
anchor
stringlengths 1
23.8k
| positive
stringlengths 1
23.8k
| negative
stringlengths 1
31k
| anchor_status
stringclasses 3
values |
|---|---|---|---|
## Inspiration
Inspired by Nicole's many trips to the ER.
## What it does
OctoBud is a chat bot for Amazon Alexa that helps decrease wait times in the ER by decreasing the amount of time that nurses have to spend with each patient and by giving alternative options to the current ER. OctoBud gets the information from the patient (currently just through the Alexa but eventually also through a computer to secure sensitive information like health card number) and runs analysis on it to determine the patient's priority and therefore their order in the queue. The patients data is then sent to the ER nurses as a card and they are given the opportunity to validate the decision made by the bot and update it if necessary or add comments. It doesn't eliminate the interaction between the patient and the ER nurses but instead decreases the time of these interactions by getting the patient's information prior to seeing the nurse and storing it in an organized fashion.
## How we built it
We utilized the StdLib api to build the Alexa skill as well as access MongoDB. The Alexa skill was written in node.js and the website for the nurse side was written in HTML(EJS)/CSS/JS.
## Challenges we ran into
StdLib did not have the functionality built in to do a session in the Alexa skill that is longer than one request and one response so we had to build that functionality ourselves and because we were using the StdLib api and not AWS lamda the solutions on the internet for this problem were not possible (at least not in the period of time that we have in the hackathon). Another problem is that amazon doesn't send the user's exact request (just the variables/slots) so we had no way of getting their answer for each reprompt without destroying the rest of the functionality or adding a trigger word/phrase. We solved this by using a trigger word/phrase that we believe still moves smoothly with the conversation with the bot and allows us to grab the values that we want.
## Accomplishments that we're proud of
No one on our team had ever built an Alexa app before last weekend (we were at another hackathon) and before this hackathon none of us had ever built a chat bot so we are proud that we were able to create a successful and useful chat bot despite the many challenges that we faced along the way.
## What we learned
We learned a lot about Alexa skills and more about persevering through challenges and building something that we can be proud of. In addition, we gained experience with database communication with MongoDB and between different files.
## What's next for OctoBud
We see a lot of potential for OctoBud. Wait times in ERs are a huge problem that we have all been affected by and is a solvable problem. The next steps that we see for OctoBud are to be able to submit information from a smart phone or smart home device at home and have your information either sent to your closest hospital or a different hospital depending on the wait times in near by hospitals and how good they are at treating your illness/injury. We also see this possibly integrating with other companies in this area such as house call doctors so that you can have a doctor come to your hospital instead of going to the hospital and spending hours waiting to see a doctor, or giving you the option and information about alternatives to ERs in hospitals such as urgent care centres. All of these things will help decrease the wait times in our emergency rooms and improve our health care system to make health care more accessible in a reasonable amount of time for everyone. | We were inspired by the daily struggle of social isolation.
Shows the emotion of a text message on Facebook
We built this using Javascript, IBM-Watson NLP API, Python https server, and jQuery.
Accessing the message string was a lot more challenging than initially anticipated.
Finding the correct API for our needs and updating in real time also posed challenges.
The fact that we have a fully working final product.
How to interface JavaScript with Python backend, and manually scrape a templated HTML doc for specific key words in specific locations
Incorporate the ability to display alternative messages after a user types their initial response. | ## Inspiration
In this era, with medicines being readily available for consumption, people take on pills without even consulting with a specialist to find out what diagnosis they have. We have created this project to find out what specific illnesses that a person can be diagnosed with, so that they can seek out the correct treatment, without self-treating themselves with pills which might in turn harm them in the long run.
## What it does
This is your personal medical assistant bot which takes in a set of symptoms you are experiencing and returns some illnesses that are most closely matched with that set of symptoms. It is powered by Machine learning which enables it to return more accurate data (tested and verified!) as to what issue the person might have.
## How we built it
We used React for building the front-end. We used Python and its vast array of libraries to design the ML model. For building the model, we used scikit-learn. We used pandas for the data processing. To connect the front end with the model, we used Fast API. We used a Random Forest multi-label classification model to give the diagnosis. Since the model takes in a string, we used the Bag-of-Words from Scikit-Learn to convert it to number-related values.
## Challenges we ran into
Since none of us had significant ML experience, we had to learn how to create an ML model specifically the multi-label classification model, train it and get it deployed on time. Furthermore, FAST API does not have good documentation, we ran into numerous errors while configuring and interfacing it between our front-end and back-end.
## Accomplishments that we're proud of
Creating a Full-Stack Application that would help the public to find a quick diagnosis for the symptoms they experience. Working on the Project as a team and brainstorming ideas for the proof of concept and how to get our app working.
We trained the model with use cases which evaluated to 97% accuracy
## What we learned
Working with Machine Learning and creating a full-stack App. We also learned how to coordinate with the team to work effectively. Reading documentation and tutorials to get an understanding of how the technologies we used work.
## What's next for Medical Chatbot
The first stage for the Medical Chatbot would be to run tests and validate that it works using different datasets. We also plan about adding more features in the front end such as authentication so that different users can register before using the feature. We can get inputs from professionals in healthcare to increase coverage and add more questions to give the correct prediction. | partial |
## Inspiration
40 million people in the world are blind, including 20% of all people aged 85 or older. Half a million people suffer paralyzing spinal cord injuries every year. 8.5 million people are affected by Parkinson’s disease, with the vast majority of these being senior citizens. The pervasive difficulty for these individuals to interact with objects in their environment, including identifying or physically taking the medications vital to their health, is unacceptable given the capabilities of today’s technology.
First, we asked ourselves the question, what if there was a vision-powered robotic appliance that could serve as a helping hand to the physically impaired? Then we began brainstorming: Could a language AI model make the interface between these individual’s desired actions and their robot helper’s operations even more seamless? We ended up creating Baymax—a robot arm that understands everyday speech to generate its own instructions for meeting exactly what its loved one wants. Much more than its brilliant design, Baymax is intelligent, accurate, and eternally diligent.
We know that if Baymax was implemented first in high-priority nursing homes, then later in household bedsides and on wheelchairs, it would create a lasting improvement in the quality of life for millions. Baymax currently helps its patients take their medicine, but it is easily extensible to do much more—assisting these same groups of people with tasks like eating, dressing, or doing their household chores.
## What it does
Baymax listens to a user’s requests on which medicine to pick up, then picks up the appropriate pill and feeds it to the user. Note that this could be generalized to any object, ranging from food, to clothes, to common household trinkets, to more. Baymax responds accurately to conversational, even meandering, natural language requests for which medicine to take—making it perfect for older members of society who may not want to memorize specific commands. It interprets these requests to generate its own pseudocode, later translated to robot arm instructions, for following the tasks outlined by its loved one. Subsequently, Baymax delivers the medicine to the user by employing a powerful computer vision model to identify and locate a user’s mouth and make real-time adjustments.
## How we built it
The robot arm by Reazon Labs, a 3D-printed arm with 8 servos as pivot points, is the heart of our project. We wrote custom inverse kinematics software from scratch to control these 8 degrees of freedom and navigate the end-effector to a point in three dimensional space, along with building our own animation methods for the arm to follow a given path. Our animation methods interpolate the arm’s movements through keyframes, or defined positions, similar to how film editors dictate animations. This allowed us to facilitate smooth, yet precise, motion which is safe for the end user.
We built a pipeline to take in speech input from the user and process their request. We wanted users to speak with the robot in natural language, so we used OpenAI’s Whisper system to convert the user commands to text, then used OpenAI’s GPT-4 API to figure out which medicine(s) they were requesting assistance with.
We focused on computer vision to recognize the user’s face and mouth. We used OpenCV to get the webcam live stream and used 3 different Convolutional Neural Networks for facial detection, masking, and feature recognition. We extracted coordinates from the model output to extrapolate facial landmarks and identify the location of the center of the mouth, simultaneously detecting if the user’s mouth is open or closed.
When we put everything together, our result was a functional system where a user can request medicines or pills, and the arm will pick up the appropriate medicines one by one, feeding them to the user while making real time adjustments as it approaches the user’s mouth.
## Challenges we ran into
We quickly learned that working with hardware introduced a lot of room for complications. The robot arm we used was a prototype, entirely 3D-printed yet equipped with high-torque motors, and parts were subject to wear and tear very quickly, which sacrificed the accuracy of its movements. To solve this, we implemented torque and current limiting software and wrote Python code to smoothen movements and preserve the integrity of instruction.
Controlling the arm was another challenge because it has 8 motors that need to be manipulated finely enough in tandem to reach a specific point in 3D space. We had to not only learn how to work with the robot arm SDK and libraries but also comprehend the math and intuition behind its movement. We did this by utilizing forward kinematics and restricted the servo motors’ degrees of freedom to simplify the math. Realizing it would be tricky to write all the movement code from scratch, we created an animation library for the arm in which we captured certain arm positions as keyframes and then interpolated between them to create fluid motion.
Another critical issue was the high latency between the video stream and robot arm’s movement, and we spent much time optimizing our computer vision pipeline to create a near instantaneous experience for our users.
## Accomplishments that we're proud of
As first-time Hackathon participants, we are incredibly proud of the incredible progress we were able to make in a very short amount of time, proving to ourselves that with hard work, passion, and a clear vision, anything is possible. Our team did a fantastic job embracing the challenge of using technology unfamiliar to us, and stepped out of our comfort zones to bring our idea to life. Whether it was building the computer vision model, or learning how to interface the robot arm’s movements with voice controls, we ended up building a robust prototype which far surpassed our initial expectations. One of our greatest successes was coordinating our work so that each function could be pieced together and emerge as a functional robot. Let’s not overlook the success of not eating our hi-chews we were using for testing!
## What we learned
We developed our skills in frameworks we were initially unfamiliar with such as how to apply Machine Learning algorithms in a real-time context. We also learned how to successfully interface software with hardware - crafting complex functions which we could see work in 3-dimensional space. Through developing this project, we also realized just how much social impact a robot arm can have for disabled or elderly populations.
## What's next for Baymax
Envision a world where Baymax, a vigilant companion, eases medication management for those with mobility challenges. First, Baymax can be implemented in nursing homes, then can become a part of households and mobility aids. Baymax is a helping hand, restoring independence to a large disadvantaged group.
This innovation marks an improvement in increasing quality of life for millions of older people, and is truly a human-centric solution in robotic form. | ## Inspiration
We are currently living through one of the largest housing crises in human history. As a result, more Canadians than ever before are seeking emergency shelter to stay off the streets and find a safe place to recuperate. However, finding a shelter is still a challenging, manual process, where no digital service exists that lets individuals compare shelters by eligibility criteria, find the nearest one they are eligible for, and verify that the shelter has room in real-time. Calling shelters in a city with hundreds of different programs and places to go is a frustrating burden to place on someone who is in need of safety and healing. Further, we want to raise the bar: people shouldn't be placed in just any shelter, they should go to the shelter best for them based on their identity and lifestyle preferences.
70% of homeless individuals have cellphones, compared to 85% of the rest of the population; homeless individuals are digitally connected more than ever before, especially through low-bandwidth mediums like voice and SMS. We recognized an opportunity to innovate for homeless individuals and make the process for finding a shelter simpler; as a result, we could improve public health, social sustainability, and safety for the thousands of Canadians in need of emergency housing.
## What it does
Users connect with the ShelterFirst service via SMS to enter a matching system that 1) identifies the shelters they are eligible for, 2) prioritizes shelters based on the user's unique preferences, 3) matches individuals to a shelter based on realtime availability (which was never available before) and the calculated priority and 4) provides step-by-step navigation to get to the shelter safely.
Shelter managers can add their shelter and update the current availability of their shelter on a quick, easy to use front-end. Many shelter managers are collecting this information using a simple counter app due to COVID-19 regulations. Our counter serves the same purpose, but also updates our database to provide timely information to those who need it. As a result, fewer individuals will be turned away from shelters that didn't have room to take them to begin with.
## How we built it
We used the Twilio SMS API and webhooks written in express and Node.js to facilitate communication with our users via SMS. These webhooks also connected with other server endpoints that contain our decisioning logic, which are also written in express and Node.js.
We used Firebase to store our data in real time.
We used Google Cloud Platform's Directions API to calculate which shelters were the closest and prioritize those for matching and provide users step by step directions to the nearest shelter. We were able to capture users' locations through natural language, so it's simple to communicate where you currently are despite not having access to location services
Lastly, we built a simple web system for shelter managers using HTML, SASS, JavaScript, and Node.js that updated our data in real time and allowed for new shelters to be entered into the system.
## Challenges we ran into
One major challenge was with the logic of the SMS communication. We had four different outgoing message categories (statements, prompting questions, demographic questions, and preference questions), and shifting between these depending on user input was initially difficult to conceptualize and implement. Another challenge was collecting the distance information for each of the shelters and sorting between the distances, since the response from the Directions API was initially confusing. Lastly, building the custom decisioning logic that matched users to the best shelter for them was an interesting challenge.
## Accomplishments that we're proud of
We were able to build a database of potential shelters in one consolidated place, which is something the city of London doesn't even have readily available. That itself would be a win, but we were able to build on this dataset by allowing shelter administrators to update their availability with just a few clicks of a button. This information saves lives, as it prevents homeless individuals from wasting their time going to a shelter that was never going to let them in due to capacity constraints, which often forced homeless individuals to miss the cutoff for other shelters and sleep on the streets. Being able to use this information in a custom matching system via SMS was a really cool thing for our team to see - we immediately realized its potential impact and how it could save lives, which is something we're proud of.
## What we learned
We learned how to use Twilio SMS APIs and webhooks to facilitate communications and connect to our business logic, sending out different messages depending on the user's responses. In addition, we taught ourselves how to integrate the webhooks to our Firebase database to communicate valuable information to the users.
This experience taught us how to use multiple Google Maps APIs to get directions and distance data for the shelters in our application. We also learned how to handle several interesting edge cases with our database since this system uses data that is modified and used by many different systems at the same time.
## What's next for ShelterFirst
One addition to make could be to integrate locations for other basic services like public washrooms, showers, and food banks to connect users to human rights resources. Another feature that we would like to add is a social aspect with tags and user ratings for each shelter to give users a sense of what their experience may be like at a shelter based on the first-hand experiences of others. We would also like to leverage the Twilio Voice API to make this system accessible via a toll free number, which can be called for free at any payphone, reaching the entire homeless demographic.
We would also like to use Raspberry Pis and/or Arduinos with turnstiles to create a cheap system for shelter managers to automatically collect live availability data. This would ensure the occupancy data in our database is up to date and seamless to collect from otherwise busy shelter managers. Lastly, we would like to integrate into municipalities "smart cities" initiatives to gather more robust data and make this system more accessible and well known. | ## Inspiration
One of our team members' grandfathers went blind after slipping and hitting his spinal cord, going from a completely independent individual to reliant on others for everything. The lack of options was upsetting, how could a man who was so independent be so severely limited by a small accident. There is current technology out there for blind individuals to navigate their home, however, there is no such technology that allows blind AND frail individuals to do so. With an increasing aging population, Elderlyf is here to be that technology. We hope to help our team member's grandfather and others like him regain his independence by making a tool that is affordable, efficient, and liberating.
## What it does
Ask your Alexa to take you to a room in the house, and Elderlyf will automatically detect which room you're currently in, mapping out a path from your current room to your target room. With vibration disks strategically located underneath the hand rests, Elderlyf gives you haptic feedback to let you know when objects are in your way and in which direction you should turn. With an intelligent turning system, Elderlyf gently helps with turning corners and avoiding obstacles.
## How I built it
With a Jetson Nano and RealSense Cameras, front view obstacles are detected and a map of the possible routes are generated. SLAM localization was also achieved using those technologies. An Alexa and AWS Speech to Text API was used to activate the mapping and navigation algorithms. By using two servo motors that could independently apply a gentle brake to the wheels to aid users when turning and avoiding obstacles. Piezoelectric vibrating disks were also used to provide haptic feedback in which direction to turn and when obstacles are close.
## Challenges I ran into
Mounting the turning assistance system was a HUGE challenge as the setup needed to be extremely stable. We ended up laser-cutting mounting pieces to fix this problem.
## Accomplishments that we're proud of
We're proud of creating a project that is both software and hardware intensive and yet somehow managing to get it finished up and working.
## What I learned
Learned that the RealSense camera really doesn't like working on the Jetson Nano.
## What's next for Elderlyf
Hoping to incorporate a microphone to the walker so that you can ask Alexa to take you to various rooms even though the Alexa may be out of range. | winning |
## Inspiration
We spend a lot of our time sitting in front of the computer. The idea is to use the video feed from webcam to determine the emotional state of the user, analyze and provide a feedback accordingly in the form of music, pictures and videos.
## How I built it
Using Microsoft Cognitive Services (Video + Emotion API) we get the emotional state of the user through the webcam feed. We parse that to the bot framework which in turn sends responses based upon the change in the values of emotional state.
## Challenges I ran into
Passing data between the bot framework and the desktop application which captured the webcam feed.
## Accomplishments that I'm proud of
A fully functional bot which provides feedback to the user based upon the changes in the emotion.
## What I learned
Visual studio is a pain to work with.
## What's next for ICare
Use Recurrent Neural Network to keep track of the emotional state of the user before and after and improve the content provided to the user over the period of time. | ## Inspiration
After years of teaching methods remaining constant, technology has not yet infiltrated the classroom to its full potential. One day in class, it occurred to us that there must be a correlation between students behaviour in classrooms and their level of comprehension.
## What it does
We leveraged Apple's existing API's around facial detection and combined it with the newly added Core ML features to track students emotions based on their facial queues. The app can follow and analyze up to ~ ten students and provide information in real time using our dashboard.
## How we built it
The iOS app integrated Apple's Core ML framework to run a [CNN](https://www.openu.ac.il/home/hassner/projects/cnn_emotions/) to detect people's emotions from facial queues. The model was then used in combination with Apple's Vision API to identify and extract student's face's. This data was then propagated to Firebase for it to be analyzed and displayed on a dashboard in real time.
## Challenges we ran into
Throughout this project, there were several issues regarding how to improve the accuracy of the facial results. Furthermore, there were issues regarding how to properly extract and track users throughout the length of the session. As for the dashboard, we ran into problems around how to display data in real time.
## Accomplishments that we're proud of
We are proud of the fact that we were able to build such a real-time solution. However, we are happy to have met such a great group of people to have worked with.
## What we learned
Ozzie learnt more regarding CoreML and Vision frameworks.
Haider gained more experience with front-end development as well as working on a team.
Nakul gained experience with real-time graphing as well as helped developed the dashboard.
## What's next for Flatline
In the future, Flatline could grow it's dashboard features to provide more insight for the teachers. Also, the accuracy of the results could be improved by training a model to detect emotions that are more closely related to learning and student's behaviours. | ## Inspiration
In a world where education has become increasingly remote and reliant on online platforms, we need human connection **more than ever**. Many students often find it difficult to express their feelings without unmuting themselves and drawing unwanted attention. As a result, teachers are unaware of how their students are feeling and if the material is engaging. This situation is especially challenging for students who struggle with communicating their feelings–such as individuals with autism, selective mutism, social anxiety, and more.
We want to help **bridge this gap** by creating a tool that will both enable students to express themselves with less effort and enable teachers to understand and respond to their overall needs.
We strongly believe in the importance of **accessibility in education** and supplementing human connection, because at the end of the day, humans are all social beings.
## What it does
Our application helps measure the general emotions of participants in a video meeting, displaying a stream of emojis representing up to **80 different emotions**. We periodically sample video frames from all participants with their cameras on at 10-second intervals, feeding this data into **Hume’s Expression Management API** to identify the most prominent expressions. From this, we generate a composite view of the general sentiment using a custom weighted algorithm.
Using this aggregated sentiment data, our frontend displays the most frequent emotions with their corresponding emojis on the screen. This way, hosts can adapt their teaching to the general sentiment of the classroom, while students can share how they’re feeling without having to experience the social anxiety that comes with typing a message in the chat or sharing a thought out loud.
## How we built it
We leveraged **LiveKit** to create our video conference infrastructure and **Vercel** to deploy our application. We also utilized **Supabase Realtime** as our communication protocol, forwarding livestream data from clients per room and saving that data to Supabase Storage.
Our backend, implemented with **FastAPI**, interfaces with the frontend to pull this data from Supabase and feed the captured facial data into Hume AI to detect human emotions.
The results are then aggregated and stored back into our Supabase table. Our frontend, built with **Next.js** and styled with **Tailwind CSS**, listens to real-time event triggers from Supabase to detect changes in the table.
From this, we’re able to display the stream of emotions in **near real-time**, finally delivering aggregated emotion data as a light-hearted fun animation to keep everyone engaged!
## Challenges we ran into
* Livekit Egress has limited documentation
* Coordination of different parts using Supabase Realtime
* Hume AI API
* First-time Frontenders
* Hosting our backend thru Vercel (lots of config)
## Accomplishments that we're proud of
* Livekit real time streaming video conference
* Streaming video data to Hume Supabase Realtime
* Emoji animation using Framer Motion
* Efficient scoring algorithm using heaps
## What we learned
We learned how to use a lot of new tools and frameworks such as Next.js and Supabase as it was some of our members' first time doing full-stack software engineering. From our members all the way from SoCal and the East Coast, we learned how to ride the BART, and we all learned LiveKit for live streaming and video conferencing.
## What's next for Moji
We see the potential of this tool in a **wide variety of industries** and have other features in mind that we want to implement. For example, we can focus on enhancing this tool to help streamers with any kind of virtual audience by:
* Implementing a dynamic **checklist** that generates to-dos based on questions or requests from viewers.
This can benefit teachers in providing efficient learning to their studies or large entertainment streamers in managing a fast-moving chat. This can also be extended to eCommerce, as livestream shopping requires sellers to efficiently navigate their chat interactions.
* Using Whisper for **real-time audio speech recognition** to automatically check off answered questions.
This provides a hands-free way for streamers to meet their viewers’ requests without having to look extensively through chat. This is especially beneficial for the livestream shopping industry as sellers are typically displaying items while reading messages
* Using **RAG** to store answers to previously asked questions and using this data to answer any future questions.
This can be a great way to save time for streamers from answering repeated questions.
Enhancing video recognition capabilities to identify more complex interactions and objects in real-time.
With video recognition, we can lean even heavier into the eCommerce industry, identifying what type of products sellers are displaying and providing a hands-free and AI enhanced way of managing their checklist of requests.
* Adding **integrations** with other streaming platforms to broaden its applicability and improve the user experience.
The possibilities are endless and we’re excited to see where Moji can go! We hope that Moji can bring a touch of humanity and help us all stay connected and engaged in the digital world. | partial |
## Inspiration
When you are prescribed medication by a Doctor, it is crucial that you complete the dosage cycle in order to ensure that you recover fully and quickly. Unfortunately forgetting to take your medication is something that we have all done. Failing to run the full course of medicine often results in a delayed recovery and leads to more suffering through the painful and annoying symptoms of illness. This has inspired us to create Re-Pill. With Re-Pill, you can automatically generate scheduling and reminders to take you medicine by simply uploading a photo of your prescription.
## What it does
A user uploads an image of their prescription which is then processed by image to text algorithms that extract the details of the medication. Data such as the name of the medication, its dosage, and total tablets is stored and presented to the user. The application synchronizes with google calendar and automatically sets reminders for taking pills into the user's schedule based on the dosage instructions on the prescription. The user can view their medication details at any time by logging into Re-Pill.
## How we built it
We built the application using the Python web framework Flask. Simple endpoints were created for login, registration, and viewing of the user's medication. User data is stored in Google Cloud's Firestore. Images are uploaded and sent to a processing endpoint through a HTTP Request which delivers the medication information. Reminders are set using the Google Calendar API.
## Challenges we ran into
We initially struggled to figure out the right tech-stack to use for building the app. We struggled with Android development before settling for a web-app. One big challenge we faced was to merge all the different part of our application into one smoothly running product. Another challenge was finding a method to inform/notify the user of his/her medication time through a web-based application.
## Accomplishments that we're proud of
There are a couple of things that we are proud of. One of them is how well our team was able to communicate with one another. All team members knew what the other members were working on and the work was divided in such a manner that all teammates worked on the projects using his/her strengths. One important accomplishment is that we were able to overcome a huge time constraint and come up with a prototype of an idea that has potential to change people's lives.
## What we learned
We learned how to set up and leverage Google API's, manage non-relational databases and process image to text using various python libraries.
## What's next for Re-Pill
The next steps for Re-Pill would be to move to a mobile environment and explore useful features that we can implement. Building a mobile application would make it easier for the user to stay connected with the schedules and upload prescription images at a click of a button using the built in camera. Some features we hope to explore are creating automated activities, such as routine appointment bookings with the family doctor and monitoring dietary considerations with regards to stronger medications that might conflict with a patients diet. | ## Inspiration
Forgetting to take a medication is a common problem in older people and is especially likely when an older patient takes several drugs simultaneously. Around 40% of Patients forget to take medicines and most of them have difficulty to differentiate between multiple medications.
1. Patients forgets to take medication
2. Patients get confused in taking multiple medications as they look similar.
3. Patients don't take medications at correct time
Such thing leads to bad health and now-a-days these cases are increasing day by day and most people think that skipping medications is normal thing, which is bad for their health.
To avoid this I wanted to make a device which automatically gives medicines to the patients.
## What it does
It is a 3D printed Vending Box actuated by using servo motor and controlled using Raspberry Pi 4 and Mobile App. The Box will automatically sort out medicine according to Time and Schedule and Vend it using Servo Motor from the Box, the App will be connected via Firebase to Store, Add and Modify the Medicine Schedule and Raspberry Pi will collect that data from Firebase and Actuate the Servos Accordingly.
1. Doctors/Care Takers Can Add Medicine Schedule via the Mobile App.
2. The Patient will hear a Buzzer and Sound Details about Medicine and how much Doses he must take of that medicine.
3. The Box will automatically rotate via servo and Drop Off the Scheduled Medicine off the Box .
## How we built it
I bought Raspberry Pi and Servos at start of Hackathon, and Started Development of App until the Hardware got Shipped.
Timeline
* Day 1-2 : Planning of Idea and Hardware Ordering
* Day 3-4 : Research Work and Planning
* Day4 -6: App Development from Flutter + Firebase
* Day 7-9: CAD Design and started 3D Printing(took 13 Hours to print)
* Day 10: Hardware Arrived and Tested
* Day 10 -Day 12 Integrated 3D Printed Parts and Motors and Done with Project
* Day 13: Video Editing, Devpost Documentation , Code Uploading
* Day 14: Minor Video Edits and Documentation
#### Initial Research and CAD Drawings:
[](https://ibb.co/KWGMGhk)
[](https://ibb.co/cJQD8ss)
[](https://ibb.co/0ZrjBjp)
## Challenges we ran into
* 3D Printing Failed and took lot of time
* Late Shipment of Hardware
* Servo Motor Gear Issues
## Accomplishments that we're proud of
1. New to 3d Printing and Printed such Big Project for First Time
2. Used Raspberry Pi for First Time
## What we learned
* CAD Design
* Flutter
* Raspberry Pi
## What's next for MediBox
1. Creating 2 Level Box, for more medicine capacity using same amount of motors. [image]
2. Add good UI to App
3. Adding Medicine Recognition and automatically ordering . | Introducing Melo-N – where your favorite tunes get a whole new vibe! Melo-N combines "melody" and "Novate" to bring you a fun way to switch up your music.
Here's the deal: You pick a song and a genre, and we do the rest. We keep the lyrics and melody intact while changing up the music style. It's like listening to your favourite songs in a whole new light!
How do we do it? We use cool tech tools like Spleeter to separate vocals from instruments, so we can tweak things just right. Then, with the help of the MusicGen API, we switch up the genre to give your song a fresh spin. Once everything's mixed up, we deliver your custom version – ready for you to enjoy.
Melo-N is all about exploring new sounds and having fun with your music. Whether you want to rock out to a country beat or chill with a pop vibe, Melo-N lets you mix it up however you like.
So, get ready to rediscover your favourite tunes with Melo-N – where music meets innovation, and every listen is an adventure! | losing |
## Inspiration
One of our teammate’s grandfathers suffers from diabetic retinopathy, which causes severe vision loss.
Looking on a broader scale, over 2.2 billion people suffer from near or distant vision impairment worldwide. After examining the issue closer, it can be confirmed that the issue disproportionately affects people over the age of 50 years old. We wanted to create a solution that would help them navigate the complex world independently.
## What it does
### Object Identification:
Utilizes advanced computer vision to identify and describe objects in the user's surroundings, providing real-time audio feedback.
### Facial Recognition:
It employs machine learning for facial recognition, enabling users to recognize and remember familiar faces, and fostering a deeper connection with their environment.
### Interactive Question Answering:
Acts as an on-demand information resource, allowing users to ask questions and receive accurate answers, covering a wide range of topics.
### Voice Commands:
Features a user-friendly voice command system accessible to all, facilitating seamless interaction with the AI assistant: Sierra.
## How we built it
* Python
* OpenCV
* GCP & Firebase
* Google Maps API, Google Pyttsx3, Google’s VERTEX AI Toolkit (removed later due to inefficiency)
## Challenges we ran into
* Slow response times with Google Products, resulting in some replacements of services (e.g. Pyttsx3 was replaced by a faster, offline nlp model from Vosk)
* Due to the hardware capabilities of our low-end laptops, there is some amount of lag and slowness in the software with average response times of 7-8 seconds.
* Due to strict security measures and product design, we faced a lack of flexibility in working with the Maps API. After working together with each other and viewing some tutorials, we learned how to integrate Google Maps into the dashboard
## Accomplishments that we're proud of
We are proud that by the end of the hacking period, we had a working prototype and software. Both of these factors were able to integrate properly. The AI assistant, Sierra, can accurately recognize faces as well as detect settings in the real world. Although there were challenges along the way, the immense effort we put in paid off.
## What we learned
* How to work with a variety of Google Cloud-based tools and how to overcome potential challenges they pose to beginner users.
* How to connect a smartphone to a laptop with a remote connection to create more opportunities for practical designs and demonstrations.
How to connect a smartphone to a laptop with a remote connection to create more opportunities for practical designs and demonstrations.
How to create docker containers to deploy google cloud-based flask applications to host our dashboard.
How to develop Firebase Cloud Functions to implement cron jobs. We tried to developed a cron job that would send alerts to the user.
## What's next for Saight
### Optimizing the Response Time
Currently, the hardware limitations of our computers create a large delay in the assistant's response times. By improving the efficiency of the models used, we can improve the user experience in fast-paced environments.
### Testing Various Materials for the Mount
The physical prototype of the mount was mainly a proof-of-concept for the idea. In the future, we can conduct research and testing on various materials to find out which ones are most preferred by users. Factors such as density, cost and durability will all play a role in this decision. | ## Inspiration
Fresh fruit, vegetables, nuts, and legumes don’t play the **central role** they need to in our food system. The result is a **chronic health epidemic**, disastrous impacts on the **climate**, and **unequal access** to food. We wanted to find a tangible solution to this very real and consequential problem.
## What it does
Cropscape analyzes location-specific **soil**, **climate**, and **hardiness** data to provide personalized crop recommendations for a thriving backyard garden. The user inputs a
## How we built it
We built our project using React, Express, Node.js, and MySQL.
## Challenges we ran into
ChatGPT required tokens that cost money. We had difficulties implementing React on the frontend, so we had to opt for vanilla HTML/CSS.
## Accomplishments that we're proud of
We are proud of our ability to leverage several APIs to create a centralized source of gardening-relevant information.
## What's next for Cropscape
Gaining access to more robust databases of soil information, implementing a better soil analysis system. | ## Inspiration
As we sat down to brainstorm ideas for our next project, we were struck by a common thread that connected all of us. Each one of us had a family member who suffered from some form of visual impairment. It was a heart-wrenching reminder of the challenges that these individuals face on a daily basis. We shared stories of our loved ones struggling to read books, watch movies, or even navigate through everyday tasks. It was a deeply emotional conversation that left us feeling both empathetic and determined to make a difference. According to the World Health Organization, approximately 2.2 billion people worldwide have a vision impairment or blindness, with the majority of cases occurring in low and middle-income countries. The impact of visual impairment is far-reaching and significantly affects various daily activities such as reading, recognizing faces, navigating unfamiliar environments, and accessing information on digital platforms. This problem is valid, and it needs to be addressed to enhance the quality of life of those affected. We are passionate about developing a solution that will make a meaningful difference in the lives of those affected by visual impairment. Our project is inspired by personal experiences and fueled by a desire to make a real-world impact. We believe that everyone deserves equal access to information and the ability to participate fully in daily life. By addressing the challenges of visual impairment, we hope to create a more inclusive world for all.
## What it does
The product aims to bridge the gap for individuals with limited vision to experience the world around them. It helps individuals with visual impairments to perform various daily activities that are otherwise challenging, such as reading, recognizing faces, and navigating unfamiliar environments. It also assists in accessing information on digital platforms. The product can be particularly helpful for those who face barriers in accessing healthcare services due to their visual impairments. It can aid in reading prescription labels, understanding medical instructions, and navigating healthcare facilities, especially for older individuals who are aging.
## How we built it
In our project, we leverage cutting-edge computer vision techniques to interpret the surrounding environment of individuals with visual impairments. By utilizing advanced algorithms and neural networks, we process real-time visual data captured by a camera, enabling us to identify and analyze objects, obstacles, and spatial cues in the user's surroundings. We integrate state-of-the-art language models and natural language generation powered by Wisp AI software to bridge the gap between the interpreted world and the user. This allows us to generate detailed and contextually relevant descriptions of the environment in real time, providing visually impaired individuals with comprehensive auditory feedback about their surroundings. Additionally, our solution extends beyond descriptive capabilities to enhance accessibility in public transportation. By leveraging the interpreted environmental data, we develop guidance systems that assist users in navigating through streets and accessing transportation hubs safely and independently. For efficient and scalable deployment of our model, we utilize Intel's AI environment, leveraging its robust infrastructure and resources to host and optimize our machine learning algorithms. Our system architecture is implemented on a Raspberry Pi embedded platform, equipped with a high-resolution camera for real-time visualization and data capture. This combination of hardware and software components enables seamless integration and efficient visual information processing, empowering visually impaired individuals with enhanced mobility and independence in their daily lives.
## Challenges we ran into
As beginners in machine learning, we faced the tough challenge of setting up a machine learning model on a Raspberry Pi and connecting it to a camera, which was quite difficult to learn. Moreover, we had to figure out a way to train our model not only to understand text but also to recognize public transportation and calculate the distance to a bus entrance, which was quite a task. Adding our Intel-AI environment to the project made things even more complicated. Additionally, finding an affordable solution that could be easily accessible to people all around the world was a significant obstacle that we had to overcome.
## Accomplishments that we're proud of
Through this process of building a hardware product from scratch and learning how to use raspberry pi with computer vision, we not only gained technical knowledge but also learned how to work as a team. There were challenges and obstacles along the way, but we figured it out by collaborating, communicating, and leveraging each other's strengths. It was a great learning experience, and we are proud of what we have achieved together.
## What we learned
We learned about LLM, real-time text analysis, real-time text comprehension, and implementation of text-to-speech.
## What's next for True-Sight
With the growing potential of Artificial Intelligence, our idea of True-Sight is expanding to include not only text recognition but also the ability to detect surroundings, which could greatly benefit public transportation users who rely on finding stops and navigating their way onto the correct buses/trains. After further development, True-Sight could potentially allow users to locate their desired stop and use environment detection to guide them towards the door with specific step-by-step instructions. In addition, we aim to make True-Sight accessible to children who are visually impaired, so they can have an immersive learning experience. Adding sensors and custom software will also allow for a more personalized and relatable experience with the AI assistant. | winning |
# 🤖🖌️ [VizArt Computer Vision Drawing Platform](https://vizart.tech)
Create and share your artwork with the world using VizArt - a simple yet powerful air drawing platform.
## 💫 Inspiration
>
> "Art is the signature of civilizations." - Beverly Sills
>
>
>
Art is a gateway to creative expression. With [VizArt](https://vizart.tech/create), we are pushing the boundaries of what's possible with computer vision and enabling a new level of artistic expression. ***We envision a world where people can interact with both the physical and digital realms in creative ways.***
We started by pushing the limits of what's possible with customizable deep learning, streaming media, and AR technologies. With VizArt, you can draw in art, interact with the real world digitally, and share your creations with your friends!
>
> "Art is the reflection of life, and life is the reflection of art." - Unknow
>
>
>
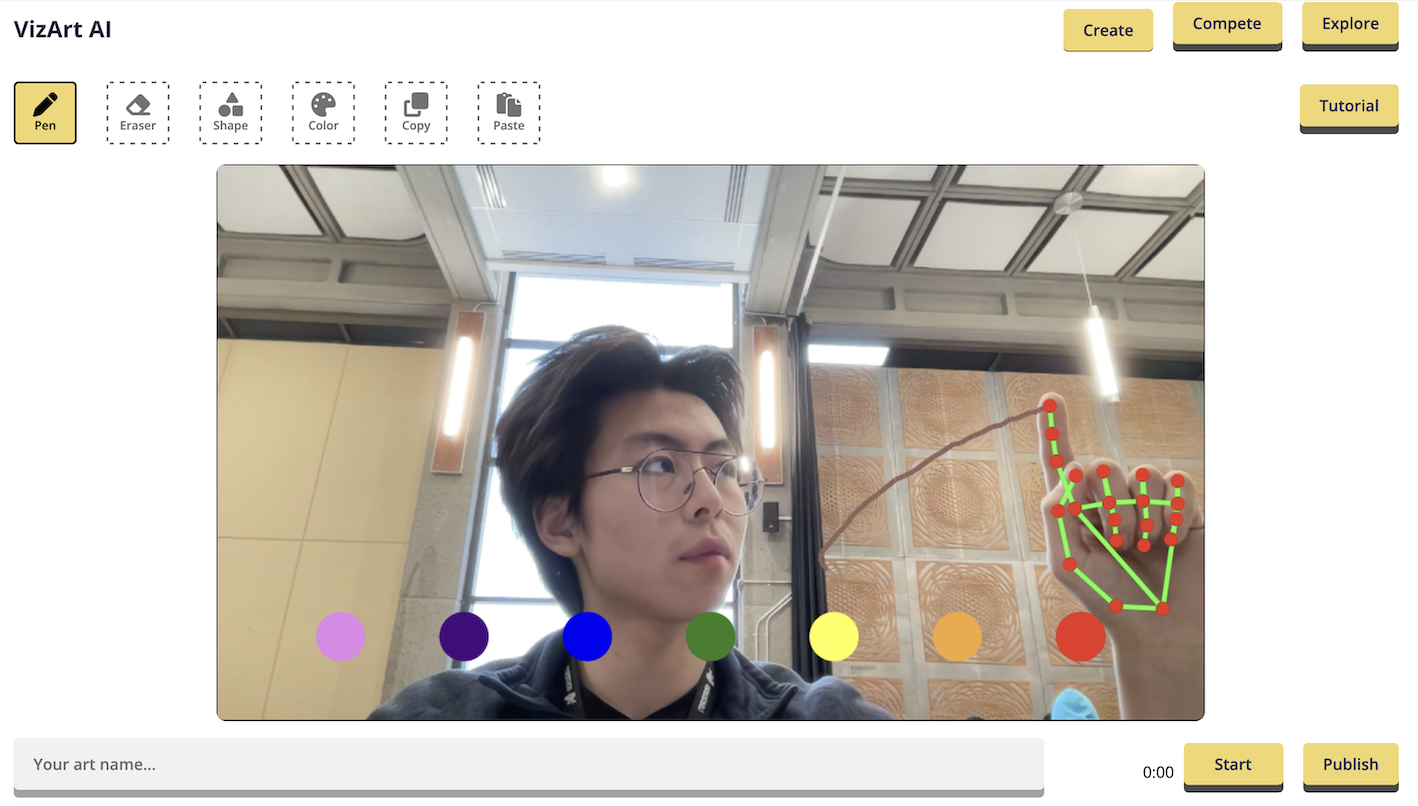
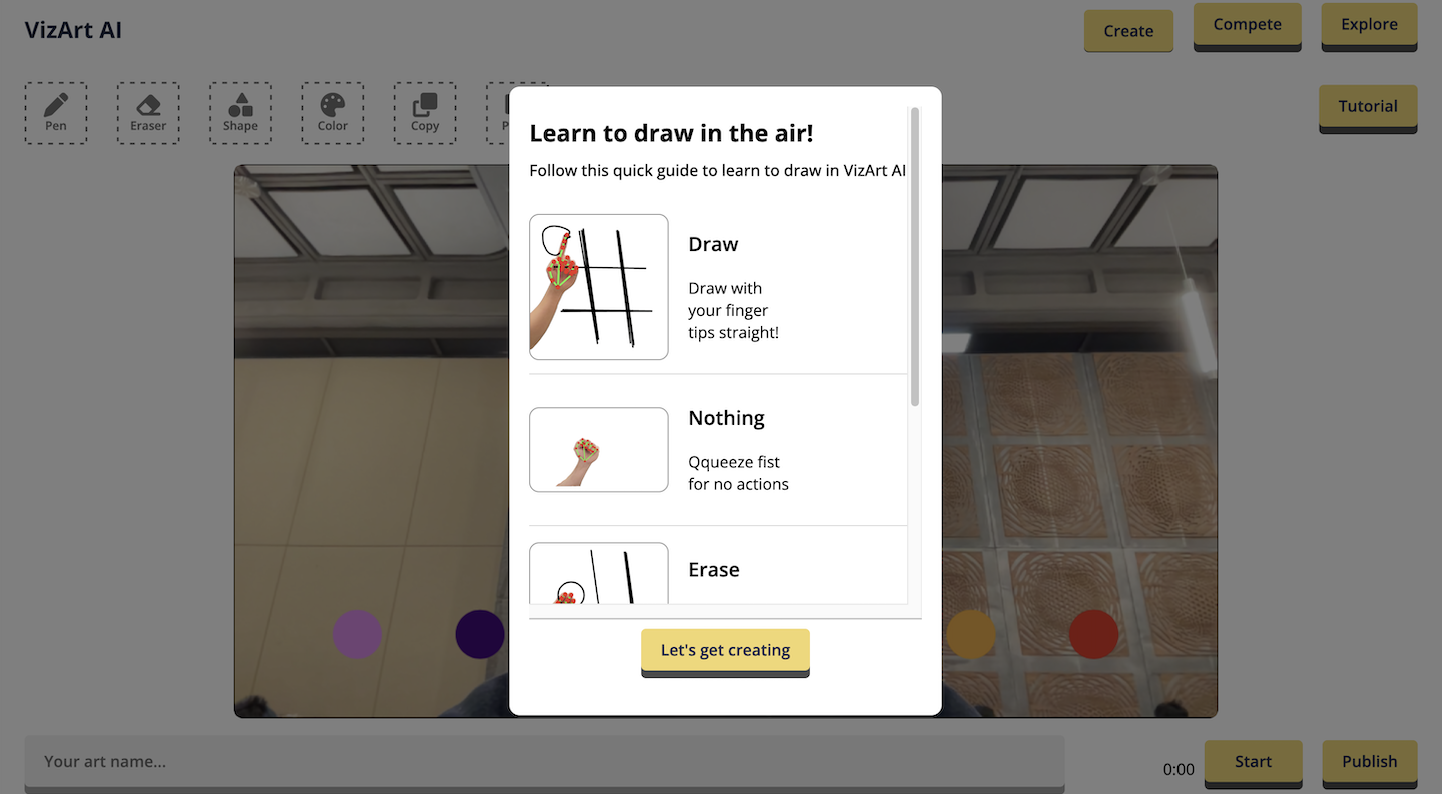
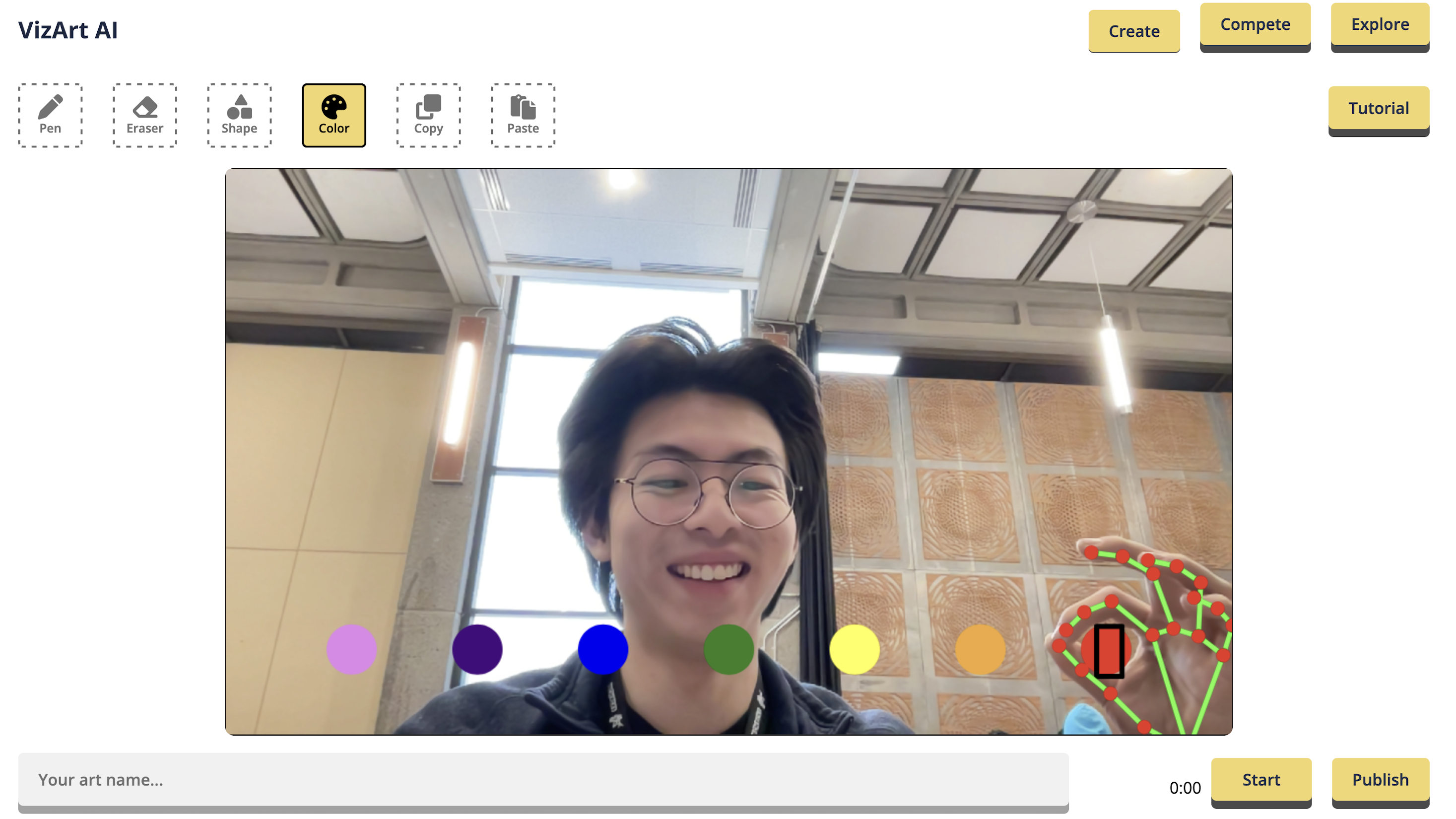
Air writing is made possible with hand gestures, such as a pen gesture to draw and an eraser gesture to erase lines. With VizArt, you can turn your ideas into reality by sketching in the air.
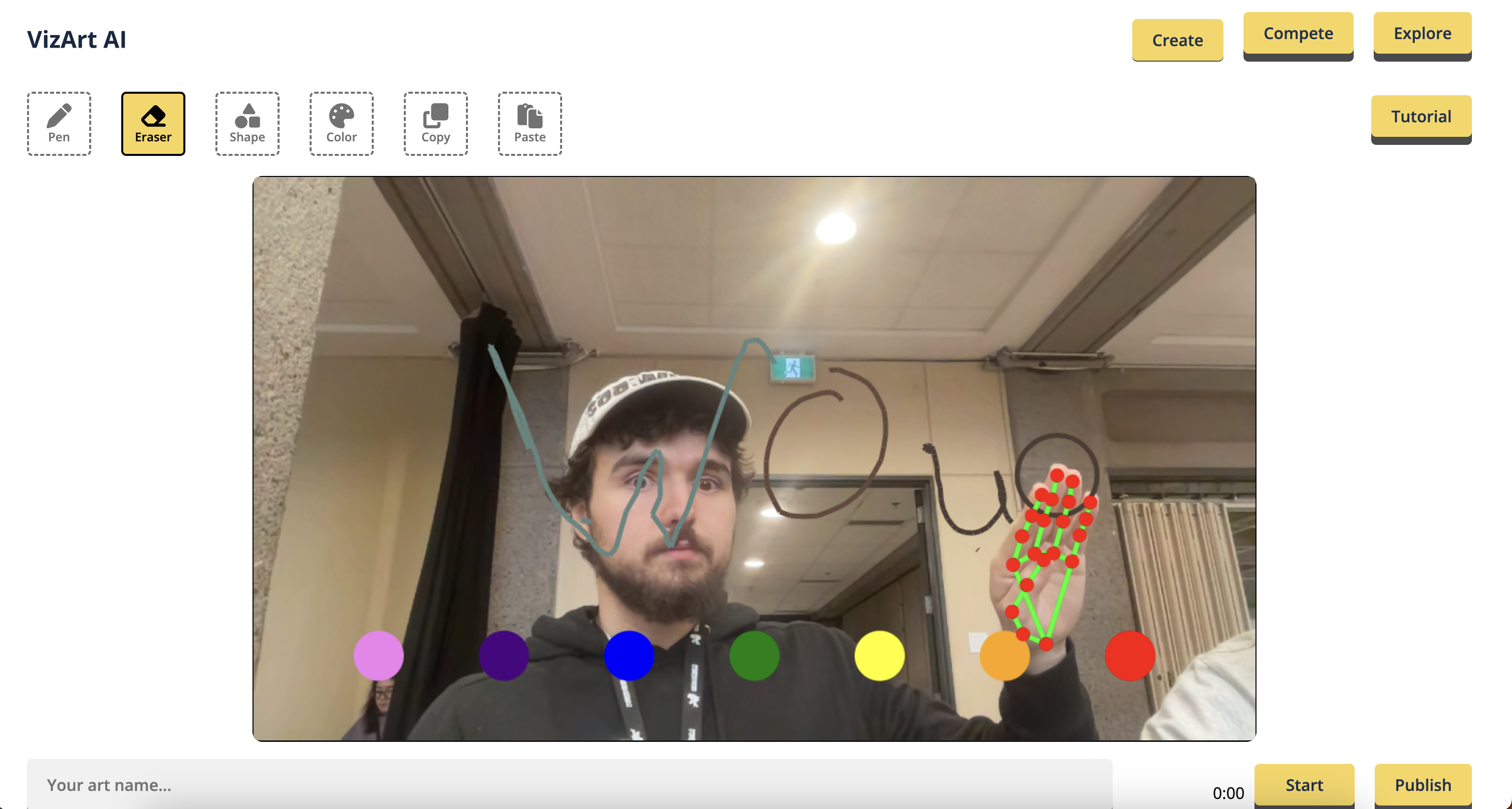
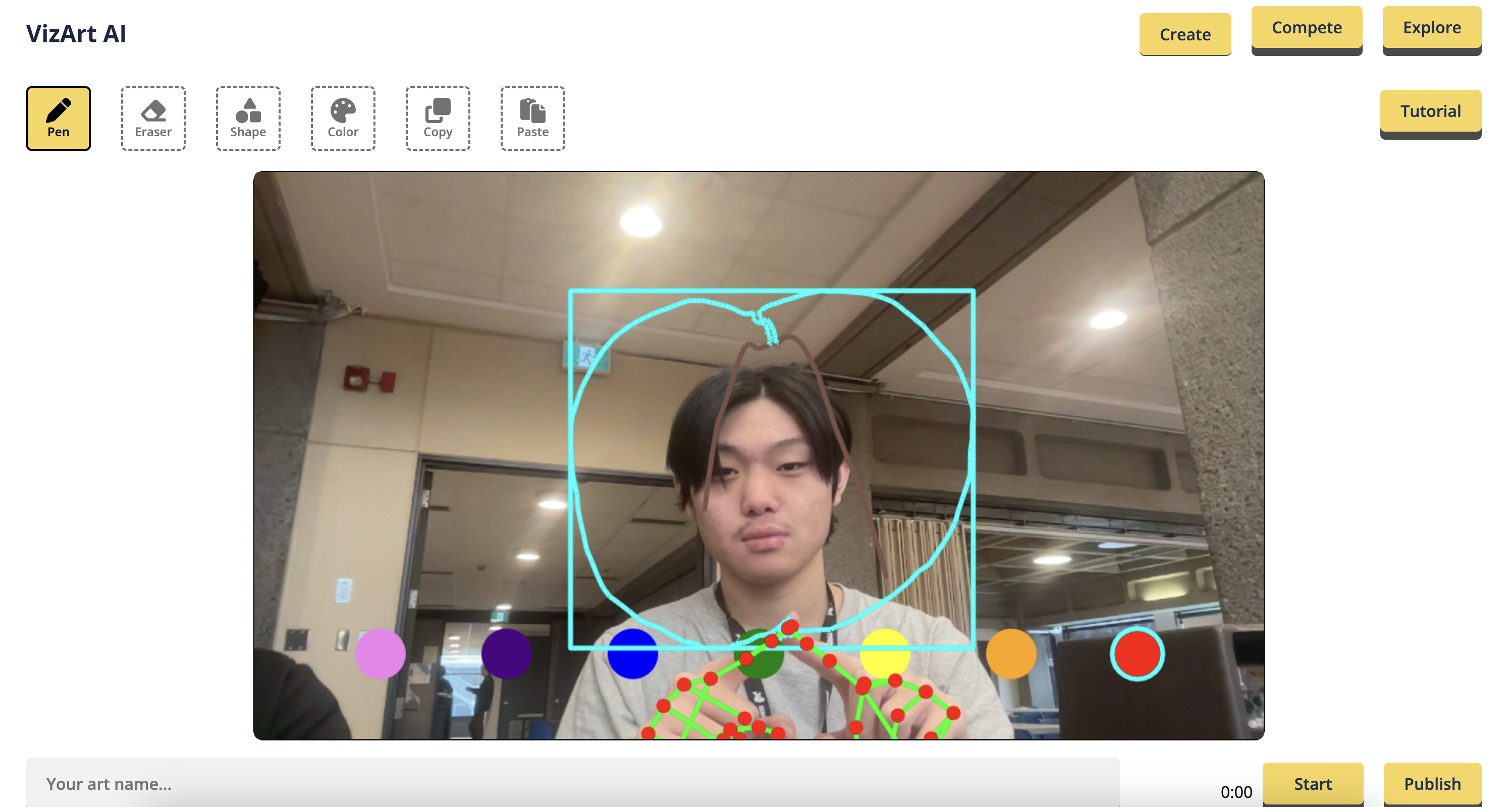
Our computer vision algorithm enables you to interact with the world using a color picker gesture and a snipping tool to manipulate real-world objects.
>
> "Art is not what you see, but what you make others see." - Claude Monet
>
>
>
The features I listed above are great! But what's the point of creating something if you can't share it with the world? That's why we've built a platform for you to showcase your art. You'll be able to record and share your drawings with friends.
I hope you will enjoy using VizArt and share it with your friends. Remember: Make good gifts, Make good art.
# ❤️ Use Cases
### Drawing Competition/Game
VizArt can be used to host a fun and interactive drawing competition or game. Players can challenge each other to create the best masterpiece, using the computer vision features such as the color picker and eraser.
### Whiteboard Replacement
VizArt is a great alternative to traditional whiteboards. It can be used in classrooms and offices to present ideas, collaborate with others, and make annotations. Its computer vision features make drawing and erasing easier.
### People with Disabilities
VizArt enables people with disabilities to express their creativity. Its computer vision capabilities facilitate drawing, erasing, and annotating without the need for physical tools or contact.
### Strategy Games
VizArt can be used to create and play strategy games with friends. Players can draw their own boards and pieces, and then use the computer vision features to move them around the board. This allows for a more interactive and engaging experience than traditional board games.
### Remote Collaboration
With VizArt, teams can collaborate remotely and in real-time. The platform is equipped with features such as the color picker, eraser, and snipping tool, making it easy to interact with the environment. It also has a sharing platform where users can record and share their drawings with anyone. This makes VizArt a great tool for remote collaboration and creativity.
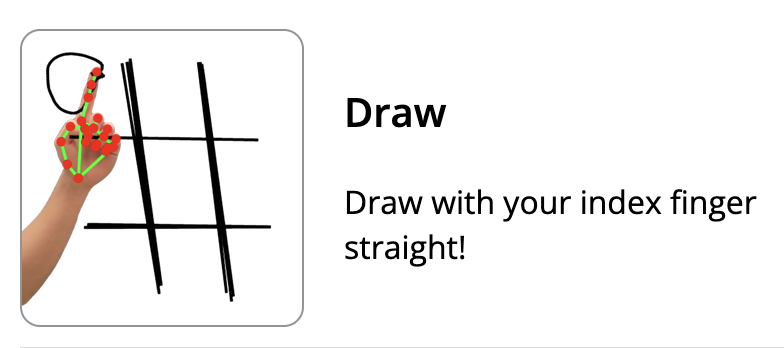
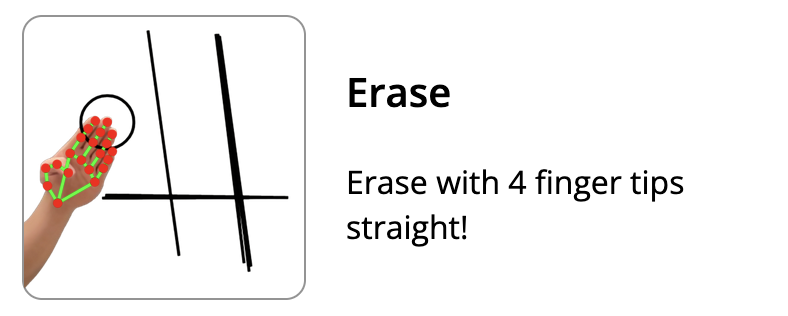
# 👋 Gestures Tutorial


# ⚒️ Engineering
Ah, this is where even more fun begins!
## Stack
### Frontend
We designed the frontend with Figma and after a few iterations, we had an initial design to begin working with. The frontend was made with React and Typescript and styled with Sass.
### Backend
We wrote the backend in Flask. To implement uploading videos along with their thumbnails we simply use a filesystem database.
## Computer Vision AI
We use MediaPipe to grab the coordinates of the joints and upload images. WIth the coordinates, we plot with CanvasRenderingContext2D on the canvas, where we use algorithms and vector calculations to determinate the gesture. Then, for image generation, we use the DeepAI open source library.
# Experimentation
We were using generative AI to generate images, however we ran out of time.
# 👨💻 Team (”The Sprint Team”)
@Sheheryar Pavaz
@Anton Otaner
@Jingxiang Mo
@Tommy He | ## Inspiration
With more people working at home due to the pandemic, we felt empowered to improve healthcare at an individual level. Existing solutions for posture detection are expensive, lack cross-platform support, and often require additional device purchases. We sought to remedy these issues by creating Upright.
## What it does
Upright uses your laptop's camera to analyze and help you improve your posture. Register and calibrate the system in less than two minutes, and simply keep Upright open in the background and continue working. Upright will notify you if you begin to slouch so you can correct it. Upright also has the Upright companion iOS app to view your daily metrics.
Some notable features include:
* Smart slouch detection with ML
* Little overhead - get started in < 2 min
* Native notifications on any platform
* Progress tracking with an iOS companion app
## How we built it
We created Upright’s desktop app using Electron.js, an npm package used to develop cross-platform apps. We created the individual pages for the app using HTML, CSS, and client-side JavaScript. For the onboarding screens, users fill out an HTML form which signs them in using Firebase Authentication and uploads information such as their name and preferences to Firestore. This data is also persisted locally using NeDB, a local JavaScript database. The menu bar addition incorporates a camera through a MediaDevices web API, which gives us frames of the user’s posture. Using Tensorflow’s PoseNet model, we analyzed these frames to determine if the user is slouching and if so, by how much. The app sends a desktop notification to alert the user about their posture and also uploads this data to Firestore. Lastly, our SwiftUI-based iOS app pulls this data to display metrics and graphs for the user about their posture over time.
## Challenges we ran into
We faced difficulties when managing data throughout the platform, from the desktop app backend to the frontend pages to the iOS app. As this was our first time using Electron, our team spent a lot of time discovering ways to pass data safely and efficiently, discussing the pros and cons of different solutions. Another significant challenge was performing the machine learning on the video frames. The task of taking in a stream of camera frames and outputting them into slouching percentage values was quite demanding, but we were able to overcome several bugs and obstacles along the way to create the final product.
## Accomplishments that we're proud of
We’re proud that we’ve come up with a seamless and beautiful design that takes less than a minute to setup. The slouch detection model is also pretty accurate, something that we’re pretty proud of. Overall, we’ve built a robust system that we believe outperforms other solutions using just the webcamera of your computer, while also integrating features to track slouching data on your mobile device.
## What we learned
This project taught us how to combine multiple complicated moving pieces into one application. Specifically, we learned how to make a native desktop application with features like notifications built-in using Electron. We also learned how to connect our backend posture data with Firestore to relay information from our Electron application to our OS app. Lastly, we learned how to integrate a machine learning model in Tensorflow within our Electron application.
## What's next for Upright
The next step is improving the posture detection model with more training data, tailored for each user. While the posture detection model we currently use is pretty accurate, by using more custom-tailored training data, it would take Upright to the next level. Another step for Upright would be adding Android integration for our mobile app, which currently only supports iOS as of now. | ## Overview
We designed fingerpaint, an app that utilizes visual image processing to implement a drawing tool through motion detection. Using OpenCV, we analyze video streams through a user's webcam footage and use that information to inform the user's interaction with a Canvas. This allows users to more easily whiteboard and prototype basic designs through drawing than with existing systems as Microsoft Paint.
## How it Works
When the app first loads, it opens up on an initialization screen that allows users to calibrate the app to their drawing tool of choice. To simplify the model required, we detected a marker on the user's finger using brightly colored electrical tape. After calibration finishes, the user's marked finger is recognized by the app and can be used to interact with the Canvas (implemented with tkinter). Informed by a history of past points, our model detects where the finger is moving and uses this information to move a cursor. When the user presses the 'a' key while the cursor moves, the user can draw on the Canvas.
## Challenges
This was our first time working with OpenCV/Computer Vision in general, so we had a lot of difficulties in determining how best to leverage all the tools the library has and the best way to accomplish the Computer Vision task we had. We had a lot of iteration playing with different approaches to figure out what would work best.
## Next Steps
Implement more advanced gesture recognition and UI related features (Undos, Saving Images to Local File, etc.) | winning |
## Inspiration
Since this was the first hackathon for most of our group, we wanted to work on a project where we could learn something new while sticking to familiar territory. Thus we settled on programming a discord bot, something all of us have extensive experience using, that works with UiPath, a tool equally as intriguing as it is foreign to us. We wanted to create an application that will allow us to track the prices and other related information of tech products in order to streamline the buying process and enable the user to get the best deals. We decided to program a bot that utilizes user input, web automation, and web-scraping to generate information on various items, focusing on computer components.
## What it does
Once online, our PriceTracker bot runs under two main commands: !add and !price. Using these two commands, a few external CSV files, and UiPath, this stores items input by the user and returns related information found via UiPath's web-scraping features. A concise display of the product’s price, stock, and sale discount is displayed to the user through the Discord bot.
## How we built it
We programmed the Discord bot using the comprehensive discord.py API. Using its thorough documentation and a handful of tutorials online, we quickly learned how to initialize a bot using Discord's personal Development Portal and create commands that would work with specified text channels. To scrape web pages, in our case, the Canada Computers website, we used a UiPath sequence along with the aforementioned CSV file, which contained input retrieved from the bot's "!add" command. In the UiPath process, each product is searched on the Canada Computers website and then through data scraping, the most relevant results from the search and all related information are processed into a csv file. This csv file is then parsed through to create a concise description which is returned in Discord whenever the bot's "!prices" command was called.
## Challenges we ran into
The most challenging aspect of our project was figuring out how to use UiPath. Since Python was such a large part of programming the discord bot, our experience with the language helped exponentially. The same could be said about working with text and CSV files. However, because automation was a topic none of us hardly had any knowledge of; naturally, our first encounter with it was rough. Another big problem with UiPath was learning how to use variables as we wanted to generalize the process so that it would work for any product inputted.
Eventually, with enough perseverance, we were able to incorporate UiPath into our project exactly the way we wanted to.
## Accomplishments that we're proud of
Learning the ins and outs of automation alone was a strenuous task. Being able to incorporate it into a functional program is even more difficult, but incredibly satisfying as well. Albeit small in scale, this introduction to automation serves as a good stepping stone for further research on the topic of automation and its capabilities.
## What we learned
Although we stuck close to our roots by relying on Python for programming the discord bot, we learned a ton of new things about how these bots are initialized, the various attributes and roles they can have, and how we can use IDEs like Pycharm in combination with larger platforms like Discord. Additionally, we learned a great deal about automation and how it functions through UiPath which absolutely fascinated us the first time we saw it in action. As this was the first Hackathon for most of us, we also got a glimpse into what we have been missing out on and how beneficial these competitions can be. Getting the extra push to start working on side-projects and indulging in solo research was greatly appreciated.
## What's next for Tech4U
We went into this project with a plethora of different ideas, and although we were not able to incorporate all of them, we did finish with something we were proud of. Some other ideas we wanted to integrate include: scraping multiple different websites, formatting output differently on Discord, automating the act of purchasing an item, taking input and giving output under the same command, and more. | ## Inspiration
As students, we have found that there are very few high-quality resources on investing for those who are interested but don't have enough resources. Furthermore, we have found that investing and saving money can be a stressful experience. We hope to change this for those who want to save better with the help of our app, hopefully making it fun in the process!
## What it does
Our app first asks a new client a brief questionnaire about themselves. Then, using their banking history, it generates 3 "demons", aka bad spending habits, to kill. Then, after the client chooses a habit to work on, it brings them to a dashboard where they can monitor their weekly progress on a task. Once the week is over, the app declares whether the client successfully beat the mission - if they did, they get rewarded with points which they can exchange for RBC Loyalty points!
## How we built it
We built the frontend using React + Tailwind, using Routes to display our different pages. We used Cohere for our AI services, both for generating personalized weekly goals and creating a more in-depth report. We used Firebase for authentication + cloud database to keep track of users. For our data of users and transactions, as well as making/managing loyalty points, we used the RBC API.
## Challenges we ran into
Piecing the APIs together was probably our most difficult challenge. Besides learning the different APIs in general, integrating the different technologies got quite tricky when we are trying to do multiple things at the same time!
Besides API integration, definitely working without any sleep though was the hardest part!
## Accomplishments that we're proud of
Definitely our biggest accomplishment was working so well together as a team. Despite only meeting each other the day before, we got along extremely well and were able to come up with some great ideas and execute under a lot of pressure (and sleep deprivation!) The biggest reward from this hackathon are the new friends we've found in each other :)
## What we learned
I think each of us learned very different things: this was Homey and Alex's first hackathon, where they learned how to work under a small time constraint (and did extremely well!). Paige learned tons about React, frontend development, and working in a team. Vassily learned lots about his own strengths and weakness (surprisingly reliable at git, apparently, although he might have too much of a sweet tooth).
## What's next for Savvy Saver
Demos! After that, we'll just have to see :) | ## Inspiration
For Watchr, we took inspiration from old-school DVR machines. You know, the kind that records your favourite television show watching at your leisure. Looking at our lives, we saw that we missed countless live web events due to other commitments. And thus, Watchr was born!
## What it does
Watchr is a simple desktop platform that records live screen events. Users can set the target source, live stream time and file directory. A small preview will be displayed to confirm all choices. Users can schedule multiple live stream recordings, perfect for all occasions. When the event rolls around, sit back and let Watchr go to work! Watchr will record live stream events, before automatically downloading and storing them on your device.
Users can also scroll through a list of past live streams recorded through Watchr and delete upcoming scheduled recordings.
## How we built it
Watchr was built on an Electron, with a React.js frontend. We relied on a couple of crucial react libraries such as “react-datetimepicker” and “react-popup” which we styled with CSS.
## Challenges we ran into
While creating Watchr, we ran into a few different problems. One key issue dealt with using unfamiliar technology and software. Getting our bearings on Electron and React took some time, but once we gave ourselves some time to become comfortable with the software, we were able to make solid progress.
Furthermore, we ran into problems with rapidly updating software. For example, many online guides and resources concerning Electron were outdated due to the quick pace at which software updates were released. We also dealt with many merge conflicts, but through this experience, we learned how to avoid and resolve them when working collaboratively.
## Accomplishments that we're proud of
We are proud of creating a working desktop application through Electron and React. This project was the first time many members came into contact with either technology, and we are proud of being able to stretch our thinking and step outside of our comfort zones.
## What we learned
By creating Watchr, we learned the importance of teamwork and communicating with one another in an effective manner. Due to the countless merge conflicts we faced, we wasted many hours that could have been spent creating new features or coding. This will be a learning lesson for all of us next time.
Furthermore, coding Watchr taught many team members fundamentals in Electron and React. Watchr helped to create core skills and helped to inspire many possible future ideas due to our newfound skills. | partial |
## Inspiration
How many times have you opened your fridge door and examined its contents for something to eat/cook/stare at and ended up finding a forgotten container of food in the back of the fridge (a month past its expiry date) instead? Are you brave enough to eat it, or does it immediately go into the trash?
The most likely answer would be to dispose of it right away for health and safety reasons, but you'd be surprised - food wastage is a problem that [many countries such as Canada](https://seeds.ca/schoolfoodgardens/food-waste-in-canada-3/) contend with every year, even as world hunger continues to increase! Big corporations and industries contribute to most of the wastage that occurs worldwide, but we as individual consumers can do our part to reduce food wastage as well by minding our fridges and pantries and making sure we eat everything that we procure for ourselves.
Enter chec:xpire - the little app that helps reduce food wastage, one ingredient at a time!
## What it does
chec:xpire takes stock of the contents of your fridge and informs you which food items are close to their best-before date. chec:xpire also provides a suggested recipe which makes use of the expiring ingredients, allowing you to use the ingredients in your next meal without letting them go to waste due to spoilage!
## How we built it
We built the backend using Express.js, which laid the groundwork for interfacing with Solace, an event broker. The backend tracks food items (in a hypothetical refrigerator) as well as their expiry dates, and picks out those that are two days away from their best-before date so that the user knows to consume them soon. The app also makes use of the co:here AI to retrieve and return recipes that make use of the expiring ingredients, thus providing a convenient way to use up the expiring food items without having to figure out what to do with them in the next couple days.
The frontend is a simple Node.js app that subscribes to "events" (in this case, food approaching their expiry date) through Solace, which sends the message to the frontend app once the two-day mark before the expiry date is reached. A notification is sent to the user detailing which ingredients (and their quantities) are expiring soon, along with a recipe that uses the ingredients up.
## Challenges we ran into
The scope of our project was a little too big for our current skillset; we ran into a few problems finding ways to implement the features that we wanted to include in the project, so we had to find ways to accomplish what we wanted to do using other methods.
## Accomplishments that we're proud of
All but one member of the team are first-time hackathon participants - we're very proud of the fact that we managed to create a working program that did what we wanted it to, despite the hurdles we came across while trying to figure out what frameworks we wanted to use for the project!
## What we learned
* planning out a project that's meant to be completed within 36 hours is difficult, especially if you've never done it before!
* there were some compromises that needed to be made due to a combination of framework-related hiccups and the limitations of our current skillsets, but there's victory to be had in seeing a project through to the end even if we weren't able to accomplish every single little thing we wanted to
* Red Bull gives you wings past midnight, apparently
## What's next for chec:xpire
A fully implemented frontend would be great - we ran out of time! | ## Inspiration
The inspiration for our food waste reduction web app stems from the everyday challenges faced by college students like us. Balancing our limited time and budget, we often found ourselves making frequent grocery runs or inadvertently wasting ingredients forgotten in the fridge. Recognizing the need to optimize resource utilization, we conceived this project. We sought to empower fellow students to minimize food waste by generating innovative recipe suggestions from their leftovers. Our goal is to help users save time, money, and the environment while making the most of their groceries. This project embodies our commitment to efficiency, sustainability, and the pursuit of a more conscientious college life.
## What it does
Our web app revolutionizes kitchen efficiency. Users simply input their available leftovers, and our AI takes charge. It crafts personalized recipe suggestions, utilizing as many mentioned ingredients as possible. This culinary wizardry provides users with a comprehensive array of cooking options for their surplus items, reducing food waste and saving money. Whether you've got a hodgepodge of ingredients or a few stragglers in the fridge, our app transforms them into delectable, resourceful dishes. It's the ultimate kitchen companion, harnessing the power of AI to make every meal a creative and waste-free delight. Say goodbye to food waste and hello to culinary innovation.
## How we built it
Initially, we crafted a user-friendly front-end webpage using HTML, CSS, and JavaScript, complete with an input slot for users to list their leftover food items. Moving to the backend, we employed Python and Flask to build a robust server-side system. This backend handled the critical logic, transforming the user's input into an API request. The magic ingredient, so to speak, came from the OpenAI API, which we integrated to convert the list of ingredients into a treasure trove of creative recipes.
## Challenges we ran into
Bridging the gap between our front-end and back-end code, particularly in a JavaScript environment, posed a significant challenge. As newcomers to commercial APIs, we grappled with the initial learning curve, navigating the intricacies of API implementation. However, through the help of our numerous mentors, we were eventually able to overcome the challenges and learn from the experience.
## Accomplishments that we're proud of
Our journey was marked by significant achievements and personal growth. For many of us, Git and API implementation were uncharted territories at the project's start. However, we are immensely proud of our collective dedication and determination, which enabled us to not only learn but also seamlessly integrate these two key skills into our project. The ability to navigate Git and harness the power of APIs has not only enriched our project but also expanded our own skill sets, making us better-equipped developers and problem solvers. These accomplishments stand as a testament to our commitment to continual learning and improvement.
## What we learned
We learned a wide range of both technical and non-technical skills from this project.
Some new technical skills that we learned, that were new to most or all of us were:
Flask,
Git,
APIs,
Hosting backed and frontend servers separately,
Javascript,
collaboration and peer programming.
## What's next for Pantry Puzzle
An additional feature that allows users to take a photo of their leftovers for an image-to-text conversion, instead of manually inserting as text. | ## Inspiration
The first step of our development process was conducting user interviews with University students within our social circles. When asked of some recently developed pain points, 40% of respondents stated that grocery shopping has become increasingly stressful and difficult with the ongoing COVID-19 pandemic. The respondents also stated that some motivations included a loss of disposable time (due to an increase in workload from online learning), tight spending budgets, and fear of exposure to covid-19.
While developing our product strategy, we realized that a significant pain point in grocery shopping is the process of price-checking between different stores. This process would either require the user to visit each store (in-person and/or online) and check the inventory and manually price check. Consolidated platforms to help with grocery list generation and payment do not exist in the market today - as such, we decided to explore this idea.
**What does G.e.o.r.g.e stand for? : Grocery Examiner Organizer Registrator Generator (for) Everyone**
## What it does
The high-level workflow can be broken down into three major components:
1: Python (flask) and Firebase backend
2: React frontend
3: Stripe API integration
Our backend flask server is responsible for web scraping and generating semantic, usable JSON code for each product item, which is passed through to our React frontend.
Our React frontend acts as the hub for tangible user-product interactions. Users are given the option to search for grocery products, add them to a grocery list, generate the cheapest possible list, compare prices between stores, and make a direct payment for their groceries through the Stripe API.
## How we built it
We started our product development process with brainstorming various topics we would be interested in working on. Once we decided to proceed with our payment service application. We drew up designs as well as prototyped using Figma, then proceeded to implement the front end designs with React. Our backend uses Flask to handle Stripe API requests as well as web scraping. We also used Firebase to handle user authentication and storage of user data.
## Challenges we ran into
Once we had finished coming up with our problem scope, one of the first challenges we ran into was finding a reliable way to obtain grocery store information. There are no readily available APIs to access price data for grocery stores so we decided to do our own web scraping. This lead to complications with slower server response since some grocery stores have dynamically generated websites, causing some query results to be slower than desired. Due to the limited price availability of some grocery stores, we decided to pivot our focus towards e-commerce and online grocery vendors, which would allow us to flesh out our end-to-end workflow.
## Accomplishments that we're proud of
Some of the websites we had to scrape had lots of information to comb through and we are proud of how we could pick up new skills in Beautiful Soup and Selenium to automate that process! We are also proud of completing the ideation process with an application that included even more features than our original designs. Also, we were scrambling at the end to finish integrating the Stripe API, but it feels incredibly rewarding to be able to utilize real money with our app.
## What we learned
We picked up skills such as web scraping to automate the process of parsing through large data sets. Web scraping dynamically generated websites can also lead to slow server response times that are generally undesirable. It also became apparent to us that we should have set up virtual environments for flask applications so that team members do not have to reinstall every dependency. Last but not least, deciding to integrate a new API at 3am will make you want to pull out your hair, but at least we now know that it can be done :’)
## What's next for G.e.o.r.g.e.
Our next steps with G.e.o.r.g.e. would be to improve the overall user experience of the application by standardizing our UI components and UX workflows with Ecommerce industry standards. In the future, our goal is to work directly with more vendors to gain quicker access to price data, as well as creating more seamless payment solutions. | losing |
## Inspiration
As university students, we are finally able to experience moving out and living on our own. Something we've realized is that shopping is an inescapable part of adult life. It can be tedious to figure out what to buy in the moment, and keeping track of items after you've decided and then searching for them throughout the store is no easy feat. Hence, we've decided to design an app that makes shopping cheap, convenient and *smart*.
## What it does
Our app has two main features, an intelligent recommendation system that can use user voice/text search to recommend products as well as a system for product image recognition. The recommendation system allows users to quickly search up relevant items by saying what they want to buy (ex. “What should I buy for my daughter’s birthday party?”, or "what is on sale this week?"). The app will then list smart suggestions pertaining to what you inputted, that can be added to the shopping list. Users can also take pictures of products to figure out the price of a product, price match and check whether it is on sale. The shopping list can then be viewed and each product will list important information such as the aisle number so that shoppers can easily find them.
## How we built it
The app was built using React Native for cross platform support on mobile and the backend was built using Flask with Heroku.
The product database was generated using Selenium to scrape every item in the Loblaws website catalog, categorized by department with other relevant information that employees can add on (aisle number specific to a store).
The smart speech to text recommendation system was built using AssemblyAI as well as Datamuse API to first convert the speech to text, then get the relevant words using AssemblyAI’s keywords feature. The words were then fed into the Datamuse api to get words that are associated and then give them a rank which were then used to search the product database. This allows users to speak in both a **direct and a casual way**, with our system detecting the context of each and recommending the best products.
The image recognition was done using a mix of google vision api as well as a custom trained vision api product search model. This model was automatically generated using selenium by connecting the loblaws listings with google images and uploading into specific buckets on google storage. By comparing these two models, we are able to narrow down the image context to either a specific product in store, or annotate its more general uses. This is then passed onto the logic used by the recommendation system to give context to the search, and finally onto our custom product mapping system developed through automated analysis of product descriptions.
## Challenges we ran into
It was our first time working with React Native and training our own model. The model had very low confidence at the start and required a lot of tweaking before it was even slightly usable, and had to be used alongside the known Vision API. This was our first time using Heroku which provided easy CI/CD integration on GitHub, and we had to understand how to insert Vision API environment variables without committing them.
## Accomplishments that we're proud of
We are proud of our user friendly design that is intuitive, especially as a team that has no designers. We were also able to successfully implement every feature that we planned, which we are very proud of.
## What's next for ShopAdvisr
Working with a company directly and having access to their whole database would greatly improve the apps database without having to scrape the website, and allow more options for expansion. | ## Inspiration
It all started a couple days ago when my brother told me he'd need over an hour to pick up a few items from a grocery store because of the weekend checkout line. This led to us reaching out to other friends of ours and asking them about the biggest pitfalls of existing shopping systems. We got a whole variety of answers, but the overwhelming response was the time it takes to shop and more particularly checkout. This inspired us to ideate and come up with an innovative solution.
## What it does
Our app uses computer vision to add items to a customer's bill as they place items in the cart. Similarly, removing an item from the cart automatically subtracts them from the bill. After a customer has completed shopping, they can checkout on the app with the tap of a button, and walk out the store. It's that simple!
## How we built it
We used react with ionic for the frontend, and node.js for the backend. Our main priority was the completion of the computer vision model that detects items being added and removed from the cart. The model we used is a custom YOLO-v3Tiny model implemented in Tensorflow. We chose Tensorflow so that we could run the model using TensorflowJS on mobile.
## Challenges we ran into
The development phase had it's fair share of challenges. Some of these were:
* Deep learning models can never have too much data! Scraping enough images to get accurate predictions was a challenge.
* Adding our custom classes to the pre-trained YOLO-v3Tiny model.
* Coming up with solutions to security concerns.
* Last but not least, simulating shopping while quarantining at home.
## Accomplishments that we're proud of
We're extremely proud of completing a model that can detect objects in real time, as well as our rapid pace of frontend and backend development.
## What we learned
We learned and got hands on experience of Transfer Learning. This was always a concept that we knew in theory but had never implemented before. We also learned how to host tensorflow deep learning models on cloud, as well as make requests to them. Using google maps API with ionic react was a fun learning experience too!
## What's next for MoboShop
* Integrate with customer shopping lists.
* Display ingredients for recipes added by customer.
* Integration with existing security systems.
* Provide analytics and shopping trends to retailers, including insights based on previous orders, customer shopping trends among other statistics. | ## Inspiration
We admired the convenience Honey provides for finding coupon codes. We wanted to apply the same concept except towards making more sustainable purchases online.
## What it does
Recommends sustainable and local business alternatives when shopping online.
## How we built it
Front-end was built with React.js and Bootstrap. The back-end was built with Python, Flask and CockroachDB.
## Challenges we ran into
Difficulties setting up the environment across the team, especially with cross-platform development in the back-end. Extracting the current URL from a webpage was also challenging.
## Accomplishments that we're proud of
Creating a working product!
Successful end-to-end data pipeline.
## What we learned
We learned how to implement a Chrome Extension. Also learned how to deploy to Heroku, and set up/use a database in CockroachDB.
## What's next for Conscious Consumer
First, it's important to expand to make it easier to add local businesses. We want to continue improving the relational algorithm that takes an item on a website, and relates it to a similar local business in the user's area. Finally, we want to replace the ESG rating scraping with a corporate account with rating agencies so we can query ESG data easier. | partial |
## Inspiration
It’s Friday afternoon, and as you return from your final class of the day cutting through the trailing winds of the Bay, you suddenly remember the Saturday trek you had planned with your friends. Equipment-less and desperate you race down to a nearby sports store and fish out $$$, not realising that the kid living two floors above you has the same equipment collecting dust. While this hypothetical may be based on real-life events, we see thousands of students and people alike impulsively spending money on goods that would eventually end up in their storage lockers. This cycle of buy-store-collect dust inspired us to develop Lendit this product aims to stagnate the growing waste economy and generate passive income for the users on the platform.
## What it does
A peer-to-peer lending and borrowing platform that allows users to generate passive income from the goods and garments collecting dust in the garage.
## How we built it
Our Smart Lockers are built with RaspberryPi3 (64bit, 1GB RAM, ARM-64) microcontrollers and are connected to our app through interfacing with Google's Firebase. The locker also uses Facial Recognition powered by OpenCV and object detection with Google's Cloud Vision API.
For our App, we've used Flutter/ Dart and interfaced with Firebase. To ensure *trust* - which is core to borrowing and lending, we've experimented with Ripple's API to create an Escrow system.
## Challenges we ran into
We learned that building a hardware hack can be quite challenging and can leave you with a few bald patches on your head. With no hardware equipment, half our team spent the first few hours running around the hotel and even the streets to arrange stepper motors and Micro-HDMI wires. In fact, we even borrowed another team's 3-D print to build the latch for our locker!
On the Flutter/ Dart side, we were sceptical about how the interfacing with Firebase and Raspberry Pi would work. Our App Developer previously worked with only Web Apps with SQL databases. However, NoSQL works a little differently and doesn't have a robust referential system. Therefore writing Queries for our Read Operations was tricky.
With the core tech of the project relying heavily on the Google Cloud Platform, we had to resolve to unconventional methods to utilize its capabilities with an internet that played Russian roulette.
## Accomplishments that we're proud of
The project has various hardware and software components like raspberry pi, Flutter, XRP Ledger Escrow, and Firebase, which all have their own independent frameworks. Integrating all of them together and making an end-to-end automated system for the users, is the biggest accomplishment we are proud of.
## What's next for LendIt
We believe that LendIt can be more than just a hackathon project. Over the course of the hackathon, we discussed the idea with friends and fellow participants and gained a pretty good Proof of Concept giving us the confidence that we can do a city-wide launch of the project in the near future. In order to see these ambitions come to life, we would have to improve our Object Detection and Facial Recognition models. From cardboard, we would like to see our lockers carved in metal at every corner of this city. As we continue to grow our skills as programmers we believe our product Lendit will grow with it. We would be honoured if we can contribute in any way to reduce the growing waste economy. | ## Inspiration 🍪
We’re fed up with our roommates stealing food from our designated kitchen cupboards. Few things are as soul-crushing as coming home after a long day and finding that someone has eaten the last Oreo cookie you had been saving. Suffice it to say, the university student population is in desperate need of an inexpensive, lightweight security solution to keep intruders out of our snacks...
Introducing **Craven**, an innovative end-to-end pipeline to put your roommates in check and keep your snacks in stock.
## What it does 📸
Craven is centered around a small Nest security camera placed at the back of your snack cupboard. Whenever the cupboard is opened by someone, the camera snaps a photo of them and sends it to our server, where a facial recognition algorithm determines if the cupboard has been opened by its rightful owner or by an intruder. In the latter case, the owner will instantly receive an SMS informing them of the situation, and then our 'security guard' LLM will decide on the appropriate punishment for the perpetrator, based on their snack-theft history. First-time burglars may receive a simple SMS warning, but repeat offenders will have a photo of their heist, embellished with an AI-generated caption, posted on [our X account](https://x.com/craven_htn) for all to see.
## How we built it 🛠️
* **Backend:** Node.js
* **Facial Recognition:** OpenCV, TensorFlow, DLib
* **Pipeline:** Twilio, X, Cohere
## Challenges we ran into 🚩
In order to have unfettered access to the Nest camera's feed, we had to find a way to bypass Google's security protocol. We achieved this by running an HTTP proxy to imitate the credentials of an iOS device, allowing us to fetch snapshots from the camera at any time.
Fine-tuning our facial recognition model also turned out to be a bit of a challenge. In order to ensure accuracy, it was important that we had a comprehensive set of training images for each roommate, and that the model was tested thoroughly. After many iterations, we settled on a K-nearest neighbours algorithm for classifying faces, which performed well both during the day and with night vision.
Additionally, integrating the X API to automate the public shaming process required specific prompt engineering to create captions that were both humorous and effective in discouraging repeat offenders.
## Accomplishments that we're proud of 💪
* Successfully bypassing Nest’s security measures to access the camera feed.
* Achieving high accuracy in facial recognition using a well-tuned K-nearest neighbours algorithm.
* Fine-tuning Cohere to generate funny and engaging social media captions.
* Creating a seamless, rapid security pipeline that requires no legwork from the cupboard owner.
## What we learned 🧠
Over the course of this hackathon, we gained valuable insights into how to circumvent API protocols to access hardware data streams (for a good cause, of course). We also deepened our understanding of facial recognition technology and learned how to tune computer vision models for improved accuracy. For our X integration, we learned how to engineer prompts for Cohere's API to ensure that the AI-generated captions were both humorous and contextual. Finally, we gained experience integrating multiple APIs (Nest, Twilio, X) into a cohesive, real-time application.
## What's next for Craven 🔮
* **Multi-owner support:** Extend Craven to work with multiple cupboards or fridges in shared spaces, creating a mutual accountability structure between roommates.
* **Machine learning improvement:** Experiment with more advanced facial recognition models like deep learning for even better accuracy.
* **Social features:** Create an online leaderboard for the most frequent offenders, and allow users to vote on the best captions generated for snack thieves.
* **Voice activation:** Add voice commands to interact with Craven, allowing roommates to issue verbal warnings when the cupboard is opened. | ## Inspiration
The inspiration for this project was from our personal experiences living with bad roommates, who overstuffed the fridge with a lot of food, that used to be expired or took our food. We wanted to tackle this problem and make a solution to manage the inventory of the fridge or a shared closet.
## What it does
The solution uses cameras to monitor, who is placing and removing items to/from the Fridge and what they are placing/removing. It achieves this using computer vision, technology to recognize the user from the registered set of users for a certain device.
## How we built it
The solution was primarily split into two parts, the machine learning side and the user interface. The machine learning side was completely built in python, from client to server, using opencv,flask, tensorflow, and using the pre trained model inception v3. The half the project also controlled the devices cameras to detect movement and detect objects to be recognized. The user interface side of the project was built on react, using bootstrap and semantic ui. The interface allowed the users to checkout the inventory of their devices, and what items each user had.
The two sides were bridged using Node.js and mongodb, which acted as the central data storage and communication point from the machine learning and the user interface.
## Challenges we ran into
The computer vision side of the project was extremely challenging in the limited time, especially detecting objects in the frame without using Deep Learning to keep the client processing load at a minimum, Furthermore, the data-sets had to curated and specially customized to fit this challenge.was
In terms of the back-end, it was difficult to connect the node server to the python machine learning scripts, so we went with a micro service solution, where the machine learning was served on two flask endpoints to the node server which handled all the further processing.
Finally, in terms of the front-end, there were challenges in terms of changing state of semantic-ui components, which finally required us to switch to bootstrap in the middle of the hack. The front-end also posed a greater time challenge, as the primary front-end developer had to catch a flight the night before the hack ended, and therefore was limited in the time she had to develop the user interface
## Accomplishments that we're proud of
The solution overall worked, in the sense that there was a minimal viable product, where all the complex moving pieces came together to actually recognize an object and the person that added the object.
The computer vision aspect of the project was quite successful for the short time, we had to develop the solution. Especially the object recognition, which had a much higher confidence than was expected for such a short hack.
## What we learned
There were a lot of takeaways from this hack, especially in terms of devops, which posted a major challenge. It made us think a lot more about how difficult deploying IoT Solutions are, and the devop complexity they create. Furthermore, the project had a lot of learning to be had from its ambitious scope, which challenged us to use a lot of new technologies which we weren't extremely comfortable with prior to the hack
## What's next for Koelkast
We hope to keep training the algorithms to get them to a higher confidence level, one that would be more production ready. Furthermore, we want to take a look at perfboards, which are custom made to our specific requirements, These boards would be cheaper to product and deploy, which would be needed for the project to be take to production | winning |
## Inspiration
Noise sensitivity is common in autism, but it can also affect individuals without autism. Research shows that 50 to 70 percent of people with autism experience hypersensitivity to everyday sounds. This inspired us to create a wearable device to help individuals with heightened sensory sensitivities manage noise pollution. Our goal is to provide a dynamic solution that adapts to changing sound environments, offering a more comfortable and controlled auditory experience.
## What it does
SoundShield is a wearable device that adapts to noisy environments by automatically adjusting calming background audio and applying noise reduction. It helps individuals with sensory sensitivities block out overwhelming sounds while keeping them connected to their surroundings. The device also alerts users if someone is behind them, enhancing both awareness and comfort. It filters out unwanted noise using real-time audio processing and only plays calming music if the noise level becomes too high. If it detects a person speaking or if the noise is low enough to be important, such as human speech, it doesn't apply filters or background music.
## How we built it
We developed SoundShield using a combination of real-time audio processing and computer vision, integrated with a Raspberry Pi Zero, a headphone, and a camera. The system continuously monitors ambient sound levels and dynamically adjusts music accordingly. It filters noise based on amplitude and frequency, applying noise reduction techniques such as Spectral Subtraction, Dynamic Range Compression to ensure users only hear filtered audio. The system plays calming background music when noise levels become overwhelming. If the detected noise is low, such as human speech, it leaves the sound unfiltered. Additionally, if a person is detected behind the user and the sound amplitude is high, the system alerts the user, ensuring they are aware of their surroundings.
## Challenges we ran into
Processing audio in real-time while distinguishing sounds based on frequency was a significant challenge, especially with the limited computing power of the Raspberry Pi Zero. Additionally, building the hardware and integrating it with the software posed difficulties, especially when ensuring smooth, real-time performance across audio and computer vision tasks.
## Accomplishments that we're proud of
We successfully integrated computer vision, audio processing, and hardware components into a functional prototype. Our device provides a real-world solution, offering a personalized and seamless sensory experience for individuals with heightened sensitivities. We are especially proud of how the system dynamically adapts to both auditory and visual stimuli.
## What we learned
We learned about the complexities of real-time audio processing and how difficult it can be to distinguish between different sounds based on frequency. We also gained valuable experience in integrating audio processing with computer vision on a resource-constrained device like the Raspberry Pi Zero. Most importantly, we deepened our understanding of the sensory challenges faced by individuals with autism and how technology can be tailored to assist them.
## What's next for SoundSheild
We plan to add a heart rate sensor to detect when the user is becoming stressed, which would increase the noise reduction score and automatically play calming music. Additionally, we want to improve the system's processing power and enhance its ability to distinguish between human speech and other noises. We're also researching specific frequencies that can help differentiate between meaningful sounds, like human speech, and unwanted noise to further refine the user experience. | ## Inspiration
Shashank Ojha, Andreas Joannou, Abdellah Ghassel, Cameron Smith
#

Clarity is an interactive smart glass that uses a convolutional neural network, to notify the user of the emotions of those in front of them. This wearable gadget has other smart glass abilities such as the weather and time, viewing daily reminders and weekly schedules, to ensure that users get the best well-rounded experience.
## Problem:
As mental health raises barriers inhibiting people's social skills, innovative technologies must accommodate everyone. Studies have found that individuals with developmental disorders such as Autism and Asperger’s Syndrome have trouble recognizing emotions, thus hindering social experiences. For these reasons, we would like to introduce Clarity. Clarity creates a sleek augmented reality experience that allows the user to detect the emotion of individuals in proximity. In addition, Clarity is integrated with unique and powerful features of smart glasses including weather and viewing daily routines and schedules. With further funding and development, the glasses can incorporate more inclusive features straight from your fingertips and to your eyes.



