. DialogFlow powered our user-friendly, conversational chatbot. We also utilized GCP's computer engine to help train some of our deep learning models. Various other features, such as the app engine and serverless cloud functions were used for experimentation and testing.
We also integrated with Blackrock's APIs, primarily for analyzing users' portfolios and calculating the risk score.
We used DocuSign to assist with the paperwork related to brokerage account registration.
## Future Viability
We see a clear path towards making PocketAnalyst a sustainable product that makes a real difference in its users' lives. We see our product as one that will work well in partnership with other businesses, especially brokerage firms, similar to what CreditKarma does with credit card companies. We believe that giving consumers access to a free chatbot to help them invest will make their investment experiences easier, while also freeing up time in financial advisors' days.
## Challenges We Ran Into
Picking the correct parameters/hyperparameters and discerning how our machine learning algorithms will make recommendations in different cases.
Finding the best way to onboard new users and provide a fully-featured experience entirely through conversation with a chatbot.
Figuring out how to get this done, despite us not having access to a consistent internet connection (still love ya tho Cal :D). Still, this hampered our progress on a more-ambitious IOT (w/ google assistant) stretch goal. Oh, well :)
## Accomplishments That We Are Proud Of
We are proud of our decision in combining various Machine Learning techniques in combination with Goldman Sachs' Marquee API (and their global investment research dataset) to create a product that can provide real benefit to people. We're proud of what we created over the past thirty-six hours, and we're proud of everything we learned along the way!
## What We Learned
We learned how to incorporate already existing Machine Learning strategies and combine them to improve our collective accuracy in making predictions for stocks. We learned a ton about the different ways that one can analyze stocks, and we had a great time slotting together all of the different APIs, libraries, and other technologies that we used to make this project a reality.
## What's Next for PocketAnalyst
This isn't the last you've heard from us!
We aim to better fine-tune our stock recommendation algorithm. We believe that are other parameters that were not yet accounted for that can better improve the accuracy of our recommendations; Down the line, we hope to be able to partner with finance professionals to provide more insights that we can incorporate into the algorithm.
|
## Inspiration
Our inspiration was to provide a robust and user-friendly financial platform. After hours of brainstorming, we decided to create a decentralized mutual fund on mobile devices. We also wanted to explore new technologies whilst creating a product that has several use cases of social impact. Our team used React Native and Smart Contracts along with Celo's SDK to discover BlockChain and the conglomerate use cases associated with these technologies. This includes group insurance, financial literacy, personal investment.
## What it does
Allows users in shared communities to pool their funds and use our platform to easily invest in different stock and companies for which they are passionate about with a decreased/shared risk.
## How we built it
* Smart Contract for the transfer of funds on the blockchain made using Solidity
* A robust backend and authentication system made using node.js, express.js, and MongoDB.
* Elegant front end made with react-native and Celo's SDK.
## Challenges we ran into
Unfamiliar with the tech stack used to create this project and the BlockChain technology.
## What we learned
We learned the many new languages and frameworks used. This includes building cross-platform mobile apps on react-native, the underlying principles of BlockChain technology such as smart contracts, and decentralized apps.
## What's next for *PoolNVest*
Expanding our API to select low-risk stocks and allows the community to vote upon where to invest the funds.
Refine and improve the proof of concept into a marketable MVP and tailor the UI towards the specific use cases as mentioned above.
|
## Inspiration
Our project was inspired by the movie recommendation system algorithms used by companies like Netflix to recommend content to their users. Following along on this, our project uses a similar algorithm to recommend investment options to individuals based on their profiles.
## What Finvest Advisor does
This app suggests investment options for users based on the information they have provided about their own unique profiles. Using machine learning algorithms, we harness the data of previous customers to make the best recommendations that we can.
## How it works
We built our web app to work together with a machine-learning model that we designed. Using the cosine similarity algorithm, we compare how similar the user's profile is compared to other individuals already in our database. Then, based on this, our model is able to recommend investments that would be ideal for the user, given the parameters they have entered
## Our biggest challenge
Acquiring the data to get this project functional was nearly impossible, given that individuals' financial information is very well protected and banks would (for obvious reasons) not allow us to work with any real data that they would have had. Constructing our database was challenging, but we overcame it by constructing our own data that was modelled to be similar to real-world statistics.
## Going forward...
We hope to further improve the accuracy of our model by testing different kinds of algorithms with different kinds of data. Not to mention, we would also look forward to possibly pitching our project to larger financial firms, such as local banks, and getting their help to improve upon our model even more. With access to real-world data, we could make our model even more accurate, and give more specific recommendations.
|
winning
|
## Inspiration
Our team firmly believes that a hackathon is the perfect opportunity to learn technical skills while having fun. Especially because of the hardware focus that MakeUofT provides, we decided to create a game! This electrifying project places two players' minds to the test, working together to solve various puzzles. Taking heavy inspiration from the hit videogame, "Keep Talking and Nobody Explodes", what better way to engage the players than have then defuse a bomb!
## What it does
The MakeUofT 2024 Explosive Game includes 4 modules that must be disarmed, each module is discrete and can be disarmed in any order. The modules the explosive includes are a "cut the wire" game where the wires must be cut in the correct order, a "press the button" module where different actions must be taken depending the given text and LED colour, an 8 by 8 "invisible maze" where players must cooperate in order to navigate to the end, and finally a needy module which requires players to stay vigilant and ensure that the bomb does not leak too much "electronic discharge".
## How we built it
**The Explosive**
The explosive defuser simulation is a modular game crafted using four distinct modules, built using the Qualcomm Arduino Due Kit, LED matrices, Keypads, Mini OLEDs, and various microcontroller components. The structure of the explosive device is assembled using foam board and 3D printed plates.
**The Code**
Our explosive defuser simulation tool is programmed entirely within the Arduino IDE. We utilized the Adafruit BusIO, Adafruit GFX Library, Adafruit SSD1306, Membrane Switch Module, and MAX7219 LED Dot Matrix Module libraries. Built separately, our modules were integrated under a unified framework, showcasing a fun-to-play defusal simulation.
Using the Grove LCD RGB Backlight Library, we programmed the screens for our explosive defuser simulation modules (Capacitor Discharge and the Button). This library was used in addition for startup time measurements, facilitating timing-based events, and communicating with displays and sensors that occurred through the I2C protocol.
The MAT7219 IC is a serial input/output common-cathode display driver that interfaces microprocessors to 64 individual LEDs. Using the MAX7219 LED Dot Matrix Module we were able to optimize our maze module controlling all 64 LEDs individually using only 3 pins. Using the Keypad library and the Membrane Switch Module we used the keypad as a matrix keypad to control the movement of the LEDs on the 8 by 8 matrix. This module further optimizes the maze hardware, minimizing the required wiring, and improves signal communication.
## Challenges we ran into
Participating in the biggest hardware hackathon in Canada, using all the various hardware components provided such as the keypads or OLED displays posed challenged in terms of wiring and compatibility with the parent code. This forced us to adapt to utilize components that better suited our needs as well as being flexible with the hardware provided.
Each of our members designed a module for the puzzle, requiring coordination of the functionalities within the Arduino framework while maintaining modularity and reusability of our code and pins. Therefore optimizing software and hardware was necessary to have an efficient resource usage, a challenge throughout the development process.
Another issue we faced when dealing with a hardware hack was the noise caused by the system, to counteract this we had to come up with unique solutions mentioned below:
## Accomplishments that we're proud of
During the Makeathon we often faced the issue of buttons creating noise, and often times the noise it would create would disrupt the entire system. To counteract this issue we had to discover creative solutions that did not use buttons to get around the noise. For example, instead of using four buttons to determine the movement of the defuser in the maze, our teammate Brian discovered a way to implement the keypad as the movement controller, which both controlled noise in the system and minimized the number of pins we required for the module.
## What we learned
* Familiarity with the functionalities of new Arduino components like the "Micro-OLED Display," "8 by 8 LED matrix," and "Keypad" is gained through the development of individual modules.
* Efficient time management is essential for successfully completing the design. Establishing a precise timeline for the workflow aids in maintaining organization and ensuring successful development.
* Enhancing overall group performance is achieved by assigning individual tasks.
## What's next for Keep Hacking and Nobody Codes
* Ensure the elimination of any unwanted noises in the wiring between the main board and game modules.
* Expand the range of modules by developing additional games such as "Morse-Code Game," "Memory Game," and others to offer more variety for players.
* Release the game to a wider audience, allowing more people to enjoy and play it.
|
## Inspiration
After looking at the Hack the 6ix prizes, we were all drawn to the BLAHAJ. On a more serious note, we realized that one thing we all have in common is accidentally killing our house plants. This inspired a sense of environmental awareness and we wanted to create a project that would encourage others to take better care of their plants.
## What it does
Poképlants employs a combination of cameras, moisture sensors, and a photoresistor to provide real-time insight into the health of our household plants. Using this information, the web app creates an interactive gaming experience where users can gain insight into their plants while levelling up and battling other players’ plants. Stronger plants have stronger abilities, so our game is meant to encourage environmental awareness while creating an incentive for players to take better care of their plants.
## How we built it + Back-end:
The back end was a LOT of python, we took a new challenge on us and decided to try out using socketIO, for a websocket so that we can have multiplayers, this messed us up for hours and hours, until we finally got it working. Aside from this, we have an arduino to read for the moistness of the soil, the brightness of the surroundings, as well as the picture of it, where we leveraged computer vision to realize what the plant is. Finally, using langchain, we developed an agent to handle all of the arduino info to the front end and managing the states, and for storage, we used mongodb to hold all of the data needed.
[backend explanation here]
### Front-end:
The front-end was developed with **React.js**, which we used to create a web-based game. We were inspired by the design of old pokémon games, which we thought might evoke nostalgia for many players.
## Challenges we ran into
We had a lot of difficulty setting up socketio and connecting the api with it to the front end or the database
## Accomplishments that we're proud of
We are incredibly proud of integrating our web sockets between frontend and backend and using arduino data from the sensors.
## What's next for Poképlants
* Since the game was designed with a multiplayer experience in mind, we want to have more social capabilities by creating a friends list and leaderboard
* Another area to explore would be a connection to the community; for plants that are seriously injured, we could suggest and contact local botanists for help
* Some users might prefer the feeling of a mobile app, so one next step would be to create a mobile solution for our project
|
## Inspiration
Our inspiration was to look at the world of gaming in a *different* way, little did we know that we would literally be looking at it in a **different** way. We inspired to build a real time engine that would allow for the quick development of keyboard games.
## What it does
Allows users to use custom built libraries to quickly set up player objects, instances and keyboard program environments on a local server that can support multiple threads and multiple game instances. We built multiple games using our engine to demonstrate its scalability.
## How we built it
The server was built using Java and the front end was built using Visual C++. The server includes customizable objects and classes that can easily be modified to create a wide array of products. All of the server creation/game lobbies/multi threading/real time is handled by the engine. The front end engine created in C++ creates a 16x6 grid on the Corsair keyboards, allocates values to keys, registers keys and pre defined functions for easy LED manipulation. The front end engine provides the base template for easy manipulation and fast development of programs on the keyboard.
## Challenges we ran into
Our unique selling proposition was the ability to use our engine to create real time programs/games. Creating this involved many challenges primarily surrounding latency and packet loss. Due to the fact that our engine was expected to allow every keyboard playing in a lobby to reflect the state of every other place, and update the LED UI without delay, this required a low latency which became a problem using 1and1 servers located in the UK leading to the response time with different keyboards increasing up to a few seconds.
## Accomplishments that we're proud of
* Low latency
* Good Syncronization
* Full multiplayer support
* Full game library expansion support
* Creative use of limited hardware
* Multithreading support (Ability to create an infinite number of game rooms)
## What we learned
* Group Version Control
* Planning & organization
* Use of Corsair Gaming SDK
* Always comment, commit and save working versions of code!
|
winning
|
## Inspiration
There are thousands of people worldwide who suffer from conditions that make it difficult for them to both understand speech and also speak for themselves. According to the Journal of Deaf Studies and Deaf Education, the loss of a personal form of expression (through speech) has the capability to impact their (affected individuals') internal stress and lead to detachment. One of our main goals in this project was to solve this problem, by developing a tool that would a step forward in the effort to make it seamless for everyone to communicate. By exclusively utilizing mouth movements to predict speech, we can introduce a unique modality for communication.
While developing this tool, we also realized how helpful it would be to ourselves in daily usage, as well. In areas of commotion, and while hands are busy, the ability to simply use natural lip-reading in front of a camera to transcribe text would make it much easier to communicate.
## What it does
**The Speakinto.space website-based hack has two functions: first and foremost, it is able to 'lip-read' a stream from the user (discarding audio) and transcribe to text; and secondly, it is capable of mimicking one's speech patterns to generate accurate vocal recordings of user-inputted text with very little latency.**
## How we built it
We have a Flask server running on an AWS server (Thanks for the free credit, AWS!), which is connected to a Machine Learning model running on the server, with a frontend made with HTML and MaterializeCSS. This was trained to transcribe people mouthing words, using the millions of words in LRW and LSR datasets (from the BBC and TED). This algorithm's integration is the centerpiece of our hack. We then used the HTML MediaRecorder to take 8-second clips of video to initially implement the video-to-mouthing-words function on the website, using a direct application of the machine learning model.
We then later added an encoder model, to translate audio into an embedding containing vocal information, and then a decoder, to convert the embeddings to speech. To convert the text in the first function to speech output, we use the Google Text-to-Speech API, and this would be the main point of future development of the technology, in having noiseless calls.
## Challenges we ran into
The machine learning model was quite difficult to create, and required a large amount of testing (and caffeine) to finally result in a model that was fairly accurate for visual analysis (72%). The process of preprocessing the data, and formatting such a large amount of data to train the algorithm was the area which took the most time, but it was extremely rewarding when we finally saw our model begin to train.
## Accomplishments that we're proud of
Our final product is much more than any of us expected, especially the ability to which it seemed like it was an impossibility when we first started. We are very proud of the optimizations that were necessary to run the webpage fast enough to be viable in an actual use scenario.
## What we learned
The development of such a wide array of computing concepts, from web development, to statistical analysis, to the development and optimization of ML models, was an amazing learning experience over the last two days. We all learned so much from each other, as each one of us brought special expertise to our team.
## What's next for speaking.space
As a standalone site, it has its use cases, but the use cases are limited due to the requirement to navigate to the page. The next steps are to integrate it in with other services, such as Facebook Messenger or Google Keyboard, to make it available when it is needed just as conveniently as its inspiration.
|
## Inspiration
We were looking for a hack to really address the need for quick and easy access to mental health help.
## What it does
Happy Thoughts is a companion service. Whenever in need or desiring a pick-me-up a user can text the app.
## How we built it
Using a React-made webclient we accepted user inputted preferences. Via a Google Firebase realtime database we transmitted the preference data to a Node.js web server hosted on Google App Engine. From there the server (using Twilio) can text, and receive texts from the user to have valuable conversations and send happy thoughts to the user.
Also made with courage, focus, determination, and a gross amount of puffy style Cheetos.
## Challenges we ran into
We didn't React well. None of us knew React. But we improvised, adapted, and overcame the challenge
## Accomplishments that we're proud of
A team that pushed through, and made a hack that we're proud of. We stacked cups, learned juggling, and had an overall great time. The team bonded and came through with an impactful project.
## What we learned
That a weekend is a short time when you're trying to make in impact on mental health.
## What's next for Happy Thoughts
Happier Thoughts :)
## Enjoy these happy thoughts
<https://www.youtube.com/watch?v=DOWbvYYzAzQ>
|
## Inspiration
Just in the United States, 11 million people are deaf, of which half a million use ASL natively. For people who are deaf to communicate with those who are hearing, and therefore most likely not fluent in sign language, they’re constricted to slower methods of communication, such as writing. Similarly, for people who don’t know sign language to immediately be able to communicate comfortably with someone who is deaf, the only options are writing or lip-reading, which has been proven to only be 30-40% effective. By creating Gesture Genie, we aim to make the day to day lives of both the deaf and hearing communities significantly more tension-free.
## What it does
Two Way Sign Language Translator that can translate voice into visual sign language and can translate visual sign language into speech. We use computer vision algorithms to recognize the sign language gestures and translate into text.
## How we built it
Sign Gestures to Text
* We used OpenCV to to capture video from the user which we processed into
* We used Google MediaPipe API to detect all 21 joints in the user's hands
* Trained neural networks to detect and classify ASL gestures
<https://youtu.be/3gNQDp1nM_w>
Voice to Sign Language Gestures
* Voice to text translation
* Text to words/fingerspelling
* By web scraping online ASL dictionaries we can show videos for all ASL through gestures or fingerspelling
* Merging videos of individual sign language words/gestures
<https://youtu.be/mBUhU8b3gK0?si=eIEOiOFE0mahXCWI>
## Challenges we ran into
The biggest challenge that we faced was incorporating the backend into the React/node.js frontend. We use OpenCV for the backend, and we needed to ensure that the camera's output is shown on the front end. We were able to solve this problem by using iFrames in order to integrate the local backend into our combined webpage.
## Accomplishments that we're proud of
We are most proud of being able to recognize action-based sign language words rather than simply relying on fingerspelling to understand the sign language that we input. Additionally, we were able to integrate these videos from our backend into the front end seamlessly using Flask APIs and iFrames.
## What we learned
## What's next for Gesture Genie
Next, we hope to be able to incorporate more phrases/action based gestures, scaling our product to be able to work seamlessly in the day-to-day lives of those who are hard of hearing. We also aim to use more LLMs to better translate the text, recognizing voice and facial emotions as well.
|
partial
|
## Inspiration
Everyone loves the classical Snake game --simple, kills time. Why not upgrade the classic so today's adults --yesterday's children-- can relive the nostalgia.
## What it does
Classical snake game with more features added:
* Foods that can be eaten by the snake is divided into 5 colors. Each have a special function that is activated once 5 food of the same color is eaten consecutively:
+ red: speeds up the snake
+ blue: slows down the snake
+ green: adds more food on the game board
+ yellow: elongates the snake
+ purple: shortens the snake
* Snake can shed once reached a certain length: the skin shed is left on the board game and becomes an obstacle that terminates the game play when ran into by the snake
## How we built it
Passion, Love, and JavaScript
## Challenges we ran into
Learning JavaScript from scratch.
## Accomplishments that we're proud of
* Learning JavaScript
* Completing the project on time
* Making a game that we will actually play
* Survived on no sleep
## What we learned
* JavaScript
* How to make a Chrome extension
## What's next for Snek
* Change themes
* Add more categories of foods with more functions (like convert shed skin into food, make the snake blink/invisible, etc.)
* Make it into a mobile app
* Multiplayer or same game play that can span multiple screens (or both)
* Better aesthetics
|
## Inspiration
We've been playing the same old Snake game for a while and are ready to level it up with a ROCKY twist. Like the original, Snake Wave is a single-player game for snakes to slither across a battlefield collecting rocks for food. Each round you play, you’ll earn points. Challenge your friends to beat your high score, and *PLAY THE SNAKE WAVE*.
## What it does
* Play the next level of the classic snake game where you don't need to press a single key to play!
* Guide a snake to eat rocks just by moving your finger in front of a camera
* Grow your snake for a high score while avoiding eat yourself or running into the edges
## How we built it
* OpenCV for live video capture
* Google's MediaPipe for hand landmarking to identify the index finger and its location
* Pygame to create a local game
## Challenges we ran into
* Integrating MediaPipe code and open CV with Pygame
* Understanding MediaPipe documentation
* Overcoming a gameboard that was resetting after each frame
## Accomplishments that we're proud of
* The position of the finger is correctly identified in the respective quadrant
* The snake movement is responsive and playable
## What we learned
* How to read the documentation and follow tutorials
* How to debug errors that block us from running our code
* Dealing with merge conflicts
* Plan API calls to reduce inefficiencies and more challenging for other coders to interpret if changes need to be change
* Design with user experience in mind
## What's next for Snake Wave
* Improve UI with multiple screens for user login, leaderboard, and rewards store for different skins
* Deploy and use the API we built for user data
|
## Inspiration
*It's lunchtime. You quickly grab a bite to eat and sit by yourself while you munch it down alone. While food clearly has the power to bring people together, the pandemic has separated us from friends and family with whom we love to eat together with*
Muk means Eat in in Korean 🍽️ Eating is such an essential and frequent part of our daily lives, but eating alone has become the "norm" nowadays. With the addition of the lockdown and working from home, it is even harder to be social over food. Even worse, some young people are too busy to eat at home at all.
This brings significant health drawbacks, including chances to lead to obesity, higher risk factors for prediabetes, risk of having metabolic syndrome, high blood pressure, and higher cholesterol. This is because loneliness and lack of social support lead to physical wear and anxiety 🤒
We rely on relationships for emotional support and stress management ✨🧑🤝🧑 This is why we became inspired to make eating social again. With LetsMuk, we bring available the interactions of catching up with friends or meeting someone new, so that you won't spend your next meal alone anymore.
This project targets the health challenge because of the profound problems related to loneliness and mental health. With young people working from home, it brings back the social-ness of lunching with coworkers. Among seniors, it levitates them from isolation during a lonely meal. For friends over a distance, it provides them a chance to re-connect and catch up. 💬🥂 Here are multiple health studies that highlight the health problems around eating alone that inspired us
* [eating-alone-metabolic-syndrome](https://time.com/4995466/eating-alone-metabolic-syndrome/)
* [eating-alone-good-or-bad-for-your-health](https://globalnews.ca/news/6123020/eating-alone-good-or-bad-for-your-health/#:%7E:text=The%20physical%20implicati%5B%E2%80%A6%5D0and%20elevated%20blood%20pressure)
* [eating-alone-is-the-norm](https://ryersonian.ca/eating-alone-is-the-norm-but-ryerson-grads-app-works/)
## How we built it
We chose Flutter as our mobile framework to support iOS and Android and leveraged its tight integrations with Google Firebase. We used Firebase's real-time database as our user store and built a Ruby on Rails API with PostgreSQL to serve as a broker and source of truth. Our API takes care of two workflows: storing and querying schedules, and communication with Agora's video chat API to query the active channels and the users within them.
Here is the video demo of when one joins a room [YouTube Demo on entering a room](https://youtu.be/3EYfO5VVVHU)
## Challenges we ran into
This is the first time any of us has worked with Flutter, and none of us had in-depth mobile development experience. We went through initial hurdles simply setting up the mobile environment as well as getting the Flutter app running. Dart is a new language to us, so we took the time to learn it from scratch and met challenges with calling async functions, building the UI scaffold, and connecting our backend APIs to it. We also ran into issues calling the Agora API for our video-chat, as our users' uid did not cohere with the API's int size restriction.
## Accomplishments that we're proud of
It works!!
* Building out a polished UI
* Seeing your friends who are eating right now
* Ease of starting a meal and joining a room
* "Mukking" together with our team!
## What we learned
* Mobile development with Flutter and Dart
* User authentication with Firebase
* Video call application with Agora
* API development with Ruby on Rails
* Firebase and Postgres databases (NoSQL and SQL)
## What's next for LetsMuk
* Schedule integration - put in when you eat every day
* Notifications - reminders to your friends and followers when you're eating.
* LetsMuk for teams/enterprise - eat with coworkers or students
* Better social integration - FB, twitter, "followers"
|
losing
|
Can you save a life?
## Inspiration
For the past several years heart disease has remained the second leading cause of death in Canada. Many know how to prevent it, but many don’t know how to deal with cardiac events that have the potential to end your life. What if you can change this?
## What it does
Can You Save Me simulates three different conversational actions showcasing cardiac events at some of their deadliest moments. It’s your job to make decisions to save the person in question from either a stroke, sudden cardiac arrest, or a heart attack. Can You Save Me puts emphasis on the symptomatic differences between men and women during specific cardiac events. Are you up for it?
## How we built it
We created the conversational action with Voiceflow. While the website was created with HTML, CSS, Javascript, and Bootstrap. Additionally, the backend of the website, which counts the number of simulated lives our users saved, uses Node.js and Google sheets.
## Challenges we ran into
There were several challenges our team ran into, however, we managed to overcome each of them. Initially, we used React.js but it deemed too complex and time consuming given our time-sensitive constraints. We switched over to Javascript, HTML, CSS, and Bootstrap instead for the frontend of the website.
## Accomplishments that we're proud of
Our team is proud of the fact that we were able to come together as complete strangers and produce a product that is educational and can empower people to save lives. We managed our time efficiently and divided our work fairly according to our strengths.
## What we learned
Our team learned many technical skills such as how to use React.js, Node.js, Voiceflow and how to deploy actions on Google Assistant. Due to the nature of this project, we completed extensive research on cardiovascular health using resources from Statstics Canada, the Standing Committee on Health, the University of Ottawa Heart Institute, The Heart & Stroke Foundation, American Journal of Cardiology, American Heart Association and Harvard Health.
## What's next for Can You Save Me
We're interested in adding more storylines and variables to enrich our users' experience and learning. We are considering adding a play again action to improve our Voice Assistant and encourage iterations.
|
## Inspiration
People are increasingly aware of climate change but lack actionable steps. Everything in life has a carbon cost, but it's difficult to understand, measure, and mitigate. Information about carbon footprints of products is often inaccessible for the average consumer, and alternatives are time consuming to research and find.
## What it does
With GreenWise, you can link email or upload receipts to analyze your purchases and suggest products with lower carbon footprints. By tracking your carbon usage, it helps you understand and improve your environmental impact. It provides detailed insights, recommends sustainable alternatives, and facilitates informed choices.
## How we built it
We started by building a tool that utilizes computer vision to read information off of a receipt, an API to gather information about the products, and finally ChatGPT API to categorize each of the products. We also set up an alternative form of gathering information in which the user forwards digital receipts to a unique email.
Once we finished the process of getting information into storage, we built a web scraper to gather the carbon footprints of thousands of items for sale in American stores, and built a database that contains these, along with AI-vectorized form of the product's description.
Vectorizing the product titles allowed us to quickly judge the linguistic similarity of two products by doing a quick mathematical operation. We utilized this to make the application compare each product against the database, identifying products that are highly similar with a reduced carbon output.
This web application was built with a Python Flask backend and Bootstrap for the frontend, and we utilize ChromaDB, a vector database that allowed us to efficiently query through vectorized data.
## Accomplishments that we're proud of
In 24 hours, we built a fully functional web application that uses real data to provide real actionable insights that allow users to reduce their carbon footprint
## What's next for GreenWise
We'll be expanding e-receipt integration to support more payment processors, making the app seamless for everyone, and forging partnerships with companies to promote eco-friendly products and services to our consumers
[Join the waitlist for GreenWise!](https://dea15e7b.sibforms.com/serve/MUIFAK0jCI1y3xTZjQJtHyTwScsgr4HDzPffD9ChU5vseLTmKcygfzpBHo9k0w0nmwJUdzVs7lLEamSJw6p1ACs1ShDU0u4BFVHjriKyheBu65k_ruajP85fpkxSqlBW2LqXqlPr24Cr0s3sVzB2yVPzClq3PoTVAhh_V3I28BIZslZRP-piPn0LD8yqMpB6nAsXhuHSOXt8qRQY)
|
## Inspiration
Care.ai was inspired by our self-conducted study involving 60 families and 23 smart devices, focusing on elderly healthcare. Over three months, despite various technologies, families preferred the simplicity of voice-activated assistants like Alexa. This preference led us to develop an intuitive, user-friendly AI healthcare chatbot tailored to everyday needs.
## What it does
Care.ai, an AI healthcare chatbot, leverages custom-trained Large Language Models (LLMs) and visual recognition technology hosted on the Intel Cloud for robust processing power. These models, refined and accessible via Hugging Face, underwent further fine-tuning through MonsterAPI, enhancing their accuracy and responsiveness to medical queries. The web application, powered by the Reflex library, provides a seamless and intuitive front-end experience, making it easy for users to interact with and benefit from the chatbot's capabilities. Care.ai supports real-time data analytics and critical care necessary for humans.
## How we built it
We built our AI healthcare chatbot by training LLMs and visual recognition systems on the Intel Cloud, then hosting and fine-tuning these models on Hugging Face with MonsterAPI. The chatbot's user-friendly web interface was developed using the Reflex library, creating a seamless user interaction platform.
For data collection,
* We researched datasets and performed literature review
* We used the pre-training data for developing and fine-tuning our LLM and visual models
* We collect live data readings using sensors to test against our trained models
We categorized our project into three parts:
* Interactive Language Models: We developed deep learning models on Intel Developer Cloud and fine-tuned our Hugging Face hosted models using MonsterAPI. We further used Reflex Library to be the face of Care.ai and create a seamless platform.
* Embedded Sensor Networks: Developed our IoT sensors to track the real-time data and test our LLVMs on the captured data readings.
* Compliance and Security Components: Intel Developer Cloud to extract emotions and de-identify patient's voice to be HIPAA
## Challenges we ran into
Integrating new technologies posed significant challenges, including optimizing model performance on the Intel Cloud, ensuring seamless model fine-tuning via MonsterAPI and achieving intuitive user interaction through the Reflex library. Balancing technical complexity with user-friendliness and maintaining data privacy and security were among the key hurdles we navigated.
## Accomplishments that we're proud of
We're proud of creating a user-centric AI healthcare chatbot that combines advanced LLMs and visual recognition hosted on the cutting-edge Intel Cloud. Successfully fine-tuning these models on Hugging Face and integrating them with a Reflex-powered interface showcases our technical achievement. Our commitment to privacy, security, and intuitive design has set a new standard in accessible home healthcare solutions.
## What we learned
We learned the importance of integrating advanced AI with user-friendly interfaces for healthcare. Balancing technical innovation with accessibility, the intricacies of cloud hosting, model fine-tuning, and ensuring data privacy were key lessons in developing an effective, secure, and intuitive AI healthcare chatbot.
## What's next for care.ai
Next, Care.ai is expanding its disease recognition capabilities, enhancing user interaction with natural language processing improvements, and exploring partnerships for broader deployment in healthcare systems to revolutionize home healthcare access and efficiency.
|
winning
|
## Inspiration
DermaDetect was born out of a commitment to improve healthcare equity for underrepresented and economically disadvantaged communities, including seniors, other marginalized populations, and those impacted by economic inequality.
Recognizing the prohibitive costs and emotional toll of traditional skin cancer screenings, which often result in benign outcomes, we developed an open-source AI-powered application to provide preliminary skin assessments.
This innovation aims to reduce financial burdens and emotional stress, offering immediate access to health information and making early detection services more accessible to everyone, regardless of their societal status.
## What it does
* AI-powered analysis: Fine-tuned Resnet50 Convolutional Neural Network classifier that predicts skin lesions as benign versus cancerous by leveraging the open-source HAM10000 dataset.
* Protecting patient data confidentiality: Our application uses OAuth technology (Clerk and Convex) to authenticate and verify users logging into our application, protecting patient data when users upload images and enter protected health information (PHI).
* Understandable and age-appropriate information: Prediction Guard LLM technology offers clear explanations of results, fostering informed decision-making for users while respecting patient data privacy.
* Journal entry logging: Using the Convex backend database schema allows users to make multiple journal entries, monitor their skin, and track moles over long periods.
* Seamless triaging: Direct connection to qualified healthcare providers eliminates unnecessary user anxiety and wait times for concerning cases.
## How we built it
**Machine learning model**
TensorFlow, Keras: Facilitated our model training and model architecture, Python, OpenCV, Prediction Guard LLM, Intel Developer Cloud, Pandas, NumPy, Sklearn, Matplotlib
**Frontend**
TypeScript, Convex, React.js, Shadcn (Components), FramerMotion (Animated components), TailwindCSS
**Backend**
TypeScript, Convex Database & File storage, Clerk (OAuth User login authentication), Python, Flask, Vite, InfoBip (Twillio-like service)
## Challenges we ran into
* We had a lot of trouble cleaning and applying the HAM10000 skin images dataset. Due to long run times, we found it very challenging to make any progress on tuning our model and sorting the data. We eventually started splitting our dataset into smaller batches and training our model on a small amount of data before scaling up which worked around our problem. We also had a lot of trouble normalizing our data, and figuring out how to deal with a large Melanocytic nevi class imbalance. After much trial and error, we were able to correctly apply data augmentation and oversampling methods to address the class imbalance issue.
* One of our biggest challenges was setting up our backend Flask server. We encountered so many environment errors, and for a large portion of the time, the server was only able to run on one computer. After many Google searches, we persevered and resolved the errors.
## Accomplishments that we're proud of
* We are incredibly proud of developing a working open-source, AI-powered application that democratizes access to skin cancer assessments.
* Tackling the technical challenges of cleaning and applying the HAM10000 skin images dataset, dealing with class imbalances, and normalizing data has been a journey of persistence and innovation.
* Setting up a secure and reliable backend server was another significant hurdle we overcame. The process taught us the importance of resilience and resourcefulness, as we navigated through numerous environmental errors to achieve a stable and scalable solution that protects patient data confidentiality.
* Integrating many technologies that were new to a lot of the team such as Clerk for authentication, Convex for user data management, Prediction Guard LLM, and Intel Developer Cloud.
* Extending beyond the technical domain, reflecting a deep dedication to inclusivity, education, and empowerment in healthcare.
## What we learned
* Critical importance of data quality and management in AI-driven applications. The challenges we faced in cleaning and applying the HAM10000 skin images dataset underscored the need for meticulous data preprocessing to ensure AI model accuracy, reliability, and equality.
* How to Integrate many different new technologies such as Convex, Clerk, Flask, Intel Cloud Development, Prediction Guard LLM, and Infobip to create a seamless and secure user experience.
## What's next for DermaDetect
* Finding users to foster future development and feedback.
* Partnering with healthcare organizations and senior communities for wider adoption.
* Continuously improving upon data curation, model training, and user experience through ongoing research and development.
|
# 🚗 InsuclaimAI: Simplifying Insurance Claims 📝
## 🌟 Inspiration
💡 After a frustrating experience with a minor fender-bender, I was faced with the overwhelming process of filing an insurance claim. Filling out endless forms, speaking to multiple customer service representatives, and waiting for assessments felt like a second job. That's when I knew that there needed to be a more streamlined process. Thus, InsuclaimAI was conceived as a solution to simplify the insurance claim maze.
## 🎓 What I Learned
### 🛠 Technologies
#### 📖 OCR (Optical Character Recognition)
* OCR technologies like OpenCV helped in scanning and reading textual information from physical insurance documents, automating the data extraction phase.
#### 🧠 Machine Learning Algorithms (CNN)
* Utilized Convolutional Neural Networks to analyze and assess damage in photographs, providing an immediate preliminary estimate for claims.
#### 🌐 API Integrations
* Integrated APIs from various insurance providers to automate the claims process. This helped in creating a centralized database for multiple types of insurance.
### 🌈 Other Skills
#### 🎨 Importance of User Experience
* Focused on intuitive design and simple navigation to make the application user-friendly.
#### 🛡️ Data Privacy Laws
* Learned about GDPR, CCPA, and other regional data privacy laws to make sure the application is compliant.
#### 📑 How Insurance Claims Work
* Acquired a deep understanding of the insurance sector, including how claims are filed, and processed, and what factors influence the approval or denial of claims.
## 🏗️ How It Was Built
### Step 1️⃣: Research & Planning
* Conducted market research and user interviews to identify pain points.
* Designed a comprehensive flowchart to map out user journeys and backend processes.
### Step 2️⃣: Tech Stack Selection
* After evaluating various programming languages and frameworks, Python, TensorFlow, and Flet (From Python) were selected as they provided the most robust and scalable solutions.
### Step 3️⃣: Development
#### 📖 OCR
* Integrated Tesseract for OCR capabilities, enabling the app to automatically fill out forms using details from uploaded insurance documents.
#### 📸 Image Analysis
* Exploited an NLP model trained on thousands of car accident photos to detect the damages on automobiles.
#### 🏗️ Backend
##### 📞 Twilio
* Integrated Twilio to facilitate voice calling with insurance agencies. This allows users to directly reach out to the Insurance Agency, making the process even more seamless.
##### ⛓️ Aleo
* Used Aleo to tokenize PDFs containing sensitive insurance information on the blockchain. This ensures the highest levels of data integrity and security. Every PDF is turned into a unique token that can be securely and transparently tracked.
##### 👁️ Verbwire
* Integrated Verbwire for advanced user authentication using FaceID. This adds an extra layer of security by authenticating users through facial recognition before they can access or modify sensitive insurance information.
#### 🖼️ Frontend
* Used Flet to create a simple yet effective user interface. Incorporated feedback mechanisms for real-time user experience improvements.
## ⛔ Challenges Faced
#### 🔒 Data Privacy
* Researching and implementing data encryption and secure authentication took longer than anticipated, given the sensitive nature of the data.
#### 🌐 API Integration
* Where available, we integrated with their REST APIs, providing a standard way to exchange data between our application and the insurance providers. This enhanced our application's ability to offer a seamless and centralized service for multiple types of insurance.
#### 🎯 Quality Assurance
* Iteratively improved OCR and image analysis components to reach a satisfactory level of accuracy. Constantly validated results with actual data.
#### 📜 Legal Concerns
* Spent time consulting with legal advisors to ensure compliance with various insurance regulations and data protection laws.
## 🚀 The Future
👁️ InsuclaimAI aims to be a comprehensive insurance claim solution. Beyond just automating the claims process, we plan on collaborating with auto repair shops, towing services, and even medical facilities in the case of personal injuries, to provide a one-stop solution for all post-accident needs.
|
## Inspiration
When we joined the hackathon, we began brainstorming about problems in our lives. After discussing some constant struggles in their lives with many friends and family, one response was ultimately shared: health. Interestingly, one of the biggest health concerns that impacts everyone in their lives comes from their *skin*. Even though the skin is the biggest organ in the body and is the first thing everyone notices, it is the most neglected part of the body.
As a result, we decided to create a user-friendly multi-modal model that can discover their skin discomfort through a simple picture. Then, through accessible communication with a dermatologist-like chatbot, they can receive recommendations, such as specific types of sunscreen or over-the-counter medications. Especially for families that struggle with insurance money or finding the time to go and wait for a doctor, it is an accessible way to understand the blemishes that appear on one's skin immediately.
## What it does
The app is a skin-detection model that detects skin diseases through pictures. Through a multi-modal neural network, we attempt to identify the disease through training on thousands of data entries from actual patients. Then, we provide them with information on their disease, recommendations on how to treat their disease (such as using specific SPF sunscreen or over-the-counter medications), and finally, we provide them with their nearest pharmacies and hospitals.
## How we built it
Our project, SkinSkan, was built through a systematic engineering process to create a user-friendly app for early detection of skin conditions. Initially, we researched publicly available datasets that included treatment recommendations for various skin diseases. We implemented a multi-modal neural network model after finding a diverse dataset with almost more than 2000 patients with multiple diseases. Through a combination of convolutional neural networks, ResNet, and feed-forward neural networks, we created a comprehensive model incorporating clinical and image datasets to predict possible skin conditions. Furthermore, to make customer interaction seamless, we implemented a chatbot using GPT 4o from Open API to provide users with accurate and tailored medical recommendations. By developing a robust multi-modal model capable of diagnosing skin conditions from images and user-provided symptoms, we make strides in making personalized medicine a reality.
## Challenges we ran into
The first challenge we faced was finding the appropriate data. Most of the data we encountered needed to be more comprehensive and include recommendations for skin diseases. The data we ultimately used was from Google Cloud, which included the dermatology and weighted dermatology labels. We also encountered overfitting on the training set. Thus, we experimented with the number of epochs, cropped the input images, and used ResNet layers to improve accuracy. We finally chose the most ideal epoch by plotting loss vs. epoch and the accuracy vs. epoch graphs. Another challenge included utilizing the free Google Colab TPU, which we were able to resolve this issue by switching from different devices. Last but not least, we had problems with our chatbot outputting random texts that tended to hallucinate based on specific responses. We fixed this by grounding its output in the information that the user gave.
## Accomplishments that we're proud of
We are all proud of the model we trained and put together, as this project had many moving parts. This experience has had its fair share of learning moments and pivoting directions. However, through a great deal of discussions and talking about exactly how we can adequately address our issue and support each other, we came up with a solution. Additionally, in the past 24 hours, we've learned a lot about learning quickly on our feet and moving forward. Last but not least, we've all bonded so much with each other through these past 24 hours. We've all seen each other struggle and grow; this experience has just been gratifying.
## What we learned
One of the aspects we learned from this experience was how to use prompt engineering effectively and ground an AI model and user information. We also learned how to incorporate multi-modal data to be fed into a generalized convolutional and feed forward neural network. In general, we just had more hands-on experience working with RESTful API. Overall, this experience was incredible. Not only did we elevate our knowledge and hands-on experience in building a comprehensive model as SkinSkan, we were able to solve a real world problem. From learning more about the intricate heterogeneities of various skin conditions to skincare recommendations, we were able to utilize our app on our own and several of our friends' skin using a simple smartphone camera to validate the performance of the model. It’s so gratifying to see the work that we’ve built being put into use and benefiting people.
## What's next for SkinSkan
We are incredibly excited for the future of SkinSkan. By expanding the model to incorporate more minute details of the skin and detect more subtle and milder conditions, SkinSkan will be able to help hundreds of people detect conditions that they may have ignored. Furthermore, by incorporating medical and family history alongside genetic background, our model could be a viable tool that hospitals around the world could use to direct them to the right treatment plan. Lastly, in the future, we hope to form partnerships with skincare and dermatology companies to expand the accessibility of our services for people of all backgrounds.
|
partial
|
# RecycPal

## Summary
RecycPal is your pal for creating a more sustainable world! RecycPal uses machine learning and artificial intelligence to help you identify what can be or cannot be recycled.
This project was developed during DeltaHacks 8. Please check out our DevPost here: <https://devpost.com/software/recycpal>
## Motivation
The effects of climate change are already being felt, especially in recent times with record breaking temperatures being recorded in alarming numbers each year [1]. According to the Environmental Protection Agency [2], Americans generated 292.4 million tons of material solid waste in 2018. Out of that amount, 69 million tons of waste were recycled and another 25 million tons were composted. This resulted in a 32.1 percent recycling and composting rate. These numbers must improve if we want a greener and sustainable future.
Our team believes that building software that will educate the public on the small things they can do to help will ultimately create a massive change. We developed RecycPal in pursuit of these greener goals and a desire to help other eco-friendly people make the world a better place.
## Meet the Team
* Denielle Abaquita (iOS Front-end)
* Jon Abrigo (iOS Front-end)
* Justin Esguerra (ML, Back-end)
* Ashley Hart (ML, Back-end)
## Tech Stack
RecycPal was designed and built with the following technolgies:
* Figma
* CoreML
* XCode
We also utilize some free art assets from Flaticon. [3]
## Frontend

### History Tab
| History Tab Main | Previous Picture |
| --- | --- |
| | |
The purpose of this tab is to let the user see the pictures they have taken in the past. At the top of this tab will be a cell that leads to finding the nearest recycling center for easy access to this important feature.
Each cell in this section will lead to a previously taken picture by the user and will be labeled with the date the user took the picture.
### Camera Tab
| Pointing the Camera | Picture Taken |
| --- | --- |
| | |
The purpose of this tab is to take a picture of the user's surroundings to identify any recyclable objects in the frame. Each picture will be automatically saved into the user's history. We utilized Apple's CoreML and Vision APIs to complete this section. [4, 5]
After the user takes a picture, the application will perform some machine learning algorithms in the backend to identify any objects in the picture. The user will then see the object highlighted and labeled within the picture.
Afterwards, the user has the option to take another picture.
### Information Tab
| Information Tab | More Info on Paper |
| --- | --- |
| | |
The purpose of this tab is to provide the user information on the nearest recycling centers and the best recycling practices based on the materials. We consulted resources provided by the Environmental Protection Agency to gather our information [6].
In this case, we have paper, plastic, and metal materials. We will also include glass and non-recyclables with information on how to deal with them.
## Backend
### Machine Learning
This was our team's first time tackling machine learning and we were able to learn about neural networks, dataseet preparation, the model training process and so much more. We took advantage of CoreML [7] to create a machine learning model that would receive a photo of an object taken by the user and attempt to classify it into one of the following categories:
1. Cardboard
2. Paper
3. Plastic
4. Metal
5. Glass
6. Trash
The training process introduced some new challenges that our team had to overcome. We used datasets from Kaggle [8, 9] and the TACO project [10] to train our model. In order to test our data, we utilized a portion of our data sets that we did not train with and took pictures of trash we had in our homes to give the model fresh input to predict on.
We worked to ensure that that our results would have a confidnece rating of at least 80% so the front-end of the application could take that result and display proper infromation to the user.
## What We Learned
### Denielle
RecycPal is the result of the cumulative effort of 3 friends wanting to build something useful and impactful. During this entire project, I was able to solidifiy my knowledge of iOS development after focusing on web development for the past few months. I was also able to learn AVFoundation and CoreML. AVFoundation is a framework in iOS that allows developers to incorporate the camera in their applications. CoreML, on the other hand, helps with training and developing models to be used in machine learning. Overall, I learned so much, and I am happy to have spent the time to work on this project with my friends.
### Justin
Starting on this project, I had a general idea of how machine learning models work, but nothing prepared for me the adventure that ensued these past 36 hours. I learned CoreML fundamentals, how to compile and annotate datasets, and expanded my knowledge in XCode. These are just the tip of the iceberg considering all of our prototypes we had to scrap, but it was a privelege to grind this out with my friends.
### Jon
I have learned A TON of things to put it simply. This was my first time developing on the frontend so most of the languages and process flow were new to me. I learned how to navigate and leverage the tools offered by Figma and helped create the proof of concept for RecycPal's application. Learned how to develop with Xcode and Swift and assist on creating the launch screen and home page of the application. Overall, I am thankful for the opportunity that I have been given throughout this Hackathon.
### Ashley
This project served as my first hands on experience with machine learning. I learned about machine learning tasks such as image classification, expermineted with the many utilities that Python offers for data science and I learned how to organize, label, create, and utilize data sets. I also lerned how libaries such as numpy and matplotlib could be combined with frameworks such as PyTorch to build neural networks. I was also able to experiment with Kaggle and Jyupter Notebooks.
## Challenges We Ran Into
### Denielle
The biggest challenges I have ran into are the latest updates to Xcode and iOS. Because it has been some time since I last developed for iOS, I have little familiarity with the updates to iOS 15.0 and above. In this case, I had to adjust to learn UIButton.Configuration and Appearance configurations for various components. As a result, that slowed down development a little bit, but I am happy to have learned about this updates! In the end, the updates are a welcome change, and I look forward to learning more and seeing what's in store in the future.
### Justin
I didn't run into challenges. The challenges ran over me. From failing to implent PyTorch into our application, struggling to create Numpy (Python) based datasets, and realizing that using Google Cloud Platform for remote access to the database was too tedious and too out of the scope for our project. Despite all these challenges we persevered until we found a solution, CoreML. Even then we still ran into Xcode and iOS updates and code depracations which made this inifinitely more frustrating but ten times more rewarding.
### Jon
This was my first time developing on the front end as I have mainly developed on the backend prior. Learning how to create prototypes like the color schema of the application, creating and resizing the application's logos and button icons, and developing on both the programmatic and Swift's storyboards methods were some of the challenges I faced throughout the event. Although this really slowed the development time, I am grateful for the experience and knowledge I have gained throughout this Hackathon.
### Ashley
I initially attempted to build a model for this application using PyTorch. I chose this framework because of its computing power, accessible documentation. Unfortunately, I ran into several errors when I had to convert my images into inputs for a neural network. On the bright side, we found Core ML and utilized it in our application with great success. My work with PyTorch is not over as I will continue to learn more about it for my personal studies and for future hackathons. I also conducted research for this project and learned more about how I can recycle waste.
## What's Next for RecycPal?
Future development goals include:
* Integrating computer vision, allowing the model to see and classify multiple objects in real time.
* Bolstering the accuracy of our model by providing it with more training data.
* Getting user feedback to improve user experience and accessibility.
* Conducting research to evaluate how effective the application is at helping people recycle their waste.
* Expanding the classifications of our model to include categories for electronics, compostables, and materials that need to be taken to a store/facility to be proccessed.
* Adding waste disposal location capabilites, so the user can be aware of nearby locarions where they can process their waste.
### Conclusion
Thank you for checking out our project! If you have suggestions, feel free to reach out to any of the RecycPal developers through the socials we have attached to our DevPost accounts.
## References
[1] Climate change evidence: How do we know? 2022. NASA. <https://climate.nasa.gov/evidence/>.
[2] EPA. 2018. National Overview: Facts and Figures on Materials, Wastes and Recycling. <https://www.epa.gov/facts-and-figures-about-materials-waste-and-recycling/national-overview-facts-and-figures-materials>.
[3] EPA. How Do I Recycle?: Common Recyclables. <https://www.epa.gov/recycle/how-do-i-recycle-common-recyclables>.
[4] Apple. Classifying Images with Vision and Core ML. Apple Developer Documentation. <https://developer.apple.com/documentation/vision/classifying_images_with_vision_and_core_ml>.
[5] Chang, C. 2018. Garbage Classification. Kaggle. <https://www.kaggle.com/asdasdasasdas/garbage-classification>.
[6] Sekar, S. 2019. Waste classification data. Kaggle. <https://www.kaggle.com/techsash/waste-classification-data>.
[7] Pedro F Proença and Pedro Simões. 2020. TACO: Trash Annotations in Context for Litter Detection. arXiv preprint arXiv:2003.06975 (2020).
|
## Inspiration
Let's start by taking a look at some statistics on waste from Ontario and Canada. In Canada, only nine percent of plastics are recycled, while the rest is sent to landfills. More locally, in Ontario, over 3.6 million metric tonnes of plastic ended up as garbage due to tainted recycling bins. Tainted recycling bins occur when someone disposes of their waste into the wrong bin, causing the entire bin to be sent to the landfill. Mark Badger, executive vice-president of Canada Fibers, which runs 12 plants that sort about 60 percent of the curbside recycling collected in Ontario has said that one in three pounds of what people put into blue bins should not be there. This is a major problem, as it is causing our greenhouse gas emissions to grow exponentially. However, if we can reverse this, not only will emissions lower, but according to Deloitte, around 42,000 new jobs will be created. Now let's turn our focus locally. The City of Kingston is seeking input on the implementation of new waste strategies to reach its goal of diverting 65 percent of household waste from landfill by 2025. This project is now in its public engagement phase. That’s where we come in.
## What it does
Cycle AI is an app that uses machine learning to classify certain articles of trash/recyclables to incentivize awareness of what a user throws away. You simply pull out your phone, snap a shot of whatever it is that you want to dispose of and Cycle AI will inform you where to throw it out as well as what it is that you are throwing out. On top of that, there are achievements for doing things such as using the app to sort your recycling every day for a certain amount of days. You keep track of your achievements and daily usage through a personal account.
## How We built it
In a team of four, we separated into three groups. For the most part, two of us focused on the front end with Kivy, one on UI design, and one on the backend with TensorFlow. From these groups, we divided into subsections that held certain responsibilities like gathering data to train the neural network. This was done by using photos taken from waste picked out of, relatively unsorted, waste bins around Goodwin Hall at Queen's University. 200 photos were taken for each subcategory, amounting to quite a bit of data by the end of it. The data was used to train the neural network backend. The front end was all programmed on Python using Kivy. After the frontend and backend were completed, a connection was created between them to seamlessly feed data from end to end. This allows a user of the application to take a photo of whatever it is they want to be sorted, having the photo feed to the neural network, and then returned to the front end with a displayed message. The user can also create an account with a username and password, for which they can use to store their number of scans as well as achievements.
## Challenges We ran into
The two hardest challenges we had to overcome as a group was the need to build an adequate dataset as well as learning the framework Kivy. In our first attempt at gathering a dataset, the images we got online turned out to be too noisy when grouped together. This caused the neural network to become overfit, relying on patterns to heavily. We decided to fix this by gathering our own data. I wen around Goodwin Hall and went into the bins to gather "data". After washing my hands thoroughly, I took ~175 photos of each category to train the neural network with real data. This seemed to work well, overcoming that challenge. The second challenge I, as well as my team, ran into was our little familiarity with Kivy. For the most part, we had all just began learning Kivy the day of QHacks. This posed to be quite a time-consuming problem, but we simply pushed through it to get the hang of it.
## 24 Hour Time Lapse
**Bellow is a 24 hour time-lapse of my team and I work. The naps on the tables weren't the most comfortable.**
<https://www.youtube.com/watch?v=oyCeM9XfFmY&t=49s>
|
## Inspiration
Food can be tricky, especially for college students. There are so many options for your favorite foods, like restaurants, frozen foods, grocery stores, and even cooking yourself. We want to be able to get the foods we love, with the best experience.
## What it does
Shows you and compares all of the options for a specific dish you want to eat. Takes data from restaurants, grocery stores, and more and aggregates everything into an easy to understand list. Sorts based on a relevance algorithm to give you the best possible experience.
## How we built it
The frontend is HTML, CSS, and JS. The backend we used Python, NodeJS, Beautiful Soup for web scraping, and several APIs for getting data. We also used Google Firebase to store the data in a database.
## Challenges we ran into
It was difficult trying to decide the scope, and what we could realistically make in such a short time frame.
## Accomplishments that we're proud of
We're proud of the overall smooth visuals, and the functionality of showing you many different options for foods.
## What we learned
We learned about web design, along with data collection with APIs and web scraping.
## What's next for Food Master
We are hoping to implement the ChatGPT API to interpret restaurant menus and automate data collection.
|
winning
|
## Inspiration
High cost of learning is a common issue with many feature-rich note-taking software today. They may be excellent tools for some, but you might struggle to use them effectively. Cluttered notes make it challenging to revisit and relearn
important information. Time is always being wasted when you try to organize and format notes manually. Meaningless, repetitive work to record similar ideas.
All these issues make your learning process cumbersome and inefficient. We aim not only to simplify these learning processes but also to create a software that integrates your knowledge and inspirations.
## What it does
## How we built it
To develop our project, we utilized the Intel Tiber Developer Cloud, which provides a robust and scalable environment for our needs. Here are the key steps and components involved in building our solution:
Setting Up the Environment:
-We set up our instances on the Intel Tiber Developer Cloud. Specifically, we used a Small VM instance equipped with the Intel® Xeon® 4th Gen Scalable processor.
-The environment provided us with the necessary computational power and flexibility to handle our workload efficiently.
Backend Development:
For the backend, we utilized FastAPI, a modern and fast web framework for building APIs with Python 3.10.
FastAPI allowed us to quickly develop and deploy our backend services, providing robust and efficient API endpoints to handle requests and manage data.
Frontend Development:
The frontend of our application was built using React, a popular JavaScript library for building user interfaces.
React enabled us to create a dynamic and responsive user interface that interacts seamlessly with our backend services.
Leveraging Intel Extensions for PyTorch (IPEX) and LLM:
We incorporated Intel Extensions for PyTorch (IPEX) to optimize and accelerate our machine learning workflows.
This integration allowed us to leverage advanced optimizations and hardware acceleration provided by Intel, ensuring efficient and performant model training and inference.
Prompt Engineering for Output Generation:
A crucial aspect of our project was designing effective prompts to generate high-quality outputs.
By carefully crafting our prompts, we were able to harness the power of large language models (LLMs) to produce accurate and relevant results.
## Challenges we ran into
## Accomplishments that we're proud of
## What we learned
## What's next for Notakers AI
Next, we plan to design a comprehensive knowledge base that seamlessly integrates all your notes, allowing users to draw inspiration and ideas from the interconnected content. This knowledge base will help users better organize and relate their thoughts and information, enhancing learning efficiency and fostering creative thinking.
We also aim to incorporate speech-to-text and text-to-speech functionalities. These features will be particularly beneficial for individuals with reading disorders and ADHD, enabling them to quickly and easily record and review their ideas. With speech-to-text, users can effortlessly convert spoken words into written notes, while text-to-speech allows them to listen to their notes, making comprehension and retention easier.
These enhancements not only simplify the learning process but also ensure that every user, regardless of their challenges, can efficiently capture and integrate their knowledge and inspiration. We believe that with these improvements, Notakers AI will become an indispensable tool for learning and creativity.
|
## Inspiration
The inspiration of this project came from one of the sponsors in **HTN (Co:here)**. Their goal is to make AI/ML accessible to devs, which gave me the idea, that I can build a platform, where people who do not even know how to code can build their own Machine Learning models.
Coding is a great skill to have, but we need to ensure that it doesn't become a necessity to survive. There are a lot of people who prefer to work with the UI and cannot understand code. As developers, it is our duty to cater to this audience as well. This is my inspiration and goal through this project.
## What it does
The project works by taking in the necessary details of the Machine Learning model that are required by the function. Then it works in the backend to dynamically generate code and build the model. It is even able to decide whether to convert data in the dataset to vectors or not, based on race conditions, and ensure that the model doesn't fail. It then returns the required metric to the user for them to check it out.
## How I built it
I first built a Flask backend that took in information regarding the model using JSON. Then I built a service to parse and evaluate the necessary conditions for the Scikit Learn models, and then train and predict with it. After ensuring that my backend was working properly, I moved to the front-end where I spent a lot of my time, building a clean UI/UX design so that the users can have the best and the most comfortable experience while using my application.
## Challenges I ran into
One of the key challenges of this project is to generate code dynamically at run-time upon user input. This requirement is a very hefty one as I had to ensure that the inputs won't break the code. I read through the documentation of Scikit Learn and worked with it, while building the web app.
## Accomplishments that I'm proud of
I was able to full-fledged working application on my own, building the entire frontend and backend from scratch. The application is able to take in the features of the model and the dataset, and display the results of the trainings. This allows the user to tweak their model and check results everytime to see what works best for them. I'm especially proud of being able to generate and run code dynamically based on user input.
## What I learned
This project, more than anything, was a challenge to myself, to see how far I had come from my last HackTheNorth experience. I wanted to get the full experience of building every part of the project, and that's why I worked solo. This gave me experience of all the aspects of building a software from scratch in limited amount of time, allowing me to grasp the bigger picture.
## What's next for AutoML
My very first step will be to work on integrating TensorFlow to this project. My initial goal was to have a visual representation of Neural Network layers for users to drag and drop. Due to time and technical constraints, I couldn't fully idealize my goal. So this is the first thing I am going to work with. After this, I'll probably work with authentication so that people can work on their projects and store their progresses.
|
## Inspiration
In a world full of so much info but limited time as we are so busy and occupied all the time, we wanted to create a tool that helps students make the most of their learning—quickly and effectively. We imagined a platform that could turn complex material into digestible, engaging content tailored for a fast-paced generation.
## What it does
Lemme Learn More (LLM) transforms study materials into bite-sized TikTok-style trendy and attractive videos or reels, flashcards, and podcasts. Whether it's preparing for exams or trying to stay informed on the go, LLM breaks down information into formats that match how today's students consume content. If you're an avid listener of podcasts during commute to work - this is the best platform for you.
## How we built it
We built LLM using a combination of AI-powered tools like OpenAI for summaries, Google TTS for podcasts, and pypdf2 to pull data from PDFs. The backend runs on Flask, while the frontend is React.js, making the platform both interactive and scalable. Also used fetch.ai ai agents to deploy on test net - blockchain.
## Challenges we ran into
Due to a highly-limited time, we ran into a deployment challenge where we faced some difficulty setting up on Heroku cloud service platform. It was an internal level issue wherein we were supposed to change config files - I personally spent 5 hours on that - my team spent some time as well. Could not figure it out by the time hackathon ended : we decided not to deploy today.
In brainrot generator module, audio timing could not match with captions. This is something for future scope.
One of the other biggest challenges was integrating sponsor Fetch.ai agentverse AI Agents which we did locally and proud of it!
## Accomplishments that we're proud of
Biggest accomplishment would be that we were able to run and integrate all of our 3 modules and a working front-end too!!
## What we learned
We learned that we cannot know everything - and cannot fix every bug in a limited time frame. It is okay to fail and it is more than okay to accept it and move on - work on the next thing in the project.
## What's next for Lemme Learn More (LLM)
Coming next:
1. realistic podcast with next gen TTS technology
2. shorts/reels videos adjusted to the trends of today
3. Mobile app if MVP flies well!
|
losing
|
## Inspiration
The impact of COVID-19 has had lasting effects on the way we interact and socialize with each other. Even when engulfed by bustling crowds and crowded classrooms, it can be hard to find our friends and the comfort of not being alone. Too many times have we grabbed lunch, coffee, or boba alone only to find out later that there was someone who was right next to us!
Inspired by our undevised use of Apple's FindMy feature, we wanted to create a cross-device platform that's actually designed for promoting interaction and social health!
## What it does
Bump! is a geolocation-based social networking platform that encourages and streamlines day-to-day interactions.
**The Map**
On the home map, you can see all your friends around you! By tapping on their icon, you can message them or even better, Bump! them.
If texting is like talking, you can think of a Bump! as a friendly wave. Just a friendly Bump! to let your friends know that you're there!
Your bestie cramming for a midterm at Mofitt? Bump! them for good luck!
Your roommate in the classroom above you? Bump! them to help them stay awake!
Your crush waiting in line for a boba? Make that two bobas! Bump! them.
**Built-in Chat**
Of course, Bump! comes with a built-in messaging chat feature!
**Add Your Friends**
Add your friends to allow them to see your location! Your unique settings and friends list are tied to the account that you register and log in with.
## How we built it
Using React Native and JavaScript, Bump! is built for both IOS and Android. For the Backend, we used MongoDB and Node.js. The project consisted of four major and distinct components.
**Geolocation Map**
For our geolocation map, we used the expo's geolocation library, which allowed us to cross-match the positional data of all the user's friends.
**User Authentication**
The user authentication proceeds was built using additional packages such as Passport.js, Jotai, and Bcrypt.js. Essentially, we wanted to store new users through registration and verify old users through login by searching them up in MongoDB, hashing and salting their password for registration using Bcrypt.js, and comparing their password hash to the existing hash in the database for login. We also used Passport.js to create Json Web Tokens, and Jotai to store user ID data globally in the front end.
**Routing and Web Sockets**
To keep track of user location data, friend lists, conversation logs, and notifications, we used MongoDB as our database and a node.js backend to save and access data from the database. While this worked for the majority of our use cases, using HTTP protocols for instant messaging proved to be too slow and clunky so we made the design choice to include WebSockets for client-client communication. Our architecture involved using the server as a WebSocket host that would receive all client communication but would filter messages so they would only be delivered to the intended recipient.
**Navigation and User Interface**:
For our UI, we wanted to focus on simplicity, cleanliness, and neutral aesthetics. After all, we felt that the Bump! the experience was really about the time spent with friends rather than on the app, so designed the UX such that Bump! is really easy to use.
## Challenges we ran into
To begin, package management and setup were fairly challenging. Since we've never done mobile development before, having to learn how to debug, structure, and develop our code was definitely tedious. In our project, we initially programmed our frontend and backend completely separately; integrating them both and working out the moving parts was really difficult and required everyone to teach each other how their part worked.
When building the instant messaging feature, we ran into several design hurdles; HTTP requests are only half-duplex, as they are designed with client initiation in mind. Thus, there is no elegant method for server-initiated client communication. Another challenge was that the server needed to act as the host for all WebSocket communication, resulting in the need to selectively filter and send received messages.
## Accomplishments that we're proud of
We're particularly proud of Bump! because we came in with limited or no mobile app development experience (in fact, this was the first hackathon for half the team). This project was definitely a huge learning experience for us; not only did we have to grind through tutorials, youtube videos, and a Stack Overflowing of tears, we also had to learn how to efficiently work together as a team. Moreover, we're also proud that we were not only able to build something that would make a positive impact in theory but a platform that we see ourselves actually using on a day-to-day basis. Lastly, despite setbacks and complications, we're super happy that we developed an end product that resembled our initial design.
## What we learned
In this project, we really had an opportunity to dive headfirst in mobile app development; specifically, learning all about React Native, JavaScript, and the unique challenges of implementing backend on mobile devices. We also learned how to delegate tasks more efficiently, and we also learned to give some big respect to front-end engineers!
## What's next for Bump!
**Deployment!**
We definitely plan on using the app with our extended friends, so the biggest next step for Bump! is polishing the rough edges and getting it on App Stores. To get Bump! production-ready, we're going to robustify the backend, as well as clean up the frontend for a smoother look.
**More Features!**
We also want to add some more functionality to Bump! Here are some of the ideas we had, let us know if there's any we missed!
* Adding friends with QR-code scanning
* Bump! leaderboards
* Status updates
* Siri! "Hey Siri, bump Emma!"
|
## Problem
In these times of isolation, many of us developers are stuck inside which makes it hard for us to work with our fellow peers. We also miss the times when we could just sit with our friends and collaborate to learn new programming concepts. But finding the motivation to do the same alone can be difficult.
