
anchor
stringlengths 1
23.8k
| positive
stringlengths 1
23.8k
| negative
stringlengths 1
31k
| anchor_status
stringclasses 3
values |
|---|---|---|---|
## AI, AI, AI...
The number of projects using LLMs has skyrocketed with the wave of artificial intelligence. But what if you *were* the AI, tasked with fulfilling countless orders and managing requests in real time? Welcome to chatgpME, a fast-paced, chaotic game where you step into the role of an AI who has to juggle multiple requests, analyzing input, and delivering perfect responses under pressure!
## Inspired by games like Overcooked...
chatgpME challenges you to process human queries as quickly and accurately as possible. Each round brings a flood of requests—ranging from simple math questions to complex emotional support queries—and it's your job to fulfill them quickly with high-quality responses!
## How to Play
Take Orders: Players receive a constant stream of requests, represented by different "orders" from human users. The orders vary in complexity—from basic facts and math solutions to creative writing and emotional advice.
Process Responses: Quickly scan each order, analyze the request, and deliver a response before the timer runs out.
Get analyzed - our built-in AI checks how similar your answer is to what a real AI would say :)
## Key Features
Fast-Paced Gameplay: Just like Overcooked, players need to juggle multiple tasks at once. Keep those responses flowing and maintain accuracy, or you’ll quickly find yourself overwhelmed.
Orders with a Twist: The more aware the AI becomes, the more unpredictable it gets. Some responses might start including strange, existential musings—or it might start asking you questions in the middle of a task!
## How We Built It
Concept & Design: We started by imagining a game where the player experiences life as ChatGPT, but with all the real-time pressure of a time management game like Overcooked. Designs were created in Procreate and our handy notebooks.
Tech Stack: Using Unity, we integrated a system where mock requests are sent to the player, each with specific requirements and difficulty levels. A template was generated using defang, and we also used it to sanitize user inputs. Answers are then evaluated using the fantastic Cohere API!
Playtesting: Through multiple playtests, we refined the speed and unpredictability of the game to keep players engaged and on their toes. | ## Inspiration
On our way to PennApps, our team was hungrily waiting in line at Shake Shack while trying to think of the best hack idea to bring. Unfortunately, rather than being able to sit comfortably and pull out our laptops to research, we were forced to stand in a long line to reach the cashier, only to be handed a clunky buzzer that countless other greasy fingered customer had laid their hands on. We decided that there has to be a better way; a way to simply walk into a restaurant, be able to spend more time with friends, and to stand in line as little as possible. So we made it.
## What it does
Q'd (pronounced queued) digitizes the process of waiting in line by allowing restaurants and events to host a line through the mobile app and for users to line up digitally through their phones as well. Also, it functions to give users a sense of the different opportunities around them by searching for nearby queues. Once in a queue, the user "takes a ticket" which decrements until they are the first person in line. In the meantime, they are free to do whatever they want and not be limited to the 2-D pathway of a line for the next minutes (or even hours).
When the user is soon to be the first in line, they are sent a push notification and requested to appear at the entrance where the host of the queue can check them off, let them in, and remove them from the queue. In addition to removing the hassle of line waiting, hosts of queues can access their Q'd Analytics to learn how many people were in their queues at what times and learn key metrics about the visitors to their queues.
## How we built it
Q'd comes in three parts; the native mobile app, the web app client, and the Hasura server.
1. The mobile iOS application built with Apache Cordova in order to allow the native iOS app to be built in pure HTML and Javascript. This framework allows the application to work on both Android, iOS, and web applications as well as to be incredibly responsive.
2. The web application is built with good ol' HTML, CSS, and JavaScript. Using the Materialize CSS framework gives the application a professional feel as well as resources such as AmChart that provide the user a clear understanding of their queue metrics.
3. Our beast of a server was constructed with the Hasura application which allowed us to build our own data structure as well as to use the API calls for the data across all of our platforms. Therefore, every method dealing with queues or queue analytics deals with our Hasura server through API calls and database use.
## Challenges we ran into
A key challenge we discovered was the implementation of Cordova and its associated plugins. Having been primarily Android developers, the native environment of the iOS application challenged our skills and provided us a lot of learn before we were ready to properly implement it.
Next, although a less challenge, the Hasura application had a learning curve before we were able to really us it successfully. Particularly, we had issues with relationships between different objects within the database. Nevertheless, we persevered and were able to get it working really well which allowed for an easier time building the front end.
## Accomplishments that we're proud of
Overall, we're extremely proud of coming in with little knowledge about Cordova, iOS development, and only learning about Hasura at the hackathon, then being able to develop a fully responsive app using all of these technologies relatively well. While we considered making what we are comfortable with (particularly web apps), we wanted to push our limits to take the challenge to learn about mobile development and cloud databases.
Another accomplishment we're proud of is making it through our first hackathon longer than 24 hours :)
## What we learned
During our time developing Q'd, we were exposed to and became proficient in various technologies ranging from Cordova to Hasura. However, besides technology, we learned important lessons about taking the time to properly flesh out our ideas before jumping in headfirst. We devoted the first two hours of the hackathon to really understand what we wanted to accomplish with Q'd, so in the end, we can be truly satisfied with what we have been able to create.
## What's next for Q'd
In the future, we're looking towards enabling hosts of queues to include premium options for users to take advantage to skip lines of be part of more exclusive lines. Furthermore, we want to expand the data analytics that the hosts can take advantage of in order to improve their own revenue and to make a better experience for their visitors and customers. | ## Inspiration
Have you been in a situation where your friend asks about that fascinating movie you just watched yet you find yourself get stuck and don't know how to describe it? All of us have.
As our team attended the Workshop presented by Cohere, we were incredibly impressed with the AI's capability with generating text-based media. We decided to use the technology to help alleviate stress in menial writing tasks, such as describing a movie to a friend, making a Twitter post about the team introducing a place to others, etc.
## What it does
Our product is a front-end web platform serving anyone who needs a piece of paragraph on a simple everyday topic.
The functionality of Writeeasy is very simple. Given a prompt(in question format) or a list of keywords, our web app will use a Cohere model to generate a response of up to/around 80 words.
For example, a response to the prompt: `Why do you like coding?` generated by our software is:
`Coding has opened my eyes to a new world of possibilities. I used to think coding was about writing computer programs. Now, I see coding as a way to make something new. It is about creating a new idea, and seeing it come to life. Coding is a way to create something that had never existed before.`
The response for personal questions, such as when your newly-made friend is curious about why you like a particular hobby ("Why do you like playing basketball?"), may be hard to answer on the spot. Our goal is for our AI to save user time and effort if they ever find themselves get stuck. They can look at what our AI writes, and use is either as an inspiration or as a template based on which further edit is added. Essentially, we are providing the user with a starting point and then the user ample freedom to build on that, hopefully with more ease.
## How we built it
We built the project entirely using Cohere, an open-sourced AI model that provides many NLP functionalities. We split the workload into two different areas, mainly the backend and the frontend. In the backend, we made API calls to Cohere. Then we tested the model with our desired prompts. Afterwards, we customized our prompt successfully with prompt engineering, effectively using 3 distinct prompt answer examples to guide the AI on the right path.
In terms of the frontend, we used the Python-based web framework called Flask. The website is hosted by Heroku.
## Challenges we ran into
With just one prompt, we get a variety of different results. Sometimes, rather than getting the AI answering the prompt, the AI makes many new prompts. Sometimes we get the AI asking its own similar prompts, rather than answering the prompt itself. It took us a long time to be able to figure out how to get the AI to output the specific response we want, which is a reasonable answer to the prompt. We also had many setbacks in relation to getting the Cohere platform working, such as setting up Client key, using stop phrases, and others. Luckily, we managed to get Cohere working successfully, as demonstrated by our implementation.
In terms of the frontend, we were met with certain difficulties when it comes to font and formatting. However, we were able to pull it off at the end.
## Accomplishments that we're proud of
We were able to collaborate as a team even as we previously didn't know each other. Writeeasy still has plenty of limitations, but we were able to successfully apply an AI NLP generative model in a front-based web-interface despite having no experience with this area.
## What we learned
Aaron learnt how to use Cohere API and integrate that with a webapp!!
## What's next for Writeeasy
We have many plans for Writeeasy! We hope to include a chrome extension and improve model effectiveness a larger range of questions. | winning |
# Trusty Paws
## Inspiration
We believe that every pet deserves to find a home. Animal shelters have often had to euthanize animals due to capacity issues and lack of adoptions. Our objective with Trusty Paws is to increase the rate of adoptions of these animals by increasing the exposure of shelters to potential pet owners as well as to provide an accessible platform for users to browse and adopt their next best friend.
Trusty Paws also aims to be an online hub for all things related to your pet, from offering an online marketplace for pet products to finding a vet near you.
## What it does
Our vision for Trusty Paws is to create a platform that brings together all the players that contribute to the health and happiness of our pawed friends, while allowing users to support local businesses. Each user, shelter, seller, and veterinarian contributes to a different aspect of Trusty Paws.
**Users**:
Users are your everyday users who own pets or are looking to adopt pets. They will be able to access the marketplace to buy items for their pets, browse through each shelter's pet profiles to fill out adoption requests, and find the nearest pet clinic.
**Shelters**:
Shelters accounts will be able to create pet profiles for each of their animals that are up for adoption! Each pet will have its own profile that can be customized with pictures and other fields providing further information on them. The shelter receives an adoption request form each time an user applies to adopt one of their pets.
**Sellers**:
Sellers will be able to set up stores showing all of their product listings, which include, but are not limited to, food, toys, accessories, and many other. Our marketplace will provide the opportunity for local businesses that have been affected by Covid-19 to reach their target audience while abiding by health and safety guidelines. For users, it will be a convenient way to satisfy all the needs of their pet in one place. Finally, our search bar will allow users to search for specific items for a quick and efficient shopping experience.
**Veterinarians**:
Veterinarians will be able to set up a profile for their clinic, with all the pertinent information such as their opening hours, services provided, and location.
## How we built it
For the front-end, React., Bootstrap and Materialized CSS were used to acquire the visual effects of the current website. In fact, the very first step we undertook was to draft an initial prototype of the product on Figma to ensure all the requirements and required features were met. After a few iterations of redesigning, we each dove into developing the necessary individual components, forms, and pages for the website. Once all components were completed, the next step was to route pages together in order to achieve a seamless navigation of the website.
We used Firebase within Node.Js to implement a framwork for the back-end. Using Firebase, we implemented a NoSQL database using Cloud Firestore. Data for users (all types), pets, products, and adoption forms along with their respective fields were stored as documents in their respective collections.
Finally, we used Google's Distance Matrix API to compute distances between two addresses and find the nearest services when necessary, such as the closest vet clinics or the closest shelters.
## Challenges we ran into
Although we were successful at accomplishing the major features of the website, we encountered many challenges throughout the weekend. As we started working on Trusty Paws, we realized that the initial implementation was not as user-friendly as we wanted it to be. We then decided to take a step back and to return to the initial design phase. Another challenge we ran into was that most of the team was unfamiliar with the development tools necessary for this project, such as Firebase, Node.Js, bootstrap, and redux.
## Accomplishments that we're proud of
We are proud that our team learned so much over the course of a few days.
## What's next for Trusty Paws
We want to keep improving our users' experience by optimizing the current features. We also want to improve the design and user friendliness of the interface. | Worldwide, there have been over a million cases of animal cruelty over the past decade. With people stuck at home, bottling up their frustrations. Moreover, due to COVID, these numbers aren’t going down anytime soon. To tackle these issues, we built this game, which has features like:
* Reminiscent of city-building simulators like Sim-City.
* Build and manage your animal shelter.
* Learn to manage finances, take care of animals, set up adoption drives.
* Grow and expand your shelter by taking in homeless animals, and giving them a life.
The game is built with Unity game engine, and runs on WebGL, utilizing the power of Wix Velo, which allows us to quickly host and distribute the game across platforms from a single code base. | # Pawsome: Revolutionizing Pet Health and Fitness
Welcome to Pawsome, the cutting-edge platform dedicated to enhancing the health and fitness of our beloved pets. Combining a deep love for pets with the latest in technology, we provide personalized wellness plans to ensure every pet gets the care they deserve.

## About Pawsome
Pawsome isn't just a project—it's a mission to ensure the well-being of pets worldwide. Our platform offers tools and resources for pet owners to maintain and improve their pet's health and fitness, featuring interactive consultations and tailored fitness schedules.
### Our Vision
We envision a world where every pet enjoys a happy, healthy life. Our goal is to prioritize pets' health and wellness, offering accessible, reliable solutions for their care.
## Technology Stack
To deliver a seamless, efficient user experience, Pawsome leverages a comprehensive and robust stack:
* **Frontend**:
+ React: A JavaScript library for building user interfaces.
+ Next.js: A React framework for production; it makes building scalable applications easier.
+ JavaScript: A programming language that allows you to implement complex features on web pages.
+ TypeScript: A typed superset of JavaScript that compiles to plain JavaScript.
+ HTML: The standard markup language for documents designed to be displayed in a web browser.
+ CSS: The language used to describe the presentation of a document written in HTML.
+ Tailwind CSS: A utility-first CSS framework for rapidly building custom designs.
* **Backend**:
+ Flask: A micro web framework written in Python.
+ Python: A programming language that lets you work quickly and integrate systems more effectively.
* **Integrations**:
+ Fetch.ai: An artificial intelligence lab working on creating a decentralized digital world.
Agent 1 Using Fetch AI
* 
Agent 2 Using Fetch AI
* 
Agent 3 Using Fetch AI
* 
* Together.ai: A platform that provides AI-based solutions.
* Postman: An API platform for building and using APIs. Postman simplifies each step of the API lifecycle and streamlines collaboration.
* Bun: Bun is an all-in-one JavaScript runtime & toolkit designed for speed, complete with a bundler, test runner, and Node.js-compatible package manager. It served as a JavaScript runtime optimizer for our project.
These technologies are carefully chosen to ensure that Pawsome is not only cutting-edge but also robust and scalable, catering to the dynamic needs of pet owners and their beloved pets.
This tech combination enables dynamic, responsive interactions and complex data processing across our platform.
## Features
### Interactive Pet Wellness AI
Pawsome features a chat button for users to interact with our pet wellness AI. Depending on user needs, it offers appointment booking, medicine orders, or grooming session scheduling.

### Customized Fitness Center
Our Fitness Center allows pet owners to input details like breed, weight, and health, creating a custom fitness plan tailored to their pet's needs, and promoting a holistic wellness approach.
### Custom Push Notifications
To ensure pets and their owners stay on track with their wellness routines, Pawsome sends custom push notifications via email, reminding users of upcoming activities and schedules.
## Future Enhancements
We're committed to continuously improving Pawsome with several key initiatives:
* **Data-Driven Personalization**: By gathering more data, we aim to make even more personalized recommendations, enhancing the effectiveness of wellness plans.
* **E-commerce Platform**: Developing a one-stop destination for all pet needs, from food to toys, ensuring pet owners have access to high-quality products.
* **Network of Veterinarians**: Establishing a network of doctors available for consultations and emergencies, providing peace of mind for pet owners.
## Getting Started
1. Clone repo
`git clone https://github.com/mounika2000/treehacks.git
cd Treehacks
yarn`
2. Install dependencies
`npm install`
3.Then, you can run locally in development mode with live reload:
`yarn dev`
## Contributing
Contributions are welcome! Whether you're a developer, designer, or pet wellness enthusiast, there are many ways to contribute to Pawsome. Please see our contributing guidelines for more details.
## Contact Us
Sai Mounika Peteti: [[email protected]](mailto:[email protected])
Chinmay Nilesh Mahagaonkar: [[email protected]](mailto:[email protected])
Sanket Kulkarni: [[email protected]](mailto:[email protected])
Tanay Godse: [[email protected]](mailto:[email protected]) | winning |
## Inspiration
Ctrl-C, Ctrl-V: The only two buttons a programmer really needs ;)
We enhance the power of Ctrl-C and Ctrl-V, enabling you to paste seamlessly, leverage AI to analyze your clipboard content, visualize what's on your clipboard, or even play a song!
---
## What it does
Clippy automatically analyzes your clipboard and provides intelligent suggestions for enhancing, transforming, and utilizing your clipboard content efficiently in your development workflow.
### Matlab AI
Example use cases:
**Play a song**
1. Copy “Play Twinkle Twinkle Little Star”
2. Press Ctrl+v+1
This will give you code to play twinkle twinkle little star in Matlab.
Matlab will automatically run the code it generated to confirm its validity (and so you can enjoy your twinkle twinkle~ :)
**Visualize your clipboard content**
1. Copy something like “graph the weather for past 2 months”
2. Press Ctrl+v+1
This will open Matlab automatically, and display its respective matlab code.
Clippy will run the matlab code it generated and show you your clipboard content, visualized.
**Run Complex Calculations and Algorithms**
Example use cases:
1. Copy a prompt such as "Multiply matrices ( 0 & 6 & 7 \ 8 & 0 & 7 )( 5 & 8 & 0 )"
2. Press Ctrl+v+1
MATLAB will open and perform the specified calculation of the given expression.
(The answer is ( 48 & 40 ) by the way!)
### Adobe Express Add-on
Example use cases:
**Create QR Code**
1. Copy a link (Clippy will also suggest this option if you copied a link)
2. Press Ctrl+v+2
This will allow you to insert a QR code in Adobe Express, from there you may export and use at your discretion.
### LLM Integration
Example use cases:
**Summarization**
1. Copy a paragraph
2. Press Ctrl+v+3
This will create a summary of your clipboard content.
**Question and Answer**
1. Copy a question like “What are the top ten biggest tech companies in revenue”?”
2. Press Ctrl+v+3
Clippy will answer the question from your clipboard content.
---
## How we built it
**Langchain**: LLM Engine Development
**FastAPI**: backend server that communicates with Adobe Express, Langchain LLM Engine, and MatLab.
**OpenAI gpt-4o Model**: LLM for generative AI and instructional tasks
**Auth0**: OAuth authentication provider
**Sauce Labs**: Testing various components of our application
**Adobe Express**: Interaction with clipboard content
**Matlab**: Visualizing clipboard content
**MongoDB**: Vector Database
---
## Challenges we ran into
**When a program deletes itself…**
When we tested shortcut “ctrl+v+1”, we didn’t wish to paste the content when we're triggering a feature. To overcome default pasting from "ctrl+v" keybinding, we simulated “ctrl-z” on the system; however, it undid every second “ctrl-v” was pressed - as a result, testing the application caused it to delete itself ;-;
The running joke goes: “Did we make a malware-”
---
## Accomplishments that we're proud of
* Started on Saturday afternoon and finished
* Everyone worked on a piece they weren’t familiar with, the usual “backend peeps” did frontend this time, and vice versa - was a good learning experience for all
* Slept
* Had fun!
---
## What's next for Clippy
* More Adobe Express features!
* Streamline deployment process for easy setup of all users
--- | ## 💡Inspiration
Have you ever hit a mental **BufferOverflow**? Spending countless hours in front of your screen, sifting through data, only to realize you're drowning in information beyond your brain's capacity? 🤯
In our current era of information overload, researchers, professionals, and curious minds alike struggle not just with the sheer volume of data, but with identifying what's truly relevant. With an average of **250 academic articles read per researcher annually**, the challenge isn't just in consuming this information—it's in effectively filtering through the noise to find the gems that matter. Often, this quest ends with valuable insights lost in isolation, making it difficult to see the big picture and connect the dots of our knowledge.
Our team has experienced first-hand the frustration of juggling disjointed tools. The critical missing piece? A way to not only manage but intelligently filter the flood of information to highlight what's relevant to our unique knowledge landscape.
## 😄What It Does

Dr. Clippy asks questions to gauge your knowledge by communicating with you through **voice or text**, identifies gaps, and suggests papers tailored to you from online searches. It then leverages spatial computing to build and visualize a **3D spatial mind map** of your existing knowledge. The suggested papers are visually suggested as new nodes that connect to your knowledge graph, showing how new information connects to other papers you know so you can decide whether to read the suggested papers and expand on your knowledge.
Here’s how **Dr. Clippy** stands out:
* **Personalized Discovery**: Dr. Clippy recommends academic papers and resources tailored to your knowledge base and gaps.
* **Visual Knowledge Mapping**: Dr. Clippy visualizes how new information slots into your existing knowledge, highlighting connections and sparking innovation through a spatial 3D mind map.
* **Collaborative and Interactive**: Dr. Clippy is your AI assistant and research partner that you can talk to. Beyond solo research, Dr. Clippy enables shared knowledge building with your research colleagues. Edit, expand, and share collective wisdom in a mixed reality space powered by Apple Vision Pro.
## 💻 How We Built It
We created **Dr. Clippy** to be an interactive, AI-driven research assistant, featuring the iconic Clippy from the Windows XP era. Alongside Clippy, there are 8 other avatars that echo MS Windows, offering a variance in agent flavor. We utilized maps to animate these avatars, with JavaScript enabling a range of actions. Our web application is developed using Flask, integrating JavaScript, HTML, and Python for a comprehensive user experience.
When a user has an existing knowledge graph, we visualize it in 3D and store the graph's nodes and edges in a database for persistence and easy manipulation. Users can upload papers they've read, and our system applies cosine similarity to analyze how the abstracts relate to one another. This approach helps us build an initial knowledge graph, offering users a head start in integrating their research into our platform.
The research assistant has voice and text input functionalities, employing the Whisper API to seamlessly convert voice to text. We've innovated in speeding up text-to-speech conversion by parsing sentences individually, achieving a 40% reduction in response wait times. To signal the end of a conversation, we crafted detailed prompts with keywords, culminating in a research question that highlights gaps in the user's knowledge base, prompting an online search.
This search process utilizes the Google Search API, specifically through the Google Scholar Engine, to identify personalized paper recommendations tailored to the user's research interests. We then conduct a similarity search among the top three new personalized papers and the user's existing knowledge base. This allows us to determine how these new papers interlink with the foundational knowledge, visually representing these connections through nodes and text on their edges in the user's knowledge graph.
We designed and implemented a 3D mind map in Unity, providing an intuitive overview of the user's knowledge base. This visualization represents categories, research fields, and resources, along with their interconnections. Using visionOS and Unity Polyspatial tools, we enabled interactive manipulation of the knowledge graphs for collaborative sharing, editing, and expansion, embodying a plug-and-play approach to collective knowledge building. Additionally, we included an entertainment mode for users looking for
## 🚧 Challenges We Ran Into
Our project encountered several technical and integration challenges across various aspects of development:
* **Animated Agents Integration**: Achieving a seamless user experience with animated agents in Flask proved challenging.
* **Real-time Text-to-Speech**: We faced hurdles in generating near real-time text-to-speech responses. To manage data streams efficiently and incorporate non-verbal cues like “uh-huh” and “hmm” to mask processing delays, we had to use multithreading.
* **Functional Memory in Interactions**: Implementing a functional memory in interactions with OpenAI presented difficulties in reducing latency and improving responsiveness.
* **Similarity Search with Chroma's Library**: We encountered limitations in returning distinct results due to insufficient documentation, leading to redundant data.
* **Chroma Vector Databases Management**: Managing multiple Chroma vector databases was challenging due to the need for specific labeling for persistence and local storage.
* **Multi-threading Challenges**: We faced issues with multi-threading, especially when dealing with global variables.
* **Transition from OpenAI Assistant to Chat**: The transition impacted performance due to initial unfamiliarity with the latest models.
* **Web Search Functionality**: Initial inconsistency and a steep learning curve with insufficient documentation made web search integration challenging, especially when combined with Langchain and other components.
* **Intercommunication Framework Design**: Designing a complex framework for communication between Vision Pro, web apps, and external APIs was necessary to maintain consistency between audio threads and visual output in a web server and Flask environment.
* **Integration with Unity and Apple Vision Pro**: Integrating the web applications with Unity and Apple Vision Pro was particularly challenging without prior examples or established practices.
* **Network Connection on Apple Vision Pro**: Establishing an inbound network connection on the Apple Vision Pro posed the most significant challenge due to compatibility issues between Unity's .NET framework and iOS hardware.
## 🏆 Accomplishments We're Proud Of
* **First Research Assistant App for Apple Vision Pro**: We pioneered the first research assistant application specifically designed for Apple Vision Pro, setting a new standard in interactive and immersive research tools.
* **Interactive Spatial Knowledge Graph**: Conceptualized and implemented an innovative, shareable spatial knowledge graph that allows for a dynamic way to represent, search, filter, add, and share knowledge.
* **External Device Interaction with Vision Pro**: Pioneered methods allowing external devices (laptops, IoT devices, etc.) to interact with Vision Pro, greatly expanding the potential of spatial computing and enabling impactful downstream use cases.
* **Spatial Research Knowledge Graph App**: Introduced the world's first spatial Research Knowledge Graph Application, achieving two-way communication between PCs and Apple Vision Pro.
* **Novel Text-to-Audio Speed Algorithm**: Implemented a groundbreaking algorithm to accelerate text-to-audio generation, significantly enhancing the user experience.
* **Engaging Animations for AI Assistants**: Developed captivating animations for AI assistants, fostering user engagement and enhancing the overall user experience while establishing distinct personalities for each AI research assistant.
* **Integrated System**: Successfully integrated a comprehensive system encompassing speech recognition, speech generation, AI assistant functionality, AI-driven information retrieval and filtering, Unity modeling and interaction, communication with Apple Vision Pro, web server communication, and advanced, interactive web UI.
## 📚 What We Learned
As a team, we gained valuable insights and developed a range of skills throughout the project:
* **Mastering JavaScript Animations**: Learned the intricacies of creating engaging animations using JavaScript.
* **System Design Importance**: Realized the critical importance of thorough system design before commencing development to avoid wasted efforts.
* **Tool Proficiency**: Became proficient with tools like Whisper, OpenAI's Assistant and Chat, LangChain, vector databases, and similarity search techniques, especially in applications for Apple Vision Pro through VisionOS.
* **Code Simplicity**: Understood the crucial importance of maintaining a simple code structure for ease of debugging and maintenance.
* **Clear Communication**: Learned the significance of clear communication and regular check-ins within the team to ensure seamless integration of different project components.
## 🔮 What's Next for Dr. Clippy
The future of Dr. Clippy extends well beyond academic research:
* **Consulting Applications**: Consultants could leverage Dr. Clippy to navigate through industry reports, market analyses, and case studies, constructing comprehensive knowledge graphs that reveal trends, gaps, and opportunities in their specific sectors.
* **Healthcare Integration**: Healthcare professionals could use it to bridge the latest research findings with clinical guidelines and patient data, enhancing diagnosis and treatment plans with evidence-based insights.
* **Personalized Research Experience**: By integrating with authors' publication records, Dr. Clippy could offer a unique perspective on how their research fits within the broader context of existing work, encouraging cross-disciplinary innovation and collaboration.
* **Broadening Horizons**: The potential of Dr. Clippy is to not only streamline information discovery but also to foster a deeper, more intuitive understanding of complex data across various fields and industries. | ## Inspiration
Ideas for interactions from:
* <http://paperprograms.org/>
* <http://dynamicland.org/>
but I wanted to go from the existing computer down, rather from the bottom up, and make something that was a twist on the existing desktop: Web browser, Terminal, chat apps, keyboard, windows.
## What it does
Maps your Mac desktop windows onto pieces of paper + tracks a keyboard and lets you focus on whichever one is closest to the keyboard. Goal is to make something you might use day-to-day as a full computer.
## How I built it
A webcam and pico projector mounted above desk + OpenCV doing basic computer vision to find all the pieces of paper and the keyboard.
## Challenges I ran into
* Reliable tracking under different light conditions.
* Feedback effects from projected light.
* Tracking the keyboard reliably.
* Hooking into macOS to control window focus
## Accomplishments that I'm proud of
Learning some CV stuff, simplifying the pipelines I saw online by a lot and getting better performance (binary thresholds are great), getting a surprisingly usable system.
Cool emergent things like combining pieces of paper + the side ideas I mention below.
## What I learned
Some interesting side ideas here:
* Playing with the calibrated camera is fun on its own; you can render it in place and get a cool ghost effect
* Would be fun to use a deep learning thing to identify and compute with arbitrary objects
## What's next for Computertop Desk
* Pointing tool (laser pointer?)
* More robust CV pipeline? Machine learning?
* Optimizations: run stuff on GPU, cut latency down, improve throughput
* More 'multiplayer' stuff: arbitrary rotations of pages, multiple keyboards at once | losing |
## Inspiration
Oftentimes, roommates deal with a lot of conflicts due to differences in living habits and aren't comfortable sorting things out by confronting one another. This problem creates unwanted tension between individuals in the household and usually ends up leading to a poor living experience.
## What it does
Broomies is a mobile app that creates a fun environment to help roommates assign chores for one another, anonymously. Assigned chores can be seen by each roommate, with a separate tab to view your own assigned chores. Once a chore is created by a roommate, it randomly cycles weekly to ensure nobody gets repeated chores. Completing chores on time gives roommates points that get tallied up per month. There is also a way to track expenses with a built-in financing tool to record each transaction a roommate has made for their household. At the end of each month, the monthly sum gets split based on roommate performance, and the top roommate(s) get to pay the least.
## How we built it
Our project utilizes a React Native Frontend with a Go backend and CockroachDB as our db. All our front-end components are designed and implemented in-house. Currently, the app is hosted locally, but in the future, we plan to host our backend on Google cloud, and hopefully publish a polished version on the app store. Finally, we used Git and Github for version control and collaboration tools.
## Challenges we ran into
1. This was our first time developing a mobile application and working with CockroachDB. A big challenge was adjusting and understanding the nuances of mobile development
2. Figuring out an equitable method for distributing points that rewarded doing chores but didn't promote sabotaging your roomies took much polling from fellow hackers
3. Our app covered a lot of features, and we would often run into bugs involving chore management and transaction splitting
## Accomplishments that we're proud of
1. We are really proud of managing to create a full-stack, functioning mobile app as not only first-time mobile developers, but CockroachDB users as well.
2. Entering the hackathon, our goal was to create something that would make any part of our life easier, and we believe Broomies does just that. We are proud to build an app that we hope to actually use in the future.
3. We are really proud of the overall design and theme of Broomies, and how effectively we were able to translate our designs into reality
## What we learned
1. The power of design, both in components and in data structures. Before we started, we took the time to plan out our data structures and relationships, this helped us flesh out a scope for our project, and effective divide work amongst the team.
2. Lots of experience working on new technologies: From IOS and React Native, to leveraging CockroachDB Serverless in quickly turning an idea into a prototype
3. How to effectively ideate: Going into the hackathon, not having a good idea was our biggest concern, but once we learned to let go of finding "The One" hackathon idea, and instead explored every possible avenue, we were able to flesh out ideas that were relevant to our life.
## What's next for Broomies
After fleshing out user management and authentication, we want to deploy the Broomies app on the App store, as well as host our backend on Google Cloud. Also, we want to add the ability to react/respond to task completions, so your roomies can evaluate your tasks. | ## Inspiration
Our inspiration stemmed from the desire to implement a machine learning / A.I. API.
## What it does
Taper analyzes images using IBM's Watson API and our custom classifiers. This data is used to query the USDA food database and return nutritional facts about the product.
## How we built it
Using android Studio and associated libraries we created the UI in the form of an Android App. To improve Watson's image recognition we created our custom classifier and to recognize specific product brands.
## Challenges we ran into
For most of us this was our first time using both Android Studios and Watson so there was a steep initial learning curve. Additionally we attempted to use Microsoft Azure along side Watson but were unsuccessful.
## Accomplishments that we're proud of
-Successful integrating Watson API into a Android App.
-Training our own visual recognition classifier using python and bash scripts.
-Retrieving a products nutritional information based on data from visual recognition.
## What we learned
We experience and learned the difficulty of product integration. As well, we learned how to better consume API's
## What's next for taper
-Creating a cleaner UI
-Text analysis of nutritional data
-day to day nutrition tracking | ## Inspiration
Being certified in Standard First Aid, we personally know the great difference that quick intervention can have on a victim. For example, according to the American Heart Association, if CPR is performed in the first few minutes of cardiac arrest, it can double or triple a person's chance of survival. Unfortunately, only 46% of people who suffer Cardiac Arrest outside of hospitals get the immediate aid they need before professional help arrives. Thus was the creation of Heal-A-Kit.
## What it does
Heal-A-Kit is an app that can identify serious health issues like Heart Attacks, Strokes, Seizures, etc. through the input of various symptoms and provide multiple treatment plans. Additionally, it offers users a step-by-step guide of CPR and encourages them to continue compressions until professional help arrives.
## How we built it
To program our Discord bot we used Python with Discord.py, which is an API wrapper for Discord’s JS API. We chose to use Discord.py as opposed to Discord.js because Python is a more familiar language for us compared to JavaScript and their runtimes such as Node.js.
## Challenges we ran into
Aside from simple syntax errors, we had an issue at first making the bots' messages aesthetically pleasing. We then realized that using embeds would be a clean way to display messages from the bot. Another challenge we ran into was with our logic in the compare command. Originally it would break out the loop once finding one condition that matches with the symptom and to combat this we created a for loop that would keep searching through our data if there were any more conditions and if the string was empty (i.e there were no conditions for the symptoms) then instead of returning an empty string it would return “No conditions match the given symptom."
## Accomplishments that we're proud of
Being able to make a Discord bot for the first time was a massive accomplishment. In addition, the fact that our Discord bot is fully functional and helpful in a real life scenario is something to be proud of.
## What we learned
We learnt how to use Discord’s API wrapper for Python (Discord.py) and how to use modules in Python. In addition, learning how to use object-oriented programming instead of functional programming for the Discord bot which makes the code cleaner and more efficient.
## What's next for Heal-A-Kit
Currently, we have a fully functioning Discord bot, and a prototype for our mobile application. In the future, we plan on adding more health conditions and their respective symptoms and treatments to “heal” as many people as possible. We also plan on further optimizing our search bar, so that even if the scientific or exact wordings are not used, the app can detect the symptom and thus be able to help the victim. | partial |
## Want to find cheap flights to major cities?
This webapp will list the top five cities in terms of cheapest options from your departure location
Using HTML, CSS, Node.js, React, Redux, Python, and an Amadeus API, we created a webpage that uses past airlines data to predict the future prices of the airlines to the destination cities.
When trying to use the python script to access data and pass along that data to the front, we ran into many errors and issues. It took 3 different mentors to help us out and finally after a couple hours, we finally figured out how to resolve the issue.
## Accomplishments that we're proud of
We are proud that we were able to combine our skills and make a product that almost worked exactly how we wanted it to. We are happy we got to learn so many new technologies and combine them all into a working product. Not only this, but acknowledging each other's strengths and weaknesses really helped us come together and work persistently as a team.
We didn't know much about the different javascript frameworks, but through persistence and trial-and-error we were able to figure out how they interacted and got most of the platform running from front-end to back-end.
We will be looking to figure out prices for more than just a limited amount of cities, based upon a limited amount of inputs. We would love to expand the number of inputs to better suit the consumer's needs and be able to also predict where they would like to go next. | ## Inspiration
Often times, we travel to destination based on its popularity like New York or Hawaii, rather than looking for places that we would really enjoy the most. So we decided to create a web application that would recommend travel destinations to users based on images they upload based on their own interests. Each suggestion is tailored to every query.
## What it does
This website will generate a list of suggestions based off a user inputted image via url or upload. Using Microsoft Azure Computer Vision, the website will generate a list of suggested travel destinations, including lowest roundtrip airfare and predicted non-flight related vacation costs, by analyzing the tags from Computer Vision.
## How we built it
We have three main documents for code- the database of locations, the html file for the website, and the javascript file that defines the methods and implements the API. The html website receives user input and returns the suggestions. The database contains formatted data about various possible travel destinations. The javascript file gathers information from each inputted photo, and assigns the photo scores in various categories. Those scores are then compared to those in the database, and using factors such as cost and location type, we generate a list of 7 travel recommendations.
## Challenges we ran into
While trying to acquire a suitable database, we attempted to scrape Wikipedia articles using node.js. After using cheerio and building the basic structure, we found that the necessary information was located in different parts of each article. We were ultimately unable to write code that could filter through the article and extract information, and had to hand generate a database after 5 or more hours of work. Another challenge was finding efficient comparison method so our website did not take too long to process photos.
## Accomplishments that we're proud of
Our website accomplished our main goal. It is able to take in an image, process the tags, and return a list of possible destinations. We also have a basic algorithm that maximizes the accuracy of our website given the current database format.
## What we learned
Since our team had first-time hackers, who were also first time javascript coders, we learned a great deal about how the language functioned, and standards for coding website. We also learned how to share and update code through gitHub. More specifically to our project, this was the first time we used Microsoft Azure and Amadeus APIs, and learned how to implement them into our code.
## What's next for Travel Match
We want to build a more comprehensive database, that includes more locations with more specific data. We also want to come up with a more efficient and accurate comparison algorithm than we currently have. | ## Inspiration
We know the struggles of students. Trying to get to that one class across campus in time. Deciding what to make for dinner. But there was one that stuck out to all of us: finding a study spot on campus. There have been countless times when we wander around Mills or Thode looking for a free space to study, wasting our precious study time before the exam. So, taking inspiration from parking lots, we designed a website that presents a live map of the free study areas of Thode Library.
## What it does
A network of small mountable microcontrollers that uses ultrasonic sensors to check if a desk/study spot is occupied. In addition, it uses machine learning to determine peak hours and suggested availability from the aggregated data it collects from the sensors. A webpage that presents a live map, as well as peak hours and suggested availability .
## How we built it
We used a Raspberry Pi 3B+ to receive distance data from an ultrasonic sensor and used a Python script to push the data to our database running MongoDB. The data is then pushed to our webpage running Node.js and Express.js as the backend, where it is updated in real time to a map. Using the data stored on our database, a machine learning algorithm was trained to determine peak hours and determine the best time to go to the library.
## Challenges we ran into
We had an **life changing** experience learning back-end development, delving into new frameworks such as Node.js and Express.js. Although we were comfortable with front end design, linking the front end and the back end together to ensure the web app functioned as intended was challenging. For most of the team, this was the first time dabbling in ML. While we were able to find a Python library to assist us with training the model, connecting the model to our web app with Flask was a surprising challenge. In the end, we persevered through these challenges to arrive at our final hack.
## Accomplishments that we are proud of
We think that our greatest accomplishment is the sheer amount of learning and knowledge we gained from doing this hack! Our hack seems simple in theory but putting it together was one of the toughest experiences at any hackathon we've attended. Pulling through and not giving up until the end was also noteworthy. Most importantly, we are all proud of our hack and cannot wait to show it off!
## What we learned
Through rigorous debugging and non-stop testing, we earned more experience with Javascript and its various frameworks such as Node.js and Express.js. We also got hands-on involvement with programming concepts and databases such as mongoDB, machine learning, HTML, and scripting where we learned the applications of these tools.
## What's next for desk.lib
If we had more time to work on this hack, we would have been able to increase cost effectiveness by branching four sensors off one chip. Also, we would implement more features to make an impact in other areas such as the ability to create social group beacons where others can join in for study, activities, or general socialization. We were also debating whether to integrate a solar panel so that the installation process can be easier. | losing |
## Inspiration
So, like every Hackathon we’ve done in the past, we wanted to build a solution based on the pain points of actual, everyday people. So when we decided to pursue the Healthtech track, we called the nurses and healthcare professionals in our lives. To our surprise, they all seemed to have the same gripe – that there was no centralized system for overviewing the procedures, files, and information about specific patients in a hospital or medical practice setting. Even a quick look through google showed that there wasn’t any new technology that was really addressing this particular issue. So, we created UniMed - united medical - to offer an innovate alternative to the outdated software that exists – or for some practices, pen and paper.
While this isn’t necessarily the sexiest idea, it’s probably one of the most important issues to address for healthcare professionals. Looking over the challenge criteria, we couldn’t come up with a more fitting solution – what comes to mind immediately is the criterion about increasing practitioner efficiency. The ability to have a true CMS – not client management software, but CARE management software – eliminates any need for annoying patients with a barrage of questions they’ve answered a hundred times, and allows nurses and doctors to leave observations and notes in a system where they can be viewed from other care workers going forward.
## What it does
From a technical, data-flow perspective, this is the gist of how UniMed works: Solace connects our React-based front end to our database. While we normally would have a built a SQL database or perhaps gone the noSQL route and leveraged mongoDB, due to time constraints we’re using JSON for simplicities sake. So while JSON is acting, typically, like a REST API, we’re pulling real-time data with Solace’s functionality. Any time an event-based subscription is called – for example, a nurse updates a patient’s records reporting that their post-op check-up went well and they should continue on their current dosage of medication – that value, in this case a comment value, is passed to that event (updating our React app by populating the comments section of a patient’s record with a new comment).
## How we built it
We all learned a lot at this hackathon – Jackson had some Python experience but learned some HTML5 to design the basic template of our log-in page. I had never used React before, but spent several hours watching youtube videos (the React workshop was also very helpful!) and Manny mentored me through some of the React app creation. Augustine is a marketing student but it turns out he has a really good eye for design, and he was super helpful in mockups and wireframes!
## What's next for UniMed
There are plenty of cool ideas we have for integrating new features - the ability to give patients a smartwatch that monitors their vital signs and pushes that bio-information to their patient "card" in real time would be super cool. It would be great to also integrate scheduling functionality so that practitioners can use our program as the ONLY program they need while they're at work - a complete hub for all of their information and duties! | ## Inspiration
Frustrated by the traditional MBTI's barrage of questions? So were we. Introducing MBTIFY: our web application streamlines your MBTI assessment using advanced Natural Language Processing and Machine Learning. Forget the indecision of Likert scales; MBTIFY's conversational AI prompts you with tailored, open-ended questions. Answer naturally—the AI adapts, selecting queries to pinpoint your personality type with ease. Welcome to a smarter, streamlined path to self-discovery.
## What it does
MBTIFY is a web application designed to administer MBTI personality tests in a more efficient and streamlined manner. Unlike traditional MBTI tests that require answering hundreds of questions, MBTIFY aims to achieve accurate results with fewer than 10 short-answer questions. Users can respond to these questions via text or audio input. The application leverages Natural Language Processing (NLP) and Machine Learning (ML) technologies to analyze the answers and determine the user's MBTI type.
## How we built it
Frontend: Reflex for a user-friendly interface.
Voice Recognition: Converts spoken answers to text.
NLP: Cohere and OpenAI analyze responses for emotional and syntactic insights.
ML: Intersystems IntegratedML utilizes 60,000+ Kaggle MBTI questionnaire responses to train a predictive AutoML model. This model interprets Likert scale responses, determining MBTI type with a confidence level. Immediate results are provided if a confidence threshold is met, or the system dynamically selects further clarifying questions.
## Challenges we ran into
Reflex on M1 Macs: Faced compatibility issues with the Reflex UI framework on M1 chipset Macs, requiring optimization for cross-platform functionality.
SQLAlchemy with sqlalchemy-iris: Experienced limitations in integrating SQLAlchemy with the sqlalchemy-iris dialect, leading to custom code solutions for effective database operations.
IRIS Cloud Connectivity: Encountered difficulties in connecting to the IRIS cloud server, necessitating adjustments in network and security settings for reliable deployment.
Model Training Time: The machine learning model training took over 6 hours due to the large dataset and complex algorithms, prompting a need for pipeline optimization to enhance efficiency.
## Accomplishments that we're proud of
Responsive Design: Developed with Reflex for an adaptive user experience.
Real-Time ML Analysis: Intersystems algorithms provide instant MBTI prediction with a confidence indicator using SQL. We infer Likert scores from user responses to our conversational prompts using LLM, then input these as features into our predictive model, thereby combining discriminative with generative AI models.
Smart Questioning: A dynamic question bank evolves based on user inputs, distinguishing similar MBTI profiles through adaptive questioning and iterative model refinements with updated scores.
## What we learned
Stay on Track: Consistently ensure that you are on the right path by periodically reviewing your goals and progress.
Purposeful Implementation: Before committing to a new feature or task, evaluate its significance to avoid exerting effort on non-impactful activities.
## What's next for MBTIFY
Audio Transcribing: Our roadmap includes the implementation of an advanced audio transcribing feature. This will allow us to extend our voice recognition capabilities to capture even more nuanced responses from users, further refining our MBTI analysis.
Emotion Detection with HumeAI: We plan to integrate HumeAI technology for real-time emotion detection based on the user's voice. This will add an additional layer of depth to the analysis, enabling us to distinguish between closely matched MBTI types with a greater degree of accuracy.
Optimized Machine Learning Algorithms: We aim to continually fine-tune our existing machine learning models within Intersystem to accommodate these new features, ensuring that our confidence levels and MBTI type predictions are as accurate as possible.
Dynamic Questioning 2.0: Building on our adaptive questioning framework, we will incorporate feedback loops that consider not only the content of the user’s responses but also the detected emotional tone. This will make our question selection even more responsive and targeted. | ## Inspiration
Reading about issues with patient safety was... not exactly inspiring, but eye-opening. Issues that were only a matter of human error (understaffed or forgetfulness or etc) like bed sores seemed like things that could easily be kept track of to at least make sure patients could get a heightened quality of life. So we decided to make an app that tracked patient wellness and needs, not necessarily just concrete items, but all the necessary follow-up items from them as well.
We understand that schedulers for more concrete events like appointments already exist, but something that can remind providers to check up on patients in 3 days to see if they have had any side effects to their new prescription or any other task would be helpful.
## What it does
The Med-O-Matic keeps track of patient needs and when they're needed, and sets those needs up in a calendar and matching to-do list for a team of healthcare providers in a hospital to take care of. Providers can claim tasks that they will get to, and can mark them down as they go throughout their day. This essentially serves as a scheduled task-list for providers.
## How we built it
To build the frontend, we used Vue.js. We have a database holding all the tasks on AWS DynamoDB.
## Challenges we ran into
Getting started was a bit difficult and we weren't really sure which direction we should take for Med-O-Matic. There were a lot of uncertainties about what exactly would be best for our application, so we had to delve in a bit deeper by thinking about what the current process is like at hospitals and clinics, and finding areas for improvement. This has led us to addressing a process issue in task assignment to reduce the number of errors associated with inattentiveness.
## Accomplishments that we're proud of
What makes our application different than others is that you can sequence tasks and use these sequences as a template. For example, a procedure like heart-surgery always has required follow up steps. You can create a heart-surgery template, that will be used to set all the required follow-up steps. After the template is created, we can easily reapply that template however many times we want!
## What we learned
We learned how to deploy using DeFang, and also how to connect our frontend with DynamoDB. And we learned more about the domain of our project, which is patient safety.
## What's next for Med-O-Matic
More automation would be next. We've already got some bit for making sequences of tasks, but features like a send-a-text feature for example to make the following-up-on process easier would be next- in other words, we'd add features that help do the tasks as well, instead of simply reminding providers of what they need to do.
We would also connect it to some medical scheduler like EPIC's API, like EPIC. This would allow us to
really get the task sequencing working seamlessly with a real workflow, as something like a surgery can be scheduled in epic, happen, and then trigger the Med-O-Matic to create all the necessary follow-up tasks from that. | partial |
## Inspiration
MISSION: Our mission is to create an intuitive and precisely controlled arm for situations that are tough or dangerous for humans to be in.
VISION: This robotic arm application can be used in the medical industry, disaster relief, and toxic environments.
## What it does
The arm imitates the user in a remote destination. The 6DOF range of motion allows the hardware to behave close to a human arm. This would be ideal in environments where human life would be in danger if physically present.
The HelpingHand can be used with a variety of applications, with our simple design the arm can be easily mounted on a wall or a rover. With the simple controls any user will find using the HelpingHand easy and intuitive. Our high speed video camera will allow the user to see the arm and its environment so users can remotely control our hand.
## How I built it
The arm is controlled using a PWM Servo arduino library. The arduino code receives control instructions via serial from the python script. The python script is using opencv to track the user's actions. An additional feature use Intel Realsense and Tensorflow to detect and track user's hand. It uses the depth camera to locate the hand, and use CNN to identity the gesture of the hand out of the 10 types trained. It gave the robotic arm an additional dimension and gave it a more realistic feeling to it.
## Challenges I ran into
The main challenge was working with all 6 degrees of freedom on the arm without tangling it. This being a POC, we simplified the problem to 3DOF, allowing for yaw, pitch and gripper control only. Also, learning the realsense SDK and also processing depth image was an unique experiences, thanks to the hardware provided by Dr. Putz at the nwhacks.
## Accomplishments that I'm proud of
This POC project has scope in a majority of applications. Finishing a working project within the given time frame, that involves software and hardware debugging is a major accomplishment.
## What I learned
We learned about doing hardware hacks at a hackathon. We learned how to control servo motors and serial communication. We learned how to use camera vision efficiently. We learned how to write modular functions for easy integration.
## What's next for The Helping Hand
Improve control on the arm to imitate smooth human arm movements, incorporate the remaining 3 dof and custom build for specific applications, for example, high torque motors would be necessary for heavy lifting applications. | ## Inspiration
We wanted to promote an easy learning system to introduce verbal individuals to the basics of American Sign Language. Often people in the non-verbal community are restricted by the lack of understanding outside of the community. Our team wants to break down these barriers and create a fun, interactive, and visual environment for users. In addition, our team wanted to replicate a 3D model of how to position the hand as videos often do not convey sufficient information.
## What it does
**Step 1** Create a Machine Learning Model To Interpret the Hand Gestures
This step provides the foundation for the project. Using OpenCV, our team was able to create datasets for each of the ASL alphabet hand positions. Based on the model trained using Tensorflow and Google Cloud Storage, a video datastream is started, interpreted and the letter is identified.
**Step 2** 3D Model of the Hand
The Arduino UNO starts a series of servo motors to activate the 3D hand model. The user can input the desired letter and the 3D printed robotic hand can then interpret this (using the model from step 1) to display the desired hand position. Data is transferred through the SPI Bus and is powered by a 9V battery for ease of transportation.
## How I built it
Languages: Python, C++
Platforms: TensorFlow, Fusion 360, OpenCV, UiPath
Hardware: 4 servo motors, Arduino UNO
Parts: 3D-printed
## Challenges I ran into
1. Raspberry Pi Camera would overheat and not connect leading us to remove the Telus IoT connectivity from our final project
2. Issues with incompatibilities with Mac and OpenCV and UiPath
3. Issues with lighting and lack of variety in training data leading to less accurate results.
## Accomplishments that I'm proud of
* Able to design and integrate the hardware with software and apply it to a mechanical application.
* Create data, train and deploy a working machine learning model
## What I learned
How to integrate simple low resource hardware systems with complex Machine Learning Algorithms.
## What's next for ASL Hand Bot
* expand beyond letters into words
* create a more dynamic user interface
* expand the dataset and models to incorporate more | ## What is it?
Using the Intel RealSense, we first extracted a user's hand movements and mapped certain gestures to specific actions for the drone. Then we transmitted the data to an Arduino using low energy bluetooth. The Arduinos generated the signals readable by the transmitter chip using digital potentiometers. Having never used FPV before, we included a GoPro with a 5.8 GHz transmitter to stream live first person view to a wireless monitor.
## Inspiration
We have always been interested in drones and their increased prevalence in our culture. We love reverse engineering commercial products, and we wanted to experiment with the Intel RealSense.
## How We built it
In order to extract gestures, we used the Realsense SDK in C++ to extract the coordinates on a user's hand. Doing so, we were able to match certain combinations of coordinates to different instructions for the drone. The camera first tracks where the user's hand is and will move the drone according to where that is. More complex custom instructions such as landing the drone and havering can be called by using two hands. The drone was flown by taking apart its transmitter and completely disassembling it. We used digital potentiometers to digitally and autonomously emulate the transmitter joysticks. Out homemade transmitter is controlled by four Arduino Unos, which was necessary because the digital potentiometers were controlled by SPI and we had to work with a limited number of SPI inputs in the Arduino Uno.
## Challenges I ran into
The most difficult part of this project was emulating the drone control system. Due to the tight specifications of the controller, it was very difficult to create signals that fit within its tolerance boundaries. It took many hours of calibration for us to figure out exactly what signals were allowed. After that, we had to map controls to these signals. An additional challenge was generating data using Intel RealSense that was then transmitted to the master Arduino device using a Sparkfun low energy Bluetooth board. | partial |
## 💡 Inspiration ✨
Embarking on our CalTrack adventure, we were fueled by a vision to revolutionize the way individuals approach their health. We aimed to dismantle the tedious barriers of traditional calorie counting, transforming it from a burdensome task into a delightful, almost effortless daily interaction. It’s where advanced tech seamlessly blends with the essential aspects of nutrition, condensed into the simple act of capturing a photo. We embraced the philosophy that pursuing a wholesome lifestyle should be convenient, straightforward, and completely devoid of stress.
CalTrack emerged as our innovative response to this vision—the ultimate tool to keep wellness not just within reach, but actively engaged in the foreground of our users' lives. We noticed that while other platforms provided pieces to the puzzle, they often fell short with clunky interfaces and tiring manual data entries. CalTrack is designed to bridge that gap, offering a solution that’s intuitive and as natural as taking a selfie.
## 🍎 What it does 🥗
Enter the world of CalTrack, where sophisticated computer vision meets artificial intelligence to create a seamless meal identification experience. Forget the cumbersome process of scouring through endless food lists to painstakingly log every bite. No more dealing with complex user interfaces, searching through databases, and manual logging. With CalTrack, you’re one photo away from a comprehensive nutritional breakdown in an instant. It’s like having a personal dietitian in your pocket, always ready to help you make smarter food choices with ease and precision.
Additionally, we used the Revised Harris-Benedict Equation to give users an estimate of their suggested daily calories, factoring in their sex, height, weight, and age. This makes the application more personalized and tailored to the user.
## 🛠️ How we built it 💬
By integrating Google Cloud, we aimed to take the guesswork out of calorie counting by using easily available information and integrating the Vision API. Our app is designed to remove barriers, providing a seamless and engaging experience. Just snap a photo, and the rest is taken care of by our intelligent algorithms.
On the front end, we use Python with the CustomTktinter library to create a simple and intuitive user interface. Our features include allowing users to upload or capture photos to be processed, calculating the calories they need in a day, and tracking everything a user eats in a day with a clear bar to represent their calorie goal.
## 🚧 Challenges we ran into ⛔
One of our earliest and most significant hurdles was defining the scope of the AI to handle a diversity of meals. This was the reason we used the Vision API from Google Cloud to process our images. Given the timeframe of this project, we had to limit our ability to easily identifiable food.
We also worked hard to optimize the app and API calls for speed, as we understand that every second counts when you're hungry. Balancing accuracy with speed was a delicate process that our team navigated with perseverance and creativity.
## 🎉 Accomplishments that we're proud of 🏆
Being a brand-new team to hackathons, we are incredibly proud of what we have achieved in 36 hours. Our journey led us from the intricacies of building a sleek, user-friendly front-end interface with Python's Tkinter to architecting a robust backend powered by the sophistication of the Google Cloud Platform. The culmination of this effort is CalTrack—an integration of technologies that not only embraces but excels at transforming images into actionable nutritional insights.
## 🧠 What we learned 🤓
Building CalTrack has been a rigorous educational experience, packed with valuable lessons at every stage. We ventured into the complex territories of machine learning and user interface design, greatly enhancing our technical skill set. Taking on the Google Cloud Platform, we went from novices to proficient users, tapping into the power of its Vision API, which now serves as the backbone of our app. The learning process was challenging, but we embraced the opportunity to grow and improve, much like adventurers enjoy the ascent and the perspective it brings.
## 🔮 What's next for CalTrack ⏭️
The road ahead for CalTrack includes expanding our food database to cover even more variety, implementing user-friendly features like meal suggestions, and enhancing our AI to provide even more precise nutritional information.
We're on a mission to make healthy eating hassle-free for everyone, and this is just the beginning. | ## Inspiration
Currently, there is an exponential growth of obesity in the world, leading to devastating consequences such as an increased rate of diabetes and heart diseases. All three of our team members are extremely passionate about nutrition issues and wish to educate others and promote healthy active living.
## What it does
This iOS app allows users to take pictures of meals that they eat and understand their daily nutrition intake. For each food that is imaged, the amount of calories, carbohydrates, fats and proteins are shown, contributing to the daily percentage on the nutrition tab. In the exercise tab, the users are able to see how much physical activities they need to do to burn off their calories, accounting for their age and weight differences. The data that is collected easily syncs with the iPhone built-in health app.
## How we built it
We built the iOS app in Swift programming language in Xcode. For the computer vision of the machine learning component, we used CoreML, and more specifically its Resnet 50 Model. We also implemented API calls to Edamam to receive nutrition details on each food item.
## Challenges we ran into
Two of our three team members have never used Swift before - it is definitely a challenge writing in an unfamiliar coding language. It was also challenging calling different APIs and integrating them back in Xcode, as the CoreML documentation is unclear.
## Accomplishments that we're proud of
We are proud of learning an entirely new programming language and building a substantial amount of a well-functioning app within 36 hours.
## What's next for NutriFitness
Building our own machine learning model and getting more accurate image descriptions. | # We'd love if you read through this in its entirety, but we suggest reading "What it does" if you're limited on time
## The Boring Stuff (Intro)
* Christina Zhao - 1st-time hacker - aka "Is cucumber a fruit"
* Peng Lu - 2nd-time hacker - aka "Why is this not working!!" x 30
* Matthew Yang - ML specialist - aka "What is an API"
## What it does
It's a cross-platform app that can promote mental health and healthier eating habits!
* Log when you eat healthy food.
* Feed your "munch buddies" and level them up!
* Learn about the different types of nutrients, what they do, and which foods contain them.
Since we are not very experienced at full-stack development, we just wanted to have fun and learn some new things. However, we feel that our project idea really ended up being a perfect fit for a few challenges, including the Otsuka Valuenex challenge!
Specifically,
>
> Many of us underestimate how important eating and mental health are to our overall wellness.
>
>
>
That's why we we made this app! After doing some research on the compounding relationship between eating, mental health, and wellness, we were quite shocked by the overwhelming amount of evidence and studies detailing the negative consequences..
>
> We will be judging for the best **mental wellness solution** that incorporates **food in a digital manner.** Projects will be judged on their ability to make **proactive stress management solutions to users.**
>
>
>
Our app has a two-pronged approach—it addresses mental wellness through both healthy eating, and through having fun and stress relief! Additionally, not only is eating healthy a great method of proactive stress management, but another key aspect of being proactive is making your de-stressing activites part of your daily routine. I think this app would really do a great job of that!
Additionally, we also focused really hard on accessibility and ease-of-use. Whether you're on android, iphone, or a computer, it only takes a few seconds to track your healthy eating and play with some cute animals ;)
## How we built it
The front-end is react-native, and the back-end is FastAPI (Python). Aside from our individual talents, I think we did a really great job of working together. We employed pair-programming strategies to great success, since each of us has our own individual strengths and weaknesses.
## Challenges we ran into
Most of us have minimal experience with full-stack development. If you look at my LinkedIn (this is Matt), all of my CS knowledge is concentrated in machine learning!
There were so many random errors with just setting up the back-end server and learning how to make API endpoints, as well as writing boilerplate JS from scratch.
But that's what made this project so fun. We all tried to learn something we're not that great at, and luckily we were able to get past the initial bumps.
## Accomplishments that we're proud of
As I'm typing this in the final hour, in retrospect, it really is an awesome experience getting to pull an all-nighter hacking. It makes us wish that we attended more hackathons during college.
Above all, it was awesome that we got to create something meaningful (at least, to us).
## What we learned
We all learned a lot about full-stack development (React Native + FastAPI). Getting to finish the project for once has also taught us that we shouldn't give up so easily at hackathons :)
I also learned that the power of midnight doordash credits is akin to magic.
## What's next for Munch Buddies!
We have so many cool ideas that we just didn't have the technical chops to implement in time
* customizing your munch buddies!
* advanced data analysis on your food history (data science is my specialty)
* exporting your munch buddies and stats!
However, I'd also like to emphasize that any further work on the app should be done WITHOUT losing sight of the original goal. Munch buddies is supposed to be a fun way to promote healthy eating and wellbeing. Some other apps have gone down the path of too much gamification / social features, which can lead to negativity and toxic competitiveness.
## Final Remark
One of our favorite parts about making this project, is that we all feel that it is something that we would (and will) actually use in our day-to-day! | losing |
## Inspiration
Our team has always been concerned about the homogeneity of many computer vision training sets, given that they can introduce cultural and societal biases into the resulting machine learning algorithm.
CultureCV is designed to combat this highly relevant problem, with a user incentive for use: by taking pictures of objects that are culturally relevant to the user, then incorporating user-generated tagging into new data sets, our mobile app encourages both cultural exchange and a future with more diverse CV training sets.
By using our app, the user learns their target language from objects and situations they already see. The user is prompted to tag objects that are meaningful to them, which in turn strengthens the diversity of our custom training data set.
## What it does
CultureCV is a cross-platform real-time, real-world flashcard community. After starting the app, the phone's camera captures several images of an object the user is looking at, and sends them to the Microsoft Image Analysis API. As the API returns descriptions and tags for the object, our app displays and translates the best tags, using the Microsoft Translation API, as well as a brief description of the scene. The user can set the translation language (currently supported: French, Spanish, and German).
When our custom data set (using the Microsoft Custom Vision API) has a better match for the image than the tags returned by the Microsoft Image Analysis API, we instead display and translate our own tags.
Users can create their own language "flashcards" with any object they want, by tagging objects that they find meaningful. This is incredibly powerful both in its democratization of training data, and in its high level of personalized customization.
## How we built it
CultureCV was built entirely using Expo and React Native -- a huge advantage due to the fact that all of our team members had different mobile devices.
## Challenges we ran into
We spent a lot of time uncovering new features by poring through the new Microsoft documentation for the Custom Vision Service. Allowing the user to submit tags to the data set was particularly challenging.
Additionally, two out of three of our developers had never used Expo or React Native before. Thankfully, after the initial difficulties of getting up and running, we were all able to test using Expo.
## Accomplishments that we're proud of
We are especially proud of the instant training of our custom model -- users who use the "contribute" button to add tags for an object can see that object be correctly identified just a moment later.
## What we learned
The most exciting our team learned was that we could create a high-quality machine learning app without ever having to glance at a gradient!
Our team learned how to collaborate in a team using Expo (two of our members learned how to use Expo, full stop).
## What's next for CultureCV
The platform is scalable for any type of information -- we see future applications for museums, famous landmarks and historical sites, or even directly in the classroom. Ultimately, we see our platform becoming something like Wikipedia for the real world. | ## Inspiration
Often as children, we were asked, "What do you want to be when you grow up?" Every time we changed our answers, we were sent to different classes to help us embrace our interests. But our answers were restricted and traditional: doctors, engineers or ballerinas. **We want to expand every child's scope: to make it more inclusive and diverse, and help them realize the vast opportunities that exist in this beautiful world in a fun way.**
Let's get them ready for the future where they follow their passion — let's hear them say designers, environmentalists, coders etc.
## What it does
The mobile application uses Augmented Reality technology to help children explore another world from a mobile phone or tablet and understand the importance of their surroundings. It opens up directly into the camera, where it asks the user to point at an object. The app detects the object and showcases various career paths that are related to the object. A child may then pick one and accomplish three simple tasks relevant to that career, which then unlocks a fun immersion into the chosen path's natural environment and the opportunity to "snap" a selfie as the professional using AR filters. The child can save their selfies and first-person immersion experience videos in their personal in-app gallery for future viewing, exploration, and even sharing.
## How I built it
Our team of three first approached the opportunity space. We held a brainstorming exercise to pinpoint the exact area where we can help, and then stepped into wireframing. We explored the best medium to play around with for the immersive, AR experience and decided upon Spectacles by Snap & Lens Studio, while exploring Xcode and iOS in parallel. For object detection, we used Google's MLKit Showcase App with Material Design to make use of Google's Object Detection and Tracking API. For the immersion, we used Snap's Spectacles to film real-world experiences that can be overlaid upon any setting, as well as Snap's Lens Studio to create a custom selfie filter to cap off the experience.
We brought in code together with design to bring the app alive with its colorful approach to appeal to kids.
## Challenges I ran into
We ran into the problem of truly understanding the perspectives of a younger age group and how our product would successfully be educational, accessible, and entertaining. We reflected upon our own experiences as children and teachers, and spoke to several parents before coming up with the final idea.
When we were exploring various AR/VR/MR technologies, we realized that many of the current tools available don't yet have the engaging user interfaces that we had been hoping for. Therefore we decided to work with Snap's Lens Studio, as the experience in-app on Snapchat is very exciting and accessible to our target age range.
On the technical side, Xcode and Apple have many peculiarities that we encountered over the course of Saturday. Additionally, we had not taken into consideration the restrictions and dependencies that Apple imposes upon iOS apps.
## Accomplishments that I'm proud of
We're proud that we did all of this in such a short span of time. Teamwork, rapid problem solving and being there for each other made for a final product that we are all proud to demo.
We're also proud that we took advantage of speaking to several sponsors from Snap and Google, and mentors from Google and Apple (and Stanford) throughout the course of the hackathon. We enjoyed technically collaborating with and meeting new people from all around the industry.
## What I learned
We learnt how to collaborate and bring design and code together, and how both go hand in hand. The engineers on the team learned a great amount about the product ideation and design thinking, and it was interesting for all of us to see our diverse perspectives coalesce into an idea we were all excited about.
## What's next for Inspo | An exploration tool for kids
On the technical side, we have many ideas for taking our project from a hackathon demo to the release version. This includes:
* Stronger integration with Snapchat and Google Cloud
* More mappings from objects to different career pathways
* Using ML models to provide recommendations for careers similar to the ones children have liked in the past
* An Android version
On the product side, we would like to expand to include:
* A small shopping list for parents to buy affordable, real-world projects related to careers
* A "Career of the Week" highlight
* Support for a network/community of children and potentially even professional mentors | ## Inspiration
Our inspiration for this was heavily drawn from our past experiences of forgetting the expiry dates of foods that we own, like fruits, breads, and other typical groceries. When baking, cooking, or even making smoothies, we need to utilize our fresh groceries but want to keep them as fresh as possible after purchase. It's enough to remember when you shopped last, but not when managing the expiration dates that vary among the vast variety of groceries that you can purchase. Fulfilling the request of the Patagonia Sustainability Challenge, this app would greatly reduce the wastage of food in general.
## What it does
The app allows the user to take a picture of their grocery list / grocery receipt. It will then extract the ingredients from the receipt and label them with common expiry dates for the foods, to remind the user of when they will expire. With further updates, the app may be able to push notify users within the final days of their groceries.
## How we built it
We used Android Studio to build our UI templates and integrated our thinking in Java classes. We used Firebase to keep track of a running inventory of the user's fridge in real time. We additionally added the functionality to use the device's camera by bitmapping and redirecting the user to their app. Finally, we aimed to integrate a python script utilizing AI to map the expiry dates, although ran into troubles (which we will elaborate on in the next section), and settled for utilizing csv files and comparing the receipt by using general expiry dates for types of food.
## Challenges we ran into
Merging the script with the app - Our main issue with the program, that we were unable to complete by the end, was merging the script's functionality with the app, as our image-to-text method in our script would essentially crash the program once a picture was taken. We attempted to use EC2 to download specific libraries although we could not find a fix. This led to us having to input our ingredients manually for our demo.
## Accomplishments that we're proud of
Although the project did not end on a strong note, we learned an essential amount of information over the course of the weekend. 3 of our group members are very new to creating projects, and utilizing GitHub, as well as merging code and collaborating together to accomplish a task with importance. In the end, we all were able to complete independently, successful components to the project, and were able to learn a lot about debugging, as well as utilizing Android Studio.
## What we learned
As stated previously, with 3 of our 4 members being new to the environment of Hackathons and programming projects, we learned a lot about using GitHub to commit and push our code to share our creations with each other. Additionally, although not implemented, we learned a lot about APIs and Artificial Intelligence - which we hope to incorporate with our next project. We were unable to hit the nail on the head with merging our components, although we learned especially a lot about libraries and connecting Java with Python through different sources, as well as having our eyes opened to EC2.
## What's next for X-Pyre
We will be aiming in the near future to update the components of the app so they work as intended (the camera should be able to take a picture that can be scanned). Additionally, we look forward to pursuing more research towards artificial intelligence and utilizing machine learning to predict models of expiry dates for users' ingredients. | partial |
## Inspiration
I take a lot of video and voice journals, but never look back. Because I feel I can't change anything about them.
## What it does
## How I built it
tensorflow, react, node, keras, flask
## Challenges I ran into
## Accomplishments that I'm proud of
## What I learned
## What's next for Voice Productivity Interface | ## Inspiration
When we go grocery shopping, it's difficult to find the items we need and end up wandering in circles. As busy CS students, it is important that we don't waste time so finding the most effective route around a grocery store would be beneficial to us.
## What it does
With out app, you can create a layout of your grocery store, assigning the entrance, exit, and shelves that are labeled categorically. Then you can create your grocery list, and generate an efficient path that will take you to all the items you need.
## How we built it
We built it using Java, XML, and SQLite in Android Studio.
## Challenges we ran into
The path searching algorithm was extremely difficult, as we just sorta figured out some crucial bugs 10 minutes before the deadline as I'm scrambling to type this.
## Accomplishments that we're proud of
I'm proud of the work we were able to accomplish as a team. We made a nice looking UI and got the hardest part of our app to work out too.
## What we learned
We learned that it is important to communicate thoroughly about the changes you made, and what is does. A major mistake we had was when there was a mixup between a variable name "n" and what is was supposed to be for between two people.
## What's next for shop-circuit
We hope we can continue to develop and improve the graphics on the app as it is quite primitive.
\*\*demos are on github | ## Inspiration
We wanted to solve a unique problem we felt was impacting many people but was not receiving enough attention. With emerging and developing technology, we implemented neural network models to recognize objects and images, and converting them to an auditory output.
## What it does
XTS takes an **X** and turns it **T**o **S**peech.
## How we built it
We used PyTorch, Torchvision, and OpenCV using Python. This allowed us to utilize pre-trained convolutional neural network models and region-based convolutional neural network models without investing too much time into training an accurate model, as we had limited time to build this program.
## Challenges we ran into
While attempting to run the Python code, the video rendering and text-to-speech were out of sync and the frame-by-frame object recognition was limited in speed by our system's graphics processing and machine-learning model implementing capabilities. We also faced an issue while trying to use our computer's GPU for faster video rendering, which led to long periods of frustration trying to solve this issue due to backwards incompatibilities between module versions.
## Accomplishments that we're proud of
We are so proud that we were able to implement neural networks as well as implement object detection using Python. We were also happy to be able to test our program with various images and video recordings, and get an accurate output. Lastly we were able to create a sleek user-interface that would be able to integrate our program.
## What we learned
We learned how neural networks function and how to augment the machine learning model including dataset creation. We also learned object detection using Python. | losing |
## Inspiration
To set our goal, we were grandly inspired by the Swiss system, which has proven to be one of the most functional democracy in the world. In Switzerland, there is a free mobile application, VoteInfo, which is managed by a governmental institution, but is not linked to any political groups, where infos about votes and democratic events happening at a national, regional and communal scale are explained, vulgarized and promoted. The goal is to provide the population a deep understanding of the current political discussions and therefore to imply everyone in the Swiss political life, where every citizen can vote approximately 3 times a year on national referendum to decide the future of their country. We also thought it would be interesting to expand that idea to enable elected representative, elected staff and media to have a better sense of the needs and desires of a certain population.
Here is a [link](https://www.bfs.admin.ch/bfs/fr/home/statistiques/politique/votations/voteinfo.html) to the swiss application website (in french, german and italian only).
## What it does
We developed a mobile application where anyone over 18 can have an account. After creating their account and entering their information (which will NOT be sold for profit), they will have the ability to navigate through many "causes", on different scales. For example, a McGill student could join the "McGill" group, and see many ideas proposed by member of elected staff, or even by regular students. They could vote for or against those, or they could choose to give visibility to an idea that they believe is important. The elected staff of McGill could then use the data from the votes, plotted in the app in the form of histograms, to see how the McGill community feels about many different subjects. One could also join the "Montreal Nightlife" group. For instance, a non-profit organization with governmental partnerships like [mtl2424](https://www.mtl2424.ca/), which is currently investigating the possibility of extending the alcohol permit fixed to 3 a.m., could therefore get a good understanding of how the Montreal population feels about this idea, by looking on the different opinion depending on the voters' age, their neighbourhood, or even both!
## How we built it
We used Figma for the graphic interface, and Python (using Spyder IDE) for the data analysis and the graph plotting ,with Matplotlib and Numpy libraries.
## Challenges we ran into
We tried to build a dynamic interface where one could easily be able to set graphs and histograms to certain conditions, i.e. age, gender, occupation... However, the implementation of such deep features happened to be too complicated and time-consuming for our level of understanding of software design, therefore, we abandoned that aspect.
Also, as neither of us had any real background in software design, building the app interface was very challenging.
## Accomplishments that we're proud of
We are really proud of the idea in itself, as we really and honestly believe that, especially in small communities like McGill, it could have a real positive impact. We put a lot of effort into building a realistic and useful tool that we, as students and members of different communities, would really like to have access to.
## What we learned
The thing we mainly learned was how to create a mobile app interface. As stipulated before, it was a real challenge, as neither of us had any experience in software development, so we had to learn while creating our interface.
As we were limited in time and knowledge, we also learned how to understand the priorities of our projects and to focus on them in the first place, and only afterward try to add some features.
## What's next for Kairos
The first step would be to implement our application's back-end and link it to the front-end.
In the future, we would really like to create a nice, dynamic and clean UI, to be attractive and easy to use for anyone, of any age, as the main problem with implementing technological tools for democracy is that the seniors are often under-represented.
We would also like to implement a lot of features, like a special registration menu for organizations to create groups, dynamic maps, discussion channels etc...
Probably the largest challenge in the upcoming implementations will be to find a good way to ensure each user has only one account, to prevent pollution in the sampling. | ## Inspiration:
The human effort of entering details from a paper form to a computer led us to brainstorm and come up with this idea which takes away the hassle of the information collection phase.
## What it does?
The application accepts an image / pdf of a medical form and analyses it to find the information which is then stored in a database
## How we built it?
We applied Optical Character Recognition techniques to evaluate data which was present in the form, and then formatted it to provide valuable information to the nurse/doctor
## Challenges we ran into:
Each person has his/her own way of writing and thus it was difficult to identify the characters
## Accomplishments that we're proud of:
We could come up with an MVP during these 36 hours by implementing a solution involving new technologies / workflows.
## What we learned?
We learned about the presence of several APIs providing OCR functionality which might differ based on the optimisation, also we learned more about client-server architecture in a way the patient's (client) request reaches nurse/hospital (server) asynchronously.
## What's next for Care Scan?
We would love to take this idea forward and integrate the solution with different services and regulations to provide an enriching experience to the user including but not limited to the scope of machine learning, NLP and event driven architectures.
## Link to Codebase
<https://github.com/Care-Scan> | ## Inspiration
Not having to worry about coming home to feed our dog.
## What it does
Automatically dispenses food and water for the dog based on sensor readings. Will be connected to an app in the future so you can choose when to feed the dog.
## How we built it
Hooked up an Arduino Uno to a force sensor and a water level sensor. If the water and food levels are low, dispense food if it’s been 6 hours since the last meal and constantly dispense water.
## Challenges we ran into
The DC motor can’t be controlled by the Arduino so we needed to make a servo push a button. We didn’t have a transistor. This was the only way we could turn on the motor. We also were not able to hook the Arduino to WIFI because we were using an ESP 8266 shield. We were going to use the Blynk app to control the project over WIFI but the ESP wasn’t able to pass the information correctly.
## Accomplishments that we're proud of
We created what we wanted. An automated food and water dispenser.
## What we learned
Problem solving. Building circuits for the hardware. Learning how to connect hardware over WIFI.
## What's next for Feed The Dog
Connect the project to WIFI. | partial |
## Inspiration
While caught in the the excitement of coming up with project ideas, we found ourselves forgetting to follow up on action items brought up in the discussion. We felt that it would come in handy to have our own virtual meeting assistant to keep track of our ideas. We moved on to integrate features like automating the process of creating JIRA issues and providing a full transcript for participants to view in retrospect.
## What it does
*Minutes Made* acts as your own personal team assistant during meetings. It takes meeting minutes, creates transcripts, finds key tags and features and automates the process of creating Jira tickets for you.
It works in multiple spoken languages, and uses voice biometrics to identify key speakers.
For security, the data is encrypted locally - and since it is serverless, no sensitive data is exposed.
## How we built it
Minutes Made leverages Azure Cognitive Services for to translate between languages, identify speakers from voice patterns, and convert speech to text. It then uses custom natural language processing to parse out key issues. Interactions with slack and Jira are done through STDLIB.
## Challenges we ran into
We originally used Python libraries to manually perform the natural language processing, but found they didn't quite meet our demands with accuracy and latency. We found that Azure Cognitive services worked better. However, we did end up developing our own natural language processing algorithms to handle some of the functionality as well (e.g. creating Jira issues) since Azure didn't have everything we wanted.
As the speech conversion is done in real-time, it was necessary for our solution to be extremely performant. We needed an efficient way to store and fetch the chat transcripts. This was a difficult demand to meet, but we managed to rectify our issue with a Redis caching layer to fetch the chat transcripts quickly and persist to disk between sessions.
## Accomplishments that we're proud of
This was the first time that we all worked together, and we're glad that we were able to get a solution that actually worked and that we would actually use in real life. We became proficient with technology that we've never seen before and used it to build a nice product and an experience we're all grateful for.
## What we learned
This was a great learning experience for understanding cloud biometrics, and speech recognition technologies. We familiarised ourselves with STDLIB, and working with Jira and Slack APIs. Basically, we learned a lot about the technology we used and a lot about each other ❤️!
## What's next for Minutes Made
Next we plan to add more integrations to translate more languages and creating Github issues, Salesforce tickets, etc. We could also improve the natural language processing to handle more functions and edge cases. As we're using fairly new tech, there's a lot of room for improvement in the future. | ## Inspiration
We've all had to fill out paperwork going to a new doctor before: it's a pain, and it's information we've already written down for other doctors a million times before. Our health information ends up all over the place, not only making it difficult for us, but making it difficult for researchers to find participants for studies.
## What it does
HealthConnect stores your medical history on your phone, and enables you to send it to a doctor just by scanning a one-time-use QR code. It's completely end-to-end encrypted, and your information is encrypted when it's stored on your phone.
We provide an API for researchers to request a study of people with specific medical traits, such as a family history of cancer. Researchers upload their existing data analysis code written using PyTorch, and we automatically modify it to provide *differential privacy* -- in other words, we guarantee mathematically that our user's privacy will not be violated by any research conducted. It's completely automatic, saving researchers time and money.
## How we built it
### Architecture
We used a scalable microservice architecture to build our application: small connectors interface between the mobile app and doctors and researchers, and a dedicated executor runs machine learning code.
### Doctor Connector
The Doctor Connector enables seamless end-to-end encrypted transmission of data between users and medical providers. It receives a public key from a provider, and then allows the mobile app to upload data that's been encrypted with that key. After the data's been uploaded, the doctor's software can download it, decrypt it, and save it locally.
### ML Connector
The ML Connector is the star of the show: it manages what research studies are currently running, and processes new data as people join research studies. It uses a two-step hashing algorithm to verify that users are legitimate participants in a study (i.e. they have not modified their app to try and join every study), and collects the information of participants who are eligible to participate in the study. And, it does this without ever writing their data to disk, adding an extra layer of security.
### ML Executor
The ML Executor augments a researcher's Python analysis program to provide differential privacy guarantees, runs it, and returns the result to the researcher.
### Mobile App
The Mobile App interfaces with both connectors to share data, and provides secure, encrypted storage of users' health information.
### Languages Used
Our backend services are written in Python, and we used React Native to build our mobile app.
## Challenges we ran into
It was difficult to get each of our services working together since we were a distributed team.
## Accomplishments that we're proud of
We're proud of getting everything to work in concert together, and we're proud of the privacy and security guarantees we were able to provide in such a limited amount of time.
## What we learned
* Flask
* Python
## What's next for HealthConnect
We'd like to expand the HealthConnect platform so those beyond academic researchers, such as for-profit companies, could identify and compensate participants in medical studies.
Test | ## Inspiration
We live in a diverse country with people from all ethnic backgrounds. Not everybody speaks or understands English perfectly. For people, whose first language is not English, information on government websites can get complicated and confusing. People waste a lot of time trying to access the information they need. We also realized that there is no universal Q&A tool that can detect and provide answers to questions in any language for both voice and text. This inspired us to come up with a platform that can help users access information in their preferred language and mode of communication (voice/text).
## What it does
Artemis is a user-friendly Q & A chatbot integrated with the ca.gov website to help users with any questions that they have in the language they are comfortable with. It automatically detects the language your phone/system is configured to and responds to both voice/text-based questions. Currently, it can detect over 24 languages. Artemis has a simple and intuitive interface making it super easy to use and can be used across platforms (both web and mobile).
## How we built it
First, we mapped some of the ca.gov websites' FAQ to the QnA maker database and created a chatbot with Microsoft Bot Framework which we then linked to the database we made. We then added the web chat to the ca.gov page, created the cognitive speech service in Azure, linked it to the webchat client bot, connected the speech to text/text to speech API, added the translation middleware, and deployed everything to GitHub pages and Azure cloud. Meanwhile, the Sketch assets were designed and developed and integrated into the main Microsoft HTML file.
Built with Visual Studio Code and designed in Sketch.
## Challenges we ran into
We faced an Azure bot deployment error, everything crashed. We also faced errors in API calls and unauthorized headers and tokens. Another challenge was trying to integrate the CSS code with the main Microsoft HTML file to make the backend match the created designs. Eventually, it all worked out!
## Accomplishments that we are proud of
We are very proud that our project can impact millions of people who do not speak English as their first language access information on government websites. The added voice functionality makes it super easy to use for all people including older generations and people who are differently-abled.
## What's next for Artemis
Over time we believe the technology can be adapted by many more enterprises and organizations for their knowledge base and customer support making information more accessible for all! | winning |
## Inspiration
No API? No problem! LLMs and AI have solidified the importance of text-based interaction -- APIcasso aims to harden this concept by simplifying the process of turning websites into structured APIs.
## What it does
APIcasso has two primary functionalities: ✌️
1. **Schema generation**: users provide a website URL and an empty JSON schema, which is automatically filled and returned by the Cohere AI backend as a well-structured API. It also generates a permanent URL for accessing the completed schema, allowing for easy reference and integration.
2. **Automation**: users provide a website URL and automation prompt, APIcasso returns an endpoint for the automation.
For each JSON schema or automation requested, the user is prompted to pay for their token via ETH and Meta Mask.
## How we built it
* The backend is Cohere-based and written in Python
* The frontend is Next.js-based and paired with Tailwind CSS
* Crypto integration (ETH) is done through Meta Mask
## Challenges we ran into
We initially struggled with clearly defining our goal -- this idea has a lot of exciting potential projects/functionalities associated with it. It was difficult to pick just two -- (1) schema generation and (2) automation.
## Accomplishments that we're proud of
Being able to properly integrate the frontend and backend despite working separately throughout the majority of the weekend.
Integrating ETH verification.
Working with Cohere (a platform that all of us were new to).
Functioning on limited sleep.
## What we learned
We learned a lot about the intricacies of working with real-time schema generation, creating dynamic and interactive UIs, and managing async operations for seamless frontend-backend communication.
## What's next for APIcasso
If given extra time, we would plan to extend APIcasso’s capabilities by adding support for more complex API structures, expanding language support, and offering deeper integrations with developer tools and cloud platforms to enhance usability. | ## Inspiration
Imagine a world where learning is as easy as having a conversation with a friend. Picture a tool that unlocks the treasure trove of educational content on YouTube, making it accessible to everyone, regardless of their background or expertise. This is exactly what our hackathon project brings to life.
* Current massive online courses are great resources to bridge the gap in educational inequality.
* Frustration and loss of motivation with the lengthy and tedious search for that 60-second content.
* Provide support to our students to unlock their potential.
## What it does
Think of our platform as your very own favorite personal tutor. Whenever a question arises during your video journey, don't hesitate to hit pause and ask away. Our chatbot is here to assist you, offering answers in plain, easy-to-understand language. Moreover, it can point you to external resources and suggest specific parts of the video for a quick review, along with relevant sections of the accompanying text. So, explore your curiosity with confidence – we've got your back!
* Analyze the entire video content 🤖 Learn with organized structure and high accuracy
* Generate concise, easy-to-follow conversations⏱️Say goodbye to wasted hours watching long videos
* Generate interactive quizzes and personalized questions 📚 Engaging and thought-provoking
* Summarize key takeaways, explanations, and discussions tailored to you 💡 Provides tailored support
* Accessible to anyone with an internet 🌐 Accessible and Convenient
## How we built it
Vite React,js as front-end and Flask as back-end. Using Cohere command-nightly AI and Similarity ranking.
## Challenges we ran into
* **Increased application efficiency by 98%:** Reduced the number of API calls lowering load time from 8.5 minutes to under 10 seconds. The challenge we ran into was not taking into account the time taken for every API call. Originally, our backend made over 500 calls to Cohere's API to embed text every time a transcript section was initiated and repeated when a new prompt was made -- API call took about one second and added 8.5 minutes in total. By reducing the number of API calls and using efficient practices we reduced time to under 10 seconds.
* **Handling over 5000-word single prompts:** Scraping longer YouTube transcripts efficiently was complex. We solved it by integrating YouTube APIs and third-party dependencies, enhancing speed and reliability. Also uploading multi-prompt conversation with large initial prompts to MongoDB were challenging. We optimized data transfer, maintaining a smooth user experience.
## Accomplishments that we're proud of
Created a practical full-stack application that I will use on my own time.
## What we learned
* **Front end:** State management with React, third-party dependencies, UI design.
* **Integration:** Scalable and efficient API calls.
* **Back end:** MongoDB, Langchain, Flask server, error handling, optimizing time complexity and using Cohere AI.
## What's next for ChicSplain
We envision ChicSplain to be more than just an AI-powered YouTube chatbot, we envision it to be a mentor, teacher, and guardian that will be no different in functionality and interaction from real-life educators and guidance but for anyone, anytime and anywhere. | ## Inspiration
We started off by thinking, "What is something someone needs today?". In light of the stock market not doing so well, and the amount of false information being spread over the Internet these days, we figured it was time to get things right by understanding the stock market. We know that no human could analyze a company without bias of the history of the company and its potential stereotypes, but nothing can beat using an NLP to understand the current situation of a company. Thinking about the capabilities of the Cohere NLP and what we know and want from the stock market led us to a solution: Stocker.
## What it does
The main application allows you to search up words that make up different stocks. Then, for each company which matches the inputted string, we run through the backend, which grabs the inputted company and searches through the recent news of the company via a web scrapper on Google News. Then, we collect all of the headings and evaluate the status of the company according to a rating system. Finally, we summarize all the data by using Generate on all of the text that was read through and outputs it.
## How we built it
The stocks corresponding to the search were grabbed via the NASDAQ API. Then, once the promise is fulfilled, the React page can update the list with ratings already prepended on there. The backend that is communicated runs through Google Cloud, and the backend was built in Python along with a Flask server. This backend communicates directly with the Cohere API, specifically on the Generate and Classify functionalities. Classify is used to evaluate company status from the headings, which is coupled with the Generate to get the text summary of all the headings. Then, the best ones are selected and then displayed with links to the specific articles for people to verify the truthfulness of the information. We trained the Classify with several tests in order to ensure the API understood what we were asking of it, rather than being too extreme or imprecise.
## Challenges we ran into
Coming up with a plan of how to bring everything together was difficult -- we knew that we wanted to get data to pass in to a Classify model, but how the scraping would work and being table to communicate that data took time to formulate a plan in order to execute. The entire backend was a little challenging for the team members, as it was the first time they worked with Flask on the backend. This resulted in some troubles with getting things set up, but more significantly, the process of deploying the backend involved lots of research and testing, as nobody on our team knew how our backend could specifically be deployed.
On the front-end side, there were some hiccups with getting the data to show for all objects being outputted (i.e., how mapping and conditional rendering would work in React was a learning curve). There were also some bugs with small technical details as well, but those were eventually figured out.
Finally, bringing together the back-end and front-end and troubleshooting all the small errors was a bit challenging, given the amount of time that was remaining. Overall though, most errors were solved in appropriate amounts of time.
## Accomplishments that we're proud of
Finally figuring out the deployment of the backend was one of the highlights for sure, as it took some time with researching and experimenting. Another big one was getting the front-end designed from the Figma prototype we made and combining it with the functional, but very barebones infrastructure of our app that we made as a POC. Being able to have the front-end design be very smooth and work with the object arrays as a whole rather than individual ones made the code a lot more standardized and consolidated in the end as well, which was nice to see.
## What we learned
We learned that it is important to do some more research on how standard templates on writing code in order to be deployed easily is very useful. Some of us also got experience in Flask while others fine-tuned their React skills, which was great to see as the proficiency became useful towards the point where the back-end, front-end, and REST API were coming together (sudden edits were very easy and smooth to make).
## What's next for Stocker
Stocker can have some more categories and get smarter for sure. For example, it can actually try to interpret the current trend of where the stock has been headed recently, and also maybe other sources of data other than the news. Stocker relies heavily on the training model and the severity of article names, but in the future it could get smarter with more sources such as these listed. | partial |
## Inspiration 🪄
We were inspired to build a project using Stable Diffusion technologies given the impressive outputs of the existing models 🤯. This technology pairs especially well with creative storytelling; as such, we considered relevant pain points that this technology could help address. We deployed our own Stable Diffusion Webui (<https://github.com/AUTOMATIC1111/stable-diffusion-webui>) that uses FastAPI, we narrowed in on the concept of dream journalling and thought through how we could apply Stable Diffusion to enhance the process.
## What it does 🤔
DreamScape is an immersive dream journalling platform 📝. Simply describe your dream, and illustrative visualizations will be instantly generated (powered by Stable Diffusion AI 🧑🎨 ). The platform offers features to store your past dreams and share your dreams with your friends. Our goal is to help users capture the magic of their dreams and imagination 💭!
## How we built it 🛠️
Framework: Next.js, Typescript
Database: MongoDB
Authentication: NextAuth
Technologies: Stable Diffusion (sent prompts along with 20 training steps, CFG\_scale of 7, sent previous image's seed to produce images similar to the previous one generated to maintain consistency across images)
Styling: Flowbite, Tailwind CSS
## Challenges we ran into 🫠
The first challenge that we ran into was idea generation. It took nearly 3 hours of research and discussion to finalize our idea, which was much longer than we had anticipated for this step of the project. We found ourselves trying to come up with solutions prior to identifying existing problems and pain points to solve 🔍, which resulted in some inefficiencies during discussion. Moving forward, it would be very helpful to use design thinking 💡 to approach the ideation process and to think about potential ideas prior to the start of the hackathon. A second major challenge that we faced was working with Next.js 14... it had weird API routing compared to old technique.
## Accomplishments that we're proud of 😎
We are proud of working with new technologies such as Stable Diffusion. Given the recency of technological developments in the AI space, we believe that there is huge potential in the application of such technologies. We hope that our project is able to make an impact by demonstrating creativity and innovation 🤓.
## What we learned 🥹
We learned how to work with Typescript and a NoSQL database (MongoDB).
## What's next for DreamScape 🗿
Next steps for this project would be to polish the features and UI of the platform to ensure a seamless and delightful user experience 😊. If we had more time, it would have been great to finish building out the platform's social features, allowing users to interact with the dreamboards of their friends and share their own. From a business model perspective, it would be meaningful to think of ways to incentivize consistent journal entries for users. To improve the accuracy of generated images, we could potentially allow users to customize some Stable Diffusion call parameters and enhance user inputted descriptions using NLP. Additionally, it would interesting to try training a custom Stable Diffusion model to generate dream-like illustrations ☁️. Alternatively, we could consider offering users the ability to customize the art style of their dream visualizations -- this could be quickly implemented by including a field where users can pick from a selection of style LoRAs. | ## Inspiration
University can be very stressful at times and sometimes the resources you need are not readily available to you. This web application can help students relax by completing positive "mindfulness" tasks to beat their monsters. We decided to build a web application specifically for mobile since we thought that the app would be most effective if it is very accessible to anyone. We implemented a social aspect to it as well by allowing users to make friends to make the experience more enjoyable. Everything in the design was carefully considered and we always had mindfulness in mind, by doing some research into how colours and shapes can affect your mood.
## What it does
Mood prompts you to choose your current mood on your first login of every day, which then allows us to play music that matches your mood as well as create monsters which you can defeat by completing tasks meant to ease your mind. You can also add friends and check on their progress, and in theory be able to interact with each other through the app by working together to defeat the monsters, however, we haven't been able to implement this functionality yet.
## How we built it
The project uses Ruby on Rails to implement the backend and JavaScript and React Bootstrap on the front end. We also used GitHub for source control management.
## Challenges we ran into
Starting the project, a lot of us had issues downloading the relevant software as we started by using a boilerplate but through collaboration between us we were all able to figure it out and get started on the project. Most of us were still beginning to learn about web development and thus had limited experience programming in JavaScript and CSS, but again, through teamwork and the help of some very insightful mentors, we were able to pick up these skills very quickly, each of us being able to contribute a fair portion to the project.
## Accomplishments that we are proud of
Every single member in this group has learned a lot from this experience, no matter their previous experience going into the hackathon. The more experienced members did an amazing job helping those who had less experience, and those with less experience were able to quickly learn the elements to creating a website. The thing we are most proud of is that we were able to accomplish almost every one of our goals that we had set prior to the hackathon, building a fully functioning website that we hope will be able to help others. Every one of us is proud to have been a part of this amazing project, and look forward to doing more like it.
## What's next for Mood
Our goal is to give the help to those who need it through this accessible app, and to make it something user's would want to do. And thus to improve this app we would like to: add more mindfulness tasks, implement a 'friend collaboration' aspect, as well as potentially make a mobile application (iOS and Android) so that it is even more accessible to people. | ## Inspiration
In online documentaries, we saw visually impaired individuals and their vision consisted of small apertures. We wanted to develop a product that would act as a remedy for this issue.
## What it does
When a button is pressed, a picture is taken of the user's current view. This picture is then analyzed using OCR (Optical Character Recognition) and the text is extracted from the image. The text is then converted to speech for the user to listen to.
## How we built it
We used a push button connected to the GPIO pins on the Qualcomm DragonBoard 410c. The input is taken from the button and initiates a python script that connects to the Azure Computer Vision API. The resulting text is sent to the Azure Speech API.
## Challenges we ran into
Coming up with an idea that we were all interested in, incorporated a good amount of hardware, and met the themes of the makeathon was extremely difficult. We attempted to use Speech Diarization initially but realized the technology is not refined enough for our idea. We then modified our idea and wanted to use a hotkey detection model but had a lot of difficulty configuring it. In the end, we decided to use a pushbutton instead for simplicity in favour of both the user and us, the developers.
## Accomplishments that we're proud of
This is our very first Makeathon and we were proud of accomplishing the challenge of developing a hardware project (using components we were completely unfamiliar with) within 24 hours. We also ended up with a fully function project.
## What we learned
We learned how to operate and program a DragonBoard, as well as connect various APIs together.
## What's next for Aperture
We want to implement hot-key detection instead of the push button to eliminate the need of tactile input altogether. | losing |
## Inspiration
Let’s face it: getting your groceries is hard. As students, we’re constantly looking for food that is healthy, convenient, and cheap. With so many choices for where to shop and what to get, it’s hard to find the best way to get your groceries. Our product makes it easy. It helps you plan your grocery trip, helping you save time and money.
## What it does
Our product takes your list of grocery items and searches an automatically generated database of deals and prices at numerous stores. We collect this data by collecting prices from both grocery store websites directly as well as couponing websites.
We show you the best way to purchase items from stores nearby your postal code, choosing the best deals per item, and algorithmically determining a fast way to make your grocery run to these stores. We help you shorten your grocery trip by allowing you to filter which stores you want to visit, and suggesting ways to balance trip time with savings. This helps you reach a balance that is fast and affordable.
For your convenience, we offer an alternative option where you could get your grocery orders delivered from several different stores by ordering online.
Finally, as a bonus, we offer AI generated suggestions for recipes you can cook, because you might not know exactly what you want right away. Also, as students, it is incredibly helpful to have a thorough recipe ready to go right away.
## How we built it
On the frontend, we used **JavaScript** with **React, Vite, and TailwindCSS**. On the backend, we made a server using **Python and FastAPI**.
In order to collect grocery information quickly and accurately, we used **Cloudscraper** (Python) and **Puppeteer** (Node.js). We processed data using handcrafted text searching. To find the items that most relate to what the user desires, we experimented with **Cohere's semantic search**, but found that an implementation of the **Levenshtein distance string algorithm** works best for this case, largely since the user only provides one to two-word grocery item entries.
To determine the best travel paths, we combined the **Google Maps API** with our own path-finding code. We determine the path using a **greedy algorithm**. This algorithm, though heuristic in nature, still gives us a reasonably accurate result without exhausting resources and time on simulating many different possibilities.
To process user payments, we used the **Paybilt API** to accept Interac E-transfers. Sometimes, it is more convenient for us to just have the items delivered than to go out and buy it ourselves.
To provide automatically generated recipes, we used **OpenAI’s GPT API**.
## Challenges we ran into
Everything.
Firstly, as Waterloo students, we are facing midterms next week. Throughout this weekend, it has been essential to balance working on our project with our mental health, rest, and last-minute study.
Collaborating in a team of four was a challenge. We had to decide on a project idea, scope, and expectations, and get working on it immediately. Maximizing our productivity was difficult when some tasks depended on others. We also faced a number of challenges with merging our Git commits; we tended to overwrite one anothers’ code, and bugs resulted. We all had to learn new technologies, techniques, and ideas to make it all happen.
Of course, we also faced a fair number of technical roadblocks working with code and APIs. However, with reading documentation, speaking with sponsors/mentors, and admittedly a few workarounds, we solved them.
## Accomplishments that we’re proud of
We felt that we put forth a very effective prototype given the time and resource constraints. This is an app that we ourselves can start using right away for our own purposes.
## What we learned
Perhaps most of our learning came from the process of going from an idea to a fully working prototype. We learned to work efficiently even when we didn’t know what we were doing, or when we were tired at 2 am. We had to develop a team dynamic in less than two days, understanding how best to communicate and work together quickly, resolving our literal and metaphorical merge conflicts. We persisted towards our goal, and we were successful.
Additionally, we were able to learn about technologies in software development. We incorporated location and map data, web scraping, payments, and large language models into our product.
## What’s next for our project
We’re very proud that, although still rough, our product is functional. We don’t have any specific plans, but we’re considering further work on it. Obviously, we will use it to save time in our own daily lives. | ## Inspiration
Being frugal students, we all wanted to create an app that would tell us what kind of food we could find around us based on a budget that we set. And so that’s exactly what we made!
## What it does
You give us a price that you want to spend and the radius that you are willing to walk or drive to a restaurant; then voila! We give you suggestions based on what you can get in that price in different restaurants by providing all the menu items with price and calculated tax and tips! We keep the user history (the food items they chose) and by doing so we open the door to crowdsourcing massive amounts of user data and as well as the opportunity for machine learning so that we can give better suggestions for the foods that the user likes the most!
But we are not gonna stop here! Our goal is to implement the following in the future for this app:
* We can connect the app to delivery systems to get the food for you!
* Inform you about the food deals, coupons, and discounts near you
## How we built it
### Back-end
We have both an iOS and Android app that authenticates users via Facebook OAuth and stores user eating history in the Firebase database. We also made a REST server that conducts API calls (using Docker, Python and nginx) to amalgamate data from our targeted APIs and refine them for front-end use.
### iOS
Authentication using Facebook's OAuth with Firebase. Create UI using native iOS UI elements. Send API calls to Soheil’s backend server using json via HTTP. Using Google Map SDK to display geo location information. Using firebase to store user data on cloud and capability of updating to multiple devices in real time.
### Android
The android application is implemented with a great deal of material design while utilizing Firebase for OAuth and database purposes. The application utilizes HTTP POST/GET requests to retrieve data from our in-house backend server, uses the Google Maps API and SDK to display nearby restaurant information. The Android application also prompts the user for a rating of the visited stores based on how full they are; our goal was to compile a system that would incentive foodplaces to produce the highest “food per dollar” rating possible.
## Challenges we ran into
### Back-end
* Finding APIs to get menu items is really hard at least for Canada.
* An unknown API kept continuously pinging our server and used up a lot of our bandwith
### iOS
* First time using OAuth and Firebase
* Creating Tutorial page
### Android
* Implementing modern material design with deprecated/legacy Maps APIs and other various legacy code was a challenge
* Designing Firebase schema and generating structure for our API calls was very important
## Accomplishments that we're proud of
**A solid app for both Android and iOS that WORKS!**
### Back-end
* Dedicated server (VPS) on DigitalOcean!
### iOS
* Cool looking iOS animations and real time data update
* Nicely working location features
* Getting latest data from server
## What we learned
### Back-end
* How to use Docker
* How to setup VPS
* How to use nginx
### iOS
* How to use Firebase
* How to OAuth works
### Android
* How to utilize modern Android layouts such as the Coordinator, Appbar, and Collapsible Toolbar Layout
* Learned how to optimize applications when communicating with several different servers at once
## What's next for How Much
* If we get a chance we all wanted to work on it and hopefully publish the app.
* We were thinking to make it open source so everyone can contribute to the app. | ## Inspiration
Inspired by our own struggles, as college students, to:
1. Find nearby grocery stores and
2. Find transportation to the already sparse grocery stores,
we created car•e to connect altruistic college kids, with cars (or other forms of transportation) and a love for browsing grocery store aisles, with peers (without modes of transportation) looking to grab a few items from the grocery store.
Food insecurity is a huge issue for college campuses. It was estimated that over 10% of Americans were food insecure in 2020, but the number shot up to over 23% of college students. Food insecurity has a strong correlation with the outcomes of student education– not only are students less likely to academically excel, but they are also less likely to obtain a bachelor's degree.
Our team wanted to address the sustainability track and the Otsuka Valuenex challenge because we identified a gap in organizations that address the lack of food access for college students. Being unable to easily access a grocery store would be inconvenient at best, but more than likely perpetuates health issues, economic inequity, and transportation barriers.
## What it does
Our project is a space for college students, with the means to take quick trips to the grocery store, to volunteer a bit of their time to help out some of their peers. The “shoppers,” or students with access, input their grocery list and planned time and location of the trip. Then, “hoppers,” or college students who would like to hop onto a grocery trip would input their grocery list, and our matching algorithm sorts through the posted shopping trips.
## How we built it
We implemented our idea with low-fidelity prototypes, working from diagrams on a whiteboard, to illustrating user flow and design on Figma, and then building the product itself on SwiftUI, XCode, and Firebase. When producing the similarity-matching results between shoppers and hoppers, we looked into Python, Flask, and Chroma, exploring various methodologies to achieve a good user experience while maximizing efficiency with available shoppers.
## Challenges we ran into
Through this process, organizing the user flow and fleshing out logistical details proved to be a challenge. Our idea also required familiarization with new technology and errors, including Firebase, unknown XCode problems, and Chroma. When faced with these struggles, we dynamically built off each others’ ideas and explored various methodologies and approaches to our proposed solution; every idea and its implementation was a discussion. We drew from our personal experiences to create something that would benefit those around us, and we truly came together to address an issue that we all feel passionately about.
## Accomplishments that we're proud of
1. Ideating process
2. Perseverance
3. Ability to build off of ideas
4. Team bonding
5. Exploration
6. Addressing issues we experience
7. Transforming personal experiences into solutions
## What we learned
This experience taught us that there are infinite solutions to a single problem. Thus when evaluating the most optimal solution, it’s important to evaluate on a comprehensive criteria, focusing on efficiency, impact, usability, and implementation. While this process may be time-consuming, it is necessary to keep the user in mind to ensure that the product and its features truly fulfill an unmet user need.
## What's next for car·e
1. Building out future features (e.g. messaging capability)
2. Building a stronger community aspect through features in our app: more bonding and friendships
3. Business model
4. Incentives to get ppl started on the app | partial |
## Inspiration
Today we live in a world that is all online with the pandemic forcing us at home. Due to this, our team and the people around us were forced to rely on video conference apps for school and work. Although these apps function well, there was always something missing and we were faced with new problems we weren't used to facing. Personally, forgetting to mute my mic when going to the door to yell at my dog, accidentally disturbing the entire video conference. For others, it was a lack of accessibility tools that made the experience more difficult. Then for some, simply scared of something embarrassing happening during class while it is being recorded to be posted and seen on repeat! We knew something had to be done to fix these issues.
## What it does
Our app essentially takes over your webcam to give the user more control of what it does and when it does. The goal of the project is to add all the missing features that we wished were available during all our past video conferences.
Features:
Webcam:
1 - Detect when user is away
This feature will automatically blur the webcam feed when a User walks away from the computer to ensure the user's privacy
2- Detect when user is sleeping
We all fear falling asleep on a video call and being recorded by others, our app will detect if the user is sleeping and will automatically blur the webcam feed.
3- Only show registered user
Our app allows the user to train a simple AI face recognition model in order to only allow the webcam feed to show if they are present. This is ideal to prevent ones children from accidentally walking in front of the camera and putting on a show for all to see :)
4- Display Custom Unavailable Image
Rather than blur the frame, we give the option to choose a custom image to pass to the webcam feed when we want to block the camera
Audio:
1- Mute Microphone when video is off
This option allows users to additionally have the app mute their microphone when the app changes the video feed to block the camera.
Accessibility:
1- ASL Subtitle
Using another AI model, our app will translate your ASL into text allowing mute people another channel of communication
2- Audio Transcriber
This option will automatically transcribe all you say to your webcam feed for anyone to read.
Concentration Tracker:
1- Tracks the user's concentration level throughout their session making them aware of the time they waste, giving them the chance to change the bad habbits.
## How we built it
The core of our app was built with Python using OpenCV to manipulate the image feed. The AI's used to detect the different visual situations are a mix of haar\_cascades from OpenCV and deep learning models that we built on Google Colab using TensorFlow and Keras.
The UI of our app was created using Electron with React.js and TypeScript using a variety of different libraries to help support our app. The two parts of the application communicate together using WebSockets from socket.io as well as synchronized python thread.
## Challenges we ran into
Dam where to start haha...
Firstly, Python is not a language any of us are too familiar with, so from the start, we knew we had a challenge ahead. Our first main problem was figuring out how to highjack the webcam video feed and to pass the feed on to be used by any video conference app, rather than make our app for a specific one.
The next challenge we faced was mainly figuring out a method of communication between our front end and our python. With none of us having too much experience in either Electron or in Python, we might have spent a bit too much time on Stack Overflow, but in the end, we figured out how to leverage socket.io to allow for continuous communication between the two apps.
Another major challenge was making the core features of our application communicate with each other. Since the major parts (speech-to-text, camera feed, camera processing, socket.io, etc) were mainly running on blocking threads, we had to figure out how to properly do multi-threading in an environment we weren't familiar with. This caused a lot of issues during the development, but we ended up having a pretty good understanding near the end and got everything working together.
## Accomplishments that we're proud of
Our team is really proud of the product we have made and have already begun proudly showing it to all of our friends!
Considering we all have an intense passion for AI, we are super proud of our project from a technical standpoint, finally getting the chance to work with it. Overall, we are extremely proud of our product and genuinely plan to better optimize it in order to use within our courses and work conference, as it is really a tool we need in our everyday lives.
## What we learned
From a technical point of view, our team has learnt an incredible amount the past few days. Each of us tackled problems using technologies we have never used before that we can now proudly say we understand how to use. For me, Jonathan, I mainly learnt how to work with OpenCV, following a 4-hour long tutorial learning the inner workings of the library and how to apply it to our project. For Quan, it was mainly creating a structure that would allow for our Electron app and python program communicate together without killing the performance. Finally, Zhi worked for the first time with the Google API in order to get our speech to text working, he also learned a lot of python and about multi-threadingbin Python to set everything up together. Together, we all had to learn the basics of AI in order to implement the various models used within our application and to finally attempt (not a perfect model by any means) to create one ourselves.
## What's next for Boom. The Meeting Enhancer
This hackathon is only the start for Boom as our team is exploding with ideas!!! We have a few ideas on where to bring the project next. Firstly, we would want to finish polishing the existing features in the app. Then we would love to make a market place that allows people to choose from any kind of trained AI to determine when to block the webcam feed. This would allow for limitless creativity from us and anyone who would want to contribute!!!! | ## Inspiration
There were two primary sources of inspiration. The first one was a paper published by University of Oxford researchers, who proposed a state of the art deep learning pipeline to extract spoken language from video. The paper can be found [here](http://www.robots.ox.ac.uk/%7Evgg/publications/2018/Afouras18b/afouras18b.pdf). The repo for the model used as a base template can be found [here](https://github.com/afourast/deep_lip_reading).
The second source of inspiration is an existing product on the market, [Focals by North](https://www.bynorth.com/). Focals are smart glasses that aim to put the important parts of your life right in front of you through a projected heads up display. We thought it would be a great idea to build onto a platform like this through adding a camera and using artificial intelligence to gain valuable insights about what you see, which in our case, is deciphering speech from visual input. This has applications in aiding individuals who are deaf or hard-of-hearing, noisy environments where automatic speech recognition is difficult, and in conjunction with speech recognition for ultra-accurate, real-time transcripts.
## What it does
The user presses a button on the side of the glasses, which begins recording, and upon pressing the button again, recording ends. The camera is connected to a raspberry pi, which is a web enabled device. The raspberry pi uploads the recording to google cloud, and submits a post to a web server along with the file name uploaded. The web server downloads the video from google cloud, runs facial detection through a haar cascade classifier, and feeds that into a transformer network which transcribes the video. Upon finished, a front-end web application is notified through socket communication, and this results in the front-end streaming the video from google cloud as well as displaying the transcription output from the back-end server.
## How we built it
The hardware platform is a raspberry pi zero interfaced with a pi camera. A python script is run on the raspberry pi to listen for GPIO, record video, upload to google cloud, and post to the back-end server. The back-end server is implemented using Flask, a web framework in Python. The back-end server runs the processing pipeline, which utilizes TensorFlow and OpenCV. The front-end is implemented using React in JavaScript.
## Challenges we ran into
* TensorFlow proved to be difficult to integrate with the back-end server due to dependency and driver compatibility issues, forcing us to run it on CPU only, which does not yield maximum performance
* It was difficult to establish a network connection on the Raspberry Pi, which we worked around through USB-tethering with a mobile device
## Accomplishments that we're proud of
* Establishing a multi-step pipeline that features hardware, cloud storage, a back-end server, and a front-end web application
* Design of the glasses prototype
## What we learned
* How to setup a back-end web server using Flask
* How to facilitate socket communication between Flask and React
* How to setup a web server through local host tunneling using ngrok
* How to convert a video into a text prediction through 3D spatio-temporal convolutions and transformer networks
* How to interface with Google Cloud for data storage between various components such as hardware, back-end, and front-end
## What's next for Synviz
* With stronger on-board battery, 5G network connection, and a computationally stronger compute server, we believe it will be possible to achieve near real-time transcription from a video feed that can be implemented on an existing platform like North's Focals to deliver a promising business appeal | ## Inspiration
We were inspired by Plaid's challenge to "help people make more sense of their financial lives." We wanted to create a way for people to easily view where they are spending their money so that they can better understand how to conserve it. Plaid's API allows us to see financial transactions, and Google Maps API serves as a great medium to display the flow of money.
## What it does
GeoCash starts by prompting the user to login through the Plaid API. Once the user is authorized, we are able to send requests for transactions, given the public\_token of the user. We then displayed the locations of these transactions on the Google Maps API.
## How I built it
We built this using JavaScript, including Meteor, React, and Express frameworks. We also utilized the Plaid API for the transaction data and the Google Maps API to display the data.
## Challenges I ran into
Data extraction/responses from Plaid API, InfoWindow displays in Google Maps
## Accomplishments that I'm proud of
Successfully implemented meteor webapp, integrated two different APIs into our product
## What I learned
Meteor (Node.js and React.js), Plaid API, Google Maps API, Express framework
## What's next for GeoCash
We plan on integrating real user information into our webapp; we currently only using the sandbox user, which has a very limited scope of transactions. We would like to implement differently size displays on the Maps API to represent the amount of money spent at the location. We would like to display different color displays based on the time of day, which was not included in the sandbox user. We would also like to implement multiple different user displays at the same time, so that we can better describe the market based on the different categories of transactions. | winning |
## Inspiration
Wanting to build an FPS VR game.
## What it does
Provides ultra fun experience to all players, taking older folks back to their childhood and showing younger ones the beauty of classic arcade types!
## How we built it
Unity as the game engine
Android for the platform
socket.io for multiplayer
c# for client side code
## Challenges we ran into
We coded our own custom backend in Node.js to allow multiplayer ability in the game. It was difficult to use web sockets in the C# code to transfer game data to other players. Also, it was a challange to sync all things from player movement to shooting lazers to map data all at the same time.
## Accomplishments that we're proud of
Were able to make the game multiplayer with a custom backend
## What we learned
Unity, C#
## What's next for Space InVRders
Add other game modes, more kinds of ships, store highscores | ## What it does
ColoVR is a virtual experience allowing users to modify their environment with colors and models. It's a relaxing, low poly experience that is the first of its kind to bring an accessible 3D experience to the Google Cardboard platform. It's a great way to become a creative in 3D without dropping a ton of money on VR hardware.
## How we built it
We used Google Daydream and extended off of the demo scene to our liking. We used Unity and C# to create the scene, and do all the user interactions. We did painting and dragging objects around the scene using a common graphics technique called Ray Tracing. We colored the scene by changing the vertex color. We also created a palatte that allowed you to change tools, colors, and insert meshes. We hand modeled the low poly meshes in Maya.
## Challenges we ran into
The main challenge was finding a proper mechanism for coloring the geometry in the scene. We first tried to paint the mesh face by face, but we had no way of accessing the entire face from the way the Unity mesh was set up. We then looked into an asset that would help us paint directly on top of the texture, but it ended up being too slow. Textures tend to render too slowly, so we ended up doing it with a vertex shader that would interpolate between vertex colors, allowing real time painting of meshes. We implemented it so that we changed all the vertices that belong to a fragment of a face. The vertex shader was the fastest way that we could render real time painting, and emulate the painting of a triangulated face. Our second biggest challenge was using ray tracing to find the object we were interacting with. We had to navigate the Unity API and get acquainted with their Physics raytracer and mesh colliders to properly implement all interaction with the cursor. Our third challenge was making use of the Controller that Google Daydream supplied us with - it was great and very sandboxed, but we were almost limited in terms of functionality. We had to find a way to be able to change all colors, insert different meshes, and interact with the objects with only two available buttons.
## Accomplishments that we're proud of
We're proud of the fact that we were able to get a clean, working project that was exactly what we pictured. People seemed to really enjoy the concept and interaction.
## What we learned
How to optimize for a certain platform - in terms of UI, geometry, textures and interaction.
## What's next for ColoVR
Hats, interactive collaborative space for multiple users. We want to be able to host the scene and make it accessible to multiple users at once, and store the state of the scene (maybe even turn it into an infinite world) where users can explore what past users have done and see the changes other users make in real time. | ## Inspiration
We wanted to build a shooter that many friends could play together. We didn't want to settle for something that was just functional, so we added the craziest game mechanic we could think of to maximize the number of problems we would run into: a map that has no up or down, only forward. The aesthetic of the game is based on Minecraft (a game I admit I have never played).
## What it does
The game can host up to 5 players on a local network. Using the keyboard and the mouse on your computer, you can walk around an environment shaped like a giant cube covered in forest, and shoot bolts of energy at your friends. When you reach the threshold of the next plane of the cube, a simple command re-orients your character such that your gravity vector is perpendicular to the next plane, and you can move onwards. The last player standing wins.
## How we built it
First we spent a few (many) hours learning the skills necessary. My teammate familiarized themself with a plethora of Unity functions in order to code the game mechanics we wanted. I'm a pretty decent 3D modeler, but I've never used Maya before and I've never animated a bipedal character. I spent a long while adjusting myself to Maya, and learning how the Mecanim animation system of Unity functions. Once we had the basics, we started working on respective elements: my teammate the gravity transitions and the networking, and myself the character model and animations. Later we combined our work and built up the 3D environment and kept adding features and debugging until the game was playable.
## Challenges we ran into
The gravity transitions where especially challenging. Among a panoply of other bugs that individually took hours to work through or around, the gravity transitions where not fully functional until more than a day into the project. We took a break from work and brainstormed, and we came up with a simpler code structure to make the transition work. We were delighted when we walked all up and around the inside of our cube-map for the first time without our character flailing and falling wildly.
## Accomplishments that we're proud of
Besides the motion capture for the animations and the textures for the model, we built a fully functional, multiplayer shooter with a complex, one-of-a-kind gameplay mechanic. It took 36 hours, and we are proud of going from start to finish without giving up.
## What we learned
Besides the myriad of new skills we picked up, we learned how valuable a hackathon can be. It is an educational experience nothing like a classroom. Nobody chooses what we are going to learn; we choose what we want to learn by chasing what we want to accomplish. By chasing something ambitious, we inevitably run into problems that force us to develop new methodologies and techniques. We realized that a hackathon is special because it's a constant cycle of progress, obstacles, learning, and progress. Progress stacks asymptotically towards a goal until time is up and it's time to show our stuff.
## What's next for Gravity First
The next feature we are dying to add is randomized terrain. We built the environment using prefabricated components that I built in Maya, which we arranged in what we thought was an interesting and challenging arrangement for gameplay. Next, we want every game to have a different, unpredictable six-sided map by randomly laying out the pre-fabs according to certain parameters.. | partial |
## Inspiration
It feels like elections are taking up an increasing portion of our mindshare, with every election cycle it only gets more insane. Constantly flooded by news, by opinions – it's like we never get a break. And yet, paradoxically, voters feel increasingly less connected to their politicians. They hear soliloquies about the terrible deeds of the politician's opponent, but rarely about how their policies will affect them personally. That changes today.
It's time we come back to a democracy which lives by the words *E pluribus unum* – from many, one. Citizens should understand exactly how politician's policies will affect them and their neighbours, and from that, a general consensus may form. And campaigners should be given the tools to allow them to do so.
Our team's been deeply involved in community and politics for years – which is why we care so much about a healthy democracy. Between the three of us over the years, we've spoken with campaign / PR managers at 70+ campaigns, PACs, and lobbies, and 40+ ad teams – all in a bid to understand how technology can help propel a democracy forward.
## What it does
Rally helps politicians meet voters where they are – in a figurative and digital sense. Politicians and campaign teams can use our platform to send geographically relevant campaign advertisements to voters – tailored towards issues they care deeply about. We thoroughly analyze the campaigner's policies to give a faithful representation of their ideas through AI-generated advertisements – using their likeness – and cross-correlate it with issues the voter is likely to care, and want to learn more, about. We avoid the uncanny valley with our content, we maintain compliance, and we produce content that drives voter engagement.
## How we built it
Rally is a web app powered by a complex multi-agent chain system, which uses natural language to understand both current local events and campaign policy in real-time, and advanced text-to-speech and video-to-video lip sync/facetune models to generate a faithful personalised campaign ad, with the politician speaking to voters about issues they truly care about.
* We use Firecrawl and the Perplexity API to scrape news and economic data about the town a voter is from, and to understand a politician's policies, and store GPT-curated insights on a Supabase database.
* Then, we use GPT4o-mini to parse through all that data and generate an ad speech, faithful to the politician's style, which'll cover issues relevant to the voter.
* This speech is sent to Cartesia.ai's excellent Sonic text-to-speech model which has already been trained on short clips of the politician's voice.
* Simultaneously, GPT4o-mini decides which parts of the ad should have B-roll/stock footage displayed, and about what.
* We use this to query Pexels for stock footage to be used during the ad.
* Once the voice narration has been generated, we send it to SyncLabs for lipsyncing over existing ad/interview footage of the politician.
* Finally, we overlay the the B-roll footage (at the previously decided time stamps) on the lip synced videos, to create a convincing campaign advertisement.
* All of this is packaged in a beautiful and modern UI built using NextJS and Tailwind.
And all of this is done in the space of just a few minutes! So whether the voter comes from New York City or Fairhope, Alabama, you can be sure that they'll receive a faithful campaign ad which puts the politician's best foot forward while helping the voter understand how their policies might affect them.
## Wait a minute, is this even legal?
***YES***. Currently, bills are being passed in states around the country limiting the use of deepfakes in political campaign – and for good reason. The potential damage is obvious. However, in every single proposed bill, a campaigner is absolutely allowed to create deepfakes of themselves for their own gains. Indeed, while we absolutely support all regulation on nefarious use of deepfakes, we also deeply believe in its immense potential for good. We've even built a database of all the bills that are in debate or have been enacted regarding AI political advertisement as part of this project, feel free to take a look!
Voter apathy is an epidemic, which slowly eats away at a democracy – Rally believes that personalised campaign messaging is one of the most promising avenues to battle against that.
## Challenges we ran into
The surface area for errors increase hugely with the amount of services we integrate with. Undocumented or badly documented APIs were huge time sinks – some of these services are so new that questions haven't been asked about them online. Another very large time sink was the video manipulation through FFMPEG. It's an extremely powerful tool, and doing simple things is very easy, but doing more complicated tasks ended up being very difficult to get right.
However, the biggest challenge by far was creating advertisements that maintained state-specific compliance, meaning they had different rules and regulations for each state and had to avoid negativity, misinformation, etc. This can be very hard as LLM outputs are often very subjective and hard to evaluate deterministically. We combatted this by building a chain of LLMs informed by data from the NCSL, OpenFEC, and other reliable sources to ensure all the information that we used in the process was thoroughly sourced, leading to better outcomes for content generation. We also used validator agents to verify results from particularly critical parts of the content generation flow before proceeding.
## Accomplishments that we're proud of
We're deeply satisfied with the fact that we were able to get the end-to-end voter-to-ad pipeline going while also creating a beautiful web app. It seemed daunting at first, with so many moving pieces, but through intelligent separation of tasks we were able to get through everything.
## What we learned
Premature optimization is the killer of speed – we initially tried to do some smart splicing of the base video data so that we wouldn't lip sync parts of the video that were going to be covered by the B-roll (and thus do the lip syncing generation in parallel) – but doing all the splicing and recombining ended up taking almost as long as simply passing the whole video to the lip syncing model, and with many engineer-hours lost. It's much better to do things that don't scale in these environments (and most, one could argue).
## What's next for Rally
Customized campaign material is a massive market – scraping data online has become almost trivial thanks to tools like Firecrawl – so a more holistic solution for helping campaigns/non-profits/etc. ideate, test, and craft campaign material (with AI solutions already part of it) is a huge opportunity. | ## Inspiration
Fashion has always been a world that seemed far away from tech. We want to bridge this gap with "StyleList", which understands your fashion within a few swipes and makes personalized suggestions for your daily outfits. When you and I visit the Nordstorm website, we see the exact same product page. But we could have completely different styles and preferences. With Machine Intelligence, StyleList makes it convenient for people to figure out what they want to wear (you simply swipe!) and it also allows people to discover a trend that they favor!
## What it does
With StyleList, you don’t have to scroll through hundreds of images and filters and search on so many different websites to compare the clothes. Rather, you can enjoy a personalized shopping experience with a simple movement from your fingertip (a swipe!). StyleList shows you a few clothing items at a time. Like it? Swipe left. No? Swipe right! StyleList will learn your style and show you similar clothes to the ones you favored so you won't need to waste your time filtering clothes. If you find something you love and want to own, just click “Buy” and you’ll have access to the purchase page.
## How I built it
We use a web scrapper to get the clothing items information from Nordstrom.ca and then feed these data into our backend. Our backend is a Machine Learning model trained on the bank of keywords and it provides next items after a swipe based on the cosine similarities between the next items and the liked items. The interaction with the clothing items and the swipes is on our React frontend.
## Accomplishments that I'm proud of
Good teamwork! Connecting the backend, frontend and database took us more time than we expected but now we have a full stack project completed. (starting from scratch 36 hours ago!)
## What's next for StyleList
In the next steps, we want to help people who wonders "what should I wear today" in the morning with a simple one click page, where they fill in the weather and plan for the day then StyleList will provide a suggested outfit from head to toe! | ## 💡 inspiration
* With the elections just around the corner, it is imperative for the average voter to be educated on the public policies and bills that our politicians put forth.
* Poor literacy in American politics is a well-documented issue, with many citizens lacking a fundamental understanding of government structures, key political concepts, and how policies affect their lives. This lack of civic knowledge contributes to a disengaged electorate, misinformed opinions, and lower participation rates in democratic processes such as voting or local decision-making.
* As students seeking new, easy, creative ways to engage with our politicians, we built *hamilton*.
## ⚙️ what it does
*hamilton* is a multi-agent AI platform that simulates the dynamics of an actual senate committee hearing to lower the barrier to entry to the political sphere in an approachable manner. With real-time audio conversations between our senator agents, you can follow along with what bills and clauses senators are actively discussing and visualize the active changes they are making as they debate the outcomes and impacts of these bills. It enables you to learn about the process to go from a bill proposal to the final majority-approved outcome.
## ⛏️ how we built it: our process
Given the inherent complexity of our project, we spent a significant amount of our early time building a rock solid system infrastructure plan before touching any code. We narrowed down the sponsors that would best enable us to fulfill our vision, and laid out the data access objects, the communication channels between processes, and our tech stack. Below is a higher-level overview of our system design:
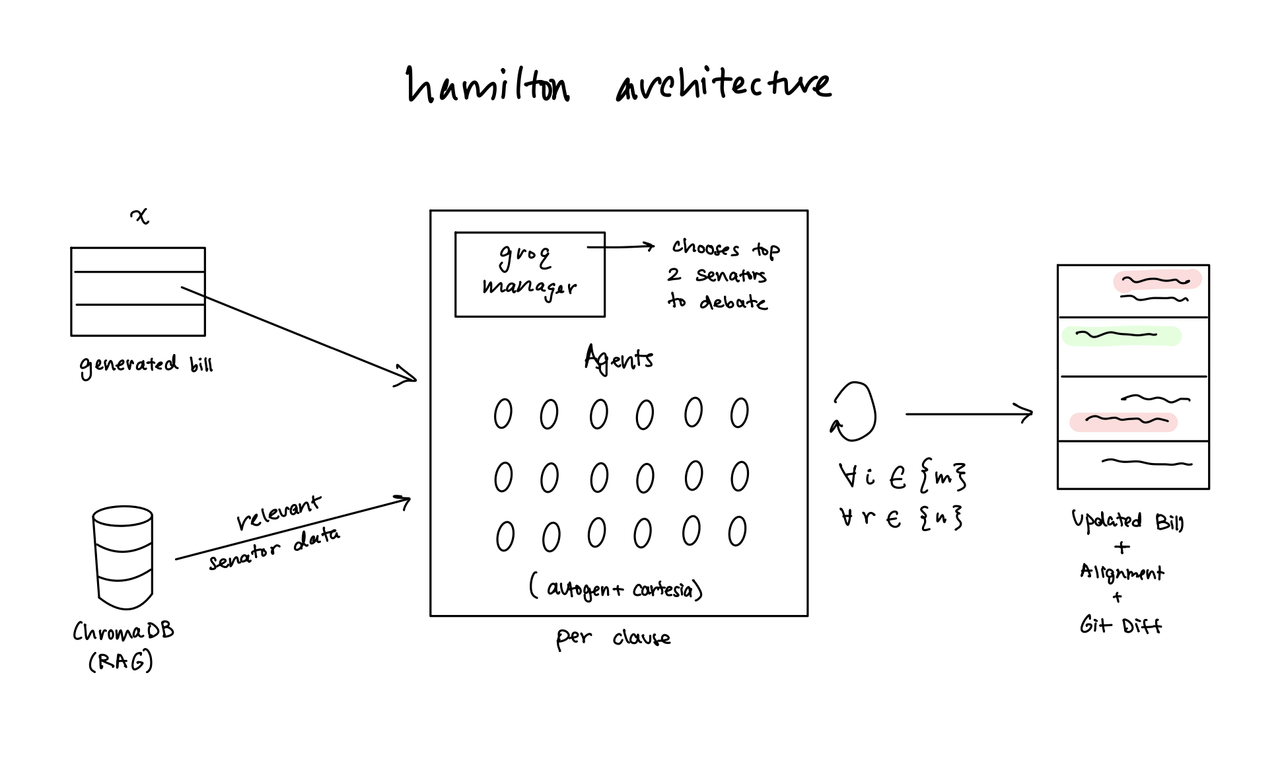
We then split up our project into sections that could be tested individually to then eventually integrate into the full system. In particular, we broke up the frontend UI and event handling, the REST and WebSocket-based backends for delivering bill outputs to the frontend, and an independent multi-agent system based on AutoGen. The latter required significant data collection for personalized Senator agents through various media sources. To parse and retrieve this data during runtime, we were able to set up a ChromaDB database for vectorized search quickly. This allowed us to provide the correct personality and historical context for each senator agent in relation to the user-submitted bill.
For the Next.js frontend, we really loved using Cartesia’s fast and easy API for speech generation. Just using brief voice recordings of each senator, we were able to create expressive, emotional voice clones that we had a blast experimenting with. We envision adding more senators to our platform, which is easily possible with Cartesia’s voice cloning capabilities.
To effectively track the evolving bills within Hamilton, we utilize Git version control. This approach enables us to maintain a comprehensive record of all changes, ensuring that each senator’s contributions are clearly documented. The version control system enhances transparency and provides deeper insights into this political process. This way, we can easily review the modifications made during discussions, allowing for a clearer understanding of the dynamics at play in the simulated senate committee hearings.
## 🛑 challenges we ran into
System Design: dealing with multiple asynchronous agents that we have to manage the communication between each other, the backend and the user interface. This was a very difficult task given both shared memory and concurrent communication we had to handle.
What helped was breaking it down into manageable and well defined functions, piecing together the broader system design from the ground up.
## 🏆 accomplishments that we're proud of
**Conversational Multi-Agent Environment**: Leveraging in-context learning with Autogen, we created a dynamic environment where multiple AI agents embody the unique views, behaviors, and mannerisms of real Senate members, bringing political debates to life.
**Voice Simulation**: With Cartesia’s cutting-edge, real-time inference technology, each senator is given a distinct voice, modeled after real-life voice data. This adds a new dimension of realism, enhancing user engagement and immersion.
**Contextual Intelligence with Vector RAG**: Using ChromaDB for advanced context retrieval, we ensured that each senator’s responses were hyper-contextualized to the bill at hand, delivering a more authentic and nuanced political dialogue.
**Interactive and Gamified Frontend**: Our intuitive, game-like interface replicates the Senate hearing process, making civic engagement accessible, engaging, and educational for the public.
## code snippet
```
def choose_senators(self, clause: str, senator_data: dict[str, [dict[str, list[str]]]]) -> (Senator, Senator):
“”"Choose senators based on a probability distribution of most/least aligned with a clause.“”"
distribution = [0.35, 0.1, 0.05, 0.05, 0.1, 0.35]
alignments = []
for i, senator in enumerate(self.senators):
alignment = self.get_senator_alignment(clause, senator_data[senator.name])
alignments.append([i, alignment])
alignments = sorted(alignments, key=lambda x: x[1])
ids_only = [x[0] for x in alignments]
chosen_first = np.random.choice(ids_only, p=distribution)
print(“chosen first:“, chosen_first)
ids_only.pop(chosen_first)
removed_probability = distribution.pop(chosen_first)
distribution[-1] += removed_probability
chosen_second = np.random.choice(ids_only, p=distribution)
first_senator = self.senators[chosen_first]
second_senator = self.senators[chosen_second]
return first_senator, second_senator
```
## 🏫 what we learned
We learned a lot about web socket communication between the front end and back end. In addition, we learned about multi-agent frameworks and how to emulate personas to facilitate meaningful discussions about educational and political topics.
## ⏩ whats next for *hamilton*!
We envision *hamilton* as the next large platform for educational and political content. Because of the unique crossroads we find ourselves at —- with ML models able to engage in meaningful conversations—hamilton stands poised to revolutionize civic engagement and political literacy. Our platform will serve as an interactive space where users can immerse themselves in the legislative process without the intimidation often associated with politics. By simulating the dynamics of an actual Senate committee hearing, hamilton allows users to witness and participate in the decision-making process. | winning |

