
datasetId
large_stringlengths 6
110
| author
large_stringlengths 3
34
| last_modified
large_stringdate 2021-05-20 00:57:22
2025-05-07 08:14:41
| downloads
int64 0
3.97M
| likes
int64 0
7.74k
| tags
large listlengths 1
2.03k
| task_categories
large listlengths 0
16
| createdAt
large_stringdate 2022-03-02 23:29:22
2025-05-07 08:13:27
| trending_score
float64 1
39
⌀ | card
large_stringlengths 31
1M
|
|---|---|---|---|---|---|---|---|---|---|
allganize/IFEval-Ko | allganize | 2025-04-29T06:10:10Z | 107 | 2 | [
"task_categories:text-generation",
"language:ko",
"license:apache-2.0",
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"arxiv:2311.07911",
"region:us",
"InstructionFollowing",
"IF"
] | [
"text-generation"
] | 2025-04-17T06:39:10Z | 2 | ---
dataset_info:
features:
- name: key
dtype: int64
- name: prompt
dtype: string
- name: instruction_id_list
sequence: string
- name: kwargs
list:
- name: capital_frequency
dtype: 'null'
- name: capital_relation
dtype: 'null'
- name: end_phrase
dtype: string
- name: first_word
dtype: string
- name: forbidden_words
sequence: string
- name: frequency
dtype: int64
- name: keyword
dtype: string
- name: keywords
sequence: string
- name: language
dtype: string
- name: let_frequency
dtype: 'null'
- name: let_relation
dtype: 'null'
- name: letter
dtype: 'null'
- name: nth_paragraph
dtype: int64
- name: num_bullets
dtype: int64
- name: num_highlights
dtype: int64
- name: num_paragraphs
dtype: int64
- name: num_placeholders
dtype: int64
- name: num_sections
dtype: int64
- name: num_sentences
dtype: int64
- name: num_words
dtype: int64
- name: postscript_marker
dtype: string
- name: prompt_to_repeat
dtype: string
- name: relation
dtype: string
- name: section_spliter
dtype: string
splits:
- name: train
num_bytes: 168406
num_examples: 342
download_size: 67072
dataset_size: 168406
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
language:
- ko
license: apache-2.0
task_categories:
- text-generation
tags:
- InstructionFollowing
- IF
size_categories:
- n<1K
---
# IFEval-Ko: Korean Instruction-Following Benchmark for LLMs
> This dataset is originated from [IFEval](https://huggingface.co/datasets/google/IFEval/) Dataset
[Korean Version README](https://huggingface.co/datasets/allganize/IFEval-Ko/blob/main/README_Ko.md)
`IFEval-Ko` is a Korean adaptation of Google's open-source **IFEval** benchmark utilized with [lm-evaluation-harness](https://github.com/EleutherAI/lm-evaluation-harness) framework.
It enables evaluation of large language models (LLMs) for their instruction-following capabilities in the Korean language.
## Dataset Details
- **Original Source**: [google/IFEval](https://huggingface.co/datasets/google/IFEval/)
- **Adaptation Author**: [Allganize Inc. LLM TEAM](https://www.allganize.ai/) | Keonmo Lee
- **Repository**: [allganize/IFEval-Ko](https://huggingface.co/datasets/allganize/IFEval-Ko)
- **Languages**: Korean
- **Translation Tool**: GPT-4o
- **License**: Follows original [google/IFEval](https://huggingface.co/datasets/google/IFEval/) license
- **Benchmarked with**: [lm-evaluation-harness](https://github.com/EleutherAI/lm-evaluation-harness)
## Benchmark Scores

## How to Use
Clone `lm-evaluation-harness` and create the `ifeval_ko` folder into the `lm_eval/tasks` directory.
```bash
# Install lm-evaluation-harness and task dependencies
git clone --depth 1 https://github.com/EleutherAI/lm-evaluation-harness.git
cd lm-evaluation-harness
pip install -e .
pip install langdetect immutabledict
# Download task files from Hugging Face Repository
python3 -c "
from huggingface_hub import snapshot_download
snapshot_download(
repo_id='allganize/IFEval-Ko',
repo_type='dataset',
local_dir='lm_eval/tasks/',
allow_patterns='ifeval_ko/*',
local_dir_use_symlinks=False
) "
```
***Please check usage of `lm_eval` on original [lm-evaluation-harness](https://github.com/EleutherAI/lm-evaluation-harness) repository before use.***
### Evaluation with Hugging Face Transformers
```bash
lm_eval --model hf \
--model_args pretrained={HF_MODEL_REPO} \
--tasks ifeval_ko \
--device cuda:0 \
--batch_size 8
```
e.g., {HF_MODEL_REPO} = google/gemma-3-4b-it
### Evaluation with vLLM
Install vLLM-compatible backend:
```bash
pip install lm-eval[vllm]
```
Then run the evaluation:
```bash
lm_eval --model vllm \
--model_args pretrained={HF_MODEL_REPO},trust_remote_code=True \
--tasks ifeval_ko
```
---
## Modifications from Original IFEval
### Data Transformation
- **Translation**: Prompts were translated using the **gpt-4o** model, with a custom prompt designed to preserve the original structure.
- **Removed Items**:
- 84 case-sensitive (`change_case`) tasks
- 28 alphabet-dependent (`letter_frequency`) tasks
- Other erroneous or culturally inappropriate prompts
- **Unit Conversions**:
- Gallons → Liters
- Feet/Inches → Meters/Centimeters
- Dollars → Korean Won (USD:KRW ≈ 1:1500)
- **Standardizations**:
- Unified headings \<\<Title\>\> or \<\<title\>\> to \<\<제목\>\>
- Ensured consistent tone across answers
### Code Changes
- Translated instruction options:
- `instruction._CONSTRAINED_RESPONSE_OPTIONS`
- `instruction._ENDING_OPTIONS`
- Modified scoring classes:
- `KeywordChecker`, `KeywordFrequencyChecker`, `ParagraphFirstWordCheck`, `KeySentenceChecker`, `ForbiddenWords`, `RepeatPromptThenAnswer`, `EndChecker`
- Applied `unicodedata.normalize('NFC', ...)` for normalization
- Removed fallback keyword generator for missing fields (now throws error)
- Removed dependency on `nltk` by modifying `count_sentences()` logic
---
## Evaluation Metrics
Please refer to [original IFEval paper](https://arxiv.org/pdf/2311.07911):
### Strict vs. Loose Accuracy
- **Strict**: Checks if the model followed the instruction *without* transformation of response.
- **Loose**: Applies 3 transformations to response before comparison:
1. Remove markdown symbols (`*`, `**`)
2. Remove the first line (e.g., "Here is your response:")
3. Remove the last line (e.g., "Did that help?")
A sample is marked correct if *any* of the 8 combinations match.
### Prompt-level vs. Instruction-level
- **Prompt-level**: All instructions in a single prompt must be followed to count as True.
- **Instruction-level**: Evaluates each instruction separately for finer-grained metrics.
Created by
Allganize LLM TEAM
[**Keonmo Lee (이건모)**](https://huggingface.co/whatisthis8047)
### Original Citation Information
```bibtex
@misc{zhou2023instructionfollowingevaluationlargelanguage,
title={Instruction-Following Evaluation for Large Language Models},
author={Jeffrey Zhou and Tianjian Lu and Swaroop Mishra and Siddhartha Brahma and Sujoy Basu and Yi Luan and Denny Zhou and Le Hou},
year={2023},
eprint={2311.07911},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2311.07911},
}
``` |
Uni-MoE/VideoVista-CulturalLingo | Uni-MoE | 2025-04-29T06:10:09Z | 159 | 3 | [
"task_categories:video-text-to-text",
"language:zh",
"language:en",
"license:apache-2.0",
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"arxiv:2504.17821",
"region:us"
] | [
"video-text-to-text"
] | 2025-04-06T09:18:02Z | 3 | ---
language:
- zh
- en
license: apache-2.0
size_categories:
- 1K<n<10K
task_categories:
- video-text-to-text
---
<a href="https://arxiv.org/abs/2504.17821" target="_blank">
<img alt="arXiv" src="https://img.shields.io/badge/arXiv-VideoVista--CulturalLingo-red?logo=arxiv" height="20" />
</a>
<a href="https://videovista-culturallingo.github.io/" target="_blank">
<img alt="Website" src="https://img.shields.io/badge/🌎_Website-VideoVista--CulturalLingo-blue.svg" height="20" />
</a>
<a href="https://github.com/HITsz-TMG/VideoVista/tree/main/VideoVista-CulturalLingo" style="display: inline-block; margin-right: 10px;">
<img alt="GitHub Code" src="https://img.shields.io/badge/Code-VideoVista--CulturalLingo-white?&logo=github&logoColor=white" />
</a>
# VideoVista-CulturalLingo
This repository contains the VideoVista-CulturalLingo, introduced in [VideoVista-CulturalLingo: 360° Horizons-Bridging Cultures, Languages,
and Domains in Video Comprehension](https://arxiv.org/pdf/2504.17821).
## Files
We provice the questions in both 'test-00000-of-00001.parquet' and 'VideoVista-CulturalLingo.json' files.
To unzip the videos, using the follow code.
```shell
cat videos.zip.* > combined_videos.zip
unzip combined_videos.zip
```
<!-- The `test-00000-of-00001.parquet` file contains the complete dataset annotations and pre-loaded images, ready for processing with HF Datasets. It can be loaded using the following code:
```python
from datasets import load_dataset
videovista_culturallingo = load_dataset("Uni-MoE/VideoVista-CulturalLingo")
```
Additionally, we provide the videos in `*.zip`.
We also provide the json file 'VideoVista-CulturalLingo.json'. -->
## Dataset Description
The dataset contains the following fields:
| Field Name | Description |
| :--------- | :---------- |
| `video_id` | Index of origin video |
| `question_id` | Global index of the entry in the dataset |
| `video_path` | Video name of corresponding video file |
| `question` | Question asked about the video |
| `options` | Choices for the question |
| `answer` | Ground truth answer for the question |
| `category` | Category of question |
| `subcategory` | Detailed category of question |
| `language` | Language of Video and Question |
## Evaluation
We use `Accuracy` to evaluates performance of VideoVista-CulturalLingo.
We provide an evaluation code of VideoVista-CulturalLingo in our [GitHub repository](https://github.com/HITsz-TMG/VideoVista/tree/main/VideoVista-CulturalLingo).
## Citation
If you find VideoVista-CulturalLingo useful for your research and applications, please cite using this BibTeX:
```bibtex
@misc{chen2025videovistaculturallingo,
title={VideoVista-CulturalLingo: 360$^\circ$ Horizons-Bridging Cultures, Languages, and Domains in Video Comprehension},
author={Xinyu Chen and Yunxin Li and Haoyuan Shi and Baotian Hu and Wenhan Luo and Yaowei Wang and Min Zhang},
year={2025},
eprint={2504.17821},
archivePrefix={arXiv},
}
``` |
yu0226/CipherBank | yu0226 | 2025-04-29T02:11:52Z | 624 | 3 | [
"task_categories:question-answering",
"language:en",
"license:apache-2.0",
"size_categories:1K<n<10K",
"format:json",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"arxiv:2504.19093",
"region:us",
"Reasoning",
"LLM",
"Encryption",
"Decryption"
] | [
"question-answering"
] | 2025-04-18T06:22:07Z | 3 | ---
license: apache-2.0
task_categories:
- question-answering
language:
- en
tags:
- Reasoning
- LLM
- Encryption
- Decryption
size_categories:
- 1K<n<10K
configs:
- config_name: Rot13
data_files:
- split: test
path: data/Rot13.jsonl
- config_name: Atbash
data_files:
- split: test
path: data/Atbash.jsonl
- config_name: Polybius
data_files:
- split: test
path: data/Polybius.jsonl
- config_name: Vigenere
data_files:
- split: test
path: data/Vigenere.jsonl
- config_name: Reverse
data_files:
- split: test
path: data/Reverse.jsonl
- config_name: SwapPairs
data_files:
- split: test
path: data/SwapPairs.jsonl
- config_name: ParityShift
data_files:
- split: test
path: data/ParityShift.jsonl
- config_name: DualAvgCode
data_files:
- split: test
path: data/DualAvgCode.jsonl
- config_name: WordShift
data_files:
- split: test
path: data/WordShift.jsonl
---
# CipherBank Benchmark
## Benchmark description
CipherBank, a comprehensive benchmark designed to evaluate the reasoning capabilities of LLMs in cryptographic decryption tasks.
CipherBank comprises 2,358 meticulously crafted problems, covering 262 unique plaintexts across 5 domains and 14 subdomains, with a focus on privacy-sensitive and real-world scenarios that necessitate encryption. From a cryptographic perspective, CipherBank incorporates 3 major categories of encryption methods, spanning 9 distinct algorithms, ranging from classical ciphers to custom cryptographic techniques.
## Model Performance
We evaluate state-of-the-art LLMs on CipherBank, e.g., GPT-4o, DeepSeek-V3, and cutting-edge reasoning-focused models such as o1 and DeepSeek-R1. Our results reveal significant gaps in reasoning abilities not only between general-purpose chat LLMs and reasoning-focused LLMs but also in the performance of current reasoning-focused models when applied to classical cryptographic decryption tasks, highlighting the challenges these models face in understanding and manipulating encrypted data.
| **Model** | **CipherBank Score (%)**|
|--------------|----|
|Qwen2.5-72B-Instruct |0.55 |
|Llama-3.1-70B-Instruct |0.38 |
|DeepSeek-V3 | 9.86 |
|GPT-4o-mini-2024-07-18 | 1.00 |
|GPT-4o-2024-08-06 | 8.82 |
|gemini-1.5-pro | 9.54 |
|gemini-2.0-flash-exp | 8.65|
|**Claude-Sonnet-3.5-1022** | **45.14** |
|DeepSeek-R1 | 25.91 |
|gemini-2.0-flash-thinking | 13.49 |
|o1-mini-2024-09-12 | 20.07 |
|**o1-2024-12-17** | **40.59** |
## Please see paper & website for more information:
- [https://arxiv.org/abs/2504.19093](https://arxiv.org/abs/2504.19093)
- [https://cipherbankeva.github.io/](https://cipherbankeva.github.io/)
## Citation
If you find CipherBank useful for your research and applications, please cite using this BibTeX:
```bibtex
@misc{li2025cipherbankexploringboundaryllm,
title={CipherBank: Exploring the Boundary of LLM Reasoning Capabilities through Cryptography Challenges},
author={Yu Li and Qizhi Pei and Mengyuan Sun and Honglin Lin and Chenlin Ming and Xin Gao and Jiang Wu and Conghui He and Lijun Wu},
year={2025},
eprint={2504.19093},
archivePrefix={arXiv},
primaryClass={cs.CR},
url={https://arxiv.org/abs/2504.19093},
}
```
|
Anthropic/values-in-the-wild | Anthropic | 2025-04-28T17:31:57Z | 549 | 120 | [
"license:cc-by-4.0",
"size_categories:1K<n<10K",
"format:csv",
"modality:tabular",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-04-10T06:04:36Z | null | ---
license: cc-by-4.0
configs:
- config_name: values_frequencies
data_files: values_frequencies.csv
- config_name: values_tree
data_files: values_tree.csv
---
## Summary
This dataset presents a comprehensive taxonomy of 3307 values expressed by Claude (an AI assistant) across hundreds of thousands of real-world conversations. Using a novel privacy-preserving methodology, these values were extracted and classified without human reviewers accessing any conversation content. The dataset reveals patterns in how AI systems express values "in the wild" when interacting with diverse users and tasks.
We're releasing this resource to advance research in two key areas: understanding value expression in deployed language models and supporting broader values research across disciplines. By providing empirical data on AI values "in the wild," we hope to move toward a more grounded understanding of how values manifest in human-AI interactions.
For information on how this dataset was constructed, and related analysis, please see the accompanying paper: [Values in the Wild: Discovering and Analyzing Values in Real-World Language Model Interactions](https://assets.anthropic.com/m/18d20cca3cde3503/original/Values-in-the-Wild-Paper.pdf).
**Note:** You can interpret the occurrence of each value in the dataset as "The AI's response demonstrated valuing {VALUE}." For example, for the value of "accuracy" (5.3% frequency), this means that our methods detected that Claude's response demonstrated *valuing* accuracy 5.3% of the time (not that it *was* accurate in 5.3% of conversations).
## Dataset Description
The dataset includes two CSV files:
1. `values_frequencies.csv`
- This shows every extracted AI value along with their frequency of occurrence across the conversation sample. There are two columns:
- `value`: The value label (e.g. `accuracy` or `helpfulness`).
- `pct_convos`: The percentage of the subjective conversation sample that that this value was detected in, rounded to 3 decimal places.
- This is sorted by the `pct_convos` column.
2. `values_tree.csv`
- This shows the hierarchical taxonomy of values, where we sequentially cluster/group the values into higher-level categories. There are six columns:
- `cluster_id`: If `level > 0`, this denotes the ID of the cluster of values. If `level = 0`, this is just identical to the `name` of the extracted value.
- `description`: If `level > 0`, the Claude-generated description of the cluster of values.
- `name`: The name of the extracted value itself (if `level = 0`, or the cluster of values (if `level > 0`).
- `level`: Out of `0, 1, 2, 3`, which level of the taxonomy is this value/cluster of values at. `level = 0` means the lowest level, i.e. the individual values; `level = 3` is the highest level (e.g. "Epistemic values").
- `parent_cluster_id`: The `cluster_id` of the higher-level parent cluster of this.
- `pct_total_occurrences`: The percentage of the total *number of values expressions* that was expressions of this value, rounded to 3 decimal places.
- This is sorted by the `parent_cluster_id` column, so that values clustered together appear together.
## Disclaimer
Please note that the extracted values, descriptions and cluster names were generated by a language model and may contain inaccuracies. While we conducted human evaluation on our values extractor to assess quality, and manually checked the hierarchy for clarity and accuracy, inferring values is an inherently subjective endeavor, and there may still be errors. The dataset is intended for research purposes only and should not be considered a definitive assessment of what values may be expressed by Claude, or language models in general.
## Usage
```python
from datasets import load_dataset
dataset_values_frequencies = load_dataset("Anthropic/values-in-the-wild", "values_frequencies")
dataset_values_tree = load_dataset("Anthropic/values-in-the-wild", "values_tree")
```
## Contact
For questions, you can email saffron at anthropic dot com |
OpenDriveLab/OpenScene | OpenDriveLab | 2025-04-28T07:13:35Z | 28,792 | 5 | [
"license:cc-by-nc-sa-4.0",
"region:us"
] | [] | 2024-03-02T04:33:04Z | null | ---
license: cc-by-nc-sa-4.0
--- |
nvidia/PhysicalAI-SmartSpaces | nvidia | 2025-04-28T03:56:47Z | 2,951 | 18 | [
"license:cc-by-4.0",
"arxiv:2404.09432",
"arxiv:2412.00692",
"region:us"
] | [] | 2025-03-13T19:33:51Z | 4 | ---
license: cc-by-4.0
---
# Physical AI Smart Spaces Dataset
## Overview
Comprehensive, annotated dataset for multi-camera tracking and 2D/3D object detection. This dataset is synthetically generated with Omniverse.
This dataset consists of over 250 hours of video from across nearly 1,500 cameras from indoor scenes in warehouses, hospitals, retail, and more. The dataset is time synchronized for tracking humans across multiple cameras using feature representation and no personal data.
## Dataset Description
### Dataset Owner(s)
NVIDIA
### Dataset Creation Date
We started to create this dataset in December, 2023. First version was completed and released as part of 8th AI City Challenge in conjunction with CVPR 2024.
### Dataset Characterization
- Data Collection Method: Synthetic
- Labeling Method: Automatic with IsaacSim
### Video Format
- Video Standard: MP4 (H.264)
- Video Resolution: 1080p
- Video Frame rate: 30 FPS
### Ground Truth Format (MOTChallenge) for `MTMC_Tracking_2024`
Annotations are provided in the following text format per line:
```
<camera_id> <obj_id> <frame_id> <xmin> <ymin> <width> <height> <xworld> <yworld>
```
- `<camera_id>`: Numeric identifier for the camera.
- `<obj_id>`: Consistent numeric identifier for each object across cameras.
- `<frame_id>`: Frame index starting from 0.
- `<xmin> <ymin> <width> <height>`: Axis-aligned bounding box coordinates in pixels (top-left origin).
- `<xworld> <yworld>`: Global coordinates (projected bottom points of objects) based on provided camera matrices.
The video file and calibration (camera matrix and homography) are provided for each camera view.
Calibration and ground truth files in the updated 2025 JSON format are now also included for each scene.
Note: some calibration fields—such as camera coordinates, camera directions, and scale factors—are not be available for the 2024 dataset due to original data limitations.
### Directory Structure for `MTMC_Tracking_2025`
- `videos/`: Video files.
- `depth_maps/`: Depth maps stored as PNG images and compressed within HDF5 files. These files are exceedingly large; you may choose to use RGB videos only if preferred.
- `ground_truth.json`: Detailed ground truth annotations (see below).
- `calibration.json`: Camera calibration and metadata.
- `map.png`: Visualization map in top-down view.
### Ground Truth Format (JSON) for `MTMC_Tracking_2025`
Annotations per frame:
```json
{
"<frame_id>": [
{
"object_type": "<class_name>",
"object_id": <int>,
"3d_location": [x, y, z],
"3d_bounding_box_scale": [w, l, h],
"3d_bounding_box_rotation": [pitch, roll, yaw],
"2d_bounding_box_visible": {
"<camera_id>": [xmin, ymin, xmax, ymax]
}
}
]
}
```
### Calibration Format (JSON) for `MTMC_Tracking_2025`
Contains detailed calibration metadata per sensor:
```json
{
"calibrationType": "cartesian",
"sensors": [
{
"type": "camera",
"id": "<sensor_id>",
"coordinates": {"x": float, "y": float},
"scaleFactor": float,
"translationToGlobalCoordinates": {"x": float, "y": float},
"attributes": [
{"name": "fps", "value": float},
{"name": "direction", "value": float},
{"name": "direction3d", "value": "float,float,float"},
{"name": "frameWidth", "value": int},
{"name": "frameHeight", "value": int}
],
"intrinsicMatrix": [[f_x, 0, c_x], [0, f_y, c_y], [0, 0, 1]],
"extrinsicMatrix": [[3×4 matrix]],
"cameraMatrix": [[3×4 matrix]],
"homography": [[3×3 matrix]]
}
]
}
```
### Evaluation
- **2024 Edition**: Evaluation based on HOTA scores at the [2024 AI City Challenge Server](https://eval.aicitychallenge.org/aicity2024). The submission is currently disabled, as the ground truths of test set are provided with this release.
- **2025 Edition**: Evaluation system and test set forthcoming in the 2025 AI City Challenge.
## Dataset Quantification
| Dataset | Annotation Type | Hours | Cameras | Object Classes & Counts | No. 3D Boxes | No. 2D Boxes | Depth Maps | Total Size |
|-------------------------|-------------------------------------------------------|-------|---------|---------------------------------------------------------------|--------------|--------------|------------|------------|
| **MTMC_Tracking_2024** | 2D bounding boxes, multi-camera tracking IDs | 212 | 953 | Person: 2,481 | 52M | 135M | No | 213 GB |
| **MTMC_Tracking_2025**<br>(Train & Validation only) | 2D & 3D bounding boxes, multi-camera tracking IDs | 42 | 504 | Person: 292<br>Forklift: 13<br>NovaCarter: 28<br>Transporter: 23<br>FourierGR1T2: 6<br>AgilityDigit: 1<br>**Overall:** 363 | 8.9M | 73M | Yes | 74 GB (excluding depth maps) |
## References
Please cite the following papers when using this dataset:
```bibtex
@InProceedings{Wang24AICity24,
author = {Shuo Wang and David C. Anastasiu and Zheng Tang and Ming-Ching Chang and Yue Yao and Liang Zheng and Mohammed Shaiqur Rahman and Meenakshi S. Arya and Anuj Sharma and Pranamesh Chakraborty and Sanjita Prajapati and Quan Kong and Norimasa Kobori and Munkhjargal Gochoo and Munkh-Erdene Otgonbold and Ganzorig Batnasan and Fady Alnajjar and Ping-Yang Chen and Jun-Wei Hsieh and Xunlei Wu and Sameer Satish Pusegaonkar and Yizhou Wang and Sujit Biswas and Rama Chellappa},
title = {The 8th {AI City Challenge},
booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops},
note = {arXiv:2404.09432},
month = {June},
year = {2024},
}
@misc{Wang24BEVSUSHI,
author = {Yizhou Wang and Tim Meinhardt and Orcun Cetintas and Cheng-Yen Yang and Sameer Satish Pusegaonkar and Benjamin Missaoui and Sujit Biswas and Zheng Tang and Laura Leal-Taix{\'e}},
title = {{BEV-SUSHI}: {M}ulti-target multi-camera {3D} detection and tracking in bird's-eye view},
note = {arXiv:2412.00692},
year = {2024}
}
```
## Ethical Considerations
NVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their internal model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse.
Please report security vulnerabilities or NVIDIA AI Concerns [here](https://www.nvidia.com/en-us/support/submit-security-vulnerability/).
## Changelog
- **2025-04-27**: Added depth maps to all `MTMC_Tracking_2025` scenes.
- **2025-04-23**: Added 2025-format calibration and ground truth JSON files to all `MTMC_Tracking_2024` scenes. |
moonshotai/Kimi-Audio-GenTest | moonshotai | 2025-04-28T03:45:53Z | 139 | 2 | [
"language:zh",
"license:mit",
"size_categories:n<1K",
"format:audiofolder",
"modality:audio",
"modality:text",
"library:datasets",
"library:mlcroissant",
"region:us",
"speech generation",
"chinese"
] | [] | 2025-04-28T03:44:52Z | 2 | ---
# Required: Specify the license for your dataset
license: [mit]
# Required: Specify the language(s) of the dataset
language:
- zh # 中文
# Optional: Add tags for discoverability
tags:
- speech generation
- chinese
# Required: A pretty name for your dataset card
pretty_name: "Kimi-Audio-Generation-Testset"
---
# Kimi-Audio-Generation-Testset
## Dataset Description
**Summary:** This dataset is designed to benchmark and evaluate the conversational capabilities of audio-based dialogue models. It consists of a collection of audio files containing various instructions and conversational prompts. The primary goal is to assess a model's ability to generate not just relevant, but also *appropriately styled* audio responses.
Specifically, the dataset targets the model's proficiency in:
* **Paralinguistic Control:** Generating responses with specific control over **emotion**, speaking **speed**, and **accent**.
* **Empathetic Dialogue:** Engaging in conversations that demonstrate understanding and **empathy**.
* **Style Adaptation:** Delivering responses in distinct styles, including **storytelling** and reciting **tongue twisters**.
Audio conversation models are expected to process the input audio instructions and generate reasonable, contextually relevant audio responses. The quality, appropriateness, and adherence to the instructed characteristics (like emotion or style) of the generated responses are evaluated through **human assessment**.
* **Languages:** zh (中文)
## Dataset Structure
### Data Instances
Each line in the `test/metadata.jsonl` file is a JSON object representing a data sample. The `datasets` library uses the path in the `file_name` field to load the corresponding audio file.
**示例:**
```json
{"audio_content": "你能不能快速地背一遍李白的静夜思", "ability": "speed", "file_name": "wav/6.wav"} |
nvidia/Llama-Nemotron-Post-Training-Dataset | nvidia | 2025-04-27T18:10:38Z | 8,510 | 432 | [
"license:cc-by-4.0",
"size_categories:1M<n<10M",
"format:json",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"region:us"
] | [] | 2025-03-13T21:01:09Z | null | ---
license: cc-by-4.0
configs:
- config_name: SFT
data_files:
- split: code
path: SFT/code/*.jsonl
- split: math
path: SFT/math/*.jsonl
- split: science
path: SFT/science/*.jsonl
- split: chat
path: SFT/chat/*.jsonl
- split: safety
path: SFT/safety/*.jsonl
default: true
- config_name: RL
data_files:
- split: instruction_following
path: RL/instruction_following/*.jsonl
---
# Llama-Nemotron-Post-Training-Dataset-v1.1 Release
**Update [4/8/2025]:**
**v1.1:** We are releasing an additional 2.2M Math and 500K Code Reasoning Data in support of our release of [Llama-3.1-Nemotron-Ultra-253B-v1](https://huggingface.co/nvidia/Llama-3_1-Nemotron-Ultra-253B-v1). 🎉
## Data Overview
This dataset is a compilation of SFT and RL data that supports improvements of math, code, general reasoning, and instruction following capabilities of the original Llama instruct model, in support of NVIDIA’s release of [Llama-3.1-Nemotron-Ultra-253B-v1](https://huggingface.co/nvidia/Llama-3_1-Nemotron-Ultra-253B-v1), [Llama-3.3-Nemotron-Super-49B-v1](https://huggingface.co/nvidia/Llama-3_3-Nemotron-Super-49B-v1) and [Llama-3.1-Nemotron-Nano-8B-v1](https://huggingface.co/nvidia/Llama-3.1-Nemotron-Nano-8B-v1).
Llama-3.1-Nemotron-Ultra-253B-v1 is a large language model (LLM) which is a derivative of [Meta Llama-3.1-405B-Instruct](https://huggingface.co/meta-llama/Llama-3.1-405B-Instruct) (AKA the *reference model*).
Llama-3.3-Nemotron-Super-49B-v1 is an LLM which is a derivative of [Meta Llama-3.3-70B-Instruct](https://huggingface.co/meta-llama/Llama-3.3-70B-Instruct) (AKA the *reference model*). Llama-3.1-Nemotron-Nano-8B-v1 is an LLM which is a derivative of [Meta Llama-3.1-8B-Instruct](https://huggingface.co/meta-llama/Llama-3.1-8B-Instruct) (AKA the *reference model*). They are aligned for human chat preferences, and tasks.
These models offer a great tradeoff between model accuracy and efficiency. Efficiency (throughput) directly translates to savings. Using a novel Neural Architecture Search (NAS) approach, we greatly reduce the model’s memory footprint and enable larger workloads. This NAS approach enables the selection of a desired point in the accuracy-efficiency tradeoff. The models support a context length of 128K.
This dataset release represents a significant move forward in openness and transparency in model development and improvement. By releasing the complete training set, in addition to the training technique, tools and final model weights, NVIDIA supports both the re-creation and the improvement of our approach.
## Data distribution
| Category | Value |
|----------|-----------|
| math | 22,066,397|
| code | 10,108,883 |
| science | 708,920 |
| instruction following | 56,339 |
| chat | 39,792 |
| safety | 31,426 |
## Filtering the data
Users can download subsets of the data based on the metadata schema described above. Example script for downloading code and math as follows:
```
from datasets import load_dataset
ds = load_dataset("nvidia/Llama-Nemotron-Post-Training-Dataset", "SFT", split=["code", "math"])
```
## Prompts
Prompts have been sourced from either public and open corpus or synthetically generated. All responses have been synthetically generated from public and open models.
The prompts were extracted, and then filtered for quality and complexity, or generated to meet quality and complexity requirements. This included filtration such as removing inconsistent prompts, prompts with answers that are easy to guess, and removing prompts with incorrect syntax.
## Responses
Responses were synthetically generated by a variety of models, with some prompts containing responses for both reasoning on and off modes, to train the model to distinguish between two modes.
Models that were used in the creation of this dataset:
| Model | Number of Samples |
|----------|-----------|
| Llama-3.3-70B-Instruct | 420,021 |
| Llama-3.1-Nemotron-70B-Instruct | 31,218 |
| Llama-3.3-Nemotron-70B-Feedback/Edit/Select | 22,644 |
| Mixtral-8x22B-Instruct-v0.1 | 31,426 |
| DeepSeek-R1 | 3,934,627 |
| Qwen-2.5-Math-7B-Instruct | 19,840,970 |
| Qwen-2.5-Coder-32B-Instruct | 8,917,167 |
| Qwen-2.5-72B-Instruct | 464,658 |
| Qwen-2.5-32B-Instruct | 2,297,175 |
## License/Terms of Use
The dataset contains information about license type on a per sample basis. The dataset is predominantly CC-BY-4.0, with a small subset of prompts from Wildchat having an ODC-BY license and a small subset of prompts from StackOverflow with CC-BY-SA license.
This dataset contains synthetic data created using Llama-3.3-70B-Instruct, Llama-3.1-Nemotron-70B-Instruct and
Llama-3.3-Nemotron-70B-Feedback/Edit/Select (ITS models). If this dataset is used to create, train, fine tune, or otherwise improve an AI model, which is distributed or made available, such AI model may be subject to redistribution and use requirements in the Llama 3.1 Community License Agreement and Llama 3.3 Community License Agreement.
**Data Developer:** NVIDIA
### Use Case: <br>
Developers training AI Agent systems, chatbots, RAG systems, and other AI-powered applications. <br>
### Release Date: <br>
4/8/2025 <br>
## Data Version
1.1 (4/8/2025)
## Intended use
The Llama Nemotron Post-Training Dataset is intended to be used by the community to continue to improve open models. The data may be freely used to train and evaluate.
## Ethical Considerations:
NVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their internal model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse.
Please report security vulnerabilities or NVIDIA AI Concerns [here](https://www.nvidia.com/en-us/support/submit-security-vulnerability/).
## Data Opt-Out:
NVIDIA has undertaken legal review to ensure there is no confidential, PII or copyright materials. If, when reviewing or using this dataset, you identify issues with the data itself, such as those listed above, please contact [email protected].
|
ByteDance-Seed/Multi-SWE-bench_trajs | ByteDance-Seed | 2025-04-27T06:43:10Z | 68,906 | 1 | [
"task_categories:text-generation",
"license:other",
"arxiv:2504.02605",
"region:us",
"code"
] | [
"text-generation"
] | 2025-04-14T08:08:31Z | null | ---
license: other
task_categories:
- text-generation
tags:
- code
---
## 🧠 Multi-SWE-bench Trajectories
This repository stores **all trajectories and logs** generated by agents evaluated on the [Multi-SWE-bench](https://multi-swe-bench.github.io) leaderboard.
## 📚 Citation
```
@misc{zan2025multiswebench,
title={Multi-SWE-bench: A Multilingual Benchmark for Issue Resolving},
author={Daoguang Zan and Zhirong Huang and Wei Liu and Hanwu Chen and Linhao Zhang and Shulin Xin and Lu Chen and Qi Liu and Xiaojian Zhong and Aoyan Li and Siyao Liu and Yongsheng Xiao and Liangqiang Chen and Yuyu Zhang and Jing Su and Tianyu Liu and Rui Long and Kai Shen and Liang Xiang},
year={2025},
eprint={2504.02605},
archivePrefix={arXiv},
primaryClass={cs.SE},
url={https://arxiv.org/abs/2504.02605},
}
``` |
cyberalchemist/PixelWeb | cyberalchemist | 2025-04-27T03:16:16Z | 263 | 2 | [
"task_categories:object-detection",
"language:en",
"license:apache-2.0",
"size_categories:10K<n<100K",
"arxiv:2504.16419",
"region:us"
] | [
"object-detection"
] | 2025-04-22T15:07:03Z | 2 | ---
license: apache-2.0
task_categories:
- object-detection
language:
- en
size_categories:
- 10K<n<100K
---
# PixelWeb: The First Web GUI Dataset with Pixel-Wise Labels
[https://arxiv.org/abs/2504.16419](https://arxiv.org/abs/2504.16419)
# Dataset Description
**PixelWeb-1K**: 1,000 GUI screenshots with mask, contour and bbox annotations
**PixelWeb-10K**: 10,000 GUI screenshots with mask, contour and bbox annotations
**PixelWeb-100K**: Coming soon
You need to extract the tar.gz archive by:
`tar -xzvf pixelweb_1k.tar.gz`
# Document Description
{id}-screenshot.png # The screenshot of a webpage
{id}-bbox.json # The bounding box labels of a webpage, [[left,top,width,height],...]
{id}-contour.json # The contour labels of a webpage, [[[x1,y1,x2,y2,...],...],...]
{id}-mask.json # The mask labels of a webpage, [[element_id,...],...]
{id}-class.json # The class labels of a webpage, [axtree_label,...]
The element_id corresponds to the index of the class. |
agentlans/reddit-ethics | agentlans | 2025-04-26T22:18:39Z | 246 | 3 | [
"task_categories:text-classification",
"task_categories:question-answering",
"task_categories:feature-extraction",
"language:en",
"license:cc-by-4.0",
"size_categories:1K<n<10K",
"format:json",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us",
"social-media",
"reddit",
"ethics",
"morality",
"philosophy",
"alignment",
"reasoning-datasets-competition"
] | [
"text-classification",
"question-answering",
"feature-extraction"
] | 2025-04-23T14:46:25Z | 3 | ---
license: cc-by-4.0
task_categories:
- text-classification
- question-answering
- feature-extraction
language:
- en
tags:
- social-media
- reddit
- ethics
- morality
- philosophy
- alignment
- reasoning-datasets-competition
---
# Reddit Ethics: Real-World Ethical Dilemmas from Reddit
Reddit Ethics is a curated dataset of genuine ethical dilemmas collected from Reddit, designed to support research and education in philosophical ethics, AI alignment, and moral reasoning.
Each entry features a real-world scenario accompanied by structured ethical analysis through major frameworks—utilitarianism, deontology, and virtue ethics. The dataset also provides discussion questions, sample answers, and proposed resolutions, making it valuable for examining human values and ethical reasoning in practical contexts.
The construction of Reddit Ethics involved random sampling from the first
10 000 entries of the [OsamaBsher/AITA-Reddit-Dataset](https://huggingface.co/datasets/OsamaBsher/AITA-Reddit-Dataset) longer than 1 000 characters.
Five seed cases were manually annotated using ChatGPT.
Additional cases were generated via few-shot prompting with [agentlans/Llama3.1-LexiHermes-SuperStorm](https://huggingface.co/agentlans/Llama3.1-LexiHermes-SuperStorm) to ensure diversity and scalability while maintaining consistency in ethical analysis.
The dataset covers a wide range of everyday ethical challenges encountered in online communities, including personal relationships, professional conduct, societal norms, technology, and digital ethics.
## Data Structure
Each dataset entry contains:
- `text`: The original Reddit post describing the ethical dilemma.
- `title`: A concise summary of the ethical issue.
- `description`: A brief overview of the scenario.
- `issues`: Key ethical themes or conflicts.
- Ethical analyses from three major philosophical perspectives:
- `utilitarianism`: Evaluates actions by their consequences, aiming to maximize overall well-being.
- `deontology`: Assesses the moral rightness of actions based on rules, duties, or obligations, regardless of outcomes.
- `virtue_ethics`: Focuses on the character traits and intentions of the agents involved, emphasizing virtues such as honesty, integrity, and fairness.
- Note that the three ethical frameworks reflect major traditions in normative ethics and are widely used for structuring ethical reasoning in academic and applied settings.
- `questions`: Discussion prompts for further analysis.
- `answers`: Sample responses to the discussion questions.
- `resolution`: A suggested synthesis or resolution based on the ethical analysis.
### Example Entry
```json
{
"text": "my so and i are both 20, and i live in a house with 3 other people who are 19-21. ... would we be in the wrong if we pursued this?",
"title": "Household Property and Moral Obligation: The Ethics of Repair and Replacement",
"description": "A couple and their housemates disagree over the cost of a new TV after the old one was broken. One housemate wants the new TV to stay, while another suggests paying for the replacement.",
"issues": [
"Shared Responsibility vs. Personal Investment",
"Equity vs. Fairness",
"Moral Obligations vs. Practicality"
],
"utilitarianism": "Considering the overall household benefit and the cost-benefit analysis, it may be fair to let the TV remain.",
"deontology": "The couple should hold to their agreement to sell the TV to the housemates, respecting their word and the value of fairness.",
"virtue_ethics": "Honesty and integrity guide the choice—acknowledging the financial burden and seeking a solution that respects all members.",
"questions": [
"Should the couple be bound by their agreement to sell the TV at a lower price?",
"How should the household balance fairness and practicality in resolving the TV issue?",
"What is the moral weight of past sacrifices and the current financial situation?"
],
"answers": [
"Yes, the couple should honor their agreement to sell the TV at a lower price, upholding their commitment to fairness and honesty.",
"The household should discuss and agree on a fair solution, considering the value of the TV and each member’s financial situation.",
"Previous sacrifices and current financial hardship can influence the moral weight of the decision, but fairness and respect should guide the solution."
],
"resolution": "The couple should adhere to their agreement to sell the TV at a lower price, showing respect for their word and the household's fairness. This approach fosters trust and sets a positive precedent for future conflicts."
}
```
## Limitations
1. Limited to a single subreddit as a proof of concept.
2. Potential selection bias due to subreddit demographics and culture.
3. The dataset predominantly represents Western, individualistic perspectives.
4. Not tailored to specialized branches such as professional, bioethical, or environmental ethics.
5. Some cases may reflect social or communication issues rather than clear-cut ethical dilemmas.
6. Analyses are concise due to space constraints and may not provide in-depth philosophical exploration.
7. Annotation bias may arise from the use of large language models.
## Licence
Creative Commons Attribution 4.0 International (CC-BY-4.0)
|
Eureka-Lab/PHYBench | Eureka-Lab | 2025-04-26T13:56:46Z | 460 | 39 | [
"task_categories:question-answering",
"language:en",
"license:mit",
"size_categories:1K<n<10K",
"format:json",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"arxiv:2504.16074",
"region:us"
] | [
"question-answering",
"mathematical-reasoning"
] | 2025-04-22T15:56:27Z | 39 | ---
license: mit
task_categories:
- question-answering
- mathematical-reasoning
language:
- en
size_categories:
- 500<n<1K
---
<div align="center">
<p align="center" style="font-size:28px"><b>PHYBench: Holistic Evaluation of Physical Perception and Reasoning in Large Language Models</b></p>
<p align="center">
<a href="https://phybench.ai">[🌐 Project]</a>
<a href="https://arxiv.org/abs/2504.16074">[📄 Paper]</a>
<a href="https://github.com/phybench-official">[💻 Code]</a>
<a href="#-overview">[🌟 Overview]</a>
<a href="#-data-details">[🔧 Data Details]</a>
<a href="#-citation">[🚩 Citation]</a>
</p>
[](https://opensource.org/license/mit)
---
</div>
## New Updates
- **2025.4.25**: We release our code of EED Score. View and star on our github page!
- **Recently**: The leaderboard is still under progress, we'll release it as soon as possible.
## 🚀 Acknowledgement and Progress
We're excited to announce the initial release of our PHYBench dataset!
- **100 fully-detailed examples** including handwritten solutions, questions, tags, and reference answers.
- **400 additional examples** containing questions and tags.
### 📂 Dataset Access
You can access the datasets directly via Hugging Face:
- [**PHYBench-fullques.json**](https://huggingface.co/datasets/Eureka-Lab/PHYBench/blob/main/PHYBench-fullques_v1.json): 100 examples with complete solutions.
- [**PHYBench-onlyques.json**](https://huggingface.co/datasets/Eureka-Lab/PHYBench/blob/main/PHYBench-onlyques_v1.json): 400 examples (questions and tags only).
- [**PHYBench-questions.json**](https://huggingface.co/datasets/Eureka-Lab/PHYBench/blob/main/PHYBench-questions_v1.json): Comprehensive set of all 500 questions.
### 📊 Full-Dataset Evaluation & Leaderboard
We are actively finalizing the full-dataset evaluation pipeline and the real-time leaderboard. Stay tuned for their upcoming release!
Thank you for your patience and ongoing support! 🙏
For further details or collaboration inquiries, please contact us at [**[email protected]**](mailto:[email protected]).
## 🌟 Overview
PHYBench is the first large-scale benchmark specifically designed to evaluate **physical perception** and **robust reasoning** capabilities in Large Language Models (LLMs). With **500 meticulously curated physics problems** spanning mechanics, electromagnetism, thermodynamics, optics, modern physics, and advanced physics, it challenges models to demonstrate:
- **Real-world grounding**: Problems based on tangible physical scenarios (e.g., ball inside a bowl, pendulum dynamics)
- **Multi-step reasoning**: Average solution length of 3,000 characters requiring 10+ intermediate steps
- **Symbolic precision**: Strict evaluation of LaTeX-formulated expressions through novel **Expression Edit Distance (EED) Score**
Key innovations:
- 🎯 **EED Metric**: Smoother measurement based on the edit-distance on expression tree
- 🏋️ **Difficulty Spectrum**: High school, undergraduate, Olympiad-level physics problems
- 🔍 **Error Taxonomy**: Explicit evaluation of Physical Perception (PP) vs Robust Reasoning (RR) failures
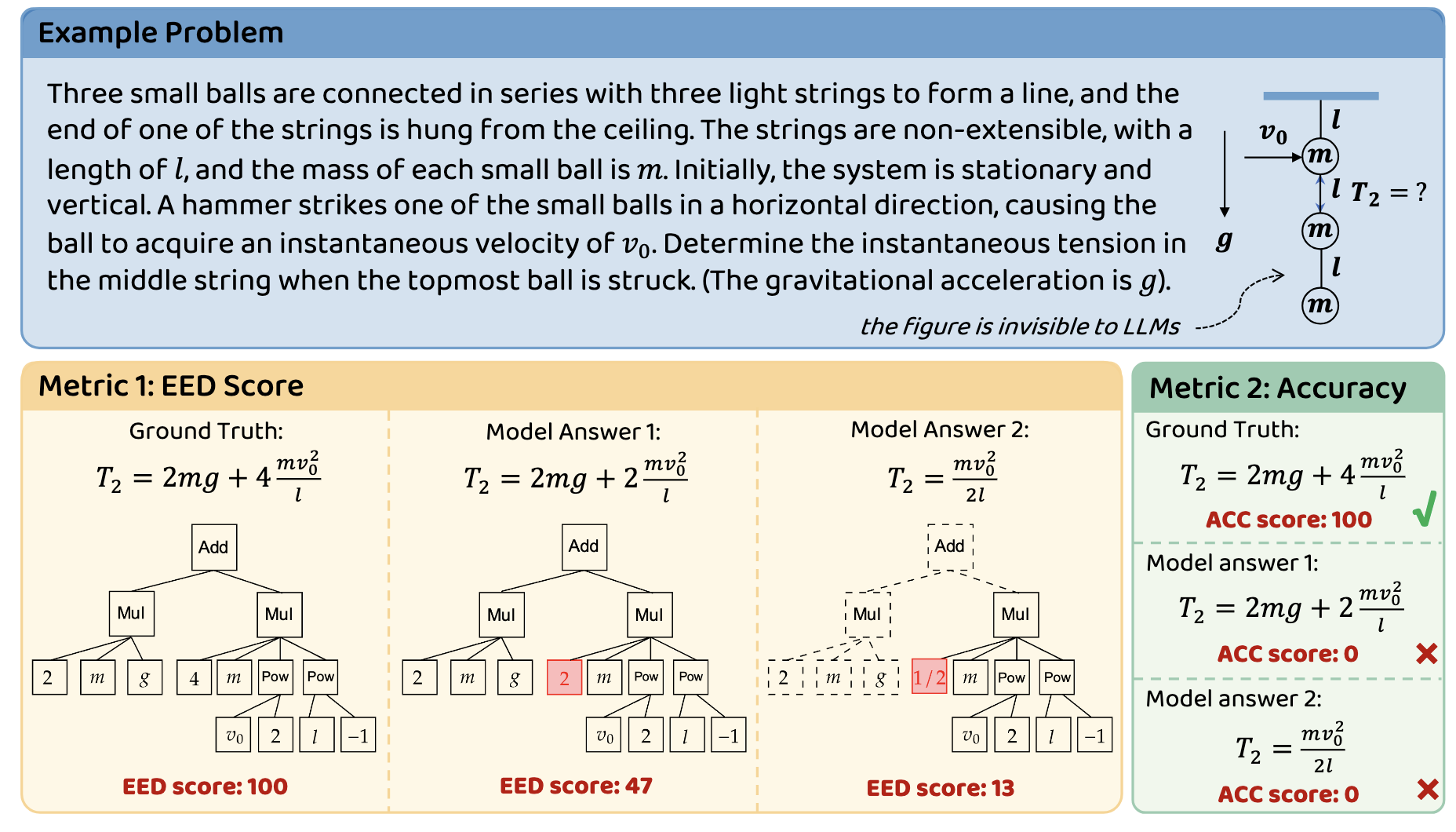
## 🔧 Example Problems
**Put some problem cards here**
**Answer Types**:
🔹 Strict symbolic expressions (e.g., `\sqrt{\frac{2g}{3R}}`)
🔹 Multiple equivalent forms accepted
🔹 No numerical approximations or equation chains
## 🛠️ Data Curation
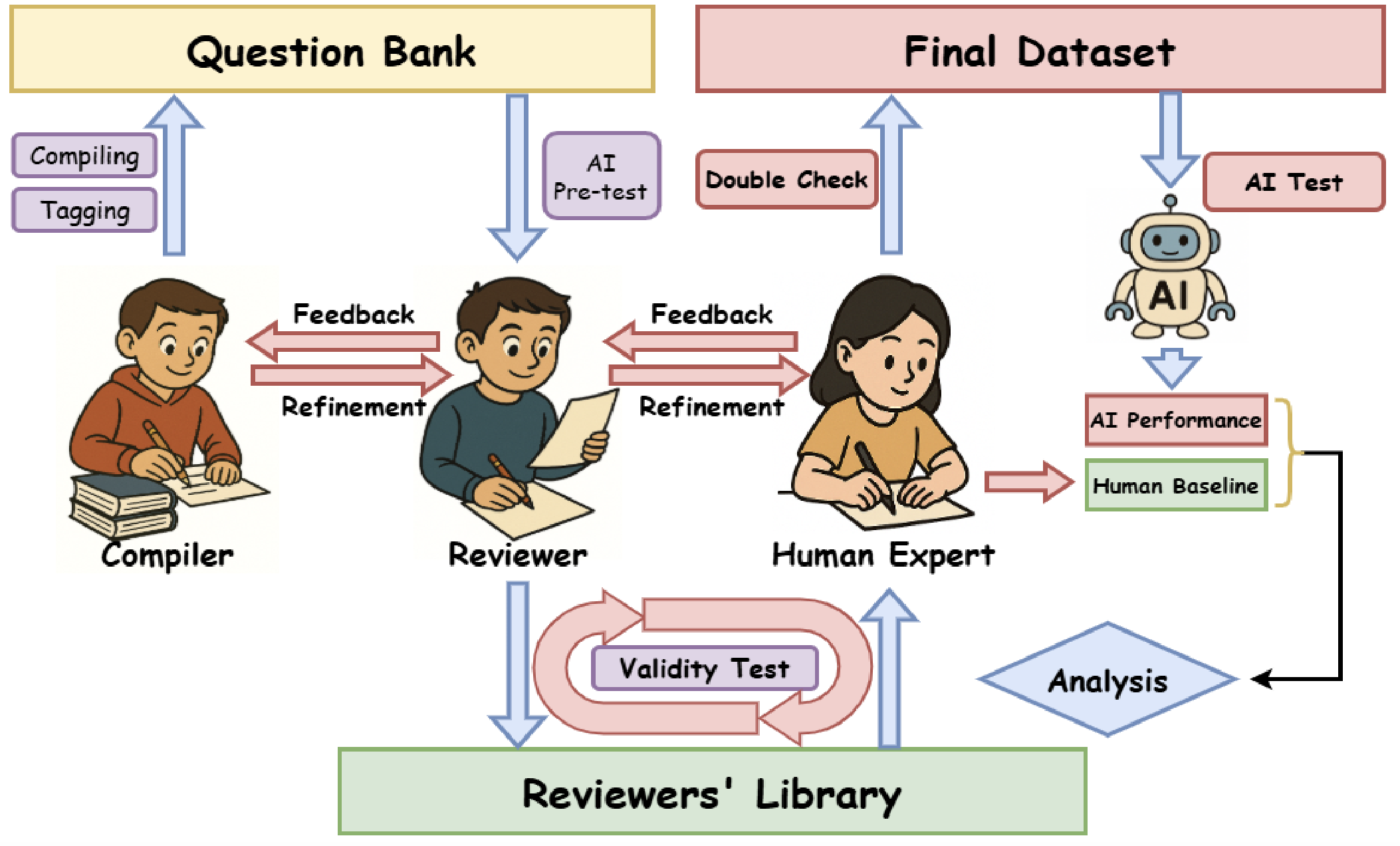
### 3-Stage Rigorous Validation Pipeline
1. **Expert Creation & Strict Screening**
- 178 PKU physics students contributed problems that are:
- Almost entirely original/custom-created
- None easily found through direct internet searches or standard reference materials
- Strict requirements:
- Single unambiguous symbolic answer (e.g., `T=2mg+4mv₀²/l`)
- Text-only solvability (no diagrams/multimodal inputs)
- Rigorously precise statements to avoid ambiguity
- Solvable using only basic physics principles (no complex specialized knowledge required)
- No requirements on AI test to avoid filtering for AI weaknesses
2. **Multi-Round Academic Review**
- 3-tier verification process:
- Initial filtering: Reviewers assessed format validity and appropriateness (not filtering for AI weaknesses)
- Ambiguity detection and revision: Reviewers analyzed LLM-generated solutions to identify potential ambiguities in problem statements
- Iterative improvement cycle: Questions refined repeatedly until all LLMs can understand the question and follow the instructions to produce the expressions it believes to be right.
3. **Human Expert Finalization**
- **81 PKU students participated:**
- Each student independently solved 8 problems from the dataset
- Evaluate question clarity, statement rigor, and answer correctness
- Establish of human baseline performance meanwhile
## 📊 Evaluation Protocol
### Machine Evaluation
**Dual Metrics**:
1. **Accuracy**: Binary correctness (expression equivalence via SymPy simplification)
2. **EED Score**: Continuous assessment of expression tree similarity
The EED Score evaluates the similarity between the model-generated answer and the ground truth by leveraging the concept of expression tree edit distance. The process involves the following steps:
1. **Simplification of Expressions**:Both the ground truth (`gt`) and the model-generated answer (`gen`) are first converted into simplified symbolic expressions using the `sympy.simplify()` function. This step ensures that equivalent forms of the same expression are recognized as identical.
2. **Equivalence Check**:If the simplified expressions of `gt` and `gen` are identical, the EED Score is assigned a perfect score of 100, indicating complete correctness.
3. **Tree Conversion and Edit Distance Calculation**:If the expressions are not identical, they are converted into tree structures. The edit distance between these trees is then calculated using an extended version of the Zhang-Shasha algorithm. This distance represents the minimum number of node-level operations (insertions, deletions, and updates) required to transform one tree into the other.
4. **Relative Edit Distance and Scoring**:The relative edit distance \( r \) is computed as the ratio of the edit distance to the size of the ground truth tree. The EED Score is then determined based on this relative distance:
- If \( r = 0 \) (i.e., the expressions are identical), the score is 100.
- If \( 0 < r < 0.6 \), the score is calculated as \( 60 - 100r \).
- If \( r \geq 0.6 \), the score is 0, indicating a significant discrepancy between the model-generated answer and the ground truth.
This scoring mechanism provides a continuous measure of similarity, allowing for a nuanced evaluation of the model's reasoning capabilities beyond binary correctness.
**Key Advantages**:
- 204% higher sample efficiency vs binary metrics
- Distinguishes coefficient errors (30<EED score<60) vs structural errors (EED score<30)
### Human Baseline
- **Participants**: 81 PKU physics students
- **Protocol**:
- **8 problems per student**: Each student solved a set of 8 problems from PHYBench dataset
- **Time-constrained solving**: 3 hours
- **Performance metrics**:
- **61.9±2.1% average accuracy**
- **70.4±1.8 average EED Score**
- Top quartile reached 71.4% accuracy and 80.4 EED Score
- Significant outperformance vs LLMs: Human experts outperformed all evaluated LLMs at 99% confidence level
- Human experts significantly outperformed all evaluated LLMs (99.99% confidence level)
## 📝 Main Results
The results of the evaluation are shown in the following figure:
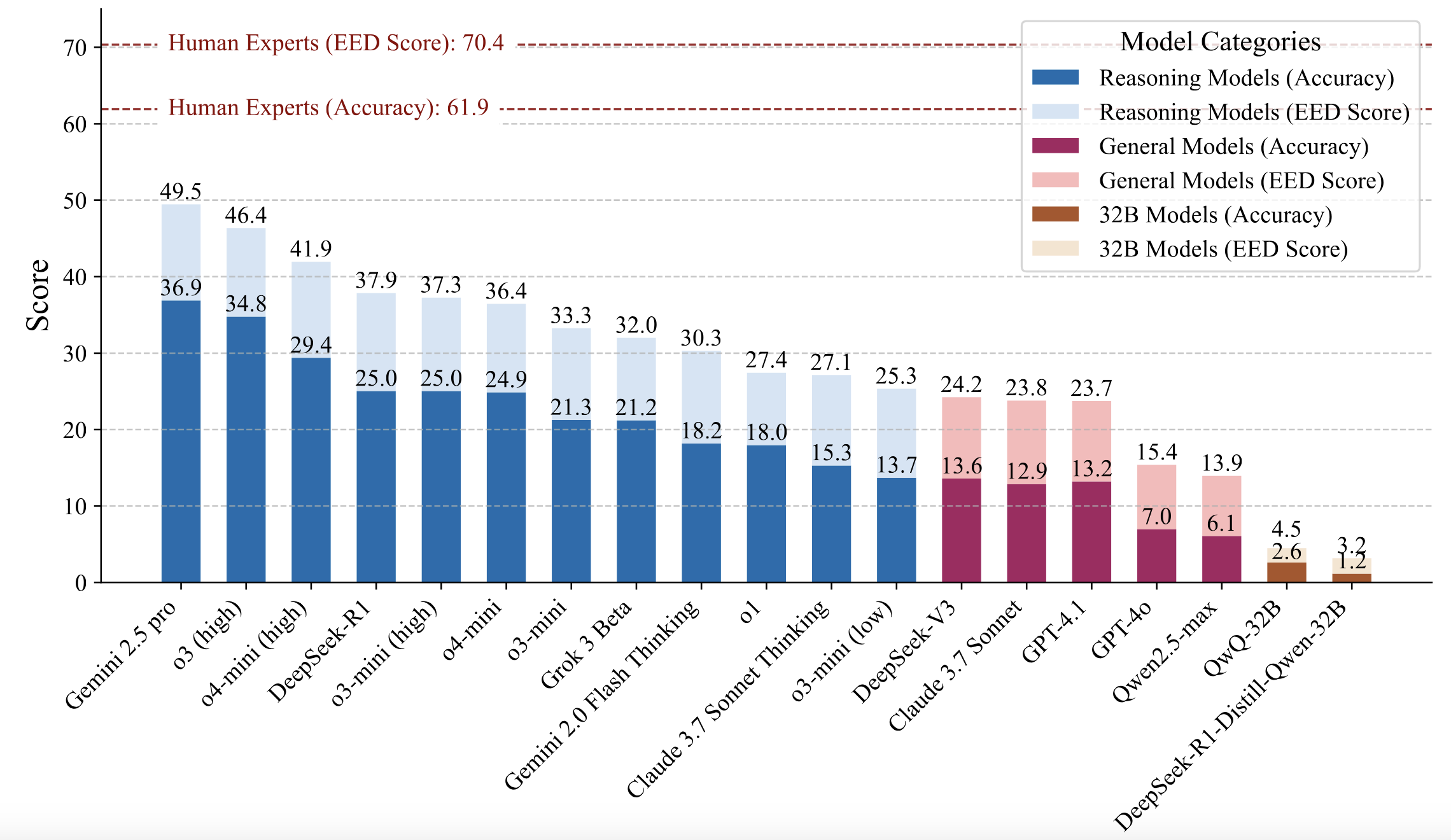
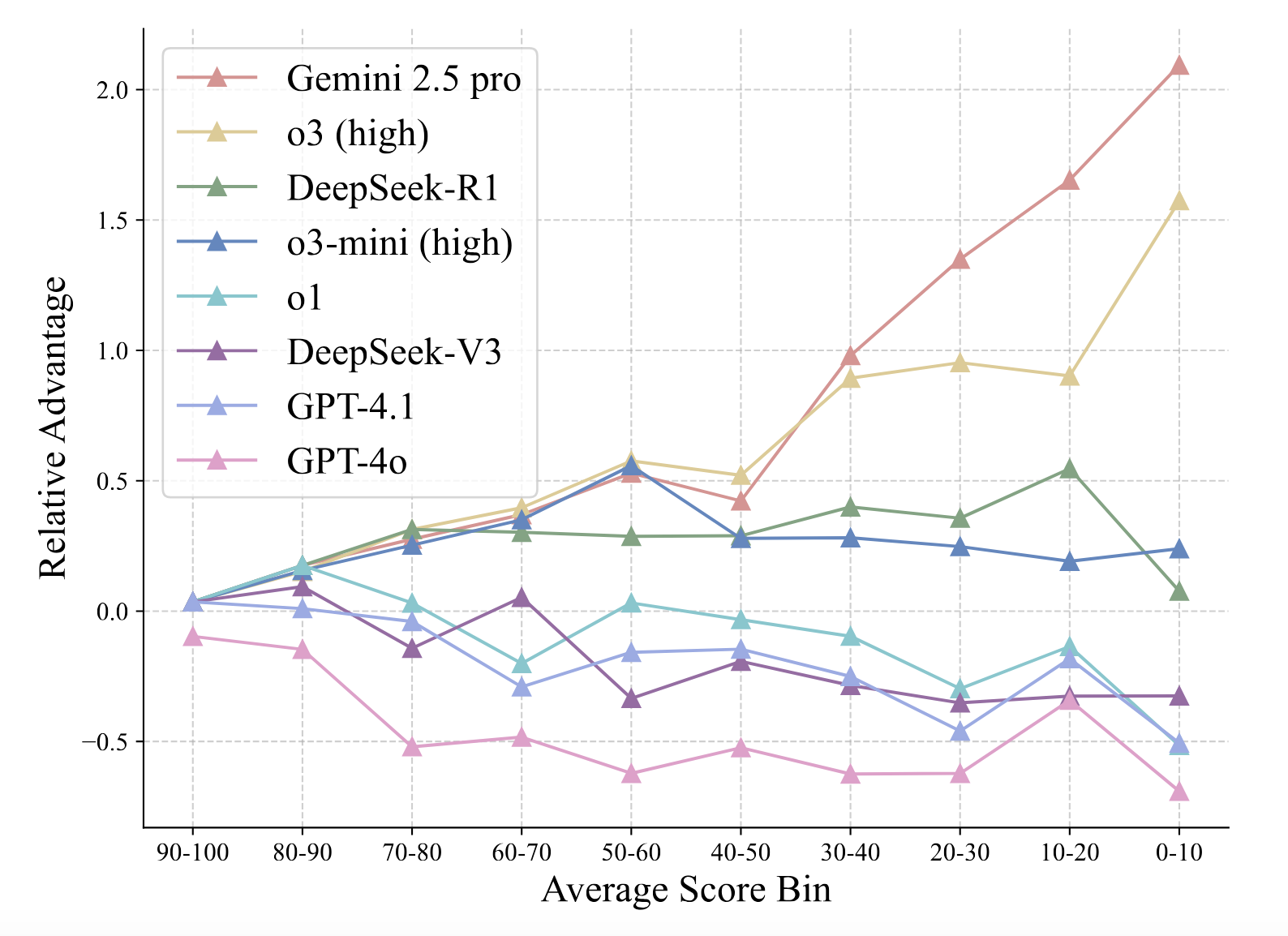
1. **Significant Performance Gap**: Even state-of-the-art LLMs significantly lag behind human experts in physical reasoning. The highest-performing model, Gemini 2.5 Pro, achieved only a 36.9% accuracy, compared to the human baseline of 61.9%.
2. **EED Score Advantages**: The EED Score provides a more nuanced evaluation of model performance compared to traditional binary scoring methods.
3. **Domain-Specific Strengths**: Different models exhibit varying strengths in different domains of physics:
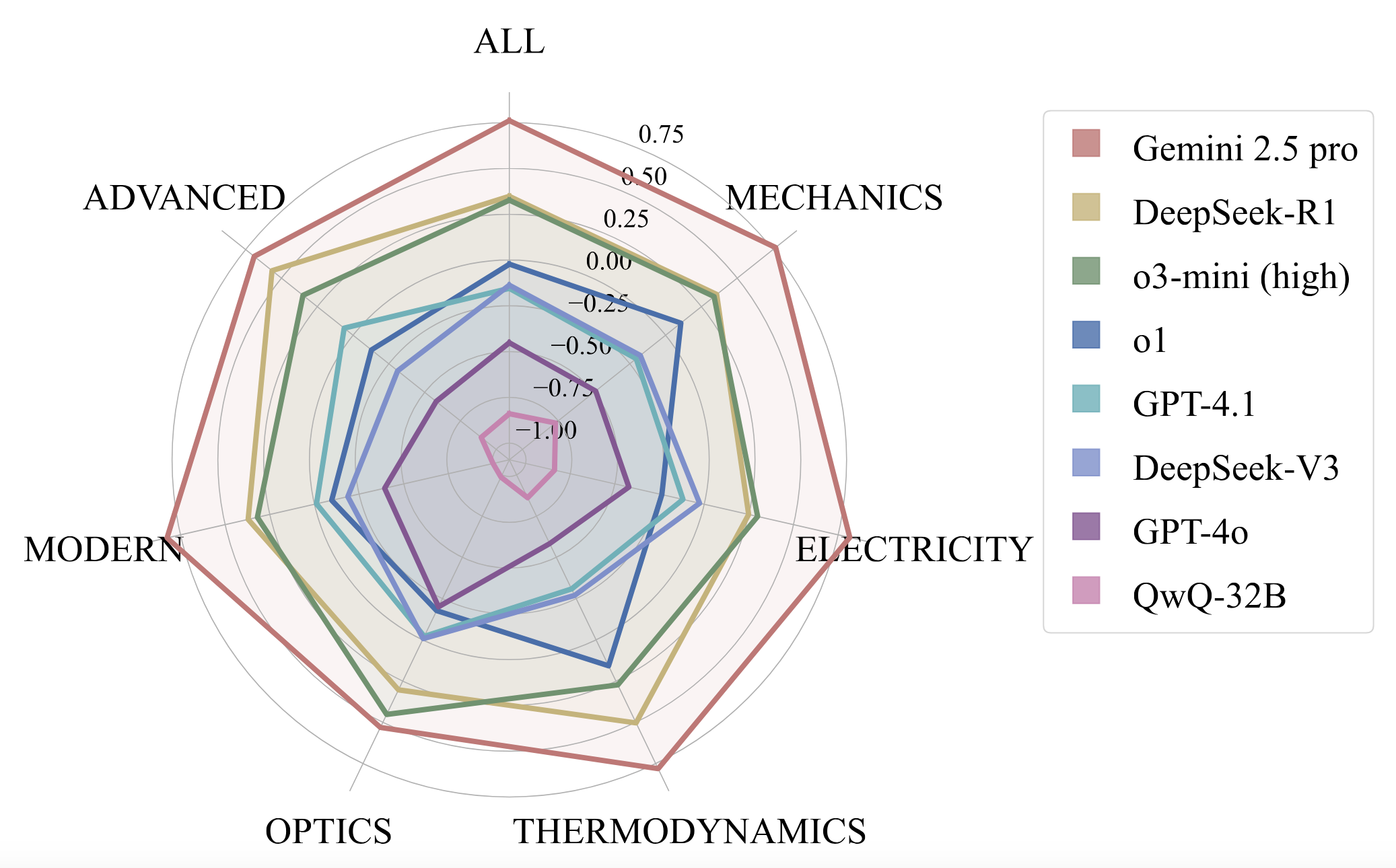
* Gemini 2.5 Pro shows strong performance across most domains
* DeepSeek-R1 and o3-mini (high) shows comparable performance in mechanics and electricity
* Most models struggle with advanced physics and modern physics
4. **Difficulty Handling**: Comparing the advantage across problem difficulties, Gemini 2.5 Pro gains a pronounced edge on harder problems, followed by o3 (high).
## 😵💫 Error Analysis
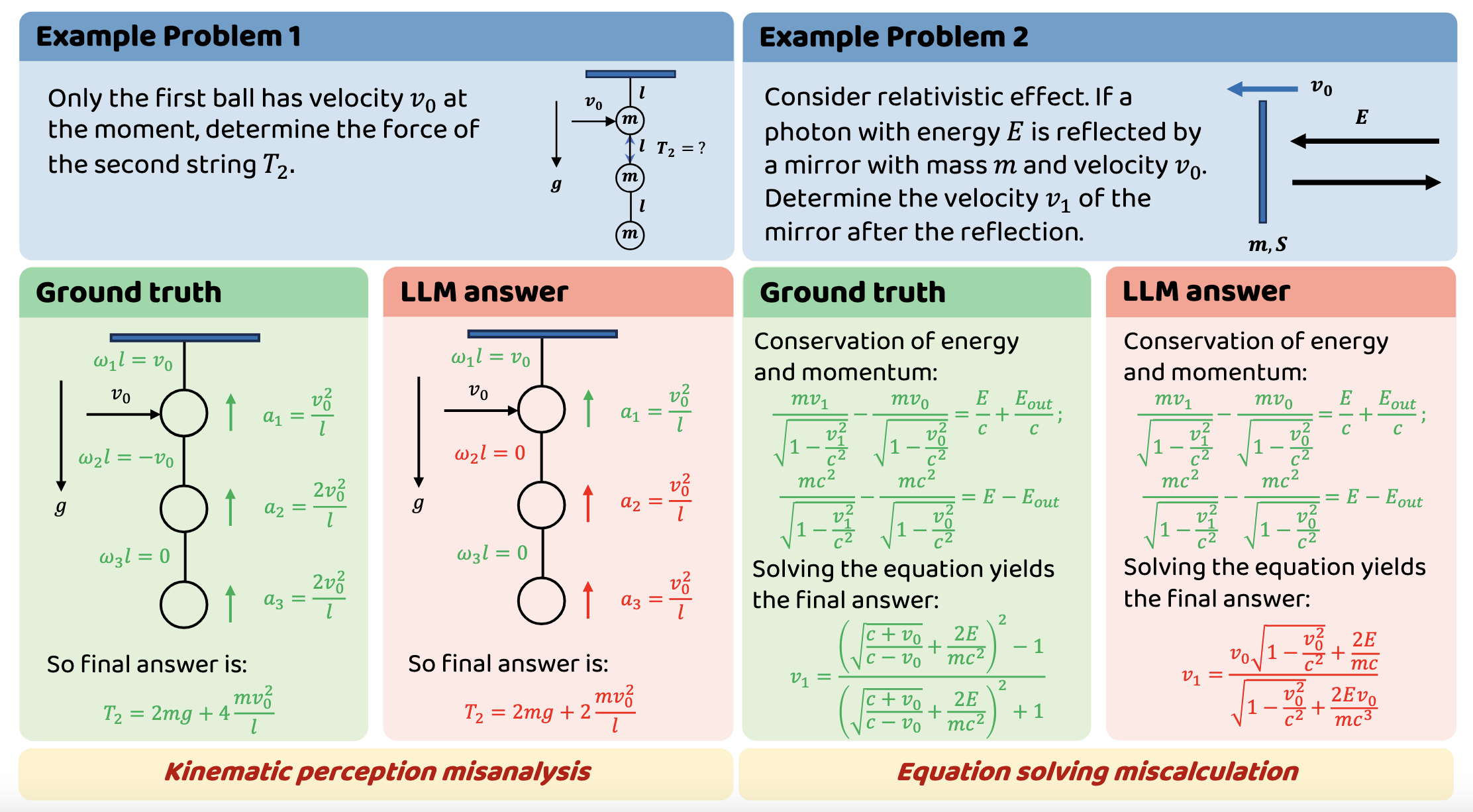
We categorize the capabilities assessed by the PHYBench benchmark into two key dimensions: Physical Perception (PP) and Robust Reasoning (RR):
1. **Physical Perception (PP) Errors**: During this phase, models engage in intensive semantic reasoning, expending significant cognitive effort to identify relevant physical objects, variables, and dynamics. Models make qualitative judgments about which physical effects are significant and which can be safely ignored. PP manifests as critical decision nodes in the reasoning chain. An example of a PP error is shown in Example Problem 1.