## Solution
To solve this issue we have created an easy to connect, all in one platform where all you and your developer friends can come together to learn, code, and brainstorm together.
## About
Our platform provides a simple yet efficient User Experience with a straightforward and easy-to-use one-page interface.
We made it one page to have access to all the tools on one screen and transition between them easier.
We identify this page as a study room where users can collaborate and join with a simple URL.
Everything is Synced between users in real-time.
## Features
Our platform allows multiple users to enter one room and access tools like watching youtube tutorials, brainstorming on a drawable whiteboard, and code in our inbuilt browser IDE all in real-time. This platform makes collaboration between users seamless and also pushes them to become better developers.
## Technologies you used for both the front and back end
We use Node.js and Express the backend. On the front end, we use React. We use Socket.IO to establish bi-directional communication between them. We deployed the app using Docker and Google Kubernetes to automatically scale and balance loads.
## Challenges we ran into
A major challenge was collaborating effectively throughout the hackathon. A lot of the bugs we faced were solved through discussions. We realized communication was key for us to succeed in building our project under a time constraints. We ran into performance issues while syncing data between two clients where we were sending too much data or too many broadcast messages at the same time. We optimized the process significantly for smooth real-time interactions.
## What's next for Study Buddy
While we were working on this project, we came across several ideas that this could be a part of.
Our next step is to have each page categorized as an individual room where users can visit.
Adding more relevant tools, more tools, widgets, and expand on other work fields to increase our User demographic.
Include interface customizing options to allow User’s personalization of their rooms.
Try it live here: <http://35.203.169.42/>
Our hopeful product in the future: <https://www.figma.com/proto/zmYk6ah0dJK7yJmYZ5SZpm/nwHacks_2021?node-id=92%3A132&scaling=scale-down>
Thanks for checking us out!
|
## Inspiration
BThere emerged from a genuine desire to strengthen friendships by addressing the subtle challenges in understanding friends on a deeper level. The team recognized that nuanced conversations often go unnoticed, hindering meaningful support and genuine interactions. In the context of the COVID-19 pandemic, the shift to virtual communication intensified these challenges, making it harder to connect on a profound level. Lockdowns and social distancing amplified feelings of isolation, and the absence of in-person cues made understanding friends even more complex. BThere aims to use advanced technologies to overcome these obstacles, fostering stronger and more authentic connections in a world where the value of meaningful interactions has become increasingly apparent.
## What it does
BThere is a friend-assisting application that utilizes cutting-edge technologies to analyze conversations and provide insightful suggestions for users to connect with their friends on a deeper level. By recording conversations through video, the application employs Google Cloud's facial recognition and speech-to-text APIs to understand the friend's mood, likes, and dislikes. The OpenAI API generates personalized suggestions based on this analysis, offering recommendations to uplift a friend in moments of sadness or providing conversation topics and activities for neutral or happy states. The backend, powered by Python Flask, handles data storage using Firebase for authentication and data persistence. The frontend is developed using React, JavaScript, Next.js, HTML, and CSS, creating a user-friendly interface for seamless interaction.
## How we built it
BThere involves a multi-faceted approach, incorporating various technologies and platforms to achieve its goals. The recording feature utilizes WebRTC for live video streaming to the backend through sockets, but also allows users to upload videos for analysis. Google Cloud's facial recognition API identifies facial expressions, while the speech-to-text API extracts spoken content. The combination of these outputs serves as input for the OpenAI API, generating personalized suggestions. The backend, implemented in Python Flask, manages data storage in Firebase, ensuring secure authentication and persistent data access. The frontend, developed using React, JavaScript, Next.js, HTML, and CSS, delivers an intuitive user interface.
## Accomplishments that we're proud of
* Successfully integrating multiple technologies into a cohesive and functional application
* Developing a user-friendly frontend for a seamless experience
* Implementing real-time video streaming using WebRTC and sockets
* Leveraging Google Cloud and OpenAI APIs for advanced facial recognition, speech-to-text, and suggestion generation
## What's next for BThere
* Continuously optimizing the speech to text and emotion analysis model for improved accuracy with different accents, speech mannerisms, and languages
* Exploring advanced natural language processing (NLP) techniques to enhance conversational analysis
* Enhancing user experience through further personalization and more privacy features
* Conducting user feedback sessions to refine and expand the application's capabilities
|
winning
|
## Inspiration
The idea behind JustChi stemmed from a desire to improve the physical and mental well-being of seniors through accessible and engaging technology. Since everyone on the team has a relative who would benefit from the gentle exercise that is Tai Chi, we thought it would be a wonderful idea to prototype a futuristic VR game targeting the growing senior population. By combining the ancient practice of Tai Chi, known for its health benefits such as improved balance, flexibility, and stress reduction, with modern Virtual Reality (VR) and Computer Vision technology, JustChi aims to provide a unique and immersive experience that is both beneficial and enjoyable for its users.
## What it does
Think "Just Dance" but instead of high-intensity dance, our users are immersed in relaxing and peaceful VR environments where they can engage in the ancient Chinese art of Tai Chi. Once set up on the Meta Quest 2, our users can select from a variety of Tai Chi styles and soothing background environments. They are then sent to these environments where they can follow along with our prerecorded Tai Chi "master" through a game-like experience. Along the way, we provide supportive feedback and calculate the accuracy of their moves, using it to display their Tai Chi score in real-time. Through Just Chi, anyone can learn Tai Chi and reap a myriad of health benefits while being educated on ancient Chinese culture.
## How we built it
We used an open-source computer vision framework called [MediaPipe](https://developers.google.com/mediapipe) to determine our user's pose by tracking keypoints (and their coordinates) displayed along the user's body, storing and transmitting these coordinates through a Flask server. We then ran these coordinates through our pose comparison Python algorithm, which compares the coordinates of the user's keypoints with the keypoints of our Tai Chi "master" using linear algebra techniques. Then, we used Figma, HTML, CSS, JavaScript, and a VR development framework called [A-Frame](https://aframe.io/) to design our VR UI/UX and environment that is displayed to the user through the Meta Quest headset.
## Challenges we ran into
Initially, it was difficult to find a way to track keypoints while interfacing with Unity (a game engine we originally thought about using). However, we eventually found A-Frame and never looked back. It was incredibly challenging to write the pose comparison algorithm because we had trouble syncing the Tai Chi "master" recording with the user in order to compare their keypoint coordinates. Even once we implemented several different versions of the algorithm, it wasn't especially accurate at times. It was also difficult for us to design the UI/UX and environment for the Meta Quest. It was all of our first time working with VR so it was quite the learning curve for us.
## Accomplishments that we're proud of
We're proud of our functional pose comparison algorithm which we finally got to work after almost an entire day of programming, testing, and debugging. We're also very proud that we were able to have a working, enjoyable, and impactful VR game done in less than 2 days. Additionally, we are proud that we were able to find A-Frame and learn a VR web development framework that was previously completely unknown to us. Finally, we are so proud that we were able to spend the weekend with so many passionate, talented, and friendly people.
## What we learned
We learned a lot about VR development frameworks such as A-Frame, the different kinds of computer vision frameworks such as MediaPipe, the amazing art of Tai Chi, and vector similarity algorithms. Particularly, we learned that there are other VR development platforms out there (besides Unity), how to use MediaPipe, different forms of Tai Chi styles (Chen, Yang, Hao, Wu, Chen, etc), and how we can vectorize information and use linear algebra to determine similarity. Most importantly, we learned more about how prevalent depression and health issues are among the elderly, motivating us to create a fitness program that combats these issues: JustChi.
## What's next for JustChi
Our roadmap is filled with exciting developments, from introducing multiplayer capabilities to integrating heart rate monitoring for health and fitness insights. We're committed to expanding JustChi's content, offering new Tai Chi styles, and creating more immersive and personalized environments. The potential for JustChi to make a significant impact is boundless, and we're thrilled to continue this journey of innovation and wellness.
|
## Why we made this
Juve is designed with the concept of "rejuvinate" in mind. We aim to help elderly individuals to recover from physical therapy by harnessing the universal appeal of games in a fulfilling way. By offering engaging and interactive methods for users to practice muscle movements and achieve better health results, we seek to craft an accessible platform where rehabilitation feels less like a chore and more like a delightful adventure.
## What Juve does
After creating an account and logging in, the user enters a page that displays their recovery statistics (games played, time taken, movements tracked, etc). They proceed by entering "game mode", which incorporates our main technology of leveraging video feed data from the user's web camera and displaying it in a video using OpenCV. We track the data of 32 x and y-coordinates of joints in a feedback loop that updates at a rate of 25 frames per second. The relevant joints being trained (such as the right palm in our current model) are tracked specifically and incorporated into the game logic. During this hackathon, we aimed for a game similar to Fruit Ninja, in which collisions between "fruits" and the user's hand are recorded and used to increment points. We improve upon the existing Fruit Ninja game by adding specifications allowing the user to change fruit size, speed, and direction for specific movement training.
## How we built it
Python3 backend, HTML/CSS/Javascript Frontend (with a substantial React/Node frontend effort), OpenCV pose detection, Google Cloud Dataflow data storage and retrieval, SocketIO for data streaming & Flask app routes for user inputs.
## Challenges we ran into
While we developed a React / Node frontend, we were ultimately unable to reconcile this frontend into our project due to the challenges of connecting the video stream to the web. In addition, Google Cloud was a new technology to us and authentication barriers would often prevent team members from running files locally. Finally, the backend technology of displaying a video stream with joint overlays was a surprisingly arduous task (at one point, our video feed contained a dizzying stream of continuous flashes).
## Accomplishments that we're proud of
Many of the tools and ideas we implemented were brand new for us, including Google Cloud, OpenCV, and the entire concept of adding a video stream to a static web page. Everyone in our team came out having learned something new.
## What's next for Juve
In the future, we would like to design more motion games (Flappy Bird, Just Dance) and fine-tune the movement detection options we make through coordinate analysis, such as differentiating between a hand wave and a hand jab by looking at the delta differences in x and y coordinates over a period of time.
|
## Inspiration
We aren't musicians. We can't dance. With AirTunes, we can try to do both! Superheroes are also pretty cool.
## What it does
AirTunes recognizes 10 different popular dance moves (at any given moment) and generates a corresponding sound. The sounds can be looped and added at various times to create an original song with simple gestures.
The user can choose to be one of four different superheroes (Hulk, Superman, Batman, Mr. Incredible) and record their piece with their own personal touch.
## How we built it
In our first attempt, we used OpenCV to maps the arms and face of the user and measure the angles between the body parts to map to a dance move. Although successful with a few gestures, more complex gestures like the "shoot" were not ideal for this method. We ended up training a convolutional neural network in Tensorflow with 1000 samples of each gesture, which worked better. The model works with 98% accuracy on the test data set.
We designed the UI using the kivy library in python. There, we added record functionality, the ability to choose the music and the superhero overlay, which was done with the use of rlib and opencv to detect facial features and map a static image over these features.
## Challenges we ran into
We came in with a completely different idea for the Hack for Resistance Route, and we spent the first day basically working on that until we realized that it was not interesting enough for us to sacrifice our cherished sleep. We abandoned the idea and started experimenting with LeapMotion, which was also unsuccessful because of its limited range. And so, the biggest challenge we faced was time.
It was also tricky to figure out the contour settings and get them 'just right'. To maintain a consistent environment, we even went down to CVS and bought a shower curtain for a plain white background. Afterward, we realized we could have just added a few sliders to adjust the settings based on whatever environment we were in.
## Accomplishments that we're proud of
It was one of our first experiences training an ML model for image recognition and it's a lot more accurate than we had even expected.
## What we learned
All four of us worked with unfamiliar technologies for the majority of the hack, so we each got to learn something new!
## What's next for AirTunes
The biggest feature we see in the future for AirTunes is the ability to add your own gestures. We would also like to create a web app as opposed to a local application and add more customization.
|
losing
|
## Inspiration
Long articles and readings on the web can be difficult to read. Having a tool to break down long paragraphs into easy-to-read bullet points can save a lot of time if we just want to catch the key points.
## What it does
A basic Chrome browser extension that allows you highlight any paragraph of text anywhere on the Internet, generate a summary (in bullet points) of that paragraph, and inject it into the same webpage below that paragraph.
|
## Inspiration
According to a 2012 Pew Research Center [report](http://www.pewinternet.org/2012/11/01/how-teens-do-research-in-the-digital-world/) investigating how teens approach research, "94% of the teachers surveyed say their students are “very likely” to use Google or other online search engines in a typical research assignment." When conducting literature reviews or aggregating sources in this manner, a major pain-point is organizing information and keeping track of where it comes from. From interviews conducted amongst our peers, we've gathered that most people maintain a Word Document where they copy and paste pertinent information that they find from various sources as they browse the web. Our interviewees frequently cited annoyance with having to flip back and forth between their source and the document to copy and paste. We decided to build Scribe to streamline this information collection process.
## What it does
Scribe is a Google Chrome extension that allows a user to copy and paste text of interest from any webpage into a Google Doc of their choosing. The Google Doc is automatically formatted so that any text a user chooses to extract from a source, is grouped together and indexed by the source's url. In essence, Scribe cuts out the steps of creating a Google Doc, switching between the Doc and the source multiple times to grab the text and url, and ultimately formatting the Doc.
## How we built it
Creating, editing, and formatting the Google Docs was done using Google App Scripts. Scribe itself was built using HTML and Javascript.
## Accomplishments that we're proud of
We are most excited about the impact Scribe can have on making student's lives easier while researching for a paper. In addition, our team had never built a Chrome Extension before so we are very excited to share our first one with you!
## What's next for Scribe
This current version of Scribe only collects the url of the webpage the text of interest is from. We've received a lot of user feedback that adding auto-citation would be a huge bonus.
## Where can you find it?
Scribe is now on the Google Chrome Extension store! You can find it [here](https://chrome.google.com/webstore/detail/scribe/cfkhahgibalbckgminkacbbblpinfgoa)
|
## Inspiration
The opioid crisis is a widespread danger, affecting millions of Americans every year. In 2016 alone, 2.1 million people had an opioid use disorder, resulting in over 40,000 deaths. After researching what had been done to tackle this problem, we came upon many pill dispensers currently on the market. However, we failed to see how they addressed the core of the problem - most were simply reminder systems with no way to regulate the quantity of medication being taken, ineffective to prevent drug overdose. As for the secure solutions, they cost somewhere between $200 to $600, well out of most people’s price ranges. Thus, we set out to prototype our own secure, simple, affordable, and end-to-end pipeline to address this problem, developing a robust medication reminder and dispensing system that not only makes it easy to follow the doctor’s orders, but also difficult to disobey.
## What it does
This product has three components: the web app, the mobile app, and the physical device. The web end is built for doctors to register patients, easily schedule dates and timing for their medications, and specify the medication name and dosage. Any changes the doctor makes are automatically synced with the patient’s mobile app. Through the app, patients can view their prescriptions and contact their doctor with the touch of one button, and they are instantly notified when they are due for prescriptions. Once they click on on an unlocked medication, the app communicates with LocPill to dispense the precise dosage. LocPill uses a system of gears and motors to do so, and it remains locked to prevent the patient from attempting to open the box to gain access to more medication than in the dosage; however, doctors and pharmacists will be able to open the box.
## How we built it
The LocPill prototype was designed on Rhino and 3-D printed. Each of the gears in the system was laser cut, and the gears were connected to a servo that was controlled by an Adafruit Bluefruit BLE Arduino programmed in C.
The web end was coded in HTML, CSS, Javascript, and PHP. The iOS app was coded in Swift using Xcode with mainly the UIKit framework with the help of the LBTA cocoa pod. Both front ends were supported using a Firebase backend database and email:password authentication.
## Challenges we ran into
Nothing is gained without a challenge; many of the skills this project required were things we had little to no experience with. From the modeling in the RP lab to the back end communication between our website and app, everything was a new challenge with a lesson to be gained from. During the final hours of the last day, while assembling our final product, we mistakenly positioned a gear in the incorrect area. Unfortunately, by the time we realized this, the super glue holding the gear in place had dried. Hence began our 4am trip to Fresh Grocer Sunday morning to acquire acetone, an active ingredient in nail polish remover. Although we returned drenched and shivering after running back in shorts and flip-flops during a storm, the satisfaction we felt upon seeing our final project correctly assembled was unmatched.
## Accomplishments that we're proud of
Our team is most proud of successfully creating and prototyping an object with the potential for positive social impact. Within a very short time, we accomplished much of our ambitious goal: to build a project that spanned 4 platforms over the course of two days: two front ends (mobile and web), a backend, and a physical mechanism. In terms of just codebase, the iOS app has over 2600 lines of code, and in total, we assembled around 5k lines of code. We completed and printed a prototype of our design and tested it with actual motors, confirming that our design’s specs were accurate as per the initial model.
## What we learned
Working on LocPill at PennApps gave us a unique chance to learn by doing. Laser cutting, Solidworks Design, 3D printing, setting up Arduino/iOS bluetooth connections, Arduino coding, database matching between front ends: these are just the tip of the iceberg in terms of the skills we picked up during the last 36 hours by diving into challenges rather than relying on a textbook or being formally taught concepts. While the skills we picked up were extremely valuable, our ultimate takeaway from this project is the confidence that we could pave the path in front of us even if we couldn’t always see the light ahead.
## What's next for LocPill
While we built a successful prototype during PennApps, we hope to formalize our design further before taking the idea to the Rothberg Catalyzer in October, where we plan to launch this product. During the first half of 2019, we plan to submit this product at more entrepreneurship competitions and reach out to healthcare organizations. During the second half of 2019, we plan to raise VC funding and acquire our first deals with healthcare providers. In short, this idea only begins at PennApps; it has a long future ahead of it.
|
losing
|
## Inspiration
Meet Doctor DoDo. He is a medical practioner, and he has a PhD degree in EVERYTHING!
Dr. DoDo is here to take care of you, and make sure you do-do your homework!
Two main problems arise with virtual learning: It's hard to verify if somebody understands content without seeing their facial expressions/body language, and students tend to forget to take care of themselves, mentally and physically. At least we definitely did.
## What it does
Doctor DoDo is a chrome extension and web-browser "pet" that will teach you about the images or text you highlight on your screen (remember his many PhD's), while keeping watch of your mood (facial expressions), time spent studying, and he'll even remind you to fix your posture (tsk tsk)!
## How we built it
With the use of:
* ChatGPT-4
* Facial Emotion recognition
* Facial Verification recognition
* Voice recognition
* Flask
* Pose recognition with mediapipe
and Procreate for the art/animation,
## Challenges we ran into
1. The initial design was hard to navigate. We didn't know if we wanted him to mainly be a study buddy, include a pomodoro timer, etc.
2. Animation (do I need to say more)
3. Integration hell, backend and frontend were not connecting
## Accomplishments that we're proud of
We're proud of our creativity! But more proud of Dr. DoDo for graduating with a PhD in every branch of knowledge to ever exist.
## What we learned
1. How to integrate backend and frontend software within a limited time
2. Integrating more
3. Animation (do I need to say more again)
## What's next for Doctor DoDo
Here are some things we're adding to Dr. DoDo's future:
Complete summaries of webpages
|
# Pose-Bot
### Inspiration ⚡
**In these difficult times, where everyone is forced to work remotely and with the mode of schools and colleges going digital, students are
spending time on the screen than ever before, it not only affects student but also employees who have to sit for hours in front of the screen. Prolonged exposure to computer screen and sitting in a bad posture can cause severe health problems like postural dysfunction and affect one's eyes. Therefore, we present to you Pose-Bot**
### What it does 🤖
We created this application to help users maintain a good posture and save from early signs of postural imbalance and protect your vision, this application uses a
image classifier from teachable machines, which is a **Google API** to detect user's posture and notifies the user to correct their posture or move away
from the screen when they may not notice it. It notifies the user when he/she is sitting in a bad position or is too close to the screen.
We first trained the model on the Google API to detect good posture/bad posture and if the user is too close to the screen. Then integrated the model to our application.
We created a notification service so that the user can use any other site and simultaneously get notified if their posture is bad. We have also included **EchoAR models to educate** the children about the harms of sitting in a bad position and importance of healthy eyes 👀.
### How We built it 💡
1. The website UI/UX was designed using Figma and then developed using HTML, CSS and JavaScript.Tensorflow.js was used to detect pose and JavaScript API to send notifications.
2. We used the Google Tensorflow.js API to train our model to classify user's pose, proximity to screen and if the user is holding a phone.
3. For training our model we used our own image as the train data and tested it in different settings.
4. This model is then used to classify the users video feed to assess their pose and detect if they are slouching or if they are too close too screen or are sitting in a generally a bad pose.
5. If the user sits in a bad posture for a few seconds then the bot sends a notificaiton to the user to correct their posture or move away from the screen.
### Challenges we ran into 🧠
* Creating a model with good acccuracy in a general setting.
* Reverse engineering the Teachable Machine's Web Plugin snippet to aggregate data and then display notification at certain time interval.
* Integrating the model into our website.
* Embedding EchoAR models to educate the children about the harms to sitting in a bad position and importance of healthy eyes.
* Deploying the application.
### Accomplishments that we are proud of 😌
We created a completely functional application, which can make a small difference in in our everyday health. We successfully made the applicaition display
system notifications which can be viewed across system even in different apps. We are proud that we could shape our idea into a functioning application which can be used by
any user!
### What we learned 🤩
We learned how to integrate Tensorflow.js models into an application. The most exciting part was learning how to train a model on our own data using the Google API.
We also learned how to create a notification service for a application. And the best of all **playing with EchoAR models** to create a functionality which could
actually benefit student and help them understand the severity of the cause.
### What's next for Pose-Bot 📈
#### ➡ Creating a chrome extension
So that the user can use the functionality on their web browser.
#### ➡ Improve the pose detection model.
The accuracy of the pose detection model can be increased in the future.
#### ➡ Create more classes to help students more concentrate.
Include more functionality like screen time, and detecting if the user is holding their phone, so we can help users to concentrate.
### Help File 💻
* Clone the repository to your local directory
* `git clone https://github.com/cryptus-neoxys/posture.git`
* `npm i -g live-server`
* Install live server to run it locally
* `live-server .`
* Go to project directory and launch the website using live-server
* Voilla the site is up and running on your PC.
* Ctrl + C to stop the live-server!!
### Built With ⚙
* HTML
* CSS
* Javascript
+ Tensorflow.js
+ Web Browser API
* Google API
* EchoAR
* Google Poly
* Deployed on Vercel
### Try it out 👇🏽
* 🤖 [Tensorflow.js Model](https://teachablemachine.withgoogle.com/models/f4JB966HD/)
* 🕸 [The Website](https://pose-bot.vercel.app/)
* 🖥 [The Figma Prototype](https://www.figma.com/file/utEHzshb9zHSB0v3Kp7Rby/Untitled?node-id=0%3A1)
### 3️⃣ Cheers to the team 🥂
* [Apurva Sharma](https://github.com/Apurva-tech)
* [Aniket Singh Rawat](https://github.com/dikwickley)
* [Dev Sharma](https://github.com/cryptus-neoxys)
|
## Inspiration
After years of teaching methods remaining constant, technology has not yet infiltrated the classroom to its full potential. One day in class, it occurred to us that there must be a correlation between students behaviour in classrooms and their level of comprehension.
## What it does
We leveraged Apple's existing API's around facial detection and combined it with the newly added Core ML features to track students emotions based on their facial queues. The app can follow and analyze up to ~ ten students and provide information in real time using our dashboard.
## How we built it
The iOS app integrated Apple's Core ML framework to run a [CNN](https://www.openu.ac.il/home/hassner/projects/cnn_emotions/) to detect people's emotions from facial queues. The model was then used in combination with Apple's Vision API to identify and extract student's face's. This data was then propagated to Firebase for it to be analyzed and displayed on a dashboard in real time.
## Challenges we ran into
Throughout this project, there were several issues regarding how to improve the accuracy of the facial results. Furthermore, there were issues regarding how to properly extract and track users throughout the length of the session. As for the dashboard, we ran into problems around how to display data in real time.
## Accomplishments that we're proud of
We are proud of the fact that we were able to build such a real-time solution. However, we are happy to have met such a great group of people to have worked with.
## What we learned
Ozzie learnt more regarding CoreML and Vision frameworks.
Haider gained more experience with front-end development as well as working on a team.
Nakul gained experience with real-time graphing as well as helped developed the dashboard.
## What's next for Flatline
In the future, Flatline could grow it's dashboard features to provide more insight for the teachers. Also, the accuracy of the results could be improved by training a model to detect emotions that are more closely related to learning and student's behaviours.
|
winning
|
## Inspiration
memes have become a cultural phenomenon and a huge recreation for many young adults including ourselves. for this hackathon, we decided to connect the sociability aspect of the popular site "twitter", and combine it with a methodology of visualizing the activity of memes in various neighborhoods. we hope that through this application, we can create a multicultural collection of memes, and expose these memes, trending from popular cities to a widespread community of memers.
## What it does
NWMeme is a data visualization of memes that are popular in different parts of the world. Entering the application, you are presented with a rich visual of a map with Pepe the frog markers that mark different cities on the map that has dank memes. Pepe markers are sized by their popularity score which is composed of retweets, likes, and replies. Clicking on Pepe markers will bring up an accordion that will display the top 5 memes in that city, pictures of each meme, and information about that meme. We also have a chatbot that is able to reply to simple queries about memes like "memes in Vancouver."
## How we built it
We wanted to base our tech stack with the tools that the sponsors provided. This started from the bottom with CockroachDB as the database that stored all the data about memes that our twitter web crawler scrapes. Our web crawler was in written in python which was Google gave an advanced level talk about. Our backend server was in Node.js which CockroachDB provided a wrapper for hosted on Azure. Calling the backend APIs was a vanilla javascript application which uses mapbox for the Maps API. Alongside the data visualization on the maps, we also have a chatbot application using Microsoft's Bot Framework.
## Challenges we ran into
We had many ideas we wanted to implement, but for the most part we had no idea where to begin. A lot of the challenge came from figuring out how to implement these ideas; for example, finding how to link a chatbot to our map. At the same time, we had to think of ways to scrape the dankest memes from the internet. We ended up choosing twitter as our resource and tried to come up with the hypest hashtags for the project.
A big problem we ran into was that our database completely crashed an hour before the project was due. We had to redeploy our Azure VM and database from scratch.
## Accomplishments that we're proud of
We were proud that we were able to use as many of the sponsor tools as possible instead of the tools that we were comfortable with. We really enjoy the learning experience and that is the biggest accomplishment. Bringing all the pieces together and having a cohesive working application was another accomplishment. It required lots of technical skills, communication, and teamwork and we are proud of what came up.
## What we learned
We learned a lot about different tools and APIs that are available from the sponsors as well as gotten first hand mentoring with working with them. It's been a great technical learning experience. Asides from technical learning, we also learned a lot of communication skills and time boxing. The largest part of our success relied on that we all were working on parallel tasks that did not block one another, and ended up coming together for integration.
## What's next for NWMemes2017Web
We really want to work on improving interactivity for our users. For example, we could have chat for users to discuss meme trends. We also want more data visualization to show trends over time and other statistics. It would also be great to grab memes from different websites to make sure we cover as much of the online meme ecosystem.
|
## Inspiration
Following the recent tragic attacks in Paris, Beirut, and other places, the world has seen the chaos that followed during and after the events. We saw how difficult it was for people to find everything they wanted to know as they searched through dozens of articles and sites to get a full perspective on these trending topics. We wanted to make learning everything there is to know about trending topics effortless.
## What it does
Our app provides varied information on trending topics aggregated from multiple news sources. Each article is automatically generated and is an aggregation of excerpts from many sources in such a way that there is as much unique information as possible. Each article also includes insights on the attitude of the writer and the political leaning of the excerpts and overall article.
**Procedure**
1. Trending topics are found on twitter (in accordance to pre-chosen location settings).
2. Find top 30 hits in each topic's Bing results.
3. Parse each article to find important name entities, keywords, etc. to be included in the article.
4. Use machine learning and our scripts to select unique excerpts and images from all articles to create a final briefing of each topic.
5. Use machine learning to collect data on political sentiment and positivity.
All of this is displayed in a user-friendly web app which features the articles on trending topics and associated data visualizations.
## How we built it
We began with the idea of aggregating news together in order to create nice-looking efficient briefings, but we quickly became aware of the additional benefits that could be included into our project.
Notably, data visualization became a core focus of ours when we realized that the Indico API was able to provide statistics on emotion and political stance. Using Charts.JS and EmojiOne, we created emoticons to indicate the general attitude towards a topic and displayed the political scattermap of each and every topic. These allow us to make very interesting finds, such as the observation that Sports articles tend to be more positive than breaking news. Indico was also able to provide us with mentioned locations, and these was subsequently plugged into the Google Places API to be verified and ultimately sent to the Wolfram API for additional insight.
A recurring object of difficulty within our project was ranking, where we had to figure out what was "better" and what was not. Ultimately, we came to the conclusion that keywords and points were scatted across all paragraphs within a news story. A challenge in itself, a solution came to our minds. If we matched each and every paragraph to each and every keyword, a graph was formed and all we needed was maximal matching! Google gods were consulted, programming rituals were done, and we finally implemented Kuhn's Max Matching algorithm to provide a concise and optimized matching of paragraphs to key points.
This recurring difficulty presented itself once again in terms of image matching, where we initially had large pools (up to 50%) of our images being logos, advertisements, and general unpleasantness. While a filtering of specific key words and image sizes eliminated the bulk of our issues, the final solution came from an important observation made by one of our team members: Unrelated images generally have either empty of poorly constructed alt tags. With this in mind, we simply sorted our images and the sky cleared up for another day.
### The list of technicalities:
* Implemented Kuhn's Max Matching
* Used Python Lambda expressions for quick and easy sorting
* Advanced angular techniques and security filters were used to provide optimal experiences
* Extensive use of CSS3 transforms allowed for faster and smoother animations (CSS Transforms and notably 3D transforms 1. utilize the GPU and 2. do not cause page content rerendering)
* Responsive design with Bootstrap made our lives easier
* Ionic Framework was used to quickly and easily build our mobile applications
* Our Python backend script had 17 imports. Seven-teen
* Used BeautifulSoup to parse images within articles, and [newspaper](http://newspaper.readthedocs.org/en/latest/) to scrape pages
## Challenges we ran into
* Not running out of API keys
* Getting our script to run at a speed faster than O(N!!) time
* Smoothly incorporating so many APIs
* Figuring out how to prioritize "better" content
## Accomplishments that we're proud of
* Finishing our project 50% ahead of schedule
* Using over 7 APIs with a script that would send 2K+ API requests per 5 minutes
* Having Mac and PC users work harmoniously in Github
* Successful implementation of Kuhn's Max Matching algorithm
## What's next for In The Loop
* Supporting all languages
|
## Inspiration
Partially inspired by the Smart Cities track, we wanted our app to have the direct utility of ordering food, while still being fun to interact with. We aimed to combine convenience with entertainment, making the experience more enjoyable than your typical drive-through order.
## What it does
You interact using only your voice. The app automatically detects when you start and stop talking, uses AI to transcribe what you say, figures out the food items (with modifications) you want to order, and adds them to your current order. It even handles details like size and flavor preferences. The AI then generates text-to-speech audio, which is played back to confirm your order in a humorous, engaging way. There is absolutely zero set-up or management necessary, as the program will completely ignore all background noises and conversation. Even then, it will still take your order with staggering precision.
## How we built it
The frontend of the app is built with React and TypeScript, while the backend uses Flask and Python. We containerized the app using Docker and deployed it using Defang. The design of the menu is also done in Canva with a dash of Harvard colors.
## Challenges we ran into
One major challenge was getting the different parts of the app—frontend, backend, and AI—to communicate effectively. From media file conversions to AI prompt engineering, we worked through each of the problems together. We struggled particularly with maintaining smooth communication once the app was deployed. Additionally, fine-tuning the AI to accurately extract order information from voice inputs while keeping the interaction natural was a big hurdle.
## Accomplishments that we're proud of
We're proud of building a fully functioning product that successfully integrates all the features we envisioned. We also managed to deploy the app, which was a huge achievement given the complexity of the project. Completing our initial feature set within the hackathon timeframe was a key success for us. Trying to work with Python data type was difficult to manage, and we were proud to navigate around that. We are also extremely proud to meet a bunch of new people and tackle new challenges that we were not previously comfortable with.
## What we learned
We honed our skills in React, TypeScript, Flask, and Python, especially in how to make these technologies work together. We also learned how to containerize and deploy applications using Docker and Docker Compose, as well as how to use Defang for cloud deployment.
## What's next for Harvard Burger
Moving forward, we want to add a business-facing interface, where restaurant staff would be able to view and fulfill customer orders. There will also be individual kiosk devices to handle order inputs. These features would allow *Harvard Burger* to move from a demo to a fully functional app that restaurants could actually use. Lastly, we can sell the product by designing marketing strategies for fast food chains.
|
partial
|
### Inspiration
Ever see a shirt and think, "Damn, I want that shirt"? But that shirt was the one that got away and you never saw it ever again? We know exactly the feeling, which is why we created and designed ProPrice for the e-Commerce loving IOS users. Now, the moment you see that shirt, that watch, that bag of Flaming Hot Cheetos, you can just simply snap a quick picture and the nearest locations and website links of stores with the most competitive prices will be provided to you. ProPrice? Every Shopper's Paradise.
### What it does
ProPrice is a commerce IOS application that lets you purchase any item from retail to groceries to technology in a matter of seconds.
## How I built it
### Tech Stack
* Front-End : Swift for native IOS
* Back-End : Java Spring Boot main service (src), along with a Node JS microservice for Amazon/Walmart web-scraping information. Both exposed as a RESTFul API.
* Ad-hoc tools: Python (Puppytier and Selenium) for web scraping, hosted with Flask and Firebase Cloud.
* Persistence & DevOps : MongoDB, Heroku, ngrox
* Moral Support : Coffee, chips, and love for the team <3
### APIS Used
Google Cloud Platform (GCP) Vision Product Search offers pre-trained machine learning models through REST and RPC APIs. It assign labels to images and quickly classify them into millions of predefined categories. For ProPrice, the Product Search API is specifically trained to detect objects from within our catalogue and identifies their similarities.
**GOOGLE MAPS PLATFORM (GMP) PLACES API**
We used GMP Places API to identify nearest stores from the user that has their desired product in stock at the lowest price!
**PRODUCT PRICE SEARCH**
We used the Best Buy Keyword Search API which offers developers access to retail data, including prices, offers, and sales by searching across several common attributes, such as item name and brand name.
We couldn't get approved API Keys for other stores in time, so we decided to develop our own web-scraping microservice module which we would query for Amazon and Walmart. Overall, with these three APIs provided by large commerce companies, a price match can be made and links to the online sites are provided to the user.
## Challenges I ran into
* Working with APIs and Google Cloud Platform (GCP) Vision AI
* Obtaining API keys from Best Buy and Macy's to access their product data (item name, price) so we developed our own microservice
* Setting AWS MongoDB up and getting it to commit
## Accomplishments that we're proud of
* Usage of complex Cloud Computing Services
* Being able to stay awake for so long
## What I learned
* AWS is hard
* We love sleep
## What's next
* Offering more features on our IOS application such as product recommendations
* Train our model to pick up more products!
* Add Apple Pay Integration for store product purchases
|
## Inspiration
We were inspired by the difficulty of filtering out the clothes we were interested in from all the available options. As a group of motivated undergraduate software developers, we were determined to find a solution.
## What it does
MatchMyStyle intelligently filters brand catalogs using past items from your personal wardrobe that you love. It aims to enhance the shopping experience for both brands and their consumers.
## How we built it
We split our tech stack into three core ecosystems. Our backend ecosystem hosted its own API to communicate with the machine learning model, Cloud Firestore, Firebase Storage and our frontend. Cloud Firestore was used to store our user dataset for training purposes with the ability to add additional images and host them on Firebase Storage.
The ML ecosystem was built using Google Cloud's Vision API and fetched images using Firebase Storage buckets. It learns from images of past items you love from your personal wardrobe to deliver intelligent filters.
Finally, the frontend ecosystem demonstrates the potential that could be achieved by a fashion brand's catalog being coupled with our backend and ML technology to filter the items that matter to an individual user.
## Challenges we ran into
We knew going into this project that we wanted to accomplish something ambitious that could have a tangible impact on people to increase productivity. One of the biggest hurdles we encountered was finding the appropriate tools to facilitate our machine learning routine in a span of 24 hours. Eventually we decided on Google Cloud's Vision API which proved successful.
Our backend was the glue that held the entire project together. Ensuring efficient and robust communication across frontend and the machine learning routine involved many endpoints and moving parts.
Our frontend was our hook that we hoped would show brands and consumers the true potential of our technology. Featuring a custom design made in Figma and developed using JavaScript, React, and CSS, it attempts to demonstrate how our backend and ML ecosystems could be integrated into any brand's pre-existing frontend catalog.
## Accomplishments that we're proud of
We're proud of finishing all of the core ecosystems and showing the potential of MatchMyStyle.
## What we learned
We learned tons in the 24 hours of development. We became more familiar with Google Cloud's Vision API and the services it offers. We worked on our Python / Flask skills and familiarized ourselves with Cloud Firestore, and Firebase Storage. Finally, we improved our design skills and got better at developing more complex frontend code to bring it to life.
## What's next for MatchMyStyle
We would love to see if fashion brands would be interested in our technology and any other ideas they may have on how we could offer value to both them and their consumers.
|
## Inspiration
It all started a couple days ago when my brother told me he'd need over an hour to pick up a few items from a grocery store because of the weekend checkout line. This led to us reaching out to other friends of ours and asking them about the biggest pitfalls of existing shopping systems. We got a whole variety of answers, but the overwhelming response was the time it takes to shop and more particularly checkout. This inspired us to ideate and come up with an innovative solution.
## What it does
Our app uses computer vision to add items to a customer's bill as they place items in the cart. Similarly, removing an item from the cart automatically subtracts them from the bill. After a customer has completed shopping, they can checkout on the app with the tap of a button, and walk out the store. It's that simple!
## How we built it
We used react with ionic for the frontend, and node.js for the backend. Our main priority was the completion of the computer vision model that detects items being added and removed from the cart. The model we used is a custom YOLO-v3Tiny model implemented in Tensorflow. We chose Tensorflow so that we could run the model using TensorflowJS on mobile.
## Challenges we ran into
The development phase had it's fair share of challenges. Some of these were:
* Deep learning models can never have too much data! Scraping enough images to get accurate predictions was a challenge.
* Adding our custom classes to the pre-trained YOLO-v3Tiny model.
* Coming up with solutions to security concerns.
* Last but not least, simulating shopping while quarantining at home.
## Accomplishments that we're proud of
We're extremely proud of completing a model that can detect objects in real time, as well as our rapid pace of frontend and backend development.
## What we learned
We learned and got hands on experience of Transfer Learning. This was always a concept that we knew in theory but had never implemented before. We also learned how to host tensorflow deep learning models on cloud, as well as make requests to them. Using google maps API with ionic react was a fun learning experience too!
## What's next for MoboShop
* Integrate with customer shopping lists.
* Display ingredients for recipes added by customer.
* Integration with existing security systems.
* Provide analytics and shopping trends to retailers, including insights based on previous orders, customer shopping trends among other statistics.
|
losing
|
## Inspiration
Our app idea came from the experience of one of our team members when he was having lunch in one of the many food courts of Toronto's CBD. At the time, he was looking around and despite being surrounded by hundreds of people - he knew nothing about any of them. Of course, there were incredible people amongst the crowd, but there was no way to know who was who, who did what, and who was open to chatting with a stranger.
Everyday, we walk past hundreds of people from all walks of life, with thousands of different (or common!) experiences. Yet, perhaps because we've grown wary of being surrounded by so many people, we casually dismiss this opportunity to learn something new. Our app aims to unearth the incredible value of people and their stories, and make connecting with strangers, easier.
## What it does
In short, Peopledex allows you to find other users within a 1 minute walking distance to them and strike up a conversation about their favourite topics. Every user's profile consists of their name, a profile photo, occupation, and three topics that they'd like people to ask them about. Nearby users are viewable in a collection view, ordered by proximity.
After viewing a nearby user's profile, you can find them via GPS-based augmented reality, which places an arrow above their current location. Then, you make an introduction! No instant-messaging allowed - only real connections. When you don't want to be approached (e.g. you're busy meeting with friends), you can enable incognito mode so you won't be discoverable.
**Use cases:**
* Finding relevant connections at large conferences or expos
* Finding potential teammates at hackathons
* Finding someone to have lunch with in a food court
* Finding friendly strangers to talk to while travelling
## How we built it
Our team split off into two groups, one responsible for building the AR functionality and the other for UI/UX. The initial wireframe was built on Balsamiq Cloud's collaborative wireframing tool. The wireframe was then developed using Xcode Interface Builder & Swift. Login and signup functionality was achieved using Firebase authentication.
The AR functionality involved two components. The front end client, using ARKit API for iOS, consumed GPS coordinates in the form of longitude and latitude, and rendered it into 3D space in the augmented reality view. The GPS coordinates were supplied by another client, which sent a POST request to a Python based API that pushed updates to the AR client. These updates were pushed in realtime, using a web socket to lower latency.
## Challenges we ran into
None of our team members came into this hackathon with iOS experience, and only half of our group had developer experience. The AR component proved to be extremely challenging as well, as overcoming the inaccuracies of location finding made us use many engineering techniques. Specifically, rendering assets in real time based on a non-deterministically moving object caused us to take many hours of calibration in order to have a demoable product.
## Accomplishments that we're proud of
We had to apply a high pass filter on the noise from the GPS to smooth out the movement of both clients. This enabled us to have a relatively stable location for the AR client to track and render. We were also able to create a smoothly running and aesthetically-pleasing user interface. We're proud of the fact that all of us learned how to use new and challenging tools in an extremely short amount of time.
## What we learned
We learned:
* ARKit
* That real-time location tracking is hard
* Xcode & Swift
* Firebase
* Balsamiq
## What's next for Peopledex
Get users onboard!
|
## Inspiration
Online shopping has been the norm for a while, but the COVID-19 pandemic has impelled even more businesses and customers alike to shift to the digital space. Unfortunately, it also accentuated the frustrations associated with online shopping. People often purchase items online, only to find out what they receive is not exactly what they want. AR is the perfect technology to bridge the gap between the digital and physical spaces; we wanted to apply that to tackle issues within online shopping to strengthen interconnection within e-commerce!
## What it does
scannAR allows its users to scan QR codes of e-commerce URLs, placing those items in front of where the user is standing. Users may also scan physical items to have them show up in AR. In either case, users may drag and drop anything that can be scanned or uploaded to the real world.
Now imagine the possibilities. Have technicians test if a component can fit into a small space, or small businesses send their products to people across the planet virtually, or teachers show off a cool concept with a QR code and the students' phones. Lastly, yes, you can finally play Minecraft or build yourself a fake house cause I know house searching in Kingston is hard.
## How we built it
We built the scannAR app using Unity with the Lean Touch and Big Furniture Pack assets. We used HTML, CSS, Javascript to create the business website for marketing purposes.
## Challenges we ran into
This project was our first time working with Unity and AR technology, so we spent many hours figuring their processes out. A particular challenge we encountered was manipulating objects on our screens the way we wanted to. With the time constraint, the scope of UI/UX design was limited, making some digital objects look less clean.
## Accomplishments that we're proud of
Through several hours of video tutorials and some difficulty, we managed to build a functioning AR application through Unity, while designing a clean website to market it. We felt even prouder about making a wide stride towards tackling e-commerce issues that many of our friends often rant about.
## What we learned
In terms of technical skills, we learned how to utilize AR technology, specifically Unity. Initially, we had trouble moving objects on Unity; after completing this project, we have new Unity skills we can apply throughout our next hackathons and projects. We learned to use our existing front-end web development skills to augment our function with form.
## What's next for scannAR
In the near future, we aim to flesh out the premium subscription features to better cater to specific professions. We also plan on cleaning up the interface to launch scannAR on the app stores. After its release, it will be a constant cycle of marketing, partnerships with local businesses, and re-evaluating processes.
|
Demo: <https://youtu.be/cTh3Q6a2OIM?t=2401>
## Inspiration
Fun Mobile AR Experiences such as Pokemon Go
## What it does
First, a single player hides a virtual penguin somewhere in the room. Then, the app creates hundreds of obstacles for the other players in AR. The player that finds the penguin first wins!
## How we built it
We used AWS and Node JS to create a server to handle realtime communication between all players. We also used Socket IO so that we could easily broadcast information to all players.
## Challenges we ran into
For the majority of the hackathon, we were aiming to use Apple's Multipeer Connectivity framework for realtime peer-to-peer communication. Although we wrote significant code using this framework, we had to switch to Socket IO due to connectivity issues.
Furthermore, shared AR experiences is a very new field with a lot of technical challenges, and it was very exciting to work through bugs in ensuring that all users have see similar obstacles throughout the room.
## Accomplishments that we're proud of
For two of us, it was our very first iOS application. We had never used Swift before, and we had a lot of fun learning to use xCode. For the entire team, we had never worked with AR or Apple's AR-Kit before.
We are proud we were able to make a fun and easy to use AR experience. We also were happy we were able to use Retro styling in our application
## What we learned
-Creating shared AR experiences is challenging but fun
-How to work with iOS's Multipeer framework
-How to use AR Kit
## What's next for ScavengAR
* Look out for an app store release soon!
|
partial
|
## TL;DR
The one-stop shop for all your hackathon tool needs. **HackMyHack** can generate a cool idea for you, generate a cool name for you, fix bugs for you, explain code snippets to you, remind you about upcoming deadlines, become a chatbot and basically anything else. Like, **seriously**. Also, feel like an absolute hacker doing all this by interacting with our *gorgeous* terminal-inspired interface.
## Inspiration
Not having inspiration. Literally. This tool was built to fill the void when inspiration is lacking when trying to find hackathon ideas/project names. We also wanted a tool to help first-time hackers who need guidance during their first couple of hacks. Especially during this pandemic era, it can be hard or demoralizing for them to learn the ropes remotely.
## What it does
Refer to **TL;DR**^.
## How we built it
Golang backend for performance. GPT-3 Deep Learning model for smarts. Twilio for SMS reminders. Super cool domain with Domain.com. React.js for the eye-candy. GCP for reliable hosting and a wowzer demo!
## Challenges we ran into
CORS, redeeming the Uber Eats coupon, asynchronous stuff in React/Javascript. Weird Golang heap corruption bug (arm64 [M1 SoC] may not be fully supported yet?)
## Accomplishments that we're proud of
Beautiful frontend that just works™. Incredible backend performance (slowed by GPT-3's API but that's ok). Hosted in prod environments for a cool demo. Learning Twilio and Golang for our first timer :)! Also try to find the easter egg embedded in the webpage :P
## What we learned
CORS, Twilio, Golang, GCP deployment.
## What's next for HackMyHack
Make our website mobile-friendly. It only works on desktop right now. Continue to iterate on features that need optimizing, as well as integrating with Discord or Slack bots to make it a cross-platform tool that Hackathon organizers that leverage. It could be extended to become the one-stop shop for not only hackathon tools, but hackathon management/organization as well.
|
## Inspiration
We meet hundreds of people throughout our lifetimes, from chance encounters at cafes, to teammates at school, to lifelong friends. With so many people bumping into and out of our lives, it may be hard to keep track of them all. Individuals with social disabilities, especially those who have a difficult time with social cues, may find it a challenge to recall any information about the background, or even facial features, of those they met in the past. Mnemonic hopes to provide a seamless platform that keeps track of all the people a user meets, along with details of how they met and the topics discussed in previous encounters.
## What it does
Mnemonic is a social memory companion that uses IBM Watson's AlchemyLanguage API and Microsoft Cognitive Service API to keep track of all the people a user meets. Along with date and location information about each first encounter, Mnemonic uses natural language processing to find relevant keywords, which serve as mnemonics. This social platform can be useful not only as a networking tool, but also as an accessibility platform that allows individuals with social disabilities to interact with others in a more seamless way.
## How we built it
There are three main components of Mnemonic: an iOS app, a Linode server, and a Raspberry Pi. When a user first meets someone, the user triggers the start of the process by pushing a button on a breadboard. This push triggers the camera of the Raspberry Pi to take three photos of the person that is met. This also sends information to the server. The iOS app constantly sends post requests to the Linode server to see whether an action is required. If one is, it either matches the photos to an existing profile using Microsoft Cognitive Services Face API, in which case the app will pull up the existing profile, or it will create a new profile by recording the audio of the conversation. Using IBM Watson's AlchemyLanguage API, we analyze this data for any relevant keywords, using these as keyword topics to be stored in that person's profile. The user can use this information to more easily recall the person the next time that person is seen again.
|
## Inspiration
We were looking for ways to use some of the most wild, inaccurate, out-there claims about the Covid-19 Vaccine to instead produce good outcomes.
## What it does
Aggregates misinformation regarding the COVID-19 vaccine in one location to empower public health officials and leaders to quickly address these false claims.
## How we built it
We built it with React front-end, Node.js back-end, and various Python libraries (pandas, matplotlib, snscrape, fuzzywuzzy, and wordcloud) to fuel our data visualizations.
## Challenges we ran into
* Fuzzy matching, figuring out how to apply method to each column without having to declare a new method each time
* Figuring out how to use python with node.js; when child\_process.spawn didn’t work I had to worked around it by using the PythonShell module in node which just ran the python scripts based on my local python environment instead of in-project.
* Figuring out how to get python code to run in both VS code and with nodejs
* We found a work around that allowed the python script to be executed by Node.js server, but it requires the local machine to have all the python dependencies installed D:
* THIS IS EVERYBODY’S FIRST HACKATHON!!!
## Accomplishments that we're proud of
We're proud to have worked with a tech stack we are not very familiar with and completed our first hackathon with a working(ish) product!
## What we learned
* How to web scrape from twitter using python and snscrape, how to perform fuzzy matching on pandas data frames, and become more comfortable and proficient in data analysis and visualization
* How to work with a web stack structure and communicate between front-end and back-end
* How to integrate multiple languages even despite incompatibilities
## What's next for COVAX (mis)Info
Addressing other types of false claims (for instance, false claims about election interference or fraud), and expanding to other social media platforms. Hopefully finding a way to more smoothly integrate Python scripts and libraries too!
|
partial
|
## About the Project
NazAR is an educational tool that automatically creates interactive visualizations of math word problems in AR, requiring nothing more than an iPhone.
## Behind the Name
*Nazar* means “vision” in Arabic, which symbolizes the driving goal behind our app – not only do we visualize math problems for students, but we also strive to represent a vision for a more inclusive, accessible and tech-friendly future for education. And, it ends with AR, hence *NazAR* :)
## Inspiration
The inspiration for this project came from each of our own unique experiences with interactive learning. As an example, we want to showcase two of the team members’ experiences, Mohamed and Rayan’s. Mohamed Musa moved to the US when he was 12, coming from a village in Sudan where he grew up and received his primary education. He did not speak English and struggled until he had an experience with a teacher that transformed his entire learning experience through experiential and interactive learning. From then on, applying those principles, Mohamed was able to pick up English fluently within a few months and reached the top of his class in both science and mathematics. Rayan Ansari had worked with many Syrian refugee students on a catch-up curriculum. One of his students, a 15 year-old named Jamal, had not received schooling since Kindergarten and did not understand arithmetic and the abstractions used to represent it. Intuitively, the only means Rayan felt he could effectively teach Jamal and bridge the connection would be through physical examples that Jamal could envision or interact with. From the diverse experiences of the team members, it was glaringly clear that creating an accessible and flexible interactive learning software would be invaluable in bringing this sort of transformative experience to any student’s work. We were determined to develop a platform that could achieve this goal without having its questions pre-curated or requiring the aid of a teacher, tutor, or parent to help provide this sort of time-intensive education experience to them.
## What it does
Upon opening the app, the student is presented with a camera view, and can press the snapshot button on the screen to scan a homework problem. Our computer vision model then uses neural network-based text detection to process the scanned question, and passes the extracted text to our NLP model.
Our NLP text processing model runs fully integrated into Swift as a Python script, and extracts from the question a set of characters to create in AR, along with objects and their quantities, that represent the initial problem setup. For example, for the question “Sally has twelve apples and John has three. If Sally gives five of her apples to John, how many apples does John have now?”, our model identifies that two characters should be drawn: Sally and John, and the setup should show them with twelve and three apples, respectively.
The app then draws this setup using the Apple RealityKit development space, with the characters and objects described in the problem overlayed. The setup is interactive, and the user is able to move the objects around the screen, reassigning them between characters. When the position of the environment reflects the correct answer, the app verifies it, congratulates the student, and moves onto the next question. Additionally, the characters are dynamic and expressive, displaying idle movement and reactions rather than appearing frozen in the AR environment.
## How we built it
Our app relies on three main components, each of which we built from the ground up to best tackle the task at hand: a computer vision (CV) component that processes the camera feed into text: an NLP model that extracts and organizes information about the initial problem setup; and an augmented-reality (AR) component that creates an interactive, immersive environment for the student to solve the problem.
We implemented the computer vision component to perform image-to-text conversion using the Apple’s Vision framework model, trained on a convolutional neural network with hundreds of thousands of data points. We customize user experience with a snapshot button that allows the student to position their in front of a question and press it to capture an image, which is then converted to a string, and passed off to the NLP model.
Our NLP model, which we developed completely from scratch for this app, runs as a Python script, and is integrated into Swift using a version of PythonKit we custom-modified to configure for iOS. It works by first tokenizing and lemmatizing the text using spaCy, and then using numeric terms as pivot points for a prioritized search relying on English grammatical rules to match each numeric term to a character, an object and a verb (action). The model is able to successfully match objects to characters even when they aren’t explicitly specified (e.g. for Sally in “Ralph has four melons, and Sally has six”) and, by using the proximate preceding verb of each numeric term as the basis for an inclusion-exclusion criteria, is also able to successfully account for extraneous information such as statements about characters receiving or giving objects, which shouldn’t be included in the initial setup. Our model also accounts for characters that do not possess any objects to begin with, but who should be drawn in the display environment as they may receive objects as part of the solution to the question. It directly returns filenames that should be executed by the AR code.
Our AR model functions from the moment a homework problem is read. Using Apple’s RealityKit environment, the software determines the plane of the paper in which we will anchor our interactive learning space. The NLP model passes objects of interest which correspond to particular USDZ assets in our library, as well as a vibrant background terrain. In our testing, we used multiple models for hand tracking and gesture classification, including a CoreML model, a custom SDK for gesture classification, a Tensorflow model, and our own gesture processing class paired with Apple’s hand pose detection library. For the purposes of Treehacks, we figured it would be most reasonable to stick with touchscreen manipulation, especially for our demo that utilizes the iPhone device itself without being worn with a separate accessory. We found this to also provide better ease of use when interacting with the environment and to be most accessible, given hardware constraints (we did not have a HoloKit Apple accessory nor the upcoming Apple AR glasses).
## Challenges we ran into
We ran into several challenges while implementing our project, which was somewhat expected given the considerable number of components we had, as well as the novelty of our implementation.
One of the first challenges we had was a lack of access to wearable hardware, such as HoloKits or HoloLenses. We decided based on this, as well as a desire to make our app as accessible and scalable as possible without requiring the purchase of expensive equipment by the user, to be able to reach as many people who need it as possible.
Another issue we ran into was with hand gesture classification. Very little work has been done on this in Swift environments, and there was little to no documentation on hand tracking available to us. As a result, we wrote and experimented with several different models, including training our own deep learning model that can identify gestures, but it took a toll on our laptop’s resources. At the end we got it working, but are not using it for our demo as it currently experiences some lag. In the future, we aim to run our own gesture tracking model on the cloud, which we will train on over 24,000 images, in order to provide lag-free hand tracking.
The final major issue we encountered was the lack of interoperability between Apple’s iOS development environment and other systems, for example with running our NLP code, which requires input from the computer vision model, and has to pass the extracted data on to the AR algorithm. We have been continually working to overcome this challenge, including by modifying the PythonKit package to bundle a Python interpreter alongside the other application assets, so that Python scripts can be successfully run on the end machine. We also used input and output to text files to allow our Python NLP script to more easily interact with the Swift code.
## Accomplishments we're proud of
We built our computer vision and NLP models completely from the ground up during the Hackathon, and also developed multiple hand-tracking models on our own, overcoming the lack of documentation for hand detection in Swift.
Additionally, we’re proud of the novelty of our design. Existing models that provide interactive problem visualization all rely on custom QR codes embedded with the questions that load pre-written environments, or rely on a set of pre-curated models; and Photomath, the only major app that takes a real-time image-to-text approach, lacks support for word problems. In contrast, our app integrates directly with existing math problems, and doesn’t require any additional work on the part of students, teachers or textbook writers in order to function.
Additionally, by relying only on an iPhone and an optional HoloKit accessory for hand-tracking which is not vital to the application (which at a retail price of $129 is far more scalable than VR sets that typically cost thousands of dollars), we maximize accessibility to our platform not only in the US, but around the world, where it has the potential to complement instructional efforts in developing countries where educational systems lack sufficient resources to provide enough one-on-one support to students. We’re eager to have NazAR make a global impact on improving students’ comfortability and experience with math in coming years.
## What we learned
* We learnt a lot from building the tracking models, which haven’t really been done for iOS and there’s practically no Swift documentation available for.
* We are truly operating on a new frontier as there is little to no work done in the field we are looking at
* We will have to manually build a lot of different architectures as a lot of technologies related to our project are not open source yet. We’ve already been making progress on this front, and plan to do far more in the coming weeks as we work towards a stable release of our app.
## What's next for NazAR
* Having the app animate the correct answer (e.g. Bob handing apples one at a time to Sally)
* Animating algorithmic approaches and code solutions for data structures and algorithms classes
* Being able to automatically produce additional practice problems similar to those provided by the user
* Using cosine similarity to automatically make terrains mirror the problem description (e.g. show an orchard if the question is about apple picking, or a savannah if giraffes are involved)
* And more!
|
## The Gist
We combine state-of-the-art LLM/GPT detection methods with image diffusion models to accurately detect AI-generated video with 92% accuracy.
## Inspiration
As image and video generation models become more powerful, they pose a strong threat to traditional media norms of trust and truth. OpenAI's SORA model released in the last week produces extremely realistic video to fit any prompt, and opens up pathways for malicious actors to spread unprecedented misinformation regarding elections, war, etc.
## What it does
BinoSoRAs is a novel system designed to authenticate the origin of videos through advanced frame interpolation and deep learning techniques. This methodology is an extension of the state-of-the-art Binoculars framework by Hans et al. (January 2024), which employs dual LLMs to differentiate human-generated text from machine-generated counterparts based on the concept of textual "surprise".
BinoSoRAs extends on this idea in the video domain by utilizing **Fréchet Inception Distance (FID)** to compare the original input video against a model-generated video. FID is a common metric which measures the quality and diversity of images using an Inception v3 convolutional neural network. We create model-generated video by feeding the suspect input video into a **Fast Frame Interpolation (FLAVR)** model, which interpolates every 8 frames given start and end reference frames. We show that this interpolated video is more similar (i.e. "less surprising") to authentic video than artificial content when compared using FID.
The resulting FID + FLAVR two-model combination is an effective framework for detecting video generation such as that from OpenAI's SoRA. This innovative application enables a root-level analysis of video content, offering a robust mechanism for distinguishing between human-generated and machine-generated videos. Specifically, by using the Inception v3 and FLAVR models, we are able to look deeper into shared training data commonalities present in generated video.
## How we built it
Rather than simply analyzing the outputs of generative models, a common approach for detecting AI content, our methodology leverages patterns and weaknesses that are inherent to the common training data necessary to make these models in the first place. Our approach builds on the **Binoculars** framework developed by Hans et al. (Jan 2024), which is a highly accurate method of detecting LLM-generated tokens. Their state-of-the-art LLM text detector makes use of two assumptions: simply "looking" at text of unknown origin is not enough to classify it as human- or machine-generated, because a generator aims to make differences undetectable. Additionally, *models are more similar to each other than they are to any human*, in part because they are trained on extremely similar massive datasets. The natural conclusion is that an observer model will find human text to be very *perplex* and surprising, while an observer model will find generated text to be exactly what it expects.
We used Fréchet Inception Distance between the unknown video and interpolated generated video as a metric to determine if video is generated or real. FID uses the Inception score, which calculates how well the top-performing classifier Inception v3 classifies an image as one of 1,000 objects. After calculating the Inception score for every frame in the unknown video and the interpolated video, FID calculates the Fréchet distance between these Gaussian distributions, which is a high-dimensional measure of similarity between two curves. FID has been previously shown to correlate extremely well with human recognition of images as well as increase as expected with visual degradation of images.
We also used the open-source model **FLAVR** (Flow-Agnostic Video Representations for Fast Frame Interpolation), which is capable of single shot multi-frame prediction and reasoning about non-linear motion trajectories. With fine-tuning, this effectively served as our generator model, which created the comparison video necessary to the final FID metric.
With a FID-threshold-distance of 52.87, the true negative rate (Real videos correctly identified as real) was found to be 78.5%, and the false positive rate (Real videos incorrectly identified as fake) was found to be 21.4%. This computes to an accuracy of 91.67%.
## Challenges we ran into
One significant challenge was developing a framework for translating the Binoculars metric (Hans et al.), designed for detecting tokens generated by large-language models, into a practical score for judging AI-generated video content. Ultimately, we settled on our current framework of utilizing an observer and generator model to get an FID-based score; this method allows us to effectively determine the quality of movement between consecutive video frames through leveraging the distance between image feature vectors to classify suspect images.
## Accomplishments that we're proud of
We're extremely proud of our final product: BinoSoRAs is a framework that is not only effective, but also highly adaptive to the difficult challenge of detecting AI-generated videos. This type of content will only continue to proliferate the internet as text-to-video models such as OpenAI's SoRA get released to the public: in a time when anyone can fake videos effectively with minimal effort, these kinds of detection solutions and tools are more important than ever, *especially in an election year*.
BinoSoRAs represents a significant advancement in video authenticity analysis, combining the strengths of FLAVR's flow-free frame interpolation with the analytical precision of FID. By adapting the Binoculars framework's methodology to the visual domain, it sets a new standard for detecting machine-generated content, offering valuable insights for content verification and digital forensics. The system's efficiency, scalability, and effectiveness underscore its potential to address the evolving challenges of digital content authentication in an increasingly automated world.
## What we learned
This was the first-ever hackathon for all of us, and we all learned many valuable lessons about generative AI models and detection metrics such as Binoculars and Fréchet Inception Distance. Some team members also got new exposure to data mining and analysis (through data-handling libraries like NumPy, PyTorch, and Tensorflow), in addition to general knowledge about processing video data via OpenCV.
Arguably more importantly, we got to experience what it's like working in a team and iterating quickly on new research ideas. The process of vectoring and understanding how to de-risk our most uncertain research questions was invaluable, and we are proud of our teamwork and determination that ultimately culminated in a successful project.
## What's next for BinoSoRAs
BinoSoRAs is an exciting framework that has obvious and immediate real-world applications, in addition to more potential research avenues to explore. The aim is to create a highly-accurate model that can eventually be integrated into web applications and news articles to give immediate and accurate warnings/feedback of AI-generated content. This can mitigate the risk of misinformation in a time where anyone with basic computer skills can spread malicious content, and our hope is that we can build on this idea to prove our belief that despite its misuse, AI is a fundamental force for good.
|
## Inspiration
Learning never ends. It's the cornerstone of societal progress and personal growth. It helps us make better decisions, fosters further critical thinking, and facilitates our contribution to the collective wisdom of humanity. Learning transcends the purpose of solely acquiring knowledge.
## What it does
Understanding the importance of learning, we wanted to build something that can make learning more convenient for anyone and everyone. Being students in college, we often find ourselves meticulously surfing the internet in hopes of relearning lectures/content that was difficult. Although we can do this, spending half an hour to sometimes multiple hours is simply not the most efficient use of time, and we often leave our computers more confused than how we were when we started.
## How we built it
A typical scenario goes something like this: you begin a Google search for something you want to learn about or were confused by. As soon as you press search, you are confronted with hundreds of links to different websites, videos, articles, news, images, you name it! But having such a vast quantity of information thrown at you isn’t ideal for learning. What ends up happening is that you spend hours surfing through different articles and watching different videos, all while trying to piece together bits and pieces of what you understood from each source into one cohesive generalization of knowledge. What if learning could be made easier by optimizing search? What if you could get a guided learning experience to help you self-learn?
