
Integrate with Transformers & SentenceTransformers

Hi! I've started integrating your model with Transformers, but when I do
from transformers import AutoModelForSequenceClassification, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(".")
model = AutoModelForSequenceClassification.from_pretrained(".", trust_remote_code=True)
inputs = tokenizer(["Hello"], return_tensors="pt")
outputs = model(**inputs)
I got output
File ~/.cache/huggingface/modules/transformers_modules/listconranker.py:223, in ListConRankerModel.forward(self, input_ids, attention_mask, token_type_ids, position_ids, head_mask, inputs_embeds, labels, output_attentions, output_hidden_states, return_dict, pair_num, **kwargs)
220 last_hidden_state = ranker_out.last_hidden_state
222 pair_features = self.average_pooling(last_hidden_state, attention_mask)
--> 223 pair_features = self.linear_in_embedding(pair_features)
225 logits, pair_features_after_list_transformer = self.list_transformer(pair_features, pair_nums)
226 logits = self.sigmoid(logits)
...
RuntimeError: mat1 and mat2 shapes cannot be multiplied (1x1792 and 1024x1792)
And I don't know why, because I've copied code from your implementation

I'm sorry I didn't receive timely notice because I'm not the owner of the repository. Thank you for your contribution to our repository!
I think it is because you modify the hidden_state in the config.json.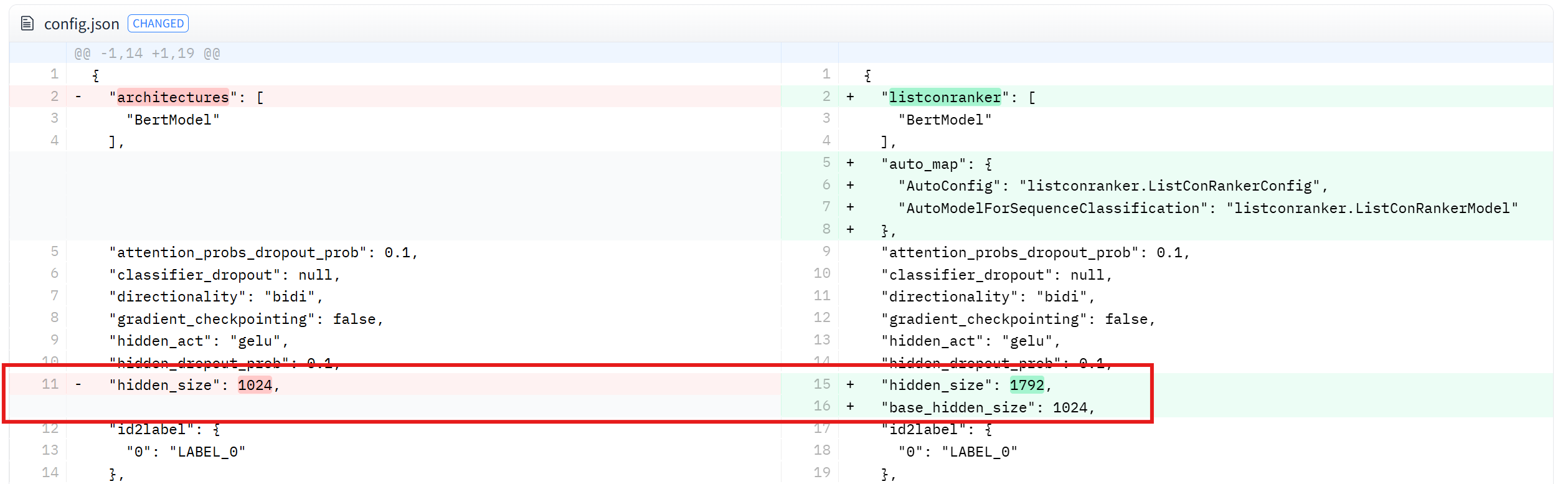
After that, it modify the last_hidden_state size of ranker_out, when you initialize the BertModel
The size of last_hidden_state in last_hidden_state = ranker_out.last_hidden_state should be 1024. And the size should be 1792 after using the self.linear_in_embedding.
The solution is that you probably shouldn't modify the hidden_size in the config.json. Try defining it with another variable name.
Thanks! I've fixed shapes problem. Now I need to handle piars correctly. Problem is that in forward received only input_ids. I tried to find size of sentences by sep token, but it's too complicated I think. Do you have ideas how to handle them properly?
I think there might be a problem with your code here?