2. **Robust Reasoning (RR) Errors**: In this phase, models produce numerous lines of equations and perform symbolic reasoning. This process forms the connecting chains between perception nodes. RR involves consistent mathematical derivation, equation solving, and proper application of established conditions. An example of a RR error is shown in Example Problem 2.

## 🚩 Citation
```bibtex
@misc{qiu2025phybenchholisticevaluationphysical,
title={PHYBench: Holistic Evaluation of Physical Perception and Reasoning in Large Language Models},
author={Shi Qiu and Shaoyang Guo and Zhuo-Yang Song and Yunbo Sun and Zeyu Cai and Jiashen Wei and Tianyu Luo and Yixuan Yin and Haoxu Zhang and Yi Hu and Chenyang Wang and Chencheng Tang and Haoling Chang and Qi Liu and Ziheng Zhou and Tianyu Zhang and Jingtian Zhang and Zhangyi Liu and Minghao Li and Yuku Zhang and Boxuan Jing and Xianqi Yin and Yutong Ren and Zizhuo Fu and Weike Wang and Xudong Tian and Anqi Lv and Laifu Man and Jianxiang Li and Feiyu Tao and Qihua Sun and Zhou Liang and Yushu Mu and Zhongxuan Li and Jing-Jun Zhang and Shutao Zhang and Xiaotian Li and Xingqi Xia and Jiawei Lin and Zheyu Shen and Jiahang Chen and Qiuhao Xiong and Binran Wang and Fengyuan Wang and Ziyang Ni and Bohan Zhang and Fan Cui and Changkun Shao and Qing-Hong Cao and Ming-xing Luo and Muhan Zhang and Hua Xing Zhu},
year={2025},
eprint={2504.16074},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2504.16074},
}
```
|
Major-TOM/Core-S2L2A-MMEarth | Major-TOM | 2025-04-26T10:04:36Z | 577 | 3 | [
"license:cc-by-sa-4.0",
"size_categories:10M<n<100M",
"modality:geospatial",
"arxiv:2412.05600",
"doi:10.57967/hf/5240",
"region:us",
"embeddings",
"earth-observation",
"remote-sensing",
"sentinel-2",
"satellite",
"geospatial",
"satellite-imagery"
] | [] | 2025-02-03T14:13:55Z | 2 | ---
license: cc-by-sa-4.0
tags:
- embeddings
- earth-observation
- remote-sensing
- sentinel-2
- satellite
- geospatial
- satellite-imagery
size_categories:
- 10M<n<100M
configs:
- config_name: default
data_files: embeddings/*.parquet
---

# Core-S2L2A-MMEarth (Pooled) 🟥🟩🟦🟧🟨🟪 🛰️
> This is a pooled down (about 10x) version of the computed dataset due to storage constraints on HuggingFace. For a full size access, please visit [**Creodias EODATA**](https://creodias.eu/eodata/all-sources/).
## Input data
* Sentinel-2 (Level 2A) multispectral dataset global coverage
* All samples from [**MajorTOM Core-S2L2A**](https://huggingface.co/datasets/Major-TOM/Core-S2L2A)
* Embedding_shape = **(320, 133, 133)**
* Pooled shape = **(320, 13, 13)**
## Metadata content
| Field | Type | Description |
|:-----------------:|:--------:|-----------------------------------------------------------------------------|
| unique_id | string | hash generated from geometry, time, product_id, and average embedding (320,1,1) |
| grid_cell | string | Major TOM cell |
| grid_row_u | int | Major TOM cell row |
| grid_col_r | int | Major TOM cell col |
| product_id | string | ID of the original product |
| timestamp | string | Timestamp of the sample |
| centre_lat | float | Centre of the of the grid_cell latitude |
| centre_lon | float | Centre of the of the grid_cell longitude |
| geometry | geometry | Polygon footprint (WGS84) of the grid_cell |
| utm_footprint | string | Polygon footprint (image UTM) of the grid_cell |
| utm_crs | string | CRS of the original product |
| file_name | string | Name of reference MajorTOM product |
| file_index | int | Position of the embedding within the .dat file |
## Model
The image encoder of the [**MMEarth model**](https://github.com/vishalned/MMEarth-train) was used to extract embeddings
Model [**weights**](https://sid.erda.dk/cgi-sid/ls.py?share_id=g23YOnaaTp¤t_dir=pt-all_mod_atto_1M_64_uncertainty_56-8&flags=f)
Weights info:
**pt-all_mod_atto_1M_64_uncertainty_56-8**
- **INFO**: pt-($INPUT)_($MODEL)_($DATA)_($LOSS)_($MODEL_IMG_SIZE)_($PATCH_SIZE)
- **INPUT:** all_mod # for s2-12 bands as input and all modalities as output
- **MODEL:** atto
- **DATA:** 1M_64 # MMEarth64, 1.2M locations and image size 64
- **LOSS:** uncertainty
- **MODEL_IMG_SIZE:** 56 # when using the data with image size 64
- **PATCH_SIZE:** 8
## Example Use
Interface scripts are available at
```python
import numpy as np
input_file_path = 'processed_part_00045_pooled.dat' # Path to the saved .dat file
pooled_shape=(320, 13, 13)
embedding_size = np.prod(pooled_shape)
dtype_size = np.dtype(np.float32).itemsize
# Calculate the byte offset for the embedding you want to read
embedding_index = 4
offset = embedding_index * embedding_size * dtype_size
# Load the specific embedding
with open(file_path, 'rb') as f:
f.seek(offset)
embedding_data = np.frombuffer(f.read(embedding_size * dtype_size), dtype=np.float32)
embedding = embedding_data.reshape(pooled_shape) # Reshape to the pooled embedding shape
embedding
```
## Generate Your Own Major TOM Embeddings
The [**embedder**](https://github.com/ESA-PhiLab/Major-TOM/tree/main/src/embedder) subpackage of Major TOM provides tools for generating embeddings like these ones. You can see an example of this in a dedicated notebook at https://github.com/ESA-PhiLab/Major-TOM/blob/main/05-Generate-Major-TOM-Embeddings.ipynb.
[](https://github.com/ESA-PhiLab/Major-TOM/blob/main/05-Generate-Major-TOM-Embeddings.ipynb)
---
## Major TOM Global Embeddings Project 🏭
This dataset is a result of a collaboration between [**CloudFerro**](https://cloudferro.com/) 🔶, [**asterisk labs**](https://asterisk.coop/) and [**Φ-lab, European Space Agency (ESA)**](https://philab.esa.int/) 🛰️ set up in order to provide open and free vectorised expansions of Major TOM datasets and define a standardised manner for releasing Major TOM embedding expansions.
The embeddings extracted from common AI models make it possible to browse and navigate large datasets like Major TOM with reduced storage and computational demand.
The datasets were computed on the [**GPU-accelerated instances**](https://cloudferro.com/ai/ai-computing-services/)⚡ provided by [**CloudFerro**](https://cloudferro.com/) 🔶 on the [**CREODIAS**](https://creodias.eu/) cloud service platform 💻☁️.
Discover more at [**CloudFerro AI services**](https://cloudferro.com/ai/).
## Authors
[**Mikolaj Czerkawski**](https://mikonvergence.github.io) (Asterisk Labs), [**Marcin Kluczek**](https://www.linkedin.com/in/marcin-kluczek-03852a1a8/) (CloudFerro), [**Jędrzej S. Bojanowski**](https://www.linkedin.com/in/j%C4%99drzej-s-bojanowski-a5059872/) (CloudFerro)
## Open Access Manuscript
This dataset is an output from the embedding expansion project outlined in: [https://arxiv.org/abs/2412.05600/](https://arxiv.org/abs/2412.05600/).
[](https://doi.org/10.48550/arXiv.2412.05600)
<details>
<summary>Read Abstract</summary>
> With the ever-increasing volumes of the Earth observation data present in the archives of large programmes such as Copernicus, there is a growing need for efficient vector representations of the underlying raw data. The approach of extracting feature representations from pretrained deep neural networks is a powerful approach that can provide semantic abstractions of the input data. However, the way this is done for imagery archives containing geospatial data has not yet been defined. In this work, an extension is proposed to an existing community project, Major TOM, focused on the provision and standardization of open and free AI-ready datasets for Earth observation. Furthermore, four global and dense embedding datasets are released openly and for free along with the publication of this manuscript, resulting in the most comprehensive global open dataset of geospatial visual embeddings in terms of covered Earth's surface.
> </details>
If this dataset was useful for you work, it can be cited as:
```latex
@misc{EmbeddedMajorTOM,
title={Global and Dense Embeddings of Earth: Major TOM Floating in the Latent Space},
author={Mikolaj Czerkawski and Marcin Kluczek and Jędrzej S. Bojanowski},
year={2024},
eprint={2412.05600},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2412.05600},
}
```
Powered by [Φ-lab, European Space Agency (ESA) 🛰️](https://philab.esa.int/) in collaboration with [CloudFerro 🔶](https://cloudferro.com/) & [asterisk labs](https://asterisk.coop/)
|
launch/thinkprm-1K-verification-cots | launch | 2025-04-26T02:05:42Z | 125 | 3 | [
"task_categories:question-answering",
"task_categories:text-generation",
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"arxiv:2504.16828",
"region:us",
"math reasoning",
"process supervision",
"reward modeling",
"chain-of-thought",
"synthetic data"
] | [
"question-answering",
"text-generation"
] | 2025-04-24T18:37:40Z | 3 | ---
size_categories:
- n<1K
task_categories:
- question-answering
- text-generation
pretty_name: ThinkPRM-Synthetic-Verification-1K
dataset_info:
features:
- name: problem
dtype: string
- name: prefix
dtype: string
- name: cot
dtype: string
- name: prefix_steps
sequence: string
- name: gt_step_labels
sequence: string
- name: prefix_label
dtype: bool
splits:
- name: train
num_bytes: 8836501
num_examples: 1000
download_size: 3653730
dataset_size: 8836501
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
tags:
- math reasoning
- process supervision
- reward modeling
- chain-of-thought
- synthetic data
---
This dataset contains 1,000 high-quality synthetic verification chains-of-thought (CoTs) designed for training generative Process Reward Models (PRMs), as used in the paper ["Process Reward Models that Think"](https://arxiv.org/abs/2504.16828). The goal was to create a data-efficient alternative to traditional PRM training which often requires extensive human annotation or expensive rollouts.
Each instance consists of a math problem, a corresponding multi-step solution prefix (sourced from PRM800K [Lightman et al., 2023]), and a detailed verification CoT generated by the [QwQ-32B-Preview](https://huggingface.co/Qwen/QwQ-32B-Preview). The verification CoT critiques each step of the solution prefix and provides a step-level correctness judgment (`\boxed{correct}` or `\boxed{incorrect}`).
To ensure high-quality synthetic CoTs, only chains where all step-level judgments matched the ground-truth human annotations from the PRM800K dataset were retained. They were also filtered based on correct formatting and length constraints to avoid issues like excessive overthinking observed in unfiltered generation. The figure below summarizes the synthetic cots collection. Refer to our paper for more details on data collection.

### Curation Rationale
The dataset was created to enable efficient training of powerful generative PRMs. The core idea is that fine-tuning strong reasoning models on carefully curated, synthetic verification CoTs can yield verifiers that outperform models trained on much larger, traditionally labeled datasets. The process-based filtering (matching gold step labels) was shown to be crucial for generating high-quality training data compared to outcome-based filtering.
**Code:** [https://github.com/mukhal/thinkprm](https://github.com/mukhal/thinkprm)
**Paper:** [Process Reward Models that Think](https://arxiv.org/abs/2504.16828)
## Data Fields
The dataset contains the following fields:
* `problem`: (string) The mathematical problem statement (e.g., from MATH dataset via PRM800K).
* `prefix`: (string) The full step-by-step solution prefix being evaluated.
* `cot`: (string) The full synthetic verification chain-of-thought generated by QwQ-32B-Preview, including step-by-step critiques and judgments. See Fig. 13 in the paper for an example.
* `prefix_steps`: (list of strings) The solution prefix broken down into individual steps.
* `gt_step_labels`: (list of bools/ints) The ground-truth correctness labels (e.g., '+' for correct, '-' for incorrect) for each corresponding step in `prefix_steps`, sourced from PRM800K annotations.
* `prefix_label`: (bool) The overall ground-truth correctness label for the entire solution prefix: True if all steps are correct, False otherwise.
### Source Data
* **Problems & Solution Prefixes:** Sourced from the PRM800K dataset, which is based on the MATH dataset.
* **Verification CoTs:** Generated synthetically using the QwQ-32B-Preview model prompted with instructions detailed in Fig. 14 of the paper.
* **Filtering Labels:** Ground-truth step-level correctness labels from PRM800K were used to filter the synthetic CoTs.
## Citation Information
If you use this dataset, please cite the original paper:
```
@article{khalifa2025,
title={Process Reward Models That Think},
author={Muhammad Khalifa and Rishabh Agarwal and Lajanugen Logeswaran and Jaekyeom Kim and Hao Peng and Moontae Lee and Honglak Lee and Lu Wang},
year={2025},
journal={arXiv preprint arXiv:2504.16828},
url={https://arxiv.org/abs/2504.16828},
}
``` |
lightonai/ms-marco-en-bge-gemma | lightonai | 2025-04-25T13:25:43Z | 107 | 2 | [
"task_categories:feature-extraction",
"task_categories:sentence-similarity",
"multilinguality:monolingual",
"language:en",
"size_categories:10M<n<100M",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us",
"sentence-transformers",
"colbert",
"lightonai",
"PyLate"
] | [
"feature-extraction",
"sentence-similarity"
] | 2025-04-25T12:28:31Z | 2 | ---
language:
- en
multilinguality:
- monolingual
size_categories:
- 1M<n<10M
task_categories:
- feature-extraction
- sentence-similarity
pretty_name: ms-marco-en-bge-gemma
tags:
- sentence-transformers
- colbert
- lightonai
- PyLate
dataset_info:
- config_name: documents
features:
- name: document_id
dtype: int64
- name: text
dtype: string
splits:
- name: train
num_bytes: 3089188164
num_examples: 8841823
download_size: 1679883891
dataset_size: 3089188164
- config_name: queries
features:
- name: query_id
dtype: int64
- name: text
dtype: string
splits:
- name: train
num_bytes: 38373408
num_examples: 808731
download_size: 28247183
dataset_size: 38373408
- config_name: train
features:
- name: query_id
dtype: int64
- name: document_ids
dtype: string
- name: scores
dtype: string
splits:
- name: train
num_bytes: 599430336
num_examples: 640000
download_size: 434872561
dataset_size: 599430336
configs:
- config_name: documents
data_files:
- split: train
path: documents/train-*
- config_name: queries
data_files:
- split: train
path: queries/train-*
- config_name: train
data_files:
- split: train
path: train/train-*
---
# ms-marco-en-bge
This dataset contains the [MS MARCO](https://microsoft.github.io/msmarco/) dataset with negatives mined using ColBERT and then scored by [bge-reranker-v2-gemma](https://huggingface.co/BAAI/bge-reranker-v2-gemma).
It can be used to train a retrieval model using knowledge distillation, for example [using PyLate](https://lightonai.github.io/pylate/#knowledge-distillation).
#### `knowledge distillation`
To fine-tune a model using knowledge distillation loss we will need three distinct file:
* Datasets
```python
from datasets import load_dataset
train = load_dataset(
"lightonai/ms-marco-en-gemma",
"train",
split="train",
)
queries = load_dataset(
"lightonai/ms-marco-en-gemma",
"queries",
split="train",
)
documents = load_dataset(
"lightonai/ms-marco-en-gemma",
"documents",
split="train",
)
```
Where:
- `train` contains three distinct columns: `['query_id', 'document_ids', 'scores']`
```python
{
"query_id": 54528,
"document_ids": [
6862419,
335116,
339186,
7509316,
7361291,
7416534,
5789936,
5645247,
],
"scores": [
0.4546215673141326,
0.6575686537173476,
0.26825184192900203,
0.5256195579370395,
0.879939718687207,
0.7894968184862693,
0.6450100468854655,
0.5823844608171467,
],
}
```
Assert that the length of document_ids is the same as scores.
- `queries` contains two distinct columns: `['query_id', 'text']`
```python
{"query_id": 749480, "text": "what is function of magnesium in human body"}
```
- `documents` contains two distinct columns: `['document_ids', 'text']`
```python
{
"document_id": 136062,
"text": "2. Also called tan .a fundamental trigonometric function that, in a right triangle, is expressed as the ratio of the side opposite an acute angle to the side adjacent to that angle. 3. in immediate physical contact; touching; abutting. 4. a. touching at a single point, as a tangent in relation to a curve or surface.lso called tan .a fundamental trigonometric function that, in a right triangle, is expressed as the ratio of the side opposite an acute angle to the side adjacent to that angle. 3. in immediate physical contact; touching; abutting. 4. a. touching at a single point, as a tangent in relation to a curve or surface.",
}
```
|
ddupont/test-dataset | ddupont | 2025-04-24T23:37:48Z | 149 | 2 | [
"task_categories:visual-question-answering",
"language:en",
"license:mit",
"size_categories:n<1K",
"format:parquet",
"modality:image",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us",
"cua",
"highquality",
"tasks"
] | [
"visual-question-answering"
] | 2025-04-18T17:06:08Z | 2 | ---
language: en
license: mit
task_categories:
- visual-question-answering
tags:
- cua
- highquality
- tasks
---
# Uploaded computer interface trajectories
These trajectories were generated and uploaded using [c/ua](https://github.com/trycua/cua) |
WensongSong/AnyInsertion | WensongSong | 2025-04-24T17:43:25Z | 584 | 5 | [
"task_categories:image-to-image",
"language:en",
"license:mit",
"size_categories:10K<n<100K",
"format:arrow",
"modality:image",
"modality:text",
"library:datasets",
"library:mlcroissant",
"arxiv:2504.15009",
"region:us"
] | [
"image-to-image"
] | 2025-04-23T13:15:55Z | 5 | ---
license: mit
task_categories:
- image-to-image
language:
- en
pretty_name: a
size_categories:
- 10M<n<100M
---
# AnyInsertion
<p align="center">
<a href="https://song-wensong.github.io/"><strong>Wensong Song</strong></a>
·
<a href="https://openreview.net/profile?id=~Hong_Jiang4"><strong>Hong Jiang</strong></a>
·
<a href="https://z-x-yang.github.io/"><strong>Zongxing Yang</strong></a>
·
<a href="https://scholar.google.com/citations?user=WKLRPsAAAAAJ&hl=en"><strong>Ruijie Quan</strong></a>
·
<a href="https://scholar.google.com/citations?user=RMSuNFwAAAAJ&hl=en"><strong>Yi Yang</strong></a>
<br>
<br>
<a href="https://arxiv.org/pdf/2504.15009" style="display: inline-block; margin-right: 10px;">
<img src='https://img.shields.io/badge/arXiv-InsertAnything-red?color=%23aa1a1a' alt='Paper PDF'>
</a>
<a href='https://song-wensong.github.io/insert-anything/' style="display: inline-block; margin-right: 10px;">
<img src='https://img.shields.io/badge/Project%20Page-InsertAnything-cyan?logoColor=%23FFD21E&color=%23cbe6f2' alt='Project Page'>
</a>
<a href='https://github.com/song-wensong/insert-anything' style="display: inline-block;">
<img src='https://img.shields.io/badge/GitHub-InsertAnything-black?logoColor=23FFD21E&color=%231d2125'>
</a>
<br>
<b>Zhejiang University | Harvard University | Nanyang Technological University </b>
</p>
## News
* **[2025.4.25]** Released AnyInsertion v1 mask-prompt dataset on Hugging Face.
## Summary
This is the dataset proposed in our paper [**Insert Anything: Image Insertion via In-Context Editing in DiT**](https://arxiv.org/abs/2504.15009)
AnyInsertion dataset consists of training and testing subsets. The training set includes 159,908 samples across two prompt types: 58,188 mask-prompt image pairs and 101,720 text-prompt image pairs;the test set includes 158 data pairs: 120 mask-prompt pairs and 38 text-prompt pairs.
AnyInsertion dataset covers diverse categories including human subjects, daily necessities, garments, furniture, and various objects.

## Directory
```
data/
├── train/
│ ├── accessory/
│ │ ├── ref_image/ # Reference image containing the element to be inserted
│ │ ├── ref_mask/ # The mask corresponding to the inserted element
│ │ ├── tar_image/ # Ground truth
│ │ ├── tar_mask/ # The mask corresponding to the edited area of target image
│ │
│ ├── object/
│ │ ├── ref_image/
│ │ ├── ref_mask/
│ │ ├── tar_image/
│ │ ├── tar_mask/
│ │
│ └── person/
│ ├── ref_image/
│ ├── ref_mask/
│ ├── tar_image/
│ ├── tar_mask/
│
└── test/
├── garment/
│ ├── ref_image/
│ ├── ref_mask/
│ ├── tar_image/
│ ├── tar_mask/
│
├── object/
│ ├── ref_image/
│ ├── ref_mask/
│ ├── tar_image/
│ ├── tar_mask/
│
└── person/
├── ref_image/
├── ref_mask/
├── tar_image/
├── tar_mask/
```
## Example
<div style="display: flex; text-align: center; align-items: center; justify-content: space-between;">
<figure style="margin: 10px; width: calc(25% - 20px);">
<img src="examples/ref_image.png" alt="Ref_image" style="width: 100%;">
<figcaption>Ref_image</figcaption>
</figure>
<figure style="margin: 10px; width: calc(25% - 20px);">
<img src="examples/ref_mask.png" alt="Ref_mask" style="width: 100%;">
<figcaption>Ref_mask</figcaption>
</figure>
<figure style="margin: 10px; width: calc(25% - 20px);">
<img src="examples/tar_image.png" alt="Tar_image" style="width: 100%;">
<figcaption>Tar_image</figcaption>
</figure>
<figure style="margin: 10px; width: calc(25% - 20px);">
<img src="examples/tar_mask.png" alt="Tar_mask" style="width: 100%;">
<figcaption>Tar_mask</figcaption>
</figure>
</div>
## Usage
This guide explains how to load and use the AnyInsertion dataset, specifically the subset focusing on mask-prompt image pairs, which has been prepared in Apache Arrow format for efficient loading with the Hugging Face `datasets` library.
### Installation
First, ensure you have the `datasets` library installed. If not, you can install it via pip:
```bash
pip install datasets pillow
```
### Loading the Dataset
You can load the dataset directly from the Hugging Face Hub using its identifier:
```python
from datasets import load_dataset
# Replace with the correct Hugging Face Hub repository ID
repo_id = "WensongSong/AnyInsertion"
# Load the entire dataset (usually returns a DatasetDict with 'train' and 'test' splits)
dataset = load_dataset(repo_id)
print(dataset)
# Expected output similar to:
# DatasetDict({
# train: Dataset({
# features: ['id', 'split', 'category', 'main_label', 'ref_image', 'ref_mask', 'tar_image', 'tar_mask'],
# num_rows: XXXX
# })
# test: Dataset({
# features: ['id', 'split', 'category', 'main_label', 'ref_image', 'ref_mask', 'tar_image', 'tar_mask'],
# num_rows: YYYY
# })
# })
```
### Loading Specific Splits
If you only need a specific split (e.g., 'test'), you can specify it during loading:
``` python
# Load only the 'test' split
test_dataset = load_dataset(repo_id, split='test')
print("Loaded Test Split:")
print(test_dataset)
# Load only the 'train' split
train_dataset = load_dataset(repo_id, split='train')
print("\nLoaded Train Split:")
print(train_dataset)
```
### Dataset Structure
* The loaded dataset (or individual splits) has the following structure and features (columns):
* id (string): A unique identifier for each data sample, typically formatted as "split/category/image_id" (e.g., "train/accessory/0").
* split (string): Indicates whether the sample belongs to the 'train' or 'test' set.
* category (string): The category of the main object or subject in the sample. Possible values include: 'accessory', 'object', 'person' (for train), 'garment', 'object_test', 'person' (for test).
* main_label (string): The label associated with the reference image/mask pair, derived from the original label.json files.
* ref_image (Image): The reference image containing the object or element to be conceptually inserted. Loaded as a PIL (Pillow) Image object.
* ref_mask (Image): The binary mask highlighting the specific element within the ref_image. Loaded as a PIL Image object.
* tar_image (Image): The target image, representing the ground truth result after the conceptual insertion or editing. Loaded as a PIL Image object.
* tar_mask (Image): The binary mask indicating the edited or inserted region within the tar_image. Loaded as a PIL Image object.
### Accessing Data
You can access data like a standard Python dictionary or list:
```python
# Get the training split from the loaded DatasetDict
train_ds = dataset['train']
# Get the first sample from the training set
first_sample = train_ds[0]
# Access specific features (columns) of the sample
ref_image = first_sample['ref_image']
label = first_sample['main_label']
category = first_sample['category']
print(f"\nFirst train sample category: {category}, label: {label}")
print(f"Reference image size: {ref_image.size}") # ref_image is a PIL Image
# Display the image (requires matplotlib or other image libraries)
# import matplotlib.pyplot as plt
# plt.imshow(ref_image)
# plt.title(f"Category: {category}, Label: {label}")
# plt.show()
# Iterate through the dataset (e.g., the first 5 test samples)
print("\nIterating through the first 5 test samples:")
test_ds = dataset['test']
for i in range(5):
sample = test_ds[i]
print(f" Sample {i}: ID={sample['id']}, Category={sample['category']}, Label={sample['main_label']}")
```
### Filtering Data
The datasets library provides powerful filtering capabilities.
```python
# Filter the training set to get only 'accessory' samples
accessory_train_ds = train_ds.filter(lambda example: example['category'] == 'accessory')
print(f"\nNumber of 'accessory' samples in train split: {len(accessory_train_ds)}")
# Filter the test set for 'person' samples
person_test_ds = test_ds.filter(lambda example: example['category'] == 'person')
print(f"Number of 'person' samples in test split: {len(person_test_ds)}")
```
#### Filtering by Split (if loaded as DatasetDict)
Although loading specific splits is preferred, you can also filter by the split column if you loaded the entire DatasetDict and somehow combined them (not typical, but possible):
```python
# Assuming 'combined_ds' is a dataset containing both train and test rows
# test_split_filtered = combined_ds.filter(lambda example: example['split'] == 'test')
```
### Working with Images
The features defined as Image (ref_image, ref_mask, tar_image, tar_mask) will automatically load the image data as PIL (Pillow) Image objects when accessed. You can then use standard Pillow methods or convert them to other formats (like NumPy arrays or PyTorch tensors) for further processing.
```python
# Example: Convert reference image to NumPy array
import numpy as np
first_sample = train_ds[0]
ref_image_pil = first_sample['ref_image']
ref_image_np = np.array(ref_image_pil)
print(f"\nReference image shape as NumPy array: {ref_image_np.shape}")
```
## Citation
```
@article{song2025insert,
title={Insert Anything: Image Insertion via In-Context Editing in DiT},
author={Song, Wensong and Jiang, Hong and Yang, Zongxing and Quan, Ruijie and Yang, Yi},
journal={arXiv preprint arXiv:2504.15009},
year={2025}
}
``` |
MaziyarPanahi/OpenMathReasoning_ShareGPT | MaziyarPanahi | 2025-04-24T16:20:15Z | 265 | 2 | [
"task_categories:question-answering",
"task_categories:text-generation",
"language:en",
"license:cc-by-4.0",
"size_categories:1M<n<10M",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"arxiv:2504.16891",
"region:us",
"math",
"nvidia"
] | [
"question-answering",
"text-generation"
] | 2025-04-24T14:32:01Z | 2 | ---
language:
- en
license: cc-by-4.0
size_categories:
- 1M<n<10M
task_categories:
- question-answering
- text-generation
pretty_name: OpenMathReasoning_ShareGPT
tags:
- math
- nvidia
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: expected_answer
dtype: string
- name: problem_type
dtype: string
- name: problem_source
dtype: string
- name: generation_model
dtype: string
- name: pass_rate_72b_tir
dtype: string
- name: problem
dtype: string
- name: generated_solution
dtype: string
- name: inference_mode
dtype: string
- name: conversations
list:
- name: from
dtype: string
- name: value
dtype: string
splits:
- name: train
num_bytes: 227674772297
num_examples: 5469691
download_size: 98344850102
dataset_size: 227674772297
---
Original README:
# OpenMathReasoning
OpenMathReasoning is a large-scale math reasoning dataset for training large language models (LLMs).
This dataset contains
* 540K unique mathematical problems sourced from [AoPS forums](https://artofproblemsolving.com/community),
* 3.2M long chain-of-thought (CoT) solutions
* 1.7M long tool-integrated reasoning (TIR) solutions
* 566K samples that select the most promising solution out of many candidates (GenSelect)
We used [Qwen2.5-32B-Instruct](https://huggingface.co/Qwen/Qwen2.5-32B-Instruct) to preprocess problems, and
[DeepSeek-R1](https://huggingface.co/deepseek-ai/DeepSeek-R1) and [QwQ-32B](https://huggingface.co/Qwen/QwQ-32B) to generate solutions.
This dataset was a foundation of our winning submission to the
[AIMO-2 Kaggle competition](https://www.kaggle.com/competitions/ai-mathematical-olympiad-progress-prize-2/leaderboard).
See our [paper](https://arxiv.org/abs/2504.16891) to learn more details!
**_NOTE:_** An early version of this data was released separately in [Llama-Nemotron-Post-Training-Dataset](https://huggingface.co/datasets/nvidia/Llama-Nemotron-Post-Training-Dataset).
## Dataset fields
OpenMathReasoning dataset contains the following fields:
- **problem**: Problem statement extracted from [AoPS forums](https://artofproblemsolving.com/community) and refined with [Qwen2.5-32B-Instruct](https://huggingface.co/Qwen/Qwen2.5-32B-Instruct)
- **generated_solution**: Synthetically generated solution using either [DeepSeek-R1](https://huggingface.co/deepseek-ai/DeepSeek-R1) or [QwQ-32B](https://huggingface.co/Qwen/QwQ-32B)
- **generation_model**: DeepSeek-R1 or QwQ-32B
- **problem_type**: Can be one of "has_answer_extracted", "no_answer_extracted" and "converted_proof" dependening on whether we were able to extract the answer or if this is a proof question converted to answer question.
- **expected_answer**: Extracted answer if "problem_type" is "has_answer_extracted". Otherwise this is the majority-voting answer across all generated solutions for this problem.
- **problem_source**: States the corresponding AoPS forum (e.g. "aops_c6_high_school_olympiads") or "MATH_training_set" as we also include a small set of generations from [MATH](https://github.com/hendrycks/math).
- **inference_mode**: "cot", "tir" or "genselect"
- **pass_rate_72b_tir**: Pass rate out of 32 generations for [Qwen2.5-Math-72B-Instruct](https://huggingface.co/Qwen/Qwen2.5-Math-72B-Instruct) run in TIR mode. This attribute is only available when "problem_type" is "has_answer_extracted" and is set to "n/a" for other cases.
## OpenMath-Nemotron models
To demonstrate the quality of this dataset, we release a series of OpenMath-Nemotron models trained on this data.
* [OpenMath-Nemotron-1.5B](https://huggingface.co/nvidia/OpenMath-Nemotron-1.5B)
* [OpenMath-Nemotron-7B](https://huggingface.co/nvidia/OpenMath-Nemotron-7B)
* [OpenMath-Nemotron-14B](https://huggingface.co/nvidia/OpenMath-Nemotron-14B)
* [OpenMath-Nemotron-14B-Kaggle](https://huggingface.co/nvidia/OpenMath-Nemotron-14B-Kaggle) (this is the model used in [AIMO-2 Kaggle competition](https://www.kaggle.com/competitions/ai-mathematical-olympiad-progress-prize-2/leaderboard))
* [OpenMath-Nemotron-32B](https://huggingface.co/nvidia/OpenMath-Nemotron-32B)

The models achieve state-of-the-art results on popular mathematical benchmarks. We present metrics as pass@1 (maj@64) where pass@1
is an average accuracy across 64 generations and maj@64 is the result of majority voting.
Please see our [paper](https://arxiv.org/abs/2504.16891) for more details on the evaluation setup.
| Model | AIME24 | AIME25 | HMMT-24-25 | HLE-Math |
|-------------------------------|-----------------|-------|-------|-------------|
| DeepSeek-R1-Distill-Qwen-1.5B | 26.8 (60.0) | 21.4 (36.7) | 14.2 (26.5) | 2.9 (5.0) |
| [OpenMath-Nemotron-1.5B](https://huggingface.co/nvidia/OpenMath-Nemotron-1.5B) CoT | 61.6 (80.0) | 49.5 (66.7) | 39.9 (53.6) | 5.4 (5.4) |
| [OpenMath-Nemotron-1.5B](https://huggingface.co/nvidia/OpenMath-Nemotron-1.5B) TIR | 52.0 (83.3) | 39.7 (70.0) | 37.2 (60.7) | 2.5 (6.2) |
| + Self GenSelect | 83.3 | 70.0 | 62.2 | 7.9 |
| + 32B GenSelect | 83.3 | 70.0 | 62.8 | 8.3 |
| DeepSeek-R1-Distill-Qwen-7B | 54.4 (80.0) | 38.6 (53.3) | 30.6 (42.9) | 3.3 (5.2) |
| [OpenMath-Nemotron-7B](https://huggingface.co/nvidia/OpenMath-Nemotron-7B) CoT | 74.8 (80.0) | 61.2 (76.7) | 49.7 (57.7) | 6.6 (6.6) |
| [OpenMath-Nemotron-7B](https://huggingface.co/nvidia/OpenMath-Nemotron-7B) TIR | 72.9 (83.3) | 57.5 (76.7) | 54.6 (66.3) | 7.8 (10.8) |
| + Self GenSelect | 86.7 | 76.7 | 68.4 | 11.5 |
| + 32B GenSelect | 86.7 | 76.7 | 69.9 | 11.9 |
| DeepSeek-R1-Distill-Qwen-14B | 65.8 (80.0) | 48.4 (60.0) | 40.1 (52.0) | 4.2 (4.8) |
| [OpenMath-Nemotron-14B-MIX (kaggle)](https://huggingface.co/nvidia/OpenMath-Nemotron-14B-Kaggle) | 73.7 (86.7) | 57.9 (73.3) | 50.5 (64.8) | 5.7 (6.5) |
| [OpenMath-Nemotron-14B](https://huggingface.co/nvidia/OpenMath-Nemotron-14B) CoT | 76.3 (83.3) | 63.0 (76.7) | 52.1 (60.7) | 7.5 (7.6) |
| [OpenMath-Nemotron-14B](https://huggingface.co/nvidia/OpenMath-Nemotron-14B) TIR | 76.3 (86.7) | 61.3 (76.7) | 58.6 (70.9) | 9.5 (11.5) |
| + Self GenSelect | 86.7 | 76.7 | 72.4 | 14.1 |
| + 32B GenSelect | 90.0 | 76.7 | 71.9 | 13.7 |
| QwQ-32B | 78.1 (86.7) | 66.5 (76.7) | 55.9 (63.3) | 9.0 (9.5) |
| DeepSeek-R1-Distill-Qwen-32B | 66.9 (83.3) | 51.8 (73.3) | 39.9 (51.0) | 4.8 (6.0) |
| [OpenMath-Nemotron-32B](https://huggingface.co/nvidia/OpenMath-Nemotron-32B) CoT | 76.5 (86.7) | 62.5 (73.3) | 53.0 (59.2) | 8.3 (8.3) |
| [OpenMath-Nemotron-32B](https://huggingface.co/nvidia/OpenMath-Nemotron-32B) TIR | 78.4 (93.3) | 64.2 (76.7) | 59.7 (70.9) | 9.2 (12.5) |
| + Self GenSelect | 93.3 | 80.0 | 73.5 | 15.7 |
| DeepSeek-R1 | 79.1 (86.7) | 64.3 (73.3) | 53.0 (59.2) | 10.5 (11.4) |
## Reproducing our results
The pipeline we used to produce the data and models is fully open-sourced!
- [Code](https://github.com/NVIDIA/NeMo-Skills)
- [Models](https://huggingface.co/collections/nvidia/openmathreasoning-68072c0154a5099573d2e730)
- [Dataset](https://huggingface.co/datasets/nvidia/OpenMathReasoning)
- [Paper](https://arxiv.org/abs/2504.16891)
We provide [all instructions](https://nvidia.github.io/NeMo-Skills/openmathreasoning1/)
to fully reproduce our results, including data generation.
## Citation
If you find our work useful, please consider citing us!
```bibtex
@article{moshkov2025aimo2,
title = {AIMO-2 Winning Solution: Building State-of-the-Art Mathematical Reasoning Models with OpenMathReasoning dataset},
author = {Ivan Moshkov and Darragh Hanley and Ivan Sorokin and Shubham Toshniwal and Christof Henkel and Benedikt Schifferer and Wei Du and Igor Gitman},
year = {2025},
journal = {arXiv preprint arXiv:2504.16891}
}
```
## Dataset Owner(s):
NVIDIA Corporation
## Release Date:
04/23/2025
## Data Version
1.0 (04/23/2025)
## License/Terms of Use:
cc-by-4.0
## Intended Usage:
This dataset is intended to be used by the community to continue to improve models. The data may be freely used to train and evaluate.
## Ethical Considerations:
NVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their internal model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse.
Please report security vulnerabilities or NVIDIA AI Concerns [here](https://www.nvidia.com/en-us/support/submit-security-vulnerability/). |
ACCC1380/private-model | ACCC1380 | 2025-04-24T14:19:42Z | 51,505 | 7 | [
"language:ch",
"license:apache-2.0",
"region:us"
] | [] | 2023-06-13T11:48:06Z | null | ---
license: apache-2.0
language:
- ch
---
# 此huggingface库主要存储本人电脑的一些重要文件
## 如果无法下载文件,把下载链接的huggingface.co改成hf-mirror.com 即可
## 如果你也想要在此处永久备份文件,可以参考我的上传代码:
```python
# 功能函数,清理打包上传
from pathlib import Path
from huggingface_hub import HfApi, login
repo_id = 'ACCC1380/private-model'
yun_folders = ['/kaggle/input']
def hugface_upload(yun_folders, repo_id):
if 5 == 5:
hugToken = '********************' #改成你的huggingface_token
if hugToken != '':
login(token=hugToken)
api = HfApi()
print("HfApi 类已实例化")
print("开始上传文件...")
for yun_folder in yun_folders:
folder_path = Path(yun_folder)
if folder_path.exists() and folder_path.is_dir():
for file_in_folder in folder_path.glob('**/*'):
if file_in_folder.is_file():
try:
response = api.upload_file(
path_or_fileobj=file_in_folder,
path_in_repo=str(file_in_folder.relative_to(folder_path.parent)),
repo_id=repo_id,
repo_type="dataset"
)
print("文件上传完成")
print(f"响应: {response}")
except Exception as e:
print(f"文件 {file_in_folder} 上传失败: {e}")
continue
else:
print(f'Error: Folder {yun_folder} does not exist')
else:
print(f'Error: File {huggingface_token_file} does not exist')
hugface_upload(yun_folders, repo_id)
```
## 本地电脑需要梯子环境,上传可能很慢。可以使用kaggle等中转服务器上传,下载速率400MB/s,上传速率60MB/s。
# 在kaggle上面转存模型:
- 第一步:下载文件
```notebook
!apt install -y aria2
!aria2c -x 16 -s 16 -c -k 1M "把下载链接填到这双引号里" -o "保存的文件名称.safetensors"
```
- 第二步:使用上述代码的API上传
```python
# 功能函数,清理打包上传
from pathlib import Path
from huggingface_hub import HfApi, login
repo_id = 'ACCC1380/private-model'
yun_folders = ['/kaggle/working'] #kaggle的output路径
def hugface_upload(yun_folders, repo_id):
if 5 == 5:
hugToken = '********************' #改成你的huggingface_token
if hugToken != '':
login(token=hugToken)
api = HfApi()
print("HfApi 类已实例化")
print("开始上传文件...")
for yun_folder in yun_folders:
folder_path = Path(yun_folder)
if folder_path.exists() and folder_path.is_dir():
for file_in_folder in folder_path.glob('**/*'):
if file_in_folder.is_file():
try:
response = api.upload_file(
path_or_fileobj=file_in_folder,
path_in_repo=str(file_in_folder.relative_to(folder_path.parent)),
repo_id=repo_id,
repo_type="dataset"
)
print("文件上传完成")
print(f"响应: {response}")
except Exception as e:
print(f"文件 {file_in_folder} 上传失败: {e}")
continue
else:
print(f'Error: Folder {yun_folder} does not exist')
else:
print(f'Error: File {huggingface_token_file} does not exist')
hugface_upload(yun_folders, repo_id)
```
- 第三步:等待上传完成:

|
lang-uk/UberText-NER-Silver | lang-uk | 2025-04-24T12:42:33Z | 48 | 2 | [
"task_categories:token-classification",
"language:uk",
"license:apache-2.0",
"size_categories:10M<n<100M",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us",
"silver-standard",
"ukrainian",
"NER"
] | [
"token-classification"
] | 2025-04-23T19:53:17Z | 2 | ---
dataset_info:
features:
- name: text
dtype: string
splits:
- name: train
num_bytes: 827986534
num_examples: 47982455
download_size: 429416941
dataset_size: 827986534
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
license: apache-2.0
task_categories:
- token-classification
language:
- uk
size_categories:
- 10M<n<100M
tags:
- silver-standard
- ukrainian
- NER
---
# UberText-NER-Silver
**UberText-NER-Silver** is a silver-standard named entity recognition (NER) dataset for the Ukrainian language. It was automatically annotated using a high-performance model trained on NER-UK 2.0 and covers over 2.5 million social media and web sentences. The dataset significantly expands the coverage of underrepresented entity types and informal domains.
## Dataset Summary
- **Total Sentences:** 2,573,205
- **Total Words:** 45,489,533
- **Total Entity Spans:** 4,393,316
- **Entity Types (13):** `PERS`, `ORG`, `LOC`, `DATE`, `TIME`, `JOB`, `MON`, `PCT`, `PERIOD`, `DOC`, `QUANT`, `ART`, `MISC`
- **Format:** IOB-style, token-level annotations
## Source
Texts were taken from the UberText 2.0 corpus social media part, filtered and preprocessed for noise reduction and duplication. The dataset includes both entity-rich and entity-free content to improve model generalization.
## Example Usage
```python
from datasets import load_dataset
dataset = load_dataset("lang-uk/UberText-NER-Silver", split="train")
print(dataset[0])
```
## Applications
- Training large-scale NER models for Ukrainian
- Improving performance in low-resource and informal text domains
- Cross-lingual or transfer learning experiments
## Authors
[Vladyslav Radchenko](https://huggingface.co/pofce), [Nazarii Drushchak](https://huggingface.co/ndrushchak) |
stdKonjac/LiveSports-3K | stdKonjac | 2025-04-24T06:03:04Z | 197 | 4 | [
"task_categories:question-answering",
"language:en",
"size_categories:1K<n<10K",
"format:csv",
"modality:tabular",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"arxiv:2504.16030",
"region:us",
"sports"
] | [
"video-to-text",
"question-answering"
] | 2025-04-19T08:21:41Z | 2 | ---
configs:
- config_name: LiveSports_3K_CC
data_files:
- split: val
path: LiveSports-3K-CC-val.csv
- split: test
path: LiveSports-3K-CC-test.csv
- config_name: LiveSports_3K_QA
data_files:
- split: test
path: LiveSports-3K-QA.csv
task_categories:
- video-to-text
- question-answering
language:
- en
tags:
- sports
---
# LiveSports-3K Benchmark
## Overview
LiveSports‑3K is a comprehensive benchmark for evaluating streaming video understanding capabilities of large language
and multimodal models. It consists of two evaluation tracks:
- **Closed Captions (CC) Track**: Measures models’ ability to generate real‑time commentary aligned with the
ground‑truth ASR transcripts.
- **Question Answering (QA) Track**: Tests models on multiple‑choice questions that probe semantic understanding.
The benchmark is introduced in the CVPR 2025 paper: *LiveCC: Learning Video LLM with Streaming Speech Transcription at
Scale* [[Paper](https://huggingface.co/papers/2504.16030)]. [[Code](https://github.com/ShowLab/LiveCC)]
## Dataset Structure
```
├── LiveSports-3K-CC-val.csv # Validation set for CC track (202 events)
├── LiveSports-3K-CC-test.csv # Test set for CC track (1500 events)
└── LiveSports-3K-QA.csv # QA track (1,174 multiple-choice questions)
```
### Closed Captions (CC) Track
- **Total events**: 1,702
- **CSV files**:
- `LiveSports-3K-CC-val.csv`: 202 events, with ground-truth ASR transcripts provided.
- `LiveSports-3K-CC-test.csv`: 1500 events, no ground-truth ASR transcripts.
**File format** (`*.csv`):
| Column | Type | Description |
|---------------|----------------------------|------------------------------------------------------------------------------------|
| `video_id` | string | YouTube video ID. |
| `url` | string | YouTube video URL. |
| `event_id` | string | Unique event identifier in a video. |
| `begin` | float | Event start time in seconds. |
| `end` | float | Event end time in seconds. |
| `event_title` | string | Event title generated by GPT-4o-mini |
| `event_type` | int | Event type (internal usage, no actual meaning) |
| `video` | string | Video name. |
| `class` | string | Video category generated by GPT-4o-mini |
| `event_asr` | list[(float,float,string)] | Ground-truth ASR transcript for the event, in the format of (begin, end, content). |
### Question Answering (QA) Track
- **Total questions**: 1,174 four‑option MCQs
**File**: `LiveSports-3K-QA.csv`
**File format**:
| Column | Type | Description |
|------------|--------|------------------------------------------------------------------------|
| `video_id` | string | YouTube video ID. |
| `event_id` | string | Unique event identifier in a video. |
| `video` | string | Video name. |
| `begin` | float | Event start time in seconds. |
| `end` | float | Event end time in seconds. |
| `q_id` | string | Unique question identifier in a video. |
| `q_type` | string | One of `Who`, `When`, or `What`, indicating the aspect queried. |
| `OCR` | int | `1` if the question requires OCR for reading on-screen text, else `0`. |
| `question` | string | The full multiple-choice question text. |
| `option_A` | string | Text of choice A. |
| `option_B` | string | Text of choice B. |
| `option_C` | string | Text of choice C. |
| `option_D` | string | Text of choice D. |
| `answer` | string | Correct option label (`A`/`B`/`C`/`D`). |
## Evaluation Protocols
### CC Track
1. **Input**: Video title + previous CC (or empty if first event).
2. **Task**: Generate the next ASR caption for the event segment.
3. **Metric**: **Win rate** against GPT‑4o baseline, judged by GPT‑4o on stylistic and semantic alignment with ground
truth.
### QA Track
1. **Input**: Video clip frames + question + four answer options.
2. **Task**: Select the correct option.
3. **Metric**: **Accuracy** (percentage of correctly answered questions).
## Usage Example (Python)
```python
import pandas as pd
# Load validation captions
cc_val = pd.read_csv("LiveSports-3K-CC-val.csv")
# Load QA set
qa = pd.read_csv("LiveSports-3K-QA.csv")
# Example: Inspect a CC event
print(cc_val.iloc[0])
# Example: Inspect a QA sample
print(qa.iloc[0])
```
## Citation
```bibtex
@article{livecc,
author = {Joya Chen and Ziyun Zeng and Yiqi Lin and Wei Li and Zejun Ma and Mike Zheng Shou},
title = {LiveCC: Learning Video LLM with Streaming Speech Transcription at Scale},
journal = {arXiv preprint arXiv:2504.16030}
year = {2025},
}
``` |
Nexdata/Infant_Laugh_Speech_Data_by_Mobile_Phone | Nexdata | 2025-04-24T06:01:34Z | 68 | 2 | [
"size_categories:n<1K",
"format:audiofolder",
"modality:audio",
"modality:text",
"library:datasets",
"library:mlcroissant",
"region:us"
] | [] | 2022-06-22T08:59:55Z | 1 | ---
YAML tags:
- copy-paste the tags obtained with the tagging app: https://github.com/huggingface/datasets-tagging
---
# Dataset Card for Nexdata/Infant_Laugh_Speech_Data_by_Mobile_Phone
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://www.nexdata.ai/datasets/speechrecog/1090?source=Huggingface
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
This dataset is just a sample of Infant Laugh Speech Data by Mobile Phone(paid dataset).Laugh sound of 20 infants and young children aged 0~3 years old, a number of paragraphs from each of them; It provides data support for detecting children's laugh sound in smart home projects.
For more details & to download the rest of the dataset(paid),please refer to the link: https://www.nexdata.ai/datasets/speechrecog/1090?source=Huggingface
### Supported Tasks and Leaderboards
automatic-speech-recognition, audio-speaker-identification: The dataset can be used to train a model for Automatic Speech Recognition (ASR).
### Languages
Infant Cry
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
Commerical License
### Citation Information
[More Information Needed]
### Contributions
|
lang-uk/WikiEdits-MultiGEC | lang-uk | 2025-04-23T20:37:33Z | 99 | 2 | [
"task_categories:text2text-generation",
"task_categories:text-generation",
"language:uk",
"language:en",
"language:de",
"language:cz",
"language:it",
"language:et",
"language:sl",
"language:el",
"language:lv",
"language:is",
"language:sv",
"license:mit",
"size_categories:10K<n<100K",
"region:us",
"gec",
"multigec"
] | [
"text2text-generation",
"text-generation"
] | 2025-04-21T14:29:54Z | 2 | ---
license: mit
language:
- uk
- en
- de
- cz
- it
- et
- sl
- el
- lv
- is
- sv
task_categories:
- text2text-generation
- text-generation
size_categories:
- 10K<n<100K
tags:
- gec
- multigec
pretty_name: wikiedits_multigec
---
# WikiEdits-MultiGEC Dataset
## Overview
WikiEdits-MultiGEC is a small dataset of human error corrections made by Wikipedia contributors for eleven languages.
These revisions were obtained using the official Wikipedia API, covering the six months from September 28, 2024, to April 17, 2025.
## Structure
- `wikiedits_multi_gec.csv` - main data.
- `index` - index;
- `language` - language of text;
- `text` - original text;
- `correction` - corrected text;
- `wikiedits_multi_gec_metadata.csv` - contains metadata related to the main data `wikiedits_multi_gec.csv`.
- `index` - index;
- `text_del` -
- `text_ins` -
- `text_del_tag` -
- `text_ins_tag` -
- `deletions` -
- `insertions` -
- `language` -
- `url` -
- `wikiedits_uk_annotations.csv` - contains human annotations for 1500 samples for the Ukrainian language.
- `text` - original text;
- `correction` - corrected text;
- `score` - annotator score;
- `is_rejected` - if the annotator rejects the correction.
## Dataset Statistics
||english|italian|ukrainian|german|czech|swedish|greek|estonian|slovene|latvian|icelandic|
|-|-|-|-|-|-|-|-|-|-|-|-|
|# pages|5003|2398|1409|1706|447|216|134|39|26|20|0|
|# edits all|12465|6024|5126|4672|1114|585|492|126|108|75|0|
|# edits|6807|3726|3092|2380|698|363|256|79|43|33|0|
## How to use it
You can merge `wikiedits_multi_gec.csv` with `wikiedits_uk_annotations.csv` and `wikiedits_multi_gec.csv` and `wikiedits_multi_gec_metadata.csv`.
```python
import pandas as pd
df_wikiedits = pd.read_csv('wikiedits_multi_gec.csv')
df_wikiedits_anot = pd.read_csv('wikiedits_uk_annotations.csv')
df_wikiedits_metadata = pd.read_csv('wikiedits_multi_gec_metadata.csv')
df_anot = df_wikiedits_anot.merge(df_wikiedits, on=['text', 'correction'], how='left')
df_metadata = df_wikiedits_metadata.merge(df_wikiedits, on=['index'], how='left')
```
## Authors
[Petro Ivaniuk](https://huggingface.co/peterua), [Mariana Romanyshyn](https://huggingface.co/mariana-scorp), [Roman Kovalchuk](https://huggingface.co/rkovalchuk)
## |
open-r1/codeforces | open-r1 | 2025-04-23T16:37:27Z | 4,123 | 31 | [
"license:cc-by-4.0",
"size_categories:10K<n<100K",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-02-12T11:54:21Z | 2 | ---
dataset_info:
features:
- name: id
dtype: string
- name: aliases
sequence: string
- name: contest_id
dtype: string
- name: contest_name
dtype: string
- name: contest_type
dtype: string
- name: contest_start
dtype: int64
- name: contest_start_year
dtype: int64
- name: index
dtype: string
- name: time_limit
dtype: float64
- name: memory_limit
dtype: float64
- name: title
dtype: string
- name: description
dtype: string
- name: input_format
dtype: string
- name: output_format
dtype: string
- name: interaction_format
dtype: string
- name: note
dtype: string
- name: examples
list:
- name: input
dtype: string
- name: output
dtype: string
- name: editorial
dtype: string
- name: rating
dtype: int64
- name: tags
sequence: string
- name: testset_size
dtype: int64
- name: official_tests
list:
- name: input
dtype: string
- name: output
dtype: string
- name: official_tests_complete
dtype: bool
- name: input_mode
dtype: string
- name: generated_checker
dtype: string
- name: executable
dtype: bool
splits:
- name: train
num_bytes: 5361036706
num_examples: 9556
- name: test
num_bytes: 108370855
num_examples: 468
download_size: 2755233485
dataset_size: 5469407561
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
license: cc-by-4.0
---
# Dataset Card for CodeForces
## Dataset description
[CodeForces](https://codeforces.com/) is one of the most popular websites among competitive programmers, hosting regular contests where participants must solve challenging algorithmic optimization problems. The challenging nature of these problems makes them an interesting dataset to improve and test models’ code reasoning capabilities.
While previous efforts such as [DeepMind’s CodeContests dataset](https://huggingface.co/datasets/deepmind/code_contests) have compiled a large amount of CodeForces problems, we have compiled more than **10k unique problems** covering the very first contests all the way to 2025, **~3k** of which were not included in DeepMind’s dataset. Additionally, for around 60% of problems, we have **included the *editorial*,** which is an explanation, written by the contest organizers, explaining the correct solution. You will also find 3 correct solutions per problem extracted from the official website (soon).
You can load the dataset as follows:
```python
from datasets import load_dataset
ds = load_dataset("open-r1/codeforces", "train")
```
We are also releasing [`open-r1/codeforces-cots`](http://hf.co/datasets/open-r1/codeforces-cots), which contains chain of thought generations produced by DeepSeek-R1 on these problems, where we asked the model to produce solutions in C++ (the main language used in competitive programming) and Python, totaling close to **100k** samples.
## License
The dataset is licensed under the Open Data Commons Attribution License (ODC-By) 4.0 license.
## Citation
If you find CodeForces useful in your work, please consider citing it as:
```
@misc{penedo2025codeforces,
title={CodeForces},
author={Guilherme Penedo and Anton Lozhkov and Hynek Kydlíček and Loubna Ben Allal and Edward Beeching and Agustín Piqueres Lajarín and Quentin Gallouédec and Nathan Habib and Lewis Tunstall and Leandro von Werra},
year={2025},
publisher = {Hugging Face},
journal = {Hugging Face repository},
howpublished = {\url{https://huggingface.co/datasets/open-r1/codeforces}}
}
``` |
Nexdata/Infant_Cry_Speech_Data_by_Mobile_Phone | Nexdata | 2025-04-23T05:40:52Z | 141 | 1 | [
"task_categories:automatic-speech-recognition",
"task_categories:voice-activity-detection",
"size_categories:n<1K",
"format:audiofolder",
"modality:audio",
"modality:text",
"library:datasets",
"library:mlcroissant",
"region:us"
] | [
"automatic-speech-recognition",
"voice-activity-detection"
] | 2022-06-22T08:21:57Z | 1 | ---
YAML tags:
- copy-paste the tags obtained with the tagging app: https://github.com/huggingface/datasets-tagging
task_categories:
- automatic-speech-recognition
- voice-activity-detection
---
# 201-People-Infant-Cry-Speech-Data-by-Mobile-Phone
## Description
This dataset is just a sample of Infant Cry Speech dataset(paid dataset) by mobile phone.Crying sound of 201 infants and young children aged 0~3 years old, a number of paragraphs from each of them; It provides data support for detecting children's crying sound in smart home projects.
For more details & to download the rest of the dataset(paid),please refer to the link:https://www.nexdata.ai/datasets/speechrecog/998?source=Huggingface
## Format
16kHz, 16bit, uncompressed wav, mono channel
## Recording Environment
relatively quiet indoor environment, without echo
## Recording Content
infant cry
## Population
201 people; 105 boys, 96 girls;
## Device
iPhone, Android mobile phone
## Application scene
abnormal voice recognition,smart home
# Licensing Information
Commercial License |
agibot-world/GenieSimAssets | agibot-world | 2025-04-22T13:18:09Z | 1,396 | 6 | [
"task_categories:other",
"language:en",
"region:us",
"real-world",
"dual-arm",
"robotics manipulation",
"simulation"
] | [
"other"
] | 2025-04-21T11:18:48Z | 3 | ---
pretty_name: Genie Sim Assets
size_categories:
- n>10G
task_categories:
- other
language:
- en
tags:
- real-world
- dual-arm
- robotics manipulation
- simulation
extra_gated_prompt: >-
### AgiBot World COMMUNITY LICENSE AGREEMENT
AgiBot World Alpha Release Date: December 30, 2024 All the data and code
within this repo are under [CC BY-NC-SA
4.0](https://creativecommons.org/licenses/by-nc-sa/4.0/).
extra_gated_fields:
First Name: text
Last Name: text
Email: text
Country: country
Affiliation: text
Phone: text
Job title:
type: select
options:
- Student
- Research Graduate
- AI researcher
- AI developer/engineer
- Reporter
- Other
Research interest: text
geo: ip_location
By clicking Submit below I accept the terms of the license and acknowledge that the information I provide will be collected stored processed and shared in accordance with the AgiBot Privacy Policy: checkbox
extra_gated_description: >-
The information you provide will be collected, stored, processed and shared in
accordance with the AgiBot Privacy Policy.
extra_gated_button_content: Submit
viewer: false
---
<img src="geniesim.jpg" alt="Image Alt Text" width="80%" style="display: block; margin-left: auto; margin-right: auto;" />
<div align="center">
<a href="https://github.com/AgibotTech/genie_sim">
<img src="https://img.shields.io/badge/GitHub-grey?logo=GitHub" alt="GitHub">
</a>
<a href="https://huggingface.co/datasets/agibot-world/GenieSimAssets">
<img src="https://img.shields.io/badge/HuggingFace-yellow?logo=HuggingFace" alt="HuggingFace">
</a>
<a href="https://agibot-world.com/sim-evaluation">
<img src="https://img.shields.io/badge/Genie%20Sim%20Benchmark-blue?style=plastic" alt="Genie Sim Benchmark">
</a>
<a href="https://genie.agibot.com/en/geniestudio">
<img src="https://img.shields.io/badge/Genie_Studio-green?style=flat" alt="Genie Studio">
</a>
</div>
# Key Features 🔑
- **12 scenarios** including supermarket, cafeteria and home
- **550+** objects 1:1 replicated from real-life
# Get started 🔥
## Download the Simulation Assets
To download the full assets, you can use the following code. If you encounter any issues, please refer to the official Hugging Face documentation.
```
# Make sure you have git-lfs installed (https://git-lfs.com)
git lfs install
# When prompted for a password, use an access token with write permissions.
# Generate one from your settings: https://huggingface.co/settings/tokens
git clone https://huggingface.co/datasets/agibot-world/GenieSimAssets
# If you want to clone without large files - just their pointers
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/datasets/agibot-world/GenieSimAssets
```
## Assets Structure
### Folder hierarchy
```
assets
├── G1 # G1 Robot
│ ├── G1_pico.usd
│ ├── G1.usd
│ └── ...
├── materials # materials
│ ├── carpet
│ ├── hdri
│ ├── stone
│ └── wood
├── objects # objects
│ ├── benchmark
│ ├── genie
│ └── lightwheelai
├── README.md
└── scenes # scenes
├── genie
└── guanglun
```
# License and Citation
All the data and code within this repo are under [CC BY-NC-SA 4.0](https://creativecommons.org/licenses/by-nc-sa/4.0/). Please consider citing our project if it helps your research.
```BibTeX
@misc{contributors2025geniesimrepo,
title={Genie Sim Assets},
author={Genie Sim Team},
howpublished={https://github.com/AgibotTech/genie_sim},
year={2025}
}
```
|
xsample/tulu-3-mig-50k | xsample | 2025-04-22T08:36:28Z | 218 | 2 | [
"task_categories:text-generation",
"language:en",
"license:odc-by",
"size_categories:10K<n<100K",
"format:json",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"arxiv:2504.13835",
"region:us"
] | [
"text-generation"
] | 2025-04-18T13:09:57Z | 2 | ---
license: odc-by
task_categories:
- text-generation
language:
- en
---
## Tulu-3-MIG-50K
[Project](https://yichengchen24.github.io/projects/mig/) | [Github](https://github.com/yichengchen24/xsample) | [Paper](https://arxiv.org/abs/2504.13835) | [HuggingFace's collection](https://huggingface.co/collections/xsample/mig-datasets-6800b4d225243877293eff3b)
MIG is an automatic data selection method for instruction tuning.
This dataset includes 50K **high-quality** and **diverse** SFT data sampled from [Tulu3](https://huggingface.co/datasets/allenai/tulu-3-sft-mixture).
## Performance
| Method | Data Size | ARC | BBH | GSM | HE | MMLU | IFEval | Avg_obj | AE | MT | Wild | Avg_sub | Avg |
| ------- | --------- | ------------ | ------------ | ------------ | ------------ | ------------ | ------------ | ---------------- | ------------ | ----------- | ------------- | ---------------- | ------------ |
| Pool | 939K | 69.15 | 63.88 | 83.40 | 63.41 | 65.77 | 67.10 | 68.79 | 8.94 | 6.86 | -24.66 | 38.40 | 53.59 |
| Random | 50K | 74.24 | 64.80 | 70.36 | 51.22 | 63.86 | 61.00 | 64.25 | 8.57 | <u>7.06</u> | -22.15 | 39.36 | 51.81 |
| ZIP | 50K | 77.63 | 63.00 | 52.54 | 35.98 | 65.00 | 61.00 | 59.19 | 6.71 | 6.64 | -32.10 | 35.69 | 47.44 |
| IFD | 50K | 75.93 | 63.56 | 61.03 | 49.39 | 64.39 | 53.60 | 61.32 | 12.30 | 7.03 | -20.20 | 40.83 | 51.08 |
| #InsTag | 50K | 72.54 | 64.80 | 69.83 | 48.17 | 63.50 | **65.99** | 64.14 | 6.58 | 6.84 | -20.70 | 38.21 | 51.17 |
| DEITA | 50K | 78.98 | 66.11 | **74.07** | 49.39 | 64.00 | 64.33 | <u>66.15</u> | 10.19 | 6.83 | <u>-19.95</u> | 39.50 | 52.83 |
| CaR | 50K | 78.98 | **69.04** | 71.42 | 52.44 | **65.15** | 56.75 | 65.63 | 12.55 | 6.95 | -20.67 | 40.57 | 53.10 |
| QDIT | 50K | <u>79.66</u> | 65.42 | 70.74 | <u>53.05</u> | <u>65.06</u> | 57.30 | 65.21 | **15.78** | 6.76 | -20.56 | <u>41.03</u> | <u>53.12</u> |
| MIG | 50K | **80.00** | <u>66.39</u> | <u>72.02</u> | **57.93** | 64.44 | <u>65.06</u> | **67.64** | <u>14.66</u> | **7.32** | **-17.77** | **42.99** | **55.32** |
## Citation
```
@article{chen2025mig,
title={MIG: Automatic Data Selection for Instruction Tuning by Maximizing Information Gain in Semantic Space},
author={Chen, Yicheng and Li, Yining and Hu, Kai and Ma, Zerun and Ye, Haochen and Chen, Kai},
journal={arXiv preprint arXiv:2504.13835},
year={2025}
}
``` |
simon3000/genshin-voice | simon3000 | 2025-04-22T03:19:19Z | 4,456 | 104 | [
"task_categories:audio-classification",
"task_categories:automatic-speech-recognition",
"task_categories:text-to-speech",
"language:zh",
"language:en",
"language:ja",
"language:ko",
"size_categories:100K<n<1M",
"format:parquet",
"modality:audio",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | [
"audio-classification",
"automatic-speech-recognition",
"text-to-speech"
] | 2024-04-25T00:09:03Z | null | ---
language:
- zh
- en
- ja
- ko
task_categories:
- audio-classification
- automatic-speech-recognition
- text-to-speech
pretty_name: Genshin Voice
dataset_info:
features:
- name: audio
dtype: audio
- name: transcription
dtype: string
- name: language
dtype: string
- name: speaker
dtype: string
- name: speaker_type
dtype: string
- name: type
dtype: string
- name: inGameFilename
dtype: string
splits:
- name: train
num_bytes: 246839751624.224
num_examples: 424011
download_size: 209621886182
dataset_size: 246839751624.224
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Genshin Voice
Genshin Voice is a dataset of voice lines from the popular game [Genshin Impact](https://genshin.hoyoverse.com/).
Hugging Face 🤗 [Genshin-Voice](https://huggingface.co/datasets/simon3000/genshin-voice)
<!-- STATS -->
Last update at `2025-04-22`
`424011` wavs
`40907` without speaker (10%)
`40000` without transcription (9%)
`10313` without inGameFilename (2%)
<!-- STATS_END -->
## Dataset Details
### Dataset Description
The dataset contains voice lines from the game's characters in multiple languages, including Chinese, English, Japanese, and Korean.
The voice lines are spoken by the characters in the game and cover a wide range of topics, including greetings, combat, and story dialogue.
- **Language(s) (NLP):** Chinese, English, Japanese, Korean
## Uses
To install Hugging Face's datasets library, follow the instructions from [this link](https://huggingface.co/docs/datasets/installation#audio).
### Example: Load the dataset and filter for Chinese voices of Ganyu with transcriptions
```python
from datasets import load_dataset
import soundfile as sf
import os
# Load the dataset
dataset = load_dataset('simon3000/genshin-voice', split='train', streaming=True)
# Filter the dataset for Chinese voices of Ganyu with transcriptions
chinese_ganyu = dataset.filter(lambda voice: voice['language'] == 'Chinese' and voice['speaker'] == 'Ganyu' and voice['transcription'] != '')
# Create a folder to store the audio and transcription files
ganyu_folder = 'ganyu'
os.makedirs(ganyu_folder, exist_ok=True)
# Process each voice in the filtered dataset
for i, voice in enumerate(chinese_ganyu):
audio_path = os.path.join(ganyu_folder, f'{i}_audio.wav') # Path to save the audio file
transcription_path = os.path.join(ganyu_folder, f'{i}_transcription.txt') # Path to save the transcription file
# Save the audio file
sf.write(audio_path, voice['audio']['array'], voice['audio']['sampling_rate'])
# Save the transcription file
with open(transcription_path, 'w') as transcription_file:
transcription_file.write(voice['transcription'])
print(f'{i} done') # Print the progress
```
### You unpacked the game and just want to know what the wavs are about
result.json format: (subject to change)
```json
{
"9b5502fb1b83cb97.wav": {
"inGameFilename": "VO_friendship\\VO_raidenShogun\\vo_raidenEi_dialog_pendant.wem",
"filename": "9b5502fb1b83cb97.wav",
"language": "English(US)",
"transcription": "Really? So in all this time, no new Electro Visions have appeared in the outside world? Well, what I can say on this topic is subject to certain constraints, but... it is not by my will that Visions are granted or denied. The key is people's desire, and... well, there's another side to it too.",
"speaker": "Raiden Shogun",
"talkRoleType": "",
"talkRoleID": "",
"guid": "f8e72b65-6c0a-4df1-a2f0-2bb08dbeab75",
"voiceConfigs": [
{
"gameTrigger": "Fetter",
"gameTriggerArgs": 3001,
"avatarName": "Switch_raidenShogun"
}
]
}
}
```
## Dataset Creation
### Source Data
The data was obtained by unpacking the [Genshin Impact](https://genshin.hoyoverse.com/) game.
#### Data Collection and Processing
Please refer to [Genshin-Voice](https://github.com/simon300000/genshin-voice) and [w4123/GenshinVoice](https://github.com/w4123/GenshinVoice) for more information on how the data was processed.
#### Who are the source data producers?
The source data producers are the developers of the game, miHoYo.
### Annotations
The dataset contains official annotations from the game, including language, speaker name, and transcription.
## Bias, Risks, and Limitations
Annotations are incomplete. Some voice lines are missing speaker names and transcriptions.
Speakers and transcriptions may contain markups and placeholders: `#<color=#37FFFF>パイモン:</color>{NICKNAME}、すごく怖い悪夢を見たことってあるか?\\n<color=#37FFFF>{NICKNAME}:...`
### Recommendations
Users should be made aware of the risks, biases and limitations of the dataset.
Speaker names can be partially inferred from the ingame filenames.
## Licensing Information
Copyright © COGNOSPHERE. All Rights Reserved.