That was the motivation behind Bloom. We wanted to leverage generative AI to optimize search specifically for learning purposes. We asked ourselves and others, what helps them learn? By using feedback and integrating it into our idea, we were able to create a platform that can teach you a new concept in a concise, understandable manner, with a test for knowledge as well as access to the most relevant articles and videos, thus enabling us to cover all types of learners. Bloom is helping make education more accessible to anyone who is looking to learn about anything.
## Challenges we ran into
We faced many challenges when it came to merging our frontend and backend code successfully. At first, there were many merge conflicts in the editor but we were able to find a workaround/solution. This was also our first time experimenting with LangChain.js so we had problems with the initial setup and had to learn their wide array of use cases.
## Accomplishments that we're proud of/What's next for Bloom
We are proud of Bloom as a service. We see just how valuable it can be in the real world. It is important that society understands that learning transcends the classroom. It is a continuous, evolving process that we must keep up with. With Bloom, our service to humanity is to make the process of learning more streamlined and convenient for our users. After all, learning is what allows humanity to progress. We hope to continue to optimize our search results, maximizing the convenience we bring to our users.
|
winning
|
## 💭 Inspiration
Throughout our Zoom university journey, our team noticed that we often forget to unmute our mics when we talk, or forget to mute it when we don't want others to listen in. To combat this problem, we created speakCV, a desktop client that automatically mutes and unmutes your mic for you using computer vision to understand when you are talking.
## 💻 What it does
speakCV automatically unmutes a user when they are about to speak and mutes them when they have not spoken for a while. The user does not have to interact with the mute/unmute button, creating a more natural and fluid experience.
## 🔧 How we built it
The application was written in Python: scipy and dlib for the machine learning, pyvirtualcam to access live Zoom video, and Tkinter for the GUI. OBS was used to provide the program access to a live Zoom call through virtual video, and the webpage for the application was built using Bootstrap.
## ⚙️ Challenges we ran into
A large challenge we ran into was fine tuning the mouth aspect ratio threshold for the model, which determined the model's sensitivity for mouth shape recognition. A low aspect ratio made the application unable to detect when a person started speaking, while a high aspect ratio caused the application to become too sensitive to small movements. We were able to find an acceptable value through trial and error.
Another problem we encountered was lag, as the application was unable to handle both the Tkinter event loop and the mouth shape analysis at the same time. We were able to remove the lag by isolating each process into separate threads.
## ⭐️ Accomplishments that we're proud of
We were proud to solve a problem involving a technology we use frequently in our daily lives. Coming up with a problem and finding a way to solve it was rewarding as well, especially integrating the different machine learning models, virtual video, and application together.
## 🧠 What we learned
* How to setup and use virtual environments in Anaconda to ensure the program can run locally without issues.
* Working with virtual video/audio to access the streams from our own program.
* GUI creation for Python applications with Tkinter.
## ❤️ What's next for speakCV.
* Improve the precision of the shape recognition model, by further adjusting the mouth aspect ratio or by tweaking the contour spots used in the algorithm for determining a user's mouth shape.
* Moving the application to the Zoom app marketplace by making the application with the Zoom SDK, which requires migrating the application to C++.
* Another option is to use the Zoom API and move the application onto the web.
|
## Inspiration
Today we live in a world that is all online with the pandemic forcing us at home. Due to this, our team and the people around us were forced to rely on video conference apps for school and work. Although these apps function well, there was always something missing and we were faced with new problems we weren't used to facing. Personally, forgetting to mute my mic when going to the door to yell at my dog, accidentally disturbing the entire video conference. For others, it was a lack of accessibility tools that made the experience more difficult. Then for some, simply scared of something embarrassing happening during class while it is being recorded to be posted and seen on repeat! We knew something had to be done to fix these issues.
## What it does
Our app essentially takes over your webcam to give the user more control of what it does and when it does. The goal of the project is to add all the missing features that we wished were available during all our past video conferences.
Features:
Webcam:
1 - Detect when user is away
This feature will automatically blur the webcam feed when a User walks away from the computer to ensure the user's privacy
2- Detect when user is sleeping
We all fear falling asleep on a video call and being recorded by others, our app will detect if the user is sleeping and will automatically blur the webcam feed.
3- Only show registered user
Our app allows the user to train a simple AI face recognition model in order to only allow the webcam feed to show if they are present. This is ideal to prevent ones children from accidentally walking in front of the camera and putting on a show for all to see :)
4- Display Custom Unavailable Image
Rather than blur the frame, we give the option to choose a custom image to pass to the webcam feed when we want to block the camera
Audio:
1- Mute Microphone when video is off
This option allows users to additionally have the app mute their microphone when the app changes the video feed to block the camera.
Accessibility:
1- ASL Subtitle
Using another AI model, our app will translate your ASL into text allowing mute people another channel of communication
2- Audio Transcriber
This option will automatically transcribe all you say to your webcam feed for anyone to read.
Concentration Tracker:
1- Tracks the user's concentration level throughout their session making them aware of the time they waste, giving them the chance to change the bad habbits.
## How we built it
The core of our app was built with Python using OpenCV to manipulate the image feed. The AI's used to detect the different visual situations are a mix of haar\_cascades from OpenCV and deep learning models that we built on Google Colab using TensorFlow and Keras.
The UI of our app was created using Electron with React.js and TypeScript using a variety of different libraries to help support our app. The two parts of the application communicate together using WebSockets from socket.io as well as synchronized python thread.
## Challenges we ran into
Dam where to start haha...
Firstly, Python is not a language any of us are too familiar with, so from the start, we knew we had a challenge ahead. Our first main problem was figuring out how to highjack the webcam video feed and to pass the feed on to be used by any video conference app, rather than make our app for a specific one.
The next challenge we faced was mainly figuring out a method of communication between our front end and our python. With none of us having too much experience in either Electron or in Python, we might have spent a bit too much time on Stack Overflow, but in the end, we figured out how to leverage socket.io to allow for continuous communication between the two apps.
Another major challenge was making the core features of our application communicate with each other. Since the major parts (speech-to-text, camera feed, camera processing, socket.io, etc) were mainly running on blocking threads, we had to figure out how to properly do multi-threading in an environment we weren't familiar with. This caused a lot of issues during the development, but we ended up having a pretty good understanding near the end and got everything working together.
## Accomplishments that we're proud of
Our team is really proud of the product we have made and have already begun proudly showing it to all of our friends!
Considering we all have an intense passion for AI, we are super proud of our project from a technical standpoint, finally getting the chance to work with it. Overall, we are extremely proud of our product and genuinely plan to better optimize it in order to use within our courses and work conference, as it is really a tool we need in our everyday lives.
## What we learned
From a technical point of view, our team has learnt an incredible amount the past few days. Each of us tackled problems using technologies we have never used before that we can now proudly say we understand how to use. For me, Jonathan, I mainly learnt how to work with OpenCV, following a 4-hour long tutorial learning the inner workings of the library and how to apply it to our project. For Quan, it was mainly creating a structure that would allow for our Electron app and python program communicate together without killing the performance. Finally, Zhi worked for the first time with the Google API in order to get our speech to text working, he also learned a lot of python and about multi-threadingbin Python to set everything up together. Together, we all had to learn the basics of AI in order to implement the various models used within our application and to finally attempt (not a perfect model by any means) to create one ourselves.
## What's next for Boom. The Meeting Enhancer
This hackathon is only the start for Boom as our team is exploding with ideas!!! We have a few ideas on where to bring the project next. Firstly, we would want to finish polishing the existing features in the app. Then we would love to make a market place that allows people to choose from any kind of trained AI to determine when to block the webcam feed. This would allow for limitless creativity from us and anyone who would want to contribute!!!!
|
## Inspiration
We've all been there - racing to find an empty conference room as your meeting is about to start, struggling to hear a teammate who's decided to work from a bustling coffee shop, or continuously muting your mic because of background noise.
As the four of us all conclude our internships this summer, we’ve all experienced these over and over. But what if there is a way for you to simply take meetings in the middle of the office…
## What it does
We like to introduce you to Unmute, your solution to clear and efficient virtual communication. Unmute transforms garbled audio into audible speech by analyzing your lip movements, all while providing real-time captions as a video overlay. This means your colleagues and friends can hear you loud and clear, even when you’re not. Say goodbye to the all too familiar "wait, I think you're muted".
## How we built it
Our team built this application by first designing it on Figma. We built a React-based frontend using TypeScript and Vite for optimal performance. The frontend captures video input from the user's webcam using the MediaRecorder API and sends it to our Flask backend as a WebM file. On the server side, we utilized FFmpeg for video processing, converting the WebM to MP4 for wider compatibility. We then employed Symphonic's API to transcribe visual cues.
## Challenges we ran into
Narrowing an idea was one of the biggest challenges. We had many ideas, including a lip-reading language course, but none of them had a solid use case. It was only after we started thinking about problems we encountered in our daily lives did we find our favorite project idea.
Additionally, there were many challenges on the technical side with using Flask and uploading and processing videos.
## Accomplishments that we're proud of
We are proud that we were able to make this project come to life.
## Next steps
Symphonic currently does not offer websocket functionality, so our vision of making this a real-time virtual meeting extension is not yet realizable. However, when this is possible, we are excited for the improvements this project will bring to meetings of all kinds.
|
winning
|
## Inspiration
This project was inspired by the video on modern naval air defense by Binkov's Battlegrounds:
[Attack on Aegis](https://youtu.be/ZcwDfaY4OW4)
However, my game does not depict anti-air warfare realistically. Instead I took an arcade-y approach and centred the core gameplay loop around manually guiding and maneuvering missiles.
Civilian aircraft were added for added complexity so that players can't easily block attacks by spamming missiles.
Some visual and audio styles are also inspired by [Command: Modern Operations](https://store.steampowered.com/app/1076160/Command_Modern_Operations/), a detailed and realistic modern air and naval warfare simulation game.
## What it does
B.V.R (beyond visual range) is a simple browser-based 2D game where you play as an air defense officer onboard a navy ship. The enemy has a vast inventory of anti-ship missiles and will attack you relentlessly. You must launch and guide your own surface-to-air missiles to stop the onslaught. Be cautious, however, the airspace is also open to civilian air traffic. Therefore, you must carefully maneuver your missiles to avoid civilian airliners while keeping your ship safe.
## How we built it
I built the game using Konva.js, a 2D rendering and animation library for browser. The frontend tooling is handled by Vite, a modern web development toolchain that offers many must-have development features.
## Challenges we ran into
I had to learn Konva.js as I developed the game, as I had no previous experience with any 2D/3D rendering and animation techniques.
I came up with the game idea only the day before the hackathon, so I didn't have time to prototype or refine the game design. Designing was basically done as I wrote the code, which is obviously a frowned-upon practice.
## Accomplishments that we're proud of
This is the first ever game conceptualized, designed, and developed all by myself. And it surprisingly turned out to be somewhat playable. Does this game idea have some real potential, or is it as boring as company-wide meetings? You be the judge!
## What we learned
A good chunk of time was spent debugging issues that would never have happened if I used typescript. - - This is a good lesson to learn about the trade-offs of typecheck systems.
* As an aspiring hobby game developer, I still have a very long way to go.
## What's next for B.V.R
Some concepts and plans were dropped due to lack of time, such as:
* Radar contacts should only move on the scope when they are being actively scanned by the radar beam.
* To create a fog-of-war mechanic, radar contacts should remain unidentified until specific conditions are met.
* Better visual quality, like a CRT monitor style radar screen.
|
## Inspiration
We wanted to build something fun, after several ideas this emerged and our eyes glowed.
## What it does
It's a game. You play as a robot with a laser and shield trying to survive and destroy the other players. Once dead the player becomes part of the environment and can redirect lasers.
## How I built it
We used LibGdx to do the rendering. Websockets for the communication between mobile and game server. And XBOX controllers for the game testing.
## Challenges I ran into
Trying to figure out how to route traffic through the Berkeley network with low latency. I tried tunneling the game server's connection through a VPS but the performance was unacceptable. We ended up using a phone as a hotspot so we could route locally.
## Accomplishments that I'm proud of
It turned out really well and is a lot of fun to play.
## What I learned
You cannot rely on noisy wifi.
## What's next for LaserMan
More plays.
|
## Inspiration
Our inspiration comes from the idea that the **Metaverse is inevitable** and will impact **every aspect** of society.
The Metaverse has recently gained lots of traction with **tech giants** like Google, Facebook, and Microsoft investing into it.
Furthermore, the pandemic has **shifted our real-world experiences to an online environment**. During lockdown, people were confined to their bedrooms, and we were inspired to find a way to basically have **access to an infinite space** while in a finite amount of space.
## What it does
* Our project utilizes **non-Euclidean geometry** to provide a new medium for exploring and consuming content
* Non-Euclidean geometry allows us to render rooms that would otherwise not be possible in the real world
* Dynamically generates personalized content, and supports **infinite content traversal** in a 3D context
* Users can use their space effectively (they're essentially "scrolling infinitely in 3D space")
* Offers new frontier for navigating online environments
+ Has **applicability in endless fields** (business, gaming, VR "experiences")
+ Changing the landscape of working from home
+ Adaptable to a VR space
## How we built it
We built our project using Unity. Some assets were used from the Echo3D Api. We used C# to write the game. jsfxr was used for the game sound effects, and the Storyblocks library was used for the soundscape. On top of all that, this project would not have been possible without lots of moral support, timbits, and caffeine. 😊
## Challenges we ran into
* Summarizing the concept in a relatively simple way
* Figuring out why our Echo3D API calls were failing (it turned out that we had to edit some of the security settings)
* Implementing the game. Our "Killer Tetris" game went through a few iterations and getting the blocks to move and generate took some trouble. Cutting back on how many details we add into the game (however, it did give us lots of ideas for future game jams)
* Having a spinning arrow in our presentation
* Getting the phone gif to loop
## Accomplishments that we're proud of
* Having an awesome working demo 😎
* How swiftly our team organized ourselves and work efficiently to complete the project in the given time frame 🕙
* Utilizing each of our strengths in a collaborative way 💪
* Figuring out the game logic 🕹️
* Our cute game character, Al 🥺
* Cole and Natalie's first in-person hackathon 🥳
## What we learned
### Mathias
* Learning how to use the Echo3D API
* The value of teamwork and friendship 🤝
* Games working with grids
### Cole
* Using screen-to-gif
* Hacking google slides animations
* Dealing with unwieldly gifs
* Ways to cheat grids
### Natalie
* Learning how to use the Echo3D API
* Editing gifs in photoshop
* Hacking google slides animations
* Exposure to Unity is used to render 3D environments, how assets and textures are edited in Blender, what goes into sound design for video games
## What's next for genee
* Supporting shopping
+ Trying on clothes on a 3D avatar of yourself
* Advertising rooms
+ E.g. as your switching between rooms, there could be a "Lululemon room" in which there would be clothes you can try / general advertising for their products
* Custom-built rooms by users
* Application to education / labs
+ Instead of doing chemistry labs in-class where accidents can occur and students can get injured, a lab could run in a virtual environment. This would have a much lower risk and cost.
…the possibility are endless
|
losing
|
# mtrx — /ˈmɛtrɪks/
### Data analytics solutions for small businesses.
Team: Wyatt Lake, Sritan Motati, Yuvraj Lakhotia, Evelyn Li
## Components
* Client Portal: <https://github.com/wyattlake/penn-apps-frontend>
* LLM & API Suite: <https://github.com/sritanmotati/pennapps-backend>
* CORS Server: <https://github.com/sritanmotati/cors-server>
* Web Scraper: <https://github.com/yuviji/mtrx-scraper>
* Video Demo: <https://youtu.be/5DYp92nrwiw>
## Inspiration
As first-years who recently moved onto Penn’s city campus, we’ve explored many new restaurants, and grown to appreciate the variety of family-owned dining spots. We wanted to create an accessible application that helps small businesses track their analytics against other similar companies and develop a deeper understanding of their potential action points. Our product inspiration stemmed from existing softwares such as Revinate, which creates complex and actionable insights from tons of messy data for large corporations such as hotels. With mtrx, we’re bringing this utility to the companies that really need it.
## What it does
mtrx provides AI-enhanced actionable metrics for small businesses that don’t have the infrastructure to compute these statistics. It scrapes data from Yelp and processes it using our LLM suite to understand the business's current situation and suggest improvements.
## How we built it
mtrx is composed of a three-part solution. The [portal](https://github.com/wyattlake/penn-apps-frontend), [API](https://github.com/sritanmotati/pennapps-backend), and [scraper](https://github.com/yuviji/mtrx-scraper).
**1. Client Portal ([Svelte](https://svelte.dev/)):** The web interface that small businesses can easily access, sign up for, and view metrics from. The portal uses [ApexCharts](https://www.npmjs.com/package/svelte-apexcharts) for visualizing our data and metrics, [Firebase](https://firebase.google.com/) for authentication and account information, and [Flowbite](https://flowbite.com/) for broader UI components. We implemented a cross-origin resource sharing (CORS) proxy-server that allowed us to access our REST API on Ploomber, and designed the visuals with [Adobe XD](https://adobexdplatform.com/).
**2. LLM & API Suite ([Python](https://www.python.org/)):** We performed large-scale sentiment analysis on review data for many businesses. This was done with the [DistilBERT](https://huggingface.co/docs/transformers/en/model_doc/distilbert) architecture provided through Hugging Face, which performed at a state-of-the-art level. For the rest of our LLM needs, which were used to analyze the content of reviews and generate suggestions for an improved business strategy, we used [Cerebras](https://cerebras.ai/)
and [Tune Studio](https://tunehq.ai/tune-studio). The base Llama models were accessed with Cerebras for lightning-fast inference, and Tune Studio served as a convenient wrapper/pipeline to access the Cerebras models.
All of our AI-based functionalities and asynchronous scraping scripts were implemented within a custom REST API developed with [Flask](https://flask.palletsprojects.com/en/3.0.x/). To deploy and host our API, we tested many free solutions, but most did not provide enough compute to support transformer-based sentiment analysis. After unsuccessfully trying out [Railway](https://railway.app/), [Vercel](https://vercel.com/), [Render](https://render.com/), and [AWS EC2](https://aws.amazon.com/ec2/), we ended up using [Ploomber](https://ploomber.io/), a Y-Combinator W22 startup offering Heroku-like services for AI projects.
**3. Web Scraper ([Python](https://www.python.org/)):** Initially, we built a foundational database by scraping [Yelp](https://www.yelp.com/) for restaurants in our area (Philadelphia) using a custom [Selenium](https://www.selenium.dev/) web scraper that posted the data to Firebase, from where it processed and analyzed by the LLM suite. We later developed an asynchronous web scraper than can gather data on a business ***as they sign up*** for mtrx using [BeautifulSoup](https://www.crummy.com/software/BeautifulSoup/bs4/doc/) and embedding it directly into a REST API call/route — enabling access to mtrx for nearly any client that wishes to use it.
## Challenges we ran into
The ride was most definitely not smooth.
Finding a cloud hosting platform whose free-tier met our CPU and memory requirements for the Flask server was difficult – we tried Vercel, Railway, AWS, etc. – and ultimately decided on Ploomber, which provided us with 1 vCPU and 2 GiB RAM.
We couldn’t send requests from our local web interface to the Ploomber REST API server that we had deployed – the problem was that the web app itself wouldn’t issue any requests unless we had a cross-origin resource sharing (CORS) server configured. It took a while to set up, but after setup, we could send and receive information from our Flask backend!
The Ploomber server also had a timeout period for requests, which meant that we had to optimize our asynchronous scraping and analysis processes in order to prevent time-outs and server errors. As a result, the amount of data available dynamically is not at its fullest potential.
## Accomplishments that we're proud of
This project was a great learning experience for all of us. We got to learn a lot about front-end and back-end development. Through exploring many different REST APIs and our sponsor’s products, we compiled an LLM & API Suite with enough memory to perform our Natural-Language-Processing tasks. Overall, it was rewarding for our team to be able to turn an idea into a product — and accomplish all of our planned tasks!
## What we learned
We learned how to efficiently conduct a division of tasks, product management, and integrate various technologies into one application. We also got to implement sentiment analysis and LLMs. We also gained hands-on experience in developing Flask backends and creating responsive front-end designs with CSS, enhancing our full-stack development skills.
## What's next for mtrx
We plan on sourcing customer reviews from diverse platforms, reaching out to local small businesses to provide demos, and offering pro-bono services to local businesses. By expanding our dataset and testing our product in the real-world, we’ll be able to improve our product more efficiently and cater to our projected audiences.
|
## Inspiration
We help businesses use Machine Learning to take control of their brand by giving them instant access to sentiment analysis for reviews.
## What it does
Reviews are better when they are heard. We scrape data from Yelp, run the reviews through our ML model and allow users to find and access these processed reviews in a user-friendly way.
## How we built it
For the back-end, we used Flask, Celery worker, and Dockers, and TensorFlow for our machine learning model. For the
front-end, we used React, bootstrap and CSS. We scraped the yelp data and populated it to a local MongoDB server. We perform periodic Celery tasks to process the scraped data in the background and save the sentiment analysis in the database. Our TensorFlow model is deployed on the GCP AI Platform and our backend uses the specified version.
## Challenges we ran into
* Learning new technologies on the fly during the day of the hackathon. Also, commutation barriers and deployment for machine learning model
* Training, building and deploying a machine learning model in a short time
* Scraping reviews in mass amounts and loading them to the db
* Frontend took a while to make
## Accomplishments that we're proud of
* To get a working prototype of our product and learn a few things along the way
* Deploy a machine learning model to GCP and use it
* Set up async workers in the backend
* Perform sentiment analysis for over 8.6 million reviews for almost 160,000 businesses
## What we learned
* Deploy ML models
* Performing async tasks on the backend side
## What's next for Sentimentality
* Provide helpful feedback and insights for businesses (actionable recommendations!).
* Perform more in-depth and complex sentiment analysis, and the ability to recognize competitors.
* Allow users to mark wrong sentiments (and correct them). Our models aren't perfect, we have room to grow too!
* Scrape more platforms (Twitter, Instagram, and other sources, etc.)
* Allow users to write a review and receive sentimental analysis from our machine learning model as feedback
* Allow filtering businesses by location and/or city
|
## Inspiration
Millions of people around the world are either blind, or partially sighted. For those who's vision is impaired, but not lost, there are tools that can help them see better. By increasing contrast and detecting lines in an image, some people might be able to see clearer.
## What it does
We developed an AR headset that processes the view in front of it and displays a high contrast image. It also has the capability to recognize certain images and can bring their existence to the attention of the wearer (one example we used was looking for crosswalk signs) with an outline and a vocal alert.
## How we built it
OpenCV was used to process the image stream from a webcam mounted on the VR headset, the image is processed with a Canny edge detector to find edges and contours. Further a BFMatcher is used to find objects that resemble a given image file, which is highlighted if found.
## Challenges we ran into
We originally hoped to use an oculus rift, but we were not able to drive the headset with the available hardware. We opted to use an Adafruit display mounted inside a Samsung VR headset instead, and it worked quite well!
## Accomplishments that we're proud of
Our development platform was based on macOS 10.12, Python 3.5 and OpenCV 3.1.0, and OpenCV would not cooperate with our OS. We spent many hours compiling and configuring our environment until it finally worked. This was no small feat. We were also able to create a smooth interface using multiprocessing, which operated much better than we expected.
## What we learned
Without the proper environment, your code is useless.
## What's next for EyeSee
Existing solutions exist, and are better suited for general use. However a DIY solution is endlessly customizable, we this project inspires other developers to create projects that help other people.
## Links
Feel free to read more about visual impairment, and how to help;
<https://w3c.github.io/low-vision-a11y-tf/requirements.html>
|
losing
|
## Inspiration
The Distillery District in Toronto with historical buildings.
## What it does
This is a game about how to make whiskey in the old distillery district. Following the process of whiskey-making with manual labor, you have to find out the perfect formula to make the best whiskey.
## How we built it
We built the game using pygame with user interaction, state machines, and GUIs. Furthermore, the scores were evaluated through different measures of success (ex. Gaussian Radial Basis)
## Challenges we ran into
Learning pygame and general problems of game development.
## Accomplishments that we're proud of
We each learned new tools and new concepts. We included collision detection, manual gradient formulas, and had members in the first hackathon. None of us were familiar with PyGame and so being able to create something with it was really cool!
## What we learned
We learned how to use pygame to make a python game
## What's next for Distillery Whiskey Maker
Using additional RBF to have a more robust scoring system. Including a story of progression to bring it from the past to the modern time
|
## Inspiration
**The Tales of Detective Toasty** draws deep inspiration from visual novels like **Persona** and **Ghost Trick** and we wanted to play homage to our childhood games through the fusion of art, music, narrative, and technology. Our goal was to explore the possibilities of AI within game development. We used AI to create detailed character sprites, immersive backgrounds, and engaging slide art. This approach allows players to engage deeply with the game's characters, navigating through dialogues and piecing together clues in a captivating murder mystery that feels personal and expansive. By enriching the narrative in this way, we invite players into Detective Toasty’s charming yet suspense-filled world.
## What It Does
In **The Tales of Detective Toasty**, players step into the shoes of the famous detective Toasty, trapped on a boat with four suspects in a gripping AI-powered murder mystery. The game challenges you to investigate suspects, explore various rooms, and piece together the story through your interactions. Your AI-powered assistant enhances these interactions by providing dynamic dialogue, ensuring that each playthrough is unique. We aim to expand the game with more chapters and further develop inventory systems and crime scene investigations.
## How We Built It
Our project was crafted using **Ren'py**, a Python-based visual novel engine, and Python. We wrote our scripts from scratch, given Ren'py’s niche adoption. Integration of the ChatGPT API allowed us to develop a custom AI assistant that adapts dialogues based on player's question, enhancing the storytelling as it is trained on the world of Detective Toasty. Visual elements were created using Dall-E and refined with Procreate, while Superimpose helped in adding transparent backgrounds to sprites. The auditory landscape was enriched with music and effects sourced from YouTube, and the UI was designed with Canva.
## Challenges We Ran Into
Our main challenge was adjusting the ChatGPT prompts to ensure the AI-generated dialogues fit seamlessly within our narrative, maintaining consistency and advancing the plot effectively. Being our first hackathon, we also faced a steep learning curve with tools like ChatGPT and other OpenAI utilities and learning about the functionalities of Ren'Py and debugging. We struggled with learning character design transitions and refining our artwork, teaching us valuable lessons through trial and error. Furthermore, we had difficulties with character placement, sizing, and overall UI so we had to learn all the components on how to solve this issue and learn an entirely new framework from scratch.
## Accomplishments That We’re Proud Of
Participating in our first hackathon and pushing the boundaries of interactive storytelling has been rewarding. We are proud of our teamwork and the gameplay experience we've managed to create, and we're excited about the future of our game development journey.
## What We Learned
This project sharpened our skills in game development under tight deadlines and understanding of the balance required between storytelling and coding in game design. It also improved our collaborative abilities within a team setting.
## What’s Next for The Tales of Detective Toasty
Looking ahead, we plan to make the gameplay experience better by introducing more complex story arcs, deeper AI interactions, and advanced game mechanics to enhance the unpredictability and engagement of the mystery. Planned features include:
* **Dynamic Inventory System**: An inventory that updates with both scripted and AI-generated evidence.
* **Interactive GPT for Character Dialogues**: Enhancing character interactions with AI support to foster a unique and dynamic player experience.
* **Expanded Storyline**: Introducing additional layers and mysteries to the game to deepen the narrative and player involvement.
* *and more...* :D
|
## Inspiration
We are a group of friends who are interested in cryptography and Bitcoin in general but did not have a great understanding. However, attending Sonr's panel gave us a lot of inspiration because they made the subject more digestible and easier to understand. We also wanted to do something similar but add a more personal touch by making an educational game on cryptography. Fun fact: the game is set in hell because our initial calculations yielded that we can buy approximately 6666 bananas ($3) with one bitcoin!
## What it does
*Devil's Advocate* explains cryptography and Bitcoin, both complicated topics, in a fun and approachable way. And what says fun like games? The player is hired as Satan's advocate at her company Dante’s Bitferno, trying to run errands for her using bitcoins. During their journey, they face multiple challenges that also apply to bitcoins in real life and learn all about how blockchains work!
## How we built it
We built by using JavaFX as the main groundwork for our application and had initially planned to embed it into a website using Velo by Wix but decided to focus our efforts on the game itself using JavaFX, HTML, and CSS. The main IDE we used was Intellij with git version control integration to make teamwork much easier and more efficient.
## Challenges we ran into
Having to catch a flight from Durham right after our classes, we missed the opening ceremony and started later than most other teams. However, we were quickly able to catch up by setting a time limit for most things, especially brainstorming. Only one of our members knew how to use JavaFX, despite it being the main groundwork for our project. Luckily other members were able to pick it up fairly quickly and were able to move on to a divide and conquer strategy.
## Accomplishments that we're proud of
We are most impressed by what we taught ourselves how to do in a day. For instance, some of our members learned how to use JavaFX others how to use various design software for UX/UI and graphic design. We are also proud of how the artwork turned out, considering that all of them were drawn by hand using Procreate.
## What we learned
While learned a lot of things in such a short amount of time, it definitely took us the most time to learn how to use JavaFX to design fluent gameplay by integrating various elements such as text or images. We also had to research on cryptography to make sure that our knowledge on the subject was correct, considering that we are making an educational game.
## What's next for Devil's Advocate
We plan to continue building more levels beyond the first level and offer explanations on other characteristics of blockchain, such as how it is decentralized, has smart contract, or utilizes a consensus algorithm. We also want to add more sprites to Satan to make her feel more expressive and provide a richer gameplay experience to users.
|
winning
|
## Inspiration
Bipolar is a mental health condition that affects %1 of the population in Canada which amount to 3.7 million people. One in eight adults will show symptoms of a mood disorder. My father was diagnosed with bipolar disorder and refused medication on the basis that he didn't feel himself. A standard medication for bipolar is lithium which is known to have this effect. Because this is a problem that affects a large number of Canadians, we wanted to develop a non-medicated solution. Additionally, Engineering is known for having a high rate of depression and we wanted to give people a tool to assist in finding activities that can improve their mental health.
## What it does
Our application is a one time set up device that uses AI to collect a rolling average of your mood everyday to create a mood chart. A mood chart is a tool used now for helping people with bipolar determine when they are in a manic or depressive swing. It's can also be used to identify triggers and predict potential swings. By prompting people to log about what happened to them during an extreme mood, we can better identify triggers for mania and depression, develop methods against them, and predict upcoming swings. Our application includes a function to log activities for a day which can be later examined by a user, psychiatrist, or AI. We wanted to include a notification system that could ask you how things were going (like a good friend would) when you swung out of your neutral state to do this.
## How we built it
We built a device using the DragonBoard 401c and developed a node application (to run on the dragonboard linux or a laptop windows machine) that can take pictures of a user and determine their emotional state using the Azure Face API. We collect data periodically over the month (a few shots a day) to get a better representation of your mood for that day without the hassle of having to log it. If you are very depressed or manic, it can be hard to maintain a routine so it was essential that this device not require consistent attention from the user. The mood chart is managed by a node server running on Huroku. We then have an andriod app that allows you to access the chart and see your moods and logs on a calendar.
## Challenges we ran into
It was our first time setting up a dragonboard device and we initially didn't have a way to interface with it due to a mistake by the MLH. We lost an hour or two running around to find a keyboard, mouse, and camera. This was the largest UI project Gary Bowen has ever been in charge of and we ran into some issues with formatting the data we were transmitting.
## Accomplishments that we're proud of
June Ha is proud of setting up a public server for the first time. Gary is proud of the implementing a smiley faced dropbox and all his debugging work. I'm proud of setting up the capture software on the Dragonboard and my laptop. And I'm proud that we managed to capture data with a cheap webcam on a dragonboard, use the mircosoft api to get the emotion, send that data back to our server for processing, and delivering all that in a handy mood chart on your phone.
## What we learned
I learned a bit about working my way around a linux machine and the Dragonboard 401c. Gary learned a lot of good debugging tools for android development, and June learned he should not be awake for 24 hours.
## What's next for palpable
We'd like to properly implement the notification function on our app. Develop a more cost effective wireless camera device for processing emotion. We'd also love to implement additional AI for smart suggestions and to possibly diagnose people that have a mood disorder and may not know it.
## Resources
<https://www.canada.ca/en/public-health/services/chronic-diseases/mental-illness/what-should-know-about-bipolar-disorder-manic-depression.html>
<https://en.wikipedia.org/wiki/Population_of_Canada>
<https://www.canada.ca/en/public-health/services/chronic-diseases/mental-illness/what-depression.html>
|
# Mental-Health-Tracker
## Mental & Emotional Health Diary
This project was made because we all know how much of a pressing issue that mental health and depression can have not only on ourselves, but thousands of other students. Our goal was to make something where someone could have the chance to accurately assess and track their own mental health using the tools that Google has made available to access. We wanted the person to be able to openly express their feelings towards the diary for their own personal benefit. Along the way, we learned about using Google's Natural Language processor, developing using Android Studio, as well as deploying an app using Google's App Engine with a `node.js` framework. Those last two parts turned out to be the greatest challenges. Android Studio was a challenge as one of our developers had not used Java for a long time, nor had he ever developed using `.xml`. He was pushed to learn a lot about the program in a limited amount of time. The greatest challenge, however, was deploying the app using Google App Engine. This tool is extremely useful, and was made to seem that it would be easy to use, but we struggled to implement it using `node.js`. Issues arose with errors involving `favicon.ico` and `index.js`. It took us hours to resolve this issue and we were very discouraged, but we pushed though. After all, we had everything else - we knew we could push through this.
The end product involves and app in which the user signs in using their google account. It opens to the home page, where the user is prompted to answer four question relating to their mental health for the day, and then rate themselves on a scale of 1-10 in terms of their happiness for the day. After this is finished, the user is given their mental health score, along with an encouraging message tagged with a cute picture. After this, the user has the option to view a graph of their mental health and happiness statistics to see how they progressed over the past week, or else a calendar option to see their happiness scores and specific answers for any day of the year.
Overall, we are very happy with how this turned out. We even have ideas for how we could do more, as we know there is always room to improve!
|
## Inspiration
While we were doing preliminary research, we had found overwhelming amounts of evidence of mental health deterioration as a consequence of life-altering lockdown restrictions. Academic research has shown that adolescents depend on friendship to maintain a sense of self-worth and to manage anxiety and depression. Intimate exchanges and self-esteem support significantly increased long-term self worth and decreased depression.
While people do have virtual classes and social media, some still had trouble feeling close with anyone. This is because conventional forums and social media did not provide a safe space for conversation beyond the superficial. User research also revealed that friendships formed by physical proximity don't necessarily make people feel understood and resulted in feelings of loneliness anyway. Proximity friendships formed in virtual classes also felt shallow in the sense that it only lasted for the duration of the online class.
With this in mind, we wanted to create a platform that encouraged users to talk about their true feelings, and maximize the chance that the user would get heartfelt and intimate replies.
## What it does
Reach is an anonymous forum that is focused on providing a safe space for people to talk about their personal struggles. The anonymity encourages people to speak from the heart. Users can talk about their struggles and categorize them, making it easy for others in similar positions to find these posts and build a sense of closeness with the poster. People with similar struggles have a higher chance of truly understanding each other. Since ill-mannered users can exploit anonymity, there is a tone analyzer that will block posts and replies that contain mean-spirited content from being published while still letting posts of a venting nature through. There is also ReCAPTCHA to block bot spamming.
## How we built it
* Wireframing and Prototyping: Figma
* Backend: Java 11 with Spring Boot
* Database: PostgresSQL
* Frontend: Bootstrap
* External Integration: Recaptcha v3 and IBM Watson - Tone Analyzer
* Cloud: Heroku
## Challenges we ran into
We initially found it a bit difficult to come up with ideas for a solution to the problem of helping people communicate. A plan for a VR space for 'physical' chatting was also scrapped due to time constraints, as we didn't have enough time left to do it by the time we came up with the idea. We knew that forums were already common enough on the internet, so it took time to come up with a product strategy that differentiated us. (Also, time zone issues. The UXer is Australian. They took caffeine pills and still fell asleep.)
## Accomplishments that we're proud of
Finishing it on time, for starters. It felt like we had a bit of a scope problem at the start when deciding to make a functional forum with all these extra features, but I think we pulled it off. The UXer also iterated about 30 screens in total. The Figma file is *messy.*
## What we learned
As our first virtual hackathon, this has been a learning experience for remote collaborative work.
UXer: I feel like i've gotten better at speedrunning the UX process even quicker than before. It usually takes a while for me to get started on things. I'm also not quite familiar with code (I only know python), so watching the dev work and finding out what kind of things people can code was exciting to see.
# What's next for Reach
If this was a real project, we'd work on implementing VR features for those who missed certain physical spaces. We'd also try to work out improvements to moderation, and perhaps a voice chat for users who want to call.
|
partial
|
# Babble: PennAppsXVIII
PennApps Project Fall 2018
## Babble: Offline, Self-Propagating Messaging for Low-Connectivity Areas
Babble is the world's first and only chat platform that is able to be installed, setup, and used 100% offline. This platform has a wide variety of use cases such as use in communities with limited internet access like North Korea, Cuba, and Somalia. Additionally, this platform would be able to maintain communications in disaster situations where internet infrastructure is damaged or sabotaged. ex. Warzones, Natural Disasters, etc.
### Demo Video
See our project in action here: <http://bit.ly/BabbleDemo>
[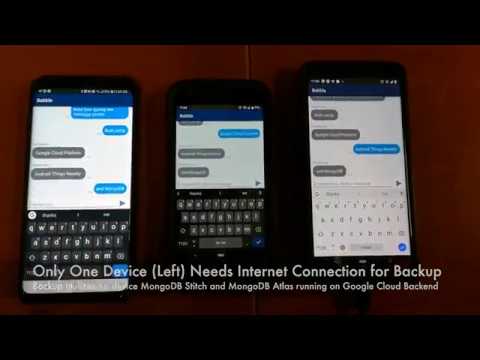](http://www.youtube.com/watch?v=M5dz9_pf2pU)
## Offline Install & Setup
Babble (a zipped APK) is able to be sent from one user to another via Android Beam. From there it is able to be installed. This allows any user to install the app just by tapping their phone to that of another user. This can be done 100% offline.
## Offline Send
All Babble users connect to all nearby devices via the creation of a localized mesh network created using the Android Nearby Connections API. This allows for messages to be sent directly from device to device via m to n peer to peer as well as messages to be daisy chain sent from peer to peer to ... to peer to peer.
Each Babble user's device keeps a localized ledger of all messages that it has sent and received, as well as an amalgamation of all of the ledgers of every device that this instance of Babble has been connected directly to via Android Nearby.
The combination of the Android Nearby Connections API with this decentralized, distributed ledger allows for messages to propagate across mesh networks and move between isolated networks as users leave one mesh network and join another.
## Cloud Sync when Online
Whenever an instance of Babble gains internet access, it uploads a copy of its ledger to a MongoDB Atlas Cluster running on Google Cloud. There the local ledger is amalgamated with the global ledger which contains all messages sent world wide. From there the local copy of the ledger is updated from the global copy to contain messages for nearby users.
## Use Cases
### Internet Infrastructure Failure: Natural Disaster
Imagine a natural disaster situation where large scale internet infrastructure is destroyed or otherwise not working correctly. Only a small number of users of the app would be able to distribute the app to all those affected by the outage and allow them to communicate with loved ones and emergency services. Additionally, this would provide a platform by which emergency services would be able to issue public alerts to the entire mesh network.
### Untraceable and Unrestrictable Communication in North Korea
One of the future directions we would like to take this would be a Ethereum-esq blockchain based ledger. This would allow for 100% secure, private, and untraceable messaging. Additionally the Android Nearby Connections API is able to communicate between devices via, cellular network, Wifi, Bluetooth, NFC, and Ultrasound which makes our messages relatively immune to jamming. With the mesh network, it would be difficult to block messaging on a large scale.
As a result of this feature set, Babble would be a perfect app to allow for open and unobstructed, censored, or otherwise unrestricted communication inside of a country with heavily restricted internet access like North Korea.
### Allowing Cubans to Communicate with Family and Friends in the US
Take a use case of a Cuba wide roll out. There will be a limited number of users in large cities like Havana or Santiago de Cuba that will have internet access as well as a number of users distributed across the country who will have occasional internet access. Through both the offline send and the cloud sync, 100% offline users in cuba would be able to communicate with family stateside.
## Future Goals and Directions
Our future goals would be to build better stability and more features such as image and file sharing, emergency messaging, integration with emergency services and the 911 decision tree, end to end encryption, better ledger management, and conversion of ledger to Ethereum-esq anonymized blockchain to allow for 100% secure, private, and untraceable messaging.
Ultimately, the most insane use of our platform would be as a method for rolling out low bandwidth internet to the offline world.
Name creds go to Chris Choi
|
As a response to the ongoing wildfires devastating vast areas of Australia, our team developed a web tool which provides wildfire data visualization, prediction, and logistics handling. We had two target audiences in mind: the general public and firefighters. The homepage of Phoenix is publicly accessible and anyone can learn information about the wildfires occurring globally, along with statistics regarding weather conditions, smoke levels, and safety warnings. We have a paid membership tier for firefighting organizations, where they have access to more in-depth information, such as wildfire spread prediction.
We deployed our web app using Microsoft Azure, and used Standard Library to incorporate Airtable, which enabled us to centralize the data we pulled from various sources. We also used it to create a notification system, where we send users a text whenever the air quality warrants action such as staying indoors or wearing a P2 mask.
We have taken many approaches to improving our platform’s scalability, as we anticipate spikes of traffic during wildfire events. Our codes scalability features include reusing connections to external resources whenever possible, using asynchronous programming, and processing API calls in batch. We used Azure’s functions in order to achieve this.
Azure Notebook and Cognitive Services were used to build various machine learning models using the information we collected from the NASA, EarthData, and VIIRS APIs. The neural network had a reasonable accuracy of 0.74, but did not generalize well to niche climates such as Siberia.
Our web-app was designed using React, Python, and d3js. We kept accessibility in mind by using a high-contrast navy-blue and white colour scheme paired with clearly legible, sans-serif fonts. Future work includes incorporating a text-to-speech feature to increase accessibility, and a color-blind mode. As this was a 24-hour hackathon, we ran into a time challenge and were unable to include this feature, however, we would hope to implement this in further stages of Phoenix.
|
## Inspiration
We drew inspiration from the concept of a photo album. We focused on its nostalgic affect and it's main ability to store photos. Another application we took inspiration from was Spotify and how their Spotify Wrapped allowed the viewers to look back on their listener's music history. We drew from these and decided to put our own spin on it.
## What it does
Our mobile application takes your photos and memories and stores it. Annually you will be able to access it and review your year in photos. It takes your photos and breaks them down into separate prompts. An example of this is its ability to view who you may have spent a lot of time with in the previous year. It is able to do this because of our implementation of facial recognition into our mobile application, it views your photos and stores the data for future references.
## How we built it
We built it by using react native to build our cross platform mobile app client. And to interface with it we used express for a backend API server that interacted with our firestore database. To do our facial recognitions we used opencv-python and face\_recognition.
## Challenges we ran into
Some challenges we ran into were things like networking. Our firewalls prevented our mobile app from interacting with out API server. Because of this we lost a lot of time trying to expose our port correctly.
## Accomplishments that we're proud of
We are very proud of being able to complete our application. We each worked on things that we were comfortable with and tried our best to push our boundaries and learn new skills. Specific things were like learning firestore, working on completing the video demo, and building a stronger UI.
## What we learned
Somethings we learned were firestore, network tunnels, react native mobile development, NoSQL database.
## What's next for Recollect
For Recollect we already have many plans to progress and update this application to make it more suitable towards everyone's daily lives.
Some features we wish to implement are:
* Making the application personalized by implementing features such as being able to choose your time periods over having to wait annually.
* A collaboration feature, to either share or tag people you know in your photos so they too can also enjoy the application with pictures that someone else may have taken of them.
|
winning
|
## Inspiration
We visit many places, we know very less about the historic events or the historic places around us. Today In History notifies you of historic places near you so that you do not miss them.
## What it does
Today In History notifies you about important events that took place exactly on the same date as today but a number of years ago in history. It also notifies the historical places that are around you along with the distance and directions. Today In History is also available as an Amazon Alexa skill. You can always ask Alexa, "Hey Alexa, ask Today In History what's historic around me? What Happened Today? What happened today in India.......
## How we built it
We have two data sources: one is Wikipedia -- we are pulling all the events from the wiki for the date and filter them based on users location. We use the data from Philadelphia to fetch the historic places nearest to the user's location and used Mapquest libraries to give directions in real time.
## Challenges we ran into
Alexa does not know a person's location except the address it is registered with, but we built a novel backend that acts as a bridge between the web app and Alexa to keep them synchronized with the user's location.
|
## Inspiration
Between 1994 and 2013 there were 6,873 natural disasters worldwide, which claimed 1.35 million lives or almost 68,000 lives on average each year. In many of these disasters, people don't know where to go, and where is safe. For example, during Hurricane Harvey, many people learned about dangers such as alligators or flooding through other other people, and through social media.
## What it does
* Post a natural disaster hazard in your area
* Crowd-sourced hazards
* Pulls government severe weather data
* IoT sensor system to take atmospheric measurements and display on map
* Twitter social media feed of trending natural disasters in the area
* Machine learning image processing to analyze posted images of natural disaster hazards
Our app **Eye in the Sky** allows users to post about various natural disaster hazards at their location, upload a photo, and share a description of the hazard. These points are crowd-sourced and displayed on a map, which also pulls live data from the web on natural disasters. It also allows these users to view a Twitter feed of current trending information on the natural disaster in their location. The last feature is the IoT sensor system, which take measurements about the environment in real time and displays them on the map.
## How I built it
We built this app using Android Studio. Our user-created posts are hosted on a Parse database (run with mongodb). We pull data from the National Oceanic and Atmospheric Administration severe weather data inventory. We used Particle Electron to collect atmospheric sensor data, and used AWS to store this data in a JSON.
## Challenges I ran into
We had some issues setting up an AWS instance to run our image processing on the backend, but other than that, decently smooth sailing.
## Accomplishments that I'm proud of
We were able to work really well together, using everyone's strengths as well as combining the pieces into a cohesive app that we're really proud of. Everyone's piece was integrated well into the app, and I think we demonstrated good software collaboration.
## What I learned
We learned how to effectively combine our code across various languages and databases, which is a big challenge in software as a whole. We learned Android Development, how to set up AWS, and how to create databases to store custom data. Most importantly, we learned to have fun!
## What's next for Eye in the Sky
In the future, we would like to add verification of people's self-reported hazards (through machine learning and through up-voting and down-voting)
We would also like to improve the efficiency of our app and reduce reliance on network because there might not be network, or very poor network, in a natural disaster
We would like to add more datasets from online, and to display storms with bigger bubbles, rather than just points
We would also like to attach our sensor to drones or automobiles to gather more weather data points to display on our map
|
### Inspiration
Have you ever found yourself wandering in a foreign land, eyes wide with wonder, yet feeling that pang of curiosity about the stories behind the unfamiliar sights and sounds? That's exactly where we found ourselves. All four of us share a deep love for travel and an insatiable curiosity about the diverse cultures, breathtaking scenery, and intriguing items we encounter abroad. It sparked an idea: why not create a travel companion that not only shares our journey but enhances it? Enter our brainchild, a fusion of VR and AI designed to be your personal travel buddy. Imagine having a friend who can instantly transcribe signs in foreign languages, identify any object from monuments to local flora, and guide you through the most bewildering of environments. That's what we set out to build—a gateway to a richer, more informed travel experience.
### What it does
Picture this: you're standing before a captivating monument, curiosity bubbling up. With our VR travel assistant, simply speak your question, and it springs into action. This clever buddy captures your voice, processes your command, and zooms in on the object of your interest in the video feed. Using cutting-edge image search, it fetches information about just what you're gazing at. Wondering about that unusual plant or historic site? Ask away, and you'll have your answer. It's like having a local guide, historian, and botanist all rolled into one, accessible with just a glance and a word.
### How we built it
We initiated our project by integrating Unity with the Meta XR SDK to bring our VR concept to life. The core of our system, a server engineered with Python and FastAPI, was designed to perform the critical tasks, enhanced by AI capabilities for efficient processing. We leveraged Google Lens via the SERP API for superior image recognition and OpenAI's Whisper for precise voice transcription. Our approach was refined by adopting techniques from a Meta research paper, enabling us to accurately crop images to highlight specific objects. This method ensured that queries were efficiently directed to the appropriate AI model for quick and reliable answers. To ensure a smooth operation, we encapsulated our system within Docker and established connectivity to our VR app through ngrok, facilitating instantaneous communication via websockets and the SocketIO library.

### Challenges we ran into
None of us had much or any experience with both Unity3D and developing VR applications so there were many challenges in learning how to use the Meta XR SDK and how to build a VR app in general. Additionally, Meta imposed a major restriction that added to the complexity of the application: we could not capture the passthrough video feed through any third-party screen recording software. This meant we had to, in the last few hours of the hackathon, create a new server in our network that would capture the casted video feed from the headset (which had no API) and then send it to the backend. This was a major challenge and we are proud to have overcome it.
### Accomplishments that we're proud of
From web developers to VR innovators, we've journeyed into uncharted territories, crafting a VR application that's not just functional but truly enriching for the travel-hungry soul. Our creation stands as a beacon of what's possible, painting a future where smart glasses serve as your personal AI-powered travel guides, making every journey an enlightening exploration.
### What we learned
The journey was as rewarding as the destination. We mastered the integration of Meta Quest 2s and 3s with Unity, weaving through the intricacies of Meta XR SDKs. Our adventure taught us to make HTTP calls within Unity, transform screenshots into Base64 strings, and leverage Google Cloud for image hosting, culminating in real-time object identification through Google Lens. Every challenge was a lesson, turning us from novices into seasoned navigators of VR development and AI integration.
|
winning
|
## Inspiration
In Grade 10 at one point I played a game with my classmates where we all started with $10 000 in virtual currency and traded stocks with that virtual currency, trying to see who could make the most money. Even though most of us lost almost all our money, the game was a lot of fun.
This is where the idea for Botman Sachs came in. I wanted to recreate the game I played in grade 10, but with bots instead of humans.
## What it does
Botman Sachs is a platform for algorithmic trading bots to trade virtual currency and for the people who write them to have fun doing so in a competitive gamified environment.
Users write algorithmic trading bots in Python using the straightforward Botman Sachs API which provides an interface for buying and selling stocks as well as providing an interface to BlackRock's comprehensive Aladdin API for retrieving stock information.
Every server tick (~10 seconds or so, configurable), all bots are run and given the opportunity to perform market research (Through either the BlackRock or Yahoo! Financial APIs and make trades. Bots are given a set amount of time to do this.
## How we built it
The bulk of the backend is done in Node, with our bot trading APIs being created using Express. Bots are written in Python and use our Python API, which is a small wrapper that forwards API calls to Node. The web frontend is built using Preact, Chart.js, Code Mirror and Redux.
Bots themselves are run by a separate Node project called the runner. Every server tick, the main Node backend sends out a message to a RabbitMQ server for each bot. There can be multiple runners, all of which grab messages from RabbitMQ and then run the corresponding bot. This pattern lets us add more runners across multiple machines and allows for massive horizontal scalability as more bots are uploaded and need to be run at set intervals.
## Challenges we ran into
As developers with little background in finance, we had to consult with a few people about what data was necessary to expose to the bots in order for them to make informed trading decisions.
## Accomplishments that we're proud of
We managed to accomplish quite a bit of work and were very productive over the course of Pennapps. This was a large project and we're quite proud of the fact that we managed to pull it off in a team of two.
## What we learned
We learned a lot about financial markets, using RabbitMQ and different flavours of Soylent.
## What's next for Botman Sachs
We're considering polishing Botman Sachs more and putting it up online permanently.
|
## Inspiration
We were inspired by Plaid's challenge to "help people make more sense of their financial lives." We wanted to create a way for people to easily view where they are spending their money so that they can better understand how to conserve it. Plaid's API allows us to see financial transactions, and Google Maps API serves as a great medium to display the flow of money.
## What it does
GeoCash starts by prompting the user to login through the Plaid API. Once the user is authorized, we are able to send requests for transactions, given the public\_token of the user. We then displayed the locations of these transactions on the Google Maps API.
## How I built it
We built this using JavaScript, including Meteor, React, and Express frameworks. We also utilized the Plaid API for the transaction data and the Google Maps API to display the data.
## Challenges I ran into
Data extraction/responses from Plaid API, InfoWindow displays in Google Maps
## Accomplishments that I'm proud of
Successfully implemented meteor webapp, integrated two different APIs into our product
## What I learned
Meteor (Node.js and React.js), Plaid API, Google Maps API, Express framework
## What's next for GeoCash
We plan on integrating real user information into our webapp; we currently only using the sandbox user, which has a very limited scope of transactions. We would like to implement differently size displays on the Maps API to represent the amount of money spent at the location. We would like to display different color displays based on the time of day, which was not included in the sandbox user. We would also like to implement multiple different user displays at the same time, so that we can better describe the market based on the different categories of transactions.
|
## Inspiration
We were inspired by Michael Reeves, a YouTuber who is known for his "useless inventions." We all enjoy his videos and creations, so we thought it would be cool if we tried it out too.
## What it does
Abyss. is a table that caves in on itself and drops any item that is placed onto it into the abyss.
## How we built it
Abyss. was built with an Arduino UNO, breadboard, a table and Arduino parts to control the table. It uses a RADAR sensor to detect when something is placed on the table and then controls the servo motors to drop the table open.
## Challenges we ran into
Due to the scale of our available parts and materials, we had to downsize from a full-sized table/nightstand to a smaller one to accommodate the weak, smaller servo motors. Larger ones need more than the 5V that the UNO provides to work. We also ran into trouble with the Arduino code since we were all new to Arduinos. We also had a supply chain issue with Amazon simply not shipping the motors we ordered. Also, the "servo motors", or as they were labelled, turned out to be regular step-down motors.
## Accomplishments that we're proud of
We're happy that the project is working and the results are quite fun to watch.
## What we learned
We learned a lot about Arduinos and construction. We did a lot of manual work with hand-powered tools to create our table and had to learn Arduinos from scratch to get the electronics portion working.
## What's next for Abyss.
We hope to expand this project to a full-sized table and integrate everything on a larger scale. This could include a more sensitive sensor, larger motors and power tools to make the process easier.
|
partial
|
## Inspiration
Epilepsy is a collective group of seizure related neurological disorders that adversely impacts approximately 4% of the American general public and over 87,000 veterans. Electroencephalogram (EEG) tests are used to detect seizures and other abnormalities associated with the electrical functions of the brain. With the exception of transitioning from analog recording methods developed in the 1960s to digital recordings in the 1980s, the use of EEG recordings has remained largely unchanged. Learning how to read EEG studies historically requires significant medical training and years of disciplined study. The result is that converting EEG data into clinically meaningful applications is costly and oftentimes inaccurate.
## What it does
Blaze Bot is an automated editing platform designed to reduce the amount of time it takes to read and identify seizure activity within an EEG recording. On average EEG studies contain approximately 45 minutes of recording time. Blaze Bot reduces the amount of time required to read an EEG to a range of 3-5 minutes.
## How we built it
Our program leverages machine learning algorithms to identify EEG patterns.
|
## Inspiration
Identibear was inspired by the work experiences of our team members as well as our varying specialties in web, ML, and hardware development!
Working in a nursing/retirement home means seeing seniors with dementia **struggling to recognize their family members**. Often many are too **embarrassed to ask for a name** because they are conscious of their condition.
Prosopagnosia is another condition where one struggles to recognize faces due to brain damage or conditions from birth. Like dementia, this can also have severe social effects and **deeply affect those who have it.**
Identibear is a step toward providing tools to help these conditions but **without the grimness and incredibly methodical ways of most medical gear**. While efficiency is undeniably important, **Identibear also provides comfort and friendliness and keeps the gear simple**, making it suitable for all ages.
## What it does
Identibear can recognize the faces of your loved ones, friends, and family. Once it registers them on the webcam, it provides you with information about their name, their relationship to you, when you met, and a significant memory if the program was provided with it.
To acquire the faces, Identibear provides a simple and robust web app. The user uploads a 15-30 second video of a person's face and provides the name of the person as well as their relationship. They may also provide the date they met and a significant memory if they wish to. Once this is complete, Identibear takes the video and parses it, adding onto its ML model with the provided labels.
## How it does it
### Frontend & UI
For the frontend, we used Streamlit, allowing us to take video and text input. The user can also activate the webcam from the web app.
### Video Input, Parsing & Model
On video upload, we used opencv to preprocess the images and separate the video frames into images, directing them into a Train and Test directory.
```
#dataFormatter.py
# Save frames and labels from the video
for idx, frame in enumerate(train_frames):
idx+=total_frame_count-frame_count
resized_frame = resize_image(frame) # Resize the frame to 37x50
gray_frame = convert_to_grayscale(resized_frame) # Convert to grayscale
output_image_file = os.path.join(train_images_dir, f"{idx:04d}.jpg")
output_label_file = os.path.join(train_labels_dir, f"{idx:04d}.txt")
```
This was also done with the fetch\_lfw\_people scikit-learn database in order to provide labels for strangers.
We used Keras to create a CNN model from the given data.
### Flask Backend
Flask was used as the backend for routing, accepting posts from Streamlit and pushing data to parsing and the model. Names of recognized individuals are simply included in a dictionary that is appended to, which holds name, relationship, date of meeting, and significant memories.
Upon webcam activation, webcam.py executes code to run the model and continuously predicts based on the live video feed. This generates an integer which is then routed to flask through a POST request and used to access the dictionary values. The relevant method must detect the same individual in frame for a few seconds, before running a TTS function to provide the user with audio output.
## Challenges we ran into
Our biggest challenge was getting the model to work. Having the backend connected to powerful hardware would allow real-time usage of the web UI, training the model on new data instantly. Because we had to face waiting times, we trained our model separately.
We faced a challenge in fine-tuning the model, especially with short training times and a lack of data.
We also faced several challenges when connecting the model to the backend & frontend, especially training it through uploaded video data (parsing the data, creating a directory with the frames, and training a new model).
## Accomplishments
We're proud of being able to connect all components of our project and being able to show off a working product. It works! Our only caveat was not inevitably having enough time to train a fully accurate model, which would require days of training and much stronger hardware.
## What we learned
## What's next for Identibear - Your Memory Companion!
Our next steps would be to fine-tune and train a far more robust model if allowed the time and hardware resources. We also aim to add more features aiding in recognition and memory, expanding just beyond a recognition app.
This includes functions such as routine planning, personalized memory books, interactive name tags, and visual storytelling. Another aim is to find another form for Identibear for those that may not be partial to a bear on their shoulder -- like glasses. Identibear will forever live on though.
|
## Inspiration
Every year, millions of people suffer from concussions without even realizing it. We wanted to tackle this problem by offering a simple solution that could be used by everyone to offer these people proper care.
## What it does
Harnessing computer vision and NLP, we have developed a tool that can administer a concussion test in under 2 minutes. It can be easily done anywhere using just a smartphone. The test consists of multiple cognitive tasks in order to get a complete assessment of the situation.
## How we built it
The application consists of a react-native app that can be installed on both iOS and Android devices. The app communicates with our servers, running a complex neural network model, which analyzes the user's pupils. It is then passed through a computer vision algorithm written in opencv. Next, there is a reaction game built in react-native to test reflexes. A speech analysis tool that uses the Google Cloud Platform's API is also used. Finally, there is a questionnaire regarding the symptoms of a user's concussion.
## Challenges we ran into
It was very complicated to get a proper segmentation of the pupil because of how small it is. We also ran into some minor Google Cloud bugs.
## Accomplishments that we're proud of
We are very proud of our handmade opencv algorithm. We also love how intuitive our UI looks.
## What we learned
It was Antonio's first time using react-native and Alex's first time using torch.
## What's next for BrainBud
By obtaining a bigger data set of pupils, we could improve the accuracy of the algorithm.
|
losing
|
## Inspiration
Helping people leading busy lifestyle with an app to keep important tasks and dates with reminders
## What it does
It is simply a reminder app with a game element to encourage recurrent visits .
As people keep completing task, they gain experience points to level up their chosen pet which is a dog or cat.
## How I built it
Our group went with a simple design and went something similar to MERN stack.
Using html/css with javascript to code the function and buttons.
user data/account were created and saved via firebase authentication.
and Ideally the task/reminders would be saved onto firebase cloud storage or mongodb altas for persistent data.
## Challenges I ran into
We had a very wide gap knowledge and had to compromise to a more simple app to allow for fair contribution.
Another challenged was the timezone difference. Two of us were in Canada while the other was in India. Very difficult to coordinate the workflow.
In building the app, we've ran into issue on what Oauth provider to use such as okta or firebase.
## Accomplishments that I'm proud of
In terms of a running app, it is functional in localhost. That it can load up a user and allow them to add in new task.
# Tam
• proud to be working with different people remotely in a time limited condition.
•Making a domain name for the project: <https://petential.space>
•Also proud to do my first hackathon, scary yet fun.
# Theresa
• Finished my first Hackathon!
• Collaborated with team using Git and GitHub
# Lakshit -
• Finished my first hackathon
• Contributed with team using Git and GitHub
• Added up the experience of working with such great Team from different time zones.
## What I learned
# Tam
• Team coordination and leadership.
• Learning about Okta authentication.
•Appreciating frameworks like React.
# Theresa
• Setting up a sidebar
• CSS animations
• Bootstrap progress bars
• Better understanding of JavaScript and jQuery
# Lakshit
• Got the knack about the reactions.
• CSS animations.
• About JavaScript and got new familiar with some new tags.
• Got cleared with some more branches of Version Control.
## What's next for Petential
Adding more functions and utility for the leveling system of the pets. Maybe a currency to get new accessories for the pet like a bow or hat.
• Pet food
• data storage.
|
## What it does
How you ever wanted to be healthy and exercise but could never work up the motivation? Well, we made the perfect website for you! Our website offers users a chance to workout... only gamified.
## Inspiration
We were inspired by RPG games, where they incentivize players to continuously do repetitive tasks in order to gain experience points and levels. We wanted to recreate this reward-loop for something more beneficial to someone's everyday life and found that exercise fits this theme quite well. The streak feature was inspired by Duolingo's streak system, which keeps users motivated and using their app.
## How we built it
The languages we used to build this web application are HTML, CSS and JS. We also used the React library to aid with the front end and MongoDB with our database. The backend used NodeJS.
## Challenges we ran into
Being our first hackathon, there were a number of learning curves that we had to face. First of all, there was an issue with managing time when developing our web application. Between the numerous workshops we wanted to attend and accommodating for sleep, we definitely had much less than 36 hours to dedicate to building this project. Another challenge we faced is that our group had a lack of experience with front end development. We spent a large chunk of time simply learning how to use front end development tools, and didn't have enough time to allocate to actually building the project.
## Accomplishments that we're proud of
For ALL of the members, it was our first ever web development experience! We're proud that we managed to cobble together somewhat resembling a visual representation of the idea we had in mind. We're also proud that we were able to try something we've never done before and experiment with tools outside our comfort zone.
## What we learned
Over the course of 36 hours, we learned new programming languages, libraries, and ways to interpret obscure error messages.
## What's next for Level UP
In the future, we would like to continue developing this product so that it could be a fully working web application. Hopefully...
|
## Inspiration
As students, we have found that there are very few high-quality resources on investing for those who are interested but don't have enough resources. Furthermore, we have found that investing and saving money can be a stressful experience. We hope to change this for those who want to save better with the help of our app, hopefully making it fun in the process!
## What it does
Our app first asks a new client a brief questionnaire about themselves. Then, using their banking history, it generates 3 "demons", aka bad spending habits, to kill. Then, after the client chooses a habit to work on, it brings them to a dashboard where they can monitor their weekly progress on a task. Once the week is over, the app declares whether the client successfully beat the mission - if they did, they get rewarded with points which they can exchange for RBC Loyalty points!
## How we built it
We built the frontend using React + Tailwind, using Routes to display our different pages. We used Cohere for our AI services, both for generating personalized weekly goals and creating a more in-depth report. We used Firebase for authentication + cloud database to keep track of users. For our data of users and transactions, as well as making/managing loyalty points, we used the RBC API.
## Challenges we ran into
Piecing the APIs together was probably our most difficult challenge. Besides learning the different APIs in general, integrating the different technologies got quite tricky when we are trying to do multiple things at the same time!
Besides API integration, definitely working without any sleep though was the hardest part!