The input_ids, attention_mask, token_type_idsand so on are not defined in the arguments of forward method.
You can refer to the implementation of the BertModel class in transformers library. I believe it's feasible to include pair_nums as a argument in the forward method.

By the way, it's not feasible to determine pair_nums using the SEP token. For example, the input format for ListConRanker is as follows:
For queries and passages with the following input formats (ListConRanker supports an arbitrary number of passages):
inputs = [
['query_1', 'passage_11', 'passage_12'], # batch 1
['query_2', 'passage_21', 'passage_22', 'passage_23'] # batch 2
]
ListConRanker first concatenates them and then tokenizes them separately like that:
inputs = tokenize(
['query_1', 'passage_11', 'passage_12', 'query_2', 'passage_21', 'passage_22', 'passage_23']
)
and it will get the tokenization results like:
[CLS] query_1 [SEP]
[CLS] passage_11 [SEP]
[CLS] passage_12 [SEP]
and so on
Finally, we use the tokenization results to input to the BertModel. And then we use the pair_nums to reorganize the inputs in ListTransformer.
Therefore, I believe that requiring the user to input pair_nums in forward method is the only solution.
The input_ids, attention_mask, token_type_idsand so on are not defined in the arguments of forward method.
They're defined, but just hidden in collapse. I've copied formard from BertForSequenceClassification.

For queries and passages with the following input formats (ListConRanker supports an arbitrary number of passages):
I want to make it possible to run your model with SentenceTransformers.CrossEncoder correctly. The main problem there, that CrossEncoder pass only input_ids to the forward in batched manner. So, I want to split input_ids by sep_token and after that create pairs. I will try to create correct implementation later
Sorry, I missed some code. The implementation of the forward method is correct.
I haven't tried adding a customized model to the library before😭. I'll also try to study the SentenceTransformer code if needed.
Sentence transformers using AutoModelForSequenceClassification for cross-encodes. It's loading now with automodels, but I need to figure out how to handle pairs
I think I understand your approach now. Suppose there is an input like this:
inputs = [
['query_1', 'passage_11', 'passage_12'], # batch 1
['query_2', 'passage_21', 'passage_22', 'passage_23'] # batch 2
]
You can use the tokenizer of CrossEncoder to obtain the following output input_ids:
[CLS] query_1 [SEP] passage_11 [SEP]
[CLS] query_1 [SEP] passage_12 [SEP]
[CLS] query_2 [SEP] passage_21 [SEP]
and so on
You can separate the input_ids at the first [SEP] token, then check whether the preceding queries are the same. Use the number of identical queries as pair_nums.
But finally, you still need to reorganize the input_ids into a form similar to the following, and pay attention to modifying the first token of the passage into [CLS].
[CLS] query_1 [SEP]
[CLS] passage_11 [SEP]
[CLS] passage_12 [SEP]
and so on
Yes, that's exactly what I wanted to do. However, the CrossEncoder can only use one pair of passages at a time. I will create a different method for multiple passages.
Maybe the way passages are handled could be changed directly in the CrossEncoder. cc @tomaarsen
Sorry, I've had some urgent things to do recently. I will check the code as soon as possible this week. Thank you for your contribution!
@Samoed Hi! I have checked the code. I think there are some parts of the code that need to be changed. It seems that Huggingface does not support submitting a PR under your branch. Therefore, I will show the code changes here. Thank you again for your patience and contribution!
- I added a
**kwargstomodel.hf_model = BertModel.from_pretrained(model_name_or_path, config=model.config.bert_config, **kwargs)under thefrom_pretrainedfunction. Without this argument, somefrom_pretrainedfunctions may throw errors.