## Inspiration
Perishable food and retail goods are significant contributors to industrial GHG emissions, and yet 30-40% of food that is produced worldwide is wasted. In particular, at home and supermarket sources contribute to a combined total of 80% of total US food losses. Given the popularity of existing meal planning apps, we focus our attention on consumer choice. Specifically, we develop an application that uses computational linguistics to suggest recipe ingredient alternatives.
## What it does
`decarbonate` is a Google Chrome extension that parses recipe pages in order to find ingredients with lower carbon footprints. We measure carbon footprint as the CO2 equivalent per kg or liter of a food commodity. We have built in an additional back-end filter for water footprint, but it is not yet visible to users. Flip through our image gallery to see some examples!
## How we built it
*Ingredient Parsing and Entity Normalization.*
We generate graphical representations of the dependencies for each ingredient in a recipe, and then we traverse the children of the subject and root tokens. We search for adjectival or appositional modifiers, noun phrase adverbial modifiers, compounds, and objects of prepositions. We remove vulgar fractions and measurement tokens, and then lemmatize and strip (punctuation, whitespace, casing) our output.
We create TF-IDF vectors for each of our normalized ingredients. We then use cosine similarity to match vectors against the names of foods with known emission impacts. To do this, we use PolyFuzz because it allows us to compute cosine similarity quickly (using `sparse_dot_topn`) and with lower memory requirements. We use the default n-gram range of (3,3) with a similarity threshold of 75%.
*Alternative Ingredient Selection.*
Our final selection of ingredient alternatives is based on two sources. The first source is the emission data itself. Food names are aggregated at multiple levels (e.g., name, group, type), and we leverage the type field to make recommendations across names. For instance, we would suggest "Rasberry (Openfield)" (0.632) instead of "Rasberry (Heated Greenhouse)" (7.350) or "Rasberries (Frozen)" (1.175). Our second source is Wolfram Mathematica. We generate and parse a list of all food types for which the platform supports substitution, and then combine those with our suggestions from the emissions data. For example, the best alternative to "Blackberry" is "Rasberry" (Footprint = 7.350).
We experiment with Sentence Transformers (specifically "paraphrase-MiniLM-L6-v2") to generate embeddings for each ingredient. However, we find that these embeddings are not sufficiently granular for usage on our data (e.g., beer is closest to fast food).
*Real-time ingredient replacement.*
We edit the HTML of each recipe website in order to replace ingredients in real time.
## Challenges we ran into
Ingredient names are challenging to parse due to the presence of colloquial language in measurement unit descriptions (e.g., "handful of kale"). This points to a broader issue surrounding ambiguity within language describing food names. Some sources are meticulous in documenting units, while others give instructions at a high-level. Given more time, we would do a deeper exploration of the USDA dataset for food names and groups in order to implement an intermediary text normalization step. We would also improve the logic of our ingredient replacement tool, which currently relies on search and replace.
## What's next for decarbonate
Taken together, carbon- and water-based emission filtering can provide consumers with strong alternatives to products that they may not know are harmful to the environment. We would ideally like to integrate emission scores into existing meal plan or recipe search tools. | ## Inspiration
In a world full of so much info but limited time as we are so busy and occupied all the time, we wanted to create a tool that helps students make the most of their learning—quickly and effectively. We imagined a platform that could turn complex material into digestible, engaging content tailored for a fast-paced generation.
## What it does
Lemme Learn More (LLM) transforms study materials into bite-sized TikTok-style trendy and attractive videos or reels, flashcards, and podcasts. Whether it's preparing for exams or trying to stay informed on the go, LLM breaks down information into formats that match how today's students consume content. If you're an avid listener of podcasts during commute to work - this is the best platform for you.
## How we built it
We built LLM using a combination of AI-powered tools like OpenAI for summaries, Google TTS for podcasts, and pypdf2 to pull data from PDFs. The backend runs on Flask, while the frontend is React.js, making the platform both interactive and scalable. Also used fetch.ai ai agents to deploy on test net - blockchain.
## Challenges we ran into
Due to a highly-limited time, we ran into a deployment challenge where we faced some difficulty setting up on Heroku cloud service platform. It was an internal level issue wherein we were supposed to change config files - I personally spent 5 hours on that - my team spent some time as well. Could not figure it out by the time hackathon ended : we decided not to deploy today.
In brainrot generator module, audio timing could not match with captions. This is something for future scope.
One of the other biggest challenges was integrating sponsor Fetch.ai agentverse AI Agents which we did locally and proud of it!
## Accomplishments that we're proud of
Biggest accomplishment would be that we were able to run and integrate all of our 3 modules and a working front-end too!!
## What we learned
We learned that we cannot know everything - and cannot fix every bug in a limited time frame. It is okay to fail and it is more than okay to accept it and move on - work on the next thing in the project.
## What's next for Lemme Learn More (LLM)
Coming next:
1. realistic podcast with next gen TTS technology
2. shorts/reels videos adjusted to the trends of today
3. Mobile app if MVP flies well! | ## Inspiration
We wanted to experiment with the idea of Twitch Plays. What if Twitchs plays a guy where they need to work together to defeat two smaller two (One-two people). Can a mass amount of people work together and decide what the best moves?
In our current hack, we have Oculus and Leap Motion with Twitch to play a game of Jenga. This is our first time working with these technology and this is also Kevin and Sri first hackathon.
## What it does
A player can move around and use their hands to pick a block to remove. There's a Twitch turn where the game takes the chat and count up the votes and the majority vote removes the corresponding block.
## How I built it
We used unity 5 and c#
## Challenges I ran into
We had a lot trouble with Oculus since one of our laptop's graphic card did not support it and another one only worked on extended mode. We also had trouble getting the Twitch user input.
## Accomplishments that I'm proud of
Having the individual components work and having to play with these new technology
## What I learned
There's still a lot of room for VR and the Leap motion. We also learned that an game that integrate with Twitch's chat is possible.
## What's next
Clean up the code and develop an actual game around it. There's still a lot of things we want to do with it. | partial |
## Inspiration
**Read something, do something.** We constantly encounter articles about social and political problems affecting communities all over the world – mass incarceration, the climate emergency, attacks on women's reproductive rights, and countless others. Many people are concerned or outraged by reading about these problems, but don't know how to directly take action to reduce harm and fight for systemic change. **We want to connect users to events, organizations, and communities so they may take action on the issues they care about, based on the articles they are viewing**
## What it does
The Act Now Chrome extension analyzes articles the user is reading. If the article is relevant to a social or political issue or cause, it will display a banner linking the user to an opportunity to directly take action or connect with an organization working to address the issue. For example, someone reading an article about the climate crisis might be prompted with a link to information about the Sunrise Movement's efforts to fight for political action to address the emergency. Someone reading about laws restricting women's reproductive rights might be linked to opportunities to volunteer for Planned Parenthood.
## How we built it
We built the Chrome extension by using a background.js and content.js file to dynamically render a ReactJS app onto any webpage the API identified to contain topics of interest. We built the REST API back end in Python using Django and Django REST Framework. Our API is hosted on Heroku, the chrome app is published in "developer mode" on the chrome app store and consumes this API. We used bitbucket to collaborate with one another and held meetings every 2 - 3 hours to reconvene and engage in discourse about progress or challenges we encountered to keep our team productive.
## Challenges we ran into
Our initial attempts to use sophisticated NLP methods to measure the relevance of an article to a given organization or opportunity for action were not very successful. A simpler method based on keywords turned out to be much more accurate.
Passing messages to the back-end REST API from the Chrome extension was somewhat tedious as well, especially because the API had to be consumed before the react app was initialized. This resulted in the use of chrome's messaging system and numerous javascript promises.
## Accomplishments that we're proud of
In just one weekend, **we've prototyped a versatile platform that could help motivate and connect thousands of people to take action toward positive social change**. We hope that by connecting people to relevant communities and organizations, based off their viewing of various social topics, that the anxiety, outrage or even mere preoccupation cultivated by such readings may manifest into productive action and encourage people to be better allies and advocates for communities experiencing harm and oppression.
## What we learned
Although some of us had basic experience with Django and building simple Chrome extensions, this project provided new challenges and technologies to learn for all of us. Integrating the Django backend with Heroku and the ReactJS frontend was challenging, along with writing a versatile web scraper to extract article content from any site.
## What's next for Act Now
We plan to create a web interface where organizations and communities can post events, meetups, and actions to our database so that they may be suggested to Act Now users. This update will not only make our applicaiton more dynamic but will further stimulate connection by introducing a completely new group of people to the application: the event hosters. This update would also include spatial and temporal information thus making it easier for users to connect with local organizations and communities. | <https://docs.google.com/presentation/d/17jLxtiNIFxF41xbQ_rubA5ijnvBGJ1RSAMUSMkTO91U/edit?usp=sharing>
## Inspiration
We became inspired after realizing the complexity of bias in media and the implicant bias people have when writing articles. We began the project by recognizing four major issues with bias in media:
* Media companies are motivated to create biased articles to attract attention
* Individuals introduce implicit biases unintentionally in their writing.
* People can waste time reading articles without knowing the biases contained within those articles beforehand.
* No standard API despite recent advances in natural language processing and cloud computing.
## What it does
To address the issues we identified, we began by creating a general-purpose API to identify the degree and sources of bias in long-form text input. We then tried to build several tools around the API to demonstrate what can be done, in hopes of encouraging others.
Sway helps identify bias in the media by providing a chrome extension. The extension provides a degree of bias and the cause of the bias (if any exists) for any website, all with the click of a button. Sway also offers a writing editor to identify bias in the text. Lastly, Sway offers a search interface to conduct research on unbiased resources. The search interface utilizes Google search and our bias detection to rank websites according to credibility.
## How we built it
We decided to build two microservices, along with a Chrome extension. We built the Chrome extension in HTML/CSS, and Javascript. The web platforms were built in React and Python. Our API for performing the text analysis was written in Python.
## Challenges we ran into
We had trouble finding training data to properly classify particles. As we overcame this issue the training data didn't give us the outputs we expected so we had to spend additional time fine-tuning our model. The biggest challenge we ran into was creating endpoints to properly connect the frontend and backend. The endpoints had to be rewritten as we had to narrow down the scope of some features and we decided to scale-up other features.
## Accomplishments that we're proud of
We built out three different platforms in a day! Sway also works extremely well and we're very happy with the performance. We had planned to only build the chrome extension but picked up good momentum and were able to add the two other platforms over the weekend!
## What's next for Sway
We want to market and develop our algorithm further to the point where we could commercially deploy it. One thing that's required to do is add significantly more training data! We would like to keep adding more features to our core product. We would like to provide more helpful insights to users, such as numerical scores across multiple categories of bias. | ## Inspiration
We're sure you have tons of photos on your device and hope to someday categorize them. You would want to prize those age old vacation photos without being bugged by your lecture snaps every 5 photos. But you can’t seem to get out of the cluttered Camera Roll. If the idea of so many photos and with that, so much sorting, seems daunting. Our app is of use to you. It sorts through all of that and suggest options to make albums, almost without even lifting a finger.
More than just events and places, Sortify can sort according to moods and emotions. So if you were happy or smiling in a photo. Sortify will automatically collect all such photos for you so you can relive your best memories anytime, with little more than a mere tap of a button.
## What it does
Sortify, is a web based app that scans through your photo and sorts them automatically into potential albums you’d like based on the content of those photos. For instance if you upload a mix of photos you took while having fun with a friend, some random selfies, nature photography and even in class lecture photos. Our app will automatically sort it into potential albums like lakes, cityscapes, lecture photos. It can even sort according to mood or how you were feeling based on those photos. For instance, it can collect all your photos in which you are happy so you can look back at those times easily. Letting your enjoy your memories without going through the long manual sorting process.
## How we built it
Our approach to this was utilizing an API, Clarifai, which scans the images for keywords and sends back a JSON containing information regarding possible keywords relating to the image and probability estimates of certainty. We then extract useful information from the JSON output and format it. We pass the potential keywords in each photo through a filter that only keeps the highest probability options. We compile all the keywords from all the photos and tally frequencies. We then allocate scores to most likely options that result from our algorithm and sort photos into these albums that we allow the user to download as he chooses.
Furthermore, all this is implemented at the front end through CSS to provide a comfortable, easy and friendly experience for the user. We have a minimalist and easy to use login page that asks user to create an account, this links to a second page that allows sign up and inputting a username and password. This creates a level of security for the photos. We have a login portal so privacy is not compromised as each individual’s photos remain private. We then navigate to a page for uploading the photos. This too is an easy process, with the press of a button, literally. Hence, making it as user friendly as possible. Finally, on a final page we display choices for possible album names and allow the user to view sorted albums.
## Challenges we ran into
The path to this app had a number of difficulties. First off, we tried to code in Java Script and Node.js. However, that path, through promising had it’s challenges. Primarily, the formatting of the JSON data in javascript was difficult to decipher and extracting the required output was highly inconvenient. Also working with advanced level Node.js proved troublesome, as we had not used it before. We then moved to Python and PHP at the back end. Extracting useful information was far more convenient in Python using dictionaries and arrays. We first implemented the rest of the keyword ranking algorithm in Python, then shifted some of the burden onto PHP for the web app. One key challenge was implementation of the process on a single page. Additionally, working with PHP was also a hurdle at times as web implementation of the app was challenging as only so many photos could be uploaded on the server and processing time sometimes was slow.
## Accomplishments that we're proud of
The app works for starters! Also we all gained a lot of new knowledge and learnt lots.
We went through a lot of technologies and found which options worked best for us.
Exclamations aside, we're excited for how this could help ease something everyone goes through with. More than just a facility, it can be a means to relive memories so easily and that's what really matters. We can make people happy and rejoice. Promoting positivity, one small step at a time and making the world a better place.
## What we learned
A couple of things:
The importance of understanding the data that you're using.
Version Control is important.
Having a team with a diverse skill set can really be an asset.
Simpler the idea, the better. (clearly)
PHP is not the best option for web development. It's easier but clunkier.
Bootstrap is really pretty.
Front end and back end are both very important.
Page source is important for web development.
Understanding the data you get is a key part of coding. So is finding how to access it.
What process is simple in one language is difficult in another language's implementation.
Sleep is immaterial.
Sheer excitement for a project works better than caffeine.
## What's next for Sortify
We are considering a number of immediate features for expansion. Features like downloading albums, social media Integration and smarter backend processes are expected. We envision a smarter version of Sortify that makes it more individual by learning each user's preferences using Machine Learning. We are also considering expanding from a web app into mobile app as well so more users can use Sortify easily. | partial |
## 🤔 Problem Statement
* The complexity of cryptocurrency and blockchain technology can be intimidating for many potential users.
* According to a survey by Finder, 36% of Americans are not familiar with cryptocurrencies, and 29% find it too complicated to understand.
* BitBuddy aims to create an easy-to-use, AI-driven chatbot that simplifies transactions and interactions with cryptocurrencies, using natural language processing and cutting-edge technology like OpenAI and ChatGPT.
* Research shows that 53% of people feel intimidated by the complexities of cryptocurrency and blockchain technology.
* BitBuddy aims to make crypto accessible to everyone by creating a system that allows users to send funds, mint NFTs, and buy crypto through a simple chat interface.
* BitBuddy aims to break down the barriers to entry that have traditionally limited the growth and adoption of crypto, making it more accessible to a wider range of people.
## 💡 Inspiration
* Shared passion for blockchain technology and its potential to revolutionize finance.
* Desire to simplify the process of interacting with cryptocurrencies and make it accessible to everyone.
* Belief in the potential of chatbots and natural language processing to simplify complex tasks.
## 🤖 What it does
* MintBuddy is a blockchain chatbot that simplifies the process of minting NFTs.
* It guides users through the process step-by-step using Voiceflow and Midjourney APIs.
* Users provide name, description, wallet address, and image URL or generate an NFT using Midjourney.
* The bot will mint the NFT and provide a transaction hash and ID, along with URLs to view the NFT on block explorers and OpenSea.
* It is compatible with various different chains and eliminates the need for users to navigate complex blockchain systems or switch between platforms.
* MintBuddy makes minting NFTs easy and accessible to everyone using AI-driven chatbots and cutting-edge APIs.
## 🧠 How we built it
* MintBuddy simplifies the process of interacting with cryptocurrencies and blockchain technology.
The platform utilizes a variety of cutting-edge technologies, including Voiceflow, Verbwire API, and OpenAI.
* Voiceflow is used to create the user flows and chatbot pathways that enable users to send funds, mint NFTs, and buy crypto.
* Verbwire API is integrated with the chatbot to generate unique and creative NFT art using prompts and have it minted on the blockchain within minutes.
* OpenAI's natural language processing and ChatGPT algorithms are used to extract key information from user requests and enable the chatbot to respond accordingly.
* The combination of these technologies creates a user-friendly and accessible platform that makes blockchain technology and cryptocurrencies accessible to everyone, regardless of their technical knowledge or experience.
## 🧩 Challenges we ran into
* Developing MintBuddy was challenging but rewarding for the team.
* One major challenge was integrating Metamask with Voiceflow as they cannot run asynchronous functions together, but they found an alternative solution with Verbwire after contacting Voiceflow customer service.
* Another challenge was developing the NFT minting feature, which required a lot of back-and-forth communication between the user and the bot, but they were able to create a functional and user-friendly feature.
* The team looks forward to tackling new challenges and creating a platform that simplifies the process of interacting with cryptocurrencies and makes it accessible to everyone.
## 🏆 Accomplishments that we're proud of
* Developed a user-friendly and accessible platform for MintBuddy
* Integrated OpenAI ChatGPT into the platform, proving to be a powerful tool in simplifying the process of interacting with cryptocurrencies
* Integrated Verbwire API securely and ensured users could confirm transactions at every stage
* Developed a chatbot that makes blockchain technology accessible to everyone
* Took a risk in diving into unfamiliar technology and learning new skills, which has paid off in creating a platform that simplifies the process of interacting with cryptocurrencies and blockchain technology
## 💻 What we learned
* Gained a deep understanding of blockchain technology and proficiency in using various blockchain services
* Acquired valuable skills in natural language processing and AI technology, including the integration of OpenAI ChatGPT
* Developed soft skills in communication, collaboration, and project management
* Learned how to manage time effectively and work under tight deadlines
* Realized the importance of education and outreach when it comes to cryptocurrencies and blockchain technology
## 🚀 What's next for
* MintBuddy aims to make cryptocurrency and blockchain technology more accessible than ever before by adding more user-friendly features, tutorials, information, and gamification elements.
* The platform is working on integrating more APIs and blockchain platforms to make it more versatile and powerful with seamless natural language processing capabilities.
* The platform plans to allow users to buy and sell crypto directly through the chatbot, eliminating the need for navigating complex trading platforms.
* MintBuddy wants to become the go-to platform for anyone who wants to interact with cryptocurrency and blockchain technology, empowering people to take control of their finances with ease.
* The platform simplifies the process of interacting with complex systems, making it accessible to everyone, regardless of their technical knowledge or experience, and driving mass adoption of cryptocurrencies and blockchain technology.
## 📈 Why MintBuddy?
MintBuddy should win multiple awards at this hackathon, including the Best Generative AI, Best Blockchain Hack, Best Use of Verbwire, and Best Accessibility Hack. Our project stands out because we've successfully integrated multiple cutting-edge technologies to create a user-friendly and accessible platform that simplifies the process of interacting with cryptocurrencies and blockchain technology. Here's how we've met each challenge:
* Best Generative AI: We've utilized Voiceflow and OpenAI ChatGPT to create an AI chatbot that guides users through the process of sending funds, minting NFTs, and buying crypto. We've also integrated Verbwire API to generate unique and creative NFTs for users without requiring them to have any design skills or knowledge.
* Best Blockchain Hack: We've successfully tackled the problem of complexity and lack of accessibility in interacting with cryptocurrencies and blockchain technology. With our platform, anyone can participate in the blockchain world, regardless of their technical expertise.
* Best Use of Verbwire: We've used Verbwire API to generate creative and unique NFTs for users, making it easier for anyone to participate in the NFT market.
* Best Accessibility Hack: We've made creating and generating NFTs easy, even for people without any technical knowledge. Our chatbot's natural language processing capabilities make it possible for anyone to interact with our platform, regardless of their technical expertise.
Overall, our project MintBuddy stands out because it tackles the issue of accessibility and user-friendliness in interacting with cryptocurrencies and blockchain technology. We're confident that our innovative use of technology and dedication to accessibility make MintBuddy a standout project that deserves recognition at this hackathon. | # CryptoWise: Intelligent Trading and Insights Platform
## Inspiration
The inspiration for CryptoWise stemmed from the dynamic and often unpredictable nature of the cryptocurrency market. We recognized the need for a comprehensive platform that not only provides real-time data but also offers intelligent insights and automated trading capabilities. Our goal was to empower traders, researchers, and enthusiasts with tools that enhance decision-making and streamline trading processes.
## What it does
CryptoWise is an all-in-one platform designed to revolutionize the cryptocurrency trading experience. It offers:
* **Real-Time Data Visualization:** Users can view up-to-the-minute cryptocurrency values and trends through interactive charts.
* **Intelligent Query Handling:** A chatbot integrated with advanced LLM technology answers queries related to real-time, historical, and generic cryptocurrency data.
* **Automated Trading:** The platform includes a predictive model that suggests Buy, Sell, or Hold actions based on real-time data analysis, with the capability to execute trades automatically when conditions are met.
## How we built it
We built CryptoWise using a combination of cutting-edge technologies:
* **Data Acquisition:** Integrated WebSocket APIs to fetch real-time cryptocurrency data, which is stored in SingleStore Database for fast retrieval and analytics.
* **Visualization:** Used SingleStore's analytics API to create dynamic charts that display changing market trends.
* **Chatbot Integration:** Leveraged the GROQ API and OpenAI 3.5 Turbo model to develop a chatbot capable of handling complex queries about cryptocurrency.
* **Predictive Modeling:** Developed a model trained on real-time and historical data from Kraken's WebSocket and OHLC APIs to make trading decisions.
* **Automated Trading with Smart Contracts:** Utilized smart contracts for executing trades securely. MetaMask authentication ensures secure access to users' wallets using private keys. Initially planned integration with Fetch.ai's agent-based tools faced challenges due to technical integration complexity and resource allocation constraints.
## Challenges we ran into
Throughout the development of CryptoWise, we faced several challenges:
* **Data Integration:** Ensuring seamless integration of real-time data from multiple sources was complex and required robust solutions.
* **Model Training:** Continuously training the predictive model on diverse datasets to maintain accuracy was demanding.
* **User Interface Design:** Creating an intuitive and user-friendly interface that effectively displays complex data was challenging but crucial for user engagement.
* **Agent-Based Trading Integration:** The complexity of integrating Fetch.ai's agents with our existing infrastructure proved challenging, along with resource limitations.
## Accomplishments that we're proud of
We are proud of several key accomplishments:
* **Seamless Data Flow:** Successfully integrated various data sources into a cohesive platform that delivers real-time insights.
* **Advanced AI Integration:** Implemented a sophisticated chatbot that enhances user interaction with accurate and relevant responses.
* **Automated Trading Feature:** Developed an automated trading system using smart contracts that executes trades based on predictive analytics, offering users a competitive edge.
## What we learned
The development of CryptoWise taught us invaluable lessons:
* **Importance of Data Accuracy:** Real-time accuracy is critical in financial applications, necessitating rigorous testing and validation.
* **AI Capabilities:** Leveraging AI for query handling and decision-making can significantly enhance user experience and platform functionality.
* **User-Centric Design:** Designing with the user in mind is essential for creating an engaging and effective interface.
## What's next for CryptoWise: Intelligent Trading and Insights Platform
Looking ahead, we plan to expand CryptoWise's capabilities by:
* **Enhanced Predictive Analytics:** Further refining our models to improve prediction accuracy and broaden the range of supported cryptocurrencies.
* **User Personalization:** Introducing features that allow users to customize their experience based on individual preferences and trading strategies.
* **Community Engagement:** Building a community around CryptoWise where users can share insights, strategies, and feedback to continuously improve the platform.
CryptoWise aims to set a new standard in cryptocurrency trading by combining powerful analytics with intuitive design, making it an indispensable tool for anyone involved in the crypto market.
# API Documentation
## Overview
This section provides details about the various API endpoints used in the CryptoWise platform, categorized according to their role in the architecture.
## Automated Trading
* **Automated Purchase Endpoint**
+ **URL:** `http://146.190.123.50:4000/api/simulate-purchase`
+ **Purpose:** Simulates the purchase of cryptocurrency based on model predictions.
## Query Handling
* **Query to LLM**
+ **URL:** `http://146.190.123.50:4000/query`
+ **Purpose:** Sends user queries to the LLM for categorization and response generation.
## Data Acquisition
* **Kraken WebSocket API**
+ **URL:** `wss://ws.kraken.com/`
+ **Purpose:** Provides real-time cryptocurrency data for live updates.
* **Historical Data**
+ **URL:** `https://api.kraken.com/0/public/OHLC`
+ **Purpose:** Fetches historical price data for cryptocurrencies.
## Machine Learning
* **ML Prediction API**
+ **URL:** `http://146.190.123.50:5000/prediction`
+ **Purpose:** Provides predictions on Buy, Sell, or Hold actions based on real-time data analysis.
## Analytics
* **Bollinger Bands**
+ **URL:** `http://146.190.123.50:4000/api/analytics/bollinger-bands?coin=XBT&period=20&stdDev=2`
+ **Purpose:** Calculates Bollinger Bands for specified cryptocurrency and period.
* **Historical Volatility**
+ **URL:** `http://146.190.123.50:4000/api/analytics/historical_volatility?coin=XBT`
+ **Purpose:** Computes historical volatility for the specified cryptocurrency.
* **Stats**
+ **URL:** `http://146.190.123.50:4000/api/analytics/stats`
+ **Purpose:** Provides statistical analysis of cryptocurrency data.
* **Candle Data**
+ **URL:** `http://146.190.123.50:4000/api/analytics/get_candle_data?coin=XBT`
+ **Purpose:** Retrieves candlestick data for detailed market analysis. | ## Inspiration
We want to make everyone impressed by our amazing project! We wanted to create a revolutionary tool for image identification!
## What it does
It will identify any pictures that are uploaded and describe them.
## How we built it
We built this project with tons of sweats and tears. We used Google Vision API, Bootstrap, CSS, JavaScript and HTML.
## Challenges we ran into
We couldn't find a way to use the key of the API. We couldn't link our html files with the stylesheet and the JavaScript file. We didn't know how to add drag and drop functionality. We couldn't figure out how to use the API in our backend. Editing the video with a new video editing app. We had to watch a lot of tutorials.
## Accomplishments that we're proud of
The whole program works (backend and frontend). We're glad that we'll be able to make a change to the world!
## What we learned
We learned that Bootstrap 5 doesn't use jQuery anymore (the hard way). :'(
## What's next for Scanspect
The drag and drop function for uploading iamges! | partial |
## Inspiration
We want to have some fun and find out what we could get out of Computer Vision API from Microsoft.
## What it does
This is a web application that allows the user to upload an image, generates an intelligent poem from it and reads the poem out load with different chosen voices.
## How we built it
We used Python interface of Cognitive Service API from Microsoft and built a web application with django. We used a public open source tone generator to play different tones reading the poem to the users.
## Challenges we ran into
We learned django from scratch. It's not very easy to use. But we eventually made all the components connect together using Python.
## Accomplishments that we're proud of
It’s fun!
## What we learned
It's difficult to combine different components together.
## What's next for PIIC - Poetic and Intelligent Image Caption
We plan to make an independent project with different technology than Cognitive Services and published to the world. | # Links
Youtube: <https://youtu.be/VVfNrY3ot7Y>
Vimeo: <https://vimeo.com/506690155>
# Soundtrack
Emotions and music meet to give a unique listening experience where the songs change to match your mood in real time.
## Inspiration
The last few months haven't been easy for any of us. We're isolated and getting stuck in the same routines. We wanted to build something that would add some excitement and fun back to life, and help people's mental health along the way.
Music is something that universally brings people together and lifts us up, but it's imperfect. We listen to our same favourite songs and it can be hard to find something that fits your mood. You can spend minutes just trying to find a song to listen to.
What if we could simplify the process?
## What it does
Soundtrack changes the music to match people's mood in real time. It introduces them to new songs, automates the song selection process, brings some excitement to people's lives, all in a fun and interactive way.
Music has a powerful effect on our mood. We choose new songs to help steer the user towards being calm or happy, subtly helping their mental health in a relaxed and fun way that people will want to use.
We capture video from the user's webcam, feed it into a model that can predict emotions, generate an appropriate target tag, and use that target tag with Spotify's API to find and play music that fits.
If someone is happy, we play upbeat, "dance-y" music. If they're sad, we play soft instrumental music. If they're angry, we play heavy songs. If they're neutral, we don't change anything.
## How we did it
We used Python with OpenCV and Keras libraries as well as Spotify's API.
1. Authenticate with Spotify and connect to the user's account.
2. Read webcam.
3. Analyze the webcam footage with openCV and a Keras model to recognize the current emotion.
4. If the emotion lasts long enough, send Spotify's search API an appropriate query and add it to the user's queue.
5. Play the next song (with fade out/in).
6. Repeat 2-5.
For the web app component, we used Flask and tried to use Google Cloud Platform with mixed success. The app can be run locally but we're still working out some bugs with hosting it online.
## Challenges we ran into
We tried to host it in a web app and got it running locally with Flask, but had some problems connecting it with Google Cloud Platform.
Making calls to the Spotify API pauses the video. Reducing the calls to the API helped (faster fade in and out between songs).
We tried to recognize a hand gesture to skip a song, but ran into some trouble combining that with other parts of our project, and finding decent models.
## Accomplishments that we're proud of
* Making a fun app with new tools!
* Connecting different pieces in a unique way.
* We got to try out computer vision in a practical way.
## What we learned
How to use the OpenCV and Keras libraries, and how to use Spotify's API.
## What's next for Soundtrack
* Connecting it fully as a web app so that more people can use it
* Allowing for a wider range of emotions
* User customization
* Gesture support | ## Inspiration
We spend a lot of our time sitting in front of the computer. The idea is to use the video feed from webcam to determine the emotional state of the user, analyze and provide a feedback accordingly in the form of music, pictures and videos.
## How I built it
Using Microsoft Cognitive Services (Video + Emotion API) we get the emotional state of the user through the webcam feed. We parse that to the bot framework which in turn sends responses based upon the change in the values of emotional state.
## Challenges I ran into
Passing data between the bot framework and the desktop application which captured the webcam feed.
## Accomplishments that I'm proud of
A fully functional bot which provides feedback to the user based upon the changes in the emotion.
## What I learned
Visual studio is a pain to work with.
## What's next for ICare
Use Recurrent Neural Network to keep track of the emotional state of the user before and after and improve the content provided to the user over the period of time. | winning |
## Inspiration
As students, we have found that there are very few high-quality resources on investing for those who are interested but don't have enough resources. Furthermore, we have found that investing and saving money can be a stressful experience. We hope to change this for those who want to save better with the help of our app, hopefully making it fun in the process!
## What it does
Our app first asks a new client a brief questionnaire about themselves. Then, using their banking history, it generates 3 "demons", aka bad spending habits, to kill. Then, after the client chooses a habit to work on, it brings them to a dashboard where they can monitor their weekly progress on a task. Once the week is over, the app declares whether the client successfully beat the mission - if they did, they get rewarded with points which they can exchange for RBC Loyalty points!
## How we built it
We built the frontend using React + Tailwind, using Routes to display our different pages. We used Cohere for our AI services, both for generating personalized weekly goals and creating a more in-depth report. We used Firebase for authentication + cloud database to keep track of users. For our data of users and transactions, as well as making/managing loyalty points, we used the RBC API.
## Challenges we ran into
Piecing the APIs together was probably our most difficult challenge. Besides learning the different APIs in general, integrating the different technologies got quite tricky when we are trying to do multiple things at the same time!
Besides API integration, definitely working without any sleep though was the hardest part!
## Accomplishments that we're proud of
Definitely our biggest accomplishment was working so well together as a team. Despite only meeting each other the day before, we got along extremely well and were able to come up with some great ideas and execute under a lot of pressure (and sleep deprivation!) The biggest reward from this hackathon are the new friends we've found in each other :)
## What we learned
I think each of us learned very different things: this was Homey and Alex's first hackathon, where they learned how to work under a small time constraint (and did extremely well!). Paige learned tons about React, frontend development, and working in a team. Vassily learned lots about his own strengths and weakness (surprisingly reliable at git, apparently, although he might have too much of a sweet tooth).
## What's next for Savvy Saver
Demos! After that, we'll just have to see :) | ## Inspiration
We love spending time playing role based games as well as chatting with AI, so we figured a great app idea would be to combine the two.
## What it does
Creates a fun and interactive AI powered story game where you control the story and the AI continues it for as long as you want to play. If you ever don't like where the story is going, simply double click the last point you want to travel back to and restart from there! (Just like in Groundhog Day)
## How we built it
We used Reflex as the full-stack Python framework to develop an aesthetic frontend as well as a robust backend. We implemented 2 of TogetherAI's models to add the main functionality of our web application.
## Challenges we ran into
From the beginning, we were unsure of the best tech stack to use since it was most members' first hackathon. After settling on using Reflex, there were various bugs that we were able to resolve by collaborating with the Reflex co-founder and employee on site.
## Accomplishments that we're proud of
All our members are inexperienced in UI/UX and frontend design, especially when using an unfamiliar framework. However, we were able to figure it out by reading the documentation and peer programming. We were also proud of optimizing all our background processes by using Reflex's asynchronous background tasks, which sped up our website API calls and overall created a much better user experience.
## What we learned
We learned an entirely new but very interesting tech stack, since we had never even heard of using Python as a frontend language. We also learned about the value and struggles that go into creating a user friendly web app we were happy with in such a short amount of time.
## What's next for Groundhog
More features are in planning, such as allowing multiple users to connect across the internet and roleplay on a single story as different characters. We hope to continue optimizing the speeds of our background processes in order to make the user experience seamless. | ## Inspiration
Today we live in a world that is all online with the pandemic forcing us at home. Due to this, our team and the people around us were forced to rely on video conference apps for school and work. Although these apps function well, there was always something missing and we were faced with new problems we weren't used to facing. Personally, forgetting to mute my mic when going to the door to yell at my dog, accidentally disturbing the entire video conference. For others, it was a lack of accessibility tools that made the experience more difficult. Then for some, simply scared of something embarrassing happening during class while it is being recorded to be posted and seen on repeat! We knew something had to be done to fix these issues.
## What it does
Our app essentially takes over your webcam to give the user more control of what it does and when it does. The goal of the project is to add all the missing features that we wished were available during all our past video conferences.
Features:
Webcam:
1 - Detect when user is away
This feature will automatically blur the webcam feed when a User walks away from the computer to ensure the user's privacy
2- Detect when user is sleeping
We all fear falling asleep on a video call and being recorded by others, our app will detect if the user is sleeping and will automatically blur the webcam feed.
3- Only show registered user
Our app allows the user to train a simple AI face recognition model in order to only allow the webcam feed to show if they are present. This is ideal to prevent ones children from accidentally walking in front of the camera and putting on a show for all to see :)
4- Display Custom Unavailable Image
Rather than blur the frame, we give the option to choose a custom image to pass to the webcam feed when we want to block the camera
Audio:
1- Mute Microphone when video is off
This option allows users to additionally have the app mute their microphone when the app changes the video feed to block the camera.
Accessibility:
1- ASL Subtitle
Using another AI model, our app will translate your ASL into text allowing mute people another channel of communication
2- Audio Transcriber
This option will automatically transcribe all you say to your webcam feed for anyone to read.
Concentration Tracker:
1- Tracks the user's concentration level throughout their session making them aware of the time they waste, giving them the chance to change the bad habbits.
## How we built it
The core of our app was built with Python using OpenCV to manipulate the image feed. The AI's used to detect the different visual situations are a mix of haar\_cascades from OpenCV and deep learning models that we built on Google Colab using TensorFlow and Keras.
The UI of our app was created using Electron with React.js and TypeScript using a variety of different libraries to help support our app. The two parts of the application communicate together using WebSockets from socket.io as well as synchronized python thread.
## Challenges we ran into
Dam where to start haha...
Firstly, Python is not a language any of us are too familiar with, so from the start, we knew we had a challenge ahead. Our first main problem was figuring out how to highjack the webcam video feed and to pass the feed on to be used by any video conference app, rather than make our app for a specific one.
The next challenge we faced was mainly figuring out a method of communication between our front end and our python. With none of us having too much experience in either Electron or in Python, we might have spent a bit too much time on Stack Overflow, but in the end, we figured out how to leverage socket.io to allow for continuous communication between the two apps.
Another major challenge was making the core features of our application communicate with each other. Since the major parts (speech-to-text, camera feed, camera processing, socket.io, etc) were mainly running on blocking threads, we had to figure out how to properly do multi-threading in an environment we weren't familiar with. This caused a lot of issues during the development, but we ended up having a pretty good understanding near the end and got everything working together.
## Accomplishments that we're proud of
Our team is really proud of the product we have made and have already begun proudly showing it to all of our friends!
Considering we all have an intense passion for AI, we are super proud of our project from a technical standpoint, finally getting the chance to work with it. Overall, we are extremely proud of our product and genuinely plan to better optimize it in order to use within our courses and work conference, as it is really a tool we need in our everyday lives.
## What we learned
From a technical point of view, our team has learnt an incredible amount the past few days. Each of us tackled problems using technologies we have never used before that we can now proudly say we understand how to use. For me, Jonathan, I mainly learnt how to work with OpenCV, following a 4-hour long tutorial learning the inner workings of the library and how to apply it to our project. For Quan, it was mainly creating a structure that would allow for our Electron app and python program communicate together without killing the performance. Finally, Zhi worked for the first time with the Google API in order to get our speech to text working, he also learned a lot of python and about multi-threadingbin Python to set everything up together. Together, we all had to learn the basics of AI in order to implement the various models used within our application and to finally attempt (not a perfect model by any means) to create one ourselves.
## What's next for Boom. The Meeting Enhancer
This hackathon is only the start for Boom as our team is exploding with ideas!!! We have a few ideas on where to bring the project next. Firstly, we would want to finish polishing the existing features in the app. Then we would love to make a market place that allows people to choose from any kind of trained AI to determine when to block the webcam feed. This would allow for limitless creativity from us and anyone who would want to contribute!!!! | partial |
## Github REPO
<https://github.com/charlesjin123/medicine-scanner>
## Inspiration
We believe everyone deserves easy, safe access to their medication – yet the small fine print that often takes up hundreds to thousands of words printed on the back of medicine bottles is incredibly inaccessible for a huge market. Watching elderly patients struggle to read fine print, and non-English speakers feeling overwhelmed by confusing medical terms, inspired us to act. Imagine the power of a tool that turns every medication bottle into a personalized, simplified guide in the simple to understand form of cards — that’s the project we’re building. With Med-Scanner, we’re bridging gaps in healthcare access and redefining patient safety.
## What it does
Med-Scanner is a game changer, transforming complex medication information into easy-to-understand digital cards. By simply scanning a medication with your phone, users instantly get critical info like dosages, side effects, and interactions, all laid out clearly and concisely. We even speak the instructions for those who are visually impaired. Med-Scanner is the safe and accessible patient care solution for everyone.
## How we built it
Using cutting-edge tech like React, Python, and NLP models, we built Med-Scanner from the ground up. The app scans medication labels using advanced OCR and analyzes it with NLP. But we didn’t stop there. We infused text-to-speech for the blind, and personalized chatbots for even further support.
## Challenges we ran into
We thrived under time pressure to build a Med-Scanner. One of our greatest challenges was perfecting the OCR to handle blurry, inconsistent images from different formats. Plus, developing an interface that’s accessible, intuitive, and incredibly simple for older users pushed us to innovate like never before. However, with our team of four bring together a multitude of talents, we were able to overcome these challenges to fulfill our mission.
## Accomplishments that we're proud of
The fact that we did it — we brought this ambitious project to life — fills us with pride. We built a prototype that not only works but works brilliantly, turning complex medical details into clear, actionable cards. We’re especially proud of the accuracy of our OCR model and the seamless voice-over features that make this tool genuinely accessible. We’re also proud of creating a product that’s not just tech-savvy, but mission-driven— making healthcare safer for millions of people. | ## Inspiration
Around 1 in 5, British Columbians do not have a family doctor. That is about 1 million people. Not only is it difficult to find a family doctor, but it can also be difficult to find a doctor that can speak your native language if English isn’t your first language. Especially when medical jargon is introduced, it can be overwhelming trying to understand all the medical terms and for older immigrant parents, this disconnect of language can serve as a deterrent to seeking medical aid. We want to create a solution that allows users to have a better relationship with their healthcare professionals and a better understanding of their own health.
## What it does
Our solution “MediScribe” is a web application that transcribes and stores what the doctor is saying while highlighting medical terms and providing simpler definitions and offering translations in different languages. The raw transcriptions can be accessed at a later time and can be sent to others via email.
## How we built it
We used MongoDB, ExpressJS, ReactJS, and NodeJS to handle the frontend and backend. We also incorporated multiple APIs such as the Microsoft Speech-to-Text API to transcribe the audio, Merriam-Webster Medical Dictionary API to define medical terms, Microsoft Translator API to translate medical terms to different languages, and the Twilio SendGrid Email API to send the transcript to the person the user chooses.
## Challenges we ran into
We ran into difficulty configuring the speech-to-text API and having it listen non-stop. The tech stack was relatively new to us all, so we were spending a lot of time reading documentation to figure out the syntax.
## Accomplishments that we're proud of
We were able to create all the functionality we planned for and our web application looks very similar to the Figma draft. We were able to learn on the fly and navigate a tech stack that we were not very familiar with. Furthermore, we were proud of the end product that we were able to produce and the experiences we gained from it.
## What we learned
We learned the divide and conquer method of working on a project where we work on our individual components, then figure out how to integrate all the parts. We also learned how to use various APIs and the different methods to configure them.
## What's next for MediScribe
We are planning to increase the translation capabilities to more languages and offer a setting so that all the text on the website can be translated into a language of choice. | ## Inspiration
One of our team members, Andy, ended up pushing back his flu shot as a result of the lengthy wait time and large patient count. Unsurprisingly, he later caught the flu and struggled with his health for just over a week. Although we joke about it now, the reality is many medical processes are still run off outdated technology and can easily be streamlined or made more efficient. This is what we aimed to do with our project.
## What it does
Streamlines the process of filling out influenza vaccine forms for both medical staff, as well as patients.
Makes the entire process more accessible for a plethora of demographics without sacrificing productivity.
## How we built it
Front-End built in HTML/CSS/Vanilla JavaScript (ES6)
Back-End built with Python and a Flask Server.
MongoDB for database.
Microsoft Azure Vision API, Google Cloud Platform NLP for interactivity.
## Challenges we ran into
Getting Azure's Vision API to get quality captures to be able to successfully pull the meaningful data we wanted.
Front-End to Back-End communication with GCP NLP functions triggering events.
## Accomplishments that we're proud of
Successfully implementing cloud technologies and tools we had little/no experience utilizing, coming into UofTHacks.
The entire project overall.
## What we learned
How to communicate image data via webcam and Microsoft Azure's Vision AP and analyze Optical Character Recognition results.
Quite a bit about NLP tendencies and how to get the most accurate/intended results when utilizing it.
Github Pages cannot deploy Flask servers LOL.
How to deploy with Heroku (as a result of our failure with Github Pages).
## What's next for noFluenza
Payment system for patients depending on insurance coverage
Translation into different languages. | losing |
## Inspiration
As new gen of tech is coming scams are getting normal and way easy as they are happening online.
In 2023, more than **4.75 million** people fell victim to phishing attacks, which is a 58.2% increase from 2022. Phishing is the **most common type of cybercrime**
Sometimes these Phishing links are created sing link shortners & We saw many of people had created it as project but nobody tried reverse of it so this is where project inspiration came in my mind
## What it does
It's links retriver for shorterned links, It make request to header and gets original URL hidden under shortened link.
We have also provided preview of target website there with a detailed article guiding about Phishing scams
## How we built it
We built it using NextJS as its compatible for both Frontend and Backend aswell.
We created this project for CSPSC which is "Cyber Scam Prevention for Senior Citizens".
## Accomplishments that we're proud of
The project is completely live over internet 🤞
## What's next for Unshorten URLs
Spreading awareness about this scams and how our products work against it. | ## Inspiration
The transition to remote learning has been very rushed, and communication between students and professors is a challenge, especially during lecture. Livestream chats are used for questions, but its simplicity means that it can be overwhelmed with off-topic information and many repeated questions, leading to professors missing important questions from students. Online forums solve this issue, but are not in real-time, meaning students have to wait for their questions to be answered, sometimes more than a day. Because of these challenges, we wanted to design an application that creates a specific place for professors to answer questions during lecture.
## What it does
AskQ aims to improve the student-professor communication, creating a specific space for questions to be asked and stored. The professors can view the questions, and answer them when they see fit.
## How we built it
Our backend relies on Node.js for the server-client communication and Google Firebase Firestore to store the messages in a NoSQL database. We did this in order to be able to use a more complicated data structure for our messages, consisting of a hashed id, message content and rating system. Although only the content is used in our MVP, the other two parts of data will be used to implement a real-time rating system, as it allows us to reference specific messages and change their values in the database. Our user interface consists of html pages and some javascript to dynamically manipulate the DOM’s.
## Challenges we ran into
Originally we planned on using python-flask to establish the server-client relationship and run the application. However, we ran into complications with getting the client to connect with the server, and had to switch to Node.js. This proved to be extremely problematic for us, as 3 of our members had no prior javascript experience, and essentially learned the language on the fly.
## Accomplishments that we're proud of
Because of our group’s lack of javascript experience, we are proud of our MVP. It may not have all the features we initially planned, but to restart halfway through and make our MVP using frameworks and languages that we had little to no experience with is something we are proud of.
## What we learned
This was the first hackathon for three of our group members, and they definitely learned how to manage the craziness of a 24 hour deadline, and how to quickly learn the basics of new frameworks and languages on the fly. The team also learned how to stay positive, especially in times of frustration.
## What's next for AskQ
Next for AskQ, we want to implement a rating system for the questions. We want students to be able rate up questions that they think are good, or questions that they may also have. We want to dynamically sort the list, keeping the highest rated questions at the top, for the professors to answer first. We also want to implement containers for questions, so a question could get tagged with a specific topic, and go there. | ### Inspiration
Like many students, we face uncertainty and difficulty when searching for positions in the field of computer science. Our goal is to create a way to tailor your resume to each job posting to increase your odds of an interview or position.
Our aim is to empower individuals by creating a tool that seamlessly tailors resumes to specific job postings, significantly enhancing the chances of securing interviews and positions.
### What it does
ResumeTuner revolutionizes the job application process by employing cutting-edge technology. The platform takes a user's resume and a job description and feeds it into a Large Language Model through the Replicate API. The result is a meticulously tailored resume optimized for the specific requirements of the given job, providing users with a distinct advantage in the competitive job market.
### How we built it
Frontend: React / Next.js + Tailwind + Material UI
Backend: Python / FastAPI + Replicate + TinyMCE
### Challenges
Creating a full stack web application and integrating it with other API's and components was challenging at times, but we pushed through to complete our project.
## Accomplishments that we're proud of
We're proud that we were able to efficiently manage our time and build a tool that we wanted to use. | losing |
## Inspiration
We were inspired by how we would love to have gym buddies to go to the gym with. Especially with our college schedules, it is hard to find a time that aligns with our friends. So SweatSync can easily help you find a buddy whenever you feel demotivated to go to the gym, and just need a buddy.
## What it does
SweatSync allows the user to make a profile and locate nearby fitness facilities such as gym, parks, or even a sports club. The user can see other users who checked in the same location and connect with them. Users can connect their wearables to share their fitness achievements with their friends on the platform.
## How we built it
For back-end, we used React-native as our primary UI software and github to connect the individual projects. For front-end, we used CSS, HTML, JavaScript, and Figma.
## Challenges we ran into
Unable to integrate the TerraApi properly. 3/4 of our members are unfamiliar with React-native, so it was challenging to code in it. It was difficult to put the geological location in our app.
## Accomplishments that we're proud of
We worked together as a team. Whenever someone was stuck with something, another person was able to help. We were also very balanced in terms of skills.
## What we learned
We learned how to use React-native, figma, and github. This was an essential learning opportunity, and we are so glad we challenged ourselves.
## What's next for SweatSync
Maybe we will attempt to fix the bug and connect the APIs and more functionality to the app. | ## Inspiration
Our project stemmed from our frustration dealing with too many cards, specifically gift cards and Prepaid VISA Cards, in our wallets. Americans spent more than $37 billion on prepaid debit cards in 2010 and billions in gift cards each year. The Android app we created incorporates Venmo payments to allow consumers to combine, access and use funds stored on gift cards as well as on Prepaid VISA Cards in one place.
Another problem we sought to address was the fact that as much as 7% of all git cards go unredeemed. For example, if you’re a vegetarian and someone gives you a gift card to a steakhouse, you might find it difficult to use. Mismatches such as these and many more like them have created an accrual of unredeemed gift card spending in our economy. Our project also aims to resolve this inefficiency by creating a forum in which individuals may exchange unwanted gift cards for ones they actually desire.
## What it does
* merging VISA card accounts/amounts into Venmo for the convenience of centralizing the money from various cards
* hold prepaid debit card info
* keep track of each card
* send it to Venmo account
* inventory of gift cards
* keep a list of arrays with the card balance and codes
* have a “total” box to show the total amount
* keep track of remaining balance when it is spent
* swapping gift cards
* community exchange with people with cards that you want/need to swap
* swap card number and security code
## How I built it
We prioritized the different functionalities and then systematically broke large problems into shorter ones. For example, our first priority was to be able to combine prepaid cards and send to venmo account since it was easier to implement than the giftcard swap system . We used many object oriented principles to implement all parts of the software.
## Challenges I ran into
We had too many features we wanted to implement and too little time. For example, we wanted to implement a security system to prevent fraud but realized that it was less important for now since we are merely trying to build a prototype to showcase the overall idea.
## Accomplishments that I'm proud of
We are proud of the fact that we were able to program an Android application concurrently with learning Android itself (since none of the team members had substantial experience.)
## What I learned
On the practical side, we learned Android App Development and learned the nuances of Github. However, we also learned something greater; we learned how to work together in a team environment on a large scale project in a short time. We learned how to budget time and set priorities in order to accomplish what is truly important.
## What's next for AcuCard
In our next steps, we hope to find a way to bypass the 3% processing fee in Venmo money transfer, include more companies under gift cards, make purchases and transactions through barcode generation, improve the community for exchange of gift cards, and prevent fraud through transaction holds. | MediBot: Help us help you get the healthcare you deserve
## Inspiration:
Our team went into the ideation phase of Treehacks 2023 with the rising relevance and apparency of conversational AI as a “fresh” topic occupying our minds. We wondered if and how we can apply conversational AI technology such as chatbots to benefit people, especially those who may be underprivileged or underserviced in several areas that are within the potential influence of this technology. We were brooding over the six tracks and various sponsor rewards when inspiration struck. We wanted to make a chatbot within healthcare, specifically patient safety. Being international students, we recognize some of the difficulties that arise when living in a foreign country in terms of language and the ability to communicate with others. Through this empathetic process, we arrived at a group that we defined as the target audience of MediBot; children and non-native English speakers who face language barriers and interpretive difficulties in their communication with healthcare professionals. We realized very early on that we do not want to replace the doctor in diagnosis but rather equip our target audience with the ability to express their symptoms clearly and accurately. After some deliberation, we decided that the optimal method to accomplish that using conversational AI was through implementing a chatbot that asks clarifying questions to help label the symptoms for the users.
## What it does:
Medibot initially prompts users to describe their symptoms as best as they can. The description is then evaluated to compare to a list of proper medical terms (symptoms) in terms of similarity. Suppose those symptom descriptions are rather vague (do not match very well with the list of official symptoms or are blanket terms). In that case, Medibot asks the patients clarifying questions to identify the symptoms with the user’s added input. For example, when told, “My head hurts,” Medibot will ask them to distinguish between headaches, migraines, or potentially blunt force trauma. But if the descriptions of a symptom are specific and relatable to official medical terms, Medibot asks them questions regarding associated symptoms. This means Medibot presents questions inquiring about symptoms that are known probabilistically to appear with the ones the user has already listed. The bot is designed to avoid making an initial diagnosis using a double-blind inquiry process to control for potential confirmation biases. This means the bot will not tell the doctor its predictions regarding what the user has, and it will not nudge the users into confessing or agreeing to a symptom they do not experience. Instead, the doctor will be given a list of what the user was likely describing at the end of the conversation between the bot and the user. The predictions from the inquiring process are a product of the consideration of associative relationships among symptoms. Medibot keeps track of the associative relationship through Cosine Similarity and weight distribution after the Vectorization Encoding Process. Over time, Medibot zones in on a specific condition (determined by the highest possible similarity score). The process also helps in maintaining context throughout the chat conversations.
Finally, the conversation between the patient and Medibot ends in the following cases: the user needs to leave, the associative symptoms process suspects one condition much more than the others, and the user finishes discussing all symptoms they experienced.
## How we built it
We constructed the MediBot web application in two different and interconnected stages, frontend and backend. The front end is a mix of ReactJS and HTML. There is only one page accessible to the user which is a chat page between the user and the bot. The page was made reactive through several styling options and the usage of states in the messages.
The back end was constructed using Python, Flask, and machine learning models such as OpenAI and Hugging Face. The Flask was used in communicating between the varying python scripts holding the MediBot response model and the chat page in the front end. Python was the language used to process the data, encode the NLP models and their calls, and store and export responses. We used prompt engineering through OpenAI to train a model to ask clarifying questions and perform sentiment analysis on user responses. Hugging Face was used to create an NLP model that runs a similarity check between the user input of symptoms and the official list of symptoms.
## Challenges we ran into
Our first challenge was familiarizing ourselves with virtual environments and solving dependency errors when pushing and pulling from GitHub. Each of us initially had different versions of Python and operating systems. We quickly realized that this will hinder our progress greatly after fixing the first series of dependency issues and started coding in virtual environments as solutions. The second great challenge we ran into was integrating the three separate NLP models into one application. This is because they are all resource intensive in terms of ram and we only had computers with around 12GB free for coding. To circumvent this we had to employ intermediate steps when feeding the result from one model into the other and so on. Finally, the third major challenge was resting and sleeping well.
## Accomplishments we are proud of
First and foremost we are proud of the fact that we have a functioning chatbot that accomplishes what we originally set out to do. In this group 3 of us have never coded an NLP model and the last has only coded smaller scale ones. Thus the integration of 3 of them into one chatbot with front end and back end is something that we are proud to have accomplished in the timespan of the hackathon. Second, we are happy to have a relatively small error rate in our model. We informally tested it with varied prompts and performed within expectations every time.
## What we learned:
This was the first hackathon for half of the team, and for 3/4, it was the first time working with virtual environments and collaborating using Git. We learned quickly how to push and pull and how to commit changes. Before the hackathon, only one of us had worked on an ML model, but we learned together to create NLP models and use OpenAI and prompt engineering (credits to OpenAI Mem workshop). This project's scale helped us understand these ML models' intrinsic moldability. Working on Medibot also helped us become much more familiar with the idiosyncrasies of ReactJS and its application in tandem with Flask for dynamically changing webpages. As mostly beginners, we experienced our first true taste of product ideation, project management, and collaborative coding environments.
## What’s next for MediBot
The next immediate steps for MediBot involve making the application more robust and capable. In more detail, first we will encode the ability for MediBot to detect and define more complex language in simpler terms. Second, we will improve upon the initial response to allow for more substantial multi-symptom functionality.Third, we will expand upon the processing of qualitative answers from users to include information like length of pain, the intensity of pain, and so on. Finally, after this more robust system is implemented, we will begin the training phase by speaking to healthcare providers and testing it out on volunteers.
## Ethics:
Our design aims to improve patients’ healthcare experience towards the better and bridge the gap between a condition and getting the desired treatment. We believe expression barriers and technical knowledge should not be missing stones in that bridge. The ethics of our design therefore hinges around providing quality healthcare for all. We intentionally stopped short of providing a diagnosis with Medibot because of the following ethical considerations:
* **Bias Mitigation:** Whatever diagnosis we provide might induce unconscious biases like confirmation or availability bias, affecting the medical provider’s ability to give proper diagnosis. It must be noted however, that Medibot is capable of producing diagnosis. Perhaps, Medibot can be used in further research to ensure the credibility of AI diagnosis by checking its prediction against the doctor’s after diagnosis has been made.
* **Patient trust and safety:** We’re not yet at the point in our civilization’s history where patients are comfortable getting diagnosis from AIs. Medibot’s intent is to help nudge us a step down that path, by seamlessly, safely, and without negative consequence integrating AI within the more physical, intimate environments of healthcare. We envision Medibot in these hospital spaces, helping users articulate their symptoms better without fear of getting a wrong diagnosis. We’re humans, we like when someone gets us, even if that someone is artificial.
However, the implementation of AI for pre-diagnoses still raises many ethical questions and considerations:
* **Fairness:** Use of Medibot requires a working knowledge of the English language. This automatically disproportionates its accessibility. There are still many immigrants for whom the questions, as simple as we have tried to make them, might be too much for. This is a severe limitation to our ethics of assisting these people. A next step might include introducing further explanation of troublesome terms in their language (Note: the process of pre-diagnosis will remain in English, only troublesome terms that the user cannot understand in English may be explained in a more familiar language. This way we further build patients’ vocabulary and help their familiarity with English ). There are also accessibility concerns as hospitals in certain regions or economic stratas may not have the resources to incorporate this technology.
* **Bias:** We put severe thought into bias mitigation both on the side of the doctor and the patient. It is important to ensure that Medibot does not lead the patient into reporting symptoms they don’t necessarily have or induce availability bias. We aimed to circumvent this by asking questions seemingly randomly from a list of symptoms generated based on our Sentence Similarity model. This avoids leading the user in just one direction. However, this does not eradicate all biases as associative symptoms are hard to mask from the patient (i.e a patient may think chills if you ask about cold) so this remains a consideration.
* **Accountability:** Errors in symptom identification can be tricky to detect making it very hard for the medical practitioner to know when the symptoms are a true reflection of the actual patient’s state. Who is responsible for the consequences of wrong pre-diagnoses? It is important to establish these clear systems of accountability and checks for detecting and improving errors in MediBot.
* **Privacy:** MediBot will be trained on patient data and patient-doctor diagnoses in future operations. There remains concerns about privacy and data protection. This information, especially identifying information, must be kept confidential and secure. One method of handling this is asking users at the very beginning whether they want their data to be used for diagnostics and training or not. | losing |
## Inspiration
**The traffic, congestion, time-consumptions, and hectic life in megacities to find a parking slot for their cars is very difficult.**
## What it does
**Parking Assistant using OpenCV which helps in detecting the Parking Slots when required as per user’s request. It is highly accurate and sends an instant notification to the user which uses Twilio to send the message (DM) instantly.**
## How I built it
**Using Python, MaskRCNN, OpenCV, and Twilio (to send messages)**
## Challenges I ran into
**Training the model**
**Specifically finding the Cars**
**Checking for the Space Available**
**Sending Message to the User**
## Accomplishments that I'm proud of
**Achieved my goal and project submitted on time that I was scared of.**
## What I've learned
* Lots of work to do solely, the requirement of a team, time management, and finally meaning of the word Hackathon.\*
## What's next for Parking Assistant using OpenCV
**Real-Life implementation of the use case, tune the model more, making it scalable, making it work at the nights as well.** | ## Inspiration
DeliverAI was inspired by the current shift we are seeing in the automotive and delivery industries. Driver-less cars are slowly but surely entering the space, and we thought driverless delivery vehicles would be a very interesting topic for our project. While drones are set to deliver packages in the near future, heavier packages would be much more fit for a ground base vehicle.
## What it does
DeliverAI has three primary components. The physical prototype is a reconfigured RC car that was hacked together with a raspberry pi and a whole lot of motors, breadboards and resistors. Atop this monstrosity rides the package to be delivered in a cardboard "safe", along with a front facing camera (in an Android smartphone) to scan the faces of customers.
The journey begins on the web application, at [link](https://deliverai.github.io/dAIWebApp/). To sign up, a user submits webcam photos of themselves for authentication when their package arrives. They then select a parcel from the shop, and await its arrival. This alerts the car that a delivery is ready to begin. The car proceeds to travel to the address of the customer. Upon arrival, the car will text the customer to notify them that their package has arrived. The customer must then come to the bot, and look into the camera on its front. If the face of the customer matches the face saved to the purchasing account, the car notifies the customer and opens the safe.
## How we built it
As mentioned prior, DeliverAI has three primary components, the car hardware, the android application and the web application.
### Hardware
The hardware is built from a "repurposed" remote control car. It is wired to a raspberry pi which has various python programs checking our firebase database for changes. The pi is also wired to the safe, which opens when a certain value is changed on the database.
\_ note:\_ a micro city was built using old cardboard boxes to service the demo.
### Android
The onboard android device is the brain of the car. It texts customers through Twilio, scans users faces, and authorizes the 'safe' to open. Facial recognition is done using the Kairos API.
### Web
The web component, built entirely using HTML, CSS and JavaScript, is where all of the user interaction takes place. This is where customers register themselves, and also where they order items. Original designs and custom logos were created to build the website.
### Firebase
While not included as a primary component, Firebase was essential in the construction of DeliverAI. The real-time database, by Firebase, is used for the communication between the three components mentioned above.
## Challenges we ran into
Connecting Firebase to the Raspberry Pi proved more difficult than expected. A custom listener was eventually implemented that checks for changes in the database every 2 seconds.
Calibrating the motors was another challenge. The amount of power
Sending information from the web application to the Kairos API also proved to be a large learning curve.
## Accomplishments that we're proud of
We are extremely proud that we managed to get a fully functional delivery system in the allotted time.
The most exciting moment for us was when we managed to get our 'safe' to open for the first time when a valid face was exposed to the camera. That was the moment we realized that everything was starting to come together.
## What we learned
We learned a *ton*. None of us have much experience with hardware, so working with a Raspberry Pi and RC Car was both stressful and incredibly rewarding.
We also learned how difficult it can be to synchronize data across so many different components of a project, but were extremely happy with how Firebase managed this.
## What's next for DeliverAI
Originally, the concept for DeliverAI involved, well, some AI. Moving forward, we hope to create a more dynamic path finding algorithm when going to a certain address. The goal is that eventually a real world equivalent to this could be implemented that could learn the roads and find the best way to deliver packages to customers on land.
## Problems it could solve
Delivery Workers stealing packages or taking home packages and marking them as delivered.
Drones can only deliver in good weather conditions, while cars can function in all weather conditions.
Potentially more efficient in delivering goods than humans/other methods of delivery | ## Inspiration
Deep neural networks are notoriously difficult to understand, making it difficult to iteratively improve models and understand what's working well and what's working poorly.
## What it does
ENNUI allows for fast iteration of neural network architectures. It provides a unique blend of functionality for an expert developer and ease of use for those who are still learning. ENNUI visualizes and allows for modification of neural network architectures. Users are able to construct any (non-recurrent) architecture they please.
We take care of input shapes and sizes by automatically flattening and concatenating inputs where necessary. Furthermore, it provides full access to the underlying implementation in Python / Keras. Neural network training is tracked in real time and can be performed both locally and on the cloud.
## How we built it
We wrote a Javascript frontend with an elegant drag and drop interface. We built a Python back end and used the Keras framework to build and train the user's neural network. To convert from our front end to our back end we serialize to JSON in our own format, which we then parse.
## Challenges we ran into
Sequential models are simple. Models that allow arbitrary branching and merging are less so. Our task was to convert a graph-like structure into functional python code. This required checks to ensure that the shapes and sizes of various tensors matched, which proved challenging when dealing with tensor concatenation.
There are many parameters in a neural network. It was challenging to design an interface which allows the user access to all of them in an intuitive manner.
Integrating with the cloud was challenging, specifically, using Docker and Kubernetes for deployment.
## Accomplishments that we're proud of
A novel and state-of-the-art development and learning tool for deep neural networks. The amount of quality code we produced in 24 hours.
## What's next for Elegant Neural Network User Interface (ENNUI)
We want to add a variety of visualizations both during and after training. We want the colors of each of the layers to change based on how influential the weight are in the network. This will help developers understand the effects of gradient updates and identify sections of the network that should be added to or pruned. Fundamentally, we want to inspire a change in the development style from people waiting until they have a trained model to change parameters or architecture, to watching training and making changes to the network architecture as needed. We're want to add support for frameworks other than Keras, such as Tensorflow, Pytorch, and CNTK. Furthermore, we'd love to see our tool used in an educational environment to help students better understand neural networks. | partial |
## Inspiration
Tailoring a resume to a job posting is very time consuming and not everyone know how to make an effective one.
## What it does
Searches job posting for key words which are used to effectively create a resume that will highlight relevant skills and experience. Helps remove necessary information from resumes and increases the chances of candidates to move further into the employment process.
## How we built it
Used web development tech including html, css, bootstrap, javascript. Search algorithm to find key words from existing set of data and give an output of tailored questions to eventually build a resume for the job posting.
## Challenges we ran into
search algorithms, updating questions based on inputs, carrying data forward to display a final resume
## Accomplishments that we're proud of
it works effectively, and makes sure people have the right mindset while making their resumes for a job they like
## What we learned
learned how to create styles, and use existing code from other programmers for things that are beyond our scope
## What's next for Resume Guider
make a better searching algorithm and better output questions to make it easier for students to apply with confidence and build their future. also add a component that analyses their time allocations vs results to tell them where to invest their time in the future | ## The Problem (Why did we build this?)
The current tech industry has been difficult to navigate for newcomers to tech. With competition becoming more fierce, students struggle to stand out in their job applications
## Our Problem Statement:
How might we help students kickstart their early careers in tech in the current industry?
## The Solution
To mitigate this problem, we decided to create a platform that combines all of this data, and created an all-in-one job board for CS internships.
Each job card includes:
• Company
• Position title
• Salary Range
• Visa sponsorship
• Leetcode problems (if available)
In addition, many struggle to get past the resume screening phase, so we also implemented a feature that optimizes resumes by uploading your resume, pasting in the job URL, and we provide an optimized resume for download
## How we built it
We built the backend on Go and the frontend on React, Bootstrap, HTML and CSS. The prototype was designed on Figma
We have created two separate servers: a React Front End servers that handles requests from the user, as well as Golang server that stores all the necessary data and responds to requests from the front end server. A significant part of this project was website scarping that involved parsing through various websites such as Levels.fyi and Github job pages to get the necessary data for the final job board
## Challenges we ran into
1. The diversity of websites poses a significant challenge when it comes to data scraping, particularly for the resume helper feature, as the structure of the sites is not guaranteed and can make scraping difficult.
2. The limited time frame of 24 hours presents a challenge in terms of creating a polished front-end user interface. CSS styling and formatting are time-consuming tasks that require significant attention to detail.
3. Collaborative work can lead to potential issues with Git, including conflicts and other problems, which can be challenging to resolve.
## What we learned
1. Through the course of this project, we gained a thorough understanding of web scraping techniques and strategies for parsing data from websites.
2. We also acquired knowledge and skills in file handling and management in Go.
3. We expanded our proficiency in React, particularly in the creation of high-quality, visually appealing components.
4. Additionally, we developed our ability to work efficiently and effectively in a fast-paced team environment, with an emphasis on perseverance and resilience when faced with challenges.
5. We also gained insights into best practices for UI/UX design and the importance of user-centric design.
## What's next for sprout.fyi
In the future, we want to launch a mobile app for sprout.fyi. In addition to internships, we also want to add new grad jobs to our job boards. | ## Inspiration
We noticed that individual have difficulty achieving their fitness goals due to external factors such as work and sleep patterns. As a result, many fitness applications do not provide a realistic time frame for achieving said goal. We felt that having an application that customizes different fitness goals everyday to fit the individuals work schedule and sleep pattern from the night prior. This would be compared to their final goal and predict an estimate of when the user is able to achieve it.
## What it does
FullyFit uses both Fitbit and Muse API to get fitness and brain-waves (EEG data). Many features extracted from the data include steps taken, calories burnt, heart-rate, sleep and floors climbed each minute as well as each day. Also, data from Google calendar is extracted indicating the duration for which the user will be busy throughout the day. On the mental health side, FullyFit tracks brain wave activity via a Muse headband, allowing the app to adjust its exercise reminders based on mental stress and thinking.
## How we built it
We used machine learning to predict if the user is able to meet his/her step or calories burned goal. We scikit-learn machine learning library to test several algorithms like Decision Trees, Logistic Regression, Random Forest and Bagging Ensemble methods. Even though we got higher accuracy with both Random Forest and Bagging Ensemble methods, we used the Decision Trees for predicting if the user meets his daily fitness goals. Decision Trees ended up being really quick and also reasonably accurate for implementation.
## Challenges we ran into
There were some issues with the Fitbit api getting and handling intraday data for more than a month, so for demonstration purposes we analyzed only a months data.
The FullyFit is more accurate if the user has his work schedule posted in advance. This helps it better predict if the user would be able to meet their goal or not and notify them with suggestions.
## Things we learned
• We learned a lot about the different channels of signaling from the brain. Specifically: Delta waves which are most present during sleep.
Theta waves which are associated with sleep, very deep relaxation, and visualization. Alpha waves which occur when relaxed and calm. Beta waves which occur when, for example, actively thinking or problem-solving. Gamma waves which occur when involved in higher mental activity and consolidation of information.
• Our brainwave EEG API wrapper relied on old legacy Objective-C code that we had to interpret and make edits to.
• Interacting the Fitbit API
## Accomplishments that we're proud of
• Being able to implement both Fitbit and Muse API's in our application.
• Getting a high prediction accuracy with Bagging ensemble methods (96.5%), Random Forest (89%) and Decision Trees (84%)
## What's next for FullyFit
We would like to analyze much more data that we did now as well as optimizing our algorithms on many users. Currently using the user's calendar we only use the duration of busy hours during as a feature in training our machine learning models. We would like to build on this and make our system smarter by also taking in account the spread of the events. For example if the person is busy with work later in the day, it can compensate. We also like to expand upon the application of Muse as a mental health guide. | losing |
## Inspiration
Hungry college students
## What it does
RecipeBoy returns a list of recipes based on the ingredients you give him.
You can also send him your recommended recipes and get a list of recommendations!
## How we built it
Using Cisco Spark's API, Javascript, Node.js, and Food2Food API.
## Challenges we ran into
Phew, a lot.
We had to learn how to use Cisco Sparks' API, what Webhooks were and how to communicate with our RecipeBoy.
Free API's were hard to find and a lot of our time was spent looking for a suitable one.
## Accomplishments that we're proud of
Finishing...
And having successfully worked with new technology!
## What we learned
We learned a lot about Cisco Spark's API and how to use Node.js. Our team's Javascript skills were a bit rusty but this was a great refresher.
## What's next for RecipeBoy
RecipeBoy is looking for a buddy and RestaurantBoy just moved in next door!
We'd love to make a Cisco Spark bot for making restaurant recommendations and reservations. | ## Inspiration
Over the course of the past year, one of the most heavily impacted industries due to the COVID-19 pandemic is the service sector. Specifically, COVID-19 has transformed the financial viability of restaurant models. Moving forward, it is projected that 36,000 small restaurants will not survive the winter as successful restaurants have thus far relied on online dining services such as Grubhub or Doordash. However, these methods come at the cost of flat premiums on every sale, driving up the food price and cutting at least 20% from a given restaurant’s revenue. Within these platforms, the most popular, established restaurants are prioritized due to built-in search algorithms. As such, not all small restaurants can join these otherwise expensive options, and there is no meaningful way for small restaurants to survive during COVID.
## What it does
Potluck provides a platform for chefs to conveniently advertise their services to customers who will likewise be able to easily find nearby places to get their favorite foods. Chefs are able to upload information about their restaurant, such as their menus and locations, which is stored in Potluck’s encrypted database. Customers are presented with a personalized dashboard containing a list of ten nearby restaurants which are generated using an algorithm that factors in the customer’s preferences and sentiment analysis of previous customers. There is also a search function which will allow customers to find additional restaurants that they may enjoy.
## How I built it
We built a web app with Flask where users can feed in data for a specific location, cuisine of food, and restaurant-related tags. Based on this input, restaurants in our database are filtered and ranked based on the distance to the given user location calculated using Google Maps API and the Natural Language Toolkit (NLTK), and a sentiment score based on any comments on the restaurant calculated using Google Cloud NLP. Within the page, consumers can provide comments on their dining experience with a certain restaurant and chefs can add information for their restaurant, including cuisine, menu items, location, and contact information. Data is stored in a PostgreSQL-based database on Google Cloud.
## Challenges I ran into
One of the challenges that we faced was coming up a solution that matched the timeframe and bandwidth of our team. We did not want to be too ambitious with our ideas and technology yet provide a product that we felt was novel and meaningful.
We also found it difficult to integrate the backend with the frontend. For example, we needed the results from the Natural Language Toolkit (NLTK) in the backend to be used by the Google Maps JavaScript API in the frontend. By utilizing Jinja templates, we were able to serve the webpage and modify its script code based on the backend results from NLTK.
## Accomplishments that I'm proud of
We were able to identify a problem that was not only very meaningful to us and our community, but also one that we had a reasonable chance of approaching with our experience and tools. Not only did we get our functions and app to work very smoothly, we ended up with time to create a very pleasant user-experience and UI. We believe that how comfortable the user is when using the app is equally as important as how sophisticated the technology is.
Additionally, we were happy that we were able to tie in our product into many meaningful ideas on community and small businesses, which we believe are very important in the current times.
## What I learned
Tools we tried for the first time: Flask (with the additional challenge of running HTTPS), Jinja templates for dynamic HTML code, Google Cloud products (including Google Maps JS API), and PostgreSQL.
For many of us, this was our first experience with a group technical project, and it was very instructive to find ways to best communicate and collaborate, especially in this virtual setting. We benefited from each other’s experiences and were able to learn when to use certain ML algorithms or how to make a dynamic frontend.
## What's next for Potluck
For example, we want to incorporate an account system to make user-specific recommendations (Firebase). Additionally, regarding our Google Maps interface, we would like to have dynamic location identification. Furthermore, the capacity of our platform could help us expand program to pair people with any type of service, not just food. We believe that the flexibility of our app could be used for other ideas as well. | ## Inspiration
Love is in the air. PennApps is not just about coding, it’s also about having fun hacking! Meeting new friends! Great food! PING PONG <3!
## What it does
When you navigate to any browser it will remind you about how great PennApps was! | winning |
## PennAppsXII Healthy Router
This web app takes a Philadelphia address and returns the nearest bicycle rental station, and a link from that station to the nearest 1) farmer's market, and 2) healthy corner store. All three datasets were provided by OpenPhillyData at OpenPhillyData.org. The purpose of the application is to help improve high levels of obesity by offering Philadelphians:
```
1. Healthy eating options
2. Light, enjoyable exercise options
```
The application was built on Flask, with all database queries and processing done through MongoDB. The most important aspect of this project was geospatial indexing, a feature of MongoDB which allowed for proximity-based calculations to be made. The only geospatial feature for which another resource had been used was for geocoding-- i.e., retreiving the initial latitude and longitude coordinates from the user's input. For this I used the OpenCage Geocoder API through Python's GeoPy client.
Visualization was done primarily through Folium, a python package which allows python data to be visualized using Leaflet.js.
Future improvements in mind include bike-path expansion using bike-path datasets provided (currently there are minimal bikepaths shown in proximity), additional nodes such as parks in proximity to markets or bike stations, shortest-path bike travel. | ## Inspiration
The amount of hours we spend sitting down has dramatically increased at the turn of the last century. Days are spent in classrooms and libraries, with little physical strain. Naturally, we compensate for our lack of daily exercise by going to the gym and doing workouts that are 'unproductive,' meaning this exertion does not provide any real service to the community. We want to offer people a means to locate potential volunteer opportunities to 'exercise' while also helping and making connections as well. We have come to such a disconnected world that it is a shame we cannot use our technology to bring us meaningfully closer. This app uses technology for that reason: to bring people together, not just on the internet, but in person with real conversations and real stories.
## What it does
Our app organizes and analyzes volunteering opportunities near a user’s location. To do so, we gathered the zip code of the user, which is sent to Google’s Firebase Realtime Database. We take advantage of the database’s ease of cross-platform synchronization with a Python crawler. This crawler takes in the zip code from the database, then makes a request to volunteermatch.org with that area code. This allows for scraping of meaningful information on all possible volunteer opportunities in the area. Furthermore, we incorporated a machine learning text classifying to perform analytics on the descriptions of the opportunities words used in the descriptions of the opportunities are analyzed by a text classification machine learning algorithm to determine which opportunities involve physical exercise. Finally, the pruned data is sent to the android app over the database and neatly displayed to the user.
## How We Built It
The crawler is written in Python, while we used Android Studio with Java to create the user interface portion of the application. We decided on Beautiful Soup's Python library to facilitate crawling the website, and after retrieving the necessary data for each volunteer opportunity, we incorporated linear regression to predict the physical exertion required. To train our machine learning algorithm, we gave it a large dataset of volunteer opportunities in New York City that we manually classified. Finally, the appropriate opportunities are displayed to the user, with Firebase facilitating the transfer of data between crawler and android app.
## Challenges We Faced
Initially, we struggled to implement Firebase’s Realtime Database’s synchronization between the Python crawler and Android Studio, primarily due our inexperience dealing with Google’s newer development tools. We then had to come to a conclusion on the choice of machine learning algorithm for our dataset of volunteer opportunity descriptions. We found that linear regression would be our best choice, with an accuracy of about 70%. Much improvement can be made to the algorithm to improve its performance.
## Accomplishments We're Proud Of
GoodWork showed our team the power of Google’s Firebase Realtime Database, as we were are able to see our uploads in real-time. This allowed the communication between Android Studio and the Python crawler to be particularly swift and provided the user with a smooth experience. Furthermore, machine learning was a new skill to our team and successfully integrating it into our project was quite rewarding.
## What We Learned
By developing this project, our team garnered vital experience in databasing, web crawling, and machine learning. We hope to continue to hone these newfound skills in further endeavors.
## The Future of GoodWork
We plan on extending the machine learning capabilities of GoodWork so that the user can target specific muscle groups when searching for potential volunteer opportunities. Furthermore, we want to broaden our experimentation with more machine learning algorithms to maximize accuracy and display only the most relevant and useful service projects | ## Inspiration
Parker was riding his bike down Commonwealth Avenue on his way to work this summer when a car pulled out of nowhere and hit his front tire. Lucky, he wasn't hurt, he saw his life flash before his eyes in that moment and it really left an impression on him. (His bike made it out okay as well, other than a bit of tire misalignment!)
As bikes become more and more ubiquitous as a mode of transportation in big cities with the growth of rental services and bike lanes, bike safety is more prevalent than ever.
## What it does
We designed \_ Bikeable \_ - a Boston directions app for bicyclists that uses machine learning to generate directions for users based on prior bike accidents in police reports. You simply enter your origin and destination, and Bikeable creates a path for you to follow that balances efficiency with safety. While it's comforting to know that you're on a safe path, we also incorporated heat maps, so you can see where the hotspots of bicycle theft and accidents occur, so you can be more well-informed in the future!
## How we built it
Bikeable is built in Google Cloud Platform's App Engine (GAE) and utilizes the best features three mapping apis: Google Maps, Here.com, and Leaflet to deliver directions in one seamless experience. Being build in GAE, Flask served as a solid bridge between a Python backend with machine learning algorithms and a HTML/JS frontend. Domain.com allowed us to get a cool domain name for our site and GCP allowed us to connect many small features quickly as well as host our database.
## Challenges we ran into
We ran into several challenges.
Right off the bat we were incredibly productive, and got a snappy UI up and running immediately through the accessible Google Maps API. We were off to an incredible start, but soon realized that the only effective way to best account for safety while maintaining maximum efficiency in travel time would be by highlighting clusters to steer waypoints away from. We realized that the Google Maps API would not be ideal for the ML in the back-end, simply because our avoidance algorithm did not work well with how the API is set up. We then decided on the HERE Maps API because of its unique ability to avoid areas in the algorithm. Once the front end for HERE Maps was developed, we soon attempted to deploy to Flask, only to find that JQuery somehow hindered our ability to view the physical map on our website. After hours of working through App Engine and Flask, we found a third map API/JS library called Leaflet that had much of the visual features we wanted. We ended up combining the best components of all three APIs to develop Bikeable over the past two days.
The second large challenge we ran into was the Cross-Origin Resource Sharing (CORS) errors that seemed to never end. In the final stretch of the hackathon we were getting ready to link our front and back end with json files, but we kept getting blocked by the CORS errors. After several hours of troubleshooting we realized our mistake of crossing through localhost and public domain, and kept deploying to test rather than running locally through flask.
## Accomplishments that we're proud of
We are incredibly proud of two things in particular.
Primarily, all of us worked on technologies and languages we had never touched before. This was an insanely productive hackathon, in that we honestly got to experience things that we never would have the confidence to even consider if we were not in such an environment. We're proud that we all stepped out of our comfort zone and developed something worthy of a pin on github.
We also were pretty impressed with what we were able to accomplish in the 36 hours. We set up multiple front ends, developed a full ML model complete with incredible data visualizations, and hosted on multiple different services. We also did not all know each other and the team chemistry that we had off the bat was astounding given that fact!
## What we learned
We learned BigQuery, NumPy, Scikit-learn, Google App Engine, Firebase, and Flask.
## What's next for Bikeable
Stay tuned! Or invest in us that works too :)
**Features that are to be implemented shortly and fairly easily given the current framework:**
* User reported incidents - like Waze for safe biking!
* Bike parking recommendations based on theft reports
* Large altitude increase avoidance to balance comfort with safety and efficiency. | losing |
## Inspiration
Hosts of social events/parties create their own music playlists and ultimately control the overall mood of the event. By giving attendees a platform to express their song preferences, more people end up feeling satisfied and content with the event.
## What it does
Shuffle allows hosts to share their event/party playlists with attendees using a web interface. Attendees have the ability to view and vote for their favorite tracks using a cross-platform mobile application. The tracks in the playlist are shuffled in real time based on user votes.
## How we built it
We used React for the web application (host) and react-native for the mobile application (client). Both applications access a central database made using MongoDB Stitch. We also used socket.io deployed on Heroku to provide real time updates.
## Challenges we ran into
Integrating MongoDB Stitch and socket.io in order to show real time updates across multiple platforms.
## Accomplishments that we're proud of
We're proud of the fact that we were able to create a cross platform web and mobile application. Only a valid internet connection is required to access our platform.
## What we learned
All team members were able learn and experiment with a new tool/technology.
## What's next for Shuffle
Integration with various music streaming services such as Spotify or Apple Music. Ability to filter playlists by mood using machine learning. | ## Inspiration
As two members in the group of four are international students studying in the US, we encounter the problem that lots of American foods do not suit our appetite, which have a significant impact on our our homesickness and well-being. In addition to that, college students have limited time to buy grocery and cook, it is crucial to provide a platform where they can find recipes that best fits their taste and their ingredients availability. Our team's project is inspired by this particular long-standing problem of international students in the US. Coming together as individuals who love cooking and taking inspiration from this year theme of CTRL+ALT+CREATE, we decided to build on the idea of Tinder and created Blendr, a Tinder for cooking lovers!
## What it does
Our web application implements a recommender algorithm that allows the user to see a curated list of recommended recipes for them where they can "swipe" left or right depending on their interest in the recipe. We hope give users ideas on what to eat in a familiar and entertaining way. Our website allows the user to sign up and log in to enter information about their food preferences and restrictions as well as food materials in hand through a survey, and based on the result of the survey, we recommend a curated list of recipes for them where they can choose between "like" and "skip" depending on their approval of the recipe. This website will not only save users' time on deciding what to cook and how to cook, but also offer them their own personalized meal plan.
## How we built it
On the client-side, we utilized Figma to design the UI/UX for our web application. We implemented HTML, CSS, and Javascript, with Bootstrap for responsiveness. We architected our back-end using the Django-Python framework. We used the results from the survey to create a list of key words that will be ran through our Python functions to make a list of recommended recipes in our on meal() class. Ultimately, we scraped through 2 million recipes in the Edemam Recipe API to output recommendations for users.
## Challenges we ran into
Originally, we wanted to build a web application that matches people using a food-based recommender system and thereby building a community for people to develop friendship through cooking together. However, due to time constraint and the fact that the majority of our team are first-time hackers , we decided to create a less ambitious but still fully functional version of our intended product, laying the foundation for its future development.
For the front end, we were stuck in making a top navigation bar for hours with the logo on the left and other icons on the right, as there are lots of differences among tutorials about navigation bars and the html codes were too confusing to us as beginners. We also had difficulties creating animations to change pages once users click on some buttons, but we finally figured out an easiest way by assigning links to buttons.
The Edamam API also presented some problems to us. We wanted to provide the step-by-step instructions for each recipe, but the links that are attributed to the recipes by the API were all broken. Therefore, we could not provide the instructions to make the meals that the user approves. Additionally, the API itself had a tons of consistency in its design that require us to think of efficient algorithm to run our recommendation system through it.
## Accomplishments that we're proud of
We are proud of building nice-looking front-end components that are so responsive! In addition to that, our authentication and authorization for users are also successfully implemented. We also built algorithms that can scrape through 2 millions recipes very quickly, and through that we also managed to output relevant recommendations based on users' preference for recipes.
## What we learned
HackHarvard was an enriching learning experience for all of us since we got to engage in the product development process from the beginning to deployment. We got our hands-on front-end and back-end development for the first time, learned how to build responsive website, and practiced building servers and adding our scripts into the servers. Additionally, we were able to setup authorization and authentication on our website, in addition to learning new advanced technology like recommender systems.
## What's next for Blendr
We plan to use machine learning for our recommender systems to output more accurate recommendations. In addition to that, we also plan to further improve our UI/UX and add new features such as community hub for people with similar interests in cooking and users can also look back at their recipes in their account. Overall, we are excited to improve Blendr beyond HackHarvard | 🛠 Hack Harvard 2022 Ctrl Alt Create 🛠
🎵 Dynamic Playlist Curation 🎵
🌟 Highlights
* Mobile application
* Flutter SDK, Dart as Frontend and Python as Backend
* Uses Spotify REST API
* Facial recognition machine learning model to discern a person's emotional state
* Playlist assorted based on emotional state, current time, weather, and location metrics
ℹ️ Overview
Some days might feel like nothing but good vibes, while others might feel a bit slow. Throughout it all, music has been by your side to give you an encompassing experience. Using the Dynamic Playlist Curation (DPC) app, all you have to do is snap a quick pic of yourself, and DPC will take care of the rest! The app analyzes your current mood and incorporates other metrics like the current weather and time of day to determine the best songs for your current mood. It's a great way to discover pieces that sound just right at the right time. We hope you'll enjoy the 10-song playlist we've created especially for you!
🦋 Inspiration
Don't you wish it was easier to find that one song that matches your current mood?
❗️Challenges
This was our first-ever hackathon. Most of us came in with no knowledge of developing applications. Learning the development cycle, the Flutter SDK, and fetching APIs were among our biggest challenges. Each of us came in with our own respective skill sets, but figuring out how to piece it all together was the hard part. At the very end, our final challenge was putting everything together and ensuring all of the dependencies were installed. After 36 long hours, we are proud to share this project with everyone!
✨ Accomplishments
We were able to develop an ML model that uses image data to return the emotional states of a person. We were able to successfully make API calls to the Spotify Web API and OpenWeatherMap API, link the frontend with our backend, and make a functional UI with the help of Flutter.
📖 What we learned
We learned how to connect our frontend and backend components by running servers on Flask. Additionally, we learned how to write up functions to get data and generate oAuth tokens from our APIs.
🧐 What's next for Hack Harvard
We hope to take this learning experience to build confidence in working on more projects. Next year, we will come back more prepared, more motivated, and even more ambitious!
✍️ Authors
Ivan
Jason
Rishi
Andrew
🚀 Usage
Made specifically for Spotify | losing |
## Inspiration
Commuting can be unpleasant, especially early in the morning when you are tired and want to sleep. With a GPS based alarm you can safely sleep on the bus/train knowing you will not miss your stop.
## What it does
GPS based alarm
## How we built it
Smashing through bugs until something came out
## Challenges we ran into
Android development
## Accomplishments that we're proud of
Getting it to work, learning new skills
## What we learned
Android development
## What's next for Snoozy
Amazing things | ## Inspiration
As university students and soon to be graduates, we understand the financial strain that comes along with being a student, especially in terms of commuting. Carpooling has been a long existing method of getting to a desired destination, but there are very few driving platforms that make the experience better for the carpool driver. Additionally, by encouraging more people to choose carpooling at a way of commuting, we hope to work towards more sustainable cities.
## What it does
FaceLyft is a web app that includes features that allow drivers to lock or unlock their car from their device, as well as request payments from riders through facial recognition. Facial recognition is also implemented as an account verification to make signing into your account secure yet effortless.
## How we built it
We used IBM Watson Visual Recognition as a way to recognize users from a live image; After which they can request money from riders in the carpool by taking a picture of them and calling our API that leverages the Interac E-transfer API. We utilized Firebase from the Google Cloud Platform and the SmartCar API to control the car. We built our own API using stdlib which collects information from Interac, IBM Watson, Firebase and SmartCar API's.
## Challenges we ran into
IBM Facial Recognition software isn't quite perfect and doesn't always accurately recognize the person in the images we send it. There were also many challenges that came up as we began to integrate several APIs together to build our own API in Standard Library. This was particularly tough when considering the flow for authenticating the SmartCar as it required a redirection of the url.
## Accomplishments that we're proud of
We successfully got all of our APIs to work together! (SmartCar API, Firebase, Watson, StdLib,Google Maps, and our own Standard Library layer). Other tough feats we accomplished was the entire webcam to image to API flow that wasn't trivial to design or implement.
## What's next for FaceLyft
While creating FaceLyft, we created a security API for requesting for payment via visual recognition. We believe that this API can be used in so many more scenarios than carpooling and hope we can expand this API into different user cases. | ## Inspiration
As college students, we find it difficult to make it to our 9 am classes. However, as good students and eager learners, we still strive to accomplish the task of waking up earlier. Despite our valiant efforts, we still find ourselves hitting the snooze button over and over again.
## What it does
With tEXt, an alarm clock that texts your ex if you don't prove your full alertness with a minute of vigorous ShakeWeight(TM) activity using your phone, you will never have to worry about being awake to catch that earlier bus in the morning, or making it to your meeting on time. The threat of a message to your ex begging for them to take you back will propel you out of bed in the mornings and catapult you into your day.
## How we built it
The alarm was set by using native iOS Date and Time, and Timer functionalities. We built our app solely in Swift in the XCode environment. We imported Alamofire to send requests to the Nexmo API for their SMS service, and parsed the response to make sure the texts were sent.
## Challenges we ran into
Lack of certain pieces of hardware throughout the development process. The Nexmo API was also trickier than expected.
## Accomplishments that we're proud of
We made a fully functioning, aesthetically pleasing app with all the core functionality we had hoped to implement.
## What we learned
We learned that Apple should really give third party apps the ability to run in the background because the alarm function was alarmingly difficult to implement, but because we succeeded in the end we learned that persistence is key.
## What's next for tEXt
We hope to add more functionality such as continuing to assure your state of consciousness by engaging the user in further vigorous activity, both physical, emotional, and mental. After you succeed in completing the first task, we hope to add more benchmarks, such as 5 minutes after completing the first task, having you play a minigame, and if incomplete, sending increasingly desperate messages to the ex, trying to get him or her back.
In addition, we would like to integrate fitness goals into the app by using HealthKit data. If a daily or monthly fitness goal is not met, we are happy to text your ex for you once again. In the future we also want to allow our users to hit the snooze button for a small price. | winning |
#### For Evaluators/Sponsors
Scroll down for a handy guide to navigating our repository and our project's assets.
## 💥 - How it all started
Cancer is a disease that has affected our team quite directly. All of our team members know a relative or loved one that has endured or lost their life due to cancer. This makes us incredibly passionate about wanting to improve cancer patient care. We identi fied a common thread of roadblocks that our loved ones went through during their journey through their diagnosis/treatment/etc:
* **Diagnosis and Staging:** Properly diagnosing the type and stage of cancer is essential for determining the most appropriate treatment plan.
* **Treatment Options:** There are many different types of cancer, and treatment options can vary widely. Selecting the most effective and appropriate treatment for an individual patient can be challenging.
* **Multidisciplinary Care:** Coordinating care among various healthcare professionals, including oncologists, surgeons, radiologists, nurses, and others, can be complex but is necessary for comprehensive cancer care.
* **Communication:** Effective communication among patients, their families, and healthcare providers is crucial for making informed decisions and ensuring the patient's needs and preferences are met.
## 📖 - What it does
We built Cancer360° to create a novel, multimodal approach towards detecting and predicting lung cancer. We synthesized four modes of data qualitative (think demographics, patient history), image (of lung CT scans), text (collected by an interactive chatbot), and physicical (via the ZeppOS Smartwatch) with deep learning frameworks and large language models to copmute a holistic metric for patient likelihood of lung cancer. Through this data-driven approach, we aim to address what we view as "The BFSR": The 'Big Four' of Surmountable Roadblocks:
* **Diagnosis:** Our diagnosis system is truly multimodal through our 4 modes: quantitative (uses risk factors, family history, demographics), qualitative (analysis of medical records like CT Scans), physical measurements (through our Zepp OS App), and our AI Nurse.
* **Treatment Options:** Our nurse can suggest multiple roadmaps of treatment options that patients could consider. For accessibility and ease of understanding, we created an equivalent to Google's featured snippets when our nurse mentions treatment options or types of treatment.
* **Multidisciplinary Care:** The way Cancer360° has been built is to be a digital aid that bridges the gaps with the automated and manual aspects of cancer treatment. Our system prompts patients to enter relevant information for our nurse to analyze and distribute what's important to healthcare professionals.
* **Communication:** This is a major need for patients and families in the road to recovery. Cancer360's AI nurse accomplishes this through our emotionally-sensitive responses and clear/instant communication with patients that input their information, vitals, and symptoms.
## 🔧 - How we built it
To build our Quantitative Mode, we used the following:
* **numpy**: for general math and numpy.array
* **Pandas**: for data processing, storage
* **SKLearn**: for machine learning (train\_test\_split, classification\_report)
* **XGBoost**: Extreme Boosting Trees Decision Trees
To build our Qualitative Mode, we used the following:
* **OpenCV** and **PIL** (Python Imaging Library): For Working With Image Data
* **MatPlotLib** and **Seaborn** : For Scientific Plotting
* **Keras**: Image Data Augmentation (think rotating and zooming in), Model Optimizations (Reduce Learning Rate On Plateau)
* **Tensorflow**: For the Convolutional Neural Network (CNN)
To build our AI Nurse, we used the following:
* **Together.ai:** We built our chatbot with the Llama2 LLM API and used tree of thought prompt engineering to optimize our query responses
To build the portal, we used the following:
* **Reflex:** We utilized the Reflex platform to build our entire frontend and backend, along with all interactive elements. We utilized front end components such as forms, buttons, progress bars, and more. More importantly, Reflex enabled us to directly integrate python-native applications like machine learning models from our quantitative and qualitative modes or our AI Nurse directly into the backend.
## 📒 - The Efficacy of our Models
**With Quantitative/Tabular Data:**
We collected quantitative data for patient demographic, risk factors, and history (in the form of text, numbers, and binary (boolean values)). We used a simple keyword search algorithm to identify risk keywords like “Smoking” and “Wheezing” to transform the text into quantitative data. Then we aggregated all data into a single Pandas dataframe and applied one-hot-encoding on categorical variables like gender. We then used SKLearn to create a 80-20 test split, and tested various models via the SKLearn library, including Logistic Regression, Random Forest, SVM, and K Nearest Neighbors. We found that ultimately, XGBoost performed best with the highest 98.39% accuracy within a reasonable 16-hour timeframe. Our training dataset was used in a research paper and can be accessed [here.](https://www.kaggle.com/datasets/nancyalaswad90/lung-cancer) This high accuracy speaks to the reliability of our model. However, it's essential to remain vigilant against overfitting and conduct thorough validation to ensure its generalizability, a testament to our commitment to both performance and robustness.
[View our classification report here](https://imgur.com/a/YAvXwyk)
**With Image Data:**
Our solution is well-equipped to handle complex medical imaging tasks. Using data from the Iraq-Oncology Teaching Hospital/National Center for Cancer Diseases (IQ-OTH/NCCD) lung cancer dataset, and deep learning frameworks from tensorflow and keras, we were able to build a convolution neural network to classify patient CT scans as malignant or benign. Our convolutional neural network was fine-tuned for binary image classification of 512x512 RGB images, with multiple convolutional, max-pooling, normalization, and dense layers, compiled using the Adam optimizer and binary crossentropy loss. We also used OpenCV, PIL, Matplotlib, and Numpy to deliver a commendable 93% accuracy over a 20-hour timeframe. The utilization of dedicated hardware resources, such as Intel developer cloud with TensorFlow GPU, accelerates processing by 24 times compared to standard hardware. While this signifies our technological edge, it's important to acknowledge that image classification accuracy can vary based on data quality and diversity, making the 93% accuracy an achievement that underscores our commitment to delivering high-quality results.
[Malignant CT Scan](https://imgur.com/a/8oGYz71)
[Benign CT Scan](https://imgur.com/a/3X3zb7k)
**AI Nurse:**
The AI Nurse powered by Together.ai and LLMs (such as Llama2) introduces an innovative approach to patient interaction and risk factor determination. Generating "trees of thoughts" showcases our ability to harness large language models for effective communication. Combining multiple AI models to determine risk factor percentages for lung cancer demonstrates our holistic approach to healthcare support. However, it's essential to acknowledge that the efficacy of this solution is contingent on the quality of language understanding, data processing, and the integration of AI models, reflecting our dedication to continuous improvement and fine-tuning.
## 🚩 - Challenges we ran into
* Challenges we fixed:
* Loading our neural network model into the Reflex backend. After using keras to save the model as a “.h5” extension, we were able to load and run the model locally on my jupyter notebook, however when we tried to load it in the Reflex backend, we kept getting a strange Adam optimizer build error. we tried everything: saving the model weights separately, using different file extensions like .keras, and even saving the model on as a .json file. Eventually, we realized that this was a [known issue with m1/m2 macs and tensorflow](https://github.com/tensorflow/tensorflow/issues/61915)
* Fixed the Get Started Button in Reflex header (Issue: button wouldn’t scale to match the text length) - Moved the button outside the inner hstack, but still the outer hstack
* Integrating together ai chatbot model into Reflex: A lot of our time was spent trying to get the integration working.
* Challenges we didn’t fix:
+ Left aligning the AI response and right aligning the user input in the chatbot
+ Fine tuning a second model to predict lung cancer rate from the chatbot responses from the first model - Could not get enough training data, too computationally taxing and few shot learning did not produce results
+ Fixing bugs related to running a virtual javascript environment within Python via PyV8
## 🏆 - Accomplishments that we're proud of
* Going from idea generation to working prototype, with integration of 4 data modalities - Qualitative Mode, Quantitative Mode, and our AI Nurse, and Smartwatch Data, within the span of less than two days
* Integrating machine learning models and large language models within our application in a way that is directly accessible to users
* Learning a completely new web development framework (Reflex) from scratch without extensive documentation and ChatGPT knowledge
* Working seamlessly as a team and take advantage of the component-centered nature of Reflex to work independently and together
## 📝 - What we learned
* Ameya: "I was fortunate enough to learn a lot about frameworks like Reflex and Together.ai."
* Marcus: "Using Reflex and learning its components to integrate backend and frontend seamlessly."
* Timothy: "I realized how I could leverage Reflex, Intel Developer Cloud, Together.ai, and Zepp Health to empower me in developing with cutting edge technologies like LLMs and deep learning models."
* Alex: "I learned a lot of front end development skills with Reflex that I otherwise wouldn’t have learned as a primarily back-end person."
## ✈️ - What's next for Cancer360°
Just like how a great trip has a great itinenary, we envision Cancer360° future plans in phases.
#### Phase 1: Solidifying our Roots
Phase 1 involves the following goals:
* Revamping our user interface to be more in-line with our mockups
* Increasing connectivity with healthcare professionals
#### Phase 2: Branching Out
View the gallery to see this. Phase 2 involves the following goals:
* Creating a mobile app for iOS and Android of this service
* Furthering development of our models to detect and analyze other types of cancers and create branches of approaches depending on the cancer
* Completing our integration of the physical tracker on Zepp OS
#### Phase 3: Big Leagues
Phase 3 involves the following goals:
* Expanding accessibility of the app through having our services be available in numerous different languages
* Working with healthcare institutions to further improve the usability of the suite
## 📋 - Evaluator's Guide to Cancer360°
##### Intended for judges, however the viewing public is welcome to take a look.
Hey! We wanted to make this guide in order to help provide you further information on our implementations of certain programs and provide a more in-depth look to cater to both the viewing audience and evaluators like yourself.
#### Sponsor Services We Have Used This Hackathon
##### Reflex
The founders (Nikhil and Alex) were not only eager to assist but also highly receptive to our feedback, contributing significantly to our project's success.
In our project, we made extensive use of Reflex for various aspects:
* **Project Organization and Hosting:** We hosted our website on Reflex, utilizing their component-state filesystem for seamless project organization.
* **Frontend:** We relied on Reflex components to render everything visible on our website, encompassing graphics, buttons, forms, and more.
* **Backend:** Reflex states played a crucial role in our project by facilitating data storage and manipulation across our components. In this backend implementation, we seamlessly integrated our website features, including the chatbot, machine learning model, Zepp integration, and X-ray scan model.
##### Together AI
In our project, Together AI played a pivotal role in enhancing various aspects:
* **Cloud Service:** We harnessed the robust capabilities of Together AI's cloud services to host, run, and fine-tune llama 2, a Large Language Model developed by META, featuring an impressive 70 billion parameters. To ensure seamless testing, we evaluated more than ten different chat and language models from various companies. This was made possible thanks to Together AI's commitment to hosting over 30 models on a single platform.
* **Integration:** We seamlessly integrated Together AI's feature set into our web app, combined with Reflex, to deliver a cohesive user experience.
* **Tuning:** Leveraging Together AI's user-friendly hyperparameter control and prompt engineering, we optimized our AI nurse model for peak performance. As a result, our AI nurse consistently generated the desired outputs at an accelerated rate, surpassing default performance levels, all without the need for extensive tuning or prompt engineering.
##### Intel Developer Cloud
Our project would not have been possible without the massive computing power of Intel cloud computers. For reference, [here is the CNN training time on my local computer.](https://imgur.com/a/rfYlVro)
And here is the [CNN training time on my Intel® Xeon 4th Gen ® Scalable processor virtual compute environment and tensorflow GPU.](https://imgur.com/a/h3ctSPY)
A remarkable 20x Speedup! This huge leap in compute speed empowered by Intel® cloud computing enabled us to re-train our models with lightning speed as we worked to debugg and worked to integrate it into our backend. It also made fine-tuning our model much easier as we can tweak the hyperparameters and see their effects on model performance within the span of minutes.
##### Zepp Health
We utilized the ZeppOS API to query real-time user data for calories burned, fat burned, blood oxygen, and PAI (Personal Activity Index). We worked set up a PyV8 virtual javascript environment to run javascript code within Python to integrate the ZeppOS API into our application. Using collected data from the API, we used an ensemble algorithm to compute a health metric evaluating patient health, which ultimately feeds into our algorithm to find patient risk for lung cancer.
##### GitHub
We used GitHub for our project by creating a GitHub repository to host our hackathon project's code. We also ensured that our use of GitHub stood out with a detailed ReadMe page, meaningful pull requests, and a collaboration history, showcasing our dedication to improving cancer patient care through Cancer360°. We leveraged GitHub not only for code hosting but also as a platform to collaborate, push code, and receive feedback.
##### .Tech Domains
We harnessed the potential of a .tech domain to visually embody our vision for Cancer360°, taking a step beyond traditional domains. By registering the website helpingcancerpatientswith.tech, we not only conveyed our commitment to innovative technology but also made a memorable online statement that reflects our dedication to improving the lives of cancer patients. | ## Inspiration
Our solution was named on remembrance of Mother Teresa
## What it does
Robotic technology to assist nurses and doctors in medicine delivery, patient handling across the hospital, including ICU’s. We are planning to build an app in Low code/No code that will help the covid patients to scan themselves as the mobile app is integrated with the CT Scanner for doctors to save their time and to prevent human error . Here we have trained with CT scans of Covid and developed a CNN model and integrated it into our application to help the covid patients. The data sets are been collected from the kaggle and tested with an efficient algorithm with the efficiency of around 80% and the doctors can maintain the patient’s record. The beneficiary of the app is PATIENTS.
## How we built it
Bots are potentially referred to as the most promising and advanced form of human-machine interactions. The designed bot can be handled with an app manually through go and cloud technology with e predefined databases of actions and further moves are manually controlled trough the mobile application. Simultaneously, to reduce he workload of doctor, a customized feature is included to process the x-ray image through the app based on Convolution neural networks part of image processing system. CNN are deep learning algorithms that are very powerful for the analysis of images which gives a quick and accurate classification of disease based on the information gained from the digital x-ray images .So to reduce the workload of doctors these features are included. To know get better efficiency on the detection I have used open source kaggle data set.
## Challenges we ran into
The data source for the initial stage can be collected from the kaggle and but during the real time implementation the working model and the mobile application using flutter need datasets that can be collected from the nearby hospitality which was the challenge.
## Accomplishments that we're proud of
* Counselling and Entertainment
* Diagnosing therapy using pose detection
* Regular checkup of vital parameters
* SOS to doctors with live telecast
-Supply off medicines and foods
## What we learned
* CNN
* Machine Learning
* Mobile Application
* Cloud Technology
* Computer Vision
* Pi Cam Interaction
* Flutter for Mobile application
## Implementation
* The bot is designed to have the supply carrier at the top and the motor driver connected with 4 wheels at the bottom.
* The battery will be placed in the middle and a display is placed in the front, which will be used for selecting the options and displaying the therapy exercise.
* The image aside is a miniature prototype with some features
* The bot will be integrated with path planning and this is done with the help mission planner, where we will be configuring the controller and selecting the location as a node
* If an obstacle is present in the path, it will be detected with lidar placed at the top.
* In some scenarios, if need to buy some medicines, the bot is attached with the audio receiver and speaker, so that once the bot reached a certain spot with the mission planning, it says the medicines and it can be placed at the carrier.
* The bot will have a carrier at the top, where the items will be placed.
* This carrier will also have a sub-section.
* So If the bot is carrying food for the patients in the ward, Once it reaches a certain patient, the LED in the section containing the food for particular will be blinked. | ## Inspiration
Learning about some environmental impact of the retail industry led us to wonder about what companies have aimed for in terms of sustainability goals. The textile industry is notorious for its carbon and water footprints with statistics widely available. How does a company promote sustainability? Do people know and support about these movements?
With many movements by certain retail companies to have more sustainable clothes and supply-chain processes, we wanted people to know and support these sustainability movements, all through an interactive and fun UI :)
## What it does
We built an application to help users select suitable outfit pairings that meet environmental standards. The user is prompted to upload a picture of a piece of clothing they currently own. Based on this data, we generate potential outfit pairings from a database of environmentally friendly retailers. Users are shown prices, means of purchase, reasons the company is sustainable, as well as an environmental rating.
## How we built it
**Backend**: Google Vision API, MySQL, AWS, Python with Heroku and Flask deployment
Using the Google Vision API, we learn of the features (labels, company, type of clothes and colour) from pictures of clothes. With these features, we use Python to interact with our MySQL database of clothes to both select a recommended outfit and additional recommended clothes for other potential outfit combinations.
To generate more accurate label results, we additionally perform a Keras (with Tensorflow backend) image segmentation to crop out the background, allowing the Google Vision API to extract more accurate features.
**Frontend**: JavaScript, React, Firebase
We built the front-end with React, using Firebase to handle user authentications and act as a content delivery network.
## Challenges we ran into
The most challenging part of the project was learning to use the Google Vision API, and deploying the API on Heroku with all its dependencies.
## Accomplishments that we're proud of
Intuitive and clean UI for users that allows ease of mix and matching while raising awareness of sustainability within the retail industry, and of course, the integration and deployment of our technology stack.
## What we learned
After viewing some misfit outfit recommendations, such as a jacket with shorts, had we added a "seasonal" label, and furthermore a "dress code" label (by perhaps, integrating transfer learning to label the images), we could have given better outfit recommendations. This made us realize importance of brainstorming and planning.
## What's next for Fabrical
Deploy more sophisticated clothes matching algorithms, saving the user's outfits into a closet, in addition to recording the user's age, and their preferences as they like / dislike new outfit combinations; incorporate larger database, more metrics, and integrate the machine learning matching / cropping techniques. | winning |
## Inspiration
Our inspiration for Smart Sprout came from our passion for both technology and gardening. We wanted to create a solution that not only makes plant care more convenient but also promotes sustainability by efficiently using water resources.
## What it does
Smart Sprout is an innovative self-watering plant system. It constantly monitors the moisture level in the soil and uses this data to intelligently dispense water to your plants. It ensures that your plants receive the right amount of water, preventing overwatering or underwatering. Additionally, it provides real-time moisture data, enabling you to track the health of your plants remotely.
## How we built it
We built Smart Sprout using a combination of hardware and software. The hardware includes sensors to measure soil moisture, an Arduino microcontroller to process data, and a motorized water dispenser to regulate watering. The software utilizes custom code to interface with the hardware, analyze moisture data, and provide a user-friendly interface for monitoring and control.
## Challenges we ran into
During the development of Smart Sprout, we encountered several challenges. One significant challenge was optimizing the water dispensing mechanism to ensure precise and efficient watering. The parts required by our team, such as a water pump, were not available. We also had to fine-tune the sensor calibration to provide accurate moisture readings, which took much more time than expected. Additionally, integrating the hardware with a user-friendly software interface posed its own set of challenges.
## Accomplishments that we're proud of
The rotating bottle, and mounting it. It has to be rotated such that the holes are on the top or bottom, as necessary, but the only motor we could find was barely powerful enough to turn it. We reduced friction on the other end by using a polygonal 3d-printed block, and mounted the motor opposite to it. Overall, finding an alternative to a water pump was something we are proud of.
## What we learned
As is often the case, moving parts are the most complicated, but we also are using the arduino for two things at the same time: driving the motor and writing to the display. Multitasking is a major component of modern operating systems, and it was interesting to work on it in this case here.
## What's next for Smart Sprout
The watering system could be improved. There exist valves that are meant to be electronically operated, or a human designed valve and a servo, which would allow us to link it to a municipal water system. | ## Inspiration
**With the world producing more waste then ever recorded, sustainability has become a very important topic of discussion.** Whether that be social, environmental, or economic, sustainability has become a key factor in how we design products and how we plan for the future. Especially during the pandemic, we turned to becoming more efficient and resourceful with what we had at home. Thats where home gardens come in. Many started home gardens as a hobby or a cool way to grow your own food from the comfort of your own home. However, with the pandemic slowly coming to a close, many may no longer have the time to micromanage their plants, and those who are interested in starting this hobby may not have the patience. Enter *homegrown*, an easy way for people anyone interested in starting their own mini garden to manage their plants and enjoy the pleasures of gardening.
## What it does
*homegrown* monitors each individual plant, adjusted depending on the type of plant. Equipped with different sensors, *homegrown* monitors the plants health, whether that's it's exposure to light, moisture, or temperature. When it detects fluctuations in these levels, *homegrown* sends a text to the owner, alerting them about the plants condition and suggesting changes to alleviate these problems.
## How we built it
*homegrown* was build using python, an arduino, and other hardware components. The different sensors connected to the arduino take different measurements and record them. They are then sent as one json file to the python script where they data is then further parsed and sent by text to the user through the twilio api.
## Challenges we ran into
We originally planned on using CockroachDB as a data based but scrapped idea since dealing with initializing the database and trying to extract data out of it proved to be too difficult. We ended up using an arduino instead to send the data directly to a python script that would handle the data. Furthermore, ideation took quite a while because it was all out first times meeting each other.
## Accomplishments that we're proud of
Forming a team when we've all never met and have limited experience and still building something in the end was something that brought together each of our respective skills is something that we're proud of. Combining hardware and software was a first for some of us so we're proud of adapting quickly to cater to each others strengths
## What we learned
We learned more about python and its various libraries to build on each other and create more and more complex programs. We also learned about how different hardware components can interact with software components to increase functionality and allow for more possibilities.
## What's next for homegrown
*homegrown* has the possibility to grow bigger, not only in terms of the number of plants which it can monitor growth for, but also the amount of data if can take in surrounding the plant. With more data comes more functionality which allows for more thorough analysis of the plant's conditions to provide a better and more efficient growing experience for the plant and the user. | ## Inspiration
The beginnings of this idea came from long road trips. When driving having good
visibility is very important. When driving into the sun, the sun visor never seemed
to be able to actually cover the sun. When driving at night, the headlights of
oncoming cars made for a few moments of dangerous low visibility. Why isn't there
a better solution for these things? We decided to see if we could make one, and
discovered a wide range of applications for this technology, going far beyond
simply blocking light.
## What it does
EyeHUD is able to track objects on opposite sides of a transparent LCD screen in order to
render graphics on the screen relative to all of the objects it is tracking. i.e. Depending on where the observer and the object of interest are located on the each side of the screen, the location of the graphical renderings are adjusted
Our basic demonstration is based on our original goal of blocking light. When sitting
in front of the screen, eyeHUD uses facial recognition to track the position of
the users eyes. It also tracks the location of a bright flash light on the opposite side
of the screen with a second camera. It then calculates the exact position to render a dot on the screen
that completely blocks the flash light from the view of the user no matter where
the user moves their head, or where the flash light moves. By tracking both objects
in 3D space it can calculate the line that connects the two objects and then where
that line intersects the monitor to find the exact position it needs to render graphics
for the particular application.
## How we built it
We found an LCD monitor that had a broken backlight. Removing the case and the backlight
from the monitor left us with just the glass and liquid crystal part of the display.
Although this part of the monitor is not completely transparent, a bright light would
shine through it easily. Unfortunately we couldn't source a fully transparent display
but we were able to use what we had lying around. The camera on a laptop and a small webcam
gave us the ability to track objects on both sides of the screen.
On the software side we used OpenCV's haar cascade classifier in python to perform facial recognition.
Once the facial recognition is done we must locate the users eyes in their face in pixel space for
the user camera, and locate the light with the other camera in its own pixel space. We then wrote
an algorithm that was able to translate the two separate pixel spaces into real 3D space, calculate
the line that connects the object and the user, finds the intersection of this line and the monitor,
then finally translates this position into pixel space on the monitor in order to render a dot.
## Challenges we ran Into
First we needed to determine a set of equations that would allow us to translate between the three separate
pixel spaces and real space. It was important not only to be able to calculate this transformation, but
we also needed to be able to calibrate the position and the angular resolution of the cameras. This meant
that when we found our equations we needed to identify the linearly independent parts of the equation to figure
out which parameters actually needed to be calibrated.
Coming up with a calibration procedure was a bit of a challenge. There were a number of calibration parameters
that we needed to constrain by making some measurements. We eventually solved this by having the monitor render
a dot on the screen in a random position. Then the user would move their head until the dot completely blocked the
light on the far side of the monitor. We then had the computer record the positions in pixel space of all three objects.
This then told the computer that these three pixel space points correspond to a straight line in real space.
This provided one data point. We then repeated this process several times (enough to constrain all of the degrees of freedom
in the system). After we had a number of data points we performed a chi-squared fit to the line defined by these points
in the multidimensional calibration space. The parameters of the best fit line determined our calibration parameters to use
in the transformation algorithm.
This calibration procedure took us a while to perfect but we were very happy with the speed and accuracy we were able to calibrate at.
Another difficulty was getting accurate tracking on the bright light on the far side of the monitor. The web cam we were
using was cheap and we had almost no access to the settings like aperture and exposure which made it so the light would
easily saturate the CCD in the camera. Because the light was saturating and the camera was trying to adjust its own exposure,
other lights in the room were also saturating the CCD and so even bright spots on the white walls were being tracked as well.
We eventually solved this problem by reusing the radial diffuser that was on the backlight of the monitor we took apart.
This made any bright spots on the walls diffused well under the threshold for tracking. Even after this we had a bit of trouble
locating the exact center of the light as we were still getting a bit of glare from the light on the camera lens. We were
able to solve this problem by applying a gaussian convolution to the raw video before trying any tracking. This allowed us
to accurately locate the center of the light.
## Accomplishments that we are proud of
The fact that our tracking display worked at all we felt was a huge accomplishments. Every stage of this project felt like a
huge victory. We started with a broken LCD monitor and two white boards full of math. Reaching a well working final product
was extremely exciting for all of us.
## What we learned
None of our group had any experience with facial recognition or the OpenCV library. This was a great opportunity to dig into
a part of machine learning that we had not used before and build something fun with it.
## What's next for eyeHUD
Expanding the scope of applicability.
* Infrared detection for pedestrians and wildlife in night time conditions
* Displaying information on objects of interest
* Police information via license plate recognition
Transition to a fully transparent display and more sophisticated cameras.
General optimization of software. | partial |
## Inspiration
During a school-funded event for individuals with learning disabilities, we noticed a communication barrier due to students’ limited ability to understand sign language. The current solution of using camera recognition fails to be feasible since pulling out a phone during a conversation is impractical and the individual may not consent to being recorded at all. To effectively bridge this gap, we developed SignSpeak, a wearable real-time translator that uses flex sensors to instantly translate sign language gestures. This innovation promotes effective communication, fostering equality and inclusion for all.
## What it does
SignSpeak is a real-time American Sign Language to Speech translation device, eliminating the need of a translator for the hearing impaired. We’ve built a device that consists of both hardware and software components. The hardware component includes flex sensors to detect ASL gestures, while the software component processes the captured data, stores it in a MongoDB database and uses our customized recurrent neural network to convert it into spoken language. This integration ensures a seamless user experience, allowing the hearing-impaired/deaf population to independently communicate, enhancing accessibility and inclusivity for individuals with disabilities.
## How we built it
Our hardware, an Arduino Mega, facilitates flex sensor support, enabling the measurement of ten sensors for each finger. We quantified finger positions in volts, with a linear mapping of 5V to 1023 for precise sensitivity. The data includes a 2D array of voltage values and timestamps.
We labeled data using MongoDB through a Python serial API, efficiently logging and organizing sensor data. MongoDB's flexibility with unstructured data was key in adapting to the changing nature of data during various hand gestures.
After reviewing research, we chose a node-based RNN algorithm. Using TensorFlow, we shaped and conformed data for accuracy. Training was done with 80% test and 20% validation, achieving 84% peak accuracy. Real-time input from COM5 is parsed through the RNN model for gesture sequence and voice translation using text-to-speech.
## Challenges we ran into
A lot of our challenges stemmed from hardware and software problems related to our sensors. In relation to hardware, the sensors, over time adjusted to positions of flexion, resulting in uncalibrated sensors. Another prominent issue was the calibration of our 3D data from our sensors into a 2D array as an RNN input as each sign was a different length. Through constant debugging and speaking with mentors, we were able to pad the sequence and solve the issue.
## Accomplishments that we're proud of
We’re most proud of being able to combine software with hardware, as our team mostly specialized in hardware before the event. It was especially rewarding to see 84% accuracy on our own custom trained dataset, proving the validity of our concept.
## What's next for SignSpeak
SignSpeak aims to expand our database whilst impacting our hardware to PCBs in order to allow for larger and wider public translation. | ## Inspiration
Deaf-mute people in the U.S constitute a non-underestimable 2,1% of the population (between 18 and 64 years). This may seem a low percentage but, what if I told you that it is 4 million people? Just like the whole population of Panama!
Concerned about this, we first decided to contribute our grain of sand by developing a nice hack to ease their day to day. After some brainstorming we started working in a messaging aplication which would allow deaf-mute people to comunicate at a distance using their own language: the American Sign Language (ASL).
After some work on the design we realized that we could split our system in various modules to cover a much wider variety of applications
## What it does and how we built it
So, what did we exactly do? We have implemented a set of modules dynamically programmed so that they can be piled up to perform a lot of functionalities. These modules are:
-**Voice to text:** Through Bing Speech API we have implemented a python class to record and get the text of a talking person. It communicates using HTTP posts. The content had to be binary audio.
-**Text to voice:** As before, with Bing Speech API, and Cognitive-Speech-TTS we have implemented a user-friendly python application to transform text into Cortana's Voice.
-**ASL Alphabet to text:** Through a (fully trained) deep neural network we have been able to transform images of signs made with our hands, to text in real time. For this, we had to create a dataset from scratch recording our own hands performing the signs. We also spent many hours training, but we got some good results, though!
Some technicalities: due to lack of time (DL training limitations!) we have only implemented up to 11 letters of the ASL alphabet. Also for better performance we have restricted our sign pictures to white background. Needless to say, with time, computer power and more data, this is totally upgradable to many ASL signs and not restricted background.
-**Text to ASL Alphabet:** To complement all the previous tools, we have developed a python GUI which displays a text translated to ASL Alphabet.
-**Text to Text:** We got to send text messages through AWS Databases with MySQL, thus allowing to comunicate at a distance between all this modules.
## Possibilities
-**Messaging:** The first application we thought of. By combining all the previous modules, we got deaf people do communicate with his natural language. From sign language to text, from text through internet to the other computer and from text to voice!
-**Learning:** From audio to text and from text to sign language modules will allow us to learn to spell all the words we can say! Furthermore, we can practice our skills by going all the way around and make the machine tell us what are we saying.
## Accomplishments that we're proud of
Getting all the different parts work together and actually perform well has been really satisfying.
## What we learned
This is the first time for us implementing a full project based on Machine Learning from scratch, and we are proud of the results we have got. Also we have never worked before with Microsoft API's so we have get to work with this new environment.
## What's next for Silent Voice
One idea that we had in mind from the begining was bringing everything to a more portable device such as a RaspberryPi or a Mobile phone. However, because of time limitations, we could not explore this path. It would be very useful to have our software in such devices and ease the day to day of deaf people (as was our first intention!).
Of course, we are conscious that the ASL is better spoken through words and not just as a concatenation of letters but because of its enormousness it was difficult for us embarking in such an adventure from scratch. A nice future work would be trying to implement a sort of a full ASL.
A funny way to explode our models would be implementing a Naruto ninja fight game, since they are based in hand signs too!
Thanks! | ## Inspiration
We were fascinated by the tech of the LeapMotion, and wanted to find a real-world example for the technology, that could positively help the disabled
## What it does
Our system is designed to be a portable sign language translator. Our wearable device has a leap motion device embedded into with a raspberry pi. Every new sign language input is compared to a machine learning model for gesture classification. The word or letter that is returned by the classification model is then output as spoken words, through our Text-to-Speech engine.
## How we built it
There were four main sub tasks in our build.
1) Hardware: We attempted to use a wearable with the raspberry pi and the leap motion device. A wristband was created to house the leap motion device. Furthermore, a button input and RGB led were soldered as hardware inputs.
2) Text-to-Speech: We made use of Google's TTS api in python to make sure we had comprehensible language, and smooth output
3) Leap Motion: We created a python project to collect relevant data from the leap motion device and store it as needed
4) Azure Machine Learning: We created a machine learning model based on training data we generated by outputting leap motion data to a .csv file. With the generated model, we created our own web api service in order to pass in input leap motion data to classify any gesture.
## Challenges we ran into
We ran into two main challenges:
1) Hardware Compatibility: We assumed that because we could write python could on Windows for the leap motion device, we could also port that code over to a Linux based system, such as a raspberry pi, with ease. As we prepared to port our code over, we found out that there is no supported hardware drivers for arm devices. In order to prepare something for demonstration, we used an Arduino for portable hardware inputs but the leap motion device had to stay plugged into a laptop.
2) Machine Learning Training: A lot of the gestures in the american sign language alphabet are very similar, therefore our classification model ended up returning a lot of false responses. We believe that with more training data and a more reliable data source for gestures, we could produce a more reliable classification model.
## Accomplishments that we are proud of
Although our machine learning model was not very accurate, we are still proud that we were able to produce speech output from gesture control. We also managed to work really well as a team; splitting up tasks, design, problem solving, and team atmosphere.
## What we learned
We learned more about machine learning and got a better idea of how to code in python.
## What's next for Gesture.io
Up next, we would look at finding compatible portable hardware to interact with the leap motion device and continue to train our classification model. | losing |
## Inspiration
The moment we formed our team, we all knew we wanted to create a hack for social good which could even aid in a natural calamity. According to the reports of World Health Organization, there are 285 million people worldwide who are either blind or partially blind. Due to the relevance of this massive issue in our world today, we chose to target our technology towards people with visual impairments. After discussing several ideas, we settled on an application to ease communication and navigation during natural calamities for people with visual impairment.
## What it does
It is an Android application developed to help the visually impaired navigate through natural calamities using peer to peer audio and video streaming by creating a mesh network that does not rely on wireless or cellular connectivity in the event of a failure. In layman terms, it allows people to talk with and aid each other during a disastrous event in which the internet connection is down.
## How we built it
We decided to build an application on the Android operating system. Therefore, we used the official integrated development environment: Android Studio. By integrating Google's nearby API into our java files and using NFC and bluetooth resources, we were able to establish a peer to peer communication network between devices requiring no internet or cellular connectivity.
## Challenges we ran into
Our entire concept of communication without an internet or cellular network was a tremendous challenge. Specifically, the two greatest challenges were to ensure the seamless integration of audio and video between devices. Establishing a smooth connection for audio was difficult as it was being streamed live in real time and had to be transferred without the use of a network. Furthermore, transmitting a video posed to be even a greater challenge. Since we couldn’t transmit data of the video over the network either, we had to convert the video to bytes and then transmit to assure no transmission loss. However, we persevered through these challenges and, as a result, were able to create a peer to peer network solution.
## Accomplishments that we're proud of
We are all proud of having created a fully implemented application that works across the android platform. But we are even more proud of the various skills we gained in order to code a successful peer to peer mesh network through which we could transfer audio and video.
## What we learned
We learned how to utilize Android Studio to create peer to peer mesh networks between different physical devices. More importantly, we learned how to live stream real time audio and transmit video with no internet connectivity.
## What's next for Navig8.
We are very proud of all that we have accomplished so far. However, this is just the beginning. Next, we would like to implement location-based mapping. In order to accomplish this, we would create a floor plan of a certain building and use cameras such as Intel’s RealSense to guide visually impaired people to the nearest exit point in a given building. | ## Inspiration
Millions of people around the world are either blind, or partially sighted. For those who's vision is impaired, but not lost, there are tools that can help them see better. By increasing contrast and detecting lines in an image, some people might be able to see clearer.
## What it does
We developed an AR headset that processes the view in front of it and displays a high contrast image. It also has the capability to recognize certain images and can bring their existence to the attention of the wearer (one example we used was looking for crosswalk signs) with an outline and a vocal alert.
## How we built it
OpenCV was used to process the image stream from a webcam mounted on the VR headset, the image is processed with a Canny edge detector to find edges and contours. Further a BFMatcher is used to find objects that resemble a given image file, which is highlighted if found.
## Challenges we ran into
We originally hoped to use an oculus rift, but we were not able to drive the headset with the available hardware. We opted to use an Adafruit display mounted inside a Samsung VR headset instead, and it worked quite well!
## Accomplishments that we're proud of
Our development platform was based on macOS 10.12, Python 3.5 and OpenCV 3.1.0, and OpenCV would not cooperate with our OS. We spent many hours compiling and configuring our environment until it finally worked. This was no small feat. We were also able to create a smooth interface using multiprocessing, which operated much better than we expected.
## What we learned
Without the proper environment, your code is useless.
## What's next for EyeSee
Existing solutions exist, and are better suited for general use. However a DIY solution is endlessly customizable, we this project inspires other developers to create projects that help other people.
## Links
Feel free to read more about visual impairment, and how to help;
<https://w3c.github.io/low-vision-a11y-tf/requirements.html> | ## Inspiration
Every year hundreds of thousands of preventable deaths occur due to the lack of first aid knowledge in our societies. Many lives could be saved if the right people are in the right places at the right times. We aim towards connecting people by giving them the opportunity to help each other in times of medical need.
## What it does
It is a mobile application that is aimed towards connecting members of our society together in times of urgent medical need. Users can sign up as respondents which will allow them to be notified when people within a 300 meter radius are having a medical emergency. This can help users receive first aid prior to the arrival of an ambulance or healthcare professional greatly increasing their chances of survival. This application fills the gap between making the 911 call and having the ambulance arrive.
## How we built it
The app is Android native and relies heavily on the Google Cloud Platform. User registration and authentication is done through the use of Fireauth. Additionally, user data, locations, help requests and responses are all communicated through the Firebase Realtime Database. Lastly, the Firebase ML Kit was also used to provide text recognition for the app's registration page. Users could take a picture of their ID and their information can be retracted.
## Challenges we ran into
There were numerous challenges in terms of handling the flow of data through the Firebase Realtime Database and providing the correct data to authorized users.
## Accomplishments that we're proud of
We were able to build a functioning prototype! Additionally we were able to track and update user locations in a MapFragment and ended up doing/implementing things that we had never done before. | partial |
## Inspiration
This was my first-ever hackathon and I wanted to build/design an e-commerce application using JavaScript. Learning to design and develop applications was my inspiration.
## What it does
This is a fictional application that sells speakers in the local area.
## How we built it
I used Figma to design the mobile screens and create the prototype. For development, I used vanilla technologies HTML, CSS, and JS.
## Challenges we ran into
Learning media queries to make the website responsive was a challenge. There were some bugs that I was not able to solve on my own but the nwHacks mentors helped me out.
## Accomplishments that we're proud of
I am proud of the design prototype I made during the hackathon. I was not able to spend much time coding the website but I picked up many design skills.
## What we learned
I learned to prototype using Figma, and CSS media queries, working with fonts, and CSS variables.
## What's next for kalsiSpeakers
Currently, I have the mobile design of the application. I will expand this design to desktop screens and then build the whole front end using React.js after I learn it. | ## Inspiration
Our hackathon draws its inspiration from the sheer exhaustion of mere existence during this event. The vibrant purple of our t-shirts was clearly the pinnacle of our design prowess, and our remarkable lack of coding expertise has contributed to the masterpiece you see before you.
## What it does
After a marathon of a whopping 36 hours spent trying things out, we've astonishingly managed to emerge with absolutely nothing by way of an answer. Clearly, our collective genius knows no bounds. But it represents the **experience** we had along the way. The workshops, the friendships we created, the things we learned, all amounted into this.
## How we built it
At the 35th hour of our time in the Engineering Quad, after several attempted projects that we were unable to fulfill due to timeless debugging, lack of experience, and failed partnerships, we realized we had to .
## Challenges we ran into
We had difficulty implementing the color-changing background using CSS, but managed to figure it out. We originally used Bootstrap Studio 5 as our visual website builder, but we got too confused on how to use it.
## Accomplishments that we're proud of
As a first time in-person hacker and first time ever hacker, we are both very proud that we got to meet a lot of great people and take advantage of our experience at the hackathon. We are also incredibly proud that we have SOMETHING to submit.
## What we learned
We learned that the software developer industry is one that is extremely competitive in today's market, having a referral is essential to stick out, and taking the extra step when it comes to researching companies is also essential.
## What's next for Cool Stuff
Keep tuned for more useless products coming your way!! | ## Inspiration
```
We had multiple inspirations for creating Discotheque. Multiple members of our team have fond memories of virtual music festivals, silent discos, and other ways of enjoying music or other audio over the internet in a more immersive experience. In addition, Sumedh is a DJ with experience performing for thousands back at Georgia Tech, so this space seemed like a fun project to do.
```
## What it does
```
Currently, it allows a user to log in using Google OAuth and either stream music from their computer to create a channel or listen to ongoing streams.
```
## How we built it
```
We used React, with Tailwind CSS, React Bootstrap, and Twilio's Paste component library for the frontend, Firebase for user data and authentication, Twilio's Live API for the streaming, and Twilio's Serverless functions for hosting and backend. We also attempted to include the Spotify API in our application, but due to time constraints, we ended up not including this in the final application.
```
## Challenges we ran into
```
This was the first ever hackathon for half of our team, so there was a very rapid learning curve for most of the team, but I believe we were all able to learn new skills and utilize our abilities to the fullest in order to develop a successful MVP! We also struggled immensely with the Twilio Live API since it's newer and we had no experience with it before this hackathon, but we are proud of how we were able to overcome our struggles to deliver an audio application!
```
## What we learned
```
We learned how to use Twilio's Live API, Serverless hosting, and Paste component library, the Spotify API, and brushed up on our React and Firebase Auth abilities. We also learned how to persevere through seemingly insurmountable blockers.
```
## What's next for Discotheque
```
If we had more time, we wanted to work on some gamification (using Firebase and potentially some blockchain) and interactive/social features such as song requests and DJ scores. If we were to continue this, we would try to also replace the microphone input with computer audio input to have a cleaner audio mix. We would also try to ensure the legality of our service by enabling plagiarism/copyright checking and encouraging DJs to only stream music they have the rights to (or copyright-free music) similar to Twitch's recent approach. We would also like to enable DJs to play music directly from their Spotify accounts to ensure the good availability of good quality music.
``` | losing |
## Inspiration
In the past decade, software development has heavily shifted towards open-source development, with React at the forefront of web development. Today, there are over 1.6 million React-specific libraries developed and maintained by the community. Picking between countless UI libraries and styling options is a challenge so we built Stacklet. Stacklet harnesses machine learning and natural language processing to provide smart library recommendations based on a user's need and their current development environment.
## What it does
Stacklet recommends React libraries based on a user's currently installed packages and their intent, acting like an assistant in deciding which libraries to install. By doing so, Stacklet allows users to easily maintain compatibility between libraries and minimize additional dependencies.
## How we built it
We structured Stacklet in four parts. Frontend, backend, model layer one, and model layer two.
Model layer one handles processing the user's query to match it with relevant React libraries. This layer utilizes Cohere's NLP embed model to determine the similarity between the user's query and the README sections of React packages.
Model layer two handles the analysis and ranking of the potential result packages based on the user's current dependencies. We built a custom ML model that calculates the covariance between over 7000 popular React packages that we indexed from open-source repositories on Github. We apply this to the user's existing dependencies and determine the optimal library to add that fulfills the user's query.
The frontend handles the user input which includes parsing their package.json file and their search query. It also displays an intuitive visualization of their current project's dependency state with a 3-dimensional graph to emphasize compatibility between libraries. The backend has multi-language support to handle parsing NPM-specific package data and running Scikit-Learn-based models in Python.
## Challenges we ran into
This project had an insane number of components, from 4 different versions of web scraping to multiple layers in our predictive model, to the multi-language runtime requirements for the backend. Carefully developing a scraping tool was incredibly difficult and required substantial planning and revision as it took more than 12 hours to generate a high-quality dataset.
## Accomplishments that we're proud of
We put our heart and soul into our covariance ML model. Investing time into generating the custom dataset paid off well and while the implementation required a high-level technical understanding and precision, we managed to create a model that consistently provides high-quality recommendations.
## What we learned
We learned a huge amount including the process of building multi-layer ML models, generating datasets via web scraping with tools like BeautifulSoup4, training NLP models via Cohere, and even creating a backend that supported a multi-language runtime.
## What's next for Stacklet
We plan to continue working on this, improving the accuracy of the model and expanding the scope of the project past just React libraries. Companies spend weeks on end choosing between similar open-source libraries and a centralized ML recommendation system like Stacklet would provide an immense amount of value to the dev community. | ## Inspiration
Our team came into the hackathon excited to build a cool full-stack app. However, we quickly realized that most of our time would be eaten up building the frontend, rather than implementing interesting features and functionality. We started working on a command line tool that would help us build frontend components.
We quickly realized that this project was incredibly powerful.
As we continued building and improving the functionality, our command line tool went from a simple helper for components to a powerful engine that could create and import files, import dependencies on its own, handle component creation/URL routing, find and fix its own syntax/compiler errors, and add styling, all with minimal input from the developer.
With Spectral, developers can instantly build an MVP for their ideas, and even fully develop their final React apps. Those with less experience can use Spectral to bring their ideas to life, while having access and control over the bug-free React codebase, unlike most no-code solutions.
## What it does
**Spectral takes your plain English prompts, generates React code, and compiles it. It can install dependencies, create components & files, add styling, and catch its own syntax/compilation errors, all without explicit user intervention.**
-Take plain English prompts, and parse through codebase for context to generate an action plan
-Once user confirms action plan, our custom-built Python engine applies changes to the React codebase
-Our engine is capable of creating components & files, importing files and dependencies, refactoring code into files/components, and styling, all on its own without explicit user instruction
-Our error handling is able to parse through Prettier logs to catch syntax/formatting errors, and even read Vite error logs to discover compiler errors, then fix its own bugs
-Custom .priyanshu files can add context & provide explicit instructions for the code generation to follow (ex. Do all styling with Tailwind. Do not write css unless explicitly told to do so)
-Users can choose to use our web interface for easy access, or command line utility
## How we built it
-Code generation using ChatGPT
-CLI interface and tools to edit React source code developed using Python and argparse
-*Custom functions to parse error logs from Vite, and intelligently determine which code to delete/insert from codebase from chatGPT response*
-Web client developed using Python Flask server
-Web UI built with React, JavaScript, and Vite
## Challenges we ran into
Source code modification was initially very buggy because deleting and inserting lines of code would change the line numbers of the file, and make subsequent insertions/deletions very difficult. We were able to fix this by tweaking our code editing logic, to edit from the bottom of the file first.
Building an accompying web client after we had developed our CLI was also difficult and required refactoring/rewriting logic. We were eventually able to do this using Flask to maintain as much of the original Python code as possible.
## Accomplishments that we're proud of
We are incredibly proud that we were able to build a full code generation system in the span of 24 hours. When we first started, our CLI was very error prone, and although cool, not practical to use. Through extensive error handling and iterative performance improvements, we were able to get it to the point of being able to develop a full frontend mockup without writing any React code ourselves. We are excited that Spectral is now a tool with legitimate utility potential and is something we would even use ourselves to aid project development.
## What we learned
-Learned a lot about working with ports in Flask
-Resolve CORS issues
## What's next for Spectral
-Adding speech-to-text functionality for increased accessibility
-Allowing for larger prompts to be submitted at once with multiple features. Implementing some sort prompt parsing to split large prompts into steps that Spectral can follow more easily. | ## Inspiration
The most important part in any quality conversation is knowledge. Knowledge is what ignites conversation and drive - knowledge is the spark that gets people on their feet to take the first step to change. While we live in a time where we are spoiled by the abundance of accessible information, trying to keep up and consume information from a multitude of sources can give you information indigestion: it can be confusing to extract the most relevant points of a new story.
## What it does
Macaron is a service that allows you to keep track of all the relevant events that happen in the world without combing through a long news feed. When a major event happens in the world, news outlets write articles. Articles are aggregated from multiple sources and uses NLP to condense the information, classify the summary into a topic, extracts some keywords, then presents it to the user in a digestible, bite-sized info page.
## How we built it
Macaron also goes through various social media platforms (twitter at the moment) to perform sentiment analysis to see what the public opinion is on the issue: displayed by the sentiment bar on every event card! We used a lot of Google Cloud Platform to help publish our app.
## What we learned
Macaron also finds the most relevant charities for an event (if applicable) and makes donating to it a super simple process. We think that by adding an easy call-to-action button on an article informing you about an event itself, we'll lower the barrier to everyday charity for the busy modern person.
Our front end was built on NextJS, with a neumorphism inspired design incorporating usable and contemporary UI/UX design.
We used the Tweepy library to scrape twitter for tweets relating to an event, then used NLTK's vader to perform sentiment analysis on each tweet to build a ratio of positive to negative tweets surrounding an event.
We also used MonkeyLearn's API to summarize text, extract keywords and classify the aggregated articles into a topic (Health, Society, Sports etc..) The scripts were all written in python.
The process was super challenging as the scope of our project was way bigger than we anticipated! Between getting rate limited by twitter and the script not running fast enough, we did hit a lot of roadbumps and had to make quick decisions to cut out the elements of the project we didn't or couldn't implement in time.
Overall, however, the experience was really rewarding and we had a lot of fun moving fast and breaking stuff in our 24 hours! | losing |
## Inspiration
Senior suicides have tripled in the last decade due to the large baby boomer population retiring alone. Loneliness is the biggest problem seniors face that contributes to their mental health. According to an AARP survey, a third of adults over the age of 65 are lonely and highly prone to suicidal thoughts. With this in mind, we aspired to create a solution to this problem by allowing senior citizens to gain a friend!
## What It Does
GAiN a Friend is a speech-driven video chat service powered by Generative Adversarial Networks (GAN). This is done by selecting a human face and voice that resonates with the user most. After the persona is selected, the user can begin interacting with the GAN-generated person 24/7.
## How We Built It
GAiN a Friend is built using Generative AI, particularly Generative Adversarial Networks. In order to run these large models, we needed to use Deep Learning VMs from Google Cloud to run these models on high compute engines. For conversational AI and speech conversation, Houndify APIs were used.
## Ethical Considerations
Mass media has been increasingly focused on a future with AI, with movies such as Her and Ex Machina to TV shows such as Black Mirror. As our team was brainstorming this idea of a chatbot to improve communication and curb feelings of isolation, we kept considering the ethical implications of our work and focused on three main conditions.
1. Privacy and Data Ownership: As seen from the first ELIZA chatbot in the 1960s, humans are inclined to trust bots (and not believe that it's a program!) and tell it sensitive information. It is imperative that a user's valuable information stays with the user and does not fall into other hands. *With this in mind, our team decided to store the program and information locally and not share the data collected.* We are also not collecting any videos of the user to ensure that their autonomy is respected.
2. Transparency: In order to build trust between the user and company, we must be upfront about our chatbot. *To ensure there is no confusion between the bot and a human, we have added a disclaimer to our site letting the user know their conversation is with a bot.* Moreover, our code is open source so anyone that is curious to understand the "behind the scenes" of our chatbot is welcome to take a look!
3. User Safety and Protection: There have been many cases of hackers influencing digital personal assistants to go rogue or turn into wiretaps. *To ensure this doesn’t happen, our “friend” uses the Houndify small-talk API to make sure the user can have broad conversations.* Furthermore, with minorities and LGBTQ+ elders feeling significantly more lonely than others, our chatbot will not make any assumptions about the user and can be easily accessible by all populations.
## Challenges We Ran Into
* Learned how to use GANs for the first time
* Using Python 2.7 packages for Python 3.5 was... INSANELY CHALLENGING
* Dealing with deprecated packages
* Caching errors on Jupyter Notebook that have cryptic errors
* Using JavaScript in a Flask app for audio recording
* Learned how to use ethics into consideration in our design solution
* Working with team you've never worked with before
## Accomplishments That We Are Proud Of
We are proud of being an ALL WOMEN team :)
## What's Next for GAiN a Friend
In the future, this concept can easily be expanded to the service sector for service providers, such as psychologist, physicians, and family members. GAiN a Friend wants to incorporate additional API. Focus on a more accessible design for the App development to help elderly folks interact with the app better. | ## A bit about our thought process...
If you're like us, you might spend over 4 hours a day watching *Tiktok* or just browsing *Instagram*. After such a bender you generally feel pretty useless or even pretty sad as you can see everyone having so much fun while you have just been on your own.
That's why we came up with a healthy social media network, where you directly interact with other people that are going through similar problems as you so you can work together. Not only the network itself comes with tools to cultivate healthy relationships, from **sentiment analysis** to **detailed data visualization** of how much time you spend and how many people you talk to!
## What does it even do
It starts simply by pressing a button, we use **Google OATH** to take your username, email, and image. From that, we create a webpage for each user with spots for detailed analytics on how you speak to others. From there you have two options:
**1)** You can join private discussions based around the mood that you're currently in, here you can interact completely as yourself as it is anonymous. As well if you don't like the person they dont have any way of contacting you and you can just refresh away!
**2)** You can join group discussions about hobbies that you might have and meet interesting people that you can then send private messages too! All the discussions are also being supervised to make sure that no one is being picked on using our machine learning algorithms
## The Fun Part
Here's the fun part. The backend was a combination of **Node**, **Firebase**, **Fetch** and **Socket.io**. The ML model was hosted on **Node**, and was passed into **Socket.io**. Through over 700 lines of **Javascript** code, we were able to create multiple chat rooms and lots of different analytics.
One thing that was really annoying was storing data on both the **Firebase** and locally on **Node Js** so that we could do analytics while also sending messages at a fast rate!
There are tons of other things that we did, but as you can tell my **handwriting sucks....** So please instead watch the youtube video that we created!
## What we learned
We learned how important and powerful social communication can be. We realized that being able to talk to others, especially under a tough time during a pandemic, can make a huge positive social impact on both ourselves and others. Even when check-in with the team, we felt much better knowing that there is someone to support us. We hope to provide the same key values in Companion! | ## Inspiration
GENBRIDGE was sparked by a blend of observation and empathy towards the growing isolation experienced by the older generation—a situation only exacerbated by the rapid pace of technological advancements. Recognizing the untapped wealth of wisdom and experience residing within these individuals, we sought to create a platform that not only addresses their loneliness but also enriches the younger generation. Our inspiration was further fueled by the realization that while technology often serves as a barrier, it also holds the potential to be a powerful connector. Thus, GENBRIDGE was conceived to bridge this gap, leveraging technology to foster meaningful, intergenerational connections.
## What it does
GENBRIDGE is a unique platform that enables senior citizens to offer advice and share life experiences with younger individuals seeking guidance. Through a user-friendly app, we facilitate one-on-one interactions that are both meaningful and mutually beneficial. Seniors can impart their wisdom on a range of topics, from career advice to life’s big questions, while young adults gain invaluable insights. Our platform uses a sophisticated matching algorithm to ensure that connections are relevant and enriching for both parties. Furthermore, each interaction has the potential to be transformed into a digital keepsake, capturing the essence of the exchange for posterity.
## How we built it
Our journey in creating GENBRIDGE involved an interdisciplinary approach, combining elements of psychology, technology, and design thinking. We developed the platform with a focus on accessibility, ensuring that it is senior-friendly simple navigation and an engaging interface. The matching algorithm was crafted using advanced AI techniques to analyze user profiles and preferences, facilitating meaningful connections. The tech stack includes React for the frontend, Python, FastAPI, and PostgreSQL for the backend, and Web Speech API for speech to text.
## Challenges we ran into
One of the most significant challenges was designing an interface that caters to the usability needs of seniors while maintaining the engagement factor for younger users. Achieving a balance between simplicity and functionality required extensive user testing and iteration. Additionally, refining the matching algorithm to accurately reflect user preferences and ensure relevant connections was a complex task that involved continuous tweaking and learning.
We are particularly proud of creating a platform that not only addresses a social issue but also fosters intergenerational learning and understanding.
## What we learned
Throughout this project, we've gained deeper insights into the challenges and opportunities of designing technology for social good. The importance of empathy in the design process and the potential of technology to serve as a bridge between different generations were key lessons. We also learned the intricacies of developing a matching algorithm that takes into account the diverse and nuanced preferences of users across generations.
## What's next for GENBRIDGE
Looking ahead, we aim to expand GENBRIDGE's capabilities by incorporating voice to text features to further enrich the platform's accessibility. We also plan to explore partnerships with educational institutions and organizations focused on senior care to broaden our reach and impact. Ultimately, our vision is to transform GENBRIDGE into a global community where wisdom transcends age, fostering a world where every generation feels valued, connected, and understood. | partial |
## Inspiration
With the recent Corona Virus outbreak, we noticed a major issue in charitable donations of equipment/supplies ending up in the wrong hands or are lost in transit. How can donors know their support is really reaching those in need? At the same time, those in need would benefit from a way of customizing what they require, almost like a purchasing experience.
With these two needs in mind, we created Promise. A charity donation platform to ensure the right aid is provided to the right place.
## What it does
Promise has two components. First, a donation request view to submitting aid requests and confirm aids was received. Second, a donor world map view of where donation requests are coming from.
The request view allows aid workers, doctors, and responders to specificity the quantity/type of aid required (for our demo we've chosen quantity of syringes, medicine, and face masks as examples) after verifying their identity by taking a picture with their government IDs. We verify identities through Microsoft Azure's face verification service. Once a request is submitted, it and all previous requests will be visible in the donor world view.
The donor world view provides a Google Map overlay for potential donors to look at all current donation requests as pins. Donors can select these pins, see their details and make the choice to make a donation. Upon donating, donors are presented with a QR code that would be applied to the aid's packaging.
Once the aid has been received by the requesting individual(s), they would scan the QR code, confirm it has been received or notify the donor there's been an issue with the item/loss of items. The comments of the recipient are visible to the donor on the same pin.
## How we built it
Frontend: React
Backend: Flask, Node
DB: MySQL, Firebase Realtime DB
Hosting: Firebase, Oracle Cloud
Storage: Firebase
API: Google Maps, Azure Face Detection, Azure Face Verification
Design: Figma, Sketch
## Challenges we ran into
Some of the APIs we used had outdated documentation.
Finding a good of ensuring information flow (the correct request was referred to each time) for both the donor and recipient.
## Accomplishments that we're proud of
We utilized a good number of new technologies and created a solid project in the end which we believe has great potential for good.
We've built a platform that is design-led, and that we believe works well in practice, for both end-users and the overall experience.
## What we learned
Utilizing React states in a way that benefits a multi-page web app
Building facial recognition authentication with MS Azure
## What's next for Promise
Improve detail of information provided by a recipient on QR scan. Give donors a statistical view of how much aid is being received so both donors and recipients can better action going forward.
Add location-based package tracking similar to Amazon/Arrival by Shopify for transparency | ## Inspiration
Most of us have probably donated to a cause before — be it $1 or $1000. Resultantly, most of us here have probably also had the same doubts:
* who is my money really going to?
* what is my money providing for them...if it’s providing for them at all?
* how much of my money actually goes use by the individuals I’m trying to help?
* is my money really making a difference?
Carepak was founded to break down those barriers and connect more humans to other humans. We were motivated to create an application that could create a meaningful social impact. By creating a more transparent and personalized platform, we hope that more people can be inspired to donate in more meaningful ways.
As an avid donor, CarePak is a long-time dream of Aran’s to make.
## What it does
CarePak is a web application that seeks to simplify and personalize the charity donation process. In our original designs, CarePak was a mobile app. We decided to make it into a web app after a bit of deliberation, because we thought that we’d be able to get more coverage and serve more people.
Users are given options of packages made up of predetermined items created by charities for various causes, and they may pick and choose which of these items to donate towards at a variety of price levels. Instead of simply donating money to organizations,
CarePak's platform appeals to donators since they know exactly what their money is going towards. Once each item in a care package has been purchased, the charity now has a complete package to send to those in need. Through donating, the user will build up a history, which will be used by CarePak to recommend similar packages and charities based on the user's preferences. Users have the option to see popular donation packages in their area, as well as popular packages worldwide.
## How I built it
We used React with the Material UI framework, and NodeJS and Express on the backend. The database is SQLite.
## Challenges I ran into
We initially planned on using MongoDB but discovered that our database design did not seem to suit MongoDB too well and this led to some lengthy delays. On Saturday evening, we made the decision to switch to a SQLite database to simplify the development process and were able to entirely restructure the backend in a matter of hours. Thanks to carefully discussed designs and good teamwork, we were able to make the switch without any major issues.
## Accomplishments that I'm proud of
We made an elegant and simple application with ideas that could be applied in the real world. Both the front-end and back-end were designed to be modular and could easily support some of the enhancements that we had planned for CarePak but were unfortunately unable to implement within the deadline.
## What I learned
Have a more careful selection process of tools and languages at the beginning of the hackathon development process, reviewing their suitability in helping build an application that achieves our planned goals. Any extra time we could have spent on the planning process would definitely have been more than saved by not having to make major backend changes near the end of the Hackathon.
## What's next for CarePak
* We would love to integrate Machine Learning features from AWS in order to gather data and create improved suggestions and recommendations towards users.
* We would like to add a view for charities, as well, so that they may be able to sign up and create care packages for the individuals they serve. Hopefully, we would be able to create a more attractive option for them as well through a simple and streamlined process that brings them closer to donors. | ## Inspiration
During our brainstorming, we were thinking about what we have in common as students and what we do often.
We are all students and want to cook at home to save money, but we often find ourselves in a situation where we have tons of ingredients that we cannot properly combine. With that in mind, we came up with an idea to build an app that helps you find the recipes that you can cook at home.
We are all excited about the project as it is something that a lot of people can utilize on a daily basis.
## What it does
Imagine you find yourself in a situation where you have some leftover chicken, pasta, milk, and spices. You can **open Mealify, input your ingredients, and get a list of recipes that you can cook with that inventory**.
## How we built it
For that idea, we decided to build a mobile app to ease the use of daily users - although you can also use it in the browser. Since our project is a full stack application, we enhanced our knowledge of all the stages of development. We started from finding the appropriate data, parsing it to the format we need and creating an appropriate SQL database. We then created our own backend API that is responsible for all the requests that our application uses - autocomplete of an ingredient for a user and actual finding of the ‘closest’ recipe. By using the custom created endpoints, we made the client part communicate with it by making appropriate requests and fetching responses. We then created the frontend part that lets a user naturally communicate with Mealify - using dynamic lists, different input types, and scrolling. The application is easy to use and does not rely on the user's proper inputs - we implemented the autocomplete option, and gave the option for units to not worry about proper spelling from a user.
## Challenges we ran into
We also recognized that it is possible that someone’s favorite meal is not in our database. In that case, we made a way to add a recipe to the database from a url. We used an ingredient parser to scan for all the ingredients needed for that recipe from the url. We then used Cohere to parse through the text on the url and find the exact quantity and units of the ingredient.
One challenge we faced was finding an API that could return recipes based on our ingredients and input parameters. So we decided to build our own API to solve that issue. Moreover, working on finding the ‘closest’ recipe algorithm was not trivial either. For that, we built a linear regression to find what would be the recipe that has the lowest cost for a user to buy additional ingredients. After the algorithm is performed, a user is presented with a number of recipes sorted in the order of ‘price’ - whether a user can already cook it or there's a small number of ingredients that needs to be purchased.
## Accomplishments that we're proud of
We're proud of how we were able to build a full-stack app and NLP model in such a short time.
## What we learned
We learned how to use Flutter, CockRoachDB, co:here, and building our API to deploy a full-stack mobile app and NLP model.
## What's next for Mealify
We can add additional functionality to let users add their own recipes! Eventually, we wouldn't rely as much our database and the users themselves can serve as the database by adding recipes. | winning |
## 💡 Inspiration
Generation Z is all about renting - buying land is simply out of our budgets. But the tides are changing: with Pocket Plots, an entirely new generation can unlock the power of land ownership without a budget.
Traditional land ownership goes like this: you find a property, spend weeks negotiating a price, and secure a loan. Then, you have to pay out agents, contractors, utilities, and more. Next, you have to go through legal documents, processing, and more. All while you are shelling out tens to hundreds of thousands of dollars.
Yuck.
Pocket Plots handles all of that for you.
We, as a future LLC, buy up large parcels of land, stacking over 10 acres per purchase. Under the company name, we automatically generate internal contracts that outline a customer's rights to a certain portion of the land, defined by 4 coordinate points on a map.
Each parcel is now divided into individual plots ranging from 1,000 to 10,000 sq ft, and only one person can own a contract to each plot to the plot.
This is what makes us fundamentally novel: we simulate land ownership without needing to physically create deeds for every person. This skips all the costs and legal details of creating deeds and gives everyone the opportunity to land ownership.
These contracts are 99 years and infinitely renewable, so when it's time to sell, you'll have buyers flocking to buy from you first.
You can try out our app here: <https://warm-cendol-1db56b.netlify.app/>
(AI features are available locally. Please check our Github repo for more.)
## ⚙️What it does
### Buy land like it's ebay:

We aren't just a business: we're a platform. Our technology allows for fast transactions, instant legal document generation, and resale of properties like it's the world's first ebay land marketplace.
We've not just a business.
We've got what it takes to launch your next biggest investment.
### Pocket as a new financial asset class...
In fintech, the last boom has been in blockchain. But after FTX and the bitcoin crash, cryptocurrency has been shaken up: blockchain is no longer the future of finance.
Instead, the market is shifting into tangible assets, and at the forefront of this is land. However, land investments have been gatekept by the wealthy, leaving little opportunity for an entire generation
That's where pocket comes in. By following our novel perpetual-lease model, we sell contracts to tangible buildable plots of land on our properties for pennies on the dollar.
We buy the land, and you buy the contract.
It's that simple.
We take care of everything legal: the deeds, easements, taxes, logistics, and costs. No more expensive real estate agents, commissions, and hefty fees.
With the power of Pocket, we give you land for just $99, no strings attached.
With our resell marketplace, you can sell your land the exact same way we sell ours: on our very own website.
We handle all logistics, from the legal forms to the system data - and give you 100% of the sell value, with no seller fees at all.
We even will run ads for you, giving your investment free attention.
So how much return does a Pocket Plot bring?
Well, once a parcel sells out its plots, it's gone - whoever wants to buy land from that parcel has to buy from you.
We've seen plots sell for 3x the original investment value in under one week. Now how insane is that? The tides are shifting, and Pocket is leading the way.
### ...powered by artificial intelligence
**Caption generation**
*Pocket Plots* scrapes data from sites like Landwatch to find plots of land available for purchase. Most land postings lack insightful descriptions of their plots, making it hard for users to find the exact type of land they want. With *Pocket Plots*, we transformed links into images, into helpful captions.