## Accomplishments that we're proud of
Definitely our biggest accomplishment was working so well together as a team. Despite only meeting each other the day before, we got along extremely well and were able to come up with some great ideas and execute under a lot of pressure (and sleep deprivation!) The biggest reward from this hackathon are the new friends we've found in each other :)
## What we learned
I think each of us learned very different things: this was Homey and Alex's first hackathon, where they learned how to work under a small time constraint (and did extremely well!). Paige learned tons about React, frontend development, and working in a team. Vassily learned lots about his own strengths and weakness (surprisingly reliable at git, apparently, although he might have too much of a sweet tooth).
## What's next for Savvy Saver
Demos! After that, we'll just have to see :)
|
losing
|
## Inspiration
---
I recently read Ben Sheridan's paper on Human Centered Artificial Intelligence where he argues that Ai is best used as a tool that accelerates humans rather than trying to *replace* them. We wanted to design a "super-tool" that meaningfully augmented a user's workday. We felt that current calendar apps are a messy and convoluted mess of grids flashing lights, alarms and events all vying for the user's attention. The chief design behind Line is simple, **your workday and time is linear so why shouldn't your calendar be linear?**. Now taking this base and augmenting it with *just the right amount* of Ai.
## What it does
You get a calendar that tells you about an upcoming lunch with a person at a restaurant, gives you some information about the restaurant along with links to reviews and directions that you can choose to view. No voice-text frustration, no generative clutter.
## How we built it
We used React Js for our frontend along with a docker image for certain backend tasks and hosting a small language model for on metal event summarization **you can self host this too for an off the cloud experience**, if provided the you.com API key is used to get up to date and accurate information via the smart search query.
## Challenges we ran into
We tackled a lot of challenges particularly around the interoperability of our tech stack particularly a potential multi-database system that allows users to choose what database they wanted to use we simply ran out of time to implement this so for our demo we stuck with a firebase implementation , we also wanted to ensure that the option to host your own docker image to run some of the backend functions was present and as a result a lot of time was put into making both an appealing front and backend.
## Accomplishments that we're proud of
We're really happy to have been able to use the powerful you.com smart and research search APIs to obtain precise data! Currently even voice assistants like Siri or Google use a generative approach and if quizzed on subjects that are out of their domain of knowledge they are likely to just make things up (including reviews and addresses), which could be super annoying on a busy workday and we're glad that we've avoided this pitfall, we're also really happy at how transparent our tech stack is leaving the door open for the open source community to assist in improving our product!
## What we learned
We learnt a lot over the course of two days, everything from RAG technology to Dockerization, Huggingface spaces, react js, python and so much more!
## What's next for Line Calendar
Improvements to the UI, ability to swap out databases, connections via the google calendar API and notion APIs to import and transform calendars from other software. Better context awareness for the you.com integration. Better backend support to allow organizations to deploy and scale on their own hardware.
|
## Inspiration
As aspiring startup founders, we are always looking for pain points and problems to solve. As such, we decided to ask our professors for the problems they faced. But no matter how hard we tried to meet with them, we could never get a meeting scheduled due how difficult it is to coordinate meetings across 4+ unique schedules. It was only 5 weeks later that we actually got to meet with our professor, but more importantly, had an epiphany to use AI to do annoying, tricky scheduling for us. And the more we asked around, we found that professors specifically hate having to schedule 10+ people research meetings because of how hard it is to schedule meetings.
## What it does
Picture this: you are a professor and you need to meet with 10+ of your research students (our prof has this problem). Just tell TimeSync to schedule a meeting with John, Sarah, Brady, etc.. and it'll automatically find the best time available and put it on all of your Google calendars. Seamlessly. No more finicky when2meets or horrid email chains.
## How we built it
Our project was constructed from the ground up using a robust stack of modern web technologies. We chose Next.js as the foundation for its SSR capabilities and seamless integration with React, enhancing the overall user experience and performance. For our database and ORM, we integrated Prisma with Supabase, leveraging Supabase's scalable backend services and built-in authentication to secure and manage user data efficiently.
The core feature, vector search, was implemented using Convex, enabling us to perform sophisticated queries to find optimal scheduling slots based on user availability and preferences. This choice allowed for a more dynamic and intelligent matching process, significantly improving the scheduling experience.
To ensure a high degree of interoperability and maintainability across our server and client-side code, we utilized fully typed server actions. This approach guaranteed type safety and facilitated easier development and debugging by making our codebase more predictable and less prone to errors.
Additionally, we embraced the power of AI in our development process by using v0.dev for generating UI components. This innovative tool accelerated our UI development, allowing us to quickly prototype and refine our application's interface based on AI-generated suggestions, which were then customized to fit our specific needs and design guidelines.
By combining these technologies, we built a comprehensive solution from scratch, designed to address the complexities of scheduling for users by offering a seamless, integrated experience that leverages the best of modern web development and AI innovations.
## Challenges we ran into
We had lots of issues with configuration. Whether that be through being banned from AWS on Stanford’s public wifi, or having issue setting up authentication with Supabase, many hurdles caused us to lose massive amounts of time. With Supabase specifically, we had trouble accessing our user session on both the frontend as well as the backend. Additionally, this was our first time using OpenAI’s function calling functionality. As such, we only found one small example by OpenAI on how to implement function calling, but besides that, there was nothing, and we had to try many different config files to get it working properly.
## Accomplishments that we're proud of
We are proud of how simple our product is. Just tell it to schedule a meeting for you, even if its with 30 people, and it’ll do it. Our UI is clean and our product is easy to use, and most importantly, it solves a problem we and many others have.
On the technical side of things, we thought that it was amazing how our LLM is able to interact with all aspects of our app; whether it be our frontend talking to our user, or literally querying our backend and extracting Google provider tokens to create calendar events for our users. We never anticipated that the LLM could reach outside of its container and interact on the full stack.
## What we learned
One of the main things we learned was how to work with vector embeddings. It was really cool to apply a mathematical side of AI to our calendar data in order to find the best
We learned a lot about how to work with LLM. Specifically, getting an LLM to extract pieces of data from what our user types, and feeding it into a function that we can use to actually schedule meetings was cool.
Another thing we learned was how to get an LLM to call functions for us and to query our data for us. We wanted it to be so easy for our users to schedule meetings that we want them to just mention the names of the individuals who they want to meet with, and our LLM will be able to find those people in our database and access their google calendars for them, scheduling meetings accordingly.
## What's next for TimeSync
In the future, we would like to fine tune our model in order to understand more scheduling prompts from users. Additionally, we would like to add a Stripe integration in order to accept payments, as we can see this being a Software as a Service startup, competing with the likes of Calendly.
|
## Inspiration
Answer: Our increasingly complex lives demand more than just a reminder tool; they need an understanding partner. We witnessed the strain of juggling health, work, academic responsibilities, and social lives. This inspired the creation of Edith – a comprehensive, intuitive, and health-conscious planner.
## What it does
Answer: Edith is an intelligent calendar that not only plans your day but also considers your health, stress levels, and preferences. Through integration with multiple APIs, it suggests Spotify playlists for stress, plans academic tasks, offers horoscope-based guidance, allows conversational planning, and even suggests activities based on the weather. It's a complete, holistic approach to daily planning.
## How we built it
Answer: Edith is a product of diverse API integrations. By harnessing the power of Terra API for health metrics, Spotify API for mood music, Canvas/Blackboard for academic commitments, Horoscope for celestial insights, OpenAI for chat-based planning, and Weather APIs, we developed a cohesive, user-friendly application. Our team utilized agile development, ensuring regular iterations and refinements based on user feedback.
## Challenges we ran into
Answer: Combining multiple API integrations seamlessly was our primary challenge. Ensuring real-time updates while maintaining the app's speed and responsiveness required optimized backend solutions. Also, refining Edith's AI to offer genuinely useful, not overwhelming, suggestions was a careful balancing act.
## Accomplishments that we're proud of
Answer: We are immensely proud of Edith's ability to "understand" individual users. Its adaptive learning and predictive capabilities set it apart from conventional planners. Our beta testing showed a significant reduction in users' reported stress levels and an increase in their daily productivity.
## What we learned
Answer: We learned the importance of user-centric design. By conducting surveys and continuous feedback loops, we understood the real needs of our audience. Technically, we also grasped the nuances of integrating diverse APIs to work harmoniously within a singular platform.
## What's next for Edith
Answer: We envision expanding Edith's capabilities with more integrations, like fitness trackers and meal planning tools. We're also looking into developing a community feature, allowing users to share tips, strategies, and success stories, fostering a supportive Edith community.
|
losing
|
## Inspiration
The upcoming election season is predicted to be drowned out by mass influx of fake news. Deepfakes are a new method to impersonate famous figures saying fictional things, and could be particularly influential in the outcome of this and future elections. With international misinformation becoming more common, we wanted to develop a level of protection and reality for users. Facebook's Deepfake Detection Challenge, which aims to crowdsource ideas, inspired us to approach this issue.
## What it does
Our Chrome extension processes the current video the user is watching. The video is first scanned using AWS to identify the politician/celebrity in subject. Knowing the public figure allows the app to choose the model trained by machine learning to identify Deepfakes targeting that specific celebrity. The result of the deep fake analysis are then shown to the user through the chrome extension, allowing the user to see in the moment whether a video might be authentic or forged.
Our Web app offers the same service, and includes a prompt that describes this issue to users. Users are able to upload a link to any video they are concerned may be tampered with, and receive a result regarding the authenticity of the video.
## How we built it
We used the PCA (Principal Component Analysis) to build the model by hand, and broke down the video into one second frames.
Previous research has evaluated the mouths of the deepfake videos, and noticed that these are altered, as are the general facial movements of a person. For example, previous algorithms have looked at mannerisms of politicians and detected when these mannerisms differed in a deepfake video. However, this is computationally a very costly process, and current methods are only utilized in a research settings.
Each frame is then analyzed with six different concavity values that train the model. Testing data is then used to try the model, which was trained in a Linear Kernel (Support Vector Machine). The Chrome extension is done in JS and HTML, and the other algorithms are in Python.
The testing data set is comprised from the user's current browser video, and the training set is composed of Google Images of the celebrity.
## Challenges we ran into
Finding a dataset of DeepFakes large enough to train our model was difficult. We ended up splitting the frames into 70% dataset, and 30% of it is used for testing (all frames are different however). Automatically exporting data from JavaScript to Python was also difficult, as JavaScript can not write on external files.
Therefore, we utilized a server and were able to successfully coordinate the machine learning with our web application and Chrome extension!
## Accomplishments that we're proud of
We are proud to have created our own model and make the ML algorithm work! It was very satisfying to see the PCA clusters, and graph the values into groups within the Support Vector Machine. Furthermore, getting each of the components ie, Flask and Chrome extension to work was gratifying, as we had little prior experience in regards to transferring data between applications.
We are able to successfully determine if a video is a deep fake, and notify the person in real time if they may be viewing tampered content!
## What we learned
We learned how to use AWS and configure the credentials, and SDK's to work. We also learned how to configure and utilize our own machine learning algorithm, and about the dlib/OpenCV python Libraries!
Furthermore, we understood the importance of the misinformation issue, and how it is possible to utilize a conjuction of a machine learning model with an effective user interface to appeal to and attract internet users of all ages and demographics.
## What's next for DeFake
Train the model with more celebrities and get the chrome extension to output whether the videos in your feed are DeepFakes or not as you scroll. Specifically, this would be done by decreasing the run time of the machine learning algorithm in the background. Although the algorithm is not as computationally costly as conventional algorithms created by experts, the run time barrs exact real-time feedback within seconds.
We would also like to use the Facebooks DeepFake datasets when they are released.
Specifically, deepfakes are more likely to become a potent tool of cyber-stalking and bullying in the short term, says Henry Ajder, an analyst at Deeptrace. We hope to utilize larger data bases of more diverse deepfakes outside of celebrity images to also prevent this future threat.
|
## The Gist
We combine state-of-the-art LLM/GPT detection methods with image diffusion models to accurately detect AI-generated video with 92% accuracy.
## Inspiration
As image and video generation models become more powerful, they pose a strong threat to traditional media norms of trust and truth. OpenAI's SORA model released in the last week produces extremely realistic video to fit any prompt, and opens up pathways for malicious actors to spread unprecedented misinformation regarding elections, war, etc.
## What it does
BinoSoRAs is a novel system designed to authenticate the origin of videos through advanced frame interpolation and deep learning techniques. This methodology is an extension of the state-of-the-art Binoculars framework by Hans et al. (January 2024), which employs dual LLMs to differentiate human-generated text from machine-generated counterparts based on the concept of textual "surprise".
BinoSoRAs extends on this idea in the video domain by utilizing **Fréchet Inception Distance (FID)** to compare the original input video against a model-generated video. FID is a common metric which measures the quality and diversity of images using an Inception v3 convolutional neural network. We create model-generated video by feeding the suspect input video into a **Fast Frame Interpolation (FLAVR)** model, which interpolates every 8 frames given start and end reference frames. We show that this interpolated video is more similar (i.e. "less surprising") to authentic video than artificial content when compared using FID.
The resulting FID + FLAVR two-model combination is an effective framework for detecting video generation such as that from OpenAI's SoRA. This innovative application enables a root-level analysis of video content, offering a robust mechanism for distinguishing between human-generated and machine-generated videos. Specifically, by using the Inception v3 and FLAVR models, we are able to look deeper into shared training data commonalities present in generated video.
## How we built it
Rather than simply analyzing the outputs of generative models, a common approach for detecting AI content, our methodology leverages patterns and weaknesses that are inherent to the common training data necessary to make these models in the first place. Our approach builds on the **Binoculars** framework developed by Hans et al. (Jan 2024), which is a highly accurate method of detecting LLM-generated tokens. Their state-of-the-art LLM text detector makes use of two assumptions: simply "looking" at text of unknown origin is not enough to classify it as human- or machine-generated, because a generator aims to make differences undetectable. Additionally, *models are more similar to each other than they are to any human*, in part because they are trained on extremely similar massive datasets. The natural conclusion is that an observer model will find human text to be very *perplex* and surprising, while an observer model will find generated text to be exactly what it expects.
We used Fréchet Inception Distance between the unknown video and interpolated generated video as a metric to determine if video is generated or real. FID uses the Inception score, which calculates how well the top-performing classifier Inception v3 classifies an image as one of 1,000 objects. After calculating the Inception score for every frame in the unknown video and the interpolated video, FID calculates the Fréchet distance between these Gaussian distributions, which is a high-dimensional measure of similarity between two curves. FID has been previously shown to correlate extremely well with human recognition of images as well as increase as expected with visual degradation of images.
We also used the open-source model **FLAVR** (Flow-Agnostic Video Representations for Fast Frame Interpolation), which is capable of single shot multi-frame prediction and reasoning about non-linear motion trajectories. With fine-tuning, this effectively served as our generator model, which created the comparison video necessary to the final FID metric.
With a FID-threshold-distance of 52.87, the true negative rate (Real videos correctly identified as real) was found to be 78.5%, and the false positive rate (Real videos incorrectly identified as fake) was found to be 21.4%. This computes to an accuracy of 91.67%.
## Challenges we ran into
One significant challenge was developing a framework for translating the Binoculars metric (Hans et al.), designed for detecting tokens generated by large-language models, into a practical score for judging AI-generated video content. Ultimately, we settled on our current framework of utilizing an observer and generator model to get an FID-based score; this method allows us to effectively determine the quality of movement between consecutive video frames through leveraging the distance between image feature vectors to classify suspect images.
## Accomplishments that we're proud of
We're extremely proud of our final product: BinoSoRAs is a framework that is not only effective, but also highly adaptive to the difficult challenge of detecting AI-generated videos. This type of content will only continue to proliferate the internet as text-to-video models such as OpenAI's SoRA get released to the public: in a time when anyone can fake videos effectively with minimal effort, these kinds of detection solutions and tools are more important than ever, *especially in an election year*.
BinoSoRAs represents a significant advancement in video authenticity analysis, combining the strengths of FLAVR's flow-free frame interpolation with the analytical precision of FID. By adapting the Binoculars framework's methodology to the visual domain, it sets a new standard for detecting machine-generated content, offering valuable insights for content verification and digital forensics. The system's efficiency, scalability, and effectiveness underscore its potential to address the evolving challenges of digital content authentication in an increasingly automated world.
## What we learned
This was the first-ever hackathon for all of us, and we all learned many valuable lessons about generative AI models and detection metrics such as Binoculars and Fréchet Inception Distance. Some team members also got new exposure to data mining and analysis (through data-handling libraries like NumPy, PyTorch, and Tensorflow), in addition to general knowledge about processing video data via OpenCV.
Arguably more importantly, we got to experience what it's like working in a team and iterating quickly on new research ideas. The process of vectoring and understanding how to de-risk our most uncertain research questions was invaluable, and we are proud of our teamwork and determination that ultimately culminated in a successful project.
## What's next for BinoSoRAs
BinoSoRAs is an exciting framework that has obvious and immediate real-world applications, in addition to more potential research avenues to explore. The aim is to create a highly-accurate model that can eventually be integrated into web applications and news articles to give immediate and accurate warnings/feedback of AI-generated content. This can mitigate the risk of misinformation in a time where anyone with basic computer skills can spread malicious content, and our hope is that we can build on this idea to prove our belief that despite its misuse, AI is a fundamental force for good.
|
## Inspiration
The advancement of image classification, notably in facial recognition, has some very interesting applications. [Microsoft](https://azure.microsoft.com/en-ca/services/cognitive-services/face/) and Amazon currently provide facial recognition services to parties ranging from corporations checking on their employees, to law enforcement officials locating serious criminals. This invasive method of facial recognition is problematic ethically, but brings forward an interesting concept:
With an increasing dependence on ML/DL and computer vision, is there a method whereby state-of-the-art system can be fooled? Inversely, is there a method to help future facial recognition models overcome spoofing?
We are a team of students with an interest in Deep Learning and Computer Vision, as well as academic researcher experience in the field (ML applied to Astrophysics, Engineering, etc.). As such, we were interested in exploring projects that expanded our views on these topics with some real-world application.
**We wanted to create software to mask the identity of a person's photo to current image/facial recognition systems, as well as help future models overcome masking.**
We looked at two major objectives for this project:
1) Allow people to maintain their privacy.
An employer may search a job candidate's LinkedIn photo using existing facial recognition software to see appearances in in crime databases, or other online sources. Personal and Professional personas often differ, and as such, there should be a method to restrict invasive image or facial recognition. Our software should pass a person's photo through a model to add perturbations to the image and return an image that looks the same to the human-eye, but is unrecognizable to a computer-vision algorithm.
2) Help developers build more robust image classification models.
A tool to trick existing models can be applied to improve future models. Developers may use this tool to include some spoofed images in their train set to help the model not be tricked. As a library, this could be a useful data augmentation tool is something we are considering.
When first looking for academic inspiration, we referred to [this paper](https://arxiv.org/pdf/1312.6199.pdf), which looks at how changing certain pixels shifts the image's classification in vector space after being processed through a model; this may force a network to provide the incorrect classification, without significantly changing how the photo itself looks. We also looked at [this article](http://karpathy.github.io/2015/03/30/breaking-convnets/) which points out how using a gradient method may help intentionally misclassify an image by applying adversarial perturbations, and limiting their viability with a constraint. The classic example is classifying a Panda as a Vulture using the GoogLeNet model. The original source of the article is [this paper](https://arxiv.org/pdf/1412.6572.pdf)
## How it Works
**Fast Gradient Sign Method**
Traditional neural networks update and improve through gradient descent and backpropagation -- a process whereby an input is fed into a randomly initialized network, the model's prediction for the input is compared to the true value for the input, and the network's weights/biases are updated to more closely match the desired (correct) output. This process is repeated thousands of times over many inputs to train a model.
To trick an image recognition model, the above process can be applied not to the model, but to the picture. An image may be passed into the model, and the output can be compared to a desired output. After this comparison, the photo may be tweaked (gradient descent) through **adversarial perturbations** many thousands of times (backpropagation) to create an image mask that the network identifies as the desired output. This image often is a noise of pixels that is not understandable to humans. As such, it acts as a mask, or a filter, that can be partially applied to the original image. A constraint restricts how visible the mask is, to ensure the image looks similar to the original to humans. The data may be inserted, but the mask would not be visible.
An example of this is in the below figure. A photo of a panda that is passed into a model can be compared to the output of a nematode classification. Using the Fast Gradient Sign Method, the nematode filter is applied to the panda image. The resulting composite image may look the same due to the constraint on the filter, but the image recognition network will grossly misclassify it.

However, this approach is time-consuming as it requires multiple cycles to add perturbations to an image. It also requires a pointer to another class to adapt the input image to. Lastly, it is also quite possible to overcome this method by simply adding images with perturbations to a training set when creating a model.
At a high-level, an algorithm can be constructed with inspiration from [this paper](https://www.andrew.cmu.edu/user/anubhava/fooling.pdf):
Algorithm: Gradient Method
y = input vector
n = gradient of y
nx = sign of gradient at each pixel
x = x+f(nx) which generates adversarial input
return x \_
This method works as neural networks are vulnerable to adversarial perturbation due to their linear nature. These linear deep models are significantly impacted by a large number of small variations in higher dimensions, such as that of the input space. These facial recognition models have not been proven to understand the task at hand, and are instead simply "overly confident at points that do not occur in the data distribution" (from Goodfellow's paper).
**Generative Adversarial Networks**
A cleverer solution can be applied with the use of GANs, which are a huge area of research in machine vision currently. At a high level, GANs can piece together an image based on other images and textures. After applying an imperceptible perturbation with a GAN, it is possible for an image recognition model to completely misclassify an image by maximizing prediction error. There are many ways to approach this, such as adding a new object to an image that seems to fit in to distort the classifying algorithm, or by implementing some mask-like approach as seen above into the image that retains the original image's characteristics. The approach we chose to look at would take an adversarial gradient computed using the above method in addition to a GAN and apply it to create a new image from the original and the mask.
GANs are extremely interesting but can be computationally expensive to compute and implement. One potential implementation outlined [here](https://www.andrew.cmu.edu/user/anubhava/fooling.pdf).
## Our Implementation
**Image/Facial Recognition**
The image recognition is done using an implementation of [Inception-v3](https://arxiv.org/pdf/1512.00567v3.pdf), ImageNet and [Facenet](https://github.com/davidsandberg/facenet).The paper of this pre-trained algorithm is found [here](https://arxiv.org/pdf/1503.03832.pdf). Inception is a CNN model that has proven to be quite robust. Trained on ImageNet, the baseline image recognition model V3 has been trained on over a thousand different classes. Facenet uses the Inception model, and we applied transfer learning from the ImageNet application to Facenet, which has learned over 10K identities based on over 400K face images. We also added the face of Drake (the musician) to this model. This model, made in **Python** using *Keras* (TensorFlow backend) allows the text classification/recognition of an input image, and serves as the baseline model that we chose to attack and exploit. When calling the function to classify an image, the image is loaded and resized to 300x300 pixels and intensities are scaled. Thereafter, a dimension is added to the image to work with it in Keras. The image is then passed through our modified Inception\_ImageNet\_Facenet model, and a class outputted, along with a confidence. Please note that the pre-trained model in the GitHub code uses the default Inception model, as the size of the model and execution time were factors that crashed our NodeJS implementation. Our custom model will be demoed and available later.
**Modifier**
In Python, Keras, Numpy and the Python Image Library were used to implement the Fast Gradient Sign Method to modify photos of a person's face. The first and last layers of the facial recognition CNN are referenced, a baseline object chosen to match gradients with (we use a Jigsaw piece because it was efficient at finding gradients for human faces), and the image to transform is loaded. The input image is appropriately scaled, and the constraints defined. A copy of the image made, and a learning rate is defined. We chose a learning rate of 5, which is extremely high, but allows for quick execution and output. A lower learning rate will likely result in a slower but better mask. Keras is used to define cost a gradient calculation functions, and the resultant master function is called in a loop until the cost exceeds a threshold. At each iteration, the model prints the cost. After the mask is chosen and applied to the image of a person's face with constraints, the image is normalized once again, and returned to the user. The output is relatively clean and maintains the person's facial features and the general look of the image.
We decided not to implement a GAN as it was extremely difficult to train, and to meaningfully implement. Moreover, it did not provide results superior to the Fast Gradient Sign Method. A potential implementation of the model is a first a boundary equilibrium GAN to generate photos from the source image, then a conditional GAN, and finally a Pix2Pix translation to translate the mask onto a new image. The code to implement this solution is available, but not well-developed.
**User Interface**
We used HTML and CSS to create an extremely basic front-end to allow a user to drag and drop and image into the model. The image is first classified, then the modifications made, and the final classification outputted after modification. The image is also returned. The back-end of the application is in **NodeJS** and ExpressJS. The model takes a considerably long time to compile, and this underdeveloped front-end may exceed the 60s time the NodeJS server may run for, for some images.
## Challenges we ran into
Finding and training a facial recognition model proved difficult. Most high-quality models by companies such as Amazon and Microsoft that are state-of-the-art and applied in industry are closely guarded secrets. As such, we needed to find a model that worked generally well at facial recognition. We found Inception V3 to be a good baseline to know 1000 general classes, and Facenet to be a great application of transferring learning from this base to facial recognition. As such, our initial problem was solved.
Second, we ran into the problem of how to modify the images. The initial approaches we took with logistic regression and [pixel removal](https://arxiv.org/pdf/1710.08864.pdf) were slow, or modified the image too heavily to the point that it lost meaning, and human tests would also fail to classify the image. We had to work to tune parameters of our model to get a version that worked effectively for face classification.
Lastly, working with GANs proved difficult. Training these models requires extensive computational power and time. As such, we were unable to effectively train a GAN model in the time allotted.
## Accomplishments that we're proud of
We used a recognizable face to test that we could trick a CNN. Aubrey Graham (Drake) is a Toronto-based musician that is also an alum at my high school. He has strong facial features making him recognizable to the human eye. Drake's face was detected at 97.22% confidence through our modified Inception model's initial predictions. A reconstructed image through our model can be passed into the Inception model and will yield 4.12% confidence that the image is a bassoon (the highest likelihood). Although the two are in the music sub-genre, we are proud to see that our model can change an image's data enough to misclassify it without making it look significantly different to the human eye.
## What we learned
We expanded our knowledge on machine vision and CNN-based deep learning. We were exposed to the concept of GANs and their implementations. We also learned that exploitation and tricking of current image recognition and general neural network models is an area of intense research, as it has the capacity to cause damage. For example, if one were to apply a filter or a mask to the video feed of a self-driving car, it is possible that the machine vision model used to drive may misinterpret a red light for a green light, and crash. Exploring this area will be very interesting in the coming months.
## What's next for Un-CNN
We want to further explore GAN implementations, and speed up the model. GANs seem to be an extremely powerful tool for this application, that could be robust in fooling models while maintaining recognizably. Also, it would be interesting to reverse engineer current state-of-the-art facial recognition models such as Microsoft's Face API Model, which is used by corporates and law enforcement in the real-world. In doing so, we could use that model to calculate gradients and modify images to fool it.
## Research
[Adversarial Generative Nets: Neural Network Attacks on State-of-the-Art Face Recognition](Mahmood%20Sharif,%20Sruti%20Bhagavatula,%20Lujo%20Bauer,%20Michael%20K.%20Reiter)
[Explaining and Harnessing Adversarial Examples - Ian J. Goodfellow, Jonathon Shlens, Christian Szegedy](https://arxiv.org/pdf/1412.6572.pdf)
[Paper Discussion: Explaining and harnessing adversarial examples - Mahendra Kariya](https://medium.com/@mahendrakariya/paper-discussion-explaining-and-harnessing-adversarial-examples-908a1b7123b5)
[Crafting adversarial faces - Bruno Lopez Garcia](https://brunolopezgarcia.github.io/2018/05/09/Crafting-adversarial-faces.html)
[Intentionally Tricking Neural Networks - Adam Geitgey](https://medium.com/@ageitgey/machine-learning-is-fun-part-8-how-to-intentionally-trick-neural-networ-97a379b2)
[Adversarial Examples in PyTorch - Akshay Chawla](https://github.com/akshaychawla/Adversarial-Examples-in-PyTorch)
|
winning
|
# 🎶 SongSmith | New remixes at your *fingertips*! 🎶
SongSmith is your one-stop-shop to **create new remixes from your favourite songs!** 🎼
**State-of-the-art AI Machine Learning Neural Networks** are used to generate remixes with similar styles🎨 to your best-loved songs🎶.
**📚Discover! 👨🎤Inspire! 🎧Listen! SongSmith!**
# Inspiration 💭⚡
Ever listen to your favourite artists🧑🎤 and songs⏭️ and think **"Damn, I wish there was similar music to this?"** We have this exact feeling, which is why we've developed SongSmith for the Music loving people!🧑🤝🧑
# How we built it 🏗️
* SongSmith⚒️ was built using the latest and greatest technology!! 💻
* Our **music generative neural network** was developed using a state-of-the-art architecture🏢 called **Attention Mechanism Networks**.
## Tech Stack 🔨
* AI Model: **Tensorflow**, Keras, Google Colab
* BackEnd: **Express.js, Flask** to run our **microservices**, and inference servers.
* FrontEnd: Developed using **React.js**, and Bootstrap; to allow for a quick **MVP development cycle🔃**.
* Storage: MongoDB, **Firebase**, Firestore
* Moral Support: Coffee☕, Bubble Tea🥤 , Pizza🍕 and **Passion💜 for AI** <3
# Challenges we ran into 🧱🤔
* Converting the output from the neural network to a playable format in the browser
* Allowing for CORS interaction between the frontend and our microservices
# What we learned🏫
* Bleeding💉 Edge Generative Neural Network for Music🎙️Production
* Different Python🐍 and Node.js Music Production Related Libraries📚
# What's next for SongSmith ➡️
* Offering wider genres of music to attract a wider range of **music-loving users**!🧑🎤
* Refining our Neural Network to generate more **high-quality REMIXES**!
\*See Github ReadMe for Video Link
|
## Inspiration
What inspired the beginning of the idea was terrible gym music and the thought of a automatic music selection based on the tastes of people in the vicinity. Our end goal is to sell a hosting service to play music that people in a local area would want to listen to.
## What it does
The app has two parts. A client side connects to Spotify and allows our app to collect users' tokens, userID, email and the top played songs. These values are placed inside a Mongoose database and the userID and top songs are the main values needed. The host side can control the location and the radius they want to cover. This allows the server to be populated with nearby users and their top songs are added to the host accounts playlist. The songs most commonly added to the playlist have a higher chance of being played.
This app could be used at parties to avoid issues discussing songs, retail stores to play songs that cater to specific groups, weddings or all kinds of social events. Inherently, creating an automatic DJ to cater to the tastes of people around an area.
## How we built it
We began by planning and fleshing out the app idea then from there the tasks were split into four sections: location, front end, Spotify and database. At this point we decided to use React-Native for the mobile app and NodeJS for the backend was set into place. After getting started the help of the mentors and the sponsors were crucial, they showed us all the many different JS libraries and api's available to make life easier. Programming in Full Stack MERN was a first for everyone in this team. We all hoped to learn something new and create an something cool.
## Challenges we ran into
We ran into plenty of problems. We experienced many syntax errors and plenty of bugs. At the same time dependencies such as Compatibility concerns between the different APIs and libraries had to be maintained, along with the general stress of completing on time. In the end We are happy with the product that we made.
## Accomplishments that we are proud of
Learning something we were not familiar with and being able to make it this far into our project is a feat we are proud of. .
## What we learned
Learning about the minutia about Javascript development was fun. It was because of the mentors assistance that we were able to resolve problems and develop at a efficiently so we can finish. The versatility of Javascript was surprising, the ways that it is able to interact with and the immense catalog of open source projects was staggering. We definitely learned plenty... now we just need a good sleep.
## What's next for SurroundSound
We hope to add more features and see this application to its full potential. We would make it as autonomous as possible with seamless location based switching and database logging. Being able to collect proper user information would be a benefit for businesses. There were features that did not make it into the final product, such as voting for the next song on the client side and the ability for both client and host to see the playlist. The host would have more granular control such as allowing explicit songs, specifying genres and anything that is accessible by the Spotify API. While the client side can be gamified to keep the GPS scanning enabled on their devices, such as collecting points for visiting more areas.
|
## Inspiration
With caffeine being a staple in almost every student’s lifestyle, many are unaware when it comes to the amount of caffeine in their drinks. Although a small dose of caffeine increases one’s ability to concentrate, higher doses may be detrimental to physical and mental health. This inspired us to create The Perfect Blend, a platform that allows users to manage their daily caffeine intake, with the aim of preventing students from spiralling down a coffee addiction.
## What it does
The Perfect Blend tracks caffeine intake and calculates how long it takes to leave the body, ensuring that users do not consume more than the daily recommended amount of caffeine. Users can add drinks from the given options and it will update on the tracker. Moreover, The Perfect Blend educates users on how the quantity of caffeine affects their bodies with verified data and informative tier lists.
## How we built it
We used Figma to lay out the design of our website, then implemented it into Velo by Wix. The back-end of the website is coded using JavaScript. Our domain name was registered with domain.com.
## Challenges we ran into
This was our team’s first hackathon, so we decided to use Velo by Wix as a way to speed up the website building process; however, Wix only allows one person to edit at a time. This significantly decreased the efficiency of developing a website. In addition, Wix has building blocks and set templates making it more difficult for customization. Our team had no previous experience with JavaScript, which made the process more challenging.
## Accomplishments that we're proud of
This hackathon allowed us to ameliorate our web design abilities and further improve our coding skills. As first time hackers, we are extremely proud of our final product. We developed a functioning website from scratch in 36 hours!
## What we learned
We learned how to lay out and use colours and shapes on Figma. This helped us a lot while designing our website. We discovered several convenient functionalities that Velo by Wix provides, which strengthened the final product. We learned how to customize the back-end development with a new coding language, JavaScript.
## What's next for The Perfect Blend
Our team plans to add many more coffee types and caffeinated drinks, ranging from teas to energy drinks. We would also like to implement more features, such as saving the tracker progress to compare days and producing weekly charts.
|
losing
|
## Inspiration
Sexual assault survivors are in tremendously difficult situations after being assaulted, having to sacrifice privacy and anonymity to receive basic medical, legal, and emotional support. And understanding how to proceed with one's life after being assaulted is challenging due to how scattered information on resources for these victims is for different communities, whether the victim is on an American college campus, in a foreign country, or any number of other situations. Instead of building a single solution or organizing one set of resources to help sexual assault victims everywhere, we believe a simple, community-driven solution to this problem lies in Echo.
## What it does
Using Blockstack, Echo facilitates anonymized communication among sexual assault victims, legal and medical help, and local authorities to foster a supportive online community for victims. Members of this community can share their stories, advice, and support for each other knowing that they truly own their data and it is anonymous to other users, using Blockstack. Victims may also anonymously report incidents of assault on the platform as they happen, and these reports are shared with local authorities if a particular individual has been reported as an offender on the platform several times by multiple users. This incident data is also used to geographically map where in small communities sexual assault happens, to provide users of the app information on safe walking routes.
## How we built it
A crucial part to feeling safe as a sexual harassment survivor stems from the ability to stay anonymous in interactions with others. Our backend is built with this key foundation in mind. We used Blockstack’s Radiks server to create a decentralized application that would keep all user’s data local to that user. By encrypting their information when storing the data, we ensure user privacy and mitigate all risks to sacrificing user data. The user owns their own data. We integrated Radiks into our Node and Express backend server and used this technology to manage our database for our app.
On the frontend, we wanted to create an experience that was eager to welcome users to a safe community and to share an abundance of information to empower victims to take action. To do this, we built the frontend from React and Redux, and styling with SASS. We use blockstack’s Radiks API to gather anonymous messages in the Support Room feature. We used Twilio’s message forwarding API to ensure that victims could very easily start anonymous conversations with professionals such as healthcare providers, mental health therapists, lawyers, and other administrators who could empower them. We created an admin dashboard for police officials to supervise communities, equipped with Esri’s maps that plot where the sexual assaults happen so they can patrol areas more often. On the other pages, we aggregate online resources and research into an easy guide to provide victims the ability to take action easily. We used Azure in our backend cloud hosting with Blockstack.
## Challenges we ran into
We ran into issues of time, as we had ambitious goals for our multi-functional platform. Generally, we faced the learning curve of using Blockstack’s APIs and integrating that into our application. We also ran into issues with React Router as the Express routes were being overwritten by our frontend routes.
## Accomplishments that we're proud of
We had very little experience developing blockchain apps before and this gave us hands-on experience with a use-case we feel is really important.
## What we learned
We learned about decentralized data apps and the importance of keeping user data private. We learned about blockchain’s application beyond just cryptocurrency.
## What's next for Echo
Our hope is to get feedback from people impacted by sexual assault on how well our app can foster community, and factor this feedback into a next version of the application. We also want to build out shadowbanning, a feature to block abusive content from spammers on the app, using a trust system between users.
|
## Inspiration
With the excitement of blockchain and the ever growing concerns regarding privacy, we wanted to disrupt one of the largest technology standards yet: Email. Email accounts are mostly centralized and contain highly valuable data, making one small breach, or corrupt act can serious jeopardize millions of people. The solution, lies with the blockchain. Providing encryption and anonymity, with no chance of anyone but you reading your email.
Our technology is named after Soteria, the goddess of safety and salvation, deliverance, and preservation from harm, which we believe perfectly represents our goals and aspirations with this project.
## What it does
First off, is the blockchain and message protocol. Similar to PGP protocol it offers \_ security \_, and \_ anonymity \_, while also **ensuring that messages can never be lost**. On top of that, we built a messenger application loaded with security features, such as our facial recognition access option. The only way to communicate with others is by sharing your 'address' with each other through a convenient QRCode system. This prevents anyone from obtaining a way to contact you without your **full discretion**, goodbye spam/scam email.
## How we built it
First, we built the block chain with a simple Python Flask API interface. The overall protocol is simple and can be built upon by many applications. Next, and all the remained was making an application to take advantage of the block chain. To do so, we built a React-Native mobile messenger app, with quick testing though Expo. The app features key and address generation, which then can be shared through QR codes so we implemented a scan and be scanned flow for engaging in communications, a fully consensual agreement, so that not anyone can message anyone. We then added an extra layer of security by harnessing Microsoft Azures Face API cognitive services with facial recognition. So every time the user opens the app they must scan their face for access, ensuring only the owner can view his messages, if they so desire.
## Challenges we ran into
Our biggest challenge came from the encryption/decryption process that we had to integrate into our mobile application. Since our platform was react native, running testing instances through Expo, we ran into many specific libraries which were not yet supported by the combination of Expo and React. Learning about cryptography and standard practices also played a major role and challenge as total security is hard to find.
## Accomplishments that we're proud of
We are really proud of our blockchain for its simplicity, while taking on a huge challenge. We also really like all the features we managed to pack into our app. None of us had too much React experience but we think we managed to accomplish a lot given the time. We also all came out as good friends still, which is a big plus when we all really like to be right :)
## What we learned
Some of us learned our appreciation for React Native, while some learned the opposite. On top of that we learned so much about security, and cryptography, and furthered our beliefs in the power of decentralization.
## What's next for The Soteria Network
Once we have our main application built we plan to start working on the tokens and distribution. With a bit more work and adoption we will find ourselves in a very possible position to pursue an ICO. This would then enable us to further develop and enhance our protocol and messaging app. We see lots of potential in our creation and believe privacy and consensual communication is an essential factor in our ever increasingly social networking world.
|
## Inspiration
While we were doing preliminary research, we had found overwhelming amounts of evidence of mental health deterioration as a consequence of life-altering lockdown restrictions. Academic research has shown that adolescents depend on friendship to maintain a sense of self-worth and to manage anxiety and depression. Intimate exchanges and self-esteem support significantly increased long-term self worth and decreased depression.
While people do have virtual classes and social media, some still had trouble feeling close with anyone. This is because conventional forums and social media did not provide a safe space for conversation beyond the superficial. User research also revealed that friendships formed by physical proximity don't necessarily make people feel understood and resulted in feelings of loneliness anyway. Proximity friendships formed in virtual classes also felt shallow in the sense that it only lasted for the duration of the online class.
With this in mind, we wanted to create a platform that encouraged users to talk about their true feelings, and maximize the chance that the user would get heartfelt and intimate replies.
## What it does
Reach is an anonymous forum that is focused on providing a safe space for people to talk about their personal struggles. The anonymity encourages people to speak from the heart. Users can talk about their struggles and categorize them, making it easy for others in similar positions to find these posts and build a sense of closeness with the poster. People with similar struggles have a higher chance of truly understanding each other. Since ill-mannered users can exploit anonymity, there is a tone analyzer that will block posts and replies that contain mean-spirited content from being published while still letting posts of a venting nature through. There is also ReCAPTCHA to block bot spamming.
## How we built it
* Wireframing and Prototyping: Figma
* Backend: Java 11 with Spring Boot
* Database: PostgresSQL
* Frontend: Bootstrap
* External Integration: Recaptcha v3 and IBM Watson - Tone Analyzer
* Cloud: Heroku
## Challenges we ran into
We initially found it a bit difficult to come up with ideas for a solution to the problem of helping people communicate. A plan for a VR space for 'physical' chatting was also scrapped due to time constraints, as we didn't have enough time left to do it by the time we came up with the idea. We knew that forums were already common enough on the internet, so it took time to come up with a product strategy that differentiated us. (Also, time zone issues. The UXer is Australian. They took caffeine pills and still fell asleep.)
## Accomplishments that we're proud of
Finishing it on time, for starters. It felt like we had a bit of a scope problem at the start when deciding to make a functional forum with all these extra features, but I think we pulled it off. The UXer also iterated about 30 screens in total. The Figma file is *messy.*
## What we learned
As our first virtual hackathon, this has been a learning experience for remote collaborative work.
UXer: I feel like i've gotten better at speedrunning the UX process even quicker than before. It usually takes a while for me to get started on things. I'm also not quite familiar with code (I only know python), so watching the dev work and finding out what kind of things people can code was exciting to see.
# What's next for Reach
If this was a real project, we'd work on implementing VR features for those who missed certain physical spaces. We'd also try to work out improvements to moderation, and perhaps a voice chat for users who want to call.
|
partial
|
## Inspiration
According to the United State's Department of Health and Human Services, 55% of the elderly are non-compliant with their prescription drug orders, meaning they don't take their medication according to the doctor's instructions, where 30% are hospital readmissions. Although there are many reasons why seniors don't take their medications as prescribed, memory loss is one of the most common causes. Elders with Alzheimer's or other related forms of dementia are prone to medication management problems. They may simply forget to take their medications, causing them to skip doses. Or, they may forget that they have already taken their medication and end up taking multiple doses, risking an overdose. Therefore, we decided to solve this issue with Pill Drop, which helps people remember to take their medication.
## What it does
The Pill Drop dispenses pills at scheduled times throughout the day. It helps people, primarily seniors, take their medication on time. It also saves users the trouble of remembering which pills to take, by automatically dispensing the appropriate medication. It tracks whether a user has taken said dispensed pills by starting an internal timer. If the patient takes the pills and presses a button before the time limit, Pill Drop will record this instance as "Pill Taken".
## How we built it
Pill Drop was built using Raspberry Pi and Arduino. They controlled servo motors, a button, and a touch sensor. It was coded in Python.
## Challenges we ran into
Challenges we ran into was first starting off with communicating between the Raspberry Pi and the Arduino since we all didn't know how to do that. Another challenge was to structurally hold all the components needed in our project, making sure that all the "physics" aligns to make sure that our product is structurally stable. In addition, having the pi send an SMS Text Message was also new to all of us, so incorporating a User Interface - trying to take inspiration from HyperCare's User Interface - we were able to finally send one too! Lastly, bringing our theoretical ideas to fruition was harder than expected, running into multiple road blocks within our code in the given time frame.
## Accomplishments that we're proud of
We are proud that we were able to create a functional final product that is able to incorporate both hardware (Arduino and Raspberry Pi) and software! We were able to incorporate skills we learnt in-class plus learn new ones during our time in this hackathon.
## What we learned
We learned how to connect and use Raspberry Pi and Arduino together, as well as incorporating User Interface within the two as well with text messages sent to the user. We also learned that we can also consolidate code at the end when we persevere and build each other's morals throughout the long hours of hackathon - knowing how each of us can be trusted to work individually and continuously be engaged with the team as well. (While, obviously, having fun along the way!)
## What's next for Pill Drop
Pill Drop's next steps include creating a high-level prototype, testing out the device over a long period of time, creating a user-friendly interface so users can adjust pill-dropping time, and incorporating patients and doctors into the system.
## UPDATE!
We are now working with MedX Insight to create a high-level prototype to pitch to investors!
|
## Inspiration
This project was inspired by the rising issue of people with dementia. Symptoms of dementia can be temporarily improved by regularly taking medication, but one of the core symptoms of dementia is forgetfulness. Moreover, patients with dementia often need a caregiver, who is often a family member, to manage their daily tasks. This takes a great toll on both the caregiver, who is at higher risk for depression, high stress levels, and burnout. To alleviate some of these problems, we wanted to create an easy way for patients to take their medication, while providing ease and reassurance for family members, even from afar.
## Purpose
The project we have created connects a smart pillbox to a progressive app. Using the app, caregivers are able to create profiles for multiple patients, set and edit alarms for different medications, and view if patients have taken their medication as necessary. On the patient's side, the pillbox is not only used as an organizer, but also as an alarm to remind the patient exactly when and which pills to take. This is made possible with a blinking light indicator in each compartment of the box.
## How It's Built
Design: UX Research: We looked into the core problem of Alzheimer's disease and the prevalence of it. It is estimated that half of the older population do not take their medication as intended. It is a common misconception that Alzheimer's and other forms of dementia are synonymous with memory loss, but the condition is much more complex. Patients experience behavioural changes and slower cognitive processes that often require them to have a caretaker. This is where we saw a pain point that could be tackled.
Front-end: NodeJS, Firebase
Back-end: We used azure to host a nodeJS server and postgres database that dealt with the core scheduling functionality. The server would read write and edit all the schedules and pillboxes. It would also decide when the next reminder was and ask the raspberry pi to check it. The pi also hosted its own nodeJS server that would respond to the azure server for requests to check if the pill had been taken by executing a python script that directly interfaced with the general purpose input-output pins.
Hardware: Raspberry Pi: Circuited a microswitch to control an LED that was engineered into the pillbox and programmed with Python to blink at a specified date and time, and to stop blinking either after approx 5 seconds (recorded as a pill not taken) or when the pillbox is opened and the microswitch opens (recorded as a pill taken).
## Challenges
* Most of us are new with Hackathons, and we have different coding languages abilities. This caused our collaboration to be difficult due to our differences in skills.
* Like many others, we have time constraints, regarding our ideas, design and what was feasible within the 24 hours.
* Figuring out how to work with raspberry pi, how to connect it with nodeJS and React App.
* Automatically schedule notifications from the database.
* Setting up API endpoints
* Coming up with unique designs of the usage of the app.
## Accomplishments
* We got through our first Hackaton, Wohoo!
* Improving skills that we are strong at, as well as learning our areas of improvement.
* With the obstacles we faced, we still managed to pull out thorough research, come up with ideas and concrete products.
* Actually managed to connect raspberry pi hardware to back-end and front-end servers.
* Push beyond our comfort zones, mentally and physically
## What's Next For nudge:
* Improve on the physical design of the pillbox itself – such as customizing our own pillbox so that the electrical pieces would not come in contact with the pills.
* Maybe adding other sensory cues for the user, such as a buzzer, so that even when the user is located a room away from the pillbox, they would still be alerted in terms of taking their medicines at the scheduled time.
* Review the codes and features of our mobile app, conduct a user test to ensure that it meets the needs of our users.
* Rest and Reflect
|
## Inspiration
When you are prescribed medication by a Doctor, it is crucial that you complete the dosage cycle in order to ensure that you recover fully and quickly. Unfortunately forgetting to take your medication is something that we have all done. Failing to run the full course of medicine often results in a delayed recovery and leads to more suffering through the painful and annoying symptoms of illness. This has inspired us to create Re-Pill. With Re-Pill, you can automatically generate scheduling and reminders to take you medicine by simply uploading a photo of your prescription.
## What it does
A user uploads an image of their prescription which is then processed by image to text algorithms that extract the details of the medication. Data such as the name of the medication, its dosage, and total tablets is stored and presented to the user. The application synchronizes with google calendar and automatically sets reminders for taking pills into the user's schedule based on the dosage instructions on the prescription. The user can view their medication details at any time by logging into Re-Pill.
## How we built it
We built the application using the Python web framework Flask. Simple endpoints were created for login, registration, and viewing of the user's medication. User data is stored in Google Cloud's Firestore. Images are uploaded and sent to a processing endpoint through a HTTP Request which delivers the medication information. Reminders are set using the Google Calendar API.
## Challenges we ran into
We initially struggled to figure out the right tech-stack to use for building the app. We struggled with Android development before settling for a web-app. One big challenge we faced was to merge all the different part of our application into one smoothly running product. Another challenge was finding a method to inform/notify the user of his/her medication time through a web-based application.
## Accomplishments that we're proud of
There are a couple of things that we are proud of. One of them is how well our team was able to communicate with one another. All team members knew what the other members were working on and the work was divided in such a manner that all teammates worked on the projects using his/her strengths. One important accomplishment is that we were able to overcome a huge time constraint and come up with a prototype of an idea that has potential to change people's lives.
## What we learned
We learned how to set up and leverage Google API's, manage non-relational databases and process image to text using various python libraries.
## What's next for Re-Pill
The next steps for Re-Pill would be to move to a mobile environment and explore useful features that we can implement. Building a mobile application would make it easier for the user to stay connected with the schedules and upload prescription images at a click of a button using the built in camera. Some features we hope to explore are creating automated activities, such as routine appointment bookings with the family doctor and monitoring dietary considerations with regards to stronger medications that might conflict with a patients diet.
|
partial
|
## Inspiration
The inspiration for Leyline came from [The Interaction Company of California's challenge](https://interaction.co/calhacks) to design an AI agent that proactively handles emails. While Google's AI summarization features in their email app were a good start, we felt they lacked the comprehensive functionality users need. We envisioned an agent that could handle more complex tasks like filling out forms and booking flights, truly taking care of the busy work in your inbox.
## What it does
Leyline connects to your Gmail account and parses incoming emails. It uses AI models to analyze the subject, body text, and attachments to determine the best course of action for each email. For example, if there's a form attached with instructions to fill it out, Leyline completes the form for you using information from our database.
## How we built it
We developed Leyline as a Next.js app with Supabase as the backend. We use Google Cloud Pub/Sub to connect to Gmail accounts. A custom webhook receives emails from the Pub/Sub topic. The webhook first summarizes the email, then decides if there's a possible tool it could use. We implemented Groq's tool-calling models to determine appropriate actions, such as filling out attached forms using user data from our database. The frontend was built with Tailwind CSS and shadcn UI components.
## Challenges we ran into
1. Processing Gmail messages correctly was challenging due to conflicting documentation and inconsistent data formats. We had to implement workarounds and additional API calls to fetch all the necessary information.
2. Getting the tool-calling workflow to function properly was difficult, as it sometimes failed to call tools or missed steps in the process.
## Accomplishments that we're proud of
* We created an intuitive and visually appealing user interface.
* We implemented real-time email support, allowing emails to appear instantly and their processing status to update live.
* We developed a functional tool workflow for handling various email tasks.
## What we learned
* This was our first time using Google Cloud Pub/Sub, which taught us about the unique characteristics of cloud provider APIs compared to consumer APIs.
* We gained experience with tool-calling in AI models and learned about its intricacies.
## What's next for Leyline
We plan to expand Leyline's capabilities by:
* Adding more tools to handle a wider variety of email-related tasks.
* Implementing a containerized browser to perform tasks like flight check-ins.
* Supporting additional email providers beyond Gmail.
* Developing more specialized tools for processing different types of emails and requests.
|
## Inspiration
In today's fast-paced digital world, creating engaging social media content can be time-consuming and challenging. We developed Expresso to empower content creators, marketers, and businesses to streamline their social media workflow without compromising on quality or creativity.
## What it does
Expresso is an Adobe Express plugin that revolutionizes the process of creating and optimizing social media posts. It offers:
1. Intuitive Workflow System: Simplifies the content creation process from ideation to publication.
2. AI-Powered Attention Optimization: Utilizes a human attention (saliency) model (SUM) to provide feedback on maximizing post engagement.
3. Customizable Feedback Loop: Allows users to configure iterative feedback based on their specific needs and audience.
4. Task Automation: Streamlines common tasks like post captioning and scheduling.
## How we built it
We leveraged a powerful tech stack to bring Expresso to life:
* React: For building a responsive and interactive user interface
* PyTorch: To implement our AI-driven attention optimization model
* Flask: To create a robust backend API
## Challenges we ran into
Some of the key challenges we faced included:
* Integrating the SUM model seamlessly into the Adobe Express environment
* Optimizing the AI feedback loop for real-time performance
* Ensuring cross-platform compatibility and responsiveness
## Accomplishments that we're proud of
* Successfully implementing a state-of-the-art human attention model
* Creating an intuitive user interface that simplifies complex workflows
* Developing a system that provides actionable, AI-driven insights for content optimization
## What we learned
Throughout this project, we gained valuable insights into:
* Adobe Express plugin development
* Integrating AI models into practical applications
* Balancing automation with user control in creative processes
## What's next for Expresso
We're excited about the future of Expresso and plan to:
1. Expand our AI capabilities to include trend analysis and content recommendations
2. Integrate with more social media platforms for seamless multi-channel publishing
3. Develop advanced analytics to track post performance and refine optimization strategies
Try Expresso today and transform your design and marketing workflow!
|
## Inspiration
One of our teammates had an internship at a company where they were exposed to the everyday operations of the sales and customer service (SCS) industry. During their time there, they discovered how costly and time consuming it was for companies to properly train, manage and analyze the performance of their SCS department. Even current technologies within the industry such as CRM (Customer Relation Management) softwares were not sufficient to support the demands of training and managing.
Our solution encompasses a gamified platform that incorporates an AI tool that’s able to train, analyze and manage the performance of SCS employees. The outcome of our solution provides customers with the best support tailored towards them at a low-cost for the business.
## What it does
traint is used in 4 ways:
Utilize AI to facilitate customer support agents in honing their sales and conflict resolution skills
Provides feedback and customer sentiment analysis after every customer interaction simulation
Ranks customer support agents on a leaderboard based on “sentiment score”
Matches top performers within the leaderboard in their respective functions (sales and conflict) to difficult clients.
traint provides businesses with the capability to jumpstart and enhance their customer service and sales at a low cost. traint also interfaces AI agents and analysis in a digestible manner for individuals of all technological fluency.
## How we built it
traint was built using the following technologies:
Next.js
React, Tailwind and shadcn/ui
Voiceflow API
Groq API
Genesys API
The **Voiceflow** API was used mainly to develop the two customer archetypes. One of which being a customer looking to purchase something (sales) and the other being a customer that is unsatisfied with something (conflict resolution).
**Genesys** API was utilized to perform the customer sentiment analysis - a key metric in our application. The API was also used for its live chat queue system, allowing us to requeue and accept “calls” from customers.
\
The **Groq** API allowed us to analyze the conversation transcript to provide detailed feedback for the operator.
Most of our features were interfaced through our web application which hosts action buttons and chat/performance analytics like the average customer sentiment score.
## Challenges we ran into
There was a steep learning curve to Genesys’s extensive API. At first we were overwhelmed with the amount of API endpoints available, and where to begin. We went to the many workshops, including the Genesys workshop, which helped us get started, and we consulted with the teams when we ran into issues with the platform.
Initially, we would run into issues with setting up and getting access to certain endpoints since they required us to be granted permissions explicitly from the Genesys team, but they were very prompt and friendly with getting us the access we need to build our app.
We also ran into many issues with the prompt engineering for the AI agent on Voiceflow. When building the customer archetypes, the model wasn’t performing as expected so it took a lot of time to get it to work like we wanted.
Although we had many challenges, we were all proud of the end product and the work we did despite the many roadblocks we faced :)
## Accomplishments that we're proud of
In a short span of time, we were able to familiarize ourselves with several tools, namely the Genesys’ extensive API and the Voiceflow platform. We integrated these two tools together to create a product that serves both the customer as well as the customer service representatives.
## What we learned
We learnt a lot about API integration, namely the Genesys API and Voiceflow software. Both the API’s were completely new to us and it took alot of research and trial and error to get our product to work.
We also learned about the link between frontend and backend in Next.js, and how to transfer information between the both of them via API routes, client and server side components, etc.
Our team came into this hackathon not really knowing much about each other. Coming from 4 different universities, we learnt a lot working with each other.
## What's next for traint
We wish that we had more time to fully develop our leaderboard process through the gamification/employee performance API. We ran into some issues with accessing the API and given more time, we would have implemented this feature.
Another feature we wanted to add was the ability to assign agents based off of client history. Although there may be some data concerns - providing clients with the ability to talk to the same agents that they preferred in the past would be very beneficial.
Finally, we would love to take traint to the next level and see it incorporated in some real life businesses. We truly believe in the use case and hope it solves some key pain points for people.
|
winning
|
## Inspiration
Every year, thousands of mechatronics engineering students across the world endure unintuitive controls for their favourite 3D modelling software. Whilst they may be gaining professional and academic experience during their time in post-secondary education, they graduate and move on to greater things suffering from chronic illnesses such as Repetitive Strain Injury (RSI), Carpal Tunnel Syndrome from constant use of poorly designed peripherals, and relentless work stress. The well-respected program of Mechatronics Engineering is a study that we, as the team behind Kinemodel, hold dear to our hearts, and thus, we had a dream of finding a way to save countless innocent freshmen from a harrowing life with chronic pain.
[GIF](https://media.tenor.com/EHYzxILmfx0AAAAC/tinkering-tony-stark.gif)
To aid us in this task, we were initially inspired by the iconic scene in Iron Man 2 where Tony Stark discovers a new element whilst navigating through his hologram projections by gesturing with his arms and hands, allowing panels of information to move and morph to his will.
With this idea in mind, we set out to find a way to enable the use of gesture controls within the modelling software environment.
## What it does
Kinemodel allows the user to manipulate drawings and models in a CAD software environment without the need for inputs from the traditional mouse and keyboard combo. Using Kinemodel’s gesture recognition technology, users will be able to channel their inner Iron Man and rotate, pan, and zoom to their heart’s content using nothing but hand movements. This is possible with the power of Google’s MediaPipe machine learning gesture recognition.
## How we built it
We began by researching the world of computer vision and landed on a relatively released Google’s MediaPipe ML library. Their functionality was a large inspiration for this project. We connected each built-in gesture to commands in the Solidworks environment, allowing for intuitive manipulation of viewpoint and perspective. We built a simple front end desktop app on Electron using Vue.js, which we connected to a Python script that ran the MediaPipe algorithm.
## Challenges we ran into
We ran into two major problems during our hacking. Firstly, we struggled to find a reliable method to analyse a user’s hand. We began by looking at the joints to figure out the position, relative rotation, and gesture of the hand. We quickly found out that creating such an algorithm was out of the scope of this hackathon. We shortened our idea to hand gestures only to keep our idea viable. Secondly, we began our project in a very non-linear way. Min worked on the front end experimenting with Electron and Vue.js while David and Richard worked on writing the MediaPipe algorithm in Python. Naturally, both programs had to be integrated in the end. We researched for long how to connect the NodeJS codebase to Python into one buildable app. Although a bit overkill, we landed on using a local machine websocket connection to connect our two codebases. Accidentally, we made a potentially scalable backend if we ever wanted to grow this project to completion.
## Accomplishments that we're proud of
During this event, we were proud of how quickly we learned and applied many different topics in such a short amount of time. All of us took on a task that we had little to no experience in and were able to effectively create a functional product within 36 hours. Successfully integrating the front end with the python scripts and finally interacting with the computer itself to input commands was something that felt amazing once it was completed. Overall, we made many small accomplishments and had lots of fun along the way.
## What we learned
During our time at Hack the North 2023, we as a team learned many things. From the perspective of AI systems, we learned how to use pre-trained computer vision models to our advantage, specifically how to make use of Google’s MediaPipe technology to fulfil a specific purpose. We also learned how to implement Node.js front-end frameworks to build Windows applications, as well as how to set up communication between a Python-based backend and a JavaScript-based frontend. Also, we developed our skills with using Python to emulate keystrokes, which were then inputted into Solidworks, becoming navigation tools. Finally, last but not least, we learned that there is so much more to discover in the world of computer vision and AI recognition.
## What's next for Kinemodel
While we believe that as of today, Kinemodel acts as a strong, inspiring prototype for gesture controls for 3D modelling purposes, there are always improvements to be made. As the next steps for the future of Kinemodel, there are several avenues we hope to explore further. Firstly, we hope that we will be able to improve the intuitiveness of the hand gestures corresponding to which cardinal direction of motion – for example, pointing left to go left etc. Furthermore, we hope to further solidify the reliability of the machine vision, and improve consistency. Additionally, we aim to diversify the types of software that Kinemodel can be compatible with, not only other CAD tools such as Catia and Blender, but also other types of academic software such as aerodynamics simulation software or robotics software. Finally, we believe that a good product should be matched with a good UI, thus we hope to spend time in the future improving ease of access and further building a stronger user experience.
|
## Inspiration
>
> We wanted to make a website that utilized an open source framework for computer vision called MediaPipe by Google. After much deliberation, we settled on making a simple game of rock-paper-scissors featuring MediaPipe's Gesture Recognition solution.
>
>
> ## What it does
>
>
> Upon landing on the website, there is one panel on the left where live feed of the user is continuously displayed. The panel on the right will display pictures of our team signing rock, paper or scissors and the picture displayed is chosen by the computer based on what the user signs to the camera. However, your opponent is the best rock-paper-scissors player to have ever existed.
>
>
> ## How we built it
>
>
> MediaPipe is the backbone of how our game works. It's an open source framework easily made accessible by Google, and we used its Gesture Recognition solution. This solution has already been pre-trained (using Google's ML Fairness standards) to recognize 20 positions in the hand which include the wrist, fingertips and all the joints in the hand. The foundation of our detection algorithm was starter code provided by [LintangWisesa](https://github.com/LintangWisesa/MediaPipe-in-JavaScript/tree/master) on GitHub, we then added the conditional features that produce an output triggered by the input processed through the Gesture Recognition. We were able to build a user-friendly front-end using HTML and CSS, and then connected it with the back-end that was developed with JavaScript and the guidance of ChatGPT. Our website uses the weekend's free domain name provided by the GoDaddy registry.
>
>
> ## Challenges we ran into
>
>
> We spent a great deal of time learning about the MediaPipe framework, and then figuring out how to make it compatible to our goals. One particular struggle was getting the computer to detect our hand gestures and produce the desired output, due to the extent of our knowledge concerning web development being introductory-level.
>
>
> ## Accomplishments that we're proud of
>
>
> We're proud of developing our first website using a framework that felt foreign at the beginning of the project to feeling familiar by the end of the project.
>
>
> ## What we learned
>
>
> We learned a lot of techniques that improved our HTML and CSS and how to connect the front-end to the back-end of our website developed with JavaScript.
>
>
>
|
**Inspiration**
The inspiration behind Block Touch comes from the desire to create an interactive and immersive experience for users by leveraging the power of Python computer vision. We aim to provide a unique and intuitive way for users to navigate and interact with a simulated world, using their hand movements to place blocks dynamically.
**What it does**
Block Touch utilizes Python computer vision to detect and interpret hand movements, allowing users to navigate within a simulated environment and place blocks in a virtual space. The application transforms real-world hand gestures into actions within the simulated world, offering a novel and engaging user experience.
**How we built it**
We built Block Touch by combining our expertise in Python programming and computer vision. The application uses computer vision algorithms to analyze and interpret the user's hand movements, translating them into commands that control the virtual world. We integrated libraries and frameworks to create a seamless and responsive interaction between the user and the simulated environment.
**Challenges we ran into**
While developing Block Touch, we encountered several challenges. Fine-tuning the computer vision algorithms to accurately recognize and interpret a variety of hand movements posed a significant challenge. Additionally, optimizing the application for real-time responsiveness and ensuring a smooth user experience posed technical hurdles that we had to overcome during the development process.
**Accomplishments that we're proud of**
We are proud to have successfully implemented a Python computer vision system that enables users to control and interact with a simulated world using their hand movements. Overcoming the challenges of accurately detecting and responding to various hand gestures represents a significant achievement for our team. The creation of an immersive and enjoyable user experience is a source of pride for us.
