
anchor
stringlengths 1
23.8k
| positive
stringlengths 1
23.8k
| negative
stringlengths 1
31k
| anchor_status
stringclasses 3
values |
|---|---|---|---|
## Inspiration
We are all a fan of Carrot, the app that rewards you for walking around. This gamification and point system of Carrot really contributed to its success. Carrot targeted the sedentary and unhealthy lives we were leading and tried to fix that. So why can't we fix our habit of polluting and creating greenhouse footprints using the same method? That's where Karbon comes in!
## What it does
Karbon gamifies how much you can reduce your CO₂ emissions by in a day. The more you reduce your carbon footprint, the more points you can earn. Users can then redeem these points at Eco-Friendly partners to either get discounts or buy items completely for free.
## How we built it
The app is created using Swift and Swift UI for the user interface. We also used HTML, CSS and Javascript to make a web app that shows the information as well.
## Challenges we ran into
Initially, when coming up with the idea and the economy of the app, we had difficulty modelling how points would be distributed by activity. Additionally, coming up with methods to track CO₂ emissions conveniently became an integral challenge to ensure a clean and effective user interface. As for technicalities, cleaning up the UI was a big issue as a lot of our time went into creating the app as we did not have much experience with the language.
## Accomplishments that we're proud of
Displaying the data using graphs
Implementing animated graphs
## What we learned
* Using animation in Swift
* Making Swift apps
* Making dynamic lists
* Debugging unexpected bugs
## What's next for Karbon
A fully functional Web app along with proper back and forth integration with the app. | ## Inspiration
We admired the convenience Honey provides for finding coupon codes. We wanted to apply the same concept except towards making more sustainable purchases online.
## What it does
Recommends sustainable and local business alternatives when shopping online.
## How we built it
Front-end was built with React.js and Bootstrap. The back-end was built with Python, Flask and CockroachDB.
## Challenges we ran into
Difficulties setting up the environment across the team, especially with cross-platform development in the back-end. Extracting the current URL from a webpage was also challenging.
## Accomplishments that we're proud of
Creating a working product!
Successful end-to-end data pipeline.
## What we learned
We learned how to implement a Chrome Extension. Also learned how to deploy to Heroku, and set up/use a database in CockroachDB.
## What's next for Conscious Consumer
First, it's important to expand to make it easier to add local businesses. We want to continue improving the relational algorithm that takes an item on a website, and relates it to a similar local business in the user's area. Finally, we want to replace the ESG rating scraping with a corporate account with rating agencies so we can query ESG data easier. | ## Inspiration
During the fall 2021 semester, the friend group made a fun contest to participate in: Finding the chonkiest squirrel on campus.
Now that we are back in quarantine, stuck inside all day with no motivation to do exercise, we wondered if we could make a timer like in the app [Forest](https://www.forestapp.cc/) to motivate us to work out.
Combine the two idea, and...
## Welcome to Stronk Chonk!
In this game, the user has a mission of the utmost importance: taking care of Mr Chonky, the neighbourhood squirrel!
Spending time working out in real life is converted, in the game, as time spent gathering acorns. Therefore, the more time spent working out, the more acorns are gathered, and the chonkier the squirrel will become, providing it excellent protection for the harsh Canadian winter ahead.
So work out like your life depends on it!

## How we built it
* We made the app using Android Studio
* Images were drawn in Krita
* Communications on Discord
## Challenges we ran into
36 hours is not a lot of time. Originally, the app was supposed to be a game involving a carnival high striker bell. Suffice to say: *we did not have time for this*.
And so, we implemented a basic stopwatch app on Android Studio... Which 3 of us had never used before. There were many headaches, many laughs.
The most challenging bits:
* Pausing the stopwatch: Android's Chronometer does not have a pre-existing pause function
* Layout: We wanted to make it look pretty *we did not have time to make every page pretty* (but the home page looks very neat)
* Syncing: The buttons were a mess and a half, data across different pages of the app are not synced yet
## Accomplishments that we're proud of
* Making the stopwatch work (thanks Niels!)
* Animating the squirrel
* The splash art
* The art in general (huge props to Angela and Aigiarn)
## What we learned
* Most team members used Android Studio for the first time
* This was half of the team's first hackathon
* Niels and Ojetta are now *annoyingly* familiar with Android's Chronometer function
* Niels and Angela can now navigate the Android Studio Layout functions like pros!
* All team members are now aware they might be somewhat squirrel-obsessed
## What's next for Stronk Chonk
* Syncing data across all pages
* Adding the game element: High Striker Squirrel | winning |
## Inspiration
Online learning is very hard. It's hard to focus, hard to take notes and hard to listen, and hard to share notes. So we created Picanote.
## What it does
It's a desktop and mobile app that allows you to screenshot images, use AI to extract text from the image and save it to a database. So you can search your screenshots and find the notes that matter to you in seconds!
## How we built it
There are two mobile apps, one for android and one for ios with different UI/UX!
The desktop portion was made using python.
The backend was written in NodeJS, GCP functions, Firebase Auth, and cockroachDB. Cockroach DB makes sure our data won't disappear. GCP Functions lets us leave the app up at a very low cost and Firebase Auth lets us focus on the more functional par t of our app.
## Challenges we ran into
The backend had some weird errors on account of javascript that were very difficult to debug.
Clean image recognition on the desktop app was also a challenge.
Blue screen of death in 2021. (Unix > windows).
google cloud not making it clear how to export functions (more from a lack of us reading the docs).
It was also tricky getting google auth to work.
## Accomplishments that we're proud of
Our project is functional. For some of us (Jack) this is the first time creating a project that actually works at the end.
## What we learned
To setup google cloud functions, to setup cockroachDB, to get data from an api and write better error messages. To use firebase to setup our mobile apps.
javascript bad, strong typing good.
Flutter good, react bad.
CockroachDB easy pgsql setup good, CockroachDB free trial fake.
Json bad, Jason good
## What's next for Picanote
We are going public and starting investements at 10$ per share with a float of 20 shares | ## Inspiration
Our team recently started an iOS bootcamp and we were inspired to make a beginner app with some of the basics we've learned as well as interact with new technologies and APIs that we would learn at the hackathon. We wanted to work on a simple, fun educational app, and wanted to bring in [Google Cloud's Vision API](https://cloud.google.com/vision/docs/) as well as the iPhone's built-in camera capabilities. The end result is a culmination of these various inspirations.
## What it does
Our app is an interactive game for young learners to come across new English words and photograph those items throughout their days. Players can track their scores throughout the day and confirm that the image matches the vocabulary word with fun audio prompts. The word and score can be reset so players can find new inspiration for their next photo journey.
## How we built it
We worked primarily with Swift on XCode, using git for our version control. We used [Google Cloud's ML Kit for Firebase](https://firebase.google.com/docs/ml-kit), a mobile SDK that allowed us to accurately label images that the player took over a certain confidence score with Google Cloud Vision. To import this library and Alamofire we used Cocoapods.
## Challenges we ran into
Because we are all beginners with mobile development, we ran into many challenges related to the intricacies of iOS development. We learned that it is difficult to collaborate on the same storyboards, which made version control and collaboration more challenging than usual. We also had trouble setting up the same environments, versions of XCode and Swift, and Apple developer teams.
After connecting to the Google Cloud Vision API, we began testing our app. To our befuddlement, the Google Cloud Vision API labeled an image of a bagel as a musical instrument and a member of our team as a vehicle. Upon closer inspection, we realized we were using the on-device API instead of the Cloud API. Switching to the Cloud API, greatly increased the accuracy of the labels.
## Accomplishments that we're proud of
Overall, we're very proud that we were able to put together this product within a day! We were able to complete our goal of connecting to the Google Cloud Vision API and using its machine learning models to analyze the objects within our images. Our game works exactly as envisioned and we're proud of our child-friendly, intuitive user design.
## What we learned
We learned an incredible amount over such a short period of time, including:
* Swift intricacies (especially optionals)
* XCode and general iOS development gotchas
* Autolayout and general design in iOS
* Connecting to an iPhone camera
* Firebase and Google Cloud setup
* importing audio files to our app
* local data persistence for our game
* the joy of pair programming with friends
* Segue modal navigation
* Loading spinners while waiting for API response.
## What's next for Learning Lens
We can envision many ways that Learning Lens can expand its offerings to more young learners, their parents, and even educators. These include:
* Accessing a more complex dictionary that can be adjusted by age or learning level as appropriate
* Parents' input to the specific word of the day or a word bank for their children
* Integrating natural language processing and/or adaptive learning techniques to provide sets of suggestions that are tailored to a learner's interests
* Integrating with school or study systems to assist educators in their existing curriculum
* Text-to-speech capability so that very young learners who have not yet learned to read will be able to play as well (and older learners can improve upon their pronunciation)
* Database integration so that learners can see previous words they've learned, as well as pictures they've taken; and parents can view their children's finds and life through their children's eyes
* A countdown timer or built-in reset feature for the app to come up with a new word at a certain time every day
* Social networking so that learners can connect with approved peers and view leaderboards for the same word as well as share images with one another
## Credits
A special thanks to Alex Takahashi (Facebook Sponsor) for providing mentorship and answering our questions.
Also thanks to Google for providing $100 credit to explore the Google Cloud API offerings.
Our logo sans text was sourced from pngtree.com. | ## What Inspired us
Due to COVID, many students like us have become accustomed to work on their schoolwork, projects and even hackathons remotely. This led students to use online resources at their disposal in order to facilitate their workload at home. One of the tools most used is “ctrl+f” which enables the user to quickly locate any text within a document. Thus, we came to a realisation that no such accurate method exists for images. This led to the birth of our project for this hackathon titled “PictoDocReader”.
## What you learned
We learned how to implement Dash in order to create a seamless user-interface for Python. We further learnt several 2D and 3D pattern matching algorithms such as, Knuth-Morris-Pratt, Bird Baker, Karp and Rabin and Aho-Corasick. However, only implemented the ones that led to the fastest and most accurate execution of the code.
Furthermore, we learnt how to convert PDFs to images (.png). This led to us learning about the colour profiles of images and how to manipulate the RGB values of any image using the numpy library along with matplotlib. We also learnt how to implement Threading in Python in order to run tasks simultaneously. We also learnt how to use Google Cloud services in order to use Google Cloud Storage to enable users to store their images and documents on the cloud.
## How you built your project
The only dependencies we required to create the project were PIL, matplotlib, numpy, dash and Google Cloud.
**PIL** - Used for converting a PDF file to a list of .png files and manipulating the colour profiles of an image.
**matplotlib** - To plot and convert an image to its corresponding matrix of RGB values.
**numpy** - Used for data manipulation on RGB matrices.
**dash** - Used to create an easy to use and seamless user-interface
**Google Cloud** - Used to enable users to store their images and documents on the cloud.
All the algorithms and techniques to parse and validate pixels were all programmed by the team members. Allowing us to cover any scenario due to complete independence from any libraries.
## Challenges we faced
The first challenge we faced was the inconsistency between the different RGB matrices for different documents. While some matrices contained RGB values, others were of the form RGBA. Therefore, this led to inconsistent results when we were traversing the matrices. The problem was solved using the slicing function from the numpy library in order to make every matrix uniform in size.
Trying to research best time complexity for 2d and 3d pattern matching algorithms. Most algorithms were designed for square images and square shaped documents. While we were working with any sized images and documents. Thus, we had to experiment and alter the algorithms to ensure they worked best for our application.
When we worked with large PDF files, the program tried to locate the image in each page one by one. Thus, we needed to shorten the time for PDFs to be fully scanned to make sure our application performs its tasks in a viable time period. Hence, we introduced threading into the project to reduce the scanning time when working with large PDF files as each page was scanned simultaneously. Although we have come to the realisation that threading is not ideal as the multi-processing greatly depends on the number of CPU cores of the user’s system. In an ideal world we would implement parallel processing instead of threading. | losing |
## Inspiration
Two of our team members are medical students and were on a medical mission trip to Honduras to perform cervical cancer screening. What we found though was that many patients were lost to follow-up due to the two-to-three week lag time between screening and diagnosis. We sought to eliminate this lag time and thus enable instant diagnosis of cervical cancer through Cerviscope.
## What it does
Cerviscope is a product that enables point-of-care detection of cervical cancer based on hand-held light microscopy of pap smear slides and subsequent image analysis using convoluted neural networks.
See our demo at [www.StudentsAtYourCervix.com](http://www.StudentsAtYourCervix.com)! (If URL forwarding doesn't work, <https://www.wolframcloud.com/objects/ecb2d3d2-c468-4c4b-80fd-3da5f2e2aa90>)
## How we built it
Our solution is two-fold. The first is using machine learning, specifically convolutional neural networks, to analyze images from a publicly available database of annotated pap smear cervical cells to be able to predict cancerous cells. We couple our algorithm with the use of a handheld, mobile phone-compatible light microscope called the Foldscope, developed by the Prakash lab at Stanford, to enable cheap and rapid point of care detection. These images were not normalized, so we performed image processing and conformation tools to standardize these images as inputs to our neural network.
## Challenges we ran into
1) Time. We would have loved to fully automate the interface between image acquisition using the hand-held microscope and machine-learning-based image analysis.
2) Data. Acquire a larger database to improve our accuracy closer to human level performance
## Accomplishments that we're proud of
We trained a neural network to detect cervical cancer cells with classification accuracies exceeding 80%. Coupled with the utilization of the Foldscope, this has the potential for huge impact in the point-of-care cervical cancer diagnosis and treatment field.
## What we learned
How to develop, train, and deploy neural networks in just a few hours. Network with students to learn about amazing work such as the Foldscope!
## What's next for CerviScope - Cervical Cancer Detection
Sleep. Krispy Kreme. Then IPO. | # Check out our [slides](https://docs.google.com/presentation/d/1K41ArhGy6HgdhWuWSoGtBkhscxycKVTnzTSsnapsv9o/edit#slide=id.g30ccbcf1a6f_0_150) and come over for a demo!
## Inspiration
The inspiration for EYEdentity came from the need to enhance patient care through technology. Observing the challenges healthcare professionals face in quickly accessing patient information, we envisioned a solution that combines facial recognition and augmented reality to streamline interactions and improve efficiency.
## What it does
EYEdentity is an innovative AR interface that scans patient faces to display their names and critical medical data in real-time. This technology allows healthcare providers to access essential information instantly, enhancing the patient experience and enabling informed decision-making on the spot.
## How we built it
We built EYEdentity using a combination of advanced facial recognition and facial tracking algorithms and the new Snap Spectacles. The facial recognition component was developed using machine learning techniques to ensure high accuracy, while the AR interface was created using cutting-edge software tools that allow for seamless integration of data visualization in a spatial format. Building on the Snap Spectacles provided us with a unique opportunity to leverage their advanced AR capabilities, resulting in a truly immersive user experience.
## Challenges we ran into
One of the main challenges we faced was ensuring the accuracy and speed of the facial recognition system in various lighting conditions and angles. Additionally, integrating real-time data updates into the AR interface required overcoming technical hurdles related to data synchronization and display.
## Accomplishments that we're proud of
We are proud of successfully developing a prototype that demonstrates the potential of our technology in a real-world healthcare setting. The experience of building on the Snap Spectacles allowed us to create a user experience that feels natural and intuitive, making it easier for healthcare professionals to engage with patient data.
## What we learned
Throughout the development process, we learned the importance of user-centered design in healthcare technology. Communicating with healthcare professionals helped us understand their needs and refine our solution to better serve them. We also gained valuable insights into the technical challenges of integrating AR with real-time data.
## What's next for EYEdentity
Moving forward, we plan to start testing in clinical environments to gather more feedback and refine our technology. Our goal is to enhance the system's capabilities, expand its features, and ultimately deploy EYEdentity in healthcare facilities to revolutionize patient care. | ## Inspiration
We were interested in developing a solution to automate the analysis of microscopic material images.
## What it does
Our program utilizes image recognition and image processing tools such as edge detection, gradient analysis, gaussian/median/average filters, morphologies, image blending etc. to determine specific shapes of a microscopic image and apply binary thresholds for analysis. In addition, the program has the ability to differentiate between light and dark materials under poor lighting conditions, as well as calculate the average surface areas of grains and the percentage of dark grains.
## How we built it
We used Python algorithms incorporated with OpenCV tools in the PyCharm developing environment.
## Challenges we ran into
Contouring for images was extremely difficult considering there were many limitations and cleaning/calibrating data and threshold values. The time constraints also impacted us, as we would have liked to be able to develop a more accurate algorithm for our image analysis software.
## Accomplishments that we're proud of
Making a breakthrough in iterative masking of the images to achieve an error percentage consistently below 0.5%. We're also incredibly proud of the fact that we were able to complete the majority of the challenge tasks as well as develop a user-friendly interface.
## What we learned
We became better equipped with Python and the opensource materials available to all of us. We also learned valuable computer vision skills through practical applications as well as a developed a better understanding of data processing algorithms.
## What's next for Material Arts 2000
We're looking to further refine our algorithms so that it will be of more practical use in the future. Potentially looking to expand from the specific field of microscopic materials to develop a more widely applicable algorithm. | partial |
# ¡Buscaría!
---
## Get Started
Chat 'help' at [¡Buscaría!](https://www.messenger.com/t/buscaria)
## Inspiration
Learning a language is hard, and keeping up language skills is nearly as hard. Sometimes work gets in the way, and at other times there just isn?t anyone else around that knows the language. That?s where ¡Buscaría! can help! By connecting people who want to learn a language to those who are willing to teach others through messenger, we help people maintain and develop language skills in a convenient and interpersonal way.
## What it does
¡Buscaría! determines the languages that a person is willing to teach and wants to learn, recording the proficiency of the user at each language. Next, the user who wishes to learn a language is anonymously connected to another user who wishes to teach the language and has a greater proficiency in the language. After conversing for some time, either user can choose to end the interaction, at which point both users have the opportunity to rate the interaction. We keep track of a user?s ?karma points? to make sure that there are no free riders--learn too many times without teaching anyone else, and you?ll find yourself out of karma! Users can also gain karma through positive ratings.
## How we built it
¡Buscaría! is built on the Facebook Messenger platform, which enables users to have quick and easy access to the platform. Using the Facebook Developer API, we built a Messenger chatbot, allowing users to interact with the service by messaging the ¡Buscaría! facebook page. The backend server is written using Ruby on Rails, and it is hosted on Linode.
## Challenges we ran into
We were faced with many choices of what technology to use for various pieces of functionality, and each offered its own positives and negatives. We settled with Ruby on Rails due to its combination of extendability and intuitiveness, though we definitely faced a few problems in setting up the server. Messenger offered a few obstacles in that it was hard to communicate properly with facebook at first, as well as with redirecting messages from one user to another. Further challenges we faced involved redirecting not only text, but also a variety of multimedia, such as photos, video, audio, and emojis! Some of us did not have much prior programming experience, and had to learn the Ruby language from scratch, and setting up a reliable online server with functioning handshakes was a new challenge.
## Accomplishments that we're proud of
Most of the members of the team had never used Ruby before, let alone Ruby on Rails. In addition, most members of this team had never programmed a chatbot before. We?re proud to have developed our technical skills, but more importantly we believe we have built a product that can truly be useful to many people around the world, perhaps after making a few more tweaks.
## What we learned
Ruby, Ruby on Rails framework, Facebook Messenger API, server setup on Linode
## What's next for ¡Buscaría!
We hope to build a user base by first sharing this app on our social media networks, then potentially connecting with the Stanford Language Center when we have made the app a bit more polished. In terms of features, we hope to further flesh out the pairing of student and teacher, in particular taking into account how often the teacher has been willing to help in the past, and also building on the ratings received by both student and teacher over an extended period of time. In addition, we hope to add live video and group chat features to the community, and we also wish to let users invite their friends to use the app through a phone number. | ## Inspiration
Throughout high school and college, I've tutored students in my free time and have noticed that many of them find or incorrect information online. In particular, low-income students often fall prey to sites such as Yahoo! Answers, which provide inaccurate or misleading information. In a world where information is always at our fingertips, this is inexcusable. Students deserve to find relevant and accurate information, and our chat bot will empower them to do so.
## What it does
CARA (Curated Academic Resource Assistant) is a friendly chat bot who can provide students with trusted online resources in subjects that range from economic and precalculus to chemistry and Spanish. Students can also get practice exams and quizzes to bolster their education.
## How we built it
Students' chat messages are parsed through LUIS (Language Understanding Intelligent Service), an incredibly intelligent Natural Language Machine Learning processor pioneered by Microsoft. We extract each message's intent, deciphering what topic students need help with. Then, these queries are autocorrected by the Bing Autocorrect API and fed through the Bing Web-search API. By narrowing our search to specific websites relevant to the student's query, we return a list of the highest-quality, most relevant web pages to help the student.
## Challenges we ran into
Connecting the front end to the back end was very challenging for us.
## Accomplishments that we're proud of
Using so many technologies in concert to bring together a very tangible project that will definitively help people.
## What we learned
We learned a great deal about the various Microsoft APIs we've used in this project, and have had a lot of fun learning about the intricacies of LUIS in particular.
## What's next for Cara
First and foremost we plan on deploying our app for immediate impact. Additionally, drawing on our team's linguistic abilities, we've already created a second LUIS parser for Spanish and have translated the training data into Spanish as well. The next step will be to find high-quality resources in Spanish and allow the ability to toggle language on the chat bot itself. | ## Inspiration
Throughout Quarantine and the global pandemic that we are all currently experiencing, I have begun to reflect on my own life and health in general. We may believe we have a particular ailment when, in fact, it is actually our fear getting the best of us. But how can one be sure that the symptoms they are having are as severe as they seem to be? As a result, we developed the Skin Apprehensiveness Valdiator and Educator App to help not only maintain our mental balance in regards to paranoia about our own health, but also to help front line staff solve the major pandemic that has plagued the planet.
## What it does
The home page is the most critical aspect of the app. It has a simple user interface that allows the user to choose between using an old photo or taking a new photo of any skin issues they may have. They can then pick or take a screenshot, and then, after submission, we can use the cloud to run our model and receive results from it, thanks to Google's Cloud ML Kit. We get our overall diagnosis of what illness our Model thinks it is, as well as our trust level. Following that, we have the choice of viewing more information about this disease through a wikipedia link or sending this to a specialist for confirmation.
Tensorflow and a convolutional neural network with several hidden layers were used to build the first Machine Learning Algorithm. It uses the Adam optimizer and has a relu activation layer. We've also improved the accuracy by using cross validation.
The second section of the app is the specialist section, where you can view doctors whose diagnoses you can check online. You may send them a text, email, or leave a voicemail to request a consultation and learn more about your diagnosis. This involves questions like what should my treatment be, when should I begin, where should I go, and how much will it cost, as well as some others.
The third section of the app is the practices section, which helps you to locate dermatology practices in your area that can assist you with your care. You can see a variety of information about a location, including its Google Review Average ranking, total number of reviews, phone number, address, and other relevant information. You also get a glimpse into how their office is decorated. You may also click on the location to be redirected to Google Maps directions to that location.
The tips section of the app is where you can find different links from reputable sources that will help you get advice on care, diagnosis, or skin disorders in a geological environment.
## How we built it
ReactJS, Expo, Google Cloud ML Kit, Tensorflow, practoAPI, Places API | losing |
As a tourist, one faces many difficulties from the moment he lands. Finding the right tourist guide, getting them at the right price and getting rid of the same old monotonous itinerary; These are some of the problems which motivated us to build Travelogue.
Travelogue's greatest strength is that it creates a personalized user experience in every event or interaction that the user has or is related to the user's interest in some way or the other. It successfully matches customers to signed up local guides using it's advanced matching allgorithm.
The project is based with its front end developed in HTML, CSS, JavaScript, PHP, jQuery and Bootstrap. This is supported by a strong back end Flask framework (Python). We used the basic SQLite3 database for instant prototype deployment of the idea and used Java and Faker library to create massive amounts of training data.
Throughout the project, we ran into designing issues such as frame layouts and how to display the data in the most effective manner, we believe in this constant update of design which would result in the creation of the best design suited for our web application. We also faced some difficulty while integrating the back end of the application written in Python with the front end created using JavaScript and PHP.
This hack was a solution to the common existing problem of matching people with similar interests. We brainstormed a lot and came up with a 3 step algorithm to tackle the issue. The algorithm focuses on the importance of features and how a customer relates to the guide using those features.
Working with a team of diverse skill sets, all of us learned a lot from each other and by overcoming the challenges we faced during the development of this web application.
We have planned to incorporate Facebook's massive data and widely popular Graph API to extract features and interests for matching customers with the local guides. After implementing these ideas, the user has a simple one click Facebook login which helps our matching algorithm work on large amount of meaningful data. | ## Instago
Instago! Your goto **travel planner app**! We're taking the most annoying parts about planning for a trip and leaving only the funnest parts to you! Just give us your destination and we'll quickly generate you a trip to the 5 most attractive tourist destinations starting at the most ideally located hotel at your destination.
We were inspired by our experiences with planning trips with our friends. Often times, it would take us a few days to find the best places we were interested to see, in a city. Unfortunately, we also had to spend time filtering away the destinations that we were uninterested in or did not fulfil our constraints. We hoped that by building Instago, we can help reduce the time it takes for people to plan their trips and get straight to the exciting preparation for the big day!
In this project, we chose to run our front-end with **React** and build our back-end with **Stdlib**, a technology we have never used before.
On the front-end side, we used **Google Maps API** for the first time in conjunction with React. This proved to be more challenging than expected as Google does not provide any in-house APIs that primarily support React. We also lost a significant amount of time trying many npm wrapper packages for google maps. They either did not support Google Directions, a key feature we needed for our project or were poorly documented. We ended up discovering the possibility of introducing script tag elements in React which allowed us to import the vanilla Google Maps JS API which supported all map features.
The largest challenge was in the back-end. While Stdlib was phenomenally flexible and easy to set up, test, debug and deploy, we needed to write our own algorithm to determine how to rank tourist attractions. We considered factors such as tourist attraction location, type of tourist attraction, number of ratings and average rating to calculate a score for each attraction. Since our API required making multiple requests to Google Places to get tourist attraction information, we had to make compromises to ensure the speed of our algorithm was reasonable for users.
The number of next steps for our project is boundless! We have plans to integrate Facebook/Google login so that we can take in user likes and preferences to make even more tailored travel plans (Users can also store and share their trips on their associated accounts)! We want to apply a semantic similarity calculation using **Word2vec** models and compare a city's tourist attraction names and types with the interests of users to gather a list of places a user would most likely visit. Concerts or sport games that are happening around the time of the user's trip could also be added to an iteniary. We also have plans to add budget constraints and modes of travel to the calculation. It was too much to add all these cool features into our project before demoing, but we are excited to add them in later!
Overall, this was an awesome project and we are so proud of what we made! :) | ## Inspiration
We always that moment when you're with your friends, have the time, but don't know what to do! Well, SAJE will remedy that.
## What it does
We are an easy-to-use website that will take your current location, interests, and generate a custom itinerary that will fill the time you have to kill. Based around the time interval you indicated, we will find events and other things for you to do in the local area - factoring in travel time.
## How we built it
This webapp was built using a `MEN` stack. The frameworks used include: MongoDB, Express, and Node.js. Outside of the basic infrastructure, multiple APIs were used to generate content (specifically events) for users. These APIs were Amadeus, Yelp, and Google-Directions.
## Challenges we ran into
Some challenges we ran into revolved around using APIs, reading documentation and getting acquainted to someone else's code. Merging the frontend and backend also proved to be tough as members had to find ways of integrating their individual components while ensuring all functionality was maintained.
## Accomplishments that we're proud of
We are proud of a final product that we legitimately think we could use!
## What we learned
We learned how to write recursive asynchronous fetch calls (trust me, after 16 straight hours of code, it's really exciting)! Outside of that we learned to use APIs effectively.
## What's next for SAJE Planning
In the future we can expand to include more customizable parameters, better form styling, or querying more APIs to be a true event aggregator. | losing |
## Inspiration
Physical health and **mental health** are equally important. People often forget how important mental health is and it often goes unnoticed. Beware of your own emotion and be honest about it is very important. We believe it is the key to maintain a healthy mental state. This app aims to help the users to understand themselves better.
## What it does
Ideally, the user would take a picture of themselves and the Azure emotion API will detect the emotion of the user. Then, the user will rate how accurate that emotion represents their feeling at that moment. The user can take more than one picture to use multiple emotions to represent their day. Then, they can create tags like #family # academic to denote that why they are feeling this way. There will be a calendar page to show how often the users are using this app. The emotions will be sorted into categories like #anger, #happy, #sad and show statistics about the frequency of the user are feeling this way over time as well as in each emotional category, what labels and how many of them are present.
## How I built it
We used the android studio to make the app.
We did not finish the whole project but we managed to make a tiny version of it that allows the user to log in, take a picture, then save the picture locally. There is also a manual bar.
## Challenges I ran into
We felt it would be great if we have more time to develop the project. 36 hours is just not enough!
We did not have experience working with APIs so we spent time learning what that is and how to implement APIs.
We only have a team of two.
## Accomplishments that I'm proud of
We successfully implemented the camera API.
## What I learned
Important teamwork skills.
## What's next for FeelTheDay
Next, we hope the app will generate random motivative quotes to our users on the phone screen. Also, we hope it can host a page that displays information about mental health. | ## Inspiration
The pandemic has exacerbated pre-existing mental health challenges. We took inspiration to make an app that can support the user when navigating daily life. As mental illnesses come in different shades, we wanted to make an app that can accommodate and at the same time, not overwhelm.
## About ***Check In***
Through *Check In*, users can input reminders for drinking water, stretching, and getting enough sleep, all tasks that can get to be overwhelming in the current environment. Additionally, the user will be soothed by affirmations that will change throughout the day to encourage and center them. Users can also access a series of resources tailored to their current emotional state through the 'How are you feeling?' portal. They will be suggested to choose among five emotional states:
* I am feeling anxious.
* I am feeling depressed.
* I am feeling angry.
* I am feeling overwhelmed.
* I am okay!
According to the choice made above, the user will be led to a page where, alongside an encouraging message, they will have access to a series of resources to tackle their emotions.
## How we built it
*Check In* is built using Flutter in an Android development environment, and Firebase as the backend using MaterialUI guidelines.
## Challenges we ran into
Developing a product using an SDK not experimented with previously, offered plenty of positive challenges. Additionally, when there is a time crunch, it is inevitable that concessions will have to be made. We originally intended for the user to have push notifications, but adding this functionality proved to be too complex for the allocated time, so it was replaced by a carousel at the top of the home page. The challenges faced, we believe, have made us just that much wiser.
## Accomplishments that we're proud of
The team is proud of having developed a complete product in the span of a weekend. Not only that, but we are proud of having had the courage to experiment with and develop this app through flutter, dart, and firebase - all tools previously foreign to us.
## What we learned
Although we had to make concessions, we learned that sometimes having to make such sacrifices can end up having a positive effect. Adding some of the features we had originally planned could overwhelm the user and ultimately work against our overarching goal.
## What's next for ***Check In***
These are the features we hope to implement as we continue working on *Check In*:
* Providing users with the option to connect their Spotify accounts, so *Check In* can recommend songs and playlists that match their mood. The music will be filtered according to tone, beats per minute (BPM), key, volume, pitch, and cadence.
* Customizing reminders outside of the three that are offered currently.
* Enabling push notifications so users can see reminders on their home screens.
* Linking the user's personal calendar for a more streamlined experience. | ## Inspiration
I, Jennifer Wong, went through many mental health hurdles and struggled to get the specific help that I needed. I was fortunate to find a relatable therapist that gave me an educational understanding of my mental health, which helped me understand my past and accept it. I was able to afford this access to mental health care and connect with a therapist similar to me, but that's not the case for many racial minorities. I saw the power of mental health education and wanted to spread it to others.
## What it does
Takes a personalized assessment of your background and mental health in order to provide a curated and self-guided educational program based on your cultural experiences.
You can journal about your reflections as you learn through watching each video. Videos are curated as an MVP, but eventually, we want to hire therapists to create these educational videos.
## How we built it
## Challenges we ran into
* We had our engineers drop the project or couldn't attend the working sessions, so there were issues with the workload. Also, there were issues with technical feasibility since knowledge on Swift was limited.
## Accomplishments that we're proud of
Proud that overall, we were able to create a fully functioning app that still achieves our mission. We were happy to get the journal tool completed, which was the most complicated.
## What we learned
We learned how to cut scope when we lost engineers on the team.
## What's next for Empathie (iOS)
We will get more customer validation about the problem and see if our idea resonates with people. We are currently getting feedback from therapists who work with people of color.
In the future, we would love to partner with schools to provide these types of self-guided services since there's a shortage of therapists, especially for underserved school districts. | losing |
## Inspiration
We wanted to be able to play chess alone.
## What it does
Allows people to play chess against another player, or an AI.
## How we built it
Using Python and recursive algorithms.
## Challenges we ran into
We had a few difficulties using Deep and Shallow Copy Operations.
## Accomplishments that we're proud of
We got the application up and running.
## What we learned
How to properly incorporate the Minimax Algorithm for our AI.
## What's next for Chess
We develop a better AI that presents a greater challenge. | ## Inspiration
Our project was inspired by the age old, famously known prisoner's dilemma. A fairly simple problem to understand, yet a difficult one to come up with a solution to. Individuals can either defect or cooperate, however they must come to a decision based on what they believe the other prisoner will do. If two individuals defect, then they each get 10 years in prison. If only one defects, and another cooperates, the one who defects gets 1 year, and the one who cooperates gets 5 years. If both decide to cooperate, they both get 3 years. It's truly a battle of wits, luck, and strategy. We decided to do a hardware implementation fo the game in a form of points.
## What it does
Our project has two interface boards with three buttons each. The first button allows a player to defect. The second button allows a player to cooperate. The third button allows players to speed up the round time. Once both players agree to speed up round time, or the timer hits zero, the points are calculated and the results are revealed. The game can be played with player versus player or player versus bot. The bots have various algorithms on them that make different decisions based on previous player output/ For example, one algorithm may solely cooperate, but once it sees that its opponent has defected once, it only defects from then on. We have various messages on LCD screens for an easier to use interface
## How we built it
We build the hardware portion of it using Arduino to connect our hardware inputs. We used digital design to develop our interface which allows the user to seemlessly navigate and understand that their inputs have been processed. The bot is built using C++ Arduino code that implements the main logic.
## Challenges we ran into
One of the major challenges we ran into was power consumption. Initially our interface had much more circuitry and wiring, but this ate up our power sources, as well as required a high constant voltage. We had to reduce the amount of circuitry involved within the project to be able to develop a feasible project. It took a lot of effort to build some portions of the circuit, but they had to be removed just due to the immense power consumption. We also did not have enough time to implement the algorithm with the hardware, thus parts of firmware is incomplete.
## Accomplishments that we're proud of
We are proud of being able to develop a cohesive project as a group which uses all the fundamentals we learned in school. This being logic design, circuit design and analysis, as well as coding. We are also proud of developing good code which incorporates the principles of object oriented design, as well as created a good player interface with the circuitry despite the major setbacks we faced along the way.
## What we learned
We definitely learned a lot from this project. We learned a lot about the design process of embedded systems which incorporate both hardware and software portions, as well as how to divide work between teams and seemlessly integrate work between them.
## What's next for Programmer's Dilemma
For the prisoner's dilemma, we hope to be able to find a way to implement all the cirucitry we had in the initial prototyping, but with much less power consumption. Furthermore, add more algorithms, as well as store statistics from previous games. | ## Inspiration
<https://www.youtube.com/watch?v=lxuOxQzDN3Y>
Robbie's story stuck out to me at the endless limitations of technology. He was diagnosed with muscular dystrophy which prevented him from having full control of his arms and legs. He was gifted with a Google home that crafted his home into a voice controlled machine. We wanted to take this a step further and make computers more accessible for people such as Robbie.
## What it does
We use a Google Cloud based API that helps us detect words and phrases captured from the microphone input. We then convert those phrases into commands for the computer to execute. Since the python script is run in the terminal it can be used across the computer and all its applications.
## How I built it
The first (and hardest) step was figuring out how to leverage Google's API to our advantage. We knew it was able to detect words from an audio file but there was more to this project than that. We started piecing libraries to get access to the microphone, file system, keyboard and mouse events, cursor x,y coordinates, and so much more. We build a large (~30) function library that could be used to control almost anything in the computer
## Challenges I ran into
Configuring the many libraries took a lot of time. Especially with compatibility issues with mac vs. windows, python2 vs. 3, etc. Many of our challenges were solved by either thinking of a better solution or asking people on forums like StackOverflow. For example, we wanted to change the volume of the computer using the fn+arrow key shortcut, but python is not allowed to access that key.
## Accomplishments that I'm proud of
We are proud of the fact that we had built an alpha version of an application we intend to keep developing, because we believe in its real-world applications. From a technical perspective, I was also proud of the fact that we were able to successfully use a Google Cloud API.
## What I learned
We learned a lot about how the machine interacts with different events in the computer and the time dependencies involved. We also learned about the ease of use of a Google API which encourages us to use more, and encourage others to do so, too. Also we learned about the different nuances of speech detection like how to tell the API to pick the word "one" over "won" in certain context, or how to change a "one" to a "1", or how to reduce ambient noise.
## What's next for Speech Computer Control
At the moment we are manually running this script through the command line but ideally we would want a more user friendly experience (GUI). Additionally, we had developed a chrome extension that numbers off each link on a page after a Google or Youtube search query, so that we would be able to say something like "jump to link 4". We were unable to get the web-to-python code just right, but we plan on implementing it in the near future. | losing |
## Inspiration
After contemplating ideas for days on end, we finally started on whatever the next idea came to mind. That was, to build an app that encourages people to go out for walks, runs, hikes, or maybe even a whole day's worth of adventure! Walking is one of the most primitive exercises and the majority of people can do it as a form of exercise. It has been proven to improve [physical](https://pubmed.ncbi.nlm.nih.gov/34417979/) and [mental](https://www.tandfonline.com/doi/full/10.1080/16078055.2018.1445025) health. The inspiration for this app comes from both Pokemon Go and Sweatcoin, but it provides the best of both worlds!
## What it does
Every day, you get a random list of 5 challenges from which you may complete up to 3 per day. These challenges require you to go out and take pictures of certain things. Depending on the difficulty of the challenges, you are awarded points. The app also keeps track of how many challenges you complete throughout your entire journey with us and a count of your daily streak which is just another way of motivating you to keep moving!
## How we built it
We built the app using React on the front end and we were going to use Node+Express in the back end along with MongoDB as our database. However, not too many things went as planned since it was our first-ever hackathon. But we've learned so much more about working together and have gained lots of new skills throughout working on this project!
## Challenges we ran into
Having to learn a lot of things from scratch because none of us have ever worked on big projects before. Some of our members are not in computer science, which only increased the amount of content to be learned for them.
## Accomplishments that we're proud of
Just going out of your way to participate in such events should make you proud!
## What we learned
We believe we now learned the basics of React, CSS, and MUI. We also can collaborate more effectively. We'll truly find out what we've learned once we put them into practice for our next project!
## What's next for Walk-E
Stick around and find out :)) | ## Inspiration:
For many people, keeping track of day-to-day items can be difficult. This is only exacerbated with the progression of age with many senior citizens either forced to adopt increasingly simplistic lifestyles or risk forgetting crucial actions.
## What it does
This application seeks to remedy this problem by providing a straightforward daily planner to keep seniors on track and eliminate forgetful errors in their day-to-day life.
## How we built it
Using React JavaScript Next.js framework, we created a web-based application which presents users with prompts regarding the required actions for the day. The user responds with a 'yes' or 'no' on whether they have yet completed the task. Once done the program outputs a summary of the completed tasks and notifies the user on the tasks still needing to be done.
## Challenges we ran into
For most of our group, this was the first time using React and thus, the learning curve regarding the software was quite steep. It took a considerable amount of time to learn enough to complete the app.
## Accomplishments that we're proud of
This project served as a great learning experience for React and the related environments. Even though this was our first time using the software, we still managed to create a functioning application.
## What we learned
On a technical front, we learned the basics of React programming as well as git commands, Vercel web hosting, Next.js, and Node.js. On a general side, this was the first Hackathon for most of our team members and we learned about problem identification, solution conception, and project evolution. Most importantly we learned that there is a lot we don't know about coding in general and were motivated to further explore the vast world of computer programming.
## What's next for To Do or !To Do
We could look into adding role based access control to allow loved ones or other friends of the user to upload daily checklists. We could also look into improving the user interface and adding timer-based notifications to the app. | ## Inspiration
We were inspired by recent advances in deep learning, which allow you to transfer style from one picture, say a famous painting, to your own pictures. We wanted to add tight integration with Facebook to allow people to experience the magic of this new technology in as accessible a manner as possible.
## What it does
Semantic style transfer is a new deep-learning technique which takes images and applies styles to them -- we've drawn these styles from collections of paintings from history.
Unfortunately Facebook requires app verification before allowing us to open it to non-developers (which takes a few days), so you can't run this yourself yet. We'd love to demo the integration for you with our own Facebook accounts, or you can see how it looks on an example photo at <http://tapioca.byron.io> !
## How we built it
AWS GPU instances running the deep-learning library torch, served by Flask. A mess of JS and hacked-together CSS on the front end in a desperate attempt to make things align, as is the way of such things.
## Challenges we ran into
Centering things is hard.
## Accomplishments that we're proud of
Got cutting-edge deep learning techniques working -- and integrated with Facebook! -- in only 36 hours. And it looks spiffy!
## What we learned
Don't stay up so late.
## What's next for tapioca
Taking over the world. But Instagram integration before that most likely. | losing |
## Inspiration–A Tale of Bothersome Bookings
**Picture this:** you have deadlines fast approaching with things to do and people to meet, and on top of it all, you have to figure out *where* you’re going to work.
Current digital booking systems make this a pain! You seldom know what rooms are available to you and where, and you often struggle to have all availability information at your fingertips. Don’t you wish you could see booking information? Well fret no more.
## Search it! Pick it! Book it! With map.it.
map.it is your one-stop shop for all your room-booking needs. It’s an intuitive and accessible web application that works by showing you a visual floor plan of the building you wish to book a room in. The best part is that you don’t even need to read the floor plan to figure out which room to book; simply type in what you need a booking for, and map.it will intelligently determine your best booking options from the rooms scanned on the floor plan.
From there, you get a glanceable view of all the room statuses pertaining to your needs throughout the day (red for occupied, green for available). Simply click on any available room and confirm to complete your room booking.
## How We Built It
At the heart of map.it is the Cohere classification API, which takes as input a set of training examples categorizing when you might want to book the room (morning, afternoon, and evening), what kind of space they are looking for, whether its a classroom space, a meeting room, or simply a study space to focus in, and the duration of your booking. The highest confidence scores for each sub-category are captured in a Node endpoint, which the front-end React web application hooks up to, in order to filter the spaces and times accordingly.
The Google Cloud Platform is also heavily leveraged; the Google Vision API is used to extract the labelled room numbers from the map and corresponding coordinates of the label bounding boxes used to create the overlaying clickable areas of the map. Google Storage is used to store a reference to the map passed into the Vision API. Google Firestore enables the storing of room availabilities for each time of the day, which the web application reads and writes to.
## Accomplishments
Having experienced the grievances of confusing booking systems, we’re proud to have created a platform that meaningfully enhances the utility of something that is instrumental to our daily lives. As we leave behind the era of online schooling, shared spaces on university campuses are needed more than ever before to support continued learning and sustain community growth. At the same time, hybrid working models have popularized immensely, and many institutions are adapting by shrinking their needlessly large workspaces. As such, a technology like map.it could help facilitate a navigable, frictionless shared workspace model.
## Learning Opportunities
There were several obstacles faced while building map.it, particularly with getting all the pieces to work together. However, working on this project opened our eyes to the power of machine learning and natural language processing; having such power so easily accessible through Cohere's developer-friendly API is inspiring and motivates us to continue to envision ways to apply artificial intelligence to enhance applications, for the better of society.
## The Future of map.it
Going forward, we hope to implement functional administrative features that allow institutions to upload their building’s floor plans and generate shareable links for their constituents to use and start booking rooms. Furthermore, integration with popular online calendar tools would allow users to seamlessly integrate map.it’s booking abilities into their digital schedules and create prompts based around their currently-scheduled events. | ## Inspiration
26% of UBC buildings are inaccessible. Students with disabilities face daily challenges to get to their classrooms, whether this be through a lack of wheelchair access or assistive listening-enabled spaces.
Additionally, 31.3% of UBC students find the current process of booking a study room terrible and inefficient. It is hard to navigate, confusing, and unclear. However, as students, we often find ourselves needing a study room to cram with a lack of means to do so. (Ex. see [Woodward](https://libcal.library.ubc.ca/reserve/woodward_group_study))
"Navigate" is an all-encompassing 3D interactive map with multiple features, such as viewing indoor accommodations, navigation to a room, and booking various services.
## What it does
An all-in-one interactive map of the UBC campus where one can view the indoor accommodations (such as wheelchair accessibility), book a study room, and book an appointment with community primary care. The maps offer navigation routes, as well as visual representations of available study rooms.
## How we built it
We build our project using the MERN stack. We implemented the MappedIn Maker SDK by creating a custom map of the ICICS building using floorplans. This allowed us to create custom functions to display room bookings and navigation paths. Our data is handled by MongoDB. Additionally, we re-engineered the 1Password Passage authentication to include JWT authentication using HTTPOnly cookies to prevent XSS attacks, thus making it fully protected from XSS, CSRF, SQL injection, and phishing attacks.
For Project management, we used Github Projects to create issues and tickets. Our PR required at least one peer review before squashing and merging into the main branch. UI/UX design was created using Figma.
## Challenges we ran into
We ran into technical challenges when attempting to implement the MappedIn Maker, as it was recently released and many features were unavailable.
## Accomplishments that we're proud of
Despite our challenges and delays, we completed an MVP version of our product with a functional back-end and custom UI.
## What's next for Navigate
The next step is to implement a quick-book feature that automatically books you a study room based on your current location. Furthermore, the health services feature requires implementation that can be built upon many existing functionalities. | ## Inspiration
One of our teammate’s grandfathers suffers from diabetic retinopathy, which causes severe vision loss.
Looking on a broader scale, over 2.2 billion people suffer from near or distant vision impairment worldwide. After examining the issue closer, it can be confirmed that the issue disproportionately affects people over the age of 50 years old. We wanted to create a solution that would help them navigate the complex world independently.
## What it does
### Object Identification:
Utilizes advanced computer vision to identify and describe objects in the user's surroundings, providing real-time audio feedback.
### Facial Recognition:
It employs machine learning for facial recognition, enabling users to recognize and remember familiar faces, and fostering a deeper connection with their environment.
### Interactive Question Answering:
Acts as an on-demand information resource, allowing users to ask questions and receive accurate answers, covering a wide range of topics.
### Voice Commands:
Features a user-friendly voice command system accessible to all, facilitating seamless interaction with the AI assistant: Sierra.
## How we built it
* Python
* OpenCV
* GCP & Firebase
* Google Maps API, Google Pyttsx3, Google’s VERTEX AI Toolkit (removed later due to inefficiency)
## Challenges we ran into
* Slow response times with Google Products, resulting in some replacements of services (e.g. Pyttsx3 was replaced by a faster, offline nlp model from Vosk)
* Due to the hardware capabilities of our low-end laptops, there is some amount of lag and slowness in the software with average response times of 7-8 seconds.
* Due to strict security measures and product design, we faced a lack of flexibility in working with the Maps API. After working together with each other and viewing some tutorials, we learned how to integrate Google Maps into the dashboard
## Accomplishments that we're proud of
We are proud that by the end of the hacking period, we had a working prototype and software. Both of these factors were able to integrate properly. The AI assistant, Sierra, can accurately recognize faces as well as detect settings in the real world. Although there were challenges along the way, the immense effort we put in paid off.
## What we learned
* How to work with a variety of Google Cloud-based tools and how to overcome potential challenges they pose to beginner users.
* How to connect a smartphone to a laptop with a remote connection to create more opportunities for practical designs and demonstrations.
How to connect a smartphone to a laptop with a remote connection to create more opportunities for practical designs and demonstrations.
How to create docker containers to deploy google cloud-based flask applications to host our dashboard.
How to develop Firebase Cloud Functions to implement cron jobs. We tried to developed a cron job that would send alerts to the user.
## What's next for Saight
### Optimizing the Response Time
Currently, the hardware limitations of our computers create a large delay in the assistant's response times. By improving the efficiency of the models used, we can improve the user experience in fast-paced environments.
### Testing Various Materials for the Mount
The physical prototype of the mount was mainly a proof-of-concept for the idea. In the future, we can conduct research and testing on various materials to find out which ones are most preferred by users. Factors such as density, cost and durability will all play a role in this decision. | partial |
## Inspiration
Nowadays, we have been using **all** sorts of development tools for web development, from the simplest of HTML, to all sorts of high-level libraries, such as Bootstrap and React. However, what if we turned back time, and relived the *nostalgic*, good old times of programming in the 60s? A world where the programming language BASIC was prevalent. A world where coding on paper and on **office memo pads** were so popular. It is time, for you all to re-experience the programming of the **past**.
## What it does
It's a programming language compiler and runtime for the BASIC programming language. It allows users to write interactive programs for the web with the simple syntax and features of the BASIC language. Users can read our sample the BASIC code to understand what's happening, and write their own programs to deploy on the web. We're transforming code from paper to the internet.
## How we built it
The major part of the code is written in TypeScript, which includes the parser, compiler, and runtime, designed by us from scratch. After we parse and resolve the code, we generate an intermediate representation. This abstract syntax tree is parsed by the runtime library, which generates HTML code.
Using GitHub actions and GitHub Pages, we are able to implement a CI/CD pipeline to deploy the webpage, which is **entirely** written in BASIC! We also have GitHub Dependabot scanning for npm vulnerabilities.
We use Webpack to bundle code into one HTML file for easy deployment.
## Challenges we ran into
Creating a compiler from scratch within the 36-hour time frame was no easy feat, as most of us did not have prior experience in compiler concepts or building a compiler. Constructing and deciding on the syntactical features was quite confusing since BASIC was such a foreign language to all of us. Parsing the string took us the longest time due to the tedious procedure in processing strings and tokens, as well as understanding recursive descent parsing. Last but **definitely not least**, building the runtime library and constructing code samples caused us issues as minor errors can be difficult to detect.
## Accomplishments that we're proud of
We are very proud to have successfully "summoned" the **nostalgic** old times of programming and deployed all the syntactical features that we desired to create interactive features using just the BASIC language. We are delighted to come up with this innovative idea to fit with the theme **nostalgia**, and to retell the tales of programming.
## What we learned
We learned the basics of making a compiler and what is actually happening underneath the hood while compiling our code, through the *painstaking* process of writing compiler code and manually writing code samples as if we were the compiler.
## What's next for BASIC Web
This project can be integrated with a lot of modern features that is popular today. One of future directions can be to merge this project with generative AI, where we can feed the AI models with some of the syntactical features of the BASIC language and it will output code that is translated from the modern programming languages. Moreover, this can be a revamp of Bootstrap and React in creating interactive and eye-catching web pages. | ## **1st Place!**
## Inspiration
Sign language is a universal language which allows many individuals to exercise their intellect through common communication. Many people around the world suffer from hearing loss and from mutism that needs sign language to communicate. Even those who do not experience these conditions may still require the use of sign language for certain circumstances. We plan to expand our company to be known worldwide to fill the lack of a virtual sign language learning tool that is accessible to everyone, everywhere, for free.
## What it does
Here at SignSpeak, we create an encouraging learning environment that provides computer vision sign language tests to track progression and to perfect sign language skills. The UI is built around simplicity and useability. We have provided a teaching system that works by engaging the user in lessons, then partaking in a progression test. The lessons will include the material that will be tested during the lesson quiz. Once the user has completed the lesson, they will be redirected to the quiz which can result in either a failure or success. Consequently, successfully completing the quiz will congratulate the user and direct them to the proceeding lesson, however, failure will result in the user having to retake the lesson. The user will retake the lesson until they are successful during the quiz to proceed to the following lesson.
## How we built it
We built SignSpeak on react with next.js. For our sign recognition, we used TensorFlow with a media pipe model to detect points on the hand which were then compared with preassigned gestures.
## Challenges we ran into
We ran into multiple roadblocks mainly regarding our misunderstandings of Next.js.
## Accomplishments that we're proud of
We are proud that we managed to come up with so many ideas in such little time.
## What we learned
Throughout the event, we participated in many workshops and created many connections. We engaged in many conversations that involved certain bugs and issues that others were having and learned from their experience using javascript and react. Additionally, throughout the workshops, we learned about the blockchain and entrepreneurship connections to coding for the overall benefit of the hackathon.
## What's next for SignSpeak
SignSpeak is seeking to continue services for teaching people to learn sign language. For future use, we plan to implement a suggestion box for our users to communicate with us about problems with our program so that we can work quickly to fix them. Additionally, we will collaborate and improve companies that cater to phone audible navigation for blind people. | [Example brainrot output](https://youtube.com/shorts/vmTmjiyBTBU)
[Demo](https://youtu.be/W5LNiKc7FB4)
## Inspiration
Graphic design is a skill like any other, that if honed, allows us to communicate and express ourselves in marvellous ways. To do so, it's massively helpful to receive specific feedback on your designs. Thanks to recent advances in multi-modal models, such as GPT-4o, even computers can provide meaningful design feedback.
What if we put a sassy spin on it?
## What it does
Adobe Brainrot is an unofficial add-on for Adobe Express that analyzes your design, creates a meme making fun of it, and generates a TikTok-subway-surfers-brainrot-style video with a Gordon Ramsey-esque personality roasting your design. (Watch the attached video for an example!)
## How we built it
The core of this app is an add-on for Adobe Express. It talks to a server (which we operate locally) that handles AI, meme-generation, and video-generation.
Here's a deeper breakdown:
1. The add-on screenshots the Adobe Express design and passes it to a custom-prompted session of GPT-4o using the ChatGPT API. It then receives the top design issue & location of it (if applicable).
2. It picks a random meme format, and asks ChatGPT for the top & bottom text of said meme in relation to the design flaw (e.g. "Too many colours"). Using the memegen.link API, it then generates the meme on-the-fly and insert it into the add-on UI.
3. Using yt-dlp, it downloads a "brainrot" background clip (e.g. Subway Surfers gameplay). It then generates a ~30-second roast using ChatGPT based on the design flaw & creates a voiceover using it, using OpenAI Text-to-Speech. Finally, it uses FFmpeg to overlay the user's design on top of the "brainrot" clip, add the voiceover in the background, and output a video file to the user's computer.
## Challenges we ran into
We were fairly unfamiliar with the Adobe Express SDK, so it was a learning curve getting the hang of it! It was especially hard due to having two SDKs (UI & Sandbox). Thankfully, it makes use of existing standards like JSX.
In addition, we researched prompt-engineering techniques to ensure that our ChatGPT API calls would return responses in expected formats, to avoid unexpected failure.
There were quite a few challenges generating the video. We referenced a project that did something similar, but we had to rewrite most of it to get it working. We had to use a different yt-dl core due to extraction issues. FFmpeg would often fail even with no changes to the code or parameters.
## Accomplishments that we're proud of
* It generates brainrot (for better or worse) videos
* Getting FFmpeg to work (mostly)
* The AI outputs feedback
* Working out the SDK
## What we learned
* FFmpeg is very fickle
## What's next for Adobe Brainrot
We'd like to flesh out the UI further so that it more *proactively* provides design feedback, to become a genuinely helpful (and humorous) buddy during the design process. In addition, adding subtitles matching the text-to-speech would perfect the video. | winning |
## Inspiration
Have either of the following happened to you?
* Ever since elementary school you've been fascinated by 17th century Turkish ethnography. Luckily, you just discovered a preeminent historian's blog about the collapse of the Ottoman Empire. Overjoyed, you start to text your friends, but soon remember that they're into 19th century Victorian poetry. If only you could share your love of historical discourse with another intellectual.
* Because you're someone with good taste, you're browsing Buzzfeed. Somehow "27 Extremely Disturbing Wikipedia Pages That Will Haunt Your Dreams" is not cutting it for you. Dang. If only you could see what your best friend Alicia was browsing. She would definitely know how to help you procrastinate on your TreeHacks project.
* On a Friday night, all your close friends have gone to a party, and you are bored to death. You look through the list of your Facebook friends. There are hundreds of people online, but you feel awkward and don’t know how to start a conversation with any of them.
Great! Because we built PageChat for you. We all have unique interests, many of which are expressed through our internet browsing. We believe that building simple connections through those interests is a powerful way to improve well-being. We built a *convenient* and *efficient* tool to connect people through their internet browsing.
## What it does
PageChat is a Google Chrome extension designed to promote serendipitous connections by offering one-on-one text chats centered on internet browsing. When active, Pagechat
* displays what you are your friends are currently reading, allowing you to discover and share interesting articles
* centers the conversation around web pages by giving friends the opportunity to chat each other directly through Chrome
* intelligently connects users with similar interests by creating one-on-one chats for users all over the world visiting the same webpage
## How we built it
### Chatting
The chrome extension was built with Angular. The background script keeps track of the tab updates and activations, and this live information is sent to the backend. The Angular App retrieves the list of friends and other users online and displays it on to the chrome extension. For friends, the title of the page they are currently reading is displayed. For users that are not friends, only those who are on the same web page are displayed. For each user displayed on the Chrome extension, we can start a chat. Then, the list view is changed to a chat room where users can have a discussion.
Instead of maintaining our own server, we used Firebase extensively. The live connections are managed by Realtime Database. Yet, since Firestore is easier to work with, we use Cloud Function to reflect the changes of live usage to Firestore using Cloud Function. Thus, there is a ‘status’ collection that contains live information about the connection state and the url and page title each user is looking at. The friends relations are maintained with ‘friends’ collection. We use Firechat, which is an open-source realtime chatting app using Firebase. Thus, all the chatting activities and histories are saved in the chats collection.
One interesting collection is the ‘feature’ collection. It stores the feature vector, which is an array of 256 numbers, for each user. Whenever a user visits a new page (in the future we plan to change the feature vector update criterion), a Cloud Function is triggered, and using our model, the feature vector is updated. The feature vector is used to find better matches i.e. people that would have similar interests among friends and other users using PageChat. As more data is accumulated, the curated list of people users would want to talk to would improve.
### User Recommendations
If several people are browsing the same website and want to chat with each other, how do we pair them up? Intuitively, people who have similar browsing histories will have more in common to talk about, so we should group them together. We maintain a dynamic **feature vector** for each user, which is based off of their reading history. We want feature vectors with small cosine distance to be similar.
When is active on PageChat and visits a site on our whitelist (we don't want sites with generic titles, so we stick to mostly news sites), we obtain the title of the page. We make the assumption that the title is representative of the content our user is reading. For example, we would expect that "27 Extremely Disturbing Wikipedia Pages That Will Haunt Your Dreams" has different content from "Ethnography Museum of Ankara". To obtain a reasonable embedding of our title, we use [SBERT](https://arxiv.org/abs/1908.10084), a BERT-based language model trained to predict the representation of sentences. SBERT can attend to the salient keywords in each title and can obtain a global representation of the title.
Next, we need some way to update feature vectors whenever a user visits a new page. This is well-suited for a recurrent neural network. These models maintain a hidden state that is continually updated with each new query. We will use an [LSTM](http://colah.github.io/posts/2015-08-Understanding-LSTMs/) to update our feature vectors. It takes in the previous feature vector and new title and outputs the new feature vector.
Finally, we need to train our LSTM. Fortunately, UCI has released a [dataset](https://archive.ics.uci.edu/ml/datasets/News+Aggregator) of news headlines along with their respective category (business, science and technology, entertainment, health). We feed these headlines as training data for the model. Before training, we preprocess the headlines, embedding all of them with SBERT. This greatly reduces training times. We use the following three-step procedure to train the model:
1. *Train an [autoencoder](https://arxiv.org/abs/1502.04681) to learn a compressed representation of the feature title.* SBERT outputs features vectors with 768 elements, which is large and unwieldy. An autoencoder is an unsupervised learning model that is able to learn high-fidelity compressed representations of the input sequence. The encoder (an LSTM) encodes a sequence of headlines into a lower-dimensional (128) space and the decoder (another LSTM) decodes the sequence. The model's goal is to output a sequence as close as possible to the original input sequence. After training, we will end up with an encoder LSTM that is able to faithfully map 768 element input vector to a 128 element space and maintain the information of the representation. We use a [contractive autoencoder](https://icml.cc/2011/papers/455_icmlpaper.pdf), which adds an extra loss term to promote the encoder to be less sensitive to variance in the input.
2. *Train the encoder to condense feature vectors that share a category.* Suppose that Holo reads several business articles and Lawrence also reads several business articles. Ideally, they should have similar feature vectors. To train, we build sequences of 5 headlines, where each headline in a sequence is drawn from the same category. The encoder LSTM from the previous step encodes these sequences to feature vectors. We train it to obtain a higher cosine similarity for vectors that share a category than for vectors that don't.
3. *Train the encoder to condense feature vectors that share a story.* The dataset also has a feature corresponding to the specific news story an article covers. Similar to step 2, we build sequences of 5 headlines, where each headline in a sequence is drawn from the same story. By training the encoder to predict a high cosine similarity for vectors that share a story, we further improve the representation of the feature vectors.
We provide some evaluations for our model and document our training process in this [Google notebook](https://colab.research.google.com/drive/1B4eWINVyWntF0VESUUgRt2opA4QFoS-M?usp=sharing). Feel free to make a copy and tinker with it!
## What's next for Pagechat
* Implementation of more features (e.g. group chatting rooms, voice chats, reading pattern analysis per user) that make the app more fun to use. | **To Access:**
Download Expo on your device and then open this link: <http://bit.ly/recoverybotdemo>. Our mobile app can be publicly accessed through this link.
## Inspiration
Over 22 million Americans today struggle with an alcohol or drug addiction. More than 130 people every day in the US die from drug overdoses, and this number is only expected to rise. To address this massive public health crisis, we created a solution that will reduce drug related deaths, strengthen support systems among addicts, and increase the rate of recovery at an individual level.
## What it does
Recovery Bot directly addresses the three major aspects of addiction intervention: emotional, mental, and physical needs. Through Recovery Bot, a user can request a conversation from a loved one, mental health specialist, or the National Drug Helpline regarding their addiction. Through Recovery Bot, a user can have a personalized, one-on-one conversation with a private and anonymous Chat Bot. We have trained Chat Bot responses to mimic the style most addiction therapists use with clients, and we have also trained the Chat Bot to provide cognitive behavioral exercises catered towards a user's history and substance. Recovery Bot also monitors the heart rate of a user on a fitbit and sends notifications to loved ones if a user's heart rate dramatically increases, a common sign of withdrawal.
## How I built it
We used react native and xcode to build the app. We used fitbit ionic to build the heart rate monitor. We used Microsoft Azure's language sentiment and language analytics to create a chat bot that can produce and respond to content in a human-like way. We used twilio to connect users with the contacts they inputted on the app and the National Drug Hotline. We also used twilio to send messages to loved ones if a user experiences extremely high heart rate levels.
## Challenges I ran into
We had issues with setting up the ECG heart monitor graphic on the app home screen and working with the fitbit. We also had to do an extensive amount of research on cognitive behavioral therapy because we wanted to make the Chat Bot's dialogue as accurate as possible. We also had some issues initially with connecting the Chat Bot to the app.
## Accomplishments that I'm proud of
We are incredibly proud of our Chat Bot and our fitbit heart monitor. These two unique features have the potential to de-stigmatize addiction and save lives.
## What I learned
Fitbit Ionic, Microsoft Azure Natural Language Processing, Twilio, Expo. We also learned more about cognitive behavioral therapy, addiction therapy, and the relapse and withdrawal process.
## What's next for Recovery Bot
Creating more dialogue for Chat Bot and also making the heart monitor detect irregular heart rates (another common withdrawal symptom) | ## Inspiration
While we were doing preliminary research, we had found overwhelming amounts of evidence of mental health deterioration as a consequence of life-altering lockdown restrictions. Academic research has shown that adolescents depend on friendship to maintain a sense of self-worth and to manage anxiety and depression. Intimate exchanges and self-esteem support significantly increased long-term self worth and decreased depression.
While people do have virtual classes and social media, some still had trouble feeling close with anyone. This is because conventional forums and social media did not provide a safe space for conversation beyond the superficial. User research also revealed that friendships formed by physical proximity don't necessarily make people feel understood and resulted in feelings of loneliness anyway. Proximity friendships formed in virtual classes also felt shallow in the sense that it only lasted for the duration of the online class.
With this in mind, we wanted to create a platform that encouraged users to talk about their true feelings, and maximize the chance that the user would get heartfelt and intimate replies.
## What it does
Reach is an anonymous forum that is focused on providing a safe space for people to talk about their personal struggles. The anonymity encourages people to speak from the heart. Users can talk about their struggles and categorize them, making it easy for others in similar positions to find these posts and build a sense of closeness with the poster. People with similar struggles have a higher chance of truly understanding each other. Since ill-mannered users can exploit anonymity, there is a tone analyzer that will block posts and replies that contain mean-spirited content from being published while still letting posts of a venting nature through. There is also ReCAPTCHA to block bot spamming.
## How we built it
* Wireframing and Prototyping: Figma
* Backend: Java 11 with Spring Boot
* Database: PostgresSQL
* Frontend: Bootstrap
* External Integration: Recaptcha v3 and IBM Watson - Tone Analyzer
* Cloud: Heroku
## Challenges we ran into
We initially found it a bit difficult to come up with ideas for a solution to the problem of helping people communicate. A plan for a VR space for 'physical' chatting was also scrapped due to time constraints, as we didn't have enough time left to do it by the time we came up with the idea. We knew that forums were already common enough on the internet, so it took time to come up with a product strategy that differentiated us. (Also, time zone issues. The UXer is Australian. They took caffeine pills and still fell asleep.)
## Accomplishments that we're proud of
Finishing it on time, for starters. It felt like we had a bit of a scope problem at the start when deciding to make a functional forum with all these extra features, but I think we pulled it off. The UXer also iterated about 30 screens in total. The Figma file is *messy.*
## What we learned
As our first virtual hackathon, this has been a learning experience for remote collaborative work.
UXer: I feel like i've gotten better at speedrunning the UX process even quicker than before. It usually takes a while for me to get started on things. I'm also not quite familiar with code (I only know python), so watching the dev work and finding out what kind of things people can code was exciting to see.
# What's next for Reach
If this was a real project, we'd work on implementing VR features for those who missed certain physical spaces. We'd also try to work out improvements to moderation, and perhaps a voice chat for users who want to call. | partial |
## Inspiration
We were interested in AI with the recent development in AI and release of ChatGPT. After hearing the Co:here presentation, we decided to give it a try!
We've used journals and journal apps before but never stuck with one. We thought it would be cool to have a 'Spotify Wrapped at the end of your yearly, monthly, and even weekly journal entries.
## What it does
Have you ever found yourself at the end of a hectic month and thought, "What even happened last week"? *dAIly* is the AI diary tool you can count on to keep you grounded and remind you just what you've been up to.
dAIly is an online diary that you can write to that will give you a summary of things that happened in the past week and month. There is also a calendar view where you can see all of your entries and click in to specific entries.
## How we built it
Basic Web App, combined with NLP model that we created original prompt to extract and summarize the daily activities, so you can have an AAR (AI-generated Accurate Review). The user inputs text in the React frontend, and our server communicates with co:here's *Generate* API to summarize the key events from each diary entry. The results are then passed back to the frontend for the user to explore and introspect.
## Challenges we ran into
Communication between designers and programmers during a time crunch.
## Accomplishments that we're proud of
Creating both a low-fidelity and high-fidelity prototype in Figma within 48 hours.
Learning lots of React hooks and creating an infinite calendar!
## What we learned
Have a strong vision for your product
Check-ins are helpful most of the time
## What's next for dAIly by HackShack
Our next goal would be to allow users to add their own images. Then using keywords or themes, AI mood recognition for the entries to create a visual analysis/mood tracker at the end of the month. | ## Inspiration
Recently we've all started to notice a trend at restaurants. When you get there, one of the biggest challenges is what do we order? And there are a few ways people try to tackle this:
* Ask for recommendations of food
* Text their foodie friend for help
* Start browsing yelp and reading reviews to try to grasp what is the best thing to order
However, sometimes recommendations by other people don't necessarily fit our taste, which can lead to a possibly less than ideal meal. This is where we come in, trying to create the optimal meal for people.
## What it does
The app serves to not only allow for better food recommendations for the diner, but also give restaurants a means of more powerful data analysis. From a very high level, the app serves as a means for massive data aggregation that aides both restaurants and users alike.
From the consumer side the app allows users to find a given restaurant and the associated menu. From here, the back end will also provide recommendations based upon a heuristic naive bayes algorithm.
## How we built it
In terms of the tools we used: we built an app with a Flask framework frontend that is linked to a MySQL database and mobile development was done in swift. In order to aid our development, we leveraged a variety of APIs including locu (menus), yelp (restaurants), google search (autocompletion), and facebook-graph-api (future development and social network connectivity).
## Challenges we ran into
In order to provide a reasonable proof of concept recommendation system that took into account the user's preferences we utilized the "yelp-academic-dataset." This led to some difficulties when dealing with the sparsely populated feature matrix and applying appropriate algorithms to achieve a reasonable result.
## Accomplishments that we're proud of
For us, deciding on such a large project that included an extensive front and back end, in the end the experience was challenging yet really rewarding.
## What we learned
For us some of the most valuable experience was learning to work as a team on such a large project (from both the front and back end). And this was truly our defining experience, where we're working with few hours of sleep on a large project, it honestly came down to delegation and team work that allowed us to finish.
## What's next for chewyTime
For us, we still look forwards to continually improving and further developing the app and see where it takes us. This would mean hashing out more of the restaurant side of the application and building deeper functionality by leveraging networks. | ## Inspiration..
This web-app was inspired by our group's interest in internal combustion engines. We are a group of Mechanical Engineering students and in our major course dealing with Thermodynamics, Heat Transfer, and Internal Combustion Engines, it has been difficult for us to visualize the effects of various inputs on an engine's total performance. We were inspired to create an app in MATLAB that would help us solve this problem. MATLAB was chosen as the programming language for this app since MATLAB was a part of our standard curriculum for Mechanical Engineering.
## What it does
The Internal Combustion Engine (ICE) Analyzer calculates mean effective pressures, efficiency, and work produced given compression ratio, bore, stroke, connecting rod length, and displacement volume. A pressure-volume or p-v diagram is also made for the combustion cycle, and each of the four strokes (intake, compression, combustion, exhaust) are outlined in the p-v diagram.
## How we built it
We used MATLAB App Designer to develop our app.
## Challenges we ran into
A challenge we ran into was getting started on how to approach our problem. Before this weekend, we have never heard of MATLAB's App Designer tool. With some familiarity with GUI, we decided that this was the route to take as it allows for a clean and easy to use interface. By watching some videos on YouTube and learning from the Mathworks website, we became familiar with this new tool.
## Accomplishments that we're proud of
We're proud to have completed a project that we hope engineers will find useful. We're also proud to have learned a new tool.
## What we learned
We learned how to use MATLAB's App Designer.
## What's next for Internal Combustion Engine Analyzer
We can add more output parameters and fix up some bugs in our program. We can also make the graph more dynamic. | losing |
# Things2Do
Minimize time spent planning and maximize having fun with Things2Do!
## Inspiration
The idea for Things2Do came from the difficulties that we experienced when planning events with friends. Planning events often involve venue selection which can be a time-consuming, tedious process. Our search for solutions online yielded websites like Google Maps, Yelp, and TripAdvisor, but each fell short of our needs and often had complicated filters or cluttered interfaces. More importantly, we were unable to find event planning that accounts for the total duration of an outing event and much less when it came to scheduling multiple visits to venues accounting for travel time. This inspired us to create Things2Do which minimizes time spent planning and maximizes time spent at meaningful locations for a variety of preferences on a tight schedule. Now, there's always something to do with Things2Do!
## What it does
Share quality experiences with people that you enjoy spending time with. Things2Do provides the top 3 suggested venues to visit given constraints of the time spent at each venue, distance, and select category of place to go. Furthermore, the requirements surrounding the duration of a complete event plan across multiple venues can become increasingly complex when trying to account for the tight schedules of attendees, a wide variety of preferences, and travel time between multiple venues throughout the duration of an event.
## How we built it
The functionality of Things2Do is powered by various APIs to retrieve the details of venues and spatiotemporal analysis with React for the front end, and express.js/node.js for the backend functionality.
APIs:
* openrouteservice to calculate travel time
* Geoapify for location search autocomplete and geocoding
* Yelp to retrieve names, addresses, distances, and ratings of venues
Languages, tools, and frameworks:
* JavaScript for compatibility with React, express.js/node.js, Verbwire, and other APIs
* Express.js/node.js backend server
* TailwindCSS for styling React components
Other services:
* Verbwire to mint NFTs (for memories!) from event pictures
## Challenges we ran into
Initially, we wanted to use Google Maps API to find locations of venues but these features were not part of the free tier and even if we were to implement these ourselves it would still put us at risk of spending more than the free tier would allow. This resulted in us switching to node.js for the backend to work with JavaScript for better support for the open-source APIs that we used. We also struggled to find a free geocoding service so we settled for Geoapify which is open-source. JavaScript was also used so that Verbwire could be used to mint NFTs based on images from the event. Researching all of these new APIs and scouring documentation to determine if they fulfilled the desired functionality that we wanted to achieve with Things2Do was an enormous task since we never had experience with them before and were forced to do so for compatibility with the other services that we were using. Finally, we underestimated the time it would take to integrate the front-end to the back-end and add the NFT minting functionality on top of debugging.
A challenge we also faced was coming up with an optimal method of computing an optimal event plan in consideration of all required parameters. This involved looking into algorithms like the Travelling Salesman, Dijkstra's and A\*.
## Accomplishments that we're proud of
Our team is most proud of meeting all of the goals that we set for ourselves coming into this hackathon and tackling this project. Our goals consisted of learning how to integrate front-end and back-end services, creating an MVP, and having fun! The perseverance that was shown while we were debugging into the night and parsing messy documentation was nothing short of impressive and no matter what comes next for Things2Do, we will be sure to walk away proud of our achievements.
## What we learned
We can definitively say that we learned everything that we set out to learn during this project at DeltaHacks IX.
* Integrate front-end and back-end
* Learn new languages, libraries, frameworks, or services
* Include a sponsor challenge and design for a challenge them
* Time management and teamwork
* Web3 concepts and application of technology
## Things to Do
The working prototype that we created is a small segment of everything that we would want in an app like this but there are many more features that could be implemented.
* Multi-user voting feature using WebSockets
* Extending categories of hangouts
* Custom restaurant recommendations from attendees
* Ability to have a vote of "no confidence"
* Send out invites through a variety of social media platforms and calendars
* Scheduling features for days and times of day
* Incorporate hours of operation of venues | ## Inspiration
We recognized that packages left on porch are unsafe and can be easily stolen by passerby and mailmen. Delivery that requires signatures is safer, but since homeowners are not always home, deliveries often fail, causing inconvenience for both homeowners and mailmen.
The act of picking up packages and carrying packages into home can also be physically straining for some.
Package storage systems are available in condos and urban locations, such as concierge or Amazon lockers, but unavailable in the suburbs or rural region, such as many areas of Brampton.
Because of these pain points, we believe there is market potential for homeowners in rural areas for a personal delivery storage solution. With smart home hacking and AI innovation in mind, we improve the lives of all homeowners by ensuring their packages are efficiently delivered and securely stored.
## What it does
OWO is a novel package storage system designed to prevent theft in residential homes. It uses facial recognition, user ID, and passcode to verify the identity of mailman before unlocking the device and placing the package on the device. The automated device is connected to the interior of the house and contains a uniquely designed joint to securely bring packages into home. Named "One Way Only", it effectively prevents any possible theft by passerby or even another mailman who have access to the device.
## How I built it
We built a fully animated CAD design with Fusion 360. Then, we proceeded with an operating and automated prototype and user interface using Arduino, C++, light fabrication, 3D printing. Finally, we set up an environment to integrate facial recognition and other Smart Home monitoring measures using Huawei Atlas 310 AI processor.
## What's next for One Way Only (OWO)
Build a 1:1 scaled high fidelity prototype for real-world testing. Design for manufacturing and installation. Reach out to potential partners to implement the system, such as Amazon. | ## Inspiration
We are all software/game devs excited by new and unexplored game experiences. We originally came to PennApps thinking of building an Amazon shopping experience in VR, but eventaully pivoted to Project Em - a concept we all found mroe engaging. Our swtich was motivated by the same force that is driving us to create and improve Project Em - the desire to venture into unexplored territory, and combine technologies not often used together.
## What it does
Project Em is a puzzle exploration game driven by Amazon's Alexa API - players control their character with the canonical keyboard and mouse controls, but cannot accomplish anything relevant in the game without talking to a mysterious, unknown benefactor who calls out at the beginning of the game.
## How we built it
We used a combination of C++, Pyhon, and lots of shell scripting to create our project. The client-side game code runs on Unreal Engine 4, and is a combination of C++ classes and Blueprint (Epic's visual programming language) scripts. Those scripts and classes communicate an intermediary server running Python/Flask, which in turn communicates with the Alexa API. There were many challenges in communicating RESTfully out of a game engine (see below for more here), so the two-legged approach lent itself well to focusing on game logic as much as possible. Sacha and Akshay worked mostly on the Python, TCP socket, and REST communication platform, while Max and Trung worked mainly on the game, assets, and scripts.
The biggest challenge we faced was networking. Unreal Engine doesn't naively support running a webserver inside a game, so we had to think outside of the box when it came to networked communication.
The first major hurdle was to find a way to communicate from Alexa to Unreal - we needed to be able to communicate back the natural language parsing abilities of the Amazon API to the game. So, we created a complex system of runnable threads and sockets inside of UE4 to pipe in data (see challenges section for more info on the difficulties here). Next, we created a corresponding client socket creation mechanism on the intermediary Python server to connect into the game engine. Finally, we created a basic registration system where game clients can register their publicly exposed IPs and Ports to Python.
The second step was to communicate between Alexa and Python. We utilitzed [Flask-Ask](https://flask-ask.readthedocs.io/en/latest/) to abstract away most of the communication difficulties,. Next, we used [VaRest](https://github.com/ufna/VaRest), a plugin for handing JSON inside of unreal, to communicate from the game directly to Alexa.
The third and final step was to create a compelling and visually telling narrative for the player to follow. Though we can't describe too much of that in text, we'd love you to give the game a try :)
## Challenges we ran into
The challenges we ran into divided roughly into three sections:
* **Threading**: This was an obvious problem from the start. Game engines rely on a single main "UI" thread to be unblocked and free to process for the entirety of the game's life-cycle. Running a socket that blocks for input is a concept in direct conflict with that idiom. So, we dove into the FSocket documentation in UE4 (which, according to Trung, hasn't been touched since Unreal Tournament 2...) - needless to say it was difficult. The end solution was a combination of both FSocket and FRunnable that could block and certain steps in the socket process without interrupting the game's main thread. Lots of stuff like this happened:
```
while (StopTaskCounter.GetValue() == 0)
{
socket->HasPendingConnection(foo);
while (!foo && StopTaskCounter.GetValue() == 0)
{
Sleep(1);
socket->HasPendingConnection(foo);
}
// at this point there is a client waiting
clientSocket = socket->Accept(TEXT("Connected to client.:"));
if (clientSocket == NULL) continue;
while (StopTaskCounter.GetValue() == 0)
{
Sleep(1);
if (!clientSocket->HasPendingData(pendingDataSize)) continue;
buf.Init(0, pendingDataSize);
clientSocket->Recv(buf.GetData(), buf.Num(), bytesRead);
if (bytesRead < 1) {
UE_LOG(LogTemp, Error, TEXT("Socket did not receive enough data: %d"), bytesRead);
return 1;
}
int32 command = (buf[0] - '0');
// call custom event with number here
alexaEvent->Broadcast(command);
clientSocket->Close();
break; // go back to wait state
}
}
```
Notice a few things here: we are constantly checking for a stop call from the main thread so we can terminate safely, we are sleeping to not block on Accept and Recv, and we are calling a custom event broadcast so that the actual game logic can run on the main thread when it needs to.
The second point of contention in threading was the Python server. Flask doesn't natively support any kind of global-to-request variables. So, the canonical approach of opening a socket once and sending info through it over time would not work, regardless of how hard we tried. The solution, as you can see from the above C++ snippet, was to repeatedly open and close a socket to the game on each Alexa call. This ended up causing a TON of problems in debugging (see below for difficulties there) and lost us a bit of time.
* **Network Protocols**: Of all things to deal with in terms of networks, we spent he largest amount of time solving the problems for which we had the least control. Two bad things happened: heroku rate limited us pretty early on with the most heavily used URLs (i.e. the Alexa responders). This prompted two possible solutions: migrate to DigitalOcean, or constantly remake Heroku dynos. We did both :). DigitalOcean proved to be more difficult than normal because the Alexa API only works with HTTPS addresses, and we didn't want to go through the hassle of using LetsEncrypt with Flask/Gunicorn/Nginx. Yikes. Switching heroku dynos it was.
The other problem we had was with timeouts. Depending on how we scheduled socket commands relative to REST requests, we would occasionally time out on Alexa's end. This was easier to solve than the rate limiting.
* **Level Design**: Our levels were carefully crafted to cater to the dual player relationship. Each room and lighting balance was tailored so that the player wouldn't feel totally lost, but at the same time, would need to rely heavily on Em for guidance and path planning.
## Accomplishments that we're proud of
The single largest thing we've come together in solving has been the integration of standard web protocols into a game engine. Apart from matchmaking and data transmission between players (which are both handled internally by the engine), most HTTP based communication is undocumented or simply not implemented in engines. We are very proud of the solution we've come up with to accomplish true bidirectional communication, and can't wait to see it implemented in other projects. We see a lot of potential in other AAA games to use voice control as not only an additional input method for players, but a way to catalyze gameplay with a personal connection.
On a more technical note, we are all so happy that...
THE DAMN SOCKETS ACTUALLY WORK YO
## Future Plans
We'd hope to incorporate the toolchain we've created for Project Em as a public GItHub repo and Unreal plugin for other game devs to use. We can't wait to see what other creative minds will come up with!
### Thanks
Much <3 from all of us, Sacha (CIS '17), Akshay (CGGT '17), Trung (CGGT '17), and Max (ROBO '16). Find us on github and say hello anytime. | partial |
## Inspiration
A common problem faced by college students and working professionals alike is finding a compatible roommate to live with. We wanted to create a solution to make this an easier process.
## What it does
Roomify allows users to create profiles and returns matched profiles based on categories such as location, age, and optionally, gender.
## How we built it
This web application was built using Java and Netbeans. The front end was built using HTML. We used the Apache Tomcat server.
## Challenges we ran into
Starting off since neither of us have much experience with Full Stack development, we were a little lost with where to begin for creating a web application. Using our prior knowledge of Java and HTML, we decided to use NetBeans. This entire project was a lot of learning as we were implementing - how servers work, the differences between .xml, html files, and how to design the interaction between servlets. Understand the Java framework that was used along with the server interaction, took the most amount of time. Having prior knowledge of the programming languages came in *clutch* the most in regard to confidence, but the learning an entirely new framework and interface on-the-go took the most brain power.
## What's next for Roomify?
Eventually, we would like to implement a server or database for saving all of our user’s profiles and allow the end user to scroll through multiple matches rather than have only one match. Due to time constraints and lack of previous experience, we had to manually create most of the existing profiles. Moreover, we plan to implement a login/authentication mechanism for the application, and a built-in messenger for users to be able to communicate with each other solely through our app. | ## Inspiration
Finding someone to swap rooms with at college is hard. Every year, many students (especially freshmen) get stuck in dorms they don't want to live in, but end up having to, well, live with it, because they can't find someone who wants to switch with them. With so many students not getting their first choice dorms, it must be conceivable that a few could perform mutual room swaps and both be happy with their new rooms. But out of 10,000 undergraduates, it can be impossible to find someone who actually wants to switch with you. We built this application to make the process of finding mutual swappers easier.