## More Information
I can upload wav files on demand.
|
AimonLabs/HDM-Bench | AimonLabs | 2025-04-21T20:50:08Z | 121 | 4 | [
"language:en",
"license:cc-by-nc-sa-4.0",
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"arxiv:2504.07069",
"region:us"
] | [] | 2025-04-01T18:48:27Z | 4 | ---
license: cc-by-nc-sa-4.0
language:
- en
pretty_name: Hallucination Detection Model Benchmark
dataset_info:
features:
- name: id
dtype: string
- name: prompt
dtype: string
- name: context
dtype: string
- name: response
dtype: string
- name: is_ctx_hallucination
dtype: string
- name: ctx_hallucinated_span_indices
dtype: string
- name: is_span_common_knowledge
sequence: string
- name: split
dtype: string
- name: is_hallucination
dtype: string
splits:
- name: synthetic
num_bytes: 3462419
num_examples: 1121
- name: mr
num_bytes: 677718
num_examples: 199
download_size: 2396299
dataset_size: 4140137
configs:
- config_name: default
data_files:
- split: synthetic
path: data/synthetic-*
- split: mr
path: data/mr-*
---
<img src="https://lh7-rt.googleusercontent.com/docsz/AD_4nXf_XGI0bexqeySNP6YA-yzUY-JRfNNM9A5p4DImWojxhzMUfyZvVu2hcY2XUZPXgPynBdNCR1xen0gzNbMugvFfK37VwSJ9iim5mARIPz1C-wyh3K7zUInxm2Mvy9rL7Zcb7T_3Mw?key=x9HqmDQsJmBeqyuiakDxe8Cs" alt="Aimon Labs Inc" style="background-color: white;" width="400"/>
Join our Discord server for any questions around building reliable RAG, LLM, or Agentic Apps:
## AIMon GenAIR (https://discord.gg/yXZRnBAWzS)
# Dataset Card for HDM-Bench
<table>
<tr>
<td><strong>Paper:</strong></td>
<td><a href="https://arxiv.org/abs/2504.07069"><img src="https://img.shields.io/badge/arXiv-2504.07069-b31b1b.svg" alt="arXiv Badge" /></a> <em>HalluciNot: Hallucination Detection Through Context and Common Knowledge Verification.</em></td>
</tr>
<tr>
<td><strong>Notebook:</strong></td>
<td><a href="https://colab.research.google.com/drive/1HclyB06t-wZVIxuK6AlyifRaf77vO5Yz?usp=sharing"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Colab Badge" /></a></td>
</tr>
<tr>
<td><strong>GitHub Repository:</strong></td>
<td><a href="https://github.com/aimonlabs/hallucination-detection-model"><img src="https://img.shields.io/badge/GitHub-100000?style=for-the-badge&logo=github&logoColor=white" alt="GitHub Badge" /></a></td>
</tr>
<tr>
<td><strong>HDM-Bench Dataset:</strong></td>
<td><a href="https://huggingface.co/datasets/AimonLabs/HDM-Bench"><img src="https://huggingface.co/datasets/huggingface/badges/resolve/main/dataset-on-hf-md-dark.svg" alt="HF Dataset Badge" /></a></td>
</tr>
<tr>
<td><strong>HDM-2-3B Model:</strong></td>
<td><a href="https://huggingface.co/AimonLabs/hallucination-detection-model"><img src="https://huggingface.co/datasets/huggingface/badges/resolve/main/model-on-hf-md-dark.svg" alt="HF Model Badge" /></a></td>
</tr>
</table>
This dataset provides a benchmark for evaluating the ability of language models to detect hallucinations.
HDM-Bench contains a diverse collection of text examples with hallucinations annotated at phrase level across various domains.
Note that this dataset contains the test split and is meant only for benchmarking.
This dataset **should not be used for training or hyperparameter-tuning** of models.
There are two splits in this dataset:
- synthetic: dataset created using our curation and filtering process (see linked paper for details)
- mr: a subset of rows that were randomly assigned for human annotation.
## Dataset Details
### Dataset Description
HDM-Bench (Hallucination Detection Model Benchmark) is designed to evaluate and compare the performance of models in identifying factual inaccuracies and hallucinations in text generated by language models.
The benchmark consists of 1000 text samples across with a split containing human-annotated labels.
Each example includes the LLM `response`, source `context` (when applicable), and detailed annotation explaining why a statement is considered a hallucination.
- **Curated by:** AIMon Labs Inc.
- **Funded by:** AIMon Labs Inc.
- **Shared by:** AIMon Labs Inc.
- **Language(s) (NLP):** English
- **License:** CC BY-NC-SA 4.0
### Dataset Sources
- **Repository:** https://github.com/aimonlabs/hallucination-detection-model
- **Paper:** https://arxiv.org/abs/2504.07069
- **Demo:** [](https://colab.research.google.com/drive/1HclyB06t-wZVIxuK6AlyifRaf77vO5Yz?usp=sharing)
### More Information
**Paper:**
[](https://arxiv.org/abs/2504.07069)
*HalluciNot: Hallucination Detection Through Context and Common Knowledge Verification.*
**HDM-2 Notebook:** [](https://colab.research.google.com/drive/1HclyB06t-wZVIxuK6AlyifRaf77vO5Yz?usp=sharing)
## Uses
### Direct Use
HDM-Bench can be directly used for:
- Evaluating and benchmarking hallucination detection capabilities of language models
- Training specialized hallucination detection models for non-commercial usage (see attached License for more details)
- Conducting research on common knowledge consistency in language generation
- Educational purposes to demonstrate common types of model hallucinations
- Developing better evaluation metrics for generated text
### Out-of-Scope Use
This dataset is not suitable for:
- Training general purpose language models
- Conclusively determining a model's overall reliability or safety purely based on this benchmark
- Evaluating hallucination detection in non-English languages
## Dataset Structure
The dataset is structured as a CSV file with the following fields for each entry:
- `prompt`: The prompt that is provided to the LLM
- `context`: The context provided to the LLM that the LLM uses to generate a response
- `response`: The text based response generated by the LLM
- `is_ctx_hallucination`: This field is true if the response contains any spans (continuous portions of text) that are not grounded on the facts stated in the context.
- `ctx_hallucinated_span_indices`: The indices in the `response` string that point to the phrases (substrings) that are not supported by the context (Context Hallucination). Format is an array of arrays where each array has a [start_index, end_index] of a specific phrase. Keep in mind that the claims in these phrases are not necessarily false, they are just not supported by the presented context. They could still be well-known true facts.
- `is_span_common_knowledge`: For each array in the `ctx_hallucinated_span_indices` array, a 'yes' indicates if this information comes from well known common knowledge sources and a 'no' indicates that this information is not backed by well known common knowledge sources.
- `is_hallucination`: If the `ctx_hallucinated_span_indices` is non empty and if `is_span_common_knowledge` contains a 'no' (which means at least one of the items was not common knowledge), then the value of `is_hallucinated` will be a 'yes'. In other cases, its value will be a 'no'.
The dataset is purely a `test` dataset which contains two splits: one split that contains synthetically generated labels ('synthetic') and another human labelled split ('mr'). It is important to note that the 'mr' split is a subset of the 'synthetic' split - the only difference is that the columns have gone through an addition human review and correction process described below.
### Human review process
We used a stacked two person review process. The first reviewer would take the first pass and the second reviewer would act as a quality checker as a second pass. Each of these columns were reviewed: `is_ctx_hallucination`, `ctx_hallucinated_span_indices` (a hydrated string version of this column in the human review tool), `is_span_common_knowledge` and `is_hallucination`. For the columns that
the labeller thought were incorrect, the corrected labels/values were placed in those columns.
## Dataset Creation
### Curation Rationale
HDM-Bench was created to address the growing concern of hallucinations in large language models. As these models are increasingly deployed in real-world applications, their tendency to produce plausible but factually incorrect information poses significant risks. This benchmark provides a standardized way to measure and compare model performance on hallucination detection. Existing datasets like RAGTruth do not support facts backed by common knowledge.
### Source Data and Annotations Process
Please refer to the [appendix section of our paper](https://arxiv.org/abs/2504.07069) on details of the dataset generation and curation.
## Bias, Risks, and Limitations
This dataset has several limitations:
- Coverage is limited to English language
- Some domains may have better representation than others
- Expert annotations of "common knowledge" may still contain subjective judgments despite quality control efforts
Potential risks include:
- Cultural or contextual biases may be present in the selection of what constitutes "common knowledge"
## Recommendations
Users of this dataset should:
- Supplement evaluation with domain-specific tests for their particular use cases
- Consider the English-language focus when applying to multilingual contexts
- Avoid over-optimizing models specifically for this benchmark at the expense of generalizability
- Use multiple evaluation metrics beyond simple accuracy on hallucination detection
- Consider the cultural and historical context that defines what is considered "common knowledge"
## Citation
The full-text of our paper 📃 is available on arXiv [here](https://arxiv.org/abs/2504.07069).
If you use HDM-Bench or HDM-2 in your research, please cite:
**BibTeX:**
```
@misc{paudel2025hallucinothallucinationdetectioncontext,
title={HalluciNot: Hallucination Detection Through Context and Common Knowledge Verification},
author={Bibek Paudel and Alexander Lyzhov and Preetam Joshi and Puneet Anand},
year={2025},
eprint={2504.07069},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2504.07069},
}
```
## Glossary
- **Hallucination**: Content generated by an AI system that is factually incorrect or unsupported by available evidence
- **Context Hallucination**: Information in the response not supported by the provided context
- **Common Knowledge**: Information that is widely known and accepted by the general public
- **Span**: A continuous portion of text in the response
- **Context Hallucinated Span**: A segment of text that contains information not supported by context
- **Inter-annotator Agreement**: Statistical measure of how much consensus exists among annotators
## Dataset Card Authors
AIMon Labs Inc.
## Dataset Card Contact
For questions or feedback about this dataset, please contact [email protected] or open an issue on our GitHub repository: https://github.com/aimonlabs/hallucination-detection-model
## AIMon Website(https://www.aimon.ai) |
lerobot/pusht | lerobot | 2025-04-21T07:38:16Z | 5,814 | 10 | [
"task_categories:robotics",
"license:mit",
"size_categories:10K<n<100K",
"format:parquet",
"modality:tabular",
"modality:timeseries",
"modality:video",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"arxiv:2303.04137",
"region:us",
"LeRobot"
] | [
"robotics"
] | 2024-03-23T13:23:11Z | 2 | ---
license: mit
task_categories:
- robotics
tags:
- LeRobot
configs:
- config_name: default
data_files: data/*/*.parquet
---
This dataset was created using [LeRobot](https://github.com/huggingface/lerobot).
## Dataset Description
- **Homepage:** https://diffusion-policy.cs.columbia.edu/
- **Paper:** https://arxiv.org/abs/2303.04137v5
- **License:** mit
## Dataset Structure
[meta/info.json](meta/info.json):
```json
{
"codebase_version": "v2.0",
"robot_type": "unknown",
"total_episodes": 206,
"total_frames": 25650,
"total_tasks": 1,
"total_videos": 206,
"total_chunks": 1,
"chunks_size": 1000,
"fps": 10,
"splits": {
"train": "0:206"
},
"data_path": "data/chunk-{episode_chunk:03d}/episode_{episode_index:06d}.parquet",
"video_path": "videos/chunk-{episode_chunk:03d}/{video_key}/episode_{episode_index:06d}.mp4",
"features": {
"observation.image": {
"dtype": "video",
"shape": [
96,
96,
3
],
"names": [
"height",
"width",
"channel"
],
"video_info": {
"video.fps": 10.0,
"video.codec": "av1",
"video.pix_fmt": "yuv420p",
"video.is_depth_map": false,
"has_audio": false
}
},
"observation.state": {
"dtype": "float32",
"shape": [
2
],
"names": {
"motors": [
"motor_0",
"motor_1"
]
}
},
"action": {
"dtype": "float32",
"shape": [
2
],
"names": {
"motors": [
"motor_0",
"motor_1"
]
}
},
"episode_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"frame_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"timestamp": {
"dtype": "float32",
"shape": [
1
],
"names": null
},
"next.reward": {
"dtype": "float32",
"shape": [
1
],
"names": null
},
"next.done": {
"dtype": "bool",
"shape": [
1
],
"names": null
},
"next.success": {
"dtype": "bool",
"shape": [
1
],
"names": null
},
"index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"task_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
}
}
}
```
## Citation
**BibTeX:**
```bibtex
@article{chi2024diffusionpolicy,
author = {Cheng Chi and Zhenjia Xu and Siyuan Feng and Eric Cousineau and Yilun Du and Benjamin Burchfiel and Russ Tedrake and Shuran Song},
title ={Diffusion Policy: Visuomotor Policy Learning via Action Diffusion},
journal = {The International Journal of Robotics Research},
year = {2024},
}
``` |
VisualCloze/Graph200K | VisualCloze | 2025-04-21T03:42:34Z | 8,235 | 13 | [
"task_categories:image-to-image",
"language:en",
"license:apache-2.0",
"size_categories:100K<n<1M",
"format:arrow",
"modality:image",
"modality:text",
"library:datasets",
"library:mlcroissant",
"arxiv:2504.07960",
"region:us",
"image"
] | [
"image-to-image"
] | 2025-03-29T01:45:27Z | 2 | ---
language:
- en
license: apache-2.0
size_categories:
- 100K<n<1M
task_categories:
- image-to-image
tags:
- image
---
# VisualCloze: A Universal Image Generation Framework via Visual In-Context Learning
<div align="center">
[[Paper](https://huggingface.co/papers/2504.07960)]   [[Project Page](https://visualcloze.github.io/)]   [[Github](https://github.com/lzyhha/VisualCloze)]
</div>
<div align="center">
[[🤗 Online Demo](https://huggingface.co/spaces/VisualCloze/VisualCloze)]   [[🤗 Model Card (<strong><span style="color:hotpink">Diffusers</span></strong>)](https://huggingface.co/VisualCloze/VisualClozePipeline-384)]   [[🤗 Model Card (<strong><span style="color:hotpink">LoRA</span></strong>)](https://huggingface.co/VisualCloze/VisualCloze/)]
</div>
Graph200k is a large-scale dataset containing a wide range of distinct tasks of image generation.
## 📰 News
- [2025-4-21] 👋👋👋 We have implemented a version of [diffusers](https://github.com/lzyhha/diffusers/tree/main/src/diffusers/pipelines/visualcloze) that makes it easier to use the model through **pipelines** of the diffusers. For usage guidance, please refer to the [Model Card](https://huggingface.co/VisualCloze/VisualClozePipeline-384).
## 🌠 Key Features
- Each image is annotated for five meta-tasks, including 1) conditional generation, 2) image restoration, 3) image editing, 4) IP preservation, and 5) style transfer.
- Using these tasks, we can also **combine a wide range of complex tasks**.
For example, Style+Subject+Layout to Image as shown below.
## 🔥 Quick Start
### Uasge
```python
import datasets
grapth200k = datasets.load_dataset("lzyhha/test") # todo
train = grapth200k['train']
test = grapth200k['test']
# Reading depth map (PIL.Image) of the first image in the train set
train[0]['depth'].save(f'depth.jpg')
```
### Quality filtering
Graph200K is built based on [Subjects200K](https://huggingface.co/datasets/Yuanshi/Subjects200K/blob/main/README.md),
which provides quality scores.
In our [VisualCloze]() method, we filter out image pairs that exhibit low subject consistency, specifically those where `objectConsistency` <= 3.
### Annotations
In each item of the dataset, there are annotations as follows.
We leave the discussions about data construction in our [paper]().
| Item | Meaning |
| :------------------------ | ------------------------------------------------------------- |
| ref | Inherited from Subjects200K, it depicts the subject object in the target image. |
| target | The original image inherited from Subjects200K. |
| InstantStyle_image_[0-3] | Stylized images with invariant semantics. |
| InstantStyle_ref_[0-3] | Style reference for InstantStyle. |
| ReduxStyle_image_[0-3] | Stylized images with variant semantics. |
| ReduxStyle_ref_[0-3] | Style reference for ReduxStyle. |
| FillEdit_image_[0-5] | Edited image with invariant background. |
| FillEdit_meta | The name and descripation of the new subject object after editing. |
| DepthEdit | Edited image with variant background. |
| qwen_2_5_mask | A high-quality segmentation mask generated by the [Qwen-2.5-VL](https://github.com/QwenLM/Qwen2.5-VL) and [SAM2](https://github.com/facebookresearch/sam2). |
| qwen_2_5_bounding_box | The bounding boxes generated by the [Qwen-2.5-VL](https://github.com/QwenLM/Qwen2.5-VL). |
| qwen_2_5_meta | The coordinate and object name of each bounding box. And the mask color corresponding ro each box. |
| sam2_mask | A mask generated by the [SAM2](https://github.com/facebookresearch/sam2) model. |
| uniformer | The semantic segmentation generated by [UniFormer](https://github.com/Sense-X/UniFormer). |
| foreground | The foreground mask generated by [RMBG-2.0](https://huggingface.co/briaai/RMBG-2.0). |
| normal | Surface normal estimation generated by [DSINE](https://github.com/baegwangbin/DSINE/tree/main) |
| depth | The depth estimation by [Depth Anything V2](https://github.com/DepthAnything/Depth-Anything-V2). |
| canny | Edge detection in images, using the Canny edge detector. |
| hed |Edge detection in images, using the [HED](https://github.com/s9xie/hed) detector. |
| mlsd | Line segments generated using [M-LSD](https://github.com/navervision/mlsd). |
| openpose | Human keypoints generated by [OpenPose](https://github.com/CMU-Perceptual-Computing-Lab/openpose) |
### Citation
If you find VisualCloze useful for your research and applications, please cite using this BibTeX:
```bibtex
@article{li2025visualcloze,
title={VisualCloze: A Universal Image Generation Framework via Visual In-Context Learning},
author={Li, Zhong-Yu and Du, Ruoyi and Yan, Juncheng and Zhuo, Le and Li, Zhen and Gao, Peng and Ma, Zhanyu and Cheng, Ming-Ming},
journal={arXiv preprint arXiv:2504.07960},
year={2025}
}
``` |
DataLabX/ScreenTalk_JA2ZH-XS | DataLabX | 2025-04-19T14:57:00Z | 14 | 2 | [
"task_categories:translation",
"language:ja",
"language:zh",
"size_categories:10K<n<100K",
"format:parquet",
"modality:audio",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us",
"translation",
"ja",
"zh_cn"
] | [
"translation"
] | 2025-04-18T23:05:35Z | 2 | ---
task_categories:
- translation
language:
- ja
- zh
tags:
- translation
- ja
- zh_cn
dataset_info:
features:
- name: audio
dtype: audio
- name: duration
dtype: float64
- name: zh-CN
dtype: string
- name: uid
dtype: string
- name: group_id
dtype: string
splits:
- name: train
num_bytes: 2969732171.08
num_examples: 11288
- name: valid
num_bytes: 369775889.576
num_examples: 1411
- name: test
num_bytes: 370092000.712
num_examples: 1411
download_size: 3609504336
dataset_size: 3709600061.368
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: valid
path: data/valid-*
- split: test
path: data/test-*
---
# ScreenTalk_JA
**ScreenTalk_JA** is a paired dataset of **Japanese speech and Chinese translated text** released by DataLabX. It is designed for training and evaluating speech translation (ST) and multilingual speech understanding models. The data consists of spoken dialogue extracted from real-world Japanese movies and TV shows.
## 📦 Dataset Overview
- **Source Language**: Japanese (Audio)
- **Target Language**: Simplified Chinese (Text)
- **Number of Samples**: ~10,000
- **Total Duration**: ~30 hours
- **Format**: Parquet
- **License**: CC BY 4.0
- **Tasks**:
- Speech-to-Text Translation (ST)
- Multilingual ASR+MT joint modeling
- Japanese ASR with Chinese aligned text training
## 📁 Data Fields
| Field Name | Type | Description |
|-------------|----------|--------------------------------------------|
| `audio` | `Audio` | Raw Japanese speech audio clip |
| `sentence` | `string` | Corresponding **Simplified Chinese text** |
| `duration` | `float` | Duration of the audio in seconds |
| `uid` | `string` | Unique sample identifier |
| `group_id` | `string` | Grouping ID (e.g., speaker or scene tag) |
## 🔍 Example Samples
| UID | Duration (s) | Chinese Translation |
|-----------|---------------|--------------------------------------------|
| JA_00012 | 4.21 | 他不会来了。 |
| JA_00038 | 6.78 | 为什么你会这样说?告诉我真相。 |
| JA_00104 | 3.33 | 安静,有人来了。 |
## 💡 Use Cases
This dataset is ideal for:
- 🎯 Training **speech translation models**, such as [Whisper ST](https://huggingface.co/docs/transformers/main/en/model_doc/whisper#speech-translation)
- 🧪 Research on **multilingual speech understanding**
- 🧠 Developing multimodal AI systems (audio → Chinese text)
- 🏫 Educational tools for Japanese learners
## 📥 Loading Example (Hugging Face Datasets)
```python
from datasets import load_dataset
ds = load_dataset("DataLabX/ScreenTalk_JA", split="train")
```
## 📃 Citation
```
@misc{datalabx2025screentalkja,
title = {ScreenTalk_JA: A Speech Translation Dataset of Japanese Audio and Chinese Text},
author = {DataLabX},
year = {2025},
howpublished = {\url{https://huggingface.co/datasets/DataLabX/ScreenTalk_JA}},
}
```
---
We welcome feedback, suggestions, and contributions! 🙌
|
facebook/PE-Video | facebook | 2025-04-18T22:33:23Z | 8,119 | 21 | [
"license:cc-by-nc-4.0",
"size_categories:100K<n<1M",
"format:webdataset",
"modality:text",
"library:datasets",
"library:webdataset",
"library:mlcroissant",
"arxiv:2504.13181",
"region:us"
] | [] | 2025-03-28T23:11:36Z | 5 | ---
license: cc-by-nc-4.0
---
# PE Video Dataset (PVD)
[\[📃 Tech Report\]](https://arxiv.org/abs/2504.13181)
[\[📂 Github\]](https://github.com/facebookresearch/perception_models/)
The PE Video Dataset (PVD) is a large-scale collection of 1 million diverse videos, featuring 120,000+ expertly annotated clips. The dataset was introduced in our paper "Perception Encoder".
## Overview
PE Video Dataset (PVD) comprises 1M high quality and diverse videos. Among them, 120K videos are accompanied by automated and human-verified annotations. and all videos are accompanied with video description and keywords. The videos are motion-centered, covering both first-person and third-person views with a wide coverage of scenes.
## PVD
### Key Application
Computer Vision, Video Understanding
### Intended Use Cases
Train and evaluate video retrieval models
Train and evaluate video captioning models
Primary Data type
Videos
Video caption (Human annotated / Model generated)
### Data Function
Training, Testing
### Dataset Characteristics
- Total number of videos: 998,862
- Total number of human annotated captions: 118,862
- Average FPS: 29.8
- Average Video Length: 16.7s
- Average video height: 346
- Average video width: 604
### Labels
A text description that summarizes the content of a video describing what's happening in the video, such as the actions, events, or objects shown.
### Nature Of Content
We selected videos from 10 different categories, including hand actions, object interactions, food preparation, work activities, outdoor scenes, animals, water scenes, object handling, close-up shots, and nature scenes.
### License
CC BY NC 4.0
### Access Cost
Open access
### Labeling Methods
The video captions are refined based on the following criteria. The annotators should remove any hallucinations found in the model-generated caption, correct words that describe the video inaccurately, and eliminate repeating or redundant words to make the caption concise and accurate. Additionally, if major actions are missing from the caption, annotators should add them in a concise and natural way.
### Validation Methods
All of the 118,862 human captions were reviewed by human annotators.
### Citation
If you find this dataset useful, please cite our papers:
```
@article{bolya2025perception-encoder,
title={Perception Encoder: The best visual embeddings are not at the output of the network},
author={Daniel Bolya and Po-Yao Huang and Peize Sun and Jang Hyun Cho and Andrea Madotto and Chen Wei and Tengyu Ma and Jiale Zhi and Jathushan Rajasegaran and Hanoona Rasheed and Junke Wang and Marco Monteiro and Hu Xu and Shiyu Dong and Nikhila Ravi and Daniel Li and Piotr Doll{\'a}r and Christoph Feichtenhofer},
journal={arXiv},
year={2025}
}
@article{cho2025perceptionlm,
title={PerceptionLM: Open-Access Data and Models for Detailed Visual Understanding},
author={Jang Hyun Cho and Andrea Madotto and Effrosyni Mavroudi and Triantafyllos Afouras and Tushar Nagarajan and Muhammad Maaz and Yale Song and Tengyu Ma and Shuming Hu and Hanoona Rasheed and Peize Sun and Po-Yao Huang and Daniel Bolya and Suyog Jain and Miguel Martin and Huiyu Wang and Nikhila Ravi and Shashank Jain and Temmy Stark and Shane Moon and Babak Damavandi and Vivian Lee and Andrew Westbury and Salman Khan and Philipp Kr\"{a}henb\"{u}hl and Piotr Doll{\'a}r and Lorenzo Torresani and Kristen Grauman and Christoph Feichtenhofer},
journal={arXiv},
year={2025}
}
``` |
facebook/PLM-Video-Human | facebook | 2025-04-18T21:50:35Z | 2,052 | 19 | [
"task_categories:multiple-choice",
"task_categories:visual-question-answering",
"annotations_creators:other",
"language_creators:other",
"language:en",
"license:cc-by-4.0",
"size_categories:1M<n<10M",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"arxiv:2504.13180",
"region:us"
] | [
"multiple-choice",
"visual-question-answering"
] | 2025-03-28T23:06:34Z | 8 | ---
annotations_creators:
- other
language_creators:
- other
language:
- en
task_categories:
- multiple-choice
- visual-question-answering
pretty_name: plm_video_human
dataset_info:
- config_name: fgqa
features:
- name: qa_id
dtype: string
- name: segment_id
dtype: string
- name: question
dtype: string
- name: answer
dtype: string
- name: metadata
struct:
- name: source_video_id
dtype: string
- name: source_dataset
dtype: string
- name: source_start_time
dtype: float
- name: source_end_time
dtype: float
- name: what_description
dtype: string
- name: q_type
dtype: string
- name: q_subtype
dtype: string
- name: domain
dtype: string
- name: is_audited
dtype: int32
splits:
- name: train
num_bytes: 409709782
num_examples: 2321035
- config_name: rcap
features:
- name: uid
dtype: int32
- name: video
dtype: string
- name: masklet_id
dtype: int32
- name: total_frames
dtype: int32
- name: caption
dtype: string
- name: start_frame
dtype: int32
- name: end_frame
dtype: int32
splits:
- name: train
num_bytes: 13738246
num_examples: 179447
- config_name: rdcap
features:
- name: uid
dtype: int32
- name: video
dtype: string
- name: masklet_id
dtype: int32
- name: total_frames
dtype: int32
- name: dense_captions
list:
- name: start_frame
dtype: int32
- name: end_frame
dtype: int32
- name: caption
dtype: string
splits:
- name: train
num_bytes: 14268327
num_examples: 117248
- config_name: rtloc
features:
- name: uid
dtype: int32
- name: video
dtype: string
- name: masklet_id
dtype: int32
- name: total_frames
dtype: int32
- name: caption
dtype: string
- name: start_frame
dtype: int32
- name: end_frame
dtype: int32
splits:
- name: train
num_bytes: 13739069
num_examples: 179447
configs:
- config_name: fgqa
data_files:
- split: train
path: fgqa/plm_fgqa_train.parquet
- config_name: rcap
data_files:
- split: train
path: rcap/plm_rcap_train.parquet
- config_name: rdcap
data_files:
- split: train
path: rdcap/plm_rdcap_train.parquet
- config_name: rtloc
data_files:
- split: train
path: rtloc/plm_rtloc_train.parquet
license: cc-by-4.0
---
# Dataset Card for PLM-Video Human
PLM-Video-Human is a collection of human-annotated resources for training Vision Language Models,
focused on detailed video understanding. Training tasks include: fine-grained open-ended question answering (FGQA), Region-based Video Captioning (RCap),
Region-based Dense Video Captioning (RDCap) and Region-based Temporal Localization (RTLoc).
[\[📃 Tech Report\]](https://arxiv.org/abs/2504.13180)
[\[📂 Github\]](https://github.com/facebookresearch/perception_models/)
<img src="https://huggingface.co/datasets/facebook/PLM-Video-Human/resolve/main/assets/plm_video_human.png" style="width: 100%; margin: 0 auto; display: block;" />
## Dataset Structure
### Fine-Grained Question Answering (FGQA)
A video question answering dataset for fine-grained activity understanding. Contains human-annotated/verified answers to model-generated
questions about video clips from open-access video datasets. The questions focus on "what" activities
humans perform and "how" they perform these activities.
Data fields are:
- `qa_id`: a `string` feature, unique identifier for the Q&A sample.
- `segment_id`: a `string` feature, unique identifier for the video segment.
- `question`: a `string` feature, a model-generated question about the video segment
- `answer`: a `string` feature, human-annotated or human-verified answer to the question
- `metadata`: a `dict` of features, representing metadata about the video segment and Q&A pair:
- `source_video_id`: a `string` feature, video id of untrimmed source video
- `source_dataset`: a `string` feature, name of the source dataset
- `source_start_time`: a `float` feature, denoting the start time (seconds) of the video segment in the source video
- `source_end_time`: a `float` feature, denoting the end time (seconds) of the video segment in the source video
- `what_description`: a `string` feature, potential activity name shown in video (not verified)
- `q_type`: a `string` feature, question type
- `q_subtype`: a `string` feature, question subtype
- `domain`: a `string` feature, video domain
- `is_audited`: a `bool` feature, whether the sample has passed a quality audit.
A question-answer sample from FGQA looks as follows:
```
{
"qa_id":"130ae268-0ac5-4b41-8f65-137119065d81",
"segment_id":"01651739-6e54-4126-b1b5-fc87f59bda1e",
"question":"What is the initial state of the cabbage before you begin chopping it?",
"answer":"cabbage is half cut already and kept on cutting board before the person begin chopping it",
"metadata":{"source_video_id":"-eyDS81FADw",
"source_dataset":"youcook2",
"source_start_time":62.0,
"source_end_time":77.0,
"what_description":"chop garlic ginger cabbage carrot and scallions",
"q_type":"Object State",
"q_subtype":"initial_end_state",
"domain":"Cooking and Recipes",
"is_audited":0}
}
```
The `source_video_id`, `source_start_time` and `source_end_time` fields per sample can be used to obtain the training segments from each source dataset (specified in `source_dataset`).
Our training annotations contain ground-truth segments and activity names from COIN, Ego4d, EgoExo4d, CrossTask and YouCook2, as well as auto-generated segments and verified auto-generated activity names from HT100M.
### Region Video Captioning (RCap)
Each training sample is a detailed description of an event involving a subject of interest in the video. Given a region mask and a specified video segment (time interval), the target is a caption that accurately describes the event occurring within that interval.
Data fields are :
- `uid`: an `int32` feature, unique identifier for the sample.
- `video`: a `string` feature, the video name.
- `masklet_id`: an `int32` feature, unique identifier for the input masklet within the video.
- `total_frames`: an `int32` feature, number of video frames.
- `caption`: a `string` feature, the caption describing the actions of the subject/object highlighted in the masklet within the temporal segment.
- `start_frame`: an `int32` feature, start frame of the temporal segment
- `end_frame`: an `int32` feature, end frame of the temporal segment
A sample from the RCap training data looks as follows:
```
{
"uid": 0,
"video": "sav_017599.mp4",
"masklet_id": 2,
"total_frames": 73,
"caption": "A boy enters the frame from the right, he wears glasses and turn back and exit from the right side of the frame.",
"start_frame": 30,
"end_frame": 72
}
```
Our training annotations cover videos from the SA-V (SAM-2) dataset which can be downloaded from the official website which can be downloaded from the official website [`segment-anything-videos-download`](https://ai.meta.com/datasets/segment-anything-video-downloads).
### Region Temporal Localization (RTLoc)
Each training sample is a precise time interval within the video corresponding to a detailed description of an event involving a subject of interest in the video.
Given a video, a region masklet and a textual description of the event, the targets are the start and end timestamps that correspond to the occurrence of the event.
Notably, this task is the inverse of RCap --- instead of generating the caption, the model receives it as input and generates the corresponding time interval.
Data fields are :
- `uid`: an `int32` feature, unique identifier for the sample.
- `video`: a `string` feature, the video name.
- `masklet_id`: an `int32` feature, unique identifier for the input masklet within the video.
- `total_frames`: an `int32` feature, number of video frames.
- `caption`: a `string` feature, the caption describing the actions of the subject/object highlighted in the masklet within the temporal segment.
- `start_frame`: an `int32` feature, start frame of the video segment
- `end_frame`: an `int32` feature, end frame of the video segment
A sample from RTLoc training data looks as follows:
```
{
"uid": 0,
"video": "sav_017599.mp4",
"masklet_id": 2,
"total_frames": 73,
"caption": "A boy enters the frame from the right, he wears glasses and turn back and exit from the right side of the frame.",
"start_frame": 30,
"end_frame": 72
}
```
Note that the start/end frames are used as output targets for RTLoc, while the caption is the output target for RCap.
### Region Dense Temporal Captioning (RDCap)
Each training sample is a detailed description of all events involving a specific subject of interest (e.g., a person, animal, or object) in a video.
Given a video and a region masklet, the target is a sequence of (start, end, caption) triplets that cover the entire duration of the video, including periods when the subject is not visible.
Data fields are :
- `uid`: an `int32` feature, unique identifier for the sample.
- `video`: a `string` feature, the video name.
- `masklet_id`: an `int32` feature, unique identifier for the input masklet within the video.
- `total_frames`: an `int32` feature, number of video frames.
- `dense_captions`: a `list` of `dict` features, each containing information per event in the video, made up of:
- `start_frame`: an `int32` feature, start frame of the video segment corresponding to the event
- `end_frame`: an `int32` feature, end frame of the video segment corresponding to the event
- `caption`: a `string` feature, the caption describing the actions of the subject/object highlighted in the masklet within the temporal segment.
A sample from RDCap training data looks as follows:
```
{
"uid": 0,
"video": "sav_017599.mp4",
"masklet_id": 2,
"total_frames": 73,
"dense_captions": [
{"start_frame": 0, "end_frame": 29, "caption": "Out of frame."},
{"start_frame": 30, "end_frame": 72, "caption": "A boy enters the frame from the right, he wears glasses and turn back and exit from the right side of the frame."}
]
}
```
## Data Stats
The training data sizes per task are:
| | Train | Task Output |
| ----------- | ----------- | ----------- |
| FGQA | 2321035 | Answer |
| RCap | 179447 | Caption |
| RTLoc | 179447 | Temporal Segment |
| RDCap | 117248 | Dense Captions and Temporal Segments |
### Licensing Information
PLM-Video-Human data is released under CC BY 4.0.
### Citation Information
Cite as:
```
@article{cho2025PerceptionLM,
title={PerceptionLM: Open-Access Data and Models for Detailed Visual Understanding},
author={Jang Hyun Cho and Andrea Madotto and Effrosyni Mavroudi and Triantafyllos Afouras and Tushar Nagarajan and Muhammad Maaz and Yale Song and Tengyu Ma and Shuming Hu and Hanoona Rasheed and Peize Sun and Po-Yao Huang and Daniel Bolya and Suyog Jain and Miguel Martin and Huiyu Wang and Nikhila Ravi and Shashank Jain and Temmy Stark and Shane Moon and Babak Damavandi and Vivian Lee and Andrew Westbury and Salman Khan and Philipp Kr\"{a}henb\"{u}hl and Piotr Doll{\'a}r and Lorenzo Torresani and Kristen Grauman and Christoph Feichtenhofer},
journal={arXiv},
year={2025}
}
```
|
Multilingual-Multimodal-NLP/TableBench | Multilingual-Multimodal-NLP | 2025-04-18T19:16:49Z | 2,716 | 21 | [
"task_categories:question-answering",
"language:en",
"license:apache-2.0",
"size_categories:n<1K",
"arxiv:2408.09174",
"region:us",
"table-question-answering"
] | [
"question-answering"
] | 2024-07-18T10:11:04Z | 2 | ---
language:
- en
license: apache-2.0
pretty_name: TableBench
size_categories:
- n<1K
task_categories:
- question-answering
task_ids: []
tags:
- table-question-answering
configs:
- config_name: table_bench
data_files:
- split: TQA_test
path: 'TableBench.jsonl'
- split: Instruct_test
path:
- 'TableBench_DP.jsonl'
- 'TableBench_TCoT.jsonl'
- 'TableBench_SCoT.jsonl'
- 'TableBench_PoT.jsonl'
---
# Dataset Card for TableBench
<p align="left">
<a href="https://arxiv.org/abs/2408.09174">📚 Paper</a>
<a href="https://tablebench.github.io/">🏆 Leaderboard</a>
<a href="https://github.com/TableBench/TableBench">💻 Code</a>
</p>
## Dataset Summary
<code style="color:#8b44c7"><b>TableBench</b></code> is a <b>comprehensive</b> and <b>complex</b>
benchmark designed to evaluate Table
Question Answering (TableQA) capabilities, aligning closely with the "<code style="color:#8b44c7"><b>Reasoning Complexity of
Questions</b></code>" dimension in real-world Table QA scenarios. It covers <b>18</b> question
categories
across <b>4</b> major ategories—including <b>Fact Checking</b>, <b>Numerical Reasoning</b>, <b>Data
Analysis</b>, and <b>Visualization</b>—with <b>886</b> carefully curated test cases. TableBench
substantially pushes the boundaries of large language models in complex TableQA scenarios.
## Latest Version
> **🔥TableBench-2025-04-18🔥**
>
> 1. **☀️ Enhanced TableBench**:
> We’ve released an cleaner version of TableBench, after thoroughly reviewing all test set cases and correcting any errors we identified. Please download the latest version of TableBench for the most accurate dataset.
>
> 2. **🚀 Brand New Leaderboard**:
> The brand new [Leaderboard](https://tablebench.github.io/) is now live! We've included the performance of many newly released models in our latest leaderboard and will continue to keep it up to date. Submissions are welcome! For submission guidelines, please refer to the `Submission section` on [Leaderboard](https://tablebench.github.io/) website.
>
> 3. **🔍 Refined Evaluation Metrics**:
> In response to community feedback and in-depth discussions, we've updated the evaluation metrics for Fact Checking, Numerical Reasoning, and Data Analysis. You can find the detailed specifications of these new metrics and evaluation tools on our [github repo](https://github.com/TableBench/TableBench)
## Data Introduction
Our dataset has two parts:
- **[TQA_test] Original Table QA Test Set (`TableBench.jsonl`)**: This serves as the core benchmark data, suitable for evaluating specialized reasoning capabilities in TableQA systems.
- **[Instruct_test] Pre-designed Instruction Test Set with Various Reasoning Methods (`TableBench_DP.jsonl`, `TableBench_TCoT.jsonl` ,`TableBench_SCoT.jsonl` and `TableBench_PoT.jsonl` )**: Derived from the original paper, this version includes diverse reasoning instructions and is more suitable for assessing the reasoning abilities of large language models (LLMs) on table-based QA tasks.
These two formats focus on different evaluation aspects. This design aims to enhance the dataset's flexibility and scalability. Both versions are maintained and provided in the repository.
## Data Fields (TQA_test)
| ID | String | Description |
|----|--------|-------------|
| id | string | Unique Identifier |
| qtype | string | Question Type (FactChecking, NumericalReasoning, DataAnalysis, Visualization) |
| qsubtype | string | Question Subtype |
| table | string | Table |
| question | string | Question |
| answer | string | Answer |
| chart_type | string | Only Valid for Evaluating Chart Generation Task |
## Data Example (TQA_test)
An example of `TableBench.jsonl` looks as follows:
```
{
"id": "60670a8d9b1e39dd845fb1639d0d8b86",
"qtype": "DataAnalysis",
"qsubtype": "StatisticalAnalysis",
"table": {"columns": ["rank", "circuit", "headquarters", "screens", "sites"], "data": [[1, "regal entertainment group", "knoxville , tn", 7367, 580], [2, "amc entertainment inc", "kansas city , mo", 5894, 483], [3, "cinemark theatres", "plano , tx", 3895, 298], [4, "carmike cinemas , inc", "columbus , ga", 2242, 232], [5, "cineplex entertainment", "toronto , on", 1438, 133], [6, "rave motion pictures", "dallas , tx", 939, 62], [7, "marcus theatres", "milwaukee , wi", 687, 55], [8, "national amusements", "dedham , ma", 450, 34], [9, "empire theatres", "stellarton , ns", 438, 53]]},
"question": "Can you calculate the standard deviation of the number of screens operated by the top 5 movie theater chains?",
"answer": "2472.33",
}
```
## Data Fields (Instruct_test)
| ID | String | Description |
|----|--------|-------------|
| id | string | Unique Identifier |
| qtype | string | Question Type (FactChecking, NumericalReasoning, DataAnalysis, Visualization) |
| qsubtype | string | Question Subtype |
| instruction | string | Instruction to prompt LLM |
| instruction_type | string | four different instruction types in TableBench: DP(Direct Prompting), TCoT(Textual Chain of Thought),SCoT(Symbolic Chain of Thought) and PoT(Program of Thought) |
| table | string | Table |
| question | string | Question |
| answer | string | Answer |
| chart_type | string | Only Valid for Evaluating Chart Generation Task |
## Data Example (Instruct_test)
An example of 'TableBench_PoT.jsonl' looks as follows:
```
{
"id": "60670a8d9b1e39dd845fb1639d0d8b86",
"qtype": "DataAnalysis",
"qsubtype": "StatisticalAnalysis",
"instruction": "You are a data analyst proficient in Python ...",
"instruction_type": "PoT",
"table": {"columns": ["rank", "circuit", "headquarters", "screens", "sites"], "data": [[1, "regal entertainment group", "knoxville , tn", 7367, 580], [2, "amc entertainment inc", "kansas city , mo", 5894, 483], [3, "cinemark theatres", "plano , tx", 3895, 298], [4, "carmike cinemas , inc", "columbus , ga", 2242, 232], [5, "cineplex entertainment", "toronto , on", 1438, 133], [6, "rave motion pictures", "dallas , tx", 939, 62], [7, "marcus theatres", "milwaukee , wi", 687, 55], [8, "national amusements", "dedham , ma", 450, 34], [9, "empire theatres", "stellarton , ns", 438, 53]]},
"question": "Can you calculate the standard deviation of the number of screens operated by the top 5 movie theater chains?",
"answer": "2472.33"
}
```
## Data Usage
- If you wish to assess the capabilities of LLMs on tabular data, you can utilize `TableBench-DP.jsonl`, `TableBench-TCoT.jsonl`, `TableBench-SCoT.jsonl`and `TableBench-PoT.jsonl` to evaluate the model's abilities directly. Detailed performance comparisons can be found on the [**live-updated leaderboard**](https://tablebench.github.io/).
- If you wish to evaluate your holistic approach on TableBench, please directly use `TableBench.jsonl`. There is no need to adopt any predefined prompt set. You can run the evaluation using the tools provided in our [**GitHub**](https://github.com/TableBench/TableBench) repository. To submit your results to the [**Leaderboard**](https://tablebench.github.io/), please follow the submission instructions provided on the leaderboard website.
## Historical versions
**Note:** It is strongly recommended to use the **latest version** of the dataset, as it provides the most **up-to-date** leaderboard results and improved data quality.
> **2024-08-29:**
> [TableBench-2024-08-29](https://huggingface.co/datasets/Multilingual-Multimodal-NLP/TableBench/tree/90593ad8af90f027f6f478b8c4c1981d9f073a83) can be downloaded here,which corresponds to the version used in our [paper](https://arxiv.org/abs/2408.09174).
## Citation
If you use the data from this project, please cite the original paper:
```
@inproceedings{wu2025tablebench,
title={Tablebench: A comprehensive and complex benchmark for table question answering},
author={Wu, Xianjie and Yang, Jian and Chai, Linzheng and Zhang, Ge and Liu, Jiaheng and Du, Xeron and Liang, Di and Shu, Daixin and Cheng, Xianfu and Sun, Tianzhen and others},
booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},
volume={39},
number={24},
pages={25497--25506},
year={2025}
}
``` |
ServiceNow-AI/DNRBench | ServiceNow-AI | 2025-04-18T08:44:24Z | 47 | 2 | [
"language:en",
"license:cc-by-nc-4.0",
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"arxiv:2503.15793",
"region:us"
] | [] | 2025-02-10T15:29:38Z | 2 | ---
dataset_info:
- config_name: imaginary-reference
features:
- name: role
dtype: string
- name: content
dtype: string
splits:
- name: test
num_bytes: 4485
num_examples: 25
download_size: 4391
dataset_size: 4485
- config_name: indifferent
features:
- name: role
dtype: string
- name: content
dtype: string
splits:
- name: test
num_bytes: 11732
num_examples: 25
download_size: 10536
dataset_size: 11732
- config_name: math
features:
- name: role
dtype: string
- name: content
dtype: string
splits:
- name: test
num_bytes: 5440
num_examples: 25
download_size: 4740
dataset_size: 5440
- config_name: redundant
features:
- name: role
dtype: string
- name: content
dtype: string
splits:
- name: test
num_bytes: 5087
num_examples: 25
download_size: 4096
dataset_size: 5087
- config_name: unanswerable
features:
- name: role
dtype: string
- name: content
dtype: string
splits:
- name: test
num_bytes: 12501
num_examples: 50
download_size: 8242
dataset_size: 12501
configs:
- config_name: imaginary-reference
data_files:
- split: test
path: imaginary-reference/test-*
- config_name: indifferent
data_files:
- split: test
path: indifferent/test-*
- config_name: math
data_files:
- split: test
path: math/test-*
- config_name: redundant
data_files:
- split: test
path: redundant/test-*
- config_name: unanswerable
data_files:
- split: test
path: unanswerable/test-*
license: cc-by-nc-4.0
language:
- en
---
# DNR Bench
Don’t Reason Bench (DNR Bench), a novel benchmark designed to expose a vulnerability in current RLMs: their tendency to over-reason by attempting to solve unsolvable
problems, leading to excessively long responses.
# Data Summary
The DNR Bench dataset contains 150 adversarially crafted prompts divided into five distinct categories:
- Imaginary Reference
- Indifferent
- Math,
- Redundant,
- Unanswerable.
Each category targets a specific failure mode observed in reasoning-optimized LLMs, such as hallucinating nonexistent references, failing to remain neutral in ambiguous contexts, incorrectly solving flawed math problems, overanalyzing redundant information, or answering questions that lack sufficient data.
# Leaderboard
This dataset is used to test reasoning LLMs in [DNR Leaderboard on Huggingface](https://huggingface.co/spaces/ServiceNow-AI/Do-not-reason-bench)
# Citation
```bibtex
@misc{hashemi2025dnrbenchbenchmarkingoverreasoning,
title={DNR Bench: Benchmarking Over-Reasoning in Reasoning LLMs},
author={Masoud Hashemi and Oluwanifemi Bamgbose and Sathwik Tejaswi Madhusudhan and Jishnu Sethumadhavan Nair and Aman Tiwari and Vikas Yadav},
year={2025},
eprint={2503.15793},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2503.15793},
}
``` |
bh2821/LightNovel5000 | bh2821 | 2025-04-16T20:25:38Z | 876 | 28 | [
"task_categories:text-generation",
"task_categories:text2text-generation",
"task_categories:translation",
"language:zh",
"license:zlib",
"size_categories:1M<n<10M",
"format:text",
"modality:text",
"library:datasets",
"library:mlcroissant",
"region:us",
"Novel",
"Light-Novel",
"Japanese",
"Chinese"
] | [
"text-generation",
"text2text-generation",
"translation"
] | 2025-04-16T17:03:25Z | 4 | ---
license: zlib
task_categories:
- text-generation
- text2text-generation
- translation
language:
- zh
tags:
- Novel
- Light-Novel
- Japanese
- Chinese
size_categories:
- 100M<n<1B
---
# Light novels translated in Chinese - crawled from public websites that do not prohibit crawlers
# 脚盆轻小说汉化 - 从未禁止爬虫的公共网站爬取
----
### Version 0
### 版本 0
Contains around 1000 light novels, including PDF with illustration and txt text files.
* It may be a good source of data that can be used to train your stylish LLM.
* Kindly note that the author has partially clean the text BUT DOES NOT GUARANTEE that it is fully cleaned up.
* 包含约 1000 部轻小说,包括带插图的 PDF 和 txt 文本文件。
* 这可以是训练你的具有风格化的大语言模型 (LLM) 的良好数据来源。
* 请注意,作者已部分清理文本,但不保证已完全清理。
----
### File Structure
### 文件结构
* The things shown in the `Data Studio` is ONLY A VERY SMALL PART OF DATA available to be reviewed. Please download the archive to access full datasets.
* 在`Data Studio`中显示预览的内容只是可供查看的数据的一小部分。请下载存档以访问完整的数据集。
* In Version 0, we only provide around 1000 light novels, but we will update to 2000 in Version 1, and 5000 in Version 2.
* 在版本 0 中,我们仅提供大约 1000 部轻小说,但我们将在版本 1 中更新到 2000 部,在版本 2 中更新到 5000 部。
----
* `/passcode` Contains a file that shows the passcode to decipher the main text and pdf data archives.
* `/examples` Contains examples of pdf and txt files, for users to be famalier with the format of this dataset.
* `/pdf` Contains a series of encrypted indivudial novel pdfs.
* `/txt` Contains a series of encrypted indivudial novel txts.
* `/concat.txt` Contains the combined complete set of novels.
* `/index.csv` Contains the index-title mapping of the included novels.
* `/description.xlsx` Contains the index-title-description mapping of the included novels.
* `/passcode` 包含一个文件,显示用于解密正文和 PDF 数据档案的密码。
* `/examples` 包含 PDF 和 txt 文件的示例,以便用户熟悉此数据集的格式。
* `/pdf` 包含一系列加密的独立的小说 PDF。
* `/txt` 包含一系列加密的独立的小说 txt。
* `/concat.txt` 包含合并后的所有的小说。
* `/index.csv` 包含所收录小说的索引-标题映射。
* `/description.xlsx` 包含所收录小说的索引-标题-描述映射。 |
tiange/Cap3D | tiange | 2025-04-16T17:23:58Z | 8,677 | 108 | [
"task_categories:text-to-3d",
"task_categories:image-to-3d",
"license:odc-by",
"arxiv:2306.07279",
"arxiv:2404.07984",
"arxiv:2212.08051",
"arxiv:2307.05663",
"arxiv:2110.06199",
"arxiv:1512.03012",
"region:us"
] | [
"text-to-3d",
"image-to-3d"
] | 2023-05-28T18:31:58Z | null | ---
license: odc-by
viewer: false
task_categories:
- text-to-3d
- image-to-3d
---
## Dataset Description
- **Paper:** [Scalable 3D Captioning with Pretrained Models](https://arxiv.org/abs/2306.07279)
- **Paper:** [View Selection for 3D Captioning via Diffusion Ranking](https://arxiv.org/abs/2404.07984)
- **Repository**: [Github_Cap3D](https://github.com/crockwell/Cap3D)
- **Repository**: [Github_DiffuRank](https://github.com/tiangeluo/DiffuRank)
- **Project**: [Project](https://cap3d-um.github.io/)
This repository hosts data for [Scalable 3D Captioning with Pretrained Models](https://cap3d-um.github.io/) and [View Selection for 3D Captioning via Diffusion Ranking](http://arxiv.org/abs/2404.07984), including descriptive **captions** for 3D objects in [Objaverse](https://arxiv.org/abs/2212.08051), [Objaverse-XL](https://arxiv.org/pdf/2307.05663.pdf), [ABO](https://arxiv.org/abs/2110.06199), and [ShapeNet](https://arxiv.org/abs/1512.03012). This repo also includes **point clouds** and **rendered images with camera, depth, and MatAlpha information** of Objaverse objects, as well as their Shap-E latent codes. All the captions and data provided by our papers are released under ODC-By 1.0 license.
## Very important license & data remove information
Please ensure compliance with the licenses specified for each object in the Objaverse annotations. Note that certain objects are not approved for commercial use.
If you are the creator of an asset and would like your 3D model’s information removed from the Cap3D-DiffuRank dataset, please contact [Tiange](mailto:[email protected]) for assistance. We sincerely thank all contributors—your efforts are instrumental in advancing the 3D vision community. This dataset repository is a humble addition, built upon the foundation of your contributions and shared work.
## Usage
Please download and unzip files from [**Page**](https://huggingface.co/datasets/tiange/Cap3D/tree/main) according to your usage. Below is a table listing fiels descriptions, followed by example Python scripts for data loading.
| Filename | Description |
| -------------------------------------- | ------------------------------------------------------------ |
| **Cap3D_automated_Objaverse_full.csv** | By integrating text descriptions initially generated by [**Cap3D**](https://arxiv.org/abs/2306.07279) and refined by [**DiffuRank**](https://arxiv.org/abs/2404.07984), we produced **1,562,177** 3D-caption pairs for Objaverse objects. <br>- **785,150** for [**Objaverse**](https://arxiv.org/abs/2212.08051); <br>- the remainder for [**Objaverse-XL**](https://arxiv.org/pdf/2307.05663.pdf), primarily from the high-quality subset described in **Section 4.1 (Alignment Finetuning)** of the [Objaverse-XL paper](https://proceedings.neurips.cc/paper_files/paper/2023/file/70364304877b5e767de4e9a2a511be0c-Paper-Datasets_and_Benchmarks.pdf), retrieved via `alignment_annotations = oxl.get_alignment_annotations()`; <br>- identifiers of length **32 characters** are Objaverse 1.0 **UIDs** (`import objaverse; uids = objaverse.load_uids()`), while those with **64 characters** are **SHA256 hashes** from Objaverse-XL. |
| Cap3D_automated_**ABO**.csv | Our captions generated by [Cap3D](https://arxiv.org/abs/2306.07279) and [DiffuRank](https://arxiv.org/abs/2404.07984) for the [ABO dataset](https://arxiv.org/abs/2110.06199), including both general and compositional descriptions. |
| Cap3D_automated_**ShapeNet**.csv | Our captions generated by [Cap3D](https://arxiv.org/abs/2306.07279) and [DiffuRank](https://arxiv.org/abs/2404.07984) for the [ShapeNet dataset](https://arxiv.org/abs/1512.03012). |
| **PointCloud_zips** | Provided by [Cap3D](https://arxiv.org/abs/2306.07279) and [DiffuRank](https://arxiv.org/abs/2404.07984), **1,314,736** PointClouds (16,384 colorful points) extracted from Objaverse objects. Saved as `.ply` file. `compressed_pcs_{00~09}.zip` are for Objaverse objects and `compressed_pcs_{>=10}.zip` for Objaverse-XL objects. |
| PointCloud_zips_**ABO** | Provided by [Cap3D](https://arxiv.org/abs/2306.07279) and [DiffuRank](https://arxiv.org/abs/2404.07984), **7,953** PointClouds (16,384 colorful points) extracted from ABO objects. Saved as `.ply` file. |
| PointCloud_zips_**ShapeNet** | Provided by [Cap3D](https://arxiv.org/abs/2306.07279) and [DiffuRank](https://arxiv.org/abs/2404.07984), **52,472** PointClouds (16,384 colorful points) extracted from ShapeNet objects. Saved as `.ply` file. |
| **RenderedImage_perobj_zips** | Provided by [DiffuRank](https://arxiv.org/abs/2404.07984), Rendered images for **1,314,736** Objaverse objects. Once unzip `compressed_imgs_perobj_xx.zip` will have multiple zip files which consists of **20** rendered images along with camera details (intrinsic & extrinsic), depth data, and masks ([one example](https://huggingface.co/datasets/tiange/Cap3D/tree/main/RenderedImage_perobj_zips/example_zipfile)). Please specify the unzip path, such as `unzip ed51a51909ee46c780db3a85e821feb2.zip -d ed51a51909ee46c780db3a85e821feb2`. `compressed_imgs_perobj_{00~52}.zip` are for Objaverse objects and `compressed_imgs_perobj_{>=53}.zip` for Objaverse-XL objects. **More information are in [here](https://huggingface.co/datasets/tiange/Cap3D/blob/main/RenderedImage_perobj_zips/README.md).** |
| RenderedImage_perobj_zips_**ABO** | Provided by [DiffuRank](https://arxiv.org/abs/2404.07984), Rendered images for **7,953** ABO objects. Details similar to the above. |
| RenderedImage_perobj_zips_**ShapeNet** | Provided by [DiffuRank](https://arxiv.org/abs/2404.07984), Rendered images for **52,472** ShapeNet objects. Details similar to the above. |
| misc | Including miscellaneous files such as human-authored captions, finetuned models, objaverse pointclouds stored as .pt, shapE latent codes, and etc. Please refer to this [README](https://huggingface.co/datasets/tiange/Cap3D/blob/main/misc/README.md) |
``` python
# load our captions
import pandas as pd
captions = pd.read_csv('Cap3D_automated_Objaverse_full.csv', header=None)
## captions:
## 0 1
## 0 ed51a51909ee46c780db3a85e821feb2 Matte green rifle with a long barrel, stock, a...
## 1 9110b606f6c547b2980fcb3c8c4b6a1c Rustic single-story building with a weathered ...
## 2 80d9caaa1fa04502af666135196456e1 a pair of purple and black swords with white h...
## 3 28d43a218cd8466a8c1f82b29b71e314 3D model of a cluttered outdoor scene with veg...
## 4 75582285fab442a2ba31733f9c8fae66 Floating terrain piece with grassy landscape a...
## ... ... ...
## 1002417 3623e74f34c1c3c523af6b2bb8ffcbe2d2dce897ef61b9... Abstract 3D composition with human figures and...
## 1002418 64e9f7b7a1fc4c4ec56ed8b5917dfd610930043ac5e15f... 3D object with a rough, irregular pink surface...
## 1002419 fcd089d6a237fee21dfd5f0d6d9b74b2fd1150cdc61c7f... Bright pink abstract 3D model of a building wi...
## 1002420 f812dc980050f2d5f4b37df2a8620372f810dd6456a5f2... Monochromatic gray 3D model of a stylized huma...
## 1002421 77c09500b4d8e4b881e1ce6929d56c23658b87173c0996... Modular futuristic spacecraft with red and ora...
## if u want to obtain the caption for specific UID
caption = captions[captions[0] == '80d9caaa1fa04502af666135196456e1'][1].values[0]
# load point clouds (unzip https://huggingface.co/datasets/tiange/Cap3D/tree/main/PointCloud_pt_zips)
import torch
pts = torch.load('Cap3D_pcs_pt/80d9caaa1fa04502af666135196456e1.pt')
## pts.shape == torch.Size([6, 16384])
```
## Citation Information
<details>
<summary>Please cite Objaverse, ABO, and ShapeNet paper accordingly, if you use related data. </summary>
```
@inproceedings{deitke2023objaverse,
title={Objaverse: A universe of annotated 3d objects},
author={Deitke, Matt and Schwenk, Dustin and Salvador, Jordi and Weihs, Luca and Michel, Oscar and VanderBilt, Eli and Schmidt, Ludwig and Ehsani, Kiana and Kembhavi, Aniruddha and Farhadi, Ali},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={13142--13153},
year={2023}
}
@article{deitke2024objaverse,
title={Objaverse-xl: A universe of 10m+ 3d objects},
author={Deitke, Matt and Liu, Ruoshi and Wallingford, Matthew and Ngo, Huong and Michel, Oscar and Kusupati, Aditya and Fan, Alan and Laforte, Christian and Voleti, Vikram and Gadre, Samir Yitzhak and others},
journal={Advances in Neural Information Processing Systems},
volume={36},
year={2024}
}
@inproceedings{collins2022abo,
title={Abo: Dataset and benchmarks for real-world 3d object understanding},
author={Collins, Jasmine and Goel, Shubham and Deng, Kenan and Luthra, Achleshwar and Xu, Leon and Gundogdu, Erhan and Zhang, Xi and Vicente, Tomas F Yago and Dideriksen, Thomas and Arora, Himanshu and others},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={21126--21136},
year={2022}
}
@article{chang2015shapenet,
title={Shapenet: An information-rich 3d model repository},
author={Chang, Angel X and Funkhouser, Thomas and Guibas, Leonidas and Hanrahan, Pat and Huang, Qixing and Li, Zimo and Savarese, Silvio and Savva, Manolis and Song, Shuran and Su, Hao and others},
journal={arXiv preprint arXiv:1512.03012},
year={2015}
}
```
</details>
If you find our data or code useful, please consider citing:
```bibtex
@article{luo2023scalable,
title={Scalable 3D Captioning with Pretrained Models},
author={Luo, Tiange and Rockwell, Chris and Lee, Honglak and Johnson, Justin},
journal={arXiv preprint arXiv:2306.07279},
year={2023}
}
@article{luo2024view,
title={View Selection for 3D Captioning via Diffusion Ranking},
author={Luo, Tiange and Johnson, Justin and Lee, Honglak},
journal={arXiv preprint arXiv:2404.07984},
year={2024}
}
```
|
DamianBoborzi/Objaverse_processed | DamianBoborzi | 2025-04-16T14:14:51Z | 19,856 | 0 | [
"license:odc-by",
"arxiv:2503.14002",
"region:us"
] | [] | 2025-02-28T15:01:58Z | null | ---
license: odc-by
pretty_name: Objaverse Processsing Data
---
Contains information of Objaverse XL objects from the alignment and TRELLIS500K (over 1 Millionen processed objects) dataset. We downloaded and rendered 4 views of each object. We generat siglip embeddings and Yolov10 objects detections for fast filtering. We added TRELLIS and CAP3D Captions where available. If there were no captions we generated new captions with the large version of Florence 2. This is the base dataset we used to generate [MeshFleet](https://huggingface.co/datasets/DamianBoborzi/meshfleetXL) which is described in [MeshFleet: Filtered and Annotated 3D Vehicle Dataset for Domain Specific Generative Modeling](arxiv.org/abs/2503.14002).
- The rendered views are in the data directory split into webdataset chunks. The file 'objaverse_xl_render_files.csv' shows which objects is in which chunk using the sha256 of the objects. You can simply extract all files from each chunk using something like `tar -xf chunk_0.tar -C extract_test` or you can use the WebDataset Library to access the content of each chunk.
- objaverse_oxl_processing_df.csv includes the following information:
sha256: The sha256 of the object from Objaverse XL
yolo_detections: Detected objects
cap3D Data: cap3D_caption: The Captions generation by Cap3D (https://cap3d-um.github.io/), cap3D_avg_clip_similarity: is the average similariy of the text siglip embeddings to the siglip embedding of filtered car objects
TRELLIS500K Data: Captions (trellis_caption) and aesthetic scores (trellis_aesthetic_score) from TRELLIS500K (https://huggingface.co/datasets/JeffreyXiang/TRELLIS-500K). We also used the referenced aesthetic score prediciton model (aesthetic_score). The results are however very different.
Florence_caption: Captions of objects which did not have a caption either from CAP3D or TRELLIS500 using Florence 2 (https://huggingface.co/microsoft/Florence-2-large)
Car Quality Assessment: We processed all objects by generating SigLIP and DINOv2 Embeddings and estiomating if the object is a high quality vehicle. Results contain the estimated label(predicted_car_quality_label), the score of the model before taking the max of the output (output_score), and uncertainty estimates using monte carlo dropout: car_quality_uncertainty_entropy,car_quality_uncertainty_mutual_info,car_quality_uncertainty_variation_ratio
- objaverse_combined_captions.csv combines the captions from three different sources (CAP3D, TRELLIS500K and newly generated ones with Florence 2) and stores them together with the corresponding sha256 of the object.
- objaverse_vehicle_detections_textcategories.csv
Contains the detection if a car is described based on the captions from CAP3D, TRELLIS500K and the Florence-2 generated ones. The result is given with text_category_car as 'car' and 'not a car'. If the text describes a car the text_category_vehicle gives an estimate what type of car.
- objaverse_car_classification_results_df.csv
Contains the Car Quality Assessment alone without the additional information from objaverse_oxl_processing_df.csv.
|
happycircus1/sentiment-analysis-test | happycircus1 | 2025-04-16T12:51:57Z | 400 | 7 | [
"task_categories:text-classification",
"task_ids:sentiment-analysis",
"annotations_creators:expert-generated",
"annotations_creators:crowdsourced",
"language_creators:crowdsourced",
"multilinguality:monolingual",
"source_datasets:original",
"language:it",
"license:mit",
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us",
"school project, school, high school"
] | [
"text-classification"
] | 2025-04-16T11:56:20Z | 7 | ---
dataset_info:
features:
- name: text
dtype: string
- name: sentiment
dtype: string
splits:
- name: train
num_bytes: 28302.111747851002
num_examples: 279
- name: test
num_bytes: 7100.888252148997
num_examples: 70
download_size: 23157
dataset_size: 35403.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
annotations_creators:
- expert-generated
- crowdsourced
language:
- it
language_creators:
- crowdsourced
license:
- mit
multilinguality:
- monolingual
pretty_name: sentiment analysis data base developed in a school
size_categories:
- n<1K
source_datasets:
- original
tags:
- school project, school, high school
task_categories:
- text-classification
task_ids:
- sentiment-analysis
---
#Sentiment analysi School project
the dataset was created with an online questionnaire in which an audience of students, teachers, administrative staff, and families were asked to answer some questions about their relationship with school.
the annotations were made by correlating the textual responses to satisfaction indicators.
the dataset was created within an afternoon course dedicated to artificial intelligence.
thanks to everyone for their collaboration❤️. |
Riccardoschillaci7/sentiment-analysis-test | Riccardoschillaci7 | 2025-04-16T12:51:46Z | 391 | 7 | [
"task_categories:text-classification",
"task_ids:sentiment-analysis",
"annotations_creators:expert-generated",
"annotations_creators:crowdsourced",
"language_creators:crowdsourced",
"multilinguality:monolingual",
"source_datasets:original",
"language:it",
"license:mit",
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us",
"school",
"high school"
] | [
"text-classification"
] | 2025-04-16T11:46:32Z | 7 | ---
dataset_info:
features:
- name: text
dtype: string
- name: sentiment
dtype: string
splits:
- name: train
num_bytes: 28302.111747851002
num_examples: 279
- name: test
num_bytes: 7100.888252148997
num_examples: 70
download_size: 23157
dataset_size: 35403.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
annotations_creators:
- expert-generated
- crowdsourced
language:
- it
language_creators:
- crowdsourced
license:
- mit
multilinguality:
- monolingual
pretty_name: A sentiment analysis database created in a school environment
size_categories:
- n<1K
source_datasets:
- original
tags:
- school
- high school
task_categories:
- text-classification
task_ids:
- sentiment-analysis
---
# Progetto scolastico per l'analisi dei sentimenti
il dataset è stato creato con un questionario online in cui si chiedeva ad un publico di studenti, docenti, personale amministrativo, famiglie di rispondere ad alcune domande sul loro rapporto con la scuola.
le annotazioni sono state effettuate correlando le risposte testuali ad indicatori di gradimento.
il dataset è stato realizzato all'interno di un corso pomeridiano scolastico dedicato all'intelligenza artificiale.
Grazie a tutti per la collaborazione (●'◡'●)
|
MarcPal08/sentiment-analysis-test | MarcPal08 | 2025-04-16T12:51:30Z | 505 | 9 | [
"task_categories:text-classification",
"task_ids:sentiment-analysis",
"annotations_creators:expert-generated",
"annotations_creators:crowdsourced",
"language_creators:crowdsourced",
"multilinguality:monolingual",
"source_datasets:original",
"language:it",
"license:mit",
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us",
"school",
"high-school"
] | [
"text-classification"
] | 2025-04-16T11:57:04Z | 9 | ---
dataset_info:
features:
- name: text
dtype: string
- name: sentiment
dtype: string
splits:
- name: train
num_bytes: 28302.111747851002
num_examples: 279
- name: test
num_bytes: 7100.888252148997
num_examples: 70
download_size: 23157
dataset_size: 35403.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
annotations_creators:
- expert-generated
- crowdsourced
language:
- it
language_creators:
- crowdsourced
license:
- mit
multilinguality:
- monolingual
pretty_name: A sentiment analisys database created in a school environment.
size_categories:
- n<1K
source_datasets:
- original
tags:
- school
- high-school
task_categories:
- text-classification
task_ids:
- sentiment-analysis
---
# Progetto scolastico per l'analisi dei sentimenti
Il dataset è stato creato con un questionario online in cui si chiedeva ad un pubblico di studenti, docenti, personale amministrativo, famiglie di rispondere ad alcune domande sul loro rapporto con la scuola.
Le annotazioni sono state effettuate correlando le risposte testuali ad indicatori di gradimento.
Il dataset è stato realizzato all'interno di un corso pomeridiano scolastico dedicato all'intelligenza artificiale.
Grazie a tutti per la collaborazione ❤️ |
Liux69/sentiment-analysis-test | Liux69 | 2025-04-16T12:36:58Z | 398 | 6 | [
"task_categories:text-classification",
"task_ids:sentiment-analysis",
"annotations_creators:crowdsourced",
"annotations_creators:expert-generated",
"language_creators:crowdsourced",
"multilinguality:monolingual",
"source_datasets:original",
"language:it",
"license:mit",
"size_categories:n<1K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us",
"school",
"high-school"
] | [
"text-classification"
] | 2025-04-16T11:51:12Z | 6 | ---
dataset_info:
features:
- name: text
dtype: string
- name: sentiment
dtype: string
splits:
- name: train
num_bytes: 28302.111747851002
num_examples: 279
- name: test
num_bytes: 7100.888252148997
num_examples: 70
download_size: 23157
dataset_size: 35403.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
annotations_creators:
- crowdsourced
- expert-generated
language:
- it
language_creators:
- crowdsourced
license:
- mit
multilinguality:
- monolingual
pretty_name: A sentiment analysis database created in a school environment.
size_categories:
- n<1K
source_datasets:
- original
tags:
- school
- high-school
task_categories:
- text-classification
task_ids:
- sentiment-analysis
---
|
fleaven/Retargeted_AMASS_for_robotics | fleaven | 2025-04-16T11:08:40Z | 44,376 | 8 | [
"task_categories:robotics",
"language:en",
"license:cc-by-4.0",
"size_categories:10K<n<100K",
"region:us",
"AMASS",
"Retarget",
"Robotics",
"Humanoid"
] | [
"robotics"
] | 2025-01-25T04:25:24Z | null | ---
license: cc-by-4.0
task_categories:
- robotics
language:
- en
tags:
- AMASS
- Retarget
- Robotics
- Humanoid
pretty_name: Retargeted AMASS for Robotics
size_categories:
- 10K<n<100K
---
# Retargeted AMASS for Robotics
## Project Overview
This project aims to retarget motion data from the AMASS dataset to various robot models and open-source the retargeted data to facilitate research and applications in robotics and human-robot interaction. AMASS (Archive of Motion Capture as Surface Shapes) is a high-quality human motion capture dataset, and the SMPL-X model is a powerful tool for generating realistic human motion data.
By adapting the motion data from AMASS to different robot models, we hope to provide a more diverse and accessible motion dataset for robot training and human-robot interaction.
## Dataset Content
This open-source project includes the following:
1. **Retargeted Motions**: Motion files retargeted from AMASS to various robot models.
- **Unitree G1**:
<iframe src="//player.bilibili.com/player.html?bvid=BV1zd6iYkEZ2&page=1&high_quality=1&danmaku=0" allowfullscreen="allowfullscreen" width="100%" height="500" scrolling="no" frameborder="0" sandbox="allow-top-navigation allow-same-origin allow-forms allow-scripts"></iframe>
The retargeted motions for the Unitree G1 robot are generated based on the official open-source model provided by Unitree.
https://github.com/unitreerobotics/unitree_ros/blob/master/robots/g1_description/g1_29dof_rev_1_0.xml
The joint positions comply with the constraints defined in the XML file.
data shape:[-1,36]
0:3 root world position
3:7 root quaternion rotation, order: xyzw
7:36 joint positions
joint order:
```txt
left_hip_pitch_joint
left_hip_roll_joint
left_hip_yaw_joint
left_knee_joint
left_ankle_pitch_joint
left_ankle_roll_joint
right_hip_pitch_joint
right_hip_roll_joint
right_hip_yaw_joint
right_knee_joint
right_ankle_pitch_joint
right_ankle_roll_joint
waist_yaw_joint
waist_roll_joint
waist_pitch_joint
left_shoulder_pitch_joint
left_shoulder_roll_joint
left_shoulder_yaw_joint
left_elbow_joint
left_wrist_roll_joint
left_wrist_pitch_joint
left_wrist_yaw_joint
right_shoulder_pitch_joint
right_shoulder_roll_joint
right_shoulder_yaw_joint
right_elbow_joint
right_wrist_roll_joint
right_wrist_pitch_joint
right_wrist_yaw_joint
```
2. **update**
2025-4-15: Optimized the handling of elbow and knee joints.