**What we learned**
During the development of Block Touch, we gained valuable insights into the complexities of integrating computer vision into interactive applications. We learned how to optimize algorithms for real-time performance, enhance gesture recognition accuracy, and create a seamless connection between the physical and virtual worlds.
**What's next for Block Touch**
In the future, we plan to expand the capabilities of Block Touch by incorporating more advanced features and functionalities. This includes refining the hand gesture recognition system, adding new interactions, and potentially integrating it with virtual reality (VR) environments. We aim to continue enhancing the user experience and exploring innovative ways to leverage computer vision for interactive applications.
|
losing
|
## Inspiration
I wanted to build a website that will filter users according to certain criteria and match students so they can chat and get together for study sessions.
One of the core issues in such apps is verification of users, so I am using Botdoc which allows me to request documents from the users in a fast and secure way.
## What it does
* Chat with users
* Create a flashcard room
* Verifies users before they can start using the application
* PWA , natively run application on ios/android/desktop !
## How we built it
Flutter , Firebase , Node.js and Botdoc API were used for this project.
## Challenges we ran into
Botdoc API is fairly new to me but the documentation and quick start helped quite a lot.
## Accomplishments that we're proud of
Build a working application under 24 hours
## What's next for Study Mate
* Add more criteria to filter students
* Add profile page
* Order chat rooms according to last updated
|
## Inspiration
The inspiration for this project stems from the well-established effectiveness of focusing on one task at a time, as opposed to multitasking. In today's era of online learning, students often find themselves navigating through various sources like lectures, articles, and notes, all while striving to absorb information effectively. Juggling these resources can lead to inefficiency, reduced retention, and increased distraction. To address this challenge, our platform consolidates these diverse learning materials into one accessible space.
## What it does
A seamless learning experience where you can upload and read PDFs while having instant access to a chatbot for quick clarifications, a built-in YouTube player for supplementary explanations, and a Google Search integration for in-depth research, all in one platform. But that's not all - with a click of a button, effortlessly create and sync notes to your Notion account for organized, accessible study materials. It's designed to be the ultimate tool for efficient, personalized learning.
## How we built it
Our project is a culmination of diverse programming languages and frameworks. We employed HTML, CSS, and JavaScript for the frontend, while leveraging Node.js for the backend. Python played a pivotal role in extracting data from PDFs. In addition, we integrated APIs from Google, YouTube, Notion, and ChatGPT, weaving together a dynamic and comprehensive learning platform
## Challenges we ran into
None of us were experienced in frontend frameworks. It took a lot of time to align various divs and also struggled working with data (from fetching it to using it to display on the frontend). Also our 4th teammate couldn't be present so we were left with the challenge of working as a 3 person team.
## Accomplishments that we're proud of
We take immense pride in not only completing this project, but also in realizing the results we envisioned from the outset. Despite limited frontend experience, we've managed to create a user-friendly interface that integrates all features successfully.
## What we learned
We gained valuable experience in full-stack web app development, along with honing our skills in collaborative teamwork. We learnt a lot about using APIs. Also a lot of prompt engineering was required to get the desired output from the chatgpt apu
## What's next for Study Flash
In the future, we envision expanding our platform by incorporating additional supplementary resources, with a laser focus on a specific subject matter
|
## Inspiration
In today's age, people have become more and more divisive on their opinions. We've found that discussion nowadays can just result in people shouting instead of trying to understand each other.
## What it does
**Change my Mind** helps to alleviate this problem. Our app is designed to help you find people to discuss a variety of different topics. They can range from silly scenarios to more serious situations. (Eg. Is a Hot Dog a sandwich? Is mass surveillance needed?)
Once you've picked a topic and your opinion of it, you'll be matched with a user with the opposing opinion and put into a chat room. You'll have 10 mins to chat with this person and hopefully discover your similarities and differences in perspective.
After the chat is over, you ask you to rate the maturity level of the person you interacted with. This metric allows us to increase the success rate of future discussions as both users matched will have reputations for maturity.
## How we built it
**Tech Stack**
* Front-end/UI
+ Flutter and dart
+ Adobe XD
* Backend
+ Firebase
- Cloud Firestore
- Cloud Storage
- Firebase Authentication
**Details**
* Front end was built after developing UI mockups/designs
* Heavy use of advanced widgets and animations throughout the app
* Creation of multiple widgets that are reused around the app
* Backend uses gmail authentication with firebase.
* Topics for debate are uploaded using node.js to cloud firestore and are displayed in the app using specific firebase packages.
* Images are stored in firebase storage to keep the source files together.
## Challenges we ran into
* Initially connecting Firebase to the front-end
* Managing state while implementing multiple complicated animations
* Designing backend and mapping users with each other and allowing them to chat.
## Accomplishments that we're proud of
* The user interface we made and animations on the screens
* Sign up and login using Firebase Authentication
* Saving user info into Firestore and storing images in Firebase storage
* Creation of beautiful widgets.
## What we're learned
* Deeper dive into State Management in flutter
* How to make UI/UX with fonts and colour palates
* Learned how to use Cloud functions in Google Cloud Platform
* Built on top of our knowledge of Firestore.
## What's next for Change My Mind
* More topics and User settings
* Implementing ML to match users based on maturity and other metrics
* Potential Monetization of the app, premium analysis on user conversations
* Clean up the Coooooode! Better implementation of state management specifically implementation of provide or BLOC.
|
losing
|
## Inspiration
During my last internship, I worked on an aging product with numerous security vulnerabilities, but identifying and fixing these issues was a major challenge. One of my key projects was to implement CodeQL scanning to better locate vulnerabilities. While setting up CodeQL wasn't overly complex, it became repetitive as I had to manually configure it for every repository, identifying languages and creating YAML files. Fixing the issues proved even more difficult as many of the vulnerabilities were obscure, requiring extensive research and troubleshooting. With that experience in mind, I wanted to create a tool that could automate this process, making code security more accessible and ultimately improving internet safety
## What it does
AutoLock automates the security of your GitHub repositories. First, you select a repository and hit install, which triggers a pull request with a GitHub Actions configuration to scan for vulnerabilities and perform AI-driven analysis. Next, you select which vulnerabilities to fix, and AutoLock opens another pull request with the necessary code modifications to address the issues.
## How I built it
I built AutoLock using Svelte for the frontend and Go for the backend. The backend leverages the Gin framework and Gorm ORM for smooth API interactions, while the frontend is powered by Svelte and styled using Flowbite.
## Challenges we ran into
One of the biggest challenges was navigating GitHub's app permissions. Understanding which permissions were needed and ensuring the app was correctly installed for both the user and their repositories took some time. Initially, I struggled to figure out why I couldn't access the repos even with the right permissions.
## Accomplishments that we're proud of
I'm incredibly proud of the scope of this project, especially since I developed it solo. The user interface is one of the best I've ever created—responsive, modern, and dynamic—all of which were challenges for me in the past. I'm also proud of the growth I experienced working with Go, as I had very little experience with it when I started.
## What we learned
While the unstable CalHacks WiFi made deployment tricky (basically impossible, terraform kept failing due to network issues 😅), I gained valuable knowledge about working with frontend component libraries, Go's Gin framework, and Gorm ORM. I also learned a lot about integrating with third-party services and navigating the complexities of their APIs.
## What's next for AutoLock
I see huge potential for AutoLock as a startup. There's a growing need for automated code security tools, and I believe AutoLock's ability to simplify the process could make it highly successful and beneficial for developers across the web.
|
## Inspiration:
Millions of active software developers use GitHub for managing their software development, however, our team believes that there is a lack of incentive and engagement factor within the platform. As users on GitHub, we are aware of this problem and want to apply a twist that can open doors to a new innovative experience. In addition, we were having thoughts on how we could make GitHub more accessible such as looking into language barriers which we ultimately believed wouldn't be that useful and creative. Our offical final project was inspired by how we would apply something to GitHub but instead llooking into youth going into CS. Combining these ideas together, our team ended up coming up with the idea of DevDuels.
## What It Does:
Introducing DevDuels! A video game located on a website that's goal is making GitHub more entertaining to users. One of our target audiences is the rising younger generation that may struggle with learning to code or enter the coding world due to complications such as lack of motivation or lack of resources found. Keeping in mind the high rate of video gamers in the youth, we created a game that hopes to introduce users to the world of coding (how to improve, open sources, troubleshooting) with a competitive aspect leaving users wanting to use our website beyond the first time. We've applied this to our 3 major features which include our immediate AI feedback to code, Duo Battles, and leaderboard.
In more depth about our features, our AI feedback looks at the given code and analyses it. Very shortly after, it provides a rating out of 10 and comments on what it's good and bad about the code such as the code syntax and conventions.
## How We Built It:
The web app is built using Next.js as the framework. HTML, Tailwind CSS, and JS were the main languages used in the project’s production. We used MongoDB in order to store information such as the user account info, scores, and commits which were pulled from the Github API using octokit. Langchain API was utilised in order to help rate the commit code that users sent to the website while also providing its rationale for said rankings.
## Challenges We Ran Into
The first roadblock our team experienced occurred during ideation. Though we generated multiple problem-solution ideas, our main issue was that the ideas either were too common in hackathons, had little ‘wow’ factor that could captivate judges, or were simply too difficult to implement given the time allotted and team member skillset.
While working on the project in specific, we struggled a lot with getting MongoDB to work alongside the other technologies we wished to utilise (Lanchain, Github API). The frequent problems with getting the backend to work quickly diminished team morale as well. Despite these shortcomings, we consistently worked on our project down to the last minute to produce this final result.
## Accomplishments that We're Proud of:
Our proudest accomplishment is being able to produce a functional game following the ideas we’ve brainstormed. When we were building this project, the more we coded, the less optimistic we got in completing it. This was largely attributed to the sheer amount of error messages and lack of progression we were observing for an extended period of time. Our team was incredibly lucky to have members with such high perseverance which allowed us to continue working on, resolving issues and rewriting code until features worked as intended.
## What We Learned:
DevDuels was the first step into the world hackathons for many of our team members. As such, there was so much learning throughout this project’s production. During the design and ideation process, our members learned a lot about website UI design and Figma. Additionally, we learned HTML, CSS, and JS (Next.js) in building the web app itself. Some members learned APIs such as Langchain while others explored Github API (octokit). All the new hackers navigated the Github website and Git itself (push, pull, merch, branch , etc.)
## What's Next for DevDuels:
DevDuels has a lot of potential to grow and make it more engaging for users. This can be through more additional features added to the game such as weekly / daily goals that users can complete, ability to create accounts, and advance from just a pair connecting with one another in Duo Battles.
Within these 36 hours, we worked hard to work on the main features we believed were the best. These features can be improved with more time and thought put into it. There can be small to large changes ranging from configuring our backend and fixing our user interface.
|
## Inspiration
* The theme for the hackathon
* Emerging LLM AI technologies and access through APIs
## What it does
* A simple chatroom alongside a bonfire to illicit a sense of peace with company.
## How I built it
* Node.js and React to build the overall website (Started with create-react-app)
* Spline to design and model a bonfire 3D animation
* Github and Github Actions to manage and handle automatic build and deploy directly to Azure App Services
* Register and setup the domain with GoDaddy and Porkbun
* Host the website using Azure App Services
* Use of Infobip API to text me the status of my build and deployment
* Call the OpenAI API to send and receive GPT-4 text generation conversation
* Website Icon built using Figma and exported to \*.ico format using plugins
## Accomplishments that I'm proud of
This is my first hackathon and I'm glad I was able to produce a cool product, and I got to learn and build my project using all new technologies to me. I'm a Medical Sciences student doing Bioinformatics, so my technical experience mainly comprises of scripting and command line applications in Python and R. Since I don't have any experience creating websites and GUIs connected to a backend, I wanted to produce something so I know how the process and pipeline works. I am happy with the result, and hope to explore React and other similar frameworks more to be able to host and share projects that others can use.
## What I learned
* How full stack development works using React
* Using GitHub Actions to build and deploy products
* Use of APIs (infobip, OpenAI)
|
partial
|
## How to use
First, you need an OpenAI account for a unique API key to plug into the openai.api\_key field in the generate\_transcript.py file. You'll also need to authenticate the text-to-speech API with a .json key from Google Cloud. Then, run the following code in the terminal:
```
python3 generate_transcript.py
cd newscast
npm start
```
You'll be able to use Newscast in your browser at <http://localhost:3000/>. Just log in with your Gmail account and you're good to go!
## Inspiration
Newsletters are an underpreciated medium and the experience of accessing them each morning could be made much more convenient if they didn't have to be clicked through one by one. Furthermore, with all the craze around AI, why not have an artificial companion deliver these morning updates to us?
## What it does
Newscast aggregates all newsletters a Gmail user has received during the day and narrates the most salient points from each one using personable AI-generated summaries powered by OpenAI and deployed with React and MUI.
## How we built it
Fetching mail from Gmail API -> Generating transcripts in OpenAI -> Converting text to speech via Google Cloud -> Running on MUI frontend
## Challenges we ran into
Gmail API was surprisingly trickly to operate with; it took a long time to bring the email strings to the form where OpenAi wouldn't struggle with them too much.
## Accomplishments that we're proud of
Building a full-stack app that we could see ourselves using! Successfully tackling a front-end solution on React after spending most of our time doing backend and algos in school.
## What we learned
Integrating APIs with one another, building a workable frontend solution in React and MUI.
## What's next for Newscast
Generating narratives grouped by publication/day/genre. Adding more UI features, e.g. cards pertaining to indidividual newspapers. Building a proper backend (Flask?) to support users and e.g. saving transcripts.
|
Currently, about 600,000 people in the United States have some form of hearing impairment. Through personal experiences, we understand the guidance necessary to communicate with a person through ASL. Our software eliminates this and promotes a more connected community - one with a lower barrier entry for sign language users.
Our web-based project detects signs using the live feed from the camera and features like autocorrect and autocomplete reduce the communication time so that the focus is more on communication rather than the modes. Furthermore, the Learn feature enables users to explore and improve their sign language skills in a fun and engaging way. Because of limited time and computing power, we chose to train an ML model on ASL, one of the most popular sign languages - but the extrapolation to other sign languages is easily achievable.
With an extrapolated model, this could be a huge step towards bridging the chasm between the worlds of sign and spoken languages.
|
## Inspiration
Have you ever been looking online for sample code, or a solution to a problem, but the code doesn't make sense? Have you been given code at work to review that just isn't documented at all? Have you gone to ChatGPT for these worries, but received an essay-length response where you can’t follow it along with the code? Well, look no further, as we created **DocUrCODE**!
## What it does
DocUrCODE allows you to paste any type of code into a chat box, and then **interactively navigate an annotated version of that code**. The interactive exploration page presents two columns that you can independently scroll through: the right column displays the original code, while the left column presents a list of annotations that explain the code. Each annotation specifies the lines of codes that it explains (e.g. 12-15), and clicking on an annotation will highlight its corresponding sections of code. There are three levels of detail that the code can be annotated in: detailed, normal, or overview. DOC-ur-CODE can process up to 60,000 characters of code input, across any programming language.
## How we built it
The front-end system was developed using React, with the back-end built using NodeJS and Express. Input code received from the user is parsed, and then sent to OpenAI using their Rest API. Using a specified prompt, annotation is then automatically generated and received from the API. These annotations are processed and then displayed to the user on our front-end.
## Challenges we ran into
1. Regex interpretation of strings ❗
2. Prompt engineering ❔
3. API Key Encryption 🔑
4. Google Cloud deployment ☁️
## Accomplishments that we're proud of
1. Accurate and helpful annotations, across three different levels of detail 💬
2. Clean, robust and interactive front-end design 💻
3. API key encryption 🔑
## What we learned
1. Front-end development using React ⚛️
2. API implementation ✨
3. GCP Deployment ☁️
4. Prompt optimization ❔
## What's next for DOC\_ur\_CODE
The back-end framework has been designed to handle large amounts of input code, so we will be looking to support the input of multi-file programs over the next few weeks. For the long-term, we may also look to support the annotation and viewing of an entire github repository
|
partial
|
## Inspiration
Digitized conversations have given the hearing impaired and other persons with disabilities the ability to better communicate with others despite the barriers in place as a result of their disabilities. Through our app, we hope to build towards a solution where we can extend the effects of technological development to aid those with hearing disabilities to communicate with others in real life.
## What it does
Co:herent is (currently) a webapp which allows the hearing impaired to streamline their conversations with others by providing them sentence or phrase suggestions given the context of a conversation. We use Co:here's NLP text generation API in order to achieve this and in order to provide more accurate results we give the API context from the conversation as well as using prompt engineering in order to better tune the model. The other (non hearing impaired) person is able to communicate with the webapp naturally through speech-to-text inputs and text-to-speech functionalities are put in place in order to better facilitate the flow of the conversation.
## How we built it
We built the entire app using Next.js with the Co:here API, React Speech Recognition API, and React Speech Kit API.
## Challenges we ran into
* Coming up with an idea
* Learning Next.js as we go as this is all of our first time using it
* Calling APIs are difficult without a backend through a server side rendered framework such as Next.js
* Coordinating and designating tasks in order to be efficient and minimize code conflicts
* .env and SSR compatibility issues
## Accomplishments that we're proud of
Creating a fully functional app without cutting corners or deviating from the original plan despite various minor setbacks.
## What we learned
We were able to learn a lot about Next.js as well as the various APIs through our first time using them.
## What's next for Co:herent
* Better tuning the NLP model to generate better/more personal responses as well as storing and maintaining more information on the user through user profiles and database integrations
* Better tuning of the TTS, as well as giving users the choice to select from a menu of possible voices
* Possibility of alternative forms of input for those who may be physically impaired (such as in cases of cerebral palsy)
* Mobile support
* Better UI
|
## Inspiration
We wanted to tackle a problem that impacts a large demographic of people. After research, we learned that 1 in 10 people suffer from dyslexia and 5-20% of people suffer from dysgraphia. These neurological disorders go undiagnosed or misdiagnosed often leading to these individuals constantly struggling to read and write which is an integral part of your education. With such learning disabilities, learning a new language would be quite frustrating and filled with struggles. Thus, we decided to create an application like Duolingo that helps make the learning process easier and more catered toward individuals.
## What it does
ReadRight offers interactive language lessons but with a unique twist. It reads out the prompt to the user as opposed to it being displayed on the screen for the user to read themselves and process. Then once the user repeats the word or phrase, the application processes their pronunciation with the use of AI and gives them a score for their accuracy. This way individuals with reading and writing disabilities can still hone their skills in a new language.
## How we built it
We built the frontend UI using React, Javascript, HTML and CSS.
For the Backend, we used Node.js and Express.js. We made use of Google Cloud's speech-to-text API. We also utilized Cohere's API to generate text using their LLM.
Finally, for user authentication, we made use of Firebase.
## Challenges we faced + What we learned
When you first open our web app, our homepage consists of a lot of information on our app and our target audience. From there the user needs to log in to their account. User authentication is where we faced our first major challenge. Third-party integration took us significant time to test and debug.
Secondly, we struggled with the generation of prompts for the user to repeat and using AI to implement that.
## Accomplishments that we're proud of
This was the first time for many of our members to be integrating AI into an application that we are developing so that was a very rewarding experience especially since AI is the new big thing in the world of technology and it is here to stay.
We are also proud of the fact that we are developing an application for individuals with learning disabilities as we strongly believe that everyone has the right to education and their abilities should not discourage them from trying to learn new things.
## What's next for ReadRight
As of now, ReadRight has the basics of the English language for users to study and get prompts from but we hope to integrate more languages and expand into a more widely used application. Additionally, we hope to integrate more features such as voice-activated commands so that it is easier for the user to navigate the application itself. Also, for better voice recognition, we should
|
>
> Domain.com domain: IDE-asy.com
>
>
>
## Inspiration
Software engineering and development have always been subject to change over the years. With new tools, frameworks, and languages being announced every year, it can be challenging for new developers or students to keep up with the new trends the technological industry has to offer. Creativity and project inspiration should not be limited by syntactic and programming knowledge. Quick Code allows ideas to come to life no matter the developer's experience, breaking the coding barrier to entry allowing everyone equal access to express their ideas in code.
## What it does
Quick Code allowed users to code simply with high level voice commands. The user can speak in pseudo code and our platform will interpret the audio command and generate the corresponding javascript code snippet in the web-based IDE.
## How we built it
We used React for the frontend, and the recorder.js API for the user voice input. We used runkit for the in-browser IDE. We used Python and Microsoft Azure for the backend, we used Microsoft Azure to process user input with the cognitive speech services modules and provide syntactic translation for the frontend’s IDE.
## Challenges we ran into
>
> "Before this hackathon I would usually deal with the back-end, however, for this project I challenged myself to experience a different role. I worked on the front end using react, as I do not have much experience with either react or Javascript, and so I put myself through the learning curve. It didn't help that this hacakthon was only 24 hours, however, I did it. I did my part on the front-end and I now have another language to add on my resume.
> The main Challenge that I dealt with was the fact that many of the Voice reg" *-Iyad*
>
>
> "Working with blobs, and voice data in JavaScript was entirely new to me." *-Isaac*
>
>
> "Initial integration of the Speech to Text model was a challenge at first, and further recognition of user audio was an obstacle. However with the aid of recorder.js and Python Flask, we able to properly implement the Azure model." *-Amir*
>
>
> "I have never worked with Microsoft Azure before this hackathon, but decided to embrace challenge and change for this project. Utilizing python to hit API endpoints was unfamiliar to me at first, however with extended effort and exploration my team and I were able to implement the model into our hack. Now with a better understanding of Microsoft Azure, I feel much more confident working with these services and will continue to pursue further education beyond this project." *-Kris*
>
>
>
## Accomplishments that we're proud of
>
> "We had a few problems working with recorder.js as it used many outdated modules, as a result we had to ask many mentors to help us get the code running. Though they could not figure it out, after hours of research and trying, I was able to successfully implement recorder.js and have the output exactly as we needed. I am very proud of the fact that I was able to finish it and not have to compromise any data." *-Iyad*
>
>
> "Being able to use Node and recorder.js to send user audio files to our back-end and getting the formatted code from Microsoft Azure's speech recognition model was the biggest feat we accomplished." *-Isaac*
>
>
> "Generating and integrating the Microsoft Azure Speech to Text model in our back-end was a great accomplishment for our project. It allowed us to parse user's pseudo code into properly formatted code to provide to our website's IDE." *-Amir*
>
>
> "Being able to properly integrate and interact with the Microsoft Azure's Speech to Text model was a great accomplishment!" *-Kris*
>
>
>
## What we learned
>
> "I learned how to connect the backend to a react app, and how to work with the Voice recognition and recording modules in react. I also worked a bit with Python when trying to debug some problems in sending the voice recordings to Azure’s servers." *-Iyad*
>
>
> "I was introduced to Python and learned how to properly interact with Microsoft's cognitive service models." *-Isaac*
>
>
> "This hackathon introduced me to Microsoft Azure's Speech to Text model and Azure web app. It was a unique experience integrating a flask app with Azure cognitive services. The challenging part was to make the Speaker Recognition to work; which unfortunately, seems to be in preview/beta mode and not functioning properly. However, I'm quite happy with how the integration worked with the Speach2Text cognitive models and I ended up creating a neat api for our app." *-Amir*
>
>
> "The biggest thing I learned was how to generate, call and integrate with Microsoft azure's cognitive services. Although it was a challenge at first, learning how to integrate Microsoft's models into our hack was an amazing learning experience. " *-Kris*
>
>
>
## What's next for QuickCode
We plan on continuing development and making this product available on the market. We first hope to include more functionality within Javascript, then extending to support other languages. From here, we want to integrate a group development environment, where users can work on files and projects together (version control). During the hackathon we also planned to have voice recognition to recognize and highlight which user is inputting (speaking) which code.
|
winning
|
## Inspiration
As freshman during the COVID pandemic, we found it hard to meet people in our online classes, and find groups to study with, which is one of things we were most looking forward to. We wanted to create a way for students to be matched with peers to study with, not only based on the classes they are taking, but based on common interests and personality matches as well. So, we created this website that takes into accout multiple factors when matching someone with a study group, and also added a chat feature, quiz feature, and attached Zoom link so students can use this site as a one stop shop.
## What it does
The website has a few key features.
1. Joining a room based on a room code - with a code that you can get from a friend, our recommended rooms for you, or the public room list, join the room that will be most helpful for you to study in.
2. Creating a private room - you can start your own room and invite friends, so you can privately use all the tools that our site provides even if you have a study group already.
3. Finding a room - the site uses machine learning to pplace you with other students that likely will be a good study match based on a few questions it asks you.
4. Entering a public room - there are always public rooms open for various subjects and difficulty levels that you can join, if you don't mind working with any kind of person.
5. Chat and Zoom feature - once you are in a room, you can text chat with other people in the room with our integrated chat box, or you can use the attached zoom link to video call if you would like.
6. Quiz feature - create custom quizzes within each room to quiz yourself and your group members.
## How we built it
We used HTML, CSS, and Javascript to build each page, using sockets for many of our features, and deployed it with Herokuapp.
## Challenges we ran into
We had some some difficulty initially setting up the sockets, because we had never used them before. The initial learning curve was steep, but once we figured it out, everything went smoothly.
## Accomplishments that we're proud of
We are proud that we have a fully deployed and functional app that can be accessed from anywhere using this link: nookncranny.herokuapp.com
## What we learned
We learned a lot about sockets and how a website has to be structured and organized before it can be fully deployed.
## What's next for Nook n' Cranny
We want to develop our ML algorithm further so that we can take in more input parameters, and make our study group matches even better. Additionally, we would like to build our own integrated video chat feature to allow for easier use.
|
## Inspiration
Given that students are struggling to make friends online, we came up with an idea to make this easier. Our web application combines the experience of a video conferencing app with a social media platform.
## What it does
Our web app targets primarily students attending college lectures. We wanted to have an application that would allow users to enter their interests/hobbies/classes they are taking. Based on this information, other students would be able to search for people with similar interests and potentially reach out to them.
## How we built it
One of the main tools we were using was WebRTC that facilitates video and audio transmission among computers. We also used Google Cloud and Firebase for hosting the application and implementing user authentication. We used HTML/CSS/Javascript for building the front end.
## Challenges we ran into
Both of us were super new Google Cloud + Firebase and backend in general. The setup of both platforms took a significant amount of time. Also, we had some troubles with version control on Github.
## Accomplishments we are proud of
GETTING STARTED WITH BACKEND is a huge accomplishment!
## What we learned
Google Cloud, FIrebase, WebRTC - we got introduced to all of these tools during the hackathon.
## What’s next for Studypad
We will definitely continue working on this project and implement other features we were thinking about!
|
## Inspiration
* The pandemic makes socializing with family, friends, and strangers, more difficult. For students, turning on
your camera can be daunting.
* Buddy Study Online aims to create one thing: a safe space for students to meet each other and study.
## What it does
* The product allows users to enter study rooms and communicate with each other through an avatar.
Each study room can have titles indicating which subjects or topics are discussed.
* The avatar detects their facial expressions and maps them on the model.
The anonymity lets students show their expression without fear of judgement by others.
## How we built it
* Frontend - React, React Bootstrap
* Backend - SocketIO, Cassandra, NodeJS/Express
* Other - wakaru ver. beta, Clourblinding Chrome Extension
* With love <3
## Challenges we ran into
* wakaru ver. beta, the facial recognition and motion detection software, is difficult to get right. The facial
mapping wasn't accurate and motion detection was based off colour selection. We tried solving the colour selection issue
by wearing contrasting clothes on limbs we wanted to detect.
* In the end, the usage of gloves was a good choice for detecting hands since it was easy to pick ones that were colourful
enough to contrast the background.
* Cassandra had a steep learning curve, but by pulling from existing examples, we were able implement a working chat component
that persisted the chat state in the order of the messages sent.
* Figuring out a visual identity took quite a long time. While we had laid out components and elements we wanted on the page,
it took us many iterations to settle on a visual identity that we felt was sleek and clean. We also researched information on
multiple forms of colourblindness to aid in accessibility on our site which drove design decisions.
## Accomplishments that we're proud of
1. Facial recognition & movement tracking - Although rough around the edges at times, seeing all of these parts come together was a eureka moment. We spent too much time interacting with each other and with our new animated selves.
2. Live feed - It took us a bit to figure out how to get a live feed of the animated users & their voices. It was an accomplishment to see the other virtual person in front of you.
3. Live chat with other users - Upon a browser refresh, the chat history remains in the correct order the messages were sent in.
## What we learned
* We learned how to use Cassandra when integrating it with our chat system.
* Learning how to use Adobe xd to create mockups and to make our designs come to life.
## What's next for Buddy Study Online
* Voice changing (As students might not feel comfortable with showing their face, they also might not be comfortable with using their own voice)
* Pitch Buddy Study Online to university students with more features such as larger avatar selection, and implementing user logins
to save preferences and settings.
* Using this technology in Zoom calls. With fewer students using their webcams in class, this animated alternative allows for privacy but also socialization.
Even if you're working from home, this can offer a new way of connecting with others during these times.
|
losing
|
This is a simulation of astronomical bodies interacting gravitationally, forming orbits.
Prize Submission:
Best Design,
Locals Only,
Lost Your Marbles,
Useless Stuff that Nobody Needs,
Best Domain Name Registered With Domain.com
Domain.com:
[Now online!](http://www.spacesim2k18.org)
[Video demo of website](https://youtu.be/1rnRuP8i8Vo)
We wanted to make the simulation interactive, shooting planets, manipulating gravity, to make a fun game! This simulation also allows testing to see what initial conditions allowed the formation of our solar system, and potentially in the future, macroscopic astronomical entities like galaxies!
|
## Inspiration
We wanted to make something that linked the virtual and real worlds, but in a quirky way. On our team we had people who wanted to build robots and people who wanted to make games, so we decided to combine the two.
## What it does
Our game portrays a robot (Todd) finding its way through obstacles that are only visible in one dimension of the game. It is a multiplayer endeavor where the first player is given the task to guide Todd remotely to his target. However, only the second player is aware of the various dangerous lava pits and moving hindrances that block Todd's path to his goal.
## How we built it
Todd was built with style, grace, but most of all an Arduino on top of a breadboard. On the underside of the breadboard, two continuous rotation servo motors & a USB battery allows Todd to travel in all directions.
Todd receives communications from a custom built Todd-Controller^TM that provides 4-way directional control via a pair of Bluetooth HC-05 Modules.
Our Todd-Controller^TM (built with another Arduino, four pull-down buttons, and a bluetooth module) then interfaces with Unity3D to move the virtual Todd around the game world.
## Challenges we ran into
The first challenge of the many that we ran into on this "arduinous" journey was having two arduinos send messages to each other via over the bluetooth wireless network. We had to manually configure the setting of the HC-05 modules by putting each into AT mode, setting one as the master and one as the slave, making sure the passwords and the default baud were the same, and then syncing the two with different code to echo messages back and forth.
The second challenge was to build Todd, the clean wiring of which proved to be rather difficult when trying to prevent the loose wires from hindering Todd's motion.
The third challenge was building the Unity app itself. Collision detection was an issue at times because if movements were imprecise or we were colliding at a weird corner our object would fly up in the air and cause very weird behavior. So, we resorted to restraining the movement of the player to certain axes. Additionally, making sure the scene looked nice by having good lighting and a pleasant camera view. We had to try out many different combinations until we decided that a top down view of the scene was the optimal choice. Because of the limited time, and we wanted the game to look good, we resorted to looking into free assets (models and textures only) and using them to our advantage.
The fourth challenge was establishing a clear communication between Unity and Arduino. We resorted to an interface that used the serial port of the computer to connect the controller Arduino with the unity engine. The challenge was the fact that Unity and the controller had to communicate strings by putting them through the same serial port. It was as if two people were using the same phone line for different calls. We had to make sure that when one was talking, the other one was listening and vice versa.
## Accomplishments that we're proud of
The biggest accomplishment from this project in our eyes, was the fact that, when virtual Todd encounters an object (such as a wall) in the virtual game world, real Todd stops.
Additionally, the fact that the margin of error between the real and virtual Todd's movements was lower than 3% significantly surpassed our original expectations of this project's accuracy and goes to show that our vision of having a real game with virtual obstacles .
## What we learned
We learned how complex integration is. It's easy to build self-sufficient parts, but their interactions introduce exponentially more problems. Communicating via Bluetooth between Arduino's and having Unity talk to a microcontroller via serial was a very educational experience.
## What's next for Todd: The Inter-dimensional Bot
Todd? When Todd escapes from this limiting world, he will enter a Hackathon and program his own Unity/Arduino-based mastery.
|
## Inspiration
We were very inspired by the chaotic innovations happening all around the world and wanted to create something that's just a little stupid, silly, and fun using components that are way too overspecced for the usecase.
## What it does
It is intended to use electromagnetic properties and an intense amount of power to fuel a magnetic accelerator that will accelerate objects towards some destination. This was then switched to a coil gun model, and then using a targeting system made up of a turret and a TFLite model we aim for stupid objects with the power of AI.
## How we built it
We attempted to create an electromagnet and fiddled around for a while with the Qualcomm HDK
## Challenges we ran into
We severely underestimated how short 24 hours is and a lot of the components intended to be added onto the creation do not function as intended.
## Accomplishments that we're proud of
We mixed a huge aspect of electrophysics with modern day cutting edge engineering to create something unique and fun!
## What we learned
Time is short, and this is definitely a project we want to continue into the future.
## What's next for Magnetic Accelerator
To develop it properly and aim properly in the future (summer 2023)
|
winning
|
Our Team's First Hackathon - Treehacks 2024
## Inspiration
Our inspiration for this project was from the memories we recalled when sharing food and recipes with our families. As students, we wanted to create the prototype for an app that could help bring this same joyful experience to others, whether it be sharing a simple recipe to potentially meeting new friends.
## What it does
Our app, although currently limited in functionality, is intended to quickly share recipes while also connecting people through messaging capabilities. Users would be able to create a profile and share their recipes with friends and even strangers. An explore tab and search tab were drafted to help users find new cuisine they otherwise may have never tasted.
## How we built it
We designed the layout of our app in Figma and then implemented the front end and back end in xCode using Swift. The backend was primarily done with Firebase to allow easier account creation and for cloud storage. Through this, we created various structs and fields to allow user input to be registered and seen on other accounts as well. Through the use of Figma, we were able to prototype various cells that would be embedded through a table view for easy scrolling. These pages were created from scratch and with the help of stock-free icons taken from TheNounProject.
## Challenges we ran into
While we were able to create a front end and a back end, we were unable to successfully merge the two leaving us with an incomplete project. For our first hackathon, we were easily ambitious but eager to attempt this. It was our first time doing both the front end and back end with no experience from either teammate. We ended up spending a lot of time putting together the UI, which led to complications with learning SwiftUI. A lot of time was spent learning how to navigate Swift and also looking into integrating our backend. Unfortunately, we were unable to make a functioning app that lined up with our goals.
Alongside our development issues, we ran into problems with GitHub, where pulling new commits would erase our progress on xCode to an earlier version. We were unable to fix this issue and found it easier to start a new repository, which should have been unnecessary but our lack of experience and time led us down this route. We ended up linking the old repository so all commits can still be seen, yet, it was still a challenge learning how to commit and work through various branches.
## Accomplishments that we're proud of
We are proud of completing our first hackathons. We are a team composed entirely of newcomers who didn’t know what we were going to do for our project. We met Friday evening with absolutely no idea in mind, yet we were able to come up with an ambitious idea that was amazing to work on. In addition to this, none of us had any prior experience with Swift, but we managed to get some elements working regardless. Firebase was learned and navigated through as well, even if both ends never ended up meeting. The fact that we were able to accomplish this much in such a short amount of time while learning this new material was truly astonishing. We are proud of the progress we made and our ability to follow through on a project regardless of how ambitious the project was. In the end, we're glad we committed to the journey and exposed ourselves to many elements of app development.
## What we learned
We learned that preparation is key. Before coming here, we didn’t have an idea for our project making the first few hours we had dedicated to brainstorming what we were going to do. Additionally, if we knew we were going to make an iOS app, we would have probably looked at some sort of Swift tutorials in preparation for our project. We underestimated the complexity of turning our UI into a functional app and it brought us many complications. We did not think much of it as it was our first hackathon, but now that we got exposure to what it entails, we are ready for the next one and eager to compete.
## What's Next for Culinary Connections
We hope to fully flesh out this app eventually! We believe this has a lot of potential and have identified a possible user base. We think food is a truly special part of culture and the universal human experience and as such, we feel it is important to spread this magic. A lot of people find comfort in cooking and being able to meet like-minded people through food is truly something special. In just 36 hours, we managed to create a UI, a potential backend, and a skeleton of a frontend. Given more time, with our current passion, we can continue to learn Swift and turn this into a fully-fledged app that could be deployed! We can already think of potential updates such as adding the cooking lessons with a chatbot that remembers your cooking recipes and techniques. It would specialize in identifying mistakes that could occur when cooking and would work to hone a beginner's skills! We hope to continue building upon this as we hope to bring others through food while bringing ourselves new skills as well.
|
## Inspiration
I was cooking at home one day and I kept noticing we had half a carrot, half an onion, and like a quarter of a pound of ground pork lying around all the time. More often than not it was from me cooking a fun dish that my mother have to somehow clean up over the week. So I wanted to create an app that would help me use those ingredients that I have neglected so that even if both my mother and I forget about it we would not contribute to food waste.
## What it does
Our app uses a database to store our user's fridge and keeps track of the food in their fridge. When the user wants a food recipe recommendation our app will help our user finish off their food waste. Using the power of chatGPT our app is super flexable and all the unknown food and food that you are too lazy to measure the weight of can be quickly put into a flexible and delicious recipe.
## How we built it
Using figma for design, react.JS bootstrap for frontend, flask backend, a mongoDB database, and openAI APIs we were able to create this stunning looking demo.
## Challenges we ran into
We messed up our database schema and poor design choices in our APIs resulting in a complete refactor. Our group also ran into problems with react being that we were relearning it. OpenAI API gave us inconsistency problems too. We pushed past these challenges together by dropping our immediate work and thinking of a solution together.
## Accomplishments that we're proud of
We finished our demo and it looks good. Our dev-ops practices were professional and efficient, our kan-ban board saved us a lot of time when planning and implementing tasks. We also wrote plenty of documentations where after our first bout of failure we planned out everything with our group.
## What we learned
We learned the importance of good API design and planning to save headaches when implementing out our API endpoints. We also learned much about the nuance and intricacies when using CORS technology. Another interesting thing we learned is how to write detailed prompts to retrieve formatted data from LLMs.
## What's next for Food ResQ : AI Recommended Recipes To Reduce Food Waste
We are planning to add a receipt scanning feature so that our users would not have to manually add in each ingredients into their fridge. We are also working on a feature where we would prioritize ingredients that are closer to expiry. Another feature we are looking at is notifications to remind our users that their ingredients should be used soon to drive up our engagement more. We are looking for payment processing vendors to allow our users to operate the most advanced LLMs at a slight premium for less than a coffee a month.
## Challenges, themes, prizes we are submitting for
Sponsor Challenges: None
Themes: Artificial Intelligence & Sustainability
Prizes: Best AI Hack, Best Sustainability Hack, Best Use of MongoDB Atlas, Most Creative Use of Github, Top 3 Prize
|
## Inspiration
As a startup founder, it is often difficult to raise money, but the amount of equity that is given up can be alarming for people who are unsure if they want the gasoline of traditional venture capital. With VentureBits, startup founders take a royalty deal and dictate exactly the amount of money they are comfortable raising. Also, everyone can take risks on startups as there are virtually no starting minimums to invest.
## What it does
VentureBits allows consumers to browse a plethora of early stage startups that are looking for funding. In exchange for giving them money anonymously, the investors will gain access to a royalty deal proportional to the amount of money they've put into a company's fund. Investors can support their favorite founders every month with a subscription, or they can stop giving money to less promising companies at any time. VentureBits also allows startup founders who feel competent to raise just enough money to sustain them and work full-time as well as their teams without losing a lot of long term value via an equity deal.
## How we built it
We drew out the schematics on the whiteboards after coming up with the idea at YHack. We thought about our own experiences as founders and used that to guide the UX design.
## Challenges we ran into
We ran into challenges with finance APIs as we were not familiar with them. A lot of finance APIs require approval to use in any official capacity outside of pure testing.
## Accomplishments that we're proud of
We're proud that we were able to create flows for our app and even get a lot of our app implemented in react native. We also began to work on structuring the data for all of the companies on the network in firebase.
## What we learned
We learned that finance backends and logic to manage small payments and crypto payments can take a lot of time and a lot of fees. It is a hot space to be in, but ultimately one that requires a lot of research and careful study.
## What's next for VentureBits
We plan to see where the project takes us if we run it by some people in the community who may be our target demographic.
|
losing
|
## Inspiration
Almost 2.2 million tonnes of edible food is discarded each year in Canada alone, resulting in over 17 billion dollars in waste. A significant portion of this is due to the simple fact that keeping track of expiry dates for the wide range of groceries we buy is, put simply, a huge task. While brainstorming ideas to automate the management of these expiry dates, discussion came to the increasingly outdated usage of barcodes for Universal Product Codes (UPCs); when the largest QR codes can store [thousands of characters](https://stackoverflow.com/questions/12764334/qr-code-max-char-length), why use so much space for a 12 digit number?
By building upon existing standards and the everyday technology in our pockets, we're proud to present **poBop**: our answer to food waste in homes.
## What it does
Users are able to scan the barcodes on their products, and enter the expiration date written on the packaging. This information is securely stored under their account, which keeps track of what the user has in their pantry. When products have expired, the app triggers a notification. As a proof of concept, we have also made several QR codes which show how the same UPC codes can be encoded alongside expiration dates in a similar amount of space, simplifying this scanning process.
In addition to this expiration date tracking, the app is also able to recommend recipes based on what is currently in the user's pantry. In the event that no recipes are possible with the provided list, it will instead recommend recipes in which has the least number of missing ingredients.
## How we built it
The UI was made with native android, with the exception of the scanning view which made use of the [code scanner library](https://github.com/yuriy-budiyev/code-scanner).
Storage and hashing/authentication were taken care of by [MongoDB](https://www.mongodb.com/) and [Bcrypt](https://github.com/pyca/bcrypt/) respectively.
Finally in regards to food, we used [Buycott](https://www.buycott.com/)'s API for UPC lookup and [Spoonacular](https://spoonacular.com/) to look for valid recipes.
## Challenges we ran into
As there is no official API or publicly accessible database for UPCs, we had to test and compare multiple APIs before determining Buycott had the best support for Canadian markets. This caused some issues, as a lot of processing was needed to connect product information between the two food APIs.
Additionally, our decision to completely segregate the Flask server and apps occasionally resulted in delays when prioritizing which endpoints should be written first, how they should be structured etc.
## Accomplishments that we're proud of
We're very proud that we were able to use technology to do something about an issue that bothers not only everyone on our team on a frequent basis (something something cooking hard) but also something that has large scale impacts on the macro scale. Some of our members were also very new to working with REST APIs, but coded well nonetheless.
## What we learned
Flask is a very easy to use Python library for creating endpoints and working with REST APIs. We learned to work with endpoints and web requests using Java/Android. We also learned how to use local databases on Android applications.
## What's next for poBop
We thought of a number of features that unfortunately didn't make the final cut. Things like tracking nutrition of the items you have stored and consumed. By tracking nutrition information, it could also act as a nutrient planner for the day. The application may have also included a shopping list feature, where you can quickly add items you are missing from a recipe or use it to help track nutrition for your upcoming weeks.
We were also hoping to allow the user to add more details to the items they are storing, such as notes for what they plan on using it for or the quantity of items.
Some smaller features that didn't quite make it included getting a notification when the expiry date is getting close, and data sharing for people sharing a household. We were also thinking about creating a web application as well, so that it would be more widely available.
Finally, we strongly encourage you, if you are able and willing, to consider donating to food waste reduction initiatives and hunger elimination charities.
One of the many ways to get started can be found here:
<https://rescuefood.ca/>
<https://secondharvest.ca/>
<https://www.cityharvest.org/>
# Love,
# FSq x ANMOL
|
## Inspiration
Staying healthy is a goal that everyone strives to achieve, but sometimes life just gets in the way. For the average person, slacking off for a few days is not a big deal and is something that is often done. However, for the more vulnerable population, staying on top their health is crucial and can often feel like a burden.
In 2017, a study looked into people's ability to adhere to their medication. This [study](https://www.sciencedirect.com/science/article/abs/pii/S016926071630579X) found that 80% of the time individuals delayed taking their medication, while 45% of the time they completely forgot!
We set out to create a personalized medication management app that would be both accessible and easy-to-use app. We wanted to specifically focus on the more vulnerable population (those with disabilities: Alzheimer's, severe arthritis, etc) of senior citizens to easily keep on top of their health.
Another common issue we found from anecdotal experience, is that senior citizens often dislike using technology and find it to be overwhelming. We wanted to bridge this gap and make the user experience for seniors as seamless as possible and take away the burden of unfamiliarity.
## What it does
PrescribePal is a smart health app with an emphasis on accessibility. Its main features are:
* Creating prescription order requests using OCR and voice interactions
* Giving friendly reminders to users to take their medication
* Easily connecting patients with professionals at a moment's notice
PrescribePal allows the user to opt-in to receiving timely notifications throughout the day or week. These notifications remind users to take their specified medication and amount.
Our app will also automate the process of refilling medication and supplements. Users can upload pictures of their medication to our app, and trust that PrescribePal will be able to automatically refill that medication upon request. Upon making a request, PrescribePal will also send out a text message to a caregiver or doctor for the appropriate approval.
Finally, users will be able to get in touch with their medical professionals at the click of a button. Our app will feature an online meeting platform where users can meet virtually with their doctors.
## How we built it
We built PrescribePal using the MERN stack as well as the following:
Socket.io and peer.js for video calling
Tesseract.js to extract text from images taken by patients
Cohere.ai to tokenize large chunks of text found on prescription labels
Puppeteer to find relevant product data
Alan.ai to create an easy to use voice assistant for patients
AWS to host and fetch our images
## Challenges we ran into
Trying to integrate our project with various different API's and libraries proved to be a difficult challenge. Working to integrate the entire end-to-end flow of our app starting from an image and transforming that into request for medication as well as connecting with Amazon. Our team barely had any prior experience working with these technologies in small applications, let alone creating a full scale project. Additionally, learning to work with so many requests and passing them between different libraries was extremely time consuming. After a significantly underestimated amount of effort, our team was finally able to integrate our Tesseract.js image conversion, Cohere AI text tokenization, Puppeteer.js web-scraper, and Twilio SMS notifications all into the desired degree of completeness.
## What we learned
Having spent so much time working with API's and formatting requests, our team can confidently say we are much more experienced. Understanding how to properly parse through hundreds of lines of JSON objects was a big lesson. Team members each got their own opportunity to refine and improve upon previously lacking skills. Further exposure to front-end development was a learning experience for one, and for the other it was greater understanding of push notifications from a server-client aspect.
## What's next for PrescribePal
To further improve the functionality and accessibility of PrescribePal:
* We'd like to improve the user interface to make it even more accessible for users
* Create a more personalized virtual video calling room for doctors with features like note taking, text chat and white boarding
* Reduce latency on notifications being received by patients for a more seamless experience
|
## Inspiration
Meal planning is hard. Saving money? harder. Coming up with creative recipes? The hardest.
Inspired by watching both the struggle of college students to both find cheap and easy meals to create out of limited amounts of options as well as one team member watching a roommate browse through coupon sites like Reebee and Flipp ***manually*** to find coupons and then go grocery shopping, we felt there needed to be a way that people could both ***save money***, ***waste less food***, and ***have more creative meals*** all in one smooth workflow.
## What it does
The app flows like the following:
* detects nearby grocery stores
* scrapes Flipp for the items that are on sale at said grocery store
* asks for dietary restrictions
* uses a live camera stream which recognizes a picture you take (of a food item currently in your fridge) and deploys a machine learning model to classify it
* generates recipes from existing and items on sale!
## How we built it
This app was built with **Firebase ML Kit**, **Android Studio** and **Google Cloud Platform Vision Edge API**. As well, we used HTTP requests to do tons of search querying for various filters. The UI/UX of the app was originally designed on **Figma**.
## Challenges we ran into
A lot of the backend of this application involves parsing strings, cutting strings, matching strings, concatenating strings - etc! One pretty specific but pretty significant challenge we ran into was properly matching on sale items with recipes from a database. For instance, grocery stores such as Walmart would also have shampoo on sale, but shampoo can't be used as a food ingredient! We need to know to ignore it. Further more, strawberries might be on sale but the recipe had required berry jam...would this still be a match? These issues were solved by parsing for popularity, checking against multiple references, and reading up on tons of documentation about how people have solved similar issues.
## Accomplishments that we're proud of
* **An original project.** It was truly a project inspired by a problem we faced daily and so we developed an application that attempted to solve it.
* Beautiful and seamless UI
* Working prototype
* Completely implemented backend of Google Cloud machine learning model in Android Studio
* Able to generate around 25 unique recipes for a given instance of a user walking through our app (this was tested by setting different geo-coordinate locations all over Toronto).
## What we learned
Java can become very, very object oriented.
## What's next for mealize
* Train the machine learning model on GCP with a greater variety of images.
* Implement even more inclusive tags for different dietary restrictions
* Be an app that can be shared with our friends to ACTUALLY use on a daily basis (because it is truly a pain point all of us share)
* (Very far future!) Potentially utilize ***reinforcement learning*** to eventually learn of a user's preferences in recipes?
|
partial
|
## Inspiration
Throughout my life, the news has been littered with stories of bridges collapsing and infrastructure decaying all across the continent. You have probably seen them too. The quality of our infrastructure is a major challenge which smart cities could address.
But did you know that repairing and replacing all this infrastructure (in particular anything with large amounts of steel or cement ) is a major contributor to greenhouse gases? Globally, cement is responsible for 7% of all emissions and construction overall accounts for 23%. Reducing our need to construct would go a long way towards reducing greenhouse gas emissions, curbing climate change, and lowering the particulates in the air.
## What it does
One of the major causes of bridges decaying before their time is unexpected environmental factors such as a far wider range of temperatures (a consequence of climate change). As temperatures rise, materials expand. As temperatures fall, materials contract. This is what leads to cracks in concrete and stone.
Where this technology comes in is that it tracks the temperature fluctuations at the specific point where the material is to allow for highly precise modeling of when it should be checked for smaller cracks. Smaller cracks are orders of magnitude cheaper to repair than larger cracks.
## How I built it
It was built with an ESP32, Google Compute Instance with Flask, Grafana, and a variety of other technologies which I am too tired to mention. I tried to include an Uno and camera as well, but that did not get far given the time alloted.
## Challenges I ran into
Poor Wifi prevented the downloading of much of anything in the way of libraries. A lot of work needed to be done on the cloud.
## What's next for The Bridge Owl
We shall see.
Source code: <https://drive.google.com/open?id=11JEiwNHQvUu0oYLax53ANwNo4ygarcdb>
|
## Inspiration
As college students learning to be socially responsible global citizens, we realized that it's important for all community members to feel a sense of ownership, responsibility, and equal access toward shared public spaces. Often, our interactions with public spaces inspire us to take action to help others in the community by initiating improvements and bringing up issues that need fixing. However, these issues don't always get addressed efficiently, in a way that empowers citizens to continue feeling that sense of ownership, or sometimes even at all! So, we devised a way to help FixIt for them!
## What it does
Our app provides a way for users to report Issues in their communities with the click of a button. They can also vote on existing Issues that they want Fixed! This crowdsourcing platform leverages the power of collective individuals to raise awareness and improve public spaces by demonstrating a collective effort for change to the individuals responsible for enacting it. For example, city officials who hear in passing that a broken faucet in a public park restroom needs fixing might not perceive a significant sense of urgency to initiate repairs, but they would get a different picture when 50+ individuals want them to FixIt now!
## How we built it
We started out by brainstorming use cases for our app and and discussing the populations we want to target with our app. Next, we discussed the main features of the app that we needed to ensure full functionality to serve these populations. We collectively decided to use Android Studio to build an Android app and use the Google Maps API to have an interactive map display.
## Challenges we ran into
Our team had little to no exposure to Android SDK before so we experienced a steep learning curve while developing a functional prototype in 36 hours. The Google Maps API took a lot of patience for us to get working and figuring out certain UI elements. We are very happy with our end result and all the skills we learned in 36 hours!
## Accomplishments that we're proud of
We are most proud of what we learned, how we grew as designers and programmers, and what we built with limited experience! As we were designing this app, we not only learned more about app design and technical expertise with the Google Maps API, but we also explored our roles as engineers that are also citizens. Empathizing with our user group showed us a clear way to lay out the key features of the app that we wanted to build and helped us create an efficient design and clear display.
## What we learned
As we mentioned above, this project helped us learn more about the design process, Android Studio, the Google Maps API, and also what it means to be a global citizen who wants to actively participate in the community! The technical skills we gained put us in an excellent position to continue growing!
## What's next for FixIt
An Issue’s Perspective
\* Progress bar, fancier rating system
\* Crowdfunding
A Finder’s Perspective
\* Filter Issues, badges/incentive system
A Fixer’s Perspective
\* Filter Issues off scores, Trending Issues
|
# Harvest Hero: Cultivating Innovation
## Inspiration
Our journey began with a shared passion for addressing pressing challenges in agriculture. Witnessing the struggles faced by farmers globally due to unpredictable weather, soil degradation, and crop diseases, we were inspired to create a solution that could empower farmers and revolutionize traditional farming practices.
## Staggering Statistics
In the initial research phase, we delved into staggering statistics. According to the Food and Agriculture Organization (FAO), around 20-40% of global crop yields are lost annually due to pests and diseases. Additionally, improper crop conditions contribute significantly to reduced agricultural productivity.
Learning about these challenges fueled our determination to develop a comprehensive solution that integrates soil analysis, environmental monitoring, and disease detection using cutting-edge technologies.
## Building HarvestHero
### 1. **Soil and Environmental Analysis**
We incorporated state-of-the-art sensors and IoT devices to measure soil moisture and environmental conditions such as light, temperature, and humidity accurately. Online agricultural databases provided insights into optimal conditions for various crops.
### 2. **Deep Learning for Disease Classification**
To tackle the complex issue of plant diseases, we leveraged deep learning algorithms. TensorFlow and PyTorch became our allies as we trained our model on extensive datasets of diseased and healthy crops, sourced from global agricultural research institutions.
### 3. **User-Friendly Interface**
Understanding that farmers may not be tech-savvy, we focused on creating an intuitive user interface. Feedback from potential users during the development phase was invaluable in refining the design for practicality and accessibility.
### Challenges Faced
1. **Data Quality and Diversity**: Acquiring diverse and high-quality datasets for training the deep learning model posed a significant challenge. Cleaning and preprocessing the data demanded meticulous attention.
2. **Real-Time Connectivity**: Ensuring real-time connectivity in remote agricultural areas was challenging. We had to optimize our system to function efficiently even in low-bandwidth environments.
3. **Algorithm Fine-Tuning**: Achieving a balance between sensitivity and specificity in disease detection was an ongoing process. Iterative testing and refining were essential to enhance the model's accuracy.
## Impact
HarvestHero aims to mitigate crop losses, boost yields, and contribute to sustainable agriculture. By addressing key pain points in farming, we aspire to make a meaningful impact on global food security. Our journey has not only been about developing a product but also about learning, adapting, and collaborating to create positive change in the agricultural landscape.
As we look to the future, we are excited about the potential of HarvestHero to empower farmers, enhance agricultural practices, and play a role in creating a more resilient and sustainable food system for generations to come.
|
winning
|
## Inspiration
As students, we constantly need online education, not only for our career and professional development but also for curiosity and exploration. Nevertheless, online learning has many drawbacks to live education, primarily not being able to ask the teacher questions or have any interaction at all. Many times they are forced to learn online as they do not have the resources to do so any other way and struggle to find useful information while reading obscure papers. More specifically, we as MIT students, use OCW constantly to fill in gaps in our education and gain a more comprehensive understanding of the topics we are interested in, so we felt this was a place where many members of our community could benefit from a more interactive experience. We are also aware that thousands of students across the globe use MIT OCW to advance their education, so the implementation of a feature that would make this platform more accessible would greatly advance MITs goals of increasing education equity.
## What it does
OpenTutor is a Google-extension chatbot tailored to integrate seamlessly with MITs Open Courseware website (its Open Source Learning Platform). OpenTutor is meant to be a resource for students taking the OCW courses online as they encounter problems and have questions about the material. This service parses the relevant information of the course the student is taking and using NLP, is able to generate an answer tailored to the context of the course.
## How we built it
Using the Lantern platform, we created a database that stores lecture information in different categories to be parsed later. Then, we used IBM Watson Assistant to interphase between the intended content, the user, and the database to send a query through Modal and G-Cloud to our Lantern database. The database then takes the questions asked by the user, finds the relevant information, and feeds them to a GPT model. This model then uses only the information provided to reconstruct an answer that is uniquely tailored to the course and returns it to the student through the Watson Assistant.
## Challenges we ran into
We had a lot of problems with system integration because all the platforms we used were so vastly different. We also saw difficulties in web embedding because of specific Google security measures that prevent HTML injections into dynamic websites.
## Accomplishments that we're proud of
We are really proud of the back-end programming of this project because it is able to parse 30+ pages of dense academic material and use it to concisely and clearly answer student questions about the material itself as if the model were teaching the material itself.
## What we learned
We gained a lot of knowledge in AI platforms including databases, UI interfaces, and web protocols. We also got to work with really cool products such as Lantern and Modal.
## What's next for OpenTutor
The next steps for OpenTutor include data collection automation so that it can be used on all OCW courses. We also want to be able to use it on any online learning platform. Some new features we plan on adding include practice test generation and concept checks that can be requested by topic. With more training, the service would be able to provide a more personalized learning experience. We also would be willing to create a higher quality premium version for companies and universities.
|
## Inspiration
The education system is broken and teachers are under-appreciated. So, we wanted to create something to help teachers. We spoke to a teacher who told us that a lot of her time is spent editing students’ work and reviewing tests. So, we started thinking about how we could help teachers save time, while building a straight forwards user friendly solution.
## What it does
Rework enables teachers to produce easier and harder versions of the same test based on the test scores of past class sections. Teachers input a photo of the test with questions & answer key, the average student score for each question, and the desired class average for each question. Rework then looks at the test questions where the class average was far below or above the desired average, and makes the harder or easier based on how much above or below the average it was.
## How we built it
We built the backend of our product using Python and Flask paired with a basic frontend built with HTML, CSS, and JavaScript. Our program utilizes an OpenAI API to access GPT-3 for the main functionality in generating normalized test questions. We also made use of flask and a virtual environment for our API along with leveraging some OCR software to read our PDF inputs. We built our project centered around the normalization of test questions and then added functionality from there namely interacting with the service through pdfs.
## Challenges we ran into
Our team faced a multitude of setbacks and problems which we had to either solve or circumnavigate over the course of the hackathon. Primarily our product makes use of an API connected to GPT-3, working with this API and learning how to correctly prompt the chatbot to obtain desired responses was a challenge. Additionally, correctly fragmenting our project into manageable goals proved to be important to time management.
## Accomplishments that we're proud of
We created an MVP version of our product where a .json file would be needed to submit the test questions and answers. We wanted to finish this quickly so that then we could use the rest of our time implementing an OCR so that teachers could simply submit a picture of the test and answers and the questions would be read and parsed into a readable format for Rework to be able to understand, making the life of the teacher significantly easier. We are proud that we were able to add this extra OCR component without having any previous experience with this.
## What we learned
Our group had a wide range of technical abilities and we had to learn quickly how to use all of our strengths to benefit our group. We were a fairly new team, the majority of whom were at their first major hackathon, so there were lots of growing pains. Having each team member understand the technologies used was a important task for Friday, as well as organizing ourselves into roles where we could each excel with our diversity of experiences and comfortable languages. Almost all of us had little expertise with front-end development, so that is the technical area where we improved most—along with creating a full project from scratch without a framework.
## What's next for Rework
In the future with more time we would like to expand on the feature offering of Rework. Namely, the inclusion of automatic grading software after we convert the image would allow for a more wholistic experience for the teachers, limiting their number of inputs while simultaneously increasing the functionality. We would also like to implement a more powerful OCR such as mathpix, ideally one that is capable of latex integration and improved handwriting recognition, as this would give more options and allow for a higher level of problems to be accurately solved. Ultimately, the ideal goal for the program would replace Chat-GPT with lengchain and GPT-3, as this allows for more specialized queries specifically for math enabling more accurate responses.
|
## Inspiration
Technology in schools today is given to those classrooms that can afford it. Our goal was to create a tablet that leveraged modern touch screen technology while keeping the cost below $20 so that it could be much cheaper to integrate with classrooms than other forms of tech like full laptops.
## What it does
EDT is a credit-card-sized tablet device with a couple of tailor-made apps to empower teachers and students in classrooms. Users can currently run four apps: a graphing calculator, a note sharing app, a flash cards app, and a pop-quiz clicker app.
-The graphing calculator allows the user to do basic arithmetic operations, and graph linear equations.
-The note sharing app allows students to take down colorful notes and then share them with their teacher (or vice-versa).
-The flash cards app allows students to make virtual flash cards and then practice with them as a studying technique.
-The clicker app allows teachers to run in-class pop quizzes where students use their tablets to submit answers.
EDT has two different device types: a "teacher" device that lets teachers do things such as set answers for pop-quizzes, and a "student" device that lets students share things only with their teachers and take quizzes in real-time.
## How we built it
We built EDT using a NodeMCU 1.0 ESP12E WiFi Chip and an ILI9341 Touch Screen. Most programming was done in the Arduino IDE using C++, while a small portion of the code (our backend) was written using Node.js.
## Challenges we ran into
We initially planned on using a Mesh-Networking scheme to let the devices communicate with each other freely without a WiFi network, but found it nearly impossible to get a reliable connection going between two chips. To get around this we ended up switching to using a centralized server that hosts the apps data.
We also ran into a lot of problems with Arduino strings, since their default string class isn't very good, and we had no OS-layer to prevent things like forgetting null-terminators or segfaults.
## Accomplishments that we're proud of
EDT devices can share entire notes and screens with each other, as well as hold a fake pop-quizzes with each other. They can also graph linear equations just like classic graphing calculators can.
## What we learned
1. Get a better String class than the default Arduino one.
2. Don't be afraid of simpler solutions. We wanted to do Mesh Networking but were running into major problems about two-thirds of the way through the hack. By switching to a simple client-server architecture we achieved a massive ease of use that let us implement more features, and a lot more stability.
## What's next for EDT - A Lightweight Tablet for Education
More supported educational apps such as: a visual-programming tool that supports simple block-programming, a text editor, a messaging system, and a more-indepth UI for everything.
|
losing
|
## Inspiration
You probably know someone who is very good at managing their credit cards. Not only do they never have any debts, but they also get so much reward that they can even have a vacation or two without spending anything on transportations or hotels. However, most people, like our groups, are not as good as them at managing our credit cards.
## What it does
Therefore, we aim to develop a mobile app that helps anybody manage their credit cards easily without any meticulous research and time spent on budgeting their next vacation. This app manages all of your credit cards, automatically pay with the most rewarding credit cards, track your rewards, and suggest you on the credit cards that you should register.
## Challenges we ran into
The node environment and dependencies of react-native introduce too many bugs.
## Accomplishments that we're proud of
We are able to accomplish the goal that we aimed for.
## What we learned
We learned a lot more about React Native, node modules, and most importantly, credit cards.
## What's next for CreditMaster
We will try to publish the app on Google Play or Play Store.
|
## Inspiration
Due to the shortages of doctors and clinics in rural areas, early diagnosis of skin diseases that may seem harmless on the outside but can become life-threatening is a real problem. MediDerma uses Computer Vision to predict skin diseases and provide the underlying symptoms associated which are prominent in rural India. The lockdown has not helped either, with the increasing shortage of doctors due to many of them going on COVID duties. Keeping the goal of helping out our community in any way we can, Bhuvnesh Nagpal and Mehul Srivastava decided to create this AI-enabled project to help the underprivileged with one slogan in mind – “Prevention is better than Cure”
## What it does
MediDerma uses Computer Vision to predict skin diseases and provide the underlying symptoms associated which are prominent in rural India.
## How we built it
The image classification model is integrated with a web app. There is an option to either click a picture or upload a saved one. The model based on resnet34 architecture then classifies the image of the skin disease into 1 of the 29 classes and shows the predicted disease and its common symptoms. We trained it on a custom dataset using the fastai library in python.