## What it does
Takes the dorm you are living in and the dorms you want to live in, and matches you with a student who fits your preferences.
## How we built it
Built with Html5, Css3, Bootstrap, JQuery, and Javascript
## Challenges we ran into
We ran into a ton of problems joining the front end and the back end. Also had to give up on some more complex css and html things.
## Accomplishments that we're proud of
Getting a project done on time.
## What we learned
Simplicity does not necessarily mean a less useful application
## What's next for College Room Swap
Adding more universities and getting a better UI for when a match is found | ## Problem
In these times of isolation, many of us developers are stuck inside which makes it hard for us to work with our fellow peers. We also miss the times when we could just sit with our friends and collaborate to learn new programming concepts. But finding the motivation to do the same alone can be difficult.
## Solution
To solve this issue we have created an easy to connect, all in one platform where all you and your developer friends can come together to learn, code, and brainstorm together.
## About
Our platform provides a simple yet efficient User Experience with a straightforward and easy-to-use one-page interface.
We made it one page to have access to all the tools on one screen and transition between them easier.
We identify this page as a study room where users can collaborate and join with a simple URL.
Everything is Synced between users in real-time.
## Features
Our platform allows multiple users to enter one room and access tools like watching youtube tutorials, brainstorming on a drawable whiteboard, and code in our inbuilt browser IDE all in real-time. This platform makes collaboration between users seamless and also pushes them to become better developers.
## Technologies you used for both the front and back end
We use Node.js and Express the backend. On the front end, we use React. We use Socket.IO to establish bi-directional communication between them. We deployed the app using Docker and Google Kubernetes to automatically scale and balance loads.
## Challenges we ran into
A major challenge was collaborating effectively throughout the hackathon. A lot of the bugs we faced were solved through discussions. We realized communication was key for us to succeed in building our project under a time constraints. We ran into performance issues while syncing data between two clients where we were sending too much data or too many broadcast messages at the same time. We optimized the process significantly for smooth real-time interactions.
## What's next for Study Buddy
While we were working on this project, we came across several ideas that this could be a part of.
Our next step is to have each page categorized as an individual room where users can visit.
Adding more relevant tools, more tools, widgets, and expand on other work fields to increase our User demographic.
Include interface customizing options to allow User’s personalization of their rooms.
Try it live here: <http://35.203.169.42/>
Our hopeful product in the future: <https://www.figma.com/proto/zmYk6ah0dJK7yJmYZ5SZpm/nwHacks_2021?node-id=92%3A132&scaling=scale-down>
Thanks for checking us out! | losing |
## Inspiration
Do you ever wish you could just walk down the street and chat up will.i.am? Do you ever want the motivation to explore your city, with the spontaneity and fun of encountering virtual friends as an incentive? Do you want to build friendships with AI characters? 👬🏙️🗺️
## What it does
Walk around and discover virtual friends through the camera view. Think Pokemon-Go, but for virtual friends! The use cases are numerous and caters to individual needs.
1. **Converse with whomever you wish.** Whether they are fantasy or real, dead or alive, you can create virtual friends from scratch and start building a connection! 💬
2. **Mimic real-life social situations.** Wishing to practice your interview or networking skills with a virtual friend before heading into the real thing? Wanting someone to keep you on track while you study, but have no one available around you to do so? A virtual friend is your go-to choice! 📚
3. **Find motivation to explore the outside.** Wander around and spontaneously encounter virtual friends! Chat up with them and build friendship points. 🌃
## How we built it
React Native, Express, SQL server on CockroachDB, Postgresql, AssemblyAI, Cohere API
## Challenges we ran into
## Accomplishments that we're proud of
## What we learned
## What's next for FriendScape - explore a different way to connect | ## What it does
Build a friend with our starter questions, then have conversations with it to build up its context. It will remember previous conversations and use them to build responses. Our original intention was to offer a user friendly model generation experience by ingesting specialized conversation, but we chose to dial it down in favour of making sure we can complete our project.
## How we built it
### Backend
We decided to use Flask (Python) as the API backend partly because the Cohere API provided documentation in Python, but mostly because Python has a tendency to get out of your way as a programmer and let you focus on the business logic. This choice made initializing the endpoints a breeze and let the frontend guys start playing around pretty quickly.
Built personas with the help of conversant library.
### Frontend
The UI/UX is powered by React + TypeScript. Most of our members familiar with frontend favoured React over other choices primarily due to experience as well as the vast ecosystem at our disposal.
## Challenges we ran into
### Concurrently Programming
One of the more difficult challenges that we came across as a team was making sure everyone had a task to complete at all times. There were many cases in which a design choice caused a lot of work for the members working on frontend, and very little work for the backend. Utilizing our time most efficiently was a noticeable challenge at times.
## Accomplishments that we're proud of
At the end of the day, we're most proud of getting something usable across the line. We didn't have over-the-top expectations from our first hackathon, so we're happy to get to a functional state with most of the features we initially planned for.
## What we learned
1. Time management
2. Splitting up/Assigning tasks
3. Pair programming
4. How to interact with the Cohere API
## What's next for Build-A-Buddy
We'll either take it public and make millions from lonely programmers or shut it down and make real friends. Time will tell. | # About Us
Discord Team Channel: #Team-25
secretage001#6705, Null#8324, BluCloos#8986
<https://friendzr.tech/>
## Inspiration
Over the last year the world has been faced with an ever-growing pandemic. As a result, students have faced increased difficulty in finding new friends and networking for potential job offers. Based on Tinder’s UI and LinkedIn’s connect feature, we wanted to develop a web-application that would help students find new people to connect and network with in an accessible, familiar, and easy to use environment. Our hope is that people will be able Friendz to network successfully using our web-application.
## What it does
Friendzr allows users to login with their email or Google account and connect with other users. Users can record a video introduction of themselves for other users to see. When looking for connections, users can choose to connect or skip on someone’s profile. Selecting to connect allows the user to message the other party and network.
## How we built it
The front-end was built with HTML, CSS, and JS using React. On our back-end, we used Firebase for authentication, CockroachDB for storing user information, and Google Cloud to host our service.
## Challenges we ran into
Throughout the development process, our team ran into many challenges. Determining how to upload videos recorded in the app directly to the cloud was a long and strenuous process as there are few resources about this online. Early on, we discovered that the scope of our project may have been too large, and towards the end, we ended up being in a time crunch. Real-time messaging also proved incredibly difficult to implement.
## Accomplishments that we're proud of
As a team, we are proud of our easy-to-use UI. We are also proud of getting the video to record users then directly upload to the cloud. Additionally, figuring out how to authenticate users and develop a viable platform was very rewarding.
## What we learned
We learned that when collaborating on a project, it is important to communicate, and time manage. Version control is important, and code needs to be organized and planned in a well-thought manner. Video and messaging is difficult to implement, but rewarding once completed.
In addition to this, one member learned how to use HTML, CSS, JS, and react over the weekend. The other two members were able to further develop their database management skills and both front and back-end development.
## What's next for Friendzr
Moving forward, the messaging system can be further developed. Currently, the UI of the messaging service is very simple and can be improved. We plan to add more sign-in options to allow users more ways of logging in. We also want to implement AssembyAI’s API for speech to text on the profile videos so the platform can reach people who aren't as able. Friendzr functions on both mobile and web, but our team hopes to further optimize each platform. | losing |
## Inspiration
There is a growing number of people sharing gardens in Montreal. As a lot of people share apartment buildings, it is indeed more convenient to share gardens than to have their own.
## What it does
With that in mind, we decided to create a smart garden platform that is meant to make sharing gardens as fast, intuitive, and community friendly as possible.
## How I built it
We use a plethora of sensors that are connected to a Raspberry Pi. Sensors range from temperature to light-sensitivity, with one sensor even detecting humidity levels. Through this, we're able to collect data from the sensors and post it on a google sheet, using the Google Drive API.
Once the data is posted on the google sheet, we use a python script to retrieve the 3 latest values and make an average of those values. This allows us to detect a change and send a flag to other parts of our algorithm.
For the user, it is very simple. They simply have to text a number dedicated to a certain garden. This will allow them to create an account and to receive alerts if a plant needs attention.
This part is done through the Twilio API and python scripts that are triggered when the user sends an SMS to the dedicated cell-phone number.
We even thought about implementing credit and verification systems that allow active users to gain points over time. These points are earned once the user decides to take action in the garden after receiving a notification from the Twilio API. The points can be redeemed through the app via Interac transfer or by simply keeping the plant once it is fully grown. In order to verify that the user actually takes action in the garden, we use a visual recognition software that runs the Azure API. Through a very simple system of QR codes, the user can scan its QR code to verify his identity. | ## Inspiration
We wanted to create a proof-of-concept for a potentially useful device that could be used commercially and at a large scale. We ultimately designed to focus on the agricultural industry as we feel that there's a lot of innovation possible in this space.
## What it does
The PowerPlant uses sensors to detect whether a plant is receiving enough water. If it's not, then it sends a signal to water the plant. While our proof of concept doesn't actually receive the signal to pour water (we quite like having working laptops), it would be extremely easy to enable this feature.
All data detected by the sensor is sent to a webserver, where users can view the current and historical data from the sensors. The user is also told whether the plant is currently being automatically watered.
## How I built it
The hardware is built on an Arduino 101, with dampness detectors being used to detect the state of the soil. We run custom scripts on the Arduino to display basic info on an LCD screen. Data is sent to the websever via a program called Gobetwino, and our JavaScript frontend reads this data and displays it to the user.
## Challenges I ran into
After choosing our hardware, we discovered that MLH didn't have an adapter to connect it to a network. This meant we had to work around this issue by writing text files directly to the server using Gobetwino. This was an imperfect solution that caused some other problems, but it worked well enough to make a demoable product.
We also had quite a lot of problems with Chart.js. There's some undocumented quirks to it that we had to deal with - for example, data isn't plotted on the chart unless a label for it is set.
## Accomplishments that I'm proud of
For most of us, this was the first time we'd ever created a hardware hack (and competed in a hackathon in general), so managing to create something demoable is amazing. One of our team members even managed to learn the basics of web development from scratch.
## What I learned
As a team we learned a lot this weekend - everything from how to make hardware communicate with software, the basics of developing with Arduino and how to use the Charts.js library. Two of our team member's first language isn't English, so managing to achieve this is incredible.
## What's next for PowerPlant
We think that the technology used in this prototype could have great real world applications. It's almost certainly possible to build a more stable self-contained unit that could be used commercially. | ## Inspiration
Coming out from across the country, we were struggling to find a team for the UC Berkley AI Hackathon. Although the in-person team formation process is helpful, it takes away from our precious hacking time and delays the ideation phase -- we don't want to miss a single minute that could be spent coding! This is how and why we were inspired to create TeamUP, an application to help streamline the team formation process online by matching hackers with the power of AI tools via an interface similar to Tinder.
## What it does
TeamUP is designed to help match hackers with potential teammates with based on a combination of technical and soft skills. When creating your hacker profile, you'll be asked to list some of the libraries, frameworks, and tools you're experiences in so that our recommendation-system can try to suggest other hackers with skills that complement yours based on the theme of the specific hackathon. However, as often is the case with teamwork, we also want to make sure that you'll get along with your potential teammates which is why TeamUP also analyzes your "about" section to match you with people who will likely create the optimal collaborative space. This makes sure teams are well-rounded and equipped with a variety of different skillsets to create the best projects possible.
## How we built it
For the web app, we used the React (node.js) framework for the frontend and Express framework for the backend. We hosted the database in MongoDB Atlas and used AWS to host our backend APIs. For the matching system, we utilized HuggingFace's Inference module, specifically the deepset/roberta-base-squad2 model.
## Challenges we ran into
Finding a team! We spent quite a lot of time finalizing our team due some hiccups in communication... but we eventually got there. On the technical side, one of the biggest challenges was integrating the frontend and backend services because there were so many components. It also took us some time to get the AI model working with our react app -- it was a time crunch for sure!
## Accomplishments that we're proud of
We are proud of our web application and integrating AI for the matching system. It was a time crunch, but each and everyone of us learned something new which is the greatest reward.
## What we learned
We learned that full-stack development is fun but challenging at times. We also gained an appreciation for the ideation and prototyping phases because even if you put in more time there, it will make the rest of the hacking process smoother since everyone has a clear idea of what they need to be working on. Additionally, we got hands-on experience and enhanced our skillset in a variety of technologies, including MongoDB, Express, React, AWS, and more. All-in-all, this was another great opportunity to see how we can harness the power of AI to enhance our daily lives through accessible applications.
## What's next for TeamUP
Although TeamUP is initially designed for AI-themed hackathons like this one, we would like to broaden the scope to all annual collegiate hackathons (themed or not!) so that we can find better skill matches based on the specific hackathon(s) the user selects. We would also like to improve our hacker matching system to make it more sophisticated, such as by noting post-hackathon feedback so that it can get a better sense of your teamwork preferences. This would require more research into just how recommendation-systems work from the ground up, in addition to making our app more powerful to personalize the experience for every hacker. | winning |
## Inspiration
We were inspired by futuristic novels about A.I., the growing interest in machine learning concepts, and simply the idea of human-robot interaction (possibly in the near future!)
## What it does
Visualyrics is a game/quiz in which the player guesses the song based on the sentiment analysis that the machine has performed on the lyrics.
## How We built it
For text input, we had a playlist of most emotionally interesting songs on Spotify, which we translated as queries into Genius APIs for song lyrics. This way we retrieve clean data that is ready for processing. We used Watson (IBM) and Semantria (Lexalytics) APIs to do natural language processing and perform sentiment analysis, respectively. We used OpenGL (WebGL after we migrated to web) to visualize our analysis. Additionally, we used simple HTML/CSS/Javascript to output our project as a simple, accessible webapp.
## Challenges We ran into
Retrieving lyrics was a hassle, due to multiple multiple data formats, proprietary restrictions, software versions, installations and web authentication problems.
Finding a proper library for WebGL, because all of them were waaaay too complex and time-consuming for our simple visual output.
## Accomplishments that We're proud of
Taking on the craziest API ideas and scraping websites like a pro.
Working with both Watson and Lexalytics machine learning APIs - certainly a lot of fun!
## What We learned
MACHINE LEARNING!!
OpenGL into WebGL!
Extra networking protocol stuff!
There are a lot of different curious utensils.
## What's next for Visualyrics
We're gonna improve our program to output more accurate results! Yay! | ## Inspiration
The current situation with Gamestop inspired us to create this project
## What it does
It allows the user to find subreddit posts about the memestock he is interested in and also to check which one are popular on reddit.
## How we built it
We build the app using python and the Reddit API.
## Challenges we ran into
This was the first time that we used this kind of API, a challenging part of our project was to understand and correctly use Praw and the data that it gives us
## Accomplishments that we're proud of
This was our first Hackathon for the most of us and we're proud to have managed to do a project on a constraint amount of time, and accomplishing all the goals that we were setting out to do.
## What we learned
-Use Praw (a Reddit Scraper for Python) to get the data that we wanted
-Build a simple UI in Python using tkinter
## What's next for MemeStocks Finder
Implementing other social networks such as Twitter on it
Improving the UI and the performance of the program | ## Inspiration
Let's face it: Museums, parks, and exhibits need some work in this digital era. Why lean over to read a small plaque when you can get a summary and details by tagging exhibits with a portable device?
There is a solution for this of course: NFC tags are a fun modern technology, and they could be used to help people appreciate both modern and historic masterpieces. Also there's one on your chest right now!
## The Plan
Whenever a tour group, such as a student body, visits a museum, they can streamline their activities with our technology. When a member visits an exhibit, they can scan an NFC tag to get detailed information and receive a virtual collectible based on the artifact. The goal is to facilitate interaction amongst the museum patrons for collective appreciation of the culture. At any time, the members (or, as an option, group leaders only) will have access to a live slack feed of the interactions, keeping track of each other's whereabouts and learning.
## How it Works
When a user tags an exhibit with their device, the Android mobile app (built in Java) will send a request to the StdLib service (built in Node.js) that registers the action in our MongoDB database, and adds a public notification to the real-time feed on slack.
## The Hurdles and the Outcome
Our entire team was green to every technology we used, but our extensive experience and relentless dedication let us persevere. Along the way, we gained experience with deployment oriented web service development, and will put it towards our numerous future projects. Due to our work, we believe this technology could be a substantial improvement to the museum industry.
## Extensions
Our product can be easily tailored for ecotourism, business conferences, and even larger scale explorations (such as cities and campus). In addition, we are building extensions for geotags, collectibles, and information trading. | losing |
## Inspiration
As computer science and math students, many of the classes we've taken have required us to use LaTeX - and we all know just how much of a struggle it can be to memorize each and every formula exactly. We knew there had to be a better way, and decided that this weekend would be as good a time as any to tackle this challenge.
## What it does
VerbaTeX converts speech to LaTeX code, performs server-side compilation, and renders an image preview in real-time.
## How we built it
The web app is built with React, TypeScript, and Flask. Firebase and AWS were used for database management and authentication. A custom fine-tuned ChatGPT API was used for NLP and LaTeX translation.
## Challenges we ran into
Although the 32 hours we were given sounded like more than enough at the start, the amount of times we changed plans and ran into bugs quickly made us change our minds.
## Accomplishments that we're proud of
We are proud of building a fully functional full-stack application in such a short time span. We spent a lot of time and effort trying to meet all of our ambitious goals. We truly felt that we dreamed big at Hack the North 2024.
## What we learned
We learned that choosing new and unfamiliar technologies can sometimes be better than sticking to what we're used to. Although none of us had much experience with Defang before Hack the North, we learned about them during workshops and sponsor boothings and were intrigued - and choosing to build our project on it was definitely a good idea!
## What's next for VerbaTeX
LaTeX has so many more functionalities that could be simplified through VerbaTeX, from creating anything from diagrams to tables to charts. We want to make even more of these functions accessible and easier to use for LaTeX users all over the world. | ## Inspiration
The US and the broader continent is in the midst of a drug crisis affecting a large fraction of the population: the opioid crisis. The direct spark that led us to develop Core was the recent publication of a study that used a model to predict the effects of different intervention methods on reducing overdose deaths and frequency of individuals developing dependencies on opiates. The [model's predictions](https://med.stanford.edu/news/all-news/2018/08/researchers-model-could-help-stem-opioid-crisis.html) were pretty bleak in the short term.
## What it does
Core seeks to provide individuals looking to overcome opiate and other drug addictions with strong and supportive connections with volunteer mentors. At the same time, it fills another need -- many college students, retirees, and moderately unfulfilled professionals are looking for a way to help bring about positive change without wasting time on transportation or prep. Core brings a human-centered, meaningful volunteer experience opportunity directly to people in the form of an app.
## How we built it
We used Flask for the backend and jQuery for the frontend. We incorporated various APIs, such as the IBM Watson Personality Insights API, the Facebook API, and the GIPHY API.
## Challenges we ran into
It took us a while to get the Facebook OAuth API working correctly. We initially worked separately on different parts of the app. It was an interesting experience to stitch together all of our individual components into a streamlined and cohesive app.
## Accomplishments that we're proud of
We're proud of Core!
## What we learned
We learned a lot about all the natural language processing APIs that IBM Watson has to offer and the workings of the Facebook OAuth API.
## What's next for Core
Lots of features are in the works including a rating system to enable mentees to rate mentors to ensure productive relationships and more detailed chat pairing based on location information and desired level of user engagement. | ## Inspiration
As a software engineering student who writes notes in LaTeX, Mars found that there were no solutions for creating and easily generating flashcards from their notes. When brainstorming ideas, the team noticed alliteration between LaTeX and Latte, hence the coffee theme.
## What it does
LaTeXLatte allows a user to upload .tex files with custom commands that allows for the site to generate flashcards where students can view and study from. Flashcards are categorized by their corresponding course, which follows the standard naming convention of Carleton University and University of Ottawa.
## How we built it
Using MongoDB and ExpressJS, the team built both a backend server to handle files and a frontend to browse and to study the flashcards.
## Challenges we ran into
Dealing with regex, handling tex files, centering divs, and managing GitHub branches caused many problems for our team.
## Accomplishments that we're proud of
Considering this is our first MLH-sponsored hackathon, we are proud to have a product with lots of functionality. We all learned many things and met many interesting and inspiring individuals which pushed us forward. As mentioned, there were many challenges, but we are proud to have solved our unique problems with unique solutions.
## What we learned
Benjamin, while being the least experienced, contributed to the best of his ability, having learned server architecture and databases from scratch. Every team member learned a lot about writing code for servers, configuring files, regex, parsing data, using GitHub collaboratively, and most importantly, how to center a div
## What's next for LaTeXLatte
For LaTeX notes writers like Mars, this tool is already extremely useful for generating flashcards. In the future, we would like to add multiplayer functionality, allowing students to gamify their studies and enjoy learning further. | partial |
## Inspiration
We were inspired by the impact plants have on battling climate change. We wanted something that not only identifies and gives information about our plants, but also provides an indication about what others think about the plant.
## What it does
You can provide an image of a plant, either by uploading a local image or URL to an image. It takes the plant image and matches it with a species, giving you a similarity score, a scientific name, as well as common names. You can click on it to open a modal that displays more information, including the sentiment analysis of its corresponding Wikipedia page as well as a more detailed description of the plant.
## How we built it
We used an API from [Pl@ntNet](https://identify.plantnet.org/) that utilizes image recognition to identify plants. To upload the image, we needed to provide a link to the image path as a parameter. In order to make this compatible with locally uploaded images, we first saved these into Firebase. Then, we passed the identified species through an npm web scraping library called WikiJS to pull the text content from the Wikipedia page. Finally, we used Google Cloud's Natural Language API to perform sentiment analysis on Wikipedia.
## Challenges we ran into
* Finding sources that we can perform sentiment analysis on our plant
* Being able to upload a local image to be identified, which we resolved using Firebase
* Finding the appropriate API/database for plants
* Connecting frontend with backend
## Accomplishments that we're proud of
* Trying out Firebase and Google Cloud for the first time
* Learning frontier image recognition and NLP softwares
* Integrating API's to gather data
* Our beautiful UI
## What we learned
* How to manage and use the Google Cloud's Natural Language API and the PlantNet API
* There are a lot of libraries and API's that already exist to make our life easier
## What's next for Plantr
* Find ways to get carbon sequestration data about the plant
* Apply sentiment analysis on blog posts about plants to obtain better data | ## Inspiration
With the effects of climate change becoming more and more apparent, we wanted to make a tool that allows users to stay informed on current climate events and stay safe by being warned of nearby climate warnings.
## What it does
Our web app has two functions. One of the functions is to show a map of the entire world that displays markers on locations of current climate events like hurricanes, wildfires, etc. The other function allows users to submit their phone numbers to us, which subscribes the user to regular SMS updates through Twilio if there are any dangerous climate events in their vicinity. This SMS update is sent regardless of whether the user has the app open or not, allowing users to be sure that they will get the latest updates in case of any severe or dangerous weather patterns.
## How we built it
We used Angular to build our frontend. With that, we used the Google Maps API to show the world map along with markers, with information we got from our server. The server gets this climate data from the NASA EONET API. The server also uses Twilio along with Google Firebase to allow users to sign up and receive text message updates about severe climate events in their vicinity (within 50km).
## Challenges we ran into
For the front end, one of the biggest challenges was the markers on the map. Not only, did we need to place markers on many different climate event locations, but we wanted the markers to have different icons based on weather events. We also wanted to be able to filter the marker types for a better user experience. For the back end, we had challenges to figure out Twilio to be able to text users, Google firebase for user sign-in, and MongoDB for database operation. Using these tools was a challenge at first because this was our first time using these tools. We also ran into problems trying to accurately calculate a user's vicinity to current events due to the complex nature of geographical math, but after a lot of number crunching, and the use of a helpful library, we were accurately able to determine if any given event is within 50km of a users position based solely on the coordiantes.
## Accomplishments that we're proud of
We are really proud to make an app that not only informs users but can also help them in dangerous situations. We are also proud of ourselves for finding solutions to the tough technical challenges we ran into.
## What we learned
We learned how to use all the different tools that we used for the first time while making this project. We also refined our front-end and back-end experience and knowledge.
## What's next for Natural Event Tracker
We want to perhaps make the map run faster and have more features for the user, like more information, etc. We also are interested in finding more ways to help our users stay safer during future climate events that they may experience. | ## Inspiration
Living in the big city, we're often conflicted between the desire to get more involved in our communities, with the effort to minimize the bombardment of information we encounter on a daily basis. NoteThisBoard aims to bring the user closer to a happy medium by allowing them to maximize their insights in a glance. This application enables the user to take a photo of a noticeboard filled with posters, and, after specifying their preferences, select the events that are predicted to be of highest relevance to them.
## What it does
Our application uses computer vision and natural language processing to filter any notice board information in delivering pertinent and relevant information to our users based on selected preferences. This mobile application lets users to first choose different categories that they are interested in knowing about and can then either take or upload photos which are processed using Google Cloud APIs. The labels generated from the APIs are compared with chosen user preferences to display only applicable postings.
## How we built it
The the mobile application is made in a React Native environment with a Firebase backend. The first screen collects the categories specified by the user and are written to Firebase once the user advances. Then, they are prompted to either upload or capture a photo of a notice board. The photo is processed using the Google Cloud Vision Text Detection to obtain blocks of text to be further labelled appropriately with the Google Natural Language Processing API. The categories this returns are compared to user preferences, and matches are returned to the user.
## Challenges we ran into
One of the earlier challenges encountered was a proper parsing of the fullTextAnnotation retrieved from Google Vision. We found that two posters who's text were aligned, despite being contrasting colours, were mistaken as being part of the same paragraph. The json object had many subfields which from the terminal took a while to make sense of in order to parse it properly.
We further encountered troubles retrieving data back from Firebase as we switch from the first to second screens in React Native, finding the proper method of first making the comparison of categories to labels prior to the final component being rendered. Finally, some discrepancies in loading these Google APIs in a React Native environment, as opposed to Python, limited access to certain technologies, such as ImageAnnotation.
## Accomplishments that we're proud of
We feel accomplished in having been able to use RESTful APIs with React Native for the first time. We kept energy high and incorporated two levels of intelligent processing of data, in addition to smoothly integrating the various environments, yielding a smooth experience for the user.
## What we learned
We were at most familiar with ReactJS- all other technologies were new experiences for us. Most notably were the opportunities to learn about how to use Google Cloud APIs and what it entails to develop a RESTful API. Integrating Firebase with React Native exposed the nuances between them as we passed user data between them. Non-relational database design was also a shift in perspective, and finally, deploying the app with a custom domain name taught us more about DNS protocols.
## What's next for notethisboard
Included in the fullTextAnnotation object returned by the Google Vision API were bounding boxes at various levels of granularity. The natural next step for us would be to enhance the performance and user experience of our application by annotating the images for the user manually, utilizing other Google Cloud API services to obtain background colour, enabling us to further distinguish posters on the notice board to return more reliable results. The app can also be extended to identifying logos and timings within a poster, again catering to the filters selected by the user. On another front, this app could be extended to preference-based information detection from a broader source of visual input. | partial |
## The ultimate visualization method with your Roomba
With the ever-increasing proliferation of data comes the need to understand and visualize it in new and intuitive ways. Wolfram's Mathematica allows mathematicians and physicists to calculate and plot their data with functions like Plot and Plot3D. Now with PlotRoomba we are able to see our data on a macroscopic and easily accessible scale.
Using the Wolfram Development Interface, we were able to create a `PlotRoomba` function which takes in a function for plotting (`PolarPlotRoomba` is available for plotting polar functions). Upon execution, Mathematica will plot the function internally as well as post the graph data to our endpoint. Our internet-connected Roomba will read the function data and subsequently follow the path of the curve. | ## Inspiration
Minecraft has an interesting map mechanic where your character holds a map which "draws itself" while exploring the world. I am also very interested in building a plotter, which is a printer that uses a pen and (XY) gantry to produce images. These ideas seemed to fit together quite well.
## What it does
Press a button, copy GPS coordinates and run the custom "gcode" compiler to generate machine/motor driving code for the arduino. Wait around 15 minutes for a 48 x 48 output.
## How we built it
Mechanical assembly - Tore apart 3 dvd drives and extracted a multitude of components, including sled motors (linear rails). Unfortunately, they used limit switch + DC motor rather than stepper, so I had to saw apart the enclosure and **glue** in my own steppers with a gear which (you guessed it) was also glued to the motor shaft.
Electronics - I designed a simple algorithm to walk through an image matrix and translate it into motor code, that looks a lot like a video game control. Indeed, the stepperboi/autostepperboi main source code has utilities to manually control all three axes like a tiny claw machine :)
U - Pen Up
D - Pen Down
L - Pen Left
R - Pen Right
Y/T - Pen Forward (top)
B - Pen Backwards (bottom)
Z - zero the calibration
O - returned to previous zeroed position
## Challenges we ran into
* I have no idea about basic mechanics / manufacturing so it's pretty slipshod, the fractional resolution I managed to extract is impressive in its own right
* Designing my own 'gcode' simplification was a little complicated, and produces strange, pointillist results. I like it though.
## Accomplishments that we're proud of
* 24 hours and a pretty small cost in parts to make a functioning plotter!
* Connected to mapbox api and did image processing quite successfully, including machine code generation / interpretation
## What we learned
* You don't need to take MIE243 to do low precision work, all you need is superglue, a glue gun and a dream
* GPS modules are finnicky and need to be somewhat near to a window with built in antenna
* Vectorizing an image is quite a complex problem
* Mechanical engineering is difficult
* Steppers are *extremely* precise, and I am quite surprised at the output quality given that it's barely held together.
* Iteration for mechanical structure is possible, but difficult
* How to use rotary tool and not amputate fingers
* How to remove superglue from skin (lol)
## What's next for Cartoboy
* Compacting the design it so it can fit in a smaller profile, and work more like a polaroid camera as intended. (Maybe I will learn solidworks one of these days)
* Improving the gcode algorithm / tapping into existing gcode standard | # INSPIRATION
Never before than now, existed something which can teach out about managing your money the right way practically. Our team REVA brings FinLearn, not another budgeting app.
Money has been one thing around which everyone’s life revolves. Yet, no one teaches us how to manage it effectively. As much as earning money is not easy, so is managing it. As a student, when you start to live alone, take a student loan, or plans to study abroad, all this becomes a pain for you if you don’t understand how to manage your personal finances. We faced this problem ourselves and eventually educated ourselves. Hence, we bring a solution for all.
Finlearn is a fin-ed mobile application that can teach you about money management in a practical way. You can set practical finance goals for yourself and learn while achieving them. Now, learning personal finances is easier than ever with FinLearn,
# WHAT IT DOES
Finlearn is a fin-ed-based mobile application that can teach you about money and finances in a practical way. You can set practical finance goals for yourself and learn while achieving them. Now, learning personal finances is easier than ever with FinLearn.
It has features like Financial Learning Track, Goal Streaks, Reward-Based Learning Management, News Feed for all the latest cool information in the business world.
# HOW WE BUILT IT
* We built the mobile application on Flutter Framework and designed it on Figma.
* It consists of Learning and Goal Tracker APIs built with Flask and Cosmos DB
* The learning track has a voice-based feature too built with Azure text-to-speech cognitive services.
* Our Budget Diary feature helps you to record all your daily expenses into major categories which can be visualized over time and can help in forecasting your future expenses.
* These recorded expenses aid in managing your financial goals in the app.
* The rewards-based learning system unlocks more learning paths to you as you complete your goal.
# CHALLENGES WE RAN INTO
Building this project in such a short time was quite a challenge. Building logic for the whole reward-based learning was not easy. Yet we were able to pull it off. Integrating APIs by using proper data/error handling and maintaining the sleek UI along with great performance was a tricky task. Making reusable/extractable snippets of Widgets helped a lot to overcome this challenge.
# ACCOMPLISHMENTS WE ARE PROUD OF
We are proud of the efforts that we put in and pulled off the entire application within 1.5 days. Only from an idea to building an entire beautiful application is more than enough to make us feel content. The whole Learning Track we made is the charm of the application.
# WHAT’S NEXT
FinLearn would have a lot of other things in the future. Our first agenda would be to build a community feature for the students on our app. Building a learning community is gonna give it an edge.
# Credits
Veideo editing: Aaditya VK | winning |
## Inspiration
We express emotions in our everyday lives when we communicate with our loved ones, our neighbors, our friends, our local Loblaw store customer service, our doctors or therapists. These emotions can be examined by cues such as gesture, text and facial expressions. The goal of Emotional.AI is to provide a tool for businesses (customer service, etc), or doctors/therapists to identify emotions and enhance their services.
## What it does
Uses natural language processing (from audio transcription via Assembly AI) and computer vision to determine emotion of people.
## How we built it
#### **Natural Language processing**
* First we took emotion classified data from public sources (Kaggle and research studies).
* We preprocessed, cleaned, transformed, created features, and performed light EDA on the dataset.
* Used TF-IDF tokenizer to deal with numbers, punctuation marks, non letter symbols, etc.
* Scaled the data using Robust Scaler and made 7 models. (MNB, Linear Regression, KNN, SVM, Decision Tree, Random Forrest, XGB)
#### **Computer Vision**
Used Mediapipe to generate points on face, then use those points to get training data set. We used Jupyter Notebook to run OpenCV and Mediapipe. Upon running our data in Mediapipe, we were able to get a skeleton map of the face with 468 points. These points can be mapped in 3-dimension as it contains X, Y, and Z axis. We processed these features (468 points x 3) by saving them into a spreadsheet. Then we divided the spreadsheet into training and testing data. Using the training set, we were able to create 6 Machine learning models and choose the best one.
#### **Assembly AI**
We converted video/audio from recordings (whether it’s a therapy session or customer service audio from 1000s of Loblaws customers 😉) to text using Assembly API.
#### **Amazon Web Services**
We used the S3 services to host the video files uploaded by the user. These video files were then sent the Assembly AI Api.
#### **DCP**
For Computing (ML)
## Challenges we ran into
* Collaborating virtually is challenging
* Deep learning training takes a lot of computing power and time
* Connecting our front-end with back-end (and ML)
* Time management
* Working with react + flask server
* Configuring amazon buckets and users to make the app work with the s3 services
## Accomplishments that we're proud of
Apart from completing this hack, we persevered through each challenge as a team and succeeded in what we put ourselves up to.
## What we learned
* Working as a team
* Configuration management
* Working with Flask
## What's next for Emotional.AI
* We hope to have a more refined application with cleaner UI.
* We want to train our models further with more data and have more classifications.
* We want to make a platform for therapists to connect with their clients and use our tech.
* Make our solution work in real-time. | ## Inspiration
COVID revolutionized the way we communicate and work by normalizing remoteness. **It also created a massive emotional drought -** we weren't made to empathize with each other through screens. As video conferencing turns into the new normal, marketers and managers continue to struggle with remote communication's lack of nuance and engagement, and those with sensory impairments likely have it even worse.
Given our team's experience with AI/ML, we wanted to leverage data to bridge this gap. Beginning with the idea to use computer vision to help sensory impaired users detect emotion, we generalized our use-case to emotional analytics and real-time emotion identification for video conferencing in general.
## What it does
In MVP form, empath.ly is a video conferencing web application with integrated emotional analytics and real-time emotion identification. During a video call, we analyze the emotions of each user sixty times a second through their camera feed.
After the call, a dashboard is available which displays emotional data and data-derived insights such as the most common emotions throughout the call, changes in emotions over time, and notable contrasts or sudden changes in emotion
**Update as of 7.15am: We've also implemented an accessibility feature which colors the screen based on the emotions detected, to aid people with learning disabilities/emotion recognition difficulties.**
**Update as of 7.36am: We've implemented another accessibility feature which uses text-to-speech to report emotions to users with visual impairments.**
## How we built it
Our backend is powered by Tensorflow, Keras and OpenCV. We use an ML model to detect the emotions of each user, sixty times a second. Each detection is stored in an array, and these are collectively stored in an array of arrays to be displayed later on the analytics dashboard. On the frontend, we built the video conferencing app using React and Agora SDK, and imported the ML model using Tensorflow.JS.
## Challenges we ran into
Initially, we attempted to train our own facial recognition model on 10-13k datapoints from Kaggle - the maximum load our laptops could handle. However, the results weren't too accurate, and we ran into issues integrating this with the frontend later on. The model's still available on our repository, and with access to a PC, we're confident we would have been able to use it.
## Accomplishments that we're proud of
We overcame our ML roadblock and managed to produce a fully-functioning, well-designed web app with a solid business case for B2B data analytics and B2C accessibility.
And our two last minute accessibility add-ons!
## What we learned
It's okay - and, in fact, in the spirit of hacking - to innovate and leverage on pre-existing builds. After our initial ML model failed, we found and utilized a pretrained model which proved to be more accurate and effective.
Inspiring users' trust and choosing a target market receptive to AI-based analytics is also important - that's why our go-to-market will focus on tech companies that rely on remote work and are staffed by younger employees.
## What's next for empath.ly
From short-term to long-term stretch goals:
* We want to add on AssemblyAI's NLP model to deliver better insights. For example, the dashboard could highlight times when a certain sentiment in speech triggered a visual emotional reaction from the audience.
* We want to port this to mobile and enable camera feed functionality, so those with visual impairments or other difficulties recognizing emotions can rely on our live detection for in-person interactions.
* We want to apply our project to the metaverse by allowing users' avatars to emote based on emotions detected from the user. | ## Inspiration
Our project was conceived out of the need to streamline the outdated process of updating IoT devices. Historically, this was an unmanageable task that required manual connections to each device, a daunting challenge when deploying at scale. Moreover, it often incurs significant expenses, particularly when relying on services like Amazon IoT Core.
## What it does
UpdateMy.Tech addresses these issues head-on. Gone are the days of laborious manual updates and the high Amazon costs. With our system, you can effortlessly upload your firmware and your IoT device will flash itself with zero downtime.
## How we built it
To realize this vision, we used Taipy for the front and back end, MongoDB Atlas for storing binary images, Google Cloud to host the VM and API, Flask to communicate with Mongo and IoT devices, ESP-IDF to build firmware for the ESP32, all to enable OTA (Over-The-Air): The underlying technology that enables automatic updates, eliminating the need for manual intervention.
## Accomplishments that we're proud of
Our proudest achievement is creating a user-friendly and cost-effective IoT device management system that liberates users from the complexities and expenses of previous methods, including reliance on costly services like Amazon IoT Core. Technology should be accessible to all, and this project embodies that ethos.
## What we learned
This project served as a profound learning experience for our team. We gained insights into IoT device management, cloud technologies, and user-centric interface design. Additionally, we honed our expertise in firmware development, skills that will prove invaluable in future endeavours.
## What's next for UpdateMy.Tech
Our goal is to reduce the barrier of entry for hardware hacks by simplifying IoT device management. The future of "UpdateMy.Tech" is to enhance and broaden our solution's capabilities. This includes adding more features on top of updates and extending compatibility to a broader array of IoT devices. | winning |
## Inspiration
<http://stackoverflow.com/> but for exam problems
## What it does
Peridot offers a social platform that allows students to post questions and receive help from their peers in advancing their learning. Through voting and answering questions, Peridot provides the perfect environment for every student to have the same chance at success in a much more augmented way than just traditional learning.
## How I built it
1. A web scraper that mines the internet for exam questions and parses the data through NLP
2. A front end written in React and Redux
## Challenges I ran into
1. Doing the hackathon solo
2. No sleep
3. Not enough time to write a more elaborate devpost
## Accomplishments that I'm proud of
1. Finishing the product
2. Great UX
3. No hard coded data
## What I learned
I learned FeathersJS, a REST and realtime API layer for modern applications.
## What's next for Peridot
I intend to polish this project a little bit more and provide this service free of charge to the open source community. | ## Inspiration
We decided to create Squiz in desire to address the struggles students face in revision, such as difficulty in digesting extensive study materials, and lack of opportunities to test for their understanding on the course topics. Recognizing the potential of ChatGPT, we aimed at creating a web app that simplifies complex course materials and enhances student’s revision process.
## What it does
Squiz revolutionizes the revision process by converting dense study materials into interactive quizzes. Using ChatGPT, it intelligently generates personalized multiple-choice questions, making revision more engaging and effective. The app's customization options allow users to choose the difficulty levels, number of questions and save the quiz for future revision purposes. By transforming traditional study sessions into interactive quizzes, Squiz not only saves time but also enhances active learning, improving retention for a more efficient and enjoyable revision experience.
## How we built it
This project boasts a captivating mobile-friendly web app, with React.js at the forefront for seamlessly transitioning pages and incorporating advanced features. CSS takes center stage to elevate the user experience with captivating animations and transitions.
On the backend, Node.js and Express.js efficiently manages requests while seamlessly integrating with the powerful OpenAI API. Collaboration is done through the extensive use of Git among developers, ensuring a smooth and synchronized workflow within the GitHub repository.
The interface was designed with cute graphics, including a squid mascot, and vibrant colors to offer an engaging user experience and thus an interesting learning process.
## Challenges we ran into
Our main struggle in the hackathon was figuring out how to make a button work. This button lets users upload PDFs, and we convert the text into a special file that OpenAI uses to create quiz questions. We relied on the pdfjs-dist library for this, but its documentation was incomplete, making things tough. Despite the challenges, we tackled it by experimenting step by step and trying different ways to fix issues. Eventually, we got it working which is absolutely rewarding.
Another challenge was the tight time limit of this hackathon. This constraint underscored the importance of efficient collaboration, pushing us to divide our work wisely, optimize processes and make collective decisions swiftly.
Through coordinated efforts, we overcame this challenge, highlighting the importance of teamwork and adaptability in project execution.
## Accomplishments that we're proud of
1. We use the useContext hook for the first time.
2. We've developed more than 90% of the Hi-Fi prototype designed by the UX designer in 24 hours!
3. We've designed an original cartoon squid logo, which established brand personality and consistency.
## What we learned
What you learned
This hackathon experience taught us the importance of adaptability and innovation in educational technology. We learned to harness the power of natural language processing to cater to diverse learning styles. Building this tool deepened our understanding of AI's potential to enhance the educational experience.
Working on Squiz also enhanced our teamwork skills, such as communication and collaborative problem-solving skills. We discovered that effective teamwork is as crucial as technical expertise in delivering successful projects.
## What's next for Squiz
We would like to further developed the History function of the app, which allows users to save the quizzes that they have done. | ## Inspiration
Across the globe, a critical shortage of qualified teachers poses a significant challenge to education. The average student-to-teacher ratio in primary schools worldwide stands at an alarming **23:1!** In some regions of Africa, this ratio skyrockets to an astonishing **40:1**. [Research 1](https://data.worldbank.org/indicator/SE.PRM.ENRL.TC.ZS) and [Research 2](https://read.oecd-ilibrary.org/education/education-at-a-glance-2023_e13bef63-en#page11)
As populations continue to explode, the demand for quality education has never been higher, yet the *supply of capable teachers is dwindling*. This results in students receiving neither the attention nor the **personalized support** they desperately need from their educators.
Moreover, a staggering **20% of students** experience social anxiety when seeking help from their teachers. This anxiety can severely hinder their educational performance and overall learning experience. [Research 3](https://www.cambridge.org/core/journals/psychological-medicine/article/much-more-than-just-shyness-the-impact-of-social-anxiety-disorder-on-educational-performance-across-the-lifespan/1E0D728FDAF1049CDD77721EB84A8724)
While many educational platforms leverage generative AI to offer personalized support, we envision something even more revolutionary. Introducing **TeachXR—a fully voiced, interactive, and hyper-personalized AI** teacher that allows students to engage just like they would with a real educator, all within the immersive realm of extended reality.
*Imagine a world where every student has access to a dedicated tutor who can cater to their unique learning styles and needs. With TeachXR, we can transform education, making personalized learning accessible to all. Join us on this journey to revolutionize education and bridge the gap in teacher shortages!*
## What it does
**Introducing TeachVR: Your Interactive XR Study Assistant**
TeachVR is not just a simple voice-activated Q&A AI; it’s a **fully interactive extended reality study assistant** designed to enhance your learning experience. Here’s what it can do:
* **Intuitive Interaction**: Use natural hand gestures to circle the part of a textbook page that confuses you.
* **Focused Questions**: Ask specific questions about the selected text for summaries, explanations, or elaborations.
* **Human-like Engagement**: Interact with TeachVR just like you would with a real person, enjoying **milliseconds response times** and a human voice powered by **Vapi.ai**.
* **Multimodal Learning**: Visualize the concepts you’re asking about, aiding in deeper understanding.
* **Personalized and Private**: All interactions are tailored to your unique learning style and remain completely confidential.
### How to Ask Questions:
1. **Circle the Text**: Point your finger and circle the paragraph you want to inquire about.
2. **OK Gesture**: Use the OK gesture to crop the image and submit your question.
### TeachVR's Capabilities:
* **Summarization**: Gain a clear understanding of the paragraph's meaning. TeachVR captures both book pages to provide context.
* **Examples**: Receive relevant examples related to the paragraph.
* **Visualization**: When applicable, TeachVR can present a visual representation of the concepts discussed.
* **Unlimited Queries**: Feel free to ask anything! If it’s something your teacher can answer, TeachVR can too!
### Interactive and Dynamic:
TeachVR operates just like a human. You can even interrupt the AI if you feel it’s not addressing your needs effectively!
## How we built it
**TeachXR: A Technological Innovation in Education**
TeachXR is the culmination of advanced technologies, built on a microservice architecture. Each component focuses on delivering essential functionalities:
### 1. Gesture Detection and Image Cropping
We have developed and fine-tuned a **hand gesture detection system** that reliably identifies gestures for cropping based on **MediaPipe gesture detection**. Additionally, we created a custom **bounding box cropping algorithm** to ensure that the desired paragraphs are accurately cropped by users for further Q&A.
### 2. OCR (Word Detection)
Utilizing **Google AI OCR service**, we efficiently detect words within the cropped paragraphs, ensuring speed, accuracy, and stability. Given our priority on latency—especially when simulating interactions like pointing at a book—this approach aligns perfectly with our objectives.
### 3. Real-time Data Orchestration
Our goal is to replicate the natural interaction between a student and a teacher as closely as possible. As mentioned, latency is critical. To facilitate the transfer of image and text data, as well as real-time streaming from the OCR service to the voiced assistant, we built a robust data flow system using the **SingleStore database**. Its powerful real-time data processing and lightning-fast queries enable us to achieve sub-1-second cropping and assistant understanding for prompt question-and-answer interactions.
### 4. Voiced Assistant
To ensure a natural interaction between students and TeachXR, we leverage **Vapi**, a natural voice interaction orchestration service that enhances our feature development. By using **DeepGram** for transcription, **Google Gemini 1.5 flash model** as the AI “brain,” and **Cartesia** for a natural voice, we provide a unique and interactive experience with your virtual teacher—all within TeachXR.
## Challenges we ran into
### Challenges in Developing TeachXR
Building the architecture to keep the user-cropped image in sync with the chat on the frontend posed a significant challenge. Due to the limitations of the **Meta Quest 3**, we had to run local gesture detection directly on the headset and stream the detected image to another microservice hosted in the cloud. This required us to carefully adjust the size and details of the images while deploying a hybrid model of microservices. Ultimately, we successfully navigated these challenges.
Another difficulty was tuning our voiced assistant. The venue we were working in was quite loud, making background noise inevitable. We had to fine-tune several settings to ensure our assistant provided a smooth and natural interaction experience.
## Accomplishments that we're proud of
### Achievements
We are proud to present a complete and functional MVP! The cropped image and all related processes occur in **under 1 second**, significantly enhancing the natural interaction between the student and **TeachVR**.
## What we learned
### Developing a Great AI Application
We successfully transformed a solid idea into reality by utilizing the right tools and technologies.
There are many excellent pre-built solutions available, such as **Vapi**, which has been invaluable in helping us implement a voice interface. It provides a user-friendly and intuitive experience, complete with numerous settings and plug-and-play options for transcription, models, and voice solutions.
## What's next for TeachXR
We’re excited to think of the future of **TeachXR** holds even greater innovations! we’ll be considering\**adaptive learning algorithms*\* that tailor content in real-time based on each student’s progress and engagement.
Additionally, we will work on integrating **multi-language support** to ensure that students from diverse backgrounds can benefit from personalized education. With these enhancements, TeachXR will not only bridge the teacher shortage gap but also empower every student to thrive, no matter where they are in the world! | losing |
## Why
Type 2 diabetes can be incredibly tough, especially when it leads to complications. I've seen it firsthand with my uncle, who suffers from peripheral neuropathy. Watching him struggle with insensitivity in his feet, having to go to the doctor regularly for new insoles just to manage the pain and prevent further damage—it’s really painful. It's constantly on my mind how easily something like a pressure sore could become something more serious, risking amputation. It's heartbreaking to see how diabetes quietly affects his everyday life in ways people do not even realize.
## What
Our goal is to create a smart insole for diabetic patients living with type 2 diabetes. This insole is designed with several pressure sensors placed at key points to provide real-time data on the patient’s foot pressure. By continuously processing this data, it can alert both the user and their doctor when any irregularities or issues are detected. What’s even more powerful is that, based on this data, the insole can adjust to help correct the patient’s walking stance. This small but important correction can help prevent painful foot ulcers and, hopefully, make a real difference in their quality of life.
## How we built it
We build an insole with 3 sensors on it (the sensors are a hackathon project on their own), that checks the plantar pressure exerted by the patient. We stream and process the data and feed it to another model sole that changes shape based on the gait analysis so it helps correct the patients walk in realtime.
Concurrently we stream the data out to our dashboard to show recent activity, alerts and live data about a patient's behavior so that doctors can monitor them remotely- and step in if any early signs of neural-degradation .
## Challenges we ran into and Accomplishments that we're proud of
So, we hit a few bumps in the road since most of the hackathon projects were all about software, and we needed hardware to bring our idea to life. Cue the adventure! We were running all over the city—Trader Joe's, Micro Center, local makerspaces—you name it, we were there, hunting for parts to build our force sensor. When we couldn’t find what we needed, we got scrappy. We ended up making our own sensor from scratch using PU foam and a pencil (yep, a pencil!). It was a wild ride of custom electronics, troubleshooting hardware problems, and patching things up with software when we couldn’t get the right parts.
In the end, we’re super proud of what we pulled off—our own custom-built sensor, plus the software to bring it all together. It was a challenge, but we had a blast, and we're thrilled with what we made in the time we had!
## What we learned
Throughout this project, we learned that flexibility and resourcefulness are key when working with hardware, especially under tight time constraints, as we had to get creative with available materials.
As well as this - we learnt a lot about preventative measures that can be taken to reduce the symptoms of diabetes and we have optimistic prospects about how we will can continue to help people with diabetes.
## What's next for Diabeteasy
Everyone in our team has close family affected by diabetes, meaning this is a problem very near and dear to all of us. We strive to continue developing and delivering a prototype to those around us who we can see, first hand, the impact and make improvements to refine the design and execution. We aim to build relations with remote patient monitoring firms to assist within elderly healthcare, since we can provide one value above all; health. | # waitER
One of the biggest causes of crowding and wait times in emergency departments is “boarding,” a term for holding an admitted patient in the ER for hours or even days until an inpatient bed becomes available. Long wait times can affect patient outcomes in various ways: patients may get tired of waiting and leave without receiving medical treatment, especially when resources of the emergency department are overwhelmed. In order to alleviate some of the anxiety and stress associated with the process, we created a web application that aims to bring transparency to patient wait times in the emergency room.
---
### Features
1. **Homepage**: Upon arrival at the ER, the patient recieves a unique user ID used to access their personal homepage, mainly featuring the placement they are currently in the queue along with other supplementary educational information that may be of interest.
2. **Triage page**: (only accessible to admin) Features a series of triage questions used to determine the ESI of that particular patient.
3. **Admin dashboard**: (only accessible to admin) Features a scrollable queue of all patients in line, along with their ID, arrival time, and ESI. The admin is able to add users to the queue using the triage page and to remove users when it is their turn for care. This then alerts the patient through the homepage.
*Note*: When any update occurs, all pages are updated to reflect the latest changes.
---
### Running this program
1. Make sure node and npm are installed on the system.
2. Install all node modules with `npm install`.
3. Build the application with `npm run build`.
4. Run the application with `npm run start`.
5. Access the triage page at `localhost:8080/triage` and add a patient to the queue.
6. After adding the patient to the queue, the page will display a link to the patient's individual page along with a link to the dashboard. | ## What inspired you?
The inspiration behind this project came from my grandmother, who has struggled with poor vision for years. Growing up, I witnessed firsthand how her limited sight made daily tasks and walking in unfamiliar environments increasingly difficult for her. I remember one specific instance when she tripped on an uneven curb outside the grocery store. Though she wasn’t hurt, the fall shook her confidence, and she became hesitant to go on walks or run errands by herself. This incident helped spark the idea of creating something that could help people like her feel safer and more secure while navigating their surroundings.
I wanted to develop a solution that would give visually impaired individuals not just mobility but confidence. The goal became clear: to create a product that could intuitively guide users through their environment, detecting obstacles like curbs, steps, and uneven terrain, and providing feedback they could easily understand. By incorporating haptic feedback, pressure-based sensors, and infrared technology, this system is designed to give users more control and awareness over their movements, helping them move through the world with greater independence and assurance. My hope is that this technology can empower people like my grandmother to reclaim their confidence and enjoy everyday activities without fear.
## What it does
This project is a smart shoe system designed to help visually impaired individuals safely navigate their surroundings by detecting obstacles and terrain changes. It uses infrared sensors located on both the front and bottom of the shoe to detect the distance to obstacles like curbs and stairs. When the user approaches an obstacle, the system provides real-time feedback through 5 servos. 3 servos are responsible for haptic feedback related to the distance from the ground, and distance in front of them, while the remaining servos are related to help guiding the user through navigation. The infrared sensors detect how far the foot is off the ground, and the servos respond accordingly. The vibrational motors, labeled 1a and 2a, are used when the distance exceeds 6 inches, delivering pulsating signals to inform the user of upcoming terrain changes. This real-time feedback ensures users can sense potential dangers and adjust their steps to prevent falls or missteps. Additionally the user would connect to the shoe based off of bluetooth.
The shoe system operates using three key zones of detection: the walking range (0-6 inches), the far walking range (6-12 inches), and the danger zone (12+ inches). In the walking range, the haptic feedback is minimal but precise, giving users gentle vibrations when the shoe detects small changes, such as a flat surface or minor elevation shifts. As the shoe moves into the far walking range (6-12 inches), where curbs or stairs may appear, the intensity of the feedback increases, and the vibrational motors start to pulse more frequently. This alert serves as a warning that the user is approaching a significant elevation change. When the distance exceeds 12 inches—the danger zone—the vibrational motors deliver intense, rapid feedback to indicate a drop-off or large obstacle, ensuring the user knows to take caution and adjust their step. These zones are carefully mapped to provide a seamless understanding of the terrain without overwhelming the user.
The system also integrates seamlessly with a mobile app, offering GPS-based navigation via four directional haptic feedback sensors that guide the user forward, backward, left, or right. Users can set their route through voice commands, unfortunately we had trouble integrating Deepgram AI, which would assist by understanding speech patterns, accents, and multiple languages, making it accessible to people who are impaired lingually. Additionally we had trouble integrating Skylo, which the idea would be to serve areas where Wi-Fi is unavailable, or connection unstable, the system automatically switches to Skylo via their Type1SC circuit board and antenna, a satellite backup technology, to ensure constant connectivity. Skylo sends out GPS updates every 1-2 minutes, preventing the shoe from losing its route data. If the user strays off course, Skylo triggers immediate rerouting instructions through google map’s api in the app which we did set up in our app, ensuring that they are safely guided back on track. This combination of sensor-driven feedback, haptic alerts, and robust satellite connectivity guarantees that visually impaired users can move confidently through diverse environments.
## How we built it
We built this project using a combination of hardware components and software integrations. To start, we used infrared sensors placed at the front and bottom of the shoe to detect distance and obstacles. We incorporated five servos into the design: three for haptic feedback based on distance sensing 3 and two for GPS-related feedback. Additionally, we used vibrational motors (1a and 2a) to provide intense feedback when larger drops or obstacles were detected. The app we developed integrates the Google Maps API for route setting and navigation. To ensure connectivity in areas with limited Wi-Fi, we integrated Skylo’s Type 1SC satellite hardware, allowing for constant GPS data transmission even in remote areas.
For the physical prototype, we constructed a 3D model of a shoe out of cardboard. Attached to this model are two 5000 milliamp-hour batteries, providing a total of 10000 mAh to power the system. We used an ESP32 microcontroller to manage the various inputs and outputs, along with a power distribution board to efficiently allocate power to the servos, sensors, and vibrational motors. All components were securely attached to the cardboard shoe prototype to create a functional model for testing.
## Challenges we ran into
One of the main challenges we encountered was working with the Skylo Type 1SC hardware. While the technology itself was impressive, the PDF documentation and schematics were quite advanced, requiring us to dive deeper into understanding the technical details. We successfully established communication between the Arduino and the Type 1SC circuit but faced difficulties in receiving a response back from the modem, which required further troubleshooting. Additionally, distinguishing between the different components on the circuit, such as data pins and shorting components, proved challenging, as the labeling was intricate and required careful attention. These hurdles allowed us to refine our skills in circuit analysis and deepen our knowledge of satellite communication systems.
On the software side, we had to address several technical challenges. Matching the correct Java version for our app development was more complex than expected, as version discrepancies affected performance. We also encountered difficulties creating a Bluetooth hotspot that could seamlessly integrate with the Android UI for smooth user interaction. On the hardware end, ensuring reliable connections was another challenge; we found that some of our solder joints for the pins weren’t as stable as needed, leading to occasional issues with connectivity. Through persistent testing and adjusting our approaches, we were able to resolve most of these challenges while gaining valuable experience in both hardware and software integration.
## Accomplishments that we're proud of
One of the accomplishments we’re most proud of is successfully setting up Skylo services and establishing satellite connectivity, allowing the system to access LTE data in areas with low or no Wi-Fi. This was a key component of the project, and getting the hardware to communicate with satellites smoothly was a significant milestone. Despite the initial challenges with understanding the complex schematics, we were able to wire the Arduino to the Type 1SC board correctly, ensuring that the system could relay GPS data and maintain consistent communication. The experience gave us a deeper appreciation for satellite technology and its role in enhancing connectivity for projects like ours.
Additionally, we’re proud of how well the array of sensors was set up and how all the hardware components functioned together. Each sensor, whether for terrain detection or obstacle awareness, worked seamlessly with the servos and haptic feedback system, resulting in better-than-expected performance. The responsiveness of the hardware components was more precise and reliable than we had originally anticipated, which demonstrated the strength of our design and implementation. This level of integration and functionality validates our approach and gives us confidence in the potential impact this project can have for the visually impaired community.
## What we learned
Throughout this project, we gained a wide range of new skills that helped bring the system to life. One of our team members learned to solder, which was essential for securing the hardware components and making reliable connections. We also expanded our knowledge in React system programming, which allowed us to create the necessary interactions and controls for the app. Additionally, learning to use Flutter enabled us to develop a smooth and responsive mobile interface that integrates with the hardware components.
On the hardware side, we became much more familiar with the ESP32 microcontroller, particularly its Bluetooth connectivity functions, which were crucial for communication between the shoe and the mobile app. We also had the opportunity to dive deep into working with the Type 1SC board, becoming comfortable with its functionality and satellite communication features. These new skills not only helped us solve the challenges within the project but also gave us valuable experience for future work in both hardware and software integration.
## What's next for PulseWalk
Next for PulseWalk, we plan to enhance the system's capabilities by refining the software to provide even more precise feedback and improve user experience. We aim to integrate additional features, such as obstacle detection for more complex terrains and improved GPS accuracy with real-time rerouting. Expanding the app’s functionality to include more languages and customization options using Deepgram AI will ensure greater accessibility for a diverse range of users. Additionally, we’re looking into optimizing battery efficiency and exploring more durable materials for the shoe design, moving beyond the cardboard prototype. Ultimately, we envision PulseWalk evolving into a fully commercialized product that offers a seamless, dependable mobility aid for the visually impaired which partners with shoe brands to bring a minimalist approach to the brand and make it look less like a medical device and more like an everyday product. | winning |
## Inspiration
We wanted to make eco-friendly travel accessible and enjoyable for all, while also supporting local businesses.
## What it does
The Eco-Friendly Travel Planner is an AI-driven platform that offers personalized travel recommendations with a strong focus on sustainability. It provides travellers with eco-conscious destination suggestions, and budget-friendly options, and supports local businesses. By leveraging AI, it tailors recommendations to each traveller's preferences, making eco-friendly travel easier and more enjoyable.
## How we built it
We used HTML, CSS, JS, Node.js, MongoDB, Google Maps API, Carbon Footprint API, GPT-3 API, and more to build this.
## Challenges we ran into
How to use and link the APIs, we spend hours trying to make the APIs run as they should.
## Accomplishments that we're proud of
We are all proud that we were able to develop this project within so many hours, we are also happy that we were able to learn new technologies and APIs to build this project.
## What we learned
How to use APIs, how to use Mongo DB and we learned about frameworks such as bootstrap and more
## What's next for Eco-Friendly Travel Planner | ## 🌱 Inspiration
With the ongoing climate crisis, we recognized a major gap in the incentives for individuals to make greener choices in their day-to-day lives. People want to contribute to the solution, but without tangible rewards, it can be hard to motivate long-term change. That's where we come in! We wanted to create a fun, engaging, and rewarding way for users to reduce their carbon footprint and make eco-friendly decisions.
## 🌍 What it does
Our web app is a point-based system that encourages users to make greener choices. Users can:
* 📸 Scan receipts using AI, which analyzes purchases and gives points for buying eco-friendly products from partner companies.
* 🚴♂️ Earn points by taking eco-friendly transportation (e.g., biking, public transit) by tapping their phone via NFC.
* 🌿 See real-time carbon emission savings and get rewarded for making sustainable choices.
* 🎯 Track daily streaks, unlock milestones, and compete with others on the leaderboard.
* 🎁 Browse a personalized rewards page with custom suggestions based on trends and current point total.
## 🛠️ How we built it
We used a mix of technologies to bring this project to life:
* **Frontend**: Remix, React, ShadCN, Tailwind CSS for smooth, responsive UI.
* **Backend**: Express.js, Node.js for handling server-side logic.
* **Database**: PostgreSQL for storing user data and points.
* **AI**: GPT-4 for receipt scanning and product classification, helping to recognize eco-friendly products.
* **NFC**: We integrated NFC technology to detect when users make eco-friendly transportation choices.
## 🔧 Challenges we ran into
One of the biggest challenges was figuring out how to fork the RBC points API, adapt it, and then code our own additions to match our needs. This was particularly tricky when working with the database schemas and migration files. Sending image files across the web also gave us some headaches, especially when incorporating real-time processing with AI.
## 🏆 Accomplishments we're proud of
One of the biggest achievements of this project was stepping out of our comfort zones. Many of us worked with a tech stack we weren't very familiar with, especially **Remix**. Despite the steep learning curve, we managed to build a fully functional web app that exceeded our expectations.
## 🎓 What we learned
* We learned a lot about integrating various technologies, like AI for receipt scanning and NFC for tracking eco-friendly transportation.
* The biggest takeaway? Knowing that pushing the boundaries of what we thought was possible (like the receipt scanner) can lead to amazing outcomes!
## 🚀 What's next
We have exciting future plans for the app:
* **Health app integration**: Connect the app to health platforms to reward users for their daily steps and other healthy behaviors.
* **Mobile app development**: Transfer the app to a native mobile environment to leverage all the features of smartphones, making it even easier for users to engage with the platform and make green choices. | ## Inspiration
Between 1994 and 2013 there were 6,873 natural disasters worldwide, which claimed 1.35 million lives or almost 68,000 lives on average each year. In many of these disasters, people don't know where to go, and where is safe. For example, during Hurricane Harvey, many people learned about dangers such as alligators or flooding through other other people, and through social media.
## What it does
* Post a natural disaster hazard in your area
* Crowd-sourced hazards
* Pulls government severe weather data
* IoT sensor system to take atmospheric measurements and display on map
* Twitter social media feed of trending natural disasters in the area
* Machine learning image processing to analyze posted images of natural disaster hazards
Our app **Eye in the Sky** allows users to post about various natural disaster hazards at their location, upload a photo, and share a description of the hazard. These points are crowd-sourced and displayed on a map, which also pulls live data from the web on natural disasters. It also allows these users to view a Twitter feed of current trending information on the natural disaster in their location. The last feature is the IoT sensor system, which take measurements about the environment in real time and displays them on the map.
## How I built it
We built this app using Android Studio. Our user-created posts are hosted on a Parse database (run with mongodb). We pull data from the National Oceanic and Atmospheric Administration severe weather data inventory. We used Particle Electron to collect atmospheric sensor data, and used AWS to store this data in a JSON.
## Challenges I ran into
We had some issues setting up an AWS instance to run our image processing on the backend, but other than that, decently smooth sailing.
## Accomplishments that I'm proud of
We were able to work really well together, using everyone's strengths as well as combining the pieces into a cohesive app that we're really proud of. Everyone's piece was integrated well into the app, and I think we demonstrated good software collaboration.
## What I learned
We learned how to effectively combine our code across various languages and databases, which is a big challenge in software as a whole. We learned Android Development, how to set up AWS, and how to create databases to store custom data. Most importantly, we learned to have fun!
## What's next for Eye in the Sky
In the future, we would like to add verification of people's self-reported hazards (through machine learning and through up-voting and down-voting)
We would also like to improve the efficiency of our app and reduce reliance on network because there might not be network, or very poor network, in a natural disaster
We would like to add more datasets from online, and to display storms with bigger bubbles, rather than just points
We would also like to attach our sensor to drones or automobiles to gather more weather data points to display on our map | partial |
## Inspiration
Imagine you're sitting in your favorite coffee shop and a unicorn startup idea pops into your head. You open your laptop and choose from a myriad selection of productivity tools to jot your idea down. It’s so fresh in your brain, you don’t want to waste any time so, fervently you type, thinking of your new idea and its tangential components. After a rush of pure ideation, you take a breath to admire your work, but disappointment. Unfortunately, now the hard work begins, you go back though your work, excavating key ideas and organizing them.
***Eddy is a brainstorming tool that brings autopilot to ideation. Sit down. Speak. And watch Eddy organize your ideas for you.***
## Learnings
Melding speech recognition and natural language processing tools required us to learn how to transcribe live audio, determine sentences from a corpus of text, and calculate the similarity of each sentence. Using complex and novel technology, each team-member took a holistic approach and learned news implementation skills on all sides of the stack.
## Features
1. **Live mindmap**—Automatically organize your stream of consciousness by simply talking. Using semantic search, Eddy organizes your ideas into coherent groups to help you find the signal through the noise.
2. **Summary Generation**—Helpful for live note taking, our summary feature converts the graph into a Markdown-like format.
3. **One-click UI**—Simply hit the record button and let your ideas do the talking.
4. **Team Meetings**—No more notetakers: facilitate team discussions through visualizations and generated notes in the background.

## Challenges
1. **Live Speech Chunking** - To extract coherent ideas from a user’s speech, while processing the audio live, we had to design a paradigm that parses overlapping intervals of speech, creates a disjoint union of the sentences, and then sends these two distinct groups to our NLP model for similarity.
2. **API Rate Limits**—OpenAI rate-limits required a more efficient processing mechanism for the audio and fewer round trip requests keyword extraction and embeddings.
3. **Filler Sentences**—Not every sentence contains a concrete and distinct idea. Some sentences go nowhere and these can clog up the graph visually.
4. **Visualization**—Force graph is a premium feature of React Flow. To mimic this intuitive design as much as possible, we added some randomness of placement; however, building a better node placement system could help declutter and prettify the graph.
## Future Directions
**AI Inspiration Enhancement**—Using generative AI, it would be straightforward to add enhancement capabilities such as generating images for coherent ideas, or business plans.
**Live Notes**—Eddy can be a helpful tool for transcribing and organizing meeting and lecture notes. With improvements to our summary feature, Eddy will be able to create detailed notes from a live recording of a meeting.
## Built with
**UI:** React, Chakra UI, React Flow, Figma
**AI:** HuggingFace, OpenAI Whisper, OpenAI GPT-3, OpenAI Embeddings, NLTK
**API:** FastAPI
# Supplementary Material
## Mindmap Algorithm
 | ## Inspiration
Meet Doctor DoDo. He is a medical practioner, and he has a PhD degree in EVERYTHING!
Dr. DoDo is here to take care of you, and make sure you do-do your homework!
Two main problems arise with virtual learning: It's hard to verify if somebody understands content without seeing their facial expressions/body language, and students tend to forget to take care of themselves, mentally and physically. At least we definitely did.
## What it does
Doctor DoDo is a chrome extension and web-browser "pet" that will teach you about the images or text you highlight on your screen (remember his many PhD's), while keeping watch of your mood (facial expressions), time spent studying, and he'll even remind you to fix your posture (tsk tsk)!
## How we built it
With the use of:
* ChatGPT-4
* Facial Emotion recognition
* Facial Verification recognition
* Voice recognition
* Flask
* Pose recognition with mediapipe
and Procreate for the art/animation,
## Challenges we ran into
1. The initial design was hard to navigate. We didn't know if we wanted him to mainly be a study buddy, include a pomodoro timer, etc.
2. Animation (do I need to say more)
3. Integration hell, backend and frontend were not connecting
## Accomplishments that we're proud of
We're proud of our creativity! But more proud of Dr. DoDo for graduating with a PhD in every branch of knowledge to ever exist.
## What we learned
1. How to integrate backend and frontend software within a limited time
2. Integrating more
3. Animation (do I need to say more again)
## What's next for Doctor DoDo
Here are some things we're adding to Dr. DoDo's future:
Complete summaries of webpages | ## Inspiration
In the fast-paced world of networking and professional growth, connecting with students, peers, mentors, and like-minded individuals is essential. However, the need to manually jot down notes in Excel or the risk of missing out on valuable follow-up opportunities can be a real hindrance.
## What it does
Coffee Copilot transcribes, summarizes, and suggests talking points for your conversations, eliminating manual note-taking and maximizing networking efficiency. Also able to take forms with genesys.
## How we built it
**Backend**:
* Python + FastAPI was used to serve CRUD requests
* Cohere was used for both text summarization and text generation using their latest Coral model
* CockroachDB was used to store user and conversation data
* AssemblyAI was used for speech-to-text transcription and speaker diarization (i.e. identifying who is talking)
**Frontend**:
* We used Next.js for its frontend capabilities
## Challenges we ran into
We ran into a few of the classic problems - going in circles about what idea we wanted to implement, biting off more than we can chew with scope creep and some technical challenges that **seem** like they should be simple (such as sending an audio file as a blob to our backend 😒).
## Accomplishments that we're proud of
A huge last minute push to get us over the finish line.
## What we learned
We learned some new technologies like working with LLMs at the API level, navigating heavily asynchronous tasks and using event-driven patterns like webhooks. Aside of technologies, we learned how to disagree but move forwards, when to cut our losses and how to leverage each others strengths!
## What's next for Coffee Copilot
There's quite a few things on the horizon to look forwards to:
* Adding sentiment analysis
* Allow the user to augment the summary and the prompts that get generated
* Fleshing out the user structure and platform (adding authentication, onboarding more users)
* Using smart glasses to take pictures and recognize previous people you've met before | winning |
## Inspiration 💭
With the current staffing problem in hospitals due to the lingering effects of COVID-19, we wanted to come up with a solution for the people who are the backbone of healthcare. **Personal Support Workers** (or PSWs) are nurses that travel between personal and nursing homes to help the elderly and disabled to complete daily tasks such as bathing and eating. PSWs are becoming increasingly more needed as the aging population grows in upcoming years and these at-home caregivers become even more sought out.
## What it does 🙊
Navcare is our solution to improve the scheduling and traveling experience for Personal Support Workers in Canada. It features an optimized shift schedule with vital information about where and when each appointment is happening and is designed to be within an optimal traveling distance. Patients are assigned to nurses such that the nurse will not have to travel more than 30 mins outside of their home radius to treat a patient. Additionally, it features a map that allows a nurse to see all the locations of their appointments in a day, as well as access the address to each one so they can easily travel there.
## How we built it 💪
Django & ReactJS with google maps API.
## Challenges we ran into 😵
Many many challenges. To start off, we struggled to properly connect our backend API to our front end, which was essential to pass the information along to the front end and display the necessary data. This was resolved through extensive exploration of the documentation, and experimentation. Next while integrating the google maps API, we continuously faced various dependency issues as well as worked to resolve more issues relating to fetching data through our Django rest API. Since it was our first time implementing such an infrastructure, to this extent, we struggled at first to find our footing and correctly connect and create the necessary elements between the front and back end. However, after experimenting with the process and testing out different elements and methods, we found a combination that worked!
## Accomplishments that we're proud of 😁
We made it! We all felt as though we have learned a tremendous amount. This weekend, we really stepped out of our comfort zones with our assignments and worked on new things that we didn't think we would work on. Despite our shortcomings in our knowledge, we were still able to create an adequately functioning app with a sign-in feature, the ability to make API requests, and some of our own visuals to make the app stand out. If given a little more time, we could have definitely built an industry-level app that could be used by PSWs anywhere. The fact we were able to solve a breadth of challenges in such little time gives us hope that we BELONG in STEM!
## What's next for Navcare 😎
Hopefully, we can keep working on Navcare and add/change features based on testing with actual PSWs. Some features include easier input and tracking of information from previous visits, as well as a more robust infrastructure to support more PSWs. | ## Inspiration
We wanted to get home safe
## What it does
Stride pairs you with walkers just like UBC SafeWalk, but outside of campus grounds, to get you home safe!
## How we built it
React Native, Express JS, MongoDB
## Challenges we ran into
Getting environment setups working
## Accomplishments that we're proud of
Finishing the app
## What we learned
Mobile development
## What's next for Stride
Improve the app | ## Inspiration
As children of immigrants, we have seen how the elderly in our respective communities struggle to communicate and find suitable PSWs that can provide the care that they need in their homes.
Currently, finding a personal support worker in Canada is not as easy as it should be. Connecting PSWs with patients based on different criteria ensures better satisfaction for both PSWs and patients. Ultimately, we want to eliminate barriers so that all Canadians can get the full care that they are comfortable with.
## What it does
We thought of creating this web app to match patients based on various attributes, including language, patient needs, and location. The app matches PSWs with patients who may communicate better and provide better care, as well as ensuring that PSWs don't need to travel great distances.
## How we built it
We built this web app using React, HTML, and CSS for the front-end, and JavaScript processing for the back-end. This was built entirely on Repl.it, allowing for easy team collaboration and debugging.
## Challenges we ran into
We encountered some challenges with the form functionality of the web app, including obtaining and processing the data using `states`. With some help from a mentor, we were able to process form data in the back-end according to the app requirements.
## Accomplishments that we're proud of
We created a full-stack website using React.
## What we learned
We learned many React functions, states, and its use in the processing of data.
## What's next for CareConnect
For scalability, we could implement a database to store user data and PSW data.
Further, we can also implement the entire process dynamically from the perspectives of the PSWs, allowing a similar user experience for them. | winning |
## Inspiration
Given the upcoming presidential election, we wanted there to be a fun way for people to determine which candidate aligned more with their interests, if they were to throw away all their pre-conceived notions about each candidate. We were interested in using Natural Language Processing and we all love reading xkcd comics, so we decided there was an interesting way we could integrate these two traditionally disparate tasks – reading funny comics vs. reading about presidential candidate election info/platforms.
## What it does
Essentially, we boiled it down to the very basics. Our users visit our site to find what appears to be a very simple quiz. You flip through a series of xkcd comics, and you either upvote it or downvote it to indicate whether you found it interesting/funny. At the end, we determine which candidate you have a closer affinity with and show you the collective data of all the people who've participated!
## How we built it
We curated the speeches of Trump and Clinton from their election campaigns, as well as nearly all of Trump's tweets from the last year. From this text corpus, we ran the latent Dirichlet allocation (LDA) algorithm in order to get a collection of 'topics' (Trump topics and Clinton topics) – these topics were then mapped to the most closely corresponding xkcd comics.
From there, we built a front-end interface where users could indicate their interest in each xkcd comic, which we tracked the results of to display a diagnosis at the end, regarding whether they displayed more interest in Clinton topics vs Trump topics.
## Challenges we ran into
* Finding good, equal sources of data
* Cleaning the data in a way that the LDA algorithm could accept it
* Making sense of the LDA algorithm's results (tendency to give garbage topics)
* Making the bar graph show up with data results
## Accomplishments that we're proud of
* It works!!
* We've found a good deal of interested users, originally we weren't sure if people would like it :)
## What's next for xkcd For America
We definitely think there's a lot of fun to be had with the data we have and our platform.
* Collecting more user data to make better visualizations and possibly compare with how this measures up to their preconceived candidate preference.
* Comparing the frequency that candidates used of SAT words in their speeches to determine who'd be more likely to attend college in 2016
* And more! | ## 🤔 Problem Statement
* The complexity of cryptocurrency and blockchain technology can be intimidating for many potential users.
* According to a survey by Finder, 36% of Americans are not familiar with cryptocurrencies, and 29% find it too complicated to understand.
* BitBuddy aims to create an easy-to-use, AI-driven chatbot that simplifies transactions and interactions with cryptocurrencies, using natural language processing and cutting-edge technology like OpenAI and ChatGPT.
* Research shows that 53% of people feel intimidated by the complexities of cryptocurrency and blockchain technology.
* BitBuddy aims to make crypto accessible to everyone by creating a system that allows users to send funds, mint NFTs, and buy crypto through a simple chat interface.
* BitBuddy aims to break down the barriers to entry that have traditionally limited the growth and adoption of crypto, making it more accessible to a wider range of people.
## 💡 Inspiration
* Shared passion for blockchain technology and its potential to revolutionize finance.
* Desire to simplify the process of interacting with cryptocurrencies and make it accessible to everyone.
* Belief in the potential of chatbots and natural language processing to simplify complex tasks.
## 🤖 What it does
* MintBuddy is a blockchain chatbot that simplifies the process of minting NFTs.
* It guides users through the process step-by-step using Voiceflow and Midjourney APIs.
* Users provide name, description, wallet address, and image URL or generate an NFT using Midjourney.
* The bot will mint the NFT and provide a transaction hash and ID, along with URLs to view the NFT on block explorers and OpenSea.
* It is compatible with various different chains and eliminates the need for users to navigate complex blockchain systems or switch between platforms.
* MintBuddy makes minting NFTs easy and accessible to everyone using AI-driven chatbots and cutting-edge APIs.
## 🧠 How we built it
* MintBuddy simplifies the process of interacting with cryptocurrencies and blockchain technology.
The platform utilizes a variety of cutting-edge technologies, including Voiceflow, Verbwire API, and OpenAI.
* Voiceflow is used to create the user flows and chatbot pathways that enable users to send funds, mint NFTs, and buy crypto.
* Verbwire API is integrated with the chatbot to generate unique and creative NFT art using prompts and have it minted on the blockchain within minutes.
* OpenAI's natural language processing and ChatGPT algorithms are used to extract key information from user requests and enable the chatbot to respond accordingly.
* The combination of these technologies creates a user-friendly and accessible platform that makes blockchain technology and cryptocurrencies accessible to everyone, regardless of their technical knowledge or experience.
## 🧩 Challenges we ran into
* Developing MintBuddy was challenging but rewarding for the team.
* One major challenge was integrating Metamask with Voiceflow as they cannot run asynchronous functions together, but they found an alternative solution with Verbwire after contacting Voiceflow customer service.
* Another challenge was developing the NFT minting feature, which required a lot of back-and-forth communication between the user and the bot, but they were able to create a functional and user-friendly feature.
* The team looks forward to tackling new challenges and creating a platform that simplifies the process of interacting with cryptocurrencies and makes it accessible to everyone.
## 🏆 Accomplishments that we're proud of
* Developed a user-friendly and accessible platform for MintBuddy
* Integrated OpenAI ChatGPT into the platform, proving to be a powerful tool in simplifying the process of interacting with cryptocurrencies
* Integrated Verbwire API securely and ensured users could confirm transactions at every stage
* Developed a chatbot that makes blockchain technology accessible to everyone
* Took a risk in diving into unfamiliar technology and learning new skills, which has paid off in creating a platform that simplifies the process of interacting with cryptocurrencies and blockchain technology
## 💻 What we learned
* Gained a deep understanding of blockchain technology and proficiency in using various blockchain services
* Acquired valuable skills in natural language processing and AI technology, including the integration of OpenAI ChatGPT
* Developed soft skills in communication, collaboration, and project management
* Learned how to manage time effectively and work under tight deadlines
* Realized the importance of education and outreach when it comes to cryptocurrencies and blockchain technology
## 🚀 What's next for
* MintBuddy aims to make cryptocurrency and blockchain technology more accessible than ever before by adding more user-friendly features, tutorials, information, and gamification elements.
* The platform is working on integrating more APIs and blockchain platforms to make it more versatile and powerful with seamless natural language processing capabilities.
* The platform plans to allow users to buy and sell crypto directly through the chatbot, eliminating the need for navigating complex trading platforms.
* MintBuddy wants to become the go-to platform for anyone who wants to interact with cryptocurrency and blockchain technology, empowering people to take control of their finances with ease.
* The platform simplifies the process of interacting with complex systems, making it accessible to everyone, regardless of their technical knowledge or experience, and driving mass adoption of cryptocurrencies and blockchain technology.
## 📈 Why MintBuddy?
MintBuddy should win multiple awards at this hackathon, including the Best Generative AI, Best Blockchain Hack, Best Use of Verbwire, and Best Accessibility Hack. Our project stands out because we've successfully integrated multiple cutting-edge technologies to create a user-friendly and accessible platform that simplifies the process of interacting with cryptocurrencies and blockchain technology. Here's how we've met each challenge:
* Best Generative AI: We've utilized Voiceflow and OpenAI ChatGPT to create an AI chatbot that guides users through the process of sending funds, minting NFTs, and buying crypto. We've also integrated Verbwire API to generate unique and creative NFTs for users without requiring them to have any design skills or knowledge.
* Best Blockchain Hack: We've successfully tackled the problem of complexity and lack of accessibility in interacting with cryptocurrencies and blockchain technology. With our platform, anyone can participate in the blockchain world, regardless of their technical expertise.
* Best Use of Verbwire: We've used Verbwire API to generate creative and unique NFTs for users, making it easier for anyone to participate in the NFT market.
* Best Accessibility Hack: We've made creating and generating NFTs easy, even for people without any technical knowledge. Our chatbot's natural language processing capabilities make it possible for anyone to interact with our platform, regardless of their technical expertise.
Overall, our project MintBuddy stands out because it tackles the issue of accessibility and user-friendliness in interacting with cryptocurrencies and blockchain technology. We're confident that our innovative use of technology and dedication to accessibility make MintBuddy a standout project that deserves recognition at this hackathon. | ## What it does
From Here to There (FHTT) is an app that shows users their options for travel and allows them to make informed decisions about their form of transportation. The app shows statistics about different methods of transportation, including calories burned, CO2 emitted and estimated gas prices. See a route you like? Tap to open the route details in Google Maps.
## How we built it
Everything is written in Java using Android Studio. We are using the Google Maps Directions API to get most of our data. Other integrations include JSON simple and Firebase analytics.
## Challenges we ran into
We wanted to find ways to more positively influence users and have the app be more useful. The time pressure was both motivating and challenging.
## Accomplishments that we're proud of
Interaction with the Google Maps Directions API. The card based UI.
## What we learned
From this project, we have gained more experience working with JSON and AsyncTasks. We know more about the merits and limitations of various Google APIs and have a bit more practice implementing Material Design guidelines. We also used git with Android Studio for the first time.