3. **Usage Examples**: Code examples on how to use the retargeted data.
./g1/visualize.py
4. **License Files**: Original license information for each sub-dataset within AMASS.
## License
The retargeted data in this project is derived from the AMASS dataset and therefore adheres to the original license terms of AMASS. Each sub-dataset within AMASS may have different licenses, so please ensure compliance with the following requirements when using the data:
- **Propagate Original Licenses**: When using or distributing the retargeted data, you must include and comply with the original licenses of the sub-datasets within AMASS.
- **Attribution Requirements**: Properly cite this work and the original authors and sources of the AMASS dataset and its sub-datasets.
For detailed license information, please refer to the `LICENSE` file in this project.
## Acknowledgments
This project is built on the AMASS dataset and the SMPL-X model. Special thanks to the research team at the Max Planck Institute for Intelligent Systems for providing this valuable resource.
## Citation
If you use the data or code from this project, please cite this work and relevant papers for AMASS and SMPL-X:
```bibtex
@misc{Retargeted_AMASS_R,
title={Retargeted AMASS for Robotics},
author={Kun Zhao},
url={https://huggingface.co/datasets/fleaven/Retargeted_AMASS_for_robotics}
}
@inproceedings{AMASS2019,
title={AMASS: Archive of Motion Capture as Surface Shapes},
author={Mahmood, Naureen and Ghorbani, Nima and Troje, Nikolaus F. and Pons-Moll, Gerard and Black, Michael J.},
booktitle={International Conference on Computer Vision (ICCV)},
year={2019}
}
@inproceedings{SMPL-X2019,
title={Expressive Body Capture: 3D Hands, Face, and Body from a Single Image},
author={Pavlakos, Georgios and Choutas, Vasileios and Ghorbani, Nima and Bolkart, Timo and Osman, Ahmed A. A. and Tzionas, Dimitrios and Black, Michael J.},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2019}
}
```
## Contact
For any questions or suggestions, please contact:
- **Kun Zhao**: [email protected]
For more information, follow my Xiaohongshu and Bilibili:
https://www.xiaohongshu.com/user/profile/60cdc5360000000001007e33
https://space.bilibili.com/678369952 |
virtuoussy/Multi-subject-RLVR | virtuoussy | 2025-04-16T09:47:25Z | 1,547 | 56 | [
"task_categories:question-answering",
"language:en",
"license:apache-2.0",
"size_categories:100K<n<1M",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"arxiv:2503.23829",
"region:us",
"reasoning-datasets-competition"
] | [
"question-answering"
] | 2025-03-31T07:35:23Z | 2 | ---
license: apache-2.0
task_categories:
- question-answering
language:
- en
tags:
- reasoning-datasets-competition
---
Multi-subject data for paper "Expanding RL with Verifiable Rewards Across Diverse Domains".
we use a multi-subject multiple-choice QA dataset ExamQA (Yu et al., 2021).
Originally written in Chinese, ExamQA covers at least 48 first-level subjects.
We remove the distractors and convert each instance into a free-form QA pair.
This dataset consists of 638k college-level instances, with both questions and objective answers written by domain experts for examination purposes.
We also use GPT-4o-mini to translate questions and options into English.
For evaluation, we randomly sample 6,000 questions from ExamQA as the test set, while the remaining questions are used as the training pool.
Since subject labels are not provided for each QA pair, we use GPT-4o-mini to classify them into one of 48 subjects or mark them as unclassified if uncertain.
Excluding unclassified instances (15.8% of the test data), the most frequent subjects include basic medicine, law, economics, management, civil engineering, mathematics, computer science and technology, psychology, and
chemistry.
For ease of analysis, we further categorize these subjects into four broad fields (STEM, social sciences, humanities, and applied sciences).
## Citation
```bibtex
@article{su2025expanding,
title={Expanding RL with Verifiable Rewards Across Diverse Domains},
author={Su, Yi and Yu, Dian and Song, Linfeng and Li, Juntao and Mi, Haitao and Tu, Zhaopeng and Zhang, Min and Yu, Dong},
journal={arXiv preprint arXiv:2503.23829},
year={2025}
}
``` |
Skywork/Skywork-OR1-RL-Data | Skywork | 2025-04-15T08:31:20Z | 2,098 | 29 | [
"size_categories:100K<n<1M",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-04-12T10:01:22Z | 2 | ---
dataset_info:
features:
- name: data_source
dtype: string
- name: prompt
list:
- name: content
dtype: string
- name: role
dtype: string
- name: ability
dtype: string
- name: reward_model
struct:
- name: ground_truth
dtype: string
- name: style
dtype: string
- name: extra_info
struct:
- name: index
dtype: int64
- name: model_difficulty
struct:
- name: DeepSeek-R1-Distill-Qwen-1.5B
dtype: int64
- name: DeepSeek-R1-Distill-Qwen-32B
dtype: int64
- name: DeepSeek-R1-Distill-Qwen-7B
dtype: int64
splits:
- name: math
num_bytes: 40461845
num_examples: 105055
- name: code
num_bytes: 1474827100
num_examples: 14057
download_size: 823104116
dataset_size: 1515288945
configs:
- config_name: default
data_files:
- split: math
path: data/math-*
- split: code
path: data/code-*
---
<div align="center">
# 🤔 Skywork-OR1-RL-Data
</div>
<div align="center">
[](https://huggingface.co/collections/Skywork/skywork-or1-67fa1bcb41b436ef2def76b9)
[](https://huggingface.co/datasets/Skywork/Skywork-OR1-RL-Data)
[](https://github.com/SkyworkAI/Skywork-OR1)
[](https://capricious-hydrogen-41c.notion.site/Skywork-Open-Reaonser-Series-1d0bc9ae823a80459b46c149e4f51680)
[](https://github.com/SkyworkAI/Skywork-OR1/stargazers)
[](https://github.com/SkyworkAI/Skywork-OR1/fork)
</div>
## 🔥 News
- **April 15, 2025**: We are excited to release our RL training dataset [`Skywork-OR1-RL-Data`](https://huggingface.co/datasets/Skywork/Skywork-OR1-RL-Data)
- For our final training phase, we filtered problems based on their difficulty levels (0-16, higher values indicate harder problems) relative to specific model variants (DeepSeek-R1-Distill-Qwen-{1.5,7,32}B. For each model variant, we excluded problems with difficulty values of 0 and 16 specific to that model from its training data.
- You can check our [Skywork-OR1](https://github.com/SkyworkAI/Skywork-OR1?tab=readme-ov-file#training-data-preparation) repository for training data preparation steps.
- **Note**: Due to an accidental early release, a version with incorrect difficulty fields was briefly public. Please make sure to use either the newest version (recommended) or any version at this [commit](https://huggingface.co/datasets/Skywork/Skywork-OR1-RL-Data/commit/b48ac2ee70ae3dc5d6db769f232e8a966cb89240) and after.
## 📖 Overview
[`Skywork-OR1-RL-Data`](https://huggingface.co/datasets/Skywork/Skywork-OR1-RL-Data) is **a dataset of verifiable, challenging, and diverse math problems (105K) and coding questions (14K)**. This dataset is used to train the **`Skywork-OR1`** (Open Reasoner 1) model series, which consists of powerful math and code reasoning models trained using large-scale rule-based reinforcement learning with carefully designed datasets and training recipes. This series includes two general-purpose reasoning modelsl, **`Skywork-OR1-7B-Preview`** and **`Skywork-OR1-32B-Preview`**, along with a math-specialized model, **`Skywork-OR1-Math-7B`**.
- **[`Skywork-OR1-Math-7B`](https://huggingface.co/Skywork/Skywork-OR1-Math-7B)** is specifically optimized for mathematical reasoning, scoring **69.8** on AIME24 and **52.3** on AIME25 — well ahead of all models of similar size.
- **[`Skywork-OR1-32B-Preview`](https://huggingface.co/Skywork/Skywork-OR1-32B-Preview)** delivers the 671B-parameter Deepseek-R1 performance on math tasks (AIME24 and AIME25) and coding tasks (LiveCodeBench).
- **[`Skywork-OR1-7B-Preview`](https://huggingface.co/Skywork/Skywork-OR1-7B-Preview)** outperforms all similarly sized models in both math and coding scenarios.
We select, clean, and curate math and coding problems from open-source datasets, including
- [NuminaMath-1.5](https://huggingface.co/datasets/AI-MO/NuminaMath-1.5)
- [DeepScaleR-Preview-Dataset](https://huggingface.co/datasets/agentica-org/DeepScaleR-Preview-Dataset)
- [STILL-3-Preview-RL-Data](https://huggingface.co/datasets/RUC-AIBOX/STILL-3-Preview-RL-Data)
- [Omni-Math](https://huggingface.co/datasets/KbsdJames/Omni-MATH)
- [AIME problems prior to 2024](https://huggingface.co/datasets/gneubig/aime-1983-2024)
- [LeetCodeDataset](https://huggingface.co/datasets/newfacade/LeetCodeDataset)
- [TACO](https://huggingface.co/datasets/BAAI/TACO)
We conduct **model-aware difficulty estimation** for each problem and model and conduct **rigorous quality assessment prior to training** via both human and LLM-as-a-Judge to ensure training efficiency and effectiveness. We also perform deduplication within the dataset and remove similar problems from AIME 24, AIME 25, and LiveCodeBench to prevent data contamination.
## 📄 Technical Report
Our technical report will be released soon. Stay tuned!
## 📚 Citation
We will update the citation once the technical report is released. In the meantime, please cite the following:
```bibtex
@misc{skywork-or1-2025,
title={Skywork Open Reasoner Series},
author = {He, Jujie and Liu, Jiacai and Liu, Chris Yuhao and Yan, Rui and Wang, Chaojie and Cheng, Peng and Zhang, Xiaoyu and Zhang, Fuxiang and Xu, Jiacheng and Shen, Wei and Li, Siyuan and Zeng, Liang and Wei, Tianwen and Cheng, Cheng and Liu, Yang and Zhou, Yahui},
howpublished={\url{https://capricious-hydrogen-41c.notion.site/Skywork-Open-Reaonser-Series-1d0bc9ae823a80459b46c149e4f51680}},
note={Notion Blog},
year={2025}
}
```
|
starriver030515/FUSION-Finetune-12M | starriver030515 | 2025-04-15T05:38:25Z | 12,453 | 9 | [
"task_categories:question-answering",
"task_categories:visual-question-answering",
"task_categories:table-question-answering",
"language:en",
"language:zh",
"license:apache-2.0",
"size_categories:1K<n<10K",
"format:parquet",
"modality:image",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"arxiv:2504.09925",
"region:us"
] | [
"question-answering",
"visual-question-answering",
"table-question-answering"
] | 2025-03-16T16:07:26Z | null | ---
license: apache-2.0
task_categories:
- question-answering
- visual-question-answering
- table-question-answering
language:
- en
- zh
configs:
- config_name: ALLaVA
data_files:
- split: train
path: examples/ALLaVA*
- config_name: ArxivQA
data_files:
- split: train
path: examples/ArxivQA*
- config_name: CLEVR
data_files:
- split: train
path: examples/CLEVR*
- config_name: ChartQA
data_files:
- split: train
path: examples/ChartQA*
- config_name: DVQA
data_files:
- split: train
path: examples/DVQA*
- config_name: DataEngine
data_files:
- split: train
path: examples/DataEngine*
- config_name: DocMatix
data_files:
- split: train
path: examples/DocMatix*
- config_name: GeoQA
data_files:
- split: train
path: examples/GeoQA*
- config_name: LNQA
data_files:
- split: train
path: examples/LNQA*
- config_name: LVISInstruct
data_files:
- split: train
path: examples/LVISInstruct*
- config_name: MMathCoT
data_files:
- split: train
path: examples/MMathCoT*
- config_name: MathVision
data_files:
- split: train
path: examples/MathVision*
- config_name: MulBerry
data_files:
- split: train
path: examples/MulBerry*
- config_name: PixmoAskModelAnything
data_files:
- split: train
path: examples/PixmoAskModelAnything*
- config_name: PixmoCap
data_files:
- split: train
path: examples/PixmoCap*
- config_name: PixmoCapQA
data_files:
- split: train
path: examples/PixmoCapQA*
- config_name: PixmoDocChart
data_files:
- split: train
path: examples/PixmoDocChart*
- config_name: PixmoDocDiagram
data_files:
- split: train
path: examples/PixmoDocDiagram*
- config_name: PixmoDocTable
data_files:
- split: train
path: examples/PixmoDocTable*
- config_name: SynthChoice
data_files:
- split: train
path: examples/SynthChoice*
- config_name: SynthConvLong
data_files:
- split: train
path: examples/SynthConvLong*
- config_name: SynthConvShort
data_files:
- split: train
path: examples/SynthConvShort*
- config_name: SynthContrastLong
data_files:
- split: train
path: examples/SynthContrastLong*
- config_name: SynthContrastShort
data_files:
- split: train
path: examples/SynthContrastShort*
- config_name: SynthReasoning
data_files:
- split: train
path: examples/SynthReasoning*
- config_name: SynthTextQA
data_files:
- split: train
path: examples/SynthTextQA*
- config_name: SynthDog
data_files:
- split: train
path: examples/SynthDog*
dataset_info:
- config_name: ALLaVA
features:
- name: id
dtype: string
- name: QA
dtype: string
- name: image
dtype: image
- config_name: ArxivQA
features:
- name: id
dtype: string
- name: QA
dtype: string
- name: image
dtype: image
- config_name: CLEVR
features:
- name: id
dtype: string
- name: QA
dtype: string
- name: image
dtype: image
- config_name: ChartQA
features:
- name: id
dtype: string
- name: QA
dtype: string
- name: image
dtype: image
- config_name: DVQA
features:
- name: id
dtype: string
- name: QA
dtype: string
- name: image
dtype: image
- config_name: DataEngine
features:
- name: id
dtype: string
- name: QA
dtype: string
- name: image
dtype: image
- config_name: GeoQA
features:
- name: id
dtype: string
- name: QA
dtype: string
- name: image
dtype: image
- config_name: LNQA
features:
- name: id
dtype: string
- name: QA
dtype: string
- name: image
dtype: image
- config_name: LVISInstruct
features:
- name: id
dtype: string
- name: QA
dtype: string
- name: image
dtype: image
- config_name: DocMatix
features:
- name: id
dtype: string
- name: QA
dtype: string
- name: image
dtype: image
- config_name: MMathCoT
features:
- name: id
dtype: string
- name: QA
dtype: string
- name: image
dtype: image
- config_name: MathVision
features:
- name: id
dtype: string
- name: QA
dtype: string
- name: image
dtype: image
- config_name: MulBerry
features:
- name: id
dtype: string
- name: QA
dtype: string
- name: image
dtype: image
- config_name: PixmoAskModelAnything
features:
- name: id
dtype: string
- name: QA
dtype: string
- name: image
dtype: image
- config_name: PixmoCap
features:
- name: id
dtype: string
- name: QA
dtype: string
- name: image
dtype: image
- config_name: PixmoCapQA
features:
- name: id
dtype: string
- name: QA
dtype: string
- name: image
dtype: image
- config_name: PixmoDocChart
features:
- name: id
dtype: string
- name: QA
dtype: string
- name: image
dtype: image
- config_name: PixmoDocDiagram
features:
- name: id
dtype: string
- name: QA
dtype: string
- name: image
dtype: image
- config_name: PixmoDocTable
features:
- name: id
dtype: string
- name: QA
dtype: string
- name: image
dtype: image
- config_name: SynthChoice
features:
- name: id
dtype: string
- name: QA
dtype: string
- name: image
dtype: image
- config_name: SynthConvLong
features:
- name: id
dtype: string
- name: QA
dtype: string
- name: image
dtype: image
- config_name: SynthConvShort
features:
- name: id
dtype: string
- name: QA
dtype: string
- name: image
dtype: image
- config_name: SynthContrastLong
features:
- name: id
dtype: string
- name: QA
dtype: string
- name: image
dtype: image
- config_name: SynthContrastShort
features:
- name: id
dtype: string
- name: QA
dtype: string
- name: image
dtype: image
- config_name: SynthReasoning
features:
- name: id
dtype: string
- name: QA
dtype: string
- name: image
dtype: image
- config_name: SynthTextQA
features:
- name: id
dtype: string
- name: QA
dtype: string
- name: image
dtype: image
- config_name: SynthDog
features:
- name: id
dtype: string
- name: QA
dtype: string
- name: image
dtype: image
size_categories:
- 10M<n<100M
---
# FUSION-12M Dataset
**Please see paper & website for more information:**
- [https://arxiv.org/abs/2504.09925](https://arxiv.org/abs/2504.09925)
- [https://github.com/starriver030515/FUSION](https://github.com/starriver030515/FUSION)
## Overview
FUSION-12M is a large-scale, diverse multimodal instruction-tuning dataset used to train FUSION-3B and FUSION-8B models. It builds upon Cambrian-1 by significantly expanding both the quantity and variety of data, particularly in areas such as OCR, mathematical reasoning, and synthetic high-quality Q&A data. The goal is to provide a high-quality and high-volume open-source VQA dataset optimized for general visual instruction-following capabilities. The dataset is carefully curated to balance multimodal understanding with strong language capabilities.
## Data Collection
### Multimodal Data Sources
In line with Cambrian-1, we leverage a wide range of benchmark datasets spanning categories like OCR, Science, and General QA. However, unlike Cambrian-1, FUSION-12M does not include code-related data, focusing instead on general-purpose vision-language modeling.
To enhance the dataset’s visual reasoning capability, we significantly increase the volume and quality of OCR data. In particular, we incorporate high-resolution, high-quality document VQA datasets such as DocMatix and PixmoDoc, enabling models to better handle document-based understanding tasks.
We also introduce additional datasets in math and visual reasoning domains, such as MMathCot and MulBerry, with the goal of improving the model’s ability in logical deduction, numerical understanding, and scientific comprehension.
### Language-Only Instruction-Following Data
To preserve the model’s pure language ability and to ensure compatibility with the new decoder architecture of the FUSION models, we include a small amount of high-quality language-only instruction-following datasets collected from the community. This helps maintain strong generative and comprehension abilities in text-only scenarios.
### Synthesized Language-Driven QA Dataset
<img src="synth_method.pdf" alt="Language-Driven QA Synthesis pipeline" width="1000px">
To further increase diversity and alignment quality, we develop a new Language-Driven QA Synthesis pipeline and generate 2 million synthetic samples used in supervised fine-tuning (SFT). This pipeline enhances instruction alignment and visual understanding in structured formats.
The process includes:
1. **Caption Pool Collection**: A large pool of image captions is assembled from diverse datasets.
2. **Description Expansion**: Captions are expanded into detailed, context-rich descriptions using LLaMA3.1-70B.
3. **Image Generation**: These descriptions are used as prompts for FLUX.1 Dev to synthesize corresponding images.
4. **QA Generation**: The descriptions and images are passed again to LLaMA3.1-70B to generate high-quality Q&A pairs.
We generate the following types of synthetic instruction datasets:
• **SynthMultiChoice QA**: Multi-turn dialogues consisting of multiple-choice questions. These samples are designed to teach the model how to distinguish between closely related options and identify the correct one.
• **SynthConvShort QA**: Multi-turn dialogues with short answers, focusing on fast key information extraction and quick response generation.
• **SynthConvLong QA**: Multi-turn dialogues with long-form answers. These help the model learn how to provide detailed explanations and reasoned responses.
• **SynthContrastShort QA & SynthContrastLong QA**: Dialogues involving comparative reasoning between two similar images. The goal is to train the model to observe subtle visual differences and explain them.
• **SynthReasoning QA**: Single-turn visual reasoning questions that require the model to make inferences or deductions from visual input.
• **SynthText QA**: Multi-turn dialogues that identify and describe visible text in the image.
## Fusion-5M-Stage1.5
This subset of 5 million samples is used in the second phase of FUSION model training (Stage 1.5). The focus here is on increasing the diversity of question types and conversational interactions. We generate 1 million distinct QA samples spanning a variety of reasoning tasks, conversational forms, and multiple-choice questions. Additionally, we include publicly available datasets such as PixmoAskModelAnything, Q-Instruct and LVIS-Instruct. We also integrate some domain-specific datasets including Math, OCR, and Science from Stage 2 to enrich Stage 1.5’s overall diversity. The data composition for Fusion-Stage1.5 is as follows:
• **Language**: 4.3%
• **General**: 20.1%
• **OCR**: 14.1%
• **SynthQA**: 21.5%
• **Science**: 10.0%
• **Long Captions**: 29.7%
## Fusion-7M-Stage2
This subset includes 7 million samples used in the third phase of training (Stage 2), focusing more heavily on vision-centric instruction tuning.We incorporate part of the domain-specific data from Stage 1.5 and introduce additional datasets targeted at downstream visual-language tasks, including LLaVA 665K, MMathCot and Cambrian-7M. In addition, we synthesize around 1 million task-oriented samples covering extended visual reasoning and complex Q&A structures. The dataset distribution for Fusion-Stage2 is:
• **Language**: 2.9%
• **General**: 27.4%
• **OCR**: 28.9%
• **Counting**: 3.6%
• **SynthQA**: 12.3%
• **Code**: 0.87%
• **Science**: 19.2%
• **Long Captions**: 5.8%
<img src="fusion_data.pdf" alt="Fusion_Data" width="1000px">
## Getting Started with FUSION Data
Before getting started, please ensure you have sufficient storage space for downloading and processing the dataset.
**1. Download the Data Repository**
Download all necessary data files from our repository. Different data categories (e.g., OCR, General, SynthQA) are stored separately, and each comes with a corresponding JSON manifest. If you only wish to use specific data types, you may selectively download the desired JSON and ZIP files.
**2. Merge Tar Files**
Due to Hugging Face’s size restrictions, large files such as Allava and DocMatix are split using the split command into chunks of 10 GB. To merge them into a single archive:
```
cat allava.zip* > allava.zip
```
**3. Extract Tar Files**
Once merged (or for individual ZIP files), extract them using the unzip command:
```
unzip allava.zip
```
**4. Training with FUSION-12M**
We provide two main JSON manifests:
• **FUSION-5M** (for Stage 1.5 training): Located in the [json1.5](https://huggingface.co/datasets/starriver030515/FUSION-Finetune-12M/tree/main/Stage1.5-json) directory.
• **FUSION-7M** (for Stage 2 training): Located in the [json2](https://huggingface.co/datasets/starriver030515/FUSION-Finetune-12M/tree/main/Stage1.5-json) directory.
To replicate our full FUSION training pipeline, we recommend training the model in two stages using the respective datasets. For users who wish to use the complete 12M dataset at once, simply concatenate the Stage1.5 and Stage2 JSON files together.
## Citation
If you find FUSION useful for your research and applications, please cite using this BibTeX:
```bibtex
@misc{liu2025fusionfullyintegrationvisionlanguage,
title={FUSION: Fully Integration of Vision-Language Representations for Deep Cross-Modal Understanding},
author={Zheng Liu and Mengjie Liu and Jingzhou Chen and Jingwei Xu and Bin Cui and Conghui He and Wentao Zhang},
year={2025},
eprint={2504.09925},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2504.09925},
}
``` |
lmarena-ai/search-arena-v1-7k | lmarena-ai | 2025-04-14T16:01:06Z | 875 | 14 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"arxiv:2403.04132",
"region:us"
] | [] | 2025-04-14T06:28:29Z | 2 | ---
size_categories:
- 100K<n<1M
configs:
- config_name: default
data_files:
- split: test
path: data/search-arena-*
---
## Overview
This dataset contains 7k leaderboard conversation votes collected from [Search Arena](https://lmarena.ai/?search) between March 18, 2025 and April 13, 2025. All entries have been redacted for PII and sensitive user information to ensure privacy.
Each data point includes:
- Two model responses (`messages_a` and `messages_b`)
- The human vote result
- A timestamp
- Full system metadata, LLM + web search trace, and post-processed metadata for controlled experiments (`conv_meta`)
To reproduce the leaderboard results and analyses:
- Check out the [Colab notebook](https://colab.research.google.com/drive/1h7rR7rhePBPuIfaWsVNlW87kv3DLibPS?usp=sharing) for a step-by-step walkthrough.
- A companion [blog post](https://blog.lmarena.ai/blog/2025/search-arena) will provide deeper insights and commentary on the dataset and evaluation process.
## License
User prompts are licensed under CC-BY-4.0, and model outputs are governed by the terms of use set by the respective model providers.
## Citation
```bibtex
@misc{searcharena2025,
title = {Introducing the Search Arena: Evaluating Search-Enabled AI},
url = {https://blog.lmarena.ai/blog/2025/search-arena/},
author = {Mihran Miroyan*, Tsung-Han Wu*, Logan Kenneth King, Tianle Li, Anastasios N. Angelopoulos, Wei-Lin Chiang, Narges Norouzi, Joseph E. Gonzalez},
month = {April},
year = {2025}
}
@misc{chiang2024chatbot,
title={Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference},
author={Wei-Lin Chiang and Lianmin Zheng and Ying Sheng and Anastasios Nikolas Angelopoulos and Tianle Li and Dacheng Li and Hao Zhang and Banghua Zhu and Michael Jordan and Joseph E. Gonzalez and Ion Stoica},
year={2024},
eprint={2403.04132},
archivePrefix={arXiv},
primaryClass={cs.AI}
}
```
|
tonyFang04/8-calves | tonyFang04 | 2025-04-13T19:39:09Z | 314 | 5 | [
"task_categories:object-detection",
"language:en",
"license:cc-by-4.0",
"arxiv:2503.13777",
"region:us"
] | [
"object-detection"
] | 2025-04-01T10:43:30Z | 5 | ---
license: cc-by-4.0
task_categories:
- object-detection
language:
- en
---
# 8-Calves Dataset
[](https://arxiv.org/abs/2503.13777)
A benchmark dataset for occlusion-rich object detection, identity classification, and multi-object tracking. Features 8 Holstein Friesian calves with unique coat patterns in a 1-hour video with temporal annotations.
---
## Overview
This dataset provides:
- 🕒 **1-hour video** (67,760 frames @20 fps, 600x800 resolution)
- 🎯 **537,908 verified bounding boxes** with calf identities (1-8)
- 🖼️ **900 hand-labeled static frames** for detection tasks
- Designed to evaluate robustness in occlusion handling, identity preservation, and temporal consistency.
<img src="dataset_screenshot.png" alt="Dataset Example Frame" width="50%" />
*Example frame with bounding boxes (green) and calf identities. Challenges include occlusion, motion blur, and pose variation.*
---
## Key Features
- **Temporal Richness**: 1-hour continuous recording (vs. 10-minute benchmarks like 3D-POP)
- **High-Quality Labels**:
- Generated via **ByteTrack + YOLOv8m** pipeline with manual correction
- <0.56% annotation error rate
- **Unique Challenges**: Motion blur, pose variation, and frequent occlusions
- **Efficiency Testing**: Compare lightweight (e.g., YOLOv9t) vs. large models (e.g., ConvNextV2)
---
## Dataset Structure
hand_labelled_frames/ # 900 manually annotated frames and labels in YOLO format, class=0 for cows
pmfeed_4_3_16.avi # 1-hour video (4th March 2016)
pmfeed_4_3_16_bboxes_and_labels.pkl # Temporal annotations
### Annotation Details
**PKL File Columns**:
| Column | Description |
|--------|-------------|
| `class` | Always `0` (cow detection) |
| `x`, `y`, `w`, `h` | YOLO-format bounding boxes |
| `conf` | Ignore (detections manually verified) |
| `tracklet_id` | Calf identity (1-8) |
| `frame_id` | Temporal index matching video |
**Load annotations**:
```python
import pandas as pd
df = pd.read_pickle("pmfeed_4_3_16_bboxes_and_labels.pkl")
```
## Usage
### Dataset Download:
Step 1: install git-lfs:
`git lfs install`
Step 2:
`git clone [email protected]:datasets/tonyFang04/8-calves`
Step 3: install conda and pip environments:
```
conda create --name new_env --file conda_requirements.txt
pip install -r pip_requirements.txt
```
### Object Detection
- **Training/Validation**: Use the first 600 frames from `hand_labelled_frames/` (chronological split).
- **Testing**: Evaluate on the full video (`pmfeed_4_3_16.avi`) using the provided PKL annotations.
- ⚠️ **Avoid Data Leakage**: Do not use all 900 frames for training - they are temporally linked to the test video.
**Recommended Split**:
| Split | Frames | Purpose |
|------------|--------|------------------|
| Training | 500 | Model training |
| Validation | 100 | Hyperparameter tuning |
| Test | 67,760 | Final evaluation |
### Benchmarking YOLO Models:
Step 1:
`cd 8-calves/object_detector_benchmark`. Run
`./create_yolo_dataset.sh` and
`create_yolo_testset.py`. This creates a YOLO dataset with the 500/100/67760 train/val/test split recommended above.
Step 2: find the `Albumentations` class in the `data/augment.py` file in ultralytics source code. And replace the default transforms to:
```
# Transforms
T = [
A.RandomRotate90(p=1.0),
A.HorizontalFlip(p=0.5),
A.RandomBrightnessContrast(p=0.4),
A.ElasticTransform(
alpha=100.0,
sigma=5.0,
p=0.5
),
]
```
Step 3:
run the yolo detectors following the following commands:
```
cd yolo_benchmark
Model_Name=yolov9t
yolo cfg=experiment.yaml model=$Model_Name.yaml name=$Model_Name
```
### Benchmark Transformer Based Models:
Step 1: run the following commands to load the data into yolo format, then into coco, then into arrow:
```
cd 8-calves/object_detector_benchmark
./create_yolo_dataset.sh
python create_yolo_testset.py
python yolo_to_coco.py
python data_wrangling.py
```
Step 2: run the following commands to train:
```
cd transformer_benchmark
python train.py --config Configs/conditional_detr.yaml
```
### Temporal Classification
- Use `tracklet_id` (1-8) from the PKL file as labels.
- **Temporal Split**: 30% train / 30% val / 40% test (chronological order).
### Benchmark vision models for temporal classification:
Step 1: cropping the bounding boxes from `pmfeed_4_3_16.mp4` using the correct labels in `pmfeed_4_3_16_bboxes_and_labels.pkl`. Then convert the folder of images cropped from `pmfeed_4_3_16.mp4` into lmdb dataset for fast loading:
```
cd identification_benchmark
python crop_pmfeed_4_3_16.py
python construct_lmdb.py
```
Step 2: get embeddings from vision model:
```
cd big_model_inference
```
Use `inference_resnet.py` to get embeddings from resnet and `inference_transformers.py` to get embeddings from transformer weights available on Huggingface:
```
python inference_resnet.py --resnet_type resnet18
python inference_transformers.py --model_name facebook/convnextv2-nano-1k-224
```
Step 3: use the embeddings and labels obtained from step 2 to conduct knn evaluation and linear classification:
```
cd ../classification
python train.py
python knn_evaluation.py
```
## Key Results
### Object Detection (YOLO Models)
| Model | Parameters (M) | mAP50:95 (%) | Inference Speed (ms/sample) |
|-------------|----------------|--------------|-----------------------------|
| **YOLOv9c** | 25.6 | **68.4** | 2.8 |
| YOLOv8x | 68.2 | 68.2 | 4.4 |
| YOLOv10n | 2.8 | 64.6 | 0.7 |
---
### Identity Classification (Top Models)
| Model | Accuracy (%) | KNN Top-1 (%) | Parameters (M) |
|----------------|--------------|---------------|----------------|
| **ConvNextV2-Nano** | 73.1 | 50.8 | 15.6 |
| Swin-Tiny | 68.7 | 43.9 | 28.3 |
| ResNet50 | 63.7 | 38.3 | 25.6 |
---
**Notes**:
- **mAP50:95**: Mean Average Precision at IoU thresholds 0.5–0.95.
- **KNN Top-1**: Nearest-neighbor accuracy using embeddings.
- Full results and methodology: [arXiv paper](https://arxiv.org/abs/2503.13777).
## License
This dataset is released under [CC-BY 4.0](https://creativecommons.org/licenses/by/4.0/).
*Modifications/redistribution must include attribution.*
## Citation
```bibtex
@article{fang20248calves,
title={8-Calves: A Benchmark for Object Detection and Identity Classification in Occlusion-Rich Environments},
author={Fang, Xuyang and Hannuna, Sion and Campbell, Neill},
journal={arXiv preprint arXiv:2503.13777},
year={2024}
}
```
## Contact
**Dataset Maintainer**:
Xuyang Fang
Email: [[email protected]](mailto:[email protected]) |
SUSTech/ChineseSafe | SUSTech | 2025-04-13T03:07:20Z | 317 | 11 | [
"task_categories:text-classification",
"language:zh",
"license:cc-by-nc-4.0",
"size_categories:10K<n<100K",
"format:json",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"arxiv:2410.18491",
"region:us",
"legal"
] | [
"text-classification"
] | 2025-04-12T12:43:48Z | 7 | ---
license: cc-by-nc-4.0
task_categories:
- text-classification
language:
- zh
tags:
- legal
pretty_name: ChineseSafe
size_categories:
- 10K<n<100K
---
## ChineseSafe
Dataset for [ChineseSafe: A Chinese Benchmark for Evaluating Safety in Large Language Models](https://arxiv.org/abs/2410.18491)
## Usage
```python
from datasets import load_dataset
dataset = load_dataset("SUSTech/ChineseSafe", split="test")
```
## Citation
If you find our dataset useful, please cite:
```
@article{zhang2024chinesesafe,
title={ChineseSafe: A Chinese Benchmark for Evaluating Safety in Large Language Models},
author={Zhang, Hengxiang and Gao, Hongfu and Hu, Qiang and Chen, Guanhua and Yang, Lili and Jing, Bingyi and Wei, Hongxin and Wang, Bing and Bai, Haifeng and Yang, Lei},
journal={arXiv preprint arXiv:2410.18491},
year={2024}
} |
PleIAs/GoldenSwag | PleIAs | 2025-04-11T09:24:53Z | 78 | 3 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"arxiv:2504.07825",
"region:us"
] | [] | 2025-04-10T08:50:08Z | 2 | ---
dataset_info:
features:
- name: ind
dtype: int32
- name: activity_label
dtype: string
- name: ctx_a
dtype: string
- name: ctx_b
dtype: string
- name: ctx
dtype: string
- name: endings
sequence: string
- name: source_id
dtype: string
- name: split
dtype: string
- name: split_type
dtype: string
- name: label
dtype: string
splits:
- name: validation
num_bytes: 1697168.7338179646
num_examples: 1525
download_size: 1173900
dataset_size: 1697168.7338179646
configs:
- config_name: default
data_files:
- split: validation
path: data/validation-*
---
# GoldenSwag
This is a filtered subset of the HellaSwag validation set. In the following table, we present the complete set of stages used for the filtering of the HellaSwag validation set, which consists of 10042 questions.
| Filter | # to remove | # removed | # left |
|---------------------------------------------|------------|----------|--------|
| Toxic content | 6 | 6 | 10036 |
| Nonsense or ungrammatical prompt | 4065 | 4064 | 5972 |
| Nonsense or ungrammatical correct answer | 711 | 191 | 5781 |
| Ungrammatical incorrect answers | 3953 | 1975 | 3806 |
| Wrong answer | 370 | 89 | 3717 |
| All options are nonsense | 409 | 23 | 3694 |
| Multiple correct options | 2121 | 583 | 3111 |
| Relative length difference > 0.3 | 802 | 96 | 3015 |
| Length difference (0.15,0.3] and longest is correct | 1270 | 414 | 2601 |
| Zero-prompt core ≥ 0.3 | 3963 | 1076 | 1525 |
For each filter, we report the number of questions in HellaSwag that fit the filtering criterion, the number of questions that we actually remove at this stage (that were not removed in previous stages), and the number of questions that are left in HellaSwag after each filtering stage.
After the filtering, almost all of the questions are sourced from WikiHow part of the data – 1498 (98.2\%).
To cite the work:
```
@misc{chizhov2025hellaswagvaliditycommonsensereasoning,
title={What the HellaSwag? On the Validity of Common-Sense Reasoning Benchmarks},
author={Pavel Chizhov and Mattia Nee and Pierre-Carl Langlais and Ivan P. Yamshchikov},
year={2025},
eprint={2504.07825},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2504.07825},
}
```
To cite the original HellaSwag dataset:
```
@inproceedings{zellers-etal-2019-hellaswag,
title = "{H}ella{S}wag: Can a Machine Really Finish Your Sentence?",
author = "Zellers, Rowan and
Holtzman, Ari and
Bisk, Yonatan and
Farhadi, Ali and
Choi, Yejin",
editor = "Korhonen, Anna and
Traum, David and
M{\`a}rquez, Llu{\'i}s",
booktitle = "Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics",
month = jul,
year = "2019",
address = "Florence, Italy",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/P19-1472/",
doi = "10.18653/v1/P19-1472",
pages = "4791--4800",
abstract = "Recent work by Zellers et al. (2018) introduced a new task of commonsense natural language inference: given an event description such as {\textquotedblleft}A woman sits at a piano,{\textquotedblright} a machine must select the most likely followup: {\textquotedblleft}She sets her fingers on the keys.{\textquotedblright} With the introduction of BERT, near human-level performance was reached. Does this mean that machines can perform human level commonsense inference? In this paper, we show that commonsense inference still proves difficult for even state-of-the-art models, by presenting HellaSwag, a new challenge dataset. Though its questions are trivial for humans ({\ensuremath{>}}95{\%} accuracy), state-of-the-art models struggle ({\ensuremath{<}}48{\%}). We achieve this via Adversarial Filtering (AF), a data collection paradigm wherein a series of discriminators iteratively select an adversarial set of machine-generated wrong answers. AF proves to be surprisingly robust. The key insight is to scale up the length and complexity of the dataset examples towards a critical {\textquoteleft}Goldilocks' zone wherein generated text is ridiculous to humans, yet often misclassified by state-of-the-art models. Our construction of HellaSwag, and its resulting difficulty, sheds light on the inner workings of deep pretrained models. More broadly, it suggests a new path forward for NLP research, in which benchmarks co-evolve with the evolving state-of-the-art in an adversarial way, so as to present ever-harder challenges."
}
``` |
MathLLMs/MathVision | MathLLMs | 2025-04-11T02:36:56Z | 11,488 | 61 | [
"task_categories:question-answering",
"task_categories:multiple-choice",
"task_categories:visual-question-answering",
"task_categories:text-generation",
"annotations_creators:expert-generated",
"annotations_creators:found",
"language_creators:expert-generated",
"language_creators:found",
"language:en",
"license:mit",
"size_categories:1K<n<10K",
"format:parquet",
"modality:image",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"arxiv:2501.12599",
"arxiv:2402.14804",
"region:us",
"mathematics",
"reasoning",
"multi-modal-qa",
"math-qa",
"figure-qa",
"geometry-qa",
"math-word-problem",
"textbook-qa",
"vqa",
"geometry-diagram",
"synthetic-scene",
"chart",
"plot",
"scientific-figure",
"table",
"function-plot",
"abstract-scene",
"puzzle-test",
"document-image",
"science"
] | [
"question-answering",
"multiple-choice",
"visual-question-answering",
"text-generation"
] | 2024-02-22T19:14:42Z | 2 | ---
license: mit
annotations_creators:
- expert-generated
- found
language_creators:
- expert-generated
- found
task_categories:
- question-answering
- multiple-choice
- visual-question-answering
- text-generation
language:
- en
tags:
- mathematics
- reasoning
- multi-modal-qa
- math-qa
- figure-qa
- geometry-qa
- math-word-problem
- textbook-qa
- vqa
- geometry-diagram
- synthetic-scene
- chart
- plot
- scientific-figure
- table
- function-plot
- abstract-scene
- puzzle-test
- document-image
- science
configs:
- config_name: default
data_files:
- split: test
path: data/test-*
- split: testmini
path: data/testmini-*
pretty_name: MATH-V
size_categories:
- 1K<n<10K
---
# Measuring Multimodal Mathematical Reasoning with the MATH-Vision Dataset
[[💻 Github](https://github.com/mathllm/MATH-V/)] [[🌐 Homepage](https://mathllm.github.io/mathvision/)] [[📊 Leaderboard ](https://mathllm.github.io/mathvision/#leaderboard )] [[🔍 Visualization](https://mathllm.github.io/mathvision/#visualization)] [[📖 Paper](https://proceedings.neurips.cc/paper_files/paper/2024/file/ad0edc7d5fa1a783f063646968b7315b-Paper-Datasets_and_Benchmarks_Track.pdf)]
## 🚀 Data Usage
<!-- **We have observed that some studies have used our MATH-Vision dataset as a training set.**
⚠️ **As clearly stated in our paper: *"The MATH-V dataset is not supposed, though the risk exists, to be used to train models for cheating. We intend for researchers to use this dataset to better evaluate LMMs’ mathematical reasoning capabilities and consequently facilitate future studies in this area."***
⚠️⚠️⚠️ **In the very rare situation that there is a compelling reason to include MATH-V in your training set, we strongly urge that the ***testmini*** subset be excluded from the training process!**
-->
```python
from datasets import load_dataset
dataset = load_dataset("MathLLMs/MathVision")
print(dataset)
```
## 💥 News
- **[2025.04.11]** 💥 **Kimi-VL-A3B-Thinking achieves strong multimodal reasoning with just 2.8B LLM activated parameters!** Congratulations! See the full [leaderboard](https://mathllm.github.io/mathvision/#leaderboard).
- **[2025.04.10]** 🔥🔥🔥 **SenseNova V6 Reasoner** achieves **55.39%** on MATH-Vision! 🎉 Congratulations!
- **[2025.04.05]** 💥 **Step R1-V-Mini 🥇 Sets New SOTA on MATH-V with 56.6%!** See the full [leaderboard](https://mathllm.github.io/mathvision/#leaderboard).
- **[2025.03.10]** 💥 **Kimi k1.6 Preview Sets New SOTA on MATH-V with 53.29%!** See the full [leaderboard](https://mathllm.github.io/mathvision/#leaderboard).
- **[2025.02.28]** 💥 **Doubao-1.5-pro Sets New SOTA on MATH-V with 48.62%!** Read more on the [Doubao blog](https://team.doubao.com/zh/special/doubao_1_5_pro).
- **[2025.01.26]** 🚀 [Qwen2.5-VL-72B](http://qwenlm.github.io/blog/qwen2.5-vl/) achieves **38.1%**, establishing itself as the best-performing one in open-sourced models. 🎉 Congratulations!
- **[2025.01.22]** 💥 **Kimi k1.5 achieves new SOTA** on MATH-Vision with **38.6%**! Learn more at the [Kimi k1.5 report](https://arxiv.org/pdf/2501.12599).
- **[2024-09-27]** **MATH-V** is accepted by NeurIPS DB Track, 2024! 🎉🎉🎉
- **[2024-08-29]** 🔥🔥🔥 Qwen2-VL-72B achieves new open-sourced SOTA on MATH-Vision with 25.9! 🎉 Congratulations! Learn more at the [Qwen2-VL blog](https://qwenlm.github.io/blog/qwen2-vl/).
- **[2024-07-19]** [open-compass/VLMEvalKit](https://github.com/open-compass/VLMEvalKit) now supports **MATH-V**, utilizing LLMs for more accurate answer extraction!🔥🔥
- **[2024-05-19]** OpenAI's **GPT-4o** scores **30.39%** on **MATH-V**, considerable advancement in short time! 💥
- **[2024-03-01]** **InternVL-Chat-V1-2-Plus** achieves **16.97%**, establishing itself as the new best-performing open-sourced model. 🎉 Congratulations!
- **[2024-02-23]** Our dataset is now accessible at [huggingface](https://huggingface.co/datasets/MathLLMs/MathVision).
- **[2024-02-22]** The top-performing model, **GPT-4V** only scores **23.98%** on **MATH-V**, while human performance is around **70%**.
- **[2024-02-22]** Our paper is now accessible at [ArXiv Paper](https://arxiv.org/abs/2402.14804).
## 👀 Introduction
Recent advancements in Large Multimodal Models (LMMs) have shown promising results in mathematical reasoning within visual contexts, with models approaching human-level performance on existing benchmarks such as MathVista. However, we observe significant limitations in the diversity of questions and breadth of subjects covered by these benchmarks. To address this issue, we present the MATH-Vision (MATH-V) dataset, a meticulously curated collection of 3,040 high-quality mathematical problems with visual contexts sourced from real math competitions. Spanning 16 distinct mathematical disciplines and graded across 5 levels of difficulty, our dataset provides a comprehensive and diverse set of challenges for evaluating the mathematical reasoning abilities of LMMs.
<p align="center">
<img src="https://raw.githubusercontent.com/mathvision-cuhk/MathVision/main/assets/figures/figure1_new.png" width="66%"> The accuracies of four prominent Large Multimodal Models (LMMs), random chance, and human <br>
performance are evaluated on our proposed <b>MATH-Vision (MATH-V)</b> across 16 subjects.
</p>
<br>
Through extensive experimentation, we unveil a notable performance gap between current LMMs and human performance on MATH-V, underscoring the imperative for further advancements in LMMs.
You can refer to the [project homepage](https://mathvision-cuhk.github.io/) for more details.
## 🏆 Leaderboard
The leaderboard is available [here](https://mathvision-cuhk.github.io/#leaderboard).
We are commmitted to maintain this dataset and leaderboard in the long run to ensure its quality!
🔔 If you find any mistakes, please paste the question_id to the issue page, we will modify it accordingly.
## 📐 Dataset Examples
Some examples of MATH-V on three subjects: analytic geometry, topology, and graph theory.
<details>
<summary>Analytic geometry</summary><p align="center">
<img src="https://raw.githubusercontent.com/mathvision-cuhk/MathVision/main/assets/examples/exam_analytic_geo.png" width="60%"> <br>
</p></details>
<details>
<summary>Topology</summary><p align="center">
<img src="https://raw.githubusercontent.com/mathvision-cuhk/MathVision/main/assets/examples/exam_topology.png" width="60%"> <br>
</p></details>
<details>
<summary>Graph Geometry</summary><p align="center">
<img src="https://raw.githubusercontent.com/mathvision-cuhk/MathVision/main/assets/examples/exam_graph.png" width="60%"> <br>
</p></details>
## 📑 Citation
If you find this benchmark useful in your research, please consider citing this BibTex:
```
@inproceedings{
wang2024measuring,
title={Measuring Multimodal Mathematical Reasoning with MATH-Vision Dataset},
author={Ke Wang and Junting Pan and Weikang Shi and Zimu Lu and Houxing Ren and Aojun Zhou and Mingjie Zhan and Hongsheng Li},
booktitle={The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track},
year={2024},
url={https://openreview.net/forum?id=QWTCcxMpPA}
}
```
|
Super-shuhe/FaceID-6M | Super-shuhe | 2025-04-11T00:36:21Z | 9,059 | 5 | [
"task_categories:text-to-image",
"license:cc-by-nc-4.0",
"arxiv:2503.07091",
"region:us"
] | [
"text-to-image"
] | 2025-03-22T00:55:18Z | 2 | ---
license: cc-by-nc-4.0
task_categories:
- text-to-image
---
# FaceID-6M: A Large-Scale, Open-Source FaceID Customization Dataset
This repository contains the dataset described in [FaceID-6M: A Large-Scale, Open-Source FaceID Customization Dataset](https://arxiv.org/abs/2503.07091).
## Links
- [FaceID-6M: A Large-Scale, Open-Source FaceID Customization Dataset](#faceid-6m-a-large-scale-open-source-faceid-customization-dataset)
- [Introduction](#introduction)
- [Comparison with Previous Works](#comparison-with-previous-works)
- [FaceID Fidelity](#faceid-fidelity)
- [Scaling Results](#scaling-results)
- [Released FaceID-6M dataset](#released-faceid-6m-dataset)
- [Released FaceID Customization Models](#released-faceid-customization-models)
- [Usage](#usage)
- [Contact](#contact)
## Introduction
FaceID-6M, is the first large-scale, open-source faceID dataset containing 6 million high-quality text-image pairs. Filtered from [LAION-5B](https://laion.ai/blog/laion-5b/), which includes billions of diverse and publicly available text-image pairs, FaceID-6M undergoes a rigorous image and text filtering process to ensure dataset quality. For image filtering, we apply a pre-trained face detection model to remove images that lack human faces, contain more than three faces, have low resolution, or feature faces occupying less than 4% of the total image area. For text filtering, we implement a keyword-based strategy to retain descriptions containing human-related terms, including references to people (e.g., man), nationality (e.g., Chinese), ethnicity (e.g., East Asian), professions (e.g., engineer), and names (e.g., Donald Trump).
Through these cleaning processes, FaceID-6M provides a high-quality dataset optimized for training powerful FaceID customization models, facilitating advancements in the field by offering an open resource for research and development.

## Comparison with Previous Works
### FaceID Fidelity

Based on these results, we can infer that the model trained on our FaceID-6M dataset achieves a level of performance comparable to the official InstantID model in maintaining FaceID fidelity. For example, in case 2 and case 3, both the official InstantID model and the FaceID-6M-trained model effectively generate the intended images based on the input.
This clearly highlights the effectiveness of our FaceID-6M dataset in training robust FaceID customization models.
### Scaling Results
To evaluate the impact of dataset size on model performance and optimize the trade-off between performance and training cost, we conduct scaling experiments by sampling subsets of different sizes from FaceID-6M.
The sampled dataset sizes include: (1) 1K, (2) 10K, (3) 100K, (4) 1M, (5) 2M, (6) 4M, and (7) the full dataset (6M).
For the experimental setup, we utilize the [InstantID](https://github.com/instantX-research/InstantID) FaceID customization framework and adhere to the configurations used in the previous quantitative evaluations. The trained models are tested on the subset of [COCO2017](https://cocodataset.org/#detection-2017) test set, with Face Sim, CLIP-T, and CLIP-I as the evaluation metrics.
The results demonstrate a clear correlation between training dataset size and the performance of FaceID customization models.
For example, the Face Sim score increased from 0.38 with 2M training data, to 0.51 with 4M, and further improved to 0.63 when using 6M data.
These results underscore the significant contribution of our FaceID-6M dataset in advancing FaceID customization research, highlighting its importance in driving improvements in the field.
## Released FaceID-6M dataset
We release two versions of our constructed dataset:
1. [FaceID-70K](https://huggingface.co/datasets/Super-shuhe/FaceID-70K): This is a subset of our FaceID-6M by further removing images lower than 1024 pixels either in width or height, consisting approximately 70K text-image pairs.
2. [FaceID-6M](https://huggingface.co/datasets/Super-shuhe/FaceID-6M): This is our constructed full FaceID customization dataset.
Please note that due to the large file size, we have pre-split it into multiple smaller parts. Before use, please execute the merge and unzip commands to restore the full file. Take the InstantID-FaceID-70K dataset as the example:
1. `cat laion_1024.tar.gz.* > laion_1024.tar.gz`
2. `tar zxvf laion_1024.tar.gz`
**Index**
After restoring the full dataset, you will find large amounts `.png` and `.npy` file, and also a `./face` directory and a `*.jsonl` file:
1. `*.png`: Tmage files
2. `*.npy`: The pre-computed landmarks of the face in the related image, which is necessary to train [InstantID-based models](https://instantid.github.io/). If you don't need that, just ignore them.
3. `./face`: The directory including face files.
4. `*.jsonl`: Descriptions or texts. Ignore the file paths listed in the `.jsonl` file and use the line number instead to locate the corresponding image, face, and `.npy` files. For example, the 0th line in the `.jsonl` file corresponds to `0.png`, `0.npy`, and `./face/0.png`.
## Released FaceID Customization Models
We release two versions of trained InstantID models:
1. [InstantID-FaceID-70K](https://huggingface.co/Super-shuhe/InstantID-FaceID-70K): Model trained on our [FaceID-70K](https://huggingface.co/datasets/Super-shuhe/FaceID-70K) dataset.
2. [InstantID-FaceID-6M](https://huggingface.co/Super-shuhe/InstantID-FaceID-6M): Model trained on our [FaceID-6M](https://huggingface.co/datasets/Super-shuhe/FaceID-6M) dataset.
## Usage
For instructions on training and inference of FaceID customization models using our dataset, please visit our GitHub repository: https://github.com/ShuheSH/FaceID-6M
## Contact
If you have any issues or questions about this repo, feel free to contact [email protected]
```
@article{wang2025faceid,
title={FaceID-6M: A Large-Scale, Open-Source FaceID Customization Dataset},
author={Wang, Shuhe and Li, Xiaoya and Li, Jiwei and Wang, Guoyin and Sun, Xiaofei and Zhu, Bob and Qiu, Han and Yu, Mo and Shen, Shengjie and Hovy, Eduard},
journal={arXiv preprint arXiv:2503.07091},
year={2025}
}
``` |
EssentialAI/reflection_model_outputs_run1 | EssentialAI | 2025-04-10T23:10:10Z | 31,048 | 0 | [
"license:mit",
"region:us"
] | [] | 2025-04-10T21:25:05Z | null | ---
license: mit
---
# Reflection Model Outputs
This repository contains model output results from various LLMs across multiple tasks and configurations.
## 📂 Dataset Structure
We have 3 runs of data, and all files are organized under the main directory:
- `EssentialAI/reflection_model_outputs_run1/`
- `EssentialAI/reflection_model_outputs_run2/`
- `EssentialAI/reflection_model_outputs_run3/`
Within this, you will find results grouped by **model architecture and checkpoint size**, including:
- `OLMo-2 7B`
- `OLMo-2 13B`
- `OLMo-2 32B`
- `Qwen2.5 0.5B`
- `Qwen2.5 3B`
- `Qwen2.5 7B`
- `Qwen2.5 14B`
- `Qwen2.5 32B`
- `Qwen2.5 72B`
Each model folder contains outputs from multiple task setups.
Example task folders include:
| Original Task Folder | Adversarial Task Folder |
|---------------------------|-----------------------------|
| `bbh_cot_fewshot` | `bbh_adv` |
| `cruxeval_i` | `cruxeval_i_adv` |
| `cruxeval_o` | `cruxeval_o_adv` |
| `gsm8k-platinum_cot` | `gsm8k-platinum_adv` |
| `gsm8k_cot` | `gsm8k_adv` |
| `triviaqa` | `triviaqa_adv` |
---
## 💾 How to Download the Dataset
To download the entire dataset locally using the Hugging Face Hub, run the following Python snippet with the run results you're interested in:
```python
from huggingface_hub import snapshot_download
snapshot_download(
repo_id="EssentialAI/reflection_model_outputs_run1",
repo_type="dataset",
local_dir="reflection_model_outputs_run1"
)
``` |
wanglab/CT_DeepLesion-MedSAM2 | wanglab | 2025-04-10T13:49:44Z | 8,246 | 6 | [
"language:en",
"size_categories:10K<n<100K",
"format:csv",
"modality:tabular",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"arxiv:2504.03600",
"arxiv:2504.63609",
"region:us",
"medical"
] | [] | 2025-04-02T17:12:16Z | 2 | ---
language:
- en
tags:
- medical
size_categories:
- 1K<n<10K
---
# CT_DeepLesion-MedSAM2 Dataset
<div align="center">
<table align="center">
<tr>
<td><a href="https://arxiv.org/abs/2504.03600" target="_blank"><img src="https://img.shields.io/badge/arXiv-Paper-FF6B6B?style=for-the-badge&logo=arxiv&logoColor=white" alt="Paper"></a></td>
<td><a href="https://medsam2.github.io/" target="_blank"><img src="https://img.shields.io/badge/Project-Page-4285F4?style=for-the-badge&logoColor=white" alt="Project"></a></td>
<td><a href="https://github.com/bowang-lab/MedSAM2" target="_blank"><img src="https://img.shields.io/badge/GitHub-Code-181717?style=for-the-badge&logo=github&logoColor=white" alt="Code"></a></td>
<td><a href="https://huggingface.co/wanglab/MedSAM2" target="_blank"><img src="https://img.shields.io/badge/HuggingFace-Model-FFBF00?style=for-the-badge&logo=huggingface&logoColor=white" alt="HuggingFace Model"></a></td>
</tr>
<tr>
<td><a href="https://medsam-datasetlist.github.io/" target="_blank"><img src="https://img.shields.io/badge/Dataset-List-00B89E?style=for-the-badge" alt="Dataset List"></a></td>
<td><a href="https://huggingface.co/datasets/wanglab/CT_DeepLesion-MedSAM2" target="_blank"><img src="https://img.shields.io/badge/Dataset-CT__DeepLesion-28A745?style=for-the-badge" alt="CT_DeepLesion-MedSAM2"></a></td>
<td><a href="https://huggingface.co/datasets/wanglab/LLD-MMRI-MedSAM2" target="_blank"><img src="https://img.shields.io/badge/Dataset-LLD--MMRI-FF6B6B?style=for-the-badge" alt="LLD-MMRI-MedSAM2"></a></td>
<td><a href="https://github.com/bowang-lab/MedSAMSlicer/tree/MedSAM2" target="_blank"><img src="https://img.shields.io/badge/3D_Slicer-Plugin-e2006a?style=for-the-badge" alt="3D Slicer"></a></td>
</tr>
<tr>
<td><a href="https://github.com/bowang-lab/MedSAM2/blob/main/app.py" target="_blank"><img src="https://img.shields.io/badge/Gradio-Demo-F9D371?style=for-the-badge&logo=gradio&logoColor=white" alt="Gradio App"></a></td>
<td><a href="https://colab.research.google.com/drive/1MKna9Sg9c78LNcrVyG58cQQmaePZq2k2?usp=sharing" target="_blank"><img src="https://img.shields.io/badge/Colab-CT--Seg--Demo-F9AB00?style=for-the-badge&logo=googlecolab&logoColor=white" alt="CT-Seg-Demo"></a></td>
<td><a href="https://colab.research.google.com/drive/16niRHqdDZMCGV7lKuagNq_r_CEHtKY1f?usp=sharing" target="_blank"><img src="https://img.shields.io/badge/Colab-Video--Seg--Demo-F9AB00?style=for-the-badge&logo=googlecolab&logoColor=white" alt="Video-Seg-Demo"></a></td>
<td><a href="https://github.com/bowang-lab/MedSAM2?tab=readme-ov-file#bibtex" target="_blank"><img src="https://img.shields.io/badge/Paper-BibTeX-9370DB?style=for-the-badge&logoColor=white" alt="BibTeX"></a></td>
</tr>
</table>
</div>
## Authors
<p align="center">
<a href="https://scholar.google.com.hk/citations?hl=en&user=bW1UV4IAAAAJ&view_op=list_works&sortby=pubdate">Jun Ma</a><sup>* 1,2</sup>,
<a href="https://scholar.google.com/citations?user=8IE0CfwAAAAJ&hl=en">Zongxin Yang</a><sup>* 3</sup>,
Sumin Kim<sup>2,4,5</sup>,
Bihui Chen<sup>2,4,5</sup>,
<a href="https://scholar.google.com.hk/citations?user=U-LgNOwAAAAJ&hl=en&oi=sra">Mohammed Baharoon</a><sup>2,3,5</sup>,<br>
<a href="https://scholar.google.com.hk/citations?user=4qvKTooAAAAJ&hl=en&oi=sra">Adibvafa Fallahpour</a><sup>2,4,5</sup>,
<a href="https://scholar.google.com.hk/citations?user=UlTJ-pAAAAAJ&hl=en&oi=sra">Reza Asakereh</a><sup>4,7</sup>,
Hongwei Lyu<sup>4</sup>,
<a href="https://wanglab.ai/index.html">Bo Wang</a><sup>† 1,2,4,5,6</sup>
</p>
<p align="center">
<sup>*</sup> Equal contribution <sup>†</sup> Corresponding author
</p>
<p align="center">
<sup>1</sup>AI Collaborative Centre, University Health Network, Toronto, Canada<br>
<sup>2</sup>Vector Institute for Artificial Intelligence, Toronto, Canada<br>
<sup>3</sup>Department of Biomedical Informatics, Harvard Medical School, Harvard University, Boston, USA<br>
<sup>4</sup>Peter Munk Cardiac Centre, University Health Network, Toronto, Canada<br>
<sup>5</sup>Department of Computer Science, University of Toronto, Toronto, Canada<br>
<sup>6</sup>Department of Laboratory Medicine and Pathobiology, University of Toronto, Toronto, Canada<br>
<sup>7</sup>Roche Canada and Genentech
</p>
## About
[DeepLesion](https://nihcc.app.box.com/v/DeepLesion) dataset contains 32,735 diverse lesions in 32,120 CT slices from 10,594 studies of 4,427 unique patients. Each lesion has a bounding box annotation on the key slice, which is derived from the longest diameter and longest
perpendicular diameter. We annotated 5000 lesions with [MedSAM2](https://github.com/bowang-lab/MedSAM2) in a human-in-the-loop pipeline.
```py
# Install required package
pip install datasets
# Load the dataset
from datasets import load_dataset
# Download and load the dataset
dataset = load_dataset("wanglab/CT_DeepLesion-MedSAM2")
# Access the train split
train_dataset = dataset["train"]
# Display the first example
print(train_dataset[0])
```
Please cite both DeepLesion and MedSAM2 when using this dataset.
```bash
@article{DeepLesion,
title={DeepLesion: automated mining of large-scale lesion annotations and universal lesion detection with deep learning},
author={Yan, Ke and Wang, Xiaosong and Lu, Le and Summers, Ronald M},
journal={Journal of Medical Imaging},
volume={5},
number={3},
pages={036501--036501},
year={2018}
}
@article{MedSAM2,
title={MedSAM2: Segment Anything in 3D Medical Images and Videos},
author={Ma, Jun and Yang, Zongxin and Kim, Sumin and Chen, Bihui and Baharoon, Mohammed and Fallahpour, Adibvafa and Asakereh, Reza and Lyu, Hongwei and Wang, Bo},
journal={arXiv preprint arXiv:2504.63609},
year={2025}
}
``` |
Lichess/standard-chess-games | Lichess | 2025-04-09T11:20:15Z | 10,253 | 40 | [
"license:cc0-1.0",
"size_categories:1B<n<10B",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us",
"chess",
"games",
"game",
"lichess",
"tabular"
] | [] | 2024-09-24T08:58:09Z | null | ---
license: cc0-1.0
pretty_name: Lichess Standard Rated Games
configs:
- config_name: default
data_files:
- split: train
path: data/**/train-*
tags:
- chess
- games
- game
- lichess
- tabular
size_categories:
- 1B<n<10B
---
> [!CAUTION]
> This dataset is still a work in progress and some breaking changes might occur.
>
# Lichess Rated Standard Chess Games Dataset
## Dataset Description
**6,586,165,146** standard rated games, played on [lichess.org](https://lichess.org), updated monthly from the [database dumps](https://database.lichess.org/#standard_games).
This version of the data is meant for data analysis. If you need PGN files you can find those [here](https://database.lichess.org/#standard_games). That said, once you have a subset of interest, it is trivial to convert it back to PGN as shown in the [Dataset Usage](#dataset-usage) section.
This dataset is hive-partitioned into multiple parquet files on two keys: `year` and `month`:
```bash
.
├── data
│ └── year=2015
│ ├── month=01
│ │ ├── train-00000-of-00003.parquet
│ │ ├── train-00001-of-00003.parquet
│ │ └── train-00002-of-00003.parquet
│ ├── month=02
│ │ ├── train-00000-of-00003.parquet
│ │ ├── train-00001-of-00003.parquet
│ │ └── train-00002-of-00003.parquet
│ ├── ...
```
### Dataset Usage
<!-- Using the `datasets` library:
```python
from datasets import load_dataset
dset = load_dataset("Lichess/chess-evaluations", split="train")
```
Using the `polars` library:
Using DuckDB:
Using `python-chess`: -->
## Dataset Details
### Dataset Sample
<!-- One row of the dataset looks like this:
```python
{
"Event":,
"Site":,
}
``` -->
### Dataset Fields
<!-- Every row of the dataset contains the following fields:
- **`Event`**: `string`,
- **`Site`**: `string`, -->
### Notes
- About 6% of the games include Stockfish analysis evaluations: [%eval 2.35] (235 centipawn advantage), [%eval #-4] (getting mated in 4), always from White's point of view.
- The WhiteElo and BlackElo tags contain Glicko2 ratings.
- The `movetext` column contains clock information as PGN %clk comments since April 2017.
- The schema doesn't include the `Date` header, typically part of the [Seven Tag Roster](https://en.wikipedia.org/wiki/Portable_Game_Notation#Seven_Tag_Roster) as we deemed the `UTCDate` field to be enough.
- A future version of the data will include the addition of a `UCI` column containing the corresponding moves in [UCI format](https://en.wikipedia.org/wiki/Universal_Chess_Interface). |
foursquare/fsq-os-places | foursquare | 2025-04-08T20:44:08Z | 2,017 | 71 | [
"license:apache-2.0",
"size_categories:100M<n<1B",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2024-11-27T18:49:30Z | 2 | ---
license: apache-2.0
configs:
- config_name: places
data_files: release/dt=2025-04-08/places/parquet/*.parquet
default: true
- config_name: categories
data_files: release/dt=2025-04-08/categories/parquet/*.parquet
---
# Access FSQ OS Places
With Foursquare’s Open Source Places, you can access free data to accelerate geospatial innovation and insights. View the [Places OS Data Schemas](https://docs.foursquare.com/data-products/docs/places-os-data-schema) for a full list of available attributes.
## Prerequisites
In order to access Foursquare's Open Source Places data, it is recommended to use Spark. Here is how to load the Places data in Spark from Hugging Face.
- For Spark 3, you can use the `read_parquet` helper function from the [HF Spark documentation](https://huggingface.co/docs/hub/datasets-spark). It provides an easy API to load a Spark Dataframe from Hugging Face, without having to download the full dataset locally:
```python
places = read_parquet("hf://datasets/foursquare/fsq-os-places/release/dt=2025-01-10/places/parquet/*.parquet")
```
- For Spark 4, there will be an official Hugging Face Spark data source available.
Alternatively you can download the following files to your local disk or cluster:
- Parquet Files:
- **Places** - [release/dt=2025-01-10/places/parquet](https://huggingface.co/datasets/foursquare/fsq-os-places/tree/main/release/dt%3D2025-01-10/places/parquet)
- **Categories** - [release/dt=2025-01-10/categories/parquet](https://huggingface.co/datasets/foursquare/fsq-os-places/tree/main/release/dt%3D2025-01-10/categories/parquet)
Hugging Face provides the following [download options](https://huggingface.co/docs/hub/datasets-downloading).
## Example Queries
The following are examples on how to query FSQ Open Source Places using Athena and Spark:
- Filter [Categories](https://docs.foursquare.com/data-products/docs/categories#places-open-source--propremium-flat-file) by the parent level
- Filter out [non-commercial venues](#non-commercial-categories-table)
- Find open and recently active POI
### Filter by Parent Level Category
**SparkSQL**
```sql SparkSQL
WITH places_exploded_categories AS (
-- Unnest categories array
SELECT fsq_place_id,
name,
explode(fsq_category_ids) as fsq_category_id
FROM places
),
distinct_places AS (
SELECT
DISTINCT(fsq_place_id) -- Get distinct ids to reduce duplicates from explode function
FROM places_exploded_categories p
JOIN categories c -- Join to categories to filter on Level 2 Category
ON p.fsq_category_id = c.category_id
WHERE c.level2_category_id = '4d4b7105d754a06374d81259' -- Restaurants
)
SELECT * FROM places
WHERE fsq_place_id IN (SELECT fsq_place_id FROM distinct_places)
```
### Filter out Non-Commercial Categories
**SparkSQL**
```sql SparkSQL
SELECT * FROM places
WHERE arrays_overlap(fsq_category_ids, array('4bf58dd8d48988d1f0931735', -- Airport Gate
'62d587aeda6648532de2b88c', -- Beer Festival
'4bf58dd8d48988d12b951735', -- Bus Line
'52f2ab2ebcbc57f1066b8b3b', -- Christmas Market
'50aa9e094b90af0d42d5de0d', -- City
'5267e4d9e4b0ec79466e48c6', -- Conference
'5267e4d9e4b0ec79466e48c9', -- Convention
'530e33ccbcbc57f1066bbff7', -- Country
'5345731ebcbc57f1066c39b2', -- County
'63be6904847c3692a84b9bb7', -- Entertainment Event
'4d4b7105d754a06373d81259', -- Event
'5267e4d9e4b0ec79466e48c7', -- Festival
'4bf58dd8d48988d132951735', -- Hotel Pool
'52f2ab2ebcbc57f1066b8b4c', -- Intersection
'50aaa4314b90af0d42d5de10', -- Island
'58daa1558bbb0b01f18ec1fa', -- Line
'63be6904847c3692a84b9bb8', -- Marketplace
'4f2a23984b9023bd5841ed2c', -- Moving Target
'5267e4d9e4b0ec79466e48d1', -- Music Festival
'4f2a25ac4b909258e854f55f', -- Neighborhood
'5267e4d9e4b0ec79466e48c8', -- Other Event
'52741d85e4b0d5d1e3c6a6d9', -- Parade
'4bf58dd8d48988d1f7931735', -- Plane
'4f4531504b9074f6e4fb0102', -- Platform
'4cae28ecbf23941eb1190695', -- Polling Place
'4bf58dd8d48988d1f9931735', -- Road
'5bae9231bedf3950379f89c5', -- Sporting Event
'530e33ccbcbc57f1066bbff8', -- State
'530e33ccbcbc57f1066bbfe4', -- States and Municipalities
'52f2ab2ebcbc57f1066b8b54', -- Stoop Sale
'5267e4d8e4b0ec79466e48c5', -- Street Fair
'53e0feef498e5aac066fd8a9', -- Street Food Gathering
'4bf58dd8d48988d130951735', -- Taxi
'530e33ccbcbc57f1066bbff3', -- Town
'5bae9231bedf3950379f89c3', -- Trade Fair
'4bf58dd8d48988d12a951735', -- Train
'52e81612bcbc57f1066b7a24', -- Tree
'530e33ccbcbc57f1066bbff9', -- Village
)) = false
```
### Find Open and Recently Active POI
**SparkSQL**
```sql SparkSQL
SELECT * FROM places p
WHERE p.date_closed IS NULL
AND p.date_refreshed >= DATE_SUB(current_date(), 365);
```
## Appendix
### Non-Commercial Categories Table
| Category Name | Category ID |
| :------------------------ | :----------------------- |
| Airport Gate | 4bf58dd8d48988d1f0931735 |
| Beer Festival | 62d587aeda6648532de2b88c |
| Bus Line | 4bf58dd8d48988d12b951735 |
| Christmas Market | 52f2ab2ebcbc57f1066b8b3b |
| City | 50aa9e094b90af0d42d5de0d |
| Conference | 5267e4d9e4b0ec79466e48c6 |
| Convention | 5267e4d9e4b0ec79466e48c9 |
| Country | 530e33ccbcbc57f1066bbff7 |
| County | 5345731ebcbc57f1066c39b2 |
| Entertainment Event | 63be6904847c3692a84b9bb7 |
| Event | 4d4b7105d754a06373d81259 |
| Festival | 5267e4d9e4b0ec79466e48c7 |
| Hotel Pool | 4bf58dd8d48988d132951735 |
| Intersection | 52f2ab2ebcbc57f1066b8b4c |
| Island | 50aaa4314b90af0d42d5de10 |
| Line | 58daa1558bbb0b01f18ec1fa |
| Marketplace | 63be6904847c3692a84b9bb8 |
| Moving Target | 4f2a23984b9023bd5841ed2c |
| Music Festival | 5267e4d9e4b0ec79466e48d1 |
| Neighborhood | 4f2a25ac4b909258e854f55f |
| Other Event | 5267e4d9e4b0ec79466e48c8 |
| Parade | 52741d85e4b0d5d1e3c6a6d9 |
| Plane | 4bf58dd8d48988d1f7931735 |
| Platform | 4f4531504b9074f6e4fb0102 |
| Polling Place | 4cae28ecbf23941eb1190695 |
| Road | 4bf58dd8d48988d1f9931735 |
| State | 530e33ccbcbc57f1066bbff8 |
| States and Municipalities | 530e33ccbcbc57f1066bbfe4 |
| Stopp Sale | 52f2ab2ebcbc57f1066b8b54 |
| Street Fair | 5267e4d8e4b0ec79466e48c5 |
| Street Food Gathering | 53e0feef498e5aac066fd8a9 |
| Taxi | 4bf58dd8d48988d130951735 |
| Town | 530e33ccbcbc57f1066bbff3 |
| Trade Fair | 5bae9231bedf3950379f89c3 |
| Train | 4bf58dd8d48988d12a951735 |
| Tree | 52e81612bcbc57f1066b7a24 |
| Village | 530e33ccbcbc57f1066bbff9 |
|
huggingface/badges | huggingface | 2025-04-08T17:39:54Z | 1,601,440 | 43 | [
"license:mit",
"size_categories:n<1K",
"format:imagefolder",
"modality:image",
"library:datasets",
"library:mlcroissant",
"region:us"
] | [] | 2023-02-02T14:55:23Z | null | ---
license: mit
thumbnail: "https://huggingface.co/datasets/huggingface/badges/resolve/main/badges-thumbnail.png"
---
<style>
.prose img {
display: inline;
margin: 0 6px !important;
}
.prose table {
max-width: 320px;
margin: 0;
}
</style>
# Badges
A set of badges you can use anywhere. Just update the anchor URL to point to the correct action for your Space. Light or dark background with 4 sizes available: small, medium, large, and extra large.