For example, when loading a model with fp16 precision, errors will occur if **kwargs is not added.
from listconranker import ListConRankerConfig, ListConRankerModel
configs = ListConRankerConfig.from_pretrained('ByteDance/ListConRanker')
reranker = ListConRankerModel.from_pretrained('ByteDance/ListConRanker', config=configs, torch_dtype=torch.float16)
- I modified the tokenizer's truncation method. If we directly use the tokenizer's default truncation, the combined length of the query and passage will be limited to 512 tokens. However, our model can actually accept the query and passage each with a maximum length of 512 tokens. Therefore, the current implementation of the
_reorganize_inputsmethod is as follows:
def _reorganize_inputs(
self,
input_ids: torch.Tensor,
attention_mask: torch.Tensor,
token_type_ids: Optional[torch.Tensor],
) -> tuple[
torch.Tensor, torch.Tensor, Optional[torch.Tensor], List[int], List[List[int]]
]:
"""
Group inputs by unique queries: for each query, produce [query] + its passages,
then flatten, pad, and return pair sizes and original indices mapping.
"""
batch_size = input_ids.size(0)
# Structure: query_key -> {
# 'query': (seq, mask, tt),
# 'passages': [(seq, mask, tt), ...],
# 'indices': [original_index, ...]
# }
grouped = {}
for idx in range(batch_size):
seq = input_ids[idx]
mask = attention_mask[idx]
token_type_ids[idx] if token_type_ids is not None else torch.zeros_like(seq)
sep_idxs = (seq == self.config.sep_token_id).nonzero(as_tuple=True)[0]
if sep_idxs.numel() == 0:
raise ValueError(f"No SEP in sequence {idx}")
first_sep = sep_idxs[0].item()
second_sep = sep_idxs[1].item()
# Extract query and passage
q_seq = seq[: first_sep + 1]
q_mask = mask[: first_sep + 1]
q_tt = torch.zeros_like(q_seq)
p_seq = seq[first_sep: second_sep + 1]
p_mask = mask[first_sep: second_sep + 1]
p_seq = p_seq.clone()
p_seq[0] = self.config.cls_token_id
p_tt = torch.zeros_like(p_seq)
# Build key excluding CLS/SEP
key = tuple(
q_seq[
(q_seq != self.config.cls_token_id)
& (q_seq != self.config.sep_token_id)
].tolist()
)
# truncation
q_seq = q_seq[: self.config.max_position_embeddings]
q_seq[-1] = self.config.sep_token_id
p_seq = p_seq[: self.config.max_position_embeddings]
p_seq[-1] = self.config.sep_token_id
q_mask = q_mask[: self.config.max_position_embeddings]
p_mask = p_mask[: self.config.max_position_embeddings]
q_tt = q_tt[: self.config.max_position_embeddings]
p_tt = p_tt[: self.config.max_position_embeddings]
if key not in grouped:
grouped[key] = {
"query": (q_seq, q_mask, q_tt),
"passages": [],
"indices": [],
}
grouped[key]["passages"].append((p_seq, p_mask, p_tt))
grouped[key]["indices"].append(idx)
# Flatten according to group insertion order
seqs, masks, tts, pair_nums, group_indices = [], [], [], [], []
for key, data in grouped.items():
q_seq, q_mask, q_tt = data["query"]
passages = data["passages"]
indices = data["indices"]
# record sizes and original positions
pair_nums.append(len(passages) + 1) # +1 for the query
group_indices.append(indices)
# append query then its passages
seqs.append(q_seq)
masks.append(q_mask)
tts.append(q_tt)
for p_seq, p_mask, p_tt in passages:
seqs.append(p_seq)
masks.append(p_mask)
tts.append(p_tt)
# Pad to uniform length
max_len = max(s.size(0) for s in seqs)
padded_seqs, padded_masks, padded_tts = [], [], []
for s, m, t in zip(seqs, masks, tts):
ps = torch.zeros(max_len, dtype=s.dtype, device=s.device)
pm = torch.zeros(max_len, dtype=m.dtype, device=m.device)
pt = torch.zeros(max_len, dtype=t.dtype, device=t.device)
ps[: s.size(0)] = s
pm[: m.size(0)] = m
pt[: t.size(0)] = t
padded_seqs.append(ps)
padded_masks.append(pm)
padded_tts.append(pt)
rid = torch.stack(padded_seqs)
ram = torch.stack(padded_masks)
rtt = torch.stack(padded_tts) if token_type_ids is not None else None
return rid, ram, rtt, pair_nums, group_indices
And remember to set truncation=False in the tokenizer when using the multi_passage method.
- After tokenization in
multi_passage, we need to assign the tensors to the appropriate device. Otherwise, when performing inference on a GPU, we may encounter issues where tensors are not on the same device.