## What's next for From Here to There
Integrating a API for fuel cost updates. Improving the accuracy of calorie/gas/CO2 estimates by setting up Firebase Authentication and Realtime Database to collect user data such as height, weight and car type. Using a user system to show "lifetime" impact of trips.
A compiled apk has been uploaded to the Github, try it out and let us know what you think! | partial |
## Inspiration
We were excited
## What it does
GirAFFE analyses and minimizes the average wait time for all commuters so that they can have a positive start to their day.
## How we built it
There were 3 big components in building this project. Finding an appropriate algorithm to calculate the minimal wait time, coding and heavily testing on railway system on Python 3, and creating a unique visualization of the code
## Challenges we ran into
Difficulty setting up GitHub environment.
Testing and debugging computed algorithms
Transfer of inputted data into a .csv file
## Accomplishments that we're proud of
Creating a tester that calculates wait time accurately.
Finding an optimal algorithm to minimize wait time
Setting up a beautiful visualizer
## What we learned
Setting and merging GitHub properly
Computing an efficient algorithm with minimal data
Using Pygame
## What's next for GirAFFe
Accumulating more data so that we can run on a global scale | ## Inspiration
The issue of traffic is one that affects all. We found ourselves frustrated with how the problem of traffic is continually getting worse with urbanization and how their is no solution in site. We wanted to tackle this issue in a way that benefits not just the individual but societies as a whole.
## What it does
Commute uses ML to determine suggested alternative routes to users on their morning commute that reduce traffic congestion in the effort to reduce urban smog.
## How we built it
This was all accomplished using Android Studio (Java) along with the google maps API, and JSON files. Along with sweat, tears and a lot of hard-work and collaboration.
## Challenges we ran into
We ran into multiple challenges whilst completing this challenging yet rewarding project of ours. Our first challenge was figuring out how to extrapolate the traffic data from our API and use it to determine which route would have the least congestion. Our other major challenge would be generating our paths for our users to take and creating an algorithm that fairly rewarded points for each less congested route.
## Accomplishments that we're proud of
We were so proud to accomplish this in our limited time with emphasis on our amazing collaboration and relentless effort to produce something not only beneficial to drivers, but also the environment and many other social factors.
## What we learned
From this we learned how to collaborate with the goal of developing projects that benefit a range of factors and in no way negatively impact the public, which reaffirmed our belief in the power of using software design to help society.
## What's next for Commute
In the future we hope to further improve Commute with rewarding users for taking public transportation, biking or using any other more Eco-friendly route to their destination, allowing us to create not only a cleaning environment but clearer roadways as well. | ## Inspiration
Have you ever tried learning the piano but never had the time to do so? Do you want to play your favorite songs right away without any prior experience? This is the app for you. We required something like this even for our personal use. It helps an immense lot in building muscle memory to play the piano for any song you can find on Youtube directly.
## What it does
Use AR to project your favorite digitally-recorded piano video song from Youtube over your piano to learn by following along.
## Category
Best Practicable/Scalable, Music Tech
## How we built it
Using Unity, C# and the EasyAR SDK for Augmented Reality
## Challenges we ran into
* Some Youtube URLs had cipher signatures and could not be loaded asynchronously directly
* App crashes before submission, fixed barely on time
## Accomplishments that we're proud of
We built a fully functioning and user friendly application that perfectly maps the AR video onto your piano, with perfect calibration. It turned out to be a lot better than we expected. We can use it for our own personal use to learn and master the piano.
## What we learned
* Creating an AR app from scratch in Unity with no prior experience
* Handling asynchronously loading of Youtube videos and using YoutubeExplode
* Different material properties, video cipher signatures and various new components!
* Developing a touch gesture based control system for calibration
## What's next for PianoTunesAR
* Tunes List to save the songs you have played before by name into a playlist so that you do not need to copy URLs every time
* Machine learning based AR projection onto piano with automatic calibration and marker-less spatial/world mapping
* All supported Youtube URLs as well as an Upload your own Video feature
* AR Cam tutorial UI and icons/UI improvements
* iOS version
# APK Releases
<https://github.com/hamzafarooq009/PianoTunesAR-Wallifornia-Hackathon/releases/tag/APK> | losing |
## Inspiration
Have you ever wished to get more likes on Instagram? Have you ever felt terrible when your number of followers is lower than the number of following? Conquer the attention economy with this modern Terminator bot! Login, mass follow, mass like, and grow your follower base with this cheat code!
Many more people have put much of their emotions and social life on their internet presence. We hope to make people feel good and empower them to put their best face to the world by giving them the confidence to become overnight successes!
## What it does
Our proprietary software is the cheat code every influencer wants their hands on. Our first bot, miles\_of\_smiles\_999, will automatically follow and like posts throughout the day, spreading smiles throughout the universe!
## How we built it
We used selenium on top of chromedriver, to automate our bot's actions. We wrote in Python.
## Challenges we ran into
At a certain point, the bot ran into the same posts that it liked and toggled the button, turning the like off. We had to find the needle (an attribute called aria-label in a tiny web element) in the haystack of HTML to detect the state of the button.
Scrolling was also difficult but we finally made it work with a line of JavaScript.
## Accomplishments that we're proud of
We swam through the sea of HTML to find what we needed to get our bot clicking on the right things. We also figured out how to scroll and click in a human-like manner, and accept follow requests!
## What we learned
We learned a lot about how selenium works and how to make bots. They're usually described as a force of evil but we're determined for them to do good.
## What's next for insta\_click
We're going to introduce even more features to make our likes and follows even more worthwhile. Features include uploading original, computer-generated text and even pictures!
Follow Robert's channel: <https://www.youtube.com/channel/UCe_7XCUdzKzKmc5MMZwURIw/featured>
and Michael's:
<https://www.youtube.com/channel/UC5kZacVDbeRZICywyzQihRQ>
...to keep up with latest developments! Reach out early for exclusive partnerships. | ## Inspiration
With the flood of daily emails, it's easy to lose track of important deadlines and tasks buried within. We needed a solution that could help organize and prioritize emails efficiently, saving time and reducing the risk of missing crucial deadlines. The idea was to build an intuitive email tool that fetches emails, summarizes them, and highlights the most critical information, such as deadlines, while categorizing them based on priority.
## What it does
Ezemail is a Chrome extension that:
* Connects to your Gmail account using the Gmail API.
* Fetches emails over a selected time range.
* Uses the OpenAI API to summarize the content of the emails.
* Categorizes emails based on urgency, importance, and subject.
* Extracts and highlights deadlines or time-sensitive information.
* Sends an email to the user with a summary of all emails within the selected period, including deadlines and categorized insights.
## How we built it
* Frontend: We built the Chrome extension UI using HTML, CSS, and JavaScript. We focused on creating a clean and easy-to-navigate interface for reading email summaries and deadlines.
* Backend: The core logic integrates Gmail's API to retrieve emails and the OpenAI API to process and summarize the email content. After the summarization process is completed, the summary is emailed back to the user with organized insights.
* Email Categorization: By analyzing the email content, we used the OpenAI API to determine the importance and urgency, automatically grouping emails into categories like "High Priority," "Reminders," "Tasks," etc.
* Deadline Extraction: By scanning the email text, the tool pulls out dates and times and organizes them into a visual calendar.
## Challenges we ran into
* Authentication for Gmail and OpenAI APIs: The procedure involved many settings on the Google Cloud Platform, the Chrome extension, and our code. We visited some online resources but they did not work. This was quite challenging for us as we have never done that. It required deep understanding of the interaction between the user and the extension.
* API Rate Limits: We encountered challenges with the Gmail and OpenAI API rate limits, which required us to batch requests and handle throttling.
* Parsing complex emails: Some emails contain attachments, rich formatting, or embedded media, making it difficult to summarize the key points accurately.
## Accomplishments that we're proud of
* Successfully integrating two powerful APIs (Gmail and OpenAI) to create a seamless email management solution.
* Creating a user-friendly extension that simplifies email workflows and makes important information (like deadlines) easily accessible.
* Implementing deadline extraction and reminder features, helping users stay on top of important tasks and dates.
* Automating the process to send users email summaries, eliminating the need to check emails frequently.
## What we learned
* Deepened our understanding of API integrations and handling their limitations.
* Gained insights into how AI-driven summarization can vastly improve email management.
* Learned the importance of UX design in productivity tools, making sure the tool is intuitive for users.
## What's next for Ezemail
* Smart Notifications: Implement push notifications for approaching deadlines or high-priority emails.
* Advanced Email Filtering: Improve categorization by learning from the user's interaction with emails (e.g., marking something as high/low priority).
* Attachment Summarization: Extend the summarization feature to attachments like PDFs and documents.
* Multiple Email Accounts: Allow users to connect and manage multiple Gmail accounts from within the extension. | ## Inspiration
It is nearly a year since the start of the pandemic and going back to normal still feels like a distant dream.
As students, most of our time is spent attending online lectures, reading e-books, listening to music, and playing online games. This forces us to spend immense amounts of time in front of a large monitor, clicking the same monotonous buttons.
Many surveys suggest that this has increased the anxiety levels in the youth.
Basically, we are losing the physical stimulus of reading an actual book in a library, going to an arcade to enjoy games, or play table tennis with our friends.
## What it does
It does three things:
1) Controls any game using hand/a steering wheel (non-digital) such as Asphalt9
2) Helps you zoom-in, zoom-out, scroll-up, scroll-down only using hand gestures.
3) Helps you browse any music of your choice using voice commands and gesture controls for volume, pause/play, skip, etc.
## How we built it
The three main technologies used in this project are:
1) Python 3
The software suite is built using Python 3 and was initially developed in the Jupyter Notebook IDE.
2) OpenCV
The software uses the OpenCV library in Python to implement most of its gesture recognition and motion analysis tasks.
3) Selenium
Selenium is a web driver that was extensively used to control the web interface interaction component of the software.
## Challenges we ran into
1) Selenium only works with google version 81 and is very hard to debug :(
2) Finding the perfect HSV ranges corresponding to different colours was a tedious task and required me to make a special script to make the task easier.
3) Pulling an all-nighter (A coffee does NOT help!)
## Accomplishments that we're proud of
1) Successfully amalgamated computer vision, speech recognition and web automation to make a suite of software and not just a single software!
## What we learned
1) How to debug selenium efficiently
2) How to use angle geometry for steering a car using computer vision
3) Stabilizing errors in object detection
## What's next for E-Motion
I plan to implement more components in E-Motion that will help to browse the entire computer and make the voice commands more precise by ignoring background noise. | losing |
## Inspiration
We wanted to provide an easy, interactive, and ultimately fun way to learn American Sign Language (ASL). We had the opportunity to work with the Leap Motion hardware which allowed us to track intricate real-time data surrounding hand movements. Using this data, we thought we would be able to decipher complex ASL gestures.
## What it does
Using the Leap Motion's motion tracking technology, it prompts to user to replicate various ASL gestures. With real-time feedback, it tells the user how accurate their gesture was compared to the actual hand motion. Using this feedback, users can immediately adjust their technique and ultimately better perfect their ASL!

## How I built it
Web app using Javascript, HTML, CSS. We had to train our data using various machine learning repositories to ensure accurate recognitions, as well as other plugins which allowed us to visualize the hand movements in real time.
## Challenges I ran into
Training the data was difficult as gestures are complex forms of data, composed of many different data points in the hand's joints and bones but also in the progression of hand "frames". As a result, we had to take in a lot of data to ensure a thorough data-set that matched these data features to an actual classification of the correct ASL label (or phrase)
## Accomplishments that I'm proud of
User Interface. Training the data. Working on a project that could actually potentially impact others!
## What I learned
Hard work and dedication. Computer vision. Machine Learning.
## What's next for Leap Motion ASL
More words? Game mode? Better training? More phrases? More complex combos of gestures?
 | # Signal
We tried to build a leap motion application that allowed deaf users to use sign language to communicate.
# What does the service do?
So far, we've gotten A, B, C, and D done (with some success). We learnt quite a lot over the last 16 hours, learning how to use the Leap Motion API, learnt Javascript, and learnt how to implement a neural network to teach our program the different types of signs for each letter. We also learnt the taste of Soylent, and the various forms that Octocat comes in.
# Features
We used Brain.js to teach program all the gestures we've implemented thus far and anytime the program reads a gesture incorrectly, it will learn to correct itself over time. | ## What it does
What our project does is introduce ASL letters, words, and numbers to you in a flashcard manner.
## How we built it
We built our project with React, Vite, and TensorFlowJS.
## Challenges we ran into
Some challenges we ran into included issues with git commits and merging. Over the course of our project we made mistakes while resolving merge conflicts which resulted in a large part of our project being almost discarded. Luckily we were able to git revert back to the correct version but time was misused regardless. With our TensorFlow model we had trouble reading the input/output and getting webcam working.
## Accomplishments that we're proud of
We are proud of the work we got done in the time frame of this hackathon with our skill level. Out of the workshops we attended I think we learned a lot and can't wait to implement them in future projects!
## What we learned
Over the course of this hackathon we learned that it is important to clearly define our project scope ahead of time. We spent a lot of our time on day 1 thinking about what we could do with the sponsor technologies and should have looked into them more in depth before the hackathon.
## What's next for Vision Talks
We would like to train our own ASL image detection model so that people can practice at home in real time. Additionally we would like to transcribe their signs into plaintext and voice so that they can confirm what they are signing. Expanding our project scope beyond ASL to other languages is also something we wish to do. | partial |
## Inspiration
We are tired of being forgotten and not recognized by others for our accomplishments. We built a software and platform that helps others get to know each other better and in a faster way, using technology to bring the world together.
## What it does
Face Konnex identifies people and helps the user identify people, who they are, what they do, and how they can help others.
## How we built it
We built it using Android studio, Java, OpenCV and Android Things
## Challenges we ran into
Programming Android things for the first time. WiFi not working properly, storing the updated location. Display was slow. Java compiler problems.
## Accomplishments that we're proud of.
Facial Recognition Software Successfully working on all Devices, 1. Android Things, 2. Android phones.
Prototype for Konnex Glass Holo Phone.
Working together as a team.
## What we learned
Android Things, IOT,
Advanced our android programming skills
Working better as a team
## What's next for Konnex IOT
Improving Facial Recognition software, identify and connecting users on konnex
Inputting software into Konnex Holo Phone | ## Inspiration
Our inspiration was to provide a robust and user-friendly financial platform. After hours of brainstorming, we decided to create a decentralized mutual fund on mobile devices. We also wanted to explore new technologies whilst creating a product that has several use cases of social impact. Our team used React Native and Smart Contracts along with Celo's SDK to discover BlockChain and the conglomerate use cases associated with these technologies. This includes group insurance, financial literacy, personal investment.
## What it does
Allows users in shared communities to pool their funds and use our platform to easily invest in different stock and companies for which they are passionate about with a decreased/shared risk.
## How we built it
* Smart Contract for the transfer of funds on the blockchain made using Solidity
* A robust backend and authentication system made using node.js, express.js, and MongoDB.
* Elegant front end made with react-native and Celo's SDK.
## Challenges we ran into
Unfamiliar with the tech stack used to create this project and the BlockChain technology.
## What we learned
We learned the many new languages and frameworks used. This includes building cross-platform mobile apps on react-native, the underlying principles of BlockChain technology such as smart contracts, and decentralized apps.
## What's next for *PoolNVest*
Expanding our API to select low-risk stocks and allows the community to vote upon where to invest the funds.
Refine and improve the proof of concept into a marketable MVP and tailor the UI towards the specific use cases as mentioned above. | ## Inspiration
It all started a couple days ago when my brother told me he'd need over an hour to pick up a few items from a grocery store because of the weekend checkout line. This led to us reaching out to other friends of ours and asking them about the biggest pitfalls of existing shopping systems. We got a whole variety of answers, but the overwhelming response was the time it takes to shop and more particularly checkout. This inspired us to ideate and come up with an innovative solution.
## What it does
Our app uses computer vision to add items to a customer's bill as they place items in the cart. Similarly, removing an item from the cart automatically subtracts them from the bill. After a customer has completed shopping, they can checkout on the app with the tap of a button, and walk out the store. It's that simple!
## How we built it
We used react with ionic for the frontend, and node.js for the backend. Our main priority was the completion of the computer vision model that detects items being added and removed from the cart. The model we used is a custom YOLO-v3Tiny model implemented in Tensorflow. We chose Tensorflow so that we could run the model using TensorflowJS on mobile.
## Challenges we ran into
The development phase had it's fair share of challenges. Some of these were:
* Deep learning models can never have too much data! Scraping enough images to get accurate predictions was a challenge.
* Adding our custom classes to the pre-trained YOLO-v3Tiny model.
* Coming up with solutions to security concerns.
* Last but not least, simulating shopping while quarantining at home.
## Accomplishments that we're proud of
We're extremely proud of completing a model that can detect objects in real time, as well as our rapid pace of frontend and backend development.
## What we learned
We learned and got hands on experience of Transfer Learning. This was always a concept that we knew in theory but had never implemented before. We also learned how to host tensorflow deep learning models on cloud, as well as make requests to them. Using google maps API with ionic react was a fun learning experience too!
## What's next for MoboShop
* Integrate with customer shopping lists.
* Display ingredients for recipes added by customer.
* Integration with existing security systems.
* Provide analytics and shopping trends to retailers, including insights based on previous orders, customer shopping trends among other statistics. | winning |
## Inspiration
This project was inspired by the Professional Engineering course taken by all first year engineering students at McMaster University (1P03). The final project for the course was to design a solution to a problem of your choice that was given by St. Peter's Residence at Chedoke, a long term residence care home located in Hamilton, Ontario. One of the projects proposed by St. Peter's was to create a falling alarm to notify the nurses in the event of one of the residents having fallen.
## What it does
It notifies nurses if a resident falls or stumbles via a push notification to the nurse's phones directly, or ideally a nurse's station within the residence. It does this using an accelerometer in a shoe/slipper to detect the orientation and motion of the resident's feet, allowing us to accurately tell if the resident has encountered a fall.
## How we built it
We used a Particle Photon microcontroller alongside a MPU6050 gyro/accelerometer to be able to collect information about the movement of a residents foot and determine if the movement mimics the patterns of a typical fall. Once a typical fall has been read by the accelerometer, we used Twilio's RESTful API to transmit a text message to an emergency contact (or possibly a nurse/nurse station) so that they can assist the resident.
## Challenges we ran into
Upon developing the algorithm to determine whether a resident has fallen, we discovered that there are many cases where a resident's feet could be in a position that can be interpreted as "fallen". For example, lounge chairs would position the feet as if the resident is laying down, so we needed to account for cases like this so that our system would not send an alert to the emergency contact just because the resident wanted to relax.
To account for this, we analyzed the jerk (the rate of change of acceleration) to determine patterns in feet movement that are consistent in a fall. The two main patterns we focused on were:
1. A sudden impact, followed by the shoe changing orientation to a relatively horizontal position to a position perpendicular to the ground. (Critical alert sent to emergency contact).
2. A non-sudden change of shoe orientation to a position perpendicular to the ground, followed by a constant, sharp movement of the feet for at least 3 seconds (think of a slow fall, followed by a struggle on the ground). (Warning alert sent to emergency contact).
## Accomplishments that we're proud of
We are proud of accomplishing the development of an algorithm that consistently is able to communicate to an emergency contact about the safety of a resident. Additionally, fitting the hardware available to us into the sole of a shoe was quite difficult, and we are proud of being able to fit each component in the small area cut out of the sole.
## What we learned
We learned how to use RESTful API's, as well as how to use the Particle Photon to connect to the internet. Lastly, we learned that critical problem breakdowns are crucial in the developent process.
## What's next for VATS
Next steps would be to optimize our circuits by using the equivalent components but in a much smaller form. By doing this, we would be able to decrease the footprint (pun intended) of our design within a clients shoe. Additionally, we would explore other areas we could store our system inside of a shoe (such as the tongue). | ## Problem Statement
As the number of the elderly population is constantly growing, there is an increasing demand for home care. In fact, the market for safety and security solutions in the healthcare sector is estimated to reach $40.1 billion by 2025.
The elderly, disabled, and vulnerable people face a constant risk of falls and other accidents, especially in environments like hospitals, nursing homes, and home care environments, where they require constant supervision. However, traditional monitoring methods, such as human caregivers or surveillance cameras, are often not enough to provide prompt and effective responses in emergency situations. This potentially has serious consequences, including injury, prolonged recovery, and increased healthcare costs.
## Solution
The proposed app aims to address this problem by providing real-time monitoring and alert system, using a camera and cloud-based machine learning algorithms to detect any signs of injury or danger, and immediately notify designated emergency contacts, such as healthcare professionals, with information about the user's condition and collected personal data.
We believe that the app has the potential to revolutionize the way vulnerable individuals are monitored and protected, by providing a safer and more secure environment in designated institutions.
## Developing Process
Prior to development, our designer used Figma to create a prototype which was used as a reference point when the developers were building the platform in HTML, CSS, and ReactJs.
For the cloud-based machine learning algorithms, we used Computer Vision, Open CV, Numpy, and Flask to train the model on a dataset of various poses and movements and to detect any signs of injury or danger in real time.
Because of limited resources, we decided to use our phones as an analogue to cameras to do the live streams for the real-time monitoring.
## Impact
* **Improved safety:** The real-time monitoring and alert system provided by the app helps to reduce the risk of falls and other accidents, keeping vulnerable individuals safer and reducing the likelihood of serious injury.
* **Faster response time:** The app triggers an alert and sends notifications to designated emergency contacts in case of any danger or injury, which allows for a faster response time and more effective response.
* **Increased efficiency:** Using cloud-based machine learning algorithms and computer vision techniques allow the app to analyze the user's movements and detect any signs of danger without constant human supervision.
* **Better patient care:** In a hospital setting, the app could be used to monitor patients and alert nurses if they are in danger of falling or if their vital signs indicate that they need medical attention. This could lead to improved patient care, reduced medical costs, and faster recovery times.
* **Peace of mind for families and caregivers:** The app provides families and caregivers with peace of mind, knowing that their loved ones are being monitored and protected and that they will be immediately notified in case of any danger or emergency.
## Challenges
One of the biggest challenges have been integrating all the different technologies, such as live streaming and machine learning algorithms, and making sure they worked together seamlessly.
## Successes
The project was a collaborative effort between a designer and developers, which highlights the importance of cross-functional teams in delivering complex technical solutions. Overall, the project was a success and resulted in a cutting-edge solution that can help protect vulnerable individuals.
## Things Learnt
* **Importance of cross-functional teams:** As there were different specialists working on the project, it helped us understand the value of cross-functional teams in addressing complex challenges and delivering successful results.
* **Integrating different technologies:** Our team learned the challenges and importance of integrating different technologies to deliver a seamless and effective solution.
* **Machine learning for health applications:** After doing the research and completing the project, our team learned about the potential and challenges of using machine learning in the healthcare industry, and the steps required to build and deploy a successful machine learning model.
## Future Plans for SafeSpot
* First of all, the usage of the app could be extended to other settings, such as elderly care facilities, schools, kindergartens, or emergency rooms to provide a safer and more secure environment for vulnerable individuals.
* Apart from the web, the platform could also be implemented as a mobile app. In this case scenario, the alert would pop up privately on the user’s phone and notify only people who are given access to it.
* The app could also be integrated with wearable devices, such as fitness trackers, which could provide additional data and context to help determine if the user is in danger or has been injured. | ## 💡Inspiration and Purpose
Our group members are from all around the U.S., from Dallas to Boston, but one thing that we have in common is that we have a grandparent living by themselves. Due to various family situations, we have elderly loved ones who spend a few hours alone each day, putting them at risk of a fatal accident like a fall. After researching current commercial solutions for fall detection, devices can range from anywhere from twenty-four to fifty dollars per device monthly. While this is affordable for our families, it is distinctly out of reach for many disadvantaged families.
In 2020, falls among Americans 65 and older caused over 36,000 deaths - the leading cause of injury death for that demographic group. Furthermore, these falls led to some three million emergency hospital visits and $50 billion in medical costs, creating an immense strain on our healthcare system.
## 🎖️ What It Does
Despite these sobering statistics, very few accessible solutions exist to assist seniors who may experience a fall at home. More worryingly, many of these products rely on the individual who has just become seriously injured to report the incident and direct emergency medical services to their location. Oftentimes, someone might not be able to alert the proper authorities and suffer needlessly as a result.
Guardian Angel aims to solve this growing problem by automating the process of fall detection using machine learning and deploying it in an easy-to-use, accurate, and portable system. From there, the necessary authorities can be notified, even if an individual is critically injured.
By using data-based trackers such as position, this application will adequately calculate and determine if a person has fallen based on a point and confidence system. This can be used for risk prevention profiles as it can detect shuffling or skipping. The application will shine red if it is confident that the person has fallen and it is not a false positive.
## 🧠 Development and Challenges
The application overall was built using React, alongside TailwindCSS and ML5. Using the create-react-app boilerplate, we were able to minimize the initial setup and invest more time in fixing bugs. In general, the website works by obtaining the model, metadata, and weights from the tensorflow.js model, requests a webcam input, and then pushes that webcam input into the machine learning model. The result of the model, as well as the confidence, is then displayed to the user.
The machine learning side of the project was developed using TensorFlow through tensorflow.js. As a result, we were able to primarily focus on gathering proper samples for the model, rather than optimization. The samples used for training were gathered by capturing dozens of videos of people falling in various backgrounds, isolating the frames, and manually labeling the data. We also augmented the samples to improve the model's ability to generalize.
For training, we used around 5 epochs, a learning rate of 0.01, and a batch size of 16. Other than that, every other parameter was default.
We also ran into a few major challenges during the creation of the project. Firstly, the complexity of detecting movement made obtaining samples and training particularly difficult. Our solution was to gather a number of samples from different orientations, allowing for the model to be accurate in a wide variety of situations. Specifically speaking for the website, one of the main challenges we ran implementing video rendering within React. We were eventually able to implement our desired functionality using HTML videos, uncommon react dependency components, and complex Tensorflow-React interactions.
## 🎖️ Accomplishments that we're proud of
First and foremost, we are proud of successfully completing the project while getting to meet with several mentors and knowledgeable professionals, such as the great teams at CareYaya and Y Combinator.
Second, we are proud of our model's accuracy. Classifying a series of images with movement was no small undertaking, particularly because we needed to ignore unintentional movements while continuing to accurately identify sudden changes in motion.
Lastly, we are very proud of the usability and functionality of our application. Despite being a very complex undertaking, our front end wraps up our product into an incredibly easy-to-use platform that is highly intuitive. We hope that this project, with minimal modifications, could be deployed commercially and begin to make a difference.
## 🔜 Next Steps
We would soon like to integrate our app with smart devices such as Amazon Alexa and Apple Smart Watch to obtain more data and verify our predictions. With accessible devices like Alexa already on the market, we will continue to ensure this service is as scalable as possible. We also want to detect fall audio, as audio can help make our results more accurate. Audio also would allow our project to be active in more locations in a household, and cover for the blind spots cameras typically have.
Guardian Angel is a deployable and complete application in itself, but we hope to take extra steps to make our project even more user-friendly. One thing we want to implement in the near future is to create an API for our application so that we can take advantage of existing home security systems. By utilizing security cameras that are already present, we can lower the barriers to entry for consumers as well as improve our reach. | winning |
## The Idea Behind the App
When you're grabbing dinner at a restaurant, how do you choose which meal to order?
Perhaps you look at the price, calorie count, or, if you're trying to be environmentally-conscious, the carbon footprint of your meal.
COyou is an Android app which reveals the carbon footprint of the meals on a restaurant menu, so that you can make the most informed choice about the food you eat.
### Why is this important?
Food production is responsible for a quarter of all greenhouse gas emissions which contribute to global warming. In particular, meat and other animal products are responsible for more than half of food-related greenhouse gas emissions. However, even among fruits and vegetables, the environmental impact of different foods varies considerably. Therefore, being able to determine the carbon footprint of what you eat can make a difference to the planet.
## How COyou Works
Using pandas, we cleaned our [carbon emissions per ingredients data](https://link.springer.com/article/10.1007/s11367-019-01597-8#Sec24) and mapped it by ingredient-emission.
We used Firebase to enable OCR, so that the app recognizes the text of the menu items. Using Google Cloud's Natural Language API, we broke each menu item name down into entities. For example:
```
1. scrambled eggs -> "eggs",
2. yogurt & granola -> "yogurt", "granola"
```
If an entry is found (for simpler menu items such as "apple juice"), the CO2 emission is immediately returned. Otherwise, we make an API call to USDA Food Central's database, which returns a list of ingredients for the menu item. Then, we map the ingredients to its CO2 emissions and sum the individual CO2 emissions of each ingredient in the dish. Finally, we display a list of the ingredients and the total CO2 emissions of each dish.
## The Creation of COyou
We used Android Studio, Google Firebase, Google NLP API, and an enthusiasm for food and restaurants in the creation of COyou.
## Sources and Further Reading
1. [Determining the climate impact of food for use in a climate tax—design of a consistent and transparent model](https://link.springer.com/article/10.1007/s11367-019-01597-8#Sec24)
2. [Carbon Footprint Factsheet](http://css.umich.edu/factsheets/carbon-footprint-factsheet)
3. [Climate change food calculator: What's your diet's carbon footprint?](https://www.bbc.com/news/science-environment-4645971)
4. [USDA Food Data Central API](https://fdc.nal.usda.gov/index.htm) | ## Inspiration
Over one-fourth of Canadians during their lifetimes will have to deal with water damage in their homes. This is an issue that causes many Canadians overwhelming stress from the sheer economical and residential implications.
As an effort to assist and solve these very core issues, we have designed a solution that will allow for future leaks to be avoidable. Our prototype system made, composed of software and hardware will ensure house leaks are a thing of the past!
## What is our planned solution?
To prevent leaks, we have designed a system of components that when functioning together, would allow the user to monitor the status of their plumbing systems.
Our system is comprised of:
>
> Two types of leak detection hardware
>
>
> * Acoustic leak detectors: monitors abnormal sounds of pipes.
> * Water detection probes: monitors the presence of water in unwanted areas.
>
>
>
Our hardware components will have the ability to send data to a local network, to then be stored in the cloud.
>
> Software components
>
>
> * Secure cloud to store vital information regarding pipe leakages.
> * Future planned app/website with the ability to receive such information
>
>
>
## Business Aspect of Leakio
Standalone, this solution is profitable through the aspect of selling the specific hardware to consumers. Although for insurance companies, this is a vital solution that has the potential to save millions of dollars.
It is far more economical to prevent a leak, rather than fix it when it already happens. The time of paying the average cost of $10,900 US dollars to fix water damage or a freezing claim is now avoidable!
In addition to saved funds, our planned system will be able to send information to insurance companies for specific data purposes such as which houses or areas have the most leaks, or individual risk assessment. This would allow insurance companies to more appropriately create better rates for the consumer, for the benefit of both consumer and insurance company.
### Software
Front End:
This includes our app design in Figma, which was crafted using knowledge on proper design and ratios. Specifically, we wanted to create an app design that looked simple but had all the complex features that would seem professional. This is something we are proud of, as we feel this component was successful.
Back End:
PHP, MySQL, Python
### Hardware
Electrical
* A custom PCB is designed from scratch using EAGLE
* Consists of USBC charging port, lithium battery charging circuit, ESP32, Water sensor connector, microphone connector
* The water sensor and microphone are extended from the PCB which is why they need a connector
3D-model
* Hub contains all the electronics and the sensors
* Easy to install design and places the microphone within the walls close to the pipes
## Challenges we ran into
Front-End:
There were many challenges we ran into, especially regarding some technical aspects of Figma. Although the most challenging aspect in this would’ve been the implementation of the design.
Back-End:
This is where most challenges were faced, which includes the making of the acoustic leak detector, proper sound recognition, cloud development, and data transfer.
It was the first time any of us had used MySQL, and we created it on the Google Cloud SQL platform. We also had to use both Python and PHP to retrieve and send data, two languages we are not super familiar with.
We also had no idea how to set up a neural network with PyTorch. Also finding the proper data that can be used to train was also very difficult.
## Accomplishments that we're proud of
Learning a lot of new things within a short period of time.
## What we learned
Google Cloud:
Creating a MySQL database and setting up a Deep Learning VM.
MySQL:
Using MySQL and syntaxes, learning PHP.
Machine Learning:
How to set up Pytorch.
PCB Design:
Learning how to use EAGLE to design PCBs.
Raspberry Pi:
Autorun Python scripts and splitting .wav files.
Others:
Not to leave the recording to the last hour. It is hard to cut to 3 minutes with an explanation and demo.
## What's next for Leakio
* Properly implement audio classification using PyTorch
* Possibly create a network of devices to use in a single home
* Find more economical components
* Code for ESP32 to PHP to Web Server
* Test on an ESP32 | ## Inspiration
In the United States, 250,000 drivers fall asleep at the wheel every day. This translates to more than 72,000 crashes each year. I've personally felt road fatigue and it's incredibly hard to fight, so dozing off while on the highway can happen to even the best of us. Wayke could be the app that could save your friend, your parent, your child, or even you.
## What it does
We've created a mobile app that is integrated with the MUSE headband, pebble watch, and Grove so that it monitors your brainwaves. You can get in your car, put the MUSE headband on, turn the app on, and start driving. We use your Alpha brainwaves to gauge your drowsiness, and while your driving, if your Alphas rise above our "Doze threshold" for a prolonged period of time, your phone will emit sharp sounds and vibrate crazily while reminding you to take a break.
## How we built it
The MUSE headband is a recently released innovation that includes sensors in a headband that monitors your brainwaves - it's basically like a portable EEG. However right now, it's mainly used for meditation. We've hacked it to the point where there's nothing chill or relaxing about Wayze. We want to keep you wide awake and on the edge of your seat. I'm personally not completely sure about the details of the app development and hardware hacking, so if you have any questions, you should Alex Jin, Jofo Domingo, or Michael Albinson.
## Challenges we ran into
Alex and Jofo ran into a bunch of bugs while figuring out how to get the output from the MUSE to show up properly as well as automating the connection from the android app all the way to the Grove. Understanding how brainwaves work hurt our brains.
## Accomplishments that we're proud of
Actually building the damn thing!
## What we learned
You can do amazing things in 2 days. The fact that you can hack 4-5 different things to fit together perfectly is phenomenal!
## What's next for Wayke
We think there are so many practical applications for Wayke. Moving forward, I think our product could be used for pilots or any workers that operate heavy machinery or any situations where you can't fall asleep. Additionally, we want to find a way to get something to physically vibrate on your body (like integrating it with a Jawbone or Fitbit)! | winning |
**## Inspiration**
According to the United Nations in 2013– Global forced displacements tops over fifty million for the first time since the second world war . The largest groups are from Afghanistan, Syria, and Somalia. A large percentage of the people leaving these war-torn countries apply to be refugees but sadly only a small percentage are accepted, this is because of the amount of people that can be accepted and the extensive time to get accepted to be refugee for. The processing time for refugees to come to Canada can take up to fifty-two months and multiple trips to the visa office that can be stationed countries away, interviews, and background checks.
As hackers it is our moral obligation to extend our hand to provide solutions for those in need. Therefore, investing our time and resources into making RefyouFree come to reality would substantially help the lives of individuals looking to refuge or asylum. With so many individuals that are experiencing the hardship of leaving everything behind in hopes for a better future they need all the assistance they can get. Children that are brought up in war-torn countries only know of war and believe that their reason for being alive is to either run away or join the war. There is so much more to life than just war and hardships and RefYouFree will support refugees while finding a better reason for being alive. With this mobile application, there is a way for individuals to message their families, call them, find refuge, and have real-time updates of what is happen around them.
**## What it does**
The purpose of RefyouFree – is to provide a faster, and a more convenient resource to allow those in need to apply to countries as refugee’s to start a better life. It would be end up to be a web + mobile application for iOS.
**## How we built it**
The iOS app was built using xCode, using Objective-C, and Swift. API's used for iOS were Sinch. For the Web app, AWS servers were used to run Ruby on Rails thats front end was written in HTML and CSS.
**## Challenges we ran into**
Challenges that the team and I ran into was how many refugee's had access to smart phones, a computer or the internet. After a bit of research we learned that in Syria, they have 87 phones to 100 people. We are hoping that if people do not have access to these resources that they go to the immigration offices, airports, or seaports where they could apply and hopefully get to use the app.
**## Accomplishments that I'm proud of**
Getting the code to run without an error is always an accomplishment.
**## What I learned**
Team work is key. Without such an amazing and dedicated team I do not believe we could have gotten so far. We come from different places, did not know each other until the hackathon but were able to put our heads together and got it to work! For the iOS developers we learned a ton about API intergration, as well as Swift. For Web Developers, they had learned a lot about server side, backend, frontend, and ruby of rails.
**## What's next for RefyouFree**
Working on this project is happening right after we get out of the hackathon. We have messaged various United Nation Members along with members part of the Canadian Immigration Office to see if we would be allowed to do this idea. Although the team met this weekend, it has a high compatibility and a great work ethic to get stuff done. | ## Inspiration
In 2012 in the U.S infants and newborns made up 73% of hospitals stays and 57.9% of hospital costs. This adds up to $21,654.6 million dollars. As a group of students eager to make a change in the healthcare industry utilizing machine learning software, we thought this was the perfect project for us. Statistical data showed an increase in infant hospital visits in recent years which further solidified our mission to tackle this problem at its core.
## What it does
Our software uses a website with user authentication to collect data about an infant. This data considers factors such as temperature, time of last meal, fluid intake, etc. This data is then pushed onto a MySQL server and is fetched by a remote device using a python script. After loading the data onto a local machine, it is passed into a linear regression machine learning model which outputs the probability of the infant requiring medical attention. Analysis results from the ML model is passed back into the website where it is displayed through graphs and other means of data visualization. This created dashboard is visible to users through their accounts and to their family doctors. Family doctors can analyze the data for themselves and agree or disagree with the model result. This iterative process trains the model over time. This process looks to ease the stress on parents and insure those who seriously need medical attention are the ones receiving it. Alongside optimizing the procedure, the product also decreases hospital costs thereby lowering taxes. We also implemented a secure hash to uniquely and securely identify each user. Using a hyper-secure combination of the user's data, we gave each patient a way to receive the status of their infant's evaluation from our AI and doctor verification.
## Challenges we ran into
At first, we challenged ourselves to create an ethical hacking platform. After discussing and developing the idea, we realized it was already done. We were challenged to think of something new with the same amount of complexity. As first year students with little to no experience, we wanted to tinker with AI and push the bounds of healthcare efficiency. The algorithms didn't work, the server wouldn't connect, and the website wouldn't deploy. We persevered and through the help of mentors and peers we were able to make a fully functional product. As a team, we were able to pick up on ML concepts and data-basing at an accelerated pace. We were challenged as students, upcoming engineers, and as people. Our ability to push through and deliver results were shown over the course of this hackathon.
## Accomplishments that we're proud of
We're proud of our functional database that can be accessed from a remote device. The ML algorithm, python script, and website were all commendable achievements for us. These components on their own are fairly useless, our biggest accomplishment was interfacing all of these with one another and creating an overall user experience that delivers in performance and results. Using sha256 we securely passed each user a unique and near impossible to reverse hash to allow them to check the status of their evaluation.
## What we learned
We learnt about important concepts in neural networks using TensorFlow and the inner workings of the HTML code in a website. We also learnt how to set-up a server and configure it for remote access. We learned a lot about how cyber-security plays a crucial role in the information technology industry. This opportunity allowed us to connect on a more personal level with the users around us, being able to create a more reliable and user friendly interface.
## What's next for InfantXpert
We're looking to develop a mobile application in IOS and Android for this app. We'd like to provide this as a free service so everyone can access the application regardless of their financial status. | ## Inspiration
Back in the day, when farmers wanted to build a barn, they knew they could not do it alone. Thus they held barn raisings, where everyone in the community was invited to attend and work for a day building a barn. Everyone came and enjoyed a productive day that also ended in a large party and a lot of community building. Fast forward to our current era.
Silicon Valley has done a superb job of allowing you to get almost anything you want on demand, whether that be food, transportation, groceries, etc. However, despite the immense amount of good that has come about because of these services, many of us are now helping out our friends/community and receiving help from them much less than we did before. Thus often times, our communities are not as strong as they were in the past.
## What it does
Barn allows you to easily help other people around you and get help yourself when you need it. It's not really for emergencies (call 911 for that!), nor for stuff you can get done using the myriad of on demand apps. But if you want a friend from Stanford to help you loft your bed or something, barn is for you!
## How we built it
Used the MapBox API to make a beautiful map of Stanford and OAuth login for Facebook.
## Challenges we ran into
Security is hard, especially since many interactions will be face to face! We decided to restrict to to Stanford students at first to reduce the chance of awkward and potentially dangerous encounters.
## What's next for Barn
We are going to put the finishing touches on Barn and let you folks at Stanford use it! | winning |
# Flash Computer Vision®
### Computer Vision for the World
Github: <https://github.com/AidanAbd/MA-3>
Try it Out: <http://flash-cv.com>
## Inspiration
Over the last century, computers have gained superhuman capabilities in computer vision. Unfortunately, these capabilities are not yet empowering everyday people because building an image classifier is still a fairly complicated task.
The easiest tools that currently exist still require a good amount of computing knowledge. A good example is [Google AutoML: Vision](https://cloud.google.com/vision/automl/docs/quickstart) which is regarded as the "simplest" solution and yet requires an extensive knowledge of web skills and some coding ability. We are determined to change that.
We were inspired by talking to farmers in Mexico who wanted to identify ready / diseased crops easily without having to train many workers. Despite the technology existing, their walk of life had not lent them the opportunity to do so. We were also inspired by people in developing countries who want access to the frontier of technology but lack the education to unlock it. While we explored an aspect of computer vision, we are interested in giving individuals the power to use all sorts of ML technologies and believe similar frameworks could be set up for natural language processing as well.
## The product: Flash Computer Vision
### Easy to use Image Classification Builder - The Front-end
Flash Magic is a website with an extremely simple interface. It has one functionality: it takes in a variable amount of image folders and gives back an image classification interface. Once the user uploads the image folders, he simply clicks the Magic Flash™ button. There is a short training process during which the website displays a progress bar. The website then returns an image classifier and a simplistic interface for using it. The user can use the interface (which is directly built on the website) to upload and classify new images. The user never has to worry about any of the “magic” that goes on in the backend.
### Magic Flash™ - The Backend
The front end’s connection to the backend sets up a Train image folder on the server. The name of each folder is the category that the pictures inside of it belong to. The backend will take the folder and transfer it into a CSV file. From this CSV file it creates a [Pytorch.utils.Dataset](https://pytorch.org/docs/stable/_modules/torch/utils/data/dataset.html) Class by inheriting Dataset and overriding three of its methods. When the dataset is ready, the data is augmented using a combination of 6 different augmentations: CenterCrop, ColorJitter, RandomAffine, RandomRotation, and Normalize. By doing those transformations, we ~10x the amount of data that we have for training. Once the data is in a CSV file and has been augmented, we are ready for training.
We import [SqueezeNet](https://pytorch.org/hub/pytorch_vision_squeezenet/) and use transfer learning to adjust it to our categories. What this means is that we erase the last layer of the original net, which was originally trained for ImageNet (1000 categories), and initialize a layer of size equal to the number of categories that the user defined, making sure to accurately match dimensions. We then run back-propagation on the network with all the weights “frozen” in place with exception to the ones in the last layer. As the model is training, it is informing the front-end that progress being made, allowing us to display a progress bar. Once the model converges, the final model is saved into a file that the API can easily call for inference (classification) when the user asks for prediction on new data.
## How we built it
The website was built using Node.js and javascript and it has three main functionalities: allowing the user to upload pictures into folders, sending the picture folders to the backend, making API calls to classify new images once the model is ready.
The backend is built in Python and PyTorch. On top of Python we used torch, torch.nn as nn, torch.optim as optim, torch.optim import lr\_scheduler, numpy as np, torchvision, from torchvision import datasets, models, and transforms, import matplotlib.pyplot as plt, import time, import os, import copy, import json, import sys.
## Accomplishments that we're proud of
Going into this, we were not sure if 36 hours were enough to build this product. The proudest moment of this project was the successful testing round at 1am on Sunday. While we had some machine learning experience on our team, none of us had experience with transfer learning or this sort of web application. At the beginning of our project, we sat down, learned about each task, and then drew a diagram of our project. We are especially proud of this step because coming into the coding portion with a clear API functionality understanding and delegated tasks saved us a lot of time and helped us integrate the final product.
## Obstacles we overcame and what we learned
Machine learning models are often finicky in their training patterns. Because our application allows users with little experience, we had to come up with a robust training pipeline. Designing this pipeline took a lot of thought and a few failures before we converged on a few data augmentation techniques that do the trick. After this hurdle, integrating a deep learning backend with the website interface was quite challenging, as the training pipeline requires very specific labels and file structure. Iterating the website to reflect the rigid protocol without over complicating the interface was thus a challenge. We learned a ton over this weekend. Firstly, getting the transfer learning to work was enlightening as freezing parts of the network and writing a functional training loop for specific layers required diving deep into the pytorch API. Secondly, the human-design aspect was a really interesting learning opportunity as we had to come up with the right line between abstraction and functionality. Finally, and perhaps most importantly, constantly meeting and syncing code taught us the importance of keeping a team on the same page at all times.
## What's next for Flash Computer Vision
### Application companion + Machine Learning on the Edge
We want to build a companion app with the same functionality as the website. The companion app would be even more powerful than the website because it would have the ability to quantize models (compression for ml) and to transfer them into TensorFlow Lite so that **models can be stored and used within the device.** This would especially benefit people in developing countries, where they sometimes cannot depend on having a cellular connection.
### Charge to use
We want to make a payment system within the website so that we can scale without worrying about computational cost. We do not want to make a business model out of charging per API call, as we do not believe this will pave a path forward for rapid adoption. **We want users to own their models, this will be our competitive differentiator.** We intentionally used a smaller neural network to reduce hosting and decrease inference time. Once we compress our already small models, this vision can be fully realized as we will not have to host anything, but rather return a mobile application. | ## Inspiration
We want to make everyone impressed by our amazing project! We wanted to create a revolutionary tool for image identification!
## What it does
It will identify any pictures that are uploaded and describe them.
## How we built it
We built this project with tons of sweats and tears. We used Google Vision API, Bootstrap, CSS, JavaScript and HTML.
## Challenges we ran into
We couldn't find a way to use the key of the API. We couldn't link our html files with the stylesheet and the JavaScript file. We didn't know how to add drag and drop functionality. We couldn't figure out how to use the API in our backend. Editing the video with a new video editing app. We had to watch a lot of tutorials.
## Accomplishments that we're proud of
The whole program works (backend and frontend). We're glad that we'll be able to make a change to the world!
## What we learned
We learned that Bootstrap 5 doesn't use jQuery anymore (the hard way). :'(
## What's next for Scanspect
The drag and drop function for uploading iamges! | ## Inspiration
A walk across campus looking at all the historical buildings and statues of the University of Pennsylvania.
## What it does
The project will be in the form of a web/mobile app. One or several locations are provided to the user. Along with each location an image is provided. The user aims to find the actual location and take a photo that best possibly replicates the image provided. The user has now "unlocked" said location.
The images that are intended to be used are historical images of landmarks, which are displayed to the user with a relatively low opacity and some interesting facts about the landmark. Making it both a thrilling geocaching-like and an educational experience (re-live history!).
## How we built it
Computer vision, API-handling, and web development will be critical elements of this project.
The biggest part of the application was to find a way to accurately decide if two pictures contain the same landmark, thus we spent a fairly big chunk of our development period just trying to make a model that worked as intended.
We built the web app by making a Flask backend, where we provided the utility to upload a picture to compare with, as well as implemented our Siamese Neural Network.
## Challenges we ran into
As the hackathon format doesn't allow for thoughtful and methodical development of AI, we decided to use a pre-existing Computer Vision model to be able to recognize a place, instead of having to train a model for ourselves. A problem we ran into was that most Open Source Computer Vision models are intended for object detection and classification, rather than comparison between two pictures of the same object. Unable to find a suitable model, we were forced to train our own, settling on a Siamese neural network.
## Accomplishments that we're proud of
We're especially proud of providing a proof of concept, with a self-trained Siamese neural network that works as intended. (with the pictures about the same angle)
## What we learned
We learned that getting everything to run smoothly and deploying a functioning model is more of a challenge than expected. Our plane also arrived very late, so we definitely learned that it's beneficial to get stated as soon as possible.
## What's next for Photo cache
A natural next move would be to make the concept into a functioning app for IOS/Android, and fully implement the more educational part of the application.
A website link should be provided in the GitHub repo. | winning |
## Inspiration
Since this was the first hackathon for most of our group, we wanted to work on a project where we could learn something new while sticking to familiar territory. Thus we settled on programming a discord bot, something all of us have extensive experience using, that works with UiPath, a tool equally as intriguing as it is foreign to us. We wanted to create an application that will allow us to track the prices and other related information of tech products in order to streamline the buying process and enable the user to get the best deals. We decided to program a bot that utilizes user input, web automation, and web-scraping to generate information on various items, focusing on computer components.
## What it does
Once online, our PriceTracker bot runs under two main commands: !add and !price. Using these two commands, a few external CSV files, and UiPath, this stores items input by the user and returns related information found via UiPath's web-scraping features. A concise display of the product’s price, stock, and sale discount is displayed to the user through the Discord bot.
## How we built it
We programmed the Discord bot using the comprehensive discord.py API. Using its thorough documentation and a handful of tutorials online, we quickly learned how to initialize a bot using Discord's personal Development Portal and create commands that would work with specified text channels. To scrape web pages, in our case, the Canada Computers website, we used a UiPath sequence along with the aforementioned CSV file, which contained input retrieved from the bot's "!add" command. In the UiPath process, each product is searched on the Canada Computers website and then through data scraping, the most relevant results from the search and all related information are processed into a csv file. This csv file is then parsed through to create a concise description which is returned in Discord whenever the bot's "!prices" command was called.
## Challenges we ran into
The most challenging aspect of our project was figuring out how to use UiPath. Since Python was such a large part of programming the discord bot, our experience with the language helped exponentially. The same could be said about working with text and CSV files. However, because automation was a topic none of us hardly had any knowledge of; naturally, our first encounter with it was rough. Another big problem with UiPath was learning how to use variables as we wanted to generalize the process so that it would work for any product inputted.
Eventually, with enough perseverance, we were able to incorporate UiPath into our project exactly the way we wanted to.
## Accomplishments that we're proud of
Learning the ins and outs of automation alone was a strenuous task. Being able to incorporate it into a functional program is even more difficult, but incredibly satisfying as well. Albeit small in scale, this introduction to automation serves as a good stepping stone for further research on the topic of automation and its capabilities.
## What we learned
Although we stuck close to our roots by relying on Python for programming the discord bot, we learned a ton of new things about how these bots are initialized, the various attributes and roles they can have, and how we can use IDEs like Pycharm in combination with larger platforms like Discord. Additionally, we learned a great deal about automation and how it functions through UiPath which absolutely fascinated us the first time we saw it in action. As this was the first Hackathon for most of us, we also got a glimpse into what we have been missing out on and how beneficial these competitions can be. Getting the extra push to start working on side-projects and indulging in solo research was greatly appreciated.
## What's next for Tech4U
We went into this project with a plethora of different ideas, and although we were not able to incorporate all of them, we did finish with something we were proud of. Some other ideas we wanted to integrate include: scraping multiple different websites, formatting output differently on Discord, automating the act of purchasing an item, taking input and giving output under the same command, and more. | ## Inspiration
Our inspiration all stems from one of our users terrible experiences building a PC. Building a PC can be an incredibly rewarding but also frustrating experience, especially for first-time builders. Our team member had a particularly disastrous PC build - incorrect parts that weren't compatible, unstable overclocking leading to crashes, and way over budget. It was a valuable learning experience but very costly in both time and money. We realized there had to be a better way than trial and error for PC novices to configure and buy the right components for their needs and budget. Our project aims to leverage AI and data to match users with PC parts tailored to their individual use case, whether that's high-end gaming, media editing, programming, etc.
## What it does
The website takes in a user's custom PC build needs and budget, then gets to work finding the optimal parts combination. Users simply describe what they plan to use the computer for, such as high-end 3D editing under $2,000. Within seconds, the website outputs a complete part list with prices, specs, and descriptions tailored to the user's intended workload.
## How we built it
Utilizing a Convex fullstack, we looked for cutting edge, pioneering softwares to help propel our project. We landed on utilizing together.ai to base our main AI system. Our fined-tuned llama-7b was trained on countless data-points, and works to create accurate and timely recommendations. Going further down, we used a secondary AI in MindsDB for bulk jobs to generate accurate descriptions of Pc Parts. We pulled from a scraped database in
## Challenges we ran into
Along the way, there were many challenges. One included running on only caffeine, but that was deemed worth the trouble knowing the amazing project we built. On a more technical level, as the technologies we planned on using were newer, there wasnt that large of a network of integrations. To combat this, we produced our own implementations. Specifically for a MindsDB integration for together.ai. To further the usefulness of together.ai, we also created an integration for Discord. Furthermore, obtaining data was a monumental obstacle. As a group of 4 without much capital, we had to create our own legal web scrapping tools. We ran into countless issues but eventually created a capable web scrapping tool to gather publicly available data to train our model on. Eventually, we intend to invest into purchasing data from large PC Parts databases to finalize and secure data.
## Accomplishments that we're proud of
We are definitely proud of the project we built, keeping in mind we are not all trained and seasoned hackathon veterans. More specifically, the revolutionary integrations are definitely a high-point for our project. Coming from knowing nothing about integrations, LLM creation and ethical data-scraping, we now know how to implement these systems in the future. And even when we would get frustrated, we always encouraged and pushed eachother forward in new and creative ways.
## What we learned
We learned that even if we start from a basic understanding of how LLMs AIs and databases work, through passion and hard work we can become experts in this field.
## What's next for EasyPC
Scaling this project will be easy. With an already fully-functioning AI system, the possibilites would be endless. We can keep feeding it more data, and we plan on implementing a text-feature where you could ask a fined-tuned LLM on any pc related questions. | Intro: Hello Deer hack Judges, we are a group of 3 first-year CS Students, Shyan, Vishal and Rabten.
Overall: We have created an encryption/decryption application with our own custom algorithm. You can select any type of file, and our application will encrypt the data of said file and return to you the password to decrypt the file.
GUI: We have created a GUI that will allow you to search through your File Explorer and after it is selected you are presented with the option to encrypt or decrypt.
Decrypt: For the Decryption process, the application itself has an encrypted master list of passwords for all files the user has encrypted before. The user DOES NOT have access to this master list. If the user wishes to access/ decrypt one of their files, they must enter the password associated with that file. Furthermore, the file they’re trying to decrypt MUST be a file that has already been encrypted. If any of the clauses are not met, the application will inform the user of the clause not met and prompt them to try again. | partial |
## Inspiration
Inspired by personal experience of commonly getting separated in groups and knowing how inconvenient and sometimes dangerous it can be, we aimed to create an application that kept people together. We were inspired by how interlinked and connected we are today by our devices and sought to address social issues while using the advancements in decentralized compute and communication. We also wanted to build a user experience that is unique and can be built upon with further iterations and implementations.
## What it does
Huddle employs mesh networking capability to maintain a decentralized network among a small group of people, but can be scaled to many users. By having a mesh network of mobile devices, Huddle manages the proximity of its users. When a user is disconnected, Huddle notifies all of the devices on its network, thereby raising awareness, should someone lose their way.
The best use-case for Huddle is in remote areas where cell-phone signals are unreliable and managing a group can be cumbersome. In a hiking scenario, should a unlucky hiker choose the wrong path or be left behind, Huddle will reduce risks and keep the team together.
## How we built it
Huddle is an Android app built with the RightMesh API. With many cups of coffee, teamwork, brainstorming, help from mentors, team-building exercises, and hours in front of a screen, we produced our first Android app.
## Challenges we ran into
Like most hackathons, our first challenge was deciding on an idea to proceed with. We employed the use of various collaborative and brainstorming techniques, approached various mentors for their input, and eventually we decided on this scalable idea.
As mentioned, none of us developed an Android environment before, so we had a large learning curve to get our environment set-up, developing small applications, and eventually building the app you see today.
## Accomplishments that we're proud of
One of our goals was to be able to develop a completed product at the end. Nothing feels better than writing this paragraph after nearly 24 hours of non-stop hacking.
Once again, developing a rather complete Android app without any developer experience was a monumental achievement for us. Learning and stumbling as we go in a hackathon was a unique experience and we are really happy we attended this event, no matter how sleepy this post may seem.
## What we learned
One of the ideas that we gained through this process was organizing and running a rather tightly-knit developing cycle. We gained many skills in both user experience, learning how the Android environment works, and how we make ourselves and our product adaptable to change. Many design changes occured, and it was great to see that changes were still what we wanted and what we wanted to develop.
Aside from the desk experience, we also saw many ideas from other people, different ways of tackling similar problems, and we hope to build upon these ideas in the future.
## What's next for Huddle
We would like to build upon Huddle and explore different ways of using the mesh networking technology to bring people together in meaningful ways, such as social games, getting to know new people close by, and facilitating unique ways of tackling old problems without centralized internet and compute.
Also V2. | # Catch! (Around the World)
## Our Inspiration
Catch has to be one of our most favourite childhood games. Something about just throwing and receiving a ball does wonders for your serotonin. Since all of our team members have relatives throughout the entire world, we thought it'd be nice to play catch with those relatives that we haven't seen due to distance. Furthermore, we're all learning to social distance (physically!) during this pandemic that we're in, so who says we can't we play a little game while social distancing?
## What it does
Our application uses AR and Unity to allow you to play catch with another person from somewhere else in the globe! You can tap a button which allows you to throw a ball (or a random object) off into space, and then the person you send the ball/object to will be able to catch it and throw it back. We also allow users to chat with one another using our web-based chatting application so they can have some commentary going on while they are playing catch.
## How we built it
For the AR functionality of the application, we used **Unity** with **ARFoundations** and **ARKit/ARCore**. To record the user sending the ball/object to another user, we used a **Firebase Real-time Database** back-end that allowed users to create and join games/sessions and communicated when a ball was "thrown". We also utilized **EchoAR** to create/instantiate different 3D objects that users can choose to throw. Furthermore for the chat application, we developed it using **Python Flask**, **HTML** and **Socket.io** in order to create bi-directional communication between the web-user and server.
## Challenges we ran into
Initially we had a separate idea for what we wanted to do in this hackathon. After a couple of hours of planning and developing, we realized that our goal is far too complex and it was too difficult to complete in the given time-frame. As such, our biggest challenge had to do with figuring out a project that was doable within the time of this hackathon.
This also ties into another challenge we ran into was with initially creating the application and the learning portion of the hackathon. We did not have experience with some of the technologies we were using, so we had to overcome the inevitable learning curve.
There was also some difficulty learning how to use the EchoAR api with Unity since it had a specific method of generating the AR objects. However we were able to use the tool without investigating too far into the code.
## Accomplishments
* Working Unity application with AR
* Use of EchoAR and integrating with our application
* Learning how to use Firebase
* Creating a working chat application between multiple users | ## Inspiration
The only thing worse than no WiFi is slow WiFi. Many of us have experienced the frustrations of terrible internet connections. We have too, so we set out to create a tool to help users find the best place around to connect.
## What it does
Our app runs in the background (completely quietly) and maps out the WiFi landscape of the world. That information is sent to a central server and combined with location and WiFi data from all users of the app. The server then processes the data and generates heatmaps of WiFi signal strength to send back to the end user. Because of our architecture these heatmaps are real time, updating dynamically as the WiFi strength changes.
## How we built it
We split up the work into three parts: mobile, cloud, and visualization and had each member of our team work on a part. For the mobile component, we quickly built an MVP iOS app that could collect and push data to the server and iteratively improved our locationing methodology. For the cloud, we set up a Firebase Realtime Database (NoSQL) to allow for large amounts of data throughput. For the visualization, we took the points we received and used gaussian kernel density estimation to generate interpretable heatmaps.
## Challenges we ran into
Engineering an algorithm to determine the location of the client was significantly more difficult than expected. Initially, we wanted to use accelerometer data, and use GPS as well to calibrate the data, but excessive noise in the resulting data prevented us from using it effectively and from proceeding with this approach. We ran into even more issues when we used a device with less accurate sensors like an Android phone.
## Accomplishments that we're proud of
We are particularly proud of getting accurate paths travelled from the phones. We initially tried to use double integrator dynamics on top of oriented accelerometer readings, correcting for errors with GPS. However, we quickly realized that without prohibitively expensive filtering, the data from the accelerometer was useless and that GPS did not function well indoors due to the walls affecting the time-of-flight measurements. Instead, we used a built in pedometer framework to estimate distance travelled (this used a lot of advanced on-device signal processing) and combined this with the average heading (calculated using a magnetometer) to get meter-level accurate distances.
## What we learned
Locationing is hard! Especially indoors or over short distances.
Firebase’s realtime database was extremely easy to use and very performant
Distributing the data processing between the server and client is a balance worth playing with
## What's next for Hotspot
Next, we’d like to expand our work on the iOS side and create a sister application for Android (currently in the works). We’d also like to overlay our heatmap on Google maps.
There are also many interesting things you can do with a WiFi heatmap. Given some user settings, we could automatically switch from WiFi to data when the WiFi signal strength is about to get too poor. We could also use this app to find optimal placements for routers. Finally, we could use the application in disaster scenarios to on-the-fly compute areas with internet access still up or produce approximate population heatmaps. | partial |
## Inspiration
MonitorMe was inspired by the fact that the numbers on the display screen of a blood pressure monitor don’t give enough information to the user. What MonitorMe aims to do is to make these pressure readings more understandable. MonitorMe is a very simple and user-friendly program that allows the user to know if their blood pressure puts them in danger and what needs to be done to prevent or reduce their blood pressure if needed.
## What it does
MonitorMe makes understanding a blood pressure monitor really easy! After the user inputs the systolic, diastolic, and pulse readings from the blood pressure machine into MonitorMe, it will tell the user if their readings are low, normal, or high. If the user’s blood pressure is high, MonitorMe will suggest solutions and remedies that may help the user.
## How we built it
The frontend is developed using HTML/CSS, Bootstrap.
The backend component is built using PHP and Laravel.
## Challenges we ran into
Our original idea was to make a mobile app that would transfer data directly into the mobile app by taking a picture using artificial intelligence, but that proved to be a challenge in the 36-hour time span as many of the programs/frameworks were fairly new to us.
## Accomplishments that we're proud of
One of the accomplishments that we’re proud of is integrating the front and back end to work together. We made a functional prototype and are really proud of the results!
## What we learned
We learned how to effectively time manage and problem solve in a very short amount of time.
## What's next for MonitorMe
What’s next for MonitorMe is trying to incorporate a weekly report for the user to monitor their blood pressure. All the readings and the dates of the readings will be saved on a cloud, and whenever the user would like to check on previous readings, it will be readily available to them. We also would like to incorporate more ways to educate the users about what the reading actually means, and what ways the user can avoid getting hypertension. MonitorMe is also planning on creating a mobile app where the user has an option to take a photograph of their blood pressure monitor, and using machine learning the app will read the pressure readings and store systolic and diastolic on the app. This would make the user experience more convenient and user-friendly! | **Previously named NeatBeat**
## Inspiration
We wanted to make it easier to understand your pressure, so you **really** are not pressured about what your heart deserves.
## What it does
**Track and chart blood pressure readings** 📈❤️
* Input your systolic and diastolic to be stored on the cloud
* See and compare your current and past blood pressure readings
**Doctor and Patient system** 🩺
* Create doctor and patient accounts
* Doctors will be able to see all their patients and their associated blood pressure readings
* Doctors are able to make suggestions based on their patient readings
* Patients can see suggestions that their doctor makes
## How we built it
Using Django web framework, backend with Python and front development with HTML, Bootstrap and chart.js for charting.
## Challenges we ran into
* Too many front end issues to count 😞
## Accomplishments that we're proud of
* Being able to come together to collaborate and complete a project solely over the internet.
* Successfully splitting the projects into parts and integrating them together for a functioning product
## What we learned
* Hacking under a monumental school workload and a global pandemic
## What's next for NeatBeat
* Mobile-friendly interface | ## Inspiration
With the advent of smartwatches, personal health data is one glance at your wrist away. With the rise of streaming, there are hundreds of playlists for every activity. Despite both of these innovations, people still waste *minutes* every day adjusting their music to their current activity. **Heartmonics** bridges this gap to save time and encourage healthy habits.
## What it does
Heartmonics tunes your music to your current fitness activity level. Our device reads your heart rate, then adjusts the mood of your music to suit resting, light exercise, and intense work-outs. This functionality helps to encourage exercise and keep users engaged and enjoying their workouts.
## How we built it
Our device is runs on a Raspberry Pi platform housed in an exercise armband. It reads heart rate data from a sensor connected via i2c and comfortably attached to the users forearm. A button integrated into the armband provides easy control of music like any other player, allowing the user to play, pause, skip, and rewind songs.
## Challenges we ran into
In building Heartmonics, we faced several challenges with integrating all the components of our design together. The heart rate sensor was found to be very sensitive and prone to giving inaccurate results, but by reading documentation and making careful adjustments, as well as reinforcing our hardware connections, we were able to get the sensor calibrated and working reliably. Integrating our solution with SpotifyAPI using the spotipi library also came with a set of integration challenges, compounded by our unfamiliarity with the platform. Despite all of these challenges, we persevered to produce a polished and functional prototype.
## Accomplishments that we're proud of
We are proud of the ease of use of our final design. Since the concept is designed as a time saver, we're glad it can deliver on everything we set out to do. We also went above and beyond our original goals, adding music control via a button, mood indication on an RGB LED, sensor and song information on an LCD display, and an elevated heart rate warning indicator. These features elevate Heartmonics and
## What we learned
We learned the importance of careful hardware selection, and reading documentation. We leveraged and reinforced our teamwork and planning abilities to quickly build a functioning prototype.
## What's next for Heartmonics
The functionality of Heartmonics could be integrated into a smartwatch app for a more elegant implementation of our concept. With wearable integration, users could employ our concept with potentially no additional cost, making Heartmonics widely accessible.
Another potential addition is to make configuring which songs play for each mode user-accessible, so everyone can tune their Heartmonics to the tune of their heart. | losing |
Envision an expanse of sea – that's the rejuvenating essence Canadians crave. A refreshing breeze for the well-being of the mind.
# Inspiration
In the fast-paced digital age, achieving a balance between work productivity and personal well-being is a universal challenge. This inspired us to create Pomodoo, a chrome extension pet that combines productivity and self-care through engaging quests.
# What it does
Pomodoo is a cute and chaotic chrome extension pet designed to remind users to take breaks and prioritize self-care. It offers a mix of physical and virtual elements, providing an All-in-One Solution for consolidating productivity and health goals.
# How we built it
We built Pomodoo with a focus on customization and flexibility. Users can tailor the extension to their unique preferences and needs. The development process involved incorporating magical elements to make the experience delightful and engaging.
# Challenges we ran into
During the development of Pomodoo, we encountered several challenges. These ranged from technical issues to design considerations. Overcoming these challenges required creative problem-solving and collaboration within the team.
* Chrome extension plan did not work out:( very specific way to use it
# Accomplishments that we're proud of
* We're proud to have created Pomodoo, a unique and whimsical chrome extension that seamlessly integrates productivity and well-being. The successful combination of physical and virtual elements and the customization options make it a standout solution.
* This was Darren's first hackathon and it was great to see him adapt and work alongside us debugging and adding features
# What we learned
The development of Pomodoo taught us valuable lessons about creating a balanced and fulfilling user experience. We gained insights into the intersection of productivity tools and wellness apps, leading to a deeper understanding of user needs in the digital age.
# What's next for Pomodoo
Our journey doesn't end here. We plan to further enhance Pomodoo by continuously refining its features and incorporating user feedback. Additionally, we're exploring partnerships and collaborations to expand its reach. Download Pomodoo now and redefine your approach to work and wellness! | ## Inspiration
Many people are unaware of how their daily actions are affecting the world and the community that they live in. We wanted to make an app that lets people know exactly what impact they have.
## What it does
Impact is a very "action -> consequence" based app that aims to encourage people to live a life that betters the earth and society. By creating a Carbon Footprint calculation software and volunteering registrations, Impact is able to award and deduct "points" which is the main motivation for the user, because it gives them a visual indication of their contribution to society. The goal is to have positive points by the of the week.
## How we built it
We created our own algorithms to calculate all the carbon footprints of several activities. We used Bootstrap and Material for the frontend of the website. Meanwhile, swift and chart graphics were employed for the iOS frontend. Finally, we incorporated Google Cloud Platform to tie both ends together to provide a fully immersive experience for the user.
## Challenges we ran into
No API existed for Cars or Carbon Emission so we had to develop our own at the hackathon.
## Accomplishments that we're proud of
The actual completetion of an API
## What we learned
How to use HealthKIT and CoreMotion.
## What's next for Impact
Check's peoples opinion. | ## Inspiration
Open-world AR applications like Pokemon Go that bring AR into everyday life and the outdoors were major inspirations for this project. Additionally, in thinking about how to integrate smartphones with Spectacles, we found inspiration in video games like Phasmophobia's EMP sensors that react more strongly in the presence of ghosts or The Legend of Zelda: Skyward Sword that contained an in-game tracking functionality that pulsates more strongly when facing the direction of and walking closer to a target.
## What it does
This game integrates the Spectacles gear and smartphones together by allowing users to leverage the gyroscopic, haptic, and tactile functionalities of phones to control or receive input about their AR environment. In the game, users have to track down randomly placed treasure chests in their surrounding environment by using their phone as a sensor that begins vibrating when the user is facing a treasure and enters stronger modes of haptic feedback as users get closer to the treasure spots.
These chests come in three types: monetary, puzzle, and challenge. Monetary chests immediately give users in-game rewards. Puzzle chests engage users in a single-player mini-game that may require cognitive or physical activity. Finally, challenge chests similarly engage users in activities not necessarily games, and a stretch goal for multiplayers was that if multiple users were near a spot that another user found a treasure in, the other n users could challenge the treasure finder in a n vs. 1 duel, with the winner(s) taking the rewards.
## How we built it
Once we figured out our direction for the project, we built a user flow architecture in Figma to brainstorm the game design for our application ([link](https://www.figma.com/design/pyG5hlpYkWwVcyvIQJCnY3/Treasure-Hunt-UX-Architecture?node-id=0-1&node-type=canvas&t=clqInR0JpOM6tEnv-0)), and we also visualized how to implement the system for integrating phone haptic feedback with the spectacles depending on distance and directional conditions.
From there, we each took on specific aspects of the user flow architecture to primarily work on: (1) the treasure detection mechanism, (2) spawning the treasure once the user entered within a short distance from the target, and (3) the content of the treasure chests (i.e. rewards or activities). Nearly everything was done using in-house libraries, assets, and the GenAI suite within Snap's Lens Studio.
## Challenges we ran into
As we were working with Spectacles for the first time (compounded with internet problems), we initially encountered technical issues with setting up our development environment and linking the Spectacles for debugging. Due to limited documentation and forums since it is limited-access technology, we had to do a lot of trial-and-error and guessing to figure out how to get our code to work, but luckily, Snap's documentation provided templates to work off of and the Snap staff was able to provide technical assistance to guide us in the right direction. Additionally, given one Spectacle to work with, parallelizing our development work was quite challenging as we had to integrate everything onto one computer while dealing with merge conflicts between our code.
## Accomplishments that we're proud of
In a short span of time, we were able to successfully build a game that provides a unique immersive experience! We've come across and solved errors that didn't have solutions on the internet. For a couple of members of our team, this sparks a newfound interest in the AR space.
## What we learned
This was our first time working with Lens Studio and it's unanimously been a smooth and great software to work with.
For the experienced members on our team, it's been a rewarding experience to make an AR application using JS/TS instead of C# which is the standard language used in Unity.
## What's next for SnapChest
We're excited to push this app forward by adding more locations for treasures, implementing a point system, and also a voice agent integration that provides feedback based on where you're going so you won't get bored on your journey!
If Spectacles would be made available to the general public, a multiplayer functionality would definitely gain a lot of traction and we're looking forward to the future! | losing |
## Inspiration
This project was inspired by the desire to develop an engaging and instructional dice rolling game while also addressing statistical principles in a practical environment. We wanted to create a simple game in which two players may roll dice while learning about statistical measurements like mean, median, mode, and range.
## What it does
Our project is a two-player dice rolling game written in Python. The program simulates 2 players rolling a die. Based on the outcomes of the rolls, the game tracks and displays several statistical measures. It gives players instant feedback on statistics such as mean, median, mode, and range, allowing them to compare and analyze their performance.
## How we built it
Python was our major programming language for creating the game and doing statistical calculations. We used the Colorama library to add colorful text to the terminal output. Matplotlib was used to generate visualizations of the statistics acquired during the game, such as histograms, scatter plots, and box plots.
## Challenges we ran into
We improved our Python programming skills, especially when it came to working with classes and libraries. I learned more about statistical ideas and their practical applications. Using Matplotlib, we learned how to include data visualization into our projects. We improved our problem-solving abilities by tackling game logic and user interaction issues.
## Accomplishments that we're proud of
We began by constructing a Player class and simulating dice rolls before designing the game's structure. We eventually added statistics monitoring tools including calculating the mean, median, mode, variance, standard deviation, and range. We also used Matplotlib to visualize data and collect user input.
## What we learned
Creating game logic that is intuitive and pleasant for the user. Implementing statistics calculations within the game in a precise and efficient manner. Overcoming technical difficulties in integrating Matplotlib for data visualization.
## What's next for Dice Simulator
Extend the game by adding more types of dice or customizing the settings. Integrate extra statistical measures or provide users the option of selecting which statistics to display. Improve the user interface to make it more professional and user-friendly. | # About Us
Discord Team Channel: #Team-25
secretage001#6705, Null#8324, BluCloos#8986
<https://friendzr.tech/>
## Inspiration
Over the last year the world has been faced with an ever-growing pandemic. As a result, students have faced increased difficulty in finding new friends and networking for potential job offers. Based on Tinder’s UI and LinkedIn’s connect feature, we wanted to develop a web-application that would help students find new people to connect and network with in an accessible, familiar, and easy to use environment. Our hope is that people will be able Friendz to network successfully using our web-application.
## What it does
Friendzr allows users to login with their email or Google account and connect with other users. Users can record a video introduction of themselves for other users to see. When looking for connections, users can choose to connect or skip on someone’s profile. Selecting to connect allows the user to message the other party and network.
## How we built it
The front-end was built with HTML, CSS, and JS using React. On our back-end, we used Firebase for authentication, CockroachDB for storing user information, and Google Cloud to host our service.
## Challenges we ran into
Throughout the development process, our team ran into many challenges. Determining how to upload videos recorded in the app directly to the cloud was a long and strenuous process as there are few resources about this online. Early on, we discovered that the scope of our project may have been too large, and towards the end, we ended up being in a time crunch. Real-time messaging also proved incredibly difficult to implement.
## Accomplishments that we're proud of
As a team, we are proud of our easy-to-use UI. We are also proud of getting the video to record users then directly upload to the cloud. Additionally, figuring out how to authenticate users and develop a viable platform was very rewarding.
## What we learned
We learned that when collaborating on a project, it is important to communicate, and time manage. Version control is important, and code needs to be organized and planned in a well-thought manner. Video and messaging is difficult to implement, but rewarding once completed.
In addition to this, one member learned how to use HTML, CSS, JS, and react over the weekend. The other two members were able to further develop their database management skills and both front and back-end development.
## What's next for Friendzr
Moving forward, the messaging system can be further developed. Currently, the UI of the messaging service is very simple and can be improved. We plan to add more sign-in options to allow users more ways of logging in. We also want to implement AssembyAI’s API for speech to text on the profile videos so the platform can reach people who aren't as able. Friendzr functions on both mobile and web, but our team hopes to further optimize each platform. | ## Inspiration
Our game stems from the current global pandemic we are grappling with and the importance of getting vaccinated. As many of our loved ones are getting sick, we believe it is important to stress the effectiveness of vaccines and staying protected from Covid in a fun and engaging game.
## What it does
An avatar runs through a school terrain while trying to avoid obstacles and falling Covid viruses. The player wins the game by collecting vaccines and accumulating points, successfully dodging Covid, and delivering the vaccines to the hospital.
Try out our game by following the link to github!
## How we built it
After brainstorming our game, we split the game components into 4 parts for each team member to work on. Emily created the educational terrain using various assets, Matt created the character and its movements, Veronica created the falling Covid virus spikes, and Ivy created the vaccines and point counter. After each of the components were made, we brought it all together, added music, and our game was completed.
## Challenges we ran into
As all our team members had never used Unity before, there was a big learning curve and we faced some difficulties while navigating the new platform.
As every team member worked on a different scene on our Unity project, we faced some tricky merge conflicts at the end when we were bringing our project together.
## Accomplishments that we're proud of
We're proud of creating a fun and educational game that teaches the importance of getting vaccinated and avoiding Covid.
## What we learned
For this project, it was all our first time using the Unity platform to create a game. We learned a lot about programming in C# and the game development process. Additionally, we learned a lot about git management through debugging and resolving merge conflicts.
## What's next for CovidRun
We want to especially educate the youth on the importance of vaccination, so we plan on introducing the game into k-12 schools and releasing the game on steam. We would like to add more levels and potentially have an infinite level that is procedurally generated. | partial |
## Inspiration
The inspiration behind CareerFairy stemmed from a desire to transform traditional career fairs into a more accessible and efficient virtual experience. We aimed to leverage technology to streamline the recruitment process, making it easier for both job seekers and employers to connect in a 2D spatial calling web application.
## What it does
CareerFairy is a revolutionary platform that facilitates virtual career fairs, allowing job seekers to explore booths and engage with recruiters seamlessly. Utilizing React, Flask, PeerJS, WebRTC, SocketIO, and OpenAI's GPT-3.5, the application not only provides a user-friendly interface but also incorporates AI-generated candidate overviews for recruiters, optimizing the hiring process.
## How we built it
We built CareerFairy using React for the front end, Flask for the backend, and integrated PeerJS, WebRTC, and SocketIO for real-time communication. The inclusion of OpenAI's GPT-3.5 ensures that recruiters receive instant, AI-generated insights into candidate qualifications and skills.
## Challenges we ran into
Integrating multiple technologies posed challenges in terms of synchronization and seamless communication. Overcoming the learning curve associated with WebRTC and ensuring a smooth user experience were additional hurdles that our team successfully addressed during the development process.
## Accomplishments that we're proud of
We are proud to have created a functional and innovative platform that enhances the virtual recruitment experience. The successful integration of AI-driven candidate overviews and the collaborative efforts of our team in overcoming technical challenges stand out as notable accomplishments.
## What we learned
Throughout the development of CareerFairy, our team gained valuable insights into the intricacies of real-time communication, virtual environments, and the application of AI in recruitment processes. We refined our skills in React, Flask, PeerJS, WebRTC, and SocketIO, further enhancing our capabilities.
## What's next for Fairy
Looking ahead, CareerFairy aims to expand its features and capabilities. We plan to refine the AI models for more nuanced candidate assessments, incorporate additional interactive elements for job seekers and recruiters, and continually enhance the overall user experience. Our vision is to make CareerFairy the go-to platform for efficient, AI-driven virtual recruitment. | ## Inspiration
Time doesn't wait -- it moves regardless whether we are ready. Realizing that as college students, we've probably spent more than 90% of the time we will ever spent with our parents already, that we only have so many more winters, and that we should live consciously and reflect often -- not letting the time meaninglessly pass us by. We came up with an app that gives us context to the years gone by and the years to come in our lives.
## What Lifely does
1) Visualizes the user's age on a chart relative to a long human life
2) Provides contextual visualizations of a typical American life and also average age for other events, such as getting married or starting a successful startup
3) Insights on years past, such as: how old they were in a particular year, what significant events happened in that year (pulled using the WolframAlpha API), and how much an investment they made that year could be worth today.
## How we built it
Rapid ideation burning through a bunch of ideas, user testing to a pivot, learning a new tech stack we never used before, and lots of food.
## Challenges we ran into
The app started as a very depressing venture, both on the insights it gave and our progress. We spent 16 hours trying to build an MVP, and realized its only working functionality was something any three year old could have done -- count. We also decided to try Angular with no experience, and spent 4 man hours debugging a one-character error.
## Accomplishments that we're proud of
First Hackathon experience -- **We did it!** \_ (not sure how) \_
## What we learned
Coding is hard. CSS positioning is painful. Learn Angular ahead of time.
## What's next for Lifely
We would like to expand our MVP to include key functionality such as:
1) **Personalization** -- Give users the ability to integrate with Facebook and connect their Moments onto their Lifely Life Calendar, add their own notable events, and potentially save and share their calendars
2) **Business Development Opportunities** -- We would like to expand Lifely Insights to better connect users to products or services that solve their problems, such as investing platforms, health advice, career guidance, and going back to school
3) **Data Visualization** -- Our core value is around building context for the user with data, and we want to continue to develop the way we present our visualizations to be more relevant and impactful to our users such as by adding a weekly or monthly view | ## What Does "Catiator" Mean?
**Cat·i·a·tor** (*noun*): Cat + Gladiator! In other words, a cat wearing a gladiator helmet 🐱
## What It Does
*Catiator* is an educational VR game that lets players battle gladiator cats by learning and practicing American Sign Language. Using finger tracking, players gesture corresponding letters on the kittens to fight them. In order to survive waves of fierce but cuddly warriors, players need to leverage quick memory recall. If too many catiators reach the player, it's game over (and way too hard to focus with so many chonky cats around)!
## Inspiration
There are approximately 36 million hard of hearing and deaf individuals live in the United States, and many of them use American Sign Language (ASL). By learning ASL, you'd be able to communicate with 17% more of the US population. For each person who is hard of hearing or deaf, there are many loved ones who hope to have the means to communicate effectively with them.
### *"Signs are to eyes as words are to ears."*
As avid typing game enthusiasts who have greatly improved typing speeds ([TypeRacer](https://play.typeracer.com/), [Typing of the Dead](https://store.steampowered.com/agecheck/app/246580/)), we wondered if we could create a similar game to improve the level of understanding of common ASL terms by the general populace. Through our Roman Vaporwave cat-gladiator-themed game, we hope to instill a low barrier and fun alternative to learning American Sign Language.
## Features
**1. Multi-mode gameplay.**
Learn the ASL alphabet in bite sized Duolingo-style lessons before moving on to "play mode" to play the game! Our in-app training allows you to reinforce your learning, and practice your newly-learned skills.
**2. Customized and more intuitive learning.**
Using the debug mode, users can define their own signs in Catiator to practice and quiz on. Like Quizlet flash cards, creating your own gestures allows you to customize your learning within the game. In addition to this, being able to see a 3D model of the sign you're trying to learn gives you a much better picture on how to replicate it compared to a 2D image of the sign.
## How We Built It
* **VR**: Oculus Quest, Unity3D, C#
* **3D Modeling & Animation**: Autodesk Maya, Adobe Photoshop, Unity3D
* **UX & UI**: Figma, Unity2D, Unity3D
* **Graphic Design**: Adobe Photoshop, Procreate
## Challenges We Ran Into
**1. Limitations in gesture recognition.** Similar gestures that involve crossing fingers (ASL letters M vs. N) were limited by Oculus' finger tracking system in differential recognition. Accuracy in finger tracking will continue to improve, and we're excited to see the capabilities that could bring to our game.
**2. Differences in hardware.** Three out of four of our team members either own a PC with a graphics card or an Oculus headset. Since both are necessary to debug live in Unity, the differences in hardware made it difficult for us to initially get set up by downloading the necessary packages and get our software versions in sync.
**3. Lack of face tracking.** ASL requires signers to make facial expressions while signing which we unfortunately cannot track with current hardware. The Tobii headset, as well as Valve's next VR headset both plan to include eye tracking so with the increased focus on facial tracking in future VR headsets we would better be able to judge signs from users.