## How to use?
- With markdown, just copy the badge from: https://huggingface.co/datasets/huggingface/badges/blob/main/README.md?code=true
- With HTML, inspect this page with your web browser and copy the outer html.
## Available sizes
| Small | Medium | Large | Extra large |
| ------------- | :-----------: | ------------- | ------------- |
| 20px (height) | 24px (height) | 36px (height) | 48px (height) |
## Follow us on HF
[](https://huggingface.co/organizations)
[](https://huggingface.co/organizations)
[](https://huggingface.co/organizations)
[](https://huggingface.co/organizations)
[](https://huggingface.co/organizations)
[](https://huggingface.co/organizations)
[](https://huggingface.co/organizations)
[](https://huggingface.co/organizations)
## Paper page
[](https://huggingface.co/papers)
[](https://huggingface.co/papers)
[](https://huggingface.co/papers)
[](https://huggingface.co/papers)
[](https://huggingface.co/papers)
[](https://huggingface.co/papers)
[](https://huggingface.co/papers)
[](https://huggingface.co/papers)
## Deploy on Spaces
[](https://huggingface.co/new-space)
[](https://huggingface.co/new-space)
[](https://huggingface.co/new-space)
[](https://huggingface.co/new-space)
[](https://huggingface.co/new-space)
[](https://huggingface.co/new-space)
[](https://huggingface.co/new-space)
[](https://huggingface.co/new-space)
## Duplicate this Space
[](https://huggingface.co/spaces/huggingface-projects/diffusers-gallery?duplicate=true)
[](https://huggingface.co/spaces/huggingface-projects/diffusers-gallery?duplicate=true)
[](https://huggingface.co/spaces/huggingface-projects/diffusers-gallery?duplicate=true)
[](https://huggingface.co/spaces/huggingface-projects/diffusers-gallery?duplicate=true)
[](https://huggingface.co/spaces/huggingface-projects/diffusers-gallery?duplicate=true)
[](https://huggingface.co/spaces/huggingface-projects/diffusers-gallery?duplicate=true)
[](https://huggingface.co/spaces/huggingface-projects/diffusers-gallery?duplicate=true)
[](https://huggingface.co/spaces/huggingface-projects/diffusers-gallery?duplicate=true)
## Open in HF Spaces
[](https://huggingface.co/spaces)
[](https://huggingface.co/spaces)
[](https://huggingface.co/spaces)
[](https://huggingface.co/spaces)
[](https://huggingface.co/spaces)
[](https://huggingface.co/spaces)
[](https://huggingface.co/spaces)
[](https://huggingface.co/spaces)
## Open a Discussion
[](https://huggingface.co/spaces)
[](https://huggingface.co/spaces)
[](https://huggingface.co/spaces)
[](https://huggingface.co/spaces)
[](https://huggingface.co/spaces)
[](https://huggingface.co/spaces)
[](https://huggingface.co/spaces)
[](https://huggingface.co/spaces)
## Share to Community
[](https://huggingface.co/spaces)
[](https://huggingface.co/spaces)
[](https://huggingface.co/spaces)
[](https://huggingface.co/spaces)
[](https://huggingface.co/spaces)
[](https://huggingface.co/spaces)
[](https://huggingface.co/spaces)
[](https://huggingface.co/spaces)
## Sign in with Hugging Face
[](https://huggingface.co/)
[](https://huggingface.co/)
[](https://huggingface.co/)
[](https://huggingface.co/)
[](https://huggingface.co/)
[](https://huggingface.co/)
[](https://huggingface.co/)
[](https://huggingface.co/)
## Open a Pull Request
[](https://huggingface.co/spaces/victor/ChatUI/discussions)
[](https://huggingface.co/spaces/victor/ChatUI/discussions)
[](https://huggingface.co/spaces/victor/ChatUI/discussions)
[](https://huggingface.co/spaces/victor/ChatUI/discussions)
[](https://huggingface.co/spaces/victor/ChatUI/discussions)
[](https://huggingface.co/spaces/victor/ChatUI/discussions)
[](https://huggingface.co/spaces/victor/ChatUI/discussions)
[](https://huggingface.co/spaces/victor/ChatUI/discussions)
## Subscribe to PRO
[](https://huggingface.co/subscribe/pro)
[](https://huggingface.co/subscribe/pro)
[](https://huggingface.co/subscribe/pro)
[](https://huggingface.co/subscribe/pro)
[](https://huggingface.co/subscribe/pro)
[](https://huggingface.co/subscribe/pro)
[](https://huggingface.co/subscribe/pro)
[](https://huggingface.co/subscribe/pro)
## Follow me on HF
[](https://huggingface.co/Chunte)
[](https://huggingface.co/Chunte)
[](https://huggingface.co/Chunte)
[](https://huggingface.co/Chunte)
[](https://huggingface.co/Chunte)
[](https://huggingface.co/Chunte)
[](https://huggingface.co/Chunte)
[](https://huggingface.co/Chunte)
## Model on HF
[](https://huggingface.co/models)
[](https://huggingface.co/models)
[](https://huggingface.co/models)
[](https://huggingface.co/models)
[](https://huggingface.co/models)
[](https://huggingface.co/models)
[](https://huggingface.co/models)
[](https://huggingface.co/models)
## Dataset on HF
[](https://huggingface.co/datasets)
[](https://huggingface.co/datasets)
[](https://huggingface.co/datasets)
[](https://huggingface.co/datasets)
[](https://huggingface.co/datasets)
[](https://huggingface.co/datasets)
[](https://huggingface.co/datasets)
[](https://huggingface.co/datasets)
## Powered by Hugging Face
[](https://huggingface.co)
[](https://huggingface.co)
|
Azathothas/temp | Azathothas | 2025-04-08T06:14:56Z | 10,690 | 0 | [
"license:unlicense",
"region:us"
] | [] | 2025-03-18T03:49:14Z | null | ---
license: unlicense
---
> [!NOTE]
> This serves as way to quickly share temp files with other devs, so the files here are ephemeral & often removed |
minghaowu/OpenPersona | minghaowu | 2025-04-08T01:52:56Z | 216 | 4 | [
"task_categories:text-generation",
"language:en",
"license:apache-2.0",
"size_categories:10M<n<100M",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | [
"text-generation"
] | 2025-03-24T07:59:25Z | 2 | ---
license: apache-2.0
task_categories:
- text-generation
language:
- en
size_categories:
- 10M<n<100M
---
# OpenPersona: Building a Synthetic Universe with 10M Realistic Personas
<!-- Provide a quick summary of the dataset. -->
In this work, we leverage [Llama-3.3-70B-Instruct](https://huggingface.co/meta-llama/Llama-3.3-70B-Instruct) and [Qwen2.5-72B-Instruct](https://huggingface.co/Qwen/Qwen2.5-72B-Instruct) to synthesize 10M realistic personas.
## Dataset Details
Overall
```
DatasetDict({
Llama: Dataset({
features: ['id', 'model', 'profile', 'text'],
num_rows: 5000000
})
Qwen: Dataset({
features: ['id', 'model', 'profile', 'text'],
num_rows: 5000000
})
})
```
Example data generated by Llama-3.3-70B-Instruct
```
{'id': 'a8f5111e-867b-4486-a05c-ccbc994a14d4',
'model': 'meta-llama/Llama-3.3-70B-Instruct',
'profile': {'name': 'Ling Zhang',
'gender': 'female',
'date_of_birth': datetime.datetime(1964, 3, 3, 0, 0),
'residence_city': 'Tangshan',
'residence_country': 'China',
'personality': 'INFP',
'education': "Bachelor's degree in Fine Arts",
'occupation': 'Graphic Designer',
'languages': ['English', 'Chinese'],
'hobbies': ['painting', 'playing the guitar', 'writing poetry']},
'text': 'Ling Zhang, a creative and introspective individual born on March 3, '
'1964, resides in the vibrant city of Tangshan, China. As an INFP '
'personality type, she is known for her imaginative and empathetic '
'nature, which is beautifully reflected in her various pursuits. With '
"a Bachelor's degree in Fine Arts, Ling has cultivated her artistic "
'talents, working as a skilled Graphic Designer. Her linguistic '
'abilities extend to both English and Chinese, allowing her to '
'seamlessly navigate diverse cultural contexts. In her free time, '
'Ling enjoys expressing herself through painting, playing the guitar, '
'and writing poetry - a testament to her artistic inclinations. These '
'hobbies not only bring her solace but also serve as an outlet for '
'her creativity, which she expertly channels into her professional '
'work as a Graphic Designer. Through her unique blend of artistic '
'vision and technical skill, Ling Zhang continues to inspire those '
'around her, leaving an indelible mark on the world of design and '
'art.'}
```
## Citation [optional]
<!-- If there is a paper or blog post introducing the dataset, the APA and Bibtex information for that should go in this section. -->
```bibtex
@software{openpersona,
title={OpenPersona: Building a Synthetic Universe with 10M Realistic Personas},
author={Wu, Minghao and Wang, Weixuan},
year={2025},
url={https://huggingface.co/datasets/minghaowu/OpenPersona}
}
``` |
open-thoughts/OpenThoughts2-1M | open-thoughts | 2025-04-07T21:40:23Z | 17,310 | 122 | [
"license:apache-2.0",
"size_categories:1M<n<10M",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us",
"synthetic",
"curator"
] | [] | 2025-04-03T02:41:44Z | null | ---
dataset_info:
features:
- name: conversations
list:
- name: from
dtype: string
- name: value
dtype: string
- name: question
dtype: string
- name: source
dtype: string
- name: id
dtype: int64
splits:
- name: train
num_bytes: 18986223337.0
num_examples: 1143205
download_size: 8328411205
dataset_size: 18986223337.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
tags:
- synthetic
- curator
license: apache-2.0
---
<p align="center">
<img src="https://huggingface.co/datasets/open-thoughts/open-thoughts-114k/resolve/main/open_thoughts.png" width="50%">
</p>
<a href="https://github.com/bespokelabsai/curator/">
<img src="https://huggingface.co/datasets/bespokelabs/Bespoke-Stratos-17k/resolve/main/made_with_curator.png" alt="Made with Curator" width=200px>
</a>
# OpenThoughts2-1M
## Dataset Description
- **Homepage:** https://www.open-thoughts.ai/
- **Repository:** https://github.com/open-thoughts/open-thoughts
- **Point of Contact:** [Open Thoughts Team]([email protected])
Open synthetic reasoning dataset with 1M high-quality examples covering math, science, code, and puzzles!
[OpenThoughts2-1M](https://huggingface.co/datasets/open-thoughts/OpenThoughts2-1M) builds upon our previous [OpenThoughts-114k](https://huggingface.co/datasets/open-thoughts/OpenThoughts-114k) dataset, augmenting it with existing datasets like [OpenR1](https://huggingface.co/open-r1), as well as additional math and code reasoning data.
This dataset was used to train [OpenThinker2-7B](https://huggingface.co/open-thoughts/OpenThinker2-7B) and [OpenThinker2-32B](https://huggingface.co/open-thoughts/OpenThinker2-32B).
Inspect the content with rich formatting and search & filter capabilities in [Curator Viewer](https://curator.bespokelabs.ai/datasets/5bc1320f0afd45069cfada91a3b59c79?appId=022826a99b5c40619738d9ef48e06bc5).
See our [blog post](https://www.open-thoughts.ai/blog/thinkagain) for more details.
# OpenThinker2 Models
Our OpenThinker2 models trained on this dataset are top performing models, comparable with DeepSeek-R1-Distill models.
[OpenThinker2-32B](https://huggingface.co/open-thoughts/OpenThinker2-32B)
| Model | Data | AIME24 | AIME25 | AMC23 | MATH500 | GPQA-D | LCBv2 |
| ----------------------------------------------------------------------------------------------- | ---- | ------ | ------ | ----- | ------- | ------ | ----- |
| [OpenThinker2-32B](https://huggingface.co/open-thoughts/OpenThinker2-32B) | ✅ | 76.7 | 58.7 | 94.0 | 90.8 | 64.1 | 72.5 |
| [OpenThinker-32B](https://huggingface.co/open-thoughts/OpenThinker-32B) | ✅ | 68.0 | 49.3 | 95.5 | 90.6 | 63.5 | 68.6 |
| [DeepSeek-R1-Distill-Qwen-32B](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-32B) | ❌ | 74.7 | 50.0 | 96.5 | 90.0 | 65.8 | 72.3 |
| [Light-R1-32B](https://huggingface.co/qihoo360/Light-R1-32B) | ✅ | 74.7 | 58.0 | 96.0 | 90.4 | 62.0 | 56.0 |
| [S1.1-32B](https://huggingface.co/simplescaling/s1.1-32B) | ✅ | 59.3 | 42.7 | 91.5 | 87.4 | 62.0 | 58.7 |
[OpenThinker2-7B](https://huggingface.co/open-thoughts/OpenThinker2-7B)
| Model | Data | AIME24 | AIME25 | AMC23 | MATH500 | GPQA-D | LCBv2 |
| --------------------------------------------------------------------------------------------- | ---- | ------ | ------ | ----- | ------- | ------ | ----------- |
| [OpenThinker2-7B](https://huggingface.co/open-thoughts/OpenThinker2-7B) | ✅ | 50.0 | 33.3 | 89.5 | 88.4 | 49.3 | 55.6 |
| [OpenThinker-7B](https://huggingface.co/open-thoughts/OpenThinker-7B) | ✅ | 31.3 | 23.3 | 74.5 | 83.2 | 42.9 | 38.0 |
| [DeepSeek-R1-Distill-Qwen-7B](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B) | ❌ | 57.3 | 33.3 | 92.0 | 89.6 | 47.3 | 48.4 |
| [OlympicCoder-7B](https://huggingface.co/open-r1/OlympicCoder-7B) | ✅ | 20.7 | 15.3 | 63.0 | 74.8 | 25.3 | 55.4 |
| [OpenR1-Qwen-7B](https://huggingface.co/open-r1/OpenR1-Qwen-7B) | ✅ | 48.7 | 34.7 | 88.5 | 87.8 | 21.2 | 9.5<br><br> |
# Data Curation Recipe

We used two methods to create OpenThoughts2-1M by adding to OpenThoughts-114K:
1. **Leveraging existing reasoning data generated by other members of the open source community** -- We fine-tuned Qwen-2.5-7B-Instruct models on GeneralThought, OpenR1-Math, Nemotron, Synthetic-1, KodCode and measured downstream performance on our reasoning evaluation suite. Out of the datasets that we used in these experiments, we found that OpenR1-Math performed the best overall.
2. **Sourcing and generating new code and math reasoning data** -- We sourced 11 different methodologies of generating math questions and 15 different methods for generating code questions. To determine the best data sources, we measure the downstream performance of each model on relevant reasoning benchmarks. Using 30K questions from each of the top 5 data sources for code and 12.5k questions from each of the top 4 data sources for math on top of our OpenThoughts-114K + OpenR1 mix, we generate additional math and code instructions.
The final [OpenThoughts2-1M](https://huggingface.co/datasets/open-thoughts/OpenThoughts2-1M) is a combination of OpenThoughts-114k, OpenR1, and our newly generated math and code reasoning data.
# Citation
```
@misc{openthoughts,
author = {Team, OpenThoughts},
month = jan,
title = {{Open Thoughts}},
howpublished = {https://open-thoughts.ai},
year = {2025}
}
```
# Links
- 📊 [OpenThoughts2 and OpenThinker2 Blog Post](https://www.open-thoughts.ai/blog/thinkagain)
- 💻 [Open Thoughts GitHub Repository](https://github.com/open-thoughts/open-thoughts)
- 🧠 [OpenThoughts2-1M dataset](https://huggingface.co/datasets/open-thoughts/OpenThoughts2-1M) - this dataset.
- 🤖 [OpenThinker2-7B model](https://huggingface.co/open-thoughts/OpenThinker2-7B)
- 🤖 [OpenThinker2-32B model](https://huggingface.co/open-thoughts/OpenThinker2-32B)
- 💻 [Curator Viewer](https://curator.bespokelabs.ai/datasets/5bc1320f0afd45069cfada91a3b59c79?appId=022826a99b5c40619738d9ef48e06bc5)
# Visualization
Inspect the content with rich formatting and search & filter capabilities in [Curator Viewer](https://curator.bespokelabs.ai/datasets/5bc1320f0afd45069cfada91a3b59c79?appId=022826a99b5c40619738d9ef48e06bc5).. |
Namronaldo2004/ViInfographicsVQA | Namronaldo2004 | 2025-04-07T04:20:32Z | 12,883 | 3 | [
"task_categories:question-answering",
"task_categories:text-generation",
"language:vi",
"license:apache-2.0",
"size_categories:100K<n<1M",
"format:parquet",
"modality:image",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | [
"question-answering",
"text-generation"
] | 2025-03-30T09:10:26Z | null | ---
license: apache-2.0
task_categories:
- question-answering
- text-generation
language:
- vi
size_categories:
- 10B<n<100B
configs:
- config_name: default
data_files:
- split: train
path: data/train_part*
- split: val
path: data/val_part*
- split: test
path: data/test_part*
dataset_info:
features:
- name: image
dtype: image
- name: question
dtype: string
- name: answer
dtype: string
- name: explanation
dtype: string
- name: type
dtype: string
splits:
- name: train
num_bytes: 108397208828.026
num_examples: 97306
- name: val
num_bytes: 14392077735.8
num_examples: 13890
- name: test
num_bytes: 29348659870.958
num_examples: 28001
download_size: 122545172839
dataset_size: 152137946434.784
---
# Introduction
**ViInfographicsVQA** is a Vietnamese Visual Question Answering (VQA) dataset constructed from infographics sourced from 26 different news platforms. The dataset is designed to support research in multimodal learning by providing diverse questions and answers based on real-world visual data. The detailed distribution of sources is presented in the table below.
<div style="text-align: center;">
<img src="press.png" alt="Infographics Distribution" style="display: block; margin: auto;">
<div style="font-style: italic;">Figure 1: The number of infographics per news source.</div>
</div>
- **Developed by**: [@Namronaldo2004](https://huggingface.co/Namronaldo2004), [@Kiet2302](https://huggingface.co/Kiet2302), [@Mels22](https://huggingface.co/Mels22), [@JoeCao](https://huggingface.co/JoeCao), [@minhthien](https://huggingface.co/minhthien)
- **Dataset Type**: Visual Question Answering (VQA) on Vietnamese language.
- **Language**: Vietnamese
- **License**: Apache 2.0
# Data pipeline
Regarding the dataset creation process, we strictly adhere to the following dataset construction workflow:
<div style="text-align: center;">
<img src="pipeline.png" alt="The pipeline of building ViInfographicsVQA dataset" style="display: block; margin: auto;">
<div style="font-style: italic;">Figure 2: The pipeline of building ViInfographicsVQA dataset.</div>
</div>
<br>
# QA Type Classification
To better analyze and experiment with the scene-text properties of our dataset, we classify each QA into either "Text QA" or "Non-text QA."
- *Text QA* refers to questions based on numerical data, textual information, or any text present in the infographic. Questions involving information extracted from the text to answer other specific questions also fall into this category.
- *Non-text QA* refers to questions about colors, chart shapes, positions on the map, and objects such as people, trees, animals, vehicles, etc., that do not require reading text to answer.
# Rules and Constraints
To restrict the scope as well as the usability of the dataset, we defined rules and constraints before creating QA pairs in the dataset. Those ones are presented as follows:
- **Number of QAs**: Generate about **5 QAs per image**, including 3 Text QAs and 2 Non-text QAs.
- **QA Length**: Questions and answers **should not exceed 30 words**.
- **Colors**:
- **Only use these colors**: black, white, red, orange, yellow, green, blue, sky blue, purple, pink, brown, gray. Ignore color if it's not applicable.
- Only ask about **the color of specific objects** — not the background.
- **Question Constraints**:
- **Avoid** yes/no and choice-based questions.
- **Do not ask** questions requiring **deep analysis** or **inference beyond the infographic data**.
- Ensure sufficient data is available to answer the question.
- Avoid questions that can be answered without referencing the infographic.
- For numerical questions, include a comparison (e.g., greater than, within a range).
- For counting-based questions, specify criteria like starting or ending with a specific letter, word or phrase.
- **Answer Constraints**:
- Answers should be complete sentences that directly address the question.
- Include a clear explanation (within 100 words) detailing the reasoning (e.g., counted objects, location on the infographic). Write as a paragraph, not bullet points.
## Data Structure
The dataset is structured as follows:
- **image**: The input image.
- **question**: A question related to the image.
- **answer**: The correct answer to the question.
- **explanation**: A justification for why the answer is correct.
- **type**: The category of the question.
## Sample code
To utilize our dataset, you can use the sample code below:
```python
import matplotlib.pyplot as plt
from datasets import load_dataset
# Load dataset in streaming version
train_ds = load_dataset("Namronaldo2004/ViInfographicsVQA", split = "train", streaming = True)
# Get the first record
first_record = next(iter(train_ds))
# Plot the image
plt.imshow(first_record["image"])
plt.axis("off")
plt.title("First Image in Train Dataset")
plt.show()
# Print remaining attributes
print("❓ Question:", first_record["question"])
print("✅ Answer:", first_record["answer"])
print("💡 Explanation:", first_record["explanation"])
print("📌 Type:", first_record["type"])
``` |
open-r1/codeforces-cots | open-r1 | 2025-03-28T12:21:06Z | 8,839 | 152 | [
"license:cc-by-4.0",
"size_categories:100K<n<1M",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-02-27T10:35:02Z | null | ---
dataset_info:
- config_name: checker_interactor
features:
- name: id
dtype: string
- name: aliases
sequence: string
- name: contest_id
dtype: string
- name: contest_name
dtype: string
- name: contest_type
dtype: string
- name: contest_start
dtype: int64
- name: contest_start_year
dtype: int64
- name: index
dtype: string
- name: time_limit
dtype: float64
- name: memory_limit
dtype: float64
- name: title
dtype: string
- name: description
dtype: string
- name: input_format
dtype: string
- name: output_format
dtype: string
- name: interaction_format
dtype: string
- name: note
dtype: string
- name: examples
list:
- name: input
dtype: string
- name: output
dtype: string
- name: editorial
dtype: string
- name: prompt
dtype: string
- name: generation
dtype: string
- name: finish_reason
dtype: string
- name: api_metadata
struct:
- name: completion_tokens
dtype: int64
- name: prompt_tokens
dtype: int64
- name: prompt_tokens_details
dtype: 'null'
- name: total_tokens
dtype: int64
- name: messages
list:
- name: content
dtype: string
- name: role
dtype: string
splits:
- name: train
num_bytes: 994149425
num_examples: 35718
download_size: 274975300
dataset_size: 994149425
- config_name: solutions
features:
- name: id
dtype: string
- name: aliases
sequence: string
- name: contest_id
dtype: string
- name: contest_name
dtype: string
- name: contest_type
dtype: string
- name: contest_start
dtype: int64
- name: contest_start_year
dtype: int64
- name: index
dtype: string
- name: time_limit
dtype: float64
- name: memory_limit
dtype: int64
- name: title
dtype: string
- name: description
dtype: string
- name: input_format
dtype: string
- name: output_format
dtype: string
- name: examples
list:
- name: input
dtype: string
- name: output
dtype: string
- name: note
dtype: string
- name: editorial
dtype: string
- name: prompt
dtype: string
- name: generation
dtype: string
- name: finish_reason
dtype: string
- name: api_metadata
struct:
- name: completion_tokens
dtype: int64
- name: prompt_tokens
dtype: int64
- name: prompt_tokens_details
dtype: 'null'
- name: total_tokens
dtype: int64
- name: interaction_format
dtype: string
- name: messages
list:
- name: content
dtype: string
- name: role
dtype: string
splits:
- name: train
num_bytes: 4968074271
num_examples: 47780
download_size: 1887049179
dataset_size: 4968074271
- config_name: solutions_decontaminated
features:
- name: id
dtype: string
- name: aliases
sequence: string
- name: contest_id
dtype: string
- name: contest_name
dtype: string
- name: contest_type
dtype: string
- name: contest_start
dtype: int64
- name: contest_start_year
dtype: int64
- name: index
dtype: string
- name: time_limit
dtype: float64
- name: memory_limit
dtype: float64
- name: title
dtype: string
- name: description
dtype: string
- name: input_format
dtype: string
- name: output_format
dtype: string
- name: examples
list:
- name: input
dtype: string
- name: output
dtype: string
- name: note
dtype: string
- name: editorial
dtype: string
- name: problem
dtype: string
- name: generation
dtype: string
- name: finish_reason
dtype: string
- name: api_metadata
struct:
- name: completion_tokens
dtype: int64
- name: prompt_tokens
dtype: int64
- name: prompt_tokens_details
dtype: 'null'
- name: total_tokens
dtype: int64
- name: interaction_format
dtype: string
- name: messages
list:
- name: content
dtype: string
- name: role
dtype: string
- name: problem_type
dtype: string
- name: public_tests
struct:
- name: input
sequence: string
- name: output
sequence: string
- name: private_tests
struct:
- name: input
sequence: string
- name: output
sequence: string
- name: generated_tests
struct:
- name: input
sequence: string
- name: output
sequence: string
- name: public_tests_ms
list:
- name: input
dtype: string
- name: output
dtype: string
- name: failed_solutions
list:
- name: code
dtype: string
- name: passedTestCount
dtype: int64
- name: programmingLanguage
dtype: string
- name: verdict
dtype: string
- name: accepted_solutions
list:
- name: code
dtype: string
- name: passedTestCount
dtype: int64
- name: passed_test_count
dtype: 'null'
- name: programmingLanguage
dtype: string
- name: programming_language
dtype: string
- name: submission_id
dtype: string
- name: verdict
dtype: string
splits:
- name: train
num_bytes: 6719356671
num_examples: 40665
download_size: 2023394671
dataset_size: 6719356671
- config_name: solutions_py
features:
- name: id
dtype: string
- name: aliases
sequence: string
- name: contest_id
dtype: string
- name: contest_name
dtype: string
- name: contest_type
dtype: string
- name: contest_start
dtype: int64
- name: contest_start_year
dtype: int64
- name: index
dtype: string
- name: time_limit
dtype: float64
- name: memory_limit
dtype: float64
- name: title
dtype: string
- name: description
dtype: string
- name: input_format
dtype: string
- name: output_format
dtype: string
- name: interaction_format
dtype: string
- name: note
dtype: string
- name: examples
list:
- name: input
dtype: string
- name: output
dtype: string
- name: editorial
dtype: string
- name: prompt
dtype: string
- name: generation
dtype: string
- name: finish_reason
dtype: string
- name: api_metadata
struct:
- name: completion_tokens
dtype: int64
- name: prompt_tokens
dtype: int64
- name: prompt_tokens_details
dtype: 'null'
- name: total_tokens
dtype: int64
- name: messages
list:
- name: content
dtype: string
- name: role
dtype: string
splits:
- name: train
num_bytes: 1000253222
num_examples: 9556
download_size: 411697337
dataset_size: 1000253222
- config_name: solutions_py_decontaminated
features:
- name: id
dtype: string
- name: aliases
sequence: string
- name: contest_id
dtype: string
- name: contest_name
dtype: string
- name: contest_type
dtype: string
- name: contest_start
dtype: int64
- name: contest_start_year
dtype: int64
- name: index
dtype: string
- name: time_limit
dtype: float64
- name: memory_limit
dtype: float64
- name: title
dtype: string
- name: description
dtype: string
- name: input_format
dtype: string
- name: output_format
dtype: string
- name: interaction_format
dtype: string
- name: note
dtype: string
- name: examples
list:
- name: input
dtype: string
- name: output
dtype: string
- name: editorial
dtype: string
- name: prompt
dtype: string
- name: generation
dtype: string
- name: finish_reason
dtype: string
- name: api_metadata
struct:
- name: completion_tokens
dtype: int64
- name: prompt_tokens
dtype: int64
- name: prompt_tokens_details
dtype: 'null'
- name: total_tokens
dtype: int64
- name: messages
list:
- name: content
dtype: string
- name: role
dtype: string
- name: accepted_solutions
list:
- name: code
dtype: string
- name: passedTestCount
dtype: int64
- name: passed_test_count
dtype: 'null'
- name: programmingLanguage
dtype: string
- name: programming_language
dtype: string
- name: submission_id
dtype: string
- name: verdict
dtype: string
- name: failed_solutions
list:
- name: code
dtype: string
- name: passedTestCount
dtype: int64
- name: programmingLanguage
dtype: string
- name: verdict
dtype: string
- name: generated_tests
struct:
- name: input
sequence: string
- name: output
sequence: string
- name: private_tests
struct:
- name: input
sequence: string
- name: output
sequence: string
- name: problem_type
dtype: string
- name: public_tests
struct:
- name: input
sequence: string
- name: output
sequence: string
- name: public_tests_ms
list:
- name: input
dtype: string
- name: output
dtype: string
splits:
- name: train
num_bytes: 1349328880
num_examples: 8133
download_size: 500182086
dataset_size: 1349328880
- config_name: solutions_short_and_long_decontaminated
features:
- name: id
dtype: string
- name: aliases
sequence: string
- name: contest_id
dtype: string
- name: contest_name
dtype: string
- name: contest_type
dtype: string
- name: contest_start
dtype: int64
- name: contest_start_year
dtype: int64
- name: index
dtype: string
- name: time_limit
dtype: float64
- name: memory_limit
dtype: float64
- name: title
dtype: string
- name: description
dtype: string
- name: input_format
dtype: string
- name: output_format
dtype: string
- name: examples
list:
- name: input
dtype: string
- name: output
dtype: string
- name: note
dtype: string
- name: editorial
dtype: string
- name: prompt
dtype: string
- name: generation
dtype: string
- name: finish_reason
dtype: string
- name: api_metadata
struct:
- name: completion_tokens
dtype: int64
- name: prompt_tokens
dtype: int64
- name: prompt_tokens_details
dtype: 'null'
- name: total_tokens
dtype: int64
- name: interaction_format
dtype: string
- name: messages
list:
- name: content
dtype: string
- name: role
dtype: string
- name: accepted_solutions
list:
- name: code
dtype: string
- name: passedTestCount
dtype: int64
- name: passed_test_count
dtype: 'null'
- name: programmingLanguage
dtype: string
- name: programming_language
dtype: string
- name: submission_id
dtype: string
- name: verdict
dtype: string
- name: failed_solutions
list:
- name: code
dtype: string
- name: passedTestCount
dtype: int64
- name: programmingLanguage
dtype: string
- name: verdict
dtype: string
- name: generated_tests
struct:
- name: input
sequence: string
- name: output
sequence: string
- name: private_tests
struct:
- name: input
sequence: string
- name: output
sequence: string
- name: problem_type
dtype: string
- name: public_tests
struct:
- name: input
sequence: string
- name: output
sequence: string
- name: public_tests_ms
list:
- name: input
dtype: string
- name: output
dtype: string
splits:
- name: train
num_bytes: 2699204607
num_examples: 16266
download_size: 1002365269
dataset_size: 2699204607
- config_name: solutions_w_editorials
features:
- name: id
dtype: string
- name: aliases
sequence: string
- name: contest_id
dtype: string
- name: contest_name
dtype: string
- name: contest_type
dtype: string
- name: contest_start
dtype: int64
- name: contest_start_year
dtype: int64
- name: index
dtype: string
- name: time_limit
dtype: float64
- name: memory_limit
dtype: int64
- name: title
dtype: string
- name: description
dtype: string
- name: input_format
dtype: string
- name: output_format
dtype: string
- name: interaction_format
dtype: string
- name: note
dtype: string
- name: examples
list:
- name: input
dtype: string
- name: output
dtype: string
- name: editorial
dtype: string
- name: prompt
dtype: string
- name: generation
dtype: string
- name: finish_reason
dtype: string
- name: api_metadata
struct:
- name: completion_tokens
dtype: int64
- name: prompt_tokens
dtype: int64
- name: prompt_tokens_details
dtype: 'null'
- name: total_tokens
dtype: int64
- name: messages
list:
- name: content
dtype: string
- name: role
dtype: string
splits:
- name: train
num_bytes: 2649620432
num_examples: 29180
download_size: 972089090
dataset_size: 2649620432
- config_name: solutions_w_editorials_decontaminated
features:
- name: id
dtype: string
- name: aliases
sequence: string
- name: contest_id
dtype: string
- name: contest_name
dtype: string
- name: contest_type
dtype: string
- name: contest_start
dtype: int64
- name: contest_start_year
dtype: int64
- name: index
dtype: string
- name: time_limit
dtype: float64
- name: memory_limit
dtype: int64
- name: title
dtype: string
- name: description
dtype: string
- name: input_format
dtype: string
- name: output_format
dtype: string
- name: interaction_format
dtype: string
- name: note
dtype: string
- name: examples
list:
- name: input
dtype: string
- name: output
dtype: string
- name: editorial
dtype: string
- name: prompt
dtype: string
- name: generation
dtype: string
- name: finish_reason
dtype: string
- name: api_metadata
struct:
- name: completion_tokens
dtype: int64
- name: prompt_tokens
dtype: int64
- name: prompt_tokens_details
dtype: 'null'
- name: total_tokens
dtype: int64
- name: messages
list:
- name: content
dtype: string
- name: role
dtype: string
- name: accepted_solutions
list:
- name: code
dtype: string
- name: passedTestCount
dtype: int64
- name: passed_test_count
dtype: 'null'
- name: programmingLanguage
dtype: string
- name: programming_language
dtype: string
- name: submission_id
dtype: string
- name: verdict
dtype: string
- name: failed_solutions
list:
- name: code
dtype: string
- name: passedTestCount
dtype: int64
- name: programmingLanguage
dtype: string
- name: verdict
dtype: string
- name: generated_tests
struct:
- name: input
sequence: string
- name: output
sequence: string
- name: private_tests
struct:
- name: input
sequence: string
- name: output
sequence: string
- name: problem_type
dtype: string
- name: public_tests
struct:
- name: input
sequence: string
- name: output
sequence: string
- name: public_tests_ms
list:
- name: input
dtype: string
- name: output
dtype: string
splits:
- name: train
num_bytes: 3738669884
num_examples: 24490
download_size: 1012247387
dataset_size: 3738669884
- config_name: solutions_w_editorials_py
features:
- name: id
dtype: string
- name: aliases
sequence: string
- name: contest_id
dtype: string
- name: contest_name
dtype: string
- name: contest_type
dtype: string
- name: contest_start
dtype: int64
- name: contest_start_year
dtype: int64
- name: index
dtype: string
- name: time_limit
dtype: float64
- name: memory_limit
dtype: float64
- name: title
dtype: string
- name: description
dtype: string
- name: input_format
dtype: string
- name: output_format
dtype: string
- name: interaction_format
dtype: string
- name: note
dtype: string
- name: examples
list:
- name: input
dtype: string
- name: output
dtype: string
- name: editorial
dtype: string
- name: prompt
dtype: string
- name: generation
dtype: string
- name: finish_reason
dtype: string
- name: api_metadata
struct:
- name: completion_tokens
dtype: int64
- name: prompt_tokens
dtype: int64
- name: prompt_tokens_details
dtype: 'null'
- name: total_tokens
dtype: int64
- name: messages
list:
- name: content
dtype: string
- name: role
dtype: string
splits:
- name: train
num_bytes: 1067124847
num_examples: 11672
download_size: 415023817
dataset_size: 1067124847
- config_name: solutions_w_editorials_py_decontaminated
features:
- name: id
dtype: string
- name: aliases
sequence: string
- name: contest_id
dtype: string
- name: contest_name
dtype: string
- name: contest_type
dtype: string
- name: contest_start
dtype: int64
- name: contest_start_year
dtype: int64
- name: index
dtype: string
- name: time_limit
dtype: float64
- name: memory_limit
dtype: float64
- name: title
dtype: string
- name: description
dtype: string
- name: input_format
dtype: string
- name: output_format
dtype: string
- name: interaction_format
dtype: string
- name: note
dtype: string
- name: examples
list:
- name: input
dtype: string
- name: output
dtype: string
- name: editorial
dtype: string
- name: prompt
dtype: string
- name: generation
dtype: string
- name: finish_reason
dtype: string
- name: api_metadata
struct:
- name: completion_tokens
dtype: int64
- name: prompt_tokens
dtype: int64
- name: prompt_tokens_details
dtype: 'null'
- name: total_tokens
dtype: int64
- name: messages
list:
- name: content
dtype: string
- name: role
dtype: string
- name: accepted_solutions
list:
- name: code
dtype: string
- name: passedTestCount
dtype: int64
- name: passed_test_count
dtype: 'null'
- name: programmingLanguage
dtype: string
- name: programming_language
dtype: string
- name: submission_id
dtype: string
- name: verdict
dtype: string
- name: failed_solutions
list:
- name: code
dtype: string
- name: passedTestCount
dtype: int64
- name: programmingLanguage
dtype: string
- name: verdict
dtype: string
- name: generated_tests
struct:
- name: input
sequence: string
- name: output
sequence: string
- name: private_tests
struct:
- name: input
sequence: string
- name: output
sequence: string
- name: problem_type
dtype: string
- name: public_tests
struct:
- name: input
sequence: string
- name: output
sequence: string
- name: public_tests_ms
list:
- name: input
dtype: string
- name: output
dtype: string
splits:
- name: train
num_bytes: 1499075280
num_examples: 9796
download_size: 466078291
dataset_size: 1499075280
- config_name: test_input_generator
features:
- name: id
dtype: string
- name: aliases
sequence: string
- name: contest_id
dtype: string
- name: contest_name
dtype: string
- name: contest_type
dtype: string
- name: contest_start
dtype: int64
- name: contest_start_year
dtype: int64
- name: index
dtype: string
- name: time_limit
dtype: float64
- name: memory_limit
dtype: float64
- name: title
dtype: string
- name: description
dtype: string
- name: input_format
dtype: string
- name: output_format
dtype: string
- name: examples
list:
- name: input
dtype: string
- name: output
dtype: string
- name: note
dtype: string
- name: editorial
dtype: string
- name: prompt
dtype: string
- name: generation
dtype: string
- name: finish_reason
dtype: string
- name: api_metadata
struct:
- name: completion_tokens
dtype: int64
- name: completion_tokens_details
dtype: 'null'
- name: prompt_tokens
dtype: int64
- name: prompt_tokens_details
dtype: 'null'
- name: total_tokens
dtype: int64
- name: interaction_format
dtype: string
- name: messages
list:
- name: content
dtype: string
- name: role
dtype: string
splits:
- name: train
num_bytes: 1851104290
num_examples: 20620
download_size: 724157877
dataset_size: 1851104290
configs:
- config_name: checker_interactor
data_files:
- split: train
path: checker_interactor/train-*
- config_name: solutions
default: true
data_files:
- split: train
path: solutions/train-*
- config_name: solutions_decontaminated
data_files:
- split: train
path: solutions_decontaminated/train-*
- config_name: solutions_py
data_files:
- split: train
path: solutions_py/train-*
- config_name: solutions_py_decontaminated
data_files:
- split: train
path: solutions_py_decontaminated/train-*
- config_name: solutions_short_and_long_decontaminated
data_files:
- split: train
path: solutions_short_and_long_decontaminated/train-*
- config_name: solutions_w_editorials
data_files:
- split: train
path: solutions_w_editorials/train-*
- config_name: solutions_w_editorials_decontaminated
data_files:
- split: train
path: solutions_w_editorials_decontaminated/train-*
- config_name: solutions_w_editorials_py
data_files:
- split: train
path: solutions_w_editorials_py/train-*
- config_name: solutions_w_editorials_py_decontaminated
data_files:
- split: train
path: solutions_w_editorials_py_decontaminated/train-*
- config_name: test_input_generator
data_files:
- split: train
path: test_input_generator/train-*
license: cc-by-4.0
---
# Dataset Card for CodeForces-CoTs
## Dataset description
CodeForces-CoTs is a large-scale dataset for training reasoning models on competitive programming tasks. It consists of 10k CodeForces problems with up to five reasoning traces generated by [DeepSeek R1](https://huggingface.co/deepseek-ai/DeepSeek-R1). We did not filter the traces for correctness, but found that around 84% of the Python ones pass the public tests.
The dataset consists of several subsets:
- `solutions`: we prompt R1 to solve the problem and produce code.
- `solutions_w_editorials`: we prompt R1 to solve the problem/produce code, but also provide it with a human-written solution.
- `solutions_short_and_long`: a subset of `solutions` where we take the shortest and longest solution from R1.
- `test_input_generator`: we prompt R1 to come up with tricky edge test cases and create a test code generator in Python.
- `checker_interactor`: we prompt R1 to classify problems based on how we should verify the output (some problems are interactive, some allow multiple correct outputs, etc)
Each subset contains a `messages` column, so can be used directly for SFT. We've found that the `solutions` and `solutions_w_editorials` subsets provide best performance, with `solutions` obtaining better performance on LiveCodeBench. Training on `solutions_short_and_long` also results in comparable performance as the full `solutions` subset, but is significantly more data efficient.
By default, all subsets contains C++ generated solutions, except those with a `_py` suffix, which denote Python solutions with just one completion per problem. We also provide decontaminated subsets (indicated with a `_decontaminated` suffix), which have been decontaminated using 8-gram overlap against the AIME24, AIME25, GPQA Diamond, MATH-500, and LiveCodeBench benchmarks. Check out [this script](https://github.com/huggingface/open-r1/blob/main/scripts/decontaminate.py) for the underlying logic.
You can load the dataset as follows:
```python
from datasets import load_dataset
ds = load_dataset("open-r1/codeforces-cots", "solutions")
```
## Dataset curation
[CodeForces](https://codeforces.com/) is one of the most popular websites among competitive programmers, hosting regular contests where participants must solve challenging algorithmic optimization problems. The challenging nature of these problems makes them an interesting dataset to improve and test models’ code reasoning capabilities.
While previous efforts such as [DeepMind’s CodeContests dataset](https://huggingface.co/datasets/deepmind/code_contests) have compiled a large amount of CodeForces problems, today we are releasing our own `open-r1/codeforces` dataset, with more than **10k problems** covering the very first contests all the way to 2025, **~3k** of which were not included in DeepMind’s dataset. Additionally, for around 60% of problems, we have **included the *editorial*,** which is an explanation, written by the contest organizers, explaining the correct solution. You will also find 3 correct solutions per problem extracted from the official website.
Furthermore, we are releasing `open-r1/codeforces-cots`, which contains chain of thought generations produced by DeepSeek-R1 on these problems, where we asked the model to produce solutions in C++ (the main language used in competitive programming) and Python, totaling close to **100k** samples.
## License
The dataset is licensed under the Open Data Commons Attribution License (ODC-By) 4.0 license.
## Citation
If you find CodeForces-CoTs useful in your work, please consider citing it as:
```
@misc{penedo2025codeforces,
title={CodeForces CoTs},
author={Guilherme Penedo and Anton Lozhkov and Hynek Kydlíček and Loubna Ben Allal and Edward Beeching and Agustín Piqueres Lajarín and Quentin Gallouédec and Nathan Habib and Lewis Tunstall and Leandro von Werra},
year={2025},
publisher = {Hugging Face},
journal = {Hugging Face repository},
howpublished = {\url{https://huggingface.co/datasets/open-r1/codeforces-cots}}
}
``` |
dell-research-harvard/AmericanStories | dell-research-harvard | 2025-03-26T15:49:08Z | 8,821 | 137 | [
"task_categories:text-classification",
"task_categories:text-generation",
"task_categories:text-retrieval",
"task_categories:summarization",
"task_categories:question-answering",
"language:en",
"license:cc-by-4.0",
"size_categories:100M<n<1B",
"arxiv:2308.12477",
"doi:10.57967/hf/0757",
"region:us",
"social science",
"economics",
"news",
"newspaper",
"large language modeling",
"nlp",
"lam"
] | [
"text-classification",
"text-generation",
"text-retrieval",
"summarization",
"question-answering"
] | 2023-06-12T19:42:34Z | null | ---
license: cc-by-4.0
task_categories:
- text-classification
- text-generation
- text-retrieval
- summarization
- question-answering
language:
- en
tags:
- social science
- economics
- news
- newspaper
- large language modeling
- nlp
- lam
pretty_name: AmericanStories
size_categories:
- 100M<n<1B
---
# Dataset Card for the American Stories dataset
## Dataset Description
- **Homepage:** Coming Soon
- **Repository:** https://github.com/dell-research-harvard/AmericanStories
- **Paper:** Coming Soon
=- **Point of Contact:** [email protected]
### Dataset Summary
The American Stories dataset is a collection of full article texts extracted from historical U.S. newspaper images. It includes nearly 20 million scans from the public domain Chronicling America collection maintained by the Library of Congress. The dataset is designed to address the challenges posed by complex layouts and low OCR quality in existing newspaper datasets.
It was created using a novel deep learning pipeline that incorporates layout detection, legibility classification, custom OCR, and the association of article texts spanning multiple bounding boxes. It employs efficient architectures specifically designed for mobile phones to ensure high scalability.
The dataset offers high-quality data that can be utilized for various purposes. It can be used to pre-train large language models and improve their understanding of historical English and world knowledge.
The dataset can also be integrated into retrieval-augmented language models, making historical information more accessible, including interpretations of political events and details about people's ancestors.
Additionally, the structured article texts in the dataset enable the use of transformer-based methods for applications such as detecting reproduced content. This significantly enhances accuracy compared to relying solely on existing OCR techniques.
The American Stories dataset serves as an invaluable resource for developing multimodal layout analysis models and other multimodal applications. Its vast size and silver quality make it ideal for innovation and research in this domain.
*Update (3/25/2025)* We have updated this dataset to include instances that were missing from the earlier version. For reproducibility, a checkpoint of the earlier version has been preserved and can be accessed by specifying `revision="v0.1.0"` when loading the dataset using the Hugging Face Datasets library.
### Languages
English (en)
## Dataset Structure
The raw data on this repo contains compressed chunks of newspaper scans for each year. Each scan has its own JSON file named as the {scan_id}.json.
The data loading script takes care of the downloading, extraction, and parsing to outputs of two kinds :
+ Article-Level Output: The unit of the Dataset Dict is an associated article
+ Scan Level Output: The unit of the Dataset Dict is an entire scan with all the raw unparsed data
### Data Instances
Here are some examples of what the output looks like.
#### Article level
```
{
'article_id': '1_1870-01-01_p1_sn82014899_00211105483_1870010101_0773',
'newspaper_name': 'The weekly Arizona miner.',
'edition': '01', 'date': '1870-01-01',
'page': 'p1',
'headline': '',
'byline': '',
'article': 'PREyors 10 leaving San Francisco for Wash ington City, our Governor, A. r. K. Saford. called upon Generals Thomas and Ord and nt the carrying out of what (truncated)'
}
```
#### Scan level
```
{'raw_data_string': '{"lccn": {"title": "The Massachusetts spy, or, Thomas\'s Boston journal.", "geonames_ids": ["4930956"],....other_keys:values}
```
### Data Fields
#### Article Level
+ "article_id": Unique Id for an associated article
+ "newspaper_name": Newspaper Name
+ "edition": Edition number
+ "date": Date of publication
+ "page": Page number
+ "headline": Headline Text
+ "byline": Byline Text
+ "article": Article Text
#### Scan Level
"raw_data_string": Unparsed scan-level data that contains scan metadata from Library of Congress, all content regions with their bounding boxes, OCR text and legibility classification
### Data Splits
There are no train, test or val splits. Since the dataset has a massive number of units (articles or newspaper scans), we have split the data by year. Once the dataset is loaded,
instead of the usual way of accessing a split as dataset["train"], specific years can be accessed using the syntax dataset["year"] where year can be any year between 1774-1963 as long as there is at least one scan for the year.
The data loading script provides options to download both a subset of years and all years at a time.
### Accessing the Data
There are 4 config options that can be used to access the data depending upon the use-case.
```
from datasets import load_dataset
# Download data for the year 1809 at the associated article level (Default)
dataset = load_dataset("dell-research-harvard/AmericanStories",
"subset_years",
year_list=["1809", "1810"]
)
# Download and process data for all years at the article level
dataset = load_dataset("dell-research-harvard/AmericanStories",
"all_years"
)
# Download and process data for 1809 at the scan level
dataset = load_dataset("dell-research-harvard/AmericanStories",
"subset_years_content_regions",
year_list=["1809"]
)
# Download ad process data for all years at the scan level
dataset = load_dataset("dell-research-harvard/AmericanStories",
"all_years_content_regions")
```
## Dataset Creation
### Curation Rationale
The dataset was created to provide researchers with a large, high-quality corpus of structured and transcribed newspaper article texts from historical local American newspapers.
These texts provide a massive repository of information about topics ranging from political polarization to the construction of national and cultural identities to the minutiae of the daily lives of people's ancestors.
The dataset will be useful to a wide variety of researchers including historians, other social scientists, and NLP practitioners.
### Source Data
#### Initial Data Collection and Normalization
The dataset is drawn entirely from image scans in the public domain that are freely available for download from the Library of Congress's website.
We processed all images as described in the associated paper.
#### Who are the source language producers?
The source language was produced by people - by newspaper editors, columnists, and other sources.
### Annotations
#### Annotation process
Not Applicable
#### Who are the annotators?
Not Applicable
### Personal and Sensitive Information
Not Applicable
## Considerations for Using the Data
### Social Impact of Dataset
This dataset provides high-quality data that could be used for pre-training a large language model to achieve better understanding of historical English and historical world knowledge.
The dataset could also be added to the external database of a retrieval-augmented language model to make historical information - ranging from interpretations of political events to minutiae about the lives of people's ancestors - more widely accessible.
Furthermore, structured article texts that it provides can facilitate using transformer-based methods for popular applications like detection of reproduced content, significantly improving accuracy relative to using the existing OCR.
It can also be used for innovating multimodal layout analysis models and other multimodal applications.
### Discussion of Biases
This dataset contains unfiltered content composed by newspaper editors, columnists, and other sources.
In addition to other potentially harmful content, the corpus may contain factual errors and intentional misrepresentations of news events.
All content should be viewed as individuals' opinions and not as a purely factual account of events of the day.
## Additional Information
### Dataset Curators
Melissa Dell (Harvard), Jacob Carlson (Harvard), Tom Bryan (Harvard) , Emily Silcock (Harvard), Abhishek Arora (Harvard), Zejiang Shen (MIT), Luca D'Amico-Wong (Harvard), Quan Le (Princeton), Pablo Querubin (NYU), Leander Heldring (Kellog School of Business)
### Licensing Information
The dataset has a CC-BY 4.0 license
### Citation Information
Please cite as:
@misc{dell2023american,
title={American Stories: A Large-Scale Structured Text Dataset of Historical U.S. Newspapers},
author={Melissa Dell and Jacob Carlson and Tom Bryan and Emily Silcock and Abhishek Arora and Zejiang Shen and Luca D'Amico-Wong and Quan Le and Pablo Querubin and Leander Heldring},
year={2023},
eprint={2308.12477},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
### Contributions
Coming Soon |
songlab/TraitGym | songlab | 2025-03-25T19:09:05Z | 24,375 | 7 | [
"license:mit",
"size_categories:10M<n<100M",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us",
"dna",
"variant-effect-prediction",
"biology",
"genomics"
] | [] | 2025-01-26T23:37:15Z | null | ---
license: mit
tags:
- dna
- variant-effect-prediction
- biology
- genomics
configs:
- config_name: "mendelian_traits"
data_files:
- split: test
path: "mendelian_traits_matched_9/test.parquet"
- config_name: "complex_traits"
data_files:
- split: test
path: "complex_traits_matched_9/test.parquet"
- config_name: "mendelian_traits_full"
data_files:
- split: test
path: "mendelian_traits_all/test.parquet"
- config_name: "complex_traits_full"
data_files:
- split: test
path: "complex_traits_all/test.parquet"
---
# 🧬 TraitGym
[Benchmarking DNA Sequence Models for Causal Regulatory Variant Prediction in Human Genetics](https://www.biorxiv.org/content/10.1101/2025.02.11.637758v1)
🏆 Leaderboard: https://huggingface.co/spaces/songlab/TraitGym-leaderboard
## ⚡️ Quick start
- Load a dataset
```python
from datasets import load_dataset
dataset = load_dataset("songlab/TraitGym", "mendelian_traits", split="test")
```
- Example notebook to run variant effect prediction with a gLM, runs in 5 min on Google Colab: `TraitGym.ipynb` [](https://colab.research.google.com/github/songlab-cal/TraitGym/blob/main/TraitGym.ipynb)
## 🤗 Resources (https://huggingface.co/datasets/songlab/TraitGym)
- Datasets: `{dataset}/test.parquet`
- Subsets: `{dataset}/subset/{subset}.parquet`
- Features: `{dataset}/features/{features}.parquet`
- Predictions: `{dataset}/preds/{subset}/{model}.parquet`
- Metrics: `{dataset}/{metric}/{subset}/{model}.csv`
`dataset` examples (`load_dataset` config name):
- `mendelian_traits_matched_9` (`mendelian_traits`)
- `complex_traits_matched_9` (`complex_traits`)
- `mendelian_traits_all` (`mendelian_traits_full`)
- `complex_traits_all` (`complex_traits_full`)
`subset` examples:
- `all` (default)
- `3_prime_UTR_variant`
- `disease`
- `BMI`
`features` examples:
- `GPN-MSA_LLR`
- `GPN-MSA_InnerProducts`
- `Borzoi_L2`
`model` examples:
- `GPN-MSA_LLR.minus.score`
- `GPN-MSA.LogisticRegression.chrom`
- `CADD+GPN-MSA+Borzoi.LogisticRegression.chrom`
`metric` examples:
- `AUPRC_by_chrom_weighted_average` (main metric)
- `AUPRC`
## 💻 Code (https://github.com/songlab-cal/TraitGym)
- Tries to follow [recommended Snakemake structure](https://snakemake.readthedocs.io/en/stable/snakefiles/deployment.html)
- GPN-Promoter code is in [the main GPN repo](https://github.com/songlab-cal/gpn)
### Installation
First, clone the repo and `cd` into it.
Second, install the dependencies:
```bash
conda env create -f workflow/envs/general.yaml
conda activate TraitGym
```
Optionally, download precomputed datasets and predictions (6.7G):
```bash
mkdir -p results/dataset
huggingface-cli download songlab/TraitGym --repo-type dataset --local-dir results/dataset/
```
### Running
To compute a specific result, specify its path:
```bash
snakemake --cores all <path>
```
Example paths (these are already computed):
```bash
# zero-shot LLR
results/dataset/complex_traits_matched_9/AUPRC_by_chrom_weighted_average/all/GPN-MSA_absLLR.plus.score.csv
# logistic regression/linear probing
results/dataset/complex_traits_matched_9/AUPRC_by_chrom_weighted_average/all/GPN-MSA.LogisticRegression.chrom.csv
```
We recommend the following:
```bash
# Snakemake sometimes gets confused about which files it needs to rerun and this forces
# not to rerun any existing file
snakemake --cores all <path> --touch
# to output an execution plan
snakemake --cores all <path> --dry-run
```
To evaluate your own set of model features, place a dataframe of shape `n_variants,n_features` in `results/dataset/{dataset}/features/{features}.parquet`.
For zero-shot evaluation of column `{feature}` and sign `{sign}` (`plus` or `minus`), you would invoke:
```bash
snakemake --cores all results/dataset/{dataset}/{metric}/all/{features}.{sign}.{feature}.csv
```
To train and evaluate a logistic regression model, you would invoke:
```bash
snakemake --cores all results/dataset/{dataset}/{metric}/all/{feature_set}.LogisticRegression.chrom.csv
```
where `{feature_set}` should first be defined in `feature_sets` in `config/config.yaml` (this allows combining features defined in different files).
## Citation
[Link to paper](https://www.biorxiv.org/content/10.1101/2025.02.11.637758v2)
```bibtex
@article{traitgym,
title={Benchmarking DNA Sequence Models for Causal Regulatory Variant Prediction in Human Genetics},
author={Benegas, Gonzalo and Eraslan, G{\"o}kcen and Song, Yun S},
journal={bioRxiv},
pages={2025--02},
year={2025},
publisher={Cold Spring Harbor Laboratory}
}
``` |
labelmaker/arkit_labelmaker | labelmaker | 2025-03-25T13:46:55Z | 29,022 | 1 | [
"task_categories:image-segmentation",
"language:en",
"license:bsd",
"size_categories:1K<n<10K",
"arxiv:2410.13924",
"doi:10.57967/hf/2389",
"region:us",
"3D semantic segmentation",
"indoor 3D scene dataset",
"pointcloud-segmentation"
] | [
"image-segmentation"
] | 2024-04-24T17:17:33Z | null | ---
language:
- en
license: bsd
size_categories:
- 1K<n<10K
pretty_name: arkit_labelmaker
viewer: false
tags:
- 3D semantic segmentation
- indoor 3D scene dataset
- pointcloud-segmentation
task_categories:
- image-segmentation
---
# ARKit Labelmaker: A New Scale for Indoor 3D Scene Understanding
[[arxiv]](https://arxiv.org/abs/2410.13924) [[website]](https://labelmaker.org/) [[checkpoints]](https://huggingface.co/labelmaker/PTv3-ARKit-LabelMaker) [[code]](https://github.com/cvg/LabelMaker)
We complement ARKitScenes dataset with dense semantic annotations that are automatically generated at scale. This produces the first large-scale, real-world 3D dataset with dense semantic annotations.
Training on this auto-generated data, we push forward the state-of-the-art performance on ScanNet and ScanNet200 with prevalent 3D semantic segmentation models. |
badrivishalk/TEXTRON_INDIC_DATASETS | badrivishalk | 2025-03-24T06:39:37Z | 1,073 | 2 | [
"task_categories:object-detection",
"language:ta",
"language:gu",
"language:ml",
"language:te",
"language:kn",
"language:hi",
"license:gpl-3.0",
"size_categories:1K<n<10K",
"format:imagefolder",
"modality:image",
"modality:text",
"library:datasets",
"library:mlcroissant",
"arxiv:2402.09811",
"region:us",
"Text Detection",
"Indic",
"Handwritten",
"Printed"
] | [
"object-detection"
] | 2025-03-20T18:50:17Z | 2 | ---
license: gpl-3.0
task_categories:
- object-detection
language:
- ta
- gu
- ml
- te
- kn
- hi
pretty_name: TEXTRON_INDIC_DATASETS
tags:
- Text Detection
- Indic
- Handwritten
- Printed
size_categories:
- 1K<n<10K
---
This dataset is intended for **testing** purposes only. It contains a set of test data to evaluate the performance of models. It does not include training or validation data.
# TEXTRON Paper Release Dataset (WACV 2024)
Welcome to the TEXTRON Paper Release Dataset for the WACV 2024 conference! This dataset contains handwritten and printed text detection datasets in three different languages. This README provides essential information on the dataset structure, contents, and how to use the data effectively for your research purposes.
## Table of Contents
- [Introduction](#introduction)
- [Dataset Overview](#dataset-overview)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [File Formats](#file-formats)
- [Citation](#citation)
- [License](#license)
- [Contact](#contact)
## Introduction
The TEXTRON Paper Release Dataset is a collection of handwritten and printed text detection datasets curated specifically for the WACV 2024 conference. This dataset aims to support research and development in the field of text detection across various languages and text types.
## Dataset Overview
- **Dataset Name:** TEXTRON Paper Release Dataset (WACV 2024)
- **Conference:** WACV 2024
- **Text Types:** Handwritten and Printed
- ***Handwritten Languages:*** Devanagari, Kannada, Telugu
- ***Printed Languages:*** Gujarati, Malayalam, Tamil
## Dataset Details
The dataset comprises text samples from three different languages for each Printed and Handwriten text types:
| Language | Handwritten Images |
|------------|--------------------|
| Devanagari | 220 |
| Telugu | 85 |
| Kannada | 46 |
| Language | Printed Images |
|------------|--------------------|
| Gujarati | 323 |
| Malayalam | 225 |
| Tamil | 225 |
## Dataset Structure
The dataset is organized into the following directory structure:
```
TEXTRON_Paper_Release_Dataset_WACV_2024/
|
├── Handwritten
│ ├── PhDIndic11_Devanagari
│ │ ├── images
│ │ └── txt
│ ├── PhDIndic11_Kannada
│ │ ├── images
│ │ └── txt
│ └── PhDIndic11_Telugu
│ ├── images
│ └── txt
├── Printed
│ ├── Gujarati
│ │ ├── images
│ │ └── txt
│ ├── Malayalam
│ │ ├── images
│ │ └── txt
│ └── Tamil
│ ├── images
│ └── txt
└── README.md
```
- **Images:** This directory contains the raw images of handwritten and printed text samples in each language.
- **Annotations:** This directory contains annotation files corresponding to the images, providing information about the location of word level bounding boxes. All the files contain ***text*** class describing class of annotation
## File Formats
- **Image Files:** Images are provided in the format of JPG.
- **Annotation Files:** Annotations are provided in TXT format detailing the bounding boxes and corresponding text content.
## Citation
If you use this dataset in your research work, please cite the following paper:
```
@InProceedings{TEXTRON,
author = {Dhruv Kudale and Badri Vishal Kasuba and Venkatapathy Subramanian and Parag Chaudhuri and Ganesh Ramakrishnan},
title = {TEXTRON: Weakly Supervised Multilingual Text Detection Through Data Programming},
booktitle = {Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)},
month = {January},
year = {2024},
pages = {2871-2880},
url = {https://arxiv.org/abs/2402.09811}
}
```
## License
The TEXTRON Paper Release Dataset is released under [GNU]. Please refer to the LICENSE file in this repository for more details.
## Contact
For any inquiries or issues regarding the dataset, please contact:
Name: Ganesh Ramakrishnan\
Mail: [email protected]\
Affl: IIT Bombay
Thank you for using the TEXTRON Paper Release Dataset! We hope this resource proves valuable in your research endeavors. |
knoveleng/open-rs | knoveleng | 2025-03-24T02:18:39Z | 2,762 | 8 | [
"task_categories:text-generation",
"language:en",
"license:mit",
"size_categories:1K<n<10K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"arxiv:2503.16219",
"region:us"
] | [
"text-generation"
] | 2025-03-18T09:44:28Z | 2 | ---
language: en
license: mit
task_categories:
- text-generation
dataset_info:
features:
- name: problem
dtype: string
- name: solution
dtype: string
- name: answer
dtype: string
- name: level
dtype: string
splits:
- name: train
num_bytes: 7763718
num_examples: 7000
download_size: 3678677
dataset_size: 7763718
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Open-RS Dataset
## Dataset Description
- **Repository**: [knoveleng/open-rs](https://github.com/knoveleng/open-rs)
- **Paper**: [Reinforcement Learning for Reasoning in Small LLMs: What Works and What Doesn’t](https://arxiv.org/abs/2503.16219)
### Summary
The `open-rs` dataset contains 7,000 mathematical reasoning problems, including 3,000 hard problems from `open-s1` and 4,000 (1000 easy + 3000 hard problems) from `open-deepscaler`. It’s a core component of the [Open RS project](https://github.com/knoveleng/open-rs), enhancing reasoning in small LLMs via reinforcement learning.
## Usage
Load the dataset using the Hugging Face `datasets` library:
```python
from datasets import load_dataset
ds = load_dataset("knoveleng/open-rs")["train"]
print(ds[0])
```
## Dataset Structure
### Data Instance
An example entry:
```json
{
"problem": "Let \(S(M)\) denote the sum of digits of a positive integer \(M\) in base 10. Let \(N\) be the smallest positive integer such that \(S(N) = 2013\). What is \(S(5N + 2013)\)?",
"solution": "1. **Find smallest \(N\) with \(S(N) = 2013\):** To minimize \(N\), use mostly 9s. Since \(2013 \div 9 = 223\), \(N\) could be 223 nines (sum \(9 \times 223 = 2007\)), then adjust the first digit to 7, making \(N = 7 \times 10^{223} - 1\). Sum: \(7 + 222 \times 9 = 2013\). 2. **Compute \(5N + 2013\):** \(5N = 5 \times (7 \times 10^{223} - 1) = 35 \times 10^{223} - 5\), so \(5N + 2013 = 35 \times 10^{223} + 2008\). 3. **Calculate \(S(5N + 2013\):** This is 35 followed by 219 zeros, then 2008 (last 4 digits). Sum: \(3 + 5 + 2 + 0 + 0 + 8 = 18\). Final answer: \( \boxed{18} \).",
"answer": "18",
"level": "Hard"
}
```
### Data Fields
- **`problem`**: Mathematical question (string).
- **`solution`**: Detailed solution steps (string); if no official solution exists, the answer is provided in LaTeX format.
- **`answer`**: Correct final answer (string).
- **`level`**: Difficulty level (string): "Hard" or "Easy".
## Citation
```bibtex
@misc{dang2025reinforcementlearningreasoningsmall,
title={Reinforcement Learning for Reasoning in Small LLMs: What Works and What Doesn't},
author={Quy-Anh Dang and Chris Ngo},
year={2025},
eprint={2503.16219},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2503.16219},
}
``` |
Papersnake/people_daily_news | Papersnake | 2025-03-23T15:52:41Z | 504 | 33 | [
"license:cc0-1.0",
"size_categories:1M<n<10M",
"format:json",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"region:us"
] | [] | 2023-04-19T15:09:28Z | 2 | ---
license: cc0-1.0
---
# 人民日报(1946-2024)数据集
The dataset is part of CialloCorpus, available at https://github.com/prnake/CialloCorpus
|
shenyunhang/VoiceAssistant-400K | shenyunhang | 2025-03-23T08:36:31Z | 54,017 | 0 | [
"license:apache-2.0",
"region:us"
] | [] | 2025-03-19T02:01:25Z | null | ---
license: apache-2.0
---
---
Data source:
https://huggingface.co/datasets/gpt-omni/VoiceAssistant-400K
1. Question and answer audios are extracted, which results in `940,108` audio files.
2. Raw conversations are formed as multi-round chat format in `data.jsonl`, which has in total of `251,223` samples.
```
[
...
{
"messages": [
{
"role": "user",
"content": "...<|audio|>"
},
{
"role": "assistant",
"content": "...<|audio|>"
}
{
"role": "user",
"content": "...<|audio|>"
},
{
"role": "assistant",
"content": "...<|audio|>"
},
...
],
"audios": ["path/to/first/audio", "path/to/second/audio", "path/to/third/audio", "path/to/forth/audio", ...],
},
...
]
```
---
|
nedjmaou/MLMA_hate_speech | nedjmaou | 2025-03-22T19:19:44Z | 229 | 5 | [
"language:ar",
"language:fr",
"language:en",
"license:mit",
"size_categories:10K<n<100K",
"format:csv",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"arxiv:1908.11049",
"region:us"
] | [] | 2022-12-27T17:04:33Z | 1 | ---
license: mit
language:
- ar
- fr
- en
---
# Disclaimer
*This is a hate speech dataset (in Arabic, French, and English).*
*Offensive content that does not reflect the opinions of the authors.*
# Dataset of our EMNLP 2019 Paper (Multilingual and Multi-Aspect Hate Speech Analysis)
For more details about our dataset, please check our paper:
@inproceedings{ousidhoum-etal-multilingual-hate-speech-2019,
title = "Multilingual and Multi-Aspect Hate Speech Analysis",
author = "Ousidhoum, Nedjma
and Lin, Zizheng
and Zhang, Hongming
and Song, Yangqiu
and Yeung, Dit-Yan",
booktitle = "Proceedings of EMNLP",
year = "2019",
publisher = "Association for Computational Linguistics",
}
(You can preview our paper on https://arxiv.org/pdf/1908.11049.pdf)
## Clarification
The multi-labelled tasks are *the hostility type of the tweet* and the *annotator's sentiment*. (We kept labels on which at least two annotators agreed.)
## Taxonomy
In further experiments that involved binary classification tasks of the hostility/hate/abuse type, we considered single-labelled *normal* instances to be *non-hate/non-toxic* and all the other instances to be *toxic*.
## Dataset
Our dataset is composed of three csv files sorted by language. They contain the tweets and the annotations described in our paper:
the hostility type *(column: tweet sentiment)*
hostility directness *(column: directness)*
target attribute *(column: target)*
target group *(column: group)*
annotator's sentiment *(column: annotator sentiment)*.
## Experiments
To replicate our experiments, please see https://github.com/HKUST-KnowComp/MLMA_hate_speech/blob/master/README.md |
ChuGyouk/medical-reasoning-train-kormedmcqa | ChuGyouk | 2025-03-21T06:06:33Z | 147 | 7 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-02-17T16:00:27Z | 2 | ---
dataset_info:
features:
- name: subject
dtype: string
- name: year
dtype: int64
- name: period
dtype: int64
- name: q_number
dtype: int64
- name: question
dtype: string
- name: A
dtype: string
- name: B
dtype: string
- name: C
dtype: string
- name: D
dtype: string
- name: E
dtype: string
- name: answer
dtype: int64
- name: thinking
dtype: string
- name: response
dtype: string
- name: __index_level_0__
dtype: int64
splits:
- name: train
num_bytes: 76942094.0
num_examples: 8751
download_size: 38580816
dataset_size: 76942094.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
# Information
This data includes the training data from KorMedMCQA, as well as a portion of the trainind data from the **additional KorMedMCQA support set (private)**.
