|
--- |
|
library_name: transformers |
|
license: apache-2.0 |
|
datasets: |
|
- pints-ai/Expository-Prose-V1 |
|
language: |
|
- en |
|
inference: false |
|
--- |
|
|
|
# wordpiece-tokenizer-32k-en_code-msp |
|
|
|
A 'modern' uncased wordpiece tokenizer for MLM, analogous to `bert-base-uncased`'s tokenizer. |
|
|
|
- 32k vocab size, uncased. Trained with max alphabet of 1000 and min_freq of 5 |
|
- Unique WordPiece tokenizer that preserves whitespace information. |
|
- Done through ~~witchcraft~~ a combination of `Metaspace()` and custom grouping/filtering logic |
|
- trained on english/code via `pints-ai/Expository-Prose-V1` to leverage ^ |
|
|
|
## Usage |
|
|
|
```py |
|
from transformers import AutoTokenizer |
|
|
|
repo_id = "BEE-spoke-data/wordpiece-tokenizer-32k-en_code-msp" |
|
tokenizer = AutoTokenizer.from_pretrained(repo_id) |
|
# same usage as any other tokenizer for encoder models |
|
``` |
|
|
|
|
|
## Comparison vs bert-base-uncased |
|
|
|
### vocab |
|
|
|
<details> |
|
<summary>Click to see comparison code</summary> |
|
|
|
Code to run the below comparison: |
|
|
|
```py |
|
import random |
|
|
|
from transformers import AutoTokenizer |
|
|
|
tk_base = AutoTokenizer.from_pretrained("bert-base-uncased") |
|
tk_retrained = AutoTokenizer.from_pretrained("BEE-spoke-data/wordpiece-tokenizer-32k-en_code-msp") |
|
|
|
# Get vocabularies as sets |
|
vocab_base = set(tk_base.get_vocab().keys()) |
|
vocab_retrained = set(tk_retrained.get_vocab().keys()) |
|
|
|
# Compare vocabularies |
|
common_tokens = vocab_base.intersection(vocab_retrained) |
|
unique_to_base = vocab_base.difference(vocab_retrained) |
|
unique_to_retrained = vocab_retrained.difference(vocab_base) |
|
|
|
# Print results |
|
print(f"Total tokens in base tokenizer: {len(vocab_base)}") |
|
print(f"Total tokens in retrained tokenizer: {len(vocab_retrained)}") |
|
print(f"Number of common tokens: {len(common_tokens)}") |
|
print(f"Tokens unique to base tokenizer: {len(unique_to_base)}") |
|
print(f"Tokens unique to retrained tokenizer: {len(unique_to_retrained)}") |