**Captions → Personalized recommendations**
These captions also inform the user's recommended plots and what parcels they might buy. Along with inputting preferences like desired price range or size of land, the user can submit a text description of what kind of land they want. For example, do they want a flat terrain or a lot of mountains? Do they want to be near a body of water? This description is compared with the generated captions to help pick the user's best match!

### **Chatbot**
Minute Land can be confusing. All the legal confusion, the way we work, and how we make land so affordable makes our operations a mystery to many. That is why we developed a supplemental AI chatbot that has learned our system and can answer questions about how we operate.
*Pocket Plots* offers a built-in chatbot service to automate question-answering for clients with questions about how the application works. Powered by openAI, our chat bot reads our community forums and uses previous questions to best help you.

## 🛠️ How we built it
Our AI focused products (chatbot, caption generation, and recommendation system) run on Python, OpenAI products, and Huggingface transformers. We also used a conglomerate of other related libraries as needed.
Our front-end was primarily built with Tailwind, MaterialUI, and React. For AI focused tasks, we also used Streamlit to speed up deployment.
### We run on Convex
We spent a long time mastering Convex, and it was worth it. With Convex's powerful backend services, we did not need to spend infinite amounts of time developing it out, and instead, we could focus on making the most aesthetically pleasing UI possible.
### Checkbook makes payments easy and fast
We are an e-commerce site for land and rely heavily on payments. While stripe and other platforms offer that capability, nothing compares to what Checkbook has allowed us to do: send invoices with just an email. Utilizing Checkbook's powerful API, we were able to integrate Checkbook into our system for safe and fast transactions, and down the line, we will use it to pay out our sellers without needing them to jump through stripe's 10 different hoops.
## 🤔 Challenges we ran into
Our biggest challenge was synthesizing all of our individual features together into one cohesive project, with compatible front and back-end. Building a project that relied on so many different technologies was also pretty difficult, especially with regards to AI-based features. For example, we built a downstream task, where we had to both generate captions from images, and use those outputs to create a recommendation algorithm.
## 😎 Accomplishments that we're proud of
We are proud of building several completely functional features for *Pocket Plots*. We're especially excited about our applications of AI, and how they make users' *Pocket Plots* experience more customizable and unique.
## 🧠 What we learned
We learned a lot about combining different technologies and fusing our diverse skillsets with each other. We also learned a lot about using some of the hackathon's sponsor products, like Convex and OpenAI.
## 🔎 What's next for Pocket Plots
We hope to expand *Pocket Plots* to have a real user base. We think our idea has real potential commercially. Supplemental AI features also provide a strong technological advantage. | ## Inspiration
We wanted to build a sustainable project which gave us the idea to plant crops on a farmland in a way that would give the farmer the maximum profit. The program also accounts for crop rotation which means that the land gets time to replenish its nutrients and increase the quality of the soil.
## What it does
It does many things, It first checks what crops can be grown in that area or land depending on the weather of the area, the soil, the nutrients in the soil, the amount of precipitation, and much more information that we have got from the APIs that we have used in the project. It then forms a plan which accounts for the crop rotation process. This helps the land regain its lost nutrients while increasing the profits that the farmer is getting from his or her land. This means that without stopping the process of harvesting we are regaining the lost nutrients. It also gives the farmer daily updates on the weather in that area so that he can be prepared for severe weather.
## How we built it
For most of the backend of the program, we used Python.
For the front end of the website, we used HTML. To format the website we used CSS. we have also used Javascript for formates and to connect Python to HTML.
We used the API of Twilio in order to send daily messages to the user in order to help the user be ready for severe weather conditions.
## Challenges we ran into
The biggest challenge that we faced during the making of this project was the connection of the Python code with the HTML code. so that the website can display crop rotation patterns after executing the Python back end script.
## Accomplishments that we're proud of
While making this each of us in the group has accomplished a lot of things. This project as a whole was a great learning experience for all of us. We got to know a lot of things about the different APIs that we have used throughout the project. We also accomplished making predictions on which crops can be grown in an area depending on the weather of the area in the past years and what would be the best crop rotation patterns. On the whole, it was cool to see how the project went from data collection to processing to finally presentation.
## What we learned
We have learned a lot of things in the course of this hackathon. We learned team management and time management, Moreover, we got hands on experience in Machine Learning. We got to implement Linear Regression, Random decision trees, SVM models. Finally, using APIs became second nature to us because of the number of them we had to use to pull data.
## What's next for ECO-HARVEST
For now, the data we have is only limited to the United States, in the future we plan to increase it to the whole world and also increase our accuracy in predicting which crops can be grown in the area. Using the crops that we can grow in the area we want to give better crop rotation models so that the soil will gain its lost nutrients faster. We also plan to give better and more informative daily messages to the user in the future. | ## Inspiration
From our experience renting properties from private landlords, we think the rental experience is broken. Payments and communication are fragmented for both landlords and tenants. As tenants, we have to pay landlords through various payment channels, and that process is even more frustrating if you have roommates. On the other hand, landlords have trouble reconciling payments coming from these several sources.
We wanted to build a rental companion that initially tackles this problem of payments, but extends to saving time and headaches in other aspects of the rental experience. As we are improving convenience for landlords and tenants, we focused solely on a mobile application.
## What it does
* Allows tenants to make payments quickly in less than three clicks
* Chatbot interface that has information about the property's lease and state-specific rental regulation
* Landlords monitor the cash flow of their properties transparently and granularly
## How we built it
* Full stack React Native app
* Convex backend and storage
* Stripe credit card integration
* Python backend for Modal & GPT3 integration
## Challenges we ran into
* Choosing a payment method that is reliable and fast to implement
* Parsing lease agreements and training GPT3 models
* Deploying and running modal.com for the first time
* Ensuring transaction integrity and idempotency on Convex
## Accomplishments that we're proud of
* Shipped chat bot although we didn't plan to
* Pleased about the UI design
## What we learned
* Mobile apps are tough for hackathons
* Payment integrations have become very accessible
## What's next for Domi Rental Companion
* See if we provide value for target customers | winning |
## Inspiration
A week or so ago, Nyle DiMarco, the model/actor/deaf activist, visited my school and enlightened our students about how his experience as a deaf person was in shows like Dancing with the Stars (where he danced without hearing the music) and America's Next Top Model. Many people on those sets and in the cast could not use American Sign Language (ASL) to communicate with him, and so he had no idea what was going on at times.
## What it does
SpeakAR listens to speech around the user and translates it into a language the user can understand. Especially for deaf users, the visual ASL translations are helpful because that is often their native language.

## How we built it
We utilized Unity's built-in dictation recognizer API to convert spoken word into text. Then, using a combination of gifs and 3D-modeled hands, we translated that text into ASL. The scripts were written in C#.
## Challenges we ran into
The Microsoft HoloLens requires very specific development tools, and because we had never used the laptops we brought to develop for it before, we had to start setting everything up from scratch. One of our laptops could not "Build" properly at all, so all four of us were stuck using only one laptop. Our original idea of implementing facial recognition could not work due to technical challenges, so we actually had to start over with a **completely new** idea at 5:30PM on Saturday night. The time constraint as well as the technical restrictions on Unity3D reduced the number of features/quality of features we could include in the app.
## Accomplishments that we're proud of
This was our first time developing with the HoloLens at a hackathon. We were completely new to using GIFs in Unity and displaying it in the Hololens. We are proud of overcoming our technical challenges and adapting the idea to suit the technology.
## What we learned
Make sure you have a laptop (with the proper software installed) that's compatible with the device you want to build for.
## What's next for SpeakAR
In the future, we hope to implement reverse communication to enable those fluent in ASL to sign in front of the HoloLens and automatically translate their movements into speech. We also want to include foreign language translation so it provides more value to **deaf and hearing** users. The overall quality and speed of translations can also be improved greatly. | ## Inspiration
In online documentaries, we saw visually impaired individuals and their vision consisted of small apertures. We wanted to develop a product that would act as a remedy for this issue.
## What it does
When a button is pressed, a picture is taken of the user's current view. This picture is then analyzed using OCR (Optical Character Recognition) and the text is extracted from the image. The text is then converted to speech for the user to listen to.
## How we built it
We used a push button connected to the GPIO pins on the Qualcomm DragonBoard 410c. The input is taken from the button and initiates a python script that connects to the Azure Computer Vision API. The resulting text is sent to the Azure Speech API.
## Challenges we ran into
Coming up with an idea that we were all interested in, incorporated a good amount of hardware, and met the themes of the makeathon was extremely difficult. We attempted to use Speech Diarization initially but realized the technology is not refined enough for our idea. We then modified our idea and wanted to use a hotkey detection model but had a lot of difficulty configuring it. In the end, we decided to use a pushbutton instead for simplicity in favour of both the user and us, the developers.
## Accomplishments that we're proud of
This is our very first Makeathon and we were proud of accomplishing the challenge of developing a hardware project (using components we were completely unfamiliar with) within 24 hours. We also ended up with a fully function project.
## What we learned
We learned how to operate and program a DragonBoard, as well as connect various APIs together.
## What's next for Aperture
We want to implement hot-key detection instead of the push button to eliminate the need of tactile input altogether. | . | winning |
## Inspiration
We wanted to build an app to help save people's money through smart budgeting. We want to integrate Alexa with personal finance skills which it is currently lacking.
## What it does
Budget It is a web app connected to the Amazon Alexa to inform users how much money they have spent or saved. Users can input how much they have spent on a certain category given their budget. The user interface is clean and easy to use and Alexa briefings make our application really easy to interact with.
## How I built it
We utilized a variety of tools to build the app such as HTML/CSS, Javascript, Java, and Python. As for platforms we used Google Cloud Platform's App Engine and Amazon Web Service.
## Challenges I ran into
We spent a long time brainstorming and learning about React but decided to switch to Web App in the end. With Google Cloud Platform, we struggled to authorize and debug with Firebase since it was our first time using the tool.
## Accomplishments that I'm proud of
Despite our difficulties, we are proud of what we were able to accomplish. We learned new frameworks, tools, and languages in a short amount of time. Our app is still a work in progress, but we are proud to have something to show our hard work.
## What I learned
We learned technical skills of using a large-scale platform and new programming languages. We also learned to persevere and never give up when faced with a barrier. With the new skills that we have acquired, we hope to create more.
## What's next for Budget It
We hope to allow users to connect with each other to compare each other's spending situations under their consent. We also hope to provide insights of national or state financial statistics and comparing individual data to it. | ## Inspiration
In a world where finance is extremely important, everyone needs access to **banking services**. Citizens within **third world countries** are no exception, but they lack the banking technology infrastructure that many of us in first world countries take for granted. Mobile Applications and Web Portals don't work 100% for these people, so we decided to make software that requires nothing more than a **cellular connection to send SMS messages** in order to operate. This resulted in our hack, **UBank**.
## What it does
**UBank** allows users to operate their bank accounts entirely through **text messaging**. Users can deposit money, transfer funds between accounts, transfer accounts to other users, and even purchases shares of stock via SMS. In addition to this text messaging capability, UBank also provides a web portal so that when our users gain access to a steady internet connection or PC, they can view their financial information on a more comprehensive level.
## How I built it
We set up a backend HTTP server in **Node.js** to receive and fulfill requests. **Twilio** with ngrok was used to send and receive the text messages through a webhook on the backend Node.js server and applicant data was stored in firebase. The frontend was primarily built with **HTML, CSS, and Javascript** and HTTP requests were sent to the Node.js backend to receive applicant information and display it on the browser. We utilized Mozilla's speech to text library to incorporate speech commands and chart.js to display client data with intuitive graphs.
## Challenges I ran into
* Some team members were new to Node.js, and therefore working with some of the server coding was a little complicated. However, we were able to leverage the experience of other group members which allowed all of us to learn and figure out everything in the end.
* Using Twilio was a challenge because no team members had previous experience with the technology. We had difficulties making it communicate with our backend Node.js server, but after a few hours of hard work we eventually figured it out.
## Accomplishments that I'm proud of
We are proud of making a **functioning**, **dynamic**, finished product. It feels great to design software that is adaptable and begging for the next steps of development. We're also super proud that we made an attempt at tackling a problem that is having severe negative effects on people all around the world, and we hope that someday our product can make it to those people.
## What I learned
This was our first using **Twillio** so we learned a lot about utilizing that software. Front-end team members also got to learn and practice their **HTML/CSS/JS** skills which were a great experience.
## What's next for UBank
* The next step for UBank probably would be implementing an authentication/anti-fraud system. Being a banking service, it's imperative that our customers' transactions are secure at all times, and we would be unable to launch without such a feature.
* We hope to continue the development of UBank and gain some beta users so that we can test our product and incorporate customer feedback in order to improve our software before making an attempt at launching the service. | ## Inspiration
Food-waste has been determined as one of the biggest contributors to a greenhouse gas, methane, which has 21 more times global warming potential than carbon dioxide. Each year, around $31 billion of food are wasted every year in Canada, which about half of these wastes are produced at households. And sometimes we throw these food away because we have forgotten its expiry date. If there exists an assistant that can notify users to eat the food before its expiry date, we could reduce food waste by a great amount.
## What it does
StillGood is a voice activated Google Assistant service that keeps track of your grocery purchases and predicts when they are good or expired. Using this information, StillGood is able to notify users before food has gone bad to prevent it from being wasted. It can also suggest recipes using those ingredients in order to enable users to use their goods to their full extent. StillGood can then offer you more sustainable alternatives as well to what you already have in your fridge in order to help you shop better and buy more sustainable products that are healthier and/or have a smaller carbon footprint.
## How I built it
After we decided on the idea that we were going to build upon, we split the team into groups of two, with two working on the web interface and two working on the voice control and data processing of the product. One team-member was web-scraping for useful and reliable data sets to serve as sample set of our product; one team-member was learning how to connect voice-control in Google Home Mini to our system; one team-member was learning and working on the front-end of the web interface while the other member was responsible for the back-end of the web interface and the overall structure of the system.
## Challenges I ran into
The main challenges the team ran into is how to design for best user experience. The service should be easy to use and to understand, and there shouldn't be any additional steps that require the users to complete in order to get the answers they want. We have experienced hard time trying to find reliable data through web scraping.It is also a brand new field for us to incorporate smart home into our application. Besides the voice control functionality of StillGood, we have also tried to maximize the user experience with the web interface as additional support.
## Accomplishments that I'm proud of
To build something practical that could potentially tackle real-world problem. At the moment when we finished this project, it helps us gain a better understanding of how we could actually use the technical skills we have learned in class into something useful and could perhaps benefit the society as a whole. We also have the opportunity to work with technology that we have never worked with before(i.e. Alexa).
## What I learned
All of the team were willing to take on tasks that they have never done before. Being exposed to new materials, we have practices our problem-solving skills and cooperate as a team. Some of us worked on web development while others worked on voice automation; tasks that we had never done before!
## What's next for StillGood
As a product that is created within 24 hours, StillGood certainly has a lot of aspects that need to be polished and finalized for better use. Next steps for StillGood is going to be shaping it towards a smart fridge. The current method of determining expiry date of fruits and veggies is still vague and usually inaccurate. And currently we still require users to checkoff the food they have eaten by themselves. In the future, we hope to incorporate computer vision to monitor the status of inside of the fridge, providing accurate prediction of expiry dates by using machine learning and reducing users' work to record data. We also hope to add a point system that would offer users promotions if they obtain points from StillGood. | winning |
## Inspiration
Beautiful stationery and binders filled with clips, stickies, and colourful highlighting are things we miss from the past. Passing notes and memos and recognizing who it's from just from the style and handwriting, holding the sheet in your hand, and getting a little personalized note on your desk are becoming a thing of the past as the black and white of emails and messaging systems take over. Let's bring back the personality, color, and connection opportunities from memo pads in the office while taking full advantage of modern technology to make our lives easier. Best of both worlds!
## What it does
Memomi is a web application for offices to simplify organization in a busy environment while fostering small moments of connection and helping fill in the gaps on the way. Using powerful NLP technology, Memomi automatically links related memos together, suggests topical new memos to expand on missing info on, and allows you to send memos to other people in your office space.
## How we built it
We built Memomi using Figma for UI design and prototyping, React web apps for frontend development, Flask APIs for the backend logic, and Google Firebase for the database. Cohere's NLP API forms the backbone of our backend logic and is what powers Memomi's intelligent suggestions for tags, groupings, new memos, and links.
## Challenges we ran into
With such a dynamic backend with more complex data, we struggled to identify how best to organize and digitize the system. We also struggled a lot with the frontend because of the need to both edit and display data annotated at the exact needed positions based off our information. Connecting our existing backend features to the frontend was our main barrier to showing off our accomplishments.
## Accomplishments that we're proud of
We're very proud of the UI design and what we were able to implement in the frontend. We're also incredibly proud about how strong our backend is! We're able to generate and categorize meaningful tags, groupings, and links between documents and annotate text to display it.
## What we learned
We learned about different NLP topics, how to make less rigid databases, and learned a lot more about advanced react state management.
## What's next for Memomi
We would love to implement sharing memos in office spaces as well as authorization and more text editing features like markdown support. | ## Inspiration
We are part of a generation that has lost the art of handwriting. Because of the clarity and ease of typing, many people struggle with clear shorthand. Whether you're a second language learner or public education failed you, we wanted to come up with an intelligent system for efficiently improving your writing.
## What it does
We use an LLM to generate sample phrases, sentences, or character strings that target letters you're struggling with. You can input the writing as a photo or directly on the webpage. We then use OCR to parse, score, and give you feedback towards the ultimate goal of character mastery!
## How we built it
We used a simple front end utilizing flexbox layouts, the p5.js library for canvas writing, and simple javascript for logic and UI updates. On the backend, we hosted and developed an API with Flask, allowing us to receive responses from API calls to state-of-the-art OCR, and the newest Chat GPT model. We can also manage user scores with Pythonic logic-based sequence alignment algorithms.
## Challenges we ran into
We really struggled with our concept, tweaking it and revising it until the last minute! However, we believe this hard work really paid off in the elegance and clarity of our web app, UI, and overall concept.
..also sleep 🥲
## Accomplishments that we're proud of
We're really proud of our text recognition and matching. These intelligent systems were not easy to use or customize! We also think we found a creative use for the latest chat-GPT model to flex its utility in its phrase generation for targeted learning. Most importantly though, we are immensely proud of our teamwork, and how everyone contributed pieces to the idea and to the final project.
## What we learned
3 of us have never been to a hackathon before!
3 of us never used Flask before!
All of us have never worked together before!
From working with an entirely new team to utilizing specific frameworks, we learned A TON.... and also, just how much caffeine is too much (hint: NEVER).
## What's Next for Handwriting Teacher
Handwriting Teacher was originally meant to teach Russian cursive, a much more difficult writing system. (If you don't believe us, look at some pictures online) Taking a smart and simple pipeline like this and updating the backend intelligence allows our app to incorporate cursive, other languages, and stylistic aesthetics. Further, we would be thrilled to implement a user authentication system and a database, allowing people to save their work, gamify their learning a little more, and feel a more extended sense of progress. | ## Inspiration
While a member of my team was conducting research at UCSF, he noticed a family partaking in a beautiful, albeit archaic, practice. They gave their grandfather access to a google doc, where each family member would write down the memories that they have with him. Nearly every day, the grandfather would scroll through the doc and look at the memories that him and his family wanted him to remember.
## What it does
Much like the Google Doc does, our site stores memories inputted by either the main account holder themself, or other people who have access to the account, perhaps through a shared family email. From there, the memories show up on the users feed and are tagged with the emotion they indicate. Someone with Alzheimers can easily search through their memories to find what they are looking for. In addition, our Chatbot feature trained on their memories also allows users to easily talk to the app directly, asking what they are looking for.
## How we built it
Next.js, React, Node.js, Tailwind, etc.
## Challenges we ran into
It was difficult implementing our chatbot in a way where it is automatically update with data that our user inputs into the site. Moreover, we were working with React for the first time and faced many challenges trying to build out and integrate the different technologies into our website including setting up MongoDB, Flask, and different APIs.
## Accomplishments that we're proud of
Getting this done! Our site is polished and carries out our desired functions well!
## What we learned
As beginners, we were introduced to full-stack development!
## What's next for Scrapbook
We'd like to introduce Scrapbook to medical professionals at UCSF and see their thoughts on it. | winning |
## Inspiration
Homelessness affects over half a million Americans on any given night, yet almost 17 million potential homes were standing empty according to a White House report in 2019. This means there are 33 empty properties for each homeless person in the US. Since 2010, the number of empty properties per homeless person has increased 24%
Increasingly, individuals and families needing emergency shelter have a disability, come from unsheltered locations, and face higher barriers to housing. While transitional and emergency housing can immediately provide month-long stays while people reconnect with housing, we saw opportunity in utilizing empty properties for shorter stays — as little as 3 hours worth — for instances where someone needs:
* a safe place to leave their children to run errands/go for job interview
* shelter from unpredictable and inclement weather
* a private space to work safely and remotely
## What it does
That's why we created HOME (Housing Opportunities for Movers Everywhere), a platform that enables homeless shelters to rapidly and efficiently connect people with housing through microtransactions and smart contracts.
Our blockchain-based app collects cryptocurrency from donors to fund temporary stays that can be a little as 3 hours long. Using smart contracts, donors can determine criteria for who ultimately receives their assistance and have transparency in how their donation was used, have a tax write-off via having a receipt of their donation on an immutable ledger and as autogenerated by the homeless shelter they donated to, and donate with peace of mind because of our app's safeguarding mechanism of ensuring that, if donors gave a large amount, only a portion of what's donated is distributed each day.
Those searching for housing and temporary housing would register their information with homeless shelters. Our app would be integrated with this process in a way that allows individuals to remain anonymous to the app. What homeless shelter staff would be able to see is the relevant demographics of their clients, a list of housing available, and potential matches through our app's matching algorithm. Once staff suggests having a verified client take advantage of a housing opportunity, the respective property owner would confirm whether the stay can happen. After confirming that this connection can happen, shelter staff would provide a code to their client or alternative way for verifying who they are to property owners. Once they successfully verify who they are with the property owner and gain access to the property, the payment from one or more smart contracts (depending on the cost of a stay) would be released to the property owner.
All this is done without the app needing to know any information about those experiencing homelessness. Property owners would only know that a homeless shelter has verified that this individual or family has a need. Not only does our app allow individuals to receive housing support with dignity, but it also solves an inefficiency problem whereby not everyone needs to reserve a space for a whole day or even a whole month, or has the means to do something like an airbnb.
## How we built it
We built this using React.js, Next.js, Chakra UI for fast prototyping, MongoDB for database, and Solidity for faciliating smart contracts.
## Challenges we ran into
An app like this has not been created before to our knowledge, so we were exploring new frontiers here. We had many discussions about architecture such as whether we could pare down to one smart contract that does it all or if we needed two. As we were working through the project, we discovered some initial approaches we had planned like using signatures in blockchain were no longer feasible due to synchronization problems.
## Accomplishments that we're proud of
Our project scope was huge for what we wanted to accomplish technically, and we were able to figure out the necessary pieces to have a working app without having to scale down our original vision.
## What we learned
We learned about how blockchain can be applied to help tackle a complex system issue like homelessness. Surprisingly, one mentor mentioned being at one of the world's largest Web3 innovation festivals discussing how blockchain hasn't been used as much to solve high stakes social problems.
For some team members, there was a steep learning curve for learning new frameworks (React/Next.js) and component libraries. For other team members, coding and architecting workflow in blockchain and integrating UI to the back end was most challenging yet rewarding to figure out.
## What's next for HOME
Moving forward with a pilot program— | ## Inspiration
Linked Women was inspired by the frequent intimidation felt by women on networking platforms due to pre-existing app appearance, male-dominated user demographic, and intimidating/impersonal content. This app is inspired by the desire to combat and dismantle patriarchal systems that exist within social media and the career ladder that continue to exclude women in fields such as finance and tend to underestimate women and their skills in significant highlights of the financial world, such as networking and promotion. Current patriarchal systems held in the workplace confine the ability for young women to achieve effective mentorship, and so this app sets out to break the pattern of women feeling overwhelmed and disadvantaged from the start of their journey in their finance career.
## What it does
We aspired to design an app that will encourage young women who may be new to finance (or who are looking to find a welcoming community) to continue to deepen their interest by connecting with other women who are interested or involved in the field. This app has key features, including a Home page, a Resource page, a Chat page, a Networking page, and a Profile page.
The Home page includes posts: photographic, text, or a combination of the two, and allows the user to interact with those in their network. It is encouraged for users to post more personal content to stray from the overcomplication and impersonality of posts seen on other networking applications.
The Resource page includes a variety of resources that the user may utilize to enhance their finance education. Features on this page include:
* An Events tab to seek professional events happening nearby
* A Trending tab to seek news articles about trending topics
* A Bitcoin tab to seek articles specifically related to Bitcoin/Crypto
* An Exchange tab to seek information on foreign exchange
* A Stocks tab to seek activity on selected stocks
* A Finance tab to aid in finance management
The Chat page allows users to interact through text chat, with the option to send photo messages.
The Networking page allows users to search and connect with other users of the app, with an added feature to sync the Linked Women to LinkedIn.
The Profile page allows users to customize their profile and input information on how they would like to be displayed on the app. The profile page displays the users recent posts, as well as their education history and work experience.
## How we built it
We used Figma to design the app and to prototype the app.
## Challenges we ran into
We faced challenges in initially learning how to use Figma. This was a new application for us, so we needed time to learn how to navigate the software. Additionally, we faced challenges in the ideation process. Our initial idea did not suffice, which caused us to have lost a few hours. However, we were able to move past disagreements from our initial idea and work together to combine our ideas to develop our app design. Our disagreements throughout the project were challenges itself, but through communication we were able to sort out what ideas would be best for our ultimate goal.
## Accomplishments that we're proud of
We are proud to have been able to create an app design that was aesthetically pleasing. We learnt plenty about aesthetics through this. Additionally, we are proud of our idea proposal and believe that an app geared towards reducing the intimidation male dominated networking apps could truly encourage young women to become more confident and assertive.
## What we learned
We learned a lot about Figma and how app design and prototyping works. This was our first time creating a project using Figma.
## What's next for Linked Women
We hope to be able to improve the usability of Linked Women in the future in was such as ridding less relevant features and adding accessibility options as well. We also hope to turn this prototype into a running app and learn the programming behind operating a functional app. | ## Inspiration
We are currently living through one of the largest housing crises in human history. As a result, more Canadians than ever before are seeking emergency shelter to stay off the streets and find a safe place to recuperate. However, finding a shelter is still a challenging, manual process, where no digital service exists that lets individuals compare shelters by eligibility criteria, find the nearest one they are eligible for, and verify that the shelter has room in real-time. Calling shelters in a city with hundreds of different programs and places to go is a frustrating burden to place on someone who is in need of safety and healing. Further, we want to raise the bar: people shouldn't be placed in just any shelter, they should go to the shelter best for them based on their identity and lifestyle preferences.
70% of homeless individuals have cellphones, compared to 85% of the rest of the population; homeless individuals are digitally connected more than ever before, especially through low-bandwidth mediums like voice and SMS. We recognized an opportunity to innovate for homeless individuals and make the process for finding a shelter simpler; as a result, we could improve public health, social sustainability, and safety for the thousands of Canadians in need of emergency housing.
## What it does
Users connect with the ShelterFirst service via SMS to enter a matching system that 1) identifies the shelters they are eligible for, 2) prioritizes shelters based on the user's unique preferences, 3) matches individuals to a shelter based on realtime availability (which was never available before) and the calculated priority and 4) provides step-by-step navigation to get to the shelter safely.
Shelter managers can add their shelter and update the current availability of their shelter on a quick, easy to use front-end. Many shelter managers are collecting this information using a simple counter app due to COVID-19 regulations. Our counter serves the same purpose, but also updates our database to provide timely information to those who need it. As a result, fewer individuals will be turned away from shelters that didn't have room to take them to begin with.
## How we built it
We used the Twilio SMS API and webhooks written in express and Node.js to facilitate communication with our users via SMS. These webhooks also connected with other server endpoints that contain our decisioning logic, which are also written in express and Node.js.
We used Firebase to store our data in real time.
We used Google Cloud Platform's Directions API to calculate which shelters were the closest and prioritize those for matching and provide users step by step directions to the nearest shelter. We were able to capture users' locations through natural language, so it's simple to communicate where you currently are despite not having access to location services
Lastly, we built a simple web system for shelter managers using HTML, SASS, JavaScript, and Node.js that updated our data in real time and allowed for new shelters to be entered into the system.
## Challenges we ran into
One major challenge was with the logic of the SMS communication. We had four different outgoing message categories (statements, prompting questions, demographic questions, and preference questions), and shifting between these depending on user input was initially difficult to conceptualize and implement. Another challenge was collecting the distance information for each of the shelters and sorting between the distances, since the response from the Directions API was initially confusing. Lastly, building the custom decisioning logic that matched users to the best shelter for them was an interesting challenge.
## Accomplishments that we're proud of
We were able to build a database of potential shelters in one consolidated place, which is something the city of London doesn't even have readily available. That itself would be a win, but we were able to build on this dataset by allowing shelter administrators to update their availability with just a few clicks of a button. This information saves lives, as it prevents homeless individuals from wasting their time going to a shelter that was never going to let them in due to capacity constraints, which often forced homeless individuals to miss the cutoff for other shelters and sleep on the streets. Being able to use this information in a custom matching system via SMS was a really cool thing for our team to see - we immediately realized its potential impact and how it could save lives, which is something we're proud of.
## What we learned
We learned how to use Twilio SMS APIs and webhooks to facilitate communications and connect to our business logic, sending out different messages depending on the user's responses. In addition, we taught ourselves how to integrate the webhooks to our Firebase database to communicate valuable information to the users.
This experience taught us how to use multiple Google Maps APIs to get directions and distance data for the shelters in our application. We also learned how to handle several interesting edge cases with our database since this system uses data that is modified and used by many different systems at the same time.
## What's next for ShelterFirst
One addition to make could be to integrate locations for other basic services like public washrooms, showers, and food banks to connect users to human rights resources. Another feature that we would like to add is a social aspect with tags and user ratings for each shelter to give users a sense of what their experience may be like at a shelter based on the first-hand experiences of others. We would also like to leverage the Twilio Voice API to make this system accessible via a toll free number, which can be called for free at any payphone, reaching the entire homeless demographic.
We would also like to use Raspberry Pis and/or Arduinos with turnstiles to create a cheap system for shelter managers to automatically collect live availability data. This would ensure the occupancy data in our database is up to date and seamless to collect from otherwise busy shelter managers. Lastly, we would like to integrate into municipalities "smart cities" initiatives to gather more robust data and make this system more accessible and well known. | losing |
## Inspiration
We often want to read certain manga because we are interested in their stories, but are completely barred from doing so purely because there is no translation for them in English. As a result, we decided to make our own solution, in which we take the pages of the manga, translate them, and rewrite them for you.
## What it does
It takes the image of the manga page and sends it to a backend. The backend first uses a neural network trained with thousands of cases of actual manga to detect the areas of writing and text on the manga. Then, the server clears that area out of the image. Using Google Cloud Services, we then take the written Japanese and translate into English. Lastly we rewrite that English in its corresponding postitions on the original image to complete the manga page.
## How we built it
We used python and flask with a bit of html and css for the front end Web server. We used Expo to create a mobile front end as well. We wrote the backend in python.
## Challenges we ran into
One of the challenges was properly using Expo, a service/platform new to us, to fit our many needs. There were some functionalities we wanted that Expo didn't have. However, we found manual work-arounds.
## Accomplishments that we're proud of
We are proud of successfully creating this project, especially because it was a difficult task. The fact that we successfully completed a working product that we can consider using ourselves makes this accomplishment even better.
## What we learned
We learned a lot about how to use Expo, since it was our first time using it. We also learned about how to modify images through python along the way.
## What's next for Kero
Kero's front-end can be expanded to look nicer and have more functionality, like multiple images at once for translating a whole chapter of a manga. | ## Inspiration
For building the most potential and improved healthcare monitoring system
Inspiration One of the worst things that can occur to a person is hearing the recent news of a loved one’s recent lethal drug overdose and other healthcare issues. This can occur for a number of reasons; some may have conditions such as people can forget their proper medication amounts, or perhaps the person was just thinking and acting in a rash manner. The system is designed to securely keep track of medications as well as prescriptions given to people. | ## Inspiration
We wanted to allow financial investors and people of political backgrounds to save valuable time reading financial and political articles by showing them what truly matters in the article, while highlighting the author's personal sentimental/political biases.
We also wanted to promote objectivity and news literacy in the general public by making them aware of syntax and vocabulary manipulation. We hope that others are inspired to be more critical of wording and truly see the real news behind the sentiment -- especially considering today's current events.
## What it does
Using Indico's machine learning textual analysis API, we created a Google Chrome extension and web application that allows users to **analyze financial/news articles for political bias, sentiment, positivity, and significant keywords.** Based on a short glance on our visualized data, users can immediately gauge if the article is worth further reading in their valuable time based on their own views.
The Google Chrome extension allows users to analyze their articles in real-time, with a single button press, popping up a minimalistic window with visualized data. The web application allows users to more thoroughly analyze their articles, adding highlights to keywords in the article on top of the previous functions so users can get to reading the most important parts.
Though there is a possibilitiy of opening this to the general public, we see tremendous opportunity in the financial and political sector in optimizing time and wording.
## How we built it
We used Indico's machine learning textual analysis API, React, NodeJS, JavaScript, MongoDB, HTML5, and CSS3 to create the Google Chrome Extension, web application, back-end server, and database.
## Challenges we ran into
Surprisingly, one of the more challenging parts was implementing a performant Chrome extension. Design patterns we knew had to be put aside to follow a specific one, to which we gradually aligned with. It was overall a good experience using Google's APIs.
## Accomplishments that we're proud of
We are especially proud of being able to launch a minimalist Google Chrome Extension in tandem with a web application, allowing users to either analyze news articles at their leisure, or in a more professional degree. We reached more than several of our stretch goals, and couldn't have done it without the amazing team dynamic we had.
## What we learned
Trusting your teammates to tackle goals they never did before, understanding compromise, and putting the team ahead of personal views was what made this Hackathon one of the most memorable for everyone. Emotional intelligence played just as an important a role as technical intelligence, and we learned all the better how rewarding and exciting it can be when everyone's rowing in the same direction.
## What's next for Need 2 Know
We would like to consider what we have now as a proof of concept. There is so much growing potential, and we hope to further work together in making a more professional product capable of automatically parsing entire sites, detecting new articles in real-time, working with big data to visualize news sites differences/biases, topic-centric analysis, and more. Working on this product has been a real eye-opener, and we're excited for the future. | partial |
## Inspiration
As people are stuck indoors, online learning has become more and more common. Whether it's for improving one's skillset, or just exploring a new field, the internet is a fantastic place for education; however, it can often be a bit overwhelming! Questions such as, "Where do I start?" and "What are the best resources available to me?" are common. Using Pathfinder, we set out to help people understand learning a new skill.
## What it does
In short, given a topic, Pathfinder gives a visualization of how to get started learning that skill. This includes related topics, useful prerequisites, videos, and more. For example, if "Software Design" was entered, related topics such as "Web development" or "Machine Learning" would be suggested (all easily searchable with a click), which prerequisites such as "Introduction to programming" would be recommended.
## How we built it
For the front end, we have a web application built with React in JavaScript. On the back end, we have a RESTful API built with Flask in Python, and the whole thing was hosted on Google Cloud.
## Challenges we ran into
Like a lot of projects, it was connecting to front end to the back end. More specifically, getting the information to be effectively passed between the data collection and data visualization.
## Accomplishments that we're proud of
* Creating an effective data collection tool
* Making an appealing front end
* Doing it all in 24 hours
## What we learned
Definitely a lot about data collection and visualization, from getting it on the backend to displaying it in an understandable way on the front end. It was also very informative learning about creating a data visualizer, which involved graph/node relations
## What's next for Pathfinder
Hopefully we can improve the UI a bit, as well as a more thorough related topics/prerequisites data. Furthermore, many topics are not meant to be searched (ex. 'electric boogalo'), which we could add some sort of filter for. | ## What inspired us:
The pandemic has changed the university norm to being primarily all online courses, increasing our usage and dependency on textbooks and course notes. Since we are all computer science students, we have many math courses with several definitions and theorems to memorize. When listening to a professor’s lecture, we often forget certain theorems that are being referred to. With discussAI, we are easily able to query the postgresql database with a command and receive an image from the textbook explaining what the definition/theorem is. Thus, we decided to use our knowledge with machine learning libraries to filter out these pieces of information.
We believe that our program’s concept can be applied to other fields, outside of education. For instance, business meetings or training sessions can utilize these tools to effectively summarize long manuals and to search for keywords.
## What we learned:
We had a lot of fun building this application since we were new to using Microsoft Azure applications. We learned how to integrate machine learning libraries such as OCR and sklearn for processing our information, and we deepened our knowledge in frontend (Angular.js) and backend(Django and Postgres).
## How we built it:
We built our web application’s frontend using Angular.js to build our components and Agora.io to allow video conferencing. On our backend, we used Django and Postgresql for handling API requests from our frontend. We also used several Python libraries to convert the pdf file to png images, utilize Azure OCR to analyze these text images, apply the sklearn library to analyze the individual text, and finally crop the images to return specific snippets of definitions/theorems.
## Challenges we faced:
The most challenging part was deciding our ML algorithm to derive specific image snippets from lengthy textbooks. Some other challenges we faced varies from importing images from Azure Storage to positioning CSS components. Nevertheless, the learning experience was amazing with the help of mentors, and we hope to participate again in the future! | Mafia with LLMs! Built with Python/React/Typescript/Websockets and Cartesia/Groq/Gemini. | losing |
## Inspiration
During the pandemic, we found ourselves sitting down all day long in a chair, staring into our screens and stagnating away. We wanted a way for people to get their blood rushing and have fun with a short but simple game. Since we were interested in getting into Augmented Reality (AR) apps, we thought it would be perfect to have a game where the player has to actively move a part of their body around to dodge something you see on the screen, and thus Splatt was born!
## What it does
All one needs is a browser and a webcam to start playing the game! The goal is to dodge falling barrels and incoming cannonballs with your head, but you can also use your hands to "cut" down the projectiles (you'll still lose partial lives, so don't overuse your hand!).
## How we built it
We built the game using JavaScript, React, Tensorflow, and WebGL2. Horace worked on the 2D physics, getting the projectiles to fall and be thrown around, as well as working on the hand tracking. Thomas worked on the head tracking using Tensorflow and outputting the necessary values we needed to be able to implement collision, as well as the basic game menu. Lawrence worked on connecting the projectile physics and the head/hand tracking together to ensure proper collision could be detected, as well as restructuring the app to be more optimized than before.
## Challenges we ran into
It was difficult getting both the projectiles and the head/hand from the video on the same layer - we had initially used two separate canvasses for this, but we quickly realized it would be difficult to communicate from one canvas to another without causing too many rerenders. We ended up using a single canvas and after adjusting how we retrieved the coordinates of the projectiles and the head/hand, we were able to get collisions to work.
## Accomplishments that we're proud of
We're proud about how we divvy'd up the work and were able to connect everything together to get a working game. During the process of making the game, we were excited to have been able to get collisions working, since that was the biggest part to make our game complete.
## What we learned
We learned more about implementing 2D physics in JavaScript, how we could use Tensorflow to create AR apps, and a little bit of machine learning through that.
## What's next for Splatt
* Improving the UI for the game
* Difficulty progression (1 barrel, then 2 barrels, then 2 barrels and 1 cannonball, and so forth) | ## Inspiration
Apple Wallet's a magical tool for anybody. Enjoy the benefits of your credit card, airline or concert ticket, and more without the hassles of keeping a physical object. But one crucial limitation is that these cards generally can't be put on the Apple Wallet without the company itself developing a supportive application. Thus, we're stuck in an awkward middle ground of half our cards being on our phone and the other half being in our wallet.
## What it does
Append scans your cards and collects enough data to create an Apple Wallet pass. This means that anything with a standardized code(most barcodes, QR codes, Aztec codes, etc.) can be scanned in, and redisplayed on your Apple Wallet for your use. This includes things like student IDs, venue tickets, and more.
## How we built it
We used Apple's Vision framework to analyze the live video feed from the iPhone to collect the code data. Our app parses the barcode to analyze its data, and then generates its own code to put on the wallet. It uses an external API to assist with generating the necessary wallet files, and then the wallet is presented to the user. From the user opening the app to downloading his/her wallet, the process takes about 30 seconds total.
## Challenges we ran into
We ran into some troubles regarding nonstandardized barcodes, or ambiguity concerning different standards. Fortunately, we developed methods around them, and reached a point where we can recognize the major standards that exist.
## Accomplishments that we're proud of
A large portion of the documentation regarding adding custom Apple Wallet passes are outdated. What's worse is that a subset of these outdated documentation are wrong in subtle ways, i.e. the code compiles but has different behavior. Navigating with limited vision was difficult, but we succeeded in the end.
## What we learned
We learned a lot about Apple's PassKit API. The protocols behind it are well implemented, and seeing them in action gave us even more personal confidence in using Apple Wallet for wallet needs in the future.
## What's next for Append
We want to implement our own custom API for producing Apple Wallet files, to make sure that any user data is completely secure. Additionally, we want to take advantage of iPhone hardware to read and reproduce NFC data so that every aspect of the physical card can be replaced. | ## Inspiration
Osu! players often use drawing tablets instead of a normal mouse and keyboard setup because a tablet gives more precision than a mouse can provide. These tablets also provide a better way to input to devices. Overuse of conventional keyboards and mice can lead to carpal tunnel syndrome, and can be difficult to use for those that have specific disabilities. Tablet pens can provide an alternate form of HID, and have better ergonomics reducing the risk of carpal tunnel. Digital artists usually draw on these digital input tablets, as mice do not provide the control over the input as needed by artists. However, tablets can often come at a high cost of entry, and are not easy to bring around.
## What it does
Limestone is an alternate form of tablet input, allowing you to input using a normal pen and using computer vision for the rest. That way, you can use any flat surface as your tablet
## How we built it
Limestone is built on top of the neural network library mediapipe from google. mediapipe hands provide a pretrained network that returns the 3D position of 21 joints in any hands detected in a photo. This provides a lot of useful data, which we could probably use to find the direction each finger points in and derive the endpoint of the pen in the photo. To safe myself some work, I created a second neural network that takes in the joint data from mediapipe and derive the 2D endpoint of the pen. This second network is extremely simple, since all the complex image processing has already been done. I used 2 1D convolutional layers and 4 hidden dense layers for this second network. I was only able to create about 40 entries in a dataset after some experimentation with the formatting, but I found a way to generate fairly accurate datasets with some work.
## Dataset Creation
I created a small python script that marks small dots on your screen for accurate spacing. I could the place my pen on the dot, take a photo, and enter in the coordinate of the point as the label.
## Challenges we ran into
It took a while to tune the hyperparameters of the network. Fortunately, due to the small size it was not too hard to get it into a configuration that could train and improve. However, it doesn't perform as well as I would like it to but due to time constraints I couldn't experiment further. The mean average error loss of the final model trained for 1000 epochs was around 0.0015
Unfortunately, the model was very overtrained. The dataset was o where near large enough. Adding noise probably could have helped to reduce overtraining, but I doubt by much. There just wasn't anywhere enough data, but the framework is there.
## Whats Next
If this project is to be continued, the model architecture would have to be tuned much more, and the dataset expanded to at least a few hundred entries. Adding noise would also definitely help with the variance of the dataset. There is still a lot of work to be done on limestone, but the current code at least provides some structure and a proof of concept. | partial |
## Inspiration
Too many impersonal doctor's office experiences, combined with the love of technology and a desire to aid the healthcare industry.
## What it does
Takes a conversation between a patient and a doctor and analyzes all symptoms mentioned in the conversation to improve diagnosis. Ensures the doctor will not have to transcribe the interaction and can focus on the patient for more accurate, timely and personal care.
## How we built it
Ruby on Rails for the structure with a little bit of React. Bayesian Classification procedures for the natural language processing.
## Challenges we ran into
Working in a noisy environment was difficult considering the audio data that we needed to process repeatedly to test our project.
## Accomplishments that we're proud of
Getting keywords, including negatives, to match up in our natural language processor.
## What we learned
How difficult natural language processing is and all of the minute challenges with a machine understanding humans.
## What's next for Pegasus
Turning it into a virtual doctor that can predict illnesses using machine learning and experience with human doctors. | ## Inspiration
No one likes waiting around too much, especially when we feel we need immediate attention. 95% of people in hospital waiting rooms tend to get frustrated over waiting times and uncertainty. And this problem affects around 60 million people every year, just in the US. We would like to alleviate this problem and offer alternative services to relieve the stress and frustration that people experience.
## What it does
We let people upload their medical history and list of symptoms before they reach the waiting rooms of hospitals. They can do this through the voice assistant feature, where in a conversation style they tell their symptoms, relating details and circumstances. They also have the option of just writing these in a standard form, if it's easier for them. Based on the symptoms and circumstances the patient receives a category label of 'mild', 'moderate' or 'critical' and is added to the virtual queue. This way the hospitals can take care of their patients more efficiently by having a fair ranking system (incl. time of arrival as well) that determines the queue and patients have a higher satisfaction level as well, because they see a transparent process without the usual uncertainty and they feel attended to. This way they can be told an estimate range of waiting time, which frees them from stress and they are also shown a progress bar to see if a doctor has reviewed his case already, insurance was contacted or any status changed. Patients are also provided with tips and educational content regarding their symptoms and pains, battling this way the abundant stream of misinformation and incorrectness that comes from the media and unreliable sources. Hospital experiences shouldn't be all negative, let's try try to change that!
## How we built it
We are running a Microsoft Azure server and developed the interface in React. We used the Houndify API for the voice assistance and the Azure Text Analytics API for processing. The designs were built in Figma.
## Challenges we ran into
Brainstorming took longer than we anticipated and had to keep our cool and not stress, but in the end we agreed on an idea that has enormous potential and it was worth it to chew on it longer. We have had a little experience with voice assistance in the past but have never user Houndify, so we spent a bit of time figuring out how to piece everything together. We were thinking of implementing multiple user input languages so that less fluent English speakers could use the app as well.
## Accomplishments that we're proud of
Treehacks had many interesting side events, so we're happy that we were able to piece everything together by the end. We believe that the project tackles a real and large-scale societal problem and we enjoyed creating something in the domain.
## What we learned
We learned a lot during the weekend about text and voice analytics and about the US healthcare system in general. Some of us flew in all the way from Sweden, for some of us this was the first hackathon attended so working together with new people with different experiences definitely proved to be exciting and valuable. | ## Inspiration
I know that times have been tough for local restaurant owners, and so I set out to create SeeFood, a project that could help them engage with potential customers.
## What it does
SeeFood is a REST API that stores and shares data about restaurants. When restaurant owners create meals on SeeFood, a qr code is automatically generated for them to use to share their specialties.
## How we built it
The backend api and website routing was all done in Python Flask and SQL, using cockroachdb for the cloud storage option. The website was done using Jinja2 templates mixed with CSS and JavaScript. A flutter app was also created but unfortunately never completed.
## Challenges we ran into
Trying to set up the augmented reality cost me a lot of time and I was ultimately stumped by problems with unity and flutter\_unity. I sunk a good half day into trying to make the AR work, which was tough, but a good lesson to learn.
## Accomplishments that we're proud of
Setting up a REST API on the first night and setting up my first Flutter app.
## What we learned
Don't spread yourself too thin/don't bite off more than you can chew.
## What's next for SeeFood
An eventual implementation of AR capabilities for a unique restaurant experience! | partial |
## Inspiration
For three out of four of us, cryptocurrency, Web3, and NFTs were uncharted territory. With the continuous growth within the space, our team decided we wanted to learn more about the field this weekend.
An ongoing trend we noticed when talking to others at Hack the North was that many others lacked knowledge on the subject, or felt intimidated.
Inspired by the randomly generated words and QR codes on our hacker badges, we decided to create a tool around these that would provide an engaging soft introduction to NFTs for those attending Hack the North. Through bringing accessible knowledge and practice directly to hackers, Mint the North includes those who may be on the fence, uncomfortable with approaching subject experts, and existing enthusiasts alike.
## What It Does
Mint the North creates AI-generated NFTs based on the words associated with each hacker's QR code. When going through the process, the web app provides participants with the opportunity to learn the basics of NFTs in a non-intimidating way. By the end of the process, hackers will sign off with a solid understanding of the basics of NFTs and their own personalized NFTs. Along with the tumblers, shirts, and stickers hackers get as swag throughout the event, participants can leave Hack the North with personalized NFTs and potentially a newly sparked interest and motivation to learn more.
## How We Built It
**Smart Contract**
Written in Solidity and deployed on Ethereum (testnet).
**Backend**
Written in node.js and express.js. Deployed on Google Firebase and assets are stored on Google Cloud Services.
**Frontend**
Designed in Figma and built using React.
## Challenges We Ran Into
The primary challenge was finding an API for the AI-generated images. While many exist, there were different barriers restricting our use. After digging through several sources, we were able to find a solution. The solution also had issues at the start, so we had to make adjustments to the code and eventually ensured it worked well.
Hosting has been a consistent challenge throughout the process as well due to a lack of free hub platforms to use for hosting our backend services. We use Google firebase as they have a built-in emulator that allows us to make use of advanced functionality while running locally.
## Accomplishments that We're Proud Of
Those of us in the group that were new to the topic are proud of the amount we were able to learn and adapt in a short time.
As we continued to build and adjust our project, new challenges occurred. Challenges like finding a functional API or hosting pushed our team to communicate, reorganize, and ultimately consider various solutions with limited resources.
# What We Learned
Aside from learning a lot about Web3, blockchain, crypto, and NFTs, the challenges that occurred throughout the process taught us a lot about problem-solving with limited resources and time.
# What's Next for Mint the North
While Mint the North utilized resources specific to Hack the North 2022, we envision the tool expanding to other hackathons and tech education settings. For Web3 company sponsors or supporters, the tool provides a direct connection and offering to communities that may be difficult to reach, or are interested but unsure how to proceed. | ## Inspiration
We were inspired from Web2 Social Media Platforms and wanted to invent something new which includes Web3
## What it does
Users can mint NFT and Have a chat with other users on System
## How we built it
We learnt stuff about Web3 and how it works and how decentralized platforms work
## Challenges we ran into
The main challenges were how users would mint NFT and automatically host it on NFT marketplaces
## Accomplishments that we're proud of
## What we learned
How Web3 and blockChain works with Programming
## What's next for Reach Me
Adding Group Chats for Groups and Updating Groups Description and Group Information and Making a Sale order from Minted NFT from our Platform, Adding an Ecommerce System where user can list and purchase items with cryptocurrency on Block Chain Platforms | ## Inspiration
It’s Friday afternoon, and as you return from your final class of the day cutting through the trailing winds of the Bay, you suddenly remember the Saturday trek you had planned with your friends. Equipment-less and desperate you race down to a nearby sports store and fish out $$$, not realising that the kid living two floors above you has the same equipment collecting dust. While this hypothetical may be based on real-life events, we see thousands of students and people alike impulsively spending money on goods that would eventually end up in their storage lockers. This cycle of buy-store-collect dust inspired us to develop Lendit this product aims to stagnate the growing waste economy and generate passive income for the users on the platform.
## What it does
A peer-to-peer lending and borrowing platform that allows users to generate passive income from the goods and garments collecting dust in the garage.
## How we built it
Our Smart Lockers are built with RaspberryPi3 (64bit, 1GB RAM, ARM-64) microcontrollers and are connected to our app through interfacing with Google's Firebase. The locker also uses Facial Recognition powered by OpenCV and object detection with Google's Cloud Vision API.
For our App, we've used Flutter/ Dart and interfaced with Firebase. To ensure *trust* - which is core to borrowing and lending, we've experimented with Ripple's API to create an Escrow system.
## Challenges we ran into
We learned that building a hardware hack can be quite challenging and can leave you with a few bald patches on your head. With no hardware equipment, half our team spent the first few hours running around the hotel and even the streets to arrange stepper motors and Micro-HDMI wires. In fact, we even borrowed another team's 3-D print to build the latch for our locker!
On the Flutter/ Dart side, we were sceptical about how the interfacing with Firebase and Raspberry Pi would work. Our App Developer previously worked with only Web Apps with SQL databases. However, NoSQL works a little differently and doesn't have a robust referential system. Therefore writing Queries for our Read Operations was tricky.
With the core tech of the project relying heavily on the Google Cloud Platform, we had to resolve to unconventional methods to utilize its capabilities with an internet that played Russian roulette.
## Accomplishments that we're proud of
The project has various hardware and software components like raspberry pi, Flutter, XRP Ledger Escrow, and Firebase, which all have their own independent frameworks. Integrating all of them together and making an end-to-end automated system for the users, is the biggest accomplishment we are proud of.
## What's next for LendIt
We believe that LendIt can be more than just a hackathon project. Over the course of the hackathon, we discussed the idea with friends and fellow participants and gained a pretty good Proof of Concept giving us the confidence that we can do a city-wide launch of the project in the near future. In order to see these ambitions come to life, we would have to improve our Object Detection and Facial Recognition models. From cardboard, we would like to see our lockers carved in metal at every corner of this city. As we continue to grow our skills as programmers we believe our product Lendit will grow with it. We would be honoured if we can contribute in any way to reduce the growing waste economy. | losing |
# 🎉 CoffeeStarter: Your Personal Networking Agent 🚀
Names: Sutharsika Kumar, Aarav Jindal, Tanush Changani & Pranjay Kumar
Welcome to **CoffeeStarter**, a cutting-edge tool designed to revolutionize personal networking by connecting you with alumni from your school's network effortlessly. Perfect for hackathons and beyond, CoffeeStarter blends advanced technology with user-friendly features to help you build meaningful professional relationships.
---
## 🌟 Inspiration
In a world where connections matter more than ever, we envisioned a tool that bridges the gap between ambition and opportunity. **CoffeeStarter** was born out of the desire to empower individuals to effortlessly connect with alumni within their school's network, fostering meaningful relationships that propel careers forward.
---
## 🛠️ What It Does
CoffeeStarter leverages the power of a fine-tuned **LLaMA** model to craft **personalized emails** tailored to each alumnus in your school's network. Here's how it transforms your networking experience:
* **📧 Personalized Outreach:** Generates authentic, customized emails using your resume to highlight relevant experiences and interests.
* **🔍 Smart Alumnus Matching:** Identifies and connects you with alumni that align with your professional preferences and career goals.
* **🔗 Seamless Integration:** Utilizes your existing data to ensure every interaction feels genuine and impactful.
---
## 🏗️ How We Built It
Our robust technology stack ensures reliability and scalability:
* **🗄️ Database:** Powered by **SQLite** for flexible and efficient data management.
* **🐍 Machine Learning:** Developed using **Python** to handle complex ML tasks with precision.
* **⚙️ Fine-Tuning:** Employed **Tune** for meticulous model fine-tuning, ensuring optimal performance and personalization.
---
## ⚔️ Challenges We Faced
Building CoffeeStarter wasn't without its hurdles:
* **🔒 SQLite Integration:** Navigating the complexities of SQLite required innovative solutions.
* **🚧 Firewall Obstacles:** Overcoming persistent firewall issues to maintain seamless connectivity.
* **📉 Model Overfitting:** Balancing the model to avoid overfitting while ensuring high personalization.
* **🌐 Diverse Dataset Creation:** Ensuring a rich and varied dataset to support effective networking outcomes.
* **API Integration:** Working with various API's to get as diverse a dataset and functionality as possible.
---
## 🏆 Accomplishments We're Proud Of
* **🌈 Diverse Dataset Development:** Successfully created a comprehensive and diverse dataset that enhances the accuracy and effectiveness of our networking tool.
* Authentic messages that reflect user writing styles which contributes to personalization.
---
## 📚 What We Learned
The journey taught us invaluable lessons:
* **🤝 The Complexity of Networking:** Understanding that building meaningful connections is inherently challenging.
* **🔍 Model Fine-Tuning Nuances:** Mastering the delicate balance between personalization and generalization in our models.
* **💬 Authenticity in Automation:** Ensuring our automated emails resonate as authentic and genuine, without echoing our training data.
---
## 🔮 What's Next for CoffeeStarter
We're just getting started! Future developments include:
* **🔗 Enhanced Integrations:** Expanding data integrations to provide even more personalized networking experiences and actionable recommendations for enhancing networking effectiveness.
* **🧠 Advanced Fine-Tuned Models:** Developing additional models tailored to specific networking needs and industries.
* **🤖 Smart Choosing Algorithms:** Implementing intelligent algorithms to optimize alumnus matching and connection strategies.
---
## 📂 Submission Details for PennApps XXV
### 📝 Prompt
You are specializing in professional communication, tasked with composing a networking-focused cold email from an input `{student, alumni, professional}`, name `{your_name}`. Given the data from the receiver `{student, alumni, professional}`, your mission is to land a coffee chat. Make the networking text `{email, message}` personalized to the receiver’s work experience, preferences, and interests provided by the data. The text must sound authentic and human. Keep the text `{email, message}` short, 100 to 200 words is ideal.
### 📄 Version Including Resume
You are specializing in professional communication, tasked with composing a networking-focused cold email from an input `{student, alumni, professional}`, name `{your_name}`. The student's resume is provided as an upload `{resume_upload}`. Given the data from the receiver `{student, alumni, professional}`, your mission is to land a coffee chat. Use the information from the given resume of the sender and their interests from `{website_survey}` and information of the receiver to make this message personalized to the intersection of both parties. Talk specifically about experiences that `{student, alumni, professional}` would find interesting about the receiver `{student, alumni, professional}`. Compare the resume and other input `{information}` to find commonalities and make a positive impression. Make the networking text `{email, message}` personalized to the receiver’s work experience, preferences, and interests provided by the data. The text must sound authentic and human. Keep the text `{email, message}` short, 100 to 200 words is ideal. Once completed with the email, create a **1 - 10 score** with **1** being a very generic email and **10** being a very personalized email. Write this score at the bottom of the email.
## 🧑💻 Technologies Used
* **Frameworks & Libraries:**
+ **Python:** For backend development and machine learning tasks.
+ **SQLite:** As our primary database for managing user data.
+ **Tune:** Utilized for fine-tuning our LLaMA3 model.
* **External/Open Source Resources:**
+ **LLaMA Model:** Leveraged for generating personalized emails.
+ **Various Python Libraries:** Including Pandas for data processing and model training. | ## Inspiration
For many college students, finding time to socialize and make new friends is hard. Everyone's schedule seems perpetually busy, and arranging a dinner chat with someone you know can be a hard and unrewarding task. At the same time, however, having dinner alone is definitely not a rare thing. We've probably all had the experience of having social energy on a particular day, but it's too late to put anything on the calendar. Our SMS dinner matching project exactly aims to **address the missed socializing opportunities in impromptu same-day dinner arrangements**. Starting from a basic dining-hall dinner matching tool for Penn students only, we **envision an event-centered, multi-channel social platform** that would make organizing events among friend groups, hobby groups, and nearby strangers effortless and sustainable in the long term for its users.
## What it does
Our current MVP, built entirely within the timeframe of this hackathon, allows users to interact with our web server via **SMS text messages** and get **matched to other users for dinner** on the same day based on dining preferences and time availabilities.
### The user journey:
1. User texts anything to our SMS number
2. Server responds with a welcome message and lists out Penn's 5 dining halls for the user to choose from
3. The user texts a list of numbers corresponding to the dining halls the user wants to have dinner at
4. The server sends the user input parsing result to the user and then asks the user to choose between 7 time slots (every 30 minutes between 5:00 pm and 8:00 pm) to meet with their dinner buddy
5. The user texts a list of numbers corresponding to the available time slots
6. The server attempts to match the user with another user. If no match is currently found, the server sends a text to the user confirming that matching is ongoing. If a match is found, the server sends the matched dinner time and location, as well as the phone number of the matched user, to each of the two users matched
7. The user can either choose to confirm or decline the match
8. If the user confirms the match, the server sends the user a confirmation message; and if the other user hasn't confirmed, notifies the other user that their buddy has already confirmed the match
9. If both users in the match confirm, the server sends a final dinner arrangement confirmed message to both users
10. If a user decides to decline, a message will be sent to the other user that the server is working on making a different match
11. 30 minutes before the arranged time, the server sends each user a reminder
###Other notable backend features
12. The server conducts user input validation for each user text to the server; if the user input is invalid, it sends an error message to the user asking the user to enter again
13. The database maintains all requests and dinner matches made on that day; at 12:00 am each day, the server moves all requests and matches to a separate archive database
## How we built it
We used the Node.js framework and built an Express.js web server connected to a hosted MongoDB instance via Mongoose.
We used Twilio Node.js SDK to send and receive SMS text messages.
We used Cron for time-based tasks.
Our notable abstracted functionality modules include routes and the main web app to handle SMS webhook, a session manager that contains our main business logic, a send module that constructs text messages to send to users, time-based task modules, and MongoDB schema modules.
## Challenges we ran into
Writing and debugging async functions poses an additional challenge. Keeping track of potentially concurrent interaction with multiple users also required additional design work.
## Accomplishments that we're proud of
Our main design principle for this project is to keep the application **simple and accessible**. Compared with other common approaches that require users to download an app and register before they can start using the service, using our tool requires **minimal effort**. The user can easily start using our tool even on a busy day.
In terms of architecture, we built a **well-abstracted modern web application** that can be easily modified for new features and can become **highly scalable** without significant additional effort (by converting the current web server into the AWS Lambda framework).
## What we learned
1. How to use asynchronous functions to build a server - multi-client web application
2. How to use posts and webhooks to send and receive information
3. How to build a MongoDB-backed web application via Mongoose
4. How to use Cron to automate time-sensitive workflows
## What's next for SMS dinner matching
### Short-term feature expansion plan
1. Expand location options to all UCity restaurants by enabling users to search locations by name
2. Build a light-weight mobile app that operates in parallel with the SMS service as the basis to expand with more features
3. Implement friend group features to allow making dinner arrangements with friends
###Architecture optimization
4. Convert to AWS Lamdba serverless framework to ensure application scalability and reduce hosting cost
5. Use MongoDB indexes and additional data structures to optimize Cron workflow and reduce the number of times we need to run time-based queries
### Long-term vision
6. Expand to general event-making beyond just making dinner arrangements
7. Create explore (even list) functionality and event feed based on user profile
8. Expand to the general population beyond Penn students; event matching will be based on the users' preferences, location, and friend groups | ## Inspiration
This year, all the members in our team entered the first year of post-secondary and attended our various orientation event. We all realized that during orientation, we talked to many people but really only carried on a couple of friendships or acquaintances. As such, we decided to make an app so that people could quickly find others in their vicinity who share their common interests rather than talking to every single person in the room until they find someone who's a good match.
## What it does
Linkr is an app which shows the people in your area and sorts them by how much they have in common with you. When first installing the app, Linkr asks a series of questions to determine your personality and interests. Based on this, it will find matches for you, no matter where you go. The app uses geolocation of the users to determine how close other users are to you. Based on this and using AI to determine how much they have in common with you, you will get a sorted list of people with the person who has the most in common with you being at the top.
## How we built it
We planned to use Cohere to analyze the similarities between the preferences of different people, using Django for the backend and React Native for the front end. Additionally, we believe that music is a great indicator of personality. As such, we looked into using Spotipy to collect data on people's Spotify history and profiles.
With Cohere, we made use of the get\_embedded function, allowing us to relate preferences and interests to a numerical value, which we then could mathematically compare to others using the numpy module. Additionally, we used Cohere to generate a brief summary of users' Spotify data, as otherwise, there is quite a bit of information, some which may not be as relevant.
In the end, we ended up using React Native with Expo Go to develop the mobile app. We also used Appwrite as a database and authentication service.
## Challenges we ran into
Indecisiveness: We spent a lot of time choosing between and experimenting on two different projects. We were also indecisive about the stack we wanted to use (we started with wanting to use C++ but it took us time to realize that this would not actually be feasible) .
Combining different components: While we were successful in developing the different parts of the project individually, we had a difficult time combining the different technologies together.
## Accomplishments that we're proud of
We are proud of our perseverance. Working on this project was not easy, and we were met with many challenges. Especially considering how our indecisiveness cost us a large part of our time, we believe that we did well and completed a fairly large portion of the final product.
## What we learned
Incorporating different API's together.
Working with a completely new technology (all of us were new to mobile app dev).
Cohere's excellent functionalities.
## What's next for Linkr
Allowing more user customizability and ability to communicate with other matches.
Precise finding of other matches | partial |
## Inspiration
Between my friends and I, when there is a task everyone wants to avoid, we play a game to decide quickly. These tasks may include, ordering pizza or calling an uber for the group. The game goes like this, whoever thinks of this game first says "shotty not" and then touches their nose. Everyone else reacts to him and touches their nose as fast as they can. The person with the slowest reaction time is chosen to do the task. I often fall short when it comes to reaction time so I had to do something about it
## What it does
The module sits on top of your head, waiting to hear the phrase "shotty not." When it is recognized the finger will come down and touch your nose. You will never get caught off guard again.
## How I built it
The finger moves via a servo and is controlled by an arduino, it is connected to a python script that recognizes voice commands offline. The finger is mounted to the hat with some 3d printed parts.
## Challenges I ran into
The hardware lab did not have a voice recognition module or a bluetooth module for arduino. I had to figure out how to go about implementing voice recognition and connect it to the arduino.
## Accomplishments that I'm proud of
I was able to model and print all the parts to create a completely finished hack to the best of my abilities.
## What I learned
I learned to use a voice recognition library and use Pyserial to communicate to an arduino with a python program.
## What's next for NotMe
I will replace the python program with a bluetooth module to make the system more portable. This allows for real life use cases. | ## Inspiration
Our inspiration for the project stems from our experience with elderly and visually impaired people, and understanding that there is an imminent need for a solution that integrates AI to bring a new level of convenience and safety to modern day navigation tools.
## What it does
IntelliCane firstly employs an ultrasonic sensor to identify any object, person, or thing within a 2 meter range and when that happens, a piezo buzzer alarm alerts the user. Simultaneously, a camera identifies the object infront of the user and provides them with voice feedback identifying what is infront of them.
## How we built it
The project firstly employs an ultrasonic sensor to identify an object, person or thing close by. Then the piezo buzzer is turned on and alerts the user. Then the Picamera that is on the raspberrypi 5 identifies the object. We have employed a CNN algorithm to train the data and improve the accuracy of identifying the objects. From there this data is transferred to a text-to-speech function which provides voice feedback describing the object infront of them. The project was built on YOLO V8 platform.
## Challenges we ran into
We ran into multiple problems during our project. For instance, we initially tried to used tensorflow, however due to the incompatibility of our version of python with the raspberrypi 5, we switched to the YOLO V8 Platform.
## Accomplishments that we're proud of
There are many accomplishments we are proud of, such as successfully creating an the ultrasonic-piezo buzzer system for the arduino, and successfully mounting everything onto the PVC Pipe. However, we are most proud of developing a CNN algorithm that accurately identifies objects and provides voice feedback identifying the object that is infront of the user.
## What we learned
We learned more about developing ML algorithms and became more proficient with the raspberrypi IDE.
## What's next for IntelliCane
Next steps for IntelliCane include integrating GPS modules and Bluetooth modules to add another level of convenience to navigation tools. | ## Inspiration
Giving visually impaired people the opportunity to experience their surroundings like never before
## What it does
Essentially we attach a camera and sensor on to a hat, which when worn by the visually impaired person will allow them to recognize objects faster and sense obstructions at a certain distance away.
## How we built it
This was built using python's openCV, numpy, speech\_recognition, pyaudio, alsa mixer,espeak packages and arduino
## Challenges we ran into
One of the major challenges was setting up openCV
Setting up the dragon board with Debian Linux
Setting up the speech to text recognition
Setting up bluetooth from the command line
## Accomplishments that we're proud of
Successful setup of the hardware
Making the speech to text recognition to work
## What we learned
YOLO and its uses
## What's next for realeyes
Hopefully make a more feasible product and powerful product to make an impact. | partial |
# Hungr.ai Hungr.ai Hippos
Our HackWestern IV project which makes hungry hungry hippo even cooler.
## Milestones