## Accomplishments We're Proud Of
We're very proud of successfully integrating multiple artistic visions into one project. From Ryan's idea of including chonky cats to Mitchell's idea of a learning game to Nancy's vaporwave aesthetics to Jieying's concept art, we're so proud to see our game come together both aesthetically and conceptually. Also super proud of all the ASL we learned as a team in order to survive in *Catiator*, and for being a proud member of OhYay's table1.
## What We Learned
Each member of the team utilized challenging technology, and as a result learned a lot about Unity during the last 36 hours! We learned how to design, train and test a hand recognition system in Unity and build 3D models and UI elements in VR.
This project really helped us have a better understanding of many of the capabilities within Oculus, and in utilizing hand tracking to interpret gestures to use in an educational setting. We learned so much through this project and from each other, and had a really great time working as a team!
## Next Steps
* Create more lessons for users
* Fix keyboard issues so users can define gestures without debug/using the editor
* Multi-hand gesture support
* Additional mini games for users to practice ASL
## Install Instructions
To download, use password "Treehacks" on <https://trisol.itch.io/catiators>, because this is an Oculus Quest application you must sideload the APK using Sidequest or the Oculus Developer App.
## Project Credits/Citations
* Thinker Statue model: [Source](https://poly.google.com/u/1/view/fEyCnpGMZrt)
* ASL Facts: [ASL Benefits of Communication](https://smackhappy.com/2020/04/asl-benefits-communication/)
* Music: [Cassette Tape by Blue Moon](https://youtu.be/9lO_31BP7xY) |
[RESPECOGNIZE by Diamond Ortiz](https://www.youtube.com/watch?v=3lnEIXrmxNw) |
[Spirit of Fire by Jesse Gallagher](https://www.youtube.com/watch?v=rDtZwdYmZpo) |
* SFX: [Jingle Lose](https://freesound.org/people/LittleRobotSoundFactory/sounds/270334/) |
[Tada2 by jobro](https://freesound.org/people/jobro/sounds/60444/) |
[Correct by Eponn](https://freesound.org/people/Eponn/sounds/421002/) |
[Cat Screaming by InspectorJ](https://freesound.org/people/InspectorJ/sounds/415209/) |
[Cat2 by Noise Collector](https://freesound.org/people/NoiseCollector/sounds/4914/) | partial |
## Inspiration
We are all a fan of Carrot, the app that rewards you for walking around. This gamification and point system of Carrot really contributed to its success. Carrot targeted the sedentary and unhealthy lives we were leading and tried to fix that. So why can't we fix our habit of polluting and creating greenhouse footprints using the same method? That's where Karbon comes in!
## What it does
Karbon gamifies how much you can reduce your CO₂ emissions by in a day. The more you reduce your carbon footprint, the more points you can earn. Users can then redeem these points at Eco-Friendly partners to either get discounts or buy items completely for free.
## How we built it
The app is created using Swift and Swift UI for the user interface. We also used HTML, CSS and Javascript to make a web app that shows the information as well.
## Challenges we ran into
Initially, when coming up with the idea and the economy of the app, we had difficulty modelling how points would be distributed by activity. Additionally, coming up with methods to track CO₂ emissions conveniently became an integral challenge to ensure a clean and effective user interface. As for technicalities, cleaning up the UI was a big issue as a lot of our time went into creating the app as we did not have much experience with the language.
## Accomplishments that we're proud of
Displaying the data using graphs
Implementing animated graphs
## What we learned
* Using animation in Swift
* Making Swift apps
* Making dynamic lists
* Debugging unexpected bugs
## What's next for Karbon
A fully functional Web app along with proper back and forth integration with the app. | ## Inspiration
Minecraft has an interesting map mechanic where your character holds a map which "draws itself" while exploring the world. I am also very interested in building a plotter, which is a printer that uses a pen and (XY) gantry to produce images. These ideas seemed to fit together quite well.
## What it does
Press a button, copy GPS coordinates and run the custom "gcode" compiler to generate machine/motor driving code for the arduino. Wait around 15 minutes for a 48 x 48 output.
## How we built it
Mechanical assembly - Tore apart 3 dvd drives and extracted a multitude of components, including sled motors (linear rails). Unfortunately, they used limit switch + DC motor rather than stepper, so I had to saw apart the enclosure and **glue** in my own steppers with a gear which (you guessed it) was also glued to the motor shaft.
Electronics - I designed a simple algorithm to walk through an image matrix and translate it into motor code, that looks a lot like a video game control. Indeed, the stepperboi/autostepperboi main source code has utilities to manually control all three axes like a tiny claw machine :)
U - Pen Up
D - Pen Down
L - Pen Left
R - Pen Right
Y/T - Pen Forward (top)
B - Pen Backwards (bottom)
Z - zero the calibration
O - returned to previous zeroed position
## Challenges we ran into
* I have no idea about basic mechanics / manufacturing so it's pretty slipshod, the fractional resolution I managed to extract is impressive in its own right
* Designing my own 'gcode' simplification was a little complicated, and produces strange, pointillist results. I like it though.
## Accomplishments that we're proud of
* 24 hours and a pretty small cost in parts to make a functioning plotter!
* Connected to mapbox api and did image processing quite successfully, including machine code generation / interpretation
## What we learned
* You don't need to take MIE243 to do low precision work, all you need is superglue, a glue gun and a dream
* GPS modules are finnicky and need to be somewhat near to a window with built in antenna
* Vectorizing an image is quite a complex problem
* Mechanical engineering is difficult
* Steppers are *extremely* precise, and I am quite surprised at the output quality given that it's barely held together.
* Iteration for mechanical structure is possible, but difficult
* How to use rotary tool and not amputate fingers
* How to remove superglue from skin (lol)
## What's next for Cartoboy
* Compacting the design it so it can fit in a smaller profile, and work more like a polaroid camera as intended. (Maybe I will learn solidworks one of these days)
* Improving the gcode algorithm / tapping into existing gcode standard | ## Inspiration
The majority of cleaning products in the United States contain harmful chemicals. Although many products pass EPA regulations, it is well known that many products still contain chemicals that can cause rashes, asthma, allergic reactions, and even cancer. It is important that the public has easy access to information of the chemicals that may be harmful to them as well as the environment.
## What it does
Our app allows users to scan a product's ingredient label and retrieves information on which ingredients to avoid for the better of the environment as well as their own health.
## How we built it
We used Xcode and Swift to design the iOS app. We then used Vision for iOS to detect text based off a still image. We used a Python scrapper to collect data from ewg.org, providing the product's ingredients as well as the side affects of certain harmful additives.
## Challenges we ran into
We had very limited experience for the idea that we have in developing an iOS app but, we wanted to challenge ourselves. The challenges the front end had were incorporating the camera feature and the text detector into a single app. As well as trying to navigate the changes between the newer version of Swift 11 from older versions. For our backend members, they had difficulties incorporating databases from Microsoft/Google, but ended up using JSON.
## Accomplishments that we're proud of
We are extremely proud of pushing ourselves to do something we haven't done before. Initially, we had some doubt in our project because of how difficult it was. But, as a team we were able to help each other along the way. We're very proud of creating a single app that can do both a camera feature and Optical Character Recognition because as we found out, it's very complicated and error prone. Additionally, for data scrapping, even though the HTML code was not consistent we managed to successfully scrap the necessary data by taking all corner cases into consideration with 100% success rate from more than three thousand HTML files and we are very proud of it.
## What we learned
Our teammates working in the front end learned how to use Xcode and Swift in under 24 hours. Our backend team members learned how to scrap the data from a website for the first time as well. Together, we learned how to alter our original expectations of our final product based on time constraint.
## What's next for Ingredient Label Scanner
Currently our project is specific to cleaning products, however in the future we would like to incorporate other products such as cosmetics, hair care, skin care, medicines, and food products. Additionally, we hope to alter the list of ingredients in a more visual way so that users can clearly understand which ingredients are more dangerous than others. | winning |
This code allows the user to take photos of animals, and the app determines whether the photos are pleasing enough for people to see the cuteness of the animals. | ## Inspiration
In the exciting world of hackathons, where innovation meets determination, **participants like ourselves often ask "Has my idea been done before?"** While originality is the cornerstone of innovation, there's a broader horizon to explore - the evolution of an existing concept. Through our AI-driven platform, hackers can gain insights into the uniqueness of their ideas. By identifying gaps or exploring similar projects' functionalities, participants can aim to refine, iterate, or even revolutionize existing concepts, ensuring that their projects truly stand out.
For **judges, the evaluation process is daunting.** With a multitude of projects to review in a short time frame, ensuring an impartial and comprehensive assessment can become extremely challenging. The introduction of an AI tool doesn't aim to replace the human element but rather to enhance it. By swiftly and objectively analyzing projects based on certain quantifiable metrics, judges can allocate more time to delve into the intricacies, stories, and the passion driving each team
## What it does
This project is a smart tool designed for hackathons. The tool measures the similarity and originality of new ideas against similar projects if any exist, we use web scraping and OpenAI to gather data and draw conclusions.
**For hackers:**
* **Idea Validation:** Before diving deep into development, participants can ascertain the uniqueness of their concept, ensuring they're genuinely breaking new ground.
* **Inspiration:** By observing similar projects, hackers can draw inspiration, identifying ways to enhance or diversify their own innovations.
**For judges:**
* **Objective Assessment:** By inputting a project's Devpost URL, judges can swiftly gauge its novelty, benefiting from AI-generated metrics that benchmark it against historical data.
* **Informed Decisions:** With insights on a project's originality at their fingertips, judges can make more balanced and data-backed evaluations, appreciating true innovation.
## How we built it
**Frontend:** Developed using React JS, our interface is user-friendly, allowing for easy input of ideas or Devpost URLs.
**Web Scraper:** Upon input, our web scraper dives into the content, extracting essential information that aids in generating objective metrics.
**Keyword Extraction with ChatGPT:** OpenAI's ChatGPT is used to detect keywords from the Devpost project descriptions, which are used to capture project's essence.
**Project Similarity Search:** Using the extracted keywords, we query Devpost for similar projects. It provides us with a curated list based on project relevance.
**Comparison & Analysis:** Each incoming project is meticulously compared with the list of similar ones. This analysis is multi-faceted, examining the number of similar projects and the depth of their similarities.
**Result Compilation:** Post-analysis, we present users with an 'originality score' alongside explanations for the determined metrics, keeping transparency.
**Output Display:** All insights and metrics are neatly organized and presented on our frontend website for easy consumption.
## Challenges we ran into
**Metric Prioritization:** Given the timeline restricted nature of a hackathon, one of the first challenges was deciding which metrics to prioritize. Striking the balance between finding meaningful data points that were both thorough and feasible to attain were crucial.
**Algorithmic Efficiency:** We struggled with concerns over time complexity, especially with potential recursive scenarios. Optimizing our algorithms, prompt engineering, and simplifying architecture was the solution.
*Finding a good spot to sleep.*
## Accomplishments that we're proud of
We took immense pride in developing a solution directly tailored for an environment we're deeply immersed in. By crafting a tool for hackathons, while participating in one, we felt showcases our commitment to enhancing such events. Furthermore, not only did we conceptualize and execute the project, but we also established a robust framework and thoughtfully designed architecture from scratch.
Another general Accomplishment was our team's synergy. We made efforts to ensure alignment, and dedicated time to collectively invest in and champion the idea, ensuring everyone was on the same page and were equally excited and comfortable with the idea. This unified vision and collaboration were instrumental in bringing HackAnalyzer to life.
## What we learned
We delved into the intricacies of full-stack development, gathering hands-on experience with databases, backend and frontend development, as well as the integration of AI. Navigating through API calls and using web scraping were also some key takeaways. Prompt Engineering taught us to meticulously balance the trade-offs when leveraging AI, especially when juggling cost, time, and efficiency considerations.
## What's next for HackAnalyzer
We aim to amplify the metrics derived from the Devpost data while enhancing the search function's efficiency. Our secondary and long-term objective is to transition the application to a mobile platform. By enabling students to generate a QR code, judges can swiftly access HackAnalyzer data, ensuring a more streamlined and effective evaluation process. | ## Inspiration
I wanted a platform that incentivizes going outside and taking photos. This also helps with people who want to build a portfolio in photography
## What it does
Every morning, a random photography prompt will appear on the app/website. The users will be able to then go out and take a photo of said prompt. The photo will be objectively rated upon focus quality, which is basically asking if the subject is in focus, plus if there is any apparent motion blur. The photo will also be rated upon correct exposure (lighting). They will be marked out of 100, using interesting code to determine the scores. We would also like to implement a leaderboard of best photos taken of said subject.
## How we built it
Bunch of python, and little bit of HTML. The future holds react coding to make everything run and look much better.
## Challenges we ran into
everything.
## Accomplishments that we're proud of
Managed to get a decent scoring method for both categories, which had pretty fair outcomes. Also I got to learn a lot about flask.
## What we learned
A lot of fun flask information, and how to connect backend with frontend.
## What's next for PictureDay
Many things mentioned above, such as:
* Leaderboard
* Photo gallery/portfolio
* pretty website
* social aspects such as adding friends. | winning |
# Pythia Camera
Check out the [github](https://github.com/philipkiely/Pythia).
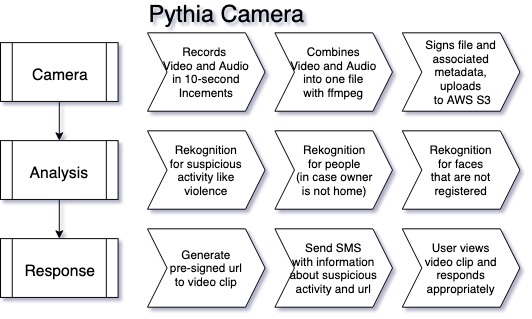
## Inspiration
#### Original Idea:
Deepfakes and more standard edits are a difficult threat to detect. Rather than reactively analyzing footage to attempt to find the marks of digital editing, we sign footage on the camera itself to allow the detection of edited footage.
#### Final Idea:
Using the same technology, but with a more limited threat model allowing for a narrower scope, we can create the world's most secure and intelligent home security camera.
## What it does
Pythia combines robust cryptography with AI video processing to bring you a unique home security camera. The system notifies you in near-real-time of potential incidents and lets you verify by viewing the video. Videos are signed by the camera and the server to prove their authenticity in courts and other legal matters. Improvements of the same technology have potential uses in social media, broadcasting, political advertising, and police body cameras.
## How we built it
* Records video and audio on a camera connected to a basic WIFI-enabled board, in our case a Raspberry Pi 4
At regular intervals:
* Combines video and audio into .mp4 file
* Signs combined file
* Sends file and metadata to AWS
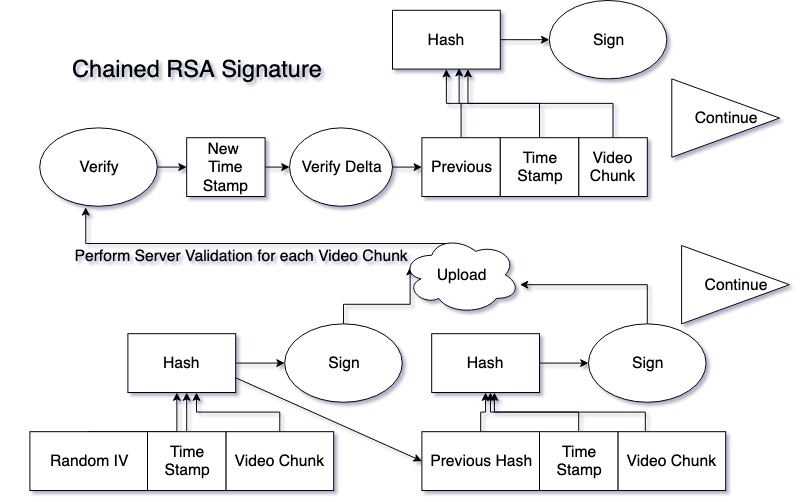
On AWS:
* Verifies signature and adds server signature
* Uses Rekognition to detect violence or other suspicious behavior
* Uses Rekognition to detect the presence of people
* If there are people with detectable faces, uses Rekognition to
* Uses SMS to notify the property owner about the suspicious activity and links a video clip
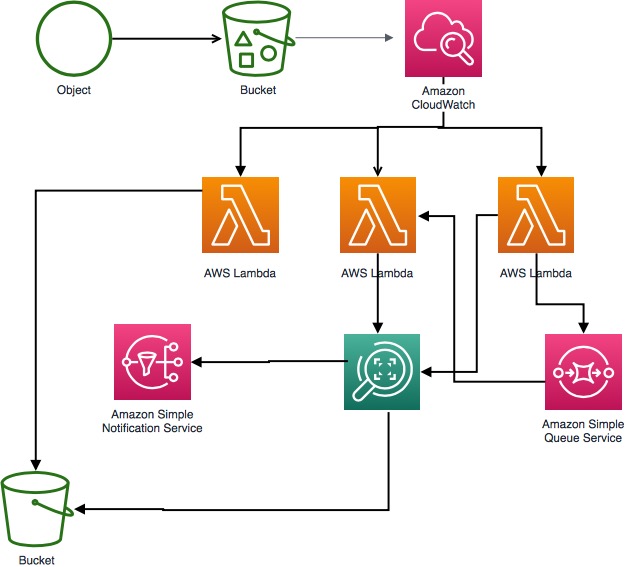
## Challenges we ran into
None.
Just Kidding:
#### Hardware
Raspberry Pi
* All software runs on Raspberry Pi
* Wifi Issues
* Compatibility issues
* Finding a Screwdriver
Hardware lab didn't have the type of sensors we were hoping for so no heat map :(.
#### Software
* Continuous batched recording
* Creating complete .mp4 files
* Processing while recording
#### Web Services
* Asynchronous Architecture has lots of race conditions
## Accomplishments that we're proud of
* Complex AWS deployment
* Chained RSA Signature
* Proper video encoding and processing, combining separate frame and audio streams into a single .mp4
## What we learned
#### Bogdan
* Gained experience designing and implementing a complex, asynchronous AWS Architecture
* Practiced with several different Rekognition functions to generate useful results
#### Philip
* Video and audio encoding is complicated but fortunately we have great command-line tools like `ffmpeg`
* Watchdog is a Python library for watching folders for a variety fo events and changes. I'm excited to use it for future automation projects.
* Raspberry Pi never works right the first time
## What's next for Pythia Camera
A lot of work is required to fully realize our vision for Pythia Camera as a whole solution that resists a wide variety of much stronger threat models including state actors. Here are a few areas of interest:
#### Black-box resistance:
* A camera pointed at a screen will record and verify the video from the screen
* Solution: Capture IR footage to create a heat map of the video and compare the heat map against rekognition's object analysis (people should be hot, objects should be cold, etc.
* Solution: Use a laser dot projector like the iPhone's faceID sensor to measure distance and compare to machine learning models using Rekognition
#### Flexible Cryptography:
* Upgrade Chained RSA Signature to Chained RSA Additive Map Signature to allow for combining videos
* Allow for basic edits like cuts and filters while recording a signed record of changes
#### More Robust Server Architecture:
* Better RBAC for online assets
* Multi-region failover for constant operation | ## Inspiration
GetSense was developed in an attempt to create low latency live streaming for countries with slow internet so that they could still have security regardless of their internet speed.
## What it does
GetSense is an AI powered flexible security solution that uses low-level IoT devices (laptop camera systems or Raspberry Pi) to detect, classify, and identify strangers and friends in your circle. A GetSense owner uploads images of authorized faces through an user-facing mobile application. Through the application, the user has access to a live-stream of all connected camera devices, and authorized friend list.
Under the hood, when an user uploads authorized faces, these are sent as data to Firebase storage through a REST API which generates dynamic image URLs. These are then sent to serverless functions (FAAS) which connects to the computer vision microservices setup in Clarifai. The IoT devices communicate via RTSP and streams the video-feed using low-latency.
## How we built it
We used stdlib to generate serverless functions for obtaining the probability score through Clarifai facial recognition, push notifications via Slack alerts to notify the user of an unrecognizable face, and managing the image model training route to Clarifai. For the facial detection process, we used OpenCV with multithreading to detect faces (through Clarifai) for optimization purposes - this was done in Python.
An iOS application was exposed to the user for live-streaming all camera sources, adding authorized faces, and visualizing current friend list. All the data involving images and streaming was handled through Firebase storage and database, which the iOS application heavily interfaced with.
## Challenges we ran into
Our initial goal was to use AWS kinesis to process everything originating from a Raspberry Pi camera module. We had lots of issues with the binaries and overall support of AWS kinesis, so we had to pivot and explore camera modules on local machines. We had to explore using Clarifai for facial detection, running serverless functions with stdlib, and push notifications through an external service.
## Accomplishments that we're proud of
It works.
## What we learned
We learned how to use StdLib, Clarifai for image processing, OpenCV, and building an iOS application.
## What's next for GetSense
We want to improve it to make it more user friendly. | ## Inspiration
With recent booms in AI development, deepfakes have been getting more and more convincing. Social media is an ideal medium for deepfakes to spread, and can be used to seed misinformation and promote scams. Our goal was to create a system that could be implemented in image/video-based social media platforms like Instagram, TikTok, Reddit, etc. to warn users about potential deepfake content.
## What it does
Our model takes in a video as input and analyzes frames to determine instances of that video appearing on the internet. It then outputs several factors that help determine if a deepfake warning to a user is necessary: URLs corresponding to websites where the video has appeared, dates of publication scraped from websites, previous deepfake IDs (i.e. if the website already mention the words "deepfake"), and similarity scores between the content of the video being examined and previous occurrences of the deepfake. A warning should be sent to the user if content similarity scores between it and very similar videos are low (indicating the video has been tampered with) or if the video has been previously IDed as a deepfake by a different website.
## How we built it
Our project was split into several main steps:
**a) finding web instances of videos similar to the video under investigation**
We used Google Cloud's Cloud Vision API to detect web entities that have content matching the video being examined (including full matching and partial matching images).
**b) scraping date information from potential website matches**
We utilized the htmldate python library to extract original and updated publication dates from website matches.
**c) determining if a website has already identified the video as a deepfake**
We again used Google Cloud's Cloud Vision API to determine if the flags "deepfake" or "fake" appeared in website URLs. If they did, we immediately flagged the video as a possible deepfake.
**d) calculating similarity scores between the contents of the examined video and similar videos**
If no deepfakes flags have been raised by other websites (step c), we use Google Cloud's Speech-to-Text API to acquire transcripts of the original video and similar videos found in step a). We then compare pairs of transcripts using a cosine similarity algorithm written in python to determine how similar the contents of two texts are (common, low-meaning words like "the", "and", "or", etc. are ignored when calculating similarity).
## Challenges we ran into
Neither of us had much experience using Google Cloud, which ended up being a major tool in our project. It took us a while to figure out all the authentication and billing procedures, but it was an extremely useful framework for us once we got it running.
We also found that it was difficult to find a deepfake online that wasn't already IDed as one (to test out our transcript similarity algorithm), so our solution to this was to create our own amusing deepfakes and test it on those.
## Accomplishments that we're proud of
We're proud that our project mitigates an important problem for online communities. While most current deepfake detection uses AI, malignant AI can simply continually improve to counter detection mechanisms. Our project takes an innovative approach that avoids this problem by instead tracking and analyzing the online history of a video (something that the creators of a deepfake video have no control over).
## What we learned
While working on this project, we gained experience in a wide variety of tools that we've never been exposed to before. From Google Cloud to fascinating text analysis algorithms, we got to work with existing frameworks as well as write our own code. We also learned the importance of breaking down a big project into smaller, manageable parts. Once we had organized our workflow into reachable goals, we found that we could delegate tasks to each other and make rapid progress.
## What's next for Deepfake ID
Since our project is (ideally) meant to be integrated with an existing social media app, it's currently a little back-end heavy. We hope to expand this project and get social media platforms onboard to using our deepfake detection method to alert their users when a potential deepfake video begins to spread. Since our method of detection has distinct advantages and disadvantages from existing AI deepfake detection, the two methods can be combined to create an even more powerful deepfake detection mechanism.
Reach us on Discord: **spica19** | winning |
## What it does
ColoVR is a virtual experience allowing users to modify their environment with colors and models. It's a relaxing, low poly experience that is the first of its kind to bring an accessible 3D experience to the Google Cardboard platform. It's a great way to become a creative in 3D without dropping a ton of money on VR hardware.
## How we built it
We used Google Daydream and extended off of the demo scene to our liking. We used Unity and C# to create the scene, and do all the user interactions. We did painting and dragging objects around the scene using a common graphics technique called Ray Tracing. We colored the scene by changing the vertex color. We also created a palatte that allowed you to change tools, colors, and insert meshes. We hand modeled the low poly meshes in Maya.
## Challenges we ran into
The main challenge was finding a proper mechanism for coloring the geometry in the scene. We first tried to paint the mesh face by face, but we had no way of accessing the entire face from the way the Unity mesh was set up. We then looked into an asset that would help us paint directly on top of the texture, but it ended up being too slow. Textures tend to render too slowly, so we ended up doing it with a vertex shader that would interpolate between vertex colors, allowing real time painting of meshes. We implemented it so that we changed all the vertices that belong to a fragment of a face. The vertex shader was the fastest way that we could render real time painting, and emulate the painting of a triangulated face. Our second biggest challenge was using ray tracing to find the object we were interacting with. We had to navigate the Unity API and get acquainted with their Physics raytracer and mesh colliders to properly implement all interaction with the cursor. Our third challenge was making use of the Controller that Google Daydream supplied us with - it was great and very sandboxed, but we were almost limited in terms of functionality. We had to find a way to be able to change all colors, insert different meshes, and interact with the objects with only two available buttons.
## Accomplishments that we're proud of
We're proud of the fact that we were able to get a clean, working project that was exactly what we pictured. People seemed to really enjoy the concept and interaction.
## What we learned
How to optimize for a certain platform - in terms of UI, geometry, textures and interaction.
## What's next for ColoVR
Hats, interactive collaborative space for multiple users. We want to be able to host the scene and make it accessible to multiple users at once, and store the state of the scene (maybe even turn it into an infinite world) where users can explore what past users have done and see the changes other users make in real time. | [Repository](https://github.com/BradenC82/A_Treble-d_Soul/)
## Inspiration
Mental health is becoming decreasingly stigmatized and more patients are starting to seek solutions to well-being. Music therapy practitioners face the challenge of diagnosing their patients and giving them effective treatment. We like music. We want patients to feel good about their music and thus themselves.
## What it does
Displays and measures the qualities of your 20 most liked songs on Spotify (requires you to log in). Seven metrics are then determined:
1. Chill: calmness
2. Danceability: likeliness to get your groove on
3. Energy: liveliness
4. Focus: helps you concentrate
5. Audacity: absolute level of sound (dB)
6. Lyrical: quantity of spoken words
7. Positivity: upbeat
These metrics are given to you in bar graph form. You can also play your liked songs from this app by pressing the play button.
## How I built it
Using Spotify API to retrieve data for your liked songs and their metrics.
For creating the web application, HTML5, CSS3, and JavaScript were used.
React was used as a framework for reusable UI components and Material UI for faster React components.
## Challenges I ran into
Learning curve (how to use React). Figuring out how to use Spotify API.
## Accomplishments that I'm proud of
For three out of the four of us, this is our first hack!
It's functional!
It looks presentable!
## What I learned
React.
API integration.
## What's next for A Trebled Soul
Firebase.
Once everything's fine and dandy, registering a domain name and launching our app.
Making the mobile app presentable. | ## Inspiration
Some things can only be understood through experience, and Virtual Reality is the perfect medium for providing new experiences. VR allows for complete control over vision, hearing, and perception in a virtual world, allowing our team to effectively alter the senses of immersed users. We wanted to manipulate vision and hearing in order to allow players to view life from the perspective of those with various disorders such as colorblindness, prosopagnosia, deafness, and other conditions that are difficult to accurately simulate in the real world. Our goal is to educate and expose users to the various names, effects, and natures of conditions that are difficult to fully comprehend without first-hand experience. Doing so can allow individuals to empathize with and learn from various different disorders.
## What it does
Sensory is an HTC Vive Virtual Reality experience that allows users to experiment with different disorders from Visual, Cognitive, or Auditory disorder categories. Upon selecting a specific impairment, the user is subjected to what someone with that disorder may experience, and can view more information on the disorder. Some examples include achromatopsia, a rare form of complete colorblindness, and prosopagnosia, the inability to recognize faces. Users can combine these effects, view their surroundings from new perspectives, and educate themselves on how various disorders work.
## How we built it
We built Sensory using the Unity Game Engine, the C# Programming Language, and the HTC Vive. We imported a rare few models from the Unity Asset Store (All free!)
## Challenges we ran into
We chose this project because we hadn't experimented much with visual and audio effects in Unity and in VR before. Our team has done tons of VR, but never really dealt with any camera effects or postprocessing. As a result, there are many paths we attempted that ultimately led to failure (and lots of wasted time). For example, we wanted to make it so that users could only hear out of one ear - but after enough searching, we discovered it's very difficult to do this in Unity, and would've been much easier in a custom engine. As a result, we explored many aspects of Unity we'd never previously encountered in an attempt to change lots of effects.
## What's next for Sensory
There's still many more disorders we want to implement, and many categories we could potentially add. We envision this people a central hub for users, doctors, professionals, or patients to experience different disorders. Right now, it's primarily a tool for experimentation, but in the future it could be used for empathy, awareness, education and health. | partial |
## Overview
AOFS is an automatic sanitization robot that navigates around spaces, detecting doorknobs using a custom trained machine-learning algorithm and sanitizing them using antibacterial agent.
## Inspiration
It is known that in hospitals and other public areas, infections spread via our hands. Door handles, in particular, are one such place where germs accumulate. Cleaning such areas is extremely important, but hospitals are often at a short of staff and the sanitization may not be done as often as should be. We therefore wanted to create a robot that would automate this, which both frees up healthcare staff to do more important tasks and ensures that public spaces remain clean.
## What it does
AOFS travels along walls in public spaces, monitoring the walls. When a door handle is detected, the robot stops automatically sprays it with antibacterial agent to sanitize it.
## How we built it
The body of the robot came from a broken roomba. Using two ultrasonic sensors for movement and a mounted web-cam for detection, it navigates along walls and scans for doors. Our doorknob-detecting computer vision algorithm is trained via transfer learning on the [YOLO network](https://pjreddie.com/darknet/yolo/) (one of the state of the art real-time object detection algorithms) using custom collected and labelled data: using the pre-trained weights for the network, we froze all 256 layers except the last three, which we re-trained on our data using a Google Cloud server. The trained algorithm runs on a Qualcomm Dragonboard 410c which then relays information to the arduino.
## Challenges we ran into
Gathering and especially labelling our data was definitely the most painstaking part of the project, as all doorknobs in our dataset of over 3000 pictures had to be boxed by hand. Training the network then also took a significant amount of time. Some issues also occured as the serial interface is not native to the qualcomm dragonboard.
## Accomplishments that we're proud of
We managed to implement all hardware elements such as pump, nozzle and electrical components, as well as an algorithm that navigated using wall-following. Also, we managed to train an artificial neural network with our own custom made dataset, in less than 24h!
## What we learned
Hacking existing hardware for a new purpose, creating a custom dataset and training a machine learning algorithm.
## What's next for AOFS
Increasing our training dataset to incorporate more varied images of doorknobs and training the network on more data for a longer period of time. Using computer vision to incorporate mapping of spaces as well as simple detection, in order to navigate more intelligently. | ## Inspiration
## What it does
## It searches for a water Bottle!
## How we built it
## We built it using a roomba, raspberrypi with a picamera, python, and Microsoft's Custom Vision
## Challenges we ran into
## Attaining wireless communications between the pi and all of our PCs was tricky. Implementing Microsoft's API was troublesome as well. A few hours before judging we exceeded the call volume for the API and were forced to create a new account to use the service. This meant re-training the AI and altering code, and loosing access to our higher accuracy recognition iterations during final tests.
## Accomplishments that we're proud of
## Actually getting the wireless networking to consistently. Surpassing challenges like framework indecision between IBM and Microsoft. We are proud of making things that lacked proper documentation, like the pi camera, work.
## What we learned
## How to use Github, train AI object recognition system using Microsoft APIs, write clean drivers
## What's next for Cueball's New Pet
## Learn to recognize other objects. | ## Inspiration
The failure of a certain project using Leap Motion API motivated us to learn it and use it successfully this time.
## What it does
Our hack records a motion password desired by the user. Then, when the user wishes to open the safe, they repeat the hand motion that is then analyzed and compared to the set password. If it passes the analysis check, the safe unlocks.
## How we built it
We built a cardboard model of our safe and motion input devices using Leap Motion and Arduino technology. To create the lock, we utilized Arduino stepper motors.
## Challenges we ran into
Learning the Leap Motion API and debugging was the toughest challenge to our group. Hot glue dangers and complications also impeded our progress.
## Accomplishments that we're proud of
All of our hardware and software worked to some degree of success. However, we recognize that there is room for improvement and if given the chance to develop this further, we would take it.
## What we learned
Leap Motion API is more difficult than expected and communicating with python programs and Arduino programs is simpler than expected.
## What's next for Toaster Secure
-Wireless Connections
-Sturdier Building Materials
-User-friendly interface | partial |
## Inspiration
Dynamic Pantry was inspired by the pressing issue of food waste and the desire to impact sustainability positively. The idea was born from a realization that a significant amount of food is wasted daily due to improper inventory management. Our mission is to empower individuals to reduce waste and maximize their available ingredients.
## What it does
Dynamic Pantry is a phone/web application designed to help users efficiently manage their pantry items, reduce food waste, and cook delicious recipes while saving money. Key features include:
* Scanning and Auto-adding Ingredients: Users can effortlessly scan receipts or barcodes to automatically add ingredients to their pantry, eliminating the need for manual data entry.
* Sustainability Stats: Users can track their contributions to sustainability, viewing statistics on the amount of food saved from waste and the money saved over time.
* Expiry Date Management: The application intelligently manages pantry items' expiry dates and generates recipes based on ingredients nearing expiration, thus reducing waste.
* User Notifications: Users receive timely notifications about items close to expiry and receive recipe suggestions to make the best use of these items.
* User Profiles: Personalized profiles allow users to track their food and cost savings over time.
## How we built it
Dynamic Pantry was built using a modern tech stack. Here's how we brought this project to life:
* **Frontend**: Web - HTML, CSS, and JavaScript, Phone (Beta) - Adobe XD Prototype
* **Backend**: Our backend is powered by Python and Flask, which handle the application's core functionalities.
* **Database**: MongoDB Atlas is our chosen database to store information about pantry items, expiration dates, and sustainability stats.
* **APIs**: We integrated with the Spoonacular API and built a RESTful API to access external services and retrieve recipe information.
## Challenges we ran into
Throughout the development process, we encountered several challenges. These included integrating the barcode scanning feature, optimizing recipe recommendation algorithms, and ensuring data security and privacy.
## Accomplishments that we're proud of
Despite having a teammate leaving for emergency reasons, we are proud of the idea and its impact and potential.
## What we learned
While building Dynamic Pantry, we gained valuable experience in web application development, barcode scanning, and machine learning for recipe recommendations. We also deepened our understanding of sustainability and food waste reduction.
## What's next for Dynamic Pantry
In the future, we have exciting plans for Dynamic Pantry:
* Expanding the database to include a broader range of ingredients and recipes.
* Integrating with additional sustainability-focused services to provide users with even more insights and options for reducing food waste.
* Exploring mobile app development to make the application more accessible and user-friendly.
Dynamic Pantry is a continually evolving project, and we're committed to making it an indispensable tool for sustainable and cost-effective pantry management. | ## Inspiration
In today's fast-paced world, we're all guilty of losing ourselves in the vast digital landscape. The countless hours we spend on our computers can easily escape our attention, as does the accumulating stress that can result from prolonged focus. Screen Sense is here to change that. It's more than just a screen time tracking app; it's your personal guide to a balanced digital life. We understand the importance of recognizing not only how much time you spend on your devices but also how these interactions make you feel.
## What it does
Screen Sense is a productivity tool that monitors a user's emotions while tracking their screen time on their device. Our app analyzes visual data using the Hume API and presents it to the user in an simple graphical interface that displays their strongest emotions along with a list of the user's most frequented digital activities.
## How we built it
Screen Sense is a desktop application built with the React.js, Python, and integrates the Hume AI API. Our project required us to execute of multiple threads to handle tasks such as processing URL data from the Chrome extension, monitoring active computer programs, and transmitting image data from a live video stream to the Hume AI.
## Challenges we ran into
We encountered several challenges during the development process. Initially, our plan involved creating a Chrome extension for its cross-platform compatibility. However, we faced security obstacles that restricted our access to the user's webcam. As a result, we pivoted to developing a desktop application capable of processing a webcam stream in the background, while also serving as a fully compatible screen time tracker for all active programs.
Although nearly half of the codebase was written in Python, none of our group members had ever coded using that language. This presented a significant learning curve, and we encountered a variety of issues. The most complex challenge we faced was Python's nature as a single-threaded language.
## Accomplishments that we're proud of
As a team of majority beginner coders, we were able to create a functional productivity application that integrates the Hume AI, especially while coding in a language none of us were familiar with beforehand.
## What we learned
Throughout this journey, we gained valuable experience in adaptability, as demonstrated by how we resolved our HTTP communication issues and successfully shifted our development platform when necessary.
## What's next for Screen Sense
Our roadmap includes refining the user interface and adding more visual animations to enhance the overall experience, expanding our reach to mobile devices, and integrating user notifications to proactively alert users when their negative emotions reach unusually high levels. | ## Inspiration
As university students, we often find that we have groceries in the fridge but we end up eating out and the groceries end up going bad.
## What It Does
After you buy groceries from supermarkets, you can use our app to take a picture of your receipt. Our app will parse through the items in the receipts and add the items into the database representing your fridge. Using the items you have in your fridge, our app will be able to recommend recipes for dishes for you to make.
## How We Built It
On the back-end, we have a Flask server that receives the image from the front-end through ngrok and then sends the image of the receipt to Google Cloud Vision to get the text extracted. We then post-process the data we receive to filter out any unwanted noise in the data.
On the front-end, our app is built using react-native, using axios to query from the recipe API, and then stores data into Firebase.
## Challenges We Ran Into
Some of the challenges we ran into included deploying our Flask to Google App Engine, and styling in react. We found that it was not possible to write into Google App Engine storage, instead we had to write into Firestore and have that interact with Google App Engine.
On the frontend, we had trouble designing the UI to be responsive across platforms, especially since we were relatively inexperienced with React Native development. We also had trouble finding a recipe API that suited our needs and had sufficient documentation. | losing |
## Inspiration & What it does
You're walking down the road, and see a belle rocking an exquisite one-piece. *"Damn, that would look good on me (or my wife)"*.
You go home and try to look for it: *"beautiful red dress"*. Google gives you 110,000,000 results in 0.54 seconds. Well that helped a lot. You think of checking the fashion websites, but the number of these e-commerce websites makes you refrain from spending more than a few hours. *"This is impossible..."*. You perseverance only lasts so long - you give up.
Fast forward to 2017. We've got everything from Neural Forests to Adversarial Networks.
You go home to look for it: Launch **Dream.it**
You make a chicken-sketch of the dress - you just need to get the curves right. You select the pattern on the dress, a couple of estimates about the dress. **Dream.it** synthesizes elegant dresses based on your sketch. It then gives you search results from different stores based on similar dresses, and an option to get on custom made. You love the internet. You love **Dream.it**. Its a wonderful place to make your life wonderful.
Sketch and search for anything and everything from shoes and bracelets to dresses and jeans: all at your slightest whim. **Dream.it** lets you buy existing products or get a new one custom-made to fit you.
## How we built it
**What the user sees**
**Dream.it** uses a website as the basic entry point into the service, which is run on a **linode server**. It has a chatbot interface, through which users can initially input the kind of garment they are looking for with a few details. The service gives the user examples of possible products using the **Bing Search API**.
The voice recognition for the chatbot is created using the **Bing Speech to Text API**. This is classified using a multiclassifier from **IBM Watson Natural Language Classifier** trained on custom labelled data into the clothing / accessory category. It then opens a custom drawing board for you to sketch the contours of your clothing apparel / accessories / footwear and add color to it.
Once the sketch is finalized, the image is converted to more detailed higher resolution image using [**Pixel Recursive Super Resolution**](https://arxiv.org/pdf/1702.00783.pdf).
We then use **Google's Label Detection Vision ML** and **IBM Watson's Vision** APIs to generate the most relevant tags for the final synthesized design which give additional textual details for the synthesized design.
The tags, in addition to the image itself are used to scour the web for similar dresses available for purchase
**Behind the scenes**
We used a **Deep Convolutional Generative Adversarial Network (GAN)** which runs using **Theano** and **cuDNN** on **CUDA**. This is connected to our web service through websockets. The brush strokes from the drawing pad on the website get sent to the **GAN** algorithm, which sends back the synthesized fashion design to match the user's sketch.
## Challenges we ran into
* Piping all the APIs together to create a seamless user experience. It took a long time to optimize the data (*mpeg1*) we were sending over the websocket to prevent lags and bugs.
* Running the Machine learning algorithm asynchronously on the GPU using CUDA.
* Generating a high-quality image of the synthesized design.
* Customizing **Fabric.js** to send data appropriately formatted to be processed by the machine learning algorithm.
## Accomplishments that we're proud of
* We reverse engineered the **Bing real-time Speech Recognition API** to create a Node.js library. We also added support for **partial audio frame streaming for voice recognition**.
* We applied transfer learning from Deep Convolutional Generative Adversarial Networks and implemented constraints on its gradients and weights to customize user inputs for synthesis of fashion designs.
* Creating a **Python-Node.js** stack which works asynchronously with our machine learning pipeline
## What we learned
This was a multi-faceted educational experience for all of us in different ways. Overall:
* We learnt to asynchronously run machine learning algorithms without threading issues.
* Setting up API calls and other infrastructure for the app to run on.
* Using the IBM Watson APIs for speech recognition and label detection for images.
* Setting up a website domain, web server, hosting a website, deploying code to a server, connecting using web-sockets.
* Using pip, npm; Using Node.js for development; Customizing fabric.js to send us custom data for image generation.
* Explored machine learning tools learnt how to utlize them most efficiently.
* Setting up CUDA, cuDNN, and Theano on an Ubuntu platform to use with ML algorithm.
## What's next for Dream.it
Dream.it currently is capable of generating shoes, shirts, pants, and handbags from user sketches. We'd like to expand our training set of images and language processing to support a greater variety of clothing, materials, and other accessories.
We'd like to switch to a server with GPU support to run the cuDNN-based algorithm on CUDA.
The next developmental step for Dream.it is to connect it to a 3D fabric printer which can print the designs instantly without needing the design to be sent to manufacturers. This can be supported at particular facilities in different parts of the country to enable us to be in control of the entire process. | ## Inspiration
## What it does
## It searches for a water Bottle!
## How we built it
## We built it using a roomba, raspberrypi with a picamera, python, and Microsoft's Custom Vision
## Challenges we ran into
## Attaining wireless communications between the pi and all of our PCs was tricky. Implementing Microsoft's API was troublesome as well. A few hours before judging we exceeded the call volume for the API and were forced to create a new account to use the service. This meant re-training the AI and altering code, and loosing access to our higher accuracy recognition iterations during final tests.
## Accomplishments that we're proud of
## Actually getting the wireless networking to consistently. Surpassing challenges like framework indecision between IBM and Microsoft. We are proud of making things that lacked proper documentation, like the pi camera, work.
## What we learned
## How to use Github, train AI object recognition system using Microsoft APIs, write clean drivers
## What's next for Cueball's New Pet
## Learn to recognize other objects. | ## Inspiration
The inspiration for our project stems from the increasing trend of online shopping and the declining foot traffic in physical stores. Our goal was to provide a unique and engaging experience for customers, encouraging them to visit physical stores and rediscover the joy of in-person shopping. We wanted to create an interactive and entertaining shopping experience that would entice customers to visit stores more frequently and foster a deeper connection between them and the store's brand.
## What it does
Our project is an AR scavenger hunt experience that gamifies the shopping experience. The scavenger hunt encourages customers to explore the store and discover new products they may have otherwise overlooked. As customers find specific products, they can earn points which can be redeemed for exclusive deals and discounts on future purchases. This innovative marketing scheme not only provides customers with an entertaining experience but also incentivizes them to visit stores more frequently and purchase products they may have otherwise overlooked.
## How we built it
To create the AR component of our project, we used Vuforia and Unity, two widely used platforms for building AR applications. The Vuforia platform allowed us to create and track image targets, while Unity was used to design the 3D models for the AR experience. We then integrated the AR component into an Android application by importing it as a Gradle project. Our team utilized agile development methodologies to ensure efficient collaboration and problem-solving throughout the development process.
## Challenges we ran into
One of the challenges we faced was integrating multiple APIs and ensuring that they worked together seamlessly. Another challenge was importing the AR component and creating the desired functionality within our project. We also faced issues with debugging and resolving technical errors that arose during the development process.
## Accomplishments that we're proud of
Despite the challenges we faced, we were able to achieve successful teamwork and collaboration. Despite forming the team later than other groups, we were able to effectively communicate and work together to bring our project to fruition. We are proud of the end result, which was a polished and functional AR scavenger hunt experience that met our objectives.
## What we learned
We learned how difficult it is to truly ship out software, and we are grateful to have joined the hackathon. We gained a deeper understanding of the importance of project planning, effective communication, and collaboration among team members. We also learned that the development process can be challenging and unpredictable, and that it requires perseverance and problem-solving skills. Additionally, participating in the hackathon taught us valuable technical skills such as integrating APIs, creating AR functionality, and importing projects onto an Android application.
## What's next for Winnur
Looking forward, we plan to incorporate Computer Vision technology into our project to prevent potential damage to our product's packaging. We also aim to expand the reach of our AR scavenger hunt experience by partnering with more retailers and enhancing the user interface and experience. We are excited about the potential for future development and growth of Winnur. | partial |
## Inspiration
Agriculture is the backbone of our society. Not only providing a supply of food, agriculture is responsible for the production of raw materials such as textiles, sugar, coffee, cocoa, and oils. For many, agriculture is not only an occupation but it is a way of life. This is especially true for those farmers in developing regions around the world. Without having access to smart agriculture technology and mass amounts of weather data, these farmers face challenges such as diminishing crop yields due to inconsistent weather patterns.
Due to climate change in recent years, large-scale developed farms have experienced a declination of nearly 17% in crop yield despite having massive amounts of resources and support to back up their losses. For those in developing countries, these responses cannot be replicated, and farmers are left with insufficient harvests after a season of growing. The widespread impact of agriculture on communities in developing countries lead to the creation of Peak PerFARMance - a data-driven tool designed to provide farmers with the information necessary to make informed decisions about crop production.
## What it does
Peak PerFARMance is a holistic platform providing real-time hardware data and historical weather indexes to allow small-scale farmers to grow crops efficiently and tackle the challenges introduced by climate change. Our platform features a unique map that allows users to draw a polygon of any shape on the map in order to retrieve in-depth data about the geographical area such as normalized difference vegetation index, UV index, temperature, humidity, pressure, cloud coverage, and wind conditions. Not only retrieving real-time data, but our platform also provides historical data and compares it with current conditions to allow farmers to get a holistic understanding of weather trends allowing them to make more informed decisions about the crops they grow. In addition, our platform combines data retrieved from real-time hardware beacons composed of environmental sensors to provide further information about the conditions on the farm.
## How we built it
The backend of the project was built in Go. We created APIs for creating polygons, retrieving polygons, and retrieving specific data for the polygon. We integrated the backend with external APIs such as Agro APIs and Open Weather APIs. This allowed us to retrieve data for specific date ranges. The frontend would make API requests to the backend in order to display the data in the frontend dashboards.
The frontend of the project was built using ReactJS. This is the user entry of the project and it is where the user will draw the polygon to retrieve the data. The hardware sensor data is retrieved by the frontend from Google Firebase where it is then processed and displayed. We integrated the frontend with several styling APIs such as ApexChartJS and Bootstrap in order to create the UI for the website.
The hardware for the project was built on top of the Arduino platform and the data was communicated over serial to a host computer where we read the data using a Python script and uploaded it to a Google Real-time Firebase.
## Challenges we ran into
A challenge we faced when building the backend was working with Go. None of our team members had any prior knowledge working with Go in creating web applications. We wanted to learn a new language during this hackathon, which was challenging but rewarding. An issue we ran into was converting the data between json and structs in Go. Furthermore, the APIs had limited number of past dates that we could get data for.
## Accomplishments that we're proud of
For the backend, an accomplishment we’re proud of was how we were able to learn using a new language for creating multiple APIs and also successfully integrating it to the rest of the project. While there were multiple hours spent debugging, we’re proud of how our team members collaborated in troubleshooting bugs and issues together.
## What we learned
Having had no experience with Go prior to this weekend, we were able to learn the language and how to leverage it in creating web applications.
From the frontend perspective, I have not had experience working with SASS before. I was also to leverage this new styling format to create more effective stylesheets for our React app.
Also, for several of our team members, this was their first online hackathon so we spent a lot of time learning how to create an effective virtual pitch and to make a video for our virtual submission.
## What's next for Peak PerFARMance
With Peak PerFARMance, we were able to combine a ton of data from numerous sources into a simple-to-use dashboard. In the future, we would like to use machine learning to extract even more insight out of this wealth of data and provide tailored suggestions to farmers.
For this project, we wanted to incorporate LoRaWAN (long range low-power wide-area network) technology to connect many of the IoT sensors over vast distances --- a feat which would be impossible and/or expensive with traditional Wi-Fi and cellular technologies. Unfortunately, the hardware components for this did not arrive in time for this hackathon. We are really excited for it to arrive --- we believe that Peak PerFARMance is the perfect project to show off this technology. | ## Inspiration
The inspiration behind LeafHack stems from a shared passion for sustainability and a desire to empower individuals to take control of their food sources. Witnessing the rising grocery costs and the environmental impact of conventional agriculture, we were motivated to create a solution that not only addresses these issues but also lowers the barriers to home gardening, making it accessible to everyone.
## What it does
Our team introduces "LeafHack" an application that leverages computer vision to detect the health of vegetables and plants. The application provides real-time feedback on plant health, allowing homeowners to intervene promptly and nurture a thriving garden. Additionally, the images uploaded can be stored within a database custom to the user. Beyond disease detection, LeafHack is designed to be a user-friendly companion, offering personalized tips and fostering a community of like-minded individuals passionate about sustainable living
## How we built it
LeafHack was built using a combination of cutting-edge technologies. The core of our solution lies in the custom computer vision algorithm, ResNet9, that analyzes images of plants to identify diseases accurately. We utilized machine learning to train the model on an extensive dataset of plant diseases, ensuring robust and reliable detection. The database and backend were built using Django and Sqlite. The user interface was developed with a focus on simplicity and accessibility, utilizing next.js, making it easy for users with varying levels of gardening expertise
## Challenges we ran into
We encountered several challenges that tested our skills and determination. Fine-tuning the machine learning model to achieve high accuracy in disease detection posed a significant hurdle as there was a huge time constraint. Additionally, integrating the backend and front end required careful consideration. The image upload was a major hurdle as there were multiple issues with downloading and opening the image to predict with. Overcoming these challenges involved collaboration, creative problem-solving, and continuous iteration to refine our solution.
## Accomplishments that we're proud of
We are proud to have created a solution that not only addresses the immediate concerns of rising grocery costs and environmental impact but also significantly reduces the barriers to home gardening. Achieving a high level of accuracy in disease detection, creating an intuitive user interface, and fostering a sense of community around sustainable living are accomplishments that resonate deeply with our mission.
## What we learned
Throughout the development of LeafHack, we learned the importance of interdisciplinary collaboration. Bringing together our skills, we learned and expanded our knowledge in computer vision, machine learning, and user experience design to create a holistic solution. We also gained insights into the challenges individuals face when starting their gardens, shaping our approach towards inclusivity and education in the gardening process.
## What's next for LeafHack
We plan to expand LeafHack's capabilities by incorporating more plant species and diseases into our database. Collaborating with agricultural experts and organizations, we aim to enhance the application's recommendations for personalized gardening care. | ## Overview
Crop diseases pose a significant threat to global food security, especially in regions lacking proper infrastructure for rapid disease identification. To address this challenge, we present a web application that leverages the widespread adoption of smartphones and cutting-edge transfer learning models. Our solution aims to streamline the process of crop disease diagnosis, providing users with insights into disease types, suitable treatments, and preventive measures.
## Key Features
* **Disease Detection:** Our web app employs advanced transfer learning models to accurately identify the type of disease affecting plants. Users can upload images of afflicted plants for real-time diagnosis.
* **Treatment Recommendations:** Beyond disease identification, the app provides actionable insights by recommending suitable treatments for the detected diseases. This feature aids farmers and agricultural practitioners in promptly addressing plant health issues.
* **Prevention Suggestions:** The application doesn't stop at diagnosis; it also offers preventive measures to curb the spread of diseases. Users receive valuable suggestions on maintaining plant health and preventing future infections.
* **Generative AI Interaction:** To enhance user experience, we've integrated generative AI capabilities for handling additional questions users may have about their plants. This interactive feature provides users with insightful information and guidance.
## How it Works ?
* **Image Upload:** Users upload images of plant specimens showing signs of disease through the web interface.
* **Transfer Learning Model:** The uploaded images undergo real-time analysis using advanced transfer learning model, enabling the accurate identification of diseases with the help of PlantID API.
* **Treatment and Prevention Recommendations:** Once the disease is identified, the web app provides detailed information on suitable treatments and preventive measures, empowering users with actionable insights.
* **Generative AI Interaction:** Users can engage with generative AI to seek additional information, ask questions, or gain knowledge about plant care beyond disease diagnosis. | winning |
Inspiration:
Recognizing the demand in our market for automation of human tasks in indoor environments and our group having the experience with building and training neural networks and working with hardware, we decided to functionalize a fundamental feature that mobile robots operating in indoor environments would need - door opening recognition.
What it does:
After collecting our own data using an ultrasonic sensor we built and trained a neural network model that can be uploaded to a microprocessor to allow a robot with an ultrasonic sensor to identify whether a door in front of it is open or closed after scanning it. This has been tested by uploading data from a scanner and resulted in 92% accuracy of predictions.
Challenges:
Working in different time zones, formatting collected data, visualizing collected data, converting the model into a format that can be used by the robot.
What I am proud of:
We are proud that we got to accomplish so much in such a short timeframe with so many obstacles before us!
What I learned:
-Workflow on github as a member of a team.
-Neural Networks and how they work
-Tensorflow
What's Next:
We will keep working on loading the model onto the esp32 microprocessor and start working on real-world applications of our model as it is uploaded to the robot. | ## Inspiration
Our inspiration came from the recent surge (and subsequent meme'ing) of the whole r/WallStreetBets $GME saga. Our thought process then became: "So the big Wall Street firms obviously have a way of determining whether a stock is worth the risk of shorting.. How do they determine that?". Now what most people don't realize, is that a lot of this information is readily available online. However, it is hard to understand what the terms and numbers mean to the average retail investor. Our goal with our web app is to provide an *idea* of whether a stock is in that prime position to be short squeezed.
## What it does
Our web app takes in a stock ticker (i.e GME, AAPL, etc..), calculates whether the stock is either: Healthy, low chance of a Short Squeeze, or high chance of a Short Squeeze through a scoring system we created though stats collected from Yahoo Finance.
## How we built it
For this challenge, and it being both of our first Hackathon's, we wanted to use it as an opportunity to learn new skills. We decided to use React for the frontend. For the backend, we used python's request library to obtain the needed info from Yahoo Finance, and then created our own API endpoint with Flask for our frontend to retrieve relevant and calculated data. Next, we built our scoring system for the stocks, and then deployed the whole thing using AWS and docker.
## Challenges we ran into
DevOps. We had 0 experience deploying a full-stack type of web app online. One or two fatal crashes later and we were able to finally get it up and running!
## Accomplishments that we're proud of
Learning how to use AWS and Docker more, building something outside of school, especially during COVID where it seems every waking hour has been devoted to McGill.
## What we learned
Building a front-end with a new framework and a time crunch is harder than it seems. A lot of functionality we would've liked to have takes much longer to implement.
## What's next for Eat My Shorts
If time permits, expanding its functionality and possibly creating a database to track trends over a long period. | ## Inspiration
We wanted to learn about machine learning. There are thousands of sliding doors made by Black & Decker and they're all capable of sending data about the door. With this much data, the natural thing to consider is a machine learning algorithm that can figure out ahead of time when a door is broken, and how it can be fixed. This way, we can use an app to send a technician a notification when a door is predicted to be broken. Since technicians are very expensive for large corporations, something like this can save a lot of time, and money that would otherwise be spent with the technician figuring out if a door is broken, and what's wrong with it.
## What it does
DoorHero takes attributes (eg. motor speed) from sliding doors and determines if there is a problem with the door. If it detects a problem, DoorHero will suggest a fix for the problem.
## How we built it
DoorHero uses a Tensorflow Classification Neural Network to determine fixes for doors. Since we didn't have actual sliding doors at the hackathon, we simulated data and fixes. For example, we'd assign high motor speed to one row of data, and label it as a door with a problem with the motor, or we'd assign normal attributes for a row of data and label it as a working door.
The server is built using Flask and runs on [Floydhub](https://floydhub.com). It has a Tensorflow Neural Network that was trained with the simulated data. The data is simulated in an Android app. The app generates the mock data, then sends it to the server. The server evaluates the data based on what it was trained with, adds the new data to its logs and training data, then responds with the fix it has predicted.
The android app takes the response, and displays it, along with the mock data it sent.
In short, an Android app simulates the opening and closing of a door and generates mock data about the door, which is sends everytime the door "opens", to a server using a Flask REST API. The server has a trained Tensorflow Neural Network, which evaluates the data and responds with either "No Problems" if it finds the data to be normal, or a fix suggestion if it finds that the door has an issue with it.
## Challenges we ran into
The hardest parts were:
* Simulating data (with no background in sliding doors, the concept of sliding doors sending data was pretty abstract).
* Learning how to use machine learning (turns out this isn't so easy) and implement tensorflow
* Running tensorflow on a live server.
## Accomplishments that we're proud of
## What we learned
* A lot about modern day sliding doors
* The basics of machine learning with tensorflow
* Discovered floydhub
## What we could have improve on
There are several things we could've done (and wanted to do) but either didn't have time or didn't have enough data to. ie:
* Instead of predicting a fix and returning it, the server can predict a set of potential fixes in order of likelihood, then send them to the technician who can look into each suggestion, and select the suggestion that worked. This way, the neural network could've learned a lot faster over time. (Currently, it adds the predicted fix to its training data, which would make for bad results
* Instead of having a fixed set of door "problems" for the door, we could have built the app so that in the beginning, when the neural network hasn't learned yet, it asks the technician for input after everytime the fix the door (So it can learn without data we simulated as this is what would have to happen in the normal environment)
* We could have made a much better interface for the app
* We could have added support for a wider variety of doors (eg. different models of sliding doors)
* We could have had a more secure (encrypted) data transfer method
* We could have had a larger set of attributes for the door
* We could have factored more into decisions (for example, detecting a problem if a door opens, but never closes). | losing |
**Youtube video editor processing error at 1:09; "Beam Complete" notification was blurred out accidentally, but you can see the transfer icon starts immediately after the NFC beam**
## Keeper was chosen as a HT6 Finalist!!!
---
## Project Overview
Keeper is a mobile application that digitizes the collection of receipts onto a comprehensive cloud and local platform, making smart receipts a reality. A simple installation of Keeper would enable users to manage their receipts in an efficient manner, back it up safely on the cloud, while simultaneously contributing to the elimination of environmental concerns associated with paper receipt production. Businesses save on the cost of buying receipt rolls, and increase customer service (no more jammed printers!). Plus, no need to worry about losing your receipts for returns or warranties anymore - it’s backed up on the cloud.
## Inspiration
We all make purchases on a daily basis, whether it be on food, tech, or movie tickets for a Friday evening. In any of these transactions, receipts play a vital role in confirming purchases, tracking spendings, and processing returns and warranties. Furthermore, receipts waste time. Organizing receipts for tax returns and reimbursements is a time-consuming and arduous task that can be automated.
However, the use of such an obvious part of our daily purchases has a less obvious impact on the environment, generating at least 302 million pounds of waste and over 4 billion pounds of CO2 in just the United States alone (ClimateAction, 2019). It is evident that this outdated process has to be revisited and revamped.
Plus, one of our members has a receipt hoarding problem 👀.
## What it does
1. Users enable NFC on their phone and tap on the store’s machine equipped with a NFC chip.
2. The receipt data of the purchased item is transferred as a JSON file via NFC, even if the user doesn’t 3. have the app. They can always download the app to view and upload/retrieve the receipt later.
3. Users can view their NFC receipt (stored locally) immediately on the Keeper app OR
4. Users can upload their receipt to the cloud for backup, and retrieve their old receipts from the cloud.
5. Users can view past receipts individually and see individual items and prices.
## Features to be added
1. Users will be able to search for individual items (not yet implemented).
2. Users will be able to sort by merchant, amount paid, and date (date already implemented)
3. UserID tagging system to tie user IDs to receipts to prevent duplication.
4. Machine learning to analyze and categorize purchases into types
## How we built it
We wireframed the app’s interface and design on Figma and draw.io. We then built the Keeper app natively in Java with Android Studio, and connected it to a Flask instance hosted on Heroku and MySQL instance hosted on Google Cloud Platform. A recycled Galaxy S6 stood-in as the merchant’s NFC-capable device, which sent the receipt data (JSON file) to the customer’s phone (Galaxy A8) via the Near Field Communication (NFC)/Android Beam API. The data was then converted on the Android app to a Java String and sent using an async POST request to the Heroku Flask Python instance, and stored in the MySQL cloud database hosted on Google Cloud. The data was then retrieved using a similar method to send a GET request, and converted from JSONArray back to string.
## Challenges we ran into & Complexities
The biggest challenge we faced was using the Android SDK Near-Field Communication API to send the JSON file via NFC and displaying the result (JSON file contents of the receipt) using Java JSON libraries on the frontend of the app. Connecting the android app to the databases through GET and POST requests was also difficult due to the lack of documentation and libraries for Java (compared to Python). We also used IO and JSON libraries for input stream and JSON parsing, Asynctasks for network requests, and the java.Net library for sending GET and POST requests directly from the Android phone. This was the first time the main android app developer learned these libraries, and applying it was tough. It was challenging to become familiar with Android Studio as it was our first time using it, but we quickly adapted and began to get the hang of it. Learning to use databases, Flask, and hosting on cloud was a challenge, but we got through it.
## Accomplishments that we're proud of
We are glad that we managed to execute the functionality of the NFC chip in transferring data via tap. We are proud of finishing the database of the app where the receipt file can be stored and displayed on the app. Overall, we had a valuable experience learning about both back and frontend development for mobile applications. Combining our unique skills and experiences, our team collaborated very well and the members were always willing to help one another out when needed. With an average of less than 3 hackathons each, it was the first time our members have developed an Android app, first time using Flask, and the first time using and linking to a cloud-hosted database.
## What we learned
* NFC and app integration
* Project Management; Integrating Frontend and Backend
* Flask, SQL and Databases
* Hosting databases on Cloud
* Sending HTTP requests from an Android app
* Java and Android Studio
* The power of persistence (I’m looking at you NFC 😫)
## Try keeper\_app on our website
[http://csclub.uwaterloo.ca/~t4shu/website\_frontend/index.html](http://csclub.uwaterloo.ca/%7Et4shu/website_frontend/index.html)
## What's next for Keeper
* Host-based card emulation instead of Android Beam
* Revolutionize your next social gathering by pooling receipts and splitting bills through a Groups feature
* Integrate machine learning data analysis to monitor the users’ spending patterns and assist them with - financial goal setting
* Allow users to access their receipt collections from multiple devices through an account/login system
* Offer a user feedback system for product quality assessment
* Improve UI/UX design
* Develop dedicated, low-cost NFC kiosk
## References:
ClimateAction. (2019, August 2019). Report: Skip the Slip - Environmental Costs & Human Health Risks of Paper Receipts. Retrieved from <https://www.climateaction.org/news/report-skip-the-slip-environmental-costs-human-health-risks-of-paper-receip> | ## Inspiration and Beginning
The journey of developing our food transparency app began with a simple yet powerful idea: to empower consumers with the knowledge they need to make informed decisions about the food they buy and consume. Inspired by the vision of Open Food Facts, we were driven by the belief that everyone should have access to transparent information about the products they consume daily. This vision resonated deeply with our team, igniting a passion to contribute to a more transparent and sustainable food system.
## What it does
Health Receipt is a revolutionary app designed to provide consumers with comprehensive information about the food products they purchase. Its core functionalities include:
1. **OCR-Based Receipt Scanning**: Using optical character recognition (OCR) technology, Health Receipt scans grocery store receipts to extract detailed information about the food items listed.
2. **Nutrition Information**: The app retrieves nutrition facts for each scanned product, including calorie count, macronutrient breakdown, and ingredient list.
3. **Eco-Scores and Packaging Information**: Health Receipt evaluates the environmental impact of each product by analyzing packaging materials and carbon footprint, providing users with eco-scores to guide sustainable purchasing decisions.
4. **Allergen Warnings**: The app identifies potential allergens present in scanned products, helping users with dietary restrictions make safe choices.
5. **Recipe Creation**: Health Receipt offers a unique feature that allows users to generate recipes based on the ingredients scanned from their receipts, promoting creative and healthy meal planning.
## How we built it
1. **Typescript**: We chose TypeScript for its strong typing system and scalability, enabling us to write cleaner and more maintainable code.
2. [Bun](https://bun.sh/): The backend of Health Receipt is powered by Bun, providing a fast and efficient server environment for processing user requests and handling data.
3. **npm**: We utilized npm, the package manager for JavaScript, to integrate various libraries and dependencies into our project, streamlining development and ensuring compatibility.
4. [Convex](https://www.convex.dev/): Leveraging the Convex framework, we implemented features such as text search, server functions, and real-time updates, enhancing the performance and functionality of our app's backend.
5. [Google Vision API](https://cloud.google.com/vision?hl=en): For OCR functionality, we integrated the Google Vision API, which enabled us to extract text data from grocery store receipts with high accuracy and reliability.
6. [Together AI](https://www.together.ai/): Collaborating with Together AI, we incorporated innovative features like recipe creation into Health Receipt, enriching the user experience and adding value to the app.
## Challenges we ran into
Throughout the hackathon, we encountered numerous challenges that tested our perseverance and problem-solving skills. From overcoming technical hurdles to refining user interfaces for optimal usability, each obstacle presented an opportunity for growth and innovation. One of our significant challenges was ensuring the accuracy and reliability of OCR data extraction, requiring meticulous fine-tuning and validation processes.
With each hurdle overcame, we emerged stronger and more resilient, fueled by our passion for catalyzing positive change in the food industry.
## Accomplishments that we're proud of
Our integration with the Open Food Facts database has enabled us to contribute to the broader movement for food transparency. By leveraging this vast repository of product data, we're facilitating greater transparency and accountability within the food industry.
## What we learned
Through the development of Health Receipt, we gained invaluable insights into the importance of teamwork and collaboration. Our team dynamics played a crucial role in driving the project forward, with each member contributing their unique strengths and expertise. We learned to leverage individual strengths to overcome challenges and capitalize on opportunities, fostering a supportive and cohesive working environment. Additionally, we became more attuned to recognizing and addressing our team's weaknesses, embracing a culture of continuous improvement and open communication. Ultimately, our journey with Health Receipt reinforced the significance of teamwork in achieving shared goals and delivering impactful solutions to real-world problems. | ## Inspiration
As a team we wanted to pursue a project that we could see as a creative solution to an important issue currently and may have a significant impact for the future. GM's sponsorship challenge provided us with the most exciting problem to tackle - overcoming the limitations in electric vehicle (EV) charging times. We as a team believe that EVs are the future in transportation and our project reflects those ideals.
## What it does
Due to the rapid adoption of EVs in the near future and the slower progress of charging station infrastructure, waiting for charging time could become a serious issue. Sharger is a mobile/web application that connects EV drivers with EV owners. If charging stations are full and waitlists are too long, EV drivers cannot realistically wait for other drivers for hours to finish charging. Hence, we connect them to EV owners who rent their charging stations from their home. Drivers have access to a map with markers of nearby homes made available by the owners. Through the app they can book availability at the homes and save time from waiting at public charging stations. Home owners are able to fully utilize their home chargers by using them during the night for their own EVs and renting them out to other EV owners during the day.
## How we built it
The app was written in JavaScript and built using React, Express, and MongoDB technologies . It starts with a homepage with a login and signup screen. From there, drivers can utilize the map that was developed with Google Cloud API . The map allows drivers to find nearby homes by displaying markers for all nearby homes made available by the owners. The drivers can then book a time slot. The owners have access to a separate page that allows them to list their homes similar to Airbnb's format. Instead of bedrooms and bathrooms though, they can list their charger type, charger voltage, bedding availability in addition to a photo of the home and address. Home owners have the option to make their homes available whenever they want. Making a home unavailable will remove the marker from the drivers' map.
## Challenges we ran into
As a team we faced many challenges both technical and non-technical. The concept of our project is complex so we were heavily constrained by time. Also all of us learned a new tool in order to adapt to our project requirements.
## Accomplishments that we're proud of
As a team we are really proud of our idea and our team effort. We truly believe that our idea, through its capability to utilize a convenient resource in unused home chargers, will help contribute to the widespread adoption of EVs in the near future. All of our team members worked very hard and learned new technologies and skills to overcome challenges, in order to develop the best possible product we could in our given time.
## What we learned
* Express.js
* Bootstrap
* Google Cloud API
## What's next for Sharger
* implement a secure authorization feature
* implement a built-in navigation system or outsource navigation to google maps
* outsource bedding feature to Airbnb
* home rating feature
* develop a bookmark feature for drivers to save home locations
* implement an estimated waiting time based off past home charging experiences | losing |
## Inspiration
Nisha got the idea for this game from a 1D RPG crawler that she played in an arcade over her summer internship.
## What it does
You play as our valiant hero, the blue pixel! Your goal is to fight off the evil gremlins (the roving white pixels) on the battlefield that are between you and your goal, Castle Green (the green pixel).
Player has two modes:
* Regular mode, where the player is allowed to attack by holding the one button.
* Recharge mode, where the player is allowed to recharge by holding the B button. However, if the player gets attacked in this mode, they are instantly dead.
Controller is a sideways Wii remote. Controls:
* D-pad down on Wiimote: move right (inverted because Wiimote is used sideways)
* D-pad up on Wiimote: move up (inverted because Wiimote is used sideways)
* One button: hold to attack, but after key press is registered, player is locked out of attacking for four more moves
* Two button: hold to switch player modes
* B: hold to recharge while in recharge mode
## How we built it
First, we found some LED strips and a compatible Arduino library, and figured out how to program the strip.
Then, using an existing library for help, we obtained input from the Wii controllers.
Using this input/output, we then built up the game logic, resulting in the final product.
## Challenges we ran into
Wrangling the Wii library and debugging the game logic took us much longer than expected. There were many bugs in both, but because we did not build the Wii library, it took a while to figure out how to fix the issues. The I/O system also wasn't finalized until after we finished writing the game logic, so we were basically writing a game without being able to test it!
## Accomplishments that we're proud of
We finished it! We took our project from a concept to a real, playable game - that's pretty awesome!
## What we learned
We learned how to structure our project such that the Arduino, Wiimote, and C++ code all talked to each other. We plan to use these connections for projects in the future - we really like LEDs!
## What's next for Pixel Hero
We have two hundred-foot long LED strips that run all the way down our hall and we plan to try to play the game on there! We want to try to make a two-player version where people race to the end. | ## Inspiration
The inspiration of our game came from the arcade game Cyclone, where the goal is to click the button when the LED lands on a signaled part of the circle.
## What it does
The goal of our game is to click the button when the LED reaches a designated part of the circle (the very last LED). Upon successfully doing this it will add 1 to your score, as well as increasing the speed of the LED, continually making it harder and harder to achieve this goal. The goal is for the player to get as high of a score as possible, as the higher your score is, the harder it will get. Upon clicking the wrong designated LED, the score will reset, as well as the speed value, effectively resetting the game.
## How we built it
The project was split into two parts; one was the physical building of the device and another was the making of the code.
In terms of building the physical device, at first we weren’t too sure what we wanted to do, so we ended up with a mix up of parts we could use. All of us were pretty new to using the Arduino, and its respective parts, so it was initially pretty complicated, before things started to fall into place. Through the use of many Youtube videos, and tinkering, we were able to get the physical device up and running. Much like our coding process, the building process was very dynamic. This is because at first, we weren’t completely sure which parts we wanted to use, so we had multiple components running at once, which allowed for more freedom and possibilities. When we figured out which components we would be using, everything sort of fell into place.
For the code process, it was quite messy at first. This was because none of us were completely familiar with the Arduino libraries, and so it was a challenge to write the proper code. However, with the help of online guides and open source material, we were eventually able to piece together what we needed. Furthermore, our coding process was very dynamic. We would switch out components constantly, and write many lines of code that was never going to be used. While this may have been inefficient, we learned much throughout the process, and it kept our options open and ideas flowing.
## Challenges we ran into
In terms of main challenges that we ran into along the way, the biggest challenge was getting our physical device to function the way we wanted it to. The initial challenge came from understanding our device, specifically the Arduino logic board, and all the connecting parts, which then moved to understanding the parts, as well as getting them to function properly.
## Accomplishments that we're proud of
In terms of main accomplishments, our biggest accomplishment is overall getting the device to work, and having a finished product. After running into many issues and challenges regarding the physical device and its functions, putting our project together was very satisfying, and a big accomplishment for us. In terms of specific accomplishments, the most important parts of our project was getting our physical device to function, as well as getting the initial codebase to function with our project. Getting the codebase to work in our favor was a big accomplishment, as we were mostly reliant on what we could find online, as we were essentially going in blind during the coding process (none of us knew too much about coding with Arduino).
## What we learned
During the process of building our device, we learned a lot about the Arduino ecosystem, as well as coding for it. When building the physical device, a lot of learning went into it, as we didn’t know that much about using it, as well as applying programs for it. We learned how important it is to have a strong connection for our components, as well as directly linking our parts with the Arduino board, and having it run proper code.
## What's next for Cyclone
In terms of what’s next for Cyclone, there are many possibilities for it. Some potential changes we could make would be making it more complex, and adding different modes to it. This would increase the challenge for the player, and give it more replay value as there is more to do with it. Another potential change we could make is to make it on a larger scale, with more LED lights and make attachments, such as the potential use of different types of sensors. In addition, we would like to add an LCD display or a 4 digit display to display the player’s current score and high score. | ## Inspiration
We wanted to make something that linked the virtual and real worlds, but in a quirky way. On our team we had people who wanted to build robots and people who wanted to make games, so we decided to combine the two.
## What it does
Our game portrays a robot (Todd) finding its way through obstacles that are only visible in one dimension of the game. It is a multiplayer endeavor where the first player is given the task to guide Todd remotely to his target. However, only the second player is aware of the various dangerous lava pits and moving hindrances that block Todd's path to his goal.
## How we built it
Todd was built with style, grace, but most of all an Arduino on top of a breadboard. On the underside of the breadboard, two continuous rotation servo motors & a USB battery allows Todd to travel in all directions.
Todd receives communications from a custom built Todd-Controller^TM that provides 4-way directional control via a pair of Bluetooth HC-05 Modules.
Our Todd-Controller^TM (built with another Arduino, four pull-down buttons, and a bluetooth module) then interfaces with Unity3D to move the virtual Todd around the game world.
## Challenges we ran into
The first challenge of the many that we ran into on this "arduinous" journey was having two arduinos send messages to each other via over the bluetooth wireless network. We had to manually configure the setting of the HC-05 modules by putting each into AT mode, setting one as the master and one as the slave, making sure the passwords and the default baud were the same, and then syncing the two with different code to echo messages back and forth.
The second challenge was to build Todd, the clean wiring of which proved to be rather difficult when trying to prevent the loose wires from hindering Todd's motion.
The third challenge was building the Unity app itself. Collision detection was an issue at times because if movements were imprecise or we were colliding at a weird corner our object would fly up in the air and cause very weird behavior. So, we resorted to restraining the movement of the player to certain axes. Additionally, making sure the scene looked nice by having good lighting and a pleasant camera view. We had to try out many different combinations until we decided that a top down view of the scene was the optimal choice. Because of the limited time, and we wanted the game to look good, we resorted to looking into free assets (models and textures only) and using them to our advantage.
The fourth challenge was establishing a clear communication between Unity and Arduino. We resorted to an interface that used the serial port of the computer to connect the controller Arduino with the unity engine. The challenge was the fact that Unity and the controller had to communicate strings by putting them through the same serial port. It was as if two people were using the same phone line for different calls. We had to make sure that when one was talking, the other one was listening and vice versa.
## Accomplishments that we're proud of
The biggest accomplishment from this project in our eyes, was the fact that, when virtual Todd encounters an object (such as a wall) in the virtual game world, real Todd stops.
Additionally, the fact that the margin of error between the real and virtual Todd's movements was lower than 3% significantly surpassed our original expectations of this project's accuracy and goes to show that our vision of having a real game with virtual obstacles .
## What we learned
We learned how complex integration is. It's easy to build self-sufficient parts, but their interactions introduce exponentially more problems. Communicating via Bluetooth between Arduino's and having Unity talk to a microcontroller via serial was a very educational experience.
## What's next for Todd: The Inter-dimensional Bot
Todd? When Todd escapes from this limiting world, he will enter a Hackathon and program his own Unity/Arduino-based mastery. | losing |
This code allows the user to take photos of animals, and the app determines whether the photos are pleasing enough for people to see the cuteness of the animals. | ## Inspiration
There are two types of pets wandering unsupervised in the streets - ones that are lost and ones that don't have a home to go to. Pet's Palace portable mini-shelters services these animals and connects them to necessary services while leveraging the power of IoT.
## What it does
The units are placed in streets and alleyways. As an animal approaches the unit, an ultrasonic sensor triggers the door to open and dispenses a pellet of food. Once inside, a live stream of the interior of the unit is sent to local animal shelters which they can then analyze and dispatch representatives accordingly. Backend analysis of the footage provides information on breed identification, custom trained data, and uploads an image to a lost and found database. A chatbot is implemented between the unit and a responder at the animal shelter.
## How we built it
Several Arduino microcontrollers distribute the hardware tasks within the unit with the aide of a wifi chip coded in Python. IBM Watson powers machine learning analysis of the video content generated in the interior of the unit. The adoption agency views the live stream and related data from a web interface coded with Javascript.
## Challenges we ran into
Integrating the various technologies/endpoints with one Firebase backend.
## Accomplishments that we're proud of
A fully functional prototype! | ## Inspiration
As certified pet owners, we understand that our pets are part of our family. Our companions deserve the best care and attention available. We envisioned the goal of simplifying and modernizing pet care, all in one convenient and elegant app. Our idea began with our longing for our pets. Being international students ourselves, we constantly miss our pets and wish to see them. We figured that a pet livestream would allow us to check in on our pals, and from then on pet boarding, and our many other services arose.
## What it does
Playground offers readily available and affordable pet care. Our services include:
Pet Grooming: Flexible grooming services with pet-friendly products.
Pet Walking: Real-time tracking of your pet as it is being walked by our friendly staff.
Pet Boarding: In-home and out-of-home live-streamed pet-sitting services.
Pet Pals™: Adoption services, meet-and-greet areas, and pet-friendly events.
PetU™: Top-tier training with positive reinforcement for all pets
Pet Protect™: Life insurance and lost pet recovery
Pet Supplies: Premium quality, chew-resistant, toys and training aids.
## How we built it
First, we carefully created our logo using Adobe Illustrator. After scratching several designs, we settled on a final product. Then, we designed the interface using Figma. We took our time to ensure an appealing design. We programmed the front end with Flutter in Visual Studio Code. Finally, we used the OpenAI API GPT3.5 to implement a personalized chat system to suggest potential services and products to our users.
## Challenges we ran into
We ran into several bugs when making the app, and used our debugging skills from previous CS work and eventually solved them. One of the bugs involved an image overflow when coding the front end. Our icons were too large for the containers we used, but with adjustments to the dimensions of the containers and some cropping, we managed to solve this issue.
## Accomplishments that we're proud of
We’re proud of our resilience when encountering bugs on Flutter. Despite not being as experienced with this language as we are with others, we were able to identify and solve the problems we faced. Furthermore, we’re proud of our effort to make our logo because we are not the best artists, but our time spent on the design paid off. We feel that our logo reflects the quality and niche of our app.
## What we learned
We learned that programming the front end is as important if not more important than the back end of an app. Without a user-friendly interface, no app could function seeing as customer retention would be minimal. Our approachable interface allows users of all levels of digital literacy to get the best care for their beloved pets.
## What's next for Playground
After polishing the app, we plan on launching it in Peru and gathering as much feedback as we can. Then we plan on working on implementing our users’ suggestions and fixing any issues that arise. After finishing the new and improved version of Playground, we plan on launching internationally and bringing the best care for all our pets. More importantly, 10% of our earnings will go to animal rescue organizations! | winning |
## Inspiration: Supporting individuals with learning disabilities such as ADHD and autism in academia and work scenarios.
## What it does: Blossom is a friendly pomodoro study space website. Pomodoro is a study technique where work and break time are separated into time intervals in order to boost productivity, combat procrastination and reduce stress. While maintaining our dedication to simplicity, fun, and efficiency, we gamified pomodoro to make work and study time appealing to our desired userbase. As the pomodoro counter goes down, your plant progressively grows and flourishes. Collect more plants to raise a garden/collection of 'Blossom'ing flowers!
## How we built it: Was built using HTML, CSS, and JS.
## Challenges we ran into: First time with JS
## Accomplishments that we're proud of: First time in frontend and JS development.
## What we learned
## What's next for blossom.io: Including more accessible functions for Blossom such as colorblind mode, invite/study with friends, custom flashcards, data visualization on time usage and garden/collection elements. | ## Inspiration
Pomogarden was inspired by the *Pomodoro technique* developed by Francesco Cirillo. We aim to provide a functional and relaxing Pomodoro timer for the user, with extra special features for your hard work! These days, studying can be a tiresome grind, and we hope that this little virtual garden will bring you some comfort between breaks.
## What it does
Pomogarden packages the following features into an adorable, garden themed web app:
* **Three** cute, interactive plants that grow as you complete Pomodoro cycles, to help you track your progress!
* Get to know the tranquil bonsai, the grumpy cactus, and the dandy daffodil! They love to talk during the breaks between your Pomodoro cycles, and each of them has their own style of wisdom to share!
* Listen to relaxing music (or mute it, and listen to your own music - up to you!)
* Be alerted when your focus/break sessions have ended!
## How we built it
We used Flask to build the Pomogarden web app. Our delightfully cozy UI was almost entirely hand-drawn and assembled with HTML/CSS and Javascript, which we connected to a Python backend using Flask. We made use of Cohere's Chat API to generate the speech for our plants' varying personalities.
## Challenges we ran into
A major challenge that we faced in this project was the fact that our Cohere API trial key was rate-limited and very slow, which made the UX rather unresponsive. We managed to scrape together a short-term solution by pre-generating some messages from the Chat API, but ideally, Pomogarden acquires an API key with higher rate limits.
## Accomplishments that we're proud of
We're proud of our warm and inviting UI and we're proud that we managed to put together a project with Flask and Cohere despite knowing nothing about these two tools prior to DeerHacks!
## What we learned
We learned how to use Flask to build web apps and we learned how to use Cohere's various LLMs and associated APIs.