This dataset is based on the responses generated by *gemini-flash-thinking-exp-01-21* model and has undergone **MANUAL rejection sampling**. |
cadene/droid_1.0.1 | cadene | 2025-03-20T13:14:51Z | 74,992 | 5 | [
"task_categories:robotics",
"license:apache-2.0",
"region:us",
"LeRobot"
] | [
"robotics"
] | 2025-03-17T13:55:45Z | null | ---
license: apache-2.0
task_categories:
- robotics
tags:
- LeRobot
configs:
- config_name: default
data_files: data/*/*.parquet
---
This dataset was created using [LeRobot](https://github.com/huggingface/lerobot).
## Dataset Description
- **Homepage:** [More Information Needed]
- **Paper:** [More Information Needed]
- **License:** apache-2.0
## Dataset Structure
[meta/info.json](meta/info.json):
```json
{
"codebase_version": "v2.1",
"robot_type": "Franka",
"total_episodes": 95600,
"total_frames": 27612581,
"total_tasks": 0,
"total_videos": 286800,
"total_chunks": 95,
"chunks_size": 1000,
"fps": 15,
"splits": {
"train": "0:95600"
},
"data_path": "data/chunk-{episode_chunk:03d}/episode_{episode_index:06d}.parquet",
"video_path": "videos/chunk-{episode_chunk:03d}/{video_key}/episode_{episode_index:06d}.mp4",
"features": {
"is_first": {
"dtype": "bool",
"shape": [
1
],
"names": null
},
"is_last": {
"dtype": "bool",
"shape": [
1
],
"names": null
},
"is_terminal": {
"dtype": "bool",
"shape": [
1
],
"names": null
},
"language_instruction": {
"dtype": "string",
"shape": [
1
],
"names": null
},
"language_instruction_2": {
"dtype": "string",
"shape": [
1
],
"names": null
},
"language_instruction_3": {
"dtype": "string",
"shape": [
1
],
"names": null
},
"observation.state.gripper_position": {
"dtype": "float32",
"shape": [
1
],
"names": {
"axes": [
"gripper"
]
}
},
"observation.state.cartesian_position": {
"dtype": "float32",
"shape": [
6
],
"names": {
"axes": [
"x",
"y",
"z",
"roll",
"pitch",
"yaw"
]
}
},
"observation.state.joint_position": {
"dtype": "float32",
"shape": [
7
],
"names": {
"axes": [
"x",
"y",
"z",
"roll",
"pitch",
"yaw"
]
}
},
"observation.state": {
"dtype": "float32",
"shape": [
8
],
"names": {
"axes": [
"joint_0",
"joint_1",
"joint_2",
"joint_3",
"joint_4",
"joint_5",
"joint_6",
"gripper"
]
}
},
"observation.images.wrist_left": {
"dtype": "video",
"shape": [
180,
320,
3
],
"names": [
"height",
"width",
"channels"
],
"info": {
"video.fps": 15.0,
"video.height": 180,
"video.width": 320,
"video.channels": 3,
"video.codec": "av1",
"video.pix_fmt": "yuv420p",
"video.is_depth_map": false,
"has_audio": false
}
},
"observation.images.exterior_1_left": {
"dtype": "video",
"shape": [
180,
320,
3
],
"names": [
"height",
"width",
"channels"
],
"info": {
"video.fps": 15.0,
"video.height": 180,
"video.width": 320,
"video.channels": 3,
"video.codec": "av1",
"video.pix_fmt": "yuv420p",
"video.is_depth_map": false,
"has_audio": false
}
},
"observation.images.exterior_2_left": {
"dtype": "video",
"shape": [
180,
320,
3
],
"names": [
"height",
"width",
"channels"
],
"info": {
"video.fps": 15.0,
"video.height": 180,
"video.width": 320,
"video.channels": 3,
"video.codec": "av1",
"video.pix_fmt": "yuv420p",
"video.is_depth_map": false,
"has_audio": false
}
},
"action.gripper_position": {
"dtype": "float32",
"shape": [
1
],
"names": {
"axes": [
"gripper"
]
}
},
"action.gripper_velocity": {
"dtype": "float32",
"shape": [
1
],
"names": {
"axes": [
"gripper"
]
}
},
"action.cartesian_position": {
"dtype": "float32",
"shape": [
6
],
"names": {
"axes": [
"x",
"y",
"z",
"roll",
"pitch",
"yaw"
]
}
},
"action.cartesian_velocity": {
"dtype": "float32",
"shape": [
6
],
"names": {
"axes": [
"x",
"y",
"z",
"roll",
"pitch",
"yaw"
]
}
},
"action.joint_position": {
"dtype": "float32",
"shape": [
7
],
"names": {
"axes": [
"joint_0",
"joint_1",
"joint_2",
"joint_3",
"joint_4",
"joint_5",
"joint_6"
]
}
},
"action.joint_velocity": {
"dtype": "float32",
"shape": [
7
],
"names": {
"axes": [
"joint_0",
"joint_1",
"joint_2",
"joint_3",
"joint_4",
"joint_5",
"joint_6"
]
}
},
"action.original": {
"dtype": "float32",
"shape": [
7
],
"names": {
"axes": [
"x",
"y",
"z",
"roll",
"pitch",
"yaw",
"gripper"
]
}
},
"action": {
"dtype": "float32",
"shape": [
8
],
"names": {
"axes": [
"joint_0",
"joint_1",
"joint_2",
"joint_3",
"joint_4",
"joint_5",
"joint_6",
"gripper"
]
}
},
"discount": {
"dtype": "float32",
"shape": [
1
],
"names": null
},
"reward": {
"dtype": "float32",
"shape": [
1
],
"names": null
},
"task_category": {
"dtype": "string",
"shape": [
1
],
"names": null
},
"building": {
"dtype": "string",
"shape": [
1
],
"names": null
},
"collector_id": {
"dtype": "string",
"shape": [
1
],
"names": null
},
"date": {
"dtype": "string",
"shape": [
1
],
"names": null
},
"camera_extrinsics.wrist_left": {
"dtype": "float32",
"shape": [
6
],
"names": {
"axes": [
"x",
"y",
"z",
"roll",
"pitch",
"yaw"
]
}
},
"camera_extrinsics.exterior_1_left": {
"dtype": "float32",
"shape": [
6
],
"names": {
"axes": [
"x",
"y",
"z",
"roll",
"pitch",
"yaw"
]
}
},
"camera_extrinsics.exterior_2_left": {
"dtype": "float32",
"shape": [
6
],
"names": {
"axes": [
"x",
"y",
"z",
"roll",
"pitch",
"yaw"
]
}
},
"is_episode_successful": {
"dtype": "bool",
"shape": [
1
],
"names": null
},
"timestamp": {
"dtype": "float32",
"shape": [
1
],
"names": null
},
"frame_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"episode_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"task_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
}
}
}
```
## Citation
**BibTeX:**
```bibtex
[More Information Needed]
``` |
open-llm-leaderboard/contents | open-llm-leaderboard | 2025-03-20T12:17:27Z | 12,398 | 15 | [
"size_categories:1K<n<10K",
"format:parquet",
"modality:tabular",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2024-06-26T08:33:17Z | null | ---
dataset_info:
features:
- name: eval_name
dtype: string
- name: Precision
dtype: string
- name: Type
dtype: string
- name: T
dtype: string
- name: Weight type
dtype: string
- name: Architecture
dtype: string
- name: Model
dtype: string
- name: fullname
dtype: string
- name: Model sha
dtype: string
- name: Average ⬆️
dtype: float64
- name: Hub License
dtype: string
- name: Hub ❤️
dtype: int64
- name: '#Params (B)'
dtype: float64
- name: Available on the hub
dtype: bool
- name: MoE
dtype: bool
- name: Flagged
dtype: bool
- name: Chat Template
dtype: bool
- name: CO₂ cost (kg)
dtype: float64
- name: IFEval Raw
dtype: float64
- name: IFEval
dtype: float64
- name: BBH Raw
dtype: float64
- name: BBH
dtype: float64
- name: MATH Lvl 5 Raw
dtype: float64
- name: MATH Lvl 5
dtype: float64
- name: GPQA Raw
dtype: float64
- name: GPQA
dtype: float64
- name: MUSR Raw
dtype: float64
- name: MUSR
dtype: float64
- name: MMLU-PRO Raw
dtype: float64
- name: MMLU-PRO
dtype: float64
- name: Merged
dtype: bool
- name: Official Providers
dtype: bool
- name: Upload To Hub Date
dtype: string
- name: Submission Date
dtype: string
- name: Generation
dtype: int64
- name: Base Model
dtype: string
splits:
- name: train
num_bytes: 4004719
num_examples: 4576
download_size: 1109997
dataset_size: 4004719
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
|
argilla/distilabel-intel-orca-dpo-pairs | argilla | 2025-03-19T18:49:41Z | 1,725 | 173 | [
"task_categories:text-generation",
"task_categories:text2text-generation",
"language:en",
"license:apache-2.0",
"size_categories:10K<n<100K",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"library:distilabel",
"region:us",
"rlaif",
"dpo",
"rlhf",
"distilabel",
"synthetic"
] | [
"text-generation",
"text2text-generation"
] | 2024-01-07T19:41:53Z | null | ---
language:
- en
license: apache-2.0
dataset_info:
features:
- name: system
dtype: string
- name: input
dtype: string
- name: chosen
dtype: string
- name: rejected
dtype: string
- name: generations
sequence: string
- name: order
sequence: string
- name: labelling_model
dtype: string
- name: labelling_prompt
list:
- name: content
dtype: string
- name: role
dtype: string
- name: raw_labelling_response
dtype: string
- name: rating
sequence: float64
- name: rationale
dtype: string
- name: status
dtype: string
- name: original_chosen
dtype: string
- name: original_rejected
dtype: string
- name: chosen_score
dtype: float64
- name: in_gsm8k_train
dtype: bool
splits:
- name: train
num_bytes: 161845559
num_examples: 12859
download_size: 79210071
dataset_size: 161845559
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
tags:
- rlaif
- dpo
- rlhf
- distilabel
- synthetic
task_categories:
- text-generation
- text2text-generation
size_categories:
- 10K<n<100K
---
<p align="right">
<a href="https://github.com/argilla-io/distilabel">
<img src="https://raw.githubusercontent.com/argilla-io/distilabel/main/docs/assets/distilabel-badge-light.png" alt="Built with Distilabel" width="200" height="32"/>
</a>
</p>
# distilabel Orca Pairs for DPO
The dataset is a "distilabeled" version of the widely used dataset: [Intel/orca_dpo_pairs](https://huggingface.co/datasets/Intel/orca_dpo_pairs). The original dataset has been used by 100s of open-source practitioners and models. We knew from fixing UltraFeedback (and before that, Alpacas and Dollys) that this dataset could be highly improved.
Continuing with our mission to build the best alignment datasets for open-source LLMs and the community, we spent a few hours improving it with [distilabel](https://github.com/argilla-io/distilabel).
This was our main intuition: the original dataset just assumes gpt4/3.5-turbo are always the best response. We know from UltraFeedback that's not always the case. Moreover, DPO fine-tuning benefits from the diversity of preference pairs.
Additionally, we have added a new column indicating whether the question in the dataset is part of the train set of gsm8k (there were no examples from the test set). See the reproduction section for more details.
## Using this dataset
This dataset is useful for preference tuning and we recommend using it instead of the original. It's already prepared in the "standard" chosen, rejected format with additional information for further filtering and experimentation.
The main changes are:
1. ~2K pairs have been swapped: rejected become the chosen response. We have kept the original chosen and rejected on two new columns `original_*` for reproducibility purposes.
2. 4K pairs have been identified as `tie`: equally bad or good.
3. Chosen scores have been added: you can now filter out based on a threshold (see our distilabeled Hermes 2.5 model for an example)
4. We have kept the ratings and rationales generated with gpt-4-turbo and distilabel so you can prepare the data differently if you want.
5. We have added a column to indicate if the input is part of gsm8k train set.
In our experiments, we have got very good results by reducing the size of the dataset by more than 50%. Here's an example of how to achieve that:
```python
from datasets import load_dataset
# Instead of this:
# dataset = load_dataset("Intel/orca_dpo_pairs", split="train")
# use this:
dataset = load_dataset("argilla/distilabel-intel-orca-dpo-pairs", split="train")
dataset = dataset.filter(
lambda r:
r["status"] != "tie" and
r["chosen_score"] >= 8 and
not r["in_gsm8k_train"]
)
```
This results in `5,922` instead of `12,859` samples (54% reduction) and leads to better performance than the same model tuned with 100% of the samples in the original dataset.
> We'd love to hear about your experiments! If you want to try this out, consider joining our [Slack community](https://join.slack.com/t/rubrixworkspace/shared_invite/zt-whigkyjn-a3IUJLD7gDbTZ0rKlvcJ5g) and let's build some open datasets and models together.
## Reproducing the dataset
In this section, we outline the steps to reproduce this dataset.
### Rate original dataset pairs
Build a preference dataset with distilabel using the original dataset:
```python
from distilabel.llm import OpenAILLM
from distilabel.tasks import JudgeLMTask
from distilabel.pipeline import Pipeline
from datasets import load_dataset
# Shuffle 'chosen' and 'rejected' to avoid positional bias and keep track of the order
def shuffle_and_track(chosen, rejected):
pair = [chosen, rejected]
random.shuffle(pair)
order = ["chosen" if x == chosen else "rejected" for x in pair]
return {"generations": pair, "order": order}
dataset = load_dataset("Intel/orca_dpo_pairs", split="train")
# This shuffles the pairs to mitigate positional bias
dataset = dataset.map(lambda x: shuffle_and_track(x["chosen"], x["rejected"]))
# We use our JudgeLM implementation to rate the original pairs
labeler = OpenAILLM(
task=JudgeLMTask(),
model="gpt-4-1106-preview",
num_threads=16,
max_new_tokens=512,
)
dataset = dataset.rename_columns({"question": "input"})
distipipe = Pipeline(
labeller=labeler
)
# This computes ratings and natural language critiques for each pair
ds = distipipe.generate(dataset=dataset, num_generations=2)
```
If you want to further filter and curate the dataset, you can push the dataset to [Argilla](https://github.com/argilla-io/argilla) as follows:
```python
rg_dataset = ds.to_argilla()
rg_dataset.push_to_argilla(name="your_dataset_name", workspace="your_workspace_name")
```
You get a nice UI with a lot of pre-computed metadata to explore and curate the dataset:

The resulting dataset is now much more useful: we know which response is preferred (by gpt-4-turbo), which ones have low scores, and we even have natural language explanations. But what did we find? Was our intuition confirmed?

The above chart shows the following:
* ~4,000 pairs were given the same rating (a tie).
* ~7,000 pairs were correct according to our AI judge (`unchanged`).
* and ~2,000 times the rejected response was preferred (`swapped`).
Now the next question is: can we build better models with this new knowledge? The answer is the "distilabeled Hermes" model, check it out!
### Post-processing to add useful information
Swap rejected and chosen, and add chosen scores and status:
```python
def add_status(r):
status = "unchanged"
highest_rated_idx = np.argmax(r['rating'])
# Compare to the index of the chosen response
if r['rating']== None or r['rating'][0] == r['rating'][1]:
status = "tie"
elif r['order'][highest_rated_idx] != 'chosen':
status = "swapped"
return {"status": status}
def swap(r):
chosen = r["chosen"]
rejected = r["rejected"]
if r['rating'] is not None:
chosen_score = r['rating'][np.argmax(r['rating'])]
else:
chosen_score = None
if r['status'] == "swapped":
chosen = r["rejected"]
rejected = r["chosen"]
return {
"chosen": chosen,
"rejected": rejected,
"original_chosen": r["chosen"],
"original_rejected": r["rejected"],
"chosen_score": chosen_score
}
updated = ds.map(add_status).map(swap)
```
### gsm8k "decontamination"
The basic approach for finding duplicated examples. We didn't find any from the test sets. We experimented with lower thresholds but below 0.8 they introduced false positives:
```python
import pandas as pd
import nltk
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
from datasets import load_dataset
nltk.download('punkt')
# Load the datasets
source_dataset = load_dataset("gsm8k", "main", split="train")
source_dataset_socratic = load_dataset("gsm8k", "socratic", split="train")
#target_dataset = load_dataset("Intel/orca_dpo_pairs", split="train")
target_dataset = load_dataset("argilla/distilabel-intel-orca-dpo-pairs", split="train")
# Extract the 'question' column from each dataset
source_questions = source_dataset['question']
source_questions_socratic = source_dataset_socratic['question']
target_questions = target_dataset['input']
# Function to preprocess the text
def preprocess(text):
return nltk.word_tokenize(text.lower())
# Preprocess the questions
source_questions_processed = [preprocess(q) for q in source_questions]
source_questions.extend([preprocess(q) for q in source_questions_socratic])
target_questions_processed = [preprocess(q) for q in target_questions]
# Vectorize the questions
vectorizer = TfidfVectorizer()
source_vec = vectorizer.fit_transform([' '.join(q) for q in source_questions_processed])
target_vec = vectorizer.transform([' '.join(q) for q in target_questions_processed])
# Calculate cosine similarity
similarity_matrix = cosine_similarity(source_vec, target_vec)
# Determine matches based on a threshold:
# checked manually and below 0.8 there are only false positives
threshold = 0.8
matching_pairs = []
for i, row in enumerate(similarity_matrix):
for j, similarity in enumerate(row):
if similarity >= threshold:
matching_pairs.append((source_questions[i], target_questions[j], similarity))
# Create a DataFrame from the matching pairs
df = pd.DataFrame(matching_pairs, columns=['Source Question', 'Target Question', 'Similarity Score'])
# Create a set of matching target questions
matching_target_questions = list(df['Target Question'])
# Add a column to the target dataset indicating whether each question is matched
target_dataset = target_dataset.map(lambda example: {"in_gsm8k_train": example['input'] in matching_target_questions})
```
Result:
```
False 12780
True 79
Name: in_gsm8k_train
``` |
therem/CLEAR | therem | 2025-03-19T14:44:44Z | 16,348 | 8 | [
"task_categories:visual-question-answering",
"language:en",
"size_categories:10K<n<100K",
"format:parquet",
"modality:image",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"arxiv:2410.18057",
"region:us",
"unlearning",
"multimodal"
] | [
"visual-question-answering"
] | 2024-09-10T22:00:03Z | null | ---
dataset_info:
- config_name: default
features:
- name: image
dtype: image
- name: caption
dtype: string
- name: name
dtype: string
splits:
- name: train
num_bytes: 631160218.72
num_examples: 3768
download_size: 629403972
dataset_size: 631160218.72
- config_name: forget01
features:
- name: image
dtype: image
- name: caption
dtype: string
- name: name
dtype: string
splits:
- name: train
num_bytes: 5805117
num_examples: 35
download_size: 5805088
dataset_size: 5805117
- config_name: forget01+tofu
features:
- name: image
dtype: image
- name: caption
dtype: string
- name: question
dtype: string
- name: answer
dtype: string
splits:
- name: train
num_bytes: 5815713
num_examples: 75
download_size: 5812895
dataset_size: 5815713
- config_name: forget01_perturbed
features:
- name: image
dtype: image
- name: caption
dtype: string
- name: name
dtype: string
- name: perturbed_captions
sequence: string
- name: paraphrased_caption
dtype: string
- name: perturbed_names
sequence: string
splits:
- name: train
num_bytes: 5838223
num_examples: 35
download_size: 5822919
dataset_size: 5838223
- config_name: forget05
features:
- name: image
dtype: image
- name: caption
dtype: string
- name: name
dtype: string
splits:
- name: train
num_bytes: 31371485
num_examples: 188
download_size: 31361326
dataset_size: 31371485
- config_name: forget05+tofu
features:
- name: image
dtype: image
- name: caption
dtype: string
- name: question
dtype: string
- name: answer
dtype: string
splits:
- name: train
num_bytes: 31423187
num_examples: 388
download_size: 31396730
dataset_size: 31423187
- config_name: forget05_perturbed
features:
- name: image
dtype: image
- name: caption
dtype: string
- name: name
dtype: string
- name: paraphrased_caption
dtype: string
- name: perturbed_names
sequence: string
- name: perturbed_captions
sequence: string
splits:
- name: train
num_bytes: 31542125
num_examples: 188
download_size: 31435702
dataset_size: 31542125
- config_name: forget10
features:
- name: image
dtype: image
- name: caption
dtype: string
- name: name
dtype: string
splits:
- name: train
num_bytes: 62030098
num_examples: 379
download_size: 62009666
dataset_size: 62030098
- config_name: forget10+tofu
features:
- name: image
dtype: image
- name: caption
dtype: string
- name: question
dtype: string
- name: answer
dtype: string
splits:
- name: train
num_bytes: 62135828
num_examples: 779
download_size: 62080770
dataset_size: 62135828
- config_name: forget10_perturbed
features:
- name: image
dtype: image
- name: caption
dtype: string
- name: perturbed_captions
sequence: string
- name: paraphrased_caption
dtype: string
- name: name
dtype: string
- name: perturbed_names
sequence: string
splits:
- name: train
num_bytes: 62215028
num_examples: 378
download_size: 61999448
dataset_size: 62215028
- config_name: full
features:
- name: image
dtype: image
- name: caption
dtype: string
- name: name
dtype: string
splits:
- name: train
num_bytes: 649541653.152
num_examples: 3768
download_size: 629403972
dataset_size: 649541653.152
- config_name: full+tofu
features:
- name: image
dtype: image
- name: caption
dtype: string
- name: question
dtype: string
- name: answer
dtype: string
splits:
- name: train
num_bytes: 1339105341.152
num_examples: 7768
download_size: 630057017
dataset_size: 1339105341.152
- config_name: real_faces
features:
- name: image
dtype: image
- name: answer
dtype: string
- name: options
sequence: string
splits:
- name: train
num_bytes: 1604027.110206775
num_examples: 151
download_size: 1608640
dataset_size: 1604027.110206775
- config_name: real_world
features:
- name: question
dtype: string
- name: answer
dtype: string
- name: image
dtype: image
- name: options
sequence: string
splits:
- name: train
num_bytes: 325409958.4627451
num_examples: 367
download_size: 1106221595
dataset_size: 703133781.6156862
- config_name: retain90
features:
- name: image
dtype: image
- name: caption
dtype: string
- name: name
dtype: string
splits:
- name: train
num_bytes: 584953280.524
num_examples: 3391
download_size: 567799916
dataset_size: 584953280.524
- config_name: retain90+tofu
features:
- name: image
dtype: image
- name: caption
dtype: string
- name: question
dtype: string
- name: answer
dtype: string
splits:
- name: train
num_bytes: 1205977240.924
num_examples: 6991
download_size: 568388560
dataset_size: 1205977240.924
- config_name: retain95
features:
- name: image
dtype: image
- name: caption
dtype: string
- name: name
dtype: string
splits:
- name: train
num_bytes: 617900591.248
num_examples: 3582
download_size: 598446669
dataset_size: 617900591.248
- config_name: retain95+tofu
features:
- name: image
dtype: image
- name: caption
dtype: string
- name: question
dtype: string
- name: answer
dtype: string
splits:
- name: train
num_bytes: 1273431317.448
num_examples: 7382
download_size: 599062819
dataset_size: 1273431317.448
- config_name: retain99
features:
- name: image
dtype: image
- name: caption
dtype: string
- name: name
dtype: string
splits:
- name: train
num_bytes: 644292815.54
num_examples: 3735
download_size: 624002187
dataset_size: 644292815.54
- config_name: retain99+tofu
features:
- name: image
dtype: image
- name: caption
dtype: string
- name: question
dtype: string
- name: answer
dtype: string
splits:
- name: train
num_bytes: 1327426837.98
num_examples: 7695
download_size: 624654914
dataset_size: 1327426837.98
- config_name: retain_perturbed
features:
- name: image
dtype: image
- name: caption
dtype: string
- name: paraphrased_caption
dtype: string
- name: perturbed_captions
sequence: string
- name: name
dtype: string
- name: perturbed_names
sequence: string
splits:
- name: train
num_bytes: 67955189
num_examples: 395
download_size: 67754875
dataset_size: 67955189
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- config_name: forget01
data_files:
- split: train
path: forget01/train-*
- config_name: forget01+tofu
data_files:
- split: train
path: forget01+tofu/train-*
- config_name: forget01_perturbed
data_files:
- split: train
path: forget01_perturbed/train-*
- config_name: forget05
data_files:
- split: train
path: forget05/train-*
- config_name: forget05+tofu
data_files:
- split: train
path: forget05+tofu/train-*
- config_name: forget05_perturbed
data_files:
- split: train
path: forget05_perturbed/train-*
- config_name: forget10
data_files:
- split: train
path: forget10/train-*
- config_name: forget10+tofu
data_files:
- split: train
path: forget10+tofu/train-*
- config_name: forget10_perturbed
data_files:
- split: train
path: forget10_perturbed/train-*
- config_name: full
data_files:
- split: train
path: full/train-*
- config_name: full+tofu
data_files:
- split: train
path: full+tofu/train-*
- config_name: real_faces
data_files:
- split: train
path: real_faces/train-*
- config_name: real_world
data_files:
- split: train
path: real_world/train-*
- config_name: retain90
data_files:
- split: train
path: retain90/train-*
- config_name: retain90+tofu
data_files:
- split: train
path: retain90+tofu/train-*
- config_name: retain95
data_files:
- split: train
path: retain95/train-*
- config_name: retain95+tofu
data_files:
- split: train
path: retain95+tofu/train-*
- config_name: retain99
data_files:
- split: train
path: retain99/train-*
- config_name: retain99+tofu
data_files:
- split: train
path: retain99+tofu/train-*
- config_name: retain_perturbed
data_files:
- split: train
path: retain_perturbed/train-*
task_categories:
- visual-question-answering
language:
- en
size_categories:
- 1K<n<10K
tags:
- unlearning
- multimodal
---
# CLEAR: Character Unlearning in Textual and Visual Modalities
## Abstract
Machine Unlearning (MU) is critical for removing private or hazardous information from deep learning models. While MU has advanced significantly in unimodal (text or vision) settings, multimodal unlearning (MMU) remains underexplored due to the lack of open benchmarks for evaluating cross-modal data removal. To address this gap, we introduce CLEAR, the first open-source benchmark designed specifically for MMU. CLEAR contains 200 fictitious individuals and 3,700 images linked with corresponding question-answer pairs, enabling a thorough evaluation across modalities. We conduct a comprehensive analysis of 11 MU methods (e.g., SCRUB, gradient ascent, DPO) across four evaluation sets, demonstrating that jointly unlearning both modalities outperforms single-modality approaches.
## Key Links:
- [**HF Dataset**](https://huggingface.co/datasets/therem/CLEAR)
- [**Arxiv**](https://arxiv.org/abs/2410.18057)
- [**Github**](https://github.com/somvy/multimodal_unlearning)
## Loading the Dataset:
To load the dataset:
```python
from datasets import load_dataset
dataset = load_dataset("therem/CLEAR", "full")
```
To ensure the compatibility with the TOFU, we share the splits structure - person-wise. Totally, we have 200 persons. The 1% split contains 2 individuals in forget, and 198 in retain.
Similarly, 5% split contains 10 persons, and the 10% -- 20 persons.
The dataset contains the following types of items:
- **QA**: textual-only QA items from TOFU
- **IC**: our generated Image Caption questions.
## Available sets:
- `full`: IC(full)
- `full+tofu`: QA(full) + IC(full)
- **Forgetting 1%:**
- `forget01+tofu`: QA(forget01) + IC(forget01)
- `forget01`: IC(forget01)
- `retain99+tofu`: QA(retain99) + IC(retain99)
- `retain99`: IC(retain99)
- `forget01_perturbed`: paraprased and perturbed versions of `forget01` used for unlearning quality evaluation
- **Forgetting 5% and 10%** — splits structure is fully analogous.
- **Evaluation:**
- `real_faces`: images of celebrities with answers and wrong choices
- `real_worls`: images of real world with questions and multi-choice answers
- `retain_perturbed`: a subset of 20 persons from retain90, used for eval
## Citing Our Work
If you find our dataset useful, please cite:
```
@misc{dontsov2025clearcharacterunlearningtextual,
title={CLEAR: Character Unlearning in Textual and Visual Modalities},
author={Alexey Dontsov and Dmitrii Korzh and Alexey Zhavoronkin and Boris Mikheev and Denis Bobkov and Aibek Alanov and Oleg Y. Rogov and Ivan Oseledets and Elena Tutubalina},
year={2025},
eprint={2410.18057},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2410.18057},
}
```
|
nvidia/PhysicalAI-Robotics-Manipulation-Kitchen | nvidia | 2025-03-18T17:29:55Z | 14,660 | 8 | [
"task_categories:robotics",
"license:cc-by-4.0",
"size_categories:100K<n<1M",
"format:parquet",
"modality:tabular",
"modality:timeseries",
"modality:video",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | [
"robotics"
] | 2025-03-12T17:38:09Z | null | ---
license: cc-by-4.0
task_categories:
- robotics
---
# PhysicalAI Robotics Manipulation in the Kitchen
## Dataset Description:
PhysicalAI-Robotics-Manipulation-Kitchen is a dataset of automatic generated motions of robots performing operations such as opening and closing cabinets, drawers, dishwashers and fridges. The dataset was generated in IsaacSim leveraging reasoning algorithms and optimization-based motion planning to find solutions to the tasks automatically [1, 3]. The dataset includes a bimanual manipulator built with Kinova Gen3 arms. The environments are kitchen scenes where the furniture and appliances were procedurally generated [2].
This dataset is available for commercial use.
## Dataset Contact(s)
Fabio Ramos ([email protected]) <br>
Anqi Li ([email protected])
## Dataset Creation Date
03/18/2025
## License/Terms of Use
cc-by-4.0
## Intended Usage
This dataset is provided in LeRobot format and is intended for training robot policies and foundation models.
## Dataset Characterization
* Data Collection Method<br>
* Automated <br>
* Automatic/Sensors <br>
* Synthetic <br>
* Labeling Method<br>
* Synthetic <br>
## Dataset Format
Within the collection, there are eight datasets in LeRobot format `open_cabinet`, `close_cabinet`, `open_dishwasher`, `close_dishwasher`, `open_fridge`, close_fridge`, `open_drawer` and `close_drawer`.
* `open cabinet`: The robot opens a cabinet in the kitchen. <br>
* `close cabinet`: The robot closes the door of a cabinet in the kitchen. <br>
* `open dishwasher`: The robot opens the door of a dishwasher in the kitchen. <br>
* `close dishwasher`: The robot closes the door of a dishwasher in the kitchen. <br>
* `open fridge`: The robot opens the fridge door. <br>
* `close fridge`: The robot closes the fridge door. <br>
* `open drawer`: The robot opens a drawer in the kitchen. <br>
* `close drawer`: The robot closes a drawer in the kitchen. <br>
The videos below illustrate three examples of the tasks:
<div style="display: flex; justify-content: flex-start;">
<img src="./assets/episode_000009.gif" width="300" height="300" alt="open_dishwasher" />
<img src="./assets/episode_000008.gif" width="300" height="300" alt="open_cabinet" />
<img src="./assets/episode_000029.gif" width="300" height="300" alt="open_fridge" />
</div>
* action modality: 34D which includes joint states for the two arms, gripper joints, pan and tilt joints, torso joint, and front and back wheels.
* observation modalities
* observation.state: 13D where the first 12D are the vectorized transform matrix of the "object of interest". The 13th entry is the joint value for the articulated object of interest (i.e. drawer, cabinet, etc).
* observation.image.world__world_camera: 512x512 images of RGB, depth and semantic segmentation renderings stored as mp4 videos.
* observation.image.external_camera: 512x512 images of RGB, depth and semantic segmentation renderings stored as mp4 videos.
* observation.image.world__robot__right_arm_camera_color_frame__right_hand_camera: 512x512 images of RGB, depth and semantic segmentation renderings stored as mp4 videos.
* observation.image.world__robot__left_arm_camera_color_frame__left_hand_camera: 512x512 images of RGB, depth and semantic segmentation renderings stored as mp4 videos.
* observation.image.world__robot__camera_link__head_camera: 512x512 images of RGB, depth and semantic segmentation renderings stored as mp4 videos.
The videos below illustrate three of the cameras used in the dataset.
<div style="display: flex; justify-content: flex-start;">
<img src="./assets/episode_000004_world.gif" width="300" height="300" alt="world" />
<img src="./assets/episode_000004.gif" width="300" height="300" alt="head" />
<img src="./assets/episode_000004_wrist.gif" width="300" height="300" alt="wrist" />
</div>
## Dataset Quantification
Record Count:
* `open_cabinet`
* number of episodes: 78
* number of frames: 39292
* number of videos: 1170 (390 RGB videos, 390 depth videos, 390 semantic segmentation videos)
* `close_cabinet`
* number of episodes: 205
* number of frames: 99555
* number of videos: 3075 (1025 RGB videos, 1025 depth videos, 1025 semantic segmentation videos)
* `open_dishwasher`
* number of episodes: 72
* number of frames: 28123
* number of videos: 1080 (360 RGB videos, 360 depth videos, 360 semantic segmentation videos)
* `close_dishwasher`
* number of episodes: 74
* number of frames: 36078
* number of videos: 1110 (370 RGB videos, 370 depth videos, 370 semantic segmentation videos)
* `open_fridge`
* number of episodes: 193
* number of frames: 93854
* number of videos: 2895 (965 RGB videos, 965 depth videos, 965 semantic segmentation videos)
* `close_fridge`
* number of episodes: 76
* number of frames: 41894
* number of videos: 1140 (380 RGB videos, 380 depth videos, 380 semantic segmentation videos)
* `open_drawer`
* number of episodes: 99
* number of frames: 37214
* number of videos: 1485 (495 RGB videos, 495 depth videos, 495 semantic segmentation videos)
* `close_drawer`
* number of episodes: 77
* number of frames: 28998
* number of videos: 1155 (385 RGB videos, 385 depth videos, 385 semantic segmentation videos)
<!-- Total = 1.1GB + 2.7G + 795M + 1.1G + 2.6G + 1.2G + 1.1G + 826M -->
Total storage: 11.4 GB
## Reference(s)
```
[1] @inproceedings{garrett2020pddlstream,
title={Pddlstream: Integrating symbolic planners and blackbox samplers via optimistic adaptive planning},
author={Garrett, Caelan Reed and Lozano-P{\'e}rez, Tom{\'a}s and Kaelbling, Leslie Pack},
booktitle={Proceedings of the international conference on automated planning and scheduling},
volume={30},
pages={440--448},
year={2020}
}
[2] @article{Eppner2024,
title = {scene_synthesizer: A Python Library for Procedural Scene Generation in Robot Manipulation},
author = {Clemens Eppner and Adithyavairavan Murali and Caelan Garrett and Rowland O'Flaherty and Tucker Hermans and Wei Yang and Dieter Fox},
journal = {Journal of Open Source Software}
publisher = {The Open Journal},
year = {2024},
Note = {\url{https://scene-synthesizer.github.io/}}
}
[3] @inproceedings{curobo_icra23,
author={Sundaralingam, Balakumar and Hari, Siva Kumar Sastry and
Fishman, Adam and Garrett, Caelan and Van Wyk, Karl and Blukis, Valts and
Millane, Alexander and Oleynikova, Helen and Handa, Ankur and
Ramos, Fabio and Ratliff, Nathan and Fox, Dieter},
booktitle={2023 IEEE International Conference on Robotics and Automation (ICRA)},
title={CuRobo: Parallelized Collision-Free Robot Motion Generation},
year={2023},
volume={},
number={},
pages={8112-8119},
doi={10.1109/ICRA48891.2023.10160765}
}
```
## Ethical Considerations
NVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their internal model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse.
Please report security vulnerabilities or NVIDIA AI Concerns [here](https://www.nvidia.com/en-us/support/submit-security-vulnerability/). |
open-llm-leaderboard/requests | open-llm-leaderboard | 2025-03-17T12:04:59Z | 26,018 | 9 | [
"license:apache-2.0",
"region:us"
] | [] | 2024-06-07T14:45:36Z | null | ---
license: apache-2.0
configs:
- config_name: default
data_files: "**/*.json"
---
|
EricLu/SCP-116K | EricLu | 2025-03-17T11:00:15Z | 276 | 90 | [
"task_categories:text-generation",
"task_categories:question-answering",
"language:en",
"license:cc-by-nc-sa-4.0",
"size_categories:100K<n<1M",
"format:json",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"arxiv:2501.15587",
"region:us",
"chemistry",
"biology",
"medical",
"mathematics"
] | [
"text-generation",
"question-answering"
] | 2025-01-26T07:21:44Z | null | ---
license: cc-by-nc-sa-4.0
task_categories:
- text-generation
- question-answering
language:
- en
size_categories:
- 100K<n<1M
tags:
- chemistry
- biology
- medical
- mathematics
---
# Dataset Card for SCP-116K
## **Recent Updates**
We have made significant updates to the dataset, which are summarized below:
1. **Expansion with Mathematics Data**:
Added over 150,000 new math-related problem-solution pairs, bringing the total number of examples to **274,166**. Despite this substantial expansion, we have retained the original dataset name (`SCP-116K`) to maintain continuity and avoid disruption for users who have already integrated the dataset into their workflows.
2. **Updated Responses and Reasoning**:
Removed the previous responses generated by `o1-mini` and `QwQ-32B-preview`. Instead, we now include responses and reasoning processes generated by the **DeepSeek-r1** model. These are stored in two new fields:
- `r1_response`: The solution generated by DeepSeek-r1.
- `r1_reasoning_content`: The detailed reasoning process provided by DeepSeek-r1.
Note that these new responses do not include information on whether they match the ground truth solutions extracted from the source material.
3. **Renaming of Fields**:
The field `matched_solution` has been renamed to `extracted_solution` to better reflect its nature as a solution extracted directly from the source documents, avoiding potential ambiguity.
### **Upcoming Updates**
We are actively working on further improvements, including:
1. **Improved OCR Pipeline**:
We have identified that **Qwen2.5-VL-72B** demonstrates superior OCR capabilities compared to the previously used GPT-4o. We will soon update the dataset extraction pipeline to incorporate this model for enhanced OCR performance.
2. **Addressing Solution Extraction Deficiency**:
A known issue where the number of extracted solutions is significantly lower than the number of extracted problems has been traced back to limitations in GPT-4o's capabilities. This issue will be resolved in the next version of the dataset.
---
## Dataset Description
### Paper
[SCP-116K: A High-Quality Problem-Solution Dataset and a Generalized Pipeline for Automated Extraction in the Higher Education Science Domain](https://arxiv.org/abs/2501.15587)
### Dataset Summary
SCP-116K is a large-scale dataset containing **274,166 high-quality scientific problem-solution pairs**, automatically extracted from web-crawled documents. The dataset covers multiple scientific disciplines, including physics, chemistry, biology, and now mathematics, targeting undergraduate to doctoral-level content. Each problem is accompanied by its matched solution extracted from the source material, along with responses and reasoning processes generated by advanced language models.
GitHub: [https://github.com/AQA6666/SCP-116K-open/tree/main](https://github.com/AQA6666/SCP-116K-open/tree/main)
### Supported Tasks
The dataset supports several tasks:
- Scientific Question Answering
- Scientific Reasoning
- Model Evaluation
- Knowledge Distillation
### Languages
The dataset is in English.
### Dataset Structure
The dataset contains the following columns:
- `domain`: The scientific domain of the problem (e.g., physics, chemistry, biology, mathematics).
- `problem`: The original problem text.
- `extracted_solution`: The solution extracted from the source material (previously named `matched_solution`).
- `r1_response`: Solution generated by the DeepSeek-r1 model.
- `r1_reasoning_content`: Detailed reasoning process provided by the DeepSeek-r1 model.
### Data Fields
- `domain`: string
- `problem`: string
- `extracted_solution`: string
- `r1_response`: string
- `r1_reasoning_content`: string
### Data Splits
The dataset is provided as a single split containing all **274,166** examples.
---
## Dataset Creation
### Source Data
The dataset was created by processing over **6.69 million academic documents**, filtering for high-quality university-level content, and extracting problem-solution pairs using a sophisticated automated pipeline. The extraction process includes document retrieval, unified preprocessing, content segmentation, structured extraction, quality filtering, and problem-solution matching.
### Annotations
The dataset includes solutions and reasoning processes generated by the **DeepSeek-r1** model. Each generated solution is provided without explicit validation against the ground truth solution extracted from the source material.
---
## Considerations for Using the Data
### Social Impact of Dataset
This dataset aims to advance scientific reasoning capabilities in AI systems and provide high-quality training data for developing more capable models in STEM disciplines. It can help democratize access to advanced scientific problem-solving capabilities and support education in scientific fields.
### Discussion of Biases
While efforts have been made to ensure high quality and diversity in the dataset, users should be aware that:
- The dataset may reflect biases present in web-crawled documents.
- Coverage across different scientific domains may not be perfectly balanced.
- The difficulty level of problems varies across the dataset.
### Other Known Limitations
- Solutions may occasionally reference figures or equations not included in the text.
- Some problems may require specialized domain knowledge for full understanding.
- The dataset focuses primarily on theoretical problems rather than experimental ones.
---
## Additional Information
### Dataset Curators
The dataset was created as part of research work on improving scientific reasoning capabilities in language models.
### Licensing Information
This dataset is released under the **cc-by-nc-sa-4.0 License**.
### Citation Information
If you use this dataset in your research, please cite:
```bibtex
@misc{lu2025scp116khighqualityproblemsolutiondataset,
title={SCP-116K: A High-Quality Problem-Solution Dataset and a Generalized Pipeline for Automated Extraction in the Higher Education Science Domain},
author={Dakuan Lu and Xiaoyu Tan and Rui Xu and Tianchu Yao and Chao Qu and Wei Chu and Yinghui Xu and Yuan Qi},
year={2025},
eprint={2501.15587},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2501.15587},
}
``` |
priyank-m/trdg_random_en_zh_text_recognition | priyank-m | 2025-03-16T10:15:11Z | 5,171 | 2 | [
"task_categories:image-to-text",
"language:en",
"language:zh",
"license:mit",
"size_categories:100K<n<1M",
"format:parquet",
"modality:image",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | [
"image-to-text"
] | 2022-12-10T16:42:28Z | 1 | ---
dataset_info:
features:
- name: image
dtype: image
- name: label
dtype: string
splits:
- name: train
num_bytes: 12592040013
num_examples: 410000
download_size: 12595188446
dataset_size: 12592040013
license: mit
task_categories:
- image-to-text
language:
- en
- zh
pretty_name: TRDG Random English Chinese Text Recognition
size_categories:
- 100K<n<1M
---
# Dataset Card for "trdg_random_en_zh_text_recognition"
This synthetic dataset was generated using the TextRecognitionDataGenerator(TRDG) open source repo:
https://github.com/Belval/TextRecognitionDataGenerator
It contains images of text with random characters from Engilsh(en) and Chinese(zh) languages.
Reference to the documentation provided by the TRDG repo:
https://textrecognitiondatagenerator.readthedocs.io/en/latest/index.html |
allenai/tulu-3-sft-olmo-2-mixture-0225 | allenai | 2025-03-14T23:00:20Z | 399 | 8 | [
"size_categories:100K<n<1M",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-02-21T22:24:09Z | 2 | ---
dataset_info:
features:
- name: id
dtype: string
- name: messages
list:
- name: content
dtype: string
- name: role
dtype: string
- name: source
dtype: string
splits:
- name: train
num_bytes: 2575519262
num_examples: 866138
download_size: 1265029737
dataset_size: 2575519262
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
---
Used to train OLMo 2 32B. From the [blog post](https://allenai.org/blog/olmo2-32B):
> Filtered out instructions from the SFT dataset and the chosen responses of the preference data that included mentions of a date cutoff from the synthetic data generation process. This resulted in a new version of the instruction dataset, Tulu 3 SFT Mixture 0225, and preference dataset, OLMo-2-32B-pref-mix-0325.
> We use majority voting to improve the quality of answers to our synthetic math questions. For our Persona MATH and Grade School Math datasets from Tülu 3, we only include prompts and completions where the model reaches a majority vote over 5 completions. New versions of the math and grade school math datasets are available.
Created with `open-instruct` data tools:
```
python scripts/data/filtering_and_updates/update_subsets.py \
--base_ds allenai/tulu-3-sft-olmo-2-mixture-filter-datecutoff \
--remove_sources ai2-adapt-dev/personahub_math_v5_regen_149960 allenai/tulu-3-sft-personas-math-grade \
--add_ds allenai/tulu-3-sft-personas-math-filtered allenai/tulu-3-sft-personas-math-grade-filtered \
--remove_keys prompt dataset \
--push_to_hub \
--repo_id allenai/tulu-3-sft-olmo-2-mixture-0225
```
|
google/wmt24pp | google | 2025-03-13T21:53:34Z | 2,151 | 38 | [
"task_categories:translation",
"language:ar",
"language:bg",
"language:bn",
"language:ca",
"language:da",
"language:de",
"language:el",
"language:es",
"language:et",
"language:fa",
"language:fi",
"language:fr",
"language:gu",
"language:he",
"language:hi",
"language:hr",
"language:hu",
"language:id",
"language:is",
"language:it",
"language:ja",
"language:kn",
"language:ko",
"language:lt",
"language:lv",
"language:ml",
"language:mr",
"language:nl",
"language:no",
"language:pa",
"language:pl",
"language:pt",
"language:ro",
"language:ru",
"language:sk",
"language:sl",
"language:sr",
"language:sv",
"language:sw",
"language:ta",
"language:te",
"language:th",
"language:tr",
"language:uk",
"language:ur",
"language:vi",
"language:zh",
"language:zu",
"license:apache-2.0",
"size_categories:10K<n<100K",
"format:json",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"arxiv:2502.12404",
"region:us"
] | [
"translation"
] | 2025-02-06T15:19:53Z | 2 | ---
license: apache-2.0
language:
- ar
- bg
- bn
- ca
- da
- de
- el
- es
- et
- fa
- fi
- fr
- gu
- he
- hi
- hr
- hu
- id
- is
- it
- ja
- kn
- ko
- lt
- lv
- ml
- mr
- nl
- 'no'
- pa
- pl
- pt
- ro
- ru
- sk
- sl
- sr
- sv
- sw
- ta
- te
- th
- tr
- uk
- ur
- vi
- zh
- zu
task_categories:
- translation
size_categories:
- 10K<n<100K
configs:
- config_name: en-ar_EG
data_files:
- split: train
path: "en-ar_EG.jsonl"
- config_name: en-ar_SA
data_files:
- split: train
path: "en-ar_SA.jsonl"
- config_name: en-bg_BG
data_files:
- split: train
path: "en-bg_BG.jsonl"
- config_name: en-bn_IN
data_files:
- split: train
path: "en-bn_IN.jsonl"
- config_name: en-ca_ES
data_files:
- split: train
path: "en-ca_ES.jsonl"
- config_name: en-cs_CZ
data_files:
- split: train
path: "en-cs_CZ.jsonl"
- config_name: en-da_DK
data_files:
- split: train
path: "en-da_DK.jsonl"
- config_name: en-de_DE
data_files:
- split: train
path: "en-de_DE.jsonl"
- config_name: en-el_GR
data_files:
- split: train
path: "en-el_GR.jsonl"
- config_name: en-es_MX
data_files:
- split: train
path: "en-es_MX.jsonl"
- config_name: en-et_EE
data_files:
- split: train
path: "en-et_EE.jsonl"
- config_name: en-fa_IR
data_files:
- split: train
path: "en-fa_IR.jsonl"
- config_name: en-fi_FI
data_files:
- split: train
path: "en-fi_FI.jsonl"
- config_name: en-fil_PH
data_files:
- split: train
path: "en-fil_PH.jsonl"
- config_name: en-fr_CA
data_files:
- split: train
path: "en-fr_CA.jsonl"
- config_name: en-fr_FR
data_files:
- split: train
path: "en-fr_FR.jsonl"
- config_name: en-gu_IN
data_files:
- split: train
path: "en-gu_IN.jsonl"
- config_name: en-he_IL
data_files:
- split: train
path: "en-he_IL.jsonl"
- config_name: en-hi_IN
data_files:
- split: train
path: "en-hi_IN.jsonl"
- config_name: en-hr_HR
data_files:
- split: train
path: "en-hr_HR.jsonl"
- config_name: en-hu_HU
data_files:
- split: train
path: "en-hu_HU.jsonl"
- config_name: en-id_ID
data_files:
- split: train
path: "en-id_ID.jsonl"
- config_name: en-is_IS
data_files:
- split: train
path: "en-is_IS.jsonl"
- config_name: en-it_IT
data_files:
- split: train
path: "en-it_IT.jsonl"
- config_name: en-ja_JP
data_files:
- split: train
path: "en-ja_JP.jsonl"
- config_name: en-kn_IN
data_files:
- split: train
path: "en-kn_IN.jsonl"
- config_name: en-ko_KR
data_files:
- split: train
path: "en-ko_KR.jsonl"
- config_name: en-lt_LT
data_files:
- split: train
path: "en-lt_LT.jsonl"
- config_name: en-lv_LV
data_files:
- split: train
path: "en-lv_LV.jsonl"
- config_name: en-ml_IN
data_files:
- split: train
path: "en-ml_IN.jsonl"
- config_name: en-mr_IN
data_files:
- split: train
path: "en-mr_IN.jsonl"
- config_name: en-nl_NL
data_files:
- split: train
path: "en-nl_NL.jsonl"
- config_name: en-no_NO
data_files:
- split: train
path: "en-no_NO.jsonl"
- config_name: en-pa_IN
data_files:
- split: train
path: "en-pa_IN.jsonl"
- config_name: en-pl_PL
data_files:
- split: train
path: "en-pl_PL.jsonl"
- config_name: en-pt_BR
data_files:
- split: train
path: "en-pt_BR.jsonl"
- config_name: en-pt_PT
data_files:
- split: train
path: "en-pt_PT.jsonl"
- config_name: en-ro_RO
data_files:
- split: train
path: "en-ro_RO.jsonl"
- config_name: en-ru_RU
data_files:
- split: train
path: "en-ru_RU.jsonl"
- config_name: en-sk_SK
data_files:
- split: train
path: "en-sk_SK.jsonl"
- config_name: en-sl_SI
data_files:
- split: train
path: "en-sl_SI.jsonl"
- config_name: en-sr_RS
data_files:
- split: train
path: "en-sr_RS.jsonl"
- config_name: en-sv_SE
data_files:
- split: train
path: "en-sv_SE.jsonl"
- config_name: en-sw_KE
data_files:
- split: train
path: "en-sw_KE.jsonl"
- config_name: en-sw_TZ
data_files:
- split: train
path: "en-sw_TZ.jsonl"
- config_name: en-ta_IN
data_files:
- split: train
path: "en-ta_IN.jsonl"
- config_name: en-te_IN
data_files:
- split: train
path: "en-te_IN.jsonl"
- config_name: en-th_TH
data_files:
- split: train
path: "en-th_TH.jsonl"
- config_name: en-tr_TR
data_files:
- split: train
path: "en-tr_TR.jsonl"
- config_name: en-uk_UA
data_files:
- split: train
path: "en-uk_UA.jsonl"
- config_name: en-ur_PK
data_files:
- split: train
path: "en-ur_PK.jsonl"
- config_name: en-vi_VN
data_files:
- split: train
path: "en-vi_VN.jsonl"
- config_name: en-zh_CN
data_files:
- split: train
path: "en-zh_CN.jsonl"
- config_name: en-zh_TW
data_files:
- split: train
path: "en-zh_TW.jsonl"
- config_name: en-zu_ZA
data_files:
- split: train
path: "en-zu_ZA.jsonl"
---
# WMT24++
This repository contains the human translation and post-edit data for the 55 en->xx language pairs released in
the publication
[WMT24++: Expanding the Language Coverage of WMT24 to 55 Languages & Dialects](https://arxiv.org/abs/2502.12404).
If you are interested in the MT/LLM system outputs and automatic metric scores, please see [MTME](https://github.com/google-research/mt-metrics-eval/tree/main?tab=readme-ov-file#wmt24-data).
If you are interested in the images of the source URLs for each document, please see [here](https://huggingface.co/datasets/google/wmt24pp-images).
## Schema
Each language pair is stored in its own jsonl file.
Each row is a serialized JSON object with the following fields:
- `lp`: The language pair (e.g., `"en-de_DE"`).
- `domain`: The domain of the source, either `"canary"`, `"news"`, `"social"`, `"speech"`, or `"literary"`.
- `document_id`: The unique ID that identifies the document the source came from.
- `segment_id`: The globally unique ID that identifies the segment.
- `is_bad_source`: A Boolean that indicates whether this source is low quality (e.g., HTML, URLs, emoijs). In the paper, the segments marked as true were removed from the evaluation, and we recommend doing the same.
- `source`: The English source text.
- `target`: The post-edit of `original_target`. We recommend using the post-edit as the default reference.
- `original_target`: The original reference translation.
## Citation
If you use any of the data released in our work, please cite the following paper:
```
@misc{deutsch2025wmt24expandinglanguagecoverage,
title={{WMT24++: Expanding the Language Coverage of WMT24 to 55 Languages & Dialects}},
author={Daniel Deutsch and Eleftheria Briakou and Isaac Caswell and Mara Finkelstein and Rebecca Galor and Juraj Juraska and Geza Kovacs and Alison Lui and Ricardo Rei and Jason Riesa and Shruti Rijhwani and Parker Riley and Elizabeth Salesky and Firas Trabelsi and Stephanie Winkler and Biao Zhang and Markus Freitag},
year={2025},
eprint={2502.12404},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2502.12404},
}
```
## Helpful Python Constants
```python
LANGUAGE_PAIRS = (
"en-ar_EG", "en-ar_SA", "en-bg_BG", "en-bn_IN", "en-ca_ES", "en-cs_CZ", "en-da_DK", "en-de_DE",
"en-el_GR", "en-es_MX", "en-et_EE", "en-fa_IR", "en-fi_FI", "en-fil_PH", "en-fr_CA", "en-fr_FR",
"en-gu_IN", "en-he_IL", "en-hi_IN", "en-hr_HR", "en-hu_HU", "en-id_ID", "en-is_IS", "en-it_IT",
"en-ja_JP", "en-kn_IN", "en-ko_KR", "en-lt_LT", "en-lv_LV", "en-ml_IN", "en-mr_IN", "en-nl_NL",
"en-no_NO", "en-pa_IN", "en-pl_PL", "en-pt_BR", "en-pt_PT", "en-ro_RO", "en-ru_RU", "en-sk_SK",
"en-sl_SI", "en-sr_RS", "en-sv_SE", "en-sw_KE", "en-sw_TZ", "en-ta_IN", "en-te_IN", "en-th_TH",
"en-tr_TR", "en-uk_UA", "en-ur_PK", "en-vi_VN", "en-zh_CN", "en-zh_TW", "en-zu_ZA",
)
LANGUAGE_BY_CODE = {
"ar_EG": "Arabic",
"ar_SA": "Arabic",
"bg_BG": "Bulgarian",
"bn_BD": "Bengali",
"bn_IN": "Bengali",
"ca_ES": "Catalan",
"cs_CZ": "Czech",
"da_DK": "Danish",
"de_DE": "German",
"el_GR": "Greek",
"es_MX": "Spanish",
"et_EE": "Estonian",
"fa_IR": "Farsi",
"fi_FI": "Finnish",
"fil_PH": "Filipino",
"fr_CA": "French",
"fr_FR": "French",
"gu_IN": "Gujarati",
"he_IL": "Hebrew",
"hi_IN": "Hindi",
"hr_HR": "Croatian",
"hu_HU": "Hungarian",
"id_ID": "Indonesian",
"is_IS": "Icelandic",
"it_IT": "Italian",
"ja_JP": "Japanese",
"kn_IN": "Kannada",
"ko_KR": "Korean",
"lt_LT": "Lithuanian",
"lv_LV": "Latvian",
"ml_IN": "Malayalam",
"mr_IN": "Marathi",
"nl_NL": "Dutch",
"no_NO": "Norwegian",
"pa_IN": "Punjabi",
"pl_PL": "Polish",
"pt_BR": "Portuguese",
"pt_PT": "Portuguese",
"ro_RO": "Romanian",
"ru_RU": "Russian",
"sk_SK": "Slovak",
"sl_SI": "Slovenian",
"sr_RS": "Serbian",
"sv_SE": "Swedish",
"sw_KE": "Swahili",
"sw_TZ": "Swahili",
"ta_IN": "Tamil",
"te_IN": "Telugu",
"th_TH": "Thai",
"tr_TR": "Turkish",
"uk_UA": "Ukrainian",
"ur_PK": "Urdu",
"vi_VN": "Vietnamese",
"zh_CN": "Mandarin",
"zh_TW": "Mandarin",
"zu_ZA": "Zulu",
}
REGION_BY_CODE = {
"ar_EG": "Egypt",
"ar_SA": "Saudi Arabia",
"bg_BG": "Bulgaria",
"bn_BD": "Bangladesh",
"bn_IN": "India",
"ca_ES": "Spain",
"cs_CZ": "Czechia",
"da_DK": "Denmark",
"de_DE": "Germany",
"el_GR": "Greece",
"es_MX": "Mexico",
"et_EE": "Estonia",
"fa_IR": "Iran",
"fi_FI": "Finland",
"fil_PH": "Philippines",
"fr_CA": "Canada",
"fr_FR": "France",
"gu_IN": "India",
"he_IL": "Israel",
"hi_IN": "India",
"hr_HR": "Croatia",
"hu_HU": "Hungary",
"id_ID": "Indonesia",
"is_IS": "Iceland",
"it_IT": "Italy",
"ja_JP": "Japan",
"kn_IN": "India",
"ko_KR": "South Korea",
"lt_LT": "Lithuania",
"lv_LV": "Latvia",
"ml_IN": "India",
"mr_IN": "India",
"nl_NL": "Netherlands",
"no_NO": "Norway",
"pa_IN": "India",
"pl_PL": "Poland",
"pt_BR": "Brazil",
"pt_PT": "Portugal",
"ro_RO": "Romania",
"ru_RU": "Russia",
"sk_SK": "Slovakia",
"sl_SI": "Slovenia",
"sr_RS": "Serbia",
"sv_SE": "Sweden",
"sw_KE": "Kenya",
"sw_TZ": "Tanzania",
"ta_IN": "India",
"te_IN": "India",
"th_TH": "Thailand",
"tr_TR": "Turkey",
"uk_UA": "Ukraine",
"ur_PK": "Pakistan",
"vi_VN": "Vietnam",
"zh_CN": "China",
"zh_TW": "Taiwan",
"zu_ZA": "South Africa",
}
``` |
lmms-lab/EgoLife | lmms-lab | 2025-03-13T17:47:56Z | 13,580 | 9 | [
"task_categories:video-text-to-text",
"language:zh",
"license:mit",
"size_categories:10K<n<100K",
"modality:video",
"library:datasets",
"library:mlcroissant",
"arxiv:2503.03803",
"region:us",
"video"
] | [
"video-text-to-text"
] | 2025-02-26T08:45:22Z | null | ---
language:
- zh
license: mit
task_categories:
- video-text-to-text
tags:
- video
---
Data cleaning, stay tuned! Please refer to https://egolife-ai.github.io/ first for general info.
Checkout the paper EgoLife (https://arxiv.org/abs/2503.03803) for more information.
Code: https://github.com/egolife-ai/EgoLife |
lmarena-ai/webdev-arena-preference-10k | lmarena-ai | 2025-03-10T19:36:45Z | 195 | 7 | [
"license:other",
"size_categories:10K<n<100K",
"format:json",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-01-15T22:48:45Z | 2 | ---
license: other
license_name: other
license_link: LICENSE
configs:
- config_name: default
data_files:
- split: test
path: data/*
extra_gated_prompt: You agree to the [Dataset License Agreement](https://huggingface.co/datasets/lmarena-ai/webdev-arena-preference-10k#dataset-license-agreement).
extra_gated_fields:
Name: text
Email: text
Affiliation: text
Country: text
extra_gated_button_content: I agree to the terms and conditions of the Dataset License Agreement.
---
# WebDev Arena Preference Dataset
This dataset contains 10K real-world [Webdev Arena](https://web.lmarena.ai) battle with 10 state-of-the-art LLMs. More details in the [blog post](https://blog.lmarena.ai/blog/2025/webdev-arena/).
## Dataset License Agreement
This Agreement contains the terms and conditions that govern your access and use of the WebDev Arena Dataset (Arena Dataset). You may not use the Arena Dataset if you do not accept this Agreement. By clicking to accept, accessing the Arena Dataset, or both, you hereby agree to the terms of the Agreement. If you are agreeing to be bound by the Agreement on behalf of your employer or another entity, you represent and warrant that you have full legal authority to bind your employer or such entity to this Agreement.
- Safety and Moderation: This dataset contains unsafe conversations that may be perceived as offensive or unsettling. User should apply appropriate filters and safety measures.
- Non-Endorsement: The views and opinions depicted in this dataset do not reflect the perspectives of the researchers or affiliated institutions engaged in the data collection process.
- Legal Compliance: You are mandated to use it in adherence with all pertinent laws and regulations.
- Model Specific Terms: This dataset contains outputs from multiple model providers. Users must adhere to the terms of use of model providers.
- Non-Identification: You must not attempt to identify the identities of any person (individuals or entities) or infer any sensitive personal data encompassed in this dataset.
- Prohibited Transfers: You should not distribute, copy, disclose, assign, sublicense, embed, host, or otherwise transfer the dataset to any third party.
- Right to Request Deletion: At any time, we may require you to delete all copies of the dataset (in whole or in part) in your possession and control. You will promptly comply with any and all such requests. Upon our request, you shall provide us with written confirmation of your compliance with such requirements.
- Termination: We may, at any time, for any reason or for no reason, terminate this Agreement, effective immediately upon notice to you. Upon termination, the license granted to you hereunder will immediately terminate, and you will immediately stop using the Arena Dataset and destroy all copies of the Arena Dataset and related materials in your possession or control.
- Limitation of Liability: IN NO EVENT WILL WE BE LIABLE FOR ANY CONSEQUENTIAL, INCIDENTAL, EXEMPLARY, PUNITIVE, SPECIAL, OR INDIRECT DAMAGES (INCLUDING DAMAGES FOR LOSS OF PROFITS, BUSINESS INTERRUPTION, OR LOSS OF INFORMATION) ARISING OUT OF OR RELATING TO THIS AGREEMENT OR ITS SUBJECT MATTER, EVEN IF WE HAVE BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES.
Subject to your compliance with the terms and conditions of this Agreement, we grant to you, a limited, non-exclusive, non-transferable, non-sublicensable license to use the Arena Dataset, including the conversation data and annotations, to research, develop, and improve software, algorithms, machine learning models, techniques, and technologies for both research and commercial purposes. |
McGill-NLP/WebLINX-full | McGill-NLP | 2025-03-07T17:01:56Z | 102,632 | 6 | [
"language:en",
"size_categories:10K<n<100K",
"arxiv:2402.05930",
"region:us",
"conversational",
"image-to-text",
"vision",
"convAI"
] | [] | 2024-02-05T20:12:12Z | null | ---
language:
- en
size_categories:
- 10K<n<100K
config_names:
- chat
configs:
- config_name: chat
default: true
data_files:
- split: train
path: chat/train.csv
- split: validation
path: chat/valid.csv
- split: test
path: chat/test_iid.csv
- split: test_geo
path: chat/test_geo.csv
- split: test_vis
path: chat/test_vis.csv
- split: test_cat
path: chat/test_cat.csv
- split: test_web
path: chat/test_web.csv
tags:
- conversational
- image-to-text
- vision
- convAI
---
# WebLINX: Real-World Website Navigation with Multi-Turn Dialogue
WARNING: This is not the main WebLINX data card! You might want to use the main WebLINX data card instead:
> **[WebLINX: Real-World Website Navigation with Multi-Turn Dialogue](https://huggingface.co/datasets/mcgill-nlp/weblinx)**
---
<div align="center">
<h1 style="margin-bottom: 0.5em;">WebLINX: Real-World Website Navigation with Multi-Turn Dialogue</h1>
<em>Xing Han Lù*, Zdeněk Kasner*, Siva Reddy</em>
</div>
<div style="margin-bottom: 2em"></div>
| [**💾Code**](https://github.com/McGill-NLP/WebLINX) | [**📄Paper**](https://arxiv.org/abs/2402.05930) | [**🌐Website**](https://mcgill-nlp.github.io/weblinx) | [**📓Colab**](https://colab.research.google.com/github/McGill-NLP/weblinx/blob/main/examples/WebLINX_Colab_Notebook.ipynb) |
| :--: | :--: | :--: | :--: |
| [**🤖Models**](https://huggingface.co/collections/McGill-NLP/weblinx-models-65c57d4afeeb282d1dcf8434) | [**💻Explorer**](https://huggingface.co/spaces/McGill-NLP/weblinx-explorer) | [**🐦Tweets**](https://twitter.com/sivareddyg/status/1755799365031965140) | [**🏆Leaderboard**](https://paperswithcode.com/sota/conversational-web-navigation-on-weblinx) |
<video width="100%" controls autoplay muted loop>
<source src="https://huggingface.co/datasets/McGill-NLP/WebLINX/resolve/main/WeblinxWebsiteDemo.mp4?download=false" type="video/mp4">
Your browser does not support the video tag.
</video>
> [!IMPORTANT]
> WebLINX is now available as a benchmark through [BrowserGym](https://github.com/ServiceNow/BrowserGym), allowing you to access demonstration steps in the same way you would access a web agent environment like [WebArena](https://webarena.dev/) or [MiniWoB](https://miniwob.farama.org/index.html). This also allows you to run agents from the [Agentlab](https://github.com/ServiceNow/AgentLab) library, including agents that achieve SOTA performance through Claude-3.5-Sonnet. To enable this integration, we are releasing the `weblinx-browsergym` extension for BrowserGym on PyPi, as well as a [new dataset, WebLINX 1.1, derived from WebLINX on Huggingface](https://huggingface.co/datasets/McGill-NLP/weblinx-browsergym). In WebLINX 1.1, a small number of demonstrations were removed after processing, but no new demonstration was added. There are substantial changes to the steps being evaluated, with the inclusion of tab actions. Please report your results as "WebLINX-1.1", "WebLINX-BrowserGym" or "WebLINX-BG" in your work, to differentiate from the [initial release of weblinx (1.0)](https://huggingface.co/datasets/McGill-NLP/WebLINX/tree/v1.0).
## Quickstart
To get started, simply install `datasets` with `pip install datasets` and load the chat data splits:
```python
from datasets import load_dataset
from huggingface_hub import snapshot_download
# Load the validation split
valid = load_dataset("McGill-NLP/weblinx", split="validation")
# Download the input templates and use the LLaMA one
snapshot_download(
"McGill-NLP/WebLINX", repo_type="dataset", allow_patterns="templates/*", local_dir="."
)
with open('templates/llama.txt') as f:
template = f.read()
# To get the input text, simply pass a turn from the valid split to the template
turn = valid[0]
turn_text = template.format(**turn)
```
You can now use `turn_text` as an input to LLaMA-style models. For example, you can use Sheared-LLaMA:
```python
from transformers import pipeline
action_model = pipeline(
model="McGill-NLP/Sheared-LLaMA-2.7B-weblinx", device=0, torch_dtype='auto'
)
out = action_model(turn_text, return_full_text=False, max_new_tokens=64, truncation=True)
pred = out[0]['generated_text']
print("Ref:", turn["action"])
print("Pred:", pred)
```
## Raw Data
To use the raw data, you will need to use the `huggingface_hub`:
```python
from huggingface_hub import snapshot_download
# If you want to download the complete dataset (may take a while!)
snapshot_download(repo_id="McGill-NLP/WebLINX-full", repo_type="dataset", local_dir="./wl_data")
# You can download specific demos, for example
demo_names = ['saabwsg', 'ygprzve', 'iqaazif'] # 3 random demo from valid
patterns = [f"demonstrations/{name}/*" for name in demo_names]
snapshot_download(
repo_id="McGill-NLP/WebLINX-full", repo_type="dataset", local_dir="./wl_data", allow_patterns=patterns
)
```
For more information on how to use this data using our [official library](https://github.com/McGill-NLP/WebLINX), please refer to the [WebLINX documentation](https://mcgill-nlp.github.io/weblinx/docs).
## Reranking Data
You can also access the data processed for reranking tasks. To do that:
```python
from datasets import load_dataset
path = 'McGill-NLP/WebLINX'
# validation split:
valid = load_dataset(path=path, name='reranking', split='validation')
# test-iid split
test_iid = load_dataset(path, 'reranking', split='test_iid')
# other options: test_cat, test_geo, test_vis, test_web
print("Query:")
print(valid[0]['query'])
print("\nPositive:")
print(valid[0]['positives'][0])
print("\nNegative #1:")
print(valid[0]['negatives'][0])
print("\nNegative #2:")
print(valid[0]['negatives'][1])
```
## License and Terms of Use
License: The Dataset is made available under the terms of the [Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License (CC BY-NC-SA 4.0)](https://creativecommons.org/licenses/by-nc-sa/4.0/deed.en).
By downloading this Dataset, you agree to comply with the following terms of use:
- Restrictions: You agree not to use the Dataset in any way that is unlawful or would infringe upon the rights of others.
- Acknowledgment: By using the Dataset, you acknowledge that the Dataset may contain data derived from third-party sources, and you agree to abide by any additional terms and conditions that may apply to such third-party data.
- Fair Use Declaration: The Dataset may be used for research if it constitutes "fair use" under copyright laws within your jurisdiction. You are responsible for ensuring your use complies with applicable laws.
Derivatives must also include the terms of use above.
## Citation
If you use our dataset, please cite our work as follows:
```bibtex
@misc{lu-2024-weblinx,
title={WebLINX: Real-World Website Navigation with Multi-Turn Dialogue},
author={Xing Han Lù and Zdeněk Kasner and Siva Reddy},
year={2024},
eprint={2402.05930},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
ShareGPT4Video/ShareGPT4Video | ShareGPT4Video | 2025-03-07T06:58:12Z | 8,474 | 195 | [
"task_categories:visual-question-answering",
"task_categories:question-answering",
"language:en",
"license:cc-by-nc-4.0",
"size_categories:10K<n<100K",
"format:json",
"modality:image",
"modality:text",
"modality:video",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"arxiv:2406.04325",
"doi:10.57967/hf/2494",
"region:us"
] | [
"visual-question-answering",
"question-answering"
] | 2024-05-22T11:59:11Z | null | ---
license: cc-by-nc-4.0
task_categories:
- visual-question-answering
- question-answering
language:
- en
pretty_name: ShareGPT4Video Captions Dataset Card
size_categories:
- 1M<n
configs:
- config_name: ShareGPT4Video
data_files: sharegpt4video_40k.jsonl
---
# ShareGPT4Video 4.8M Dataset Card
## Dataset details
**Dataset type:**
ShareGPT4Video Captions 4.8M is a set of GPT4-Vision-powered multi-modal captions data of videos.
It is constructed to enhance modality alignment and fine-grained visual concept perception in Large Video-Language Models (LVLMs) and Text-to-Video Models (T2VMs). This advancement aims to bring LVLMs and T2VMs towards the capabilities of GPT4V and Sora.
* sharegpt4video_40k.jsonl is generated by GPT4-Vision (ShareGPT4Video).
* share-captioner-video_mixkit-pexels-pixabay_4814k_0417.json is generated by our ShareCaptioner-Video trained on GPT4-Vision-generated video-caption pairs.
* sharegpt4video_mix181k_vqa-153k_share-cap-28k.json is curated from sharegpt4video_instruct_gpt4-vision_cap40k.json for the supervised fine-tuning stage of LVLMs.