## Mission Statement:
At Clarity, we are determined to make everyone’s lives easier, specifically to help facilitate social interactions for individuals with developmental disorders. Everyone knows someone impacted by mental health or cognitive disabilities and how meaningful those precious interactions are. Clarity wants to leap forward to make those interactions more memorable, so they can be cherished for a lifetime.


We are first-time Makeathon participants who are determined to learn what it takes to make this project come to life and to impact as many lives as possible. Throughout this Makeathon, we have challenged ourselves to deliver a well-polished product that, with the purpose of doing social good. We are second-year students from Queen's University who are very passionate about designing innovative solutions to better the lives of everyone. We share a mindset to give any task our all and obtain the best results. We have a diverse skillset and throughout the hackathon, we utilized everyone's strengths to work efficiently. This has been a great learning experience for our first makeathon, and even though we have some respective experiences, this was a new journey that proved to be intellectually stimulating for all of us.
## About:
### Market Scope:

Although the main purpose of this device is to help individuals with mental disorders, the applications of Clarity are limitless. Other integral market audiences to our device include:
• Educational Institutions can use Clarity to help train children to learn about emotions and feelings at a young age. Through exposure to such a powerful technology, students can be taught fundamental skills such as sharing, and truly caring by putting themselves in someone else's shoes, or lenses in this case.
• The interview process for social workers can benefit from our device to create a dynamic and thorough experience to determine the ideal person for a task. It can also be used by social workers and emotional intelligence researchers to have better studies and results.
• With further development, this device can be used as a quick tool for psychiatrists to analyze and understand their patients at a deeper level. By assessing individuals in need of help at a faster level, more lives can be saved and improved.
### Whats In It For You:

The first stakeholder to benefit from Clarity is our users. This product provides accessibility right to the eye for almost 75 million users (number of individuals in the world with developmental disorders). The emotion detection system is accessible at a user's disposal and makes it easy to recognize anyone's emotions. Whether one watching a Netflix show or having a live casual conversation, Clarity has got you covered.
Next, Qualcomm could have a significant partnership in the forthcoming of Clarity, as they would be an excellent distributor and partner. With professional machining and Qualcomm's Snapdragon processor, the model is guaranteed to have high performance in a small package.
Due to the various applications mentioned of this product, this product has exponential growth potential in the educational, research, and counselling industry, thus being able to offer significant potential in profit/possibilities for investors and researchers.
## Technological Specifications
## Hardware:
At first, the body of the device was a simple prism with an angled triangle to reflect the light at 90° from the user. The initial intention was to glue the glass reflector to the outer edge of the triangle to complete the 180° reflection. This plan was then scrapped in favour of a more robust mounting system, including a frontal clip for the reflector and a modular cage for the LCD screen. After feeling confident in the primary design, a CAD prototype was printed via a 3D printer. During the construction of the initial prototype, a number of challenges surfaced including dealing with printer errors, component measurement, and manufacturing mistakes. One problem with the prototype was the lack of adhesion to the printing bed. This resulted in raised corners which negatively affected component cooperation. This issue was overcome by introducing a ring of material around the main body. Component measurements and manufacturing mistakes further led to improper fitting between pieces. This was ultimately solved by simplifying the initial design, which had fewer points of failure. The evolution of the CAD files can be seen below.

The material chosen for the prototypes was PLA plastic for its strength to weight ratio and its low price. This material is very lightweight and strong, allowing for a more comfortable experience for the user. Furthermore, inexpensive plastic allows for inexpensive manufacturing.
Clarity runs on a Raspberry Pi Model 4b. The RPi communicates with the OLED screen using the I2C protocol. It additionally powers and communicates with the camera module and outputs a signal to a button to control the glasses. The RPi handles all the image processing, to prepare the image for emotion recognition and create images to be output to the OLED screen.
### Optics:
Clarity uses two reflections to project the image from the screen to the eye of the wearer. The process can be seen in the figure below. First, the light from the LCD screen bounces off the mirror which has a normal line oriented at 45° relative to the viewer. Due to the law of reflection, which states that the angle of incidence is equal to the angle of reflection relative to the normal line, the light rays first make a 90° turn. This results in a horizontal flip in the projected image. Then, similarly, this ray is reflected another 90° against a transparent piece of polycarbonate plexiglass with an anti-reflective coating. This flips the image horizontally once again, resulting in a correctly oriented image. The total length that the light waves must travel should be equivalent to the straight-line distance required for an image to be discernible. This minimum distance is roughly 25 cm for the average person. This led to shifting the screen back within the shell to create a clearer image in the final product.

## Software:

The emotion detection capabilities of Clarity smart glasses are powered by Google Cloud Vision API. The glasses capture a photo of the people in front of the user, runs the photo through the Cloud Vision model using an API key, and outputs a discrete probability distribution of the emotions. This probability distribution is analyzed by Clarity’s code to determine the emotion of the people in the image. The output of the model is sent to the user through the OLED screen using the Pillow library.
The additional features of the smart glasses include displaying the current time, weather, and the user’s daily schedule. These features are implemented using various Python libraries and a text file-based storage system. Clarity allows all the features of the smart glasses to be run concurrently through the implementation of asynchronous programming. Using the asyncio library, the user can iterate through the various functionalities seamlessly.
The glasses are interfaced through a button and the use of Siri. Using an iPhone, Siri can remotely power on the glasses and start the software. From there, users can switch between the various features of Clarity by pressing the button on the side of the glasses.
The software is implemented using a multi-file program that calls functions based on the current state of the glasses, acting as a finite state machine. The program looks for the rising edge of a button impulse to receive inputs from the user, resulting in a change of state and calling the respective function.
## Next Steps:
The next steps include integrating a processor/computer inside the glasses, rather than using raspberry pi. This would allow for the device to take the next step from a prototype stage to a mock mode. The model would also need to have Bluetooth and Wi-Fi integrated, so that the glasses are modular and easily customizable. We may also use magnifying lenses to make the images on the display bigger, with the potential of creating a more dynamic UI.
## Timelines:
As we believe that our device can make a drastic impact in people’s lives, the following diagram is used to show how we will pursue Clarity after this Makathon:

## References:
• <https://cloud.google.com/vision>
• Python Libraries
### Hardware:
All CADs were fully created from scratch. However, inspiration was taken from conventional DIY smartglasses out there.
### Software:
### Research:
• <https://www.vectorstock.com/royalty-free-vector/smart-glasses-vector-3794640>
• <https://www.ncbi.nlm.nih.gov/pmc/articles/PMC2781897/>
• <https://www.google.com/search?q=how+many+people+have+autism&rlz=1C1CHZN_enCA993CA993&oq=how+many+people+have+autism+&aqs=chrome..69i57j0i512l2j0i390l5.8901j0j9&sourceid=chrome&ie=UTF-8>
• (<http://labman.phys.utk.edu/phys222core/modules/m8/human_eye.html>)
• <https://mammothmemory.net/physics/mirrors/flat-mirrors/normal-line-and-two-flat-mirrors-at-right-angles.html> | ## Inspiration:
We are a team of four who are really into tech and music, We always wanted to have a platform where we could connect to our friends and also review our favorite albums. Our inspiration has come up from that very thing.
## What it does:
So we made a platform for Music geeks who are into music and give them a platform to express their views about certain albums and also share their ratings and reviews with their friends.
## How we built it:
We used Figma and Canva for our UI design. Next.js, React, and TypeScript provided a solid foundation for the intuitive user interface and frontend functionality.
PostgreSQL served as the database, while tRPC and Prisma facilitated efficient data management and interaction.Vercel ensured smooth deployment and the potential for TunedIn to reach a global audience. We also used features like Vercel Postgres for database hosting
## Challenges we ran into:
We had some front-end UI related issues when trying to export to our frontend code from Canva and Figma, so we had to go with a backup plan.
## Accomplishments that we're proud of:
We completed the entirety within 36 hours and we have been coding for 24 hours straight
## What we learned:
We learned a lot about how the backend framework works
## What's next for TunedIn?:
We are planning to launch an app based on it and further add more features to it. We can use AI features to recommend songs, determine overlap between friends, and so on. | winning |
## Inspiration
Online shopping has been the norm for a while, but the COVID-19 pandemic has impelled even more businesses and customers alike to shift to the digital space. Unfortunately, it also accentuated the frustrations associated with online shopping. People often purchase items online, only to find out what they receive is not exactly what they want. AR is the perfect technology to bridge the gap between the digital and physical spaces; we wanted to apply that to tackle issues within online shopping to strengthen interconnection within e-commerce!
## What it does
scannAR allows its users to scan QR codes of e-commerce URLs, placing those items in front of where the user is standing. Users may also scan physical items to have them show up in AR. In either case, users may drag and drop anything that can be scanned or uploaded to the real world.
Now imagine the possibilities. Have technicians test if a component can fit into a small space, or small businesses send their products to people across the planet virtually, or teachers show off a cool concept with a QR code and the students' phones. Lastly, yes, you can finally play Minecraft or build yourself a fake house cause I know house searching in Kingston is hard.
## How we built it
We built the scannAR app using Unity with the Lean Touch and Big Furniture Pack assets. We used HTML, CSS, Javascript to create the business website for marketing purposes.
## Challenges we ran into
This project was our first time working with Unity and AR technology, so we spent many hours figuring their processes out. A particular challenge we encountered was manipulating objects on our screens the way we wanted to. With the time constraint, the scope of UI/UX design was limited, making some digital objects look less clean.
## Accomplishments that we're proud of
Through several hours of video tutorials and some difficulty, we managed to build a functioning AR application through Unity, while designing a clean website to market it. We felt even prouder about making a wide stride towards tackling e-commerce issues that many of our friends often rant about.
## What we learned
In terms of technical skills, we learned how to utilize AR technology, specifically Unity. Initially, we had trouble moving objects on Unity; after completing this project, we have new Unity skills we can apply throughout our next hackathons and projects. We learned to use our existing front-end web development skills to augment our function with form.
## What's next for scannAR
In the near future, we aim to flesh out the premium subscription features to better cater to specific professions. We also plan on cleaning up the interface to launch scannAR on the app stores. After its release, it will be a constant cycle of marketing, partnerships with local businesses, and re-evaluating processes. | Energy is the future. More and more, that future relies on community efforts toward sustainability, and often, the best form of accountability occurs within peer networks. That's why we built SolarTrack, a energy tracker app that allows Birksun users to connect and collaborate with like-minded members of their community.
In our app, the user profile reflects lifetime energy generated using Birksun, as well as a point conversion system that allows for the future development of gameified rewards. We also have a community map, where you can find a heatmap that describes where people generate the most energy using Birksun bags. In the future, this community map would also include nearby events and gatherings. Finally, there's the option to find family and friends and compete amongst them to accumulate the most points using Birksun bags.
Here's to building a greener future for wearable tech, one bag at a time! | ## Inspiration
Covid-19 has turned every aspect of the world upside down. Unwanted things happen, situation been changed. Lack of communication and economic crisis cannot be prevented. Thus, we develop an application that can help people to survive during this pandemic situation by providing them **a shift-taker job platform which creates a win-win solution for both parties.**
## What it does
This application offers the ability to connect companies/manager that need employees to cover a shift for their absence employee in certain period of time without any contract. As a result, they will be able to cover their needs to survive in this pandemic. Despite its main goal, this app can generally be use to help people to **gain income anytime, anywhere, and with anyone.** They can adjust their time, their needs, and their ability to get a job with job-dash.
## How we built it
For the design, Figma is the application that we use to design all the layout and give a smooth transitions between frames. While working on the UI, developers started to code the function to make the application work.
The front end was made using react, we used react bootstrap and some custom styling to make the pages according to the UI. State management was done using Context API to keep it simple. We used node.js on the backend for easy context switching between Frontend and backend. Used express and SQLite database for development. Authentication was done using JWT allowing use to not store session cookies.
## Challenges we ran into
In the terms of UI/UX, dealing with the user information ethics have been a challenge for us and also providing complete details for both party. On the developer side, using bootstrap components ended up slowing us down more as our design was custom requiring us to override most of the styles. Would have been better to use tailwind as it would’ve given us more flexibility while also cutting down time vs using css from scratch.Due to the online nature of the hackathon, some tasks took longer.
## Accomplishments that we're proud of
Some of use picked up new technology logins while working on it and also creating a smooth UI/UX on Figma, including every features have satisfied ourselves.
Here's the link to the Figma prototype - User point of view: [link](https://www.figma.com/proto/HwXODL4sk3siWThYjw0i4k/NwHacks?node-id=68%3A3872&scaling=min-zoom)
Here's the link to the Figma prototype - Company/Business point of view: [link](https://www.figma.com/proto/HwXODL4sk3siWThYjw0i4k/NwHacks?node-id=107%3A10&scaling=min-zoom)
## What we learned
We learned that we should narrow down the scope more for future Hackathon so it would be easier and more focus to one unique feature of the app.
## What's next for Job-Dash
In terms of UI/UX, we would love to make some more improvement in the layout to better serve its purpose to help people find an additional income in job dash effectively. While on the developer side, we would like to continue developing the features. We spent a long time thinking about different features that will be helpful to people but due to the short nature of the hackathon implementation was only a small part as we underestimated the time that it will take. On the brightside we have the design ready, and exciting features to work on. | partial |
## Inspiration
Trump's statements include some of the most outrageous things said recently, so we wanted to see whether someone could distinguish between a fake statement and something Trump would say.
## What it does
We generated statements using markov chains (<https://en.wikipedia.org/wiki/Markov_chain>) that are based off of the things trump actually says. To show how difficult it is to distinguish between the machine generated text and the real stuff he says, we made a web app to test whether someone could determine which was the machine generated text (Drumpf) and which was the real Trump speech.
## How we built it
python+regex for parsing Trump's statementsurrent tools you use to find & apply to jobs?
html/css/js frontend
azure and aws for backend/hosting
## Challenges we ran into
Machine learning is hard. We tried to use recurrent neural networks at first for speech but realized we didn't have a large enough data set, so we switched to markov chains which don't need as much training data, but also have less variance in what is generated.
We actually spent a bit of time getting <https://github.com/jcjohnson/torch-rnn> up and running, but then figured out it was actually pretty bad as we had a pretty small data set (<100kB at that point)
Eventually got to 200kB and we were half-satisfied with the results, so we took the good ones and put it up on our web app.
## Accomplishments that we're proud of
First hackathon we've done where our front end looks good in addition to having a decent backend.
regex was interesting.
## What we learned
bootstrap/javascript/python to generate markov chains
## What's next for MakeTrumpTrumpAgain
scrape trump's twitter and add it
get enough data to use a neural network
dynamically generate drumpf statements
If you want to read all the machine generated text that we deemed acceptable to release to the public, open up your javascript console, open up main.js. Line 4599 is where the hilarity starts. | ## Inspiration
I've been really interested in Neural Networks and I wanted to step up my game by learning deep learning (no pun intended). I built an Recurrent Neural Network that learns and predicts words based on its training. I chose Trump because I expected to get a funny outcome, but it seems that my AI is obsessed with "controlling this country" (seriously)... so I turned out to be a little more political than expected. I wanted a challenge, to make something fun. I used 2 programming languages, did the app UI, implemented speech-text, NLP, did the backend, trained 2 models of ~10h each, learned a lot and had a lot of fun.
## What it does
Using Nuance API, I am able to get user input as voice and in real time the iOS app gives feedback to the user. The user then submits its text (which he can edit in case Nuance didn't recognize everything properly) and I send it to my server (which is physically located in my home, at this right moment :D). In my server, I built a RESTfull API in Python using Flask. There, I get the request sent from iOS, take the whole sentences given by Nuance, then I use the Lexalytics API (Semantria) to get the sense of the sentence, to finally feed my Trump AI model which is going to generate a sentence automatically.
## How I built it
First I built the RNN which works with characters instead of words. Instead of finding probabilities of words, I do with characters. I used the Keras library. After, I trained two models with two different parameters and I chose the best one (Unfortunately, the best one means that it has a 0.97 LOSS -remember the closer to 0, the better it is). The RNN didn't have enough time and resources to learn punctuation properly and grammar sometimes is... Trumpish. Later I built the API in Python using flask, where I implemented Semantria. I exposed an endpoint to receive a string so magic could happen. With Semantria I get the sense of the string (which is submitted by the user as VOICE), and I Trumpify it. The IOS app is built on Swift and I use two pods: Nuance SpeechKit and Alamofire (to make my requests cleaner). The UI is beautiful (trust me, the best) and I interact with the user with text, sound and change of colours.
## Challenges I ran into
Building the RNN was really difficult. I didn't know where to start but fortunately it went good. I am happy with the results, and I am definitely going to spend more time improving it.
Also, the Simantria API has not so good documentation. I had to figure out how everything worked by tracking sample codes and THAT made it a challenge. I can't recall of something that was still valid in the current code while reading the current documentation. I still thank all the Lexalytics peoplele assistance over Slack.. you guys are great.
## Accomplishments that I'm proud of
Pretty much everything. Learning deep learning and building a Recurrent Neural Network is... something to be proud of. I learned python over the past week, and today I built two major things with it (an API and a RNN). I am proud of my Swift skills but I consider myself an iOS developer so it is nothing new. Mmmm... I'm also proud of the way I implemented all those services, which are complex (RNN, NLP, Voice-To-Speech, the API, etc), alone. I solo'd this hackathon and I am also proud of that. I think that today I achieved a new level of knowledge and it feels great. My main goal was to step up my game, and it indeed happened.
## What I learned
Flask, Python, Nuance API, Simantria API... I even learned some Photoshop while working on the UI. I learned how to build an API (I had no idea before)... I learned about RNNs... Wow. A lot.
## What's next for Trumpify
Since I already have a server at home, I can host Trumpify backend without much cost. I'd say that the next step for Trumpify would be improving the Recurrent Neural Network so Trumpify gets smarter and says less non sense. I'll also publish this app in the App Store, so people can interact with trump, but in a funny way. If someone is interested I could also feature this app somewhere... who knows. I may even use this technology to create things in a more serious approach, instead of Trump. | ## Inspiration
We believe current reCAPTCHA v.3 has few problems. First, it is actually hard to prove myself to be not robot. It is because Machine Learning is advancing everyday, and ImageToText's (Computer Vision) accuracy is also skyrocketing. Thus, CAPTCHA question images have to be more difficult and vague. Second, the dataset used for current CAPTCHA is limited. It becomes predictable as it's repeating its questions or images (All of you should have answered "check all the images with traffic lights"). In this regard, several research paper has been published through Black Hat using Machine learning models to break CAPTCHA.
## What it does
Therefore, we decided to build a CAPTCHA system that would generate a totally non-sensical picture, and making humans to select the description for that AI-created photo of something 'weird'. As it will be an image of something that is non-existent in this world, machine learning models like ImageToText will have to idea what the matching prompt would be. However, it will be very clear for human even though the images might not be 100% accurate of the description, it's obvious to tell which prompt the AI try to draw. Also, it will randomly create image from scratch every time, we don't need a database having thousands of photos and prompts. Therefore, we will be able to have non-repeating 'im not a robot' question every single time -> No pattern, or training data for malicious programs.
Very easy and fun 'Im not a robot' challenge.
## How we built it
We used AI-painting model called 'Stable Diffusion', which takes a prompt as an input, and creates an image of the prompt. The key of our CAPTCHA is that the prompt that we feed in to this model is absurd and non-existent in real world. We used NLP APIs provided by Cohere in order to generate this prompts. Firstly, we gathered 4,000 English sentences and clustered them to groups based on the similarity of topics using Cohere's embed model. Then, from each clusters, we extracted on key words and using that keywords generated a full sentence prompt using Cohere's generate model. And with that prompt, we created an image using stable diffusion.
## Challenges we ran into
As stable-diffusion is a heavy computation and for sure needed GPU power, we needed to use a cloud GPU. However, cloud GPU that we used from paperspace had its own firewall, which prevented us to deploy server from the environment that we were running tests.
## Accomplishments that we're proud of
We incorporated several modern machine learning techniques to tackle a real world problem and suggested a possible solution. CAPTCHA is especially a security protocol that basically everyone who uses internet encounters. By making it less-annoying and safer, we think it could have a positive impact in a large scale, and are proud of that.
## What we learned
We learned about usability of Cohere APIs and stable diffusion. Also learned a lot about computer vision and ImageToText model, a possible threat model for all CAPTCHA versions. Additionally, we learned a lot about how to open a server and sending arguments in real-time.
## What's next for IM NOT A ROBOT - CAPTCHA v.4
As not everyone can run stable diffusion on their local computer, we need to create a server, which the server does the calculation and creation for the prompt and image. | partial |
## Inspiration
After seeing the breakout success that was Pokemon Go, my partner and I were motivated to create our own game that was heavily tied to physical locations in the real-world.
## What it does
Our game is supported on every device that has a modern web browser, absolutely no installation required. You walk around the real world, fighting your way through procedurally generated dungeons that are tied to physical locations. If you find that a dungeon is too hard, you can pair up with some friends and tackle it together.
Unlike Niantic, who monetized Pokemon Go using micro-transactions, we plan to monetize the game by allowing local businesses to to bid on enhancements to their location in the game-world. For example, a local coffee shop could offer an in-game bonus to players who purchase a coffee at their location.
By offloading the cost of the game onto businesses instead of players we hope to create a less "stressful" game, meaning players will spend more time having fun and less time worrying about when they'll need to cough up more money to keep playing.
## How We built it
The stack for our game is built entirely around the Node.js ecosystem: express, socket.io, gulp, webpack, and more. For easy horizontal scaling, we make use of Heroku to manage and run our servers. Computationally intensive one-off tasks (such as image resizing) are offloaded onto AWS Lambda to help keep server costs down.
To improve the speed at which our website and game assets load all static files are routed through MaxCDN, a continent delivery network with over 19 datacenters around the world. For security, all requests to any of our servers are routed through CloudFlare, a service which helps to keep websites safe using traffic filtering and other techniques.
Finally, our public facing website makes use of Mithril MVC, an incredibly fast and light one-page-app framework. Using Mithril allows us to keep our website incredibly responsive and performant. | ## Inspiration
Our inspiration comes from the idea that the **Metaverse is inevitable** and will impact **every aspect** of society.
The Metaverse has recently gained lots of traction with **tech giants** like Google, Facebook, and Microsoft investing into it.
Furthermore, the pandemic has **shifted our real-world experiences to an online environment**. During lockdown, people were confined to their bedrooms, and we were inspired to find a way to basically have **access to an infinite space** while in a finite amount of space.
## What it does
* Our project utilizes **non-Euclidean geometry** to provide a new medium for exploring and consuming content
* Non-Euclidean geometry allows us to render rooms that would otherwise not be possible in the real world
* Dynamically generates personalized content, and supports **infinite content traversal** in a 3D context
* Users can use their space effectively (they're essentially "scrolling infinitely in 3D space")
* Offers new frontier for navigating online environments
+ Has **applicability in endless fields** (business, gaming, VR "experiences")
+ Changing the landscape of working from home
+ Adaptable to a VR space
## How we built it
We built our project using Unity. Some assets were used from the Echo3D Api. We used C# to write the game. jsfxr was used for the game sound effects, and the Storyblocks library was used for the soundscape. On top of all that, this project would not have been possible without lots of moral support, timbits, and caffeine. 😊
## Challenges we ran into
* Summarizing the concept in a relatively simple way
* Figuring out why our Echo3D API calls were failing (it turned out that we had to edit some of the security settings)
* Implementing the game. Our "Killer Tetris" game went through a few iterations and getting the blocks to move and generate took some trouble. Cutting back on how many details we add into the game (however, it did give us lots of ideas for future game jams)
* Having a spinning arrow in our presentation
* Getting the phone gif to loop
## Accomplishments that we're proud of
* Having an awesome working demo 😎
* How swiftly our team organized ourselves and work efficiently to complete the project in the given time frame 🕙
* Utilizing each of our strengths in a collaborative way 💪
* Figuring out the game logic 🕹️
* Our cute game character, Al 🥺
* Cole and Natalie's first in-person hackathon 🥳
## What we learned
### Mathias
* Learning how to use the Echo3D API
* The value of teamwork and friendship 🤝
* Games working with grids
### Cole
* Using screen-to-gif
* Hacking google slides animations
* Dealing with unwieldly gifs
* Ways to cheat grids
### Natalie
* Learning how to use the Echo3D API
* Editing gifs in photoshop
* Hacking google slides animations
* Exposure to Unity is used to render 3D environments, how assets and textures are edited in Blender, what goes into sound design for video games
## What's next for genee
* Supporting shopping
+ Trying on clothes on a 3D avatar of yourself
* Advertising rooms
+ E.g. as your switching between rooms, there could be a "Lululemon room" in which there would be clothes you can try / general advertising for their products
* Custom-built rooms by users
* Application to education / labs
+ Instead of doing chemistry labs in-class where accidents can occur and students can get injured, a lab could run in a virtual environment. This would have a much lower risk and cost.
…the possibility are endless | ## Inspiration
Personal assistant AI like Siri, Cortana and Alexa were the inspiration for our project.
## What it does
Our mirror displays information about the weather, date, social media, news and nearby events.
## How we built it
The mirror works by placing a monitor behind a two-way mirror and displaying information using multiple APIs. We integrated a Kinect so users can select that's being displayed using various gestures. We hosted our project with Azure
## Challenges we ran into
Integrating the Kinect
## Accomplishments that we're proud of
Integrating as many components as we did including the Kinect
## What we learned
How to use Microsoft Azure and work with various APIs as well as use Visual Studio to interact with the Kinect
## What's next for Microsoft Mirror
Implementing more features! We would like to explore more of Microsoft's Cognitive Services as well as utilize the Kinect in a more refined fashion. | winning |
## Inspiration
Due to the pandemic, we missed out on a lot of opportunities to partake in fun winter activities, so we created a game as a way to still feel that enjoyment.
## What it does
y = mx + snow is a single-player game where you can control a character to ski down a hill dodging obstacles.
## How we built it
we built it using python pygame.
## Challenges we ran into
some challenges we ran into would be figuring out how to collaborate. We ended up using VSCode liveshare. Another challenge we faced was
## Accomplishments that we're proud of
We are proud of our abillity to learn about pygame in a short period of time, as we were more comfortable with using unity but we wanted to try something new.
## What we learned
about the basics of using pygame, and how to create a game using it. | # YouTrack - Track Flights whenever you want, wherever you want!
##### Check out the [Figma demo](https://www.figma.com/proto/fH3WbytL5GgfbafKiKVi0N/YouTrack?node-id=13%3A182&scaling=contain&page-id=0%3A1&starting-point-node-id=13%3A182) (if the demo appears too large on the screen then click **options -> fit-scale down to fit** and press the search and dropdown buttons for the full experience of the prototype)
#### Check out the [YouTrack video](https://www.youtube.com/watch?v=wtQyaDmGpHk)
#### Check out [the code on Github for the actual website](https://github.com/omarabdiwali/YouTrack)
## What YouTrack is all about
YouTrack is an online website created for the purpose of tracking flights. Flying is one of the most common forms of travel and it comes as no surprise that roughly 115,000 commercial flights are operated worldwide every single day. Trying to keep up with one flight amongst hundreds of thousands of flights can be incredibly challenging, which is why we came up with an idea for a website that will serve as a guide for those wanting to keep up with active, previous, and future flights. Whether it be checking up on a loved one on a flight or tracking your own, YouTrack is the absolute best option for your flight tracking needs.
## How YouTrack will make your life easier:
Have you ever wanted to track a flight on any flight tracking website and have been bombarded with extremely detailed and specific questions? Questions like: Exact time of departures or arrival, specific airline codes, gate numbers, and specific airport names are not always known to those who aren't keeping up with specific flights which is why YouTrack only requires you to enter the departure airport as well as the arrival airport and returns all the flights that match those categories. We hope that you will be able to track down exact flights from the list of matched flights.
## Our work
We came up with the idea of building a flight-tracking website spontaneously and decided that we would have two aspects to this project. The first is the project itself and the second is a prototype/demo which shows tracked flights from one specific destination to another (Regina International Airport, Regina, Saskatchewan, Canada to Toronto Pearson International Airport, Toronto, Ontario, Canada).
* **Website itself** -> Website was built using HTML, CSS, JS, React and data was obtained using aviationstack (limited to 100 requests/month) and air-port-codes APIs.
* **Demo** -> The demo/prototype of YouTrack was built entirely on Figma. The working drop-down menus and the basic (yet aesthetic) user interface is the perfect representation of what YouTrack is all about -- simple yet effective.
## Challenges that we ran into
* Coming up with an idea that would challenge our thinking while not being overly difficult
* Executing YouTrack
* Familiarizing ourselves with Figma to come up with a pleasing UI prototype design
* Executing YouTrack within the time frame of the hackathon
## Accomplishments that we are proud of
* Coming up with a great idea and then executing that idea to the best of our abilities
* Putting in an immense amount of effort over a very short period of time to come up with an idea that could be groundbreaking
* Managing our time to cover all the different aspects of this project
## What we learned
* A time constraint forces us to work harder and be more productive
* With the advancement of technology, there are always new ways to make our lives easier
* If a task is focused on for long enough -- it can be completed surprisingly quickly no matter how difficult it may seem.
## What's next for YouTrack
* Expand our website into including all different kinds of airports including regional and domestic airports.
* Get constructive criticism from users and improve our website to benefit everyone, this includes but is not limited to the user interface, website support and accessibility, performance and more.
* YouTrack could grow into something more than a hackathon project with the right attention.
#### Built by: Omar Abdiwali and Abrar Tarafder | ## Inspiration
The post-COVID era has increased the number of in-person events and need for public speaking. However, more individuals are anxious to publicly articulate their ideas, whether this be through a presentation for a class, a technical workshop, or preparing for their next interview. It is often difficult for audience members to catch the true intent of the presenter, hence key factors including tone of voice, verbal excitement and engagement, and physical body language can make or break the presentation.
A few weeks ago during our first project meeting, we were responsible for leading the meeting and were overwhelmed with anxiety. Despite knowing the content of the presentation and having done projects for a while, we understood the impact that a single below-par presentation could have. To the audience, you may look unprepared and unprofessional, despite knowing the material and simply being nervous. Regardless of their intentions, this can create a bad taste in the audience's mouths.
As a result, we wanted to create a judgment-free platform to help presenters understand how an audience might perceive their presentation. By creating Speech Master, we provide an opportunity for presenters to practice without facing a real audience while receiving real-time feedback.
## Purpose
Speech Master aims to provide a practice platform for practice presentations with real-time feedback that captures details in regard to your body language and verbal expressions. In addition, presenters can invite real audience members to practice where the audience member will be able to provide real-time feedback that the presenter can use to improve.
While presenting, presentations will be recorded and saved for later reference for them to go back and see various feedback from the ML models as well as live audiences. They are presented with a user-friendly dashboard to cleanly organize their presentations and review for upcoming events.
After each practice presentation, the data is aggregated during the recording and process to generate a final report. The final report includes the most common emotions expressed verbally as well as times when the presenter's physical body language could be improved. The timestamps are also saved to show the presenter when the alerts rose and what might have caused such alerts in the first place with the video playback.
## Tech Stack
We built the web application using [Next.js v14](https://nextjs.org), a React-based framework that seamlessly integrates backend and frontend development. We deployed the application on [Vercel](https://vercel.com), the parent company behind Next.js. We designed the website using [Figma](https://www.figma.com/) and later styled it with [TailwindCSS](https://tailwindcss.com) to streamline the styling allowing developers to put styling directly into the markup without the need for extra files. To maintain code formatting and linting via [Prettier](https://prettier.io/) and [EsLint](https://eslint.org/). These tools were run on every commit by pre-commit hooks configured by [Husky](https://typicode.github.io/husky/).
[Hume AI](https://hume.ai) provides the [Speech Prosody](https://hume.ai/products/speech-prosody-model/) model with a streaming API enabled through native WebSockets allowing us to provide emotional analysis in near real-time to a presenter. The analysis would aid the presenter in depicting the various emotions with regard to tune, rhythm, and timbre.
Google and [Tensorflow](https://www.tensorflow.org) provide the [MoveNet](https://www.tensorflow.org/hub/tutorials/movenet#:%7E:text=MoveNet%20is%20an%20ultra%20fast,17%20keypoints%20of%20a%20body.) model is a large improvement over the prior [PoseNet](https://medium.com/tensorflow/real-time-human-pose-estimation-in-the-browser-with-tensorflow-js-7dd0bc881cd5) model which allows for real-time pose detection. MoveNet is an ultra-fast and accurate model capable of depicting 17 body points and getting 30+ FPS on modern devices.
To handle authentication, we used [Next Auth](https://next-auth.js.org) to sign in with Google hooked up to a [Prisma Adapter](https://authjs.dev/reference/adapter/prisma) to interface with [CockroachDB](https://www.cockroachlabs.com), allowing us to maintain user sessions across the web app. [Cloudinary](https://cloudinary.com), an image and video management system, was used to store and retrieve videos. [Socket.io](https://socket.io) was used to interface with Websockets to enable the messaging feature to allow audience members to provide feedback to the presenter while simultaneously streaming video and audio. We utilized various services within Git and Github to host our source code, run continuous integration via [Github Actions](https://github.com/shahdivyank/speechmaster/actions), make [pull requests](https://github.com/shahdivyank/speechmaster/pulls), and keep track of [issues](https://github.com/shahdivyank/speechmaster/issues) and [projects](https://github.com/users/shahdivyank/projects/1).
## Challenges
It was our first time working with Hume AI and a streaming API. We had experience with traditional REST APIs which are used for the Hume AI batch API calls, but the streaming API was more advantageous to provide real-time analysis. Instead of an HTTP client such as Axios, it required creating our own WebSockets client and calling the API endpoint from there. It was also a hurdle to capture and save the correct audio format to be able to call the API while also syncing audio with the webcam input.
We also worked with Tensorflow for the first time, an end-to-end machine learning platform. As a result, we faced many hurdles when trying to set up Tensorflow and get it running in a React environment. Most of the documentation uses Python SDKs or vanilla HTML/CSS/JS which were not possible for us. Attempting to convert the vanilla JS to React proved to be more difficult due to the complexities of execution orders and React's useEffect and useState hooks. Eventually, a working solution was found, however, it can still be improved to better its performance and bring fewer bugs.
We originally wanted to use the Youtube API for video management where users would be able to post and retrieve videos from their personal accounts. Next Auth and YouTube did not originally agree in terms of available scopes and permissions, but once resolved, more issues arose. We were unable to find documentation regarding a Node.js SDK and eventually even reached our quota. As a result, we decided to drop YouTube as it did not provide a feasible solution and found Cloudinary.
## Accomplishments
We are proud of being able to incorporate Machine Learning into our applications for a meaningful purpose. We did not want to reinvent the wheel by creating our own models but rather use the existing and incredibly powerful models to create new solutions. Although we did not hit all the milestones that were hoping to achieve, we are still proud of the application that we were able to make in such a short amount of time and be able to deploy the project as well.
Most notably, we are proud of our Hume AI and Tensorflow integrations that took our application to the next level. Those 2 features took the most time, but they were also the most rewarding as in the end, we got to see real-time updates of our emotional and physical states. We are proud of being able to run the application and get feedback in real-time, which gives small cues to the presenter on what to improve without risking distracting the presenter completely.
## What we learned
Each of the developers learned something valuable as each of us worked with a new technology that we did not know previously. Notably, Prisma and its integration with CockroachDB and its ability to make sessions and general usage simple and user-friendly. Interfacing with CockroachDB barely had problems and was a powerful tool to work with.
We also expanded our knowledge with WebSockets, both native and Socket.io. Our prior experience was more rudimentary, but building upon that knowledge showed us new powers that WebSockets have both when used internally with the application and with external APIs and how they can introduce real-time analysis.
## Future of Speech Master
The first step for Speech Master will be to shrink the codebase. Currently, there is tons of potential for components to be created and reused. Structuring the code to be more strict and robust will ensure that when adding new features the codebase will be readable, deployable, and functional. The next priority will be responsiveness, due to the lack of time many components appear strangely on different devices throwing off the UI and potentially making the application unusable.
Once the current codebase is restructured, then we would be able to focus on optimization primarily on the machine learning models and audio/visual. Currently, there are multiple instances of audio and visual that are being used to show webcam footage, stream footage to other viewers, and sent to HumeAI for analysis. By reducing the number of streams, we should expect to see significant performance improvements with which we can upgrade our audio/visual streaming to use something more appropriate and robust.
In terms of new features, Speech Master would benefit greatly from additional forms of audio analysis such as speed and volume. Different presentations and environments require different talking speeds and volumes of speech required. Given some initial parameters, Speech Master should hopefully be able to reflect on those measures. In addition, having transcriptions that can be analyzed for vocabulary and speech, ensuring that appropriate language is used for a given target audience would drastically improve the way a presenter could prepare for a presentation. | losing |
## Inspiration
I got annoyed at Plex's lack of features
## What it does
Provides direct database and disk access to Plex configuration
## How I built it
Python
## Challenges I ran into
## Accomplishments that I'm proud of
## What I learned
## What's next for InterPlex | ## Inspiration
There is no such data-set available which can be used to do aspect based analysis of the user reviews. We wanted to make something which helps companies get detailed analysis of reviews with respect to various aspects of their service and help them improve based on it.
## What it does
Our algorithm works in two steps:
1) We create aspect vectors' into 3 dimensional space and given a review as a data point we break it into vector and project it into aspect vector space to find most associated aspect to it. Here we used "customer service","punctuality","cancellation","comfort" and "miscellaneous" as aspects for JetBlue airlines review.
2) After the clustering of aspects we do sentimental analysis of the review and categorize it as either "positive","negative" or "neutral". It can be used to get insights on which aspects are good and which aspects needs improvement.
## How I built it
First we scraped review data from various sources such as Twitter, Instagram, TripAdvisor, Reddit, Airquality.com,etc. In total we collected around 25000 reviews.
Then we used Google's Natural Language API do sentimental analysis of reviews and categorize it as either "positive","negative" or "neutral".
For each review we used cosine similarity between all aspect vectors and review vector and get closest vector to associate the review with that aspect. That way we know where given review is about customer service, comfort, cancellation or punctuality. It is very easy to add new aspects into our application. After that we analyzed sentiment of the review to get information about user's experience with that aspect.
Finally, we build front end using React to display results of our algorithm.
## Challenges I ran into
As there is no readily available data-set about airline reviews, It was difficult to collect such amount of review data-set which can give reasonable performance. So first challenge was gathering data.
To get accurate results we needed aspect vectors which strongly represented the aspects which we wanted to learn. After that we had to experiment with various distance functions between vectors to see which one gave most reasonable results and we settled on cosine similarity function.
Then combining the data from sentimental analysis of reviews using Google's Natural Language API and results of our aspect association algorithm was a bit of a challenge as well as getting a front end dashboard that can visualize the results as we wanted.
## Accomplishments that I'm proud of
Getting highly functional aspect predictions in unsupervised manner.
## What I learned
Thinking through how to implement a data science project end-to-end from data collection to data cleaning to modelling and visualization of results.
## What's next for DeepFly
This project can be easily extended for other kinds of aspects and for reviews of any kind of services. | ## Inspiration
We love to cook for and eat with our friends and family! Sometimes though, we need to accommodate certain dietary restrictions to make sure everyone can enjoy the food. What changes need to be made? Will it be a huge change? Will it still taste good? So much research and thought goes into this, and we all felt as though an easy resource was needed to help ease the planning of our cooking and make sure everyone can safely enjoy our tasty recipes!
## What is Let Them Cook?
First, a user selects the specific dietary restrictions they want to accommodate. Next, a user will copy the list of ingredients that are normally used in their recipe into a text prompt. Then, with the push of a button, our app cooks up a modified, just as tasty, and perfectly accommodating recipe, along with expert commentary from our "chef"! Our "chef" also provides suggestions for other similar recipes which also accomidate the user's specific needs.
## How was Let Them Cook built?
We used React to build up our user interface. On the main page, we implemented a rich text editor from TinyMCE to serve as our text input, allong with various applicable plugins to make the user input experience as seamless as possible.
Our backend is Python based. We set up API responses using FastAPI. Once the front end posts the given recipe, our backend passes the recipe ingredients and dietary restrictions into a fine-tuned large language model - specifically GPT4.
Our LLM had to be fine-tuned using a combination of provided context, hyper-parameter adjustment, and prompt engineering. We modified its responses with a focus on both dietary restrictions knowledge and specific output formatting.
The prompt engineering concepts we employed to receive the most optimal outputs were n-shot prompting, chain-of-thought (CoT) prompting, and generated knowledge prompting.
## UI/UX
### User Personas

*We build some user personas to help us better understand what needs our application could fulfil*
### User Flow

*The user flow was made to help us determine the necessary functionality we wanted to implement to make this application useful*
### Lo-fi Prototypes

*These lo-fi mockups were made to determine what layout we would present to the user to use our primary functionality*
### Hi-fi Prototypes
 
*Here we finalized the styling choice of a blue and yellow gradient, and we started planning for incorporating our extra feature as well - the recipe recomendations*
## Engineering

Frontend: React, JS, HTML, CSS, TinyMCE, Vite
Backend: FastAPI, Python
LLM: GPT4
Database: Zilliz
Hosting: Vercel (frontend), Render (backend)
## Challenges we ran into
### Frontend Challenges
Our recipe modification service is particularly sensitive to the format of the user-provided ingredients and dietary restrictions. This put the responsibility of vetting user input onto the frontend. We had to design multiple mechanisms to sanitize inputs before sending them to our API for further pre-processing. However, we also wanted to make sure that recipes were still readable by the humans who inputted them. Using the TinyMCE editor solved this problem effortlessly as it allowed us to display text in the format it was pasted, while simultaneously allowing our application to access a "raw", unformatted version of the text.
To display our modified recipe, we had to brainstorm the best ways to highlight any substitutions we made. We tried multiple different approaches including some pre-built components online. In the end, we decided to build our own custom component to render substitutions from the formatting returned by the backend.
We also had to design a user flow that would provide feedback while users wait for a response from our backend. This materialized in the form of an interim loading screen with a moving GIF indicating that our application had not timed out. This loading screen is dynamic, and automatically re-routes users to the relevant pages upon hearing back from our API.
### Backend Challenges
The biggest challenge we ran into was selecting a LLM that could produce consistent results based off different input recipes and prompt engineering. We started out with Together.AI, but found that it was inconsistent in formatting and generating valid allergy substitutions. After trying out other open-source LLMs, we found that they also produced undesirable results. Eventually, we compromised with GPT-4, which could produce the results we wanted after some prompt engineering; however, it it is not a free service.
Another challenge was with the database. After implementing the schema and functionality, we realized that we partitioned our design off of the incorrect data field. To finish our project on time, we had to store more values into our database in order for similarity search to still be implemented.