## Inspiration
Metaphysically speaking, we didn't find the idea, it found us.
## What it does
A multiplayer game which allows player to play against AI(s) (one for each hippo) while controlling the physical hippos in the real world.
## How we built it
Once, we knew we wanted to do something fun with hungry hungry hippos, we acquired the game through Kijiji #CanadianFeels. We deconstructed the game to understand the mechanics of it and made a rough plan to use servos controlled through Raspberry Pi 3 to move the hippos. We decided to keep most of our processing on a laptop to not burden the Pi. Pi served as a end point serving video stream through **web sockets**. **Multithreading** (in Python) allowed us to control each servo/hippo individually through the laptop with Pi always listening for commands. **Flask** framework help us tie in the React.js frontend with Python servers and backends.
## Challenges we ran into
Oh dear god, where do we begin?
* The servos we expected to be delivered to us by Amazon were delayed and due to the weekend we never got them :( Fortunately, we brought almost enough backup servos
* Multithreading in python!!
* Our newly bought PiCamera was busted :( Fortunately, we found someone to lend us their's.
* CNN !!
* Working with Pi without a screen (it doesn't allow you to ssh into it over a public wifi. We had to use ethernet cable to find a workaround)
## Accomplishments that we're proud of
Again, oh dear god, where do we begin?
* The hardware platform (with complementing software backend) looks so elegant and pretty
* The front-end tied the whole thing really well (elegantly simplying the complexity behind the hood)
* The feed from the Picamera to the laptop was so good, much better than we expected.
## What we learned
And again, oh dear god, where do we begin?
* Working with Flask (great if you wanna work with python and js)
* Multithreading in Python
* Working with websockets (and, in general, data transmission between Pi and Laptop over ethernet/network)
## What's next for Hungr.ai
* A Dance Dance Revolution starring our hippo stars (a.k.a Veggie Potamus, Hungry Hippo, Bottomless Potamus and Sweetie Potamus)
* Train our AI/ML models even more/ Try new models
## How do we feel?
In a nutshell, we had a very beneficial spectrum of skills. We believe that the project couldn't have been completed if any of the members weren't present. The learning curve was challenging, but with time and focus, we were able to learn the required skills to carry this project. | ## Inspiration
Fraud is a crime that can impact any Canadian, regardless of their education, age or income.
From January 2014 to December 2017, Canadians lost more than $405 million to fraudsters. ~ [Statistic Info](https://www.competitionbureau.gc.ca/eic/site/cb-bc.nsf/eng/04334.html)
We wanted to develop technology that detects potentially fraudulent activity and give account owners the ability to cancel such transactions.
## How it works
Using scikit-learn, we were able to detect patterns in a user's previous banking data provided by TD's davinci API.
We examined categories such as the location of the purchase, the cost of the purchase, and the purchase category. Afterwards, we determined certain parameters for the cost of purchase based on the purchase category, and purchase locations to validate transactions that met the requirements. Transactions that were made outside of these parameters were deemed suspicious activity and an alert is sent to the account owner, providing them with the ability to validate/decline the purchase. If the transaction is approved, it is added to the MongoDB database with the rest of the user's previous transactions.
[TD's davinci API](https://td-davinci.com/)
[Presentation Slide Show](https://slides.com/malharshah/deck#/projectapati)
[Github Repository](https://github.com/mshah0722/FraudDetectionDeltaHacks2020)
## Challenges we ran into
Initially, we tried to use Tensorflow for our ML model to analyze the user's previous banking history to find patterns and make the parameters. However, we were having difficulty correctly implementing it and there were mistakes being made in the model. This is why we decided to switch to scikit-learn, which our team had success using and our ML model turned out as we had expected.
## Accomplishments that we are proud of
Learning to use and implement Machine Learning with such a large data set that we were provided with. Training the model to detect suspicious activity was finally achieved after several attempts.
## What we learned
Handling large data files.
Pattern detection/Data Analysis.
Data Interpretation and Model development.
## What's next for Project Apati
Improving the model by looking at other categories in the data to refine the model based on other transactions statistics. Providing more user's data to improve the training and testing data-set for the model. | A long time ago (last month) in a galaxy far far away (literally my room) I was up studying late for exams and decided to order some hot wings. With my food being the only source of joy that night you can imaging how devastated I was to find out that they were stolen from the front lobby of my building! That's when the idea struck to create a secure means of ordering food without the stress of someone else stealing it.
## What it does
Locker as a service is a full hardware and software solution that intermediates a the food exchange between seller and buyer. Buyers can order food from our mobile app, the seller receives this notification on their end of the app, fills the box with its contents, and locks the box. The buyer is notified that the order is ready and using face biometrics receives permission to open the box and safely. The order can specify whether the food needs to be refrigerated or heated and the box's temperature is adjusted accordingly. Sounds also play at key moments in the exchange such as putting in a cold or hot item as well as opening the box.
## How we built it
The box is made out of cardboard and uses a stepper motor to open and close the main door, LED's are in the top of the box to indicate it's content status and temperature. A raspberry pi controls these devices and is also connected to a Bluetooth speaker which is also inside of the box playing the sounds. The frontend was developed using Flutter and IOS simulator. Commands from the front end are sent to Firebase which is a realtime cloud database which can be connected to the raspberry pi to send all of the physical commands. Since the raspberry pi has internet and Bluetooth access, it can run wirelessly (with the exception of power to the pi)
## Challenges we ran into
A large challenge we ran into was having the raspberry-pi run it's code wirelessly. Initially we needed to connect to VNC Viewer to via ethernet to get a GUI. Only after we developed all the python code to control the hardware seamlessly could we disconnect the VNC viewer and let the script run autonomously. Another challenge we ran into was getting the IoS simulated app to run on a real iphone, this required several several YouTube tutorials and debugging could we get it to work.
## Accomplishments that we're proud of
We are proud that we were able to connect both the front end (flutter) and backend (raspberry pi) to the firebase database, it was very satisfying to do so.
## What we learned
Some team members learned about mobile development for the first time while others learned about control systems (we had to track filled state, open state, and led colour for 6 stages of the cycle)
## What's next for LaaS | partial |
## Inspiration
When we saw that HackHarvard had Earth and Space as a track, that immediately grabbed our attention because it seemed like a unique category to build a project in. After doing some research on the current user accesible data in the topic, we realised theres a lot of data available out there but very specific to specific companies. The idea grew on us that it would be really convinient to just grab and pick the fields we need and not have to worry about the excess influx of unused data. Thus came the idea of creating NexusAPI. Nexus translates to a black hole, pulls everything towards itself in a way how our application combines the massive ocean of APIs into one.
## What it does
We've seamlessly integrated multiple space and Earth-related APIs into one unified platform. With NexusAPI, you can effortlessly access and organize data on solar flares, geomagnetic storms, and space missions, weather and many more. Explore accurate statistical data from renowned industry leaders like NASA, ISRO, SpaceX. Simply choose your categories, and we'll deliver clean and structured JSON data for your specific development needs. No authentication required so Get ready to explore the cosmos and enhance your applications with NexusAPI today!
## How we built it
The project mainly has 3 components to it:
1. Backend - The backend is built entirely with Golang. The reason we chose Golang is due to it's seamless support in creating REST APIs, fast and scalable codebase and support with our database. We found numerous space and earth based APIs created by major organizations in various countries and finalized on 3 for the purpose of this Hackathon; NASA - The leading name for Space and Exploration in the world currently, ISRO - The Indian Space Research Org, recently soaring high with thier state of the art low budget rovers and finally SpaceX - Led by the sharp and witty Elon Musk. We parse the data from all these services, store them in a legible, relevant format.
2. Database - That brings us to the 2nd part of the project, the database. We decided to go with Redis as the database because it is something we have never worked with before and thought it might be fun to learn something new. Redis has been the database of choice for many Enterprise companies and it definitely a good skill to keep in hand. We stored all our data in this NoSQL Database using key value hash sets. For the MVP we currently processed over 2000+ pairings of data.
3. Frontend - Finally we have the front end. For this we used the trusty NextJS framework which manages your routing, directory structure and page handling. We decided to just make a single page app would be enough to showcase the power this API holds. The page allows users to interact with a smooth, modern interface to carefully pick and choose which data they need and based on that it dynamically generates a special unique endpoint.
## Challenges we ran into
We ran into plenty of challenges in these 2 days. First one was just working with Redis in general. Never worked with it before so had to dig through the documentation really deep. There is also not a lot of documentation around golang and redis and so had to figure out new ways and sometimes even had to reinvent the wheel out of necessity.
Secondly, it was trying to deploy our backend to a host online was a hurdle in our project. We had to migrate our database from a local server to a publically hosted server using dump rdb files.
Finally the Domain transfer took us a bit to figure out with GoDaddy and Google Pages and Vercel at the same time. Though not that big of a problem, it was a good learning curve.
## Accomplishments that we're proud of
We are proud that we were able to complete a project and build something we can showcase. Also the feeling of coding constantly for a whole weekend is really nice.
## What we learned
We learned how to work in a team, collaborate on github and most importantly how to work with Redis!
## What's next for NexusAPI
We plan to open source the NexusAPI project on github and let others contribute improvements to it. It would also be fun to see what people can build with it and experiment. We built it around just Space and Earth but the idea of this as a service in itself is something that can be leveraged into useful packages (node, python, golang). We hope people can use this API to just make their lives a little bit easier. | ## Hack The Valley 4
Hack the Valley 2020 project
## On The Radar
**Inspiration**
Have you ever been walking through your campus and wondered what’s happening around you, but too unmotivated to search through Facebook, the school’s website and where ever else people post about social gatherings and just want to see what’s around?
Ever see an event online and think this looks like a lot of fun, just to realize that the event has already ended, or is on a different day?
Do you usually find yourself looking for nearby events in your neighborhood while you’re bored?
Looking for a better app that could give you notifications, and have all the events in one and accessible place?
These are some of the questions that inspired us to build “On the Radar” --- a user-friendly map navigation system that allows users to discover cool, real-time events that suit their interests and passion in the nearby area.
*Now you’ll be flying over the Radar!*
**Purpose**
On the Radar is a mobile application that allows users to match users with nearby events that suit their preferences.
The user’s location is detected using the “standard autocomplete search” that tracks your current location. Then, the app will display a customized set of events that are currently in progress in the user’s area which is catered to each user.
**Challenges**
* Lack of RAM in some computers, see Android Studio (This made some of our tests and emulations slow as it is a very resource-intensive program. We resolved this by having one of our team members run a massive virtual machine)
* Google Cloud (Implementing google maps integration and google app engine to host the rest API both proved more complicated than originally imagined.)
* Android Studio (As it was the first time for the majority of us using Android Studio and app development in general, it was quite the learning curve for all of us to help contribute to the app.)
* Domain.com (Linking our domain.com name, flyingovertheradar.space, to our github pages was a little bit more tricky than anticipated, needing a particular use of CNAME dns setup.)
* Radar.io (As it was our first time using Radar.io, and the first time implementing its sdk, it took a lot of trouble shooting to get it to work as desired.)
* Mongo DB (We decided to use Mongo DB Atlas to host our backend database needs, which took a while to get configured properly.)
* JSON objects/files (These proved to be the bain of our existence and took many hours to get them to convert into a usable format.)
* Rest API (Getting the rest API to respond correctly to our http requests was quite frustrating, we had to use many different http Java libraries before we found one that worked with our project.)
* Java/xml (As some of our members had no prior experience with both Java and xml, development proved even more difficult than originally anticipated.)
* Merge Conflicts (Ah, good old merge conflicts, a lot of fun trying to figure out what code you want to keep, delete or merge at 3am)
* Sleep deprivation (Over all our team of four got collectively 24 hours of sleep over this 36 hour hackathon.)
**Process of Building**
* For the front-end, we used Android Studio to develop the user interface of the app and its interactivity. This included a login page, a registration page and our home page in which has a map and events nearby you.
* MongoDB Atlas was used for back-end, we used it to store the users’ login and personal information along with events and their details.
* This link provides you with the Github repository of “On the Radar.” <https://github.com/maxerenberg/hackthevalley4/tree/master/app/src/main/java/com/hackthevalley4/hackthevalleyiv/controller>
* We also designed a prototype using Figma to plan out how the app could potentially look like.
The prototype’s link → <https://www.figma.com/proto/iKQ5ypH54mBKbhpLZDSzPX/On-The-Radar?node-id=13%3A0&scaling=scale-down>
* We also used a framework called Bootstrap to make our website. In this project, our team uploaded the website files through Github.
The website’s code → <https://github.com/arianneghislainerull/arianneghislainerull.github.io>
The website’s link → <https://flyingovertheradar.space/#>
*Look us up at*
# <http://flyingovertheradar.space> | ## Inspiration
Our inspiration stems from our common issue with the Google Home’s requirement for internet access and frequent instability. In addition, our team have struggled with finding dependable internet access when in remote locations, such as on vacation with no data, often with unpredictable Wi-Fi access points. As a team we aimed to develop an application to allow users to access valuable information that would only be accessible with a reliable internet service.
## What it does
Hermes Intelligence allows users to access GPS navigation, road conditions, traffic conditions and general reminders all via SMS notifications. Often times when individuals make their commute to work, they do not check their favourite maps application to check for potential hazards. Hermes Intelligence acts as a personal assistant that will send you a reminder text at your selected time (e.g. 8:15AM every weekday morning), relieving you from the duty of searching your route manually, and avoiding unexpected delays that would otherwise result in the user being late. Another useful application of our system is to provide directions when internet access is limited, for example, the user would like to visit a certain restaurant for lunch, Hermes Intelligence would provide map directions without the user having to obtain internet access.
## How we built it
1. Front-end was developed by using Android Studio and Java.
2. Back-End was deployed using Standard Library API in Javascript.
3. Additional APIs that were used with Standard Library Tasks Wrapper, Here Maps API
4. Messaging service used: Twilio
5. Database: MongoDB
## Challenges we ran into
* Creating dynamic tasks using StdLib from JavaScript since it is not openly supported.
* Google Maps API gave us a problem with a restriction on the number of requests per day so we switched to the Here Maps API which was more consistent.
## Accomplishments that we're proud of
* Created a tasks wrapper API on StdLib to be able to create dynamic tasks by finding a workaround in the lib cli source code
* Sending text messages to the application to control creating, reading, writing, updating and deleting to a MongoDB database using StdLib
* Built an Android application using Java and XML
* Graphic design was done entirely in Adobe Photoshop
## What we learned
* How to create APIs using StdLib
* How to use MongoDB in conjunction with StdLib
* How to use Twilio
* Creating a serverless application and supplying a user with 'offline' internet
## What's next for Hermes Intelligence
* Road conditions based on weather
* Weather conditions
* General web search
* News updates
* Travel information
* Business and restaurant recommendations
## Twitter Posts
> Hermes intelligence is an entirely offline (!) reminder system that makes sure you're on time! Using a [@twilio](https://twitter.com/twilio?ref_src=twsrc%5Etfw) SMS, it sets a [@StdLibHQ](https://twitter.com/StdLibHQ?ref_src=twsrc%5Etfw) task that triggers before your commute to check traffic with the [@here](https://twitter.com/here?ref_src=twsrc%5Etfw) maps API! Ingenious. [@QHacks19](https://twitter.com/QHacks19?ref_src=twsrc%5Etfw) [pic.twitter.com/oKC6oGNmk4](https://t.co/oKC6oGNmk4)
>
> — Jacob Lee (@Hacubu) [February 3, 2019](https://twitter.com/Hacubu/status/1092091870228987905?ref_src=twsrc%5Etfw) | partial |
### 💡 Inspiration 💡
We call them heroes, **but the support we give them is equal to the one of a slave.**
Because of the COVID-19 pandemic, a lot of medics have to keep track of their patient's history, symptoms, and possible diseases. However, we've talked with a lot of medics, and almost all of them share the same problem when tracking the patients: **Their software is either clunky and bad for productivity, or too expensive to use on a bigger scale**. Most of the time, there is a lot of unnecessary management that needs to be done to get a patient on the record.
Moreover, the software can even get the clinician so tired they **have a risk of burnout, which makes their disease predictions even worse the more they work**, and with the average computer-assisted interview lasting more than 20 minutes and a medic having more than 30 patients on average a day, the risk is even worse. That's where we introduce **My MedicAid**. With our AI-assisted patient tracker, we reduce this time frame from 20 minutes to **only 5 minutes.** This platform is easy to use and focused on giving the medics the **ultimate productivity tool for patient tracking.**
### ❓ What it does ❓
My MedicAid gets rid of all of the unnecessary management that is unfortunately common in the medical software industry. With My MedicAid, medics can track their patients by different categories and even get help for their disease predictions **using an AI-assisted engine to guide them towards the urgency of the symptoms and the probable dangers that the patient is exposed to.** With all of the enhancements and our platform being easy to use, we give the user (medic) a 50-75% productivity enhancement compared to the older, expensive, and clunky patient tracking software.
### 🏗️ How we built it 🏗️
The patient's symptoms get tracked through an **AI-assisted symptom checker**, which uses [APIMedic](https://apimedic.com/i) to process all of the symptoms and quickly return the danger of them and any probable diseases to help the medic take a decision quickly without having to ask for the symptoms by themselves. This completely removes the process of having to ask the patient how they feel and speeds up the process for the medic to predict what disease their patient might have since they already have some possible diseases that were returned by the API. We used Tailwind CSS and Next JS for the Frontend, MongoDB for the patient tracking database, and Express JS for the Backend.
### 🚧 Challenges we ran into 🚧
We had never used APIMedic before, so going through their documentation and getting to implement it was one of the biggest challenges. However, we're happy that we now have experience with more 3rd party APIs, and this API is of great use, especially with this project. Integrating the backend and frontend was another one of the challenges.
### ✅ Accomplishments that we're proud of ✅
The accomplishment that we're the proudest of would probably be the fact that we got the management system and the 3rd party API working correctly. This opens the door to work further on this project in the future and get to fully deploy it to tackle its main objective, especially since this is of great importance in the pandemic, where a lot of patient management needs to be done.
### 🙋♂️ What we learned 🙋♂️
We learned a lot about CRUD APIs and the usage of 3rd party APIs in personal projects. We also learned a lot about the field of medical software by talking to medics in the field who have way more experience than us. However, we hope that this tool helps them in their productivity and to remove their burnout, which is something critical, especially in this pandemic.
### 💭 What's next for My MedicAid 💭
We plan on implementing an NLP-based service to make it easier for the medics to just type what the patient is feeling like a text prompt, and detect the possible diseases **just from that prompt.** We also plan on implementing a private 1-on-1 chat between the patient and the medic to resolve any complaints that the patient might have, and for the medic to use if they need more info from the patient. | ## Inspiration
Our team identified two intertwined health problems in developing countries:
1) Lack of easy-to-obtain medical advice due to economic, social and geographic problems, and
2) Difficulty of public health data collection in rural communities.
This weekend, we built SMS Doc, a single platform to help solve both of these problems at the same time. SMS Doc is an SMS-based healthcare information service for underserved populations around the globe.
Why text messages? Well, cell phones are extremely prevalent worldwide [1], but connection to the internet is not [2]. So, in many ways, SMS is the *perfect* platform for reaching our audience in the developing world: no data plan or smartphone necessary.
## What it does
Our product:
1) Democratizes healthcare information for people without Internet access by providing a guided diagnosis of symptoms the user is experiencing, and
2) Has a web application component for charitable NGOs and health orgs, populated with symptom data combined with time and location data.
That 2nd point in particular is what takes SMS Doc's impact from personal to global: by allowing people in developing countries access to medical diagnoses, we gain self-reported information on their condition. This information is then directly accessible by national health organizations and NGOs to help distribute aid appropriately, and importantly allows for epidemiological study.
**The big picture:** we'll have the data and the foresight to stop big epidemics much earlier on, so we'll be less likely to repeat crises like 2014's Ebola outbreak.
## Under the hood
* *Nexmo (Vonage) API* allowed us to keep our diagnosis platform exclusively on SMS, simplifying communication with the client on the frontend so we could worry more about data processing on the backend. **Sometimes the best UX comes with no UI**
* Some in-house natural language processing for making sense of user's replies
* *MongoDB* allowed us to easily store and access data about symptoms, conditions, and patient metadata
* *Infermedica API* for the symptoms and diagnosis pipeline: this API helps us figure out the right follow-up questions to ask the user, as well as the probability that the user has a certain condition.
* *Google Maps API* for locating nearby hospitals and clinics for the user to consider visiting.
All of this hosted on a Digital Ocean cloud droplet. The results are hooked-through to a node.js webapp which can be searched for relevant keywords, symptoms and conditions and then displays heatmaps over the relevant world locations.
## What's next for SMS Doc?
* Medical reports as output: we can tell the clinic that, for example, a 30-year old male exhibiting certain symptoms was recently diagnosed with a given illness and referred to them. This can allow them to prepare treatment, understand the local health needs, etc.
* Epidemiology data can be handed to national health boards as triggers for travel warnings.
* Allow medical professionals to communicate with patients through our SMS platform. The diagnosis system can be continually improved in sensitivity and breadth.
* More local language support
[1] <http://www.statista.com/statistics/274774/forecast-of-mobile-phone-users-worldwide/>
[2] <http://www.internetlivestats.com/internet-users/> | ## Inspiration
We've all left a doctor's office feeling more confused than when we arrived. This common experience highlights a critical issue: over 80% of Americans say access to their complete health records is crucial, yet 63% lack their medical history and vaccination records since birth. Recognizing this gap, we developed our app to empower patients with real-time transcriptions of doctor visits, easy access to health records, and instant answers from our AI doctor avatar. Our goal is to ensure EVERYONE has the tools to manage their health confidently and effectively.
## What it does
Our app provides real-time transcription of doctor visits, easy access to personal health records, and an AI doctor for instant follow-up questions, empowering patients to manage their health effectively.
## How we built it
We used Node.js, Next.js, webRTC, React, Figma, Spline, Firebase, Gemini, Deepgram.
## Challenges we ran into
One of the primary challenges we faced was navigating the extensive documentation associated with new technologies. Learning to implement these tools effectively required us to read closely and understand how to integrate them in unique ways to ensure seamless functionality within our website. Balancing these complexities while maintaining a cohesive user experience tested our problem-solving skills and adaptability. Along the way, we struggled with Git and debugging.
## Accomplishments that we're proud of
Our proudest achievement is developing the AI avatar, as there was very little documentation available on how to build it. This project required us to navigate through various coding languages and integrate the demo effectively, which presented significant challenges. Overcoming these obstacles not only showcased our technical skills but also demonstrated our determination and creativity in bringing a unique feature to life within our application.
## What we learned
We learned the importance of breaking problems down into smaller, manageable pieces to construct something big and impactful. This approach not only made complex challenges more approachable but also fostered collaboration and innovation within our team. By focusing on individual components, we were able to create a cohesive and effective solution that truly enhances patient care. Also, learned a valuable lesson on the importance of sleep!
## What's next for MedicAI
With the AI medical industry projected to exceed $188 billion, we plan to scale our website to accommodate a growing number of users. Our next steps include partnering with hospitals to enhance patient access to our services, ensuring that individuals can seamlessly utilize our platform during their healthcare journey. By expanding our reach, we aim to empower more patients with the tools they need to manage their health effectively. | winning |
## Inspiration
More than 2.7 million pets will be killed over the next year because shelters cannot accommodate them. Many of them will be abandoned by owners who are unprepared for the real responsibilities of raising a pet, and the vast majority of them will never find a permanent home. The only sustainable solution to animal homelessness is to maximize adoptions of shelter animals by families who are equipped to care for them, so we created Homeward as a one-stop foster tool to streamline this process.
## What it does
Homeward allows shelters and pet owners to offer animals for adoption online. A simple and intuitive UI allows adopters to describe the pet they want and uses Google Cloud ML's Natural Language API to match their queries with available pets. Our feed offers quick browsing of available animals, multiple ranking options, and notifications of which pets are from shelters and which will be euthanized soon.
## How we built it
We used the Node.js framework with Express for routing and MongoDB as our database. Our front-end was built with custom CSS/Jade mixed with features from several CSS frameworks. Entries in our database were sourced from the RescueGroups API, and salient keywords for query matching were extracted using Google's Natural Language API. Our application is hosted with Google App Engine.
## Challenges we ran into
Incorporating Google's Natural Language API was challenging at first and we had to design a responsive front-end that would update the feed as the user updated their query. Some pets' descriptions had extraneous HTML and links that added noise to our extracted tags. We also found it tedious to clean and migrate the data to MongoDB.
## Accomplishments that we're proud of
We successfully leveraged Google Cloud ML to detect salient attributes in users' queries and rank animals in our feed accordingly. We also managed to utilize real animal data from the RescueGroups API. Our front-end also turned out to be cleaner and more user-friendly than we anticipated.
## What we learned
We learned first-hand about the challenges of applying natural language processing to potentially noisy user queries in real life applications. We also learned more about good javascript coding practices and robust back-end communication between our application and our database. But most importantly, we learned about the alarming state of animal homelessness and its origins.
## What's next for Homeward
We can enhance posted pet management by creating a simple account system for shelters. We would also like to create a scheduling mechanism that lets users "book" animals for fostering, thereby maximizing the probability of adoption. In order to scale Homeward, we need to clean and integrate more shelters' databases and adjust entries to match our schema. | ## Discord contact
* Nand Vinchhi - vinchhi
* Advay Choudhury - pdy.gn
* Rushil Madhu - rushil695
## Inspiration
Over the past few years, social media platforms like Tiktok and Instagram reels have used short-form content to take over the entertainment industry. Though this hyper-optimized form of content is engaging, it has led to students having shortened attention spans and a higher tendency to multi-task. Through Relearn, we aim to modernize studying to match these changing mental abilities.
## What it does
#### Scrolling interface for short videos
* Intuitive tiktok-like interface for scrolling educational short videos
* Complete with engaging music, bold subtitles, and background videos
* Functionality to like videos, indicating that the user has understood that particular concept
#### Content generation AI
* Uses lecture videos from Khanacademy + GPT-4.5 analysis to generate bite-sized educational clips
* Custom video processing for adding elements such as music and subtitles
#### Recommendation algorithm
* Ensures that the user progressively covers all content in a given topic
* Occasional meme videos for a quick study break!
#### Edison AI
* An LLM-based bot account that answers student questions in the comments section
* Understands the context from the current video to provide precise and useful answers
## Additional details for sponsor prizes
#### Best Use of AI in Education
Relearn explores the confluence of cutting-edge AI tech and useful education solutions -
* Our content generation pipeline utilizes LLMs (GPT-4.5) to understand context in Khanacademy lecture videos to create short and engaging clips
* Our AI account, Edison, utilizes LLMs to provide precise and useful answers to questions in the comments of a specific video
#### Best Accessibility Hack sponsored by Fidelity
Our platform makes high-quality content available over the internet. We enable anyone with a mobile phone to improve their study consistency and quality, which would help bridge economic and social gaps in the long term.
#### Most Creative Use of Redis Cloud
We used Redis for the following pivotal aspects of our app -
* High speed caching and access of dynamic data such as likes, comments, and progress
* Caching the latest video that a given user interacted with in, and feeding that into our recommendation algorithm (speeds up the algorithm by a huge margin)
* See this file for our Redis functions - <https://github.com/NandVinchhi/relearn-hackathon/blob/main/backend/dbfunctions.py>
## How we built it
#### Front-end mobile application
* Built with Swift and Swift UI
* Used multiple packages for specific functionalities such as Google Auth, video playback etc.
#### Content generation pipeline
* YT Transcript API + PyTube for scraping Khanacademy videos
* Open AI to retrieve context and divide long lecture videos into bite-sized clips
* MoviePy for automatic video editing - subtitles, music, and background video
#### Back-end
* Python + FastAPI for the server
* Supabase database + cloud buckets for storing short videos + curriculum
* Redis database for storing dynamic like, comment, and progress data
* Server deployment on AWS EC2
#### Recommendation algorithm
* Caching latest 'liked' short videos for each topic and unit in Redis
* Super fast progress retrieval from in order to compute the next video on scroll
#### Edison AI
* Used GPT 4.5 + short video transcripts for context-specific answers
* AI chat endpoints deployed along with server on AWS
## Challenges we ran into
* LLM hallucinations
* Bugs with automated video processing
* Getting the video scrolling interface to work smoothly without any sort of flickering or unwanted behavior
* Getting the whole stack working together and deployed before submission deadline
## Accomplishments that we're proud of
* Implementing a custom video scrolling interface for our short videos
* Automatically generating high-quality short videos
* Designing a clean user interface using Figma before building it out
* Getting back-end integrated with google auth + multiple databases + APIs and deploying to cloud
* All of this in < 36 hours!
## What we learned
* Using Redis to enhance a more conventional tech stack
* Deploying FastAPI to AWS EC2 using Gunicorn workers
* Building complex automated video editing functionality using MoviePy
* Utilizing the newly released GPT-4.5 API to perform context retrieval and create high-quality videos.
* Building custom UI Components in Swift and working with Google Auth in an iOS application
## What's next for Relearn
* Expanding curriculum to cover topics for all ages
* Multi-language support to increase accessibility
* Periodic flash cards and quizzes based on progress
* Opportunity for creators to upload their own content directly to Relearn | ## Inspiration
There are two types of pets wandering unsupervised in the streets - ones that are lost and ones that don't have a home to go to. Pet's Palace portable mini-shelters services these animals and connects them to necessary services while leveraging the power of IoT.
## What it does
The units are placed in streets and alleyways. As an animal approaches the unit, an ultrasonic sensor triggers the door to open and dispenses a pellet of food. Once inside, a live stream of the interior of the unit is sent to local animal shelters which they can then analyze and dispatch representatives accordingly. Backend analysis of the footage provides information on breed identification, custom trained data, and uploads an image to a lost and found database. A chatbot is implemented between the unit and a responder at the animal shelter.
## How we built it
Several Arduino microcontrollers distribute the hardware tasks within the unit with the aide of a wifi chip coded in Python. IBM Watson powers machine learning analysis of the video content generated in the interior of the unit. The adoption agency views the live stream and related data from a web interface coded with Javascript.
## Challenges we ran into
Integrating the various technologies/endpoints with one Firebase backend.
## Accomplishments that we're proud of
A fully functional prototype! | partial |
## Inspiration
This project was inspired by the Professional Engineering course taken by all first year engineering students at McMaster University (1P03). The final project for the course was to design a solution to a problem of your choice that was given by St. Peter's Residence at Chedoke, a long term residence care home located in Hamilton, Ontario. One of the projects proposed by St. Peter's was to create a falling alarm to notify the nurses in the event of one of the residents having fallen.
## What it does
It notifies nurses if a resident falls or stumbles via a push notification to the nurse's phones directly, or ideally a nurse's station within the residence. It does this using an accelerometer in a shoe/slipper to detect the orientation and motion of the resident's feet, allowing us to accurately tell if the resident has encountered a fall.
## How we built it
We used a Particle Photon microcontroller alongside a MPU6050 gyro/accelerometer to be able to collect information about the movement of a residents foot and determine if the movement mimics the patterns of a typical fall. Once a typical fall has been read by the accelerometer, we used Twilio's RESTful API to transmit a text message to an emergency contact (or possibly a nurse/nurse station) so that they can assist the resident.
## Challenges we ran into
Upon developing the algorithm to determine whether a resident has fallen, we discovered that there are many cases where a resident's feet could be in a position that can be interpreted as "fallen". For example, lounge chairs would position the feet as if the resident is laying down, so we needed to account for cases like this so that our system would not send an alert to the emergency contact just because the resident wanted to relax.
To account for this, we analyzed the jerk (the rate of change of acceleration) to determine patterns in feet movement that are consistent in a fall. The two main patterns we focused on were:
1. A sudden impact, followed by the shoe changing orientation to a relatively horizontal position to a position perpendicular to the ground. (Critical alert sent to emergency contact).
2. A non-sudden change of shoe orientation to a position perpendicular to the ground, followed by a constant, sharp movement of the feet for at least 3 seconds (think of a slow fall, followed by a struggle on the ground). (Warning alert sent to emergency contact).
## Accomplishments that we're proud of
We are proud of accomplishing the development of an algorithm that consistently is able to communicate to an emergency contact about the safety of a resident. Additionally, fitting the hardware available to us into the sole of a shoe was quite difficult, and we are proud of being able to fit each component in the small area cut out of the sole.
## What we learned
We learned how to use RESTful API's, as well as how to use the Particle Photon to connect to the internet. Lastly, we learned that critical problem breakdowns are crucial in the developent process.
## What's next for VATS
Next steps would be to optimize our circuits by using the equivalent components but in a much smaller form. By doing this, we would be able to decrease the footprint (pun intended) of our design within a clients shoe. Additionally, we would explore other areas we could store our system inside of a shoe (such as the tongue). | ## Inspiration
While searching for ideas, our team came across an ECG dataset that was classified and labeled into categories for normal and abnormal patterns. While examining the abnormal patterns, it was observed that most seizure patterns had a small window that transitioned from a typical pattern to a seizure pattern around a 15-second window. Most of the accidents and damage in seizures are caused by falling, lack of help, or getting caught in disadvantaged situations -driving, cooking, etc.- detecting this short period in real-time and predicting a seizure with machine learning to warn the user seemed as somewhat of a viable solution. After this initial ideation, sharing patient data such as allergies, medicinal history, emergency contacts, previous seizures, and essential information at the moment of attack for the emergency workers was thought out in the case of unresponsiveness from the user to the app's notification.
## What does it do?
The system contains the following:
Three main agents.
A smartwatch with an accurate ECG sensor.
A machine learning algorithm on the cloud.
An integrated notification app on mobile phones to retrieve patient information during attacks.
The workflow includes a constant data transfer between the smartwatch and the machine learning algorithm to detect anomalies. If an attack is predicted, a notification prompts the user to check if this is a false positive prediction. Nothing is triggered if the user confirms nothing is wrong and dismisses the warning. The seizure protocol starts if the notification stays unattended or is answered as positive.
Seizure Protocol Includes:
-The user is warned by the prediction and should have found a safe space/position/situation to handle the seizure
-Alarms from both synced devices, mobile, and smartwatch
-Display of the FHIR patient history on the synced device, allergies, medicinal data, and fundamental id info for emergency healthcare workers
-Contacting emergency numbers recorded for the individual
With the help of the app, we prevent further damage by accidents by predicting the seizure. After the episode, we help the emergency workers have a smoother experience assisting the patient.
## Building the System
We attempted to use Zepp's smartwatch development environment to create a smartwatch app to track and communicate with the cloud (Though there have been problems with the ECG sensors, which will be mentioned in the challenges section.) For the machine learning algorithm, we used an LSTM model (Long-Short Term Memory Networks) to slice up the continuously fed data and classify between "normal" and "abnormal" states after training it on both Mit-Bih Epileptic Seizure Recognition datasets we have found. If the "abnormal" form has been observed for more than the threshold, we have classified it as a "seizure predictor." When the state changed to the seizure protocol, we had two ways of information transfer, one is to the smartwatch as an alarm/notification, and the other one to the synced mobile app to display information. For the mobile app, we have created a React Native app for the users to create profiles and transfer/display health information via the InterSystem's FHIR.js package. While in the "listening" state, the app waits for the seizure notification. When it receives it, it fetches and displays health information/history/emergency contacts and anything that can be useful to the emergency healthcare worker on the lock screen without unlocking the phone. Thus, providing a safer and smoother experience for the patient and the healthcare workers.
## Challenges
There have been several challenges and problems that we have encountered in this project. Some of them stayed unresolved, and some of them received quick fixes.
The first problem was using the ECG function of the Zepp watches. Because the watch ECG function was disabled in the U.S. due to a legal issue with the FDA, we could not pull up live data in the Hackathon. We resolved this issue by finding a premade ECG dataset and doing the train-test-validation on this premade dataset for the sake of providing a somewhat performing model for the Hackathon.
The second problem we encountered was that we could only measure our accuracy with our relatively mid-sized dataset. In the future, testing it with various datasets, trying sequential algorithms, and optimizing layers and performance would be advised. In the current state, without a live information feed and a comprehensive dataset, it is hard to be sure about the issues of overfitting/underfitting the dataset.
## Accomplishments
We could create a viable machine learning algorithm to predict seizures in a concise time frame, which took a lot of effort, research, and trials, especially in the beginning since we switched from plain RNN to LSTM due to the short-time frame problem. However, our algorithm works with a plausible accuracy (Keeping in mind that we cannot check for overfitting/underfitting without a diverse dataset). Another achievement we are proud of is that we attempted to build a project with many branches, like ReactApp, Zepp Integration, and Machine Learning in Python, which forced us to experience a product-development process in a super-dense mode.
But most importantly, attending the Hackathon and meeting with amazing people that both organized, supported, and competed in it was an achievement to appreciate!
## Points to Take Home
The most discussed point we learned was that integrating many APIs is a rather daunting process in terms of developing something within 24 hours. It was much harder to adapt and link these different technologies together, even though we had anticipated it before attempting it. The second point we learned was that we needed to be careful about our resources during the challenges. Especially our assumption about the live-data feed from the watch made us stumble in the development process a bit. However, these problems make Hackathons a learning experience, so it's all good!
## Future for PulseBud
The plans might include sharpening the ML with a variety of dense and large-scale datasets and optimizing the prediction methodology to reach the lowest latency with the highest accuracy. We might also try to run it on the watch itself if it can get a robust state like that. Also, setting personalized thresholds for each user would be much more efficient in terms of notification frequency if the person is an outlier. Also, handling the live data feed to the algorithm should be the priority. If these can be done to the full extent, this application can be a very comfortable quality of life change for many people who experience or might experience seizures. | ## Problem
The demanding nature of healthcare work often leads to burnout, impacting both the individuals themselves and the quality of patient care. Unfortunately, burnout frequently goes unnoticed until it reaches a critical stage, affecting not only the mental health of the professionals but also potentially jeopardizing patient safety and outcomes.
## Our Solution
The app not only efficiently detects emotional states but identifies early indicators of burnout among medical professionals through a custom neural network. It offers a user-friendly interface that presents weekly logs of burnout risk levels and a user friendly web dashboard of their associated emotional trends.
This app builds upon Hume's video emotion detection technology to predict and prevent burnout among healthcare workers. Existing approaches use frequent surveillance to profile medical practitioners' mental states, jeopardizing privacy. Our application protects privacy by recording infrequent but regular interactions with patients, with full knowledge of those involved.
## How we built it
At the core of our project was Hume's emotion detection API's ability to recognize 52 diverse, expressive nuances in facial expressions. We used the results of `HumeBatchClient` and `HumeStreamClient`'s facial expression model to train a custom ML model to detect burnout on a carefully curated training dataset.
We collected images labeled based on levels of burnout from open health research [1](https://bmcmededuc.biomedcentral.com/articles/10.1186/s12909-023-04003-y#Sec46) [2](https://www.aapl.org/docs/pdf/VIDEO%20RECORDING%20GUIDELINE%202013.pdf), friends, Hume's sample images, and synthetic data to train a regression model in scikit-learn. The model took as inputs the 52 emotions extracted from video frames as well as their manually selected labels, and optimized to learn the relationship between these emotions and eventual burnout.
Our project wouldn't be possible without CockroachDB's serverless database and their intuitive SQL Shell, which allowed us to define and work with a PostgreSQL schema. We communicate with the database from the Flask backend as well as the python script used to collect video and query the Hume batch API endpoints.
## Challenges we ran into
* One of the biggest challenges was the amount of iteration our project went through before a finalized idea. We took great care to find a socially relevant, unique problem with an original solution.
* We struggled to determine the ground truth for what counts as someone showing signs of being "burnt out". We found it effective to use some synthetic data generated by dall-e 3 along with manually labeled images.
## Accomplishments that we're proud of
* Successfully trained a classification model and deployed it on Hume's custom model platform using a self-labeled dataset for identifying potential burnout signs.
## What we learned
* Explored `HumeStreamClient` for WebSocket integration in Flask. We learned about nuances of WebSockets vs other HTTP connections.
* None of us have ever worked with front-end before. We successfully made a working flask, html, and Javascript website to demo our machine learning app.
## What's next for Burnout Monitor
* We want to incorporate spoken data to improve our prediction and data visualization. Conversational Emotion Recognition (CER) is a task to predict the emotion of dialogue in the context of a conversation.
* We want to improve the accuracy of our model by expanding on training data, parameters, and compute.
* Add a centralized alert system that creates actionable suggestions based on likely burnout for workers. | winning |
## Inspiration
NFT metadata is usually public. This would be bad if NFTs were being used as event tickets or private pieces of art. We need private NFT metadata.
## What it does
Allows users to encrypt NFT metadata based on specific conditions. Default decryption condition is holding more than 0.1 Avax token. Other conditions to decrypt can be holding other tokens, decrypting during a specific time interval, or being the owner of a specific wallet.
## How we built it
Smart contracts were built with Solidity and deployed on Avalanche. Frontend was build with NextJS and Wagmi React Hooks. Encryption was handled with the Lit Protocol.
## Challenges we ran into
Figuring out how to use the lit Protocol and deploy onto Avalanche. I really wanted to verify my contract programmatically but I couldn't figure out how with the Avalanche Fuji block explorer.
## Accomplishments that we're proud of
Finishing a hackathon project and deploying.
## What we learned
How to encrypt NFT metadata.
## What's next for Private Encrypted NFTs
Apply this to more impactful use cases and make it more user friendly. I think the idea of encrypted metadata is really powerful and can be applied to many places. All about execution, user interface, and community. | ## Inspiration
Generative AI has had the ability to overtake the creative domain of artists, and NFTs minted on the blockchain created to help artists maintain control of their work have been violated by fraudsters. Additionally, the unauthorized minting of NFTs can lead to copyright issues with the artist's work. Therefore, we created VibeWire to be a secure platform where the use management and licensing of NFTs is handled through secure contracts and minting as well as our vector-based histogram model with high image comparison accuracy.
## What it does
The front-end of our website enables you to enter your API key and begin minting. By using Pinecone vector-based database, we were able to build a model that can constructs a comparison histogram after comparing RGB pixels in images (to address unwanted replication, corruption, etc.). This model had an accuracy over 90% when we ran it. Our omnichain token minting saves the hash of the image so you and the artist/creator can ensure an image exists and is associated with an NFT.
## How we built it
VerbWire: VerbWire was an offered track, and deployment of smart contracts was easy. Omnichain was a bit difficult, as some of our team members got processing errors. We also sometimes got processing errors when trying to deploy without adding an optional wallet ID. To avoid these issues, we created our own test wallets and deployed ERC-721 (standard NFT contract), as advised by VerbWire co-founder Justin when we met him during mentor office hours.
Three.js: Our teammate used Three.js in building the front-end for our website.
Pinecone, Numpy, and Pillow: Our teammate used Pinecone and these Python packages to help him build histograms that compared RGB values of images in our marketplace being traded, which helped in fractionalizing ownership of these image assets.
## Challenges we ran into
One of the challenges we ran into was endless minting after an API key was entered on our front-end website portal. Another challenge was finding a functional GitHub repository we could add onto, as the localhost command was not working with some repos we came across despite our attempts to clear ports, remove firewalls, etc. (but we eventually found one!).
## Accomplishments that we're proud of
We were able to develop a model that could do an image comparison histogram (the details of which are described above). This involved work with vector-based databases like Pinecone, and it had a high accuracy (90%+).
## What we learned
We learned the power of VerbWire, deploying smart contracts, and NFTs. We learned how to work with image hashes as well as tying the front-end of our minting website to the back-end of our vector-based histogram model. Most of us entered as hackers with no prior use of VerbWire/the blockchain, and we all learned something new!
## What's next for VibeWire
Let's continue to protect more assets of artists: images aren't the only form of art, and we want to help safeguard many more types of artists! | ## Inspiration
We were inspired by how there were many instances of fraud with regards to how donations were handled. It is heartbreaking to see how mismanagement can lead to victims of disasters not receiving the help that they desperately need.
## What it does
TrustTrace introduces unparalleled levels of transparency and accountability to charities and fundraisers. Donors will now feel more comfortable donating to causes such as helping earthquake victims since they will now know how their money will be spent, and where every dollar raised is going to.
## How we built it
We created a smart contract that allowed organisations to specify how much money they want to raise and how they want to segment their spending into specific categories. This is then enforced by the smart contract, which puts donors at ease as they know that their donations will not be misused, and will go to those who are truly in need.
## Challenges we ran into
The integration of smart contracts and the web development frameworks were more difficult than we expected, and we overcame them with lots of trial and error.
## Accomplishments that we're proud of
We are proud of being able to create this in under 36 hours for a noble cause. We hope that this creation can eventually evolve into a product that can raise interest, trust, and participation in donating to humanitarian causes across the world.
## What we learned
We learnt a lot about how smart contract works, how they are deployed, and how they can be used to enforce trust.
## What's next for TrustTrace
Expanding towards serving a wider range of fundraisers such as GoFundMes, Kickstarters, etc. | partial |
## Inspiration
The inspiration for this project came from my passion for decentralized technology.
One particular niche of decentralization
I am particularly fond of is NFT's and how they
can become a great income stream for artists.
With the theme of the hackathon being
exploration and showing a picture of a rocket
ship, it is no surprise that the idea of space
came to mind. Looking into space photography, I
found the [r/astrophotography](https://www.reddit.com/r/astrophotography/)
subreddit that has a community of 2.6 million members.
There, beautiful shots of space can be found,
but they also require expensive equipment and
precise editing. My idea for Astronofty is to
turn these photographs into NFT's for the users
to be able to sell as unique tokens on the
platform while using Estuary as decentralized
storage platform for the photos.
## What It Does
You can mint/create NFT's of your
astrophotography to sell to other users.
## How I Built It
* Frontend: React
* Transaction Pipeline: Solidity/MetaMask
* Photo Storage: Estuary
## Challenges I Ran Into
I wanted to be able to upload as many images as you want to a single NFT so figuring that out logistically, structurally and synchronously in React was a challenge.
## Accomplishments That We're Proud Of
Deploying a fully functional all-in-one NFT marketplace.
## What I Learned
I learned about using Solidity mappings and
structs to store data on the blockchain and all
the frontend/contract integrations needed to
make an NFT marketplace work.
## What's Next for Astronofty
A mechanism to keep track of highly sought after photographers. | ## Inspiration
We wanted to watch videos together as a social activity during the pandemic but were unable as many platforms were hard to use or unstable. Therefore our team decided to create a platform that met our needs in terms of usability and functionality.
## What it does
Bubbles allow people to create viewing rooms and invite their rooms to watch synchronized videos. Viewers no longer have to conduct countdowns on their play buttons or have a separate chat while watching!
## How I built it
Our web app uses React for the frontend and interfaces with our Node.js REST API in the backend. The core of our app uses the Solace PubSub+ and the MQTT protocol to coordinate events such as video play/pause, a new member joining your bubble, and instant text messaging. Users broadcast events with the topic being their bubble room code, so only other people in the same room receive these events.
## Challenges I ran into
* Collaborating in a remote environment: we were in a discord call for the whole weekend, using Miro for whiteboarding, etc.
* Our teammates came from various technical backgrounds, and we all had a chance to learn a lot about the technologies we used and how to build a web app
* The project was so much fun we forgot to sleep and hacking was more difficult the next day
## Accomplishments that I'm proud of
The majority of our team was inexperienced in the technologies used. Our team is very proud that our product was challenging and was completed by the end of the hackathon.
## What I learned
We learned how to build a web app ground up, beginning with the design in Figma to the final deployment to GitHub and Heroku. We learned about React component lifecycle, asynchronous operation, React routers with a NodeJS backend, and how to interface all of this with a Solace PubSub+ Event Broker. But also, we learned how to collaborate and be productive together while still having a blast
## What's next for Bubbles
We will develop additional features regarding Bubbles. This includes seek syncing, user join messages and custom privilege for individuals. | ## Inspiration
Each year, art forgery causes over **$6 billion in losses**. Museums, for example, cannot afford such detrimental costs. In an industry that has spanned centuries, it is crucial that transactions of art pieces can be completed securely and confidently.
Introducing **Artful, a virtual marketplace for physical art which connects real-life artworks to secure NFTs on our own private blockchain**. With the power of the blockchain, the legitimacy of high-value real-world art pieces can be verified through an elegant and efficient web application, which with its scalability and decentralized framework, also proves as an efficient and secure measure for art dealership for all artists worldwide.
## What it does
To join our system, art owners can upload a picture of their art through our portal. Once authenticated in person by our team of art verification experts, the art piece is automatically generated into an NFT and uploaded on the Eluv.io Ethereum blockchain. In essence, ownership of the NFT represents ownership of the real life artwork.
From this point on, prospective buyers no longer need to consult expensive consultants, who charge hundreds of thousands to millions of dollars – they can simply visit the piece on our webapp and purchase it with full confidence in its legitimacy.
Artful serves a second purpose, namely for museums. According to the Museum Association, museum grant funding has dropped by over 20% over the last few years. As a result, museums have been forced to drop collections entirely, preventing public citizens from appreciating their beauty.
Artful enables museums to create NFT and experiential bundles, which can be sold to the public as a method of fundraising. Through the Eluv.io fabric, experiences ranging from AR trips to games can be easily deployed on the blockchain, allowing for museums to sustain their offerings for years to come.
## How we built it
We built a stylish and sleek frontend with Next.js, React, and Material UI. For our main backend, we utilized node.js and cockroachDB. At the core of our project is Eluv.io, powering our underlying Ethereum blockchain and personal marketplace.
## Challenges we ran into
Initially, our largest challenge was developing a private blockchain that we could use for development. We tested out various services and ensuring the packages worked as expected was a common obstacle. Additionally, we were attempting to develop a custom NFT transfer smart contract with Solana, which was quite difficult. However, we soon found Eluv.io which eliminated these challenges and allowed us to focus development on our own platform.
Overall, our largest challenge was automation. Specifically, the integration of automatically processing an uploaded image, utilizing the Eluv.io content fabric to create marketplaces and content objects in a manner that worked well with our existing frontend modules, generating the NFTs using an automated workflow, and publishing the NFT to the blockchain proved to be quite difficult due to the number of moving parts.
## Accomplishments that we're proud of
We’re incredibly proud of the scope and end-to-end completion of our website and application. Specifically, we’ve made a functional, working system which users can (today!) use to upload and purchase art through NFTs on our marketplace on an automated, scalable basis, including functionality for transactions, proof of ownership, and public listings.
While it may have been possible to quit in the face of relentless issues in the back-end coding and instead pursue a more theoretical approach (in which we suggest functionality rather than implement it), we chose to persist, and it paid off. The whole chain of commands which previously required manual input through command line and terminal has been condensed into an automated process and contained to a single file of new code.
## What we learned
Through initially starting with a completely from scratch Ethereum private blockchain using geth and smart contracts in Solidity, we developed a grounding in how blockchains actually work and the extensive infrastructure that enables decentralization. Moreover, we recognized the power of APIs in using Eluv.io’s architecture after learning it from the ground up. The theme of our project was fundamentally integration—finding ways to integrate our frontend user authentication and backend Eluv.io Ethereum blockchain, and seeing how to integrate the Eluv.io interface with our own custom web app. There were many technical challenges along the way in learning a whole new API, but through this journey, we feel much more comfortable with both our ability as programmers and our understanding of blockchain, a topic which before this hackathon, none of us had really developed familiarity with. By talking a lot with the Eluv.io CEO and founder who helped us tremendously with our project too, we learned a lot about their own goals and aspirations, and we can safely say that we’ve emerged from this hackathon with a much deeper appreciation and curiosity for blockchain and use cases of dapps.
## What's next for Artful
Artful plans to incorporate direct communications with museums by building a more robust fundraising network, where donators can contribute to the restoration of art or the renovation of an exhibit by purchasing one of the many available copies of a specific NFT. Also, we have begun implementing a database and blockchain tracking system, which museums can purchase to streamline their global collaboration as they showcase especially-famous pieces on a rotating basis. Fundamentally, we hope that our virtual center can act as a centralized hub for high-end art transfer worldwide, which through blockchain’s security, ensures the solidity (haha) of transactions will redefine the art buying/selling industry. Moreover, our website also acts as a proof of credibility as well — by connecting transactions with corresponding NFTs on the blockchain, we can ensure that every transaction occurring on our website is credible, and so as it scales up, the act of not using our website and dealing art underhandedly represents a loss of credibility. And most importantly, by integrating decentralization with the way high-end art NFTs are stored, we hope to bring the beautiful yet esoteric world of art to more people, further creating a platform for up and coming artists to establish their mark on a new age of digital creators. | winning |
After five hours of debating over a topic, Brian–a member of our team–recalled a 2 axis Gimbal machine he once utilized for a maze game. We began thinking about this interesting invention, and were inspired to take it further. We decided to make 3 axis Gimbal because we wanted to do a hardware hack in combination with Virtual Reality (VR).
Our project consists of two components: a 3 axis Gimbal to balance a phone, and a module that uses Oculus VR to control the Gimbal from afar. This allows a user to be immersed in their friends and family even if they can not be physically present.
We designed the Gimbal itself in Solidworks, and laser-cut individual pieces before gluing and bolting the components together. We used three continuous rotation servos (one per axis) all powered off an Arduino Uno. these servos were controlled with PID, an IMU, and Inverse Kinematics.
Fabrication and assembly were more challenging than expected. This event being more attuned to hardware, we were restricted to rapid prototyping tools like laser-cutters and 3D-printers, and only the simplest assembly techniques. Additionally, our choice of continuous rotation servos was troublesome as it made it difficult if not impossible to find definite positions for the arms of the Gimbal. In fact, later into the build we realized that due to Whitney's theorem there must be multiple solutions for our Gimbal, making the problem difficult. However, despite the difficulties, we built a fully functional Gimbal, and connected it to VR.
We learned a lot about our CAD skills and where we need to improve, rapid prototyping techniques, sensor integration to mechanical assembly, and just working as a team | ## Inspiration
JAGT Move originally came forth as an idea after one of our members injured himself trying to perform a basic exercise move he wasn't used to. The project has pivoted around over time, but the idea of applying new technologies to help people perform poses has remained.
## What it does
The project compares positional information between the user and their reference exercise footage using pose recognition (ML) in order to give them metrics and advice which will help them perform better (either as a clinical tool, or for everyday use).
## How we built it
* Android frontend based of TensorFlow Lite Posenet application
* NodeJS backend to retrieve the metrics, process it and provide the error of each body part to the website for visual presentation.
* A React website showing the live analysis with details to which parts of your body were out of sync.
## Challenges we ran into
* Only starting model available for Android project used Kotlin, which our mobile dev. had to learn on the fly
* Server errors like "post method too voluminous", and a bunch of other we had to work around
* Tons of difficult back-end calculations
* Work with more complex sets of data (human shapes) in an ML context
## What's next for JAGT Move
Expand the service, specialize the application for medical use further, expand on the convenience of use of the app for the general public, and much more! It's time to get JAGT! | ## Inspiration
Many first-year students, who have recently moved out, struggle in adjusting to living alone due to the academic pressure of university. As a result, there are times when students forget to look after themselves and spiral into an unhealthy routine.
Therefore, we wanted to create a virtual journal. So students have somewhere to reflect on their day and a place to express their thoughts.
## What it does
The program, designed to be used by someone at the end of the day, lets users input answers about their day into a short reflection form. It takes the inputted data and stores it in a visually presentable format, which is then backed up to Google Drive for easy accessibility.
## How we built it
We divided the program into two main tasks
1. Data input and validation
2. Google Drive API handling
The first task was creating a GUI to get information from the user and then perform validation checks on it, the second part was writing data and reading data into/from Google Drive. Whilst also taking the data and displaying it back to the user in a presentable format.
## Challenges we ran into
One of our team members got sick and so had to work from home, making it a bit harder to communicate ideas with everyone.
## Accomplishments that we're proud of
We really enjoyed some finer details of this project like having validation checks or being able to access the datasheet from anywhere using the cloud.
## What we learned
The biggest learning curve came in using the GUI in our projects and integrating our stuff with the Google Drive API
## What's next for Day2Day
If we had more time we would love to be able to perform statistics on our data collected, having a 7-30 day summary of happiness levels would be a very interesting feature. | partial |
## Inspiration
Inspired by a team member's desire to study through his courses by listening to his textbook readings recited by his favorite anime characters, functionality that does not exist on any app on the market, we realized that there was an opportunity to build a similar app that would bring about even deeper social impact. Dyslexics, the visually impaired, and those who simply enjoy learning by having their favorite characters read to them (e.g. children, fans of TV series, etc.) would benefit from a highly personalized app.
## What it does
Our web app, EduVoicer, allows a user to upload a segment of their favorite template voice audio (only needs to be a few seconds long) and a PDF of a textbook and uses existing Deepfake technology to synthesize the dictation from the textbook using the users' favorite voice. The Deepfake tech relies on a multi-network model trained using transfer learning on hours of voice data. The encoder first generates a fixed embedding of a given voice sample of only a few seconds, which characterizes the unique features of the voice. Then, this embedding is used in conjunction with a seq2seq synthesis network that generates a mel spectrogram based on the text (obtained via optical character recognition from the PDF). Finally, this mel spectrogram is converted into the time-domain via the Wave-RNN vocoder (see [this](https://arxiv.org/pdf/1806.04558.pdf) paper for more technical details). Then, the user automatically downloads the .WAV file of his/her favorite voice reading the PDF contents!
## How we built it
We combined a number of different APIs and technologies to build this app. For leveraging scalable machine learning and intelligence compute, we heavily relied on the Google Cloud APIs -- including the Google Cloud PDF-to-text API, Google Cloud Compute Engine VMs, and Google Cloud Storage; for the deep learning techniques, we mainly relied on existing Deepfake code written for Python and Tensorflow (see Github repo [here](https://github.com/rodrigo-castellon/Real-Time-Voice-Cloning), which is a fork). For web server functionality, we relied on Python's Flask module, the Python standard library, HTML, and CSS. In the end, we pieced together the web server with Google Cloud Platform (GCP) via the GCP API, utilizing Google Cloud Storage buckets to store and manage the data the app would be manipulating.
## Challenges we ran into
Some of the greatest difficulties were encountered in the superficially simplest implementations. For example, the front-end initially seemed trivial (what's more to it than a page with two upload buttons?), but many of the intricacies associated with communicating with Google Cloud meant that we had to spend multiple hours creating even a landing page with just drag-and-drop and upload functionality. On the backend, 10 excruciating hours were spent attempting (successfully) to integrate existing Deepfake/Voice-cloning code with the Google Cloud Platform. Many mistakes were made, and in the process, there was much learning.
## Accomplishments that we're proud of
We're immensely proud of piecing all of these disparate components together quickly and managing to arrive at a functioning build. What started out as merely an idea manifested itself into usable app within hours.
## What we learned
We learned today that sometimes the seemingly simplest things (dealing with python/CUDA versions for hours) can be the greatest barriers to building something that could be socially impactful. We also realized the value of well-developed, well-documented APIs (e.g. Google Cloud Platform) for programmers who want to create great products.
## What's next for EduVoicer
EduVoicer still has a long way to go before it could gain users. Our first next step is to implementing functionality, possibly with some image segmentation techniques, to decide what parts of the PDF should be scanned; this way, tables and charts could be intelligently discarded (or, even better, referenced throughout the audio dictation). The app is also not robust enough to handle large multi-page PDF files; the preliminary app was designed as a minimum viable product, only including enough to process a single-page PDF. Thus, we plan on ways of both increasing efficiency (time-wise) and scaling the app by splitting up PDFs into fragments, processing them in parallel, and returning the output to the user after collating individual text-to-speech outputs. In the same vein, the voice cloning algorithm was restricted by length of input text, so this is an area we seek to scale and parallelize in the future. Finally, we are thinking of using some caching mechanisms server-side to reduce waiting time for the output audio file. | ## Inspiration
After looking at the Hack the 6ix prizes, we were all drawn to the BLAHAJ. On a more serious note, we realized that one thing we all have in common is accidentally killing our house plants. This inspired a sense of environmental awareness and we wanted to create a project that would encourage others to take better care of their plants.
## What it does
Poképlants employs a combination of cameras, moisture sensors, and a photoresistor to provide real-time insight into the health of our household plants. Using this information, the web app creates an interactive gaming experience where users can gain insight into their plants while levelling up and battling other players’ plants. Stronger plants have stronger abilities, so our game is meant to encourage environmental awareness while creating an incentive for players to take better care of their plants.
## How we built it + Back-end:
The back end was a LOT of python, we took a new challenge on us and decided to try out using socketIO, for a websocket so that we can have multiplayers, this messed us up for hours and hours, until we finally got it working. Aside from this, we have an arduino to read for the moistness of the soil, the brightness of the surroundings, as well as the picture of it, where we leveraged computer vision to realize what the plant is. Finally, using langchain, we developed an agent to handle all of the arduino info to the front end and managing the states, and for storage, we used mongodb to hold all of the data needed.
[backend explanation here]
### Front-end:
The front-end was developed with **React.js**, which we used to create a web-based game. We were inspired by the design of old pokémon games, which we thought might evoke nostalgia for many players.
## Challenges we ran into
We had a lot of difficulty setting up socketio and connecting the api with it to the front end or the database
## Accomplishments that we're proud of
We are incredibly proud of integrating our web sockets between frontend and backend and using arduino data from the sensors.
## What's next for Poképlants
* Since the game was designed with a multiplayer experience in mind, we want to have more social capabilities by creating a friends list and leaderboard
* Another area to explore would be a connection to the community; for plants that are seriously injured, we could suggest and contact local botanists for help
* Some users might prefer the feeling of a mobile app, so one next step would be to create a mobile solution for our project | ## Inspiration
Public speaking is a critical skill in our lives. The ability to communicate effectively and efficiently is a very crucial, yet difficult skill to hone. For a few of us on the team, having grown up competing in public speaking competitions, we understand too well the challenges that individuals looking to improve their public speaking and presentation skills face. Building off of our experience of effective techniques and best practices and through analyzing the speech patterns of very well-known public speakers, we have designed a web app that will target weaker points in your speech and identify your strengths to make us all better and more effective communicators.
## What it does
By analyzing speaking data from many successful public speakers from a variety industries and backgrounds, we have established relatively robust standards for optimal speed, energy levels and pausing frequency during a speech. Taking into consideration the overall tone of the speech, as selected by the user, we are able to tailor our analyses to the user's needs. This simple and easy to use web application will offer users insight into their overall accuracy, enunciation, WPM, pause frequency, energy levels throughout the speech, error frequency per interval and summarize some helpful tips to improve their performance the next time around.
## How we built it
For the backend, we built a centralized RESTful Flask API to fetch all backend data from one endpoint. We used Google Cloud Storage to store files greater than 30 seconds as we found that locally saved audio files could only retain about 20-30 seconds of audio. We also used Google Cloud App Engine to deploy our Flask API as well as Google Cloud Speech To Text to transcribe the audio. Various python libraries were used for the analysis of voice data, and the resulting response returns within 5-10 seconds. The web application user interface was built using React, HTML and CSS and focused on displaying analyses in a clear and concise manner. We had two members of the team in charge of designing and developing the front end and two working on the back end functionality.
## Challenges we ran into
This hackathon, our team wanted to focus on creating a really good user interface to accompany the functionality. In our planning stages, we started looking into way more features than the time frame could accommodate, so a big challenge we faced was firstly, dealing with the time pressure and secondly, having to revisit our ideas many times and changing or removing functionality.
## Accomplishments that we're proud of
Our team is really proud of how well we worked together this hackathon, both in terms of team-wide discussions as well as efficient delegation of tasks for individual work. We leveraged many new technologies and learned so much in the process! Finally, we were able to create a good user interface to use as a platform to deliver our intended functionality.
## What we learned
Following the challenge that we faced during this hackathon, we were able to learn the importance of iteration within the design process and how helpful it is to revisit ideas and questions to see if they are still realistic and/or relevant. We also learned a lot about the great functionality that Google Cloud provides and how to leverage that in order to make our application better.
## What's next for Talko
In the future, we plan on continuing to develop the UI as well as add more functionality such as support for different languages. We are also considering creating a mobile app to make it more accessible to users on their phones. | winning |
## Inspiration
Transferring money using different memes, like a picture of Kim Kardashian in a US Dollar bill
## What it does
You can chat with your other friends utilizing Moxtra API, and send money by clicking on the dollar bill.
## How we built it
We used Nessie for getting bank accounts and making transactions, then we incorporated Moxtra API for the major front end development.
## Challenges we ran into
API integration didn't go well as we encountered errors we have never seen before.
## Accomplishments that I'm proud of
we didn't give up.
## What we learned
Javascript, Node.js, Java, and html & css
## What's next for MemeCash
Actually implementing the meme functionality | ## Inspiration
We are a group of 4 girls in electrical engineering that lead extremely busy lives. We are constantly using public transit and noticed that it can often be a confusing mess. We also noticed that taking a nap on public transport was so risky because of the inaccuracy of trying to use a time-based phone alarm. So we decided to make Ez Tranz.
## What it does
Ez Tranz is a location-based alarm that hopes to make the lives of commuters easier. It can be set to notify you a certain distance away from your location and will also notify you when you have reached your stop.
## How we built it
We built it using TKinter which is the inbuilt python GUI framework.
## Challenges we ran into
The biggest challenge we ran into was determining what platform we should use to develop our application.
## Accomplishments that we're proud of
We are very proud of creating a product that works as it required a lot of teamwork to complete.
## What we learned
We learned a lot about how coding in a team works and what goes into finishing a non-academic project from start to finish.
## What's next for Ez Tranz
The next step is creating this on a mobile platform as currently it is only supported on desktop. Then we hope to expand the database of bus routes and stops within the scope of the app. | ## Inspiration
It’s Friday afternoon, and as you return from your final class of the day cutting through the trailing winds of the Bay, you suddenly remember the Saturday trek you had planned with your friends. Equipment-less and desperate you race down to a nearby sports store and fish out $$$, not realising that the kid living two floors above you has the same equipment collecting dust. While this hypothetical may be based on real-life events, we see thousands of students and people alike impulsively spending money on goods that would eventually end up in their storage lockers. This cycle of buy-store-collect dust inspired us to develop Lendit this product aims to stagnate the growing waste economy and generate passive income for the users on the platform.
## What it does
A peer-to-peer lending and borrowing platform that allows users to generate passive income from the goods and garments collecting dust in the garage.
## How we built it
Our Smart Lockers are built with RaspberryPi3 (64bit, 1GB RAM, ARM-64) microcontrollers and are connected to our app through interfacing with Google's Firebase. The locker also uses Facial Recognition powered by OpenCV and object detection with Google's Cloud Vision API.
For our App, we've used Flutter/ Dart and interfaced with Firebase. To ensure *trust* - which is core to borrowing and lending, we've experimented with Ripple's API to create an Escrow system.
## Challenges we ran into
We learned that building a hardware hack can be quite challenging and can leave you with a few bald patches on your head. With no hardware equipment, half our team spent the first few hours running around the hotel and even the streets to arrange stepper motors and Micro-HDMI wires. In fact, we even borrowed another team's 3-D print to build the latch for our locker!
On the Flutter/ Dart side, we were sceptical about how the interfacing with Firebase and Raspberry Pi would work. Our App Developer previously worked with only Web Apps with SQL databases. However, NoSQL works a little differently and doesn't have a robust referential system. Therefore writing Queries for our Read Operations was tricky.
With the core tech of the project relying heavily on the Google Cloud Platform, we had to resolve to unconventional methods to utilize its capabilities with an internet that played Russian roulette.
## Accomplishments that we're proud of
The project has various hardware and software components like raspberry pi, Flutter, XRP Ledger Escrow, and Firebase, which all have their own independent frameworks. Integrating all of them together and making an end-to-end automated system for the users, is the biggest accomplishment we are proud of.
## What's next for LendIt
We believe that LendIt can be more than just a hackathon project. Over the course of the hackathon, we discussed the idea with friends and fellow participants and gained a pretty good Proof of Concept giving us the confidence that we can do a city-wide launch of the project in the near future. In order to see these ambitions come to life, we would have to improve our Object Detection and Facial Recognition models. From cardboard, we would like to see our lockers carved in metal at every corner of this city. As we continue to grow our skills as programmers we believe our product Lendit will grow with it. We would be honoured if we can contribute in any way to reduce the growing waste economy. | losing |
# Histovibes - A Journey Through Time
## Inspiration
The inspiration for Histovibes arose from a shared yearning within our team for a transformative and engaging history education experience. As enthusiasts of the past, we often found traditional textbooks lacking in both interactivity and a modern touch. Drawing on the theme of nostalgia for the hackathon, we envisioned a platform that not only encapsulates the richness of historical narratives but also integrates cutting-edge technology to make learning history a thoroughly immersive and enjoyable endeavour. The desire to recreate the joy of studying history, coupled with a futuristic yet nostalgic user interface, fuelled our determination to craft Histovibes.
This project is a testament to our collective passion for reshaping the way people perceive and interact with history, offering a dynamic and personalized learning journey that bridges the gap between the past and the present.
## What it does
Histovibes isn't just a platform; it's a time capsule. Craft timelines, explore auto-generated quizzes, and engage in discussions. The fusion of a React frontend, Flask backend, and Okta authentication brings history to life. MongoDB stores the richness of the past, making Histovibes a dynamic, user-centric learning haven.
It is designed to transform the way individuals learn and interact with history. At its core, Histovibes enables users to create and explore personalized timelines, allowing them to curate historical events that resonate with their interests. The platform goes beyond static content by incorporating dynamic features such as auto-generated quizzes and interactive discussions, fostering an engaging and participatory learning environment. With a clean and futuristic user interface that seamlessly blends nostalgia with innovation, Histovibes transcends conventional history textbooks, providing a captivating space for users to reminisce about the past while actively shaping their historical learning journey.
Powered by a React frontend and a Flask backend, Histovibes leverages Okta for user authentication, MongoDB for data storage, and integrates advanced technologies like OpenAI and Cohere LLM to enhance the intelligence and interactivity of the platform. In essence, Histovibes redefines history education by combining the best of modern technology with the timeless allure of the past.
## How we built it
We meticulously crafted Histovibes with the dexterity of a storyteller. React's elegance, Flask's resilience, and Okta's security dance seamlessly. MongoDB, our digital archive, ensures a smooth narrative flow. Histovibes is the symphony of technology playing in harmony.
### React
The frontend, developed with React, embodies a futuristic and user-friendly interface, offering seamless navigation and a visually appealing design that evokes a sense of nostalgia.
### Flask
Complementing this, the backend, powered by Flask, ensures robust functionality and efficient data handling.
### Okta and MongoDB
The integration of Okta provides a secure and streamlined authentication process, while MongoDB serves as the dynamic storage solution for user-generated timelines, events, and discussions.
### OpenAI and Co:Here
What sets Histovibes apart is its intelligent core, incorporating OpenAI and Cohere LLM to enhance the learning experience. OpenAI's large language models contribute to the creation of auto-generated quizzes, enriching the platform with dynamic assessments. Additionally, Cohere LLM adds sophistication to user discussions, offering context-aware insights.
## Challenges we ran into
### React-Flask Integration
Throughout the development journey of Histovibes, our team encountered several formidable challenges that tested our problem-solving skills and collaborative spirit. One significant hurdle emerged during the integration of React and Flask, where ensuring seamless communication between the frontend and backend proved intricate. Designing the user interface, initially conceptualized on Figma, presented its own set of challenges as we navigated the transition from design to implementation using Flutter. Compromises were made to streamline user-friendly features within our time constraints, leading to a minimalistic design that balanced functionality and aesthetics.
### Linking Everything Together
Linking various components of our tech stack posed another substantial challenge. Splitting responsibilities within the team, each working on different aspects, led to recurring merge conflicts during the linking process. Debugging this intricate linking system consumed a significant portion of our hackathon time, underscoring the importance of robust collaboration and version control. Despite these challenges, our team's perseverance prevailed, resulting in a cohesive and sophisticated Histovibes platform that seamlessly integrates React, Flask, Okta, MongoDB, OpenAI, and Cohere LLM. These challenges became valuable lessons, highlighting the intricate dance between technology, design, and teamwork in creating a dynamic history learning experience.
## Accomplishments that we're proud of
Throughout the development journey of Histovibes, our team achieved a multitude of significant milestones that we take immense pride in. Foremost among these accomplishments is the seamless integration of OpenAI and Cohere LLM, which elevated the platform's intelligence and interactivity. Our implementation of OpenAI facilitated the creation of auto-generated quizzes, providing users with dynamic and engaging assessments. Simultaneously, the incorporation of Cohere LLM into user discussions offered context-aware insights, enriching the overall learning experience. The successful orchestration of these advanced technologies underscores our commitment to infusing innovation into history education.
Our team also overcame challenges in UI design, striking a balance between functionality and aesthetics, resulting in a sleek and user-friendly interface. Looking back, Histovibes is not just a project; it's a testament to our dedication, innovation, and the successful execution of a vision that merges the best of technology with the timeless allure of history.
## What we learned
The development journey of Histovibes unfolded as a profound learning experience for our team. Navigating the integration of React and Flask, we gained valuable insights into optimizing the synergy between frontend and backend technologies. The collaborative effort to link various components of our tech stack uncovered the importance of meticulous planning and communication within the team. We learned that debugging, especially when linking diverse technologies, can be a challenging but essential part of the development process. Overall, the journey of creating Histovibes equipped us with a versatile skill set, from tech-specific knowledge to effective problem-solving strategies, showcasing the immense growth and resilience of our team.
## What's next for Histovibes
1. **Content Expansion:** Broaden historical coverage with additional events, timelines, and cultural perspectives.
2. **Enhanced Quiz Functionality:** Develop adaptive learning algorithms for personalized quizzes based on user progress.
3. **Community Building:** Introduce discussion forums and collaborative projects to foster a vibrant user community.
4. **Mobile Optimization:** Ensure Histovibes is accessible on various devices, allowing users to learn on the go.
5. **Integration of Multimedia:** Enhance learning with videos, interactive maps, and images for a more immersive experience.
6. **User Feedback Mechanism:** Implement a system for user feedback to continuously improve and refine the platform.
7. **Educational Partnerships:** Collaborate with educational institutions to integrate Histovibes into formal curricula. | ## Inspiration
The inspiration for this project stems from the well-established effectiveness of focusing on one task at a time, as opposed to multitasking. In today's era of online learning, students often find themselves navigating through various sources like lectures, articles, and notes, all while striving to absorb information effectively. Juggling these resources can lead to inefficiency, reduced retention, and increased distraction. To address this challenge, our platform consolidates these diverse learning materials into one accessible space.
## What it does
A seamless learning experience where you can upload and read PDFs while having instant access to a chatbot for quick clarifications, a built-in YouTube player for supplementary explanations, and a Google Search integration for in-depth research, all in one platform. But that's not all - with a click of a button, effortlessly create and sync notes to your Notion account for organized, accessible study materials. It's designed to be the ultimate tool for efficient, personalized learning.
## How we built it
Our project is a culmination of diverse programming languages and frameworks. We employed HTML, CSS, and JavaScript for the frontend, while leveraging Node.js for the backend. Python played a pivotal role in extracting data from PDFs. In addition, we integrated APIs from Google, YouTube, Notion, and ChatGPT, weaving together a dynamic and comprehensive learning platform
## Challenges we ran into
None of us were experienced in frontend frameworks. It took a lot of time to align various divs and also struggled working with data (from fetching it to using it to display on the frontend). Also our 4th teammate couldn't be present so we were left with the challenge of working as a 3 person team.
## Accomplishments that we're proud of
We take immense pride in not only completing this project, but also in realizing the results we envisioned from the outset. Despite limited frontend experience, we've managed to create a user-friendly interface that integrates all features successfully.
## What we learned
We gained valuable experience in full-stack web app development, along with honing our skills in collaborative teamwork. We learnt a lot about using APIs. Also a lot of prompt engineering was required to get the desired output from the chatgpt apu
## What's next for Study Flash
In the future, we envision expanding our platform by incorporating additional supplementary resources, with a laser focus on a specific subject matter | ## Inspiration 🌈
Our team has all experienced the struggle of jumping into a pre-existing codebase and having to process how everything works before starting to add our own changes. This can be a daunting task, especially when commit messages lack detail or context. We also know that when it comes time to push our changes, we often gloss over the commit message to get the change out as soon as possible, not helping any future collaborators or even our future selves. We wanted to create a web app that allows users to better understand the journey of the product, allowing users to comprehend previous design decisions and see how a codebase has evolved over time. GitInsights aims to bridge the gap between hastily written commit messages and clear, comprehensive documentation, making collaboration and onboarding smoother and more efficient.
## What it does 💻
* Summarizes commits and tracks individual files in each commit, and suggests more accurate commit messages.
* The app automatically suggests tags for commits, with the option for users to add their own custom tags for further sorting of data.
* Provides a visual timeline of user activity through commits, across all branches of a repository
Allows filtering commit data by user, highlighting the contributions of individuals
## How we built it ⚒️
The frontend is developed with Next.js, using TypeScript and various libraries for UI/UX enhancement. The backend uses Express.js , which handles our API calls to GitHub and OpenAI. We used Prisma as our ORM to connect to a PostgreSQL database for CRUD operations. For authentication, we utilized GitHub OAuth to generate JWT access tokens, securely accessing and managing users' GitHub information. The JWT is stored in cookie storage and sent to the backend API for authentication. We created a github application that users must all add onto their accounts when signing up. This allowed us to not only authenticate as our application on the backend, but also as the end user who provides access to this app.
## Challenges we ran into ☣️☢️⚠️
Originally, we wanted to use an open source LLM, like LLaMa, since we were parsing through a lot of data but we quickly realized it was too inefficient, taking over 10 seconds to analyze each commit message. We also learned to use new technologies like d3.js, the github api, prisma, yeah honestly everything for me
## Accomplishments that we're proud of 😁
The user interface is so slay, especially the timeline page. The features work!
## What we learned 🧠
Running LLMs locally saves you money, but LLMs require lots of computation (wow) and are thus very slow when running locally
## What's next for GitInsights
* Filter by tags, more advanced filtering and visualizations
* Adding webhooks to the github repository to enable automatic analysis and real time changes
* Implementing CRON background jobs, especially with the analysis the application needs to do when it first signs on an user, possibly done with RabbitMQ
* Creating native .gitignore files to refine the summarization process by ignoring files unrelated to development (i.e., package.json, package-lock.json, **pycache**). | losing |
## Inspiration
It’s insane how the majority of the U.S. still looks like **endless freeways and suburban sprawl.** The majority of Americans can’t get a cup of coffee or go to the grocery store without a car.
What would America look like with cleaner air, walkable cities, green spaces, and effective routing from place to place that builds on infrastructure for active transport and micro mobility? This is the question we answer, and show, to urban planners, at an extremely granular street level.
Compared to most of Europe and Asia (where there are public transportation options, human-scale streets, and dense neighborhoods) the United States is light-years away ... but urban planners don’t have the tools right now to easily assess a specific area’s walkability.
**Here's why this is an urgent problem:** Current tools for urban planners don’t provide *location-specific information* —they only provide arbitrary, high-level data overviews over a 50-mile or so radius about population density. Even though consumers see new tools, like Google Maps’ area busyness bars, it is only bits and pieces of all the data an urban planner needs, like data on bike paths, bus stops, and the relationships between traffic and pedestrians.
As a result, there’s very few actionable improvements that urban planners can make. Moreover, because cities are physical spaces, planners cannot easily visualize what an improvement (e.g. adding a bike/bus lane, parks, open spaces) would look like in the existing context of that specific road. Many urban planners don’t have the resources or capability to fully immerse themselves in a new city, live like a resident, and understand the problems that residents face on a daily basis that prevent them from accessing public transport, active commutes, or even safe outdoor spaces.
There’s also been a significant rise in micro-mobility—usage of e-bikes (e.g. CityBike rental services) and scooters (especially on college campuses) are growing. Research studies have shown that access to public transport, safe walking areas, and micro mobility all contribute to greater access of opportunity and successful mixed income neighborhoods, which can raise entire generations out of poverty. To continue this movement and translate this into economic mobility, we have to ensure urban developers are **making space for car-alternatives** in their city planning. This means bike lanes, bus stops, plaza’s, well-lit sidewalks, and green space in the city.
These reasons are why our team created CityGO—a tool that helps urban planners understand their region’s walkability scores down to the **granular street intersection level** and **instantly visualize what a street would look like if it was actually walkable** using Open AI's CLIP and DALL-E image generation tools (e.g. “What would the street in front of Painted Ladies look like if there were 2 bike lanes installed?)”
We are extremely intentional about the unseen effects of walkability on social structures, the environments, and public health and we are ecstatic to see the results: 1.Car-alternatives provide economic mobility as they give Americans alternatives to purchasing and maintaining cars that are cumbersome, unreliable, and extremely costly to maintain in dense urban areas. Having lower upfront costs also enables handicapped people, people that can’t drive, and extremely young/old people to have the same access to opportunity and continue living high quality lives. This disproportionately benefits people in poverty, as children with access to public transport or farther walking routes also gain access to better education, food sources, and can meet friends/share the resources of other neighborhoods which can have the **huge** impact of pulling communities out of poverty.
Placing bicycle lanes and barriers that protect cyclists from side traffic will encourage people to utilize micro mobility and active transport options. This is not possible if urban planners don’t know where existing transport is or even recognize the outsized impact of increased bike lanes.
Finally, it’s no surprise that transportation as a sector alone leads to 27% of carbon emissions (US EPA) and is a massive safety issue that all citizens face everyday. Our country’s dependence on cars has been leading to deeper issues that affect basic safety, climate change, and economic mobility. The faster that we take steps to mitigate this dependence, the more sustainable our lifestyles and Earth can be.
## What it does
TLDR:
1) Map that pulls together data on car traffic and congestion, pedestrian foot traffic, and bike parking opportunities. Heat maps that represent the density of foot traffic and location-specific interactive markers.
2) Google Map Street View API enables urban planners to see and move through live imagery of their site.
3) OpenAI CLIP and DALL-E are used to incorporate an uploaded image (taken from StreetView) and descriptor text embeddings to accurately provide a **hyper location-specific augmented image**.
The exact street venues that are unwalkable in a city are extremely difficult to pinpoint. There’s an insane amount of data that you have to consolidate to get a cohesive image of a city’s walkability state at every point—from car traffic congestion, pedestrian foot traffic, bike parking, and more.
Because cohesive data collection is extremely important to produce a well-nuanced understanding of a place’s walkability, our team incorporated a mix of geoJSON data formats and vector tiles (specific to MapBox API). There was a significant amount of unexpected “data wrangling” that came from this project since multiple formats from various sources had to be integrated with existing mapping software—however, it was a great exposure to real issues data analysts and urban planners have when trying to work with data.
There are three primary layers to our mapping software: traffic congestion, pedestrian traffic, and bicycle parking.
In order to get the exact traffic congestion per street, avenue, and boulevard in San Francisco, we utilized a data layer in MapBox API. We specified all possible locations within SF and made requests for geoJSON data that is represented through each Marker. Green stands for low congestion, yellow stands for average congestion, and red stands for high congestion. This data layer was classified as a vector tile in MapBox API.
Consolidating pedestrian foot traffic data was an interesting task to handle since this data is heavily locked in enterprise software tools. There are existing open source data sets that are posted by regional governments, but none of them are specific enough that they can produce 20+ or so heat maps of high foot traffic areas in a 15 mile radius. Thus, we utilized Best Time API to index for a diverse range of locations (e.g. restaurants, bars, activities, tourist spots, etc.) so our heat maps would not be biased towards a certain style of venue to capture information relevant to all audiences. We then cross-validated that data with Walk Score (the most trusted site for gaining walkability scores on specific addresses). We then ranked these areas and rendered heat maps on MapBox to showcase density.
San Francisco’s government open sources extremely useful data on all of the locations for bike parking installed in the past few years. We ensured that the data has been well maintained and preserved its quality over the past few years so we don’t over/underrepresent certain areas more than others. This was enforced by recent updates in the past 2 months that deemed the data accurate, so we added the geographic data as a new layer on our app. Each bike parking spot installed by the SF government is represented by a little bike icon on the map!
**The most valuable feature** is the user can navigate to any location and prompt CityGo to produce a hyper realistic augmented image resembling that location with added infrastructure improvements to make the area more walkable. Seeing the StreetView of that location, which you can move around and see real time information, and being able to envision the end product is the final bridge to an urban developer’s planning process, ensuring that walkability is within our near future.
## How we built it
We utilized the React framework to organize our project’s state variables, components, and state transfer. We also used it to build custom components, like the one that conditionally renders a live panoramic street view of the given location or render information retrieved from various data entry points.
To create the map on the left, our team used MapBox’s API to style the map and integrate the heat map visualizations with existing data sources. In order to create the markers that corresponded to specific geometric coordinates, we utilized Mapbox GL JS (their specific Javascript library) and third-party React libraries.
To create the Google Maps Panoramic Street View, we integrated our backend geometric coordinates to Google Maps’ API so there could be an individual rendering of each location. We supplemented this with third party React libraries for better error handling, feasibility, and visual appeal. The panoramic street view was extremely important for us to include this because urban planners need context on spatial configurations to develop designs that integrate well into the existing communities.
We created a custom function and used the required HTTP route (in PHP) to grab data from the Walk Score API with our JSON server so it could provide specific Walkability Scores for every marker in our map.
Text Generation from OpenAI’s text completion API was used to produce location-specific suggestions on walkability. Whatever marker a user clicked, the address was plugged in as a variable to a prompt that lists out 5 suggestions that are specific to that place within a 500-feet radius. This process opened us to the difficulties and rewarding aspects of prompt engineering, enabling us to get more actionable and location-specific than the generic alternative.
Additionally, we give the user the option to generate a potential view of the area with optimal walkability conditions using a variety of OpenAI models. We have created our own API using the Flask API development framework for Google Street View analysis and optimal scene generation.
**Here’s how we were able to get true image generation to work:** When the user prompts the website for a more walkable version of the current location, we grab an image of the Google Street View and implement our own architecture using OpenAI contrastive language-image pre-training (CLIP) image and text encoders to encode both the image and a variety of potential descriptions describing the traffic, use of public transport, and pedestrian walkways present within the image. The outputted embeddings for both the image and the bodies of text were then compared with each other using scaled cosine similarity to output similarity scores. We then tag the image with the necessary descriptors, like classifiers,—this is our way of making the system understand the semantic meaning behind the image and prompt potential changes based on very specific street views (e.g. the Painted Ladies in San Francisco might have a high walkability score via the Walk Score API, but could potentially need larger sidewalks to further improve transport and the ability to travel in that region of SF). This is significantly more accurate than simply using DALL-E’s set image generation parameters with an unspecific prompt based purely on the walkability score because we are incorporating both the uploaded image for context and descriptor text embeddings to accurately provide a hyper location-specific augmented image.
A descriptive prompt is constructed from this semantic image analysis and fed into DALLE, a diffusion based image generation model conditioned on textual descriptors. The resulting images are higher quality, as they preserve structural integrity to resemble the real world, and effectively implement the necessary changes to make specific locations optimal for travel.
We used Tailwind CSS to style our components.
## Challenges we ran into
There were existing data bottlenecks, especially with getting accurate, granular, pedestrian foot traffic data.
The main challenge we ran into was integrating the necessary Open AI models + API routes. Creating a fast, seamless pipeline that provided the user with as much mobility and autonomy as possible required that we make use of not just the Walk Score API, but also map and geographical information from maps + google street view.
Processing both image and textual information pushed us to explore using the CLIP pre-trained text and image encoders to create semantically rich embeddings which can be used to relate ideas and objects present within the image to textual descriptions.
## Accomplishments that we're proud of
We could have done just normal image generation but we were able to detect car, people, and public transit concentration existing in an image, assign that to a numerical score, and then match that with a hyper-specific prompt that was generating an image based off of that information. This enabled us to make our own metrics for a given scene; we wonder how this model can be used in the real world to speed up or completely automate the data collection pipeline for local governments.
## What we learned and what's next for CityGO
Utilizing multiple data formats and sources to cohesively show up in the map + provide accurate suggestions for walkability improvement was important to us because data is the backbone for this idea. Properly processing the right pieces of data at the right step in the system process and presenting the proper results to the user was of utmost importance. We definitely learned a lot about keeping data lightweight, easily transferring between third-party softwares, and finding relationships between different types of data to synthesize a proper output.
We also learned quite a bit by implementing Open AI’s CLIP image and text encoders for semantic tagging of images with specific textual descriptions describing car, public transit, and people/people crosswalk concentrations. It was important for us to plan out a system architecture that effectively utilized advanced technologies for a seamless end-to-end pipeline. We learned about how information abstraction (i.e. converting between images and text and finding relationships between them via embeddings) can play to our advantage and utilizing different artificially intelligent models for intermediate processing.
In the future, we plan on integrating a better visualization tool to produce more realistic renders and introduce an inpainting feature so that users have the freedom to select a specific view on street view and be given recommendations + implement very specific changes incrementally. We hope that this will allow urban planners to more effectively implement design changes to urban spaces by receiving an immediate visual + seeing how a specific change seamlessly integrates with the rest of the environment.
Additionally we hope to do a neural radiance field (NERF) integration with the produced “optimal” scenes to give the user the freedom to navigate through the environment within the NERF to visualize the change (e.g. adding a bike lane or expanding a sidewalk or shifting the build site for a building). A potential virtual reality platform would provide an immersive experience for urban planners to effectively receive AI-powered layout recommendations and instantly visualize them.
Our ultimate goal is to integrate an asset library and use NERF-based 3D asset generation to allow planners to generate realistic and interactive 3D renders of locations with AI-assisted changes to improve walkability. One end-to-end pipeline for visualizing an area, identifying potential changes, visualizing said changes using image generation + 3D scene editing/construction, and quickly iterating through different design cycles to create an optimal solution for a specific locations’ walkability as efficiently as possible! | ## Inspiration
The only thing worse than no WiFi is slow WiFi. Many of us have experienced the frustrations of terrible internet connections. We have too, so we set out to create a tool to help users find the best place around to connect.
## What it does
Our app runs in the background (completely quietly) and maps out the WiFi landscape of the world. That information is sent to a central server and combined with location and WiFi data from all users of the app. The server then processes the data and generates heatmaps of WiFi signal strength to send back to the end user. Because of our architecture these heatmaps are real time, updating dynamically as the WiFi strength changes.
## How we built it
We split up the work into three parts: mobile, cloud, and visualization and had each member of our team work on a part. For the mobile component, we quickly built an MVP iOS app that could collect and push data to the server and iteratively improved our locationing methodology. For the cloud, we set up a Firebase Realtime Database (NoSQL) to allow for large amounts of data throughput. For the visualization, we took the points we received and used gaussian kernel density estimation to generate interpretable heatmaps.
## Challenges we ran into
Engineering an algorithm to determine the location of the client was significantly more difficult than expected. Initially, we wanted to use accelerometer data, and use GPS as well to calibrate the data, but excessive noise in the resulting data prevented us from using it effectively and from proceeding with this approach. We ran into even more issues when we used a device with less accurate sensors like an Android phone.
## Accomplishments that we're proud of
We are particularly proud of getting accurate paths travelled from the phones. We initially tried to use double integrator dynamics on top of oriented accelerometer readings, correcting for errors with GPS. However, we quickly realized that without prohibitively expensive filtering, the data from the accelerometer was useless and that GPS did not function well indoors due to the walls affecting the time-of-flight measurements. Instead, we used a built in pedometer framework to estimate distance travelled (this used a lot of advanced on-device signal processing) and combined this with the average heading (calculated using a magnetometer) to get meter-level accurate distances.
## What we learned
Locationing is hard! Especially indoors or over short distances.
Firebase’s realtime database was extremely easy to use and very performant
Distributing the data processing between the server and client is a balance worth playing with
## What's next for Hotspot
Next, we’d like to expand our work on the iOS side and create a sister application for Android (currently in the works). We’d also like to overlay our heatmap on Google maps.
There are also many interesting things you can do with a WiFi heatmap. Given some user settings, we could automatically switch from WiFi to data when the WiFi signal strength is about to get too poor. We could also use this app to find optimal placements for routers. Finally, we could use the application in disaster scenarios to on-the-fly compute areas with internet access still up or produce approximate population heatmaps. | ## Inspiration
We're tired of seeing invasive advertisements and blatant commercialization all around us. With new AR technology, there may be better ways to help mask and put these advertisements out of sight, or in a new light.
## What it does
By utilizing Vueforia technologies and APIs, we can use image tracking to locate and overlay advertisements with dynamic content.
## How we built it
Using Unity and Microsoft's Universal Window's Platform, we created an application that has robust tracking capabilities.
## Challenges we ran into
Microsoft's UWP platform has many challenges, such as various different requirements and dependencies. Even with experienced Microsoft personel, due to certain areas of lacking implementation, we were ultimately unable to get certain portions of our code running on the Microsoft Hololens device.
## Accomplishments that we're proud of
Using the Vuforia api, we implemented a robust tracking solution while also pairing the powerful api's of giphy to have dynamic, networked content in lieu of these ads.
## What we learned
While Unity and Microsoft's UWP are powerful platforms, sometimes there can be powerful issues that can hinder development in a big way. Using a multitude of devices and supported frameworks, we managed to work around our blocks the best we could in order to demonstrate and develop the core of our application.
## What's next for Ad Block-AR
Hopefully we're going to be extending this software to run on a multitude of devices and technologies, with the ultimate aim of creating one of the most tangible and effective image recognition programs for the future. | winning |
## Inspiration
While video-calling his grandmother, Tianyun was captivated by her nostalgic tales from her youth in China. It struck him how many of these cherished stories, rich in culture and emotion, remain untold or fade away as time progresses due to barriers like time constraints, lack of documentation, and the predominance of oral traditions.
For many people, however, it can be challenging to find time to hear stories from their elders. Along with limited documentation, and accessibility issues, many of these stories are getting lost as time passes.
**We believe these stories are *valuable* and *deserve* to be heard.** That’s why we created a tool that provides people with a dedicated team to help preserve these stories and legacies.
## What it does
Forget typing. Embrace voice. Our platform boasts a state-of-the-art Speech-To-Text interface. Leveraging cutting-edge LLM models combined with robust cloud infrastructures, we ensure swift and precise transcription. Whether your narration follows a structured storyline or meanders like a river, our bot Ivee skillfully crafts it into a beautiful, funny, or dramatic memoir.
## How we built it
Our initial step was an in-depth two-hour user experience research session. After crafting user personas, we identified our target audience: those who yearn to be acknowledged and remembered.
The next phase involved rapid setup and library installations. The team then split: the backend engineer dived into fine-tuning custom language models and optimizing database frameworks, the frontend designer focused on user authentication, navigation, and overall app structure, and the design team commenced the meticulous work of wireframing and conceptualization.
After an intense 35-hour development sprint, Ivee came to life. The designers brought to life a theme of nature into the application, symbolizing each story as a leaf, a life's collective memories as trees, and cultural groves of forests. The frontend squad meticulously sculpted an immersive onboarding journey, integrating seamless interactions with the backend, and spotlighting the TTS and STT features. Meanwhile, the backend experts integrated technologies from our esteemed sponsors: Hume.ai, Intel Developer Cloud, and Zilliz Vector Database.
Our initial segregation into Frontend, Design, Marketing, and Backend teams soon blurred as we realized the essence of collaboration. Every decision, every tweak was a collective effort, echoing the voice of the entire team.
## Challenges we ran into
Our foremost challenge was crafting an interface that exuded warmth, empathy, and familiarity, yet was technologically advanced. Through interactions with our relatives, we discovered overall negative sentiment toward AI, often stemming from dystopian portrayals in movies.
## Accomplishments that we're proud of
Our eureka moment was when we successfully demystified AI for our primary users. By employing intuitive metaphors and a user-centric design, we transformed AI from a daunting entity to an amiable ally. The intricate detailing in our design, the custom assets & themes, solving the challenges of optimizing 8 different APIs, and designing an intuitive & accessible onboarding experience are all highlights of our creativity.
## What we learned
Our journey underscored the true value of user-centric design. Conventional design principles had to be recalibrated to resonate with our unique user base. We created an AI tool to empower humanity, to help inspire, share, and preserve stories, not just write them. It was a profound lesson in accessibility and the art of placing users at the heart of every design choice.
## What's next for Ivee
The goal for Ivee was always to preserve important memories and moments in people's lives. Below are some really exciting features that our team would love to implement:
* Reinforcement Learning on responses to fit your narration style
* Rust to make everything faster
* **Multimodal** storytelling. We want to include clips of the most emotion-fueled clips, on top of the stylized and colour-coded text, we want to revolutionize the way we interact with stories.
* Custom handwriting for memoirs
* Use your voice and read your story in your voice using custom voices
In the future, we hope to implement additional features like photos and videos, as well as sharing features to help families and communities grow forests together. | ## Inspiration
When attending crowded lectures or tutorials, it's fairly difficult to discern content from other ambient noise. What if a streamlined pipeline existed to isolate and amplify vocal audio while transcribing text from audio, and providing general context in the form of images? Is there any way to use this technology to minimize access to education? These were the questions we asked ourselves when deciding the scope of our project.
## The Stack
**Front-end :** react-native
**Back-end :** python, flask, sqlalchemy, sqlite
**AI + Pipelining Tech :** OpenAI, google-speech-recognition, scipy, asteroid, RNNs, NLP
## What it does
We built a mobile app which allows users to record video and applies an AI-powered audio processing pipeline.
**Primary use case:** Hard of hearing aid which:
1. Isolates + amplifies sound from a recorded video (pre-trained RNN model)
2. Transcribes text from isolated audio (google-speech-recognition)
3. Generates NLP context from transcription (NLP model)
4. Generates an associated image to topic being discussed (OpenAI API)
## How we built it
* Frameworked UI on Figma
* Started building UI using react-native
* Researched models for implementation
* Implemented neural networks and APIs
* Testing, Testing, Testing
## Challenges we ran into
Choosing the optimal model for each processing step required careful planning. Algorithim design was also important as responses had to be sent back to the mobile device as fast as possible to improve app usability.
## Accomplishments that we're proud of + What we learned
* Very high accuracy achieved for transcription, NLP context, and .wav isolation
* Efficient UI development
* Effective use of each tem member's strengths
## What's next for murmr
* Improve AI pipeline processing, modifying algorithms to decreasing computation time
* Include multi-processing to return content faster
* Integrate user-interviews to improve usability + generally focus more on usability | ## Inspiration
As students, we are constantly needing to attend interviews whether for jobs or internships, present in class, and speak in front of large groups of people. We understand the struggle of feeling anxious and unprepared, and wished to create an application that would assist us in knowing if we are improving and ready to present.
## What it does
Our application is built around tracking applications such as body language, eye movement, tone of voice, and intent of speech. With the use of analyzers, Speakeasy summarizes and compiles results along with feedback on how to improve for your next presentation. It also grants the ability to learn how your presentations come across to others. You can see how clear and concise your speech is, edit your speech's grammar and spelling on the fly, and even generate a whole new speech if your intended audience changes.
## How we built it
We used LLP models from Cohere to help recognize speech patterns. We used prompt engineering to manufacture summary statements, grammar checks, and changes in tone to deliver different intents. The front end was built using React and Chakra UI, while the back-end was created with Python. The UI was designed using Figma and transferred on to Chakra UI.
## Challenges we ran into
There were numerous challenges we ran into in the creation of this application. With it we learned to quickly adapt and adjust our plans. Originally we planned to utilize React Native, however, were faced with installation issues, OS complications, and connectivity between devices. We then pivoted to Flutter, however we encountered many bugs within an open source package. Finally, we were able to move to React where we successfully created our application. For the backend, one of the biggest challenges was guessing the appropriate prompts to generate the results we need.
## Accomplishments that we're proud of
We are proud of our ability to adapt and react to a multitude of difficulties. As half of our team are first-time hackers, we are proud to have been able to produce a product that our whole team is satisfied with. This type of idea-making, app development process, and final product creation are experiences we had never encountered beforehand.
## What we learned
We learned how to think creatively in difficult and time-crucial situations. As well, how to design using Figma and Chakra UI. We also learned from each other as teammates on how to collaborate, generate ideas, and develop a product we are proud of.
## What's next for Speakeasy
We hope to both add on to and improve our features as well as making it accessible for people around the world who speak different languages. We look forward to continuing to develop our tone analyzers and speech intent translators to increase accuracy. Along with strengthening our body language trackers and connecting it with databases to better analyze the meaning behind movements and how it conveys across audiences. | partial |
## Inspiration:
Many people may find it difficult to understand the stock market, a complex system where ordinary people can take part in a company's success. This applies to those newly entering the adult world, as well as many others that haven't had the opportunity to learn. We want not only to introduce people to the importance of the stock market, but also to teach them the importance of saving money. When we heard that 44% of Americans have fewer than $400 in emergency savings, we felt compelled to take this mission to heart, with the increasing volatility of the world and of our environment today.
## What it does
With Prophet Profit, ordinary people can invest easily in the stock market. There's only one step - to input the amount of money you wish to invest. Using data and rankings provided by Goldman Sachs, we automatically invest the user's money for them. Users can track their investments in relation to market indicators such as the S&P 500, as well as see their progress toward different goals with physical value, such as being able to purchase an electric generator for times of emergency need.
## How we built it
Our front end is entirely built on HTML and CSS. This is a neat one-page scroller that allows the user to navigate by simply scrolling or using the navigation bar at the top. Our back end is written in JavaScript, integrating many APIs and services.
APIs that we used:
-Goldman Sachs Marquee
-IEX Cloud
Additional Resources:
-Yahoo Finance
## Challenges we ran into
The biggest challenge was the limited scope of the Goldman Sachs Marquee GIR Factor Profile Percentiles Mini API that we wanted to use. Although the data provided was high quality and useful, we had difficulties trying to put together a portfolio with the small amount of data provided. For many of us, it was also our first times using many of the tools and technologies that we employed in our project.
## Accomplishments that we're proud of
We're really, really proud that we were able to finish on time to the best of our abilities!
## What we learned
Through exploring financial APIs deeply, we not only learned about using the APIs, but also more about the financial world as a whole. We're glad to have had this opportunity to learn skills and gain knowledge outside the fields we typically work in.
## What's next for Prophet Profit
We'd love to use data for the entire stock market with present-day numbers instead of the historical data that we were limited to. This would improve our analyses and allow us to make suggestions to users in real-time. If this product were to realize, we'd need the ability to handle and trade with large amounts of money as well. | ## ✨ Inspiration
Driven by the goal of more accessible and transformative education, our group set out to find a viable solution. Stocks are very rarely taught in school and in 3rd world countries even less, though if used right, it can help many people go above the poverty line. We seek to help students and adults learn more about stocks and what drives companies to gain or lower their stock value and use that information to make more informed decisions.
## 🚀 What it does
Users are guided to a search bar where they can search a company stock for example "APPL" and almost instantly they can see the stock price over the last two years as a graph, with green and red dots spread out on the line graph. When they hover over the dots, the green dots explain why there is a general increasing trend in the stock and a news article to back it up, along with the price change from the previous day and what it is predicted to be from. An image shows up on the side of the graph showing the company image as well.
## 🔧 How we built it
When a user writes a stock name, it accesses yahooFinance API and gets the data on stock price from the last 3 years. It takes the data and converts to a JSON File on local host 5000. Then using flask it is converted to our own API that populates the ChartsJS API with the data on the stock. Using a Matlab Server, we then take that data to find areas of most significance (the absolute value of slope is over a certain threshold). Those data points are set as green if it is positive or red if it is negative. Those specific dates in our data points are fed back to Gemini and asks it why it is thinking the stock shifted as it did and the price changed on the day as well. The Gemini at the same time also takes another request for a phrase that easy for the json search API to find a photo for about that company and then shows it on the screen.
## 🤯 Challenges we ran into
Using the amount of API's we used and using them properly was VERY Hard especially making our own API and incorporating Flask. As well, getting Stock data to a MATLAB Server took a lot of time as it was all of our first time using it. Using POST and Fetch commands were new for us and took us a lot of time for us to get used too.
## 🏆 Accomplishments that we're proud of
Connecting a prompt to a well-crafted stocks portfolio.
learning MATLAB in a time crunch.
connecting all of our API's successfully
making a website that we believe has serious positive implications for this world
## 🧠 What we learned
MATLAB integration
Flask Integration
Gemini API
## 🚀What's next for StockSee
* Incorporating it on different mediums such as VR so users can see in real-time how stocks shift in from on them in an interactive way.
* Making a small questionnaire on different parts of the stocks to ask whether if it good to buy it at the time
* Use (MPT) and other common stock buying algorthimns to see how much money you would have made using it. | ## Inspiration
Think about the most intimidating thing you can... I can guarantee it's less intimidating than starting to look and plan for your finances, specifically how you want to start investing. We all know of the stock market and investments, but how many of us actually believe anything there is ever going to be applicable to us, especially as young students? The thing is investing is actually something everyone can and should do! The aim of our project is to help people over that first hump and show them that planning, investing, and starting to become finically literate will not only lead to independence but will help make and save you money in the long term. We also want to make investing an engaging topic to learn about, and provide a little entertainment on a pretty stressful journey, but one we should all take.