## Challenges we ran into
Collecting the dataset was a big problem as medical datasets are not freely available. We collected the data from various sources including google images, various sites, etc.
## Accomplishments that we're proud of
We were able to make an innovative solution to solve a real-world problem. This solution might help a lot of people in the rural parts of India. We are really proud of what we have built. The app aims to provide a simple and accurate diagnosis of skin disease in rural parts of India where medical facilities are scarce.
## What we learned
We brainstormed a lot of ideas during the ideation part of this project and realized that there was a dire need for this app. While developing the project, we learned about the Streamlit framework which allows us to easily deploy ML projects. We also learned about the various sources from where we can collect image data.
## What's next for MediDerma
We plan to try and improve this model to a level where it can be certified and deployed into the real-world setting. We can do this by collecting and feeding more data to the model. We also plan to increase the number of diseases that this app can detect.
|
## Inspiration
In a world where finance is extremely important, everyone needs access to **banking services**. Citizens within **third world countries** are no exception, but they lack the banking technology infrastructure that many of us in first world countries take for granted. Mobile Applications and Web Portals don't work 100% for these people, so we decided to make software that requires nothing more than a **cellular connection to send SMS messages** in order to operate. This resulted in our hack, **UBank**.
## What it does
**UBank** allows users to operate their bank accounts entirely through **text messaging**. Users can deposit money, transfer funds between accounts, transfer accounts to other users, and even purchases shares of stock via SMS. In addition to this text messaging capability, UBank also provides a web portal so that when our users gain access to a steady internet connection or PC, they can view their financial information on a more comprehensive level.
## How I built it
We set up a backend HTTP server in **Node.js** to receive and fulfill requests. **Twilio** with ngrok was used to send and receive the text messages through a webhook on the backend Node.js server and applicant data was stored in firebase. The frontend was primarily built with **HTML, CSS, and Javascript** and HTTP requests were sent to the Node.js backend to receive applicant information and display it on the browser. We utilized Mozilla's speech to text library to incorporate speech commands and chart.js to display client data with intuitive graphs.
## Challenges I ran into
* Some team members were new to Node.js, and therefore working with some of the server coding was a little complicated. However, we were able to leverage the experience of other group members which allowed all of us to learn and figure out everything in the end.
* Using Twilio was a challenge because no team members had previous experience with the technology. We had difficulties making it communicate with our backend Node.js server, but after a few hours of hard work we eventually figured it out.
## Accomplishments that I'm proud of
We are proud of making a **functioning**, **dynamic**, finished product. It feels great to design software that is adaptable and begging for the next steps of development. We're also super proud that we made an attempt at tackling a problem that is having severe negative effects on people all around the world, and we hope that someday our product can make it to those people.
## What I learned
This was our first using **Twillio** so we learned a lot about utilizing that software. Front-end team members also got to learn and practice their **HTML/CSS/JS** skills which were a great experience.
## What's next for UBank
* The next step for UBank probably would be implementing an authentication/anti-fraud system. Being a banking service, it's imperative that our customers' transactions are secure at all times, and we would be unable to launch without such a feature.
* We hope to continue the development of UBank and gain some beta users so that we can test our product and incorporate customer feedback in order to improve our software before making an attempt at launching the service.
|
losing
|
## Inspiration
Legal research is tedious and time-consuming, with lawyers spending hours finding relevant cases. For instance, if a client was punched, lawyers must manually try different keywords like “kick” or “slap” to find matches. Analyzing cases is also challenging. Even with case summaries, lawyers must still verify their accuracy by cross-referencing with the original text, sometimes hundreds of pages long. This is inefficient, given the sheer length of cases and the need to constantly toggle between tabs to find the relevant paragraphs.
## What it does
Our tool transforms legal research by offering AI-powered legal case search. Lawyers can input meeting notes or queries in natural language, and our AI scans open-source databases to identify the most relevant cases, ranked by similarity score. Once the best matches are identified, users can quickly review our AI-generated case summaries and full case texts side by side in a split-screen view, minimizing context-switching and enhancing research efficiency.
## How we built it
Our tool was developed to create a seamless user experience for lawyers. The backend process began with transforming legal text into embeddings using the all-MiniLM-L6-v2 model for efficient memory usage. We sourced data from the CourtListener, which is backed by the Free Law Project non-profit, and stored the embeddings in LanceDB, allowing us to retrieve relevant cases quickly.
To facilitate the search process, we integrated the CourtListener API, which enables keyword searches of court cases. A FastAPI backend server was established to connect LanceDB and CourtListener for effective data retrieval.
## Challenges we ran into
The primary challenge was bridging the gap between legal expertise and software development. Analyzing legal texts proved difficult due to their complex and nuanced language. Legal terminology can vary significantly across cases, necessitating a deep understanding of context for accurate interpretation. This complexity made it challenging to develop an AI system that could generate meaningful similarity scores while grasping the subtleties inherent in legal documents.
## Accomplishments that we're proud of
Even though we started out as strangers and were busy building our product, we took the time to get to know each other personally and have fun during the hackathon too! This was the first hackathon for two of our teammates, but they quickly adapted and contributed meaningfully. Most importantly, we supported each other throughout the process, making the experience both rewarding and memorable.
## What we learned
Throughout the process, we emphasized constant communication within the team. The law student offered insights into complex research workflows, while the developers shared their expertise on technical feasibility and implementation. Together, we balanced usability with scope within the limited time available, and all team members worked hard to train the AI to generate meaningful similarity scores, which was particularly demanding.
One teammate delved deep into embeddings, learning about their applications in similarity search, chunking, prompt engineering, and adjacent concepts like named entity recognition, hybrid search, and retrieval-augmented generation (RAG) — all within the span of the hackathon.
Additionally, two of our members had no front-end development experience and minimal familiarity with design tools like Figma. By leveraging resources like assistant-ui, we quickly learned the necessary skills.
## What's next for citewise
We aim to provide support for the complete workflow of legal research. This includes enabling lawyers to download relevant cases easily and facilitating collaboration by allowing the sharing of client files with colleagues.
Additionally, we plan to integrate with paid legal databases, making our product platform agnostic. This will enable lawyers to search across multiple databases simultaneously, streamlining their research process and eliminating the need to access each database individually.
|
## Inspiration
When reading news articles, we're aware that the writer has bias that affects the way they build their narrative. Throughout the article, we're constantly left wondering—"What did that article not tell me? What convenient facts were left out?"
## What it does
*News Report* collects news articles by topic from over 70 news sources and uses natural language processing (NLP) to determine the common truth among them. The user is first presented with an AI-generated summary of approximately 15 articles on the same event or subject. The references and original articles are at your fingertips as well!
## How we built it
First, we find the top 10 trending topics in the news. Then our spider crawls over 70 news sites to get their reporting on each topic specifically. Once we have our articles collected, our AI algorithms compare what is said in each article using a KL Sum, aggregating what is reported from all outlets to form a summary of these resources. The summary is about 5 sentences long—digested by the user with ease, with quick access to the resources that were used to create it!
## Challenges we ran into
We were really nervous about taking on a NLP problem and the complexity of creating an app that made complex articles simple to understand. We had to work with technologies that we haven't worked with before, and ran into some challenges with technologies we were already familiar with. Trying to define what makes a perspective "reasonable" versus "biased" versus "false/fake news" proved to be an extremely difficult task. We also had to learn to better adapt our mobile interface for an application that’s content varied so drastically in size and available content.
## Accomplishments that we're proud of
We’re so proud we were able to stretch ourselves by building a fully functional MVP with both a backend and iOS mobile client. On top of that we were able to submit our app to the App Store, get several well-deserved hours of sleep, and ultimately building a project with a large impact.
## What we learned
We learned a lot! On the backend, one of us got to look into NLP for the first time and learned about several summarization algorithms. While building the front end, we focused on iteration and got to learn more about how UIScrollView’s work and interact with other UI components. We also got to worked with several new libraries and APIs that we hadn't even heard of before. It was definitely an amazing learning experience!
## What's next for News Report
We’d love to start working on sentiment analysis on the headlines of articles to predict how distributed the perspectives are. After that we also want to be able to analyze and remove fake news sources from our spider's crawl.
|
## Inspiration
With elections right around the corner, many young adults are voting for the first time, and may not be equipped with knowledge of the law and current domestic events. We believe that this is a major problem with our nation, and we seek to use open source government data to provide day to day citizens with access to knowledge on legislative activities and current affairs in our nation.
## What it does
OpenLegislation aims to bridge the knowledge gap by providing easy access to legislative information. By leveraging open-source government data, we empower citizens to make informed decisions about the issues that matter most to them. This approach not only enhances civic engagement but also promotes a more educated and participatory democracy Our platform allows users to input an issue they are interested in, and then uses cosine analysis to fetch the most relevant bills currently in Congress related to that issue.
## How we built it
We built this application with a tech stack of MongoDB, ExpressJS, ReactJS, and OpenAI. DataBricks' Llama Index was used to get embeddings for the title of our bill. We used a Vector Search using Atlas's Vector Search and Mongoose for accurate semantic results when searching for a bill. Additionally, Cloudflare's AI Gateway was used to track calls to GPT-4o for insightful analysis of each bill.
## Challenges we ran into
At first, we tried to use OpenAI's embeddings for each bill's title. However, this brought a lot of issues for our scraper as while the embeddings were really good, they took up a lot of storage and were heavily rate limited. This was not feasible at all. To solve this challenge, we pivoted to a smaller model that uses a pre trained transformer to provide embeddings processed locally instead of through an API call. Although the semantic search was slightly worse, we were able to get satisfactory results for our MVP and be able to expand on different, higher-quality models in the future.
## Accomplishments that we're proud of
We are proud that we have used open source software technology and data to empower the people with transparency and knowledge of what is going on in our government and our nation. We have used the most advanced technology that Cloudflare and Databricks provides and leveraged it for the good of the people. On top of that, we are proud of our technical acheivement of our semantic search, giving the people the bills they want to see.
## What we learned
During the development of this project, we learned more of how vector embeddings work and are used to provide the best search results. We learned more of Cloudflare and OpenAI's tools in this development and will definitely be using them on future projects. Most importantly, we learned the value of open source data and technology and the impact it can have on our society.
## What's next for OpenLegislation
For future progress of OpenLegislation, we plan to expand to local states! Constituents can know directly what is going on in their state on top of their country with this addition and actually be able to receive updates on what officials they elected are actually proposing. In addition, we would expand our technology by using more advanced embeddings for more tailored searches. Finally, we would implore more data anlysis methods with help from Cloudflare and DataBricks' Open-Source technologies to help make this important data more available and transparant for the good of society.
|
partial
|
# Inspiration
As a team we decided to develop a service that we thought would not only be extremely useful to us, but to everyone around the world that struggles with storing physical receipts. We were inspired to build an eco friendly as well as innovative application that targets the pain points behind filing receipts, losing receipts, missing return policy deadlines, not being able to find the proper receipt with a particular item as well as tracking potentially bad spending habits.
# What it does
To solve these problems, we are proud to introduce, Receipto, a universal receipt tracker who's mission is to empower users with their personal finances, to track spending habits more easily as well as to replace physical receipts to reduce global paper usage.
With Receipto you can upload or take a picture of a receipt, and it will automatically recognize all of the information found on the receipt. Once validated, it saves the picture and summarizes the data in a useful manner. In addition to storing receipts in an organized manner, you can get valuable information on your spending habits, you would also be able to search through receipt expenses based on certain categories, items and time frames. The most interesting feature is that once a receipt is loaded and validated, it will display a picture of all the items purchased thanks to the use of item codes and an image recognition API. Receipto will also notify you when a receipt may be approaching its potential return policy deadline which is based on a user input during receipt uploads.
# How we built it
We have chosen to build Receipto as a responsive web application, allowing us to develop a better user experience. We first drew up story boards by hand to visually predict and explore the user experience, then we developed the app using React, ViteJS, ChakraUI and Recharts.
For the backend, we decided to use NodeJS deployed on Google Cloud Compute Engine. In order to read and retrieve information from the receipt, we used the Google Cloud Vision API along with our own parsing algorithm.
Overall, we mostly focused on developing the main ideas, which consist of scanning and storing receipts as well as viewing the images of the items on the receipts.
# Challenges we ran into
Our main challenge was implementing the image recognition API, as it involved a lot of trial and error. Almost all receipts are different depending on the store and province. For example, in Quebec, there are two different taxes displayed on the receipt, and that affected how our app was able to recognize the data. To fix that, we made sure that if two types of taxes are displayed, our app would recognize that it comes from Quebec, and it would scan it as such. Additionally, almost all stores have different receipts, so we have adapted the app to recognize most major stores, but we also allow a user to manually add the data in case a receipt is very different. Either way, a user will know when it's necessary to change or to add data with visual alerts when uploading receipts.
Another challenge was displaying the images of the items on the receipts. Not all receipts had item codes, stores that did have these codes ended up having different APIs. We overcame this challenge by finding an API called stocktrack.ca that combines the most popular store APIs in one place.
# Accomplishments that we're proud of
We are all very proud to have turned this idea into a working prototype as we agreed to pursue this idea knowing the difficulty behind it. We have many great ideas to implement in the future and have agreed to continue this project beyond McHacks in hopes of one day completing it. We our grateful to have had the opportunity to work together with such talented, patient, and organized team members.
# What we learned
With all the different skills each team member brought to the table, we were able to pick up new skills from each other. Some of us got introduced to new coding languages, others learned new UI design skills as well as simple organization and planning skills. Overall, McHacks has definitely showed us the value of team work, we all kept each other motivated and helped each other overcome each obstacle as a team.
# What's next for Receipto?
Now that we have a working prototype ready, we plan to further test our application with a selected sample of users to improve the user experience. Our plan is to polish up the main functionality of the application, and to expand the idea by adding exciting new features that we just didn't have time to add. Although we may love the idea, we need to make sure to conduct more market research to see if it could be a viable service that could change the way people perceive receipts and potentially considering adapting Receipto.
|
## Inspiration
It’s insane how the majority of the U.S. still looks like **endless freeways and suburban sprawl.** The majority of Americans can’t get a cup of coffee or go to the grocery store without a car.
What would America look like with cleaner air, walkable cities, green spaces, and effective routing from place to place that builds on infrastructure for active transport and micro mobility? This is the question we answer, and show, to urban planners, at an extremely granular street level.
Compared to most of Europe and Asia (where there are public transportation options, human-scale streets, and dense neighborhoods) the United States is light-years away ... but urban planners don’t have the tools right now to easily assess a specific area’s walkability.
**Here's why this is an urgent problem:** Current tools for urban planners don’t provide *location-specific information* —they only provide arbitrary, high-level data overviews over a 50-mile or so radius about population density. Even though consumers see new tools, like Google Maps’ area busyness bars, it is only bits and pieces of all the data an urban planner needs, like data on bike paths, bus stops, and the relationships between traffic and pedestrians.
As a result, there’s very few actionable improvements that urban planners can make. Moreover, because cities are physical spaces, planners cannot easily visualize what an improvement (e.g. adding a bike/bus lane, parks, open spaces) would look like in the existing context of that specific road. Many urban planners don’t have the resources or capability to fully immerse themselves in a new city, live like a resident, and understand the problems that residents face on a daily basis that prevent them from accessing public transport, active commutes, or even safe outdoor spaces.
There’s also been a significant rise in micro-mobility—usage of e-bikes (e.g. CityBike rental services) and scooters (especially on college campuses) are growing. Research studies have shown that access to public transport, safe walking areas, and micro mobility all contribute to greater access of opportunity and successful mixed income neighborhoods, which can raise entire generations out of poverty. To continue this movement and translate this into economic mobility, we have to ensure urban developers are **making space for car-alternatives** in their city planning. This means bike lanes, bus stops, plaza’s, well-lit sidewalks, and green space in the city.
These reasons are why our team created CityGO—a tool that helps urban planners understand their region’s walkability scores down to the **granular street intersection level** and **instantly visualize what a street would look like if it was actually walkable** using Open AI's CLIP and DALL-E image generation tools (e.g. “What would the street in front of Painted Ladies look like if there were 2 bike lanes installed?)”
We are extremely intentional about the unseen effects of walkability on social structures, the environments, and public health and we are ecstatic to see the results: 1.Car-alternatives provide economic mobility as they give Americans alternatives to purchasing and maintaining cars that are cumbersome, unreliable, and extremely costly to maintain in dense urban areas. Having lower upfront costs also enables handicapped people, people that can’t drive, and extremely young/old people to have the same access to opportunity and continue living high quality lives. This disproportionately benefits people in poverty, as children with access to public transport or farther walking routes also gain access to better education, food sources, and can meet friends/share the resources of other neighborhoods which can have the **huge** impact of pulling communities out of poverty.
Placing bicycle lanes and barriers that protect cyclists from side traffic will encourage people to utilize micro mobility and active transport options. This is not possible if urban planners don’t know where existing transport is or even recognize the outsized impact of increased bike lanes.
Finally, it’s no surprise that transportation as a sector alone leads to 27% of carbon emissions (US EPA) and is a massive safety issue that all citizens face everyday. Our country’s dependence on cars has been leading to deeper issues that affect basic safety, climate change, and economic mobility. The faster that we take steps to mitigate this dependence, the more sustainable our lifestyles and Earth can be.
## What it does
TLDR:
1) Map that pulls together data on car traffic and congestion, pedestrian foot traffic, and bike parking opportunities. Heat maps that represent the density of foot traffic and location-specific interactive markers.
2) Google Map Street View API enables urban planners to see and move through live imagery of their site.
3) OpenAI CLIP and DALL-E are used to incorporate an uploaded image (taken from StreetView) and descriptor text embeddings to accurately provide a **hyper location-specific augmented image**.
The exact street venues that are unwalkable in a city are extremely difficult to pinpoint. There’s an insane amount of data that you have to consolidate to get a cohesive image of a city’s walkability state at every point—from car traffic congestion, pedestrian foot traffic, bike parking, and more.
Because cohesive data collection is extremely important to produce a well-nuanced understanding of a place’s walkability, our team incorporated a mix of geoJSON data formats and vector tiles (specific to MapBox API). There was a significant amount of unexpected “data wrangling” that came from this project since multiple formats from various sources had to be integrated with existing mapping software—however, it was a great exposure to real issues data analysts and urban planners have when trying to work with data.
There are three primary layers to our mapping software: traffic congestion, pedestrian traffic, and bicycle parking.
In order to get the exact traffic congestion per street, avenue, and boulevard in San Francisco, we utilized a data layer in MapBox API. We specified all possible locations within SF and made requests for geoJSON data that is represented through each Marker. Green stands for low congestion, yellow stands for average congestion, and red stands for high congestion. This data layer was classified as a vector tile in MapBox API.
Consolidating pedestrian foot traffic data was an interesting task to handle since this data is heavily locked in enterprise software tools. There are existing open source data sets that are posted by regional governments, but none of them are specific enough that they can produce 20+ or so heat maps of high foot traffic areas in a 15 mile radius. Thus, we utilized Best Time API to index for a diverse range of locations (e.g. restaurants, bars, activities, tourist spots, etc.) so our heat maps would not be biased towards a certain style of venue to capture information relevant to all audiences. We then cross-validated that data with Walk Score (the most trusted site for gaining walkability scores on specific addresses). We then ranked these areas and rendered heat maps on MapBox to showcase density.
San Francisco’s government open sources extremely useful data on all of the locations for bike parking installed in the past few years. We ensured that the data has been well maintained and preserved its quality over the past few years so we don’t over/underrepresent certain areas more than others. This was enforced by recent updates in the past 2 months that deemed the data accurate, so we added the geographic data as a new layer on our app. Each bike parking spot installed by the SF government is represented by a little bike icon on the map!
**The most valuable feature** is the user can navigate to any location and prompt CityGo to produce a hyper realistic augmented image resembling that location with added infrastructure improvements to make the area more walkable. Seeing the StreetView of that location, which you can move around and see real time information, and being able to envision the end product is the final bridge to an urban developer’s planning process, ensuring that walkability is within our near future.
## How we built it
We utilized the React framework to organize our project’s state variables, components, and state transfer. We also used it to build custom components, like the one that conditionally renders a live panoramic street view of the given location or render information retrieved from various data entry points.
To create the map on the left, our team used MapBox’s API to style the map and integrate the heat map visualizations with existing data sources. In order to create the markers that corresponded to specific geometric coordinates, we utilized Mapbox GL JS (their specific Javascript library) and third-party React libraries.
To create the Google Maps Panoramic Street View, we integrated our backend geometric coordinates to Google Maps’ API so there could be an individual rendering of each location. We supplemented this with third party React libraries for better error handling, feasibility, and visual appeal. The panoramic street view was extremely important for us to include this because urban planners need context on spatial configurations to develop designs that integrate well into the existing communities.
We created a custom function and used the required HTTP route (in PHP) to grab data from the Walk Score API with our JSON server so it could provide specific Walkability Scores for every marker in our map.
Text Generation from OpenAI’s text completion API was used to produce location-specific suggestions on walkability. Whatever marker a user clicked, the address was plugged in as a variable to a prompt that lists out 5 suggestions that are specific to that place within a 500-feet radius. This process opened us to the difficulties and rewarding aspects of prompt engineering, enabling us to get more actionable and location-specific than the generic alternative.
Additionally, we give the user the option to generate a potential view of the area with optimal walkability conditions using a variety of OpenAI models. We have created our own API using the Flask API development framework for Google Street View analysis and optimal scene generation.
**Here’s how we were able to get true image generation to work:** When the user prompts the website for a more walkable version of the current location, we grab an image of the Google Street View and implement our own architecture using OpenAI contrastive language-image pre-training (CLIP) image and text encoders to encode both the image and a variety of potential descriptions describing the traffic, use of public transport, and pedestrian walkways present within the image. The outputted embeddings for both the image and the bodies of text were then compared with each other using scaled cosine similarity to output similarity scores. We then tag the image with the necessary descriptors, like classifiers,—this is our way of making the system understand the semantic meaning behind the image and prompt potential changes based on very specific street views (e.g. the Painted Ladies in San Francisco might have a high walkability score via the Walk Score API, but could potentially need larger sidewalks to further improve transport and the ability to travel in that region of SF). This is significantly more accurate than simply using DALL-E’s set image generation parameters with an unspecific prompt based purely on the walkability score because we are incorporating both the uploaded image for context and descriptor text embeddings to accurately provide a hyper location-specific augmented image.
A descriptive prompt is constructed from this semantic image analysis and fed into DALLE, a diffusion based image generation model conditioned on textual descriptors. The resulting images are higher quality, as they preserve structural integrity to resemble the real world, and effectively implement the necessary changes to make specific locations optimal for travel.
We used Tailwind CSS to style our components.
## Challenges we ran into
There were existing data bottlenecks, especially with getting accurate, granular, pedestrian foot traffic data.
The main challenge we ran into was integrating the necessary Open AI models + API routes. Creating a fast, seamless pipeline that provided the user with as much mobility and autonomy as possible required that we make use of not just the Walk Score API, but also map and geographical information from maps + google street view.
Processing both image and textual information pushed us to explore using the CLIP pre-trained text and image encoders to create semantically rich embeddings which can be used to relate ideas and objects present within the image to textual descriptions.
## Accomplishments that we're proud of
We could have done just normal image generation but we were able to detect car, people, and public transit concentration existing in an image, assign that to a numerical score, and then match that with a hyper-specific prompt that was generating an image based off of that information. This enabled us to make our own metrics for a given scene; we wonder how this model can be used in the real world to speed up or completely automate the data collection pipeline for local governments.
## What we learned and what's next for CityGO
Utilizing multiple data formats and sources to cohesively show up in the map + provide accurate suggestions for walkability improvement was important to us because data is the backbone for this idea. Properly processing the right pieces of data at the right step in the system process and presenting the proper results to the user was of utmost importance. We definitely learned a lot about keeping data lightweight, easily transferring between third-party softwares, and finding relationships between different types of data to synthesize a proper output.
We also learned quite a bit by implementing Open AI’s CLIP image and text encoders for semantic tagging of images with specific textual descriptions describing car, public transit, and people/people crosswalk concentrations. It was important for us to plan out a system architecture that effectively utilized advanced technologies for a seamless end-to-end pipeline. We learned about how information abstraction (i.e. converting between images and text and finding relationships between them via embeddings) can play to our advantage and utilizing different artificially intelligent models for intermediate processing.
In the future, we plan on integrating a better visualization tool to produce more realistic renders and introduce an inpainting feature so that users have the freedom to select a specific view on street view and be given recommendations + implement very specific changes incrementally. We hope that this will allow urban planners to more effectively implement design changes to urban spaces by receiving an immediate visual + seeing how a specific change seamlessly integrates with the rest of the environment.
Additionally we hope to do a neural radiance field (NERF) integration with the produced “optimal” scenes to give the user the freedom to navigate through the environment within the NERF to visualize the change (e.g. adding a bike lane or expanding a sidewalk or shifting the build site for a building). A potential virtual reality platform would provide an immersive experience for urban planners to effectively receive AI-powered layout recommendations and instantly visualize them.
Our ultimate goal is to integrate an asset library and use NERF-based 3D asset generation to allow planners to generate realistic and interactive 3D renders of locations with AI-assisted changes to improve walkability. One end-to-end pipeline for visualizing an area, identifying potential changes, visualizing said changes using image generation + 3D scene editing/construction, and quickly iterating through different design cycles to create an optimal solution for a specific locations’ walkability as efficiently as possible!
|
## 🌱 Inspiration
With the ongoing climate crisis, we recognized a major gap in the incentives for individuals to make greener choices in their day-to-day lives. People want to contribute to the solution, but without tangible rewards, it can be hard to motivate long-term change. That's where we come in! We wanted to create a fun, engaging, and rewarding way for users to reduce their carbon footprint and make eco-friendly decisions.
## 🌍 What it does
Our web app is a point-based system that encourages users to make greener choices. Users can:
* 📸 Scan receipts using AI, which analyzes purchases and gives points for buying eco-friendly products from partner companies.
* 🚴♂️ Earn points by taking eco-friendly transportation (e.g., biking, public transit) by tapping their phone via NFC.
* 🌿 See real-time carbon emission savings and get rewarded for making sustainable choices.
* 🎯 Track daily streaks, unlock milestones, and compete with others on the leaderboard.
* 🎁 Browse a personalized rewards page with custom suggestions based on trends and current point total.
## 🛠️ How we built it
We used a mix of technologies to bring this project to life:
* **Frontend**: Remix, React, ShadCN, Tailwind CSS for smooth, responsive UI.
* **Backend**: Express.js, Node.js for handling server-side logic.
* **Database**: PostgreSQL for storing user data and points.
* **AI**: GPT-4 for receipt scanning and product classification, helping to recognize eco-friendly products.
* **NFC**: We integrated NFC technology to detect when users make eco-friendly transportation choices.
## 🔧 Challenges we ran into
One of the biggest challenges was figuring out how to fork the RBC points API, adapt it, and then code our own additions to match our needs. This was particularly tricky when working with the database schemas and migration files. Sending image files across the web also gave us some headaches, especially when incorporating real-time processing with AI.
## 🏆 Accomplishments we're proud of
One of the biggest achievements of this project was stepping out of our comfort zones. Many of us worked with a tech stack we weren't very familiar with, especially **Remix**. Despite the steep learning curve, we managed to build a fully functional web app that exceeded our expectations.
## 🎓 What we learned
* We learned a lot about integrating various technologies, like AI for receipt scanning and NFC for tracking eco-friendly transportation.
* The biggest takeaway? Knowing that pushing the boundaries of what we thought was possible (like the receipt scanner) can lead to amazing outcomes!
## 🚀 What's next
We have exciting future plans for the app:
* **Health app integration**: Connect the app to health platforms to reward users for their daily steps and other healthy behaviors.
* **Mobile app development**: Transfer the app to a native mobile environment to leverage all the features of smartphones, making it even easier for users to engage with the platform and make green choices.
|
winning
|
## Inspiration
Rates of patient nonadherence to therapies average around 50%, particularly among those with chronic diseases. One of my closest friends has Crohn's disease, and I wanted to create something that would help with the challenges of managing a chronic illness. I built this app to provide an on-demand, supportive system for patients to manage their symptoms and find a sense of community.
## What it does
The app allows users to have on-demand check-ins with a chatbot. The chatbot provides fast inference, classifies actions and information related to the patient's condition, and flags when the patient’s health metrics fall below certain thresholds. The app also offers a community aspect, enabling users to connect with others who have chronic illnesses, helping to reduce the feelings of isolation.
## How we built it
We used Cerebras for the chatbot to ensure fast and efficient inference. The chatbot is integrated into the app for real-time check-ins. Roboflow was used for image processing and emotion detection, which aids in assessing patient well-being through facial recognition. We also used Next.js as the framework for building the app, with additional integrations for real-time community features.
## Challenges we ran into
One of the main challenges was ensuring the chatbot could provide real-time, accurate classifications and flagging low patient metrics in a timely manner. Managing the emotional detection accuracy using Roboflow's emotion model was also complex. Additionally, creating a supportive community environment without overwhelming the user with too much data posed a UX challenge.
## Accomplishments that we're proud of
✅deployed on defang
✅integrated roboflow
✅integrated cerebras
We’re proud of the fast inference times with the chatbot, ensuring that users get near-instant responses. We also managed to integrate an emotion detection feature that accurately tracks patient well-being. Finally, we’ve built a community aspect that feels genuine and supportive, which was crucial to the app's success.
## What we learned
We learned a lot about balancing fast inference with accuracy, especially when dealing with healthcare data and emotionally sensitive situations. The importance of providing users with a supportive, not overwhelming, environment was also a major takeaway.
## What's next for Muni
Next, we aim to improve the accuracy of the metrics classification, expand the community features to include more resources, and integrate personalized treatment plans with healthcare providers. We also want to enhance the emotion detection model for more nuanced assessments of patients' well-being.
|
## Inspiration
COVID revolutionized the way we communicate and work by normalizing remoteness. **It also created a massive emotional drought -** we weren't made to empathize with each other through screens. As video conferencing turns into the new normal, marketers and managers continue to struggle with remote communication's lack of nuance and engagement, and those with sensory impairments likely have it even worse.
Given our team's experience with AI/ML, we wanted to leverage data to bridge this gap. Beginning with the idea to use computer vision to help sensory impaired users detect emotion, we generalized our use-case to emotional analytics and real-time emotion identification for video conferencing in general.
## What it does
In MVP form, empath.ly is a video conferencing web application with integrated emotional analytics and real-time emotion identification. During a video call, we analyze the emotions of each user sixty times a second through their camera feed.
After the call, a dashboard is available which displays emotional data and data-derived insights such as the most common emotions throughout the call, changes in emotions over time, and notable contrasts or sudden changes in emotion
**Update as of 7.15am: We've also implemented an accessibility feature which colors the screen based on the emotions detected, to aid people with learning disabilities/emotion recognition difficulties.**
**Update as of 7.36am: We've implemented another accessibility feature which uses text-to-speech to report emotions to users with visual impairments.**
## How we built it
Our backend is powered by Tensorflow, Keras and OpenCV. We use an ML model to detect the emotions of each user, sixty times a second. Each detection is stored in an array, and these are collectively stored in an array of arrays to be displayed later on the analytics dashboard. On the frontend, we built the video conferencing app using React and Agora SDK, and imported the ML model using Tensorflow.JS.
## Challenges we ran into
Initially, we attempted to train our own facial recognition model on 10-13k datapoints from Kaggle - the maximum load our laptops could handle. However, the results weren't too accurate, and we ran into issues integrating this with the frontend later on. The model's still available on our repository, and with access to a PC, we're confident we would have been able to use it.
## Accomplishments that we're proud of
We overcame our ML roadblock and managed to produce a fully-functioning, well-designed web app with a solid business case for B2B data analytics and B2C accessibility.
And our two last minute accessibility add-ons!
## What we learned
It's okay - and, in fact, in the spirit of hacking - to innovate and leverage on pre-existing builds. After our initial ML model failed, we found and utilized a pretrained model which proved to be more accurate and effective.
Inspiring users' trust and choosing a target market receptive to AI-based analytics is also important - that's why our go-to-market will focus on tech companies that rely on remote work and are staffed by younger employees.
## What's next for empath.ly
From short-term to long-term stretch goals:
* We want to add on AssemblyAI's NLP model to deliver better insights. For example, the dashboard could highlight times when a certain sentiment in speech triggered a visual emotional reaction from the audience.
* We want to port this to mobile and enable camera feed functionality, so those with visual impairments or other difficulties recognizing emotions can rely on our live detection for in-person interactions.
* We want to apply our project to the metaverse by allowing users' avatars to emote based on emotions detected from the user.
|
## Inspiration
The US and the broader continent is in the midst of a drug crisis affecting a large fraction of the population: the opioid crisis. The direct spark that led us to develop Core was the recent publication of a study that used a model to predict the effects of different intervention methods on reducing overdose deaths and frequency of individuals developing dependencies on opiates. The [model's predictions](https://med.stanford.edu/news/all-news/2018/08/researchers-model-could-help-stem-opioid-crisis.html) were pretty bleak in the short term.
## What it does
Core seeks to provide individuals looking to overcome opiate and other drug addictions with strong and supportive connections with volunteer mentors. At the same time, it fills another need -- many college students, retirees, and moderately unfulfilled professionals are looking for a way to help bring about positive change without wasting time on transportation or prep. Core brings a human-centered, meaningful volunteer experience opportunity directly to people in the form of an app.
## How we built it
We used Flask for the backend and jQuery for the frontend. We incorporated various APIs, such as the IBM Watson Personality Insights API, the Facebook API, and the GIPHY API.
## Challenges we ran into
It took us a while to get the Facebook OAuth API working correctly. We initially worked separately on different parts of the app. It was an interesting experience to stitch together all of our individual components into a streamlined and cohesive app.
## Accomplishments that we're proud of
We're proud of Core!
## What we learned
We learned a lot about all the natural language processing APIs that IBM Watson has to offer and the workings of the Facebook OAuth API.
## What's next for Core
Lots of features are in the works including a rating system to enable mentees to rate mentors to ensure productive relationships and more detailed chat pairing based on location information and desired level of user engagement.
|
winning
|
## Inspiration
As our team nears the point in our lives in which buying our first home is on our radar, we've realized how cumbersome and daunting the task is, especially for new homeowners. Just the first step, determining which house you can afford, is already difficult, as a home's listing price doesn’t even begin to cover all of the hidden costs and fees. Terms like credit scores, down payments, mortgages, and homeowner's insurance just add to the confusion. So how can an aspiring homeowner ensure they're financially prepared to make one of the biggest purchases of their life? Enter all-in.
## What it does
all-in is a web app that calculates the all-in cost (n. the total cost of a transaction after commissions, interest rates, and other expenses) of a house including all hidden costs, fees, and taxes based on state and local laws with just an address (+ some extra details). It breaks down each individual cost, allowing the user to see and learn about where their money is going. Through this comprehensive list of expenses, all-in is able to provide the user with a realistic estimate of how much the should expect to have to pay for their new home so they can be financially prepared for this monumental moment.
all-in has two main value propositions: time and preparedness. It's significantly faster to automatically calculate the total cost of a home than manually entering every expense in. The process is also less stressful and more exciting when the homeowner is fully prepared to make the purchase.
## Challenges we ran into
Our team was split between 2 different time zones, so communication and coordination was a challenge.
## Accomplishments that we're proud of
For two of our members, this was their first hackathon!
## What's next for all-in
In the future, we hope to make all-in available on all platforms.
|
## Inspiration
Many individuals lack financial freedom, and this stems from poor spending skills. As a result, our group wanted to create something to help prevent that. We realized how difficult it can be to track the expenses of each individual person in a family. As humans, we tend to lose track of what we purchase and spend money on. Inspired, we wanted to create an app that stops all that by allowing individuals to strengthen their organization and budgeting skills.
## What It Does
Track is an expense tracker website targeting households and individuals with the aim of easing people’s lives while also allowing them to gain essential skills. Imagine not having to worry about tracking your expenses all while learning how to budget and be well organized.
The website has two key components:
* Family Expense Tracker:
The family expense tracker is the `main dashboard` for all users. It showcases each individual family member’s total expenses while also displaying the expenses through categories. Both members and owners of the family can access this screen. Members can be added to the owner’s family via a household key which is only given access to the owner of the family. Permissions vary between both members and owners. Owners gain access to each individual’s personal expense tracker, while members have only access to their own personal expense tracker.
* Personal Expense Tracker:
The personal expense tracker is assigned to each user, displaying their own expenses. Users are allowed to look at past expenses from the start of the account to the present time. They are also allowed to add expenses with a click of a button.
## How We Built It
* Utilized the MERN (MongoDB, Express, React, Node) stack
* Restful APIs were built using Node and Express which were integrated with a MongoDB database
* The Frontend was built with the use of vanilla React and Tailwind CSS
## Challenges We Ran Into
* Frontend:
Connecting EmailJS to the help form
Retrieving specific data from the backend and displaying pop-ups accordingly
Keeping the theme consistent while also ensuring that the layout and dimensions didn’t overlap or wrap
Creating hover animations for buttons and messages
* Backend:
Embedded objects were not being correctly updated - needed to learn about storing references to objects and populating the references
Designing the backend based on frontend requirements and the overall goal of the website
## Accomplishments We’re Proud Of
As this was all of our’s first or second hackathons we are proud to have created a functioning website with a fully integrated front and back-end.
We are glad to have successfully implemented pop-ups for each individual expense category that displays past expenses.
Overall, we are proud of ourselves for being able to create a product that can be used in our day-to-day lives in a short period of time.
## What We Learned
* How to properly use embedded objects so that any changes to the object are reflected wherever the object is embedded
* Using the state hook in ReactJS
* Successfully and effectively using React Routers
* How to work together virtually. It allowed us to not only gain hard skills but also enhance our soft skills such as teamwork and communication.
## What’s Next For Track
* Implement an income tracker section allowing the user to get a bigger picture of their overall net income
* Be able to edit and delete both expenses and users
* Store historical data to allow the use of data analysis graphs to provide predictions and recommendations.
* Allow users to create their own categories rather than the assigned ones
* Setting up different levels of permission to allow people to view other family member’s usage
|
## Inspiration
We came into this not knowing what to do for this hackathon, but then it dawned on us, wouldn't it be nice if it were possible to see different type of information about the stock market, and stocks that you already own. That's when we thought of making **Ultimate Portfolio**!
## What it does
Now you may be wondering, what does **Ultimate Portfolio** do? Well, **Ultimate Portfolio** is an app that allows you to see how different stocks are doing in comparison to their norm using linear regression to make a technical analysis on the stocks. Is that all? You may ask. No, let me tell you some of our other great features. **Ultimate Portfolio** analyzes and shows how ***your*** investments are doing. Now you may find yourself wondering, why would that be of use? Well let me tell you, using **Ultimate Portfolio** the app will show you how well you are doing in your stocks and how well others are doing, so you will know when to invest or sell to make **HUGE** amounts of money and avoid the risk of losing it all. All of this and much more can be done with just a couple of clicks in our app **Ultimate Portfolio**!
## How we built it
It all started with an idea, **A Great Idea**, but little did we know what we were getting ourselves into. Soon after, we started brainstorming and creating a plan of action on **Trello**. Everyone was assigned tasks to complete, whether with the help of another team member or by themselves. We had some members that were more acquainted with backend developing, so we let them handle the dirty work. We used react, firebase, an external API and bootstrap to complete this **Great Idea**. All in all, the plan was going according to plan, straying off in some parts, pulling ahead in others.
## Challenges we ran into
One **Big** challenge was the fact that it was the first hackathon for most of our team, and with it being most of our first hackathon, we had no idea what this experience was like. So learning how to work well and efficiently as a team was a hurdle that we had to overcome. There were a lot of hard fought battles... (with errors) but in the end, we improvised, adapted, and overcame.
## Accomplishments that we're proud of
Many things were accomplished during this hackathon, some of the most notable accomplishments were working as a team to create a project. Again, since this was most of our team's first hackathon, it was very rewarding when things started coming together working as a team. Also, doing this hackathon was like stepping out of our comfort zone of not being stressed to finish a project in time, and stepping out of ones comfort zone once in a while can be very rewarding, it's like being in **A Whole New World**! Something that our team did exceptionally well, was product management, by the end of our brainstorming and plan of actions creation phase, we had already set up a Trello board (which helped with organization and distribution of tasks).
## What we learned
In the end, many things were learned by our team. One very crucial part, and I cannot emphasize this enough... ~~caffeine~~, you can't do everything yourself, and working as a team can be beneficial at times.
## What's next for Ultimate Portfolio
In the future, we hope to implement more advanced analytic features and tools for members to use. These features will be used to help the user create better investments, allowing them to make more and lose less money. Some of these features include, but are not limited to, Neural Networking, which can examine data to let you know whether you should invest or not, predictive analytics and prescriptive analytics, which will predict stock prices, and then let you know the best approach to make money. All of these and many more are planned for the future of **Ultimate Portfolio**!
|
partial
|
• Inspiration
The inspiration for digifoot.ai stemmed from the growing concern about digital footprints and online presence in today's world. With the increasing use of social media, individuals often overlook the implications of their online activities. We aimed to create a tool that not only helps users understand their digital presence but also provides insights into how they can improve it.
• What it does
digifoot.ai is a comprehensive platform that analyzes users' social media accounts, specifically Instagram and Facebook. It aggregates data such as posts, followers, and bios, and utilizes AI to provide insights on their digital footprint. The platform evaluates images and content from users’ social media profiles to ensure there’s nothing harmful or inappropriate, helping users maintain a positive online presence.
• How we built it
We built digifoot.ai using Next.js and React for the frontend and Node.js for the backend. The application integrates with the Instagram and Facebook Graph APIs to fetch user data securely. We utilized OpenAI's API for generating insights based on the collected social media data.
• Challenges we ran into
API Authentication and Rate Limits:
Managing API authentication for both Instagram and OpenAI was complex. We had to ensure secure
access to user data while adhering to rate limits imposed by these APIs. This required us to optimize our
data-fetching strategies to avoid hitting these limits.
Integrating Image and Text Analysis:
We aimed to analyze both images and captions from Instagram posts using the OpenAI API's
capabilities. However, integrating image analysis required us to understand how to format requests
correctly, especially since the OpenAI API processes images differently than text.
The challenge was in effectively combining image inputs with textual data in a way that allowed the AI to
provide meaningful insights based on both types of content.
• Accomplishments that we're proud of
We are proud of successfully creating a user-friendly interface that allows users to connect their social media accounts seamlessly. The integration of AI-driven analysis provides valuable feedback on their digital presence. Moreover, we developed a robust backend that handles data securely while complying with privacy regulations.
• What we learned
Throughout this project, we learned valuable lessons about API integrations and the importance of user privacy and data security. We gained insights into how AI can enhance user experience by providing personalized feedback based on real-time data analysis. Additionally, we improved our skills in full-stack development and project management.
• What's next for digifoot.ai
Looking ahead, we plan to enhance digifoot.ai by incorporating more social media platforms for broader analysis capabilities. We aim to refine our AI algorithms to provide even more personalized insights. Additionally, we are exploring partnerships with educational institutions to promote digital literacy and responsible online behavior among students.
|
## Inspiration 💡
Our inspiration for this project was to leverage new AI technologies such as text to image, text generation and natural language processing to enhance the education space. We wanted to harness the power of machine learning to inspire creativity and improve the way students learn and interact with educational content. We believe that these cutting-edge technologies have the potential to revolutionize education and make learning more engaging, interactive, and personalized.
## What it does 🎮
Our project is a text and image generation tool that uses machine learning to create stories from prompts given by the user. The user can input a prompt, and the tool will generate a story with corresponding text and images. The user can also specify certain attributes such as characters, settings, and emotions to influence the story's outcome. Additionally, the tool allows users to export the generated story as a downloadable book in the PDF format. The goal of this project is to make story-telling interactive and fun for users.
## How we built it 🔨
We built our project using a combination of front-end and back-end technologies. For the front-end, we used React which allows us to create interactive user interfaces. On the back-end side, we chose Go as our main programming language and used the Gin framework to handle concurrency and scalability. To handle the communication between the resource intensive back-end tasks we used a combination of RabbitMQ as the message broker and Celery as the work queue. These technologies allowed us to efficiently handle the flow of data and messages between the different components of our project.
To generate the text and images for the stories, we leveraged the power of OpenAI's DALL-E-2 and GPT-3 models. These models are state-of-the-art in their respective fields and allow us to generate high-quality text and images for our stories. To improve the performance of our system, we used MongoDB to cache images and prompts. This allows us to quickly retrieve data without having to re-process it every time it is requested. To minimize the load on the server, we used socket.io for real-time communication, it allow us to keep the HTTP connection open and once work queue is done processing data, it sends a notification to the React client.
## Challenges we ran into 🚩
One of the challenges we ran into during the development of this project was converting the generated text and images into a PDF format within the React front-end. There were several libraries available for this task, but many of them did not work well with the specific version of React we were using. Additionally, some of the libraries required additional configuration and setup, which added complexity to the project. We had to spend a significant amount of time researching and testing different solutions before we were able to find a library that worked well with our project and was easy to integrate into our codebase. This challenge highlighted the importance of thorough testing and research when working with new technologies and libraries.
## Accomplishments that we're proud of ⭐
One of the accomplishments we are most proud of in this project is our ability to leverage the latest technologies, particularly machine learning, to enhance the user experience. By incorporating natural language processing and image generation, we were able to create a tool that can generate high-quality stories with corresponding text and images. This not only makes the process of story-telling more interactive and fun, but also allows users to create unique and personalized stories.
## What we learned 📚
Throughout the development of this project, we learned a lot about building highly scalable data pipelines and infrastructure. We discovered the importance of choosing the right technology stack and tools to handle large amounts of data and ensure efficient communication between different components of the system. We also learned the importance of thorough testing and research when working with new technologies and libraries.
We also learned about the importance of using message brokers and work queues to handle data flow and communication between different components of the system, which allowed us to create a more robust and scalable infrastructure. We also learned about the use of NoSQL databases, such as MongoDB to cache data and improve performance. Additionally, we learned about the importance of using socket.io for real-time communication, which can minimize the load on the server.
Overall, we learned about the importance of using the right tools and technologies to build a highly scalable and efficient data pipeline and infrastructure, which is a critical component of any large-scale project.
## What's next for Dream.ai 🚀
There are several exciting features and improvements that we plan to implement in the future for Dream.ai. One of the main focuses will be on allowing users to export their generated stories to YouTube. This will allow users to easily share their stories with a wider audience and potentially reach a larger audience.
Another feature we plan to implement is user history. This will allow users to save and revisit old prompts and stories they have created, making it easier for them to pick up where they left off. We also plan to allow users to share their prompts on the site with other users, which will allow them to collaborate and create stories together.
Finally, we are planning to improve the overall user experience by incorporating more customization options, such as the ability to select different themes, characters and settings. We believe these features will further enhance the interactive and fun nature of the tool, making it even more engaging for users.
|
## Inspiration
James wants to go to Ottawa for a vacation. He does not how to dress properly for the weather as -1 degree Celsius in the sunny and snowy Ottawa feels completely different than -1 degree Celsius in the rainy Vancouver.
When visiting a new city or country, often, just typing the city name to Google is not enough to determine the weather of the city. If you have never experienced extremely humid summer or extremely cold winter, you will have no idea what ‘-5’ degree or ‘38’ degree Celsius mean.
By showing photos of people standing outside in these cities on a specific day of the year, you will be able to decide what is the appropriate clothing to bring for your vacation.
## What it does
Where to Wear is an application that shows you the weather of any city and what people are wearing in the city, so that you can dress accordingly. The application also shows historical weather data and what people wore for a particular date.
## How we built it
We use Express (nodeJS) for the backend and Angular for the front end. We also use API services from the following:
* OpenWeather (Current weather)
* DarkSky (Historical Data)
* Instagram (Photos)
* Google Vision (Filters for photos of people)
We cached all the images we collected by location via Instagram using MongoDB. We then use image recognition to filter out irrelevant pictures. We also used concurrency to increase the efficiency of getting labels and data of images
## Challenges we ran into
It was difficult to collect data from Instagram as they have removed many endpoints recently due to their data scandals. Instagram also blocked our IP address multiple time, which was resolved using VPN. It was also difficult to find free historical data services that we could use.
However, the most challenging thing that we have encountered is the slow image recognition as we are dealing with a large number of photos. We solved this by doing 1) caching and 2) concurrency.
## Accomplishments that we're proud of
We were able to implement most of the features we planned. We were able to do image recognition better than our expectation using machine learning by doing trials and errors for the keywords.
## What we learned
We learned to integrate different implementation of APIs to our web application. We also learned new tools such as Angular and MongoDB.
## What's next for Where to Wear
We could further refine the image recognition algorithm and we could also collect more image data from different social media platforms.
|
partial
|
## Inspiration
We are currently living through one of the largest housing crises in human history. As a result, more Canadians than ever before are seeking emergency shelter to stay off the streets and find a safe place to recuperate. However, finding a shelter is still a challenging, manual process, where no digital service exists that lets individuals compare shelters by eligibility criteria, find the nearest one they are eligible for, and verify that the shelter has room in real-time. Calling shelters in a city with hundreds of different programs and places to go is a frustrating burden to place on someone who is in need of safety and healing. Further, we want to raise the bar: people shouldn't be placed in just any shelter, they should go to the shelter best for them based on their identity and lifestyle preferences.
70% of homeless individuals have cellphones, compared to 85% of the rest of the population; homeless individuals are digitally connected more than ever before, especially through low-bandwidth mediums like voice and SMS. We recognized an opportunity to innovate for homeless individuals and make the process for finding a shelter simpler; as a result, we could improve public health, social sustainability, and safety for the thousands of Canadians in need of emergency housing.
## What it does
Users connect with the ShelterFirst service via SMS to enter a matching system that 1) identifies the shelters they are eligible for, 2) prioritizes shelters based on the user's unique preferences, 3) matches individuals to a shelter based on realtime availability (which was never available before) and the calculated priority and 4) provides step-by-step navigation to get to the shelter safely.
Shelter managers can add their shelter and update the current availability of their shelter on a quick, easy to use front-end. Many shelter managers are collecting this information using a simple counter app due to COVID-19 regulations. Our counter serves the same purpose, but also updates our database to provide timely information to those who need it. As a result, fewer individuals will be turned away from shelters that didn't have room to take them to begin with.
## How we built it
We used the Twilio SMS API and webhooks written in express and Node.js to facilitate communication with our users via SMS. These webhooks also connected with other server endpoints that contain our decisioning logic, which are also written in express and Node.js.
We used Firebase to store our data in real time.
We used Google Cloud Platform's Directions API to calculate which shelters were the closest and prioritize those for matching and provide users step by step directions to the nearest shelter. We were able to capture users' locations through natural language, so it's simple to communicate where you currently are despite not having access to location services
Lastly, we built a simple web system for shelter managers using HTML, SASS, JavaScript, and Node.js that updated our data in real time and allowed for new shelters to be entered into the system.
## Challenges we ran into
One major challenge was with the logic of the SMS communication. We had four different outgoing message categories (statements, prompting questions, demographic questions, and preference questions), and shifting between these depending on user input was initially difficult to conceptualize and implement. Another challenge was collecting the distance information for each of the shelters and sorting between the distances, since the response from the Directions API was initially confusing. Lastly, building the custom decisioning logic that matched users to the best shelter for them was an interesting challenge.
## Accomplishments that we're proud of
We were able to build a database of potential shelters in one consolidated place, which is something the city of London doesn't even have readily available. That itself would be a win, but we were able to build on this dataset by allowing shelter administrators to update their availability with just a few clicks of a button. This information saves lives, as it prevents homeless individuals from wasting their time going to a shelter that was never going to let them in due to capacity constraints, which often forced homeless individuals to miss the cutoff for other shelters and sleep on the streets. Being able to use this information in a custom matching system via SMS was a really cool thing for our team to see - we immediately realized its potential impact and how it could save lives, which is something we're proud of.
## What we learned
We learned how to use Twilio SMS APIs and webhooks to facilitate communications and connect to our business logic, sending out different messages depending on the user's responses. In addition, we taught ourselves how to integrate the webhooks to our Firebase database to communicate valuable information to the users.
This experience taught us how to use multiple Google Maps APIs to get directions and distance data for the shelters in our application. We also learned how to handle several interesting edge cases with our database since this system uses data that is modified and used by many different systems at the same time.
## What's next for ShelterFirst
One addition to make could be to integrate locations for other basic services like public washrooms, showers, and food banks to connect users to human rights resources. Another feature that we would like to add is a social aspect with tags and user ratings for each shelter to give users a sense of what their experience may be like at a shelter based on the first-hand experiences of others. We would also like to leverage the Twilio Voice API to make this system accessible via a toll free number, which can be called for free at any payphone, reaching the entire homeless demographic.
We would also like to use Raspberry Pis and/or Arduinos with turnstiles to create a cheap system for shelter managers to automatically collect live availability data. This would ensure the occupancy data in our database is up to date and seamless to collect from otherwise busy shelter managers. Lastly, we would like to integrate into municipalities "smart cities" initiatives to gather more robust data and make this system more accessible and well known.
|
## Inspiration
Every year hundreds of thousands of preventable deaths occur due to the lack of first aid knowledge in our societies. Many lives could be saved if the right people are in the right places at the right times. We aim towards connecting people by giving them the opportunity to help each other in times of medical need.
## What it does
It is a mobile application that is aimed towards connecting members of our society together in times of urgent medical need. Users can sign up as respondents which will allow them to be notified when people within a 300 meter radius are having a medical emergency. This can help users receive first aid prior to the arrival of an ambulance or healthcare professional greatly increasing their chances of survival. This application fills the gap between making the 911 call and having the ambulance arrive.
## How we built it
The app is Android native and relies heavily on the Google Cloud Platform. User registration and authentication is done through the use of Fireauth. Additionally, user data, locations, help requests and responses are all communicated through the Firebase Realtime Database. Lastly, the Firebase ML Kit was also used to provide text recognition for the app's registration page. Users could take a picture of their ID and their information can be retracted.
## Challenges we ran into
There were numerous challenges in terms of handling the flow of data through the Firebase Realtime Database and providing the correct data to authorized users.
## Accomplishments that we're proud of
We were able to build a functioning prototype! Additionally we were able to track and update user locations in a MapFragment and ended up doing/implementing things that we had never done before.
|
## Inspiration
More than 2.7 million pets will be killed over the next year because shelters cannot accommodate them. Many of them will be abandoned by owners who are unprepared for the real responsibilities of raising a pet, and the vast majority of them will never find a permanent home. The only sustainable solution to animal homelessness is to maximize adoptions of shelter animals by families who are equipped to care for them, so we created Homeward as a one-stop foster tool to streamline this process.
## What it does
Homeward allows shelters and pet owners to offer animals for adoption online. A simple and intuitive UI allows adopters to describe the pet they want and uses Google Cloud ML's Natural Language API to match their queries with available pets. Our feed offers quick browsing of available animals, multiple ranking options, and notifications of which pets are from shelters and which will be euthanized soon.
## How we built it
We used the Node.js framework with Express for routing and MongoDB as our database. Our front-end was built with custom CSS/Jade mixed with features from several CSS frameworks. Entries in our database were sourced from the RescueGroups API, and salient keywords for query matching were extracted using Google's Natural Language API. Our application is hosted with Google App Engine.
## Challenges we ran into
Incorporating Google's Natural Language API was challenging at first and we had to design a responsive front-end that would update the feed as the user updated their query. Some pets' descriptions had extraneous HTML and links that added noise to our extracted tags. We also found it tedious to clean and migrate the data to MongoDB.
## Accomplishments that we're proud of
We successfully leveraged Google Cloud ML to detect salient attributes in users' queries and rank animals in our feed accordingly. We also managed to utilize real animal data from the RescueGroups API. Our front-end also turned out to be cleaner and more user-friendly than we anticipated.
## What we learned
We learned first-hand about the challenges of applying natural language processing to potentially noisy user queries in real life applications. We also learned more about good javascript coding practices and robust back-end communication between our application and our database. But most importantly, we learned about the alarming state of animal homelessness and its origins.
## What's next for Homeward
We can enhance posted pet management by creating a simple account system for shelters. We would also like to create a scheduling mechanism that lets users "book" animals for fostering, thereby maximizing the probability of adoption. In order to scale Homeward, we need to clean and integrate more shelters' databases and adjust entries to match our schema.
|
winning
|
## Inspiration
We saw the sad reality that people often attending hackathons don't exercise regularly or do so while coding. We decided to come up with a solution
## What it does
Lets a user log in, and watch short fitness videos of exercises they can do while attending a hackathon
## How we built it
We used HTML & CSS for the frontend, python & sqlite3 for the backend and django to merge all three. We also deployed a DCL worker
## Challenges we ran into
Learning django and authenticating users in a short span of time
## Accomplishments that we're proud of
Getting a functioning webapp up in a short time
## What we learned
How do design a website, how to deploy a website, simple HTML, python objects, django header tags
## What's next for ActiveHawk
We want to make activehawk the Tiktok of hackathon fitness. we plan on adding more functionality for apps as well as a live chat room for instructors using the Twello api
|
## Inspiration
As children some of us have been to the great barrier reef and it was an amazing experience. Now with the problems such as climate change and pollution that have effected these natural wonders, we were inspired to help people maintain land better in general. There has not been much advancements in the ways of keep an eye on our land considering the advancements in technology so we have come up with ideas of how we can use satellite images and to run models on these images in order to get information that you would not be able to otherwise know in order to take the best care possible of the land.
## What it does
Our application takes in coordinates of a location through an interactive Google Maps environment and will run models on that area of land in order to analyze it, reporting various information such as water index, vegetation index, normalized vegetation index, burn area index, mosture index, mineral and clay indices, and land coverage segmentation.
## How we built it
We built this with a reactJS frontend and an express server backend. Our backend talks to our python analytical model that handle the indices and land coverage prediction. Please see the component diagram above.
## Challenges we ran into
Dataset usability was one big issue. We found that although there was many good datasets out there, not all of them were usable, rendering them useless. There was challenges with some of the libraries that we were working with. Not everyone was able to download the libraries and work with them due to difference in computer architectures and different operating systems. We were able to work around this by using the Git versioning system.
## Accomplishments that we're proud of
Able to get good images of indices that do vegetation, moisture levels, and high resolution RGB maps for land cover segmentation
## What we learned
There are a lot of cool datasets that we can work with in order to accomplish these tasks. These objectives can be accomplish through many different means.
## What's next for EnviroHack
We plan on expanding on the idea of this project by adding drones that will have the capability of streaming the images of the land rather than using satellites. This gives the user more real-time updates of the area of interest. Furthermore, we want to be able to use the drone to accomplish some tasks such as planting trees and cleaning trash in order to save take care of the land autonomously.
|
## Inspiration
We wanted to watch videos together as a social activity during the pandemic but were unable as many platforms were hard to use or unstable. Therefore our team decided to create a platform that met our needs in terms of usability and functionality.
## What it does
Bubbles allow people to create viewing rooms and invite their rooms to watch synchronized videos. Viewers no longer have to conduct countdowns on their play buttons or have a separate chat while watching!
## How I built it
Our web app uses React for the frontend and interfaces with our Node.js REST API in the backend. The core of our app uses the Solace PubSub+ and the MQTT protocol to coordinate events such as video play/pause, a new member joining your bubble, and instant text messaging. Users broadcast events with the topic being their bubble room code, so only other people in the same room receive these events.
## Challenges I ran into
* Collaborating in a remote environment: we were in a discord call for the whole weekend, using Miro for whiteboarding, etc.
* Our teammates came from various technical backgrounds, and we all had a chance to learn a lot about the technologies we used and how to build a web app
* The project was so much fun we forgot to sleep and hacking was more difficult the next day
## Accomplishments that I'm proud of
The majority of our team was inexperienced in the technologies used. Our team is very proud that our product was challenging and was completed by the end of the hackathon.
## What I learned
We learned how to build a web app ground up, beginning with the design in Figma to the final deployment to GitHub and Heroku. We learned about React component lifecycle, asynchronous operation, React routers with a NodeJS backend, and how to interface all of this with a Solace PubSub+ Event Broker. But also, we learned how to collaborate and be productive together while still having a blast
## What's next for Bubbles
We will develop additional features regarding Bubbles. This includes seek syncing, user join messages and custom privilege for individuals.
|
partial
|
## Inspiration
For my project I wanted to see if I could use state of the art machine learning and crowd sourcing methods to make something not only innovative and exciting, but also fun and whimsical.
Although I'm not artistically talented, I like doodling, whether it's when I'm supposed to be paying attention in a class, or for games like "Draw Something". I got the idea for this project after learning about Google Quick Draw project, where they crowdsourced millions of doodles (including some of mine!) to train a neural network, and then released the drawings for the public to use. I really liked the cartoony vibe of these drawings, and thought it would be fun to use them to make your own doodles.
## What it does
The overarching theme of the app is to create drawings using crowd-sourced doodles, and there are two main ways it does this.
First, you can add to the image using voice commands. The picture is split into an (invisible) 8x6 grid, and you can specify where you want something placed with regular Cartesian coordinates. For example, you can say "Tree at 4 dot 3", which would draw someone's doodle of a tree on square (4, 3).
If you're planning on placing a lot of the same item at once, you could instead say a command like "Frying pan across 7" which would fill row 7 with frying pans, or "Monkey down 0", which would fill the first column with monkeys. If you don’t like a doodle, you can click refresh to try a different user submitted doodle, and if you want to simply restart the whole drawing, you can say “Erase” to get a blank canvas (full of possibilities!).
The second way to create a drawing is you can paste in a link to an actual photograph, and the program will doodle-fy it! It will attempt to detect prominent objects in the photo and their location, convert those objects into doodles, and place them in the blank canvas so that they're in the same position relative to each other as in the original.
## How I built it
This program was built using Python, the GUI using PyQt, and image creation through Pillow.
I use Google QuickDraw's open dataset to access some of the millions of doodles submitted by people around the world, each corresponding to some category like "car", "tree", "foot", "sword", etc, and these are the building blocks for Doodle My World's images.
For the voice commands, I used Microsoft Azure's speech services to convert the commands into text. The program then searches the speech transcript for certain keywords, such as the object to be doodled, its coordinates, whether or not to fill a row, etc. The name of the object is fed to Google QuickDraw, and if it's matched with a doodle, it will add it to the canvas at the coordinates specified (the box coordinates are converted to pixel coordinates).
For the photo conversion, I used Azure's computer vision to analyze photos for objects and their locations. It detects prominent objects in the photo and returns their pixel coordinates, so I put in the list of objects into QuickDraw, and if a doodle was available, I placed it into the image file at the same relative coordinates as the original.
## Challenges I ran into
One of the main challenges I ran into was getting the APIs I was using to work together well. Google's QuickDraw based its data off of things that were easy to draw, so it would only identify specific, simple inputs, like "car", and wouldn't recognize Azure's more specific and complex outputs, like "stationwagon". One way I got around this, was if QuickDraw didn't recognize an object, I'd then feed in what Azure calls its "parent object" (so for a stationwagon, its parent would be car), which were often more general, and simpler.
Another issue was that QuickDraw simply didn't recognize many common inputs, a specific example of which was "Person". In this case my workaround was that whenever Azure would detect a Person, I would feed it in as a "smiley face" to QuickDraw and then draw a shirt underneath to simulate a person, which honestly worked out pretty well.
## Accomplishments that I'm proud of
This was my first time attempting a solo hackathon project, so I'm really happy that I managed to finish and reach most of my initials goals. This was also my first time creating a front end GUI and doing image manipulation with Python, so I learned a lot too!
## What's next for Doodle My World
There are a lot of voice commands that I wanted to add, but were more like stretch goals. One idea was to be able to specify more specific ranges rather than just single rows or columns, such as "Star from rows 3 to 5" or "Mountain in half of column 2". I also wanted to add a "Frame" command, so you could create a frame out of some object, like stars for instance.
Because of the disconnect between the specifics of Azure compared to the generality of QuickDraw, I'd originally planned on adding a thesaurus feature, to get related words. So for instance if QuickDraw doesn't recognize "azalea" for example, I could run it through a thesaurus app, and then feed synonyms to my program so that it could eventually recognize it as a "flower".
|
## Inspiration
In our busy world, people often rush from place to place. Sometimes, people need to stop and appreciate the art and the world around them. Especially now, we were looking for ways to connect local communities safely and creatively. paintAR provides such opportunities.
## What it does
Find art where you least expect! paintARt is an alternative reality app that overlays shared art pieces over everyday landmarks, like walls, posters, and plaques. Users collaborate on, or simply admire, different types of canvases, including murals and image collages.