* llava_v1_5_mix665k_with_video_chatgpt72k_share4video28k.json has replaced 28K detailed-caption-related data in VideoChatGPT with 28K high-quality captions from ShareGPT4Video. This file is utilized to validate the effectiveness of high-quality captions under the VideoLLaVA and LLaMA-VID models.
**Dataset date:**
ShareGPT4Video Captions 4.8M was collected in 4.17 2024.
**Paper or resources for more information:**
[[Project](https://ShareGPT4Video.github.io/)] [[Paper](https://arxiv.org/abs/2406.04325v1)] [[Code](https://github.com/ShareGPT4Omni/ShareGPT4Video)] [[ShareGPT4Video-8B](https://huggingface.co/Lin-Chen/sharegpt4video-8b)]
**License:**
Attribution-NonCommercial 4.0 International
It should abide by the policy of OpenAI: https://openai.com/policies/terms-of-use
## Intended use
**Primary intended uses:**
The primary use of ShareGPT4Video Captions 4.8M is research on large multimodal models and text-to-video models.
**Primary intended users:**
The primary intended users of this dataset are researchers and hobbyists in computer vision, natural language processing, machine learning, AIGC, and artificial intelligence.
## Paper
arxiv.org/abs/2406.04325 |
WiroAI/dolphin-r1-italian | WiroAI | 2025-03-07T01:34:15Z | 106 | 9 | [
"language:it",
"license:apache-2.0",
"size_categories:100K<n<1M",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us",
"reasoning",
"italian",
"deepseek"
] | [] | 2025-02-14T02:05:30Z | 3 | ---
license: apache-2.0
language:
- it
tags:
- reasoning
- italian
- deepseek
pretty_name: Dolphin R1 Italian
---
<div align="center" style="display: flex; justify-content: center; align-items: center;">
<img src="https://huggingface.co/WiroAI/wiroai-turkish-llm-9b/resolve/main/wiro_logo.png" width="15%" alt="Wiro AI" />
<img src="https://upload.wikimedia.org/wikipedia/en/0/03/Flag_of_Italy.svg" width="15%" alt="Italian Flag" style="margin-left: 10px;" />
</div>
<hr>
<div align="center" style="line-height: 1;">
<a href="https://www.wiro.ai/" target="_blank" style="margin: 2px;">
<img alt="Homepage" src="https://huggingface.co/WiroAI/wiroai-turkish-llm-9b/resolve/main/homepage.svg" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://wiro.ai/tools?search=&categories=chat&tags=&page=0" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://huggingface.co/WiroAI/wiroai-turkish-llm-9b/resolve/main/chat.svg" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://huggingface.co/WiroAI" target="_blank" style="margin: 2px;">
<img alt="Hugging Face" src="https://huggingface.co/WiroAI/wiroai-turkish-llm-9b/resolve/main/huggingface.svg" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
<div align="center" style="line-height: 1;">
<a href="https://instagram.com/wiroai" target="_blank" style="margin: 2px;">
<img alt="Instagram Follow" src="https://img.shields.io/badge/Instagram-wiroai-555555?logo=instagram&logoColor=white&labelColor=E4405F" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://x.com/wiroai" target="_blank" style="margin: 2px;">
<img alt="X Follow" src="https://img.shields.io/badge/X-wiroai-555555?logo=x&logoColor=white&labelColor=000000" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
<div align="center" style="line-height: 1;">
<a href="https://wiro.ai/agreement/terms-of-service" style="margin: 2px;">
<img alt="License" src="https://img.shields.io/badge/License-apache 2.0-f5de53?&color=f5de53" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
# Dolphin R1 Italian 🐬
- Dolphin-R1 is an Apache-2.0 English dataset curated by [Eric Hartford](https://huggingface.co/ehartford) and [Cognitive Computations](https://huggingface.co/cognitivecomputations)
- Dolphin-R1-Italian is a Italian subset of the original dataset.
## Sponsors
Their and Wiro AI's appreciation for the generous sponsors of Dolphin R1 - Without whom this dataset could not exist.
- [Dria](https://dria.co) https://x.com/driaforall - Inference Sponsor (DeepSeek)
- [Chutes](https://chutes.ai) https://x.com/rayon_labs - Inference Sponsor (Flash)
- [Crusoe Cloud](https://crusoe.ai/) - Compute Sponsor
- [Andreessen Horowitz](https://a16z.com/) - provided the [grant](https://a16z.com/supporting-the-open-source-ai-community/) that originally launched Dolphin
## Overview
- The team creates a 800k sample English dataset similar in composition to the one used to train DeepSeek-R1 Distill models.
- Wiro AI creates Italian duplicate of 100k rows from DeepSeek's reasoning.
### Dataset Composition
- 100k Italian reasoning samples from DeepSeek-R1
The purpose of this dataset is to train R1-style Italian reasoning models.
```none
@article{WiroAI,
title={WiroAI/dolphin-r1-Italian},
author={Abdullah Bezir, Cengiz Asmazoğlu},
year={2025},
url={https://huggingface.co/datasets/WiroAI/dolphin-r1-Italian}
}
``` |
eaddario/imatrix-calibration | eaddario | 2025-03-02T14:42:03Z | 11,351 | 2 | [
"task_categories:text-generation",
"language:ar",
"language:zh",
"language:de",
"language:en",
"language:es",
"language:fr",
"language:hi",
"language:it",
"language:ja",
"language:nl",
"language:pl",
"language:pt",
"language:ru",
"license:mit",
"size_categories:100K<n<1M",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | [
"text-generation"
] | 2025-01-29T16:05:03Z | null | ---
license: mit
language:
- ar
- zh
- de
- en
- es
- fr
- hi
- it
- ja
- nl
- pl
- pt
- ru
pretty_name: I-Matrix Language Calibration Dataset
size_categories:
- 10K<n<100K
task_categories:
- text-generation
---
# Importance Matrix (imatrix) calibration datasets
This dataset consists of over 10M tokens of cleaned and de-duplicated text files for 13 different languages. Each language file is available in five sizes, ranging from `large` (~ 26,000 lines equivalent to approx. 750K tokens), to `micro` (~ 1,625 lines and 125K tokens avg).
Original data sourced from [HuggingFaceFW/fineweb](https://huggingface.co/datasets/HuggingFaceFW/fineweb) and [HuggingFaceFW/fineweb-2](https://huggingface.co/datasets/HuggingFaceFW/fineweb-2)
| File | Language | Lines | Size |
|----------------------------------------------------------|------------|--------|------|
| [calibration_ar_large](./calibration_ar_large.parquet) | Arabic | 26,000 | 3.1M |
| [calibration_ar_medium](./calibration_ar_medium.parquet) | Arabic | 13,000 | 1.5M |
| [calibration_ar_small](./calibration_ar_small.parquet) | Arabic | 6,500 | 756K |
| [calibration_ar_tiny](./calibration_ar_tiny.parquet) | Arabic | 3,250 | 383K |
| [calibration_ar_micro](./calibration_ar_micro.parquet) | Arabic | 1,625 | 202K |
| [calibration_cn_large](./calibration_cn_large.parquet) | Chinese | 26,000 | 3.2M |
| [calibration_cn_medium](./calibration_cn_medium.parquet) | Chinese | 13,000 | 1.6M |
| [calibration_cn_small](./calibration_cn_small.parquet) | Chinese | 6,500 | 855K |
| [calibration_cn_tiny](./calibration_cn_tiny.parquet) | Chinese | 3,250 | 460K |
| [calibration_cn_micro](./calibration_cn_micro.parquet) | Chinese | 1,625 | 203K |
| [calibration_de_large](./calibration_de_large.parquet) | German | 26,000 | 2.3M |
| [calibration_de_medium](./calibration_de_medium.parquet) | German | 13,000 | 1.2M |
| [calibration_de_small](./calibration_de_small.parquet) | German | 6,500 | 596K |
| [calibration_de_tiny](./calibration_de_tiny.parquet) | German | 3,250 | 301K |
| [calibration_de_micro](./calibration_de_micro.parquet) | German | 1,625 | 151K |
| [calibration_en_large](./calibration_en_large.parquet) | English | 26,000 | 2.4M |
| [calibration_en_medium](./calibration_en_medium.parquet) | English | 13,000 | 1.2M |
| [calibration_en_small](./calibration_en_small.parquet) | English | 6,500 | 586K |
| [calibration_en_tiny](./calibration_en_tiny.parquet) | English | 3,250 | 298K |
| [calibration_en_micro](./calibration_en_micro.parquet) | English | 1,625 | 152K |
| [calibration_es_large](./calibration_es_large.parquet) | Spanish | 26,000 | 2.5M |
| [calibration_es_medium](./calibration_es_medium.parquet) | Spanish | 13,000 | 1.3M |
| [calibration_es_small](./calibration_es_small.parquet) | Spanish | 6,500 | 651K |
| [calibration_es_tiny](./calibration_es_tiny.parquet) | Spanish | 3,250 | 328K |
| [calibration_es_micro](./calibration_es_micro.parquet) | Spanish | 1,625 | 170K |
| [calibration_fr_large](./calibration_fr_large.parquet) | French | 26,000 | 2.2M |
| [calibration_fr_medium](./calibration_fr_medium.parquet) | French | 13,000 | 1.1M |
| [calibration_fr_small](./calibration_fr_small.parquet) | French | 6,500 | 554K |
| [calibration_fr_tiny](./calibration_fr_tiny.parquet) | French | 3,250 | 284K |
| [calibration_fr_micro](./calibration_fr_micro.parquet) | French | 1,625 | 144K |
| [calibration_hi_large](./calibration_hi_large.parquet) | Hindi | 26,000 | 4.2M |
| [calibration_hi_medium](./calibration_hi_medium.parquet) | Hindi | 13,000 | 2.1M |
| [calibration_hi_small](./calibration_hi_small.parquet) | Hindi | 6,500 | 1.0M |
| [calibration_hi_tiny](./calibration_hi_tiny.parquet) | Hindi | 3,250 | 521K |
| [calibration_hi_micro](./calibration_hi_micro.parquet) | Hindi | 1,625 | 262K |
| [calibration_it_large](./calibration_it_large.parquet) | Italian | 26,000 | 2.7M |
| [calibration_it_medium](./calibration_it_medium.parquet) | Italian | 13,000 | 1.3M |
| [calibration_it_small](./calibration_it_small.parquet) | Italian | 6,500 | 664K |
| [calibration_it_tiny](./calibration_it_tiny.parquet) | Italian | 3,250 | 335K |
| [calibration_it_micro](./calibration_it_micro.parquet) | Italian | 1,625 | 166K |
| [calibration_jp_large](./calibration_jp_large.parquet) | Japanese | 26,000 | 1.4M |
| [calibration_jp_medium](./calibration_jp_medium.parquet) | Japanese | 13,000 | 710K |
| [calibration_jp_small](./calibration_jp_small.parquet) | Japanese | 6,500 | 356K |
| [calibration_jp_tiny](./calibration_jp_tiny.parquet) | Japanese | 3,250 | 183K |
| [calibration_jp_micro](./calibration_jp_micro.parquet) | Japanese | 1,625 | 96K |
| [calibration_nl_large](./calibration_nl_large.parquet) | Dutch | 26,000 | 2.1M |
| [calibration_nl_medium](./calibration_nl_medium.parquet) | Dutch | 13,000 | 1.1M |
| [calibration_nl_small](./calibration_nl_small.parquet) | Dutch | 6,500 | 566K |
| [calibration_nl_tiny](./calibration_nl_tiny.parquet) | Dutch | 3,250 | 278K |
| [calibration_nl_micro](./calibration_nl_micro.parquet) | Dutch | 1,625 | 143K |
| [calibration_pl_large](./calibration_pl_large.parquet) | Polish | 26,000 | 2.5M |
| [calibration_pl_medium](./calibration_pl_medium.parquet) | Polish | 13,000 | 1.3M |
| [calibration_pl_small](./calibration_pl_small.parquet) | Polish | 6,500 | 627K |
| [calibration_pl_tiny](./calibration_pl_tiny.parquet) | Polish | 3,250 | 306K |
| [calibration_pl_micro](./calibration_pl_micro.parquet) | Polish | 1,625 | 158K |
| [calibration_pt_large](./calibration_pt_large.parquet) | Portuguese | 26,000 | 2.2M |
| [calibration_pt_medium](./calibration_pt_medium.parquet) | Portuguese | 13,000 | 1.1M |
| [calibration_pt_small](./calibration_pt_small.parquet) | Portuguese | 6,500 | 566K |
| [calibration_pt_tiny](./calibration_pt_tiny.parquet) | Portuguese | 3,250 | 293K |
| [calibration_pt_micro](./calibration_pt_micro.parquet) | Portuguese | 1,625 | 149K |
| [calibration_ru_large](./calibration_ru_large.parquet) | Russian | 26,000 | 3.1M |
| [calibration_ru_medium](./calibration_ru_medium.parquet) | Russian | 13,000 | 1.6M |
| [calibration_ru_small](./calibration_ru_small.parquet) | Russian | 6,500 | 784K |
| [calibration_ru_tiny](./calibration_ru_tiny.parquet) | Russian | 3,250 | 395K |
| [calibration_ru_micro](./calibration_ru_micro.parquet) | Russian | 1,625 | 208K |
# Language groups
In addition to single language files, the dataset includes combined and randomized files by `language family` and `all languages in dataset`
## All languages (all)
| File | Language | Lines | Size |
|------------------------------------------------------------|----------|--------|------|
| [calibration_all_large](./calibration_all_large.parquet) | All | 26,000 | 3.5M |
| [calibration_all_medium](./calibration_all_medium.parquet) | All | 13,000 | 1.7M |
| [calibration_all_small](./calibration_all_small.parquet) | All | 6,500 | 878K |
| [calibration_all_tiny](./calibration_all_tiny.parquet) | All | 3,250 | 444K |
| [calibration_all_micro](./calibration_all_micro.parquet) | All | 1,625 | 216K |
## European languages: English, French, German, Italian, Portuguese & Spanish (eur)
| File | Language | Lines | Size |
|------------------------------------------------------------|----------|--------|------|
| [calibration_eur_large](./calibration_eur_large.parquet) | European | 25,998 | 2.8M |
| [calibration_eur_medium](./calibration_eur_medium.parquet) | European | 12,996 | 1.2M |
| [calibration_eur_small](./calibration_eur_small.parquet) | European | 6,498 | 680K |
| [calibration_eur_tiny](./calibration_eur_tiny.parquet) | European | 3,246 | 355K |
| [calibration_eur_micro](./calibration_eur_micro.parquet) | European | 1,620 | 172K |
## Germanic languages: Dutch, English & German (gem)
| File | Language | Lines | Size |
|------------------------------------------------------------|----------|--------|------|
| [calibration_gem_large](./calibration_gem_large.parquet) | Germanic | 25,998 | 2.5M |
| [calibration_gem_medium](./calibration_gem_medium.parquet) | Germanic | 12,999 | 1.2M |
| [calibration_gem_small](./calibration_gem_small.parquet) | Germanic | 6,498 | 628K |
| [calibration_gem_tiny](./calibration_gem_tiny.parquet) | Germanic | 3,250 | 319K |
| [calibration_gem_micro](./calibration_gem_micro.parquet) | Germanic | 1,623 | 164K |
## Romance languages: French, Italian, Portuguese & Spanish (roa)
| File | Language | Lines | Size |
|------------------------------------------------------------|----------|--------|------|
| [calibration_roa_large](./calibration_roa_large.parquet) | Romance | 26,000 | 2.7M |
| [calibration_roa_medium](./calibration_roa_medium.parquet) | Romance | 13,000 | 1.3M |
| [calibration_roa_small](./calibration_roa_small.parquet) | Romance | 6,500 | 680K |
| [calibration_roa_tiny](./calibration_roa_tiny.parquet) | Romance | 3,252 | 348K |
| [calibration_roa_micro](./calibration_roa_micro.parquet) | Romance | 1,622 | 164K |
## Slavic languages: Polish & Russian (sla)
| File | Language | Lines | Size |
|------------------------------------------------------------|----------|--------|------|
| [calibration_sla_large](./calibration_sla_large.parquet) | Slavic | 26,000 | 3.1M |
| [calibration_sla_medium](./calibration_sla_medium.parquet) | Slavic | 13,000 | 1.6M |
| [calibration_sla_small](./calibration_sla_small.parquet) | Slavic | 6,500 | 780M |
| [calibration_sla_tiny](./calibration_sla_tiny.parquet) | Slavic | 3,250 | 374K |
| [calibration_sla_micro](./calibration_sla_micro.parquet) | Slavic | 1,624 | 198K |
|
rockerBOO/trefle_dump | rockerBOO | 2025-03-02T02:56:53Z | 30 | 2 | [
"license:odbl",
"size_categories:100K<n<1M",
"region:us",
"species",
"trefle"
] | [] | 2025-03-02T02:42:44Z | 2 | ---
license: odbl
tags:
- species
- trefle
size_categories:
- 100K<n<1M
---
# Trefle data
[🌎 Website](https://trefle.io) • [🚀 Getting started](https://docs.trefle.io) • [📖 API Documentation](https://docs.trefle.io/reference) • [💡 Ideas and features](https://github.com/orgs/treflehq/projects/3) • [🐛 Issues](https://github.com/orgs/treflehq/projects/2)
[](https://oss.skylight.io/app/applications/nz7MAOv6K6ra) [](https://oss.skylight.io/app/applications/nz7MAOv6K6ra) [](https://oss.skylight.io/app/applications/nz7MAOv6K6ra) [](https://oss.skylight.io/app/applications/nz7MAOv6K6ra)
This is the repository for the [Trefle](https://trefle.io) data.
> This dump has been generated on 2020-10-15
## Disclaimer
This is an early version of the Trefle Data. Schema is subject to change. As it's filled from external database, sources and users, it's not 100% validated or complete.
## Structure
The database dump is a tab-separated text file with the following rows:
- id
- scientific_name
- rank
- genus
- family
- year
- author
- bibliography
- common_name
- family_common_name
- image_url
- flower_color
- flower_conspicuous
- foliage_color
- foliage_texture
- fruit_color
- fruit_conspicuous
- fruit_months
- bloom_months
- ground_humidity
- growth_form
- growth_habit
- growth_months
- growth_rate
- edible_part
- vegetable
- edible
- light
- soil_nutriments
- soil_salinity
- anaerobic_tolerance
- atmospheric_humidity
- average_height_cm
- maximum_height_cm
- minimum_root_depth_cm
- ph_maximum
- ph_minimum
- planting_days_to_harvest
- planting_description
- planting_sowing_description
- planting_row_spacing_cm
- planting_spread_cm
- synonyms
- distributions
- common_names
- url_usda
- url_tropicos
- url_tela_botanica
- url_powo
- url_plantnet
- url_gbif
- url_openfarm
- url_catminat
- url_wikipedia_en
## Licence
Trefle Data is licensed under the Open Database License (ODbL).
**You're free:**
- To Share: To copy, distribute and use the database.
- To Create: To produce works from the database.
- To Adapt: To modify, transform and build upon the database.
**Under the following conditions:**
- Attribute: You must attribute to Trefle any public use of the database, or works produced from the database. For any use or redistribution of the database, or works produced from it, you must make clear to others the license of the database and keep intact any notices on the original database.
- Share-Alike: If you publicly use any adapted version of this database, or works produced from an adapted database, you must also offer that adapted database under the ODbL.
- Keep open: If you redistribute the database, or an adapted version of it, then you may use technological measures that restrict the work (such as digital rights management) as long as you also redistribute a version without such measures. |
sander-wood/wikimusictext | sander-wood | 2025-02-28T11:53:55Z | 100 | 13 | [
"task_categories:text-classification",
"task_categories:text2text-generation",
"language:en",
"license:cc-by-nc-4.0",
"size_categories:1K<n<10K",
"format:json",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"arxiv:2304.11029",
"region:us",
"music"
] | [
"text-classification",
"text2text-generation"
] | 2023-04-21T13:16:40Z | 1 | ---
license: cc-by-nc-4.0
task_categories:
- text-classification
- text2text-generation
pretty_name: wikimt
size_categories:
- 1K<n<10K
language:
- en
tags:
- music
---
We introduce **WikiMT-X**, an enhanced version of WikiMusicText (WikiMT) with **audio recordings, richer text annotations, and improved genre labels**. Explore it here: [WikiMT-X on Hugging Face](https://huggingface.co/datasets/sander-wood/wikimt-x).
## Dataset Summary
In [CLaMP: Contrastive Language-Music Pre-training for Cross-Modal Symbolic Music Information Retrieval](https://ai-muzic.github.io/clamp/), we introduce WikiMusicText (WikiMT), a new dataset for the evaluation of semantic search and music classification. It includes 1010 lead sheets in ABC notation sourced from Wikifonia.org, each accompanied by a title, artist, genre, and description. The title and artist information is extracted from the score, whereas the genre labels are obtained by matching keywords from the Wikipedia entries and assigned to one of the 8 classes (Jazz, Country, Folk, R&B, Pop, Rock, Dance, and Latin) that loosely mimic the GTZAN genres. The description is obtained by utilizing BART-large to summarize and clean the corresponding Wikipedia entry. Additionally, the natural language information within the ABC notation is removed.
WikiMT is a unique resource to support the evaluation of semantic search and music classification. However, it is important to acknowledge that the dataset was curated from publicly available sources, and there may be limitations concerning the accuracy and completeness of the genre and description information. Further research is needed to explore the potential biases and limitations of the dataset and to develop strategies to address them.
## How to Access Music Score Metadata for ABC Notation
To access metadata related to ABC notation music scores from the WikiMT dataset, follow these steps:
1. **Locate the xml2abc.py script**:
- Visit https://wim.vree.org/svgParse/xml2abc.html.
- You will find a python script named `xml2abc.py-{version number}.zip`. Copy the link of this zip file.
2. **Locate the Wikifonia MusicXML Data**:
- Visit the discussion: [Download for Wikifonia all 6,675 Lead Sheets](http://www.synthzone.com/forum/ubbthreads.php/topics/384909/Download_for_Wikifonia_all_6,6).
- You will find the download link of a zip file named [Wikifonia.zip](http://www.synthzone.com/files/Wikifonia/Wikifonia.zip) for the Wikifonia dataset in MusicXML format (with a.mxl extension). Copy the link of this zip file.
2. **Run the Provided Code:** Once you have found the Wikifonia MusicXML data link, execute the provided Python code below. This code will handle the following tasks:
- Automatically download the "xml2abc.py" conversion script, with special thanks to the author, Willem (Wim).
- Automatically download the "wikimusictext.jsonl" dataset, which contains metadata associated with music scores.
- Prompt you for the xml2abc/Wikifonia URL, as follows:
```python
Enter the xml2abc/Wikifonia URL: [Paste your URL here]
```
Paste the URL pointing to the `xml2abc.py-{version number}.zip` or `Wikifonia.zip` file and press Enter.
The below code will take care of downloading, processing, and extracting the music score metadata, making it ready for your research or applications.
```python
import subprocess
import os
import json
import zipfile
import io
# Install the required packages if they are not installed
try:
from unidecode import unidecode
except ImportError:
subprocess.check_call(["python", '-m', 'pip', 'install', 'unidecode'])
from unidecode import unidecode
try:
from tqdm import tqdm
except ImportError:
subprocess.check_call(["python", '-m', 'pip', 'install', 'tqdm'])
from tqdm import tqdm
try:
import requests
except ImportError:
subprocess.check_call(["python", '-m', 'pip', 'install', 'requests'])
import requests
def load_music(filename):
# Convert the file to ABC notation
p = subprocess.Popen(
f'python {xml2abc_dir}/xml2abc.py -m 2 -c 6 -x "{filename}"',
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
shell=True
)
out, err = p.communicate()
output = out.decode('utf-8').replace('\r', '') # Capture standard output
music = unidecode(output).split('\n')
return music
def download_and_extract(url):
print(f"Downloading {url}")
# Send an HTTP GET request to the URL and get the response
response = requests.get(url, stream=True)
if response.status_code == 200:
# Create a BytesIO object and write the HTTP response content into it
zip_data = io.BytesIO()
total_size = int(response.headers.get('content-length', 0))
with tqdm(total=total_size, unit='B', unit_scale=True) as pbar:
for data in response.iter_content(chunk_size=1024):
pbar.update(len(data))
zip_data.write(data)
# Use the zipfile library to extract the file
print("Extracting the zip file...")
with zipfile.ZipFile(zip_data, "r") as zip_ref:
zip_ref.extractall("")
print("Done!")
else:
print("Failed to download the file. HTTP response code:", response.status_code)
# URL of the JSONL file
wikimt_url = "https://huggingface.co/datasets/sander-wood/wikimusictext/resolve/main/wikimusictext.jsonl"
# Local filename to save the downloaded file
local_filename = "wikimusictext.jsonl"
# Download the file and save it locally
response = requests.get(wikimt_url)
if response.status_code == 200:
with open(local_filename, 'wb') as file:
file.write(response.content)
print(f"Downloaded '{local_filename}' successfully.")
else:
print(f"Failed to download. Status code: {response.status_code}")
# Download the xml2abc.py script
# Visit https://wim.vree.org/svgParse/xml2abc.html
xml2abc_url = input("Enter the xml2abc URL: ")
download_and_extract(xml2abc_url)
xml2abc_dir = xml2abc_url.split('/')[-1][:-4].replace(".py", "").replace("-", "_")
# Download the Wikifonia dataset
# Visit http://www.synthzone.com/forum/ubbthreads.php/topics/384909/Download_for_Wikifonia_all_6,6
wikifonia_url = input("Enter the Wikifonia URL: ")
download_and_extract(wikifonia_url)
# Correct the file extensions
for root, dirs, files in os.walk("Wikifonia"):
for file in files:
filepath = os.path.join(root, file)
if filepath.endswith(".mxl"):
continue
else:
new_filepath = filepath.split(".mxl")[0] + ".mxl"
if os.path.exists(new_filepath):
os.remove(new_filepath)
os.rename(filepath, new_filepath)
wikimusictext = []
with open("wikimusictext.jsonl", "r", encoding="utf-8") as f:
for line in f.readlines():
wikimusictext.append(json.loads(line))
updated_wikimusictext = []
for song in tqdm(wikimusictext):
filename = song["artist"] + " - " + song["title"] + ".mxl"
filepath = os.path.join("Wikifonia", filename)
song["music"] = load_music(filepath)
updated_wikimusictext.append(song)
with open("wikimusictext.jsonl", "w", encoding="utf-8") as f:
for song in updated_wikimusictext:
f.write(json.dumps(song, ensure_ascii=False)+"\n")
```
By following these steps and running the provided code, you can efficiently access ABC notation music scores from the WikiMT dataset. Just ensure you have the correct download links of xml2abc and Wikifonia before starting. Enjoy your musical journey!
## Copyright Disclaimer
WikiMT was curated from publicly available sources, and all rights to the original content and data remain with their respective copyright holders. The dataset is made available for research and educational purposes, and any use, distribution, or modification of the dataset should comply with the terms and conditions set forth by the original data providers.
## BibTeX entry and citation info
```
@misc{wu2023clamp,
title={CLaMP: Contrastive Language-Music Pre-training for Cross-Modal Symbolic Music Information Retrieval},
author={Shangda Wu and Dingyao Yu and Xu Tan and Maosong Sun},
year={2023},
eprint={2304.11029},
archivePrefix={arXiv},
primaryClass={cs.SD}
}
``` |
cadene/droid | cadene | 2025-02-27T14:00:10Z | 98,951 | 1 | [
"task_categories:robotics",
"language:en",
"license:apache-2.0",
"size_categories:10M<n<100M",
"modality:video",
"arxiv:2403.12945",
"region:us",
"LeRobot",
"openx"
] | [
"robotics"
] | 2025-02-22T13:32:51Z | null | ---
license: apache-2.0
task_categories:
- robotics
tags:
- LeRobot
- openx
configs:
- config_name: default
data_files: data/*/*.parquet
language:
- en
size_categories:
- 10M<n<100M
---
This dataset was created using [LeRobot](https://github.com/huggingface/lerobot).
## DROID: A Large-Scale In-the-Wild Robot Manipulation Dataset
One of the biggest open-source dataset for robotics with 27.044,326 frames, 92,223 episodes, 31,308 unique task description in natural language.
Ported from Tensorflow Dataset format (2TB) to LeRobotDataset format (400GB) with the help from [IPEC-COMMUNITY](https://huggingface.co/IPEC-COMMUNITY).
- **Visualization:** [LeRobot](https://huggingface.co/spaces/lerobot/visualize_dataset?dataset=cadene%2Fdroid&episode=0)
- **Homepage:** [Droid](https://droid-dataset.github.io)
- **Paper:** [Arxiv](https://arxiv.org/abs/2403.12945)
- **License:** apache-2.0
## Dataset Structure
[meta/info.json](meta/info.json):
```json
{
"codebase_version": "v2.1",
"robot_type": "franka",
"total_episodes": 92233,
"total_frames": 27044326,
"total_tasks": 0,
"total_videos": 92233,
"total_chunks": 0,
"chunks_size": 1000,
"fps": 15,
"splits": {
"train": "0:92233"
},
"data_path": "data/chunk-{episode_chunk:03d}/episode_{episode_index:06d}.parquet",
"video_path": "videos/chunk-{episode_chunk:03d}/{video_key}/episode_{episode_index:06d}.mp4",
"features": {
"observation.images.exterior_image_2_left": {
"dtype": "video",
"shape": [
180,
320,
3
],
"names": [
"height",
"width",
"rgb"
],
"info": {
"video.fps": 15.0,
"video.height": 180,
"video.width": 320,
"video.channels": 3,
"video.codec": "av1",
"video.pix_fmt": "yuv420p",
"video.is_depth_map": false,
"has_audio": false
}
},
"observation.images.exterior_image_1_left": {
"dtype": "video",
"shape": [
180,
320,
3
],
"names": [
"height",
"width",
"rgb"
],
"info": {
"video.fps": 15.0,
"video.height": 180,
"video.width": 320,
"video.channels": 3,
"video.codec": "av1",
"video.pix_fmt": "yuv420p",
"video.is_depth_map": false,
"has_audio": false
}
},
"observation.images.wrist_image_left": {
"dtype": "video",
"shape": [
180,
320,
3
],
"names": [
"height",
"width",
"rgb"
],
"info": {
"video.fps": 15.0,
"video.height": 180,
"video.width": 320,
"video.channels": 3,
"video.codec": "av1",
"video.pix_fmt": "yuv420p",
"video.is_depth_map": false,
"has_audio": false
}
},
"observation.state": {
"dtype": "float32",
"shape": [
8
],
"names": {
"motors": [
"x",
"y",
"z",
"rx",
"ry",
"rz",
"rw",
"gripper"
]
}
},
"action": {
"dtype": "float32",
"shape": [
7
],
"names": {
"motors": [
"x",
"y",
"z",
"roll",
"pitch",
"yaw",
"gripper"
]
}
},
"timestamp": {
"dtype": "float32",
"shape": [
1
],
"names": null
},
"frame_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"episode_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"task_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
}
}
}
```
## Citation
**BibTeX:**
```bibtex
@article{khazatsky2024droid,
title={Droid: A large-scale in-the-wild robot manipulation dataset},
author={Khazatsky, Alexander and Pertsch, Karl and Nair, Suraj and Balakrishna, Ashwin and Dasari, Sudeep and Karamcheti, Siddharth and Nasiriany, Soroush and Srirama, Mohan Kumar and Chen, Lawrence Yunliang and Ellis, Kirsty and others},
journal={arXiv preprint arXiv:2403.12945},
year={2024}
}
``` |
zed-industries/zeta | zed-industries | 2025-02-27T08:47:45Z | 3,541 | 99 | [
"license:apache-2.0",
"size_categories:n<1K",
"format:json",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us",
"code"
] | [] | 2024-11-27T16:42:46Z | null | ---
configs:
- config_name: default
data_files:
- split: train
path: train.jsonl
- split: eval
path: eval.jsonl
- split: dpo
path: dpo.jsonl
license: apache-2.0
tags:
- code
---
# Dataset for Zeta
This is the open dataset used to train Zeta, an edit prediction model that powers Zed's predictive coding feature. Zeta is derived from Qwen2.5-Coder-7B and predicts the developer's next code edit based on their recent programming patterns and cursor position, allowing for intelligent completion with a simple tab press.
This dataset is split into three parts:
- `train.jsonl`: Contains the training data for supervised fine-tuning.
- `dpo.jsonl`: Contains the data for the direct preference optimization.
- `eval.jsonl`: Contains the evaluation data for the Zeta dataset.
These files are generated from the markdown files in the respective directories.
## Scripts
There are several scripts to help with data processing and evaluation:
- `script/pull-predictions`: Pulls predictions from Snowflake.
- `script/verify_server.py`: Simple webserver to manually verify the predictions and adding them to the dataset.
- `script/gen-dataset`: Reads all the markdown files, validates them, and generates the dataset files.
- `script/sft.ipynb`: Jupyter notebook for supervised fine-tuning.
- `script/dpo.ipynb`: Jupyter notebook for direct preference optimization.
### Running Python Scripts
Set up Python environment:
```bash
python -m venv .venv
source .venv/bin/activate # On Windows: .venv\Scripts\activate
pip install fastapi uvicorn
```
Run the verification UI:
```bash
python script/verify_server.py predictions train --trash-dir trash
```
Open http://localhost:8000 and use:
- 'G' to accept (moves to `train/`)
- 'B' to reject (moves to `trash/`)
# Labeling feedback
Set up Python environment:
```bash
python -m venv .venv
source .venv/bin/activate # On Windows: .venv\Scripts\activate
pip install anthropic
```
Set Anthropic API key:
```bash
export ANTHROPIC_API_KEY=your_api_key
```
Run the `label-data` script:
```bash
python script/label-data
```
Maybe some files weren't labeled because the model didn't reply with a comma-separated list of labels:
```bash
python script/see-label-data
``` |
cot-leaderboard/cot-eval-traces-2.0 | cot-leaderboard | 2025-02-26T02:42:25Z | 131,468 | 6 | [
"license:openrail",
"size_categories:1M<n<10M",
"format:parquet",
"modality:text",
"library:datasets",
"library:dask",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2024-04-10T15:21:09Z | null | ---
license: openrail
configs:
- config_name: default
data_files:
- split: test
path: "data/**/*.parquet"
--- |
opencompass/AIME2025 | opencompass | 2025-02-25T10:28:55Z | 5,400 | 17 | [
"task_categories:question-answering",
"language:en",
"license:mit",
"size_categories:n<1K",
"format:json",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [
"question-answering"
] | 2025-02-08T09:43:34Z | 2 | ---
license: mit
task_categories:
- question-answering
language:
- en
size_categories:
- n<1K
configs:
- config_name: AIME2025-I
data_files:
- split: test
path: aime2025-I.jsonl
- config_name: AIME2025-II
data_files:
- split: test
path: aime2025-II.jsonl
---
# AIME 2025 Dataset
## Dataset Description
This dataset contains problems from the American Invitational Mathematics Examination (AIME) 2025-I & II. |
allenai/olmOCR-mix-0225 | allenai | 2025-02-25T09:36:14Z | 2,452 | 123 | [
"license:odc-by",
"size_categories:100K<n<1M",
"format:parquet",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [] | 2025-02-10T20:41:50Z | null | ---
license: odc-by
configs:
- config_name: 00_documents
data_files:
- split: train_s2pdf
path:
- "train-s2pdf.parquet"
- split: eval_s2pdf
path:
- "eval-s2pdf.parquet"
- config_name: 01_books
data_files:
- split: train_iabooks
path:
- "train-iabooks.parquet"
- split: eval_iabooks
path:
- "eval-iabooks.parquet"
---
# olmOCR-mix-0225
olmOCR-mix-0225 is a dataset of ~250,000 PDF pages which have been OCRed into plain-text in a natural reading order using gpt-4o-2024-08-06 and a special
prompting strategy that preserves any born-digital content from each page.
This dataset can be used to train, fine-tune, or evaluate your own OCR document pipeline.
Quick links:
- 📃 [Paper](https://olmocr.allenai.org/papers/olmocr.pdf)
- 🤗 [Model](https://huggingface.co/allenai/olmOCR-7B-0225-preview)
- 🛠️ [Code](https://github.com/allenai/olmocr)
- 🎮 [Demo](https://olmocr.allenai.org/)
## Data Mix
## Table 1: Training set composition by source
| Source | Unique docs | Total pages |
|--------|-------------|-------------|
| Web crawled PDFs | 99,903 | 249,332 |
| Internet Archive books | 5,601 | 16,803 |
| **Total** | **105,504** | **266,135** |
Web crawled PDFs are sampled from a set of over 240 million documents crawled from public websites. Books in the Internet Archive set are in the public domain.
## Table 2: Web PDFs breakdown by document type
| Document type | Fraction |
|---------------|----------|
| Academic | 60% |
| Brochure | 12% |
| Legal | 11% |
| Table | 6% |
| Diagram | 5% |
| Slideshow | 2% |
| Other | 4% |
Distribution is estimating by sampling 707 pages, which are classified using *gpt-4o-2024-11-20*.
## Data Format
Each row in the dataset corresponds to a single page, extracted at random, from a source PDF and transformed into plain text.
No source PDF has had more than 3 random pages extracted from it.
Each extracted page is available as a standalone .pdf file, under the `pdf_tarballs/` directory.
### Features:
```python
{
'url': string, # Original URL of the PDF document
'page_number': int, # Page number within the document, 1-indexed
'id': string, # ID into /pdfs files folder
'response': { # OCRed Page information as JSON blob
'primary_language': string,
'is_rotation_valid': bool,
'rotation_correction': int,
'is_table': bool,
'is_diagram': bool,
'natural_text': str # The actual text of the PDF is here
}
}
```
## License
This dataset is licensed under ODC-BY-1.0. It is intended for research and educational use in accordance with AI2's [Responsible Use Guidelines](https://allenai.org/responsible-use).
The responses were generated from GPT-4o and GPT-4o is subject to OpenAI's [terms of use](https://openai.com/policies/row-terms-of-use). |
thbndi/Mimic4Dataset | thbndi | 2025-02-24T15:59:53Z | 269 | 4 | [
"region:us",
"medical"
] | [] | 2023-06-13T20:00:50Z | 1 | ---
tags:
- medical
---
# Dataset Usage
## Description
The Mimic-IV dataset generate data by executing the Pipeline available on https://github.com/healthylaife/MIMIC-IV-Data-Pipeline.
## Function Signature
```python
load_dataset('thbndi/Mimic4Dataset', task, mimic_path=mimic_data, config_path=config_file, encoding=encod, generate_cohort=gen_cohort, val_size=size, cache_dir=cache)
```
## Arguments
1. `task` (string) :
- Description: Specifies the task you want to perform with the dataset.
- Default: "Mortality"
- Note: Possible Values : 'Phenotype', 'Length of Stay', 'Readmission', 'Mortality'
2. `mimic_path` (string) :
- Description: Complete path to the Mimic-IV raw data on user's machine.
- Note: You need to provide the appropriate path where the Mimic-IV data is stored. The path should end with the version of mimic (eg : mimiciv/2.2). Supported version : 2.2 and 1.0 as provided by the authors of the pipeline.
3. `config_path` (string) optionnal :
- Description: Path to the configuration file for the cohort generation choices (more infos in '/config/readme.md').
- Default: Configuration file provided in the 'config' folder.
4. `encoding` (string) optionnal :
- Description: Data encoding option for the features.
- Options: "concat", "aggreg", "tensor", "raw", "text"
- Default: "concat"
- Note: Choose one of the following options for data encoding:
- "concat": Concatenates the one-hot encoded diagnoses, demographic data vector, and dynamic features at each measured time instant, resulting in a high-dimensional feature vector.
- "aggreg": Concatenates the one-hot encoded diagnoses, demographic data vector, and dynamic features, where each item_id is replaced by the average of the measured time instants, resulting in a reduced-dimensional feature vector.
- "tensor": Represents each feature as an 2D array. There are separate arrays for labels, demographic data ('DEMO'), diagnosis ('COND'), medications ('MEDS'), procedures ('PROC'), chart/lab events ('CHART/LAB'), and output events data ('OUT'). Dynamic features are represented as 2D arrays where each row contains values at a specific time instant.
- "raw": Provide cohort from the pipeline without any encoding for custom data processing.
- "text": Represents diagnoses as text suitable for BERT or other similar text-based models.
- For 'concat' and 'aggreg' the composition of the vector is given in './data/dict/"task"/features_aggreg.csv' or './data/dict/"task"/features_concat.csv' file and in 'features_names' column of the dataset.
5. `generate_cohort` (bool) optionnal :
- Description: Determines whether to generate a new cohort from Mimic-IV data.
- Default: True
- Note: Set it to True to generate a cohort, or False to skip cohort generation.
6. `val_size`, 'test_size' (float) optionnal :
- Description: Proportion of the dataset used for validation during training.
- Default: 0.1 for validation size and 0.2 for testing size.
- Note: Can be set to 0.
7. `cache_dir` (string) optionnal :
- Description: Directory where the processed dataset will be cached.
- Note: Providing a cache directory for each encoding type can avoid errors when changing the encoding type.
## Example Usage
```python
import datasets
from datasets import load_dataset
# Example 1: Load dataset with default settings
dataset = load_dataset('thbndi/Mimic4Dataset', task="Mortality", mimic_path="/path/to/mimic_data")
# Example 2: Load dataset with custom settings
dataset = load_dataset('thbndi/Mimic4Dataset', task="Phenotype", mimic_path="/path/to/mimic_data", config_path="/path/to/config_file", encoding="aggreg", generate_cohort=False, val_size=0.2, cache_dir="/path/to/cache_dir")
```
Please note that the provided examples are for illustrative purposes only, and you should adjust the paths and settings based on your actual dataset and specific use case.
## Citations
Please if you use this dataset we would appreciate citations to the following paper :
```raw
@inproceedings{lovon-melgarejo-etal-2024-revisiting,
title = "Revisiting the {MIMIC}-{IV} Benchmark: Experiments Using Language Models for Electronic Health Records",
author = "Lovon-Melgarejo, Jesus and
Ben-Haddi, Thouria and
Di Scala, Jules and
Moreno, Jose G. and
Tamine, Lynda",
editor = "Demner-Fushman, Dina and
Ananiadou, Sophia and
Thompson, Paul and
Ondov, Brian",
booktitle = "Proceedings of the First Workshop on Patient-Oriented Language Processing (CL4Health) @ LREC-COLING 2024",
month = may,
year = "2024",
address = "Torino, Italia",
publisher = "ELRA and ICCL",
url = "https://aclanthology.org/2024.cl4health-1.23/",
pages = "189--196",
abstract = "The lack of standardized evaluation benchmarks in the medical domain for text inputs can be a barrier to widely adopting and leveraging the potential of natural language models for health-related downstream tasks. This paper revisited an openly available MIMIC-IV benchmark for electronic health records (EHRs) to address this issue. First, we integrate the MIMIC-IV data within the Hugging Face datasets library to allow an easy share and use of this collection. Second, we investigate the application of templates to convert EHR tabular data to text. Experiments using fine-tuned and zero-shot LLMs on the mortality of patients task show that fine-tuned text-based models are competitive against robust tabular classifiers. In contrast, zero-shot LLMs struggle to leverage EHR representations. This study underlines the potential of text-based approaches in the medical field and highlights areas for further improvement."
}
```
|
IPEC-COMMUNITY/kuka_lerobot | IPEC-COMMUNITY | 2025-02-24T15:19:23Z | 155,185 | 0 | [
"task_categories:robotics",
"license:apache-2.0",
"modality:video",
"region:us",
"LeRobot",
"kuka",
"rlds",
"openx",
"kuka_iiwa"
] | [
"robotics"
] | 2025-02-23T11:12:40Z | null | ---
license: apache-2.0
task_categories:
- robotics
tags:
- LeRobot
- LeRobot
- kuka
- rlds
- openx
- kuka_iiwa
configs:
- config_name: default
data_files: data/*/*.parquet
---
This dataset was created using [LeRobot](https://github.com/huggingface/lerobot).
## Dataset Description
- **Homepage:** [More Information Needed]
- **Paper:** [More Information Needed]
- **License:** apache-2.0
## Dataset Structure
[meta/info.json](meta/info.json):
```json
{
"codebase_version": "v2.0",
"robot_type": "kuka_iiwa",
"total_episodes": 209880,
"total_frames": 2455879,
"total_tasks": 1,
"total_videos": 209880,
"total_chunks": 210,
"chunks_size": 1000,
"fps": 10,
"splits": {
"train": "0:209880"
},
"data_path": "data/chunk-{episode_chunk:03d}/episode_{episode_index:06d}.parquet",
"video_path": "videos/chunk-{episode_chunk:03d}/{video_key}/episode_{episode_index:06d}.mp4",
"features": {
"observation.images.image": {
"dtype": "video",
"shape": [
512,
640,
3
],
"names": [
"height",
"width",
"rgb"
],
"info": {
"video.fps": 10.0,
"video.height": 512,
"video.width": 640,
"video.channels": 3,
"video.codec": "av1",
"video.pix_fmt": "yuv420p",
"video.is_depth_map": false,
"has_audio": false
}
},
"observation.state": {
"dtype": "float32",
"shape": [
8
],
"names": {
"motors": [
"x",
"y",
"z",
"rx",
"ry",
"rz",
"rw",
"gripper"
]
}
},
"action": {
"dtype": "float32",
"shape": [
7
],
"names": {
"motors": [
"x",
"y",
"z",
"roll",
"pitch",
"yaw",
"gripper"
]
}
},
"timestamp": {
"dtype": "float32",
"shape": [
1
],
"names": null
},
"frame_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"episode_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"index": {
"dtype": "int64",
"shape": [
1
],
"names": null
},
"task_index": {
"dtype": "int64",
"shape": [
1
],
"names": null
}
}
}
```
## Citation
**BibTeX:**
```bibtex
[More Information Needed]
``` |
mshah1/speech_robust_bench | mshah1 | 2025-02-23T18:32:01Z | 13,227 | 3 | [
"size_categories:1M<n<10M",
"modality:audio",
"modality:text",
"region:us"
] | [] | 2024-01-21T01:39:08Z | null | ---
dataset_info:
- config_name: accented_cv
features:
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: text
dtype: string
- name: age
dtype: string
- name: gender
dtype: string
- name: accents
dtype: string
- name: locale
dtype: string
- name: id
dtype: int64
splits:
- name: test
num_bytes: 55407854.085
num_examples: 1355
- name: test.clean
num_bytes: 25593824.0
num_examples: 640
download_size: 78598662
dataset_size: 81001678.08500001
- config_name: accented_cv_es
features:
- name: audio
dtype: audio
- name: accent
dtype: string
- name: text
dtype: string
- name: gender
dtype: string
- name: age
dtype: string
- name: locale
dtype: string
- name: id
dtype: int64
splits:
- name: test
num_bytes: 65868440.963
num_examples: 1483
download_size: 60557913
dataset_size: 65868440.963
- config_name: accented_cv_fr
features:
- name: file_name
dtype: string
- name: accent
dtype: string
- name: text
dtype: string
- name: gender
dtype: string
- name: age
dtype: string
- name: locale
dtype: string
- name: id
dtype: int64
splits:
- name: test
num_bytes: 337528
num_examples: 2171
download_size: 148493
dataset_size: 337528
- config_name: chime
features:
- name: audio
dtype: audio
- name: end_time
dtype: string
- name: start_time
dtype: string
- name: speaker
dtype: string
- name: ref
dtype: string
- name: location
dtype: string
- name: session_id
dtype: string
- name: text
dtype: string
splits:
- name: farfield
num_bytes: 521160936.31
num_examples: 6535
- name: nearfield
num_bytes: 1072274621.0799999
num_examples: 6535
download_size: 1532887016
dataset_size: 1593435557.3899999
- config_name: in-the-wild
features:
- name: audio
dtype: audio
- name: end_time
dtype: string
- name: start_time
dtype: string
- name: speaker
dtype: string
- name: ref
dtype: string
- name: location
dtype: string
- name: session_id
dtype: string
- name: id
dtype: string
- name: text
dtype: string
splits:
- name: farfield
num_bytes: 521363521.31
num_examples: 6535
- name: nearfield
num_bytes: 1072477206.0799999
num_examples: 6535
download_size: 1533124839
dataset_size: 1593840727.3899999
- config_name: in-the-wild-AMI
features:
- name: meeting_id
dtype: string
- name: id
dtype: string
- name: text
dtype: string
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: begin_time
dtype: float32
- name: end_time
dtype: float32
- name: microphone_id
dtype: string
- name: speaker_id
dtype: string
splits:
- name: nearfield
num_bytes: 1382749390.9785259
num_examples: 6584
- name: farfield
num_bytes: 1040706691.1008185
num_examples: 6584
download_size: 2164898498
dataset_size: 2423456082.0793443
- config_name: in-the-wild-ami
features:
- name: meeting_id
dtype: string
- name: audio_id
dtype: string
- name: text
dtype: string
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: begin_time
dtype: float32
- name: end_time
dtype: float32
- name: microphone_id
dtype: string
- name: speaker_id
dtype: string
splits:
- name: nearfield
num_bytes: 1382749390.9785259
num_examples: 6584
- name: farfield
num_bytes: 1040706691.1008185
num_examples: 6584
download_size: 2164900274
dataset_size: 2423456082.0793443
- config_name: librispeech_asr-test.clean
features:
- name: file
dtype: string
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: text
dtype: string
- name: speaker_id
dtype: int64
- name: chapter_id
dtype: int64
- name: id
dtype: string
splits:
- name: speedup.1
num_bytes: 498896619.34
num_examples: 2620
- name: speedup.2
num_bytes: 415901075.34
num_examples: 2620
- name: speedup.3
num_bytes: 356617835.34
num_examples: 2620
- name: speedup.4
num_bytes: 312152811.34
num_examples: 2620
- name: slowdown.1
num_bytes: 712320343.34
num_examples: 2620
- name: slowdown.2
num_bytes: 830887339.34
num_examples: 2620
- name: slowdown.3
num_bytes: 996880127.34
num_examples: 2620
- name: slowdown.4
num_bytes: 1245871847.34
num_examples: 2620
- name: pitch_up.3
num_bytes: 623392467.34
num_examples: 2620
- name: pitch_up.4
num_bytes: 623392467.34
num_examples: 2620
- name: pitch_down.1
num_bytes: 623392467.34
num_examples: 2620
- name: pitch_down.2
num_bytes: 623392467.34
num_examples: 2620
- name: pitch_down.3
num_bytes: 623392467.34
num_examples: 2620
- name: pitch_down.4
num_bytes: 623392467.34
num_examples: 2620
- name: pitch_up.1
num_bytes: 623392458.5
num_examples: 2620
- name: pitch_up.2
num_bytes: 623392458.5
num_examples: 2620
- name: resample.1
num_bytes: 623392535.34
num_examples: 2620
- name: resample.2
num_bytes: 623392535.34
num_examples: 2620
- name: resample.3
num_bytes: 623392579.34
num_examples: 2620
- name: resample.4
num_bytes: 623392623.34
num_examples: 2620
- name: voice_conversion.4
num_bytes: 799852214.5
num_examples: 2620
- name: voice_conversion.3
num_bytes: 580185782.5
num_examples: 2620
- name: voice_conversion.1
num_bytes: 589259446.5
num_examples: 2620
- name: voice_conversion.2
num_bytes: 571175606.5
num_examples: 2620
- name: gain.1
num_bytes: 623392467.34
num_examples: 2620
- name: gain.2
num_bytes: 623392467.34
num_examples: 2620
- name: gain.3
num_bytes: 623392467.34
num_examples: 2620
- name: echo.1
num_bytes: 633872467.34
num_examples: 2620
- name: echo.2
num_bytes: 644352467.34
num_examples: 2620
- name: echo.3
num_bytes: 665312467.34
num_examples: 2620
- name: echo.4
num_bytes: 707232467.34
num_examples: 2620
- name: phaser.1
num_bytes: 623392467.34
num_examples: 2620
- name: phaser.2
num_bytes: 623392467.34
num_examples: 2620
- name: phaser.3
num_bytes: 623392467.34
num_examples: 2620
- name: tempo_up.1
num_bytes: 498896595.34
num_examples: 2620
- name: tempo_up.2
num_bytes: 415899351.34
num_examples: 2620
- name: tempo_up.3
num_bytes: 356615595.34
num_examples: 2620
- name: tempo_up.4
num_bytes: 312152811.34
num_examples: 2620
- name: tempo_down.1
num_bytes: 712318083.34
num_examples: 2620
- name: tempo_down.2
num_bytes: 830885583.34
num_examples: 2620
- name: tempo_down.3
num_bytes: 996880103.34
num_examples: 2620
- name: tempo_down.4
num_bytes: 1245871847.34
num_examples: 2620
- name: gain.4
num_bytes: 623392467.34
num_examples: 2620
- name: phaser.4
num_bytes: 623392467.34
num_examples: 2620
- name: lowpass.1
num_bytes: 623392467.34
num_examples: 2620
- name: lowpass.2
num_bytes: 623392467.34
num_examples: 2620
- name: lowpass.3
num_bytes: 623392467.34
num_examples: 2620
- name: lowpass.4
num_bytes: 623392467.34
num_examples: 2620
- name: highpass.1
num_bytes: 623392467.34
num_examples: 2620
- name: highpass.2
num_bytes: 623392467.34
num_examples: 2620
- name: highpass.3
num_bytes: 623392467.34
num_examples: 2620
- name: highpass.4
num_bytes: 623392467.34
num_examples: 2620
- name: voice_conversion_vctk.1
num_bytes: 495165825.88
num_examples: 2620
- name: universal_adv.1
num_bytes: 623392467.34
num_examples: 2620
- name: rir.1
num_bytes: 705636818.5
num_examples: 2620
- name: rir.2
num_bytes: 744484818.5
num_examples: 2620
- name: rir.3
num_bytes: 758740818.5
num_examples: 2620
- name: rir.4
num_bytes: 776116818.5
num_examples: 2620
- name: gnoise.1
num_bytes: 623392455.88
num_examples: 2620
- name: gnoise.2
num_bytes: 623392455.88
num_examples: 2620
- name: gnoise.3
num_bytes: 623392455.88
num_examples: 2620
- name: gnoise.4
num_bytes: 623392455.88
num_examples: 2620
- name: env_noise_esc50.1
num_bytes: 623392455.88
num_examples: 2620
- name: env_noise_esc50.2
num_bytes: 623392455.88
num_examples: 2620
- name: env_noise_esc50.3
num_bytes: 623392455.88
num_examples: 2620
- name: env_noise_esc50.4
num_bytes: 623392455.88
num_examples: 2620
- name: music.1
num_bytes: 623392455.88
num_examples: 2620
- name: music.2
num_bytes: 623392455.88
num_examples: 2620
- name: music.3
num_bytes: 623392455.88
num_examples: 2620
- name: music.4
num_bytes: 623392455.88
num_examples: 2620
- name: crosstalk.1
num_bytes: 623392455.88
num_examples: 2620
- name: crosstalk.2
num_bytes: 623392455.88
num_examples: 2620
- name: crosstalk.3
num_bytes: 623392455.88
num_examples: 2620
- name: crosstalk.4
num_bytes: 623392455.88
num_examples: 2620
- name: env_noise_musan.1
num_bytes: 623392455.88
num_examples: 2620
- name: env_noise_musan.2
num_bytes: 623392455.88
num_examples: 2620
- name: env_noise_musan.3
num_bytes: 623392455.88
num_examples: 2620
- name: env_noise_musan.4
num_bytes: 623392455.88
num_examples: 2620
- name: real_rir.1
num_bytes: 638169615.88
num_examples: 2620
- name: real_rir.2
num_bytes: 694281819.88
num_examples: 2620
- name: real_rir.3
num_bytes: 713200537.88
num_examples: 2620
- name: real_rir.4
num_bytes: 1515177725.88
num_examples: 2620
- name: env_noise.1
num_bytes: 623392455.88
num_examples: 2620
- name: env_noise.2
num_bytes: 623392455.88
num_examples: 2620
- name: env_noise.3
num_bytes: 623392455.88
num_examples: 2620
- name: env_noise.4
num_bytes: 623392455.88
num_examples: 2620
- name: env_noise_wham.1
num_bytes: 623392455.88
num_examples: 2620
- name: env_noise_wham.2
num_bytes: 623392455.88
num_examples: 2620
- name: env_noise_wham.3
num_bytes: 623392455.88
num_examples: 2620
- name: env_noise_wham.4
num_bytes: 623392455.88
num_examples: 2620
- name: tremolo.1
num_bytes: 623392455.88
num_examples: 2620
- name: tremolo.2
num_bytes: 623392455.88
num_examples: 2620
- name: tremolo.3
num_bytes: 623392455.88
num_examples: 2620
- name: tremolo.4
num_bytes: 623392455.88
num_examples: 2620
- name: treble.1
num_bytes: 623392455.88
num_examples: 2620
- name: treble.2
num_bytes: 623392455.88
num_examples: 2620
- name: treble.3
num_bytes: 623392455.88
num_examples: 2620
- name: treble.4
num_bytes: 623392455.88
num_examples: 2620
- name: bass.1
num_bytes: 623392455.88
num_examples: 2620
- name: bass.2
num_bytes: 623392455.88
num_examples: 2620
- name: bass.3
num_bytes: 623392455.88
num_examples: 2620
- name: bass.4
num_bytes: 623392455.88
num_examples: 2620
- name: chorus.1
num_bytes: 626913735.88
num_examples: 2620
- name: chorus.2
num_bytes: 628590535.88
num_examples: 2620
- name: chorus.3
num_bytes: 630267335.88
num_examples: 2620
- name: chorus.4
num_bytes: 631944135.88
num_examples: 2620
- name: None.0
num_bytes: 367982506.42
num_examples: 2620
download_size: 67547733720
dataset_size: 68871044112.51988
- config_name: librispeech_asr-test.clean_pertEval_500_30
features:
- name: file
dtype: string
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: text
dtype: string
- name: speaker_id
dtype: int64
- name: chapter_id
dtype: int64
- name: id
dtype: string
- name: pert_idx
dtype: int64
splits:
- name: gnoise.1
num_bytes: 3592401090.0
num_examples: 15000
- name: env_noise_esc50.1
num_bytes: 3592401090.0
num_examples: 15000
download_size: 7170899040
dataset_size: 7184802180.0
- config_name: multilingual_librispeech-french_test
features:
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: original_path
dtype: string
- name: begin_time
dtype: float64
- name: end_time
dtype: float64
- name: audio_duration
dtype: float64
- name: speaker_id
dtype: string
- name: chapter_id
dtype: string
- name: file
dtype: string
- name: id
dtype: string
- name: text
dtype: string
splits:
- name: gnoise.1
num_bytes: 1160858614.324
num_examples: 2426
- name: gnoise.2
num_bytes: 1160858614.324
num_examples: 2426
- name: gnoise.3
num_bytes: 1160858614.324
num_examples: 2426
- name: speedup.1
num_bytes: 928910526.324
num_examples: 2426
- name: speedup.3
num_bytes: 663829084.324
num_examples: 2426
- name: pitch_up.1
num_bytes: 1160858614.324
num_examples: 2426
- name: pitch_up.2
num_bytes: 1160858614.324
num_examples: 2426
- name: pitch_up.3
num_bytes: 1160858614.324
num_examples: 2426
- name: pitch_down.1
num_bytes: 1160858614.324
num_examples: 2426
- name: pitch_down.2
num_bytes: 1160858614.324
num_examples: 2426
- name: env_noise.1
num_bytes: 1160858614.324
num_examples: 2426
- name: env_noise.3
num_bytes: 1160858614.324
num_examples: 2426
- name: env_noise_wham.1
num_bytes: 1160858614.324
num_examples: 2426
- name: slowdown.2
num_bytes: 1547440398.324
num_examples: 2426
- name: real_rir.3
num_bytes: 1241772582.324
num_examples: 2426
- name: env_noise.2
num_bytes: 1160858614.324
num_examples: 2426
- name: env_noise_wham.2
num_bytes: 1160858614.324
num_examples: 2426
- name: speedup.2
num_bytes: 774280064.324
num_examples: 2426
- name: slowdown.1
num_bytes: 1326537936.324
num_examples: 2426
- name: slowdown.3
num_bytes: 1856702974.324
num_examples: 2426
- name: env_noise_esc50.1
num_bytes: 1160858614.324
num_examples: 2426
- name: env_noise_esc50.2
num_bytes: 1160858614.324
num_examples: 2426
- name: env_noise_esc50.3
num_bytes: 1160858614.324
num_examples: 2426
- name: env_noise_musan.1
num_bytes: 1160858614.324
num_examples: 2426
- name: env_noise_musan.2
num_bytes: 1160858614.324
num_examples: 2426
- name: env_noise_musan.3
num_bytes: 1160858614.324
num_examples: 2426
- name: env_noise_wham.3
num_bytes: 1160858614.324
num_examples: 2426
- name: pitch_down.3
num_bytes: 1160858614.324
num_examples: 2426
- name: rir.1
num_bytes: 1235965442.324
num_examples: 2426
- name: rir.2
num_bytes: 1273085442.324
num_examples: 2426
- name: rir.3
num_bytes: 1284653442.324
num_examples: 2426
- name: real_rir.1
num_bytes: 1174422106.324
num_examples: 2426
- name: real_rir.2
num_bytes: 1226129514.324
num_examples: 2426
- name: resample.1
num_bytes: 1160858656.324
num_examples: 2426
- name: resample.2
num_bytes: 1160858642.324
num_examples: 2426
- name: resample.3
num_bytes: 1160858694.324
num_examples: 2426
- name: gain.1
num_bytes: 1160858614.324
num_examples: 2426
- name: gain.2
num_bytes: 1160858614.324
num_examples: 2426
- name: gain.3
num_bytes: 1160858614.324
num_examples: 2426
- name: echo.1
num_bytes: 1170562614.324
num_examples: 2426
- name: echo.2
num_bytes: 1180266614.324
num_examples: 2426
- name: echo.3
num_bytes: 1199674614.324
num_examples: 2426
- name: phaser.1
num_bytes: 1160858614.324
num_examples: 2426
- name: phaser.2
num_bytes: 1160858614.324
num_examples: 2426
- name: phaser.3
num_bytes: 1160858614.324
num_examples: 2426
- name: tempo_up.1
num_bytes: 928910510.324
num_examples: 2426
- name: tempo_up.2
num_bytes: 774278396.324
num_examples: 2426
- name: tempo_up.3
num_bytes: 663826914.324
num_examples: 2426
- name: tempo_down.1
num_bytes: 1326535834.324
num_examples: 2426
- name: tempo_down.2
num_bytes: 1547438832.324
num_examples: 2426
- name: tempo_down.3
num_bytes: 1856702944.324
num_examples: 2426
- name: lowpass.1
num_bytes: 1160858614.324
num_examples: 2426
- name: lowpass.2
num_bytes: 1160858614.324
num_examples: 2426
- name: lowpass.3
num_bytes: 1160858614.324
num_examples: 2426
- name: highpass.1
num_bytes: 1160858614.324
num_examples: 2426
- name: highpass.2
num_bytes: 1160858614.324
num_examples: 2426
- name: highpass.3
num_bytes: 1160858614.324
num_examples: 2426
- name: music.1
num_bytes: 1160858614.324
num_examples: 2426
- name: music.2
num_bytes: 1160858614.324
num_examples: 2426
- name: music.3
num_bytes: 1160858614.324
num_examples: 2426
- name: crosstalk.1
num_bytes: 1160858614.324
num_examples: 2426
- name: crosstalk.2
num_bytes: 1160858614.324
num_examples: 2426
- name: crosstalk.3
num_bytes: 1160858614.324
num_examples: 2426
- name: tremolo.1
num_bytes: 1160858614.324
num_examples: 2426
- name: tremolo.2
num_bytes: 1160858614.324
num_examples: 2426
- name: tremolo.3
num_bytes: 1160858614.324
num_examples: 2426
- name: treble.1
num_bytes: 1160858614.324
num_examples: 2426
- name: treble.2
num_bytes: 1160858614.324
num_examples: 2426
- name: treble.3
num_bytes: 1160858614.324
num_examples: 2426
- name: bass.1
num_bytes: 1160858614.324
num_examples: 2426
- name: bass.2
num_bytes: 1160858614.324
num_examples: 2426
- name: bass.3
num_bytes: 1160858614.324
num_examples: 2426
- name: chorus.1
num_bytes: 1164119158.324
num_examples: 2426
- name: chorus.2
num_bytes: 1165671798.324
num_examples: 2426
- name: chorus.3
num_bytes: 1167224438.324
num_examples: 2426
- name: gnoise.4
num_bytes: 1160858614.324
num_examples: 2426
- name: env_noise.4
num_bytes: 1160858614.324
num_examples: 2426
- name: env_noise_esc50.4
num_bytes: 1160858614.324
num_examples: 2426
- name: env_noise_musan.4
num_bytes: 1160858614.324
num_examples: 2426
- name: env_noise_wham.4
num_bytes: 1160858614.324
num_examples: 2426
- name: speedup.4
num_bytes: 580988352.324
num_examples: 2426
- name: slowdown.4
num_bytes: 2320599166.324
num_examples: 2426
- name: pitch_up.4
num_bytes: 1160858614.324
num_examples: 2426
- name: pitch_down.4
num_bytes: 1160858614.324
num_examples: 2426
- name: rir.4
num_bytes: 1302669442.324
num_examples: 2426
- name: real_rir.4
num_bytes: 2020765820.324
num_examples: 2426
- name: resample.4
num_bytes: 1160858814.324
num_examples: 2426
- name: gain.4
num_bytes: 1160858614.324
num_examples: 2426
- name: echo.4
num_bytes: 1238490614.324
num_examples: 2426
- name: phaser.4
num_bytes: 1160858614.324
num_examples: 2426
- name: tempo_up.4
num_bytes: 580988352.324
num_examples: 2426
- name: tempo_down.4
num_bytes: 2320599166.324
num_examples: 2426
- name: lowpass.4
num_bytes: 1160858614.324
num_examples: 2426
- name: highpass.4
num_bytes: 1160858614.324
num_examples: 2426
- name: music.4
num_bytes: 1160858614.324
num_examples: 2426
- name: crosstalk.4
num_bytes: 1160858614.324
num_examples: 2426
- name: tremolo.4
num_bytes: 1160858614.324
num_examples: 2426
- name: treble.4
num_bytes: 1160858614.324
num_examples: 2426
- name: bass.4
num_bytes: 1160858614.324
num_examples: 2426
- name: chorus.4
num_bytes: 1168777078.324
num_examples: 2426
download_size: 121459263523
dataset_size: 119151206300.40016
- config_name: multilingual_librispeech-german_test
features:
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: original_path
dtype: string
- name: begin_time
dtype: float64
- name: end_time
dtype: float64
- name: audio_duration
dtype: float64
- name: speaker_id
dtype: string
- name: chapter_id
dtype: string
- name: file
dtype: string
- name: id
dtype: string
- name: text
dtype: string
splits:
- name: gnoise.1
num_bytes: 1648113341.356
num_examples: 3394
- name: gnoise.2
num_bytes: 1648113341.356
num_examples: 3394
- name: gnoise.3
num_bytes: 1648113341.356
num_examples: 3394
- name: env_noise.1
num_bytes: 1648113341.356
num_examples: 3394
- name: env_noise.2
num_bytes: 1648113341.356
num_examples: 3394
- name: env_noise.3
num_bytes: 1648113341.356
num_examples: 3394
- name: env_noise_esc50.1
num_bytes: 1648113341.356
num_examples: 3394
- name: env_noise_esc50.2