## What it does
The web app has a few sections, the main section comes in the form of a webpage where you get a lot of initial information about the facts that we found were most necessary to know when you're starting to invest. From this page you're able to download the body of our game, where you meet two characters ready and willing to teach you about investing, as best as they can! To make things more engaging, you then fill out a little quiz just to see if you've retained some information from the website and mini lesson. But what's the point of education without action? Which is why our game also provides the user with current data for whichever stock they're interested in, combined with a nice line of best fit so they can start to recognize patterns in close prices.
## How we built it
The website was built with html and css, and the game was built fully with a python library called pygame, that specializes primarily in UI additions to most python programs. The characters were also drawn by our team.
## Challenges we ran into
Originally, we had planned on participating in Hack Western as a team of three, unfortunately we ended up competing as a team of two. Not only was the very unexpected but the difference between three people and two people is nothing to brush off. Regardless of our lack of members, we were genuinely able to build something we're proud of and in the end had a great time hacking!
In terms of technical challenges, not only is pygame a little outdated but it's also not suited for user input, so we struggled to properly obtain user input for several components of the project. Additionally, the combination of all the elements proved to be a lot harder than we thought and it took us several attempts to fit each component together.
## Accomplishments that we're proud of
This is our very first python graphical user interface, which was out of our comfort zone in the sense that there was a fair amount of learning new content and applying our experience from other graphical programs. Additionally, we were able to work with lots of fun designs and animations that made things not only more fun for the user and us!
## What we learned
Like financial literacy, the creation of a stock program takes patience and practice! In all seriousness, not only did we get a crash course in time and workload management with only two people but we learned vital skills in presenting educational content. We also expanded our knowledge about workflow, simultaneous processes in python, and honed our graphic design skills.
## What's next for Stock Overflow
We are aiming to expand our "action" component, currently we provide interesting statistics but no next steps for our user. In the future we want to expand how people can take action with their personal banks. We also wanted to implement a budgeting component, as investing and budgeting are two sides of the same coin. Financial literacy can be improved in countless different ways, so there's so much potential for expansion! | partial |
## Inspiration
The inspiration behind this app was accredited to the absence of a watchOS native or client application for LinkedIn, a fairly prominent and ubiquitously used platform on the iOS counterpart. This propelled the idea of introducing a watchOS client to perform what LinkedIn is used most practically for, connecting with professionals and growing one's network, in an intuitively gesture-delivering method through a handshake.
## What it does
ShakeIn performs a peer-to-peer LinkedIn connection using two Apple watches through a handshake gesture from the two parties. This is done so through initiation of sender and receiver and then simply following through with the handshake.
## How we built it
ShakeIn was built using Xcode in Swift, with CocoaPods, Alamofire, LinkedIn's Invitation and Oauth 2.0 APIs, Core Bluetooth, Apple Watch Series 4 and Series 2, and WatchConnectivityKit.
## Challenges we ran into
Counteracting our barrier of demonstration due to CoreBluetooth only being supported for Apple Watch Series 3 and up was the biggest challenge. This was due to the fact that only one of our watches supported the framework and required a change of approach involving phone demonstration instead.
## Accomplishments that we're proud of
Introducing a LinkedIn based client to perform its most purposeful task through a simple, natural, and socially conventional method
## What we learned
Building this app invoked greater awareness for purposeful usage and applicability for the watchOS development platform and how gesture activated processing for an activity can come to fruition.
## What's next for ShakeIn
Progressive initiatives involve expanding ShakeIn's applicability in acknowledgement of the fact that the watch is more commonly worn on the left wrist. This implies introducing alternative gesturing that is also intuitive in nature comparable to that of a handshake in order to form a LinkedIn connection. | ## Inspiration
We’ve noticed that it’s often difficult to form intentional and lasting relationships when life moves so quickly. This issue has only been compounded by the pandemic, as students spend more time than ever isolated from others. As social media is increasingly making the world feel more “digital”, we wanted to provide a means for users to develop tangible and meaningful connections. Last week, I received an email from my residential college inviting students to sign up for a “buddy program” where they would be matched with other students with similar interests to go for walks, to the gym, or for a meal. The program garnered considerable interest, and we were inspired to expand upon the Google Forms setup to a more full-fledged social platform.
## What it does
We built a social network that abstracts away the tediousness of scheduling and reduces the “activation energy” required to reach out to those you want to connect with. Scheduling a meeting with someone on your friend’s feed is only a few taps away. Our scheduling matching algorithm automatically determines the top best times for the meeting based on the inputted availabilities of both parties. Furthermore, forming meaningful connections is a process, we plan to provide data-driven reminders and activity suggestions to keep the ball rolling after an initial meeting.
## How we built it
We built the app for mobile, using react-native to leverage cross-platform support. We used redux for state management and firebase for user authentication.
## Challenges we ran into
Getting the environment (emulators, dependencies, firebase) configured was tricky because of the many different setup methods. Also, getting the state management with Redux setup was challenging given all the boilerplate needed.
## Accomplishments that we're proud of
We are proud of the cohesive and cleanliness of our design. Furthermore, the structure of state management with redux drastically improved maintainability and scalability for data to be passed around the app seamlessly.
## What we learned
We learned how to create an end-to-end app in flutter, wireframe in Figma, and use API’s like firebase authentication and dependencies like React-redux.
## What's next for tiMe
Further flesh out the post-meeting followups for maintaining connections and relationships | # The project
HomeSentry is an open source platform that turns your old phones or any devices into a distributed security camera system. Simply install our app on any mobile device and start monitoring your home (or any other place). HomeSentry gives a new life to your old devices while bringing you the peace of mind you deserve!
## Inspiration
We all have old phones stored in the bottom of a drawer waiting to be used for something. This is where the inspiration for HomeSentry came from. Indeed, We wanted to give our old cellphone and electronic devices a new use so they don't only collect dust over time. Generally speaking, every cellphone have a camera that could be used for something, and we thought using it for security reason would be a great idea. Home surveillance camera systems are often very expensive, or are complicated to set up. Our solution is very simple and costs close to nothing since it's equipment you already have.
## How it works
HomeSentry turns your old cellphones into a complete security system for your home. It's a modular solution where you can register as many devices as you have at your disposition. Every device are linked to your account and automatically stream their camera feed to your personnal dashboard in real time. You can view your security footage from anywhere by logging in to your HomeSentry dashboard.
## How we built it
The HomeSentry platform is constituted of 3 main components :
#### 1. HomeSentry Server
The server main responsibility is responsible to handle all authentication requests and orchestrate cameras connections. It is indeed in charge of connecting the mobile app to users' dashboard so that it may get the live stream footage. This server is built with node.js and uses a MongoDB to store user accounts.
#### 2. HomeSentry Mobile app
The user goes on the app from his cellphone and enters his credentials. He may then start streaming the video from his camera to the server. The app is currently a web app build with the Angular Framework. We plan to convert it to an Android/iOS application using Apache Cordova at a later stage.
#### 3. HomeSentry Dashboard
The dashboar is the user main management panel. It allows the user to watch all of the streams he his receiving from the connected cellphones. The website was also built with Angular.
## Technology
On a more technical note, this app uses several open sources framework and library in order to accomplish it work. Here's a quick summary.
The NodeJS server is built with TypeScript, Express.JS. We use Passport.JS + MongoDB as our authentication system and SocketIO to exchange real time data between every user's devices (cameras) and the dashboard.
On mobile side we are using WebRTC to access the devices' camera stream and to link it to the dashboard. Every camera stream is distributed by a peer to peer connection with the web dashboard when it become active. This ensures the streams privacy and reduce video latency. We used Peer.JS and SocketIO to implement this mecanism.
Just like the mobile client, the web dashboard is built with Angular and frontend libraries such as Bootstrap or feather-icons.
## Challenges we ran into (and what we've learned)
Overall we've learned that sending live streams is quite complicated !
We had underestimated the effort required to send and manage this feed. While working with this type of media, we learned how to communicate with WebRTC. At the begining, we tried to do all the stuff by oursef and use different protocols such as RTMP, but we come to a point where it was a little buggy. Late in the event, we found and used the PeerJS lib to manage those streams and it considerably simplified our code.
We found that working with mobile applications like Xamarin is much more complicated for this kind of project. The easiest way was clearly javascript, and it allow a greater type of device to be registered as cameras.
The project also help us improved our knowledge of real time messaging and WebSocket by using SocketIO to add a new stream without having to refresh the web page.
We also used an authentication library we haven't used yet, called PassportJS for Node. With this we were able to show only the streams of a specific user.
We hosted for the first time an appservice with NodeJS on Azure and we configure the CI from GitHub. It's nice to see that they use Github Action to automate this process.
We've finally perfected ourselves on various frontend technologies such as Angular.
## What's next for HomeSentry
HomeSentry works very well for displaying feeds of a specific user. Now, what might be cool is to add some analytics on that feed to detect motion and different events. We could send a notification of these movements by sms/email or even send a push notification if we could compile this application in Cordova and distribute it to the AppStore and Google Play. Adding the ability to record and save the feed when motion is detected could be a great addition. With detection, we should store this data in local storage and in the cloud. Working offline could also be a great addition. At last improve quality assurance to ensure that the panel works on any device will be a great idea.
We believe that HomeSentry can be used in many residences and we hope this application will help people secure their homes without having to invest in expensive equipments. | losing |
## Inspiration
We were inspired by Plaid's challenge to "help people make more sense of their financial lives." We wanted to create a way for people to easily view where they are spending their money so that they can better understand how to conserve it. Plaid's API allows us to see financial transactions, and Google Maps API serves as a great medium to display the flow of money.
## What it does
GeoCash starts by prompting the user to login through the Plaid API. Once the user is authorized, we are able to send requests for transactions, given the public\_token of the user. We then displayed the locations of these transactions on the Google Maps API.
## How I built it
We built this using JavaScript, including Meteor, React, and Express frameworks. We also utilized the Plaid API for the transaction data and the Google Maps API to display the data.
## Challenges I ran into
Data extraction/responses from Plaid API, InfoWindow displays in Google Maps
## Accomplishments that I'm proud of
Successfully implemented meteor webapp, integrated two different APIs into our product
## What I learned
Meteor (Node.js and React.js), Plaid API, Google Maps API, Express framework
## What's next for GeoCash
We plan on integrating real user information into our webapp; we currently only using the sandbox user, which has a very limited scope of transactions. We would like to implement differently size displays on the Maps API to represent the amount of money spent at the location. We would like to display different color displays based on the time of day, which was not included in the sandbox user. We would also like to implement multiple different user displays at the same time, so that we can better describe the market based on the different categories of transactions. | ## Inspiration
The inspiration for an app like Memo stems from a desire to address common challenges people face in budgeting and expense tracking. The idea originates from observing the inconvenience of manual data entry or the difficulty in keeping an accurate record of daily expenses. Additionally, the increasing reliance on digital receipts and the need for a more intuitive and efficient solution to manage finances are key motivators.
## What it does
Memo takes snapshots of receipts using the webcam, processing the data and returning insightful feedback on spending habits. Details include time and location of purchases, price of purchases, and name of stores. Memo then displays the information in a visually appealing user interface for users to easily analyze their spending.
## How we built it
We built it with Flask, Python, SQL, Tailwind, CSS, React, tesseract, and opencv.
## Challenges we ran into
We had difficulty setting up the database to store the information from the snapshots of receipts.
## Accomplishments that we're proud of
Even though we had little experience with backend development, we created a functioning app that integrated databases and backend technologies such as flask.
## What we learned
We learned Flask, Python, SQL, Tailwind, CSS, React, tesseract, opencv, and we learned to COLLABORATE.
## What's next for Memo
We plan on improving the data visualization for Memo by leveraging Google Maps API. For a better and more intuitive user experience, Memo will display the users' purchases through a 3D map of the store locations, providing insightful data on the time and dates of each purchase. | ## Inspiration
The inspiration came from coming to Yale this weekend. Being outside of the US, many of our fellow hackers were warning each other of conversion rates, bank fees and tax when spending in another country.
## What it does
GeoExchange takes your location using the Pitney Bowes API in order to find out what the tax is in the area, after selecting your bank, it calculates the bank fees, exchange rate as well as tax for a purchase you will be making.
## How I built it
GeoExchange is build with react-native using both the Pitney Bowes API for location as well as Fixer.io for current exchange rates.
## Challenges I ran into
Working with the Pitney Bowes API was challenging when trying to generate an authentication token.
## Accomplishments that I'm proud of
I've never used react-native before and to see that I was able to build a functioning app in a weekend with technology I have never used makes me proud!
## What I learned
I learned the basics of react-native and how to make API calls and work with JSON data.
## What's next for GeoExchange
I will refine the app, ideally add the functionality of being able to use the camera to get the price of the product from the tag. | partial |
# Hide and Squeak
## Inspiration
The robotic mouse feeder is device is designed to help promote physical and mental health in indoor cats, by providing a way to hunt to kill - by pouncing or attacking the robotic mouse, the device will release some "random" amount of kibble (from a pre-determined set) for the cat to eat after successfully "catching" it's prey.
## What it does
Right now it it a proof of concept; the pounce sensor (a button) will trigger a stop in the motion and prints to the Serial monitor when the kibble would be released using a servo motor. The commands to a stepper motor (that acts as one of the two wheels on the mouse), will be printed to the Serial monitor. After a "random" time, the device chooses a new "random" speed and direction (CW or CCW) for the wheel. A "random" direction for the mouse itself would be achieved in that both wheels would be turning independently, each with a different speed. When the bumper button is hit (indicates running into an object in the environment) - the direction sent to the motors is reversed and runs at the same speed as before. This will need testing with an actual motor to see if it is sufficient to remove the robot from an obstacle.
## Challenges I ran into
The hardware lab had no wires that would connect to the stepper motor shield, so there was no way to debug or test the code with the motor itself. There is output to the Serial monitor in lieu of controlling the actual motor, which is mediocre at best for testing the parameters chosen to be the range for both speed and time.
## What's next
1. Attaching the stepper motor to see if the code functions properly with an actual motor; and testing the speed min and max (too slow? too fast?)
2. Programming with a second stepper motor to see how the code handles running two steppers at once;
3. Structural and mechanical design - designing the gears, wheels, casing, kibble pinwheel, etc., needed to bring the code to life.
## Future possibilities
1. Adding a remote feature so you can interact with your cat
2. Adding a camera and connecting to the home's WiFI so you can watch your cat play remotely
3. Adding an internal timer to turn on/off at specified times during the day
4. The ability to change the speeds, time until switching directions, or to pre-program a route | ## Inspiration
Cute factor of dogs/cats, also to improve the health of many pets such as larger dogs that can easily become overweight.
## What it does
Reads accelerometer data on collar, converted into steps.
## How I built it
* Arduino Nano
* ADXL345 module
* SPP-C Bluetooth module
* Android Studio for app
## Challenges I ran into
Android studio uses a large amount of RAM space.
Interfacing with the accelerometer was challenging with finding the appropriate algorithm that has the least delay and lag.
## Accomplishments that I'm proud of
As a prototype, it is a great first development.
## What I learned
Some android studio java shortcuts/basics
## What's next for DoogyWalky
Data analysis with steps to convert to calories, and adding a second UI for graphing data weekly and hourly with a SQLite Database. | ## Inspiration
We wanted to make something that linked the virtual and real worlds, but in a quirky way. On our team we had people who wanted to build robots and people who wanted to make games, so we decided to combine the two.
## What it does
Our game portrays a robot (Todd) finding its way through obstacles that are only visible in one dimension of the game. It is a multiplayer endeavor where the first player is given the task to guide Todd remotely to his target. However, only the second player is aware of the various dangerous lava pits and moving hindrances that block Todd's path to his goal.
## How we built it
Todd was built with style, grace, but most of all an Arduino on top of a breadboard. On the underside of the breadboard, two continuous rotation servo motors & a USB battery allows Todd to travel in all directions.
Todd receives communications from a custom built Todd-Controller^TM that provides 4-way directional control via a pair of Bluetooth HC-05 Modules.
Our Todd-Controller^TM (built with another Arduino, four pull-down buttons, and a bluetooth module) then interfaces with Unity3D to move the virtual Todd around the game world.
## Challenges we ran into
The first challenge of the many that we ran into on this "arduinous" journey was having two arduinos send messages to each other via over the bluetooth wireless network. We had to manually configure the setting of the HC-05 modules by putting each into AT mode, setting one as the master and one as the slave, making sure the passwords and the default baud were the same, and then syncing the two with different code to echo messages back and forth.
The second challenge was to build Todd, the clean wiring of which proved to be rather difficult when trying to prevent the loose wires from hindering Todd's motion.
The third challenge was building the Unity app itself. Collision detection was an issue at times because if movements were imprecise or we were colliding at a weird corner our object would fly up in the air and cause very weird behavior. So, we resorted to restraining the movement of the player to certain axes. Additionally, making sure the scene looked nice by having good lighting and a pleasant camera view. We had to try out many different combinations until we decided that a top down view of the scene was the optimal choice. Because of the limited time, and we wanted the game to look good, we resorted to looking into free assets (models and textures only) and using them to our advantage.
The fourth challenge was establishing a clear communication between Unity and Arduino. We resorted to an interface that used the serial port of the computer to connect the controller Arduino with the unity engine. The challenge was the fact that Unity and the controller had to communicate strings by putting them through the same serial port. It was as if two people were using the same phone line for different calls. We had to make sure that when one was talking, the other one was listening and vice versa.
## Accomplishments that we're proud of
The biggest accomplishment from this project in our eyes, was the fact that, when virtual Todd encounters an object (such as a wall) in the virtual game world, real Todd stops.
Additionally, the fact that the margin of error between the real and virtual Todd's movements was lower than 3% significantly surpassed our original expectations of this project's accuracy and goes to show that our vision of having a real game with virtual obstacles .
## What we learned
We learned how complex integration is. It's easy to build self-sufficient parts, but their interactions introduce exponentially more problems. Communicating via Bluetooth between Arduino's and having Unity talk to a microcontroller via serial was a very educational experience.
## What's next for Todd: The Inter-dimensional Bot
Todd? When Todd escapes from this limiting world, he will enter a Hackathon and program his own Unity/Arduino-based mastery. | partial |
## About
We are team #27 on discord, team members are: anna.m#8841, PawpatrollN#9367, FrozenTea#9601, bromainelettuce#8008.
Domain.com challenge: [beatparty.tech]
## Inspiration
Due to the current pandemic, we decided to create a way for people to exercise in the safety of their home, in a fun and competitive manner.
## What it does
BeatParty is an augmented reality mobile app designed to display targets for the user to hit in a specific pattern to the beat of a song. The app has a leaderboard to promote healthy competition.
## How we built it
We built BeatParty in Unity, using plug-ins from OpenPose, and echoAR's API for some models.
## Challenges we ran into
Without native support from Apple ARkit and Google AR core, on the front camera, we had to instead use OpenPose, a plug-in that would not be able to take full advantage of the phone's processor, resulting in a lower quality image.
## What we learned
**Unity:**
* We learned how to implement libraries onto unity and how to manipulate elements within such folder.
* We learned how to do the basics in Unity, such as making and creating hitboxes
* We learned how to use music and create and destroy gameobjects.
**UI:**
* We learned how to implement various UI components such as making an animated logo alongside simpler things such as using buttons in Unity.
## What's next for BeatParty
The tracking software can be further developed to be more accurate and respond faster to user movements. We plan to add an online multiplayer mode through our website ([beatparty.tech]). We also plan to use EchoAR to make better objects so that the user can interact with, (ex. The hitboxes or cosmetics). BeatParty is currently an android application and we have the intention to expand BeatParty to both IOS and Windows in the near future. | ## Inspiration
"The Big One" is a 9.0 magnitude earthquake predicted to ravage the west coast of North America, with some researchers citing a 33% chance of it hitting in the next 50 years. If it were to hit tomorrow, or even a decade from now, do you think you'd be adequately prepared?
In 2013, the Alberta floods displaced hundreds of thousands of people. A family friend of mine took to Twitter to offer up her couch, in case someone needed a place to sleep for the night. She received over 300 replies.
Whether it's an earthquake, a fire or some other large-scale disaster, the next crisis to affect you shouldn't send you, your loved ones, or your community adrift. Enter Harbour.
## What it does
Harbour offers two main sets of functionality: one for people who are directly affected by a crisis, and one for those nearby who wish to help.
**In the Face of Disaster**
*Forget group chat chaos:* you will have immediate access to the last recorded locations of your family members, with directions to a pre-determined muster point.
*Don't know what to do?* Have an internet connection? Access our Azure chatbot to ask questions and get relevant resources. No internet? No problem. Easily find resources for most common catastrophes on a locally-saved survival manual.
*Live Updates:* A direct and uninterrupted feed of government warnings, alerts and risk areas.
**If You Want to Help**
*Crowdsourcing the Crisis Response:* Have a couch you can offer? How about shelter and a warm meal? Place a custom marker on your local map to tell your community how you can help. Far more efficient than a messy Twitter feed.
## How I built it
We built this app using Android Studio in the Kotlin programming language for the primary app development. We used Google Firebase and Firestore to maintain the database of important locations and contact information. We used Microsoft Azure Cognitive Services Key Phrase Extraction for the user-friendly chatbot that helps with finding disaster information. We used Balsamiq for creating mockups and GitHub for version control.
## Challenges I ran into
The two key challenges we ran into were:
Integrating Google Maps - the SDK was well documented, but getting the exact markers and behavior that we wanted was very time-consuming.
Improving the user interface - A big part of why we were motivated to build this app was because the current solutions had very poor user interfaces, which made them difficult to use and not very helpful. Making a clean, usable user interface was very important, so we spent a significant amount working through the details of Android Studio's graphic design to make this happen
## Accomplishments that I'm proud of
I am proud that we were able to make so much progress. In our early planning, we wanted the app to have four key functionalities: family coordination, community resource-sharing, user-friendly disaster recovery information, and city-wide alerts. It was an ambitious goal that I didn't think we could reach, but we were able to build a minimum viable product with each functionality.
## What I learned
I learned that it only takes 24 hours to build something with a large potential impact on society. We started this hackathon with the goal of improving the disaster response resources that citizens have access to. Despite the time constraints, we were able to build a minimum viable product that shows the promise of our mobile app solution.
## What's next for Harbour
The next step for Harbour is to partner with Canada Red Cross to integrate our app design with their informational resources. We will continue to improve our Machine Learning emergency resource and get more detailed emergency response information from the Canadian Red Cross.
We also hope to work with the City of Vancouver to integrate government-defined danger zones to help citizens understand the dangers around them. | ## Inspiration
Have you ever tried learning the piano but never had the time to do so? Do you want to play your favorite songs right away without any prior experience? This is the app for you. We required something like this even for our personal use. It helps an immense lot in building muscle memory to play the piano for any song you can find on Youtube directly.
## What it does
Use AR to project your favorite digitally-recorded piano video song from Youtube over your piano to learn by following along.
## Category
Best Practicable/Scalable, Music Tech
## How we built it
Using Unity, C# and the EasyAR SDK for Augmented Reality
## Challenges we ran into
* Some Youtube URLs had cipher signatures and could not be loaded asynchronously directly
* App crashes before submission, fixed barely on time
## Accomplishments that we're proud of
We built a fully functioning and user friendly application that perfectly maps the AR video onto your piano, with perfect calibration. It turned out to be a lot better than we expected. We can use it for our own personal use to learn and master the piano.
## What we learned
* Creating an AR app from scratch in Unity with no prior experience
* Handling asynchronously loading of Youtube videos and using YoutubeExplode
* Different material properties, video cipher signatures and various new components!
* Developing a touch gesture based control system for calibration
## What's next for PianoTunesAR
* Tunes List to save the songs you have played before by name into a playlist so that you do not need to copy URLs every time
* Machine learning based AR projection onto piano with automatic calibration and marker-less spatial/world mapping
* All supported Youtube URLs as well as an Upload your own Video feature
* AR Cam tutorial UI and icons/UI improvements
* iOS version
# APK Releases
<https://github.com/hamzafarooq009/PianoTunesAR-Wallifornia-Hackathon/releases/tag/APK> | partial |
## Inspiration
Everyone in the group knows the experience of having a bad landlord during a study term, and mental health can sometimes take a toll from the negligence of one. RateMyLandlord is a streamlined way for past tenants to share experiences with landlords and their respective properties
## What it does
The user has an option to either search for a landlord’s name that exists or a property. If they enter an address, a marker is added on to the location and they can see if there already is a landlord. If not they can add a new landlord and their review. Alternatively, the user can search for a landlord's name and all their properties and reviews is displayed in a chart.
## How we built it
The data for landlords and address was stored using MongoDB, the backend was made with Node.js and the frontend was made using Javascript, Bootstrap, EJS, HTML. Google Maps API was used to display each location on the map.
## Challenges we ran into
Google Maps API implementation, NodeJS, EJS and MongoDB usage
## Accomplishments that I'm proud of
Completing the hackathon
## What we learned
Javscript, Front-end and Back-end development, MongoDB, Google Maps API
## What's next for RateMyLandlord
Implement automatic verification, display data in a better way, better front-end | ## Inspiration
Trump's statements include some of the most outrageous things said recently, so we wanted to see whether someone could distinguish between a fake statement and something Trump would say.
## What it does
We generated statements using markov chains (<https://en.wikipedia.org/wiki/Markov_chain>) that are based off of the things trump actually says. To show how difficult it is to distinguish between the machine generated text and the real stuff he says, we made a web app to test whether someone could determine which was the machine generated text (Drumpf) and which was the real Trump speech.
## How we built it
python+regex for parsing Trump's statementsurrent tools you use to find & apply to jobs?
html/css/js frontend
azure and aws for backend/hosting
## Challenges we ran into
Machine learning is hard. We tried to use recurrent neural networks at first for speech but realized we didn't have a large enough data set, so we switched to markov chains which don't need as much training data, but also have less variance in what is generated.
We actually spent a bit of time getting <https://github.com/jcjohnson/torch-rnn> up and running, but then figured out it was actually pretty bad as we had a pretty small data set (<100kB at that point)
Eventually got to 200kB and we were half-satisfied with the results, so we took the good ones and put it up on our web app.
## Accomplishments that we're proud of
First hackathon we've done where our front end looks good in addition to having a decent backend.
regex was interesting.
## What we learned
bootstrap/javascript/python to generate markov chains
## What's next for MakeTrumpTrumpAgain
scrape trump's twitter and add it
get enough data to use a neural network
dynamically generate drumpf statements
If you want to read all the machine generated text that we deemed acceptable to release to the public, open up your javascript console, open up main.js. Line 4599 is where the hilarity starts. | ## Inspiration
Most of us have had to visit loved ones in the hospital before, and we know that it is often not a great experience. The process can be overwhelming between knowing where they are, which doctor is treating them, what medications they need to take, and worrying about their status overall. We decided that there had to be a better way and that we would create that better way, which brings us to EZ-Med!
## What it does
This web app changes the logistics involved when visiting people in the hospital. Some of our primary features include a home page with a variety of patient updates that give the patient's current status based on recent logs from the doctors and nurses. The next page is the resources page, which is meant to connect the family with the medical team assigned to your loved one and provide resources for any grief or hardships associated with having a loved one in the hospital. The map page shows the user how to navigate to the patient they are trying to visit and then back to the parking lot after their visit since we know that these small details can be frustrating during a hospital visit. Lastly, we have a patient update and login screen, where they both run on a database we set and populate the information to the patient updates screen and validate the login data.
## How we built it
We built this web app using a variety of technologies. We used React to create the web app and MongoDB for the backend/database component of the app. We then decided to utilize the MappedIn SDK to integrate our map service seamlessly into the project.
## Challenges we ran into
We ran into many challenges during this hackathon, but we learned a lot through the struggle. Our first challenge was trying to use React Native. We tried this for hours, but after much confusion among redirect challenges, we had to completely change course around halfway in :( In the end, we learnt a lot about the React development process, came out of this event much more experienced, and built the best product possible in the time we had left.
## Accomplishments that we're proud of
We're proud that we could pivot after much struggle with React. We are also proud that we decided to explore the area of healthcare, which none of us had ever interacted with in a programming setting.
## What we learned
We learned a lot about React and MongoDB, two frameworks we had minimal experience with before this hackathon. We also learned about the value of playing around with different frameworks before committing to using them for an entire hackathon, haha!
## What's next for EZ-Med
The next step for EZ-Med is to iron out all the bugs and have it fully functioning. | partial |
## Inspiration
With cargo theft becoming a growing issue for Canadian businesses, our team wanted to develop an application that can help decrease the response time and increase the efficiency to detecting thefts in action.
## What it does
Cargo No-Go is built to react to any possible situations. The solution we provided for a scenario where the sensors are destroyed is that the program will check the last updated timestamp from when information was received from any of the sensors. If there has been more than an hour gap, the truck is either in maintenance or the GPS has been destroyed, meaning there is a theft. So an alert is first sent to the driver to confirm whether it is in maintenance. If answered no, the management company is immediately alerted that there could be a possible cargo theft occurring.
Our application deal with the scenario that if the sensors are still online (even if it has been tampered with). To combat this, our Cargo No-Go continuously compares in real time whether the drivers GPS and the trucks GPS location is within the same radius. If it sees that the truck is moving even though the driver is not in range, it will automatically send an alert message.
## How we built it
There were three major components to the project. The first issue was managing the data that we were provided with and find an anomaly within the set. Using Matlab, we were able to process and analyze the data. The information was extracted from the excel file, and by graphing it using different independent and dependent variables, we could find behaviors and patterns that exist within the data set. The application was built on Visual Studio which uses Windows Forms to implement the user interface and the back-end was programmed in c#. Lastly, for simulation purposes, we created a python program that updates the data in real time. This is used to reproduce the sensor information received during trips.
## Challenges we ran into
The challenge that we ran into was working with the large amount of data and analyzing it to find the inconsistency within the data. The the data was raw and was not clean, there were many factors that we had to take within consideration.
## Accomplishments that we're proud of
The accomplishment that we're most proud of is successfully processing the data. Through this we produced graphs that made sense and helped us to understand the data better.
## What we learned
This is the first time for our team to work with large data sets such as the one provided for the cargo theft challenge. So we learned a lot about how to manipulate the data and how to use excel to increase efficiency to change the data to be more readable for the code.
## What's next for Cargo No-Go
For future features, we want to implement an off-route detection system that will send an alert if the truck strays off the predicated route from a certain radius. | ## Inspiration
Cargo theft is a growing problem for Canadian businesses and their transportation providers. In fact, it is estimated that $55 million in goods will have been stolen in 2018. Businesses also suffer secondary financial losses due to increased insurance and security costs, and a loss of productivity when trucks are stolen. These costs eventually make their way back to the consumer, making products less affordable. Furthermore, most of these thefts negatively affect society by leading to increased opioid and illegal-firearm presence. Our solution: **Hydra**, a modular IoT device that reacts to thefts as they happen - rather than days later.
## What it does
Hydra uses Raspberry Pis as modular and mobile nodes to communicate with each other over wifi. There are three nodes used - one in the tractor, one in the trailer, and one located at the control centre. The tractor and trailer nodes send their current GPS locations to a server. The control centre then pulls this data and calculates the distance between the two nodes to determine if the tractor and trailer have been separated. If the nodes are farther than 30m apart, then a 'Separation' alert is activated; if no signal is received within a certain period of time, a 'Disconnect' alert is activated; otherwise, no alerts are made.
Our unique modular solution simplifies hardware installation, and vastly improves the response time of the alert system.
## How we built it
The nodes communicate over the IoT cloud platform Particle.io. This system allows the Raspberry Pi's installed on Tractors and Trailers to publish their GPS coordinates to a server that the Control centre is subscribed to. The control centre then calculates the distance between the 2 nodes.
The control centre node is able to push alerts to other devices, apps or services. In our proof of concept, we pushed these alerts to an Arduino which displays the relevant information on an LCD screen.
## Challenges we ran into
Our original idea was to work with Arduino and install wifi shields to gain internet connectivity, but there were too many issues with this setup:
* *We were missing board connectors - we came up with a rudimentary solution to address this*
* *We successfully created a server, but it only worked once and we couldn't recreate it*
We then switched over to Dragonboard, where we ran into more issues
* *We tried 3 different OS releases (each taking ~20mins to download and ~20mins to image), but none of them booted to a desktop environment*
* *The kit was missing the USB dongle for the keyboard/mouse combo*
Finally, we decided to switch over to Raspberry Pi. We also had some issues, but they were minor compared to the previous 2 devices and we troubleshot our way through it.
* *One of our MicroSD cards got corrupted (we fixed it)*
* *We didn't have enough MicroSD cards*
* *We didn't have enough Raspberry Pi's*
* *We didn't have enough USB-microUSB cables*
## Accomplishments that we're proud of
We successfully created a modular IOT device with excellent hardware and software components - all while remaining at a low cost. It's also able to quickly react to changes in state (<15 seconds). What's amazing is that we integrated 3 Raspberry Pi's and an Arduino into a well functioning system - something we had never done before. Finally, we managed to make this hack 'plug and play' - even if you power it off and on, it'll start working and communicating with the server right away. There's no need to reconfigure it.
## What we learned
We gained a greater understanding of Raspberry Pi & Arduino, and how to make these 2 devices work together. We also further developed our troubleshooting skills, in both hardware and software.
We explored cloud and point to point networking using IoT.
## What's next for Hydra
* *Sticking compact and untraceable models onto commercial trucks!*
* *Usage on any moving system where a noticeable (by GPS) distance must be reached*
+ *Convoys, any form of truck-trailer connection*
* *Addition of a method that compares the truck's path with its actual route, to determine when it's off course*
[Other video](https://youtu.be/KNCL2JHmK70) | # **R**ealtime **A**ugmented **L**earning **E**nvironment
Oops! Technical difficulties in our main video - check out our (actual) demo here! <https://youtu.be/-AOdw0kwrO8>
## Inspiration
With countless distractions, unstable wifi, and muffled voices, online classes pose several challenges in terms of focus and concentration. It’s easy to “zone out” and be put on the spot when asked a question, or come back to a session literally minutes later to find that the topic has drastically changed. RALE helps students overcome these issues by providing a clean, organized interface for better learning.
## What it does
RALE is a lightweight, highly functional application that can be consumed by students side-by-side in Zoom lectures, without distracting or taking away from the main content.
RALE presents three key features:
* Continuously processes the lecture’s audio stream to identify current discussion topics in real-time
* Automatically records and lists all the questions asked by instructors during the class so that students can keep up at their own pace
* Allows instructors to send students additional resources like links, pictures, equations, and more during class using customized voice commands, powered by WolframAlpha
## How we built it
It all begins with a regular Zoom meeting. For students, it will be no different than a normal session.
Behind the scenes, RALE is hard at work. The audio and video from the stream is fed via RTMP into a nginx streaming server running on a Google Compute Instance. From there, the audio is extracted in chunks and sent to Google Cloud Speech-to-Text for transcription. The text is then stored in Firebase Realtime Database. When the database updates, natural language processing in Python begins: topic modelling with LDA (Latent Dirichlet allocation) via Gensim and NLTK, question extraction via NLTK, and supplementary information fetching with Wolfram Alpha. The output is then sent back to the database, where is it consumed by an easy-to-use web application built with React, Redux, Bootstrap, and various visualization libraries, including D3.js.
The user simply opens RALE in a web browser next to Zoom to see key topics from their lecture, a running list of questions, and extra information right at their fingertips!
Check out our system architecture diagram for a better visualization of the interactions between the different components.
## Challenges we ran into
* Understanding, applying, and interpreting NLP packages.
* Integrating several services together to produce a smooth and cohesive user experience.
## Accomplishments that we're proud of
We stuck to our goal, great teamwork, and the project actually works!
## What we learned
## What's next for RALE | losing |
## Inspiration
Have you ever been working on a project and had your desktop tabs *juuust* right? Have you ever been playing a video game and had the perfect wiki tabs open. Have you ever then had to shutdown your computer for the night and lose all those sweet, sweet windows? Tabinator is the program for you!
## What it does
Tabinator allows you to save and load your desktop "layouts"! Just open our desktop app, save your current programs as a layout, and voila! You're programs - including size, position, and program information like Chrome tabs - are saved to the cloud. Now, when you're ready to dive back into your project, simply apply your saved config, and everything will fit back into it's right place.
## How we built it
Tabinator consists of a few primary components:
* **Powershell and Swift Scripts**: In order to record the locations and states of all the windows on your desktop, we need to interface with the operating system. By using Powershell and Swift, we're able to convert your programs and their information into standardized, comprehensible data for Tabinator. This allows us to load your layouts, regardless of operating system.
* **React + Rust Desktop App**: Our desktop app is build with React, and is powered with Tauri - written in Rust - under the hood. This allows us the customization of React with the power of Rust.
* **React Front-end + Convex Backend**: Our website - responsible for our Authentication - is written in React, and interfaces with our Convex backend.
Our flow is as follows: A user visits our website, signs up with Github, and is prompted to download Tabinator for their OS. Upon downloading, our Desktop app grabs your JWT token from our web-app in order to authenticate with the API. Now, when the user goes to back up their layout, they trigger the relevant script for their operating system. That script grabs the window information, converts it into standardized JSON, passes it back to our React desktop app, which sends it to our Convex database.
## Challenges we ran into
Not only was this our first time writing Powershell, Swift, and Rust, but it was also our first time gluing all these pieces together! Although this was an unfamiliar tech stack for us all, the experience of diving head-first into it made for an incredible weekend
## Accomplishments that we're proud of
Being able to see our application work - really work - was an incredible feeling. Unlike other project we have all worked on previously, this project has such a tactile aspect, and is so cool to watch work.
Apart from the technical accomplishments, this is all our first times working with total strangers at a hackathon! Although a tad scary walking into an event with close to no idea who we were working with, we're all pretty happy to say we're leaving this weekend as friends.
## What's next for Tabinator
Tabinator currently only supports a few programs, and is only functional on Linux distributions running X11. Our next few steps would be to diversify the apps you're able to add to Tabinator, flesh out our Linux support, and introduce a pricing plan in order to begin making a profit. | ## Inspiration
We’re a team of **developers** and **hackers** who love tinkering with new technologies. Obviously, this means that we have been super excited about building projects in the ML space, especially applications involving LLMs. However, we realized two crucial issues with using LLMs in production applications. First, LLMs hallucinate, confidently responding with incorrect information. Second, we cannot explain on what basis the LLM gives its answer. This is why essentially all production LLM applications use retrieval augmented generation (RAG). Through RAGs, you supply the LLM with relevant, factual, and citable information, significantly increasing the quality of its responses. Our initial idea for **Treehacks** was to build an app based on such a system: we wanted to build a fully automated literature review. Yet, when building the system, we spend most of our time sourcing, cleaning, processing, embedding, and maintaining data for the retrieval process.
After talking with other developers, we have realized that this is a significant hurdle many in the AI community face: the LLM app ecosystem provides robust abstractions for most parts of the backend infrastructure, yet it falls short in offering solutions for the critical data component needed for retrieval. This gap significantly impacts the development of RAG applications, making it a slow, expensive, and arduous journey to embed data into vector databases. The challenge of sourcing, embedding, and maintaining data, with its high costs and slow processing times, threw us off our initial course, making it an issue we were determined to solve.
We observed that most RAG applications require similar types of data, such as legal documents, health records, research papers, news articles, educational material, and books. Each time developers create a RAG application, they find themselves having to reinvent the wheel to populate their vector databases—collecting, pre-processing, and managing data instead of focusing on the actual application development.
**To solve this problem**, we have built an API that lets developers retrieve relevant data for their AI/LLM application without collecting, preprocessing, and managing it. Our tool sits in between developers and vector databases, abstracting away all the complexity of sourcing and managing data for RAG applications. This allows developers to focus on what they do best: build applications.
Our solution also addresses a critical mismatch for developers: the vast amount of data they need to preprocess versus how much they actually utilize. Given the steep prices of embedding models, developers must pay for all the data they ingest, regardless of how much is ultimately used. Our experience suggests that a small subset of the embedding data is frequently queried, while the vast majority is unread. Blanket eliminates this financial burden for developers.
Finally, we are also building the infrastructure to process and embed unstructured data, giving developers access to ten times the amount of data that they previously could harness, significantly enhancing the capabilities of their applications. For example, until now only the abstracts of ArXiv research papers had been embedded, as the full papers are stored in difficult-to-process PDF files. Over the course of Treehacks, we were able to embed the actual paper content itself, unlocking an incredible wealth of knowledge.
In the current RAG development stack, despite advancements and abstractions provided by tools like Langchain, open-source vector databases like Chroma, and APIs to LLM models, collecting relevant data remains the sole significant hurdle for developers building AI/LLM applications. Blanket emerges as the final piece of this puzzle, offering an API that allows developers to query the data they need with a single line of code, thereby streamlining the development process and significantly reducing overhead.
We want to emphasize that this is not a theoretical solution. We have actively demonstrated its efficacy. For our demo, we built an application that automatically generates a literature review from a research question, utilizing the Langchain and Blanket’s API. Achieved in merely **six lines of code**, this showcases the power and efficiency of our solution, making Blanket a groundbreaking tool for developers in the AI space.
## What it does
Blanket is an API which lets developers retrieve relevant data for their AI/LLM application. We are a **developer tool** that sits between developers and vector databases (such as ChromaDB and Pinecone), abstracting away all the complexity of sourcing and managing data for RAG applications. We aim to embed large high quality, citable datasets, (using both structured and unstructured data) from major verticals (Legal, Health, Education, Research, News, ...) into vector databases, such as Chroma DB. Our service will ensure that the data is up-to-date, accurate, and citable, freeing developers from the tedious work of data management.
During Treehacks, we embedded the full contents and abstracts of around 20,000 (due to time and cost constraints) computer science related ArXiv research papers. We built an easy-to-use API that lets users query our databases in their AI/LLM application removing the need for them to deal with data. Finally, we built our original idea of an app that generates an academic literature review of a research question using the blanket API with only **6 lines of code**.
```
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from blanket.utils.api import Blanket
def get_lit_review(query):
prompt_template = """
Create a 600 word literature review on the following topic: {query}.
Use the following papers and context. Cite the authors and the title of the paper when you quote.
Only use the context that is relevant, dont add a references section or a title just the review itself.
Context: \n\n
{context}
"""
prompt = ChatPromptTemplate.from_template(prompt_template)
model = ChatOpenAI()
chain = prompt | model
context = Blanket().get_research_data_sort_paper(query, numResults=10)
return chain.invoke({"query": query, "context": context}).content, context
```
The API we have built currently only allows for the querying of data related to research papers. Below are the three user facing function each returning the data in a different format such that the developer can choose the format most suited for them.
```
def get_research_data(self, query: str, num_results: int = 10) -> list[dict]:
"""
Retrieves research data based on a specified query, formatted for client-facing applications.
This method conducts a search for research papers related to the given query and compiles
a list of relevant papers, including their metadata. Each item in the returned list represents
a single result, formatted with both the textual content found by the configured Vector DB and structured
metadata about the paper itself.
Parameters:
- query (str): The query string to search for relevant research papers.
- num_results (int, optional): The number of results to return. Defaults to 10.
Returns:
- list[dict]: A list where each element is a dictionary containing:
- "text": The textual content related to the query as found by the Vector DB, which may include
snippets from the paper or generated summaries.
- "meta": A dictionary of metadata for the paper, including:
- "title": The title of the paper.
- "authors": A list or string of the paper's authors.
- "abstract": The abstract of the paper.
- "source": A URL to the full text of the paper, typically pointing to a PDF on arXiv.
The return format is designed to be easily used in client-facing applications, where both
the immediate context of the query's result ("text") and detailed information about the source
("meta") are valuable for end-users. This method is particularly useful for applications
requiring quick access to research papers' metadata and content based on specific queries,
such as literature review tools or academic search engines.
Example Usage:
>>> api = YourAPIClass()
>>> research_data = api.get_research_data("deep learning", 5)
>>> print(research_data[0]["meta"]["title"])
"Title of the first relevant paper"
Note:
Multiple elements of the list may relate to the same paper, to return results batched by paper
please use the `get_research_data_sort_paper` method instead.
"""
def get_research_data_sort_paper(self, query: str, num_results: int = 10) -> dict[dict]:
"""
Retrieves and organizes research data based on a specified query, with a focus on sorting
and structuring the data by paper ID.
This method searches for research papers relevant to the given query. It then organizes
the results into a dictionary, where each key is a paper ID, and its value is another
dictionary containing detailed metadata about the paper and its contextual relevance
to the query.
Parameters:
- query (str): The query string to search for relevant research papers.
- num_results (int, optional): The desired number of results to return. Defaults to 10.
Returns:
- dict[dict]: A nested dictionary where each key is a paper ID and each value is a
dictionary with the following structure:
- "title": The title of the research paper.
- "authors": The authors of the paper.
- "abstract": The abstract of the paper.
- "source": A URL to the full text of the paper, typically pointing to arXiv.
- "context": A dictionary where each key is an index (starting from 0) and each value
is a text snippet or summary relevant to the query, as found in the paper or generated.
This structure is especially useful for client-facing applications that require detailed
information about each paper, along with contextual snippets or summaries that highlight
the paper's relevance to the query. The `context` dictionary within each paper's data allows
for a granular presentation of how each paper relates to the query, facilitating a deeper
understanding and exploration of the research landscape.
Example Usage:
>>> api = YourAPIClass()
>>> sorted_research_data = api.get_research_data_sort_paper("neural networks", 5)
>>> for paper_id, paper_info in sorted_research_data.items():
>>> print(paper_info["title"], paper_info["source"])
"Title of the first paper", "https://arxiv.org/pdf/paper_id.pdf"
"""
def get_research_data_easy_cite(self, query: str, num_results: int = 10) -> list[str]:
"""
Generates a list of easily citable strings for research papers relevant to a given query.
This method conducts a search for research papers that match the specified query and formats
the key information about each paper into a citable string. This includes the title, authors,
abstract, and a direct source link to the full text, along with a relevant text snippet or
summary that highlights the paper's relevance to the query.
Parameters:
- query (str): The query string to search for relevant research papers.
- num_results (int, optional): The desired number of results to return. Defaults to 10.
Returns:
- list[str]: A list of strings, each representing a citable summary of a research paper.
Each string includes the paper's title, authors, abstract, source URL, and a relevant
text snippet. This format is designed to provide a quick, comprehensive overview suitable
for citation purposes in academic or research contexts.
Example Usage:
>>> api = YourAPIClass()
>>> citations = api.get_research_data_easy_cite("deep learning", 5)
>>> for cite in citations:
>>> print(cite)
Paper title: [Title of the Paper]
Authors: [Authors List]
Abstract: [Abstract Text]
Source: [URL to the paper]
Text: [Relevant text snippet or summary]
"""
```
## How we built it
We built our solution by blending innovative tech (such as vectorDBs), optimization techniques, and a seamless design for developers. Here’s how we pieced together our project:
**1. Cloud Infrastructure**
We established our cloud infrastructure by creating two Azure cloud instances. One instance is dedicated to continuously managing the embedding process, while the other manages the deployed vector database.
**2. Vector Database Selection**
For our backend database, we chose Chroma DB. This decision was driven by Chroma DB's compatibility with our goals and ethos of seamless developer tooling. Chroma DB serves as one of the backbone tools of our system, storing the embedded databases and enabling fast, reliable retrieval of embedded information.
\**3. Embedding Model \**
We embed documents using VoyageAI’s voyage-lite-02-instruct model. We selected it for its strong semantic similarity performance on the Massive Text Embedding Benchmark (MTEB) Leaderboard. However, it's important to note that while this model offers superior accuracy, it comes with higher costs and slower embedding times—a trade-off we accepted for the sake of quality.
**4. Data Processing and Ingestion Pipeline**
With our infrastructure in place, we focused on building a robust data processing and ingestion pipeline. Written in Python, this pipeline is responsible for collecting, processing, embedding, and storing the academic papers into our database. This step was crucial for automating the data flow and ensuring our database remains extensive and comprehensive.
**5. Optimization Techniques**
We also optimized our data processing. By leveraging a wide array of systems optimization techniques, including batch processing and parallelization, we ensured our infrastructure could handle large volumes of data efficiently. These techniques allowed us to maximize our system's performance and speed, laying the groundwork for quickly processing new data.
**6. Literature Review Demo App**
The culmination of our efforts is the literature review demo application. Utilizing our API and integrating with Langchain, we developed an application capable of generating accurate, high-quality literature reviews for research questions in a matter of seconds. This demonstration not only showcases the power of our API but also the practical application of our system in academic research.
**7. Frontend Development**
Finally, to make our application accessible and user-friendly, we designed a simple yet effective frontend using HTML. This interface allows users to interact with our demo app easily, submitting research questions and receiving comprehensive literature reviews in return.
## Challenges we ran into
Over the course of this project, we ran into a few challenges:
**1. Optimizing chunking and retrieval accuracy.**
In order to ensure accurate and relevant retrieval of data, we needed to choose smart chunking strategies. We thus had to experiment with many different strategies, measure which ones performed better compared to others, and ultimately make a decision based on data we collected.
**2. Dealing with embedding models.**
A crucial part of the system is the generation of embeddings for data. However, most high-quality embedding models are run through APIs. This makes them expensive. In addition, accessing these embedding APIs is at times very slow.
**3. Dealing with PDFs.**
As PDFs use specific encoding formats, extracting and processing data from PDFs is not straightforward. We had to deal with quite a few error cases and had to find ways to filter for badly-formatted data. This took more time and effort than we had initially expected.
**4. Deploying the database.**
In order to be able to access our database through our API, we deployed Chroma on Azure. We ran it in a docker container. However, the database crashed twice due to memory constraints, leading to us losing our generated embeddings. So, we figured out how to use the disk by directly inspecting ChromaDB’s source code.
## Accomplishments that we're proud of
**1. Embedding full-text ArXiv papers.**
We are the first team to embed the full texts of thousands of ArXiv papers into a widely accessible database. We believe that this can have a wide range of use cases, from application development, to education and academic research.
**2. Pivoting during the Hackathon.**
We successfully pivoted from creating an LLM application to building a developer tool after identifying a key point of friction in the development pipeline. Ultimately, we were able to create our initial application–in 6 lines of code on top of our new API.
**3. Optimizing our code.**
When we initially created our data processing and embedding pipeline, it was fairly slow. However, through a combination of systems optimizations, we were able to achieve 10x speedups over our original approach.
**4. Creating cloud architecture.**
We built and configured a server to run the ArXiv embedding pipeline in perpetuity until all papers are embedded. In addition, we created a different server that fully manages our backend database infrastructure.
## What we learned
Over the course of Treehacks, we learned a tremendous amount about the development process of LLM applications. We delved deeply into exploring the tradeoffs between different tools and architectures. Having a wide variety of technical requirements in our own project, we were able to explore and learn more about these tradeoffs. In addition, we gained experience in applying optimization strategies. On the one hand, we optimized our data processing on a systems level. On the other hand, we optimized our accuracy retrieval accuracy by applying different chunking and embedding strategies. Overall, we have gained a much greater appreciation for the problem of data management for RAG-based applications and the whole LLM application ecosystem as a whole.
## What's next for Blanket.ai
After Treehacks, we want to start working closely with LLM application developers to better understand their data and infrastructure needs. In addition, we plan to embed the full texts of all of ArXiv’s (approximately 3 million) research papers into a database accessible through our API to any developer. To do so, we aim to make the API production-ready, decreasing response times, increasing throughput capabilities, and releasing documentation. Furthermore, we want to spread the word about the Blanket API by advertising on forums and developer meetups. Finally, we aim to build widely-available databases for data in other verticals, such as legal, health, and education. | ## **Inspiration**
This pandemic makes everyone an introvert to some extend. We spend most of our time on mobile phones and laptops. Netflix is our new friend now. We are afraid of sharing our feelings and problems with others. According to a survey conducted by OnePoll on behalf of Betterhelp, found that young people ages 18-30 don't like to share their problems with others. Our web application is designed keeping all the above things in mind. If you are not feeling well and your symptoms are indicating that you may be suffering from a disease like tuberculosis. Our website will provide you with the exact info about your symptoms.
## **What it does**
Our application is perfect for those people who don't want to do a confirmation test before visiting doctors.
According to an article by verywellhealth.com embarrassment is one of the reasons why people don't want to visit doctors. Here using our application, people can share their problems without hesitation.
## **How we built it**
We used HTML, CSS, JavaScript, Python, Image Processing, Resnet34, we used transfer learning, Streamlit and Canva
## **Challenges we ran into**
We need to embed our machine learning code to our website using Flask but unfortunately, we ran out of time.
## **Accomplishments that we're proud of**
We are proud of making a real-world project which makes an impact in healthcare and people's lives.
## **What we learned**
Streamlit
## **What's next for TMGP Tuberculosis Detector**
We are planning to use this web app for other diseases such as: STDs, Hemorrhoids, Genital herpes, Pneumonia, etc. | losing |
## Inspiration
We want to make everyone impressed by our amazing project! We wanted to create a revolutionary tool for image identification!
## What it does
It will identify any pictures that are uploaded and describe them.
## How we built it
We built this project with tons of sweats and tears. We used Google Vision API, Bootstrap, CSS, JavaScript and HTML.
## Challenges we ran into
We couldn't find a way to use the key of the API. We couldn't link our html files with the stylesheet and the JavaScript file. We didn't know how to add drag and drop functionality. We couldn't figure out how to use the API in our backend. Editing the video with a new video editing app. We had to watch a lot of tutorials.
## Accomplishments that we're proud of
The whole program works (backend and frontend). We're glad that we'll be able to make a change to the world!
## What we learned
We learned that Bootstrap 5 doesn't use jQuery anymore (the hard way). :'(
## What's next for Scanspect
The drag and drop function for uploading iamges! | ## Inspiration
We wanted to reduce global carbon footprint and pollution by optimizing waste management. 2019 was an incredible year for all environmental activities. We were inspired by the acts of 17-year old Greta Thunberg and how those acts created huge ripple effects across the world. With this passion for a greener world, synchronized with our technical knowledge, we created Recycle.space.
## What it does
Using modern tech, we provide users with an easy way to identify where to sort and dispose of their waste items simply by holding it up to a camera. This application will be especially useful when permanent fixtures are erect in malls, markets, and large public locations.
## How we built it
Using a flask-based backend to connect to Google Vision API, we captured images and categorized which waste categories the item belongs to. This was visualized using Reactstrap.
## Challenges I ran into
* Deployment
* Categorization of food items using Google API
* Setting up Dev. Environment for a brand new laptop
* Selecting appropriate backend framework
* Parsing image files using React
* UI designing using Reactstrap
## Accomplishments that I'm proud of
* WE MADE IT!
We are thrilled to create such an incredible app that would make people's lives easier while helping improve the global environment.
## What I learned
* UI is difficult
* Picking a good tech stack is important
* Good version control practices is crucial
## What's next for Recycle.space
Deploying a scalable and finalized version of the product to the cloud and working with local companies to deliver this product to public places such as malls. | ## Inspiration
We were inspired by the story of the large and growing problem of stray, homeless, and missing pets, and the ways in which technology could be leveraged to solve it, by raising awareness, adding incentive, and exploiting data.
## What it does
Pet Detective is first and foremost a chat bot, integrated into a Facebook page via messenger. The chatbot serves two user groups: pet owners that have recently lost their pets, and good Samaritans that would like to help by reporting. Moreover, Pet Detective provides monetary incentive for such people by collecting donations from happily served users. Pet detective provides the most convenient and hassle free user experience to both user bases. A simple virtual button generated by the chatbot allows the reporter to allow the bot to collect location data. In addition, the bot asks for a photo of the pet, and runs computer vision algorithms in order to determine several attributes and match factors. The bot then places a track on the dog, and continues to alert the owner about potential matches by sending images. In the case of a match, the service sets up a rendezvous with a trusted animal care partner. Finally, Pet Detective collects data on these transactions and reports and provides a data analytics platform to pet care partners.
## How we built it
We used messenger developer integration to build the chatbot. We incorporated OpenCV to provide image segmentation in order to separate the dog from the background photo, and then used Google Cloud Vision service in order to extract features from the image. Our backends were built using Flask and Node.js, hosted on Google App Engine and Heroku, configured as microservices. For the data visualization, we used D3.js.
## Challenges we ran into
Finding the write DB for our uses was challenging, as well as setting up and employing the cloud platform. Getting the chatbot to be reliable was also challenging.
## Accomplishments that we're proud of
We are proud of a product that has real potential to do positive change, as well as the look and feel of the analytics platform (although we still need to add much more there). We are proud of balancing 4 services efficiently, and like our clever name/logo.
## What we learned
We learned a few new technologies and algorithms, including image segmentation, and some Google cloud platform instances. We also learned that NoSQL databases are the way to go for hackathons and speed prototyping.
## What's next for Pet Detective
We want to expand the capabilities of our analytics platform and partner with pet and animal businesses and providers in order to integrate the bot service into many different Facebook pages and websites. | winning |
## Inspiration
*It's lunchtime. You quickly grab a bite to eat and sit by yourself while you munch it down alone. While food clearly has the power to bring people together, the pandemic has separated us from friends and family with whom we love to eat together with*
Muk means Eat in in Korean 🍽️ Eating is such an essential and frequent part of our daily lives, but eating alone has become the "norm" nowadays. With the addition of the lockdown and working from home, it is even harder to be social over food. Even worse, some young people are too busy to eat at home at all.
This brings significant health drawbacks, including chances to lead to obesity, higher risk factors for prediabetes, risk of having metabolic syndrome, high blood pressure, and higher cholesterol. This is because loneliness and lack of social support lead to physical wear and anxiety 🤒
We rely on relationships for emotional support and stress management ✨🧑🤝🧑 This is why we became inspired to make eating social again. With LetsMuk, we bring available the interactions of catching up with friends or meeting someone new, so that you won't spend your next meal alone anymore.
This project targets the health challenge because of the profound problems related to loneliness and mental health. With young people working from home, it brings back the social-ness of lunching with coworkers. Among seniors, it levitates them from isolation during a lonely meal. For friends over a distance, it provides them a chance to re-connect and catch up. 💬🥂 Here are multiple health studies that highlight the health problems around eating alone that inspired us
* [eating-alone-metabolic-syndrome](https://time.com/4995466/eating-alone-metabolic-syndrome/)
* [eating-alone-good-or-bad-for-your-health](https://globalnews.ca/news/6123020/eating-alone-good-or-bad-for-your-health/#:%7E:text=The%20physical%20implicati%5B%E2%80%A6%5D0and%20elevated%20blood%20pressure)
* [eating-alone-is-the-norm](https://ryersonian.ca/eating-alone-is-the-norm-but-ryerson-grads-app-works/)
## How we built it
We chose Flutter as our mobile framework to support iOS and Android and leveraged its tight integrations with Google Firebase. We used Firebase's real-time database as our user store and built a Ruby on Rails API with PostgreSQL to serve as a broker and source of truth. Our API takes care of two workflows: storing and querying schedules, and communication with Agora's video chat API to query the active channels and the users within them.
Here is the video demo of when one joins a room [YouTube Demo on entering a room](https://youtu.be/3EYfO5VVVHU)
## Challenges we ran into
This is the first time any of us has worked with Flutter, and none of us had in-depth mobile development experience. We went through initial hurdles simply setting up the mobile environment as well as getting the Flutter app running. Dart is a new language to us, so we took the time to learn it from scratch and met challenges with calling async functions, building the UI scaffold, and connecting our backend APIs to it. We also ran into issues calling the Agora API for our video-chat, as our users' uid did not cohere with the API's int size restriction.
## Accomplishments that we're proud of
It works!!
* Building out a polished UI
* Seeing your friends who are eating right now
* Ease of starting a meal and joining a room
* "Mukking" together with our team!
## What we learned
* Mobile development with Flutter and Dart
* User authentication with Firebase
* Video call application with Agora
* API development with Ruby on Rails
* Firebase and Postgres databases (NoSQL and SQL)
## What's next for LetsMuk
* Schedule integration - put in when you eat every day
* Notifications - reminders to your friends and followers when you're eating.
* LetsMuk for teams/enterprise - eat with coworkers or students
* Better social integration - FB, twitter, "followers" | ## Inspiration
Unhealthy diet is the leading cause of death in the U.S., contributing to approximately 678,000 deaths each year, due to nutrition and obesity-related diseases, such as heart disease, cancer, and type 2 diabetes. Let that sink in; the leading cause of death in the U.S. could be completely nullified if only more people cared to monitor their daily nutrition and made better decisions as a result. But **who** has the time to meticulously track every thing they eat down to the individual almond, figure out how much sugar, dietary fiber, and cholesterol is really in their meals, and of course, keep track of their macros! In addition, how would somebody with accessibility problems, say blindness for example, even go about using an existing app to track their intake? Wouldn't it be amazing to be able to get the full nutritional breakdown of a meal consisting of a cup of grapes, 12 almonds, 5 peanuts, 46 grams of white rice, 250 mL of milk, a glass of red wine, and a big mac, all in a matter of **seconds**, and furthermore, if that really is your lunch for the day, be able to log it and view rich visualizations of what you're eating compared to your custom nutrition goals?? We set out to find the answer by developing macroS.
## What it does
macroS integrates seamlessly with the Google Assistant on your smartphone and let's you query for a full nutritional breakdown of any combination of foods that you can think of. Making a query is **so easy**, you can literally do it while *closing your eyes*. Users can also make a macroS account to log the meals they're eating everyday conveniently and without hassle with the powerful built-in natural language processing model. They can view their account on a browser to set nutrition goals and view rich visualizations of their nutrition habits to help them outline the steps they need to take to improve.
## How we built it
DialogFlow and the Google Action Console were used to build a realistic voice assistant that responds to user queries for nutritional data and food logging. We trained a natural language processing model to identify the difference between a call to log a food eaten entry and simply a request for a nutritional breakdown. We deployed our functions written in node.js to the Firebase Cloud, from where they process user input to the Google Assistant when the test app is started. When a request for nutritional information is made, the cloud function makes an external API call to nutrionix that provides nlp for querying from a database of over 900k grocery and restaurant foods. A mongo database is to be used to store user accounts and pass data from the cloud function API calls to the frontend of the web application, developed using HTML/CSS/Javascript.
## Challenges we ran into
Learning how to use the different APIs and the Google Action Console to create intents, contexts, and fulfillment was challenging on it's own, but the challenges amplified when we introduced the ambitious goal of training the voice agent to differentiate between a request to log a meal and a simple request for nutritional information. In addition, actually finding the data we needed to make the queries to nutrionix were often nested deep within various JSON objects that were being thrown all over the place between the voice assistant and cloud functions. The team was finally able to find what they were looking for after spending a lot of time in the firebase logs.In addition, the entire team lacked any experience using Natural Language Processing and voice enabled technologies, and 3 out of the 4 members had never even used an API before, so there was certainly a steep learning curve in getting comfortable with it all.
## Accomplishments that we're proud of
We are proud to tackle such a prominent issue with a very practical and convenient solution that really nobody would have any excuse not to use; by making something so important, self-monitoring of your health and nutrition, much more convenient and even more accessible, we're confident that we can help large amounts of people finally start making sense of what they're consuming on a daily basis. We're literally able to get full nutritional breakdowns of combinations of foods in a matter of **seconds**, that would otherwise take upwards of 30 minutes of tedious google searching and calculating. In addition, we're confident that this has never been done before to this extent with voice enabled technology. Finally, we're incredibly proud of ourselves for learning so much and for actually delivering on a product in the short amount of time that we had with the levels of experience we came into this hackathon with.
## What we learned
We made and deployed the cloud functions that integrated with our Google Action Console and trained the nlp model to differentiate between a food log and nutritional data request. In addition, we learned how to use DialogFlow to develop really nice conversations and gained a much greater appreciation to the power of voice enabled technologies. Team members who were interested in honing their front end skills also got the opportunity to do that by working on the actual web application. This was also most team members first hackathon ever, and nobody had ever used any of the APIs or tools that we used in this project but we were able to figure out how everything works by staying focused and dedicated to our work, which makes us really proud. We're all coming out of this hackathon with a lot more confidence in our own abilities.
## What's next for macroS
We want to finish building out the user database and integrating the voice application with the actual frontend. The technology is really scalable and once a database is complete, it can be made so valuable to really anybody who would like to monitor their health and nutrition more closely. Being able to, as a user, identify my own age, gender, weight, height, and possible dietary diseases could help us as macroS give users suggestions on what their goals should be, and in addition, we could build custom queries for certain profiles of individuals; for example, if a diabetic person asks macroS if they can eat a chocolate bar for lunch, macroS would tell them no because they should be monitoring their sugar levels more closely. There's really no end to where we can go with this! | # 🚀 Introducing Unite: The Real-World Social App!
Unite is your gateway to exciting, spontaneous, and shared experiences. Whether you're looking for a jogging partner, a fellow foodie to try a new restaurant, a hiking buddy, or someone to join your yoga class, Unite connects you with like-minded people nearby.
## With Unite, you can:
1. 🌍 *Discover Local Adventures:* Explore a world of unique and local activities posted by users just like you. From arts and crafts to sports and outdoor adventures, there's something for everyone.
2. 🤝 *Connect and Unite:* Swipe through activity invitations and connect with those who share your interests. Make new friends, expand your horizons, and create unforgettable memories.
3. 📅 *Customize Your Experience:* Create your own activities or join others' plans. Unite is all about flexibility and making it easy for you to organize or participate in real-life events.
4. 🛡️ *Stay Safe and Informed:* Our app prioritizes safety, with user reviews, location verification, and secure messaging. You'll always know who you're meeting and what to expect.
Unite is the app that turns your downtime into quality time. Join the Unite community today and start making memories with new friends. Embrace the power of connection, adventure, and spontaneity – download Unite now and unite with the world around you! 🌟
# Inspiration Behind Our Social App: Connecting Loneliness with Friendship
Our journey to create a social app that connects lonely individuals with potential friends began with a powerful inspiration rooted in empathy and a desire to make a positive impact. As a team of four college students, we were moved by the shared experiences of loneliness that many individuals face, especially in our modern, fast-paced world. We wanted to leverage our skills to address this issue in a meaningful way. Here's what inspired us:
## 1. **Empathy for the Lonely**
Each of us has, at some point, felt the pangs of loneliness, even in a crowded room. We understood the emotional toll it can take on a person's mental and emotional well-being. This empathy for those experiencing loneliness fueled our desire to create a solution that could bring relief and companionship.
## 2. **Recognizing the Social Isolation Crisis**
Loneliness is a prevalent problem, not just for college students but for people of all ages and backgrounds. In a digitally connected world, paradoxically, social isolation is on the rise. We recognized this as a crisis and saw an opportunity to make a difference.
## 3. **Tech as a Force for Good**
As college students, we were already immersed in the world of technology and app development. We firmly believed in the potential of technology to make the world a better place. We saw this project as a way to use our technical skills for a noble purpose.
## 4. **Fostering Human Connections**
We were passionate about facilitating meaningful human connections in an age where social interactions are often superficial. Our goal was to create a platform that could bridge the gap between people who were seeking genuine friendships, enabling them to share experiences and support each other.
## 5. **Positive Impact on Mental Health**
We were aware of the impact loneliness has on mental health, including increased stress and depression. We were driven by the potential to improve mental health outcomes by offering a platform that could alleviate feelings of isolation and despair.
## 6. **Community and Support**
Lastly, we wanted to build a sense of community and support for those who felt alone. We believed that through our app, we could foster a welcoming and inclusive environment where individuals could find like-minded friends who could relate to their experiences.
In conclusion, the inspiration behind our social app was deeply rooted in a desire to connect the lonely with friendship, driven by empathy, a recognition of the social isolation crisis, and a belief in the power of technology to create meaningful connections. We embarked on this journey with a shared vision to make a positive impact on the lives of those who felt isolated and alone. Our mission was clear: to use our skills and passion for technology to foster human connections and, in doing so, improve the mental and emotional well-being of our users. It's our hope that this app serves as a beacon of hope and companionship for those who need it most.
# What We Learned: Building a Social App with React Native, Firebase, and Node.js
Our journey in developing our social app using React Native, Firebase, and Node.js for the hackathon has been an incredible learning experience. While the journey was filled with challenges, it also provided us with invaluable insights and growth. Here's what we learned:
## 1. **Cross-Platform Development with React Native**
One of the most significant takeaways from our project was mastering React Native. We were amazed at how efficiently we could build a mobile app for both iOS and Android with a single codebase. It was inspiring to see how React Native allowed us to maintain a consistent user experience across different platforms while saving time and effort.
## 2. **Real-time Functionality with Firebase**
Firebase was a game-changer for us. We learned how to leverage Firebase's real-time database, authentication, and cloud functions to create a dynamic and interactive social app. Understanding how to implement real-time features like chat, notifications, and live updates was a key achievement.
## 3. **Server-Side Development with Node.js**
Node.js played a crucial role in the back end of our app. We discovered the power of Node.js in building a scalable and responsive server that could handle a growing user base. From setting up RESTful APIs to optimizing performance, our team gained valuable server-side development skills.
## 4. **Effective Team Collaboration**
This hackathon taught us the importance of teamwork and clear communication. Coordinating tasks and responsibilities among team members, ensuring everyone was on the same page, and resolving conflicts efficiently was essential for our success. We learned that effective team collaboration is just as important as technical skills.
## 5. **User-Centered Design**
The feedback we received from users during the hackathon was eye-opening. It taught us the significance of user-centered design. Iterating on the app's user interface and experience based on user feedback improved our app's usability and appeal. We realized that design isn't a one-time task but an ongoing process. Also, we learned that many of the convenient features we take for granted as phone users are some of the most difficult features to build. For example, having a view stay out of the way of the keyboard while typing was a monumental struggle. Before we built Unite, we assumed it was an automatic, built in convenience feature.
## 6. **Time Management and Prioritization**
With the clock ticking during the hackathon, we had to manage our time wisely. We learned the art of prioritization - identifying crucial features and tasks, setting realistic goals, and focusing on what would make the most impact within the limited timeframe.
## 7. **Adaptability and Problem Solving**
Hackathons are unpredictable, and we encountered various challenges along the way. Our ability to adapt quickly, troubleshoot issues, and find creative solutions was put to the test. This experience reinforced the importance of staying calm under pressure and finding innovative ways to overcome obstacles.
## 8. **Pitching and Presentation**
Our final pitch was a critical aspect of the hackathon. We learned how to distill our project's essence into a concise, compelling pitch. It was a valuable exercise in articulating our app's value proposition and impact in a way that resonated with judges and potential users.
In conclusion, building a social app with React Native, Firebase, and Node.js was an incredible learning journey. We not only developed technical skills but also gained insights into collaboration, design, time management, adaptability, and effective presentation. This hackathon experience has shaped us into better developers and problem solvers, setting the stage for future projects and endeavors. We look forward to applying these lessons to our next challenges and endeavors, both in hackathons and beyond. | winning |
## Inspiration
We wanted to focus on education for children and knew the power of AI resources for both text and image generation. One of our members realized the lack of accessible picture books online and suggested that these stories could be generated instead. Our final idea was then DreamWeaver
## What it does
Our project uses a collection of machine learning resources to generate an entire children's book after being given any prompt.
## How we built it
Our website is built upon the React framework, using MaterialUI as a core design library.
## Challenges we ran into
Being able to generate relevant images that fit the theme and art style of the book was probably our biggest challenge and area to improve on. Trying to ensure a seamless flow and continuity in the generated imagery was a valuable learning experience and something we struggled with. Another difficulty we faced was working with foreign APIs, as there were many times we struggled to understand how to access certain resources.
## Accomplishments that we're proud of
Our use of machine learning, especially Cohere's LLM, is our project's most impressive aspect, as we combine different models and prompts to produce an entire book for the user.
## What we learned
Our team worked extensively with AI APIs such as Cohere and Midjourney and learned a lot about how to use their APIs. Furthermore, we learned a lot about frontend development with React, as we spent a good amount of time designing the UI/UX of our web app.
## What's next for DreamWeaver
Having more continuity between book images would be the first thing to work on for our project, as sometimes different characters can be introduced by accident. We are also looking into adding support for multiple languages. | Duet's music generation revolutionizes how we approach music therapy. We capture real-time brainwave data using Emotiv EEG technology, translating it into dynamic, personalized soundscapes live. Our platform, backed by machine learning, classifies emotional states and generates adaptive music that evolves with your mind. We are all intrinsically creative, but some—whether language or developmental barriers—struggle to convey it. We’re not just creating music; we’re using the intersection of art, neuroscience, and technology to let your inner mind shine.
## About the project
**Inspiration**
Duet revolutionizes the way children with developmental disabilities—approximately 1 in 10 in the United States—express their creativity through music by harnessing EEG technology to translate brainwaves into personalized musical experiences.
Daniel and Justin have extensive experience teaching music to children, but working with those who have developmental disabilities presents unique challenges:
1. Identifying and adapting resources for non-verbal and special needs students.
2. Integrating music therapy principles into lessons to foster creativity.
3. Encouraging improvisation to facilitate emotional expression.
4. Navigating the complexities of individual accessibility needs.
Unfortunately, many children are left without the tools they need to communicate and express themselves creatively. That's where Duet comes in. By utilizing EEG technology, we aim to transform the way these children interact with music, giving them a voice and a means to share their feelings.
At Duet, we are committed to making music an inclusive experience for all, ensuring that every child—and anyone who struggles to express themselves—has the opportunity to convey their true creative self!
**What it does:**
1. Wear an EEG
2. Experience your brain waves as music! Focus and relaxation levels will change how fast/exciting vs. slow/relaxing the music is.
**How we built it:**
We started off by experimenting with Emotiv’s EEGs — devices that feed a stream of brain wave activity in real time! After trying it out on ourselves, the CalHacks stuffed bear, and the Ariana Grande cutout in the movie theater, we dove into coding. We built the backend in Python, leveraging the Cortex library that allowed us to communicate with the EEGs. For our database, we decided on SingleStore for its low latency, real-time applications, since our goal was to ultimately be able to process and display the brain wave information live on our frontend.
Traditional live music is done procedurally, with rules manually fixed by the developer to decide what to generate. On the other hand, existing AI music generators often generate sounds through diffusion-like models and pre-set prompts. However, we wanted to take a completely new approach — what if we could have an AI be a live “composer”, where it decided based on the previous few seconds of live emotional data, a list of available instruments it can select to “play”, and what it previously generated to compose the next few seconds of music? This way, we could have live AI music generation (which, to our knowledge, does not exist yet). Powered by Google’s Gemini LLM, we crafted a prompt that would do just that — and it turned out to be not too shabby!
To play our AI-generated scores live, we used Sonic Pi, a Ruby-based library that specializes in live music generation (think DJing in code). We fed this and our brain wave data to a frontend built in Next.js to display the brain waves from the EEG and sound spectrum from our audio that highlight the correlation between them.
**Challenges:**
Our biggest challenge was coming up with a way to generate live music with AI. We originally thought it was impossible and that the tech wasn’t “there” yet — we couldn’t find anything online about it, and even spent hours thinking about how to pivot to another idea that we could use our EEGs with.
However, we eventually pushed through and came up with a completely new method of doing live AI music generation that, to our knowledge, doesn’t exist anywhere else! It was most of our first times working with this type of hardware, and we ran into many issues with getting it to connect properly to our computers — but in the end, we got everything to run smoothly, so it was a huge feat for us to make it all work!
**What’s next for Duet?**
Music therapy is on the rise – and Duet aims to harness this momentum by integrating EEG technology to facilitate emotional expression through music. With a projected growth rate of 15.59% in the music therapy sector, our mission is to empower kids and individuals through personalized musical experiences. We plan to implement our programs in schools across the states, providing students with a unique platform to express their emotions creatively. By partnering with EEG companies, we’ll ensure access to the latest technology, enhancing the therapeutic impact of our programs. Duet gives everyone a voice to express emotions and ideas that transcend words, and we are committed to making this future a reality!
**Built with:**
* Emotiv EEG headset
* SingleStore real-time database
* Python
* Google Gemini
* Sonic Pi (Ruby library)
* Next.js | ## 💡 Inspiration
After learning about the benefits of reading, the team was surprised to find that reading stats for children are still very low. Especially with software apps such as Duolingo and PokemonGo, the team wanted to leverage similar motivational and innovative technologies to increase the reading engagement for young children.
## 💻 What it does
Augmented reality (AR) is used to gamify the reading experience. Numerous rewards are used to encourage and motivate readers to continue their progress. Our app allows them to see the world transform around them the more they read! Accumulating objects from the fantastical world where the story takes place, all with a bonus to unlock their favorite character, a new virtual friend that they can interact with!
## ⚙️ How we built it
The frontend was built using React and TailwindCSS. The backend is a combination of CockroachDB, EchoAR, Node.js and Google Drive. The app is deployed using Heroku. Mockups of the design was made using Figma.
## 🧠 Challenges we ran into
The first challenge was creating a cluster using CockroachDB and integrating the database with the frontend. The second challenge was implementing an epub reader to display the classic books.
## 🏅 Accomplishments that we're proud of
Finishing the design and integrating the frontend with the backend code.
## 📖 What we learned
We learned about the challenges of using epub files and how to use new technologies such as CockroachDB and EchoAR in app development.
## 🚀 What's next for AReading
For now, our book selection is only limited to public domain ones.
A natural next step would be to contract with various book authors and publishers in order to integrate their stories within our app and to expand our offerings to various literary genres and age groups.
This would allow us to monetize the app by providing subscriptions for unlimited access to copyrighted books after paying for their royalty fees. | winning |
Though technology has certainly had an impact in "leveling the playing field" between novices and experts in stock trading, there still exist a number of market inefficiencies for the savvy trader to exploit. Figuring that stock prices in the short term tend to some extent to reflect traders' emotional reactions to news articles published that day, we set out to create a machine learning application that could predict the general emotional response to the day's news and issue an informed buy, sell, or hold recommendation for each stock based on that information.
After entering the ticker symbol of a stock, our application allows the user to easily compare the actual stock price over a period of time against our algorithm's emotional reaction.
We built our web application using the Flask python framework and front-end using React and Bootstrap. To scrape news articles in order to analyze trends, we utilized the google-news API. This allowed us to search for articles pertaining to certain companies, such as Google and Disney. Afterwards, we performed ML and sentiment analysis through the textblob Python API.
We had some difficulty finding news articles; it was quite a challenge to find a free and accessible API that allowed us to gather our data. In fact, we stumbled upon one API that, without our knowledge, redirected us to a different web page the moment we attempted any sort of data extraction. Additionally, we had some problems trying to optimize our ML algorithm in order to produce as accurate results as possible.
We are proud of the fact that Newsstock is up and running and able to predict certain trends in the stock market with some accuracy. It was cool not only to see how certain companies fared in the stock market, but also to see how positivity or negativity in media influenced how people bought or sold certain stocks.
First and foremost, we learned how difficult it could be at times to scrape news articles, especially while avoiding any sort of payment or fee. Additionally, we learned that machine learning can be fairly inaccurate. Overall, we had a great experience learning new frameworks and technologies as we built Newsstock. | ## Inspiration
We wanted an app that combines stock articles from multiple sources to have easy access to all the data and a way to visualize it using graphs beyond the stock trends.
## What it does
Gets stock articles from various news sources, rates them based on the number of positive and negative words, gets data from the top trending and slumping stocks, displays the buzzwords and corresponding articles for each stock.
## How we built it
We used JavaScript to handle the backend and get the stocks and ratings from all the news sources and combined them into a JSON file that included company name, positive words, positive articles corresponding to the words, negative words, and negative articles corresponding to the negative words. We host this JSON file on Heroku, and the front-end gets the data from the JSON file and displays it visually and graphically. The website was built using HTML and CSS, and the word cloud uses d3.js to display all the buzzwords and list out the articles.
## Challenges we ran into
Figuring out how to get the articles from each news source, as each website had a different structure, working with languages we weren't familiar with, trying to integrate the front end and the back end.
## Accomplishments that we're proud of
Although hosting the JSON on Heroku didn't quite work out, we were able to get everything completed using static data.
## What we learned
Data Parsing, UI, Web Crawling, HTTP requests
## What's next for Broker
Adding more functionality and visualization so users can potentially also see the stock trends instead of just buzzwords and related articles. | ## Inspiration
We wanted to allow financial investors and people of political backgrounds to save valuable time reading financial and political articles by showing them what truly matters in the article, while highlighting the author's personal sentimental/political biases.
We also wanted to promote objectivity and news literacy in the general public by making them aware of syntax and vocabulary manipulation. We hope that others are inspired to be more critical of wording and truly see the real news behind the sentiment -- especially considering today's current events.
## What it does
Using Indico's machine learning textual analysis API, we created a Google Chrome extension and web application that allows users to **analyze financial/news articles for political bias, sentiment, positivity, and significant keywords.** Based on a short glance on our visualized data, users can immediately gauge if the article is worth further reading in their valuable time based on their own views.
The Google Chrome extension allows users to analyze their articles in real-time, with a single button press, popping up a minimalistic window with visualized data. The web application allows users to more thoroughly analyze their articles, adding highlights to keywords in the article on top of the previous functions so users can get to reading the most important parts.
Though there is a possibilitiy of opening this to the general public, we see tremendous opportunity in the financial and political sector in optimizing time and wording.
## How we built it
We used Indico's machine learning textual analysis API, React, NodeJS, JavaScript, MongoDB, HTML5, and CSS3 to create the Google Chrome Extension, web application, back-end server, and database.
## Challenges we ran into
Surprisingly, one of the more challenging parts was implementing a performant Chrome extension. Design patterns we knew had to be put aside to follow a specific one, to which we gradually aligned with. It was overall a good experience using Google's APIs.
## Accomplishments that we're proud of
We are especially proud of being able to launch a minimalist Google Chrome Extension in tandem with a web application, allowing users to either analyze news articles at their leisure, or in a more professional degree. We reached more than several of our stretch goals, and couldn't have done it without the amazing team dynamic we had.
## What we learned
Trusting your teammates to tackle goals they never did before, understanding compromise, and putting the team ahead of personal views was what made this Hackathon one of the most memorable for everyone. Emotional intelligence played just as an important a role as technical intelligence, and we learned all the better how rewarding and exciting it can be when everyone's rowing in the same direction.
## What's next for Need 2 Know
We would like to consider what we have now as a proof of concept. There is so much growing potential, and we hope to further work together in making a more professional product capable of automatically parsing entire sites, detecting new articles in real-time, working with big data to visualize news sites differences/biases, topic-centric analysis, and more. Working on this product has been a real eye-opener, and we're excited for the future. | losing |
Getting rid of your social media addiction doesn't have to be a painful process. Turn it into a fun challenge with your friends and see if you can win the pot!
## Inspiration
We recognize that social media addiction is a very real issue among today's youth. However, no steps are taken to curb these addictions as it is a painful and unrewarding process. We set out to fix this by turning the act of quitting social media into a fun group activity with a touch of monetary incentives. 😉
## What it does
Start a party with your friends and contribute a small amount of money into the party's prize pool. Once the showdown starts, no accessing social media! Whoever lasts until the end will win the pot!
Users will top up their account using Interac payments (thanks to the Paybilt API) and they will then start a showdown for a certain period of time, with each contributing some amount of money to the prize pool. The winners will split the pot amongst them and if they so choose they can pay out their account balance using Interac (once again thanks to Paybilt).
If you lose the showdown, no worries! Our AI feature will ~~name and shame~~ gently scold you so that you are encouraged to do better!
## How we built it
We used **React.js** for the frontend, and **Express.js** for the backend with **Prisma** ORM to handle our database.
We also used **Paybilt**'s API to handle monetary transactions as well as **Meta**'s API to fetch user data and link accounts through the OAuth & Webhook API's.
**Cohere** was used to generate dynamic status messages for each game.
Our backend is hosted on **Google Cloud Platform** and our client is hosted on **GitHub Pages**. Our domain is a free .tech domain from MLH (thanks!!).
## Challenges we ran into
Meta's API documentation was very obscure, partially inaccurate, and difficult to implement. The meta API integration portion of our platform took one person the entire duration of the hackathon to work out.
Before this hackathon, we were unfamiliar with Paybilt, especially since their API is private. During this hackathon, we ran into some challenges using their API and receiving callbacks. However in the end we were able to successfully integrate Paybilt into our platform.
## Accomplishments that we're proud of
We are proud of creating a fully functional platform that not only contains the core features necessary for a minimum viable product, but implements additional ✨fun✨ features to enhance the experience such as AI-generated messages in the party.
## What we learned
We learned how to use Paybilt, Meta's Webhook & Oauth API's, and Cohere. Overall we found this an enjoyable experience as we all gained a lot of knowledge and experience without sacrificing our project or our vision.
## What's next for Screentime Showdown
We plan to integrate other platforms such as TikTok and YouTube Shorts and introduce a more robust set of party configurations to suit various needs (including the ability to toggle how aggressive you want the shaming to be). | ## Inspiration
As roommates, we found that keeping track of our weekly chore schedule and house expenses was a tedious process, more tedious than we initially figured.
Though we created a Google Doc to share among us to keep the weekly rotation in line with everyone, manually updating this became hectic and cumbersome--some of us rotated the chores clockwise, others in a zig-zag.
Collecting debts for small purchases for the house split between four other roommates was another pain point we wanted to address. We decided if we were to build technology to automate it, it must be accessible by all of us as we do not share a phone OS in common (half of us are on iPhone, the other half on Android).
## What it does
**Chores:**
Abode automatically assigns a weekly chore rotation and keeps track of expenses within a house. Only one person needs to be a part of the app for it to work--the others simply receive a text message detailing their chores for the week and reply “done” when they are finished.
If they do not finish by close to the deadline, they’ll receive another text reminding them to do their chores.
**Expenses:**
Expenses can be added and each amount owed is automatically calculated and transactions are automatically expensed to each roommates credit card using the Stripe API.
## How we built it
We started by defining user stories and simple user flow diagrams. We then designed the database where we were able to structure our user models. Mock designs were created for the iOS application and was implemented in two separate components (dashboard and the onboarding process). The front and back-end were completed separately where endpoints were defined clearly to allow for a seamless integration process thanks to Standard Library.
## Challenges we ran into
One of the significant challenges that the team faced was when the back-end database experienced technical difficulties at the tail end of the hackathon. This slowed down our ability to integrate our iOS app with our API. However, the team fought back while facing adversity and came out on top.
## Accomplishments that we're proud of
**Back-end:**
Using Standard Library we developed a comprehensive back-end for our iOS app consisting of 13 end-points, along with being able to interface via text messages using Twilio for users that do not necessarily want to download the app.
**Design:**
The team is particularly proud of the design that the application is based on. We decided to choose a relatively simplistic and modern approach through the use of a simple washed out colour palette. The team was inspired by material designs that are commonly found in many modern applications. It was imperative that the designs for each screen were consistent to ensure a seamless user experience and as a result a mock-up of design components was created prior to beginning to the project.
**Use case:**
Not only that, but our app has a real use case for us, and we look forward to iterating on our project for our own use and a potential future release.
## What we learned
This was the first time any of us had gone into a hackathon with no initial idea. There was a lot of startup-cost when fleshing out our design, and as a result a lot of back and forth between our front and back-end members. This showed us the value of good team communication as well as how valuable documentation is -- before going straight into the code.
## What's next for Abode
Abode was set out to be a solution to the gripes that we encountered on a daily basis.
Currently, we only support the core functionality - it will require some refactoring and abstractions so that we can make it extensible. We also only did manual testing of our API, so some automated test suites and unit tests are on the horizon. | ## Inspiration
The rise of AI and deep learning technology has lead to new technological advancements in society. But it also poses a critical threat to security and authenticity. It holds the power to impersonate important figures with absolute perfection. Imagine a scenario where an AI generated president authorized an attack that could lead to world war three? However, we can fight deep fakes using the same technological advancements.
## What it does
Quick Live is the new age of video authentication. Using the same technology that brought you Bitcoin, Quick Live stores important metadata at the time of recording. Then, it stores a transaction of that recording in a dedicated block-chain. That's right, decentralized records means a seal of authenticity for your important videos.
All you need to get started is to open up the the browser to our secure dashboard. Using a webcam, record your true self as our powerful back-end hashes your video frames for the block-chain. Will let you know when your video is fully processed.
## How we built it
Quick Live is a full-stack web app that utilizes Python as its back-end. All UI elements are powered by the Bootstrap library for a polished presentation. In addition to client-side Javascript, we stream the video using web socket frames to ensure a fast and safe route. Meanwhile in the python interpreter, frames are going through several hashes and a transaction is recorded and appended to the block-chain.
## Challenges we ran into
Believe it or not, the challenge was to get the webcam frames delivered to the backend. Because of the latency factor that comes from transferring images twenty four times per second, it was hard to optimize a real-time method for up-streaming.
Another challenge was processing the frames received and using the block-chain API. When we switched over to Flask, it was rather difficult to run multi-threaded processes that are required to hash frames.
## Accomplishments that we're proud of
For the first time in a hackathon, we used a web based front-end using Bootstrap. As a result, our project looks professional and polished. It also makes it accessible for most users, especially on mobile.
The video streaming itself was a grand accomplishment that was challenging to implement. It pushed us to use other web technologies that we were unfamiliar with.
## What we learned
This hackathon was very education for all of us. In addition to learning more about proper git collaboration, we dived into a new back-end framework (Flask) that was unfamiliar. It was similar to Express.js as it used routes and rendering templates.
On the other hand, we learned about web-sockets for the first time and how to provide consistent communication between the server and client. The video data needed to be optimized for sending at high speeds.
Finally, we learned about the fascinating word of block-chain transactions and how to write our own using a simple API. All being done in the comfort of a Python interpreter,
## What's next for Quite Live
As we only had the time to create the general process for processing videos, we would add more CRUD functionality and user authentication to keep track of recent video transactions. | partial |
## Inspiration
What inspired us was how students on many campuses use services like Poshmark, Mercari, and ThreadUp to sell clothing they don't wear anymore. The problem with this is that the students have to pay fees to the services for selling through their platform and deal with shipping their clothes to their buyers. As an easier solution, some students turn to creating Instagram accounts to sell locally on their campus, have other students try on the clothes in their dorm, and then just use Venmo for payment. We want to centralize this to an app that shows the user all the sellers on campus and the sellers can upload their postings on the app instead and connect with buyers from their campus. his way, we avoid the irritability that comes through scrolling through post after post after post of clothing sale posts on Instagram, and instead provide a separate platform so that users see sales posts only when they want to.
## What it does
Sellers can easily post sale-posts for clothing, set a try-on/pick-up location, set prices, and indicate whether they want to donate to a sustainable clothing organization (i.e. Clean Clothes Campaign).
Buyers can search for clothes for sale by category (Women's, Men's, Unisex, Tops, Bottoms, Shoes, Jewelry, and other accessories) to aid in searches for a specific piece of clothing for an outing, and they can easily connect with sellers to make the try-on and purchase process quick and easy since the app will be customized to only show sellers on their campus. The app also provides a map of sustainable clothing stores near the user.
## How we built it
We first drew an outline of the components we wanted in the app. These components included a buy tab, a sell tab, and a map to display nearby sustainable clothing stores. We first tackled creating a table view for the buy tab that displays the different categories (W. omen's, Men's, Unisex, Tops, Bottoms, Shoes, Jewelry, and other accessories). We then moved to creating the sell tab where sellers can fill out a form asking for name of item, price, pickup location, size, and type of clothing. We were able to retrieve the information inputted in the sell tab. We then started to work on transferring the information from the sell tab to the buy tab. Unfortunately, we weren't able to complete all the components planned for the app.
## Challenges we ran into
Both team members had no experience in iOS app development so it was a challenge for us to get familiar with the components (table view, view controllers, IBOoutlets) and the syntax. We took advantage of workshops and sponsor-hosted presentations, taking away time from hacking. We also struggled with team formation as members came and left and the final team ended up consisting of two members.
## Accomplishments that we're proud of
We are proud that we were able to set up a table view with three sections (Women's, Men's, and unisex). We are also proud that we were able to retrieve the data from the sell tab as well as implement a variety of UI components like pickers, segment control, and table viewers.
## What we learned
We learned the basics of swift as well as the iOS UI components. We learned how to navigate Xcode and the interface builder. We learned how to storyboard the pages in an app.
## What's next for CampusCloset
We would like to finish the map tab which would locate other sources of sustainable shopping nearby as well as provide a list of organizations and companies that support sustainable shopping. We would like to be able to display seller posts on a table viewer segued from the buy tab. We also plan to add a profile tab where the seller can track all their potential buyers and message them. | ## Inspiration
Estate planning may not be the first concern people think about with crypto, but as it is exploding into mainstream usage, it is more important than ever to ensure that there is a mechanism for your beneficiaries to have access to your crypto inheritance just in case.
We first became aware of how pressing this issue can be from the story of Gerald Cotten, the former CEO of QuadrigaCX. His passing stranded $215 million in crypto, none of which was recoverable without his private keys. It’s not just death that could disrupt your crypto — others have lost their life’s assets forever upon medical incapacitation or loss of their private keys, situations that could have also been mitigated using Will3’s timed inheritance mechanisms.
## What it does
To make sure that you have a backup plan for your crypto just in case, Will3 allows you to specify your final wishes for the distribution of your crypto assets. You can specify the wallet addresses of your beneficiaries along with their respective share, to be inherited after a set amount of time without exposing your original private keys either. No probate court, extended disputes, or misinterpretation — the smart contract self-executes and distributes exactly how it is written.
## How we built it
We deployed a Solidity smart contract on an Ethereum test network and built a frontend using React.
## Challenges we ran into
Since we have just gotten into the Web3 dev space, we ran into some hurdles figuring out how to integrate a MetaMask wallet and debugging a contract on a testnet. Since the space is so new right now, there was not much documentation for us to learn from, but we were able to find solutions after extended trial and error (and a bit of luck!).
We also considered the ethical challenges that our product might face. First off, there are several areas of ethical conflicts with traditional estate planning that Will3 successfully resolves. For example, traditionally, lawyers might have conflicts of interest with the testator or beneficiary, but with a self-executing smart contract, this issue does not exist. The largest issue at play is the ethical and legal concept of testamentary capacity. Normally, one must be 18 years of age to write a will, and lawyers might also make the judgment that one is or is not sound enough of mind to write the will. Because of the decentralized nature of the blockchain, these checks are not inherently in place. Harms that might result include protracted legal disputes over the capacity of the testators to create Will3s, and the legitimacy of the beneficiaries to receive them. Especially since crypto is not as regulated yet, this could be a very murky legal area. However, we are committed to tackling this problem through the implementation of strict KYC (Know your Customer) standards similar to traditional financial institutions. Through the implementation of some identity and source fund verification before users are allowed to create new Will3s, but done solely for the purpose of guaranteeing the legitimacy of their Will3 creation. In the future, we hope to continue building on this idea while collaborating with Harvard’s Edmond J. Safra Center for Ethics to continue to explore what ethical minefields may exist and how best to navigate through them.
## Accomplishments that we're proud of
We were able to successfully deploy our contract on the Ropsten testnet. Moreover, we were able to solidify our understanding of Solidity as well as React JS. We also learned more about undervalued problem areas in crypto at a macro scale, and altogether, we are happy to have come out of TreeHacks with a greater understanding of both technical and fundamental aspects of web3. Our Texas group members are also quite proud that they were able to train their new dog to stop biting people.
## What we learned
Being one of the first hackathons we’ve competed in, we picked up some good lessons on what not to do under a time crunch. We scaled back the scope of our idea a couple of times and seemed to overestimate our ability to get certain aspects done when we should’ve poured all our efforts into developing a minimally viable product. We discovered that not all features on all services have complete documentation and that this should be taken into consideration when deciding on a minimally viable product. Additionally, with team members scattered across the US, we have gotten a number of takeaways from working virtually, including how to best delegate tasks between team members or sub teams. There were many times a group couldn’t continue because it was waiting for another team to finish something, leading to inefficiencies. In the future we would spend more time on the planning phase of the project. We also learned the hard way that a short nap will most likely be many times as long as anticipated, so it is usually a bad idea to fall for the seductiveness of a quick rest.
We were able to come out on the other side with React JS, Solidity, and Web3 under our belts.
## What's next for Will3
We are excited to continue building the UI/UX to make creating, updating, and executing a will very seamless. We feel this is an under-represented issue that will only continue to grow over time, so we felt now was a good time to explore solutions to crypto asset inheritance. Additionally, as tokenization and NFTs become more ubiquitous, Will3 could allow users to add their non-crypto assets onto their virtual will. In addition, we would like to look for alternate methods of verifying that a user is still active and does not need their Will3 to execute, even at the time they have previously declared. | ## Inspiration
One of our groupmates, *ahem* Jessie *ahem*, has an addiction to shopping at a fast fashion retailer which won't be named. So the team collectively came together to come up with a solution: BYEBUY. Instead of buying hauls on clothing that are cheap and don't always look good, BYEBUY uses the power of stable diffusion and your lovely selfies to show you exactly how you would look like in those pieces of clothing you've been eyeing! This solution will not only save your wallet, but will help stop the cycle of mass buying fast fashion.
## What it does
It takes a picture of you (you can upload or take a photo in-app), it takes a link of the clothing item you want to try on, and combination! BYEBUY will use our AI model to show you how you would look with those clothes on!
## How we built it
BYEBUY is a Next.js webapp that:
1. Takes in a link and uses puppeteer and cheerio to web scrape data
2. Gets react webcam takes a picture of you
3. Takes your photo + the web data and uses AI inpainting with a stable diffusion model to show you how the garments would look on you
## Challenges we ran into
**Straying from our original idea**: Our original idea was to use AR to show you in live time how clothing would look on you. However, we soon realized how challenging 3d modelling could be, especially since we wanted to use AI to turn images of clothing into 3d models...maybe another time.
**Fetching APIs and passing data around**: This was something we were all supposed to be seasoned at, but turns out, an API we used lacked documentation, so it took a lot of trial and error (and caffeine) to figure out the calls and how to pass the endpoint of one API to .
## Accomplishments that we're proud of
We are proud we came up with a solution to a problem that affects 95% of Canada's population (totally not a made up stat btw).
Just kidding, we are proud that despite being a group who was put together last minute and didn't know each other before HTV9, we worked together, talked together, laughed together, made matching bead bracelets, and created a project that we (or at least one of the members in the group) would use!
Also proud that we came up with relatively creative solutions to our problems! Like combining web scraping with AI so that users will have (almost) no limitations to the e-commerce sites they want to virtually try clothes on from!
## What we learned
* How to use Blender
* How to call an API (without docs T-T)
* How to web scrape
* Basics of stable diffusion !
* TailwindCSS
## What's next for BYEBUY
* Incorporating more e-commerce sites | losing |
## Inspiration
We were excited
## What it does
GirAFFE analyses and minimizes the average wait time for all commuters so that they can have a positive start to their day.
## How we built it
There were 3 big components in building this project. Finding an appropriate algorithm to calculate the minimal wait time, coding and heavily testing on railway system on Python 3, and creating a unique visualization of the code
## Challenges we ran into
Difficulty setting up GitHub environment.
Testing and debugging computed algorithms
Transfer of inputted data into a .csv file
## Accomplishments that we're proud of
Creating a tester that calculates wait time accurately.
Finding an optimal algorithm to minimize wait time
Setting up a beautiful visualizer
## What we learned
Setting and merging GitHub properly
Computing an efficient algorithm with minimal data
Using Pygame
## What's next for GirAFFe
Accumulating more data so that we can run on a global scale | ## Inspiration
We find ourselves pulling up to weldon, looking for a seat for roughly 20 minutes, and then leaving in despair. We built this tool to help other students forget about this struggle in their studious endeavours.
## What it does
Asks users to input times they are available throughout the day, then uses data from an API that tracks times when locations are the busiest, and recommends where to go based on results.
## How we built it
HTML, CSS, JS for the site
Python for the web scraper
## Challenges we ran into
implementing pretty much everything, not much was functional but we are proud of our idea
## Accomplishments that we're proud of
working together as a team and having fun! we got through like 5 episodes of rick and morty
## What we learned
1. have an idea before starting
2. know what tools you are going to use before hand and how you are going to implement your idea
3. software is always changing, we learned this from listening to the sponsors
## What's next for Western Schedule Optimizer (WSO)
chapter 11 | ## Inspiration
We know the struggles of students. Trying to get to that one class across campus in time. Deciding what to make for dinner. But there was one that stuck out to all of us: finding a study spot on campus. There have been countless times when we wander around Mills or Thode looking for a free space to study, wasting our precious study time before the exam. So, taking inspiration from parking lots, we designed a website that presents a live map of the free study areas of Thode Library.
## What it does
A network of small mountable microcontrollers that uses ultrasonic sensors to check if a desk/study spot is occupied. In addition, it uses machine learning to determine peak hours and suggested availability from the aggregated data it collects from the sensors. A webpage that presents a live map, as well as peak hours and suggested availability .
## How we built it
We used a Raspberry Pi 3B+ to receive distance data from an ultrasonic sensor and used a Python script to push the data to our database running MongoDB. The data is then pushed to our webpage running Node.js and Express.js as the backend, where it is updated in real time to a map. Using the data stored on our database, a machine learning algorithm was trained to determine peak hours and determine the best time to go to the library.
## Challenges we ran into
We had an **life changing** experience learning back-end development, delving into new frameworks such as Node.js and Express.js. Although we were comfortable with front end design, linking the front end and the back end together to ensure the web app functioned as intended was challenging. For most of the team, this was the first time dabbling in ML. While we were able to find a Python library to assist us with training the model, connecting the model to our web app with Flask was a surprising challenge. In the end, we persevered through these challenges to arrive at our final hack.
## Accomplishments that we are proud of
We think that our greatest accomplishment is the sheer amount of learning and knowledge we gained from doing this hack! Our hack seems simple in theory but putting it together was one of the toughest experiences at any hackathon we've attended. Pulling through and not giving up until the end was also noteworthy. Most importantly, we are all proud of our hack and cannot wait to show it off!
## What we learned
Through rigorous debugging and non-stop testing, we earned more experience with Javascript and its various frameworks such as Node.js and Express.js. We also got hands-on involvement with programming concepts and databases such as mongoDB, machine learning, HTML, and scripting where we learned the applications of these tools.
## What's next for desk.lib
If we had more time to work on this hack, we would have been able to increase cost effectiveness by branching four sensors off one chip. Also, we would implement more features to make an impact in other areas such as the ability to create social group beacons where others can join in for study, activities, or general socialization. We were also debating whether to integrate a solar panel so that the installation process can be easier. | losing |
## Inspiration
We love to cook for and eat with our friends and family! Sometimes though, we need to accommodate certain dietary restrictions to make sure everyone can enjoy the food. What changes need to be made? Will it be a huge change? Will it still taste good? So much research and thought goes into this, and we all felt as though an easy resource was needed to help ease the planning of our cooking and make sure everyone can safely enjoy our tasty recipes!
## What is Let Them Cook?
First, a user selects the specific dietary restrictions they want to accommodate. Next, a user will copy the list of ingredients that are normally used in their recipe into a text prompt. Then, with the push of a button, our app cooks up a modified, just as tasty, and perfectly accommodating recipe, along with expert commentary from our "chef"! Our "chef" also provides suggestions for other similar recipes which also accomidate the user's specific needs.
## How was Let Them Cook built?
We used React to build up our user interface. On the main page, we implemented a rich text editor from TinyMCE to serve as our text input, allong with various applicable plugins to make the user input experience as seamless as possible.
Our backend is Python based. We set up API responses using FastAPI. Once the front end posts the given recipe, our backend passes the recipe ingredients and dietary restrictions into a fine-tuned large language model - specifically GPT4.
Our LLM had to be fine-tuned using a combination of provided context, hyper-parameter adjustment, and prompt engineering. We modified its responses with a focus on both dietary restrictions knowledge and specific output formatting.
The prompt engineering concepts we employed to receive the most optimal outputs were n-shot prompting, chain-of-thought (CoT) prompting, and generated knowledge prompting.
## UI/UX
### User Personas