## Takeaways
### Accomplishments that we're proud of
From coming in with no knowledge, we were able to build a full stack web applications making use of the latest offerings in the LLM space. We experimented with prompt engineering, vector databases, similarity search, UI/UX design, and more to create a polished product. Not only are we able to demonstrate our learnings through our own devices, but we are also able to share them out with the world by deploying our application.
**All that said**, our proudest accomplishment was creating a service which can provide significant help to many in a common everyday experience: cooking and enjoying food with friends and family.
### What we learned
For some of us on the team, this entire project was built in technologies that were unfamiliar. Some of us had little experience with React or FastAPI so that was something the more experienced members got to teach on the job.
One of the concepts we spent the most time learning was about prompt engineering.
We also learned about the importance of branching on our repository as we had to build 3 different components to our project all at the same time on the same application.
Lastly, we spent a good chunk of time learning how to implement and improve our similarity search.
### What's next for Let Them Cook
We're very satisfied with the MVP we built this weekend, but we know there is far more work to be done.
First, we would like to deploy our recipe similarity service currently working on a local environment to our production environment. We would also like to incorporate a ranking system that will allow our LLM to take in crowdsourced user feedback in generating recipe substitutions.
Additionally, we would like to enhance our recipe substitution service to make use of recipe steps rather than solely *ingredients*. We believe that the added context of how ingredients come together will result in even higher quality substitutions.
Finally, we hope to add an option for users to directly insert a recipe URL rather than copy-and-pasting the ingredients. We would write another service to scrape the site and extract the information a user would previously paste. | losing |
PathiFind
Your one-stop web app designed to provide you with all the skill needs of your dream career.
How does it work?
1) Make an account
2) Search for a job
3) Learn the Skills
Its THAT easy
Plus, all the courses are online, so you can complete them in your own time, and at your own pace!
Designed by Azan Muhammad, Danyal Babar and Hazyefah Khan
To run the project yourself, download it here and run with yarn start
<https://drive.google.com/file/d/1r3CVoZ5UrrFUQa1A-TQM4n0SKtzE9o8v/view> | ## Inspiration
This quarter while taking a class called Biosecurity and Bioterrorism Response, I've been exposed to the current reality of a significant lack in protection against dangerous biological agents across the world. While the threat of mass casualties due to biological attacks doesn't seem to be imminent, a goal of detecting infections in societies and protecting/helping citizens is a step in the right direction towards an overall more safe society. In pursuit of trying to develop an application to contribute to solutions to this issue, I decided to formulate a solution incorporating the many useful products and API's demonstrated at TreeHacks. This solution would improve community preparedness if an outbreak were to occur.
## What it does
Campus Health serves as a central portal for students to report their recent symptoms, locations and for administrators to track down sources of infections, perform analytics on the safety of the community, see the most commonly affected parts (nose, face, throat, etc...) derived from the symptoms, and be alerted of any outlying threat to then take the best course of action.
Administrators can search reports by name, common symptoms, or common previous locations using elasticsearch, and analyze the most commonly affected part (nose, face, throat, etc...) from the NLP by Google Cloud. Administrators can opt to be alerted if the threshold for sum of a part per person is exceeded. (For example, be notified if more than 15 people report a problem with their throat like (sore throat).)
## How I built it
The web application was built using Wix and Wix Code. The frontend was made from the Wix WYSIWYG Designer. Wix Code allowed the possibility of writing frontend and backend javascript while also importing necessary libraries such as elasticsearch, google cloud natural language, and twilio. Google Cloud Platform was used to host a virtual instance which utilized Docker and Docker-Compose to run multiple containers of elasticsearch connected via a private network. Twilio was utilized to send alerts to administrators once the threshold for the number of parts infected was passed (for example when more than 15 people report having a problem with their nose(runny nose, stuffed nose, etc...)). Wix Code Backend Modules were used to connect to these endpoints and seamlessly integrate with the frontend as well.
## Challenges I ran into
Figuring it out how Wix Code works including the function events that get triggered on the frontend, creating database collections and datasets connected to forms.
One of the most interesting challenges was implementing elasticsearch into Wix Code instead of the native search methods. I used the database hook functions to add/remove documents from elastic search whenever a form was submitted by a student and a row was added to the collection of responses. The search bar on the admin page can then search the table of responses by their name, symptoms, or recent locations with lenient mistypes instead of three different search bars.
## Accomplishments that I'm proud of
I am proud of learning many new technologies and integrating them into one solution.
## What I learned
Wix Code Design, Frontend, Backend; Improved by comprehension of Dockerfiles and docker-compose.yml; Google Cloud Natural Language API;
## What's next for Campus Health
Campus Health can initially be put into use at university campuses, and if successful, even be expanded to the larger communities such as counties, cities, or states. | # Course Connection
## Inspiration
College is often heralded as a defining time period to explore interests, define beliefs, and establish lifelong friendships. However the vibrant campus life has recently become endangered as it is becoming easier than ever for students to become disconnected. The previously guaranteed notion of discovering friends while exploring interests in courses is also becoming a rarity as classes adopt hybrid and online formats. The loss became abundantly clear when two of our members, who became roommates this year, discovered that they had taken the majority of the same courses despite never meeting before this year. We built our project to combat this problem and preserve the zeitgeist of campus life.
## What it does
Our project provides a seamless tool for a student to enter their courses by uploading their transcript. We then automatically convert their transcript into structured data stored in Firebase. With all uploaded transcript data, we create a graph of people they took classes with, the classes they have taken, and when they took each class. Using a Graph Attention Network and domain-specific heuristics, we calculate the student’s similarity to other students. The user is instantly presented with a stunning graph visualization of their previous courses and the course connections to their most similar students.
From a commercial perspective, our app provides businesses the ability to utilize CheckBook in order to purchase access to course enrollment data.
## High-Level Tech Stack
Our project is built on top of a couple key technologies, including React (front end), Express.js/Next.js (backend), Firestore (real time graph cache), Estuary.tech (transcript and graph storage), and Checkbook.io (payment processing).
## How we built it
### Initial Setup
Our first task was to provide a method for students to upload their courses. We elected to utilize the ubiquitous nature of transcripts. Utilizing python we parse a transcript, sending the data to a node.js server which serves as a REST api point for our front end. We chose Vercel to deploy our website. It was necessary to generate a large number of sample users in order to test our project. To generate the users, we needed to scrape the Stanford course library to build a wide variety of classes to assign to our generated users. In order to provide more robust tests, we built our generator to pick a certain major or category of classes, while randomly assigning different category classes for a probabilistic percentage of classes. Using this python library, we are able to generate robust and dense networks to test our graph connection score and visualization.
### Backend Infrastructure
We needed a robust database infrastructure in order to handle the thousands of nodes. We elected to explore two options for storing our graphs and files: Firebase and Estuary. We utilized the Estuary API to store transcripts and the graph “fingerprints” that represented a students course identity. We wanted to take advantage of the web3 storage as this would allow students to permanently store their course identity to be easily accessed. We also made use of Firebase to store the dynamic nodes and connections between courses and classes.
We distributed our workload across several servers.
We utilized Nginx to deploy a production level python server that would perform the graph operations described below and a development level python server. We also had a Node.js server to serve as a proxy serving as a REST api endpoint, and Vercel hosted our front-end.
### Graph Construction
Treating the firebase database as the source of truth, we query it to get all user data, namely their usernames and which classes they took in which quarters. Taking this data, we constructed a graph in Python using networkX, in which each person and course is a node with a type label “user” or “course” respectively. In this graph, we then added edges between every person and every course they took, with the edge weight corresponding to the recency of their having taken it.
Since we have thousands of nodes, building this graph is an expensive operation. Hence, we leverage Firebase’s key-value storage format to cache this base graph in a JSON representation, for quick and easy I/O. When we add a user, we read in the cached graph, add the user, and update the graph. For all graph operations, the cache reduces latency from ~15 seconds to less than 1.
We compute similarity scores between all users based on their course history. We do so as the sum of two components: node embeddings and domain-specific heuristics. To get robust, informative, and inductive node embeddings, we periodically train a Graph Attention Network (GAT) using PyG (PyTorch Geometric). This training is unsupervised as the GAT aims to classify positive and negative edges. While we experimented with more classical approaches such as Node2Vec, we ultimately use a GAT as it is inductive, i.e. it can generalize to and embed new nodes without retraining. Additionally, with their attention mechanism, we better account for structural differences in nodes by learning more dynamic importance weighting in neighborhood aggregation. We augment the cosine similarity between two users’ node embeddings with some more interpretable heuristics, namely a recency-weighted sum of classes in common over a recency-weighted sum over the union of classes taken.
With this rich graph representation, when a user queries, we return the induced subgraph of the user, their neighbors, and the top k most people most similar to them, who they likely have a lot in common with, and whom they may want to meet!
## Challenges we ran into
We chose a somewhat complicated stack with multiple servers. We therefore had some challenges with iterating quickly for development as we had to manage all the necessary servers.
In terms of graph management, the biggest challenges were in integrating the GAT and in maintaining synchronization between the Firebase and cached graph.
## Accomplishments that we're proud of
We’re very proud of the graph component both in its data structure and in its visual representation.
## What we learned
It was very exciting to work with new tools and libraries. It was impressive to work with Estuary and see the surprisingly low latency. None of us had worked with next.js. We were able to quickly ramp up to using it as we had react experience and were very happy with how easily it integrated with Vercel.
## What's next for Course Connections
There are several different storyboards we would be interested in implementing for Course Connections. One would be a course recommendation. We discovered that chatGPT gave excellent course recommendations given previous courses. We developed some functionality but ran out of time for a full implementation. | losing |
## Inspiration
One of the 6 most common medication problems in an ageing population comes from the scheduling and burden of taking several medications several times a day. At best, this can be a hassle and an annoying process. However, it is often more likely than not that many may simply forget to take certain medication without supervision and reminders which may result in further deterioration of their health. In order to address this issue to make living healthy a smoother process for the ageing population as well as provide better support for their healthcare providers, MediDate was born. Designed with the user in mind, the UI is simple and intuitive while the hardware is also clean and dependable. The diversity of features ensures that all aspects of the medication and caretaking process can be managed effectively through one comprehensive platform. A senior citizen now has a technological solution to one of their daily problems, which can all be managed easily by a caretaker or nurse.
## What it does
MediDate is a combination of hardware components and a web application. The hardware aspect is responsible for tracking dosage & supply for the patient as well as communicate issues (such as low supply of medication) to the web application and the caretaker. The web application is made up of several different features to best serve both patient and caretaker. Users are first brought to a welcome page with a daily schedule of their medications as well as a simulation of the pillbox below to keep track of total medication supply. When the web app detects that supply is below a certain threshold, it will make calls to local pharmacies to reorder the medication.
Along the side navigation bar, there are several features that the users can take advantage of including a notifications page, monitoring pharmacy orders, uploading new subscriptions, and descriptions of their current medication. The notifications page is pretty self-explanatory, it keeps track of any notifications patients and/or caretakers should be aware of, such as successful prescription uploads, low medication supply, and errors in uploads. The upload page allows users to take photos of new prescriptions to upload to the web app which will then make the appropriate processes in order to add it to both the schedule and the explanation bar through RX numbers, dates, etc... Finally, the prescription pages offer quick shortcuts for descriptions of the medication to make understanding meds easier for users.
In order to be as accessible as possible, an Alexa skill has also been created to support functionality from the web application for users to interact more directly with the caretaking solution. It currently supports limited functionality including querying for today's prescription, descriptions of different medication on the patients' schedules, as well as a call for help function should the need arise. This aspect of MediDate will allow more efficient service for a larger population, directly targeting those with vision impairment.
Another feature was integrated using Twilio's SMS API. For the convenience of the user, a notification text would be sent to a registered Pharmacy phone number with details of prescription requirements when the current pill inventory fell below an adjustable threshold. Pharmacies could then respond to the text to notify the user when their prescription was ready for pick-up. This enables seamless prescription refills and reduces the time spent in the process.
## How I built it
**Hardware**
Powered by an Arduino UNO, buttons were attached to the bottom of the pillbox to act as weight sensors for pills. When pills are removed, the button would click "off", sending data to the web application for processing. We used CoolTerm and a Python script to store Arduino inputs before passing it off to the web app. This aspect allows for physical interaction with the user and helps to directly manage medication schedules.
**Google Cloud Vision**
In order to turn images of prescriptions into text files that could be processed by our web app, we used Google Cloud Vision to parse the image and scan for relevant text. Instead of running a virtual machine, we made API calls through our web app to take advantage of the free Cloud Credits.
**Backend**
Scripting was done using JavaScript and Python/Flask, processing information from Cloud Vision, the Arduino, and user inputs. The goal here was to send consistent, clear outputs to the user at all times.
**Frontend**
Built with HTML, CSS, bootstrap, and javascript, the design is meant to be clean and simple for the user. We chose a friendly UI/UX design, bright colours, and great interface flow.
**Alexa Skill**
Built with Voiceflow, the intents are simple and the skill does a good job of walking the user through each option carefully with many checks along the way to ensure the user is following. Created with those who may not be as familiar communicating with technology verbally, MediDate is an excellent way to integrate future support technologies seamlessly into users' lives.
**Twilio SMS**
The Twilio SMS API was integrated using Python/Flask. Once the pill inventory fell below an adjustable pill quantity, the Twilio outbound notification text workflow is triggered. Following receipt of the text by pharmacies and the preparation of prescriptions, a return text triggers a notification status on the user's home page.
## Challenges I ran into
Flask proved to be a difficult tool to work with, causing us many issues with static and application file paths. Dhruv and Allen spent a long time working on this problem. We were also a bit rusty with hardware and didn't realize how important resistors were. Because of that, we ran into some issues getting a basic model set up, but it was all smooth sailing from there. The reactive calendar with the time blocks also turned out to be a very complex problem. There were many different ways to take on the difference arrays, which was the big hurdle to solving the problem. Finding an efficient solution was definitely a big challenge.
## Accomplishments that I'm proud of
Ultimately, getting the full model off the ground is certainly something to be proud of. We followed Agile methodology and tried (albeit unsuccessfully at times) to get a minimum viable product with each app functionality we took on. This was a fun and challenging project, and we're all glad to have learned so much in the process.
## What's next for MediDate
The future of MediDate is bright! With a variety of areas to spread into in order to support accessible treatment for ALL users, MediDate is hoping to improve the hardware. Many elderly also suffer from tremors and other physical ailments that may make taking pills a more difficult process. As a result, implementing a better switch system to open the pillbox is an area the product could expand towards. | View presentation at the following link: <https://youtu.be/Iw4qVYG9r40>
## Inspiration
During our brainstorming stage, we found that, interestingly, two-thirds (a majority, if I could say so myself) of our group took medication for health-related reasons, and as a result, had certain external medications that result in negative drug interactions. More often than not, one of us is unable to have certain other medications (e.g. Advil, Tylenol) and even certain foods.
Looking at a statistically wider scale, the use of prescription drugs is at an all-time high in the UK, with almost half of the adults on at least one drug and a quarter on at least three. In Canada, over half of Canadian adults aged 18 to 79 have used at least one prescription medication in the past month. The more the population relies on prescription drugs, the more interactions can pop up between over-the-counter medications and prescription medications. Enter Medisafe, a quick and portable tool to ensure safe interactions with any and all medication you take.
## What it does
Our mobile application scans barcodes of medication and outputs to the user what the medication is, and any negative interactions that follow it to ensure that users don't experience negative side effects of drug mixing.
## How we built it
Before we could return any details about drugs and interactions, we first needed to build a database that our API could access. This was done through java and stored in a CSV file for the API to access when requests were made. This API was then integrated with a python backend and flutter frontend to create our final product. When the user takes a picture, the image is sent to the API through a POST request, which then scans the barcode and sends the drug information back to the flutter mobile application.
## Challenges we ran into
The consistent challenge that we seemed to run into was the integration between our parts.
Another challenge that we ran into was one group member's laptop just imploded (and stopped working) halfway through the competition, Windows recovery did not pull through and the member had to grab a backup laptop and set up the entire thing for smooth coding.
## Accomplishments that we're proud of
During this hackathon, we felt that we *really* stepped out of our comfort zone, with the time crunch of only 24 hours no less. Approaching new things like flutter, android mobile app development, and rest API's was daunting, but we managed to preserver and create a project in the end.
Another accomplishment that we're proud of is using git fully throughout our hackathon experience. Although we ran into issues with merges and vanishing files, all problems were resolved in the end with efficient communication and problem-solving initiative.
## What we learned
Throughout the project, we gained valuable experience working with various skills such as Flask integration, Flutter, Kotlin, RESTful APIs, Dart, and Java web scraping. All these skills were something we've only seen or heard elsewhere, but learning and subsequently applying it was a new experience altogether. Additionally, throughout the project, we encountered various challenges, and each one taught us a new outlook on software development. Overall, it was a great learning experience for us and we are grateful for the opportunity to work with such a diverse set of technologies.
## What's next for Medisafe
Medisafe has all 3-dimensions to expand on, being the baby app that it is. Our main focus would be to integrate the features into the normal camera application or Google Lens. We realize that a standalone app for a seemingly minuscule function is disadvantageous, so having it as part of a bigger application would boost its usage. Additionally, we'd also like to have the possibility to take an image from the gallery instead of fresh from the camera. Lastly, we hope to be able to implement settings like a default drug to compare to, dosage dependency, etc. | ## Inspiration
Medical technology has greatly advanced in the past decades, but what is the point of having tablets if patients forget to take them? According to the FDA, 50% of prescribed medication isn’t taken as directed by doctors and pharmacists, and the root cause of this is simply because users tend to forget when to take their prescriptions. This can lead to significant consequences, as it’s crucial to take certain medications at specific times of the day—for example, taking blood pressure drugs at night before going to bed can prevent heart attacks and strokes, and birth control pills must be taken at the same time every day to ensure optimal efficacy. Each year, 7,000 to 9,000 people die as a result of a medication error.
As young people in the tech industry, we rarely see people designing things for the elderly even though they face the highest risk in life-threatening health conditions. Thus, our team decided to create an all-in-one tool that helps adults manage their prescriptions while prioritizing ease of use and accessibility.
## What it does
*MediScan* is a medication management app that creates a personalized schedule from uploaded prescription images. Our concept is two-fold: first, we target the issue of adults forgetting to take their daily prescriptions; and second, we acknowledge the technology gap across generations and make medication management as accessible as possible.
#### Scheduled reminders
MediScan creates a personalized schedule for the user every day based on their current prescriptions. It then sends a notification at the appropriate time to remind the user to take their medication(s) as directed. There is also a daily view to allow users to keep track of their medicine intake. These frequent daily notifications will ensure users take all of their prescriptions on time.
#### Add prescription from image
The concept of a pill reminder app is not new; there already exists multiple functional apps that achieve the same goal of helping users take their prescriptions on time. However, these existing apps require the user to manually enter their prescription based on the label. This could be an issue to users with limited health literacy or those who are visually impaired, both of which are common among the elderly. As a result, errors can occur when users misread their prescriptions or input incorrect information into the app, which could be fatal.
To target this problem, we incorporate a novel feature that allows users to take or upload a photo of their prescription. *MediScan* then analyzes the image and extracts the relevant information from the prescription (name of drug as well as quantity and frequency) so that the user doesn’t have to. They then confirm this information and *MediScan* will automatically import the prescription to their profile and calendar. No other user inputs are necessary!
## How we built it
The backend of *MediScan* relies on optical character recognition (OCR) and natural language processing (NLP) techniques. We leverage the use of the Tesseract OCR engine to extract prescription information from images of prescription bottles that users upload. From there, we perform NLP that analyzes the extracted text to parse information such as the name of the drug, how often it should be taken, and how many pills/tablets should be taken at once. Both OCR and NLP are done with javascript. This information is then compiled into a calendar-esque application that is user-friendly and easy to manage. The frontend of MediScan is built with React Native and designed from scratch with Figma.
## Challenges we ran into
We ran into two significant challenges: extracting text accurately from the images and also creating a native iOS app for the first time. Extracting text from the images was made difficult from the inconsistencies of the image, from the background to the skewness to the variation in colors and font color/size. To tackle this, we used image preprocessing techniques to aid in the accuracy of the optical character recognition (OCR). We binarized and blurred the image, turning it into a high-contrast and slightly blurred gray-scale image that makes OCR significantly more effective. To tackle the challenge of building an iOS app, we relied on what we were familiar with to build our ideas before developing it in react native. We transferred our experience in React.js over to React native while also relying on Figma to design components. We also created standalone scripts for the OCR and natural language processing steps of the app as proof of concepts before integrating the code with the iOS app.
## Accomplishments that we're proud of
We’re proud of the design and concept of the application. We were able to design a thoroughly thought out application that’s clean, functional, and user-friendly. On top of that, our application tackles an important demographic in the elderly that is often overlooked, and it has the potential to create a large impact on the lives of many people. Most importantly, we’re proud of how we were able to build our first react native iOS app while multiple team members learned JavaScript for the first time. We were each able to pick up new skills to contribute significantly to the application, growing both as hackers and collaborators.
## What we learned
We learned tremendously about the end-to-end development of a standalone application. We learned how to put together and combine the design elements, front-end, and back-end of the application. In each of these parts, we also developed new skills using different technologies such as Figma, React Native, and Javascript. We also learned how to develop an iOS application for the first time, as well as how to streamline workflow between each of the team members.
## What's next for *MediScan*
Next steps for *MediScan* include fine tuning the OCR and text processing to be faster and more robust, adding push notifications to the application, and adding the app to the app store for the public to use. There are further improvements that can be made with the OCR that involve more complex image processing techniques and potentially machine learning additions, and this will benefit the text processing as well, which could be further expanded to be more robust with the type and format of the description. Finally, we want to continue to polish the application in order to publish it on the app store and have it be enjoyed by the general public. | winning |
## Inspiration
The inspiration behind our innovative personal desk assistant was ignited by the fond memories of Furbys, those enchanting electronic companions that captivated children's hearts in the 2000s. These delightful toys, resembling a charming blend of an owl and a hamster, held an irresistible appeal, becoming the coveted must-haves for countless celebrations, such as Christmas or birthdays. The moment we learned that the theme centered around nostalgia, our minds instinctively gravitated toward the cherished toys of our youth, and Furbys became the perfect representation of that cherished era.
Why Furbys? Beyond their undeniable cuteness, these interactive marvels served as more than just toys; they were companions, each one embodying the essence of a cherished childhood friend. Thinking back to those special childhood moments, the idea for our personal desk assistant was sparked. Imagine it as a trip down memory lane to the days of playful joy and the magic of having an imaginary friend. It reflects the real bonds many of us formed during our younger years. Our goal is to bring the spirit of those adored Furbies into a modern, interactive personal assistant—a treasured piece from the past redesigned for today, capturing the memories that shaped our childhoods.
## What it does
Our project is more than just a nostalgic memory; it's a practical and interactive personal assistant designed to enhance daily life. Using facial recognition, the assistant detects the user's emotions and plays mood-appropriate songs, drawing from a range of childhood favorites, such as tunes from the renowned Kidz Bop musical group. With speech-to-text and text-to-speech capabilities, communication is seamless. The Furby-like body of the assistant dynamically moves to follow the user's face, creating an engaging and responsive interaction. Adding a touch of realism, the assistant engages in conversation and tells jokes to bring moments of joy. The integration of a dashboard website with the Furby enhances accessibility and control. Utilizing a chatbot that can efficiently handle tasks, ensuring a streamlined and personalized experience. Moreover, incorporating home security features adds an extra layer of practicality, making our personal desk assistant a comprehensive and essential addition to modern living.
## How we built it
Following extensive planning to outline the implementation of Furby's functions, our team seamlessly transitioned into the execution phase. The incorporation of Cohere's AI platform facilitated the development of a chatbot for our dashboard, enhancing user interaction. To infuse a playful element, ChatGBT was employed for animated jokes and interactive conversations, creating a lighthearted and toy-like atmosphere. Enabling the program to play music based on user emotions necessitated the integration of the Spotify API. Google's speech-to-text was chosen for its cost-effectiveness and exceptional accuracy, ensuring precise results when capturing user input. Given the project's hardware nature, various physical components such as microcontrollers, servos, cameras, speakers, and an Arduino were strategically employed. These elements served to make the Furby more lifelike and interactive, contributing to an enhanced and smoother user experience. The meticulous planning and thoughtful execution resulted in a program that seamlessly integrates diverse functionalities for an engaging and cohesive outcome.
## Challenges we ran into
During the development of our project, we encountered several challenges that required demanding problem-solving skills. A significant hurdle was establishing a seamless connection between the hardware and software components, ensuring the smooth integration of various functionalities for the intended outcome. This demanded a careful balance to guarantee that each feature worked harmoniously with others. Additionally, the creation of a website to display the Furby dashboard brought its own set of challenges, as we strived to ensure it not only functioned flawlessly but also adhered to the desired aesthetic. Overcoming these obstacles required a combination of technical expertise, attention to detail, and a commitment to delivering a cohesive and visually appealing user experience.
## Accomplishments that we're proud of
While embarking on numerous software projects, both in an academic setting and during our personal endeavors, we've consistently taken pride in various aspects of our work. However, the development of our personal assistant stands out as a transformative experience, pushing us to explore new techniques and skills. Venturing into unfamiliar territory, we successfully integrated Spotify to play songs based on facial expressions and working with various hardware components. The initial challenges posed by these tasks required substantial time for debugging and strategic thinking. Yet, after investing dedicated hours in problem-solving, we successfully incorporated these functionalities for Furby. The journey from initial unfamiliarity to practical application not only left us with a profound sense of accomplishment but also significantly elevated the quality of our final product.
## What we learned
Among the many lessons learned, machine learning stood out prominently as it was still a relatively new concept for us!
## What's next for FurMe
The future goals for FurMe include seamless integration with Google Calendar for efficient schedule management, a comprehensive daily overview feature, and productivity tools such as phone detection and a Pomodoro timer to assist users in maximizing their focus and workflow. | ## Inspiration Behind DejaVu 🌍
The inspiration behind DejaVu is deeply rooted in our fascination with the human experience and the power of memories. We've all had those moments where we felt a memory on the tip of our tongues but couldn't quite grasp it, like a fleeting dream slipping through our fingers. These fragments of the past hold immense value, as they connect us to our personal history, our emotions, and the people who have been a part of our journey. 🌟✨
We embarked on the journey to create DejaVu with the vision of bridging the gap between the past and the present, between what's remembered and what's forgotten. Our goal was to harness the magic of technology and innovation to make these elusive memories accessible once more. We wanted to give people the power to rediscover the treasures hidden within their own minds, to relive those special moments as if they were happening all over again, and to cherish the emotions they evoke. 🚀🔮
The spark that ignited DejaVu came from a profound understanding that our memories are not just records of the past; they are the essence of our identity. We wanted to empower individuals to be the architects of their own narratives, allowing them to revisit their life's most meaningful chapters. With DejaVu, we set out to create a tool that could turn the faint whispers of forgotten memories into vibrant, tangible experiences, filling our lives with the warmth of nostalgia and the joy of reconnection. 🧠🔑
## How We Built DejaVu 🛠️
It all starts with the hardware component. There is a video/audio-recording Python script running on a laptop, to which a webcam is connected. This webcam is connected to the user's hat, which they wear on their head and it records video. Once the video recording is stopped, the video is uploaded to a storage bucket on Google Cloud. 🎥☁️
The video is retrieved by the backend, which can then be processed. Vector embeddings are generated for both the audio and the video so that semantic search features can be integrated into our Python-based software. After that, the resulting vectors can be leveraged to deliver content to the front-end through a Flask microservice. Through the Cohere API, we were able to vectorize audio and contextual descriptions, as well as summarize all results on the client side. 🖥️🚀
Our front-end, which was created using Next.js and hosted on Vercel, features a landing page and a search page. On the search page, a user can search a query for a memory which they are attempting to recall. After that, the query text is sent to the backend through a request, and the necessary information relating to the location of this memory is sent back to the frontend. After this occurs, the video where this memory occurs is displayed on the screen and allows the user to get rid of the ominous feeling of déjà vu. 🔎🌟
## Challenges We Overcame at DejaVu 🚧
🧩 Overcoming Hardware Difficulties 🛠️
One of the significant challenges we encountered during the creation of DejaVu was finding the right hardware to support our project. Initially, we explored using AdHawk glasses, which unfortunately removed existing functionality critical to our project's success. Additionally, we found that the Raspberry Pi, while versatile, didn't possess the computing power required for our memory time machine. To overcome these hardware limitations, we had to pivot and develop Python scripts for our laptops, ensuring we had the necessary processing capacity to bring DejaVu to life. This adaptation proved to be a critical step in ensuring the project's success. 🚫💻
📱 Navigating the Complex World of Vector Embedding 🌐
Another formidable challenge we faced was in the realm of vector embedding. This intricate process, essential for capturing and understanding the essence of memories, presented difficulties throughout our development journey. We had to work diligently to fine-tune and optimize the vector embedding techniques to ensure the highest quality results. Overcoming this challenge required a deep understanding of the underlying technology and relentless dedication to refining the process. Ultimately, our commitment to tackling this complexity paid off, as it is a crucial component of DejaVu's effectiveness. 🔍📈
🌐 Connecting App Components and Cloud Hosting with Google Cloud 🔗
Integrating the various components of the DejaVu app and ensuring seamless cloud hosting were additional challenges we had to surmount. This involved intricate work to connect user interfaces, databases, and the cloud infrastructure with Google Cloud services. The complexity of this task required meticulous planning and execution to create a cohesive and robust platform. We overcame these challenges by leveraging the expertise of our team and dedicating considerable effort to ensure that all aspects of the app worked harmoniously, providing users with a smooth and reliable experience. 📱☁️
## Accomplishments We Celebrate at DejaVu 🏆
🚀 Navigating the Hardware-Software Connection Challenge 🔌
One of the most significant hurdles we faced during the creation of DejaVu was connecting hardware and software seamlessly. The integration of our memory time machine with the physical devices and sensors posed complex challenges. It required a delicate balance of engineering and software development expertise to ensure that the hardware effectively communicated with our software platform. Overcoming this challenge was essential to make DejaVu a user-friendly and reliable tool for capturing and reliving memories, and our team's dedication paid off in achieving this intricate connection. 💻🤝
🕵️♂️ Mastering Semantic Search Complexity 🧠
Another formidable challenge we encountered was the implementation of semantic search. Enabling DejaVu to understand the context and meaning behind users' search queries proved to be a significant undertaking. Achieving this required advanced natural language processing and machine learning techniques. We had to develop intricate algorithms to decipher the nuances of human language, ensuring that DejaVu could provide relevant results even for complex or abstract queries. This challenge was a testament to our commitment to delivering a cutting-edge memory time machine that truly understands and serves its users. 📚🔍
🔗 Cloud Hosting and Cross-Component Integration 🌐
Integrating the various components of the DejaVu app and hosting data on Google Cloud presented a multifaceted challenge. Creating a seamless connection between user interfaces, databases, and cloud infrastructure demanded meticulous planning and execution. Ensuring that the app operated smoothly and efficiently, even as it scaled, required careful design and architecture. We dedicated considerable effort to overcome this challenge, leveraging the robust capabilities of Google Cloud to provide users with a reliable and responsive platform for preserving and reliving their cherished memories. 📱☁️
## Lessons Learned from DejaVu's Journey 📚
💻 Innate Hardware Limitations 🚀
One of the most significant lessons we've gleaned from creating DejaVu is the importance of understanding hardware capabilities. We initially explored using Arduinos and Raspberry Pi's for certain aspects of our project, but we soon realized their innate limitations. These compact and versatile devices have their place in many projects, but for a memory-intensive and complex application like DejaVu, they proved to be improbable choices. 🤖🔌
📝 Planning Before Executing 🤯
A crucial takeaway from our journey of creating DejaVu was the significance of meticulous planning for user flow before diving into coding. There were instances where we rushed into development without a comprehensive understanding of how users would interact with our platform. This led to poor systems design, resulting in unnecessary complications and setbacks. We learned that a well-thought-out user flow and system architecture are fundamental to the success of any project, helping to streamline development and enhance user experience. 🚀🌟
🤖 Less Technology is More Progress💡
Another valuable lesson revolved around the concept that complex systems can often be simplified by reducing the number of technologies in use. At one point, we experimented with a CockroachDB serverless database, hoping to achieve certain functionalities. However, we soon realized that this introduced unnecessary complexity and redundancy into our architecture. Simplifying our technology stack and focusing on essential components allowed us to improve efficiency and maintain a more straightforward and robust system. 🗃️🧩
## The Future of DejaVu: Where Innovation Thrives! 💫
🧩 Facial Recognition and Video Sorting 📸
With our eyes set on the future, DejaVu is poised to bring even more remarkable features to life. This feature will play a pivotal role in enhancing the user experience. Our ongoing development efforts will allow DejaVu to recognize individuals in your video archives, making it easier than ever to locate and relive moments featuring specific people. This breakthrough in technology will enable users to effortlessly organize their memories, unlocking a new level of convenience and personalization. 🤳📽️
🎁 Sharing Memories In-App 📲
Imagine being able to send a cherished memory video from one user to another, all within the DejaVu platform. Whether it's a heartfelt message, a funny moment, or a shared experience, this feature will foster deeper connections between users, making it easy to celebrate and relive memories together, regardless of physical distance. DejaVu aims to be more than just a memory tool; it's a platform for creating and sharing meaningful experiences. 💌👥
💻 Integrating BCI (Brain-Computer Interface) Technology 🧠
This exciting frontier will open up possibilities for users to interact with their memories in entirely new ways. Imagine being able to navigate and interact with your memory archives using only your thoughts. This integration could revolutionize the way we access and relive memories, making it a truly immersive and personal experience. The future of DejaVu is all about pushing boundaries and providing users with innovative tools to make their memories more accessible and meaningful. 🌐🤯 | ## Inspiration
Our inspiration came from our first year in University, as we all lived without our parents for the first time. We had to cook and buy groceries for ourselves while trying to manage the school on top of that. More often than not, we found that the food in our fridge or pantries would go bad, while we spent money on food from fast-food restaurants. In the end, we were all eating unhealthy food while spending a ton of money and wasting way too much food.
## What it does
iFridge helps you keep track of all the food you have at home. It has a built-in database of expiration dates of certain foods. Each food has a "type of food", "days to expire", "quantity", and "name" attribute. This helps the user sort their fridge items based on what they are looking for. It is also able to find recipes that match your ingredients or the foods that will expire first. It has a shopping list where you can see the food you have in a horizontal scroll. The vertical scroll on the page will show what you need to buy in a checklist format. The shopping list feature helps the user while they are shopping for groceries. No more wondering whether or not you have the ingredients for a recipe you just searched up, everything is all in one place. When the user checks a food off the list, it will ask for the quantity of the food and input it automatically into your fridge. Lastly, our input has a camera feature that allows the user scan their food into their fridge. The user can manually input it as well, however, we thought that providing a scanning function would be better.
## How we built it
We built our project using flutter dart. We built-in login authentication with the use of Firebase Authentication and connected each user's food to the Cloud Firestore database. We used google photo API to take pictures for our input and scan the items in the photo into the app.
## Challenges we ran into
A challenge we ran into was working with dart streams specifically so that the stream only read the current user data and added only to the current user's database. Also learning about the different Widgets, Event Loops, Futures and Async that's unique to flutter and that are new concepts was challenging but lots of fun!
Another challenge we ran into was keeping track of whether the user was logged in or not. Depending on if there is an account active, the app must display different widgets to accommodate the needs of the user. This required the use of Streams to track the activity of the user.
We weren't familiar with git either. So, in the beginning, a lot of work was lost because of merging problems.
## Accomplishments that we're proud of
We are so proud to have a physical app that allows users create accounts and input data. This was our first time using databases (we never heard of firebase before today) and our first time using flutter. We’ve never even used github before to push and pull files. The google photo API was an enormous challenge as this was also a first for us.
## What we learned
We learned a lot about flutter dart and how it works, how to implement google photo APIs, and how to access and rewrite information in a database.
## What's next for iFridge
There are many features that we want to implement. This includes a healthy eating tracker that helps the user analyze what food categories they need more of. Eventually, the recipes can also cater to the likes and dislikes of the user. We also want to implement a feature that allows the user to add all the ingredients they need (ones that aren't already in their fridge) into their shopping cart. Overall we want to make our app user friendly. We don't want to over-complicate the environment, however, we want our design to be efficient and accomplish any needs of the user. | winning |
## Inspiration
The post-COVID era has increased the number of in-person events and need for public speaking. However, more individuals are anxious to publicly articulate their ideas, whether this be through a presentation for a class, a technical workshop, or preparing for their next interview. It is often difficult for audience members to catch the true intent of the presenter, hence key factors including tone of voice, verbal excitement and engagement, and physical body language can make or break the presentation.
A few weeks ago during our first project meeting, we were responsible for leading the meeting and were overwhelmed with anxiety. Despite knowing the content of the presentation and having done projects for a while, we understood the impact that a single below-par presentation could have. To the audience, you may look unprepared and unprofessional, despite knowing the material and simply being nervous. Regardless of their intentions, this can create a bad taste in the audience's mouths.
As a result, we wanted to create a judgment-free platform to help presenters understand how an audience might perceive their presentation. By creating Speech Master, we provide an opportunity for presenters to practice without facing a real audience while receiving real-time feedback.
## Purpose
Speech Master aims to provide a practice platform for practice presentations with real-time feedback that captures details in regard to your body language and verbal expressions. In addition, presenters can invite real audience members to practice where the audience member will be able to provide real-time feedback that the presenter can use to improve.
While presenting, presentations will be recorded and saved for later reference for them to go back and see various feedback from the ML models as well as live audiences. They are presented with a user-friendly dashboard to cleanly organize their presentations and review for upcoming events.
After each practice presentation, the data is aggregated during the recording and process to generate a final report. The final report includes the most common emotions expressed verbally as well as times when the presenter's physical body language could be improved. The timestamps are also saved to show the presenter when the alerts rose and what might have caused such alerts in the first place with the video playback.
## Tech Stack
We built the web application using [Next.js v14](https://nextjs.org), a React-based framework that seamlessly integrates backend and frontend development. We deployed the application on [Vercel](https://vercel.com), the parent company behind Next.js. We designed the website using [Figma](https://www.figma.com/) and later styled it with [TailwindCSS](https://tailwindcss.com) to streamline the styling allowing developers to put styling directly into the markup without the need for extra files. To maintain code formatting and linting via [Prettier](https://prettier.io/) and [EsLint](https://eslint.org/). These tools were run on every commit by pre-commit hooks configured by [Husky](https://typicode.github.io/husky/).
[Hume AI](https://hume.ai) provides the [Speech Prosody](https://hume.ai/products/speech-prosody-model/) model with a streaming API enabled through native WebSockets allowing us to provide emotional analysis in near real-time to a presenter. The analysis would aid the presenter in depicting the various emotions with regard to tune, rhythm, and timbre.
Google and [Tensorflow](https://www.tensorflow.org) provide the [MoveNet](https://www.tensorflow.org/hub/tutorials/movenet#:%7E:text=MoveNet%20is%20an%20ultra%20fast,17%20keypoints%20of%20a%20body.) model is a large improvement over the prior [PoseNet](https://medium.com/tensorflow/real-time-human-pose-estimation-in-the-browser-with-tensorflow-js-7dd0bc881cd5) model which allows for real-time pose detection. MoveNet is an ultra-fast and accurate model capable of depicting 17 body points and getting 30+ FPS on modern devices.
To handle authentication, we used [Next Auth](https://next-auth.js.org) to sign in with Google hooked up to a [Prisma Adapter](https://authjs.dev/reference/adapter/prisma) to interface with [CockroachDB](https://www.cockroachlabs.com), allowing us to maintain user sessions across the web app. [Cloudinary](https://cloudinary.com), an image and video management system, was used to store and retrieve videos. [Socket.io](https://socket.io) was used to interface with Websockets to enable the messaging feature to allow audience members to provide feedback to the presenter while simultaneously streaming video and audio. We utilized various services within Git and Github to host our source code, run continuous integration via [Github Actions](https://github.com/shahdivyank/speechmaster/actions), make [pull requests](https://github.com/shahdivyank/speechmaster/pulls), and keep track of [issues](https://github.com/shahdivyank/speechmaster/issues) and [projects](https://github.com/users/shahdivyank/projects/1).
## Challenges
It was our first time working with Hume AI and a streaming API. We had experience with traditional REST APIs which are used for the Hume AI batch API calls, but the streaming API was more advantageous to provide real-time analysis. Instead of an HTTP client such as Axios, it required creating our own WebSockets client and calling the API endpoint from there. It was also a hurdle to capture and save the correct audio format to be able to call the API while also syncing audio with the webcam input.
We also worked with Tensorflow for the first time, an end-to-end machine learning platform. As a result, we faced many hurdles when trying to set up Tensorflow and get it running in a React environment. Most of the documentation uses Python SDKs or vanilla HTML/CSS/JS which were not possible for us. Attempting to convert the vanilla JS to React proved to be more difficult due to the complexities of execution orders and React's useEffect and useState hooks. Eventually, a working solution was found, however, it can still be improved to better its performance and bring fewer bugs.
We originally wanted to use the Youtube API for video management where users would be able to post and retrieve videos from their personal accounts. Next Auth and YouTube did not originally agree in terms of available scopes and permissions, but once resolved, more issues arose. We were unable to find documentation regarding a Node.js SDK and eventually even reached our quota. As a result, we decided to drop YouTube as it did not provide a feasible solution and found Cloudinary.
## Accomplishments
We are proud of being able to incorporate Machine Learning into our applications for a meaningful purpose. We did not want to reinvent the wheel by creating our own models but rather use the existing and incredibly powerful models to create new solutions. Although we did not hit all the milestones that were hoping to achieve, we are still proud of the application that we were able to make in such a short amount of time and be able to deploy the project as well.
Most notably, we are proud of our Hume AI and Tensorflow integrations that took our application to the next level. Those 2 features took the most time, but they were also the most rewarding as in the end, we got to see real-time updates of our emotional and physical states. We are proud of being able to run the application and get feedback in real-time, which gives small cues to the presenter on what to improve without risking distracting the presenter completely.
## What we learned
Each of the developers learned something valuable as each of us worked with a new technology that we did not know previously. Notably, Prisma and its integration with CockroachDB and its ability to make sessions and general usage simple and user-friendly. Interfacing with CockroachDB barely had problems and was a powerful tool to work with.
We also expanded our knowledge with WebSockets, both native and Socket.io. Our prior experience was more rudimentary, but building upon that knowledge showed us new powers that WebSockets have both when used internally with the application and with external APIs and how they can introduce real-time analysis.
## Future of Speech Master
The first step for Speech Master will be to shrink the codebase. Currently, there is tons of potential for components to be created and reused. Structuring the code to be more strict and robust will ensure that when adding new features the codebase will be readable, deployable, and functional. The next priority will be responsiveness, due to the lack of time many components appear strangely on different devices throwing off the UI and potentially making the application unusable.
Once the current codebase is restructured, then we would be able to focus on optimization primarily on the machine learning models and audio/visual. Currently, there are multiple instances of audio and visual that are being used to show webcam footage, stream footage to other viewers, and sent to HumeAI for analysis. By reducing the number of streams, we should expect to see significant performance improvements with which we can upgrade our audio/visual streaming to use something more appropriate and robust.
In terms of new features, Speech Master would benefit greatly from additional forms of audio analysis such as speed and volume. Different presentations and environments require different talking speeds and volumes of speech required. Given some initial parameters, Speech Master should hopefully be able to reflect on those measures. In addition, having transcriptions that can be analyzed for vocabulary and speech, ensuring that appropriate language is used for a given target audience would drastically improve the way a presenter could prepare for a presentation. | ## **1st Place!**
## Inspiration
Sign language is a universal language which allows many individuals to exercise their intellect through common communication. Many people around the world suffer from hearing loss and from mutism that needs sign language to communicate. Even those who do not experience these conditions may still require the use of sign language for certain circumstances. We plan to expand our company to be known worldwide to fill the lack of a virtual sign language learning tool that is accessible to everyone, everywhere, for free.
## What it does
Here at SignSpeak, we create an encouraging learning environment that provides computer vision sign language tests to track progression and to perfect sign language skills. The UI is built around simplicity and useability. We have provided a teaching system that works by engaging the user in lessons, then partaking in a progression test. The lessons will include the material that will be tested during the lesson quiz. Once the user has completed the lesson, they will be redirected to the quiz which can result in either a failure or success. Consequently, successfully completing the quiz will congratulate the user and direct them to the proceeding lesson, however, failure will result in the user having to retake the lesson. The user will retake the lesson until they are successful during the quiz to proceed to the following lesson.
## How we built it
We built SignSpeak on react with next.js. For our sign recognition, we used TensorFlow with a media pipe model to detect points on the hand which were then compared with preassigned gestures.
## Challenges we ran into
We ran into multiple roadblocks mainly regarding our misunderstandings of Next.js.
## Accomplishments that we're proud of
We are proud that we managed to come up with so many ideas in such little time.
## What we learned
Throughout the event, we participated in many workshops and created many connections. We engaged in many conversations that involved certain bugs and issues that others were having and learned from their experience using javascript and react. Additionally, throughout the workshops, we learned about the blockchain and entrepreneurship connections to coding for the overall benefit of the hackathon.
## What's next for SignSpeak
SignSpeak is seeking to continue services for teaching people to learn sign language. For future use, we plan to implement a suggestion box for our users to communicate with us about problems with our program so that we can work quickly to fix them. Additionally, we will collaborate and improve companies that cater to phone audible navigation for blind people. | ## Inspiration
As avid readers ourselves, we love the work that authors put out, and we are deeply saddened by the relative decline of the medium. We believe that democratizing the writing process and giving power back to the writers is the way to revitalize the art form literature, and we believe that utilizing blockchain technology can help us get closer to that ideal.
## What it does
LitHub connects authors with readers through eluv.io's NFT trading platform, allowing authors to sell their literature as exclusive NFTs and readers to have exclusive access to their purchases on our platform.
## How we built it
We utilized the eluv.io API to enable upload, download, and NFT trading functionality for our backend. We leveraged CockroachDB to store user information and we used HTML/CSS to create our user-facing frontend, and deployed our application we used Microsoft Azure.
## Challenges we ran into
One of the main challenges we ran into was understanding the various APIs that we were working with over a short period of time. As this was our first time working with NFTs/blockchain, eluv.io was a particularly new experience to us, and it took some time, but we were able to overcome many of the challenges we faced thanks to the help from mentors from eluv.io. Another challenge we ran into was actually connecting the pieces of our project together as we used many different pieces of technology, but careful coordination and well-planned functional abstraction made the ease of integration a pleasant surprise.
## Accomplishments that we're proud of
We're proud of coming up with an innovative solution that can help level the playing field for writers and for creating a platform that accomplishes this using many of the platforms that event sponsors provided. We are also proud of gaining familiarity with a variety of different platforms in a short period of time and showing resilience in the face of such a large task.
## What we learned
We learned quite a few things while working on this project. Firstly, we learned a lot about blockchain space, and how to utilize this technology during development, and what problems they can solve. Before this event, nobody in our group had much exposure to this field, so it was a welcome experience In addition, some of us who were less familiar with full-stack development got exposure to Node and Express, and we all got to reapply concepts we learned when working with other databases to CockroachDB's user-friendly interface.
## What's next for LitHub
The main next step for LitHub would be to scale our application to handle a larger user base. From there we hope to share LitHub amongst authors and readers around the world so that they too can take partake in the universe of NFTs to safely share their passion. | winning |
## Inspiration
We were inspired by the idea of using technology to help people in difficult situations, such as natural disasters, medical emergencies, or social isolation. We wanted to create a rover that could be controlled remotely from anywhere in the world, and that could deliver essential items to those who need them.
## What it does
Armtastic Aid Rover is a rover that you can control remotely from anywhere, allowing you to aid those in need, through the use of its robotic arm and built-in camera, to bring them their urgent needs. You can use a web interface or mobile interface to see what the rover sees, and to control its movement and arm. In future iterations, the rover would be able to carry items such as food, water, medicine, or even a teddy bear, and deliver them to the person in need.
## How we built it
We built the rover using a Raspberry Pi, a camera module, a motor driver, several DC and servo motors, along with a 3D printed robotic arm. We used Python to program the rover's functionality, and Flask to create the web interface. We used HTML, CSS, and JavaScript to design the web interface, and a rigid plastic frame to be able to withstand harsh environments.
## Challenges we ran into
We faced many challenges while building the rover, such as:
* Finding the right components and materials for the rover and its arm
* Connecting the components and wiring them correctly
* Programming the rover's movement and arm control
* Creating a responsive and user-friendly web interface
* Testing the rover's functionality and performance
* Reinstalling Raspbian three times due to corrupted SD cards
## Accomplishments that we're proud of
We are proud of:
* Building a working rover that can be controlled remotely and that can deliver items to people in need
* Learning how to use various hardware and software tools and technologies
* Overcoming the challenges and difficulties we faced
* Having fun and collaborating as a team
## What we learned
We learned a lot from this project, such as:
* How to use a Raspberry Pi and its peripherals
* How to program in Python and Flask
* How to use HTML, CSS, JavaScript, and Socket.IO
* How to design and build a robotic arm
* How to test and debug hardware and software issues
* How to work as a team and communicate effectively
## What's next for Armtastic Aid Rover
We have many ideas for improving and expanding our project, such as:
* Adding more sensors and features to the rover, such as GPS, temperature, humidity, etc.
* Improving the rover's design and durability, using more robust materials and components
* Enhancing the web interface's functionality and appearance, using more advanced frameworks and libraries
* Deploying the rover in real-world scenarios and testing its impact and usefulness
* Adding microphone and speaker functionality, and improving the overall real-world usability of the project.
* Sharing our project with others and inspiring them to use technology for good | ## Inspiration
We wanted to build something that would help those with limited mobility or eyesight. We wanted to make something that was as simple and intuitive as possible, while performing complex tasks. To this end, we designed a system to allow users to locate items around their home they might not normally be able to see.
## What it does
Our fleet of robots allows the user to speak the name of the object they are looking for, and will then set off autonomously to track down the item. They will report back to the user once they have found the item, while the user can watch at every step along the way with a live video stream. The user can also take manual control of the robots at any time if they so wish.
## How I built it
The robots were built using laser cut plates, a raspberry pi, DC motors, and a dual voltage power system. The software used a TCP/IP library for streaming video called FireEye to send video and data from the Raspberry Pi to our Node.js server. This server performed image processing and natural language processing to determine what the user was trying to find, and identify it when the camera picked the object up. The front end was built using React.js, with Socket.io acting as the method of communication between server and UI.
## Challenges I ran into
We ran into many challenges. Many.
Our first problems lay with trying to get a consistent video stream from the robot to our server, and then only grew more difficult. We faces challenges trying to communicate data from our server to the robot, and from our server to the front-end UI. We also have very little experience designing user interfaces, and ran into many implementation problems. Additionally, this was the first undertaking we have coded with Node.js, which we learned was substantially different than Python. (Looking back Python probably should have been the way to go...)
## Accomplishments that I'm proud of
We are particularly proud of the overall tech stack we ended up using. There are many technologies that we had to get working, and then get to communicate before our system would become functional. We learned about TCP and Web sockets, as well as coding for hardware constraints, and how to perform cloud image processing.
## What I learned
We learned a substantial amount overall, mostly as it related to socket programming, and how to have multiple components share stateful data. We also learned how to deal with the constraints of network speed, and raspberry pi processing power. As such we learned about multi-threading programs to make them run more efficiently.
## What's next for MLE
We would like to expand our robots to include a robot arm, such that they would be able to retrieve and interact with the objects they are searching for. We would also like to make the robots bigger such that they can more effectively navigate. We also have plans to increase the overall speed of the system, and try to eliminate network and streaming latency. | ## Inspiration
DeliverAI was inspired by the current shift we are seeing in the automotive and delivery industries. Driver-less cars are slowly but surely entering the space, and we thought driverless delivery vehicles would be a very interesting topic for our project. While drones are set to deliver packages in the near future, heavier packages would be much more fit for a ground base vehicle.
## What it does
DeliverAI has three primary components. The physical prototype is a reconfigured RC car that was hacked together with a raspberry pi and a whole lot of motors, breadboards and resistors. Atop this monstrosity rides the package to be delivered in a cardboard "safe", along with a front facing camera (in an Android smartphone) to scan the faces of customers.
The journey begins on the web application, at [link](https://deliverai.github.io/dAIWebApp/). To sign up, a user submits webcam photos of themselves for authentication when their package arrives. They then select a parcel from the shop, and await its arrival. This alerts the car that a delivery is ready to begin. The car proceeds to travel to the address of the customer. Upon arrival, the car will text the customer to notify them that their package has arrived. The customer must then come to the bot, and look into the camera on its front. If the face of the customer matches the face saved to the purchasing account, the car notifies the customer and opens the safe.
## How we built it
As mentioned prior, DeliverAI has three primary components, the car hardware, the android application and the web application.
### Hardware
The hardware is built from a "repurposed" remote control car. It is wired to a raspberry pi which has various python programs checking our firebase database for changes. The pi is also wired to the safe, which opens when a certain value is changed on the database.
\_ note:\_ a micro city was built using old cardboard boxes to service the demo.
### Android
The onboard android device is the brain of the car. It texts customers through Twilio, scans users faces, and authorizes the 'safe' to open. Facial recognition is done using the Kairos API.
### Web
The web component, built entirely using HTML, CSS and JavaScript, is where all of the user interaction takes place. This is where customers register themselves, and also where they order items. Original designs and custom logos were created to build the website.
### Firebase
While not included as a primary component, Firebase was essential in the construction of DeliverAI. The real-time database, by Firebase, is used for the communication between the three components mentioned above.
## Challenges we ran into
Connecting Firebase to the Raspberry Pi proved more difficult than expected. A custom listener was eventually implemented that checks for changes in the database every 2 seconds.
Calibrating the motors was another challenge. The amount of power
Sending information from the web application to the Kairos API also proved to be a large learning curve.
## Accomplishments that we're proud of
We are extremely proud that we managed to get a fully functional delivery system in the allotted time.
The most exciting moment for us was when we managed to get our 'safe' to open for the first time when a valid face was exposed to the camera. That was the moment we realized that everything was starting to come together.
## What we learned
We learned a *ton*. None of us have much experience with hardware, so working with a Raspberry Pi and RC Car was both stressful and incredibly rewarding.
We also learned how difficult it can be to synchronize data across so many different components of a project, but were extremely happy with how Firebase managed this.
## What's next for DeliverAI
Originally, the concept for DeliverAI involved, well, some AI. Moving forward, we hope to create a more dynamic path finding algorithm when going to a certain address. The goal is that eventually a real world equivalent to this could be implemented that could learn the roads and find the best way to deliver packages to customers on land.
## Problems it could solve
Delivery Workers stealing packages or taking home packages and marking them as delivered.
Drones can only deliver in good weather conditions, while cars can function in all weather conditions.
Potentially more efficient in delivering goods than humans/other methods of delivery | losing |
## Inspiration
Garbage in bins around cities are constantly overflowing. Our goal was to create a system that better allocates time and resources to help prevent this problem, while also positively impacting the environment.
## What it does
Urbins provides a live monitoring web application that displays the live capacity of both garbage and recycling compartments using ultrasonic sensors. This functionality can be seen inside the prototype garbage bin. The bin uses a cell phone camera to send an image to the custom learning model built with IBM Watson. The results from the Watson model is used to classify each object placed in the bin so that it can be sorted into either garbage or recycling. Based on the classification, the Android application controls the V-shaped platform using a servo motor to tilt the platform and drop the item into it's correct bin. Once a garbage/recycling bin nears full-capacity, STDlib is used to notify city workers via SMS that bins at a given address are full.
Machine learning is applied when an object cannot be classified. When this happens, the image of the object is sent via STDlib to Slack. Along with the image, response buttons are displayed in Slack, which allows a city worker to manually classify the item. Once a selection is made, the new classification is used to further train the Watson model. This updated model is then used by all the connected smart garbage bins, allowing for all the bins to learn.
## Challenges we ran into
Integrating all components
Learning to use IBM Watson
Providing the set of images for IBM Watson (Needed to be a zip file containing at least 10 photos to update the model)
## Accomplishments that we're proud of
Integrating all the components.
Getting IBM Watson working
Getting STDlib working
Training IBM Watson using STDLib
## What we learned
How to use IBM Watson
How to effectively plan a project
Designing an effective architecture
How to use STDlib
## What's next for Urbins
Accounts
Algorithm for optimal route for shift
Dashboard with map areas, floor plans, housing plans, and event maps
Heat map on google maps
Bar chart of stats over past 6 months (which bin was the most frequently filled?)
Product Information and Brand data | ## Inspiration
We wanted to reduce global carbon footprint and pollution by optimizing waste management. 2019 was an incredible year for all environmental activities. We were inspired by the acts of 17-year old Greta Thunberg and how those acts created huge ripple effects across the world. With this passion for a greener world, synchronized with our technical knowledge, we created Recycle.space.
## What it does
Using modern tech, we provide users with an easy way to identify where to sort and dispose of their waste items simply by holding it up to a camera. This application will be especially useful when permanent fixtures are erect in malls, markets, and large public locations.
## How we built it
Using a flask-based backend to connect to Google Vision API, we captured images and categorized which waste categories the item belongs to. This was visualized using Reactstrap.
## Challenges I ran into
* Deployment
* Categorization of food items using Google API
* Setting up Dev. Environment for a brand new laptop
* Selecting appropriate backend framework
* Parsing image files using React
* UI designing using Reactstrap
## Accomplishments that I'm proud of
* WE MADE IT!
We are thrilled to create such an incredible app that would make people's lives easier while helping improve the global environment.
## What I learned
* UI is difficult
* Picking a good tech stack is important
* Good version control practices is crucial
## What's next for Recycle.space
Deploying a scalable and finalized version of the product to the cloud and working with local companies to deliver this product to public places such as malls. | # Welcome to TrashCam 🚮🌍♻️
## Where the Confusion of Trash Sorting Disappears for Good
### The Problem 🌎
* ❓ Millions of people struggle with knowing how to properly dispose of their trash. Should it go in compost, recycling, or garbage?
* 🗑️ Misplaced waste is a major contributor to environmental pollution and the growing landfill crisis.
* 🌐 Local recycling rules are confusing and inconsistent, making proper waste management a challenge for many.
### Our Solution 🌟
TrashCam simplifies waste sorting through real-time object recognition, turning trash disposal into a fun, interactive experience.
* 🗑️ Instant Sorting: With TrashCam, you never have to guess. Just scan your item, and our app will tell you where it belongs—compost, recycling, or garbage.
* 🌱 Gamified Impact: TrashCam turns eco-friendly habits into a game, encouraging users to reduce their waste through challenges and a leaderboard.
* 🌍 Eco-Friendly: By helping users properly sort their trash, TrashCam reduces contamination in recycling and compost streams, helping protect the environment.
### Experience It All 🎮
* 📸 Snap and Sort: Take a picture of your trash and TrashCam will instantly categorize it using advanced object recognition.
* 🧠 AI-Powered Classification: After detecting objects with Cloud Vision and COCO-SSD, we pass them to Gemini, which accurately classifies the items, ensuring they’re sorted into the correct waste category.
* 🏆 Challenge Friends: Compete on leaderboards to see who can make the biggest positive impact on the environment.
* ♻️ Learn as You Play: Discover more about what can be recycled, composted, or thrown away with each interaction.
### Tech Stack 🛠️
* ⚛️ Next.js & TypeScript: Powering our high-performance web application for smooth, efficient user experiences.
* 🛢️ PostgreSQL & Prisma: Storing and managing user data securely, ensuring fast and reliable access to information.
* 🌐 Cloud Vision API & COCO-SSD: Using state-of-the-art object recognition to accurately identify and classify waste in real time.
* 🤖 Gemini AI: Ensuring accurate classification of waste objects to guide users in proper disposal practices.
### Join the Movement 🌿
TrashCam isn’t just about proper waste management—it’s a movement toward a cleaner, greener future.
* 🌍 Make a Difference: Every time you sort your trash correctly, you help reduce landfill waste and protect the planet.
* 🎯 Engage and Compete: By playing TrashCam, you're not just making eco-friendly choices—you're inspiring others to do the same.
* 🏆 Be a Waste Warrior: Track your progress, climb the leaderboard, and become a leader in sustainable living. | winning |
## Inspiration
Children diagnosed with Autism generally have a more difficult time reading facial expressions and detecting sentiment. This can trickle down to not fully understanding other people's emotions during conversations. Furthermore, it can be difficult to give an objective way of interpreting people's emotions when receiving autism therapy to help with social interactions.
## What it does
Emotify is an all-in-one resource for people with trouble recognizing and interpreting emotion. One of the features is a game where users attempt to boost the mood of others with a limited number of messages. Learning to speak on topic and stating your points concisely is a key skill, and one that we wanted to target. As such, each message sent is parsed using Google NLP, giving us a sentiment score from -1 to 1.
Additionally, we built results and history pages to allow users the chance to see their progress over time. We think it's especially motivating to see your own growth - and it's our hope that the users will too.
## How we built it
We set up a React front-end, splitting the different features of our web app into tabs for easy navigation. On the back-end, we ran our app on Google cloud and used their SQL database service as well as running a natural language processing API offered by Google Cloud Platform.
## Challenges we ran into
We had envisioned a very different app on Friday, one build out of Unity where users could interact with a Sim like world. This way, users will have a more realistic, 3d feel for how to interact with others in a variety of situations. However, none of us were particularly familiar with Unity, so picking that up from scratch was difficult. In the end, we pivoted over to a web app, where we found much more success.
## Accomplishments that we're proud of
We managed to successfully integrate Google's Natural Language Processing API to enable the analysis of our user input and expanding Emotify's functionality despite not having much experience with ML.
We are proud of our clean front-end design and simple UI using React as well as being able to leverage tools such as avatar builders and a complex interaction with our back-end.
## What we learned
We worked through several communication issues and working as a team to be more efficient in the distribution of our tasks and leveraging our unique skills to maximize Emotify's functionality.
## What's next for Emotify
Of course, we would like to upgrade this project by transitioning it over to Unity. We still believe that the best way for people to practice interactions and reading facial expressions is through realistic scenarios. Looking ahead, we hope that this idea will benefit many people in world who struggle to pick up on social cues, idioms, and hidden text. | ## Inspiration
A new study has found that leaks of methane, the main ingredient in natural gas and itself a potent greenhouse gas, are twice as big as official tallies suggest in major cities along the U.S. eastern seaboard. The study suggests many of these fugitive leaks come from homes and businesses—and could represent a far bigger problem than leaks from the industrial extraction of the fossil fuel itself.
## How we built it
Our app consists of 3 main components: the flask web server, ReactJS front-end, and Pygame 2D simulation. The simulation is simplistic visually, but accomplishes the task of generating pipe leaks and simulating how a real drone might detect such leaks. The simulation also simulates how the drone might communicate with a server to notify about the leaks. The server, built in flask, communicates with the simulation and the front-end to build a bridge between the drone and the "user experience". The front-end, built with ReactJS and P5, shows a map of the simulation and displays location pings of where the drone detects leaks.
## Challenges we ran into
We are all first year students and this was our first Hackathon, and even though our programming concepts were very strong, we lacked the insights to build the simulation in 3D. We also had some issues linking the server to the front-end but we eventually figured it out.
## Accomplishments that we're proud of
We all worked and finished the project on time, so our time-management skills were fantastic. We managed to accomplish what we set out to do and were very happy with our final model.
## What we learned
We learned how to work as a team and what the development cycle for such apps looks like. We also learned how a full-stack app connects components from different software areas to make a system that works together to accomplish a task, in this case, a simulation connected to a web server. Although we each had some minimal experience in the parts we worked on, we learned from each other. For example, only one of us knew Flask at the start, but now we all know it! Same goes for ReactJS in the frontend, and pygame which we used to simulate basic 2D physics and pipe leaks.
## What's next for Pipro
In the future, Pipro's server and frontend could be made faster and more intuitive. We could add account creation ability which would link to someone's "drone". Currently, our "drone" runs within a very simplified 2D simulation. In the future, this simulation might move into 3D, but someday, maybe into the real world through robotics. We hope that Pipro helps robotics experts around the world simulate specific real-world scenarios. The problem domain is huge and we are sure there are several other applications for Pipro | ## A bit about our thought process...
If you're like us, you might spend over 4 hours a day watching *Tiktok* or just browsing *Instagram*. After such a bender you generally feel pretty useless or even pretty sad as you can see everyone having so much fun while you have just been on your own.
That's why we came up with a healthy social media network, where you directly interact with other people that are going through similar problems as you so you can work together. Not only the network itself comes with tools to cultivate healthy relationships, from **sentiment analysis** to **detailed data visualization** of how much time you spend and how many people you talk to!
## What does it even do
It starts simply by pressing a button, we use **Google OATH** to take your username, email, and image. From that, we create a webpage for each user with spots for detailed analytics on how you speak to others. From there you have two options:
**1)** You can join private discussions based around the mood that you're currently in, here you can interact completely as yourself as it is anonymous. As well if you don't like the person they dont have any way of contacting you and you can just refresh away!
**2)** You can join group discussions about hobbies that you might have and meet interesting people that you can then send private messages too! All the discussions are also being supervised to make sure that no one is being picked on using our machine learning algorithms
## The Fun Part
Here's the fun part. The backend was a combination of **Node**, **Firebase**, **Fetch** and **Socket.io**. The ML model was hosted on **Node**, and was passed into **Socket.io**. Through over 700 lines of **Javascript** code, we were able to create multiple chat rooms and lots of different analytics.
One thing that was really annoying was storing data on both the **Firebase** and locally on **Node Js** so that we could do analytics while also sending messages at a fast rate!
There are tons of other things that we did, but as you can tell my **handwriting sucks....** So please instead watch the youtube video that we created!
## What we learned
We learned how important and powerful social communication can be. We realized that being able to talk to others, especially under a tough time during a pandemic, can make a huge positive social impact on both ourselves and others. Even when check-in with the team, we felt much better knowing that there is someone to support us. We hope to provide the same key values in Companion! | losing |
## Inspiration
We were driven by the need for real-time logging systems to ensure buildings could implement an efficient and secure access management system.
## What it does
OmniWatched is an advanced access management system that provides real-time logging and instant access status updates for every entry into a building, ensuring a high level of security and efficient flow management. It leverages cutting-edge technology to offer insights into access patterns, enhance safety protocols, and optimize space utilization, making it an essential tool for any facility.
## How we built it
We used React for the front end and Solace to communicate with our back end. We used an Event Driven Architecture to implement our real-time updates and to show it to the front end. The front end is effectively a subscriber, and the events are pushed by another application that publishes events to our Solace PubSub+.
## Challenges we ran into
The first challenge that we faced was setting up Solace, originally we used RestAPIs, and we wrote it in Node.js. We had to completely rewrite our backend in Python, to properly take advantage of the Event Driven Architecture.
## Accomplishments that we're proud of
Setting up Solace PubSub+, and finally achieving real-time data in our front end was challenging, but really rewarding. We are also really proud of how we delegated tasks and finished our application, even though we still wish to add more features.
## What we learned
We learned the advantages of Event Driven Architecture, and how it compares to RestAPIs, and why Event Driven Architectures can be effective when it comes to real-time data.
## What's next for Omniwatch
We think that our application has a lot of potential, and we're excited to continue working on it even outside of this hackathon. Implementing more users, organizations, and other features. | ## Overview
We made a gorgeous website to plan flights with Jet Blue's data sets. Come check us out! | ## Inspiration
Saw a **huge Problem** in the current K-Pop Production system:
1) Tremendous Resource Waste (5+ Years and 100s of MUSD to train & manufacture a single group)
2) Gamble Factor (99.9% fail utterly)
**Why K-Pop?**
K-Pop isn’t just a music genre, but a very unique BM that builds upon the economy of fandom based on integrative contents business
## Solution
**Interactive test-bed platform** that
1) Match-makes aspiring K-Pop Performers and music producers, giving more autonomy and direct access to potential collaborators and resources
2) Enables to test their marketability out, through real-time fan-enabled voting system on the collaborated contents
## Key Features
**1. Profile Dashboard**
: Aspiring performers can find the amateur music producers and vice versa, where the Self-Production gets enabled through direct access to talent pool
**2. Matchmaking**
: Many of the aspiring performers have passion yet no knowledge what to expect & where to look to to pursue they passion, thus platform provides excellent place where to “start”, by matchmaking and recommendations individual combinations to collaborate with based on preferences questionnaire
**3. Voting & Real-time Ranking**
: Provides real-time testbed to check the reaction of the market for different contents the performers publish through showing the relative ranking compared to other aspiring performers
## Business Model & Future Vision:
Narrowly: monetizing from the vote Giving incentives such as special videos & exclusive merch
Broadly: Having access to the future talent pool with high supply & the first mover to filter “proven” to be successful, turning them into Intellectual Property
## How we built it
**All features written:**
* Sign-Up/Login
* Create Profile
* Upload Media
* User Voting
* Matching
* Ranking
* Liking Media
**Technology Used:**
Front-End:
* REACT
* HTML
* CSS
Back-End:
* JavaScript
* Node.js
* Typescript
* Convex Tools for backend, SQL database, File Storage
Design:
* Figma
## Challenges we ran into
* 2 People team, not pre-matched
* First time for both of us working with a non-developer <-> developer
## Accomplishments that we're proud of
* Have 10+ interested potential users already
* Could integrate a lot in time crunch: Matchmaking & Real Time Voting Integration | partial |
## Inspiration
Natural disasters are big and terrible and frightening to think about. So, people don't tend to think about them. But then when they or those they love find themselves facing a potential tsunami, earthquake, or forest fire, they don't know what to think or to do. And that's what we want to change.
We said to ourselves: instead of piling a bunch of rigid, scary information in front people all at once, wouldn't it be more effective if we introduce them to disaster preventions and preparations in a gentler, friendlier way? And how better could that be achieved than with a nice, fun game?
We think that if people like our game, then they might be interested to know more about how to recognize and handle different kinds of natural disasters. This might be especially helpful with cultivating attention to natural disasters in children and young adults.
It could begin with a fleeting thought, a temporary curiosity, a quick Wikipedia search into telling the signs of a tsunami or choosing where to go during an earthquake; but if and when those terrible things do happen, this knowledge might just save many lives.
## What it does
We built an app that presents several mini-games in the contexts of different natural disasters. In particular, to succeed in the games, people need to learn where to run during a tsunami, where to go during an earthquake, how to treat a wound, as well as the importance of putting resources in memorable places and alerting authorities of forest fires ASAP. At the end of the games we also have flashcards with more information about natural disasters.
## How we built it
We built the game app with C# and Unity.
## Challenges we ran into
Designing the different mini-games that aim to present the natural disaster scenarios in a friendly but respectful way.
## Accomplishments that we're proud of
Two members of our team have little to no experience in Unity. We are very happy that the four of us can work effectively together in an environment that fosters learning and creativity.
## What we learned
How to better use Unity and to work better as a team.
## What's next for Disaster Simulator
We would love to expand the natural disaster topics that we cover. | ## Inspiration
With the numerous natural disasters over the past few years, we feel it is extremely important to people to be informed and prepared to face such events. We provide people who lack the resources to stay safe and comfortable with the option to efficiently request such items from others. Danger is inevitable, and we must always prepare for the worst.
## What it does
Our app Relievaid strives to inform users of the importance of making preparations for natural disasters. By connecting users to detailed websites and providing a fun quiz, we encourage people to research ways to stay safe in emergency situations. We also provide an option for users in inconvenient situations to quickly request potentially valuable equipment by connecting the app to SMS messages.