## What's next for Pomogarden - A Plant-Inspired Pomodoro App
The next step is to implement more personalizable features, such as allowing the user to choose the amount of time they want to set on the timer or choosing their own music. | ## Inspiration
Productivity is hard to harness especially at hackathons with many distractions, but a trick we software developing students found to stay productive while studying was using the “Pomodoro Technique”. The laptop is our workstation and could be a source of distraction, so what better place to implement the Pomodoro Timer as a constant reminder? Since our primary audience is going to be aspiring young tech students, we chose to further incentivize them to focus until their “breaks” by rewarding them with a random custom-generated and minted NFT to their name every time they succeed. This unique inspiration provided an interesting way to solve a practical problem while learning about current blockchain technology and implementing it with modern web development tools.
## What it does
An innovative modern “Pomodoro Timer” running on your browser enables users to sign in and link their MetaMask Crypto Account addresses. Such that they are incentivized to be successful with the running “Pomodoro Timer” because upon reaching “break times” undisrupted our website rewards the user with a random custom-generated and minted NFT to their name, every time they succeed. This “Ethereum Based NFT” can then be both viewed on “Open Sea” or on a dashboard of the website as they both store the user’s NFT collection.
## How we built it
TimeToken's back-end is built with Django and Sqlite and for our frontend, we created a beautiful and modern platform using React and Tailwind, to give our users a dynamic webpage. A benefit of using React, is that it works smoothly with our Django back-end, making it easy for both our front-end and back-end teams to work together
## Challenges we ran into
We had set up the website originally as a MERN stack (MongoDB/Express.js/REACT/Node.js) however while trying to import dependencies for the Verbwire API, to mint our images into NFTs to the user’s wallets we ran into problems. After solving dependency issues a “git merge” produced many conflicts, and on the way to resolving conflicts, we discovered some difficult compatibility issues with the API SDK and JS option for our server. At this point we had to pivot our plan, so we decided to implement the Verbwire Python-provided API solution, and it worked out very well. We intended here to just pass the python script and its functions straight to our front-end but learned that direct front-end to Python back-end communication is very challenging. It involved Ajax/XML file formatting and solutions heavily lacking in documentation, so we were forced to keep searching for a solution. We realized that we needed an effective way to make back-end Python communicate with front-end JS with SQLite and discovered that the Django framework was the perfect suite. So we were forced to learn Serialization and the Django framework quickly in order to meet our needs.
## Accomplishments that we're proud of
We have accomplished many things during the development of TimeToken that we are very proud of. One of our proudest moments was when we pulled an all-nighter to code and get everything just right. This experience helped us gain a deeper understanding of technologies such as Axios, Django, and React, which helped us to build a more efficient and user-friendly platform. We were able to implement the third-party VerbWire API, which was a great accomplishment, and we were able to understand it and use it effectively. We also had the opportunity to talk with VerbWire professionals to resolve bugs that we encountered, which allowed us to improve the overall user experience. Another proud accomplishment was being able to mint NFTs and understanding how crypto and blockchains work, this was a great opportunity to learn more about the technology. Finally, we were able to integrate crypto APIs, which allowed us to provide our users with a complete and seamless experience.
## What we learned
When we first started working on the back-end, we decided to give MongoDB, Express, and NodeJS a try. At first, it all seemed to be going smoothly, but we soon hit a roadblock with some dependencies and configurations between a third-party API and NodeJS. We talked to our mentor and decided it would be best to switch gears and give the Django framework a try. We learned that it's always good to have some knowledge of different frameworks and languages, so you can pick the best one for the job. Even though we had a little setback with the back-end, and we were new to Django, we learned that it's important to keep pushing forward.
## What's next for TimeToken
TimeToken has come a long way and we are excited about the future of our application. To ensure that our application continues to be successful, we are focusing on several key areas. Firstly, we recognize that storing NFT images locally is not scalable, so we are working to improve scalability. Secondly, we are making security a top priority and working to improve the security of wallets and crypto-related information to protect our users' data. To enhance user experience, we are also planning to implement a media hosting website, possibly using AWS, to host NFT images. To help users track the value of their NFTs, we are working on implementing an API earnings report with different time spans. Lastly, we are working on adding more unique images to our NFT collection to keep our users engaged and excited. | losing |
## Inspiration
We've all had to fill out paperwork going to a new doctor before: it's a pain, and it's information we've already written down for other doctors a million times before. Our health information ends up all over the place, not only making it difficult for us, but making it difficult for researchers to find participants for studies.
## What it does
HealthConnect stores your medical history on your phone, and enables you to send it to a doctor just by scanning a one-time-use QR code. It's completely end-to-end encrypted, and your information is encrypted when it's stored on your phone.
We provide an API for researchers to request a study of people with specific medical traits, such as a family history of cancer. Researchers upload their existing data analysis code written using PyTorch, and we automatically modify it to provide *differential privacy* -- in other words, we guarantee mathematically that our user's privacy will not be violated by any research conducted. It's completely automatic, saving researchers time and money.
## How we built it
### Architecture
We used a scalable microservice architecture to build our application: small connectors interface between the mobile app and doctors and researchers, and a dedicated executor runs machine learning code.
### Doctor Connector
The Doctor Connector enables seamless end-to-end encrypted transmission of data between users and medical providers. It receives a public key from a provider, and then allows the mobile app to upload data that's been encrypted with that key. After the data's been uploaded, the doctor's software can download it, decrypt it, and save it locally.
### ML Connector
The ML Connector is the star of the show: it manages what research studies are currently running, and processes new data as people join research studies. It uses a two-step hashing algorithm to verify that users are legitimate participants in a study (i.e. they have not modified their app to try and join every study), and collects the information of participants who are eligible to participate in the study. And, it does this without ever writing their data to disk, adding an extra layer of security.
### ML Executor
The ML Executor augments a researcher's Python analysis program to provide differential privacy guarantees, runs it, and returns the result to the researcher.
### Mobile App
The Mobile App interfaces with both connectors to share data, and provides secure, encrypted storage of users' health information.
### Languages Used
Our backend services are written in Python, and we used React Native to build our mobile app.
## Challenges we ran into
It was difficult to get each of our services working together since we were a distributed team.
## Accomplishments that we're proud of
We're proud of getting everything to work in concert together, and we're proud of the privacy and security guarantees we were able to provide in such a limited amount of time.
## What we learned
* Flask
* Python
## What's next for HealthConnect
We'd like to expand the HealthConnect platform so those beyond academic researchers, such as for-profit companies, could identify and compensate participants in medical studies.
Test | ## Inspiration
Last week, one of our team members was admitted to the hospital with brain trauma. Doctors hesitated to treat them because of their lack of insight into the patient’s medical history. This prompted us to store EVERYONE’s health records on a single, decentralized chain. The catch? The process is end-to-end encrypted, ensuring only yourself and your designated providers can access your data.
## How we built it
Zorg was built across 3 verticals: a frontend client, a backend server, and the chain.
The frontend client…
We poured our hearts and ingenuity into crafting a seamless user interface, a harmonious blend of aesthetics and functionality designed to resonate across the spectrum of users. Our aim? To simplify the process for patients to effortlessly navigate and control their medical records while enabling doctors and healthcare providers to seamlessly access and request patient information. Leveraging the synergy of Bun, React, Next, and Shadcn, we crafted a performant portal. To safeguard privacy, we fortified client-side interactions with encryption, ensuring sensitive data remains inaccessible to central servers. This fusion of technology and design principles heralds a new era of secure, user-centric digital healthcare record keeping.
The backend server…
The backend server of Zorg is the crux of our mission to revolutionize healthcare records management, ensuring secure, fast, and reliable access to encrypted patient data. Utilizing Zig for its performance and security advantages, our backend encrypts health records using a doctor's public key and stores them on IPFS for decentralized access. These records are then indexed on the blockchain via unique identifiers (CIDs), ensuring both privacy and immutability.
Upon request, the system retrieves and decrypts the data for authorized users, transforming it into a vectorized format suitable for semantic search. This process not only safeguards patient information but also enables healthcare providers to efficiently parse through detailed medical histories. Our use of Zig ensures that these operations are executed swiftly, maintaining our commitment to providing immediate access to critical medical information while prioritizing patient privacy and data integrity.
The chain…
The chain stores the encrypted key and the CID, allowing seemless access to a patient’s file stored on decentralized storage (IPFS). The cool part? The complex protocols and keys governing this system is completely abstracted away and wrapped up modern UI/UX, giving easy access to senior citizens and care providers.
## Challenges we ran into
Our biggest challenges were during integration, near the end of the hackathon. We had divided the project, with each person focusing on a different area—machine learning and queries, blockchain and key sharing, encryption and IPFS, and the frontend design. However, when we began to put things together, we quickly realized that we had failed to communicate with each other the specific details of how each of our systems worked. As a result we had to spend a few hours just tweaking each of our systems so that they could work with each other.
Another smaller (but enjoyable!) challenge we faced was learning to use a new language (Zig!). We ended up building our entire encryption and decryption system in Zig (as it needed to be incredibly fast due to the potentially vast amounts of data it would be processing) and had to piece together both how to build these systems in Zig, and how to integrate the resulting Zig binaries into the rest of our project.
## What's next for Zorg
In the future, we hope to devise a cryptographically sound way to revoke access to records after they have been granted. Additionally, our system would best benefit the population if we were able to partner with the government to include patient private keys in something everyone carries with them like their phone or ID so that in an emergency situation, first responders can access the patient data and identify things like allergies to medications. | ## Inspiration
We wanted to make the world a better place by giving patients control over their own data and allow easy and intelligent access of patient data.
## What it does
We have built an intelligent medical record solution where we provide insights on reports saved in the application and also make the personal identifiable information anonymous before saving it in our database.
## How we built it
We have used Amazon Textract Service as OCR to extract text information from images. Then we use the AWS Medical Comprehend Service to redact(Mask) sensitive information(PII) before using Groq API to extract inferences that explain the medical document to the user in the layman language. We have used React, Node.js, Express, DynamoDB, and Amazon S3 to implement our project.
## Challenges we ran into
## Accomplishments that we're proud of
We were able to fulfill most of our objectives in this brief period of time.We also got to talk to a lot of interesting people and were able to bring our project to completion despite a team member not showing up.We also got to learn about a lot of cool stuff that companies like Groq, Intel, Hume, and You.com are working on and we had fun talking to everyone.
## What we learned
## What's next for Pocket AI | winning |
## Inspiration
Partially inspired by the Smart Cities track, we wanted our app to have the direct utility of ordering food, while still being fun to interact with. We aimed to combine convenience with entertainment, making the experience more enjoyable than your typical drive-through order.
## What it does
You interact using only your voice. The app automatically detects when you start and stop talking, uses AI to transcribe what you say, figures out the food items (with modifications) you want to order, and adds them to your current order. It even handles details like size and flavor preferences. The AI then generates text-to-speech audio, which is played back to confirm your order in a humorous, engaging way. There is absolutely zero set-up or management necessary, as the program will completely ignore all background noises and conversation. Even then, it will still take your order with staggering precision.
## How we built it
The frontend of the app is built with React and TypeScript, while the backend uses Flask and Python. We containerized the app using Docker and deployed it using Defang. The design of the menu is also done in Canva with a dash of Harvard colors.
## Challenges we ran into
One major challenge was getting the different parts of the app—frontend, backend, and AI—to communicate effectively. From media file conversions to AI prompt engineering, we worked through each of the problems together. We struggled particularly with maintaining smooth communication once the app was deployed. Additionally, fine-tuning the AI to accurately extract order information from voice inputs while keeping the interaction natural was a big hurdle.
## Accomplishments that we're proud of
We're proud of building a fully functioning product that successfully integrates all the features we envisioned. We also managed to deploy the app, which was a huge achievement given the complexity of the project. Completing our initial feature set within the hackathon timeframe was a key success for us. Trying to work with Python data type was difficult to manage, and we were proud to navigate around that. We are also extremely proud to meet a bunch of new people and tackle new challenges that we were not previously comfortable with.
## What we learned
We honed our skills in React, TypeScript, Flask, and Python, especially in how to make these technologies work together. We also learned how to containerize and deploy applications using Docker and Docker Compose, as well as how to use Defang for cloud deployment.
## What's next for Harvard Burger
Moving forward, we want to add a business-facing interface, where restaurant staff would be able to view and fulfill customer orders. There will also be individual kiosk devices to handle order inputs. These features would allow *Harvard Burger* to move from a demo to a fully functional app that restaurants could actually use. Lastly, we can sell the product by designing marketing strategies for fast food chains. | ## Inspiration
The inspiration for our project stems from the increasing trend of online shopping and the declining foot traffic in physical stores. Our goal was to provide a unique and engaging experience for customers, encouraging them to visit physical stores and rediscover the joy of in-person shopping. We wanted to create an interactive and entertaining shopping experience that would entice customers to visit stores more frequently and foster a deeper connection between them and the store's brand.
## What it does
Our project is an AR scavenger hunt experience that gamifies the shopping experience. The scavenger hunt encourages customers to explore the store and discover new products they may have otherwise overlooked. As customers find specific products, they can earn points which can be redeemed for exclusive deals and discounts on future purchases. This innovative marketing scheme not only provides customers with an entertaining experience but also incentivizes them to visit stores more frequently and purchase products they may have otherwise overlooked.
## How we built it
To create the AR component of our project, we used Vuforia and Unity, two widely used platforms for building AR applications. The Vuforia platform allowed us to create and track image targets, while Unity was used to design the 3D models for the AR experience. We then integrated the AR component into an Android application by importing it as a Gradle project. Our team utilized agile development methodologies to ensure efficient collaboration and problem-solving throughout the development process.
## Challenges we ran into
One of the challenges we faced was integrating multiple APIs and ensuring that they worked together seamlessly. Another challenge was importing the AR component and creating the desired functionality within our project. We also faced issues with debugging and resolving technical errors that arose during the development process.
## Accomplishments that we're proud of
Despite the challenges we faced, we were able to achieve successful teamwork and collaboration. Despite forming the team later than other groups, we were able to effectively communicate and work together to bring our project to fruition. We are proud of the end result, which was a polished and functional AR scavenger hunt experience that met our objectives.
## What we learned
We learned how difficult it is to truly ship out software, and we are grateful to have joined the hackathon. We gained a deeper understanding of the importance of project planning, effective communication, and collaboration among team members. We also learned that the development process can be challenging and unpredictable, and that it requires perseverance and problem-solving skills. Additionally, participating in the hackathon taught us valuable technical skills such as integrating APIs, creating AR functionality, and importing projects onto an Android application.
## What's next for Winnur
Looking forward, we plan to incorporate Computer Vision technology into our project to prevent potential damage to our product's packaging. We also aim to expand the reach of our AR scavenger hunt experience by partnering with more retailers and enhancing the user interface and experience. We are excited about the potential for future development and growth of Winnur. | ## Inspiration
The world today has changed significantly because of COVID 19, with the increased prominence of food delivery services. We decided to get people back into the kitchen to cook for themselves again. Additionally, everyone has a lot of groceries that they never get around to eating because they don't know what to make. We wanted to make a service that would make it easier than ever to cook based on what you already have.
## What it does
Recognizes food ingredients through pictures taken on a smartphone, to build a catalog of ingredients lying around the house. These ingredients are then processed into delicious recipes that you can make at home. Common ingredients and the location of users are also stored to help reduce waste from local grocery stores through better demographic data.
## How we built it
We used to express and Node for the backend and react native for the front end. To process the images we used the Google Vision API to detect the ingredients. The final list of ingredients was then sent to the Spoonacular API to find recipes that best match the ingredients at hand. Finally, we used CockroachDB to store the locational and ingredient data of users, so they can be used for data analysis in the future.
## Challenges we ran into
* Working with Android is much more challenging than expected.
* Filtering food words for the image recognition suggestion.
* Team members having multiple time zones.
* Understanding and formatting inputs and outputs of APIs used
## Accomplishments that we're proud of
* We have an awesome-looking UI prototype to demonstrate our vision with our app.
* We were able to build our app with tools that we are unfamiliar with prior to the hackathon.
* We have a functional app apk that's ready to demonstrate to everyone at the hackathon.
* We were able to create something collaboratively in a team of people each with a drastically different skill set.
## What we learned
* Spoonacular API
* React Native
* Google Vision API
* CockroachDB
## What's next for Foodeck
* Implement personalized recipe suggestions using machine learning techniques. ( Including health and personal preferences )
* Learn user behavior of a certain region and make more localized recipe recommendations for each region.
* Implement an optional login system for increased personalization that can be transferred through d
* Extend to multi-platform, allowing users to sync the profile throughout different devices.
Integrate with grocery delivery services such as instacart, uber eats. | winning |
## Inspiration
Most of us have had to visit loved ones in the hospital before, and we know that it is often not a great experience. The process can be overwhelming between knowing where they are, which doctor is treating them, what medications they need to take, and worrying about their status overall. We decided that there had to be a better way and that we would create that better way, which brings us to EZ-Med!
## What it does
This web app changes the logistics involved when visiting people in the hospital. Some of our primary features include a home page with a variety of patient updates that give the patient's current status based on recent logs from the doctors and nurses. The next page is the resources page, which is meant to connect the family with the medical team assigned to your loved one and provide resources for any grief or hardships associated with having a loved one in the hospital. The map page shows the user how to navigate to the patient they are trying to visit and then back to the parking lot after their visit since we know that these small details can be frustrating during a hospital visit. Lastly, we have a patient update and login screen, where they both run on a database we set and populate the information to the patient updates screen and validate the login data.
## How we built it
We built this web app using a variety of technologies. We used React to create the web app and MongoDB for the backend/database component of the app. We then decided to utilize the MappedIn SDK to integrate our map service seamlessly into the project.
## Challenges we ran into
We ran into many challenges during this hackathon, but we learned a lot through the struggle. Our first challenge was trying to use React Native. We tried this for hours, but after much confusion among redirect challenges, we had to completely change course around halfway in :( In the end, we learnt a lot about the React development process, came out of this event much more experienced, and built the best product possible in the time we had left.
## Accomplishments that we're proud of
We're proud that we could pivot after much struggle with React. We are also proud that we decided to explore the area of healthcare, which none of us had ever interacted with in a programming setting.
## What we learned
We learned a lot about React and MongoDB, two frameworks we had minimal experience with before this hackathon. We also learned about the value of playing around with different frameworks before committing to using them for an entire hackathon, haha!
## What's next for EZ-Med
The next step for EZ-Med is to iron out all the bugs and have it fully functioning. | ## Inspiration
We wanted to make an app that helped people to be more environmentally conscious. After we thought about it, we realised that most people are not because they are too lazy to worry about recycling, turning off unused lights, or turning off a faucet when it's not in use. We figured that if people saw how much money they lose by being lazy, they might start to change their habits. We took this idea and added a full visualisation aspect of the app to make a complete budgeting app.
## What it does
Our app allows users to log in, and it then retrieves user data to visually represent the most interesting data from that user's financial history, as well as their utilities spending.
## How we built it
We used HTML, CSS, and JavaScript as our front-end, and then used Arduino to get light sensor data, and Nessie to retrieve user financial data.
## Challenges we ran into
To seamlessly integrate our multiple technologies, and to format our graphs in a way that is both informational and visually attractive.
## Accomplishments that we're proud of
We are proud that we have a finished product that does exactly what we wanted it to do and are proud to demo.
## What we learned
We learned about making graphs using JavaScript, as well as using Bootstrap in websites to create pleasing and mobile-friendly interfaces. We also learned about integrating hardware and software into one app.
## What's next for Budge
We want to continue to add more graphs and tables to provide more information about your bank account data, and use AI to make our app give personal recommendations catered to an individual's personal spending. | ## Inspiration
Coming into this hackathon I wanted to create a project that I found interesting and one that I could see being used. Many of my projects I have done in the past were interesting, but there were factors that would always keep them from being widely used. Often this is a barrier to entry. They required extensive setup for the more minimal reward that they give. For Hack Western one of my goals was the create something that had a low barrier to entry. However a low barrier to entry means nothing if the use is not up to par. I wanted to create a project that many people could use. Based on these two concepts, ease of use and wide ranging use, I decided to create a chat bot that automates answering science questions.
## What it does
What my project does is very simple. On the messaging platform, discord, you message my bot a question. It will attempt to search for a relevant answer. If one is found then it will give you a bit of context and the answer that it found.
## How I built it
I built this project in three main sections. The first section is my sleuther. This searches the web for various science based questions as well as their answers. When a question is found, I use IBM's natural language processing api to determine tags that represent the topic of the question. All of this data is then stored on an Algolia database where it can be quickly accessed later.
The second section of my project is the server. To implement this server I used StdLib to easily create a web api. When this api is accessed it queries the Algolia database to retrieve any relevant questions and returns the best entry.
The third and final part of my project is the front end Discord bot. When you send the bot a message it will generate tags to determine the general topic of the question and using these it will query the Algolia index. It does this by calling the StdLib endpoint that was setup as the server.
Overall these three sections combine to create my final project.
## Challenges I ran into
The first challenge that I ran into was unfamiliar technology. I had never used StdLib before and getting it to work was a struggle at times. Thankfully the mentors from StdLib were very helpful and allowed me to get my service up an running with not too much stress.
The main challenge for this project though it trying to match questions. As a user's questions and my database questions will not be worded the exact same way a simple string match would not suffice. In order to match the questions the general meaning of the question would need to be found and then those could be roughly matched. To try and work around this I tried various methods before setting on a sort of tag based system.
## Accomplishments that I'm proud of
To be honest this project was not my initial hackathon project. When I first started the idea was very different. The same base theme of low barrier to entry and widely usable, but the actual subject was quite different. Unfortunately part way through that project there was an insurmountable issue that did not really allow that project to progress. This forced me to pivot and find a new idea. This pivot came many hours into the hackathon already which severely reduced the time for my current hack. Because of this, the accomplishment that I think I am most proud of is the fact that I am here able to submit this hack.
## What I learned
Because I was forced to pivot on my idea partway through the hackathon a fair amount of stress was created for me. This fact really taught me the value of planning - most particularly determining the scope of the project. If I had planned ahead and wrote out everything that my first hack would have entailed then many of the issues that were encountered in it would have been able to be avoided.
## What's next for Science-Bot
I want to continue to improve my question matching algorithm so that it more questions can be matched. But beyond simply improving current functionality, I would like to add new scope to the questions my bot handles. This could be either increasing in scope, or increasing the depth of the questions. An interesting new topic would be questions about a very specific scientific area. I would likely need to be much more selective in the questions I match and this is something I think would pose a difficult and interesting challenge. | winning |
## Inspiration
Our team firmly believes that a hackathon is the perfect opportunity to learn technical skills while having fun. Especially because of the hardware focus that MakeUofT provides, we decided to create a game! This electrifying project places two players' minds to the test, working together to solve various puzzles. Taking heavy inspiration from the hit videogame, "Keep Talking and Nobody Explodes", what better way to engage the players than have then defuse a bomb!
## What it does
The MakeUofT 2024 Explosive Game includes 4 modules that must be disarmed, each module is discrete and can be disarmed in any order. The modules the explosive includes are a "cut the wire" game where the wires must be cut in the correct order, a "press the button" module where different actions must be taken depending the given text and LED colour, an 8 by 8 "invisible maze" where players must cooperate in order to navigate to the end, and finally a needy module which requires players to stay vigilant and ensure that the bomb does not leak too much "electronic discharge".
## How we built it
**The Explosive**
The explosive defuser simulation is a modular game crafted using four distinct modules, built using the Qualcomm Arduino Due Kit, LED matrices, Keypads, Mini OLEDs, and various microcontroller components. The structure of the explosive device is assembled using foam board and 3D printed plates.
**The Code**
Our explosive defuser simulation tool is programmed entirely within the Arduino IDE. We utilized the Adafruit BusIO, Adafruit GFX Library, Adafruit SSD1306, Membrane Switch Module, and MAX7219 LED Dot Matrix Module libraries. Built separately, our modules were integrated under a unified framework, showcasing a fun-to-play defusal simulation.
Using the Grove LCD RGB Backlight Library, we programmed the screens for our explosive defuser simulation modules (Capacitor Discharge and the Button). This library was used in addition for startup time measurements, facilitating timing-based events, and communicating with displays and sensors that occurred through the I2C protocol.
The MAT7219 IC is a serial input/output common-cathode display driver that interfaces microprocessors to 64 individual LEDs. Using the MAX7219 LED Dot Matrix Module we were able to optimize our maze module controlling all 64 LEDs individually using only 3 pins. Using the Keypad library and the Membrane Switch Module we used the keypad as a matrix keypad to control the movement of the LEDs on the 8 by 8 matrix. This module further optimizes the maze hardware, minimizing the required wiring, and improves signal communication.
## Challenges we ran into
Participating in the biggest hardware hackathon in Canada, using all the various hardware components provided such as the keypads or OLED displays posed challenged in terms of wiring and compatibility with the parent code. This forced us to adapt to utilize components that better suited our needs as well as being flexible with the hardware provided.
Each of our members designed a module for the puzzle, requiring coordination of the functionalities within the Arduino framework while maintaining modularity and reusability of our code and pins. Therefore optimizing software and hardware was necessary to have an efficient resource usage, a challenge throughout the development process.
Another issue we faced when dealing with a hardware hack was the noise caused by the system, to counteract this we had to come up with unique solutions mentioned below:
## Accomplishments that we're proud of
During the Makeathon we often faced the issue of buttons creating noise, and often times the noise it would create would disrupt the entire system. To counteract this issue we had to discover creative solutions that did not use buttons to get around the noise. For example, instead of using four buttons to determine the movement of the defuser in the maze, our teammate Brian discovered a way to implement the keypad as the movement controller, which both controlled noise in the system and minimized the number of pins we required for the module.
## What we learned
* Familiarity with the functionalities of new Arduino components like the "Micro-OLED Display," "8 by 8 LED matrix," and "Keypad" is gained through the development of individual modules.
* Efficient time management is essential for successfully completing the design. Establishing a precise timeline for the workflow aids in maintaining organization and ensuring successful development.
* Enhancing overall group performance is achieved by assigning individual tasks.
## What's next for Keep Hacking and Nobody Codes
* Ensure the elimination of any unwanted noises in the wiring between the main board and game modules.
* Expand the range of modules by developing additional games such as "Morse-Code Game," "Memory Game," and others to offer more variety for players.
* Release the game to a wider audience, allowing more people to enjoy and play it. | ## Inspiration
Rates of patient nonadherence to therapies average around 50%, particularly among those with chronic diseases. One of my closest friends has Crohn's disease, and I wanted to create something that would help with the challenges of managing a chronic illness. I built this app to provide an on-demand, supportive system for patients to manage their symptoms and find a sense of community.
## What it does
The app allows users to have on-demand check-ins with a chatbot. The chatbot provides fast inference, classifies actions and information related to the patient's condition, and flags when the patient’s health metrics fall below certain thresholds. The app also offers a community aspect, enabling users to connect with others who have chronic illnesses, helping to reduce the feelings of isolation.
## How we built it
We used Cerebras for the chatbot to ensure fast and efficient inference. The chatbot is integrated into the app for real-time check-ins. Roboflow was used for image processing and emotion detection, which aids in assessing patient well-being through facial recognition. We also used Next.js as the framework for building the app, with additional integrations for real-time community features.
## Challenges we ran into
One of the main challenges was ensuring the chatbot could provide real-time, accurate classifications and flagging low patient metrics in a timely manner. Managing the emotional detection accuracy using Roboflow's emotion model was also complex. Additionally, creating a supportive community environment without overwhelming the user with too much data posed a UX challenge.
## Accomplishments that we're proud of
✅deployed on defang
✅integrated roboflow
✅integrated cerebras
We’re proud of the fast inference times with the chatbot, ensuring that users get near-instant responses. We also managed to integrate an emotion detection feature that accurately tracks patient well-being. Finally, we’ve built a community aspect that feels genuine and supportive, which was crucial to the app's success.
## What we learned
We learned a lot about balancing fast inference with accuracy, especially when dealing with healthcare data and emotionally sensitive situations. The importance of providing users with a supportive, not overwhelming, environment was also a major takeaway.
## What's next for Muni
Next, we aim to improve the accuracy of the metrics classification, expand the community features to include more resources, and integrate personalized treatment plans with healthcare providers. We also want to enhance the emotion detection model for more nuanced assessments of patients' well-being. | ## Inspiration
Although we are a team of male-identifying students we were surprised by the lack of representation of women in STEM, a concern voiced by several of our peers, friends, and family. Hence, we were motivated in creating a website that would empower women within the STEM field and hopefully inspire future generations. So, we felt that the only way to understand what women want to see on our website is by asking women themselves. Thus, we collected data from our friends and family within the STEM field.
These were the three key concepts they wished to see: Representation of women in STEM, Networking opportunities,
Promoting STEM education
## What it does
Our website includes a home page that highlights a woman of the week in STEM and allows you to connect with them through Linkedin. The site also finds and showcases articles and videos created by female professionals. Users are able to search their preferred STEM topics and even filter the results based on their interests. They can also choose to find or create blog posts about current developments in the STEM field, or any related topics. The website also locates nearby upcoming events related to women in STEM offering a chance for users to gain opportunities to network.
Another prominent feature of our event is letting users create or find blog posts about current developments in the STEM field or related topics. While creating blog posts, our application utilizes machine learning APIs like OpenAI's gpt3 API and Cohere's API to increase user experience for writers and assist them. With gpt3, we suggest an outline idea for the post and give an introduction paragraph using Cohere API. We also recommend related research papers from the Google Scholar database for the writer to read before starting to write the article.
## How we built it
We meticulously built our website utilizing React (HTML, CSS, and JavaScript) for the frontend and Django for backend development. Our project was designed and developed using Figma, which allowed for efficient collaboration and streamlined the design process. The following tools were utilized to make this project a reality:
Tech Stack:
Frontend: React
Major libraries used on the frontend: Redux, bootstrap, firebase
Backend: Django
Library: Django Rest Framework
AI APIs:
OpenAI's latest gpt3 model text-davinci-003 to generate outline ideas for the writer
Cohere API to generate a sample introductory paragraph to a blog post given a blog title, audience, and tone of voice.
Other APIs:
SerpAPI to suggest related research papers from Google Scholars according to the given title by the writer
Other APIs for data population:
Developed 3 additional python scripts to populate our database.
We will be using task schedulers like crontab or Amazon CloudWatch Events to regularly update the external events, articles, and Youtube videos we're providing to users.
## Challenges we ran into
The first challenge we had run into was deciding on a topic for our project. With the theme being quite open-ended, and the urge of meeting the sponsor requirements, lots of ideas were bounced off one another during an exciting brainstorming session. This was the first of many hurdles to pass.
The next challenge was how to implement the Cohere API, as we wanted to compete for the specific sponsorship category. We looked over the available features provided by Cohere and decided on implementing at least one of the features, thus, generating the outline and first paragraph for our blog posts. Speaking of APIs, trying to populate data with the existing API’s deemed difficult as most weren’t providing the data we were looking or their free features were quite limited.
## Accomplishments that we're proud of
Our overall accomplishment that we are most proud of is the completion of our project. It wasn't easy forming a group with individuals we'd never worked with before, brainstorming together, and coding together. But the fact that we were able to complete it on a project that empowers women in STEM is truly an honor we all hold proudly.
## What we learned
Our group's skills in coding varied drastically. We had one member who has only ever done an introductory python course in the first year of university. He was guided through working on backend development, and graphical design of the website on Figma. All group members were introduced to new APIs such as Cohere's API.
## What's next for Curie
When considering the future, we have big plans for our website. We aim to make it more advanced by incorporating new technologies and creative ideas.
Some of the features we plan to add include a summarization tool for blog post descriptions and external articles.
Furthermore, we hope to develop our own web scraper with Machine Learning (ML) algorithms to provide more accurate external resources for our users.
The web scraper would use the ML model to efficiently locate success stories of women in articles, rather than manually inputting keywords.
Finally, we intend to use task schedulers like Crontab or Amazon CloudWatch Events to regularly update the external events, articles, and Youtube videos we're providing to users. | winning |
## Inspiration
Traffic congestion is already the most painful part of city life, and it's only going to worsen as cities grow. We need clever solutions, and those solutions need data. But that data is sorely lacking: even today, traffic counting is often done by hand, making it prohibitively expensive to deploy on a large scale.
Thankfully, machine vision has improved by leaps and bounds in the last couple of years, meaning that the problem can now be solved in 24 hours by four college students in a basement.
## GoWithTheFlow
GoWithTheFlow is an open source app that enables any group with a simple camera to quickly and easily analyze the flow of objects in the camera frame. The user inputs a video, and the software counts the number of objects of interest moving between different exit and entry points within the frame. The user can also manually select intersections for additional information.
While this project was initially created to monitor traffic flow and eliminate the need for manual traffic counting, due to the versatile nature of the machine learning algorithms, we were able to modify the detection scheme so that it is able to detect any kind of object moving in the camera's view. This means that this simple piece of software can be used to monitor the movement of people, cars, animals, basically anything that might stand out as "of interest" in an environment.
## Applications
While flow and movement analysis is hugely important in countless areas of society, one of the most immediate applications of this software is when it comes to hosting events. The hosts may want to know what areas of the venue get the most attention, how the crowd develops, or even just how to best guide people as they move about when planning for an event, and this app can be a great asset in doing just that.
It could also be a great asset in monitoring the movement of herds of groups of animals for ecological reasons. While it may be very difficult to manually comb through countless hours of footage to try and make sense of the large-scale movements of animals, our system provides a simple accessible way to do much of this analysis automatically.
While we could go on, suffice it to say that we have a created a generalizable way to monitor and analyze the movement patterns of almost any macroscopic system using just a camera.
## How we built it
The user interface was written using PyQt5. The input video is split into frames, then each frame is fed into the YOLO-9000 image classifier. The large size of this classifier is what ultimately allows our project to work as a generalizable flow monitoring system. The classifier returns the positions of interesting objects in each frame. This data is then linked and analyzed using an unsupervised machine learning algorithm to determine the probable location of entrance/exit points. The data is then analyzed and the flow rates in and out of each entrance and exit are provided. The user can also manually adjust the exit/entrance locations, and see what the probable flow rates and patterns would be for their setup. We used an AWS 2.2xlarge instance to run the majority of our video analysis for two main reasons: one, the GPU support enabled us to process large videos very quickly for testing purposes and two, it was a community instance that already had the majority the software required for our project already installed. The image overlays are drawn using OpenCV. | ## Inspiration
The only thing worse than no WiFi is slow WiFi. Many of us have experienced the frustrations of terrible internet connections. We have too, so we set out to create a tool to help users find the best place around to connect.
## What it does
Our app runs in the background (completely quietly) and maps out the WiFi landscape of the world. That information is sent to a central server and combined with location and WiFi data from all users of the app. The server then processes the data and generates heatmaps of WiFi signal strength to send back to the end user. Because of our architecture these heatmaps are real time, updating dynamically as the WiFi strength changes.
## How we built it
We split up the work into three parts: mobile, cloud, and visualization and had each member of our team work on a part. For the mobile component, we quickly built an MVP iOS app that could collect and push data to the server and iteratively improved our locationing methodology. For the cloud, we set up a Firebase Realtime Database (NoSQL) to allow for large amounts of data throughput. For the visualization, we took the points we received and used gaussian kernel density estimation to generate interpretable heatmaps.
## Challenges we ran into
Engineering an algorithm to determine the location of the client was significantly more difficult than expected. Initially, we wanted to use accelerometer data, and use GPS as well to calibrate the data, but excessive noise in the resulting data prevented us from using it effectively and from proceeding with this approach. We ran into even more issues when we used a device with less accurate sensors like an Android phone.
## Accomplishments that we're proud of
We are particularly proud of getting accurate paths travelled from the phones. We initially tried to use double integrator dynamics on top of oriented accelerometer readings, correcting for errors with GPS. However, we quickly realized that without prohibitively expensive filtering, the data from the accelerometer was useless and that GPS did not function well indoors due to the walls affecting the time-of-flight measurements. Instead, we used a built in pedometer framework to estimate distance travelled (this used a lot of advanced on-device signal processing) and combined this with the average heading (calculated using a magnetometer) to get meter-level accurate distances.
## What we learned
Locationing is hard! Especially indoors or over short distances.
Firebase’s realtime database was extremely easy to use and very performant
Distributing the data processing between the server and client is a balance worth playing with
## What's next for Hotspot
Next, we’d like to expand our work on the iOS side and create a sister application for Android (currently in the works). We’d also like to overlay our heatmap on Google maps.
There are also many interesting things you can do with a WiFi heatmap. Given some user settings, we could automatically switch from WiFi to data when the WiFi signal strength is about to get too poor. We could also use this app to find optimal placements for routers. Finally, we could use the application in disaster scenarios to on-the-fly compute areas with internet access still up or produce approximate population heatmaps. | ## Inspiration'
With the rise of IoT devices and the backbone support of the emerging 5G technology, BVLOS drone flights are becoming more readily available. According to CBInsights, Gartner, IBISworld, this US$3.34B market has the potential for growth and innovation.
## What it does
**Reconnaissance drone software that utilizes custom object recognition and machine learning to track wanted targets.** It performs close to real-time speed with nearly 100% accuracy and allows a single operator to operate many drones at once. Bundled with a light sleek-designed web interface, it is highly inexpensive to maintain and easy to operate.
**There is a Snapdragon Dragonboard that runs physically on the drones capturing real-time data and processing the video feed to identify targets. Identified targets are tagged and sent to an operator that is operating several drones at a time. This information can then be relayed to the appropriate parties.**
## How I built it
There is a Snapdragon Dragonboard that runs physically on the drones capturing real-time data and processing the video feed to identify targets. This runs on a Python script that then sends the information to a backend server built using NodeJS (coincidentally also running on the Dragonboard for the demo) to do processing and to use Microsoft Azure to identify the potential targets. Operators use a frontend to access this information.
## Challenges I ran into
Determining a way to reliably demonstrate this project became a challenge considering the drone is not moving and the GPS is not moving as well during the demonstration. The solution was to feed the program a video feed with simulated moving GPS coordinates so that the system believes it is moving in the air.
The training model also required us to devote multiple engineers to spending most of their time training the model over the hackathon.
## Accomplishments that I'm proud of
The code flow is adaptable to virtually an infinite number of scenarios with virtually **no hardcoding for the demo** except feeding it the video and GPS coordinates rather than the camera feed and actual GPS coordinates
## What I learned
We learned a great amount on computer vision and building/training custom classification models. We used Node.js which is a highly versatile environment and can be configured to relay information very efficiently. Also, we learned a few javascript tricks and some pitfalls to avoid.
## What's next for Recognaissance
Improving the classification model using more expansive datasets. Enhancing the software to be able to distinguish several objects at once allowing for more versatility. | winning |
## Inspiration
I listen to a lot of music from archive.org. While the internet archive has the ability to stream music, the only decent option to stream is through their website, which gets annoying.
Here is a link if you are not familiar. There are more well known artists on here, such as John Mayer and Jack Johnson.
<https://archive.org/details/etree>
I wanted to take advantage of being able to search by voice to play music from the archive at home, so using google actions seemed like the best option given that I already had a Google Home!
## What it does
You can start the app by asking google to talk with "Live Music Archive".
Afterwards, it will prompt you what artist you want to listen to. You can use key words like "give me the latest show" or "play me a show from 1979" and it will deliver!
If it cant find a show, it will let you know.
Once a show is found, it will load it up onto Logitech Media Server ( Google actions doesnt support casting sound longer than 120 seconds yet =( ) and give you some details about what you're listening to.
## How I built it
The majority of the app is written in nodejs. There is a webhook that listens for user input in order to control the Logitech Media Server.
The user interaction and NLP is done through Dialogflow. I use it to parse all the artist names, dates, and key words like if they would like the newest show. If not all of the data is received, it will prompt the user to say it.
## Challenges I ran into
My biggest challenge was lack of time. With the long drive and working by myself, I only had about 20 hours to work on the entire project from start to finsh. I am very happy with how it turned out, but if I had a full 36 hours to work I definitely could have added more features. Overall, I did not run into any significant road bumps.
## Accomplishments that I'm proud of
Figuring out how archive.org's insane catalog works through the API. There is a lot of data to filter and sort through, so it took a while to figure out how to get what I wanted!
I am also glad to have figured out how to actually stream the music to a player without any need for downloading. This really makes the user experience great.
## What I learned
archive.org has a LOT of data to use. You can do some cool things
NLP has also became super easy to make it do what you want it to. I remember trying to make a google home application over a year ago and it was a major headache. This time it was nearly seamless.
## What's next for Live Music Archive with Google Actions
I'll be using this project for sure! I hope to add some card data with the new version 2 API (it was recommended to use version 1 for now) so that I can view the archive page from my phone after it chooses something.
I also plan to add more features in terms of choosing a specific date, choosing between multiple sources, and other odds and ends. By building up more features, the voice interaction will become more and more natural, and you really will be able to ask it to play something exactly how you want to. | ## Inspiration
Life is Strange
Polaroid Cameras
Wanting a playlist based off memories.
## What it does
**Retro Vu** is an album archive that allows you to reminisce about the past in a whole new way. The program uses AI facial emotion recognition to identify the mood, vibe, and sentiment of the entire album and convert that into a perfectly curated playlist. In addition, **Retro Vu** also applies a vintage-feeling filter over your photo album so you can see your memories in a new light.
## How we built it
We used Python for the backend and React.js with Vite for the front end. Various wrappers and libraries were used, including Spotify API, Google Vision AI, and technologies such as Kintone and Docker.
## Challenges we ran into
I think it's safe to say, our path was mainly challenging throughout the run. Docker gave us headaches in the beginning, as it was our first time using it. Spotify's API, specifically the access token, was incredibly frustrating to deal with and took most of our time. However, we did learn a lot through these challenges, and were are confident if we were to do it again, it would be a breeze.
## Accomplishments that we're proud of
We're proud of the fact that we created a full-stack application in only 36 hours. We are also happy with how well we collaborated. And frankly, we're proud that we all made it through.
## What we learned
Don't use Spotify's API
## What's next for **Retro Vu**
We planned to create a system to share your albums and playlists with friends. Additionally, we hope to gather data about the age of the user to better tailor their nostalgic experience to them.
Check out this Google Slides for [additional info](https://docs.google.com/presentation/d/1qeuN_b5boB9uUgGK7yhIGD1s4iWuEW0AuK1LWN4c-jA/edit?usp=sharing)! | Presentation Link: <https://docs.google.com/presentation/d/1_4Yy5c729_TXS8N55qw7Bi1yjCicuOIpnx2LxYniTlY/edit?usp=sharing>
SHORT DESCRIPTION (Cohere generated this)
Enjoy music from the good old days? your playlist will generate songs from your favourite year (e.g. 2010) and artist (e.g. Linkin Park)
## Inspiration
We all love listening to music on Spotify, but depending on the mood of the day, we want to listen to songs on different themes. Impressed by the cool natural language processing tech that Cohere offers, we decided to create Songify that uses Cohere to create Spotify playlists based on the user's request.
## What it does
The purpose of Songify is to make the process of discovering new music seamless and hopefully provide our users with some entertainment. The algorithm is not limited in search words so anything that Songify is prompted will generate a playlist whether it be for serious music interest or for laughs.
Songify uses a web based platform to collect user input which Cohere then scans and extracts keywords from. Cohere then sends those keywords to the Spotify API which looks for songs containing the data, creates a new playlist under the user's account and populates the songs into the playlist. Songify will then return a webpage with an embedded playlist where you can examine the songs that were added instantly.
## How we built it
The project revolved around 4 main tasks; Implementing the Spotify API, the Cohere API, creating a webpage and integrating our webpage and backend. Python was the language of choice since it supported the Spotify API, Cohere and Spotipy which extensively saved us time in learning to use Spotify's API. Our team then spent time learning about and executing our specific tasks and came together finally for the integration.
## Challenges we ran into
For most of our team, this was our first time working with Python, APIs and integrating front and back end code. Learning all these skills in the span of 3 days was extremely challenging and time consuming. The first hurdle that we had to overcome was learning to read API documentation. The documentation was very intimidating to look at and understanding the key concepts such as API keys, Authorizations, REST calls was very confusing at first. The learning process included watching countless YouTube videos, asking mentors and sponsors for help and hours of trial and error.
## Accomplishments that we're proud of
Although our project is not the most flashy, our team has a lot to be proud of. Creating a product with the limited knowledge we had and building an understanding of Python, APIs, integration and front end development in a tight time frame is an accomplishment to be celebrated. Our goal for this hackathon was to make a tangible product and we succeeded in that regard.
## What we learned
Working with Spotify's API provided a lot of insight on how companies store data and work with data. Through Songify, we learned that most Spotify information is stored in JSON objects spanning several hundred lines per song and several thousands for albums. Understanding the Authentication process was also a headache since it had many key details such as client ids, API keys, redirect addresses and scopes.
Flask was very challenging to tackle, since it was our first time dealing with virtual environments, extensive use of windows command prompt and new notations such as @app.route. Integrating Flask with our HTML skeleton and back end Python files was also difficult due to our limited knowledge in integration.
Hack Western was a very enriching experience for our team, exposing us to technologies we may not have encountered if not for this opportunity.
## What's next for HackWesternPlaylist
In the future, we hope to implement a search algorithm not only for names, but for artists, artist genres, and the ability to scrub other people's playlists that the user enjoys listening to. The appearance of our product is also suboptimal and cleaning up the front end of the site will make it more appealing to users. We believe that Songify has a lot of flexibility in terms of what it can grow into in the future and are excited to work on it in the future. | losing |
We created this app in light of the recent wildfires that have raged across the west coast. As California Natives ourselves, we have witnessed the devastating effects of these fires first-hand. Not only do these wildfires pose a danger to those living around the evacuation area, but even for those residing tens to hundreds of miles away, the after-effects are lingering.
For many with sensitive respiratory systems, the wildfire smoke has created difficulty breathing and dizziness as well. One of the reasons we like technology is its ability to impact our lives in novel and meaningful ways. This is extremely helpful for people highly sensitive to airborne pollutants, such as some of our family members that suffer from asthma, and those who also own pets to find healthy outdoor spaces. Our app greatly simplifies the process of finding a location with healthier air quality amidst the wildfires and ensures that those who need essential exercise are able to do so.
We wanted to develop a web app that could help these who are particularly sensitive to smoke and ash to find a temporary respite from the harmful air quality in their area. With our app air.ly, users can navigate across North America to identify areas where the air quality is substantially better. Each dot color indicates a different air quality level ranging from healthy to hazardous. By clicking on a dot, users will be shown a list of outdoor recreation areas, parks, and landmarks they can visit to take a breather at.
We utilized a few different APIs in order to build our web app. The first step was to implement the Google Maps API using JavaScript. Next, we scraped location and air quality index data for each city within North America. After we were able to source real-time data from the World Air Quality Index API, we used the location information to connect to our Google Maps API implementation. Our code took in longitude and latitude data to place a dot on the location of each city within our map. This dot was color-coded based on its city AQI value.
At the same time, the longitude and latitude data was passed into our Yelp Fusion API implementation to find parks, hiking areas, and outdoor recreation local to the city. We processed the Yelp city and location data using Python and Flask integrations. The city-specific AQI value, as well as our local Yelp recommendations, were coded in HTML and CSS to display an info box upon clicking on a dot to help a user act on the real-time data. As a final touch, we also included a legend that indicated the AQI values with their corresponding dot colors to allow ease with user experience.
We really embraced the hacker resilience mindset to create a user-focused product that values itself on providing safe and healthy exploration during the current wildfire season. Thank you :) | ## Inspiration:
The single biggest problem and bottleneck in training large AI models today is compute. Just within the past week, Sam Altman tried raising an $8 trillion dollar fund to build a large network of computers for training larger multimodal models. | ## Inspiration
With COVID-19 forcing many public spaces and recreational facilities to close, people have been spending time outdoors more than ever. It can be boring, though, to visit the same places in your neighbourhood all the time. We created Explore MyCity to generate trails and paths for London, Ontario locals to explore areas of their city they may not have visited otherwise. Using machine learning, we wanted to creatively improve people’s lives.
## Benefits to Community
There are many benefits to this application to the London community. Firstly, this web app encourages people to explore London and can result in accessing city resources and visiting small businesses. It also motivates the community to be physically active and improve their physical and mental health.
## What it does
The user visits the web page and starts the application by picking their criteria for what kind of path they would like to walk on. The two criteria are 1) types of attractions, and 2) distance of the desired path. From the types of attractions, users can select whether they would like to visit trails, parks, public art, and/or trees. From the distance of their desired path, users can pick between ranges of 1-3, 3-5, 5-7, and 7-10 kilometres. Once users have specified their criteria, they click the Submit button and the application displays a trail using a GoogleMaps API with the calculated trail based on the criteria. The trail will be close in length to the input number of kilometres.
Users can also report a maintenance issue they notice on a path by using the dropdown menu on the home page to report an issue. These buttons lead to Service London’s page where issues are reported.
## How we built it
The program uses data from opendata.london.ca for the types of attractions and their addresses or coordinates and use them as .csv files. A python file reads the .csv files, parses each line for the coordinates or address of each attraction for each file, and stores it in a list.
The front-end of the web app was made using HTML pages. To connect the front and back-ends of the web app, we created a Flask web framework. We also connected the GoogleMaps API through Flask.
To get user input, we requested data through Flask and stored them in variables, which were then used as inputs to a python function. When the app loads, the user’s current location is retrieved through the browser using geolocation. Using these inputs, the python file checks which criteria the user selected and calls the appropriate functions. These functions calculate the distance between the user’s location and the nearest attraction; if the distance is within the distance input given, the attraction is added as a stop on the user’s path until no more attractions can be added.
This list of addresses and coordinates is given to the API, which displays the GoogleMaps route to users.
## Challenges we ran into
A challenge we ran into was creating the flask web framework; our team had never done this before so it took some time to learn how to implement it properly. We also ran into challenges with pulling python variables into Javascript. Using the API to display information was also a challenge because we were unfamiliar with the APIs and had to spend more time learning about them.
## Accomplishments that we're proud of
An accomplishment we’re proud of is implementing the GoogleMaps API and GeocodingAPI to create a user-friendly display like that of GoogleMaps. This brought our app to another level in terms of display and was an exciting feature to include. We were also proud of the large amounts of data parsing we did on the government’s data and how we were able to use it so well in combination with the two APIs mentioned above. A big accomplishment was also getting the Flask web framework to work properly, as it was a new skill and was a challenge to complete.
## What we learned
In this hack, we learned how to successfully create a Flask web framework, implement APIs, link python files between each other, and use GitHub correctly. We learned that time management should be a larger priority when it comes to timed hackathons and that ideas should be chosen earlier, even if the idea chosen is not the best. Lastly, we learned that collaboration is very important between team members and between mentors and volunteers.
## What's next for Explore MyCity
Explore MyCity’s next steps are to grow its features and expand its reach to other cities in Ontario and Canada.
Some features that we would add include:
* An option to include recreational (ie. reaching a tennis court, soccer field, etc.) and errand-related layovers; this would encourage users to take a walk and reach the desired target
* Compiling a database of paths generated by the program and keeping a count of how many users have gone on each of these paths. The municipality can know which paths are most used and which attractions are most visited and can allocate more resources to those areas.
* An interactive, social media-like feature that gives users a profile; users can take and upload pictures of the paths they walk on, share these with other local users, add their friends and family on the web app, etc. | winning |
## Inspiration
Being freshmen in college, we walk a lot. Living in the farthest dorm from campus, we walk even more. At some point, it's too much walking for any regular person, so we had to find another solution. We tried bikes, scooters, and skateboards, but carrying them around and managing them were just too much to handle. So we decided to make our own. CruisePack, the backpack with an integrated skateboard for transportation and open pockets for easy storage.
## What it does
CruisePack looks like a normal backpack from the outside, but the skateboard can fold out of the bottom of the bag, onto the ground. The battery pack, which is located inside a separate pocket for easy access, is connected to the board, allowing for the using to use the remote control to coast along on the CruisePack. We also created a basic companion app, which offers a few useful functionalities, including crash notifications, emergency settings, location services, and remote locking.
## How we built it
The process of building the CruisePack involved usage of a variety of materials, including aluminum posts, many nuts and nails, the backpack, and the skateboard. We used the aluminum posts to create a frame within the backpack upon which we stored the divided skateboard. We created a latching system which, upon release, would allow the board to slide out of the backpack onto the ground, while aligning it with the rear half of the board.
## Challenges we ran into
We ran into a few challenges on the implementation of the CruisePack, specifically on the sizing of our aluminum posts versus the frame of the board and the rest of the backpack. This meant we had to go back and be more accurate with our cuts, oftentimes cutting less than we had to and slowly cutting more until we had what we wanted.
## What's next for CruisePack
We will remain in development until the point that mass production becomes feasible through some sort of standardized procedure. Until then, stay cool, and have fun cruisin' on the CruisePack! | ## Inspiration
We were inspired to learn Arduino and get familiar with microcontrollers and electronics. Some members have a goal of doing embedded programming, and we agreed this would be a great start before moving on to more complex architectures like STM32. At first we wanted to build a quadcopter, but we decided to scale it down a bit to a helicopter to get used to flight controls first.
## What it does
The machine is able to communicate - via the bluetooth module, with any suitable bluetooth device connected to the ArduDroid app - an app that allows easy interface between arduino bluetooth devices and the arduino.
Through the ArduDroid app, the user will be able to power on the machine, and have it go vertically up or down with the app’s controls. The user will also be able to power on the tail motor to rotate the device in mid air.
The machine also has an accelerometer sensor which allows for the user to get real time data about the acceleration that the machine experiences.
## How we built it
Before any work was done on the machine itself, our group first met up and brainstormed the functionality that we wanted to achieve for this model. We then created a BOM of the various sensors and other equipment that we would need for the project.
After completing the BOM, we then designed a frame that could accommodate for the various pieces of hardware that we had chosen to use. Due to our intentional material limitation of making our frame out of common materials, the frame design incorporated simple shapes that can be easily manufactured.
We then moved on to writing the control software for the machine. By applying our previous knowledge of Arduino programing, and researching into AVR architecture, we were able to create the necessary software needed to interface and effectively control our machine. (More details about our software can also be found in the “What we learned” section).
Finally, with all preliminary designs and software finished, we were able to physically construct our frame, attach our hardware on the frame, and electronically connect all essential electrical components.
## Challenges we ran into
A few challenges that we ran into while completing the project include the following:
On the software side, although our group had some experience working with the Arduino IDE, we however, did not have any experience working with specific sensors, such as the bluetooth module, or the accelerometer.
The hardware issue was also a small issue as we had to order various parts that had to arrive within the window of this event. This slightly reduced the hardware that was available for us to use.
Furthermore, due to external circumstances, we were unable to use the Arduino UNO R3 which we originally intended to use for the controller board for our machine.
## Accomplishments that we're proud of
Some accomplishments we are proud of include establishing communication between the laptop and the bluetooth module (early test before moving to the ArduDroid app, which we did not get fully working). By treating the bluetooth module like another COM port, we were able to send keystroke data to the Arduino Uno to increase and decrease motor speed via the ESCs. In the same vein, we were able to successfully establish communication with the IMU after several failed attempts, and via formulae were able to process accelerometer and gyroscope data to find roll, pitch, and yaw data.
## What we learned
We learned a lot about the AVR architecture and how to make use of an Arduino Uno’s pin configuration to meet certain design needs. For example, we needed to reserve certain analog pins for the inertial measurement unit (IMU) we used in our project for its data and clock lines. We also learned more about electronics speed controllers (ESCs) and how to control them via pulse width modulation (PWM). In general, we gained insight on incoming and outgoing board communication with components like bluetooth modules, ESCs, and IMUs, as well as methods of data transfer like serial communication and the I2C protocol. More importantly, we learned how to better design under material constraints, given that we wanted to honour our initial budget.
## What's next for Flying Garbage Machine
* Upgrading the chassis. Currently the chassis is not 3D-printed, and the CAD to assembly transition did not fully keep the integrity of the original design.
* Finding better propellers. Right now, we had to chip the tail propeller to make it smaller than the top propeller.
* Seating the top propeller on a tiltable sheet. This way, the helicopter can actually move forward, backward, and lean in the direction of intended movement due to an imbalance in lift.
* Designing a custom control app, and maybe swapping the bluetooth module for a more powerful and faster means of communication. | ## Inspiration
With a vision to develop an innovative solution for portable videography, Team Scope worked over this past weekend to create a device that allows for low-cost, high-quality, and stable motion and panoramic photography for any user. Currently, such equipment exists only for high-end dslr cameras, is expensive, and is extremely difficult to transport. As photographers ourselves, such equipment has always felt out of reach, and both amateurs and veterans would substantially benefit from a better solution, which provides us with a market ripe for innovation.
## What it does
In contrast to current expensive, unwieldy designs, our solution is compact and modular, giving us the capability to quickly set over 20ft of track - while still fitting all the components into a single backpack. There are two main assemblies to SCOPE: first, our modular track whose length can be quickly extended, and second, our carriage which houses all electronics and controls the motion of the mounted camera.
## Design and performance
The hardware was designed in Solidworks and OnShape (a cloud based CAD program), and rapidly prototyped using both laser cutters and 3d printers. All materials we used are readily available, such as mdf fiberboard and acrylic plastic, which would drive down the cost of our product. On the software side, we used an Arduino Uno to power three full-rotation continuous servos, which provide us with a wide range of possible movements. With simple keyboard inputs, the user can interact with the system and control the lateral and rotational motion of the mounted camera, all the while maintaining a consistent quality of footage. We are incredibly proud of the performance of this design, which is able to capture extended time-lapse footage easily and at a professional level. After extensive testing, we are pleased to say that SCOPE has beaten our expectations for ease of use, modularity, and quality of footage.
## Challenges and lessons
Given that this was our first hackathon, and that all team members are freshman with limited experience, we faced numerous challenges in implementing our vision. Foremost among these was learning to code in the Arduino language, which none of us had ever used previously - something that was made especially difficult by our inexperience with software in general. But with the support of the PennApps community, we are happy to have learned a great deal over the past 36 hours, and are now fully confident in our ability to develop similar arduino-controlled products in the future. In addition, As we go forward, we are excited to apply our newly-acquired skills to new passions, and to continue to hack. The people we've met at PennApps have helped us with everything from small tasks, such as operating a specific laser cutter, to intangible advice about navigating the college world and life in general. The four of us are better engineers as a result.
## What's next?
We believe that there are many possibilities for the future of SCOPE, which we will continue to explore. Among these are the introduction of a curved track for the camera to follow, the addition of a gimbal for finer motion control, and the development of preset sequences of varying speeds and direction for the user to access. Additionally, we believe there is significant room for weight reduction to enhance the portability of our product. If produced on a larger scale, our product will be cheap to develop, require very few components to assemble, and still be just as effective as more expensive solutions.
## Questions?
Contact us at [[email protected]](mailto:[email protected]) | losing |
## Inspiration
Our inspiration all stems from one of our users terrible experiences building a PC. Building a PC can be an incredibly rewarding but also frustrating experience, especially for first-time builders. Our team member had a particularly disastrous PC build - incorrect parts that weren't compatible, unstable overclocking leading to crashes, and way over budget. It was a valuable learning experience but very costly in both time and money. We realized there had to be a better way than trial and error for PC novices to configure and buy the right components for their needs and budget. Our project aims to leverage AI and data to match users with PC parts tailored to their individual use case, whether that's high-end gaming, media editing, programming, etc.
## What it does
The website takes in a user's custom PC build needs and budget, then gets to work finding the optimal parts combination. Users simply describe what they plan to use the computer for, such as high-end 3D editing under $2,000. Within seconds, the website outputs a complete part list with prices, specs, and descriptions tailored to the user's intended workload.
## How we built it
Utilizing a Convex fullstack, we looked for cutting edge, pioneering softwares to help propel our project. We landed on utilizing together.ai to base our main AI system. Our fined-tuned llama-7b was trained on countless data-points, and works to create accurate and timely recommendations. Going further down, we used a secondary AI in MindsDB for bulk jobs to generate accurate descriptions of Pc Parts. We pulled from a scraped database in
## Challenges we ran into
Along the way, there were many challenges. One included running on only caffeine, but that was deemed worth the trouble knowing the amazing project we built. On a more technical level, as the technologies we planned on using were newer, there wasnt that large of a network of integrations. To combat this, we produced our own implementations. Specifically for a MindsDB integration for together.ai. To further the usefulness of together.ai, we also created an integration for Discord. Furthermore, obtaining data was a monumental obstacle. As a group of 4 without much capital, we had to create our own legal web scrapping tools. We ran into countless issues but eventually created a capable web scrapping tool to gather publicly available data to train our model on. Eventually, we intend to invest into purchasing data from large PC Parts databases to finalize and secure data.
## Accomplishments that we're proud of
We are definitely proud of the project we built, keeping in mind we are not all trained and seasoned hackathon veterans. More specifically, the revolutionary integrations are definitely a high-point for our project. Coming from knowing nothing about integrations, LLM creation and ethical data-scraping, we now know how to implement these systems in the future. And even when we would get frustrated, we always encouraged and pushed eachother forward in new and creative ways.
## What we learned
We learned that even if we start from a basic understanding of how LLMs AIs and databases work, through passion and hard work we can become experts in this field.
## What's next for EasyPC
Scaling this project will be easy. With an already fully-functioning AI system, the possibilites would be endless. We can keep feeding it more data, and we plan on implementing a text-feature where you could ask a fined-tuned LLM on any pc related questions. | ## Inspiration
The inspiration for the project was our desire to make studying and learning more efficient and accessible for students and educators. Utilizing advancements in technology, like the increased availability and lower cost of text embeddings, to make the process of finding answers within educational materials more seamless and convenient.
## What it does
Wise Up is a website that takes many different types of file format, as well as plain text, and separates the information into "pages". Using text embeddings, it can then quickly search through all the pages in a text and figure out which ones are most likely to contain the answer to a question that the user sends. It can also recursively summarize the file at different levels of compression.
## How we built it
With blood, sweat and tears! We used many tools offered to us throughout the challenge to simplify our life. We used Javascript, HTML and CSS for the website, and used it to communicate to a Flask backend that can run our python scripts involving API calls and such. We have API calls to openAI text embeddings, to cohere's xlarge model, to GPT-3's API, OpenAI's Whisper Speech-to-Text model, and several modules for getting an mp4 from a youtube link, a text from a pdf, and so on.
## Challenges we ran into
We had problems getting the backend on Flask to run on a Ubuntu server, and later had to instead run it on a Windows machine. Moreover, getting the backend to communicate effectively with the frontend in real time was a real challenge. Extracting text and page data from files and links ended up taking more time than expected, and finally, since the latency of sending information back and forth from the front end to the backend would lead to a worse user experience, we attempted to implement some features of our semantic search algorithm in the frontend, which led to a lot of difficulties in transferring code from Python to Javascript.
## Accomplishments that we're proud of
Since OpenAI's text embeddings are very good and very new, and we use GPT-3.5 based on extracted information to formulate the answer, we believe we likely equal the state of the art in the task of quickly analyzing text and answer complex questions on it, and the ease of use for many different file formats makes us proud that this project and website can be useful for so many people so often. To understand a textbook and answer questions about its content, or to find specific information without knowing any relevant keywords, this product is simply incredibly good, and costs pennies to run. Moreover, we have added an identification system (users signing up with a username and password) to ensure that a specific account is capped at a certain usage of the API, which is at our own costs (pennies, but we wish to avoid it becoming many dollars without our awareness of it.
## What we learned
As time goes on, not only do LLMs get better, but new methods are developed to use them more efficiently and for greater results. Web development is quite unintuitive for beginners, especially when different programming languages need to interact. One tool that has saved us a few different times is using json for data transfer, and aws services to store Mbs of data very cheaply. Another thing we learned is that, unfortunately, as time goes on, LLMs get bigger and so sometimes much, much slower; api calls to GPT3 and to Whisper are often slow, taking minutes for 1000+ page textbooks.
## What's next for Wise Up
What's next for Wise Up is to make our product faster and more user-friendly. A feature we could add is to summarize text with a fine-tuned model rather than zero-shot learning with GPT-3. Additionally, a next step is to explore partnerships with educational institutions and companies to bring Wise Up to a wider audience and help even more students and educators in their learning journey, or attempt for the website to go viral on social media by advertising its usefulness. Moreover, adding a financial component to the account system could let our users cover the low costs of the APIs, aws and CPU running Whisper. | ## 🌍 Inspiration Behind visioncraft.ai 🚀
When staring at the increasing heaps of discarded gadgets and electronics, a question invariably arose in our minds: "Can we make a difference here?" 🤔❓
Introducing... the tech waste dilemma. It's no secret that our world is swamped with discarded tech. These devices, once marvels of their time, now contribute to an ever-growing environmental concern. We produce 40 million tons of electronic waste every year, worldwide. That's like throwing 800 laptops away every second. 🌏💔
Instead of seeing these gadgets as waste, we started seeing potential. The idea: leverage the power of deep learning to infuse old tech with new life. This wasn't about recycling; it was about reimagining. 🔄🔍
We believed that there was a way to reduce this waste by allowing users to reuse their spare electronic parts to create Arduino projects. Through visioncraft.ai, we are confident that we can encourage the pillars of reducing, reusing, and recycling, solving an ever-evolving problem in the world around us. 💡✨
## 🚀 What visioncraft.ai Does 🛠️
The user starts on a landing page where they can view the functionalities of our product demo. By clicking the "Get Started" button, they are directed to a form where they can fill out some basic information. Here, they are prompted for their idea, the materials they already have, their budget, and an option to upload a photo of the materials. Once done, they hit the submit button, and the magic of tutorial generation begins!💡💸
Immediately after, a POST request is sent to the server, where the image is dissected using a deep learning model hosted on Roboflow, ensuring any electronic parts are detected. Then, the idea, budget, and identified parts (including those manually entered by the user) get fed into OpenAI's GPT-35-turbo and DALLE-2 APIs for deeper magic. Through cleverly crafted prompts, these engines whip up the body text and images for the tutorial. Once all the data is ready, it's transformed into a neat PDF 📄 using the Python fPDF library. And voilà! A new tab pops up, delivering the PDF to the user, all powered by the decentralized IPFS file systems 🌐📤.
## 🤖 How We Built visioncraft.ai 🎨
First, we used Figma to visualize our design and create a prototype for how we envisioned our website. To actually build the front-end, we used Next.js and Tailwind CSS for styling. We incorporated features like the Typewriter effect and fade animations for the cards to create a minimalist and modern aesthetic. Then, we used Vercel to ship the deployment given it's a non-static full-stack application 🖥️🌌.
The backend is powered by Python, with a Flask application serving as the base of our app . A deep learning model was accessed, modified, and hosted on Roboflow.com, and we call an API on the image taken by the individual to identify individual parts and return a list in JSON. The list is scraped and combined with the manually entered list, and duplicates are removed. DALLE-2 and GPT-35-Turbo were used to generate the text and images for the tutorial using engineered prompts, and using the fPDF/PyPDF2 libraries, we were able to format the PDF for user accessibility. The generated PDF was uploaded to Interplanetary File Storage (IPFS) via the NFTPort.XYZ via an API, and a link is returned to the front-end to be opened in a new tab for the user to see 📜🌐.
To integrate the front-end and the back-end, the redirects feature provided by next.js in the next.config.js feature was used so that the server API was accessible by the client. Here is a link for reference: <https://nextjs.org/docs/pages/api-reference/next-config-js/redirects> 🔄📗.
One problem that was encountered during this integration was the default proxy time limit of Next.js, which was too short for our server call. Luckily, there was an experimental property named 'proxyTimeout' that could be adjusted to avoid time-out errors ⏳🛠️.
## 🚧 Challenges on the Road to visioncraft.ai 🌪️
Diving into the world of tech innovation often comes with its set of challenges. Our journey to create VisionCraft.ai was no exception, and here's a snapshot of the hurdles of our journey. 🛤️🔍
### 🌩️ Cloudy Days with Flask and Google Cloud ☁️
When we started with our Flask backend, hosting it on Google Cloud seemed like the perfect idea. But alas, it wasn't a walk in the park. The numerous intricacies and nuances of deploying a Flask application on Google Cloud led to two sleepless nights, Yet, each challenge only solidified our resolve and, in the process, made us experts in cloud deployment nuances as we used App Engine to deploy our back-end. 💪🌪️
### 📜 Typewriter: Bringing Life to the Front-end 🎭
Web apps can't just be functional; they need to be dynamic and engaging! And that's where Typewriter stepped in. By leveraging its capabilities, our front-end wasn't just a static display but a lively, interactive canvas that responded and engaged with the user. 🖥️💃
### 🔄 Bridging Two Worlds: Vercel and Google Cloud 🌉
Our choice of hosting the front end on Vercel while having the back-end on Google Cloud was, to some, unconventional. Yet, it was essential for our vision of having a hosted website. The challenge? Ensuring seamless integration. With a slew of API calls, endpoints tweaking, and consistent testing, we built a bridge between the two, ensuring that the user experience remained smooth and responsive. However, it was most definitely not easy, since we had to figure out how to work with generated files without ever saving them. 🌐🤖
## 🏆 Our Proud Accomplishments with visioncraft.ai 🎉
Embarking on the journey of creating visionxraft.ai has been nothing short of transformative. Along the way, we faced challenges, celebrated victories, and took leaps into the unknown. Here's a glimpse of the milestones that fill us with pride. 🌟🛤️
### 🧠 Embracing YOLO for Deep Learning 🎯
We wanted visioncraft.ai to stand out, and what better way than by integrating state-of-the-art object detection? Implementing deep learning through YOLO (You Only Look Once) detection was ambitious, but we dove right in! The result? Swift and accurate object detection, paving the way for our app to recognize and repurpose tech waste effectively. Every detected item stands as a testament to our commitment to precision. 🔍✨
### 🖥️ Venturing into the World of Next.js 🚀
Taking on Next.js was a first for us. But who said firsts were easy (they're not, source: trust us lol)? Navigating its features and capabilities was like deciphering an intricate puzzle. But piece by piece, the picture became clearer. The result was a robust, efficient, and dynamic front-end, tailored to provide an unparalleled user experience. With every click and interaction on our platform, we're reminded of our bold plunge into Next.js and how it paid off. 💡🌐
### 📄 Perfecting PDFs with PyPDF2 📁
Documentation matters, and we wanted ours to be impeccable. Enter PyPDF2! Utilizing its capabilities, we were able to craft, format, and output PDF files with finesse. The satisfaction of seeing a perfectly formatted PDF, ready for our users, was unmatched. It wasn't just about providing information but doing it with elegance and clarity. 🌟📜
## 📚 Key Learnings from Crafting visioncraft.ai 🌟
While building visioncraft.ai, our journey wasn't solely about developing an application. It was a profound learning experience, encompassing technical nuances, deep learning intricacies, and design philosophies. Here's a peek into our treasure trove of knowledge gained. 🛤️🔎
### 🌐 Hosting Across Platforms: Google Cloud & Vercel 🚀
Navigating the hosting landscape was both a challenge and an enlightening journey:
* Flask on Google Cloud: Deploying our Flask backend on Google Cloud introduced us to the multifaceted world of cloud infrastructure. From understanding VM instances to managing security protocols, our cloud expertise expanded exponentially. ☁️🔧
* Next.js on Vercel: Hosting our Next.js front-end on Vercel was a dive into serverless architecture. We learned about efficient scaling, seamless deployments, and ensuring low-latency access for users globally. 🌍🖥️
### 🧠 Delving Deep into Deep Learning and YOLO3 🤖
Our venture into the realm of deep learning was both deep and enlightening:
* Training Models: The art and science of training deep learning models unraveled before us. From data preprocessing to tweaking hyperparameters, we delved into the nuances of ensuring optimal model performance. 📊🔄
* YOLO3 Functionality: YOLO3 (You Only Look Once v3) opened up a world of real-time object detection. We learned about its unique architecture, how it processes images in one pass, and its efficiency in pinpointing objects with precision. 🔍🎯
### 🎨 Crafting Engaging Web Experiences 🌈
Designing visioncraft.ai was more than just putting pixels on a screen:
* User-Centric Design: We realized that effective design starts with understanding user needs. This led us to prioritize user journeys, ensuring each design choice enhanced the user experience. 🤝🖌️
* Interactive Elements: Making our website interactive wasn't just about adding flashy elements. We learned the subtle art of balancing engagement with functionality, ensuring each interaction added value. 💡🕹️
* Consistency is Key: An engaging website isn't just about standout elements but ensuring a cohesive design language. From typography to color palettes, maintaining consistency was a lesson we'll carry forward. 🎨🔗
## 🌟 The Road Ahead for visioncraft.ai 🛣️
visioncraft.ai's journey so far has been incredibly enriching, but it's just the beginning. The world of tech is vast, and our mission to reduce tech waste is ever-evolving. Here's a glimpse into the exciting developments and plans we have in store for the future. 🚀🔮
### 🌐 Expanding our Cloud Capabilities ☁️
We're diving deeper into cloud integrations, exploring newer, more efficient ways to scale and optimize our application. This will ensure a faster, more reliable experience for our users, no matter where they are on the globe. 🌍💡
### 🤖 Advanced AI Integrations 🧠
While YOLO has served us well, the realm of deep learning is vast:
* Enriched Object Detection: We're looking into further refinements in our AI models, allowing for even more precise object recognition. 🔍🎯
* Personalized Recommendations: Using AI, we aim to offer users personalized suggestions for tech waste reduction based on their unique usage patterns. 📊👤
### 🎨 Elevating User Experience 🖌️
Design will always remain at the heart of visioncraft.ai:
* Mobile-First Approach: With increasing mobile users, we're focusing on optimizing our platform for mobile devices, ensuring a seamless experience across all devices. 📱✨
* Interactive Guides: To help users navigate the world of tech waste reduction, we're working on creating interactive guides and tutorials, making the journey engaging and informative. 📘🚀
### 🌱 Community and Collaboration 🤝
Believing in the power of community, we have plans to:
* Open Source: We're considering opening up certain aspects of our platform for the developer community. This will foster innovation and collaborative growth. 💼💡
* Workshops and Webinars: To spread awareness and knowledge, we aim to host interactive sessions, focusing on the importance of reducing tech waste and the role of AI in it. 🎤👥
The horizon is vast, and visioncraft.ai is geared up to explore uncharted territories. With passion, innovation, and a commitment to our mission, the future looks bright and promising. 🌅🌱
Join us on this exhilarating journey toward a sustainable, tech-aware future! 🌍❤️🤖 | partial |
## Inspiration
When my friends and I are planning on going out, we often text someone we know who is already at the event or party and ask them for a "vibe check", so that we know if it's worth the long treck in -20 degree weather. Sometimes though, we don't know anyone there (yet) and we end up spending up to 10$ on a cover charge and walking 30 minutes in the snow just to leave 10 minutes later. This is when Vibe Check comes in!
## What it does
Vibe Check is a mobile app that allows users to view or post real-time reviews of events, clubs, bars, and other (mainly) night-time events. This way, users can check if the event they are thinking of attending has the energy they are looking for, based on the crowd, price, music, and other variables. Newest reviews are pushed to the top of the main feed so that users are getting the most real-time information possible.
## How we built it
We decided to use the Google-provided Flutter API and Firebase database. Neither of us were familiar with these platforms and we thought this was the perfect opportunity to dive in at the deep end. Both platforms were relatively easy to pick-up, disregarding the initial set-up phase which was a bit of a learning curve. We developed the app in Android Studio, and since neither of us had Android devices, we used a provided Android emulator on the Android IDE.
## Challenges we ran into
The main challenge we ran into was setting up our Flutter/Firebase app since neither of us had used either platform before. This set-up took more time than expected, but once we had a "functioning" app, it was easier to get the ball rolling using the Flutter/Firebase documentation and online forums.
## Accomplishments that we're proud of
We are very proud that we were able to learn so much about Flutter and Firebase in such a short time. We are also proud of how much we were able to get done in the given time. We also like the look of our app, which has a darker theme since it is for night-time events.
## What we learned
We learned a lot about Flutter and Firebase. This was our first Hackathon, so we also learned what a Hackathon environment was like, and how to make a functional app in less than 24 hours!
## What's next for Vibe Check
Our vision of the final version will be integrated with Google Maps so that users can see which events in their area have positive reviews for the night. There is a search feature, but we would like to implement filters so that users can filter reviews based on their priorities. For now, posts will be anonymous, but in the future users will be able to create accounts to keep track of their past reviews. From a business perspective, this app could be monetized through sponsored posts and deals from locations and an Uber/Lyft integration could be added as well. | ## Inspiration
As students, we have found that there are very few high-quality resources on investing for those who are interested but don't have enough resources. Furthermore, we have found that investing and saving money can be a stressful experience. We hope to change this for those who want to save better with the help of our app, hopefully making it fun in the process!
## What it does
Our app first asks a new client a brief questionnaire about themselves. Then, using their banking history, it generates 3 "demons", aka bad spending habits, to kill. Then, after the client chooses a habit to work on, it brings them to a dashboard where they can monitor their weekly progress on a task. Once the week is over, the app declares whether the client successfully beat the mission - if they did, they get rewarded with points which they can exchange for RBC Loyalty points!
## How we built it
We built the frontend using React + Tailwind, using Routes to display our different pages. We used Cohere for our AI services, both for generating personalized weekly goals and creating a more in-depth report. We used Firebase for authentication + cloud database to keep track of users. For our data of users and transactions, as well as making/managing loyalty points, we used the RBC API.
## Challenges we ran into
Piecing the APIs together was probably our most difficult challenge. Besides learning the different APIs in general, integrating the different technologies got quite tricky when we are trying to do multiple things at the same time!
Besides API integration, definitely working without any sleep though was the hardest part!
## Accomplishments that we're proud of
Definitely our biggest accomplishment was working so well together as a team. Despite only meeting each other the day before, we got along extremely well and were able to come up with some great ideas and execute under a lot of pressure (and sleep deprivation!) The biggest reward from this hackathon are the new friends we've found in each other :)
## What we learned
I think each of us learned very different things: this was Homey and Alex's first hackathon, where they learned how to work under a small time constraint (and did extremely well!). Paige learned tons about React, frontend development, and working in a team. Vassily learned lots about his own strengths and weakness (surprisingly reliable at git, apparently, although he might have too much of a sweet tooth).
## What's next for Savvy Saver
Demos! After that, we'll just have to see :) | ## Inspiration
We wanted to watch videos together as a social activity during the pandemic but were unable as many platforms were hard to use or unstable. Therefore our team decided to create a platform that met our needs in terms of usability and functionality.
## What it does
Bubbles allow people to create viewing rooms and invite their rooms to watch synchronized videos. Viewers no longer have to conduct countdowns on their play buttons or have a separate chat while watching!
## How I built it
Our web app uses React for the frontend and interfaces with our Node.js REST API in the backend. The core of our app uses the Solace PubSub+ and the MQTT protocol to coordinate events such as video play/pause, a new member joining your bubble, and instant text messaging. Users broadcast events with the topic being their bubble room code, so only other people in the same room receive these events.
## Challenges I ran into
* Collaborating in a remote environment: we were in a discord call for the whole weekend, using Miro for whiteboarding, etc.
* Our teammates came from various technical backgrounds, and we all had a chance to learn a lot about the technologies we used and how to build a web app
* The project was so much fun we forgot to sleep and hacking was more difficult the next day
## Accomplishments that I'm proud of
The majority of our team was inexperienced in the technologies used. Our team is very proud that our product was challenging and was completed by the end of the hackathon.
## What I learned
We learned how to build a web app ground up, beginning with the design in Figma to the final deployment to GitHub and Heroku. We learned about React component lifecycle, asynchronous operation, React routers with a NodeJS backend, and how to interface all of this with a Solace PubSub+ Event Broker. But also, we learned how to collaborate and be productive together while still having a blast
## What's next for Bubbles
We will develop additional features regarding Bubbles. This includes seek syncing, user join messages and custom privilege for individuals. | partial |
## Inspiration
Public speaking is greatly feared by many, yet it is a part of life that most of us have to go through. Despite this, preparing for presentations effectively is *greatly limited*. Practicing with others is good, but that requires someone willing to listen to you for potentially hours. Talking in front of a mirror could work, but it does not live up to the real environment of a public speaker. As a result, public speaking is dreaded not only for the act itself, but also because it's *difficult to feel ready*. If there was an efficient way of ensuring you aced a presentation, the negative connotation associated with them would no longer exist . That is why we have created Speech Simulator, a VR web application used for practice public speaking. With it, we hope to alleviate the stress that comes with speaking in front of others.
## What it does
Speech Simulator is an easy to use VR web application. Simply login with discord, import your script into the site from any device, then put on your VR headset to enter a 3D classroom, a common location for public speaking. From there, you are able to practice speaking. Behind the user is a board containing your script, split into slides, emulating a real powerpoint styled presentation. Once you have run through your script, you may exit VR, where you will find results based on the application's recording of your presentation. From your talking speed to how many filler words said, Speech Simulator will provide you with stats based on your performance as well as a summary on what you did well and how you can improve. Presentations can be attempted again and are saved onto our database. Additionally, any adjustments to the presentation templates can be made using our editing feature.
## How we built it
Our project was created primarily using the T3 stack. The stack uses **Next.js** as our full-stack React framework. The frontend uses **React** and **Tailwind CSS** for component state and styling. The backend utilizes **NextAuth.js** for login and user authentication and **Prisma** as our ORM. The whole application was type safe ensured using **tRPC**, **Zod**, and **TypeScript**. For the VR aspect of our project, we used **React Three Fiber** for rendering **Three.js** objects in, **React XR**, and **React Speech Recognition** for transcribing speech to text. The server is hosted on Vercel and the database on **CockroachDB**.
## Challenges we ran into
Despite completing, there were numerous challenges that we ran into during the hackathon. The largest problem was the connection between the web app on computer and the VR headset. As both were two separate web clients, it was very challenging to communicate our sites' workflow between the two devices. For example, if a user finished their presentation in VR and wanted to view the results on their computer, how would this be accomplished without the user manually refreshing the page? After discussion between using web-sockets or polling, we went with polling + a queuing system, which allowed each respective client to know what to display. We decided to use polling because it enables a severless deploy and concluded that we did not have enough time to setup websockets. Another challenge we had run into was the 3D configuration on the application. As none of us have had real experience with 3D web applications, it was a very daunting task to try and work with meshes and various geometry. However, after a lot of trial and error, we were able to manage a VR solution for our application.
## What we learned
This hackathon provided us with a great amount of experience and lessons. Although each of us learned a lot on the technological aspect of this hackathon, there were many other takeaways during this weekend. As this was most of our group's first 24 hour hackathon, we were able to learn to manage our time effectively in a day's span. With a small time limit and semi large project, this hackathon also improved our communication skills and overall coherence of our team. However, we did not just learn from our own experiences, but also from others. Viewing everyone's creations gave us insight on what makes a project meaningful, and we gained a lot from looking at other hacker's projects and their presentations. Overall, this event provided us with an invaluable set of new skills and perspective.
## What's next for VR Speech Simulator
There are a ton of ways that we believe can improve Speech Simulator. The first and potentially most important change is the appearance of our VR setting. As this was our first project involving 3D rendering, we had difficulty adding colour to our classroom. This reduced the immersion that we originally hoped for, so improving our 3D environment would allow the user to more accurately practice. Furthermore, as public speaking infers speaking in front of others, large improvements can be made by adding human models into VR. On the other hand, we also believe that we can improve Speech Simulator by adding more functionality to the feedback it provides to the user. From hand gestures to tone of voice, there are so many ways of differentiating the quality of a presentation that could be added to our application. In the future, we hope to add these new features and further elevate Speech Simulator. | ## Problem Statement
As the number of the elderly population is constantly growing, there is an increasing demand for home care. In fact, the market for safety and security solutions in the healthcare sector is estimated to reach $40.1 billion by 2025.
The elderly, disabled, and vulnerable people face a constant risk of falls and other accidents, especially in environments like hospitals, nursing homes, and home care environments, where they require constant supervision. However, traditional monitoring methods, such as human caregivers or surveillance cameras, are often not enough to provide prompt and effective responses in emergency situations. This potentially has serious consequences, including injury, prolonged recovery, and increased healthcare costs.