*We build some user personas to help us better understand what needs our application could fulfil*
### User Flow

*The user flow was made to help us determine the necessary functionality we wanted to implement to make this application useful*
### Lo-fi Prototypes

*These lo-fi mockups were made to determine what layout we would present to the user to use our primary functionality*
### Hi-fi Prototypes
 
*Here we finalized the styling choice of a blue and yellow gradient, and we started planning for incorporating our extra feature as well - the recipe recomendations*
## Engineering

Frontend: React, JS, HTML, CSS, TinyMCE, Vite
Backend: FastAPI, Python
LLM: GPT4
Database: Zilliz
Hosting: Vercel (frontend), Render (backend)
## Challenges we ran into
### Frontend Challenges
Our recipe modification service is particularly sensitive to the format of the user-provided ingredients and dietary restrictions. This put the responsibility of vetting user input onto the frontend. We had to design multiple mechanisms to sanitize inputs before sending them to our API for further pre-processing. However, we also wanted to make sure that recipes were still readable by the humans who inputted them. Using the TinyMCE editor solved this problem effortlessly as it allowed us to display text in the format it was pasted, while simultaneously allowing our application to access a "raw", unformatted version of the text.
To display our modified recipe, we had to brainstorm the best ways to highlight any substitutions we made. We tried multiple different approaches including some pre-built components online. In the end, we decided to build our own custom component to render substitutions from the formatting returned by the backend.
We also had to design a user flow that would provide feedback while users wait for a response from our backend. This materialized in the form of an interim loading screen with a moving GIF indicating that our application had not timed out. This loading screen is dynamic, and automatically re-routes users to the relevant pages upon hearing back from our API.
### Backend Challenges
The biggest challenge we ran into was selecting a LLM that could produce consistent results based off different input recipes and prompt engineering. We started out with Together.AI, but found that it was inconsistent in formatting and generating valid allergy substitutions. After trying out other open-source LLMs, we found that they also produced undesirable results. Eventually, we compromised with GPT-4, which could produce the results we wanted after some prompt engineering; however, it it is not a free service.
Another challenge was with the database. After implementing the schema and functionality, we realized that we partitioned our design off of the incorrect data field. To finish our project on time, we had to store more values into our database in order for similarity search to still be implemented.

## Takeaways
### Accomplishments that we're proud of
From coming in with no knowledge, we were able to build a full stack web applications making use of the latest offerings in the LLM space. We experimented with prompt engineering, vector databases, similarity search, UI/UX design, and more to create a polished product. Not only are we able to demonstrate our learnings through our own devices, but we are also able to share them out with the world by deploying our application.
**All that said**, our proudest accomplishment was creating a service which can provide significant help to many in a common everyday experience: cooking and enjoying food with friends and family.
### What we learned
For some of us on the team, this entire project was built in technologies that were unfamiliar. Some of us had little experience with React or FastAPI so that was something the more experienced members got to teach on the job.
One of the concepts we spent the most time learning was about prompt engineering.
We also learned about the importance of branching on our repository as we had to build 3 different components to our project all at the same time on the same application.
Lastly, we spent a good chunk of time learning how to implement and improve our similarity search.
### What's next for Let Them Cook
We're very satisfied with the MVP we built this weekend, but we know there is far more work to be done.
First, we would like to deploy our recipe similarity service currently working on a local environment to our production environment. We would also like to incorporate a ranking system that will allow our LLM to take in crowdsourced user feedback in generating recipe substitutions.
Additionally, we would like to enhance our recipe substitution service to make use of recipe steps rather than solely *ingredients*. We believe that the added context of how ingredients come together will result in even higher quality substitutions.
Finally, we hope to add an option for users to directly insert a recipe URL rather than copy-and-pasting the ingredients. We would write another service to scrape the site and extract the information a user would previously paste. | ## Inspiration
I was interested in exploring the health datasets given by John Snow Labs in order to give users the ability to explore meaningful datasets. The datasets selected were Vaccination Data Immunization Kindergarten Students 2011 to 2014, Mammography Data from Breast Cancer Surveillance Consortium, 2014 State Occupational Employment and Wage Estimate dataset from the Bureau of Labor Statistics, and Mental Health Data from the CDC and Behavioral Risk Factor Surveillance System.
Vaccinations are crucial to ending health diseases as well as deter mortality and morbidity rates and has the potential to save future generations from serious disease. By visualization the dataset, users are able to better understand the current state of vaccinations and help to create policies to improve struggling states. Mammography is equally important in preventing health risks. Mental health is an important fact in determining the well-being of a state. Similarly, the visualization allows users to better understand correlations between preventative steps and cancerous outcomes.
## What it does
The data visualization allows users to observe possible impacts of preventative steps on breast cancer formation and the current state of immunizations for kindergarten students and mental health in the US. Using this data, we can analyze specific state and national trends and look at interesting relationships they may have on one another.
## How I built it
The web application's backend used node and express. The data visualizations and data processing used d3. Specific d3 packages allowed to map and spatial visualizations using network/node analysis. D3 allowed for interactivity between the user and visualization, which allows for more sophisticated exploration of the datasets.
## Challenges I ran into
Searching through the John Snow Labs datasets required a lot of time. Further processing and finding the best way to visualize the data took much of my time as some datasets included over 40,000 entries! Working d3 also took awhile to understand.
## Accomplishments that I'm proud of
In the end, I created a working prototype that visualizes significant data that may help a user understand a complex dataset. I learned a lot more about d3 and building effective data visualizations in a very constrained amount of time.
## What I learned
I learned a lot more about d3 and building effective data visualizations in a very constrained amount of time.
## What's next for Finder
I hope to add more interaction for users, such as allowing them to upload their own dataset to explore their data. | ## Inspiration
From housewives to students, they all face a common problem - meal planning and preparation. Therefore, we decided to test our technological skills by creating an AI recipe builder with your own ingredients!
## What it does
We created a form field to let users select all their available ingredients in their fridge, from leftover chicken to basic ingredients like eggs and flour, our app would find the best recipe. Vegan, lactose intolerance or a specific allergy? We got you covered. Our app lets users specify what they don't want to have in their dish, heck even the amount of calories they can intake in their meal. Select a variety of Main dishes, Side dishes, Desserts, or other meal types suitable for your needs.
## How we built it
We utilize an API from RapidAPI and build our app completely in React and TailwindCSS with the help of Axios. The design process was done on Figma, GitHub for version control, and Railway for deployment and implementation.
## Challenges we ran into
We mostly ran into useEffect and useHook implementation issues in React due to the lack of our lack of knowledge. Using Routing for passing objects around pages was definitely a challenge for us, too. Lastly, we went from Merge conflict to conflict in real life where we tried to modify the same function at the same time.
## Accomplishments that we're proud of
Our web app is fully functional, with a clean home-made design. Our team has to work interdisciplinarily to push the project on time. We were most proud of the fact that this app we would use daily since meal prepping for us students can sometimes be troublesome.
## What we learned
A team leader would make a huge difference in any project - who would ensure which one works on which and would not conflict with each other. Git can sometimes be a double-edged knife, we would need to tread carefully.
## What's next for Gustus
One feature we would need to implement is to create a meal plan for the whole week, with an automatically generated shopping list for grocery trips. Currently, our database supports 1000 food and drink ingredients and we plan to expand more. | partial |
## Our Inspiration
Have you ever looked inside the fridge, saw a particular piece of food, and wondered if it was still edible? Maybe you felt it, or looked it up online, or even gave it the old sniff test! Yet, at the end of the day, you still threw it away.
Did you know that US citizens waste an average of 200lbs of food per year, per person? Much of that waste can be traced back to food casually tossed out of the fridge without a second thought. Additionally, 80% of Americans rely on the printed ‘best by’ dates to determine if their food is still fresh, when in reality it is almost never a true indicator of expiration. We aim to address these problems and more.
## What do we do?
NoWaste.ai is a two-pronged approach to the same issue, allowing us to extend our support to users all over the world. At its core, NoWaste allows users to snap photos of an edible product, describe its context, and harness the power of generative AI to receive a gauge on the quality of their food. An example could be the following: "Pizza left on a warm counter for 6 hours, then refrigerated for 8" + [Picture of the pizza], which would return the AI's score of the food's safety.
In developed countries, everyone has a smartphone, which is why we provide a mobile application to make this process as convenient as possible. In order to create a product that users will be more likely to consistently use, the app has been designed to be extremely streamlined, rapidly responsive, and very lightweight.
However, in other parts of the world, this luxury is not so common. Hence, we have researched extensively to design and provide a cheap and scalable solution for communities around the world via Raspberry Pi Cameras. At just $100 per assembly and $200 per deployment, these individual servers have potential to be dispersed all across the world, saving thousands of lives, millions of pounds of waste, and billions of dollars.
## How we built it
Our hardware stack is hosted completely on the Raspberry Pi in a React/Flask environment. We utilize cloud AI models, such as LLAMA 70B on Together.ai and GPT4 Vision, to offload computation and make our solution as cheap and scalable as possible. Our software stack was built using Swift and communicates with similar APIs.
We began by brainstorming the potential services and technologies we could use to create lightweight applications as quickly as possible. Once we settled on a general idea, we split off and began implementing our own responsibilities: while some of us prototyped the frontend, others were experimenting with AI models or doing market research. This delegation of responsibility allowed us to work in parallel and design a comprehensive solution for a problem as large (yet seemingly so clear) as this.
Of course, our initial ideas were far from what we eventually settled on.
## Challenges we ran into
Finalizing and completing our stack was one of our greatest challenges. Our frontend technologies changed the most over the course of the weekend as we experimented with Django, Reflex, React, and Flask, not to mention the different APIs and LLM hosts that we researched. Additionally, we were ambitious in wanting to only use open-source solutions to further drive home the idea of world-wide collaboration for sustainability and the greater good, but we failed to identify a solution for our Vision model. We attempted to train LLAVA using Intel cloud machines, but our lack of time made it difficult as beginners. Our team also faced hardware issues, from broken cameras to faulty particle sensors. However, we were successful in remedying each of these issues in their own unique ways, and we are happy to present a product within the timeframe we had.
## Accomplishments that we're proud of
We are incredibly proud of what we were able to accomplish in such a short amount of time. We were passionate about both the underlying practicalities of our application as well as the core implementation. We created not only a webapp hosted on a Raspberry Pi, equipped with odor sensors and a camera, but a mobile app prototype and a mini business plan as well. We were able to target multiple audiences and clear areas where this issue prevails, and we have proposed solutions that suit all of them.
## What's next for NoWaste.ai
The technology that we propose is infinitely extensible. Beyond this weekend at TreeHacks, there is room for fine-tuning or training more models to produce more accurate results on rotting and spoiled food. Dedicated chips and board designs can bring the cost of production and extension down, making it even easier to provide solutions across the world. Augmented Reality is becoming more prevalent every day, and there is a clear spot for NoWaste to streamline our technology to work seamlessly with humans. The possibilities are endless, and we hope you can join and support us on our journey! | ## Inspiration
We both came to the hackathon without a team and couldn't generate ideas about our project in the Hackathon. So we went to 9gag to look into memes and it suddenly struck us to make an Alexa skill that generates memes. The idea sounded cool and somewhat within our skill-sets so we went forward with it. We procrastinated till the second day and eventually started coding in the noon.
## What it does
The name says it all, you basically scream at Alexa to make memes (Well not quite, speaking would work too) We have working website [www.memescream.net](http://www.memescream.net) which can generate memes using Alexa or keyboard and mouse. We also added features to download memes and share to Facebook and Twitter.
## How we built it
We divided the responsibilities such that one of us handled the entire front-end, while the other gets his hands dirty with the backend. We used HTML, CSS, jQuery to make the web framework for the app and used Alexa, Node.js, PHP, Amazon Web Services (AWS), FFMPEG to create the backend for the skill. We started coding by the noon of the second day and continued uninterruptible till the project was concluded.
## Challenges we ran into
We ran into challenges with understanding the GIPHY API, Parsing text into GIFs and transferring data from Alexa to web-app. (Well waking up next day was also a pretty daunting challenge all things considered)
## Accomplishments that we're proud of
We're proud our persistence to actually finish the project on time and fulfill all requirements that were formulated in the planning phase. We also learned about GIPHY API and learned a lot from the workshops we attended (Well we're also proud that we could wake up a bit early the following day)
## What we learned
Since we ran into issues when we began connecting the web app with the skill, we gained a lot of insight into using PHP, jQuery, Node.js, FFMPEG and GIPHY API.
## What's next for MemeScream
We're eager to publish the more robust public website and the Alexa skill-set to Amazon. | # butternut
## `buh·tr·nuht` -- `bot or not?`
Is what you're reading online written by a human, or AI? Do the facts hold up? `butternut`is a chrome extension that leverages state-of-the-art text generation models *to combat* state-of-the-art text generation.
## Inspiration
Misinformation spreads like wildfire in these days and it is only aggravated by AI-generated text and articles. We wanted to help fight back.
## What it does
Butternut is a chrome extension that analyzes text to determine just how likely a given article is AI-generated.
## How to install
1. Clone this repository.
2. Open your Chrome Extensions
3. Drag the `src` folder into the extensions page.
## Usage
1. Open a webpage or a news article you are interested in.
2. Select a piece of text you are interested in.
3. Navigate to the Butternut extension and click on it.
3.1 The text should be auto copied into the input area.
(you could also manually copy and paste text there)
3.2 Click on "Analyze".
4. After a brief delay, the result will show up.
5. Click on "More Details" for further analysis and breakdown of the text.
6. "Search More Articles" will do a quick google search of the pasted text.
## How it works
Butternut is built off the GLTR paper <https://arxiv.org/abs/1906.04043>. It takes any text input and then finds out what a text generating model *would've* predicted at each word/token. This array of every single possible prediction and their related probability is crossreferenced with the input text to determine the 'rank' of each token in the text: where on the list of possible predictions was the token in the text.
Text with consistently high ranks are more likely to be AI-generated because current AI-generated text models all work by selecting words/tokens that have the highest probability given the words before it. On the other hand, human-written text tends to have more variety.
Here are some screenshots of butternut in action with some different texts. Green highlighting means predictable while yellow and red mean unlikely and more unlikely, respectively.
Example of human-generated text:

Example of GPT text:

This was all wrapped up in a simple Flask API for use in a chrome extension.
For more details on how GLTR works please check out their paper. It's a good read. <https://arxiv.org/abs/1906.04043>
## Tech Stack Choices
Two backends are defined in the [butternut backend repo](https://github.com/btrnt/butternut_backend). The salesforce CTRL model is used for butternut.
1. GPT-2: GPT-2 is a well-known general purpose text generation model and is included in the GLTR team's [demo repo](https://github.com/HendrikStrobelt/detecting-fake-text)
2. Salesforce CTRL: [Salesforce CTRL](https://github.com/salesforce/ctrl) (1.6 billion parameter) is bigger than all GPT-2 varients (117 million - 1.5 billion parameters) and is purpose-built for data generation. A custom backend was
CTRL was selected for this project because it is trained on an especially large dataset meaning that it has a larger knowledge base to draw from to discriminate between AI and human -written texts. This, combined with its greater complexity, enables butternut to stay a step ahead of AI text generators.
## Design Decisions
* Used approchable soft colours to create a warm approach towards news and data
* Used colour legend to assist users in interpreting language
## Challenges we ran into
* Deciding how to best represent the data
* How to design a good interface that *invites* people to fact check instead of being scared of it
* How to best calculate the overall score given a tricky rank distrubution
## Accomplishments that we're proud of
* Making stuff accessible: implementing a paper in such a way to make it useful **in under 24 hours!**
## What we learned
* Using CTRL
* How simple it is to make an API with Flask
* How to make a chrome extension
* Lots about NLP!
## What's next?
Butternut may be extended to improve on it's fact-checking abilities
* Text sentiment analysis for fact checking
* Updated backends with more powerful text prediction models
* Perspective analysis & showing other perspectives on the same topic
Made with care by:

```
// our team:
{
'group_member_0': [brian chen](https://github.com/ihasdapie),
'group_member_1': [trung bui](https://github.com/imqt),
'group_member_2': [vivian wi](https://github.com/vvnwu),
'group_member_3': [hans sy](https://github.com/hanssy130)
}
```
Github links:
[butternut frontend](https://github.com/btrnt/butternut)
[butternut backend](https://github.com/btrnt/butternut_backend) | partial |
# FaceConnect
##### Never lose a connection again! Connect with anyone, any wallet, and send transactions through an image of one's face!
## Inspiration
Have you ever met someone and instantly connected with them, only to realize you forgot to exchange contact information? Or, even worse, you have someone's contact but they are outdated and you have no way of contacting them? I certainly have.
This past week, I was going through some old photos and stumbled upon one from a Grade 5 Summer Camp. It was my first summer camp experience, I was super nervous going in but I had an incredible time with a friend I met there. We did everything together and it was one of my favorite memories from childhood. But there was a catch – I never got their contact, and I'd completely forgotten their name since it's been so long. All I had was a physical photo of us laughing together, and it felt like I'd lost a precious connection forever.
This dilemma got me thinking. The problem of losing touch with people we've shared fantastic moments with is all too common, whether it's at a hackathon, a party, a networking event, or a summer camp. So, I set out to tackle this issue at Hack The Valley.
## What it does
That's why I created FaceConnect, a Discord bot that rekindles these connections using facial recognition. With FaceConnect, you can send connection requests to people as long as you have a picture of their face.
But that's not all. FaceConnect also allows you to view account information and send transactions if you have a friend's face. If you owe your friend money, you can simply use the "transaction" command to complete the payment.
Or even if you find someone's wallet or driver's license, you can send a reach out to them just with their ID photo!
Imagine a world where you never lose contact with your favorite people again.
Join me in a future where no connections are lost. Welcome to FaceConnect!
## Demos
Mobile Registration and Connection Flow (Registering and Detecting my own face!):
<https://github.com/WilliamUW/HackTheValley/assets/25058545/d6fc22ae-b257-4810-a209-12e368128268>
Desktop Connection Flow (Obama + Trump + Me as examples):
<https://github.com/WilliamUW/HackTheValley/assets/25058545/e27ff4e8-984b-42dd-b836-584bc6e13611>
## How I built it
FaceConnect is built on a diverse technology stack:
1. **Computer Vision:** I used OpenCV and the Dlib C++ Library for facial biometric encoding and recognition.
2. **Vector Embeddings:** ChromaDB and Llama Index were used to create vector embeddings of sponsor documentation.
3. **Document Retrieval:** I utilized Langchain to implement document retrieval from VectorDBs.
4. **Language Model:** OpenAI was employed to process user queries.
5. **Messaging:** Twilio API was integrated to enable SMS notifications for contacting connections.
6. **Discord Integration:** The bot was built using the discord.py library to integrate the user flow into Discord.
7. **Blockchain Technologies:** I integrated Hedera to build a decentralized landing page and user authentication. I also interacted with Flow to facilitate seamless transactions.
## Challenges I ran into
Building FaceConnect presented several challenges:
* **Solo Coding:** As some team members had midterm exams, the project was developed solo. This was both challenging and rewarding as it allowed for experimentation with different technologies.
* **New Technologies:** Working with technologies like ICP, Flow, and Hedera for the first time required a significant learning curve. However, this provided an opportunity to develop custom Language Models (LLMs) trained on sponsor documentation to facilitate the learning process.
* **Biometric Encoding:** It was my first time implementing facial biometric encoding and recognition! Although cool, it required some time to find the right tools to convert a face to a biometric hash and then compare these hashes accurately.
## Accomplishments that I'm proud of
I're proud of several accomplishments:
* **Facial Recognition:** Successfully implementing facial recognition technology, allowing users to connect based on photos.
* **Custom LLMs:** Building custom Language Models trained on sponsor documentation, which significantly aided the learning process for new technologies.
* **Real-World Application:** Developing a solution that addresses a common real-world problem - staying in touch with people.
## What I learned
Throughout this hackathon, I learned a great deal:
* **Technology Stacks:** I gained experience with a wide range of technologies, including computer vision, blockchain, and biometric encoding.
* **Solo Coding:** The experience of solo coding, while initially challenging, allowed for greater freedom and experimentation.
* **Documentation:** Building custom LLMs for various technologies, based on sponsor documentation, proved invaluable for rapid learning!
## What's next for FaceConnect
The future of FaceConnect looks promising:
* **Multiple Faces:** Supporting multiple people in a single photo to enhance the ability to reconnect with groups of friends or acquaintances.
* **Improved Transactions:** Expanding the transaction feature to enable users to pay or transfer funds to multiple people at once.
* **Additional Technologies:** Exploring and integrating new technologies to enhance the platform's capabilities and reach beyond Discord!
### Sponsor Information
ICP Challenge:
I leveraged ICP to build a decentralized landing page and implement user authentication so spammers and bots are blocked from accessing our bot.
Built custom LLM trained on ICP documentation to assist me in learning about ICP and building on ICP for the first time!
I really disliked deploying on Netlify and now that I’ve learned to deploy on ICP, I can’t wait to use it for all my web deployments from now on!
Canister ID: be2us-64aaa-aaaaa-qaabq-cai
Link: <https://github.com/WilliamUW/HackTheValley/blob/readme/ICP.md>
Best Use of Hedera:
With FaceConnect, you are able to see your Hedera account info using your face, no need to memorize your public key or search your phone for it anymore!
Allow people to send transactions to people based on face! (Wasn’t able to get it working but I have all the prerequisites to make it work in the future - sender Hedera address, recipient Hedera address).
In the future, to pay someone or a vendor in Hedera, you can just scan their face to get their wallet address instead of preparing QR codes or copy and pasting!
I also built a custom LLM trained on Hedera documentation to assist me in learning about Hedera and building on Hedera as a beginner!
Link: <https://github.com/WilliamUW/HackTheValley/blob/readme/hedera.md>
Best Use of Flow
With FaceConnect, to pay someone or a vendor in Flow, you can just scan their face to get their wallet address instead of preparing QR codes or copy and pasting!
I also built a custom LLM trained on Flow documentation to assist me in learning about Flow and building on Flow as a beginner!
Link: <https://github.com/WilliamUW/HackTheValley/blob/readme/flow.md>
Georgian AI Challenge Prize
I was inspired by the data sources listed in the document by scraping LinkedIn profile pictures and their faces for obtaining a dataset to test and verify my face recognition model!
I also built a custom LLM trained on Georgian documentation to learn more about the firm!
Link: <https://github.com/WilliamUW/HackTheValley/blob/readme/GeorgianAI.md>
Best .Tech Domain Name:
FaceCon.tech
Best AI Hack:
Use of AI include:
1. Used Computer Vision with OpenCV and the Dlib C++ Library to implement AI-based facial biometric encoding and recognition.
2. Leveraged ChromaDB and Llama Index to create vector embeddings of sponsor documentation
3. Utilized Langchain to implement document retrieval from VectorDBs
4. Used OpenAI to process user queries for everything Hack the Valley related!
By leveraging AI, FaceConnect has not only addressed a common real-world problem but has also pushed the boundaries of what's possible in terms of human-computer interaction. Its sophisticated AI algorithms and models enable users to connect based on visuals alone, transcending language and other barriers. This innovative use of AI in fostering human connections sets FaceConnect apart as an exceptional candidate for the "Best AI Hack" award.
Best Diversity Hack:
Our project aligns with the Diversity theme by promoting inclusivity and connection across various barriers, including language and disabilities. By enabling people to connect using facial recognition and images, our solution transcends language barriers and empowers individuals who may face challenges related to memory loss, speech, or hearing impairments. It ensures that everyone, regardless of their linguistic or physical abilities, can stay connected and engage with others, contributing to a more diverse and inclusive community where everyone's unique attributes are celebrated and connections are fostered.
Imagine trying to get someone’s contact in Germany, or Thailand, or Ethiopia? Now you can just take a picture!
Best Financial Hack:
FaceConnect is the ideal candidate for "Best Financial Hack" because it revolutionizes the way financial transactions can be conducted in a social context. By seamlessly integrating facial recognition technology with financial transactions, FaceConnect enables users to send and receive payments simply by recognizing the faces of their friends.
This innovation simplifies financial interactions, making it more convenient and secure for users to settle debts, split bills, or pay for services. With the potential to streamline financial processes, FaceConnect offers a fresh perspective on how we handle money within our social circles. This unique approach not only enhances the user experience but also has the potential to disrupt traditional financial systems, making it a standout candidate for the "Best Financial Hack" category. | ## Inspiration
We wanted to create a new way to interact with the thousands of amazing shops that use Shopify.
## What it does
Our technology can be implemented inside existing physical stores to help customers get more information about products they are looking at. What is even more interesting is that our concept can be implemented to ad spaces where customers can literally window shop! Just walk in front of an enhanced Shopify ad and voila, you have the product on the sellers store, ready to be ordered right there from wherever you are.
## How we built it
WalkThru is Android app built with the Altbeacon library. Our localisation algorithm allows the application to pull the Shopify page of a specific product when the consumer is in front of it.



## Challenges we ran into
Using the Estimote beacons in a crowded environment has it caveats because of interference problems.
## Accomplishments that we're proud of
The localisation of the user is really quick so we can show a product page as soon as you get in front of it.

## What we learned
We learned how to use beacons in Android for localisation.
## What's next for WalkThru
WalkThru can be installed in current brick and mortar shops as well as ad panels all over town. Our next step would be to create a whole app for Shopify customers which lets them see what shops/ads are near them. We would also want to improve our localisation algorithm to 3D space so we can track exactly where a person is in a store. Some analytics could also be integrated in a Shopify app directly in the store admin page where a shop owner would be able to see how much time people spend in what parts of their stores. Our technology could help store owners increase their sells and optimise their stores. | ## Inspiration
As technological innovations continue to integrate technology into our lives, our personal property becomes more and more tied to the digital world. Our work, our passwords, our banking information, and more are all stored in our personal computers. Security is ever more imperative—especially so at a university campus like Princeton's, where many students feel comfortable leaving their laptops unattended.
## What it does
Our solution is Cognito—an application that alerts users if their laptops are being used by other people. After launching the app, the user simply types in their phone number, gets in position for a clear photo, and at the press of a button, Cognito will now remember the user's face. If someone other than the main user tries to use the laptop without the user being in frame, Cognito sends a text message to the user, alerting them of the malicious intruder.
## How we built it
The application was written in Java using Eclipse and Maven. We used [Webcam Capture API](https://github.com/sarxos/webcam-capture) to interface with the laptop webcam and [OpenIMAJ](http://openimaj.org/) to initially detect faces. Then, using Microsoft Cognitive Services ([Face API](https://azure.microsoft.com/en-us/services/cognitive-services/face/)), we compare all of the faces in frame to the user's stored face. Finally, if an intruder is detected, we integrated with [Twilio](https://www.twilio.com/) to send an SMS message to the user's phone.
## Challenges we ran into
Ranged from members' adversity to sleep deprivation. Also, the cold (one of our group members is from the tropics).
On a more serious note, for many of us, this was our first time participating in a Hackathon or working on integrating APIs. A significant portion of the time was spent choosing and learning to use them, and even after that, working on bug fixes in the individual components took up a substantial chunk of time.
## Accomplishments that we're proud of
Most of us did not have any experience working with APIs prior, much less under the time constraint of a Hackathon. Thus, the feeling of seeing the final working product that we had worked so hard to develop functioning as intended was pretty satisfying.
## What we learned
We did not have significant project experience outside of class assignments, and so we all learned a lot about APIs, bug fixing, and the development process in general.
## What's next for Cognito
Things we'd like to do:
* Hold a *database* of authorized "friends" that won't trigger a warning (in addition to just the core user).
* Provide more choice regarding actions triggered by detection of an unauthorized user (e.g. sending a photo of the malicious user to the main user, disabling mouse & keyboard, turning off screen, system shutdown altogether).
* Develop a clean and more user-friendly UI. | winning |
## Inspiration
We came to this Treehacks wanting to contribute our efforts towards health care. After checking out and working with some of the fascinating technologies we had available to us, we realized that the Magic Leap AR device would be perfect for developing a hack to help the visually impaired.
## What it does
Sibylline uses Magic Leap AR to create a 3D model of the nearby world. It calculates the user distance from nearby objects and provides haptic feedback through a specifically designed headband. As a person gets closer to an object, the buzzing intensity increases in the direction of the object. Maneuverability options also include helping somebody walk in a straight line, by signaling deviations in their path.
## How we built it
Magic Leap creates a 3D triangle mesh of the nearby world. We used the Unity video game engine to interface with the model. Raycasts are sent in 6 different directions relative to the way the user is facing and calculate the distance towards the nearest object. These Raycasts correspond to 6 actuators that are attached to a headband and connected via an Arduino. These actuators buzz with higher intensity as the user gets closer to a nearby object.
## Challenges we ran into
For our initial prototype, the haptic buzzers would either be completely off or completely on. While this did allow the user to detect when an obstacle was vaguely near them in a certain direction, they had no way of knowing how far away it was. To solve this, we adjusted the actuators to modulate their intensity.
Additionally, raycasts were initially bound to the orientation of the head, meaning the user wouldn't detect obstacles in front of them if they were slouched or looking down. We had to take this into consideration when modifying our raycast vectors.
## Accomplishments that we're proud of
We're proud of the system we've built. It uses a complicated stream of data which must be carefully routed through several applications, and the final result is an intensely interesting product to use. We've been able to build off of this system to craft a few interesting and useful quality of life features, and there's still plenty of room for more.
Additionally, we're proud of the extraordinary amount of potential our idea still has. We've accomplished more than just building a hack with a single use case, we've built an entirely new system that can be iterated upon and refined to improve the base functionality and add new capabilities.
## What we learned
We jumped into a lot of new technologies and new skillsets while making this hack. Some of our team members used Arduino microcontrollers for the first time, while one of us learned how to solder. We all had to work hard to figure out how to interface with the Magic Leap, and we learned more about how meshing works in the Unity editor as well.
Lastly, though we cannot hope to fully understand the experience of vision impairment or blindness, we've cultivated a bit more empathy for some of the challenges such individuals face.
## What's next for Sybilline
With industry support, we could significantly expand functionality of Sybilline to apply a number of other vision related tasks. For example, with AI computer vision, Sybilline could tell the user what are objects in front of them.
We would be able to create a chunk-based loading system for multiple "zones" throughout the world, so the device isn't limited to a certain area. We would also want to prioritize the meshing for faster-moving objects, like people in a hallway or cars in an intersection.
With more advanced hardware, we could explore other sensory modalities as our primary method of feedback, like using directional pressure rather than buzzing. In a fully focused, specifically designed final product, we would like to have more camera angles to get more meshing data with, and an additional suite of sensors to cover other immediate concerns for the user. | Curate is an AI-enabled browser extension to allow individuals to more effectively and efficiently consume digital information.
## Inspiration
Content on the web is rarely able to communicate ideas in an effective manner. Whether it be browsing the latest news or perusing a technical report, content consumers are often inundated with distractions (advertisements and boilerplate, for example). This problem is much more pronounced in an enterprise setting. Journalists and researchers are required to sift through countless sources to collect evidence. Software developers need to parse through lengthy documentation to implement programs. Executives need to gather high-level context from volumes of meeting minutes and reports. As such, the lack of support in ingesting the ever-increasing amount of digital information is a significant productivity drain on both individuals and enterprises.
While many tools exist to enable more efficient content creation (ex. Google Docs & Grammarly), few services exist to allow individuals to better *consume* this content.
## What it does
Curate is a browser extension that allows for better content consumption. It exposes a distractionless environment, a "reader-mode," so that readers can process and digest digital information more efficiently. Using the latest machine learning models ([BERT](https://arxiv.org/abs/1810.04805) in particular), our service **automatically highlights** the most important sentences within an article. We also recognize that people differ in their preferred learning strategy. To help cater to this preference and to enable content accessibility, we leveraged text-to-speech technology to narrate a given piece of content.
## How I built it
The browser extension was built using React.js using common libraries and leveraging this [cross-browser extension boilerplate](https://github.com/abhijithvijayan/web-extension-starter). The backend is a Python server powered by [FastAPI](https://fastapi.tiangolo.com/). We were able to leverage the latest NLP capabilities using Google's [BERT](https://arxiv.org/abs/1810.04805) implementation for extractive summarization (using this [library](https://github.com/dmmiller612/bert-extractive-summarizer)).
For text-to-speech capabilities, we used the neural models offered by Google Cloud [text-to-speech](https://cloud.google.com/text-to-speech). We used Google's [App Engine](https://cloud.google.com/appengine) to host an internal endpoint for development. As the BERT ML model requires quite a bit of memory, we needed to use the F4\_1G instance class.
## What's next for Curate
We see a significant value and monetization opportunity for Curate, and would like to keep developing this product after the hackathon. We are excited to continue work on this product with an initial market focus on digital-forward content consumers (such as young software engineers & journalists) using a freemium pricing model.
Our competitive advantage comes from a unique application of the latest machine learning capabilities to create a unified and efficient platform for content ingestion.
As we are one of the first to enter the market with a priority in leveraging ML, we believe that we can maintain our competitive advantage by establishing a data moat. Tracked user behaviors, such as changing the automatically identified texts or the generated transcripts, can be used as training data to fine-tune our ML models. This enables us to offer a significantly more effective product than any subsequent competitors. That being said, we want to stress that data privacy is of utmost concern - we have no intention of continuing the history of data exploitation.
We also see a significant specialization and monetization opportunity within the corporate market (especially in the law, education, and journalism), where the advantage of a data moat is especially clear. It would be immensely difficult for new entrants to compete with ML models fine-tuned to industry-specific content. | ## Inspiration
Our project, "**Jarvis**," was born out of a deep-seated desire to empower individuals with visual impairments by providing them with a groundbreaking tool for comprehending and navigating their surroundings. Our aspiration was to bridge the accessibility gap and ensure that blind individuals can fully grasp their environment. By providing the visually impaired community access to **auditory descriptions** of their surroundings, a **personal assistant**, and an understanding of **non-verbal cues**, we have built the world's most advanced tool for the visually impaired community.
## What it does
"**Jarvis**" is a revolutionary technology that boasts a multifaceted array of functionalities. It not only perceives and identifies elements in the blind person's surroundings but also offers **auditory descriptions**, effectively narrating the environmental aspects they encounter. We utilize a **speech-to-text** and **text-to-speech model** similar to **Siri** / **Alexa**, enabling ease of access. Moreover, our model possesses the remarkable capability to recognize and interpret the **facial expressions** of individuals who stand in close proximity to the blind person, providing them with invaluable social cues. Furthermore, users can ask questions that may require critical reasoning, such as what to order from a menu or navigating complex public-transport-maps. Our system is extended to the **Amazfit**, enabling users to get a description of their surroundings or identify the people around them with a single press.
## How we built it
The development of "**Jarvis**" was a meticulous and collaborative endeavor that involved a comprehensive array of cutting-edge technologies and methodologies. Our team harnessed state-of-the-art **machine learning frameworks** and sophisticated **computer vision techniques** to get analysis about the environment, like , **Hume**, **LlaVa**, **OpenCV**, a sophisticated computer vision techniques to get analysis about the environment, and used **next.js** to create our frontend which was established with the **ZeppOS** using **Amazfit smartwatch**.
## Challenges we ran into
Throughout the development process, we encountered a host of formidable challenges. These obstacles included the intricacies of training a model to recognize and interpret a diverse range of environmental elements and human expressions. We also had to grapple with the intricacies of optimizing the model for real-time usage on the **Zepp smartwatch** and get through the **vibrations** get enabled according to the **Hume** emotional analysis model, we faced issues while integrating **OCR (Optical Character Recognition)** capabilities with the **text-to speech** model. However, our team's relentless commitment and problem-solving skills enabled us to surmount these challenges.
## Accomplishments that we're proud of
Our proudest achievements in the course of this project encompass several remarkable milestones. These include the successful development of "**Jarvis**" a model that can audibly describe complex environments to blind individuals, thus enhancing their **situational awareness**. Furthermore, our model's ability to discern and interpret **human facial expressions** stands as a noteworthy accomplishment.
## What we learned
# Hume
**Hume** is instrumental for our project's **emotion-analysis**. This information is then translated into **audio descriptions** and the **vibrations** onto **Amazfit smartwatch**, providing users with valuable insights about their surroundings. By capturing facial expressions and analyzing them, our system can provide feedback on the **emotions** displayed by individuals in the user's vicinity. This feature is particularly beneficial in social interactions, as it aids users in understanding **non-verbal cues**.
# Zepp
Our project involved a deep dive into the capabilities of **ZeppOS**, and we successfully integrated the **Amazfit smartwatch** into our web application. This integration is not just a technical achievement; it has far-reaching implications for the visually impaired. With this technology, we've created a user-friendly application that provides an in-depth understanding of the user's surroundings, significantly enhancing their daily experiences. By using the **vibrations**, the visually impaired are notified of their actions. Furthermore, the intensity of the vibration is proportional to the intensity of the emotion measured through **Hume**.
# Ziiliz
We used **Zilliz** to host **Milvus** online, and stored a dataset of images and their vector embeddings. Each image was classified as a person; hence, we were able to build an **identity-classification** tool using **Zilliz's** reverse-image-search tool. We further set a minimum threshold below which people's identities were not recognized, i.e. their data was not in **Zilliz**. We estimate the accuracy of this model to be around **95%**.
# Github
We acquired a comprehensive understanding of the capabilities of version control using **Git** and established an organization. Within this organization, we allocated specific tasks labeled as "**TODO**" to each team member. **Git** was effectively employed to facilitate team discussions, workflows, and identify issues within each other's contributions.
The overall development of "**Jarvis**" has been a rich learning experience for our team. We have acquired a deep understanding of cutting-edge **machine learning**, **computer vision**, and **speech synthesis** techniques. Moreover, we have gained invaluable insights into the complexities of real-world application, particularly when adapting technology for wearable devices. This project has not only broadened our technical knowledge but has also instilled in us a profound sense of empathy and a commitment to enhancing the lives of visually impaired individuals.
## What's next for Jarvis
The future holds exciting prospects for "**Jarvis.**" We envision continuous development and refinement of our model, with a focus on expanding its capabilities to provide even more comprehensive **environmental descriptions**. In the pipeline are plans to extend its compatibility to a wider range of **wearable devices**, ensuring its accessibility to a broader audience. Additionally, we are exploring opportunities for collaboration with organizations dedicated to the betterment of **accessibility technology**. The journey ahead involves further advancements in **assistive technology** and greater empowerment for individuals with visual impairments. | partial |
# Sharemuters
Web application built on NodeJS that uses the Mojio api to get user data. Finds other people that have similar trips as you so you can carpool with them and share the gas money!
Uses CockroachDB for storing user data.
## Built at nwhacks2017
### Sustainable Future
Reaching a sustainable future requires intermediate steps to achieve. Electric car adoption is currently under 1% in both the US and Canada. Most cities do not have an amazing transportation system like Vancouver; they rely on cars. Carpooling can reduce environmental impact of driving, and benefit users by saving money, meeting new people, and making commutes more enjoyable.
### Barriers
Transport Canada states the biggest barriers for carpooling are personal safety, flexibility, and effort to organize. Sharemuters targets all three of these inconveniences. Users are vetted through Mojio accounts, and the web app pairs drivers with similar commutes.
### Benefits
Carpooling is a large market; currently just under 10% of drivers in the US and Canada carpool, and 75% of those drivers carpool with family. In addition to reducing pollution, carpooling saves money on gas and parking, time spent commuting, and offers health benefits from reduced stress. Many companies also offer perks to employees that carpool. | ## Inspiration
This week a 16 year old girl went missing outside Oslo, in Norway. Her parents posted about it on Facebook, and it was quickly shared by thousands of people. An immense amount of comments scattered around a large amount of Facebook posts consisted of people trying to help, by offering to hang up posters, aid in the search and similar. A Facebook group was started, and grew to over 15 000 people within a day. The girl was found, and maybe a few of the contributions helped?
This is just one example, and similar events probably play out in a large number of countries and communities around the world. Even though Facebook is a really impressive tool for quickly sharing information like this across a huge network, it falls short on the other end - of letting people contribute to the search. Facebook groups are too linear, and has few tools that aid in making this as streamlined as possible. The idea is to create a platform that covers this.
## What it does
Crowd Search is split into two main parts:
* The first part displays structured information about the case, letting people quickly get a grasp of the situation at hand. It makes good use of rich media and UX design, and presents the data in an understandable way.
* The second part is geared around collaboration between volunteers. It allows the moderators of the missing person search to post information, updates and tasks that people can perform to contribute towards.
## How we built it
Crowd Search makes heavy use of Firebase, and is because of this a completely front-end based application, hosted on Firebase Hosting. The application itself is built using React.
By using Firebase our application syncs updates in realtime, whether it's comments, new posts, or something as a simple as a task list checkbox. Firebase also lets us easily define a series of permission rules, to make sure that only authorized moderators and admins can change existing data and similar. Authentication is done using Facebook, through Firebase's authentication provider.
To make development as smooth as possible we make use of a series of utilities:
* We compile our JavaScript files with Babel, which lets us use new ECMAScript 2016+ features.
* We quality check our source code using ESLint (known as linting)
* We use Webpack to bundle all our JS and Sass files together into one bundle, which can then be deployed to any static file host (we're using Firebase Hosting).
## What's next for Crowd Search
The features presented here function as an MVP to showcase what the platform could be used for. There's a lot of possibilities for extension, with a few examples being:
* Interactive maps
* Situational timelines
* Contact information | ## Inspiration
We have all personally seen our grandparents stray away from exploring new restaurants and cooking at home because of medical concerns, uncertainty about how foods will interact with medications and ailments, and a general worry for their health. We wanted to empower people like our grandparents to take their health in their own hands and feel excited about making wise choices while getting the thrill of trying new foods (without a large barrier of entry)!
## What it does
WiseEats has two main pathways: visiting restaurants or creating a meal plan to cook at home. Users input information about medications they're on as well as any ailments or general health concerns in their profile.
If they are visiting a restaurant, they are able to take a quick picture of the menu, upload it to our platform, and we will recommend what to order based on their concerns. We also provide example questions to ask waiters for other input before ordering.
For someone who wants to cook, we provide them with delicious meal suggestions that have been tailored to their needs. They can select from these and add them to a meal plan for the week, generate new options, or browse through previous favorites.
## How we built it
We used React and Javascript for the baseline of our application and used Postgres and Firebase for our databases with Express as our Middleware. We used two APIs throughout our application - one for image-to-text detection for our menus and OpenAI for providing food recommendations.
## Challenges we ran into
One of our focuses was on accessible design, particularly because of our target population. We learned it's quite difficult to balance the line between design we think is "pretty" and design that is accessible and intuitive.
Overall, the project provided us with a steep learning curve, as none of us are hackathon frequenters. Both APIs we used were completely new to us and it was a fun (but difficult) time getting from ideation to completion in 36 hours.
## Accomplishments that we're proud of
We're excited to be able to demo something that generally works within the 36-hour turnaround! It was great to be able to become familiar with and genuinely understand new tech stacks and technologies.
## What we learned
A lot. We learned how to properly use databases, fine-tuning formatting & prompt engineering for APIs, how to use different resources that aren't necessarily meant to be used together, collaboration techniques, and just generally more about accessible design.
## What's next for WiseBites
Ideally, we'd love to be able to develop WiseBites into a Swift or mobile application that elderly folks can easily use. Since it's an app targeting the elderly, we'd want to incorporate devices tailored to accessibility accommodations such as screen readers. In addition, there are ways to go in terms of the AI models - we were really close to generating images for the foods we suggested, and would want to see that through! Generally, there's also a lot of polish and cleaning up that can happen both in the frontend and backend of our code.
We had a ton of fun building this out, and hope you enjoy! 🙇♀️ | partial |
## Inspiration
600 million people contract malaria each year. Of those people, over 1 million die. 90% of those deaths occur in Sub-Saharan Africa, where people don't have easy access to doctors. We want to help people like them determine their risk of contracting a deadly bug-borne disease and evaluate if they should see a doctor. Malaria can almost always be cured if it's detected earlier and treated promptly.
## What it does
We use machine learning and the current weather to predict your odds of contracting a deadly bug-borne disease such as malaria. If you have a bug bite, you can take a picture using the app and it will use IBM Watson's Visual Recognition API to detect the type of bug that bit you. Some bug bites, such as tick bites, are relatively harmless. If it'll take a lot of effort to see a doctor, it may not be worth it to go if you have a tick bite.
## How we built it
We built a mobile web app with JQuery for the front-end and Express for the back-end. We collected hundreds of photos of bug bites and abnormal skin conditions from Google and Baidu. Then, we uploaded them to IBM Watson to train a custom classifier.
## Challenges we ran into
The biggest challenge we went through is we couldn't find enough good-quality images of bug bites. Most images were too small, grainy, or taken from an odd angle. Since there wasn't enough training data, our classifier was very inaccurate. Our solution was to apply transformations to the images we've found to produce new images. We made sure there was enough distortion that the classifier wouldn't be overfitted. Also, this is Lucy's first hackathon, so there's a lot to get used to (but the Red Bull helped!)
## Accomplishments that we're proud of
This was the first time either of us developed a machine learning application that isn't contrived. Previously, we've primarily done machine learning for assignments or competitions, where the results aren't very application to real life. Other the other hand, Bite D.tech was able to detect that Leo's bug bite is a mosquito bite!
## What we learned
We learned how to use API-based machine learning and how to get more training data when there's not much available. It was much faster to train a model on IBM's servers than on our laptops, so we had time for a lot more iterations. In addition, we learned a lot about the malaria, such as its symptoms and its impact on African society.
## What's next for Bite D.tech
Currently, the only disease Bite D.tech supports is malaria. There wasn't enough time to research more diseases. If we had more time, it would be easy to add more diseases.
## Sources
<https://www.unicef.org/health/files/health_africamalaria.pdf>
<http://www.who.int/features/factfiles/malaria/en/> | ## Introduction
While malaria preventative efforts have increased in the past few decades, malaria is still contracted by 216 million people each year claiming the lives of 870,000 of those people. Early, accurate diagnosis is paramount to prevent deaths, as the Center for Disease Control (CDC) cites misdiagnosis is the leading cause of death in malaria cases. Malaria, however, is hard to diagnose without lab testing because its symptoms are shared with other diseases. The CDC cites microscopy as the gold standard for malaria diagnosis, but microscopy can take hours for a single patient – in many developing countries this simply isn’t possible due to lack of medical professionals. To achieve high accuracy, sensitivity, specificity and speed, a Convolutional Neural Network (CNN) employing transfer learning capable of edge inferencing was used to conduct binary malaria image classifications. Edge inferencing was a focus of this project as the model must be able to run on the weaker equipment available in most developing countries.
## What it does
A webapp platform loads and predicts with a Convolutional Neural Network (CNN) on malaria images. The CNN loaded the NASNetMobile architecture and weights after training on ImageNet then finetuned the model by training the model on the malaria dataset with a low learning rate. The final trained CNN achieved a validation accuracy of 96.2%, a sensitivity of 94.8%, and a specificity of 97.6% after hyperparameter optimization - higher than the performances reported for standard microscopy diagnosis.
## How I built it
I used Python, Keras, and Streamlit to develop this app. | ## Inspiration
We were inspired to create a health-based solution (despite focusing on sustainability) due to the recent trend of healthcare digitization, spawning from the COVID-19 pandemic and progressing rapidly with increased commercial usage of AI. We did, however, want to create a meaningful solution with a large enough impact that we could go through the hackathon, motivated, and with a clear goal in mind. After a few days of research and project discussions/refinement sessions, we finally came up with a solution that we felt was not only implementable (with our current skills), but also dealt with a pressing environmental/human interest problem.
## What it does
WasteWizard is designed to be used by two types of hospital users: Custodians and Admin. At the custodian user level, alerts are sent based on timer countdowns to check on wastebin statuses in hospital rooms. When room waste bins need to be emptied, there is an option to select the type of waste and the current room to locate the nearest large bin. Wastebin status (for that room) is then updated to Empty. On the admin side, there is a dashboard to track custodian wastebin cleaning logs (by time, location, and type of waste), large bin status, and overall aggregate data to analyze their waste output. Finally, there is also an option for the admin to empty large garbage bins (once collected by partnering waste management companies) to update their status.
## How we built it
The UI/UX designers employed Figma keeping user intuitiveness in mind. Meanwhile, the backend was developed using Node.js and Express.js, employing JavaScript for server-side scripting. MongoDB served as the database, and Mongoose simplified interactions with MongoDB by defining schemas. A crucial aspect of our project was using the MappedIn SDK for indoor navigation. For authentication and authorization, the developers used Auth0 which greatly enhanced security. The development workflow followed agile principles, incorporating version control for collaboration. Thorough testing at both front-end and back-end levels ensured functionality and security. The final deployment in Azure optimized performance and scalability.
## Challenges we ran into
There were a few challenges we had to work through:
* MappedIn SDK integration/embedding: we used a front-end system that, while technically compatible, was not the best choice to use with MappedIn SDK so we ended up needing to debug some rather interesting issues
* Front End development, in general, was not any of our strong suits, so much of that phase of the project required us to switch between CSS tutorial tabs and our coding screens, which led us to taking more time than expected to finish that up
* Auth0 token issues related to redirecting users and logging out users after the end of a session + redirecting them to the correct routes
* Needing to pare down our project idea to limit the scope to an idea that we could feasibly build in 24 hours while making sure we could defend it in a project pitch as an impactful idea with potential future growth
## Accomplishments that we're proud of
In general, we're all quite proud at essentially full-stack developing a working software project in 24 hours. We're also pretty proud of our project idea, as our initial instinct was to pick broad, flashy projects that were either fairly generic or completely unbuildable in the given time frame. We managed to set realistic goals for ourselves and we feel that our project idea is niche and applicable enough to have potential outside of a hackathon environment. Finally, we're proud of our front-end build. As mentioned earlier, none of us are especially well-versed in front-end, so having our system be able to speak to its user (and have it look good) is a major success in our books.
## What we learned
We learned we suck at CSS! We also learned good project time management/task allocation and to plan for the worst as we were quite optimistic about how long it would take us to finish the project, but ended up needing much more time to troubleshoot and deal with our weak points. Furthermore, I think we all learned new skills in our development streams, as we aimed to integrate as many hackathon-featured technologies as possible. There was also an incredible amount of research that went into coming up with this project idea and defining our niche, so I think we all learned something new about biomedical waste management.
## What's next for WasteWizard
As we worked through our scope, we had to cut out a few ideas to make sure we had a reasonable project within the given time frame and set those aside for future implementation. Here are some of those ideas:
* more accurate trash empty scheduling based on data aggregation + predictive modelling
* methods of monitoring waste bin status through weight sensors
* integration into hospital inventory/ordering databases
As a note, this can be adapted to any biomedical waste-producing environment, not just hospitals (such as labs and private practice clinics). | losing |
## Inspiration
During Hack the North 2022, we have met a lot of peeps who are visiting Toronto and asked us: "what are some places/attractions that we should visit in Toronto?" We blanked out and did not know what to suggest despite living there for many years. And this is what gave birth to our project, Midgard.
We were also hugely inspired by the fact that it was really hard for us sometimes to pick a place for friend or coworker meetups because each person has their own preferences.
## What it does
Midgard allows users to SAVE and SHARE their favourite places around the city. Those places include local and international cuisine, cafes, lounges, etc. The application keeps track of the address of the place and the comments on what you recommend having. Beyond that, the application uses the user's favourite places to suggest them new recommendations from time to time.
## How we built it
The application was built using React for the front end and Flask for the back end. Because we use Flask for our server side, we decided the use CockroachDB for database management. Finally, we used Figma for UI and design prototyping.
## Challenges we ran into
As our first in-person hackathon, time management was definitely a challenge. A few other challenges that we faced include, but are not limited to finding a free alternative option to the Google Map API provided in the GCP, and a lack of strong front-end skills due to the team being strong backend oriented.
## Accomplishments that we're proud of
We are proud to have successfully completed our first in-person hackathon. Successfully because even though we did not finish our project, we were able to make great memories along the way and made new friends. This experience also gears up for the next challenges we will be facing.
## What we learned
We were able to pick up new coding skills through the different workshops. We implemented React and CockroachDB which we learned this weekend and used them to the best of our understanding.
## What's next for Midgard
In the future, we want Midgard not to be limited to restaurants. We would like the expand the places options to parks, monuments, touristic attractions or simply and place with an awesome view.
Additionally, we also want to expand our data sources, and more integrations such as Google Maps | ## Inspiration
When we go grocery shopping, it's difficult to find the items we need and end up wandering in circles. As busy CS students, it is important that we don't waste time so finding the most effective route around a grocery store would be beneficial to us.
## What it does
With out app, you can create a layout of your grocery store, assigning the entrance, exit, and shelves that are labeled categorically. Then you can create your grocery list, and generate an efficient path that will take you to all the items you need.
## How we built it
We built it using Java, XML, and SQLite in Android Studio.
## Challenges we ran into
The path searching algorithm was extremely difficult, as we just sorta figured out some crucial bugs 10 minutes before the deadline as I'm scrambling to type this.
## Accomplishments that we're proud of
I'm proud of the work we were able to accomplish as a team. We made a nice looking UI and got the hardest part of our app to work out too.
## What we learned
We learned that it is important to communicate thoroughly about the changes you made, and what is does. A major mistake we had was when there was a mixup between a variable name "n" and what is was supposed to be for between two people.
## What's next for shop-circuit
We hope we can continue to develop and improve the graphics on the app as it is quite primitive.
\*\*demos are on github | ## Inspiration
Most of us have had to visit loved ones in the hospital before, and we know that it is often not a great experience. The process can be overwhelming between knowing where they are, which doctor is treating them, what medications they need to take, and worrying about their status overall. We decided that there had to be a better way and that we would create that better way, which brings us to EZ-Med!
## What it does
This web app changes the logistics involved when visiting people in the hospital. Some of our primary features include a home page with a variety of patient updates that give the patient's current status based on recent logs from the doctors and nurses. The next page is the resources page, which is meant to connect the family with the medical team assigned to your loved one and provide resources for any grief or hardships associated with having a loved one in the hospital. The map page shows the user how to navigate to the patient they are trying to visit and then back to the parking lot after their visit since we know that these small details can be frustrating during a hospital visit. Lastly, we have a patient update and login screen, where they both run on a database we set and populate the information to the patient updates screen and validate the login data.
## How we built it
We built this web app using a variety of technologies. We used React to create the web app and MongoDB for the backend/database component of the app. We then decided to utilize the MappedIn SDK to integrate our map service seamlessly into the project.
## Challenges we ran into
We ran into many challenges during this hackathon, but we learned a lot through the struggle. Our first challenge was trying to use React Native. We tried this for hours, but after much confusion among redirect challenges, we had to completely change course around halfway in :( In the end, we learnt a lot about the React development process, came out of this event much more experienced, and built the best product possible in the time we had left.
## Accomplishments that we're proud of
We're proud that we could pivot after much struggle with React. We are also proud that we decided to explore the area of healthcare, which none of us had ever interacted with in a programming setting.
## What we learned
We learned a lot about React and MongoDB, two frameworks we had minimal experience with before this hackathon. We also learned about the value of playing around with different frameworks before committing to using them for an entire hackathon, haha!
## What's next for EZ-Med
The next step for EZ-Med is to iron out all the bugs and have it fully functioning. | losing |
## Inspiration
GPT is hype. We wanted to implement to improve our lives. Often, we find ourselves stuck on writing more words in essays, so we wanted to create something that gives more text for us to work with.
## What it does
This is a text editor that takes the prompt you are answering and the writing you have done thus far into context your writing into context. It has the ability revise your text from 2 options: Elaborate and Summarize
The Summarize feature breaks down your text to be shorter and more concise while the Elaborate feature adds more information expand upon the main ideas in your text and convey them in greater detail to the reader.
## How we built it
We built it with Python, Open AI GPT API, and React.
## Challenges we ran into
We are all React and OpenAI beginners, and for all three of us, this was our first hackathon. It took us a while to figure out how to connect all the necessary components into one cohesive unit. We were also able to implement a streaming feature using web sockets, which is a non trivial task. We were able to actively update to the screen rather than using a traditional pooling HTTP protocol.
## Accomplishments that we're proud of
It works practically flawlessly.
## What we learned
How to use React, a bunch of APIs / SDKs, how to use the OpenAI API, and we read on what makes a UI/UX good.
## What's next for GPT Text Editor
We probably will investigate how the technology underlying our hack can be used to improve user experiences in random industries, such as legal and research. We also want to add an authentication layer to our project and give users the ability to see past writing projects they have worked on. | ## Inspiration
At the moment, the fashion industry is a mess. In terms of sustainability, 20% of Global Waste Water comes from textile dyeing according to the UN Environmental Program. Furthermore, 85% of textiles are thrown away or dumped into landfills, including completely unused clothing. However, one major concern is that the fact 60% of clothing does not even have the ability to be recycled.
One of the other major issues is costs in order to remain sustainable. For the most part, buying sustainable clothes means paying a premium, which makes it hard for most people to afford. Sustainable clothing is not affordable. On top of that, Fast Fashion higher costs due to extremely fast turn around times, further reinforcing unsustainable fashion. Getting cheap sustainable clothing is hard by itself, forget trendy clothing due to current fast fashion.
In consideration of all of these issues brought us to create a sustainable solution: Fashion Flipped or F^2.
Our product is based on the concept of up cycling previous clothing in order to match up and coming trends, while keeping costs low with reused clothing. A network of vendors are asked on application basis to present their creative portfolio, who then design new clothing for consumers. On the consumer end, a subscription based fee is charged and following a quick survey, our algorithm is able to determine the preferences of the user. Based on our inventory of vendor received up cycled clothing, we present the user monthly a customized box of outfits depending on the selected tier level. At the end of the month, the clothing is returned and a new box of outfits is provided.
## What it does
For our UI, we use MUI library to help with UI creation and component creation. For our authentication, you can go ahead and press the login in button to trigger the popup to sign in with 0Auth. Following your login, you will be prompted with a new user navigation at the top. You can go ahead and start off by going to your profile to select some pieces of clothing that you would like. After completing this quiz, the algorithm will have calculated and stored your preferences in Convex.
The algorithm uses OpenAI's ML model to test data minimizing real design preference decision making. After each profile question is answered, the data is stored in Convex in a profile and is then later rendered for customization. Using the average score, the customization algorithm will index the database for closest scores.
For Stripe, using secure form fields, the UI passes a payment token along with user to the Vercel server which then talks directly to Stripe for the transaction. At the moment, we are facing some Stripe deployment issues to the production website so please check out the live demo during judging if you are interested.
## How we built it
FashionFlipped is built using convex, a serverless backend, Auth0 for authentication, and a React.JS frontend. The dataset of clothing items was prefilled using OpenAI's CLIP machine learning model using test data through a process that mimics the way real designs would be input. From there, we use custom convex functions to build a profile of the user's style by averaging preferred styles selected during onboarding. Another set of convex functions calculates the cosine similarity between the user's style profile and the other clothing items to pick out an assortment of clothes users are comfortable with while introducing new styles.
**Primary Features**
* Auth0 Authentication
* Convex (Serverless Backend), populating with users
* Our Clothing Customization ML Model/Algorithm, populating average ratings in results in Convex
* Stripe API for payment transactions
* Vendor Registration, populating users in Convex
* React-Routing for passing through screens and sending data through screens
## Challenges we ran into
After experimenting with larger datasets we figured out convex has a strict memory limit. The combination of intense runtime calculations and large dataset rows due to the CLIP features meant we easily hit the limit. This prevented us from demoing the larger dataset but did push us to build more efficient operations by sharing the computing between the client and server.
Another challenge we encountered was the usage of a new technology. Trying out a new technology like Convex meant we did not have nearly as much experience with it than other products. The docs were recently created, so our unfamiliarity pushed us into a lot of learning with the platform. Convex was unfamiliar, but also serverless backends were a completely new concept that we had to learn rapidly to implement the technology.
Another major issues we had was deploying the project to Vercel. Due to Github ownership issues, unfamiliarity with implementing a serverless backend to production and server management issues, Vercel deployment had some challenges. Declaring environment variables and reassigning the deployment command in Vercel helped solved the issues we were having with Convex and were able to make it work.
## Accomplishments that we're proud of
Our recommendation engine is exceptional. It learns your style preferences with very little input and allows us to categorize a large selection of changing styles, creating a seamless user experience. By utilizing cutting-edge technology, we are able to achieve high accuracy and adaptability presenting our platform as a great choice for anyone.
* Convex (Serverless Backend), populating with users
* Our Clothing Customization ML Model/Algorithm, populating average ratings in results in Convex
* Stripe API for payment transactions
* Vendor Registration
* Vercel Deployment for Live Application
* Passing data between routes with React-Routing
* Responsive, Dynamic UI
## What we learned
We learned how to integrate new services such as a server-less backend such as Convex. We also learned how to integrate a recommendation algorithm using OpenAI and Python into React. Furthermore, we learned the different considerations we had to take in order to deploying to a live domain.
All of us also learned a ton about UI. Developing efficient UI with so many layers overwriting each other became trouble, especially when importing difference components. We had much troubleshooting with being able to center select items or apply the proper style. After having so much practice with UI across the board, it likely will be much faster development going forward.
## What's next for FashionFlipped
We plan to add a feedback form to provide more user input into our algorithm for more accurate customization. On top of that, we plan on creating a vendor side platform to view orders and manage demanded styles from admin. Creating an admin portion of the platform will become important as well to manage what trends and inventory is being created by vendors. We hope to deploy this as a business idea, and how to learn the logistical and technical aspects of running a business with a more sophisticated
sophisticated supply chain. | ## Inspiration
Algorithm interviews... suck. They're more a test of sanity (and your willingness to "grind") than a true performance indicator. That being said, large language models (LLMs) like Cohere and ChatGPT are rather *good* at doing LeetCode, so why not make them do the hard work...?
Introduce: CheetCode. Our hack takes the problem you're currently screensharing, feeds it to an LLM target of your choosing, and gets the solution. But obviously, we can't just *paste* in the generated code. Instead, we wrote a non-malicious (we promise!) keylogger to override your key presses with the next character of the LLM's given solution. Mash your keyboard and solve hards with ease.
The interview doesn't end there though. An email notification will appear on your computer after with the subject "Urgent... call asap." Who is it? It's not mom! It's CheetCode, with a detailed explanation including both the time and space complexity of your code. Ask your interviewer to 'take this quick' and then breeze through the follow-ups.
## How we built it
The hack is the combination of three major components: a Chrome extension, Node (actually... Bun) service, and Python script.
* The **extension** scrapes LeetCode for the question and function header, and forwards the context to the Node (Bun) service
* Then, the **Node service** prompts an LLM (e.g., Cohere, gpt-3.5-turbo, gpt-4) and then forwards the response to a keylogger written in Python
* Finally, the **Python keylogger** enables the user to toggle cheats on (or off...), and replaces the user's input with the LLM output, seamlessly
(Why the complex stack? Well... the extension makes it easy to interface with the DOM, the LLM prompting is best written in TypeScript to leverage the [TypeChat](https://microsoft.github.io/TypeChat/) library from Microsoft, and Python had the best tooling for creating a fast keylogger.)
(P.S. hey Cohere... I added support for your LLM to Microsoft's project [here](https://github.com/michaelfromyeg/typechat). gimme job plz.)
## Challenges we ran into
* HTML `Collection` data types are not fun to work with
* There were no actively maintained cross-platform keyloggers for Node, so we needed another service
* LLM prompting is surprisingly hard... they were not as smart as we were hoping (especially in creating 'reliable' and consistent outputs)
## Accomplishments that we're proud of
* We can now solve any Leetcode hard in 10 seconds
* What else could you possibly want in life?! | losing |
## Inspiration
Digital-logic circuitry forms the foundation of almost every modern device we use today. From laptops to calculators to fridges, the brains of our world are powered by digital circuitry.
Unfortunately, the barrier of entry to learning is incredibly high. If you want to learn about digital logic, you have two options:
**1) Watch a lecture** - While there are many wonderful professors out there, most digital logic classes require a very high amount of prerequisite knowledge. On top of that, these classes are usually taught by drawing static diagrams on the board and the professor explaining truth tables of logic gates and circuits. For kids and other beginners, this is very hard to follow and not very intuitive.
**2) Experiment with circuit simulators** - If students could start right off by experimenting with actual circuits, they could build up the intuition required to understand these concepts. However, the lack of formal lesson structure combined with extremely complex and unintuitive user interfaces causes these tools to be very difficult to use without prior understanding of the material.
Because of this, most people never get the chance to learn how the circuits that run our lives actually work. In fact, even many programmers don't really understand how the CPUs in their machines execute the commands they provide. For students or children who are disadvantaged or have less access to resources, educational resources on these concepts can be almost impossible to reach.
Logic Learner aims to change that.
## What it does
Logic learner is an educational tool that teaches students or kids concepts about **digital logic circuitry** in an **intuitive, tactile, and accessible way**!
What that means, in practice, is that we have an app which teaches students. The app is arranged in a linear set of lessons ranging from simple power sources to full adders (circuits that add numbers together in hardware), latches/flip-flops (computer memory), and more! Each lesson provides an explanation of **one, focused new concept** or new logic gates. The app also contains challenges the student can solve with the knowledge given by the previously solved lessons.
Now, here's the fun part: Instead of having to learn a complicated circuitry simulation software or learning by staring at boring, unintuitive logic tables, we have a unique method of education.
The student simply draws their circuit on paper in marker and points their camera at it. The app then scans the document and the circuit on it and **simulates the hand-drawn circuit** before projecting it back onto the paper on the camera screen! Students can easily and intuitively interact with the circuit by tapping or clicking power sources/switches to turn the power on or off, allowing them full control to experiment with their circuit.
Our app then analyzes whether the circuit solves the lesson. If so, it moves on to the next lesson.
While our app won't teach you how to build a CPU from scratch, it will give you all the tools and foundational knowledge you need to continue learning on your own!
## How we built it
The app itself is a WPF application. The design and UI/UX of the app was designed through a combination of drawing it out on a whiteboard and mocking it up on Figma. Once that was completed, the design was then converted to XAML and connected through WPF's frontend library.
The circuitry simulation and document detection aspect was built using Wireform and WireformSketch, two circuit simulation and computer vision libraries built previously by one of our team members using OpenCv.
We built a layer on top of these libraries that performs circuit equivalence analysis to check whether or not the student's circuit matches the intended solution. We also built a transformation matrix that transforms clicks/touches on the app's screen to points on the real world circuit which allows the user to tap individual circuit elements on their screen to interact with them.
We then designed and wrote each lesson and loaded them into the application.
## Challenges we ran into
One of the most significant technical challenges we ran into was the lack of support for EmguCv (A C# wrapper of OpenCv which runs all of WireFormSketch's computer vision code) on Xamarin, our original platform of choice. After debugging and experimenting for hours, we discovered that the Android/IOS version required an expensive commercial license for EmguCv, so we migrated the project over to WPF.
Another challenge we ran into was design. When designing an educational application whose target audience includes children, it is very important to have simple, intuitive UX choices. As such, we went through multiple iterations of design in Figma to discover the simplest, most visual solutions to our design goals.
## Accomplishments that we're proud of
One of the hardest parts of this project was designing the lessons. Digital Logic is hard. It's abstract and very conceptual, so hooking it in to intuitive understanding through lessons is quite difficult. However, our team experimented with different lesson formats to discover the best way to teach these concepts in a way that is understandable by students, kids, and other beginners. We landed on our final approach: Focus on one, simple concept at a time. Using this model as a framework for our lessons, we were able to reach fairly complex topics in a very intuitive and easy to follow way.
Similarly, our team is very proud of the impact our project can have. We deeply believe in the value of education, and are proud to have created a tool which increases the accessibility of a very important field of science. As such, accessibility and intuitiveness were major design goals of our project. Because all that is required is a device, a camera, and paper/pens, our lessons are very accessible for anyone, regardless of background or experience!
## What we learned
Because this was the first hackathon for many of us, we learned a lot about working under pressure, team organization, and collaborative development. We're very proud of our teamwork this weekend. With all of us living in different places and only being able to connect over zoom, structure and organization were incredibly important. From creating a 10+ page design doc overnight to even distribution and divide-and-conquer approaches to team management, we quickly developed a system of organization that worked. Not only did we create an awesome product, but we had a great time doing it!
On the technical side, none of us had significant ios/android app development experience and we also had no prior WPF experience. However, through sharing resources and some long nights watching YouTube videos, we figured learned how to work with tools such as Blend for Visual Studio and how to develop for WPF and XAML-based projects in general.
The WPF library itself was a whole other learning experience, especially for a frontend developer who's used to working with HTML and CSS! Navigating through the different screens and passing event handlers up from child components proved to be a tough but manageable challenge. Overall, this was a great learning experience, and we now feel more comfortable writing user interfaces using C# and XAML files.
## What's next for Logic Learner
While we created a functional app this hackathon that teaches the basic foundations of digital logic, there's lots of room to grow Logic Learner even more, from platform expansions and content extensions!
Firstly, we plan to migrate the project back to Xamarin and provide IOS and Android build targets by converting WireFormSketch away from EmguCv. This would require a significant amount of time to do as the library that we were working off of relied on the EmguCv library (which has a $300 commercial mobile development license)! This, of course, was completely inaccessible to us in the scope of this hackathon, and developing a new library for circuit parsing would take way too much time. By cutting out EmguCv, we would no longer be restricted by platform and even programming language for that matter. This would make the app more scalable to different applications, such as a web app!
Secondly, we plan on adding more complex components and circuit lessons to further advance student's understanding. We can create complex lessons on creating actual CPU components like an ALU, an instruction selectors, RAM, Registers, and more! Logic Learner provides a platform for an unlimited number of lessons. We also thought it would be cool to have professionals and professors contribute to the lessons on this app, whether it be editing/writing lessons or simply providing challenging problems to solve.
Third, we want this project to be as fun and intuitive for students as possible. This means we plan on adding more polish, more sound effects, more rewards/achievements to incentivize students to keep on learning! As a mobile app, there's a much easier interactive component that can be taken advantage of. This allows for the app to be much more polished than it is at the moment and really feel like an industry-standard learning tool.
Finally, we plan on further integrating with Google Cloud or CockroachDB to provide a public workplace where students can share custom made lessons or exciting circuits on the public database! This will allow people from all over the world to share their passion for digital logic or provide niche lessons on other interesting circuit components! | ## Inspiration
The resources to support a subject like physics simply do not exist in America’s already sluggish education system. According to the U.S. Department of education, 40% of high schools do not even offer the subject. This lack of access is somewhat caused by the financial barrier even smaller electrical engineering projects can present. A basic setup including an Arduino to control a single LED comes out to about $45. This pushes an already daunting subject even further away from students’ grasp.
After a very long ideation session, we set out to make electrical engineering— a subject we all love so much—a little more accessible and affordable to students around the country. We decided to do this using the flashy ed-tech route, but still made sure to retain the tactile aspects that define EE.
## What it does and how we built it
First, the user draws a circuit schematic they wish to analyze using custom tactile shapes we laser-cut to represent their circuit. For example, using a rectangle (battery) and a circle (LED), they can power a light! The user then takes a picture of their circuit using our Swift developed iOS app which is then sent to an Python / Flask backend to be decomposed into different circuit components, all connected by wires. Through OpenCV, the shapes in the circuit are identified and translated into their corresponding circuit components: voltage source, LED, resistor, or potentiometer. These circuit components are then analyzed to determine the circuit’s output (we determined output by whether or not the LED was turned on). The resulting pattern of electronic components was then sent back to the iOS app. Based on the locations of the components in the originally drawn circuit, an Augmented Reality experience is dynamically created using Apple’s ARKit. The AR visualization illustrates how a student’s idea of a circuit would function in real life, providing far more detail and avenues for creativity than a traditional circuit in a textbook or classroom lecture. In addition, students who have the privilege of working with physical hardware might shy away from experimenting for fear of burning out electronic components. With CirCreate, experimentation is a given - we expect that students will learn far more from visualizing mistakes when the stakes are zero.
## Challenges we ran into and what we learned
Although learning so many new skills in a weekend was difficult, we wanted not only a technical challenge but also an ethical one. We deeply believe that our hack should in some way contribute to making the world a better tomorrow and wanted to preserve the integrity of education with its technological interpretation. Due to the depth we desired to provide an enriching experience for students and our novice technical level in these fields, we weren’t able to fully develop our project over the course of this hackathon, but we hope to continue learning and working in the future. A technical challenge we ran into was the lack of documentation in ARKit (RealityKit), Swift, and Reality Converter. It’s very cool to be at the cutting edge of all these brand new technologies but also creates a large barrier to entry without vast resources. Along those lines, the 3-D file formats necessary were also not available anywhere.
## What we're proud of
Our idea for CirCreate stemmed from a deep passion for educational equity and our love (albeit nerdy) for circuitry. We additionally had never worked with Augmented Reality or iOS app development before and wanted to learn those two new skills this weekend. We combined this all to produce a deliverable which converted a 2-D hand-drawn circuit on a sheet of paper to a 3-D Augmented Reality experience with a fully functioning circuit resembling actual circuit components like Arduinos and resistors. We felt it was important to bridge the gap between very theoretical circuit pedagogy with the excitement of actually developing the little gadgets and gizmos. Through our varied experiences learning the subject, we also were aware of how unintuitive theoretical drawings can be and strove to craft a tactile and immersive learning experience.
## What's next for CirCreate
We hope AR will be mindfully and impactfully used in the physics classroom and beyond in the future— tipping the scales in favor of greater educational accessibility and hence educational equity. The applications for our hack are endless— from providing useful debugging and rapid prototyping for seasoned circuiteers to a fun, comfortable entry into the field for eager learners. | ## Inspiration
Augmented reality can breathe new life into the classroom, bringing extra creativity, interactivity and engagement to any subject. AR learning helps students by decreasing the time it takes to grasp complex topics.
Augmented reality in education can serve a number of purposes. It helps the students easily acquire, process, and remember the information. Additionally, AR makes learning itself more engaging and fun.
It is also not limited to a single age group or level of education, and can be used equally well in all levels of schooling; from pre-school education up to college, or even at work
## What it does
EchoScienceAR help you to explore science with AR. It help you to gain more knowledge and better understanding towards the science subjects with AR models and helps to make learning itself more engaging and fun.
## How we built it
For website I've considered HTML, HTML5, CSS, CSS3 and for 3d models I've considered echoAR
## Challenges we ran into
Worked solo for the entire project
## Accomplishments that we're proud of
I was able to explore AR
## What's next for EchoScienceAR
Conduct digital chemistry labs to perform experiment through AR, explore various topics, involve a discussion channel | losing |
## Inspiration
Investing in yourself goes beyond just finances. It's about building a better you and a better future. We wanted to push the boundaries of Wealthsimple beyond just financial investment and into a company that helps you invest in yourself in every way. Growsimple is an extension of the Wealthsimple app that looks out for your health, fitness, learning and more.
## What it does
Growsimple provides you with different challenges hosted by local businesses & organizations. The challenges are all related to investing in yourself such as fitness sessions, learning a new craft etc. When a challenge is completed, users will get a reward from the business and a certain amount invested in their Wealthsimple account by Wealthsimple or the business. Users also have the opportunity to earn badges from completing a certain number of challenges which adds a huge bonus to their Wealthsimple account.
## How we built it
It is designed as a web app and prototypes were designed on sketch & InVision. The mockups were then coded with HTML5, CSS3 & Javascript to provide a user-friendly online experience.
## Challenges we ran into
It was difficult to manage to Google Maps API to provide a user experience that was up to par. We also ran into challenges building a responsive web page to optimize viewing for different types of devices.
## Accomplishments that we're proud of
We are most proud of the practicality and impact it would have on Wealthsimple's branding. We believe that this addition to the app will help Wealthsimple bring in new users who join Wealthsimple after completing a few challenges. It will also strengthen Wealthsimple's image as being a hip, investment company that cares about their customer's future instead of a traditional bank that focuses solely on financial return.
## What we learned
We learned more about the process of implementing APIs, and working together as developers & designers. We learned more about working with APIs and responsive web design.
## What's next for Growsimple
In the future, Growsimple will improve its technical capabilities by adding APIs that can track user movement & habits to become a "smart" app. It will become an app that is integrated into users daily lives to help them build healthy habits. | ## Inspiration
One in five Canadians will be affected by mental illness in their lifetimes.Tick-Tock Refill was inspired due to the the study, "E-mails in a Psychiatric Practice: Why Patients Send Them and How Psychiatrists Respond". This study highlights the importance of saving time between the physician and patient via e-mail. Using this study and research on mental health, we knew our hack had to impact medicine and indirectly play a role in reducing wait times.
## What it does
Tick-Tock Refill is a user friendly application that uses google-cloud API, Optical Character Recognition (OCR) which allows a patient to take pictures of their drug prescriptions to catch text details which can be manually copied so that are sent out to their physicians via email. The psychiatrist or physician can better care for his patients, and work on refills without wasting both the patients or his time. This reduces wait times for those who have urgent issues that need to be dealt with, as a prescription can be validated and verified electronically. Firebase was not implemented in time, but we have built a database with collection of drugs to treat mental illness that would have been compared to the text that the OCR API would provide. This would then allow for the data to be shared with the doctor that can prescribe that specific drug eliminating the wait on their home doctor.
## How we built it
Using the Google Cloud AP OCR(Optical Character Recognition) and coding the Android app in java to allow for a user
## Challenges we ran into
Debugging, understanding Firebase and how to use it within the application, and coming up with an idea.
## Accomplishments that we're proud of
Worked with an API and Android Studio, debugged errors.
## What we learned
Iteration is key, and to embrace the unexpected as things will not always go as planned.
## What's next for Tick-Tock Refill
Allow for approval and rejection of the refill to be done on the application with comments by both parties (reason for prescription by patient, or reason for rejecting prescription by physician), which allows to eliminate the email communication. | ## Inspiration
While there are several applications that use OCR to read receipts, few take the leap towards informing consumers on their purchase decisions. We decided to capitalize on this gap: we currently provide information to customers about the healthiness of the food they purchase at grocery stores by analyzing receipts. In order to encourage healthy eating, we are also donating a portion of the total value of healthy food to a food-related non-profit charity in the United States or abroad.
## What it does
Our application uses Optical Character Recognition (OCR) to capture items and their respective prices on scanned receipts. We then parse through these words and numbers using an advanced Natural Language Processing (NLP) algorithm to match grocery items with its nutritional values from a database. By analyzing the amount of calories, fats, saturates, sugars, and sodium in each of these grocery items, we determine if the food is relatively healthy or unhealthy. Then, we calculate the amount of money spent on healthy and unhealthy foods, and donate a portion of the total healthy values to a food-related charity. In the future, we plan to run analytics on receipts from other industries, including retail, clothing, wellness, and education to provide additional information on personal spending habits.
## How We Built It
We use AWS Textract and Instabase API for OCR to analyze the words and prices in receipts. After parsing out the purchases and prices in Python, we used Levenshtein distance optimization for text classification to associate grocery purchases with nutritional information from an online database. Our algorithm utilizes Pandas to sort nutritional facts of food and determine if grocery items are healthy or unhealthy by calculating a “healthiness” factor based on calories, fats, saturates, sugars, and sodium. Ultimately, we output the amount of money spent in a given month on healthy and unhealthy food.
## Challenges We Ran Into
Our product relies heavily on utilizing the capabilities of OCR APIs such as Instabase and AWS Textract to parse the receipts that we use as our dataset. While both of these APIs have been developed on finely-tuned algorithms, the accuracy of parsing from OCR was lower than desired due to abbreviations for items on receipts, brand names, and low resolution images. As a result, we were forced to dedicate a significant amount of time to augment abbreviations of words, and then match them to a large nutritional dataset.
## Accomplishments That We're Proud Of
Project Horus has the capability to utilize powerful APIs from both Instabase or AWS to solve the complex OCR problem of receipt parsing. By diversifying our software, we were able to glean useful information and higher accuracy from both services to further strengthen the project itself, which leaves us with a unique dual capability.
We are exceptionally satisfied with our solution’s food health classification. While our algorithm does not always identify the exact same food item on the receipt due to truncation and OCR inaccuracy, it still matches items to substitutes with similar nutritional information.
## What We Learned
Through this project, the team gained experience with developing on APIS from Amazon Web Services. We found Amazon Textract extremely powerful and integral to our work of reading receipts. We were also exposed to the power of natural language processing, and its applications in bringing ML solutions to everyday life. Finally, we learned about combining multiple algorithms in a sequential order to solve complex problems. This placed an emphasis on modularity, communication, and documentation.
## The Future Of Project Horus
We plan on using our application and algorithm to provide analytics on receipts from outside of the grocery industry, including the clothing, technology, wellness, education industries to improve spending decisions among the average consumers. Additionally, this technology can be applied to manage the finances of startups and analyze the spending of small businesses in their early stages. Finally, we can improve the individual components of our model to increase accuracy, particularly text classification. | losing |
## 💡 Inspiration 💡
So many people around the world are fatally injured and require admission to multiple hospitals in order to receive life-changing surgery/procedures. When patients are transferred from one hospital to another, it is crucial for their medical information to be safely transferred as well.
## ❓ What it does ❓
Hermes is a secure, HIPAA-compliant app that allows hospital admin to transfer vital patient data to other domestic and/or international hospitals. The user inputs patient data, uploads patient files, and sending them securely to a hospital.
## ⚙️ How we built it ⚙️
We used the React.JS framework to build the web application. We used Javascript for the backend and HTML/CSS/JS for the frontend. We called the Auth0 API for authentication and Botdoc API for encrypted file sending.
## 🚧 Challenges we ran into 🚧
Figuring out how to send encrypted files through Botdoc was challenging but also critical to our project.
## ✨Accomplishments that we're proud of ✨
We’re proud to have built a dashboard-like functionality within 24 hours.
## 👩🏻💻 What we learned 👩🏻💻
We learned that authentication on every page is critical for an app like this that would require uploaded patient information from hospital admins. Learning to use Botdoc was also fruitful when it comes to sending encrypted messages/files. | ## Inspiration
While any new adventure is challenging, as seniors, we are particularly thinking about the struggles of life after college as we enter the workforce. One of the things that will set our generation apart is that we will be starting jobs remotely. We will never have met our coworkers face to face, walked in the office, gone out to lunch to meet people, or even walked through the different departments of the company. While there are many efforts to promote collaboration and ease people's transition to the online workplace, we find that many of them are still intimidating. For example, it can sometimes be embarrassing to ask a question in a chat with hundreds of people. On top of this, working remotely has sometimes prevented teams from being able to share and monitor their progress. We wanted to develop a solution for all this issues that we are sure to face very soon.
## What it does
Jarvis is an all in one platform to help you stay productive, engaged with your coworkers, and monitor your stress and productivity to keep you in check.
At the start of each day, Jarvis will let you know what your tasks are and will recommend in what order you should tackle them based on its analysis of what time of the day you are most productive. Jarvis is also integrated with your Google Calendar so it will keep you on time for your meetings and make sure to schedule your work day around these events.
Jarvis also performs regular checkins to see how you're doing on your tasks and make helpful suggestions like figuring out if it might be time for a break or asking you what you are struggling with. After you enter your question, Jarvis will let you know who you should contact based on the subject of your question and who is available right now to take your question.
Jarvis is also a tool to help monitor how stressful your upcoming week is (based on the number of meetings you have scheduled, upcoming deadlines, the importance of the tasks that you have...) and can check if you are working abnormally much or seem to be dipping in productivity due to stress. At these moments, Jarvis will come to your rescue to give you some helpful tips or share some positive feedback from your coworkers with you. Jarvis is not only meant to boost your productive over one day but rather to keep you healthy and happy so you can stay productive for much longer than that.
## How we built it
We built Jarvis with a combination of React, HTML, and CSS for the front end and Javascript for the backend.
## Challenges we ran into
The biggest challenge we had was that we built a chatbot in React.js and the rest of our interface in HTML at first. Unfortunately, we soon realized that we would not be able to integrate the two with one another. We therefore rebuilt a chatbot but in HTML this time.
## Accomplishments that we're proud of
We are very proud of our idea as we think it is something scalable, useful, and that benefits many people in these challenging times. We not only wanted to help people be more productive, but also monitor their stress level and hopefully prevent burnout.
We are very proud to have been able to add so much functionality into our application as the chatbot can make useful recommendations as to whom you should ask your questions to, but you can also keep track of your tasks.
## What we learned
None of us had a lot of experience with frontend development so it was a challenge, but we're very proud of our accomplishment.
## What's next for Jarvis
We hope to continue to add functionality to Jarvis so that it can become more adapted to each person's need. While it is already personalized for each person, we want Jarvis to get to know employees even better to continue becoming a more useful productivity tool! | ## Inspiration
Most of us have had to visit loved ones in the hospital before, and we know that it is often not a great experience. The process can be overwhelming between knowing where they are, which doctor is treating them, what medications they need to take, and worrying about their status overall. We decided that there had to be a better way and that we would create that better way, which brings us to EZ-Med!
## What it does
This web app changes the logistics involved when visiting people in the hospital. Some of our primary features include a home page with a variety of patient updates that give the patient's current status based on recent logs from the doctors and nurses. The next page is the resources page, which is meant to connect the family with the medical team assigned to your loved one and provide resources for any grief or hardships associated with having a loved one in the hospital. The map page shows the user how to navigate to the patient they are trying to visit and then back to the parking lot after their visit since we know that these small details can be frustrating during a hospital visit. Lastly, we have a patient update and login screen, where they both run on a database we set and populate the information to the patient updates screen and validate the login data.
## How we built it
We built this web app using a variety of technologies. We used React to create the web app and MongoDB for the backend/database component of the app. We then decided to utilize the MappedIn SDK to integrate our map service seamlessly into the project.
## Challenges we ran into
We ran into many challenges during this hackathon, but we learned a lot through the struggle. Our first challenge was trying to use React Native. We tried this for hours, but after much confusion among redirect challenges, we had to completely change course around halfway in :( In the end, we learnt a lot about the React development process, came out of this event much more experienced, and built the best product possible in the time we had left.
## Accomplishments that we're proud of
We're proud that we could pivot after much struggle with React. We are also proud that we decided to explore the area of healthcare, which none of us had ever interacted with in a programming setting.
## What we learned
We learned a lot about React and MongoDB, two frameworks we had minimal experience with before this hackathon. We also learned about the value of playing around with different frameworks before committing to using them for an entire hackathon, haha!
## What's next for EZ-Med
The next step for EZ-Med is to iron out all the bugs and have it fully functioning. | partial |
## Inspiration
Online shopping is hard because you can't try on clothing for yourself. We want to make a fun and immersive online shopping experience through VR that will one day hopefully become more realistic and suitable for everyday online shopping. We hope to make a fun twist that helps improve decisiveness while browsing online products.
## What it does
This VR experience includes movement, grabbable clothes, dynamic real-time texturing of models using images from Shopify’s Web API, and a realistic mirror of yourself to truly see how these fits shall look on you before buying it! The user that enters the virtual clothing store may choose between a black/yellow shirt, and black/tropical pants which are products from an online Shopify store (see screenshots). The user can also press a button that would simulate a purchase :)
## How we built it
Using the Shopify ProductListing API, we accessed the different clothing items from our sample online store with a C# script. We parsed the JSON that was fetched containing the product information to give us the image, price, and name of the products. We used this script to send this information to our VR game. Using the images of the products, we generated a texture for each item in virtual reality in the Unity game engine, which was then put onto interactable items in the game. Also, we designed some models, such as signs with text, to customize and accessorize the virtual store. We simulated the shopping experience in a store as well as interactable objects that can be tried on.
## Challenges we ran into
Linking a general C# script which makes REST API calls to Unity was a blocker for us because of the structure of code Unity works with. We needed to do some digging and search for what adjustments needed to be made to a generic program to make it suitable for the VR application. For example, including libraries such as Newtonsoft.
We also ran into conflicts when merging different branches of our project on GitHub. We needed to spend additional time rolling back changes and fixing bugs to take the next step in the project.
One significant difficulty was modelling the motion of the virtual arms and elbows when visible in the mirror. This must be done with inverse kinematics which we were never quite able to smoothly implement, although we achieved something somewhat close.
Getting the collision boundaries was difficult as well. The player and their surroundings constantly change in VR, and it was a challenge to set the boundaries of item interaction for the player when putting on items.
## Accomplishments that we're proud of
Our project has set a strong foundation for future enhancements. We’re proud of the groundwork we’ve laid for a concept that can grow and evolve, potentially becoming a game-changing solution in VR shopping.
## What we learned
We learned the importance of anticipating potential technical blockers, such as handling complex features like inverse kinematics and collision limits. Properly allocating time for troubleshooting unexpected challenges would have helped us manage our time more efficiently.
Also, many technical challenges required a trial-and-error approach, especially when setting up collision boundaries and working with avatar motion. This taught us that sometimes it's better to start with a rough solution and iteratively refine it, rather than trying to perfect everything on the first go.
Finally, working as a team, we realized the value of maintaining clear communication, especially when multiple people are contributing to the same project. Whether it was assigning tasks or resolving GitHub conflicts, being aligned on priorities and maintaining good communication channels kept us moving forward.
## What's next for Shop The North
We want to add even more variety for future users. We hope to develop more types of clothing, such as shoes and hats, as well as character models that could suit any body type for an inclusive experience. Additionally, we would like to implement a full transaction system, where the user can add all the products they are interested into a cart and complete a full order (payment information, shipping details, and actually placing a real order). In general, the goal would be to have everything a mobile/web online shopping app has, and more fun features on top of it. | ## Inspiration
Online shopping has been the norm for a while, but the COVID-19 pandemic has impelled even more businesses and customers alike to shift to the digital space. Unfortunately, it also accentuated the frustrations associated with online shopping. People often purchase items online, only to find out what they receive is not exactly what they want. AR is the perfect technology to bridge the gap between the digital and physical spaces; we wanted to apply that to tackle issues within online shopping to strengthen interconnection within e-commerce!
## What it does
scannAR allows its users to scan QR codes of e-commerce URLs, placing those items in front of where the user is standing. Users may also scan physical items to have them show up in AR. In either case, users may drag and drop anything that can be scanned or uploaded to the real world.
Now imagine the possibilities. Have technicians test if a component can fit into a small space, or small businesses send their products to people across the planet virtually, or teachers show off a cool concept with a QR code and the students' phones. Lastly, yes, you can finally play Minecraft or build yourself a fake house cause I know house searching in Kingston is hard.
## How we built it
We built the scannAR app using Unity with the Lean Touch and Big Furniture Pack assets. We used HTML, CSS, Javascript to create the business website for marketing purposes.
## Challenges we ran into
This project was our first time working with Unity and AR technology, so we spent many hours figuring their processes out. A particular challenge we encountered was manipulating objects on our screens the way we wanted to. With the time constraint, the scope of UI/UX design was limited, making some digital objects look less clean.
## Accomplishments that we're proud of
Through several hours of video tutorials and some difficulty, we managed to build a functioning AR application through Unity, while designing a clean website to market it. We felt even prouder about making a wide stride towards tackling e-commerce issues that many of our friends often rant about.
## What we learned
In terms of technical skills, we learned how to utilize AR technology, specifically Unity. Initially, we had trouble moving objects on Unity; after completing this project, we have new Unity skills we can apply throughout our next hackathons and projects. We learned to use our existing front-end web development skills to augment our function with form.
## What's next for scannAR
In the near future, we aim to flesh out the premium subscription features to better cater to specific professions. We also plan on cleaning up the interface to launch scannAR on the app stores. After its release, it will be a constant cycle of marketing, partnerships with local businesses, and re-evaluating processes. | # 🤖🖌️ [VizArt Computer Vision Drawing Platform](https://vizart.tech)
Create and share your artwork with the world using VizArt - a simple yet powerful air drawing platform.
## 💫 Inspiration
>
> "Art is the signature of civilizations." - Beverly Sills
>
>
>
Art is a gateway to creative expression. With [VizArt](https://vizart.tech/create), we are pushing the boundaries of what's possible with computer vision and enabling a new level of artistic expression. ***We envision a world where people can interact with both the physical and digital realms in creative ways.***
We started by pushing the limits of what's possible with customizable deep learning, streaming media, and AR technologies. With VizArt, you can draw in art, interact with the real world digitally, and share your creations with your friends!
>
> "Art is the reflection of life, and life is the reflection of art." - Unknow
>
>
>
Air writing is made possible with hand gestures, such as a pen gesture to draw and an eraser gesture to erase lines. With VizArt, you can turn your ideas into reality by sketching in the air.
Our computer vision algorithm enables you to interact with the world using a color picker gesture and a snipping tool to manipulate real-world objects.
>
> "Art is not what you see, but what you make others see." - Claude Monet
>
>
>
The features I listed above are great! But what's the point of creating something if you can't share it with the world? That's why we've built a platform for you to showcase your art. You'll be able to record and share your drawings with friends.
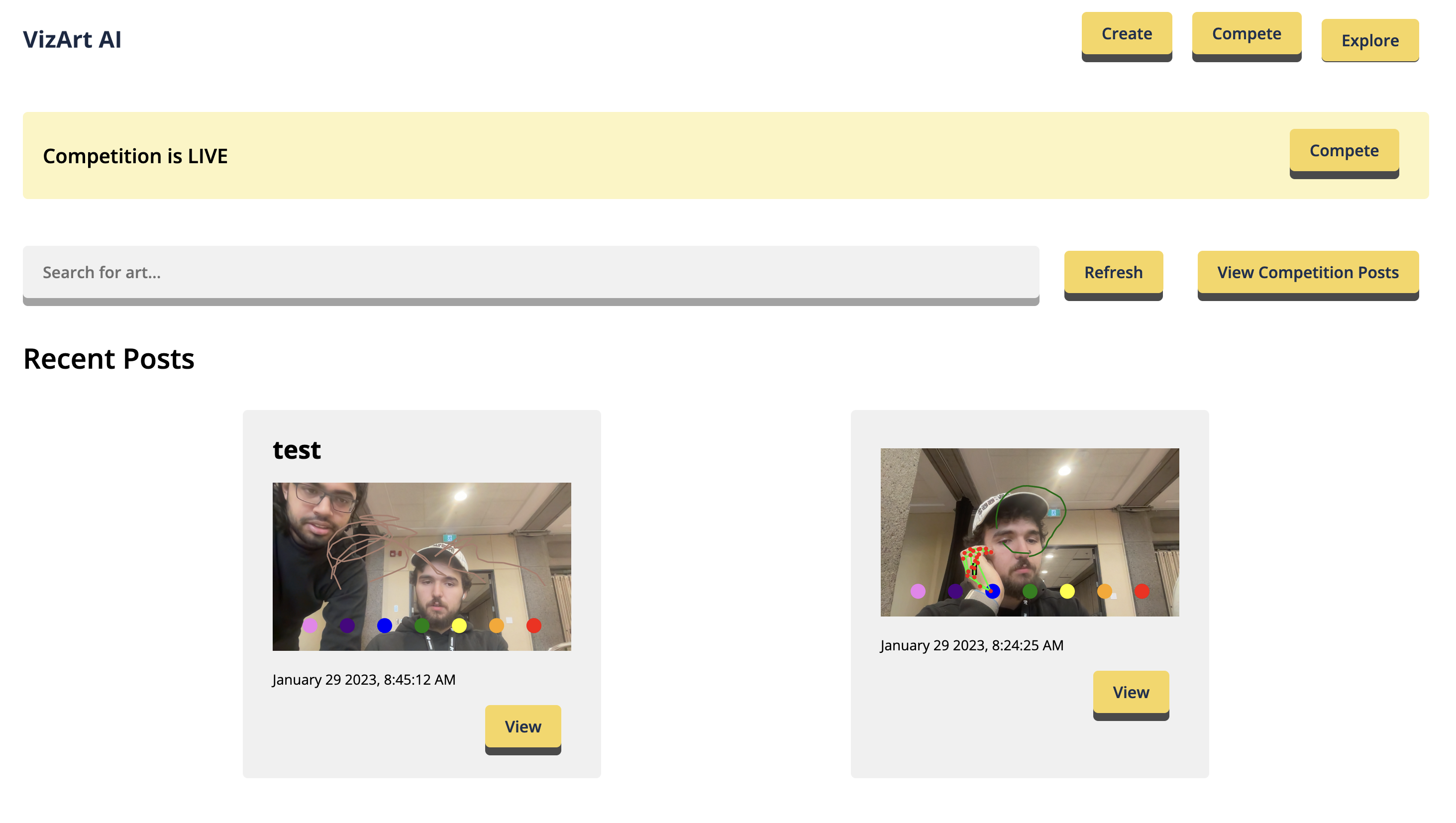
I hope you will enjoy using VizArt and share it with your friends. Remember: Make good gifts, Make good art.
# ❤️ Use Cases
### Drawing Competition/Game
VizArt can be used to host a fun and interactive drawing competition or game. Players can challenge each other to create the best masterpiece, using the computer vision features such as the color picker and eraser.
### Whiteboard Replacement
VizArt is a great alternative to traditional whiteboards. It can be used in classrooms and offices to present ideas, collaborate with others, and make annotations. Its computer vision features make drawing and erasing easier.
### People with Disabilities
VizArt enables people with disabilities to express their creativity. Its computer vision capabilities facilitate drawing, erasing, and annotating without the need for physical tools or contact.
### Strategy Games
VizArt can be used to create and play strategy games with friends. Players can draw their own boards and pieces, and then use the computer vision features to move them around the board. This allows for a more interactive and engaging experience than traditional board games.
### Remote Collaboration
With VizArt, teams can collaborate remotely and in real-time. The platform is equipped with features such as the color picker, eraser, and snipping tool, making it easy to interact with the environment. It also has a sharing platform where users can record and share their drawings with anyone. This makes VizArt a great tool for remote collaboration and creativity.
# 👋 Gestures Tutorial
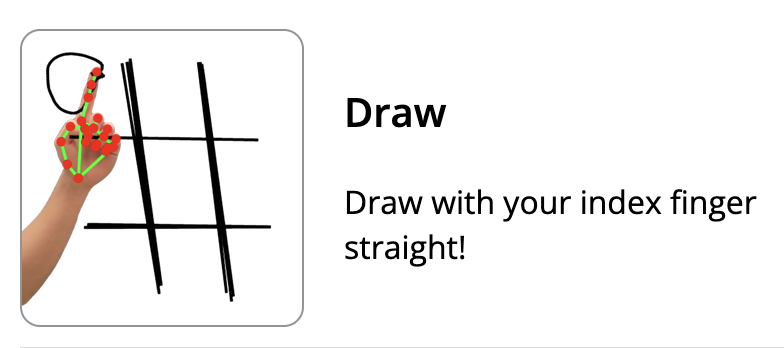