## How we built it
We used Android Studio to develop our application. We coded the layout of the app using XML and user interface component with Java. We primarily used intents to navigate between different activities in the app, send SMS messages, and open web browsers from within the application. We researched credible sources to learn more about the value of emergency preparation for natural disasters and shared our knowledge through an interactive quiz.
## Challenges we ran into
The biggest challenge was getting started with Android Studio for app development. While most members had some experience in Java, the Android Studio IDE had numerous unique features, including dependence on the XML markup language to develop layouts. The AsyncTask used for background processing in Android also had a steep learning curve, so we were unable to learn the mechanism sufficiently in our limited time. Troubleshooting bugs in Android Sutdio was particularly difficult due to our unfamiliarity.
## Accomplishments that we're proud of
We are proud of creating a useful product despite our limited experience in programming. Learning the basics of Android Studio, in particular, was a great accomplishment.
## What We learned
This weekend, we learned how to use Android Studio for app development as well as basics of the XML markup language for design. We also learned that while skill and experience are immensely important, creativity is needed to carry out meaningful ideas and develop useful products. We came to the hackathon with a bit of fear at our inexperience, but we now feel more confident in our abilities. We also learned the value of taking advantage of every member's strengths when working on a team project. Combining technical and artistic talents will create the most successful application.
## What's next for Relievaid
In the future, we plan to utilize APIs provided by services like Google Maps, which will enable us to obtain real-time data on climate and weather changes. We will also make use of open source data sets to acquire a more thorough understanding of the conditions, including time and location, natural disasters are most likely to occur. | ## Inspiration
"The Big One" is a 9.0 magnitude earthquake predicted to ravage the west coast of North America, with some researchers citing a 33% chance of it hitting in the next 50 years. If it were to hit tomorrow, or even a decade from now, do you think you'd be adequately prepared?
In 2013, the Alberta floods displaced hundreds of thousands of people. A family friend of mine took to Twitter to offer up her couch, in case someone needed a place to sleep for the night. She received over 300 replies.
Whether it's an earthquake, a fire or some other large-scale disaster, the next crisis to affect you shouldn't send you, your loved ones, or your community adrift. Enter Harbour.
## What it does
Harbour offers two main sets of functionality: one for people who are directly affected by a crisis, and one for those nearby who wish to help.
**In the Face of Disaster**
*Forget group chat chaos:* you will have immediate access to the last recorded locations of your family members, with directions to a pre-determined muster point.
*Don't know what to do?* Have an internet connection? Access our Azure chatbot to ask questions and get relevant resources. No internet? No problem. Easily find resources for most common catastrophes on a locally-saved survival manual.
*Live Updates:* A direct and uninterrupted feed of government warnings, alerts and risk areas.
**If You Want to Help**
*Crowdsourcing the Crisis Response:* Have a couch you can offer? How about shelter and a warm meal? Place a custom marker on your local map to tell your community how you can help. Far more efficient than a messy Twitter feed.
## How I built it
We built this app using Android Studio in the Kotlin programming language for the primary app development. We used Google Firebase and Firestore to maintain the database of important locations and contact information. We used Microsoft Azure Cognitive Services Key Phrase Extraction for the user-friendly chatbot that helps with finding disaster information. We used Balsamiq for creating mockups and GitHub for version control.
## Challenges I ran into
The two key challenges we ran into were:
Integrating Google Maps - the SDK was well documented, but getting the exact markers and behavior that we wanted was very time-consuming.
Improving the user interface - A big part of why we were motivated to build this app was because the current solutions had very poor user interfaces, which made them difficult to use and not very helpful. Making a clean, usable user interface was very important, so we spent a significant amount working through the details of Android Studio's graphic design to make this happen
## Accomplishments that I'm proud of
I am proud that we were able to make so much progress. In our early planning, we wanted the app to have four key functionalities: family coordination, community resource-sharing, user-friendly disaster recovery information, and city-wide alerts. It was an ambitious goal that I didn't think we could reach, but we were able to build a minimum viable product with each functionality.
## What I learned
I learned that it only takes 24 hours to build something with a large potential impact on society. We started this hackathon with the goal of improving the disaster response resources that citizens have access to. Despite the time constraints, we were able to build a minimum viable product that shows the promise of our mobile app solution.
## What's next for Harbour
The next step for Harbour is to partner with Canada Red Cross to integrate our app design with their informational resources. We will continue to improve our Machine Learning emergency resource and get more detailed emergency response information from the Canadian Red Cross.
We also hope to work with the City of Vancouver to integrate government-defined danger zones to help citizens understand the dangers around them. | losing |
## About the Project
### TLDR:
Caught a fish? Take a snap. Our AI-powered app identifies the catch, keeps track of stats, and puts that fish in your 3d, virtual, interactive aquarium! Simply click on any fish in your aquarium, and all its details — its rarity, location, and more — appear, bringing your fishing memories back to life. Also, depending on the fish you catch, reel in achievements, such as your first fish caught (ever!), or your first 20 incher. The cherry on top? All users’ catches are displayed on an interactive map (built with Leaflet), where you can discover new fishing spots, or plan to get your next big catch :)
### Inspiration
Our journey began with a simple observation: while fishing creates lasting memories, capturing those moments often falls short. We realized that a picture might be worth a thousand words, but a well-told fish tale is priceless. This spark ignited our mission to blend the age-old art of fishing with cutting-edge AI technology.
### What We Learned
Diving into this project was like casting into uncharted waters – exhilarating and full of surprises. We expanded our skills in:
* Integrating AI models (Google's Gemini LLM) for image recognition and creative text generation
* Crafting seamless user experiences in React
* Building robust backend systems with Node.js and Express
* Managing data with MongoDB Atlas
* Creating immersive 3D environments using Three.js
But beyond the technical skills, we learned the art of transforming a simple idea into a full-fledged application that brings joy and preserves memories.
### How We Built It
Our development process was as meticulously planned as a fishing expedition:
1. We started by mapping out the user journey, from snapping a photo to exploring their virtual aquarium.
2. The frontend was crafted in React, ensuring a responsive and intuitive interface.
3. We leveraged Three.js to create an engaging 3D aquarium, bringing caught fish to life in a virtual environment.
4. Our Node.js and Express backend became the sturdy boat, handling requests and managing data flow.
5. MongoDB Atlas served as our net, capturing and storing each precious catch securely.
6. The Gemini AI was our expert fishing guide, identifying species and spinning yarns about each catch.
### Challenges We Faced
Like any fishing trip, we encountered our fair share of challenges:
* **Integrating Gemini AI**: Ensuring accurate fish identification and generating coherent, engaging stories required fine-tuning and creative problem-solving.
* **3D Rendering**: Creating a performant and visually appealing aquarium in Three.js pushed our graphics programming skills to the limit.
* **Data Management**: Structuring our database to efficiently store and retrieve diverse catch data presented unique challenges.
* **User Experience**: Balancing feature-rich functionality with an intuitive, streamlined interface was a constant tug-of-war.
Despite these challenges, or perhaps because of them, our team grew stronger and more resourceful. Each obstacle overcome was like landing a prized catch, making the final product all the more rewarding.
As we cast our project out into the world, we're excited to see how it will evolve and grow, much like the tales of fishing adventures it's designed to capture. | ## Inspiration
Between 1994 and 2013 there were 6,873 natural disasters worldwide, which claimed 1.35 million lives or almost 68,000 lives on average each year. In many of these disasters, people don't know where to go, and where is safe. For example, during Hurricane Harvey, many people learned about dangers such as alligators or flooding through other other people, and through social media.
## What it does
* Post a natural disaster hazard in your area
* Crowd-sourced hazards
* Pulls government severe weather data
* IoT sensor system to take atmospheric measurements and display on map
* Twitter social media feed of trending natural disasters in the area
* Machine learning image processing to analyze posted images of natural disaster hazards
Our app **Eye in the Sky** allows users to post about various natural disaster hazards at their location, upload a photo, and share a description of the hazard. These points are crowd-sourced and displayed on a map, which also pulls live data from the web on natural disasters. It also allows these users to view a Twitter feed of current trending information on the natural disaster in their location. The last feature is the IoT sensor system, which take measurements about the environment in real time and displays them on the map.
## How I built it
We built this app using Android Studio. Our user-created posts are hosted on a Parse database (run with mongodb). We pull data from the National Oceanic and Atmospheric Administration severe weather data inventory. We used Particle Electron to collect atmospheric sensor data, and used AWS to store this data in a JSON.
## Challenges I ran into
We had some issues setting up an AWS instance to run our image processing on the backend, but other than that, decently smooth sailing.
## Accomplishments that I'm proud of
We were able to work really well together, using everyone's strengths as well as combining the pieces into a cohesive app that we're really proud of. Everyone's piece was integrated well into the app, and I think we demonstrated good software collaboration.
## What I learned
We learned how to effectively combine our code across various languages and databases, which is a big challenge in software as a whole. We learned Android Development, how to set up AWS, and how to create databases to store custom data. Most importantly, we learned to have fun!
## What's next for Eye in the Sky
In the future, we would like to add verification of people's self-reported hazards (through machine learning and through up-voting and down-voting)
We would also like to improve the efficiency of our app and reduce reliance on network because there might not be network, or very poor network, in a natural disaster
We would like to add more datasets from online, and to display storms with bigger bubbles, rather than just points
We would also like to attach our sensor to drones or automobiles to gather more weather data points to display on our map | ## Inspiration
*“The hardest part is starting. Once you get that out of the way, you’ll find the rest of the journey much easier.” - Simon Sinek*
Oftentimes, we become unmotivated and stressed when faced with seemingly unachievable goals. This motivated us to build an interactive mobile app that helps break these goals down into daily doable tasks – all while fostering a motivating community to keep each other accountable. By sending the user daily reminders to complete a task in a category of their choice, we take away the stress of having to take those daunting first steps. In doing so, we are removing the barriers preventing users from fully exploring their interests and evolving beyond the scope of their current self. Re:New provides anybody and everybody with endless possibilities to ***reimagine a new you***.
## What it does
Re:New sends the user one notification a day, reminding them to complete a randomized task that is customized towards their specific well-being goals. This includes fitness, wellness, academics, and skill learning. Once they complete the task, they can post a picture to verify their completion, as well as the chance verify the tasks of other users.
## How we built it
We began by creating UI/UX designs using Figma. Then, we built the front-end of the mobile application using React Native and Redux for state management. For the back-end, we used Boto3 for AWS S3 for image file storage and AWS DynamoDB for our image metadata database. In addition, we also used the co:here natural language processing API to create AI-generated tasks, based on task categories chosen by the user. To link all of our back-end to the front-end of the mobile application, we used Flask to establish a REST API.
## Challenges we ran into
1. Establishing the REST API and learning Flask
2. Learning how to upload and retrieve image files of BLOB type to and from the AWS S3 service
3. Translating some of the UI/UX designs to React Native code
4. Trying to link the metadata of images from AWS DynamoDB to corresponding images in AWS S3
5. Linking the back-end code to the front-end code seamlessly
## What we learned and accomplished through this process
It was exciting to learn more about performing mentally-relieving tasks to improve mental health while providing users with new opportunities to explore beyond their horizons. In this short timeframe, we’re proud of the various APIs, tools, and frameworks we were able to implement, especially as it was our first time using them. To name a few, this included REST API development with Flask, API testing with Postman, the co:here (NLP) API, AWS S3 image storage, and Figma UI/UX designs.
## What's next for Re:New
We envisioned Re:New to be a globally connected app, therefore we are looking to create a more interactive platform to create more opportunity for community-building and social interaction. To help with user customization, we want to be able to provide more personalized task packages that could recommend the next step for users. | winning |
## Care Me
**Overworked nurses are linked with a 40 percent of risk of death in patients**
Our solution automates menial tasks like serving food and water, so medical professionals can focus on the important human-necessary interactions. It uses a robotic delivery system which acts autonomously based on voice recognition demand. One robot is added to each hospital wing with a microphone available for patient use.
Our product is efficient, increasing valuable life-saving time for medical professionals and patients alike, reducing wait-time for everyone. It prioritizes safety, really addressing the issue of burnout and dangerous levels of stress and tiredness that medical professionals face head on. Hospitals and medical facilities will see a huge boost in productivity because of the decreased stress and additional freed time.
Our product integrates multiple hardware components seamlessly through different methods of connectivity. A Raspberry Pi drives the Google Natural Language Processing Libraries to analyze the user’s request at a simple button press as a user. Using radio communications, the robot is quickly notified of the request and begins retrieving the item, delivering it to the user. | ## Inspiration
No one likes waiting around too much, especially when we feel we need immediate attention. 95% of people in hospital waiting rooms tend to get frustrated over waiting times and uncertainty. And this problem affects around 60 million people every year, just in the US. We would like to alleviate this problem and offer alternative services to relieve the stress and frustration that people experience.
## What it does
We let people upload their medical history and list of symptoms before they reach the waiting rooms of hospitals. They can do this through the voice assistant feature, where in a conversation style they tell their symptoms, relating details and circumstances. They also have the option of just writing these in a standard form, if it's easier for them. Based on the symptoms and circumstances the patient receives a category label of 'mild', 'moderate' or 'critical' and is added to the virtual queue. This way the hospitals can take care of their patients more efficiently by having a fair ranking system (incl. time of arrival as well) that determines the queue and patients have a higher satisfaction level as well, because they see a transparent process without the usual uncertainty and they feel attended to. This way they can be told an estimate range of waiting time, which frees them from stress and they are also shown a progress bar to see if a doctor has reviewed his case already, insurance was contacted or any status changed. Patients are also provided with tips and educational content regarding their symptoms and pains, battling this way the abundant stream of misinformation and incorrectness that comes from the media and unreliable sources. Hospital experiences shouldn't be all negative, let's try try to change that!
## How we built it
We are running a Microsoft Azure server and developed the interface in React. We used the Houndify API for the voice assistance and the Azure Text Analytics API for processing. The designs were built in Figma.
## Challenges we ran into
Brainstorming took longer than we anticipated and had to keep our cool and not stress, but in the end we agreed on an idea that has enormous potential and it was worth it to chew on it longer. We have had a little experience with voice assistance in the past but have never user Houndify, so we spent a bit of time figuring out how to piece everything together. We were thinking of implementing multiple user input languages so that less fluent English speakers could use the app as well.
## Accomplishments that we're proud of
Treehacks had many interesting side events, so we're happy that we were able to piece everything together by the end. We believe that the project tackles a real and large-scale societal problem and we enjoyed creating something in the domain.
## What we learned
We learned a lot during the weekend about text and voice analytics and about the US healthcare system in general. Some of us flew in all the way from Sweden, for some of us this was the first hackathon attended so working together with new people with different experiences definitely proved to be exciting and valuable. | ## Inspiration
We had never worked in depth with AI before, and wanted to try out a computer vision related project. After brainstorming ideas that could have practical applications, we landed on an MRI image classification project, designed to aid hospitals in viewing and detecting abnormalities in their patients' scans.
## What it does
This project takes in MRI scans of the brain, knee, or lungs, and then detects the presence of brain tumors, arthritis, and illness in the lungs.
## How we built it
We built a full stack application to tackle this problem. The frontend was built using React, and the backend uses tensorflow and keras for the computer vision implementation, as well as Flask for handling requests. We used multiple online datasets to train our models, which are listed below.
<https://www.kaggle.com/datasets/paultimothymooney/chest-xray-pneumonia>
<https://www.kaggle.com/datasets/farjanakabirsamanta/osteoarthritis-prediction>
<https://www.kaggle.com/datasets/navoneel/brain-mri-images-for-brain-tumor-detection>
## Challenges we ran into
As most of us were unfamiliar with the tech stack used to create this process, our largest challenges revolved around learning the new modules and frameworks used to make this project succeed.
## Accomplishments that we're proud of
We are proud of learning new frameworks, especially tensorflow, which none of us had used before. After rigorously adjusting our models, we are very proud to have created accurate representations of the MRI scans passed through them.
## What we learned
We learned how to use an unfamiliar tech stack, as well as computer vision concepts using tensorflow and opencv.
## What's next for you?
We would like to continue expanding the project to use even more accurate models, as well as process a larger amount of diseases. | partial |
## Inspiration
```
We want to create an efficient, seamless method of transferring files from android to PC and Mac.
```
## What it does
```
Using an NFC chip or Pebble smartwatch, we can **bblip** (transfer/send) the file that was on your phone, to your computer, in one fluid step.
```
## How We built it
```
Using NFC or Pebble technology, an event is triggered on an android device, this shares the open file to our ownCloud server, which is then pushed to your desktop.
```
## Challenges We ran into
```
From struggling with sleep deprivation, to having an NFC tag suck the life out of the team, we worked together to provide a solution for every obstacle we encountered.
The list of challenges is much too long to fit into this text area, but a couple of them include database optimization in Amazon Web Service, ridiculous naming schemes from downloaded files, and having our security certificates break as we write this post.
```
## Accomplishments that We're proud of
```
We are pleased things work at all. We're also proud of our technology, learning how to integrate so many services and platforms together was tough, but we successfully created one unified product.
```
## What We learned
```
Our team learned how to integrate ownCloud with Amazon Web Service. We also learned that Visual Basic Script is actually garbage. _ Visual Basic will **never** be a tool that you will need or use. _ Pebble technology is surprisingly easy, not to mention extremely spiffy, to use and integrate into android development.
```
## What's next for bblip
```
Optimizing transfer speeds and adding more accepted file formats is definitely the current priority, following that we would like to work on a subscription model, in order to better the web service.
``` | *A dictionary is at the end for reference to biology terms.*
## Inspiration
We're at a hackathon right? So I thought, why stop at coding with 1s and 0s when we can code with A, T, G, and C? 🧬 Genetic engineering is a cornerstone of the modern world, whether its for agriculture, medicine, and more; but let's face it, it's got a bit of a learning curve. That's where GenomIQ comes in. I wanted to create a tool that lets anyone – yes, even you – play around with editing plasmids and dive into genetic engineering. But here's the kicker: we're not just making it easier, we're turbocharging it with the expressive ability of LLMs to potentially generate functional protein-coding DNA strings.
## What it does
GenomIQ streamlines plasmid engineering by combining AI-powered gene generation with a curated gene database. It uses a custom-finetuned Cohere model to create novel DNA sequences, validated for biological plausibility via AlphaFold 2 and iterated on. Alternatively, you can rapidly search for existing genes stored in our Chroma vectordb. The platform automatically optimizes restriction sites and integrates essential genetic elements. Users can easily design, modify, and export plasmids ready for real-world synthesis, bridging the gap between computational design and practical genetic engineering.
## How I built it
This is a Flask web app built with python, and vanilla html/css/js on the frontend. The vectordb is powered by Chroma. LLM is Cohere fine tuned on a short custom dataset included in the github repo. Restriction sites are automatically scored and sorted based on usefulness for clean insertion. Verification is performed by a local instance of Alphafold 2, which based on the provided DNA sequence will give you a structure file. I found a website that implements Prosa, a scoring metric for proteins, and built a web scrapper/bot that uploads your structure file and gathers the z-score from there. The plasmid viewer is a canvas that is updated whenever a route returns new features.
The repo also includes a file for a short fine tuning dataset builder tool with a GUI, that I put together to make it easier to fine tune my model.
I developed a benchmark set and performed an evaluation of the standard cohere model vs the fine tuned model, and compared their z-score across. As displayed in the image, the fine tune is much more capable of producing biologically plausible strings of DNA.

## Challenges I ran into
Cohere api timeouts: lots of requests would not work randomly, had to use threading to check how long it was running, and be able to cut it off if it takes too long.
Frontend as a whole was a big challenge, I have hardly built web apps before so this was a lot of back and forth, wondering why X element wont go to the center of the page no matter how hard I try.
## Accomplishments that I'm proud of
Building a cool project in a day and a half :)
## What I learned
Vector db, alphafold, genetic engineering,
## What's next for GenomIQ
I want to evaluate what a tool like GenomIQ's place in the world could be. I want to reach out to people who would be interested in such a tool, and see what direction to take it in. There are a lot of improvements that can be made, as well as opportunity for some incredible new features.
## Dictionary
**Plasmid**: Small circular ring of DNA. These are typically cut up and have new genes inserted into them. Afterwards, these plasmids are inserted into organisms like yeast, bacteria, etc who will now express the new gene.
**Restriction site**: The zones on the plasmid where we do the cutting. Some sites are more desirable than others, typically given by uniqueness (only want to cut in one spot) and distance from other genes/features (don't want to cut up something important).
*Sorry if any of this seems jumbled... im really tired.* | ## 🍀 Our Inspiration
We thought the best way to kick this off was to share this classic meme:

We can all chuckle at this, but let's be real: climate change is no joke. Just look at how the [Earth set its global temperature record](https://abcnews.go.com/International/earth-sets-daily-global-temperature-record-2nd-day/story?id=112233810) two weeks ago! The problem isn't just that the climate is heating up – it's that people often aren’t motivated to act unless there's something in it for them. Think about it: volunteering often comes with certificates, and jobs come with paychecks. People need incentives to get moving!
## 🙌 How does WattWise solve the problem
We’ve created a prototype that would plugs directly into your office/home’s main power supply. This device streams real-time data to our dashboard using protocols like MQTT and HTTPS, where you can watch your power usage, get a sneak peek at your upcoming electricity bill and much more.
Imagine this: normally, we’re all a bit clueless about whether we’ve left the lights on or are using power-hungry gadgets, until the dreaded bill arrives. With WattWise, it’s like having a personal energy coach. Just like how whoop made tracking your fitness addictive, WattWise lets you track your energy usage and bill predictions.
Picture this scenario: You’re relaxing on a holiday when WattWise sends you a notification about your current power usage being higher than the daily average. This alert prompts you to check the stats, giving you valuable insights on which appliances to turn off. After making a few adjustments, you’re back to enjoying your holiday with the satisfaction of knowing you’ll have a lower bill at the end of the month.
We just took a household as an example – think about offices and corporations. With WattWise, you could be saving tons of electricity and cash without breaking a sweat.
## 🧑💻 Technical implementation
This project was one of our most technical yet! We aimed to simulate not just one but two devices streaming data to a single dashboard. Picture a company with two buildings, each outfitted with our **Arduino** setups. These setups included current and voltage sensors, a switch, a DC motor, a 9V battery, and a diode. When the switch is flipped, the sensors measure the current and voltage produced by the motor, giving us the power using:
```
Power = Voltage × Current
```
Power in watts per hour equals energy, and multiplying this by the local rate gives the cost.
To share this data, we used the **MQTT** protocol. Our devices publish power data to an MQTT broker, and an **Express.js** backend subscribes to this data, receiving updates every second. This data is stored in **DynamoDB**, and we provide API routes for other services to access it with custom queries.
We containerized everything using **Docker** and **Docker Compose**, creating a local setup with DynamoDB, an MQTT client and broker, and our API. These services interact through a Docker network.
Next, we tackled future price predictions using a custom model with a RandomForestRegressor in **scikit-learn**, hosted on a **Python Flask** server.
Finally, our **Next.js** dashboard brings it all together. The frontend is also integrated with **Google Gemini GenAI** to detect unusual usage patterns and alert users. It features a bar chart for current usage, a pie chart for device comparison, and a line chart for predicted usage. Basic math operations show the end-of-month cost predictions and GenAI alerts for any unusual activity.
## 😭 Challenges we ran into
Handling time zones has always been a developer's nightmare, and of course, our whole MQTT and DynamoDB setup crashed at midnight because of this. It took a while to sort out the mess and reset everything.
Additionally, we also had to buy our voltage and current sensors from Amazon. Since local stores didn’t carry them, we had to arrange for delivery to a friend's house.
Our team had diverse strengths: backend, frontend, and DevOps. This meant we were often using technologies unfamiliar to each other. We spent a lot of time learning on the fly, which was both challenging and rewarding.
And now for the embarrassing part: we spent three hours last night debugging a single API call because the React state refused to update.
## 😤 Accomplishments that we're proud of
* Everything worked as intended. Both Arduinos streamed data accurately, the calculations were correct, our machine learning model made precise predictions, GenAI integration was seamless, and the frontend supported real-time updates.
* Built a highly technical project from scratch in just 36 hours.
* Acquired new skills and applied them effectively throughout the project.
* Tackled a significant real-world problem, contributing to a solution for one of the most prevalent issues humanity faces today, climate change and excess consumption of natural resources.
* Successfully integrated hardware with advanced software.
## 🧐 What we learned
* Training our own model using Scikit-Learn was a valuable learning experience. It taught us how to format data precisely to meet our needs.
* Using Docker and Docker Compose was highly effective. We managed to run multiple services simultaneously, which streamlined our development process.
* Working with several backends and setting up TCP tunnels using ngrok to access each other’s computers for accessing local servers.
* Gained hands-on experience with circuitry, electronics, Arduinos, and serial ports to stream live data.
* Working with IoT technology and integrating hardware with software in real-time was demanding, but research and experience helped us overcome the challenges.
* Working in a team provided valuable insights into soft skills like communication and coordination.
* Each hackathon teaches us new skills and improves our efficiency. We learned to better utilize APIs, templates, and open-source software, as well as improve time management and planning.
## 🔜 What's next for WattWise
* Currently, our tool focuses on providing information, but it doesn't offer control over devices. A potential enhancement would be to enable users to control smart devices directly from the dashboard and view real-time updates.
* We aim to introduce detailed progress statistics similar to what you’d find on a fitness tracker like a Fitbit. This enhancement would provide users with a comprehensive view of their energy usage trends over a selectable timeframe (e.g., weekly, monthly). | partial |
## Inspiration
Our inspiration comes from the idea that the **Metaverse is inevitable** and will impact **every aspect** of society.
The Metaverse has recently gained lots of traction with **tech giants** like Google, Facebook, and Microsoft investing into it.
Furthermore, the pandemic has **shifted our real-world experiences to an online environment**. During lockdown, people were confined to their bedrooms, and we were inspired to find a way to basically have **access to an infinite space** while in a finite amount of space.
## What it does
* Our project utilizes **non-Euclidean geometry** to provide a new medium for exploring and consuming content
* Non-Euclidean geometry allows us to render rooms that would otherwise not be possible in the real world
* Dynamically generates personalized content, and supports **infinite content traversal** in a 3D context
* Users can use their space effectively (they're essentially "scrolling infinitely in 3D space")
* Offers new frontier for navigating online environments
+ Has **applicability in endless fields** (business, gaming, VR "experiences")
+ Changing the landscape of working from home
+ Adaptable to a VR space
## How we built it
We built our project using Unity. Some assets were used from the Echo3D Api. We used C# to write the game. jsfxr was used for the game sound effects, and the Storyblocks library was used for the soundscape. On top of all that, this project would not have been possible without lots of moral support, timbits, and caffeine. 😊
## Challenges we ran into
* Summarizing the concept in a relatively simple way
* Figuring out why our Echo3D API calls were failing (it turned out that we had to edit some of the security settings)
* Implementing the game. Our "Killer Tetris" game went through a few iterations and getting the blocks to move and generate took some trouble. Cutting back on how many details we add into the game (however, it did give us lots of ideas for future game jams)
* Having a spinning arrow in our presentation
* Getting the phone gif to loop
## Accomplishments that we're proud of
* Having an awesome working demo 😎
* How swiftly our team organized ourselves and work efficiently to complete the project in the given time frame 🕙
* Utilizing each of our strengths in a collaborative way 💪
* Figuring out the game logic 🕹️
* Our cute game character, Al 🥺
* Cole and Natalie's first in-person hackathon 🥳
## What we learned
### Mathias
* Learning how to use the Echo3D API
* The value of teamwork and friendship 🤝
* Games working with grids
### Cole
* Using screen-to-gif
* Hacking google slides animations
* Dealing with unwieldly gifs
* Ways to cheat grids
### Natalie
* Learning how to use the Echo3D API
* Editing gifs in photoshop
* Hacking google slides animations
* Exposure to Unity is used to render 3D environments, how assets and textures are edited in Blender, what goes into sound design for video games
## What's next for genee
* Supporting shopping
+ Trying on clothes on a 3D avatar of yourself
* Advertising rooms
+ E.g. as your switching between rooms, there could be a "Lululemon room" in which there would be clothes you can try / general advertising for their products
* Custom-built rooms by users
* Application to education / labs
+ Instead of doing chemistry labs in-class where accidents can occur and students can get injured, a lab could run in a virtual environment. This would have a much lower risk and cost.
…the possibility are endless | ## Inspiration
We were inspired by the Instagram app, which set out to connect people using photo media.
We believe that the next evolution of connectivity is augmented reality, which allows people to share and bring creations into the world around them. This revolutionary technology has immense potential to help restore the financial security of small businesses, which can no longer offer the same in-person shopping experiences they once did before the pandemic.
## What It Does
Metagram is a social network that aims to restore the connection between people and small businesses. Metagram allows users to scan creative works (food, models, furniture), which are then converted to models that can be experienced by others using AR technology.
## How we built it
We built our front-end UI using React.js, Express/Node.js and used MongoDB to store user data. We used Echo3D to host our models and AR capabilities on the mobile phone. In order to create personalized AR models, we hosted COLMAP and OpenCV scripts on Google Cloud to process images and then turn them into 3D models ready for AR.
## Challenges we ran into
One of the challenges we ran into was hosting software on Google Cloud, as it needed CUDA to run COLMAP. Since this was our first time using AR technology, we faced some hurdles getting to know Echo3D. However, the documentation was very well written, and the API integrated very nicely with our custom models and web app!
## Accomplishments that we're proud of
We are proud of being able to find a method in which we can host COLMAP on Google Cloud and also connect it to the rest of our application. The application is fully functional, and can be accessed by [clicking here](https://meta-match.herokuapp.com/).
## What We Learned
We learned a great deal about hosting COLMAP on Google Cloud. We were also able to learn how to create an AR and how to use Echo3D as we have never previously used it before, and how to integrate it all into a functional social networking web app!
## Next Steps for Metagram
* [ ] Improving the web interface and overall user experience
* [ ] Scan and upload 3D models in a more efficient manner
## Research
Small businesses are the backbone of our economy. They create jobs, improve our communities, fuel innovation, and ultimately help grow our economy! For context, small businesses made up 98% of all Canadian businesses in 2020 and provided nearly 70% of all jobs in Canada [[1]](https://www150.statcan.gc.ca/n1/pub/45-28-0001/2021001/article/00034-eng.htm).
However, the COVID-19 pandemic has devastated small businesses across the country. The Canadian Federation of Independent Business estimates that one in six businesses in Canada will close their doors permanently before the pandemic is over. This would be an economic catastrophe for employers, workers, and Canadians everywhere.
Why is the pandemic affecting these businesses so severely? We live in the age of the internet after all, right? Many retailers believe customers shop similarly online as they do in-store, but the research says otherwise.
The data is clear. According to a 2019 survey of over 1000 respondents, consumers spend significantly more per visit in-store than online [[2]](https://www.forbes.com/sites/gregpetro/2019/03/29/consumers-are-spending-more-per-visit-in-store-than-online-what-does-this-man-for-retailers/?sh=624bafe27543). Furthermore, a 2020 survey of over 16,000 shoppers found that 82% of consumers are more inclined to purchase after seeing, holding, or demoing products in-store [[3]](https://www.businesswire.com/news/home/20200102005030/en/2020-Shopping-Outlook-82-Percent-of-Consumers-More-Inclined-to-Purchase-After-Seeing-Holding-or-Demoing-Products-In-Store).
It seems that our senses and emotions play an integral role in the shopping experience. This fact is what inspired us to create Metagram, an AR app to help restore small businesses.
## References
* [1] <https://www150.statcan.gc.ca/n1/pub/45-28-0001/2021001/article/00034-eng.htm>
* [2] <https://www.forbes.com/sites/gregpetro/2019/03/29/consumers-are-spending-more-per-visit-in-store-than-online-what-does-this-man-for-retailers/?sh=624bafe27543>
* [3] <https://www.businesswire.com/news/home/20200102005030/en/2020-Shopping-Outlook-82-Percent-of-Consumers-More-Inclined-to-Purchase-After-Seeing-Holding-or-Demoing-Products-In-Store> | ## Inspiration
Online shopping is hard because you can't try on clothing for yourself. We want to make a fun and immersive online shopping experience through VR that will one day hopefully become more realistic and suitable for everyday online shopping. We hope to make a fun twist that helps improve decisiveness while browsing online products.
## What it does
This VR experience includes movement, grabbable clothes, dynamic real-time texturing of models using images from Shopify’s Web API, and a realistic mirror of yourself to truly see how these fits shall look on you before buying it! The user that enters the virtual clothing store may choose between a black/yellow shirt, and black/tropical pants which are products from an online Shopify store (see screenshots). The user can also press a button that would simulate a purchase :)
## How we built it
Using the Shopify ProductListing API, we accessed the different clothing items from our sample online store with a C# script. We parsed the JSON that was fetched containing the product information to give us the image, price, and name of the products. We used this script to send this information to our VR game. Using the images of the products, we generated a texture for each item in virtual reality in the Unity game engine, which was then put onto interactable items in the game. Also, we designed some models, such as signs with text, to customize and accessorize the virtual store. We simulated the shopping experience in a store as well as interactable objects that can be tried on.
## Challenges we ran into
Linking a general C# script which makes REST API calls to Unity was a blocker for us because of the structure of code Unity works with. We needed to do some digging and search for what adjustments needed to be made to a generic program to make it suitable for the VR application. For example, including libraries such as Newtonsoft.
We also ran into conflicts when merging different branches of our project on GitHub. We needed to spend additional time rolling back changes and fixing bugs to take the next step in the project.
One significant difficulty was modelling the motion of the virtual arms and elbows when visible in the mirror. This must be done with inverse kinematics which we were never quite able to smoothly implement, although we achieved something somewhat close.
Getting the collision boundaries was difficult as well. The player and their surroundings constantly change in VR, and it was a challenge to set the boundaries of item interaction for the player when putting on items.
## Accomplishments that we're proud of
Our project has set a strong foundation for future enhancements. We’re proud of the groundwork we’ve laid for a concept that can grow and evolve, potentially becoming a game-changing solution in VR shopping.
## What we learned
We learned the importance of anticipating potential technical blockers, such as handling complex features like inverse kinematics and collision limits. Properly allocating time for troubleshooting unexpected challenges would have helped us manage our time more efficiently.
Also, many technical challenges required a trial-and-error approach, especially when setting up collision boundaries and working with avatar motion. This taught us that sometimes it's better to start with a rough solution and iteratively refine it, rather than trying to perfect everything on the first go.
Finally, working as a team, we realized the value of maintaining clear communication, especially when multiple people are contributing to the same project. Whether it was assigning tasks or resolving GitHub conflicts, being aligned on priorities and maintaining good communication channels kept us moving forward.
## What's next for Shop The North
We want to add even more variety for future users. We hope to develop more types of clothing, such as shoes and hats, as well as character models that could suit any body type for an inclusive experience. Additionally, we would like to implement a full transaction system, where the user can add all the products they are interested into a cart and complete a full order (payment information, shipping details, and actually placing a real order). In general, the goal would be to have everything a mobile/web online shopping app has, and more fun features on top of it. | winning |
## Inspiration
We are tired of studying at home, the sheer amount of times we've left campus after checking the libraries and seeing it was completely full IS INSANE.
## What it does
It checks the real-time data of the course database hosted in each building. Then we retrieve the ones from today and calculate the next availability and the current availability of lecture rooms in certain McMaster buildings.
## How we built it
Frontend: Next.js & JavaScript
Backend: Flask, Python, Selenium, & Heroku
## Challenges we ran into
We have never done a project in Next.js, or Selenium or Heroku.
This was definitely very new to us since we were also very new to deployment systems such as Heroku and Vercel.
The McMaster course database is also only accessible through McMaster's VPN system which caused a lot of our security issues and confusion.
## Accomplishments that we're proud of
We are proud that we produced something. :)
## What we learned
We learned how even a simple idea can be very hard to implement.
## What's next for Study Spotter
We add more buildings >:) All of McMaster will be in our hands.
Edit: The password to our website is any of our names! "raymond" or "gayan" | ## Inspiration
Being graduate engineering students at the University of Pennsylvania, my teammate and I often need to study on campus in order to get our projects done on time. Throughout the years, we found that we waste much time trying to find available study locations that suit our needs.
## What it does
StudySpotter is a dynamic web application that shows its users available study locations for a given time period. Users are able to search for available locations in our database or view all locations. We currently support coffee shops and bookstores in the Philadelphia area, classrooms in Levine Hall, and group study rooms in Van Pelt. When the user views the details of a location, it shows them the address, the available times, a picture of the location, and a map. Users can log in to provide updates on which locations are available at which times.
## How we built it
We build this web app using Bootstrap with jade and html5. We are hosting this site on a Linux server, on which we installed MongoDB and Node.js. We are using Node.js for networking and MongoDB to store our user information.
## Challenges we ran into
The first challenge we ran into was configuring our local environment with Node.js and MongoDB for testing purposes. We originally ran the code on our machines (localhost) in order to test changes more quickly. The next challenge we had was deciding how we would host our website. We originally had planned on hosting it on Microsoft Azure, but after having challenges getting MongoDB to run on it we decided to abandon this idea and simply provision a Linux server from Linode and host our website there. The final challenge we had was getting our code to run on the Linux server. After FTPing our code, we found that we had to make some changes to the folder structure to get the website to display correctly.
## Accomplishments that we're proud of
One accomplishment of which we are proud is getting the web app hosted on the Linux server and running correctly. Not having much experience with Linux and hosting websites, my teammate and I overcame many challenges. Another accomplishment of which we are proud is developing a modern-looking website. We decided to use high-resolution pictures that took up the entire screen and large buttons to make the user interface more intuitive. We found that this not only tested our coding ability, but also our designing skills.
## What we learned
We learned much about coding in throughout this hackathon, and especially improved our front-end skills. We learned how to divide the workload in an efficient manner so that both team members can be contributing simultaneously to the project. We learned about website design, and how to draw mock-ups.
## What's next for StudySpotter
We plan on integrating other functionality into our web app. Some examples include adding support for OpenID logins such as Facebook, Google, and Microsoft for users who are more comfortable logging into those platforms rather than our system. We also plan on integrating Uber functionality for users to request rides to study locations. | ## Inspiration
As University of Waterloo students who are constantly moving in and out of many locations, as well as constantly changing roommates, there are many times when we discovered friction or difficulty in communicating with each other to get stuff done around the house.
## What it does
Our platform allows roommates to quickly schedule and assign chores, as well as provide a messageboard for common things.
## How we built it
Our solution is built on ruby-on-rails, meant to be a quick simple solution.
## Challenges we ran into
The time constraint made it hard to develop all the features we wanted, so we had to reduce scope on many sections and provide a limited feature-set.
## Accomplishments that we're proud of
We thought that we did a great job on the design, delivering a modern and clean look.
## What we learned
Prioritize features beforehand, and stick to features that would be useful to as many people as possible. So, instead of overloading features that may not be that useful, we should focus on delivering the core features and make them as easy as possible.
## What's next for LiveTogether
Finish the features we set out to accomplish, and finish theming the pages that we did not have time to concentrate on. We will be using LiveTogether with our roommates, and are hoping to get some real use out of it! | losing |
## Inspiration
Americans waste about 425 beverage containers per capita per year in landfill, litter, etc. Bottles are usually replaced with cans and bottles made from virgin materials which are more energy-intensive than recycled materials. This causes emissions of a host of toxics to the air and water and increases greenhouse gas emissions.
The US recycling rate is about 33% while that in stats what have container deposit laws have a 70% average rate of beverage recycling rate. This is a significant change in the amount of harm we do to the planet.
While some states already have a program for exchanging cans for cash, EarthCent brings some incentive to states to make this a program and something available. Eventually when this software gets accurate enough, there will not be as much labor needed to make this happen.
## What it does
The webapp allows a GUI for the user to capture an image of their item in real time. The EarthCents image recognizer recognizes the users bottles and dispenses physical change through our change dispenser. The webapp then prints a success or failure message to the user.
## How we built it
Convolutional Neural Networks were used to scan the image to recognize cans and bottles.
Frontend and Flask presents a UI as well as processes user data.
The Arduino is connected up to the Flask backend and responds with a pair of angle controlled servos to spit out coins.
Change dispenser: The change dispenser is built from a cardboard box with multiple structural layers to keep the Servos in place. The Arduino board is attached to the back and is connected to the Servos by a hole in the cardboard box.
## Challenges we ran into
Software: Our biggest challenge was connect the image file from the HTML page to the Flask backend for processing through a TensoFlow model. Flask was also a challenge since complex use of it was new to us.
Hardware: Building the cardboard box for the coin dispenser was quite difficult. We also had to adapt the Servos with the Arduino so that the coins can be successfully spit out.
## Accomplishments that we're proud of
With very little tools, we could build with hardware a container for coins, a web app, and artificial intelligence all within 36 hours. This project is also very well rounded (hardware, software, design, web development) and let us learn a lot about connecting everything together.
## What we learned
We learned about Arduino/hardware hacking. We learned about the pros/cons of Flask vs. using something like Node.js. In general, there was a lot of light shed on the connectivity of all the elements in this project. We both had skills here and there, but this project brought it all together. Learned how to better work together and manage our time effectively through the weekend to achieve as much as possible without being too overly ambitious.
## What's next for EarthCents
EarthCents could deposit Cryptocurrency/venmo etc and hold more coins. If this will be used, we would want to connect it to a weight to ensure that the user exchanged their can/bottle. More precise recognition. | ## Inspiration
During extreme events such as natural disasters or virus outbreaks, crisis managers are the decision makers. Their job is difficult since the right decision can save lives while the wrong decision can lead to their loss. Making such decisions in real-time can be daunting when there is insufficient information, which is often the case.
Recently, big data has gained a lot of traction in crisis management by addressing this issue; however it creates a new challenge. How can you act on data when there's just too much of it to keep up with? One example of this is the use of social media during crises. In theory, social media posts can give crisis managers an unprecedented level of real-time situational awareness. In practice, the noise-to-signal ratio and volume of social media is too large to be useful.
I built CrisisTweetMap to address this issue by creating a dynamic dashboard for visualizing crisis-related tweets in real-time. The focus of this project was to make it easier for crisis managers to extract useful and actionable information. To showcase the prototype, I used tweets about the current coronavirus outbreak.
## What it does
* Scrape live crisis-related tweets from Twitter;
* Classify tweets in relevant categories with deep learning NLP model;
* Extract geolocation from tweets with different methods;
* Push classified and geolocated tweets to database in real-time;
* Pull tweets from database in real-time to visualize on dashboard;
* Allows dynamic user interaction with dashboard
## How I built it
* Tweepy + custom wrapper for scraping and cleaning tweets;
* AllenNLP + torch + BERT + CrisisNLP dataset for model training/deployment;
* Spacy NER + geotext for extracting location names from text
* geopy + gazetteer elasticsearch docker container for extracting geolocation from locations;
* shapely for sampling geolocation from bounding boxes;
* SQLite3 + pandas for database push/pull;
* Dash + plotly + mapbox for live visualizations;
## Challenges I ran into
* Geolocation is hard;
* Stream stalling due to large/slow neural network;
* Responsive visualization of large amounts of data interactively;
## Accomplishments that I'm proud of
* A working prototype
## What I learned
* Different methods for fuzzy geolocation from text;
* Live map visualizations with Dash;
## What's next for CrisisTweetMap
* Other crises like extreme weather events; | ## Inspiration
My teammate and I grew up in Bolivia, where recycling has not taken much of a hold in society unfortunately. As such, once we moved to the US and had to deal with properly throwing away the trash to the corresponding bin, we were a bit lost sometimes on how to determine which bin to use. What better way to solve this problem than creating an app that will do it for us?
## What it does
By opening EcoSnap, you can take a picture of a piece of trash using the front camera, after which the image will be processed by a machine learning algorithm that will classify the primary object and give the user an estimate of the confidence percentage and in which bin the trash should go to.
## How we built it
We decided to use Flutter to make EcoSnap because of its ability to run on multiple platforms with only one main source file. Furthermore, we also really liked its "Hot Reload" feature which allowed us to see the changes in our app instantly. After creating the basic UI and implementing image capturing capabilities, we connected to Google's Cloud Vision and OpenAI's GPT APIs. With this done, we fed Vision the image that was captured, which then returned its classification. Then, we fed this output to GPT, which told us which bin we should put it in. Once all of this information was acquired, a new screen propped up informing the user of the relevant information!
## Challenges we ran into
Given this was our first hackathon and we did not come into it with an initial idea, we spent a lot of time deciding what we should do. After coming up with the idea and deciding on using Flutter, we had to learn from 0 how to use it as well as Dart, which took also a long time. Afterwards, we had issue implementing multiple pages in our app, acquiring the right information from the APIs, feeding correct state variables, creating a visually-appealing UI, and other lesser issues.
## Accomplishments that we're proud of
This is the first app we create, a huge step towards our career in the industry and a nice project we can add to our resume. Our dedication and resilience to keep pushing and absorbing information created an experience we will never forget. It was great to learn Flutter given its extreme flexibility in front-end development. Last but not least, we are proud by our dedication to the end goal of never having to doubt whether the trash we are throwing away is going into the wrong bin.
## What we learned
We learned Flutter. We learned Dart. We learned how to implement multiple APIs into one application to provide the user with very relevant information. We learned how to read documentation. We learned how to learn a language quickly.
## What's next for EcoSnap
Hopefully, win some prizes at the Hackathon and keep developing the app for an AppStore release over Thanksgiving! Likewise, we were also thinking of connecting a hardware component in the future. Basically, it would be a tiny microprocessor connected to a tiny camera connected to an LED light/display. This hardware would be placed on top of trash bins so that people can know very quickly where to throw their trash! | winning |
## Inspiration
Inspired by R2D2, our team crafted a robotic arm in 24 hours. Since R2D2 only moves on wheels and has a 2-D moving arm, it reminded us of people with accessibility issues. Therefore, we wanted to extend upon the design and create a hack that helps people who struggle to grip, grab and move items such as patients with arthritis or elderly people so that they can live comfortably at home. This project incorporates sophisticated 3-D printing, advanced computer vision and object detection, wireless data transformation and motion localization. This project reflects the endless possibilities of artificial intelligence and robotics to improve people's quality of life and help those in need.
## What it does
Our robotics arm features a sophisticated suite of capabilities, which uses 3-D printing technology, OpenCV and YOLOv5 object detection, wireless data transformation through Python and Bluetooth (Internet of Things) and motion localization to achieve. Our hack hopes to help people with accessibility issues such as an older population or patients with arthritis. Our arm uses AI recognition to locate, grab and move specified items for people in need. The arm adeptly identifies objects by dimensions, colour and name through trained AI software with YOLOv5 and provides accurate coordinates which our arm uses to navigate to it. The computer processes the raw information from the camera, translates it into precise movement controls through a process derivative of forward and inverse kinematics and sends it to the arm through a seamless Bluetooth connection. Notably, our robot has endless possibilities as you can even incorporate other custom object detection software with YOLOv5.
## How we built it
In this robot, we used a variety of different technologies and skills such as 3-D printing, OpenCV, YOLOv5, Wireless Data Transformation with Python and Arduino and motion localization.
Computer Vision:
Using OpenCV, we were able to categorize objects based on size and colour and return an accurate location of the object. With “cv2.findContours”, we were able to correctly identify the contours of the object which were used to determine the size and location and the centroid of the object. With the “cv2.cvtColor”, we could also use it to identify objects based on colour. On the other hand, we also used YOLOv5 to categorize objects by name through pre-trained AI object recognition software. Using “torch.hub.load('ultralytics/yolov5:v6.0', 'yolov5s')”, we could access the YOLOv5 Open Source library and use its AI directly.
Wireless Data Transformation and Motion Localization:
Using an Arduino Bluetooth Module, we were able to connect seamlessly to a computer where we processed the data. By using the computer vision data, we processed using an onboard script on a computer which sends movement commands via Bluetooth to the Arduino Mega board that controls the arm—using a serial connection such as the function serial.Serial('COM5', 9600), we were able to establish a wireless, high-speed connection with the board and send the board anything we wanted.
Mobile User Interface for Arm Control:
We crafted a mobile application utilizing MIT App Inventor, facilitating direct communication between a smartphone and a robotic arm. This innovative application leverages MIT App Inventor's block programming capability to capture user inputs via a specially designed interface, which then translates into commands for our Arduino-based control system.
Our robotic arm is driven by five servo motors, each governing the movement of the arm's joints with a rotation range of -30 to 180 degrees. The application features adjustable slider bars on its interface, enabling users to manually fine-tune the rotation of each joint.
Additionally, our system is equipped with the capability to record and store sequences of movements. This allows users to create and replay complex motion patterns with ease, simply by interacting with the "save" and "run" buttons on the app’s interface.
## Challenges we ran into
Throughout the hackathon, we ran into multiple different challenges. First, we were challenged when first determining the viability of our plan. Because of the sophistication of the arm, it required a predicted 3-D printing time of 50 hours, which seemed impossible. However, to navigate through this problem, we set up three 3-D printers in parallel, which were able to print the whole arm in just under 20 hours.
The second challenge we ran into was the computer vision implementation. We struggled with the camera's live feed transmission, frame rate, accuracy of object detection, and focus of the video. Our team effectively bypassed this problem by debugging code, modifying object detection parameters and adjusting the port of the camera module.
## Accomplishments that we're proud of
Even though this is our team’s second Hackathon, we were ambitious. Even though this is just a proof of concept, we were proud of the fact that we were able to implement computer vision, assemble and learn how to 3-D print and program the arm to move all within 24 hours. Therefore, we are proud of the progress our team made in the last 24 hours despite having little to no experience in most of the aspects of the project.
## What we learned
Throughout the hackathon, we learned many essential skills of this project. For instance, we were able to assemble three 3-D printers and learn how to slice model and print effectively the structure of our arm within 24 hours. Furthermore, we also learned how to implement our ideas into reality. Since our group is composed of all novices, we had little prior experience. However, we were able to learn how to implement OpenCV, YOLOv5, Bluetooth data transmission, motion localizing, app development and 3-D printing all in 24 hours. Lastly, we learned the joy of participating in a hackathon together, the teamwork needed and the challenges we would face in this scenario.
## What's next for The Arm of R2D2
Since The Arm of R2D2 is only a proof of concept with many parts unfinished, we wish to polish the final product and be able to share it with the world. By fine-tuning computer vision, completing the integration of computer vision and robotic motion and adding more axis of motion would be our next steps. We want The Arm of R2D2 to not only be a proof of concept, but a vision of our bright future, not only with smart homes but in all aspects of our lives. | ## Inspiration
At conferences and hackathons, it is impossible to add people on desirable social medias because you often meet so many people at once. We wanted to take a system that already exists for a single app and scale it to many other extremely popular apps.
## What it does
Holla provides the User with a Alternative QR Code-like system that we created ourselves, so that in order to add someone's Phone Number, Facebook, twitter, snapchat, LinkedIn, and Instagram all through a single tap
## How we built it
We used an iOS app, and a mongo DB database on a Node.JS server
## Challenges we ran into
Using OpenCV to detect the current state of the QR Code system we created ourselves, since just installing OpenCV on most computers can take hours on end. In addition, applying all the different API's and finding ways to use them to add people's accounts.
## Accomplishments that we're proud of
Finishing
## What we learned
A lot
## What's next for Holla
Actual use by very real people | ## 💡 Inspiration
You have another 3-hour online lecture, but you’re feeling sick and your teacher doesn’t post any notes. You don’t have any friends that can help you, and when class ends, you leave the meet with a blank document. The thought lingers in your mind “Will I ever pass this course?”
If you experienced a similar situation in the past year, you are not alone. Since COVID-19, there have been many struggles for students. We created AcadeME to help students who struggle with paying attention in class, missing class, have a rough home environment, or just want to get ahead in their studies.
We decided to build a project that we would personally use in our daily lives, and the problem AcadeME tackled was the perfect fit.
## 🔍 What it does
First, our AI-powered summarization engine creates a set of live notes based on the current lecture.
Next, there are toggle features for simplification, definitions, and synonyms which help you gain a better understanding of the topic at hand. You can even select text over videos!
Finally, our intuitive web app allows you to easily view and edit previously generated notes so you are never behind.
## ⭐ Feature List
* Dashboard with all your notes
* Summarizes your lectures automatically
* Select/Highlight text from your online lectures
* Organize your notes with intuitive UI
* Utilizing Google Firestore, you can go through your notes anywhere in the world, anytime
* Text simplification, definitions, and synonyms anywhere on the web
* DCP, or Distributing Computing was a key aspect of our project, allowing us to speed up our computation, especially for the Deep Learning Model (BART), which through parallel and distributed computation, ran 5 to 10 times faster.
## ⚙️ Our Tech Stack
* Chrome Extension: Chakra UI + React.js, Vanilla JS, Chrome API,
* Web Application: Chakra UI + React.js, Next.js, Vercel
* Backend: AssemblyAI STT, DCP API, Google Cloud Vision API, DictionariAPI, NLP Cloud, and Node.js
* Infrastructure: Firebase/Firestore
## 🚧 Challenges we ran into
* Completing our project within the time constraint
* There was many APIs to integrate, making us spend a lot of time debugging
* Working with Google Chrome Extension, which we had never worked with before.
## ✔️ Accomplishments that we're proud of
* Learning how to work with Google Chrome Extensions, which was an entirely new concept for us.
* Leveraging Distributed Computation, a very handy and intuitive API, to make our application significantly faster and better to use.
## 📚 What we learned
* The Chrome Extension API is incredibly difficult, budget 2x as much time for figuring it out!
* Working on a project where you can relate helps a lot with motivation
* Chakra UI is legendary and a lifesaver
* The Chrome Extension API is very difficult, did we mention that already?
## 🔭 What's next for AcadeME?
* Implementing a language translation toggle to help international students
* Note Encryption
* Note Sharing Links
* A Distributive Quiz mode, for online users! | losing |
# yhack\_project
Created a model that predicts a meal plan for a student under budget constraints. This program has implemented subset sum problem. This application also considers calorie intake. | ## Inspiration
Our inspiration behind this project stemmed from our own experience with social media and the consequences it can have on young impressionable youth. So often, kids and teens are oblivious to misinformation and bias that exists in the media. With Newsflix, we were committed to building **equitable learning opportunities**, creating a platform that could provide inclusive and deeper understandings.
## What it does
Newsflix is an interactive, curated web application designed to broaden users' political perspectives. Our unique personalized approach ensures accessibility for our intended audience, promoting nuanced learning across all ages. Users begin by selecting an age level, which sets the application's literacy level. A live news catalog page then allows users to browse trending political topics. After choosing multiple articles from various news outlets, the application generates a comprehensive analysis, highlighting the political bias of the articles and providing a newly generated unbiased summary.
## How we built it
On the frontend, we built Newsflix using **React.js** and styled it using **Tailwind CSS** for a dynamic and appealing user interface. On the backend, we integrated Python's **Beautiful Soup** package to collect real-time news article data from current web pages. The parsed information was then analyzed by an AI algorithm powered by **OpenAI** to assess political metrics and generate an unbiased summary. Finally, this information was connected to our frontend for deployment to users.
## Challenges we ran into
* ChatGPT's inability to browse links on the internet presented a significant challenge during development. Our article search algorithm initially depended on ChatGPT to read articles via URL links.
* When testing this API within our program, we discovered restrictions on the requests we could make. This forced us to make a critical change to our data collection algorithm. In response, we implemented a web scraping algorithm to filter specific data, which we then fed to an offline API.
## Accomplishments that we're proud of
Figuring out ChatGPT API, connecting the front end to the backend API, and learning new technologies.
## What we learned
The biggest lesson coming out of this project is to expect the worst and assume that whenever things are going well, there will always be new bugs and issues.
## What's next for Newsflix
The next step for Newsflix is to introduce live one-on-one support through AI chats, enabling users to receive immediate clarifications tailored to their individual comprehension levels. | ## Inspiration
We wanted to make an app that helped people to be more environmentally conscious. After we thought about it, we realised that most people are not because they are too lazy to worry about recycling, turning off unused lights, or turning off a faucet when it's not in use. We figured that if people saw how much money they lose by being lazy, they might start to change their habits. We took this idea and added a full visualisation aspect of the app to make a complete budgeting app.
## What it does
Our app allows users to log in, and it then retrieves user data to visually represent the most interesting data from that user's financial history, as well as their utilities spending.
## How we built it
We used HTML, CSS, and JavaScript as our front-end, and then used Arduino to get light sensor data, and Nessie to retrieve user financial data.
## Challenges we ran into
To seamlessly integrate our multiple technologies, and to format our graphs in a way that is both informational and visually attractive.
## Accomplishments that we're proud of
We are proud that we have a finished product that does exactly what we wanted it to do and are proud to demo.
## What we learned
We learned about making graphs using JavaScript, as well as using Bootstrap in websites to create pleasing and mobile-friendly interfaces. We also learned about integrating hardware and software into one app.
## What's next for Budge
We want to continue to add more graphs and tables to provide more information about your bank account data, and use AI to make our app give personal recommendations catered to an individual's personal spending. | losing |
## Inspiration
UV-Vis spectrophotometry is a powerful tool within the chemical world, responsible for many diagnostic tests (including water purity assessments, ELISA tests, Bradford protein quantity assays) and tools used within the environmental and pharmaceutical industry. This technique uses a detector to measure a liquid’s absorption of light, which can then be correlated to its molarity (the amount of a substance within the solution). Most UV-Vis spectrophotometers, however, are either extremely expensive or bulky, making them inideal for low-resource situations. Here, we implement an image processing and RGB sensing algorithm to convert a smartphone into a low-cost spectrophotometer to be used anywhere and everywhere.
Inspired by a team member’s experience using an expensive spectrophotometer to complete protein analysis during a lab internship, the Hydr8 team quickly realized this technology could easily be scaled into a smartphone, creating a more efficient, low-cost device.
## What it does
In this project, we have designed and developed a smartphone-based system that acts as a cheap spectrophotometer to detect and quantify contaminants in a solution.
## How I built it
We used the OpenCV Python package to segment images, isolate samples, and detect the average Red-Green-Blue color. We then wrote an algorithm to convert this color average into an absorbancy metric. Finally, we wrote functions that plot the absorbance vs concentration of the calibration images, and then use linear regression to quantify the contaminant concentration of the unknown solution.
## Challenges I ran into
Configuring various unfamiliar packages and libraries to work within our proposed computational framework
## Accomplishments that I'm proud of
For most of the team, this was the first hackathon we have participated in-- experience proved to be fun but challenging. Coming up with a novel idea as well as working together to create the necessary components are aspects of the projects we feel especially proud of.
## What's next for HYDR8
With time and effort, we hope to improve and streamline Hydr8 to create a more sensitive sensor algorithm that can detect lower concentrations of analyte. Our ultimate goal is to finalize implementation of the graphic user interface and release the app so that it can be used where most needed, in places such as developing countries and disaster-relief zones to ensure safe drinking water. | ## Inspiration
Our team wanted improve the daily lives of our society and third world countries. We realized that a lot of fatigue is caused by dehydration, and that it is easily improved by drinking more water. However, we often forget as our lives get very busy, but what we don't forget to do is to check our phones every minute! We wanted to incorporate a healthier habit with our phones, to help remind us to drink enough water every day. We also realized the importance of drinking clean, and pure water, and that some people in this world are not priveledged enough to have pure water. Our product promotes the user's physical well being, and shows them how to drink different, and also raises awareness of the impure water that many individuals have to drink.
## What it does
The bottle senses the resistance of the water, and uses this data to determine whether or not the water is safe to drink. The bottle also senses the change in mass of the bottle to determine your daily intake. Using this data, it will send a text message to your phone to remind you to drink water, and if the water you are about to drink is safe or not.
## How we built it
The resistance sensor is essentially a voltage divider. The voltage produced from the Photon is split between a known resistance and the water of unknown resistance. The voltage of the water, the total voltage and the resistance from one resistor is known. From there, the program conducts multiple trials and chooses the most accurate data to calculate its resistance. The pressure sensor senses the pressure placed and changes the resistance accordingly. Its voltage is then recorded and processed within our code.
The changes in pressure and resistance that are sent from the sensors first passes through the Google Cloud Platform publisher/subscriber API. Then they proceed to a python script which will send the data back to the Google Cloud, but this time to the datastore, which, optimally, would use machine learning to analyze the data and figure out the information to return. This processed information would then be sent to a Twilio script in order to be sent as a text message to the designated individual's phone number.
## Challenges we ran into
Our biggest challenge was learning the new material is a short amount of time. A lot of the concepts were quite foreign to us, and learning these new concepts took a lot of time and effort. Furthermore, there were several issues and inconsistancies with our circuits and sensors. They were quite time consuming to fix, and required us to trace back our circuits and modify the program. However, these challenges were more than enjoyable to overcome and an amazing learning opportunity for our entire team.
## Accomplishments that we're proud of
Our team is firstly proud of finishing the entire project while using foreign software and hardware. It was the first time we used Google Cloud Platform and the Particle Photon, and a lot of the programming was quite foreign. The project required a lot of intricate design and programming. There were a lot of small and complex parts of the project, and given the time restraint and minor malfunctions, it was very difficult to accomplish everything.
## What we learned
Our team developed our previous knowledge in programming and sensors. We learned how to integrate things with Google Cloud Platform, how to operate Twilio, and how setup and use a Particle Photon. Our team also learned about the engineering process of design, prototyping and pitching a novel idea. This improves what to expect if any of us decide to do a startup.
## What's next for SmartBottle
In the future, we want to develop an app that sends notifications to your phone instead of texts, and use machine learning to monitor your water intake, and recommend how you should incorporate it in your life. More importantly, we want to integrate the electrical components within the bottle instead of the external prototype we have. We imagine the force sensor sill being at the bottom, and a more slick design for the resistance sensor. | ## Inspiration 🐳
The inception of our platform was fueled by the growing water crises and the lack of accessible, real-time data on water quality. We recognized the urgent need for a tool that could offer immediate insights and predictive analyses on water quality. We aimed to bridge the gap between complex data and actionable insights, ensuring that every individual, community, and authority is equipped with precise information to make informed decisions.
## What it does❓
Our platform offers a dual solution of real-time water quality tracking and predictive analytics. It integrates data from 11 diverse sources, offering live, metric-based water quality indices. The predictive model, trained on a rich dataset of over 18,000 points, including 400 events, delivers 99.7% accurate predictions of water quality influenced by various parameters and events. Users can visualize these insights through intuitive heat maps and graphs, making the data accessible and actionable for a range of stakeholders, from concerned individuals and communities to governments and engineers.
We also developed an AR experience that allows users to interact with and visualize real time data points that the application provides, in addition to heat map layering to demonstrate the effectiveness and strength of the model.
## How we built it 🛠️
We harnessed the power of big data analytics and machine learning to construct our robust platform. The real-time tracking feature consolidates data from 11 different APIs, databases, and datasets, utilizing advanced algorithms to generate live water quality indices. The predictive model is a masterpiece of regression analysis, trained on a dataset enriched with 18,000 data points on >400 events, webscraped from three distinct big data sources. Our technology stack is scalable and versatile, ensuring accurate predictions and visualizations that empower users to monitor, plan, and act upon water quality data effectively.
## Challenges we ran into 😣
Collecting and consolidating a large enough dataset from numerous sources to attain unbiased information, finding sufficiently detailed 3D models, vectorizing the 1000s of text-based data points into meaningful vectors, hyperparameter optimization of the model to reduce errors to negligible amounts (1x10^-6 margin of error for values 1-10), and using the model's predictions and mathematical calculations to interpolate heat maps to accurately represent and visualize the data.
## Accomplishments that we're proud of 🔥
* A 99.7% accurate model that was self-trained on >18000 data points that we consolidated!
* Finding/scraping/consolidating data from turbidity indices & pH levels to social gatherings & future infrastructure projects!
* Providing intuitive, easily-understood visualizations of incredibly large and complex data sets!
* Using numerous GCP services ranging from compute, ML, satellite datasets, and more!
## What we learned 🤔
Blender, data sourcing, model optimization, and error handling were indubitably the greatest learning experiences for us over the course of these 36 hours! | losing |
## Inspiration
We built PicoPet because we crave companionship and sustainable tweets.
## What it does
PicoPet is a pair of virtual frogs that you can interact with. Watch your adorable amphibious friends drive a car, listen to music, and read tweets on their phone.
## How we built it
PicoPet is a React app built with Javascript, CSS, and HTML. We also used python and Twython to scrape tweets.
## Challenges we ran into
We struggled with integrating the tweet streaming directly into our React app. Our solution was to run the tweet scraping in python and save to a json file. We also struggled with how we wanted to use our assets. Our first attempt used animations and an SVG file, but for the sake of time we went back to using PNG files.
## Accomplishments that we're proud of
We're proud of the functionality of our app. We aimed at creating a cute virtual pet that you could interact with, which we did!
## What we learned
We strengthened our React skills and learned how to scrape Tweets.
## What's next for PicoPet
I heard the frogs are looking at buying a time share in Palm Desert. | ## Inspiration
We wished to create an environmentally friendly streaming service, which is why our creation focuses on only natural issues. We took inspiration from Hack the Valley's colour palette to form our own user interface and other streaming services to provide a more specialized field of topics.
## What it does
Our web application, DubeTube, aims to be a green streaming service! With DubeTube, you can broaden your horizons as a good citizen of the planet by uploading videos about nature and the like, or watching and commenting on videos about nature and similar things. DubeTube has many cool features such as automatic video transcription and summarization; video search by tags or title using heuristics and algorithms; and home page recommendations based on cookies. You can also share videos with your friends using a QR code as the web is constantly evolving.
## How we built it
We used Flask for our backend, which allowed us to access several other neat features that Python has—such as Cohere's natural language processing, a library for processing QR codes, speech recognition, and other tools.
To create an attractive and neat interface for the user, we used CSS to stylize our html templates, and javascript to facilitate certain operations.
## Challenges we ran into
* We faced many issues while trying to design a modern website interface with CSS—many times, we wouldn't get the result that we wished for.
* The process of classifying a video as being relevant to nature or not also proved a challenge. It took lots of debugging before we were properly able to extract the audio file, covert it from speech to text, and finally classify it.
* Merge conflicts often caused us to spend more time than necessary fixing issues when our written code would disappear.
* Connecting to WiFi also proved a challenge sometimes as at one point, two of our four members didn't have access to WiFi on their laptops.
* Domain procuring
* Gradle
## Accomplishments that we're proud of
We decided to build something using technology that we haven't used before. By constantly working, learning, and persevering throughout the night, we were able to create a functional product before the end of the hackathon.
## What we learned
* How to use Cohere
* Usage of cookies
* CSS
* Flask
* How to work as a team
+ How to work together effectively (e.g. splitting tasks)
+ How to communicate effectively
* How to do speech to text
* How to split audio files from video files
* How to create QR codes
* How to navigate documentation
* How to debug effectively
* How to research
## What's next for DubeTube
* Creating web3 authentication
* Improving security
* Mobile integration | ## Inspiration
The inspiration for our project stems from the increasing trend of online shopping and the declining foot traffic in physical stores. Our goal was to provide a unique and engaging experience for customers, encouraging them to visit physical stores and rediscover the joy of in-person shopping. We wanted to create an interactive and entertaining shopping experience that would entice customers to visit stores more frequently and foster a deeper connection between them and the store's brand.
## What it does
Our project is an AR scavenger hunt experience that gamifies the shopping experience. The scavenger hunt encourages customers to explore the store and discover new products they may have otherwise overlooked. As customers find specific products, they can earn points which can be redeemed for exclusive deals and discounts on future purchases. This innovative marketing scheme not only provides customers with an entertaining experience but also incentivizes them to visit stores more frequently and purchase products they may have otherwise overlooked.
## How we built it
To create the AR component of our project, we used Vuforia and Unity, two widely used platforms for building AR applications. The Vuforia platform allowed us to create and track image targets, while Unity was used to design the 3D models for the AR experience. We then integrated the AR component into an Android application by importing it as a Gradle project. Our team utilized agile development methodologies to ensure efficient collaboration and problem-solving throughout the development process.
## Challenges we ran into
One of the challenges we faced was integrating multiple APIs and ensuring that they worked together seamlessly. Another challenge was importing the AR component and creating the desired functionality within our project. We also faced issues with debugging and resolving technical errors that arose during the development process.
## Accomplishments that we're proud of
Despite the challenges we faced, we were able to achieve successful teamwork and collaboration. Despite forming the team later than other groups, we were able to effectively communicate and work together to bring our project to fruition. We are proud of the end result, which was a polished and functional AR scavenger hunt experience that met our objectives.
## What we learned
We learned how difficult it is to truly ship out software, and we are grateful to have joined the hackathon. We gained a deeper understanding of the importance of project planning, effective communication, and collaboration among team members. We also learned that the development process can be challenging and unpredictable, and that it requires perseverance and problem-solving skills. Additionally, participating in the hackathon taught us valuable technical skills such as integrating APIs, creating AR functionality, and importing projects onto an Android application.
## What's next for Winnur
Looking forward, we plan to incorporate Computer Vision technology into our project to prevent potential damage to our product's packaging. We also aim to expand the reach of our AR scavenger hunt experience by partnering with more retailers and enhancing the user interface and experience. We are excited about the potential for future development and growth of Winnur. | losing |
## Inspiration
Software engineering interviews are really tough. How best to prepare? You can mock interview, but that requires two people. We wanted an easy way for speakers to gauge how well they're speaking and see how they improve over time.
## What it does
Provides a thoughtful interview prompt and analyzes speaking patterns according to four metrics - clarity, hesitations, words per minute, and word spacing. Users can access data from past sessions on their profile page.
## How we built it
An Express backend and MongoDB database that interfaces with the Nuance ASR API and IBM Watson Speech-to-Text.
## Challenges we ran into
* Determining a heuristic for judging speech
* Working with the speech services through web sockets
* Seeing what we could do with the supplied data
## Accomplishments that we're proud of
A clean, responsive UI!
## What we learned
Speech detection is really difficult and technologies that explore this area are still in their early stages. Knowing what content to expect can make things easier, and it's cool how Nuance is exploring the possibilities of machine learning through Bolt.
## What's next for rehearse
We want to take advantage of Nuance's contextual models by implementing rehearse modes for different use cases. For example, a technical interview module that identifies algorithm names and gives reactive hints/comments on a practice question. | ## Inspiration
Our team wanted to try to create a tool that would help its users access better medical care. When discussing what kind of barriers to access we wanted to target, we came to the topic of having to act as your own advocate when seeking a medical diagnosis, which can be challenging and frustrating. So, we decided to try to build a tool to make this process easier!
## What it does
MedSpeak is a platform that is meant to help users who may be seeking a medical diagnosis or are living with an ongoing health condition. It lets them document their day-to-day experiences, investigate symptoms using trusted resources and helps them contact medical providers.
## How we built it
We built this platform as a web application using python with a Google Custom Search API and MongoDB to create a database and function for recommending trusted sources to research their symptoms. We used html to create the frontend.
## Challenges we ran into
This is a platform that has a large number of different potential features that can be implemented, so deciding which features to prioritize implementing during the span of the hackathon was challenging.
## Accomplishments that we're proud of
We're happy to say that we were able to build a working application that is able to give a glimpse into the possibilities we envisioned for a project like this one!
## What we learned
This project really tested our ability to put the idea we were visualizing into code. Working together to do this really helped us improve both our technical skills and our ability to work as a team.
## What's next for MedSpeak
Going forward, we want to improve the 'Add an Entry' function. Ideally, we want to use it to guide a user to give potentially insightful information about their condition so we can give them better resources and help them word their concerns to healthcare providers. | # talko
Hello! talko is a project for nwHacks 2022.
Interviews can be scary, but they don't have to be! We believe that practice and experience is what gives you the
confidence you need to show interviewers what you're made of. talko is made for students and new graduates who want to
learn to fully express their skills in interviews. With everything online, it's even more important now that you can
get your thoughts across clearly virtually.
As students who have been and will be looking for co-ops, we know very well how stressful interview season can be;
we took this as our source of inspiration for talko.
talko is an app that helps you practice for interviews. Record and time your answers to interview questions to get
feedback on how fast you're talking and view previous answers.
## Features
* View answer history for previous answers- playback recordings, words per minute, standard deviation of talking speed and overall answer quality.
* Integrated question bank with a variety of topics.
* Skip answers you aren't ready to answer.
* Adorable robots!!
## Technical Overview
For Talko’s front-end, we used React to create a web app that can be used on both desktop and mobile devices.
We used Figma for the wireframing and Adobe Fresco for some of the aesthetic touches and character designs.
We created the backend using Nodejs and Express. The api handles uploading, saving and retrieving recordings, as well as
fetching random questions from our question bank. We used Google Cloud Firestore to save data about past answers, and Microsoft
Azure to store audio files and use speech-to-text on our clips. In our api, we calculate the average words per minute over
the entire answer, as well as the variance in the rate of speech.
## Challenges & Accomplishments
Creating this project in just 24 hours was quite the challenge! While we have worked with some of these tools before,
it was our first time working with Microsoft Azure. We're really proud of what we managed to put together over this weekend.
Another issue we had is that it can take a while to get speech-to-text results from Azure. We wanted to send
a response back to the frontend quickly, so we decided to calculate the rate of speech variance afterwards and
patch our data in Firestore.
## What's next for talko?
* Tagged questions: get questions most relevant to your industry
* Better answer analysis: use different NLP APIs and assess the text to give better stats and pointers
+ Are there lots of pauses and filler words in the answer?
+ Is the answer related to the question?
+ Given a job description selected or supplied by the user, does the answer cover the keywords?
+ Is the tone of the answer formal, assertive?
* View answer history in more detail: option to show transcript and play back audio recordings
* Settings to personalize your practice experience: customize number of questions and answer time limit.
## Built using