|
|
|
# Optionally print a few examples |
|
print("\nExamples of common tokens:", random.sample(list(common_tokens), k=10)) |
|
print("\nExamples of tokens unique to base:", random.sample(list(unique_to_base), k=20)) |
|
print( |
|
"\nExamples of tokens unique to retrained:", |
|
random.sample(list(unique_to_retrained), k=20) |
|
) |
|
``` |
|
|
|
|
|
</details> |
|
|
|
``` |
|
Total tokens in base tokenizer: 30522 |
|
Total tokens in retrained tokenizer: 31999 |
|
Number of common tokens: 19481 |
|
Tokens unique to base tokenizer: 11041 |
|
Tokens unique to retrained tokenizer: 12518 |
|
|
|
Examples of common tokens: |
|
['mayo', 'halo', 'tad', 'isles', '##hy', 'molecular', '##43', '##へ', 'mike', 'reaction'] |
|
|
|
Examples of tokens unique to base: |
|
['##ingdon', 'vikram', '##worm', '##mobile', 'saxophonist', 'azerbaijani', 'flared', 'picasso', 'modernized', 'brothel', '##cytes', '[unused933]', 'humming', 'pontiac', '##ła', 'wembley', '14th', '##runa', '##eum', '劉'] |
|
|
|
Examples of tokens unique to retrained: |
|
['discrimin', '##emporal', 'tabern', 'mund', '##jud', 'schrodinger', '##oscope', 'resp', '##imento', '▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁', 'caterpillar', '##374', '##endentry', 'undoubted', 'subpro', 'indispensable', '##ushed', '##sein', 'utterance', 'disambigu'] |
|
``` |
|
|
|
|
|
### whitespace encoding |
|
|
|
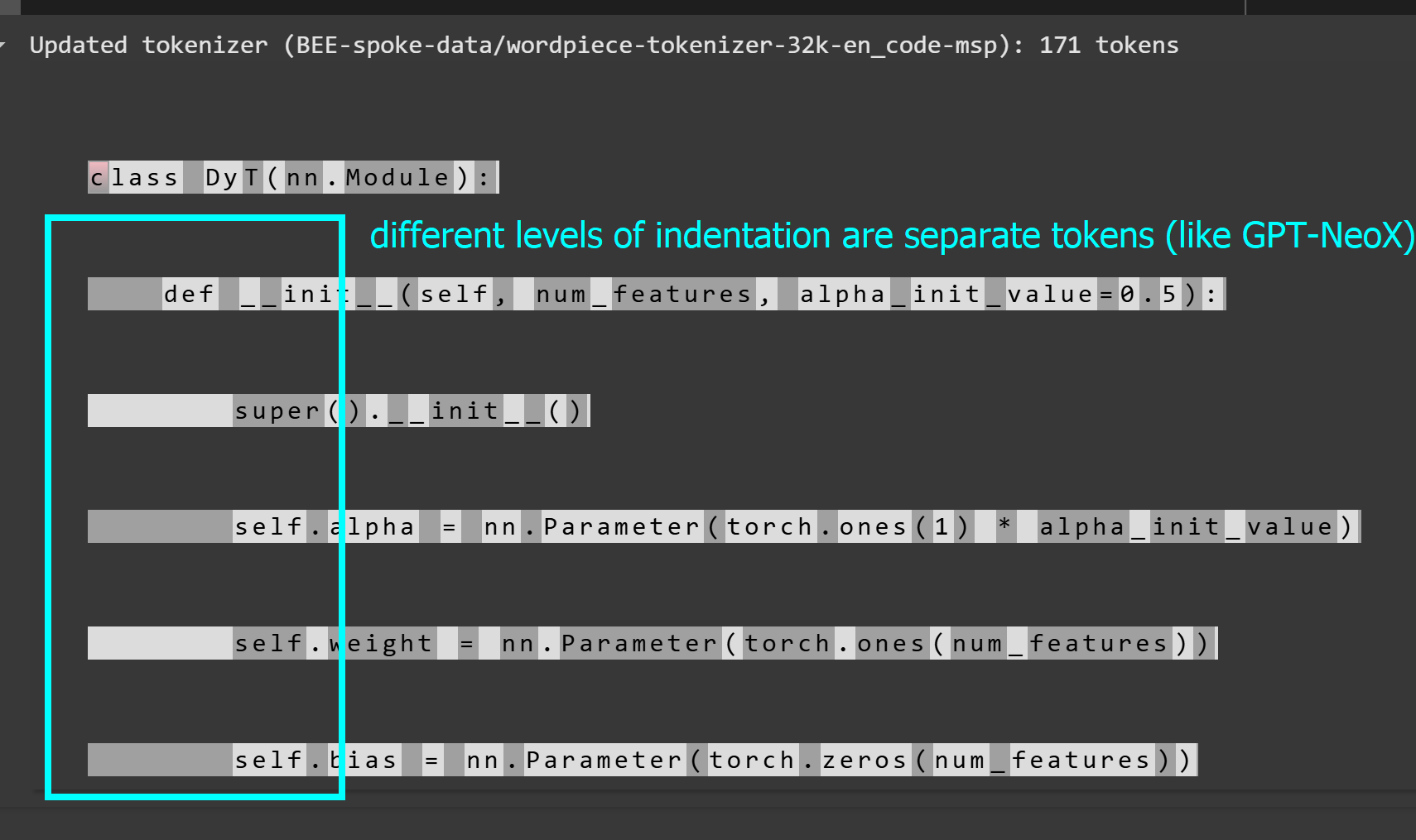
Let's say we want to tokenize the below class: |
|
|
|
```py |
|
class DyT(nn.Module): |
|
def __init__(self, num_features, alpha_init_value=0.5): |
|
super().__init__() |
|
self.alpha = nn.Parameter(torch.ones(1) * alpha_init_value) |
|
self.weight = nn.Parameter(torch.ones(num_features)) |
|
self.bias = nn.Parameter(torch.zeros(num_features)) |
|
|
|
def forward(self, x): |
|
x = torch.tanh(self.alpha * x) |
|
return x * self.weight + self.bias |
|
``` |
|
|
|
`bert-base-uncased` ignores the indentations for python, while our tokenizer does not: |
|
|
|
|
|
 |
|
|
|
this tokenizer: |
|
|
|
|
|
 |
|
|