## Solution
The proposed app aims to address this problem by providing real-time monitoring and alert system, using a camera and cloud-based machine learning algorithms to detect any signs of injury or danger, and immediately notify designated emergency contacts, such as healthcare professionals, with information about the user's condition and collected personal data.
We believe that the app has the potential to revolutionize the way vulnerable individuals are monitored and protected, by providing a safer and more secure environment in designated institutions.
## Developing Process
Prior to development, our designer used Figma to create a prototype which was used as a reference point when the developers were building the platform in HTML, CSS, and ReactJs.
For the cloud-based machine learning algorithms, we used Computer Vision, Open CV, Numpy, and Flask to train the model on a dataset of various poses and movements and to detect any signs of injury or danger in real time.
Because of limited resources, we decided to use our phones as an analogue to cameras to do the live streams for the real-time monitoring.
## Impact
* **Improved safety:** The real-time monitoring and alert system provided by the app helps to reduce the risk of falls and other accidents, keeping vulnerable individuals safer and reducing the likelihood of serious injury.
* **Faster response time:** The app triggers an alert and sends notifications to designated emergency contacts in case of any danger or injury, which allows for a faster response time and more effective response.
* **Increased efficiency:** Using cloud-based machine learning algorithms and computer vision techniques allow the app to analyze the user's movements and detect any signs of danger without constant human supervision.
* **Better patient care:** In a hospital setting, the app could be used to monitor patients and alert nurses if they are in danger of falling or if their vital signs indicate that they need medical attention. This could lead to improved patient care, reduced medical costs, and faster recovery times.
* **Peace of mind for families and caregivers:** The app provides families and caregivers with peace of mind, knowing that their loved ones are being monitored and protected and that they will be immediately notified in case of any danger or emergency.
## Challenges
One of the biggest challenges have been integrating all the different technologies, such as live streaming and machine learning algorithms, and making sure they worked together seamlessly.
## Successes
The project was a collaborative effort between a designer and developers, which highlights the importance of cross-functional teams in delivering complex technical solutions. Overall, the project was a success and resulted in a cutting-edge solution that can help protect vulnerable individuals.
## Things Learnt
* **Importance of cross-functional teams:** As there were different specialists working on the project, it helped us understand the value of cross-functional teams in addressing complex challenges and delivering successful results.
* **Integrating different technologies:** Our team learned the challenges and importance of integrating different technologies to deliver a seamless and effective solution.
* **Machine learning for health applications:** After doing the research and completing the project, our team learned about the potential and challenges of using machine learning in the healthcare industry, and the steps required to build and deploy a successful machine learning model.
## Future Plans for SafeSpot
* First of all, the usage of the app could be extended to other settings, such as elderly care facilities, schools, kindergartens, or emergency rooms to provide a safer and more secure environment for vulnerable individuals.
* Apart from the web, the platform could also be implemented as a mobile app. In this case scenario, the alert would pop up privately on the user’s phone and notify only people who are given access to it.
* The app could also be integrated with wearable devices, such as fitness trackers, which could provide additional data and context to help determine if the user is in danger or has been injured. | ## Inspiration
Our team was united in our love for animals, and our anger about the thousands of shelter killings that happen every day due to overcrowding. In order to raise awareness and educate others about the importance of adopting rather than shopping for their next pet, we framed this online web application from a dog's perspective of the process of trying to get adopted.
## What it does
In *Overpupulation,* users can select a dog who they will control in order to try to convince visitors to adopt them.
To illustrate the realistic injustices some breeds face in shelters, different dogs in the game have different chances of getting adopted. After each rejection from a potential adoptee, we expose some of their faulty reasoning behind their choices to try to debunk false misconceptions. At the conclusion of the game, we present ways for individuals to get involved and support their local shelters.
## How we built it
This web application is built in Javascript/JQuery, HTML, and CSS.
## Accomplishments that we're proud of
For most of us, this was our first experience working in a team coding environment. We all walked away with a better understanding of git, the front-end languages we utilized, and design.
We have purchased the domain name overpupulation.com, but are still trying to work through redirecting issues. :) | winning |
## Inspiration
Misha wanted to teach Alice mechatronics, and we wanted to stop littering. We're not sure if we succeeded at either.
## What it does
It's a trash can that rolls around.
## How we built it
We took some cardboard boxes from the trash, put some stepper motors on, cut out wheels freehand, wrote a
program in Arduino C++, and connected it all with zip ties and hot glue.
## Challenges we ran into
The wheels keep falling off, since they're just hot glued directly to motor shafts. The USB battery we found doesn't have enough current to run all of our motors, and also a servo to open the lid, so we zip tied the lid open. The structure was too flimsy to hold a laptop/real computer, so we didn't use any advanced APIs.
## Accomplishments that we're proud of
It move. Marketing.
## What we learned
Alice learned how to use Arduino with no prior experience, including digital and analog I/O, servo, and stepper motors.
## What's next for Snashcan
It's going in the snash. | ## Inspiration
We drew inspiration from recognizing the laziness of people when they are sitting at their desks yet they wish to throw away their garbage. Hence, to solve this problem, we decided to have a robot that can shoot garbage to the trash bin without the need to get up.
## What it does
It transforms garbage throwing into a game. You can control the robot with a joystick, moving it forward and backwards, and side-to-side, and turning it left and right. After you decided on the position you wish for the robot to shoot, you can toggle to the arm by pressing the joystick, allowing you to change the angle at which the garbage is aimed at. You are able to toggle back and forth. When you are satisfied with the position, you can launch the garbage by pulling the elastic band, which will cause an impact with the garbage, sending it to your desired location.
## How we built it
We built it using C/C++ with two Arduino Uno and two NRF24L01 so it could have a wireless connection between the joystick controller and the robot itself. We have also connected the motors to the motor driver, allowing the motor to actually spin.
## Challenges we ran into
A major challenge we ran into was transmitting values from one NRF24L01 to the other. We kept on receiving "0"s as the output in the receiver, which was not what the receiver should be receiving.
## Accomplishments that we're proud of
We are proud of creating a project using C/C++ and Arduino as it was our first time working with these programming languages.
## What we learned
We learned how to use C/C++ and Arduino in a professional setting. We had no/little prior experience when it comes to coding in Arduino. Yet, during the entire hackathon, not only did we learn how to write codes in Arduino, we also learned how to connect the wires on the hardwires, allowing the robot to actually run.
## What's next for Garbage Shooter
The next steps for Garbage Shooter is to have a shooting mechanism where the user would have to control how much they want to stretch the rubber band through a joystick instead of manually launching the garbage. | ## Inspiration
I was walking down the streets of Toronto and noticed how there always seemed to be cigarette butts outside of any building. It felt disgusting for me, especially since they polluted the city so much. After reading a few papers on studies revolving around cigarette butt litter, I noticed that cigarette litter is actually the #1 most littered object in the world and is toxic waste. Here are some quick facts
* About **4.5 trillion** cigarette butts are littered on the ground each year
* 850,500 tons of cigarette butt litter is produced each year. This is about **6 and a half CN towers** worth of litter which is huge! (based on weight)
* In the city of Hamilton, cigarette butt litter can make up to **50%** of all the litter in some years.
* The city of San Fransico spends up to $6 million per year on cleaning up the cigarette butt litter
Thus our team decided that we should develop a cost-effective robot to rid the streets of cigarette butt litter
## What it does
Our robot is a modern-day Wall-E. The main objectives of the robot are to:
1. Safely drive around the sidewalks in the city
2. Detect and locate cigarette butts on the ground
3. Collect and dispose of the cigarette butts
## How we built it
Our basic idea was to build a robot with a camera that could find cigarette butts on the ground and collect those cigarette butts with a roller-mechanism. Below are more in-depth explanations of each part of our robot.
### Software
We needed a method to be able to easily detect cigarette butts on the ground, thus we used computer vision. We made use of this open-source project: [Mask R-CNN for Object Detection and Segmentation](https://github.com/matterport/Mask_RCNN) and [pre-trained weights](https://www.immersivelimit.com/datasets/cigarette-butts). We used a Raspberry Pi and a Pi Camera to take pictures of cigarettes, process the image Tensorflow, and then output coordinates of the location of the cigarette for the robot. The Raspberry Pi would then send these coordinates to an Arduino with UART.
### Hardware
The Arduino controls all the hardware on the robot, including the motors and roller-mechanism. The basic idea of the Arduino code is:
1. Drive a pre-determined path on the sidewalk
2. Wait for the Pi Camera to detect a cigarette
3. Stop the robot and wait for a set of coordinates from the Raspberry Pi to be delivered with UART
4. Travel to the coordinates and retrieve the cigarette butt
5. Repeat
We use sensors such as a gyro and accelerometer to detect the speed and orientation of our robot to know exactly where to travel. The robot uses an ultrasonic sensor to avoid obstacles and make sure that it does not bump into humans or walls.
### Mechanical
We used Solidworks to design the chassis, roller/sweeper-mechanism, and mounts for the camera of the robot. For the robot, we used VEX parts to assemble it. The mount was 3D-printed based on the Solidworks model.
## Challenges we ran into
1. Distance: Working remotely made designing, working together, and transporting supplies challenging. Each group member worked on independent sections and drop-offs were made.
2. Design Decisions: We constantly had to find the most realistic solution based on our budget and the time we had. This meant that we couldn't cover a lot of edge cases, e.g. what happens if the robot gets stolen, what happens if the robot is knocked over ...
3. Shipping Complications: Some desired parts would not have shipped until after the hackathon. Alternative choices were made and we worked around shipping dates
## Accomplishments that we're proud of
We are proud of being able to efficiently organize ourselves and create this robot, even though we worked remotely, We are also proud of being able to create something to contribute to our environment and to help keep our Earth clean.
## What we learned
We learned about machine learning and Mask-RCNN. We never dabbled with machine learning much before so it was awesome being able to play with computer-vision and detect cigarette-butts. We also learned a lot about Arduino and path-planning to get the robot to where we need it to go. On the mechanical side, we learned about different intake systems and 3D modeling.
## What's next for Cigbot
There is still a lot to do for Cigbot. Below are some following examples of parts that could be added:
* Detecting different types of trash: It would be nice to be able to gather not just cigarette butts, but any type of trash such as candy wrappers or plastic bottles, and to also sort them accordingly.
* Various Terrains: Though Cigbot is made for the sidewalk, it may encounter rough terrain, especially in Canada, so we figured it would be good to add some self-stabilizing mechanism at some point
* Anti-theft: Cigbot is currently small and can easily be picked up by anyone. This would be dangerous if we left the robot in the streets since it would easily be damaged or stolen (eg someone could easily rip off and steal our Raspberry Pi). We need to make it larger and more robust.
* Environmental Conditions: Currently, Cigbot is not robust enough to handle more extreme weather conditions such as heavy rain or cold. We need a better encasing to ensure Cigbot can withstand extreme weather.
## Sources
* <https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3397372/>
* <https://www.cbc.ca/news/canada/hamilton/cigarette-butts-1.5098782>
* [https://www.nationalgeographic.com/environment/article/cigarettes-story-of-plastic#:~:text=Did%20You%20Know%3F-,About%204.5%20trillion%20cigarettes%20are%20discarded%20each%20year%20worldwide%2C%20making,as%20long%20as%2010%20years](https://www.nationalgeographic.com/environment/article/cigarettes-story-of-plastic#:%7E:text=Did%20You%20Know%3F-,About%204.5%20trillion%20cigarettes%20are%20discarded%20each%20year%20worldwide%2C%20making,as%20long%20as%2010%20years). | losing |
## Inspiration
Travel planning is a pain. Even after you find the places you want to visit, you still need to find out when they're open, how far away they are from one another, and work within your budget. With Wander, automatically create an itinerary based on your preferences – just pick where you want to go, and we'll handle the rest for you.
## What it does
Wander shows you the top destinations, events, and eats wherever your travels take you, with your preferences, budget, and transportation in mind. For each day of your trip, Wander creates a schedule for you with a selection of places to visit, lunch, and dinner. It plans around your meals, open hours, event times, and destination proximity to make each day run as smoothly as possible.
## How we built it
We built the backend on Node.js and Express which uses the Foursquare API to find relevant food and travel destinations and schedules the itinerary based on the event type, calculated distances, and open hours. The native iOS client is built in Swift.
## Challenges we ran into
We had a hard time finding all the event data that we wanted in one place. In addition, we found it challenging to sync the information between the backend and the client.
## Accomplishments that we're proud of
We’re really proud of our mascot, Little Bloop, and the overall design of our app – we worked hard to make the user experience as smooth as possible. We’re also proud of the way our team worked together (even in the early hours of the morning!), and we really believe that Wander can change the way we travel.
## What we learned
It was surprising to discover that there were so many ways to build off of our original idea for Wander and make it more useful for travelers. After laying the technical foundation for Wander, we kept brainstorming new ways that we could make the itinerary scheduler even more useful, and thinking of more that we could account for – for instance, how open hours of venues could affect the itinerary. We also learned a lot about the importance of design and finding the best user flow in the context of traveling and being mobile.
## What's next for Wander
We would love to continue working on Wander, iterating on the user flow to craft the friendliest end experience while optimizing the algorithms for creating itineraries and generating better destination suggestions. | ## Inspiration 🌱
Climate change is affecting every region on earth. The changes are widespread, rapid, and intensifying. The UN states that we are at a pivotal moment and the urgency to protect our Earth is at an all-time high. We wanted to harness the power of social media for a greater purpose: promoting sustainability and environmental consciousness.
## What it does 🌎
Inspired by BeReal, the most popular app in 2022, BeGreen is your go-to platform for celebrating and sharing acts of sustainability. Everytime you make a sustainable choice, snap a photo, upload it, and you’ll be rewarded with Green points based on how impactful your act was! Compete with your friends to see who can rack up the most Green points by performing more acts of sustainability and even claim prizes once you have enough points 😍.
## How we built it 🧑💻
We used React with Javascript to create the app, coupled with firebase for the backend. We also used Microsoft Azure for computer vision and OpenAI for assessing the environmental impact of the sustainable act in a photo.
## Challenges we ran into 🥊
One of our biggest obstacles was settling on an idea as there were so many great challenges for us to be inspired from.
## Accomplishments that we're proud of 🏆
We are really happy to have worked so well as a team. Despite encountering various technological challenges, each team member embraced unfamiliar technologies with enthusiasm and determination. We were able to overcome obstacles by adapting and collaborating as a team and we’re all leaving uOttahack with new capabilities.
## What we learned 💚
Everyone was able to work with new technologies that they’ve never touched before while watching our idea come to life. For all of us, it was our first time developing a progressive web app. For some of us, it was our first time working with OpenAI, firebase, and working with routers in react.
## What's next for BeGreen ✨
It would be amazing to collaborate with brands to give more rewards as an incentive to make more sustainable choices. We’d also love to implement a streak feature, where you can get bonus points for posting multiple days in a row! | ## Inspiration
We always that moment when you're with your friends, have the time, but don't know what to do! Well, SAJE will remedy that.
## What it does
We are an easy-to-use website that will take your current location, interests, and generate a custom itinerary that will fill the time you have to kill. Based around the time interval you indicated, we will find events and other things for you to do in the local area - factoring in travel time.
## How we built it
This webapp was built using a `MEN` stack. The frameworks used include: MongoDB, Express, and Node.js. Outside of the basic infrastructure, multiple APIs were used to generate content (specifically events) for users. These APIs were Amadeus, Yelp, and Google-Directions.
## Challenges we ran into
Some challenges we ran into revolved around using APIs, reading documentation and getting acquainted to someone else's code. Merging the frontend and backend also proved to be tough as members had to find ways of integrating their individual components while ensuring all functionality was maintained.
## Accomplishments that we're proud of
We are proud of a final product that we legitimately think we could use!
## What we learned
We learned how to write recursive asynchronous fetch calls (trust me, after 16 straight hours of code, it's really exciting)! Outside of that we learned to use APIs effectively.
## What's next for SAJE Planning
In the future we can expand to include more customizable parameters, better form styling, or querying more APIs to be a true event aggregator. | winning |
## Inspiration
As university students, we are finally able to experience moving out and living on our own. Something we've realized is that shopping is an inescapable part of adult life. It can be tedious to figure out what to buy in the moment, and keeping track of items after you've decided and then searching for them throughout the store is no easy feat. Hence, we've decided to design an app that makes shopping cheap, convenient and *smart*.
## What it does
Our app has two main features, an intelligent recommendation system that can use user voice/text search to recommend products as well as a system for product image recognition. The recommendation system allows users to quickly search up relevant items by saying what they want to buy (ex. “What should I buy for my daughter’s birthday party?”, or "what is on sale this week?"). The app will then list smart suggestions pertaining to what you inputted, that can be added to the shopping list. Users can also take pictures of products to figure out the price of a product, price match and check whether it is on sale. The shopping list can then be viewed and each product will list important information such as the aisle number so that shoppers can easily find them.
## How we built it
The app was built using React Native for cross platform support on mobile and the backend was built using Flask with Heroku.
The product database was generated using Selenium to scrape every item in the Loblaws website catalog, categorized by department with other relevant information that employees can add on (aisle number specific to a store).
The smart speech to text recommendation system was built using AssemblyAI as well as Datamuse API to first convert the speech to text, then get the relevant words using AssemblyAI’s keywords feature. The words were then fed into the Datamuse api to get words that are associated and then give them a rank which were then used to search the product database. This allows users to speak in both a **direct and a casual way**, with our system detecting the context of each and recommending the best products.
The image recognition was done using a mix of google vision api as well as a custom trained vision api product search model. This model was automatically generated using selenium by connecting the loblaws listings with google images and uploading into specific buckets on google storage. By comparing these two models, we are able to narrow down the image context to either a specific product in store, or annotate its more general uses. This is then passed onto the logic used by the recommendation system to give context to the search, and finally onto our custom product mapping system developed through automated analysis of product descriptions.
## Challenges we ran into
It was our first time working with React Native and training our own model. The model had very low confidence at the start and required a lot of tweaking before it was even slightly usable, and had to be used alongside the known Vision API. This was our first time using Heroku which provided easy CI/CD integration on GitHub, and we had to understand how to insert Vision API environment variables without committing them.
## Accomplishments that we're proud of
We are proud of our user friendly design that is intuitive, especially as a team that has no designers. We were also able to successfully implement every feature that we planned, which we are very proud of.
## What's next for ShopAdvisr
Working with a company directly and having access to their whole database would greatly improve the apps database without having to scrape the website, and allow more options for expansion. | ## Inspiration
Let’s face it: getting your groceries is hard. As students, we’re constantly looking for food that is healthy, convenient, and cheap. With so many choices for where to shop and what to get, it’s hard to find the best way to get your groceries. Our product makes it easy. It helps you plan your grocery trip, helping you save time and money.
## What it does
Our product takes your list of grocery items and searches an automatically generated database of deals and prices at numerous stores. We collect this data by collecting prices from both grocery store websites directly as well as couponing websites.
We show you the best way to purchase items from stores nearby your postal code, choosing the best deals per item, and algorithmically determining a fast way to make your grocery run to these stores. We help you shorten your grocery trip by allowing you to filter which stores you want to visit, and suggesting ways to balance trip time with savings. This helps you reach a balance that is fast and affordable.
For your convenience, we offer an alternative option where you could get your grocery orders delivered from several different stores by ordering online.
Finally, as a bonus, we offer AI generated suggestions for recipes you can cook, because you might not know exactly what you want right away. Also, as students, it is incredibly helpful to have a thorough recipe ready to go right away.
## How we built it
On the frontend, we used **JavaScript** with **React, Vite, and TailwindCSS**. On the backend, we made a server using **Python and FastAPI**.
In order to collect grocery information quickly and accurately, we used **Cloudscraper** (Python) and **Puppeteer** (Node.js). We processed data using handcrafted text searching. To find the items that most relate to what the user desires, we experimented with **Cohere's semantic search**, but found that an implementation of the **Levenshtein distance string algorithm** works best for this case, largely since the user only provides one to two-word grocery item entries.
To determine the best travel paths, we combined the **Google Maps API** with our own path-finding code. We determine the path using a **greedy algorithm**. This algorithm, though heuristic in nature, still gives us a reasonably accurate result without exhausting resources and time on simulating many different possibilities.
To process user payments, we used the **Paybilt API** to accept Interac E-transfers. Sometimes, it is more convenient for us to just have the items delivered than to go out and buy it ourselves.
To provide automatically generated recipes, we used **OpenAI’s GPT API**.
## Challenges we ran into
Everything.
Firstly, as Waterloo students, we are facing midterms next week. Throughout this weekend, it has been essential to balance working on our project with our mental health, rest, and last-minute study.
Collaborating in a team of four was a challenge. We had to decide on a project idea, scope, and expectations, and get working on it immediately. Maximizing our productivity was difficult when some tasks depended on others. We also faced a number of challenges with merging our Git commits; we tended to overwrite one anothers’ code, and bugs resulted. We all had to learn new technologies, techniques, and ideas to make it all happen.
Of course, we also faced a fair number of technical roadblocks working with code and APIs. However, with reading documentation, speaking with sponsors/mentors, and admittedly a few workarounds, we solved them.
## Accomplishments that we’re proud of
We felt that we put forth a very effective prototype given the time and resource constraints. This is an app that we ourselves can start using right away for our own purposes.
## What we learned
Perhaps most of our learning came from the process of going from an idea to a fully working prototype. We learned to work efficiently even when we didn’t know what we were doing, or when we were tired at 2 am. We had to develop a team dynamic in less than two days, understanding how best to communicate and work together quickly, resolving our literal and metaphorical merge conflicts. We persisted towards our goal, and we were successful.
Additionally, we were able to learn about technologies in software development. We incorporated location and map data, web scraping, payments, and large language models into our product.
## What’s next for our project
We’re very proud that, although still rough, our product is functional. We don’t have any specific plans, but we’re considering further work on it. Obviously, we will use it to save time in our own daily lives. | ## Inspiration
The inspiration for this project was from our personal experiences living with bad roommates, who overstuffed the fridge with a lot of food, that used to be expired or took our food. We wanted to tackle this problem and make a solution to manage the inventory of the fridge or a shared closet.
## What it does
The solution uses cameras to monitor, who is placing and removing items to/from the Fridge and what they are placing/removing. It achieves this using computer vision, technology to recognize the user from the registered set of users for a certain device.
## How we built it
The solution was primarily split into two parts, the machine learning side and the user interface. The machine learning side was completely built in python, from client to server, using opencv,flask, tensorflow, and using the pre trained model inception v3. The half the project also controlled the devices cameras to detect movement and detect objects to be recognized. The user interface side of the project was built on react, using bootstrap and semantic ui. The interface allowed the users to checkout the inventory of their devices, and what items each user had.
The two sides were bridged using Node.js and mongodb, which acted as the central data storage and communication point from the machine learning and the user interface.
## Challenges we ran into
The computer vision side of the project was extremely challenging in the limited time, especially detecting objects in the frame without using Deep Learning to keep the client processing load at a minimum, Furthermore, the data-sets had to curated and specially customized to fit this challenge.was
In terms of the back-end, it was difficult to connect the node server to the python machine learning scripts, so we went with a micro service solution, where the machine learning was served on two flask endpoints to the node server which handled all the further processing.
Finally, in terms of the front-end, there were challenges in terms of changing state of semantic-ui components, which finally required us to switch to bootstrap in the middle of the hack. The front-end also posed a greater time challenge, as the primary front-end developer had to catch a flight the night before the hack ended, and therefore was limited in the time she had to develop the user interface
## Accomplishments that we're proud of
The solution overall worked, in the sense that there was a minimal viable product, where all the complex moving pieces came together to actually recognize an object and the person that added the object.
The computer vision aspect of the project was quite successful for the short time, we had to develop the solution. Especially the object recognition, which had a much higher confidence than was expected for such a short hack.
## What we learned
There were a lot of takeaways from this hack, especially in terms of devops, which posted a major challenge. It made us think a lot more about how difficult deploying IoT Solutions are, and the devop complexity they create. Furthermore, the project had a lot of learning to be had from its ambitious scope, which challenged us to use a lot of new technologies which we weren't extremely comfortable with prior to the hack
## What's next for Koelkast
We hope to keep training the algorithms to get them to a higher confidence level, one that would be more production ready. Furthermore, we want to take a look at perfboards, which are custom made to our specific requirements, These boards would be cheaper to product and deploy, which would be needed for the project to be take to production | partial |
## Inspiration
Whenever friends and I want to hang out, we always ask about our schedule. Trying to find a free spot could take a long time when I am with a group of friends. I wanted to create an app that simplifies that process.
## What it does
The website will ask the duration of the event and ask to fill out each person's schedule. The app will quickly find the best period for everyone.
## How we built it
We built it using HTML/CSS and Javascript. We also used a calendar plugin.
## Challenges we ran into
The integration of the calendar plugin is hard and the algorithm that finds the best time slot is also hard to implement.
## Accomplishments that we're proud of
Although the site is not finished, we have the overall website structure done.
## What we learned
It was hard to work on this project in a team of 2.
## What's next for MeetUp
We will try to finish this project after pennapps. | ## Inspiration
We were inspired by [Radish](https://radish.coop), one of this year's sponsors for McHacks10, a food delivery service whose mission is to bring forth a more equitable relationship between restaurateurs, delivery drivers and consumers. We wanted to create a place where people can learn and understand others' opinions regarding various food delivery services, hopefully inspiring them to move away from large-scale delivery platforms and towards food delivery collectives that put members first. We think that's pretty rad.
## What it does
RadCompare collects tweets regarding existing food delivery services, filters out retweets and spam and runs natural language processing (NLP) on the data to gather user and employee sentiment regarding food delivery services.
## How we built it
For the backend functionality, we used Python, NumPy, pandas, Tweepy and Co:here.
For the frontend design, we used HTML/CSS and JavaScript and used Figma to design the site's logos.
## Main Challenges
* Getting permission to use the Tweepy API
* Configuring and understanding Co:here for NLP
* Our .DS\_Store being chaotic
## Accomplishments we're proud of
* Using technology to change the way people think about large-scale food delivery services
* Learning how to use Co:here for the first time
* Adapting to various challenges by using different frameworks
* The overall website design and our *rad* logo :)
## What we learned
* The power of natural language processing (and how cool it is)!
* More about Radish's mission and values and how they're changing the game when it comes to food delivery services
## What's next for RadCompare
* Full integration of the frontend and backend
* Expanding our website | ## Inspiration
As college students, one of the biggest issues we face in our classes is finding a study group we love and are comfortable in. We created this project to solve this problem.
## What it does
Our website provides an interface for students to create and join study groups, as well as invite their friends to join their groups, and chat with other members of the group.
## How I built it
We used the Google Calendar API with a node.js / Python backend to build our website.
## Challenges I ran into
One of the biggest challenges we faced during the construction of this project was using the Google Calendar API with server-side authentication with a default email address, as opposed to requesting the user for authentication.
## Accomplishments that I'm proud of
## What I learned
## What's next for StudyGroupMe
We need to work on and improve the User Interface. Secondly, once we have access to logging in through Harvard Key, we no longer need to scrape for information, and will directly have access to class/student information on login | losing |
The idea started with the desire to implement a way to throw trash away efficiently and in an environmentally friendly way. Sometimes, it is hard to know what bin trash might go to due to time or carelessness. Even though there are designated spots to throw different type of garbage, it is still not 100% reliable as you are relying on the human to make the decision correctly. We thought of making it easier for the human to throw trash by putting it on a platform and having an AI make the decision for them. Basically, a weight sensor will activate a camera that will take a picture of the object and run through its database to see which category the trash belongs in. There is already a database containing a lot of pictures of trash, but that database can constantly grow as more pictures are taken.
We think this will be a good way to reduce the difficulty in separating trash after it's taken to the dump sites, which should definitely make a positive impact on the environment. The device can be small enough and inexpensive enough at one point that it can be implemented everywhere.
We used azure custom vision to do the image analysis and image data storage, the telus iot starter kit for giving sensor data to the azure iot hub, and an arduino to control the motor that switches between plastic trash and tin can trash. | ## Inspiration
We inherently know importance of recycling, but we get lazy and sometimes forget. People often throw their waste in the wrong recycling bin (e.g. bottles for compost or food waste for landfill) which negates the entire purpose of recycling. Therefore, we wanted to create a project to solve this issue.
## What it does
Introducing **sorta**, a project that combines computer vision and hardware components to make recycling more convenient and effective. Our system utilizes image recognition via a mounted camera to recognize waste and identify which kind of recycling bin it best belongs in. Our system will communicate with the recycling bins to ensure that only the identified bin will open for the user. Therefore, people have no choice but to correctly dispose their waste.
## How we built it
For capturing images and opening specific bins properly, our system utilizes a Raspberry Pi 3 Microcontroller with an Arducam, an ultrasonic range sensor, and three servo motors. The Arducam captures images and the microcontroller sends the images to a storage account in Microsoft Azure. The Arducam only takes pictures when a user is within a certain range of the waste disposal system so that we do not have excessive, superfluous data; our system detects range with the ultrasonic range sensor. Finally, our system manages the opening and closing of the recycling bins through three standard servo motors.
In terms of software, after the Raspberry Pi takes the picture of the piece of waste it is uploaded into a Microsoft blob storage so that the list of pictures taken are easily iterated through and turned into the proper format (URL). The system then utilises the Microsoft cognitive services, computer vision API to detect the type of waste it is (eg. plastic bottle, plastic bag, can). A category hierarchy is then built on top of it to sort the detected objects into more general categories. This builds up until each object is sorted into the 3 categories of a typical recycling bin in Stanford: Compostable (fruits, vegetables), Recycle (glass, plastic, metal, paper), landfill. For extra accuracy the system then also runs the pictures through the Microsoft custom vision API which we manually trained with a mixture of categorised waste pictures from ImageNet and manually taken pictures of food wrapper waste lying around in the Hackathon. Our original plan also involved training this API to detect brand names and company logos.
The data coming in from both APIs are then stored up in a Microsoft cosmos db with Mongodb. If company brand logos, type of waste and location (trivial data because the physical system is stationary and it can be hardcoded) are successfully obtained. This has potential to be used in data analytics applications (eg. displaying in a heatmap showing which company is producing what type of waste at high levels in different locations)
## Challenges we ran into
Waste sorting isn’t completely a visual problem. People sort waste according to what the wastes are, but what the wastes are depends not only on our vision of those objects. A piece of metal is categorized into recycled because it feels like a metal in our hands. Therefore, we are working on problems that contain more factors that we can tackle currently. Thus, we have to optimize under inevitably biased sub-optimal situations.
No one in our team had a strong background regarding hardware. Therefore, implementing all the Raspberry Pi features was a challenge. Although we managed to implement the camera capture with aspects of distance detection and image transfer to the Microsoft Azure data storage space, we were not able to implement the opening and closing of recycling bins through the servo motors.
Data selection was challenging, as we didn’t have access to database with good quality control. In the end, we have to manually select general and valid photos of glass, plastic, metal, paper, etc. so that our model developed with the Microsoft custom vision API could be better trained.
Along the way we came across many small bugs that really tripped up the teams progress. Many of those bugs, involved calling APIs because the errors returned were generally unclear on which parameter was missing in the call. So a large amount of time it came down to trial and error on guessing the conventions of these API calls.
## Accomplishments that we're proud of
For all the members in our team, this event was the first hackathon we ever attended. Therefore, we’re very proud of submitting an idea and project we felt could an beneficial impact on society.
Although the learning curve at times was steep, we are proud that we stuck with it throughout the whole event. We definitely learned a lot and were exposed to a ton of amazing resources we can use for future projects.
We also had a blast discovering the collaborative, innovative, and inspiring nature of hackathons. We met a lot of people this weekend that we otherwise would never have the chance to meet. To conclude, we are really looking forward to attending our next hackathon!
## What we learned
Hardware, Database, Raspberry Pi, Microsoft Cognitive Services (including computer vision API and custom vision API)
## What's next for sorta
We could integrate more sensors into our system so that it’s easier to distinguish certain material like metal.
We could also integrate motors into our system that we were not able to finish this time, so that the user only needs to place the trash on a plate, and our system can categorize it and place it into the right trash bin.
If company logo brand and location data is also collected at a larger scale with sharpener waste classification, we believe that the data collected can be very useful. It can be used to detect consumer patterns in different locations as well as waste data for environmental purposes. | ## Inspiration
With the ubiquitous and readily available ML/AI turnkey solutions, the major bottlenecks of data analytics lay in the consistency and validity of datasets.
**This project aims to enable a labeller to be consistent with both their fellow labellers and their past self while seeing the live class distribution of the dataset.**
## What it does
The UI allows a user to annotate datapoints from a predefined list of labels while seeing the distribution of labels this particular datapoint has been previously assigned by another annotator. The project also leverages AWS' BlazingText service to suggest labels of incoming datapoints from models that are being retrained and redeployed as it collects more labelled information. Furthermore, the user will also see the top N similar data-points (using Overlap Coefficient Similarity) and their corresponding labels.
In theory, this added information will motivate the annotator to remain consistent when labelling data points and also to be aware of the labels that other annotators have assigned to a datapoint.
## How we built it
The project utilises Google's Firestore realtime database with AWS Sagemaker to streamline the creation and deployment of text classification models.
For the front-end we used Express.js, Node.js and CanvasJS to create the dynamic graphs. For the backend we used Python, AWS Sagemaker, Google's Firestore and several NLP libraries such as SpaCy and Gensim. We leveraged the realtime functionality of Firestore to trigger functions (via listeners) in both the front-end and back-end. After K detected changes in the database, a new BlazingText model is trained, deployed and used for inference for the current unlabeled datapoints, with the pertinent changes being shown on the dashboard
## Challenges we ran into
The initial set-up of SageMaker was a major timesink, the constant permission errors when trying to create instances and assign roles were very frustrating. Additionally, our limited knowledge of front-end tools made the process of creating dynamic content challenging and time-consuming.
## Accomplishments that we're proud of
We actually got the ML models to be deployed and predict our unlabelled data in a pretty timely fashion using a fixed number of triggers from Firebase.
## What we learned
Clear and effective communication is super important when designing the architecture of technical projects. There were numerous times where two team members were vouching for the same structure but the lack of clarity lead to an apparent disparity.
We also realized Firebase is pretty cool.
## What's next for LabelLearn
Creating more interactive UI, optimizing the performance, have more sophisticated text similarity measures. | losing |
## Inspiration
Inspiration comes from nature. Many mammals use evaporation as a cooling mechanism. Many ancient cultures in warm climates also use clay to store water because its pores allows water to evaporate, cooling it.
## What it does
A cold storage.
## How I built it
Used C++ to code Maxim integrated microcontrollers (MAX32630FTHR) and digital temperature sensors (MAX31723).
## Challenges I ran into
Trying to output the sensor reading to terminal was hard.
## Accomplishments that I'm proud of
The diagrams in the presentation are good.
## What I learned
How to work with the Maxim Integrated API to control sensors.
## What's next for MediCool
Actually building the system! | ## Inspiration
Often, people are afraid to post their opinions in the Internet because their words are attached to an identity. We wanted to create a community where people can express their thoughts freely and completely anonymously.
## What it does
Posts are shared by anonymous users, which are then voted and discussed upon by peers, who also remain anonymous.
## How we built it
The client is HTML5 with JavaScript, communicating through a RESTful API with the Go backend running on an Azure VM and distributed through AWS CloudFront.
## Challenges we ran into
Writing an entire application in less than 24 hours was the main challenge. | ## Inspiration
We were inspired by how there were many instances of fraud with regards to how donations were handled. It is heartbreaking to see how mismanagement can lead to victims of disasters not receiving the help that they desperately need.
## What it does
TrustTrace introduces unparalleled levels of transparency and accountability to charities and fundraisers. Donors will now feel more comfortable donating to causes such as helping earthquake victims since they will now know how their money will be spent, and where every dollar raised is going to.
## How we built it
We created a smart contract that allowed organisations to specify how much money they want to raise and how they want to segment their spending into specific categories. This is then enforced by the smart contract, which puts donors at ease as they know that their donations will not be misused, and will go to those who are truly in need.
## Challenges we ran into
The integration of smart contracts and the web development frameworks were more difficult than we expected, and we overcame them with lots of trial and error.
## Accomplishments that we're proud of
We are proud of being able to create this in under 36 hours for a noble cause. We hope that this creation can eventually evolve into a product that can raise interest, trust, and participation in donating to humanitarian causes across the world.
## What we learned
We learnt a lot about how smart contract works, how they are deployed, and how they can be used to enforce trust.
## What's next for TrustTrace
Expanding towards serving a wider range of fundraisers such as GoFundMes, Kickstarters, etc. | losing |
## Inspiration 💡
Back at university, we had a friend who couldn't see the professor's notes during lectures so he needed to take pictures, and often fell behind in class. But what if there was a way to take the pictures and convert them straight to notes? Introducing NoteSense, the fast and easy way to digitize captured photos and audio into ready to use typed up notes.
## What it does 🤔
NoteSense is a notes accessibility app that allows users to create notes based on images or audio snippets. Through harnessing technologies such as speech recognition and optical character recognition (OCR) users who have hearing deficits or vision impairment can create notes in a format they can access quickly and conveniently! Our platform quickly converts their image or audio they took from their mobile device to a PDF that is sent to their email! This way users can quickly stay on track during their lectures and not feel behind or at a disadvantage compared to their colleagues. Users also have the ability to view their generated PDFs on their device for quick viewing as well!
## How we built it 🖥️
When building out NotesSense, we chose 3 key design principles to help ensure our product meets the design challenge of accessibility! Simplicity, Elegance and Scalability.
We wanted NotesSense to be simple to design, upgrade and debug. This led to us harnessing the lightweight framework of Flask and the magic of Python to design our backend infrastructure. To ensure our platform is scalable and efficient we harnessed the Google Cloud Platform to perform both our speech and image conversions harnessing its vision and speech api respectively. Using GCP as our backbone allowed our product to be efficient and responsive! We then used various python libraries to create our email and file conversion services, enabling us to harness the output from GCP to rapidly send pdfs of their notes to our users' emails!
To create an elegant and user-friendly experience we leveraged React Native and various design libraries to present our users with a new, accessible platform to create notes for individuals who may have hearing and/or seeing difficulties. React Native also worked seamlessly with our Flask backend and our third party APIs. This integration also allowed for a concurrent development stream for both our front end and back end teams.
## Challenges we ran into 🔧
Throughout the course of this hackathon, we faced a variety of challenges before producing our final product. Issues with PDF reading and writing, audio conversion, and cross platform compatibility were the most notable of the bunch.
Since this was our first time manipulating a phone’s filesystem using React Native, we had a few hiccups during the development of the PDF code to write to and read from the phone’s document directory. More specifically, we were confused as to how to create and populate a file with a stream of data of a PDF file type in the local filesystem. After some thorough research, we discovered that we could encode our data in a Base64 format and asynchronously write the string to a file in the local filesystem. Consequently, we could read this same file asynchronously and decode the Base64 to display the PDF in the app.
Audio conversion was initially a big issue as both the frontend and backend did not have in-built or 3rd-party library functionality to convert between two specific file types that we believed we could not avoid. However, we later found that the client-side recording can be saved as a file type that was compatible with the Google Cloud Platform’s speech to text API.
Cross platform compatibility was an issue that arose in multiple places throughout the course of development. Some UI elements would appear and behave differently on different operating systems. Fortunately, we had the ability to test on both Android and IOS devices. Therefore, we were able to pinpoint the cross platform issues and fix them by adding conditionals to change UI based on what platform the app is running on.
Although we had to face various obstacles during the development of our app, we were able to overcome every single one of them and created a functional application with our desired outcome.
## What we learned 🤓
Hack the 6ix really helped develop our hard and soft skills. For starters, for many of us it was our first time using Google Cloud platform and other various google services! Learning GCP in a high pressure and fast paced environment was definitely a great and unique experience. This was also the first hackathon where we targeted a specific challenge (accessibility and GCP) and designed a product accordingly. As a result, this event enabled us to hone both our technical and design skills to create a product to help solve a specific problem. Furthermore, we also learned how to deal with file conversions in both Python and in React Native!
Participating in this hackathon in a virtual setting definitely tested our team work and communication skills. We collaborated through Discord to coordinate our issues and track progress, as well as play music on our server to keep our morale at a high :).
## What's next for NoteSense 🏃♂️
For the future we have many ideas to improve the accessibility and scalability of NoteSense. A feature we weren’t able to develop currently but are planning is to improve our image recognition to handle detailed diagrams and drawings. Diagrams often paint a better picture and improve one's understanding which is something we would want to take advantage of in Note Sense. Due to the limitations of Google Cloud Platform currently our speech to text functionality is limited to only 60 seconds. This is fine for shorter recordings, however in the future we would want to look into options that allow for longer audio files for the purpose of recording live lectures, meetings or calls. Another feature that we would like to explore is using video to not only convert the audio into notes, but also capture any visual aid provided in the video to enhance the PDF notes we create. | ## Inspiration
As usual, we wanted to build something useless (yet still aesthetic). As math students, the answer came naturally to us - an animation of orbits of Lie groups!
## What it does
This site simulates the orbits of matrix Lie groups. For a fixed matrix and a few set starting points in 3d space, we compute the orbit of these points via the action of this matrix. This gives us a set of lines in 3d. Then, by varying the matrix, we can twist and warp these lines! We've provided several one-parameter variations for you to choose between, and you can even write your own matrices. [Check out our live demo](https://abrandenberger.github.io/mchacks-2021/)!
## How we built it
We built this using the amazing 3D rendering three.js library, and otherwise pure Javascript/HTML/CSS.
## Challenges we ran into
Some computations were very time and memory intensive, and we had to find ways to speed them up.
## Accomplishments that we're proud of
We're very happy that these lines look so interesting!
## What's next for *Lie for Me*
Make sharing custom matrix expressions easier by embedding it in the website link. | ## **Education Track**
## Inspiration
We were brainstorming ideas of how to best fit this hackathon into our schedule and still be prepared for our exams the following Monday. We knew that we wanted something where we could learn new skills but also something useful in our daily lives. Specifically, we wanted to create a tool that could help transcribe our lectures and combine them into easy-to-access formats.
## What it does
This tool allows users to upload video files or links and get a PDF transcript of it. This creates an easy way for users who prefer to get the big ideas to save time and skip the lectures as well as act as a resource for open-note exams.
## How we built it
The website is a react.js application whilst the backend is made up of Firebase for the database, and an express API to access the Google Speech to Text API to help with our transcribing.
## Challenges we ran into
Both of us being novices to using APIs such as Google's we spent quite a bit of time troubleshooting and figuring out how they worked. This left us with less time than desired but we were able to complete a web app that captures the big picture of our app.
## Accomplishments that we're proud of
We are both proud that we were able to learn so many new skills in so little time and are excited to continue this project and create new ones as well. And most importantly we had fun!
## What we learned
We learned quite a lot this weekend.
* Google Cloud APIs
* Firebase
* WikiRaces (How to get from Tigers to Microphones in record time)
* Having Fun!
## What's next for EZNotes
We hope to finish out the app's other features as well as create a summarizing tool using AI so that the notes are even more useful. | partial |
## Inspiration
Being university students who are currently engulfed in the process of finding summer co-op jobs, we were inspired to create this project after reflecting on the struggles each of us have faced. We decided to build an advanced interview practice web application that would allow students like us to practice our skills and gain valuable feedback so that we can walk into any interview with the confidence that we will get the job.
## What it does
Ace is an interview practice web application that will allow users to start their mock interview using our easy-to-use UI and that provides the user with randomly generated interview questions to answer. Throughout the practice interview, the audio is recorded and after the questions have been asked, the Ace application will analyze the user's full verbal response to see how the user can improve as well as improvements on facial expressions such as smiling
## How we built it
We built the backend using Python and many libraries for the software that handles the webcam and audio recording in addition to providing the user with questions and valuable feedback. The frontend with the UI/UX was created using React and then the frontend web application was connected to the Python backend using a Flask server. We built the majority of our analysis software using AWS and other analytical software and used the MongoDB database to store our vast amount of collected to data to be used in the future.
## Challenges we ran into
Some challenges we ran into was the lack of time, the creation process of our Flask server, and the integration of all the components of our project due to a large number of individual parts that had to be put together in order for the final product to function cohesively. Though 36 hours may seem like a lot of time, because we chose to do a more difficult and demanding project, we found ourselves racing against the clock to finish, especially after hitting a wall during the creating of our Flask server. We faced many challenges when building our Flask server because none of us had very much previous experience working with Flask and we got to a point where we couldn't continue with building our project until we found a way to get our Flask server to function properly and link our frontend to our backend.
## Accomplishments that we're proud of
We finished, we are all proud of the final product, it brings good to the lives of others
## What we learned
We learned how to use AWS, Flask, MongoDB, React
## What's next for Ace
More intuitive user interface and a stronger variety of ways to practice | ## MAGIC CLIENT MANAGER
## *User-friendly web app uses data analytics and machine learning to dig up demographics and predict insurance premiums*
---
## Inspiration
While our interest originally stemmed from the desire to pick up basic machine learning and data analysis techniques, we loved the interdisciplinary aspect of the ViTech insurance hack, which emphasized both creating a user interface and analyzing the data itself and presenting it successfully on the UI.
It really challenged us to work with linking our application to backend since the challenge was so reliant on dynamically provided data.
The web app is simple and user-friendly because we want to help you! Whether "you" are a company executive or a prospective client, we want you to clearly understand and visualize data. Our application is minimalistic and has massive potential for growth.
## What It Does
Magic Client Manager is an online tool designed with the user experience in mind. We took the dataset provided by Vitech and analyzed it using various techniques, including but not limited to regressions and dimensionality reduction.
Clients can filter through and find users in the database by name, address, city, state, and/or several other fields who meet those parameters.
We created a multi-linear model in R which we implemented in Angular as an interactive Insurance Premium Predictor.
We have also integrated beautiful visualizations of data analytics to paint a comprehensive big picture overview of 1.4 million data points.
## How We Built It
The user interface was constructed using Angular4 with Firebase acting as our backend. We used R to create the predictive models used in our UI to estimate premium rates. Python and Matlab were used to analyze the Vitech dataset and libraries were imported into Python in order to create the visualizations.
## Challenges
* This was one of our first times successfully connecting Angular4 to Firebase.
* Dealing with outdated versions of Angular and the various modules I worked with since the community is so dynamic.
* Acquiring the data from SOLR was really difficult. The wifi was really slow and it took several minutes to load 10 rows into the Jupyter notebook.
* Under unfortunate circumstances, one of our teammates arrived 12 hours late.
* The majority of us had practically no experience with data analysis and machine learning. It was hard though we learned a lot!
* Everyone was proficient in a different programming language, so we have an odd selection of programs and trying to sync up was a little difficult.
## Accomplishments We're Proud Of
* Learning Angular4 and Firebase!
* We learned a lot and we had relatively accurate predictions regarding the data we were able to query from SOLR.
* Our app works pretty well!
* Tapped into multiple fields (interdisciplinary!)
## What We Learned
* Brushing up on Angular4 and dealing with dependencies errors between Angular4, Materials2, and Firebase 5.0 proved to be a fairly difficult challenge.
* Working with big data was especially difficult, especially because the wifi was slow during peak times of the Hackathon, making data updating almost impossible.
* How to use SOLR, Firebase, and interesting and useful Python libraries
* A variety of machine learning techniques; there are so many and all of them have different pros and cons.
* Cleaning up and working with massive data
* For two of us, it was our second hackathon - so we're finally learning how to submit a hack, which we accidentally failed to submit the first time haha
* For a majority of us, it was our first time working with someone we had never met before.
## What's Next
* Integrate more advanced machine learning and prediction models.
* Feeding in more data into Firebase.
* Smooth out any corner cases that we might've missed | >
> Domain.com domain: IDE-asy.com
>
>
>
## Inspiration
Software engineering and development have always been subject to change over the years. With new tools, frameworks, and languages being announced every year, it can be challenging for new developers or students to keep up with the new trends the technological industry has to offer. Creativity and project inspiration should not be limited by syntactic and programming knowledge. Quick Code allows ideas to come to life no matter the developer's experience, breaking the coding barrier to entry allowing everyone equal access to express their ideas in code.
## What it does
Quick Code allowed users to code simply with high level voice commands. The user can speak in pseudo code and our platform will interpret the audio command and generate the corresponding javascript code snippet in the web-based IDE.
## How we built it
We used React for the frontend, and the recorder.js API for the user voice input. We used runkit for the in-browser IDE. We used Python and Microsoft Azure for the backend, we used Microsoft Azure to process user input with the cognitive speech services modules and provide syntactic translation for the frontend’s IDE.
## Challenges we ran into
>
> "Before this hackathon I would usually deal with the back-end, however, for this project I challenged myself to experience a different role. I worked on the front end using react, as I do not have much experience with either react or Javascript, and so I put myself through the learning curve. It didn't help that this hacakthon was only 24 hours, however, I did it. I did my part on the front-end and I now have another language to add on my resume.
> The main Challenge that I dealt with was the fact that many of the Voice reg" *-Iyad*
>
>
> "Working with blobs, and voice data in JavaScript was entirely new to me." *-Isaac*
>
>
> "Initial integration of the Speech to Text model was a challenge at first, and further recognition of user audio was an obstacle. However with the aid of recorder.js and Python Flask, we able to properly implement the Azure model." *-Amir*
>
>
> "I have never worked with Microsoft Azure before this hackathon, but decided to embrace challenge and change for this project. Utilizing python to hit API endpoints was unfamiliar to me at first, however with extended effort and exploration my team and I were able to implement the model into our hack. Now with a better understanding of Microsoft Azure, I feel much more confident working with these services and will continue to pursue further education beyond this project." *-Kris*
>
>
>
## Accomplishments that we're proud of
>
> "We had a few problems working with recorder.js as it used many outdated modules, as a result we had to ask many mentors to help us get the code running. Though they could not figure it out, after hours of research and trying, I was able to successfully implement recorder.js and have the output exactly as we needed. I am very proud of the fact that I was able to finish it and not have to compromise any data." *-Iyad*
>
>
> "Being able to use Node and recorder.js to send user audio files to our back-end and getting the formatted code from Microsoft Azure's speech recognition model was the biggest feat we accomplished." *-Isaac*
>
>
> "Generating and integrating the Microsoft Azure Speech to Text model in our back-end was a great accomplishment for our project. It allowed us to parse user's pseudo code into properly formatted code to provide to our website's IDE." *-Amir*
>
>
> "Being able to properly integrate and interact with the Microsoft Azure's Speech to Text model was a great accomplishment!" *-Kris*
>
>
>
## What we learned
>
> "I learned how to connect the backend to a react app, and how to work with the Voice recognition and recording modules in react. I also worked a bit with Python when trying to debug some problems in sending the voice recordings to Azure’s servers." *-Iyad*
>
>
> "I was introduced to Python and learned how to properly interact with Microsoft's cognitive service models." *-Isaac*
>
>
> "This hackathon introduced me to Microsoft Azure's Speech to Text model and Azure web app. It was a unique experience integrating a flask app with Azure cognitive services. The challenging part was to make the Speaker Recognition to work; which unfortunately, seems to be in preview/beta mode and not functioning properly. However, I'm quite happy with how the integration worked with the Speach2Text cognitive models and I ended up creating a neat api for our app." *-Amir*
>
>
> "The biggest thing I learned was how to generate, call and integrate with Microsoft azure's cognitive services. Although it was a challenge at first, learning how to integrate Microsoft's models into our hack was an amazing learning experience. " *-Kris*
>
>
>
## What's next for QuickCode
We plan on continuing development and making this product available on the market. We first hope to include more functionality within Javascript, then extending to support other languages. From here, we want to integrate a group development environment, where users can work on files and projects together (version control). During the hackathon we also planned to have voice recognition to recognize and highlight which user is inputting (speaking) which code. | losing |
# MediConnect ER
## Problem Statement
In emergency healthcare situations, accessing timely and accurate patient information is critical for healthcare providers to deliver effective and urgent care. However, the current process of sharing essential information between individuals in need of emergency care and healthcare professionals is often inefficient and prone to delays. Moreover, locating and scheduling an appointment in the nearest Emergency Room (ER) can be challenging, leading to unnecessary treatment delays and potential health risks. There is a pressing need for a solution that streamlines the transmission of vital patient information to healthcare providers and facilitates the seamless booking of ER appointments, ultimately improving the efficiency and effectiveness of emergency healthcare delivery.
## Introduction
We have developed an app designed to streamline the process for individuals involved in accidents or requiring emergency care to provide essential information to doctors beforehand in a summarized format for Electronic Health Record (EHR) integration. Leveraging Language Model (LLM) technology, the app facilitates the efficient transmission of pertinent details, ensuring healthcare providers have access to critical information promptly and also allows doctors to deal with more volume of paitents.
Moreover, the app includes functionality for users to locate and schedule an appointment in the nearest Emergency Room (ER), enhancing accessibility and ensuring timely access to care in urgent situations. By combining pre-emptive data sharing with convenient ER booking features, the app aims to improve the efficiency and effectiveness of emergency healthcare delivery, potentially leading to better patient outcomes.
## About MediConnect ER
1. Content Summarization with LLM -
"MediConnect ER" revolutionizes emergency healthcare by seamlessly integrating with Electronic Health Records (EHRs) and utilizing advanced Language Model (LLM) technology. Users EHR medical data, which the LLM summarizer condenses into EHR-compatible summaries. This automation grants healthcare providers immediate access to crucial patient information upon ER arrival, enabling swift and informed decision-making. By circumventing manual EHR searches, the app reduces wait times, allowing doctors to prioritize and expedite care effectively. This streamlined process enhances emergency healthcare efficiency, leading to improved patient outcomes and satisfaction.
1. Geolocation and ER Booking -
MediConnect ER includes functionality for users to quickly locate and book the nearest Emergency Room (ER). By leveraging geolocation technology, the app identifies nearby healthcare facilities, providing users with real-time information on wait times, available services, and directions to the chosen ER. This feature eliminates the uncertainty and
1. Medi-Chatbot -
The chatbot feature in "MediConnect ER" offers users a user-friendly interface to engage with and access essential information about their treatment plans. Patients can interact with the chatbot to inquire about various aspects of their treatment, including medication instructions, follow-up appointments, and potential side effects. By providing immediate responses to user queries, the chatbot improves accessibility to crucial treatment information, empowering patients to take a more active role in their healthcare journey.
## Building Process
Our application leverages a sophisticated tech stack to deliver a seamless user experience. At the forefront, we utilize JavaScript, HTML, and CSS to craft an intuitive and visually appealing frontend interface. This combination of technologies ensures a smooth and engaging user interaction, facilitating effortless navigation and information access.
Backing our frontend, we employ Flask, a powerful Python web framework, to orchestrate our backend operations. Flask provides a robust foundation for handling data processing, storage, and communication between our frontend and other components of our system. It enables efficient data management and seamless integration of various functionalities, enhancing the overall performance and reliability of our application.
Central to our data summarization capabilities is Mistral 7B, a state-of-the-art language model meticulously fine-tuned to summarize clinical health records. Through extensive tuning on the Medalpaca dataset, we have optimized Misteral 7B to distill complex medical information into concise and actionable summaries. This tailored approach ensures that healthcare professionals receive relevant insights promptly, facilitating informed decision-making and personalized patient care.
Additionally, our chatbot functionality is powered by GPT-3.5, one of the most advanced language models available. GPT-3.5 enables natural and contextually relevant conversations, allowing users to interact seamlessly and obtain pertinent information about their treatment plans. By leveraging cutting-edge AI technology, our chatbot enhances user engagement and accessibility, providing users with immediate support and guidance throughout their healthcare journey.
# EHR Datageneration
To validate the effectiveness of our data summarization capabilities, we utilize Mistral 7B, a sophisticated language model specifically tailored for summarizing clinical health records. By running Mistral 7B through our synthetic EHR data records generated by Synteha, we validate the accuracy and relevance of the summarized information. This validation process ensures that our summarization process effectively captures essential medical insights and presents them in a concise and actionable format.
# Challenges we Ran into
1. One of the major challenges that we ran into are , bascially finding what EHR data looks like , after much research we found Syntheta that can generate the data we are looking into.
2. We found that fine tunning dataset were not avaliable to fine tune datasets that were even remotely sdimilar to EHR data.
# Future Directions
In the future, our aim is to seamlessly integrate Amanuensis into established Electronic Health Record (EHR) systems like Epic and Cerner, offering physicians an AI-powered assistant to enhance their clinical decision-making processes. Additionally, we intend to augment our Natural Language Processing (NLP) pipeline by incorporating actual patient data rather than relying solely on synthetic EHR records. We will complement this with meticulously curated annotations provided by physicians, ensuring the accuracy and relevance of the information processed by our system. | # Inspiration
In a world increasingly connected by technology, ensuring equitable access to healthcare information is more vital than ever. Today, we present to you the "MediSum" a groundbreaking project designed to address a critical issue within the U.S. healthcare system — structural racism and disparities in healthcare treatment.
MediSum directly addresses structural racism within the U.S. healthcare system, a deeply rooted issue that has led to significant disparities in healthcare access and outcomes. Structural racism has resulted in unequal treatment, misdiagnoses, and disparities in healthcare delivery for minority communities. These disparities persist despite efforts to reform the system, making it clear that innovative solutions are needed.
By making hospital ratings and reviews easily accessible, we aim to shine a light on these disparities, empowering patients to make informed choices and holding healthcare institutions accountable for providing equitable care. Our project is a step toward dismantling the structural barriers that have perpetuated healthcare disparities for far too long.
# Key Features
### Interactive Hospital Map:
* Users can explore an interactive map of Massachusetts displaying the locations of various hospitals.
Hospitals are marked with pins, and users can click on a pin to view detailed information about a specific hospital.
### Review Summaries:
* Hugging face (bart large cnn): Leverage the model's abilities to generate concise and informative summaries of user reviews for each hospital.
* Natural Language Understanding: The system extracts key insights, sentiment analysis, and common themes from patient reviews to provide a summarized overview.
### User Feedback and Improvement:
* Include a feedback mechanism for users to report inaccuracies or provide suggestions for improving the platform.
* Continuously update hospital information and reviews to maintain data accuracy and relevance.
### Mobile Responsiveness:
* Ensure that the website is responsive and user-friendly on various devices, including smartphones and tablets.
### Scalability:
* Design the system to accommodate potential expansion to cover healthcare facilities in other states or regions.
# Challenges Faced:
### Data Quality and Availability:
* Obtaining accurate and up-to-date data on hospital locations, ratings, and reviews can be challenging. Data sources may vary in quality and accessibility.
### Data Integration:
* Integrating data from multiple sources and formats into a cohesive system can be technically challenging.
### Natural Language Processing (NLP):
* Implementing IBM Watson tools to generate review summaries requires expertise in NLP and may present challenges in accurately summarizing diverse reviews.
### User-generated Content:
* Managing user-generated reviews and ensuring their accuracy and appropriateness can be a significant challenge.
### Structural Racism Awareness:
* Addressing structural racism in healthcare is a sensitive and complex issue.
* Balancing educational content with user engagement and avoiding controversy may be challenging.
### Platform Scalability:
* As the user base grows, ensuring that the platform remains scalable and performs well under increased load is a technical challenge.
### Community Building:
* Building an engaged user community around healthcare quality and equity may take time and effort. Encouraging user participation and discussions can be challenging.
### Accessibility and Inclusivity:
* Ensuring that the platform is accessible to users with disabilities and available in multiple languages may require additional development and testing.
### Data Security:
* Protecting user data and ensuring its security is a top priority. Implementing robust security measures and staying updated on evolving security threats is challenging.
### Technical Expertise:
Developing and maintaining a web-based platform with interactive maps, user accounts, and NLP capabilities requires a team with diverse technical skills, which can be challenging to assemble.
### User Engagement:
* Encouraging users to actively contribute reviews and engage with the platform may require strategies for gamification, incentives, or content marketing.
### Educational Content:
* Creating informative and unbiased educational content on structural racism in healthcare can be challenging, as it involves addressing sensitive issues.
### Continuous Improvement:
* Continuously updating hospital information, reviews, and summaries to ensure relevance and accuracy is an ongoing challenge.
# Future Enhancements:
### Expanded Geographic Coverage:
While we currently focus on hospitals in Massachusetts, we have plans to expand our coverage to other states and regions, providing users with a broader view of healthcare quality nationwide.
### Personalized Recommendations:
In the future, we aim to implement machine learning algorithms that can provide users with personalized hospital recommendations based on their specific healthcare needs and preferences.
### Real-time Data Updates:
We're working on incorporating real-time data updates for hospital ratings and reviews, ensuring that users always have access to the latest information.
### Multilingual Support:
To reach a more diverse audience, we plan to offer support for multiple languages, making our platform accessible to non-English speakers.
### Mobile Applications:
Developing dedicated mobile applications for iOS and Android devices will enable users to access our platform conveniently on their smartphones and tablets.
### Enhanced NLP Capabilities:
We're continuously improving our natural language processing capabilities to provide even more accurate and context-aware summaries of user reviews.
### Community Engagement Features:
Encouraging user engagement and discussions on healthcare-related topics is a priority. We're exploring features like forums, expert Q&A sessions, and community-driven content.
### Education Initiatives:
We plan to expand our educational content on healthcare disparities and structural racism, aiming to raise awareness and promote positive change in the healthcare industry.
### Advanced Data Visualization:
Enhancing our data visualization tools will provide users with more interactive and insightful ways to explore hospital data and trends.
# Conclusion:
In conclusion, our healthcare project strives to address a critical need for transparency and accessibility in healthcare information. By providing users with an intuitive platform to explore hospital ratings and reviews, we aim to empower individuals to make informed healthcare decisions.
This project is not only about improving the patient experience but also about shedding light on the issues of structural racism in the U.S. healthcare system. It's crucial to acknowledge that structural racism persists in healthcare, leading to disparities in the quality of care and health outcomes among different racial and ethnic groups. Our platform aims to contribute to the ongoing conversation about this issue by providing information and resources to users.
As we look ahead, our commitment to improving and expanding our platform remains steadfast. We envision a future where everyone has access to accurate healthcare information and the tools to advocate for their own health. We invite you to join us on this journey as we work towards a more equitable and transparent healthcare system. | ## Inspiration
While we were brainstorming for ideas, we realized that two of our teammates are international students from India also from the University of Waterloo. Their inspiration to create this project was based on what they had seen in real life. Noticing how impactful access to proper healthcare can be, and how much this depends on your socioeconomic status, we decided on creating a healthcare kiosk that can be used by people in developing nations. By designing interface that focuses heavily on images; it can be understood by those that are illiterate as is the case in many developing nations, or can bypass language barriers. This application is the perfect combination of all of our interests; and allows us to use tech for social good by improving accessibility in the healthcare industry.
## What it does
Our service, Medi-Stand is targeted towards residents of regions who will have the opportunity to monitor their health through regular self administered check-ups. By creating healthy citizens, Medi-Stand has the potential to curb the spread of infectious diseases before they become a bane to the society and build a more productive society. Health care reforms are becoming more and more necessary for third world nations to progress economically and move towards developed economies that place greater emphasis on human capital. We have also included supply-side policies and government injections through the integration of systems that have the ability to streamline this process through the creation of a database and eliminating all paper-work thus making the entire process more streamlined for both- patients and the doctors. This service will be available to patients through kiosks present near local communities to save their time and keep their health in check. By creating a profile the first time you use this system in a government run healthcare facility, users can create a profile and upload health data that is currently on paper or in emails all over the interwebs. By inputting this information for the first time manually into the database, we can access it later using the system we’ve developed. Overtime, the data can be inputted automatically using sensors on the Kiosk and by the doctor during consultations; but this depends on 100% compliance.
## How I built it
In terms of the UX/UI, this was designed using Sketch. By beginning with the creation of mock ups on various sheets of paper, 2 members of the team brainstormed customer requirements for a healthcare system of this magnitude and what features we would be able to implement in a short period of time. After hours of deliberation and finding ways to present this, we decided to create a simple interface with 6 different screens that a user would be faced with. After choosing basic icons, a font that could be understood by those with dyslexia, and accessible colours (ie those that can be understood even by the colour blind); we had successfully created a user interface that could be easily understood by a large population.
In terms of developing the backend, we wanted to create the doctor’s side of the app so that they could access patient information. IT was written in XCode and connects to Firebase database which connects to the patient’s information and simply displays this visually on an IPhone emulator. The database entries were fetched in Json notation, using requests.
In terms of using the Arduino hardware, we used Grove temperature sensor V1.2 along with a Grove base shield to read the values from the sensor and display it on the screen. The device has a detectable range of -40 to 150 C and has an accuracy of ±1.5 C.
## Challenges I ran into
When designing the product, one of the challenges we chose to tackle was an accessibility challenge. We had trouble understanding how we can turn a healthcare product more accessible. Oftentimes, healthcare products exist from the doctor side and the patients simply take home their prescription and hold the doctors to an unnecessarily high level of expectations. We wanted to allow both sides of this interaction to understand what was happening, which is where the app came in. After speaking to our teammates, they made it clear that many of the people from lower income households in a developing nation such as India are not able to access hospitals due to the high costs; and cannot use other sources to obtain this information due to accessibility issues. I spent lots of time researching how to make this a user friendly app and what principles other designers had incorporated into their apps to make it accessible. By doing so, we lost lots of time focusing more on accessibility than overall design. Though we adhered to the challenge requirements, this may have come at the loss of a more positive user experience.
## Accomplishments that I'm proud of
For half the team, this was their first Hackathon. Having never experienced the thrill of designing a product from start to finish, being able to turn an idea into more than just a set of wireframes was an amazing accomplishment that the entire team is proud of.
We are extremely happy with the UX/UI that we were able to create given that this is only our second time using Sketch; especially the fact that we learned how to link and use transactions to create a live demo. In terms of the backend, this was our first time developing an iOS app, and the fact that we were able to create a fully functioning app that could demo on our phones was a pretty great feat!
## What I learned
We learned the basics of front-end and back-end development as well as how to make designs more accessible.
## What's next for MediStand
Integrate the various features of this prototype.
How can we make this a global hack?
MediStand is a private company that can begin to sell its software to the governments (as these are the people who focus on providing healthcare)
Finding more ways to make this product more accessible | losing |
## Inspiration
In the wake of a COVID-altered reality, where the lack of resources continuously ripples throughout communities, Heckler.AI emerges as a beacon for students, young professionals, those without access to mentorship and individuals seeking to harness vital presentation skills. Our project is a transformative journey, empowering aspiring leaders to conquer their fears. In a world, where connections faltered, Heckler.AI fills the void, offering a lifeline for growth and social resurgence. We're not just cultivating leaders; we're fostering a community of resilient individuals, breaking barriers, and shaping a future where every voice matters. Join us in the journey of empowerment, where opportunities lost become the stepping stones for a brighter tomorrow. Heckler.AI: Where anxiety transforms into confidence, and leaders emerge from every corner.
## What it does
Heckler.AI is your personalized guide to mastering the art of impactful communication. Our advanced system meticulously tracks hand and arm movements, decodes facial cues from smiles to disinterest, and assesses your posture. This real-time analysis provides actionable feedback, helping you refine your presentation skills. Whether you're a student, young professional, or seeking mentorship, Heckler.AI is the transformative tool that not only empowers you to convey confidence but also builds a community of resilient communicators. Join us in this journey where your every move becomes a step towards becoming a compelling and confident leader. Heckler.AI: Precision in every gesture, resonance in every presentation.
## How we built it
We used OpenCV and the MediaPipe framework to detect movements and train machine learning models. The resulting model could identify key postures that affect your presentation skills and give accurate feedback to fast-track your soft skills development. To detect pivotal postures in the presentation, we used several Classification Models, such as Logistic Regression, Ridge Classifier, Random Forest Classifier, and Gradient Boosting Classifier. Afterwards, we select the best performing model, and use the predictions personalized to our project's needs.
## Challenges we ran into
Implementing webcam into taipy was difficult since there was no pre-built library. Our solution was to use a custom GUI component, which is an extension mechanism that allows developers to add their own visual elements into Taipy's GUI. In the beginning we also wanted to use a websocket to provide real-time feedback, but we deemed it too difficult to build with our limited timeline. Incorporating a custom webcam into Taipy was full of challenges, and each developer's platform was different and required different setups. In hindsight, we could've also used Docker to containerize the images for a more efficient process.
Furthermore, we had difficulties deploying Taipy to our custom domain name, "hecklerai.tech". Since Taipy is built of Flask, we tried different methods, such as deploying on Vercel, using Heroku, and Gunicorn, but our attempts were in vain. A potential solution would be deploying on a virtual machine through cloud hosting platforms like AWS, which could be implemented in the future.
## Accomplishments that we're proud of
We are proud of ourselves for making so much progress in such little time with regards to a project that we thought was too ambitious. We were able to clear most of the key milestones of the project.
## What we learned
We learnt how to utilize mediapipe and use it as the core technology for our project. We learnt about how to manipulate the different points of the body to accurately use these quantifiers to assess the posture and other key metrics of presenters, such as facial expression and hand gestures. We also took the time to learn more about taipy and use it to power our front end, building a beautiful user friendly interface that displays a video feed through the user's webcam.
## What's next for Heckler.ai
At Heckler.AI, we're committed to continuous improvement. Next on our agenda is refining the model's training, ensuring unparalleled accuracy in analyzing hand and arm movements, facial cues, and posture. We're integrating a full-scale application that not only addresses your presentation issues live but goes a step further. Post-video analysis will be a game-changer, offering in-depth insights into precise moments that need improvement. Our vision is to provide users with a comprehensive tool, empowering them not just in the moment but guiding their growth beyond, creating a seamless journey from identifying issues to mastering the art of compelling communication. Stay tuned for a Heckler.AI that not only meets your needs but anticipates and addresses them before you even realize. Elevate your communication with Heckler.AI: Your growth, our commitment. | ## Inspiration
Today we live in a world that is all online with the pandemic forcing us at home. Due to this, our team and the people around us were forced to rely on video conference apps for school and work. Although these apps function well, there was always something missing and we were faced with new problems we weren't used to facing. Personally, forgetting to mute my mic when going to the door to yell at my dog, accidentally disturbing the entire video conference. For others, it was a lack of accessibility tools that made the experience more difficult. Then for some, simply scared of something embarrassing happening during class while it is being recorded to be posted and seen on repeat! We knew something had to be done to fix these issues.
## What it does
Our app essentially takes over your webcam to give the user more control of what it does and when it does. The goal of the project is to add all the missing features that we wished were available during all our past video conferences.
Features:
Webcam:
1 - Detect when user is away
This feature will automatically blur the webcam feed when a User walks away from the computer to ensure the user's privacy
2- Detect when user is sleeping
We all fear falling asleep on a video call and being recorded by others, our app will detect if the user is sleeping and will automatically blur the webcam feed.
3- Only show registered user
Our app allows the user to train a simple AI face recognition model in order to only allow the webcam feed to show if they are present. This is ideal to prevent ones children from accidentally walking in front of the camera and putting on a show for all to see :)
4- Display Custom Unavailable Image
Rather than blur the frame, we give the option to choose a custom image to pass to the webcam feed when we want to block the camera
Audio:
1- Mute Microphone when video is off
This option allows users to additionally have the app mute their microphone when the app changes the video feed to block the camera.
Accessibility:
1- ASL Subtitle
Using another AI model, our app will translate your ASL into text allowing mute people another channel of communication
2- Audio Transcriber
This option will automatically transcribe all you say to your webcam feed for anyone to read.
Concentration Tracker:
1- Tracks the user's concentration level throughout their session making them aware of the time they waste, giving them the chance to change the bad habbits.
## How we built it
The core of our app was built with Python using OpenCV to manipulate the image feed. The AI's used to detect the different visual situations are a mix of haar\_cascades from OpenCV and deep learning models that we built on Google Colab using TensorFlow and Keras.
The UI of our app was created using Electron with React.js and TypeScript using a variety of different libraries to help support our app. The two parts of the application communicate together using WebSockets from socket.io as well as synchronized python thread.
## Challenges we ran into
Dam where to start haha...
Firstly, Python is not a language any of us are too familiar with, so from the start, we knew we had a challenge ahead. Our first main problem was figuring out how to highjack the webcam video feed and to pass the feed on to be used by any video conference app, rather than make our app for a specific one.
The next challenge we faced was mainly figuring out a method of communication between our front end and our python. With none of us having too much experience in either Electron or in Python, we might have spent a bit too much time on Stack Overflow, but in the end, we figured out how to leverage socket.io to allow for continuous communication between the two apps.
Another major challenge was making the core features of our application communicate with each other. Since the major parts (speech-to-text, camera feed, camera processing, socket.io, etc) were mainly running on blocking threads, we had to figure out how to properly do multi-threading in an environment we weren't familiar with. This caused a lot of issues during the development, but we ended up having a pretty good understanding near the end and got everything working together.
## Accomplishments that we're proud of
Our team is really proud of the product we have made and have already begun proudly showing it to all of our friends!
Considering we all have an intense passion for AI, we are super proud of our project from a technical standpoint, finally getting the chance to work with it. Overall, we are extremely proud of our product and genuinely plan to better optimize it in order to use within our courses and work conference, as it is really a tool we need in our everyday lives.
## What we learned
From a technical point of view, our team has learnt an incredible amount the past few days. Each of us tackled problems using technologies we have never used before that we can now proudly say we understand how to use. For me, Jonathan, I mainly learnt how to work with OpenCV, following a 4-hour long tutorial learning the inner workings of the library and how to apply it to our project. For Quan, it was mainly creating a structure that would allow for our Electron app and python program communicate together without killing the performance. Finally, Zhi worked for the first time with the Google API in order to get our speech to text working, he also learned a lot of python and about multi-threadingbin Python to set everything up together. Together, we all had to learn the basics of AI in order to implement the various models used within our application and to finally attempt (not a perfect model by any means) to create one ourselves.
## What's next for Boom. The Meeting Enhancer
This hackathon is only the start for Boom as our team is exploding with ideas!!! We have a few ideas on where to bring the project next. Firstly, we would want to finish polishing the existing features in the app. Then we would love to make a market place that allows people to choose from any kind of trained AI to determine when to block the webcam feed. This would allow for limitless creativity from us and anyone who would want to contribute!!!! | ## Inspiration & What it does
You're walking down the road, and see a belle rocking an exquisite one-piece. *"Damn, that would look good on me (or my wife)"*.
You go home and try to look for it: *"beautiful red dress"*. Google gives you 110,000,000 results in 0.54 seconds. Well that helped a lot. You think of checking the fashion websites, but the number of these e-commerce websites makes you refrain from spending more than a few hours. *"This is impossible..."*. You perseverance only lasts so long - you give up.
Fast forward to 2017. We've got everything from Neural Forests to Adversarial Networks.
You go home to look for it: Launch **Dream.it**
You make a chicken-sketch of the dress - you just need to get the curves right. You select the pattern on the dress, a couple of estimates about the dress. **Dream.it** synthesizes elegant dresses based on your sketch. It then gives you search results from different stores based on similar dresses, and an option to get on custom made. You love the internet. You love **Dream.it**. Its a wonderful place to make your life wonderful.
Sketch and search for anything and everything from shoes and bracelets to dresses and jeans: all at your slightest whim. **Dream.it** lets you buy existing products or get a new one custom-made to fit you.
## How we built it
**What the user sees**
**Dream.it** uses a website as the basic entry point into the service, which is run on a **linode server**. It has a chatbot interface, through which users can initially input the kind of garment they are looking for with a few details. The service gives the user examples of possible products using the **Bing Search API**.
The voice recognition for the chatbot is created using the **Bing Speech to Text API**. This is classified using a multiclassifier from **IBM Watson Natural Language Classifier** trained on custom labelled data into the clothing / accessory category. It then opens a custom drawing board for you to sketch the contours of your clothing apparel / accessories / footwear and add color to it.
Once the sketch is finalized, the image is converted to more detailed higher resolution image using [**Pixel Recursive Super Resolution**](https://arxiv.org/pdf/1702.00783.pdf).
We then use **Google's Label Detection Vision ML** and **IBM Watson's Vision** APIs to generate the most relevant tags for the final synthesized design which give additional textual details for the synthesized design.
The tags, in addition to the image itself are used to scour the web for similar dresses available for purchase
**Behind the scenes**
We used a **Deep Convolutional Generative Adversarial Network (GAN)** which runs using **Theano** and **cuDNN** on **CUDA**. This is connected to our web service through websockets. The brush strokes from the drawing pad on the website get sent to the **GAN** algorithm, which sends back the synthesized fashion design to match the user's sketch.
## Challenges we ran into
* Piping all the APIs together to create a seamless user experience. It took a long time to optimize the data (*mpeg1*) we were sending over the websocket to prevent lags and bugs.
* Running the Machine learning algorithm asynchronously on the GPU using CUDA.
* Generating a high-quality image of the synthesized design.
* Customizing **Fabric.js** to send data appropriately formatted to be processed by the machine learning algorithm.
## Accomplishments that we're proud of
* We reverse engineered the **Bing real-time Speech Recognition API** to create a Node.js library. We also added support for **partial audio frame streaming for voice recognition**.
* We applied transfer learning from Deep Convolutional Generative Adversarial Networks and implemented constraints on its gradients and weights to customize user inputs for synthesis of fashion designs.
* Creating a **Python-Node.js** stack which works asynchronously with our machine learning pipeline
## What we learned
This was a multi-faceted educational experience for all of us in different ways. Overall:
* We learnt to asynchronously run machine learning algorithms without threading issues.
* Setting up API calls and other infrastructure for the app to run on.
* Using the IBM Watson APIs for speech recognition and label detection for images.
* Setting up a website domain, web server, hosting a website, deploying code to a server, connecting using web-sockets.
* Using pip, npm; Using Node.js for development; Customizing fabric.js to send us custom data for image generation.
* Explored machine learning tools learnt how to utlize them most efficiently.
* Setting up CUDA, cuDNN, and Theano on an Ubuntu platform to use with ML algorithm.
## What's next for Dream.it
Dream.it currently is capable of generating shoes, shirts, pants, and handbags from user sketches. We'd like to expand our training set of images and language processing to support a greater variety of clothing, materials, and other accessories.
We'd like to switch to a server with GPU support to run the cuDNN-based algorithm on CUDA.
The next developmental step for Dream.it is to connect it to a 3D fabric printer which can print the designs instantly without needing the design to be sent to manufacturers. This can be supported at particular facilities in different parts of the country to enable us to be in control of the entire process. | winning |
# Accel - Placed in Intel Track (to be updated by organizers)
Your empathetic chemistry tutor
[**GitHub »**](https://github.com/DavidSMazur/AI-Berkeley-Hackathon)
[Alex Talreja](https://www.linkedin.com/in/alexander-talreja)
·
[Cindy Yang](https://www.linkedin.com/in/2023cyang/)
·
[David Mazur](https://www.linkedin.com/in/davidsmazur/)
·
[Selina Sun](https://www.linkedin.com/in/selina-sun-550301227/)
## About The Project
Traditional study methods and automated tutoring systems often focus solely on providing answers. This approach neglects the emotional and cognitive processes that are crucial for effective learning. Students are left feeling overwhelmed, anxious, and disconnected from the material.
Accel is designed to address these challenges by offering a unique blend of advanced AI technology and emotional intelligence. Here's how Accel transforms the study experience:
* **Concept Breakdown**: Accel deconstructs complex chemistry topics into easy-to-understand segments, ensuring that students grasp foundational concepts thoroughly.
* **Emotional Intelligence**: Using cutting-edge vocal emotion recognition technology, Accel detects frustration, confusion, or boredom, tailoring its responses to match the student’s emotional state, offering encouragement and hints instead of immediate answers.
* **Adaptive Learning**: With Quiz Mode, students receive feedback on their progress, highlighting their strengths and areas for improvement, fostering a sense of accomplishment.
### Built With
[](https://nextjs.org/)
[](https://reactjs.org/)
[](https://tailwindcss.com/)
[](https://flask.palletsprojects.com/en/3.0.x/)
[](https://aws.amazon.com/bedrock/?gclid=CjwKCAjw7NmzBhBLEiwAxrHQ-R43KC_xeXdqadUZrt7upH8LYrZMbCOi-j7Hn7RHxfyKg1tJdlt2FBoCr_IQAvD_BwE&trk=0eaabb80-ee46-4e73-94ae-368ffb759b62&sc_channel=ps&ef_id=CjwKCAjw7NmzBhBLEiwAxrHQ-R43KC_xeXdqadUZrt7upH8LYrZMbCOi-j7Hn7RHxfyKg1tJdlt2FBoCr_IQAvD_BwE:G:s&s_kwcid=AL!4422!3!692006004688!p!!g!!amazon%20bedrock!21048268554!159639952935)
[](https://www.langchain.com/)
[](https://www.intel.com/content/www/us/en/developer/topic-technology/artificial-intelligence/overview.html)
[](https://beta.hume.ai/)
## Technologies
Technical jargon time 🙂↕️
### Intel AI
To build the core capabilities of Accel, we used both Intel Gaudi and the Intel AI PC. Intel Gaudi allowed us to distill a model ("selinas/Accel3") by fine-tuning with synthetic data we generated from Llama 70B model to 3B, allowing us to successfully run our app on the Intel AI PC. The prospect of distributing AI apps with local compute to deliver a cleaner and more secure user experience was very exciting, and we also enjoyed thinking about the distributed systems implications of NPUs.
### Amazon Bedrock
To further enhance the capabilities of Accel, we utilized Amazon Bedrock to integrate Retrieval-Augmented Generation (RAG) and AI agents. This integration allows the chatbot to provide more accurate, contextually relevant, and detailed responses, ensuring a comprehensive learning experience for students.
When a student asks a question, the RAG mechanism first retrieves relevant information from a vast database of chemistry resources. It then uses this retrieved information to generate detailed and accurate responses. This ensures that the answers are not only contextually relevant but also backed by reliable sources.
Additionally, we utilized agents to service the chat and quiz features of Accel. Accel dynamically routes queries to the appropriate agent, which work in coordination to deliver a seamless and multi-faceted tutoring experience. When a student queries, the relevant agent is activated to provide a specialized response.
### Hume EVI
The goal of Accel is to not only provides accurate academic support but also understands and responds to the emotional states of students, fostering a more supportive and effective learning environment.
Hume's EVI model was utilized for real-time speech to text (and emotion) conversion. The model begins listening when the user clicks the microphone input button, updating the input bar with what the model has heard so far. When the user turns their microphone off, this text is automatically sent as a message to Accel, along with the top 5 emotions picked up by EVI. Accel uses these cues to generate an appropriate response using our fine-tuned LLM.
Additionally, the users' current mood gauge is displayed on the frontend for a deeper awareness of their own study tendencies.
## Contact
Alex Talreja (LLM agents, Amazon Bedrock, RAG) - [[email protected]](mailto:[email protected])
Cindy Yang (frontend, design, systems integration) - [[email protected]](mailto:[email protected])
David Mazur (model distillation, model integration into web app) - [[email protected]](mailto:[email protected])
Selina Sun (synthetic data generation, scalable data for training, distribution through HuggingFace) - [[email protected]](mailto:[email protected]) | ## Inspiration and what it does
As smart as our homes (or offices) become, they do not fully account for the larger patterns in electricity grids and weather systems.
their environments. They still waste energy cooling empty buildings, or waste money by purchasing electricity during peak periods. Our project, The COOLest hACk, solves these problems. We use sensors to detect both ambient temperature in the room and on-body temperature. We also increase the amount of cooling when electricity prices are cheaper, which in effect uses your building as a energy storage device. These features simultaneously save you money and the environment.
## How we built it
We built it using particle photons and infrared and ambient temperature sensors. These photons also control a fan motor and leds, representing air conditioning. We have a machine learning stack to forecast electricity prices. Finally, we built an iPhone app to show what's happening behind the scenes
## Challenges we ran into
Our differential equation models for room temperature were not solvable, so we used a stepwise approach. In addition, we needed to find a reliable source of time-of-day peek electricity prices.