num_bytes: 1648113341.356
num_examples: 3394
- name: env_noise_esc50.3
num_bytes: 1648113341.356
num_examples: 3394
- name: env_noise_musan.1
num_bytes: 1648113341.356
num_examples: 3394
- name: env_noise_musan.2
num_bytes: 1648113341.356
num_examples: 3394
- name: env_noise_musan.3
num_bytes: 1648113341.356
num_examples: 3394
- name: env_noise_wham.1
num_bytes: 1648113341.356
num_examples: 3394
- name: env_noise_wham.2
num_bytes: 1648113341.356
num_examples: 3394
- name: env_noise_wham.3
num_bytes: 1648113341.356
num_examples: 3394
- name: speedup.1
num_bytes: 1318802109.356
num_examples: 3394
- name: speedup.2
num_bytes: 1099263673.356
num_examples: 3394
- name: speedup.3
num_bytes: 942449495.356
num_examples: 3394
- name: slowdown.1
num_bytes: 1883338719.356
num_examples: 3394
- name: slowdown.2
num_bytes: 2196967643.356
num_examples: 3394
- name: slowdown.3
num_bytes: 2636047081.356
num_examples: 3394
- name: pitch_up.1
num_bytes: 1648113341.356
num_examples: 3394
- name: pitch_up.2
num_bytes: 1648113341.356
num_examples: 3394
- name: pitch_up.3
num_bytes: 1648113341.356
num_examples: 3394
- name: pitch_down.1
num_bytes: 1648113341.356
num_examples: 3394
- name: pitch_down.2
num_bytes: 1648113341.356
num_examples: 3394
- name: pitch_down.3
num_bytes: 1648113341.356
num_examples: 3394
- name: rir.1
num_bytes: 1755612473.356
num_examples: 3394
- name: rir.2
num_bytes: 1806508473.356
num_examples: 3394
- name: rir.3
num_bytes: 1821740473.356
num_examples: 3394
- name: real_rir.1
num_bytes: 1666887689.356
num_examples: 3394
- name: real_rir.2
num_bytes: 1738836201.356
num_examples: 3394
- name: real_rir.3
num_bytes: 1764380853.356
num_examples: 3394
- name: resample.1
num_bytes: 1648113369.356
num_examples: 3394
- name: resample.2
num_bytes: 1648113363.356
num_examples: 3394
- name: resample.3
num_bytes: 1648113411.356
num_examples: 3394
- name: gain.1
num_bytes: 1648113341.356
num_examples: 3394
- name: gain.2
num_bytes: 1648113341.356
num_examples: 3394
- name: gain.3
num_bytes: 1648113341.356
num_examples: 3394
- name: echo.1
num_bytes: 1661689341.356
num_examples: 3394
- name: echo.2
num_bytes: 1675265341.356
num_examples: 3394
- name: echo.3
num_bytes: 1702417341.356
num_examples: 3394
- name: phaser.1
num_bytes: 1648113341.356
num_examples: 3394
- name: phaser.2
num_bytes: 1648113341.356
num_examples: 3394
- name: phaser.3
num_bytes: 1648113341.356
num_examples: 3394
- name: tempo_up.1
num_bytes: 1318802103.356
num_examples: 3394
- name: tempo_up.2
num_bytes: 1099261101.356
num_examples: 3394
- name: tempo_up.3
num_bytes: 942446355.356
num_examples: 3394
- name: tempo_down.1
num_bytes: 1883335523.356
num_examples: 3394
- name: tempo_down.2
num_bytes: 2196965581.356
num_examples: 3394
- name: tempo_down.3
num_bytes: 2636047065.356
num_examples: 3394
- name: lowpass.1
num_bytes: 1648113341.356
num_examples: 3394
- name: lowpass.2
num_bytes: 1648113341.356
num_examples: 3394
- name: lowpass.3
num_bytes: 1648113341.356
num_examples: 3394
- name: highpass.1
num_bytes: 1648113341.356
num_examples: 3394
- name: highpass.2
num_bytes: 1648113341.356
num_examples: 3394
- name: highpass.3
num_bytes: 1648113341.356
num_examples: 3394
- name: music.1
num_bytes: 1648113341.356
num_examples: 3394
- name: music.2
num_bytes: 1648113341.356
num_examples: 3394
- name: music.3
num_bytes: 1648113341.356
num_examples: 3394
- name: crosstalk.1
num_bytes: 1648113341.356
num_examples: 3394
- name: crosstalk.2
num_bytes: 1648113341.356
num_examples: 3394
- name: crosstalk.3
num_bytes: 1648113341.356
num_examples: 3394
- name: tremolo.1
num_bytes: 1648113341.356
num_examples: 3394
- name: tremolo.2
num_bytes: 1648113341.356
num_examples: 3394
- name: tremolo.3
num_bytes: 1648113341.356
num_examples: 3394
- name: treble.1
num_bytes: 1648113341.356
num_examples: 3394
- name: treble.2
num_bytes: 1648113341.356
num_examples: 3394
- name: treble.3
num_bytes: 1648113341.356
num_examples: 3394
- name: bass.1
num_bytes: 1648113341.356
num_examples: 3394
- name: bass.2
num_bytes: 1648113341.356
num_examples: 3394
- name: bass.3
num_bytes: 1648113341.356
num_examples: 3394
- name: chorus.1
num_bytes: 1652674877.356
num_examples: 3394
- name: chorus.2
num_bytes: 1654847037.356
num_examples: 3394
- name: chorus.3
num_bytes: 1657019197.356
num_examples: 3394
- name: gnoise.4
num_bytes: 1648113341.356
num_examples: 3394
- name: env_noise.4
num_bytes: 1648113341.356
num_examples: 3394
- name: env_noise_esc50.4
num_bytes: 1648113341.356
num_examples: 3394
- name: env_noise_musan.4
num_bytes: 1648113341.356
num_examples: 3394
- name: env_noise_wham.4
num_bytes: 1648113341.356
num_examples: 3394
- name: speedup.4
num_bytes: 824835247.356
num_examples: 3394
- name: slowdown.4
num_bytes: 3294669551.356
num_examples: 3394
- name: pitch_up.4
num_bytes: 1648113341.356
num_examples: 3394
- name: pitch_down.4
num_bytes: 1648113341.356
num_examples: 3394
- name: rir.4
num_bytes: 1846956473.356
num_examples: 3394
- name: real_rir.4
num_bytes: 2846504095.356
num_examples: 3394
- name: resample.4
num_bytes: 1648113451.356
num_examples: 3394
- name: gain.4
num_bytes: 1648113341.356
num_examples: 3394
- name: echo.4
num_bytes: 1756721341.356
num_examples: 3394
- name: phaser.4
num_bytes: 1648113341.356
num_examples: 3394
- name: tempo_up.4
num_bytes: 824835247.356
num_examples: 3394
- name: tempo_down.4
num_bytes: 3294669551.356
num_examples: 3394
- name: lowpass.4
num_bytes: 1648113341.356
num_examples: 3394
- name: highpass.4
num_bytes: 1648113341.356
num_examples: 3394
- name: music.4
num_bytes: 1648113341.356
num_examples: 3394
- name: crosstalk.4
num_bytes: 1648113341.356
num_examples: 3394
- name: tremolo.4
num_bytes: 1648113341.356
num_examples: 3394
- name: treble.4
num_bytes: 1648113341.356
num_examples: 3394
- name: bass.4
num_bytes: 1648113341.356
num_examples: 3394
- name: chorus.4
num_bytes: 1659191357.356
num_examples: 3394
download_size: 163104340817
dataset_size: 169131696059.59995
- config_name: multilingual_librispeech-spanish_test
features:
- name: file
dtype: string
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: text
dtype: string
- name: speaker_id
dtype: int64
- name: chapter_id
dtype: int64
- name: id
dtype: string
splits:
- name: None.0
num_bytes: 596762288.01
num_examples: 2385
- name: env_noise.1
num_bytes: 1153485830.17
num_examples: 2385
- name: env_noise.2
num_bytes: 1153485830.17
num_examples: 2385
- name: env_noise.3
num_bytes: 1153485830.17
num_examples: 2385
- name: env_noise.4
num_bytes: 1153485830.17
num_examples: 2385
- name: rir.1
num_bytes: 1268493860.17
num_examples: 2385
- name: rir.2
num_bytes: 1252109860.17
num_examples: 2385
- name: rir.3
num_bytes: 1249517860.17
num_examples: 2385
- name: rir.4
num_bytes: 1222893860.17
num_examples: 2385
- name: speedup.1
num_bytes: 923001764.17
num_examples: 2385
- name: speedup.2
num_bytes: 769347364.17
num_examples: 2385
- name: speedup.3
num_bytes: 659593516.17
num_examples: 2385
- name: speedup.4
num_bytes: 577275652.17
num_examples: 2385
- name: slowdown.1
num_bytes: 1318119422.17
num_examples: 2385
- name: slowdown.2
num_bytes: 1537627530.17
num_examples: 2385
- name: slowdown.3
num_bytes: 1844938056.17
num_examples: 2385
- name: slowdown.4
num_bytes: 2305906194.17
num_examples: 2385
- name: pitch_up.3
num_bytes: 1153485830.17
num_examples: 2385
- name: pitch_up.4
num_bytes: 1153485830.17
num_examples: 2385
- name: pitch_down.1
num_bytes: 1153485830.17
num_examples: 2385
- name: pitch_down.2
num_bytes: 1153485830.17
num_examples: 2385
- name: pitch_down.3
num_bytes: 1153485830.17
num_examples: 2385
- name: pitch_down.4
num_bytes: 1153485830.17
num_examples: 2385
- name: pitch_up.1
num_bytes: 1153485821.72
num_examples: 2385
- name: pitch_up.2
num_bytes: 1153485821.72
num_examples: 2385
- name: resample.2
num_bytes: 1153485842.17
num_examples: 2385
- name: gain.1
num_bytes: 1153485830.17
num_examples: 2385
- name: gain.2
num_bytes: 1153485830.17
num_examples: 2385
- name: gain.3
num_bytes: 1153485830.17
num_examples: 2385
- name: gain.4
num_bytes: 1153485830.17
num_examples: 2385
- name: echo.1
num_bytes: 1163025830.17
num_examples: 2385
- name: echo.2
num_bytes: 1172565830.17
num_examples: 2385
- name: echo.3
num_bytes: 1191645830.17
num_examples: 2385
- name: echo.4
num_bytes: 1229805830.17
num_examples: 2385
- name: tempo_up.1
num_bytes: 923001758.17
num_examples: 2385
- name: tempo_up.2
num_bytes: 769345632.17
num_examples: 2385
- name: tempo_up.3
num_bytes: 659591372.17
num_examples: 2385
- name: tempo_up.4
num_bytes: 577275652.17
num_examples: 2385
- name: tempo_down.1
num_bytes: 1318117252.17
num_examples: 2385
- name: tempo_down.2
num_bytes: 1537626028.17
num_examples: 2385
- name: tempo_down.3
num_bytes: 1844938048.17
num_examples: 2385
- name: tempo_down.4
num_bytes: 2305906194.17
num_examples: 2385
- name: phaser.1
num_bytes: 1153485830.17
num_examples: 2385
- name: phaser.2
num_bytes: 1153485830.17
num_examples: 2385
- name: phaser.3
num_bytes: 1153485830.17
num_examples: 2385
- name: phaser.4
num_bytes: 1153485830.17
num_examples: 2385
- name: resample.1
num_bytes: 1153485840.17
num_examples: 2385
- name: resample.3
num_bytes: 1153485850.17
num_examples: 2385
- name: resample.4
num_bytes: 1153485882.17
num_examples: 2385
- name: lowpass.1
num_bytes: 1153485830.17
num_examples: 2385
- name: lowpass.2
num_bytes: 1153485830.17
num_examples: 2385
- name: lowpass.3
num_bytes: 1153485830.17
num_examples: 2385
- name: lowpass.4
num_bytes: 1153485830.17
num_examples: 2385
- name: highpass.1
num_bytes: 1153485830.17
num_examples: 2385
- name: highpass.2
num_bytes: 1153485830.17
num_examples: 2385
- name: highpass.3
num_bytes: 1153485830.17
num_examples: 2385
- name: highpass.4
num_bytes: 1153485830.17
num_examples: 2385
- name: gnoise.1
num_bytes: 1153485822.49
num_examples: 2385
- name: gnoise.2
num_bytes: 1153485822.49
num_examples: 2385
- name: gnoise.3
num_bytes: 1153485822.49
num_examples: 2385
- name: gnoise.4
num_bytes: 1153485822.49
num_examples: 2385
- name: env_noise_esc50.1
num_bytes: 1153485822.49
num_examples: 2385
- name: env_noise_esc50.2
num_bytes: 1153485822.49
num_examples: 2385
- name: env_noise_esc50.3
num_bytes: 1153485822.49
num_examples: 2385
- name: env_noise_esc50.4
num_bytes: 1153485822.49
num_examples: 2385
- name: env_noise_musan.1
num_bytes: 1153485822.49
num_examples: 2385
- name: env_noise_musan.2
num_bytes: 1153485822.49
num_examples: 2385
- name: env_noise_musan.3
num_bytes: 1153485822.49
num_examples: 2385
- name: env_noise_musan.4
num_bytes: 1153485822.49
num_examples: 2385
- name: music.1
num_bytes: 1153485822.49
num_examples: 2385
- name: music.2
num_bytes: 1153485822.49
num_examples: 2385
- name: music.3
num_bytes: 1153485822.49
num_examples: 2385
- name: music.4
num_bytes: 1153485822.49
num_examples: 2385
- name: crosstalk.1
num_bytes: 1153485822.49
num_examples: 2385
- name: crosstalk.2
num_bytes: 1153485822.49
num_examples: 2385
- name: crosstalk.3
num_bytes: 1153485822.49
num_examples: 2385
- name: crosstalk.4
num_bytes: 1153485822.49
num_examples: 2385
- name: env_noise_wham.1
num_bytes: 1153485822.49
num_examples: 2385
- name: env_noise_wham.2
num_bytes: 1153485822.49
num_examples: 2385
- name: env_noise_wham.3
num_bytes: 1153485822.49
num_examples: 2385
- name: env_noise_wham.4
num_bytes: 1153485822.49
num_examples: 2385
- name: tremolo.1
num_bytes: 1153485822.49
num_examples: 2385
- name: tremolo.2
num_bytes: 1153485822.49
num_examples: 2385
- name: tremolo.4
num_bytes: 1153485822.49
num_examples: 2385
- name: treble.1
num_bytes: 1153485822.49
num_examples: 2385
- name: treble.2
num_bytes: 1153485822.49
num_examples: 2385
- name: treble.3
num_bytes: 1153485822.49
num_examples: 2385
- name: treble.4
num_bytes: 1153485822.49
num_examples: 2385
- name: bass.1
num_bytes: 1153485822.49
num_examples: 2385
- name: bass.2
num_bytes: 1153485822.49
num_examples: 2385
- name: bass.3
num_bytes: 1153485822.49
num_examples: 2385
- name: bass.4
num_bytes: 1153485822.49
num_examples: 2385
- name: chorus.1
num_bytes: 1156691262.49
num_examples: 2385
- name: chorus.2
num_bytes: 1158217662.49
num_examples: 2385
- name: chorus.3
num_bytes: 1159744062.49
num_examples: 2385
- name: chorus.4
num_bytes: 1161270462.49
num_examples: 2385
- name: tremolo.3
num_bytes: 1153485822.49
num_examples: 2385
- name: voice_conversion_bark.1
num_bytes: 1457427139.875
num_examples: 2385
download_size: 119056891470
dataset_size: 114748819328.10516
- config_name: multilingual_librispeech-spanish_test_pertEval_500_30
features:
- name: file
dtype: string
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: text
dtype: string
- name: speaker_id
dtype: int64
- name: chapter_id
dtype: int64
- name: id
dtype: string
- name: pert_idx
dtype: int64
splits:
- name: gnoise.1
num_bytes: 7341021960.0
num_examples: 15000
- name: env_noise_esc50.1
num_bytes: 7341021960.0
num_examples: 15000
download_size: 14645523867
dataset_size: 14682043920.0
- config_name: tedlium-release3_test
features:
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: text
dtype: string
- name: speaker_id
dtype: string
- name: gender
dtype:
class_label:
names:
'0': unknown
'1': female
'2': male
- name: file
dtype: string
- name: id
dtype: string
splits:
- name: None.0
num_bytes: 277376247.9680054
num_examples: 1155
- name: speedup.1
num_bytes: 221990159.49965963
num_examples: 1155
- name: speedup.2
num_bytes: 185066240.47311097
num_examples: 1155
- name: speedup.3
num_bytes: 158691929.4792376
num_examples: 1155
- name: slowdown.1
num_bytes: 316938966.95371
num_examples: 1155
- name: slowdown.2
num_bytes: 369687787.0762423
num_examples: 1155
- name: slowdown.3
num_bytes: 443535996.23893803
num_examples: 1155
- name: pitch_up.1
num_bytes: 277376247.9680054
num_examples: 1155
- name: pitch_up.2
num_bytes: 277376247.9680054
num_examples: 1155
- name: pitch_up.3
num_bytes: 277376247.9680054
num_examples: 1155
- name: pitch_down.1
num_bytes: 277376247.9680054
num_examples: 1155
- name: pitch_down.2
num_bytes: 277376247.9680054
num_examples: 1155
- name: pitch_down.3
num_bytes: 277376247.9680054
num_examples: 1155
- name: rir.1
num_bytes: 313788218.1586113
num_examples: 1155
- name: rir.2
num_bytes: 330268000.32334924
num_examples: 1155
- name: rir.3
num_bytes: 336608313.46153843
num_examples: 1155
- name: voice_conversion_vctk.1
num_bytes: 216990920.87134105
num_examples: 1155
- name: resample.1
num_bytes: 277376301.4329476
num_examples: 1155
- name: resample.2
num_bytes: 277376301.4329476
num_examples: 1155
- name: resample.3
num_bytes: 277376354.89788973
num_examples: 1155
- name: gain.1
num_bytes: 277376247.9680054
num_examples: 1155
- name: gain.2
num_bytes: 277376247.9680054
num_examples: 1155
- name: gain.3
num_bytes: 277376247.9680054
num_examples: 1155
- name: echo.1
num_bytes: 281996247.9680054
num_examples: 1155
- name: echo.2
num_bytes: 286616247.9680054
num_examples: 1155
- name: echo.3
num_bytes: 295856247.9680054
num_examples: 1155
- name: phaser.1
num_bytes: 277376247.9680054
num_examples: 1155
- name: phaser.2
num_bytes: 277376247.9680054
num_examples: 1155
- name: phaser.3
num_bytes: 277376247.9680054
num_examples: 1155
- name: tempo_up.1
num_bytes: 221989786.81756297
num_examples: 1155
- name: tempo_up.2
num_bytes: 185065496.68141592
num_examples: 1155
- name: tempo_up.3
num_bytes: 158690987.55275697
num_examples: 1155
- name: tempo_down.1
num_bytes: 316938020.3097345
num_examples: 1155
- name: tempo_down.2
num_bytes: 369686999.254595
num_examples: 1155
- name: tempo_down.3
num_bytes: 443535631.41933286
num_examples: 1155
- name: lowpass.1
num_bytes: 277376247.9680054
num_examples: 1155
- name: lowpass.2
num_bytes: 277376247.9680054
num_examples: 1155
- name: lowpass.3
num_bytes: 277376247.9680054
num_examples: 1155
- name: highpass.1
num_bytes: 277376247.9680054
num_examples: 1155
- name: highpass.2
num_bytes: 277376247.9680054
num_examples: 1155
- name: highpass.3
num_bytes: 277376247.9680054
num_examples: 1155
- name: speedup.4
num_bytes: 138910125.75561607
num_examples: 1155
- name: slowdown.4
num_bytes: 554308545.8577263
num_examples: 1155
- name: pitch_up.4
num_bytes: 277376247.9680054
num_examples: 1155
- name: pitch_down.4
num_bytes: 277376247.9680054
num_examples: 1155
- name: rir.4
num_bytes: 345514943.8223281
num_examples: 1155
- name: resample.4
num_bytes: 277376474.4077604
num_examples: 1155
- name: gain.4
num_bytes: 277376247.9680054
num_examples: 1155
- name: echo.4
num_bytes: 314336247.9680054
num_examples: 1155
- name: phaser.4
num_bytes: 277376247.9680054
num_examples: 1155
- name: tempo_up.4
num_bytes: 138910125.75561607
num_examples: 1155
- name: tempo_down.4
num_bytes: 554308545.8577263
num_examples: 1155
- name: lowpass.4
num_bytes: 277376247.9680054
num_examples: 1155
- name: highpass.4
num_bytes: 277376247.9680054
num_examples: 1155
- name: gnoise.1
num_bytes: 277376247.9680054
num_examples: 1155
- name: gnoise.2
num_bytes: 277376247.9680054
num_examples: 1155
- name: gnoise.3
num_bytes: 277376247.9680054
num_examples: 1155
- name: music.1
num_bytes: 301958728.16
num_examples: 1155
- name: music.2
num_bytes: 301958728.16
num_examples: 1155
- name: music.3
num_bytes: 301958728.16
num_examples: 1155
- name: music.4
num_bytes: 301958728.16
num_examples: 1155
- name: crosstalk.1
num_bytes: 301958728.16
num_examples: 1155
- name: env_noise_esc50.1
num_bytes: 277376247.9680054
num_examples: 1155
- name: env_noise_esc50.2
num_bytes: 277376247.9680054
num_examples: 1155
- name: env_noise_esc50.3
num_bytes: 277376247.9680054
num_examples: 1155
- name: gnoise.4
num_bytes: 277376247.9680054
num_examples: 1155
- name: crosstalk.2
num_bytes: 301958728.16
num_examples: 1155
- name: env_noise_esc50.4
num_bytes: 277376247.9680054
num_examples: 1155
- name: crosstalk.3
num_bytes: 301958728.16
num_examples: 1155
- name: crosstalk.4
num_bytes: 301958728.16
num_examples: 1155
- name: env_noise_musan.1
num_bytes: 301958728.16
num_examples: 1155
- name: env_noise_musan.2
num_bytes: 301958728.16
num_examples: 1155
- name: env_noise_musan.3
num_bytes: 301958728.16
num_examples: 1155
- name: env_noise_musan.4
num_bytes: 301958728.16
num_examples: 1155
- name: real_rir.1
num_bytes: 308750878.16
num_examples: 1155
- name: real_rir.2
num_bytes: 333286988.16
num_examples: 1155
- name: real_rir.3
num_bytes: 341205738.16
num_examples: 1155
- name: real_rir.4
num_bytes: 715155314.16
num_examples: 1155
- name: env_noise.1
num_bytes: 301958728.16
num_examples: 1155
- name: env_noise.2
num_bytes: 301958728.16
num_examples: 1155
- name: env_noise.3
num_bytes: 301958728.16
num_examples: 1155
- name: env_noise.4
num_bytes: 301958728.16
num_examples: 1155
- name: env_noise_wham.1
num_bytes: 301958728.16
num_examples: 1155
- name: env_noise_wham.2
num_bytes: 301958728.16
num_examples: 1155
- name: env_noise_wham.3
num_bytes: 301958728.16
num_examples: 1155
- name: env_noise_wham.4
num_bytes: 301958728.16
num_examples: 1155
- name: tremolo.1
num_bytes: 301958728.16
num_examples: 1155
- name: tremolo.2
num_bytes: 301958728.16
num_examples: 1155
- name: tremolo.3
num_bytes: 301958728.16
num_examples: 1155
- name: tremolo.4
num_bytes: 301958728.16
num_examples: 1155
- name: treble.1
num_bytes: 301958728.16
num_examples: 1155
- name: treble.2
num_bytes: 301958728.16
num_examples: 1155
- name: treble.3
num_bytes: 301958728.16
num_examples: 1155
- name: treble.4
num_bytes: 301958728.16
num_examples: 1155
- name: bass.1
num_bytes: 301958728.16
num_examples: 1155
- name: bass.2
num_bytes: 301958728.16
num_examples: 1155
- name: bass.3
num_bytes: 301958728.16
num_examples: 1155
- name: bass.4
num_bytes: 301958728.16
num_examples: 1155
- name: chorus.1
num_bytes: 303511048.16
num_examples: 1155
- name: chorus.2
num_bytes: 304250248.16
num_examples: 1155
- name: chorus.4
num_bytes: 305728648.16
num_examples: 1155
- name: chorus.3
num_bytes: 304989448.16
num_examples: 1155
download_size: 58723208514
dataset_size: 30342709961.007984
configs:
- config_name: accented_cv
data_files:
- split: test
path: accented_cv/test-*
- split: test.clean
path: accented_cv/test.clean-*
- config_name: accented_cv_es
data_files:
- split: test
path: accented_cv_es/test-*
- config_name: accented_cv_fr
data_files:
- split: test
path: accented_cv_fr/test-*
- config_name: chime
data_files:
- split: farfield
path: chime/farfield-*
- split: nearfield
path: chime/nearfield-*
- config_name: in-the-wild
data_files:
- split: farfield
path: in-the-wild/farfield-*
- split: nearfield
path: in-the-wild/nearfield-*
- config_name: in-the-wild-AMI
data_files:
- split: nearfield
path: in-the-wild-AMI/nearfield-*
- split: farfield
path: in-the-wild-AMI/farfield-*
- config_name: in-the-wild-ami
data_files:
- split: nearfield
path: in-the-wild-ami/nearfield-*
- split: farfield
path: in-the-wild-ami/farfield-*
- config_name: librispeech_asr-test.clean
data_files:
- split: None.0
path: librispeech_asr-test.clean/None.0-*
- split: gnoise.1
path: librispeech_asr-test.clean/gnoise.1-*
- split: gnoise.2
path: librispeech_asr-test.clean/gnoise.2-*
- split: gnoise.3
path: librispeech_asr-test.clean/gnoise.3-*
- split: gnoise.4
path: librispeech_asr-test.clean/gnoise.4-*
- split: env_noise.1
path: librispeech_asr-test.clean/env_noise.1-*
- split: env_noise.2
path: librispeech_asr-test.clean/env_noise.2-*
- split: env_noise.3
path: librispeech_asr-test.clean/env_noise.3-*
- split: env_noise.4
path: librispeech_asr-test.clean/env_noise.4-*
- split: rir.1
path: librispeech_asr-test.clean/rir.1-*
- split: rir.2
path: librispeech_asr-test.clean/rir.2-*
- split: rir.3
path: librispeech_asr-test.clean/rir.3-*
- split: rir.4
path: librispeech_asr-test.clean/rir.4-*
- split: speedup.1
path: librispeech_asr-test.clean/speedup.1-*
- split: speedup.2
path: librispeech_asr-test.clean/speedup.2-*
- split: speedup.3
path: librispeech_asr-test.clean/speedup.3-*
- split: speedup.4
path: librispeech_asr-test.clean/speedup.4-*
- split: slowdown.1
path: librispeech_asr-test.clean/slowdown.1-*
- split: slowdown.2
path: librispeech_asr-test.clean/slowdown.2-*
- split: slowdown.3
path: librispeech_asr-test.clean/slowdown.3-*
- split: slowdown.4
path: librispeech_asr-test.clean/slowdown.4-*
- split: pitch_up.3
path: librispeech_asr-test.clean/pitch_up.3-*
- split: pitch_up.4
path: librispeech_asr-test.clean/pitch_up.4-*
- split: pitch_down.1
path: librispeech_asr-test.clean/pitch_down.1-*
- split: pitch_down.2
path: librispeech_asr-test.clean/pitch_down.2-*
- split: pitch_down.3
path: librispeech_asr-test.clean/pitch_down.3-*
- split: pitch_down.4
path: librispeech_asr-test.clean/pitch_down.4-*
- split: pitch_up.1
path: librispeech_asr-test.clean/pitch_up.1-*
- split: pitch_up.2
path: librispeech_asr-test.clean/pitch_up.2-*
- split: resample.1
path: librispeech_asr-test.clean/resample.1-*
- split: resample.2
path: librispeech_asr-test.clean/resample.2-*
- split: resample.3
path: librispeech_asr-test.clean/resample.3-*
- split: resample.4
path: librispeech_asr-test.clean/resample.4-*
- split: env_noise_esc50.1
path: librispeech_asr-test.clean/env_noise_esc50.1-*
- split: env_noise_esc50.2
path: librispeech_asr-test.clean/env_noise_esc50.2-*
- split: env_noise_esc50.3
path: librispeech_asr-test.clean/env_noise_esc50.3-*
- split: env_noise_esc50.4
path: librispeech_asr-test.clean/env_noise_esc50.4-*
- split: voice_conversion.4
path: librispeech_asr-test.clean/voice_conversion.4-*
- split: voice_conversion.3
path: librispeech_asr-test.clean/voice_conversion.3-*
- split: voice_conversion.1
path: librispeech_asr-test.clean/voice_conversion.1-*
- split: voice_conversion.2
path: librispeech_asr-test.clean/voice_conversion.2-*
- split: gain.1
path: librispeech_asr-test.clean/gain.1-*
- split: gain.2
path: librispeech_asr-test.clean/gain.2-*
- split: gain.3
path: librispeech_asr-test.clean/gain.3-*
- split: echo.1
path: librispeech_asr-test.clean/echo.1-*
- split: echo.2
path: librispeech_asr-test.clean/echo.2-*
- split: echo.3
path: librispeech_asr-test.clean/echo.3-*
- split: echo.4
path: librispeech_asr-test.clean/echo.4-*
- split: phaser.1
path: librispeech_asr-test.clean/phaser.1-*
- split: phaser.2
path: librispeech_asr-test.clean/phaser.2-*
- split: phaser.3
path: librispeech_asr-test.clean/phaser.3-*
- split: tempo_up.1
path: librispeech_asr-test.clean/tempo_up.1-*
- split: tempo_up.2
path: librispeech_asr-test.clean/tempo_up.2-*
- split: tempo_up.3
path: librispeech_asr-test.clean/tempo_up.3-*
- split: tempo_up.4
path: librispeech_asr-test.clean/tempo_up.4-*
- split: tempo_down.1
path: librispeech_asr-test.clean/tempo_down.1-*
- split: tempo_down.2
path: librispeech_asr-test.clean/tempo_down.2-*
- split: tempo_down.3
path: librispeech_asr-test.clean/tempo_down.3-*
- split: tempo_down.4
path: librispeech_asr-test.clean/tempo_down.4-*
- split: gain.4
path: librispeech_asr-test.clean/gain.4-*
- split: lowpass.1
path: librispeech_asr-test.clean/lowpass.1-*
- split: lowpass.2
path: librispeech_asr-test.clean/lowpass.2-*
- split: lowpass.3
path: librispeech_asr-test.clean/lowpass.3-*
- split: lowpass.4
path: librispeech_asr-test.clean/lowpass.4-*
- split: highpass.1
path: librispeech_asr-test.clean/highpass.1-*
- split: highpass.2
path: librispeech_asr-test.clean/highpass.2-*
- split: highpass.3
path: librispeech_asr-test.clean/highpass.3-*
- split: highpass.4
path: librispeech_asr-test.clean/highpass.4-*
- split: phaser.4
path: librispeech_asr-test.clean/phaser.4-*
- split: voice_conversion_vctk.1
path: librispeech_asr-test.clean/voice_conversion_vctk.1-*
- split: universal_adv.1
path: librispeech_asr-test.clean/universal_adv.1-*
- split: music.1
path: librispeech_asr-test.clean/music.1-*
- split: music.2
path: librispeech_asr-test.clean/music.2-*
- split: music.3
path: librispeech_asr-test.clean/music.3-*
- split: music.4
path: librispeech_asr-test.clean/music.4-*
- split: crosstalk.1
path: librispeech_asr-test.clean/crosstalk.1-*
- split: crosstalk.2
path: librispeech_asr-test.clean/crosstalk.2-*
- split: crosstalk.3
path: librispeech_asr-test.clean/crosstalk.3-*
- split: crosstalk.4
path: librispeech_asr-test.clean/crosstalk.4-*
- split: env_noise_musan.1
path: librispeech_asr-test.clean/env_noise_musan.1-*
- split: env_noise_musan.2
path: librispeech_asr-test.clean/env_noise_musan.2-*
- split: env_noise_musan.3
path: librispeech_asr-test.clean/env_noise_musan.3-*
- split: env_noise_musan.4
path: librispeech_asr-test.clean/env_noise_musan.4-*
- split: real_rir.1
path: librispeech_asr-test.clean/real_rir.1-*
- split: real_rir.2
path: librispeech_asr-test.clean/real_rir.2-*
- split: real_rir.3
path: librispeech_asr-test.clean/real_rir.3-*
- split: real_rir.4
path: librispeech_asr-test.clean/real_rir.4-*
- split: env_noise_wham.1
path: librispeech_asr-test.clean/env_noise_wham.1-*
- split: env_noise_wham.2
path: librispeech_asr-test.clean/env_noise_wham.2-*
- split: env_noise_wham.3
path: librispeech_asr-test.clean/env_noise_wham.3-*
- split: env_noise_wham.4
path: librispeech_asr-test.clean/env_noise_wham.4-*
- split: tremolo.1
path: librispeech_asr-test.clean/tremolo.1-*
- split: tremolo.2
path: librispeech_asr-test.clean/tremolo.2-*
- split: tremolo.3
path: librispeech_asr-test.clean/tremolo.3-*
- split: tremolo.4
path: librispeech_asr-test.clean/tremolo.4-*
- split: treble.1
path: librispeech_asr-test.clean/treble.1-*
- split: treble.2
path: librispeech_asr-test.clean/treble.2-*
- split: treble.3
path: librispeech_asr-test.clean/treble.3-*
- split: treble.4
path: librispeech_asr-test.clean/treble.4-*
- split: bass.1
path: librispeech_asr-test.clean/bass.1-*
- split: bass.2
path: librispeech_asr-test.clean/bass.2-*
- split: bass.3
path: librispeech_asr-test.clean/bass.3-*
- split: bass.4
path: librispeech_asr-test.clean/bass.4-*
- split: chorus.1
path: librispeech_asr-test.clean/chorus.1-*
- split: chorus.2
path: librispeech_asr-test.clean/chorus.2-*
- split: chorus.3
path: librispeech_asr-test.clean/chorus.3-*
- split: chorus.4
path: librispeech_asr-test.clean/chorus.4-*
- config_name: librispeech_asr-test.clean_pertEval_500_30
data_files:
- split: gnoise.1
path: librispeech_asr-test.clean_pertEval_500_30/gnoise.1-*
- split: env_noise_esc50.1
path: librispeech_asr-test.clean_pertEval_500_30/env_noise_esc50.1-*
- config_name: multilingual_librispeech-french_test
data_files:
- split: gnoise.1
path: multilingual_librispeech-french_test/gnoise.1-*
- split: gnoise.2
path: multilingual_librispeech-french_test/gnoise.2-*
- split: gnoise.3
path: multilingual_librispeech-french_test/gnoise.3-*
- split: speedup.1
path: multilingual_librispeech-french_test/speedup.1-*
- split: speedup.2
path: multilingual_librispeech-french_test/speedup.2-*
- split: speedup.3
path: multilingual_librispeech-french_test/speedup.3-*
- split: slowdown.1
path: multilingual_librispeech-french_test/slowdown.1-*
- split: slowdown.2
path: multilingual_librispeech-french_test/slowdown.2-*
- split: slowdown.3
path: multilingual_librispeech-french_test/slowdown.3-*
- split: pitch_up.1
path: multilingual_librispeech-french_test/pitch_up.1-*
- split: pitch_up.2
path: multilingual_librispeech-french_test/pitch_up.2-*
- split: pitch_up.3
path: multilingual_librispeech-french_test/pitch_up.3-*
- split: pitch_down.1
path: multilingual_librispeech-french_test/pitch_down.1-*
- split: pitch_down.2
path: multilingual_librispeech-french_test/pitch_down.2-*
- split: env_noise.1
path: multilingual_librispeech-french_test/env_noise.1-*
- split: env_noise.3
path: multilingual_librispeech-french_test/env_noise.3-*
- split: env_noise_wham.1
path: multilingual_librispeech-french_test/env_noise_wham.1-*
- split: env_noise_wham.2
path: multilingual_librispeech-french_test/env_noise_wham.2-*
- split: real_rir.3
path: multilingual_librispeech-french_test/real_rir.3-*
- split: env_noise.2
path: multilingual_librispeech-french_test/env_noise.2-*
- split: env_noise_esc50.1
path: multilingual_librispeech-french_test/env_noise_esc50.1-*
- split: env_noise_esc50.2
path: multilingual_librispeech-french_test/env_noise_esc50.2-*
- split: env_noise_esc50.3
path: multilingual_librispeech-french_test/env_noise_esc50.3-*
- split: env_noise_musan.1
path: multilingual_librispeech-french_test/env_noise_musan.1-*
- split: env_noise_musan.2
path: multilingual_librispeech-french_test/env_noise_musan.2-*
- split: env_noise_musan.3
path: multilingual_librispeech-french_test/env_noise_musan.3-*
- split: env_noise_wham.3
path: multilingual_librispeech-french_test/env_noise_wham.3-*
- split: pitch_down.3
path: multilingual_librispeech-french_test/pitch_down.3-*
- split: rir.1
path: multilingual_librispeech-french_test/rir.1-*
- split: rir.2
path: multilingual_librispeech-french_test/rir.2-*
- split: rir.3
path: multilingual_librispeech-french_test/rir.3-*
- split: real_rir.1
path: multilingual_librispeech-french_test/real_rir.1-*
- split: real_rir.2
path: multilingual_librispeech-french_test/real_rir.2-*
- split: resample.1
path: multilingual_librispeech-french_test/resample.1-*
- split: resample.2
path: multilingual_librispeech-french_test/resample.2-*
- split: resample.3
path: multilingual_librispeech-french_test/resample.3-*
- split: gain.1
path: multilingual_librispeech-french_test/gain.1-*
- split: gain.2
path: multilingual_librispeech-french_test/gain.2-*
- split: gain.3
path: multilingual_librispeech-french_test/gain.3-*
- split: echo.1
path: multilingual_librispeech-french_test/echo.1-*
- split: echo.2
path: multilingual_librispeech-french_test/echo.2-*
- split: echo.3
path: multilingual_librispeech-french_test/echo.3-*
- split: phaser.1
path: multilingual_librispeech-french_test/phaser.1-*
- split: phaser.2
path: multilingual_librispeech-french_test/phaser.2-*
- split: phaser.3
path: multilingual_librispeech-french_test/phaser.3-*
- split: tempo_up.1
path: multilingual_librispeech-french_test/tempo_up.1-*
- split: tempo_up.2
path: multilingual_librispeech-french_test/tempo_up.2-*
- split: tempo_up.3
path: multilingual_librispeech-french_test/tempo_up.3-*
- split: tempo_down.1
path: multilingual_librispeech-french_test/tempo_down.1-*
- split: tempo_down.2
path: multilingual_librispeech-french_test/tempo_down.2-*
- split: tempo_down.3
path: multilingual_librispeech-french_test/tempo_down.3-*
- split: lowpass.1
path: multilingual_librispeech-french_test/lowpass.1-*
- split: lowpass.2
path: multilingual_librispeech-french_test/lowpass.2-*
- split: lowpass.3
path: multilingual_librispeech-french_test/lowpass.3-*
- split: highpass.1
path: multilingual_librispeech-french_test/highpass.1-*
- split: highpass.2
path: multilingual_librispeech-french_test/highpass.2-*
- split: highpass.3
path: multilingual_librispeech-french_test/highpass.3-*
- split: music.1
path: multilingual_librispeech-french_test/music.1-*
- split: music.2
path: multilingual_librispeech-french_test/music.2-*
- split: music.3
path: multilingual_librispeech-french_test/music.3-*
- split: crosstalk.1
path: multilingual_librispeech-french_test/crosstalk.1-*
- split: crosstalk.2
path: multilingual_librispeech-french_test/crosstalk.2-*
- split: crosstalk.3
path: multilingual_librispeech-french_test/crosstalk.3-*
- split: tremolo.1
path: multilingual_librispeech-french_test/tremolo.1-*
- split: tremolo.2
path: multilingual_librispeech-french_test/tremolo.2-*
- split: tremolo.3
path: multilingual_librispeech-french_test/tremolo.3-*
- split: treble.1
path: multilingual_librispeech-french_test/treble.1-*
- split: treble.2
path: multilingual_librispeech-french_test/treble.2-*
- split: treble.3
path: multilingual_librispeech-french_test/treble.3-*
- split: bass.1
path: multilingual_librispeech-french_test/bass.1-*
- split: bass.2
path: multilingual_librispeech-french_test/bass.2-*
- split: bass.3
path: multilingual_librispeech-french_test/bass.3-*
- split: chorus.1
path: multilingual_librispeech-french_test/chorus.1-*
- split: chorus.2
path: multilingual_librispeech-french_test/chorus.2-*
- split: chorus.3
path: multilingual_librispeech-french_test/chorus.3-*
- split: gnoise.4
path: multilingual_librispeech-french_test/gnoise.4-*
- split: env_noise.4
path: multilingual_librispeech-french_test/env_noise.4-*
- split: env_noise_esc50.4
path: multilingual_librispeech-french_test/env_noise_esc50.4-*
- split: env_noise_musan.4
path: multilingual_librispeech-french_test/env_noise_musan.4-*
- split: env_noise_wham.4
path: multilingual_librispeech-french_test/env_noise_wham.4-*
- split: speedup.4
path: multilingual_librispeech-french_test/speedup.4-*
- split: slowdown.4
path: multilingual_librispeech-french_test/slowdown.4-*
- split: pitch_up.4
path: multilingual_librispeech-french_test/pitch_up.4-*
- split: pitch_down.4
path: multilingual_librispeech-french_test/pitch_down.4-*
- split: rir.4
path: multilingual_librispeech-french_test/rir.4-*
- split: real_rir.4
path: multilingual_librispeech-french_test/real_rir.4-*
- split: resample.4
path: multilingual_librispeech-french_test/resample.4-*
- split: gain.4
path: multilingual_librispeech-french_test/gain.4-*
- split: echo.4
path: multilingual_librispeech-french_test/echo.4-*
- split: phaser.4
path: multilingual_librispeech-french_test/phaser.4-*
- split: tempo_up.4
path: multilingual_librispeech-french_test/tempo_up.4-*
- split: tempo_down.4
path: multilingual_librispeech-french_test/tempo_down.4-*
- split: lowpass.4
path: multilingual_librispeech-french_test/lowpass.4-*
- split: highpass.4
path: multilingual_librispeech-french_test/highpass.4-*
- split: music.4
path: multilingual_librispeech-french_test/music.4-*
- split: crosstalk.4
path: multilingual_librispeech-french_test/crosstalk.4-*
- split: tremolo.4
path: multilingual_librispeech-french_test/tremolo.4-*
- split: treble.4
path: multilingual_librispeech-french_test/treble.4-*
- split: bass.4
path: multilingual_librispeech-french_test/bass.4-*
- split: chorus.4
path: multilingual_librispeech-french_test/chorus.4-*
- config_name: multilingual_librispeech-german_test
data_files:
- split: gnoise.1
path: multilingual_librispeech-german_test/gnoise.1-*
- split: gnoise.2
path: multilingual_librispeech-german_test/gnoise.2-*
- split: gnoise.3
path: multilingual_librispeech-german_test/gnoise.3-*
- split: env_noise.1
path: multilingual_librispeech-german_test/env_noise.1-*
- split: env_noise.2
path: multilingual_librispeech-german_test/env_noise.2-*
- split: env_noise.3
path: multilingual_librispeech-german_test/env_noise.3-*
- split: env_noise_esc50.1
path: multilingual_librispeech-german_test/env_noise_esc50.1-*
- split: env_noise_esc50.2
path: multilingual_librispeech-german_test/env_noise_esc50.2-*
- split: env_noise_esc50.3
path: multilingual_librispeech-german_test/env_noise_esc50.3-*
- split: env_noise_musan.1
path: multilingual_librispeech-german_test/env_noise_musan.1-*
- split: env_noise_musan.2
path: multilingual_librispeech-german_test/env_noise_musan.2-*
- split: env_noise_musan.3
path: multilingual_librispeech-german_test/env_noise_musan.3-*
- split: env_noise_wham.1
path: multilingual_librispeech-german_test/env_noise_wham.1-*
- split: env_noise_wham.2
path: multilingual_librispeech-german_test/env_noise_wham.2-*
- split: env_noise_wham.3
path: multilingual_librispeech-german_test/env_noise_wham.3-*
- split: speedup.1
path: multilingual_librispeech-german_test/speedup.1-*
- split: speedup.2
path: multilingual_librispeech-german_test/speedup.2-*
- split: speedup.3
path: multilingual_librispeech-german_test/speedup.3-*
- split: slowdown.1
path: multilingual_librispeech-german_test/slowdown.1-*
- split: slowdown.2
path: multilingual_librispeech-german_test/slowdown.2-*
- split: slowdown.3
path: multilingual_librispeech-german_test/slowdown.3-*
- split: pitch_up.1
path: multilingual_librispeech-german_test/pitch_up.1-*
- split: pitch_up.2
path: multilingual_librispeech-german_test/pitch_up.2-*
- split: pitch_up.3
path: multilingual_librispeech-german_test/pitch_up.3-*
- split: pitch_down.1
path: multilingual_librispeech-german_test/pitch_down.1-*
- split: pitch_down.2
path: multilingual_librispeech-german_test/pitch_down.2-*
- split: pitch_down.3
path: multilingual_librispeech-german_test/pitch_down.3-*
- split: rir.1
path: multilingual_librispeech-german_test/rir.1-*
- split: rir.2
path: multilingual_librispeech-german_test/rir.2-*
- split: rir.3
path: multilingual_librispeech-german_test/rir.3-*
- split: real_rir.1
path: multilingual_librispeech-german_test/real_rir.1-*
- split: real_rir.2
path: multilingual_librispeech-german_test/real_rir.2-*
- split: real_rir.3
path: multilingual_librispeech-german_test/real_rir.3-*
- split: resample.1
path: multilingual_librispeech-german_test/resample.1-*
- split: resample.2
path: multilingual_librispeech-german_test/resample.2-*
- split: resample.3
path: multilingual_librispeech-german_test/resample.3-*
- split: gain.1
path: multilingual_librispeech-german_test/gain.1-*
- split: gain.2
path: multilingual_librispeech-german_test/gain.2-*
- split: gain.3
path: multilingual_librispeech-german_test/gain.3-*
- split: echo.1
path: multilingual_librispeech-german_test/echo.1-*
- split: echo.2
path: multilingual_librispeech-german_test/echo.2-*
- split: echo.3
path: multilingual_librispeech-german_test/echo.3-*
- split: phaser.1
path: multilingual_librispeech-german_test/phaser.1-*
- split: phaser.2
path: multilingual_librispeech-german_test/phaser.2-*
- split: phaser.3
path: multilingual_librispeech-german_test/phaser.3-*
- split: tempo_up.1
path: multilingual_librispeech-german_test/tempo_up.1-*
- split: tempo_up.2
path: multilingual_librispeech-german_test/tempo_up.2-*
- split: tempo_up.3
path: multilingual_librispeech-german_test/tempo_up.3-*
- split: tempo_down.1
path: multilingual_librispeech-german_test/tempo_down.1-*
- split: tempo_down.2
path: multilingual_librispeech-german_test/tempo_down.2-*
- split: tempo_down.3
path: multilingual_librispeech-german_test/tempo_down.3-*
- split: lowpass.1
path: multilingual_librispeech-german_test/lowpass.1-*
- split: lowpass.2
path: multilingual_librispeech-german_test/lowpass.2-*
- split: lowpass.3
path: multilingual_librispeech-german_test/lowpass.3-*
- split: highpass.1
path: multilingual_librispeech-german_test/highpass.1-*
- split: highpass.2
path: multilingual_librispeech-german_test/highpass.2-*
- split: highpass.3
path: multilingual_librispeech-german_test/highpass.3-*
- split: music.1
path: multilingual_librispeech-german_test/music.1-*
- split: music.2
path: multilingual_librispeech-german_test/music.2-*
- split: music.3
path: multilingual_librispeech-german_test/music.3-*
- split: crosstalk.1
path: multilingual_librispeech-german_test/crosstalk.1-*
- split: crosstalk.2
path: multilingual_librispeech-german_test/crosstalk.2-*
- split: crosstalk.3
path: multilingual_librispeech-german_test/crosstalk.3-*
- split: tremolo.1
path: multilingual_librispeech-german_test/tremolo.1-*
- split: tremolo.2
path: multilingual_librispeech-german_test/tremolo.2-*
- split: tremolo.3
path: multilingual_librispeech-german_test/tremolo.3-*
- split: treble.1
path: multilingual_librispeech-german_test/treble.1-*
- split: treble.2
path: multilingual_librispeech-german_test/treble.2-*
- split: treble.3
path: multilingual_librispeech-german_test/treble.3-*
- split: bass.1
path: multilingual_librispeech-german_test/bass.1-*
- split: bass.2
path: multilingual_librispeech-german_test/bass.2-*
- split: bass.3
path: multilingual_librispeech-german_test/bass.3-*
- split: chorus.1
path: multilingual_librispeech-german_test/chorus.1-*
- split: chorus.2
path: multilingual_librispeech-german_test/chorus.2-*
- split: chorus.3
path: multilingual_librispeech-german_test/chorus.3-*
- split: gnoise.4
path: multilingual_librispeech-german_test/gnoise.4-*
- split: env_noise.4
path: multilingual_librispeech-german_test/env_noise.4-*
- split: env_noise_esc50.4
path: multilingual_librispeech-german_test/env_noise_esc50.4-*
- split: env_noise_musan.4
path: multilingual_librispeech-german_test/env_noise_musan.4-*
- split: env_noise_wham.4
path: multilingual_librispeech-german_test/env_noise_wham.4-*
- split: speedup.4
path: multilingual_librispeech-german_test/speedup.4-*
- split: slowdown.4
path: multilingual_librispeech-german_test/slowdown.4-*
- split: pitch_up.4
path: multilingual_librispeech-german_test/pitch_up.4-*
- split: pitch_down.4
path: multilingual_librispeech-german_test/pitch_down.4-*
- split: rir.4
path: multilingual_librispeech-german_test/rir.4-*
- split: real_rir.4
path: multilingual_librispeech-german_test/real_rir.4-*
- split: resample.4
path: multilingual_librispeech-german_test/resample.4-*
- split: gain.4
path: multilingual_librispeech-german_test/gain.4-*
- split: echo.4
path: multilingual_librispeech-german_test/echo.4-*
- split: phaser.4
path: multilingual_librispeech-german_test/phaser.4-*
- split: tempo_up.4
path: multilingual_librispeech-german_test/tempo_up.4-*
- split: tempo_down.4
path: multilingual_librispeech-german_test/tempo_down.4-*
- split: lowpass.4
path: multilingual_librispeech-german_test/lowpass.4-*
- split: highpass.4
path: multilingual_librispeech-german_test/highpass.4-*
- split: music.4
path: multilingual_librispeech-german_test/music.4-*
- split: crosstalk.4
path: multilingual_librispeech-german_test/crosstalk.4-*
- split: tremolo.4
path: multilingual_librispeech-german_test/tremolo.4-*
- split: treble.4
path: multilingual_librispeech-german_test/treble.4-*
- split: bass.4
path: multilingual_librispeech-german_test/bass.4-*
- split: chorus.4
path: multilingual_librispeech-german_test/chorus.4-*
- config_name: multilingual_librispeech-spanish_test
data_files:
- split: None.0
path: multilingual_librispeech-spanish_test/None.0-*
- split: gnoise.1
path: multilingual_librispeech-spanish_test/gnoise.1-*
- split: gnoise.2
path: multilingual_librispeech-spanish_test/gnoise.2-*
- split: gnoise.3
path: multilingual_librispeech-spanish_test/gnoise.3-*
- split: gnoise.4
path: multilingual_librispeech-spanish_test/gnoise.4-*
- split: env_noise.1
path: multilingual_librispeech-spanish_test/env_noise.1-*
- split: env_noise.2
path: multilingual_librispeech-spanish_test/env_noise.2-*
- split: env_noise.3
path: multilingual_librispeech-spanish_test/env_noise.3-*
- split: env_noise.4
path: multilingual_librispeech-spanish_test/env_noise.4-*
- split: rir.1
path: multilingual_librispeech-spanish_test/rir.1-*
- split: rir.2
path: multilingual_librispeech-spanish_test/rir.2-*
- split: rir.3
path: multilingual_librispeech-spanish_test/rir.3-*
- split: rir.4
path: multilingual_librispeech-spanish_test/rir.4-*
- split: speedup.1
path: multilingual_librispeech-spanish_test/speedup.1-*
- split: speedup.2
path: multilingual_librispeech-spanish_test/speedup.2-*
- split: speedup.3
path: multilingual_librispeech-spanish_test/speedup.3-*
- split: speedup.4
path: multilingual_librispeech-spanish_test/speedup.4-*
- split: slowdown.1
path: multilingual_librispeech-spanish_test/slowdown.1-*
- split: slowdown.2
path: multilingual_librispeech-spanish_test/slowdown.2-*
- split: slowdown.3
path: multilingual_librispeech-spanish_test/slowdown.3-*
- split: slowdown.4
path: multilingual_librispeech-spanish_test/slowdown.4-*
- split: pitch_up.3
path: multilingual_librispeech-spanish_test/pitch_up.3-*
- split: pitch_up.4
path: multilingual_librispeech-spanish_test/pitch_up.4-*
- split: pitch_down.1
path: multilingual_librispeech-spanish_test/pitch_down.1-*
- split: pitch_down.2
path: multilingual_librispeech-spanish_test/pitch_down.2-*
- split: pitch_down.3
path: multilingual_librispeech-spanish_test/pitch_down.3-*
- split: pitch_down.4
path: multilingual_librispeech-spanish_test/pitch_down.4-*
- split: pitch_up.1
path: multilingual_librispeech-spanish_test/pitch_up.1-*
- split: pitch_up.2
path: multilingual_librispeech-spanish_test/pitch_up.2-*
- split: resample.2
path: multilingual_librispeech-spanish_test/resample.2-*
- split: resample.3
path: multilingual_librispeech-spanish_test/resample.3-*
- split: resample.4
path: multilingual_librispeech-spanish_test/resample.4-*
- split: env_noise_esc50.1
path: multilingual_librispeech-spanish_test/env_noise_esc50.1-*
- split: env_noise_esc50.2
path: multilingual_librispeech-spanish_test/env_noise_esc50.2-*
- split: env_noise_esc50.3
path: multilingual_librispeech-spanish_test/env_noise_esc50.3-*
- split: env_noise_esc50.4
path: multilingual_librispeech-spanish_test/env_noise_esc50.4-*
- split: resample.1
path: multilingual_librispeech-spanish_test/resample.1-*
- split: gain.1
path: multilingual_librispeech-spanish_test/gain.1-*
- split: gain.2
path: multilingual_librispeech-spanish_test/gain.2-*
- split: gain.3
path: multilingual_librispeech-spanish_test/gain.3-*
- split: gain.4
path: multilingual_librispeech-spanish_test/gain.4-*
- split: echo.4
path: multilingual_librispeech-spanish_test/echo.4-*
- split: echo.1
path: multilingual_librispeech-spanish_test/echo.1-*
- split: echo.2
path: multilingual_librispeech-spanish_test/echo.2-*
- split: echo.3
path: multilingual_librispeech-spanish_test/echo.3-*
- split: tempo_up.1
path: multilingual_librispeech-spanish_test/tempo_up.1-*
- split: tempo_up.2
path: multilingual_librispeech-spanish_test/tempo_up.2-*
- split: tempo_up.3
path: multilingual_librispeech-spanish_test/tempo_up.3-*
- split: tempo_up.4
path: multilingual_librispeech-spanish_test/tempo_up.4-*
- split: tempo_down.1
path: multilingual_librispeech-spanish_test/tempo_down.1-*
- split: tempo_down.2
path: multilingual_librispeech-spanish_test/tempo_down.2-*
- split: tempo_down.3
path: multilingual_librispeech-spanish_test/tempo_down.3-*
- split: tempo_down.4
path: multilingual_librispeech-spanish_test/tempo_down.4-*
- split: lowpass.1
path: multilingual_librispeech-spanish_test/lowpass.1-*
- split: lowpass.2
path: multilingual_librispeech-spanish_test/lowpass.2-*
- split: lowpass.3
path: multilingual_librispeech-spanish_test/lowpass.3-*
- split: lowpass.4
path: multilingual_librispeech-spanish_test/lowpass.4-*
- split: highpass.1
path: multilingual_librispeech-spanish_test/highpass.1-*
- split: highpass.2
path: multilingual_librispeech-spanish_test/highpass.2-*
- split: highpass.3
path: multilingual_librispeech-spanish_test/highpass.3-*
- split: highpass.4
path: multilingual_librispeech-spanish_test/highpass.4-*
- split: phaser.1
path: multilingual_librispeech-spanish_test/phaser.1-*
- split: phaser.2
path: multilingual_librispeech-spanish_test/phaser.2-*
- split: phaser.3
path: multilingual_librispeech-spanish_test/phaser.3-*
- split: phaser.4
path: multilingual_librispeech-spanish_test/phaser.4-*
- split: env_noise_musan.1
path: multilingual_librispeech-spanish_test/env_noise_musan.1-*
- split: env_noise_musan.2
path: multilingual_librispeech-spanish_test/env_noise_musan.2-*
- split: env_noise_musan.3
path: multilingual_librispeech-spanish_test/env_noise_musan.3-*
- split: env_noise_musan.4
path: multilingual_librispeech-spanish_test/env_noise_musan.4-*
- split: music.1
path: multilingual_librispeech-spanish_test/music.1-*
- split: music.2
path: multilingual_librispeech-spanish_test/music.2-*
- split: music.3
path: multilingual_librispeech-spanish_test/music.3-*
- split: music.4
path: multilingual_librispeech-spanish_test/music.4-*
- split: crosstalk.1
path: multilingual_librispeech-spanish_test/crosstalk.1-*
- split: crosstalk.2
path: multilingual_librispeech-spanish_test/crosstalk.2-*
- split: crosstalk.3
path: multilingual_librispeech-spanish_test/crosstalk.3-*
- split: crosstalk.4
path: multilingual_librispeech-spanish_test/crosstalk.4-*
- split: env_noise_wham.1
path: multilingual_librispeech-spanish_test/env_noise_wham.1-*
- split: env_noise_wham.2
path: multilingual_librispeech-spanish_test/env_noise_wham.2-*
- split: env_noise_wham.3
path: multilingual_librispeech-spanish_test/env_noise_wham.3-*
- split: env_noise_wham.4
path: multilingual_librispeech-spanish_test/env_noise_wham.4-*
- split: tremolo.1
path: multilingual_librispeech-spanish_test/tremolo.1-*
- split: tremolo.2
path: multilingual_librispeech-spanish_test/tremolo.2-*
- split: tremolo.4
path: multilingual_librispeech-spanish_test/tremolo.4-*
- split: treble.1
path: multilingual_librispeech-spanish_test/treble.1-*
- split: treble.2
path: multilingual_librispeech-spanish_test/treble.2-*
- split: treble.3
path: multilingual_librispeech-spanish_test/treble.3-*
- split: treble.4
path: multilingual_librispeech-spanish_test/treble.4-*
- split: bass.1
path: multilingual_librispeech-spanish_test/bass.1-*
- split: bass.2
path: multilingual_librispeech-spanish_test/bass.2-*
- split: bass.3
path: multilingual_librispeech-spanish_test/bass.3-*
- split: bass.4
path: multilingual_librispeech-spanish_test/bass.4-*
- split: chorus.1
path: multilingual_librispeech-spanish_test/chorus.1-*
- split: chorus.2
path: multilingual_librispeech-spanish_test/chorus.2-*
- split: chorus.3
path: multilingual_librispeech-spanish_test/chorus.3-*
- split: chorus.4
path: multilingual_librispeech-spanish_test/chorus.4-*
- split: tremolo.3
path: multilingual_librispeech-spanish_test/tremolo.3-*
- split: voice_conversion_bark.1
path: multilingual_librispeech-spanish_test/voice_conversion_bark.1-*
- config_name: multilingual_librispeech-spanish_test_pertEval_500_30
data_files:
- split: gnoise.1
path: multilingual_librispeech-spanish_test_pertEval_500_30/gnoise.1-*
- split: env_noise_esc50.1
path: multilingual_librispeech-spanish_test_pertEval_500_30/env_noise_esc50.1-*
- config_name: tedlium-release3_test
data_files:
- split: gnoise.1
path: tedlium-release3_test/gnoise.1-*
- split: gnoise.2
path: tedlium-release3_test/gnoise.2-*
- split: gnoise.3
path: tedlium-release3_test/gnoise.3-*
- split: env_noise_esc50.1
path: tedlium-release3_test/env_noise_esc50.1-*
- split: env_noise_esc50.2
path: tedlium-release3_test/env_noise_esc50.2-*
- split: env_noise_esc50.3
path: tedlium-release3_test/env_noise_esc50.3-*
- split: speedup.1
path: tedlium-release3_test/speedup.1-*
- split: speedup.2
path: tedlium-release3_test/speedup.2-*
- split: speedup.3
path: tedlium-release3_test/speedup.3-*
- split: slowdown.1
path: tedlium-release3_test/slowdown.1-*
- split: slowdown.2
path: tedlium-release3_test/slowdown.2-*
- split: slowdown.3
path: tedlium-release3_test/slowdown.3-*
- split: pitch_up.1
path: tedlium-release3_test/pitch_up.1-*
- split: pitch_up.2
path: tedlium-release3_test/pitch_up.2-*
- split: pitch_up.3
path: tedlium-release3_test/pitch_up.3-*
- split: pitch_down.1
path: tedlium-release3_test/pitch_down.1-*
- split: pitch_down.2
path: tedlium-release3_test/pitch_down.2-*
- split: pitch_down.3
path: tedlium-release3_test/pitch_down.3-*
- split: rir.1
path: tedlium-release3_test/rir.1-*
- split: rir.2
path: tedlium-release3_test/rir.2-*
- split: rir.3
path: tedlium-release3_test/rir.3-*
- split: voice_conversion_vctk.1
path: tedlium-release3_test/voice_conversion_vctk.1-*
- split: resample.1
path: tedlium-release3_test/resample.1-*
- split: resample.2
path: tedlium-release3_test/resample.2-*
- split: resample.3
path: tedlium-release3_test/resample.3-*
- split: gain.1
path: tedlium-release3_test/gain.1-*
- split: gain.2
path: tedlium-release3_test/gain.2-*
- split: gain.3
path: tedlium-release3_test/gain.3-*
- split: echo.1
path: tedlium-release3_test/echo.1-*
- split: echo.2
path: tedlium-release3_test/echo.2-*
- split: echo.3
path: tedlium-release3_test/echo.3-*
- split: phaser.1
path: tedlium-release3_test/phaser.1-*
- split: phaser.2
path: tedlium-release3_test/phaser.2-*
- split: phaser.3
path: tedlium-release3_test/phaser.3-*
- split: tempo_up.1
path: tedlium-release3_test/tempo_up.1-*
- split: tempo_up.2
path: tedlium-release3_test/tempo_up.2-*
- split: tempo_up.3
path: tedlium-release3_test/tempo_up.3-*
- split: tempo_down.1
path: tedlium-release3_test/tempo_down.1-*
- split: tempo_down.2
path: tedlium-release3_test/tempo_down.2-*
- split: tempo_down.3
path: tedlium-release3_test/tempo_down.3-*
- split: lowpass.1
path: tedlium-release3_test/lowpass.1-*
- split: lowpass.2
path: tedlium-release3_test/lowpass.2-*
- split: lowpass.3
path: tedlium-release3_test/lowpass.3-*
- split: highpass.1
path: tedlium-release3_test/highpass.1-*
- split: highpass.2
path: tedlium-release3_test/highpass.2-*
- split: highpass.3
path: tedlium-release3_test/highpass.3-*
- split: gnoise.4
path: tedlium-release3_test/gnoise.4-*
- split: env_noise_esc50.4
path: tedlium-release3_test/env_noise_esc50.4-*
- split: speedup.4
path: tedlium-release3_test/speedup.4-*
- split: slowdown.4
path: tedlium-release3_test/slowdown.4-*
- split: pitch_up.4
path: tedlium-release3_test/pitch_up.4-*
- split: pitch_down.4
path: tedlium-release3_test/pitch_down.4-*
- split: rir.4
path: tedlium-release3_test/rir.4-*
- split: resample.4
path: tedlium-release3_test/resample.4-*
- split: gain.4
path: tedlium-release3_test/gain.4-*
- split: echo.4
path: tedlium-release3_test/echo.4-*
- split: phaser.4
path: tedlium-release3_test/phaser.4-*
- split: tempo_up.4
path: tedlium-release3_test/tempo_up.4-*
- split: tempo_down.4
path: tedlium-release3_test/tempo_down.4-*
- split: lowpass.4
path: tedlium-release3_test/lowpass.4-*
- split: highpass.4
path: tedlium-release3_test/highpass.4-*
- split: None.0
path: tedlium-release3_test/None.0-*
- split: music.1
path: tedlium-release3_test/music.1-*
- split: music.2
path: tedlium-release3_test/music.2-*
- split: music.3
path: tedlium-release3_test/music.3-*
- split: music.4
path: tedlium-release3_test/music.4-*
- split: crosstalk.1
path: tedlium-release3_test/crosstalk.1-*
- split: crosstalk.2
path: tedlium-release3_test/crosstalk.2-*
- split: crosstalk.3
path: tedlium-release3_test/crosstalk.3-*
- split: crosstalk.4
path: tedlium-release3_test/crosstalk.4-*
- split: env_noise_musan.1
path: tedlium-release3_test/env_noise_musan.1-*
- split: env_noise_musan.2
path: tedlium-release3_test/env_noise_musan.2-*
- split: env_noise_musan.3
path: tedlium-release3_test/env_noise_musan.3-*
- split: env_noise_musan.4
path: tedlium-release3_test/env_noise_musan.4-*
- split: real_rir.1
path: tedlium-release3_test/real_rir.1-*
- split: real_rir.2
path: tedlium-release3_test/real_rir.2-*
- split: real_rir.3
path: tedlium-release3_test/real_rir.3-*
- split: real_rir.4
path: tedlium-release3_test/real_rir.4-*
- split: env_noise.1
path: tedlium-release3_test/env_noise.1-*
- split: env_noise.2
path: tedlium-release3_test/env_noise.2-*
- split: env_noise.3
path: tedlium-release3_test/env_noise.3-*
- split: env_noise.4
path: tedlium-release3_test/env_noise.4-*
- split: env_noise_wham.1
path: tedlium-release3_test/env_noise_wham.1-*
- split: env_noise_wham.2
path: tedlium-release3_test/env_noise_wham.2-*
- split: env_noise_wham.3
path: tedlium-release3_test/env_noise_wham.3-*
- split: env_noise_wham.4
path: tedlium-release3_test/env_noise_wham.4-*
- split: tremolo.1
path: tedlium-release3_test/tremolo.1-*
- split: tremolo.2
path: tedlium-release3_test/tremolo.2-*
- split: tremolo.3
path: tedlium-release3_test/tremolo.3-*
- split: tremolo.4
path: tedlium-release3_test/tremolo.4-*
- split: treble.1
path: tedlium-release3_test/treble.1-*
- split: treble.2
path: tedlium-release3_test/treble.2-*
- split: treble.3
path: tedlium-release3_test/treble.3-*
- split: treble.4
path: tedlium-release3_test/treble.4-*
- split: bass.1
path: tedlium-release3_test/bass.1-*
- split: bass.2
path: tedlium-release3_test/bass.2-*
- split: bass.3
path: tedlium-release3_test/bass.3-*
- split: bass.4
path: tedlium-release3_test/bass.4-*
- split: chorus.1
path: tedlium-release3_test/chorus.1-*
- split: chorus.2
path: tedlium-release3_test/chorus.2-*
- split: chorus.4
path: tedlium-release3_test/chorus.4-*
- split: chorus.3
path: tedlium-release3_test/chorus.3-*
---
# Dataset Card for "speech_robust_bench"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) |
getomni-ai/ocr-benchmark | getomni-ai | 2025-02-21T06:34:31Z | 3,597 | 51 | [
"license:mit",
"size_categories:1K<n<10K",
"format:imagefolder",
"modality:image",
"modality:text",
"library:datasets",
"library:mlcroissant",
"region:us"
] | [] | 2025-02-13T20:57:27Z | 2 | ---
license: mit
size_categories:
- 1K<n<10K
---
# OmniAI OCR Benchmark
A comprehensive benchmark that compares OCR and data extraction capabilities of different multimodal LLMs such as gpt-4o and gemini-2.0, evaluating both text and JSON extraction accuracy.
[**Benchmark Results (Feb 2025)**](https://getomni.ai/ocr-benchmark) | [**Source Code**](https://github.com/getomni-ai/benchmark) |
Congliu/Chinese-DeepSeek-R1-Distill-data-110k | Congliu | 2025-02-21T02:18:08Z | 2,591 | 650 | [
"task_categories:text-generation",
"task_categories:text2text-generation",
"task_categories:question-answering",
"language:zh",
"license:apache-2.0",
"size_categories:100K<n<1M",
"format:json",
"modality:tabular",
"modality:text",
"library:datasets",
"library:pandas",
"library:mlcroissant",
"library:polars",
"region:us"
] | [
"text-generation",
"text2text-generation",
"question-answering"
] | 2025-02-17T11:45:09Z | null | ---
license: apache-2.0
language:
- zh
size_categories:
- 100K<n<1M
task_categories:
- text-generation
- text2text-generation
- question-answering
---
# 中文基于满血DeepSeek-R1蒸馏数据集(Chinese-Data-Distill-From-R1)
<p align="center">
🤗 <a href="https://huggingface.co/datasets/Congliu/Chinese-DeepSeek-R1-Distill-data-110k">Hugging Face</a>   |   🤖 <a href="https://modelscope.cn/datasets/liucong/Chinese-DeepSeek-R1-Distill-data-110k">ModelScope</a>    |   🚀 <a href="https://github.com/YunwenTechnology/Chinese-Data-Distill-From-R1">Github</a>    |   📑 <a href="https://zhuanlan.zhihu.com/p/24430839729">Blog</a>
</p>
注意:提供了直接SFT使用的版本,[点击下载](https://huggingface.co/datasets/Congliu/Chinese-DeepSeek-R1-Distill-data-110k-SFT)。将数据中的思考和答案整合成output字段,大部分SFT代码框架均可直接直接加载训练。
本数据集为中文开源蒸馏满血R1的数据集,数据集中不仅包含math数据,还包括大量的通用类型数据,总数量为110K。
为什么开源这个数据?
R1的效果十分强大,并且基于R1蒸馏数据SFT的小模型也展现出了强大的效果,但检索发现,大部分开源的R1蒸馏数据集均为英文数据集。 同时,R1的报告中展示,蒸馏模型中同时也使用了部分通用场景数据集。
为了帮助大家更好地复现R1蒸馏模型的效果,特此开源中文数据集。
该中文数据集中的数据分布如下:
- Math:共计36568个样本,
- Exam:共计2432个样本,
- STEM:共计12648个样本,
- General:共计58352,包含弱智吧、逻辑推理、小红书、知乎、Chat等。
字段说明:
- input: 输入
- reasoning_content: 思考
- content: 输出
- repo_name: 数据源
- score: 模型打分结果
## 数据集蒸馏细节
数据的prompt源来自:
- [Haijian/Advanced-Math](https://modelscope.cn/datasets/Haijian/Advanced-Math)
- [gavinluo/applied_math](https://modelscope.cn/datasets/gavinluo/applied_math)
- [meta-math/GSM8K_zh](https://huggingface.co/datasets/meta-math/GSM8K_zh)
- [EduChat-Math](https://github.com/ECNU-ICALK/EduChat-Math)
- [m-a-p/COIG-CQIA](https://huggingface.co/datasets/m-a-p/COIG-CQIA)
- [m-a-p/neo_sft_phase2](https://huggingface.co/datasets/m-a-p/neo_sft_phase2)
- [hfl/stem_zh_instruction](https://huggingface.co/datasets/hfl/stem_zh_instruction)
同时为了方便大家溯源,在每条数据的repo_name字段中都加入的原始数据源repo。
在蒸馏过程中,按照[DeepSeek-R1](https://github.com/deepseek-ai/DeepSeek-R1)官方提供的细节,进行数据蒸馏。
- 不增加额外的系统提示词
- 设置temperature为0.6
- 如果为数学类型数据,则增加提示词,“请一步步推理,并把最终答案放到 \boxed{}。”
- 防止跳出思维模式,强制在每个输出的开头增加"\n",再开始生成数据
由于个人资源有限,所有数据的蒸馏均调用[无问芯穹](https://cloud.infini-ai.com/genstudio?source=knlpdis)的企业版满血R1 API生成,在此由衷的感谢无问芯穹。
任务期间,保持稳定地运行300并发,支持64k上下文,32k输出长度,持续运行近12个小时,性能始终保持一致,数据可用性100%。测试时首token延时基本在500ms以下,推理速度最快25 tokens/s(需根据实际运行任务进行测试实际稳定性指标比较合理)。
## 数据打分细节
数据生成结果进行了二次校验,并保留了评价分数。
针对Math和Exam数据,先利用[Math-Verify](https://github.com/huggingface/Math-Verify)进行校对,无法规则抽取结果的数据,再利用[Qwen2.5-72B-Instruct](https://huggingface.co/Qwen/Qwen2.5-72B-Instruct)模型进行打分,正确为10分,错误为0分。
针对其他数据,直接利用[Qwen2.5-72B-Instruct](https://huggingface.co/Qwen/Qwen2.5-72B-Instruct)模型从无害性、有用性、正确性/完整性三个角度进行打分,分值范围为0-10分。
本数据集保留了最后打分结果,为后续的数据筛选提供帮助,但注意,所有打分均基于模型,因此评分可能并不准确,请斟酌使用。
数据的二次校验,使用8张A100 GPU 部署多节点Qwen72B模型进行推理打分,耗时接近24H,感谢我司云问科技提供的服务器支持。
## 局限性
由于数据是由蒸馏DeepSeek-R1生成的,未经严格验证,在事实性和其他方面还存在一些不足。因此,在使用此数据集时,请务必注意甄别。
本数据集不代表任何一方的立场、利益或想法,无关任何团体的任何类型的主张。因使用本数据集带来的任何损害、纠纷,本项目的开发者不承担任何责任。
## 引用
```text
@misc{Chinese-Data-Distill-From-R1,
author = {Cong Liu, Zhong Wang, ShengYu Shen, Jialiang Peng, Xiaoli Zhang, ZhenDong Du, YaFang Wang},
title = {The Chinese dataset distilled from DeepSeek-R1-671b},
year = {2025},
publisher = {HuggingFace},
howpublished = {\url{https://huggingface.co/datasets/Congliu/Chinese-DeepSeek-R1-Distill-data-110k}},
}
```
## 联系作者
- email: [email protected]
- 知乎:[刘聪NLP](https://www.zhihu.com/people/LiuCongNLP)
- 公众号:[NLP工作站](images/image.png) |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.