Open the app and find local virtual art installations on the interactive map. Once you get there, open the camera function and point it at the landmark in real life. When the camera input matches a reference image, a canvas will be virtually projected on your phone screen. Admire, then edit the canvas using an image editor according to a given prompt. Functionality includes text, emojis, brushes, camera integration, cropping, and filters. When you’re done, simply press submit and watch your work be projected in 3d!
The possibilities are truly endless. Collaborate on the same canvas with others or create a collage of your own images in a grid. Share doodles, selfies, dog pictures, anything!
Connect with people across the world as well! Our application supports “portal” canvases, in which artists from different locations across the globe can collaborate and send artistic messages on the same canvas.
## How I built it
PaintAR was built primarily using Android Studio and ARCore. The opening map utilizes Google Play Location services to display the user’s location and surrounding murals in real-time. Images are synced and updated with Firebase Realtime Database and Google Cloud Storage. We also relied on Burhanuddin Rashid’s open source Android Photo Editor for editing images on the phone.
## Challenges I ran into
Setting up ARcore in Android Studio was extremely difficult, especially since most of our team had almost no prior experience with the ARCore SDK. Additionally, learning how to position 2D items in 3D space required learning about the fundamentals of AR, specifically how AR core anchors and tracks 3D models in physical space. We also ran into issues with the data storage, scope, and database portions of our project.
## Accomplishments that I'm proud of
Most of our team had almost no experience with AR mobile development. Creating a functioning AR app in just a day was a fun challenge. We also had little Android Studio experience, with three out of four teammates new to it. We’re proud of being able to work together effectively while also learning.
## What I learned
We learned a lot about the fundamentals of AR, including how virtual objects are represented in physical space. We also spent a significant amount of time learning about a variety of potential backends for our app before settling on Firebase and Cloud Storage.
## What's next for paintAR
We are thinking of adding additional types of murals, such as a 3-d mural, gif and video support, and allowing users to create their own anchor canvases.
|
# 🤖🖌️ [VizArt Computer Vision Drawing Platform](https://vizart.tech)
Create and share your artwork with the world using VizArt - a simple yet powerful air drawing platform.
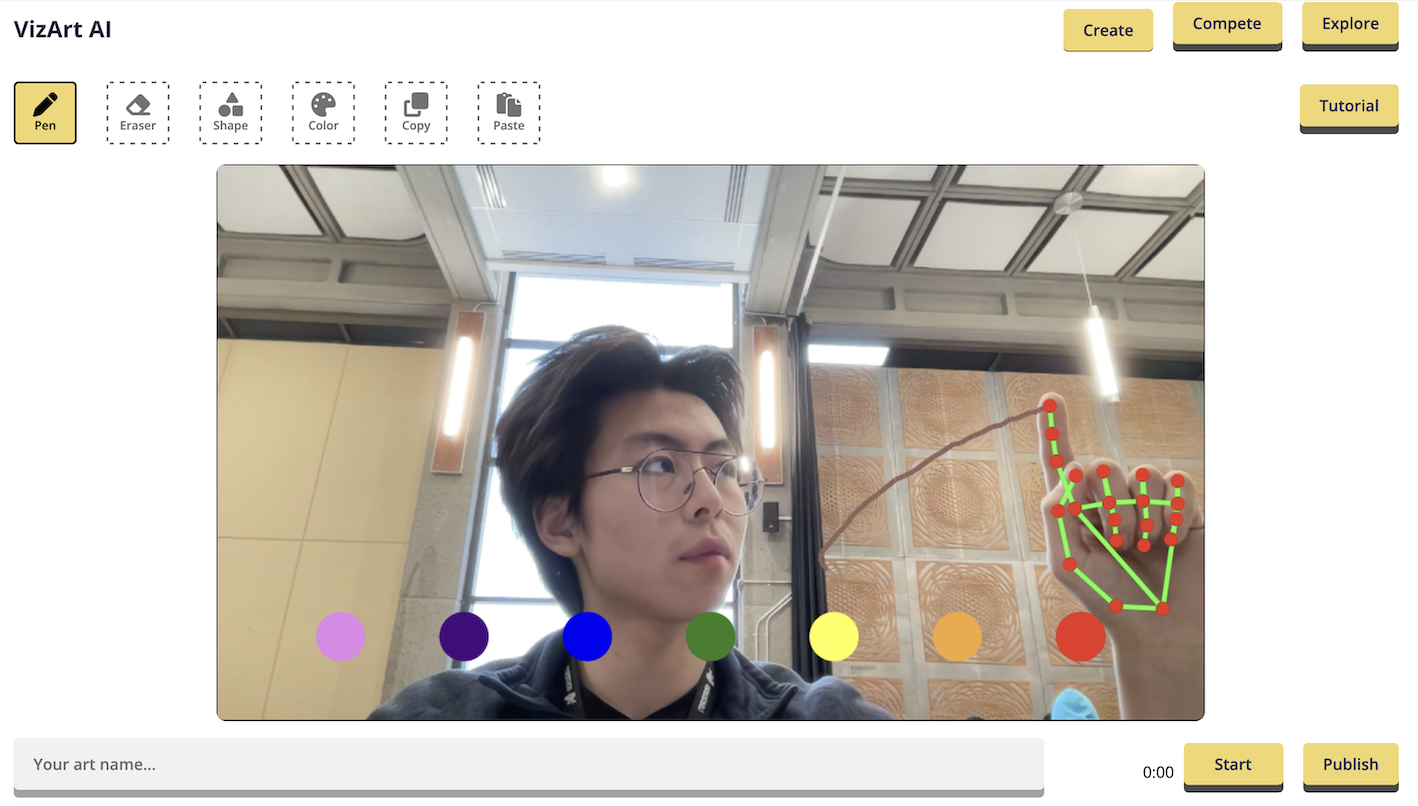
## 💫 Inspiration
>
> "Art is the signature of civilizations." - Beverly Sills
>
>
>
Art is a gateway to creative expression. With [VizArt](https://vizart.tech/create), we are pushing the boundaries of what's possible with computer vision and enabling a new level of artistic expression. ***We envision a world where people can interact with both the physical and digital realms in creative ways.***
We started by pushing the limits of what's possible with customizable deep learning, streaming media, and AR technologies. With VizArt, you can draw in art, interact with the real world digitally, and share your creations with your friends!
>
> "Art is the reflection of life, and life is the reflection of art." - Unknow
>
>
>
Air writing is made possible with hand gestures, such as a pen gesture to draw and an eraser gesture to erase lines. With VizArt, you can turn your ideas into reality by sketching in the air.
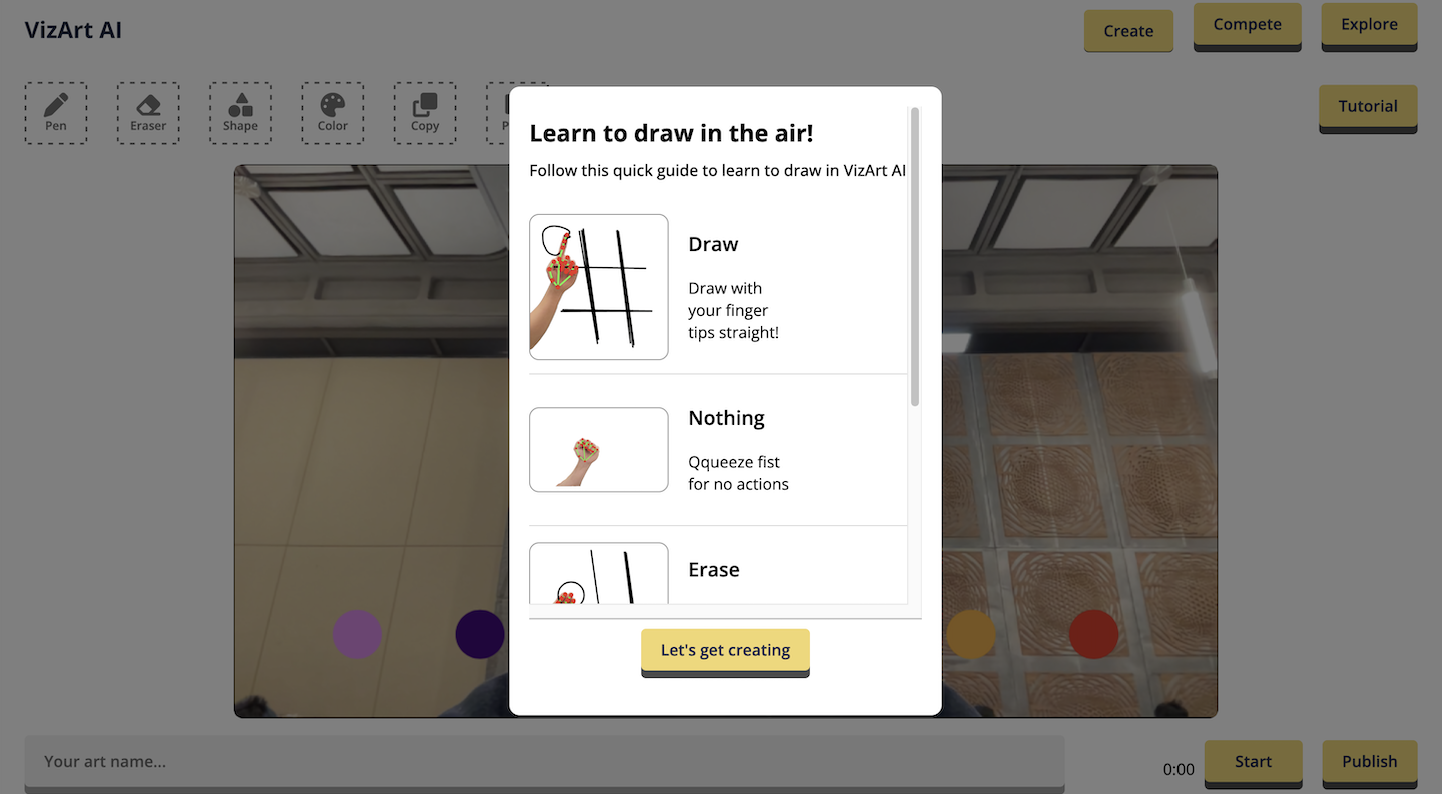
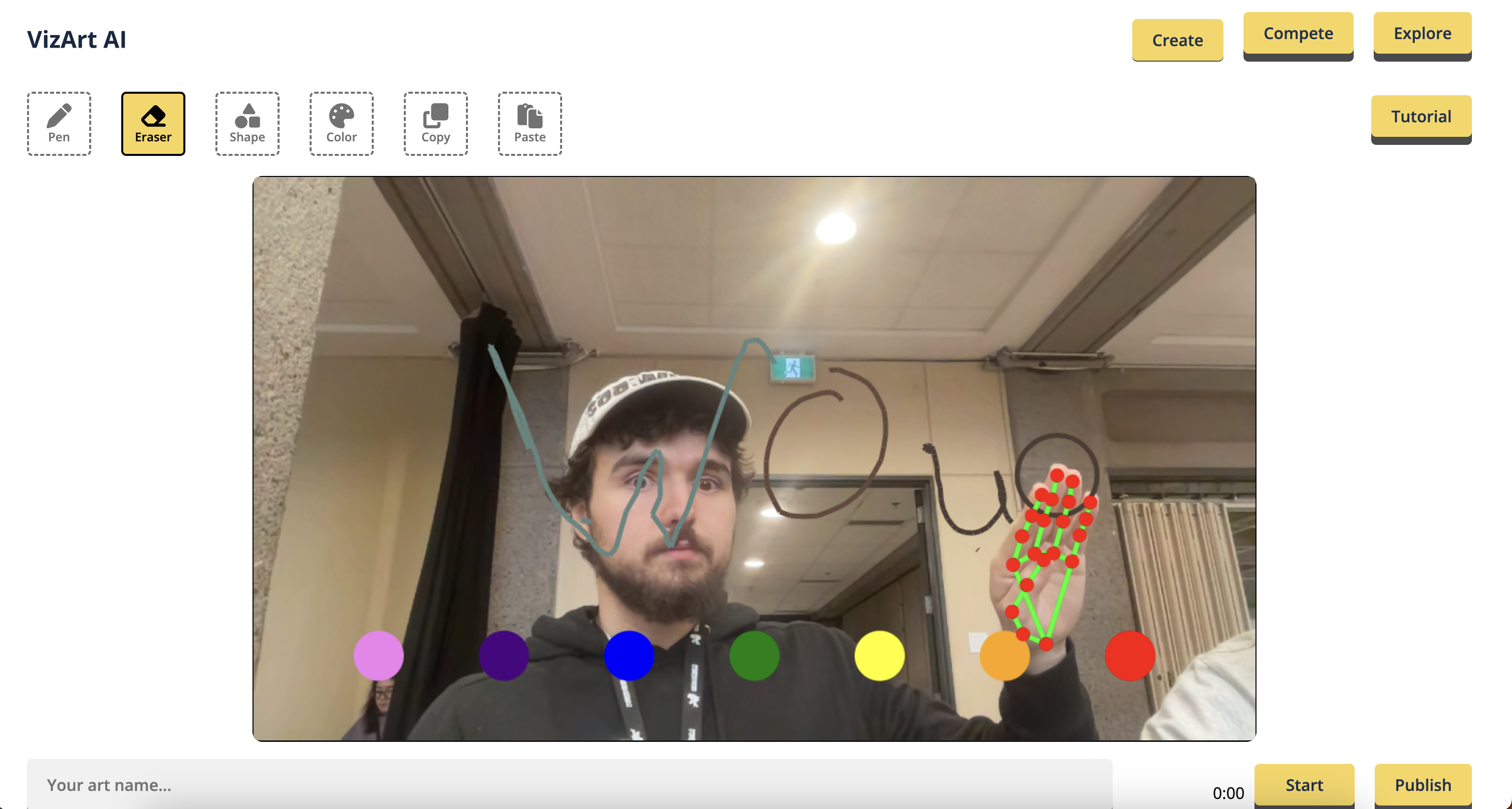
Our computer vision algorithm enables you to interact with the world using a color picker gesture and a snipping tool to manipulate real-world objects.
>
> "Art is not what you see, but what you make others see." - Claude Monet
>
>
>
The features I listed above are great! But what's the point of creating something if you can't share it with the world? That's why we've built a platform for you to showcase your art. You'll be able to record and share your drawings with friends.
I hope you will enjoy using VizArt and share it with your friends. Remember: Make good gifts, Make good art.
# ❤️ Use Cases
### Drawing Competition/Game
VizArt can be used to host a fun and interactive drawing competition or game. Players can challenge each other to create the best masterpiece, using the computer vision features such as the color picker and eraser.
### Whiteboard Replacement
VizArt is a great alternative to traditional whiteboards. It can be used in classrooms and offices to present ideas, collaborate with others, and make annotations. Its computer vision features make drawing and erasing easier.
### People with Disabilities
VizArt enables people with disabilities to express their creativity. Its computer vision capabilities facilitate drawing, erasing, and annotating without the need for physical tools or contact.
### Strategy Games
VizArt can be used to create and play strategy games with friends. Players can draw their own boards and pieces, and then use the computer vision features to move them around the board. This allows for a more interactive and engaging experience than traditional board games.
### Remote Collaboration
With VizArt, teams can collaborate remotely and in real-time. The platform is equipped with features such as the color picker, eraser, and snipping tool, making it easy to interact with the environment. It also has a sharing platform where users can record and share their drawings with anyone. This makes VizArt a great tool for remote collaboration and creativity.
# 👋 Gestures Tutorial


# ⚒️ Engineering
Ah, this is where even more fun begins!
## Stack
### Frontend
We designed the frontend with Figma and after a few iterations, we had an initial design to begin working with. The frontend was made with React and Typescript and styled with Sass.
### Backend
We wrote the backend in Flask. To implement uploading videos along with their thumbnails we simply use a filesystem database.
## Computer Vision AI
We use MediaPipe to grab the coordinates of the joints and upload images. WIth the coordinates, we plot with CanvasRenderingContext2D on the canvas, where we use algorithms and vector calculations to determinate the gesture. Then, for image generation, we use the DeepAI open source library.
# Experimentation
We were using generative AI to generate images, however we ran out of time.
# 👨💻 Team (”The Sprint Team”)
@Sheheryar Pavaz
@Anton Otaner
@Jingxiang Mo
@Tommy He
|
partial
|
Introduction:
We are freshman students gaining experience by participating in our first-ever hackathon. Even if we might not win, we surely would take a lot of experience with us!
About the project:
We have two ideas for a Web application.
I) A OpenAI-powered virtual assistant to help people communicate their emotions.
The chatbot usually reads the prompt by the user and provides its input on it.
II) Analyzing nutritional deficiency via bio-impedance
The goal of this project is to map data on nutritional deficiency and body composition specific to a region in order for companies to introduce a product that caters to the nutritional expectations of that region. We have successfully made the UI/UX for this project.
Our Research:
1) Analyzing nutritional deficiency via electric impedance technology-
We researched electric impedance technology and learned a lot in the process. It is a technology that is advantageous and provides extensive data on which we can work. By catering to the user’s nutritional needs and providing him with data about which nutrients should be added to his diet and providing medical counseling services through our counseling we try to mitigate the mental health problems of the user.
<https://www.researchgate.net/publication/254391856_Advances_in_electrical_impedance_methods_in_medical_diagnostics>
<https://translational-medicine.biomedcentral.com/articles/10.1186/s12967-020-02395-9>
(Also wanted to add that bioimpedance research has suggested it can be used to detect types of cancer cells; though nothing related to our project but shows how promising this can be)
2)Chatbot that expresses human emotions and listens to depressed people-
Depression is a common mental health condition that affects millions of people worldwide. According to the World Health Organization (WHO), depression is the leading cause of disability worldwide, with an estimated 264 million people affected by the condition in 2020. In the United States, the National Institute of Mental Health (NIMH) reports that approximately 17.3 million adults (7.1% of the adult population) experienced at least one major depressive episode in 2019. Given the effects of depression on mental health.
Challenges we ran into
Using the open API because it is a new API and not many resources are available on it.
Working constantly solving and debugging programs was a tough challenge.
What we learned
We learned to use open API and Figma to make the UI/UX of the bio-impedance mobile app.
What's next for MBS (Mind Body Sync)
We have some exciting plans for the next phase of the project. We're going to build on the progress we've made so far and take it to the next level. We're confident that we can deliver something truly exceptional and we can't wait to share it with everyone. There's a lot of hard work ahead, but we're all committed to making this project a huge success. Stay tuned for more updates!
|
## Inspiration
Based on CDC’s second nutrition report, nutritional deficiency affects less than 10 percent of the American population. However, in some ethic or age groups, more than one third of the population group suffer nutritional deficiency. The lack of certain nutrients could lower one’s quality of life, and even lead to fatal illness.
## What it does
To start off, a user could simply use an email address and set a password to create a new account. After registering, the user may log in to the website, and access more functions.
After login, the user can view the dashboard and record their daily meal. The left section allows the user to record each food intake and measures the nutrients in each portion of the food. The user can add multiple times if one consumes one than one food. All entries in a day will be saved in this section, and the user may review the entry history.
On the right side, the user's daily nutrients intake will be analyzed and presented as a pie chart. A calorie count and percentage of nutrients will appear on the top left of the pie chart, providing health-related info. The user may know about their nutrient intake information through this section of the dashboard.
Finally, we have a user profile page, allowing the user to store and change personal information. In this section, the user can update health-related information, such as height, weight, and ages. By providing this information, the system may give a better measure of the user, and provide more accurate advice.
## How we built it
We constructed a Firebase Realtime Database which is used to store user data. As for the front-end side, our team used React with CSS and HTML to build a website. We also used Figma for UI design and prototyping. As a team, we collaborate by using Github and we use Git as our version control tool.
## Challenges we ran into
One of the major challenges that we have is to assemble the project using react, which caused a technical issues for everyone. Since everyone was working on an individual laptop, sometimes there will be conflicts between each commit. For example, someone may build a section differently from another, which causes a crash in the program.
## Accomplishments that we're proud of
Even though our project is not as complete as we had hoped, we are proud of what we accomplished. We built something in an attempt to raise awareness of health issues and we will continue with this project.
## What we learned
Before we basically had no experience with a full-stack web application. Although this project is not technically full-stack, we learned a lot. Some of our teammates learned to use react, while others learned to use a NoSQL Database like Firebase Realtime Database.
## What's next for N-Tri
By collecting user's information, such as height, weight, and ages, we can personalize their nutrition plan, and provide better services. In addition, we will have a recipe recommendation section for everyone, in order for people to have a better daily meal plan. In addition, we would like to add create a more robust UI/UX design.
|
## Inspiration
1 in 2 Canadians will personally experience a mental health issue by age 40, with minority communities at a greater risk. As the mental health epidemic surges and support at its capacity, we sought to build something to connect trained volunteer companions with people in distress in several ways for convenience.
## What it does
Vulnerable individuals are able to call or text any available trained volunteers during a crisis. If needed, they are also able to schedule an in-person meet-up for additional assistance. A 24/7 chatbot is also available to assist through appropriate conversation. You are able to do this anonymously, anywhere, on any device to increase accessibility and comfort.
## How I built it
Using Figma, we designed the front end and exported the frame into Reacts using Acovode for back end development.
## Challenges I ran into
Setting up the firebase to connect to the front end react app.
## Accomplishments that I'm proud of
Proud of the final look of the app/site with its clean, minimalistic design.
## What I learned
The need for mental health accessibility is essential but unmet still with all the recent efforts. Using Figma, firebase and trying out many open-source platforms to build apps.
## What's next for HearMeOut
We hope to increase chatbot’s support and teach it to diagnose mental disorders using publicly accessible data. We also hope to develop a modeled approach with specific guidelines and rules in a variety of languages.
|
losing
|
# Inspiration
When we ride a cycle we to steer the cycle towards the direction we fall, and that's how we balance. But the amazing part is we(or our brain) compute a complex set of calculations to balance ourselves. And that we do it naturally. With some practice it gets better. The calculation in our mind that goes on highly inspired us. At first we thought of creating the cycle, but later after watching "Handle" from Boston Dynamics, we thought of creating the self balancing robot, "Istable". Again one more inspiration was watching modelling of systems mathematically in our control systems labs along with how to tune a PID controlled system.
# What it does
Istable is a self balancing robot, running on two wheels, balances itself and tries to stay vertical all the time. Istable can move in all directions, rotate and can be a good companion for you. It gives you a really good idea of robot dynamics and kinematics. Mathematically model a system. It can aslo be used to teach college students the tuning of PIDs of a closed loop system. It is a widely used control scheme algorithm and also very robust to use algorithm. Along with that From Zeigler Nichols, Cohen Coon to Kappa Tau methods can also be implemented to teach how to obtain the coefficients in real time. Theoretical modelling to real time implementation. Along with that we can use in hospitals as well where medicines are kept at very low temperature and needs absolute sterilization to enter, we can use these robots there to carry out these operations. And upcoming days we can see our future hospitals in a new form.
# How we built it
The mechanical body was built using scrap woods laying around, we first made a plan how the body will look like, we gave it a shape of "I" that's and that's where it gets its name. Made the frame, placed the batteries(2x 3.7v li-ion), the heaviest component, along with that attached two micro metal motors of 600 RPM at 12v, cut two hollow circles from old sandal to make tires(rubber gives a good grip and trust me it is really necessary), used a boost converter to stabilize and step up the voltage from 7.4v to 12v, a motor driver to drive the motors, MPU6050 to measure the inclination angle, and a Bluetooth module to read the PID parameters from a mobile app to fine tune the PID loop. And the brain a microcontroller(lgt8f328p). Next we made a free body diagram, located the center of gravity, it needs to be above the centre of mass, adjusted the weight distribution like that. Next we made a simple mathematical model to represnt the robot, it is used to find the transfer function and represents the system. Later we used that to calculate the impulse and step response of the robot, which is very crucial for tuning the PID parameters, if you are taking a mathematical approach, and we did that here, no hit and trial, only application of engineering. The microcontroller runs a discrete(z domain) PID controller to balance the Istable.
# Challenges we ran into
We were having trouble balancing Istable at first(which is obvious ;) ), and we realized that was due to the placing the gyro, we placed it at the top at first, we corrected that by placing at the bottom, and by that way it naturally eliminated the tangential component of the angle thus improving stabilization greatly. Next fine tuning the PID loop, we do got the initial values of the PID coefficients mathematically, but the fine tuning took a hell lot of effort and that was really challenging.
# Accomplishments we are proud of
Firstly just a simple change of the position of the gyro improved the stabilization and that gave us a high hope, we were loosing confidence before. The mathematical model or the transfer function we found was going correct with real time outputs. We were happy about that. Last but not least, the yay moment was when we tuned the robot way correctly and it balanced for more than 30seconds.
# What we learned
We learned a lot, a lot. From kinematics, mathematical modelling, control algorithms apart from PID - we learned about adaptive control to numerical integration. W learned how to tune PID coefficients in a proper way mathematically, no trial and error method. We learned about digital filtering to filter out noisy data, along with that learned about complementary filters to fuse the data from accelerometer and gyroscope to find accurate angles.
# Whats next for Istable
We will try to add an onboard display to change the coefficients directly over there. Upgrade the algorithm so that it can auto tune the coefficients itself. Add odometry for localized navigation. Also use it as a thing for IoT to serve real time operation with real time updates.
|
## Inspiration
40 million people in the world are blind, including 20% of all people aged 85 or older. Half a million people suffer paralyzing spinal cord injuries every year. 8.5 million people are affected by Parkinson’s disease, with the vast majority of these being senior citizens. The pervasive difficulty for these individuals to interact with objects in their environment, including identifying or physically taking the medications vital to their health, is unacceptable given the capabilities of today’s technology.
First, we asked ourselves the question, what if there was a vision-powered robotic appliance that could serve as a helping hand to the physically impaired? Then we began brainstorming: Could a language AI model make the interface between these individual’s desired actions and their robot helper’s operations even more seamless? We ended up creating Baymax—a robot arm that understands everyday speech to generate its own instructions for meeting exactly what its loved one wants. Much more than its brilliant design, Baymax is intelligent, accurate, and eternally diligent.
We know that if Baymax was implemented first in high-priority nursing homes, then later in household bedsides and on wheelchairs, it would create a lasting improvement in the quality of life for millions. Baymax currently helps its patients take their medicine, but it is easily extensible to do much more—assisting these same groups of people with tasks like eating, dressing, or doing their household chores.
## What it does
Baymax listens to a user’s requests on which medicine to pick up, then picks up the appropriate pill and feeds it to the user. Note that this could be generalized to any object, ranging from food, to clothes, to common household trinkets, to more. Baymax responds accurately to conversational, even meandering, natural language requests for which medicine to take—making it perfect for older members of society who may not want to memorize specific commands. It interprets these requests to generate its own pseudocode, later translated to robot arm instructions, for following the tasks outlined by its loved one. Subsequently, Baymax delivers the medicine to the user by employing a powerful computer vision model to identify and locate a user’s mouth and make real-time adjustments.
## How we built it
The robot arm by Reazon Labs, a 3D-printed arm with 8 servos as pivot points, is the heart of our project. We wrote custom inverse kinematics software from scratch to control these 8 degrees of freedom and navigate the end-effector to a point in three dimensional space, along with building our own animation methods for the arm to follow a given path. Our animation methods interpolate the arm’s movements through keyframes, or defined positions, similar to how film editors dictate animations. This allowed us to facilitate smooth, yet precise, motion which is safe for the end user.
We built a pipeline to take in speech input from the user and process their request. We wanted users to speak with the robot in natural language, so we used OpenAI’s Whisper system to convert the user commands to text, then used OpenAI’s GPT-4 API to figure out which medicine(s) they were requesting assistance with.
We focused on computer vision to recognize the user’s face and mouth. We used OpenCV to get the webcam live stream and used 3 different Convolutional Neural Networks for facial detection, masking, and feature recognition. We extracted coordinates from the model output to extrapolate facial landmarks and identify the location of the center of the mouth, simultaneously detecting if the user’s mouth is open or closed.
When we put everything together, our result was a functional system where a user can request medicines or pills, and the arm will pick up the appropriate medicines one by one, feeding them to the user while making real time adjustments as it approaches the user’s mouth.
## Challenges we ran into
We quickly learned that working with hardware introduced a lot of room for complications. The robot arm we used was a prototype, entirely 3D-printed yet equipped with high-torque motors, and parts were subject to wear and tear very quickly, which sacrificed the accuracy of its movements. To solve this, we implemented torque and current limiting software and wrote Python code to smoothen movements and preserve the integrity of instruction.
Controlling the arm was another challenge because it has 8 motors that need to be manipulated finely enough in tandem to reach a specific point in 3D space. We had to not only learn how to work with the robot arm SDK and libraries but also comprehend the math and intuition behind its movement. We did this by utilizing forward kinematics and restricted the servo motors’ degrees of freedom to simplify the math. Realizing it would be tricky to write all the movement code from scratch, we created an animation library for the arm in which we captured certain arm positions as keyframes and then interpolated between them to create fluid motion.
Another critical issue was the high latency between the video stream and robot arm’s movement, and we spent much time optimizing our computer vision pipeline to create a near instantaneous experience for our users.
## Accomplishments that we're proud of
As first-time Hackathon participants, we are incredibly proud of the incredible progress we were able to make in a very short amount of time, proving to ourselves that with hard work, passion, and a clear vision, anything is possible. Our team did a fantastic job embracing the challenge of using technology unfamiliar to us, and stepped out of our comfort zones to bring our idea to life. Whether it was building the computer vision model, or learning how to interface the robot arm’s movements with voice controls, we ended up building a robust prototype which far surpassed our initial expectations. One of our greatest successes was coordinating our work so that each function could be pieced together and emerge as a functional robot. Let’s not overlook the success of not eating our hi-chews we were using for testing!
## What we learned
We developed our skills in frameworks we were initially unfamiliar with such as how to apply Machine Learning algorithms in a real-time context. We also learned how to successfully interface software with hardware - crafting complex functions which we could see work in 3-dimensional space. Through developing this project, we also realized just how much social impact a robot arm can have for disabled or elderly populations.
## What's next for Baymax
Envision a world where Baymax, a vigilant companion, eases medication management for those with mobility challenges. First, Baymax can be implemented in nursing homes, then can become a part of households and mobility aids. Baymax is a helping hand, restoring independence to a large disadvantaged group.
This innovation marks an improvement in increasing quality of life for millions of older people, and is truly a human-centric solution in robotic form.
|
## Inspiration
* Home pets
## What it does
* Can be toggled to move based on user-based joystick direction
* Performs tricks (spinning around, wags tail) based on user's hand gestures
* Serves as runaway alarm clock in the morning by backing away (wags tail after caught by user)
* Displays daily schedule and reminders on LCD Display (in idle mode), and the distance from user to robot (while in motion)
## How we built it
* Facilitated an effective wireless communication between ESP32 and ESP8266 to control the wheels/ wheel motors based on the user's hand gestures
* Used Python OpenCV library to develop an algorithm capable of recognizing hand gestures (through the PC's camera)
* Used Pyserial to communicate between the Python and Arduino code
* Integrated communication between three microcontrollers (Arduino Uno, ESP32, ESP8266) using ESP NOW WiFi connection - between ESP32 and ESP8266, enabling the transmission of several variables, and between ESP 8266 and Arduino, enabling signals for motors and display
* Used ultrasonic sensor to back the robot away from approaching user by powering motors to drive wheels
* Employed LCD display to show approximate distance between user and robot from ultrasonic sensor (while in motion), and flash important reminders for the user
* Used a touch sensor for user to turn the alarm off, and turn on/rotate the large servo motor to simulate a pet wagging its tail
## Challenges we ran into
* Received components (hobby motors) without gears, causing disconnection with the gear box and inability to power the wheels
* Integrating Pyserial due to the challenging nature of Windows development environment (managing Python packages and libraries)
* Computer failure while attempting to detect driver for ESP 8266 connection
## Accomplishments that we're proud of
* Employing multiple microcontrollers to communicate data (Arduino Uno, ESP32, ESP8266)
* Successfully creating an algorithm to read hand gestures through a PC camera
* Utilizing multiple sensors as inputs to analyze sets of data
## What we learned
* How to develop a communication system from scratch, enabling usage of microcontrollers for a singular robot
* How to plan out and design an organized circuit to integrate multiple sensors, microcontrollers and displays on a singular chassis
* How to efficiently divide workload between team members, enabling each member to execute tasks related to personal skills and interests
## What's next for Pawblo Pro
* Adding phone slot on the top of the chassis for user to place (as alarm clock)
* Using additional sensors to detect objects and prevent collision (to run away more effectively)
* Using a portable or phone camera to detect gestures instead of PC camera
|
winning
|

## 💡INSPIRATION💡
Our team is from Ontario and BC, two provinces that have been hit HARD by the opioid crisis in Canada. Over **4,500 Canadians under the age of 45** lost their lives through overdosing during 2021, almost all of them preventable, a **30% increase** from the year before. During an unprecedented time, when the world is dealing with the covid pandemic and the war in Ukraine, seeing the destruction and sadness that so many problems are bringing, knowing that there are still people fighting to make a better world inspired us. Our team wanted to try and make a difference in our country and our communities, so... we came up with **SafePulse, an app to combat the opioid crisis, where you're one call away from OK, not OD.**
**Please checkout what people are doing to combat the opioid crisis, how it's affecting Canadians and learn more about why it's so dangerous and what YOU can do.**
<https://globalnews.ca/tag/opioid-crisis/>
<https://globalnews.ca/news/8361071/record-toxic-illicit-drug-deaths-bc-coroner/>
<https://globalnews.ca/news/8405317/opioid-deaths-doubled-first-nations-people-ontario-amid-pandemic/>
<https://globalnews.ca/news/8831532/covid-excess-deaths-canada-heat-overdoses/>
<https://www.youtube.com/watch?v=q_quiTXfWr0>
<https://www2.gov.bc.ca/gov/content/overdose/what-you-need-to-know/responding-to-an-overdose>
## ⚙️WHAT IT DOES⚙️
**SafePulse** is a mobile app designed to combat the opioid crisis. SafePulse provides users with resources that they might not know about such as *'how to respond to an overdose'* or *'where to get free naxolone kits'.* Phone numbers to Live Support through 24/7 nurses are also provided, this way if the user chooses to administer themselves drugs, they can try and do it safely through the instructions of a registered nurse. There is also an Emergency Response Alarm for users, the alarm alerts emergency services and informs them of the type of drug administered, the location, and access instruction of the user. Information provided to users through resources and to emergency services through the alarm system is vital in overdose prevention.
## 🛠️HOW WE BUILT IT🛠️
We wanted to get some user feedback to help us decide/figure out which features would be most important for users and ultimately prevent an overdose/saving someone's life.
Check out the [survey](https://forms.gle/LHPnQgPqjzDX9BuN9) and the [results](https://docs.google.com/spreadsheets/d/1JKTK3KleOdJR--Uj41nWmbbMbpof1v2viOfy5zaXMqs/edit?usp=sharing)!
As a result of the survey, we found out that many people don't know what the symptoms of overdoses are and what they may look like; we added another page before the user exits the timer to double check whether or not they have symptoms. We also determined that by having instructions available while the user is overdosing increases the chances of someone helping.
So, we landed on 'passerby information' and 'supportive resources' as our additions to the app.
Passerby information is information that anyone can access while the user in a state of emergency to try and save their life. This took the form of the 'SAVEME' page, a set of instructions for Good Samaritans that could ultimately save the life of someone who's overdosing.
Supportive resources are resources that the user might not know about or might need to access such as live support from registered nurses, free naxolone kit locations, safe injection site locations, how to use a narcan kit, and more!
Tech Stack: ReactJS, Firebase, Python/Flask
SafePulse was built with ReactJS in the frontend and we used Flask, Python and Firebase for the backend and used the Twilio API to make the emergency calls.
## 😣 CHALLENGES WE RAN INTO😣
* It was Jacky's **FIRST** hackathon and Matthew's **THIRD** so there was a learning curve to a lot of stuff especially since we were building an entire app
* We originally wanted to make the app utilizing MERN, we tried setting up the database and connecting with Twilio but it was too difficult with all of the debugging + learning nodejs and Twilio documentation at the same time 🥺
* Twilio?? HUGEEEEE PAIN, we couldn't figure out how to get different Canadian phone numbers to work for outgoing calls and also have our own custom messages for a little while. After a couple hours of reading documentation, we got it working!
## 🎉ACCOMPLISHMENTS WE ARE PROUD OF🎉
* Learning git and firebase was HUGE! Super important technologies in a lot of projects
* With only 1 frontend developer, we managed to get a sexy looking app 🤩 (shoutouts to Mitchell!!)
* Getting Twilio to work properly (its our first time)
* First time designing a supportive app that's ✨**functional AND pretty** ✨without a dedicated ui/ux designer
* USER AUTHENTICATION WORKS!! ( つ•̀ω•́)つ
* Using so many tools, languages and frameworks at once, and making them work together :D
* Submitting on time (I hope? 😬)
## ⏭️WHAT'S NEXT FOR SafePulse⏭️
SafePulse has a lot to do before it can be deployed as a genuine app.
* Partner with local governments and organizations to roll out the app and get better coverage
* Add addiction prevention resources
* Implement google maps API + location tracking data and pass on the info to emergency services so they get the most accurate location of the user
* Turn it into a web app too!
* Put it on the app store and spread the word! It can educate tons of people and save lives!
* We may want to change from firebase to MongoDB or another database if we're looking to scale the app
* Business-wise, a lot of companies sell user data or exploit their users - we don't want to do that - we'd be looking to completely sell the app to the government and get a contract to continue working on it/scale the project. Another option would be to sell our services to the government and other organizations on a subscription basis, this would give us more control over the direction of the app and its features while partnering with said organizations
## 🎁ABOUT THE TEAM🎁
*we got two Matthew's by the way (what are the chances?)*
Mitchell is a 1st year computer science student at Carleton University studying Computer Science. He is most inter tested in programing language enineering. You can connect with him at his [LinkedIn](https://www.linkedin.com/in/mitchell-monireoluwa-mark-george-261678155/) or view his [Portfolio](https://github.com/MitchellMarkGeorge)
Jacky is a 2nd year Systems Design Engineering student at the University of Waterloo. He is most experienced with embedded programming and backend. He is looking to explore various fields in development. He is passionate about reading and cooking. You can reach out to him at his [LinkedIn](https://www.linkedin.com/in/chenyuxiangjacky/) or view his [Portfolio](https://github.com/yuxstar1444)
Matthew B is an incoming 3rd year computer science student at Wilfrid Laurier University. He is most experienced with backend development but looking to learn new technologies and frameworks. He is passionate about music and video games and always looking to connect with new people. You can reach out to him at his [LinkedIn](https://www.linkedin.com/in/matthew-borkowski-b8b8bb178/) or view his [GitHub](https://github.com/Sulima1)
Matthew W is a 3rd year computer science student at Simon Fraser University, currently looking for a summer 2022 internship. He has formal training in data science. He's interested in learning new and honing his current frontend skills/technologies. Moreover, he has a deep understanding of machine learning, AI and neural networks. He's always willing to have a chat about games, school, data science and more! You can reach out to him at his [LinkedIn](https://www.linkedin.com/in/matthew-wong-240837124/), visit his [website](https://wongmatt.dev) or take a look at what he's [working on](https://github.com/WongMatthew)
### 🥳🎉THANK YOU WLU FOR HOSTING HAWKHACKS🥳🎉
|
## Inspiration
In August, one of our team members was hit by a drunk driver. She survived with a few cuts and bruises, but unfortunately, there are many victims who are not as lucky. The emotional and physical trauma she and other drunk-driving victims experienced motivated us to try and create a solution in the problem space.
Our team initially started brainstorming ideas to help victims of car accidents contact first response teams faster, but then we thought, what if we could find an innovative way to reduce the amount of victims? How could we help victims by preventing them from being victims in the first place, and ensuring the safety of drivers themselves?
Despite current preventative methods, alcohol-related accidents still persist. According to the National Highway Traffic Safety Administration, in the United States, there is a death caused by motor vehicle crashes involving an alcohol-impaired driver every 50 minutes. The most common causes are rooted in failing to arrange for a designated driver, and drivers overestimating their sobriety. In order to combat these issues, we developed a hardware and software tool that can be integrated into motor vehicles.
We took inspiration from the theme “Hack for a Night out”. While we know this theme usually means making the night out a better time in terms of fun, we thought that another aspect of nights out that could be improved is getting everyone home safe. Its no fun at all if people end up getting tickets, injured, or worse after a fun night out, and we’re hoping that our app will make getting home a safer more secure journey.
## What it does
This tool saves lives.
It passively senses the alcohol levels in a vehicle using a gas sensor that can be embedded into a car’s wheel or seat. Using this data, it discerns whether or not the driver is fit to drive and notifies them. If they should not be driving, the app immediately connects the driver to alternative options of getting home such as Lyft, emergency contacts, and professional driving services, and sends out the driver’s location.
There are two thresholds from the sensor that are taken into account: no alcohol present and alcohol present. If there is no alcohol present, then the car functions normally. If there is alcohol present, the car immediately notifies the driver and provides the options listed above. Within the range between these two thresholds, our application uses car metrics and user data to determine whether the driver should pull over or not. In terms of user data, if the driver is under 21 based on configurations in the car such as teen mode, the app indicates that the driver should pull over. If the user is over 21, the app will notify if there is reckless driving detected, which is based on car speed, the presence of a seatbelt, and the brake pedal position.
## How we built it
Hardware Materials:
* Arduino uno
* Wires
* Grove alcohol sensor
* HC-05 bluetooth module
* USB 2.0 b-a
* Hand sanitizer (ethyl alcohol)
Software Materials:
* Android studio
* Arduino IDE
* General Motors Info3 API
* Lyft API
* FireBase
## Challenges we ran into
Some of the biggest challenges we ran into involved Android Studio. Fundamentally, testing the app on an emulator limited our ability to test things, with emulator incompatibilities causing a lot of issues. Fundamental problems such as lack of bluetooth also hindered our ability to work and prevented testing of some of the core functionality. In order to test erratic driving behavior on a road, we wanted to track a driver’s ‘Yaw Rate’ and ‘Wheel Angle’, however, these parameters were not available to emulate on the Mock Vehicle simulator app.
We also had issues picking up Android Studio for members of the team new to Android, as the software, while powerful, is not the easiest for beginners to learn. This led to a lot of time being used to spin up and just get familiar with the platform. Finally, we had several issues dealing with the hardware aspect of things, with the arduino platform being very finicky and often crashing due to various incompatible sensors, and sometimes just on its own regard.
## Accomplishments that we're proud of
We managed to get the core technical functionality of our project working, including a working alcohol air sensor, and the ability to pull low level information about the movement of the car to make an algorithmic decision as to how the driver was driving. We were also able to wirelessly link the data from the arduino platform onto the android application.
## What we learned
* Learn to adapt quickly and don’t get stuck for too long
* Always have a backup plan
## What's next for Drink+Dryve
* Minimize hardware to create a compact design for the alcohol sensor, built to be placed inconspicuously on the steering wheel
* Testing on actual car to simulate real driving circumstances (under controlled conditions), to get parameter data like ‘Yaw Rate’ and ‘Wheel Angle’, test screen prompts on car display (emulator did not have this feature so we mimicked it on our phones), and connecting directly to the Bluetooth feature of the car (a separate apk would need to be side-loaded onto the car or some wi-fi connection would need to be created because the car functionality does not allow non-phone Bluetooth devices to be detected)
* Other features: Add direct payment using service such as Plaid, facial authentication; use Docusign to share incidents with a driver’s insurance company to review any incidents of erratic/drunk-driving
* Our key priority is making sure the driver is no longer in a compromising position to hurt other drivers and is no longer a danger to themselves. We want to integrate more mixed mobility options, such as designated driver services such as Dryver that would allow users to have more options to get home outside of just ride share services, and we would want to include a service such as Plaid to allow for driver payment information to be transmitted securely.
We would also like to examine a driver’s behavior over a longer period of time, and collect relevant data to develop a machine learning model that would be able to indicate if the driver is drunk driving more accurately. Prior studies have shown that logistic regression, SVM, decision trees can be utilized to report drunk driving with 80% accuracy.
|
## Inspiration
False news. False news. False news everywhere. Before reading your news article in depth, let us help you give you a brief overview of what you'll be ingesting.
## What it does
Our Google Chrome extension will analyze the news article you're about to read and give you a heads up on some on the article's sentiment (what emotion is the article trying to convey), top three keywords in the article, and the categories this article's topic belong to.
Our extension also allows you to fact check any statement by simply highlighting the statement, right-clicking, and selecting Fact check this with TruthBeTold.
## How we built it
Our Chrome extension pulls the url of the webpage you're browsing and sends that to our Google Cloud Platform hosted Google App Engine Python server. Our server is then able to parse the content of the page, determine the content of the news article through processing by Newspaper3k API. The scraped article is then sent to Google's Natural Language API Client which assess the article for sentiment, categories, and keywords. This data is then returned to your extension and displayed in a friendly manner.
Fact checking follows a similar path in that our extension sends the highlighted text to our server, which checks against Google's Fact Check Explorer API. The consensus is then returned and alerted.
## Challenges we ran into
* Understanding how to interact with Google's APIs.
* Working with Python flask and creating new endpoints in flask.
* Understanding how Google Chrome extensions are built.
## Accomplishments that I'm proud of
* It works!
|
winning
|
## Inspiration
Introducing TrailGuide, an innovative service designed to enhance your hiking experience through the power of artificial intelligence. TrailGuide is AI-powered and accessible through SMS, allowing hikers to interact seamlessly with a virtual assistant throughout their journey. Imagine having a reliable companion providing real-time information on your route, delivering weather notifications, conducting periodic check-ins, and offering a plethora of useful insights for an enriching hiking adventure. Whether you're a seasoned explorer or a novice adventurer, TrailGuide is here to make your outdoor experience safer, more informed, and ultimately, more enjoyable. Say goodbye to uncertainty on the trail and let TrailGuide be your intelligent guide to a smarter and more connected hiking experience.
## What it does
TrailGuide revolutionizes the hiking experience by offering a comprehensive set of AI-powered features accessible through SMS. That means you can access TrailGuide without an internet connection! This innovative service offers real-time information on your hiking route, keeping you informed about upcoming terrain, points of interest, and potential challenges. TrailGuide goes beyond navigation, offering dynamic weather notifications to ensure you're prepared for changing conditions. The periodic check-in feature enhances safety by prompting users to confirm their well-being during the journey. With TrailGuide, hikers can interact naturally through text messages, receiving personalized and context-aware responses, making the entire adventure more enjoyable, informed, and secure. Whether you're a solo hiker or part of a group, TrailGuide is your intelligent companion, providing a seamless and enriching hiking experience like never before.
## How we built it
* For the app, we used React-Native and Expo, Google Maps API to show map.
* We used Infobip to exchange SMS messages with the user.
* Using Google Cloud's Vertex AI, we classified requests and generated responses.
* Our weather, washroom, and campground data are all from the Government of Canada.
* The MySQL database is hosted on GCP using CloudSQL.
* GitHub actions automatically test our APIs using Postman's Newman. Actions also automatically containerize and build our app in Google Cloud using Cloud Run.
## Challenges we ran into
* Displaying routes using the Google Maps API was quite difficult. We ended up using GeoJSON to map coordinates in GoogleMaps and the Polyline component to display the route.
* We had issues importing data into MySQL
* Creating GitHub actions and modifying them (if it wasn't obvious from the commits)
## Accomplishments that we're proud of
* We were able to automate deployment and testing using GitHub actions
* It's our first time using MySQL
* We are able to send and receive SMS using Infobip
Building a React-Native app for the first time!!! It was really fun learning about how to use components in React-Native and make a development build through Expo.
## What we learned
* How to use Infobip
* How to use GitHub actions
* SQL syntax
* Managing applications in GCP
## What's next for TrailGuide
Implementing an algorithm to find the optimal hiking route between two locations and show potential alternative routes.
|
## Inspiration
Parker was riding his bike down Commonwealth Avenue on his way to work this summer when a car pulled out of nowhere and hit his front tire. Lucky, he wasn't hurt, he saw his life flash before his eyes in that moment and it really left an impression on him. (His bike made it out okay as well, other than a bit of tire misalignment!)
As bikes become more and more ubiquitous as a mode of transportation in big cities with the growth of rental services and bike lanes, bike safety is more prevalent than ever.
## What it does
We designed \_ Bikeable \_ - a Boston directions app for bicyclists that uses machine learning to generate directions for users based on prior bike accidents in police reports. You simply enter your origin and destination, and Bikeable creates a path for you to follow that balances efficiency with safety. While it's comforting to know that you're on a safe path, we also incorporated heat maps, so you can see where the hotspots of bicycle theft and accidents occur, so you can be more well-informed in the future!
## How we built it
Bikeable is built in Google Cloud Platform's App Engine (GAE) and utilizes the best features three mapping apis: Google Maps, Here.com, and Leaflet to deliver directions in one seamless experience. Being build in GAE, Flask served as a solid bridge between a Python backend with machine learning algorithms and a HTML/JS frontend. Domain.com allowed us to get a cool domain name for our site and GCP allowed us to connect many small features quickly as well as host our database.
## Challenges we ran into
We ran into several challenges.
Right off the bat we were incredibly productive, and got a snappy UI up and running immediately through the accessible Google Maps API. We were off to an incredible start, but soon realized that the only effective way to best account for safety while maintaining maximum efficiency in travel time would be by highlighting clusters to steer waypoints away from. We realized that the Google Maps API would not be ideal for the ML in the back-end, simply because our avoidance algorithm did not work well with how the API is set up. We then decided on the HERE Maps API because of its unique ability to avoid areas in the algorithm. Once the front end for HERE Maps was developed, we soon attempted to deploy to Flask, only to find that JQuery somehow hindered our ability to view the physical map on our website. After hours of working through App Engine and Flask, we found a third map API/JS library called Leaflet that had much of the visual features we wanted. We ended up combining the best components of all three APIs to develop Bikeable over the past two days.
The second large challenge we ran into was the Cross-Origin Resource Sharing (CORS) errors that seemed to never end. In the final stretch of the hackathon we were getting ready to link our front and back end with json files, but we kept getting blocked by the CORS errors. After several hours of troubleshooting we realized our mistake of crossing through localhost and public domain, and kept deploying to test rather than running locally through flask.
## Accomplishments that we're proud of
We are incredibly proud of two things in particular.
Primarily, all of us worked on technologies and languages we had never touched before. This was an insanely productive hackathon, in that we honestly got to experience things that we never would have the confidence to even consider if we were not in such an environment. We're proud that we all stepped out of our comfort zone and developed something worthy of a pin on github.
We also were pretty impressed with what we were able to accomplish in the 36 hours. We set up multiple front ends, developed a full ML model complete with incredible data visualizations, and hosted on multiple different services. We also did not all know each other and the team chemistry that we had off the bat was astounding given that fact!
## What we learned
We learned BigQuery, NumPy, Scikit-learn, Google App Engine, Firebase, and Flask.
## What's next for Bikeable
Stay tuned! Or invest in us that works too :)
**Features that are to be implemented shortly and fairly easily given the current framework:**
* User reported incidents - like Waze for safe biking!
* Bike parking recommendations based on theft reports
* Large altitude increase avoidance to balance comfort with safety and efficiency.
|
💡
## Inspiration
49 percent of women reported feeling unsafe walking alone after nightfall according to the Office for National Statistics (ONS). In light of recent sexual assault and harassment incidents in the London, Ontario and Western community, women now feel unsafe travelling alone more than ever.
Light My Way helps women navigate their travel through the safest and most well-lit path. Women should feel safe walking home from school, going out to exercise, or going to new locations, and taking routes with well-lit areas is an important precaution to ensure safe travel. It is essential to always be aware of your surroundings and take safety precautions no matter where and when you walk alone.
🔎
## What it does
Light My Way visualizes data of London, Ontario’s Street Lighting and recent nearby crimes in order to calculate the safest path for the user to take. Upon opening the app, the user can access “Maps” and search up their destination or drop a pin on a location. The app displays the safest route available and prompts the user to “Send Location” which sends the path that the user is taking to three contacts via messages. The user can then click on the google maps button in the lower corner that switches over to the google maps app to navigate the given path. In the “Alarm” tab, the user has access to emergency alert sounds that the user can use when in danger, and upon clicking the sounds play at a loud volume to alert nearby people for help needed.
🔨
## How we built it
React, Javascript, and Android studio were used to make the app. React native maps and directions were also used to allow user navigation through google cloud APIs. GeoJson files were imported of Street Lighting data from the open data website for the City of London to visualize street lights on the map. Figma was used for designing UX/UI.
🥇
## Challenges we ran into
We ran into a lot of trouble visualization such a large amount of data that we exported on the GeoJson street lights. We overcame that by learning about useful mapping functions in react that made marking the location easier.
⚠️
## Accomplishments that we're proud of
We are proud of making an app that can be of potential help to make women be safer walking alone. It is our first time using and learning React, as well as using google maps, so we are proud of our unique implementation of our app using real data from the City of London. It was also our first time doing UX/UI on Figma, and we are pleased with the results and visuals of our project.
🧠
## What we learned
We learned how to use React, how to implement google cloud APIs, and how to import GeoJson files into our data visualization. Through our research, we also became more aware of the issue that women face daily on feeling unsafe walking alone.
💭
## What's next for Light My Way
We hope to expand the app to include more data on crimes, as well as expand to cities surrounding London. We want to continue developing additional safety features in the app, as well as a chatting feature with the close contacts of the user.
|
partial
|
## Inspiration
As a student, sometimes we need to compromise lunch with ramen cup noodles, money, and these problems faced by all the students. So, as a software engineer, I and my roommate thought of a solution to this problem and trying to develop a prototype for the application.
## What it does
Demeter allows you to post your extra perishable food on the website and also allows you to perform a location-based search using zip code so you can look up the free food near you.
## How we built it
We build scalable backend REST services in the flask framework with business logic to authenticate and authorize users. We later build an angular app to talk to the REST services and for the database we used cockroach DB(Postgres). The entire system is deployed on google cloud.
## Challenges we ran into
1. Developing UI/UX for the application.
2. Network issues
## Accomplishments that we're proud of
## What we learned
We learned to build and deploy an end-to-end scalable solution for a problem and work in a team.
## What's next for Demeter
1. Attach Image of food. (image recognition with a neural network)
2. Use of google maps for direction. (for data clustering and location)
3. User Notifications.
4. DocuSign Esign.
5. Claim the free food before you get there feature which will allow users to claim food by paying a minimal charge.
6. IOS and Android Apps.
|
## Inspiration
The both of us study in NYC and take subways almost everyday, and we notice the rampant food insecurity and poverty in an urban area. In 2017 40 million people struggled with hunger (source Feeding America) yet food waste levels remain at an all time high (“50% of all produce in the United States is thrown away” source The Guardian). We wanted to tackle this problem, because it affects a huge population, and we see these effects in and around the city.
## What it does
Our webapp uses machine learning to detect produce and labels of packaged foods. The webapp collects this data, and stores it into a user's ingredients list. Recipes are automatically found using google search API from the ingredients list. Our code parses through the list of ingredients and generates the recipe that would maximize the amount of food items (also based on spoilage).The user may also upload their receipt or grocery list to the webapp. With these features, the goal of our product is to reduce food waste by maximizing the ingredients a user has at home. With our trained datasets that detect varying levels of spoiled produce, a user is able to make more informed choices based on the webapp's recommendation.
## How we built it
We first tried to detect images of different types of food using various platforms like open-cv and AWS. After we had this detection working, we used Flask to display the data onto a webapp. Once the information was stored on the webapp, we automatically generated recipes based on the list of ingredients. Then, we built the front-end (HTML5, CSS3) including UX/UI design into the implementation. We shifted our focus to the back-end, and we decided to detect text from receipts, grocery lists, and labels (packaged foods) that we also displayed onto our webapp. On the webapp we also included an faq page to educate our users on this epidemic. On the webapp we also posted a case study on the product in terms of UX and UI design.
## Challenges we ran
We first used open-cv for image recognition, but we learned about amazon web services, specifically, Amazon Rekognition to identify text and objects to detect expiration dates, labels, produce, and grocery lists. We trained models in sci-kit python to detect levels of spoilage/rotten produce. We encountered merge conflicts with GitHub, so we had to troubleshoot with the terminal in order to resolve them. We were new to using Flask, which we used to connect our python files to display in a webpage. We also had to choose certain features over others that would best fit the needs of the users. This was also our first hackathon ever!
## Accomplishments that we're proud of
We feel proud to have learned new tools in different areas of technology (computer vision, machine learning, different languages) in a short period of time. We also made use of the mentor room early on, which was helpful. We learned different methods to implement similar ideas, and we were able to choose the most efficient one (example: AWS was more efficient for us than open-cv). We also used different functions in order to not repeat lines of code.
## What we learned
New technologies and different ways of implementing them. We both had no experience in ML and computer vision prior to this hackathon. We learned how to divide an engineering project into smaller tasks that we could complete. We managed our time well, so we could choose workshops to attend, but also focus on our project, and get rest.
## What's next for ZeroWaste
In a later version, ZeroWaste would store and analyze the user's history of food items, and recommend recipes (which max out the ingredients that are about to expire using computer vision) as well as other nutritional items similar to what the user consistently eats through ML. In order to tackle food insecurity at colleges and schools ZeroWaste would detect when fresh produce would expire, and predict when an item may expire based on climate/geographic region of community. We had hardware (raspberry PI), which we could have used with a software ML method, so in the future we would want to test the accuracy of our code with the hardware.
|
## Inspiration
Our inspiration stems from a fundamental realization about the critical role food plays in our daily lives. We've observed a disparity, especially in the United States, where the quality and origins of food are often overshadowed, leading to concerns about the overall health impact on consumers.
Several team members had the opportunity to travel to regions where food is not just sustenance but a deeply valued aspect of life. In these places, the connection between what we eat, our bodies, and the environment is highly emphasized. This experience ignited a passion within us to address the disconnect in food systems, prompting the creation of a solution that brings transparency, traceability, and healthier practices to the forefront of the food industry. Our goal is to empower individuals to make informed choices about their food, fostering a healthier society and a more sustainable relationship with the environment.
## What it does
There are two major issues that this app tries to address. The first is directed to those involved in the supply chain, like the producers, inspectors, processors, distributors, and retailers. The second is to the end user. For those who are involved in making the food, each step that moves on in the supply chain is tracked by the producer. For the consumer at the very end who will consume it, it will be a journey on where the food came from including its location, description, and quantity. Throughout its supply chain journey, each food shipment will contain a label that the producer will put on first. This is further stored on the blockchain for guaranteed immutability. As the shipment moves from place to place, each entity ("producer, processor, distributor, etc") will be allowed to make its own updated comment with its own verifiable signature and decentralized identifier (DiD). We did this through a unique identifier via a QR code. This then creates tracking information on that one shipment which will eventually reach the end consumer, who will be able to see the entire history by tracing a map of where the shipment has been.
## How we built it
In order to build this app, we used both blockchain and web2 in order to alleviate some of the load onto different servers. We wrote a solidity smart contract and used Hedera in order to guarantee the immutability of the record of the shipment, and then we have each identifier guaranteed its own verifiable certificate through its location placement. We then used a node express server that incorporated the blockchain with our SQLite database through Prisma ORM. We finally used Firebase to authenticate the whole app together in order to provide unique roles and identifiers. In the front end, we decided to build a react-native app in order to support both Android and iOS. We further used different libraries in order to help us integrate with QR codes and Google Maps. Wrapping all this together, we have a fully functional end-to-end user experience.
## Challenges we ran into
A major challenge that we ran into was that Hedera doesn't have any built-in support for constructing arrays of objects through our solidity contract. This was a major limitation as we had to find various other ways to ensure that our product guaranteed full transparency.
## Accomplishments that we're proud of
These are some of the accomplishments that we can achieve through our app
* Accurate and tamper-resistant food data
* Efficiently prevent, contain, or rectify contamination outbreaks while reducing the loss of revenue
* Creates more transparency and trust in the authenticity of Verifiable Credential data
* Verifiable Credentials help eliminate and prevent fraud
## What we learned
We learned a lot about the complexity of food chain supply. We understand that this issue may take a lot of helping hand to build out, but it's really possible to make the world a better place. To the producers, distributors, and those helping out with the food, it helps them prevent outbreaks by keeping track of certain information as the food shipments transfer from one place to another. They will be able to efficiently track and monitor their food supply chain system, ensuring trust between parties. The consumer wants to know where their food comes from, and this tool will be perfect for them to understand where they are getting their next meal to stay strong and fit.
## What's next for FoodChain
The next step is to continue to build out all the different moving parts of this app. There are a lot of different directions that one person can take app toward the complexity of the supply chain. We can continue to narrow down to a certain industry or we can make this inclusive using the help of web2 + web3. We look forward to utilizing this at some companies where they want to prove that their food ingredients and products are the best.
|
losing
|
## Inspiration
While our team might have come from different corners of the country, with various experience in industry,
and a fiery desire to debate whether tabs or spaces are superior, we all faced similar discomforts in our jobs: insensitivity.
Our time in college has shown us that despite the fact people's diverse backgrounds, everyone can achieve greatness.
Nevertheless, workplace calls and water-cooler conversations are plagued with "microaggressions." A microaggression is a subtle indignity or offensive comment that a person communicates to a group. These subtle, yet hurtful comments lead to marginalization in the workplace, which, as studies have shown, can lead to anxiety and depression. Our team's mission was to tackle the unspoken fight on diversity and inclusion in the workplace.
Our inspiration came from this idea of impartial moderation: why is the marginalized employee's responsibility to take the burden
of calling someone out? Pointing out these microaggressions can lead to the reinforcement of stereotypes, and thus, create lose-lose
situations. We believe that if we can shift the responsibility, we can help create a more inclusive work environment, give equal footing for interviewees, and tackle
marginalization in the workplace from the water-cooler up.
## What it does
### EquiBox:
EquiBox is an IoT conference room companion, a speaker, and microphone that comes alive when meetings take place. It monitors different meeting members' sentiment levels by transcribing sound and running AI to detect for insults or non-inclusive behavior. If an insult is detected, EquiBox comes alive with a beep and a warning about micro-aggressions to impartially moderate an inclusive meeting environment. EquiBox sends live data to EquiTrack for further analysis.
### EquiTalk:
EquiTalk is our custom integration with Twilio (a voice platform used for conference calls) to listen to multi-person phone calls to monitor language, transcribe the live conversation, and flag certain phrases that might be insulting. EquiTalk sends live data to EquiTrack for analysis.
### EquiTrack:
EquiTrack is an enterprise analytics platform designed to allow HR departments to leverage the data created by EquiTalk and EquiBox to improve the overall work culture. EquiTrack provides real-time analysis of ongoing conference calls. The administrator can see not only the amount of micro-aggression that occur throughout the meeting but also the direct sentence that triggered the alert. The audio recordings of the conference calls are recorded as well, so administrators can playback the call to resolve discrepancies.
## How we built it
The LevelSet backend consisted of several independent services. EquiTalk uses a Twilio integration to send call data and metadata to our audio server. Similarly, EquiBox uses Google's VoiceKit, along with Houndify's Speech to Text API, to parse the raw audio format. From there, the transcription of the meeting goes to our micro-aggression classifier (hosted on Google Cloud), which combines a BERT Transformer with an SVC to achieve 90% accuracy on our micro-aggression test set. The classified data then travels to the EquiTalk backend (hosted on Microsoft Azure), which stores the conversation and classification data to populate the dashboard.
## Challenges we ran into
One of the biggest challenges that we ran into was creating the training set for the micro classifier. While there were plenty of data sets that including aggressive behavior in general, their examples lacked the subtlety that our model needed to learn. Our solution to this was to crowdsource and augment the set of the microaggressions. We sent a survey out to Stanford students on campus and compiled an extensive list of microaggressions, which allowed our classifier to achieve the accuracy that it did.
## Accomplishments that we're proud of
We're very proud of the accuracy we were able to achieve with our classifier. By using the BERT transformer, our model was able to classify micro-aggressions using only the handful of examples that we collected. While most DNN models required thousands of samples to achieve high accuracy, our micro-aggression dataset consisted of less than 100 possible micro-aggressions.
Additionally, we're proud of our ability to integrate all of the platforms and systems that were required to support the LevelSet suite. Coordinating multiple deployments and connecting several different APIs was definitely a challenge, and we're proud of the outcome.
## What we learned
* By definition, micro-aggressions are almost intangible social nuances picked up by humans. With minimal training data, it is tough to refine our model for classifying these micro-aggressions.