### Thanks for visiting! | losing |
## Inspiration:
The inspiration behind Pisces stemmed from our collective frustration with the time-consuming and often tedious process of creating marketing materials from scratch. We envisioned a tool that could streamline this process, allowing marketers to focus on strategy rather than mundane tasks.
## Learning:
Throughout the development of Pisces, we learned the intricate nuances of natural language processing and machine learning algorithms. We delved into the psychology of marketing, understanding how to tailor content to specific target audiences effectively.
## Building:
We started by gathering a diverse team with expertise in marketing, software development, and machine learning. Collaborating closely, we designed Pisces to utilize cutting-edge algorithms to analyze input data and generate high-quality marketing materials autonomously.
## Challenges:
One of the main challenges we faced was training the machine learning models to accurately understand and interpret product descriptions. We also encountered hurdles in fine-tuning the algorithms to generate diverse and engaging content consistently. Despite the challenges, our dedication and passion for innovation drove us forward. Pisces is not just a project; it's a testament to our perseverance and commitment to revolutionizing the marketing industry.
## Interested to Learn More?
**Read from the PROS!**
Pisces has the power to transform marketing teams by reducing the need for extensive manpower. With traditional methods, it might take a team of 50 individuals to create comprehensive marketing campaigns. However, with Pisces, this workforce can be streamlined to just 5 people or even less. Imagine the time saved by automating the creation of ads, videos, and audience insights! Instead of spending weeks on brainstorming sessions and content creation, marketers can now allocate their time more strategically, focusing on refining their strategies and analyzing campaign performance. This tool isn't just a time-saver; it's a game-changer for the future of marketing. By harnessing the efficiency of Pisces, companies can launch campaigns faster, adapt to market trends more seamlessly, and ultimately, achieve greater success in their marketing endeavors. Pisces can be effectively used across various industries and marketing verticals. Whether you're a small startup looking to establish your brand presence or a multinational corporation aiming to scale your marketing efforts globally, Pisces empowers you to create compelling campaigns with minimal effort and maximum impact.
## Demos
Walkthrough (bad compression): [YouTube Link](https://www.youtube.com/watch?v=VGiHuQ7Ha9w)
Muted Demo (for ui/ux purposes): [YouTube Link](https://youtu.be/56MRUErwfPc) | ## Inspiration
Companies lack insight into their users, audiences, and marketing funnel.
This is an issue I've run into on many separate occasions. Specifically,
* while doing cold marketing outbound, need better insight onto key variables of successful outreach
* while writing a blog, I have no idea who reads it
* while triaging inbound, which users do I prioritize
Given a list of user emails, Cognito scrapes the internet finding public information about users and the companies they work at. With this corpus of unstructured data, Cognito allows you to extract any relevant piece of information across users. An unordered collection of text and images becomes structured data relevant to you.
## A Few Example Use Cases
* Startups going to market need to identify where their power users are and their defining attributes. We allow them to ask questions about their users, helping them define their niche and better focus outbound marketing.
* SaaS platforms such as Modal have trouble with abuse. They want to ensure people joining are not going to abuse it. We provide more data points to make better judgments such as taking into account how senior of a developer a user is and the types of companies they used to work at.
* VCs such as YC have emails from a bunch of prospective founders and highly talented individuals. Cognito would allow them to ask key questions such as what companies are people flocking to work at and who are the highest potential people in my network.
* Content creators such as authors on Substack looking to monetize their work have a much more compelling case when coming to advertisers with a good grasp on who their audience is.
## What it does
Given a list of user emails, we crawl the web, gather a corpus of relevant text data, and allow companies/creators/influencers/marketers to ask any question about their users/audience.
We store these data points and allow for advanced querying in natural language.
[video demo](https://www.loom.com/share/1c13be37e0f8419c81aa731c7b3085f0)
## How we built it
we orchestrated 3 ML models across 7 different tasks in 30 hours
* search results person info extraction
* custom field generation from scraped data
* company website details extraction
* facial recognition for age and gender
* NoSQL query generation from natural language
* crunchbase company summary extraction
* email extraction
This culminated in a full-stack web app with batch processing via async pubsub messaging. Deployed on GCP using Cloud Run, Cloud Functions, Cloud Storage, PubSub, Programmable Search, and Cloud Build.
## What we learned
* how to be really creative about scraping
* batch processing paradigms
* prompt engineering techniques
## What's next for Cognito
1. predictive modeling and classification using scraped data points
2. scrape more data
3. more advanced queries
4. proactive alerts
[video demo](https://www.loom.com/share/1c13be37e0f8419c81aa731c7b3085f0) | ## Inspiration
A common skill one needs in business management is the ability to know how the customer feels and reacts to a system of services provided by the business in question. Thus, having computers in this day and age make it an essential tool for analyzing these important sources of customer feedback. Automatically making a machine gather uncoerced customer "feedback" data can easily indicate how the last few interactions were for the customer. Making this tool accessible was our inspiration behind this project.
## What it does
This web application gathers data from Twitter, Reddit, Kayak, TripAdvisor and Influenster at the moment with room to expand into many more social review websites. The data it gathers from these websites are represented as graphs, ratios and other symbolic representations that help the user easily conclude how the company is perceived by its customers and even compare it to how customers perceive other airline companies as well.
## How we built it
We built it using languages and packages we were familiar with, along with packages we did not know existed before yHacks 2019. An extremely careful design process was laid out well before we started working on the implementation of the webApp and we believe that is the reason behind its simplicity for the user. We prioritized making the implementation as simple as possible such that any user can easily understand the observations of the data.
## Challenges we ran into
Importing and utilizing some packages did not play well with our implementation process, thus we had to make sure we covered our design checklist via working around the issues we ran into. This includes building data scrapers, data representers and other packages from scratch. This issue increasing became prominent the more we pressed on making the webApp user-friendly as more functions and code had to be shoveled in the back-end.
## Accomplishments that we're proud of
The data scrapers and representative models for collected data are accomplishments we're most proud of as they are simple yet extremely effective when it comes to analyzing customer feedback. In particular, getting data from giant resources of customer reactions such as TripAdvisor, Reddit and Twitter make the application highly relevant and effective. This practical idea and ease of access development we implemented for the user is what we are most proud of.
## What we learned
We learned a lot more about several of the infinite number of packages available online. There is so much information out on the internet that these 2 continuous days of coding and research have not even scratched the surface in terms of all the implementable ideas out there. Our implementation is just a representation of what a final sentiment analyzer could look like. Given there are many more areas to grow upon, we learned about customer feedback analysis and entrepreneur skills along the way.
## What's next for feelBlue
Adding more sources of data such as FaceBook, Instagram and other large social media websites will help increase the pool of data to perform sentiment analysis. This implementation can even help high-level managers of JetBlue decide which area of service they can improve upon! Given enough traction and information, feelBlue could even be used as a universal sentiment analyzer for multiple subjects alongside JetBlue Airlines! The goals are endless! | winning |
## AI, AI, AI...
The number of projects using LLMs has skyrocketed with the wave of artificial intelligence. But what if you *were* the AI, tasked with fulfilling countless orders and managing requests in real time? Welcome to chatgpME, a fast-paced, chaotic game where you step into the role of an AI who has to juggle multiple requests, analyzing input, and delivering perfect responses under pressure!
## Inspired by games like Overcooked...
chatgpME challenges you to process human queries as quickly and accurately as possible. Each round brings a flood of requests—ranging from simple math questions to complex emotional support queries—and it's your job to fulfill them quickly with high-quality responses!
## How to Play
Take Orders: Players receive a constant stream of requests, represented by different "orders" from human users. The orders vary in complexity—from basic facts and math solutions to creative writing and emotional advice.
Process Responses: Quickly scan each order, analyze the request, and deliver a response before the timer runs out.
Get analyzed - our built-in AI checks how similar your answer is to what a real AI would say :)
## Key Features
Fast-Paced Gameplay: Just like Overcooked, players need to juggle multiple tasks at once. Keep those responses flowing and maintain accuracy, or you’ll quickly find yourself overwhelmed.
Orders with a Twist: The more aware the AI becomes, the more unpredictable it gets. Some responses might start including strange, existential musings—or it might start asking you questions in the middle of a task!
## How We Built It
Concept & Design: We started by imagining a game where the player experiences life as ChatGPT, but with all the real-time pressure of a time management game like Overcooked. Designs were created in Procreate and our handy notebooks.
Tech Stack: Using Unity, we integrated a system where mock requests are sent to the player, each with specific requirements and difficulty levels. A template was generated using defang, and we also used it to sanitize user inputs. Answers are then evaluated using the fantastic Cohere API!
Playtesting: Through multiple playtests, we refined the speed and unpredictability of the game to keep players engaged and on their toes. | ## Inspiration
**The Tales of Detective Toasty** draws deep inspiration from visual novels like **Persona** and **Ghost Trick** and we wanted to play homage to our childhood games through the fusion of art, music, narrative, and technology. Our goal was to explore the possibilities of AI within game development. We used AI to create detailed character sprites, immersive backgrounds, and engaging slide art. This approach allows players to engage deeply with the game's characters, navigating through dialogues and piecing together clues in a captivating murder mystery that feels personal and expansive. By enriching the narrative in this way, we invite players into Detective Toasty’s charming yet suspense-filled world.
## What It Does
In **The Tales of Detective Toasty**, players step into the shoes of the famous detective Toasty, trapped on a boat with four suspects in a gripping AI-powered murder mystery. The game challenges you to investigate suspects, explore various rooms, and piece together the story through your interactions. Your AI-powered assistant enhances these interactions by providing dynamic dialogue, ensuring that each playthrough is unique. We aim to expand the game with more chapters and further develop inventory systems and crime scene investigations.
## How We Built It
Our project was crafted using **Ren'py**, a Python-based visual novel engine, and Python. We wrote our scripts from scratch, given Ren'py’s niche adoption. Integration of the ChatGPT API allowed us to develop a custom AI assistant that adapts dialogues based on player's question, enhancing the storytelling as it is trained on the world of Detective Toasty. Visual elements were created using Dall-E and refined with Procreate, while Superimpose helped in adding transparent backgrounds to sprites. The auditory landscape was enriched with music and effects sourced from YouTube, and the UI was designed with Canva.
## Challenges We Ran Into
Our main challenge was adjusting the ChatGPT prompts to ensure the AI-generated dialogues fit seamlessly within our narrative, maintaining consistency and advancing the plot effectively. Being our first hackathon, we also faced a steep learning curve with tools like ChatGPT and other OpenAI utilities and learning about the functionalities of Ren'Py and debugging. We struggled with learning character design transitions and refining our artwork, teaching us valuable lessons through trial and error. Furthermore, we had difficulties with character placement, sizing, and overall UI so we had to learn all the components on how to solve this issue and learn an entirely new framework from scratch.
## Accomplishments That We’re Proud Of
Participating in our first hackathon and pushing the boundaries of interactive storytelling has been rewarding. We are proud of our teamwork and the gameplay experience we've managed to create, and we're excited about the future of our game development journey.
## What We Learned
This project sharpened our skills in game development under tight deadlines and understanding of the balance required between storytelling and coding in game design. It also improved our collaborative abilities within a team setting.
## What’s Next for The Tales of Detective Toasty
Looking ahead, we plan to make the gameplay experience better by introducing more complex story arcs, deeper AI interactions, and advanced game mechanics to enhance the unpredictability and engagement of the mystery. Planned features include:
* **Dynamic Inventory System**: An inventory that updates with both scripted and AI-generated evidence.
* **Interactive GPT for Character Dialogues**: Enhancing character interactions with AI support to foster a unique and dynamic player experience.
* **Expanded Storyline**: Introducing additional layers and mysteries to the game to deepen the narrative and player involvement.
* *and more...* :D | # Click through our slideshow for a neat overview!!
# Check out our demo [video](https://www.youtube.com/watch?v=hyWJAuR7EVY)
## The future of computing 🍎 👓 ⚙️ 🤖 🍳 👩🍳
How could Mixed Reality, Spatial Computing, and Generative AI transform our lives?
And what happens when you combine Vision Pro and AI? (spoiler: magic! 🔮)
Our goal was to create an interactive **VisionOS** app 🍎 powered by AI. While our app could be applied towards many things (like math tutoring, travel planning, etc.), we decided to make the demo use case fun.
We loved playing the game Cooking Mama 👩🍳 as kids so we made a **voice-activated conversational AI agent** that teaches you to cook healthy meals, invents recipes based on your preferences, and helps you find and order ingredients.
Overall, we want to demonstrate how the latest tech advances could transform our lives. Food is one of the most important, basic needs so we felt that it was an interesting topic. Additionally, many people struggle with nutrition so our project could help people eat healthier foods and live better, longer lives.
## What we created
* Conversational Vision Pro app that lets you talk to an AI nutritionist that speaks back to you in a realistic voice with low latency.
* Built-in AI agent that will create a custom recipe according to your preferences, identify the most efficient and cheapest way to purchase necessary ingredients in your area (least stores visited, least cost), and finally creates Instacart orders using their simulated API.
* Web version of agent at [recipes.reflex.run](https://recipes.reflex.run/) in a chat interface
* InterSystems IRIS vector database of 10k recipes with HyDE enabled semantic search
* Pretrained 40M LLM from scratch to create recipes
* Fine-tuned Mistral-7b using MonsterAPI to generate recipes
## How we built it
We divided tasks efficiently given the time frame to make sure we weren't bottlenecked by each other. For instance, Gao's first priority was to get a recipe LLM deployed so Molly and Park could use it in their tasks.
While we split up tasks, we also worked together to help each other debug and often pair programmed and swapped tasks if needed.
Various tools used: Xcode, Cursor, OpenAI API, MonsterAI API, IRIS Vector Database, Reflex.dev, SERP API,...
### Vision OS
* Talk to Vision Mama by running Whisper fully on device using CoreML and Metal
* Chat capability powered by GPT-3.5-turbo, our custom recipe-generating LLM (Mistral-7b backbone), and our agent endpoint.
* To ensure that you are able to see both Vision Mama's chats and her agentic skills, we have a split view that shows your conversation and your generated recipes
* Lastly, we use text-to-speech synthesis using ElevenLabs API for Vision Mama's voice
### AI Agent Pipeline for Recipe Generation, Food Search, and Instacart Ordering
We built an endpoint that we hit from our Vision Pro and our Reflex site.
Basically what happens is we submit a user's desired food such as "banana soup". We pass that to our fine-tuned Mistral-7b LLM to generate a recipe. Then, we quickly use GPT-4-turbo to parse the recipe and extract the ingredients. Then we use the SERP API on each ingredient to find where it can be purchased nearby. We prioritize cheaper ingredients and use an algorithm to try to visit the least number of stores to buy all ingredients. Finally, we populate an Instacart Order API call to purchase the ingredients (simulated for now since we do not have actual partner access to Instacart's API)
### Pre-training (using nanogpt architecture):
Created large dataset of recipes.
Tokenized our recipe dataset using BPE (GPT2 tokenizer)
Dataset details (9:1 split):
train: 46,826,468 tokens
val: 5,203,016 tokens
Trained for 1000 iterations with settings:
layers = 12
attention heads = 12
embedding dimension = 384
batch size = 32
In total, the LLM had 40.56 million parameters!
It took several hours to train on an M3 Mac with Metal Performance Shaders.
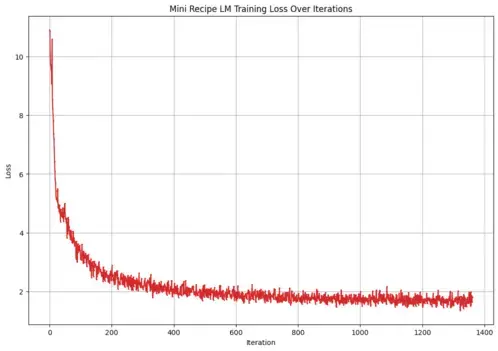
### Fine-tuning
While the pre-trained LLM worked ok and generated coherent (but silly) English recipes for the most part, we couldn't figure out how to deploy it in the time frame and it still wasn't good enough for our agent. So, we tried fine-tuning Mistral-7b, which is 175 times bigger and is much more capable. We curated fine-tuning datasets of several sizes (10k recipes, 50k recipes, 250k recipes). We prepared them into a specific prompt/completion format:
```
You are an expert chef. You know about a lot of diverse cuisines. You write helpful tasty recipes.\n\n###Instruction: please think step by step and generate a detailed recipe for {prompt}\n\n###Response:{completion}
```
We fine-tuned and deployed the 250k-fine-tuned model on the **MonsterAPI** platform, one of the sponsors of TreeHacks. We observed that using more fine-tuning data led to lower loss, but at diminishing returns.
### Reflex.dev Web Agent
Most people don't have Vision Pros so we wrapped our versatile agent endpoint into a Python-based Reflex app that you can chat with! [Try here](https://recipes.reflex.run/)
Note that heavy demand may overload our agent.
### IRIS Semantic Recipe Discovery
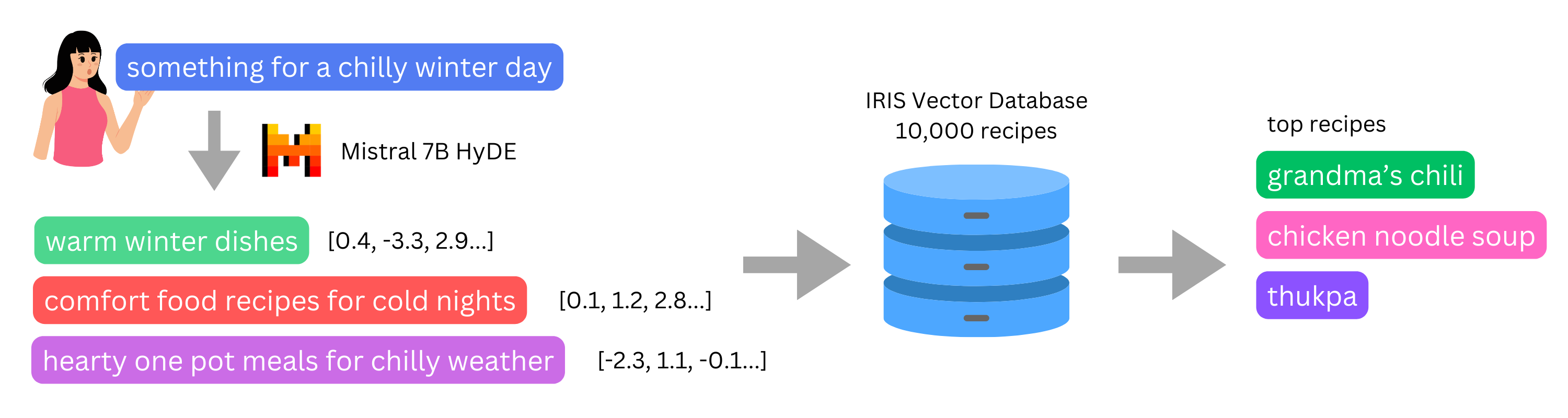
We used the IRIS Vector Database, running it on a Mac with Docker. We embedded 10,000 unique recipes from diverse cuisines using **OpenAI's text-ada-002 embedding**. We stored the embeddings and the recipes in an IRIS Vector Database. Then, we let the user input a "vibe", such as "cold rainy winter day". We use **Mistral-7b** to generate three **Hypothetical Document Embedding** (HyDE) prompts in a structured format. We then query the IRIS DB using the three Mistral-generated prompts. The key here is that regular semantic search does not let you search by vibe effectively. If you do semantic search on "cold rainy winter day", it is more likely to give you results that are related to cold or rain, rather than foods. Our prompting encourages Mistral to understand the vibe of your input and convert it to better HyDE prompts.
Real example:
User input: something for a chilly winter day
Generated Search Queries: {'queries': ['warming winter dishes recipes', 'comfort food recipes for cold days', 'hearty stews and soups for chilly weather']}
Result: recipes that match the intent of the user rather than the literal meaning of their query
## Challenges we ran into
Programming for the Vision Pro, a new way of coding without that much documentation available
Two of our team members wear glasses so they couldn't actually use the Vision Pro :(
Figuring out how to work with Docker
Package version conflicts :((
Cold starts on Replicate API
A lot of tutorials we looked at used the old version of the OpenAI API which is no longer supported
## Accomplishments that we're proud of
Learning how to hack on Vision Pro!
Making the Vision Mama 3D model blink
Pretraining a 40M parameter LLM
Doing fine-tuning experiments
Using a variant of HyDE to turn user intent into better semantic search queries
## What we learned
* How to pretrain LLMs and adjust the parameters
* How to use the IRIS Vector Database
* How to use Reflex
* How to use Monster API
* How to create APIs for an AI Agent
* How to develop for Vision Pro
* How to do Hypothetical Document Embeddings for semantic search
* How to work under pressure
## What's next for Vision Mama: LLM + Vision Pro + Agents = Fun & Learning
Improve the pre-trained LLM: MORE DATA, MORE COMPUTE, MORE PARAMS!!!
Host the InterSystems IRIS Vector Database online and let the Vision Mama agent query it
Implement the meal tracking photo analyzer into VisionOs app
Complete the payment processing for the Instacart API once we get developer access
## Impacts
Mixed reality and AI could enable more serious use cases like:
* Assisting doctors with remote robotic surgery
* Making high quality education and tutoring available to more students
* Amazing live concert and event experiences remotely
* Language learning practice partner
## Concerns
* Vision Pro is very expensive so most people can't afford it for the time being. Thus, edtech applications are limited.
* Data privacy
Thanks for checking out Vision Mama! | winning |
## Inspiration
We visit many places, we know very less about the historic events or the historic places around us. Today In History notifies you of historic places near you so that you do not miss them.
## What it does
Today In History notifies you about important events that took place exactly on the same date as today but a number of years ago in history. It also notifies the historical places that are around you along with the distance and directions. Today In History is also available as an Amazon Alexa skill. You can always ask Alexa, "Hey Alexa, ask Today In History what's historic around me? What Happened Today? What happened today in India.......
## How we built it
We have two data sources: one is Wikipedia -- we are pulling all the events from the wiki for the date and filter them based on users location. We use the data from Philadelphia to fetch the historic places nearest to the user's location and used Mapquest libraries to give directions in real time.
## Challenges we ran into
Alexa does not know a person's location except the address it is registered with, but we built a novel backend that acts as a bridge between the web app and Alexa to keep them synchronized with the user's location. | ## Inspiration
The only thing worse than no WiFi is slow WiFi. Many of us have experienced the frustrations of terrible internet connections. We have too, so we set out to create a tool to help users find the best place around to connect.
## What it does
Our app runs in the background (completely quietly) and maps out the WiFi landscape of the world. That information is sent to a central server and combined with location and WiFi data from all users of the app. The server then processes the data and generates heatmaps of WiFi signal strength to send back to the end user. Because of our architecture these heatmaps are real time, updating dynamically as the WiFi strength changes.
## How we built it
We split up the work into three parts: mobile, cloud, and visualization and had each member of our team work on a part. For the mobile component, we quickly built an MVP iOS app that could collect and push data to the server and iteratively improved our locationing methodology. For the cloud, we set up a Firebase Realtime Database (NoSQL) to allow for large amounts of data throughput. For the visualization, we took the points we received and used gaussian kernel density estimation to generate interpretable heatmaps.
## Challenges we ran into
Engineering an algorithm to determine the location of the client was significantly more difficult than expected. Initially, we wanted to use accelerometer data, and use GPS as well to calibrate the data, but excessive noise in the resulting data prevented us from using it effectively and from proceeding with this approach. We ran into even more issues when we used a device with less accurate sensors like an Android phone.
## Accomplishments that we're proud of
We are particularly proud of getting accurate paths travelled from the phones. We initially tried to use double integrator dynamics on top of oriented accelerometer readings, correcting for errors with GPS. However, we quickly realized that without prohibitively expensive filtering, the data from the accelerometer was useless and that GPS did not function well indoors due to the walls affecting the time-of-flight measurements. Instead, we used a built in pedometer framework to estimate distance travelled (this used a lot of advanced on-device signal processing) and combined this with the average heading (calculated using a magnetometer) to get meter-level accurate distances.
## What we learned
Locationing is hard! Especially indoors or over short distances.
Firebase’s realtime database was extremely easy to use and very performant
Distributing the data processing between the server and client is a balance worth playing with
## What's next for Hotspot
Next, we’d like to expand our work on the iOS side and create a sister application for Android (currently in the works). We’d also like to overlay our heatmap on Google maps.
There are also many interesting things you can do with a WiFi heatmap. Given some user settings, we could automatically switch from WiFi to data when the WiFi signal strength is about to get too poor. We could also use this app to find optimal placements for routers. Finally, we could use the application in disaster scenarios to on-the-fly compute areas with internet access still up or produce approximate population heatmaps. | ## Inspiration
As we began thinking about potential projects to make, we realized that there was no real immersive way to speak to those that have impacted the world in a major way. It is just not as fun to look up Wikipedia articles and simply read the information that is presented there, especially for the attention deficient current generation. Thinking of ways to make this a little more fun, we came up with the idea of bringing these characters to life, in order to give the user the feeling that they are actually talking and learning directly from the source(s), the individual(s) that actually came up with the ideas that the users are interested in. In terms of the initial idea, we were inspired by the Keeling Curve, where we wanted to talk to Charles David Keeling, who unfortunately passed away in 2005, about his curve.
## What it does
Our application provides an interactive way for people to learn in a more immersive manner about climate change or other history. It consists of two pages, the first in which the user can input a historical character to chat with, and the second to "time travel" into the past and spectate on a conversation between two different historical figures. The conversation utilizes voice as input, but also displays the input and the corresponding response on the screen for the user to see.
## How we built it
The main technologies that we used are the Hume AI, Intel AI, Gemini, and VITE (a react framework). Hume AI is used for the text and voice generation, in order to have the responses be expressive, which would hopefully engage the user a bit more. Intel AI is used to generate images using Stable Diffusion to accompany the text that is generated, again to hopefully increase the immersiveness. Gemini is used to generate the conversations between two different historical figures, in the "time travel" screen. Finally, we used VITE to create a front end that merges everything together and provides an interface to the user to interact with the other technologies that we used.
## Challenges we ran into
One challenge we faced was just with the idea generation phase, as it took us a while to polish the idea enough to make this an awesome application. We went through a myriad of other ideas, eventually settling in on this idea of interacting with historical figures, as we believed this would provide the best form of enrichment to a potential user.
We also tried switching from Gemini to Open AI, but due to the way that the APIs are implemented, it was unfortunately not as easy to just drop-in replace Open AI everywhere Gemini was used. Thus, we decided that it was best to stick with Gemini, as it still does quite a good job at generating responses for what we require.
Another challenge that we faced was the fact that it is quite difficult to manage conversations between different assistants, like for instance in the "time travel" page, where two different historical figures (two different assistants) are supposed to have a productive conversation.
## Accomplishments that we're proud of
We are quite proud of the immersiveness of the application. It does really feel as if the user is speaking to the person in question, and not a cheap knockoff trying to pretend to be that person. The assistant is also historically accurate, and does not deviate off of what was requested, such as discussing topics that the historical figure has no possibility of having the knowledge of, such as events or discoveries after they passed away. In addition to this, we are also proud of the features that we managed to include in our final application, such as the ability to change the historical figure that the user wants to talk to, in addition to the "time travel" feature which allows for the user to experience how different historical figures would interact with each other.
## What we learned
We would say that the most important skill that we learned was the art of working together as a team. When we had issues or were confused about certain parts of our application, talking through and explaining different parts proved to be quite an invaluable act to perform. In addition to this, we learned how to integrate various APIs and technologies, and making them work together in a seamless fashion in order to make a successful and cohesive application. We also learned the difficult process of coming up with the idea in the first place, especially one that is good enough to be viable.
## What's next for CLIMATE CHANGE IS BEST LEARNED FROM THE EXPERTS THEMSELVES
The next steps would be to include more features, such as having a video feed that feels as if the user is video chatting with the historical figure, furthering the immersiveness of our application. It would also definitely be quite nice to figure out Open AI integration, and have the user choose the AI assistant they would like to use in the future. | winning |
## Inspiration
The failure of a certain project using Leap Motion API motivated us to learn it and use it successfully this time.
## What it does
Our hack records a motion password desired by the user. Then, when the user wishes to open the safe, they repeat the hand motion that is then analyzed and compared to the set password. If it passes the analysis check, the safe unlocks.
## How we built it
We built a cardboard model of our safe and motion input devices using Leap Motion and Arduino technology. To create the lock, we utilized Arduino stepper motors.
## Challenges we ran into
Learning the Leap Motion API and debugging was the toughest challenge to our group. Hot glue dangers and complications also impeded our progress.
## Accomplishments that we're proud of
All of our hardware and software worked to some degree of success. However, we recognize that there is room for improvement and if given the chance to develop this further, we would take it.
## What we learned
Leap Motion API is more difficult than expected and communicating with python programs and Arduino programs is simpler than expected.
## What's next for Toaster Secure
-Wireless Connections
-Sturdier Building Materials
-User-friendly interface | ## Inspiration
Kingston's website is the place to go when having questions about having life in Kingston or when searching for events going on in the city, but navigating through the hundreds of the city's webpages for an answer can be gruesome. We were all interested in AI and wanted to challenge ourselves to build a chatbot website.
## What it does
Kingsley is a chatbot built to help residents in Kingston with their inquiries. It takes in user input, and responds with a helpful answer along with a link to where more information can be found on the city of Kingston website if applicable. It has an option for voice input and output for greater accessibility.
## How we built it
* Kingsley uses a GPT-3 model fine-tuned on data from the city of Kingston website.
* The data was scraped using Beautiful Soup.
* A GloVe model was used to find website links relevant to the user's question.
* Jaccard similarity was used to find relevant text that specifically mentioned key words in the user's question.
* Relevant texts were narrowed down and passed as part of the prompt to GPT-3 for an answer completion.
* The website along with the voice functionality were created using React.
## Challenges we ran into
The CityOfKingston website has a huge amount of pages, a lot of which are archived, calendars, or not very useful. OpenAI's API on the other hand only allowed a limited context. so to have the bot be able to read relevant pages as its context, we had to go through multiple methods of data filtering to find the relevant pages.
We spent a great amount of time implementing speech-to-text and text-to-speech for our webapp. Many of the solutions on the internet were of little help, and we tried using several npm packages before being successful in the end.
## Accomplishments that we're proud of
We successfully made a working chatbot!
And it references real facts! (sometimes)
## What we learned
Throughout the project, we gained experience working with various APIs. We learned how to use and combine different natural language processing techniques to optimize accuracy and computation time. We learned React hooks useState and useEffect, Javascript functions, and how to use React developer tools to debug components in Chrome. We figured out how to link backend Flask with frontend app, setup a domain, and use text-to-speech and speech-to-text libraries.
## What's next for Kingsley
Due to free trial limits, we chose to use the Ada GPT model for our chatbot. In the future if we had more credits, we could use a better version of GPT-3 in order to produce more relevant and helpful results.
We are also interested in expanding Kingsley to reference data from other websites. It can also be adapted as an extension or floating popup that can be used directly on top of Kingston's website. | ## Inspiration
As a team, we were immediately intrigued by the creative freedom involved in building a ‘useless invention’ and inspiration was drawn from the ‘useless box’ that turns itself off. We thought ‘why not have it be a robot arm and give it an equally intriguing personality?’ and immediately got to work taking our own spin on the concept.
## What It Does
The robot has 3 servos that allow the robot to move with personality. Whenever the switch is pressed, the robot executes a sequence of actions in order to flick the switch and then shut down.
## How We Built It
We started by dividing tasks between members: the skeleton of the code, building the physical robot, and electronic components. A CAD model was drawn up to get a gauge for scale, and then it was right into cutting and glueing popsicle sticks. An Exacto blade was used to create holes in the base container for components to fit through to keep everything neat and compact. Simultaneously, as much of the code and electronic wiring was done to not waste time.
After the build was complete, a test code was run and highlighted areas that needed to be reinforced. While that was happening, calculations were being done to determine the locations the servo motors would need to reach in order to achieve our goal. Once a ‘default’ sequence was achieved, team members split to write 3 of our own sequences before converging to achieve the 5th and final sequence. After several tests were run and the code was tweaked, a demo video was filmed.
## Challenges We Ran Into
The design itself is rather rudimentary, being built out of a Tupperware container, popsicle sticks and various electronic components to create the features such as servo motors and a buzzer. Challenges consisted of working with materials as fickle as popsicle sticks – a decision driven mainly by the lack of realistic accessibility to 3D printers. The wood splintered and was weaker than expected, therefore creative design was necessary so that it held together.
Another challenge was the movement. Working with 3 servo motors proved difficult when assigning locations and movement sequences, but once we found a ‘default’ sequence that worked, the other following sequences slid into place. Unfortunately, our toils were not over as now the robot had to be able to push the switch, and initial force proved to be insufficient.
## Accomplishments That We’re Proud Of
About halfway through, while we were struggling with getting the movement to work, thoughts turned toward what we would do in different sequences. Out of inspiration from other activities occurring during the event, it was decided that we would add a musical element to our ‘useless machine’ in the form of a buzzer playing “Tequila” by The Champs. This was our easiest success despite involving transposing sheet music and changing rhythms until we found the desired effect.
We also got at least 3 sequences into the robot! That is more than we were expecting 12 hours into the build due to difficulties with programming the servos.
## What We Learned
When we assigned tasks, we all chose roles that we were not normally accustomed to. Our mechanical member worked heavily in software while another less familiar with design focused on the actual build. We all exchanged roles over the course of the project, but this rotation of focus allowed us to get the most out of the experience. You can do a lot with relatively few components; constraint leads to innovation.
## What’s Next for Little Dunce
So far, we have only built in the set of 5 sequences, but we want Little Dunce to have more of a personality and more varied and random reactions. As of now, it is a sequence of events, but we want Little Dunce to act randomly so that everyone can get a unique experience with the invention. We also want to add an RGB LED light for mood indication dependent on the sequence chosen. This would also serve as the “on/off” indicator since the initial proposal was to have a robot that goes to sleep. | winning |
## Inspiration
Amid the fast-paced rhythm of university life at Waterloo, one universal experience ties us all together: the geese. Whether you've encountered them on your way to class, been woken up by honking at 7 am, or spent your days trying to bypass flocks of geese during nesting season, the geese have established themselves as a central fixture of the Waterloo campus. How can we turn the staple bird of the university into a asset? Inspired by the quintessential role the geese play in campus life, we built an app to integrate our feather friends into our academic lives. Our app, Goose on the Loose allows you to take pictures of geese around the campus and turn them into your study buddies! Instead of being intimidated by the fowl fowl, we can now all be friends!
## What it does
Goose on the Loose allows the user to "capture" geese across the Waterloo campus and beyond by snapping a photo using their phone camera. If there is a goose in the image, it is uniquely converted into a sprite added to the player's collection. Each goose has its own student profile and midterm grade. The more geese in a player's collection, the higher each goose's final grade becomes, as they are all study buddies who help one another. The home page also contains a map where the player can see their own location, as well as locations of nearby goose sightings.
## How we built it
This project is made using Next.js with Typescript and TailwindCSS. The frontend was designed using Typescript React components and styled with TailwindCSS. MongoDB Atlas was used to store various data across our app, such as goose data and map data. We used the @React Google Maps library to integrate the Google maps display into our app. The player's location data is retrieved from the browser. Cohere was used to help generate names and quotations assigned to each goose. OpenAI was used for goose identification as well as converting the physical geese into sprites. All in all, we used a variety of different technologies to power our app, many of which we were beginners to.
## Challenges we ran into
We were very unfamiliar with Cohere and found ourselves struggling to use some of its generative AI technologies at first. After playing around with it for a bit, we were able to get it to do what we wanted, and this saved us a lot of head pain.
Another major challenge we underwent was getting the camera window to display properly on a smartphone. While it worked completely fine on computer, only a fraction of the window would be able to display on the phone and this really harmed the user experience in our app. After hours of struggle, debugging, and thinking, we were able to fix this problem and now our camera window is very functional and polished.
One severely unexpected challenge we went through was one of our computers' files corrupting. This caused us HOURS of headache and we spent a lot of effort in trying to identify and rectify this problem. What made this problem worse was that we were at first using Microsoft VS Code Live Share with that computer happening to be the host. This was a major setback in our initial development timeline and we were absolutely relieved to figure out and finally solve this problem.
A last minute issue that we discovered had to do with our Cohere API. Since the prompt did not always generate a response within the required bounds, looped it until it landed in the requirements. We fixed this by setting a max limit on the amount of tokens that could be used per response.
One final issue that we ran into was the Google Maps API. For some reason, we kept running into a problem where the map would force its centre to be where the user was located, effectively prohibiting the user from being able to view other areas of the map.
## Accomplishments that we're proud of
During this hacking period, we built long lasting relationships and an even more amazing project. There were many things throughout this event that were completely new to us: various APIs, frameworks, libraries, experiences; and most importantly: the sleep deprivation. We are extremely proud to have been able to construct, for the very first time, a mobile friendly website developed using Next.js, Typescript, and Tailwind. These were all entirely new to many of our team and we have learned a lot about full stack development throughout this weekend. We are also proud of our beautiful user interface. We were able to design extremely funny, punny, and visually appealing UIs, despite this being most of our's first time working with such things. Most importantly of all, we are proud of our perseverance; we never gave up throughout the entire hacking period, despite all of the challenges we faced, especially the stomach aches from staying up for two nights straight. This whole weekend has been an eye-opening experience, and has been one that will always live in our hearts and will remind us of why we should be proud of ourselves whenever we are working hard.
## What we learned
1. We learned how to use many new technologies that we never laid our eyes upon.
2. We learned of a new study spot in E7 that is open to any students of UWaterloo.
3. We learned how to problem solve and deal with problems that affected the workflow; namely those that caused our program to be unable to run properly.
4. We learned that the W store is open on weekend.
5. We learned one another's stories!
## What's next for GooseOnTheLoose
In the future, we hope to implement more visually captivating transitional animations which will really enhance the UX of our app. Furthermore, we would like to add more features surrounding the geese, such as having a "playground" where the geese can interact with one another in a funny and entertaining way. | [Repository](https://github.com/BradenC82/A_Treble-d_Soul/)
## Inspiration
Mental health is becoming decreasingly stigmatized and more patients are starting to seek solutions to well-being. Music therapy practitioners face the challenge of diagnosing their patients and giving them effective treatment. We like music. We want patients to feel good about their music and thus themselves.
## What it does
Displays and measures the qualities of your 20 most liked songs on Spotify (requires you to log in). Seven metrics are then determined:
1. Chill: calmness
2. Danceability: likeliness to get your groove on
3. Energy: liveliness
4. Focus: helps you concentrate
5. Audacity: absolute level of sound (dB)
6. Lyrical: quantity of spoken words
7. Positivity: upbeat
These metrics are given to you in bar graph form. You can also play your liked songs from this app by pressing the play button.
## How I built it
Using Spotify API to retrieve data for your liked songs and their metrics.
For creating the web application, HTML5, CSS3, and JavaScript were used.
React was used as a framework for reusable UI components and Material UI for faster React components.
## Challenges I ran into
Learning curve (how to use React). Figuring out how to use Spotify API.
## Accomplishments that I'm proud of
For three out of the four of us, this is our first hack!
It's functional!
It looks presentable!
## What I learned
React.
API integration.
## What's next for A Trebled Soul
Firebase.
Once everything's fine and dandy, registering a domain name and launching our app.
Making the mobile app presentable. | # q
The first come first serve system is a great tool to maintain order, but no one likes wasting time standing in line. The only real value you get out of it is knowing when it’s your turn and who’s next. With Q, you can get the best of both worlds and know who’s next without standing around. It has three simple steps that make waiting a painless process: open up app and select event (using location services), “Q me!” and show up for your time slot. Simple as that. Wait in style. | partial |
## Inspiration
When travelling in a new place, it is often the case that one doesn't have an adequate amount of mobile data to search for information they need.
## What it does
Mr.Worldwide allows the user to send queries and receive responses regarding the weather, directions, news and translations in the form of sms and therefore without the need of any data.
## How I built it
A natural language understanding model was built and trained with the use of Rasa nlu. This model has been trained to work as best possible with many variations of query styles to act as a chatbot. The queries are sent up to a server by sms with the twill API. A response is then sent back the same way to function as a chatbot.
## Challenges I ran into
Implementing the Twilio API was a lot more time consuming than we assumed it would be. This was due to the fact that a virtual environment had to be set up and our connection to the server originally was not directly connecting.
Another challenge was providing the NLU model with adequate information to train on.
## Accomplishments that I'm proud of
We are proud that our end result works as we intended it to.
## What I learned
A lot about NLU models and implementing API's.
## What's next for Mr.Worldwide
Potentially expanding the the scope of what services/information it can provide to the user. | ## Inspiration
*"I have an old Nokia mobile phones, that doesn't have internet access nor acess to download & install the Lyft app; How can I still get access to Lyft?"*
>
> Allow On-Demand Services Like Uber, Lyft to be more mainstream in developing world where there is limitied to no internet access. Lyft-powered SMS.
>
>
>
## What it does
>
> Have all the functionalities that a Lyft Application would have via SMS only. No wifi or any type of internet access. Functionalities include and are not limited to request a ride, set origin and destination, pay and provide review/feedback.
>
>
>
## How I built it
>
> Used Google Polymer to build the front end. For the backend we used the Lyft API to take care of rides. The location/address have been sanitize using Google Places API before it gets to the Lyft API. The database is powered by MongoDB, spun off the application using Node.js via Cloud9 cloud IDE. Finally, Twilio API which allow user/client to interface with only SMS.
>
>
>
## Challenges I ran into
>
> The Lyft API did not have a NodeJS wrapper so we had to create our own such that we were able to perform all the necessary functions needed for our project.
>
>
>
## Accomplishments that I'm proud of
>
> Our biggest accomplishment has to be that we completed all of our objectives for this project. We completed this project such that it is in a deployable state and anybody can test out the application from their own device. In addition, all of us learned new technologies such as Google Polymer, Twilio API, Lyft API, and NodeJS.
>
>
>
## What I learned
>
> Emerging markets
>
>
>
## What's next for Lyft Offline
>
> We plan to polish the application and fix any bugs found as well as get approval from Lyft to launch our application for consumers to use.
>
>
>
## Built With
* Google Polymer
* Node.js
* Express
* MongoDB
* Mongoose
* Passport
* Lyft API & Auth
* Google API & user end-points
* Twilio API | ## Inspiration
Being alone sucks. We understand that seniors (not the school type) often feel isolated, yet don't always have access to the right technology to abate that. With Elder.ly, we are providing a clean, easy-to-use platform for the elderly to communicate, stay active, and have a little fun too.
## What it does
A fun and simple video chat platform that carefully matches users in private chat rooms with messaging and audio/video capabilities
## How we built it
HTML/CSS, Node, JS
## Challenges we ran into
Video chat configuration, sockets
## Accomplishments that we're proud of
We really like the UI, and the fact that the video and chat works.
## What we learned
More about sockets, SimpleWebRTC, live messaging
## What's next for elder.ly
Mind stimulating games to keep elderly minds active, AI suggestions for chats, autofill messages | partial |
## Inspiration
One of our team members is an undergraduate intern at Boston Children's Hospital in the epilepsy center. Sudden unexpected death in epilepsy (SUDEP) is the most prevalent cause of epilepsy related deaths, most often causing respiratory arrest during sleep. The American Epilepsy Society estimates that as many as 42,000 deaths are caused by seizures each year. SUDEP accounts for 8-17% of the total deaths in people with epilepsy according to a study by New York Methodist Hospital. A Harvard-MIT study indicates a strong correlation between skin conductance and generalized tonic-clonic seizures, which indicate a higher risk of SUDEP. Traditional seizure monitoring technologies fail to provide any effective means to assist in the prevention of epilepsy related deaths.
## What it does
Seisir is designed to detect life-threatening seizures, and then trigger text notifications to a caretaker for help or signal an implantable device that could release medication. Although still in development, our current version of Seisir intakes data from a custom built biosensor that identifies changes in skin conductance as well as a six-axis accelerometer and gyroscope. Data is processed in real time locally on an Arduino 101 board powered by Intel. Data is uploaded to a secure server and can be accessed via a mobile Android device. In cases where Seisir detects a high likelihood of seizure activity, the program contacts a caretaker or medical staff via text, or could signal an implantable device. Seisir has a strong potential to save lives by notifying others in emergency cases.
## How we built it
Our current program utilizes a combination of technologies starting with the an Arduino 101 board powered by Intel. The program connects the android device via Bluetooth with a mobile application to obtain various sensor data. This data is then passed through the app to the cloud. Our program identifies seizure activity from the sensor data originally recorded by custom biosensors. The cloud system, android app and Arduino board all monitor for abnormal activity, specifically moments when seizure activity is identified. Upon receiving a seizure alert, the android app notifies emergency contacts via a traditional text message.
We intend to improve the accuracy of our machine-learning platform by creating a research database wherein healthcare providers can manually mark seizure activity as well, minimizing any false detection rate.
## Challenges we ran into
Since the Seizure platform requires integrating a combination of multiple different technologies, devices and programming languages. This cross compatibility created the majority of our implementation challenges.
## Accomplishments that we're proud of
We successfully developed a custom biosensor using only wires, resistors and code that can successfully detect changes in skin conductance, a major factor in identifying seizure activity.
## What we learned
We learned how to implement and code on an Arduino 101 board and connect biosensors. We believe that Seisir demonstrates that the Arduino board could spearhead significant clinical advancements.
## What's next for Seisir - Epilepsy Detection and Treatment Device
It is our hope that the Intel technologies behind Seisir have the opportunity to be used in a research setting that is clinically relevant to seizures and other epileptiform activity. Since one of our team members interns within the neurology department at Boston Children's Hospital and works with epilepsy patients on a daily basis, it is our hope that the Seisir / Intel combination platform have the opportunity to be tested within a clinical setting. | ## Inspiration
Being students in a technical field, we all have to write and submit resumes and CVs on a daily basis. We wanted to incorporate multiple non-supervised machine learning algorithms to allow users to view their resumes from different lenses, all the while avoiding the bias introduced from the labeling of supervised machine learning.
## What it does
The app accepts a resume in .pdf or image format as well as a prompt describing the target job. We wanted to judge the resume based on layout and content. Layout encapsulates font, color, etc., and the coordination of such features. Content encapsulates semantic clustering for relevance to the target job and preventing repeated mentions.
### Optimal Experience Selection
Suppose you are applying for a job and you want to mention five experiences, but only have room for three. cv.ai will compare the experience section in your CV with the job posting's requirements and determine the three most relevant experiences you should keep.
### Text/Space Analysis
Many professionals do not use the space on their resume effectively. Our text/space analysis feature determines the ratio of characters to resume space in each section of your resume and provides insights and suggestions about how you could improve your use of space.
### Word Analysis
This feature analyzes each bullet point of a section and highlights areas where redundant words can be eliminated, freeing up more resume space and allowing for a cleaner representation of the user.
## How we built it
We used a word-encoder TensorFlow model to provide insights about semantic similarity between two words, phrases or sentences. We created a REST API with Flask for querying the TF model. Our front end uses Angular to deliver a clean, friendly user interface.
## Challenges we ran into
We are a team of two new hackers and two seasoned hackers. We ran into problems with deploying the TensorFlow model, as it was initially available only in a restricted Colab environment. To resolve this issue, we built a RESTful API that allowed us to process user data through the TensorFlow model.
## Accomplishments that we're proud of
We spent a lot of time planning and defining our problem and working out the layers of abstraction that led to actual processes with a real, concrete TensorFlow model, which is arguably the hardest part of creating a useful AI application.
## What we learned
* Deploy Flask as a RESTful API to GCP Kubernetes platform
* Use most Google Cloud Vision services
## What's next for cv.ai
We plan on adding a few more features and making cv.ai into a real web-based tool that working professionals can use to improve their resumes or CVs. Furthermore, we will extend our application to include LinkedIn analysis between a user's LinkedIn profile and a chosen job posting on LinkedIn. | ## Inspiration
Members of our team know multiple people who suffer from permanent or partial paralysis. We wanted to build something that could be fun to develop and use, but at the same time make a real impact in people's everyday lives. We also wanted to make an affordable solution, as most solutions to paralysis cost thousands and are inaccessible. We wanted something that was modular, that we could 3rd print and also make open source for others to use.
## What it does and how we built it
The main component is a bionic hand assistant called The PulseGrip. We used an ECG sensor in order to detect electrical signals. When it detects your muscles are trying to close your hand it uses a servo motor in order to close your hand around an object (a foam baseball for example). If it stops detecting a signal (you're no longer trying to close) it will loosen your hand back to a natural resting position. Along with this at all times it sends a signal through websockets to our Amazon EC2 server and game. This is stored on a MongoDB database, using API requests we can communicate between our games, server and PostGrip. We can track live motor speed, angles, and if it's open or closed. Our website is a full-stack application (react styled with tailwind on the front end, node js on the backend). Our website also has games that communicate with the device to test the project and provide entertainment. We have one to test for continuous holding and another for rapid inputs, this could be used in recovery as well.
## Challenges we ran into
This project forced us to consider different avenues and work through difficulties. Our main problem was when we fried our EMG sensor, twice! This was a major setback since an EMG sensor was going to be the main detector for the project. We tried calling around the whole city but could not find a new one. We decided to switch paths and use an ECG sensor instead, this is designed for heartbeats but we managed to make it work. This involved wiring our project completely differently and using a very different algorithm. When we thought we were free, our websocket didn't work. We troubleshooted for an hour looking at the Wifi, the device itself and more. Without this, we couldn't send data from the PulseGrip to our server and games. We decided to ask for some mentor's help and reset the device completely, after using different libraries we managed to make it work. These experiences taught us to keep pushing even when we thought we were done, and taught us different ways to think about the same problem.
## Accomplishments that we're proud of
Firstly, just getting the device working was a huge achievement, as we had so many setbacks and times we thought the event was over for us. But we managed to keep going and got to the end, even if it wasn't exactly what we planned or expected. We are also proud of the breadth and depth of our project, we have a physical side with 3rd printed materials, sensors and complicated algorithms. But we also have a game side, with 2 (questionable original) games that can be used. But they are not just random games, but ones that test the user in 2 different ways that are critical to using the device. Short burst and hold term holding of objects. Lastly, we have a full-stack application that users can use to access the games and see live stats on the device.
## What's next for PulseGrip
* working to improve sensors, adding more games, seeing how we can help people
We think this project had a ton of potential and we can't wait to see what we can do with the ideas learned here.
## Check it out
<https://hacks.pulsegrip.design>
<https://github.com/PulseGrip> | partial |
## Inspiration
My printer is all the way in the cold, dark, basement. The Wi-Fi down there is not great either. So for the days where I need to print important documents but lack the strength to venture down into the basement's depths, I need a technological solution.
## What it does
The Raspberry Pi 4 hosts a server for the local network that allows printing from any device connected to Wi-Fi. Useful when you want to print on a mobile device or Chromebook that doesn't support printer drivers.
## How we built it
I was initially going to make an arcade station with my Pi but because of a snowstorm, out of all the hardware I ordered, only the Pi arrived on time. Thus, I had to pivot and think of a hardware project using only a Pi and some old Micro SD cards.
## Challenges I ran into
At first, the Pi refused to connect through SSH. Since I did not have a video adapter (who thought it was a good idea to replace the HDMI ports with Micro HDMI??) I could not change the settings on the device manually, for there was no display output. It was at that moment I realized I would have to do this headless.
Then there was the issue where my printer was so old that the drivers were no longer available. With some forum browsing and sketchy workarounds, I was able to get it working. Most of the time.
## What I learned
It is probably easier to just print the old-fashioned way, but why do things faster when you can over-engineer a solution?
## What's next
Finding ways to make it reliably work with all devices. | ## Inspiration
When looking at the themes from the Make-a-thon, one specifically stood out to us: accessibility. We thought about common disabilities, and one that we see on a regular basis is people who are visually impaired. We thought about how people who are visually impaired navigate around the world, and we realized there isn't a good solution besides holding your phone out that allows them to get around the world. We decided we would create a device that uses Google Maps API to read directions and sense the world around it to be able to help people who are blind navigate the world without running into things.
## What it does
Based on the user's desired destination, the program reads from Google API the checkpoints needed to cross in our path and audibly directs the user on how far they are from it. Their location is also repeatedly gathered through Google API to determine their longitude and latitude. Once the user reaches
the nearest checkpoint, they will be directed to the next checkpoint until they reach their destination.
## How we built it
Under a local hotspot host, we connected a phone and Google API to a Raspberry Pi 4. The phone would update the Raspberry Pi with our current location and Google API to determine the necessary checkpoints to get there. With all of the data being compiled on the microcontroller, it is then connected to a speaker through a Stereo Audio Amplifier Module (powered by an external power supply), which amplifies the audio sent out into the Raspberry Pi's audio jack. With all that, the directions conveyed to the user can be heard clearly.
## Challenges we ran into
Some of the challenges we faced were getting the stereo speaker to work and indicating to the user the distance from their next checkpoint, frequently within the range of the local network.
## Accomplishments that we're proud of
We were proud to have the user's current position updated according to the movement of the phone connected to the local network and be able to update the user's distance from a checkpoint in real time.
## What we learned
We learned to set up and work with a Raspberry Pi 4 through SSH.
We also learned how to use text-to-speech for the microcontroller using Python and how we can implement it in a practical application.
Finally, we were
## What's next for GPS Tracker for the Visually Impaired
During the hackathon, we were unable to implement the camera sensing the world around it to give the user live directions on what the world looks like in front of them and if they are going to run into anything or not. The next steps would include a depth camera implementation as well as an OpenCV object detection model to be able to sense the distance of things in front of you | ## Inspiration
Gun violence is a dire problem in the United States. When looking at case studies of mass shootings in the US, there is often surveillance footage of the shooter *with their firearm* **before** they started to attack. That's both the problem and the solution. Right now, surveillance footage is used as an "after-the-fact" resource. It's used to *look back* at what transpired during a crisis. This is because even the biggest of surveillance systems only have a handful of human operators who simply can't monitor all the incoming footage. But think about it: most schools, malls, etc. have security cameras in almost every hallway and room. It's a wasted resource. What if we could use surveillance footage as an **active and preventive safety measure**? That's why we turned *surveillance* into **SmartVeillance**.
## What it does
SmartVeillance is a system of security cameras with *automated firearm detection*. Our system simulates a CCTV network that can intelligently classify and communicate threats for a single operator to easily understand and act upon. When a camera in the system detects a firearm, the camera number is announced and is displayed on every screen. The screen associated with the camera gains a red banner for the operator to easily find. The still image from the moment of detection is displayed so the operator can determine if a firearm is actually present or if it was a false positive. Lastly, the history of detections among cameras is displayed at the bottom of the screen so that the operator can understand the movement of the shooter when informing law enforcement.
## How we built it
Since we obviously can't have real firearms here at TreeHacks, we used IBM's Cloud Annotation tool to train an object detection model in TensorFlow for *printed cutouts of guns*. We integrated this into a React.js web app to detect firearms visible in the computer's webcam. We then used PubNub to communicate between computers in the system when a camera detected a firearm, the image from the moment of detection, and the recent history of detections. Lastly, we built onto the React app to add features like object highlighting, sounds, etc.
## Challenges we ran into
Our biggest challenge was creating our gun detection model. It was really poor the first two times we trained it, and it basically recognized everything as a gun. However, after some guidance from some lovely mentors, we understood the different angles, lightings, etc. that go into training a good model. On our third attempt, we were able to take that advice and create a very reliable model.
## Accomplishments that we're proud of
We're definitely proud of having excellent object detection at the core of our project despite coming here with no experience in the field. We're also proud of figuring out to transfer images between our devices by encoding and decoding them from base64 and sending the String through PubNub to make communication between cameras almost instantaneous. But above all, we're just proud to come here and build a 100% functional prototype of something we're passionate about. We're excited to demo!
## What we learned
We learned A LOT during this hackathon. At the forefront, we learned how to build a model for object detection, and we learned what kinds of data we should train it on to get the best model. We also learned how we can use data streaming networks, like PubNub, to have our devices communicate to each other without having to build a whole backend.
## What's next for SmartVeillance
Real cameras and real guns! Legitimate surveillance cameras are much better quality than our laptop webcams, and they usually capture a wider range too. We would love to see the extent of our object detection when run through these cameras. And obviously, we'd like to see how our system fares when trained to detect real firearms. Paper guns are definitely appropriate for a hackathon, but we have to make sure SmartVeillance can detect the real thing if we want to save lives in the real world :) | losing |
## Inspiration
We wanted to create a platform for people to find new music, but with a fun and more engaging spin on it: betting. We all have that one friend who swears they have the "ear" for music and found it before anyone else. We wanted to turn music discovery into a game and built an app to do that.
## What it does
Users can place bets on artists and their score will go up when the artist's plays go up.
## How I built it
We used the Spotify API and the React/Router/Redux + Express/Postgres paradigms to build this project.
## Challenges I ran into
We realized there are so many features that have to be built to make a successful social platform. It was a lot for this hackathon, but we tried our best to demonstrate what the it could look like.
## Accomplishments that I'm proud of | ## Inspiration
What inspired the beginning of the idea was terrible gym music and the thought of a automatic music selection based on the tastes of people in the vicinity. Our end goal is to sell a hosting service to play music that people in a local area would want to listen to.
## What it does
The app has two parts. A client side connects to Spotify and allows our app to collect users' tokens, userID, email and the top played songs. These values are placed inside a Mongoose database and the userID and top songs are the main values needed. The host side can control the location and the radius they want to cover. This allows the server to be populated with nearby users and their top songs are added to the host accounts playlist. The songs most commonly added to the playlist have a higher chance of being played.
This app could be used at parties to avoid issues discussing songs, retail stores to play songs that cater to specific groups, weddings or all kinds of social events. Inherently, creating an automatic DJ to cater to the tastes of people around an area.
## How we built it
We began by planning and fleshing out the app idea then from there the tasks were split into four sections: location, front end, Spotify and database. At this point we decided to use React-Native for the mobile app and NodeJS for the backend was set into place. After getting started the help of the mentors and the sponsors were crucial, they showed us all the many different JS libraries and api's available to make life easier. Programming in Full Stack MERN was a first for everyone in this team. We all hoped to learn something new and create an something cool.
## Challenges we ran into
We ran into plenty of problems. We experienced many syntax errors and plenty of bugs. At the same time dependencies such as Compatibility concerns between the different APIs and libraries had to be maintained, along with the general stress of completing on time. In the end We are happy with the product that we made.
## Accomplishments that we are proud of
Learning something we were not familiar with and being able to make it this far into our project is a feat we are proud of. .
## What we learned
Learning about the minutia about Javascript development was fun. It was because of the mentors assistance that we were able to resolve problems and develop at a efficiently so we can finish. The versatility of Javascript was surprising, the ways that it is able to interact with and the immense catalog of open source projects was staggering. We definitely learned plenty... now we just need a good sleep.
## What's next for SurroundSound
We hope to add more features and see this application to its full potential. We would make it as autonomous as possible with seamless location based switching and database logging. Being able to collect proper user information would be a benefit for businesses. There were features that did not make it into the final product, such as voting for the next song on the client side and the ability for both client and host to see the playlist. The host would have more granular control such as allowing explicit songs, specifying genres and anything that is accessible by the Spotify API. While the client side can be gamified to keep the GPS scanning enabled on their devices, such as collecting points for visiting more areas. | ## Inspiration
```
We had multiple inspirations for creating Discotheque. Multiple members of our team have fond memories of virtual music festivals, silent discos, and other ways of enjoying music or other audio over the internet in a more immersive experience. In addition, Sumedh is a DJ with experience performing for thousands back at Georgia Tech, so this space seemed like a fun project to do.
```
## What it does
```
Currently, it allows a user to log in using Google OAuth and either stream music from their computer to create a channel or listen to ongoing streams.
```
## How we built it
```
We used React, with Tailwind CSS, React Bootstrap, and Twilio's Paste component library for the frontend, Firebase for user data and authentication, Twilio's Live API for the streaming, and Twilio's Serverless functions for hosting and backend. We also attempted to include the Spotify API in our application, but due to time constraints, we ended up not including this in the final application.
```
## Challenges we ran into
```
This was the first ever hackathon for half of our team, so there was a very rapid learning curve for most of the team, but I believe we were all able to learn new skills and utilize our abilities to the fullest in order to develop a successful MVP! We also struggled immensely with the Twilio Live API since it's newer and we had no experience with it before this hackathon, but we are proud of how we were able to overcome our struggles to deliver an audio application!
```
## What we learned
```
We learned how to use Twilio's Live API, Serverless hosting, and Paste component library, the Spotify API, and brushed up on our React and Firebase Auth abilities. We also learned how to persevere through seemingly insurmountable blockers.
```
## What's next for Discotheque
```
If we had more time, we wanted to work on some gamification (using Firebase and potentially some blockchain) and interactive/social features such as song requests and DJ scores. If we were to continue this, we would try to also replace the microphone input with computer audio input to have a cleaner audio mix. We would also try to ensure the legality of our service by enabling plagiarism/copyright checking and encouraging DJs to only stream music they have the rights to (or copyright-free music) similar to Twitch's recent approach. We would also like to enable DJs to play music directly from their Spotify accounts to ensure the good availability of good quality music.
``` | losing |
Pitch: <https://docs.google.com/presentation/d/1_g1_yQqOr09MJuFnaF1nemwTx04hDNAnwJqKbiW7E_U/edit#slide=id.g2948d3c0d06_0_4> | ## Inspiration
Since we are a group of students, we have been seeing our peers losing motivation for school due to un-engaging lectures. Young adults are more stressed due to added responsibilities of taking care of younger siblings at home and supporting their family financially. Thus, students who have more responsibilities due to the pandemic miss a lot of classes, and they clearly don't have a lot of time to re-watch a one-hour lecture that they've missed.
This was me, during the earlier months of the pandemic. By having to work extra hours due to the financial impacts of the Coronavirus, alongside the inaccessibility of the internet when being outside, I missed the most important classes to finish my requirements for my degree.
That's where the inspiration of this project came from. I personally know people in different fields facing the same issue, and with my team, I wanted to help them out.
## What it does
By taking an audio file as the input, we use the Google Cloud API's function to turn the audio into text. We then analyze that text to determine the main topics by word frequency which we display to the user. We then display all sentences containing words with the highest frequency to the user.
## How we built it
First, we laid out the wireframe on Figma; after further discussion, the dev team went on working on the backend while the design team worked on the high-fidelity prototype.
After the high-fidelity prototype was handed off to the developers, the dev team then built the frontend aspect of our product to allow the user to select audios which they want to condense.
## Challenges we ran into
While building the backend, we ran into numerous bugs when developing algorithms to detect the main topics of the audio converted text. After resolving that issue, we had to figure out how to use the Google Cloud API to convert the audio files into text to pass into our processing algorithms. Finally, we had to find a way to connect our website to our backend containing our text-processing algorithms.
## Accomplishments that we're proud of
Our team figured out to convert speech to text and to display the output of our text processing algorithms to the user. Our team is also proud of creating a website that displays what our product does, acting as a portfolio of our product.
## What we learned
We learned how to utilize APIs, develop algorithms to process our text using patterns, debugging our code while learning under a time limit with new teammates.
## What's next for Xalta
* Integration with Zoom and Canvas for a more seamless user experience
* A desktop/mobile native app for stability | ## Inspiration
For building the most potential and improved healthcare monitoring system
Inspiration One of the worst things that can occur to a person is hearing the recent news of a loved one’s recent lethal drug overdose and other healthcare issues. This can occur for a number of reasons; some may have conditions such as people can forget their proper medication amounts, or perhaps the person was just thinking and acting in a rash manner. The system is designed to securely keep track of medications as well as prescriptions given to people. | losing |
## Inspiration
Every first year CS student (ourselves included!) struggles with base conversion calculations. We wanted to develop a tool for students to learn and explore base conversions.
## What it does
BaseCalculator can perform base conversions for bases two through sixteen. It can execute simple arithmetic, using numbers with different bases as inputs and converting to any base for output.
## How we built it
The JavaFx application was built in IntelliJ.
## Accomplishments that we're proud of
We are proud that our project works and everything we wanted to do was completed before the deadline. We were able to implement it in a timely manner and were able to break down tasks effectively.
## What we learned
As we were all working on a larger scale project for the first time, we learned a lot about version control and the use of git. We learned about the development of simple user interfaces.
## What's next for BaseCalculator
We would like to work on developing a more dynamic user interface that could include longer mathematical expresses, with the use of brackets and other operators. We would also like to implement the use of the keyboard in the application. | ## What it does
The FancyCalc is capable of doing simple arithmetic and trigonometric functions
## How we built it
I built FancyCalc through Eclipse using a Java WindowBuilder.
## Challenges I ran into
I had planned to join a team as it is my second hackathon but unfortunately could not join one. I was previously only proficient in the basic language of Java, no frontend development, which I was hoping to offload to my teammates. Originally, I had planned to make an educational game, but I was running into major holes in my understanding of platforms such as Android Studio, as well as movement in Java. I did not even know what a GUI was!
After much struggling, I decided to stick with Eclipse, and that was when I learned about GUIs and Eclipse's Java WindowBuilder. After solely text-based projects, this was a big step up.
## What I've learned
Throughout the course of these few days, I've used various PennApps workshops, Oracle Docs, and of course, YouTube, to learn the basics of building a GUI: swing methods and elements such as panels, layouts, buttons, and text fields. I've also broadened my understanding of Eclipse through WindowBuilder. I've learned that platforms like Android Studio and XCode are widely useful but take time to acquire, and I'm excited to use them in the future! | ## Inspiration
We wanted to make an app that helped people to be more environmentally conscious. After we thought about it, we realised that most people are not because they are too lazy to worry about recycling, turning off unused lights, or turning off a faucet when it's not in use. We figured that if people saw how much money they lose by being lazy, they might start to change their habits. We took this idea and added a full visualisation aspect of the app to make a complete budgeting app.
## What it does
Our app allows users to log in, and it then retrieves user data to visually represent the most interesting data from that user's financial history, as well as their utilities spending.
## How we built it
We used HTML, CSS, and JavaScript as our front-end, and then used Arduino to get light sensor data, and Nessie to retrieve user financial data.
## Challenges we ran into
To seamlessly integrate our multiple technologies, and to format our graphs in a way that is both informational and visually attractive.
## Accomplishments that we're proud of
We are proud that we have a finished product that does exactly what we wanted it to do and are proud to demo.
## What we learned
We learned about making graphs using JavaScript, as well as using Bootstrap in websites to create pleasing and mobile-friendly interfaces. We also learned about integrating hardware and software into one app.
## What's next for Budge
We want to continue to add more graphs and tables to provide more information about your bank account data, and use AI to make our app give personal recommendations catered to an individual's personal spending. | losing |
## Inspiration
As college students swamped with PSets and Essays all the time, we figured one part of our day which could use an efficiency boost is our study sessions. We thought maybe something to do with the Pomodoro Technique of working in blocks of 25min on 5min could be useful, and we quickly realized one flaw with existing Pomodoro timers which is that they do not account for the case in which your feeling on a roll and want to keep working for longer periods of time. This is where Stud comes in.
## What it does
Stud the study bud is a web-app/chrome-extension combo that helps you study efficiently with periodic breaks but has the flexibility to allow you to continue working if you're on a roll. From our dashboard, you can begin a study session, which first entails establishing your work time goals. Then, a timer will display how long you're supposed to work for before a check-in. When the timer runs out, Stud will ask you how you're feeling (thumbs up or thumbs down). If thumbs down, it's time for a break. If not, keep on pushing! The entire time while you are working, the Stud chrome extension will be monitoring the time spent on different tabs in your browser and classify those tabs as productive or unproductive. At the end of your study session, you can reflect back on your goals to see how productive you were based on metrics such as time spent on "good" tabs or total time spent taking breaks, and at anytime you can review your past study sessions and productivity report.
## How we built it
We used a Next.js stack with tailwind and typescript for our front-end and our back-end is run on Firebase.
## What we learned
Through this project, our team members learned how to use a number of new technologies. Firebase and Next.js were largely novel services for our team, and one of our members learned react/typescript/tailwind/HTML for the project.
## What's next?
In the future, we would love to add a social feature to Stud where you can high-five your friends while they are studying to provide encouragement and social accountability, both of which should increase productivity. | ## Inspiration
Since the reintroduction of in-person schooling, we found it difficult to manage our time and focus on studying. As a result, we decided to make an app that tracks study habits and rewards them with points.
## What it does
After a user logs in, they are directed to a stopwatch page that logs the time elapsed during a study session. The data is then saved to a cloud database which can be viewed when users visit their profile, displaying interactive statistics on their study habits.
## How we built it
We used Flutter for the frontend and Firebase for auth and general backend requirements.
## Challenges we ran into
We originally were planning on training and deploying a machine learning model that determines whether a user is fatigued or not from a video feed, but it turned out too tedious and we were unable to implement it. Another challenge was learning mobile development in a short period of time, as this was our first mobile app.
## Accomplishments that we're proud of
Learning the essentials of mobile development in a short period of time.
## What we learned
We learned how widgets in Flutter worked, and how retrieving and updating documents from Firebase worked. We also ironically learned to have better time management as we ran out of time for a video.
## What's next for Session
We plan on implementing a machine learning model that analyzes the study session data and determines the optimal study duration for a user (displaying it in a chart). We also plan on reattempting the user fatigue model and generally just improve the frontend design of our app. | ## Inspiration
Our inspiration for this project was our experience as students. We believe students need more a digestible feed when it comes to due dates. Having to manually plan for homework, projects, and exams can be annoying and time consuming. StudyHedge is here to lift the scheduling burden off your shoulders!
## What it does
StudyHedge uses your Canvas API token to compile a list of upcoming assignments and exams. You can configure a profile detailing personal events, preferred study hours, number of assignments to complete in a day, and more. StudyHedge combines this information to create a manageable study schedule for you.
## How we built it
We built the project using React (Front-End), Flask (Back-End), Firebase (Database), and Google Cloud Run.
## Challenges we ran into
Our biggest challenge resulted from difficulty connecting Firebase and FullCalendar.io. Due to inexperience, we were unable to resolve this issue in the given time. We also struggled with using the Eisenhower Matrix to come up with the right formula for weighting assignments. We discovered that there are many ways to do this. After exploring various branches of mathematics, we settled on a simple formula (Rank= weight/time^2).
## Accomplishments that we're proud of
We are incredibly proud that we have a functional Back-End and that our UI is visually similar to our wireframes. We are also excited that we performed so well together as a newly formed group.
## What we learned
Keith used React for the first time. He learned a lot about responsive front-end development and managed to create a remarkable website despite encountering some issues with third-party software along the way. Gabriella designed the UI and helped code the front-end. She learned about input validation and designing features to meet functionality requirements. Eli coded the back-end using Flask and Python. He struggled with using Docker to deploy his script but managed to conquer the steep learning curve. He also learned how to use the Twilio API.
## What's next for StudyHedge
We are extremely excited to continue developing StudyHedge. As college students, we hope this idea can be as useful to others as it is to us. We want to scale this project eventually expand its reach to other universities. We'd also like to add more personal customization and calendar integration features. We are also considering implementing AI suggestions. | losing |
## Inspiration
Multiplayer game that teaches players the right way to throw garbage!
## What it does
## How we built it
## Challenges we ran into
## Accomplishments that we're proud of
## What we learned
## What's next for DropThat | ## Inspiration
All of our parents like to recycle plastic bottles and cans to make some extra money, but we always thought it was a hassle. After joining this competition and seeing sustainability as one of the prize tracks, we realized it would be interesting to create something that makes the recycling process more engaging and incentivized on a larger scale.
## What it does
We gamify recycling. People can either compete against friends to see who recycles the most, or compete against others for a prize pool given by sponsors (similar to how Kaggle competitions work). To verify if a person recycles, there's a camera section where it uses an object detection model to check if a valid bottle and recycling bin are in sight.
## How we built it
We split the project into 3 major parts. The app itself, the object detection model, and another ML model that predicted how trash in a city would move so users can move with it to pick up the most amount of trash. We implemented an object detection model, where we created our own dataset of cans and bottles at PennApps with pictures around the building, and used Roboflow to create the dataset. Our app was created using Swift, and it was inspired by a previous GitHub that deployed a model of the same type as ours onto IOS. The UI was designed using Figma. The ML model that predicted the movement of trash concentration was a CNN that had a differential equation as a loss function which had better results than just the vanilla loss functions.
## Challenges we ran into
None of us had coded an app before, so it was difficult doing anything with Swift. It actually took us 2 hours just to get things set up and get the build running, so this was for sure the hardest part of the project. We also ran into problems finding good datasets for both of the models, as they were either poor quality or didn't have the aspects that we wanted.
## Accomplishments that we're proud of
Everyone on our team specializes in backend, so with limited initial experience in frontend, we're especially proud of the app we’ve created—it's our first time working on such a project. Integrating all the components posed significant challenges too. Getting everything to work seamlessly, including the CNN model and object detection camera within the same app, required countless attempts. Despite the challenges, we've learned a great amount throughout the process and are incredibly proud of what we've achieved so far.
## What we learned
How to create an IOS app, finding datasets, integrating models into apps.
## What's next for EcoRush
A possible quality change to the app would be to find a way to differentiate bottles from each other so people can't "hack" the system. We are also looking for more ways to incentivize people to recycle litter they see everyday other than with money. After all, our planet would be a whole lot greener if every citizen of Earth does just a small part! | # Catch! (Around the World)
## Our Inspiration
Catch has to be one of our most favourite childhood games. Something about just throwing and receiving a ball does wonders for your serotonin. Since all of our team members have relatives throughout the entire world, we thought it'd be nice to play catch with those relatives that we haven't seen due to distance. Furthermore, we're all learning to social distance (physically!) during this pandemic that we're in, so who says we can't we play a little game while social distancing?
## What it does
Our application uses AR and Unity to allow you to play catch with another person from somewhere else in the globe! You can tap a button which allows you to throw a ball (or a random object) off into space, and then the person you send the ball/object to will be able to catch it and throw it back. We also allow users to chat with one another using our web-based chatting application so they can have some commentary going on while they are playing catch.
## How we built it
For the AR functionality of the application, we used **Unity** with **ARFoundations** and **ARKit/ARCore**. To record the user sending the ball/object to another user, we used a **Firebase Real-time Database** back-end that allowed users to create and join games/sessions and communicated when a ball was "thrown". We also utilized **EchoAR** to create/instantiate different 3D objects that users can choose to throw. Furthermore for the chat application, we developed it using **Python Flask**, **HTML** and **Socket.io** in order to create bi-directional communication between the web-user and server.
## Challenges we ran into
Initially we had a separate idea for what we wanted to do in this hackathon. After a couple of hours of planning and developing, we realized that our goal is far too complex and it was too difficult to complete in the given time-frame. As such, our biggest challenge had to do with figuring out a project that was doable within the time of this hackathon.
This also ties into another challenge we ran into was with initially creating the application and the learning portion of the hackathon. We did not have experience with some of the technologies we were using, so we had to overcome the inevitable learning curve.
There was also some difficulty learning how to use the EchoAR api with Unity since it had a specific method of generating the AR objects. However we were able to use the tool without investigating too far into the code.
## Accomplishments
* Working Unity application with AR
* Use of EchoAR and integrating with our application
* Learning how to use Firebase
* Creating a working chat application between multiple users | losing |
## Inspiration
On our way to PennApps, our team was hungrily waiting in line at Shake Shack while trying to think of the best hack idea to bring. Unfortunately, rather than being able to sit comfortably and pull out our laptops to research, we were forced to stand in a long line to reach the cashier, only to be handed a clunky buzzer that countless other greasy fingered customer had laid their hands on. We decided that there has to be a better way; a way to simply walk into a restaurant, be able to spend more time with friends, and to stand in line as little as possible. So we made it.
## What it does
Q'd (pronounced queued) digitizes the process of waiting in line by allowing restaurants and events to host a line through the mobile app and for users to line up digitally through their phones as well. Also, it functions to give users a sense of the different opportunities around them by searching for nearby queues. Once in a queue, the user "takes a ticket" which decrements until they are the first person in line. In the meantime, they are free to do whatever they want and not be limited to the 2-D pathway of a line for the next minutes (or even hours).
When the user is soon to be the first in line, they are sent a push notification and requested to appear at the entrance where the host of the queue can check them off, let them in, and remove them from the queue. In addition to removing the hassle of line waiting, hosts of queues can access their Q'd Analytics to learn how many people were in their queues at what times and learn key metrics about the visitors to their queues.
## How we built it
Q'd comes in three parts; the native mobile app, the web app client, and the Hasura server.
1. The mobile iOS application built with Apache Cordova in order to allow the native iOS app to be built in pure HTML and Javascript. This framework allows the application to work on both Android, iOS, and web applications as well as to be incredibly responsive.
2. The web application is built with good ol' HTML, CSS, and JavaScript. Using the Materialize CSS framework gives the application a professional feel as well as resources such as AmChart that provide the user a clear understanding of their queue metrics.
3. Our beast of a server was constructed with the Hasura application which allowed us to build our own data structure as well as to use the API calls for the data across all of our platforms. Therefore, every method dealing with queues or queue analytics deals with our Hasura server through API calls and database use.
## Challenges we ran into
A key challenge we discovered was the implementation of Cordova and its associated plugins. Having been primarily Android developers, the native environment of the iOS application challenged our skills and provided us a lot of learn before we were ready to properly implement it.
Next, although a less challenge, the Hasura application had a learning curve before we were able to really us it successfully. Particularly, we had issues with relationships between different objects within the database. Nevertheless, we persevered and were able to get it working really well which allowed for an easier time building the front end.
## Accomplishments that we're proud of
Overall, we're extremely proud of coming in with little knowledge about Cordova, iOS development, and only learning about Hasura at the hackathon, then being able to develop a fully responsive app using all of these technologies relatively well. While we considered making what we are comfortable with (particularly web apps), we wanted to push our limits to take the challenge to learn about mobile development and cloud databases.
Another accomplishment we're proud of is making it through our first hackathon longer than 24 hours :)
## What we learned
During our time developing Q'd, we were exposed to and became proficient in various technologies ranging from Cordova to Hasura. However, besides technology, we learned important lessons about taking the time to properly flesh out our ideas before jumping in headfirst. We devoted the first two hours of the hackathon to really understand what we wanted to accomplish with Q'd, so in the end, we can be truly satisfied with what we have been able to create.
## What's next for Q'd
In the future, we're looking towards enabling hosts of queues to include premium options for users to take advantage to skip lines of be part of more exclusive lines. Furthermore, we want to expand the data analytics that the hosts can take advantage of in order to improve their own revenue and to make a better experience for their visitors and customers. | ## Inspiration
We were inspired by Katie's 3-month hospital stay as a child when she had a difficult-to-diagnose condition. During that time, she remembers being bored and scared -- there was nothing fun to do and no one to talk to. We also looked into the larger problem and realized that 10-15% of kids in hospitals develop PTSD from their experience (not their injury) and 20-25% in ICUs develop PTSD.
## What it does
The AR iOS app we created presents educational, gamification aspects to make the hospital experience more bearable for elementary-aged children. These features include:
* An **augmented reality game system** with **educational medical questions** that pop up based on image recognition of given hospital objects. For example, if the child points the phone at an MRI machine, a basic quiz question about MRIs will pop-up.
* If the child chooses the correct answer in these quizzes, they see a sparkly animation indicating that they earned **gems**. These gems go towards their total gem count.
* Each time they earn enough gems, kids **level-up**. On their profile, they can see a progress bar of how many total levels they've conquered.
* Upon leveling up, children are presented with an **emotional check-in**. We do sentiment analysis on their response and **parents receive a text message** of their child's input and an analysis of the strongest emotion portrayed in the text.
* Kids can also view a **leaderboard of gem rankings** within their hospital. This social aspect helps connect kids in the hospital in a fun way as they compete to see who can earn the most gems.
## How we built it
We used **Xcode** to make the UI-heavy screens of the app. We used **Unity** with **Augmented Reality** for the gamification and learning aspect. The **iOS app (with Unity embedded)** calls a **Firebase Realtime Database** to get the user’s progress and score as well as push new data. We also use **IBM Watson** to analyze the child input for sentiment and the **Twilio API** to send updates to the parents. The backend, which communicates with the **Swift** and **C# code** is written in **Python** using the **Flask** microframework. We deployed this Flask app using **Heroku**.
## Accomplishments that we're proud of
We are proud of getting all the components to work together in our app, given our use of multiple APIs and development platforms. In particular, we are proud of getting our flask backend to work with each component.
## What's next for HealthHunt AR
In the future, we would like to add more game features like more questions, detecting real-life objects in addition to images, and adding safety measures like GPS tracking. We would also like to add an ALERT button for if the child needs assistance. Other cool extensions include a chatbot for learning medical facts, a QR code scavenger hunt, and better social interactions. To enhance the quality of our quizzes, we would interview doctors and teachers to create the best educational content. | TARGET: Mayors Innovation Challenge
ecolocation.io
## Inspiration
Employees of the City of Kingston frequently travel across the City for interdepartmental meetings, which is important as the City has many diverse groups, which benefit greatly from information sharing and collaboration. While teleconferencing can be used in some instances, certain meetings require staff attendance. However, the optimal meeting location may not always be chosen for these meetings, leading attendees to use single-occupancy-vehicles, which produce significant GHGs. How can the City of Kingston optimize preferred meeting locations, taking into account the points of origin for each attendee and the requirements of the meeting space in order to reduce the City’s GHG emissions?
## What it does
Eco Location takes various preferences (Transportation method, max distance, location type) to find the lowest carbon footprint meeting location among the users in the meeting.
## How I built it
Prototype: Figma
Implementation: MERN Stack
MongoDB: Document-Oriented Database
Express: Back-End Framework
React: Front-End Library
Node.js: JS Runtime Environment
## Challenges I ran into
One of our biggest challenges was working with mapbox API and getting it to work as intended. We also had a tough time formulating and completing the algorithm. As with any challenge we face as developers, we just worked them out to the best we could.
## Accomplishments that I'm proud of
We are very proud of the effectiveness of the algorithm and the overall UI of the app.
## What I learned
We learned a lot about full-stack developing, getting everything to communicate with each other, etc. We also learned teamwork and how to have fun even under constraints.
## What's next for Eco Location
* Optimize Algorithm
* More responsive UI | winning |
## Inspiration
This project was heavily inspired by the poor experience of software used in university to view our courses, specifically, Avenue (D2L). As university students, navigating through these platforms proved to be cumbersome and time-consuming, impacting our overall productivity and hindering our ability to learn effectively.
Faced with these challenges, we recognized the need for a streamlined and user-friendly solution to enhance the educational experience. Our goal was to develop a tool that not only addressed the difficulties we encountered but also provided a seamless and efficient way to access concise course information.
With a vision for an improved learning platform, our project aims to overcome the limitations of existing systems by focusing on user experience and quick accessibility to vital course details. Leveraging the growth of AI, our project focuses using AI as not a medium to do the work for students, but as an aid to further improve their learning experience online.
Our aspiration is to contribute to the enhancement of educational platforms, making them more intuitive, responsive, and tailored to the needs of students. By doing so, we believe we can positively impact the learning journey for students like ourselves, fostering a conducive environment for academic success and knowledge attainment.
## What it does
Each course is equipped with its own personalized chatbot, creating a dynamic and responsive communication channel. This tailored approach ensures that students receive information and assistance that is directly relevant to their specific coursework. Whether it's generating practice questions for assessments or keeping students organized with updates on due dates and important announcements, the chatbot is a versatile companion for academic success.
In addition to academic support, tAI acts as a central hub for organizational updates. Students can effortlessly stay informed about due dates, assignment submissions, and crucial announcements. This ensures that important information is easily accessible, reducing the likelihood of missed deadlines and enhancing overall productivity.
The integration of tAI into the learning environment is aimed at enhancing students' overall learning experiences. By providing seamless interaction and unparalleled convenience, tAI becomes an indispensable tool for students looking to navigate their academic journey more efficiently. The platform's commitment to personalized communication, study assistance, and organizational support reflects our dedication to fostering an environment where students can thrive and achieve their academic goals.
## How we built it
To bring our chatbot to life and enhance its capabilities, we harnessed the power of the **Cohere API**. Cohere played a pivotal role in empowering our chatbot to respond intelligently to user queries and effectively summarize course content material. Leveraging Cohere's advanced natural language processing capabilities, our chatbot not only understands the nuances of user inputs but also generates contextually relevant and coherent responses.
The user interface was crafted using **HTMX**, a cutting-edge library that extends HTML to facilitate dynamic and real-time updates, which formed the foundation of our interactive UI. This allowed us to create a responsive and engaging user interface that adapts to user interactions without the need for constant page reloads.
Furthermore, for our backend, **FastAPI**, a modern, fast, web framework for building APIs with Python 3.7+ based on standard Python type hints, served as the backend framework. Its asynchronous capabilities and efficient design enabled us to handle concurrent requests, ensuring a smooth and responsive chatbot experience.
Finally, Tailwind CSS, a utility-first CSS framework, was employed for styling the user interface. Its simplicity and utility-first approach allowed us to rapidly design and customize the UI, ensuring a visually appealing and user-friendly experience. The combination of Tailwind CSS and **Jinja2**, a modern and designer-friendly templating engine for Python, enabled us to dynamically render content on the server-side and present it in a cohesive manner.
## Challenges we ran into
In terms of challenges, working with Cohere proved to be quite a challenge. While the API was very coherent and easy to read/follow, finding the right parameters to use was quite difficult. We had to test various different methods to get the prompts we wanted which also proved very challenging. Finally after many attempts we found the right parameters in order to get our project working as attended
## Accomplishments that we're proud of
We take immense pride in the substantial progress achieved within the 24-hour timeframe of this project. Witnessing our initial vision transform into a tangible reality has been a source of great joy and satisfaction. The collaborative efforts of our team, fueled by dedication and creativity, have not only met but exceeded our expectations.
## What we learned
We learnt a multitude of things, especially the stack we decided to use. For many of us, it was our first time using HTMX along with Flask to create a fully functional website. It was also most of our first time experiencing Cohere and using their API.
## What's next for tAI
We truly believe AI will will only get better from now on. It is only its worse at this very moment so why not leverage its amazing capabilities and use it to further the learning of students for the future. We also understand how it can abused easily, however it is still a powerful tool we students should leverage while it is still young and fresh, to pave a path and create restrictions around them before it is too late. Some future features include: Reading and summarizing course content, etc. | ## Inspiration
My inspiration was to build a single platform for both travel agencies and tourists.
## What it does
This platform connects travel agencies and tour operators with tourists and visitors.
## How I built it
I build it using different frontend tools like HTML, CSS, JavaScript, Bootstrap, Material-UI, Reactjs
## Challenges I ran into
One of the main challenges was to develop user interactive and attractive user interface design.
## Accomplishments that we're proud of
I feel proud that I have developed a platform which helps travel agencies and tourists.
## What I learned
I learned how to make user interactive UI design, and responsive web pages, how to create react components and how to reuse them.
## What's next for Yadgar Safar - Memorable Journey
The next step is to develop other modules of the website. And connect it with the backend. The backend will be using Nodejs and MongoDB. | # Annotate.io
## Inspiration 💡
With school being remote, and online lectures being prominent. It is sometimes hard making clear and concise notes because profs may have a hard accent you are not used to, or perhaps your audio on your laptop is not the best or even because the house is too loud! What if there was an application that can transcribe your online lectures and summarize as well as point out key concepts! This would improve your study productivity and even promote active learning! Well that's exactly what we wanted to build! Using Assembly AI and Twilio we built a notes assistant to help build concise and elegant study sheets based on your lectures! Our product boosts productivity, as we create interactive study sheets to increase active learning and recall!
## What it does 🤔
Annotate.io is an education & productivity platform that allows users to create dynamic notes based on lecture content, users are able to submit a .mp4 file or even a YouTube link and get interactive notes! We use Assembly AI to perform topic analysis to summarize content and highlight key topics that are in the material! Users can also email a pdf version of their notes to themselves and also share their notes to others (thanks Twillio!).
## How we built it 🖥️
When building out Annotate.io, we chose 3 key design principles to help ensure our product meets the design challenge of productivity! Simplicity, Elegance and Scalability.
We wanted Annotate.io to be simple to design, upgrade and debug. This led to us harnessing the lightweight framework of Flask and the magic of Python to design our backend infrastructure. To ensure our platform is scalable and efficient we harnessed Assembly AI to perform both our topic and summary analysis harnessing its topic-detection and speech API respectively. Using Assembly AI as our backbone allowed our NLP analysis to be efficient and responsive! We then used various python libraries to create our YouTube and file conversion services, enabling us to integrate into the Assembly AI infrastructure. We then use Twilio to harness the output from Assembly AI to rapidly send pdfs of their notes to our users’ emails!
To create an elegant and user-friendly experience we leveraged React and various design libraries to present our users with a new, productivity focused platform to create dynamic and interactive study notes! React also worked seamlessly with our Flask backend and our third party APIs. This integration also allowed for a concurrent development stream for both our front end and back end teams.
## Challenges we ran into 🔧
One of the first challenges we faced was trying to integrate with Assembly AI, at first we weren’t having much success interfacing with Assembly AI API, however going through their documentation and looking over some sample code they provided we were able to leverage Assembly AI in our project.
Another issue we initially didn’t anticipate was communicating both backend and frontend services together, due to cross-origin resource policy we initially couldn’t pass information between the two. However we managed to implement CORS which solved the issue.
This year was the first time we decided to use Figma to mock up our UI although tedious it definitely helped the frontend team speed up their development process. The hackathon really challenged our normal development process. We had to make quick decisions and factor the pros and cons of various decisions.
Sleep or technically the lack of sleep, was another challenge we had to overcome. Luckily now that we are done we can get some.
## What we learned 🤓
In this hack we definitely learnt a lot about the development process and bringing the best out of each of our abilities. Figma was a design tool we used for the first time and it definitely helped us with our frontend development and is a skill we will definitely be taking with us for our future careers. We also got greater insights into integrating third-party APIs and http requests. To pass our audio and video files we used ‘formdata’ which had some nuances we never knew.
We also learned the importance of git ignore and managing keys correctly, and how leaking a key can be really annoying to remove :(((
## What's next for Annotate.io 🏃♂️
For the future we have many ideas to improve the accessibility and scalability of Annotate.io. A feature we weren’t able to develop currently but are planning to is add image recognition to handle detailed diagrams and drawings. Diagrams often paint a better picture and improve one's understanding which is something we would want to take advantage of in Annotate.io. This feature would be a game changer as annotated diagrams based on the video would improve productivity even more! | losing |
## ✨ Inspiration
In the era of online communications, where online meetings are already draining enough [1], st-st-stammering and uh, uhm, filler words seem to creep into every conversation. Filler words—like, uh, um, you know—have been found to lower listeners’ comprehension, interrupt the natural flow of speech, and reduce credibility [2].
Relevate, my project for Hack the North 2023, helps to tackle this issue by using multiple neural networks, one trained on my own synthesized dataset, to automatically perfect oration.
## 🚀 What it does
Relevate is a desktop app that elevates discussions by removing irrelevant filler words and stuttering in **real-time**. It receives your voice from your microphone, and then creates a virtual microphone that is completely stutter and filler word free. You can use this virtual microphone anywhere you could use a regular microphone as an input source: during chats with friends on Discord, interviews with recruiters on Zoom, or even recordings of podcasts on Voice Memos!
**relevate = relevant and elevated oration 🧩**
## ⚙️ How I built it