## Accomplishments that we're proud of
We're proud that we created an impactful system to reduce energy used by the #1 energy hungry appliance, Air Conditioning. Our solution has minimal costs and works through automated means.
## What we learned
We learned how to work with hardware, Photons, and Azure.
## What's next for The COOLest hACk
For the developers: sleep, at the right temperature ~:~ | ## Inspiration
The inspiration for this project comes from the simple fact that the current educational system is in urgent need of innovation at all levels. Our team comes from very a wide variety of backgrounds that has allowed us to gather insights and envision a tool that could be useful to improve students' learning experience. We thought about the amazing reservoir of online learning content and lectures that are waiting to be consumed, but that are locked behind a language barrier and therefore difficult to access. We seek to utilize AI in order to make it easier for students to learn a new and difficult concept, even in a language unfamiliar to them.
This project was inspired by and based on earlier code created by our teammate Ricardo for an earlier project. We expanded on and refactored the code, implementing a new frontend and working to tie a new web interface with the Chrome extension in order to allow students to access a wider array of related resources and better manage their learning of the new material.
## What it does
Currently, our application functions as a Chrome extension that activates whenever you watch a YouTube video. At any time, you can rate your current understanding or grasp of the focus topic, which will guide our application's recommendations on what videos and material to study next. We additionally have a website that functions as a main hub for the extension, tracking your progress of learning any given subject and suggesting how to continue learning.
## How we built it
Our Chrome extension runs on a Flask application server, utilizing both YouTube's and OpenAI's APIs to guide our recommendations. Our web application utilizes a Flask backend with a React frontend. The learning model we chose to implement is GPT-3 due to its efficiency in using deep learning to produce human-like text.
## Challenges we ran into
Our application involves multiple moving parts, including a Flask backend server, a React frontend website, and a Chrome extension script. Our biggest challenge was working out how those components could all work together in harmony, setting up the integration between GPT-3 and Youtube in order to make the best possible content recommendation was one that really stood out. We had to be careful with the way in which we were passing in parameters used by the ML models to process the data and make an accurate suggestion.
## Accomplishments that we're proud of
We are proud of both sides of our application that we have created: the Flask + React web server that hosts the main web hub for the application, and the Chrome extension that utilizes AI to offer a functional product on its own. These components have huge potential even independently, so we can't wait to see the possibilities of combining their capabilities.
## What we learned
As a team of relative beginners, we learned a great deal from working on this project, including general design and coding principles, as well as wider perspective concerns such as scalability, partnerships, and business models. We learned about different ML models and the effect that they each have on the prediction of what the best fit (in our case best educational video) is.
## What's next for Indigena
The first thing to do would be to configure the Chrome extension and React web application to be able to apply changes across the different levels more efficiently. We then want to utilize our backend capabilities for translating text, images, and documents in order to facilitate learning in other languages. | partial |
"This video is too long!!! I want to navigate to the part where Pusheen is like Pikachu!!"
"Don't we have AI to analyze videos and tell us that already?"
And thus, the idea for AIsee was born.
We found the Clarifai API to help us out and now, AIsee can analyze YouTube videos and tell you where certain components (i.e. cats, cute things, etc.) appear in a video. You can even visualize these components in terms of a graph. It's so convenient that it's a Chrome extension, and you can view it with your open Pusheen YouTube video! Yay, I can now click on a part of the timeline and find Pusheen's cutest moment! :) | ## Inspiration
As YouTube consumers, we find it extremely frustrating to deal with unnecessarily long product reviews that deliver numerous midroll ads rather than providing useful and convenient information. Inspired, we wanted to create an application that stops all that by allowing users to glean the important information from a video without wasting time.
## What It Does
* Determines whether a YouTube product review is positive or negative.
* Summarizes the contents of the review.
## How We Built It
* The auto-generated closed captions for a YouTube video are obtained
* Punctuation is added to YouTube auto-generated closed captions.
* The punctuated script retrieved is then fed into Cohere, an NLP toolkit.
* Cohere performs an analysis of the script and returns sentiment and summary.
* Chrome extension is then utilized to display the information to the user.
## Challenges We Ran Into
* Settling on a use of Cohere.
* Punctuating the auto-generated YouTube closed captions.
## Accomplishments That We're Proud Of
* Deftly transitioning between ideas.
* Combining many new technologies.
* Figuring out the puntuator2 library.
## What We Learned
* How to develop chrome extensions.
* How to utilize Cohere to perform analysis and process summaries.
## What's Next For The Project
* Implement a mobile app component that allows the user's to make use of the service at the convenience of their phone.
* Keep track of users' past history and engagement.
* Incorporate a points system that encourages and drives individuals to continue to make use of the application. | ## Inspiration
2020 had us indoors more than we'd like to admit and we turned to YouTube cooking videos for solace. From Adam Ragusea to Binging with Babish, these personalities inspired some of us to start learning to cook. The problem with following along with these videos is that you have to keep pausing the video while you cook. Or even worse, you have to watch the entire video and write down the steps if they're not provided in the video description. We wanted an easier way to summarize cooking videos into clear steps.
## What it does
Get In My Belly summarizes Youtube cooking videos into text recipes. You simply give it a YouTube link and the web app generates a list of ingredients and a series of steps for making the dish (with pictures), just like a recipe in a cook book. No more wondering where they made the lamb sauce. :eyes:
## How we built it
We used React for front-end and Flask for back-end. We used [Youtube-Transcript-API](https://pypi.org/project/youtube-transcript-api/) to convert Youtube videos to transcripts. The transcripts are filtered and parsed into the resulting recipe using Python with the help of the [Natural Language Toolkit](https://www.nltk.org/) library and various text-based, cooking-related datasets that we made by scraping our favourite cooking videos. Further data cleaning and processing was done to ensure the output included quantities and measurements alongside the ingredients. Finally, [OpenCV](https://opencv.org/) was used to extract screenshots based on time-stamps.
## Challenges we ran into
Determining the intent of a sentence is pretty difficult, especially when someone like Binging with Babish says things that range from very simple (`add one cup of water`) to semantically-complex (`to our sauce we add flour; throw in two heaping tablespoons, then add salt to taste`). We converted each line of the transcription into a Trie structure to separate out the ingredients, cooking verbs, and measurements.
## Accomplishments that we're proud of
We really like the simplicity of our web app and how clean it looks. We wanted users to be able to use our system without any instruction and we're proud of achieving this.
## What we learned
This was the first hackathon for two of our three members. We had to quickly learn how to budget our time since it's a 24-hour event. Perhaps most importantly, we gained experience in deciding when a feature was too ambitious to achieve within time constraints. For other members, it was their first exposure to web-dev and learning about Flask and React was mind boggling.
## What's next for Get In My Belly
Future changes to GIMB include a more robust parsing system and refactoring the UI to make it cleaner. We would also like to support other languages and integrate the project with other APIs to get more information about what you're cooking. | losing |
## **Inspiration**
Ever had to wipe your hands constantly to search for recipes and ingredients while cooking?
Ever wondered about the difference between your daily nutrition needs and the nutrition of your diets?
Vocal Recipe is an integrated platform where users can easily find everything they need to know about home-cooked meals! Information includes recipes with nutrition information, measurement conversions, daily nutrition needs, cooking tools, and more! The coolest feature of Vocal Recipe is that users can access the platform through voice control, which means they do not need to constantly wipe their hands to search for information while cooking. Our platform aims to support healthy lifestyles and make cooking easier for everyone.
## **How we built Vocal Recipe**
Recipes and nutrition information is implemented by retrieving data from Spoonacular - an integrated food and recipe API.
The voice control system is implemented using Dasha AI - an AI voice recognition system that supports conversation between our platform and the end user.
The measurement conversion tool is implemented using a simple calculator.
## **Challenges and Learning Outcomes**
One of the main challenges we faced was the limited trials that Spoonacular offers for new users. To combat this difficulty, we had to switch between team members' accounts to retrieve data from the API.
Time constraint is another challenge that we faced. We do not have enough time to formulate and develop the whole platform in just 36 hours, thus we broke down the project into stages and completed the first three stages.
It is also our first time using Dasha AI - a relatively new platform which little open source code could be found. We got the opportunity to explore and experiment with this tool. It was a memorable experience. | ## Inspiration
Using “nutrition” as a keyword in the Otsuka valuenex visualization tool, we found that there is a cluster of companies creating personalized nutrition and fitness plans. But when we used the “and” function to try to find intersections with mental wellness, we found that none of those companies that offer a personalized plan really focused on either stress or mental health. This inspired us to create a service where we use a data-driven, personalized, nutritional approach to reduce stress.
## What it does
We offer healthy recipe recommendations that are likely to reduce stress. We do this by looking at how the nutrients in the users’ past diets contributed to changes in stress. We combine this with their personal information to generate a model of which nutrients are likely to improve their mental wellness and recommend recipes that contain those nutrients. Most people do want to eat healthier, but they don’t because it is inconvenient and perceived to be less delicious. Our service makes it easy and convenient to eat delicious healthy food by making the recipe selection and ingredient collection processes simpler.
To personally tailor each user's recipe suggestions to their stress history, we have users save food items to their food log and fill out a daily questionnaire with common stress indicators. We then use the USDA food database to view the specific nutrients each food item has and use this data to calculate the relationship between the user's stress and the specific nutrients they consumed. Finally, we use this model to suggest future recipes that contain nutrients likely to reduce stress for that user.
In order to proactively reduce user's stress, we offer a simple interface to plan meals in advance for your entire week, an auto-generated ingredients list based on selected recipes for the week, and a seamless way to order and pay for the ingredients using the Checkbook API service. To make it easier for users, the food log will automatically populate each day with the ingredients from the recipes the user selected to eat for that day.
## How we built it
We used Bubble to build a no-code front end by dragging and dropping the design elements we needed. We used Bubble's USDA plugin to let users search for and enter foods that they consumed. The USDA food database is also used to determine the nutrients present in each of the foods the user reports consuming. We also used Bubble's Toolbox plugin to write Javascript code that allows us to run the Checkbook API. We use the Spoonacular API to get the recipe suggestions based on the user's personalized preference quiz answers where they give the types of cuisines they like and their dietary restrictions. We use a linear regression model to suggest future recipes for users based on the nutrients that are likely to reduce their stress.
## Challenges we ran into
One challenge for us was using Bubble. Only one team member had previous design experience, but everyone on the team wanted to contribute to building the front-end, so we faced a huge learning curve for all members of the team to learn about good design principles and how to space elements out on Bubble. Grouping elements together was sometimes weird on Bubble and caused issues with parts of our header not lining up the way we wanted it to. Elements would sometimes disappear under other elements and it would become hard to get them out. Formatting was weird because our laptops had different aspect ratios, so what looked good on one person's laptop looked bad on another person's laptop. We were debugging Bubble until the end of the hackathon.
## Accomplishments that we're proud of
Our team had little to no front-end design experience coming into this hackathon. We are proud of how much we all learned about front-end design through Bubble. We feel that moving forward, we can create better front-end designs for our future projects.
We are also proud of finding and figuring out how to use the Spoonacular API to get recipe recommendations. This API had very thorough documentation, so it was relatively easy to pick it up and figure out how to implement it.
## What we learned
The first thing we learned was how to use the Otsuka valuenex visualization tool for ideation. We found this tool to be extremely helpful with our brainstorming process and when coming up with our idea.
We learned how to use Bubble to create a front-end without needing to write code. Despite the struggles we initially faced, we grew to find Bubble more intuitive and fun to use with more practice and managed to create a pretty nice front-end for our service. We hosted our server on Bubble.
We also learned how to use the Checkbook API to seamlessly send and receive payments.
Finally, we learned how to use the Spoonacular API to generate recipe recommendations based on a set of parameters that includes preferred types of cuisines, dietary restrictions, and nutrients present in each dish.
## What's next for mood food
We feel very passionate about exploring this project in more depth by applying more complex machine learning models to determine better recipe recommendations for users. We would also like to have the opportunity to deploy this service to collect real data to analyze.
## Thanks
Thank you very much to Koji Yamada from Otsuka for meeting up with our team to discuss our idea and offer us feedback. We are very grateful to you for offering our team support in this form.
Thank you to the amazing TreeHacks organizers for putting together this awesome event. Everyone on our team learned a lot and had fun. | ## Inspiration
We have all been there, stuck on a task, with no one to turn to for help. We all love wikiHow but there isn't always a convenient article there for you to follow. So we decided to do something about it! What if we could leverage the knowledge of the entire internet to get the nicely formatted and entertaining tutorials we need. That's why we created wikiNow. With the power of Cohere's natural language processing and stable diffusion, we can combine the intelligence of millions of people to get the tutorials we need.
## What it does
wikiNow is a tool that can generate entire wikiHow articles to answer any question! A user simply has to enter a query and our tool will generate a step-by-step article with images that provides a detailed answer tailored to their exact needs. wikiNow enables users to find information more efficiently and to have a better understanding of the steps involved.
## How we built it
wikiNow was built using a combination of Cohere's natural language processing and stable diffusion algorithms. We trained our models on a large dataset of existing wikiHow articles and used this data to generate new articles and images that are specific to the user's query. The back-end was built using Flask and the front-end was created using Next.js.
## Challenges we ran into
One of the biggest challenges we faced was engineering the prompts that would generate the articles. We had to experiment with a lot of different methods before we found something that worked well with multi-layer prompts. Another challenge was creating a user interface that was both easy to use and looked good. We wanted to make sure that the user would be able to find the information they need without being overwhelmed by the amount of text on the screen.
Properly dealing with Flask concurrency and long-running network requests was another large challenge. For an average wiki page creation, we require ~20 cohere generate calls. In order to make sure the wiki page returns in a reasonable time, we spent a considerable amount of time developing asynchronous functions and multi-threading routines to speed up the process.
## Accomplishments that we're proud of
We're proud that we were able to create a tool that can generate high-quality articles. We're also proud of the user interface that we created, which we feel is both easy to use and visually appealing. The generated articles are both hilarious and informative, which was our main goal. We are also super proud of our optimization work. When running in a single thread synchronously, the articles can take up to *5 minutes* to generate. We have managed to bring that down to around **30 seconds**, which a near 10x improvement!
## What we learned
We learned a lot about using natural language processing and how powerful it can be in real world applications. We also learned a lot about full stack web development. For two of us, this was our first time working on a full stack web application, and we learned a lot about running back-end servers and writing a custom API's. We solved a lot of unique optimization and threading problems as well which really taught us a lot.
## What's next for wikiNow
In the future, we would like to add more features to wikiNow, such as the ability to generate articles in other languages and the ability to generate articles for other types of content, such as recipes or instructions. We would also like to make the articles more interactive so that users can ask questions and get clarification on the steps involved. It would also be handy to add the ability to cache previous user generated articles to make it easier for the project to scale without re-generating existing articles. | winning |
## Inspiration
Our inspiration for the project stems from our experience with elderly and visually impaired people, and understanding that there is an imminent need for a solution that integrates AI to bring a new level of convenience and safety to modern day navigation tools.
## What it does
IntelliCane firstly employs an ultrasonic sensor to identify any object, person, or thing within a 2 meter range and when that happens, a piezo buzzer alarm alerts the user. Simultaneously, a camera identifies the object infront of the user and provides them with voice feedback identifying what is infront of them.
## How we built it
The project firstly employs an ultrasonic sensor to identify an object, person or thing close by. Then the piezo buzzer is turned on and alerts the user. Then the Picamera that is on the raspberrypi 5 identifies the object. We have employed a CNN algorithm to train the data and improve the accuracy of identifying the objects. From there this data is transferred to a text-to-speech function which provides voice feedback describing the object infront of them. The project was built on YOLO V8 platform.
## Challenges we ran into
We ran into multiple problems during our project. For instance, we initially tried to used tensorflow, however due to the incompatibility of our version of python with the raspberrypi 5, we switched to the YOLO V8 Platform.
## Accomplishments that we're proud of
There are many accomplishments we are proud of, such as successfully creating an the ultrasonic-piezo buzzer system for the arduino, and successfully mounting everything onto the PVC Pipe. However, we are most proud of developing a CNN algorithm that accurately identifies objects and provides voice feedback identifying the object that is infront of the user.
## What we learned
We learned more about developing ML algorithms and became more proficient with the raspberrypi IDE.
## What's next for IntelliCane
Next steps for IntelliCane include integrating GPS modules and Bluetooth modules to add another level of convenience to navigation tools. | ## Inspiration
There are over 1.3 billion people in the world who live with some form of vision impairment. Often, retrieving small objects, especially off the ground, can be tedious for those without complete seeing ability. We wanted to create a solution for those people where technology can not only advise them, but physically guide their muscles in their daily life interacting with the world.
## What it does
ForeSight was meant to be as intuitive as possible in assisting people with their daily lives. This means tapping into people's sense of touch and guiding their muscles without the user having to think about it. ForeSight straps on the user's forearm and detects objects nearby. If the user begins to reach the object to grab it, ForeSight emits multidimensional vibrations in the armband which guide the muscles to move in the direction of the object to grab it without the user seeing its exact location.
## How we built it
This project involved multiple different disciplines and leveraged our entire team's past experience. We used a Logitech C615 camera and ran two different deep learning algorithms, specifically convolutional neural networks, to detect the object. One CNN was using the Tensorflow platform and served as our offline solution. Our other object detection algorithm uses AWS Sagemaker recorded significantly better results, but only works with an Internet connection. Thus, we use a two-sided approach where we used Tensorflow if no or weak connection was available and AWS Sagemaker if there was a suitable connection. The object detection and processing component can be done on any computer; specifically, a single-board computer like the NVIDIA Jetson Nano is a great choice. From there, we powered an ESP32 that drove the 14 different vibration motors that provided the haptic feedback in the armband. To supply power to the motors, we used transistor arrays to use power from an external Lithium-Ion battery. From a software side, we implemented an algorithm that accurately selected and set the right strength level of all the vibration motors. We used an approach that calculates the angular difference between the center of the object and the center of the frame as well as the distance between them to calculate the given vibration motors' strength. We also built a piece of simulation software that draws a circular histogram and graphs the usage of each vibration motor at any given time.
## Challenges we ran into
One of the major challenges we ran into was the capability of Deep Learning algorithms on the market. We had the impression that CNN could work like a “black box” and have nearly-perfect accuracy. However, this is not the case, and we experienced several glitches and inaccuracies. It then became our job to prevent these glitches from reaching the user’s experience.
Another challenge we ran into was fitting all of the hardware onto an armband without overwhelming the user. Especially on a body part as used as an arm, users prioritize movement and lack of weight on their devices. Therefore, we aimed to provide a device that is light and small.
## Accomplishments that we're proud of
We’re very proud that we were able to create a project that solves a true problem that a large population faces. In addition, we're proud that the project works and can't wait to take it further!
Specifically, we're particularly happy with the user experience of the project. The vibration motors work very well for influencing movement in the arms without involving too much thought or effort from the user.
## What we learned
We all learned how to implement a project that has mechanical, electrical, and software components and how to pack it seamlessly into one product.
From a more technical side, we gained more experience with Tensorflow and AWS. Also, working with various single board computers taught us a lot about how to use these in our projects.
## What's next for ForeSight
We’re looking forward to building our version 2 by ironing out some bugs and making the mechanical design more approachable. In addition, we’re looking at new features like facial recognition and voice control. | ## Inspiration
This generation of technological innovation and human factor design focuses heavily on designing for individuals with disabilities. As such, the inspiration for our project was an application of object detection (Darknet YOLOv3) for visually impaired individuals. This user group in particular has limited visual modality, which the project aims to provide.
## What it does
Our project aims to provide the visually impaired with sufficient awareness of their surroundings to maneuver. We created a head-mounted prototype that provides the user group real-time awareness of their surroundings through haptic feedback. Our smart wearable technology uses a computer-vision ML algorithm (convolutional neural network) to help scan the user’s environment to provide haptic feedback as a warning of a nearby obstacle. These obstacles are further categorized by our algorithm to be dynamic (moving, live objects), as well as static (stationary) objects. For our prototype, we filtered through all the objects detected to focus on the nearest object to provide immediate feedback to the user, as well as providing a stronger or weaker haptic feedback if said object is near or far respectively.
## Process
While our idea is relatively simple in nature, we had no idea going in just how difficult the implementation was.
Our main goal was to meet a minimum deliverable product that was capable of vibrating based on the position, type, and distance of an object. From there, we had extra goals like distance calibration, optimization/performance improvements, and a more complex human interface.
Originally, the processing chip (the one with the neural network preloaded) was intended to be the Huawei Atlas. With the additional design optimizations unique to neural networks, it was perfect for our application. After 5 or so hours of tinkering with no progress however, we realized this would be far too difficult for our project.
We turned to a Raspberry Pi and uploaded Google’s pre-trained image analysis network. To get the necessary IO for the haptic feedback, we also had this hooked up to an Arduino which was connected to a series of haptic motors. This showed much more promise than the Huawei board and we had a functional object identifier in no time. The rest of the night was spent figuring out data transmission to the Arduino board and the corresponding decoding/output.
With only 3 hours to go, we still had to finish debugging and assemble the entire hardware rig.
## Key Takeaways
In the future, we all learned just how important having a minimum deliverable product (MDP) was. Our solution could be executed with varying levels of complexity and we wasted a significant amount of time on unachievable pipe dreams instead of focusing on the important base implementation.
The other key takeaway of this event was to be careful with new technology. Since the Huawei boards were so new and relatively complicated to set up, they were incredibly difficult to use. We did not even use the Huawei Atlas in our final implementation meaning that all our work was not useful to our MDP.
## Possible Improvements
If we had more time, there are a few things we would seek to improve.
First, the biggest improvement would be to get a better processor. Either a Raspberry Pi 4 or a suitable replacement would significantly improve the processing framerate. This would make it possible to provide more robust real-time tracking instead of tracking with significant delays.
Second, we would expand the recognition capabilities of our system. Our current system only filters for a very specific set of objects, particular to an office/workplace environment. Our ideal implementation would be a system applicable to all aspects of daily life. This means more objects that are recognized with higher confidence.
Third, we would add a robust distance measurement tool. The current project uses object width to estimate the distance to an object. This is not always accurate unfortunately and could be improved with minimal effort. | partial |
## Inspiration
With the advent of smartwatches, personal health data is one glance at your wrist away. With the rise of streaming, there are hundreds of playlists for every activity. Despite both of these innovations, people still waste *minutes* every day adjusting their music to their current activity. **Heartmonics** bridges this gap to save time and encourage healthy habits.
## What it does
Heartmonics tunes your music to your current fitness activity level. Our device reads your heart rate, then adjusts the mood of your music to suit resting, light exercise, and intense work-outs. This functionality helps to encourage exercise and keep users engaged and enjoying their workouts.
## How we built it
Our device is runs on a Raspberry Pi platform housed in an exercise armband. It reads heart rate data from a sensor connected via i2c and comfortably attached to the users forearm. A button integrated into the armband provides easy control of music like any other player, allowing the user to play, pause, skip, and rewind songs.
## Challenges we ran into
In building Heartmonics, we faced several challenges with integrating all the components of our design together. The heart rate sensor was found to be very sensitive and prone to giving inaccurate results, but by reading documentation and making careful adjustments, as well as reinforcing our hardware connections, we were able to get the sensor calibrated and working reliably. Integrating our solution with SpotifyAPI using the spotipi library also came with a set of integration challenges, compounded by our unfamiliarity with the platform. Despite all of these challenges, we persevered to produce a polished and functional prototype.
## Accomplishments that we're proud of
We are proud of the ease of use of our final design. Since the concept is designed as a time saver, we're glad it can deliver on everything we set out to do. We also went above and beyond our original goals, adding music control via a button, mood indication on an RGB LED, sensor and song information on an LCD display, and an elevated heart rate warning indicator. These features elevate Heartmonics and
## What we learned
We learned the importance of careful hardware selection, and reading documentation. We leveraged and reinforced our teamwork and planning abilities to quickly build a functioning prototype.
## What's next for Heartmonics
The functionality of Heartmonics could be integrated into a smartwatch app for a more elegant implementation of our concept. With wearable integration, users could employ our concept with potentially no additional cost, making Heartmonics widely accessible.
Another potential addition is to make configuring which songs play for each mode user-accessible, so everyone can tune their Heartmonics to the tune of their heart. | ## Inspiration
Vehicle emissions account for a large percentage of North America's yearly carbon dioxide emissions. However, despite many efforts in the past, people remain reluctant to proactively make even small contributions to this generational issue. We believe that this lack of proactivity is due to a lack of reliable metrics to inform people about the changes they are able to enact upon their livlihoods to improve the world. To help people better visualize the changes they are capable of, we were inspired to create our DeltaHacks project.
## What it does
ClearSky Travelytics is a travel companion that grants insightful information about travel routes. Beyond just location data, Travelytics shares detailed information to promote good health and well being as well as environmental stewardship. Our vision is to provide travelers with a convenient way to analyze their carbon footprint along with various other greenhouse gas metrics accrued throughout their journey. Additionally, Travelytics encourages users to proactively seek a healthier lifestyle by demonstrating how walking and cycling can be an effective form of exercise, posing the question: "does practicing environmental mindfulness necessarily have to come as a disadvantage to yourself?"
## How we built it
We used the Google Maps API platform to create a Progressive Web App along with basic HTML, CSS, and JavaScript.
We chose Google Maps because we knew that we would need to retrieve location data in order to plot trips for our users, calculate various environmental and wellness metrics, and display a map of the overall route.
After discussing relevant features and the tools we wanted to use, we set off creating a simple prototype of our web app's design, building up important features one at a time.
Eventually, we were able to produce a solid final iteration of the app after major reworks, and we used Google Firebase to host our app online.
## Challenges we ran into
One of the most difficult challenges we ran into was decyphering the Google Maps API documentation. We had great trouble interpreting the code demos made available to us, and many times we felt that we found
seemingly blatant contradictions and impossibilities. Our team was able to come up with the idea for our project very early on, but we were unable to quickly agree upon a final design which met all our expectations.
Only in the very end, did we produce something we are proud to display.
## Accomplishments that we're proud of
We are proud of coming together to work together on an ambitious project, despite the fact that none of us are very well-versed in back-end architecture.
We are proud of the effort we put into creating such a difficult project, and we are happy that our app might present genuine utility to people who are concerned about their carbon footprint and health.
We are exceedingly proud that our project did not fail in its final stages!
## What we learned
We learned that during web design, it is never a good idea to develop responsive design starting from the desktop version. A small screen translates much better to a big screen than the other way around, where you have to squeeze around elements to make them fit on the page!
We learned that it is important to ideate and come together with a cohesive idea of what the project should strive to be.
We learned that Hackathons are exceedingly fun, and we are all looking forwards to more events in the future.
## What's next for ClearSky Travelytics
One of our group members has expressed interest in maintaining the current version of our app, perhaps even improving upon it and marketing it in the future. | ## Inspiration
I took inspiration from an MLH rubber ducky sticker that I found on my desk. It's better to make *something* rather than nothing, so why not make a cool looking website? There's no user authentification or statistical analysis to it, it's just five rubber duckies vibing out in the neverending vacuum of space. Wouldn't you want to do the same?
## What it does
Sits there and looks pretty (cute).
## How I built it + challenges + accomplishments
I drew everything on my own and used some nifty HTML/CSS to put it all together in the end. It was a pretty simple idea, so the execution reflected it. There were next to no challenges/obstacles save for the obligatory CSS frustration when something doesn't work exactly like you want to. In the end, however, I'm proud that I was able to handle everything from the design to the execution with little to no hassle and finish up within only a few hours. All in all, it was pretty cool. | partial |
One summer I saw my Dad was clearing out the fridge. I was astounded at the sheer amount of forgotten food that was left to expire and destined to end up in the trash. Something needed to be done about this.
FunnelFoods aims to cut down food waste as its source. Using NLP to understand receipts and food items that you have, the app suggests recipes to you based on what you have and what's healthy, but more importantly, prioritizes ingredients that are about to expire – so that we can all waste less and eat healthier.
Please come visit us at CalHacks! We'd love to talk about our project :) | ## Inspiration
How many times have you opened your fridge door and examined its contents for something to eat/cook/stare at and ended up finding a forgotten container of food in the back of the fridge (a month past its expiry date) instead? Are you brave enough to eat it, or does it immediately go into the trash?
The most likely answer would be to dispose of it right away for health and safety reasons, but you'd be surprised - food wastage is a problem that [many countries such as Canada](https://seeds.ca/schoolfoodgardens/food-waste-in-canada-3/) contend with every year, even as world hunger continues to increase! Big corporations and industries contribute to most of the wastage that occurs worldwide, but we as individual consumers can do our part to reduce food wastage as well by minding our fridges and pantries and making sure we eat everything that we procure for ourselves.
Enter chec:xpire - the little app that helps reduce food wastage, one ingredient at a time!
## What it does
chec:xpire takes stock of the contents of your fridge and informs you which food items are close to their best-before date. chec:xpire also provides a suggested recipe which makes use of the expiring ingredients, allowing you to use the ingredients in your next meal without letting them go to waste due to spoilage!
## How we built it
We built the backend using Express.js, which laid the groundwork for interfacing with Solace, an event broker. The backend tracks food items (in a hypothetical refrigerator) as well as their expiry dates, and picks out those that are two days away from their best-before date so that the user knows to consume them soon. The app also makes use of the co:here AI to retrieve and return recipes that make use of the expiring ingredients, thus providing a convenient way to use up the expiring food items without having to figure out what to do with them in the next couple days.
The frontend is a simple Node.js app that subscribes to "events" (in this case, food approaching their expiry date) through Solace, which sends the message to the frontend app once the two-day mark before the expiry date is reached. A notification is sent to the user detailing which ingredients (and their quantities) are expiring soon, along with a recipe that uses the ingredients up.
## Challenges we ran into
The scope of our project was a little too big for our current skillset; we ran into a few problems finding ways to implement the features that we wanted to include in the project, so we had to find ways to accomplish what we wanted to do using other methods.
## Accomplishments that we're proud of
All but one member of the team are first-time hackathon participants - we're very proud of the fact that we managed to create a working program that did what we wanted it to, despite the hurdles we came across while trying to figure out what frameworks we wanted to use for the project!
## What we learned
* planning out a project that's meant to be completed within 36 hours is difficult, especially if you've never done it before!
* there were some compromises that needed to be made due to a combination of framework-related hiccups and the limitations of our current skillsets, but there's victory to be had in seeing a project through to the end even if we weren't able to accomplish every single little thing we wanted to
* Red Bull gives you wings past midnight, apparently
## What's next for chec:xpire
A fully implemented frontend would be great - we ran out of time! | ## Inspiration
Herpes Simplex Virus-2 (HSV-2) is the cause of Genital Herpes, a lifelong and contagious disease characterized by recurring painful and fluid-filled sores. Transmission occurs through contact with fluids from the sores of the infected person during oral, anal, and vaginal sex; transmission can occur in asymptomatic carriers. HSV-2 is a global public health issue with an estimated 400 million people infected worldwide and 20 million new cases annually - 1/3 of which take place Africa (2012). HSV-2 will increase the risk of acquiring HIV by 3 fold, profoundly affect the psychological well being of the individual, and pose as a devastating neonatal complication. The social ramifications of HSV-2 are enormous. The social stigma of sexual transmitted diseases (STDs) and the taboo of confiding others means that patients are often left on their own, to the detriment of their sexual partners. In Africa, the lack of healthcare professionals further exacerbates this problem. Further, the 2:1 ratio of female to male patients is reflective of the gender inequality where women are ill-informed and unaware of their partners' condition or their own. Most importantly, the symptoms of HSV-2 are often similar to various other dermatological issues which are less severe, such as common candida infections and inflammatory eczema. It's very easy to dismiss Genital Herpes as these latter conditions which are much less severe and non-contagious.
## What it does
Our team from Johns Hopkins has developed the humanitarian solution “Foresight” to tackle the taboo issue of STDs. Offered free of charge, Foresight is a cloud-based identification system which will allow a patient to take a picture of a suspicious skin lesion with a smartphone and to diagnose the condition directly in the iOS app. We have trained the computer vision and machine-learning algorithm, which is downloaded from the cloud, to differentiate between Genital Herpes and the less serious eczema and candida infections.
We have a few main goals:
1. Remove the taboo involved in treating STDs by empowering individuals to make diagnostics independently through our computer vision and machine learning algorithm.
2. Alleviate specialist shortages
3. Prevent misdiagnosis and to inform patients to seek care if necessary
4. Location service allows for snapshots of local communities and enables more potent public health intervention
5. Protects the sexual relationship between couples by allowing for transparency- diagnose your partner!
## How I built it
We first gathered 90 different images of 3 categories (30 each) of skin conditions that are common around the genital area: "HSV-2", "Eczema", and "Yeast Infections". We realized that a good way to differentiate between these different conditions are the inherent differences in texture, which are although subtle to the human eye, very perceptible via good algorithms. ] We take advantage of the Bag of Words model common in the field of Web Crawling and Information Retrieval, and apply a similar algorithm, which is written from scratch except for the feature identifier (SIFT). The algorithm follows:
Part A) Training the Computer Vision and Machine Learning Algorithm (Python)
1. We use a Computer Vision feature identifying algorithm called SIFT to process each image and to identify "interesting" points like corners and other patches that are highly unique
2. We consider each patch around the "interesting" points as textons, or units of characteristic textures
3. We build a vocabulary of textons by identifying the SIFT points in all of our training images, and use the machine learning algorithm k-means clustering to narrow down to a list of 1000 "representative" textons
4. For each training image, we can build our own version of a descriptor by representation of a vector, where each element of the vector is the normalized frequency of the texton. We further use tf-idf (term frequency, inverse document frequency) optimization to improve the representation capabilities of each vector. (all this is manually programmed)
5. Finally, we save these vectors in memory. When we want to determine whether a test image depicts either of the 3 categories, we encode the test image into the same tf-idf vector representation, and apply k-nearest neighbors search to find the optimal class. We have found through experimentation that k=4 works well as a trade-off between accuracy and speed.
6. We tested this model with a randomly selected subset that is 10% the size of our training set and achieved 89% accuracy of prediction!
Part B) Ruby on Rails Backend
1. The previous machine learning model can be expressed as an aggregate of 3 files: cluster centers in SIFT space, tf-idf statistics, and classified training vectors in cluster space
2. We output the machine learning model as csv files from python, and write an injector in Ruby that inserts the trained model into our PostgreSQL database on the backend
3. We expose the API such that our mobile iOS app can download our trained model directly through an HTTPS endpoint.
4. Beyond storage of our machine learning model, our backend also includes a set of API endpoints catered to public health purposes: each time an individual on the iOS app make a diagnosis, the backend is updated to reflect the demographic information and diagnosis results of the individual's actions. This information is visible on our web frontend.
Part C) iOS app
1. The app takes in demographic information from the user and downloads a copy of the trained machine learning model from our RoR backend once
2. Once the model has been downloaded, it is possible to make diagnosis even without internet access
3. The user can take an image directly or upload one from the phone library for diagnosis, and a diagnosis is given in several seconds
4. When the diagnosis is given, the demographic and diagnostic information is uploaded to the backend
Part D) Web Frontend
1. Our frontend leverages the stored community data (pooled from diagnoses made from individual phones) accessible via our backend API
2. The actual web interface is a portal for public health professionals like epidemiologists to understand the STD trends (as pertaining to our 3 categories) in a certain area. The heat map is live.
3. Used HTML5,CSS3,JavaScript,jQuery
## Challenges I ran into
It is hard to find current STD prevalence incidence data report outside the United States. Most of the countries have limited surveilliance data among African countries, and the conditions are even worse among stigmatized diseases. We collected the global HSV-2 prevalence and incidence report from World Health Organization(WHO) in 2012. Another issue we faced is the ethical issue in collecting disease status from the users. We were also conflicted on whether we should inform the user's spouse on their end result. It is a ethical dilemma between patient confidentiality and beneficence.
## Accomplishments that I'm proud of
1. We successfully built a cloud-based picture recognition system to distinguish the differences between HSV-2, yeast infection and eczema skin lesion by machine learning algorithm, and the accuracy is 89% for a randomly selected test set that is 10% the training size.
2. Our mobile app which provide users to anonymously send their pictures to our cloud database for recognition, avoid the stigmatization of STDs from the neighbors.
3. As a public health aspect, the function of the demographic distribution of STDs in Africa could assist the prevention of HSV-2 infection and providing more medical advice to the eligible patients.
## What I learned
We learned much more about HSV-2 on the ground and the ramifications on society. We also learned about ML, computer vision, and other technological solutions available for STD image processing.
## What's next for Foresight
Extrapolating our workflow for Machine Learning and Computer Vision to other diseases, and expanding our reach to other developing countries. | losing |
## Inspiration
We wanted to make something to help improve the in-person learning experience feel less restrictive, while still remaining safe at school.
## What it does
GuChecker lets students securely check-in for school through a QR code that they must have scanned before entering rooms in a school. To be able to receive their unique QR code, they must complete the official Ontario Covid-screening, and then they will be added to a database for teachers to use as attendance and quickly complete Covid screenings.
## How we built it
We used Flask to create the webserver and generate QR Codes, with OpenCV and Pyzbar to scan the codes. Lastly, we used Firebase's real-time database to store student information.
## Challenges we ran into
Some challenges we ran into was setting up the Firebase database, and successfully getting information to be uploaded. Another challenge was getting the QR Codes to generate properly and be able check if someone has already registered.
## Accomplishments that we're proud of
We are proud to have the QR generation and scanning successfully work, and correctly upload user information to the Firebase database.
## What we learned
We learned more about Flask, how to use Firebase, and using Computer Vision in a practical setting.
## What's next for GuChecker
Next would be better designing the website better, and adding more functionality such as proper email authentication. | ## Inspiration
mind maps, how you can group items by theme, or some sort of connection.
you know that effect in windows solitaire where when you complete a stack of 13 cards it does that fireworks effect and pops out of its slot? That was sort of a spiritual inspiration to the colour coordination mechanic.
## What it does
it allows you to group creative concepts, like song verses, maybe key plot points of a story, in a non-linear, graphical fashion. you can connect them in the desired order after the fact, and rearrange as needed.
## How I built it
with blood, sweat, monster energy, and tears. also, python for the backend, python with tkinter for frontend.
## Challenges I ran into
Difficulty determining scope of project. There was constant conflict between my desire to implement endless features and the time constraints of the hackathon.
## Accomplishments that I'm proud of
making a tool that is useful to, and will bring immeasurable joy to at least 1 person in this world (me). I'm proud of adding front-end development experience to my resume
## What I learned
front end development.
## What's next for versenotes
cloud-based hosting? multi-platform application (or web-based). image support. | ## Inspiration
Technology in schools today is given to those classrooms that can afford it. Our goal was to create a tablet that leveraged modern touch screen technology while keeping the cost below $20 so that it could be much cheaper to integrate with classrooms than other forms of tech like full laptops.
## What it does
EDT is a credit-card-sized tablet device with a couple of tailor-made apps to empower teachers and students in classrooms. Users can currently run four apps: a graphing calculator, a note sharing app, a flash cards app, and a pop-quiz clicker app.
-The graphing calculator allows the user to do basic arithmetic operations, and graph linear equations.
-The note sharing app allows students to take down colorful notes and then share them with their teacher (or vice-versa).
-The flash cards app allows students to make virtual flash cards and then practice with them as a studying technique.
-The clicker app allows teachers to run in-class pop quizzes where students use their tablets to submit answers.
EDT has two different device types: a "teacher" device that lets teachers do things such as set answers for pop-quizzes, and a "student" device that lets students share things only with their teachers and take quizzes in real-time.
## How we built it
We built EDT using a NodeMCU 1.0 ESP12E WiFi Chip and an ILI9341 Touch Screen. Most programming was done in the Arduino IDE using C++, while a small portion of the code (our backend) was written using Node.js.
## Challenges we ran into
We initially planned on using a Mesh-Networking scheme to let the devices communicate with each other freely without a WiFi network, but found it nearly impossible to get a reliable connection going between two chips. To get around this we ended up switching to using a centralized server that hosts the apps data.
We also ran into a lot of problems with Arduino strings, since their default string class isn't very good, and we had no OS-layer to prevent things like forgetting null-terminators or segfaults.
## Accomplishments that we're proud of
EDT devices can share entire notes and screens with each other, as well as hold a fake pop-quizzes with each other. They can also graph linear equations just like classic graphing calculators can.
## What we learned
1. Get a better String class than the default Arduino one.
2. Don't be afraid of simpler solutions. We wanted to do Mesh Networking but were running into major problems about two-thirds of the way through the hack. By switching to a simple client-server architecture we achieved a massive ease of use that let us implement more features, and a lot more stability.
## What's next for EDT - A Lightweight Tablet for Education
More supported educational apps such as: a visual-programming tool that supports simple block-programming, a text editor, a messaging system, and a more-indepth UI for everything. | losing |
## Inspiration
Navigating the streets of Peru we were lost trying to speak the natural tongue. The pocket dictionary did not help much. Forced to use improper grammar from our translate apps on our phone we looked like fools navigating the local villages. We wondered if there was a better solution rather than hiring a local guide...
## What it does
Utilizing Clarifai's API, Object Lens is able to use visual recognition to depict photos taken by the user. The photo is immediately understood and broken down into what is in the picture. The backend then uses Google Translate to translate the language the user wants. All the pictures are saved and over time a database of objects that the user is familiar with is created. This allows Object Lens to challenge the user by testing their vocabulary against objects they are already familiar with.
## How we built it
We used a plethora of technologies to make Object Lens happen. Using a MEAN stack we created a mobile friendly website using Clarifai's API to recognize objects from the camera. The backend saves the image and the tags associated with it. The tags are then fed to Google Translate and the translated information is displayed to the user.
## Challenges we ran into
We had some trouble with integrating all our work together, luckily we were able to finish in time.
## Accomplishments that we are proud of
We love that we were able to put the project together this weekend! Its something we would love to work the kinks out so we can use it in real life.
## What we learned
It was the first time for some of the team members using the MEAN stack. It was also our first time using Clarifai's API.
## What's next for Object Lens
We want to improve the tagging of objects and generate relevant sentences are created for the user. By utilizing pictures already taken by the user, we also want to introduce pictures that are similar to the ones the user took and add them to the quiz. This will challenge the user and improve their vocabulary. | ## Inspiration
We all love learning languages, but one of the most frustrating things is seeing an object that you don't know the word for and then trying to figure out how to describe it in your target language. Being students of Japanese, it is especially frustrating to find the exact characters to describe an object that you see. With this app, we want to change all that. Huge advances have been made in computer vision in recent years that have allowed us to accurately detect all kinds of different image matter. Combined with advanced translation software, we found the perfect recipe to make an app that could capitalize upon these technologies and help foreign languages students all around the world.
## What it does
The app allows you to either take a picture of an object or scene with your iPhone camera or upload an image from your photo library. You then select a language that would like to translate words into. The app then remotely contacts the Microsoft Azure Cognitive Services using an HTTP request from within the app to create tags from the image you uploaded. These tags are then uploaded to the Google Cloud Platform services to translate those tags into your target language. After doing this, a list of english-foreign language word pairs is displayed, relating to the image tags.
## How we built it
The app was built using Xcode and was coded in Swift. We split up to work on different parts of the project. Kent worked on interfacing with Microsoft's computer vision AI and created the basic app structure. Isaiah worked on setting up Google Cloud Platform translation and contributed to adding functionality for multiple languages. Ivan worked on designing the logo for the app and most of the visuals.
## Challenges we ran into
A lot of time was spent figuring out how to deal with HTTP requests and json, two things none of us have much experience with, and then using them in swift to contact remote services through our app. After this major hurdle was overcome, there was a concurrency issue as both the vision AI and translation requests were designed to be run in parallel to the main thread of the app's execution, however this created some problems for updating the app's UI. We ended up fixing all the issues though!
## Accomplishments that we're proud of
We are very proud that we managed to utilize some really awesome cloud services like Microsoft Azure's Cognitive Services and Google Cloud Platform, and are happy that we managed to create an app that worked at the end of the day!
## What we learned
This was a great learning experience for all of us, both in terms of the technical skills we acquired in connecting to cloud services and in terms of the teamwork skills we acquired.
## What's next for Literal
Firstly, we would add more languages to translate and make much cleaner UI. Then we would enable it to run on cloud services indefinitely instead of just on a temporary treehacks-based license. After that, there are many more cool ideas that we could implement into the app! | ## Inspiration
Imagine a world where your best friend is standing in front of you, but you can't see them. Or you go to read a menu, but you are not able to because the restaurant does not have specialized brail menus. For millions of visually impaired people around the world, those are not hypotheticals, they are facts of life.
Hollywood has largely solved this problem in entertainment. Audio descriptions allow the blind or visually impaired to follow the plot of movies easily. With Sight, we are trying to bring the power of audio description to everyday life.
## What it does
Sight is an app that allows the visually impaired to recognize their friends, get an idea of their surroundings, and have written text read aloud. The app also uses voice recognition to listen for speech commands to identify objects, people or to read text.
## How we built it
The front-end is a native iOS app written in Swift and Objective-C with XCode. We use Apple's native vision and speech API's to give the user intuitive control over the app.
---
The back-end service is written in Go and is served with NGrok.
---
We repurposed the Facebook tagging algorithm to recognize a user's friends. When the Sight app sees a face, it is automatically uploaded to the back-end service. The back-end then "posts" the picture to the user's Facebook privately. If any faces show up in the photo, Facebook's tagging algorithm suggests possibilities for who out of the user's friend group they might be. We scrape this data from Facebook to match names with faces in the original picture. If and when Sight recognizes a person as one of the user's friends, that friend's name is read aloud.
---
We make use of the Google Vision API in three ways:
* To run sentiment analysis on people's faces, to get an idea of whether they are happy, sad, surprised etc.
* To run Optical Character Recognition on text in the real world which is then read aloud to the user.
* For label detection, to indentify objects and surroundings in the real world which the user can then query about.
## Challenges we ran into
There were a plethora of challenges we experienced over the course of the hackathon.
1. Each member of the team wrote their portion of the back-end service a language they were comfortable in. However when we came together, we decided that combining services written in different languages would be overly complicated, so we decided to rewrite the entire back-end in Go.
2. When we rewrote portions of the back-end in Go, this gave us a massive performance boost. However, this turned out to be both a curse and a blessing. Because of the limitation of how quickly we are able to upload images to Facebook, we had to add a workaround to ensure that we do not check for tag suggestions before the photo has been uploaded.
3. When the Optical Character Recognition service was prototyped in Python on Google App Engine, it became mysteriously rate-limited by the Google Vision API. Re-generating API keys proved to no avail, and ultimately we overcame this by rewriting the service in Go.
## Accomplishments that we're proud of
Each member of the team came to this hackathon with a very disjoint set of skills and ideas, so we are really glad about how well we were able to build an elegant and put together app.
Facebook does not have an official algorithm for letting apps use their facial recognition service, so we are proud of the workaround we figured out that allowed us to use Facebook's powerful facial recognition software.
We are also proud of how fast the Go back-end runs, but more than anything, we are proud of building a really awesome app.
## What we learned
Najm taught himself Go over the course of the weekend, which he had no experience with before coming to YHack.
Nathaniel and Liang learned about the Google Vision API, and how to use it for OCR, facial detection, and facial emotion analysis.
Zak learned about building a native iOS app that communicates with a data-rich APIs.
We also learned about making clever use of Facebook's API to make use of their powerful facial recognition service.
Over the course of the weekend, we encountered more problems and bugs than we'd probably like to admit. Most of all we learned a ton of valuable problem-solving skills while we worked together to overcome these challenges.
## What's next for Sight
If Facebook ever decides to add an API that allows facial recognition, we think that would allow for even more powerful friend recognition functionality in our app.
Ultimately, we plan to host the back-end on Google App Engine. | losing |
## Inspiration
An idea to bring together ppl to play a sport they love, in a different more engaged way
## What it does
Connects people wanting to play basketball, segregating on the basis of locality and allowing team formation,etc.
Uses Facebook API's to bring in and connect with users. Can keep track of all your basketball tracks.
The app runs algorithms and ranks each team, and suggests who which team you can play next. To start with we start as a very simple linear algo.
## How I built it
Node.js for backend, Angular bootstrap & HTML for frontend, deployed on Azure
## Challenges I ran into
Uploading photos & videos on facebook thought the app
## Accomplishments that I'm proud of
Was able to create something which uses Facebook, to have all i need regarding basketball
## What I learned
Start the project as small
Modularize and split work better.
## What's next for Hood
Streamline the overall flow
Android & IOS App, improvement in UX. | ## What it does
What our project does is introduce ASL letters, words, and numbers to you in a flashcard manner.
## How we built it
We built our project with React, Vite, and TensorFlowJS.
## Challenges we ran into
Some challenges we ran into included issues with git commits and merging. Over the course of our project we made mistakes while resolving merge conflicts which resulted in a large part of our project being almost discarded. Luckily we were able to git revert back to the correct version but time was misused regardless. With our TensorFlow model we had trouble reading the input/output and getting webcam working.
## Accomplishments that we're proud of
We are proud of the work we got done in the time frame of this hackathon with our skill level. Out of the workshops we attended I think we learned a lot and can't wait to implement them in future projects!
## What we learned
Over the course of this hackathon we learned that it is important to clearly define our project scope ahead of time. We spent a lot of our time on day 1 thinking about what we could do with the sponsor technologies and should have looked into them more in depth before the hackathon.
## What's next for Vision Talks
We would like to train our own ASL image detection model so that people can practice at home in real time. Additionally we would like to transcribe their signs into plaintext and voice so that they can confirm what they are signing. Expanding our project scope beyond ASL to other languages is also something we wish to do. | ## A bit about our thought process...
If you're like us, you might spend over 4 hours a day watching *Tiktok* or just browsing *Instagram*. After such a bender you generally feel pretty useless or even pretty sad as you can see everyone having so much fun while you have just been on your own.
That's why we came up with a healthy social media network, where you directly interact with other people that are going through similar problems as you so you can work together. Not only the network itself comes with tools to cultivate healthy relationships, from **sentiment analysis** to **detailed data visualization** of how much time you spend and how many people you talk to!
## What does it even do
It starts simply by pressing a button, we use **Google OATH** to take your username, email, and image. From that, we create a webpage for each user with spots for detailed analytics on how you speak to others. From there you have two options:
**1)** You can join private discussions based around the mood that you're currently in, here you can interact completely as yourself as it is anonymous. As well if you don't like the person they dont have any way of contacting you and you can just refresh away!
**2)** You can join group discussions about hobbies that you might have and meet interesting people that you can then send private messages too! All the discussions are also being supervised to make sure that no one is being picked on using our machine learning algorithms
## The Fun Part
Here's the fun part. The backend was a combination of **Node**, **Firebase**, **Fetch** and **Socket.io**. The ML model was hosted on **Node**, and was passed into **Socket.io**. Through over 700 lines of **Javascript** code, we were able to create multiple chat rooms and lots of different analytics.
One thing that was really annoying was storing data on both the **Firebase** and locally on **Node Js** so that we could do analytics while also sending messages at a fast rate!
There are tons of other things that we did, but as you can tell my **handwriting sucks....** So please instead watch the youtube video that we created!
## What we learned
We learned how important and powerful social communication can be. We realized that being able to talk to others, especially under a tough time during a pandemic, can make a huge positive social impact on both ourselves and others. Even when check-in with the team, we felt much better knowing that there is someone to support us. We hope to provide the same key values in Companion! | losing |
🛠 Hack Harvard 2022 Ctrl Alt Create 🛠
🎵 Dynamic Playlist Curation 🎵
🌟 Highlights
* Mobile application
* Flutter SDK, Dart as Frontend and Python as Backend
* Uses Spotify REST API
* Facial recognition machine learning model to discern a person's emotional state
* Playlist assorted based on emotional state, current time, weather, and location metrics
ℹ️ Overview
Some days might feel like nothing but good vibes, while others might feel a bit slow. Throughout it all, music has been by your side to give you an encompassing experience. Using the Dynamic Playlist Curation (DPC) app, all you have to do is snap a quick pic of yourself, and DPC will take care of the rest! The app analyzes your current mood and incorporates other metrics like the current weather and time of day to determine the best songs for your current mood. It's a great way to discover pieces that sound just right at the right time. We hope you'll enjoy the 10-song playlist we've created especially for you!
🦋 Inspiration
Don't you wish it was easier to find that one song that matches your current mood?
❗️Challenges
This was our first-ever hackathon. Most of us came in with no knowledge of developing applications. Learning the development cycle, the Flutter SDK, and fetching APIs were among our biggest challenges. Each of us came in with our own respective skill sets, but figuring out how to piece it all together was the hard part. At the very end, our final challenge was putting everything together and ensuring all of the dependencies were installed. After 36 long hours, we are proud to share this project with everyone!
✨ Accomplishments
We were able to develop an ML model that uses image data to return the emotional states of a person. We were able to successfully make API calls to the Spotify Web API and OpenWeatherMap API, link the frontend with our backend, and make a functional UI with the help of Flutter.
📖 What we learned
We learned how to connect our frontend and backend components by running servers on Flask. Additionally, we learned how to write up functions to get data and generate oAuth tokens from our APIs.
🧐 What's next for Hack Harvard
We hope to take this learning experience to build confidence in working on more projects. Next year, we will come back more prepared, more motivated, and even more ambitious!
✍️ Authors
Ivan
Jason
Rishi
Andrew
🚀 Usage
Made specifically for Spotify | ## Inspiration
Amidst the hectic lives and pandemic struck world, mental health has taken a back seat. This thought gave birth to our inspiration of this web based app that would provide activities customised to a person’s mood that will help relax and rejuvenate.
## What it does
We planned to create a platform that could detect a users mood through facial recognition, recommends yoga poses to enlighten the mood and evaluates their correctness, helps user jot their thoughts in self care journal.
## How we built it
Frontend: HTML5, CSS(frameworks used:Tailwind,CSS),Javascript
Backend: Python,Javascript
Server side> Nodejs, Passport js
Database> MongoDB( for user login), MySQL(for mood based music recommendations)
## Challenges we ran into
Incooperating the open CV in our project was a challenge, but it was very rewarding once it all worked .
But since all of us being first time hacker and due to time constraints we couldn't deploy our website externally.
## Accomplishments that we're proud of
Mental health issues are the least addressed diseases even though medically they rank in top 5 chronic health conditions.
We at umang are proud to have taken notice of such an issue and help people realise their moods and cope up with stresses encountered in their daily lives. Through are app we hope to give people are better perspective as well as push them towards a more sound mind and body
We are really proud that we could create a website that could help break the stigma associated with mental health. It was an achievement that in this website includes so many features to help improving the user's mental health like making the user vibe to music curated just for their mood, engaging the user into physical activity like yoga to relax their mind and soul and helping them evaluate their yoga posture just by sitting at home with an AI instructor.
Furthermore, completing this within 24 hours was an achievement in itself since it was our first hackathon which was very fun and challenging.
## What we learned
We have learnt on how to implement open CV in projects. Another skill set we gained was on how to use Css Tailwind. Besides, we learned a lot about backend and databases and how to create shareable links and how to create to do lists.
## What's next for Umang
While the core functionality of our app is complete, it can of course be further improved .
1)We would like to add a chatbot which can be the user's guide/best friend and give advice to the user when in condition of mental distress.
2)We would also like to add a mood log which can keep a track of the user's daily mood and if a serious degradation of mental health is seen it can directly connect the user to medical helpers, therapist for proper treatement.
This lays grounds for further expansion of our website. Our spirits are up and the sky is our limit | ## Inspiration ✨
Seeing friends' lives being ruined through **unhealthy** attachment to video games. Struggling with regulating your emotions properly is one of the **biggest** negative effects of video games.
## What it does 🍎
YourHP is a webapp/discord bot designed to improve the mental health of gamers. By using ML and AI, when specific emotion spikes are detected, voice recordings are queued *accordingly*. When the sensor detects anger, calming reassurance is played. When happy, encouragement is given, to keep it up, etc.
The discord bot is an additional fun feature that sends messages with the same intention to improve mental health. It sends advice, motivation, and gifs when commands are sent by users.
## How we built it 🔧
Our entire web app is made using Javascript, CSS, and HTML. For our facial emotion detection, we used a javascript library built using TensorFlow API called FaceApi.js. Emotions are detected by what patterns can be found on the face such as eyebrow direction, mouth shape, and head tilt. We used their probability value to determine the emotional level and played voice lines accordingly.
The timer is a simple build that alerts users when they should take breaks from gaming and sends sound clips when the timer is up. It uses Javascript, CSS, and HTML.
## Challenges we ran into 🚧
Capturing images in JavaScript, making the discord bot, and hosting on GitHub pages, were all challenges we faced. We were constantly thinking of more ideas as we built our original project which led us to face time limitations and was not able to produce some of the more unique features to our webapp. This project was also difficult as we were fairly new to a lot of the tools we used. Before this Hackathon, we didn't know much about tensorflow, domain names, and discord bots.
## Accomplishments that we're proud of 🏆
We're proud to have finished this product to the best of our abilities. We were able to make the most out of our circumstances and adapt to our skills when obstacles were faced. Despite being sleep deprived, we still managed to persevere and almost kept up with our planned schedule.
## What we learned 🧠
We learned many priceless lessons, about new technology, teamwork, and dedication. Most importantly, we learned about failure, and redirection. Throughout the last few days, we were humbled and pushed to our limits. Many of our ideas were ambitious and unsuccessful, allowing us to be redirected into new doors and opening our minds to other possibilities that worked better.
## Future ⏭️
YourHP will continue to develop on our search for a new way to combat mental health caused by video games. Technological improvements to our systems such as speech to text can also greatly raise the efficiency of our product and towards reaching our goals! | partial |
# FireNet: Wildfire Risk Forecaster
Try our web-based risk forecasting tool [here](https://kkraoj.users.earthengine.app/view/wildfire-danger).
## Why forecast wildfire risk?
Climate change is exacerbating wildfire likelihood and severity in the western USA. For instance, in the state of California, USA, in the last century, 12 of the largest wildfires, 13 of the most destructive wildfires, and 7 of the deadliest wildfires occurred during the last decade. Wildfires emit massive amounts of harmful particulate matter posing a direct threat to humans. The severity of wildfire's effects combined with the probability of them worsening in the future due to climate change prompts an urgent need to understand, estimate, and forecast wildfire risk. Our FireNet, a deep-learning-powered system, helps improve the forecasting of wildfire risk by the following "PR. S^3" solutions:
1. P--Prevent smoke inhalation : Wildfire smoke is known to cause serious respiratory disorders. Wildfire exposure ratings can help better forecast the severity and probability of wildfire smoke.
2. R--Reallocate disaster relief resources : By knowing when and where fires are likely to occur, fire managers can better allocate their resources to be well-prepared when wildfires do occur.
3. S--Save lives : High resolution maps of wildfire risk, if prepared periodically, can help evacuate people in advance of an occurrence of wildfire.
4. S--Sustainability : Wildfires not only cause damages to human society, but also decrease species diversity and increase greenhouse gas emissions.
5. S--Social Equality: People from different backgrounds, such as wealth, urban proximity, race, and ethnicity, are unequally exposed to wildfire risk. Poor communities and black, Hispanic or Native American experience greater vulnerability to wildfires compared with other communities. We are dedicated to eliminate the "unnatural" humanity crisis and consequences of natural disasters, such as wildfires.
## What does our tool do?
**FireNet is a rapid risk forecasting tool to characterize the three fundamental components of risk--hazard, exposure, and vulnerability--by combining high resolution remote sensing imagery with deep learning.** The system integrates microwave remote sensing (Sentinel-1) and optical remote sensing (Landsat-8) information over 3 months to produce accurate estimates of fuel conditions (cross-validated r-squared = 0.63) exceeding previous methods by a wide margin (r-squared = 0.3). Moreover, by linking the Long Short Term Memory (LSTM) outputs for fuel conditions with data on human settlements and population density, FireNet indicates the aggregate risk imposed by wildfires on humans. FireNet is hosted as a Google Earth Engine App.
## Wait, but what is wildfire risk exactly?
Wildfire risk depends on 3 fundamental quantities - hazard, exposure, and vulnerability. It can be assessed by combining the extent of its exposure (e.g., how likely is a fire), severity of the hazard (e.g., how big a fire can occur) and the magnitude of its effects (e.g., how much property could be destroyed). Assessing wildfire risk presents several challenges due to uncertainty in fuel flammability and ignition potential. Due to complex physiological mechanisms, estimating fuel flammability and ignition potential has not been possible on landscape scales. Current wildfire risk estimation methods are simply insufficient to accurately and efficiently estimate wildfire risk because of the lack of direct flammability-associated inputs.
## Is FireNet better than other risk estimation methods out there?
**Absolutely!** FireNet is the first wildfire risk forecasting system that operates at 250 m spatial resolution. The best wildfire danger models like the National Fire Danger Rating System operate at approximate 25 Kms. This was possible because of the system's unique use of microwave as well as optical remote sensing. Moreover, existing systems have lesser accuracy in predicting fuel flammability (r-squared = 0.3) than our system (r-squared = 0.63).
## This sounds like yet another deep learning fad without any explainability?
FireNet is fully transparent and explainable. We anticipated the need for explainability for FireNet and thus did NOT use deep learning to estimate fire risk. The deep learning model (LSTM) merely estimates fuel flammability (how wet or dry the forests are) using supervised learning on remote sensing. The flammability estimates are then combined with fuel availability (observed) and urban proximity (census data) to produce a transparent estimate.
## I am sold! Where can I checkout FireNet?
[Here](https://kkraoj.users.earthengine.app/view/wildfire-danger)
## What did we learn from this project?
1. Training a deep learning model is child's play compared to the amount of work required in data cleaning.
2. Data cleaning is child's play compared to the amount of time needed to design an app with UX in mind | # RiskWatch
## Inspiration
## What it does
Our project allows users to report fire hazards with images to a central database. False images could be identified using machine learning (image classification). Also, we implemented methods for people to find fire stations near them. We additionally implemented a way for people to contact Law enforcement and fire departments for a speedy resolution. In return, the users get compensation from insurance companies. Idea is relevant because of large wildfires in California and other states.
## How we built it
We build the site from the ground up using ReactJS, HTML, CSS and JavaScript. We also created a MongoDB database to hold some location data and retrieve them in the website. Python was also used to connect the frontend to the database.
## Challenges we ran into
We initially wanted to create a physical hardware device using a Raspberry Pi 2 and a RaspiCamera. Our plan was to create a device that could utilize object recognition to classify general safety issues. We understood that performance would suffer greatly when going in, as we thought 1-2 FPS would be enough. After spending hours compiling OpenCV, Tensorflow and Protobuf on the Pi, it was worth it. It was surprising to achieve 2-3 FPS after object recognition using Google's SSDLiteNetv2Coco algorithm. But unfortunately, the Raspberry Pi camera would disconnect often and eventually fail due to a manufacturing defect. Another challenge we faced at the final hours was that our original domain choice was mistakenly marked available by the registry when it really was taken, but we eventually resolved it by talking to a customer support representative.
## Accomplishments that we're proud of
We are proud of being able to quickly get back on track after we had issues with our initial hardware idea and repurpose it to become a website. We were all relatively new to React and quickly transitioned from using Materialize.CSS at all the other hackathons we went to.
### Try it out (production)!
* clone the repository: `git clone https://github.com/dwang/RiskWatch.git`
* run `./run.sh`
### Try it out (development)!
* clone the repository: `git clone https://github.com/dwang/RiskWatch.git`
* `cd frontend` then `npm install`
* run `npm start` to run the app - the application should now open in your browser
* start the backend with `./run.sh`
## What we learned
Our group learned how to construct and manage databases with MongoDB, along with seamlessly integrating them into our website. We also learned how to make a website with React, making a chatbot, using image recognition and even more!
## What's next for us?
We would like to make it so that everyone uses our application to be kept safe - right now, it is missing a few important features, but once we add those, RiskWatch could be the next big thing in information consumption.
Check out our GitHub repository at: <https://github.com/dwang/RiskWatch> | ## Inspiration
According to APA, in 2018, 39% of researched Americans reported that they don't go to therapists because they could not afford the therapy cost, time, and daycare. Our team believes that after the pandemic and also the recent high rate of price inflation, such concern is more alert. "Follow Up" is an attempt to lower the therapy cost. We aimed at reducing expensive in-person therapy sessions with accurate remote AI-powered diagnoses, requiring less therapist input and more flexibility for the patients. For now, we are focusing on determining *depression*.
## What it does
"Follow Up" creates a platform for therapists and patients to communicate after a traditional in-person session:
### - From the patient:
They will be asked to answer a questionnaire provided by the therapists, and also upload the video URLs where they answer the questions.
### - From the therapist:
After a traditional therapy session, the therapist will jot down some relevant questions. Those questions can be some self-report questions regarding how the patient feels.
The therapist will also require their patients to upload a video answering some critical questions, which they think will best reflect the patient's mental state. We introduce *Hume* to help us detect the emotion based on their video answer.
The 5 emotions we used to suggest that a person has depression were: *Anxiety, Guilt, Tiredness, Sadness, and Distress*. We planned to create a model to train how much each emotion weighs in terms of reflecting depression.
## How we built it
We used *Flask, HTML, and CSS* mainly to create the full-stack development. We set up the database using *CockroachDB* serverless, and utilize *Hume* to help us analyze the emotion from the uploaded video.
## Challenges we ran into
Honestly, just try to make everything run. The first problem we had was connecting the local machine to the *CockroachDB*, as we did not have *PostgresDB* ready. Secondly, we could not just feed any URL to the *Hume* model, so we tried to incorporate using Google Cloud API for that. We could not find any data regarding how much each emotion relates to depression, so the emotions' weights are untrained. Lastly, we also have some problems with the *Flask* backend.
## Accomplishments that we're proud of
This is our first hackathon so we were quite lost in brainstorming the idea at the beginning, not to mention that one teammate disappeared unannouncedly. We are proud that we stayed until the end and did not give up.
## What we learned
I personally never searched "What is" or "How to" in 24 hours this much in my life. So, in other words, a lot.
## What's next for Follow Up
We believe this has a lot of potential. This current version only focuses on *depression*, but there are a lot more symptoms we can analyze. Also, because of the lack of training data for the weight of each emotion, we believe that more research on how much of each dominant emotion is reflected in mentally ill patients will put our idea into more multi-dimensional use.
Some research links:
[link](https://www.verywellmind.com/depression-statistics-everyone-should-know-4159056)
[link](https://www.apa.org/monitor/2020/07/datapoint-care)
Pictures are license-free from Pinterest\* | partial |
## Inspiration
As both team members have always been involved with athletics and fitness since childhood, we wanted to build something that can help more people stay safe in the gym and achieve their goals faster.
## What it does
The hardware attaches to a barbell and sends real-time data of movement during exercise, which is analysed and visualized for the user in an app. By tracking the travel path of the bar, suggestions can be made to improve safety and form. The aggregated data can be used to help the users set and achieve their fitness goals.
## How I built it
The hardware system is built around a Dragonboard 410c, and a 10DOF IMU sensor measures the data. This data is pushed to a database and the analysis is done on GCP. This is then visualized in an app built with React Native.
## Challenges I ran into
The most difficult aspect was configuring the dragonboard to push the data to the database. The team members were not familiar with C or the MySQL API, and we could not get the device to push data in real time.
## Accomplishments that I'm proud of
Ultimately, we were able to build a prototype of something that we could personally use to help us achieve our goals. Even though we were not familiar with a majority of the tools needed to create our project, we were able to think on the spot and create a working version of the Smart Barbell.
## What's next for Smart Barbell
We are putting together a pitch to present at our University's pitch competition. We will continue to iterate on our idea and develop newer, better MVPs | ## Inspiration
After learning that deadlifts are of the most dangerous exercises responsible for serious injury, we wanted to create a product that could help track form of deadlifts. We wanted to make a wearable product that could notify the wearer when their angular velocity was changing too quickly, to reduce the risk of injury when deadlifting/training.
## What it does
The user will wear the device on their chest because that's the part of the body that should ideally be in the same position at all times. In this position, the Arduino will be able to monitor if the back is bent at a different angle and will tell the user that they're out of form. Our app currently tracks the angular velocity and acceleration of the body and will report to the user if the body is shifting from optimal position.
A phone is connected to the Arduino via Bluetooth and will take in the data to present to the user.
Also using the phone app, the user can open the app using their voice and it will begin tracking their movements.
## How we built it
Using Google Cloud API, Evothings, Arduino 101, Android Studio!
**Communication:**
Using the Bluetooth low energy (BLE) communication, gyroscope, and accelerometer built into the Arduino 101, we had an IoT solution with peripherals we needed for our hack.
**Frontend:**
We used Evothings, a mobile app development environment made specifically for IoT applications. This allowed us to program in Javacript and html for our layout and graphing of data.
**Backend:**
With Android studio and Google Cloud API, we created an extension of our main app, so that users of FLEX could start the main program with their voice. This would allow the weightlifter to put the phone in front of them and monitor progress and notifications without stopping their set.
## Challenges we ran into
The main challenge we faced in this project was learning how to use the equipment. Evothings, and the Arduino 101 have very limited documentation which made debugging and programming much more difficult.
## Accomplishments that we're proud of
It's most of our first times working with the Arduino 101, Evothings, and gyros/accelerometers, so we're glad to have learned something and explored what was available.
## What we learned
1. How accelerometers, gyroscopes work!
2. Evothings is very useful for quick testing of mobile apps
3. Javascript isn't
4. smoothie.js is useful for graphs
## What's next for FLEX
We want to incorporate the fitbit in our design to measure heart rate, provide haptic feedback, and be able to create an app that can get all the fitness data from the regular fitbit applications.
By adding in heart rate, we'll be able to track how intense the workout is based on velocity of movement and heart rate and provide warnings in both the app, and on the fitbit.
For motivation, a feature that could be implemented would be to be able to compare results to friends and track friendly competition.
<https://www.hackster.io/137915/flex-dd258d> | ## Inspiration
It’'s pretty common that you will come back from a grocery trip, put away all the food you bought in your fridge and pantry, and forget about it. Even if you read the expiration date while buying a carton of milk, chances are that a decent portion of your food will expire. After that you’ll throw away food that used to be perfectly good. But, that’s only how much food you and I are wasting. What about everything that Walmart or Costco trashes on a day to day basis?
Each year, 119 billion pounds of food is wasted in the United States alone. That equates to 130 billion meals and more than $408 billion in food thrown away each year.
About 30 percent of food in American grocery stores is thrown away. US retail stores generate about 16 billion pounds of food waste every year.
But, if there was a solution that could ensure that no food would be needlessly wasted, that would change the world.
## What it does
PantryPuzzle will scan in images of food items as well as extract its expiration date, and add it to an inventory of items that users can manage. When food nears expiration, it will notify users to incentivize action to be taken. The app will take actions to take with any particular food item, like recipes that use the items in a user’s pantry according to their preference. Additionally, users can choose to donate food items, after which they can share their location to food pantries and delivery drivers.
## How we built it
We built it with a React frontend and a Python flask backend. We stored food entries in a database using Firebase. For the food image recognition and expiration date extraction, we used a tuned version of Google Vision API’s object detection and optical character recognition (OCR) respectively. For the recipe recommendation feature, we used OpenAI’s GPT-3 DaVinci large language model. For tracking user location for the donation feature, we used Nominatim open street map.
## Challenges we ran into
React to properly display
Storing multiple values into database at once (food item, exp date)
How to display all firebase elements (doing proof of concept with console.log)
Donated food being displayed before even clicking the button (fixed by using function for onclick here)
Getting location of the user to be accessed and stored, not just longtitude/latitude
Needing to log day that a food was gotten
Deleting an item when expired.
Syncing my stash w/ donations. Don’t wanna list if not wanting to donate anymore)
How to delete the food from the Firebase (but weird bc of weird doc ID)
Predicting when non-labeled foods expire. (using OpenAI)
## Accomplishments that we're proud of
* We were able to get a good computer vision algorithm that is able to detect the type of food and a very accurate expiry date.
* Integrating the API that helps us figure out our location from the latitudes and longitudes.
* Used a scalable database like firebase, and completed all features that we originally wanted to achieve regarding generative AI, computer vision and efficient CRUD operations.
## What we learned
We learnt how big of a problem the food waste disposal was, and were surprised to know that so much food was being thrown away.
## What's next for PantryPuzzle
We want to add user authentication, so every user in every home and grocery has access to their personal pantry, and also maintains their access to the global donations list to search for food items others don't want.
We integrate this app with the Internet of Things (IoT) so refrigerators can come built in with this product to detect food and their expiry date.
We also want to add a feature where if the expiry date is not visible, the app can predict what the likely expiration date could be using computer vision (texture and color of food) and generative AI. | losing |
## LiveBoard is an easy-to-use tool to live stream classroom blackboard view.
It's half past 1 and you rush into the lecture hall, having to sit in the back of class for being late. Your professor has a microphone but the board is stuck at the same size, looming farther away the higher you climb the steps to an open seat. The professor is explaining the latest lesson, but he's blocking the ever-important diagram. As soon as you seem to understand, your eyes wander away, and in less than a second you're lost in your dreams. If only you could have seen the board up close!
LiveBoard is here to help! With a two-camera setup and a web-facing server, the board is rendered online, ready to be studied, understood and even saved for a later date. Functioning as either a broadcast or a recording, along with a Matlab backend and Django server, LiveBoard is here to facilitate studying for everyone.
Setup for use is easy. As phones can easily operate as IP cameras, any board can be captured and displayed with full convenience. | ## Inspiration
The growing destruction of ecosystem and also growing market of social media apps inspired me to do this project. I thought of fusing this both by creating a social media app which promotes green ecosystem.
## What it does
EcoConnect connects all the people and inspire them to promote green ecosystem in a fun way by posting their contribution towards green ecosystem. Other people can support by giving them Greenpoints. One can only give ten Greenpoints in a day. By this method, we can improve our ecosystem.
## How I built it
I built it using html and css. This is just a prototype or a design about the website.
## Challenges I ran into
I had a great challenge in designing the whole website in short span of time.
## Accomplishments that I'm proud of
I'm proud that my project would make a good impact on society.
## What I learned
I learned that tech and green ecosystem are not really edged opposites but if fused in a good way, it can be used to make a good impact
## What's next for EcoConnect
Promoting EcoConnect and making it look more professional | ## Inspiration
We were inspired by hard working teachers and students. Although everyone was working hard, there was still a disconnect with many students not being able to retain what they learned. So, we decided to create both a web application and a companion phone application to help target this problem.
## What it does
The app connects students with teachers in a whole new fashion. Students can provide live feedback to their professors on various aspects of the lecture, such as the volume and pace. Professors, on the other hand, get an opportunity to receive live feedback on their teaching style and also give students a few warm-up exercises with a built-in clicker functionality.
The web portion of the project ties the classroom experience to the home. Students receive live transcripts of what the professor is currently saying, along with a summary at the end of the lecture which includes key points. The backend will also generate further reading material based on keywords from the lecture, which will further solidify the students’ understanding of the material.
## How we built it
We built the mobile portion using react-native for the front-end and firebase for the backend. The web app is built with react for the front end and firebase for the backend. We also implemented a few custom python modules to facilitate the client-server interaction to ensure a smooth experience for both the instructor and the student.
## Challenges we ran into
One major challenge we ran into was getting and processing live audio and giving a real-time transcription of it to all students enrolled in the class. We were able to solve this issue through a python script that would help bridge the gap between opening an audio stream and doing operations on it while still serving the student a live version of the rest of the site.
## Accomplishments that we’re proud of
Being able to process text data to the point that we were able to get a summary and information on tone/emotions from it. We are also extremely proud of the
## What we learned
We learned more about React and its usefulness when coding in JavaScript. Especially when there were many repeating elements in our Material Design. We also learned that first creating a mockup of what we want will facilitate coding as everyone will be on the same page on what is going on and all thats needs to be done is made very evident. We used some API’s such as the Google Speech to Text API and a Summary API. We were able to work around the constraints of the API’s to create a working product. We also learned more about other technologies that we used such as: Firebase, Adobe XD, React-native, and Python.
## What's next for Gradian
The next goal for Gradian is to implement a grading system for teachers that will automatically integrate with their native grading platform so that clicker data and other quiz material can instantly be graded and imported without any issues. Beyond that, we can see the potential for Gradian to be used in office scenarios as well so that people will never miss a beat thanks to the live transcription that happens. | losing |
## Inspiration
Bullying is an issue prevalent worldwide - regardless of race, age or gender. Having seen it up close in our daily school lives, yet having done nothing about it, we decided to take a stand and try to tackle this issue using the skills at our disposal. We don't believe that bullies always deserve punishment - instead, we should reach out to them and help them overcome whatever reasons may be causing them to bully. Because of this, we decided to implement both a short time as well as a long term solution.
## What it does
No Duckling Is Ugly is an IoT system that listens to conversations by students in classrooms, performs real time sentiment analysis on their interactions and displays the most recent and relevant bullying events, identifying the students involved in the interaction. In the short run, teachers are able to see real time when bullying occurs and intervene if necessary - in the long run, data on such events is collected and displayed in a user friendly manner, to help teachers decide on how to guide their class down the healthiest and most peaceful path.
## How we built it
Hardware: We used Qualcomm Dragonboard 410c boards to serve as the listening IoT device, and soldered analog microphones onto them (the boards did not come with microphones inbuilt).
Software: We used PyAudio and webrtcvad to read a constant stream of audio and break it into chunks to perform processing on. We then used Google Speech Recognition to convert this speech to text, and performed sentiment analysis using the Perspective API to determine the toxicity of the statement. If toxic, we use Microsoft's Cognitive Services API to determine who said the statement, and use Express to create a REST API, which finally interfaces with the MongoDB Stitch service to store the relevant data.
## Challenges we ran into
1. **Audio encoding PCM** - The speaker recognition service we use requires audio input in a specific PCM format, with a 16K sampling rate and 16 bit encoding. Figuring out how to convert real time audio to this format was a challenge.
2. **No mic on Dragonboard** - The boards we were provided with didn't come with onboard microphones, and the GPIO pins seemed to be dysfunctional, so we ended up soldering the mics directly onto the board after analyzing the chip architecture.
3. **Integrating MongoDB Stitch with Python and Angular** - MongoDB Stitch does not have an SDK for either Python or Angular, so we had to create a middleman service (using Express) based on Node.js to act as a REST API, handling requests from Python and interfacing with MongoDB.
4. **Handling streaming audio** - None of the services we used supported constantly streaming audio, so we had to determine how exactly to split up the audio into chunks. We eventually used webrtcvad to detect if voices were present in the frames being recorded, creating temporary WAV files with the necessary encodings to send to the necessary APIs
## Accomplishments that we're proud of
Being able to work together and distribute work effectively. This project had too many components to seem feasible in 36 hours, especially taking into account the obstacles we faced, yet we are proud that we managed to implement a working project in this time. Not only did we create something we were passionate about, we also managed to create something that will hopefully help people
## What we learned
We had never worked with any of the technologies used in this project before, except AngularJS and Python - we learned how to use a Dragonboard, how to set up a MongoDB Stitch service, as well as audio formatting and detection. Most of all, we learned how to work together well as a team.
## What's next for No Duckling Is Ugly
The applications for this technology reaches far beyond the classroom - in the future, this could even be applied to detecting crimes happening real time, prompting faster police response times and potentially saving lives. The possibilities are endless | ## Inspiration
Almost all undergraduate students, especially at large universities like the University of California Berkeley, will take a class that has a huge lecture format, with several hundred students listening to a single professor speak. At Berkeley, students (including three of us) took CS61A, the introductory computer science class, alongside over 2000 other students. Besides forcing some students to watch the class on webcasts, the sheer size of classes like these impaired the ability of the lecturer to take questions from students, with both audience and lecturer frequently unable to hear the question and notably the question not registering on webcasts at all. This led us to seek out a solution to this problem that would enable everyone to be heard in a practical manner.
## What does it do?
*Questions?* solves this problem using something that we all have with us at all times: our phones. By using a peer to peer connection with the lecturer’s laptop, a student can speak into their smartphone’s microphone and have that audio directly transmitted to the audio system of the lecture hall. This eliminates the need for any precarious transfer of a physical microphone or the chance that a question will be unheard.
Besides usage in lecture halls, this could also be implemented in online education or live broadcasts to allow participants to directly engage with the speaker instead of feeling disconnected through a traditional chatbox.
## How we built it
We started with a fail-fast strategy to determine the feasibility of our idea. We did some experiments and were then confident that it should work. We split our working streams and worked on the design and backend implementation at the same time. In the end, we had some time to make it shiny when the whole team worked together on the frontend.
## Challenges we ran into
We tried the WebRTC protocol but ran into some problems with the implementation and the available frameworks and the documentation. We then shifted to WebSockets and tried to make it work on mobile devices, which is easier said than done. Furthermore, we had some issues with web security and therefore used an AWS EC2 instance with Nginx and let's encrypt TLS/SSL certificates.
## Accomplishments that we're (very) proud of
With most of us being very new to the Hackathon scene, we are proud to have developed a platform that enables collaborative learning in which we made sure whatever someone has to say, everyone can hear it.
With *Questions?* It is not just a conversation between a student and a professor in a lecture; it can be a discussion between the whole class. *Questions?* enables users’ voices to be heard.
## What we learned
WebRTC looks easy but is not working … at least in our case. Today everything has to be encrypted … also in dev mode. Treehacks 2020 was fun.
## What's next for *Questions?*
In the future, we could integrate polls and iClicker features and also extend functionality for presenters and attendees at conferences, showcases, and similar events. \_ Questions? \_ could also be applied even broader to any situation normally requiring a microphone—any situation where people need to hear someone’s voice. | ## Inspiration
Imagine: A major earthquake hits. Thousands call 911 simultaneously. In the call center, a handful of operators face an impossible task. Every line is ringing. Every second counts. There aren't enough people to answer every call.
This isn't just hypothetical. It's a real risk in today's emergency services. A startling **82% of emergency call centers are understaffed**, pushed to their limits by non-stop demands. During crises, when seconds mean lives, staffing shortages threaten our ability to mitigate emergencies.
## What it does
DispatchAI reimagines emergency response with an empathetic AI-powered system. It leverages advanced technologies to enhance the 911 call experience, providing intelligent, emotion-aware assistance to both callers and dispatchers.
Emergency calls are aggregated onto a single platform, and filtered based on severity. Critical details such as location, time of emergency, and caller's emotions are collected from the live call. These details are leveraged to recommend actions, such as dispatching an ambulance to a scene.
Our **human-in-the-loop-system** enforces control of human operators is always put at the forefront. Dispatchers make the final say on all recommended actions, ensuring that no AI system stands alone.
## How we built it
We developed a comprehensive systems architecture design to visualize the communication flow across different softwares.