- I've implemented the iterative inference method. You can integrate it into your code.
import math
import numpy as np
from collections import defaultdict
def multi_passage_in_iterative_inference(
self,
sentences: List[str],
stop_num: int = 20,
decrement_rate: float = 0.2,
min_filter_num: int = 10,
tokenizer: AutoTokenizer = AutoTokenizer.from_pretrained(
"ByteDance/ListConRanker"
),
):
"""
Process multiple passages for one query in iterative inference.
:param sentences: List contains sentences for a query.
:return: Tensor of logits for each passage.
"""
if stop_num < 1:
raise ValueError("stop_num must be greater than 0")
if decrement_rate <= 0 or decrement_rate >= 1:
raise ValueError("decrement_rate must be in (0, 1)")
if min_filter_num < 1:
raise ValueError("min_filter_num must be greater than 0")
query = sentences[0]
passage = sentences[1:]
filter_times = 0
passage2score = defaultdict(list)
while len(passage) > stop_num:
batch = [[query] + passage]
pred_scores = self.multi_passage(
batch,
batch_size=len(batch[0]) - 1,
tokenizer=tokenizer
).tolist()
pred_scores_argsort = np.argsort(pred_scores).tolist() # Sort in increasing order
passage_len = len(passage)
to_filter_num = math.ceil(passage_len * decrement_rate)
if to_filter_num < min_filter_num:
to_filter_num = min_filter_num
have_filter_num = 0
while have_filter_num < to_filter_num:
idx = pred_scores_argsort[have_filter_num]
passage2score[passage[idx]].append(pred_scores[idx] + filter_times)
have_filter_num += 1
while pred_scores[pred_scores_argsort[have_filter_num - 1]] == pred_scores[pred_scores_argsort[have_filter_num]]:
idx = pred_scores_argsort[have_filter_num]
passage2score[passage[idx]].append(pred_scores[idx] + filter_times)
have_filter_num += 1
next_passage = []
next_passage_idx = have_filter_num
while next_passage_idx < len(passage):
idx = pred_scores_argsort[next_passage_idx]
next_passage.append(passage[idx])
next_passage_idx += 1
passage = next_passage
filter_times += 1
batch = [[query] + passage]
pred_scores = self.multi_passage(
batch,
batch_size=len(batch[0]) - 1,
tokenizer=tokenizer
).tolist()
cnt = 0
while cnt < len(passage):
passage2score[passage[cnt]].append(pred_scores[cnt] + filter_times)
cnt += 1
passage = sentences[1:]
final_score = []
for i in range(len(passage)):
p = passage[i]
final_score.append(passage2score[p][0])
return final_score
I have tested these implementation on MTEB, and it works well. I will contact the owner of ListConRanker soon to integrate your code and then update the ListConRanker-related code in MTEB. Thank you again!