I built the user-facing GUI with Python and Tkinter, and used PyAudio for the audio interfacing. The user GUI uses WebSockets to communicate to the backend server, which is written in Python and FastAPI. The backend server runs OpenAI’s state-of-the-art speech-to-text model, Whisper, locally (using the API would be too slow because an entire file would need to be streamed). OpenAI Whisper usually ignores filler words, so I needed to write a custom few-shot prompt to bring those back. To map the transcripts from Whisper to actual timestamps, I used [dynamic time warping](https://github.com/linto-ai/whisper-timestamped#plot-of-word-alignment). Using Whisper, the backend has a transcript of the chunk of audio; next, the backend needs to detect the filler words and stammering in the transcript and link it back to timestamps in the audio.
Detecting filler words and stammering is non-trivial because it is often context-dependent (because of filler words such as the word "like''; “I like hackathons” vs. “I, like, don’t know”), so I trained my own bi-directional transformer (BERT style) to detect stammering and filler words. Specifically, I trained RoBERTa-large for the token classification task (whether the word should be removed or not) on a dataset that I synthesized myself by taking many sentences from OpenWebText, adding random filler words, and adding stammer to the text. After training, the backend uses this model to find the spans of text that need to be removed and the corresponding timestamps of the audio that need to be removed. After the timestamps are removed in real-time, the resulting audio is streamed directly to BlackHole, a virtual audio loopback driver, to make the virtual audio microphone work.
## 🚧 Challenges I ran into
* Latency in machine learning models and existing APIs was a major issue while building this app
+ OpenAI’s Whisper API was not sufficient as they require you to upload an entire file and cannot easily stream it; hence, I hosted it locally (where streaming is possible)
* Real-time audio processing is very error-prone and I ran into lots of difficult-to-debug issues
## 😁 Accomplishments I’m proud of
I’m extremely proud of being able to complete this project on my own. Dealing with audio processing (especially real-time streaming) was a first for me (and I found it quite challenging), so I’m pleased about being able to learn and turn my project into a usable app.
## 📚 What I learned
* How to deal with real-time audio processing
* Frameworks/libraries: PyAudio, Tkinter, BlackHole
* On another note, I learned that speech therapy doesn’t work for some 20% of people who stutter, according to one study [3]; this tool is highly critical for these people
## ⏭ What’s next for Relevate
Overall I’m really happy with what I made! In the future, I plan to…
* Package this as an application
* Make it work for Windows (BlackHole only works for macOS currently, but it should be fairly straightforward to support a Windows alternative)
**References**
1. Troje, Nikolaus F. “[Zoom disrupts eye contact behaviour: problems and solutions](https://www.sciencedirect.com/science/article/pii/S1364661323000487)” Trends in Cognitive Sciences, Volume 27, Issue 5, May 2023
2. Seals, Douglas, et al. “[We, um, have, like, a problem: excessive use of fillers in scientific speech](https://journals.physiology.org/doi/full/10.1152/advan.00110.2022)”, Advances in Physiology Education, Volume 46 Issue 4, December 2022
3. Langevin, Marilyn, et al. “[Five-year longitudinal treatment outcomes of the ISTAR Comprehensive Stuttering Program](https://www.sciencedirect.com/science/article/pii/S0094730X10000380)”, Journal of Fluency Disorders, Volume 35, Issue 2, June 2010 | ## Inspiration
editing
## What it does
This application serves to remind users to take their medications and/or supplements via an application that supports a SMS notification system, as opposed to the typical push notification that we tend to neglect.
## How we built it
We built a back-end using MongoDB and developed REST API web service with Express.js/Node.js then integrated the Twilio Messaging API. The front-end was designed using JavaScript and HTML/CSS. Versioning control was dealt with using GitHub.
## Challenges we ran into
Given a limited time and that a lot of us were beginners in coding, we had challenges to learn and adapt to new technologies. Furthermore, there were restrictions to accessibility to messaging APIs that required payments and/or formal requests.
## Accomplishments that we're proud of
We are proud of how far we've had to come given our technical expertise, the time constraints, and budget restrictions to access to certain technologies.
## What we learned
We learned various different new technologies such as REST APIs, Express.js/Node.js, JavaScript, and the Twilio API. As well, we learned common software engineering techniques such as working on a team, communicating with each other, development, and debugging.
## What's next for reMEDy
It would be great to create mobile application versions for reMEDy to be accessible across Android/iOS. As well, some future improvements of our applications include supporting different timezones and creating/signing into various user profiles. | ## What it does
"ImpromPPTX" uses your computer microphone to listen while you talk. Based on what you're speaking about, it generates content to appear on your screen in a presentation in real time. It can retrieve images and graphs, as well as making relevant titles, and summarizing your words into bullet points.
## How We built it
Our project is comprised of many interconnected components, which we detail below:
#### Formatting Engine
To know how to adjust the slide content when a new bullet point or image needs to be added, we had to build a formatting engine. This engine uses flex-boxes to distribute space between text and images, and has custom Javascript to resize images based on aspect ratio and fit, and to switch between the multiple slide types (Title slide, Image only, Text only, Image and Text, Big Number) when required.
#### Voice-to-speech
We use Google’s Text To Speech API to process audio on the microphone of the laptop. Mobile Phones currently do not support the continuous audio implementation of the spec, so we process audio on the presenter’s laptop instead. The Text To Speech is captured whenever a user holds down their clicker button, and when they let go the aggregated text is sent to the server over websockets to be processed.
#### Topic Analysis
Fundamentally we needed a way to determine whether a given sentence included a request to an image or not. So we gathered a repository of sample sentences from BBC news articles for “no” examples, and manually curated a list of “yes” examples. We then used Facebook’s Deep Learning text classificiation library, FastText, to train a custom NN that could perform text classification.
#### Image Scraping
Once we have a sentence that the NN classifies as a request for an image, such as “and here you can see a picture of a golden retriever”, we use part of speech tagging and some tree theory rules to extract the subject, “golden retriever”, and scrape Bing for pictures of the golden animal. These image urls are then sent over websockets to be rendered on screen.
#### Graph Generation
Once the backend detects that the user specifically wants a graph which demonstrates their point, we employ matplotlib code to programmatically generate graphs that align with the user’s expectations. These graphs are then added to the presentation in real-time.
#### Sentence Segmentation
When we receive text back from the google text to speech api, it doesn’t naturally add periods when we pause in our speech. This can give more conventional NLP analysis (like part-of-speech analysis), some trouble because the text is grammatically incorrect. We use a sequence to sequence transformer architecture, *seq2seq*, and transfer learned a new head that was capable of classifying the borders between sentences. This was then able to add punctuation back into the text before the rest of the processing pipeline.
#### Text Title-ification
Using Part-of-speech analysis, we determine which parts of a sentence (or sentences) would best serve as a title to a new slide. We do this by searching through sentence dependency trees to find short sub-phrases (1-5 words optimally) which contain important words and verbs. If the user is signalling the clicker that it needs a new slide, this function is run on their text until a suitable sub-phrase is found. When it is, a new slide is created using that sub-phrase as a title.
#### Text Summarization
When the user is talking “normally,” and not signalling for a new slide, image, or graph, we attempt to summarize their speech into bullet points which can be displayed on screen. This summarization is performed using custom Part-of-speech analysis, which starts at verbs with many dependencies and works its way outward in the dependency tree, pruning branches of the sentence that are superfluous.
#### Mobile Clicker
Since it is really convenient to have a clicker device that you can use while moving around during your presentation, we decided to integrate it into your mobile device. After logging into the website on your phone, we send you to a clicker page that communicates with the server when you click the “New Slide” or “New Element” buttons. Pressing and holding these buttons activates the microphone on your laptop and begins to analyze the text on the server and sends the information back in real-time. This real-time communication is accomplished using WebSockets.
#### Internal Socket Communication
In addition to the websockets portion of our project, we had to use internal socket communications to do the actual text analysis. Unfortunately, the machine learning prediction could not be run within the web app itself, so we had to put it into its own process and thread and send the information over regular sockets so that the website would work. When the server receives a relevant websockets message, it creates a connection to our socket server running the machine learning model and sends information about what the user has been saying to the model. Once it receives the details back from the model, it broadcasts the new elements that need to be added to the slides and the front-end JavaScript adds the content to the slides.
## Challenges We ran into
* Text summarization is extremely difficult -- while there are many powerful algorithms for turning articles into paragraph summaries, there is essentially nothing on shortening sentences into bullet points. We ended up having to develop a custom pipeline for bullet-point generation based on Part-of-speech and dependency analysis.
* The Web Speech API is not supported across all browsers, and even though it is "supported" on Android, Android devices are incapable of continuous streaming. Because of this, we had to move the recording segment of our code from the phone to the laptop.
## Accomplishments that we're proud of
* Making a multi-faceted application, with a variety of machine learning and non-machine learning techniques.
* Working on an unsolved machine learning problem (sentence simplification)
* Connecting a mobile device to the laptop browser’s mic using WebSockets
* Real-time text analysis to determine new elements
## What's next for ImpromPPTX
* Predict what the user intends to say next
* Scraping Primary sources to automatically add citations and definitions.
* Improving text summarization with word reordering and synonym analysis. | losing |
## Inspiration
The problems that dog owners face on a day to day basis inspired us to come up with this idea. For example, many dog owners are wanting to rehome their dogs but are unable to find the right dog adopters. Dog owners with a lack of time to take care of their dogs (due to personal/business trips/long working hours) need dog sitters but are unable to find good ones. Getting dog products can be expensive with different websites having different prices. These mismatches and gaps have yet to be filled and there is no integrated platform that solves all of such multi-faceted issues faced by dog owners.
## What it does
One-stop integrated matchmaking platform for:
1. Dog Adoption -- Matchmaking Dog Owners and Dog Adopters
2. Dog Sitting -- Matchmaking Dog Owners and Dog Sitters
3. Dog Products and Services -- Matchmaking Dog Owners to Dog Products and Services
## How we built it
We built the front-end of the web application using HTML,CSS, JavaScript and Bootstrap Classes. We used the Google Cloud Platform to host our database and managed sign ins and user authentication through firebase. The back end was programmed in Java and the connected to the front-end using the Vaadin Framework and Maven.
## Challenges we ran into
By far the biggest challenge that we ran into was connecting the Java backend to the front-end, as it is not very common for a web application to have a fully Java backend. Another issue we ran into is deploying our application on Google Cloud Platform as it does not support Java as a back-end.
## Accomplishments that we're proud of
We are very proud that we were able to use firebase to manage our users and authenticate accounts. The biggest thing for us is that we all learned something new this weekend, such as GCP, BootStrap, Firebase and Vaadin/Maven.
## What we learned
We learned that we should be more selective when choosing our tech stack in the future.
## What's next for FETCH
We are looking to expand into apps - ios and android. We were also looking into implementing a tensor flow computer vision algorithm that would detect the breed of a dog based on it being trained on a large amount of photos. It would be pretty useful as sometimes you see a dog in the park and you want to know the breed of a specific dog but you're not comfortable approaching the owner. | ## Inspiration
Shelters are almost always swarmed with dogs, and so many people want a dog, but they may not know what's out there in there local area.
Our goal is to find homes for dogs, whether they are in shelters and need to be adopted, were lost in a natural disaster, or simply found in the city.
## What it does
It's currently a platform that allows for shelters to advertise dogs Tinder style. We hope to add fatrues for users who found a lost dog to connect it with a shelter or the owner.
## How we built it
It's a React Native app using Azure for backend services
## Challenges we ran into
Our team really does not know React Native, so it's been an awesome learning experience for React. Some of the problems with the backend came from us, not realizing the components were firewalled from each other and Azure VNets aren't allowed for App Services on the pricing tier we were operating under.
Of course, React Native uses npm and yarn to manage packages, so it's a fun time if we make a mistake and add a library using the wrong platform.
## Accomplishments that we're proud of
We're using the industry standard JWT for access authorization, and we have a simple authentication setup based on bcrypt, and we have most the barebones React app built.
## What we learned
* React Native
* Azure Networking
* Azure Blob storage
* JWTs
* DocuSign APIs
## What's next for TinDog
* Allowing for shelters to see more information about local area adoption rates
* Connecting shelters to Google and Facebook for targeted advertising with the aim of improving their adoption rates
* Helping owners to connect back to shelters, in case of disasters or dogs that don't have a chip or collar | ## Inspiration
College students often times find themselves taking the first job they see. However this often leaves them with a job that is stressful, hard, or pays less than what they're worth. We realized that students don't have a good tool to discover the best job in their area. Job boards like LinkedIn and Glassdoor typically don't have lowkey part time jobs, while university job boards are limited to university specific jobs. We wanted to create a means for students to post reviews for job postings within their university area. This would allow students to share experiences and inform students of the best job options for them.
## What it does
Rate My University Job is a job postings website created for college students. To access the website, a user must first create an account using a .edu email address. Users can search for job postings based on tags or the job title. The search results are filter are filtered by .edu domain name for users from the same University. A job posting contains information like the average pay reviewers received at the job, the location, a description, an average rating out of 5 stars. If a job posting doesn't exist for their position, they can create a new posting and provide the title, description, location, and a tag. Other students can read these posts and contribute with their own reviews.
## How we built it
We created the front end using vanilla HTML, CSS and JavaScript. We implemented Firebase Firestore to update and query a database where all job postings and reviews are stored. We also use Firebase Auth to authenticate emails and ensure a .edu email is used. We designed the interactive components using JavaScript to create a responsive user interface. The website is hosted using both GitHub Pages and Domain.com
## Challenges we ran into
(1) Website Design UI/UX
(2) Developing a schema and using a database
## Accomplishments that we're proud of
(1) Being able to store account data of multiple users and authenticate the .edu domain.
(2) Completing a first project in a collaborative environment
(3) Curating a list of job postings from the same university email domains.
(4) A robust search engine based on titles and search tags.
## What we learned
In general, we learned how to format and beatify HTML files with CSS, in addition to connecting a HTML. We learned how to use the FireStore database and how to query, upload, and update data.
## What's next for Rate My University Job
We would seek to improve the UI/UX. We would also look to add additional feature such as upvoting and downvoting posts and a reporting system for malicious/false posts. We also look to improve the search engine to allow for more concise searches and allow the searches to be sorted based on rating/pay/tags/etc. Overall there are a lot of additional features we can add to make this project even better. | losing |
## Inspiration
How long does class attendance take? 3 minutes? With 60 classes, 4 periods a day, and 180 school days in a year, this program will save a cumulative 72 days every year! Our team recognized that the advent of neural networks yields momentous potential, and one such opportunity is face recognition. We utilized this cutting-edge technology to save time in regards to attendance.
## What it does
The program uses facial recognition to determine who enters and exits the room. With this knowledge, we can keep track of everyone who is inside, everyone who is outside, and the unrecognized people that are inside the room. Furthermore, we can display all of this on a front end html application.
## How I built it
A camera that is mounted by the door sends a live image feed to Raspberry pi, which then transfers that information to Flask. Flask utilizes neural networks and machine learning to study previous images of faces, and when someone enters the room, the program matches the face to a person in the database. Then, the program stores the attendees in the room, the people that are absent, and the unrecognized people. Finally, the front end program uses html, css, and javascript to display the live video feed, the people that are attending or absent, the faces of all unrecognized people.
## Challenges I ran into
When we were using the AWS, we uploaded to the bucket, and that triggered a Lamda. In short, we had too many problematic middle-men, and this was fixed by removing them and communicating directly. Another issue was trying to read from cameras that are not designed for Raspberry pi. Finally, we accidentally pushed the wrong html2 file, causing a huge merge conflict problem.
## Accomplishments that I'm proud of
We were successfully able to integrate neural networks with Flask to recognize faces. We were also able to make everything much more efficient than before.
## What I learned
We learned that it is often better to directly communicate with the needed software. There is no point in having middlemen unless they have a specific use. Furthermore, we also improved our server creating skills and gained many valuable insights. We also taught a team member how to use GIT and how to program in html.
## What's next for Big Brother
We would like to match inputs from external social media sites so that unrecognized attendees could be checked into an event. We also would like to export CSV files that display the attendees, their status, and unrecognized people. | ## Inspiration
In a lot of mass shootings, there is a significant delay from the time at which police arrive at the scene, and the time at which the police engage the shooter. They often have difficulty determining the number of shooters and their location. ViGCam fixes this problem.
## What it does
ViGCam spots and tracks weapons as they move through buildings. It uses existing camera infrastructure, location tags and Google Vision to recognize weapons. The information is displayed on an app which alerts users to threat location.
Our system could also be used to identify wounded people after an emergency incident, such as an earthquake.
## How we built it
We used Raspberry Pi and Pi Cameras to simulate an existing camera infrastructure. Each individual Pi runs a Python script where all images taken from the cameras are then sent to our Django server. Then, the images are sent directly to Google Vision API and return a list of classifications. All the data collected from the Raspberry Pis can be visualized on our React app.
## Challenges we ran into
SSH connection does not work on the HackMIT network and because of this, our current setup involves turning one camera on before activating the second. In a real world situation, we would be using an existing camera network, and not our raspberry pi cameras to collect video data.
We also have had a difficult time getting consistent identification of our objects as weapons. This is largely because, for obvious reasons, we cannot bring in actual weapons. Up close however, we have consistent identification of team member items.
Using our current server set up, we consistently get server overload errors. So we have an extended delay between each image send. Given time, we would implement an actual camera network, and also modify our system so that it would perform object recognition on videos as opposed to basic pictures. This would improve our accuracy. Web sockets can be used to display the data collected in real time.
## Accomplishments that we’re proud of
1) It works!!! (We successfully completed our project in 24 hours.)
2) We learned to use Google Cloud API.
3) We also learned how to use raspberry pi. Prior to this, none on our team had any hardware experience.
## What we learned
1) We learned about coding in a real world environment
2) We learned about working on a team.
## What's next for ViGCam
We are planning on working through our kinks and adding video analysis. We could add sound detection for gunshots to detect emergent situations more accurately. We could also use more machine learning models to predict where the threat is going and distinguish between threats and police officers. The system can be made more robust by causing the app to update in real time. Finally, we would add the ability to use law enforcement emergency alert infrastructure to alert people in the area of shooter location in real time. If we are successful in these aspects, we are hoping to either start a company, or sell our idea. | ## Inspiration
* The pandemic makes socializing with family, friends, and strangers, more difficult. For students, turning on
your camera can be daunting.
* Buddy Study Online aims to create one thing: a safe space for students to meet each other and study.
## What it does
* The product allows users to enter study rooms and communicate with each other through an avatar.
Each study room can have titles indicating which subjects or topics are discussed.
* The avatar detects their facial expressions and maps them on the model.
The anonymity lets students show their expression without fear of judgement by others.
## How we built it
* Frontend - React, React Bootstrap
* Backend - SocketIO, Cassandra, NodeJS/Express
* Other - wakaru ver. beta, Clourblinding Chrome Extension
* With love <3
## Challenges we ran into
* wakaru ver. beta, the facial recognition and motion detection software, is difficult to get right. The facial
mapping wasn't accurate and motion detection was based off colour selection. We tried solving the colour selection issue
by wearing contrasting clothes on limbs we wanted to detect.
* In the end, the usage of gloves was a good choice for detecting hands since it was easy to pick ones that were colourful
enough to contrast the background.
* Cassandra had a steep learning curve, but by pulling from existing examples, we were able implement a working chat component
that persisted the chat state in the order of the messages sent.
* Figuring out a visual identity took quite a long time. While we had laid out components and elements we wanted on the page,
it took us many iterations to settle on a visual identity that we felt was sleek and clean. We also researched information on
multiple forms of colourblindness to aid in accessibility on our site which drove design decisions.
## Accomplishments that we're proud of
1. Facial recognition & movement tracking - Although rough around the edges at times, seeing all of these parts come together was a eureka moment. We spent too much time interacting with each other and with our new animated selves.
2. Live feed - It took us a bit to figure out how to get a live feed of the animated users & their voices. It was an accomplishment to see the other virtual person in front of you.
3. Live chat with other users - Upon a browser refresh, the chat history remains in the correct order the messages were sent in.
## What we learned
* We learned how to use Cassandra when integrating it with our chat system.
* Learning how to use Adobe xd to create mockups and to make our designs come to life.
## What's next for Buddy Study Online
* Voice changing (As students might not feel comfortable with showing their face, they also might not be comfortable with using their own voice)
* Pitch Buddy Study Online to university students with more features such as larger avatar selection, and implementing user logins
to save preferences and settings.
* Using this technology in Zoom calls. With fewer students using their webcams in class, this animated alternative allows for privacy but also socialization.
Even if you're working from home, this can offer a new way of connecting with others during these times. | winning |
## Inspiration
Humans left behind nearly $1,000,000 in change at airports worldwide in 2018. Imagine what that number is outside of airports. Now, imagine the impact we could make if that leftover money went toward charities that make the world a better place. This is why we should SpareChange - bringing change, with change.
## What it does
This app rounds up spending from each purchase to the nearest dollar and uses that accumulated money to donate it to charities & nonprofits.
## How we built it
We built a cross platform mobile app using Flutter, powered by a Firebase backend. We setup Firebase authentication to ensure secure storage of user info, and used Firebase Cloud Functions to ensure we keep developer credentials locked away in our secure cloud. We used the CapitalOne Hackathon API to simulate bank accounts, transactions between bank accounts and withdrawals.
## Challenges we ran into
1. Implementing a market place or organizations that could automatically update the user of tangible items to donate to the non-profits in lieu of directly gifting money.
2. Getting cloud functions to work.
3. Properly implementing the API's the way we need them to function.
## Accomplishments that we're proud of
Making a functioning app. This was some of our first times at a hackathon so it was amazing to have such a first great experience.
Overcoming obstacles - it was empowering to prevail over hardships that we previously thought would be impossible to hurdle.
Creating something with the potential to help other people live better lives.
## What we learned
On the surface, software such as Flutter, Dart & Firebase. We found them very useful.
More importantly, realizing how quickly an idea can come to fruition. The perspective was really enlightening. If we could make something this helpful in a weekend, what could we do in a year? Or a lifetime?
## What's next for SpareChange
We believe that SpareChange could be a large scale application. We would love to experiment and try out with real bank accounts and see how it works, and also build more features, such as using Machine Learning to provide the best charities to donate to based on real-time news. | ## Inspiration
Everyone in society is likely going to buy a home at some point in their life. They will most likely meet realtors, see a million listings, gather all the information they can about the area, and then make a choice. But why make the process so complicated?
MeSee lets users pick and recommend regions of potential housing interest based on their input settings, and returns details such as: crime rate, public transportation accessibility, number of schools, ratings of local nearby business, etc.
## How we built it
Data was sampled by an online survey on what kind of things people looked for when house hunting. The most repeated variables were then taken and data on them was collected. Ratings were pulled from Yelp, crime data was provided by CBC, public transportation data by TTC, etc. The result is a very friendly web-app.
## Challenges we ran into
Collecting data in general was difficult because it was hard to match different datasets with each other and consistently present them since they were all from from different sources. It's still a little patchy now, but the data is now there!
## Accomplishments that we're proud of
Finally choosing an idea 6 hours into the hackathon, get the data, get at least four hours of sleep, and establish open communication with each other as we didn't really know each other until today!
## What we learned
Our backend learned to use different callbacks, front end learned that googlemaps API is definitely out to get him, and our designer learned Adobe Xd to better illustrate what the design looked like and how it functioned.
## What's next for MeSee
There's still a long ways before Mesee can cover more regions, but if it continues, it'd definitely be something our team would look into. Furthermore, collecting more sampling data would definitely be beneficial in improving the variables available to users by Mesee. Finally, making Mesee mobile would also be a huge plus. | ## Inspiration
Only 50% of the world have internet access today. But around 65% have SMS access. That's over 1.3 billion people who have SMS access but don't have any access to the internet. Especially in developing countries, the growth of access to the internet is slowing down due to many barriers of access such as . In a world where internet connectivity is essential for fast information retrieval and for a lot of other applications, we set out to bring the world a bit closer by providing internet access to those in need.
## What it does
We built a web browser that allows users to access websites completely offline without the need of WiFi or mobile data, powered by SMS technology.
## How we built it
There are three components to our app. We used Flutter for the front-end, to allow user URL entry. We then SMS the URL to our Twilio number. The back-end was written in Python and waits for incoming SMS messages and scrapes the webpage to get HTML content from it. We then return the HTML using SMS to the front-end where we parse and render the webpage.
## Challenges we ran into
Integrating Twilio's API was a challenge to make sure we adhere by the character limits as well as implementing the logic behind waiting for incoming messages and replying to them. In addition, SMS technology is difficult to work with because of the unreliability of the speed of the message and order.
## Accomplishments that we're proud of
We're proud of our parsing algorithm that's able to take HTML and render it as a webpage on Flutter. We're also proud of our SMS communication technology that's verified using message IDs and our algorithm to accumulate all the individual SMS messages and aggregate them to form the HTML.
## What we learned
This is the first time we're making a mobile app using Flutter and we learned a lot about mobile app development! We also learned how to use Twilio and a lot about how SMS technology works on mobile phones. Accumulating data about internet access, we learned that there are a lot of people out there who sometimes or all the times have access to SMS but not the internet via WiFi or mobile data.
## What's next for Telebrowser
Instead of parsing just HTML, we'd like to implement a full-on browser (using for example, Chromium) that supports CSS, JavaScript and assets. We'd also like to utilize SMS messaging directly without Twilio for optimal performance | partial |
## Inspiration
editing
## What it does
This application serves to remind users to take their medications and/or supplements via an application that supports a SMS notification system, as opposed to the typical push notification that we tend to neglect.
## How we built it
We built a back-end using MongoDB and developed REST API web service with Express.js/Node.js then integrated the Twilio Messaging API. The front-end was designed using JavaScript and HTML/CSS. Versioning control was dealt with using GitHub.
## Challenges we ran into
Given a limited time and that a lot of us were beginners in coding, we had challenges to learn and adapt to new technologies. Furthermore, there were restrictions to accessibility to messaging APIs that required payments and/or formal requests.
## Accomplishments that we're proud of
We are proud of how far we've had to come given our technical expertise, the time constraints, and budget restrictions to access to certain technologies.
## What we learned
We learned various different new technologies such as REST APIs, Express.js/Node.js, JavaScript, and the Twilio API. As well, we learned common software engineering techniques such as working on a team, communicating with each other, development, and debugging.
## What's next for reMEDy
It would be great to create mobile application versions for reMEDy to be accessible across Android/iOS. As well, some future improvements of our applications include supporting different timezones and creating/signing into various user profiles. | ## 🎇 Inspiration 🎇
Since the last few years have been full of diseases, illness, a huge number of people have been in need of medical assistance. Our elders suffer from certain illnesses and have a hard time remembering which medications to take, in what amount and what time. So, Similarly We made an app that saves all medical records and prescription either in email form, scanned copy or written form and setting medicine reminders that enables client to determine the pill amount and timings to take pills for everyday.
## ❓ What it does ❓
* Problem 1 - Most of the patients frequently have difficulty in remembering or managing multiple medications .Many a times they forget medicine name and how they look like, especially for elders. Medication non-adherence leads to 125,000 preventable deaths each year, and about $300 billion in avoidable healthcare costs.
* Problem 2 - We all have multiple folders in back of our closets full of medical records, prescriptions , test reports etc. which lets all agree are a hassle to carry everytime a doctor asks for our medical history .
* Problem 3 - In times of emergency every minute counts and in that minute finding contacts of our caregivers, nearby hospitals, pharmacies and doctors is extremely difficult.
## 🤷♂️ How we built it 🤷♂️
We built it with technologies like Firebase, flutter for providing better contents and SQL lite for storage.
## 🤔 Challenges we ran into 🤔
* CRUD operations in firebase took a lot more of our time than expected.
* Pushing image notifications was another obstacle but with constant Hard work and support we finally completed it .
* Handling this project with the college classes was a test of our time management and that's totally worth it at end.
## 👏 What we learned 👏
* We learned how to worked quickly with Dart along with that we also learned how to use packages like contact picker, airplane mode checker in a effective way.
* It was my [ Aditya Singh ] second time using Swift and I had a lot of fun and learnings while using it.
* Design all the logo's as well as the UI part was handled by me [ Sanyam Saini ] , I learned many new features in Figma that I didn't knew before.
## 🚀 What's next for Med-Zone 🚀
* In the future, we can add additional features like providing diet charts, health tips, exercises / Yogas to follow for better health and nutrition, and some expert insights as well for which we can charge the subscription fee.
* We can add different types of tunes/ringtones according to which medications to take at which time. | ## Inspiration
Before the coronavirus pandemic, vaccine distribution and waste was a little known issue. Now it's one of the most relevant and pressing problems that world faces. Our team had noticed that government vaccine rollout plans were often vague and lacked the coordination needed to effectively distribute the vaccines. In light of this issue we created Vaccurate, a data powered vaccine distribution app which is able to effectively prioritize at risk groups to receive the vaccine.
## What it does
To apply for a vaccine, an individual will enter Vaccurate and fill out a short questionnaire based off of government research and rollout plans. We will then be able to process their answers and assign weights to each response. Once the survey is done all the user needs to do is to wait for a text to be sent to them with their vaccination location and date! As a clinic, you can go into the Vaccurate clinic portal and register with us. Once registered we are able to send you a list of individuals our program deems to be the most at risk so that all doses received can be distributed effectively. Under the hood, we process your data using weights we got based off of government distribution plans and automatically plan out the distribution and also contact the users for the clinics!
## How I built it
For the frontend, we drafted up a wireframe in Figma first, then used HTML, CSS, and Bootstrap to bring it to life. To store user and clinic information, we used a Firestore database. Finally, we used Heroku to host our project and Twilio to send text notifications to users.
## Challenges I ran into
On the backend, it was some of our team's first time working with a Firestore database, so there was a learning curve trying to figure out how to work with it. We also ran into a lot of trouble when trying to set up a Heroku, but eventually got it running after several hours (can we get an F in chat). And although none of us thought it was a huge deal in the beginning, the time constraint of this 24 hour hackathon really caught up on us and we ran into a lot of challenges that forced us to adapt and reconstruct our idea throughout the weekend so we weren't biting off more than we could chew.
## Accomplishments that I'm proud of
Overall, we are very proud of the solution we made as we believe that with a little more polish our project has great value to the real world. Additionally, each and every member was able to explore a new language, framework, or concept in this project allowing us to learn more too while solving issues. We were really impressed by the end product especially as it was produced in this short time span as we not only learnt but immediately applied our knowledge.
## What I learned
Our team was able to learn more about servers with Gradle, frontend development, connecting to databases online, and also more about how we can contribute to a global issue with a time relevant solution! We were also able to learn how to compact as much work and learning as possible into a small timespan while maintaining communications between team members.
## What's next for Vaccurate
The statistics and guidelines we presented in our project were made based off of reliable online resources, however it's important that we consult an official healthcare worker to create a more accurate grading scheme and better vaccination prioritization. Additionally, we would like to add features to make the UX more accessible, such as a booking calendar for both users and clinics, and the ability to directly modify appointments on the website. | losing |
## Inspiration
Is it possible to get a refrigerator from New York to Boston in less than a day without shelling out exorbitant delivery fees? How can we make the shopping experience for disabled persons more convenient, cheap, and independent?
## What it does
OnTheWay is an innovative P2P delivery system that harnesses the power of pre-existing routes to minimize the need for inconvenient, long-distance trips and therefore reduce environmental impact. Users are automatically matched to drivers who have the user item and pick-up spot along their route. Drivers are compensated by the user for the resulting minor detour.
## How we built it
We used two apps, one for the user side and one for the driver side. Both apps were created using Java/Kotlin in Android Studio, with the driver app being optimized for General Motors vehicles with the General Motors API and the user app being optimized for mobile devices. Backend server api's were created using node.js and the Distance Matrix API on Google Cloud Platform.
## What we learned
We learned a lot about Android development, APIs, and time management!!! | ## Inspiration
Parker was riding his bike down Commonwealth Avenue on his way to work this summer when a car pulled out of nowhere and hit his front tire. Lucky, he wasn't hurt, he saw his life flash before his eyes in that moment and it really left an impression on him. (His bike made it out okay as well, other than a bit of tire misalignment!)
As bikes become more and more ubiquitous as a mode of transportation in big cities with the growth of rental services and bike lanes, bike safety is more prevalent than ever.
## What it does
We designed \_ Bikeable \_ - a Boston directions app for bicyclists that uses machine learning to generate directions for users based on prior bike accidents in police reports. You simply enter your origin and destination, and Bikeable creates a path for you to follow that balances efficiency with safety. While it's comforting to know that you're on a safe path, we also incorporated heat maps, so you can see where the hotspots of bicycle theft and accidents occur, so you can be more well-informed in the future!
## How we built it
Bikeable is built in Google Cloud Platform's App Engine (GAE) and utilizes the best features three mapping apis: Google Maps, Here.com, and Leaflet to deliver directions in one seamless experience. Being build in GAE, Flask served as a solid bridge between a Python backend with machine learning algorithms and a HTML/JS frontend. Domain.com allowed us to get a cool domain name for our site and GCP allowed us to connect many small features quickly as well as host our database.
## Challenges we ran into
We ran into several challenges.
Right off the bat we were incredibly productive, and got a snappy UI up and running immediately through the accessible Google Maps API. We were off to an incredible start, but soon realized that the only effective way to best account for safety while maintaining maximum efficiency in travel time would be by highlighting clusters to steer waypoints away from. We realized that the Google Maps API would not be ideal for the ML in the back-end, simply because our avoidance algorithm did not work well with how the API is set up. We then decided on the HERE Maps API because of its unique ability to avoid areas in the algorithm. Once the front end for HERE Maps was developed, we soon attempted to deploy to Flask, only to find that JQuery somehow hindered our ability to view the physical map on our website. After hours of working through App Engine and Flask, we found a third map API/JS library called Leaflet that had much of the visual features we wanted. We ended up combining the best components of all three APIs to develop Bikeable over the past two days.
The second large challenge we ran into was the Cross-Origin Resource Sharing (CORS) errors that seemed to never end. In the final stretch of the hackathon we were getting ready to link our front and back end with json files, but we kept getting blocked by the CORS errors. After several hours of troubleshooting we realized our mistake of crossing through localhost and public domain, and kept deploying to test rather than running locally through flask.
## Accomplishments that we're proud of
We are incredibly proud of two things in particular.
Primarily, all of us worked on technologies and languages we had never touched before. This was an insanely productive hackathon, in that we honestly got to experience things that we never would have the confidence to even consider if we were not in such an environment. We're proud that we all stepped out of our comfort zone and developed something worthy of a pin on github.
We also were pretty impressed with what we were able to accomplish in the 36 hours. We set up multiple front ends, developed a full ML model complete with incredible data visualizations, and hosted on multiple different services. We also did not all know each other and the team chemistry that we had off the bat was astounding given that fact!
## What we learned
We learned BigQuery, NumPy, Scikit-learn, Google App Engine, Firebase, and Flask.
## What's next for Bikeable
Stay tuned! Or invest in us that works too :)
**Features that are to be implemented shortly and fairly easily given the current framework:**
* User reported incidents - like Waze for safe biking!
* Bike parking recommendations based on theft reports
* Large altitude increase avoidance to balance comfort with safety and efficiency. | ## Inspiration
With all team members living in urban cities, it was easy to use up all of our mobile data while on the go. From looking up restaurants nearby and playing pokemon go, it was easy to chew threw the limited data we had. We would constantly be looking for a nearby Tim Hortons, just to leech their wifi and look for a bus route to get home safely. Therefore, we drew our inspiration from living out the reality that our phones simply are not as useful with mobile data, and we know that many people around the globe depend on mobile data for both safety and convenience with their devices. With **NAVIGATR**, users will not have to rely on their mobile data to find travel information, weather, and more.
## What it does
NAVIGATR uses machine learning and scrapes real-time data to respond to any inquiry you might have when data isn't available to you. We have kept in mind that the main issues that people may have when on the go and running out of mobile data are travel times, bus routes, destination information, and weather information. So, NAVIGATR is able to pull all this information together to allow users to use their phone to the fullest even if they do not have access to mobile data; additionally, we are able to allow users to have peace of mind when on the go - they will always have the information they need to get home safely.
## How we built it
We built NAVIGATR using a variety of different technical tools; more specifically, we started by using Twilio. Twilio catches the SMS messages that are sent, and invokes a webhook to reply back to the message. Next, we use Beautifulsoup to scrape and provide data from Google seaches to answer queries; additionally, our machine learning model, GPT-3, can respond to general inquiries. Lastly, this is all tied together using Python, which facilitates communication between tools and catches user input errors.
## Challenges we ran into
Mainly, the TTC API was outdated by twelve years; therefore, we had to shift our focus to webscraping. Webscraping is more reliable than the TTC API, and we were able to create our application knowing all information is accurate. Furthermore, the client is allowed to input any starting point and destination they wish, and our application is now not limited to just the Toronto area.
## Accomplishments that we're proud of
We believe that we were able to address a very relevant issue in modern day society, which is safety in urban environments and mobile-data paywalls. With the explosion of technology in the last two decades, there is no reason why innovation can not be used to streamline information in this way. Moreover, we wanted to try and create an application that has geniune use for people around the globe; additionally, this goal lead us to innovate with the idea in mind of improving the daily lives of a variety of people.
## What we learned
We learned how to handle webscraping off Google, as well as creating webhooks and utilizing machine learning models to bring our ideas to life.
## What's next for NAVIGATR
Next, we would like to implement a wider variety of tools that align with our mission of providing users with simple answers to questions that they may have. Continuing on the theme of safety, we would like to add features which provide a user with information about high density areas vs. low density areas, weather warnings, as well as secure travel route vs. low risk travel routes. We believe that all of these features would greatly increase the impact NAVIGATR would have in a user's everyday life. | partial |
## Inspiration
In large corporations, such as RBC, the help desk gets called hundreds phone calls every hour, lasting about 8 minutes on average and costing the company $15 per hour. We thought this was both a massive waste of time and resources, not to mention it being quite ineffective and inefficient. We wanted to create a product that accelerated the efficiency of a help-desk to optimize productivity. We designed a product that has the ability to wrap a custom business model and a help service together in an accessible SMS link. This is a novel innovation that is heavily needed in today's businesses.
## What it does
SMS Assist offers the ability for a business to **automate their help-desk** using SMS messages. This allows requests to be answered both online and offline, an innovating accessibility perk that many companies need. Our system has no limit to concurrent users, unlike a live help-desk. It provides assistance for exactly what you need, and this is ensured by our IBM Watson model, which trains off client data and uses Machine Learning/NLU to interpret client responses to an extremely high degree of accuracy.
**Assist** also has the ability to recieve orders from customers if the businesses so chose. The order details and client information is all stored by the Node server, so that employees can view orders in realtime.
Finally, **Assist** utilizes text Sentiment Analysis to analyse each client's tone in their texts. It then sends a report to the console so that the company can receive feedback from customers automatically, and improve their systems.
## How we built it
We used Node.js, Twilio, and IBM watson to create SMS Assist.
**IBM Watson** was used to create the actual chatbots, and we trained it on user data in order to recognize the user's intent in their SMS messages. Through several data sets, we utilized Watson's machine learning and Natural Language & Sentiment analysis to make communication with Assist hyper efficient.
**Twilio** was used for the front end- connecting an SMS client with the server. Using our Twilio number, messages can be sent and received from any number globally!
**Node.js** was used to create the server on which SMS Assist runs on. Twilio first recieves data from a user, and sends it to the server. The server feeds it into our Watson chatbot, which then interprets the data and generates a formulated response. Finally, the response is relayed back to the server and into Twilio, where the user recieves the respons via SMS.
## Challenges we ran into
There were many bugs involving the Node.js server. Since we didn't have much initial experience with Node or the IBM API, we encountered many problems, such as the SessionID not being saved and the messages not being sent via Twilio. Through hours of hard work, we persevered and solved these problems, resulting in a perfected final product.
## Accomplishments that we're proud of
We are proud that we were able to learn the new API's in such a short time period. All of us were completely new to IBM Watson and Twilio, so we had to read lots of documentation to figure things out. Overall, we learned a new useful skill and put it to good use with this project. This idea has the potential to change the workflow of any business for the better.
## What we learned
We learned how to use the IBM Watson API and Twilio to connect SMS messages to a server. We also discovered that working with said API's is quite complex, as many ID's and Auth factors need to be perfectly matched for everything to execute.
## What's next for SMS Assist
With some more development and customization for actual businesses, SMS Assist has the capability to help thousands of companies with their automated order systems and help desk features. More features can also be added | ## Inspiration
While caught in the the excitement of coming up with project ideas, we found ourselves forgetting to follow up on action items brought up in the discussion. We felt that it would come in handy to have our own virtual meeting assistant to keep track of our ideas. We moved on to integrate features like automating the process of creating JIRA issues and providing a full transcript for participants to view in retrospect.
## What it does
*Minutes Made* acts as your own personal team assistant during meetings. It takes meeting minutes, creates transcripts, finds key tags and features and automates the process of creating Jira tickets for you.
It works in multiple spoken languages, and uses voice biometrics to identify key speakers.
For security, the data is encrypted locally - and since it is serverless, no sensitive data is exposed.
## How we built it
Minutes Made leverages Azure Cognitive Services for to translate between languages, identify speakers from voice patterns, and convert speech to text. It then uses custom natural language processing to parse out key issues. Interactions with slack and Jira are done through STDLIB.
## Challenges we ran into
We originally used Python libraries to manually perform the natural language processing, but found they didn't quite meet our demands with accuracy and latency. We found that Azure Cognitive services worked better. However, we did end up developing our own natural language processing algorithms to handle some of the functionality as well (e.g. creating Jira issues) since Azure didn't have everything we wanted.
As the speech conversion is done in real-time, it was necessary for our solution to be extremely performant. We needed an efficient way to store and fetch the chat transcripts. This was a difficult demand to meet, but we managed to rectify our issue with a Redis caching layer to fetch the chat transcripts quickly and persist to disk between sessions.
## Accomplishments that we're proud of
This was the first time that we all worked together, and we're glad that we were able to get a solution that actually worked and that we would actually use in real life. We became proficient with technology that we've never seen before and used it to build a nice product and an experience we're all grateful for.
## What we learned
This was a great learning experience for understanding cloud biometrics, and speech recognition technologies. We familiarised ourselves with STDLIB, and working with Jira and Slack APIs. Basically, we learned a lot about the technology we used and a lot about each other ❤️!
## What's next for Minutes Made
Next we plan to add more integrations to translate more languages and creating Github issues, Salesforce tickets, etc. We could also improve the natural language processing to handle more functions and edge cases. As we're using fairly new tech, there's a lot of room for improvement in the future. | ## Inspiration
We like walking at night, but we don't like getting mugged. 💅🤷♀️We can't program personal bodyguards (yet) so preventative measures are our best bet! Accessibility and intuitiveness are 🔑in our idea.
## What it does
HelpIs allows users to contact services when they feel unsafe. 📱Location trackers integrate tech into emergency services, which tend to lag behind corporations in terms of tech advancements. 🚀🚔🚓
## How we built it
We heavily relied on the use of APIs from Twilio and MapBox to create our project. 💪Specifically, we employed Twilio Programmable Voice for calling 🗣️🗣️, Mapbox GL JS for map display and geolocation 🗺️🗺️, and Mapbox Directions API for route finding and travel time prediction 📍📍. The web app itself is built with [VanillaJS](http://vanilla-js.com/) (:p), HTML, and CSS. 🙆
## Challenges we ran into
Our original design centered on mobile connectivity through a phone app and a wider range of extendable features. Unfortunately, one of our teammates couldn't make it as scheduled 💔, and we had to make some trade-offs 💀💀. Eventually, we pulled through and are thrilled to exceed many goals we set for ourselves at the start of the hack! 💥🔥💯
🚩🚩🚩Also, Alison thought the name was HelpIs (as in like Help is coming!) but Alex (who came up with the name) assumed she could tell it was Helpls (like Help + pls = Helpls). 🐒He even wrote about it in the footnotes of his mockup. You can go read it. Embarrassing... 🚩🚩🚩
## Accomplishments that we're proud of
We are so proud of the concept behind HelpIs that we decided to make our **first ever** pitch! ⚾
Thanks Alex for redoing it like four times! 💔😅
## What we learned
Differentiating our program from existing services is important in product ideation! 🤑
Also, putting emojis into our about page is super funny 🦗🦟🦗🦟🦗🦟🦗🦟
## What's next for HelpIs
We want to make it mobile! There are a few more features that we had planned for the mobile version. Specifically, we were looking to use speech-to-text and custom "code words" to let a user contact authorities without alerting those around them, inspired by the famous [911 call disguised as pizza order](https://www.youtube.com/watch?v=ZJL_8kNFmTI)! 🤩🤩🤩 | winning |
## Inspiration
Water pollution is more and more serious now. This is not a solid solution to solve the water quality. Instead, we design the game to make more people be aware of the damage we do to the water system. With more people involved and motivated, the water system will be restored for sure.
## What it does
A web RPG game to show you how tough it is to survive as a fish. Play as a fish, pass four mini-games and try to survive in an open world.
## How we built it
html+css+js(for the first time)
## Challenges we ran into
Since this is the first time we build a web game with javascript, there is a lot to learn about. Due to the time limit, only part of the code is completed.
## Accomplishments that we're proud of
I love the idea of the game, especially the open world at the end. What players are going to play as is totally by chance, and the only goal here is to survive!
## What we learned
A lot of programming skills and game design knowledge for sure.
## What's next for Back to sea
I'll complete the project after the hackathon and put it online. | ## Inspiration
Sometimes we don’t think too much about how infrastructure impacts the way we live our lives. Unalerted icy sidewalks or a dimly lit alleyway could pose as an inconvenience or potential danger to a person’s life. Living in the age of information, we believe that the spread of knowledge through community is very important if we are given so many resources that could provide a safer place for every day living. Though this project is only focused on the local areas of the users, these small reports can provide a way for incremental impact – logistical analysis to improve infrastructure, safety, and awareness.
## What It does
SusMap addresses the problem of infrastructure by providing a map of all pinpointed data collected from users. With this data, users from around the local area would be notified of the locations (longitude/latitude coordinates) of hazardous, suspicious and accessibility issues. When a user submits the information, they will choose what type of activity (hazard, suspicion, accessibility) they would like to report, and under that activity they will choose a subtype (for instance if the user choose hazard, they can then report what kind of hazard: slippery stair way, or icicle droppings). This would be submitted to the database that we have set up with Firebase. Our database stores each data entry, which consists of 5 fields – description, latitude, longitude, type and subtype – in individual documents. In order to keep track of how many incidents have been reported in the same area, the algorithm will tally each time the coordinates match up or are within proximity to one another. These counts will also help us access the credibility of the reports – the lower the count after a certain amount of time will lower the priority of the report.
## How we built it
Our app is built on Esri’s Feature and Map APIs. This played a huge part in the foundation of our code because it gave us a user interface to work with geolocations to pinpoint the different issue areas. We bounced back and forth a lot on whether or not we should use Javascript/HTML or to create a React.js app and just add a map on top of that. After speaking to different mentors, we stuck with what was known best by majority of the group: Javascript/HTML. We used Firebase to create a database to store our data on the cloud. This allows us to easily add and retrieve data after asking for user inputs. Then we used the App Engine to deploy our web application.
**Challenges we ran into:**
Although we were using Esri’s Feature and Map APIs, a challenge we had was deciding whether or not we would use React.js or Javascript/Html to implement our project. After speaking to different mentors, we stuck with what was known best by majority of the group: Javascript/HTML/CSS.
**Accomplishments that we’re proud of:**
We're super excited that we were able to successfully utilize and integrate Esri's APIs into our application. In addition, we were able to host our project on the Google Cloud Platform. Lastly, we're proud of designing our project focusing on UI/UX first, allowing for an easy to use and seamless experience for the user.
## What we learned
As a beginner team in web development, we all had to refresh our skills and/or learn HTML/CSS/JavaScript. In addition, we learned so much about integrating API's into our project. In addition, we learned how to test and deploy our web app using Googe-compute-engine and Google-app-engine.
## What’s next for SusMap?
We would like to turn this into a mobile app for better accessibility and to create an easier way for reporting and retrieving data. We would also like to create a function that would allow for interested parties, such as school administration and government officials who overlook public work, to query the information in the database in order to make any necessary improvements. | ## Inspiration
The first step of our development process was conducting user interviews with University students within our social circles. When asked of some recently developed pain points, 40% of respondents stated that grocery shopping has become increasingly stressful and difficult with the ongoing COVID-19 pandemic. The respondents also stated that some motivations included a loss of disposable time (due to an increase in workload from online learning), tight spending budgets, and fear of exposure to covid-19.
While developing our product strategy, we realized that a significant pain point in grocery shopping is the process of price-checking between different stores. This process would either require the user to visit each store (in-person and/or online) and check the inventory and manually price check. Consolidated platforms to help with grocery list generation and payment do not exist in the market today - as such, we decided to explore this idea.
**What does G.e.o.r.g.e stand for? : Grocery Examiner Organizer Registrator Generator (for) Everyone**
## What it does
The high-level workflow can be broken down into three major components:
1: Python (flask) and Firebase backend
2: React frontend
3: Stripe API integration
Our backend flask server is responsible for web scraping and generating semantic, usable JSON code for each product item, which is passed through to our React frontend.
Our React frontend acts as the hub for tangible user-product interactions. Users are given the option to search for grocery products, add them to a grocery list, generate the cheapest possible list, compare prices between stores, and make a direct payment for their groceries through the Stripe API.
## How we built it
We started our product development process with brainstorming various topics we would be interested in working on. Once we decided to proceed with our payment service application. We drew up designs as well as prototyped using Figma, then proceeded to implement the front end designs with React. Our backend uses Flask to handle Stripe API requests as well as web scraping. We also used Firebase to handle user authentication and storage of user data.
## Challenges we ran into
Once we had finished coming up with our problem scope, one of the first challenges we ran into was finding a reliable way to obtain grocery store information. There are no readily available APIs to access price data for grocery stores so we decided to do our own web scraping. This lead to complications with slower server response since some grocery stores have dynamically generated websites, causing some query results to be slower than desired. Due to the limited price availability of some grocery stores, we decided to pivot our focus towards e-commerce and online grocery vendors, which would allow us to flesh out our end-to-end workflow.
## Accomplishments that we're proud of
Some of the websites we had to scrape had lots of information to comb through and we are proud of how we could pick up new skills in Beautiful Soup and Selenium to automate that process! We are also proud of completing the ideation process with an application that included even more features than our original designs. Also, we were scrambling at the end to finish integrating the Stripe API, but it feels incredibly rewarding to be able to utilize real money with our app.
## What we learned
We picked up skills such as web scraping to automate the process of parsing through large data sets. Web scraping dynamically generated websites can also lead to slow server response times that are generally undesirable. It also became apparent to us that we should have set up virtual environments for flask applications so that team members do not have to reinstall every dependency. Last but not least, deciding to integrate a new API at 3am will make you want to pull out your hair, but at least we now know that it can be done :’)
## What's next for G.e.o.r.g.e.
Our next steps with G.e.o.r.g.e. would be to improve the overall user experience of the application by standardizing our UI components and UX workflows with Ecommerce industry standards. In the future, our goal is to work directly with more vendors to gain quicker access to price data, as well as creating more seamless payment solutions. | losing |
[Repository](https://github.com/BradenC82/A_Treble-d_Soul/)
## Inspiration
Mental health is becoming decreasingly stigmatized and more patients are starting to seek solutions to well-being. Music therapy practitioners face the challenge of diagnosing their patients and giving them effective treatment. We like music. We want patients to feel good about their music and thus themselves.
## What it does
Displays and measures the qualities of your 20 most liked songs on Spotify (requires you to log in). Seven metrics are then determined:
1. Chill: calmness
2. Danceability: likeliness to get your groove on
3. Energy: liveliness
4. Focus: helps you concentrate
5. Audacity: absolute level of sound (dB)
6. Lyrical: quantity of spoken words
7. Positivity: upbeat
These metrics are given to you in bar graph form. You can also play your liked songs from this app by pressing the play button.
## How I built it
Using Spotify API to retrieve data for your liked songs and their metrics.
For creating the web application, HTML5, CSS3, and JavaScript were used.
React was used as a framework for reusable UI components and Material UI for faster React components.
## Challenges I ran into
Learning curve (how to use React). Figuring out how to use Spotify API.
## Accomplishments that I'm proud of
For three out of the four of us, this is our first hack!
It's functional!
It looks presentable!
## What I learned
React.
API integration.
## What's next for A Trebled Soul
Firebase.
Once everything's fine and dandy, registering a domain name and launching our app.
Making the mobile app presentable. | ## Inspiration
We wanted to find a way to use music to help users with improving their mental health. Music therapy is used to improve cognitive brain functions like memory, regulate mood, improve the quality of sleep, managing stress and it can even help with depression. What's more is that music therapy has been proven to help with physical wellbeing as well when paired with usual treatment in clinical settings. Music is also a great way to improve productivity such as listening to pink noise or white noise to aid in focus or sleep
We wanted to see if it was possible to this music to a user's music taste when given a music therapy goal, enhancing the experience of music therapy for the individual. This can be even more application in challenging times such as COVID-19 due to a decline in mental health for the general population.
This is where Music Remedy comes in: understanding the importance of music therapy and all its applications, can we *personalize this experience even further*?
## What it does
Users can log in to the app using their Spotify credentials where the app then has access to the user's Spotify data. As the users navigate through the app, they are asked to select what their goal for music therapy is.
Upon this, when the music therapy goal is chosen, the app creates a playlist for the user according to their Spotify listening history and pre-existing playlists to help them with emotional and physical health and healing. Through processing the user's taste in music, it will allow the app to create a playlist that's more favorable to the user's likes and needs while still accomplishing the goals of music therapy.
Described above allows the user to experience music therapy in a more enhanced and personalized way by ensuring that the user is listening to music to aid in their therapy while also ensuring that it is from songs and artists that they enjoy.
## How we built it
We used the Spotify API to aid with authentication and the users' music taste and history. This gave details on what artists and genres the user typically listened to and enjoyed
We built the web app representing the user interface using NodeJS paired with ExpressJS on the backend and JavaScript, HTML, CSS on the front end through the use of EJS templating, Bootstrap and jQuery.
A prototype for the mobile app representing the event participant interface was built using Figma.
## Challenges we ran into
There are definitely many areas of the Musical Remedy app that can be improved upon if we were given more time. Deciding on the idea and figuring out how much was feasible within the time given was a bit of a challenge. We tried to find the simplest way to effectively express our point across.
Additionally, this hackathon was our first introduction to the Spotify API and using user's data to generate new data for other uses.
## Accomplishments that we're proud of
We are proud of how much we learned about the Spotify API and how to use it over the course of the weekend. Additionally, learning to become more efficient in HTML, CSS and JavaScript using EJS templating is something we'd definitely use in the future with other projects.
## What we learned
We've learned how to effectively manage my time during the hackathon. We tried to work on most of my work during the peak hours of my productivity and took breaks whenever I got too overwhelmed or frustrated.
Additionally, we learned more about the Spotify API and the use of APIs in generals.
## What's next for Musical Remedy
Musical Remedy has the potential to expand its base of listeners from just Spotify users. So far, we are imaging to be able to hook up a database to store user's music preferences which would be recorded using a survey of their favourite genres, artists, etc. Additionally, we'd like to increase the number and specificity of parameters when generating recommended playlists to tailor to the specific categories (pain relief, etc.)
## Domain.Com Entry
Our domains is registered as `whatsanothernameforapplejuice-iphonechargers.tech` | ## Inspiration
The project was inspired by looking at the challenges that artists face when dealing with traditional record labels and distributors. Artists often have to give up ownership of their music, lose creative control, and receive only a small fraction of the revenue generated from streams. Record labels and intermediaries take the bulk of the earnings, leaving the artists with limited financial security. Being a music producer and a DJ myself, I really wanted to make a product with potential to shake up this entire industry for the better. The music artists spend a lot of time creating high quality music and they deserve to be paid for it much more than they are right now.
## What it does
Blockify lets artists harness the power of smart contracts by attaching them to their music while uploading it and automating the process of royalty payments which is currently a very time consuming process. Our primary goal is to remove the record labels and distributors from the industry since they they take a majority of the revenue which the artists generate from their streams for the hard work which they do. By using a decentralized network to manage royalties and payments, there won't be any disputes regarding missed or delayed payments, and artists will have a clear understanding of how much money they are making from their streams since they will be dealing with the streaming services directly. This would allow artists to have full ownership over their work and receive a fair compensation from streams which is currently far from the reality.
## How we built it
BlockChain: We used the Sui blockchain for its scalability and low transaction costs. Smart contracts were written in Move, the programming language of Sui, to automate royalty distribution.
Spotify API: We integrated Spotify's API to track streams in real time and trigger royalty payments.
Wallet Integration: Sui wallets were integrated to enable direct payments to artists, with real-time updates on royalties as songs are streamed.
Frontend: A user-friendly web interface was built using React to allow artists to connect their wallets, and track their earnings. The frontend interacts with the smart contracts via the Sui SDK.
## Challenges we ran into
The most difficult challenge we faced was the Smart Contract Development using the Move language. Unlike commonly known language like Ethereum, Move is relatively new and specifically designed to handle asset management. Another challenge was trying to connect the smart wallets in the application and transferring money to the artist whenever a song was streamed, but thankfully the mentors from the Sui team were really helpful and guided us in the right path.
## Accomplishments that we're proud of
This was our first time working with blockchain, and me and my teammate were really proud of what we were able to achieve over the two days. We worked on creating smart contracts and even though getting started was the hardest part but we were able to complete it and learnt some great stuff along the way. My teammate had previously worked with React but I had zero experience with JavaScript, since I mostly work with other languages, but we did the entire project in Node and React and I was able to learn a lot of the concepts in such a less time which I am very proud of myself for.
## What we learned
We learned a lot about Blockchain technology and how can we use it to apply it to the real-world problems. One of the most significant lessons we learned was how smart contracts can be used to automate complex processes like royalty payments. We saw how blockchain provides an immutable and auditable record of every transaction, ensuring that every stream, payment, and contract interaction is permanently recorded and visible to all parties involved. Learning more and more about this technology everyday just makes me realize how much potential it holds and is certainly one aspect of technology which would rule the future. It is already being used in so many aspects of life and we are still discovering the surface.
## What's next for Blockify
We plan to add more features, such as NFTs for exclusive content or fan engagement, allowing artists to create new revenue streams beyond streaming. There have been some real-life examples of artists selling NFT's to their fans and earning millions from it, so we would like to tap into that industry as well. Our next step would be to collaborate with other streaming services like Apple Music and eliminate record labels to the best of our abilities. | partial |
## Inspiration
Everyday we spend hours filling out our Google Calendars to stay organized with our events. How can we get the most out of our effort planning ahead? While Spotify already recommends music by our individual tastes, how can we utilize artificial intelligence and software integration to get music that fits our daily routine?
## What it does
By integrating Google Calendar, Spotify, and Wolfram technologies, we can create a simple but powerful web application that parses your events and generates playlists specifically for your events.
Going on a date? Romance playlist.
Lot's of studying? Focus playlist.
Time for bed? Sleep playlist.
## How we built it
After identifying a problem and working on a solution, we worked on designing our site in Figma. This gave us an idea of what our final product would look like. We then integrated Google Calendar and Spotify APIs into our application. This way, we can get information about a user's upcoming events, process them, and suggest Spotify playlists that meet their mood. We implemented Wolfram's Cloud API to understand the user's GCal events and route to related spotify playlists for each event accordingly. Finally, to make sure our app was robust, we tested various events that a typical student might list on their calendar. We added some styling so that the final product looks clean and is easy to use.
## Challenges we ran into
API's
## Accomplishments that we're proud of
Integrating Google Calendar, Spotify, and Wolfram.
## What we learned
Integration of various API's
## What's next for music.me
As of now, music.me is only a web application. Going forward, we want to offer this product as an app on phones, watches, and tablets as well. We want users to be able to control their own music as well. If they want to listen to a custom playlist every time they have a specific event, they should be able to "link" an event with a playlist. | ## Inspiration
Cargo ships are the primary ways of transporting produce across oceans. However, their sensitive nature makes them sensitive to degrading in transit -- resulting in unnecessary waste. About 33% of global fresh produce is thrown away due to their quality degrading during shipment. Additionally, every year, at the US-Mexican border, 35-45 millions pounds of fruits and vegetables are thrown away due to not meeting standards. This hurts both consumers and suppliers alike.
## What it does
Uses sensors, Computer Vision, and ML to improve the efficiency of current supply chain management. Using IOT, we build smart containers that can detect if a produce is fresh or not and then creates a bidding system based on how fresh a produce is and uses it to distribute it.
[Input]: Suppliers create a product page on their shipment and sync the device to it.
[Bidding]: Prospective buyers can bid on the product shipment by inputting two parameters: their bid amount and their maximum freshness threshold. After the bid winning, it is locked to them.
[Monitoring/Rebidding]: The order is shipped and monitored by the hardware to provide interested parties with details such as location, humidity, temperature, CO2, and the like. If it falls below a set freshness threshold, the customer can back-out and re-open bidding. Otherwise, it works like a typical B2B ordering site and remains locked to the customer.
The freshness score is calculated by using an Ensemble Machine Learning approach that incorporates multivariate Ordinary Least Squares and Computer Vision to predict how fresh a produce is.
The image is then updated onto the database after ever hour. | ## Inspiration
What inspired the beginning of the idea was terrible gym music and the thought of a automatic music selection based on the tastes of people in the vicinity. Our end goal is to sell a hosting service to play music that people in a local area would want to listen to.
## What it does
The app has two parts. A client side connects to Spotify and allows our app to collect users' tokens, userID, email and the top played songs. These values are placed inside a Mongoose database and the userID and top songs are the main values needed. The host side can control the location and the radius they want to cover. This allows the server to be populated with nearby users and their top songs are added to the host accounts playlist. The songs most commonly added to the playlist have a higher chance of being played.
This app could be used at parties to avoid issues discussing songs, retail stores to play songs that cater to specific groups, weddings or all kinds of social events. Inherently, creating an automatic DJ to cater to the tastes of people around an area.
## How we built it
We began by planning and fleshing out the app idea then from there the tasks were split into four sections: location, front end, Spotify and database. At this point we decided to use React-Native for the mobile app and NodeJS for the backend was set into place. After getting started the help of the mentors and the sponsors were crucial, they showed us all the many different JS libraries and api's available to make life easier. Programming in Full Stack MERN was a first for everyone in this team. We all hoped to learn something new and create an something cool.
## Challenges we ran into
We ran into plenty of problems. We experienced many syntax errors and plenty of bugs. At the same time dependencies such as Compatibility concerns between the different APIs and libraries had to be maintained, along with the general stress of completing on time. In the end We are happy with the product that we made.
## Accomplishments that we are proud of
Learning something we were not familiar with and being able to make it this far into our project is a feat we are proud of. .
## What we learned
Learning about the minutia about Javascript development was fun. It was because of the mentors assistance that we were able to resolve problems and develop at a efficiently so we can finish. The versatility of Javascript was surprising, the ways that it is able to interact with and the immense catalog of open source projects was staggering. We definitely learned plenty... now we just need a good sleep.
## What's next for SurroundSound
We hope to add more features and see this application to its full potential. We would make it as autonomous as possible with seamless location based switching and database logging. Being able to collect proper user information would be a benefit for businesses. There were features that did not make it into the final product, such as voting for the next song on the client side and the ability for both client and host to see the playlist. The host would have more granular control such as allowing explicit songs, specifying genres and anything that is accessible by the Spotify API. While the client side can be gamified to keep the GPS scanning enabled on their devices, such as collecting points for visiting more areas. | partial |
## Inspiration
With the numerous social justice issues being brought to light in the past while, demonstrations and protests have swept the world for reform. We as a team wanted to address this issue.
Also, we have seen UIPath as a sponsor for a few hackathons now and wanted to try it out in a project.
## What it does
Protest RPA scrapes the web for protest information and dates from articles, effortlessly converts raw data written by people into a machine-friendly format, and uploads the newly created file directly to Google Drive - all without human help.
## How we built it
Protest RPA is heavily based on the UIPath software for scraping data, automating connections, exporting, and uploading to Google Calendar without human intervention. The bulk of the data processing is done through Excel queries and formulas to convert unformatted text to a computer friendly file.
## Challenges we ran into
We both had no prior experience with UIPath or other RPAs. It was both fun and challenging to work on a project that was entirely graphical with no code.
## Accomplishments that we're proud of
We learned a new technology and got everything polished and working smoothly.
## What we learned
We learned how to use RPA software, something that is highly applicable to other projects and automation tasks in general.
## What's next for Protest RPA
Next we want to work on deployment. How can we get this tool in the hands of others? | ## Inspiration
Since this was the first hackathon for most of our group, we wanted to work on a project where we could learn something new while sticking to familiar territory. Thus we settled on programming a discord bot, something all of us have extensive experience using, that works with UiPath, a tool equally as intriguing as it is foreign to us. We wanted to create an application that will allow us to track the prices and other related information of tech products in order to streamline the buying process and enable the user to get the best deals. We decided to program a bot that utilizes user input, web automation, and web-scraping to generate information on various items, focusing on computer components.
## What it does
Once online, our PriceTracker bot runs under two main commands: !add and !price. Using these two commands, a few external CSV files, and UiPath, this stores items input by the user and returns related information found via UiPath's web-scraping features. A concise display of the product’s price, stock, and sale discount is displayed to the user through the Discord bot.
## How we built it
We programmed the Discord bot using the comprehensive discord.py API. Using its thorough documentation and a handful of tutorials online, we quickly learned how to initialize a bot using Discord's personal Development Portal and create commands that would work with specified text channels. To scrape web pages, in our case, the Canada Computers website, we used a UiPath sequence along with the aforementioned CSV file, which contained input retrieved from the bot's "!add" command. In the UiPath process, each product is searched on the Canada Computers website and then through data scraping, the most relevant results from the search and all related information are processed into a csv file. This csv file is then parsed through to create a concise description which is returned in Discord whenever the bot's "!prices" command was called.
## Challenges we ran into
The most challenging aspect of our project was figuring out how to use UiPath. Since Python was such a large part of programming the discord bot, our experience with the language helped exponentially. The same could be said about working with text and CSV files. However, because automation was a topic none of us hardly had any knowledge of; naturally, our first encounter with it was rough. Another big problem with UiPath was learning how to use variables as we wanted to generalize the process so that it would work for any product inputted.
Eventually, with enough perseverance, we were able to incorporate UiPath into our project exactly the way we wanted to.
## Accomplishments that we're proud of
Learning the ins and outs of automation alone was a strenuous task. Being able to incorporate it into a functional program is even more difficult, but incredibly satisfying as well. Albeit small in scale, this introduction to automation serves as a good stepping stone for further research on the topic of automation and its capabilities.
## What we learned
Although we stuck close to our roots by relying on Python for programming the discord bot, we learned a ton of new things about how these bots are initialized, the various attributes and roles they can have, and how we can use IDEs like Pycharm in combination with larger platforms like Discord. Additionally, we learned a great deal about automation and how it functions through UiPath which absolutely fascinated us the first time we saw it in action. As this was the first Hackathon for most of us, we also got a glimpse into what we have been missing out on and how beneficial these competitions can be. Getting the extra push to start working on side-projects and indulging in solo research was greatly appreciated.
## What's next for Tech4U
We went into this project with a plethora of different ideas, and although we were not able to incorporate all of them, we did finish with something we were proud of. Some other ideas we wanted to integrate include: scraping multiple different websites, formatting output differently on Discord, automating the act of purchasing an item, taking input and giving output under the same command, and more. | ## Inspiration
We as a team shared the same interest in knowing more about Machine Learning and its applications. upon looking at the challenges available, we were immediately drawn to the innovation factory and their challenges, and thought of potential projects revolving around that category. We started brainstorming, and went through over a dozen design ideas as to how to implement a solution related to smart cities. By looking at the different information received from the camera data, we landed on the idea of requiring the raw footage itself and using it to look for what we would call a distress signal, in case anyone felt unsafe in their current area.
## What it does
We have set up a signal that if done in front of the camera, a machine learning algorithm would be able to detect the signal and notify authorities that maybe they should check out this location, for the possibility of catching a potentially suspicious suspect or even being present to keep civilians safe.
## How we built it
First, we collected data off the innovation factory API, and inspected the code carefully to get to know what each part does. After putting pieces together, we were able to extract a video footage of the nearest camera to us. A member of our team ventured off in search of the camera itself to collect different kinds of poses to later be used in training our machine learning module. Eventually, due to compiling issues, we had to scrap the training algorithm we made and went for a similarly pre-trained algorithm to accomplish the basics of our project.
## Challenges we ran into
Using the Innovation Factory API, the fact that the cameras are located very far away, the machine learning algorithms unfortunately being an older version and would not compile with our code, and finally the frame rate on the playback of the footage when running the algorithm through it.
## Accomplishments that we are proud of
Ari: Being able to go above and beyond what I learned in school to create a cool project
Donya: Getting to know the basics of how machine learning works
Alok: How to deal with unexpected challenges and look at it as a positive change
Sudhanshu: The interesting scenario of posing in front of a camera while being directed by people recording me from a mile away.
## What I learned
Machine learning basics, Postman, working on different ways to maximize playback time on the footage, and many more major and/or minor things we were able to accomplish this hackathon all with either none or incomplete information.
## What's next for Smart City SOS
hopefully working with innovation factory to grow our project as well as inspiring individuals with similar passion or desire to create a change. | partial |
## Inspiration
Students entering University are often faced with many financial burdens that prevent them from reaching their highest levels of success. Many students succumb to the increased costs and avoid signing up for or receiving benefits that hinder them in their educational path. We believe that students should not face these difficulties and should have an easy way to allow people to support their journey. Current solutions such as creating a goFundMe or wishlist of products often fail to have their desired impact since students cannot fully explain their backstory or motivation. Donors often have no way to hold the student accountable to success and are completely in the darkness about how their funds are used. We aim to solve these issues by providing a transparent portal for students to list the products they need for their University and be able to receive support from generous benefactors. Donors have the peace of mind that their funds are directly being used to procure resources that will benefit the student and not have to worry about fund misappropriation. Our end goal is to create a trackable portal for students that will maximize their open opportunities.
## What it does
Our application creates a portal where students can create a custom list of items that they require to be able to attend university. Upon entering our site, donors will be able to browse through the list of items and subsequently choose how they wish to empower the students. They will be able to select and item to learn more about it. Finally, they will be prompted to pay for it which will take the user information and pass it to stdlib that will make stripe api calls to charge payments.
## How I built it
We used Vue.js, an innovative framework that combines multiple aspects of web development such as templates, scripts and designs together into singular files. Without having experience in this particular framework, it involved a steep learning curve for our teammates but was made easier by the framework that allows easy importing of libraries and components. To execute our api calls, we decided to use Standard Library. This was motivated due to several reasons. The primary reason was the ability to encapsulate multiple api calls and functions together into a new simplified api call. We were able to assign redundant variables in advance and only pass in relevant information. The second reason that motivated us to make use of standard library was security. Adding api calls to our codebase would have exposed api-keys and sensitive data. By wrapping these calls, we were able to secure our information and prevent malicious use of the code even if inspected. Within standard library, we used their latest Autocode feature to develop supported api calls to send text messages upon payment for a product. Furthermore, we designed custom actions that would create invoice items, bundle them together into an invoice and finally bill a customer. These were carried out with the Stripe API and allows for quick and easy billing of users. Together, this system allows students to receive immediate confirmation for products that were purchased for them and the donor to be charged automatically in a secure manner.
## Challenges I ran into
Vue.js was a completely new framework to us and we were unfamiliar with how to use it. The framework is different from typical web development by combining the various different parts of web development together into one file. Another challenge we ran into was deploying to google app engine. There was not much documentation on how to deploy a vue project.
## Accomplishments that I'm proud of
Proud of having learned how to use std library and the many benefits of using it. We managed to secure our api calls and not expose any vital information in the process.
## What I learned
We learned how to use Vue.js and hope to use it in future projects. Also worked in a team where all teammates met each other on the day of the hackathon. Learned how to quickly understand teammates skills and get effective in finishing a project.
## What's next for Empower Me
Creating a way to keep track and hold students accountable. Add loading bars and progress trackers as well as dynamic changing of the site as different payments are processed. | ## Our Inspiration, what it does, and how we built it
We wanted to work on something that challenged the engineering of today’s consumer economy. As college students across different campuses we noticed the common trend of waste, hoarding, and overspending among students. At the core of this issue is a first-instinct to buy a solution, whether service or product, when a problem arises. We did some market research among fellow hackers and on our college's subreddits – finding that students have no choice but to pay for items/services or go without them. To solve this we wanted to introduce a platform to allow students an alternative way to pay for items, allowing students to leverage the typically illiquid assets that they already have.
## Challenges we ran into
We wanted to keep development light, so we chose to use React and Convex to abstract away many of the details associated with full stack development. Still, however, among our biggest challenges was getting everyone up to par in terms of technical ability. We are students from all sorts of backgrounds (from cognitive science to business to CS majors!) and who all had varying levels of experience with development.
## Accomplishments that we're proud of and what we learned.
That’s why, as we finished up the final steps of the Hackathon, we felt so proud of being able to power through and produce a functional product of our vision. All of us grew and learned immensely about software development, converting ideas into tangible visions (using tools such as Figma and Dall-E), and - most importantly - the “hacker” mindset. We all have had so much to take away from this experience.
## What's next for BarterBuddies
Our long-term vision for the app is to become the go-to platform for bartering and item trading among young adults. We plan to expand and grow beyond the college student market by developing partnerships with other organizations and by continually iterating on the platform to meet the changing needs of our users. | ## Inspiration
We have a problem! We have a new generation of broke philanthropists.
The majority of students do not have a lot of spare cash so it can be challenging for them to choose between investing in their own future or the causes that they believe in to build a better future for others.
On the other hand, large companies have the capital needed to make sizeable donations but many of these acts go unnoticed or quickly forgotten.
## What it does
What if I told you that there is a way to support your favourite charities while also saving money? Students no longer need to choose between investing and donating!
Giving tree changes how we think about investing. Giving tree focuses on a charity driven investment model providing the ability to indulge in philanthropy while still supporting your future financially.
We created a platform that connects students to companies that make donations to the charities that they are interested in. Students will be able to support charities they believe in by investing in companies that are driven to make donations to such causes.
Our mission is to encourage students to invest in companies that financially support the same causes they believe in. Students will be able to not only learn more about financial planning but also help support various charities and services.
## How we built it
### Backend
The backend of this application was built using python. In the backend, we were able to overcome one of our largest obstacles, that this concept has never been done before! We really struggled finding a database or API that would provide us with information on what companies were donating to which charities.
So, how did we overcome this? We wanted to avoid having to manually input the data we needed as this was not a sustainable solution. Additionally, we needed a way to get data dynamically. As time passes, companies will continue to donate and we needed recent and topical data.
Giving Tree overcomes these obstacles using a 4 step process:
1. Using a google search API, search for articles about companies donating to a specified category or charity.
2. Identify all the nouns in the header of the search result.
3. Using the nouns, look for companies with data in Yahoo Finance that have a strong likeness to the noun.
4. Get the financial data of the company mentioned in the article and return the financial data to the user.
This was one of our greatest accomplishments of this project. We were able to overcome and obstacle that almost made us want to do a different project. Although the algorithm can occasionally produce false positives, it works more often than not and allows for us to have a self-sustaining platform to build off of.
### Flask
```shell script
$ touch application.py
from flask import Flask
application = Flask(**name**)
@application.route('/')
def hello\_world():
return 'Hello World'
```
```shell script
$ export FLASK_APP="application.py"
$ flask run
```
Now runs locally:
<http://127.0.0.1:5000/>
### AWS Elastic Beanstalk
Create a Web Server Environment:
```shell script
AWS -> Services -> Elastic beanstalk
Create New Application called hack-western-8 using Python
Create New Environment called hack-western-8-env using Web Server Environment
```
### AWS CodePipeline
Link to Github for Continuous Deployment:
```shell script
Services -> Developer Tools -> CodePipeline
Create Pipeline called hack-western-8
GitHub Version 2 -> Connect to Github
Connection Name -> Install a New App -> Choose Repo Name -> Skip Build Stage -> Deploy to AWS Elastic Beanstalk
```
This link is no longer local:
<http://hack-western-8-env.eba-a5injkhs.us-east-1.elasticbeanstalk.com/>
### AWS Route 53
Register a Domain:
```shell script
Route 53 -> Registered Domains -> Register Domain -> hack-western-8.com -> Check
Route 53 -> Hosted zones -> Create Record -> Route Traffic to IPv4 Address -> Alias -> Elastic Beanstalk -> hack-western-8-env -> Create Records
Create another record but with alias www.
```
Now we can load the website using:<br/>
[hack-western-8.com](http://hack-western-8.com)<br/>
www.hack-western-8.com<br/>
http://hack-western-8.com<br/>
http://www.hack-western-8.com<br/>
Note that it says "Not Secure" beside the link<br/>
### AWS Certificate Manager
Add SSL to use HTTPS:
```shell script
AWS Certificate Manager -> Request a Public Certificate -> Domain Name "hack-western-8.com" and "*.hack-western-8.com" -> DNS validation -> Request
$ dig +short CNAME -> No Output? -> Certificate -> Domains -> Create Records in Route 53
Elastic Beanstalk -> Environments -> Configuration -> Capacity -> Enable Load Balancing
Load balancer -> Add listener -> Port 443 -> Protocol HTTPS -> SSL certificate -> Save -> Apply
```
Now we can load the website using:
<https://hack-western-8.com>
<https://www.hack-western-8.com>
Note that there is a lock icon beside the link to indicate that we are using a SSL certificate so we are secure
## Challenges we ran into
The most challenging part of the project was connecting the charities to the companies. We allowed the user to either type the charity name or choose a category that they would like to support. Once we knew what charity they are interested in, we could use this query to scrape information concerning donations from various companies and then display the stock information related to those companies. We were able to successfully complete this query and we can display the donations made by various companies in the command line, however further work would need to be done in order to display all of this information on the website. Despite these challenges, the current website is a great prototype and proof of concept!
## Accomplishments that we're proud of
We were able to successfully use the charity name or category to scrape information concerning donations from various companies. We not only tested our code locally, but also deployed this website on AWS using Elastic Beanstalk. We created a unique domain for the website and we made it secure through a SSL certificate.
## What we learned
We learned how to connect Flask to AWS, how to design an eye-catching website, how to create a logo using Photoshop and how to scrape information using APIs.
We also learned about thinking outside the box. To find the data we needed we approached the problem from several different angles. We looked for ways to see what companies were giving to charities, where charities were receiving their money, how to minimize false positives in our search algorithm, and how to overcome seemingly impossible obstacles.
## What's next for Giving Tree
Currently, students have 6 categories they can choose from, in the future we would be able to divide them into more specific sub-categories in order to get a better query and find charities that more closely align with their interests.
Health
- Medical Research
- Mental Health
- Physical Health
- Infectious Diseases
Environment
- Ocean Conservation
- Disaster Relief
- Natural Resources
- Rainforest Sustainability
- Global Warming
Human Rights
- Women's Rights
- Children
Community Development
- Housing
- Poverty
- Water
- Sanitation
- Hunger
Education
- Literacy
- After School Programs
- Scholarships
Animals
- Animal Cruelty
- Animal Health
- Wildlife Habitats
We would also want to connect the front and back end. | losing |
## Inspiration
We're all told that stocks are a good way to diversify our investments, but taking the leap into trading stocks is daunting. How do I open a brokerage account? What stocks should I invest in? How can one track their investments? We learned that we were not alone in our apprehensions, and that this problem is even worse in other countries. For example, in Indonesia (Scott's home country), only 0.3% of the population invests in the stock market.
A lack of active retail investor community in the domestic stock market is very problematic. Investment in the stock markets is one of the most important factors that contribute to the economic growth of a country. That is the problem we set out to address. In addition, the ability to invest one's savings can help people and families around the world grow their wealth -- we decided to create a product that makes it easy for those people to make informed, strategic investment decisions, wrapped up in a friendly, conversational interface.
## What It Does
PocketAnalyst is a Facebook messenger and Telegram chatbot that puts the brain of a financial analyst into your pockets, a buddy to help you navigate the investment world with the tap of your keyboard. Considering that two billion people around the world are unbanked, yet many of them have access to cell/smart phones, we see this as a big opportunity to push towards shaping the world into a more egalitarian future.
**Key features:**
* A bespoke investment strategy based on how much risk users opt to take on, based on a short onboarding questionnaire, powered by several AI models and data from Goldman Sachs and Blackrock.
* In-chat brokerage account registration process powered DocuSign's API.
* Stock purchase recommendations based on AI-powered technical analysis, sentiment analysis, and fundamental analysis based on data from Goldman Sachs' API, GIR data set, and IEXFinance.
* Pro-active warning against the purchase of a high-risk and high-beta assets for investors with low risk-tolerance powered by BlackRock's API.
* Beautiful, customized stock status updates, sent straight to users through your messaging platform of choice.
* Well-designed data visualizations for users' stock portfolios.
* In-message trade execution using your brokerage account (proof-of-concept for now, obviously)
## How We Built it
We used multiple LSTM neural networks to conduct both technical analysis on features of stocks and sentiment analysis on news related to particular companies
We used Goldman Sachs' GIR dataset and the Marquee API to conduct fundamental analysis. In addition, we used some of their data in verifying another one of our machine learning models. Goldman Sachs' data also proved invaluable for the creation of customized stock status "cards", sent through messenger.
We used Google Cloud Platform extensively. DialogFlow powered our user-friendly, conversational chatbot. We also utilized GCP's computer engine to help train some of our deep learning models. Various other features, such as the app engine and serverless cloud functions were used for experimentation and testing.
We also integrated with Blackrock's APIs, primarily for analyzing users' portfolios and calculating the risk score.
We used DocuSign to assist with the paperwork related to brokerage account registration.
## Future Viability
We see a clear path towards making PocketAnalyst a sustainable product that makes a real difference in its users' lives. We see our product as one that will work well in partnership with other businesses, especially brokerage firms, similar to what CreditKarma does with credit card companies. We believe that giving consumers access to a free chatbot to help them invest will make their investment experiences easier, while also freeing up time in financial advisors' days.
## Challenges We Ran Into
Picking the correct parameters/hyperparameters and discerning how our machine learning algorithms will make recommendations in different cases.
Finding the best way to onboard new users and provide a fully-featured experience entirely through conversation with a chatbot.
Figuring out how to get this done, despite us not having access to a consistent internet connection (still love ya tho Cal :D). Still, this hampered our progress on a more-ambitious IOT (w/ google assistant) stretch goal. Oh, well :)
## Accomplishments That We Are Proud Of
We are proud of our decision in combining various Machine Learning techniques in combination with Goldman Sachs' Marquee API (and their global investment research dataset) to create a product that can provide real benefit to people. We're proud of what we created over the past thirty-six hours, and we're proud of everything we learned along the way!
## What We Learned
We learned how to incorporate already existing Machine Learning strategies and combine them to improve our collective accuracy in making predictions for stocks. We learned a ton about the different ways that one can analyze stocks, and we had a great time slotting together all of the different APIs, libraries, and other technologies that we used to make this project a reality.
## What's Next for PocketAnalyst
This isn't the last you've heard from us!
We aim to better fine-tune our stock recommendation algorithm. We believe that are other parameters that were not yet accounted for that can better improve the accuracy of our recommendations; Down the line, we hope to be able to partner with finance professionals to provide more insights that we can incorporate into the algorithm. | ## Inspiration
My father put me in charge of his finances and in contact with his advisor, a young, enterprising financial consultant eager to make large returns. That might sound pretty good, but to someone financially conservative like my father doesn't really want that kind of risk in this stage of his life. The opposite happened to my brother, who has time to spare and money to lose, but had a conservative advisor that didn't have the same fire. Both stopped their advisory services, but that came with its own problems. The issue is that most advisors have a preferred field but knowledge of everything, which makes the unknowing client susceptible to settling with someone who doesn't share their goals.
## What it does
Resonance analyses personal and investment traits to make the best matches between an individual and an advisor. We use basic information any financial institution has about their clients and financial assets as well as past interactions to create a deep and objective measure of interaction quality and maximize it through optimal matches.
## How we built it
The whole program is built in python using several libraries for gathering financial data, processing and building scalable models using aws. The main differential of our model is its full utilization of past data during training to make analyses more wholistic and accurate. Instead of going with a classification solution or neural network, we combine several models to analyze specific user features and classify broad features before the main model, where we build a regression model for each category.
## Challenges we ran into
Our group member crucial to building a front-end could not make it, so our designs are not fully interactive. We also had much to code but not enough time to debug, which makes the software unable to fully work. We spent a significant amount of time to figure out a logical way to measure the quality of interaction between clients and financial consultants. We came up with our own algorithm to quantify non-numerical data, as well as rating clients' investment habits on a numerical scale. We assigned a numerical bonus to clients who consistently invest at a certain rate. The Mathematics behind Resonance was one of the biggest challenges we encountered, but it ended up being the foundation of the whole idea.
## Accomplishments that we're proud of
Learning a whole new machine learning framework using SageMaker and crafting custom, objective algorithms for measuring interaction quality and fully utilizing past interaction data during training by using an innovative approach to categorical model building.
## What we learned
Coding might not take that long, but making it fully work takes just as much time.
## What's next for Resonance
Finish building the model and possibly trying to incubate it. | ## Inspiration
"*Agua.*" These four letters dropped Coca-Cola's market value by $4 billion dollars in just a few minutes. In a 2021 press conference, Cristiano Ronaldo shows just how much impact public opinion has on corporate finance. We all know about hedge fund managers who have to analyze and trade stocks every waking minute. These people look at graphs to get paid hundreds of thousands of dollars, yet every single one of them overlooks the arguably most important metric for financial success. Public opinion. That's where our team was inspired to create twittertrader.
## What it does
twittertrader is a react application that displays crucial financial information regarding the day's top traded stocks. For each of the top ten most active stocks, our project analyzes the most recent relevant tweets and displays the general public opinion.
## How we built it
**Backend**: Python, yahoo\_fin, Tweepy, NLTK
**Frontend**: React, Material UI
**Integration**: Flask
## Challenges we ran into
Integrating backend and frontend.
## Accomplishments that we're proud of
Every single one of us was pushed to learn and do more than we have ever done in such a short amount of time! Furthermore, we are proud that all of us were able to commit so much time and effort even in the midst of final exams.
## What we learned
Don't take part in a hackathon during exam season. I'm being serious.
## What's next for twittertrader
1. **Interactions**
As a team we had big ambitious and small amounts of time. We wanted to include a feature where users would be able to add stocks to also be analyzed however we were unable to implement it in time.
2. **Better Analytics!**
Our current project relies on NLTK's natural language processing which has limitations analyzing text in niche fields. We plan on integrating a trained ML model that more accurately describes sentiments in the context of stocks. ("Hit the moon" will make our positivity "hit the moon")
3. **Analytics+**
This information is cool and all but what am I supposed to do with it? We plan on implementing further functionality that analyses significant changes in public opinion and recommends buying or selling these stocks.
4. **Scale**
We worked so hard on this cool project and we want to share this functionality with the world! We plan on hosting this project on a real domain.
## The Team
Here is our team's Githubs and LinkedIns:
Jennifer Li: [Github](https://github.com/jennifer-hy-li) & [LinkedIn](https://www.linkedin.com/in/jennifer-hy-li/)
McCowan Zhang: [Github](https://github.com/mccowanzhang) & [LinkedIn](https://www.linkedin.com/in/mccowanzhang/)
Yuqiao Jiang: [Github](https://github.com/yuqiaoj) & [LinkedIn](https://www.linkedin.com/in/yuqiao-jiang/) | winning |
## Inspiration
Love is in the air. PennApps is not just about coding, it’s also about having fun hacking! Meeting new friends! Great food! PING PONG <3!
## What it does
When you navigate to any browser it will remind you about how great PennApps was! | ## Inspiration
Studies show that drawing, coloring, and other art-making activities can help people express themselves artistically and explore their art's psychological and emotional undertones [1]. Before this project, many members of our team had already caught on to the stress-relieving capabilities of art-centered events, especially when they involved cooperative interaction. We realized that we could apply this concept in a virtual setting in order to make stress-relieving art events accessible to those who are homeschooled, socially-anxious, unable to purchase art materials, or otherwise unable to access these groups in real life. Furthermore, virtual reality provides an open sandbox suited exactly to the needs of a stressed person that wants to relieve their emotional buildup. Creating art in a therapeutic environment not only reduces stress, depression, and anxiety in teens and young adults, but it is also rooted in spiritual expression and analysis [2]. We envision an **online community where people can creatively express their feelings, find healing, and connect with others through the creative process of making art in Virtual Reality.**
## VIDEOS:
<https://youtu.be/QXY9UfquwNI>
<https://youtu.be/u-3l8vwXHvw>
## What it does
We built a VR application that **learns from the user's subjective survey responses** and then **connects them with a support group who might share some common interests and worries.** Within the virtual reality environment, they can **interact with others through anonymous avatars, see others' drawings in the same settings, and improve their well-being by interacting with others in a liberating environment.** To build the community outside of VR, there is an accompanying social media website allowing users to share their creative drawings with others.
## How we built it
* We used SteamVR with the HTC Vive HMD and Oculus HMD, as well as Unity to build the interactive environments and develop the softwares' functionality.
* The website was built with Firebase, Node.js, React, Redux, and Material UI.
## Challenges we ran into
* Displaying drawing real-time on a server-side, rather than client-side output posed a difficulty due to the restraints on broadcasting point-based cloud data through Photon. Within the timeframe of YHack, we were able to build the game that connects multiple players and allows them to see each other's avatars. We also encountered difficulties with some of the algorithmic costs of the original line-drawing methods we attempted to use.
## Citation:
[1] <https://www.psychologytoday.com/us/groups/art-therapy/connecticut/159921?sid=5db38c601a378&ref=2&tr=ResultsName>
[2] <https://www.psychologytoday.com/us/therapy-types/art-therapy> | # PotholePal
## Pothole Filling Robot - UofTHacks VI
This repo is meant to enable the Pothole Pal proof of concept (POC) to detect changes in elevation on the road using an ultrasonic sensor thereby detecting potholes. This POC is to demonstrate the ability for a car or autonomous vehicle to drive over a surface and detect potholes in the real world.
Table of Contents
1.Purpose
2.Goals
3.Implementation
4.Future Prospects
**1.Purpose**
By analyzing city data and determining which aspects of city infrastructure could be improved, potholes stood out. Ever since cities started to grow and expand, potholes have plagued everyone that used the roads. In Canada, 15.4% of Quebec roads are very poor according to StatsCan in 2018. In Toronto, 244,425 potholes were filled just in 2018. Damages due to potholes averaged $377 per car per year. There is a problem that can be better addressed. In order to do that, we decided that utilizing Internet of Things (IoT) sensors like the ulstrasound sensor, we can detect potholes using modern cars already mounted with the equipment, or mount the equipment on our own vehicles.
**2.Goals**
The goal of the Pothole Pal is to help detect potholes and immediately notify those in command with the analytics. These analytics can help decision makers allocate funds and resources accordingly in order to quickly respond to infrastructure needs. We want to assist municipalities such as the City of Toronto and the City of Montreal as they both spend millions each year assessing and fixing potholes. The Pothole Pal helps reduce costs by detecting potholes immediately, and informing the city where the pothole is.
**3.Implementation**
We integrated an arduino on a RedBot Inventors Kit car. By attaching an ultrasonic sensor module to the arduino and mounting it to the front of the vehicle, we are able to detect changes in elevation AKA detect potholes. After the detection, the geotag of the pothole and an image of the pothole is sent to a mosquito broker, which then directs the data to an iOS app which a government worker can view. They can then use that information to go and fix the pothole.