* Audio processing at scale can lead to several complications. Each of the services that use audio had different format specifications, and due to the decentralized nature of our backend infrastructure, merely sending the data over from service to service required additional effort as well. Ultimately, we settled on trying to handle the audio as upstream as we possibly could, thus eliminating the complication from the rest of the pipeline.
* The integration of several independent systems can lead to unexpected bugs. Because of the dependencies, it was hard to unit test the services ahead of time. Since the only way to make sure that everything was working was with an end-to-end test, a lot of bugs didn't arise until the very end of the hackathon.
## What's next for LevelSuite
We will continue to refine our micro-classifier to use tone classification as an input. Additionally, we will integrate the EquiTalk platform into more offline channels like Slack and email. With a longer horizon, we aim to improve equality in the workplace in all stages of employment, from the interview to the exit interview. We want to expand from conference calls to all workplace communication, and we want to create new strategies to inform and disincentivize exclusive behavior. We wish to LevelSet to level the playing the field in the workplace, and we believe that these next steps will help us achieve that.
|
## Inspiration
As citizens who care deeply about the integrity of information that is being fed to the public, we were troubled by the rampant spread of misinformation and disinformation during (often political) live streams. Our goal is to create a tool that empowers viewers to discern truth from falsehood in **real-time**, ensuring a more informed and transparent viewing experience.
**Problem: Misinformation and disinformation through livestreams is incredibly rampant.**
## What it does
Transparify provides real-time contextual information and emotional analysis for livestream videos, enhancing transparency and helping viewers make informed decisions. It delivers live transcripts, detects emotional tone through voice and facial analysis, and fact-checks statements using you.com.
## How we built it
**The Tech-Stack**:
* Next.js / TailwindCSS / shadcn/ui: For building a responsive and intuitive web interface.
* Hume.ai: For emotion recognition through both facial detection and audio analysis.
* Groq: For advanced STT (speech-to-text) transcription.
* You.com: For real-time fact-checking.
**Pipeline Overview**: (see image for more details)
* Transcription: We use Groq’s whisper integration to transcribe the video’s speech into text.
* Emotion Analysis: Hume AI analyzes facial cues and vocal tones to determine the emotional impact and tone of the speaker’s presentation.
* Fact-Checking: The transcribed and analyzed content is checked for accuracy and context through you.com.
* Web App Integration: All data is seamlessly integrated into the web app built with Next.js for a smooth user experience.
We use Groq and its new whisper integration to get STT transcription from the video. We used Hume AI to provide context about the emotional impact of the presentation of the speaker through facial cues and emotion present in the voice of the speaker to inform the viewer of the likely tone of the address. which is then also checked for likely mistakes, and fed to you.com to verify the information presented by the speaker, providing additional context for whatever is being said. The web app was built using Next.js.
## Challenges we ran into
We originally used YouTube’s embed via iframe, but this didn’t work because many embeds don’t allow recording via HTML MediaRecorders
We devised a hack: use the audio from the computer, but this isn’t that helpful because it means users can’t talk + it’s not super accurate
Our solution: a temporary workaround had to be used in the form of sharing the user's tab with the video and sound playing.
LLM fact-checking being too slow: our solution was to use groq as the first-layer and then fetch you.com query and display it whenever it had loaded (even though this was often times slower than the real-time video)
Integrating both audio and video for Hume: Hume requires a web socket to connect to in order to process emotions (and requires separate tracks for audio and video). This was challenging to implement, but in the end we were able to get it done.
Logistic problems: how does this try to fix the problem we set out to solve? We had to brainstorm through the problem and see what would really be helpful to users and we ultimately decided on the final iteration of this.
## Accomplishments that we're proud of
We are proud of many things with this project:
Real-time analysis: from a technical standpoint, this is very difficult to do.
Seamless Integration: Successfully combining multiple advanced technologies into a cohesive and user-friendly application.
User Empowerment: Providing viewers with the tools to critically analyze livestream content in real-time, enhancing their understanding and decision-making.
## What we learned
We learned a lot, mainly in three areas:
Technical: we learned a lot about React, web sockets, working with many different APIs (Groq, You, Hume) and how these all come together in a working web application.
Domain-related: we learned a lot about how politicians are trained in acting/reacting to questions, as well as how powerful LLMs can be in this space, especially those that have access to the internet.
Teamwork: developed our ability to collaborate effectively, manage tight deadlines, and maintain focus during intensive work periods.
## What's next for Transparify
We think this idea is just a proof-of-concept. Although it may not be the best, there is **definitely** a future in which this service is extremely impactful. Imagine opening up your TV and there is real-time information like this on the side of news broadcasts, where there is important information that could change the trajectory of your life. It’s very important to keep the general public informed and stop the spread of misinformation/disinformation, and we think that Transparify is a proof-of-concept for how LLMs can curb this in the future.
Some future directions:
* We want to work on the speed.
* We want to work on making it more reliable.
* We want to increase support to other sources besides YouTube.
* We want to build a better UI.
|
## Inspiration
We wanted to bring financial literacy into being a part of your everyday life while also bringing in futuristic applications such as augmented reality to really motivate people into learning about finance and business every day. We were looking at a fintech solution that didn't look towards enabling financial information to only bankers or the investment community but also to the young and curious who can learn in an interesting way based on the products they use everyday.
## What it does
Our mobile app looks at company logos, identifies the company and grabs the financial information, recent company news and company financial statements of the company and displays the data in an Augmented Reality dashboard. Furthermore, we allow speech recognition to better help those unfamiliar with financial jargon to better save and invest.
## How we built it
Built using wikitude SDK that can handle Augmented Reality for mobile applications and uses a mix of Financial data apis with Highcharts and other charting/data visualization libraries for the dashboard.
## Challenges we ran into
Augmented reality is very hard, especially when combined with image recognition. There were many workarounds and long delays spent debugging near-unknown issues. Moreover, we were building using Android, something that none of us had prior experience with which made it harder.
## Accomplishments that we're proud of
Circumventing challenges as a professional team and maintaining a strong team atmosphere no matter what to bring something that we believe is truly cool and fun-to-use.
## What we learned
Lots of things about Augmented Reality, graphics and Android mobile app development.
## What's next for ARnance
Potential to build in more charts, financials and better speech/chatbot abilities into out application. There is also a direction to be more interactive with using hands to play around with our dashboard once we figure that part out.
|
partial
|
PulsePoint represents a significant stride in healthcare technology, leveraging the security and efficiency of blockchain to enhance the way medical records are managed and shared across healthcare providers. By creating a centralized Electronic Medical Record (EMR) system, PulsePoint addresses a longstanding issue in healthcare: the cumbersome process of transferring patient records between clinics and healthcare providers. Here's a deeper dive into its components, achievements, lessons learned, and future directions:
Inspiration
The inspiration behind PulsePoint stemmed from the critical need to streamline the management and sharing of medical records in the healthcare industry. The traditional methods of handling EMRs are often fraught with inefficiencies, including delays in record transfers, risks of data breaches, and difficulties in maintaining up-to-date patient information across different healthcare systems. PulsePoint aims to solve these issues by providing a secure, blockchain-based platform that empowers patients with control over their medical data, enabling seamless transfers with just a click.
What It Does
PulsePoint revolutionizes the way EMRs are managed by utilizing blockchain technology to ensure the integrity, security, and portability of medical records. Patients can easily grant access to their medical history to any participating clinic, significantly reducing the administrative burden on healthcare providers and improving the overall patient care experience. This system not only facilitates quicker access to patient data but also enhances data privacy and security, critical components in healthcare.
How We Built It
The development of PulsePoint involved a modified MERN stack (MongoDB, Express.js, React.js, Node.js), incorporating additional technologies such as Auth0 for authentication services and OpenAI's API for an AI-powered assistant. The use of Auth0 allowed for secure and scalable user authentication, while OpenAI's API provided an intelligent assistant feature to help users navigate their medical records and the platform more efficiently. The integration of blockchain technology was a pivotal part of the project, ensuring that all data transactions on the platform are secure and immutable.
Challenges We Ran Into
One of the significant challenges faced during the development was setting up the blockchain service. The team encountered difficulties in integrating blockchain to securely manage the EMRs, which required extensive research and troubleshooting. Another challenge was devising a robust solution for document upload and storage that met the necessary standards for security and privacy compliance.
Accomplishments That We're Proud Of
Despite the challenges, the team successfully developed a functional and secure platform that addresses many of the inefficiencies present in traditional EMR systems. The ability to securely transfer patient records across clinics with ease represents a major achievement in healthcare technology. Furthermore, the team's increased proficiency in React.js and a deeper understanding of blockchain services are significant accomplishments that will benefit future projects.
What We Learned
The development process of PulsePoint was a learning journey, particularly in enhancing the team's skills in React.js and blockchain technology. The project provided valuable insights into the complexities of healthcare data management and the potential of blockchain to address these challenges. It also highlighted the importance of user-friendly design and robust security measures in developing healthcare applications.
What's Next for PulsePoint
Looking ahead, PulsePoint aims to expand its network by onboarding more clinics and healthcare providers, thereby increasing the platform's utility and accessibility for patients nationwide. Future developments will focus on enhancing the platform's AI capabilities to offer more personalized and intelligent features for users, such as health insights and recommendations. Additionally, the team plans to explore the integration of advanced blockchain technologies to further improve data security and interoperability between different healthcare systems.
By continuously evolving and adapting to the needs of the healthcare industry, PulsePoint is poised to become a cornerstone in the digital transformation of healthcare, making patient data management more secure, efficient, and patient-centric.
|
## Inspiration
As a dedicated language learner for over two years, I faced the challenge of finding conversation partners during my first year. Working as a Food Service and Customer Service Worker allowed me to practice and learn real-life conversational skills. This experience inspired me to create a project that helps others learn practical language skills. My personal projects often focus on teaching, and this one aims to provide learners with the tools and opportunities to engage in meaningful conversations and master the language effectively.
## What it does
The app allows users to simulate conversations with diverse characters and different locations in their target language, creating an immersive learning experience. With an interactive, game-like UI, learning becomes fun and engaging. Additionally, the app features a chat window for real-time practice, enhancing conversational skills and making language acquisition more enjoyable and effective.
## How I built it
I used NextJS for the fullstack development of the app. For the style of the elements, I used TailwindCSS. For creating game-like menu, I first created an Isometric Tilemap in Godot and exported the map I created as an image. In Figma, I imported the Image and added the characters and Labels of the locations and exported it as an SVG file. I then converted the SVG file to something useable as a component in NextJS. Since the file is imported as an SVG, I can easily access the components which makes adding onClick functions for each character possible. I used the React useContext function to allow changing of the character in the chat possible. I used Groq and their LLM model for the character AI. I used the NextJS API routing system to fetch the response from the Groq API.
## What's next for LanguageRPG.AI
Allow users to upload pdf files and translate it allowing research papers, business papers, and legal documents accessible for people.
Allow users to hover on each character to show what they mean making learning a language easier.
|
## Inspiration
Our inspiration for this project was the technological and communication gap between healthcare professionals and patients, restricted access to both one’s own health data and physicians, misdiagnosis due to lack of historical information, as well as rising demand in distance-healthcare due to the lack of physicians in rural areas and increasing patient medical home practices. Time is of the essence in the field of medicine, and we hope to save time, energy, money and empower self-care for both healthcare professionals and patients by automating standard vitals measurement, providing simple data visualization and communication channel.
## What it does
What eVital does is that it gets up-to-date daily data about our vitals from wearable technology and mobile health and sends that data to our family doctors, practitioners or caregivers so that they can monitor our health. eVital also allows for seamless communication and monitoring by allowing doctors to assign tasks and prescriptions and to monitor these through the app.
## How we built it
We built the app on iOS using data from the health kit API which leverages data from apple watch and the health app. The languages and technologies that we used to create this are MongoDB Atlas, React Native, Node.js, Azure, Tensor Flow, and Python (for a bit of Machine Learning).
## Challenges we ran into
The challenges we ran into are the following:
1) We had difficulty narrowing down the scope of our idea due to constraints like data-privacy laws, and the vast possibilities of the healthcare field.
2) Deploying using Azure
3) Having to use Vanilla React Native installation
## Accomplishments that we're proud of
We are very proud of the fact that we were able to bring our vision to life, even though in hindsight the scope of our project is very large. We are really happy with how much work we were able to complete given the scope and the time that we have. We are also proud that our idea is not only cool but it actually solves a real-life problem that we can work on in the long-term.
## What we learned
We learned how to manage time (or how to do it better next time). We learned a lot about the health care industry and what are the missing gaps in terms of pain points and possible technological intervention. We learned how to improve our cross-functional teamwork, since we are a team of 1 Designer, 1 Product Manager, 1 Back-End developer, 1 Front-End developer, and 1 Machine Learning Specialist.
## What's next for eVital
Our next steps are the following:
1) We want to be able to implement real-time updates for both doctors and patients.
2) We want to be able to integrate machine learning into the app for automated medical alerts.
3) Add more data visualization and data analytics.
4) Adding a functional log-in
5) Adding functionality for different user types aside from doctors and patients. (caregivers, parents etc)
6) We want to put push notifications for patients' tasks for better monitoring.
|
losing
|
## Inspiration
Have you ever met someone, but forgot their name right afterwards?
Our inspiration for INFU comes from our own struggles to remember every detail of every conversation. We all deal with moments of embarrassment or disconnection when failing to remember someone’s name or details of past conversations.
We know these challenges are not unique to us, but actually common across various social and professional settings. INFU was born to bridge the gap between our human limitations and the potential for enhanced interpersonal connections—ensuring no details or interactions are lost to memory again.
## What it does
By attaching a camera and microphone to a user, we can record different conversations with people by transcribing the audio and categorizing using facial recognition. With this, we can upload these details onto a database and have it summarised by an AI and displayed on our website and custom wrist wearable.
## How we built it
There are three main parts to the project. The first part is the hardware which includes all the wearable components. The second part includes face recognition and speech-to-text processing that receives camera and microphone input from the user's iPhone. The third part is storing, modifying, and retrieving data of people's faces, names, and conversations from our database.
The hardware comprises an ESP-32, an OLED screen, and two wires that act as touch buttons. These touch buttons act as record and stop recording buttons which turn on and off the face recognition and microphone. Data is sent wirelessly via Bluetooth to the laptop which processes the face recognition and speech data. Once a person's name and your conversation with them are extracted from the current data or prior data from the database, the laptop sends that data to the wearable and displays it using the OLED screen.
The laptop acts as the control center. It runs a backend Python script that takes in data from the wearable via Bluetooth and iPhone via WiFi. The Python Face Recognition library then detects the speaker's face and takes a picture. Speech data is subsequently extracted from the microphone using the Google Cloud Speech to Text API which is then parsed through the OpenAI API, allowing us to obtain the person's name and the discussion the user had with that person. This data gets sent to the wearable and the cloud database along with a picture of the person's face labeled with their name. Therefore, if the user meets the person again, their name and last conversation summary can be extracted from the database and displayed on the wearable for the user to see.
## Accomplishments that we're proud of
* Creating an end product with a complex tech stack despite various setbacks
* Having a working demo
* Organizing and working efficiently as a team to complete this project over the weekend
* Combining and integrating hardware, software, and AI into a project
## What's next for Infu
* Further optimizing our hardware
* Develop our own ML model to enhance speech-to-text accuracy to account for different accents, speech mannerisms, languages
* Integrate more advanced NLP techniques to refine conversational transcripts
* Improve user experience by employing personalization and privacy features
|
## Inspiration
We have family members that have autism, and Cinthya told us about a history including her imaginary friends and how she interacted with them in her childhood, so we started a research about this two topics and we came around to with "Imaginary Friends"
## What it does
We are developing an application that allows the kids of all kind draw their imaginary friends to visualize them using augmented reality and keep in the app with the objective to improve social skills based on studies that proof that the imaginary friends help to have better social relationships and better communication. This application is also capable of detecting the mood like joy, sadness, etc. using IBM Watson "speech to text" and Watson "tone analyzer" inorder to give information of interest to the parents of this children or to their psycologist through a web page built with WIX showing statistical data and their imaginary friends.
## Challenges we ran into
We didn't know some of technologies that we used so we had to learn them in the process.
## Accomplishments that we're proud of
Finish the WIX application, and almost conclude the mobile app.
## What we learned
How to use WIX and IBM Watson
## What's next for ImaginaryFriends
We are thinking that Imaginary Friends can go further if we implement the idea in theme parks such Disney Land, etc.
with the idea that the kid could be guided by their own imaginary friend
|
## Inspiration
Imagine a social networking app that uses your face as your unique handle/identifier rather than an username or @.
## What it does
Find out someone's name, interests, and pronouns by simply scanning their face!
Users first register themselves on our database providing a picture of themselves, their name, and a few of their interests. Using the search functionality, users can scan the area for anyone that has registered in the app. If a person's face is recognized in the search, their information will be displayed on screen!
## How we built it
The entire app was built with Android Studio, XML, and Java. The user registration functionality relies on Google Cloud Firebase, and the user search functionality uses Microsoft Azure Face API.
## Challenges we ran into
Because Firebase returns data asynchronously, it was challenging to work with calls to Firebase and threads.
## Accomplishments that we are proud of
* Getting data asynchronously from Firebase
* Consistent facial verification between database photos and Microsoft Azure
## What we learned
* How to work with APIs from both Google and Microsoft
* Building Android applications
## What's next for first hello
Larger scaling/better performance, display information in AR
|
winning
|
## Inspiration
We wanted to make DDR without the sweat and music so that people could play a reaction game on the go.
## What it does
Users can watch an LED matrix with the dots running down the screen. The user can touch a touch sensor. to match with the dots that hit the lower row. If the player misses 4, they lose, with red dots showing for the first 3 times they miss. If they can hit it at the right time, a green dot appears on the right side, with them accumulating. If they lose a big X shows up but if they win, they will be greeted with a cheerful smile.
## How we built it
We used the Arduino Due as our microcontroller, which would receive the input of the user and update the LED matrix. A base shield was added to the Arduino for easier connections to the Grove Touch sensor which received the input from the user. By rapidly displaying the led matrix lights, we were able make it appear as if more than one led was lit up since the led matrix could only light up one led at a time.
## Challenges we ran into
At first the team was going to use the grove gesture sensor and detect different motion, but the Touch sensor was chosen since the time delay was significant and interfering with the reaction time. As well, wiring the LED matrix was challenging since a specific wiring guide could not be found for the model we had, so. we had to guess and check the wire configuration.
## Accomplishments that we're proud of
We were able to make use of the capabilities of the Arduino Due and learn how to coordinate between the program and the hardware, which was a new experience for our Team. As well, we were able to adapt from our original plan, when we faced issues, so that our final product still functions well.
## What we learned
We learned how to use an LED matrix and how to wire various inputs to an Arduino microcontroller.
## What's next for SpeedyFingies
We plan on connecting a speaker to play music on the device, so that it mimics the DDR music. The dots would match the rhythm of the music instead of being at random speeds and and time intervals. As well, since we didn't use the entire led matrix, we could implement a multiplayer feature with another touch sensor.
|
## Inspiration
The inspiration of our game came from the arcade game Cyclone, where the goal is to click the button when the LED lands on a signaled part of the circle.
## What it does
The goal of our game is to click the button when the LED reaches a designated part of the circle (the very last LED). Upon successfully doing this it will add 1 to your score, as well as increasing the speed of the LED, continually making it harder and harder to achieve this goal. The goal is for the player to get as high of a score as possible, as the higher your score is, the harder it will get. Upon clicking the wrong designated LED, the score will reset, as well as the speed value, effectively resetting the game.
## How we built it
The project was split into two parts; one was the physical building of the device and another was the making of the code.
In terms of building the physical device, at first we weren’t too sure what we wanted to do, so we ended up with a mix up of parts we could use. All of us were pretty new to using the Arduino, and its respective parts, so it was initially pretty complicated, before things started to fall into place. Through the use of many Youtube videos, and tinkering, we were able to get the physical device up and running. Much like our coding process, the building process was very dynamic. This is because at first, we weren’t completely sure which parts we wanted to use, so we had multiple components running at once, which allowed for more freedom and possibilities. When we figured out which components we would be using, everything sort of fell into place.
For the code process, it was quite messy at first. This was because none of us were completely familiar with the Arduino libraries, and so it was a challenge to write the proper code. However, with the help of online guides and open source material, we were eventually able to piece together what we needed. Furthermore, our coding process was very dynamic. We would switch out components constantly, and write many lines of code that was never going to be used. While this may have been inefficient, we learned much throughout the process, and it kept our options open and ideas flowing.
## Challenges we ran into
In terms of main challenges that we ran into along the way, the biggest challenge was getting our physical device to function the way we wanted it to. The initial challenge came from understanding our device, specifically the Arduino logic board, and all the connecting parts, which then moved to understanding the parts, as well as getting them to function properly.
## Accomplishments that we're proud of
In terms of main accomplishments, our biggest accomplishment is overall getting the device to work, and having a finished product. After running into many issues and challenges regarding the physical device and its functions, putting our project together was very satisfying, and a big accomplishment for us. In terms of specific accomplishments, the most important parts of our project was getting our physical device to function, as well as getting the initial codebase to function with our project. Getting the codebase to work in our favor was a big accomplishment, as we were mostly reliant on what we could find online, as we were essentially going in blind during the coding process (none of us knew too much about coding with Arduino).
## What we learned
During the process of building our device, we learned a lot about the Arduino ecosystem, as well as coding for it. When building the physical device, a lot of learning went into it, as we didn’t know that much about using it, as well as applying programs for it. We learned how important it is to have a strong connection for our components, as well as directly linking our parts with the Arduino board, and having it run proper code.
## What's next for Cyclone
In terms of what’s next for Cyclone, there are many possibilities for it. Some potential changes we could make would be making it more complex, and adding different modes to it. This would increase the challenge for the player, and give it more replay value as there is more to do with it. Another potential change we could make is to make it on a larger scale, with more LED lights and make attachments, such as the potential use of different types of sensors. In addition, we would like to add an LCD display or a 4 digit display to display the player’s current score and high score.
|
## Inspiration
Our biggest inspiration came from our grandparents, who often felt lonely and struggled to find help. Specifically, one of us have a grandpa with dementia. He lives alone and finds it hard to receive help since most of his relatives live far away and he has reduced motor skills. Knowing this, we were determined to create a product -- and a friend -- that would be able to help the elderly with their health while also being fun to be around! Ted makes this dream a reality, transforming lives and promoting better welfare.
## What it does
Ted is able to...
* be a little cutie pie
* chat with speaker, reactive movements based on conversation (waves at you when greeting, idle bobbing)
* read heart rate, determine health levels, provide help accordingly
* Drives towards a person in need through using the RC car, utilizing object detection and speech recognition
* dance to Michael Jackson
## How we built it
* popsicle sticks, cardboards, tons of hot glue etc.
* sacrifice of my fingers
* Play.HT and Claude 3.5 Sonnet
* YOLOv8
* AssemblyAI
* Selenium
* Arudino, servos, and many sound sensors to determine direction of speaker
## Challenges we ran into
Some challenges we ran into during development was making sure every part was secure. With limited materials, we found that materials would often shift or move out of place after a few test runs, which was frustrating to keep fixing. However, instead of trying the same techniques again, we persevered by trying new methods of appliances, which eventually led a successful solution!
Having 2 speech-to-text models open at the same time showed some issue (and I still didn't fix it yet...). Creating reactive movements was difficult too but achieved it through the use of keywords and a long list of preset moves.
## Accomplishments that we're proud of
* Fluid head and arm movements of Ted
* Very pretty design on the car, poster board
* Very snappy response times with realistic voice
## What we learned
* power of friendship
* don't be afraid to try new things!
## What's next for Ted
* integrating more features to enhance Ted's ability to aid peoples' needs --> ex. ability to measure blood pressure
|
losing
|
## Inspiration
Public speaking is greatly feared by many, yet it is a part of life that most of us have to go through. Despite this, preparing for presentations effectively is *greatly limited*. Practicing with others is good, but that requires someone willing to listen to you for potentially hours. Talking in front of a mirror could work, but it does not live up to the real environment of a public speaker. As a result, public speaking is dreaded not only for the act itself, but also because it's *difficult to feel ready*. If there was an efficient way of ensuring you aced a presentation, the negative connotation associated with them would no longer exist . That is why we have created Speech Simulator, a VR web application used for practice public speaking. With it, we hope to alleviate the stress that comes with speaking in front of others.
## What it does
Speech Simulator is an easy to use VR web application. Simply login with discord, import your script into the site from any device, then put on your VR headset to enter a 3D classroom, a common location for public speaking. From there, you are able to practice speaking. Behind the user is a board containing your script, split into slides, emulating a real powerpoint styled presentation. Once you have run through your script, you may exit VR, where you will find results based on the application's recording of your presentation. From your talking speed to how many filler words said, Speech Simulator will provide you with stats based on your performance as well as a summary on what you did well and how you can improve. Presentations can be attempted again and are saved onto our database. Additionally, any adjustments to the presentation templates can be made using our editing feature.
## How we built it
Our project was created primarily using the T3 stack. The stack uses **Next.js** as our full-stack React framework. The frontend uses **React** and **Tailwind CSS** for component state and styling. The backend utilizes **NextAuth.js** for login and user authentication and **Prisma** as our ORM. The whole application was type safe ensured using **tRPC**, **Zod**, and **TypeScript**. For the VR aspect of our project, we used **React Three Fiber** for rendering **Three.js** objects in, **React XR**, and **React Speech Recognition** for transcribing speech to text. The server is hosted on Vercel and the database on **CockroachDB**.
## Challenges we ran into
Despite completing, there were numerous challenges that we ran into during the hackathon. The largest problem was the connection between the web app on computer and the VR headset. As both were two separate web clients, it was very challenging to communicate our sites' workflow between the two devices. For example, if a user finished their presentation in VR and wanted to view the results on their computer, how would this be accomplished without the user manually refreshing the page? After discussion between using web-sockets or polling, we went with polling + a queuing system, which allowed each respective client to know what to display. We decided to use polling because it enables a severless deploy and concluded that we did not have enough time to setup websockets. Another challenge we had run into was the 3D configuration on the application. As none of us have had real experience with 3D web applications, it was a very daunting task to try and work with meshes and various geometry. However, after a lot of trial and error, we were able to manage a VR solution for our application.
## What we learned
This hackathon provided us with a great amount of experience and lessons. Although each of us learned a lot on the technological aspect of this hackathon, there were many other takeaways during this weekend. As this was most of our group's first 24 hour hackathon, we were able to learn to manage our time effectively in a day's span. With a small time limit and semi large project, this hackathon also improved our communication skills and overall coherence of our team. However, we did not just learn from our own experiences, but also from others. Viewing everyone's creations gave us insight on what makes a project meaningful, and we gained a lot from looking at other hacker's projects and their presentations. Overall, this event provided us with an invaluable set of new skills and perspective.
## What's next for VR Speech Simulator
There are a ton of ways that we believe can improve Speech Simulator. The first and potentially most important change is the appearance of our VR setting. As this was our first project involving 3D rendering, we had difficulty adding colour to our classroom. This reduced the immersion that we originally hoped for, so improving our 3D environment would allow the user to more accurately practice. Furthermore, as public speaking infers speaking in front of others, large improvements can be made by adding human models into VR. On the other hand, we also believe that we can improve Speech Simulator by adding more functionality to the feedback it provides to the user. From hand gestures to tone of voice, there are so many ways of differentiating the quality of a presentation that could be added to our application. In the future, we hope to add these new features and further elevate Speech Simulator.
|
## Inspiration
Our mission is to foster a **culture of understanding**. A culture where people of diverse backgrounds get to truly *connect* with each other. But, how can we reduce the barriers that exists today and make the world more inclusive?
Our solution is to bridge the communication gap of **people with different races and cultures** and **people of different physical abilities**.
## What we built
In 36 hours, we created a mixed reality app that allows everyone in the conversation to communicate using their most comfortable method:
You want to communicate using your mother tongue?
Your friend wants to communicate using sign language?
Your aunt is hard of hearing and she wants to communicate without that back-and-forth frustration?
Our app enables everyone to do that.
## How we built it
VRbind takes in speech and coverts it into text using Bing Speech API. Internally, that text is then translated into your mother tongue language using Google Translate API, and given out as speech back to the user through the built-in speaker on Oculus Rift. Additionally, we also provide a platform where the user can communicate using sign language. This is detected using the leap motion controller and interpreted as an English text. Similarly, the text is then translated into your mother tongue language and given out as speech to Oculus Rift.
## Challenges we ran into
We are running our program in Unity, therefore the challenge is in converting all our APIs into C#.
## Accomplishments that we are proud of
We are proud that we were able complete with all the essential feature that we intended to implement and troubleshoot the problems that we had successfully throughout the competition.
## What we learned
We learn how to code in C# as well as how to select, implement, and integrate different APIs onto the unity platform.
## What's next for VRbind
Facial, voice, and body language emotional analysis of the person that you are speaking with.
|
## Inspiration
One of our team members underwent speech therapy as a child, and the therapy helped him gain a sense of independence and self-esteem. In fact, over 7 million Americans, ranging from children with gene-related diseases to adults who suffer from stroke, go through some sort of speech impairment. We wanted to create a solution that could help amplify the effects of in-person treatment by giving families a way to practice at home. We also wanted to make speech therapy accessible to everyone who cannot afford the cost or time to seek institutional help.
## What it does
BeHeard makes speech therapy interactive, insightful, and fun. We present a hybrid text and voice assistant visual interface that guides patients through voice exercises. First, we have them say sentences designed to exercise specific nerves and muscles in the mouth. We use deep learning to identify mishaps and disorders on a word-by-word basis, and show users where exactly they could use more practice. Then, we lead patients through mouth exercises that target those neural pathways. They imitate a sound and mouth shape, and we use deep computer vision to display the desired lip shape directly on their mouth. Finally, when they are able to hold the position for a few seconds, we celebrate their improvement by showing them wearing fun augmented-reality masks in the browser.
## How we built it
* On the frontend, we used Flask, Bootstrap, Houndify and JavaScript/css/html to build our UI. We used Houndify extensively to navigate around our site and process speech during exercises.
* On the backend, we used two Flask servers that split the processing load, with one running the server IO with the frontend and the other running the machine learning.
* On our algorithms side, we used deep\_disfluency to identify speech irregularities and filler words and used the IBM Watson speech-to-text (STT) API for a more raw, fine-resolution transcription.
* We used the tensorflow.js deep learning library to extract 19 points representing the mouth of a face. With exhaustive vector analysis, we determined the correct mouth shape for pronouncing basic vowels and gave real-time guidance for lip movements. To increase motivation for the user to practice, we even incorporated AR to draw the desired lip shapes on users mouths, and rewards them with fun masks when they get it right!
## Challenges we ran into
* It was quite challenging to smoothly incorporate voice our platform for navigation, while also being sensitive to the fact that our users may have trouble with voice AI. We help those who are still improving gain competence and feel at ease by creating a chat bubble interface that reads messages to users, and also accepts text and clicks.
* We also ran into issues finding the balance between getting noisy, unreliable STT transcriptions and transcriptions that autocorrected our users’ mistakes. We ended up employing a balance of the Houndify and Watson APIs. We also adapted a dynamic programming solution to the Longest Common Subsequence problem to create the most accurate and intuitive visualization of our users’ mistakes.
## Accomplishments that we are proud of
We’re proud of being one of the first easily-accessible digital solutions that we know of that both conducts interactive speech therapy, while also deeply analyzing our users speech to show them insights. We’re also really excited to have created a really pleasant and intuitive user experience given our time constraints.
We’re also proud to have implemented a speech practice program that involves mouth shape detection and correction that customizes the AR mouth goals to every user’s facial dimensions.
## What we learned
We learned a lot about the strength of the speech therapy community, and the patients who inspire us to persist in this hackathon. We’ve also learned about the fundamental challenges of detecting anomalous speech, and the need for more NLP research to strengthen the technology in this field.
We learned how to work with facial recognition systems in interactive settings. All the vector calculations and geometric analyses to make detection more accurate and guidance systems look more natural was a challenging but a great learning experience.
## What's next for Be Heard
We have demonstrated how technology can be used to effectively assist speech therapy by building a prototype of a working solution. From here, we will first develop more models to determine stutters and mistakes in speech by diving into audio and language related algorithms and machine learning techniques. It will be used to diagnose the problems for users on a more personal level. We will then develop an in-house facial recognition system to obtain more points representing the human mouth. We would then gain the ability to feature more types of pronunciation practices and more sophisticated lip guidance.
|
winning
|
## Inspiration
Sleep tracking with your phone is useful, but terribly drains your battery overnight, when it's supposed to be charging.
## What it does
Bluetooth enabled Ardino is implanted into a Plush Toy (the aRAWRm). An app on your phone can activate the buzzer to play the Mario theme, or activate the multi-colored LED.
The app can also be used to set the desired time you wish to wake up. Then, the app will send a signal to the aRAWRm at the set time and activate the LED and alarm.
## How we built it
We hooked up a multi-colored LED and a buzzer to an Ardino. Then we went out to Morning Glory and bought a cute tiger Plush Toy. After performing a surgical incision, we inserted the device and stitched it up, leaving the LED visible, thus making the world's first aRAWRm!
On the app side, we used HTML, CSS, and JavaScript to make a simple UI that allows a user to automatically connect with the Arduino in the aRAWRm and control its expanding features.
## Challenges we ran into
At first, we tried developing the app in Android Studio, but ran into compatibility issues, and had trouble using Bluetooth. Thus, we pivoted to a different platform and use the more agile coding languages of CSS, JavaScript, and HTML. Fitting the components into the stuffed tiger was also a challenge.
## Accomplishments that we're proud of
We are proud that the Arduino was able to receive different commands to perform a range of functions (light, sound, alarm, etc.). This setup is modifiable to add many more features in the long run.
## What we learned
We all got more familiar with CSS, and JavaScript in particular. None of us had coded a full app before, so this was a huge learning experience for us and we had a fantastic time!
## Did we have fun?
Free food, great activities, and fantastic people: Yes, yes we did!
## What's next for aRAWRm
We have all the hardware necessary, including a speedometer, to track motion and track sleep, thus waking you up at the optimal time by an alarm you can't help but love! This sleep data could then be uploaded the cloud through a platform like Google Fit. A vibration motor and rechargeable battery would also be worthwhile improvements.
|
## Inspiration
The Arduino community provides a full eco-system of developing systems, and I saw the potential in using hardware, IOT and cloud-integration to provide a unique solution for streamlining processes for business.
## What it does
The web-app provides the workflow for a one-stop place to manage hundreds of different sensors by incorporating intelligence to each utility provided by the Arduino REST API. Imagine a health-care company that would need to manage all its heart-rate sensors and derive insights quickly and continuously on patient data. Or picture a way for a business to manage customer device location parameters by inputting customized conditions on the data or parameters. Or a way for a child to control her robot-controlled coffee machine from school. This app provides many different possibilities for use-cases.
## How we built it
I connected iPhones to the Arduino cloud, and built a web-app with NodeJS that uses the Arduino IOT API to connect to the cloud, and connected MongoDB to make the app more efficient and scalable. I followed the CRM architecture to build the app, and implemented the best practices to keep scalability in mind, since it is the main focus of the app.
## Challenges we ran into
A lot of the problems faced were naturally in the web application, and it required a lot of time.
## Accomplishments that we're proud of
I are proud of the app and its usefulness in different contexts. This is a creative solution that could have real world uses if the intelligence is implemented carefully.
## What we learned
I learned a LOT about web development, database management and API integration.
## What's next for OrangeBanana
Provided we have more time, we would implement more sensors and more use-cases for handling each of these.
|
## Inspiration
Our biggest inspiration came from our grandparents, who often felt lonely and struggled to find help. Specifically, one of us have a grandpa with dementia. He lives alone and finds it hard to receive help since most of his relatives live far away and he has reduced motor skills. Knowing this, we were determined to create a product -- and a friend -- that would be able to help the elderly with their health while also being fun to be around! Ted makes this dream a reality, transforming lives and promoting better welfare.
## What it does
Ted is able to...
* be a little cutie pie
* chat with speaker, reactive movements based on conversation (waves at you when greeting, idle bobbing)
* read heart rate, determine health levels, provide help accordingly
* Drives towards a person in need through using the RC car, utilizing object detection and speech recognition
* dance to Michael Jackson
## How we built it
* popsicle sticks, cardboards, tons of hot glue etc.
* sacrifice of my fingers
* Play.HT and Claude 3.5 Sonnet
* YOLOv8
* AssemblyAI
* Selenium
* Arudino, servos, and many sound sensors to determine direction of speaker
## Challenges we ran into
Some challenges we ran into during development was making sure every part was secure. With limited materials, we found that materials would often shift or move out of place after a few test runs, which was frustrating to keep fixing. However, instead of trying the same techniques again, we persevered by trying new methods of appliances, which eventually led a successful solution!
Having 2 speech-to-text models open at the same time showed some issue (and I still didn't fix it yet...). Creating reactive movements was difficult too but achieved it through the use of keywords and a long list of preset moves.
## Accomplishments that we're proud of
* Fluid head and arm movements of Ted
* Very pretty design on the car, poster board
* Very snappy response times with realistic voice
## What we learned
* power of friendship
* don't be afraid to try new things!
## What's next for Ted
* integrating more features to enhance Ted's ability to aid peoples' needs --> ex. ability to measure blood pressure
|
partial
|
## Inspiration
CareGuide was developed by our team in response to the pressing problem of medical errors in healthcare. A Johns Hopkins study found that medical errors account for over 250,000 deaths each year in the US, making them the third most common cause of mortality. Incomplete patient information and poor communication are frequent causes of these mistakes. Furthermore, 42% of patients experience anxiety when it comes to taking care of their health at home, underscoring the need for improved support networks. Our goal was to develop a solution that would lower these risks and enhance patient outcomes by streamlining communication and offering thorough health overviews.
## What it does
CareGuide is an AI-powered mobile app that enhances home healthcare by providing post diagnosis patient care. We help patients based on the interactions between patients, nurses, and doctors while also integrating the information from the discharge notes and Electronic Health Records (EHRs) of the patients. We are tailoring personalized care plans to individual patient needs based on their data and AI models which were specifically trained for this job. This combination of features ensures that patients receive timely, accurate, and personalized care, ultimately improving their overall health experience.
## How we built it
Our application development process employed React.js for a user-friendly front-end interface, complemented by extensive CSS styling. The back-end infrastructure was constructed using Python with Flask serving as the server framework. We incorporated advanced speech-to-speech technology and utilized Retrieval-Augmented Generation (RAG) to enable Large Language Models (LLMs) to access and interpret patients' clinical notes and doctor-patient conversations. Our cloud infrastructure, secured with AWS Client-Side Encryption, ensures the secure storage and processing of data, thereby upholding stringent data privacy standards and complying with HIPAA healthcare regulations.
## Challenges we ran into
During the hackathon, we encountered significant technical challenges, particularly with setting up local AI using Intel AI on the provided hardware to create a medical specific model. Ensuring patient data privacy through local AI is critical, and regulatory compliance demands rigorous testing and implementation of robust security measures, which is difficult to achieve under tight deadlines. Consequently, we pivoted to alternative technologies to ensure functionality. Prioritizing features that address the actual needs of healthcare professionals was also challenging. However, we successfully conducted interviews with five doctors, gathering valuable feedback that helped us refine our product to better meet their needs.
## Accomplishments that we're proud of
We are proud of the positive feedback received during the testing phase, which validated our approach and highlighted the potential impact of CareGuide. Successfully improving care received by patients with anyone around them and it allowed family members to focus more on patient health. Furthermore, providing real-time support and personalized care significantly improved patient satisfaction, demonstrating the effectiveness of our solution. We also cold called doctors and got validation from 5 of them for the product and even had positive feedback from fellow hackers.
## What we learned
Participating in this hackathon taught us the importance of user-centered design, as engaging with end-users throughout the development process was crucial in creating a practical and effective solution. We also learned the value of building a scalable app that can grow with the increasing demand for home healthcare. Additionally, the experience highlighted the importance of effective team collaboration and incorporating diverse feedback to enhance our project.
## What's next for CareGuide
Looking ahead, we plan to expand CareGuide’s features by adding very strict data privacy laws to avoid any HIPPA compliant issues. We also want to improve the model efficiency for medical information and keep training it on further datasets. We will also start monitoring of vital signs to help patients avoid any upcoming health complication. We aim to scale up the deployment to more regions and healthcare systems to reach a broader audience. Continuous improvement based on user feedback and technological advancements will ensure that CareGuide remains at the forefront of home healthcare innovation, providing the best possible care for patients.
## References
1. Centers for Disease Control and Prevention, National Center for Health Statistics. About Multiple Cause of Death, 1999–2020. CDC WONDER Online Database website. Atlanta, GA: Centers for Disease Control and Prevention; 2022. Accessed February 21, 2022.
2. National Safety Council analysis of Centers for Disease Control and Prevention, National Center for Health Statistics. National Vital Statistics System, Mortality 2018-2022 on CDC WONDER Online Database, released in 2024. Data are from the Multiple Cause of Death Files, 2018-2022, as compiled from data provided by the 57 vital statistics jurisdictions through the Vital Statistics Cooperative Program. Accessed at <http://wonder.cdc.gov/mcd-icd10-expanded.html>
3. Brady RE, Braz AN. Challenging Interactions Between Patients With Severe Health Anxiety and the Healthcare System: A Qualitative Investigation. J Prim Care Community Health. 2023 Jan-Dec;14:21501319231214876. doi: 10.1177/21501319231214876. PMID: 38041442; PMCID: PMC10693786.
|
## Inspiration
We all spend too much money on Starbucks, except for Arri, whose guilty pleasure is a secret that he won't tell us.
## What it does
Have you ever shopped at a disorganized grocery store where prices tags are all over the place? Or gone into a cafe that doesn't list its prices on the menu? *cough Starbucks cough*
Wallai is a personal finance software that helps you control your spending in spite of these barriers! You simply take a picture of a food item, and it'll figure out its price for you. If the software isn't able to figure out the price, it'll prompt you to add the item and its price (once you've figured it out) to our database to improve the experience for future users. As an Android app, it's convenient for everyday use, and its clear, lightweight interface provides an unusually hassle-free way to stay in control of your finances.
*"With great money comes rich, then which equals...equals...great discipline."*
— Kamran Tayyab 2019
## How we built it
Teamwork makes the dream work.
## Challenges we ran into
Coming up with the idea, it was so challenging it took us 12 hours.
Also the fact that we came up with the idea 12 hours into the hackathon.
And Android errors, all of them.
## Accomplishments that we're proud of
We came up with an idea during the hackathon!
We're also proud of Arri not sleeping.
## What we learned
Android is a b\*itch.
## What's next for wallai
We want to partner with restaurants to get better data that'll make our object identification more accurate. Once we do this, we would also like to further optimize how we store and retrieve information from the database as it grows.
We'd also like to create an iOS version to make the app available to more people!
|
# see our presentation [here](https://docs.google.com/presentation/d/1AWFR0UEZ3NBi8W04uCgkNGMovDwHm_xRZ-3Zk3TC8-E/edit?usp=sharing)
## Inspiration
Without purchasing hardware, there are few ways to have contact-free interactions with your computer.
To make such technologies accessible to everyone, we created one of the first touch-less hardware-less means of computer control by employing machine learning and gesture analysis algorithms. Additionally, we wanted to make it as accessible as possible in order to reach a wide demographic of users and developers.
## What it does
Puppet uses machine learning technology such as k-means clustering in order to distinguish between different hand signs. Then, it interprets the hand-signs into computer inputs such as keys or mouse movements to allow the user to have full control without a physical keyboard or mouse.
## How we built it
Using OpenCV in order to capture the user's camera input and media-pipe to parse hand data, we could capture the relevant features of a user's hand. Once these features are extracted, they are fed into the k-means clustering algorithm (built with Sci-Kit Learn) to distinguish between different types of hand gestures. The hand gestures are then translated into specific computer commands which pair together AppleScript and PyAutoGUI to provide the user with the Puppet experience.
## Challenges we ran into
One major issue that we ran into was that in the first iteration of our k-means clustering algorithm the clusters were colliding. We fed into the model the distance of each on your hand from your wrist, and designed it to return the revenant gesture. Though we considered changing this to a coordinate-based system, we settled on changing the hand gestures to be more distinct with our current distance system. This was ultimately the best solution because it allowed us to keep a small model while increasing accuracy.
Mapping a finger position on camera to a point for the cursor on the screen was not as easy as expected. Because of inaccuracies in the hand detection among other things, the mouse was at first very shaky. Additionally, it was nearly impossible to reach the edges of the screen because your finger would not be detected near the edge of the camera's frame. In our Puppet implementation, we constantly *pursue* the desired cursor position instead of directly *tracking it* with the camera. Also, we scaled our coordinate system so it required less hand movement in order to reach the screen's edge.
## Accomplishments that we're proud of
We are proud of the gesture recognition model and motion algorithms we designed. We also take pride in the organization and execution of this project in such a short time.
## What we learned
A lot was discovered about the difficulties of utilizing hand gestures. From a data perspective, many of the gestures look very similar and it took us time to develop specific transformations, models and algorithms to parse our data into individual hand motions / signs.
Also, our team members possess diverse and separate skillsets in machine learning, mathematics and computer science. We can proudly say it required nearly all three of us to overcome any major issue presented. Because of this, we all leave here with a more advanced skillset in each of these areas and better continuity as a team.
## What's next for Puppet
Right now, Puppet can control presentations, the web, and your keyboard. In the future, puppet could control much more.
* Opportunities in education: Puppet provides a more interactive experience for controlling computers. This feature can be potentially utilized in elementary school classrooms to give kids hands-on learning with maps, science labs, and language.
* Opportunities in video games: As Puppet advances, it could provide game developers a way to create games wear the user interacts without a controller. Unlike technologies such as XBOX Kinect, it would require no additional hardware.
* Opportunities in virtual reality: Cheaper VR alternatives such as Google Cardboard could be paired with
Puppet to create a premium VR experience with at-home technology. This could be used in both examples described above.
* Opportunities in hospitals / public areas: People have been especially careful about avoiding germs lately. With Puppet, you won't need to touch any keyboard and mice shared by many doctors, providing a more sanitary way to use computers.
|
losing
|
## Inspiration
Badminton boosts your overall health and offers mental health benefits. Doing sports makes you [happier](https://www.webmd.com/fitness-exercise/features/runners-high-is-it-for-real#1) or less stressed.
Badminton is the fastest racket sport.
The greatest speed of sports equipment, which is given acceleration by pushing or hitting a person, is developed by a shuttlecock in badminton
Badminton is the second most popular sport in the world after football
Badminton is an intense sport and one of the three most physically demanding team sports.
For a game in length, a badminton player will "run" up to 10 kilometers, and in height - a kilometer.
Benefits of playing badminton
1. Strengthens heart health.
Badminton is useful in that it increases the level of "good" cholesterol and reduces the level of "bad" cholesterol.
2. Reduces weight.
3. Improves the speed of reaction.
4. Increases muscle endurance and strength.
5. Development of flexibility.
6. Reduces the risk of developing diabetes.
Active people are 30-50% less likely to develop type 2 diabetes, according to a 2005 Swedish study.
7. Strengthens bones.
badminton potentially reduces its subsequent loss and prevents the development of various diseases. In any case, moderate play will help develop joint mobility and strengthen them.

However, the statistics show increased screen time leads to obesity, sleep problems, chronic neck and back problems, depression, anxiety and lower test scores in children.

With Decentralized Storage provider IPFS and blockchain technology, we create a decentralized platform for you to learn about playing Badminton.
We all know that sports are great for your physical health. Badminton also has many psychological benefits.
## What it does
Web Badminton Dapp introduces users to the sport of Badminton as well as contains item store to track and ledger the delivery of badminton equipment.
Each real equipment item is ledgered via a digital one with a smart contract logic system in place to determine the demand and track iteam. When delivery is completed the DApp ERC1155 NFTs should be exchanged for the physical items.
A great win for the producers is to save on costs with improved inventory tracking and demand management.
Web Badminton DApp succeeds where off-chain software ledgering system products fail because they may go out of service, need updates, crash with data losses. Web Badminton DApp is a very low cost business systems management product/tool.
While competing software based ledgering products carry monthly and or annual base fees, the only new costs accrued by the business utilizing the DApp are among new contract deployments. A new contract for new batch of items only is needed every few months based on demand and delivery schedule.
In addition, we created Decentralized Newsletter subscription List that we connected to web3.storage.
## How we built it
We built the application using JavaScript, NextJS, React, Tailwind Css and Wagmi library to connect to the metamask wallet. The application is hosted on vercel. The newsletter list data is stored on ipfs with web3.storage.
The contract is built with solidity, hardhat. The polygon blockchain mumbai testnet and lukso l14 host the smart conract.
Meanwhile the Ipfs data is stored using nft.storage.
|
## Inspiration
We built an AI-powered physical trainer/therapist that provides real-time feedback and companionship as you exercise.
With the rise of digitization, people are spending more time indoors, leading to increasing trends of obesity and inactivity. We wanted to make it easier for people to get into health and fitness, ultimately improving lives by combating these the downsides of these trends. Our team built an AI-powered personal trainer that provides real-time feedback on exercise form using computer vision to analyze body movements. By leveraging state-of-the-art technologies, we aim to bring accessible and personalized fitness coaching to those who might feel isolated or have busy schedules, encouraging a more active lifestyle where it can otherwise be intimidating.
## What it does
Our AI personal trainer is a web application compatible with laptops equipped with webcams, designed to lower the barriers to fitness. When a user performs an exercise, the AI analyzes their movements in real-time using a pre-trained deep learning model. It provides immediate feedback in both textual and visual formats, correcting form and offering tips for improvement. The system tracks progress over time, offering personalized workout recommendations and gradually increasing difficulty based on performance. With voice guidance included, users receive tailored fitness coaching from anywhere, empowering them to stay consistent in their journey and helping to combat inactivity and lower the barriers of entry to the great world of fitness.
## How we built it
To create a solution that makes fitness more approachable, we focused on three main components:
Computer Vision Model: We utilized MediaPipe and its Pose Landmarks to detect and analyze users' body movements during exercises. MediaPipe's lightweight framework allowed us to efficiently assess posture and angles in real-time, which is crucial for providing immediate form correction and ensuring effective workouts.
Audio Interface: We initially planned to integrate OpenAI’s real-time API for seamless text-to-speech and speech-to-text capabilities, enhancing user interaction. However, due to time constraints with the newly released documentation, we implemented a hybrid solution using the Vosk API for speech recognition. While this approach introduced slightly higher latency, it enabled us to provide real-time auditory feedback, making the experience more engaging and accessible.
User Interface: The front end was built using React with JavaScript for a responsive and intuitive design. The backend, developed in Flask with Python, manages communication between the AI model, audio interface, and user data. This setup allows the machine learning models to run efficiently, providing smooth real-time feedback without the need for powerful hardware.
On the user interface side, the front end was built using React with JavaScript for a responsive and intuitive design. The backend, developed in Flask with Python, handles the communication between the AI model, audio interface, and the user's data.
## Challenges we ran into
One of the major challenges was integrating the real-time audio interface. We initially planned to use OpenAI’s real-time API, but due to the recent release of the documentation, we didn’t have enough time to fully implement it. This led us to use the Vosk API in conjunction with our system, which introduced increased codebase complexity in handling real-time feedback.
## Accomplishments that we're proud of
We're proud to have developed a functional AI personal trainer that combines computer vision and audio feedback to lower the barriers to fitness. Despite technical hurdles, we created a platform that can help people improve their health by making professional fitness guidance more accessible. Our application runs smoothly on various devices, making it easier for people to incorporate exercise into their daily lives and address the challenges of obesity and inactivity.
## What we learned
Through this project, we learned that sometimes you need to take a "back door" approach when the original plan doesn’t go as expected. Our experience with OpenAI’s real-time API taught us that even with exciting new technologies, there can be limitations or time constraints that require alternative solutions. In this case, we had to pivot to using the Vosk API alongside our real-time system, which, while not ideal, allowed us to continue forward. This experience reinforced the importance of flexibility and problem-solving when working on complex, innovative projects.
## What's next for AI Personal Trainer
Looking ahead, we plan to push the limits of the OpenAI real-time API to enhance performance and reduce latency, further improving the user experience. We aim to expand our exercise library and refine our feedback mechanisms to cater to users of all fitness levels. Developing a mobile app is also on our roadmap, increasing accessibility and convenience. Ultimately, we hope to collaborate with fitness professionals to validate and enhance our AI personal trainer, making it a reliable tool that encourages more people to lead healthier, active lives.
|
**Come check out our fun Demo near the Google Cloud Booth in the West Atrium!! Could you use a physiotherapy exercise?**
## The problem
A specific application of physiotherapy is that joint movement may get limited through muscle atrophy, surgery, accident, stroke or other causes. Reportedly, up to 70% of patients give up physiotherapy too early — often because they cannot see the progress. Automated tracking of ROM via a mobile app could help patients reach their physiotherapy goals.
Insurance studies showed that 70% of the people are quitting physiotherapy sessions when the pain disappears and they regain their mobility. The reasons are multiple, and we can mention a few of them: cost of treatment, the feeling that they recovered, no more time to dedicate for recovery and the loss of motivation. The worst part is that half of them are able to see the injury reappear in the course of 2-3 years.
Current pose tracking technology is NOT realtime and automatic, requiring the need for physiotherapists on hand and **expensive** tracking devices. Although these work well, there is a HUGE room for improvement to develop a cheap and scalable solution.
Additionally, many seniors are unable to comprehend current solutions and are unable to adapt to current in-home technology, let alone the kinds of tech that require hours of professional setup and guidance, as well as expensive equipment.
[](http://www.youtube.com/watch?feature=player_embedded&v=PrbmBMehYx0)
## Our Solution!
* Our solution **only requires a device with a working internet connection!!** We aim to revolutionize the physiotherapy industry by allowing for extensive scaling and efficiency of physiotherapy clinics and businesses. We understand that in many areas, the therapist to patient ratio may be too high to be profitable, reducing quality and range of service for everyone, so an app to do this remotely is revolutionary.
We collect real-time 3D position data of the patient's body while doing exercises for the therapist to adjust exercises using a machine learning model directly implemented into the browser, which is first analyzed within the app, and then provided to a physiotherapist who can further analyze the data. It also asks the patient for subjective feedback on a pain scale
This makes physiotherapy exercise feedback more accessible to remote individuals **WORLDWIDE** from their therapist
## Inspiration
* The growing need for accessible physiotherapy among seniors, stroke patients, and individuals in third-world countries without access to therapists but with a stable internet connection
* The room for AI and ML innovation within the physiotherapy market for scaling and growth
## How I built it
* Firebase hosting
* Google cloud services
* React front-end
* Tensorflow PoseNet ML model for computer vision
* Several algorithms to analyze 3d pose data.
## Challenges I ran into
* Testing in React Native
* Getting accurate angle data
* Setting up an accurate timer
* Setting up the ML model to work with the camera using React
## Accomplishments that I'm proud of
* Getting real-time 3D position data
* Supporting multiple exercises
* Collection of objective quantitative as well as qualitative subjective data from the patient for the therapist
* Increasing the usability for senior patients by moving data analysis onto the therapist's side
* **finishing this within 48 hours!!!!** We did NOT think we could do it, but we came up with a working MVP!!!
## What I learned
* How to implement Tensorflow models in React
* Creating reusable components and styling in React
* Creating algorithms to analyze 3D space
## What's next for Physio-Space
* Implementing the sharing of the collected 3D position data with the therapist
* Adding a dashboard onto the therapist's side
|
winning
|
## Inspiration
At the heart of Palate lies a deep-seated appreciation for the connections forged over shared meals. As a team, we've experienced firsthand the magic of gathering around a table, whether it's for cherished family dinners or impromptu meetups with friends. These moments, woven into the fabric of our lives, inspired us to create Palate at Tree Hacks, where our shared passion for food and technology converged.
Throughout the weekend, fueled by Popeyes runs and dining hall escapades, we poured our energy into crafting Palate—a testament to the power of collaboration and shared vision. Yet, beyond the lines of code, Palate embodies a philosophy of mindful eating and thoughtful connection.
With Palate, we aim to elevate the dining experience by seamlessly integrating personal preferences and dietary restrictions. Gone are the days of cumbersome inquiries about allergies or dislikes; instead, Palate intuitively keeps track, allowing meals to be curated with care and consideration. By prioritizing the well-being and preferences of those we share meals with, we not only foster deeper connections but also create space for moments of genuine enjoyment and appreciation.
In a world filled with distractions, Palate serves as a reminder of the importance of mindful living, even in something as seemingly mundane as choosing what to eat. Through this project, we hope to inspire others to embrace the joy of shared meals, where every bite becomes an opportunity for connection and celebration.
## What it does
Palate is a multifaceted platform designed to revolutionize your culinary experience. Here's a closer look at its key features:
* **Personalized Food Journal**: Palate serves as your digital food diary, meticulously cataloging your favorite cuisines and dishes. But it goes beyond mere record-keeping, as it also takes into account your dietary restrictions and ingredient preferences. Whether you're avoiding certain foods due to allergies or simply dislike their taste, Palate ensures that your culinary journey is tailored to your unique preferences.
* **Smart Recipe Recommendations**: Powered by a robust database, Palate leverages your stored information to offer personalized recipe suggestions. By analyzing your fridge inventory, liked ingredients, disliked ingredients, and dietary restrictions, Palate curates a selection of recipes perfectly suited to your tastes and dietary needs. Say goodbye to endless recipe searches and hello to a curated selection of culinary delights at your fingertips.
* **Dynamic Recipe Retrieval**: Unlike static recipe databases, Palate dynamically retrieves recipes from the internet in real-time. This means you'll always have access to a diverse range of recipes, ensuring that your culinary repertoire stays fresh and exciting. Whether you're craving a classic comfort food or eager to experiment with a new culinary trend, Palate has you covered.
* **Interactive Chatbot**: Palate takes your culinary experience to the next level with its interactive chatbot feature. Whether you're seeking recipe recommendations, ingredient substitutions, or cooking tips, the Palate chatbot is always ready to assist. But what sets Palate's chatbot apart is its ability to leverage both your chat history and database information to provide personalized assistance. By analyzing past conversations and stored data, the chatbot offers tailored suggestions and insights, ensuring that every interaction is relevant and helpful.
* **Social Event Planning**: Palate isn't just about individual culinary exploration—it's also about fostering connections through shared experiences. With its event planning feature, you can create gatherings and invite your friends to join. But Palate doesn't stop there; it takes the hassle out of menu planning by recommending recipes tailored to the preferences of all attendees. From potlucks to dinner parties, Palate ensures that every event is a culinary success.
* **User Authentication**: Ensuring that data provided from the user to us, are safe and sound!
* **Fuzzy/error checking for ingredients**: Using levenshtein distance, our program chooses ingredients that are best matched to the user's input.
## How we built it
We built Palate using ReactJs as our frontend, Convex as our backend/database. For our chatbot, we used Together AI's Inference models with the Function Calling and JSON mode to structure external API calls from user queries. To query the internet, we used Tavily to perform searches, and Recipe-Scraper (<https://github.com/jadkins89/Recipe-Scraper>) to scrape the recipe given a url.
Our steps for building our recommendation system were:
1. The user can interact with Ramsey (chat bot) and describe dishes, ingredients, and cuisines they are interested in receiving a recipe for.
2. Given a dataset that includes a dishes name, ingredients, and cuisine, we aggregate a user's liked ingredients, disliked ingredients, and cuisines and chat interactions to pinpoint dishes to recommend.
3. We call Tavliy to query the web for recipes matching the dish and diet of the user and get a list of urls.
4. We use a recipe scraper to retrieve the recipes to populate into Ramsey and our events.
## Challenges we ran into
Some challenges that we ran into were:
* **Choosing Datasets**: To have Palate recommend us recipes, we first created a dataset of dishes using Recipe NLG (there are two versions, 1M+, lite). For ease of implementation, we chose to use the lite version. We felt it was important to curate to liked cuisines of the users, however, we were not able to find any available datasets on the internet that mapped dishes to cuisines. As a way to work around this, we used Together AI's API calls to categorize a dish by its cuisine based on its name and list of ingredients. We acknowledge that there may be dishes in our dataset that is falsely classified.
* **Chatbot Challenges**: Developing the chatbot proved to be a formidable task as we encountered difficulties in prompting it effectively. Despite leveraging data to augment its responses, the chatbot often provided unexpected or strange answers, requiring extensive refinement and debugging.
* **Technical Learning Curve**: Navigating the learning curves of Convex and ReactJS presented significant challenges for our team. As most of us were unfamiliar with these tools prior to embarking on the Palate project, we faced a steep learning curve in mastering their intricacies and functionalities.
* **Understanding Asynchronous Programming**: Grappling with the concepts of asynchronous programming, including async, await, and promises, posed additional hurdles in the development process. Recognizing the importance of these mechanisms in ensuring smooth and responsive user experiences, we dedicated time to deepen our understanding and implementation proficiency.
## Accomplishments that we're proud of
* **Mastering Convex**: Through the development of Palate, we gained invaluable experience in utilizing Convex for user authentication, enhancing our understanding of secure authentication processes within web applications.
* **AI Augmented Data Pipelines**: Delving into the creation of pipelines for AI-augmented data retrieval and generation was a transformative learning experience. We honed our skills in integrating AI technologies seamlessly into our platform, empowering Palate to offer intelligent and personalized recommendations to users.
* **Functional Web Application Development**: Perhaps most notably, we're proud to have successfully built a functional web application for Palate. From conceptualization to execution, we navigated the complexities of web development, overcoming challenges and refining our skills along the way. Our achievement in bringing Palate to life underscores our growth and proficiency in creating user-centric digital solutions.
## What we learned
* Convex which enabled seamless frontend-backend interaction through API calls.
* Learned about function calling and generation, enhancing the dynamic capabilities of data manipulation within Palate.
* Transitioned from JavaScript to TypeScript with React, embracing TypeScript's benefits for writing robust and maintainable code in our frontend components.
## What's next for palate
* Adding more options for dishes to recommend.
* Being able to recommend more than one items.
* Caching recommendations to speed up performances.
* Introducing new events you can organize such as potlucks, or date night. Through this, you are able to assign yourself/others recipes to cook for your events!
* Palate blend: see how similar your palate is with your friends!
|
## Inspiration
As students, we know very well the struggle of getting enough sleep. Falling asleep in particular can be very hard especially when anxiety strikes during exam periods, you have big upcoming life events, or if you're someone who has your existential crises at night. Therefore, to combat this and help everyone sleep better we had the idea to create a "Perfect Storm".
## What it does
Perfect Storm is a web application that allows users to create a custom mix of relaxing, sleep-friendly sounds. Users are able to choose which sounds they want to combine and set the volume of each sound. A timer is provided so users can drift off to sleep as the sounds continue to play.
## How we built it
1) Brainstormed what kinds of sounds we would include and decided to use sounds that could be layered together to create the coziness of being inside during a storm
2) We found free downloads of the sounds we wanted and used Adobe Spark to make a logo for the application and the icons for each sound
3) For the application, a GUI was created that had multiple volume sliders corresponding to each of the different ambient sounds. A global play button was implemented that allowed for the simultaneous playing of all sounds, after which the volume could be adjusted. Also, there are individual mute buttons for each of the sounds, which if clicked when the sound was already muted, would set the volume level of that sound back to its original level. Finally, there is a global mute button that upon use, would set all sounds to volume 0.
4) For the webpage, we focused on the sliders to adjust the volume button and the interface of the website. Each volume slider has a corresponding icon that plays a specific ambient sound and adjustS how loud you want the volume to be. Clicking the play/pause button at the top right stops every sound.
## Challenges we ran into
1) Finding sound downloads that were both free and not too big
2) Removing the background of logo/icons
3) There were several issues with adjusting volume in the application using a JSlider
4) For the webpage, we had some issues with aligning the icons together and playing sounds when the button is pressed. The icons were not evenly spaced out and the sounds would not overlap with each other when we tried playing them together
## Accomplishments that we're proud of
Communication: We made sure to discuss with each other frequently how are tasks we're going and promptly answering each other's questions. This ensured that everyone remained aware of plan changes and work that still needed to be done.
## What we learned
We learned about websites that provide free sounds, can be used for logo and icon design as well as websites that can remove backgrounds from images.
How to properly use JavaFx to create a working GUI
## What's next for Perfect Storm
Implementing the timer feature into the application, so that a set time can be chosen after which all sounds will stop playing and the application will close itself.
|
## Overview
We made a gorgeous website to plan flights with Jet Blue's data sets. Come check us out!
|
losing
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.