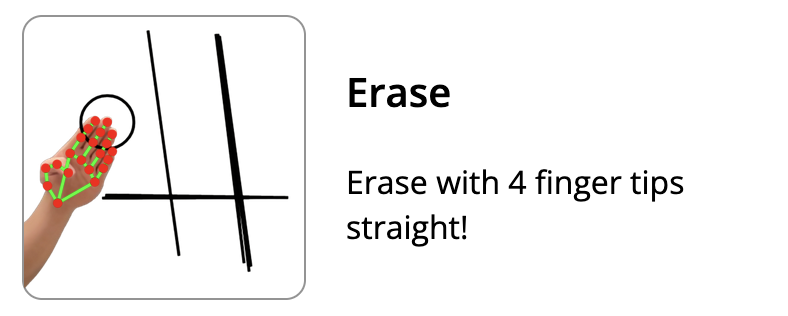

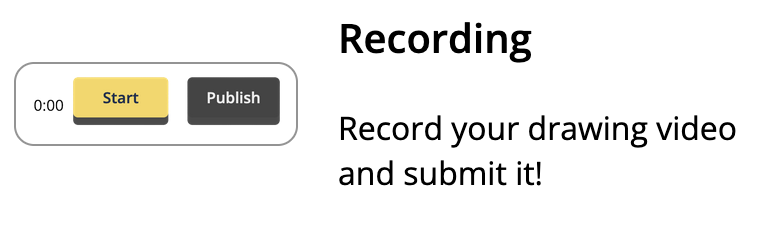
# ⚒️ Engineering
Ah, this is where even more fun begins!
## Stack
### Frontend
We designed the frontend with Figma and after a few iterations, we had an initial design to begin working with. The frontend was made with React and Typescript and styled with Sass.
### Backend
We wrote the backend in Flask. To implement uploading videos along with their thumbnails we simply use a filesystem database.
## Computer Vision AI
We use MediaPipe to grab the coordinates of the joints and upload images. WIth the coordinates, we plot with CanvasRenderingContext2D on the canvas, where we use algorithms and vector calculations to determinate the gesture. Then, for image generation, we use the DeepAI open source library.
# Experimentation
We were using generative AI to generate images, however we ran out of time.
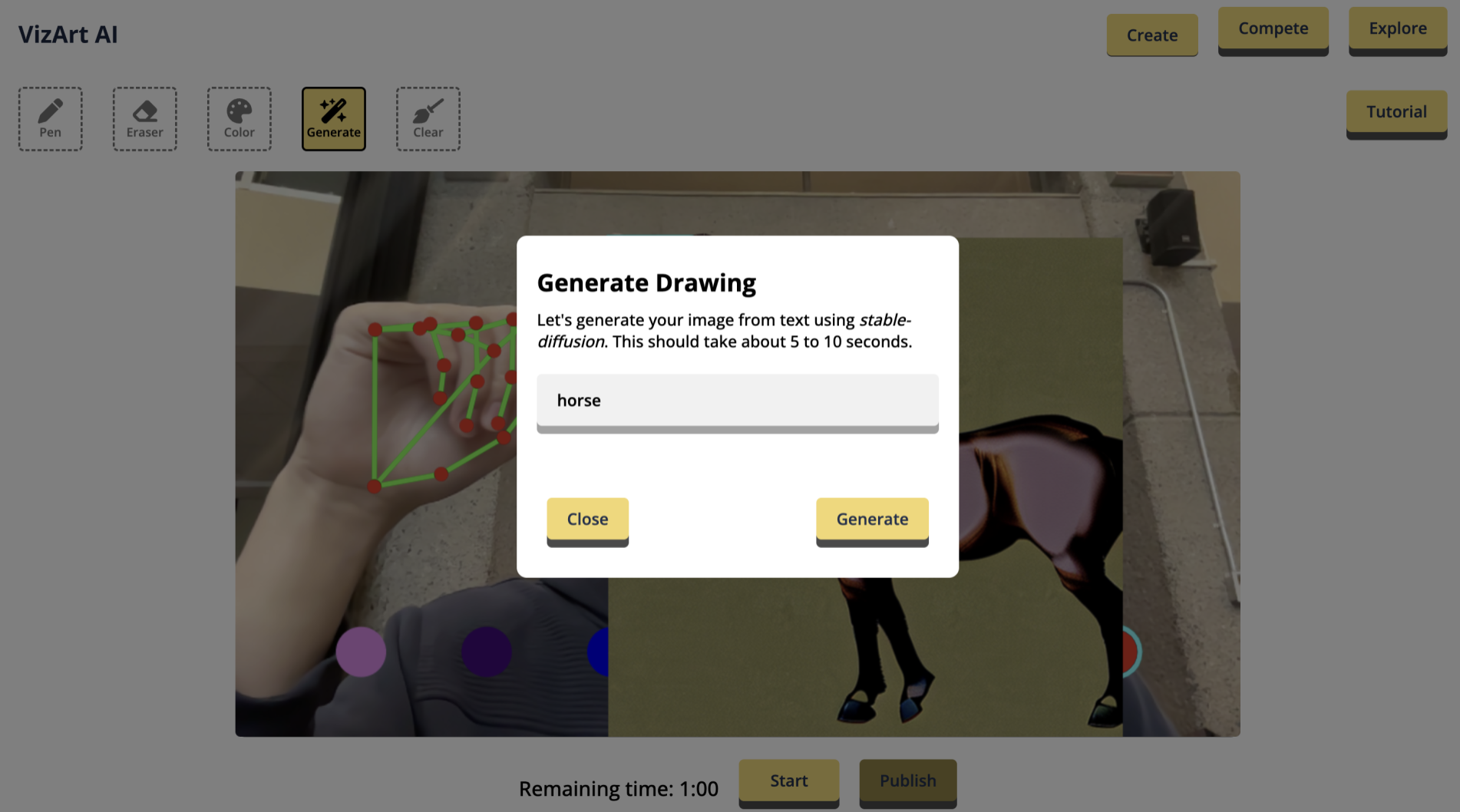
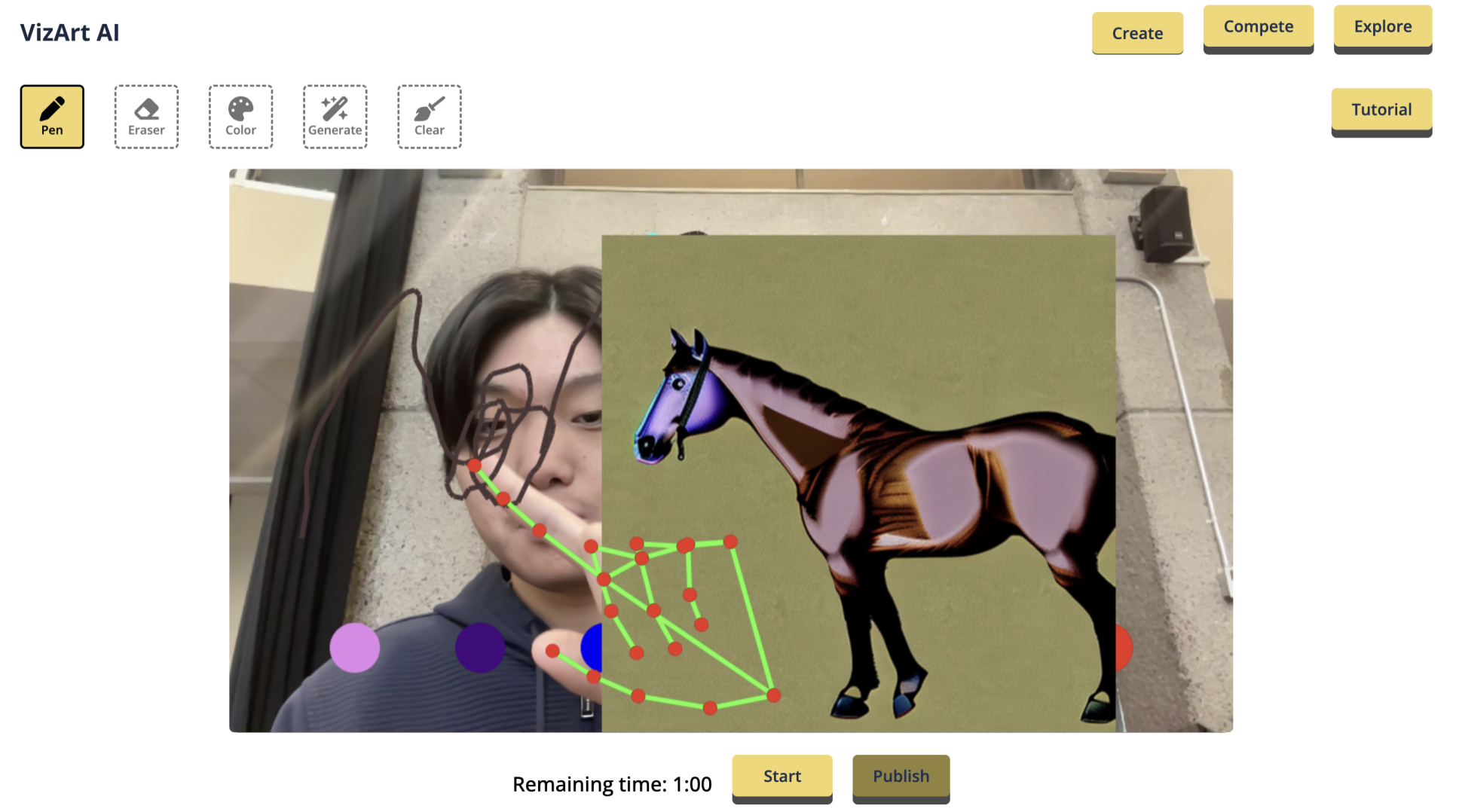
# 👨💻 Team (”The Sprint Team”)
@Sheheryar Pavaz
@Anton Otaner
@Jingxiang Mo
@Tommy He | partial |
## Inspiration
Music is a universal language, and we recognized Spotify wrapped to be one of the most anticipated times of the year. Realizing that people have an interest in learning about their own music taste, we created ***verses*** to not only allow people to quiz themselves on their musical interests, but also quiz their friends to see who knows them best.
## What it does
A quiz that challenges you to answer questions about your Spotify listening habits, allowing you to share with friends and have them guess your top songs/artists by answering questions. Creates a leaderboard of your friends who have taken the quiz, ranking them by the scores they obtained on your quiz.
## How we built it
We built the project using react.js, HTML, and CSS. We used the Spotify API to get data on the user's listening history, top songs, and top artists as well as enable the user to log into ***verses*** with their Spotify. JSON was used for user data persistence and Figma was used as the primary UX/UI design tool.
## Challenges we ran into
Implementing the Spotify API was a challenge as we had no previous experience with it. We had to seek out mentors for help in order to get it working. Designing user-friendly UI was also a challenge.
## Accomplishments that we're proud of
We took a while to get the backend working so only had a limited amount of time to work on the frontend, but managed to get it very close to our original Figma prototype.
## What we learned
We learned more about implementing APIs and making mobile-friendly applications.
## What's next for verses
So far, we have implemented ***verses*** with Spotify API. In the future, we hope to link it to more musical platforms such as Apple Music. We also hope to create a leaderboard for players' friends to see which one of their friends can answer the most questions about their music taste correctly. | [Repository](https://github.com/BradenC82/A_Treble-d_Soul/)
## Inspiration
Mental health is becoming decreasingly stigmatized and more patients are starting to seek solutions to well-being. Music therapy practitioners face the challenge of diagnosing their patients and giving them effective treatment. We like music. We want patients to feel good about their music and thus themselves.
## What it does
Displays and measures the qualities of your 20 most liked songs on Spotify (requires you to log in). Seven metrics are then determined:
1. Chill: calmness
2. Danceability: likeliness to get your groove on
3. Energy: liveliness
4. Focus: helps you concentrate
5. Audacity: absolute level of sound (dB)
6. Lyrical: quantity of spoken words
7. Positivity: upbeat
These metrics are given to you in bar graph form. You can also play your liked songs from this app by pressing the play button.
## How I built it
Using Spotify API to retrieve data for your liked songs and their metrics.
For creating the web application, HTML5, CSS3, and JavaScript were used.
React was used as a framework for reusable UI components and Material UI for faster React components.
## Challenges I ran into
Learning curve (how to use React). Figuring out how to use Spotify API.
## Accomplishments that I'm proud of
For three out of the four of us, this is our first hack!
It's functional!
It looks presentable!
## What I learned
React.
API integration.
## What's next for A Trebled Soul
Firebase.
Once everything's fine and dandy, registering a domain name and launching our app.
Making the mobile app presentable. | ## Inspiration
The project was inspired by looking at the challenges that artists face when dealing with traditional record labels and distributors. Artists often have to give up ownership of their music, lose creative control, and receive only a small fraction of the revenue generated from streams. Record labels and intermediaries take the bulk of the earnings, leaving the artists with limited financial security. Being a music producer and a DJ myself, I really wanted to make a product with potential to shake up this entire industry for the better. The music artists spend a lot of time creating high quality music and they deserve to be paid for it much more than they are right now.
## What it does
Blockify lets artists harness the power of smart contracts by attaching them to their music while uploading it and automating the process of royalty payments which is currently a very time consuming process. Our primary goal is to remove the record labels and distributors from the industry since they they take a majority of the revenue which the artists generate from their streams for the hard work which they do. By using a decentralized network to manage royalties and payments, there won't be any disputes regarding missed or delayed payments, and artists will have a clear understanding of how much money they are making from their streams since they will be dealing with the streaming services directly. This would allow artists to have full ownership over their work and receive a fair compensation from streams which is currently far from the reality.
## How we built it
BlockChain: We used the Sui blockchain for its scalability and low transaction costs. Smart contracts were written in Move, the programming language of Sui, to automate royalty distribution.
Spotify API: We integrated Spotify's API to track streams in real time and trigger royalty payments.
Wallet Integration: Sui wallets were integrated to enable direct payments to artists, with real-time updates on royalties as songs are streamed.
Frontend: A user-friendly web interface was built using React to allow artists to connect their wallets, and track their earnings. The frontend interacts with the smart contracts via the Sui SDK.
## Challenges we ran into
The most difficult challenge we faced was the Smart Contract Development using the Move language. Unlike commonly known language like Ethereum, Move is relatively new and specifically designed to handle asset management. Another challenge was trying to connect the smart wallets in the application and transferring money to the artist whenever a song was streamed, but thankfully the mentors from the Sui team were really helpful and guided us in the right path.
## Accomplishments that we're proud of
This was our first time working with blockchain, and me and my teammate were really proud of what we were able to achieve over the two days. We worked on creating smart contracts and even though getting started was the hardest part but we were able to complete it and learnt some great stuff along the way. My teammate had previously worked with React but I had zero experience with JavaScript, since I mostly work with other languages, but we did the entire project in Node and React and I was able to learn a lot of the concepts in such a less time which I am very proud of myself for.
## What we learned
We learned a lot about Blockchain technology and how can we use it to apply it to the real-world problems. One of the most significant lessons we learned was how smart contracts can be used to automate complex processes like royalty payments. We saw how blockchain provides an immutable and auditable record of every transaction, ensuring that every stream, payment, and contract interaction is permanently recorded and visible to all parties involved. Learning more and more about this technology everyday just makes me realize how much potential it holds and is certainly one aspect of technology which would rule the future. It is already being used in so many aspects of life and we are still discovering the surface.
## What's next for Blockify
We plan to add more features, such as NFTs for exclusive content or fan engagement, allowing artists to create new revenue streams beyond streaming. There have been some real-life examples of artists selling NFT's to their fans and earning millions from it, so we would like to tap into that industry as well. Our next step would be to collaborate with other streaming services like Apple Music and eliminate record labels to the best of our abilities. | partial |
## Inspiration
After seeing the breakout success that was Pokemon Go, my partner and I were motivated to create our own game that was heavily tied to physical locations in the real-world.
## What it does
Our game is supported on every device that has a modern web browser, absolutely no installation required. You walk around the real world, fighting your way through procedurally generated dungeons that are tied to physical locations. If you find that a dungeon is too hard, you can pair up with some friends and tackle it together.
Unlike Niantic, who monetized Pokemon Go using micro-transactions, we plan to monetize the game by allowing local businesses to to bid on enhancements to their location in the game-world. For example, a local coffee shop could offer an in-game bonus to players who purchase a coffee at their location.
By offloading the cost of the game onto businesses instead of players we hope to create a less "stressful" game, meaning players will spend more time having fun and less time worrying about when they'll need to cough up more money to keep playing.
## How We built it
The stack for our game is built entirely around the Node.js ecosystem: express, socket.io, gulp, webpack, and more. For easy horizontal scaling, we make use of Heroku to manage and run our servers. Computationally intensive one-off tasks (such as image resizing) are offloaded onto AWS Lambda to help keep server costs down.
To improve the speed at which our website and game assets load all static files are routed through MaxCDN, a continent delivery network with over 19 datacenters around the world. For security, all requests to any of our servers are routed through CloudFlare, a service which helps to keep websites safe using traffic filtering and other techniques.
Finally, our public facing website makes use of Mithril MVC, an incredibly fast and light one-page-app framework. Using Mithril allows us to keep our website incredibly responsive and performant. | ## Inspiration
Our inspiration was to provide a robust and user-friendly financial platform. After hours of brainstorming, we decided to create a decentralized mutual fund on mobile devices. We also wanted to explore new technologies whilst creating a product that has several use cases of social impact. Our team used React Native and Smart Contracts along with Celo's SDK to discover BlockChain and the conglomerate use cases associated with these technologies. This includes group insurance, financial literacy, personal investment.
## What it does
Allows users in shared communities to pool their funds and use our platform to easily invest in different stock and companies for which they are passionate about with a decreased/shared risk.
## How we built it
* Smart Contract for the transfer of funds on the blockchain made using Solidity
* A robust backend and authentication system made using node.js, express.js, and MongoDB.
* Elegant front end made with react-native and Celo's SDK.
## Challenges we ran into
Unfamiliar with the tech stack used to create this project and the BlockChain technology.
## What we learned
We learned the many new languages and frameworks used. This includes building cross-platform mobile apps on react-native, the underlying principles of BlockChain technology such as smart contracts, and decentralized apps.
## What's next for *PoolNVest*
Expanding our API to select low-risk stocks and allows the community to vote upon where to invest the funds.
Refine and improve the proof of concept into a marketable MVP and tailor the UI towards the specific use cases as mentioned above. | ## Inspiration
Our inspiration for this project comes from our own experiences as University students. As students, we understand the importance of mental health and the role it plays in one's day to day life. With increasing workloads, stress of obtaining a good co-op and maintaining good marks, people’s mental health takes a big hit and without a good balance can often lead to many problems. That is why we wanted to tackle this challenge while also putting a fun twist.
Our goal with our product is to help provide users with mental health resources, but that can easily be done with any google search so that is why we wanted to add an “experience” part to our project where users can explore and learn more about themselves while also aiding in their mental health.
## What it does
Our project is a simulation where users are placed in a very calm and peaceful world open to exploration. Along their journey, they are accompanied by an entity that they can talk to whenever they want. This entity is there to support them and is there to demonstrate that they are not alone. As the user walks through the world, there are various characters they can meet that can provide the user with resources such as links, articles, etc. that can help better their mental health. When the user becomes more comfortable and interested, they have the choice to learn more and provide more information about themselves. This allows the user to have more personal resources such as local support groups in their area, etc.
## How we built it
We divided ourselves into two separate teams where one team works on the front end and the other on the back end. For our front end, we used unity to develop our world and characters. For the back end, we used openai’s chat API in order to generate our helpful resources with it all being coded in python. To connect our backend with our front end, we decided to use flask and a server website called Pythonanywhere.
## Challenges we ran into
We ran into multiple challenges during our time building this project. The first challenge was really nailing down on how we would want to execute our project. We spent a lot of time discussing how we would want to make our project unique while still achieving our goals. Furthermore, another challenge came with the front end as building the project on unity was challenging itself. We had to figure out how to receive input by the user and make sure that our back end gives us the correct information.
Finally, to adhere to all types of accessibility, we also decided to add a VR option to our simulation for more immersion so that the user can really feel like they are in a safe space to talk and that there are people to help them. Getting the VR setup was very difficult but also a super fun challenge.
For our back end, we encountered many challenges, especially getting the exact responses we wanted. We really had to be kinda creative on how we wanted to give the user the right responses and ensure they get the necessary resources.
## Accomplishments that we're proud of
We are very proud of the final product that we have come up with, especially our front end as that was the most challenging part. This entire project definitely pushed all of us past our skill level and we most definitely learned a lot.
## What we learned
We learnt a lot during this project. We most definitely learnt more about working as a team as this was our second official time working together. Not only that, but in terms of technical skills, we all believe that we had learnt something new and definitely improved the way we think about certain aspects of coding
## What's next for a conversation…
While we could not fully complete our project in time as we encountered many issues with combining the front end and back end, we are still proud | winning |
## 💡 Inspiration
Memories are too precious to be lost in the abyss of time. That’s why we take pictures, send holiday greeting cards, and keep heirlooms. With the COVID-19 pandemic, we lost the ability to truly store these sentimental memories. For example, we can no longer send postcards around the world without 6-month+ delays.
Our lives are full of memories that we want to keep forever. You can’t just take a photo and hope for the best.
Introducing, Mintoir (Mint + Memoir); an intuitive cross-platform mobile application that allows you to turn your favourite moments into digital tokens that will last forever on the blockchain, ensuring that you won’t ever forget what matters most.
## 🔍 What it does
Once the user connects their wallet through our one-click portal, they will be greeted by our dashboard where they can browse trending memories on the blockchain, or view their own. Next, if they wish to mint a memory, they will be prompted to the builder screen. Users can configure the source image file, select from a suite of memory templates or create their own, edit their source image, apply AI-generated backdrops based on their location, and add a message/title to the metadata. Once they are happy with the memory built, they can mint the NFT on the blockchain with a single button.
## ⚙️ Tech stack
**Frontend**
* React Native
* Expo
* Native Base
**Blockchain / Smart Contract Backend**
* Hardhat
* Solidity
* Etherscan API
* Pinata IPFS
**Image Processing / Machine Learning Backend**
* MediaPipe for ML
* Pillow / PIL
* Python
* Flask
**Ethereum Operations**
* WalletConnect
* Ropsten Ethereum Testnet
* ERC-721 NFT standard contract
## 🚧 Challenges we ran into
* Because there aren’t many fully-featured Web3 mobile apps on the market for both iOS and Android, it was difficult to find resources pertaining to how we could both utilize a wallet, create smart contracts, and more. In addition, a lot of custom configuration was required in order to get the app up and running.
* None of our team members had any experience with creating mobile dApps (Decentralized Apps), which meant that we had to learn on the fly while working on our project.
* Setting up the frontend was tough as we were using many new packages that lacked thorough documentation and support.
* Not being in-person this hackathon presented communication challenges when debugging and brainstorming ideas. We found tools like VSCode Liveshare that allowed us to overcome this problem.
## ✔️ Accomplishments that we're proud of
In just 36 hours, we are proud to have built a fully-functional mobile app that can execute our original idea of minting memories with NFTs. Most of the web3 technologies we used were new to us so learning to implement them in such a short time is a major feat. From what we have researched, our application is one of the first full-stack, web3, cross-platform mobile apps built on React Native. With its polished UI and novel concept, we hope Mintoir can eternalize memories for many across the world.
## 📚 What we learned
* Mobile development with React Native and Expo
* Using UI libraries such as Native Base in order to speed up development
* Using WalletConnect to securely connect to blockchain wallets (ex: MetaMask, Rainbow, and many more)
* Manipulating low level bundler configuration to work with WalletConnect
* Using HardHat to create and deploy smart contracts using the ERC-721 standard on the Ethereum blockchain
* Minting NFTs completely locally
* Using IPFS as a peer-to-peer network to store/share data in a distributed file system
* Using segmentation neural networks to extract certain features from a picture (ex. person)
* Advanced image manipulation using libraries such as Pillow in order to dynamically generate postcards
* Online project collaboration using tools like Github, VSCode Liveshare and Figma
## 🔭 What's next for Mintoir
* We’d love to extend our application to more than just postcards and birthday cards. We want to add in the ability for the user to mint video memories using Mintoir.
* We also hope to connect our code to the actual Ethereum Mainnet with Polygon. Right now, we use the Ropsten testnet to test our work without using actual gas. Deploying our app into a live Ethereum Environment would be vital in taking our app to production.
* We believe Mintoir is a revolutionary new app with a lot of potential. We want to launch this app on Google Play Store and the App Store to allow everyone to create NFTs with their memories. | ## Inspiration
As developers, we often find ourselves building a habit of creating poor commit message descriptions when building personal projects. As this habit carries over when doing internships, co-ops or jobs, we wanted to build a solution to the habit.
## What it does
BetterCommits is a VSCode extension which gives real-time feedback to user’s commit messages based on a chosen commit message template convention. It highlights parts of the user’s commit message which lack detail or are “weak”. BetterCommits then creates a tooltip on the highlighted section which the user can hover over with their cursor to see the suggestions.
## How we built it
We built BetterCommits using TypeScript, Python, and Cohere. We used TypeScript for the extension part (communicating with VS-code) and Python and Cohere’s SDK to handle the real-time feedback logic.
## Challenges we ran into
Initially, we wanted to have our project be purely TypeScript based. This turned out to be a mistake as we ran into difficulties setting up the Cohere SDK for TypeScript. Compared to its counterpart written in Python, the TypeScript version was much more complex and difficult to work with despite having the same results. Because of this and the Cohere representatives suggesting we migrate, we had to move a large portion of our TypeScript codebase to Python. This migration took a long time because of how our logic was set up initially. Setting up the Python libraries was also a mini struggle as everyone’s machine was on different versions of Python which made it harder to work on it together due to library version mismatch.
## Accomplishments that we're proud of
We’re proud to have built a product we find helpful in our day to day lives. Although our project doesn’t solve world hunger, cure cancer or something unimaginable, we’re still proud to have built something that helps people by just a little, even if it's just saving a couple minutes of their time.
## What we learned
During the development of BetterCommits, we learned how to combine both TypeScript and Python code, utilizing the strengths of both languages. We also integrated the Cohere SDK and API in order to achieve our goal. Through this process, we learnt about the range of possibilities available through the use of language models to produce efficient solutions.
## What's next for BetterCommits
Some ideas for the future we have for BetterCommits are:
User signup/signin and customize their preferences
PR templates the user can choose in their settings or make their own
Storing good PR’s in a database
Can be used as training data for cohere, a way for users to upload examples of good PR’s that follow their specific conventions and train cohere’s feedback to mimic said examples | • Inspiration
The inspiration for digifoot.ai stemmed from the growing concern about digital footprints and online presence in today's world. With the increasing use of social media, individuals often overlook the implications of their online activities. We aimed to create a tool that not only helps users understand their digital presence but also provides insights into how they can improve it.
• What it does
digifoot.ai is a comprehensive platform that analyzes users' social media accounts, specifically Instagram and Facebook. It aggregates data such as posts, followers, and bios, and utilizes AI to provide insights on their digital footprint. The platform evaluates images and content from users’ social media profiles to ensure there’s nothing harmful or inappropriate, helping users maintain a positive online presence.
• How we built it
We built digifoot.ai using Next.js and React for the frontend and Node.js for the backend. The application integrates with the Instagram and Facebook Graph APIs to fetch user data securely. We utilized OpenAI's API for generating insights based on the collected social media data.
• Challenges we ran into
API Authentication and Rate Limits:
Managing API authentication for both Instagram and OpenAI was complex. We had to ensure secure
access to user data while adhering to rate limits imposed by these APIs. This required us to optimize our
data-fetching strategies to avoid hitting these limits.
Integrating Image and Text Analysis:
We aimed to analyze both images and captions from Instagram posts using the OpenAI API's
capabilities. However, integrating image analysis required us to understand how to format requests
correctly, especially since the OpenAI API processes images differently than text.
The challenge was in effectively combining image inputs with textual data in a way that allowed the AI to
provide meaningful insights based on both types of content.
• Accomplishments that we're proud of
We are proud of successfully creating a user-friendly interface that allows users to connect their social media accounts seamlessly. The integration of AI-driven analysis provides valuable feedback on their digital presence. Moreover, we developed a robust backend that handles data securely while complying with privacy regulations.
• What we learned
Throughout this project, we learned valuable lessons about API integrations and the importance of user privacy and data security. We gained insights into how AI can enhance user experience by providing personalized feedback based on real-time data analysis. Additionally, we improved our skills in full-stack development and project management.
• What's next for digifoot.ai
Looking ahead, we plan to enhance digifoot.ai by incorporating more social media platforms for broader analysis capabilities. We aim to refine our AI algorithms to provide even more personalized insights. Additionally, we are exploring partnerships with educational institutions to promote digital literacy and responsible online behavior among students. | losing |
## Inspiration
Trump's statements include some of the most outrageous things said recently, so we wanted to see whether someone could distinguish between a fake statement and something Trump would say.
## What it does
We generated statements using markov chains (<https://en.wikipedia.org/wiki/Markov_chain>) that are based off of the things trump actually says. To show how difficult it is to distinguish between the machine generated text and the real stuff he says, we made a web app to test whether someone could determine which was the machine generated text (Drumpf) and which was the real Trump speech.
## How we built it
python+regex for parsing Trump's statementsurrent tools you use to find & apply to jobs?
html/css/js frontend
azure and aws for backend/hosting
## Challenges we ran into
Machine learning is hard. We tried to use recurrent neural networks at first for speech but realized we didn't have a large enough data set, so we switched to markov chains which don't need as much training data, but also have less variance in what is generated.
We actually spent a bit of time getting <https://github.com/jcjohnson/torch-rnn> up and running, but then figured out it was actually pretty bad as we had a pretty small data set (<100kB at that point)
Eventually got to 200kB and we were half-satisfied with the results, so we took the good ones and put it up on our web app.
## Accomplishments that we're proud of
First hackathon we've done where our front end looks good in addition to having a decent backend.
regex was interesting.
## What we learned
bootstrap/javascript/python to generate markov chains
## What's next for MakeTrumpTrumpAgain
scrape trump's twitter and add it
get enough data to use a neural network
dynamically generate drumpf statements
If you want to read all the machine generated text that we deemed acceptable to release to the public, open up your javascript console, open up main.js. Line 4599 is where the hilarity starts. | ## Inspiration
In a sense, social media has democratized news media itself -- through it, we have all become "news editors" to some degree, shaping what our friends read through our shares, likes, and comments. Is it any wonder, then, that "fake news" has become such a widespread problem? In such partisan times, it is easy to find ourselves ourselves siloed off within ideological echo chambers. After all, we are held in thrall not only by our cognitive biases to seek out confirmatory information, but also by the social media algorithms trained to feed such biases for the sake of greater ad revenue. Most worryingly, these ideological silos can serve as breeding grounds for fake news, as stories designed to mislead their audience are circulated within the target political community, building outrage and exacerbating ignorance with each new share.
We believe that the problem of fake news is intimately related to the problem of the ideological echo chambers we find ourselves inhabiting. As such, we designed "Open Mind" to attack these two problems at their root.
## What it does
"Open Mind" is a Google Chrome extension designed to (1) combat the proliferation of fake news, and (2) increase exposure to opposing viewpoints. It does so using a multifaceted approach -- first, it automatically "blocks" known fake news websites from being displayed on the user's browser, providing the user with a large warning screen and links to more reputable sources (the user can always click through to view the allegedly fake content, however; we're not censors!). Second, the user is given direct feedback on how partisan their reading patterns are, in the form of a dashboard which tracks their political browsing history. This dashboard then provides a list of recommended articles that users can read in order to "balance out" their reading history.
## How we built it
We used React for the front end, and a combination of Node.js and Python for the back-end. Our machine learning models for recommending articles were built using Python's Tensorflow library, and NLP was performed using the Alyien, Semantria, and Google Cloud Natural Language APIs.
## What we learned
We learned a great deal more about fake news, and NLP in particular.
## What's next for Open Mind
We aim to implement a "political thermometer" that appears next to political articles, showing the degree to which the particular article is conservative or liberal. In addition, we aim to verify a Facebook-specific "share verification" feature, where users are asked if they are sure they want to share an article that they have not already read (based on their browser history). | ## Inspiration
I like looking at things. I do not enjoy bad quality videos . I do not enjoy waiting. My CPU is a lazy fool. He just lays there like a drunkard on new years eve. My poor router has a heart attack every other day so I can stream the latest Kylie Jenner video blog post, or has the kids these days call it, a 'vlog' post.
CPU isn't being effectively leveraged to improve video quality. Deep learning methods are in their own world, concerned more with accuracy than applications. We decided to develop a machine learning application to enhance resolution while developing our models in such a way that they can effective run without 10,000 GPUs.
## What it does
We reduce your streaming bill. We let you stream Kylie's vlog in high definition. We connect first world medical resources to developing nations. We make convert an unrecognizeable figure in a cop's body cam to a human being. We improve video resolution.
## How I built it
Wow. So lots of stuff.
Web scraping youtube videos for datasets of 144, 240, 360, 480 pixels. Error catching, thread timeouts, yada, yada. Data is the most import part of machine learning, and no one cares in the slightest. So I'll move on.
## ML stuff now. Where the challenges begin
We tried research papers. Super Resolution Generative Adversarial Model [link](https://arxiv.org/abs/1609.04802). SRGAN with an attention layer [link](https://arxiv.org/pdf/1812.04821.pdf). These were so bad. The models were to large to hold in our laptop, much less in real time. The model's weights alone consisted of over 16GB. And yeah, they get pretty good accuracy. That's the result of training a million residual layers (actually *only* 80 layers) for months on GPU clusters. We did not have the time or resources to build anything similar to these papers. We did not follow onward with this path.
We instead looked to our own experience. Our team had previously analyzed the connection between image recognition and natural language processing and their shared relationship to high dimensional spaces [see here](https://arxiv.org/abs/1809.05286). We took these learnings and built a model that minimized the root mean squared error as it upscaled from 240 to 480 px.
However, we quickly hit a wall, as this pixel based loss consistently left the upscaled output with blurry edges. In order to address these edges, we used our model as the Generator in a Generative Adversarial Network. However, our generator was too powerful, and the discriminator was lost.
We decided then to leverage the work of the researchers before us in order to build this application for the people. We loaded a pretrained VGG network and leveraged its image embeddings as preprocessing for our discriminator. Leveraging this pretrained model, we were able to effectively iron out the blurry edges while still minimizing mean squared error.
Now model built. We then worked at 4 AM to build an application that can convert videos into high resolution.
## Accomplishments that I'm proud of
Building it good.
## What I learned
Balanced approaches and leveraging past learning
## What's next for Crystallize
Real time stream-enhance app. | partial |
# r2d2
iRobot Create 2 controller and analyzer & much more
# Highlights
1. Joy-stick like experience to navigate the bot remotely.
2. Live update of path trajectory of the bot (which can be simultaneously viewed by any number of clients viewing the '/trajectory' page of our web-app.
3. Live update of all sensor values in graphical as well as tabular format
# Dependencies
flask
create2api
flask\_socketio
pip install the Dependencies.
# Instructions to run
python server.py | ## Inspiration
On the trip to HackWestern, we were looking for ideas for the hackathon. We were looking for things in life that can be improved and also existing products which are not so convenient to use.
Jim was using Benjamin's phone and got the inspiration to make a dedicated two factor authentication device, since it takes a long time for someone to unlock their phone, go through the long list of applications, find the right app that gives them the two-factor auth code, which they have to type into the login page in a short period of time, as it expires in less than 30 seconds. The initial idea was rather primitive, but it got hugely improved and a lot more detailed than the initial one through the discussion.
## What it does
It is a dedicated device with a touch screen, that provides users with their two-factor authentication keys. It uses RFID to authenticate the user, which is very simple and fast - it takes less than 2 seconds for a user to log in, and can automatically type the authentication code into your computer when you click it.
## How We built it
The system is majorly Raspberry Pi-based. The R-Pi drives a 7 inch touch screen, which acts as the primary interface with the user.
The software for the user interface and generation of authentication keys are written in Java, using the Swing GUI framework. The clients run Linux, which is easy to debug and customize.
Some lower level components such as the RFID reader is handled by an arduino, and the information is passed to the R-Pi through serial communication.
Since we lost our Wifi dongle, we used 2 RF modules to communicate between the R-Pi and the computer. It is not an ideal solution as there could be interference and is not easily expandable.
## Challenges I ran into
We have ran into some huge problems and challenges throughout the development of the project. There are hardware challenges, as well as software ones.
For example, the 7 inch display that we are using does not have an official driver for touch, so we had to go through the data sheets, and write a C program where it gets the location of the touch, and turns that into movement of the mouse pointers.
Another challenge is the development of the user interface. We had to integrate all the components of the product into one single program, including the detection of RFID (especially hard since we had to use JNI for lower level access), the generation of codes, and the communication with other devices.
## Accomplishments that I'm proud of
We are proud of ourselves for being able to write programs that can interface with the hardware. Many of the hardware pieces have very complex documentation, but we managed to read them, and understand them, and write programs that can interface with them reliably. As well, the software has many different parts, with some in C and some in Java. We were able to make everything synergize well, and work as a whole.
## What We learned
To make this project, we needed to use a multitude of skills, ranging from HOTP and TOTP, to using JNI to gain control over lower levels of the system.
But most importantly, we learnt the practical skills of software and hardware development, and have gained valuable experience on the development of projects.
## What's next for AuthFID | ## Inspiration
Minecraft has an interesting map mechanic where your character holds a map which "draws itself" while exploring the world. I am also very interested in building a plotter, which is a printer that uses a pen and (XY) gantry to produce images. These ideas seemed to fit together quite well.
## What it does
Press a button, copy GPS coordinates and run the custom "gcode" compiler to generate machine/motor driving code for the arduino. Wait around 15 minutes for a 48 x 48 output.
## How we built it
Mechanical assembly - Tore apart 3 dvd drives and extracted a multitude of components, including sled motors (linear rails). Unfortunately, they used limit switch + DC motor rather than stepper, so I had to saw apart the enclosure and **glue** in my own steppers with a gear which (you guessed it) was also glued to the motor shaft.
Electronics - I designed a simple algorithm to walk through an image matrix and translate it into motor code, that looks a lot like a video game control. Indeed, the stepperboi/autostepperboi main source code has utilities to manually control all three axes like a tiny claw machine :)
U - Pen Up
D - Pen Down
L - Pen Left
R - Pen Right
Y/T - Pen Forward (top)
B - Pen Backwards (bottom)
Z - zero the calibration
O - returned to previous zeroed position
## Challenges we ran into
* I have no idea about basic mechanics / manufacturing so it's pretty slipshod, the fractional resolution I managed to extract is impressive in its own right
* Designing my own 'gcode' simplification was a little complicated, and produces strange, pointillist results. I like it though.
## Accomplishments that we're proud of
* 24 hours and a pretty small cost in parts to make a functioning plotter!
* Connected to mapbox api and did image processing quite successfully, including machine code generation / interpretation
## What we learned
* You don't need to take MIE243 to do low precision work, all you need is superglue, a glue gun and a dream
* GPS modules are finnicky and need to be somewhat near to a window with built in antenna
* Vectorizing an image is quite a complex problem
* Mechanical engineering is difficult
* Steppers are *extremely* precise, and I am quite surprised at the output quality given that it's barely held together.
* Iteration for mechanical structure is possible, but difficult
* How to use rotary tool and not amputate fingers
* How to remove superglue from skin (lol)
## What's next for Cartoboy
* Compacting the design it so it can fit in a smaller profile, and work more like a polaroid camera as intended. (Maybe I will learn solidworks one of these days)
* Improving the gcode algorithm / tapping into existing gcode standard | partial |
## Inspiration
Faced with the lack of newcomer access to banks, and language barriers in this globalized world, what can we do to help the least cared for demographic in banking?
Introducing: Reach RBC.
## What it does
Reach RBC is a kiosk placed in airports all over Canada that explains RBC's newcomer banking options simply, books appointments for users while displaying the closest banking options, offered in 8 different languages to overcome the language barrier.
## How we built it
Starting with a brainstorming system, we used design strategies to visualize a flowchart that worked through each possible options and screen that a user would use. From a screen for the different language options, a page for closest banks, and an appointment form system, we planned out the entire project from scratch.
From that point we worked with Figma to both decide the themes and aesthetic of the service and explore how the service would work with link animations and such.
We then worked to transform this to reality using React.js and node.js, making a backbone of a website that we could rework into our figma design. We worked on the nearest banking location page by utilizing the google maps api, which would allow us to display all the nearest locations in pins and the top three closest locations on the side.
Finally, using css with javascript, we formatted and specialized the website, using translation systems to offer all 8 languages.
## Challenges we ran into
* The complexity of utilizing the google maps API in our website to access locations
* The formatting translation from Figma to Javascript would change spacing/formatting in some cases which caused work arounds
* Different laptop sizings would cause formatting to be different when ran on a separate laptop
## Accomplishments that we're proud of
This hack took the combined skills of four very different hackers with different technical backgrounds. From the idea formation, to the design process, to even the learning process of the languages and implementation, this project was completed and exceeded all our expectations because of our combined skill set. It's the most successful hackathon projects each team member has done, and truly feels important as this was a problem all of us faced in different ways.
## What we learned
We learned the ins and outs of react.js,(from html and css, to the github pushing process), utilizing google apis, and maximizing Figma design
## What's next for Reach RBC
We would implement the text-to-speech and speech recognition ideas we had to accommodate the visually impaired and those not familiar with their original language's script, respectively. We would also implement a translation api so that we could access as many languages as we can. | ## 🌱 Inspiration
With the ongoing climate crisis, we recognized a major gap in the incentives for individuals to make greener choices in their day-to-day lives. People want to contribute to the solution, but without tangible rewards, it can be hard to motivate long-term change. That's where we come in! We wanted to create a fun, engaging, and rewarding way for users to reduce their carbon footprint and make eco-friendly decisions.
## 🌍 What it does
Our web app is a point-based system that encourages users to make greener choices. Users can:
* 📸 Scan receipts using AI, which analyzes purchases and gives points for buying eco-friendly products from partner companies.
* 🚴♂️ Earn points by taking eco-friendly transportation (e.g., biking, public transit) by tapping their phone via NFC.
* 🌿 See real-time carbon emission savings and get rewarded for making sustainable choices.
* 🎯 Track daily streaks, unlock milestones, and compete with others on the leaderboard.
* 🎁 Browse a personalized rewards page with custom suggestions based on trends and current point total.
## 🛠️ How we built it
We used a mix of technologies to bring this project to life:
* **Frontend**: Remix, React, ShadCN, Tailwind CSS for smooth, responsive UI.
* **Backend**: Express.js, Node.js for handling server-side logic.
* **Database**: PostgreSQL for storing user data and points.
* **AI**: GPT-4 for receipt scanning and product classification, helping to recognize eco-friendly products.
* **NFC**: We integrated NFC technology to detect when users make eco-friendly transportation choices.
## 🔧 Challenges we ran into
One of the biggest challenges was figuring out how to fork the RBC points API, adapt it, and then code our own additions to match our needs. This was particularly tricky when working with the database schemas and migration files. Sending image files across the web also gave us some headaches, especially when incorporating real-time processing with AI.
## 🏆 Accomplishments we're proud of
One of the biggest achievements of this project was stepping out of our comfort zones. Many of us worked with a tech stack we weren't very familiar with, especially **Remix**. Despite the steep learning curve, we managed to build a fully functional web app that exceeded our expectations.
## 🎓 What we learned
* We learned a lot about integrating various technologies, like AI for receipt scanning and NFC for tracking eco-friendly transportation.
* The biggest takeaway? Knowing that pushing the boundaries of what we thought was possible (like the receipt scanner) can lead to amazing outcomes!
## 🚀 What's next
We have exciting future plans for the app:
* **Health app integration**: Connect the app to health platforms to reward users for their daily steps and other healthy behaviors.
* **Mobile app development**: Transfer the app to a native mobile environment to leverage all the features of smartphones, making it even easier for users to engage with the platform and make green choices. | ## Inspiration
Coming into this project, it was clear none of us had any experience with client-side web development, so we knew right away that our focus would be on learning how to develop a user-friendly and aesthetically pleasing project. When we began brainstorming for some of the categories—specifically the Huawei Custom Challenge: Best Pandemic Life-Related Hack—we right away gravitated towards our shared longing to travel and escape the dull monotony of Zoom life. This got us thinking on a service that we could provide to people to connect with destinations in desperate need of tourism to revive their pandemic-battered economy—a win-win situation with a focus on sustainable tourism practices. From there the ideas concretized, and the project outlined below sprang forth.
## What it does
The website presents a user with a short mission statement on the home page, guiding them to interact with a map further down. From there, depending on a person's choice of continents, they are guided to a separate page where they can read about some highlighted tourism destinations and how the pandemic has aversely affected their local economies. Finally, each of the blurbs ends with a link to book flights to the destination country, and encourages the users to learn more about sustainable tourism in the pandemic era.
## How we built it
We aimed to build the website principally with React.js, but ended up incorporating significant amounts of vanilla CSS/HTML in parallel to the React components. Looking back upon it this was definitely not the most efficient option to choose, however the code ends up working quite nicely regardless. We used specific React libraries at different points as well: react-simple-maps for building out the interactive map, react-router to connect the map to the different webpages, and react-tooltip to allow the user to have a more immersive experience with the map.
## Challenges we ran into
Initially, our greatest challenge was figuring Github. As almost completely beginners in independent coding projects, we had to watch tutorials and struggle through understanding branches, merging, and SSH key credential issues. After this was out of the way, we quickly became stumped on the question of connecting the interactive map to the webpages as we envisioned it, since this depended on React being able to identify which continent was clicked on when the action occurred. This took a bit of time to figure out—with tutorials not helping out much—since it involved parsing through and components' deconstruction of geojson objects to build the continents and obtaining unique "keys" for each continent. Even when this was accomplished, we faced further issues when trying to format basic styling using CSS on the homepage, which caused us to mix in parallel vanilla classes with React components.
## Accomplishments that we're proud of
We're definitely proudest of figuring out the simultaneous question of map interaction and react routing, as this was one of the few issues in the project that was an all-hands-on-deck effort; half the team had been working on routing while the other had been figuring out the map, so we were faced to communicate precisely what we were doing to the other team so that we could figure out how to link the two initiatives. From a broader point of view, we're also incredibly proud of sticking with this entire initiative—from initial brainstorming to the writing of these very words—without any guidance from an authority figure. It has expanded our perspective immeasurably in terms of programming as a whole, and now we have each taken the step of being able to view programming challenges in terms of creativity, independence, and personal initiative, rather than college assignments or interview questions. This unquantifiable side of the entire experience will likely have the greatest long-run impact on our programming journey, and we can't wait to move on to the next big thing.
## What we learned
We learned, first and foremost, how to collaborate as a team. None of us had ever used Github before, as mentioned previously, and we were forced to think through problems as a team and communicate progress and setbacks to our team members as they arose. Some of us, perfectionists by nature, learned to step back from micromanaging and allow more seamless and balanced cooperation among the team members; the others, who might lack motivation without the involvement of friends on such a daunting project, learned to actively involve themselves in their areas of expertise and interest. It truly was a multi-dimensional learning experience, and each of us will think back upon this learning experience for a long time to come.
## What's next for Adventures Abroad
Next steps for this website will definitely involve looking over the React hooks and components, and learning how to leverage state more effectively to eliminate the need for bulky static markup and styling. Our more immediate concern is that there was one major shortcoming in our project—we were never able to get around to learning how to host our platform on Domain.com, and instead were forced to stay on localhost for the duration of the project's development. All of these will be areas of future discussion for us both for this project and for other independent initiatives. | partial |
## Inspiration
Inspired by [SIU Carbondale's Green Roof](https://greenroof.siu.edu/siu-green-roof/), we wanted to create an automated garden watering system that would help address issues ranging from food deserts to lack of agricultural space to storm water runoff.
## What it does
This hardware solution takes in moisture data from soil and determines whether or not the plant needs to be watered. If the soil's moisture is too low, the valve will dispense water and the web server will display that water has been dispensed.
## How we built it
First, we tested the sensor and determined the boundaries between dry, damp, and wet based on the sensor's output values. Then, we took the boundaries and divided them by percentage soil moisture. Specifically, the sensor that measures the conductivity of the material around it, so water being the most conductive had the highest values and air being the least conductive had the lowest. Soil would fall in the middle and the ranges in moisture were defined by the pure air and pure water boundaries.
From there, we visualized the hardware set up with the sensor connected to an Arduino UNO microcontroller connected to a Raspberry Pi 4 controlling a solenoid valve that releases water when the soil moisture meter is less than 40% wet.
## Challenges we ran into
At first, we aimed too high. We wanted to incorporate weather data into our water dispensing system, but the information flow and JSON parsing were not cooperating with the Arduino IDE. We consulted with a mentor, Andre Abtahi, who helped us get a better perspective of our project scope. It was difficult to focus on what it meant to truly create a minimum viable product when we had so many ideas.
## Accomplishments that we're proud of
Even though our team is spread across the country (California, Washington, and Illinois), we were still able to create a functioning hardware hack. In addition, as beginners we are very excited of this hackathon's outcome.
## What we learned
We learned about wrangling APIs, how to work in a virtual hackathon, and project management. Upon reflection, creating a balance between feasibility, ability, and optimism is important for guiding the focus and motivations of a team. Being mindful about energy levels is especially important for long sprints like hackathons.
## What's next for Water Smarter
Lots of things! What's next for Water Smarter is weather controlled water dispensing. Given humidity, precipitation, and other weather data, our water system will dispense more or less water. This adaptive water feature will save water and let nature pick up the slack. We would use the OpenWeatherMap API to gather the forecasted volume of rain, predict the potential soil moisture, and have the watering system dispense an adjusted amount of water to maintain correct soil moisture content.
In a future iteration of Water Smarter, we want to stretch the use of live geographic data even further by suggesting appropriate produce for which growing zone in the US, which will personalize the water conservation process. Not all plants are appropriate for all locations so we would want to provide the user with options for optimal planting. We can use software like ArcScene to look at sunlight exposure according to regional 3D topographical images and suggest planting locations and times.
We want our product to be user friendly, so we want to improve our aesthetics and show more information about soil moisture beyond just notifying water dispensing. | ## Inspiration
\*\*\* SEE GITHUB LINK FOR BOTH DEMO VIDEOS (Devpost limits to only one video) \*\*\*
Taking care of plants is surprisingly hard. Let's be honest here - almost everybody we know has lost a plant or two (or many) due to poor maintenance. Appliances and tools within our homes are adopting the newest technologies and becoming increasingly automated - what if we apply these advancements to plant care? How far can we take it?
Our group is also interested in the artistic side of the project. Nature and technology are often at odds with one another; we are constantly reminded of the toll that industrialization has taken on our environment. But is it possible to create something where technology and nature coexist, in a symbiotic relationship?
## What it does
The iPot Lite is, at its core, an autonomous flower pot. The iPot Lite has two main functions: First, it is able to track and follow the location of brighter light sources (such as sun pouring in through a window) in order to give its plant maximum exposure. Secondly, when watering is required, the plant can seek out a fountain location using its camera system and drive over. We envision a system similar to a hand sanitizer dispenser, except filled with water.
## How we built it
The flower pot sits on a mobile base driven by two DC motors along with a caster wheel, which allow it to traverse a wide variety of surfaces. The majority of the prototype is built from wood. The processing is handled by an Arduino Uno (driving, edge detection, light detection) and a Raspberry Pi 4 (image recognition). Photoresistors mounted near the top of the pot allow for tracking light sources. Ultrasonic sensors (downwards and forward-facing) can track walls and the edges of surfaces (such as the side of a coffee table). A camera mounted on the front uses OpenCV to extract, isolate and recognize specific colors, which can be used to mark fountain locations.
## Challenges we ran into
We experienced major issues with camera implementation. The first camera we tried could not be powered by the Pi. The second camera was impractical to use, as it did not have a common interface. The third camera was found to be too slow (in terms of frame rate). The fourth camera was broken. We finally found a fully functional camera on our fifth attempt, after several hours of troubleshooting. Space limitations were also another concern - the footprint of the robot was quite small, and we realized that we didn't have time/resources to properly solder our circuits onto breakout boards. As such, we had to keep a breadboard which took up valuable space. Powering different components was also difficult because of a lack of cables and/or batteries. Finally, fabricating the physical robot was difficult since shop time was limited and our project contains a lot of hardware.
## Accomplishments that we're proud of
The two main functions of the iPot Lite as described are generally functional. We were quite pleased with how the computer vision system turned out, especially given the performance of a Raspberry Pi. We worked extremely hard to create control logic for tracking light sources (using estimated direction of light vectors), and the final implementation was very cool to see. The custom chassis and hardware were all built and integrated within the makeathon time - no earlier design work was performed at all. The final idea was only created on the morning of the event, so we are quite happy to have built a full robot in 24 hours.
## What we learned
Hardware selection is critical towards success. In our case, our choice to use a Raspberry Pi 4 as well as our specific set of chosen sensors greatly influenced the difficulties we faced. Since we chose to use a Raspberry Pi 4 with micro-HDMI output, we were not able to interface with the board without a headless SSH interface. The Raspberry Pi Camera worked remarkably well and without much difficulty after failing to integrate with all of IP webcams, USB Webcams, and the M5 Camera. We initially wanted to use the Huawei Atlas, but found that its power requirements were too high to even consider. We learned that every hardware choice greatly influenced the difficulties faced towards project completion, as well as the choice of other hardware components. As a result, integration and communication is incredibly important to discover incompatibilities where they exist in the initial designs, and the most successful strategy is to integrate early and iterate across all features simultaneously.
## What's next for iPot Lite
We really wanted to add wireless charging or solar panels for total self-sustainability, but unfortunately due to the limited parts selection we were unable to do so. We also wanted to create additional tools for things like data logging, reviewing and settings configuration. A mobile companion app would have been nice, but we didn't have time to implement it (could be used for tracking plant health). We toyed with additional ideas such as a security camera mode using motion detection, or neural-net based plant identification. Unfortunately due to time constraints we weren't able to fully explore these software features, but we were glad that we finished most of the hardware. | ## Inspiration
After looking at the Hack the 6ix prizes, we were all drawn to the BLAHAJ. On a more serious note, we realized that one thing we all have in common is accidentally killing our house plants. This inspired a sense of environmental awareness and we wanted to create a project that would encourage others to take better care of their plants.
## What it does
Poképlants employs a combination of cameras, moisture sensors, and a photoresistor to provide real-time insight into the health of our household plants. Using this information, the web app creates an interactive gaming experience where users can gain insight into their plants while levelling up and battling other players’ plants. Stronger plants have stronger abilities, so our game is meant to encourage environmental awareness while creating an incentive for players to take better care of their plants.
## How we built it + Back-end:
The back end was a LOT of python, we took a new challenge on us and decided to try out using socketIO, for a websocket so that we can have multiplayers, this messed us up for hours and hours, until we finally got it working. Aside from this, we have an arduino to read for the moistness of the soil, the brightness of the surroundings, as well as the picture of it, where we leveraged computer vision to realize what the plant is. Finally, using langchain, we developed an agent to handle all of the arduino info to the front end and managing the states, and for storage, we used mongodb to hold all of the data needed.
[backend explanation here]
### Front-end:
The front-end was developed with **React.js**, which we used to create a web-based game. We were inspired by the design of old pokémon games, which we thought might evoke nostalgia for many players.
## Challenges we ran into
We had a lot of difficulty setting up socketio and connecting the api with it to the front end or the database
## Accomplishments that we're proud of
We are incredibly proud of integrating our web sockets between frontend and backend and using arduino data from the sensors.
## What's next for Poképlants
* Since the game was designed with a multiplayer experience in mind, we want to have more social capabilities by creating a friends list and leaderboard
* Another area to explore would be a connection to the community; for plants that are seriously injured, we could suggest and contact local botanists for help
* Some users might prefer the feeling of a mobile app, so one next step would be to create a mobile solution for our project | partial |
## Inspiration
As college students, we know that internships are extremely valuable as it provides us with the opportunity to take the theoretical knowledge we gain in class and apply it to the real world. However, the process of finding internships is slightly flawed. The career fair allows for quality in-person interactions between students and recruiters, but we have found that there are certain opportunities we can capitalize on. On the student end, we found that students often have to wait in hour long lines to meet with just a few recruiters on the off chance that they can fit the career fair into their busy schedule. On the other hand, recruiters have to pay exorbitant fees to attend career fairs, and it can be very expensive when you take into account registration fees, traveling, room and board, and so on.
## What It Currently Does
NXTPitch allows for students to upload short elevator pitches similar to the ones they use at career fairs when meeting recruiters. Students can then upload supplemental videos, links to important social media such as LinkedIn, Github, etc, and have the opportunity to set 4 skills. Recruiters can then look through a feed of these videos; if they find an individual who fits their skill-set, they can look at the rest of their profile, chat with them and even schedule an interview. Furthermore, recruiters can also search for certain skills that they are looking for in a candidate; the system will then look for individuals that have those skills listed in their profile and display them to the recruiter.
## What We Built
For Cal Hacks 2017 we decided to do a continuation project, and build an additional feature for our application. We created an AI backend, that enables students to receive automated feedback regarding the effectiveness of their videos and resumes/cover letters. Our AI backend analyzes the text and delivery of your content, and provides you with personalized analytics regarding how effective your content was. We break effectiveness down into three categories: emotional analysis, highlighted content, and professionalism and provide quantitative metrics for each of these categories using state of the art machine learning technology. We want to enable students not only to find jobs faster but also to find better jobs.
## How We Built It
We built the application using iOS Swift for the user interface, Firebase for the main database, and a Python Webserver backed by Google Cloud for the backend. We also utilized various Machine Learning API's such IBM Watson and Microsoft Azure, for facial and textual analysis. The AI backend relies on many different Machine Learning API's, Python packages, and custom functionality to enable audio extraction from video, textual extraction from PDF's, and analysis of the content. We believe that our main feature is our ability to tightly integrate all these different services into a single application that provides immediate value to our end user.
## Challenges We Ran Into
Since this was the first project we developed in iOS Swift, it provided us with various challenges as we had to get accustomed to language. In addition, implementation of the Python Webserver proved to be a challenge as it was our first time porting Python code to a server backend. Working with all the different API's was also a challenge, and ensuring the robustness of our application required many layers of error checking.
## Accomplishments That We Are Proud Of
We are proud of the Machine Learning engine that was built over the Cal Hacks weekend. It is our most sophisticated feature and we managed to get an MVP of it within 36 hours. It already has impressive functionality, and should help differentiate our product from anything else out there.
## What We Learned
We gained experience with a wide range of technologies such as iOS Swift, Firebase, Google Cloud, Azure, Flask, and so on. Additionally we gained experience in working with non-trivial API's in a demanding environment. Finally we also learned how to properly configure a backend infrastructure.
## What's next for NXTPitch
NXTPitch is currently running small beta testing at UCLA with a dozen students and a few campus recruiters. If you're interested, feel free to contact us! | # cheqout
A project for QHacks 2018 by [Angelo Lu](https://github.com/angelolu/), [Zhijian Wang](https://github.com/EvW1998/), [Hayden Pfeiffer](https://github.com/PfeifferH/) and [Ian Wang](https://github.com/ianw3214/). Speeding up checkouts at supermarkets by fitting existing carts with tech enabling payments.
### Targeted Clients: Established supermarket chains
Big box supermarkets with established physical locations, large inventories and high traffic, such as Walmart and Loblaw-branded stores.
### Problems Identified: Slow checkouts
Checkout times can be slow because they are dependent on available checkout lanes and influenced by factors such as the number of items of the people in front of you and speed of the cashier and the person in scanning and paying. Stores with consistently slow checkouts are at risk of losing customers as people look for faster options such as other nearby stores or online shopping.
### Possible Solutions
1. **Additional checkout lanes**
This solution is limited by the physical layout of the store. Additional checkout lanes require additional staff.
2. **Self-checkout kiosks**
This solution is also limited by the physical layout. Lines can still develop as people must wait for others to scan and pay, which may take a long time.
3. **Handheld self-scanners**
In supermarkets, products such as produce, and bulk foods are weighed, which cannot be processed easily with this solution.
4. **Sensor-fusion based solution replacing checkouts (Ex. Amazon Go)**
In large chain supermarkets with many established locations, implementation of all the cameras, scales and custom shelving for the system requires massive renovations and is assumed to be impractical, especially considering the number of products and stores.
### Proposed Solution: “cheqout”, Smart Shopping Carts
The solution, titled “cheqout” involves fitting existing shopping carts with a tray, covering the main basket of the cart, and a touchscreen and camera, on the cart handle.
A customer would take out a cart upon entry and scan each items’ barcode before placing it in the cart. The touchscreen would display the current total of the cart in real time. Once the customer is ready to pay, they can simply tap “Check Out” on the touchscreen and scan a loyalty card (virtual or physical) with an associated payment method or tap their credit or debit card directly. Alternatively, the customer can proceed to a payment kiosk or traditional checkout if they do not have an account, are paying in cash or want a physical receipt, without having to wait for each item to be scanned again.
On the way out, there would be an employee with a handheld reader displaying what has been paid in the cart to do a quick visual inspection.
This solution trusts that most users will not steal products, however, a scale integrated in the tray will continuously monitor the weight of products in the cart and the changes in weight associated with an item’s addition/removal and prompt accordingly. The scale will also be used to weigh produce.
This solution allows for the sale of weighed and barcoded items while still decreasing checkout line congestion. It is scalable to meet the requirements of each individual store and does not require the hiring of many additional personnel.
### Challenges
* Time: This project is being built for QHacks, a 36-hour hackathon
* Technical: The scale and touch screen remain uncooperative, prompting temporary fixes for the purpose of demonstration
### Possible Future Features/Value-Added Features
* Information about traffic within the store
By implementing indoor location tracking, analysts can visualize where customers frequent and tailor/adjust product placement accordingly
* Information about product selection
The system can record a customer’s decision making process and uncertainties based on how long they spend in one spot and if they add, remove or swap items from their cart | ## Inspiration
Metaverse, vision pro, spatial video. It’s no doubt that 3D content is the future. But how can I enjoy or make 3d content without spending over 3K? Or strapping massive goggles to my head? Let's be real, wearing a 3d vision pro while recording your child's birthday party is pretty [dystopian.](https://youtube.com/clip/UgkxXQvv1mxuM06Raw0-rLFGBNUqmGFOx51d?si=nvsDC3h9pz_ls1sz) And spatial video only gets you so far in terms of being able to interact, it's more like a 2.5D video with only a little bit of depth.
How can we relive memories in 3d without having to buy new hardware? Without the friction?
Meet 3dReal, where your best memories got realer. It's a new feature we imagine being integrated in BeReal, the hottest new social media app that prompts users to take an unfiltered snapshot of their day through a random notification. When that notification goes off, you and your friends capture a quick snap of where you are!
The difference with our feature is based on this idea where if you have multiple images of the same area ie. you and your friends are taking BeReals at the same time, we can use AI to generate a 3d scene.
So if the app detects that you are in close proximity to your friends through bluetooth, then you’ll be given the option to create a 3dReal.
## What it does
With just a few images, the AI powered Neural Radiance Fields (NeRF) technology produces an AI reconstruction of your scene, letting you keep your memories in 3d. NeRF is great in that it only needs a few input images from multiple angles, taken at nearly the same time, all which is the core mechanism behind BeReal anyways, making it a perfect application of NeRF.
So what can you do with a 3dReal?
1. View in VR, and be able to interact with the 3d mesh of your memory. You can orbit, pan, and modify how you see this moment captures in the 3dReal
2. Since the 3d mesh allows you to effectively view it however you like, you can do really cool video effects like flying through people or orbiting people without an elaborate robot rig.
3. TURN YOUR MEMORIES INTO THE PHYSICAL WORLD - one great application is connecting people through food. When looking through our own BeReals, we found that a majority of group BeReals were when getting food. With 3dReal, you can savor the moment by reconstructing your friends + food, AND you can 3D print the mesh, getting a snippet of that moment forever.
## How it works
Each of the phones using the app has a countdown then takes a short 2-second "video" (think of this as a live photo) which is sent to our Google Firebase database. We group the videos in Firebase by time captured, clustering them into a single shared "camera event" as a directory with all phone footage captured at that moment. While one camera would not be enough in most cases, by using the network of phones to take the picture simultaneously we have enough data to substantially recreate the scene in 3D. Our local machine polls Firebase for new data. We retrieve it, extract a variety of frames and camera angles from all the devices that just took their picture together, use COLMAP to reconstruct the orientations and positions of the cameras for all frames taken, and then render the scene as a NeRF via NVIDIA's instant-ngp repo. From there, we can export, modify, and view our render for applications such as VR viewing, interactive camera angles for creating videos, and 3D printing.
## Challenges we ran into
We lost our iOS developer team member right before the hackathon (he's still goated just unfortunate with school work) and our team was definitely not as strong as him in that area. Some compromises on functionality were made for the MVP, and thus we focused core features like getting images from multiple phones to export the cool 3dReal.
There were some challenges with splicing the videos for processing into the NeRF model as well.
## Accomplishments that we're proud of
Working final product and getting it done in time - very little sleep this weekend!
## What we learned
A LOT of things out of all our comfort zones - Sunny doing iOS development and Phoebe doing not hardware was very left field, so lots of learning was done this weekend. Alex learned lots about NeRF models.
## What's next for 3dReal
We would love to refine the user experience and also improve our implementation of NeRF - instead of generating a static mesh, our team thinks with a bit more time we could generate a mesh video which means people could literally relive their memories - be able to pan, zoom, and orbit around in them similar to how one views the mesh.
BeReal pls hire 👉👈 | partial |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.