**4.Future Prospects**
This system can be further improved on in the future, through a multitude of different methods. This system could be added to mass produced cars that already come equipped with ultrasonic sensors, as well as cameras that can send the data to the cloud for cities to analyze and use. This technology could also be used to not only detect potholes, but continously moniter road conditions and providing cities with analytics to create better solutions for road quality, reduce costs to the city to repair the roads and reduce damages to cars on the road. | partial |
## Inspiration
Suppose we go out for a run early in the morning without our wallet and cellphone, our service enables banking systems to use facial recognition as a means of payment enabling us to go cashless and cardless.
## What it does
It uses deep neural networks in the back end to detect faces at point of sale terminals and match them with those stored in the banking systems database and lets the customer purchase a product from a verified seller almost instantaneously. In addition, it allows a bill to be divided between customers using recognition of multiple faces. It works in a very non-invasive manner and hence makes life easier for everyone.
## How we built it
Used dlib as the deep learning framework for face detection and recognition, along with Flask for the web API and plain JS on the front end. The front end uses AJAX to communicate with the back end server. All requests are encrypted using SSL (self-signed for the hackathon).
## Challenges we ran into
We attempted to incorporate gesture recognition into the service, but it would cause delays in the transaction due to extensive training/inference based on hand features. This is a feature to be developed in the future, and has the potential to distinguish and popularize our unique service
## Accomplishments that we're proud of
Within 24 hours, we are able to pull up a demo for payment using facial recognition simply by having the customer stand in front of the camera using real-time image streaming. We were also able to enable payment splitting by detection of multiple faces.
## What we learned
We learned to set realistic goals and pivot in the right times. There were points where we thought we wouldn't be able to build anything but we persevered through it to build a minimum viable product. Our lesson of the day would therefore be to never give up and always keep trying -- that is the only reason we could get our demo working by the end of the 24 hour period.
## What's next for GazePay
We plan on associating this service with bank accounts from institutions such as Scotiabank. This will allow users to also see their bank balance after payment, and help us expand our project to include facial recognition ATMs, gesture detection, and voice-enabled payment/ATMs for them to be more accessible and secure for Scotiabank's clients. | ## Inspiration
Every time we go out with friends, it's always a pain to figure payments for each person. Charging people through Venmo is often tedious and requires lots of time. What we wanted to do was to make the whole process either by just easily scanning a receipt and then being able to charge your friends immediately.
## What it does
Our app takes a picture of a receipt and sends to a python server(that we made) which filters and manipulates the image before performing OCR. Afterwards, the OCR is parsed and the items and associated prices are sent to the main app where the user can then easily charge his friends for use of the service.
## How we built it
We built the front-end of the app using meteor to allow easy reactivity and fast browsing time. Meanwhile, we optimized the graphics so that the website works great on mobile screens. Afterwards, we send the photo data to a flask server where we run combination of python, c and bash code to pre-process and then analyze the sent images. Specifically, the following operations are performed for image processing:
1. RGB to Binary Thresholding
2. Canny Edge Detection
3. Probabilistic Hough Lines on Canny Image
4. Calculation of rotation disparity to warp image
5. Erosion to act as a flood-fill on letters
## Challenges we ran into
We ran into a lot of challenge actively getting the OCR from the receipts. Established libraries such Microsoft showed poor performance. As a result, we ended up testing and creating our own methods for preprocessing and then analyzing the images of receipts we received. We tried many different methods for different steps:
* Different thresholding methods (some of which are documented below)
* Different deskewing algorithms, including hough lines and bounding boxes to calculate skew angle
* Different morphological operators to increase clarity/recognition of texts.
Another difficulty we ran into was implementing UI such that it would run smoothly on mobile devices.
## Accomplishments that we're proud of
We're very proud of the robust parsing algorithm that we ended up creating to classify text from receipts.
## What we learned
The the building of SplitPay, we learned many different techniques in machine vision. We also learned about implementing communication between two web frameworks and about the reactivity used to build Meteor.
## What's next for SplitPay
In the future, we hope to continue the development of SplitPay and to make it easier to use, with easier browsing of friends and more integration with other external APIs, such as ones from Facebook, Microsoft, Uber, etc. | ## Vision vs Reality
We originally had a much more robust idea for this hackathon: an open vision doorbell to figure out who is at the door, without needing to go to the door. The plan was to use an Amazon Echo Dot to connect our vision solution, a Logitech c270 HD webcam, with our storage, a Firebase database. This final integration step between the Echo Dot and OpenCV services ended up being our downfall as the never-ending wave of vague errors kept getting thrown and we failed to learn how to swim.
Instead of focusing on our downfalls, we want to show the progress that was made in the past 36 hours that we believe shows the potential behind what our idea sought to accomplish.
Using OpenCV3 and Python3, we created multiple vision solutions such as motion detection and image detection. Ultimately, we decided that a facial recognition program would be ideal for our design. Our facial recognition program includes a vision model that has both Jet's and I's faces learned as well as an unknown catch-all type that aims to cover any unknown or masked faces. While not the most technically impressive, this does show the solid base work and the right step that we took to get to our initial idea.
## The Development Process
These past 36 hours presented us with a lot full of trials and tribulations and it would be a shame if we did not mention them considering the result.
In the beginning, we considered using the RaisingAI platform for our vision rather than OpenCV. However, when we attended their workshop, we saw that it relied on a Raspberry Pi which we originally wanted to avoid using due to our lack of server experience. Also, the performance seemed to vary and it did not seem like it was aimed for facial recognition.
We planned and were excited to use a NVIDIA Jetson due to how great the performance is and we saw that the NVIDIA booth was using a Jetson to run a resource intensive vision program smoothly. Unfortunately, we could not get the Jetson setup due to a lack of a monitor.
After not being able to successfully run the Jetson, we reluctantly switched to a Raspberry Pi but we were pleasantly surprised at how well it performed and how easily it was to setup without a monitor. At this stage is also when we started learning how to develop the Amazon Echo Dot. Since this was our first time ever using an Alexa-based device, it took a while to develop even a simple Hello, World! application. However, we definitely learned a lot about how smart devices work and got to work with many AWS utilities as a part of this development process.
As a team, we knew that integrating the vision and Alexa would not be an easy task even at the start of the hackathon. Neither of us predicated just how difficult it would actually be. As a result, this vision-Alexa integration took up a majority of our overall development time. We also took on the task of integrating Firebase for storage at this step, but since this is the one technology in this project that we have had past experience with, we thought it would be no problem.
## What We Built
At the end of the day (...more like morning), we were able to create a simple Python program and dataset that allows us to show off our base vision module. This comprises of 3 different programs: facial detection from a custom dataset of images, a ML model to associate facial features to a specific person, and applying that model to a live webcam feed. Additionally, we were also able to create our own Alexa skill that allowed us to dictate how we interact with the Echo.
## Accomplishments that I'm proud of
* Learning how to use/create Amazon Skills
* Getting our feet wet with an introduction to Raspberry Pi
* Creating our own ML model
* Utilizing OpenCV & Python to create a custom vision program
## Future Goals
* Figure out how to integrate Alexa and Python programs
* Seek mentor help in a more relaxed environment
* Use a NVIDIA Jetson
* Create a 3D printed housing for our product / overall final product refinement | partial |
## Inspiration & Instructions
Is it your birthday? Is it your 2 years anniversary today? YOU need a cake! But how? CakeBox is here for you. Sit tight and message facebook.com/cakeboxbot with "I want a cake for [name]", type your address, then choose the cake you want, and confirm with "ok" (or exit the chat and make CakeBoxBot sad). Once your order is confirmed, Postmates (and Pusheen maybe) will deliver the cake to you from the closest bakery to your location. All transactions are done in cash. NOTE THAT YOU HAVE TO AUTHORIZE THE CAKEBOX APP BEFORE YOU CAN SEND IT MESSAGES.
## What it does
CakeBoxBot is a Messenger bot that will order you a cake on-demand instantly by calling the Postmates API on our own server (with the encouragement of Pusheen and xkcd).
## How we built it
We wanted to experiment with messaging bots since they are a popular emerging technology. We built CakeBoxBot with node.js, hosted it on heroku, and we picked Facebook as our bot platform.
## Challenges we ran into
Understanding how to connect the front and back ends of our application took the most time, but we realized that we didn't actually need to add that much to our frontend if we used Facebook Messenger, which is esPUSHEENly great!
## Accomplishments that we're proud of
Cake cake cake
## What we learned
Teamwork! And bots are hard! And fun! And cake!
## What's next for CakeBoxBot
Cupcakes! | ## **What Inspired Us**
Whether you're just moving into college, starting a job in a new town, or undergoing any sort of life-changing event, making friends is both difficult and necessary.
BiteBuddies is the revolutionary social media network that helps you connect with others using the universal necessity - food! As a bonus, it reduces food waste and encourages healthier eating!
With BiteBuddies, you can simply take a picture of your grocery receipt and add its items to your virtual "pantry." When you're ready, you'll be recommended various recipes people have proposed that match the ingredients in your virtual pantry. With your BiteBuddies partner, you can combine "pantries" to cook a sustainable, healthy, and delicious meal together.
Not only does BiteBuddies remove a barrier to entry of meal prep by recommending recipes that work with what you already have, but it also helps reduce food waste by encouraging users to utilize the ingredients they already have rather than buying more.
But BiteBuddies isn't just about reducing food waste; it's also about providing a common goal that users can work towards. With this task, the awkwardness of the first meeting with a stranger is minimized by the familiar rhythm of cooking. We hope that users will be encouraged to connect with their BiteBuddies partners again and again!
Entering a new stage in your life doesn't have to be lonely. Download BiteBuddies today and start saving money, reducing waste, and connecting with others who share your love for healthy eating!
## **What We Learned**
We learned that trying to learn a programming language in just a few hours isn't practical, but it's possible to grasp the basics. We now know how to implement an API and call it using a GET API call. We also learned the benefits of creating a microservice application instead of a monolithic one. In terms of mobile app development, we learned that it differs from web development, and it's essential to consider the unique challenges that come with it. Lastly, we now understand the importance of sleep and its impact on overall productivity and health.
## **How We Built Our Project**
For our project, we first went through an ideation phase to identify the verticals we wanted to target and the everyday problems we wanted to solve. We narrowed down our focus to food and sustainability, specifically targeting the problem of new college students leaving their parents’ home cooked meals behind at home, and the inherent loneliness that comes with leaving your family. We decided to build a mobile app, primarily focusing on iOS using Swift, as a platform to solve this problem. To support our app, we built a Flask API with RESTful endpoints that performs CRUD operations on users and interfaces with the Spoonacular API for food classification and recipe recommendations based on user ingredient input. Additionally, we used the Vision.framework to implement OCR and transcribe text from images of receipts. The Flask API and Swift application are two standalone microservices that interact with each other through API calls, forming the backbone of our solution.
## **Challenges We Faced**
Our team faced various challenges while learning and implementing Swift programming language for our project. The first challenge was to adapt to Swift's unique approach to problem-solving, which was different from how we traditionally approached computer science problems. We struggled with decomposing our code and integrating microservices that worked separately but had incompatible inputs and outputs. We also faced issues with function calls and dependencies. Another challenge was the shortage of MacBooks, as we only had two for a team of four, which made collaboration difficult. Additionally, we underestimated the amount of work required for Swift and overestimated the work needed for Flask. Lastly, we encountered Info.plist issues, which prevented us from using Apple user info. Overall, our team had to overcome numerous obstacles while learning and implementing Swift, which required a great deal of effort and persistence. | ## Inspiration
As technology advances, our society is harnessing technology to acquire goods in more convenient ways than ever. With the rise of services such as Postmates, Caviar, Diner Dash, etc., it is now possible to have most basic necessities delivered in a timely fashion. However, one industry that appeals to us is the second hand goods industry. Second hand goods are often a good way to save money while getting similar quality products. One of our favourite sites is Craigslist, and we knew we could improve upon the buying experience.
## What it does
After a user has found a desirable product on Craigslist, he/she copies and pastes the URL into craig-o-mation. craig-o-mation will scrape the Craigslist post for information such as cost, and also requests a bit more necessary information from the purchaser. After the purchaser fills out this short form, the poster gets an email describing what the purchaser has offered. Should they choose to accept, after entering some information, the sale is completed. A Postmates courier is instantly dispatched to the purchaser to collect the product and deliver it to the buyer. A payment is made from the purchaser to the buyer through Capital One's APIs. Within minutes, the buyer gets his second hand goods conveniently for an affordable price.
## How I built it
* The forms are all written in HTML, CSS, and Javascript
* Forms send data to our backend written in Go
* Go backend proxies through a Python server running at home in order to bypass Craigslist's imposed restrictions on certain IPs (they are quite strict)
* Go backend talks to Postmates and Capital One APIs to facilitate the transaction and delivery of the item
* Email and datastore are provided with App Engine, where the app is hosted
* Also use Google Maps API for frontend forms to ease entering of addresses
## Challenges I ran into
Craigslist is extremely strict about bots and automation. They have IP blocked many large cloud computing companies and have imposed other restrictions to make scraping and automation extremely challenging. We were able to get a home server running that we could proxy requests through in order to scrape data from Craigslist.
## Accomplishments that I'm proud of
* The UI is simple, helpful, and intuitive
* The emails have styling beyond basic text emails
* The Craigslist proxy was challenging to implement and works quite well
* The backend is very efficient due to design decisions
* We were successfully able to integrate with Postmates and Capital One APIs
## What I learned
* Get it done mentality. There is always a way to make novel innovations, it just takes perseverance
* Some problems stumped us for many hours but in the end we did not need to compromise on functionality
## What's next for craig-o-mation
* Write browser extensions to store user data and be accessible while browsing Craigslist to decrease friction with users
* Faster and more reliable solutions for scraping Craigslist | losing |
## Inspiration
Before the coronavirus pandemic, vaccine distribution and waste was a little known issue. Now it's one of the most relevant and pressing problems that world faces. Our team had noticed that government vaccine rollout plans were often vague and lacked the coordination needed to effectively distribute the vaccines. In light of this issue we created Vaccurate, a data powered vaccine distribution app which is able to effectively prioritize at risk groups to receive the vaccine.
## What it does
To apply for a vaccine, an individual will enter Vaccurate and fill out a short questionnaire based off of government research and rollout plans. We will then be able to process their answers and assign weights to each response. Once the survey is done all the user needs to do is to wait for a text to be sent to them with their vaccination location and date! As a clinic, you can go into the Vaccurate clinic portal and register with us. Once registered we are able to send you a list of individuals our program deems to be the most at risk so that all doses received can be distributed effectively. Under the hood, we process your data using weights we got based off of government distribution plans and automatically plan out the distribution and also contact the users for the clinics!
## How I built it
For the frontend, we drafted up a wireframe in Figma first, then used HTML, CSS, and Bootstrap to bring it to life. To store user and clinic information, we used a Firestore database. Finally, we used Heroku to host our project and Twilio to send text notifications to users.
## Challenges I ran into
On the backend, it was some of our team's first time working with a Firestore database, so there was a learning curve trying to figure out how to work with it. We also ran into a lot of trouble when trying to set up a Heroku, but eventually got it running after several hours (can we get an F in chat). And although none of us thought it was a huge deal in the beginning, the time constraint of this 24 hour hackathon really caught up on us and we ran into a lot of challenges that forced us to adapt and reconstruct our idea throughout the weekend so we weren't biting off more than we could chew.
## Accomplishments that I'm proud of
Overall, we are very proud of the solution we made as we believe that with a little more polish our project has great value to the real world. Additionally, each and every member was able to explore a new language, framework, or concept in this project allowing us to learn more too while solving issues. We were really impressed by the end product especially as it was produced in this short time span as we not only learnt but immediately applied our knowledge.
## What I learned
Our team was able to learn more about servers with Gradle, frontend development, connecting to databases online, and also more about how we can contribute to a global issue with a time relevant solution! We were also able to learn how to compact as much work and learning as possible into a small timespan while maintaining communications between team members.
## What's next for Vaccurate
The statistics and guidelines we presented in our project were made based off of reliable online resources, however it's important that we consult an official healthcare worker to create a more accurate grading scheme and better vaccination prioritization. Additionally, we would like to add features to make the UX more accessible, such as a booking calendar for both users and clinics, and the ability to directly modify appointments on the website. | ## Inspiration
* My inspiration for this project is the tendency of medical facilities such as hospitals lacking in terms of technology, with this virtual automated HospQueue app, we will be saving more lives by saving more time for healthcare workers to focus on the more important tasks.
* Also amidst the global pandemic, managing the crowd has been one of the prime challenges of the government and various institutions. That is where HospQueue comes to the rescue. HospQueue is a webapp that allows you to join a queue virtually which leads to no gathering hence lesser people in hospitals that enables health workers to have the essentials handy.
* During the pandemic, we have all witnessed how patients in need have to wait in lines to get themselves treated. This led to people violating social distancing guidelines and giving the opportunity for the virus to spread further.
* I had an idea to implement HospQueue that would help hospitals to manage and check-in incoming patients smoothly.
## What it does
It saves time for healthcare workers as it takes away a task that is usually time-consuming. On HospQueue, you can check into your hospital on the app instead of in person. Essentially, you either don’t go to the hospital until it is your turn, or you stay into the car until you are next in line. This will not only make the check-in process for all hospitals easier and more convenient and safe but will also allow health care workers to focus on saving more people.
## How I built it
The frontend part was built using HTML and CSS. The backend was built using Flask and Postgresql as the database.
## Challenges I ran into
Some challenges I ran into were completing the database queries required for the system. I also had trouble with making the queue list work effectively. Hosting the website on Heroku was quite a challenge as well.
## Accomplishments that I'm proud of
I am glad to have implemented the idea of HospQueue that I thought of at the beginning of the hackathon. I made the real-time fetching and updating of the database successful.
## What I learned
* I learned how to fetch and update the database in real time.
* I learned how to deploy an app on Heroku using Heroku's Postgresql database.
## What's next for HospQueue
HospQueue will add and register hospitals so it is easier to manage. I also hope to integrate AI to make it easier for people to log in, maybe by simply scanning a QR code. Finally, I will also create a separate interface in which doctors can log in and see all the people in line instead of having to pull it from the program. | ## Inspiration
As students ourselves, we've experienced the frustration of needing a tutor for a particular subject but struggling to find a reliable platform to locate credible tutors. We realized there was a gap in the market where students like us lacked a centralized hub to easily discover trustworthy tutors tailored to our specific needs. This personal struggle inspired us to create TutorTok, a solution that not only addresses this challenge but also revolutionizes the tutoring experience for students and tutors alike.
## What it does
TutorTok serves as a comprehensive platform for students to easily discover and connect with qualified tutors, while also providing tutors with a space to showcase their expertise and reach a wider audience. Through TutorTok, users can filter tutors based on their specific needs, read reviews, and book sessions seamlessly.
## How we built it
Our development process involved utilizing React to ensure the responsiveness and dynamism of TutorTok's interface. Tailwind CSS played a significant role in styling, enabling us to create a unified and visually appealing design system efficiently. Additionally, ESLint was instrumental in maintaining code quality and consistency throughout the project. These tools collectively facilitated the creation of a robust and polished platform that prioritizes both functionality and aesthetics.
## Challenges we ran into
We encountered the need to split the website into two separate pages, each with its own unique features. However, we also had to ensure that certain buttons on one page could affect the entire platform. This presented a challenge as we aimed to maintain coherence and user-friendly navigation throughout the site.
## Accomplishments that we're proud of
One of our proudest achievements is the design of the TutorTok website. We invested significant time and effort into crafting a visually appealing and user-friendly interface that enhances the overall user experience. From intuitive navigation to aesthetically pleasing layouts, we aimed to create a platform that engages and delights users from the moment they land on the site.
Additionally, we take pride in the development of the chat feature within TutorTok. Recognizing the importance of seamless communication between students and tutors, we designed and implemented a robust chat system that facilitates real-time interaction and collaboration. This feature not only enhances the learning experience but also fosters meaningful connections between users, contributing to the sense of community within the TutorTok platform.
## What we learned
Throughout the development process, we learned the importance of prioritizing user experience and maintaining a balance between functionality and simplicity.
## What's next for TutorTok
Moving forward, we plan to further enhance the features and capabilities of TutorTok based on user feedback and market trends. We aim to expand our reach, onboard more tutors across diverse subject areas, and continue fostering a supportive community of learners and educators. Additionally, we're exploring opportunities to incorporate advanced technologies such as AI-driven matchmaking and personalized learning recommendations to further enrich the tutoring experience on our platform. | partial |
## Inspiration
Our inspiration comes from people who require immediate medical assistance when they are located in remote areas. The project aims to reinvent the way people in rural or remote settings, especially seniors who are unable to travel frequently, obtain medical assistance by remotely connecting them to medical resources available in their nearby cities.
## What it does
Tango is a tool to help people in remote areas (e.g. villagers, people on camping/hiking trips, etc.) to have access to direct medical assistance in case of an emergency. The user would have the device on him while hiking along with a smart watch. If the device senses a sudden fall, the vital signs of the user provided by the watch would be sent to the nearest doctor/hospital in the area. The doctor could then assist the user in a most appropriate way now that the user's vital signs are directly relayed to the doctor. In a case of no response from the user, medical assistance can be sent using his location.
## How we built it
The sensor is made out of the Particle Electron Kit, which based on input from an accelerometer and a sound sensor, asseses whether the user has fallen down or not. Signals from this sensor are sent to the doctor if the user has fallen along with data from smart watch about patient health.
## Challenges we ran into
One of our biggest challenges we ran into was taking the data from the cloud and loading it on the web page to display it.
## Accomplishments that we are proud of
It is our first experience with the Particle Electron and for some of us their first experience in a hardware project.
## What we learned
We learned how to use the Particle Election.
## What's next for Tango
Integration of the Pebble watch to send the vital signs to the doctors. | ## 💡 Inspiration
>
> #hackathon-help-channel
> `<hacker>` Can a mentor help us with flask and Python? We're stuck on how to host our project.
>
>
>
How many times have you created an epic web app for a hackathon but couldn't deploy it to show publicly? At my first hackathon, my team worked hard on a Django + React app that only lived at `localhost:5000`.
Many new developers don't have the infrastructure experience and knowledge required to deploy many of the amazing web apps they create for hackathons and side projects to the cloud.
We wanted to make a tool that enables developers to share their projects through deployments without any cloud infrastructure/DevOps knowledge
(Also, as 2 interns currently working in DevOps positions, we've been learning about lots of Infrastructure as Code (IaC), Configuration as Code (CaC), and automation tools, and we wanted to create a project to apply our learning.)
## 💭 What it does
InfraBundle aims to:
1. ask a user for information about their project
2. generate appropriate IaC and CaC code configurations
3. bundle configurations with GitHub Actions workflow to simplify deployment
Then, developers commit the bundle to their project repository where deployments become as easy as pushing to your branch (literally, that's the trigger).
## 🚧 How we built it
As DevOps interns, we work with Ansible, Terraform, and CI/CD pipelines in an enterprise environment. We thought that these could help simplify the deployment process for hobbyists as well
InfraBundle uses:
* Ansible (CaC)
* Terraform (IaC)
* GitHub Actions (CI/CD)
* Python and jinja (generating CaC, IaC from templates)
* flask! (website)
## 😭 Challenges we ran into
We're relatitvely new to Terraform and Ansible and stumbled into some trouble with all the nitty-gritty aspects of setting up scripts from scratch.
In particular, we had trouble connecting an SSH key to the GitHub Action workflow for Ansible to use in each run. This led to the creation of temporary credentials that are generated in each run.
With Ansible, we had trouble creating and activating a virtual environment (see: not carefully reading [ansible.builtin.pip](https://docs.ansible.com/ansible/latest/collections/ansible/builtin/pip_module.html) documentation on which parameters are mutually exclusive and confusing the multiple ways to pip install)
In general, hackathons are very time constrained. Unfortunately, slow pipelines do not care about your time constraints.
* hard to test locally
* cluttering commit history when debugging pipelines
## 🏆 Accomplishments that we're proud of
InfraBundle is capable of deploying itself!
In other news, we're proud of the project being something we're genuinely interested in as a way to apply our learning. Although there's more functionality we wished to implement, we learned a lot about the tools used. We also used a GitHub project board to keep track of tasks for each step of the automation.
## 📘 What we learned
Although we've deployed many times before, we learned a lot about automating the full deployment process. This involved handling data between tools and environments. We also learned to use GitHub Actions.
## ❓ What's next for InfraBundle
InfraBundle currently only works for a subset of Python web apps and the only provider is Google Cloud Platform.
With more time, we hope to:
* Add more cloud providers (AWS, Linode)
* Support more frameworks and languages (ReactJS, Express, Next.js, Gin)
* Improve support for database servers
* Improve documentation
* Modularize deploy playbook to use roles
* Integrate with GitHub and Google Cloud Platform
* Support multiple web servers | ## Inspiration
As students, we use discord, zoom, and many other apps that are not tailored for students. We wanted to make an app to connect students and help them study together and make new friends tailored specifically for students at their university.
## What it does
It matches students with each other based on similar categories such as enrolled courses, languages, interests, majors, assignments, and more. Once students are matched they can chat in chatrooms and will have their own personal tailored AI assistant to help them with any issues they face.
## How we built it
We used SQLite for the database to store all the students, courses, majors, languages, connecting tables, and more. We used node.js for the backend and express.js http servers. We used bootstrap and react.js along with simple html, css, and javascript for the frontend.
## Challenges we ran into
We struggled to transfer data from the database all the way to the client-side and from the client-side all the way to the database. Making chatrooms that function with multiple students was also extremely difficult for us.
## Accomplishments that we're proud of
Not giving up even when all the odds were stacked against us.
## What we learned
We learned how to use so many new technologies. And we learned that things are harder then they seem when it comes to tech.
## What's next for Study Circuit
Expand matching capabilities, and implement features such as breakout rooms, virtual study halls, and office hour support for TAs. | winning |
## Inspiration
The project was inspired by looking at the challenges that artists face when dealing with traditional record labels and distributors. Artists often have to give up ownership of their music, lose creative control, and receive only a small fraction of the revenue generated from streams. Record labels and intermediaries take the bulk of the earnings, leaving the artists with limited financial security. Being a music producer and a DJ myself, I really wanted to make a product with potential to shake up this entire industry for the better. The music artists spend a lot of time creating high quality music and they deserve to be paid for it much more than they are right now.
## What it does
Blockify lets artists harness the power of smart contracts by attaching them to their music while uploading it and automating the process of royalty payments which is currently a very time consuming process. Our primary goal is to remove the record labels and distributors from the industry since they they take a majority of the revenue which the artists generate from their streams for the hard work which they do. By using a decentralized network to manage royalties and payments, there won't be any disputes regarding missed or delayed payments, and artists will have a clear understanding of how much money they are making from their streams since they will be dealing with the streaming services directly. This would allow artists to have full ownership over their work and receive a fair compensation from streams which is currently far from the reality.
## How we built it
BlockChain: We used the Sui blockchain for its scalability and low transaction costs. Smart contracts were written in Move, the programming language of Sui, to automate royalty distribution.
Spotify API: We integrated Spotify's API to track streams in real time and trigger royalty payments.
Wallet Integration: Sui wallets were integrated to enable direct payments to artists, with real-time updates on royalties as songs are streamed.
Frontend: A user-friendly web interface was built using React to allow artists to connect their wallets, and track their earnings. The frontend interacts with the smart contracts via the Sui SDK.
## Challenges we ran into
The most difficult challenge we faced was the Smart Contract Development using the Move language. Unlike commonly known language like Ethereum, Move is relatively new and specifically designed to handle asset management. Another challenge was trying to connect the smart wallets in the application and transferring money to the artist whenever a song was streamed, but thankfully the mentors from the Sui team were really helpful and guided us in the right path.
## Accomplishments that we're proud of
This was our first time working with blockchain, and me and my teammate were really proud of what we were able to achieve over the two days. We worked on creating smart contracts and even though getting started was the hardest part but we were able to complete it and learnt some great stuff along the way. My teammate had previously worked with React but I had zero experience with JavaScript, since I mostly work with other languages, but we did the entire project in Node and React and I was able to learn a lot of the concepts in such a less time which I am very proud of myself for.
## What we learned
We learned a lot about Blockchain technology and how can we use it to apply it to the real-world problems. One of the most significant lessons we learned was how smart contracts can be used to automate complex processes like royalty payments. We saw how blockchain provides an immutable and auditable record of every transaction, ensuring that every stream, payment, and contract interaction is permanently recorded and visible to all parties involved. Learning more and more about this technology everyday just makes me realize how much potential it holds and is certainly one aspect of technology which would rule the future. It is already being used in so many aspects of life and we are still discovering the surface.
## What's next for Blockify
We plan to add more features, such as NFTs for exclusive content or fan engagement, allowing artists to create new revenue streams beyond streaming. There have been some real-life examples of artists selling NFT's to their fans and earning millions from it, so we would like to tap into that industry as well. Our next step would be to collaborate with other streaming services like Apple Music and eliminate record labels to the best of our abilities. | ## Inspiration
As college students who recently graduated high school in the last year or two, we know first-hand the sinking feeling that you experience when you open an envelope after your graduation, and see a gift card to a clothing store you'll never set foot into in your life. Instead, you can't stop thinking about the latest generation of AirPods that you wanted to buy. Well, imagine a platform where you could trade your unwanted gift card for something you would actually use... you would actually be able to get those AirPods, without spending money out of your own pocket. That's where the idea of GifTr began.
## What it does
Our website serves as a **decentralized gift card trading marketplace**. A user who wants to trade their own gift card for a different one can log in and connect to their **Sui wallet**. Following that, they will be prompted to select their gift card company and cash value. Once they have confirmed that they would like to trade the gift card, they can browse through options of other gift cards "on the market", and if they find one they like, send a request to swap. If the other person accepts the request, a trustless swap is initiated without the use of a intermediary escrow, and the swap is completed.
## How we built it
In simple terms, the first party locks the card they want to trade, at which point a lock and a key are created for the card. They can request a card held by a second party, and if the second party accepts the offers, both parties swap gift cards and corresponding keys to complete the swap. If a party wants to tamper with their object, they must use their key to do so. The single-use key would then be consumed by the smart contract, and the trade would not be possible.
Our website was built in three stages: the smart contract, the backend, and the frontend.
**The smart contract** hosts all the code responsible for automating a trustless swap between the sender and the recipient. It **specifies conditions** under which the trade will occur, such as the assets being exchanged and their values. It also has **escrow functionality**, responsible for holding the cards deposited by both parties until swap conditions have been satisfied. Once both parties have undergone **verification**, the **swap** will occur if all conditions are met, and if not, the process will terminate.
**The backend\* acts as a bridge between the smart contract and the front end, allowing for \*\*communication** between the code and the user interface. The main way it does this is by **managing all data**, which includes all the user accounts, their gift card inventories, and more. Anything that the user does on the website is communicated to the Sui blockchain. This **blockchain integration** is crucial so that users can initiate trades without having to deal with the complexities of blockchain.
**The frontend** is essentially everything the user sees and does, or the UI. It begins with **user authentication** such as the login process and connection to Sui wallet. It allows the user to **manage transactions** by initiating trades, entering in attributes of the asset they want to trade, and viewing trade offers. This is all done through React to ensure *real-time interaction* so that new offers are seen and updated without refreshing the page.
## Challenges we ran into
This was **our first step into the field** of Sui blockchain and web 3 entirely, so we found it to be really informative, but also really challenging. The first step we had to take to address this challenge was to begin learning Move through some basic tutorials and set up a development environment. Another challenge was the **many aspects of escrow functionality**, which we addressed through embedding many tests within our code. For instance, we had to test that that once an object was created, it would actually lock and unlock, and also that if the second shared party stopped responding or an object was tampered with, the trade would be terminated.
## Accomplishments that we're proud of
We're most proud of the look and functionality of our **user interface**, as user experience is one of our most important focuses. We wanted to create a platform that was clean, easy to use and navigate, which we did by maintaining a sense of consistency throughout our website and keep basic visual hierarchy elements in mind when designing the website. Beyond this, we are also proud of pulling off a project that relies so heavily on **Sui blockchain**, when we entered this hackathon with absolutely no knowledge about it.
## What we learned
Though we've designed a very simple trading project implementing Sui blockchain, we've learnt a lot about the **implications of blockchain** and the role it can play in daily life and cryptocurrency. The two most important aspects to us are decentralization and user empowerment. On such a simple level, we're able to now understand how a dApp can reduce reliance on third party escrows and automate these processes through a smart contract, increasing transparency and security. Through this, the user also gains more ownership over their own financial activities and decisions. We're interested in further exploring DeFi principles and web 3 in our future as software engineers, and perhaps even implementing it in our own life when we day trade.
## What's next for GifTr
Currently, GifTr only facilitates the exchange of gift cards, but we are intent on expanding this to allow users to trade their gift cards for Sui tokens in particular. This would encourage our users to shift from traditional banking systems to a decentralized system, and give them access to programmable money that can be stored more securely, integrated into smart contracts, and used in instant transactions. | ## Inspiration
We wanted to integrate many sensors into a design that was weather-related as well as useless, and we had the idea of creating a portable weather station - which is obviously not very useful because the station needs to be outside, and its weather analysis is very rudimentary.
## What it does
SmartStorm guesses the weather using a combination of sound, water, temperature, humidity, and light sensors, matching sensor values with a set of parameters to determine which of eight weather states it most closely matches. It incorporates user input into improving its guesses, modifying parameters when it gets guesses wrong to make subsequent guesses more accurate.
## How we built it
SmartStorm was built with an Arduino Mega 2560 along with sensors and an LCD screen that come with the Mega 2560 Starter Kit. Components were connected on a breadboard, and user input is received from a set of three pushbuttons.
## Challenges we ran into
Interfacing all the sensors and understanding the implementation of various libraries was the primary challenge we ran into - the bigger challenge was coming up with the idea and implementing it in the remaining limited time after we had exhausted prior project ideas.
## Accomplishments that we're proud of
We're proud of how well SmartStorm was implemented compared to our original vision for the design, as well as how profoundly useless the design ended up in reality.
## What we learned
We learned how to manage a considerable number of different I/O devices simultaneously without much inherent synchronicity, and how to debug sensors when they don't appear to be working.
## What's next for SmartStorm Weather Station
To improve on SmartStorm, we would like to refine the algorithm that improves SmartStorm's accuracy. As it stands, it simply shifts parameters around by constant amounts - to improve upon it, we would like to at least have it modify that shift based on previous guesses and inputs, as well as putting correct guesses to use in improving accuracy. | winning |
## Inspiration
Sign language is already difficult to learn; adding on the difficulty of learning movements from static online pictures makes it next to impossible to do without help. We came up with an elegant robotic solution to remedy this problem.
## What it does
Handy Signbot is a tool that translates voice to sign language, displayed using a set of prosthetic arms. It is a multipurpose sign language device including uses such as: a teaching model for new students, a voice to sign translator for live events, or simply a communication device between voice and sign.
## How we built it
**Physical**: The hand is built from 3D printed parts and is controlled by several servos and pulleys. Those are in turn controlled by Arduinos, housing all the calculations that allow for finger control and semi-spherical XYZ movement in the arm. The entire setup is enclosed and protected by a wooden frame.
**Software**: The bulk of the movement control is written in NodeJS, using the Johnny-Five library for servo control. Voice to text is process using the Nuance API, and text to sign is created with our own database of sign movements.
## Challenges we ran into
The Nuance library was not something we have worked with before, and took plenty of trial and error before we could eventually implement it. Other difficulties included successfully developing a database, and learning to recycle movements to create more with higher efficiency.
## Accomplishments that we're proud of
From calculating inverse trigonometry to processing audio, several areas had to work together for anything to work at all. We are proud that we were able successfully combine so many different parts together for one big project.
## What we learned
We learned about the importance of teamwork and friendship :)
## What's next for Handy Signbot
-Creating a smaller scale model that is more realistic for a home environment, and significantly reducing cost at the same time.
-Reimplement the LeapMotion to train the model for an increased vocabulary, and different accents (did you know you can have an accent in sign language too?). | ## Inspiration
As someone who has always wanted to speak in ASL (American Sign Language), I have always struggled with practicing my gestures, as I, unfortunately, don't know any ASL speakers to try and have a conversation with. Learning ASL is an amazing way to foster an inclusive community, for those who are hearing impaired or deaf. DuoASL is the solution for practicing ASL for those who want to verify their correctness!
## What it does
DuoASL is a learning app, where users can sign in to their respective accounts, and learn/practice their ASL gestures through a series of levels.
Each level has a *"Learn"* section, with a short video on how to do the gesture (ie 'hello', 'goodbye'), and a *"Practice"* section, where the user can use their camera to record themselves performing the gesture. This recording is sent to the backend server, where it is validated with our Action Recognition neural network to determine if you did the gesture correctly!
## How we built it
DuoASL is built up of two separate components;
**Frontend** - The Frontend was built using Next.js (React framework), Tailwind and Typescript. It handles the entire UI, as well as video collection during the *"Learn"* Section, which it uploads to the backend
**Backend** - The Backend was built using Flask, Python, Jupyter Notebook and TensorFlow. It is run as a Flask server that communicates with the front end and stores the uploaded video. Once a video has been uploaded, the server runs the Jupyter Notebook containing the Action Recognition neural network, which uses OpenCV and Tensorflow to apply the model to the video and determine the most prevalent ASL gesture. It saves this output to an array, which the Flask server reads and responds to the front end.
## Challenges we ran into
As this was our first time using a neural network and computer vision, it took a lot of trial and error to determine which actions should be detected using OpenCV, and how the landmarks from the MediaPipe Holistic (which was used to track the hands and face) should be converted into formatted data for the TensorFlow model. We, unfortunately, ran into a very specific and undocumented bug with using Python to run Jupyter Notebooks that import Tensorflow, specifically on M1 Macs. I spent a short amount of time (6 hours :) ) trying to fix it before giving up and switching the system to a different computer.
## Accomplishments that we're proud of
We are proud of how quickly we were able to get most components of the project working, especially the frontend Next.js web app and the backend Flask server. The neural network and computer vision setup was pretty quickly finished too (excluding the bugs), especially considering how for many of us this was our first time even using machine learning on a project!
## What we learned
We learned how to integrate a Next.js web app with a backend Flask server to upload video files through HTTP requests. We also learned how to use OpenCV and MediaPipe Holistic to track a person's face, hands, and pose through a camera feed. Finally, we learned how to collect videos and convert them into data to train and apply an Action Detection network built using TensorFlow
## What's next for DuoASL
We would like to:
* Integrate video feedback, that provides detailed steps on how to improve (using an LLM?)
* Add more words to our model!
* Create a practice section that lets you form sentences!
* Integrate full mobile support with a PWA! | ## Inspiration
MISSION: Our mission is to create an intuitive and precisely controlled arm for situations that are tough or dangerous for humans to be in.
VISION: This robotic arm application can be used in the medical industry, disaster relief, and toxic environments.
## What it does
The arm imitates the user in a remote destination. The 6DOF range of motion allows the hardware to behave close to a human arm. This would be ideal in environments where human life would be in danger if physically present.
The HelpingHand can be used with a variety of applications, with our simple design the arm can be easily mounted on a wall or a rover. With the simple controls any user will find using the HelpingHand easy and intuitive. Our high speed video camera will allow the user to see the arm and its environment so users can remotely control our hand.
## How I built it
The arm is controlled using a PWM Servo arduino library. The arduino code receives control instructions via serial from the python script. The python script is using opencv to track the user's actions. An additional feature use Intel Realsense and Tensorflow to detect and track user's hand. It uses the depth camera to locate the hand, and use CNN to identity the gesture of the hand out of the 10 types trained. It gave the robotic arm an additional dimension and gave it a more realistic feeling to it.
## Challenges I ran into
The main challenge was working with all 6 degrees of freedom on the arm without tangling it. This being a POC, we simplified the problem to 3DOF, allowing for yaw, pitch and gripper control only. Also, learning the realsense SDK and also processing depth image was an unique experiences, thanks to the hardware provided by Dr. Putz at the nwhacks.
## Accomplishments that I'm proud of
This POC project has scope in a majority of applications. Finishing a working project within the given time frame, that involves software and hardware debugging is a major accomplishment.
## What I learned
We learned about doing hardware hacks at a hackathon. We learned how to control servo motors and serial communication. We learned how to use camera vision efficiently. We learned how to write modular functions for easy integration.
## What's next for The Helping Hand
Improve control on the arm to imitate smooth human arm movements, incorporate the remaining 3 dof and custom build for specific applications, for example, high torque motors would be necessary for heavy lifting applications. | winning |
## Inspiration
I had noticed that while many of the music player applications available today are free of charge for basic usage, to make up for the free access, a user's music is often interrupted through ads. I wanted to create an application that allows people to play their music from anywhere, at anytime, without any interruptions!
## What it does
The web application allows the user to play all of their music from one spot. Users can chose to skip songs, go to previous songs, loop tracks, or shuffle play their music, without any ad interruptions!
## How we built it
The application was built using HTML, CSS, and Javascript.
## Challenges we ran into
There are a multitude of issues that I ran into while creating this project. One of the biggest challenges I faced was the workload. Another challenge was the new language. Being fairly new to Javascript made it difficult to program certain aspects of the music player, but it all worked out in the end!
## Accomplishments that we're proud of
To be able to complete this project on time and in a completely new language is an accomplishment that I'm very proud of! Although tough, the past 36 hours have proven to be incredibly insightful and rewarding!
## What we learned
Before this project, I had very minimal experience with Javascript, and since this project extensively uses Javascript, I got to really dig deep and take a very close look at how Javascript works!
## What's next for rePlaylist
In the future, some features I would like to implement in rePlaylist, are:
a) allow users to click and play any song they like (currently just goes in order)
b) allow users to add more songs to their playlist (without having to code it in) | ## Inspiration
When we got together for the first time, we instantly gravitated towards project ideas that would appeal to a broad audience, so music as a theme for our project was a very natural choice. Originally, our ideas around a music-based project were much more abstract, incorporating some notes of music perception. We eventually realized that there were too many logistical hurdles surrounding each that they would not be feasible to do during the course of the hackathon, and we realized this as we were starting to brainstorm ideas for social media apps. We started thinking of ideas for music-based social media, and that's when we came up with the idea of making an app where people would judge other's music tastes in a lighthearted fashion.
## What it does
The concept of Rate-ify is simple; users post their Spotify playlists and write a little bit about them for context. Users can also view playlists that other people have posted, have a listen to them, and then either upvote or downvote the playlist based on their enjoyment. Finally, users can stay up to date on the most popular playlists through the website's leaderboard, which ranks all playlists that have been posted to the site.
## How we built it and what we learned
Our team learned more about tooling surrounding web dev. We had a great opportunity to practice frontend development using React and Figma, learning practices that we will likely be using in future projects. Some members were additionally introduced to tools that they had never used before this hackathon, such as databases.
## Challenges we ran into
Probably the biggest challenge of the hackathon was debugging the frontend. Our team came from a limited background, so being able to figure out how to successfully send data from the backend to the frontend could sometimes be a hassle. The quintessential example of this was when we were working on the leaderboard feature. Though the server was correctly returning ranking data, we had lots of trouble getting the frontend to successfully receive the data so that we could display it, and part of this was because of the server returning ranking data as a promise. After figuring out how to correctly return the ranking data without promises, we then had trouble storing that data as part of a React component, which was fixed by using effect hooks.
## Accomplishments that we're proud of
For having done limited work on frontend for past projects, we ended up very happy with how the UI came out. It's a very simple and charming looking UI.
## What's next for Rate-ify
There were certainly some features that we wanted to include that we didn't end up working on, such as a mode of the app where you would see two playlists and say which one you would prefer and a way of allowing users to identify their preferred genres so that we could categorize the number of upvotes and downvotes of playlists based on the favorite genres of the users who rated them. If we do continue working on Rate-ify, then there are definitely more ways than one that we could refine and expand upon the basic premise that we've developed over the course of the last two days, so that would be something that we should consider. | ## Inspiration
As students who listen to music to help with our productivity, we wanted to not only create a music sharing application but also a website to allow others to discover new music, all through where they are located. We were inspired by Pokemon-Go but wanted to create a similar implementation with music for any user to listen to. Anywhere. Anytime.
## What it does
Meet Your Beat implements a live map where users are able to drop "beats" (a.k.a Spotify beacons). These beacons store a song on the map, allowing other users to click on the beacon and listen to the song. Using location data, users will be able to see other beacons posted around them that were created by others and have the ability to "tune into" the beacon by listening to the song stationed there. Multiple users can listen to the same beacon to simulate a "silent disco" as well.
## How I built it
We first customized the Google Map API to be hosted on our website, as well as fetch the Spotify data for a beacon when a user places their beat. We then designed the website and began implementing the SQL database to hold the user data.
## Challenges I ran into
* Having limited experience with Javascript and API usage
* Hosting our domain through Google Cloud, which we were unaccustomed to
## Accomplishments that I'm proud of
Our team is very proud of our ability to merge various elements for our website, such as the SQL database hosting the Spotify data for other users to access on the website. As well, we are proud of the fact that we learned so many new skills and languages to implement the API's and database
## What I learned
We learned a variety of new skills and languages to help us gather the data to implement the website. Despite numerous challenges, all of us took away something new, such as web development, database querying, and API implementation
## What's next for Meet Your Beat
* static beacons to have permanent stations at more notable landmarks. These static beacons could have songs with the highest ratings.
* share beacons with friends
* AR implementation
* mobile app implementation | losing |
## Inspiration
With the advent of smartwatches, personal health data is one glance at your wrist away. With the rise of streaming, there are hundreds of playlists for every activity. Despite both of these innovations, people still waste *minutes* every day adjusting their music to their current activity. **Heartmonics** bridges this gap to save time and encourage healthy habits.
## What it does
Heartmonics tunes your music to your current fitness activity level. Our device reads your heart rate, then adjusts the mood of your music to suit resting, light exercise, and intense work-outs. This functionality helps to encourage exercise and keep users engaged and enjoying their workouts.
## How we built it
Our device is runs on a Raspberry Pi platform housed in an exercise armband. It reads heart rate data from a sensor connected via i2c and comfortably attached to the users forearm. A button integrated into the armband provides easy control of music like any other player, allowing the user to play, pause, skip, and rewind songs.
## Challenges we ran into
In building Heartmonics, we faced several challenges with integrating all the components of our design together. The heart rate sensor was found to be very sensitive and prone to giving inaccurate results, but by reading documentation and making careful adjustments, as well as reinforcing our hardware connections, we were able to get the sensor calibrated and working reliably. Integrating our solution with SpotifyAPI using the spotipi library also came with a set of integration challenges, compounded by our unfamiliarity with the platform. Despite all of these challenges, we persevered to produce a polished and functional prototype.
## Accomplishments that we're proud of
We are proud of the ease of use of our final design. Since the concept is designed as a time saver, we're glad it can deliver on everything we set out to do. We also went above and beyond our original goals, adding music control via a button, mood indication on an RGB LED, sensor and song information on an LCD display, and an elevated heart rate warning indicator. These features elevate Heartmonics and
## What we learned
We learned the importance of careful hardware selection, and reading documentation. We leveraged and reinforced our teamwork and planning abilities to quickly build a functioning prototype.
## What's next for Heartmonics
The functionality of Heartmonics could be integrated into a smartwatch app for a more elegant implementation of our concept. With wearable integration, users could employ our concept with potentially no additional cost, making Heartmonics widely accessible.
Another potential addition is to make configuring which songs play for each mode user-accessible, so everyone can tune their Heartmonics to the tune of their heart. | ## TL; DR
* Music piracy costs the U.S. economy [$12.5 billion annually](https://www.riaa.com/wp-content/uploads/2015/09/20120515_SoundRecordingPiracy.pdf).
* Independent artists are the [fastest growing segment in the music industry](https://www.forbes.com/sites/melissamdaniels/2019/07/10/for-independent-musicians-goingyour-own-way-is-finally-starting-to-pay-off/), yet lack the funds and reach to enforce the Digital Millennium Copyright Act (DMCA).
* We let artists **OWN** their work (stored on InterPlanetary File System) by tracking it on our own Sonoverse Ethereum L2 chain (powered by Caldera).
* Artists receive **Authenticity Certificates** of their work in the form of Non-Fungible Tokens (NFTs), powered by Crossmint’s Minting API.
* We protect against parodies and remixes with our **custom dual-head LSTM neural network model** trained from scratch which helps us differentiate these fraudulent works from originals.
* We proactively query YouTube through their API to constantly find infringing work.
* We’ve integrated with **DMCA Services**, LLC. to automate DMCA claim submissions.
Interested? Keep reading!
## Inspiration
Music piracy, including illegal downloads and streaming, costs the U.S. economy $12.5 billion annually.
Independent artists are the fastest growing segment in the music industry, yet lack the funds to enforce DMCA.
We asked “Why hasn’t this been solved?” and took our hand at it. Enter Sonoverse, a platform to ensure small musicians can own their own work by automating DMCA detection using deep learning and on-chain technologies.
## The Issue
* Is it even possible to automate DMCA reports?
* How can a complex piece of data like an audio file be meaningfully compared?
* How do we really know someone OWNS an audio file?
* and more...
These are questions we had too, but by making custom DL models and chain algorithms, we have taken our hand at answering them.
## What we’ve made
We let artists upload their original music to our platform where we store it on decentralized storage (IPFS) and our blockchain to **track ownership**. We also issue Authenticity Certificates to the original artists in the form of Non-Fungible Tokens.
We compare uploaded music with all music on our blockchain to **detect** if it is a parody, remix, or other fraudulent copy of another original song, using audio processing and an LSTM deep learning model built and trained from scratch.
We proactively query YouTube through their API for “similar” music (based on our **lyric hashes**, **frequency analysis**, and more) to constantly find infringing work. For detected infringing work, we’ve integrated with DMCA Services, LLC. to **automate DMCA claim submissions**.
## How we built it
All together, we used…
* NextJS
* Postgres
* AWS SES
* AWS S3
* IPFS
* Caldera
* Crossmint
* AssemblyAI
* Cohere
* YouTube API
* DMCA Services
It’s a **lot**, but we were able to split up the work between our team. Gashon built most of the backend routes, an email magic link Auth platform, DB support, and AWS integrations.
At the same time, Varun spent his hours collecting hours of audio clips, training and improving the deep LSTM model, and writing several sound differentiation/identification algorithms. Here’s Varun’s **explanation** of his algorithms: “To detect if a song is a remix, we first used a pre-trained speech to text model to extract lyrics from mp3 files and then analyzed the mel-frequency cepstral coefficients, tempo, melody, and semantics of the lyrics to determine if any songs are very similar. Checking whether a song is a parody is much more nuanced, and we trained a dual-head LSTM neural network model in PyTorch to take in vectorized embeddings of lyrics and output the probability of one of the songs being a parody of the other.”
While Varun was doing that, Ameya built out the blockchain services with Caldera and Crossmint, and integrated DMCA Services. Ameya ran a Ethereum L2 chain specific for this project (check it out [here](https://treehacks-2024.explorer.caldera.xyz)) using Caldera. He built out significant infrastructure to upload audio files to IPFS (decentralized storage) and interact with the Caldera chain. He also created the Authenticity Certificate using Crossmint that’s delivered directly to each Sonoverse user’s account.
Ameya and Gashon came together at the end to create the Sonoverse frontend, while Varun pivoted to create our YouTube API jobs that query through recently uploaded videos to find infringing content.
## Challenges we overcame
We couldn’t find existing models to detect parodies and had to train a custom model from scratch on training data we had to find ourselves. Of course, this was quite challenging, but with audio files each being unique, we had to create a dataset of hours of audio clips.
And, like always, integration was difficult. The power of a team was a huge plus, but also a challenge. Ameya’s blockchain infrastructure had Solidity compilation challenges when porting into Gashon’s platform (which took some precious hours to sort out). Varun’s ML algorithms ran on a Python backend which had to be hosted alongside our NextJS platform. You can imagine what else we had to change and fix and update, so I won’t bore you.
Another major challenge was something we brought on ourselves, honestly. We set our aim high so we had to use several different frameworks, services, and technologies to add all the features we wanted. This included several hours of us learning new technologies and services, and figuring out how to implement them in our project.
## Accomplishments that we're proud of
Blockchain has a lot of cool and real-world applications, but we’re excited to have settled on Sonoverse. We identified a simple (yet technically complex) way to solve a problem that affects many small artists.
We also made a sleek web platform, in just a short amount of time, with scalable endpoints and backend services.
We also designed and trained a deep learning LSTM model to identify original audios vs fraudulent ones (remixes, speed ups, parodies, etc) that achieved **93% accuracy**.
## What we learned
#### About DMCA
We learned how existing DMCA processes are implemented and the large capital costs associated with them. We became **experts** on digital copyrights and media work!
#### Blockchain
We learned how to combine centralized and decentralized infrastructure solutions to create a cohesive **end-to-end** project.
## What's next for Sonoverse
We're looking forward to incorporating on-chain **royalties** for small artists by detecting when users consume their music and removing the need for formal contracts with big companies to earn revenue.
We’re excited to also add support for more public APIs in addition to YouTube API! | ## 💡Inspiration
* 2020 US Census survey showed that adults were 3x more likely to screen positive for depression or anxiety in 2020 vs 2019
* A 2019 review of 18 papers summarized that wearable data could help identify depression, and coupled with behavioral therapy can help improve mental health
* 1 in 5 americans owns wearables now, and this adoption is projected to grow 18% every year
* Pattrn aims to turn activity and mood data into actionable insights for better mental health.
## 🤔 What it does
* Digests activity monitor data and produces bullet point actionable summary on health status
* Allows users to set goals on health metrics, and provide daily, weekly, month review against goals
* Based on user mood rating and memo entry, deduce activities that correlates with good and bad days
[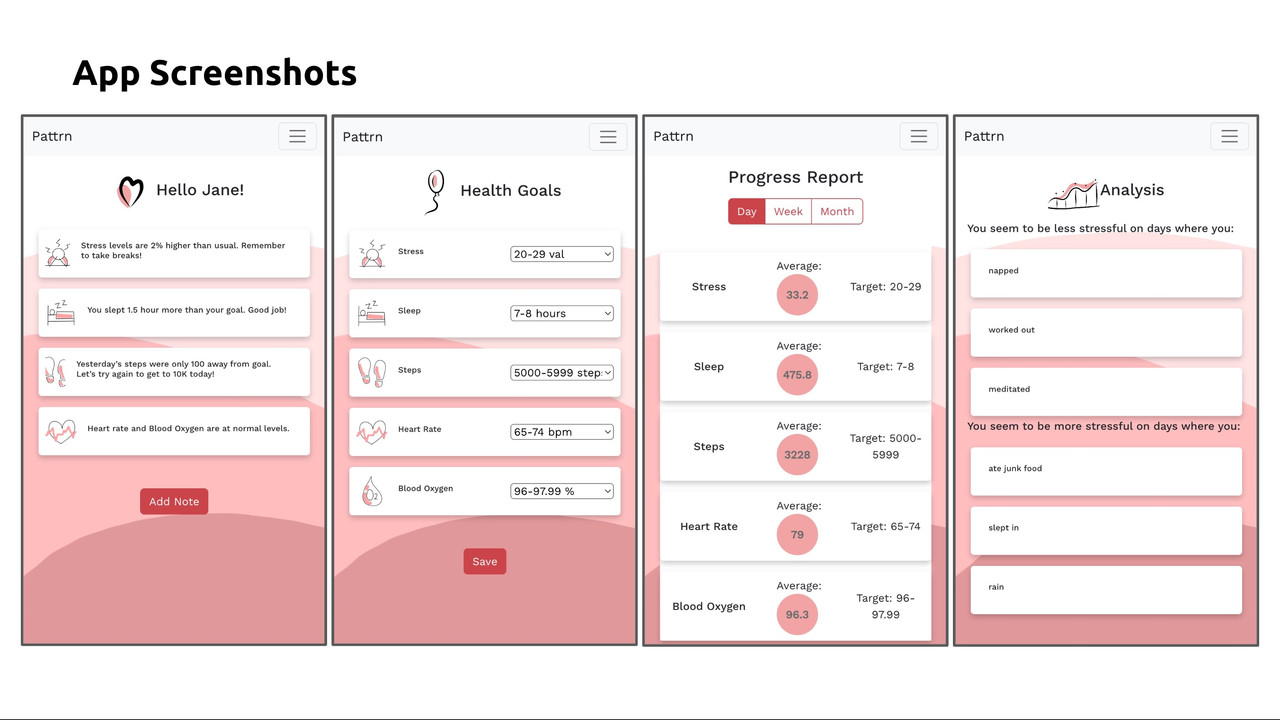](https://postimg.cc/bd9JvX3V)
[](https://postimg.cc/bDQQJ6B0)
## 🦾 How we built it
* Frontend: ReactJS
* Backend: Flask, Google Cloud App Engine, Intersystems FHIR, Cockroach Labs DB, Cohere
## 👨🏻🤝👨🏽 Challenges / Accomplishments
* Ideating and validating took up a big chunk of this 24 hour hack
* Continuous integration and deployment, and Github collaboration for 4 developers in this short hack
* Each team member pushing ourselves to try something we have never tried before
## 🛠 Hack for Health
* Pattrn currently is able to summarize actionable steps for users to take towards a healthy lifestyle
* Apart from health goal setting and reviewing, pattrn also analyses what activities have historically correlated with "good" and "bad" days
## 🛠 Intersystems Tech Prize
* We paginated a GET and POST request
* Generated synthetic data and pushed it in 2 different time resolution (Date, Minutes)
* Endpoints used: Patient, Observation, Goals, Allergy Intolerance
* Optimized API calls in pushing payloads through bundle request
## 🛠 Cockroach Labs Tech Prize
* Spawned a serverless Cockroach Lab instance
* Saved user credentials
* Stored key mapping for FHIR user base
* Stored sentiment data from user daily text input
## 🛠 Most Creative Use of GitHub
* Implemented CICD, protected master branch, pull request checks
## 🛠 Cohere Prize
* Used sentiment analysis toolkit to parse user text input, model human languages and classify sentiments with timestamp related to user text input
* Framework designed to implement a continuous learning pipeline for the future
## 🛠 Google Cloud Prize
* App Engine to host the React app and Flask observer and linked to Compute Engine
* Hosted Cockroach Lab virtual machine
## What's next for Pattrn
* Continue working on improving sentiment analysis on user’s health journal entry
* Better understand pattern between user health metrics and daily activities and events
* Provide personalized recommendations on steps to improve mental health
* Provide real time feedback eg. haptic when stressful episode are predicted
Temporary login credentials:
Username: [[email protected]](mailto:[email protected])
Password: norcal | partial |
# Stop being a payer, and start being a PayAR.
## Inspiration
We were always fascinated with AR, but were always too timid to get our hands dirty. We decided that at mchacks6, we would take the plunge and try something new.
## What it does
PayAR is an augmented reality platform that allows users to enjoy an interactive shopping experience using their mobile device.
As customers browse through the store, they can easily add items to their virtual carts through an immersive AR experience. Then, they can quickly pay for their purchase even before they collect it! Both clients and merchants are notified of the transaction through SMS.
## How we built it
We used Unity and Vuforia to create the augmented reality environment. We used Flask as our back-end framework to handle all of the business logic. We integrated Interac's E-Transfer API to handle payments and Twilio's API to handle SMS receipts. Finally, we hosted our data store in Azure.
## Challenges we ran into
We had difficulty integrating all the different components of our system together. Namely, connecting our back-end to the database hosted in Azure required a bit more than just a simple connection string. Additionally, creating high quality models for the AR component was a challenge due to difficult lighting conditions for photos, which were needed to generate these models.
## Accomplishments that we're proud of
We are very proud that we decided to take on something new for all of us, and that we were able to produce a functional proof-of-concept application. Furthermore, we could take advantage of these product databases to compare prices across retailers and suggest the best options.
## What we learned
We learned how to create augmented reality scenes using Vuforia and Unity. Most of the team had never touched either of these platforms, and so a lot of our development was in uncharted territory.
We learned also about Interac and how effortless it is to send and receive money using their E-Transfer API.
Lastly, we learned a bit about using Azure to obtain resources in the cloud.
## What's next for PayAR
A possible next step for PayAR would be to integrate with large product data sets to pre-populate our product database and have to more extensive product details. | Demo: <https://youtu.be/cTh3Q6a2OIM?t=2401>
## Inspiration
Fun Mobile AR Experiences such as Pokemon Go
## What it does
First, a single player hides a virtual penguin somewhere in the room. Then, the app creates hundreds of obstacles for the other players in AR. The player that finds the penguin first wins!
## How we built it
We used AWS and Node JS to create a server to handle realtime communication between all players. We also used Socket IO so that we could easily broadcast information to all players.
## Challenges we ran into
For the majority of the hackathon, we were aiming to use Apple's Multipeer Connectivity framework for realtime peer-to-peer communication. Although we wrote significant code using this framework, we had to switch to Socket IO due to connectivity issues.
Furthermore, shared AR experiences is a very new field with a lot of technical challenges, and it was very exciting to work through bugs in ensuring that all users have see similar obstacles throughout the room.
## Accomplishments that we're proud of
For two of us, it was our very first iOS application. We had never used Swift before, and we had a lot of fun learning to use xCode. For the entire team, we had never worked with AR or Apple's AR-Kit before.
We are proud we were able to make a fun and easy to use AR experience. We also were happy we were able to use Retro styling in our application
## What we learned
-Creating shared AR experiences is challenging but fun
-How to work with iOS's Multipeer framework
-How to use AR Kit
## What's next for ScavengAR
* Look out for an app store release soon! | ## Inspiration
Online shopping is hard because you can't try on clothing for yourself. We want to make a fun and immersive online shopping experience through VR that will one day hopefully become more realistic and suitable for everyday online shopping. We hope to make a fun twist that helps improve decisiveness while browsing online products.
## What it does
This VR experience includes movement, grabbable clothes, dynamic real-time texturing of models using images from Shopify’s Web API, and a realistic mirror of yourself to truly see how these fits shall look on you before buying it! The user that enters the virtual clothing store may choose between a black/yellow shirt, and black/tropical pants which are products from an online Shopify store (see screenshots). The user can also press a button that would simulate a purchase :)
## How we built it
Using the Shopify ProductListing API, we accessed the different clothing items from our sample online store with a C# script. We parsed the JSON that was fetched containing the product information to give us the image, price, and name of the products. We used this script to send this information to our VR game. Using the images of the products, we generated a texture for each item in virtual reality in the Unity game engine, which was then put onto interactable items in the game. Also, we designed some models, such as signs with text, to customize and accessorize the virtual store. We simulated the shopping experience in a store as well as interactable objects that can be tried on.
## Challenges we ran into
Linking a general C# script which makes REST API calls to Unity was a blocker for us because of the structure of code Unity works with. We needed to do some digging and search for what adjustments needed to be made to a generic program to make it suitable for the VR application. For example, including libraries such as Newtonsoft.
We also ran into conflicts when merging different branches of our project on GitHub. We needed to spend additional time rolling back changes and fixing bugs to take the next step in the project.
One significant difficulty was modelling the motion of the virtual arms and elbows when visible in the mirror. This must be done with inverse kinematics which we were never quite able to smoothly implement, although we achieved something somewhat close.
Getting the collision boundaries was difficult as well. The player and their surroundings constantly change in VR, and it was a challenge to set the boundaries of item interaction for the player when putting on items.
## Accomplishments that we're proud of
Our project has set a strong foundation for future enhancements. We’re proud of the groundwork we’ve laid for a concept that can grow and evolve, potentially becoming a game-changing solution in VR shopping.
## What we learned
We learned the importance of anticipating potential technical blockers, such as handling complex features like inverse kinematics and collision limits. Properly allocating time for troubleshooting unexpected challenges would have helped us manage our time more efficiently.
Also, many technical challenges required a trial-and-error approach, especially when setting up collision boundaries and working with avatar motion. This taught us that sometimes it's better to start with a rough solution and iteratively refine it, rather than trying to perfect everything on the first go.
Finally, working as a team, we realized the value of maintaining clear communication, especially when multiple people are contributing to the same project. Whether it was assigning tasks or resolving GitHub conflicts, being aligned on priorities and maintaining good communication channels kept us moving forward.
## What's next for Shop The North
We want to add even more variety for future users. We hope to develop more types of clothing, such as shoes and hats, as well as character models that could suit any body type for an inclusive experience. Additionally, we would like to implement a full transaction system, where the user can add all the products they are interested into a cart and complete a full order (payment information, shipping details, and actually placing a real order). In general, the goal would be to have everything a mobile/web online shopping app has, and more fun features on top of it. | winning |
## Inspiration
Textbooks have not fundamentally changed since their invention in the 16th century. Although there are now digital textbooks (ePubs and the like), they're still just pictures and text. From educational literature, we know that discussion and interactivity is crucial for improving student outcomes (and, particularly, those of marginalized students). But we still do the majority of our learning with static words and images on a page.
## What it does
How do we keep students engaged? Introducing *Talk To History*. This is a living textbook, where students can read about a historical figure, click on their face on the side of the page, and have an immersive conversation with them. Or, read a primary text and then directly engage to ask questions about the writing. This enables a richer, multimodal interaction. It makes history more immersive. It creates more places to engage and retain knowledge. Most importantly, it makes the textbook fun. If Civ5 can make history fun, why can’t textbooks?
## How we built it
*Talk To History* was built using TypeScript, React, Next.js, Vercel, Chakra, Python, Google Text-To-Speech, Wav2Lip, GPT, and lots of caffeine :) The platform has several components, including a frontend for students and a backend to handle user data and text analysis. We also used Google's Text-To-Speech (TTS) API to generate high-quality speech output, which we then fed into Wav2Lip, a deep generative adversarial network, to produce realistic lip movements for the characters. For accelerated inference, we deployed Wav2Lip on an NVIDIA A40 GPU server.
## Challenges we ran into
* Dealing with CUDA memory leaks when performing inference using the Wav2Lip model
* Finetuning hyperparameters of the Wav2Lip model and optimizing PyTorch loading to reduce latency
* Connecting and deploying all of the different services (TTS, GPT, Wav2Lip) into a unified product
## Accomplishments we're proud of
We're most proud of building a platform that makes learning fun and engaging for students. On the technical side, we're proud of seamlessly integrating several cutting-edge technologies, such as Wav2Lip and GPT, to create a more immersive experience; this project required advanced techniques in full-stack engineering, multi-processing, and latency optimization. The end result was more than worth the effort, as we successfully created a platform that makes education more engaging and immersive. With *Talk To History*, we hope to transform the way students learn history.
## What we learned
We learned how to integrate multiple services and optimize our code to handle large amounts of data, but perhaps more importantly, we gained a deep appreciation for the importance of creating an exciting experience for students.
## What's next
* Scalability and speed improvements for Wav2Lip GPU instances for more realtime chats
* Improved robustness against adversarial prompts
* Broader selection of articles and speakers organized into different domains, such as "Pioneers in Environmental Sustainability", "Female Heroes in Science", and "Diverse Voices in Literature"
* *Talk to History* as a platform: ability for any educational content author to add their own character (subject to content approval) given some context and voice and integrate it on their website or e-reader | ## Inspiration
Whether you’re thriving in life or really going through it, research shows that writing down your thoughts throughout the day has many benefits. We wanted to add a social element to this valuable habit and build a sense of community through sharing and acknowledging each other’s feelings. However, even on the internet, we've noticed that it is difficult for people to be vulnerable for fear of judgement, criticism, or rejection.
Thus, we centred our problem around this challenge and asked the question: How might we create a sense of community and connection among journalers without compromising their sense of safety and authenticity when sharing their thoughts?
## What it does
With Yapyap, you can write daily journal entries and share them anonymously with the public. Before posting, our AI model analyzes your written entry and provides you with an emotion, helping to label and acknowledge your feelings.
Once your thoughts are out in the world, you can see how other people's days are going too and offer mutual support and encouragement through post reactions.
Then, the next day comes, and the cycle repeats.
## How we built it
After careful consideration, we recognized that most users of our app would favour a mobile version as it is more versatile and accessible throughout the day. We used Figma to create an interesting and interactive design before implementing it in React Native. On the backend, we created an API using AWS Lambda and API Gateway to read and modify our MongoDB database. As a bonus, we prepared a sentimental analyzer using Tensorflow that could predict the overall mood of the written entry.
## Challenges we ran into
Learning new technologies and figuring out how to deploy our app so that they could all communicate were huge challenges for us.
## Accomplishments that we're proud of
Being able to apply what we learned about the new technologies in an efficient and collaborative way. We're also proud of getting a Bidirectional RNN for sentiment analysis ready in a few hours!
## What we learned
How to easily deal with merge conflicts, what it's like developing software as a group, and overall just knowing how to have fun even when you're pulling an all-nighter!
## What's next for yapyap
More personable AI Chatbots, and more emotions available for analysis! | ## What it does
Danstrument lets you video call your friends and create music together using only your actions. You can start a call which generates a code that your friend can use to join.
## How we built it
We used Node.js to create our web app which employs WebRTC to allow video calling between devices. Movements are tracked with pose estimation from tensorflow and then vector calculations are done to trigger audio files.
## Challenges we ran into
Connecting different devices with WebRTC over an unsecured site proved to be very difficult. We also wanted to have continuous sound but found that libraries that could accomplish this caused too many problems so we chose to work with discrete sound bites instead.
## What's next for Danstrument
Annoying everyone around us. | partial |
## Inspiration
We often found ourselves stuck at the start of the design process, not knowing where to begin or how to turn our ideas into something real. In large organisations these issues are not only inconvenient and costly, but also slow down development. That is why we created ConArt AI to make it easier. It helps teams get their ideas out quickly and turn them into something real without all the confusion.
## What it does
ConArt AI is a gamified design application that helps artists and teams brainstorm ideas faster in the early stages of a project. Teams come together in a shared space where each person has to create a quick sketch and provide a prompt before the timer runs out. The sketches are then turned into images and everyone votes on their team's design where points are given from 1 to 5. This process encourages fast and fun brainstorming while helping teams quickly move from ideas to concepts. It makes collaboration more engaging and helps speed up the creative process.
## How we built it
We built ConArt AI using React for the frontend to create a smooth and responsive interface that allows for real-time collaboration. On the backend, we used Convex to handle game logic and state management, ensuring seamless communication between players during the sketching, voting, and scoring phases.
For the image generation, we integrated the Replicate API, which utilises AI models like ControlNet with Stable Diffusion to transform the sketches and prompts into full-fledged concept images. These API calls are managed through Convex actions, allowing for real-time updates and feedback loops.
The entire project is hosted on Vercel, which is officially supported by Convex, ensuring fast deployment and scaling. Convex especially enabled us to have a serverless experience which allowed us to not worry about extra infrastructure and focus more on the functions of our app. The combination of these technologies allows ConArt AI to deliver a gamified, collaborative experience.
## Challenges we ran into
We faced several challenges while building ConArt AI. One of the key issues was with routing in production, where we had to troubleshoot differences between development and live environments. We also encountered challenges in managing server vs. client-side actions, particularly ensuring smooth, real-time updates. Additionally, we had some difficulties with responsive design, ensuring the app looked and worked well across different devices and screen sizes. These challenges pushed us to refine our approach and improve the overall performance of the application.
## Accomplishments that we're proud of
We’re incredibly proud of several key accomplishments from this hackathon.
Nikhil: Learned how to use a new service like Convex during the hackathon, adapting quickly to integrate it into our project.
Ben: Instead of just showcasing a local demo, he managed to finish and fully deploy the project by the end of the hackathon, which is a huge achievement.
Shireen: Completed the UI/UX design of a website in under 36 hours for the first time, while also planning our pitch and brand identity, all during her first hackathon.
Ryushen: He worked on building React components and the frontend, ensuring the UI/UX looked pretty, while also helping to craft an awesome pitch.
Overall, we’re most proud of how well we worked as a team. Every person filled their role and brought the project to completion, and we’re happy to have made new friends along the way!
## What we learned
We learned how to effectively use Convex by studying its documentation, which helped us manage real-time state and game logic for features like live sketching, voting, and scoring. We also learned how to trigger external API calls, like image generation with Replicate, through Convex actions, making the integration of AI seamless. On top of that, we improved our collaboration as a team, dividing tasks efficiently and troubleshooting together, which was key to building ConArt AI successfully.
## What's next for ConArt AI
We plan to incorporate user profiles in order to let users personalise their experience and track their creative contributions over time. We will also be adding a feature to save concept art, allowing teams to store and revisit their designs for future reference or iteration. These updates will enhance collaboration and creativity, making ConArt AI even more valuable for artists and teams working on long-term projects. | ## Inspiration
The inspiration for our project stems from the increasing trend of online shopping and the declining foot traffic in physical stores. Our goal was to provide a unique and engaging experience for customers, encouraging them to visit physical stores and rediscover the joy of in-person shopping. We wanted to create an interactive and entertaining shopping experience that would entice customers to visit stores more frequently and foster a deeper connection between them and the store's brand.
## What it does
Our project is an AR scavenger hunt experience that gamifies the shopping experience. The scavenger hunt encourages customers to explore the store and discover new products they may have otherwise overlooked. As customers find specific products, they can earn points which can be redeemed for exclusive deals and discounts on future purchases. This innovative marketing scheme not only provides customers with an entertaining experience but also incentivizes them to visit stores more frequently and purchase products they may have otherwise overlooked.
## How we built it
To create the AR component of our project, we used Vuforia and Unity, two widely used platforms for building AR applications. The Vuforia platform allowed us to create and track image targets, while Unity was used to design the 3D models for the AR experience. We then integrated the AR component into an Android application by importing it as a Gradle project. Our team utilized agile development methodologies to ensure efficient collaboration and problem-solving throughout the development process.
## Challenges we ran into
One of the challenges we faced was integrating multiple APIs and ensuring that they worked together seamlessly. Another challenge was importing the AR component and creating the desired functionality within our project. We also faced issues with debugging and resolving technical errors that arose during the development process.
## Accomplishments that we're proud of
Despite the challenges we faced, we were able to achieve successful teamwork and collaboration. Despite forming the team later than other groups, we were able to effectively communicate and work together to bring our project to fruition. We are proud of the end result, which was a polished and functional AR scavenger hunt experience that met our objectives.
## What we learned
We learned how difficult it is to truly ship out software, and we are grateful to have joined the hackathon. We gained a deeper understanding of the importance of project planning, effective communication, and collaboration among team members. We also learned that the development process can be challenging and unpredictable, and that it requires perseverance and problem-solving skills. Additionally, participating in the hackathon taught us valuable technical skills such as integrating APIs, creating AR functionality, and importing projects onto an Android application.
## What's next for Winnur
Looking forward, we plan to incorporate Computer Vision technology into our project to prevent potential damage to our product's packaging. We also aim to expand the reach of our AR scavenger hunt experience by partnering with more retailers and enhancing the user interface and experience. We are excited about the potential for future development and growth of Winnur. | ## Inspiration
Considering the recent surge in the housing crisis within Canada, we decided to build a platform that connects people to the communities of their choice. We aim to place people from all walks of life, whether you are a cash-strapped student, an ailing senior citizen, or a family man, your place is your choice! :)
## What it does
PlaceMe is the website that lets you get a gist of the society you could be a part of, and also allows you to sort by these crucial features: House Price, Crime Rate, and Convenience Score! But, wait a minute…what on Earth is the Convenience Score?! It’s our ingenious score devised on the proximity of basic necessities in a neighbourhood (grocery stores, parks, stations, and much more!) as well as the accessibility to transport and transit.
We offer two services: PlaceMe and BriefMe. PlaceMe is our premier service that allows us to place you in the best neighbourhood possible (Woohoo!) based on your preferences. BriefMe briefs you about all the stuff you need to know about a community you have already decided on.
Choose one and the process is done! (#Rhyming).
## How we built it
How we built it?
• JavaScript
• HTML
• CSS
• Figma
• Data Analysis
## Challenges we ran into
SO MANY!!!
The primary challenge was thinking about the IDEA: coming up with a solution that helps solve a real-world problem and building something that helps EVERYONE!
LIMITED DATA!!! It was quite cumbersome to get accurate, up-to-date and reliable data for all the neighbourhoods. Moreover, it took a long time to implement a sorting algorithm that would produce unbiased data (to a large extent!).
With no hands-on experience of working with CSV files in JavaScript, as well as less experience with backend web development we had to meticulously work with inputting and outputting the desired data!. We also implemented a dynamic dropdown box for inputting ranks in the PlaceMe service which was quite the task.
Another major challenge we faced was crafting the aesthetic appeal of the website. We used Figma for this purpose, but we had issues with the CSS it produced. Ultimately, it was collaboration that culminated in the successful completion of the project.
## Accomplishments that we're proud of
• Working towards an innovative solution that tackles a real world issue!
• Working with delimited data in Javascript and producing custom output based on the user input.
• Building something!
## What we learned
Developed a strong grasp on Javascript by using data in the backend. Learned data analysis skills and techniques and learned to build visually appeasing designs through Figma and CSS.
## What's next for PlaceMe
• Integration of Interactive Map GUI.
• Scaling the services globally.
• Incorporating factors such as parking, restaurants, gyms, etc.
• Collaborating with big companies such as Kijiji for house listings, etc.
## Built With
Javascript HTML5 CSS3 Figma Excel CSV | winning |
## Inspiration
I've always been inspired by the notion that even as just **one person** you can make a difference. I really took this to heart at DeltaHacks in my attempt to individually create a product that could help individuals struggling with their mental health by providing **actionable and well-studied techniques** in a digestible little Android app. As a previous neuroscientist, my educational background and research in addiction medicine has shown me the incredible need for more accessible tools for addressing mental health as well as the power of simple but elegant solutions to make mental health more approachable. I chose to employ a technique used in Cognitive Behavioral Therapy (CBT), one of (if not the most) well-studied mental health intervention in psychological and medical research. This technique is called automatic negative thought (ANT) records.
Central to CBT is the principle that psychological problems are based, in part, on faulty/unhelpful thinking and behavior patterns. People suffering from psychological problems can learn better ways of coping with them, thereby relieving their symptoms and becoming more effective in their lives.
CBT treatment often involves efforts to change thinking patterns and challenge distorted thinking, thereby enhancing problem-solving and allowing individuals to feel empowered to improve their mental health. CBT automatic negative thought (ANT) records and CBT thought challenging records are widely used by mental health workers to provide a structured way for patients to keep track of their automatic negative thinking and challenge these thoughts to approach their life with greater objectivity and fairness to their well-being.
See more about the widely studied Cognitive Behavioral Therapy at this American Psycological Association link: [link](https://www.apa.org/ptsd-guideline/patients-and-families/cognitive-behavioral)
Given the app's focus on finding objectivity in a sea of negative thinking, I really wanted the UI to be simple and direct. This lead me to take heavy inspiration from a familiar and nostalgic brand recognized for its bold simplicity, objectivity and elegance - "noname". [link](https://www.noname.ca/)
This is how I arrived at **noANTs** - i.e., no (more) automatic negative thoughts
## What it does
**noANTs** is a *simple and elegant* solution to tracking and challenging automatic negative thoughts (ANTs). It combines worksheets from research and clinical practice into a more modern Android application to encourage accessibility of automatic negative thought tracking.
See McGill worksheet which one of many resources which informed some of questions in the app: [link](https://www.mcgill.ca/counselling/files/counselling/thought_record_sheet_0.pdf)
## How I built it
I really wanted to build something that many people would be able to access and an Android application just made the most sense for something where you may need to track your thoughts on the bus, at school, at work or at home.
I challenged myself to utilize the newest technologies Android has to offer, building the app entirely in Jetpack Compose. I had some familiarity using the older Fragment-based navigation in the past but I really wanted to learn how to utilize the Compose Navigation and I can excitedly say I implemented it successfully.
I also used Room, a data persistence library which provided an abstraction layer for the SQLite database I needed to store the thought records which the user generates.
## Challenges I ran into
This is my first ever hackathon and I wanted to challenge myself to build a project alone to truly test my limits in a time crunch. I surely tested them! Designing this app with a strict adherence to NoName's branding meant that I needed to get creative making many custom components from scratch to fit the UI style I was going for. This made even ostensibly simple tasks like creating a slider, incredibly difficult, but rewarding in the end.
I also had far loftier goals with how much I wanted to accomplish, with aspirations of creating a detailed progress screen, an export functionality to share with a therapist/mental-health support worker, editing and deleting and more. I am nevertheless incredibly proud to showcase a functional app that I truly believe could make a significant difference in people's lives and I learned to prioritize creating and MVP which I would love to continue building upon in the future.
## Accomplishments that I'm proud of
I am so proud of the hours of work I put into something I can truly say I am passionate about. There are few things I think should be valued more than an individual's mental health, and knowing that my contribution could make a difference to someone struggling with unhelpful/negative thinking patterns, which I myself often struggle with, makes the sleep deprivation and hours of banging my head against the keyboard eternally worthwhile.
## What I learned
Being under a significant time crunch for DeltaHacks challenged me to be as frugal as possible with my time and design strategies. I think what I found most valuable about both the time crunch, my inexperience in software development, and working solo was that it forced me to come up with the simplest solution possible to a real problem. I think this mentality should be approached more often, especially in tech. There is no doubt a place, and an incredible allure to deeply complex solutions with tons of engineers and technologies, but I think being forced to innovate under constraints like mine reminded me of the work even one person can do to drive positive change.
## What's next for noANTs
I have countless ideas on how to improve the app to be more accessible and helpful to everyone. This would start with my lofty goals as described in the challenge section, but I would also love to extend this app to IOS users as well. I'm itching to learn cross-platform tools like KMM and React Native and I think this would be a welcomed challenge to do so. | ## Inspiration
In the past 2 years, the importance of mental health has never been so prominent on the global stage. With isolation leaving us with crippling effects, and social anxiety many have suffered in ways that could potentially be impacting them for the rest of their life. One of the difficulties that people with anxiety, depression, and some other mental health issues face, is imagination. Our main goal in this project was targeting this group (which includes our teammates) and helping them to take small steps towards bringing it back. clAIrity is a tool that offers users who are looking to express themselves with words and see a visual feedback representation of those exact words that they used to express themselves. clAIrity was inspired by the Health and Discovery portions of Hack the Valley, our team has all dealt with the effects of mental health, or lack thereof thought it would be a crazy, but awesome idea to build an app that would help promote the processing of our thoughts and emotions using words.
## What it does
The user inputs a journal entry into the app, and the app then uses co:here's NLP summarization tool to pass a JSON string of the user's journal entry into the Wombo API.
The dream API then returns an image generated by the user's journal entry prompt. Here the user can screenshot the generated image and keep a "visual diary".
The user can then save their journal entry in the app. This enables them to have a copy of the journal entries they submit
## Challenges
We ran into bundling an app that uses both java and Python was no short feat for us, using the Chaquopy plugin for Android Studio we integrated our python code to work in tandem with our java code.
## Accomplishment
We are proud of improving our development knowledge. As mentioned above this project is based on Java and Python and one of the big challenges was showcasing the received picture from API which was coded in python in the app. We overcame this challenge by lots of reading and trying different methods. The challenge was successfully solved by our group mates and we made a great group bond.
## What we learned
We learned a lot about Android Studio from a BOOK! We learned what different features do in the app and how we can modify them to achieve our goal. On the back end side, we worked with the dream API in python and used plug-ins for sending information from our python to java side of back end
##What's next
The next thing on the agenda for clAIrity is to add a voice to text feature so our users can talk and see the results | ## Inspiration
We were inspired by Katie's 3-month hospital stay as a child when she had a difficult-to-diagnose condition. During that time, she remembers being bored and scared -- there was nothing fun to do and no one to talk to. We also looked into the larger problem and realized that 10-15% of kids in hospitals develop PTSD from their experience (not their injury) and 20-25% in ICUs develop PTSD.
## What it does
The AR iOS app we created presents educational, gamification aspects to make the hospital experience more bearable for elementary-aged children. These features include:
* An **augmented reality game system** with **educational medical questions** that pop up based on image recognition of given hospital objects. For example, if the child points the phone at an MRI machine, a basic quiz question about MRIs will pop-up.
* If the child chooses the correct answer in these quizzes, they see a sparkly animation indicating that they earned **gems**. These gems go towards their total gem count.
* Each time they earn enough gems, kids **level-up**. On their profile, they can see a progress bar of how many total levels they've conquered.
* Upon leveling up, children are presented with an **emotional check-in**. We do sentiment analysis on their response and **parents receive a text message** of their child's input and an analysis of the strongest emotion portrayed in the text.
* Kids can also view a **leaderboard of gem rankings** within their hospital. This social aspect helps connect kids in the hospital in a fun way as they compete to see who can earn the most gems.
## How we built it
We used **Xcode** to make the UI-heavy screens of the app. We used **Unity** with **Augmented Reality** for the gamification and learning aspect. The **iOS app (with Unity embedded)** calls a **Firebase Realtime Database** to get the user’s progress and score as well as push new data. We also use **IBM Watson** to analyze the child input for sentiment and the **Twilio API** to send updates to the parents. The backend, which communicates with the **Swift** and **C# code** is written in **Python** using the **Flask** microframework. We deployed this Flask app using **Heroku**.
## Accomplishments that we're proud of
We are proud of getting all the components to work together in our app, given our use of multiple APIs and development platforms. In particular, we are proud of getting our flask backend to work with each component.
## What's next for HealthHunt AR
In the future, we would like to add more game features like more questions, detecting real-life objects in addition to images, and adding safety measures like GPS tracking. We would also like to add an ALERT button for if the child needs assistance. Other cool extensions include a chatbot for learning medical facts, a QR code scavenger hunt, and better social interactions. To enhance the quality of our quizzes, we would interview doctors and teachers to create the best educational content. | partial |
## Inspiration
911 call can be hectic for the both ends, specially during the time of natural disasters, wild fires and mass shooting. There will be overflow of traffic, as a result they can not help all the people who are in need of help. Hence, we try to ease the burden of the affected people by the use of AI, voice recognition tool. We have tried to make communication with the people and try to solve them go towards the safe place as much as possible. Even we tried to reduce the burden for the 911 dispatcher by reducing the number of redundant reports of the same kind, around same place and time. This will help people from both spectrum.
## What it does
It tries to minimize the 911 load and rescue system phase during emergency. It also helps to locate people to safe area when there is no personell available
## How we built it
For the backend, we used express.js
we purchased a number through Twilio API which was used for making conversation. Then we used dialogflow google cloud based API to understand the intent of people and also understand the entity that was required for front end mapping and listing.
For the frontend, we used react js to create a website which would talk back to the backend using fetch request and bring out all the details and present it to the 911 designated personnel for their ease of use
## Challenges we ran into
Training the model for the dialogflow, google cloud based conversational API was difficult and time consuming. Still, many scenarios couldn't be covered due to the time constraint. Also, due to our accent, the voice recognition software/api from twilio couldn't understand use properly to test and debug our product
## Accomplishments that we're proud of
We have developed a full stack product in this two days and also incorporated the ML/AI aspect to it, which we had done it before. Being a team of just two, we are proud of how much we have to present .
## What's next for 911 Overflow
* We are looking to train the dialogflow model more in diverse topic/conversation and make it as smart and possible.
* Also, we will definitely increase the number of topic that our IVR can converse into and help more people. | ## What it Does
MediText focuses on a feature that sends reminders through SMS to patients to take their medications. For patients, the web application lets them register for information (name, birthday, phone number) so the doctor doesn't have to do so at the office. For doctors, the web app confirms the patient's information, confirms the type and dosage of medication, if the patient must follow a strict routine (just in case it's dangerous to double-dose/skip doses), and notes down any other miscellaneous comments that a doctor might want to include for the patient. Once a doctor is done with entering all that information in, the patient then opts into a texting service that reminds them to take their medications. To keep the patient responsible for taking their medications, the service requires SMS responses. It will require that the patient responds with the text, "yes," if they took the medication, and "miss" if they either forgot to take it or skipped the dose. If neither of those responses received, the service constantly sends more messages to remind the patient to take their medications over a brief period of time. If the patient types "yes," the service will run smoothly and will schedule optimal dose-time reminders. If the patient types "miss," the doctor's miscellaneous comments will be sent to the patient and will include a reminder if the medication has a strict routine to follow.
## Inspiration Behind the Build
The build is based on multiple ideas. One member brought up how some services that people sign up for requires them to text back the word "STOP" if they wanted to opt-out of receiving those texts (text & reply feature). Another member remembered of an app that required the user to solve a puzzle in order to shut it off (text required feature). Another member brought up the importance of taking medications on time and in full in order for it to actually work for the patient ("strict" option on the doctor's application). All of these ideas and inspirations led to the team's motivation to create a build that reminds patients of the importance of taking their medications on-time and taking their medications in general.
The reason why we chose using text messages instead of using a mobile app with notifications is that not everyone has a smartphone. People, especially older people who most likely need to take medications, can have access to this service even with flip phones or blocky cell phones. People are also more inclined to be more alert to individualized interactions like text messages than an app notification: consider how many people will notice an amber alert or a text from a loved one, but not as many would notice a quick notification from Twitter or would want to take up their 4G data to check an app to turn the notifications off.
## How We Built It
We started off by making a bare skeleton of the code. We created Patients, Doctors, and drug objects to hold and have easy access to the necessary information we wanted to use in the webapp, and created the HTML pages for the frontend. We then chose Flask to connect the input from the frontend to the backend code. For our text messages, we used Twilio to send them. After integrating the website with our backend code we started bug testing our code. When we were sure that our code was in stable condition we started making it pretty with CSS, JAVA, and HTML.
## Challenges We Ran Into
The biggest challenge we ran into was just getting started with the project. This was three out of the four member’s (two non-CS members with relatively little programming experiences) first hackathon, and the fourth member, with only three hackathons under his belt, only declared into majoring in CS this school year. We all consider ourselves beginners and don't have extensive knowledge in the field especially in full stack development. It was a challenge for us to learn relevant skills while moving along with the project. We mostly had experience running python scripts with basic input and outputs to see what we’re trying to do. As a result, the transition was a bit rough when we wanted our python scripts and applications to be ran through a website and be able to get their information.
Technical difficulties we ran into included essentially learning front-end development from scratch and learning how to use Flask for the first time. Logically we were able to figure out the right algorithm in order for the system to properly send text messages, and respond to text messages in a timely manner. However, we came across a few hiccups at the beginning because we weren’t sure how to integrate it.
## What We Learned
All of the members had to take a crash course on HTML, the two CS major members who worked on backend had the opportunity to work with Flask. Also, we had the opportunity to try out implementing different functions and libraries that we have never thought about before, such as sending SMS using Python. Other than the technical skills each member gained, we also learned how to split up roles and work as a team.
## What's Next for MediText?
We are all very proud of this concept for MediText. We feel that in today’s society, we would have to reach people on different wavelengths to assist them in their everyday lives. This is our attempt at helping people who are forgetful and wish to have a daily reminder for them to take their prescribed pills. Although we initially intended for this to be used for hospitals, as we were working we acknowledged that it would be a useful application for people to use without doctors.
We plan to possibly upscale MediText so that it will be able to support a great number of users and if we were to go back on this project to improve on it, we would change the timing aspect of it and implement a database system that can be used reliably and more efficiently. | ## Inspiration
Metaverse, vision pro, spatial video. It’s no doubt that 3D content is the future. But how can I enjoy or make 3d content without spending over 3K? Or strapping massive goggles to my head? Let's be real, wearing a 3d vision pro while recording your child's birthday party is pretty [dystopian.](https://youtube.com/clip/UgkxXQvv1mxuM06Raw0-rLFGBNUqmGFOx51d?si=nvsDC3h9pz_ls1sz) And spatial video only gets you so far in terms of being able to interact, it's more like a 2.5D video with only a little bit of depth.
How can we relive memories in 3d without having to buy new hardware? Without the friction?
Meet 3dReal, where your best memories got realer. It's a new feature we imagine being integrated in BeReal, the hottest new social media app that prompts users to take an unfiltered snapshot of their day through a random notification. When that notification goes off, you and your friends capture a quick snap of where you are!
The difference with our feature is based on this idea where if you have multiple images of the same area ie. you and your friends are taking BeReals at the same time, we can use AI to generate a 3d scene.
So if the app detects that you are in close proximity to your friends through bluetooth, then you’ll be given the option to create a 3dReal.
## What it does
With just a few images, the AI powered Neural Radiance Fields (NeRF) technology produces an AI reconstruction of your scene, letting you keep your memories in 3d. NeRF is great in that it only needs a few input images from multiple angles, taken at nearly the same time, all which is the core mechanism behind BeReal anyways, making it a perfect application of NeRF.
So what can you do with a 3dReal?
1. View in VR, and be able to interact with the 3d mesh of your memory. You can orbit, pan, and modify how you see this moment captures in the 3dReal
2. Since the 3d mesh allows you to effectively view it however you like, you can do really cool video effects like flying through people or orbiting people without an elaborate robot rig.
3. TURN YOUR MEMORIES INTO THE PHYSICAL WORLD - one great application is connecting people through food. When looking through our own BeReals, we found that a majority of group BeReals were when getting food. With 3dReal, you can savor the moment by reconstructing your friends + food, AND you can 3D print the mesh, getting a snippet of that moment forever.
## How it works
Each of the phones using the app has a countdown then takes a short 2-second "video" (think of this as a live photo) which is sent to our Google Firebase database. We group the videos in Firebase by time captured, clustering them into a single shared "camera event" as a directory with all phone footage captured at that moment. While one camera would not be enough in most cases, by using the network of phones to take the picture simultaneously we have enough data to substantially recreate the scene in 3D. Our local machine polls Firebase for new data. We retrieve it, extract a variety of frames and camera angles from all the devices that just took their picture together, use COLMAP to reconstruct the orientations and positions of the cameras for all frames taken, and then render the scene as a NeRF via NVIDIA's instant-ngp repo. From there, we can export, modify, and view our render for applications such as VR viewing, interactive camera angles for creating videos, and 3D printing.
## Challenges we ran into
We lost our iOS developer team member right before the hackathon (he's still goated just unfortunate with school work) and our team was definitely not as strong as him in that area. Some compromises on functionality were made for the MVP, and thus we focused core features like getting images from multiple phones to export the cool 3dReal.
There were some challenges with splicing the videos for processing into the NeRF model as well.
## Accomplishments that we're proud of
Working final product and getting it done in time - very little sleep this weekend!
## What we learned
A LOT of things out of all our comfort zones - Sunny doing iOS development and Phoebe doing not hardware was very left field, so lots of learning was done this weekend. Alex learned lots about NeRF models.
## What's next for 3dReal
We would love to refine the user experience and also improve our implementation of NeRF - instead of generating a static mesh, our team thinks with a bit more time we could generate a mesh video which means people could literally relive their memories - be able to pan, zoom, and orbit around in them similar to how one views the mesh.
BeReal pls hire 👉👈 | losing |
## Inspiration
In online documentaries, we saw visually impaired individuals and their vision consisted of small apertures. We wanted to develop a product that would act as a remedy for this issue.
## What it does
When a button is pressed, a picture is taken of the user's current view. This picture is then analyzed using OCR (Optical Character Recognition) and the text is extracted from the image. The text is then converted to speech for the user to listen to.
## How we built it
We used a push button connected to the GPIO pins on the Qualcomm DragonBoard 410c. The input is taken from the button and initiates a python script that connects to the Azure Computer Vision API. The resulting text is sent to the Azure Speech API.
## Challenges we ran into
Coming up with an idea that we were all interested in, incorporated a good amount of hardware, and met the themes of the makeathon was extremely difficult. We attempted to use Speech Diarization initially but realized the technology is not refined enough for our idea. We then modified our idea and wanted to use a hotkey detection model but had a lot of difficulty configuring it. In the end, we decided to use a pushbutton instead for simplicity in favour of both the user and us, the developers.
## Accomplishments that we're proud of
This is our very first Makeathon and we were proud of accomplishing the challenge of developing a hardware project (using components we were completely unfamiliar with) within 24 hours. We also ended up with a fully function project.
## What we learned
We learned how to operate and program a DragonBoard, as well as connect various APIs together.
## What's next for Aperture
We want to implement hot-key detection instead of the push button to eliminate the need of tactile input altogether. | ## Inspiration
Vision—our most dominant sense—plays a critical role in every faucet and stage in our lives. Over 40 million people worldwide (and increasing) struggle with blindness and 20% of those over 85 experience permanent vision loss. In a world catered to the visually-abled, developing assistive technologies to help blind individuals regain autonomy over their living spaces is becoming increasingly important.
## What it does
ReVision is a pair of smart glasses that seamlessly intertwines the features of AI and computer vision to help blind people navigate their surroundings. One of our main features is the integration of an environmental scan system to describe a person’s surroundings in great detail—voiced through Google text-to-speech. Not only this, but the user is able to have a conversation with ALICE (Artificial Lenses Integrated Computer Eyes), ReVision’s own AI assistant. “Alice, what am I looking at?”, “Alice, how much cash am I holding?”, “Alice, how’s the weather?” are all examples of questions ReVision can successfully answer. Our glasses also detect nearby objects and signals buzzing when the user approaches an obstacle or wall.
Furthermore, ReVision is capable of scanning to find a specific object. For example—at an aisle of the grocery store—” Alice, where is the milk?” will have Alice scan the view for milk to let the user know of its position. With ReVision, we are helping blind people regain independence within society.
## How we built it
To build ReVision, we used a combination of hardware components and modules along with CV. For hardware, we integrated an Arduino uno to seamlessly communicate back and forth between some of the inputs and outputs like the ultrasonic sensor and vibrating buzzer for haptic feedback. Our features that helped the user navigate their world heavily relied on a dismantled webcam that is hooked up to a coco-ssd model and ChatGPT 4 to identify objects and describe the environment. We also used text-to-speech and speech-to-text to make interacting with ALICE friendly and natural.
As for the prototype of the actual product, we used stockpaper, and glue—held together with the framework of an old pair of glasses. We attached the hardware components to the inside of the frame, which pokes out to retain information. An additional feature of ReVision is the effortless attachment of the shade cover, covering the lens of our glasses. We did this using magnets, allowing for a sleek and cohesive design.
## Challenges we ran into
One of the most prominent challenges we conquered was soldering ourselves for the first time as well as DIYing our USB cord for this project. As well, our web camera somehow ended up getting ripped once we had finished our prototype and ended up not working. To fix this, we had to solder the wires and dissect our goggles to fix their composition within the frames.
## Accomplishments that we're proud of
Through human design thinking, we knew that we wanted to create technology that not only promotes accessibility and equity but also does not look too distinctive. We are incredibly proud of the fact that we created a wearable assistive device that is disguised as an everyday accessory.
## What we learned
With half our team being completely new to hackathons and working with AI, taking on this project was a large jump into STEM for us. We learned how to program AI, wearable technologies, and even how to solder since our wires were all so short for some reason. Combining and exchanging our skills and strengths, our team also learned design skills—making the most compact, fashionable glasses to act as a container for all the technologies they hold.
## What's next for ReVision
Our mission is to make the world a better place; step-by-step. For the future of ReVision, we want to expand our horizons to help those with other sensory disabilities such as deafness and even touch. | ## Inspiration
## What it does
## It searches for a water Bottle!
## How we built it
## We built it using a roomba, raspberrypi with a picamera, python, and Microsoft's Custom Vision
## Challenges we ran into
## Attaining wireless communications between the pi and all of our PCs was tricky. Implementing Microsoft's API was troublesome as well. A few hours before judging we exceeded the call volume for the API and were forced to create a new account to use the service. This meant re-training the AI and altering code, and loosing access to our higher accuracy recognition iterations during final tests.
## Accomplishments that we're proud of
## Actually getting the wireless networking to consistently. Surpassing challenges like framework indecision between IBM and Microsoft. We are proud of making things that lacked proper documentation, like the pi camera, work.
## What we learned
## How to use Github, train AI object recognition system using Microsoft APIs, write clean drivers
## What's next for Cueball's New Pet
## Learn to recognize other objects. | winning |
## Inspiration
We wanted to create a proof-of-concept for a potentially useful device that could be used commercially and at a large scale. We ultimately designed to focus on the agricultural industry as we feel that there's a lot of innovation possible in this space.
## What it does
The PowerPlant uses sensors to detect whether a plant is receiving enough water. If it's not, then it sends a signal to water the plant. While our proof of concept doesn't actually receive the signal to pour water (we quite like having working laptops), it would be extremely easy to enable this feature.
All data detected by the sensor is sent to a webserver, where users can view the current and historical data from the sensors. The user is also told whether the plant is currently being automatically watered.
## How I built it
The hardware is built on an Arduino 101, with dampness detectors being used to detect the state of the soil. We run custom scripts on the Arduino to display basic info on an LCD screen. Data is sent to the websever via a program called Gobetwino, and our JavaScript frontend reads this data and displays it to the user.
## Challenges I ran into
After choosing our hardware, we discovered that MLH didn't have an adapter to connect it to a network. This meant we had to work around this issue by writing text files directly to the server using Gobetwino. This was an imperfect solution that caused some other problems, but it worked well enough to make a demoable product.
We also had quite a lot of problems with Chart.js. There's some undocumented quirks to it that we had to deal with - for example, data isn't plotted on the chart unless a label for it is set.
## Accomplishments that I'm proud of
For most of us, this was the first time we'd ever created a hardware hack (and competed in a hackathon in general), so managing to create something demoable is amazing. One of our team members even managed to learn the basics of web development from scratch.
## What I learned
As a team we learned a lot this weekend - everything from how to make hardware communicate with software, the basics of developing with Arduino and how to use the Charts.js library. Two of our team member's first language isn't English, so managing to achieve this is incredible.
## What's next for PowerPlant
We think that the technology used in this prototype could have great real world applications. It's almost certainly possible to build a more stable self-contained unit that could be used commercially. | ## Inspiration:
We wanted to combine our passions of art and computer science to form a product that produces some benefit to the world.
## What it does:
Our app converts measured audio readings into images through integer arrays, as well as value ranges that are assigned specific colors and shapes to be displayed on the user's screen. Our program features two audio options, the first allows the user to speak, sing, or play an instrument into the sound sensor, and the second option allows the user to upload an audio file that will automatically be played for our sensor to detect. Our code also features theme options, which are different variations of the shape and color settings. Users can chose an art theme, such as abstract, modern, or impressionist, which will each produce different images for the same audio input.
## How we built it:
Our first task was using Arduino sound sensor to detect the voltages produced by an audio file. We began this process by applying Firmata onto our Arduino so that it could be controlled using python. Then we defined our port and analog pin 2 so that we could take the voltage reading and convert them into an array of decimals.
Once we obtained the decimal values from the Arduino we used python's Pygame module to program a visual display. We used the draw attribute to correlate the drawing of certain shapes and colours to certain voltages. Then we used a for loop to iterate through the length of the array so that an image would be drawn for each value that was recorded by the Arduino.
We also decided to build a figma-based prototype to present how our app would prompt the user for inputs and display the final output.
## Challenges we ran into:
We are all beginner programmers, and we ran into a lot of information roadblocks, where we weren't sure how to approach certain aspects of our program. Some of our challenges included figuring out how to work with Arduino in python, getting the sound sensor to work, as well as learning how to work with the pygame module. A big issue we ran into was that our code functioned but would produce similar images for different audio inputs, making the program appear to function but not achieve our initial goal of producing unique outputs for each audio input.
## Accomplishments that we're proud of
We're proud that we were able to produce an output from our code. We expected to run into a lot of error messages in our initial trials, but we were capable of tackling all the logic and syntax errors that appeared by researching and using our (limited) prior knowledge from class. We are also proud that we got the Arduino board functioning as none of us had experience working with the sound sensor. Another accomplishment of ours was our figma prototype, as we were able to build a professional and fully functioning prototype of our app with no prior experience working with figma.
## What we learned
We gained a lot of technical skills throughout the hackathon, as well as interpersonal skills. We learnt how to optimize our collaboration by incorporating everyone's skill sets and dividing up tasks, which allowed us to tackle the creative, technical and communicational aspects of this challenge in a timely manner.
## What's next for Voltify
Our current prototype is a combination of many components, such as the audio processing code, the visual output code, and the front end app design. The next step would to combine them and streamline their connections. Specifically, we would want to find a way for the two code processes to work simultaneously, outputting the developing image as the audio segment plays. In the future we would also want to make our product independent of the Arduino to improve accessibility, as we know we can achieve a similar product using mobile device microphones. We would also want to refine the image development process, giving the audio more control over the final art piece. We would also want to make the drawings more artistically appealing, which would require a lot of trial and error to see what systems work best together to produce an artistic output. The use of the pygame module limited the types of shapes we could use in our drawing, so we would also like to find a module that allows a wider range of shape and line options to produce more unique art pieces. | ## Inspiration
One of the challenges presented at qHacks is "best long-range IoT Hack". We noticed that remote communities don't have much access to the internet via wi-fi and some of those remote communities have farms and greenhouses that need to be kept properly. To build a wi-fi network across acres of farm land would not make an financial sense so a long-range IoT device that connects to a 3G network would be a better solution. There are also small greenhouses involved in hydroponics and vertical farming that would need long-range IoT because these greenhouses are outside of wi-fi range.
## What it does
We devised a long-range IoT hack that will help remote communities grow the best plants ever by measuring and optimizing moisture, temperature, humidity level, and light level. Based on the measurements, it will tell the user to adjust nutrient levels for the plants. It leads to precision agriculture and can help farmers optimize for the best yield in both numbers and quality.
## How we built it
Using a particle board electron that has an antenna and is also attached to sensors to measure those quantities. The antenna connects to a 3G network and sends that information to the Particle cloud. The Particle cloud then connects to an Android App and a web interface that a farmer can view to keep track of their yield.
## Challenges we ran into
None of us knew how to do hardware. It was our first time working with the particle board electron and we ran into many pain points. We wasted a lot of time with getting the particle board electron to run properly to only find out that the signal was weak inside the building. We tried moving around and then finally settling into the coffee shop because that was one of the few places that had a window and that could accommodate us. Our Android development skills were weak as well, and we had a lot of time struggling getting through the documentation of Particle.
## Accomplishments that we're proud of
We got the hardware the measure the environment with the sensors. And the android application shows charts. And we are proud that we learned about hardware.
## What we learned
We learned how to assemble and work with hardware. We learned about long-range IoT and the benefits of long-range IoT over short range IoT that is connected to wi-fi. We learned how to develop in Android. We learned to try something new and be daring.
## What's next for Particle Plant
Talk to farmers to see if something like this would be valuable to them. Also have a system where everyone in the supply chain can keep track and monitor the quality of the food they get from the source (farmer). | winning |
## Inspiration
We were intrigued by the idea of a fashion hack, but there are many applications out there that have similar functions. While considering underrepresented demographics, the struggles of those with colour blindness stuck out to us and we wanted to create something that would allow them to explore creatively with clothing without worrying about colour conflicts.
## What it does
Noctis [is supposed to] identify blocks of colour as individual clothing items, and labels them based on colour recognition. There are settings to trigger Propanopia, Deuteranopia or Tritanopia filters that, when activated, enhance specific colours to allow the user to see the outfit as close to its actual appearance as possible.
## How we built it
We used Android Studio for both the front end and back end.
## Challenges we ran into
While we had an ambitious goal, we lacked the technical skill and resources to execute our idea within 38 hours. It was definitely difficult pushing through knowing that we wouldn't be able to finish in time.
## Accomplishments that we're proud of
We're very excited about the idea we developed, and the perseverance we had to maintain to slog through the laborous processes of learning and making mistakes.
## What we learned
We learned that not all ideas are within our skill set to execute, but to reach for them anyway and take the necessary time to complete them to perfection.
## What's next for Noctis
We would love to develop Noctis slowly over time. Given more mentor resources and time for experimentation, we are confident that Noctis has the potential to become a fantastic product. | ## Inspiration
* Climate change is one of the most pressing global issues today. We wanted to build a platform that allows individuals to stay informed on climate news and take actionable steps in combating climate change. The idea is to connect the power of AI with easy user engagement, promoting environmental awareness.
## What It Does
* Cli-Change AI aggregates climate-related headlines, and users can interact by liking, and subscribing to newsletters, powered by Groq. The platform provides curated, AI-driven insights into the latest developments in climate science, policy, and activism, helping people stay informed and empowered.
## How We Built It
* We built the platform using Django for the backend. We also implemented a daily email system, where subscribers receive curated climate news updates directly to their inbox. They can also see news for the last week and trending news within the last 24 hours and have these summarized by the AI model automatically.
## Challenges We Ran Into
* The API was very limited and we could only show 3 articles per day on the free plan. It was also difficult to test the daily email service and we over-spent time on this.
## Accomplishments
* We're proud of developing a platform that not only keeps people informed but actively encourages engagement in climate-related topics. We hope people can stay up to date with the latest in climate change around the world while respecting their busy schedules.
## What We Learned
* We learned a lot about managing complex relational databases in Django, handling user interaction features, and ensuring a scalable architecture. We also deepened our knowledge of how AI models can be applied in practical, real-world scenarios to drive user engagement.
## What's Next For Cli-Change AI
* Next, we aim to expand the AI capabilities to provide even more personalized and impactful content. We also plan to introduce more interactive features like real-time discussions and challenges where users can contribute ideas on climate solutions. Additionally, were currently looking into how to deploy this and bypass the API rate limit. | ## Inspiration
The name of our web app, Braeburn, is named after a lightly colored red apple that was once used with green Granny Smith apples to test for colorblindness. We were inspired to create a tool to benefit individuals who are colorblind by helping to make public images more accessible. We realized that things such as informational posters or advertisements may not be as effective to those who are colorblind due to inaccessible color combinations being used. Therefore, we sought to tackle this problem with this project.
## What it does
Our web app analyzes images uploaded by users and determines whether or not the image is accessible to people who are colorblind. It identifies color combinations that are hard to distinguish for colorblind people and offers suggestions to replace them.
## How we built it
We built our web app using Django/Html/Css/Javascript for the frontend, and we used python and multiple APIs for the backend. One API we used was the Google Cloud Vision API to help us detect the different colors present in the image.
## Challenges we ran into
One challenge we ran into is handling the complexity of the different color regions within an image, which is a prevailing problem in the field of computer vision. Our current algorithm uses an api to perform image segmentation that clusters areas of similar color together. This allowed us to more easily create a graph of nodes over the image, where each node is a unique color, and each node's neighbors are different color regions on the image that are nearby. We then traverse this graph and test each pair of neighboring color regions to check for inaccessible color combinations.
We also struggled to find ways to simulate colorblindness accurately as RGB values do not map easily to the cones that allow us to see color in our eyes. After some research, we converted RGB values to a different value called LMS, which is a more accurate representation of how we view color. Thus, for an RGB, the LMS value may be different for normal and colorblind vision. To determine if a color combination is inaccessible, we compare these LMS values.
To provide our color suggestions, we researched a lot to figure out how to best approximate our suggestions. It ultimately led us to learn about daltonizers, which can color correct or simulate colorblind vision, and we utilize one to suggest more accessible colors.
Finally, we ran into many issues integrating different parts of the frontend, which ended up being a huge time sink.
Overall, this project was a good challenge for all of us, given we had no previous exposure to computer vision topics.
## Accomplishments that we're proud of
We're proud of completing a working product within the time limits of this hackathon and are proud of how our web app looks!
We are proud of the knowledge we learned, and the potential of our idea for the project. While many colorblindness simulators exist, ours is interesting for a few reasons . Firstly, we wanted to automate the process of making graphics and other visual materials accessible to those with colorblindness. We focused not only on the frequency of colors that appeared in the image; we created an algorithm that traverses the image and finds problematic pairs of colors that touch each other. We perform this task by finding all touching pairs of color areas (which is no easy task) and then comparing the distance of the pair with typical color vision and a transformed version of the pair with colorblind vision. This proved to be quite challenging, and we created a primitive algorithm that performs this task. The reach goal of this project would be to create an algorithm sophisticated enough to completely automate the task and return the image with color correction.
## What we learned
We learned a lot about complex topics such as how to best divide a graph based on color and how to manipulate color pixels to reflect how colorblind people perceive color.
Another thing we learned is that t's difficult to anticipate challenges and manage time. We also realize we were a bit ambitious and overlooked the complexity of computer vision topics.
## What's next for Braeburn
We want to refine our color suggestion algorithm, extend the application to videos, and provide support for more types of colorblindness. | losing |
## Inspiration
Testings are essential to detect and containerize COVID-19 pandemic. However, the need for testing is excessive and the equipment is in shortage around the world. Understand the situation, we provide a solution for this rising issue.
## What it does
* COVID-19 detector tentatively predicts the probability of an infected patient based on Chest CT scan images (Computed Tomography scan technology is a popular service at most hospitals). We aim to use this project to detect people with high potential of having COVID-19. Thus, health care providers can approach, test, and deliver supports to these patients faster. The detector has a high precision rate at 91% and gives prediction in only seconds.
## How we built it
* The backend was built with Python with Flask
* Front-end was built with HTML, CSS, javascript and Bootstrap
* The ML model was trained using `Custom Vision AI` from Microsoft Azure with a set of data which consists of chest CT scan images of 329 positive COVID-19 patients and 387 negative cases.
* The web app was deployed using Microsoft Azure Web Service with containerized by Docker
## Challenges we ran into
* We had a difficult time to find a good, reliable dataset of positive COVID-19 chest CT scan images.
* We had problems with deploying to Azure Web server at first because we can not set up the pipeline with GitHub.
* We also had problems with some stylings with CSS.
## Accomplishments that we're proud of
* The model that we trained has a precision rate of 91% and a recall rate of 85.6%.
* We've successfully deployed our web app to azure web service.
* The website has every functionality we planned to implement.
## What we learned
* How Flask serves 2 static folders
* How to utilize the Microsoft Azure Custom Vision to quickly train ML model
* How to deploy a web app to Azure Web Service with Docker
## What's next for COVID-19
* We look forward to improving the data set to get better predictions. | ## Inspiration
Our inspiration for building Fin came from the recent stock movements of apple and the recent responses to Facebook's privacy policies. It was clear that there was a correlation between stock movement and the media coverage that big tech companies get. This lead to the idea that a machine can read headlines faster than a human can, thus we have a higher alpha than normal humans when it comes to looking at stock movements purely based on news coverage.
## What it does
Fin scrapes news headlines and looks for keywords that convey a positive, or a negative reputation for FAANG. We then take this data and plug it into our genetic algorithm that attempts to use hourly stock predictions and their accuracy as a measures of fitness. Over multiple generation our algorithm should be able to predict stock movement with a relatively low percent error.
## How we built it
We built Fin using Python for the scraper, Java for the computational back-end, JSON for our data format, and using Android studio for the front-end.
## Challenges we ran into
The largest challenge that we ran into was how to store our data in the cloud, as well as how to communicate the changing data in real time with devices
## What's next for Fin
We can continue to improve on Fin by improving how we read data and formate it, as well as migrating the entire product to the cloud. | ## Inspiration
Our solution was named on remembrance of Mother Teresa
## What it does
Robotic technology to assist nurses and doctors in medicine delivery, patient handling across the hospital, including ICU’s. We are planning to build an app in Low code/No code that will help the covid patients to scan themselves as the mobile app is integrated with the CT Scanner for doctors to save their time and to prevent human error . Here we have trained with CT scans of Covid and developed a CNN model and integrated it into our application to help the covid patients. The data sets are been collected from the kaggle and tested with an efficient algorithm with the efficiency of around 80% and the doctors can maintain the patient’s record. The beneficiary of the app is PATIENTS.
## How we built it
Bots are potentially referred to as the most promising and advanced form of human-machine interactions. The designed bot can be handled with an app manually through go and cloud technology with e predefined databases of actions and further moves are manually controlled trough the mobile application. Simultaneously, to reduce he workload of doctor, a customized feature is included to process the x-ray image through the app based on Convolution neural networks part of image processing system. CNN are deep learning algorithms that are very powerful for the analysis of images which gives a quick and accurate classification of disease based on the information gained from the digital x-ray images .So to reduce the workload of doctors these features are included. To know get better efficiency on the detection I have used open source kaggle data set.
## Challenges we ran into
The data source for the initial stage can be collected from the kaggle and but during the real time implementation the working model and the mobile application using flutter need datasets that can be collected from the nearby hospitality which was the challenge.
## Accomplishments that we're proud of
* Counselling and Entertainment
* Diagnosing therapy using pose detection
* Regular checkup of vital parameters
* SOS to doctors with live telecast
-Supply off medicines and foods
## What we learned
* CNN
* Machine Learning
* Mobile Application
* Cloud Technology
* Computer Vision
* Pi Cam Interaction
* Flutter for Mobile application
## Implementation
* The bot is designed to have the supply carrier at the top and the motor driver connected with 4 wheels at the bottom.
* The battery will be placed in the middle and a display is placed in the front, which will be used for selecting the options and displaying the therapy exercise.
* The image aside is a miniature prototype with some features
* The bot will be integrated with path planning and this is done with the help mission planner, where we will be configuring the controller and selecting the location as a node
* If an obstacle is present in the path, it will be detected with lidar placed at the top.
* In some scenarios, if need to buy some medicines, the bot is attached with the audio receiver and speaker, so that once the bot reached a certain spot with the mission planning, it says the medicines and it can be placed at the carrier.
* The bot will have a carrier at the top, where the items will be placed.
* This carrier will also have a sub-section.
* So If the bot is carrying food for the patients in the ward, Once it reaches a certain patient, the LED in the section containing the food for particular will be blinked. | losing |
## Inspiration
Are you out in public but scared about people standing too close? Do you want to catch up on the social interactions at your cozy place but do not want to endanger your guests? Or you just want to be notified as soon as you have come in close contact to an infected individual? With this app, we hope to provide the tools to users to navigate social distancing more easily amidst this worldwide pandemic.
## What it does
The Covid Resource App aims to bring a one-size-fits-all solution to the multifaceted issues that COVID-19 has spread in our everyday lives.
Our app has 4 features, namely:
- A social distancing feature which allows you to track where the infamous "6ft" distance lies
- A visual planner feature which allows you to verify how many people you can safely fit in an enclosed area
- A contact tracing feature that allows the app to keep a log of your close contacts for the past 14 days
- A self-reporting feature which enables you to notify your close contacts by email in case of a positive test result
## How we built it
We made use primarily of Android Studio, Java, Firebase technologies and XML. Each collaborator focused on a task and bounced ideas off of each other when needed.
The social distancing feature functions based on a simple trigonometry concept and uses the height from ground and tilt angle of the device to calculate how far exactly is 6ft.
The visual planner adopts a tactile and object-oriented approach, whereby a room can be created with desired dimensions and the touch input drops 6ft radii into the room.
The contact tracing functions using Bluetooth connection and consists of phones broadcasting unique ids, in this case, email addresses, to each other. Each user has their own sign-in and stores their keys on a Firebase database.
Finally, the self-reporting feature retrieves the close contacts from the past 14 days and launches a mass email to them consisting of quarantining and testing recommendations.
## Challenges we ran into
Only two of us had experience in Java, and only one of us had used Android Studio previously. It was a steep learning curve but it was worth every frantic google search.
## What we learned
* Android programming and front-end app development
* Java programming
* Firebase technologies
## Challenges we faced
* No unlimited food | ## Inspiration
Imagine you're sitting in your favorite coffee shop and a unicorn startup idea pops into your head. You open your laptop and choose from a myriad selection of productivity tools to jot your idea down. It’s so fresh in your brain, you don’t want to waste any time so, fervently you type, thinking of your new idea and its tangential components. After a rush of pure ideation, you take a breath to admire your work, but disappointment. Unfortunately, now the hard work begins, you go back though your work, excavating key ideas and organizing them.
***Eddy is a brainstorming tool that brings autopilot to ideation. Sit down. Speak. And watch Eddy organize your ideas for you.***
## Learnings
Melding speech recognition and natural language processing tools required us to learn how to transcribe live audio, determine sentences from a corpus of text, and calculate the similarity of each sentence. Using complex and novel technology, each team-member took a holistic approach and learned news implementation skills on all sides of the stack.
## Features
1. **Live mindmap**—Automatically organize your stream of consciousness by simply talking. Using semantic search, Eddy organizes your ideas into coherent groups to help you find the signal through the noise.
2. **Summary Generation**—Helpful for live note taking, our summary feature converts the graph into a Markdown-like format.
3. **One-click UI**—Simply hit the record button and let your ideas do the talking.
4. **Team Meetings**—No more notetakers: facilitate team discussions through visualizations and generated notes in the background.