We developed DispatchAI using a comprehensive tech stack:
### Frontend:
* Next.js with React for a responsive and dynamic user interface
* TailwindCSS and Shadcn for efficient, customizable styling
* Framer Motion for smooth animations
* Leaflet for interactive maps
### Backend:
* Python for server-side logic
* Twilio for handling calls
* Hume and Hume's EVI for emotion detection and understanding
* Retell for implementing a voice agent
* Google Maps geocoding API and Street View for location services
* Custom-finetuned Mistral model using our proprietary 911 call dataset
* Intel Dev Cloud for model fine-tuning and improved inference
## Challenges we ran into
* Curated a diverse 911 call dataset
* Integrating multiple APIs and services seamlessly
* Fine-tuning the Mistral model to understand and respond appropriately to emergency situations
* Balancing empathy and efficiency in AI responses
## Accomplishments that we're proud of
* Successfully fine-tuned Mistral model for emergency response scenarios
* Developed a custom 911 call dataset for training
* Integrated emotion detection to provide more empathetic responses
## Intel Dev Cloud Hackathon Submission
### Use of Intel Hardware
We fully utilized the Intel Tiber Developer Cloud for our project development and demonstration:
* Leveraged IDC Jupyter Notebooks throughout the development process
* Conducted a live demonstration to the judges directly on the Intel Developer Cloud platform
### Intel AI Tools/Libraries
We extensively integrated Intel's AI tools, particularly IPEX, to optimize our project:
* Utilized Intel® Extension for PyTorch (IPEX) for model optimization
* Achieved a remarkable reduction in inference time from 2 minutes 53 seconds to less than 10 seconds
* This represents a 80% decrease in processing time, showcasing the power of Intel's AI tools
### Innovation
Our project breaks new ground in emergency response technology:
* Developed the first empathetic, AI-powered dispatcher agent
* Designed to support first responders during resource-constrained situations
* Introduces a novel approach to handling emergency calls with AI assistance
### Technical Complexity
* Implemented a fine-tuned Mistral LLM for specialized emergency response with Intel Dev Cloud
* Created a complex backend system integrating Twilio, Hume, Retell, and OpenAI
* Developed real-time call processing capabilities
* Built an interactive operator dashboard for data summarization and oversight
### Design and User Experience
Our design focuses on operational efficiency and user-friendliness:
* Crafted a clean, intuitive UI tailored for experienced operators
* Prioritized comprehensive data visibility for quick decision-making
* Enabled immediate response capabilities for critical situations
* Interactive Operator Map
### Impact
DispatchAI addresses a critical need in emergency services:
* Targets the 82% of understaffed call centers
* Aims to reduce wait times in critical situations (e.g., Oakland's 1+ minute 911 wait times)
* Potential to save lives by ensuring every emergency call is answered promptly
### Bonus Points
* Open-sourced our fine-tuned LLM on HuggingFace with a complete model card
(<https://huggingface.co/spikecodes/ai-911-operator>)
+ And published the training dataset: <https://huggingface.co/datasets/spikecodes/911-call-transcripts>
* Submitted to the Powered By Intel LLM leaderboard (<https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard>)
* Promoted the project on Twitter (X) using #HackwithIntel
(<https://x.com/spikecodes/status/1804826856354725941>)
## What we learned
* How to integrate multiple technologies to create a cohesive, functional system
* The potential of AI to augment and improve critical public services
## What's next for Dispatch AI
* Expand the training dataset with more diverse emergency scenarios
* Collaborate with local emergency services for real-world testing and feedback
* Explore future integration | partial |
## Inspiration
As computer science and math students, many of the classes we've taken have required us to use LaTeX - and we all know just how much of a struggle it can be to memorize each and every formula exactly. We knew there had to be a better way, and decided that this weekend would be as good a time as any to tackle this challenge.
## What it does
VerbaTeX converts speech to LaTeX code, performs server-side compilation, and renders an image preview in real-time.
## How we built it
The web app is built with React, TypeScript, and Flask. Firebase and AWS were used for database management and authentication. A custom fine-tuned ChatGPT API was used for NLP and LaTeX translation.
## Challenges we ran into
Although the 32 hours we were given sounded like more than enough at the start, the amount of times we changed plans and ran into bugs quickly made us change our minds.
## Accomplishments that we're proud of
We are proud of building a fully functional full-stack application in such a short time span. We spent a lot of time and effort trying to meet all of our ambitious goals. We truly felt that we dreamed big at Hack the North 2024.
## What we learned
We learned that choosing new and unfamiliar technologies can sometimes be better than sticking to what we're used to. Although none of us had much experience with Defang before Hack the North, we learned about them during workshops and sponsor boothings and were intrigued - and choosing to build our project on it was definitely a good idea!
## What's next for VerbaTeX
LaTeX has so many more functionalities that could be simplified through VerbaTeX, from creating anything from diagrams to tables to charts. We want to make even more of these functions accessible and easier to use for LaTeX users all over the world. | ## Inspiration
We wanted a low-anxiety tool to boost our public speaking skills. With an ever-accelerating shift of communication away from face-to-face and towards pretty much just memes, it's becoming difficult for younger generations to express themselves or articulate an argument without a screen as a proxy.
## What does it do?
DebateABot is a web-app that allows the user to pick a topic and make their point, while arguing against our chat bot.
## How did we build it?
Our website is boot-strapped with Javascript/JQuery and HTML5. The user can talk to our web app which used NLP to convert speech to text, and sends the text to our server, which was built with PHP and background written in python. We perform key-word matching and search result ranking using the indico API, after which we run Sentiment Analysis on the text. The counter-argument, as a string, is sent back to the web app and is read aloud to the user using the Mozilla Web Speech API
## Some challenges we ran into
First off, trying to use the Watson APIs and the Azure APIs lead to a lot of initial difficulties trying to get set up and get access. Early on we also wanted to use our Amazon Echo that we have, but reached a point where it wasn't realistic to use AWS and Alexa skills for what we wanted to do. A common theme amongst other challenges has simply been sleep deprivation; staying up past 3am is a sure-fire way to exponentiate your rate of errors and bugs. The last significant difficulty is the bane of most software projects, and ours is no exception- integration.
## Accomplishments that we're proud of
The first time that we got our voice input to print out on the screen, in our own program, was a big moment. We also kicked ass as a team! This was the first hackathon EVER for two of our team members, and everyone had a role to play, and was able to be fully involved in developing our hack. Also, we just had a lot of fun together. Spirits were kept high throughout the 36 hours, and we lasted a whole day before swearing at our chat bot. To our surprise, instead of echoing out our exclaimed profanity, the Web Speech API read aloud "eff-asterix-asterix-asterix you, chat bot!" It took 5 minutes of straight laughing before we could get back to work.
## What we learned
The Mozilla Web Speech API does not swear! So don't get any ideas when you're talking to our innocent chat bot...
## What's next for DebateABot?
While DebateABot isn't likely to evolve into the singularity, it definitely has the potential to become a lot smarter. The immediate next step is to port the project over to be usable with Amazon Echo or Google Home, which eliminates the need for a screen, making the conversation more realistic. After that, it's a question of taking DebateABot and applying it to something important to YOU. Whether that's a way to practice for a Model UN or practice your thesis defence, it's just a matter of collecting more data.
<https://www.youtube.com/watch?v=klXpGybSi3A> | ## Inspiration
Nowadays, we have been using **all** sorts of development tools for web development, from the simplest of HTML, to all sorts of high-level libraries, such as Bootstrap and React. However, what if we turned back time, and relived the *nostalgic*, good old times of programming in the 60s? A world where the programming language BASIC was prevalent. A world where coding on paper and on **office memo pads** were so popular. It is time, for you all to re-experience the programming of the **past**.
## What it does
It's a programming language compiler and runtime for the BASIC programming language. It allows users to write interactive programs for the web with the simple syntax and features of the BASIC language. Users can read our sample the BASIC code to understand what's happening, and write their own programs to deploy on the web. We're transforming code from paper to the internet.
## How we built it
The major part of the code is written in TypeScript, which includes the parser, compiler, and runtime, designed by us from scratch. After we parse and resolve the code, we generate an intermediate representation. This abstract syntax tree is parsed by the runtime library, which generates HTML code.
Using GitHub actions and GitHub Pages, we are able to implement a CI/CD pipeline to deploy the webpage, which is **entirely** written in BASIC! We also have GitHub Dependabot scanning for npm vulnerabilities.
We use Webpack to bundle code into one HTML file for easy deployment.
## Challenges we ran into
Creating a compiler from scratch within the 36-hour time frame was no easy feat, as most of us did not have prior experience in compiler concepts or building a compiler. Constructing and deciding on the syntactical features was quite confusing since BASIC was such a foreign language to all of us. Parsing the string took us the longest time due to the tedious procedure in processing strings and tokens, as well as understanding recursive descent parsing. Last but **definitely not least**, building the runtime library and constructing code samples caused us issues as minor errors can be difficult to detect.
## Accomplishments that we're proud of
We are very proud to have successfully "summoned" the **nostalgic** old times of programming and deployed all the syntactical features that we desired to create interactive features using just the BASIC language. We are delighted to come up with this innovative idea to fit with the theme **nostalgia**, and to retell the tales of programming.
## What we learned
We learned the basics of making a compiler and what is actually happening underneath the hood while compiling our code, through the *painstaking* process of writing compiler code and manually writing code samples as if we were the compiler.
## What's next for BASIC Web
This project can be integrated with a lot of modern features that is popular today. One of future directions can be to merge this project with generative AI, where we can feed the AI models with some of the syntactical features of the BASIC language and it will output code that is translated from the modern programming languages. Moreover, this can be a revamp of Bootstrap and React in creating interactive and eye-catching web pages. | partial |
Rapid Response aims to solve the inefficient method of locating the caller used today during 911 calls. Additionally, we aim to streamline the process of exchanging information from the user to dispatcher thus allowing for first responders to arrive in a more time efficient manner. Rapid Response utilizes the latitude, longitude, and altitude points of the phone and converts it to a street address which is then sent to the nearest dispatcher in the area along with the nature of the emergency. Furthermore, the user’s physical features are also sent to the dispatchers to help identify the victim of the incident as well the victim’s emergency contacts are also notified of the incident. With Rapid Response, victims of an incident are now able to get the help they need when they need it. | ## Inspiration
This project was a response to the events that occurred during Hurricane Harvey in Houston last year, wildfires in California, and the events that occurred during the monsoon in India this past year. 911 call centers are extremely inefficient in providing actual aid to people due to the unreliability of tracking cell phones. We are also informing people of the risk factors in certain areas so that they will be more knowledgeable when making decisions for travel, their futures, and taking preventative measures.
## What it does
Supermaritan provides a platform for people who are in danger and affected by disasters to send out "distress signals" specifying how severe their damage is and the specific type of issue they have. We store their location in a database and present it live on react-native-map API. This allows local authorities to easily locate people, evaluate how badly they need help, and decide what type of help they need. Dispatchers will thus be able to quickly and efficiently aid victims. More importantly, the live map feature allows local users to see live incidents on their map and gives them the ability to help out if possible, allowing for greater interaction within a community. Once a victim has been successfully aided, they will have the option to resolve their issue and store it in our database to aid our analytics.
Using information from previous disaster incidents, we can also provide information about the safety of certain areas. Taking the previous incidents within a certain range of latitudinal and longitudinal coordinates, we can calculate what type of incident (whether it be floods, earthquakes, fire, injuries, etc.) is most common in the area. Additionally, by taking a weighted average based on the severity of previous resolved incidents of all types, we can generate a risk factor that provides a way to gauge how safe the range a user is in based off the most dangerous range within our database.
## How we built it
We used react-native, MongoDB, Javascript, NodeJS, and the Google Cloud Platform, and various open source libraries to help build our hack.
## Challenges we ran into
Ejecting react-native from Expo took a very long time and prevented one of the members in our group who was working on the client-side of our app from working. This led to us having a lot more work for us to divide amongst ourselves once it finally ejected.
Getting acquainted with react-native in general was difficult. It was fairly new to all of us and some of the libraries we used did not have documentation, which required us to learn from their source code.
## Accomplishments that we're proud of
Implementing the Heat Map analytics feature was something we are happy we were able to do because it is a nice way of presenting the information regarding disaster incidents and alerting samaritans and authorities. We were also proud that we were able to navigate and interpret new APIs to fit the purposes of our app. Generating successful scripts to test our app and debug any issues was also something we were proud of and that helped us get past many challenges.
## What we learned
We learned that while some frameworks have their advantages (for example, React can create projects at a fast pace using built-in components), many times, they have glaring drawbacks and limitations which may make another, more 'complicated' framework, a better choice in the long run.
## What's next for Supermaritan
In the future, we hope to provide more metrics and analytics regarding safety and disaster issues for certain areas. Showing disaster trends overtime and displaying risk factors for each individual incident type is something we definitely are going to do in the future. | ## Inspiration
Witnessing the atrocities(protests, vandalism, etc.) caused by the recent presidential election, we want to make the general public (especially for the minorities and the oppressed) be more safe.
## What it does
It provides the users with live news update happening near them, alerts them if they travel near vicinity of danger, and provide them an emergency tool to contact their loved ones if they get into a dangerous situation.
## How we built it
* We crawl the latest happenings/events using Bing News API and summarize them using Smmry API.
* Thanks to Alteryx's API, we also managed to crawl tweets which will inform the users regarding the latest news surrounding them with good accuracy.
* All of these data are then projected to Google Map which will inform user about any happening near them in easy-to-understand summarized format.
* Using Pittney Bowes' API (GeoCode function), we alert the closest contacts of the user with the address name where the user is located.
## Challenges we ran into
Determining the credibility of tweets is incredibly hard
## Accomplishments that we're proud of
Actually to get this thing to work.
## What's next for BeSafe
Better UI/UX and maybe a predictive capability. | winning |
Hello and thank you for judging my project. I am listing below two different links and an explanation of what the two different videos are. Due to the time constraints of some hackathons, I have a shorter video for those who require a lower time. As default I will be placing the lower time video up above, but if you have time or your hackathon allows so please go ahead and watch the full video at the link below. Thanks!
[3 Minute Video Demo](https://youtu.be/8tns9b9Fl7o)
[5 Minute Demo & Presentation](https://youtu.be/Rpx7LNqh7nw)
For any questions or concerns, please email me at [[email protected]](mailto:[email protected])
## Inspiration
Resource extraction has tripled since 1970. That leaves us on track to run out of non-renewable resources by 2060. To fight this extremely dangerous issue, I used my app development skills to help everyone support the environment.
As a human and a person residing in this environment, I felt that I needed to used my technological development skills in order to help us take care of the environment better, especially in industrial countries such as the United States. In order to do my part in the movement to help sustain the environment. I used the symbolism of the LORAX to name LORAX app; inspired to help the environment.
\_ side note: when referencing firebase I mean firebase as a whole since two different databases were used; one to upload images and the other to upload data (ex. form data) in realtime. Firestore is the specific realtime database for user data versus firebase storage for image uploading \_
## Main Features of the App
To start out we are prompted with the **authentication panel** where we are able to either sign in with an existing email or sign up with a new account. Since we are new, we will go ahead and create a new account. After registering we are signed in and now are at the home page of the app. Here I will type in my name, email and password and log in. Now if we go back to firebase authentication, we see a new user pop up over here and a new user is added to firestore with their user associated data such as their **points, their user ID, Name and email.** Now lets go back to the main app. Here at the home page we can see the various things we can do. Lets start out with the Rewards tab where we can choose rewards depending on the amount of points we have.
If we press redeem rewards, it takes us to the rewards tab, where we can choose various coupons from companies and redeem them with the points we have. Since we start out with zero points, we can‘t redeem any rewards right now.
Let's go back to the home page.
The first three pages I will introduce are apart of the point incentive system for purchasing items that help the environment
If we press the view requests button, we are then navigated to a page where we are able to view our requests we have made in the past. These requests are used in order to redeem points from items you have purchased that help support the environment. Here we would we able to **view some details and the status of the requests**, but since we haven’t submitted any yet, we see there are none upon refreshing. Let’s come back to this page after submitting a request.
If we go back, we can now press the request rewards button. By pressing it, we are navigated to a form where we are able to **submit details regarding our purchase and an image of proof to ensure the user truly did indeed purchase the item**. After pressing submit, **this data and image is pushed to firebase’s realtime storage (for picture) and Firestore (other data)** which I will show in a moment.
Here if we go to firebase, we see a document with the details of our request we submitted and if we go to storage we are able to **view the image that we submitted**. And here we see the details. Here we can review the details, approve the status and assign points to the user based on their requests. Now let’s go back to the app itself.
Now let’s go to the view requests tab again now that we have submitted our request. If we go there, we see our request, the status of the request and other details such as how many points you received if the request was approved, the time, the date and other such details.
Now to the Footprint Calculator tab, where you are able to input some details and see the global footprint you have on the environment and its resources based on your house, food and overall lifestyle. Here I will type in some data and see the results. **Here its says I would take up 8 earths, if everyone used the same amount of resources as me.** The goal of this is to be able to reach only one earth since then Earth and its resources would be able to sustain for a much longer time. We can also share it with our friends to encourage them to do the same.
Now to the last tab, is the savings tab. Here we are able to find daily tasks we can simply do to no only save thousands and thousands of dollars but also heavily help sustain and help the environment. \**Here we have some things we can do to save in terms of transportation and by clicking on the saving, we are navigated to a website where we are able to view what we can do to achieve these savings and do it ourselves. \**
This has been the demonstration of the LORAX app and thank you for listening.
## How I built it
For the navigation, I used react native navigation in order to create the authentication navigator and the tab and stack navigators in each of the respective tabs.
## For the incentive system
I used Google Firebase’s Firestore in order to view, add and upload details and images to the cloud for reviewal and data transfer. For authentication, I also used **Google Firebase’s Authentication** which allowed me to create custom user data such as their user, the points associated with it and the complaints associated with their **user ID**. Overall, **Firebase made it EXTREMELY easy** to create a high level application. For this entire application, I used Google Firebase for the backend.
## For the UI
for the tabs such as Request Submitter, Request Viewer I used React-native-base library to create modern looking components which allowed me to create a modern looking application.
## For the Prize Redemption section and Savings Sections
I created the UI from scratch trialing and erroring with different designs and shadow effects to make it look cool. The user react-native-deeplinking to navigate to the specific websites for the savings tab.
## For the Footprint Calculator
I embedded the **Global Footprint Network’s Footprint Calculator** with my application in this tab to be able to use it for the reference of the user of this app. The website is shown in the **tab app and is functional on that UI**, similar to the website.
I used expo for wifi-application testing, allowing me to develop the app without any wires over the wifi network.
For the Request submission tab, I used react-native-base components to create the form UI elements and firebase to upload the data.
For the Request Viewer, I used firebase to retrieve and view the data as seen.
## Challenges I ran into
Some last second challenges I ran to was the manipulation of the database on Google Firebase. While creating the video in fact, I realize that some of the parameters were missing and were not being updated properly. I eventually realized that the naming conventions for some of the parameters being updated both in the state and in firebase got mixed up. Another issue I encountered was being able to retrieve the image from firebase. I was able to log the url, however, due to some issues with the state, I wasnt able to get the uri to the image component, and due to lack of time I left that off. Firebase made it very very easy to push, read and upload files after installing their dependencies.
Thanks to all the great documentation and other tutorials I was able to effectively implement the rest.
## What I learned
I learned a lot. Prior to this, I had not had experience with **data modelling, and creating custom user data points. \*\*However, due to my previous experience with \*\*firebase, and some documentation referencing** I was able to see firebase’s built in commands allowing me to query and add specific User ID’s to the the database, allowing me to search for data base on their UIDs. Overall, it was a great experience learning how to model data, using authentication and create custom user data and modify that using google firebase.
## Theme and How This Helps The Environment
Overall, this application used **incentives and educates** the user about their impact on the environment to better help the environment.
## Design
I created a comprehensive and simple UI to make it easy for users to navigate and understand the purposes of the Application. Additionally, I used previously mentioned utilities in order to create a modern look.
## What's next for LORAX (Luring Others to Retain our Abode Extensively)
I hope to create my **own backend in the future**, using **ML** and an **AI** to classify these images and details to automate the submission process and **create my own footprint calculator** rather than using the one provided by the global footprint network. | ## Inspiration
Remember the thrill of watching mom haggle like a pro at the market? Those nostalgic days might seem long gone, but here's the twist: we can help you carry out the generational legacy. Introducing our game-changing app – it's not just a translator, it’s your haggling sidekick. This app does more than break down language barriers; it helps you secure deals. You’ll learn the tricks to avoid the tourist trap and get the local price, every time.
We’re not just reminiscing about the good old days; we’re rebooting them for the modern shopper. Get ready to haggle, bargain, and save like never before!
## What it does
Back to the Market is a mobile app specifically crafted to enhance communication and negotiation for users in foreign markets. The app shines in its ability to analyze quoted prices using local market data, cultural norms, and user-set preferences to suggest effective counteroffers. This empowers users to engage in informed and culturally appropriate negotiations, without being overcharged. Additionally, Back to the Market offers a customization feature, allowing users to tailor their spending limits. The user-interface is simple and cute, making it accessible for a broad range of users regardless of their technical interface. Its integration of these diverse features positions Back to the Market not just as a tool for financial negotiation, but as a comprehensive companion for a more equitable, enjoyable, and efficient international shopping experience.
## How we built it
Back to the Market was built by separating the front-end from the back-end. The front-end consists of React-Native, Expo Go, and Javascript to develop the mobile app. The back-end consists of Python, which was used to connect the front-end to the back-end. The Cohere API was used to generate the responses and determine appropriate steps to take during the negotiation process.
## Challenges we ran into
During the development of Back to the Market, we faced two primary challenges. First was our lack of experience with React Native, a key technology for our app's development. While our team was composed of great coders, none of us had ever used React prior to the competition. This meant we had to quickly learn and master it from the ground up, a task that was both challenging and educational. Second, we grappled with front-end design. Ensuring the app was not only functional but also visually appealing and user-friendly required us to delve into UI/UX design principles, an area we had little experience with. Luckily, through the help of the organizers, we were able to adapt quickly with few problems. These challenges, while demanding, were crucial in enhancing our skills and shaping the app into the efficient and engaging version it is today.
## Accomplishments that we're proud of
We centered the button on our first try 😎
In our 36 hours journey with Back to the Market, there are several accomplishments that stand out. Firstly, successfully integrating Cohere for the both the translation and bargaining aspects of the app was a significant achievement. This integration not only provided robust functionality but also ensured a seamless user experience, which was central to our vision.
Secondly, it was amazing to see how quickly we went from zero React-Native experience to making an entire app with it in less than 24 hours. We were able to create both an aesthetically pleasing and highly functional. This rapid skill acquisition and application in a short time frame was a testament to our team's dedication and learning agility.
Finally, we take great pride in our presentation and slides. We managed to craft an engaging and dynamic presentation that effectively communicated the essence of Back to the Market. Our ability to convey complex technical details in an accessible and entertaining manner was crucial in capturing the interest and understanding of our audience.
## What we learned
Our journey with this project was immensely educational. We learned the value of adaptability through mastering React-Native, a technology new to us all, emphasizing the importance of embracing and quickly learning new tools. Furthermore, delving into the complexities of cross-cultural communication for our translation and bargaining features, we gained insights into the subtleties of language and cultural nuances in commerce. Our foray into front-end design taught us about the critical role of user experience and interface, highlighting that an app's success lies not just in its functionality but also in its usability and appeal. Finally, creating a product is the easy part, making people want it is where a lot of people fall. Thus, crafting an engaging presentation refined our storytelling and communication skills.
## What's next for Back to the Market
Looking ahead, Back to the Market is poised for many exciting developments. Our immediate focus is on enhancing the app's functionality and user experience. This includes integrating translation features to allow users to stay within the app throughout their transaction.
In parallel, we're exploring the incorporation of AI-driven personalization features. This would allow Back to the Market to learn from individual user preferences and negotiation styles, offering more tailored suggestions and improving the overall user experience. The idea can be expanded by creating a feature for users to rate suggested responses. Use these ratings to refine the response generation system by integrating the top-rated answers into the Cohere model with a RAG approach. This will help the system learn from the most effective responses, improving the quality of future answers.
Another key area of development is utilising computer vision so that users can simply take a picture of the item they are interested in purchasing instead of having to input an item name, which is especially handy in areas where you don’t know exactly what you’re buying (ex. cool souvenir).
Furthermore, we know that everyone loves a bit of competition, especially in the world of bargaining where you want the best deal possible. That’s why we plan on incorporating a leaderboard for those who save the most money via our negotiation tactics. | ## Inspiration
In the pandemic, healthcare was one of the most important things for everybody. But on the other hand, the people with medical problems were not able to access them as the social-distancing norms and lockdowns made the process very complicated. Doctors who were taking care of COVID patients could not help other patients as it could lead to an outbreak. Therefore, a platform was required to help the patients and doctors both so that medical help could be given to everybody.
## What it does
The mobile application connects the patients and the doctors. The patients as well as the doctors can signup on the platform. Patients can ask for medical advice from the doctors. They have an option to select the doctor and they can also book appointments on the app.
The medical history is saved in the account of the patient so a verified doctor can access the information to suggest treatment to the patient. All this can be done with the help of the app without the need of visiting the hospital.
## How we built it
The mobile application is built using Android-Studio and Java. It is a native android mobile application. We have made classes for doctors and patients. We used Trello for the task division and management of the project.
## Challenges we ran into
Working with new technologies is always challenging. We learned mobile application development. We had to figure out a way to add the book an appointment feature.
## Accomplishments that we're proud of
We are proud that we collaborated as a team and finally build the app. It will be very useful for the people and help save lives.
## What we learned
We learned app development, team-work, and the art of sticking to the goals for getting an outcome.
## What's next for NovaMed
We have planned few features that would love to implement which were not included due to time constraints:
* We planned to incorporate a chatbot for basic medical queries.
* A pill-verification system that could help the patients with the right medicines as wrong medicines could be dangerous for the health.
* Connecting the family doctor on the portal of the patient.
* Checking the pharmacy stock and ease the process of buying medicines.
* Remote monitoring of old-age and severe patients.
* Conduct Clinical Studies.
* Call the nearest hospital in case of any emergency.
* Fall detection for old-age people. | winning |
## Inspiration
As OEMs(Original equipment manufacturers) and consumers keep putting on brighter and brighter lights, this can be blinding for oncoming traffic. Along with the fatigue and difficulty judging distance, it becomes increasingly harder to drive safely at night. Having an extra pair of night vision would be essential to protect your eyes and that's where the NCAR comes into play. The Nighttime Collision Avoidance Response system provides those extra sets of eyes via an infrared camera that uses machine learning to classify obstacles in the road that are detected and projects light to indicate obstacles in the road and allows safe driving regardless of the time of day.
## What it does
* NCAR provides users with an affordable wearable tech that ensures driver safety at night
* With its machine learning model, it can detect when humans are on the road when it is pitch black
* The NCAR alerts users of obstacles on the road by projecting a beam of light onto the windshield using the OLED Display
* If the user’s headlights fail, the infrared camera can act as a powerful backup light
## How we built it
* Machine Learning Model: Tensorflow API
* Python Libraries: OpenCV, PyGame
* Hardware: (Raspberry Pi 4B), 1 inch OLED display, Infrared Camera
## Challenges we ran into
* Training machine learning model with limited training data
* Infrared camera breaking down, we had to use old footage of the ml model
## Accomplishments that we're proud of
* Implementing a model that can detect human obstacles from 5-7 meters from the camera
* building a portable design that can be implemented on any car
## What we learned
* Learned how to code different hardware sensors together
* Building a Tensorflow model on a Raspberry PI
* Collaborating with people with different backgrounds, skills and experiences
## What's next for NCAR: Nighttime Collision Avoidance System
* Building a more custom training model that can detect and calculate the distances of the obstacles to the user
* A more sophisticated system of alerting users of obstacles on the path that is easy to maneuver
* Be able to adjust the OLED screen with a 3d printer to display light in a more noticeable way | ## Inspiration
We wanted to pioneer the use of computationally intensive image processing and machine learning algorithms for use in low resource robotic or embedded devices by leveraging cloud computing.
## What it does
CloudChaser (or "Chase" for short) allows the user to input custom objects for chase to track. To do this Chase will first rotate counter-clockwise until the object comes into the field of view of the front-facing camera, then it will continue in the direction of the object, continually updating its orientation.
## How we built it
"Chase" was built with four continuous rotation servo motors mounted onto our custom modeled 3D-printed chassis. Chase's front facing camera was built using a raspberry pi 3 camera mounted onto a custom 3D-printed camera mount. The four motors and the camera are controlled by the raspberry pi 3B which streams video to and receives driving instructions from our cloud GPU server through TCP sockets. We interpret this cloud data using YOLO (our object recognition library) which is connected through another TCP socket to our cloud-based parser script, which interprets the data and tells the robot which direction to move.
## Challenges we ran into
The first challenge we ran into was designing the layout and model for the robot chassis. Because the print for the chassis was going to take 12 hours, we had to make sure we had the perfect dimensions on the very first try, so we took calipers to the motors, dug through the data sheets, and made test mounts to ensure we nailed the print.
The next challenge was setting up the TCP socket connections and developing our software such that it could accept data from multiple different sources in real time. We ended up solving the connection timing issue by using a service called cam2web to stream the webcam to a URL instead of through TCP, allowing us to not have to queue up the data on our server.
The biggest challenge however by far was dealing with the camera latency. We wanted to camera to be as close to live as possible so we took all possible processing to be on the cloud and none on the pi, but since the rasbian operating system would frequently context switch away from our video stream, we still got frequent lag spikes. We ended up solving this problem by decreasing the priority of our driving script relative to the video stream on the pi.
## Accomplishments that we're proud of
We're proud of the fact that we were able to model and design a robot that is relatively sturdy in such a short time. We're also really proud of the fact that we were able to interface the Amazon Alexa skill with the cloud server, as nobody on our team had done an Alexa skill before. However, by far, the accomplishment that we are the most proud of is the fact that our video stream latency from the raspberry pi to the cloud is low enough that we can reliably navigate the robot with that data.
## What we learned
Through working on the project, our team learned how to write an skill for Amazon Alexa, how to design and model a robot to fit specific hardware, and how to program and optimize a socket application for multiple incoming connections in real time with minimal latency.
## What's next for CloudChaser
In the future we would ideally like for Chase to be able to compress a higher quality video stream and have separate PWM drivers for the servo motors to enable higher precision turning. We also want to try to make Chase aware of his position in a 3D environment and track his distance away from objects, allowing him to "tail" objects instead of just chase them.
## CloudChaser in the news!
<https://medium.com/penn-engineering/object-seeking-robot-wins-pennapps-xvii-469adb756fad>
<https://penntechreview.com/read/cloudchaser> | During the hackathon, our team was inspired to create a discord bot that would allow users to play some geography games. We ended up building a bot that offered a variety of games such as guessing capitals, identifying as many countries as possible, and providing fun facts about different countries. We utilized python discord.py and the restcountries API to develop our bot. Throughout the process, we encountered several challenges, including command execution errors. Despite these hurdles, we persevered and accomplished our goal of creating a functional bot for the first time. We are proud of what we have accomplished and the skills we have acquired in the process. | winning |
## Inspiration
Two of our teammates have personal experiences with wildfires: one who has lived all her life in California, and one who was exposed to a fire in his uncle's backyard in the same state. We found the recent wildfires especially troubling and thus decided to focus our efforts on doing what we could with technology.
## What it does
CacheTheHeat uses different computer vision algorithms to classify fires from cameras/videos, in particular, those mounted on households for surveillance purposes. It calculates the relative size and rate-of-growth of the fire in order to alert nearby residents if said wildfire may potentially pose a threat. It hosts a database with multiple video sources in order for warnings to be far-reaching and effective.
## How we built it
This software detects the sizes of possible wildfires and the rate at which those fires are growing using Computer Vision/OpenCV. The web-application gives a pre-emptive warning (phone alerts) to nearby individuals using Twilio. It has a MongoDB Stitch database of both surveillance-type videos (as in campgrounds, drones, etc.) and neighborhood cameras that can be continually added to, depending on which neighbors/individuals sign the agreement form using DocuSign. We hope this will help creatively deal with wildfires possibly in the future.
## Challenges we ran into
Among the difficulties we faced, we had the most trouble with understanding the applications of multiple relevant DocuSign solutions for use within our project as per our individual specifications. For example, our team wasn't sure how we could use something like the text tab to enhance our features within our client's agreement.
One other thing we were not fond of was that DocuSign logged us out of the sandbox every few minutes, which was sometimes a pain. Moreover, the development environment sometimes seemed a bit cluttered at a glance, which we discouraged the use of their API.
There was a bug in Google Chrome where Authorize.Net (DocuSign's affiliate) could not process payments due to browser-specific misbehavior. This was brought to the attention of DocuSign staff.
One more thing that was also unfortunate was that DocuSign's GitHub examples included certain required fields for initializing, however, the description of these fields would be differ between code examples and documentation. For example, "ACCOUNT\_ID" might be a synonym for "USERNAME" (not exactly, but same idea).
## Why we love DocuSign
Apart from the fact that the mentorship team was amazing and super-helpful, our team noted a few things about their API. Helpful documentation existed on GitHub with up-to-date code examples clearly outlining the dependencies required as well as offering helpful comments. Most importantly, DocuSign contains everything from A-Z for all enterprise signature/contractual document processing needs. We hope to continue hacking with DocuSign in the future.
## Accomplishments that we're proud of
We are very happy to have experimented with the power of enterprise solutions in making a difference while hacking for resilience. Wildfires, among the most devastating of natural disasters in the US, have had a huge impact on residents of states such as California. Our team has been working hard to leverage existing residential video footage systems for high-risk wildfire neighborhoods.
## What we learned
Our team members learned concepts of various technical and fundamental utility. To list a few such concepts, we include MongoDB, Flask, Django, OpenCV, DocuSign, Fire safety.
## What's next for CacheTheHeat.com
Cache the Heat is excited to commercialize this solution with the support of Wharton Risk Center if possible. | ## Inspiration
It’s Friday afternoon, and as you return from your final class of the day cutting through the trailing winds of the Bay, you suddenly remember the Saturday trek you had planned with your friends. Equipment-less and desperate you race down to a nearby sports store and fish out $$$, not realising that the kid living two floors above you has the same equipment collecting dust. While this hypothetical may be based on real-life events, we see thousands of students and people alike impulsively spending money on goods that would eventually end up in their storage lockers. This cycle of buy-store-collect dust inspired us to develop Lendit this product aims to stagnate the growing waste economy and generate passive income for the users on the platform.
## What it does
A peer-to-peer lending and borrowing platform that allows users to generate passive income from the goods and garments collecting dust in the garage.
## How we built it
Our Smart Lockers are built with RaspberryPi3 (64bit, 1GB RAM, ARM-64) microcontrollers and are connected to our app through interfacing with Google's Firebase. The locker also uses Facial Recognition powered by OpenCV and object detection with Google's Cloud Vision API.
For our App, we've used Flutter/ Dart and interfaced with Firebase. To ensure *trust* - which is core to borrowing and lending, we've experimented with Ripple's API to create an Escrow system.
## Challenges we ran into
We learned that building a hardware hack can be quite challenging and can leave you with a few bald patches on your head. With no hardware equipment, half our team spent the first few hours running around the hotel and even the streets to arrange stepper motors and Micro-HDMI wires. In fact, we even borrowed another team's 3-D print to build the latch for our locker!
On the Flutter/ Dart side, we were sceptical about how the interfacing with Firebase and Raspberry Pi would work. Our App Developer previously worked with only Web Apps with SQL databases. However, NoSQL works a little differently and doesn't have a robust referential system. Therefore writing Queries for our Read Operations was tricky.
With the core tech of the project relying heavily on the Google Cloud Platform, we had to resolve to unconventional methods to utilize its capabilities with an internet that played Russian roulette.
## Accomplishments that we're proud of
The project has various hardware and software components like raspberry pi, Flutter, XRP Ledger Escrow, and Firebase, which all have their own independent frameworks. Integrating all of them together and making an end-to-end automated system for the users, is the biggest accomplishment we are proud of.
## What's next for LendIt
We believe that LendIt can be more than just a hackathon project. Over the course of the hackathon, we discussed the idea with friends and fellow participants and gained a pretty good Proof of Concept giving us the confidence that we can do a city-wide launch of the project in the near future. In order to see these ambitions come to life, we would have to improve our Object Detection and Facial Recognition models. From cardboard, we would like to see our lockers carved in metal at every corner of this city. As we continue to grow our skills as programmers we believe our product Lendit will grow with it. We would be honoured if we can contribute in any way to reduce the growing waste economy. | ## Inspiration
In a way, contracts form the backbone of modern society: every exchange of good or services rendered, every transaction where we seek the work and products of others is governed and regulated by these agreements. Without the ability to agree to contracts, we lose the ability to acquire services that may be vital for our well-being.
But we all know that contracts are often tedious and opaque, even for accustomed individuals. What about those groups which find this very hard?
The elderly are a large group affected by this. They have many transactions that require contracts: from medical care, to insurance policies, to financial management, and more. This is a group that tends to have trouble following long and complicated contracts. It is also a group that often has difficulty operating technology -- which can be perilous as contracts are increasingly paperless and online.
That's why we created *AgreeAble*, a contracts platform that is simple and universally welcoming to everyone. We wanted to make a platform that demystifies contracts for those who have trouble with them, making reading and signing as easy as possible.
## What it does
*AgreeAble* works as follows:
1) A family member or caretaker helps the user set up an account, storing a special "Visual Key" as their login instead of a password. This Visual Key makes it easy to verify the user's identity, without having to remember complicated logins.
2) The contract issuer enters a new contract for the individual to sign into the AgreeAble system.
3) The user gets a simple email notification that invites them to sign the contract on the AgreeAble website.
4) The user goes to the website where they can see the terms, validate using their Visual Key, and sign the contract.
The Visual Key is an important part of making the process easy. Current contract services like DocuSign require logins, which may be difficult for the elderly to remember. We wanted to make the login process as easy as "showing" the website something that proves your identity. So, that's what we made the Visual Key: to authenticate, the user just shows the website their favorite, physical object that only they have. (Facial recognition would work just as well, although that IBM service was under maintenance at the time of this hackathon.)
We wanted signing to be very easy too. That's why we chose DocuSign's Click API, which lets users sign an agreement in a single click. **We chose Click over the eSignature API because, by design, the Click API is optimized for as little interaction from the user as possible,** which is perfect for our audience. That being said, a future expansion could include integrating autofill into the form, which would be enabled by the eSignature API.
## How we built it
We built the website in python using the Django web framework. The server uses IBM Visual Recognition to process users' Visual Key, using the data return to generate a unique fingerprint for that key. We then use DocuSign's Clickwrap interface to display simple clickable contracts, retrieving the correct contract from the stored value in our Django database.
The Visual Key uses a fingerprint distance for validation; For an object to be considered a valid key, it must look sufficiently close to this fingerprint. Otherwise, it is rejected. This is an interesting use of data because we built this rather accurate fingerprint using standard vision models, without needing specific domain training.
## Challenges we ran into
Unfortunately, some services that we had wanted to use were not available at the time of this hackathon. We had wanted to use IBM Visual Recognition's Facial Recognition feature, but it was under maintenance at the time. So, we had to improvise, which is how we came up with our Visual Key technique...which arguably is even easier (and fun!) for an audience like the elderly.
## Accomplishments that we're proud of
We've successfully made a very simple and beautiful proof-of-concept for a platform that makes contracts easy for everyone! | winning |
## Inspiration
People who are mute struggle to communicate with people in their day-to-day lives as most people do not understand American Sign Language. We were inspired by the desire to empower mute individuals by bridging communication gaps and fostering global connections.
## What it does
VoiceLens uses advanced lip-reading technology to transcribe speech and translate it in real-time, allowing users to choose their preferred output language for seamless interaction.
## How we built it
We used ReactJS for the frontend and Symphonic Labs API to silently transcribe and read the lips of the user. We also then used Groq's llama3 allow for translation between various languages and used Google's Text-to-speech API to voice the sentences.
## Challenges
We faced challenges in accurately capturing and interpreting lip movements, as well as ensuring fast and reliable translations across diverse languages.
## Accomplishments that we're proud of
We're proud of achieving high accuracy in lip-reading and successfully providing real-time translations that facilitate meaningful communication.
## What we learned
We learned the importance of collaboration between technology and accessibility, and how innovative solutions can make a real difference in people's lives.
## What's next for VoiceLens
We plan to enhance our language offerings, improve speed and accuracy, and explore partnerships to expand the app's reach and impact globally. | ## Inspiration
Just in the United States, 11 million people are deaf, of which half a million use ASL natively. For people who are deaf to communicate with those who are hearing, and therefore most likely not fluent in sign language, they’re constricted to slower methods of communication, such as writing. Similarly, for people who don’t know sign language to immediately be able to communicate comfortably with someone who is deaf, the only options are writing or lip-reading, which has been proven to only be 30-40% effective. By creating Gesture Genie, we aim to make the day to day lives of both the deaf and hearing communities significantly more tension-free.
## What it does
Two Way Sign Language Translator that can translate voice into visual sign language and can translate visual sign language into speech. We use computer vision algorithms to recognize the sign language gestures and translate into text.
## How we built it
Sign Gestures to Text
* We used OpenCV to to capture video from the user which we processed into
* We used Google MediaPipe API to detect all 21 joints in the user's hands
* Trained neural networks to detect and classify ASL gestures
<https://youtu.be/3gNQDp1nM_w>
Voice to Sign Language Gestures
* Voice to text translation
* Text to words/fingerspelling
* By web scraping online ASL dictionaries we can show videos for all ASL through gestures or fingerspelling
* Merging videos of individual sign language words/gestures
<https://youtu.be/mBUhU8b3gK0?si=eIEOiOFE0mahXCWI>
## Challenges we ran into
The biggest challenge that we faced was incorporating the backend into the React/node.js frontend. We use OpenCV for the backend, and we needed to ensure that the camera's output is shown on the front end. We were able to solve this problem by using iFrames in order to integrate the local backend into our combined webpage.
## Accomplishments that we're proud of
We are most proud of being able to recognize action-based sign language words rather than simply relying on fingerspelling to understand the sign language that we input. Additionally, we were able to integrate these videos from our backend into the front end seamlessly using Flask APIs and iFrames.
## What we learned
## What's next for Gesture Genie
Next, we hope to be able to incorporate more phrases/action based gestures, scaling our product to be able to work seamlessly in the day-to-day lives of those who are hard of hearing. We also aim to use more LLMs to better translate the text, recognizing voice and facial emotions as well. | ## Inspiration
We're computer science students, need we say more?
## What it does
"Single or Nah" takes in the name of a friend and predicts if they are in a relationship, saving you much time (and face) in asking around. We pull relevant Instagram data including posts, captions, and comments to drive our Azure-powered analysis. Posts are analyzed for genders, ages, emotions, and smiles -- with each aspect contributing to the final score. Captions and comments are analyzed for their sentiment, which give insights into one's relationship status. Our final product is a hosted web-app that takes in a friend's Instagram handle and generate a percentage denoting how likely they are to be in a relationship.
## How we built it
Our first problem was obtaining Instagram data. The tool we use is a significantly improved version of an open-source Instagram scraper API (<https://github.com/rarcega/instagram-scraper>). The tool originally ran as a Python command line argument, which was impractical to use in a WebApp. We modernized the tool, giving us increased flexibility and allowing us to use it within a Python application.
We run Microsoft's Face-API on the target friend's profile picture to guess their gender and age -- this will be the age range we are interested in. Then, we run through their most recent posts, using Face-API to capture genders, ages, emotions, and smiles of people in those posts to finally derive a sub-score that will factor into the final result. We guess that the more happy and more pictures with the opposite gender, you'd be less likely to be single!
We take a similar approach to captions and comments. First, we used Google's Word2vec to generate semantically similar words to certain keywords (love, boyfriend, girlfriend, relationship, etc.) as well as assign weights to those words. Furthermore, we included Emojis (is usually a good giveaway!) into our weighting scheme[link](https://gist.github.com/chrisfischer/144191eae03e64dc9494a2967241673a). We use Microsoft's Text Analytics API on this keywords-weight scheme to obtain a sentiment sub-score and a keyword sub-score.
Once we have these sub-scores, we aggregate them into a final percentage, denoting how likely your friend is single. It was time to take it live. We integrated all the individual calculations and aggregations into a Django., then hosted all necessary computation using Azure WebApps. Finally, we designed a simple interface to allow inputs as well as to display results with a combination of HTML, CSS, JavaScript, and JQuery.
## Challenges we ran into
The main challenge was that we were limited by our resources. We only had access to basic accounts for some of the software we used, so we had to be careful how on often and how intensely we used tools to prevent exhausting our subscriptions. For example, we limited the number of posts we analyzed per person. Also, our Azure server uses the most basic service, meaning it does not have enough computing power to host more than a few clients.
The application only works on "public" Instagram ideas, so we were unable to find a good number of test subjects to fine tune our process. For the accounts we did have access to, the application produced a reasonable answer, leading us to believe that the app is a good predictor.
## Accomplishments that we're proud of
We proud that we were able to build this WebApp using tools and APIs that we haven't used before. In the end, our project worked reasonably well and accurately. We were able to try it on people and get a score which is an accomplishment in that. Finally, we're proud that we were able to create a relevant tool in today's age of social media -- I mean I know I would use this app to narrow down who to DM.
## What we learned
We learned about the Microsoft Azure API (Face API, Text Analytics API, and web hosting), NLP techniques, and full stack web development. We also learned a lot of useful software development techniques such as how to better use git to handle problems, creating virtual environments, as well as setting milestones to meet.
## What's next for Single or Nah
The next steps for Single or Nah is to make the website and computations more scalable. More scalability allows more people to use our product to find who they should DM -- and who doesn't want that?? We also want to work on accuracy, either by adjusting weights given more data to learn from or by using full-fledged Machine Learning. Hopefully more accuracy would save "Single or Nah" from some awkward moments... like asking someone out... who isn't single... | losing |
## Inspiration
In today's fast-paced digital world, creating engaging social media content can be time-consuming and challenging. We developed Expresso to empower content creators, marketers, and businesses to streamline their social media workflow without compromising on quality or creativity.
## What it does
Expresso is an Adobe Express plugin that revolutionizes the process of creating and optimizing social media posts. It offers:
1. Intuitive Workflow System: Simplifies the content creation process from ideation to publication.
2. AI-Powered Attention Optimization: Utilizes a human attention (saliency) model (SUM) to provide feedback on maximizing post engagement.
3. Customizable Feedback Loop: Allows users to configure iterative feedback based on their specific needs and audience.
4. Task Automation: Streamlines common tasks like post captioning and scheduling.
## How we built it
We leveraged a powerful tech stack to bring Expresso to life:
* React: For building a responsive and interactive user interface
* PyTorch: To implement our AI-driven attention optimization model
* Flask: To create a robust backend API
## Challenges we ran into
Some of the key challenges we faced included:
* Integrating the SUM model seamlessly into the Adobe Express environment
* Optimizing the AI feedback loop for real-time performance
* Ensuring cross-platform compatibility and responsiveness
## Accomplishments that we're proud of
* Successfully implementing a state-of-the-art human attention model
* Creating an intuitive user interface that simplifies complex workflows
* Developing a system that provides actionable, AI-driven insights for content optimization
## What we learned
Throughout this project, we gained valuable insights into:
* Adobe Express plugin development
* Integrating AI models into practical applications
* Balancing automation with user control in creative processes
## What's next for Expresso
We're excited about the future of Expresso and plan to:
1. Expand our AI capabilities to include trend analysis and content recommendations
2. Integrate with more social media platforms for seamless multi-channel publishing
3. Develop advanced analytics to track post performance and refine optimization strategies
Try Expresso today and transform your design and marketing workflow! | # see our presentation [here](https://docs.google.com/presentation/d/1AWFR0UEZ3NBi8W04uCgkNGMovDwHm_xRZ-3Zk3TC8-E/edit?usp=sharing)
## Inspiration
Without purchasing hardware, there are few ways to have contact-free interactions with your computer.
To make such technologies accessible to everyone, we created one of the first touch-less hardware-less means of computer control by employing machine learning and gesture analysis algorithms. Additionally, we wanted to make it as accessible as possible in order to reach a wide demographic of users and developers.
## What it does
Puppet uses machine learning technology such as k-means clustering in order to distinguish between different hand signs. Then, it interprets the hand-signs into computer inputs such as keys or mouse movements to allow the user to have full control without a physical keyboard or mouse.
## How we built it
Using OpenCV in order to capture the user's camera input and media-pipe to parse hand data, we could capture the relevant features of a user's hand. Once these features are extracted, they are fed into the k-means clustering algorithm (built with Sci-Kit Learn) to distinguish between different types of hand gestures. The hand gestures are then translated into specific computer commands which pair together AppleScript and PyAutoGUI to provide the user with the Puppet experience.
## Challenges we ran into
One major issue that we ran into was that in the first iteration of our k-means clustering algorithm the clusters were colliding. We fed into the model the distance of each on your hand from your wrist, and designed it to return the revenant gesture. Though we considered changing this to a coordinate-based system, we settled on changing the hand gestures to be more distinct with our current distance system. This was ultimately the best solution because it allowed us to keep a small model while increasing accuracy.
Mapping a finger position on camera to a point for the cursor on the screen was not as easy as expected. Because of inaccuracies in the hand detection among other things, the mouse was at first very shaky. Additionally, it was nearly impossible to reach the edges of the screen because your finger would not be detected near the edge of the camera's frame. In our Puppet implementation, we constantly *pursue* the desired cursor position instead of directly *tracking it* with the camera. Also, we scaled our coordinate system so it required less hand movement in order to reach the screen's edge.
## Accomplishments that we're proud of
We are proud of the gesture recognition model and motion algorithms we designed. We also take pride in the organization and execution of this project in such a short time.
## What we learned
A lot was discovered about the difficulties of utilizing hand gestures. From a data perspective, many of the gestures look very similar and it took us time to develop specific transformations, models and algorithms to parse our data into individual hand motions / signs.
Also, our team members possess diverse and separate skillsets in machine learning, mathematics and computer science. We can proudly say it required nearly all three of us to overcome any major issue presented. Because of this, we all leave here with a more advanced skillset in each of these areas and better continuity as a team.
## What's next for Puppet
Right now, Puppet can control presentations, the web, and your keyboard. In the future, puppet could control much more.
* Opportunities in education: Puppet provides a more interactive experience for controlling computers. This feature can be potentially utilized in elementary school classrooms to give kids hands-on learning with maps, science labs, and language.
* Opportunities in video games: As Puppet advances, it could provide game developers a way to create games wear the user interacts without a controller. Unlike technologies such as XBOX Kinect, it would require no additional hardware.
* Opportunities in virtual reality: Cheaper VR alternatives such as Google Cardboard could be paired with
Puppet to create a premium VR experience with at-home technology. This could be used in both examples described above.
* Opportunities in hospitals / public areas: People have been especially careful about avoiding germs lately. With Puppet, you won't need to touch any keyboard and mice shared by many doctors, providing a more sanitary way to use computers. | ## Inspiration
Our inspiration for the creation of PlanIt came from the different social circles we spend
time in. It seemed like no matter the group of people, planning an event was always
cumbersome and there were too many little factors that made it annoying.
## What it does
PlanIt allows for quick and easy construction of events. It uses Facebook and Googleplus’
APIs in order to connect people. A host chooses a date and invites people; once invited,
everyone can contribute with ideas for places, which in turn, creates a list of potential
events that are set to a vote.
The host then looks at the results and chooses an overall main event. This main event
becomes the spotlight for many features introduced by PlanIt. Some of the main features
are quite simple in its idea: Let people know when you are on the way, thereby causing
the app to track your location and instead of telling everyone your location, it lets
everybody know how far away you are from the desired destination. Another feature is the
carpool tab; people can volunteer to carpool and list their vehicle capacity, people can
sort themselves as a subpart of the driver. There are many more features that are in
play.
## How we built it
We used Microsoft Azure for cloud based server side development and Xamarin in order
to have easy cross-platform compatibility with C# as our main language.
## Challenges we ran into
Some of the challenges that we ran into were based around backend and server side
issues. We spent 3 hours trying to fix one bug and even then it still seemed to be
conflicted. All in all the frontend went by quite smoothly but the backend took some
work.
## Accomplishments that we're proud of
We were very close to quitting late into the night but we were able to take a break and
rally around a new project model in order to finish as much of it as we could. Not quitting
was probably the most notable accomplishment of the event.
## What we learned
We used two new softwares for this app. Xaramin and Microsoft Azure. We also learned
that its possible to have a semi working product with only one day of work.
## What's next for PlanIt
We were hoping to fully complete PlanIt for use within our own group of friends. If it gets
positive feedback then we could see ourselves releasing this app on the market. | winning |
MediBot: Help us help you get the healthcare you deserve
## Inspiration:
Our team went into the ideation phase of Treehacks 2023 with the rising relevance and apparency of conversational AI as a “fresh” topic occupying our minds. We wondered if and how we can apply conversational AI technology such as chatbots to benefit people, especially those who may be underprivileged or underserviced in several areas that are within the potential influence of this technology. We were brooding over the six tracks and various sponsor rewards when inspiration struck. We wanted to make a chatbot within healthcare, specifically patient safety. Being international students, we recognize some of the difficulties that arise when living in a foreign country in terms of language and the ability to communicate with others. Through this empathetic process, we arrived at a group that we defined as the target audience of MediBot; children and non-native English speakers who face language barriers and interpretive difficulties in their communication with healthcare professionals. We realized very early on that we do not want to replace the doctor in diagnosis but rather equip our target audience with the ability to express their symptoms clearly and accurately. After some deliberation, we decided that the optimal method to accomplish that using conversational AI was through implementing a chatbot that asks clarifying questions to help label the symptoms for the users.
## What it does:
Medibot initially prompts users to describe their symptoms as best as they can. The description is then evaluated to compare to a list of proper medical terms (symptoms) in terms of similarity. Suppose those symptom descriptions are rather vague (do not match very well with the list of official symptoms or are blanket terms). In that case, Medibot asks the patients clarifying questions to identify the symptoms with the user’s added input. For example, when told, “My head hurts,” Medibot will ask them to distinguish between headaches, migraines, or potentially blunt force trauma. But if the descriptions of a symptom are specific and relatable to official medical terms, Medibot asks them questions regarding associated symptoms. This means Medibot presents questions inquiring about symptoms that are known probabilistically to appear with the ones the user has already listed. The bot is designed to avoid making an initial diagnosis using a double-blind inquiry process to control for potential confirmation biases. This means the bot will not tell the doctor its predictions regarding what the user has, and it will not nudge the users into confessing or agreeing to a symptom they do not experience. Instead, the doctor will be given a list of what the user was likely describing at the end of the conversation between the bot and the user. The predictions from the inquiring process are a product of the consideration of associative relationships among symptoms. Medibot keeps track of the associative relationship through Cosine Similarity and weight distribution after the Vectorization Encoding Process. Over time, Medibot zones in on a specific condition (determined by the highest possible similarity score). The process also helps in maintaining context throughout the chat conversations.
Finally, the conversation between the patient and Medibot ends in the following cases: the user needs to leave, the associative symptoms process suspects one condition much more than the others, and the user finishes discussing all symptoms they experienced.
## How we built it
We constructed the MediBot web application in two different and interconnected stages, frontend and backend. The front end is a mix of ReactJS and HTML. There is only one page accessible to the user which is a chat page between the user and the bot. The page was made reactive through several styling options and the usage of states in the messages.
The back end was constructed using Python, Flask, and machine learning models such as OpenAI and Hugging Face. The Flask was used in communicating between the varying python scripts holding the MediBot response model and the chat page in the front end. Python was the language used to process the data, encode the NLP models and their calls, and store and export responses. We used prompt engineering through OpenAI to train a model to ask clarifying questions and perform sentiment analysis on user responses. Hugging Face was used to create an NLP model that runs a similarity check between the user input of symptoms and the official list of symptoms.
## Challenges we ran into
Our first challenge was familiarizing ourselves with virtual environments and solving dependency errors when pushing and pulling from GitHub. Each of us initially had different versions of Python and operating systems. We quickly realized that this will hinder our progress greatly after fixing the first series of dependency issues and started coding in virtual environments as solutions. The second great challenge we ran into was integrating the three separate NLP models into one application. This is because they are all resource intensive in terms of ram and we only had computers with around 12GB free for coding. To circumvent this we had to employ intermediate steps when feeding the result from one model into the other and so on. Finally, the third major challenge was resting and sleeping well.
## Accomplishments we are proud of
First and foremost we are proud of the fact that we have a functioning chatbot that accomplishes what we originally set out to do. In this group 3 of us have never coded an NLP model and the last has only coded smaller scale ones. Thus the integration of 3 of them into one chatbot with front end and back end is something that we are proud to have accomplished in the timespan of the hackathon. Second, we are happy to have a relatively small error rate in our model. We informally tested it with varied prompts and performed within expectations every time.
## What we learned:
This was the first hackathon for half of the team, and for 3/4, it was the first time working with virtual environments and collaborating using Git. We learned quickly how to push and pull and how to commit changes. Before the hackathon, only one of us had worked on an ML model, but we learned together to create NLP models and use OpenAI and prompt engineering (credits to OpenAI Mem workshop). This project's scale helped us understand these ML models' intrinsic moldability. Working on Medibot also helped us become much more familiar with the idiosyncrasies of ReactJS and its application in tandem with Flask for dynamically changing webpages. As mostly beginners, we experienced our first true taste of product ideation, project management, and collaborative coding environments.
## What’s next for MediBot
The next immediate steps for MediBot involve making the application more robust and capable. In more detail, first we will encode the ability for MediBot to detect and define more complex language in simpler terms. Second, we will improve upon the initial response to allow for more substantial multi-symptom functionality.Third, we will expand upon the processing of qualitative answers from users to include information like length of pain, the intensity of pain, and so on. Finally, after this more robust system is implemented, we will begin the training phase by speaking to healthcare providers and testing it out on volunteers.
## Ethics:
Our design aims to improve patients’ healthcare experience towards the better and bridge the gap between a condition and getting the desired treatment. We believe expression barriers and technical knowledge should not be missing stones in that bridge. The ethics of our design therefore hinges around providing quality healthcare for all. We intentionally stopped short of providing a diagnosis with Medibot because of the following ethical considerations:
* **Bias Mitigation:** Whatever diagnosis we provide might induce unconscious biases like confirmation or availability bias, affecting the medical provider’s ability to give proper diagnosis. It must be noted however, that Medibot is capable of producing diagnosis. Perhaps, Medibot can be used in further research to ensure the credibility of AI diagnosis by checking its prediction against the doctor’s after diagnosis has been made.
* **Patient trust and safety:** We’re not yet at the point in our civilization’s history where patients are comfortable getting diagnosis from AIs. Medibot’s intent is to help nudge us a step down that path, by seamlessly, safely, and without negative consequence integrating AI within the more physical, intimate environments of healthcare. We envision Medibot in these hospital spaces, helping users articulate their symptoms better without fear of getting a wrong diagnosis. We’re humans, we like when someone gets us, even if that someone is artificial.
However, the implementation of AI for pre-diagnoses still raises many ethical questions and considerations:
* **Fairness:** Use of Medibot requires a working knowledge of the English language. This automatically disproportionates its accessibility. There are still many immigrants for whom the questions, as simple as we have tried to make them, might be too much for. This is a severe limitation to our ethics of assisting these people. A next step might include introducing further explanation of troublesome terms in their language (Note: the process of pre-diagnosis will remain in English, only troublesome terms that the user cannot understand in English may be explained in a more familiar language. This way we further build patients’ vocabulary and help their familiarity with English ). There are also accessibility concerns as hospitals in certain regions or economic stratas may not have the resources to incorporate this technology.
* **Bias:** We put severe thought into bias mitigation both on the side of the doctor and the patient. It is important to ensure that Medibot does not lead the patient into reporting symptoms they don’t necessarily have or induce availability bias. We aimed to circumvent this by asking questions seemingly randomly from a list of symptoms generated based on our Sentence Similarity model. This avoids leading the user in just one direction. However, this does not eradicate all biases as associative symptoms are hard to mask from the patient (i.e a patient may think chills if you ask about cold) so this remains a consideration.
* **Accountability:** Errors in symptom identification can be tricky to detect making it very hard for the medical practitioner to know when the symptoms are a true reflection of the actual patient’s state. Who is responsible for the consequences of wrong pre-diagnoses? It is important to establish these clear systems of accountability and checks for detecting and improving errors in MediBot.
* **Privacy:** MediBot will be trained on patient data and patient-doctor diagnoses in future operations. There remains concerns about privacy and data protection. This information, especially identifying information, must be kept confidential and secure. One method of handling this is asking users at the very beginning whether they want their data to be used for diagnostics and training or not. | ## Inspiration
Pat-a-cat was inspired when Aidon Lebar said "all i want to do is pet cats" and from there started a story of heroism as David Lougheed made it happen. In the corners of McHacks you could witness the cats being drawn, meows being recorded, and code being coded.
## What it does
It does exactly what you think it does. You pat cats. In this game you can compete against your friends to pat cats, as many cats as you can using keyboard controls. This is designed to help you relax to some lofi hip hop beats and pat some cats to break from the stress of everyday life. Once a cat is patted, you get to listen to the happy meows of hackers, sponsors, and coordinators of McHacks.
With every pat, you poof a cat <3 :3
## How we built it
David Lougheed and Allan Wang made the game play mechanics happen using javascript, typescript, and html. Alvin Tan was in charge of the music and boom box mechanics. Elizabeth Poggie designed the fonts, the graphic design through One Note, and partook in meow solicitation. As well we have some honorable mentions of those who helped record the meows, thank you to Will Guthrie, Aidon Lebar, and Jonathan Ng!
Finally, thank you to everyone who gave their meows for the cause and made some art for the picture frame above the couch!
## Controls
WASD to move Player 1, E to pat with Player 1.
IJKL to move Player 2, O to pat with Player 2.
## Challenges we ran into
As we wanted to maximize aesthetics, we had some high resolution assets; this posed a problem when loaded using some devices. As we were on a time constraint, we had a backlog of features in mind that we later added on top of a working prototype. This resulted in some tightly coupled code, as we didn't take the time to make full design docs and specs.
## Accomplishments that we're proud of
We are proud of CTF (McGill Computer Taskforce) united together as one to create a project we are proud of. As well, we are are also so thrilled to have to the chance to talk to 100 different people, make a working final product, and put our skills to the test to create something fantastic.
## What we learned
Friendship <3
Game mechanics
html canvas
how to make custom fonts
## What's next for Pat-a-Cat
We want to introduce rare cats, power ups, web hosting to allow for people to verse each other on different computers, and different levels with new lofi hip hop beats. | # butternut
## `buh·tr·nuht` -- `bot or not?`
Is what you're reading online written by a human, or AI? Do the facts hold up? `butternut`is a chrome extension that leverages state-of-the-art text generation models *to combat* state-of-the-art text generation.
## Inspiration
Misinformation spreads like wildfire in these days and it is only aggravated by AI-generated text and articles. We wanted to help fight back.
## What it does
Butternut is a chrome extension that analyzes text to determine just how likely a given article is AI-generated.
## How to install
1. Clone this repository.
2. Open your Chrome Extensions
3. Drag the `src` folder into the extensions page.
## Usage
1. Open a webpage or a news article you are interested in.
2. Select a piece of text you are interested in.
3. Navigate to the Butternut extension and click on it.
3.1 The text should be auto copied into the input area.
(you could also manually copy and paste text there)
3.2 Click on "Analyze".
4. After a brief delay, the result will show up.
5. Click on "More Details" for further analysis and breakdown of the text.
6. "Search More Articles" will do a quick google search of the pasted text.
## How it works
Butternut is built off the GLTR paper <https://arxiv.org/abs/1906.04043>. It takes any text input and then finds out what a text generating model *would've* predicted at each word/token. This array of every single possible prediction and their related probability is crossreferenced with the input text to determine the 'rank' of each token in the text: where on the list of possible predictions was the token in the text.
Text with consistently high ranks are more likely to be AI-generated because current AI-generated text models all work by selecting words/tokens that have the highest probability given the words before it. On the other hand, human-written text tends to have more variety.
Here are some screenshots of butternut in action with some different texts. Green highlighting means predictable while yellow and red mean unlikely and more unlikely, respectively.
Example of human-generated text:

Example of GPT text:

This was all wrapped up in a simple Flask API for use in a chrome extension.
For more details on how GLTR works please check out their paper. It's a good read. <https://arxiv.org/abs/1906.04043>
## Tech Stack Choices
Two backends are defined in the [butternut backend repo](https://github.com/btrnt/butternut_backend). The salesforce CTRL model is used for butternut.
1. GPT-2: GPT-2 is a well-known general purpose text generation model and is included in the GLTR team's [demo repo](https://github.com/HendrikStrobelt/detecting-fake-text)
2. Salesforce CTRL: [Salesforce CTRL](https://github.com/salesforce/ctrl) (1.6 billion parameter) is bigger than all GPT-2 varients (117 million - 1.5 billion parameters) and is purpose-built for data generation. A custom backend was
CTRL was selected for this project because it is trained on an especially large dataset meaning that it has a larger knowledge base to draw from to discriminate between AI and human -written texts. This, combined with its greater complexity, enables butternut to stay a step ahead of AI text generators.
## Design Decisions
* Used approchable soft colours to create a warm approach towards news and data
* Used colour legend to assist users in interpreting language
## Challenges we ran into
* Deciding how to best represent the data
* How to design a good interface that *invites* people to fact check instead of being scared of it
* How to best calculate the overall score given a tricky rank distrubution
## Accomplishments that we're proud of
* Making stuff accessible: implementing a paper in such a way to make it useful **in under 24 hours!**
## What we learned
* Using CTRL
* How simple it is to make an API with Flask
* How to make a chrome extension
* Lots about NLP!
## What's next?
Butternut may be extended to improve on it's fact-checking abilities
* Text sentiment analysis for fact checking
* Updated backends with more powerful text prediction models
* Perspective analysis & showing other perspectives on the same topic
Made with care by:

```
// our team:
{
'group_member_0': [brian chen](https://github.com/ihasdapie),
'group_member_1': [trung bui](https://github.com/imqt),
'group_member_2': [vivian wi](https://github.com/vvnwu),
'group_member_3': [hans sy](https://github.com/hanssy130)
}
```
Github links:
[butternut frontend](https://github.com/btrnt/butternut)
[butternut backend](https://github.com/btrnt/butternut_backend) | partial |
## Inspiration
Mapcessibility was inspired by the everyday challenges faced by individuals with disabilities in navigating large buildings and venues. Recognizing that standard navigation tools often overlook the nuanced needs of this demographic, we were motivated to create a solution that makes indoor spaces more accessible and inclusive. Our goal was to harness technology to empower individuals with disabilities, ensuring they can navigate with the same ease and confidence as anyone else.
## What it does
Mapcessibility is a cutting-edge application that provides personalized, accessible indoor navigation. It integrates Mappedin’s innovative mapping technology into a global map framework, offering users detailed and disability-friendly routes inside large buildings and venues. Users can input their specific accessibility needs, and the app will map out routes that accommodate these requirements, such as wheelchair-accessible paths, areas with auditory aids, or routes with low sensory stimulation.
## How we built it
We built Mapcessibility using a combination of Mappedin's mapping technology, robust front-end frameworks like React for an intuitive user interface, and back-end technologies for data management. The application's core is powered by algorithms that consider various accessibility needs, translating them into practical, navigable routes within the mapped spaces. Integration with mobile and web platforms ensures that the service is widely accessible and easy to use.
## Challenges we ran into
One of our main challenges was accurately mapping and categorizing the vast array of accessibility features within buildings. Ensuring real-time updates and maintaining the accuracy of this data was complex. We also faced hurdles in designing an interface that was itself highly accessible, considering different types of users with varied accessibility needs. Additionally, we struggled with mobile responsive development, as again we wanted to make sure this app was accessible as possible
## Accomplishments that we're proud of
We are immensely proud of creating an application that significantly enhances the autonomy of individuals with disabilities. Our successful integration of Mappedin to cater to a diverse range of accessibility needs stands out as a notable achievement as well. We also used useful technologies like Firebase and Next.js, which taught us a lot about modern day web development.
## What we learned
Throughout this project, we gained deeper insights into the challenges faced by individuals with disabilities in indoor navigation. We also learned a lot about the intricacies of mapping and navigation technologies and the importance of user-centered design.
## What's next for Mapcessibility
Looking ahead, we aim to expand Mapcessibility's coverage to more buildings and venues worldwide. We're exploring the integration of real-time assistance features, like AI-powered text-to-speech voicebox for on-the-go navigation support. Continuous improvement of our mapping accuracy and the user interface, based on user feedback, is also a priority. Long-term, we envision Mapcessibility evolving into a holistic platform for accessible travel, both indoors and outdoors. | ## Inspiration
Freedom. Independence.
Two concepts we take for granted in our every day lives.
After reflecting on our experiences volunteering at hospitals during high school, we realized one commonality we shared was the experience of working with the visually impaired such as navigating them through hospitals.
What if we can leverage the power of audio visual recognition systems?
Our goal is to give the visually challenged the freedom and independence to re-engage with society through providing voice-guided indoor navigation and facial sentiment analysis.
## What it does
While external navigation is a common problem being dealt with, we realized that indoor navigation was often neglected. Our software can provide voice-guided indoor navigation and provide facial sentiment analysis.
## How we built it
We achieved indoor navigation through a mixture of 3 techniques: QR code recognition, paired-color pattern recognition, and ultrasonic frequency wave detection. We developed an algorithm to determine the most efficient route to the destination based on the hallway network, and used QR-codes and paired-color patterns to achieve localization and guidance. We also developed a method to provide guidance to the final destination using ultrasonic waves (22 kHz +), by developing a language of various beep patterns to transmit information. For facial sentiment analysis, we transmitted photos taken at set intervals to a firebase database, and used the google cloud platform, utilizing their sentiment analysis and object detection techniques. Keeping our stakeholders in mind, we also developed a full audio UI to provide directions and process queries.
## Challenges we ran into
React, uploading files to firebase, hardware limitations on frequency sampling rates, QR code tolerances, integration of everyone's work at the end (a result of parallel development).
## Accomplishments that we're proud of
Ultrasonic guidance, route optimization algorithm, and our ability to solve a complex problem using innovative solutions.
## What we learned
FFTs, parallel development (and what not to do in it), engineering practises, optimizations of code (when dealing with large datasets).
## What's next for nvsble
Using hardware with fewer limitations to develop the app further, more sentimental analysis, natural language processing to better structure and understand how to present a scene to a user. Partner with a local organization to implement our technology and test its functionality. | ## Inspiration
There are approximately **10 million** Americans who suffer from visual impairment, and over **5 million Americans** suffer from Alzheimer's dementia. This weekend our team decided to help those who were not as fortunate. We wanted to utilize technology to create a positive impact on their quality of life.
## What it does
We utilized a smartphone camera to analyze the surrounding and warn visually impaired people about obstacles that were in their way. Additionally, we took it a step further and used the **Azure Face API** to detect the faces of people that the user interacted with and we stored their name and facial attributes that can be recalled later. An Alzheimer's patient can utilize the face recognition software to remind the patient of who the person is, and when they last saw him.
## How we built it
We built our app around **Azure's APIs**, we created a **Custom Vision** network that identified different objects and learned from the data that we collected from the hacking space. The UI of the iOS app was created to be simple and useful for the visually impaired, so that they could operate it without having to look at it.
## Challenges we ran into
Through the process of coding and developing our idea we ran into several technical difficulties. Our first challenge was to design a simple UI, so that the visually impaired people could effectively use it without getting confused. The next challenge we ran into was attempting to grab visual feed from the camera, and running them fast enough through the Azure services to get a quick response. Another challenging task that we had to accomplish was to create and train our own neural network with relevant data.
## Accomplishments that we're proud of
We are proud of several accomplishments throughout our app. First, we are especially proud of setting up a clean UI with two gestures, and voice control with speech recognition for the visually impaired. Additionally, we are proud of having set up our own neural network, that was capable of identifying faces and objects.
## What we learned
We learned how to implement **Azure Custom Vision and Azure Face APIs** into **iOS**, and we learned how to use a live camera feed to grab frames and analyze them. Additionally, not all of us had worked with a neural network before, making it interesting for the rest of us to learn about neural networking.
## What's next for BlindSpot
In the future, we want to make the app hands-free for the visually impaired, by developing it for headsets like the Microsoft HoloLens, Google Glass, or any other wearable camera device. | losing |
## Inspiration
Our team is composed of engineering science students with a passion for software engineering. We believe that the increased reliance on virtual communication services during the COVID19 pandemic has generated new business opportunities for innovative software solutions that help people to generate meaningful social connections. Our desire to contribute to these innovations has led us to develop GetTogethr, an application which helps organizations put together virtual social events for employees to discover their common interests and build new relationships.
## What it does
GetTogethr is used to pair employees at virtual social events into breakout rooms with colleagues that share similar interests and hobbies. By asking employees to generate a short list of their interests, GetTogethr utilizes semantic text analytics through the DandelionAPI to correlate interests between employees and suggest engaging groupings to organization administrators. Administrators can specify the number of desired breakout rooms and participants per room, review employee groupings and send employees to their group breakout rooms with leading team communication clients (Zoom, Microsoft Teams, Cisco WebEx, Google Meet).
## How we built it
We built this project as a web application using React and Node.js. Our project features two core front page panels: (1) an employee used Interest Form and (2) an administrator used Dashboard. Our Interest Form page is used to collect employee interests which are then processed by our back-end to generate employee breakout room groupings. Our back-end utilizes the semantic text analytics software Dandelion to determine the similarity between employee submitted interests. A pairing algorithm is then used to find the breakout room topics and groupings which maximize the shared interests between employees. These groupings are automatically loaded into the administrator’s Dashboard where event settings can be specified and groupings can be reviewed before setting groups up in team communication clients.
## Challenges we ran into
We were challenged early on by the potential for employees to have uncommon interests without explicit crossover with other employees. This problem prompted us to research semantic text analytics, a method of correlating the similarity between words with a numerical coefficient. With this analytic method we are able to pair together employees with different but similar interests into the group most compatible with them. We utilized DandelionAPI for this purpose, which can compare text bodies and relate their similarity but not individual words. To use DandelionAPI to compare individual interest words we mapped interest words to their encyclopedia definitions and used these definition texts to compute their similarity coefficient.
## Accomplishments that we're proud of
Our team is proud of our accomplishment in designing this software project and implementing it as a proof-of-concept with the DandelionAPI over a short weekend time period. We believe in the value of this software design and think its core function is currently absent in the marketplace. With the time and resources to fully realize this design’s potential we believe organizations would benefit when facilitating team building and organizational loyalty by supporting employees in building genuine relationships with each other.
## What we learned
This project taught us more about the complexities of correlating the similarity of terms along with the conditions that help employees discover common interests and build new relationships. We identified that there is a barrier for employees to discover common interests between themselves virtually in an organization without the ease of small talk and individual conversation that in-person social events facilitate. It can be challenging for employees to build new relationships virtually in breakout rooms without “icebreaker” topics they can reliably make conversation about. This realization was the motivation for GetTogethr.
## Business viability
GetTogethr is targeted to human resource departments trying to plan social events (for e.g. with new interns at a company) that facilitate relationship building between employees and for team managers looking to encourage team building and organizational loyalty. This software solution is applicable to any company in the business sector that values team work and company culture. The software would be sold to companies as a renewable service subscription with regular updates to support new team communication clients and to add administrative controls tailored to company needs.
## What's next for GetTogethr
With more time and resources to spend on this project we would focus on the addition of more administrator event controls and the beautification of the user interface. For the purpose of this hackathon we prioritized a functional design to offer a proof-of-concept for this software. A more modern, aesthetic interface design would increase its business appeal which makes this a high priority for next steps on this project. | Definition: Live comments are comments integrated onto the screen of video or live streaming. These comments are associated with a particular time of a video, and provide a more vibrant experience of video watching and online community building.
## Inspiration
My team are all fans of bilibili, a video platform known for its community of amateur video producers and live commenting. We realize that there are much to explore in these comments indexed to specific time of video, and we want to use that information to bridge the gap between video makers and viewers by providing better video previews and comments analysis.
## What it does
It automatically generates attracting highlights and previews for videos and live streaming with live comments, and provides fluctuation and emotion analysis to video producers to better their work.
## How we built it
We trained 2 bidirectional LSTM networks for sentiment analysis and emotion classification in the context of Chinese internet slang. We scraped reviews on bilibili.com as data for sentiment analysis. We designed a video assignment algorithms that outputs highlights of a video. We also built a data visualization interface that displays the above data and highlights.
## Challenges we ran into
A big challenge we encountered is the difficulty of analyzing internet slang. Available machine learning APIs trained on formal text have bad performance on live comments, so we have to pick and train our model from scratch. Luckily there are many online resources and people at cal hacks to help, and we eventually achieved a performance much better than existing APIs.
## Accomplishments that we're proud of
Being able to output highlights that are really close to human judgement!
## What we learned
As a team with minor prior experience in Natural Language Processing, we managed to quickly pick up skills that we need and apply them in making a real project. We also have more insights into the relationship between videos and comments. Moreover, we realized that building a project is fun and not as hard as we thought.
## What's next for calhacks-danmuku-public
We want to expand its impact in real applications to help video makers and viewers better understand each other. We also look forward to integrating it with video and audio analysis for more interesting results. | ## Inspiration
Ever join a project only to be overwhelmed by all of the open tickets? Not sure which tasks you should take on to increase the teams overall productivity? As students, we know the struggle. We also know that this does not end when school ends and in many different work environments you may encounter the same situations.
## What it does
tAIket allows project managers to invite collaborators to a project. Once the user joins the project, tAIket will analyze their resume for both soft skills and hard skills. Once the users resume has been analyzed, tAIket will provide the user a list of tickets sorted in order of what it has determined that user would be the best at. From here, the user can accept the task, work on it, and mark it as complete! This helps increase productivity as it will match users with tasks that they should be able to complete with relative ease.
## How we built it
Our initial prototype of the UI was designed using Figma. The frontend was then developed using the Vue framework. The backend was done in Python via the Flask framework. The database we used to store users, projects, and tickets was Redis.
## Challenges we ran into
We ran into a few challenges throughout the course of the project. Figuring out how to parse a PDF, using fuzzy searching and cosine similarity analysis to help identify the users skills were a few of our main challenges. Additionally working out how to use Redis was another challenge we faced. Thanks to the help from the wonderful mentors and some online resources (documentation, etc.), we were able to work through these problems. We also had some difficulty working out how to make our site look nice and clean. We ended up looking at many different sites to help us identify some key ideas in overall web design.
## Accomplishments that we're proud of
Overall, we have much that we can be proud of from this project. For one, implementing fuzzy searching and cosine similarity analysis is something we are happy to have achieved. Additionally, knowing how long the process to create a UI should normally take, especially when considering user centered design, we are proud of the UI that we were able to create in the time that we did have.
## What we learned
Each team member has a different skillset and knowledge level. For some of us, this was a great opportunity to learn a new framework while for others this was a great opportunity to challenge and expand our existing knowledge. This was the first time that we have used Redis and we found it was fairly easy to understand how to use it. We also had the chance to explore natural language processing models with fuzzy search and our cosine similarity analysis.
## What's next for tAIket
In the future, we would like to add the ability to assign a task to all members of a project. Some tasks in projects *must* be completed by all members so we believe that this functionality would be useful. Additionally, the ability for "regular" users to "suggest" a task. We believe that this functionality would be useful as sometimes a user may notice something that is broken or needs to be completed but the project manager has not noticed it. Finally, something else that we would work on in the future would be the implementation of the features located in the sidebar of the screen where the tasks are displayed. | losing |
## Inspiration
In today's world, Public Speaking is one of the greatest skills any individual can have. From pitching at a hackathon to simply conversing with friends, being able to speak clearly, be passionate and modulate your voice are key features of any great speech. To tackle this problem of becoming a better public speaker, we created Talky.
## What it does
It helps you improve your speaking skills by giving you suggestions based on what you said to the phone. Once you finish presenting your speech to the app, an audio file of the speech will be sent to a flask server running on Heroku. The server will analyze the audio file by examining pauses, loudness, accuracy and how fast user spoke. In addition, the server will do a comparative analysis with the past data stored in Firebase. Then the server will return the performance of the speech.The app also provides the community functionality which allows the user to check out other people’s audio files and view community speeches.
## How we built it
We used Firebase to store the users’ speech data. Having past data will allow the server to do a comparative analysis and inform the users if they have improved or not.
The Flask server uses similar Audio python libraries to extract meaning patterns: Speech Recognition library to extract the words, Pydub to detect silences and Soundfile to find the length of the audio file.
On the iOS side, we used Alamofire to make the Http request to our server to send data and retrieve a response.
## Challenges we ran into
Everyone on our team was unfamiliar with the properties of audio, so discovering the nuances of wavelengths in particular and the information it provides was challenging and integral part of our project.
## Accomplishments that we're proud of
We successfully recognize the speeches and extract parameters from the sound file to perform the analysis.
We successfully provide the users with an interactive bot-like UI.
We successfully bridge the IOS to the Flask server and perform efficient connections.
## What we learned
We learned how to upload audio file properly and process them using python libraries.
We learned to utilize Azure voice recognition to perform operations from speech to text.
We learned the fluent UI design using dynamic table views.
We learned how to analyze the audio files from different perspectives and given an overall judgment to the performance of the speech.
## What's next for Talky
We added the community functionality while it is still basic. In the future, we can expand this functionality and add more social aspects to the existing app.
Also, the current version is focused on only the audio file. In the future, we can add the video files to enrich the post libraries and support video analyze which will be promising. | ## Inspiration
We were inspired by hard working teachers and students. Although everyone was working hard, there was still a disconnect with many students not being able to retain what they learned. So, we decided to create both a web application and a companion phone application to help target this problem.
## What it does
The app connects students with teachers in a whole new fashion. Students can provide live feedback to their professors on various aspects of the lecture, such as the volume and pace. Professors, on the other hand, get an opportunity to receive live feedback on their teaching style and also give students a few warm-up exercises with a built-in clicker functionality.
The web portion of the project ties the classroom experience to the home. Students receive live transcripts of what the professor is currently saying, along with a summary at the end of the lecture which includes key points. The backend will also generate further reading material based on keywords from the lecture, which will further solidify the students’ understanding of the material.
## How we built it
We built the mobile portion using react-native for the front-end and firebase for the backend. The web app is built with react for the front end and firebase for the backend. We also implemented a few custom python modules to facilitate the client-server interaction to ensure a smooth experience for both the instructor and the student.
## Challenges we ran into
One major challenge we ran into was getting and processing live audio and giving a real-time transcription of it to all students enrolled in the class. We were able to solve this issue through a python script that would help bridge the gap between opening an audio stream and doing operations on it while still serving the student a live version of the rest of the site.
## Accomplishments that we’re proud of
Being able to process text data to the point that we were able to get a summary and information on tone/emotions from it. We are also extremely proud of the
## What we learned
We learned more about React and its usefulness when coding in JavaScript. Especially when there were many repeating elements in our Material Design. We also learned that first creating a mockup of what we want will facilitate coding as everyone will be on the same page on what is going on and all thats needs to be done is made very evident. We used some API’s such as the Google Speech to Text API and a Summary API. We were able to work around the constraints of the API’s to create a working product. We also learned more about other technologies that we used such as: Firebase, Adobe XD, React-native, and Python.
## What's next for Gradian
The next goal for Gradian is to implement a grading system for teachers that will automatically integrate with their native grading platform so that clicker data and other quiz material can instantly be graded and imported without any issues. Beyond that, we can see the potential for Gradian to be used in office scenarios as well so that people will never miss a beat thanks to the live transcription that happens. | ## Inspiration
Our team is fighting night and day during this recruitment season to internships. As with many others, we have varied interests in the fields that we specialize in, and we spend a lot of time tailoring our Résumes to the specific position we are looking at. We believe that an automatic Résume will immensely simplify this process.
## What it does
The program takes two inputs: (1) our CV, a full list of all the projects we've done and (2) The job description of the job posting. The program will then output a new compiled resume that contains rewritten information that is most relevant to the position.
## How we built it
We designed this project to utilize the most recent AI technologies. We made use of word2vec to create word embeddings, which we store in a Convex database. Then, using Convex's built-in vector search, we compare the job postings with your list of projects and experiences, and output the 5 most relevant ones. Finally, as a last measure, we run the projects through an LLM to shape them to be a good fit for the job description.
## Challenges we ran into
We had a lot of challenges making in handling the difference cases of resumes and parsing the differences in it.
## Accomplishments that we're proud of
## What we learned
We learned all sorts of things from this project. Firstly, the power of vector embeddings and their various use cases with all sorts of media. We also learned a lot regarding the space of ML models out there that we can make use of. Lastly, we learned how to quickly run through documentations of relevant technologies and shape them to our needs.
## What's next for resumebuilder.ai
We managed to get the nearest work summaries that is associated with the job. Next, we plan to rebuild the resume such that we get pdfs formated nicely using latex | partial |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.