## Challenges
1. **Live Speech Chunking** - To extract coherent ideas from a user’s speech, while processing the audio live, we had to design a paradigm that parses overlapping intervals of speech, creates a disjoint union of the sentences, and then sends these two distinct groups to our NLP model for similarity.
2. **API Rate Limits**—OpenAI rate-limits required a more efficient processing mechanism for the audio and fewer round trip requests keyword extraction and embeddings.
3. **Filler Sentences**—Not every sentence contains a concrete and distinct idea. Some sentences go nowhere and these can clog up the graph visually.
4. **Visualization**—Force graph is a premium feature of React Flow. To mimic this intuitive design as much as possible, we added some randomness of placement; however, building a better node placement system could help declutter and prettify the graph.
## Future Directions
**AI Inspiration Enhancement**—Using generative AI, it would be straightforward to add enhancement capabilities such as generating images for coherent ideas, or business plans.
**Live Notes**—Eddy can be a helpful tool for transcribing and organizing meeting and lecture notes. With improvements to our summary feature, Eddy will be able to create detailed notes from a live recording of a meeting.
## Built with
**UI:** React, Chakra UI, React Flow, Figma
**AI:** HuggingFace, OpenAI Whisper, OpenAI GPT-3, OpenAI Embeddings, NLTK
**API:** FastAPI
# Supplementary Material
## Mindmap Algorithm
 | ## Inspiration
US export is a Trillion $ industry, with roughly $800+ Billion market share of Organic Food Exports.
Surprisingly, the functions of such a large scale industry are still massively manual (pen and paper ordering) between Suppliers, Exporters, Distributors & Retail Stores (mom-n-pop shops).
It is time to not only automate the process but also tackle some other pressing problems like
* counter the markups by middle-men/distributors
* reduce turn-around time in fulfilling orders
* insights into buying behaviors of customers
## What it does
A set of responsive web pages for suppliers, distributors and small mom-n-pop shops have been set up to automate the entire flow of information as export/import orders are processed and fulfilled.
* An intuitive "pool purchasing" option allows smaller retail stores to directly place order with international suppliers, totally bypassing the markups of the local distributors.
* Finally, analytics on order data provide insights into the purchasing behavior of the end-customers. This plays a critical role in reducing the current time to fulfill orders as suppliers can anticipate demand and pre-stock international ports.
## Challenges we ran into
* Understanding the depth of the problem statement and coming up with a shrink-wrapped solution for the same.
* Serving the app over HTTPS
* Using camera to read barcode in a web browser
## Accomplishments that we're proud of
* Design Thinking session with a probable customer (they have made an offer to purchase our system post the hackathon).
* Setting up a full-stack solution in 36 hours :)
## What we learned
The importance of co-innovation with the end-customer.
## What's next for trade-O-bundle
Setup the entire platform to scale well and handle the expected data-loads of international trade. | winning |
## Inspiration
Legal research is tedious and time-consuming, with lawyers spending hours finding relevant cases. For instance, if a client was punched, lawyers must manually try different keywords like “kick” or “slap” to find matches. Analyzing cases is also challenging. Even with case summaries, lawyers must still verify their accuracy by cross-referencing with the original text, sometimes hundreds of pages long. This is inefficient, given the sheer length of cases and the need to constantly toggle between tabs to find the relevant paragraphs.
## What it does
Our tool transforms legal research by offering AI-powered legal case search. Lawyers can input meeting notes or queries in natural language, and our AI scans open-source databases to identify the most relevant cases, ranked by similarity score. Once the best matches are identified, users can quickly review our AI-generated case summaries and full case texts side by side in a split-screen view, minimizing context-switching and enhancing research efficiency.
## How we built it
Our tool was developed to create a seamless user experience for lawyers. The backend process began with transforming legal text into embeddings using the all-MiniLM-L6-v2 model for efficient memory usage. We sourced data from the CourtListener, which is backed by the Free Law Project non-profit, and stored the embeddings in LanceDB, allowing us to retrieve relevant cases quickly.
To facilitate the search process, we integrated the CourtListener API, which enables keyword searches of court cases. A FastAPI backend server was established to connect LanceDB and CourtListener for effective data retrieval.
## Challenges we ran into
The primary challenge was bridging the gap between legal expertise and software development. Analyzing legal texts proved difficult due to their complex and nuanced language. Legal terminology can vary significantly across cases, necessitating a deep understanding of context for accurate interpretation. This complexity made it challenging to develop an AI system that could generate meaningful similarity scores while grasping the subtleties inherent in legal documents.
## Accomplishments that we're proud of
Even though we started out as strangers and were busy building our product, we took the time to get to know each other personally and have fun during the hackathon too! This was the first hackathon for two of our teammates, but they quickly adapted and contributed meaningfully. Most importantly, we supported each other throughout the process, making the experience both rewarding and memorable.
## What we learned
Throughout the process, we emphasized constant communication within the team. The law student offered insights into complex research workflows, while the developers shared their expertise on technical feasibility and implementation. Together, we balanced usability with scope within the limited time available, and all team members worked hard to train the AI to generate meaningful similarity scores, which was particularly demanding.
One teammate delved deep into embeddings, learning about their applications in similarity search, chunking, prompt engineering, and adjacent concepts like named entity recognition, hybrid search, and retrieval-augmented generation (RAG) — all within the span of the hackathon.
Additionally, two of our members had no front-end development experience and minimal familiarity with design tools like Figma. By leveraging resources like assistant-ui, we quickly learned the necessary skills.
## What's next for citewise
We aim to provide support for the complete workflow of legal research. This includes enabling lawyers to download relevant cases easily and facilitating collaboration by allowing the sharing of client files with colleagues.
Additionally, we plan to integrate with paid legal databases, making our product platform agnostic. This will enable lawyers to search across multiple databases simultaneously, streamlining their research process and eliminating the need to access each database individually. | Inspiration
We decided to try the Best Civic Hack challenge with YHack & Yale Code4Good -- the collaboration with the New Haven/León Sister City Project. The purpose of this project is to both fundraise money, and raise awareness about the impact of greenhouse gases through technology.
What it does
The Carbon Fund Bot is a Facebook messenger chat agent based on the Yale Community Carbon Fund calculator. It ensues a friendly conversation with the user - estimating the amount of carbon emission from the last trip according to the source and destination of travel as well as the mode of transport used. It serves the purpose to raise money equivalent to the amount of carbon emission - thus donating the same to a worthy organization and raising awareness about the harm to the environment.
How we built it
We built the messenger chatbot with Node.js and Heroku. Firstly, we created a new messenger app from the facebook developers page. We used a facebook webhook for enabling communication between facebook users and the node.js application. To persist user information, we also used MongoDB (mLabs). According to the user's response, an appropriate response was generated. An API was used to calculate the distance between two endpoints (either areial or road distance) and their carbon emission units were computed using it.
Challenges we ran into
There was a steep curve for us learning Node.js and using callbacks in general. We spent a lot of time figuring out how to design the models, and how a user would interact with the system. Natural Language Processing was also a problem.
Accomplishments that we're proud of
We were able to integrate the easy to use and friendly Facebook Messenger through the API with the objective of working towards a social cause through this idea
What's next
Using Api.Ai for better NLP is on the cards. Using the logged journeys of users can be mined and can be used to gain valuable insights into carbon consumption. | ## Inspiration
With the ubiquitous and readily available ML/AI turnkey solutions, the major bottlenecks of data analytics lay in the consistency and validity of datasets.
**This project aims to enable a labeller to be consistent with both their fellow labellers and their past self while seeing the live class distribution of the dataset.**
## What it does
The UI allows a user to annotate datapoints from a predefined list of labels while seeing the distribution of labels this particular datapoint has been previously assigned by another annotator. The project also leverages AWS' BlazingText service to suggest labels of incoming datapoints from models that are being retrained and redeployed as it collects more labelled information. Furthermore, the user will also see the top N similar data-points (using Overlap Coefficient Similarity) and their corresponding labels.
In theory, this added information will motivate the annotator to remain consistent when labelling data points and also to be aware of the labels that other annotators have assigned to a datapoint.
## How we built it
The project utilises Google's Firestore realtime database with AWS Sagemaker to streamline the creation and deployment of text classification models.
For the front-end we used Express.js, Node.js and CanvasJS to create the dynamic graphs. For the backend we used Python, AWS Sagemaker, Google's Firestore and several NLP libraries such as SpaCy and Gensim. We leveraged the realtime functionality of Firestore to trigger functions (via listeners) in both the front-end and back-end. After K detected changes in the database, a new BlazingText model is trained, deployed and used for inference for the current unlabeled datapoints, with the pertinent changes being shown on the dashboard
## Challenges we ran into
The initial set-up of SageMaker was a major timesink, the constant permission errors when trying to create instances and assign roles were very frustrating. Additionally, our limited knowledge of front-end tools made the process of creating dynamic content challenging and time-consuming.
## Accomplishments that we're proud of
We actually got the ML models to be deployed and predict our unlabelled data in a pretty timely fashion using a fixed number of triggers from Firebase.
## What we learned
Clear and effective communication is super important when designing the architecture of technical projects. There were numerous times where two team members were vouching for the same structure but the lack of clarity lead to an apparent disparity.
We also realized Firebase is pretty cool.
## What's next for LabelLearn
Creating more interactive UI, optimizing the performance, have more sophisticated text similarity measures. | partial |
## Inspiration
We love reddit, we want to know what they thought about the media events
## What it does
## How we built it
## Challenges we ran into
## Accomplishments that we're proud of
## What we learned
## What's next for whatDoesRedditThink? | ## Inspiration
a
## What it does
## How we built it
## Challenges we ran into
## Accomplishments that we're proud of
## What we learned
## What's next for TheArchi.Tech | ## Inspiration
Queriamos hacer una pagina interactiva la cual llamara la atencion de las personas jovenes de esta manera logrando mantenerlos durante mucho tiempo siendo leales a la familia de marcas Qualtias
## What it does
Lo que hace es
## How we built it
## Challenges we ran into
Al no tener un experiencia previa con el diseño de paginas web encontramos problemas al momento de querer imaginar el como se veria nuestra pagina.
## Accomplishments that we're proud of
Nos sentimos orgullosos de haber logrado un diseño con el cual nos senitmos orgullosos y logramos implementar las ideas que teniamos en mente.
## What we learned
Aprendimos mucho sobre diseño de paginas y de como implmentar diferentes tipos de infraestructuras y de como conectarlas.
## What's next for QualtiaPlay
Seguiremos tratando de mejorar nuestra idea para futuros proyectos y de mayor eficiencia | losing |
## Story
Mental health is a major issue especially on college campuses. The two main challenges are diagnosis and treatment.
### Diagnosis
Existing mental health apps require the use to proactively input their mood, their thoughts, and concerns. With these apps, it's easy to hide their true feelings.
We wanted to find a better solution using machine learning. Mira uses visual emotion detection and sentiment analysis to determine how they're really feeling.
At the same time, we wanted to use an everyday household object to make it accessible to everyone.
### Treatment
Mira focuses on being engaging and keeping track of their emotional state. She allows them to see their emotional state and history, and then analyze why they're feeling that way using the journal.
## Technical Details
### Alexa
The user's speech is being heard by the Amazon Alexa, which parses the speech and passes it to a backend server. Alexa listens to the user's descriptions of their day, or if they have anything on their mind, and responds with encouraging responses matching the user's speech.
### IBM Watson/Bluemix
The speech from Alexa is being read to IBM Watson which performs sentiment analysis on the speech to see how the user is actively feeling from their text.
### Google App Engine
The backend server is being hosted entirely on Google App Engine. This facilitates the connections with the Google Cloud Vision API and makes deployment easier. We also used Google Datastore to store all of the user's journal messages so they can see their past thoughts.
### Google Vision Machine Learning
We take photos using a camera built into the mirror. The photos are then sent to the Vision ML API, which finds the user's face and gets the user's emotions from each photo. They're then stored directly into Google Datastore which integrates well with Google App Engine
### Data Visualization
Each user can visualize their mental history through a series of graphs. The graphs are each color-coded to certain emotional states (Ex. Red - Anger, Yellow - Joy). They can then follow their emotional states through those time periods and reflect on their actions, or thoughts in the mood journal. | ## Inspiration
Everyone can relate to the scene of staring at messages on your phone and wondering, "Was what I said toxic?", or "Did I seem offensive?". While we originally intended to create an app to help neurodivergent people better understand both others and themselves, we quickly realized that emotional intelligence support is a universally applicable concept.
After some research, we learned that neurodivergent individuals find it most helpful to have plain positive/negative annotations on sentences in a conversation. We also think this format leaves the most room for all users to reflect and interpret based on the context and their experiences. This way, we hope that our app provides both guidance and gentle mentorship for developing the users' social skills. Playing around with Co:here's sentiment classification demo, we immediately saw that it was the perfect tool for implementing our vision.
## What it does
IntelliVerse offers insight into the emotions of whomever you're texting. Users can enter their conversations either manually or by taking a screenshot. Our app automatically extracts the text from the image, allowing fast and easy access. Then, IntelliVerse presents the type of connotation that the messages convey. Currently, it shows either a positive, negative or neutral connotation to the messages. The interface is organized similarly to a texting app, ensuring that the user effortlessly understands the sentiment.
## How we built it
We used a microservice architecture to implement this idea
The technology stack includes React Native, while users' information is stored with MongoDB and queried using GraphQL. Apollo-server and Apollo-client are used to connect both the frontend and the backend.
The sentiment estimates are powered by custom Co:here's finetunes, trained using a public chatbot dataset found on Kaggle.
Text extraction from images is done using npm's text-from-image package.
## Challenges we ran into
We were unfamiliar with many of the APIs and dependencies that we used, and it took a long to time to understand how to get the different components to come together.
When working with images in the backend, we had to do a lot of parsing to convert between image files and strings.
When training the sentiment model, finding a good dataset to represent everyday conversations was difficult. We tried numerous options and eventually settled with a chatbot dataset.
## Accomplishments that we're proud of
We are very proud that we managed to build all the features that we wanted within the 36-hour time frame, given that many of the technologies that we used were completely new to us.
## What we learned
We learned a lot about working with React Native and how to connect it to a MongoDB backend. When assembling everyone's components together, we solved many problems regarding dependency conflicts and converting between data types/structures.
## What's next for IntelliVerse
In the short term, we would like to expand our app's accessibility by adding more interactable interfaces, such as audio inputs. We also believe that the technology of IntelliVerse has far-reaching possibilities in mental health by helping introspect upon their thoughts or supporting clinical diagnoses. | ## Inspiration
One of our teammate’s grandfathers suffers from diabetic retinopathy, which causes severe vision loss.
Looking on a broader scale, over 2.2 billion people suffer from near or distant vision impairment worldwide. After examining the issue closer, it can be confirmed that the issue disproportionately affects people over the age of 50 years old. We wanted to create a solution that would help them navigate the complex world independently.
## What it does
### Object Identification:
Utilizes advanced computer vision to identify and describe objects in the user's surroundings, providing real-time audio feedback.
### Facial Recognition:
It employs machine learning for facial recognition, enabling users to recognize and remember familiar faces, and fostering a deeper connection with their environment.
### Interactive Question Answering:
Acts as an on-demand information resource, allowing users to ask questions and receive accurate answers, covering a wide range of topics.
### Voice Commands:
Features a user-friendly voice command system accessible to all, facilitating seamless interaction with the AI assistant: Sierra.
## How we built it
* Python
* OpenCV
* GCP & Firebase
* Google Maps API, Google Pyttsx3, Google’s VERTEX AI Toolkit (removed later due to inefficiency)
## Challenges we ran into
* Slow response times with Google Products, resulting in some replacements of services (e.g. Pyttsx3 was replaced by a faster, offline nlp model from Vosk)
* Due to the hardware capabilities of our low-end laptops, there is some amount of lag and slowness in the software with average response times of 7-8 seconds.
* Due to strict security measures and product design, we faced a lack of flexibility in working with the Maps API. After working together with each other and viewing some tutorials, we learned how to integrate Google Maps into the dashboard
## Accomplishments that we're proud of
We are proud that by the end of the hacking period, we had a working prototype and software. Both of these factors were able to integrate properly. The AI assistant, Sierra, can accurately recognize faces as well as detect settings in the real world. Although there were challenges along the way, the immense effort we put in paid off.
## What we learned
* How to work with a variety of Google Cloud-based tools and how to overcome potential challenges they pose to beginner users.
* How to connect a smartphone to a laptop with a remote connection to create more opportunities for practical designs and demonstrations.
How to connect a smartphone to a laptop with a remote connection to create more opportunities for practical designs and demonstrations.
How to create docker containers to deploy google cloud-based flask applications to host our dashboard.
How to develop Firebase Cloud Functions to implement cron jobs. We tried to developed a cron job that would send alerts to the user.
## What's next for Saight
### Optimizing the Response Time
Currently, the hardware limitations of our computers create a large delay in the assistant's response times. By improving the efficiency of the models used, we can improve the user experience in fast-paced environments.
### Testing Various Materials for the Mount
The physical prototype of the mount was mainly a proof-of-concept for the idea. In the future, we can conduct research and testing on various materials to find out which ones are most preferred by users. Factors such as density, cost and durability will all play a role in this decision. | partial |
## Inspiration
In the fast-paced modern world, too often do thoughts and emotions go unprocessed. Moody.ai strives to promote mental health, foster personal growth and encourage self-discovery through journal entries and personalized music experiences.
## What it does
**Users can freely navigate the user-friendly interface through these tabs...**
**Login**: Connect to Spotify Account using Spotify OAuth authentication.
**Journal**: Jot down feelings, capture thoughts and record daily events. Users can save, edit and submit their journal entries at any time of the day including submitting ones for previous days. Submitting an entry will generate a custom mood based playlist for you and a themed quote for your day!
**Calendar**: Monthly overview that allows users to click on any day to display the corresponding journal entry and their mood for the day.
## How we built it
Flask web application connected to a SQLite database.
Playlist generation done through a sentiment analysis model built with sklearn logistic regression in order to classify user songs.
Mood leverage of journal entries and quote output done with OpenAI API
**Front-end: Prioritizes aesthetics and accessibility. Cohesive and interactive all-in-one hub.** Implemented user inputs, functional save/submit/edit buttons, iframes, auto-scale textbox, calendar, navigation tabs in a creative way to offer a pleasant interface.
**Cohesion between different tabs** Despite having different features, we wanted Moodify.ai to be consistent and smart in its design choices throughout the different tabs. Therefore, we implement a navigation bar for the user to easily access all aspects of our project.
**Back-end:** Flask-based application seamlessly connects with Spotify API, dynamically curating playlists based on user moods using machine learning predictions, while also incorporating a personalized journal system for users to document and reflect on their experiences.
**Training the sentiment analysis model**
In order to personalize created playlists to a user's listening history, we trained a logistic regression model in order to classify songs as one of 4 basic types of songs: angry, relaxed, happy, sad based on 4 different features of the songs including valence, loudness, danceability, energy. The model would return a mood given a Spotify track and would judge it based on these features.
Firstly to create the training set, we took an existing CSV of 2000 Last.fm songs that have been tagged with the 4 moods. Using this we created a python script that looked up those same songs in Spotify, pulled their features (valence, loudness, etc.) using the Spotify APIand saved it to a training set. This process took around a half hour due to the rate limit of the developer API. After testing out the training data on various models in Sklearn, we chose the logistic regression model as it had the best performance overall. Given more time, we could create a larger and more comprehensive training set.
## Challenges we ran into
**Working with AI** Having a good understanding of how the AI answers to our specific prompts was very important to us to ensure relevant song and quote generation. We used the playground to experiment with and handle edge cases.
**Routing and APIs**
While having worked in flask before, routing was particularly challenging this time, as we were working simultaneously with multiple different APIs all with their own endpoints that we had to reach through redirects and return URLs. We ran into many issues such as OpenAI keys expiring quickly and Spotify's OAuth2 authentication process due to Spotify's rate limit on developer app users and API calls
**Queries for the databases** We encountered a minor issue in our process, where queries for adding journal entries to our database were causing errors. This was due to the complexity of ensuring a correct entry date that wasn't null, along with a journal entry text that would not result in null input. Since the journal had empty spaces within lines that were not occupied, we needed to address the 'not null' constraint by appending only lines with text to a list. To resolve the entry date problem, we incorporated a default entry date of the present date and inserted it into the database before checking if an entry with the associated date already existed.
## What's next for Moody.ai
Implement facial analysis to leverage mood using the OpenAi API.
Flag the different moods into categories to have a better overview of the month.
Make the web app mobile accessible for users to write entries on the go during the day.
Implement a bigger database with wider range of emotional tag lines to pull from for more tailored playlists.
Optimize run-time: generating the songs is slow as it queries over the 2000 songs. | ## Inspiration
As students who undergo a lot of stress throughout the year, we are often out of touch with our emotions and it can sometimes be difficult to tell how we are feeling throughout the day. There are days when we might be unsure of how we are really feeling based on our self-talk. Do I feel down, happy, sad, etc? We decided to develop a journal app that interprets the entries we write and quantitatively tracks our mood. This allows us to be more aware of our mental well-being at all times.
## What it does
mood.io takes your daily journal entries and returns a "mood" score for that specific day. This is calculated using Google Cloud's ML Natural Language API, which is then translated into a line graph that tracks your moods over time. The Natural Language API also identifies important subject matter in each entry, known as "entities", which mood.io displays using attractive data visualization tools. This allows you to aim for improvement in your mental health and identify issues you might have in your daily lives.
## How I built it
For our prototype, we built a web app using the Flask framework within Python, which helped with routing and rendering our HTML based homepage. We used Bootstrap to help with the front-end UI look. We also used the Google Cloud Natural Language Processing API to analyze sentiment values and provide the entity data. The data was shown using the matplotlib library within Python.
A concept of our final product was created using Figma and is attached to this submission.
## Challenges I ran into
Our very first challenge was installing python and getting it properly set up so that we didn’t have any errors. When trying to run a simple program.
We then ran into challenges in trying to understand how to interact with the Google Cloud API and how to get it set up and running with Python. After talking to some Google sponsors and mentors, we managed to get it set up properly and work with the code.
Another issue was getting a graph to display properly and making a pretty data visualization, we had tried many different applications to generate graphs but we had issues with each of them until we found one that worked.
Additionally no one in our team had a lack of experience in front end development so making the site look nice and display properly was another issue.
## Accomplishments that I'm proud of
Used a WDM for decision making process process.
Cool idea!
Real results!
Learning to use python.
Getting an api to work.
Getting a graph to display properly.
We are proud of the progress we were able to achieve through our first Hackathon experience. Thanks to all the mentors and sponsors that assisted us in our journey
## What I learned
How to program in Python, interact with an API, make a data visualization, how to build a web app from scratch, how to use Google Cloud and its various computing services
## What's next for mood.io
Add users so you can add close friends and family and track their moods.
Adding the entities feature on our prototype
Further improving our UI experience | ## Inspiration
Over the past 30 years, the percentage American adults who read literature has dropped about 14%. We found our inspiration. The issue we discovered is that due to the rise of modern technologies, movies and other films are more captivating than reading a boring book. We wanted to change that.
## What it does
By implementing Google’s Mobile Vision API, Firebase, IBM Watson, and Spotify's API, Immersify first scans text through our Android Application by utilizing Google’s Mobile Vision API. After being stored into Firebase, IBM Watson’s Tone Analyzer deduces the emotion of the text. A dominant emotional score is then sent to Spotify’s API where the appropriate music is then played to the user. With Immerisfy, text can finally be brought to life and readers can feel more engaged into their novels.
## How we built it
On the mobile side, the app was developed using Android Studio. The app uses Google’s Mobile Vision API to recognize and detect text captured through the phone’s camera. The text is then uploaded to our Firebase database.
On the web side, the application pulls the text sent by the Android app from Firebase. The text is then passed into IBM Watson’s Tone Analyzer API to determine the tone of each individual sentence with the paragraph. We then ran our own algorithm to determine the overall mood of the paragraph based on the different tones of each sentence. A final mood score is generated, and based on this score, specific Spotify playlists will play to match the mood of the text.
## Challenges we ran into
Trying to work with Firebase to cooperate with our mobile app and our web app was difficult for our whole team. Querying the API took multiple attempts as our post request to IBM Watson was out of sync. In addition, the text recognition function in our mobile application did not perform as accurately as we anticipated.
## Accomplishments that we're proud of
Some accomplishments we’re proud of is successfully using Google’s Mobile Vision API and IBM Watson’s API.
## What we learned
We learned how to push information from our mobile application to Firebase and pull it through our web application. We also learned how to use new APIs we never worked with in the past. Aside from the technical aspects, as a team, we learned collaborate together to tackle all the tough challenges we encountered.
## What's next for Immersify
The next step for Immersify is to incorporate this software with Google Glasses. This would eliminate the two step process of having to take a picture on an Android app and going to the web app to generate a playlist. | losing |
## Inspiration
In the development of Adroit, we were inspired by the design process itself - as we yearned to arrive at a chosen problem which would address healthcare, social good, fintech, education, or better yet a combination of the four. While brainstorming ideas for such problem statements, we agreed there was potential for using natural language processing to analyze frustrations and complaints, using human-centered design principles to light the way. We began designing a way to provide hackathoners and businesses with problem statements so they can focus on what they do best - solving them.
Out of this idea came Adroit, an easy-to-use reputation and sentiment analysis tool. We sought a project that would challenge us with skills and frameworks which are new to us, while also keeping human-centered design in focus. Adroit is both a business/fintech tool - intended to help companies identify their weaknesses - as well as generalizable software which allows users to discover problems in any domain. Enter a search term and see what complaints people have about it, and get a summary of the most frequent commentary!
**JetBlue use case**: As one use case, Adroit was designed to meet @jetBlue's design requirements. We hypothesized that aggregating complaints from social media and analyzing their similarities could point to services that may need attention, indicating recent major customer concerns with the company.
Although Adroit's knowledge is currently drawn specifically from Twitter and we do recommend further development using other data sources, a test run on recent data indicates, for instance, "wheelchair" and "mobility" as major concerns, identifying accessibility as potential business priorities.
## What it does
Adroit pulls data from Twitter about a certain target (e.g., "JetBlue") and uses Google's natural language API to find negative-sentiment content, indicating potential user complaints. After doing so, Adroit extracts high-importance terms from the data to indicate the general themes of those complaints.
## How we built it
The client side uses React.js and support libraries, such as Material-UI and styled-components, alongside pure CSS. We use React’s routing to handle requests. We also used Axios to asynchronously fetch data from our API. Adroit is deployed on Firebase.
The server side, hosted with PythonEverywhere, uses Python Flask to respond to requests for content analysis, which indicate the query target of the analysis and the amount of content to be analyzed. Query results are filtered using Google sentiment analysis and passed through an entity extraction step to determine a set of potential user concerns, which are returned alongside the analyzed tweets.
## Major challenges
As new hackers, we faced difficulties with environment management across the team, particularly in managing different Python and React setups. We also got the chance to work with some tools which were completely new to us, including complex APIs such as Google Cloud Language. And finally, we learned some new things about familiar concepts - for instance, we learned the ~~hard~~ **fun** way that single quotes aren’t accepted in JSON strings to JavaScript.
## Major accomplishments
With little experience and all being first-time MLH hackers, we're proud that we were able to integrate the frontend with the backend, gain an understanding of Google and Twitter APIs, and create a fully-working demo. With only a small amount of starting experience, we hacked together a cohesive and useful product.
## What we learned
* Using and maintaining web APIs. Adroit's backend is its own small API, and uses both Twitter and Google's own developer APIs.
* Principles of NLP in context. For instance, we considered how to group text in order to get the most effective sentiment and entity analysis.
* Design and adaptability as a team. Our team members were nearly complete strangers to each other two days ago, and Adroit’s development was tied to the process of learning to work with a brand new team.
## What's next for Adroit
* **Improved insight and summarization** In addition to the stream of complaints, we'd like to add better capabilities to analyze the complaints as a whole.
* **Better concern parsing.** The determination of major concerns is a beta feature and does sometimes return less-than-helpful terms.
* **Broader data sources.** Adroit, as a demo, only draws from Twitter. However, its structure is such that functionality for Facebook, Instagram, or even more exotic sources, like Youtube captions or academic articles, could be easily added. | # Customer Feedback Sentiment Analyser
## yhack2019✈️
Being naturally fascinated by data science, our team was drawn to "Best Search of Customer Feedback" challenge. Through trial and error; often trying one methodology, library, or tool, only to have to switch to another, we persevered to collect tweet data from 2013 to today (10/27/2019) and Yelp reviews for jetBlue, American, Delta, and Spirit.
Some of the biggest challenges we faced were scraping data off twitter and dealing with minor sleep deprivation. The twitter challenge was overcome by a half-scripted half-manual scraping method, which was thought of on the fly. Yelp was scraped using data crawling with requests library and HTML parsing with BeautifulSoup.
Data was then converted to JSON files, to be later consumed by **Googles Natural Language Processing API**.
Data was again converted to a JSON file holding the date of review or tweet and the sentiment and magnitude of the text.
This was later analyzed and graphed using a mixture of Jupyter Notebook and scrips that used matplotlib.
Also, collected JetBlue stock price data and plotted using pandas and Jupyter Notebook.
In the end, we also included a GUI to show the different graphs from the text sentiment analyzer.
Our teamwork itself was notable; with each member of our team becoming a specialist in one area of the project, each communicating with the others in what they were working on.
YHack was a tremendous learning opportunity and a great time to hack and collaborate with friends. | ## Inspiration
During our brainstorming phase, we cycled through a lot of useful ideas that later turned out to be actual products on the market or completed projects. After four separate instances of this and hours of scouring the web, we finally found our true calling at QHacks: building a solution that determines whether an idea has already been done before.
## What It Does
Our application, called Hack2, is an intelligent search engine that uses Machine Learning to compare the user’s ideas to products that currently exist. It takes in an idea name and description, aggregates data from multiple sources, and displays a list of products with a percent similarity to the idea the user had. For ultimate ease of use, our application has both Android and web versions.
## How We Built It
We started off by creating a list of websites where we could find ideas that people have done. We came up with four sites: Product Hunt, Devpost, GitHub, and Google Play Store. We then worked on developing the Android app side of our solution, starting with mock-ups of our UI using Adobe XD. We then replicated the mock-ups in Android Studio using Kotlin and XML.
Next was the Machine Learning part of our solution. Although there exist many machine learning algorithms that can compute phrase similarity, devising an algorithm to compute document-level similarity proved much more elusive. We ended up combining Microsoft’s Text Analytics API with an algorithm known as Sentence2Vec in order to handle multiple sentences with reasonable accuracy. The weights used by the Sentence2Vec algorithm were learned by repurposing Google's word2vec ANN and applying it to a corpus containing technical terminology (see Challenges section). The final trained model was integrated into a Flask server and uploaded onto an Azure VM instance to serve as a REST endpoint for the rest of our API.
We then set out to build the web scraping functionality of our API, which would query the aforementioned sites, pull relevant information, and pass that information to the pre-trained model. Having already set up a service on Microsoft Azure, we decided to “stick with the flow” and build this architecture using Azure’s serverless compute functions.
After finishing the Android app and backend development, we decided to add a web app to make the service more accessible, made using React.
## Challenges We Ran Into
From a data perspective, one challenge was obtaining an accurate vector representation of words appearing in quasi-technical documents such as Github READMEs and Devpost abstracts. Since these terms do not appear often in everyday usage, we saw a degraded performance when initially experimenting with pretrained models. As a result, we ended up training our own word vectors on a custom corpus consisting of “hacker-friendly” vocabulary from technology sources. This word2vec matrix proved much more performant than pretrained models.
We also ran into quite a few issues getting our backend up and running, as it was our first using Microsoft Azure. Specifically, Azure functions do not currently support Python fully, meaning that we did not have the developer tools we expected to be able to leverage and could not run the web scraping scripts we had written. We also had issues with efficiency, as the Python libraries we worked with did not easily support asynchronous action. We ended up resolving this issue by refactoring our cloud compute functions with multithreaded capabilities.
## What We Learned
We learned a lot about Microsoft Azure’s Cloud Service, mobile development and web app development. We also learned a lot about brainstorming, and how a viable and creative solution could be right under our nose the entire time.
On the machine learning side, we learned about the difficulty of document similarity analysis, especially when context is important (an area of our application that could use work)
## What’s Next for Hack2
The next step would be to explore more advanced methods of measuring document similarity, especially methods that can “understand” semantic relationships between different terms in a document. Such a tool might allow for more accurate, context-sensitive searches (e.g. learning the meaning of “uber for…”). One particular area we wish to explore are LSTM Siamese Neural Networks, which “remember” previous classifications moving forward. | losing |
## Inspiration
The inspiration behind Aazami comes from a personal experience with a loved one who had dementia. Witnessing the struggles and frustration of forgetting memories was heart-wrenching. It made us realize the need for a simple yet effective solution that could alleviate this issue. That's when the idea of Aazami was born - to create a device that could ease the burden of memory loss, not just for our family, but for millions of families worldwide. Our hope is that Aazami can help people with dementia cherish and relive their precious memories, and provide a small but significant sense of comfort in their daily lives.
## What it does
Aazami's main function is to record the last 10 seconds of voice, which can be replayed by using a voice command, "I forgot." This innovative feature helps users to retrieve lost memories and ease the frustration caused by forgetfulness. Aazami is compact and easy to use, making it a convenient companion for people with dementia, their families, and caregivers. By providing an easy and reliable way to recall memories, Aazami aims to enhance the quality of life of people with dementia and their loved ones.
Aazami has the potential to significantly support patients with reorientation therapy, a common treatment for dementia. By providing users with a reliable tool to help recall recent memories, Aazami can reduce feelings of confusion and disorientation. With the ability to record and replay the last 10 seconds of voice, patients can use Aazami as a reminder tool to help them remember their daily routines or important details about their environment. In turn, this can help patients feel more confident and in control of their lives. With continued use, Aazami can also help patients engage in reorientation therapy, as they can use the device to actively recall information and strengthen their memory skills. Ultimately, Aazami has the potential to improve the quality of life for patients with dementia, helping them to feel more independent and empowered in their daily lives.
## How we built it
To develop Aazami, we utilized a combination of hardware and software components including Arduino and Adafruit's Neopixel for the hardware, and Edge Impulse for machine learning. Our team started off by recording our own voices to create a dataset for "I forgot" voice detection, and refined it through trial and error to ensure the most appropriate dataset for our constraints.
We generated Arduino code and improved it to optimize the hardware performance, and also created an amplifier circuit to boost the sound of the device. Through these iterative processes, we combined all the components to create a functional and effective solution. Our website (aazami.netlify.app), developed using Vue.js, helped to promote our technology and increase its accessibility to those who need it most.
## Challenges we ran into
While experimenting with Arduino and Edge Impulse, we faced an issue where the sound detection interval was set to 5 seconds. However, this was not sufficient for the user to say "I forgot" in perfect timing. To overcome this problem, we had to develop a separate algorithm that could detect sound at the ideal phase, enabling us to accurately capture the user's command and trigger the playback of the previous 10 seconds of voice.
Another significant challenge we encountered was that we were consistently receiving error messages, including "ERR: MFCC failed (-1002)," "ERR: Failed to run DSP process (-1002)," and "ERR: Failed to run classifier (-5)." These errors likely resulted from limitations in the memory size of the Arduino Nano BLE 33 we were using. To address this issue, we were required to manually adjust the size of our data sets, allowing us to process the data more efficiently and minimize the likelihood of encountering these errors in the future. Our initial dataset initially had an accuracy of 100% (as provided above), but we had some tradeoffs due to this error (~97% accuracy now).
## Accomplishments that we're proud of
We take great pride in this project as we were able to identify a clear need for this technology and successfully implement it. By addressing the challenges faced by people with dementia and their caregivers, we believe that Aazami has the potential to enhance the quality of life for millions of people worldwide. Our team's dedication and hard work in creating this innovative solution has been a fulfilling and rewarding experience.
## What we learned
Through this project, we gained valuable insights into the integration of ML in hardware. Although each member of our team brought unique expertise in either hardware or ML, working together to build a complete system was a new and exciting challenge. Creating our own ML dataset and identifying the necessary components for Aazami enabled us to apply ML in a real-world context, providing us with valuable experience and skills (i.e. Edge Impulse).
## What's next for Aazami
Looking ahead, our next goal for Aazami is to expand our dataset to include voices of various ages and pitches. By incorporating a wider range of data, we can improve the accuracy of our model and provide an even more reliable solution for people with dementia. Additionally, we are eager to share this technology with individuals and groups who could benefit from it the most. Our team is committed to demonstrating the capabilities of Aazami to those in need, and we are continuously exploring ways to make it more accessible and user-friendly. | ## Inspiration
According to the United State's Department of Health and Human Services, 55% of the elderly are non-compliant with their prescription drug orders, meaning they don't take their medication according to the doctor's instructions, where 30% are hospital readmissions. Although there are many reasons why seniors don't take their medications as prescribed, memory loss is one of the most common causes. Elders with Alzheimer's or other related forms of dementia are prone to medication management problems. They may simply forget to take their medications, causing them to skip doses. Or, they may forget that they have already taken their medication and end up taking multiple doses, risking an overdose. Therefore, we decided to solve this issue with Pill Drop, which helps people remember to take their medication.
## What it does
The Pill Drop dispenses pills at scheduled times throughout the day. It helps people, primarily seniors, take their medication on time. It also saves users the trouble of remembering which pills to take, by automatically dispensing the appropriate medication. It tracks whether a user has taken said dispensed pills by starting an internal timer. If the patient takes the pills and presses a button before the time limit, Pill Drop will record this instance as "Pill Taken".
## How we built it
Pill Drop was built using Raspberry Pi and Arduino. They controlled servo motors, a button, and a touch sensor. It was coded in Python.
## Challenges we ran into
Challenges we ran into was first starting off with communicating between the Raspberry Pi and the Arduino since we all didn't know how to do that. Another challenge was to structurally hold all the components needed in our project, making sure that all the "physics" aligns to make sure that our product is structurally stable. In addition, having the pi send an SMS Text Message was also new to all of us, so incorporating a User Interface - trying to take inspiration from HyperCare's User Interface - we were able to finally send one too! Lastly, bringing our theoretical ideas to fruition was harder than expected, running into multiple road blocks within our code in the given time frame.
## Accomplishments that we're proud of
We are proud that we were able to create a functional final product that is able to incorporate both hardware (Arduino and Raspberry Pi) and software! We were able to incorporate skills we learnt in-class plus learn new ones during our time in this hackathon.
## What we learned
We learned how to connect and use Raspberry Pi and Arduino together, as well as incorporating User Interface within the two as well with text messages sent to the user. We also learned that we can also consolidate code at the end when we persevere and build each other's morals throughout the long hours of hackathon - knowing how each of us can be trusted to work individually and continuously be engaged with the team as well. (While, obviously, having fun along the way!)
## What's next for Pill Drop
Pill Drop's next steps include creating a high-level prototype, testing out the device over a long period of time, creating a user-friendly interface so users can adjust pill-dropping time, and incorporating patients and doctors into the system.
## UPDATE!
We are now working with MedX Insight to create a high-level prototype to pitch to investors! | ## Inspiration
Throughout our school careers, participation has always been a very big part of student-engagement, learning and the grading process. However, it is hard for teachers to calculate how much a student participated and remember exactly what they said to analyze this properly. We wanted to create an audio-based tool that automatically records students and tally's up the number of times they spoke automatically and records their response for future use. This way, the teacher can automatically see how much each student participated instead of having to remember hours or days after the discussion. We would use some form of data analysis to calculate a score for each student, which would allow the teacher to personalize their teaching methods
## What it does
This audio-based tool that automatically records students and tally's up the number of times they spoke automatically and records their response for future use. By using the keyword "Ok Hound", the audio detection turns on, records the student's name and their response. It puts this into a database that the teacher can access at any time and even repeat the audio. It also has a tally and a visual representation of the frequency of student responses.
## How I built it
We built the mainframe using android studio, houndify and firebase. At first, we were planning to use react-native, node.js and express but we ran into many issues with the framework and connecting the houndify to the react-native platform. Instead, we decided to use android studio because we are more familiar with java and the structure of the framework.
## Challenges I ran into
We ran into many challenges when implementing our database, with most problems arising from library version issues when connecting android studio with Firebase, while maintaining Houndify functionality. We lacked the experience necessary to address such problems, but successfully built both modules, one for speech functionality, and the other for connecting to Firebase. Due to our struggle to connect the application to the database, we could not implement our original plans for advanced data analysis for participation quality.
## What's next for Particip8
We want to keep developing particip8 in the future by connecting it to the firebase successfully and using more specific audio-detection. We need to construct the data analysis portion, in which instructors can download a spreadsheet of all the data. We also want to update the UI to make it more user friendly. | partial |
## What is Search and Protect
We created a hack that can search through public twitter timeline histories of many people and determine whether they are at a risk of self harm or depression using personality profiling and sentiment analysis.
## How would this be used?
Organizations such as the local police or mental health support groups would be able to keep a close eye on those who are not in a good state of mind or having a rough time in life. Often people will express their feelings on social media due to the feeling on semi-anonymity and the fact that they can hide behind a screen, so it is possible a lot of people may be more transparent about heavy issues.
## Technical Implementation
To connect our backend to our frontend, we took full advantage of the simplicity and utility of stdlib to create numerous functions that we used at various points to perform simple tasks such as scraping a twitter timeline for texts, sending a direct message to a specific user and one to interact with the Watson sentiment/personality analysis api. In addition, we have a website set up where an administrator would be able to view information gathered.
## The future for Search and Protect
The next step would be setting up an automated bot farm that runs this project amongst relevant users. For example, a University mental support group would run it amongst the followers of their official Twitter account. It could also implement intelligent chat AI so that people can continue to talk and ask it for help even when there is nobody available in person. | ## What it does
Danstrument lets you video call your friends and create music together using only your actions. You can start a call which generates a code that your friend can use to join.
## How we built it
We used Node.js to create our web app which employs WebRTC to allow video calling between devices. Movements are tracked with pose estimation from tensorflow and then vector calculations are done to trigger audio files.
## Challenges we ran into
Connecting different devices with WebRTC over an unsecured site proved to be very difficult. We also wanted to have continuous sound but found that libraries that could accomplish this caused too many problems so we chose to work with discrete sound bites instead.
## What's next for Danstrument
Annoying everyone around us. | Inspiration
Our project is driven by a deep-seated commitment to address the escalating issues of hate speech and crime in the digital realm. We recognized that technology holds immense potential in playing a pivotal role in combating these societal challenges and nurturing a sense of community and safety.
## What It Does
Our platform serves as a beacon of hope, empowering users to report incidents of hate speech and crime. In doing so, we have created a vibrant community of individuals wholeheartedly devoted to eradicating such toxic behaviors. Users can not only report but also engage with the reported incidents through posts, reactions, and comments, thereby fostering awareness and strengthening the bonds of solidarity among its users. Furthermore, our platform features an AI chatbot that simplifies and enhances the reporting process, ensuring accessibility and ease of use.
## How We Built It
The foundation of our platform is a fusion of cutting-edge front-end and back-end technologies. The user interface came to life through MERN stack, ensuring an engaging and user-friendly experience. The backend infrastructure, meanwhile, was meticulously crafted using Node.js, providing robust support for our APIs and server-side operations. To house the wealth of user-generated content, we harnessed the prowess of MongoDB, a NoSQL database. Authentication and user data privacy were fortified through the seamless integration of Auth0, a rock-solid authentication solution.
## Challenges We Ran Into
Our journey was not without its trials. Securing the platform, effective content moderation, and the development of a user-friendly AI chatbot presented formidable challenges. However, with unwavering dedication and substantial effort, we overcame these obstacles, emerging stronger and more resilient, ready to tackle any adversity.
## Accomplishments That We're Proud Of
Our proudest accomplishment is the creation of a platform that emboldens individuals to stand up against hate speech and crime. Our achievement is rooted in the nurturing of a safe and supportive digital environment where users come together to share their experiences, ultimately challenging and combatting hatred head-on.
## What We Learned
The journey was not just about development; it was a profound learning experience. We gained valuable insights into the vast potential of technology as a force for social good. User privacy, effective content moderation, and the vital role of community-building have all come to the forefront of our understanding, enhancing our commitment to addressing these critical issues.
## What's Next for JustIT
The future holds exciting prospects for JustIT. We envision expanding our platform's reach and impact. Plans are underway to enhance the AI chatbot's capabilities, streamline the reporting process, and implement more robust content moderation techniques. Our ultimate aspiration is to create a digital space that is inclusive, empathetic, and, above all, safe for everyone. | winning |
## Inspiration 🤔
The inspiration behind Inclusee came from our desire to make digital design accessible to everyone, regardless of their visual abilities. We recognized that many design tools lack built-in accessibility features, making it challenging for individuals with low vision, dyslexia, and other visual impairments to create and enjoy visually appealing content. Our goal was to bridge this gap and ensure that everyone can see and create beautiful designs.
## What it does 📙
Inclusee is an accessibility addon for Adobe Express that helps designers ensure their creations are accessible to individuals with low vision, dyslexia, and other visual impairments. The addon analyzes the colors, fonts, and layouts used in a design, providing real-time feedback and suggestions to improve accessibility. Inclusee highlights areas that need adjustments and offers alternatives that comply with accessibility standards, ensuring that all users can appreciate and interact with the content.
## How we built it 🚧
We built Inclusee using the Adobe Express Add-On SDK, leveraging its powerful capabilities to integrate seamlessly with the design tool. Our team used a combination of JavaScript and React to develop the addon interface. We implemented color analysis algorithms to assess contrast ratios and detect color blindness issues. Additionally, we incorporated text analysis to identify and suggest dyslexia-friendly changes. Our development process included rigorous testing to ensure the addon works smoothly across different devices and platforms.
## Challenges we ran into 🤯
One of the largest challenges we faced was working with the Adobe Express Add-On SDK. As it is a relatively new tool, there are limited usage examples and documentation available. This made it difficult to find guidance and best practices for developing our addon. We had to rely heavily on experimentation and reverse-engineering to understand how to effectively utilize the SDK's features.
Additionally, the SDK is still being fleshed out and new features are continuously being added. This meant that certain functionalities we wanted to implement were not yet available, forcing us to find creative workarounds or adjust our plans. The evolving nature of the SDK also posed challenges in terms of stability and compatibility, as updates could potentially introduce changes that affected our addon.
Despite these hurdles, we persevered and were able to successfully integrate Inclusee with Adobe Express. Our experience working with the SDK has given us valuable insights and we are excited to see how it evolves and improves in the future.
## Accomplishments that we're proud of 🥹
We are proud of creating a tool that makes digital design more inclusive and accessible. Our addon not only helps designers create accessible content but also raises awareness about the importance of accessibility in design. We successfully integrated Inclusee with Adobe Express, providing a seamless user experience. Additionally, our color and font analysis algorithms are robust and accurate, offering valuable suggestions to improve design accessibility.
## What we learned 🧑🎓
Throughout the development of Inclusee, we learned a great deal about accessibility standards and best practices in design. We gained insights into the challenges faced by individuals with visual impairments and the importance of inclusive design. Our team also enhanced our skills in using the Adobe Express Add-On SDK and optimizing performance for real-time applications.
## What's next for Inclusee 👀
* Expand Accessibility Features: Add more features, such as checking for proper text hierarchy and ensuring navigable layouts for screen readers.
* Collaboration with Accessibility Experts: Work with experts to gather feedback and continuously improve the addon.
* User Feedback Integration: Collect and implement user feedback to enhance functionality and usability.
* Partnerships with Other Design Tools: Explore partnerships to extend Inclusee's reach and impact, promoting inclusive design across various platforms.
* Educational Resources: Develop tutorials and resources to educate designers about accessibility best practices. | ## Inspiration
Art is taking a step backwards these days and still nothing can beat a simple Picasso/Van Gogh painting. It's time to give art another chance!
## What it does
The game shows you some of the special powers of the "Neural Algorithm of Artistic Style" while keeping you entertained looking at some very artistic processed-paintings!
The code renders and processes blended images without the need to access any GPU capabilities (server-side)
## How I built it
It is mostly done in javascript (jQuery)
## Challenges I ran into
There were many roadblocks with making the code run on my economy hosting plan!
## Accomplishments that I'm proud of
Finally able to render these beautiful images as well as creating videos inspired from the same idea.
## What I learned
Learned a lot about Ubuntu, definitely improved my knowledge in shell and assembly, and python.
## What's next for Leonardo
Leonardo will start to shape as a web app where you can upload a pattern image and another image you would like the magic to be performed on, receiving the rendered result in your email at the end of the process. | ## Inspiration
The name of our web app, Braeburn, is named after a lightly colored red apple that was once used with green Granny Smith apples to test for colorblindness. We were inspired to create a tool to benefit individuals who are colorblind by helping to make public images more accessible. We realized that things such as informational posters or advertisements may not be as effective to those who are colorblind due to inaccessible color combinations being used. Therefore, we sought to tackle this problem with this project.
## What it does
Our web app analyzes images uploaded by users and determines whether or not the image is accessible to people who are colorblind. It identifies color combinations that are hard to distinguish for colorblind people and offers suggestions to replace them.
## How we built it
We built our web app using Django/Html/Css/Javascript for the frontend, and we used python and multiple APIs for the backend. One API we used was the Google Cloud Vision API to help us detect the different colors present in the image.
## Challenges we ran into
One challenge we ran into is handling the complexity of the different color regions within an image, which is a prevailing problem in the field of computer vision. Our current algorithm uses an api to perform image segmentation that clusters areas of similar color together. This allowed us to more easily create a graph of nodes over the image, where each node is a unique color, and each node's neighbors are different color regions on the image that are nearby. We then traverse this graph and test each pair of neighboring color regions to check for inaccessible color combinations.
We also struggled to find ways to simulate colorblindness accurately as RGB values do not map easily to the cones that allow us to see color in our eyes. After some research, we converted RGB values to a different value called LMS, which is a more accurate representation of how we view color. Thus, for an RGB, the LMS value may be different for normal and colorblind vision. To determine if a color combination is inaccessible, we compare these LMS values.
To provide our color suggestions, we researched a lot to figure out how to best approximate our suggestions. It ultimately led us to learn about daltonizers, which can color correct or simulate colorblind vision, and we utilize one to suggest more accessible colors.
Finally, we ran into many issues integrating different parts of the frontend, which ended up being a huge time sink.
Overall, this project was a good challenge for all of us, given we had no previous exposure to computer vision topics.
## Accomplishments that we're proud of
We're proud of completing a working product within the time limits of this hackathon and are proud of how our web app looks!
We are proud of the knowledge we learned, and the potential of our idea for the project. While many colorblindness simulators exist, ours is interesting for a few reasons . Firstly, we wanted to automate the process of making graphics and other visual materials accessible to those with colorblindness. We focused not only on the frequency of colors that appeared in the image; we created an algorithm that traverses the image and finds problematic pairs of colors that touch each other. We perform this task by finding all touching pairs of color areas (which is no easy task) and then comparing the distance of the pair with typical color vision and a transformed version of the pair with colorblind vision. This proved to be quite challenging, and we created a primitive algorithm that performs this task. The reach goal of this project would be to create an algorithm sophisticated enough to completely automate the task and return the image with color correction.
## What we learned
We learned a lot about complex topics such as how to best divide a graph based on color and how to manipulate color pixels to reflect how colorblind people perceive color.
Another thing we learned is that t's difficult to anticipate challenges and manage time. We also realize we were a bit ambitious and overlooked the complexity of computer vision topics.
## What's next for Braeburn
We want to refine our color suggestion algorithm, extend the application to videos, and provide support for more types of colorblindness. | losing |
## Inspiration
The inspiration came from the really beautiful world of whales, they are a fascinating creature and people should know more about them.
## What it does
Our Web-app is an attempt on providing interesting information on Whales across the world and the scientific studies going on such as whale snot analysis using drones. Check out our video demo to learn more.
## How I built it
We used HTML, CSS and Javascript to make the frontend of the web-app. The visualisation of the whale's position was done using machine learning. Flask was used to create API and integrate with the web-app.
## What's next for WHALES-EYE
We shall expand our dataset to get information on whales at different oceans. This prototype contains data only for the whales in the southern ocean region. | ## Inspiration
Our inspiration of this project was how so much happens in terms of these catastrophes happening in the world and we barely get to know about it, let alone help. Therefore we thought to create a complete list accessible to anyone, so not only would they be able to track these calamities but try to help which is our biggest inspiration!
## What it does
We created a webpage that has a complete list of these catastrophes, from there you can filter out events by the type of catastrophe, the coordinates, a radius around the coordinates as well as a time frame filter. All in all with this you can find a list of natural disasters that happened with a very specific criterion!
## How I built it
We built it using Python and Flask for the API interactions and fetching the data and then represented the data using our HTML&CSS files. The API we used was NASA's EONET which is the Earth Observatory Natural Event Tracker.
## Challenges I ran into
Challenges we ran into were sizeable as this is all of our first hackathon, from there the biggest problem was us trying to formulate our ideas and create an actionable plan. Once we circumvented that we took to many difficulties trying to create some aspects such as piecing together the API, then running all these other filters to finally get the final information.
## Accomplishments that I'm proud of
We're really proud of what we learned, we're all very much in the beginnings of our computer science career and coming this far is just incredible. The feeling of pride in the final moments when it started working is unparalleled and something that was an amazing accomplishment.
## What I learned
We learnt how to use so many different aspects of technology in harmony with each other, we initially were puzzled with all these different aspects such as HTML for the front end, API getting results, Python formulating those results but all in all that learning curve was amazing. Another thing was getting unstuck, this was a lot easier said than done but learning how to get unstuck took a while.
## What's next for Natural Disaster Tracker
We want to build a graphical representation using a few more API's, therefore people can have a visual representation rather than a list, which would be a better representation. | ## Inspiration
✨ In a world that can sometimes feel overwhelmingly negative, we wanted to create an oasis of positivity. The inspiration for **harbor.ed** comes from the calming effect that the ocean and its inhabitants have on many people. As students, we often crave for the need to be cared for, and of course, habored. We envisioned a digital sanctuary where individuals could find comfort and companionship in the form of sea creatures, each with a unique personality designed to uplift and support. Especially to international students who may not have a chance to see their family for months at a time, it is often to feel lonely or sad with no one there to watch out for your feelings - Harbour.ed is your safe space:
## What it does
🌊 Harbor.ed is an interactive online space where individuals feeling down or distressed can find solace and encouragement. Users visit our website and choose from a variety of sea creatures to converse with. These friendly fishes engage in supportive dialogue, offering words of encouragement. Utilizing advanced emotion detection technology, our platform identifies when a user is particularly sad and prompts the sea creatures to provide extra comfort, ensuring a personalized and empathetic experience.
## How we built it
✨ Our project harnesses a diverse tech stack, as illustrated in the architecture diagram.
The client-side is supported by technologies like **React**, Sass, and JavaScript, ensuring a seamless and engaging user interface.
The server-side is bolstered by **Google Cloud** and **GoDaddy**, providing robust and scalable hosting solutions. We've leveraged **MongoDB Atlas** for our database needs, ensuring efficient data management.
The heart of Harbor.ed's empathetic interaction comes from the **OpenCV** and **AWS-powered** **emotion detection** and the innovative use of cohere APIs, which allow our sea creatures to respond intelligently to users' emotional states.
## Challenges we ran into
🌊 Integrating the emotion detection technology with real-time chat functionality posed a significant challenge. Ensuring user privacy while processing emotional data required careful planning and execution. Moreover, creating a diverse range of sea creature personalities that could appeal to different users was a complex task that demanded creativity and an understanding of psychological support principles. There were many things we ran into during both development and deployment, and being able to ship this project on time is a big accomplishment for us.
## Accomplishments that we're proud of
✨ We are particularly proud of creating an environment that not only recognizes emotions but responds in a comforting and supportive manner. Our success in integrating various technologies to create a seamless user experience is a testament to our team's dedication and technical prowess.
## What we learned
🌊 Throughout the development of harbor.ed, we learned the importance of interdisciplinary collaboration, combining elements of psychology, technology, and design. We also gained valuable insights into the technical aspects of real-time emotion detection and chatbot development. Many technologies like Langchain and OpenCV were also first time uses for some of our members, and seeing everything come together is extremely rewarding.
## What's next
✨ The future of harbor.ed is bright and bustling with potential. We plan to expand the range of sea creatures and personalities, improve our emotion detection algorithms for greater accuracy, and explore partnerships with mental health professionals to refine the support our digital creatures can provide. Our ultimate goal is to create a global community where everyone has access to a virtual sea of support. | losing |
People waste too much time re-reading things. We built a speedreading app using AWS Lambda, S3 Cloud storage and DynamoDB all operating on Android for maximum accessibility. Also, using HP's IDOL OnDemand OCR Text Recognition API, users can upload screenshotted images or pdf of text and turn them into a Spritz-style speed reading format. | ## 💡 Inspiration
After learning about the benefits of reading, the team was surprised to find that reading stats for children are still very low. Especially with software apps such as Duolingo and PokemonGo, the team wanted to leverage similar motivational and innovative technologies to increase the reading engagement for young children.
## 💻 What it does
Augmented reality (AR) is used to gamify the reading experience. Numerous rewards are used to encourage and motivate readers to continue their progress. Our app allows them to see the world transform around them the more they read! Accumulating objects from the fantastical world where the story takes place, all with a bonus to unlock their favorite character, a new virtual friend that they can interact with!
## ⚙️ How we built it
The frontend was built using React and TailwindCSS. The backend is a combination of CockroachDB, EchoAR, Node.js and Google Drive. The app is deployed using Heroku. Mockups of the design was made using Figma.
## 🧠 Challenges we ran into
The first challenge was creating a cluster using CockroachDB and integrating the database with the frontend. The second challenge was implementing an epub reader to display the classic books.
## 🏅 Accomplishments that we're proud of
Finishing the design and integrating the frontend with the backend code.
## 📖 What we learned
We learned about the challenges of using epub files and how to use new technologies such as CockroachDB and EchoAR in app development.
## 🚀 What's next for AReading
For now, our book selection is only limited to public domain ones.
A natural next step would be to contract with various book authors and publishers in order to integrate their stories within our app and to expand our offerings to various literary genres and age groups.
This would allow us to monetize the app by providing subscriptions for unlimited access to copyrighted books after paying for their royalty fees. | ## Project Title
**UniConnect** - Enhancing the College Experience
## Inspiration
🌟 Our inspiration stems from a deep understanding of the challenges that university freshmen encounter during their initial year on campus. Having personally navigated these highs and lows during our own freshman year last year, we felt compelled to create a solution that addresses these issues and assists fellow students on their academic journey. Thus, we came up with UniConnect, a platform that offers essential support and resources.
## What It Does
🚀 **CrowdSense**: Enhance your campus experience by effortlessly finding available spaces for studying, enjoying fitness sessions, outdoor activities, or meals in real-time, ensuring a stress-free and comfortable environment.
🌐 **SpaceSync**: Simplify the lives of international students by seamlessly connecting them with convenient summer storage solutions, eliminating the hassle and worries associated with storing belongings during breaks.
🖥️ Front-end: HTML/CSS/JavaScript
🔌 Backend: JavaScript with MongoDB Atlas
## Challenges We Overcame
🏆 Elevating User-Friendliness and Accessibility: We dedicated ourselves to making our solution as intuitive and accessible as possible, ensuring that every user can benefit from it.
📊 Mastering Data Analysis and Backend Representation: Tackling the intricacies of data analysis and backend operations pushed us to expand our knowledge and skills, enabling us to deliver a robust platform.
🛠️ Streamlining Complex Feature Integration: We met the challenge of integrating diverse features seamlessly, providing a unified and efficient user experience.
⏱️ Maximizing Time Efficiency: Our commitment to optimizing time efficiency drove us to fine-tune our solution, ensuring that users can accomplish more in less time.
## Proud Achievements
🌟 Successful Execution of Uniconnect's First Phase: We have successfully completed the initial phase of Uniconnect, bringing SpaceSync to fruition and making significant progress with CrowdSense.
🌐 Intuitive and Accessible Solutions: Our unwavering commitment to creating user-friendly and accessible solutions ensures that every user can derive maximum benefit from our platform.
🏆 Positive Impact on College Students: We are thrilled to have a positive impact on the college experience of students who may not have had a strong support system during their memorable four-year journey.
## Valuable Learning
📚 Efficient Integration of Multiple Webpages: We've mastered the art of seamlessly connecting various webpages using HTML, CSS, and JS to create a cohesive user experience.
📈 Data Extraction and Backend Utilization: We've acquired the skills to extract and leverage data effectively in the backend using JavaScript, enhancing the functionality of our platform.
🌐 Enhancing User-Friendliness: Through JavaScript, we've honed our ability to make our website exceptionally user-friendly, prioritizing the user experience above all else.
## What's next for UniConnect
🚀 Expanding CrowdSense: We have ambitious plans to enhance and grow the CrowdSense section of UniConnect, providing even more real-time solutions for students on campus.
💼 Introducing "Collab Center": Our next big step involves introducing a new section called \*\* "Collab Center." \*\* This feature will empower the student community to create employment opportunities for each other, fostering a supportive ecosystem where both employers and employees are college students. This initiative aims to provide financial support to those in need while offering valuable assistance to those seeking help. Together, we can make a significant impact on students' lives.
🎓 UniConnect is our solution to enhance university life, making it easier, more connected, and full of opportunities | losing |
## Inspiration
Productivity is hard to harness especially at hackathons with many distractions, but a trick we software developing students found to stay productive while studying was using the “Pomodoro Technique”. The laptop is our workstation and could be a source of distraction, so what better place to implement the Pomodoro Timer as a constant reminder? Since our primary audience is going to be aspiring young tech students, we chose to further incentivize them to focus until their “breaks” by rewarding them with a random custom-generated and minted NFT to their name every time they succeed. This unique inspiration provided an interesting way to solve a practical problem while learning about current blockchain technology and implementing it with modern web development tools.
## What it does
An innovative modern “Pomodoro Timer” running on your browser enables users to sign in and link their MetaMask Crypto Account addresses. Such that they are incentivized to be successful with the running “Pomodoro Timer” because upon reaching “break times” undisrupted our website rewards the user with a random custom-generated and minted NFT to their name, every time they succeed. This “Ethereum Based NFT” can then be both viewed on “Open Sea” or on a dashboard of the website as they both store the user’s NFT collection.
## How we built it
TimeToken's back-end is built with Django and Sqlite and for our frontend, we created a beautiful and modern platform using React and Tailwind, to give our users a dynamic webpage. A benefit of using React, is that it works smoothly with our Django back-end, making it easy for both our front-end and back-end teams to work together
## Challenges we ran into
We had set up the website originally as a MERN stack (MongoDB/Express.js/REACT/Node.js) however while trying to import dependencies for the Verbwire API, to mint our images into NFTs to the user’s wallets we ran into problems. After solving dependency issues a “git merge” produced many conflicts, and on the way to resolving conflicts, we discovered some difficult compatibility issues with the API SDK and JS option for our server. At this point we had to pivot our plan, so we decided to implement the Verbwire Python-provided API solution, and it worked out very well. We intended here to just pass the python script and its functions straight to our front-end but learned that direct front-end to Python back-end communication is very challenging. It involved Ajax/XML file formatting and solutions heavily lacking in documentation, so we were forced to keep searching for a solution. We realized that we needed an effective way to make back-end Python communicate with front-end JS with SQLite and discovered that the Django framework was the perfect suite. So we were forced to learn Serialization and the Django framework quickly in order to meet our needs.
## Accomplishments that we're proud of
We have accomplished many things during the development of TimeToken that we are very proud of. One of our proudest moments was when we pulled an all-nighter to code and get everything just right. This experience helped us gain a deeper understanding of technologies such as Axios, Django, and React, which helped us to build a more efficient and user-friendly platform. We were able to implement the third-party VerbWire API, which was a great accomplishment, and we were able to understand it and use it effectively. We also had the opportunity to talk with VerbWire professionals to resolve bugs that we encountered, which allowed us to improve the overall user experience. Another proud accomplishment was being able to mint NFTs and understanding how crypto and blockchains work, this was a great opportunity to learn more about the technology. Finally, we were able to integrate crypto APIs, which allowed us to provide our users with a complete and seamless experience.
## What we learned
When we first started working on the back-end, we decided to give MongoDB, Express, and NodeJS a try. At first, it all seemed to be going smoothly, but we soon hit a roadblock with some dependencies and configurations between a third-party API and NodeJS. We talked to our mentor and decided it would be best to switch gears and give the Django framework a try. We learned that it's always good to have some knowledge of different frameworks and languages, so you can pick the best one for the job. Even though we had a little setback with the back-end, and we were new to Django, we learned that it's important to keep pushing forward.
## What's next for TimeToken
TimeToken has come a long way and we are excited about the future of our application. To ensure that our application continues to be successful, we are focusing on several key areas. Firstly, we recognize that storing NFT images locally is not scalable, so we are working to improve scalability. Secondly, we are making security a top priority and working to improve the security of wallets and crypto-related information to protect our users' data. To enhance user experience, we are also planning to implement a media hosting website, possibly using AWS, to host NFT images. To help users track the value of their NFTs, we are working on implementing an API earnings report with different time spans. Lastly, we are working on adding more unique images to our NFT collection to keep our users engaged and excited. | ## Inspiration
The counterfeiting industry is anticipated to grow to $2.8 trillion in 2022 costing 5.4 million jobs. These counterfeiting operations push real producers to bankruptcy as cheaper knockoffs with unknown origins flood the market. In order to solve this issue we developed a blockchain powered service with tags that uniquely identify products which cannot be faked or duplicated while also giving transparency. As consumers today not only value the product itself but also the story behind it.
## What it does
Certi-Chain uses a python based blockchain to authenticate any products with a Certi-Chain NFC tag. Each tag will contain a unique ID attached to the blockchain that cannot be faked. Users are able to tap their phones on any product containing a Certi-Chain tag to view the authenticity of a product through the Certi-Chain blockchain. Additionally if the product is authentic users are also able to see where the products materials were sourced and assembled.
## How we built it
Certi-Chain uses a simple python blockchain implementation to store the relevant product data. It uses a proof of work algorithm to add blocks to the blockchain and check if a blockchain is valid. Additionally, since this blockchain is decentralized, nodes (computers that host a blockchain) have to be synced using a consensus algorithm to decide which version of the blockchain from any node should be used.
In order to render web pages, we used Python Flask with our web server running the blockchain to fetch relative information from the blockchain and displayed it to the user in a style that is easy to understand. A web client to input information into the chain was also created using Flask to communicate with the server.
## Challenges we ran into
For all of our group members this project was one of the toughest we had. The first challenge we ran into was that once our idea was decided we quickly realized only one group member had the appropriate hardware to test our product in real life. Additionally, we deliberately chose an idea in which none of us had experience in. This meant we had to spent a portion of time to understand concepts such as blockchain and also using frameworks like flask. Beyond the starting choices we also hit several roadblocks as we were unable to get the blockchain running on the cloud for a significant portion of the project hindering the development. However, in the end we were able to effectively rack our minds on these issues and achieve a product that exceeded our expectations going in. In the end we were all extremely proud of our end result and we all believe that the struggle was definitely worth it in the end.
## Accomplishments that we're proud of
Our largest achievement was that we were able to accomplish all our wishes for this project in the short time span we were given. Not only did we learn flask, some more python, web hosting, NFC interactions, blockchain and more, we were also able to combine these ideas into one cohesive project. Being able to see the blockchain run for the first time after hours of troubleshooting was a magical moment for all of us. As for the smaller wins sprinkled through the day we were able to work with physical NFC tags and create labels that we stuck on just about any product we had. We also came out more confident in the skills we already knew and also developed new skills we gained on the way.
## What we learned
In the development of Certi-Check we learnt so much about blockchains, hashes, encryption, python web frameworks, product design, and also about the counterfeiting industry too. We came into the hackathon with only a rudimentary idea what blockchains even were and throughout the development process we came to understand the nuances of blockchain technology and security. As for web development and hosting using the flask framework to create pages that were populated with python objects was certainly a learning curve for us but it was a learning curve that we overcame. Lastly, we were all able to learn more about each other and also the difficulties and joys of pursuing a project that seemed almost impossible at the start.
## What's next for Certi-Chain
Our team really believes that what we made in the past 36 hours can make a real tangible difference in the world market. We would love to continue developing and pursuing this project so that it can be polished for real world use. This includes us tightening the security on our blockchain, looking into better hosting, and improving the user experience for anyone who would tap on a Certi-Chain tag. | ## Inspiration
Non-fungible tokens (NFTs) have raised interesting questions:
* Who owns an NFT?
* What value does it provide?
* How long does it last?
We wanted to explore these three questions and push the boundaries on what an NFT means.
Furthermore, this site was inspired by [thispersondoesnotexist.com](https://thispersondoesnotexist.com), a website that generates a convincingly real, yet non-existent person.
## What it does
[ThisNFTDoesNotExist.tech](http://thisnftdoesnotexist.tech/) generates an image that could plausibly be an NFT, but is not.
* Anyone can right-click and save the image onto their hard drive.
* An individual image has no monetary value. It is not attached to a blockchain.
* The image is ephemeral. It is up to the viewer whether or not they would like to preserve the image by saving or printing it.
## How we built it
The core of the generation process is a Generative Adversarial Network (GAN). Two deep learning models, a generator and classifier, compete against one another in a zero-sum game to generate images that are indistinguishable from real images according to the classifier.
Both of our models process 64x64px images, and use two layers of 2D convolutions to generate and upscale or discriminate and downscale (depending on the model).
## Challenges we ran into
We had difficulty tuning the parameters for the models, such as convolution sizes and number of layers. To mitigate the time spent on training with different parameters, we prioritized iteration speed over fine-grained improvements per generation. This let us view changes to our parameters faster, but sacrificed image fidelity.
We also had difficulty deploying the model. Our initial goal was to transpile the generator and the training result data into JavaScript so that it could be hosted on a static site deployment provider (like GitHub). However, the interaction that TensorFlow provided between Python and the GPU proved to be too difficult to package into a browser. We eventually hosted the site and generator on an AWS EC2 instance.
## Accomplishments that we're proud of
* Creating a working machine learning model
* Making an amazing frontend website
## What we learned
* How to utilize Tensorflow to make a GAN (Generative Adversarial Network)
## What's next for This NFT Does Not Exist
* Training for longer | partial |
## Inspiration
All three of us working on the project love traveling and want to fly to new places in the world on a budget. By combining Google computer vision to recognize interesting places to go as well as JetBlue's flight deals to find the best flights- we hope we've created a product that college students can use to explore the world!
## What it does
*Envision* parses through each picture on websites the user is on and predicts a destination airport from the image given entities tracked through computer vision. It finds the best JetBlue flight deal based on current location, price, and similarity in destination and returns a hover over chrome extension best deal recommendation. It links to a website that shows more information about the flight, including flight type, fare type, etc, as well as pictures of the destination found through Google Places API. *Envision* travel effortlessly today! :))
## How we built it
We build *Envision* using JetBlue's Deals data and the Google Cloud Platform- Google Vision API, Google Places API. First, we scraped images from Google Image Search of every JetBlue airport location. Running every image through Google Vision API, we received a list of entities that are found in the most common images. By creating a chrome extension to track images in every webpage, each picture is then translate through computer vision into an entity list, and that list is used to find the best location to recommend / most similar destination. Using JetBlue's Deals data, we found the best deal flight from the closest airport based on current location, and routed to our target airport destination, using Google Places API Place Nearby Search, Text Search, Place Details combined to find the most suitable flight to take. Using Heroku and Flask to host our web services, we created a workflow that leads to a React website with more information about the recommended flights and photos of the destination similar to that of the original images on the browsed website.
## Challenges we ran into
There are many steps in our processing pipeline- which includes receiving images from the chrome extension, parsing the image to an entity list on Google Cloud Vision, finding a recommended location and the best JetBlue flight that leads to a region, as well as similar images from the area that links to the original image shown in a separate website. To connect every part together through endpoints took a lot of figuring out near the end!
## Accomplishments that we're proud of
Creating a working product!
## What we learned
Lots of web & API calling.
## What's next for Envision
Creating a more user intuitive interface for *Envision* on the chrome extension as well as the website. | ## Inspiration
We were inspired by JetBlue's challenge to utilize their data in a new way and we realized that, while there are plenty of websites and phone applications that allow you to find the best flight deal, there is none that provide a way to easily plan the trip and items you will need with your friends and family.
## What it does
GrouPlane allows users to create "Rooms" tied to their user account with each room representing an unique event, such as a flight from Toronto to Boston for a week. Within the room, users can select flight times, see the best flight deal, and plan out what they'll need to bring with them. Users can also share the room's unique ID with their friends who can then utilize this ID to join the created room, being able to see the flight plan and modify the needed items.
## How we built it
GrouPlane was built utilizing Android Studio with Firebase, the Google Cloud Platform Authentication API, and JetBlue flight information. Within Android Studio, Java code and XML was utilized.
## Challenges we ran into
The challenges we ran into was learning how to use Android Studio/GCP/Firebase, and having to overcome the slow Internet speed present at the event. In terms of Android Studio/GCP/Firebase, we were all either entirely new or very new to the environment and so had to learn how to access and utilize all the features available. The slow Internet speed was a challenge due to not only making it difficult to learn for the former tools, but, due to the online nature of the database, having long periods of time where we could not test our code due to having no way to connect to the database.
## Accomplishments that we're proud of
We are proud of being able to finish the application despite the challenges. Not only were we able to overcome these challenges but we were able to build an application there functions to the full extent we intended while having an easy to use interface.
## What we learned
We learned a lot about how to program Android applications and how to utilize the Google Cloud Platform, specifically Firebase and Google Authentication.
## What's next for GrouPlane
GrouPlane has many possible avenues for expansion, in particular we would like to integrate GrouPlane with Airbnb, Hotel chains, and Amazon Alexa. In terms of Airbnb and hotel chains, we would utilize their APIs in order to pull information about hotel deals for the flight locations picked for users can plan out their entire trip within GrouPlane. With this integration, we would also expand GrouPlane to be able to inform everyone within the "event room" about how much the event will cost each person. We would also integrate Amazon Alexa with GrouPlane in order to provide users the ability to plane out their vacation entirely through the speech interface provided by Alexa rather than having to type on their phone. | ## Inspiration
As university students and soon to be graduates, we understand the financial strain that comes along with being a student, especially in terms of commuting. Carpooling has been a long existing method of getting to a desired destination, but there are very few driving platforms that make the experience better for the carpool driver. Additionally, by encouraging more people to choose carpooling at a way of commuting, we hope to work towards more sustainable cities.
## What it does
FaceLyft is a web app that includes features that allow drivers to lock or unlock their car from their device, as well as request payments from riders through facial recognition. Facial recognition is also implemented as an account verification to make signing into your account secure yet effortless.
## How we built it
We used IBM Watson Visual Recognition as a way to recognize users from a live image; After which they can request money from riders in the carpool by taking a picture of them and calling our API that leverages the Interac E-transfer API. We utilized Firebase from the Google Cloud Platform and the SmartCar API to control the car. We built our own API using stdlib which collects information from Interac, IBM Watson, Firebase and SmartCar API's.
## Challenges we ran into
IBM Facial Recognition software isn't quite perfect and doesn't always accurately recognize the person in the images we send it. There were also many challenges that came up as we began to integrate several APIs together to build our own API in Standard Library. This was particularly tough when considering the flow for authenticating the SmartCar as it required a redirection of the url.
## Accomplishments that we're proud of
We successfully got all of our APIs to work together! (SmartCar API, Firebase, Watson, StdLib,Google Maps, and our own Standard Library layer). Other tough feats we accomplished was the entire webcam to image to API flow that wasn't trivial to design or implement.
## What's next for FaceLyft
While creating FaceLyft, we created a security API for requesting for payment via visual recognition. We believe that this API can be used in so many more scenarios than carpooling and hope we can expand this API into different user cases. | partial |
## Inspiration
I wanted to create an easier way for people to access the internet and interact with their desktop devices from afar.
## What it does
It's a mobile app that allows a user to control their web browser on their laptop/desktop in nearly every way they can imagine, from scrolling up and down, switching tabs, and going back/forth through history to advanced features such as refreshing the page, navigating and clicking on links, and even "turning off" and "turning on" the browser.
## How I built it
I built the mobile app using React Native and Expo while testing on my Google Pixel. The backend was written in Python with Selenium for the browser controls and a server that served websockets to facilitate communication between the two devices.
## Challenges I ran into
Positioning things for the front end was hard and reminded me I don't want to be a front end developer. Besides that, getting back into React Native and creating an API to communicate with the back end took some design thinking.
## Accomplishments that I'm proud of
Built alone in < 24 hours. The design also isn't too bad which is nice.
## What I learned
Learned about CSS rules/flexbox and more advanced React Native stuff. Oh, and turns out hacking without a team isn't so bad.
## What's next for Webmote
I'm going to keep building on this idea and expanding the feature set/ease of distribution. I believe there should be greater connectivity between our devices. | ## Inspiration
With the excitement of blockchain and the ever growing concerns regarding privacy, we wanted to disrupt one of the largest technology standards yet: Email. Email accounts are mostly centralized and contain highly valuable data, making one small breach, or corrupt act can serious jeopardize millions of people. The solution, lies with the blockchain. Providing encryption and anonymity, with no chance of anyone but you reading your email.
Our technology is named after Soteria, the goddess of safety and salvation, deliverance, and preservation from harm, which we believe perfectly represents our goals and aspirations with this project.
## What it does
First off, is the blockchain and message protocol. Similar to PGP protocol it offers \_ security \_, and \_ anonymity \_, while also **ensuring that messages can never be lost**. On top of that, we built a messenger application loaded with security features, such as our facial recognition access option. The only way to communicate with others is by sharing your 'address' with each other through a convenient QRCode system. This prevents anyone from obtaining a way to contact you without your **full discretion**, goodbye spam/scam email.
## How we built it
First, we built the block chain with a simple Python Flask API interface. The overall protocol is simple and can be built upon by many applications. Next, and all the remained was making an application to take advantage of the block chain. To do so, we built a React-Native mobile messenger app, with quick testing though Expo. The app features key and address generation, which then can be shared through QR codes so we implemented a scan and be scanned flow for engaging in communications, a fully consensual agreement, so that not anyone can message anyone. We then added an extra layer of security by harnessing Microsoft Azures Face API cognitive services with facial recognition. So every time the user opens the app they must scan their face for access, ensuring only the owner can view his messages, if they so desire.
## Challenges we ran into
Our biggest challenge came from the encryption/decryption process that we had to integrate into our mobile application. Since our platform was react native, running testing instances through Expo, we ran into many specific libraries which were not yet supported by the combination of Expo and React. Learning about cryptography and standard practices also played a major role and challenge as total security is hard to find.
## Accomplishments that we're proud of
We are really proud of our blockchain for its simplicity, while taking on a huge challenge. We also really like all the features we managed to pack into our app. None of us had too much React experience but we think we managed to accomplish a lot given the time. We also all came out as good friends still, which is a big plus when we all really like to be right :)
## What we learned
Some of us learned our appreciation for React Native, while some learned the opposite. On top of that we learned so much about security, and cryptography, and furthered our beliefs in the power of decentralization.
## What's next for The Soteria Network
Once we have our main application built we plan to start working on the tokens and distribution. With a bit more work and adoption we will find ourselves in a very possible position to pursue an ICO. This would then enable us to further develop and enhance our protocol and messaging app. We see lots of potential in our creation and believe privacy and consensual communication is an essential factor in our ever increasingly social networking world. | ## Problem
In these times of isolation, many of us developers are stuck inside which makes it hard for us to work with our fellow peers. We also miss the times when we could just sit with our friends and collaborate to learn new programming concepts. But finding the motivation to do the same alone can be difficult.
## Solution
To solve this issue we have created an easy to connect, all in one platform where all you and your developer friends can come together to learn, code, and brainstorm together.
## About
Our platform provides a simple yet efficient User Experience with a straightforward and easy-to-use one-page interface.
We made it one page to have access to all the tools on one screen and transition between them easier.
We identify this page as a study room where users can collaborate and join with a simple URL.
Everything is Synced between users in real-time.
## Features
Our platform allows multiple users to enter one room and access tools like watching youtube tutorials, brainstorming on a drawable whiteboard, and code in our inbuilt browser IDE all in real-time. This platform makes collaboration between users seamless and also pushes them to become better developers.
## Technologies you used for both the front and back end
We use Node.js and Express the backend. On the front end, we use React. We use Socket.IO to establish bi-directional communication between them. We deployed the app using Docker and Google Kubernetes to automatically scale and balance loads.
## Challenges we ran into
A major challenge was collaborating effectively throughout the hackathon. A lot of the bugs we faced were solved through discussions. We realized communication was key for us to succeed in building our project under a time constraints. We ran into performance issues while syncing data between two clients where we were sending too much data or too many broadcast messages at the same time. We optimized the process significantly for smooth real-time interactions.
## What's next for Study Buddy
While we were working on this project, we came across several ideas that this could be a part of.
Our next step is to have each page categorized as an individual room where users can visit.
Adding more relevant tools, more tools, widgets, and expand on other work fields to increase our User demographic.
Include interface customizing options to allow User’s personalization of their rooms.
Try it live here: <http://35.203.169.42/>
Our hopeful product in the future: <https://www.figma.com/proto/zmYk6ah0dJK7yJmYZ5SZpm/nwHacks_2021?node-id=92%3A132&scaling=scale-down>
Thanks for checking us out! | partial |
## Inspiration
We are two college students renting a house by ourselves with a high energy bill due to heating during Canada’s winter. The current solutions in the market are expensive AND permanent. We cannot make permanent changes to a house we rent, and we couldn’t afford them to begin with.
## What it does
Kafa is a thermostat enhancer with an easy installation that lets you remove it at any time with no assistance. There’s no need to get handy playing with electrical wires and screwdrivers. Just simply take Kafa out from the box, clip over your existing thermostat, and slide in the battery. If you switch apartments, offices, or dorm rooms, take Kafa with you. Simply clip off!
Kafa saves you money in installation fees, acquisition of hardware, and power bill. It keeps track of your usage patterns and even allows you to set up power saving mode.
## How we built it
The Kafa body was modelled using Fusion 360. The CAD models for the electronic components were sourced from Grab CAD. Everything else was modelled from scratch.
For the electronics we used an SG 90 servo that we hacked, an analog to digital converter, Raspberry pi Zero, a buck converter, temperature sensor, RGB LED, a potentiometer, and a battery we took from a camera light. We 3D printed the body of Kafa so that it would hold the individual components together in a compact manner. We then wired it all up together.
On the software side, Kafa is built using docker containers, which makes it highly portable, modular, secure and scalable. These containers run flask web apps that serve as controllers and actuators easily accessible by any browser enabled device; to store data we use a container running a MySQL database.
## Challenges we ran into
The most challenging aspect of the physical design was staying true to the premise of “easy installation” by coming up with non-permanent methods of attachment to the thermostats at our home. We wanted to design something that didn’t use screws, bolts, glue, tape, etc. Designing the case to be compact whilst planning for cable management was also hard.
The most challenging part of the software development was the servo calibration which allows it to adapt to any thermostat dial. To accomplish this, we had to 'hack' the servo and solder a cable to the variable resistor in order to read its position.
## Accomplishments that we're proud of
The most rewarding aspect of the physical design was accurately predicting the behaviour of the physical components and how they would fit once inside the compact case. Foreseeing and accounting for all possible issues that would come up in manufacturing whilst still in the CAD program made for the construction of our project to run much more smoothly (mostly).
The accomplishment, with regards to software, that we are most proud of is that everything is containerized. This means that in order to replicate our setup you just need to run the docker images in the destination devices.
## What we learned
One of the most important lessons we learned is effectively communicating technical information to each other regarding our respective engineering disciplines (mechanical and computer). We also learned about the potential of IoT devices to be applied in the most simple and unforeseen ways.
## What's next for Kafa - Thermostat Enhancer
To improve Kafa in future iterations we would like to:
* Optimize circuitry to use low power, Wi-Fi enabled MCU so that battery life lasts months instead of hours
* Implement a learning algorithm so that Kafa can infer your active hours and save even more electricity
* Develop universal attachment mechanisms to fit any brand and shape of thermostat.
## Acknowledgments
* [docker-alpine-pigpiod - zinen](https://github.com/zinen/docker-alpine-pigpiod)
* [Nest Thermostat Control - Dal Hundal](https://codepen.io/dalhundal/pen/KpabZB)
* [Raspberry Pi Zero W board - Vittorinco](https://grabcad.com/library/raspberry-pi-zero-w-board-1)
* [USB Cable - 3D-2D CAD Design](https://grabcad.com/library/usb-cable-31)
* [Micro USB Plug - Yuri Malina](https://grabcad.com/library/micro-usb-plug-1)
* [5V-USB-Booster - Erick Robles](https://grabcad.com/library/5v-usb-booster-1)
* [Standard Through Hole Potentiometer (Vertical & Horizontal) - Abel Villanueva](https://grabcad.com/library/standard-through-hole-potentiometer-vertical-horizontal-1)
* [SG90 - Micro Servo 9g - Tower Pro - Matheus Frasson](https://grabcad.com/library/sg90-micro-servo-9g-tower-pro-1)
* [Volume Control Rotary Knobs - Kevin Yu](https://grabcad.com/library/volume-control-rotary-knobs-1)
* [Led RGB 5mm - Terrapon Théophile](https://grabcad.com/library/led-rgb-5mm)
* [Pin Headers single row - singlefonts](https://grabcad.com/library/pin-headers-single-row-1)
* [GY-ADS1115 - jalba](https://grabcad.com/library/gy-ads1115-1) | ## Inspiration
As university students, emergency funds may not be on the top of our priority list however, when the unexpected happens, we are often left wishing that we had saved for an emergency when we had the chance. When we thought about this as a team, we realized that the feeling of putting a set amount of money away every time income rolls through may create feelings of dread rather than positivity. We then brainstormed ways to make saving money in an emergency fund more fun and rewarding. This is how Spend2Save was born.
## What it does
Spend2Save allows the user to set up an emergency fund. The user inputs their employment status, baseline amount and goal for the emergency fund and the app will create a plan for them to achieve their goal! Users create custom in-game avatars that they can take care of. The user can unlock avatar skins, accessories, pets, etc. by "buying" them with funds they deposit into their emergency fund. The user will have milestones or achievements for reaching certain sub goals while also giving them extra motivation if their emergency fund falls below the baseline amount they set up. Users will also be able to change their employment status after creating an account in the case of a new job or career change and the app will adjust their deposit plan accordly.
## How we built it
We used Flutter to build the interactive prototype of our Android Application.
## Challenges we ran into
None of us had prior experience using Flutter, let alone mobile app development. Learning to use Flutter in a short period of time can easily be agreed upon to be the greatest challenge that we faced.
We originally had more features planned, with an implementation of data being stored using Firebase, so having to compromise our initial goals and focus our efforts on what is achievable in this time period proved to be challenging.
## Accomplishments that we're proud of
This was our first mobile app we developed (as well as our first hackathon).
## What we learned
This being our first Hackathon, almost everything we did provided a learning experience. The skills needed to quickly plan and execute a project were put into practice and given opportunities to grow. Ways to improve efficiency and team efficacy can only be learned through experience in a fast-paced environment such as this one.
As mentioned before, with all of us using Flutter for the first time, anything we did involving it was something new.
## What's next for Spend2Save
There is still a long way for us to grow as developers, so the full implementation of Spend2Save will rely on our progress.
We believe there is potential for such an application to appeal to its target audience and so we have planned projections for the future of Spend2Save. These projections include but are not limited to, plans such as integration with actual bank accounts at RBC. | ## Inspiration
This project was inspired by a personal anecdote. Two of the teammates, A and B, were hanging out in friend C’s dorm room. When it was time to leave, teammate B needed to grab his bag from teammate A’s dorm room. However, to their dismay, teammate A accidentally left her keycard in friend C’s dorm room, who left to go to a party. This caused A and B to wait for hours for C to return. This event planted a seed for this project in the back of teammates A and B’s minds, hoping to bring convenience to students’ lives and eliminate the annoyance of forgetting their keycards and being unable to enter their dorm rooms.
## What it does
This device aims to automate the dorm room lock by allowing users to control the lock using a mobile application. The door lock’s movement is facilitated by a 3D-printed gear on a bar, and the gear is attached to a motor, controlled by an Arduino board. There are two simple steps to follow to enter the dorm. First, a phone needs to be paired with the device through Bluetooth. Both the “Pair with Device” button in the app and the button on the Bluetooth Arduino board are clicked. This only needs to be done for the first time the user is using this device. Once a connection is established between the Bluetooth board and the mobile app, the user can simply click the “Unlock door” button on the app, facilitating the communication between the Bluetooth board and the Motor board, causing the gear to rotate and subsequently causing the rod to bring down the door handle, unlocking the door.
## How we built it
We used Android Studio to develop the mobile application in Java. The gear and bar were designed using Fusion360 and 3D-printed. Two separate Arduino boards were attached to the ESP32-S Bluetooth module and the motor attached to the gear, respectively, and the boards are controlled by the software part of an Arduino program programmed in C++. PlatformIO was used to automate the compilation and linking of code between hardware and software components.
## Challenges we ran into
Throughout the build process, we encountered countless challenges, with a few of the greatest being understanding how the two Arduino boards communicate, figuring out the deployment mechanism of the ESP32-S module when our HC-05 was dysfunctional, and maintaining the correct circuit structure for our motor and LCD.
## Accomplishments that we're proud of
Many of our greatest accomplishments stemmed from overcoming the challenges that we faced. For example, the wiring of the motor circuit was a major concern in the initial circuit setup process: following online schematics on how to wire the Nema17 motor, the motor did not perform full rotations, and thus would not have the capability to be integrated with other hardware components. This motor is a vital component for the workings of our mechanism, and with further research and diligence, we discovered that the issue was related to our core understanding of how the circuit performs and obtaining the related drivers needed to perform our tasks. This was one of our most prominent hardware accomplishments as it functions as the backbone for our mechanism. A more lengthy, software achievement we experienced was making the ESP32-S microcontroller functional.
## What we learned
For several members of our group, this marked their initial exposure to GitHub within a collaborative environment. Given that becoming acquainted with this platform is crucial in many professional settings, this served as an immensely beneficial experience for our novice hackers. Additionally, for the entire team, this was the first experience operating with Bluetooth technology. This presented a massive learning curve, challenging us to delve into the intricacies of Bluetooth, understand its protocols, and navigate the complexities of integrating it into our project. Despite the initial hurdles, the process of overcoming this learning curve fostered a deeper understanding of wireless communication and added a valuable skill set to our collective expertise. Most importantly, however, we learned that with hard work and perseverance, even the most daunting challenges can be overcome. Our journey with GitHub collaboration and Bluetooth integration served as a testament to the power of persistence and the rewards of pushing beyond our comfort zones. Through this experience, we gained not only technical skills but also the confidence to tackle future projects with resilience and determination.
## What's next for Locked In
Some future steps for Locked In would hopefully be to create a more robust authentication system through Firebase. This would allow users to sign in via other account credentials, such as Email, Facebook, and Google, and permit recognized accounts to be stored and managed by a centralized host. This objective would not only enhance security but also streamline user management, ensuring a seamless and user-friendly experience across various platforms and authentication methods.
Another objective of Locked In is to enhance the speed of Bluetooth connections, enabling users to fully leverage the convenience of not needing a physical key or card to access their room. This enhancement would offer users a faster and smoother experience, simplifying the process of unlocking doors and ensuring swift entry.
One feature that we did not finish implementing was the gyroscope, which automatically detects when the door is open and | winning |
## Inspiration
Personal data collection is an ever growing trend with smarter and better wearable technology. Already, our sleep, exercise, and food intake can be passively monitored using smartphones, providing valuable insight into our living habits and providing powerful impetus for self-improvement. We wanted develop a technology that adds social interaction to one’s suite of personal data.
## What it does
The SocialBit measures an individual’s social interactions throughout the day. A glasses-mounted camera detects faces and references them with an existing database of the user’s friends on social media platforms. The data is then visualized in a network plot and chord diagram that showcases the length and location of one’s interaction, defined as the points in time in which the friend’s face is within view. The result is a beautiful and insightful display of our daily social interactions - at the microscale.
## How we built it
The Raspberry Pi is designed to be a wearable device that complements your visual senses.
We used a combination of HTML, CSS, Javascript, and D3.js to create our front end and generate our social interaction plots based on output from our computer vision algorithm.
On the back end, we used multiple Python libraries and OpenCV along with the Pi's live stream and fed it into an object detection algorithm that is able to recognize faces, record interaction duration and location, and subsequently record onto a database in real time.
## Challenges we ran into
Getting past internet security while connecting our raspberry pi.
And also Facebook API.
## Accomplishments that we're proud of
We're proud of our concept and for getting most of our backend figured out.
## What's next for SocialBit
Continuing to refine our technical end, while moving towards integration with other types of personal data. How many steps did you take with your friend? Which friend do you eat more with?
Incentivization is another possibility. Loneliness is a legitimate problem in an increasingly disconnected world - what if our platform could incentivize people to reach their socialization goals, like the FitBit does with exercise?
Created at HackMIT 2018. | ## Inspiration 👓
The inspiration for this project stems from the **challenges of meeting many new people at once** and struggling to *remember names, conversations, and hobbies*. For students like us first-year university students, this is common during events like **frosh week**, while for adults, it may occur when **transitioning to a new job**. The project is also designed with *older adults in mind*, such as all our grandparents, who may experience **memory difficulties**. It aims to assist them in \_recalling names, past interactions, and personal interests of those they meet, making social interactions easier and more meaningful. The inspiration behind the project is for people of every age, from young university students to wise old grandparents that people have!
## What it does 🤖
Our hack utilizes **OpenCV** and **mediapipe** to recognize faces of new friends and acquaintances. No more struggling to remember names or hobbies—our system displays each person’s name and key information right next to their face, making it easier to connect and engage with others. Additionally, we used the **Cohere** to summarize conversations, generate keywords, and extract names, helping you recall important details about each person in the future.
## How we built it 🏗️
We built a real-time facial detection system using **OpenCV** and **MediaPipe** for video input, paired with **PyAudio** for synchronized audio recording. **MongoDB** stores captured images and metadata. This project is designed for head tracking, face recognition, and efficient multimedia data storage and retrieval in real-time applications.
## Challenges we ran into 🎯
Initially, we've had way too many ideas, however, we ended up scraping off every single idea we could think of for the first night because they were either hard to accomplish, or we thought they weren't good enough. And it was frustrating not being able to think through and finally pin down on a single clear idea we could work towards. And especially since this is the first time at a hackathon for most of us, there are a lot of things we still didn't know, and had to chat with mentors and volunteers for advice, but as we kept trying, we started picking up the learning curve even more, despite many challenges we're still facing, the experience is all worth it.
## Accomplishments that we're proud of 🥇
For us, as most of us are first time hackers, we were proud of making tiny little progress through every hour of the hackathon, powering through every single stepback and challenge by working and collaborating together to solve that one little bug in our code. Especially since it's the first hackathon most of us have attended, we're proud of the fact that we were willing to put ourselves out of our comfort zone, to learn, grow, meet new people and immerse ourselves in the technology world, from tiny steps, to giant leaps.
## What we learned 💡
Thug it out. Typing this at 5:30 really shows us what it means to successfully finish a hackathon with a working project. From learning OpenCV's library to MongoDB's Pymongo all the way to just trying to integrate an audio and video file at the same time in Visual Studio; it was quite an experience for all of us, an unforgettable one we must add.
## What's next for IntroSpectacle 🔮
Our mission for IntroSpectacle is to develop it into something useful and applicable in real life. By converting this webcam to a smaller and sleeker device we want to improve the look as well as the features of the product. A large part of our inspiration started from the challenges of not being able to remember things about people, and with different and new features we will be able to take off! | ## Inspiration
Imagine a world where your best friend is standing in front of you, but you can't see them. Or you go to read a menu, but you are not able to because the restaurant does not have specialized brail menus. For millions of visually impaired people around the world, those are not hypotheticals, they are facts of life.
Hollywood has largely solved this problem in entertainment. Audio descriptions allow the blind or visually impaired to follow the plot of movies easily. With Sight, we are trying to bring the power of audio description to everyday life.
## What it does
Sight is an app that allows the visually impaired to recognize their friends, get an idea of their surroundings, and have written text read aloud. The app also uses voice recognition to listen for speech commands to identify objects, people or to read text.
## How we built it
The front-end is a native iOS app written in Swift and Objective-C with XCode. We use Apple's native vision and speech API's to give the user intuitive control over the app.
---
The back-end service is written in Go and is served with NGrok.
---
We repurposed the Facebook tagging algorithm to recognize a user's friends. When the Sight app sees a face, it is automatically uploaded to the back-end service. The back-end then "posts" the picture to the user's Facebook privately. If any faces show up in the photo, Facebook's tagging algorithm suggests possibilities for who out of the user's friend group they might be. We scrape this data from Facebook to match names with faces in the original picture. If and when Sight recognizes a person as one of the user's friends, that friend's name is read aloud.
---
We make use of the Google Vision API in three ways:
* To run sentiment analysis on people's faces, to get an idea of whether they are happy, sad, surprised etc.
* To run Optical Character Recognition on text in the real world which is then read aloud to the user.
* For label detection, to indentify objects and surroundings in the real world which the user can then query about.
## Challenges we ran into
There were a plethora of challenges we experienced over the course of the hackathon.
1. Each member of the team wrote their portion of the back-end service a language they were comfortable in. However when we came together, we decided that combining services written in different languages would be overly complicated, so we decided to rewrite the entire back-end in Go.
2. When we rewrote portions of the back-end in Go, this gave us a massive performance boost. However, this turned out to be both a curse and a blessing. Because of the limitation of how quickly we are able to upload images to Facebook, we had to add a workaround to ensure that we do not check for tag suggestions before the photo has been uploaded.
3. When the Optical Character Recognition service was prototyped in Python on Google App Engine, it became mysteriously rate-limited by the Google Vision API. Re-generating API keys proved to no avail, and ultimately we overcame this by rewriting the service in Go.
## Accomplishments that we're proud of
Each member of the team came to this hackathon with a very disjoint set of skills and ideas, so we are really glad about how well we were able to build an elegant and put together app.
Facebook does not have an official algorithm for letting apps use their facial recognition service, so we are proud of the workaround we figured out that allowed us to use Facebook's powerful facial recognition software.
We are also proud of how fast the Go back-end runs, but more than anything, we are proud of building a really awesome app.
## What we learned
Najm taught himself Go over the course of the weekend, which he had no experience with before coming to YHack.
Nathaniel and Liang learned about the Google Vision API, and how to use it for OCR, facial detection, and facial emotion analysis.
Zak learned about building a native iOS app that communicates with a data-rich APIs.
We also learned about making clever use of Facebook's API to make use of their powerful facial recognition service.
Over the course of the weekend, we encountered more problems and bugs than we'd probably like to admit. Most of all we learned a ton of valuable problem-solving skills while we worked together to overcome these challenges.
## What's next for Sight
If Facebook ever decides to add an API that allows facial recognition, we think that would allow for even more powerful friend recognition functionality in our app.
Ultimately, we plan to host the back-end on Google App Engine. | losing |
## Inspiration
We were inspired by the need to provide quick, accessible environmental feedback to users, especially in situations where understanding context through sound or visuals can enhance their experience. This inspired the creation of SnaipShot, a tool that gives users audio feedback based on real-time data, helping them stay informed without the need to check screens.
## What it does
SnaipShot fetches and summarizes key highlights of the user's day from an API. It offers an interactive HELP feature, which provides environmental context through real-time audio feedback by converting descriptions to speech. It also allows users to view summarized data from their day in a friendly dashboard format.
## How we built it
We built SnaipShot using:
Streamlit for the frontend and UI components.
APIs to fetch real-time data, including summaries, highlights, and environmental context.
A text-to-speech service to generate audio feedback based on the latest data fetched from the API.
Python for managing logic, API requests, and audio processing.
## Challenges we ran into
API Integration: Ensuring seamless communication between our frontend and various APIs, especially handling different response times and error handling.
Real-time audio generation: Implementing smooth playback of audio generated dynamically from the data without delays.
State management: Managing session states to ensure audio components and UI elements work cohesively.
## Accomplishments that we're proud of
Successfully implementing a real-time HELP feature that provides immediate environmental context through audio feedback.
Building an interactive and responsive dashboard that fetches and displays user data dynamically.
Integrating APIs to produce a smooth user experience with minimal latency.
## What we learned
We gained valuable insights into real-time data handling and the challenges that come with processing and presenting it quickly.
We improved our understanding of text-to-speech APIs and their integration into a web app.
Managing user sessions and state in a Streamlit app was a valuable experience that helped us design a better user experience.
## What's next for SnaipShot
We plan to:
Enhance the audio feedback with more natural-sounding voices and multi-language support.
Expand the HELP feature to include visual feedback through diagrams or charts.
Implement more personalized data tracking and summaries, giving users deeper insights into their daily routines. | ## **Inspiration:**
Our inspiration stemmed from the realization that the pinnacle of innovation occurs at the intersection of deep curiosity and an expansive space to explore one's imagination. Recognizing the barriers faced by learners—particularly their inability to gain real-time, personalized, and contextualized support—we envisioned a solution that would empower anyone, anywhere to seamlessly pursue their inherent curiosity and desire to learn.
## **What it does:**
Our platform is a revolutionary step forward in the realm of AI-assisted learning. It integrates advanced AI technologies with intuitive human-computer interactions to enhance the context a generative AI model can work within. By analyzing screen content—be it text, graphics, or diagrams—and amalgamating it with the user's audio explanation, our platform grasps a nuanced understanding of the user's specific pain points. Imagine a learner pointing at a perplexing diagram while voicing out their doubts; our system swiftly responds by offering immediate clarifications, both verbally and with on-screen annotations.
## **How we built it**:
We architected a Flask-based backend, creating RESTful APIs to seamlessly interface with user input and machine learning models. Integration of Google's Speech-to-Text enabled the transcription of users' learning preferences, and the incorporation of the Mathpix API facilitated image content extraction. Harnessing the prowess of the GPT-4 model, we've been able to produce contextually rich textual and audio feedback based on captured screen content and stored user data. For frontend fluidity, audio responses were encoded into base64 format, ensuring efficient playback without unnecessary re-renders.
## **Challenges we ran into**:
Scaling the model to accommodate diverse learning scenarios, especially in the broad fields of maths and chemistry, was a notable challenge. Ensuring the accuracy of content extraction and effectively translating that into meaningful AI feedback required meticulous fine-tuning.
## **Accomplishments that we're proud of**:
Successfully building a digital platform that not only deciphers image and audio content but also produces high utility, real-time feedback stands out as a paramount achievement. This platform has the potential to revolutionize how learners interact with digital content, breaking down barriers of confusion in real-time. One of the aspects of our implementation that separates us from other approaches is that we allow the user to perform ICL (In Context Learning), a feature that not many large language models don't allow the user to do seamlessly.
## **What we learned**:
We learned the immense value of integrating multiple AI technologies for a holistic user experience. The project also reinforced the importance of continuous feedback loops in learning and the transformative potential of merging generative AI models with real-time user input. | ## Inspiration
While caught in the the excitement of coming up with project ideas, we found ourselves forgetting to follow up on action items brought up in the discussion. We felt that it would come in handy to have our own virtual meeting assistant to keep track of our ideas. We moved on to integrate features like automating the process of creating JIRA issues and providing a full transcript for participants to view in retrospect.
## What it does
*Minutes Made* acts as your own personal team assistant during meetings. It takes meeting minutes, creates transcripts, finds key tags and features and automates the process of creating Jira tickets for you.
It works in multiple spoken languages, and uses voice biometrics to identify key speakers.
For security, the data is encrypted locally - and since it is serverless, no sensitive data is exposed.
## How we built it
Minutes Made leverages Azure Cognitive Services for to translate between languages, identify speakers from voice patterns, and convert speech to text. It then uses custom natural language processing to parse out key issues. Interactions with slack and Jira are done through STDLIB.
## Challenges we ran into
We originally used Python libraries to manually perform the natural language processing, but found they didn't quite meet our demands with accuracy and latency. We found that Azure Cognitive services worked better. However, we did end up developing our own natural language processing algorithms to handle some of the functionality as well (e.g. creating Jira issues) since Azure didn't have everything we wanted.
As the speech conversion is done in real-time, it was necessary for our solution to be extremely performant. We needed an efficient way to store and fetch the chat transcripts. This was a difficult demand to meet, but we managed to rectify our issue with a Redis caching layer to fetch the chat transcripts quickly and persist to disk between sessions.
## Accomplishments that we're proud of
This was the first time that we all worked together, and we're glad that we were able to get a solution that actually worked and that we would actually use in real life. We became proficient with technology that we've never seen before and used it to build a nice product and an experience we're all grateful for.
## What we learned
This was a great learning experience for understanding cloud biometrics, and speech recognition technologies. We familiarised ourselves with STDLIB, and working with Jira and Slack APIs. Basically, we learned a lot about the technology we used and a lot about each other ❤️!
## What's next for Minutes Made
Next we plan to add more integrations to translate more languages and creating Github issues, Salesforce tickets, etc. We could also improve the natural language processing to handle more functions and edge cases. As we're using fairly new tech, there's a lot of room for improvement in the future. | partial |
# QThrive
Web-based chatbot to facilitate journalling and self-care. Built for QHacks 2017 @ Queen's University. | ## Inspiration
For this hackathon, we wanted to build something that could have a positive impact on its users. We've all been to university ourselves, and we understood the toll, stress took on our minds. Demand for mental health services among youth across universities has increased dramatically in recent years. A Ryerson study of 15 universities across Canada show that all but one university increased their budget for mental health services. The average increase has been 35 per cent. A major survey of over 25,000 Ontario university students done by the American college health association found that there was a 50% increase in anxiety, a 47% increase in depression, and an 86 percent increase in substance abuse since 2009.
This can be attributed to the increasingly competitive job market that doesn’t guarantee you a job if you have a degree, increasing student debt and housing costs, and a weakening Canadian middle class and economy. It can also be contributed to social media, where youth are becoming increasingly digitally connected to environments like instagram. People on instagram only share the best, the funniest, and most charming aspects of their lives, while leaving the boring beige stuff like the daily grind out of it. This indirectly perpetuates the false narrative that everything you experience in life should be easy, when in fact, life has its ups and downs.
## What it does
One good way of dealing with overwhelming emotion is to express yourself. Journaling is an often overlooked but very helpful tool because it can help you manage your anxiety by helping you prioritize your problems, fears, and concerns. It can also help you recognize those triggers and learn better ways to control them. This brings us to our application, which firstly lets users privately journal online. We implemented the IBM watson API to automatically analyze the journal entries. Users can receive automated tonal and personality data which can depict if they’re feeling depressed or anxious. It is also key to note that medical practitioners only have access to the results, and not the journal entries themselves. This is powerful because it takes away a common anxiety felt by patients, who are reluctant to take the first step in healing themselves because they may not feel comfortable sharing personal and intimate details up front.
MyndJournal allows users to log on to our site and express themselves freely, exactly like they were writing a journal. The difference being, every entry in a persons journal is sent to IBM Watson's natural language processing tone analyzing API's, which generates a data driven image of the persons mindset. The results of the API are then rendered into a chart to be displayed to medical practitioners. This way, all the users personal details/secrets remain completely confidential and can provide enough data to counsellors to allow them to take action if needed.
## How we built it
On back end, all user information is stored in a PostgreSQL users table. Additionally all journal entry information is stored in a results table. This aggregate data can later be used to detect trends in university lifecycles.
An EJS viewing template engine is used to render the front end.
After user authentication, a journal entry prompt when submitted is sent to the back end to be fed asynchronously into all IBM water language processing API's. The results from which are then stored in the results table, with associated with a user\_id, (one to many relationship).
Data is pulled from the database to be serialized and displayed intuitively on the front end.
All data is persisted.
## Challenges we ran into
Rendering the data into a chart that was both visually appealing and provided clear insights.
Storing all API results in the database and creating join tables to pull data out.
## Accomplishments that we're proud of
Building a entire web application within 24 hours. Data is persisted in the database!
## What we learned
IBM Watson API's
ChartJS
Difference between the full tech stack and how everything works together
## What's next for MyndJournal
A key feature we wanted to add for the web app for it to automatically book appointments with appropriate medical practitioners (like nutritionists or therapists) if the tonal and personality results returned negative. This would streamline the appointment making process and make it easier for people to have access and gain referrals. Another feature we would have liked to add was for universities to be able to access information into what courses or programs are causing the most problems for the most students so that policymakers, counsellors, and people in authoritative positions could make proper decisions and allocate resources accordingly.
Funding please | ## Inspiration
Canada has started paying more and more attention to the mental health of the students. There are a lot of nonprofit organizations and other institutions who are trying to help the students. However, these organizations and institutions have not been utilizing the technology as much as they could. We are here to change that. We will give the necessary tools to these organizations and help them overcome the problems of the students, who are struggling with mental health, efficiently.
## What it does
The student's tweeter chat history is analyzed using IBM Watson Personality Insights to match them with the right student.
The student has three chat options.
**1-Chat with another student**
Students are matched according to the data from the Personality Insights, and after each chat, IBM Tone Analyzer will be used to refine the matching. The chats will be anonymous, and the privacy of the student will be guaranteed.
**2-Chat with Volunteers**
Volunteers are students who had high Altruism values according to Personality Insights and have accepted to help other students relieve through chat. The student's name will not be displayed, and the privacy of the student will be guaranteed.
**3-Chat with a Professional Text/Video**
Students will be able to request a chat with a professional in the mental health area. The professional will have access to the data generated from the Personality Insights and Tone Analyzer. The data will help the professional understand the important traits of the student's personality and show a map of the students emotional situation since the students started using the platform.
## How we built it
Our idea started with providing students a private and polite chat environment. We have then refined our idea by using IBM Watson to better match the students. Finally, we decided on making use of the already generated data to provide the professionals with the character analysis of the student and also create an emotional map of the students chat history.
## Challenges we ran into
Having to learn new things while trying to complete the project on time.
## Accomplishments that we're proud of
We are proud that we have been able to create a working demo with the core features in the allocated 36 hours.
## What we learned
We learned to implement IBM Watson and firebase.
## What's next for Vibes
We will continue to improve our algorithms for character and emotional analysis. We will incorporate the IBM Watson Visual Recognition into our video chat feature to keep track of the emotions of the student and give better data to the professional. We will create a volunteer invitation program to invite students with high altruism values. | winning |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.